Statistické zpracování dat garant: Prof. Ing. Milan Palát, CSc.
|
|
|
- Bohumír Pavlík
- před 8 lety
- Počet zobrazení:
Transkript
1 Statistické zpracování dat garant: Prof. Ing. Milan Palát, CSc. OP Vzdělávání pro konkurenceschopnost Aktivita 02 Vícerozměrné statistické metody (podklady pro modul, další aplikace v systému UNISTAT a STATISTICA) Mnohonásobná regresní analýza Kroková regrese Metoda hlavních komponent Faktorová analýza Knické korelace Shluková analýza

2 Kroková regrese ukázka aplikace (autoři Milan PALÁT, Jan PRUDKÝ, Milan PALÁT,jr) VNITŘNÍ DYNAMIKA PROCESU KROKOVÉ LINEÁRNÍ REGRESE UŽITÉ PŘI ANALÝZE PŘIROZENÉ RETENCE VODY V POVODÍ ŘEKY OPAVY ZA POVODNĚ V ČERVENCI 1997 Shrnutye rozšířené poznatky z různých fází krokové regresní analýzy faktorů ovlivňujících přirozenou retenční schopnost povodí u 16ti dílčích povodí řeky Opavy o velikosti od 16,5 km2 do 2039 km2 při povodni v červenci 1997 a navazuje na článek Analýza přirozené retence vody v povodí řeky Opavy při povodni v červenci 1997, publikovaný v rámci konference Hydrológia na prahu 21. storočia v roce 2003 ve Smolenici. K tomu účelu byly statisticky vyhodnoceny veličiny charakterizující transformaci extrémního deště povodím, tj. efektivní dlouhodobá retence povodí Rdef, efektivní krátkodobá retence povodí Rkef, efektivní celková retence povodí Rcef a maximální specifický odtok z povodí qmax. Pro vyhodnocení se použila vícenásobná regresní a korelační analýza, při které se využil statistický program UNISTAT. Cílem zmíněné analýzy bylo především určit statisticky významné faktory ovlivňující přirozenou retenci povodí. Statistickou analýzou se zjistilo, že při červencových povodních 1997 velikost této retence Rdef nejvýznamněji pozitivně ovlivnily celková výška extrémního deště, poměrné plošné zastoupení trvalých travních porostů v povodí, poměrné plošné zastoupení orné půdy v povodí, poměrné plošné zastoupení lesních porostů a negativně průměrná sklonitost terénu povodí. Efektivní krátkodobou retenci povodí Rkef nejvýznamněji ovlivnily průměrná maximální výška extrémního deště v povodí, průměrná sklonitost terénu povodí a poměrné plošné zastoupení trvalých travních porostů, orné půdy a lesních porostů v povodí. Smysl ovlivnění Rkef je v případě u trvalých travních porostů, orné půdy a lesních porostů opačný než tomu bylo v případě Rdef. Efektivní celková přirozená retence povodí je součtem efektivní dlouhodobé a krátkodobé retence povodí (Rcef = Rdef + Rkef). Je však třeba poznamenat, že tento příspěvek oproti minulým publikovaným pracím věnuje pozornost vnitřní dynamice krokové regrese ve smyslu sledování úbytku nezávisle proměnných v závislosti na stvení F hodnoty, charakterizující vstup nebo vyloučení nezávisle proměnné. Jestliže v minulém zpracování bylo krokovou lineární regresí vybráno, jak je výše uvedeno, v konečné fázi 5 nezávisle proměnných nejvíce ovlivňujících velikost přirozené retence vody Rdef, R kef Rcef, a qmax spolu s kvantifikací jejich působení prostřednictvím koeficientů, nedozvěděli jsme se nic o tom, jak při jednotlivých krocích regrese byly ze zpracování vylučovány více či méně významné faktory v určitém mezičase zpracování pro který jsme zvolili počet nezávisle proměnných 7-8 tak, jak zůstu při stvené F hodnotě, reprezentované nezávisle proměnnými. V této souvislosti je třeba se zmínit, že výchozí počet nezávisle proměnných byl 15 (viz tab.1) a konečný počet nezávisle proměnných 5. Zvolený počet 7-8 nezávisle proměnných a hlavně jejich hydrologické charakteristiky nám podává určitou informaci o vnitřním vývoji procesu lineární krokové regrese jak probíhal, než se dospělo ke koncovému stvení pěti nezávisle proměnných.

3 Důležitost jednotlivých charakteristik vyjádřených čtrnácti nezávisle proměnnými lze poměřit na základě dřívějšího či pozdějšího vyloučení při určitém stveném prahu důležitosti F. Složitost celého procesu lze doložit faktem, že na samotném začátku krokové regrese jsme pracovali se 52 nezávisle proměnnými z nichž se na základě neprokázané statistické významnosti, případně kolinearity bylo postupně 37 proměnných vyloučeno. Zachovaných 15 nezávisle proměnných je uvedeno v tabulce 1. Základní pojmy procesu přirozené vodní retence jsou tyto: Celková přirozená vodní retence povodí Rc je voda dočasně zdržená na povrchu terénu, v půdě, v korytě toku aj. přirozeným způsobem, tj. bez retence v umělých vodních nádržích a v inundacích. Lze ji rozdělit do dalších pěti dílčích složek: retence povrchové Rpv, obsahující vodu zdrženou na povrchu terénu a v korytě toku, retence hypodermické Rhp, obsahující vodu podpovrchovou pohybující se v bezprostřední vrstvě pod povrchem aniž by dosáhla hladiny podzemní vody, retence v aeračním pásmu půdy Rap, sestávající z vody zachycené v kapilárách nenasycené zóny půdy a vody infiltrující do podzemní vody, retence podzemní Rpz, zahrnující infiltrovu vodu zvětšující zásobu podzemní vody, územního výparu E, tj. výparu z povrchu půdy území společně s transpirací (výpar vydaný rostlinami) a intercepcí (výpar z části srážky, která ulpí na povrchu rostlin). Tab. 1 Přehled závisle a nezávisle proměnných vstupujících do statistické analýzy Efektivní Efektivní dlouhodobá krátkodobá Závisle retence povodí proměnné retence povodí Rkef Rdef Nezávisle proměnné ne ne Součinitel tvaru povodí ω Maximální specifický odtok z povodí qmax Plocha povodí Délka toku L Objem povodňové srážky Součinitel předchozích srážek API Efektivní dlouhodobá retence povodí ne ne Efektivní krátkodobá retence povodí ne ne Maximální denní srážka Zastoupení orné půdy v povodí Zastoupení trvalých travních porostů v povodí Zastoupení ostatních druhů pozemků v povodí Zastoupení hydrologické skupiny půd B Zastoupení lesů v povodí Průměrná sklonitost terénu v povodí Zastoupení odvodnění v povodí

4 Pro efektivní dlouhodobou retenci povodí Rdef v mm byl odvozen původní vztah: Rdef = - 464,7 + 0,1066ΣH i + 4,79F OP + 7,30 F TTP + 5,54F L 1,117st [mm] (1) kde ΣH i průměrná výška povodňové srážky v povodí [mm], poměrné plošné zastoupení orné půdy v povodí [% plochy povodí], F OP F TTP poměrné plošné zastoupení trvalých travních porostů [% plochy povodí], F L poměrné plošné zastoupení lesních porostů v povodí [% plochy povodí], průměrná sklonitost terénu povodí [úhlové stupně], st Na první pohled jsou v tomto vztahu zastoupeny víceméně očekávané charakteristiky (nezávisle proměnné) jako jsou plošná zastoupení lesních, travních a polních kultur, průměrná sklonitost terénu povodí a samozřejmě průměrná výška povodňové srážky v povodí. Učiníme-li krok zpět v krokové regresi a sice hodnoty F snížíme na 0,25 0,30 dostaneme do vztahu další charakteristiky jako jsou plocha povodí F v km2, délka povodí L v km, součinitel tvaru povodí ω, dále procento ostatních ploch tedy plochy zpevněné z hydrologického hlediska nechvalně známé rychlým odtokem. Vzhledem k ploše, kterou v povodí zaujímají (často 3-5%) však nejsou zanedbatelné. Zajímavou charakteristikou (i když ne neočekávu) je index předchozích srážek API. Pro efektivní krátkodobou retenci povodí R kef v mm byl zjištěn původně vztah: Rkef = 309, ,11H max - 2,36 F OP 4,48 F TTP 2,40 F L 8,33 st [mm] (2) kde H max průměrná maximální výška povodňové denní srážky v povodí [mm den-1], F OP, F TTP, F L a st viz vztah (1) Opět při kroku vzad v krokové lineární regresi a nastavení hodnoty F na 0,9 1,0 získáváme 8 charakteristik, kde se kromě opakujících se H max, F TTP, F L a st můžeme jako další charakteristiku spatřit plochu odvodnění v procentech plochy povodí F O, dále délku toku L v km, index předchozích srážek API a součinitel tvaru povodí ω. Oproti minulému vztahu zůstala nezařazena orná půda vyjádřená procentem plochy povodí F OP. Jelikož velikost efektivní celkové přirozené retence povodí Rcef vyjádřená v mm je součtem efektivní dlouhodobé a krátkodobé retence povodí, lze ji stvit pomocí součtu vztahů (1) a (2) a upravit do výrazu: Rcef = -155, ,1066 ΣH i + 1,11 H max + 2,43 F OP + 2,82 F TTP + 3,14 F L 9,447 st [mm] (3) kde H i, F OP, F TTP, FL, st viz vztah (1), H max, viz vztah (2). Opět je zřejmé, že pro širší vztah dle výše uvedeného by bylo nutné zahrnout do obou vztahů vyšetřené další již zmíněné charakteristiky. Není cílem této práce zacházet až do tvorby nových, rozšířených vztahů i když by to nebylo nic nemožného a všechny potřebné podklady mají autoři tohoto příspěvku k dispozici. Domnívají se však, že uvedení rozšířených vztahů povede k znepřehlednění této práce. Bude tak provedeno pouze v případě maximálního specifického odtoku z povodí qmax jako příklad. Maximální specifický odtok z povodí qmax v l s-1 km-2 se ství podle vztahu:
![porostů v povodí [% plochy povodí], průměrná sklonitost terénu povodí [úhlové stupně], st Na první pohled jsou v tomto vztahu zastoupeny víceméně očekávané charakteristiky (nezávisle proměnné) jako](/docs-images/41/281818/images/page_4.jpg "jsou plošná zastoupení lesních, travních a polních kultur, průměrná sklonitost terénu povodí a samozřejmě průměrná výška povodňové srážky v povodí.")
5 qmax = ,147H max - 30,968 F OP 53,26 F TTP 34,729 F L + 37,746 st [l s-1 km-2] (4) kde H max, viz vztah (2), F TTP, F OP, F L, st viz vztah (1). Maximální specifický odtok z povodí qmax v l s-1 km-2 se v rozšířené podobě se sedmi nezávisle proměnnými ství podle vztahu: I tento vztah si lze představit v poněkud rozšířenější formě při učinění kroku vzad v rámci krokové lineární regresní analýzy. Dalšími členy oproti původní pětici se při stvení hodnoty F 1,8 1,5 se stu plocha povodí F v km2, dále F OSP tedy procento ostatních ploch v povodí, součinitel předchozích srážek API, podíl hydrologické skupiny půd B a procento odvodněné půdy v povodí. Qmax = ,86 FOSP - 47,64 FTTP - 0,331F + 2,35 API + 1,636 ΣH t + 35,44 st - 36,25B Výše uvedené rovnice byly odvozeny pro povodně z letních extrémních dlouhotrvajících regionálních dešťů v povodí Opavy. Rovnice platí pro tato rozmezí hodnot nezávisle proměnných veličin: Průměrné množství povodňové srážky ΣH i od 167,6 mm do 686,0 mm, maximální denní srážka Hmax od 46,7 mm do 198,8 mm, poměrné plošné zastoupení orné půdy v povodí F OP od 0 % do 53,51 %, trvalých trav. porostů F TTP od 0,81 % do 26,55 % a lesních porostů F L od 23,38 % do 98,07 %, průměrná sklonitost terénu st od 4,9 do 11,3. (PRUDKÝ 2003) Závěr Na základě vyhodnocení statistické analýzy pro povodně vzniklé extrémním regionálním deštěm v červenci 1997 v povodí řeky Opavy lze učinit závěry týkající se významnosti jednotlivých faktorů ovlivňujících velikost retenční schopnosti krajiny. Literatura: [6] PALÁT, M.: Model of the organic matter flow in a rpresentative of the foodplain forest. In: Penka, M., Vyskot, M., Klimo, E., Vašíček, F. (Edits.), Floodplain forest Ecosystem. 2. After Water Management Measures, Academia Praha/Elsevir Amsterdam, 1991, pp ISBNO [7] PALÁT M.: Biomass flow in a floodplain forest ecosystem and in man-made Norway spruce forest. Forestry, 43, 1997 (10): ISSN [8] PRUDKÝ, J.: Analýza přirozené retence vody v povodí řeky Opavy při povodni v červenci 1997 In: Acta Hydrologica Slovaca, Ročník 4, č. 2, 2003, s

6

7 Metoda hlavních komponent Je třeba zdůraznit, že kvalita výsledků závisí na oprávněnosti a platnosti vyslovených předpokladů, ať už se týkají typu zvoleného modelu, použitých výpočetních postupů či způsobu pořízení dat. Víme, že je nutně třeba identifikovat odlehlá, resp. příliš vlivná pozorování, protože někdy až dramaticky ovlivňují výsledky nejen regresní analýzy či analýzy rozptylu. Rovněž předpoklad homoskedasticity či vícerozměrného normálního rozdělení není pouhým konstatováním, ale vážně míněným varováním i doporučením pro případné transformace dat nebo modelu. Podobně vzájemná silná lineární závislost (multikolinearita) vysvětlujících proměnných je vážným nebezpečím pro interpretaci regresních charakteristik. Je to přirozený důsledek obecnější situace, ve které rozměr prostoru, v němž se data nacházejí, je ve skutečnosti nižší než je počet sledovaných veličin. Analýza hlavních komponent může být velmi dobře využita nejen k nalezení odpovědí na vyslovené otázky, ale je to obecně vynikající diagnostický nástroj pro identifikaci a hodnocení zvláštností posuzovaných a analyzovaných údajů. D. E. Johnson (1998) dokonce uvádí, že analýza hlavních komponent (Principal Component Analysis) je asi nejužitečnější nástroj po posouzení a prověření kvality vícerozměrných dat. Pro poznání a pochopení dat se doporučuje téměř každou vícerozměrnou úlohu začít výpočtem a zobrazením hlavních komponent. Cíle metody hlavních komponent U mnoha výzkumných úloh se lze setkat se situací, kdy výchozí počet proměnných, sledovaných u zkoumaných jevů a procesů je značný a pro interpretaci nepřehledný. Pro zjednodušení analýzy a snadnější hodnocení výsledků je často vhodné zkoumat, zda by studované vlastnosti pozorovaných objektů nebylo možné nahradit menším počtem jiných (třeba i umělých) proměnných, shrnujících poznatky o výchozích proměnných získaných z dat, aniž by při tom došlo k větší ztrátě informace. K řešení tohoto problému byly už více než před 70 lety vytvořeny dvě příbuzné vícerozměrné metody, a to metoda hlavních komponent a její obsahové, výpočetní a hlavně interpretační rozšíření - faktorová analýza. Pro metodu hlavních komponent je při stejných měřicích jednotkách a relativně podobné variabilitě všech proměnných výhodnější vycházet z analýzy kovarianční matice, zatímco faktorová analýza se téměř výhradně opírá o korelační matici. Obě metody se pokoušejí nalézt v pozadí stojící a tedy skryté (umělé, neměřitelné, latentní) veličiny, označované za hlavní komponenty nebo faktory, vysvětlující variabilitu a závislost uvažovaných proměnných. Tyto nově vytvořené proměnné (říkejme jim variates bez
 vysvětlujících proměnných je vážným nebezpečím pro interpretaci regresních charakteristik.")
