Část 2 POROVNÁNÍ VÝKONNOSTI A POUŽITELNOSTI ARCHITEKTUR V TYPICKÝCH APLIKACÍCH
|
|
|
- Michaela Hájková
- před 8 lety
- Počet zobrazení:
Transkript
1 Část 2 POROVNÁNÍ VÝKONNOSTI A POUŽITELNOSTI ARCHITEKTUR V TYPICKÝCH APLIKACÍCH

2 Paralelizace kódu Rozdíl v přístupu k paralelizaci kódu si ukážeme na operaci násobení matice maticí: Mějme tři čtvercové matice A, B a C uložené v 2D polích Řád všech matic je size. Matice A a B vynásobíme do matice C tak, že do každého prvku C[i][j] přiřadíme hodnotu skalárního součinu i-tého řádku z matice A a j-tého sloupce z matice B. 2

3 Násobení matic (sekvenční kód) for(row = 0; row < size; row++) { }} for (column = 0; column < size; column++) { pom= 0; for(int position = 0; position < size; position++) { pom + = MA[row][position] * MB[position][column];} MC[row][column]=pom; Složitost je O(size^3) Úvaha: Každý prvek výstupní matice C je počítán nezávisle. Pak pro maximální míru paralelismu je dobré pro každý prvek vytvořit vlastní vlákno, které vypočítá jeho hodnotu. To znamená vynásobí řádek matice A sloupcem matice B. 3
![MC[row][column]=pom; Složitost je O(size^3) Úvaha: Každý prvek výstupní matice C je počítán nezávisle.](/docs-images/46/18163476/images/page_3.jpg "Pak pro maximální míru paralelismu je dobré pro každý prvek vytvořit vlastní vlákno, které vypočítá jeho hodnotu.")
4 Násobení matic ( pomocí OpenMP) #pragma parallel for numthreads(size*size) schedule(static,1) \ shared(a, B, C, size) private(column, row, position) collapse(2) for(row = 0; row < size; row++) { for (column = 0; column < size; column++) { pom=0; for(int position = 0; position < size; position++) { pom+ = MA[row][position] * MB[position][column];} MC[row][column] = pom; }} 4
 { pom+ = MA[row][position] * MB[position][column];} MC[row][column] = pom;")
5 Násobení matic (GPU kód) void kernel (int row, int column) { int position ; float pom=0.0; for(int position = 0; position < size; position++) { pom += MA[row][position] * MB[position][column]; MC[row][column]=pom;} void main() { Nakopíruj data (matice A a B) z hlavní paměti do paměti GPU. Spusť size*size vláken (instancí kernelu) s příslušnými parametry row a column. Nakopíruj data (matice C) z paměti GPU do hlavní paměti. } Zajímavé je, že se ztratily dva for cykly. 5
![MC[row][column]=pom;} void main() { Nakopíruj data (matice A a B) z hlavní paměti do paměti GPU.](/docs-images/46/18163476/images/page_5.jpg "Spusť size*size vláken (instancí kernelu) s příslušnými parametry row a column.")
6 Násobení matic (CPU) - závěry CPU verze má problémy s vytvoření velkého počtu vláken (stovky až tisíce). Výpočet má příliš velkou granularitu, paralelizace nepokryje režii tvorby, synchronizace a zániku vláken. Na CPU je nejefektivnější (u úloh tohoto typu) vytvářet počet vláken rovný počtu fyzických jader. To znamená neparalelizovat výpočet na úrovni prvků matice C, ale na úrovni bloků for cyklu pro proměnou row (cyklus nejvíce vně). Výkon upravené CPU verze není velký (toto je způsobeno naivní implementací), ale zrychlení je lineární. 6
.")
7 Násobení matic (GPU) - závěry GPU verze nemá (díky HW akceleraci) problémy s vytvoření velkého počtu vláken (stovky až tisíce). Další zjemňování nemá smysl, ale nemá velký dopad na výkon. Výkon této GPU verze není velký, toto je způsobeno naivní implementací. 7

8 ANSYS Mechanical V145sp-5 and Xeon Phi It supports only SMP in ANSYS Mechanical DMP support is part of the Intel MKL roadmap. Figure 1: Best run times for ANSYS Mechanical on V145sp-5 With two cores, the Intel Xeon Phi coprocessor provided a nearly 2X performance improvement over the baseline.

9 ANSYS Mechanical V145sp-5 and Xeon Phi With only two licensed CPU cores and the Intel Xeon Phi coprocessor (which counts as a third core for license purposes), the benchmark ran 1.72x faster with Intel Xeon Phi coprocessor support.

10 ANSYS and CUDA NVIDIA GPUs support the following products: Mechanical: ANSYS Mechanical 15.0 supports a full feature set including use on multiple GPUs. Fluids: ANSYS Fluent 15.0 offers GPU support for pressure-based coupled solver and for radiation heat transfer models. ANSYS Nexxim 15.0 supports a full feature set; ANSYS HFSS supports transient solver in 15.0.


11 ANSYS and CUDA
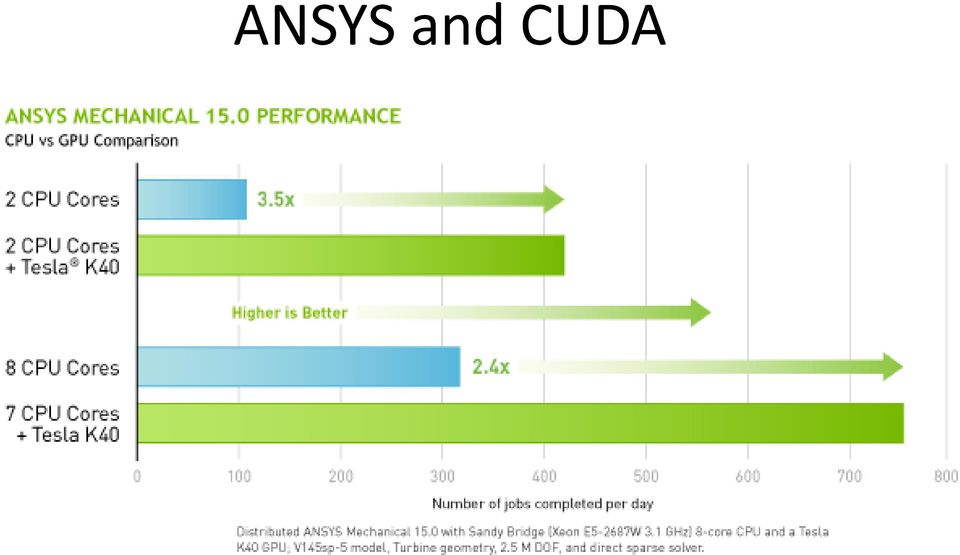

12 ANSYS and CUDA


13 LU factorization (Xeon Phi, MKL DGETRF)
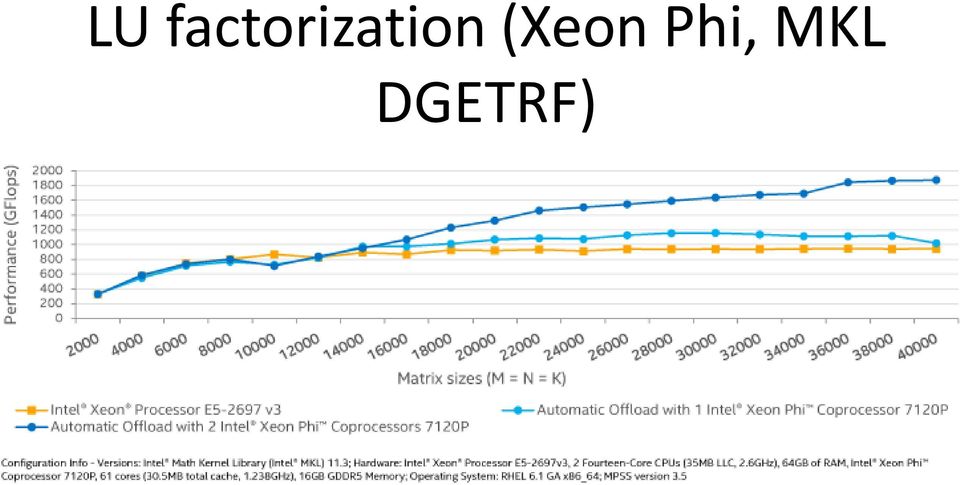
")
14 MMM (Xeon Phi, MKL)

15 cublas K40m: max. perf. 4.3 Tflops for SP and 1.3 Tflops for DP (GEMM= MMM, SYMM=MMM for symmetric matrix, TRSM= solves a triangular matrix equation, SYRK = a symmetric rank-k update)

16 cublas vs MKL cublas on K40m, ECC ON, input and output data on device. MKL on Intel IvyBridge single socket 12 - core E GHz???? operace


17 cusolver Dense vs. MKL
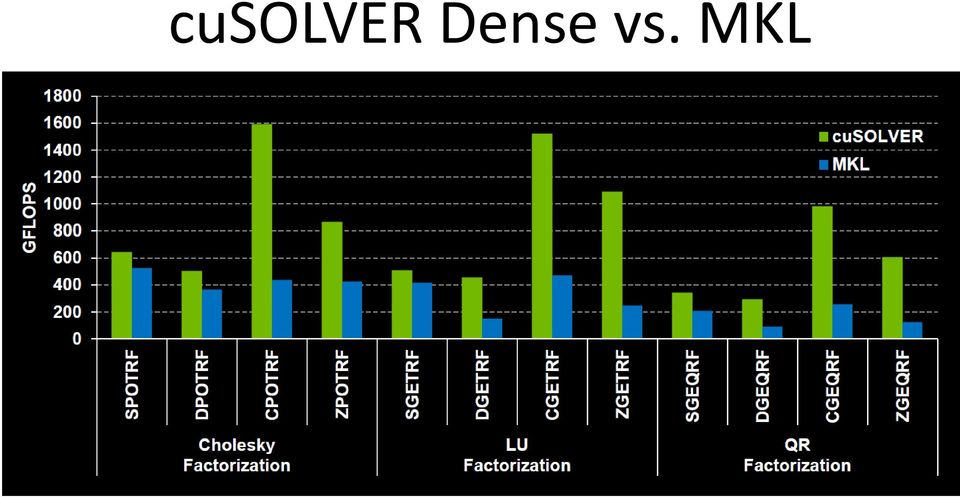
18 cusparse: Sparse linear algebra 4x Faster than MKL routines Optimized sparse linear algebra BLAS routines for matrix-vector, matrix-matrix, triangular solve Support for variety of formats (CSR, COO, block variants) Incomplete-LU and Cholesky preconditioners New in CUDA 7.0: Graph Coloring
 Incomplete-LU and Cholesky preconditioners New in CUDA 7.")

