Základy vytěžování dat
|
|
|
- Alžběta Kovářová
- před 8 lety
- Počet zobrazení:
Transkript
1 Základy vytěžování dat předmět A7Bb36vyd Vytěžování dat Filip Železný, Miroslav Čepek, Radomír Černoch, Jan Hrdlička katedra kybernetiky a katedra počítačů ČVUT v Praze, FEL Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti

2 Shluková analýza a analýza hlavních komponent Odkaz na výukové materiály: (oddíl 3) Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti

3 Vytěžování dat, přednáška 4: Shluková analýza Miroslav Čepek Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti Fakulta elektrotechnická, ČVUT 1 / 35 Shluková analýza

4 Co to je shluková analýza Je jednou ze základních úloh vytěžování dat. Jde o seskupení objektů do skupin podle jejich vlastností. Tak aby si objekty ve skupinách byly nějak podobné. A zároveň nebyly podobné objektů v jiných skupinách. 2 / 35 Shluková analýza

5 3 / 35 Shluková analýza
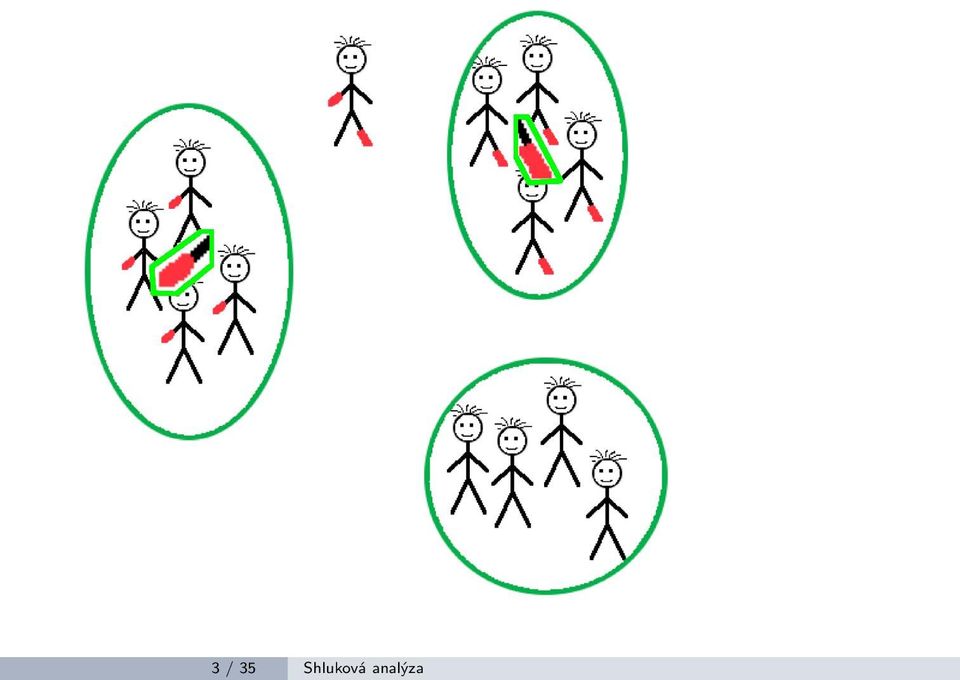
6 Co to je shluková analýza (II) V principu jde o optimalizační problém. Co se musí optimalizovat? Počet shluků (skupin) Přiřazení instancí do shluků 4 / 35 Shluková analýza
 Přiřazení instancí")
7 Jak zjistit, že jsou si dva vzory podobné? To je obecně velmi složitá otázka. Protože shlukovou analýzu budou provádět hlavně počítače, musí být výsledkem nějaké číslo. Z matematické analýzy známe pojem metrika což je jiné označení vzdálenosti. Metrika musí splňovat několik základních podmínek, aby ji bylo možné použít. d(x, y) 0 d(x, y) = d(y, x) d(x, y) = 0 x = y d(x, y) + d(y, z) d(x, y) 5 / 35 Shluková analýza

8 Metriky Jaké znáte metriky? Eukleidovská metrika Manhattanská metrika Kosinová metrika Příklady dalších metrik Editační vzdálenost (vzdálesnost dvou slov = počet změn, kterými můžu změnit jedno slovo na druhé) Grafová metrika (počet hran, které musím v grafu projít, abych se dostal do z jednoho uzlu do druhého) 6 / 35 Shluková analýza

9 Eukleidovská metrika Nejpřirozenější metrika, protože se s ní běžně setkáváme. Jak změříme vzdálenost dvou bodů na tabuli? Pravítkem :)! A když známe souřadnice, můžeme ji spočítat. Jak? 7 / 35 Shluková analýza
!")
10 Eukleidovská metrika (II) Pythagorova věta! c = a 2 + b 2 A Pythagorovu větu můžeme zobecnit pro R n x = (x 1, x 2,..., x n ), y = (y 1, y 2,..., y n ) dist( x, y) = n (x i y i ) 2 i=1 8 / 35 Shluková analýza
 dist( x, y) = n (x i y i ) 2 i=1 8 / 35")
11 Manhattanská metrika (City-block distance) Základní myšlenka: Kolik bloků ve městě musím obejít, abych se dostal z jednoho místa na druhé? Nebo také kolik tahů králem musím udělat abych se dostal z jednoho místa šachovnice na druhé? 9 / 35 Shluková analýza

 = x 1 y 1 + x 2 y 2 +.")
12 Manhattanská metrika (City-block distance) (II) Pokud znám souřadnice, vzdálenost spočítam takto: dist( x, y) = x 1 y 1 + x 2 y x n y n 10 / 35 Shluková analýza

13 Kosinová vzdálenost Vzdálenost dvou vektorů je úhel, který svírají. similarity( x, y) = n i=1 (x i y i ) n i=1 (x2 i ) n i=1 (y2 i ) Výsledky této funkce jsou v rozmezí znamená úplný opak, 0 nezávyslost a +1 naprostou shodu. Aby výsledky vyhovovali definici metriky je potřeba podobnost odečíst od jedné. dist( x, y) = 1 similarity( x, y) 11 / 35 Shluková analýza

14 Shlukování pomocí KMeans Jednostlivé shluky budou zastoupeny jedním reprezentantem, který ponese vlastnosti typické pro danou skupinu/shluk. Každá instance (vzor) v datech bude reprezentována reprezentantem, který je jí nejpodobnější. Jinými slovy který ji bude nejblíž (v dané metrice). 12 / 35 Shluková analýza
.")
15 13 / 35 Shluková analýza
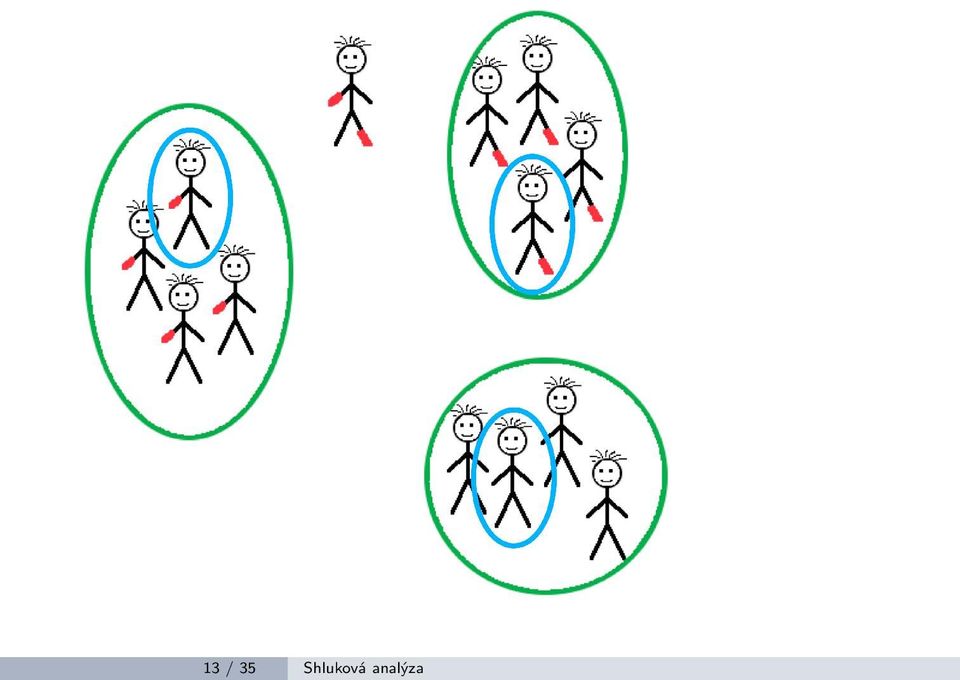
16 Shlukování pomocí KMeans Jak určit, kde je správné místo pro reprezentanty? Chceme, aby vzdálenost mezi reprezentanty a instancemi byla co nejmenší. Snažíme se vlastně minimalizovat součet všech vzdáleností mezi instancemi a jejich reprezentanty jde o optimalizační problém. Taková optimalizace se dá řešit mnoha způsoby, ale jeden z nejjednodušších je iterační. 14 / 35 Shluková analýza

17 Algoritmus KMeans značení Máme množinu n vstupních vzorů/instancí (vektorů) x k. Jednotlivé složky vektoru budeme označovat x k (s). A máme množinu K reprezentantů. means t i je i-tý reprezentant v kroku t. 15 / 35 Shluková analýza

18 Algoritmus KMeans 1. Nastav reprezentanty means 0 i do náhodných počátečních bodů. 2. Najdi a přiřaď každé instanci jeho nejbližšího reprezentanta. x najdi j tak, aby dist(x, means t j ) dist(x, means t i ) i a pro každého reprezentanta means t i vytvoř množinu nearest t i instancí, ke kterým je nejblíž. 3. Přesuň reprezentanta tak aby ležel uprostřed své množiny nejbližších instancí. means t+1 1 i (s) = nearest x t i k nearest x t k (s) i 4. Pokud se změnila poloha alespoň jednoho preprezentanta, vrať se na bod 2. Jinak skonči. 16 / 35 Shluková analýza

19 Ilustrace KMeans 17 / 35 Shluková analýza

20 Ilustrace KMeans (II) 18 / 35 Shluková analýza

21 Ilustrace KMeans (III) 19 / 35 Shluková analýza
22 Ilustrace KMeans (IV) 20 / 35 Shluková analýza

23 Ilustrace KMeans (V) 21 / 35 Shluková analýza
24 Pohádka o Algoritmu KMeans :) Once there was a land with N houses. One day K kings arrived to this land. Each house was taken by the nearest king. But the community wanted their king to be at the center of the village, so the throne was moved there Then the kings realized that some houses were closer to them now, so they took those houses, but they lost some. This went on and on... (2-3-4) Until one day they couldn t move anymore, so they settled down and lived happily ever after in their village / 35 Shluková analýza
25 Problémy a stabilita shlukování pomocí KMeans Dopadne shlukování pomocí KMeans pokaždé stejně? Jak určit správný počet středů (shluků)? Jak vyhodnotit jestli shlukování dopadlo dobře a jestli jsme zvolili přiměřené K? 23 / 35 Shluková analýza
26 Vyhodnocení shluků vytvořených KMeans algoritmem Jednou z možných metod je tzv. silueta. Silueta pro každou vstupní instanci spočítá jistotu zařazení instance do daného shluku. s(x k ) = b(x k) a(x k ) max(a(x k ), b(x k )) a(x k ) je průměrná vzdálenost x k od ostatních instancí shluku, ke kterému je přiřazena. b(x k ) je průměrná vzdálenost x k od instancí v nejbližším dalším shluku. Výsledné hodnoty jsou mezi -1 (x k do shluku úplně nepatří) a +1 (úplně patří) ftp: //ftp.win.ua.ac.be/pub/preprints/87/silgra87.pdf 24 / 35 Shluková analýza
27 Vyhodnocení shluků vytvořených KMeans algoritmem (II) Pokud vypočítáte siletu pro všechny instance a vykreslíte ji do grafu, můžete si udělat představu, jak shlukování dopadlo. 25 / 35 Shluková analýza

