TESTOVÁNÍ STATISTICKÝCH HYPOTÉZ
|
|
|
- Lucie Havlová
- před 8 lety
- Počet zobrazení:
Transkript
1 TESTOVÁNÍ STATISTICKÝCH HYPOTÉZ 1 Vytvořeno s podporou projektu Průřezová inovace studijních programů Lesnické a dřevařské fakulty MENDELU v Brně (LDF) s ohledem na discipliny společného základu (reg. č. CZ.1.07/2.2.00/ ) za přispění finančních prostředků EU a státního rozpočtu České republiky.
 za přispění finančních prostředků EU a státního rozpočtu České")
2 TESTOVÁNÍ STATISTICKÝCH HYPOTÉZ ZÁKLADNÍ POJMY teorie testů viz teorie text I, str testy pro 1 a 2 výběry teorie text I, str Statistická hypotéza je určitá domněnka (předpoklad) o jakékoli vlastnosti ZÁKLADNÍHO SOUBORU. O ZS nic nevíme jistě, stoprocentně, pokud ho neznáme celý (což je naprosto výjimečný případ). Pokud řekneme ZS má normální rozdělení, je to jen naše domněnka, protože neznáme všechny prvky ZS. Proto každé tvrzení (hypotézu) o ZS musíme testovat. Teprve na základě testu, který vychází z naměřených (výběrových) dat můžeme rozhodnout, zda tuto domněnku (hypotézu) můžeme považovat za platnou nebo za neplatnou. 2 Test statistické hypotézy je pravidlo (kritérium), které na základě dat náhodného výběru objektivně doporučuje rozhodnutí, má-li být ověřovaná hypotéza zamítnuta či nikoliv.
 dat můžeme rozhodnout, zda tuto domněnku (hypotézu) můžeme považovat za platnou nebo za neplatnou.")
3 DRUHY HYPOTÉZ Pro každý test musíme formulovat nulovou a alternativní hypotézu: Testovaná hypotéza se nazývá nulová hypotéza (H 0 ). Předpokládáme, že platí, pokud nemáme k dispozici dostatečný statistický důkaz její neplatnosti. Pokud zamítneme platnost nulové hypotézy, předpokládáme, že platí alternativní hypotéza (H 1 ). 3 H 0 a H 1 musí být formulovány tak, aby nebyla možná žádná třetí možnost. Buď platí H 0 nebo H 1, nic dalšího není možné.
.")
4 DRUHY HYPOTÉZ Hypotézy se mohou formulovat jako oboustranné nebo jako jednostranné. Oboustranná hypotéza: H 0 : µ = 50 H 1 : µ 50 všechny ostatní možnosti odpovídají platnosti H 1 50 pouze zde platí H 0 Jednostranná hypotéza: 4 H 0 : µ 50 H 1 : µ > 50 (H 0 : µ 50 H 1 : µ < 50) zde platí H 0 50 zde platí H 1

5 TESTOVÉ KRITÉRIUM Testy statistických hypotéz jsou obecně založeny na testovém kritériu (náhodná veličina, jejíž rozdělení je známo pro případ platnosti i neplatnosti nulové hypotézy). 5 toto je rozdělení testového kritéria pro nulovou hypotézu toto je rozdělení testového kritéria pro alternativní hypotézu (je to stejná náhodná veličina jako u nulové hypotézy, jen s jinými parametry)

6 TESTOVÉ KRITÉRIUM Obor možných hodnot testového kritéria je rozdělen na dvě části obor nezamítnutí (přijetí) a obor zamítnutí (nepřijetí) testované hypotézy. Obor zamítnutí je ta část všech možných hodnot testového kritéria, kde je vysoce nepravděpodobné, že by testové kritérium mohlo nabýt tyto hodnoty (za předpokladu, že platí nulová hypotéza). 6 Hranice oborů tvoří kritický bod (kritická hodnota), což je kvantil testového kritéria určený na základě hladiny významnosti α a (zpravidla) velikosti výběru n.
.")
7 OBECNÝ PRINCIP STATISTICKÉHO TESTU Budeme testovat hypotézy H 0 : µ 50 oproti H 1 : µ > 50. Za ZS zde považujeme nekonečně velký základní soubor (ZS), jehož střední hodnota µ je nejvýše rovna hodnotě 50. Jedná se tedy o jednostrannou hypotézu. Pro všechny hodnoty µ menší nebo rovno 50 platí H 0, pro ostatní hodnoty H 1. zde platí H 0 50 zde platí H 1 7 Problémem je, že my neznáme (a nikdy znát nebudeme) celý ZS. K dispozici máme pouze jeho podmnožinu výběrový soubor (VS). Otázka, kterou řešíme, tedy zní: Můžeme na základě dat z VS s dostatečnou pravděpodobností zamítnout hypotézu, že ZS (z něhož pochází náš VS) má střední hodnotu menší nebo rovnu 50?
 celý ZS. K dispozici máme pouze jeho podmnožinu výběrový soubor (VS).")
8 OBECNÝ PRINCIP STATISTICKÉHO TESTU Nejprve si musíme umět představit situaci, tj. jak by vypadala data, pokud by platila nulová hypotéza. Tento případ pro střední hodnotu 50 ukazuje obrázek. Jedná se o normální rozdělení se střední hodnotou 50. Na ose X jsou hodnoty souboru (číselná osa), na ose Y je frekvenční funkce (tj. pravděpodobnosti výskytu jednotlivých hodnot). 8

9 OBECNÝ PRINCIP STATISTICKÉHO TESTU Poté naměříme data získáme VS (data označena červenými kosočtverci). Vidíme, že střední hodnota dat bude vychýlena poněkud doprava - výpočtem zjistíme, že výběrový průměr je přibližně 52. 9

10 OBECNÝ PRINCIP STATISTICKÉHO TESTU Znamená to, že náš výběrový soubor má rozdělení (vzhledem k dostatečnému rozsahu výběru 30 hodnot - předpokládáme normální rozdělení) se střední hodnotou 52 (červená křivka). 10
 se střední")
11 OBECNÝ PRINCIP STATISTICKÉHO TESTU Otázka nyní zní: Je odchylka teoretického (modrého) a experimentálního (červeného) rozdělení tak velká, že nulovou hypotézu mohu s dostatečnou spolehlivostí zamítnout (potom bychom zamítli nulovou hypotézu a věřili v platnost alternativní hypotézy) nebo je odchylka mezi teoretickým a experimentálním rozdělením natolik malá (pouze náhodně daná naším konkrétním výběrem), že nemůžeme s dostatečnou pravděpodobností vyloučit, že kdybychom měřili velký ( nekonečný ) počet hodnot, získali bychom rozdělení odpovídající teoretickému (potom bychom nemohli nulovou hypotézu zamítnout)? 11
 počet hodnot, získali bychom rozdělení odpovídající teoretickému (potom bychom nemohli nulovou hypotézu")
12 OBECNÝ PRINCIP STATISTICKÉHO TESTU Z této otázky vyplývá, že podstatou testu je rozhodnutí, zda s dostatečnou spolehlivostí můžeme zamítnout tvrzení obsažené v nulové hypotéze. Onu dostatečnou spolehlivost si určujeme sami, nejobvyklejší hodnota je 95 %. Znamená to, že nulovou hypotézu zamítneme pouze tehdy, pokud data VS umožňují toto zamítnutí učinit s pravděpodobností nejméně 95 %. Musíme se tedy stanovit jednoznačnou hranici, která ním určí, v jakém intervalu možných hodnot testované proměnné se přikloníme k zamítnutí nulové hypotézy a v jakém intervalu k tomu ještě nebudeme mít dostatečně silný statistický důkaz (dostatečně silnou spolehlivost). 12

13 OBECNÝ PRINCIP STATISTICKÉHO TESTU Touto hranicí je kritická hodnota. Určuje se pomocí hodnoty α (u statistických testů se nazývá chyba prvního druhu podrobněji viz dále). Pokud si nastavíme např. α na hodnotu 0,05 ( 5% ), potom říkáme, že nulovou hypotézu zamítneme pouze v tom případě, kdy budeme mít minimální pravděpodobnost zamítnutí nulové hypotézy 1 0,05 = 0,95 ( 95% ). Kritickou hodnotu (KH) stanovíme tak, že musíme určit pro teoretické rozdělení hodnotu (kvantil) pro pravděpodobnost α (obvykle 0,05 - v případě oboustranného testu by tato pravděpodobnost byla dělená na poloviny, stejně jako u intervalů spolehlivosti). KH určíme např. v Excelu podle funkce INV, kde na místo čtverečku vložíme název použitého rozdělení (např. TINV pro t-rozdělení, CHIINV pro chi-kvadrát rozdělení, NORMINV pro normální rozdělení apod.). Do funkce zadáme jeho parametry, tj. požadovanou pravděpodobnost (α pro jednostranný test nebo α/2 pro oboustranný test) a zpravidla počet stupňů volnosti (obvykle n-1). Situaci ukazuje následující obrázek. 13 V tomto příkladu je KH 58,38.
. KH určíme např. v Excelu podle funkce INV, kde na místo čtverečku vložíme název použitého rozdělení (např.")
14 14 OBECNÝ PRINCIP STATISTICKÉHO TESTU
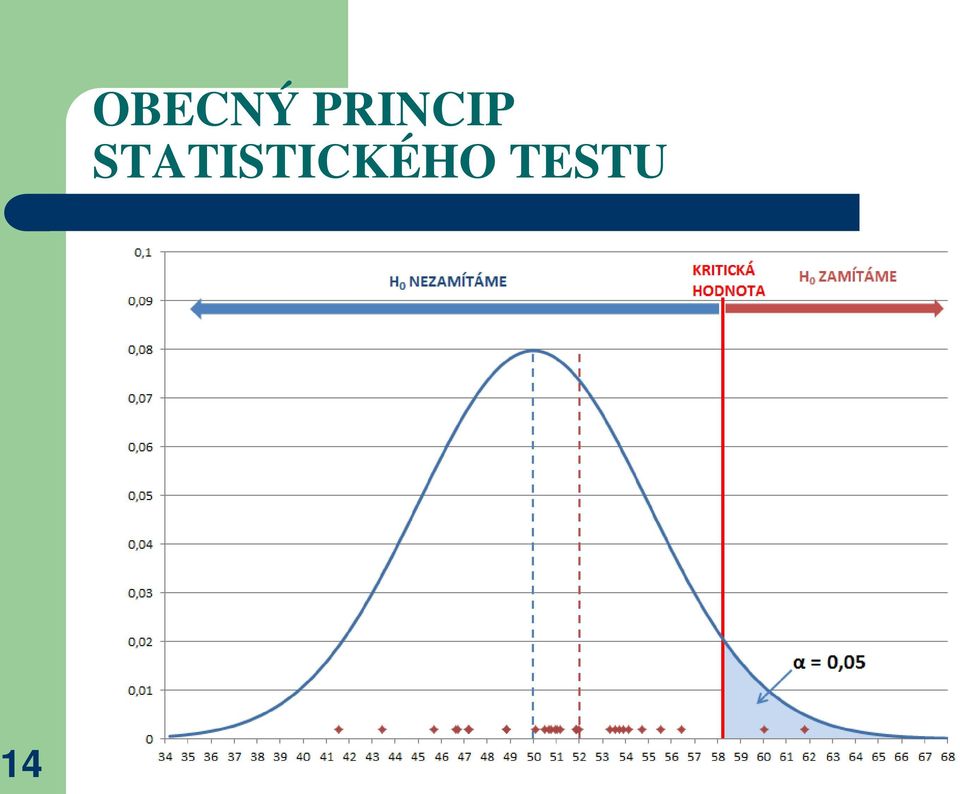
15 OBECNÝ PRINCIP STATISTICKÉHO TESTU S KH srovnáváme hodnotu vypočítanou přímo z dat VS testové kritérium (TK). Tedy srovnáváme kvantil stanovený pro teoretické rozdělení (nulovou hypotézu) KH - s kvantilem stanoveným z VS (měřených dat), tedy pro alternativní hypotézu. Pokud vypočítané TK bude vlevo od KH (TK< KH), nebudeme mít dostatečnou pravděpodobnost pro zamítnutí nulové hypotézy (protože KH určuje min. možnou pravděpodobnost zamítnutí nulové hypotézy), tedy nulovou hypotézu nezamítneme. 15 Pokud vypočítané testové kritérium bude vpravo od KH (TK > KH), budeme mít dostatečnou pravděpodobnost pro zamítnutí nulové hypotézy, neboť potom víme, že nulovou hypotézu zamítáme nejméně s (1 α)% pravděpodobností (obvykle 1-0,05 = 0,95 95% pravděpodobnost ). Pokud TK padne do tohoto intervalu, je velmi málo pravděpodobné, že by data z VS mohla pocházet z teoretického rozdělení (v našem příkladu z normálního rozdělení se střední hodnotou 50). Nulovou hypotézu tedy zamítneme. TK< KH nezamítáme nulovou hypotézu TK > KH zamítáme nulovou hypotézu
, tedy nulovou hypotézu nezamítneme.")