19 cusolver Sparse QR


20 NPP Speedup vs. Intel IPP


21 cudnn Version 2
22 SI porovnání architektur CPU +silné 1 vlákno - nejnižší max. výkonnost -- SIMD + uniformita vláken - režie synchro Xeon Phi +-slabší 1 vlákno ++ vyšší max. výkonnost - SIMD + uniformita vláken - režie synchro - vlastní paměť + paměť rychlejší + cache srovnatelná ++ možno efektivně použít OpenMP +++ jednodušší portace GPU --slabé 1 vlákno +++ nejvyšší max. výkonnost? SIMT - nutno rozdělit na bloky vláken + synchronizace / komunikace v bloku - synchronizace / komunikace mimo blok - vlastní paměť + paměť rychlejší - Nutnost CUDA
Úvod do GPGPU J. Sloup, I. Šimeček
 Úvod do GPGPU J. Sloup, I. Šimeček xsimecek@fit.cvut.cz Katedra počítačových systémů FIT České vysoké učení technické v Praze Ivan Šimeček, 2011 MI-PRC, LS2010/11, Predn.3 Příprava studijního programu
Úvod do GPGPU J. Sloup, I. Šimeček xsimecek@fit.cvut.cz Katedra počítačových systémů FIT České vysoké učení technické v Praze Ivan Šimeček, 2011 MI-PRC, LS2010/11, Predn.3 Příprava studijního programu
GPGPU. Jan Faigl. Gerstnerova Laboratoř pro inteligentní rozhodování a řízení České vysoké učení technické v Praze
 GPGPU Jan Faigl Gerstnerova Laboratoř pro inteligentní rozhodování a řízení České vysoké učení technické v Praze 8. cvičení katedra kybernetiky, FEL, ČVUT v Praze X33PTE - Programovací techniky GPGPU 1
GPGPU Jan Faigl Gerstnerova Laboratoř pro inteligentní rozhodování a řízení České vysoké učení technické v Praze 8. cvičení katedra kybernetiky, FEL, ČVUT v Praze X33PTE - Programovací techniky GPGPU 1
Obecné výpočty na GPU v jazyce CUDA. Jiří Filipovič
 Obecné výpočty na GPU v jazyce CUDA Jiří Filipovič Obsah přednášky motivace architektura GPU CUDA programovací model jaké algoritmy urychlovat na GPU? optimalizace Motivace Moorův zákon stále platí pro
Obecné výpočty na GPU v jazyce CUDA Jiří Filipovič Obsah přednášky motivace architektura GPU CUDA programovací model jaké algoritmy urychlovat na GPU? optimalizace Motivace Moorův zákon stále platí pro
GPGPU Aplikace GPGPU. Obecné výpočty na grafických procesorech. Jan Vacata
 Obecné výpočty na grafických procesorech Motivace Úvod Motivace Technologie 3 GHz Intel Core 2 Extreme QX9650 Výkon: 96 GFLOPS Propustnost paměti: 21 GB/s Orientační cena: 1300 USD NVIDIA GeForce 9800
Obecné výpočty na grafických procesorech Motivace Úvod Motivace Technologie 3 GHz Intel Core 2 Extreme QX9650 Výkon: 96 GFLOPS Propustnost paměti: 21 GB/s Orientační cena: 1300 USD NVIDIA GeForce 9800
Paralelní systémy. SIMD jeden tok instrukcí + více toků dat jedním programem je zpracováváno více různých souborů dat
 Paralelní systémy Paralelním systémem rozumíme takový systém, který paralelně zpracovává více samostatných úloh nebo zpracování určité úlohy automaticky rozdělí do menších částí a paralelně je zpracovává.
Paralelní systémy Paralelním systémem rozumíme takový systém, který paralelně zpracovává více samostatných úloh nebo zpracování určité úlohy automaticky rozdělí do menších částí a paralelně je zpracovává.
GPU A CUDA HISTORIE GPU CO JE GPGPU? NVIDIA CUDA
 GPU A CUDA HISTORIE GPU CO JE GPGPU? NVIDIA CUDA HISTORIE GPU GPU = graphics processing unit jde o akcelerátory pro algoritmy v 3D grafice a vizualizaci mnoho z nich původně vzniklo pro účely počítačových
GPU A CUDA HISTORIE GPU CO JE GPGPU? NVIDIA CUDA HISTORIE GPU GPU = graphics processing unit jde o akcelerátory pro algoritmy v 3D grafice a vizualizaci mnoho z nich původně vzniklo pro účely počítačových
Jiné výpočetní platformy J. Sloup, M. Skrbek, I. Šimeček
 Jiné výpočetní platformy J. Sloup, M. Skrbek, I. Šimeček xsimecek@fit.cvut.cz Katedra počítačových systémů FIT České vysoké učení technické v Praze Ivan Šimeček, 2011 BI-EIA, ZS2011/12, Predn.12 Příprava
Jiné výpočetní platformy J. Sloup, M. Skrbek, I. Šimeček xsimecek@fit.cvut.cz Katedra počítačových systémů FIT České vysoké učení technické v Praze Ivan Šimeček, 2011 BI-EIA, ZS2011/12, Predn.12 Příprava
Část 4 NOVÉ RYSY CUDA, NOVINKY V OBLASTI NÁSTROJŮ PRO CUDA
 Část 4 NOVÉ RYSY CUDA, NOVINKY V OBLASTI NÁSTROJŮ PRO CUDA Základní nástroje pro CUDA Linux: CUDA-gdb (debug) Memcheck (i racecheck) Visual Profiler MS Windows Nsight (integruje výše zmíněné) Společná
Část 4 NOVÉ RYSY CUDA, NOVINKY V OBLASTI NÁSTROJŮ PRO CUDA Základní nástroje pro CUDA Linux: CUDA-gdb (debug) Memcheck (i racecheck) Visual Profiler MS Windows Nsight (integruje výše zmíněné) Společná
Paralelní a distribuované výpočty (B4B36PDV)
") Paralelní a distribuované výpočty (B4B36PDV) Branislav Bošanský, Michal Jakob bosansky@fel.cvut.cz Artificial Intelligence Center Department of Computer Science Faculty of Electrical Engineering Czech
Paralelní a distribuované výpočty (B4B36PDV) Branislav Bošanský, Michal Jakob bosansky@fel.cvut.cz Artificial Intelligence Center Department of Computer Science Faculty of Electrical Engineering Czech
Jedna z nejdůležitějších součástek počítače = mozek počítače, bez něhož není počítač schopen vykonávat žádné operace.