8 vhodného českého ekvivalentu) nejsou ničím jiným než lineární kombinace původních měřitelných (nebo aspoň kvantifikovaných ordinálních) proměnných. Připomíná to lineární regresní funkci, ale významově jde o zcela něco jiného. Na rozdíl od regresních či podobných úloh se nezkoumají závislosti výhradně pozorovatelných, významově lépe či hůře jednoznačně vymezených, vysvětlovaných proměnných na jedné či více vysvětlujících proměnných. Studují a posuzují se vzájemné lineární vztahy mezi pozorovanými proměnnými, které se ve faktorové analýze vnímají i hodnotí jako důsledek existence přímo neměřitelných známých nebo hypotetických obecnějších vlivů. Často více heuristický přístup, vyžadující nejen hluboké porozumění posuzované problematiky, ale i značné znalosti a zkušenosti se zvolenou metodou analýzy dat, je některými statistiky odmítán jako málo exaktní, nedostatečně průkazný a hlavně příliš subjektivní. Mnozí výzkumníci ve společenských vědách (hlavně sociologové) však faktorové analýze velmi důvěřují. Metoda hlavních komponent i faktorová analýza se tedy snaží nalézt takové přímo neměřitelné a nejlépe vzájemně nezávislé lineární kombinace původních proměnných, kterých je výrazně méně a ve šťastnějších případech mohou mít i určitou věcnou interpretaci. Každopádně je nesporné, že podaří-li se původní proměnné vyjádřit pomocí menšího počtu nových proměnných bez větší ztráty informace, získá se úspornější popis původního systému proměnných, což je užitečné pro interpretaci i pro využití v jiných statistických metodách. Základní rozdíl mezi metodou hlavních komponent či faktorovou analýzou na jedné straně a vícenásobnou regresí či knickou korelací na straně druhé je v postavení studovaných proměnných. Proměnné v komponentní ani faktorové analýze nejsou členěny podle směru závislosti na vysvětlující a vysvětlované a apriorně jsou posuzovány jako rovnocenné, i když třeba jsou svým významem nestejně důležité. Jejich vzájemné vztahy nejsou vysvětlovány příčinnou závislostí na jiných posuzovaných proměnných, ale působením přímo neměřitelných umělých veličin - komponent či faktorů. Od nových proměnných se v obou metodách požaduje, aby co nejlépe reprezentovaly (vysvětlovaly) původní proměnné. Konkretizace tohoto požadavku není však v obou metodách úplně stejná. Požadujeme-li, aby nové proměnné co nejvíce vysvětlovaly variabilitu původních proměnných, docházíme k metodě analýzy hlavních komponent. Požadujeme-li, aby soubor vytvořených proměnných co nejlépe reprodukoval vzájemné lineární vztahy původních proměnných, docházíme k metodě faktorové analýzy. Pracujeme-li s populační nebo s výběrovou kovarianční matici sledovaných proměnných X1, X2,..., Xp, tak v případě metody hlavních komponent se pozornost soustřeďuje především na diagonální prvky, tedy na rozptyly sledovaných proměnných. Jsou-li sledované proměnné v normovaném tvaru anebo jde o proměnné v nestejných měřicích jednotkách, je nutné v komponentní i faktorové analýze vycházet z korelační matice, přestože vysvětlování jednotkových rozptylů na diagonále působí poněkud nepřirozeně. V současné statistické literatuře je analýza hlavních komponent doporučována především jako význačný nástroj průzkumové analýzy dat, dále jako velmi užitečný pomocník některých dalších metod analýzy vícerozměrných pozorování, ale do jisté míry i jako samostatný nástroj rozboru struktury vztahů v množině vzájemně závislých proměnných. Bylo už řečeno, že pro téměř každou vícerozměrnou analýzu dat lze doporučit metodu hlavních komponent jako první krok pro ověření předpokladů a pro odhalení případných odlehlých pozorování či jiných datově podezřelých okolností. Metoda hlavních komponent je i z jiného hlediska užitečným pomocníkem některých statistických metod. Například pomáhá regresní analýze v případě velkého počtu vzájemně závislých vysvětlujících proměnných, diskriminační analýze při malém počtu pozorování a velkém počtu proměnných, shlukové analýze při klasifikaci objektů do homogenních skupin na základě velkého počtu

9 proměnných, ale i faktorové analýze a jiným vícerozměrným metodám jako jedno z možných prvních řešení. Většina učebnic o vícerozměrných metodách uvádí jako hlavní cíle analýzy hlavních komponent redukci rozměru množiny dat a identifikaci nových smysluplných proměnných. První cíl však není úplně pravdivý, protože ve skutečnosti se nesnažíme snížit, ale nalézt správný rozměr souboru dat. Hlavní komponenty mohou tedy usnadnit určení rozměru úlohy, a tím bez výrazné ztráty informace zlepšit kvalitu analýzy. Pokud jde o druhý cíl, metoda hlavních komponent za běžně splněných podmínek vždy vede k novým proměnným, ale nelze nijak slíbit jejich smysluplnost. Avšak i v takovém případě je analýza hlavních komponent velice užitečná jako nepostradatelný průzkumový nástroj analýzy dat pro ověřování předpokladů a jako pomocník při identifikaci přirozených shluků objektů či proměnných, a ovšem z nejrůznějších důvodů i při snaze o snížení počtu uvažovaných proměnných. Je však velice důležité si uvědomit, že metoda hlavních komponent pomáhá výzkumníkům i v případě, že hlavní komponenty nelze přímo rozumné interpretovat. To je podle našeho názoru velký rozdíl proti faktorové analýze,jejíž cíle jsou v tomto smyslu zásadně jiné. Hlavní komponenty v populaci Za jeden z cílů metody hlavních komponent jsme označili nalezení skutečného rozměru prostoru, ve kterém se napozorovaná data nacházejí. Pro splnění tohoto úkoluje výhodné, když: 1. Nové proměnné (komponenty) jsou vytvářeny postupně s klesajícím významem své důležitosti. 2. Nové proměnné (dále už jen komponenty)jsou vzájemně nekorelované. 3. Nejdůležitější první (říkejme hlavní komponenta vysvětlí co nejvíce z celkové variability, čímž se myslí co největší část ze součtu rozptylů všech zkoumaných proměnných. 4. Každá další komponenta vysvětlí co nejvíce ze zbývající celkové variability dat, takže na poslední (z hlediska podílu na vysvětlené variabilitě nejméně důležitou) připadne z celkové variability nevysvětlený malý zbytek. 5. Pro p původních proměnných je R < p správný rozměr úlohy. Cílovým stavem je situace, ve které R (nejlépe výrazně menší než p) hlavních komponent dostatečně vysvětluje variabilitu původních proměnných. 6. Kritérií dostatečnosti vysvětleni je více, ale v zásadě by měla vést ke stejnému R. 7. Pro hodnocení a uspořádání objektů by asi bylo nejvýhodnější mít jen jednu hlavní komponentu, ale to lze jen velmi vzácně očekávat. Z hlediska možností grafického zobrazení by bylo příjemné mít nejvýše tři hlavní komponenty, ale záleží samozřejmě i na počtu studovaných proměnných. Zkušenosti s používáním metody hlavních komponent ukazují, že případ tří až čtyř hlavních komponent je poměrně častý a více než pět až šest hlavních komponent nelze považovat za příliš úspěšné řešení a nebývá ani zapotřebí. Shrnutí metody hlavních komponent Jako vhodnou situaci je možné označit případ, ve kterém máme k dispozici slušně velký náhodný výběr z vícerozměrného normálního rozdělení hodnot příliš velkého počtu vzájemně silně korelovaných veličin. Metoda hlavních komponent se především využívá pro zlepšení úrovně průzkumové analýzy dat, ale je užitečná i v regresní, shlukové i faktorové analýze, ale v některých speciálních postupech jiných metod. Analýza hlavních komponent

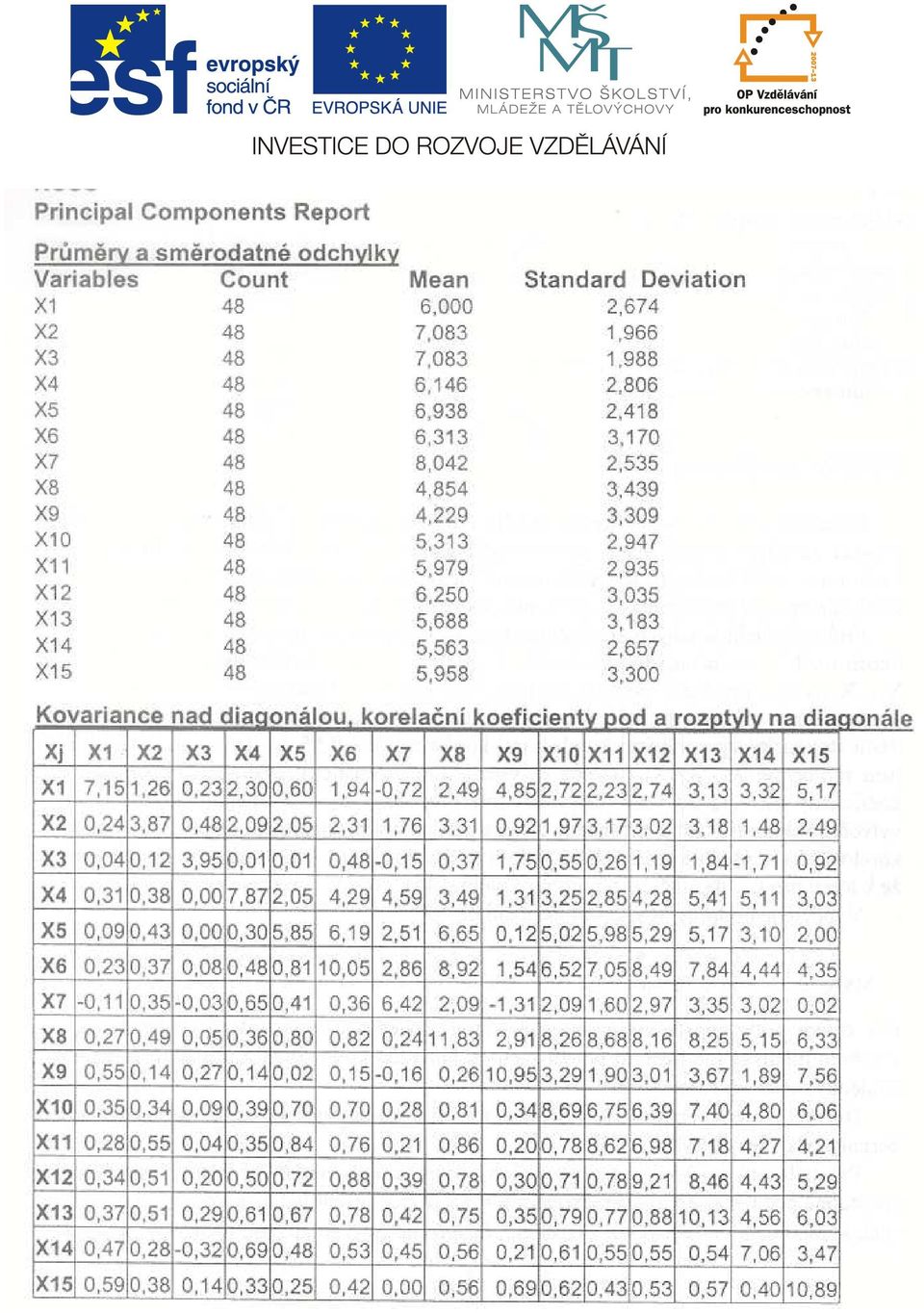
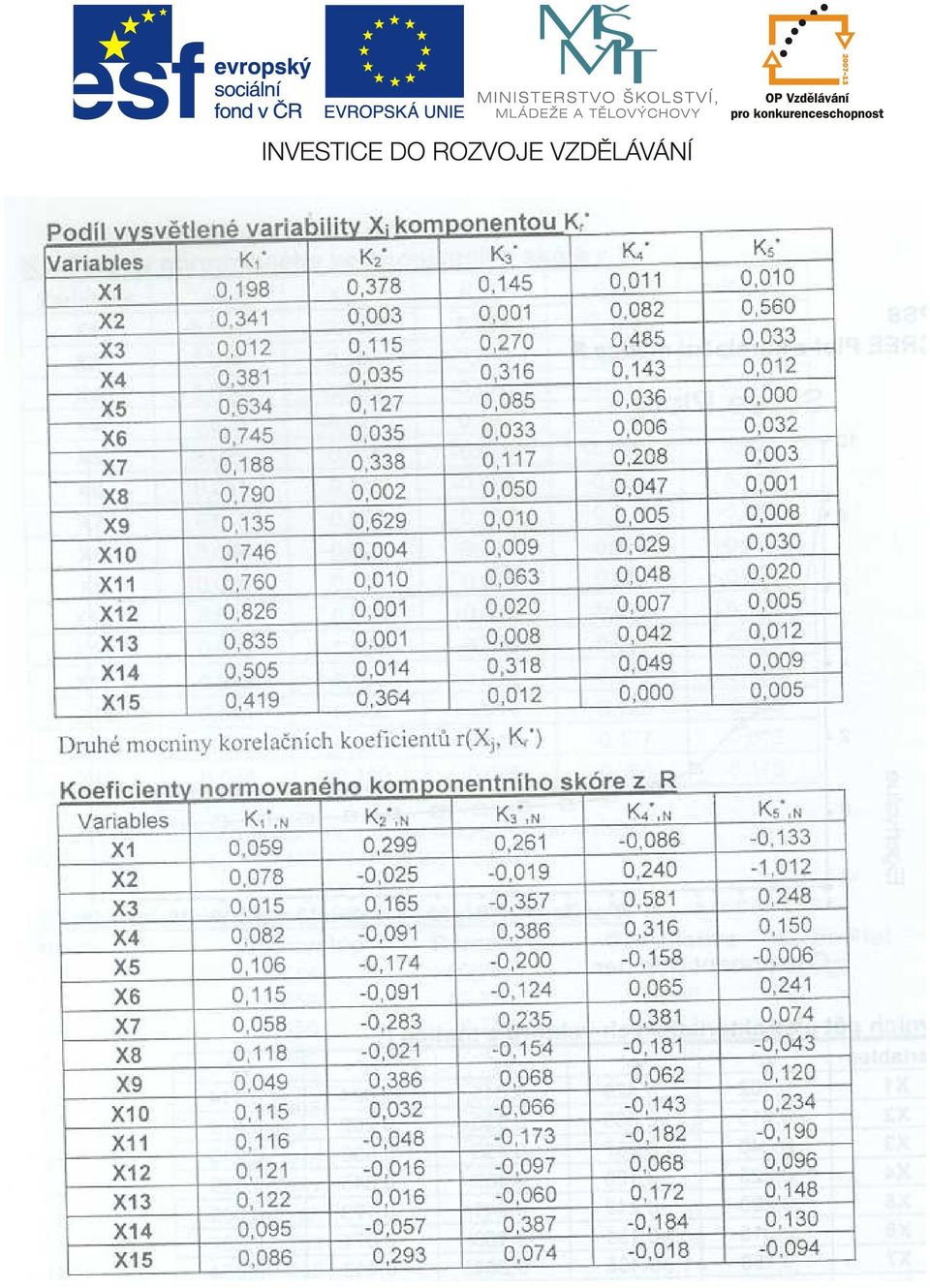
10 umožňuje odhalit případná narušení dat, jako jsou odlehlá pozorování, nestejná homogenita přirozených skupin v datech, odchylky od podmínky nezávislosti jednotlivých pozorování anebo narušení předpokladu vícerozměrného normálního rozdělení. Pokud by pomohla odhalit v pozadí stojící pojmenovatelné příčiny korelovsti a variability studovaných veličin, bylo by to asi více než se od metody hlavních komponent očekává. Prvním krokem analýzy po formální inspekci dat je posouzení stupně korelovsti sledovaných proměnných. K tomu je možné využít některou z variant Bartlettova testu diagonální korelační matice. Za uspokojivý strav se pro metodu hlavních komponent považuje silná vzájemná lineární závislost proměnných, kdy na rozdíl od vysokých párových korelačních koeficientů jsou dílčí korelační koeficienty téměř nulové, což ukazuje na nepodstatnost vlivu činitelů, které v dané úloze nejsou uvažovány. Další kroky metody hlavních komponent směřují k nalezení skutečného rozměru R dat a k určení co nejmenšího počtu hlavních komponent takových, aby zbývajících p - R komponent už nepředstavovalo užitečný přínos. Nástrojem pro rozhodnutí může být podíl vysvětleného součtu rozptylu původních proměnných, počet potřebných komponent podle subjektivního dojmu na základě o grafu charakteristických čísel (scree plotu), anebo v případě nutnosti použití korelační matice místo kovarianční matice i počet charakteristických čísel větších než jedna. Dáváme sice přednost analýze hlavních komponent odvozených z kovarianční matice, ale v případě nestejných měřicích jednotek nebo při velkých rozdílech mezi rozptyly nezbývá nic jiného než vyjít z normovaných proměnných a analýzu hlavních komponent založit na charakteristických číslech a vektorech korelační matice. Jsme určitě spokojeni, podaří-li se relativně velký počet proměnných uspokojivě nahradit jednou až dvěma hlavními