28 Ukázka Siluety shluky Kosatců 26 / 35 Shluková analýza
29 Které shlukování dopadlo lépe? Co třeba průměrná silueta přes všechny instance (ideálně přes testovací data)? 27 / 35 Shluková analýza
30 Stabilita shluků Jak zkusit, že shluky opravdu v datech jsou a výsledné shluky nejsou náhoda? Náhodným smazáním např. 10% různých instancí vygenerovat M podmnožin dat a spustit shlukování na každé podmnožině. Existuje několik ukázkových apletů/aplikací, kde si můžete zkusit, jak algoritmus funguje. tutorial_html/appletkm.html 28 / 35 Shluková analýza
31 Hierarchické shlukování úvod KMeans, jak jsme viděli, má některé mouchy. Kolik je v datech shluků? Závislost výsledků na počátečních podmínkách. Šlo by shlukování dělat i jinak? Šlo :). Jednou z možností je Hierarchické shlukování. Základní myslenka je, že vytvoříme hierarchii shluků. Vždy spojíme dva nejpodobnější shluky do jednoho většího. A takto budeme pokračovat, dokud nevytvoříme jeden mega-shluk. 29 / 35 Shluková analýza
32 Hierarchické shlukování 1. Začne ze stavu, kdy každá instance je jedním shlukem. 2. Najdi dva nejbližší shluky. 3. Spoj je do jednoho. 4. Zůstávají nějaké shluky, které lze spojit? Pokud ano, vrať se na bod / 35 Shluková analýza
33 Nejbližší shluky Jak zjistím vzdálenost dvou shluků? Dokud shluky obsahují jen jednu instanci, je spočítání vzdálenosti jednoduché. Ale pak? Vzdálenost shluků je určena Nejbližší sousedé vzdáleností nejbližších instancí ve shluku. Nejvzdálenější sousedé vzdáleností nejvzdálenějších instancí ve shluku. Vzdálenost středů vzdáleností center (středů) shluků. Průměrná vzdálenost průměrná vzdálenost mezi všemi instancemi v obo shlucích 31 / 35 Shluková analýza
34 Vzdálenost shluků ilustrace Nejkratší vzdálenost Průměrná vzdálenost Největší vzdálenost Vzdálenost mezi reprezentanty 32 / 35 Shluková analýza
, podle toho, kolik shluků potřebujeme nebo kolik vyjde jako nejvhodnější.")
35 Dendrogram Když zkusíme vizualizovat postup shlukování tj. které shluky se spojují, získáme strom dendrogram. Jak nalezneme počet shluků? Výběrem :), podle toho, kolik shluků potřebujeme nebo kolik vyjde jako nejvhodnější. 33 / 35 Shluková analýza
36 Vyhodnocení hierarchického shlukování Můžeme opět použít siluetu, stejně jak jsme ji používali v K-Means. Druhou možností je vypočítat CPCC (Cophenetic Correlation Coeffitient). CPCC je normovaná kovariance vzdáleností v původním prostoru a v dendrogramu. Pokud je hodnota CPCC menší než cca 0.8, všechny instance patří do jediného velkého shluku. Obecně platí, že čím vyšší je kofenetický koeficient korelace, tím nižší je ztráta informací, vznikající v procesu slučování objektů do shluků. 34 / 35 Shluková analýza
37 Další informace a zdroje zapis_prednasky/zapis_02/13/shlukovani.pdf seminar0304/hlukovani2.pdf 35 / 35 Shluková analýza
38 Vytěžování dat, přednáška 5: Self Organizing Map Miroslav Čepek Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti Fakulta elektrotechnická, ČVUT 1 / 44 Self Organizing Map
39 Shlukovací algoritmy a nevýhody Jaké znáte shlukovací algoritmy? KMeans Hierarchické shlukování KMeans nedopadne pokaždé stejně, musím zkoušet počet centroidů. Hiearachické shlukování musím spočítat N 2 vzdáleností. Což pro větší N není jednoduché. 2 / 44 Self Organizing Map
40 Další shlukovací algoritmy Existuje spousta dalších algoritmů pro shlukování dat. Ukáži vám ješte jeden Self Organizing Map (SOM). 3 / 44 Self Organizing Map
41 Kompetitivní učení Jedinci (reprezentanti, centroidy, neurony, jedinci) spolu soutěží o něco :). Nepotřebuji žádného arbitra (učitele), který by říkal, kam se mají jedinci přesunout. Každý jedinec to umí zjistit sám. Jedinci se učí z příkladů. Systém (populace jedinců) se v průběhu času samoorgranizuje sám. A teď to zkusíme použít na shlukování. 4 / 44 Self Organizing Map
42 Kompetitivní učení v pohádce Vzpomínáte si na pohádku o Králích z minulé přednášky? Do země s N domy přijelo K králů a někde se usídlili. A každý král zabral domy, které mu byli nejblíž a z nich vybíral daně. A protože lidé chtěli, aby jim byl král co nejblíž, král se přestěhoval do geometrického středu domů. Tím se ale některé domy ocitly blíže jinému králi a tak z nich daně začal vybírat jiný král. Králové se opět přesunout a tak dále. Nejbližší král tedy získá všechny daně z domů, které jsem mu nejblíž. 5 / 44 Self Organizing Map
43 Kompetitivní učení v KMeans KMeans také používá kompetitivní učení. Jak? KMeans je trochu skromější. Reprezentanti (centroidy) soutěží o data. A nejbližší reprezentant vyhraje zabere celou instanci a jiného reprezentant k ní nepustí. Bere vše. 6 / 44 Self Organizing Map
44 Kvantizační chyba Minule jsem v souvislosti s KMeans mluvil o optimalizaci (minimalizaci) chyby. Této chybě se říká kvantizační chyba. A vyjadřuje průměrnou vzdálenost mezi daty a odpovídajícími reprezentanty. Průměrná vzdálenost mezi krály a jejich poddanými. kvantizační chyba = 1 počet instancí k i=0 x nearest(r i ) dist(r i, x) r i je i-tý reprezentant. A nearest(r i ) je množina instancí, které jsou mu nejblíž. x je jedna z instancí. 7 / 44 Self Organizing Map
45 Vektorová kvantizace A cílem (nejen) KMeans je minimalizovat tuto chybu. Tím že minimalizuji kvantizační chybu tlačím reprezentanty do míst, kde se nachází hodně instancí. Snažím se tím aproximovat hustotu instancí pomocí (menší hustoty) reprezentantů. Do míst, kde je vysoká hustota instancí, se snažím dostat hodně reprezentatnů a naopak do míst s málo instancemi dávám málo reprezentatnů. Cílem kvantizace vektorů je aproximace hustotu pravděpodobnosti p(x) výskytu instancí x pomocí konečného počtu reprezentantů w i. 8 / 44 Self Organizing Map
46 Vítěz NEbere vše U KMeans z domu vybírá daně jen nejbližší král. Winner takes all. Co když platí, že část daní může vybírat i jiný blízký král? Pak už neplatí, že vítěz bere vše a něco zbude i na ostatní. Zde je důležité okolí tj. jak daleko se králi ještě vyplatí jet pro svůj díl daní. Malé okolí vítěz bere vše - daně vybírá jen jeden král Velké okolí komunismus - každý král dostane z každého domu kousek. 9 / 44 Self Organizing Map
47 Neuronový plyn Jiný způsob, jakým lze minimalizovat kvantizační chybu. Na rozdíl od KMeans používám okolí a jinak počítám nové pozice středů. 1. Náhodně rozmísti reprezentanty a zvol velké okolí. 2. Vyber nějakou vstupní instanci x j. 3. Spočítej vzdálenost mezi x j a všemi reprezentanty w i i. 4. Uprav pozice všech středů v závislosti na vzdálenosti od instance a okolí. 5. Zmenši okolí. 6. Pokud ještě chceš pokračovat, pokačuj bodem / 44 Self Organizing Map
48 Ilustrace iterace Neuronového plynu 11 / 44 Self Organizing Map
49 Ilustrace iterace Neuronového plynu 12 / 44 Self Organizing Map
50 Ilustrace iterace Neuronového plynu 13 / 44 Self Organizing Map
51 Ilustrace iterace Neuronového plynu 14 / 44 Self Organizing Map
52 Neuronový plyn (II) V algoritmu je několik stupňů volnosti. Vyber nějakou vstupní instanci Procházíme postupně jednotlivé instance postupně v pevném pořadí. Nevhodné protože výstup může záviset na pořadí předkládání instancí. Projde všechny instance jednou, pak v jiném pořadí podruhé, atd... Vybírá skutečně náhodně. Čili nezaručuje, že počet předložení síti bude pro všechny instance stejný. Nepoužívá se, protože není zaručeno, že nepředložím x 1 10x, pak x 2 12x, atd / 44 Self Organizing Map
53 Neuronový plyn (III) Uprav pozice všech středů v závislosti... Čím vzdálenější reprezentant, tím se posouvá méně. w t+1 i = w t i + ηt e k/λt (x w t i ) η t je adaptační krok v kroku t a určuje o kolik se maximálně může reprezentant posunout. (Typicky o dost menší než 1 a s roustoucím t klesá k 0). k pořadí ve vzdálenosti reprezentanta od instance. λ t definuje velikost okolí a s rostoucím t klesá. 16 / 44 Self Organizing Map
