Klasifikace a rozpoznávání. Bayesovská rozhodovací teorie
|
|
|
- Marek Netrval
- před 4 lety
- Počet zobrazení:
Transkript
1 Klasifikace a rozpoznávání Bayesovská rozhodovací teorie
2 Extrakce příznaků Granáty Jablka Četnost Váha [dkg]
3 Pravděpodobnosti - diskrétní příznaky Uvažujme diskrétní příznaky váhové kategorie Nechť tabulka reflektuje skutečné pravděpodobnosti jednotlivých kategorií nejlehčí lehčí lehký střední těžký těžší nejtěžší [kg]
4 Apriorní pravděpodobnost Stav věci Hádej co mám za zády, jablko nebo granát? Klasifikační pravidlo: Vyber čeho je nejvíc Třída s největší apriorní pravděpodobností (a-priori probability) P (granát) = 5 15 P ω P (ω) = 1 P (jablko) = nejlehčí. -.1 lehčí lehký střední.3.4 těžký.4.5 těžší.5.6 nejtěžší.6.7 [kg]
5 Společná pravděpodobnost Je to těžké. Hádej co to je? Klasifikační pravidlo: Ve sloupci váhové kategorie vyber nejčastější třídu Třída s největší společnou pravděpodobností (joint probability) pravděpodobnost chlívečku. ale také největší podmíněnou pravděpodobností (viz další slajd) P (granát, těžký) = P (jablko, těžký) = 6 P ω,x P (ω, x) = nejlehčí. -.1 lehčí lehký střední.3.4 těžký.4.5 těžší.5.6 nejtěžší.6.7 [kg]
6 Podmíněná pravděpodobnost Je to těžké. Z jakou pravděpodobností je to granát? Podmíněnou pravděpodobnost (conditional probability) - pravděpodobnost chlívečku dáno sloupec P (granát těžký) = nejlehčí lehčí lehký střední těžký těžší nejtěžší [kg]
7 Ještě nějaké další pravděpodobnosti P (granát) = 5 15 P(těžký) = P (granát těžký) = P (těžký granát) = 12 5 P (granát, těžký) = P (granát těžký)p (těžký) = P (granát, těžký) = P (těžký granát)p (granát) = nejlehčí lehčí lehký střední těžký těžší nejtěžší [kg]
8 Bayesův teorém Posteriorní pravděpodobnost (posterior probability) Věrohodnost (likelihood) Apriorní pravděpodobnost (prior probability) P (ω x) = P (x ω)p (ω) P (x) Evidence Věrohodnost nás zatím moc nezajímala, ale za chvíli to bude hlavní co se budeme snažit odhadovat z trénovacích dat. Již dříve jsme viděli že (product rule): Pro evidenci platí (sum rule): P (ω, x) = P (x ω)p (ω) P (x) = P ω P (ω, x) např.: P (těžký) = P (granát, těžký) + P (jablko, těžký) =
9 Maximum a-posteriori (MAP) klasifikátor Mějme 2 třídy ω 1 a ω 2 Pro daný příznak x vyber třídu ω s větší posteriorní pravděpodobností P(ω x) Vyber ω 1 pouze pokud: P (ω 1 x) > P (ω 2 x) P (x ω 1 )P (ω 1 ) P (x) > P (x ω 2)P (ω 2 ) P (x) P (ω 1, x) > P (ω 2, x)
10 Maximum a-posteriori (MAP) klasifikátor Pro každé x minimalizuje pravděpodobnost chyby: P(chyby x) = P(ω 1 x) pokud vybereme ω 2 P(chyby x) = P(ω 2 x) pokud vybereme ω 1 Pro dané x vybíráme třídu ω s větším P(ω x) minimalizace chyby Musíme ovšem znát skutečná rozložení P(ω x) nebo P(x,ω) nebo P(x ω) a P(ω), které reflektují rozpoznávaná data Obecně pro N tříd Vyber třídu s největší posteiorní pravděpodobností: arg max ω P (ω x) = arg max ω p(x ω)p (ω)
11 Spojité příznaky P(.) bude pravděpodobnost p(.) bude hodnota funkce rozložení pravděpodobnosti P (x (a, b)) = R b a p(x)dx Bude nás zajímat funkce rozložení pravděpodobnosti příznaků podmíněné třídou p(x ω) 3.5 p(x ω 1 ) p(x ω 2 ) Plocha pod funkci musí být 1 Hodnoty mohou být ale libovolné kladné.7 [kg]
12 Bayesův teorém spojité příznaky P (ω x) = p(x ω)p (ω) p(x) p(x ω) p(ω, x) = p(x ω)p(ω) p(ω x) 3.5 p(x ω 1 ) p(x ω 2 ) 2.5 p(x ω 1 )P(ω 1 ) p(x ω 2 )P(ω 2 ) 1 x x x P(ω 1 x) P(ω x) 2
13 MAP klasifikátor spojité příznaky Opět se budeme rozhodovat podle: P (ω 1, x) > P (ω 2, x) nebo P (ω 1 x) > P (ω 2 x) 2.5 p(x ω 1 )P(ω 1 ) p(x ω 2 )P(ω 2 ) p(ω, x) 1 p(ω x) Na obrazcích vidíme, že obě pravidla vedou ke stejným rozhodnutím P(ω 1 x) x P(ω 2 x) x
14 MAP klasifikátor pravděpodobnost chyby Říkali jsme, že MAP klasifikátor minimalizuje pravděpodobnost chyby Plocha pod funkci společného rozložení pravděpodobnosti p(ω,x) v určitém intervalu x je pravděpodobnost výskytu vzoru třídy ω s příznakem v daném intervalu Jaká je tedy celková pravděpodobnost, že klasifikátor udělá chybu? Pravděpodobnost, že modrá třída je chybně klasifikována jako červená p(x ω 1 )P(ω 1 ) p(x ω 2 )P(ω 2 ) Jakákoli snaha posunout hranice povede jen k větší chybě p(x ω 1 )P(ω 1 ) p(x ω 2 )P(ω 2 ) p(ω, x) p(ω, x) x x
15 Posteriorní pravděpodobnosti pro různé apriorní pravděpodobnosti Změna apriorních pravděpodobností tříd může vézt k různým rozhodnutím P (ω 1 ) = 1 3, P(ω 2) = 2 3 P (ω 1 ) = 1 2, P (ω 2) = 1 2 P (ω 1 ) = 99 1, P(ω 2) = 1 1 P(ω 1 x) P(ω 2 x) P(ω 1 x) P(ω 2 x) x x x P(ω 1 x) P(ω 2 x)

16 Vícerozměrné příznaky Místo jednorozměrného příznaku máme N rozměrný příznakový vektor x =[x 1, x 2,, x N ] např. [váha, červenost] MAP klasifikátor opět vybírá nejpravděpodobnější třídu p(ω, x) x 1 x 2
17
18 Parametrické modely Pro rozpoznávání s MAP klasifikátorem jsme doposud předpokládali, že známe skutečná rozloženi P(ω x) nebo P(x,ω) nebo P(x ω) a P(ω) Ve skutečnosti ale většinou známe jen trénovací vzory Pokusíme se tato rozložení odhadnout z dat budeme trénovat statistické modely silence unvoiced voiced
19 Parametrické modely Můžeme se pokusit modelovat přímo posteriorní pravděpodobnost, a tu použít přímo k rozpoznávání P(ω x) tzv. diskriminativní trénování Ale o tomto bude řeč až později Běžnější je odhadovat rozložení P(x ω) a P(ω) Tato rozložení popisují předpokládaný proces generování dat generativní modely Nejprve se musíme rozhodnout pro formu modelu, který použijeme. (např. gaussovské rozložení) silence unvoiced voiced
20 Gaussovské rozložení (jednorozměrné) N (x; μ, σ 2 ) = 1 σ 2π (x μ) 2 e 2σ p(x) x
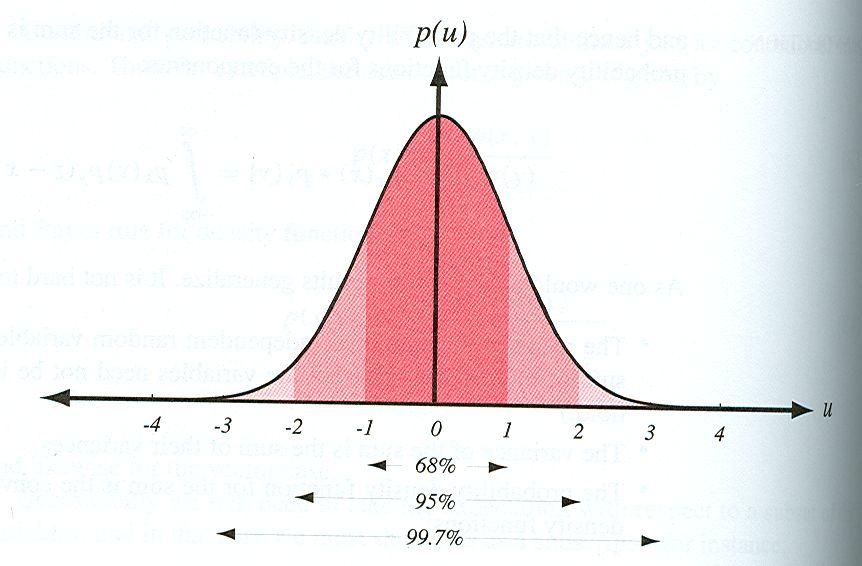
21
22 Gaussovské rozložení (dvourozměrné) 1 N (x; μ, Σ) = (2π)P Σ e 1 2 (x μ)t Σ 1 (x μ) p(x) x 2 x 1
23
24

25
26 Odhad parametrů modelu s maximální věrohodností ˆΘ class ML = arg max Θ Y x i class p(x i Θ) Hledáme taková nastavení parametrů rozložení pravděpodobnosti Θ, které maximalizuje věrohodnost trénovacích dat (Maximum Likelihood, ML) V následujících příkladech předpokládáme, že odhadujeme parametry nezávisle pro jednotlivé třídy. Pro zjednodušení notace tedy u rozložení neuvádíme závislost na třídě ω, pouze na jejích parametrech Θ. Modely kterými se budeme zabývat jsou: Gaussovské rozloženi Směs gaussovských rozložení (Gaussian Mixture Model, GMM) V následujících přednáškách přibudou další (např. HMM)