16 OBECNÝ PRINCIP STATISTICKÉHO TESTU TK se stanovuje podle vzorce specifického pro daný test. V našem případě má TK hodnotu 51,37. TK je menší než KH (51,37 < 58,4), nulovou hypotézu tedy nemůžeme zamítnout 16
, nulovou hypotézu")
17 OBECNÝ PRINCIP STATISTICKÉHO TESTU TK také vymezuje skutečnou maximální pravděpodobnost, s jakou můžeme nulovou hypotézu zamítnout. Je to plocha vlevo od TK pod teoretickým rozdělením (tj. distribuční funkce této náhodné veličiny) žlutá plocha na obrázku. 17

18 OBECNÝ PRINCIP STATISTICKÉHO TESTU 18 Tato pravděpodobnost se prakticky obvykle určuje tak, že se stanoví tzv. p-hodnota (podrobněji viz dále), což je zelená plocha na obrázku a pravděpodobnost zamítnutí nulové hypotézy se vypočítá 1 p. V tomto příkladu je p- hodnota asi 0,40, tedy maximální pravděpodobnost zamítnutí nulové hypotézy je 1 0,4 = 0,6 ( 60% ). Nedosahuje tedy požadované hranice pravděpodobnosti zamítnutí 0,95 ( 95% ), což je další důkaz toho, že nemůžeme zamítnout nulovou hypotézu.
, což je další důkaz toho, že nemůžeme zamítnout")
19 TESTOVÉ KRITÉRIUM PRO OBOUSTRANNÝ TEST U oboustranného testu (který je nejčastější) používáme dvě kritické hodnoty, které určujeme na základě pravděpodobnosti α/2. hustota pravděpodobnosti náhodné veličiny, která funguje jako testové kritérium 19 obor zamítnutí (nepřijetí) obor nezamítnutí (přijetí) obor zamítnutí (nepřijetí) α/2 α/2 a α/2 b α/2 dolní kritický bod horní kritický bod
 obor nezamítnutí (přijetí) obor zamítnutí (nepřijetí) α/2 α/2 a α/2 b α/2")
20 TESTOVÉ KRITÉRIUM PRO JEDNOSTRANNÝ TEST obor zamítnutí (nepřijetí) obor nezamítnutí (přijetí) α α b α horní kritický bod obor nezamítnutí (přijetí) obor zamítnutí (nepřijetí) U jednostranného testu (který používáme podobně jako jednostranné intervaly spolehlivosti pouze ve speciálních případech, např. při testování, zda nějaká hodnota přesáhla v ZS zadanou hranici, normu, apod.) používáme jednu kritickou hodnotu, kterou určujeme na základě pravděpodobnosti α. a α dolní kritický bod 20

21 OBECNÝ POSTUP TESTU formulace nulové hypotézy (H 0 ) a alternativní hypotézy (H 1 ). volba chyby I. druhu α (a toho vyplývající požadavku na zamítnutí H 0 s minimální pravděpodobností 1 - α. volba druhu testu a testového kritéria určení kritického oboru (oboru nepřijetí) testového kritéria na základě jejího rozdělení pravděpodobnosti a hladiny významnosti rozhodnutí o výsledku testu, tj. zda zamítnout nulovou hypotézu (jestliže vypočítaná hodnota testového kritéria padne do oboru nepřijetí), nezamítnout nulovou hypotézu (jestliže vypočítaná hodnota testového kritéria padne do oboru přijetí). Říkáme, že výsledek testu je významný (signifikantní) na hladině významnosti α, pokud jeho rozhodnutí vede k zamítnutí nulové hypotézy s využitím zvolené hodnoty α. 21 Pokud H 0 nezamítneme, neznamená to, že určitě ( stoprocentně ) platí, znamená to pouze, že nemáme dostatečný statistický důkaz její neplatnosti.
22 POSTUP TESTOVÁNÍ NA PŘÍKLADU Byla prověřována správnost měření výškoměru. Byla 15 x změřena výška, jejíž hodnota je přesně známa (µ 0 = 20 m). Z výsledků měření se získal průměr měřených výšek = 19,2 m se směrodatnou odchylkou S = 1,1 m. Stanovte, zda-li výškoměr měří správně. 22
23 POSTUP TESTOVÁNÍ NA PŘÍKLADU stanovení hodnoty α: chybu I. druhu stanovíme na 0.05, tj. pro zamítnutí nulové hypotézy potřebujeme pravděpodobnost nejméně 1 - α =
24 POSTUP TESTOVÁNÍ NA PŘÍKLADU výběr typu testu (testového kritéria) vzhledem k charakteru úlohy dané formulací hypotéz vybereme test střední hodnoty pro jeden výběr, který testuje námi zvolené hypotézy. Testové kritérium je t = (x -μ ) 0 n S 15 t = (19, 2-20) = -2,82 1,1 24 Pro tento test jako testové kritérium používáme t-rozdělení a jeho konkrétní vypočítaná hodnota pro naše zadání je 2,82. Tuto hodnotu budeme porovnávat k kritickými mezemi.
25 POSTUP TESTOVÁNÍ NA PŘÍKLADU stanovení kritické hodnoty 25 vzhledem k tomu, že pracujeme (podle formulace hypotéz a typu úlohy) s oboustranným testem, musíme zvolit 2 kritické hodnoty dolní a horní. Studentovo t-rozdělení je symetrické kolem 0 stačí nám tedy určit jednu hodnotu a použít ji s kladným i záporným znaménkem. Využijeme funkce Excelu =TINV (0,05;14), kde 0,05 je hodnota α (a funkce automaticky vrátí hodnoty pro oboustranný interval, tj. vlastně pro α = 0,025). Hodnota 14 je počet stupňů volnosti (n-1)=15-1. Výsledná hodnota je 2,145. Tím jsou určeny kritické meze 2,145 a +2,145.
26 POSTUP TESTOVÁNÍ NA PŘÍKLADU rozhodnutí o výsledku testu kritická hodnota 2,145 je menší než vypočítaná hodnota testového kritéria 2,82, znamená to, že 2,82 padlo do oboru nepřijetí tedy nulovou hypotézu zamítáme. 26 Závěr testu: Výškoměr neměří správně. Odchylka naměřených hodnot od správné hodnoty je statisticky významná tj. s pravděpodobností nejméně 95% se přikláníme k možnosti, že i kdybychom měřili velký (teoreticky nekonečný ) počet výšek, střední hodnota by se nerovnala přesně 20 m.
27 27 POSTUP TESTOVÁNÍ NA PŘÍKLADU
28 POSTUP TESTOVÁNÍ NA PŘÍKLADU Z předcházejícího obrázku vyplývá, že H 0 můžeme zamítnout s pravděpodobností vyšší než 95 % - testové kritérium (zelená šipka) je mimo modrý 95% interval, ale nemůžeme ji zamítnout s pravděpodobností 99% - testové kritérium je uvnitř červeného intervalu, který byl sestrojen pro α = 0,01. Zatím tedy můžeme konstatovat, že H 0 můžeme zamítnout s pravděpodobností mezi 95 99%. Výpočet skutečné pravděpodobnosti zamítnutí je spojen s výpočtem tzv. p-hodnoty (viz následující snímek) tato hodnota je velmi důležitá, protože poskytuje druhý způsob, jak určit výsledek statistického testu. Navíc je tento způsob prezentace výsledku testu daleko častější než srovnání kritické hodnoty a testového kritéria. V podstatě všechny statistické programy uvádí jako jediný výsledek testu právě p-hodnotu, podle které musíte umět rozhodnout o výsledku testu. 28
29 p-hodnota p-hodnota je pravděpodobnost, že získáme stejné nebo extrémnější testové kritérium než je vypočítané, za předpokladu, že ve skutečnosti platí nulová hypotéza. p-hodnota je tedy pravděpodobnost od testového kritéria (TK) směrem ven z rozdělení na obrázku zelená ploška (pro TK nižší než KH) a ploška fialově orámovaná (pro TK vyšší než KH). TK < KH TK > KH Z obrázku vyplývá: pokud TK leží v oboru zamítnutí H 0 (zelená šipka), musí platit, že p < α (zelená plocha je menší než čárkovaná). pokud TK leží v oboru nezamítnutí H 0 (fialová šipka), musí platit, že p > α (fialově ohraničená plocha je větší než čárkovaná) p < α Η 0 zamítáme p > α Η 0 nezamítáme 29 1-p skutečná pravděpodobnost, se kterou můžeme zamítnout H 0
30 ROZHODNUTÍ O VÝSLEDKU TESTU SHRNUTÍ Máme tedy k dispozici dva způsoby, jak rozhodnout o výsledku testu: TK< KH nezamítáme nulovou hypotézu TK > KH zamítáme nulovou hypotézu 30 p > α nezamítáme nulovou hypotézu p < α zamítáme nulovou hypotézu Pamatujte, že vždy můžete srovnávat mezi sebou pouze vzájemně srovnatelné hodnoty, tj. kvantily (hodnoty) rozdělení (TK a KH), resp. pravděpodobnosti (p a α). Samozřejmě pro stejná data a stejný test oba způsoby vyhodnocení musí poskytnout stejnou interpretaci.
31 p HODNOTA (jednostranný test) hodnota testového kritéria p-hodnota α 31
32 p-hodnota (oboustranný test) U oboustranného testu se p-hodnota stejně jako α dělí na poloviny na obě strany testu. 32
33 p-hodnota Podle p - hodnoty můžeme pouze zamítnout nebo nezamítnout H 0. Nemůžeme podle ní srovnávat různé testy a jejich výsledky. Není totiž možné obecně říci, že pokud dosáhneme v testu hodnotu p =0,005, je H 0 tohoto testu zamítnuta spolehlivěji než u testu, kde p = 0,01. Důvodem je to, že p-hodnota závisí na: velikosti efektu - rozdílu mezi nulovou a alternativní hypotézou velikosti výběru Příklady uvádí následující snímky. 33
34 p-hodnota Tento příklad ukazuje vliv velikosti výběru na výsledek testu (na hodnotu p), přičemž velikost efektu je stále stejná ( = 1). Pokud máme malý výběr (n = 10), velikost efektu je považována za statisticky neprůkaznou (znamená to, že na základě 10 dat VS nemůžeme zamítnout H 0, tj. tvrzení, že střední hodnota ZS se rovná 100). Ovšem pro velký výběr (n = 1000) je H 0 zamítnuta. Vyplývá z toho, že při použití hodně velkého výběru i velmi malá velikost efektu (tj. velmi malý rozdíl mezi naměřenou a teoretickou hodnotou) je prokázána jako statisticky významná. 34 Střední hodnota pro H 1 Střední hodnota pro H 0 n t t krit p ,300 2,262 0, ,995 1,984 0, ,161 1,962 0,002
35 p-hodnota Tento příklad ukazuje, že i při stejné velikosti výběru (zde n = 20) závisí výsledek testu na velikosti efektu. Pokud jsou H 0 a H 1 od sebe dostatečně vzdáleny, i malý výběr vede ke statistickému zamítnutí H 0. Střední hodnota pro H 1 Střední hodnota pro H 0 n t t krit p ,436 2,093 0, ,308 2,093 0, ,179 2,093 0, ,359 2,093 0, Musíme si ale položit otázku: jaká velikost efektu je pro řešení konkrétního praktického problému prakticky (reálně) významná?
36 STATISTICKÁ VÝZNAMNOST A PRAKTICKÁ DŮLEŽITOST VELIKOSTI EFEKTU Je nutné rozlišovat mezi statistickou významností (danou p - hodnotou) a reálnou (ekologickou, ekonomickou, biologickou, ) důležitostí studované velikosti efektu!! Praktická (reálná) důležitost rozdílu H 0 - H 1 Statistická významnost (podle p) nevýznamná významná nedůležitý n v pořádku n příliš velké důležitý n příliš malé n v pořádku 36
37 INTERVAL SPOLEHLIVOSTI EFEKTU A JEHO SPOJITOST S VÝSLEDKEM TESTU 37 Rozdíl mezi statistickou významností a praktickou důležitostí testované velikosti efektu je možné názorně vyložit na intervalu spolehlivosti (IS) efektu. Je nutné si uvědomit, že nás zajímá, zda je možné věřit tomu, že velikost efektu je prokazatelná v základním souboru. IS nám se stanovenou pravděpodobností pokryje interval, ve kterém se vyskytuje studovaný efekt v základním souboru. Vztahy mezi statistickou a reálnou významností ukazuje obrázek na následujícím snímku. Na obrázku je uvedeno 5 možností vztahu mezi statistickou a reálnou významností. Za statisticky významný efekt považujeme ten, jehož IS neobsahuje nulu (znamená to, že ani v základním souboru nemůžeme předpokládat, že by studovaný rozdíl mezi nulovou a alternativní hypotézou neexistoval). Za reálně (prakticky) důležitý ten efekt, jehož celý IS převyšuje hranici prakticky důležité velikosti efektu (zde čárkovaná čára určeno rozhodnutím výzkumníka na základě předchozích zkušeností, údajů z literatury apod. pro konkrétní řešený problém) - znamená to, prokázání daného efektu testem jako významného bude mít i praktickou důležitost pro řešení daného problému.