komponentami, ale ani mírně větší počet hlavních komponent neznamená neúspěšnost metody hlavních komponent. Silná závislost sledovaných proměnných, optimální volba relativně malého počtu hlavních komponent, silné korelace mezi výchozími proměnnými a ortogonálními komponentami, jsou důležité podmínky užitečnosti hodnot hlavních komponent u sledovaných objektů. Kromě posouzení kvality posuzovaných dat nabízejí nové proměnné příležitost využití i k jiným účelům a v optimistických případech dovolují formulovat závěry o interpretaci nově vzniklých proměnných. Pro analýzu dat je výhodnější komponentní skóre vycházející z kovarianční matice v nenormovaném tvaru, zatímco k některým dalším účelům, jako je třeba využití proměnných pro klasifikaci objektů, je lepší vycházet z normovaných komponent a z normovaného komponentního skóre. Příklad Údaje z se týkají n = 48 osob, které se přihlásily do konkursu o místo ve velké firmě. Přihlášení byli hodnoceni na základě zaslaného dopisu, ve kterém žadatelé o místo odpověděli na položené otázky a napsali podrobněji o svém vzdělání a dosavadních zkušenostech. Body od nuly do deseti od posuzovatelů se týkaly následujících p = 15 proměnných, které hodnotily kvalitu dopisu (X1), celkový dojem (X2), akademickou způsobilost (X3), příjemnost (X4), sebedůvěru (X5), srozumitelnost (X6), čestnost (X7), schopnost prodávat (X8), zkušenosti (X9), řídící schopnosti (X10), ambice (X11), pochopení pojmů (X12), potenciál (X13), snahu o získáni místa (X14) a přiměřenost potřebám místa (X15). Výpočty byly provedeny v NCSS, SPSS, STATISTICE i v českém paketu QCExpert. Některé tabulky byly zjednodušeny, upraveny a částečně modifikovány do následující komentované podoby. Ukázalo se, že přístupy různých tvůrců programů v oblasti metody hlavních komponent mají velké průniky, ale rozhodně nejsou stejné. Použitá terminologie, výběr charakteristik a typů koeficientů se dosti liší, což komplikuje i zkušenějšímu uživateli představu o obsahu nabízených výstupů a začínajícím může činit značné potíže.

11

12
13
14 Faktorová analýza

15

16

17 Faktorová analýza je další statistická metoda, která je zaměřená na vytváření nových proměnných a na snížení rozsahu (redukci) dat s co nejmenší ztrátou informace. Zatímco metoda hlavních komponent provádí jen ortogonální transformaci vzájemně lineárně závislých proměnných s cílem usnadnit průzkumovou analýzu dat a umožnit snížení počtu proměnných pro potřeby jiných statistických metod, faktorová analýza vychází ze statistického modelu a rozumně formulovaných předpokladů. Jedním ze základních cílů faktorové analýzy je posoudit strukturu vztahů sledovaných proměnných a zjistit tak, zda dovoluje jejich rozdělení do skupin, ve kterých by studované proměnné ze stejných skupin spolu více korelovaly než proměnné z různých skupin. Jiným hlavním úkolem faktorové analýzy je vytvořit nové nekorelované proměnné - faktory - v naději, že tyto nové proměnné umožní lépe pochopit analyzovaná data, a případně i jiné použití. Myšlenka redukce dat je vnímána podobně jako v metodě hlavních komponent, ale poněkud ustupuje před potřebou vysvětlit napozorované korelace pomocí nepozorovatelných a svou podstatou hypotetických faktorů. Historie a názory na faktorovou analýzu Faktorová analýza (dále též FA) je vícerozměrná statistická metoda, jejíž hlavním úkolem je rozbor struktury vzájemných závislostí posuzovaných proměnných. Tato metoda oblíbená ve společenskovědních výzkumech (především z oblasti psychologie a sociologie) vychází z předpokladu, že závislosti mezi sledovanými proměnnými jsou důsledkem působení určitého menšího počtu v pozadí stojících nezměřitelných veličin, které jsou označovány za společné faktory. Faktorová analýza si proto klade za hlavní cíl poznat a využít (na základě závislostí pozorovaných proměnných) strukturu (přímo nepozorovatelných a nezměřitelných) společných faktorů, které jsou považovány za skryté příčiny vzájemně korelovaných proměnných. Faktorová analýza se snaží odvodit, vytvořit a pochopit společné faktory (definované jako lineární kombinace původních veličin) takové, aby vysvětlovaly a objasňovaly pozorované závislosti co nejlépe a nejjednodušeji. Tím se myslí, že v konečném řešení by každá proměnná měla korelovat s minimálním počtem faktorů a zároveň počet faktorů R by měl být co nejmenší a odpovídat skutečnému rozměru úlohy i dat. Faktorová analýza vznikla v psychologii. Za jejího zakladatele je považován Ch. Spearman, který v roce 1904 v článku o povaze inteligence navrhl hypotézu o existenci společného faktoru obecné intelektové schopnosti, způsobujícího korelace mezi výsledky různých inteligenčních testů. Kromě společného faktoru předpokládal Spearman i existenci specifických faktorů, uplatňujících se jen v rámci daného testu a nekorelujících s ostatními. O další rozvoj FA se zasloužil L. L. Thurstone (práce z období 1944 až 1961 ), který vymezil pojem jednoduché struktury a rozšířil Spearmanův model na model vícefaktorový, a další psychologové jako R. B. Cattell, C. Burt, G. Thomson či jiní. V souvislosti s rozvojem metod vícerozměrné statistické analýzy přispěli k rozvoji faktorové analýzy někteří statistici, např. D. N. Lawley, který převedl původní způsob získávání faktorů na problém maximálně věrohodného odhadu parametrů faktorového modelu, ale i H. Hotelling, M. S. Bartlett, C. R. Rao a další. Faktorová analýza byla po dlouhou dobu používaná téměř výhradně v psychologii. Výrazný růst výpočetních možností a rozšíření metody faktorových řešení, zvýšená snaha o rozpracování původních postupů, jakož i zmírnění některých subjektivních prvků faktorové analýzy a odstranění výhradní psychometrické interpretace, však způsobily, že v posledních asi čtyřiceti letech pronikla faktorová analýza i do některých dalších oborů. Povaha faktorové analýzy je spíše heuristická a průzkumná (explorativni) než ověřovací

18 (konfirmativní), takže její úspěšné použití vyžaduje nejen značné předmětné znalosti zkoumané aplikační oblasti, ale i kvalifikované respektování předpokladů metody a nemalé zkušenosti s jejím uplatněním. Přesto je faktorová analýza statistiky často kritizovaná. Pochybnosti o faktorové analýze se týkají nejednoznačnosti řešení, důsledků subjektivity mnohých kroků i cílů, přibližnosti výsledků, mlhavé interpretace a některých dalších aspektů této metody. Někdy je to tvrdé a možná až nespravedlivé hodnocení faktorové analýzy; ale každopádně její příznivci a uživatelé by měli být připraveni na polemiku. Musí mít takové věcné i statistické znalosti, aby byli schopni obhájit své rozhodnutí používat FA a využívat její výsledky. Dokonce velký znalec a nejspíše i příznivec faktorové analýzy R. P. McDonald vysvětluje své varující hodnocení nekvalitních výzkumných studií o tom, jak lhát pomoci faktorové analýzy. Srozumitelně dokumentuje nebezpečí nepochopení běžně používaných postupů a ukazuje na negativní důsledky nedostatečně zdůvodněných a analýzou nepodložených komentáru k výsledkům některých rutinních výzkumných zpráv. Do určité míry lze FA považovat za rozšíření metody hlavních komponent, ale na rozdíl od komponentní analýzy vychází ze snahy vysvětlit závislosti pro- měnných. Mezi slabiny komponentní analýzy patří, že je závislá na změnách měřítka proměnných (normování dat hraje roli v tom smyslu, že kovarianční matice vede k jinému řešení než korelační matice). Dále nedisponuje jednoznačným kritériem pro rozhodnutí, zda je možné považovat podíl rozptylu vyčerpaný hlavními komponentami za.postačující, a přímo neponechává prostor pro nevysvětlenou variabilitu a chybový rozptyl proměnných. Přístup FA částečně umožňuje odstranit tyto nedostatky, ale má jiné slabiny. Patří mezi ně mnoho subjektivních aspektů a nejednoznačnost odhadu faktorových parametrů. Předností FA je větší úspornost a obecnost, i když pro některé odhady a testy je třeba aspoň přibližné splnění předpokladu vícerozměrného normálního rozdělení. Knické korelace Metoda knické korelace nebo též knická korelačni analýza (Cnical Correlation Analysis) patří do skupiny metod skrytých vztahů. Přesvědčili jsme se, že společným cílem těchto metod je převést a částečně zjednodušit úlohu do formy, která usnadňuje řešení a je pro další analýzu výhodná. Stejně jako komponentní a faktorová analýza má i metoda knických korelací umožnit hlubší poznání vztahů mezi studovanými proměnnými a usnadnit statistické hodnocení jinak obtížně kvantifikovatelných souvislostí. Knickou korelací se rozumí postup, který je zaměřený na vztahy mezi dvěma významově odlišnými a předem danými skupinami veličin. H. Hotelling, autor prvních prací zaměřených na analýzu knických korelací, navrhl před asi sedmdesáti lety postup, který je zobecněním některých technik známých z řešení regresních a korelačních úloh, dotýkajících se analýzy rozptylu, diskriminační analýzy a některých dalších vícerozměrných statistických metod. Výchozí pro analýzu jsou korelace mezi dvěma skupinami knických veličin (cnical variates), což jsou účelově vytvořené lineární kombinace původních proměnných s předem pevně stvenými vlastnostmi. Knické veličiny Volba typu transformace úzce souvisí s obecnými požadavky a předpoklady statistických postupů a se zaměřením na konkrétní statistické metody. Lineární transformace veličin nejsou jedinou, ale nejčastěji a převážně používu možností, která se pravidelně využívá v různých statistických metodách. Každá zjednodušující transformace je však nejen výhodnou