27 Gaussovské rozložení (jednorozměrné) N (x; μ, σ 2 ) = 1 σ 2π (x μ) 2 e 2σ 2 p(x) ML odhad parametrů: μ = 1 T P i x i σ 2 = 1 T Pi (x i μ) x
28 Gaussovské rozložení (dvourozměrné) 1 N (x; μ, Σ) = (2π) P Σ e 1 2 (x μ)t Σ 1 (x μ) p(x) x 2 2 ML odhad of parametrů: μ = 1 T P i x i x 1 Pi (x i μ)(x i μ) T Σ = 1 T
29 Směs gaussovských rozložení GMM p(x Θ) = P c P cn (x; μ c, Σ c ) p(x) kde Θ = {P c, μ c, Σ c } P c P c = x 2 x 1
30 Gaussian Mixture Model Evaluation: p(x Θ) = P c P cn (x; μ c, σ 2 c ) Vzoreček můžeme chápat jen jako něco co definuje tvar funkce hustoty pravděpodobnosti nebo jej můžeme vidět jako složitější generativní model,který generuje příznaky následujícím způsobem: Napřed je jedna z gaussovských komponent vybrána tak aby respektovala apriorní pravděpodobnosti P c Příznakový vektor se generuje z vybraného gaussovského rozložení. Pro vyhodnoceni modelu ale nevíme, která komponenta příznakový vektor generovala a proto musíme marginalizovat (suma přes gaussovské komponenty násobené apriorními pravděpodobnostmi)
31 Training GMM Viterbi training Intuitive and Approximate iterative algorithm for training GMM parameters. Using current model parameters, let Gaussians to classify data as the Gaussians were different classes (Even though the both data and all components corresponds to one class modeled by the GMM) Re-estimate parameters of Gaussian using the data associated with to them in the previous step. Repeat the previous two steps until the algorithm converge.
32 Training GMM EM algorithm Expectation Maximization is very general tool applicable in many cases were we deal with unobserved (hidden) data. Here, we only see the result of its application to the problem of re-estimating parameters of GMM. It guarantees to increase likelihood of training data in every iteration, however it does not guarantees to find the global optimum. The algorithm is very similar to Viterbi training presented above. Only instead of hard decisions, it uses soft posterior probabilities of Gaussians (given the old model) as a weights and weight average is used to compute new mean and variance estimates. ˆμ (new) c = ˆσ 2 c (new) = γ ci = P Pi γ cix i i γ ci Pi γ ci(x i ˆμ (new) c ) 2 P i γ ci P cn (x i ;ˆμ (old) c,ˆσ 2(old) c ) Pc P cn (x i ;ˆμ (old) c,ˆσ c 2(old) )
Klasifikace a rozpoznávání. Bayesovská rozhodovací teorie
 Klasifikace a rozpoznávání Bayesovská rozhodovací teorie Extrakce p íznaků Granáty Četnost Jablka Váha [dkg] Pravděpodobnosti - diskrétní p íznaky Uvažujme diskrétní p íznaky váhové kategorie Nechť tabulka
Klasifikace a rozpoznávání Bayesovská rozhodovací teorie Extrakce p íznaků Granáty Četnost Jablka Váha [dkg] Pravděpodobnosti - diskrétní p íznaky Uvažujme diskrétní p íznaky váhové kategorie Nechť tabulka
SRE 03 - Statistické rozpoznávání
 SRE 03 - Statistické rozpoznávání vzorů II Lukáš Burget ÚPGM FIT VUT Brno, burget@fit.vutbr.cz FIT VUT Brno SRE 03 - Statistické rozpoznávání vzorů II Lukáš Burget, ÚPGM FIT VUT Brno, 2006/07 1/29 Opakování
SRE 03 - Statistické rozpoznávání vzorů II Lukáš Burget ÚPGM FIT VUT Brno, burget@fit.vutbr.cz FIT VUT Brno SRE 03 - Statistické rozpoznávání vzorů II Lukáš Burget, ÚPGM FIT VUT Brno, 2006/07 1/29 Opakování
Klasifikace a rozpoznávání. Lineární klasifikátory
 Klasifikace a rozpoznávání Lineární klasifikátory Opakování - Skalární součin x = x1 x 2 w = w T x = w 1 w 2 x 1 x 2 w1 w 2 = w 1 x 1 + w 2 x 2 x. w w T x w Lineární klasifikátor y(x) = w T x + w 0 Vyber
Klasifikace a rozpoznávání Lineární klasifikátory Opakování - Skalární součin x = x1 x 2 w = w T x = w 1 w 2 x 1 x 2 w1 w 2 = w 1 x 1 + w 2 x 2 x. w w T x w Lineární klasifikátor y(x) = w T x + w 0 Vyber
Jan Černocký ÚPGM FIT VUT Brno, FIT VUT Brno
 SRE 2 - Statistické rozpoznávání vzorů Jan Černocký ÚPGM FIT VUT Brno, cernocky@fit.vutbr.cz FIT VUT Brno SRE 2 - Statistické rozpoznávání vzorů Jan Černocký, ÚPGM FIT VUT Brno, 25/6 1/6 Plán... SRE 2
SRE 2 - Statistické rozpoznávání vzorů Jan Černocký ÚPGM FIT VUT Brno, cernocky@fit.vutbr.cz FIT VUT Brno SRE 2 - Statistické rozpoznávání vzorů Jan Černocký, ÚPGM FIT VUT Brno, 25/6 1/6 Plán... SRE 2
Klasifikace a rozpoznávání. Extrakce příznaků
 Klasifikace a rozpoznávání Extrakce příznaků Extrakce příznaků - parametrizace Poté co jsme ze snímače obdržely data která jsou relevantní pro naši klasifikační úlohu, je potřeba je přizpůsobit potřebám
Klasifikace a rozpoznávání Extrakce příznaků Extrakce příznaků - parametrizace Poté co jsme ze snímače obdržely data která jsou relevantní pro naši klasifikační úlohu, je potřeba je přizpůsobit potřebám
oddělení Inteligentní Datové Analýzy (IDA)
") Vytěžování dat Filip Železný Katedra počítačů oddělení Inteligentní Datové Analýzy (IDA) 22. září 2014 Filip Železný (ČVUT) Vytěžování dat 22. září 2014 1 / 25 Odhad rozdělení Úloha: Vstup: data D = {
Vytěžování dat Filip Železný Katedra počítačů oddělení Inteligentní Datové Analýzy (IDA) 22. září 2014 Filip Železný (ČVUT) Vytěžování dat 22. září 2014 1 / 25 Odhad rozdělení Úloha: Vstup: data D = {
SRE 03 - Skryté Markovovy modely HMM
 SRE 03 - Skryté Markovovy modely HMM Jan Černocký ÚPGM FIT VUT Brno, cernocky@fit.vutbr.cz FIT VUT Brno SRE 03 - Skryté Markovovy modely HMM Jan Černocký, ÚPGM FIT VUT Brno 1/35 Plán... SRE 03 - Skryté
SRE 03 - Skryté Markovovy modely HMM Jan Černocký ÚPGM FIT VUT Brno, cernocky@fit.vutbr.cz FIT VUT Brno SRE 03 - Skryté Markovovy modely HMM Jan Černocký, ÚPGM FIT VUT Brno 1/35 Plán... SRE 03 - Skryté
Obr. 1: Vizualizace dat pacientů, kontrolních subjektů a testovacího subjektu.
 Řešení příkladu - klasifikace testovacího subjektu pomocí Bayesova klasifikátoru: ata si vizualizujeme (Obr. ). Objem mozkových komor 9 8 7 6 5 pacienti kontroly testovací subjekt 5 6 Objem hipokampu Obr.
Řešení příkladu - klasifikace testovacího subjektu pomocí Bayesova klasifikátoru: ata si vizualizujeme (Obr. ). Objem mozkových komor 9 8 7 6 5 pacienti kontroly testovací subjekt 5 6 Objem hipokampu Obr.