 Procesor Jedna z nejdůležitějších součástek počítače = mozek počítače, bez něhož není počítač schopen vykonávat žádné operace. Procesor v počítači plní funkci centrální jednotky (CPU - Central Processing
Procesor Jedna z nejdůležitějších součástek počítače = mozek počítače, bez něhož není počítač schopen vykonávat žádné operace. Procesor v počítači plní funkci centrální jednotky (CPU - Central Processing
Závěrečná zpráva projektu Experimentální výpočetní grid pro numerickou lineární algebru
 Závěrečná zpráva projektu Experimentální výpočetní grid pro numerickou lineární algebru Ing. Ivan Šimeček Ph.D., Zdeněk Buk xsimecek@fit.cvut.cz, bukz1fel.cvut.cz Červen, 2012 1 Zadání Paralelní zpracování
Závěrečná zpráva projektu Experimentální výpočetní grid pro numerickou lineární algebru Ing. Ivan Šimeček Ph.D., Zdeněk Buk xsimecek@fit.cvut.cz, bukz1fel.cvut.cz Červen, 2012 1 Zadání Paralelní zpracování
Elektrická měření 4: 4/ Osciloskop (blokové schéma, činnost bloků, zobrazení průběhu na stínítku )
") Elektrická měření 4: 4/ Osciloskop (blokové schéma, činnost bloků, zobrazení průběhu na stínítku ) Osciloskop měřicí přístroj umožňující sledování průběhů napětí nebo i jiných elektrických i neelektrických
Elektrická měření 4: 4/ Osciloskop (blokové schéma, činnost bloků, zobrazení průběhu na stínítku ) Osciloskop měřicí přístroj umožňující sledování průběhů napětí nebo i jiných elektrických i neelektrických
Optimalizace pomocí icc/gcc - vektorizace
 Optimalizace pomocí icc/gcc - vektorizace ICC/ICPC ICC/ICPC - překladače pro jazyky C/C++ od firmy Intel ke stažení po registraci na http://www.intel.com/cd/software/products/asmona/eng/compilers/clin/219856.htm
Optimalizace pomocí icc/gcc - vektorizace ICC/ICPC ICC/ICPC - překladače pro jazyky C/C++ od firmy Intel ke stažení po registraci na http://www.intel.com/cd/software/products/asmona/eng/compilers/clin/219856.htm
GPU a CUDA. Historie GPU. Co je GPGPU? Nvidia CUDA
 GPU a CUDA Historie GPU Co je GPGPU? Nvidia CUDA Historie GPU GPU = graphics processing unit jde o akcelerátory pro algoritmy v 3D grafice a vizualizaci mnoho z nich původně vzniklo pro účely počítačových
GPU a CUDA Historie GPU Co je GPGPU? Nvidia CUDA Historie GPU GPU = graphics processing unit jde o akcelerátory pro algoritmy v 3D grafice a vizualizaci mnoho z nich původně vzniklo pro účely počítačových
Soubory a databáze. Soubor označuje množinu dat, která jsou kompletní k určitému zpracování a popisují vybrané vlastnosti reálných objektů
 Datový typ soubor Soubory a databáze Soubor označuje množinu dat, která jsou kompletní k určitému zpracování a popisují vybrané vlastnosti reálných objektů Záznam soubor se skládá ze záznamů, které popisují
Datový typ soubor Soubory a databáze Soubor označuje množinu dat, která jsou kompletní k určitému zpracování a popisují vybrané vlastnosti reálných objektů Záznam soubor se skládá ze záznamů, které popisují
C2115 Praktický úvod do superpočítání
 C2115 Praktický úvod do superpočítání X. lekce Petr Kulhánek, Tomáš Bouchal kulhanek@chemi.muni.cz Národní centrum pro výzkum biomolekul, Přírodovědecká fakulta, Masarykova univerzita, Kotlářská 2, CZ-61137
C2115 Praktický úvod do superpočítání X. lekce Petr Kulhánek, Tomáš Bouchal kulhanek@chemi.muni.cz Národní centrum pro výzkum biomolekul, Přírodovědecká fakulta, Masarykova univerzita, Kotlářská 2, CZ-61137
REALIZACE SUPERPOČÍTAČE POMOCÍ GRAFICKÉ KARTY
 VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ BRNO UNIVERSITY OF TECHNOLOGY FAKULTA ELEKTROTECHNIKY A KOMUNIKAČNÍCH TECHNOLOGIÍ ÚSTAV TELEKOMUNIKACÍ FACULTY OF ELECTRICAL ENGINEERING AND COMMUNICATION DEPARTMENT OF TELECOMMUNICATIONS
VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ BRNO UNIVERSITY OF TECHNOLOGY FAKULTA ELEKTROTECHNIKY A KOMUNIKAČNÍCH TECHNOLOGIÍ ÚSTAV TELEKOMUNIKACÍ FACULTY OF ELECTRICAL ENGINEERING AND COMMUNICATION DEPARTMENT OF TELECOMMUNICATIONS
CUDA SDK Compiler (front/back end k existujícímu C/C++ kompilátoru) Debugger Profiler Knihovny např.: Cublas Cufft Curand Velký balík ukázkových příkl
 Debugger Profiler Knihovny např.: Cublas Cufft Curand Velký balík ukázkových příkl") Knihovny pro CUDA CUDA SDK Compiler (front/back end k existujícímu C/C++ kompilátoru) Debugger Profiler Knihovny např.: Cublas Cufft Curand Velký balík ukázkových příkladů Hlavní podporované jazyky: C/C++
Knihovny pro CUDA CUDA SDK Compiler (front/back end k existujícímu C/C++ kompilátoru) Debugger Profiler Knihovny např.: Cublas Cufft Curand Velký balík ukázkových příkladů Hlavní podporované jazyky: C/C++
Space dimension : 3D RF Module, Electromagnetic Waves, Eigenfrequency analysis
 Biologická buňka jako sférický dutinový elektromagnetický resonátor Vzorová úloha v Tento dokument byl vytvořen v rámci projektu FRVŠ 2300/2008 Úvod Biologické buňky jsou různých tvarů a jejich membrány
Biologická buňka jako sférický dutinový elektromagnetický resonátor Vzorová úloha v Tento dokument byl vytvořen v rámci projektu FRVŠ 2300/2008 Úvod Biologické buňky jsou různých tvarů a jejich membrány
Povídání na téma SUPERPOČÍTAČE DNES A ZÍTRA
 Povídání na téma SUPERPOČÍTAČE DNES A ZÍTRA (aneb krátký náhled na SC) 29. 10. 2015 Filip Staněk Osnova Co jsou to Superpočítače? Výkon SC Architektura Software Algoritmy IT4Innovations Odkazy na další
Povídání na téma SUPERPOČÍTAČE DNES A ZÍTRA (aneb krátký náhled na SC) 29. 10. 2015 Filip Staněk Osnova Co jsou to Superpočítače? Výkon SC Architektura Software Algoritmy IT4Innovations Odkazy na další
CUDA J. Sloup a I. Šimeček
 CUDA J. Sloup a I. Šimeček xsimecek@fit.cvut.cz Katedra počítačových systémů FIT České vysoké učení technické v Praze Ivan Šimeček, 2011 MI-PAP, LS2010/11, Predn.6 Příprava studijního programu Informatika
CUDA J. Sloup a I. Šimeček xsimecek@fit.cvut.cz Katedra počítačových systémů FIT České vysoké učení technické v Praze Ivan Šimeček, 2011 MI-PAP, LS2010/11, Predn.6 Příprava studijního programu Informatika
Návod na použití FEM programu RillFEM 5.01. Jevy na chladiči
 Návod na použití FEM programu RillFEM 5.01 Jevy na chladiči Freewarové FEM programy (FEM - metoda konečných prvků) jsou velice univerzální, ale jejich nevýhodou je poměrně složité nastavení a programování
Návod na použití FEM programu RillFEM 5.01 Jevy na chladiči Freewarové FEM programy (FEM - metoda konečných prvků) jsou velice univerzální, ale jejich nevýhodou je poměrně složité nastavení a programování
Algoritmizace a programování
 Pátek 14. října Algoritmizace a programování V algoritmizaci a programování je důležitá schopnost analyzovat a myslet. Všeobecně jsou odrazovým můstkem pro řešení neobvyklých, ale i každodenních problémů.
Pátek 14. října Algoritmizace a programování V algoritmizaci a programování je důležitá schopnost analyzovat a myslet. Všeobecně jsou odrazovým můstkem pro řešení neobvyklých, ale i každodenních problémů.
Od lineárních rovnic k extrémním superpočítačovým úlohám. Vít Vondrák
 Od lineárních rovnic k extrémním superpočítačovým úlohám Vít Vondrák Od lineárních rovnic k extrémním superpočítačovým úlohám Vít Vondrák + David Horák a jeho Permoník Osnova přednášky Zobrazování čísel
Od lineárních rovnic k extrémním superpočítačovým úlohám Vít Vondrák Od lineárních rovnic k extrémním superpočítačovým úlohám Vít Vondrák + David Horák a jeho Permoník Osnova přednášky Zobrazování čísel
Knihovny pro CUDA J. Sloup a I. Šimeček
 Knihovny pro CUDA J. Sloup a I. Šimeček xsimecek@fit.cvut.cz Katedra počítačových systémů FIT České vysoké učení technické v Praze Ivan Šimeček, 2011 MI-PRC, LS2010/11, Predn.10 Příprava studijního programu
Knihovny pro CUDA J. Sloup a I. Šimeček xsimecek@fit.cvut.cz Katedra počítačových systémů FIT České vysoké učení technické v Praze Ivan Šimeček, 2011 MI-PRC, LS2010/11, Predn.10 Příprava studijního programu
Katedra obecné elektrotechniky Fakulta elektrotechniky a informatiky, VŠB - TU Ostrava 16. ZÁKLADY LOGICKÉHO ŘÍZENÍ
 Katedra obecné elektrotechniky Fakulta elektrotechniky a informatiky, VŠB - TU Ostrava 16. ZÁKLADY LOGICKÉHO ŘÍZENÍ Obsah 1. Úvod 2. Kontaktní logické řízení 3. Logické řízení bezkontaktní Leden 2006 Ing.