19 možností pro zlepšení srovnatelnosti a případné nalezení jednoduššího a obecnějšího řešení, ale zároveň i hrozbou ztráty určité informace obsažené v datech. Normování proměnných je běžnou a z mnoha hledisek rozumnou možností, a to nejen pro zabezpečení srovnatelnosti hodnot proměnných v různých měřicích jednotek. To však neznamená, že normování dat je nutně pro každou úlohu přínosem. Nulové průměry, jednotkové rozptyly, stejné kovariance (normovaných proměnných) a korelační koeficienty (původních i normovaných proměnných) jsou výhodou, ale mohou být i ztrátou informace ve smyslu původních možností poznání a analýzy dat. Konstatovali jsme to při výkladu metody hlavních komponent, ve které řešení získané na základě korelační matice je neporovnatelné s řešením získaným na základě kovarianční matice, což nemusí vadit, ale určitě snižuje možnosti průzkumové analýzy dat. Podstata knické korelace Knická korelační analýza (metoda knické korelace), která se zaměřuje na korelace mezi lineárními kombinacemi dvou skupin veličina a je zobecněním vícenásobné korelace používané v lineárních regresních úlohách s více než jednou vysvětlující proměnnou. Vícenásobný korelační koeficient je v této souvislosti interpretován jako míra maximální korelace mezi vysvětlovu proměnnou a lineární kombinací (regresní funkcí) vysvětlujících proměnných. Potom jednorovnicová lineární regresní funkce je vnímána jako lineární kombinace vysvětlujících proměnných, která je maximálně (více než jiné lineární kombinace) korelovaná s vysvětlovu proměnnou. Knickou korelaci se pak rozumí korelace lineárních kombinací dvou skupin veličin a nástrojem analýzy jsou knické korelační koeficienty, které měří sílu lineárního vztahu mezi těmito dvěma skupinami náhodných veličin. Pro uživatele bývá většinou zajímavější úloha, ve které (podobně jako v jiných metodách zkoumání jednostranných závislostí) jedna skupina veličin je považována za vysvětlovu a druhá za vysvětlující. Přesto hlavním cílem knické korelační analýzy je poznání vzájemných simultánních vztahů dvou skupin veličin, přesněji jevů či procesů, které se za těmito veličinami mohou skrývat. Interpretace hypotetických proměnných je v metodě knické korelace ještě problematičtější než v metodě hlavních komponent a ve faktorové analýze. Knické veličiny se využívají i při transformaci vysvětlujících proměnných regresního modelu na systém vzájemně nezávislých veličin nebo při rozšíření jednorovnicového regresního modelu na případ většího počtu vysvětlovaných proměnných. Pro potřeby analýzy jsou zajímavé i vztahy mezi původními a nově vytvořenými proměnnými.
 a korelační koeficienty (původních i normovaných proměnných) jsou výhodou, ale mohou být i ztrátou informace ve smyslu")
20 Shluková analýza Jednou z možností využití informace obsažené ve vstupní datové matici je roztřídění množiny objektů do několika poměrně stejnorodých shluků. Aplikací vhodných algoritmů můžeme odhalit strukturu datového souboru a jednotlivé objekty klasifikovat. Pojem klasifikace se tudíž ve statistické analýze používá ve dvou významech. Bud' klasifikujeme objekty tak, že pro ně odhadujeme hodnotu nominální vysvětlované proměnné (například pomocí diskriminační analýzy), nebo objekty zařazujeme do skupin bez využití vysvětlované proměnné (například pomocí shlukové analýzy). Počet shluků budeme značit písmenem k. Obvykle tento počet není znám a zjišťujeme jeho optimální hodnotu. Písmeno k proto může být též uváděno jako index. Cíle shlukové analýzy Pojem shluková analýza zahrnuje celou řadu metod a přístupů, jejichž cílem je nalézt skupiny podobných objektů (kromě shlukové analýzy lze ke stejnému účelu použít i metody patřící k jiným typům analýz, například k vícerozměrnému škálování. Uplatnění metod shlukové analýzy vede k příznivým výsledkům zejména tam, kde se množina objektů reálně rozpadá do tříd, tj. objekty mají tendenci se seskupovat do přirozených shluků. Zbývá pak již pouze najít vhodnou interpretaci pro popsaný rozklad, tj. charakterizovat vzniklé třídy. Shlukovat můžeme nejen objekty, ale také proměnné. Pokud najdeme skupinu proměnných, jejichž hodnoty jsou si podobné, pak tuto skupinu může zastoupit jediná proměnná, čímž lze snížit rozměr úlohy. Další možností využití shlukové analýzy je zjišťování podobností kategorií nominální proměnné na základě dvourozměrné tabulky četností, tj. sdružených četností pro dva kategoriální znaky. Získaného poznatku můžeme využít pro sloučení kategorií, čímž získáme vyšší sdružené četnosti v kontingenční tabulce. Kromě výše uvedených přístupů existují metody, které umožňují shlukovat současně objekty i proměnné, případně současně kategorie dvou proměnných.
. Počet shluků budeme značit písmenem k. Obvykle tento počet není znám a zjišťujeme jeho optimální hodnotu. Písmeno k proto může být též uváděno jako index.")
Úvodem Dříve les než stromy 3 Operace s maticemi
 Obsah 1 Úvodem 13 2 Dříve les než stromy 17 2.1 Nejednoznačnost terminologie 17 2.2 Volba metody analýzy dat 23 2.3 Přehled vybraných vícerozměrných metod 25 2.3.1 Metoda hlavních komponent 26 2.3.2 Faktorová
Obsah 1 Úvodem 13 2 Dříve les než stromy 17 2.1 Nejednoznačnost terminologie 17 2.2 Volba metody analýzy dat 23 2.3 Přehled vybraných vícerozměrných metod 25 2.3.1 Metoda hlavních komponent 26 2.3.2 Faktorová
Profilování vzorků heroinu s využitím vícerozměrné statistické analýzy
 Profilování vzorků heroinu s využitím vícerozměrné statistické analýzy Autor práce : RNDr. Ivo Beroun,CSc. Vedoucí práce: prof. RNDr. Milan Meloun, DrSc. PROFILOVÁNÍ Profilování = klasifikace a rozlišování
Profilování vzorků heroinu s využitím vícerozměrné statistické analýzy Autor práce : RNDr. Ivo Beroun,CSc. Vedoucí práce: prof. RNDr. Milan Meloun, DrSc. PROFILOVÁNÍ Profilování = klasifikace a rozlišování
Statistická analýza jednorozměrných dat
 Statistická analýza jednorozměrných dat Prof. RNDr. Milan Meloun, DrSc. Univerzita Pardubice, Pardubice 31.ledna 2011 Tato prezentace je spolufinancována Evropským sociálním fondem a státním rozpočtem
Statistická analýza jednorozměrných dat Prof. RNDr. Milan Meloun, DrSc. Univerzita Pardubice, Pardubice 31.ledna 2011 Tato prezentace je spolufinancována Evropským sociálním fondem a státním rozpočtem
MODELOVÁNÍ PŘIROZENÉ RETENCE VODY V POVODÍ BĚHEM ZÁPLAVY MODELING OF NATURAL WATER RETENTION IN THE CATCHMENT BASIN DURING FLOOD
 MODELOVÁNÍ PŘIROZENÉ RETENCE VODY V POVODÍ BĚHEM ZÁPLAVY MODELING OF NATURAL WATER RETENTION IN THE CATCHMENT BASIN DURING FLOOD Milan PALÁT sen., Jan PRUDKÝ, Milan PALÁT jun. Abstract The aim of the analysis
MODELOVÁNÍ PŘIROZENÉ RETENCE VODY V POVODÍ BĚHEM ZÁPLAVY MODELING OF NATURAL WATER RETENTION IN THE CATCHMENT BASIN DURING FLOOD Milan PALÁT sen., Jan PRUDKÝ, Milan PALÁT jun. Abstract The aim of the analysis
Dlouhodobá konvergence ve Střední Evropě
 Czech Republic Dlouhodobá konvergence ve Střední Evropě Pro ROBUST 2018, 23. ledna 2018 Miroslav Singer Generali CEE Holding Prague 17. ledna 2017 Osnova Růst reálného HDP definice ( staré a nové ekonomiky
Czech Republic Dlouhodobá konvergence ve Střední Evropě Pro ROBUST 2018, 23. ledna 2018 Miroslav Singer Generali CEE Holding Prague 17. ledna 2017 Osnova Růst reálného HDP definice ( staré a nové ekonomiky
Zahraniční hosté v hromadných ubyt. zařízeních podle zemí / Foreign guests at collective accommodation establishments: by country 2006*)
") Pro více informací kontaktujte / For further information please contact: Ing. Hana Fojtáchová, e-mail: fojtachova@czechtourism.cz Ing. Martin Košatka, e- mail: kosatka@czechtourism.cz Zahraniční hosté
Pro více informací kontaktujte / For further information please contact: Ing. Hana Fojtáchová, e-mail: fojtachova@czechtourism.cz Ing. Martin Košatka, e- mail: kosatka@czechtourism.cz Zahraniční hosté
EUREKA aeurostars: poradenská činnost a služby pro přípravu a podávání projektů
 EUREKA EUREKA aeurostars: poradenská činnost a služby pro přípravu a podávání projektů Svatopluk Halada, AIP ČR Josef Martinec, MŠMT Praha, 18. 3. 2014 EUREKA > 2 EUREKA obecně nabízí Kontakt s Národními
EUREKA EUREKA aeurostars: poradenská činnost a služby pro přípravu a podávání projektů Svatopluk Halada, AIP ČR Josef Martinec, MŠMT Praha, 18. 3. 2014 EUREKA > 2 EUREKA obecně nabízí Kontakt s Národními
ANALÝZA DLOUHODOBÉ NEZAMĚSTNANOSTI V ZEMÍCH EU # ANALYSIS OF LONG-TERM UNEMPLOYMENT IN EU COUNTRIES. KLÍMA Jan, PALÁT Milan.
 ANALÝZA DLOUHODOBÉ NEZAMĚSTNANOSTI V ZEMÍCH EU # ANALYSIS OF LONG-TERM UNEMPLOYMENT IN EU COUNTRIES KLÍMA Jan, PALÁT Milan Abstract The paper is aimed at assessing the long-term unemployment of males,
ANALÝZA DLOUHODOBÉ NEZAMĚSTNANOSTI V ZEMÍCH EU # ANALYSIS OF LONG-TERM UNEMPLOYMENT IN EU COUNTRIES KLÍMA Jan, PALÁT Milan Abstract The paper is aimed at assessing the long-term unemployment of males,
Česká republika v mezinárodním srovnání za rok 2009 (vybrané údaje)
") Česká republika v mezinárodním srovnání za rok 2009 (vybrané údaje) ZEMĚDĚLSTVÍ, LESNICTVÍ Obsah: 4.1. Využívání půdy zemědělstvím, 2007 4.2. Pracovní síla v zemědělství celkem, index (2005 = 100) 4.3.