Implementace Bayesova kasifikátoru
 Implementace Bayesova kasifikátoru a diskriminačních funkcí v prostředí Matlab J. Havlík Katedra teorie obvodů Fakulta elektrotechnická České vysoké učení technické v Praze Technická 2, 166 27 Praha 6
Implementace Bayesova kasifikátoru a diskriminačních funkcí v prostředí Matlab J. Havlík Katedra teorie obvodů Fakulta elektrotechnická České vysoké učení technické v Praze Technická 2, 166 27 Praha 6
Umělá inteligence II
 Umělá inteligence II 11 http://ktiml.mff.cuni.cz/~bartak Roman Barták, KTIML roman.bartak@mff.cuni.cz Dnešní program! V reálném prostředí převládá neurčitost.! Neurčitost umíme zpracovávat pravděpodobnostními
Umělá inteligence II 11 http://ktiml.mff.cuni.cz/~bartak Roman Barták, KTIML roman.bartak@mff.cuni.cz Dnešní program! V reálném prostředí převládá neurčitost.! Neurčitost umíme zpracovávat pravděpodobnostními
AVDAT Náhodný vektor, mnohorozměrné rozdělení
 AVDAT Náhodný vektor, mnohorozměrné rozdělení Josef Tvrdík Katedra informatiky Přírodovědecká fakulta Ostravská univerzita Opakování, náhodná veličina, rozdělení Náhodná veličina zobrazuje elementární
AVDAT Náhodný vektor, mnohorozměrné rozdělení Josef Tvrdík Katedra informatiky Přírodovědecká fakulta Ostravská univerzita Opakování, náhodná veličina, rozdělení Náhodná veličina zobrazuje elementární
UČENÍ BEZ UČITELE. Václav Hlaváč
 UČENÍ BEZ UČITELE Václav Hlaváč Fakulta elektrotechnická ČVUT v Praze katedra kybernetiky, Centrum strojového vnímání hlavac@fel.cvut.cz, http://cmp.felk.cvut.cz/~hlavac 1/22 OBSAH PŘEDNÁŠKY ÚVOD Učení
UČENÍ BEZ UČITELE Václav Hlaváč Fakulta elektrotechnická ČVUT v Praze katedra kybernetiky, Centrum strojového vnímání hlavac@fel.cvut.cz, http://cmp.felk.cvut.cz/~hlavac 1/22 OBSAH PŘEDNÁŠKY ÚVOD Učení
AVDAT Mnohorozměrné metody, metody klasifikace
 AVDAT Mnohorozměrné metody, metody klasifikace Josef Tvrdík Katedra informatiky Přírodovědecká fakulta Ostravská univerzita Mnohorozměrné metody Regrese jedna náhodná veličina je vysvětlována pomocí jiných
AVDAT Mnohorozměrné metody, metody klasifikace Josef Tvrdík Katedra informatiky Přírodovědecká fakulta Ostravská univerzita Mnohorozměrné metody Regrese jedna náhodná veličina je vysvětlována pomocí jiných
Dobývání znalostí. Doc. RNDr. Iveta Mrázová, CSc. Katedra teoretické informatiky Matematicko-fyzikální fakulta Univerzity Karlovy v Praze
 Dobývání znalostí Doc. RNDr. Iveta Mrázová, CSc. Katedra teoretické informatiky Matematicko-fyzikální fakulta Univerzity Karlovy v Praze Dobývání znalostí Pravděpodobnost a učení Doc. RNDr. Iveta Mrázová,
Dobývání znalostí Doc. RNDr. Iveta Mrázová, CSc. Katedra teoretické informatiky Matematicko-fyzikální fakulta Univerzity Karlovy v Praze Dobývání znalostí Pravděpodobnost a učení Doc. RNDr. Iveta Mrázová,
EM algoritmus. Proč zahrnovat do modelu neznámé veličiny
 EM algoritmus používá se pro odhad nepozorovaných veličin. Jde o iterativní algoritmus opakující dva kroky: Estimate, který odhadne hodnoty nepozorovaných dat, a Maximize, který maximalizuje věrohodnost
EM algoritmus používá se pro odhad nepozorovaných veličin. Jde o iterativní algoritmus opakující dva kroky: Estimate, který odhadne hodnoty nepozorovaných dat, a Maximize, který maximalizuje věrohodnost
Kybernetika a umělá inteligence, cvičení 10/11
 Kybernetika a umělá inteligence, cvičení 10/11 Program 1. seminární cvičení: základní typy klasifikátorů a jejich princip 2. počítačové cvičení: procvičení na problému rozpoznávání číslic... body za aktivitu
Kybernetika a umělá inteligence, cvičení 10/11 Program 1. seminární cvičení: základní typy klasifikátorů a jejich princip 2. počítačové cvičení: procvičení na problému rozpoznávání číslic... body za aktivitu
Vytěžování znalostí z dat
 Pavel Kordík, Jan Motl (ČVUT FIT) Vytěžování znalostí z dat BI-VZD, 2012, Přednáška 7 1/27 Vytěžování znalostí z dat Pavel Kordík, Jan Motl Department of Computer Systems Faculty of Information Technology
Pavel Kordík, Jan Motl (ČVUT FIT) Vytěžování znalostí z dat BI-VZD, 2012, Přednáška 7 1/27 Vytěžování znalostí z dat Pavel Kordík, Jan Motl Department of Computer Systems Faculty of Information Technology
Pravděpodobnost, náhoda, kostky
 Pravděpodobnost, náhoda, kostky Radek Pelánek IV122 Výhled pravděpodobnost náhodná čísla lineární regrese detekce shluků Dnes lehce nesourodá směs úloh souvisejících s pravděpodobností připomenutí, souvislosti
Pravděpodobnost, náhoda, kostky Radek Pelánek IV122 Výhled pravděpodobnost náhodná čísla lineární regrese detekce shluků Dnes lehce nesourodá směs úloh souvisejících s pravděpodobností připomenutí, souvislosti
Odhady - Sdružené rozdělení pravděpodobnosti
 Odhady - Sdružené rozdělení pravděpodobnosti 4. listopadu 203 Kdybych chtěl znát maximum informací o náhodné veličině, musel bych znát všechny hodnoty, které mohou padnout, a jejich pravděpodobnosti. Tedy
Odhady - Sdružené rozdělení pravděpodobnosti 4. listopadu 203 Kdybych chtěl znát maximum informací o náhodné veličině, musel bych znát všechny hodnoty, které mohou padnout, a jejich pravděpodobnosti. Tedy
PRAVDĚPODOBNOST A STATISTIKA. Bayesovské odhady
 PRAVDĚPODOBNOST A STATISTIKA Bayesovské odhady Bayesovské odhady - úvod Klasický bayesovský přístup: Klasický přístup je založen na opakování pokusech sledujeme rekvenci nastoupení zvolených jevů Bayesovský
PRAVDĚPODOBNOST A STATISTIKA Bayesovské odhady Bayesovské odhady - úvod Klasický bayesovský přístup: Klasický přístup je založen na opakování pokusech sledujeme rekvenci nastoupení zvolených jevů Bayesovský
KYBERNETIKA A UMĚLÁ INTELIGENCE. 2. Pravděpodobnostní rozhodování a klasifikace
 KYBERNETIKA A UMĚLÁ INTELIGENCE 2. Pravděpodobnostní rozhodování a klasifikace laboratory Gerstner Gerstnerova laboratoř katedra kybernetiky fakulta elektrotechnická ČVUT v Praze Daniel Novák Poděkování:
KYBERNETIKA A UMĚLÁ INTELIGENCE 2. Pravděpodobnostní rozhodování a klasifikace laboratory Gerstner Gerstnerova laboratoř katedra kybernetiky fakulta elektrotechnická ČVUT v Praze Daniel Novák Poděkování:
Bayesovské metody. Mnohorozměrná analýza dat
 Mnohorozměrná analýza dat Podmíněná pravděpodobnost Definice: Uvažujme náhodné jevy A a B takové, že P(B) > 0. Podmíněnou pravěpodobností jevu A za podmínky, že nastal jev B, nazýváme podíl P(A B) P(A