Katedra obecné elektrotechniky Fakulta elektrotechniky a informatiky, VŠB - TU Ostrava 16. ZÁKLADY LOGICKÉHO ŘÍZENÍ Obsah 1. Úvod 2. Kontaktní logické řízení 3. Logické řízení bezkontaktní Leden 2006 Ing.
Paralelní a distribuované výpočty (B4B36PDV)
") Paralelní a distribuované výpočty (B4B36PDV) Branislav Bošanský, Michal Jakob bosansky@fel.cvut.cz Artificial Intelligence Center Department of Computer Science Faculty of Electrical Engineering Czech
Paralelní a distribuované výpočty (B4B36PDV) Branislav Bošanský, Michal Jakob bosansky@fel.cvut.cz Artificial Intelligence Center Department of Computer Science Faculty of Electrical Engineering Czech
OPERAČNÍ SYSTÉMY MS-DOS
 OPERAČNÍ SYSTÉMY MS-DOS Petr Luzar IT1/II 2007/2008 Vznik a původ MS-DOS Vznik operačního systému MS-DOS se datuje k 12.srpnu 1981, kdy společnost IBM s firmou Intel dokončovaly na počátku 80. let počítač
OPERAČNÍ SYSTÉMY MS-DOS Petr Luzar IT1/II 2007/2008 Vznik a původ MS-DOS Vznik operačního systému MS-DOS se datuje k 12.srpnu 1981, kdy společnost IBM s firmou Intel dokončovaly na počátku 80. let počítač
Úvod do OpenMP. Jiří Fürst
 Úvod do OpenMP Jiří Fürst Osnova: Úvod do paralelního programování Počítače se sdílenou pamětí Základy OpenMP Sdílené a soukromé proměnné Paralelizace cyklů Příklady Úvod do paralelního programování Počítač
Úvod do OpenMP Jiří Fürst Osnova: Úvod do paralelního programování Počítače se sdílenou pamětí Základy OpenMP Sdílené a soukromé proměnné Paralelizace cyklů Příklady Úvod do paralelního programování Počítač
Tekla Structures Multi-user Mode
 Tekla Structures Multi-user Mode Úvod V programu Tekla Structures můžete pracovat buď v režimu jednoho uživatele (single-user) nebo v režimu sdílení modelu (multi-user mode). Sdílení modelu umožňuje současný
Tekla Structures Multi-user Mode Úvod V programu Tekla Structures můžete pracovat buď v režimu jednoho uživatele (single-user) nebo v režimu sdílení modelu (multi-user mode). Sdílení modelu umožňuje současný
Databázovéa informačnísystémy NÁVRH IMPLEMENTACE 2 KONZISTENCE DATABÁZE
 Databázovéa informačnísystémy NÁVRH IMPLEMENTACE 2 KONZISTENCE DATABÁZE 1 KONZISTENCE DATABÁZE Jedním z velkých nebezpečí při provozu IS je porušení konzistence databáze. Konzistence databáze je vzájemný
Databázovéa informačnísystémy NÁVRH IMPLEMENTACE 2 KONZISTENCE DATABÁZE 1 KONZISTENCE DATABÁZE Jedním z velkých nebezpečí při provozu IS je porušení konzistence databáze. Konzistence databáze je vzájemný
Grid jako superpočítač
 Grid jako superpočítač Jiří Chudoba Fyzikální ústav AV ČR, v. v. i. Potřeba výkonných počítačů Vědecké aplikace Podnikové aplikace Internetové aplikace Microsoft datová centra Google datová centra 600
Grid jako superpočítač Jiří Chudoba Fyzikální ústav AV ČR, v. v. i. Potřeba výkonných počítačů Vědecké aplikace Podnikové aplikace Internetové aplikace Microsoft datová centra Google datová centra 600
PŘEDSTAVENÍ GRAFICKÉHO PROCESORU NVIDIA G200
 PŘEDSTAVENÍ GRAFICKÉHO PROCESORU NVIDIA G200 Bc.Adam Berger Ber 208 Historie a předchůdci G200 V červnu roku 2008 spatřila světlo světa nová grafická karta od společnosti Nvidia. Tato grafická karta opět
PŘEDSTAVENÍ GRAFICKÉHO PROCESORU NVIDIA G200 Bc.Adam Berger Ber 208 Historie a předchůdci G200 V červnu roku 2008 spatřila světlo světa nová grafická karta od společnosti Nvidia. Tato grafická karta opět
1.11 Vliv intenzity záření na výkon fotovoltaických článků
 1.11 Vliv intenzity záření na výkon fotovoltaických článků Cíle kapitoly: Cílem laboratorní úlohy je změřit výkonové a V-A charakteristiky fotovoltaického článku při změně intenzity světelného záření.
1.11 Vliv intenzity záření na výkon fotovoltaických článků Cíle kapitoly: Cílem laboratorní úlohy je změřit výkonové a V-A charakteristiky fotovoltaického článku při změně intenzity světelného záření.
Algoritmizace a programování
 Algoritmizace a programování V algoritmizaci a programování je důležitá schopnost analyzovat a myslet. Všeobecně jsou odrazovým můstkem pro řešení neobvyklých, ale i každodenních problémů. Naučí nás rozdělit
Algoritmizace a programování V algoritmizaci a programování je důležitá schopnost analyzovat a myslet. Všeobecně jsou odrazovým můstkem pro řešení neobvyklých, ale i každodenních problémů. Naučí nás rozdělit
Mikroprocesor Intel 8051
 Mikroprocesor Intel 8051 Představení mikroprocesoru 8051 Mikroprocesor as jádrem 8051 patří do rodiny MSC51 a byl prvně vyvinut firmou Intel v roce 1980, což znamená, že zanedlouho oslaví své třicáté narozeniny.
Mikroprocesor Intel 8051 Představení mikroprocesoru 8051 Mikroprocesor as jádrem 8051 patří do rodiny MSC51 a byl prvně vyvinut firmou Intel v roce 1980, což znamená, že zanedlouho oslaví své třicáté narozeniny.
Rozdělení metod tlakového odporového svařování
 Rozdělení metod tlakového odporového svařování Podle konstrukčního uspořádání elektrod a pracovního postupu tohoto elektromechanického procesu rozdělujeme odporové svařování na čtyři hlavní druhy: a) bodové
Rozdělení metod tlakového odporového svařování Podle konstrukčního uspořádání elektrod a pracovního postupu tohoto elektromechanického procesu rozdělujeme odporové svařování na čtyři hlavní druhy: a) bodové
Nabídka seminářů Finanční gramotnost
 Nabídka seminářů Finanční gramotnost Seminář 45 minut Čas (min.) Aktivita 0-2 Přivítání, představení. Poznámky 3-5 Poznání účastníků: aktivita 4 rohy Všem se položí otázka, na kterou jsou 4 možné odpovědi.
Nabídka seminářů Finanční gramotnost Seminář 45 minut Čas (min.) Aktivita 0-2 Přivítání, představení. Poznámky 3-5 Poznání účastníků: aktivita 4 rohy Všem se položí otázka, na kterou jsou 4 možné odpovědi.
Úvod do programování a práce s počítačem
 Úvod do programování a práce s počítačem Základní pojmy hardware železo technické vybavení počítače souhrnný název pro veškerá fyzická zařízení, kterými je počítač vybaven software programové vybavení
Úvod do programování a práce s počítačem Základní pojmy hardware železo technické vybavení počítače souhrnný název pro veškerá fyzická zařízení, kterými je počítač vybaven software programové vybavení
Intel 80486 (2) Intel 80486 (1) Intel 80486 (3) Intel 80486 (4) Intel 80486 (6) Intel 80486 (5) Nezřetězené zpracování instrukcí:
 Intel 80486 (1) Intel 80486 (3) Intel 80486 (4) Intel 80486 (6) Intel 80486 (5) Nezřetězené zpracování instrukcí:") Intel 80486 (1) Vyroben v roce 1989 Prodáván pod oficiálním názvem 80486DX Plně 32bitový procesor Na svém čipu má integrován: - zmodernizovaný procesor 80386 - numerický koprocesor 80387 - L1 (interní)
Intel 80486 (1) Vyroben v roce 1989 Prodáván pod oficiálním názvem 80486DX Plně 32bitový procesor Na svém čipu má integrován: - zmodernizovaný procesor 80386 - numerický koprocesor 80387 - L1 (interní)
3. Restrukturalizace nebo manipulace s údaji - práce s rastrovými daty
 3. Restrukturalizace nebo manipulace s údaji - práce s rastrovými daty Většina systémových konverzí je shodná nebo analogická jako u vektorových dat. změna formátu uložení dat změny rozlišení převzorkování
3. Restrukturalizace nebo manipulace s údaji - práce s rastrovými daty Většina systémových konverzí je shodná nebo analogická jako u vektorových dat. změna formátu uložení dat změny rozlišení převzorkování
22 Cdo 2694/2015 ze dne 25.08.2015. Výběr NS 4840/2015
 22 Cdo 2694/2015 ze dne 25.08.2015 Výběr NS 4840/2015 22 Cdo 209/2012 ze dne 04.07.2013 C 12684 Bezúplatné nabytí členského podílu v bytovém družstvu jedním z manželů od jeho rodičů nepředstavuje investici
22 Cdo 2694/2015 ze dne 25.08.2015 Výběr NS 4840/2015 22 Cdo 209/2012 ze dne 04.07.2013 C 12684 Bezúplatné nabytí členského podílu v bytovém družstvu jedním z manželů od jeho rodičů nepředstavuje investici
Dodávka tabletů VYZÝVÁ. k předložení nabídky k výše uvedené veřejné zakázce malého rozsahu za podmínek uvedených dále.