38 STATISTICKÁ vs. REÁLNÁ VÝZNAMNOST Případ 1 - efekt statisticky významný a reálně důležitý (IS neobsahuje nulu a i jeho dolní hranice je vyšší hodnota než stanovená hranice reálného významu). Případ 2 - efekt statisticky významný, ale o jeho reálné významnosti se nedá rozhodnout (IS obsahuje hodnoty vyšší i nižší než stanovená hranice reálného významu v základním souboru tedy může hodnota efektu přesáhnout tuto hranici, ale také nemusí). 38 Případ 3 - efekt statisticky významný, ale reálně nedůležitý (i horní hranice IS je nižší než stanovená hranice reálného významu). Případ 4 - efekt je statisticky nevýznamný (IS obsahuje nulu) a stejně jako u případu 2 nelze jednoznačně rozhodnout o jeho reálné významnosti). Případ 5 - je příkladem efektu statisticky nevýznamného a reálně nedůležitého (IS obsahuje nulu a ani horní hranice IS nedosahuje hranice praktické důležitosti).
39 VÝZNAM STATISTICKÉ VÝZNAMNOSTI A REÁLNÉ DŮLEŽITOSTI VELIKOSTI EFEKTU Z předchozích poznatků plyne, že cílem statistického testu je odhalit (tj. prokázat jako statisticky významný) takový rozdíl mezi nulovou a alternativní hypotézou, který má praktickou důležitost pro určitý řešený problém. Přitom bychom chtěli tohoto cíle dosáhnout při co nejmenším možném počtu měřených hodnot. Tento cíl je možné splnit pomocí tzv. analýzy síly testu. Tato analýza odpovídá na dvě otázky: jakou minimální velikost výběru potřebuji, aby použitý test prokázal jako významnou právě takovou velikost efektu, kterou považuji za prakticky důležitou? pokud mám již naměřená data, nakolik se mohu spolehnout na rozhodnutí testu, tj. jak je výsledek testu spolehlivý? 39 Analýza síly testu vychází z pojmů chyb I. a II. druhu, které budou vysvětleny na následujících snímcích.
40 CHYBY TESTU 40 Při hodnocení výsledku testu musíme mít stále na paměti, že ani test nerozhodně stoprocentně, zcela jistě, protože nemáme úplnou informaci o ZS. Pamatujte tedy, že i každý výsledek statistického testu musíme brát s rezervou, tj. s vědomím, že rozhodnutí doporučené testem může být chybné, což znamená že doporučení testu zamítnout nebo nezamítnout hypotézu nemusí být nutně v souladu s realitou ( test totiž vychází z dat VS a ta mohou být náhodou tak zvláštní, že to vede test k rozhodnutí, které ve skutečnosti v ZS neplatí). Test tedy může doporučit zamítnutí hypotézy, zatímco tato hypotéza v reálu platí nebo naopak může doporučit nezamítnutí hypotézy, která ve skutečnosti neplatí. Naší výhodou je to, že pravděpodobnosti těchto možných chybných rozhodnutí testu si můžeme nastavit a tím určit, nakolik bude náš test spolehlivý, tj. s jakou pravděpodobností mohu jeho doporučení věřit. Zdůrazňuji, že chybou testu se zde rozumí pouze možnost, že test může doporučit rozhodnutí, které je v rozporu s realitou (nikoli tedy chyba způsobená chybným výpočtem nebo numerickou chybou, apod.).
41 CHYBA I. A II. DRUHU, SÍLA TESTU Chyba I. druhu (α) pravděpodobnost, že test zamítne hypotézu, která ve skutečnosti platí. Chyba II. druhu (β) pravděpodobnost, že test NEzamítne hypotézu, která ve skutečnosti NEplatí. Síla testu (1- β) pravděpodobnost, že test správně zamítne hypotézu, která ve skutečnosti neplatí. 41
42 42 CHYBA I. A II. DRUHU
43 CHYBA I. A II. DRUHU Graficky si jednotlivé pravděpodobnosti spojené s chybami testů ukážeme na následujícím obrázku: Předpokládáme, že pracujeme s jednostranným testem (kvůli snazšímu grafickému znázornění) s hypotézami: H 0 : µ 50 oproti H 1 : µ > 50 Pokud platí, data jsou rozdělena podle modrého rozdělení (N(50,5 2 )). Neměřili jsme data výběrového souboru (červené body), jehož rozdělení je znázorněno červeně N(60,5 2 ) to je rozdělení pro případ platnosti H 1. Chyba I. druhu nastane, pokud test chybně zamítne H 0. V tom případě v reálu platí H 0 (tedy modré rozdělení), ale TK vyjde vyšší než KH pravděpodobnost této chyby je tedy plocha pod modrým rozdělením za KH tmavě žlutá čárkovaná plocha. Chyba II. druhu - nastane, pokud test chybně nezamítne H 0. V tom případě v reálu platí H 1 (tedy červené rozdělení), ale TK vyjde menší než KH pravděpodobnost této chyby je tedy plocha pod červeným rozdělením před KH oranžová plocha. 43 Síla testu je vyjádřena pravděpodobností, že test zamítne ve skutečnosti neplatnou hypotézu H 0. Znamená to, že v reálu platí H 1 (červené rozdělení) a test správně zamítne H 0, tedy platí že TK > KH, tedy síla testu je vyjádřena plochou pod červeným rozdělením za KH světle žlutá plocha
44 44 CHYBA I. A II. DRUHU
45 FAKTORY OVLIVŇUJÍCÍ SÍLU TESTU Síla testu závisí na následujících faktorech: odchylka mezi hodnotou testovaného parametru v nulové hypotéze a skutečnou hodnotou parametru velikost efektu variabilita (směrodatné odchylce nebo rozptylu) základního souboru velikost výběrového souboru na hladina významnosti α typ testu 45
46 Vytvořeno na základě animace na FAKTORY OVLIVŇUJÍCÍ SÍLU TESTU Obrázky ukazují vliv velikosti efektu (červené svorky) na sílu testu. Pokud jsou rozdělení reprezentující H 0 a H 1 blízko sebe (velikost efektu je malá), rozdělení se více překrývají a velikost chyby II. druhu (fialová plocha) je větší tedy síla testu (bílá plocha pod fialovou křivkou) menší. Se zvětšující se velikostí efektu se zvětšuje i síla testu. 46
47 FAKTORY OVLIVŇUJÍCÍ SÍLU TESTU Obrázky ukazují vliv změny variability dat na sílu testu. Variabilita dat a síla testu jsou nepřímo úměrné, tedy se zmenšující se variabilitou se zvyšuje síla testu. Rozdělení vlevo má vyšší variabilitu dat (rozdělení jsou širší, roztaženější ) a je vidět výrazně vyšší chyba II. druhu (fialová plocha). Rozdělení vpravo má nižší variabilitu (je štíhlejší ) a chyba II. druhu je menší, čímž se zvyšuje síla testu (bílá plocha pod fialovou křivkou). 47
48 FAKTORY OVLIVŇUJÍCÍ SÍLU TESTU Obrázky ukazují vliv změny velikosti výběru dat (n) na sílu testu. Velikost výběru a síla testu jsou přímo úměrné, tedy se zvětšující se velikostí výběru se zvyšuje síla testu. Rozdělení vlevo má vyšší n (rozdělení jsou štíhlejší, protože s vyšším n souvisí spolehlivější odhad střední hodnoty, prostě máme víc informací o ZS) a chyba II. druhu je menší, čímž se zvyšuje síla testu (bílá plocha pod fialovou křivkou). Rozdělení vpravo má nižší n (je širší ) a je vidět výrazně vyšší chyba II. druhu. 48
49 FAKTORY OVLIVŇUJÍCÍ SÍLU TESTU Obrázek ukazuje vliv změny chyby I. druhu (α) na sílu testu. Změna hodnoty α znamená vlastně změnu kritické hodnoty. Hodnota α a síla testu jsou přímo úměrné, se zvyšující se hodnotou chyby I. druhu se zvyšuje i síla testu (protože klesá chyba II. druhu β). Na obrázku vlevo je α přibližně 0,10 (KH je asi 2,05) a síla testu je asi 79% (1-0,21). Na pravém obrázku je α přibližně 0,05 (KH je asi 2,9) a síla testu je asi 66 % (1-0,34). 49
50 ÚČEL ANALÝZY SÍLY TESTU před provedením pokusu (apriorní analýza) zjišťujeme potřebnou velikost výběr u známe (zadáváme) - chybu I. druhu (alfa) - požadovanou sílu testu (1 - beta) - velikost efektu, kterou potřebujeme detekovat 50 Pokud předpokládáme, že naměřená data budeme vyhodnocovat statistickým testem, měla by samotnému měření předcházet analýza síly testu, která odpoví na otázku: Kolik hodnot musím minimálně naměřit, aby test detekoval jako významnou právě takovou velikost efektu, kterou považuji za prakticky důležitou a přitom zachoval akceptovatelné velikosti chyb I. i II. druhu (a tedy přijatelnou sílu testu)?
51 ÚČEL ANALÝZY SÍLY TESTU po provedení pokusu (aposteriorní analýza) zjišťujeme skutečnou sílu testu známe (zadáváme) - chybu I. druhu (alfa) - velikost výběr u (N) - velikost efektu Po provedení pokusu (měření) je analýza síly testu důležitá především tehdy, pokud nezamítneme H 0. Pokud totiž H 0 zamítneme, víme, že tak činíme nejméně s pravděpodobností 1 α (obvykle 0,95 95% a víme, že max. pravděpodobnost chyby I. druhu tedy že H 0 byla zamítnuta chybně - je α). Pokud ale H 0 nezamítneme, nevíme o velikosti chyby II. druhu tedy že H 0 byla chybně nezamítnuta, přijata nic konkrétního. Měli bychom ji tedy vypočítat a stanovit skutečnou sílu testu tím zjistíme, nakolik je závěr o nezamítnutí H 0 oprávněný. 51 Blokové schéma postupu při provedení experimentu s využitím analýzy síly testu je zde: tu.doc
52 ANALÝZA SÍLY TESTU - PŘÍKLAD V úpravně vody byly sledovány hodnoty obsahu chloru v pitné vodě po zavedení nové čistící metody vody. Dle normy je povolený obsah chloru ve vodě 0,3 mg.l -1. Určete, zda skutečný obsah chloru ve vodě odpovídá normě. Dále potřebujeme zjistit, kolik vzorků je nutné odebrat, aby možná chyba testu, která by způsobila vážné následky, nepřesáhla 5%. Předběžně bylo odebráno 23 vzorků (obsah Cl ve vodě vmg.l -1 ):
53 ANALÝZA SÍLY TESTU - PŘÍKLAD Zadání je typická úloha na jednostranný test, protože nás zajímá pouze překročení normy (pokud bude voda obsahovat méně chlóru, a přitom bude z ostatních hledisek vyhovovat kvalitě pitné vody, bude to jen dobře). Formulace hypotéz bude tedy následující: H 0 : obsah Cl 0,3 mg.l -1 H 1 : obsah Cl > 0,3 mg.l -1 53
54 ANALÝZA SÍLY TESTU - PŘÍKLAD Nyní musíme analyzovat, co by obě chyby testu znamenaly z praktického hlediska. Chyba I. druhu znamená zamítnutí ve skutečnosti platné nulové hypotézy. V tomto případě platí, že pokud je nulová hypotéza platná, je voda z hlediska obsahu chloru v pořádku. Když test chybně tuto hypotézu zamítne, znamenalo by to, že si mylně myslíme, že ve vodě je nepovolený obsah chloru, což by zřejmě znamenalo další úpravy zaváděné čistící metody, další laboratorní zkoušky, apod., Tento závěr by tedy znamenal vyšší náklady vodárny, ale neznamenal by zdravotní ohrožení obyvatel. 54 Pokud by došlo k chybě II. druhu, znamenalo by to, že vodě je vyšší než povolený obsah chloru a přitom test by doporučil nulovou hypotézu o nezávadnosti vody nezamítnout. Zde by zřejmě následky mohly být vážnější, protože zvýšený obsah chloru ve vodě by mohl citlivějším osobám způsobit i zdravotní obtíže, ostatním by přinejmenším vadil např. zvýšený zápach chloru z vody.
55 ANALÝZA SÍLY TESTU - PŘÍKLAD Pokud bychom použili k testování již odebraných 23 vzorků, použili bychom klasický jednovýběrový t-test (porovnání střední hodnoty naměřených dat s konstantou - normou). Testové kritérium se vypočítá podle vzorce kde je c daná konstanta - hodnota normy, S je bodový odhad směrodatné odchylky, n je velikost výběru. Statistická analýza potvrdila, že výběr pochází z normálního rozdělení a jeho statistické charakteristiky jsou: 55
56 ANALÝZA SÍLY TESTU - PŘÍKLAD Testové kritérium vyjde a kritická hodnota (kvantil t-rozdělení pro α = 0,05 a 22 stupňů volnosti) je (např. v Excelu =TINV(0,1;22)). Hodnota 0,1 zde musí být uvedena proto, že se jedná o jednostranný test, a Excel uvádí automaticky hodnoty pro oboustranné testy, tedy musíme použít dvojnásobnou hodnotu α. Vzhledem k tomu, že platí TK < KH, test neumožnil zamítnout nulovou hypotézu, tedy měli bychom se přiklonit k hypotéze, že voda je v pořádku. Jak již bylo uvedeno, v případě nezamítnutí nulové hypotézy je velmi důležité zjistit velikost chyby II. druhu a tím i spolehlivost závěru testu. Výpočet síly testu a potřebnou velikost výběru vypočítáme pomocí jednoduché tabulky v Excelu, kde jsou také uvedeny všechny potřebné vzorce zde: pro příklad v prezentaci použijte list velikost výběru - 1 V test 56 Různé řešené příklady na velikost výběru, minimální detekovatelný rozdíl hypotéz (velikost efektu) a sílu testu, které si můžete přepočítat pomocí excelovského souboru uvedeného výše, jsou k prostudování zde:
57 ANALÝZA SÍLY TESTU - PŘÍKLAD Vzhledem k tomu, nulová hypotéza nebyla zamítnuta, je prvním krokem je výpočet skutečné síly testu tedy aposteriorní analýza síly testu Směrodatnou odchylku převezmeme z výsledků výběru, velikost efektu je rozdíl mezi normou (0,3) a vypočítaným výběrovým průměrem (0,363), tedy 0,063. Chybu I. druhu máme nastavenou na obvyklé hodnotě 0,05, vzhledem k jednostrannému testu a konstrukci t-rozdělení v Excelu nastavíme hodnotu α na 0,10 (zadáváme dvojnásobek požadované hodnoty) 57 Výsledná síla testu je pouze 0,41, tj. asi 41 %, tedy chyba II. druhu je asi 59 %.
