Systém M-CAST (Multilingual Content Aggregation System Vícejazyčný systém agregace informací)
|
|
|
- Alexandra Macháčková
- před 8 lety
- Počet zobrazení:
Transkript
1 Systém M-CAST (Multilingual Content Aggregation System Vícejazyčný systém agregace informací) Marie BALÍKOVÁ Národní knihovna České republiky, Praha Petr STROSSA Vysoká škola ekonomická, Praha INFORUM 2007: 13. konference o profesionálních informačních zdrojích Praha, Abstrakt Vícejazyčný systém agregace informací (M-CAST, Multilingual Content Aggregation System) umožní tvorbu digitálních knihoven prostřednictvím agregace dat dostupných v různých formátech a z různých zdrojů. Systém M-CAST je založen na výsledcích projektu TRUST - Multilingual Semantic and Cognitive Search Engine for Text Retrieval Using Semantic Technologies (Vícejazyčný sémantický a kognitivní mechanismus vyhledávání textů využívající sémantické technologie, IST ), který byl financován z Pátého rámcového programu EU pro rozvoj vědy a výzkumu Multilingual Semantic and Cognitive Search Engine for Text Retrieval Using Semantic Technologies. Vyhledávací stroj TRUST umí v současnosti vyhledávat ve čtyřech jazycích (francouzštině, italštině, polštině a portugalštině). Systém je nyní obohacen o dva další jazyky: angličtinu a češtinu. Jazykové zdroje systému TRUST jsou aktualizovány a v systému nadále využity. Systém vyhledávání je obohacen o možnost zúžení dotazu pomocí standardního mezinárodního desetinného třídění (MDT), celosvětově používaného v knihovních systémech. Úvod M-CAST (Multilingual Content Aggregation System based on TRUST Search Engine) je projekt programu econtent (EDC 22249), jehož cílem bylo vyvinout vícejazyčný vyhledávací systém umožňující tvůrcům obsahu integrovat a prohledávat rozsáhlé soubory textů včetně multimédií, jako jsou internetové knihovny, informační zdroje nakladatelství a tiskových agentur nebo databáze vědeckých informací poskytující informační služby široké odborné i laické veřejnosti. Projekt M-CAST byl financován Evropskou unií v rámci víceletého komunitárního programu na podporu rozvoje a užívání evropského digitálního obsahu v globálních sítích a současně překonávání jazykové různorodosti v informační společnosti. Konsorcium Podmínkou pro zahájení prací souvisejících s projektem bylo vytvoření konsorcia participujících subjektů: Koordinátorem projektu se stala společnost Infovide S.A., Varšava, Polsko, v průběhu projektu přejmenována na Infovide-Matrix S.A.

2 2 Za vývoj lingvistických modulů, implementaci ontologie TRUST v jednotlivých jazycích a implementaci klasifikačního systému MDT v systému M-CAST odpovídají: TiP sp. z o.o., Katowice, Polsko polský a český lingvistický modul (v kooperaci s VŠE Praha); Synapse Développement SARL, Toulouse, Francie francouzský lingvistický modul; Priberam Informática Lda., Lisabon, Portugalsko portugalský lingvistický modul zahrnující evropskou i brazilskou portugalštinu); Expert System S.p.A., Modena, Itálie italský a anglický lingvistický modul; Vysoká škola ekonomická v Praze, Česko český lingvistický modul (v kooperaci s TiP sp. z o.o., Katovice). Systém M-CAST je testován ve dvou institucích: Polská internetová knihovna, Toruń, Polsko; Národní knihovna České republiky, Praha, Česko. Systém M-CAST navazuje na výsledky dvou projektů, které byly financovány z Pátého rámcového programu EU pro rozvoj vědy a výzkumu: TRUST Multilingual Semantic and Cognitive Search Engine for Text Retrieval Using Semantic Technologies (Vícejazyčný sémantický a kognitivní mechanismus vyhledávání textů využívající sémantické technologie, IST ); ICONS Inteligentní systém pro správu obsahu (Inteligent Content Management System, IST ). Projekt TRUST Vícejazyčný vyhledávací stroj TRUST umožňoval vyhledávat ve čtyřech jazycích: francouzštině, italštině, polštině a portugalštině. V rámci projektu M-CAST je rozšířen o dva další jazyky: angličtinu a češtinu. Jednouživatelská aplikace pro PC je transformována na serverovou aplikaci pro operační systém UNIX nebo Windows. Jazykové zdroje systému TRUST jsou aktualizovány a v systému nadále využity, jsou rozšířeny o další jazykové zdroje pokrývající potřebu nově připojených jazyků. Dosud využívaná jazyková ontologie (taxonomie) TRUST tvoří páteř vyhledávání i v projektu M-CAST. Možnosti vyhledávání jsou obohaceny o alternativu pokročilého hledání založenou na standardním mezinárodním desetinném třídění (MDT), celosvětově používaném v knihovních systémech. Portál systému M-CAST, zv. také M-CAP, je vyvinut podle zásad metodologie návrhu systémů pro správu obsahu založených na znalostech (Knowledge-based Content Management Application Design Methodology). Tuto metodologii vytvořila firma Infovide, S.A. v rámci jiného projektu financovaného z Pátého rámcového programu EU ICONS.