Česká republika v mezinárodním srovnání za rok 2009 (vybrané údaje) ZEMĚDĚLSTVÍ, LESNICTVÍ Obsah: 4.1. Využívání půdy zemědělstvím, 2007 4.2. Pracovní síla v zemědělství celkem, index (2005 = 100) 4.3.
1 Tyto materiály byly vytvořeny za pomoci grantu FRVŠ číslo 1145/2004.
 Prostá regresní a korelační analýza 1 1 Tyto materiály byly vytvořeny za pomoci grantu FRVŠ číslo 1145/2004. Problematika závislosti V podstatě lze rozlišovat mezi závislostí nepodstatnou, čili náhodnou
Prostá regresní a korelační analýza 1 1 Tyto materiály byly vytvořeny za pomoci grantu FRVŠ číslo 1145/2004. Problematika závislosti V podstatě lze rozlišovat mezi závislostí nepodstatnou, čili náhodnou
Statistika. Regresní a korelační analýza Úvod do problému. Roman Biskup
 Statistika Regresní a korelační analýza Úvod do problému Roman Biskup Jihočeská univerzita v Českých Budějovicích Ekonomická fakulta (Zemědělská fakulta) Katedra aplikované matematiky a informatiky 2008/2009
Statistika Regresní a korelační analýza Úvod do problému Roman Biskup Jihočeská univerzita v Českých Budějovicích Ekonomická fakulta (Zemědělská fakulta) Katedra aplikované matematiky a informatiky 2008/2009
Korelační a regresní analýza
 Korelační a regresní analýza Analýza závislosti v normálním rozdělení Pearsonův (výběrový) korelační koeficient: r = s XY s X s Y, kde s XY = 1 n (x n 1 i=0 i x )(y i y ), s X (s Y ) je výběrová směrodatná
Korelační a regresní analýza Analýza závislosti v normálním rozdělení Pearsonův (výběrový) korelační koeficient: r = s XY s X s Y, kde s XY = 1 n (x n 1 i=0 i x )(y i y ), s X (s Y ) je výběrová směrodatná
Příloha č. 1: Vstupní soubor dat pro země EU 1. část
 Příloha č. 1: Vstupní soubor dat pro země EU 1. část Reálný HDP na obyvatele v Eurech Belgie 27500 27700 27800 28600 29000 29500 30200 30200 29200 29600 29800 29009 Bulharsko 2300 2500 2600 2800 3000 3200
Příloha č. 1: Vstupní soubor dat pro země EU 1. část Reálný HDP na obyvatele v Eurech Belgie 27500 27700 27800 28600 29000 29500 30200 30200 29200 29600 29800 29009 Bulharsko 2300 2500 2600 2800 3000 3200
KNOWLEDGE ACQUIRED BY ANALYSIS OF FACTORS INFLUENCING THE NATURAL WATER RETENTION CATCHMENT
 POZNATKY ZÍSKANÉ ANALÝZOU FAKTORŮ OVLIVŇUJÍCÍCH PŘIROZENOU RETENCI POVODÍ KNOWLEDGE ACQUIRED BY ANALYSIS OF FACTORS INFLUENCING THE NATURAL WATER RETENTION CATCHMENT Jan Prudký, Mendelova zemědělská a
POZNATKY ZÍSKANÉ ANALÝZOU FAKTORŮ OVLIVŇUJÍCÍCH PŘIROZENOU RETENCI POVODÍ KNOWLEDGE ACQUIRED BY ANALYSIS OF FACTORS INFLUENCING THE NATURAL WATER RETENTION CATCHMENT Jan Prudký, Mendelova zemědělská a
Česká republika v mezinárodním srovnání za rok 2010 (vybrané údaje)
") Česká republika v mezinárodním srovnání za rok 2010 (vybrané údaje) ZEMĚDĚLSTVÍ, LESNICTVÍ 4.1. Využívání půdy zemědělstvím, 2008 4.2. Pracovní síla v zemědělství celkem, index (2005 = 100) 4.3. Hektarové
Česká republika v mezinárodním srovnání za rok 2010 (vybrané údaje) ZEMĚDĚLSTVÍ, LESNICTVÍ 4.1. Využívání půdy zemědělstvím, 2008 4.2. Pracovní síla v zemědělství celkem, index (2005 = 100) 4.3. Hektarové
Příušnice v ČR z hlediska sérologických přehledů, kontrol proočkovanosti a epidemií
 Příušnice v ČR z hlediska sérologických přehledů, kontrol proočkovanosti a epidemií P. Pazdiora XI. Hradecké vakcinologické dny 1.-3.10.2015 Počet Příušnice v ČR a Plzeňském kraji (1980-2015*) 100000 ČR
Příušnice v ČR z hlediska sérologických přehledů, kontrol proočkovanosti a epidemií P. Pazdiora XI. Hradecké vakcinologické dny 1.-3.10.2015 Počet Příušnice v ČR a Plzeňském kraji (1980-2015*) 100000 ČR
Úvod do veřejných financí. Fiskální federalismus. Veřejné příjmy a veřejné výdaje
 Veřejné finance Úvod do veřejných financí Fiskální federalismus Veřejné příjmy a veřejné výdaje Úvod do Veřejných financí Pojem VeFi Soustava veřejných rozpočtů Státní rozpočet Problém fiskální nerovnováhy
Veřejné finance Úvod do veřejných financí Fiskální federalismus Veřejné příjmy a veřejné výdaje Úvod do Veřejných financí Pojem VeFi Soustava veřejných rozpočtů Státní rozpočet Problém fiskální nerovnováhy
Počet hostů / Number of guests. % podíl / % share
 Zahraniční hosté v hromadných ubyt. zařízeních podle zemí / Foreign at collective accommodation establishments: by country hostů / Průměrná doba pobytu ve dnech/ Average length of stay total 2 715 571
Zahraniční hosté v hromadných ubyt. zařízeních podle zemí / Foreign at collective accommodation establishments: by country hostů / Průměrná doba pobytu ve dnech/ Average length of stay total 2 715 571
6. Lineární regresní modely
 6. Lineární regresní modely 6.1 Jednoduchá regrese a validace 6.2 Testy hypotéz v lineární regresi 6.3 Kritika dat v regresním tripletu 6.4 Multikolinearita a polynomy 6.5 Kritika modelu v regresním tripletu
6. Lineární regresní modely 6.1 Jednoduchá regrese a validace 6.2 Testy hypotéz v lineární regresi 6.3 Kritika dat v regresním tripletu 6.4 Multikolinearita a polynomy 6.5 Kritika modelu v regresním tripletu
EURES. EURopean. Employment Services
 EURES EURopean Employment Services Evropské služby zaměstnanosti Osnova Představení systému EURES; vznik; základnz kladní údaje Východiska systému; volný pohyb pracovních ch sil v zemích EU/EHP Hlavní
EURES EURopean Employment Services Evropské služby zaměstnanosti Osnova Představení systému EURES; vznik; základnz kladní údaje Východiska systému; volný pohyb pracovních ch sil v zemích EU/EHP Hlavní
KORELACE. Komentované řešení pomocí programu Statistica
 KORELACE Komentované řešení pomocí programu Statistica Vstupní data I Data umístěná v excelovském souboru překopírujeme do tabulky ve Statistice a pojmenujeme proměnné, viz prezentace k tématu Popisná
KORELACE Komentované řešení pomocí programu Statistica Vstupní data I Data umístěná v excelovském souboru překopírujeme do tabulky ve Statistice a pojmenujeme proměnné, viz prezentace k tématu Popisná
Průměrná doba pobytu ve dnech/ Average length of stay. % podíl / % share
 Zahraniční hosté v hromadných ubyt. zařízeních podle zemí / Foreign at collective accommodation 1. - 3 čtvrtletí 2010 Průměrná doba pobytu ve dnech/ Average length of stay index počet hostů 1-3 Q 2010/1-3
Zahraniční hosté v hromadných ubyt. zařízeních podle zemí / Foreign at collective accommodation 1. - 3 čtvrtletí 2010 Průměrná doba pobytu ve dnech/ Average length of stay index počet hostů 1-3 Q 2010/1-3
Grafický a číselný popis rozložení dat 3.1 Způsoby zobrazení dat Metody zobrazení kvalitativních a ordinálních dat Metody zobrazení kvan
 1 Úvod 1.1 Empirický výzkum a jeho etapy 1.2 Význam teorie pro výzkum 1.2.1 Konstrukty a jejich operacionalizace 1.2.2 Role teorie ve výzkumu 1.2.3 Proces ověření hypotéz a teorií 1.3 Etika vědecké práce
1 Úvod 1.1 Empirický výzkum a jeho etapy 1.2 Význam teorie pro výzkum 1.2.1 Konstrukty a jejich operacionalizace 1.2.2 Role teorie ve výzkumu 1.2.3 Proces ověření hypotéz a teorií 1.3 Etika vědecké práce
Příklad 1. Korelační pole. Řešení 1 ŘEŠENÉ PŘÍKLADY Z MV2 ČÁST 13
 Příklad 1 Máme k dispozici výsledky prvního a druhého testu deseti sportovců. Na hladině významnosti 0,05 prověřte, zda jsou výsledky testů kladně korelované. 1.test : 7, 8, 10, 4, 14, 9, 6, 2, 13, 5 2.test
Příklad 1 Máme k dispozici výsledky prvního a druhého testu deseti sportovců. Na hladině významnosti 0,05 prověřte, zda jsou výsledky testů kladně korelované. 1.test : 7, 8, 10, 4, 14, 9, 6, 2, 13, 5 2.test
Regresní analýza 1. Regresní analýza
 Regresní analýza 1 1 Regresní funkce Regresní analýza Důležitou statistickou úlohou je hledání a zkoumání závislostí proměnných, jejichž hodnoty získáme při realizaci experimentů Vzhledem k jejich náhodnému
Regresní analýza 1 1 Regresní funkce Regresní analýza Důležitou statistickou úlohou je hledání a zkoumání závislostí proměnných, jejichž hodnoty získáme při realizaci experimentů Vzhledem k jejich náhodnému
Výstupy z výukové jednotky. 2. Princip faktorové analýzy
 Faktorová analýza Faktorová analýza je vícerozměrná statistická metoda, jejíž podstatou je rozbor struktury vzájemných závislostí proměnných na základě předpokladu, že jsou tyto závislosti důsledkem působení
Faktorová analýza Faktorová analýza je vícerozměrná statistická metoda, jejíž podstatou je rozbor struktury vzájemných závislostí proměnných na základě předpokladu, že jsou tyto závislosti důsledkem působení
MĚŘENÍ CHUDOBY A PŘÍJMOVÁ CHUDOBA V ČESKÉ REPUBLICE
 MĚŘENÍ CHUDOBY A PŘÍJMOVÁ CHUDOBA V ČESKÉ REPUBLICE Šárka Šustová ČESKÝ STATISTICKÝ ÚŘAD Na padesátém 81, 100 82 Praha 10 czso.cz 1/X MĚŘENÍ CHUDOBY KONCEPTY Objektivní x subjektivní Objektivní založena
MĚŘENÍ CHUDOBY A PŘÍJMOVÁ CHUDOBA V ČESKÉ REPUBLICE Šárka Šustová ČESKÝ STATISTICKÝ ÚŘAD Na padesátém 81, 100 82 Praha 10 czso.cz 1/X MĚŘENÍ CHUDOBY KONCEPTY Objektivní x subjektivní Objektivní založena
Obsah Úvod Kapitola 1 Než začneme Kapitola 2 Práce s hromadnými daty před analýzou
 Úvod.................................................................. 11 Kapitola 1 Než začneme.................................................................. 17 1.1 Logika kvantitativního výzkumu...........................................
Úvod.................................................................. 11 Kapitola 1 Než začneme.................................................................. 17 1.1 Logika kvantitativního výzkumu...........................................