58 ANALÝZA SÍLY TESTU - PŘÍKLAD Jinými slovy, test udělá chybu II. druhu při dané velikosti výběru téměř v 60% (tj. nesprávně nezamítne nulovou hypotézu o přijatelném obsahu chloru ve vodě). S takovým testem nemůžeme být jistě spokojeni. Při stanovených parametrech testu by test téměř vždy ohlásil bezproblémový obsah chloru, zatímco ve skutečnosti by to nebylo pravda. Musíme tedy určit takovou velikost výběru, která by zabezpečila rozhodnutí testu s dostatečnou jistotou. V našem případě nás zajímá hlavně chyba II. druhu (zdůvodnění viz výše), kterou nastavíme na 5%, tj. sílu testu na 95%. Dále nastavíme prakticky důležitou velikost efektu na 0,07 mg.l -1. Tím předpokládáme (např. na základě předběžných studií, údajů z literatury, apod.), že z hlediska praktických důsledků (např. možného poškození zdraví odběratelů vody) je důležitý rozdíl 0,07 mg.l -1. Na základě takto stanovené velikosti výběru test jako statisticky významné prokáže zvýšení obsahu chloru ve vodě na 0,37 mg.l -1 a více. 58 Chceme tedy stanovit takovou velikost výběru, která zabezpečí, že tento rozdíl bude testem označen jako statisticky významný (tedy existující i v základním souboru) za předpokladu dodržení velikosti chyb I i II. druhu na hodnotě 0,05. Tytom podmínky jsou poměrně velmi přísné, předpokládají udržení úrovně síly testu na 95 %, přičemž za obecně akceptovatelnou sílu testu (kdy následky chyby II. druhu nepředstavují hlavní riziko) se považuje asi 80%).
59 ANALÝZA SÍLY TESTU - PŘÍKLAD Vzhledem k tomu, že výpočet velikosti výběru (n) je závislý na hodnotách t-rozdělení (které zase závisí na počtu stupňů volnosti, tedy n-1), výpočet probíhá iterativně, tj. v několika kolech a zastaví se tehdy, až se výsledky ve dvou za sebou následujících výpočtech nezmění. Pokud zadáme výchozí hodnoty, tj. většinu ponecháme stejných, jen velikost efektu upravíme na 0,07, chyba I. druhu zůstane na 0,1, chyba II. druhu na 0,05), získáme v prvním kroku tyto výsledky: Vycházíme z původní velikosti výběru (23 hodnot), nově vypočítaná velikost výběru je 99 a touto hodnotou zaměníme původní velikost výběru - tj. číslo 23 přepíšeme hodnotou 99 a kurzorem klepneme do jakékoliv prázdné buňky tabulky. Tím se provede další kolo výpočtu 59
60 ANALÝZA SÍLY TESTU - PŘÍKLAD Výsledkem je velikost výběru 92. Znovu tímto číslem zaměníme hodnotu 99 a spustíme další kolo výpočtu. Vidíme, že výsledek se již nezměnil vypočítaná velikost výběru je tedy 92 měření. 60
61 ANALÝZA SÍLY TESTU - PŘÍKLAD Tato velikost výběru je značně vysoká prakticky čtyřnásobná oproti původnímu počtu měření to by bylo zřejmě nepřijatelné z časového i finančního hlediska. Proto je nutné se pokusit přijatelným způsobem změnit podmínky testu (tj. tak, aby test měl stále akceptovatelnou spolehlivost). Vzhledem k tomu, že jsme si zdůvodnili, že chyba I. druhu nemá takovou závažnost, můžeme její velikost zvýšit na 0.15 (tj. připouštíme, že v 15% případů je možné, že test nesprávně zamítne nulovou hypotézu a bude nám mylně vnucovat, že voda obsahuje příliš vysoký obsah chloru). Přepíšeme hodnotu α na 0.15 (v našem případě na 0,30, protože musíme vzhledem k jednostrannému testu zadávat dvojnásobek chyby I. druhu) a vyjde potřebná velikost výběru. Přes 2 iterace dojdeme k výsledku 62 měření. 61 Pokud by i tento výsledek byl příliš vysoký, museli bychom sáhnout i na chybu II. druhu. Zkusíme ji nastavit na 0,10 (tedy sílu testu snížíme na 90 %), což je stále velmi přijatelná hodnota, která zaručuje, pouze v jednom z deseti případů bude nesprávně přijata hypotéza o správném obsahu chloru ve vodě. V tomto případě získáme jako potřebnou velikost výběru 46 měření. Tato řešení z Excelu jsou na následujícím snímku.
62 62 ANALÝZA SÍLY TESTU - PŘÍKLAD
63 ANALÝZA SÍLY TESTU - PŘÍKLAD pokud budeme tento výsledek považovat za přijatelný, můžeme jej interpretovat takto: pokud provedeme 46 měření obsahu chloru ve vodě, tato velikost výběru zaručí, že test detekuje hodnotu 0,07 mg-l -1 jako statisticky významný rozdíl střední hodnoty měřených dat od normy při zachování chyby I. druhu 0,15 a síle testu 90 %. Připouštíme tedy 15 % riziko, že test nesprávně zamítne nulovou hypotézu a 10 % riziko, že test nesprávně přijme nulovou hypotézu. 63
64 TYPY TESTŮ Parametrické testy: testují parametr základního souboru (např. střední hodnotu, rozptyl, ), mají vyšší sílu testu (tedy schopnost správně zamítnout ve skutečnosti neplatnou nulovou hypotézu) než testy neparametrické, jsou tedy přísnější na data, vyžadují splnění určitých podmínek (obvykle normální rozdělení, nepřítomnost extrémů, dostatečný rozsah výběru) pokud jsou splněny podmínky, používají se prioritně 64
65 TYPY TESTŮ 65 Neparametrické testy: testujeme jinou hypotézu o rozdělení základního souboru než je hypotéza o jeho parametru mají nižší sílu testu (tedy schopnost správně zamítnout ve skutečnosti neplatnou nulovou hypotézu) než testy parametrické, mají vyšší tendenci nezamítnout nulovou hypotézu (v hraničních případech kdy je testové kritérium velmi blízké kritické hodnotě mohou vést k nezamítnutí nulové hypotézy, zatímco parametrický test pro stejná data nulovou hypotézu zamítne) pro stejnou sílu testu je nutná větší velikost výběru než u parametrických testů širší použití než parametrické (lze testovat většinou i ZS hodnot slovních znaků, především ordinálních, tj. rozlišujících dle relace (např. pořadové testy), některé dokonce i pro hodnoty nominálních znaků, tj. zařazujících jen do skupin (např. znaménkový test) nezávislé na rozdělení a na přítomnosti extrémních hodnot, vhodné pro malé výběry všechny obvyklé parametrické testy mají své neparametrické obdoby
66 TYPY TESTŮ Pro jeden výběr používá se pro porovnávání parametru odhadnutého z měřených dat (např. střední hodnotu, rozptyl, ) P se zadanou konstantou (např. předem známou hodnotou, teoretickou hodnotou, normou, ) K 66 Pro dva výběry - používá se obvykle pro porovnání parametrů odhadnutých ze dvou výběrů, nejobvyklejší úloha je testování shody těchto parametrů (např. střední tloušťky dvou porostů se rovnají) dvouvýběrový test pro nezávislé výběry (oba výběry, ze kterých se odhadovaly parametry, jsou vzájemně nezávislé, např. dva rozdílné porosty), - zvláštním případem je porovnání dvou měření prováděných na stejných jedincích (např. dvěma metodami, dvěma přístroji, před a po provedení určitého zásahu, ve dvou časových okamžicích, obvykle se opět testuje shoda měření na určitém jedinci) dvouvýběrový test pro závislé výběry (párový test) měřené hodnoty už nejsou nezávislé, ale závisí na měřeném jedinci.
67 TYPY TESTŮ Pro více výběrů totéž jako pro dva výběry, ale testujeme simultánní hypotézu, že se zároveň rovnají střední hodnoty odhadnuté z několika (tří a více) výběrů. Používá se speciální metodika umožňující testování simultánní hypotézy blíže viz analýza rozptylu (ANOVA). 67
68 TYPY TESTŮ STATISTICKÉ TESTY PARAMETRICKÉ mají vyšší sílu testu vyžadují splnění určitých podmínek NEPARAMETRICKÉ nižší síla testu vyžadují pouze spojité rozdělení vhodné při velmi malých výběrech 68 PRO JEDEN VÝBĚR H0: P = K PRO DVA VÝBĚRY H0: P1 = P2 PRO VÍCE VÝBĚRŮ H0: P1 = P2 =...=Pk PRO JEDEN VÝBĚR PRO DVA VÝBĚRY PRO VÍCE VÝBĚRŮ
69 TYPY TESTŮ Podrobněji o jednotlivých testech pro střední hodnoty, rozptyly, četnosti apod. pro 1 a 2 výběry viz teorie text I, str dále Návody k použití statistických programů (provedení v příslušném programu a interpretace výsledků) Excel uv_test_1_vyber.exe uv_test_2_vybery.exe 69 Statistica Mann_Whitneyuv_Utest-neparam.exe
TESTOVÁNÍ STATISTICKÝCH HYPOTÉZ ZÁKLADNÍ POJMY
 TESTOVÁNÍ STATISTICKÝCH HYPOTÉZ ZÁKLADNÍ POJMY Statistická hypotéza je určitá domněnka (předpoklad) o vlastnostech ZÁKLADNÍHO SOUBORU. Test statistické hypotézy je pravidlo (kritérium), které na základě
TESTOVÁNÍ STATISTICKÝCH HYPOTÉZ ZÁKLADNÍ POJMY Statistická hypotéza je určitá domněnka (předpoklad) o vlastnostech ZÁKLADNÍHO SOUBORU. Test statistické hypotézy je pravidlo (kritérium), které na základě
676 + 4 + 100 + 196 + 0 + 484 + 196 + 324 + 64 + 324 = = 2368
 Příklad 1 Je třeba prověřit, zda lze na 5% hladině významnosti pokládat za prokázanou hypotézu, že střední doba výroby výlisku je 30 sekund. Přitom 10 náhodně vybraných výlisků bylo vyráběno celkem 540
Příklad 1 Je třeba prověřit, zda lze na 5% hladině významnosti pokládat za prokázanou hypotézu, že střední doba výroby výlisku je 30 sekund. Přitom 10 náhodně vybraných výlisků bylo vyráběno celkem 540
4ST201 STATISTIKA CVIČENÍ Č. 7
 4ST201 STATISTIKA CVIČENÍ Č. 7 testování hypotéz parametrické testy test hypotézy o střední hodnotě test hypotézy o relativní četnosti test o shodě středních hodnot testování hypotéz v MS Excel neparametrické
4ST201 STATISTIKA CVIČENÍ Č. 7 testování hypotéz parametrické testy test hypotézy o střední hodnotě test hypotézy o relativní četnosti test o shodě středních hodnot testování hypotéz v MS Excel neparametrické
Testování statistických hypotéz
 Testování statistických hypotéz 1 Testování statistických hypotéz 1 Statistická hypotéza a její test V praxi jsme nuceni rozhodnout, zda nějaké tvrzeni o parametrech náhodných veličin nebo o veličině samotné
Testování statistických hypotéz 1 Testování statistických hypotéz 1 Statistická hypotéza a její test V praxi jsme nuceni rozhodnout, zda nějaké tvrzeni o parametrech náhodných veličin nebo o veličině samotné
Určujeme neznámé hodnoty parametru základního souboru. Pomocí výběrové charakteristiky vypočtené z náhodného výběru.