 VÝZVA K PODÁNÍ NABÍDKY Veřejná zakázka malého rozsahu ZADAVATEL: Základní škola a Mateřská škola Tábor, náměstí Mikuláše z Husi 45 Sídlem: náměstí Mikuláše z Husi 45, 39001 Tábor Zastoupený: Mgr. Dagmar
VÝZVA K PODÁNÍ NABÍDKY Veřejná zakázka malého rozsahu ZADAVATEL: Základní škola a Mateřská škola Tábor, náměstí Mikuláše z Husi 45 Sídlem: náměstí Mikuláše z Husi 45, 39001 Tábor Zastoupený: Mgr. Dagmar
Digitální učební materiál
 Digitální učební materiál Číslo projektu Číslo materiálu Název školy Autor Tematický celek Ročník CZ.1.07/1.5.00/34.0029 VY_32_INOVACE_29-19 Střední průmyslová škola stavební, Resslova 2, České Budějovice
Digitální učební materiál Číslo projektu Číslo materiálu Název školy Autor Tematický celek Ročník CZ.1.07/1.5.00/34.0029 VY_32_INOVACE_29-19 Střední průmyslová škola stavební, Resslova 2, České Budějovice
Nvidia CUDA Paralelní programování na GPU
 Mendelova univerzita v Brně Provozně ekonomická fakulta Nvidia CUDA Paralelní programování na GPU 2017 O čem to bude... Trocha historie Shadery Unifikace GPGPU CUDA Využití GPGPU GPU a jeho Hardware Nvidia
Mendelova univerzita v Brně Provozně ekonomická fakulta Nvidia CUDA Paralelní programování na GPU 2017 O čem to bude... Trocha historie Shadery Unifikace GPGPU CUDA Využití GPGPU GPU a jeho Hardware Nvidia
19 Jednočipové mikropočítače
 19 Jednočipové mikropočítače Brzy po vyzkoušení mikroprocesorů ve výpočetních aplikacích se ukázalo, že se jedná o součástku mnohem universálnější, která se uplatní nejen ve výpočetních, ale i v řídicích
19 Jednočipové mikropočítače Brzy po vyzkoušení mikroprocesorů ve výpočetních aplikacích se ukázalo, že se jedná o součástku mnohem universálnější, která se uplatní nejen ve výpočetních, ale i v řídicích
Analýzy v GIS. Co se nachází na tomto místě? Kde se nachází toto? Kolik tam toho je? Co se změnilo od? Co je příčinou? Co když?
 Analýzy v GIS Přednáška 5. Co nám n m GIS můžm ůže e zodpovědět: Co se nachází na tomto místě? Kde se nachází toto? Kolik tam toho je? Co se změnilo od? Co je příčinou? Co když? - modelování Analytické
Analýzy v GIS Přednáška 5. Co nám n m GIS můžm ůže e zodpovědět: Co se nachází na tomto místě? Kde se nachází toto? Kolik tam toho je? Co se změnilo od? Co je příčinou? Co když? - modelování Analytické
Měření ph látek pomocí čidla kyselosti ph
 Zvyšování kvality výuky v přírodních a technických oblastech CZ.1.07/1.1.28/02.0055 Měření ph látek pomocí čidla kyselosti ph (laboratorní práce) Označení: EU-Inovace-Ch-8-09 Předmět: Chemie Cílová skupina:
Zvyšování kvality výuky v přírodních a technických oblastech CZ.1.07/1.1.28/02.0055 Měření ph látek pomocí čidla kyselosti ph (laboratorní práce) Označení: EU-Inovace-Ch-8-09 Předmět: Chemie Cílová skupina:
Architektura procesoru Athlon 64 X2
 Architektura procesoru Athlon 64 X2 Athlon 64 X2 je prvním dvoujádrovým procesorem od firmy AMD, určeným pro domácí využití. Tento procesor byl papírově oznámen 21.dubna 2005. V tento den byly oficiálně
Architektura procesoru Athlon 64 X2 Athlon 64 X2 je prvním dvoujádrovým procesorem od firmy AMD, určeným pro domácí využití. Tento procesor byl papírově oznámen 21.dubna 2005. V tento den byly oficiálně
Uživatelský manuál pro práci se stránkami OMS a MS provozované portálem Myslivost.cz. Verze 1.0
 Uživatelský manuál pro práci se stránkami OMS a MS provozované portálem Myslivost.cz Verze 1.0 Obsah Základní nastavení stránek po vytvoření... 3 Prázdný web... 3 Přihlášení do administrace... 3 Rozložení
Uživatelský manuál pro práci se stránkami OMS a MS provozované portálem Myslivost.cz Verze 1.0 Obsah Základní nastavení stránek po vytvoření... 3 Prázdný web... 3 Přihlášení do administrace... 3 Rozložení
Profilová část maturitní zkoušky 2015/2016
 Střední průmyslová škola, Přerov, Havlíčkova 2 751 52 Přerov Profilová část maturitní zkoušky 2015/2016 TEMATICKÉ OKRUHY A HODNOTÍCÍ KRITÉRIA Studijní obor: 78-42-M/01 Technické lyceum Předmět: TECHNIKA
Střední průmyslová škola, Přerov, Havlíčkova 2 751 52 Přerov Profilová část maturitní zkoušky 2015/2016 TEMATICKÉ OKRUHY A HODNOTÍCÍ KRITÉRIA Studijní obor: 78-42-M/01 Technické lyceum Předmět: TECHNIKA
Přednáška 1. Katedra počítačových systémů FIT, České vysoké učení technické v Praze Jan Trdlička, 2012
 Přednáška 1 Úvod do HW a OS. Katedra počítačových systémů FIT, České vysoké učení technické v Praze Jan Trdlička, 2012 Příprava studijního programu Informatika je podporována projektem financovaným z Evropského
Přednáška 1 Úvod do HW a OS. Katedra počítačových systémů FIT, České vysoké učení technické v Praze Jan Trdlička, 2012 Příprava studijního programu Informatika je podporována projektem financovaným z Evropského
Paralelní a distribuované výpočty (B4B36PDV)
") Paralelní a distribuované výpočty (B4B36PDV) Branislav Bošanský, Michal Jakob bosansky@fel.cvut.cz Artificial Intelligence Center Department of Computer Science Faculty of Electrical Engineering Czech
Paralelní a distribuované výpočty (B4B36PDV) Branislav Bošanský, Michal Jakob bosansky@fel.cvut.cz Artificial Intelligence Center Department of Computer Science Faculty of Electrical Engineering Czech
Mikromarz. CharGraph. Programovatelný výpočtový měřič fyzikálních veličin. Panel Version. Stručná charakteristika:
 Programovatelný výpočtový měřič fyzikálních veličin Stručná charakteristika: je určen pro měření libovolné fyzikální veličiny, která je reprezentována napětím nebo ji lze na napětí převést. Zpětný převod
Programovatelný výpočtový měřič fyzikálních veličin Stručná charakteristika: je určen pro měření libovolné fyzikální veličiny, která je reprezentována napětím nebo ji lze na napětí převést. Zpětný převod
PROCESORY. Typy procesorů
 PROCESORY Procesor (CPU Central Processing Unit) je ústřední výkonnou jednotkou počítače, která čte z paměti instrukce a na jejich základě vykonává program. Primárním úkolem procesoru je řídit činnost
PROCESORY Procesor (CPU Central Processing Unit) je ústřední výkonnou jednotkou počítače, která čte z paměti instrukce a na jejich základě vykonává program. Primárním úkolem procesoru je řídit činnost
Část 1 ZÁKLADNÍ RYSY VÝPOČETNÍ PROSTŘEDKŮ DOSTUPNÝCH NA IT4INNOVATIONS
 Část 1 ZÁKLADNÍ RYSY VÝPOČETNÍ PROSTŘEDKŮ DOSTUPNÝCH NA IT4INNOVATIONS Maximální výkonnost CPU Maximální výkonnost CPU je dána výrazem P max =cores*k*f, kde: cores je počet jader v CPU, k je počet FP instrukcí,
Část 1 ZÁKLADNÍ RYSY VÝPOČETNÍ PROSTŘEDKŮ DOSTUPNÝCH NA IT4INNOVATIONS Maximální výkonnost CPU Maximální výkonnost CPU je dána výrazem P max =cores*k*f, kde: cores je počet jader v CPU, k je počet FP instrukcí,
Návod k obsluze programu ERVE4
 Návod k obsluze programu ERVE4 Obsah Hlavní ovládací panel... 2 Základní tlačítka... 2 Pomocné tlačítko DETAIL... 4 Základní příprava programu... 5 Tvorba ADRESÁŘE... 5 Tvorba CENÍKU ADRESNÉ DISTRIBUCE...