Mnohorozměrná analýza dat Podmíněná pravděpodobnost Definice: Uvažujme náhodné jevy A a B takové, že P(B) > 0. Podmíněnou pravěpodobností jevu A za podmínky, že nastal jev B, nazýváme podíl P(A B) P(A
Statistická teorie učení
 Statistická teorie učení Petr Havel Marek Myslivec přednáška z 9. týdne 1 Úvod Představme si situaci výrobce a zákazníka, který si u výrobce objednal algoritmus rozpoznávání. Zákazník dodal experimentální
Statistická teorie učení Petr Havel Marek Myslivec přednáška z 9. týdne 1 Úvod Představme si situaci výrobce a zákazníka, který si u výrobce objednal algoritmus rozpoznávání. Zákazník dodal experimentální
Tino Haderlein, Elmar Nöth
 Interakce člověk počítač v přirozeném jazyce (ICP) LS 213 Klasifikace Tino Haderlein, Elmar Nöth Katedra informatiky a výpočetní techniky (KIV) Západočeská univerzita v Plzni Lehrstuhl für Mustererkennung
Interakce člověk počítač v přirozeném jazyce (ICP) LS 213 Klasifikace Tino Haderlein, Elmar Nöth Katedra informatiky a výpočetní techniky (KIV) Západočeská univerzita v Plzni Lehrstuhl für Mustererkennung
Katedra kybernetiky laboratoř Inteligentní Datové Analýzy (IDA) Katedra počítačů, Computational Intelligence Group
 Katedra počítačů, Computational Intelligence Group") Vytěžování dat Miroslav Čepek, Filip Železný Katedra kybernetiky laboratoř Inteligentní Datové Analýzy (IDA) Katedra počítačů, Computational Intelligence Group Evropský sociální fond Praha & EU: Investujeme
Vytěžování dat Miroslav Čepek, Filip Železný Katedra kybernetiky laboratoř Inteligentní Datové Analýzy (IDA) Katedra počítačů, Computational Intelligence Group Evropský sociální fond Praha & EU: Investujeme
Probability density estimation Parametric methods
 Probability density estimation Parametric methods Václav Hlaváč Czech Technical University in Prague Czech Institute of Informatics, Robotics and Cybernetics 166 36 Prague 6, Jugoslávských partyzánů 1580/3,
Probability density estimation Parametric methods Václav Hlaváč Czech Technical University in Prague Czech Institute of Informatics, Robotics and Cybernetics 166 36 Prague 6, Jugoslávských partyzánů 1580/3,
STATISTICKÉ ODHADY PARAMETRŮ
 STATISTICKÉ ODHADY PARAMETRŮ Jan Pech 21. září 2001 1 Motivace Obrazové snímače pracující ve vzdáleném infračerveném spektru jsou poměrně novou záležitostí. Ty nejkvalitnější snímače chlazené kapalným
STATISTICKÉ ODHADY PARAMETRŮ Jan Pech 21. září 2001 1 Motivace Obrazové snímače pracující ve vzdáleném infračerveném spektru jsou poměrně novou záležitostí. Ty nejkvalitnější snímače chlazené kapalným
FAKULTA INFORMAČNÍCH TECHNOLOGIÍ
 VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ BRNO UNIVERSITY OF TECHNOLOGY FAKULTA INFORMAČNÍCH TECHNOLOGIÍ ÚSTAV POČÍTAČOVÉ GRAFIKY A MULTIMÉDIÍ FACULTY OF INFORMATION TECHNOLOGY DEPARTMENT OF COMPUTER GRAPHICS AND
VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ BRNO UNIVERSITY OF TECHNOLOGY FAKULTA INFORMAČNÍCH TECHNOLOGIÍ ÚSTAV POČÍTAČOVÉ GRAFIKY A MULTIMÉDIÍ FACULTY OF INFORMATION TECHNOLOGY DEPARTMENT OF COMPUTER GRAPHICS AND
Odhady Parametrů Lineární Regrese
 Odhady Parametrů Lineární Regrese Mgr. Rudolf B. Blažek, Ph.D. prof. RNDr. Roman Kotecký, DrSc. Katedra počítačových systémů Katedra teoretické informatiky Fakulta informačních technologií České vysoké
Odhady Parametrů Lineární Regrese Mgr. Rudolf B. Blažek, Ph.D. prof. RNDr. Roman Kotecký, DrSc. Katedra počítačových systémů Katedra teoretické informatiky Fakulta informačních technologií České vysoké
Minikurz aplikované statistiky. Minikurz aplikované statistiky p.1
 Minikurz aplikované statistiky Marie Šimečková, Petr Šimeček Minikurz aplikované statistiky p.1 Program kurzu základy statistiky a pravděpodobnosti regrese (klasická, robustní, s náhodnými efekty, ev.
Minikurz aplikované statistiky Marie Šimečková, Petr Šimeček Minikurz aplikované statistiky p.1 Program kurzu základy statistiky a pravděpodobnosti regrese (klasická, robustní, s náhodnými efekty, ev.
Maximálně věrohodné odhady v časových řadách
 Univerzita Karlova v Praze Matematicko-fyzikální fakulta BAKALÁŘSKÁ PRÁCE Hana Tritová Maximálně věrohodné odhady v časových řadách Katedra pravděpodobnosti a matematické statistiky Vedoucí bakalářské
Univerzita Karlova v Praze Matematicko-fyzikální fakulta BAKALÁŘSKÁ PRÁCE Hana Tritová Maximálně věrohodné odhady v časových řadách Katedra pravděpodobnosti a matematické statistiky Vedoucí bakalářské
Úloha - rozpoznávání číslic
 Úloha - rozpoznávání číslic Vojtěch Franc, Tomáš Pajdla a Tomáš Svoboda http://cmp.felk.cvut.cz 27. listopadu 26 Abstrakt Podpůrný text pro cvičení předmětu X33KUI. Vysvětluje tři způsoby rozpoznávání
Úloha - rozpoznávání číslic Vojtěch Franc, Tomáš Pajdla a Tomáš Svoboda http://cmp.felk.cvut.cz 27. listopadu 26 Abstrakt Podpůrný text pro cvičení předmětu X33KUI. Vysvětluje tři způsoby rozpoznávání
Akvizice dat. Dekonvoluce Registrace. zobrazení INVESTICE DO ROZVOJE VZDĚLÁVÁNÍ
 a analýza signálů v perfúzním zobrazení Ústav biomedicínského inženýrství FEKT, VUT v Brně 22. 5. 2009 INVESTICE DO ROZVOJE VZDĚLÁVÁNÍ Osnova Úvod 1 Úvod 2 3 4 5 Úvod diagnostika a průběh terapie nádorových
a analýza signálů v perfúzním zobrazení Ústav biomedicínského inženýrství FEKT, VUT v Brně 22. 5. 2009 INVESTICE DO ROZVOJE VZDĚLÁVÁNÍ Osnova Úvod 1 Úvod 2 3 4 5 Úvod diagnostika a průběh terapie nádorových
Všechno, co jste chtěli vědět z teorie pravděpodobnosti, z teorie informace a
 Všechno, co jste chtěli vědět z teorie pravděpodobnosti, z teorie informace a báli jste se zeptat Jedinečnou funkcí statistiky je, že umožňuje vědci číselně vyjádřit nejistotu v jeho závěrech. (G. W. Snedecor)
Všechno, co jste chtěli vědět z teorie pravděpodobnosti, z teorie informace a báli jste se zeptat Jedinečnou funkcí statistiky je, že umožňuje vědci číselně vyjádřit nejistotu v jeho závěrech. (G. W. Snedecor)
Základy teorie pravděpodobnosti
 Základy teorie pravděpodobnosti Náhodný jev Pravděpodobnost náhodného jevu Roman Biskup (zapálený) statistik ve výslužbě, aktuálně analytik v praxi ;-) roman.biskup(at)email.cz 15. srpna 2012 Statistika
Základy teorie pravděpodobnosti Náhodný jev Pravděpodobnost náhodného jevu Roman Biskup (zapálený) statistik ve výslužbě, aktuálně analytik v praxi ;-) roman.biskup(at)email.cz 15. srpna 2012 Statistika
Agent pracující v částečně pozorovatelném prostředí udržuje na základě senzorického modelu odhaduje, jak se svět může vyvíjet.