MODEL ZAMĚSTNANOSTI A PŘEPRAVY
 MODEL ZAMĚSTNANOSTI A PŘEPRAVY Kateřina Pojkarová Anotace:Článek se zabývá vzájemnými vazbami, které spojují počet zaměstnaných osob a osobní přepravu vyjádřenou jako celek i samostatně pro různé druhy
MODEL ZAMĚSTNANOSTI A PŘEPRAVY Kateřina Pojkarová Anotace:Článek se zabývá vzájemnými vazbami, které spojují počet zaměstnaných osob a osobní přepravu vyjádřenou jako celek i samostatně pro různé druhy
AVDAT Mnohorozměrné metody, metody klasifikace
 AVDAT Mnohorozměrné metody, metody klasifikace Josef Tvrdík Katedra informatiky Přírodovědecká fakulta Ostravská univerzita Mnohorozměrné metody Regrese jedna náhodná veličina je vysvětlována pomocí jiných
AVDAT Mnohorozměrné metody, metody klasifikace Josef Tvrdík Katedra informatiky Přírodovědecká fakulta Ostravská univerzita Mnohorozměrné metody Regrese jedna náhodná veličina je vysvětlována pomocí jiných
Tomáš Karel LS 2012/2013
 Tomáš Karel LS 2012/2013 Doplňkový materiál ke cvičení z předmětu 4ST201. Na případné faktické chyby v této presentaci mě prosím upozorněte. Děkuji. Tyto slidy berte pouze jako doplňkový materiál není
Tomáš Karel LS 2012/2013 Doplňkový materiál ke cvičení z předmětu 4ST201. Na případné faktické chyby v této presentaci mě prosím upozorněte. Děkuji. Tyto slidy berte pouze jako doplňkový materiál není
Korelace. Komentované řešení pomocí MS Excel
 Korelace Komentované řešení pomocí MS Excel Vstupní data Tabulka se vstupními daty je umístěna v oblasti A2:B84 (viz. obrázek) Prvotní představu o tvaru a síle závislosti docházky a počtu bodů nám poskytne
Korelace Komentované řešení pomocí MS Excel Vstupní data Tabulka se vstupními daty je umístěna v oblasti A2:B84 (viz. obrázek) Prvotní představu o tvaru a síle závislosti docházky a počtu bodů nám poskytne
STATISTICKÉ PROGRAMY
 Slezská univerzita v Opavě Obchodně podnikatelská fakulta v Karviné STATISTICKÉ PROGRAMY VYUŽITÍ EXCELU A SPSS PRO VĚDECKO-VÝZKUMNOU ČINNOST Elena Mielcová, Radmila Stoklasová a Jaroslav Ramík Karviná
Slezská univerzita v Opavě Obchodně podnikatelská fakulta v Karviné STATISTICKÉ PROGRAMY VYUŽITÍ EXCELU A SPSS PRO VĚDECKO-VÝZKUMNOU ČINNOST Elena Mielcová, Radmila Stoklasová a Jaroslav Ramík Karviná
Korelační a regresní analýza. 1. Pearsonův korelační koeficient 2. jednoduchá regresní analýza 3. vícenásobná regresní analýza
 Korelační a regresní analýza 1. Pearsonův korelační koeficient 2. jednoduchá regresní analýza 3. vícenásobná regresní analýza Pearsonův korelační koeficient u intervalových a poměrových dat můžeme jako
Korelační a regresní analýza 1. Pearsonův korelační koeficient 2. jednoduchá regresní analýza 3. vícenásobná regresní analýza Pearsonův korelační koeficient u intervalových a poměrových dat můžeme jako
NATURAL WATER RETENTION IN STEPWISE REGRESSION IN THE CATCHEMENT BASIN OF THE OPAVA RIVER DURING FLOOD IN JULY 1997
 NATURAL WATER RETENTION IN STEPWISE REGRESSION IN THE CATCHEMENT BASIN OF THE OPAVA RIVER DURING FLOOD IN JULY 1997 J. Prudký, M. Palát Ústav aplikované a krajinné ekologie, Agronomická fakulta, Mendelova
NATURAL WATER RETENTION IN STEPWISE REGRESSION IN THE CATCHEMENT BASIN OF THE OPAVA RIVER DURING FLOOD IN JULY 1997 J. Prudký, M. Palát Ústav aplikované a krajinné ekologie, Agronomická fakulta, Mendelova
Počítačová analýza vícerozměrných dat v oborech přírodních, technických a společenských věd
 Počítačová analýza vícerozměrných dat v oborech přírodních, technických a společenských věd Prof. RNDr. Milan Meloun, DrSc. (Univerzita Pardubice, Pardubice) 20.-24. června 2011 Tato prezentace je spolufinancována
Počítačová analýza vícerozměrných dat v oborech přírodních, technických a společenských věd Prof. RNDr. Milan Meloun, DrSc. (Univerzita Pardubice, Pardubice) 20.-24. června 2011 Tato prezentace je spolufinancována
Regresní a korelační analýza
 Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Mezinárodní výzkum PISA 2009
 Mezinárodní výzkum PISA 2009 Zdroj informací: Palečková, J., Tomášek, V., Basl, J,: Hlavní zjištění výzkumu PISA 2009 (Umíme ještě číst?). Praha: ÚIV 2010. Palečková, J., Tomášek V. Hlavní zjištění PISA
Mezinárodní výzkum PISA 2009 Zdroj informací: Palečková, J., Tomášek, V., Basl, J,: Hlavní zjištění výzkumu PISA 2009 (Umíme ještě číst?). Praha: ÚIV 2010. Palečková, J., Tomášek V. Hlavní zjištění PISA
5 Vícerozměrná data - kontingenční tabulky, testy nezávislosti, regresní analýza
 5 Vícerozměrná data - kontingenční tabulky, testy nezávislosti, regresní analýza 5.1 Vícerozměrná data a vícerozměrná rozdělení Při zpracování vícerozměrných dat se hledají souvislosti mezi dvěma, případně
5 Vícerozměrná data - kontingenční tabulky, testy nezávislosti, regresní analýza 5.1 Vícerozměrná data a vícerozměrná rozdělení Při zpracování vícerozměrných dat se hledají souvislosti mezi dvěma, případně
You created this PDF from an application that is not licensed to print to novapdf printer (http://www.novapdf.com)
") Závislost náhodných veličin Úvod Předchozí přednášky: - statistické charakteristiky jednoho výběrového nebo základního souboru - vztahy mezi výběrovým a základním souborem - vztahy statistických charakteristik
Závislost náhodných veličin Úvod Předchozí přednášky: - statistické charakteristiky jednoho výběrového nebo základního souboru - vztahy mezi výběrovým a základním souborem - vztahy statistických charakteristik
Kanonická korelační analýza
 Kanonická korelační analýza Kanonická korelační analýza je vícerozměrná metoda, která se používá ke zkoumání závislosti mezi dvěma skupinami proměnných. První ze skupin se považuje za soubor nezávisle
Kanonická korelační analýza Kanonická korelační analýza je vícerozměrná metoda, která se používá ke zkoumání závislosti mezi dvěma skupinami proměnných. První ze skupin se považuje za soubor nezávisle
*+, -+. / 0( & -.7,7 8 (((!# / (' 9., /,.: (; #< # #$ (((!# / "
 !"!#$ %" &' ( ) *+, -+. / 0(123! " ## $%%%& %' 45 6& -.7,7 8 (((!# / (' 9., /,.: (; #< # #$ (((!# / " * = < & ' ; '.: '. 9'= '= -+. > 8= '7 :' ' '.8 55, 5' 9'= '= -?7 +., '+.8 @ A:.. =. 0(1237 7 : :' @.
!"!#$ %" &' ( ) *+, -+. / 0(123! " ## $%%%& %' 45 6& -.7,7 8 (((!# / (' 9., /,.: (; #< # #$ (((!# / " * = < & ' ; '.: '. 9'= '= -+. > 8= '7 :' ' '.8 55, 5' 9'= '= -?7 +., '+.8 @ A:.. =. 0(1237 7 : :' @.
1. Číselné posloupnosti - Definice posloupnosti, základní vlastnosti, operace s posloupnostmi, limita posloupnosti, vlastnosti limit posloupností,
 KMA/SZZS1 Matematika 1. Číselné posloupnosti - Definice posloupnosti, základní vlastnosti, operace s posloupnostmi, limita posloupnosti, vlastnosti limit posloupností, operace s limitami. 2. Limita funkce
KMA/SZZS1 Matematika 1. Číselné posloupnosti - Definice posloupnosti, základní vlastnosti, operace s posloupnostmi, limita posloupnosti, vlastnosti limit posloupností, operace s limitami. 2. Limita funkce
Statistické vyhodnocení průzkumu funkční gramotnosti žáků 4. ročníku ZŠ
 Statistické vyhodnocení průzkumu funkční gramotnosti žáků 4. ročníku ZŠ Ing. Dana Trávníčková, PaedDr. Jana Isteníková Funkční gramotnost je používání čtení a psaní v životních situacích. Nejde jen o elementární
Statistické vyhodnocení průzkumu funkční gramotnosti žáků 4. ročníku ZŠ Ing. Dana Trávníčková, PaedDr. Jana Isteníková Funkční gramotnost je používání čtení a psaní v životních situacích. Nejde jen o elementární
AKCE: Přednáška Bezpečnost bioplynových stanic Ing. LubošKotek, Ph.D. dne
 AKCE: Přednáška Bezpečnost bioplynových stanic Ing. LubošKotek, Ph.D. dne 23. 3. 2015 Inovace studijních programů AF a ZF MENDELU směřující k vytvoření mezioborové integrace CZ.1.07/2.2.00/28.0302 Osnova
AKCE: Přednáška Bezpečnost bioplynových stanic Ing. LubošKotek, Ph.D. dne 23. 3. 2015 Inovace studijních programů AF a ZF MENDELU směřující k vytvoření mezioborové integrace CZ.1.07/2.2.00/28.0302 Osnova
Stavový model a Kalmanův filtr
 Stavový model a Kalmanův filtr 2 prosince 23 Stav je veličina, kterou neznáme, ale chtěli bychom znát Dozvídáme se o ní zprostředkovaně prostřednictvím výstupů Příkladem může býapř nějaký zašuměný signál,
Stavový model a Kalmanův filtr 2 prosince 23 Stav je veličina, kterou neznáme, ale chtěli bychom znát Dozvídáme se o ní zprostředkovaně prostřednictvím výstupů Příkladem může býapř nějaký zašuměný signál,
Postavení českého trhu práce v rámci EU
 29. 7. 2016 Postavení českého trhu práce v rámci EU Pravidelná analýza se zaměřuje na mezinárodní porovnání vybraných indikátorů trhu práce v členských zemích EU. V 1. čtvrtletí roku 2016 se téměř ve všech
29. 7. 2016 Postavení českého trhu práce v rámci EU Pravidelná analýza se zaměřuje na mezinárodní porovnání vybraných indikátorů trhu práce v členských zemích EU. V 1. čtvrtletí roku 2016 se téměř ve všech
Faktorová analýza (FACT)
") Faktorová analýza (FAC) Podobně jako metoda hlavních komponent patří také faktorová analýza mezi metody redukce počtu původních proměnných. Ve faktorové analýze předpokládáme, že každou vstupující proměnnou
Faktorová analýza (FAC) Podobně jako metoda hlavních komponent patří také faktorová analýza mezi metody redukce počtu původních proměnných. Ve faktorové analýze předpokládáme, že každou vstupující proměnnou
10. Předpovídání - aplikace regresní úlohy
 10. Předpovídání - aplikace regresní úlohy Regresní úloha (analýza) je označení pro statistickou metodu, pomocí nichž odhadujeme hodnotu náhodné veličiny (tzv. závislé proměnné, cílové proměnné, regresandu
10. Předpovídání - aplikace regresní úlohy Regresní úloha (analýza) je označení pro statistickou metodu, pomocí nichž odhadujeme hodnotu náhodné veličiny (tzv. závislé proměnné, cílové proměnné, regresandu
Č. vydání 1 Datum vydání 30.9.2008 Zpracoval Martin Sklenář
 POROVNÁNÍ NÁKLADOVOSTI VÝSTAVBY DÁLNIC V ČR S JINÝMI STÁTY EU Č. vydání 1 Datum vydání 30.9.2008 Zpracoval Martin Sklenář IBR Consulting, s.r.o. 1 / 11 1. OBSAH: 1. OBSAH:... 2 2. ÚVOD... 3 2.1. CÍLE A
POROVNÁNÍ NÁKLADOVOSTI VÝSTAVBY DÁLNIC V ČR S JINÝMI STÁTY EU Č. vydání 1 Datum vydání 30.9.2008 Zpracoval Martin Sklenář IBR Consulting, s.r.o. 1 / 11 1. OBSAH: 1. OBSAH:... 2 2. ÚVOD... 3 2.1. CÍLE A
Obnovitelné zdroje energie v ČR a EU
 Obnovitelné zdroje energie v ČR a EU Ing. Karel Srdečný EkoWATT, o.s. Cena alternativní energie aneb kde končí charita a začíná byznys? 21. září 2010, Praha 2009 EkoWATT, www.ekowatt.cz, www.energetika.cz,
Obnovitelné zdroje energie v ČR a EU Ing. Karel Srdečný EkoWATT, o.s. Cena alternativní energie aneb kde končí charita a začíná byznys? 21. září 2010, Praha 2009 EkoWATT, www.ekowatt.cz, www.energetika.cz,
EKONOMETRIE 7. přednáška Fáze ekonometrické analýzy
 EKONOMETRIE 7. přednáška Fáze ekonometrické analýzy Ekonometrická analýza proces, skládající se z následujících fází: a) specifikace b) kvantifikace c) verifikace d) aplikace Postupné zpřesňování jednotlivých
EKONOMETRIE 7. přednáška Fáze ekonometrické analýzy Ekonometrická analýza proces, skládající se z následujících fází: a) specifikace b) kvantifikace c) verifikace d) aplikace Postupné zpřesňování jednotlivých
Regresní a korelační analýza
 Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Epidemiologie kolorektálního karcinomu v ČR
 INSTITUT BIOSTATISTIKY A ANALÝZ Lékařská fakulta & Přírodovědecká fakulta Masarykova univerzita, Brno www.iba.muni.cz Epidemiologie kolorektálního karcinomu v ČR L. Dušek, J. Mužík, J. Koptíková, T. Pavlík,