54 Neuronový plyn (IV) Zmenši okolí Okolí (λ t ) se typicky postupně zmenšuje o nějaký násobek. Např. λ t+1 = λ t 0.95 Při zmenšování okolí se podobným způsobem zmenšuje i adaptační krok. η t+1 = η t Pokud ješte chceš pokračovat... Dopředu určím, že chci pokračovat dokud je λ > 0.05 nebo skonči poté, co předložíš všechny instance 10x. Kontrolní otázka: Za jakých podmínek se přesune nejbližší reprezentant na pozici právě předložené instance? 17 / 44 Self Organizing Map
. Typicky se používá čtvercová nebo hexagonální síť.")
55 Vylepšení Neuronového plynu Jak by se dal neuronový plyn vylepšit dál? Co kdyby se neposouvali všechni reprezentanti blízko instance? Vytvoříme přátelské vztahy mezi reprezentanty. A budou se posouvat jen kamarádi vítězného reprezentanta. Když vizualizujeme přátelství mezi reprezentanty získáme pravidelnou mřížku (síť). Typicky se používá čtvercová nebo hexagonální síť. 18 / 44 Self Organizing Map
56 Inspirace pro SOM Inspirací nejsou králové, ale oblasti v lidském mozku. Řídící centra jednotlivých končetin spolu souvisí a navzájem se ovlivňují. 19 / 44 Self Organizing Map
57 SOM Neuronová síť SOM je vynálezem prof. Kohonena z Finska. Původně vznikla jako model motorického cortexu a její první aplikace byl fontetický psací stroj. A protože se prof. Kohonen zabýval umělými neuronovými sítěmi, převzal i SOM jejich terminologii. 20 / 44 Self Organizing Map
58 SOM - Pozice neuronů Každý reprezentant v terminologii SOMu neuron je opět reprezentován jeho souřadnicemi v prostoru. Souřadnice každého neuronu (reprezentanta) se označují jako váhy. Když si zkusím takovou síť vizualizovat, dostaneme například: 21 / 44 Self Organizing Map
59 SOM - Pozice neuronů (II) WTF? Ještě před chvílí byla ta síť přece pravidelná! To ano, ale to byla idealizovaná projekce, aby bylo názorně vidět vztahy! 22 / 44 Self Organizing Map
60 SOM - Algoritmus Celý SOM algoritmus vypadá pak takto: 1. Inicializuj váhy všech neuronů (souřadnice všech reprezentantů). 2. Vyber nějakou vstupní instanci x j. 3. Spočítej vzdálenost mezi x j a všemi neurony w i i. 4. Urči nejbližší neuron BMU (Best Matching Unit). 5. Uprav váhy (pozici) BMU a jeho okolí. 6. Pokud ještě chceš pokračovat, pokačuj bodem / 44 Self Organizing Map
61 Detaily algoritmu Inicializace vah: Rovnoměrné rozprostření pro prostoru. Náhodně. Výběr instancí: Opět můžeme vybírat instance úplně náhodně. Ale mnohem častější je vybrat všechny instance jednou, pak všechny podruhé (v jiném pořadí), atd... Prochází se permutace vstupní množiny. 24 / 44 Self Organizing Map
62 Detaily algoritmu (II) Výpočet vzdáleností a určení BMU je celkem jednoduchá záležitost. Určím si metriku, kterou budu využívat a tu aplikuji. Mnohem zajímavější je úprava pozice BMU a jeho okolí :). Jak vlastně určím neurony v okolí? 25 / 44 Self Organizing Map
63 Změna vah graficky 26 / 44 Self Organizing Map
64 Detaily algoritmu (III) Novou pozici neuronu w i v kroku t + 1 (po předložení vzoru x j ) určím jako: w t+1 i = w t i + µ(t)(x j w t i ) Kde µ(t) je sdružený učící koeficient, který v sobě sdružuje jak vzdálenost neuronu od BMU tak i maximální možnou změnu vah (pozice). µ(t) s postupujícím časem klesá k nule. 27 / 44 Self Organizing Map
65 Detaily algoritmu (IV) µ(t) = α(t)e dist(w i,bmu) 2σ 2 (t) α(t) představuje učící krok (tedy jak moc se maximálně mohou změnit váhy neuronu). e blabla určuje, že okolí neuron má tvar gausovky. σ 2 (t) určuje velikost okolí a postupně s časem klesá. 28 / 44 Self Organizing Map
66 Příklad Máme 3 neurony w 1 = (0, 0)w 2 = (2, 1)w 3 = (0, 3) a ty jsou na lince. w 1 je sousedem w 2, w 2 je sousedem w 3 a w 1, w 2 je sousedem w 3. A instanci x = (1, 1) Který neuron je BMU? (Použijeme eukleidovskou metriku) d(w 1, x) = (0 1) 2 + (0 1) 2 = 2 = d(w 2, x) = (2 1) 2 + (1 1) 2 = 1 = 1 d(w 3, x) = (0 1) 2 + (3 1) 2 = 5 = / 44 Self Organizing Map
67 Příklad (II) BMU je tedy w 2. Řekněme, že σ(t) = 1 a α(t) = 0.25 A zkusme vypočítat novou pozici BMU (w 2 ). µ(t) = α(t)e dist(w i,bmu) 2σ 2 (t) = 0.25 e dist(w 2,w 2 ) = 0.25 e 0 = 0.25 w t+1 2 = w t 2 + µ(t)(x w t 2) = (2, 1) ((1, 1) (2, 1)) = = (2, 1) ( 1, 0) = (1.75, 1) Pro w 1 se posune do pozice: µ(t) = α(t)e dist(w 1,w 2 ) 2σ 2 (t) = 0.25 e 1 2 = = w t+1 1 = w t 1 + µ(t)(x w t 1) = (0, 0) ((1, 1) (0, 0)) = = (0, 0) + (0.151, 0.151) = (0.151, 0.151) 30 / 44 Self Organizing Map
68 Chyba SOM Stejně jako v Hierarchickém shlukování a K-Means potřebujeme nějakou míru dobrého shluknutí. Kvantizační chyba Ale tu už známe! To je přece chyba, o které jsme mluvili na začátku přednášky! Průměrná vzdálenost mezi instancemi a nejbližšími neurony. Topografická chyba Popisuje kvalitu natažení mřížky sítě na vstupní data. Procento instancí, pro které platí, že jejich BMU a druhý nebližší neuron nejsou sousedy v mřížce sítě. err topo = 1 n n i=1 u(x i) u(x i ) = 1 BMU a druhý nejbližší neuron pro x i nejsou sousedé v mřížce. 31 / 44 Self Organizing Map
69 Vizualizace SOM Dokud máme jen 2D data, tak s vizualizací není problém. Ale co když máme více dimenzí? U-Matice Analýza hlavních komponent Sammonova projekce 32 / 44 Self Organizing Map
70 U-Matice Matice vzdáleností mezi váhovými vektory jednotlivých neuronů, typicky se vizualizuje, vzdáleností vyjádřeny barvou světlá barva = malá vzdálenost. Zobrazuje strukturu vzdáleností v prostoru dat. 33 / 44 Self Organizing Map
71 U-Matice Barva neuronu je vzdálenost je váhového vektoru od všech ostatních váhových vektorů. Tmavé váhové vektory jsou vzdáleny od ostatních datových vektorů ve vstupním prostoru. Světlé váhové vektory jsou obklopeny cizími vektory ve vstupním prostoru. 34 / 44 Self Organizing Map
72 U-Matice (III) Jak z U-Matice poznám shluky? Ze vzdáleností mezi neurony. Kopce oddělují clustery (údolí). 35 / 44 Self Organizing Map
73 Analýza hlavních komponent Jde o statistickou metodu pro redukci dimenzionality. Označuje se jako PCA z anglického Principal Component Analysis. Snaží se najít nové osy, které lépe popisují data s minimální ztrátou informace. První osa vede směrem, který má největší rozptyl hodnot, druhá osa směrem, kde je druhý největší rozptyl, atd... Vždy mi vrátí stejný počet nových os, jako mají původní data dimenzí, ale já se mohu rozhodnout některé nepoužít. 36 / 44 Self Organizing Map
. http://www.cs.otago.ac.nz/cosc453/student_ tutorials/principal_components.")
74 Analýza hlavních komponent (II) Pro výpočet nových souřadnic se používá konvariance, vlastní čísla a vlastní vektory. Tím vás nebudu trápit :). tutorials/principal_components.pdf 37 / 44 Self Organizing Map
75 Využití PCA v SOM Nyní můžu provést PCA projekci SOM sítě do 2D a zobrazit si ji. 38 / 44 Self Organizing Map
76 Využití PCA mimo SOM Samozřejmě využití PCA není nutně limitováno jen na použití v SOM, ale můžu ji použít například pro průzkumu dat. Stejně tak, některé metody vytěžování dat nemají rády příliš mnoho dimenzí a PCA jim můžete pomoci k lepším výsledkům. Nevýhodou je umělost nových os, která znesnadňuje interpretaci získaných výsledků petal_length petal_width sepal_length.0346 sepal_width 39 / 44 Self Organizing Map
77 Sammonova projekce Jinou možností je Sammonova projekce. Ta netransformuje osy, ale znovu umísťuje objekty v novém (méně dimenzionálním) prostoru. Při umisťování se snaží zachovat vztahy v datech (data, která byla blízko v původním prostoru, budou blízko i v novém prostoru). 40 / 44 Self Organizing Map
78 Sammonova projekce (2) Sammonova projekce se snaží minimalizovat následující funkci: 1 (dist E = (x i, x j ) dist(x i, x j )) 2 i<j dist (x i, x j ) dist (x i, x j ) i<j dist (x i, x j ) je vzdálenost x i a x j v původním prostoru. dist(x i, x j ) je vzdálenost x i a x j v novém prostoru (v projekci). Pro minimalizaci se používají standardní optimalizační metody pro tuto úlohu typicky iterační metody. Při minimalizaci se pohybuje body v novém prostoru (v projekci). Tím ovlivníte dist(x i, x j ) a můžete dosáhnout zmenšení E. 41 / 44 Self Organizing Map