 Umělá inteligence II Roman Barták, KTIML roman.bartak@mff.cuni.cz http://ktiml.mff.cuni.cz/~bartak Dnešní program Agent pracující v částečně pozorovatelném prostředí udržuje na základě senzorického modelu
Umělá inteligence II Roman Barták, KTIML roman.bartak@mff.cuni.cz http://ktiml.mff.cuni.cz/~bartak Dnešní program Agent pracující v částečně pozorovatelném prostředí udržuje na základě senzorického modelu
Odhad parametrů N(µ, σ 2 )
") Odhad parametrů N(µ, σ 2 ) Mějme statistický soubor x 1, x 2,, x n modelovaný jako realizaci náhodného výběru z normálního rozdělení N(µ, σ 2 ) s neznámými parametry µ a σ. Jaký je maximální věrohodný
Odhad parametrů N(µ, σ 2 ) Mějme statistický soubor x 1, x 2,, x n modelovaný jako realizaci náhodného výběru z normálního rozdělení N(µ, σ 2 ) s neznámými parametry µ a σ. Jaký je maximální věrohodný
Markovovy modely v Bioinformatice
 Markovovy modely v Bioinformatice Outline Markovovy modely obecně Profilové HMM Další použití HMM v Bioinformatice Analýza biologických sekvencí Biologické sekvence: DNA,RNA,protein prim.str. Sekvenování
Markovovy modely v Bioinformatice Outline Markovovy modely obecně Profilové HMM Další použití HMM v Bioinformatice Analýza biologických sekvencí Biologické sekvence: DNA,RNA,protein prim.str. Sekvenování
PSY117/454 Statistická analýza dat v psychologii přednáška 8. Statistické usuzování, odhady
 PSY117/454 Statistická analýza dat v psychologii přednáška 8 Statistické usuzování, odhady Výběr od deskripce k indukci Deskripce dat, odhad parametrů Usuzování = inference = indukce Počítá se s náhodným
PSY117/454 Statistická analýza dat v psychologii přednáška 8 Statistické usuzování, odhady Výběr od deskripce k indukci Deskripce dat, odhad parametrů Usuzování = inference = indukce Počítá se s náhodným
Bayesovské rozhodování - kritétium minimální střední ztráty
 Bayesovské rozhodování - kritétium imální střední ztráty Lukáš Slánský, Ivana Čapková 6. června 2001 1 Formulace úlohy JE DÁNO: X množina možných pozorování (příznaků) x K množina hodnot skrytého parametru
Bayesovské rozhodování - kritétium imální střední ztráty Lukáš Slánský, Ivana Čapková 6. června 2001 1 Formulace úlohy JE DÁNO: X množina možných pozorování (příznaků) x K množina hodnot skrytého parametru
n = 2 Sdružená distribuční funkce (joint d.f.) n. vektoru F (x, y) = P (X x, Y y)
 n. vektoru F (x, y) = P (X x, Y y)") 5. NÁHODNÝ VEKTOR 5.1. Rozdělení náhodného vektoru Náhodný vektor X = (X 1, X 2,..., X n ) T n-rozměrný vektor, složky X i, i = 1,..., n náhodné veličiny. Vícerozměrná (n-rozměrná) náhodná veličina n =
5. NÁHODNÝ VEKTOR 5.1. Rozdělení náhodného vektoru Náhodný vektor X = (X 1, X 2,..., X n ) T n-rozměrný vektor, složky X i, i = 1,..., n náhodné veličiny. Vícerozměrná (n-rozměrná) náhodná veličina n =
Pravděpodobnost a statistika, Biostatistika pro kombinované studium. Jan Kracík
 Pravděpodobnost a statistika, Biostatistika pro kombinované studium Letní semestr 2017/2018 Tutoriál č. 2:, náhodný vektor Jan Kracík jan.kracik@vsb.cz náhodná veličina rozdělení pravděpodobnosti náhodné
Pravděpodobnost a statistika, Biostatistika pro kombinované studium Letní semestr 2017/2018 Tutoriál č. 2:, náhodný vektor Jan Kracík jan.kracik@vsb.cz náhodná veličina rozdělení pravděpodobnosti náhodné
Výběrové charakteristiky a jejich rozdělení
 Katedra ekonometrie, FVL, UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Statistické šetření úplné (vyčerpávající) neúplné (výběrové) U výběrového šetření se snažíme o to, aby výběrový
Katedra ekonometrie, FVL, UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Statistické šetření úplné (vyčerpávající) neúplné (výběrové) U výběrového šetření se snažíme o to, aby výběrový
Dobývání znalostí. Doc. RNDr. Iveta Mrázová, CSc. Katedra teoretické informatiky Matematicko-fyzikální fakulta Univerzity Karlovy v Praze
 Dobývání znalostí Doc. RNDr. Iveta Mrázová, CSc. Katedra teoretické informatiky Matematicko-fyzikální fakulta Univerzity Karlovy v Praze Dobývání znalostí Bayesovské modely Doc. RNDr. Iveta Mrázová, CSc.
Dobývání znalostí Doc. RNDr. Iveta Mrázová, CSc. Katedra teoretické informatiky Matematicko-fyzikální fakulta Univerzity Karlovy v Praze Dobývání znalostí Bayesovské modely Doc. RNDr. Iveta Mrázová, CSc.
Department of Mathematical Analysis and Applications of Mathematics Faculty of Science, Palacký University Olomouc Czech Republic
 ROBUST 13. září 2016 regression regresních modelů Categorical Continuous - explanatory, Eva Fišerová Department of Mathematical Analysis and Applications of Mathematics Faculty of Science, Palacký University
ROBUST 13. září 2016 regression regresních modelů Categorical Continuous - explanatory, Eva Fišerová Department of Mathematical Analysis and Applications of Mathematics Faculty of Science, Palacký University
Základy teorie odhadu parametrů bodový odhad
 Katedra ekonometrie, FVL, UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Odhady parametrů Úkolem výběrového šetření je podat informaci o neznámé hodnotě charakteristiky základního souboru
Katedra ekonometrie, FVL, UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Odhady parametrů Úkolem výběrového šetření je podat informaci o neznámé hodnotě charakteristiky základního souboru
Radka Picková Transformace náhodných veličin
 Univerzita Karlova v Praze Matematicko-fyzikální fakulta BAKALÁŘSKÁ PRÁCE Radka Picková Transformace náhodných veličin Katedra pravděpodobnosti a matematické statistiky Vedoucí bakalářské práce: Mgr Zdeněk
Univerzita Karlova v Praze Matematicko-fyzikální fakulta BAKALÁŘSKÁ PRÁCE Radka Picková Transformace náhodných veličin Katedra pravděpodobnosti a matematické statistiky Vedoucí bakalářské práce: Mgr Zdeněk
Katedra kybernetiky, FEL, ČVUT v Praze.
 Strojové učení a dolování dat přehled Jiří Kléma Katedra kybernetiky, FEL, ČVUT v Praze http://ida.felk.cvut.cz posnova přednášek Přednáška Učitel Obsah 1. J. Kléma Úvod do předmětu, učení s a bez učitele.
Strojové učení a dolování dat přehled Jiří Kléma Katedra kybernetiky, FEL, ČVUT v Praze http://ida.felk.cvut.cz posnova přednášek Přednáška Učitel Obsah 1. J. Kléma Úvod do předmětu, učení s a bez učitele.
Definice spojité náhodné veličiny zjednodušená verze
 Definice spojité náhodné veličiny zjednodušená verze Náhodná veličina X se nazývá spojitá, jestliže existuje nezáporná funkce f : R R taková, že pro každé a, b R { }, a < b, platí P(a < X < b) = b a f
Definice spojité náhodné veličiny zjednodušená verze Náhodná veličina X se nazývá spojitá, jestliže existuje nezáporná funkce f : R R taková, že pro každé a, b R { }, a < b, platí P(a < X < b) = b a f
Úvod do teorie odhadu. Ing. Michael Rost, Ph.D.
 Úvod do teorie odhadu Ing. Michael Rost, Ph.D. Náhodný výběr Náhodným výběrem ze základního souboru populace, která je popsána prostřednictvím hustoty pravděpodobnosti f(x, θ), budeme nazývat posloupnost
Úvod do teorie odhadu Ing. Michael Rost, Ph.D. Náhodný výběr Náhodným výběrem ze základního souboru populace, která je popsána prostřednictvím hustoty pravděpodobnosti f(x, θ), budeme nazývat posloupnost
Pravděpodobnost a statistika (BI-PST) Cvičení č. 9
 Cvičení č. 9") Pravděpodobnost a statistika (BI-PST) Cvičení č. 9 R. Blažek, M. Jiřina, J. Hrabáková, I. Petr, F. Štampach, D. Vašata Katedra aplikované matematiky Fakulta informačních technologií České vysoké učení
Pravděpodobnost a statistika (BI-PST) Cvičení č. 9 R. Blažek, M. Jiřina, J. Hrabáková, I. Petr, F. Štampach, D. Vašata Katedra aplikované matematiky Fakulta informačních technologií České vysoké učení
Statistická analýza dat v psychologii. Věci, které můžeme přímo pozorovat, jsou téměř vždy pouze vzorky. Alfred North Whitehead
 PSY117/454 Statistická analýza dat v psychologii Přednáška 8 Statistické usuzování, odhady Věci, které můžeme přímo pozorovat, jsou téměř vždy pouze vzorky. Alfred North Whitehead Barevná srdíčka kolegyně
PSY117/454 Statistická analýza dat v psychologii Přednáška 8 Statistické usuzování, odhady Věci, které můžeme přímo pozorovat, jsou téměř vždy pouze vzorky. Alfred North Whitehead Barevná srdíčka kolegyně
Lesson 02. Ing. Marek Hrúz Ph.D. Univ. of West Bohemia, Faculty of Applied Sciences, Dept. of Cybernetics. Lesson 02
 Ing. Marek Hrúz Ph.D. Univ. of West Bohemia, Faculty of Applied Sciences, Dept. of Cybernetics 30. září 2016 Mean-shift Úvod Definice Modely Optimalizace Příklad - segmentace obrazu Kriteriální funkce
Ing. Marek Hrúz Ph.D. Univ. of West Bohemia, Faculty of Applied Sciences, Dept. of Cybernetics 30. září 2016 Mean-shift Úvod Definice Modely Optimalizace Příklad - segmentace obrazu Kriteriální funkce
STATISTICKÉ ODHADY Odhady populačních charakteristik
 STATISTICKÉ ODHADY Odhady populačních charakteristik Jak stanovit charakteristiky rozložení sledované veličiny v základní populaci? Populaci většinou nemáme celou k dispozici, musíme se spokojit jen s
STATISTICKÉ ODHADY Odhady populačních charakteristik Jak stanovit charakteristiky rozložení sledované veličiny v základní populaci? Populaci většinou nemáme celou k dispozici, musíme se spokojit jen s
BAYESOVSKÉ ODHADY. Michal Friesl V NĚKTERÝCH MODELECH. Katedra matematiky Fakulta aplikovaných věd Západočeská univerzita v Plzni
 BAYESOVSKÉ ODHADY V NĚKTERÝCH MODELECH Michal Friesl Katedra matematiky Fakulta aplikovaných věd Západočeská univerzita v Plzni Slunce Řidiči IQ Regrese Přežití Obvyklý model Pozorování X = (X 1,..., X
BAYESOVSKÉ ODHADY V NĚKTERÝCH MODELECH Michal Friesl Katedra matematiky Fakulta aplikovaných věd Západočeská univerzita v Plzni Slunce Řidiči IQ Regrese Přežití Obvyklý model Pozorování X = (X 1,..., X
Pravděpodobnost, náhoda, kostky
 Pravděpodobnost, náhoda, kostky Radek Pelánek IV122, jaro 2015 Výhled pravděpodobnost náhodná čísla lineární regrese detekce shluků Dnes lehce nesourodá směs úloh souvisejících s pravděpodobností krátké
Pravděpodobnost, náhoda, kostky Radek Pelánek IV122, jaro 2015 Výhled pravděpodobnost náhodná čísla lineární regrese detekce shluků Dnes lehce nesourodá směs úloh souvisejících s pravděpodobností krátké
Měření dat Filtrace dat, Kalmanův filtr
 Měření dat Filtrace dat, Matematické metody pro ITS (11MAMY) Jan Přikryl Ústav aplikované matematiky ČVUT v Praze, Fakulta dopravní 3. přednáška 11MAMY čtvrtek 28. února 2018 verze: 2018-02-28 12:20 Obsah
Měření dat Filtrace dat, Matematické metody pro ITS (11MAMY) Jan Přikryl Ústav aplikované matematiky ČVUT v Praze, Fakulta dopravní 3. přednáška 11MAMY čtvrtek 28. února 2018 verze: 2018-02-28 12:20 Obsah
Fakulta informačních technologií VUT Brno. Předmět: Srovnání klasifikátorů Autor : Jakub Mahdal Login: xmahda03 Datum:
 Fakulta informačních technologií VUT Brno Předmět: Projekt: SRE Srovnání klasifikátorů Autor : Jakub Mahdal Login: xmahda03 Datum: 9.12.2006 Zadání Vyberte si jakékoliv 2 klasifikátory, např. GMM vs. neuronová
Fakulta informačních technologií VUT Brno Předmět: Projekt: SRE Srovnání klasifikátorů Autor : Jakub Mahdal Login: xmahda03 Datum: 9.12.2006 Zadání Vyberte si jakékoliv 2 klasifikátory, např. GMM vs. neuronová
Bayesian Networks. The graph represents conditional independencies of the join probability distribution Π X V P(X pa(x)).