INSTITUT BIOSTATISTIKY A ANALÝZ Lékařská fakulta & Přírodovědecká fakulta Masarykova univerzita, Brno www.iba.muni.cz Epidemiologie kolorektálního karcinomu v ČR L. Dušek, J. Mužík, J. Koptíková, T. Pavlík,
Vývoj na trhu rezidenčního bydlení a politika ČNB
 Vývoj na trhu rezidenčního bydlení a politika ČNB Mojmír Hampl viceguvernér ČNB Setkání lídrů českého developmentu, KPMG Praha, 29.5.217 Ceny nemovitostí vesměs přesáhly předkrizové hodnoty 34 3 Index
Vývoj na trhu rezidenčního bydlení a politika ČNB Mojmír Hampl viceguvernér ČNB Setkání lídrů českého developmentu, KPMG Praha, 29.5.217 Ceny nemovitostí vesměs přesáhly předkrizové hodnoty 34 3 Index
Měření závislosti statistických dat
 5.1 Měření závislosti statistických dat Každý pořádný astronom je schopen vám předpovědět, kde se bude nacházet daná hvězda půl hodiny před půlnocí. Ne každý je však téhož schopen předpovědět v případě
5.1 Měření závislosti statistických dat Každý pořádný astronom je schopen vám předpovědět, kde se bude nacházet daná hvězda půl hodiny před půlnocí. Ne každý je však téhož schopen předpovědět v případě
Hodnocení kvality logistických procesů
 Téma 5. Hodnocení kvality logistických procesů Kvalitu logistických procesů nelze vyjádřit absolutně (nelze ji měřit přímo), nýbrž relativně porovnáním Hodnoty těchto znaků někdo buď předem stanovil (norma,
Téma 5. Hodnocení kvality logistických procesů Kvalitu logistických procesů nelze vyjádřit absolutně (nelze ji měřit přímo), nýbrž relativně porovnáním Hodnoty těchto znaků někdo buď předem stanovil (norma,
KGG/STG Statistika pro geografy
 KGG/STG Statistika pro geografy 9. Korelační analýza Mgr. David Fiedor 20. dubna 2015 Analýza závislostí v řadě geografických disciplín studujeme jevy, u kterých vyšetřujeme nikoliv pouze jednu vlastnost
KGG/STG Statistika pro geografy 9. Korelační analýza Mgr. David Fiedor 20. dubna 2015 Analýza závislostí v řadě geografických disciplín studujeme jevy, u kterých vyšetřujeme nikoliv pouze jednu vlastnost
ZÁKLADNÍ METODOLOGICKÁ PRAVIDLA PŘI ZPRACOVÁNÍ ODBORNÉHO TEXTU. Martina Cirbusová (z prezentace doc. Škopa)
") ZÁKLADNÍ METODOLOGICKÁ PRAVIDLA PŘI ZPRACOVÁNÍ ODBORNÉHO TEXTU Martina Cirbusová (z prezentace doc. Škopa) OSNOVA Metodologie vs. Metoda vs. Metodika Základní postup práce Základní vědecké metody METODOLOGIE
ZÁKLADNÍ METODOLOGICKÁ PRAVIDLA PŘI ZPRACOVÁNÍ ODBORNÉHO TEXTU Martina Cirbusová (z prezentace doc. Škopa) OSNOVA Metodologie vs. Metoda vs. Metodika Základní postup práce Základní vědecké metody METODOLOGIE
Regresní a korelační analýza
 Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Vliv vzdělanostní úrovně na kriminalitu obyvatelstva
 Ing. Erika Urbánková, PhD. Katedra ekonomických teorií Provozně ekonomická fakulta Česká zemědělská univerzita Mgr. František Hřebík, Ph.D. prorektor pro zahraniční styky a vnější vztahy Katedra managementu
Ing. Erika Urbánková, PhD. Katedra ekonomických teorií Provozně ekonomická fakulta Česká zemědělská univerzita Mgr. František Hřebík, Ph.D. prorektor pro zahraniční styky a vnější vztahy Katedra managementu
SOFTWARE STAT1 A R. Literatura 4. kontrolní skupině (viz obr. 4). Proto budeme testovat shodu středních hodnot µ 1 = µ 2 proti alternativní
. Proto budeme testovat shodu středních hodnot µ 1 = µ 2 proti alternativní") ŘEŠENÍ PRAKTICKÝCH ÚLOH UŽITÍM SOFTWARE STAT1 A R Obsah 1 Užití software STAT1 1 2 Užití software R 3 Literatura 4 Příklady k procvičení 6 1 Užití software STAT1 Praktické užití aplikace STAT1 si ukažme
ŘEŠENÍ PRAKTICKÝCH ÚLOH UŽITÍM SOFTWARE STAT1 A R Obsah 1 Užití software STAT1 1 2 Užití software R 3 Literatura 4 Příklady k procvičení 6 1 Užití software STAT1 Praktické užití aplikace STAT1 si ukažme
Interakce úrovně vzdělání a faktoru nezaměstnanosti v hospodářsky slabých a silných obcích České republiky
 Interakce úrovně vzdělání a faktoru nezaměstnanosti v hospodářsky slabých a silných obcích České republiky Vladimíra Hovorková Valentová Iva Nedomlelová 17. 6. 2010 Cíl příspěvku provedení analýz a dalších
Interakce úrovně vzdělání a faktoru nezaměstnanosti v hospodářsky slabých a silných obcích České republiky Vladimíra Hovorková Valentová Iva Nedomlelová 17. 6. 2010 Cíl příspěvku provedení analýz a dalších
Pearsonův korelační koeficient
 I I.I Pearsonův korelační koeficient Úvod Předpokládejme, že náhodně vybereme n objektů (nebo osob) ze zkoumané populace. Často se stává, že na každém z objektů měříme ne pouze jednu, ale několik kvantitativních
I I.I Pearsonův korelační koeficient Úvod Předpokládejme, že náhodně vybereme n objektů (nebo osob) ze zkoumané populace. Často se stává, že na každém z objektů měříme ne pouze jednu, ale několik kvantitativních
Kontingenční tabulky, korelační koeficienty
 Statistika II Katedra ekonometrie FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Mějme kategoriální proměnné X a Y. Vytvoříme tzv. kontingenční tabulku. Budeme tedy testovat hypotézu
Statistika II Katedra ekonometrie FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Mějme kategoriální proměnné X a Y. Vytvoříme tzv. kontingenční tabulku. Budeme tedy testovat hypotézu
První zjištění z výzkumu OECD PIAAC Prezentace pro pracovníky MŠMT, Arnošt Veselý
 Mezinárodní výzkum dospělých Programme for the International Assessment of Adult Competencies První zjištění z výzkumu OECD PIAAC Prezentace pro pracovníky MŠMT, 21.10.2013 Arnošt Veselý Tento projekt
Mezinárodní výzkum dospělých Programme for the International Assessment of Adult Competencies První zjištění z výzkumu OECD PIAAC Prezentace pro pracovníky MŠMT, 21.10.2013 Arnošt Veselý Tento projekt
Česká republika v mezinárodním srovnání 2010
 Česká republika v mezinárodním srovnání 2010 ZEMĚDĚLSTVÍ, LESNICTVÍ 4.1. Využívání půdy zemědělstvím, 2009 4.2. Pracovní síla v zemědělství celkem, index (2005 = 100) 4.3. Hektarové výnosy vybraných plodin,
Česká republika v mezinárodním srovnání 2010 ZEMĚDĚLSTVÍ, LESNICTVÍ 4.1. Využívání půdy zemědělstvím, 2009 4.2. Pracovní síla v zemědělství celkem, index (2005 = 100) 4.3. Hektarové výnosy vybraných plodin,
Business index České spořitelny
 Business index České spořitelny Index vstřícnosti podnikatelského prostředí v EU Jan Jedlička EU Office ČS, www.csas.cz/eu, EU_office@csas.cz Praha, 15. listopadu 2012 Co je Business Index České spořitelny?
Business index České spořitelny Index vstřícnosti podnikatelského prostředí v EU Jan Jedlička EU Office ČS, www.csas.cz/eu, EU_office@csas.cz Praha, 15. listopadu 2012 Co je Business Index České spořitelny?
4. Mezinárodní srovnání výdajů na zdravotní péči
 4. Mezinárodní srovnání výdajů na zdravotní péči V této části je prezentováno porovnání základních ukazatelů výdajů na zdravotní péči ve vybraných zemích Evropské unie (EU) a Evropského sdružení volného
4. Mezinárodní srovnání výdajů na zdravotní péči V této části je prezentováno porovnání základních ukazatelů výdajů na zdravotní péči ve vybraných zemích Evropské unie (EU) a Evropského sdružení volného
Kapacity a odměňování zdravotnických pracovníků v segmentu lůžkové péče. První ucelená analýza resortních statistických šetření za rok 2018 a 2019
 Kapacity a odměňování zdravotnických pracovníků v segmentu lůžkové péče První ucelená analýza resortních statistických šetření za rok 2018 a 2019 Analýza dat Národního zdravotnického informačního systému
Kapacity a odměňování zdravotnických pracovníků v segmentu lůžkové péče První ucelená analýza resortních statistických šetření za rok 2018 a 2019 Analýza dat Národního zdravotnického informačního systému
SOUČASNÁ DEMOGRAFICKÁ SITUACE ČESKÉ REPUBLIKY VE
 SOUČASNÁ DEMOGRAFICKÁ SITUACE ČEÉ REPUBLIKY VE SROVNÁNÍ S OSTATNÍMI ZEMĚMI EU Jitka Langhamrová, Tomáš Fiala Klíčová slova: Stárnutí obyvatelstva, biologické generace, index stáří, ekonomické generace,
SOUČASNÁ DEMOGRAFICKÁ SITUACE ČEÉ REPUBLIKY VE SROVNÁNÍ S OSTATNÍMI ZEMĚMI EU Jitka Langhamrová, Tomáš Fiala Klíčová slova: Stárnutí obyvatelstva, biologické generace, index stáří, ekonomické generace,
KOMISE EVROPSKÝCH SPOLEČENSTVÍ ZPRÁVA KOMISE O POUŽÍVÁNÍ SMĚRNICE RADY 99/36/ES O PŘEPRAVITELNÉM TLAKOVÉM ZAŘÍZENÍ ZE STRANY ČLENSKÝCH STÁTŮ
 KOMISE EVROPSKÝCH SPOLEČENSTVÍ V Bruselu dne 9.9.2005 KOM(2005) 415 v konečném znění ZPRÁVA KOMISE O POUŽÍVÁNÍ SMĚRNICE RADY 99/36/ES O PŘEPRAVITELNÉM TLAKOVÉM ZAŘÍZENÍ ZE STRANY ČLENSKÝCH STÁTŮ CS CS
KOMISE EVROPSKÝCH SPOLEČENSTVÍ V Bruselu dne 9.9.2005 KOM(2005) 415 v konečném znění ZPRÁVA KOMISE O POUŽÍVÁNÍ SMĚRNICE RADY 99/36/ES O PŘEPRAVITELNÉM TLAKOVÉM ZAŘÍZENÍ ZE STRANY ČLENSKÝCH STÁTŮ CS CS
RNDr. Eva Janoušová doc. RNDr. Ladislav Dušek, Dr.
 Analýza dat pro Neurovědy RNDr. Eva Janoušová doc. RNDr. Ladislav Dušek, Dr. Jaro 2014 Institut biostatistiky Janoušová, a analýz Dušek: Analýza dat pro neurovědy Blok 7 Jak hodnotit vztah spojitých proměnných
Analýza dat pro Neurovědy RNDr. Eva Janoušová doc. RNDr. Ladislav Dušek, Dr. Jaro 2014 Institut biostatistiky Janoušová, a analýz Dušek: Analýza dat pro neurovědy Blok 7 Jak hodnotit vztah spojitých proměnných
Univerzita Pardubice Fakulta chemicko technologická Katedra analytické chemie Licenční studium Management systému jakosti
 Univerzita Pardubice Fakulta chemicko technologická Katedra analytické chemie Licenční studium Management systému jakosti. Autor práce: Přednášející: Prof. RNDr. Milan Meloun, DrSc Zpracovávaná data jsou
Univerzita Pardubice Fakulta chemicko technologická Katedra analytické chemie Licenční studium Management systému jakosti. Autor práce: Přednášející: Prof. RNDr. Milan Meloun, DrSc Zpracovávaná data jsou
Zdraví: přípravy na dovolenou cestujete vždy s evropským průkazem zdravotního pojištění (EPZP)?
?") MEMO/11/406 V Bruselu dne 16. června 2011 Zdraví: přípravy na dovolenou cestujete vždy s evropským průkazem zdravotního pojištění (EPZP)? O dovolené...čekej i nečekané. Plánujete cestu po Evropské unii
MEMO/11/406 V Bruselu dne 16. června 2011 Zdraví: přípravy na dovolenou cestujete vždy s evropským průkazem zdravotního pojištění (EPZP)? O dovolené...čekej i nečekané. Plánujete cestu po Evropské unii
MÍRY ZÁVISLOSTI (KORELACE A REGRESE)
") zhanel@fsps.muni.cz MÍRY ZÁVISLOSTI (KORELACE A REGRESE) 2.5 MÍRY ZÁVISLOSTI 2.5.1 ZÁVISLOST PEVNÁ, VOLNÁ, STATISTICKÁ A KORELAČNÍ Jednorozměrné soubory - charakterizovány jednotlivými statistickými znaky
zhanel@fsps.muni.cz MÍRY ZÁVISLOSTI (KORELACE A REGRESE) 2.5 MÍRY ZÁVISLOSTI 2.5.1 ZÁVISLOST PEVNÁ, VOLNÁ, STATISTICKÁ A KORELAČNÍ Jednorozměrné soubory - charakterizovány jednotlivými statistickými znaky
2 Zpracování naměřených dat. 2.1 Gaussův zákon chyb. 2.2 Náhodná veličina a její rozdělení
 2 Zpracování naměřených dat Důležitou součástí každé experimentální práce je statistické zpracování naměřených dat. V této krátké kapitole se budeme věnovat určení intervalů spolehlivosti získaných výsledků
2 Zpracování naměřených dat Důležitou součástí každé experimentální práce je statistické zpracování naměřených dat. V této krátké kapitole se budeme věnovat určení intervalů spolehlivosti získaných výsledků
Vyhodnocení průměrných denních analýz kalcinátu ananasového typu. ( Metoda hlavních komponent )
") Vyhodnocení průměrných denních analýz kalcinátu ananasového typu. ( Metoda hlavních komponent ) Zadání : Titanová běloba (TiO ) se vyrábí ve dvou základních krystalových modifikacích - rutilové a anatasové.