Návod k obsluze programu ERVE4 Obsah Hlavní ovládací panel... 2 Základní tlačítka... 2 Pomocné tlačítko DETAIL... 4 Základní příprava programu... 5 Tvorba ADRESÁŘE... 5 Tvorba CENÍKU ADRESNÉ DISTRIBUCE...
1.3 Druhy a metody měření
 Projekt: Inovace oboru Mechatronik pro Zlínský kraj Registrační číslo: CZ.1.07/1.1.08/03.0009 1.3 Druhy a metody měření Měření je soubor činností, jejichž cílem je stanovit hodnotu měřené fyzikální veličiny.
Projekt: Inovace oboru Mechatronik pro Zlínský kraj Registrační číslo: CZ.1.07/1.1.08/03.0009 1.3 Druhy a metody měření Měření je soubor činností, jejichž cílem je stanovit hodnotu měřené fyzikální veličiny.
Vyuºití GPGPU pro zpracování dat z magnetické rezonance
 Vyuºití pro zpracování dat z magnetické rezonance Katedra matematiky, Fakulta jaderná a fyzikáln inºenýrská, ƒeské vysoké u ení technické v Praze Bakalá ská práce 2007/2008 Cíle práce Zpracování dat z
Vyuºití pro zpracování dat z magnetické rezonance Katedra matematiky, Fakulta jaderná a fyzikáln inºenýrská, ƒeské vysoké u ení technické v Praze Bakalá ská práce 2007/2008 Cíle práce Zpracování dat z
VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ BRNO UNIVERSITY OF TECHNOLOGY
 VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ BRNO UNIVERSITY OF TECHNOLOGY FAKULTA INFORMAČNÍCH TECHNOLOGIÍ ÚSTAV POČÍTAČOVÉ GRAFIKY A MULTIMÉDIÍ FACULTY OF INFORMATION TECHNOLOGY DEPARTMENT OF COMPUTER GRAPHICS AND
VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ BRNO UNIVERSITY OF TECHNOLOGY FAKULTA INFORMAČNÍCH TECHNOLOGIÍ ÚSTAV POČÍTAČOVÉ GRAFIKY A MULTIMÉDIÍ FACULTY OF INFORMATION TECHNOLOGY DEPARTMENT OF COMPUTER GRAPHICS AND
Efektivní vyuºívání programových nástroj Ansys na infrastrukturách MetaCentra / CERIT-SC
 Efektivní vyuºívání programových nástroj Ansys na infrastrukturách MetaCentra / CERIT-SC Slávek Licehammer MetaCentrum 25. listopadu 2013 S. Licehammer (MetaCentrum) Efektivní vyuºívání programových nástroj
Efektivní vyuºívání programových nástroj Ansys na infrastrukturách MetaCentra / CERIT-SC Slávek Licehammer MetaCentrum 25. listopadu 2013 S. Licehammer (MetaCentrum) Efektivní vyuºívání programových nástroj
PROUDĚNÍ V SEPARÁTORU S CYLINDRICKOU GEOMETRIÍ
 PROUDĚNÍ V SEPARÁTORU S CYLINDRICKOU GEOMETRIÍ Autoři: Ing. Zdeněk CHÁRA, CSc., Ústav pro hydrodynamiku AV ČR, v. v. i., e-mail: chara@ih.cas.cz Ing. Bohuš KYSELA, Ph.D., Ústav pro hydrodynamiku AV ČR,
PROUDĚNÍ V SEPARÁTORU S CYLINDRICKOU GEOMETRIÍ Autoři: Ing. Zdeněk CHÁRA, CSc., Ústav pro hydrodynamiku AV ČR, v. v. i., e-mail: chara@ih.cas.cz Ing. Bohuš KYSELA, Ph.D., Ústav pro hydrodynamiku AV ČR,
STAGE DESK-16 16kanálový dimmer ovladač UŽIVATELSKÁ PŘÍRUČKA
 STAGE DESK-16 16kanálový dimmer ovladač UŽIVATELSKÁ PŘÍRUČKA Funkce ovladače 16kanálový DMX dimmer ovladač Jednoduché programování 16 vestavěných programů 16 uživatelských programů Midi In, Out, a Thru
STAGE DESK-16 16kanálový dimmer ovladač UŽIVATELSKÁ PŘÍRUČKA Funkce ovladače 16kanálový DMX dimmer ovladač Jednoduché programování 16 vestavěných programů 16 uživatelských programů Midi In, Out, a Thru
ČESKÁ TECHNICKÁ NORMA
 ČESKÁ TECHNICKÁ NORMA ICS 77.140.10 1998 Oceli k zušlechťování - Část 2: Technické dodací podmínky pro nelegované jakostní oceli ČSN EN 10083-2+A1 42 0932 Květen Quenched and tempered steels - Part 2:
ČESKÁ TECHNICKÁ NORMA ICS 77.140.10 1998 Oceli k zušlechťování - Část 2: Technické dodací podmínky pro nelegované jakostní oceli ČSN EN 10083-2+A1 42 0932 Květen Quenched and tempered steels - Part 2:
Pokročilé architektury počítačů
 Pokročilé architektury počítačů Tutoriál 3 CUDA - GPU Martin Milata Výpočetní model CUDA Organizace kódu Sériově organizovaný kód určený pro CPU Paralelní kód prováděný na GPU Označuje se jako kernel GPU
Pokročilé architektury počítačů Tutoriál 3 CUDA - GPU Martin Milata Výpočetní model CUDA Organizace kódu Sériově organizovaný kód určený pro CPU Paralelní kód prováděný na GPU Označuje se jako kernel GPU
Karel Johanovský Michal Bílek. Operační paměť
 Karel Johanovský Michal Bílek SPŠ-JIA Operační paměť 1 3 SO- Paměti - úvodem Paměti můžeme dělit dle různých kritérií: podle přístupu k buňkám paměti podle možnosti změny dat podle technologie realizace
Karel Johanovský Michal Bílek SPŠ-JIA Operační paměť 1 3 SO- Paměti - úvodem Paměti můžeme dělit dle různých kritérií: podle přístupu k buňkám paměti podle možnosti změny dat podle technologie realizace
Architektura grafických ip pro Xbox 360 a PS3
 Architektura grafických ip pro Xbox 360 a PS3 Jakub Stoszek sto171 VŠB TU Ostrava 12.12.2008 Obsah Grafická karta ATI Xenox (Xbox 360)...3 ip grafické karty ATI Xenos (Xbox 360)...3 Pam grafické karty
Architektura grafických ip pro Xbox 360 a PS3 Jakub Stoszek sto171 VŠB TU Ostrava 12.12.2008 Obsah Grafická karta ATI Xenox (Xbox 360)...3 ip grafické karty ATI Xenos (Xbox 360)...3 Pam grafické karty
NÁVOD K OBSLUZE MODULU VIDEO 64 ===============================
 NÁVOD K OBSLUZE MODULU VIDEO 64 =============================== Modul VIDEO 64 nahrazuje v počítači IQ 151 modul VIDEO 32 s tím, že umožňuje na obrazovce připojeného TV monitoru nebo TV přijímače větší
NÁVOD K OBSLUZE MODULU VIDEO 64 =============================== Modul VIDEO 64 nahrazuje v počítači IQ 151 modul VIDEO 32 s tím, že umožňuje na obrazovce připojeného TV monitoru nebo TV přijímače větší
Servery s Xeon E3-1200v2 Nové servery s procesory IvyBridge Inte Xeon E3-1200v2
 Stránka č. 1 z 13 Shopping cart Search Home Software Hardware Benchmarks Services Store Support Forums About Us Home» CPU Benchmarks» Laptop & Portable CPU Performance CPU Benchmarks Video Card Benchmarks
Stránka č. 1 z 13 Shopping cart Search Home Software Hardware Benchmarks Services Store Support Forums About Us Home» CPU Benchmarks» Laptop & Portable CPU Performance CPU Benchmarks Video Card Benchmarks
GPU a CUDA. Historie GPU. Co je GPGPU? Nvidia CUDA
 GPU a CUDA Historie GPU Co je GPGPU? Nvidia CUDA Historie GPU GPU = graphics processing unit jde o akcelerátory pro algoritmy v 3D grafice a vizualizaci mnoho z nich původně vzniklo pro účely počítačových
GPU a CUDA Historie GPU Co je GPGPU? Nvidia CUDA Historie GPU GPU = graphics processing unit jde o akcelerátory pro algoritmy v 3D grafice a vizualizaci mnoho z nich původně vzniklo pro účely počítačových
Jednotný vizuální styl: podpis v emailové korespondenci.