3 3 Základní schéma systému M-CAST Portál M-CAST/M-CAP Portál M-CAST/M-CAP je schopen kombinovat různé aplikace a informační zdroje do jediné ucelené prezentace, uživatelé v různých rolích mohou vidět odlišný obsah dle svých přístupových oprávnění nebo svého profilu, uživatelé si mohou obsah přizpůsobit. Portál M-CAST/M-CAP je koncipován tak, aby umožnil integraci stávajících vyhledávacích nástrojů používaných v dané instituci. Na obrázku vidíme návrh potenciálního využití systému M-CAST v knihovně, která chce své stávající vyhledávací možnosti obohatit o rešeršní strategii dotazování v přirozeném jazyce a zvolí portál M-CAST/M-CAP jako základní nástroj. Je možný i obrácený postup: instituce zahrne portál M-CAST/M-CAP jako součást stávajícího portálu.


4 4 Po technické stránce vychází architektura systému M-CAST z tradiční třívrstvé architektury a obsahuje vrstvu klientskou, tj. browser, vrstvu aplikační, tj. web server a část bussines logic, a vrstvu datovou, tj. lingvistický procesor, který se skládá ze základních procesních prvků, tj. lingvistických modulů. Třívrstvý model podporuje vyšší úroveň stability; klient pracuje pouze s uživatelským rozhraním, datové a aplikační služby jsou od sebe odděleny do samostatných logických modulů. Lingvistický procesor představuje nejdůležitější součást systému M-CAST. Obsahuje nástroj pro detekci jazyka, analyzátor dotazů, konvertor formátů dokumentů a lingvistické moduly jednotlivých jazyků. French Language Module Italian Language Module Portuguese Polish Czech Language Language Language Module Module Module Extraction of text engine Indexation engine Documents English Language Module Index Visualization of Results