 1 Statistické odhady Určujeme neznámé hodnoty parametru základního souboru. Pomocí výběrové charakteristiky vypočtené z náhodného výběru. Odhad lze provést jako: Bodový odhad o Jedna číselná hodnota Intervalový
1 Statistické odhady Určujeme neznámé hodnoty parametru základního souboru. Pomocí výběrové charakteristiky vypočtené z náhodného výběru. Odhad lze provést jako: Bodový odhad o Jedna číselná hodnota Intervalový
ROZDĚLENÍ NÁHODNÝCH VELIČIN
 ROZDĚLENÍ NÁHODNÝCH VELIČIN 1 Vytvořeno s podporou projektu Průřezová inovace studijních programů Lesnické a dřevařské fakulty MENDELU v Brně (LDF) s ohledem na discipliny společného základu (reg. č. CZ.1.07/2.2.00/28.0021)
ROZDĚLENÍ NÁHODNÝCH VELIČIN 1 Vytvořeno s podporou projektu Průřezová inovace studijních programů Lesnické a dřevařské fakulty MENDELU v Brně (LDF) s ohledem na discipliny společného základu (reg. č. CZ.1.07/2.2.00/28.0021)
Testování hypotéz. 1. vymezení základních pojmů 2. testování hypotéz o rozdílu průměrů 3. jednovýběrový t-test
 Testování hypotéz 1. vymezení základních pojmů 2. testování hypotéz o rozdílu průměrů 3. jednovýběrový t-test Testování hypotéz proces, kterým rozhodujeme, zda přijmeme nebo zamítneme nulovou hypotézu
Testování hypotéz 1. vymezení základních pojmů 2. testování hypotéz o rozdílu průměrů 3. jednovýběrový t-test Testování hypotéz proces, kterým rozhodujeme, zda přijmeme nebo zamítneme nulovou hypotézu
Ing. Michael Rost, Ph.D.
 Úvod do testování hypotéz, jednovýběrový t-test Ing. Michael Rost, Ph.D. Testovaná hypotéza Pokud nás zajímá zda platí, či neplatí tvrzení o určitém parametru, např. o parametru Θ, pak takovéto tvrzení
Úvod do testování hypotéz, jednovýběrový t-test Ing. Michael Rost, Ph.D. Testovaná hypotéza Pokud nás zajímá zda platí, či neplatí tvrzení o určitém parametru, např. o parametru Θ, pak takovéto tvrzení
Rozhodnutí / Skutečnost platí neplatí Nezamítáme správně chyba 2. druhu Zamítáme chyba 1. druhu správně
 Testování hypotéz Nechť,, je náhodný výběr z nějakého rozdělení s neznámými parametry. Máme dvě navzájem si odporující hypotézy o parametrech daného rozdělení: Nulová hypotéza parametry (případně jediný
Testování hypotéz Nechť,, je náhodný výběr z nějakého rozdělení s neznámými parametry. Máme dvě navzájem si odporující hypotézy o parametrech daného rozdělení: Nulová hypotéza parametry (případně jediný
STATISTICKÉ TESTY VÝZNAMNOSTI
 STATISTICKÉ TESTY VÝZNAMNOSTI jsou statistické postupy, pomocí nichž ověřujeme, zda mezi proměnnými existuje vztah (závislost, rozdíl). Pokud je výsledek šetření statisticky významný (signifikantní), znamená
STATISTICKÉ TESTY VÝZNAMNOSTI jsou statistické postupy, pomocí nichž ověřujeme, zda mezi proměnnými existuje vztah (závislost, rozdíl). Pokud je výsledek šetření statisticky významný (signifikantní), znamená
Testování statistických hypotéz
 Testování statistických hypotéz Na základě náhodného výběru, který je reprezentativním vzorkem základního souboru (který přesně neznáme, k němuž se ale daná statistická hypotéza váže), potřebujeme ověřit,
Testování statistických hypotéz Na základě náhodného výběru, který je reprezentativním vzorkem základního souboru (který přesně neznáme, k němuž se ale daná statistická hypotéza váže), potřebujeme ověřit,
TESTOVÁNÍ HYPOTÉZ STATISTICKÁ HYPOTÉZA Statistické testy Testovací kritérium = B B > B < B B - B - B < 0 - B > 0 oboustranný test = B > B
 TESTOVÁNÍ HYPOTÉZ Od statistického šetření neočekáváme pouze elementární informace o velikosti některých statistických ukazatelů. Používáme je i k ověřování našich očekávání o výsledcích nějakého procesu,
TESTOVÁNÍ HYPOTÉZ Od statistického šetření neočekáváme pouze elementární informace o velikosti některých statistických ukazatelů. Používáme je i k ověřování našich očekávání o výsledcích nějakého procesu,
STATISTICKÉ TESTY VÝZNAMNOSTI
 STATISTICKÉ TESTY VÝZNAMNOSTI jsou statistické postupy, pomocí nichž ověřujeme, zda mezi proměnnými existuje vztah (závislost, rozdíl). Pokud je výsledek šetření statisticky významný (signifikantní), znamená
STATISTICKÉ TESTY VÝZNAMNOSTI jsou statistické postupy, pomocí nichž ověřujeme, zda mezi proměnnými existuje vztah (závislost, rozdíl). Pokud je výsledek šetření statisticky významný (signifikantní), znamená
Testování statistických hypotéz
 Testování statistických hypotéz Michal Fusek Ústav matematiky FEKT VUT, fusekmi@feec.vutbr.cz 11. přednáška z ESMAT Michal Fusek (fusekmi@feec.vutbr.cz) 1 / 27 Obsah 1 Testování statistických hypotéz 2
Testování statistických hypotéz Michal Fusek Ústav matematiky FEKT VUT, fusekmi@feec.vutbr.cz 11. přednáška z ESMAT Michal Fusek (fusekmi@feec.vutbr.cz) 1 / 27 Obsah 1 Testování statistických hypotéz 2
JEDNOVÝBĚROVÉ TESTY. Komentované řešení pomocí programu Statistica
 JEDNOVÝBĚROVÉ TESTY Komentované řešení pomocí programu Statistica Vstupní data Data umístěná v excelovském souboru překopírujeme do tabulky ve Statistice a pojmenujeme proměnné, viz prezentace k tématu
JEDNOVÝBĚROVÉ TESTY Komentované řešení pomocí programu Statistica Vstupní data Data umístěná v excelovském souboru překopírujeme do tabulky ve Statistice a pojmenujeme proměnné, viz prezentace k tématu
Cvičení ze statistiky - 8. Filip Děchtěrenko
 Cvičení ze statistiky - 8 Filip Děchtěrenko Minule bylo.. Dobrali jsme normální rozdělení Tyhle termíny by měly být známé: Centrální limitní věta Laplaceho věta (+ korekce na spojitost) Konfidenční intervaly
Cvičení ze statistiky - 8 Filip Děchtěrenko Minule bylo.. Dobrali jsme normální rozdělení Tyhle termíny by měly být známé: Centrální limitní věta Laplaceho věta (+ korekce na spojitost) Konfidenční intervaly
Testování hypotéz. 1 Jednovýběrové testy. 90/2 odhad času
 Testování hypotéz 1 Jednovýběrové testy 90/ odhad času V podmínkách naprostého odloučení má voák prokázat schopnost orientace v čase. Úkolem voáka e provést odhad časového intervalu 1 hodiny bez hodinek
Testování hypotéz 1 Jednovýběrové testy 90/ odhad času V podmínkách naprostého odloučení má voák prokázat schopnost orientace v čase. Úkolem voáka e provést odhad časového intervalu 1 hodiny bez hodinek
2 ) 4, Φ 1 (1 0,005)
 4, Φ 1 (1 0,005)") Příklad 1 Ze zásilky velkého rozsahu byl náhodně vybrán soubor obsahující 1000 kusů. V tomto souboru bylo zjištěno 26 kusů nekvalitních. Rozhodněte, zda je možné s 99% jistotou tvrdit, že zásilka obsahuje
Příklad 1 Ze zásilky velkého rozsahu byl náhodně vybrán soubor obsahující 1000 kusů. V tomto souboru bylo zjištěno 26 kusů nekvalitních. Rozhodněte, zda je možné s 99% jistotou tvrdit, že zásilka obsahuje
Jednostranné intervaly spolehlivosti
 Jednostranné intervaly spolehlivosti hledáme jen jednu z obou mezí Princip: dle zadání úlohy hledáme jen dolní či jen horní mez podle oboustranného vzorce s tou změnou, že výraz 1-α/2 ve vzorci nahradíme
Jednostranné intervaly spolehlivosti hledáme jen jednu z obou mezí Princip: dle zadání úlohy hledáme jen dolní či jen horní mez podle oboustranného vzorce s tou změnou, že výraz 1-α/2 ve vzorci nahradíme
Testování hypotéz. 4. přednáška 6. 3. 2010
 Testování hypotéz 4. přednáška 6. 3. 2010 Základní pojmy Statistická hypotéza Je tvrzení o vlastnostech základního souboru, o jehož pravdivosti se chceme přesvědčit. Předem nevíme, zda je pravdivé nebo
Testování hypotéz 4. přednáška 6. 3. 2010 Základní pojmy Statistická hypotéza Je tvrzení o vlastnostech základního souboru, o jehož pravdivosti se chceme přesvědčit. Předem nevíme, zda je pravdivé nebo
Intervalový odhad. Interval spolehlivosti = intervalový odhad nějakého parametru s danou pravděpodobností = konfidenční interval pro daný parametr
 StatSoft Intervalový odhad Dnes se budeme zabývat neodmyslitelnou součástí statistiky a to intervaly v nejrůznějších podobách. Toto téma je také úzce spojeno s tématem testování hypotéz, a tedy plynule
StatSoft Intervalový odhad Dnes se budeme zabývat neodmyslitelnou součástí statistiky a to intervaly v nejrůznějších podobách. Toto téma je také úzce spojeno s tématem testování hypotéz, a tedy plynule
Normální (Gaussovo) rozdělení
 rozdělení") Normální (Gaussovo) rozdělení f x = 1 2 exp x 2 2 2 f(x) je funkce hustoty pravděpodobnosti, symetrická vůči poloze maxima x = μ μ střední hodnota σ směrodatná odchylka (tzv. pološířka křivky mezi inflexními
Normální (Gaussovo) rozdělení f x = 1 2 exp x 2 2 2 f(x) je funkce hustoty pravděpodobnosti, symetrická vůči poloze maxima x = μ μ střední hodnota σ směrodatná odchylka (tzv. pološířka křivky mezi inflexními
Normální (Gaussovo) rozdělení
 rozdělení") Normální (Gaussovo) rozdělení Normální (Gaussovo) rozdělení popisuje vlastnosti náhodné spojité veličiny, která vzniká složením různých náhodných vlivů, které jsou navzájem nezávislé, kterých je velký
Normální (Gaussovo) rozdělení Normální (Gaussovo) rozdělení popisuje vlastnosti náhodné spojité veličiny, která vzniká složením různých náhodných vlivů, které jsou navzájem nezávislé, kterých je velký
Testování statistických hypotéz. Ing. Michal Dorda, Ph.D.
 Testování statistických hypotéz Ing. Michal Dorda, Ph.D. Testování normality Př. : Při simulaci provozu na křižovatce byla získána data o mezerách mezi přijíždějícími vozidly v [s]. Otestujte na hladině
Testování statistických hypotéz Ing. Michal Dorda, Ph.D. Testování normality Př. : Při simulaci provozu na křižovatce byla získána data o mezerách mezi přijíždějícími vozidly v [s]. Otestujte na hladině
Cvičení ze statistiky - 9. Filip Děchtěrenko
 Cvičení ze statistiky - 9 Filip Děchtěrenko Minule bylo.. Dobrali jsme normální rozdělení Tyhle termíny by měly být známé: Inferenční statistika Konfidenční intervaly Z-test Postup při testování hypotéz
Cvičení ze statistiky - 9 Filip Děchtěrenko Minule bylo.. Dobrali jsme normální rozdělení Tyhle termíny by měly být známé: Inferenční statistika Konfidenční intervaly Z-test Postup při testování hypotéz
Testování hypotéz. Analýza dat z dotazníkových šetření. Kuranova Pavlina
 Testování hypotéz Analýza dat z dotazníkových šetření Kuranova Pavlina Statistická hypotéza Možné cíle výzkumu Srovnání účinnosti různých metod Srovnání výsledků různých skupin Tzn. prokázání rozdílů mezi
Testování hypotéz Analýza dat z dotazníkových šetření Kuranova Pavlina Statistická hypotéza Možné cíle výzkumu Srovnání účinnosti různých metod Srovnání výsledků různých skupin Tzn. prokázání rozdílů mezi
PRAVDĚPODOBNOST A STATISTIKA
 PRAVDĚPODOBNOST A STATISTIKA Testování hypotéz Nechť X je náhodná proměnná, která má distribuční funkci F(x, ϑ). Předpokládejme, že známe tvar distribuční funkce (víme jaké má rozdělení) a neznáme parametr
PRAVDĚPODOBNOST A STATISTIKA Testování hypotéz Nechť X je náhodná proměnná, která má distribuční funkci F(x, ϑ). Předpokládejme, že známe tvar distribuční funkce (víme jaké má rozdělení) a neznáme parametr
STATISTICKÉ HYPOTÉZY
 STATISTICKÉ HYPOTÉZY ZÁKLADNÍ POJMY Bodové/intervalové odhady Maruška řešila hodnoty parametrů (průměr, rozptyl atd.) Zde bude Maruška dělat hypotézy (předpoklady) ohledně parametrů Z.S. Výsledek nebude
STATISTICKÉ HYPOTÉZY ZÁKLADNÍ POJMY Bodové/intervalové odhady Maruška řešila hodnoty parametrů (průměr, rozptyl atd.) Zde bude Maruška dělat hypotézy (předpoklady) ohledně parametrů Z.S. Výsledek nebude
STATISTICKÉ CHARAKTERISTIKY
 STATISTICKÉ CHARAKTERISTIKY 1 Vytvořeno s podporou projektu Průřezová inovace studijních programů Lesnické a dřevařské fakulty MENDELU v Brně (LDF) s ohledem na discipliny společného základu (reg. č. CZ.1.07/2.2.00/28.0021)
STATISTICKÉ CHARAKTERISTIKY 1 Vytvořeno s podporou projektu Průřezová inovace studijních programů Lesnické a dřevařské fakulty MENDELU v Brně (LDF) s ohledem na discipliny společného základu (reg. č. CZ.1.07/2.2.00/28.0021)
Testování statistických hypotéz. Ing. Michal Dorda, Ph.D. 1
 Testování statistických hypotéz Ing. Michal Dorda, Ph.D. 1 Úvodní poznámky Statistickou hypotézou rozumíme hypotézu o populaci (základním souboru) např.: Střední hodnota základního souboru je rovna 100.