).") Bayesian Networks Definition (Bayesian Network) Bayesian network is a pair (G, P), where G = (V, E) is a DAG (directed acyclic graph with set of vertexes V and set of edges E) and P is a list of conditional
Bayesian Networks Definition (Bayesian Network) Bayesian network is a pair (G, P), where G = (V, E) is a DAG (directed acyclic graph with set of vertexes V and set of edges E) and P is a list of conditional
Stochastické diferenciální rovnice
 KDM MFF UK, Praha Aplikace matematiky pro učitele 15.11.2011 Kermack-McKendrickův model Kermack-McKendrickův model s vakcinací Model pro nemoc s rychlým šířením a krátkou dobou léčby. Příkladem takovéto
KDM MFF UK, Praha Aplikace matematiky pro učitele 15.11.2011 Kermack-McKendrickův model Kermack-McKendrickův model s vakcinací Model pro nemoc s rychlým šířením a krátkou dobou léčby. Příkladem takovéto
z Matematické statistiky 1 1 Konvergence posloupnosti náhodných veličin
 Příklady k procvičení z Matematické statistiky Poslední úprava. listopadu 207. Konvergence posloupnosti náhodných veličin. Necht X, X 2... jsou nezávislé veličiny s rovnoměrným rozdělením na [0, ]. Definujme
Příklady k procvičení z Matematické statistiky Poslední úprava. listopadu 207. Konvergence posloupnosti náhodných veličin. Necht X, X 2... jsou nezávislé veličiny s rovnoměrným rozdělením na [0, ]. Definujme
Odhad parametrů N(µ, σ 2 )
") Odhad parametrů N(µ, σ 2 ) Mějme statistický soubor x 1, x 2,, x n modelovaný jako realizaci náhodného výběru z normálního rozdělení N(µ, σ 2 ) s neznámými parametry µ a σ. Jaký je maximální věrohodný
Odhad parametrů N(µ, σ 2 ) Mějme statistický soubor x 1, x 2,, x n modelovaný jako realizaci náhodného výběru z normálního rozdělení N(µ, σ 2 ) s neznámými parametry µ a σ. Jaký je maximální věrohodný
Vícerozměrná rozdělení
 Vícerozměrná rozdělení 7. září 0 Učivo: Práce s vícerozměrnými rozděleními. Sdružené, marginální, podmíněné rozdělení pravděpodobnosti. Vektorová střední hodnota. Kovariance, korelace, kovarianční matice.
Vícerozměrná rozdělení 7. září 0 Učivo: Práce s vícerozměrnými rozděleními. Sdružené, marginální, podmíněné rozdělení pravděpodobnosti. Vektorová střední hodnota. Kovariance, korelace, kovarianční matice.
1 Klasická pravděpodobnost. Bayesův vzorec. Poslední změna (oprava): 11. května 2018 ( 6 4)( 43 2 ) ( 49 6 ) 3. = (a) 1 1 2! + 1 3!
: 11. května 2018 ( 6 4)( 43 2 ) ( 49 6 ) 3. = (a) 1 1 2! + 1 3!") Výsledky příkladů na procvičení z NMSA0 Klasická pravděpodobnost. 5. ( 4( 43 ( 49 3. 8! 3! 0! = 5 Poslední změna (oprava:. května 08 4. (a! + 3! + ( n+ n! = n k= ( k+ /k! = n k=0 ( k /k!; (b n k=0 ( k
Výsledky příkladů na procvičení z NMSA0 Klasická pravděpodobnost. 5. ( 4( 43 ( 49 3. 8! 3! 0! = 5 Poslední změna (oprava:. května 08 4. (a! + 3! + ( n+ n! = n k= ( k+ /k! = n k=0 ( k /k!; (b n k=0 ( k
8-9. Pravděpodobnostní rozhodování a predikce. Gerstnerova laboratoř katedra kybernetiky fakulta elektrotechnická ČVUT v Praze
 KYBERNETIKA A UMĚLÁ INTELIGENCE 8-9. Pravděpodobnostní rozhodování a predikce laboratory Gerstner Gerstnerova laboratoř katedra kybernetiky fakulta elektrotechnická ČVUT v Praze Rozhodování za neurčitosti
KYBERNETIKA A UMĚLÁ INTELIGENCE 8-9. Pravděpodobnostní rozhodování a predikce laboratory Gerstner Gerstnerova laboratoř katedra kybernetiky fakulta elektrotechnická ČVUT v Praze Rozhodování za neurčitosti
Teorie rozhodování (decision theory)
") Umělá inteligence II Roman Barták, KTIML roman.bartak@mff.cuni.cz http://ktiml.mff.cuni.cz/~bartak Teorie pravděpodobnosti (probability theory) popisuje v co má agent věřit na základě pozorování. Teorie
Umělá inteligence II Roman Barták, KTIML roman.bartak@mff.cuni.cz http://ktiml.mff.cuni.cz/~bartak Teorie pravděpodobnosti (probability theory) popisuje v co má agent věřit na základě pozorování. Teorie
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc.
 Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika 010 1.týden (0.09.-4.09. ) Data, typy dat, variabilita, frekvenční analýza
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika 010 1.týden (0.09.-4.09. ) Data, typy dat, variabilita, frekvenční analýza
Počítačové zpracování češtiny. Kontrola pravopisu. Daniel Zeman
 Počítačové zpracování češtiny Kontrola pravopisu Daniel Zeman http://ufal.mff.cuni.cz/daniel-zeman/ Úloha Rozpoznat slovo, které není ve slovníku Triviální Těžší je rozpoznat slovo, které ve slovníku je,
Počítačové zpracování češtiny Kontrola pravopisu Daniel Zeman http://ufal.mff.cuni.cz/daniel-zeman/ Úloha Rozpoznat slovo, které není ve slovníku Triviální Těžší je rozpoznat slovo, které ve slovníku je,
Vojtěch Franc. Biometrie ZS Poděkování Janu Šochmanovi za slajdy vysvětlující AdaBoost
 Rozpoznávání tváří I Vojtěch Franc Centrum strojového vnímání, ČVUT FEL Praha Biometrie ZS 2013 Poděkování Janu Šochmanovi za slajdy vysvětlující AdaBoost Úlohy rozpoznávání tváří: Detekce Cíl: lokalizovat
Rozpoznávání tváří I Vojtěch Franc Centrum strojového vnímání, ČVUT FEL Praha Biometrie ZS 2013 Poděkování Janu Šochmanovi za slajdy vysvětlující AdaBoost Úlohy rozpoznávání tváří: Detekce Cíl: lokalizovat
Bodové odhady parametrů a výstupů
 Bodové odhady parametrů a výstupů 26. listopadu 2013 Máme rozdělení s neznámými parametry a chceme odhadnout jeden nebo několik příštích výstupů. Již víme, že úplnou informaci v této situaci nese sdružené
Bodové odhady parametrů a výstupů 26. listopadu 2013 Máme rozdělení s neznámými parametry a chceme odhadnout jeden nebo několik příštích výstupů. Již víme, že úplnou informaci v této situaci nese sdružené
Instance based learning
 Učení založené na instancích Instance based learning Charakteristika IBL (nejbližších sousedů) Tyto metody nepředpokládají určitý model nejsou strukturované a typicky nejsou příliš užitečné pro porozumění
Učení založené na instancích Instance based learning Charakteristika IBL (nejbližších sousedů) Tyto metody nepředpokládají určitý model nejsou strukturované a typicky nejsou příliš užitečné pro porozumění
5. B o d o v é o d h a d y p a r a m e t r ů
 5. B o d o v é o d h a d y p a r a m e t r ů Na základě hodnot náhodného výběru z rozdělení určitého typu odhadujeme parametry tohoto rozdělení, tak aby co nejlépe odpovídaly hodnotám výběru. Formulujme
5. B o d o v é o d h a d y p a r a m e t r ů Na základě hodnot náhodného výběru z rozdělení určitého typu odhadujeme parametry tohoto rozdělení, tak aby co nejlépe odpovídaly hodnotám výběru. Formulujme
Neparametrické odhady hustoty pravděpodobnosti
 Neparametrické odhady hustoty pravděpodobnosti Václav Hlaváč Elektrotechnická fakulta ČVUT Katedra kybernetiky Centrum strojového vnímání 121 35 Praha 2, Karlovo nám. 13 hlavac@fel.cvut.cz Statistické
Neparametrické odhady hustoty pravděpodobnosti Václav Hlaváč Elektrotechnická fakulta ČVUT Katedra kybernetiky Centrum strojového vnímání 121 35 Praha 2, Karlovo nám. 13 hlavac@fel.cvut.cz Statistické
MATEMATICKÁ STATISTIKA. Katedra matematiky a didaktiky matematiky Technická univerzita v Liberci
 MATEMATICKÁ STATISTIKA Dana Černá http://www.fp.tul.cz/kmd/ Katedra matematiky a didaktiky matematiky Technická univerzita v Liberci Matematická statistika Matematická statistika se zabývá matematickým
MATEMATICKÁ STATISTIKA Dana Černá http://www.fp.tul.cz/kmd/ Katedra matematiky a didaktiky matematiky Technická univerzita v Liberci Matematická statistika Matematická statistika se zabývá matematickým
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz
 Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická
Šárka Došlá. Matematicko-fyzikální fakulta Univerzita Karlova v Praze. Bimodální rozdělení. Šárka Došlá. Motivace. Základní pojmy
 Matematicko-fyzikální fakulta Univerzita Karlova v Praze 1/20 Joiner (1975): Histogram výšky studentů, který ilustruje bimodalitu lidské výšky. Schilling a kol. (2002): Ve skutečnosti bylo dané unimodální!
Matematicko-fyzikální fakulta Univerzita Karlova v Praze 1/20 Joiner (1975): Histogram výšky studentů, který ilustruje bimodalitu lidské výšky. Schilling a kol. (2002): Ve skutečnosti bylo dané unimodální!
Pravděpodobnost a statistika
 Pravděpodobnost a statistika Náhodné vektory Vilém Vychodil KMI/PRAS, Přednáška 8 Vytvořeno v rámci projektu 2963/2011 FRVŠ V. Vychodil (KMI/PRAS, Přednáška 8) Náhodné vektory Pravděpodobnost a statistika
Pravděpodobnost a statistika Náhodné vektory Vilém Vychodil KMI/PRAS, Přednáška 8 Vytvořeno v rámci projektu 2963/2011 FRVŠ V. Vychodil (KMI/PRAS, Přednáška 8) Náhodné vektory Pravděpodobnost a statistika
prof. RNDr. Roman Kotecký DrSc., Dr. Rudolf Blažek, PhD Pravděpodobnost a statistika Katedra teoretické informatiky Fakulta informačních technologií
 prof. RNDr. Roman Kotecký DrSc., Dr. Rudolf Blažek, PhD Katedra teoretické informatiky Fakulta informačních technologií České vysoké učení technické v Praze c Rudolf Blažek, Roman Kotecký, 2011 Pravděpodobnost
prof. RNDr. Roman Kotecký DrSc., Dr. Rudolf Blažek, PhD Katedra teoretické informatiky Fakulta informačních technologií České vysoké učení technické v Praze c Rudolf Blažek, Roman Kotecký, 2011 Pravděpodobnost
a způsoby jejího popisu Ing. Michael Rost, Ph.D.
 Podmíněná pravděpodobnost, náhodná veličina a způsoby jejího popisu Ing. Michael Rost, Ph.D. Podmíněná pravděpodobnost Pokud je jev A vázán na uskutečnění jevu B, pak tento jev nazýváme jevem podmíněným
Podmíněná pravděpodobnost, náhodná veličina a způsoby jejího popisu Ing. Michael Rost, Ph.D. Podmíněná pravděpodobnost Pokud je jev A vázán na uskutečnění jevu B, pak tento jev nazýváme jevem podmíněným
Apriorní rozdělení. Jan Kracík.
 Apriorní rozdělení Jan Kracík jan.kracik@vsb.cz Apriorní rozdělení Apriorní rozdělení (spolu s modelem) reprezentuje informaci o neznámém parametru θ, která je dostupná předem, tj. bez informace z dat.
Apriorní rozdělení Jan Kracík jan.kracik@vsb.cz Apriorní rozdělení Apriorní rozdělení (spolu s modelem) reprezentuje informaci o neznámém parametru θ, která je dostupná předem, tj. bez informace z dat.
TECHNICKÁ UNIVERZITA V LIBERCI
 TECHNICKÁ UNIVERZITA V LIBERCI Fakulta mechatroniky, informatiky a mezioborových studií Základní pojmy diagnostiky a statistických metod vyhodnocení Učební text Ivan Jaksch Liberec 2012 Materiál vznikl
TECHNICKÁ UNIVERZITA V LIBERCI Fakulta mechatroniky, informatiky a mezioborových studií Základní pojmy diagnostiky a statistických metod vyhodnocení Učební text Ivan Jaksch Liberec 2012 Materiál vznikl
ROZPOZNÁVÁNÍ S MARKOVSKÝMI MODELY
 ROZPOZNÁVÁNÍ S MARKOVSKÝMI MODELY Václav Hlaváč Fakulta elektrotechnická ČVUT v Praze katedra kybernetiky, Centrum strojového vnímání hlavac@fel.cvut.cz, http://cmp.felk.cvut.cz/ hlavac 1/31 PLÁN PŘEDNÁŠKY
ROZPOZNÁVÁNÍ S MARKOVSKÝMI MODELY Václav Hlaváč Fakulta elektrotechnická ČVUT v Praze katedra kybernetiky, Centrum strojového vnímání hlavac@fel.cvut.cz, http://cmp.felk.cvut.cz/ hlavac 1/31 PLÁN PŘEDNÁŠKY
Strukturální regresní modely. určitý nadhled nad rozličnými typy modelů
 Strukturální regresní modely určitý nadhled nad rozličnými typy modelů Jde zlepšit odhad k-nn? Odhad k-nn konverguje pro slušné k očekávané hodnotě. ALE POMALU! Jiné přístupy přidají předpoklad o funkci
Strukturální regresní modely určitý nadhled nad rozličnými typy modelů Jde zlepšit odhad k-nn? Odhad k-nn konverguje pro slušné k očekávané hodnotě. ALE POMALU! Jiné přístupy přidají předpoklad o funkci
6. ZÁKLADY STATIST. ODHADOVÁNÍ. Θ parametrický prostor. Dva základní způsoby odhadu neznámého vektoru parametrů bodový a intervalový.