79 Sammonova projekce - ukázka Ukázka několika iterací Sammonovy projekce na Iris datech. Počáteční stav 1. iterace 10. iterace 42 / 44 Self Organizing Map

80 Další vizualizace Příznakové grafy Vychází z U-Matice, ale místo vzdálenosti jednotlivých vektorů se do šestiúhelníčků kreslí hodnoty vybrané proměnné. 43 / 44 Self Organizing Map
81 Další čtení somalgorithm.shtml / 44 Self Organizing Map
82 Vytěžování dat, cvičení 5: Shlukování Miroslav Čepek Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti Fakulta elektrotechnická, ČVUT 1 / 5 Shlukování
83 Zadání domácího úkolu 1. Doimplementujte K-Means algoritmus. Přiložená funkce v Matlabu implementuje část KMeans algoritmu (nalezení nejbližších reprezentantů (centroidů)). Vaším úkolem je doplnit přesun reprezentantů do středu nových shluků a určit, zda je možné ukončit algoritmus nebo má smysl pokračovat další iterací. 2. Centroidy (reprezentanty) inicializujte náhodně a při každém spuštění jinak. 3. Shlukněte přiložená data vaším KMeans algoritmem. Zkuste různé počty reprezentantů (2,3,...,10). Spočítejte průměrnou siluetu pro všechny počty shluků a určete pro který počet reprezentantů vyjde průměrná silueta nejlépe. Pro zajímavé počty reprezentantů zobrazte grafy siluet. 2 / 5 Shlukování
84 Zadání domácího úkolu (2) 1. Pro nejlepší počet reprezentantů, který vám vyšel v minulém bodě, (alespoň 5x) spusťte algorimus KMeans s různými náhodnými počátečními pozicemi reprezentantů. 2. Shlukněte data pomocí hierarchického shlukování. Vytvořte stejný počet shluků, který vám vyšel nejlépe v algoritmu KMeans. Do zprávy vložte dendrogram, graf siluety a průměrnou siluetu. Krátce okomentujte rozdíly mezi výsledky hierarchického shlukování a KMeans algoritmu. 3 / 5 Shlukování
85 Obsah zprávy 1. Vámi doplňený zdrojový kód.!!a jeho stručný popis!! 2. Průměrné hodnoty siluety pro počty reprezentantů: 2, 3, 4,..., Dále přiložte zajímavé grafy siluet. Volitelně, pokud vám přijde zajímavý, může zpráva také obsahovat 2D/3D bodový graf se zvýrazněnými shluky. 4. Hodnoty průměrných siluet a výsledných souřadnic reprezentantů pro různé náhodné počáteční pozice reprezentantů. Pro počet reprezentantů, který vám vyšel nejlepší, v minulém bodě. 5. Dendrogram, který vám vyšel z hierarchického shlukování. A průměrná silueta a graf siluety stejný pro počet shluků, jako vám vyšel nejlepší v algoritmu KMeans. 4 / 5 Shlukování
86 Užitečné funkce silhouette kmeans linkage pdist cluster cophenet scatter 5 / 5 Shlukování
87 Vytěžování dat 6: Self Organizing Map Miroslav Čepek Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti Fakulta elektrotechnická, ČVUT 1 / 15 Slef Organizing Map
88 SOM Toolbox V dnešním cvičení vám ukážeme SOM Toolbox. Před použitím jej musíte stáhnout a rozbalit. SOM Toolbox se nachází na 2 / 15 Slef Organizing Map
89 SOM Toolbox (II) Až SOM Toolbox stáhnete, rozbalte jej do nějaké složky (ideálně tam, kde máte ostatní vaše zdrojové soubory). Doporučuji nechat soubory SOM Toolboxu v jednom podadresáři. Tento podadresář musíte přidat do cesty, kde Matlab hledá skripty. Pravým tlačítkem klikněte na adresář se SOM Tooleboxem a vyberte Add to Path Selected Folder and Subfolders. 3 / 15 Slef Organizing Map
90 SOM Toolbox demo Společně projdeme demo skripty, které ukazují všechny možnosti SOM Toolboxu. Pokud si někdy nebudete vědět rady, projděte si tato dema znovu a většinou v nich najdete, co potřebujete. Dema spoustíte příkazy som_demo1, som_demo2, som_demo3 a som_demo4. 4 / 15 Slef Organizing Map
91 Načtení dat Načtěte data pomocí load ionosphere. This radar data was collected by a system in Goose Bay, Labrador. This system consists of a phased array of 16 high-frequency antennas with a total transmitted power on the order of 6.4 kilowatts. The targets were free electrons in the ionosphere. Good radar returns are those showing evidence of some type of structure in the ionosphere. Bad returns are those that do not; their signals pass through the ionosphere. Normalizujte data pomocí data = som_normalize(x) 5 / 15 Slef Organizing Map
92 SOM příklad učení Vytvořte náhodně inicializovanou mapu pomocí som_randinit. Pokud potřebujete vytvořit prázndou mapu, použijte som_map_struct. map = som_randinit(x, 'msize', [10 8], 'lattice','hexa') Pro trénování použijte som_batchtrain(map, data) (druhá možnost je som_seqtrain). Variantou je použití funkce som_make, která vytvoří SOM síť, inicializuje ji a naučí ji. 6 / 15 Slef Organizing Map
93 PCA vizualizace dat Zobrazení dat pomocí PCA Výpočet PCA hodnot: tmp = pcaproj(data, 2) Zobrazení scatter(tmp(:,1), tmp(:,2)) Barevné rozlišení tříd: y = cell2mat(y) scatter(tmp(y == 'k',1), tmp(y == 'k',2), 'ok') hold on scatter(tmp(y == 'g',1), tmp(y == 'g',2), '+r') 7 / 15 Slef Organizing Map
94 SOM vizualizace Zobrazte U-Matici som_show. som_show(map, 'umat', 'all'). Jak zobrazit, který neuron je reprezentantem pro která data? Musíme použít som_show_add a k U-Matici přidat informace o počtu a typu dat. Nejprve je potřeba zjistit, který neuron je BMU pro které vstupní instance. K tomu slouží som_hits. h1 = som_hits(map, data(y == 'g', :)); h2 = som_hits(map, data(y == 'k', :)); som_show_add('hit', h1, 'MarkerColor', [1 0 0]); som_show_add('hit', h2, 'MarkerColor', [0 1 0]); 8 / 15 Slef Organizing Map
95 Zadání domácího úkolu Pomocí SOM vytvořte shluky dodaných dokumentů. Dokumenty obsahují zprávy z několika diskusních fór. Každé fórum má jeden adresář a každá zpráva v něm je jeden soubor. Ze stránek předmětu (cvičení) stáhněte tato data. Z dokumentů extrahujte důležitá slova a příznakové vektory pomocí rozšíření rapidmineru pro textmining. (bude náplní dalšího cvičení). Takto extrahovaná data uložte do CSV souboru. 9 / 15 Slef Organizing Map
96 Zadání domácího úkolu (2) Tento CSV soubor načtěte do MATLABu pomocí funkce dlmread (nebo podobné). Pomocí SOM Toolboxu shlukněte načtená data a pomocí různých vizualizací zobrazte výsledky shlukování. Pro počítání vzdáleností použijte Kosínovou metriku. Učiňte závěry, zda se dokumenty v jednotlivých fórech podobají nebo ne. 10 / 15 Slef Organizing Map
97 Nastavení textminingu Tokeny (slova) jsou odděleny znaky, která nejsou písmena. Doporučuji, abyste vyfiltrovali příliš krátká slova (řekněme kratší než 5 znaků) a často se vyskytující slova (stopwords) předložky, spojky,... Pro hledání kořenů slov použijte Porterův algoritmus. Volitelně můžete zkusit zkusit zkontruovat n-gramy (tokeny sestávající se z více slov) doporučuji maximálně 3 slova. Také doporučuji odstranit slova, která se vyskytují příliš řídce (příliš málo -krát). 11 / 15 Slef Organizing Map
98 Obsah zprávy Zpráva bude obsahovat: Popis proudu v Rapidmineru, kterým jste vyextrahovali příznaky z dokumentů a jeho screenshot (alespoň důležité části). Popis postupu, jakým jste vytvořili SOM síť a její vizualizace. Vytvořené vizualizace a jejich popis. Závěr o tom, zda se příspěvky v diskusních fórech podobají nebo ne. 12 / 15 Slef Organizing Map
99 Užitečné příkazy SOM Toolboxu som_demo1, som_demo2, som_demo3, som_demo4 som_randinit som_make som_quality som_show Kompletní dokumentaci všech funkcí naleznete na package/docs2/somtoolbox.html 13 / 15 Slef Organizing Map
100 Užitečné zdroje o Textminingu Pokud se chcete podívat, jak se textmining provádí v Rapidmineru, doporučuji následující sérii videí: Video přednáška o Textminingu 14 / 15 Slef Organizing Map
101 Užitečné zdroje o Textminingu (2) /01/Tutorial_Marko.pdf TextMining.pdf 15 / 15 Slef Organizing Map
102 Vytěžování dat, cvičení 7: Textmining Miroslav Čepek Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti Fakulta elektrotechnická, ČVUT 1 / 24 Textmining
103 Základní kroky pro text mining 1. Získání dokumentů a nahrání do Rapidmineru (či jiného SW) 2. Tokenizace (rozklad textu na jednotlivá slova) 3. Odfiltrování častých a nezajímavých slov 4. Převod slov na kořeny slov (stemming) Převod na jednotná čísla Převod různých časování/způsoby/vidy na infinitivy Převod mezi různými variantami slov (příslovce, přídavná jména podstatná jména). 5. Vytvoření word vectoru. (Převod slov na čísla). 6. Tvorba modelu. 2 / 24 Textmining
104 Instalace rozšíření pro Textmining Standardní instalace Rapidmineru neobsahuje rozšíření pro Textmining. Musíte nainstalovat rozšíření, ale naštěstí je to velmi jednoduché :). Z menu Help vyberte Update RapidMiner. Zde zaklikněte Text Processing a Web Mining. A klikněte na Install. 3 / 24 Textmining
105 Získání dokumentů a nahrání do Rapidmineru Existuje několik uzlů, pro nahrávání dat do RapidMineru. Pro naše účely, kdy máme dokumenty různých typů v různých složkách, nejlépe vyhovuje uzel Text Processing > Process Documents from Files. Jedná se o super-uzel, který bude obsahovat pod-proud transformující dokumenty na číselné vektory. 4 / 24 Textmining
106 Extrakce textů z HTML První krok je extrakce textů z HTML (resp. odstranění HTML tagů). Pro to budete potřebovat uzel Extract Content > HTML Processing > Extract Content. 5 / 24 Textmining
107 Tokenizace Rozklad na jednotlivá slova. Slova se rozdělují typicky podle ne písmenek. Takto získaná slova se označují jako termy. V Rapidmineru existuje uzel Tokenize, který najdete Text Processing > Tokenization > Tokenize. Možnosti rokladu na slova jsou: non-letters, specify-characters, regular expression, linguistic tokens, linguistic token. 6 / 24 Textmining
108 Tokenizace (2) Zkuste spustit proud nyní. Výsledkem bude word objekt, který si můžete prohlédnout. Uvidíte počty slov podle typů dokumentů. A také celkový počet slov. Každé slovo nakonec bude reprezentovat vstupní proměnnou. 7 / 24 Textmining
109 Filtrování častých a nezajímavých slov Protože vstupních proměnných bude i tak moc, je vhodné některé z nich eliminovat. První způsob je filtrování obvyklých a nezajímavých slov. V Rapidmineru se to děje uzlem Text Processing > Filtering > Filter Stopwords (English). Tím z dokumentu odstraníte termy (slova), která se v angličtině vyskytují příliš často. Například spojky, běžná slovesa, předložky, apod... Uzel v Rapidmineru obsahuje seznam předdefinovaných slov. 8 / 24 Textmining
110 Filtrování častých a nezajímavých slov (3) Stejně tak může (ale nemusí) být dobrý nápad vyfiltrovat slova, která jsou příliš dlouhá nebo příliš krátká. K tomu slouží Text Processing > Filtering > Filter Tokens (by Length). 9 / 24 Textmining
111 Převod slov na kořeny slov Stemming Exituje několik způsobů, jak najít kořen slova. Například hrubou silou tj tabulka mapující každé slovo a každý jeho tvar na odpovídající kořen. Jeden z dalších používaných algoritmů (pro Angličtinu) je tzv. Porterův algoritmus. Iterativně odebírá známé koncovky anglických slov. Má seznam přípon a ty se pokouší postupně odebrat (pokud to lze). Například HOPEFULNESS HOPEFUL HOPE / 24 Textmining
112 Převod slov na kořeny slov Stemming (2) 11 / 24 Textmining
113 Kombinace slov - N-Grams Někdy se v dokumentech vyskytují zajímavé kombinace (po sobě jdoucích) slov. N-Gram je term, který obsahuje posloupnost term maximální délky N. Uzel Text Processing > Transformation > Generate n-grams (Terms) vygeneruje vsechny kombinace termů. 12 / 24 Textmining
114 Kombinace slov 13 / 24 Textmining
115 Vlastnosti uzlu Process Documents from Files Jednak umožňuje zahodit málo (nebo moc) často se vyskytující termy (slova a n-gramy). Jednotlivé možnosti vybíráte combo-boxem Prune method. Další důležitá věc je zaškrtnout Create word vector. A vybrat vhodnou metodu pro Vector creation. 14 / 24 Textmining
116 Vytvoření word vectoru Nyní máme slova (termy) a jejich počty v jednotlivých dokumentech. Před předložením shlukovací (či jakékoliv jiné) metodě je potřeba tyto počty nějak přetransformovat. V Rapidmineru jsou na výběr následující možnosti: Term Frequency normalizovaný počet výskytů termu počet výskytu termu ( celkový počet termů ) Term Occurences Binary Term Occurences TF-IDF 15 / 24 Textmining
117 Term Frequency - Inverse Document Frequency Míra ukazující, jak moc je term specifický pro daný dokument. Zahrnuje v sobě dvě části Term Frequency a Inverse Document Frequency. Term Frequency je definován takto: tf(t) = počet výskytu termu celkový počet termů 16 / 24 Textmining
118 Term Frequency - Inverse Document Frequency (2) Inverse Document Frequency ukazuje, jak často se vyskytuje term v ostatních dokumentech. idf(t) = log D Celkový počet dokumentů. D {d : t d} {d : t d} Počet dokumentů, ve kterých se term t vysktytuje. 17 / 24 Textmining
119 Term Frequency - Inverse Document Frequency (3) Term Frequency - Inverse Document Frequency nakonec získáme, když tyto dvě míry vynásobíme. td idf(t, d) = tf(t, d) idf(t) 18 / 24 Textmining
120 Export dat do CSV a import do MATLABu V RapidMineru bohužel nejsou žádné vhodné shlukovací metody. Čili použijeme Matlab a SOM toolbox. K exportu z RapidMineru lze použít uzel Export > Data > Write CSV Abychom se nemuseli trápit v Matlabu s načítáním ošklivých hodnot, můžeme využít uzlu Export > Data > Write CSV k odstranění sloupců, které obhashují nečíselná a pomocná data. V mém případě jde o sloupce: Description, Keywords, Language, Robots, Title, label, metadata_date, metadata_file, metadata_path. Pro import použijeme v MATLABu funkci importdata. 19 / 24 Textmining
121 Shlukování v SOM toolboxu Vytvoření a naučení SOM mapy: map = som_make(x.data); Zobrazení UMatice: som_show(map, 'umat','all') Jak to dopadlo? 20 / 24 Textmining