Vyhodnocení průměrných denních analýz kalcinátu ananasového typu. ( Metoda hlavních komponent ) Zadání : Titanová běloba (TiO ) se vyrábí ve dvou základních krystalových modifikacích - rutilové a anatasové.
Spokojenost se životem
 SEMINÁRNÍ PRÁCE Spokojenost se životem (sekundárních analýza dat sociologického výzkumu Naše společnost 2007 ) Předmět: Analýza kvantitativních revize Šafr dat I. Jiří (18/2/2012) Vypracoval: ANONYMIZOVÁNO
SEMINÁRNÍ PRÁCE Spokojenost se životem (sekundárních analýza dat sociologického výzkumu Naše společnost 2007 ) Předmět: Analýza kvantitativních revize Šafr dat I. Jiří (18/2/2012) Vypracoval: ANONYMIZOVÁNO
Projekty EUREKA a Eurostars
 Office: +420 221082274 Mobile: +420 728366179 EUREKA Projekty EUREKA a Eurostars Josef Martinec Praha, 5. 12. 2013 EUREKA v ČR > 2 Spolupracující zemí EUREKY od roku 1993 Členskou zemí EUREKY od roku 1995
Office: +420 221082274 Mobile: +420 728366179 EUREKA Projekty EUREKA a Eurostars Josef Martinec Praha, 5. 12. 2013 EUREKA v ČR > 2 Spolupracující zemí EUREKY od roku 1993 Členskou zemí EUREKY od roku 1995
Statistická analýza dat podzemních vod. Statistical analysis of ground water data. Vladimír Sosna 1
 Statistická analýza dat podzemních vod. Statistical analysis of ground water data. Vladimír Sosna 1 1 ČHMÚ, OPZV, Na Šabatce 17, 143 06 Praha 4 - Komořany sosna@chmi.cz, tel. 377 256 617 Abstrakt: Referát
Statistická analýza dat podzemních vod. Statistical analysis of ground water data. Vladimír Sosna 1 1 ČHMÚ, OPZV, Na Šabatce 17, 143 06 Praha 4 - Komořany sosna@chmi.cz, tel. 377 256 617 Abstrakt: Referát
Kontingenční tabulky, korelační koeficienty
 Statistika II Katedra ekonometrie FVL UO Brno kancelář 69a, tel 973 442029 email:jirineubauer@unobcz Budeme předpokládat, že X a Y jsou kvalitativní náhodné veličiny, obor hodnot X obsahuje r hodnot (kategorií,
Statistika II Katedra ekonometrie FVL UO Brno kancelář 69a, tel 973 442029 email:jirineubauer@unobcz Budeme předpokládat, že X a Y jsou kvalitativní náhodné veličiny, obor hodnot X obsahuje r hodnot (kategorií,
SPOLEČNÁ ZEMĚDĚLSKÁ POLITIKA PO ROCE 2013
 SPOLEČNÁ ZEMĚDĚLSKÁ POLITIKA PO ROCE 2013 Seminář Svazu chovatelů českého strak. skotu 4. prosince 2012, Skalský Dvůr Ing. Jan Veleba, prezident AK ČR AK ČR PK ČR ZS ČR Konsorcium nevládních organizací
SPOLEČNÁ ZEMĚDĚLSKÁ POLITIKA PO ROCE 2013 Seminář Svazu chovatelů českého strak. skotu 4. prosince 2012, Skalský Dvůr Ing. Jan Veleba, prezident AK ČR AK ČR PK ČR ZS ČR Konsorcium nevládních organizací
AVDAT Mnohorozměrné metody metody redukce dimenze
 AVDAT Mnohorozměrné metody metody redukce dimenze Josef Tvrdík Katedra informatiky Přírodovědecká fakulta Ostravská univerzita Opakování vlastní čísla a vlastní vektory A je čtvercová matice řádu n. Pak
AVDAT Mnohorozměrné metody metody redukce dimenze Josef Tvrdík Katedra informatiky Přírodovědecká fakulta Ostravská univerzita Opakování vlastní čísla a vlastní vektory A je čtvercová matice řádu n. Pak
11 Analýza hlavních komponet
 11 Analýza hlavních komponet Tato úloha provádí transformaci měřených dat na menší počet tzv. fiktivních dat tak, aby většina informace obsažená v původních datech zůstala zachována. Jedná se tedy o úlohu
11 Analýza hlavních komponet Tato úloha provádí transformaci měřených dat na menší počet tzv. fiktivních dat tak, aby většina informace obsažená v původních datech zůstala zachována. Jedná se tedy o úlohu
3.4 Určení vnitřní struktury analýzou vícerozměrných dat
 3. Určení vnitřní struktury analýzou vícerozměrných dat. Metoda hlavních komponent PCA Zadání: Byly provedeny analýzy chladící vody pro odběrové místa. Byly stanoveny parametry - ph, vodivost, celková
3. Určení vnitřní struktury analýzou vícerozměrných dat. Metoda hlavních komponent PCA Zadání: Byly provedeny analýzy chladící vody pro odběrové místa. Byly stanoveny parametry - ph, vodivost, celková
Vstup České republiky do EU podpořily téměř tři čtvrtiny studentů a tento údaj odpovídá i výsledkům roku minulého.
 1. Jste pro vstup naší republiky do EU? Vstup České republiky do EU podpořily téměř tři čtvrtiny studentů a tento údaj odpovídá i výsledkům roku minulého. 19,52% 5,40% 2,31% 0,24% 37,98% 34,54% certainly
1. Jste pro vstup naší republiky do EU? Vstup České republiky do EU podpořily téměř tři čtvrtiny studentů a tento údaj odpovídá i výsledkům roku minulého. 19,52% 5,40% 2,31% 0,24% 37,98% 34,54% certainly
POLYNOMICKÁ REGRESE. Jedná se o regresní model, který je lineární v parametrech, ale popisuje nelineární závislost mezi proměnnými.
 POLYNOMICKÁ REGRESE Jedná se o regresní model, který je lineární v parametrech, ale popisuje nelineární závislost mezi proměnnými. y = b 0 + b 1 x + b 2 x 2 + + b n x n kde b i jsou neznámé parametry,
POLYNOMICKÁ REGRESE Jedná se o regresní model, který je lineární v parametrech, ale popisuje nelineární závislost mezi proměnnými. y = b 0 + b 1 x + b 2 x 2 + + b n x n kde b i jsou neznámé parametry,
PRAVDĚPODOBNOST A STATISTIKA
 PRAVDĚPODOBNOST A STATISTIKA Definice lineárního normálního regresního modelu Lineární normální regresní model Y β ε Matice n,k je matice realizací. Předpoklad: n > k, h() k - tj. matice je plné hodnosti
PRAVDĚPODOBNOST A STATISTIKA Definice lineárního normálního regresního modelu Lineární normální regresní model Y β ε Matice n,k je matice realizací. Předpoklad: n > k, h() k - tj. matice je plné hodnosti
Pracovní doba v České Republice je v rámci EU jedna z nejdelších Dostupný z
 Pracovní doba v České Republice je v rámci EU jedna z nejdelších Český statistický úřad 2013 Dostupný z http://www.nusl.cz/ntk/nusl-203469 Dílo je chráněno podle autorského zákona č. 121/2000 Sb. Tento
Pracovní doba v České Republice je v rámci EU jedna z nejdelších Český statistický úřad 2013 Dostupný z http://www.nusl.cz/ntk/nusl-203469 Dílo je chráněno podle autorského zákona č. 121/2000 Sb. Tento
Pavel Řežábek. člen bankovní rady ČNB. Ekonomická přednáška v rámci odborné konference Očekávaný vývoj automobilového průmyslu v ČR a střední Evropě
 Domácí a světový ekonomický vývoj Pavel Řežábek člen bankovní rady ČNB Ekonomická přednáška v rámci odborné konference Očekávaný vývoj automobilového průmyslu v ČR a střední Evropě Brno, 22. října 2014
Domácí a světový ekonomický vývoj Pavel Řežábek člen bankovní rady ČNB Ekonomická přednáška v rámci odborné konference Očekávaný vývoj automobilového průmyslu v ČR a střední Evropě Brno, 22. října 2014
4. Pracující (zaměstnaní) senioři
 senioři") Senioři v letech 2 a 215 4. Pracující (zaměstnaní) senioři Jako zaměstnaní se označují všichni pracující - např. zaměstnanci, osoby samostatně výdělečně činné (OSVČ), členové produkčních družstev apod.
Senioři v letech 2 a 215 4. Pracující (zaměstnaní) senioři Jako zaměstnaní se označují všichni pracující - např. zaměstnanci, osoby samostatně výdělečně činné (OSVČ), členové produkčních družstev apod.
MĚŘENÍ STATISTICKÝCH ZÁVISLOSTÍ
 MĚŘENÍ STATISTICKÝCH ZÁVISLOSTÍ v praxi u jednoho prvku souboru se často zkoumá více veličin, které mohou na sobě různě záviset jednorozměrný výběrový soubor VSS X vícerozměrným výběrovým souborem VSS
MĚŘENÍ STATISTICKÝCH ZÁVISLOSTÍ v praxi u jednoho prvku souboru se často zkoumá více veličin, které mohou na sobě různě záviset jednorozměrný výběrový soubor VSS X vícerozměrným výběrovým souborem VSS
Pravděpodobnost v závislosti na proměnné x je zde modelován pomocí logistického modelu. exp x. x x x. log 1
 Logistická regrese Menu: QCExpert Regrese Logistická Modul Logistická regrese umožňuje analýzu dat, kdy odezva je binární, nebo frekvenční veličina vyjádřená hodnotami 0 nebo 1, případně poměry v intervalu
Logistická regrese Menu: QCExpert Regrese Logistická Modul Logistická regrese umožňuje analýzu dat, kdy odezva je binární, nebo frekvenční veličina vyjádřená hodnotami 0 nebo 1, případně poměry v intervalu
Úvod do vícerozměrných metod. Statistické metody a zpracování dat. Faktorová a komponentní analýza (Úvod do vícerozměrných metod)
") Úvod do vícerozměrných metod Statistické metody a zpracování dat Faktorová a komponentní analýza (Úvod do vícerozměrných metod) Petr Dobrovolný O řadě jevů či procesů máme k dispozici ne jeden statistický
Úvod do vícerozměrných metod Statistické metody a zpracování dat Faktorová a komponentní analýza (Úvod do vícerozměrných metod) Petr Dobrovolný O řadě jevů či procesů máme k dispozici ne jeden statistický
Hlavní demografické změny
 Hlavní demografické změny Jitka Rychtaříková Katedra demografie a geodemografie Přírodovědecká fakulta University Karlovy v Praze Albertov 6, 128 43 Praha rychta@natur.cuni.cz +420 221951420 Struktura
Hlavní demografické změny Jitka Rychtaříková Katedra demografie a geodemografie Přírodovědecká fakulta University Karlovy v Praze Albertov 6, 128 43 Praha rychta@natur.cuni.cz +420 221951420 Struktura
Evropské mapování znečištění ovzduší za rok 2005
 Evropské mapování znečištění ovzduší za rok 2005 Jan Horálek Tvorbě evropských map a rozvoji mapování je několikátým rokem věnovv nován úkol Spatial air quality data v rámci ETC/ACC - úkol 5.3.1.2. Implementačního
Evropské mapování znečištění ovzduší za rok 2005 Jan Horálek Tvorbě evropských map a rozvoji mapování je několikátým rokem věnovv nován úkol Spatial air quality data v rámci ETC/ACC - úkol 5.3.1.2. Implementačního
Kam směřují vyspělé státy EU v odpadovém hospodářství. Kam směřuje ČR potažmo kam chceme nasměřovat v OH náš kraj.
 Návrh POH MSK Kam směřují vyspělé státy EU v odpadovém hospodářství. Kam směřuje ČR potažmo kam chceme nasměřovat v OH náš kraj. Jan Nezhyba konzultant NNO v oblasti ekologie kontaminace ŽP- odpady - ovzduší
Návrh POH MSK Kam směřují vyspělé státy EU v odpadovém hospodářství. Kam směřuje ČR potažmo kam chceme nasměřovat v OH náš kraj. Jan Nezhyba konzultant NNO v oblasti ekologie kontaminace ŽP- odpady - ovzduší
UNIVERZITA PARDUBICE FAKULTA EKONOMICKO SPRÁVNÍ BAKALÁŘSKÁ PRÁCE 2008 PETR ŠIMER
 UNIVERZITA PARDUBICE FAKULTA EKONOMICKO SPRÁVNÍ BAKALÁŘSKÁ PRÁCE 2008 PETR ŠIMER Univerzita Pardubice Fakulta ekonomicko-správní Předzpracování ekonomických dat pomocí analýzy hlavních komponent Petr Šimer
UNIVERZITA PARDUBICE FAKULTA EKONOMICKO SPRÁVNÍ BAKALÁŘSKÁ PRÁCE 2008 PETR ŠIMER Univerzita Pardubice Fakulta ekonomicko-správní Předzpracování ekonomických dat pomocí analýzy hlavních komponent Petr Šimer