 6. ZÁKLADY STATIST. ODHADOVÁNÍ X={X 1, X 2,..., X n } výběr z rozdělení s F (x, θ), θ={θ 1,..., θ r } - vektor reálných neznámých param. θ Θ R k. Θ parametrický prostor. Dva základní způsoby odhadu neznámého
6. ZÁKLADY STATIST. ODHADOVÁNÍ X={X 1, X 2,..., X n } výběr z rozdělení s F (x, θ), θ={θ 1,..., θ r } - vektor reálných neznámých param. θ Θ R k. Θ parametrický prostor. Dva základní způsoby odhadu neznámého
ANALÝZA A KLASIFIKACE DAT
 ANALÝZA A KLASIFIKACE DAT prof. Ing. Jiří Holčík, CSc. INVESTICE Institut DO biostatistiky ROZVOJE VZDĚLÁVÁNÍ a analýz III. PŘÍZNAKOVÁ KLASIFIKACE - ÚVOD PŘÍZNAKOVÝ POPIS Příznakový obraz x zpracovávaných
ANALÝZA A KLASIFIKACE DAT prof. Ing. Jiří Holčík, CSc. INVESTICE Institut DO biostatistiky ROZVOJE VZDĚLÁVÁNÍ a analýz III. PŘÍZNAKOVÁ KLASIFIKACE - ÚVOD PŘÍZNAKOVÝ POPIS Příznakový obraz x zpracovávaných
Nestranný odhad Statistické vyhodnocování exp. dat M. Čada
 Nestranný odhad 1 Parametr θ Máme statistický (výběrový) soubor, který je realizací náhodného výběru 1, 2, 3,, n z pravděpodobnostní distribuce, která je kompletně stanovena jedním nebo více parametry
Nestranný odhad 1 Parametr θ Máme statistický (výběrový) soubor, který je realizací náhodného výběru 1, 2, 3,, n z pravděpodobnostní distribuce, která je kompletně stanovena jedním nebo více parametry
Vlastnosti a modelování aditivního
 Vlastnosti a modelování aditivního bílého šumu s normálním rozdělením kacmarp@fel.cvut.cz verze: 0090913 1 Bílý šum s normálním rozdělením V této kapitole se budeme zabývat reálným gaussovským šumem n(t),
Vlastnosti a modelování aditivního bílého šumu s normálním rozdělením kacmarp@fel.cvut.cz verze: 0090913 1 Bílý šum s normálním rozdělením V této kapitole se budeme zabývat reálným gaussovským šumem n(t),
Pravděpodobnostní algoritmy
 Pravděpodobnostní algoritmy 17. a 18. přednáška z kryptografie Alena Gollová 1/31 Obsah 1 Diskrétní rozdělení náhodné veličiny Algoritmus Generate and Test 2 Alena Gollová 2/31 Diskrétní rozdělení náhodné
Pravděpodobnostní algoritmy 17. a 18. přednáška z kryptografie Alena Gollová 1/31 Obsah 1 Diskrétní rozdělení náhodné veličiny Algoritmus Generate and Test 2 Alena Gollová 2/31 Diskrétní rozdělení náhodné
Ústav matematiky a statistiky Masarykova univerzita Brno. workshopy Finanční matematika v praxi III Matematické modely a aplikace Podlesí
 Ústav matematiky a statistiky Masarykova univerzita Brno workshopy Finanční matematika v praxi III Matematické modely a aplikace Podlesí 3. 6. září 2013 Obsah 1 2 3 4 y Motivace y 10 0 10 20 30 40 0 5
Ústav matematiky a statistiky Masarykova univerzita Brno workshopy Finanční matematika v praxi III Matematické modely a aplikace Podlesí 3. 6. září 2013 Obsah 1 2 3 4 y Motivace y 10 0 10 20 30 40 0 5
Rozdělování dat do trénovacích a testovacích množin
 Rozdělování dat do trénovacích a testovacích množin Marcel Jiřina Rozpoznávání je důležitou metodou při zpracování reálných úloh. Rozpoznávání je definováno dvěma kroky a to pořízením dat o reálném rozpoznávaném
Rozdělování dat do trénovacích a testovacích množin Marcel Jiřina Rozpoznávání je důležitou metodou při zpracování reálných úloh. Rozpoznávání je definováno dvěma kroky a to pořízením dat o reálném rozpoznávaném
Kapitola 1. Logistická regrese. 1.1 Model
 Kapitola Logistická regrese Předpokládám, že už jsme zavedli základní pojmy jako rysy a že už máme nějaké značení Velkost trenovacich dat a pocet parametru Motivační povídání... jeden z nejpoužívanějších
Kapitola Logistická regrese Předpokládám, že už jsme zavedli základní pojmy jako rysy a že už máme nějaké značení Velkost trenovacich dat a pocet parametru Motivační povídání... jeden z nejpoužívanějších
Diskriminační analýza hodnocení rozdílů mezi 2 nebo více skupinami objektů charakterizovanými více znaky
 Diskriminační analýza hodnocení rozdílů mezi 2 nebo více skupinami objektů charakterizovanými více znaky Interpretují rozdíly mezi předem stanovenými třídami Cílem je klasifikace objektů do skupin Hledáme
Diskriminační analýza hodnocení rozdílů mezi 2 nebo více skupinami objektů charakterizovanými více znaky Interpretují rozdíly mezi předem stanovenými třídami Cílem je klasifikace objektů do skupin Hledáme
Základy počtu pravděpodobnosti a metod matematické statistiky
 Errata ke skriptu Základy počtu pravděpodobnosti a metod matematické statistiky K. Hron a P. Kunderová Autoři prosí čtenáře uvedeného studijního textu, aby případné další odhalené chyby nad rámec tohoto
Errata ke skriptu Základy počtu pravděpodobnosti a metod matematické statistiky K. Hron a P. Kunderová Autoři prosí čtenáře uvedeného studijního textu, aby případné další odhalené chyby nad rámec tohoto
KVADRATICKÁ KALIBRACE
 Petra Širůčková, prof. RNDr. Gejza Wimmer, DrSc. Finanční matematika v praxi III. a Matematické modely a aplikace 4. 9. 2013 Osnova Kalibrace 1 Kalibrace Pojem kalibrace Cíle kalibrace Předpoklady 2 3
Petra Širůčková, prof. RNDr. Gejza Wimmer, DrSc. Finanční matematika v praxi III. a Matematické modely a aplikace 4. 9. 2013 Osnova Kalibrace 1 Kalibrace Pojem kalibrace Cíle kalibrace Předpoklady 2 3
Náhodné vektory a matice
 Náhodné vektory a matice Jiří Militký Katedra textilních materiálů Technická Universita Liberec, Červeně označené slide jsou jen pro doplnění informací a nezkouší se. Symbolika A B Jev jistý S (nastane
Náhodné vektory a matice Jiří Militký Katedra textilních materiálů Technická Universita Liberec, Červeně označené slide jsou jen pro doplnění informací a nezkouší se. Symbolika A B Jev jistý S (nastane
Definice 7.1 Nechť je dán pravděpodobnostní prostor (Ω, A, P). Zobrazení. nebo ekvivalentně
. Zobrazení. nebo ekvivalentně") 7 Náhodný vektor Nezávislost náhodných veličin Definice 7 Nechť je dán pravděpodobnostní prostor (Ω, A, P) Zobrazení X : Ω R n, které je A-měřitelné, se nazývá (n-rozměrný) náhodný vektor Měřitelností
7 Náhodný vektor Nezávislost náhodných veličin Definice 7 Nechť je dán pravděpodobnostní prostor (Ω, A, P) Zobrazení X : Ω R n, které je A-měřitelné, se nazývá (n-rozměrný) náhodný vektor Měřitelností
Uni- and multi-dimensional parametric tests for comparison of sample results
 Uni- and multi-dimensional parametric tests for comparison of sample results Jedno- a více-rozměrné parametrické testy k porovnání výsledků Prof. RNDr. Milan Meloun, DrSc. Katedra analytické chemie, Universita
Uni- and multi-dimensional parametric tests for comparison of sample results Jedno- a více-rozměrné parametrické testy k porovnání výsledků Prof. RNDr. Milan Meloun, DrSc. Katedra analytické chemie, Universita
Gymnázium, Brno, Slovanské nám. 7 WORKBOOK. Mathematics. Teacher: Student:
 WORKBOOK Subject: Teacher: Student: Mathematics.... School year:../ Conic section The conic sections are the nondegenerate curves generated by the intersections of a plane with one or two nappes of a cone.
WORKBOOK Subject: Teacher: Student: Mathematics.... School year:../ Conic section The conic sections are the nondegenerate curves generated by the intersections of a plane with one or two nappes of a cone.
Pravděpodobnost a aplikovaná statistika
 Pravděpodobnost a aplikovaná statistika MGR. JANA SEKNIČKOVÁ, PH.D. 2. KAPITOLA PODMÍNĚNÁ PRAVDĚPODOBNOST 3. KAPITOLA NÁHODNÁ VELIČINA 9.11.2017 Opakování Uveďte příklad aplikace geometrické definice pravděpodobnosti
Pravděpodobnost a aplikovaná statistika MGR. JANA SEKNIČKOVÁ, PH.D. 2. KAPITOLA PODMÍNĚNÁ PRAVDĚPODOBNOST 3. KAPITOLA NÁHODNÁ VELIČINA 9.11.2017 Opakování Uveďte příklad aplikace geometrické definice pravděpodobnosti
Pravděpodobnost a statistika
 Pravděpodobnost a statistika Bodové odhady a intervaly spolehlivosti Vilém Vychodil KMI/PRAS, Přednáška 10 Vytvořeno v rámci projektu 963/011 FRVŠ V. Vychodil (KMI/PRAS, Přednáška 10) Bodové odhady a intervaly
Pravděpodobnost a statistika Bodové odhady a intervaly spolehlivosti Vilém Vychodil KMI/PRAS, Přednáška 10 Vytvořeno v rámci projektu 963/011 FRVŠ V. Vychodil (KMI/PRAS, Přednáška 10) Bodové odhady a intervaly