122 UMatice se zobrazenými třídami dokumentů 21 / 24 Textmining
Textmining a Redukce dimenzionality
 Vytěžování dat, cvičení 7: Textmining a Redukce dimenzionality Miroslav Čepek, Michael Anděl Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti Fakulta elektrotechnická, ČVUT 1 / 22 Textmining
Vytěžování dat, cvičení 7: Textmining a Redukce dimenzionality Miroslav Čepek, Michael Anděl Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti Fakulta elektrotechnická, ČVUT 1 / 22 Textmining
Státnice odborné č. 20
 Státnice odborné č. 20 Shlukování dat Shlukování dat. Metoda k-středů, hierarchické (aglomerativní) shlukování, Kohonenova mapa SOM Shlukování dat Shluková analýza je snaha o seskupení objektů do skupin
Státnice odborné č. 20 Shlukování dat Shlukování dat. Metoda k-středů, hierarchické (aglomerativní) shlukování, Kohonenova mapa SOM Shlukování dat Shluková analýza je snaha o seskupení objektů do skupin
Miroslav Čepek
 Vytěžování Dat Přednáška 5 Self Organizing Map Miroslav Čepek Katedra počítačů, Computational Intelligence Group Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti 21.10.2014 Miroslav Čepek
Vytěžování Dat Přednáška 5 Self Organizing Map Miroslav Čepek Katedra počítačů, Computational Intelligence Group Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti 21.10.2014 Miroslav Čepek
Miroslav Čepek
 Vytěžování Dat Přednáška 4 Shluková analýza Miroslav Čepek Katedra počítačů, Computational Intelligence Group Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti 14.10.2014 Miroslav Čepek
Vytěžování Dat Přednáška 4 Shluková analýza Miroslav Čepek Katedra počítačů, Computational Intelligence Group Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti 14.10.2014 Miroslav Čepek
Self Organizing Map. Michael Anděl. Praha & EU: Investujeme do vaší budoucnosti. 1 / 10 Slef Organizing Map
 Vytěžování dat 6: Self Organizing Map Michael Anděl Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti Fakulta elektrotechnická, ČVUT 1 / 10 Slef Organizing Map SOM Toolbox V dnešním cvičení
Vytěžování dat 6: Self Organizing Map Michael Anděl Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti Fakulta elektrotechnická, ČVUT 1 / 10 Slef Organizing Map SOM Toolbox V dnešním cvičení
Přednáška 13 Redukce dimenzionality
 Vytěžování Dat Přednáška 13 Redukce dimenzionality Miroslav Čepek Fakulta Elektrotechnická, ČVUT Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti ČVUT (FEL) Redukce dimenzionality 1 /
Vytěžování Dat Přednáška 13 Redukce dimenzionality Miroslav Čepek Fakulta Elektrotechnická, ČVUT Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti ČVUT (FEL) Redukce dimenzionality 1 /
Vytěžování znalostí z dat
 Pavel Kordík (ČVUT FIT) Vytěžování znalostí z dat BI-VZD, 2012, Přednáška 10 1/50 Vytěžování znalostí z dat Pavel Kordík Department of Computer Systems Faculty of Information Technology Czech Technical
Pavel Kordík (ČVUT FIT) Vytěžování znalostí z dat BI-VZD, 2012, Přednáška 10 1/50 Vytěžování znalostí z dat Pavel Kordík Department of Computer Systems Faculty of Information Technology Czech Technical
Přednáška 12: Shlukování
 České vysoké učení technické v Praze Fakulta informačních technologií Katedra teoretické informatiky Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti MI-ADM Algoritmy data miningu (2010/2011)
České vysoké učení technické v Praze Fakulta informačních technologií Katedra teoretické informatiky Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti MI-ADM Algoritmy data miningu (2010/2011)
AVDAT Mnohorozměrné metody, metody klasifikace Shluková analýza
 AVDAT Mnohorozměrné metody, metody klasifikace Shluková analýza Josef Tvrdík Katedra informatiky Přírodovědecká fakulta Ostravská univerzita Shluková analýza Cílem shlukové analýzy je nalézt v datech podmnožiny
AVDAT Mnohorozměrné metody, metody klasifikace Shluková analýza Josef Tvrdík Katedra informatiky Přírodovědecká fakulta Ostravská univerzita Shluková analýza Cílem shlukové analýzy je nalézt v datech podmnožiny
Základy vytěžování dat
 Základy vytěžování dat předmět A7Bb36vyd Vytěžování dat Filip Železný, Miroslav Čepek, Radomír Černoch, Jan Hrdlička katedra kybernetiky a katedra počítačů ČVUT v Praze, FEL Evropský sociální fond Praha
Základy vytěžování dat předmět A7Bb36vyd Vytěžování dat Filip Železný, Miroslav Čepek, Radomír Černoch, Jan Hrdlička katedra kybernetiky a katedra počítačů ČVUT v Praze, FEL Evropský sociální fond Praha
LDA, logistická regrese
 Vytěžování Dat Přednáška 9 Lineární klasifikátor, rozšíření báze, LDA, logistická regrese Miroslav Čepek Fakulta Elektrotechnická, ČVUT Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti
Vytěžování Dat Přednáška 9 Lineární klasifikátor, rozšíření báze, LDA, logistická regrese Miroslav Čepek Fakulta Elektrotechnická, ČVUT Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti
Fakulta chemicko-technologická Katedra analytické chemie. 3.2 Metody s latentními proměnnými a klasifikační metody
 Fakulta chemicko-technologická Katedra analytické chemie 3.2 Metody s latentními proměnnými a klasifikační metody Vypracoval: Ing. Tomáš Nekola Studium: licenční Datum: 21. 1. 2008 Otázka 1. Vypočtěte
Fakulta chemicko-technologická Katedra analytické chemie 3.2 Metody s latentními proměnnými a klasifikační metody Vypracoval: Ing. Tomáš Nekola Studium: licenční Datum: 21. 1. 2008 Otázka 1. Vypočtěte
Algoritmy a struktury neuropočítačů ASN P3
 Algoritmy a struktury neuropočítačů ASN P3 SOM algoritmus s učitelem i bez učitele U-matice Vektorová kvantizace Samoorganizující se mapy ( Self-Organizing Maps ) PROČ? Základní myšlenka: analogie s činností
Algoritmy a struktury neuropočítačů ASN P3 SOM algoritmus s učitelem i bez učitele U-matice Vektorová kvantizace Samoorganizující se mapy ( Self-Organizing Maps ) PROČ? Základní myšlenka: analogie s činností
Úvod do Matlabu. Praha & EU: Investujeme do vaší budoucnosti. 1 / 24 Úvod do Matlabu
 Vytěžování dat, cvičení 1: Úvod do Matlabu Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti Fakulta elektrotechnická, ČVUT 1 / 24 Úvod do Matlabu Proč proboha Matlab? Matlab je SW pro
Vytěžování dat, cvičení 1: Úvod do Matlabu Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti Fakulta elektrotechnická, ČVUT 1 / 24 Úvod do Matlabu Proč proboha Matlab? Matlab je SW pro
Úvod do RapidMineru. Praha & EU: Investujeme do vaší budoucnosti. 1 / 23 Úvod do RapidMineru
 Vytěžování dat, cvičení 2: Úvod do RapidMineru Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti Fakulta elektrotechnická, ČVUT 1 / 23 Úvod do RapidMineru Dnes vám ukážeme jeden z mnoha
Vytěžování dat, cvičení 2: Úvod do RapidMineru Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti Fakulta elektrotechnická, ČVUT 1 / 23 Úvod do RapidMineru Dnes vám ukážeme jeden z mnoha
Vícerozměrné statistické metody
 Vícerozměrné statistické metody Shluková analýza Jiří Jarkovský, Simona Littnerová FSTA: Pokročilé statistické metody Typy shlukových analýz Shluková analýza: cíle a postupy Shluková analýza se snaží o
Vícerozměrné statistické metody Shluková analýza Jiří Jarkovský, Simona Littnerová FSTA: Pokročilé statistické metody Typy shlukových analýz Shluková analýza: cíle a postupy Shluková analýza se snaží o
1 Linearní prostory nad komplexními čísly
 1 Linearní prostory nad komplexními čísly V této přednášce budeme hledat kořeny polynomů, které se dále budou moci vyskytovat jako složky vektorů nebo matic Vzhledem k tomu, že kořeny polynomu (i reálného)
1 Linearní prostory nad komplexními čísly V této přednášce budeme hledat kořeny polynomů, které se dále budou moci vyskytovat jako složky vektorů nebo matic Vzhledem k tomu, že kořeny polynomu (i reálného)
Vytěžování znalostí z dat
 Pavel Kordík, Josef Borkovec (ČVUT FIT) Vytěžování znalostí z dat BI-VZD, 2011, Cvičení 10 1/21 Vytěžování znalostí z dat Pavel Kordík, Josef Borkovec Department of Computer Systems Faculty of Information
Pavel Kordík, Josef Borkovec (ČVUT FIT) Vytěžování znalostí z dat BI-VZD, 2011, Cvičení 10 1/21 Vytěžování znalostí z dat Pavel Kordík, Josef Borkovec Department of Computer Systems Faculty of Information
Katedra kybernetiky laboratoř Inteligentní Datové Analýzy (IDA) Katedra počítačů, Computational Intelligence Group
 Katedra počítačů, Computational Intelligence Group") Vytěžování dat Miroslav Čepek, Filip Železný Katedra kybernetiky laboratoř Inteligentní Datové Analýzy (IDA) Katedra počítačů, Computational Intelligence Group Evropský sociální fond Praha & EU: Investujeme
Vytěžování dat Miroslav Čepek, Filip Železný Katedra kybernetiky laboratoř Inteligentní Datové Analýzy (IDA) Katedra počítačů, Computational Intelligence Group Evropský sociální fond Praha & EU: Investujeme
Algoritmus pro hledání nejkratší cesty orientovaným grafem
 1.1 Úvod Algoritmus pro hledání nejkratší cesty orientovaným grafem Naprogramoval jsem v Matlabu funkci, která dokáže určit nejkratší cestu v orientovaném grafu mezi libovolnými dvěma vrcholy. Nastudoval
1.1 Úvod Algoritmus pro hledání nejkratší cesty orientovaným grafem Naprogramoval jsem v Matlabu funkci, která dokáže určit nejkratší cestu v orientovaném grafu mezi libovolnými dvěma vrcholy. Nastudoval
UČENÍ BEZ UČITELE. Václav Hlaváč
 UČENÍ BEZ UČITELE Václav Hlaváč Fakulta elektrotechnická ČVUT v Praze katedra kybernetiky, Centrum strojového vnímání hlavac@fel.cvut.cz, http://cmp.felk.cvut.cz/~hlavac 1/22 OBSAH PŘEDNÁŠKY ÚVOD Učení
UČENÍ BEZ UČITELE Václav Hlaváč Fakulta elektrotechnická ČVUT v Praze katedra kybernetiky, Centrum strojového vnímání hlavac@fel.cvut.cz, http://cmp.felk.cvut.cz/~hlavac 1/22 OBSAH PŘEDNÁŠKY ÚVOD Učení
StatSoft Jak vyzrát na datum
 StatSoft Jak vyzrát na datum Tento článek se věnuje podrobně možnostem práce s proměnnými, které jsou ve formě datumu. A že jich není málo. Pokud potřebujete pracovat s datumem, pak se Vám bude tento článek
StatSoft Jak vyzrát na datum Tento článek se věnuje podrobně možnostem práce s proměnnými, které jsou ve formě datumu. A že jich není málo. Pokud potřebujete pracovat s datumem, pak se Vám bude tento článek
ZÍSKÁVÁNÍ ZNALOSTÍ Z DATABÁZÍ
 metodický list č. 1 Dobývání znalostí z databází Cílem tohoto tematického celku je vysvětlení základních pojmů z oblasti dobývání znalostí z databází i východisek dobývání znalostí z databází inspirovaných
metodický list č. 1 Dobývání znalostí z databází Cílem tohoto tematického celku je vysvětlení základních pojmů z oblasti dobývání znalostí z databází i východisek dobývání znalostí z databází inspirovaných
ANALÝZA A KLASIFIKACE BIOMEDICÍNSKÝCH DAT. Institut biostatistiky a analýz
 ANALÝZA A KLASIFIKACE BIOMEDICÍNSKÝCH DAT prof. Ing. Jiří Holčík,, CSc. NEURONOVÉ SÍTĚ otázky a odpovědi 1 AKD_predn4, slide 8: Hodnota výstupu závisí na znaménku funkce net i, tedy na tom, zda bude suma
ANALÝZA A KLASIFIKACE BIOMEDICÍNSKÝCH DAT prof. Ing. Jiří Holčík,, CSc. NEURONOVÉ SÍTĚ otázky a odpovědi 1 AKD_predn4, slide 8: Hodnota výstupu závisí na znaménku funkce net i, tedy na tom, zda bude suma
Úloha - rozpoznávání číslic
 Úloha - rozpoznávání číslic Vojtěch Franc, Tomáš Pajdla a Tomáš Svoboda http://cmp.felk.cvut.cz 27. listopadu 26 Abstrakt Podpůrný text pro cvičení předmětu X33KUI. Vysvětluje tři způsoby rozpoznávání
Úloha - rozpoznávání číslic Vojtěch Franc, Tomáš Pajdla a Tomáš Svoboda http://cmp.felk.cvut.cz 27. listopadu 26 Abstrakt Podpůrný text pro cvičení předmětu X33KUI. Vysvětluje tři způsoby rozpoznávání
logistická regrese Miroslav Čepek Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti
 Vytěžování Dat Přednáška 9 Lineární klasifikátor, rozšíření báze, LDA, logistická regrese Miroslav Čepek Fakulta Elektrotechnická, ČVUT Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti
Vytěžování Dat Přednáška 9 Lineární klasifikátor, rozšíření báze, LDA, logistická regrese Miroslav Čepek Fakulta Elektrotechnická, ČVUT Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti
Cvičení 5 - Inverzní matice
 Cvičení 5 - Inverzní matice Pojem Inverzní matice Buď A R n n. A je inverzní maticí k A, pokud platí, AA = A A = I n. Matice A, pokud existuje, je jednoznačná. A stačí nám jen jedna rovnost, aby platilo,
Cvičení 5 - Inverzní matice Pojem Inverzní matice Buď A R n n. A je inverzní maticí k A, pokud platí, AA = A A = I n. Matice A, pokud existuje, je jednoznačná. A stačí nám jen jedna rovnost, aby platilo,
Kybernetika a umělá inteligence, cvičení 10/11
 Kybernetika a umělá inteligence, cvičení 10/11 Program 1. seminární cvičení: základní typy klasifikátorů a jejich princip 2. počítačové cvičení: procvičení na problému rozpoznávání číslic... body za aktivitu
Kybernetika a umělá inteligence, cvičení 10/11 Program 1. seminární cvičení: základní typy klasifikátorů a jejich princip 2. počítačové cvičení: procvičení na problému rozpoznávání číslic... body za aktivitu
Cvičná bakalářská zkouška, 1. varianta
 jméno: studijní obor: PřF BIMAT počet listů(včetně tohoto): 1 2 3 4 5 celkem Cvičná bakalářská zkouška, 1. varianta 1. Matematická analýza Najdětelokálníextrémyfunkce f(x,y)=e 4(x y) x2 y 2. 2. Lineární
jméno: studijní obor: PřF BIMAT počet listů(včetně tohoto): 1 2 3 4 5 celkem Cvičná bakalářská zkouška, 1. varianta 1. Matematická analýza Najdětelokálníextrémyfunkce f(x,y)=e 4(x y) x2 y 2. 2. Lineární
Semestrální práce Mozaika aneb Co všechno umí pan Voronoi
 Západočeská univerzita v Plzni Fakulta aplikovaných věd Katedra informatiky a výpočetní techniky Semestrální práce Mozaika aneb Co všechno umí pan Voronoi Plzeň, 2008 Aubrecht Vladimír Obsah 1 Zadání...
Západočeská univerzita v Plzni Fakulta aplikovaných věd Katedra informatiky a výpočetní techniky Semestrální práce Mozaika aneb Co všechno umí pan Voronoi Plzeň, 2008 Aubrecht Vladimír Obsah 1 Zadání...
logistická regrese Miroslav Čepek Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti
 Vytěžování Dat Přednáška 9 Lineární klasifikátor, rozšíření báze, LDA, logistická regrese Miroslav Čepek Fakulta Elektrotechnická, ČVUT Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti
Vytěžování Dat Přednáška 9 Lineární klasifikátor, rozšíření báze, LDA, logistická regrese Miroslav Čepek Fakulta Elektrotechnická, ČVUT Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti
Projekční algoritmus. Urychlení evolučních algoritmů pomocí regresních stromů a jejich zobecnění. Jan Klíma
 Urychlení evolučních algoritmů pomocí regresních stromů a jejich zobecnění Jan Klíma Obsah Motivace & cíle práce Evoluční algoritmy Náhradní modelování Stromové regresní metody Implementace a výsledky
Urychlení evolučních algoritmů pomocí regresních stromů a jejich zobecnění Jan Klíma Obsah Motivace & cíle práce Evoluční algoritmy Náhradní modelování Stromové regresní metody Implementace a výsledky
Vytěžování znalostí z dat
 Pavel Kordík, Jan Motl (ČVUT FIT) Vytěžování znalostí z dat BI-VZD, 2012, Přednáška 1 1/32 Vytěžování znalostí z dat Pavel Kordík, Jan Motl Department of Computer Systems Faculty of Information Technology
Pavel Kordík, Jan Motl (ČVUT FIT) Vytěžování znalostí z dat BI-VZD, 2012, Přednáška 1 1/32 Vytěžování znalostí z dat Pavel Kordík, Jan Motl Department of Computer Systems Faculty of Information Technology
1 0 0 u 22 u 23 l 31. l u11
 LU dekompozice Jedná se o rozklad matice A na dvě trojúhelníkové matice L a U, A=LU. Matice L je dolní trojúhelníková s jedničkami na diagonále a matice U je horní trojúhelníková. a a2 a3 a 2 a 22 a 23
LU dekompozice Jedná se o rozklad matice A na dvě trojúhelníkové matice L a U, A=LU. Matice L je dolní trojúhelníková s jedničkami na diagonále a matice U je horní trojúhelníková. a a2 a3 a 2 a 22 a 23
Kontingenční tabulky v MS Excel 2010
 Kontingenční tabulky v MS Excel 2010 Autor: RNDr. Milan Myšák e-mail: milan.mysak@konero.cz Obsah 1 Vytvoření KT... 3 1.1 Data pro KT... 3 1.2 Tvorba KT... 3 2 Tvorba KT z dalších zdrojů dat... 5 2.1 Data
Kontingenční tabulky v MS Excel 2010 Autor: RNDr. Milan Myšák e-mail: milan.mysak@konero.cz Obsah 1 Vytvoření KT... 3 1.1 Data pro KT... 3 1.2 Tvorba KT... 3 2 Tvorba KT z dalších zdrojů dat... 5 2.1 Data
Samoučící se neuronová síť - SOM, Kohonenovy mapy
 Samoučící se neuronová síť - SOM, Kohonenovy mapy Antonín Vojáček, 14 Květen, 2006-10:33 Měření a regulace Samoorganizující neuronové sítě s učením bez učitele jsou stále více využívány pro rozlišení,
Samoučící se neuronová síť - SOM, Kohonenovy mapy Antonín Vojáček, 14 Květen, 2006-10:33 Měření a regulace Samoorganizující neuronové sítě s učením bez učitele jsou stále více využívány pro rozlišení,
Návod k práci s programem MMPI-2
 Návod k práci s programem MMPI-2 Výchozím vstupním heslem je název programu psaný malými písmeny, tedy mmpi-2. Po zadání hesla stiskněte Enter nebo tlačítko Dále. Hlavní obrazovka programu zobrazuje přehled
Návod k práci s programem MMPI-2 Výchozím vstupním heslem je název programu psaný malými písmeny, tedy mmpi-2. Po zadání hesla stiskněte Enter nebo tlačítko Dále. Hlavní obrazovka programu zobrazuje přehled
Vyhodnocení 2D rychlostního pole metodou PIV programem Matlab (zpracoval Jan Kolínský, dle programu ing. Jana Novotného)
") Vyhodnocení 2D rychlostního pole metodou PIV programem Matlab (zpracoval Jan Kolínský, dle programu ing. Jana Novotného) 1 Obecný popis metody Particle Image Velocimetry, nebo-li zkráceně PIV, je měřící
Vyhodnocení 2D rychlostního pole metodou PIV programem Matlab (zpracoval Jan Kolínský, dle programu ing. Jana Novotného) 1 Obecný popis metody Particle Image Velocimetry, nebo-li zkráceně PIV, je měřící
Výhody a nevýhody jednotlivých reprezentací jsou shrnuty na konci kapitoly.
 Kapitola Reprezentace grafu V kapitole?? jsme se dozvěděli, co to jsou grafy a k čemu jsou dobré. rzo budeme chtít napsat nějaký program, který s grafy pracuje. le jak si takový graf uložit do počítače?
Kapitola Reprezentace grafu V kapitole?? jsme se dozvěděli, co to jsou grafy a k čemu jsou dobré. rzo budeme chtít napsat nějaký program, který s grafy pracuje. le jak si takový graf uložit do počítače?
Závěrečná práce. AutoCAD Inventor 2010. (Zadání D1)
") Závěrečná práce AutoCAD Inventor 2010 (Zadání D1) Pavel Čurda 4.B 4.5. 2010 Úvod Tato práce obsahuje sestavu modelu, prezentaci a samotný výkres Pákového převodu na přiloženém CD. Pákový převod byl namalován
Závěrečná práce AutoCAD Inventor 2010 (Zadání D1) Pavel Čurda 4.B 4.5. 2010 Úvod Tato práce obsahuje sestavu modelu, prezentaci a samotný výkres Pákového převodu na přiloženém CD. Pákový převod byl namalován
Textové popisky. Typ dat
 Textové popisky Newsletter Statistica ACADEMY Téma: Možnosti softwaru, datová reprezentace Typ článku: Tipy a triky Máte ve svých datech kategorie ve formě textu? Víme, že někdy není úplně jasné, jak Statistica
Textové popisky Newsletter Statistica ACADEMY Téma: Možnosti softwaru, datová reprezentace Typ článku: Tipy a triky Máte ve svých datech kategorie ve formě textu? Víme, že někdy není úplně jasné, jak Statistica
Matematika pro geometrickou morfometrii
 Matematika pro geometrickou morfometrii Václav Krajíček Vaclav.Krajicek@mff.cuni.cz Department of Software and Computer Science Education Faculty of Mathematics and Physics Charles University Přednáška
Matematika pro geometrickou morfometrii Václav Krajíček Vaclav.Krajicek@mff.cuni.cz Department of Software and Computer Science Education Faculty of Mathematics and Physics Charles University Přednáška
VYUŽITÍ MATLABU PRO VÝUKU NUMERICKÉ MATEMATIKY Josef Daněk Centrum aplikované matematiky, Západočeská univerzita v Plzni. Abstrakt
 VYUŽITÍ MATLABU PRO VÝUKU NUMERICKÉ MATEMATIKY Josef Daněk Centrum aplikované matematiky, Západočeská univerzita v Plzni Abstrakt Současný trend snižování počtu kontaktních hodin ve výuce nutí vyučující
VYUŽITÍ MATLABU PRO VÝUKU NUMERICKÉ MATEMATIKY Josef Daněk Centrum aplikované matematiky, Západočeská univerzita v Plzni Abstrakt Současný trend snižování počtu kontaktních hodin ve výuce nutí vyučující
BPC2E_C08 Parametrické 3D grafy v Matlabu
 BPC2E_C08 Parametrické 3D grafy v Matlabu Cílem cvičení je procvičit si práci se soubory a parametrickými 3D grafy v Matlabu. Úloha A. Protože budete řešit transformaci z kartézských do sférických souřadnic,
BPC2E_C08 Parametrické 3D grafy v Matlabu Cílem cvičení je procvičit si práci se soubory a parametrickými 3D grafy v Matlabu. Úloha A. Protože budete řešit transformaci z kartézských do sférických souřadnic,
Dolování z textu. Martin Vítek
 Dolování z textu Martin Vítek Proč dolovat z textu Obrovské množství materiálu v nestrukturované textové podobě knihy časopisy vědeckéčlánky sborníky konferencí internetové diskuse Proč dolovat z textu
Dolování z textu Martin Vítek Proč dolovat z textu Obrovské množství materiálu v nestrukturované textové podobě knihy časopisy vědeckéčlánky sborníky konferencí internetové diskuse Proč dolovat z textu
Ovládání Open Office.org Calc Ukládání dokumentu : Levým tlačítkem myši kliknete v menu na Soubor a pak na Uložit jako.
 Ukládání dokumentu : Levým tlačítkem myši kliknete v menu na Soubor a pak na Uložit jako. Otevře se tabulka, v které si najdete místo adresář, pomocí malé šedočerné šipky (jako na obrázku), do kterého
Ukládání dokumentu : Levým tlačítkem myši kliknete v menu na Soubor a pak na Uložit jako. Otevře se tabulka, v které si najdete místo adresář, pomocí malé šedočerné šipky (jako na obrázku), do kterého
Metody analýzy dat I. Míry a metriky - pokračování
 Metody analýzy dat I Míry a metriky - pokračování Literatura Newman, M. (2010). Networks: an introduction. Oxford University Press. [168-193] Zaki, M. J., Meira Jr, W. (2014). Data Mining and Analysis:
Metody analýzy dat I Míry a metriky - pokračování Literatura Newman, M. (2010). Networks: an introduction. Oxford University Press. [168-193] Zaki, M. J., Meira Jr, W. (2014). Data Mining and Analysis:
Tvorba geometrického modelu a modelové sítě.
 Tvorba geometrického modelu a modelové sítě. Návod krok za krokem, jak postupovat při vytváření modelové geometrie ze zadaných geografických a geologických dat Pro řešitele bakalářských projektů!!! Nejprve
Tvorba geometrického modelu a modelové sítě. Návod krok za krokem, jak postupovat při vytváření modelové geometrie ze zadaných geografických a geologických dat Pro řešitele bakalářských projektů!!! Nejprve
Metody analýzy dat I (Data Analysis I) Rozsáhlé struktury a vlastnosti sítí (Large-scale Structures and Properties of Networks) - pokračování
 Rozsáhlé struktury a vlastnosti sítí (Large-scale Structures and Properties of Networks) - pokračování") Metody analýzy dat I (Data Analysis I) Rozsáhlé struktury a vlastnosti sítí (Large-scale Structures and Properties of Networks) - pokračování Základní (strukturální) vlastnosti sítí Stupně vrcholů a jejich
Metody analýzy dat I (Data Analysis I) Rozsáhlé struktury a vlastnosti sítí (Large-scale Structures and Properties of Networks) - pokračování Základní (strukturální) vlastnosti sítí Stupně vrcholů a jejich
Profilování vzorků heroinu s využitím vícerozměrné statistické analýzy
 Profilování vzorků heroinu s využitím vícerozměrné statistické analýzy Autor práce : RNDr. Ivo Beroun,CSc. Vedoucí práce: prof. RNDr. Milan Meloun, DrSc. PROFILOVÁNÍ Profilování = klasifikace a rozlišování