Testování statistických hypotéz Ing. Michal Dorda, Ph.D. 1 Úvodní poznámky Statistickou hypotézou rozumíme hypotézu o populaci (základním souboru) např.: Střední hodnota základního souboru je rovna 100.
Testování hypotéz testy o tvaru rozdělení. Jiří Neubauer. Katedra ekonometrie, FVL, UO Brno kancelář 69a, tel
 Katedra ekonometrie, FVL, UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Statistickou hypotézou se rozumí určité tvrzení o parametrech rozdělení zkoumané náhodné veličiny (µ, σ 2, π,
Katedra ekonometrie, FVL, UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Statistickou hypotézou se rozumí určité tvrzení o parametrech rozdělení zkoumané náhodné veličiny (µ, σ 2, π,
Stručný úvod do testování statistických hypotéz
 Stručný úvod do testování statistických hypotéz 1. Formulujeme hypotézu (předpokládáme, že pozorovaný jev je pouze náhodný). 2. Zvolíme hladinu významnosti testu a, tj. riziko, s nímž jsme ochotni se smířit.
Stručný úvod do testování statistických hypotéz 1. Formulujeme hypotézu (předpokládáme, že pozorovaný jev je pouze náhodný). 2. Zvolíme hladinu významnosti testu a, tj. riziko, s nímž jsme ochotni se smířit.
5 Parametrické testy hypotéz
 5 Parametrické testy hypotéz 5.1 Pojem parametrického testu (Skripta str. 95-96) Na základě výběru srovnáváme dvě tvrzení o hodnotě určitého parametru θ rozdělení f(x, θ). První tvrzení (které většinou
5 Parametrické testy hypotéz 5.1 Pojem parametrického testu (Skripta str. 95-96) Na základě výběru srovnáváme dvě tvrzení o hodnotě určitého parametru θ rozdělení f(x, θ). První tvrzení (které většinou
Testy statistických hypotéz
 Testy statistických hypotéz Statistická hypotéza je jakýkoliv předpoklad o rozdělení pravděpodobnosti jedné nebo několika náhodných veličin. Na základě náhodného výběru, který je reprezentativním vzorkem
Testy statistických hypotéz Statistická hypotéza je jakýkoliv předpoklad o rozdělení pravděpodobnosti jedné nebo několika náhodných veličin. Na základě náhodného výběru, který je reprezentativním vzorkem
PRAVDĚPODOBNOST A STATISTIKA. Neparametrické testy hypotéz čast 1
 PRAVDĚPODOBNOST A STATISTIKA Neparametrické testy hypotéz čast 1 Neparametrické testy hypotéz - úvod Neparametrické testy statistických hypotéz se používají v případech, kdy neznáme rozdělení pozorované
PRAVDĚPODOBNOST A STATISTIKA Neparametrické testy hypotéz čast 1 Neparametrické testy hypotéz - úvod Neparametrické testy statistických hypotéz se používají v případech, kdy neznáme rozdělení pozorované
Lineární regrese. Komentované řešení pomocí MS Excel
 Lineární regrese Komentované řešení pomocí MS Excel Vstupní data Tabulka se vstupními daty je umístěna v oblasti A1:B11 (viz. obrázek) na listu cela data Postup Základní výpočty - regrese Výpočet základních
Lineární regrese Komentované řešení pomocí MS Excel Vstupní data Tabulka se vstupními daty je umístěna v oblasti A1:B11 (viz. obrázek) na listu cela data Postup Základní výpočty - regrese Výpočet základních
Zápočtová práce STATISTIKA I
 Zápočtová práce STATISTIKA I Obsah: - úvodní stránka - charakteristika dat (původ dat, důvod zpracování,...) - výpis naměřených hodnot (v tabulce) - zpracování dat (buď bodové nebo intervalové, podle charakteru
Zápočtová práce STATISTIKA I Obsah: - úvodní stránka - charakteristika dat (původ dat, důvod zpracování,...) - výpis naměřených hodnot (v tabulce) - zpracování dat (buď bodové nebo intervalové, podle charakteru
Jednovýběrové testy. Komentované řešení pomocí MS Excel
 Jednovýběrové testy Komentované řešení pomocí MS Excel Vstupní data V dalším budeme předpokládat, že tabulka se vstupními daty je umístěna v oblasti A1:C23 (viz. obrázek) Základní statistiky vložíme vzorce
Jednovýběrové testy Komentované řešení pomocí MS Excel Vstupní data V dalším budeme předpokládat, že tabulka se vstupními daty je umístěna v oblasti A1:C23 (viz. obrázek) Základní statistiky vložíme vzorce
Testování hypotéz Biolog Statistik: Matematik: Informatik:
 Testování hypotéz Biolog, Statistik, Matematik a Informatik na safari. Zastaví džíp a pozorují dalekohledem. Biolog "Podívejte se! Stádo zeber! A mezi nimi bílá zebra! To je fantastické! " "Existují bílé
Testování hypotéz Biolog, Statistik, Matematik a Informatik na safari. Zastaví džíp a pozorují dalekohledem. Biolog "Podívejte se! Stádo zeber! A mezi nimi bílá zebra! To je fantastické! " "Existují bílé
Charakteristika datového souboru
 Zápočtová práce z předmětu Statistika Vypracoval: 10. 11. 2014 Charakteristika datového souboru Zadání: Při kontrole dodržování hygienických norem v kuchyni se prováděl odběr vzduchu a pomocí filtru Pallflex
Zápočtová práce z předmětu Statistika Vypracoval: 10. 11. 2014 Charakteristika datového souboru Zadání: Při kontrole dodržování hygienických norem v kuchyni se prováděl odběr vzduchu a pomocí filtru Pallflex
DVOUVÝBĚROVÉ A PÁROVÉ TESTY Komentované řešení pomocí programu Statistica
 DVOUVÝBĚROVÉ A PÁROVÉ TESTY Komentované řešení pomocí programu Statistica Úloha A) koncentrace glukózy v krvi V této části posoudíme pomocí párového testu, zda nový lék prokazatelně snižuje koncentraci
DVOUVÝBĚROVÉ A PÁROVÉ TESTY Komentované řešení pomocí programu Statistica Úloha A) koncentrace glukózy v krvi V této části posoudíme pomocí párového testu, zda nový lék prokazatelně snižuje koncentraci
Testování hypotéz. Testování hypotéz o rozdílu průměrů t-test pro nezávislé výběry t-test pro závislé výběry
 Testování hypotéz Testování hypotéz o rozdílu průměrů t-test pro nezávislé výběry t-test pro závislé výběry Testování hypotéz Obecný postup 1. Určení statistické hypotézy 2. Určení hladiny chyby 3. Výpočet
Testování hypotéz Testování hypotéz o rozdílu průměrů t-test pro nezávislé výběry t-test pro závislé výběry Testování hypotéz Obecný postup 1. Určení statistické hypotézy 2. Určení hladiny chyby 3. Výpočet
Porovnání dvou výběrů
 Porovnání dvou výběrů Menu: QCExpert Porovnání dvou výběrů Tento modul je určen pro podrobnou analýzu dvou datových souborů (výběrů). Modul poskytuje dva postupy analýzy: porovnání dvou nezávislých výběrů
Porovnání dvou výběrů Menu: QCExpert Porovnání dvou výběrů Tento modul je určen pro podrobnou analýzu dvou datových souborů (výběrů). Modul poskytuje dva postupy analýzy: porovnání dvou nezávislých výběrů
Příklad 1. Korelační pole. Řešení 1 ŘEŠENÉ PŘÍKLADY Z MV2 ČÁST 13
 Příklad 1 Máme k dispozici výsledky prvního a druhého testu deseti sportovců. Na hladině významnosti 0,05 prověřte, zda jsou výsledky testů kladně korelované. 1.test : 7, 8, 10, 4, 14, 9, 6, 2, 13, 5 2.test
Příklad 1 Máme k dispozici výsledky prvního a druhého testu deseti sportovců. Na hladině významnosti 0,05 prověřte, zda jsou výsledky testů kladně korelované. 1.test : 7, 8, 10, 4, 14, 9, 6, 2, 13, 5 2.test
t-test, Studentův párový test Ing. Michael Rost, Ph.D.
 Testování hypotéz: dvouvýběrový t-test, Studentův párový test Ing. Michael Rost, Ph.D. Úvod do problému... Již známe jednovýběrový t-test, při kterém jsme měli k dispozici pouze jeden výběr. Můžeme se
Testování hypotéz: dvouvýběrový t-test, Studentův párový test Ing. Michael Rost, Ph.D. Úvod do problému... Již známe jednovýběrový t-test, při kterém jsme měli k dispozici pouze jeden výběr. Můžeme se
Náhodné veličiny, náhodné chyby
 Náhodné veličiny, náhodné chyby Máme náhodnou veličinu X, jejíž vlastnosti zkoumáme. Pokud známe její rozložení (např. z nějaké dřívější studie) nebo alespoň předpokládáme znalost rozložení, můžeme ji
Náhodné veličiny, náhodné chyby Máme náhodnou veličinu X, jejíž vlastnosti zkoumáme. Pokud známe její rozložení (např. z nějaké dřívější studie) nebo alespoň předpokládáme znalost rozložení, můžeme ji
Testy. Pavel Provinský. 19. listopadu 2013
 Testy Pavel Provinský 19. listopadu 2013 Test a intervalový odhad Testy a intervalové odhady - jsou vlastně to samé. Jiný je jen úhel pohledu. Lze přecházet od jednoho k druhému. Například: Při odvozování
Testy Pavel Provinský 19. listopadu 2013 Test a intervalový odhad Testy a intervalové odhady - jsou vlastně to samé. Jiný je jen úhel pohledu. Lze přecházet od jednoho k druhému. Například: Při odvozování
Jana Vránová, 3.lékařská fakulta UK, Praha. Hypotézy o populacích
 Jana Vránová, 3.lékařská fakulta UK, Praha Hypotézy o populacích Příklad IQ test: Předpokládejme, že z nějakého důvodu ministerstvo školství věří, že studenti absolventi středních škol v Hradci Králové
Jana Vránová, 3.lékařská fakulta UK, Praha Hypotézy o populacích Příklad IQ test: Předpokládejme, že z nějakého důvodu ministerstvo školství věří, že studenti absolventi středních škol v Hradci Králové
12. cvičení z PST. 20. prosince 2017
 1 cvičení z PST 0 prosince 017 11 test rozptylu normálního rozdělení Do laboratoře bylo odesláno n = 5 stejných vzorků krve ke stanovení obsahu alkoholu X v promilích alkoholu Výsledkem byla realizace
1 cvičení z PST 0 prosince 017 11 test rozptylu normálního rozdělení Do laboratoře bylo odesláno n = 5 stejných vzorků krve ke stanovení obsahu alkoholu X v promilích alkoholu Výsledkem byla realizace
STATISTIKA A INFORMATIKA - bc studium OZW, 1.roč. (zkušební otázky)
") STATISTIKA A INFORMATIKA - bc studium OZW, 1.roč. (zkušební otázky) 1) Význam a využití statistiky v biologických vědách a veterinárním lékařství ) Rozdělení znaků (veličin) ve statistice 3) Základní a
STATISTIKA A INFORMATIKA - bc studium OZW, 1.roč. (zkušební otázky) 1) Význam a využití statistiky v biologických vědách a veterinárním lékařství ) Rozdělení znaků (veličin) ve statistice 3) Základní a
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz
 Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická
Pravděpodobnost a aplikovaná statistika
 Pravděpodobnost a aplikovaná statistika MGR. JANA SEKNIČKOVÁ, PH.D. 8. KAPITOLA STATISTICKÉ TESTOVÁNÍ HYPOTÉZ 22.11.2016 Opakování: CLV příklad 1 Zadání: Před volbami je v populaci státu 52 % příznivců
Pravděpodobnost a aplikovaná statistika MGR. JANA SEKNIČKOVÁ, PH.D. 8. KAPITOLA STATISTICKÉ TESTOVÁNÍ HYPOTÉZ 22.11.2016 Opakování: CLV příklad 1 Zadání: Před volbami je v populaci státu 52 % příznivců
Intervalové odhady. Interval spolehlivosti pro střední hodnotu v N(µ, σ 2 ) Interpretace intervalu spolehlivosti. Interval spolehlivosti ilustrace
 Interpretace intervalu spolehlivosti. Interval spolehlivosti ilustrace") Intervalové odhady Interval spolehlivosti pro střední hodnotu v Nµ, σ 2 ) Situace: X 1,..., X n náhodný výběr z Nµ, σ 2 ), kde σ 2 > 0 známe měli jsme: bodové odhady odhadem charakteristiky je číslo) nevyjadřuje
Intervalové odhady Interval spolehlivosti pro střední hodnotu v Nµ, σ 2 ) Situace: X 1,..., X n náhodný výběr z Nµ, σ 2 ), kde σ 2 > 0 známe měli jsme: bodové odhady odhadem charakteristiky je číslo) nevyjadřuje
Pravděpodobnost a statistika, Biostatistika pro kombinované studium. Tutoriál č. 5: Bodové a intervalové odhady, testování hypotéz.