 Jednotný vizuální styl: podpis v emailové korespondenci. Při elektronické komunikaci je potřeba sjednotit formát podpisu všech pracovníků. V tomto návodu naleznete postupy jak si elektronická podpis vytvořit
Jednotný vizuální styl: podpis v emailové korespondenci. Při elektronické komunikaci je potřeba sjednotit formát podpisu všech pracovníků. V tomto návodu naleznete postupy jak si elektronická podpis vytvořit
Projekt: 1.5, Registrační číslo: CZ.1.07/1.5.00/34.0304. Zoner Photo Studio
 Zoner Photo Studio Program Photo Studio je špičkový produkt pro kompletní práci s digitálními fotografiemi od importu a editace přes správu, organizaci až po publikaci. Podívejme se nyní na základní práci
Zoner Photo Studio Program Photo Studio je špičkový produkt pro kompletní práci s digitálními fotografiemi od importu a editace přes správu, organizaci až po publikaci. Podívejme se nyní na základní práci
Přehled paralelních architektur. Dělení paralelních architektur Flynnova taxonomie Komunikační modely paralelních architektur
 Přehled paralelních architektur Přehled paralelních architektur Dělení paralelních architektur Flynnova taxonomie Komunikační modely paralelních architektur Přehled I. paralelní počítače se konstruují
Přehled paralelních architektur Přehled paralelních architektur Dělení paralelních architektur Flynnova taxonomie Komunikační modely paralelních architektur Přehled I. paralelní počítače se konstruují
Operace nad celými tabulkami
 10 Operace nad celými tabulkami V předchozích kapitolách jsme se převážně zabývali sloupci tabulek. V této kapitole se naučíme provádět některé operace, které ovlivňují tabulky jako celek. Probereme vlastnosti
10 Operace nad celými tabulkami V předchozích kapitolách jsme se převážně zabývali sloupci tabulek. V této kapitole se naučíme provádět některé operace, které ovlivňují tabulky jako celek. Probereme vlastnosti
Profilová část maturitní zkoušky 2015/2016
 Střední průmyslová škola, Přerov, Havlíčkova 2 751 52 Přerov Profilová část maturitní zkoušky 2015/2016 TEMATICKÉ OKRUHY A HODNOTÍCÍ KRITÉRIA Studijní obor: 78-42-M/01 Technické lyceum Předmět: TECHNIKA
Střední průmyslová škola, Přerov, Havlíčkova 2 751 52 Přerov Profilová část maturitní zkoušky 2015/2016 TEMATICKÉ OKRUHY A HODNOTÍCÍ KRITÉRIA Studijní obor: 78-42-M/01 Technické lyceum Předmět: TECHNIKA
Povídání na téma. SUPERPOČÍTAČE DNES A ZÍTRA (aneb krátký náhled na SC) 3. 12. 2009 Filip Staněk
 3. 12. 2009 Filip Staněk") Povídání na téma SUPERPOČÍTAČE DNES A ZÍTRA (aneb krátký náhled na SC) 3. 12. 2009 Filip Staněk Co je to vlastně SC? Výpočetní systém, který určuje hranici maximálního možného výpočetního výkonu......v
Povídání na téma SUPERPOČÍTAČE DNES A ZÍTRA (aneb krátký náhled na SC) 3. 12. 2009 Filip Staněk Co je to vlastně SC? Výpočetní systém, který určuje hranici maximálního možného výpočetního výkonu......v
Repeatery pro systém GSM
 Rok / Year: Svazek / Volume: Číslo / Number: 2010 12 3 Repeatery pro systém GSM Repeaters for GSM system Petr Kejík, Jiří Hermany, Stanislav Hanus xkejik00@stud.feec.vutbr.cz Fakulta elektrotechniky a
Rok / Year: Svazek / Volume: Číslo / Number: 2010 12 3 Repeatery pro systém GSM Repeaters for GSM system Petr Kejík, Jiří Hermany, Stanislav Hanus xkejik00@stud.feec.vutbr.cz Fakulta elektrotechniky a
Maturitní témata z předmětu Programování a databázové systémy. pro šk. rok 2012/2013
 Maturitní témata z předmětu Programování a databázové systémy pro šk. rok 2012/2013 1. Základy - proměnné a datové typy a) Co je to proměnná, co znamená deklarace proměnné, a popište syntaxi deklarace
Maturitní témata z předmětu Programování a databázové systémy pro šk. rok 2012/2013 1. Základy - proměnné a datové typy a) Co je to proměnná, co znamená deklarace proměnné, a popište syntaxi deklarace
Základní rutiny pro numerickou lineární algebru. I. Šimeček, M. Šoch
 Základní rutiny pro numerickou lineární algebru I. Šimeček, M. Šoch xsimecek@fit.cvut.cz Katedra počítačových systémů FIT České vysoké učení technické v Praze Ivan Šimeček, 2011 BI-EIA, ZS2011/12, Predn.10
Základní rutiny pro numerickou lineární algebru I. Šimeček, M. Šoch xsimecek@fit.cvut.cz Katedra počítačových systémů FIT České vysoké učení technické v Praze Ivan Šimeček, 2011 BI-EIA, ZS2011/12, Predn.10
Hra Života v jednom řádku APL
 Hra Života v jednom řádku APL Tento program je k dispozici v "Dr.Dobbs", únor 2007 Vysvětlení Pokud nejste obeznámeni s zprostředkovat to Game of Life nebo APL programovací jazyk, doporučuji konzultovat
Hra Života v jednom řádku APL Tento program je k dispozici v "Dr.Dobbs", únor 2007 Vysvětlení Pokud nejste obeznámeni s zprostředkovat to Game of Life nebo APL programovací jazyk, doporučuji konzultovat
Pokročilé architektury počítačů
 Pokročilé architektury počítačů Přednáška 5 GPU - CUDA Martin Milata Obsah Obecné výpočty a GPU Grafické procesory NVIDIA Tesla Výpočetní model Paměťový model GT200 Zpracování instrukcí Vydávání instrukcí
Pokročilé architektury počítačů Přednáška 5 GPU - CUDA Martin Milata Obsah Obecné výpočty a GPU Grafické procesory NVIDIA Tesla Výpočetní model Paměťový model GT200 Zpracování instrukcí Vydávání instrukcí
Vektorové mapy. Ing. Martin Bak, vedoucí týmu vývoje martin.bak@firma.seznam.cz
 Vektorové mapy Ing., vedoucí týmu vývoje martin.bak@firma.seznam.cz Vektorové mapy Mobilní tým backend technologie, nástroje Cesta vektorů do aplikace úpravy, optimalizace kódování / komprese Jak to celé
Vektorové mapy Ing., vedoucí týmu vývoje martin.bak@firma.seznam.cz Vektorové mapy Mobilní tým backend technologie, nástroje Cesta vektorů do aplikace úpravy, optimalizace kódování / komprese Jak to celé
ODBORNÝ POSUDEK. č. 2381/21/14
 ODBORNÝ POSUDEK č. 2381/21/14 o obvyklé ceně nemovité věci bytu č. 1765/6 a podílu 622/73998 na společných částech domu a pozemcích, v katastrálním území Svitavy předměstí a obci Svitavy, vše okres Svitavy
ODBORNÝ POSUDEK č. 2381/21/14 o obvyklé ceně nemovité věci bytu č. 1765/6 a podílu 622/73998 na společných částech domu a pozemcích, v katastrálním území Svitavy předměstí a obci Svitavy, vše okres Svitavy
NÁVRHOVÝ PROGRAM VÝMĚNÍKŮ TEPLA FIRMY SECESPOL CAIRO 3.5.5 PŘÍRUČKA UŽIVATELE
 NÁVRHOVÝ PROGRAM VÝMĚNÍKŮ TEPLA FIRMY SECESPOL CAIRO 3.5.5 PŘÍRUČKA UŽIVATELE 1. Přehled možností programu 1.1. Hlavní okno Hlavní okno programu se skládá ze čtyř karet : Projekt, Zadání, Výsledky a Návrhový
NÁVRHOVÝ PROGRAM VÝMĚNÍKŮ TEPLA FIRMY SECESPOL CAIRO 3.5.5 PŘÍRUČKA UŽIVATELE 1. Přehled možností programu 1.1. Hlavní okno Hlavní okno programu se skládá ze čtyř karet : Projekt, Zadání, Výsledky a Návrhový
Paralelní architektury se sdílenou pamětí
 Paralelní architektury se sdílenou pamětí Multiprocesory Multiprocesory se sdílenou pamětí SMP architektury Přístup do paměti OpenMP Multiprocesorové architektury I. Multiprocesor se skládá z několika
Paralelní architektury se sdílenou pamětí Multiprocesory Multiprocesory se sdílenou pamětí SMP architektury Přístup do paměti OpenMP Multiprocesorové architektury I. Multiprocesor se skládá z několika
AKCELERACE EVOLUCE PRAVIDEL CELULÁRNÍCH AUTOMATŮ NA GPU
 AKCELERACE EVOLUCE PRAVIDEL CELULÁRNÍCH AUTOMATŮ NA GPU Luděk Žaloudek Výpočetní technika a informatika, 2. ročník, prezenční studium Školitel: Lukáš Sekanina Fakulta informačních technologií, Vysoké učení
AKCELERACE EVOLUCE PRAVIDEL CELULÁRNÍCH AUTOMATŮ NA GPU Luděk Žaloudek Výpočetní technika a informatika, 2. ročník, prezenční studium Školitel: Lukáš Sekanina Fakulta informačních technologií, Vysoké učení
ODBORNÝ POSUDEK. č. 2661/108/15
 ODBORNÝ POSUDEK č. 2661/108/15 o obvyklé ceně ideální 1/2 nemovité věci bytové jednotky č. 1238/13 včetně podílu 784/15632 na pozemku a společných částech domu v katastrálním území a obci Strakonice, okres
ODBORNÝ POSUDEK č. 2661/108/15 o obvyklé ceně ideální 1/2 nemovité věci bytové jednotky č. 1238/13 včetně podílu 784/15632 na pozemku a společných částech domu v katastrálním území a obci Strakonice, okres
Příručka pro uživatele ČSOB InternetBanking 24 a ČSOB BusinessBanking 24 Online s čipovou kartou v operačním systému Mac OS X
 Příručka pro uživatele ČSOB InternetBanking 24 a ČSOB BusinessBanking 24 Online s čipovou kartou v operačním systému Mac OS X Obsah 1 Úvod podmínky pro úspěšné přihlášení do služby... 2 2 Instalace SecureStore
Příručka pro uživatele ČSOB InternetBanking 24 a ČSOB BusinessBanking 24 Online s čipovou kartou v operačním systému Mac OS X Obsah 1 Úvod podmínky pro úspěšné přihlášení do služby... 2 2 Instalace SecureStore
Daniel Velek Optimalizace 2003/2004 IS1 KI/0033 LS PRAKTICKÝ PŘÍKLAD NA MINIMALIZACI NÁKLADŮ PŘI VÝROBĚ
 PRAKTICKÝ PŘÍKLAD NA MINIMALIZACI NÁKLADŮ PŘI VÝROBĚ - 1 - Firma zabývající se výrobou světlometů do aut dostala zakázku na výrobu 3 druhů světlometů do aut, respektive do Škody Fabia, Octavia a Superb.