Profilování vzorků heroinu s využitím vícerozměrné statistické analýzy Autor práce : RNDr. Ivo Beroun,CSc. Vedoucí práce: prof. RNDr. Milan Meloun, DrSc. PROFILOVÁNÍ Profilování = klasifikace a rozlišování
xrays optimalizační nástroj
 xrays optimalizační nástroj Optimalizační nástroj xoptimizer je součástí webového spedičního systému a využívá mnoho z jeho stavebních bloků. xoptimizer lze nicméně provozovat i samostatně. Cílem tohoto
xrays optimalizační nástroj Optimalizační nástroj xoptimizer je součástí webového spedičního systému a využívá mnoho z jeho stavebních bloků. xoptimizer lze nicméně provozovat i samostatně. Cílem tohoto
Vícerozměrné statistické metody
 Vícerozměrné statistické metody Podobnosti a vzdálenosti ve vícerozměrném prostoru, asociační matice II Jiří Jarkovský, Simona Littnerová Vícerozměrné statistické metody Práce s asociační maticí Vzdálenosti
Vícerozměrné statistické metody Podobnosti a vzdálenosti ve vícerozměrném prostoru, asociační matice II Jiří Jarkovský, Simona Littnerová Vícerozměrné statistické metody Práce s asociační maticí Vzdálenosti
Výsledný graf ukazuje následující obrázek.
 Úvod do problematiky GRAFY - SPOJNICOVÝ GRAF A XY A. Spojnicový graf Spojnicový graf používáme především v případě, kdy chceme graficky znázornit trend některé veličiny ve zvoleném časovém intervalu. V
Úvod do problematiky GRAFY - SPOJNICOVÝ GRAF A XY A. Spojnicový graf Spojnicový graf používáme především v případě, kdy chceme graficky znázornit trend některé veličiny ve zvoleném časovém intervalu. V
3.4 Určení vnitřní struktury analýzou vícerozměrných dat
 3. Určení vnitřní struktury analýzou vícerozměrných dat. Metoda hlavních komponent PCA Zadání: Byly provedeny analýzy chladící vody pro odběrové místa. Byly stanoveny parametry - ph, vodivost, celková
3. Určení vnitřní struktury analýzou vícerozměrných dat. Metoda hlavních komponent PCA Zadání: Byly provedeny analýzy chladící vody pro odběrové místa. Byly stanoveny parametry - ph, vodivost, celková
Aplikovaná numerická matematika
 Aplikovaná numerická matematika 6. Metoda nejmenších čtverců doc. Ing. Róbert Lórencz, CSc. České vysoké učení technické v Praze Fakulta informačních technologií Katedra počítačových systémů Příprava studijních
Aplikovaná numerická matematika 6. Metoda nejmenších čtverců doc. Ing. Róbert Lórencz, CSc. České vysoké učení technické v Praze Fakulta informačních technologií Katedra počítačových systémů Příprava studijních
Vzorce. Suma. Tvorba vzorce napsáním. Tvorba vzorců průvodcem
 Vzorce Vzorce v Excelu lze zadávat dvěma způsoby. Buď známe přesný zápis vzorce a přímo ho do buňky napíšeme, nebo použijeme takzvaného průvodce při tvorbě vzorce (zejména u složitějších funkcí). Tvorba
Vzorce Vzorce v Excelu lze zadávat dvěma způsoby. Buď známe přesný zápis vzorce a přímo ho do buňky napíšeme, nebo použijeme takzvaného průvodce při tvorbě vzorce (zejména u složitějších funkcí). Tvorba
5. Náhodná veličina. 2. Házíme hrací kostkou dokud nepadne šestka. Náhodná veličina nabývá hodnot z posloupnosti {1, 2, 3,...}.
 5. Náhodná veličina Poznámka: Pro popis náhodného pokusu jsme zavedli pojem jevového pole S jako množiny všech možných výsledků a pravděpodobnost náhodných jevů P jako míru výskytů jednotlivých výsledků.
5. Náhodná veličina Poznámka: Pro popis náhodného pokusu jsme zavedli pojem jevového pole S jako množiny všech možných výsledků a pravděpodobnost náhodných jevů P jako míru výskytů jednotlivých výsledků.
Zadání soutěžních úloh
 Zadání soutěžních úloh Kategorie žáci Soutěž v programování 24. ročník Krajské kolo 2009/2010 15. až 17. dubna 2010 Úlohy můžete řešit v libovolném pořadí a samozřejmě je nemusíte vyřešit všechny. Za každou
Zadání soutěžních úloh Kategorie žáci Soutěž v programování 24. ročník Krajské kolo 2009/2010 15. až 17. dubna 2010 Úlohy můžete řešit v libovolném pořadí a samozřejmě je nemusíte vyřešit všechny. Za každou
Stavový model a Kalmanův filtr
 Stavový model a Kalmanův filtr 2 prosince 23 Stav je veličina, kterou neznáme, ale chtěli bychom znát Dozvídáme se o ní zprostředkovaně prostřednictvím výstupů Příkladem může býapř nějaký zašuměný signál,
Stavový model a Kalmanův filtr 2 prosince 23 Stav je veličina, kterou neznáme, ale chtěli bychom znát Dozvídáme se o ní zprostředkovaně prostřednictvím výstupů Příkladem může býapř nějaký zašuměný signál,
Dobývání znalostí. Doc. RNDr. Iveta Mrázová, CSc. Katedra teoretické informatiky Matematicko-fyzikální fakulta Univerzity Karlovy v Praze
 Dobývání znalostí Doc. RNDr. Iveta Mrázová, CSc. Katedra teoretické informatiky Matematicko-fyzikální fakulta Univerzity Karlovy v Praze Dobývání znalostí Pravděpodobnost a učení Doc. RNDr. Iveta Mrázová,
Dobývání znalostí Doc. RNDr. Iveta Mrázová, CSc. Katedra teoretické informatiky Matematicko-fyzikální fakulta Univerzity Karlovy v Praze Dobývání znalostí Pravděpodobnost a učení Doc. RNDr. Iveta Mrázová,
Text Mining: SAS Enterprise Miner versus Teragram. Petr Berka, Tomáš Kliegr VŠE Praha
 Text Mining: SAS Enterprise Miner versus Teragram Petr Berka, Tomáš Kliegr VŠE Praha Text mining vs. data mining Text mining = data mining na nestrukturovaných textových dokumentech otázka vhodné reprezentace
Text Mining: SAS Enterprise Miner versus Teragram Petr Berka, Tomáš Kliegr VŠE Praha Text mining vs. data mining Text mining = data mining na nestrukturovaných textových dokumentech otázka vhodné reprezentace
pracovní list studenta
 Výstup RVP: Klíčová slova: pracovní list studenta Funkce kvadratická funkce Mirek Kubera žák načrtne grafy požadovaných funkcí, formuluje a zdůvodňuje vlastnosti studovaných funkcí, modeluje závislosti
Výstup RVP: Klíčová slova: pracovní list studenta Funkce kvadratická funkce Mirek Kubera žák načrtne grafy požadovaných funkcí, formuluje a zdůvodňuje vlastnosti studovaných funkcí, modeluje závislosti
Univerzita Pardubice 8. licenční studium chemometrie
 Univerzita Pardubice 8. licenční studium chemometrie Statistické zpracování dat při managementu jakosti Semestrální práce Metody s latentními proměnnými a klasifikační metody Ing. Jan Balcárek, Ph.D. vedoucí
Univerzita Pardubice 8. licenční studium chemometrie Statistické zpracování dat při managementu jakosti Semestrální práce Metody s latentními proměnnými a klasifikační metody Ing. Jan Balcárek, Ph.D. vedoucí
7.5.3 Hledání kružnic II
 753 Hledání kružnic II Předpoklady: 750 Pedagogická poznámka: Tato hodina patří mezi vůbec nejtěžší Není reálné předpokládat, že by většina studentů dokázala samostatně přijít na řešení, po čase na rozmyšlenou
753 Hledání kružnic II Předpoklady: 750 Pedagogická poznámka: Tato hodina patří mezi vůbec nejtěžší Není reálné předpokládat, že by většina studentů dokázala samostatně přijít na řešení, po čase na rozmyšlenou
Algoritmy pro shlukování prostorových dat
 Algoritmy pro shlukování prostorových dat Marta Žambochová Katedra matematiky a informatiky Fakulta sociálně ekonomická Univerzita J. E. Purkyně v Ústí nad Labem ROBUST 21. 26. leden 2018 Rybník - Hostouň
Algoritmy pro shlukování prostorových dat Marta Žambochová Katedra matematiky a informatiky Fakulta sociálně ekonomická Univerzita J. E. Purkyně v Ústí nad Labem ROBUST 21. 26. leden 2018 Rybník - Hostouň
Základy popisné statistiky
 Základy popisné statistiky Michal Fusek Ústav matematiky FEKT VUT, fusekmi@feec.vutbr.cz 8. přednáška z ESMAT Michal Fusek (fusekmi@feec.vutbr.cz) 1 / 26 Obsah 1 Základy statistického zpracování dat 2
Základy popisné statistiky Michal Fusek Ústav matematiky FEKT VUT, fusekmi@feec.vutbr.cz 8. přednáška z ESMAT Michal Fusek (fusekmi@feec.vutbr.cz) 1 / 26 Obsah 1 Základy statistického zpracování dat 2
Jaroslav Tuma. 8. února 2010
 Semestrální práce z předmětu KMA/MM Odstraňování šumu z obrazu Jaroslav Tuma 8. února 2010 1 1 Zpracování obrazu Zpracování obrazu je disciplína zabývající se zpracováním obrazových dat různého původu.
Semestrální práce z předmětu KMA/MM Odstraňování šumu z obrazu Jaroslav Tuma 8. února 2010 1 1 Zpracování obrazu Zpracování obrazu je disciplína zabývající se zpracováním obrazových dat různého původu.
Grafy. doc. Mgr. Jiří Dvorský, Ph.D. Katedra informatiky Fakulta elektrotechniky a informatiky VŠB TU Ostrava. Prezentace ke dni 13.
 Grafy doc. Mgr. Jiří Dvorský, Ph.D. Katedra informatiky Fakulta elektrotechniky a informatiky VŠB TU Ostrava Prezentace ke dni 13. března 2017 Jiří Dvorský (VŠB TUO) Grafy 104 / 309 Osnova přednášky Grafy
Grafy doc. Mgr. Jiří Dvorský, Ph.D. Katedra informatiky Fakulta elektrotechniky a informatiky VŠB TU Ostrava Prezentace ke dni 13. března 2017 Jiří Dvorský (VŠB TUO) Grafy 104 / 309 Osnova přednášky Grafy
Úloha: Verifikace osoby pomocí dynamického podpisu
 Cvičení z předmětu Biometrie Úloha: Verifikace osoby pomocí dynamického podpisu Jiří Wild, Jakub Schneider kontaktní email: schnejak@fel.cvut.cz 5. října 2015 1 Úvod Úloha má za cíl seznámit vás s metodami
Cvičení z předmětu Biometrie Úloha: Verifikace osoby pomocí dynamického podpisu Jiří Wild, Jakub Schneider kontaktní email: schnejak@fel.cvut.cz 5. října 2015 1 Úvod Úloha má za cíl seznámit vás s metodami
OPTIMALIZAČNÍ ÚLOHY. Modelový příklad problém obchodního cestujícího:
 OPTIMALIZAČNÍ ÚLOHY Problém optimalizace v různých oblastech: - minimalizace času, materiálu, - maximalizace výkonu, zisku, - optimalizace umístění komponent, propojení,... Modelový příklad problém obchodního
OPTIMALIZAČNÍ ÚLOHY Problém optimalizace v různých oblastech: - minimalizace času, materiálu, - maximalizace výkonu, zisku, - optimalizace umístění komponent, propojení,... Modelový příklad problém obchodního
MS EXCEL. MS Excel 2007 1
 MS Excel 2007 1 MS EXCEL Gymnázium Jiřího Wolkera v Prostějově Výukové materiály z informatiky pro gymnázia Autoři projektu Student na prahu 21. století - využití ICT ve vyučování matematiky na gymnáziu
MS Excel 2007 1 MS EXCEL Gymnázium Jiřího Wolkera v Prostějově Výukové materiály z informatiky pro gymnázia Autoři projektu Student na prahu 21. století - využití ICT ve vyučování matematiky na gymnáziu
Postupy práce se šablonami IS MPP
 Postupy práce se šablonami IS MPP Modul plánování a přezkoumávání, verze 1.20 vypracovala společnost ASD Software, s.r.o. dokument ze dne 27. 3. 2013, verze 1.01 Postupy práce se šablonami IS MPP Modul
Postupy práce se šablonami IS MPP Modul plánování a přezkoumávání, verze 1.20 vypracovala společnost ASD Software, s.r.o. dokument ze dne 27. 3. 2013, verze 1.01 Postupy práce se šablonami IS MPP Modul
NADSTAVBOVÝ MODUL MOHSA V1
 NADSTAVBOVÝ MODUL MOHSA V1 Nadstavbový modul pro hierarchické shlukování se jmenuje Mod_Sh_Hier (MOHSA V1) je součástí souboru Shluk_Hier.xls. Tento soubor je přístupný na http://jonasova.upce.cz, a je
NADSTAVBOVÝ MODUL MOHSA V1 Nadstavbový modul pro hierarchické shlukování se jmenuje Mod_Sh_Hier (MOHSA V1) je součástí souboru Shluk_Hier.xls. Tento soubor je přístupný na http://jonasova.upce.cz, a je
Zadání soutěžních úloh
 16. až 18. dubna 2015 Krajské kolo 2014/2015 Úlohy můžete řešit v libovolném pořadí a samozřejmě je nemusíte vyřešit všechny. Za každou úlohu můžete dostat maximálně 10 bodů, z nichž je většinou 9 bodů
16. až 18. dubna 2015 Krajské kolo 2014/2015 Úlohy můžete řešit v libovolném pořadí a samozřejmě je nemusíte vyřešit všechny. Za každou úlohu můžete dostat maximálně 10 bodů, z nichž je většinou 9 bodů
Tiskové sestavy. Zdroj záznamu pro tiskovou sestavu. Průvodce sestavou. Použití databází