 Pravděpodobnost a statistika, Biostatistika pro kombinované studium Letní semestr 2015/2016 Tutoriál č. 5: Bodové a intervalové odhady, testování hypotéz Jan Kracík jan.kracik@vsb.cz Obsah: Výběrová rozdělení
Pravděpodobnost a statistika, Biostatistika pro kombinované studium Letní semestr 2015/2016 Tutoriál č. 5: Bodové a intervalové odhady, testování hypotéz Jan Kracík jan.kracik@vsb.cz Obsah: Výběrová rozdělení
UNIVERZITA OBRANY Fakulta ekonomiky a managementu. Aplikace STAT1. Výsledek řešení projektu PRO HORR2011 a PRO GRAM2011 3. 11.
 UNIVERZITA OBRANY Fakulta ekonomiky a managementu Aplikace STAT1 Výsledek řešení projektu PRO HORR2011 a PRO GRAM2011 Jiří Neubauer, Marek Sedlačík, Oldřich Kříž 3. 11. 2012 Popis a návod k použití aplikace
UNIVERZITA OBRANY Fakulta ekonomiky a managementu Aplikace STAT1 Výsledek řešení projektu PRO HORR2011 a PRO GRAM2011 Jiří Neubauer, Marek Sedlačík, Oldřich Kříž 3. 11. 2012 Popis a návod k použití aplikace
Aproximace binomického rozdělení normálním
 Aproximace binomického rozdělení normálním Aproximace binomického rozdělení normálním Příklad Sybilla a Kassandra tvrdí, že mají telepatické schopnosti, a chtějí to dokázat následujícím pokusem: V jedné
Aproximace binomického rozdělení normálním Aproximace binomického rozdělení normálním Příklad Sybilla a Kassandra tvrdí, že mají telepatické schopnosti, a chtějí to dokázat následujícím pokusem: V jedné
Intervalové odhady. Interval spolehlivosti pro střední hodnotu v N(µ, σ 2 ) Interpretace intervalu spolehlivosti. Interval spolehlivosti ilustrace
 Interpretace intervalu spolehlivosti. Interval spolehlivosti ilustrace") Intervalové odhady Interval spolehlivosti pro střední hodnotu v Nµ, σ 2 ) Situace: X 1,..., X n náhodný výběr z Nµ, σ 2 ), kde σ 2 > 0 známe měli jsme: bodové odhady odhadem charakteristiky je číslo) nevyjadřuje
Intervalové odhady Interval spolehlivosti pro střední hodnotu v Nµ, σ 2 ) Situace: X 1,..., X n náhodný výběr z Nµ, σ 2 ), kde σ 2 > 0 známe měli jsme: bodové odhady odhadem charakteristiky je číslo) nevyjadřuje
Statistické metody uţívané při ověřování platnosti hypotéz
 Statistické metody uţívané při ověřování platnosti hypotéz Hypotéza Domněnka, předpoklad Nejčastěji o rozdělení, středních hodnotách, závislostech, Hypotézy ve vědeckém výzkumu pracovní, věcné hypotézy
Statistické metody uţívané při ověřování platnosti hypotéz Hypotéza Domněnka, předpoklad Nejčastěji o rozdělení, středních hodnotách, závislostech, Hypotézy ve vědeckém výzkumu pracovní, věcné hypotézy
Jednovýběrový Wilcoxonův test a jeho asymptotická varianta (neparametrická obdoba jednovýběrového t-testu)
") Jednovýběrový Wilcoxonův test a jeho asymptotická varianta (neparametrická obdoba jednovýběrového t-testu) Frank Wilcoxon (1892 1965): Americký statistik a chemik Nechť X 1,..., X n je náhodný výběr ze
Jednovýběrový Wilcoxonův test a jeho asymptotická varianta (neparametrická obdoba jednovýběrového t-testu) Frank Wilcoxon (1892 1965): Americký statistik a chemik Nechť X 1,..., X n je náhodný výběr ze
2 Zpracování naměřených dat. 2.1 Gaussův zákon chyb. 2.2 Náhodná veličina a její rozdělení
 2 Zpracování naměřených dat Důležitou součástí každé experimentální práce je statistické zpracování naměřených dat. V této krátké kapitole se budeme věnovat určení intervalů spolehlivosti získaných výsledků
2 Zpracování naměřených dat Důležitou součástí každé experimentální práce je statistické zpracování naměřených dat. V této krátké kapitole se budeme věnovat určení intervalů spolehlivosti získaných výsledků
Katedra matematické analýzy a aplikací matematiky, Přírodovědecká fakulta, UP v Olomouci
 Zpracování dat v edukačních vědách - Testování hypotéz Kamila Fačevicová Katedra matematické analýzy a aplikací matematiky, Přírodovědecká fakulta, UP v Olomouci Obsah seminářů 5.11. Úvod do matematické
Zpracování dat v edukačních vědách - Testování hypotéz Kamila Fačevicová Katedra matematické analýzy a aplikací matematiky, Přírodovědecká fakulta, UP v Olomouci Obsah seminářů 5.11. Úvod do matematické
Testy dobré shody Máme dvě veličiny, u kterých bychom chtěli prokázat závislost, TESTY DOBRÉ SHODY (angl. goodness-of-fit tests)
") Testy dobré shody Máme dvě veličiny, u kterých bychom chtěli prokázat závislost, např. hmotnost a pohlaví narozených dětí. Běžný statistický postup pro ověření závislosti dvou veličin je zamítnutí jejich
Testy dobré shody Máme dvě veličiny, u kterých bychom chtěli prokázat závislost, např. hmotnost a pohlaví narozených dětí. Běžný statistický postup pro ověření závislosti dvou veličin je zamítnutí jejich
Tomáš Karel LS 2012/2013
 Tomáš Karel LS 2012/2013 Doplňkový materiál ke cvičení z předmětu 4ST201. Na případné faktické chyby v této presentaci mě prosím upozorněte. Děkuji. Tyto slidy berte pouze jako doplňkový materiál není
Tomáš Karel LS 2012/2013 Doplňkový materiál ke cvičení z předmětu 4ST201. Na případné faktické chyby v této presentaci mě prosím upozorněte. Děkuji. Tyto slidy berte pouze jako doplňkový materiál není
STATISTICA Téma 6. Testy na základě jednoho a dvou výběrů
 STATISTICA Téma 6. Testy na základě jednoho a dvou výběrů 1) Test na velikost rozptylu Test na velikost rozptylu STATISTICA nemá. 2) Test na velikost střední hodnoty V menu Statistika zvolíme nabídku Základní
STATISTICA Téma 6. Testy na základě jednoho a dvou výběrů 1) Test na velikost rozptylu Test na velikost rozptylu STATISTICA nemá. 2) Test na velikost střední hodnoty V menu Statistika zvolíme nabídku Základní
Epidemiologické ukazatele. lních dat. analýza kategoriáln. Prof. RNDr. Jana Zvárová, DrSc. Záznam epidemiologických dat. a I E
 Testování statistických hypotéz z a analýza kategoriáln lních dat Prof. RNDr. Jana Zvárová, DrSc. Epidemiologické ukazatele Rizikový faktor Populace Přítomen Nepřítomen Celkem Nemocní a b a+b Kontroly
Testování statistických hypotéz z a analýza kategoriáln lních dat Prof. RNDr. Jana Zvárová, DrSc. Epidemiologické ukazatele Rizikový faktor Populace Přítomen Nepřítomen Celkem Nemocní a b a+b Kontroly
analýza kategoriáln lních dat Prof. RNDr. Jana Zvárová, DrSc. Záznam epidemiologických dat Epidemiologické ukazatele
 Testování statistických hypotéz z a analýza kategoriáln lních dat Prof. RNDr. Jana Zvárová, DrSc. 1 Záznam epidemiologických dat Rizikový faktor Populace Přítomen Nepřítomen Celkem Nemocní a b a+b Kontroly
Testování statistických hypotéz z a analýza kategoriáln lních dat Prof. RNDr. Jana Zvárová, DrSc. 1 Záznam epidemiologických dat Rizikový faktor Populace Přítomen Nepřítomen Celkem Nemocní a b a+b Kontroly
Předpoklad o normalitě rozdělení je zamítnut, protože hodnota testovacího kritéria χ exp je vyšší než tabulkový 2
 Na úloze ukážeme postup analýzy velkého výběru s odlehlými prvky pro určení typu rozdělení koncentrace kyseliny močové u 50 dárců krve. Jaká je míra polohy a rozptýlení uvedeného výběru? Z grafických diagnostik
Na úloze ukážeme postup analýzy velkého výběru s odlehlými prvky pro určení typu rozdělení koncentrace kyseliny močové u 50 dárců krve. Jaká je míra polohy a rozptýlení uvedeného výběru? Z grafických diagnostik
KORELACE. Komentované řešení pomocí programu Statistica
 KORELACE Komentované řešení pomocí programu Statistica Vstupní data I Data umístěná v excelovském souboru překopírujeme do tabulky ve Statistice a pojmenujeme proměnné, viz prezentace k tématu Popisná
KORELACE Komentované řešení pomocí programu Statistica Vstupní data I Data umístěná v excelovském souboru překopírujeme do tabulky ve Statistice a pojmenujeme proměnné, viz prezentace k tématu Popisná
Příklad 1. Řešení 1 ŘEŠENÉ PŘÍKLADY Z MV2 ČÁST 11
 Příklad 1 Vyhláška Ministerstva zdravotnictví předpokládala, že doba dojezdu k pacientovi od nahlášení požadavku nepřekročí 17 minut. Hodnoty deseti náhodně vybraných dob příjezdu sanitky k nemocnému byly:
Příklad 1 Vyhláška Ministerstva zdravotnictví předpokládala, že doba dojezdu k pacientovi od nahlášení požadavku nepřekročí 17 minut. Hodnoty deseti náhodně vybraných dob příjezdu sanitky k nemocnému byly:
Korelace. Komentované řešení pomocí MS Excel
 Korelace Komentované řešení pomocí MS Excel Vstupní data Tabulka se vstupními daty je umístěna v oblasti A2:B84 (viz. obrázek) Prvotní představu o tvaru a síle závislosti docházky a počtu bodů nám poskytne
Korelace Komentované řešení pomocí MS Excel Vstupní data Tabulka se vstupními daty je umístěna v oblasti A2:B84 (viz. obrázek) Prvotní představu o tvaru a síle závislosti docházky a počtu bodů nám poskytne
Náhodné (statistické) chyby přímých měření
 chyby přímých měření") Náhodné (statistické) chyby přímých měření Hodnoty náhodných chyb se nedají stanovit předem, ale na základě počtu pravděpodobnosti lze zjistit, která z možných naměřených hodnot je více a která je méně
Náhodné (statistické) chyby přímých měření Hodnoty náhodných chyb se nedají stanovit předem, ale na základě počtu pravděpodobnosti lze zjistit, která z možných naměřených hodnot je více a která je méně
Úvod do analýzy rozptylu
 Úvod do analýzy rozptylu Párovým t-testem se podařilo prokázat, že úprava režimu stravování a fyzické aktivity ve vybrané škole měla vliv na zlepšené hodnoty HDLcholesterolu u školáků. Pro otestování jsme
Úvod do analýzy rozptylu Párovým t-testem se podařilo prokázat, že úprava režimu stravování a fyzické aktivity ve vybrané škole měla vliv na zlepšené hodnoty HDLcholesterolu u školáků. Pro otestování jsme
STATISTICA Téma 7. Testy na základě více než 2 výběrů
 STATISTICA Téma 7. Testy na základě více než 2 výběrů 1) Test na homoskedasticitu Nalezneme jej v několika submenu. Omezme se na submenu Základní statistiky a tabulky základního menu Statistika. V něm
STATISTICA Téma 7. Testy na základě více než 2 výběrů 1) Test na homoskedasticitu Nalezneme jej v několika submenu. Omezme se na submenu Základní statistiky a tabulky základního menu Statistika. V něm
LINEÁRNÍ REGRESE Komentované řešení pomocí programu Statistica
 LINEÁRNÍ REGRESE Komentované řešení pomocí programu Statistica Vstupní data Data umístěná v excelovském souboru překopírujeme do tabulky ve Statistice a pojmenujeme proměnné, viz prezentace k tématu Popisná
LINEÁRNÍ REGRESE Komentované řešení pomocí programu Statistica Vstupní data Data umístěná v excelovském souboru překopírujeme do tabulky ve Statistice a pojmenujeme proměnné, viz prezentace k tématu Popisná
Testování hypotéz. Testování hypotéz o rozdílu průměrů t-test pro nezávislé výběry t-test pro závislé výběry
 Testování hypotéz Testování hypotéz o rozdílu průměrů t-test pro nezávislé výběry t-test pro závislé výběry Testování hypotéz Obecný postup 1. Určení statistické hypotézy 2. Určení hladiny chyby 3. Výpočet
Testování hypotéz Testování hypotéz o rozdílu průměrů t-test pro nezávislé výběry t-test pro závislé výběry Testování hypotéz Obecný postup 1. Určení statistické hypotézy 2. Určení hladiny chyby 3. Výpočet
Testování statistických hypotéz. Obecný postup
 poznámky k MIII, Tomečková I., poslední aktualizace 9. listopadu 016 9 Testování statistických hypotéz Obecný postup (I) Vyslovení hypotézy O datech vyslovíme doměnku, kterou chceme ověřit statistickým
poznámky k MIII, Tomečková I., poslední aktualizace 9. listopadu 016 9 Testování statistických hypotéz Obecný postup (I) Vyslovení hypotézy O datech vyslovíme doměnku, kterou chceme ověřit statistickým