PRAKTICKÝ PŘÍKLAD NA MINIMALIZACI NÁKLADŮ PŘI VÝROBĚ - 1 - Firma zabývající se výrobou světlometů do aut dostala zakázku na výrobu 3 druhů světlometů do aut, respektive do Škody Fabia, Octavia a Superb.
Generátor sítového provozu
 Generátor sítového provozu Přemysl Hrubý, HRU221 Abstrakt: Nalezení nebo naprogramování (v přenositelném jazyce) konfigurovatelného generátoru provozu simulátoru zátěže charakteristické pro různé typy
Generátor sítového provozu Přemysl Hrubý, HRU221 Abstrakt: Nalezení nebo naprogramování (v přenositelném jazyce) konfigurovatelného generátoru provozu simulátoru zátěže charakteristické pro různé typy
Zvyšování kvality výuky v přírodních a technických oblastech CZ.1.07/1.128/02.0055. Nástrahy virtuální reality (pracovní list)
") Zvyšování kvality výuky v přírodních a technických oblastech CZ.1.07/1.128/02.0055 Označení: EU-Inovace-Inf-6-03 Předmět: Informatika Cílová skupina: 6. třída Autor: Jana Čejková Časová dotace: 1 vyučovací
Zvyšování kvality výuky v přírodních a technických oblastech CZ.1.07/1.128/02.0055 Označení: EU-Inovace-Inf-6-03 Předmět: Informatika Cílová skupina: 6. třída Autor: Jana Čejková Časová dotace: 1 vyučovací
Osciloskopy. Osciloskop. Osciloskopem lze měřit
 Osciloskopy Osciloskop elektronický přístroj zobrazující průběhy napětí s použitím převodníků lze zobrazit průběhy elektrických i neelektrických veličin analogové osciloskopy umožňují zobrazit pouze periodické
Osciloskopy Osciloskop elektronický přístroj zobrazující průběhy napětí s použitím převodníků lze zobrazit průběhy elektrických i neelektrických veličin analogové osciloskopy umožňují zobrazit pouze periodické
Pokyny k vypracování absolventské práce ZŠ a MŠ Kladno, Vodárenská 2115
 Pokyny k vypracování absolventské práce ZŠ a MŠ Kladno, Vodárenská 2115 Úvod Milí žáci, vypracováním absolventské práce získáte mnoho zkušeností a především schopnost samostatné práce a uvažování, které
Pokyny k vypracování absolventské práce ZŠ a MŠ Kladno, Vodárenská 2115 Úvod Milí žáci, vypracováním absolventské práce získáte mnoho zkušeností a především schopnost samostatné práce a uvažování, které
Analýza variance (ANOVA) - jednocestná; faktor s pevným efektem; mnohonásobná srovnání
 - jednocestná; faktor s pevným efektem; mnohonásobná srovnání") Analýza variance (ANOVA) - jednocestná; faktor s pevným efektem; mnohonásobná srovnání 1. Analýzu variance (ANOVu) používáme při studiu problémů, kdy máme závislou proměnou spojitého typu a nezávislé proměnné
Analýza variance (ANOVA) - jednocestná; faktor s pevným efektem; mnohonásobná srovnání 1. Analýzu variance (ANOVu) používáme při studiu problémů, kdy máme závislou proměnou spojitého typu a nezávislé proměnné
Charakteristika dalších verzí procesorů v PC
 Charakteristika dalších verzí procesorů v PC 1 Cíl přednášky Poukázat na principy tvorby architektur nových verzí personálních počítačů. Prezentovat aktuální pojmy. 2 Úvod Zvyšování výkonu cestou paralelizace
Charakteristika dalších verzí procesorů v PC 1 Cíl přednášky Poukázat na principy tvorby architektur nových verzí personálních počítačů. Prezentovat aktuální pojmy. 2 Úvod Zvyšování výkonu cestou paralelizace
Datové struktury. Zuzana Majdišová
 Datové struktury Zuzana Majdišová 19.5.2015 Datové struktury Numerické datové struktury Efektivní reprezentace velkých řídkých matic Lze využít při výpočtu na GPU Dělení prostoru a binární masky Voxelová
Datové struktury Zuzana Majdišová 19.5.2015 Datové struktury Numerické datové struktury Efektivní reprezentace velkých řídkých matic Lze využít při výpočtu na GPU Dělení prostoru a binární masky Voxelová
TECHNICKÉ KRESLENÍ A CAD
 Přednáška č. 7 V ELEKTROTECHNICE Kótování Zjednodušené kótování základních geometrických prvků Někdy stačí k zobrazení pouze jeden pohled Tenké součásti kvádr Kótování Kvádr (základna čtverec) jehlan Kvalitativní
Přednáška č. 7 V ELEKTROTECHNICE Kótování Zjednodušené kótování základních geometrických prvků Někdy stačí k zobrazení pouze jeden pohled Tenké součásti kvádr Kótování Kvádr (základna čtverec) jehlan Kvalitativní
3 nadbytek. 4 bez starostí
 Metody měření spokojenosti zákazníka Postupy měření spokojenosti zákazníků jsou nejefektivnější činnosti při naplňování principu tzv. zpětné vazby. Tento princip patří k základním principům jakéhokoliv
Metody měření spokojenosti zákazníka Postupy měření spokojenosti zákazníků jsou nejefektivnější činnosti při naplňování principu tzv. zpětné vazby. Tento princip patří k základním principům jakéhokoliv
Problematika měření velkých průměrů v pracovních podmínkách
 Problematika měření velkých průměrů v pracovních podmínkách Zábranský Tomáš, Ing., Katedra technologie obrábění, Západočeská univerzita v Plzni, Univerzitní 22, 306 14 Plzeň, +420377638528, tzabran@kto.zcu.cz;
Problematika měření velkých průměrů v pracovních podmínkách Zábranský Tomáš, Ing., Katedra technologie obrábění, Západočeská univerzita v Plzni, Univerzitní 22, 306 14 Plzeň, +420377638528, tzabran@kto.zcu.cz;
Regulovaný vysokonapěťový zdroj 0 až 30 kv
 http://www.coptkm.cz/ Regulovaný vysokonapěťový zdroj 0 až 30 kv Popis zapojení V zapojení jsou dobře znatelné tři hlavní části. První z nich je napájecí obvod s regulátorem výkonu, druhou je pak následně
http://www.coptkm.cz/ Regulovaný vysokonapěťový zdroj 0 až 30 kv Popis zapojení V zapojení jsou dobře znatelné tři hlavní části. První z nich je napájecí obvod s regulátorem výkonu, druhou je pak následně