 Tiskové sestavy Tiskové sestavy se v aplikaci Access používají na finální tisk informací z databáze. Tisknout se dají všechny objekty, které jsme si vytvořili, ale tiskové sestavy slouží k tisku záznamů
Tiskové sestavy Tiskové sestavy se v aplikaci Access používají na finální tisk informací z databáze. Tisknout se dají všechny objekty, které jsme si vytvořili, ale tiskové sestavy slouží k tisku záznamů
Informační systémy 2006/2007
 13 Vysoká škola báňská Technická univerzita Ostrava Fakulta strojní, Katedra automatizační techniky a řízení Informační systémy 2006/2007 Ivan Kedroň 1 Obsah Analytické nástroje SQL serveru. OLAP analýza
13 Vysoká škola báňská Technická univerzita Ostrava Fakulta strojní, Katedra automatizační techniky a řízení Informační systémy 2006/2007 Ivan Kedroň 1 Obsah Analytické nástroje SQL serveru. OLAP analýza
Rosenblattův perceptron
 Perceptron Přenosové funkce Rosenblattův perceptron Rosenblatt r. 1958. Inspirace lidským okem Podle fyziologického vzoru je třívrstvá: Vstupní vrstva rozvětvovací jejím úkolem je mapování dvourozměrného
Perceptron Přenosové funkce Rosenblattův perceptron Rosenblatt r. 1958. Inspirace lidským okem Podle fyziologického vzoru je třívrstvá: Vstupní vrstva rozvětvovací jejím úkolem je mapování dvourozměrného
oddělení Inteligentní Datové Analýzy (IDA)
") Vytěžování dat Filip Železný Katedra počítačů oddělení Inteligentní Datové Analýzy (IDA) 22. září 2014 Filip Železný (ČVUT) Vytěžování dat 22. září 2014 1 / 25 Odhad rozdělení Úloha: Vstup: data D = {
Vytěžování dat Filip Železný Katedra počítačů oddělení Inteligentní Datové Analýzy (IDA) 22. září 2014 Filip Železný (ČVUT) Vytěžování dat 22. září 2014 1 / 25 Odhad rozdělení Úloha: Vstup: data D = {
Gymnázium Ostrava Hrabůvka, příspěvková organizace Františka Hajdy 34, Ostrava Hrabůvka
 Gymnázium Ostrava Hrabůvka, příspěvková organizace Františka Hajdy 34, Ostrava Hrabůvka Projekt Využití ICT ve výuce na gymnáziích, registrační číslo projektu CZ.1.07/1.1.07/02.0030 MS Power Point Metodický
Gymnázium Ostrava Hrabůvka, příspěvková organizace Františka Hajdy 34, Ostrava Hrabůvka Projekt Využití ICT ve výuce na gymnáziích, registrační číslo projektu CZ.1.07/1.1.07/02.0030 MS Power Point Metodický
ZÍSKÁVÁNÍ ZNALOSTÍ Z DATABÁZÍ
 Metodický list č. 1 Dobývání znalostí z databází Cílem tohoto tematického celku je vysvětlení základních pojmů z oblasti dobývání znalostí z databází i východisek dobývání znalostí z databází inspirovaných
Metodický list č. 1 Dobývání znalostí z databází Cílem tohoto tematického celku je vysvětlení základních pojmů z oblasti dobývání znalostí z databází i východisek dobývání znalostí z databází inspirovaných
Úvod do optimalizace, metody hladké optimalizace
 Evropský sociální fond Investujeme do vaší budoucnosti Úvod do optimalizace, metody hladké optimalizace Matematika pro informatiky, FIT ČVUT Martin Holeňa, 13. týden LS 2010/2011 O čem to bude? Příklady
Evropský sociální fond Investujeme do vaší budoucnosti Úvod do optimalizace, metody hladké optimalizace Matematika pro informatiky, FIT ČVUT Martin Holeňa, 13. týden LS 2010/2011 O čem to bude? Příklady
Spojování dvou a více map v image souborech.
 Spojování dvou a více map v image souborech. Omluvte mě za případné překlepy. Pro jistotu mapu, kterou máme na SD kartě, nebo v GPS nainstalovanou od prodejce a nemáme k ní instalační CD, DVD, tak určitě
Spojování dvou a více map v image souborech. Omluvte mě za případné překlepy. Pro jistotu mapu, kterou máme na SD kartě, nebo v GPS nainstalovanou od prodejce a nemáme k ní instalační CD, DVD, tak určitě
Shluková analýza dat a stanovení počtu shluků
 Shluková analýza dat a stanovení počtu shluků Autor: Tomáš Löster Vysoká škola ekonomická v Praze Ostrava, červen 2017 Osnova prezentace Úvod a teorie shlukové analýzy Podrobný popis shlukování na příkladu
Shluková analýza dat a stanovení počtu shluků Autor: Tomáš Löster Vysoká škola ekonomická v Praze Ostrava, červen 2017 Osnova prezentace Úvod a teorie shlukové analýzy Podrobný popis shlukování na příkladu
13 Barvy a úpravy rastrového
 13 Barvy a úpravy rastrového Studijní cíl Tento blok je věnován základním metodám pro úpravu rastrového obrazu, jako je např. otočení, horizontální a vertikální překlopení. Dále budo vysvětleny různé metody
13 Barvy a úpravy rastrového Studijní cíl Tento blok je věnován základním metodám pro úpravu rastrového obrazu, jako je např. otočení, horizontální a vertikální překlopení. Dále budo vysvětleny různé metody
UNIVERZITA PARDUBICE. 4.4 Aproximace křivek a vyhlazování křivek
 UNIVERZITA PARDUBICE Licenční Studium Archimedes Statistické zpracování dat a informatika 4.4 Aproximace křivek a vyhlazování křivek Mgr. Jana Kubátová Endokrinologický ústav V Praze, leden 2012 Obsah
UNIVERZITA PARDUBICE Licenční Studium Archimedes Statistické zpracování dat a informatika 4.4 Aproximace křivek a vyhlazování křivek Mgr. Jana Kubátová Endokrinologický ústav V Praze, leden 2012 Obsah
Povinně Volitelné a Volitelné předměty INFORMACE & ZÁPIS SIS
 Povinně Volitelné a Volitelné předměty INFORMACE & ZÁPIS SIS Zápis (před zápis) povinně volitelných kurzů (dále PVK) a volitelných předmětů (dále VP) se bude provádět pomocí SIS aplikace Zápis předmětů
Povinně Volitelné a Volitelné předměty INFORMACE & ZÁPIS SIS Zápis (před zápis) povinně volitelných kurzů (dále PVK) a volitelných předmětů (dále VP) se bude provádět pomocí SIS aplikace Zápis předmětů
Modul Zásoby IQ sestavy a jejich nastavení Materiál pro samostudium +1170
 Modul Zásoby IQ sestavy a jejich nastavení Materiál pro samostudium +1170 20.5.2014 Major Bohuslav, Ing. Datum tisku 20.5.2014 2 Modul Zásoby IQ sestavy a jejich nastavení Modul Zásoby IQ sestavy a jejich
Modul Zásoby IQ sestavy a jejich nastavení Materiál pro samostudium +1170 20.5.2014 Major Bohuslav, Ing. Datum tisku 20.5.2014 2 Modul Zásoby IQ sestavy a jejich nastavení Modul Zásoby IQ sestavy a jejich
4. Učení bez učitele. Shlukování. K-means, EM. Hierarchické shlukování. Kompetitivní učení. Kohonenovy mapy.
 GoBack 4. Učení bez učitele. Shlukování., EM. Hierarchické.. Kohonenovy mapy. Petr Pošík Katedra kybernetiky ČVUT FEL P. Pošík c 29 Aplikace umělé inteligence 1 / 53 Obsah P. Pošík c 29 Aplikace umělé
GoBack 4. Učení bez učitele. Shlukování., EM. Hierarchické.. Kohonenovy mapy. Petr Pošík Katedra kybernetiky ČVUT FEL P. Pošík c 29 Aplikace umělé inteligence 1 / 53 Obsah P. Pošík c 29 Aplikace umělé
Cvičení ze statistiky - 3. Filip Děchtěrenko
 Cvičení ze statistiky - 3 Filip Děchtěrenko Minule bylo.. Dokončili jsme základní statistiky, typy proměnných a začali analýzu kvalitativních dat Tyhle termíny by měly být známé: Histogram, krabicový graf
Cvičení ze statistiky - 3 Filip Děchtěrenko Minule bylo.. Dokončili jsme základní statistiky, typy proměnných a začali analýzu kvalitativních dat Tyhle termíny by měly být známé: Histogram, krabicový graf
ZÁKLADY STATISTICKÉHO ZPRACOVÁNÍ ÚDAJŮ 5. hodina , zapsala Veronika Vinklátová Revize zápisu Martin Holub,
 ZÁKLADY STATISTICKÉHO ZPRACOVÁNÍ ÚDAJŮ 5. hodina - 22. 3. 2018, zapsala Revize zápisu Martin Holub, 27. 3. 2018 I. Frekvenční tabulky opakování z minulé hodiny Frekvenční tabulka je nejzákladnější nástroj
ZÁKLADY STATISTICKÉHO ZPRACOVÁNÍ ÚDAJŮ 5. hodina - 22. 3. 2018, zapsala Revize zápisu Martin Holub, 27. 3. 2018 I. Frekvenční tabulky opakování z minulé hodiny Frekvenční tabulka je nejzákladnější nástroj
Hledání správné cesty
 Semestrální práce z předmětu A6M33AST Závěrečná zpráva Hledání správné cesty Nela Grimová, Lenka Houdková 2015/2016 1. Zadání Naším úkolem bylo vytvoření úlohy Hledání cesty, kterou by bylo možné použít
Semestrální práce z předmětu A6M33AST Závěrečná zpráva Hledání správné cesty Nela Grimová, Lenka Houdková 2015/2016 1. Zadání Naším úkolem bylo vytvoření úlohy Hledání cesty, kterou by bylo možné použít
1 Základní funkce pro zpracování obrazových dat
 1 Základní funkce pro zpracování obrazových dat 1.1 Teoretický rozbor 1.1.1 Úvod do zpracování obrazu v MATLABu MATLAB je primárně určen pro zpracování a analýzu numerických dat. Pro analýzu obrazových
1 Základní funkce pro zpracování obrazových dat 1.1 Teoretický rozbor 1.1.1 Úvod do zpracování obrazu v MATLABu MATLAB je primárně určen pro zpracování a analýzu numerických dat. Pro analýzu obrazových
Copyright 2013 Martin Kaňka;
 Copyright 2013 Martin Kaňka; http://dalest.kenynet.cz Popis aplikace Hlavním cílem aplikace Cubix je výpočet a procvičení výpočtu objemu a povrchu těles složených z kostek. Existují tři obtížnosti úkolů
Copyright 2013 Martin Kaňka; http://dalest.kenynet.cz Popis aplikace Hlavním cílem aplikace Cubix je výpočet a procvičení výpočtu objemu a povrchu těles složených z kostek. Existují tři obtížnosti úkolů
NÁHODNÝ VEKTOR. 4. cvičení
 NÁHODNÝ VEKTOR 4. cvičení Náhodný vektor Náhodným vektorem rozumíme sloupcový vektor X=(X, X,, X n ) složený z náhodných veličin X, X,, X n, který je charakterizován sdruženým rozdělením pravděpodobnosti.
NÁHODNÝ VEKTOR 4. cvičení Náhodný vektor Náhodným vektorem rozumíme sloupcový vektor X=(X, X,, X n ) složený z náhodných veličin X, X,, X n, který je charakterizován sdruženým rozdělením pravděpodobnosti.
Zdokonalování gramotnosti v oblasti ICT. Kurz MS Excel kurz 6. Inovace a modernizace studijních oborů FSpS (IMPACT) CZ.1.07/2.2.00/28.
 CZ.1.07/2.2.00/28.") Zdokonalování gramotnosti v oblasti ICT Kurz MS Excel kurz 6 1 Obsah Kontingenční tabulky... 3 Zdroj dat... 3 Příprava dat... 3 Vytvoření kontingenční tabulky... 3 Možnosti v poli Hodnoty... 7 Aktualizace
Zdokonalování gramotnosti v oblasti ICT Kurz MS Excel kurz 6 1 Obsah Kontingenční tabulky... 3 Zdroj dat... 3 Příprava dat... 3 Vytvoření kontingenční tabulky... 3 Možnosti v poli Hodnoty... 7 Aktualizace
Popisná statistika kvantitativní veličiny
 StatSoft Popisná statistika kvantitativní veličiny Protože nám surová data obvykle žádnou smysluplnou informaci neposkytnou, je žádoucí vyjádřit tyto ve zhuštěnější formě. V předchozím dílu jsme začali
StatSoft Popisná statistika kvantitativní veličiny Protože nám surová data obvykle žádnou smysluplnou informaci neposkytnou, je žádoucí vyjádřit tyto ve zhuštěnější formě. V předchozím dílu jsme začali
Individuální nastavení počítače
 Individuální nastavení počítače Je pro vás systém Windows 7 nový? I když má tento systém mnoho společného s verzí systému Windows, kterou jste používali dříve, můžete potřebovat pomoc, než se v něm zorientujete.
Individuální nastavení počítače Je pro vás systém Windows 7 nový? I když má tento systém mnoho společného s verzí systému Windows, kterou jste používali dříve, můžete potřebovat pomoc, než se v něm zorientujete.
Rastrové digitální modely terénu
 Rastrové digitální modely terénu Rastr je tvořen maticí buněk (pixelů), které obsahují určitou informaci. Stejně, jako mohou touto informací být typ vegetace, poloha sídel nebo kvalita ovzduší, může každá
Rastrové digitální modely terénu Rastr je tvořen maticí buněk (pixelů), které obsahují určitou informaci. Stejně, jako mohou touto informací být typ vegetace, poloha sídel nebo kvalita ovzduší, může každá
Předzpracování dat. Pavel Kordík. Department of Computer Systems Faculty of Information Technology Czech Technical University in Prague
 Předzpracování dat Pavel Kordík Department of Computer Systems Faculty of Information Technology Czech Technical University in Prague Cvičení 1: Visualizace MI-PDD, 09/2011 MI-POA Evropský sociální fond
Předzpracování dat Pavel Kordík Department of Computer Systems Faculty of Information Technology Czech Technical University in Prague Cvičení 1: Visualizace MI-PDD, 09/2011 MI-POA Evropský sociální fond