Regresní a korelační analýza
 Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
1 Tyto materiály byly vytvořeny za pomoci grantu FRVŠ číslo 1145/2004.
 Testování hypotéz na základě jednoho a dvou výběrů 1 1 Tyto materiály byly vytvořeny za pomoci grantu FRVŠ číslo 1145/004. Testování hypotéz Pokud nás zajímá zda platí, či neplatí tvrzení o určitém parametru,
Testování hypotéz na základě jednoho a dvou výběrů 1 1 Tyto materiály byly vytvořeny za pomoci grantu FRVŠ číslo 1145/004. Testování hypotéz Pokud nás zajímá zda platí, či neplatí tvrzení o určitém parametru,
Jednofaktorová analýza rozptylu
 Jednofaktorová analýza rozptylu David Hampel Ústav statistiky a operačního výzkumu, Mendelova univerzita v Brně Kurz pokročilých statistických metod Global Change Research Centre AS CR, 5 7 8 2015 Tato
Jednofaktorová analýza rozptylu David Hampel Ústav statistiky a operačního výzkumu, Mendelova univerzita v Brně Kurz pokročilých statistických metod Global Change Research Centre AS CR, 5 7 8 2015 Tato
11. cvičení z PSI prosince hodnota pozorovaná četnost n i p X (i) = q i (1 q), i N 0.
 = q i (1 q), i N 0.") 11 cvičení z PSI 12-16 prosince 2016 111 (Test dobré shody - geometrické rozdělení Realizací náhodné veličiny X jsme dostali následující četnosti výsledků: hodnota 0 1 2 3 4 5 6 pozorovaná četnost 29 15
11 cvičení z PSI 12-16 prosince 2016 111 (Test dobré shody - geometrické rozdělení Realizací náhodné veličiny X jsme dostali následující četnosti výsledků: hodnota 0 1 2 3 4 5 6 pozorovaná četnost 29 15
Základní statistické metody v rizikovém inženýrství
 Základní statistické metody v rizikovém inženýrství Petr Misák Ústav stavebního zkušebnictví Fakulta stavební, VUT v Brně misak.p@fce.vutbr.cz Základní pojmy Jev souhrn skutečností zobrazujících ucelenou
Základní statistické metody v rizikovém inženýrství Petr Misák Ústav stavebního zkušebnictví Fakulta stavební, VUT v Brně misak.p@fce.vutbr.cz Základní pojmy Jev souhrn skutečností zobrazujících ucelenou
Cvičení 9: Neparametrické úlohy o mediánech
 Cvičení 9: Neparametrické úlohy o mediánech Úkol 1.: Párový znaménkový test a párový Wilcoxonův test Při zjišťování kvality jedné složky půdy se používají dvě metody označené A a B. Výsledky: Vzorek 1
Cvičení 9: Neparametrické úlohy o mediánech Úkol 1.: Párový znaménkový test a párový Wilcoxonův test Při zjišťování kvality jedné složky půdy se používají dvě metody označené A a B. Výsledky: Vzorek 1
letní semestr 2012 Katedra pravděpodobnosti a matematické statistiky Matematicko-fyzikální fakulta Univerzity Karlovy Matematická statistika
 Šárka Hudecová Katedra pravděpodobnosti a matematické statistiky Matematicko-fyzikální fakulta Univerzity Karlovy letní semestr 2012 Opakování t- vs. neparametrické Wilcoxonův jednovýběrový test Opakování
Šárka Hudecová Katedra pravděpodobnosti a matematické statistiky Matematicko-fyzikální fakulta Univerzity Karlovy letní semestr 2012 Opakování t- vs. neparametrické Wilcoxonův jednovýběrový test Opakování
Základy biostatistiky II. Veřejné zdravotnictví 3.LF UK - II
 Základy biostatistiky II Veřejné zdravotnictví 3.LF UK - II Teoretické rozložení-matematické modely rozložení Naměřená data Výběrové rozložení Teoretické rozložení 1 e 2 x 2 Teoretické rozložení-matematické
Základy biostatistiky II Veřejné zdravotnictví 3.LF UK - II Teoretické rozložení-matematické modely rozložení Naměřená data Výběrové rozložení Teoretické rozložení 1 e 2 x 2 Teoretické rozložení-matematické
5. Závislost dvou náhodných veličin různých typů (kategoriální a metrická veličina)
") 5. Závislost dvou náhodných veličin různých typů (kategoriální a metrická veličina) Cílem tématu je správné posouzení a výběr vhodného testu v závislosti na povaze metrické a kategoriální veličiny. V následující
5. Závislost dvou náhodných veličin různých typů (kategoriální a metrická veličina) Cílem tématu je správné posouzení a výběr vhodného testu v závislosti na povaze metrické a kategoriální veličiny. V následující
ANALÝZA ROZPTYLU (ANOVA)
") ANALÝZA ROZPTYLU (ANOVA) 1 Vytvořeno s podporou projektu Průřezová inovace studijních programů Lesnické a dřevařské fakulty MENDELU v Brně (LDF) s ohledem na discipliny společného základu (reg. č. CZ.1.07/2.2.00/28.0021)
ANALÝZA ROZPTYLU (ANOVA) 1 Vytvořeno s podporou projektu Průřezová inovace studijních programů Lesnické a dřevařské fakulty MENDELU v Brně (LDF) s ohledem na discipliny společného základu (reg. č. CZ.1.07/2.2.00/28.0021)
Protokol č. 1. Tloušťková struktura. Zadání:
 Protokol č. 1 Tloušťková struktura Zadání: Pro zadané výčetní tloušťky (v cm) vypočítejte statistické charakteristiky a slovně interpretujte základní statistické vlastnosti tohoto souboru tloušťek. Dále
Protokol č. 1 Tloušťková struktura Zadání: Pro zadané výčetní tloušťky (v cm) vypočítejte statistické charakteristiky a slovně interpretujte základní statistické vlastnosti tohoto souboru tloušťek. Dále
Tomáš Karel LS 2012/2013
 Tomáš Karel LS 2012/2013 Doplňkový materiál ke cvičení z předmětu 4ST201. Na případné faktické chyby v této presentaci mě prosím upozorněte. Děkuji. Tyto slidy berte pouze jako doplňkový materiál není
Tomáš Karel LS 2012/2013 Doplňkový materiál ke cvičení z předmětu 4ST201. Na případné faktické chyby v této presentaci mě prosím upozorněte. Děkuji. Tyto slidy berte pouze jako doplňkový materiál není
Jana Vránová, 3. lékařská fakulta UK
 Jana Vránová, 3. lékařská fakulta UK Vznikají při zkoumání vztahů kvalitativních resp. diskrétních znaků Jedná se o analogii s korelační analýzou spojitých znaků Přitom předpokládáme, že každý prvek populace
Jana Vránová, 3. lékařská fakulta UK Vznikají při zkoumání vztahů kvalitativních resp. diskrétních znaků Jedná se o analogii s korelační analýzou spojitých znaků Přitom předpokládáme, že každý prvek populace
You created this PDF from an application that is not licensed to print to novapdf printer (http://www.novapdf.com)
") Testování statistických hypotéz Testování statistických hypotéz Princip: Ověřování určitého předpokladu zjišťujeme, zda zkoumaný výběr pochází ze základního souboru, který má určité rozdělení zjišťujeme,
Testování statistických hypotéz Testování statistických hypotéz Princip: Ověřování určitého předpokladu zjišťujeme, zda zkoumaný výběr pochází ze základního souboru, který má určité rozdělení zjišťujeme,
4EK211 Základy ekonometrie
 4EK211 Základy ekonometrie ZS 2015/16 Cvičení 1: Opakování ze statistiky LENKA FIŘTOVÁ KATEDRA EKONOMETRIE, FAKULTA INFORMATIKY A STATISTIKY VYSOKÁ ŠKOLA EKONOMICKÁ V PRAZE Z čeho studovat 1) Z KNIHY Krkošková,
4EK211 Základy ekonometrie ZS 2015/16 Cvičení 1: Opakování ze statistiky LENKA FIŘTOVÁ KATEDRA EKONOMETRIE, FAKULTA INFORMATIKY A STATISTIKY VYSOKÁ ŠKOLA EKONOMICKÁ V PRAZE Z čeho studovat 1) Z KNIHY Krkošková,
Testování hypotéz. testujeme (většinou) tvrzení o parametru populace. tvrzení je nutno předem zformulovat
 tvrzení o parametru populace. tvrzení je nutno předem zformulovat") Testování hypotéz testujeme (většinou) tvrzení o parametru populace tvrzení je nutno předem zformulovat najít odpovídající test, podle kterého se na základě informace z výběrového souboru rozhodneme, zda
Testování hypotéz testujeme (většinou) tvrzení o parametru populace tvrzení je nutno předem zformulovat najít odpovídající test, podle kterého se na základě informace z výběrového souboru rozhodneme, zda
Statistika, Biostatistika pro kombinované studium. Jan Kracík
 Statistika, Biostatistika pro kombinované studium Letní semestr 2014/2015 Tutoriál č. 6: ANOVA Jan Kracík jan.kracik@vsb.cz Obsah: Testování hypotéz opakování ANOVA Testování hypotéz (opakování) Testování
Statistika, Biostatistika pro kombinované studium Letní semestr 2014/2015 Tutoriál č. 6: ANOVA Jan Kracík jan.kracik@vsb.cz Obsah: Testování hypotéz opakování ANOVA Testování hypotéz (opakování) Testování
Problematika analýzy rozptylu. Ing. Michael Rost, Ph.D.
 Problematika analýzy rozptylu Ing. Michael Rost, Ph.D. Úvod do problému Již umíte testovat shodu dvou středních hodnot prostřednictvím t-testů. Otázka: Jaké předpoklady musí být splněny, abyste mohli použít
Problematika analýzy rozptylu Ing. Michael Rost, Ph.D. Úvod do problému Již umíte testovat shodu dvou středních hodnot prostřednictvím t-testů. Otázka: Jaké předpoklady musí být splněny, abyste mohli použít
STATISTICKÉ ZJIŠŤOVÁNÍ
 STATISTICKÉ ZJIŠŤOVÁNÍ ÚVOD Základní soubor Všechny ryby v rybníce, všechny holky/kluci na škole Cílem určit charakteristiky, pravděpodobnosti Průměr, rozptyl, pravděpodobnost, že Maruška kápne na toho
STATISTICKÉ ZJIŠŤOVÁNÍ ÚVOD Základní soubor Všechny ryby v rybníce, všechny holky/kluci na škole Cílem určit charakteristiky, pravděpodobnosti Průměr, rozptyl, pravděpodobnost, že Maruška kápne na toho
10. cvičení z PST. 5. prosince T = (n 1) S2 X. (n 1) s2 x σ 2 q χ 2 (n 1) (1 α 2 ). q χ 2 (n 1) 2. 2 x. (n 1) s. x = 1 6. x i = 457.
 S2 X. (n 1) s2 x σ 2 q χ 2 (n 1) (1 α 2 ). q χ 2 (n 1) 2. 2 x. (n 1) s. x = 1 6. x i = 457.") 0 cvičení z PST 5 prosince 208 0 (intervalový odhad pro rozptyl) Soubor (70, 84, 89, 70, 74, 70) je náhodným výběrem z normálního rozdělení N(µ, σ 2 ) Určete oboustranný symetrický 95% interval spolehlivosti
0 cvičení z PST 5 prosince 208 0 (intervalový odhad pro rozptyl) Soubor (70, 84, 89, 70, 74, 70) je náhodným výběrem z normálního rozdělení N(µ, σ 2 ) Určete oboustranný symetrický 95% interval spolehlivosti
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc.
 Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika 010 1.týden (0.09.-4.09. ) Data, typy dat, variabilita, frekvenční analýza
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika 010 1.týden (0.09.-4.09. ) Data, typy dat, variabilita, frekvenční analýza