5 5 Lingvistické moduly pro jednotlivé jazyky byly vytvářeny na sobě nezávisle, reflektují potřeby jednotlivých národních jazyků, sdílejí však základní obecné principy aplikované při automatizovaném zpracování přirozeného jazyka. Indexace dokumentů Společné rysy jsou patrné především v oblasti indexování dokumentů. Základním předpokladem pro úspěšné indexování dokumentů je tokenizace, kdy je text rozložen na základní selekční jednotky a v textu jsou identifikována slova, mezery, interpunkce a začátky a konce vět, dále stemming (lem(m)atizace), kdy se odstraňuje zakončení slova a ponechává se kmen / kořen (slovní základ), resp. (při lemmatizaci) je určena pro každý slovní tvar jeho základní podoba. V textech se provádí morfologická disambiguace slovních tvarů, nevýznamová a nespecifická slova jsou pomocí negativního slovníku (slovníku stop-slov) odstraněna, při indexaci textů se uplatňuje také stejná typologie dotazů a odpovědí, používá se tentýž analyzátor dotazů, aplikuje se ontologie TRUST apod. Texty jsou konvertovány do Unicodu a rozděleny do textových kilobytových bloků, dochází tak k redukci velikosti indexů. Každý textový blok je podroben morfologické, syntaktické a sémantické analýze. Na základě získaných výsledků je budováno 8 různých indexů: index základů slov, v případě homonymních a polysémních slov jejich významů; index vlastních jmen; index idiomů; index pojmenovaných entit; index konceptů, tj. uzlů ontologie TRUST; index jednotlivých pojmů ontologie TRUST; index typů otázek a odpovědí; index klíčových slov z textu. Proces indexace je ve všech jazycích stejný, extrahovaná data jsou stejné kategorie, zpracování těchto dat je tedy nezávislé na původním jazyce.
atizace), kdy se odstraňuje zakončení slova a ponechává se kmen / kořen (slovní základ), resp. (při lemmatizaci) je určena pro každý slovní tvar jeho základní podoba.")
6 6 Složitost (maximální1) struktury lingvistických modulů je patrná z následujícího schématu pro francouzský lingvistický modul: Extrakce odpovědí Uživatelův dotaz je podroben syntaktické a sémantické analýze. Je určen typ dotazu. Výsledek sémantické analýzy dotazu může být negativně ovlivněn tím, že kontext dotazu je poměrně malý, dotaz je na rozdíl od dokumentů výrazně kratší. Na základě sémantické analýzy dotazu jsou podle jejich váhy stanovena významově důležitá klíčová slova, pivots. Při vyhledávání se používají tyto výrazy, obohacené o synonyma, odpovídající koncepty a přiřazené k typu otázky. Po analýze dotazu jsou prohledávány všechny indexy a jsou vybrány textové bloky, které nejvíce odpovídají parametrům dotazu; z nich jsou vybrány jednotlivé relevantní odpovědi, u nichž je stanovena váha na základě statistickolingvistických metod a jejich pořadí. Pro vícejazyčné vyhledávání v systému M-CAST je jako propojovací jazyk použita angličtina. 1 Ve skutečnosti ne všechny lingvistické moduly uplatňují toto schéma v celé jeho komplexnosti.

7 7 Český lingvistický modul v systému M-CAST Český lingvistický modul byl vyvíjen v těsné návaznosti na modul polský, v úzké spolupráci se dvěma firmami zaměřenými na lingvistické technologie: polskou TiP, garantem polského modulu, a portugalskou Priberam Informática, jejíž programové nástroje jsme se po zvážení různých možností rozhodli použít jako finální řešení pro zpracování polštiny i češtiny. Během práce se potvrdilo, že tyto nástroje skutečně lze použít i pro zpracování slovanských jazyků potřebné v systému M-CAST, přestože byly původně navrženy pro portugalštinu. Některé zvláštnosti slovanských jazyků si nicméně vyžádaly menší úpravy zvolených nástrojů. Vzorce pro rozpoznávání typů dotazů a potenciálních odpovědí Základní lingvistickou datovou strukturu podporující funkce systému M-CAST představují formální definice předem vyčleněných kategorií dotazů a potenciálních odpovědí na ně v indexovaných textech. Rozlišujeme 86 sémantických typů dotazů a odpovědí, ke kterým v rámci vývoje svých technologií a prvků systému M-CAST dospěl francouzský partner, firma Synapse Développement. Definice pro jejich rozpoznávání v češtině formulujeme pomocí nástroje SintaGest (čti sintažešt ) portugalské firmy Priberam Informática. Následující příklad ukazuje jednu takovou definici pro dotazy a odpovědi týkající se hmotnosti. Question(WEIGHT) : Root("jaký")? Dist(0,5) WeightNoun = 20 // Jaká je hmotnost Země? : Wrd(jak) WeightAdj = 20 // Jak těžký může být slon? : Wrd(kolik) WeightUnit = 20 // Kolik kg má dospělý kapr? : Wrd(kolik) Root("vážit") = 20 // Kolik váží kapr? Answer : WeightNoun Definition With Pivot Dist(0,5) {Number6 WeightUnit} = 20 // Váha kapra může dosáhnout až 5 kg. : Pivot Dist(0,5) Cat(V) Dist(0,5) {Number6 WeightUnit} = 20 // Roční kapr může dosáhnout 5 kg tělesné váhy. ; Answer(WEIGHT) : Number6 WeightUnit = 20 ; Blok nadepsaný Answer(WEIGHT) se uplatňuje při předběžném rozpoznávání potenciálních odpovědí na tento typ dotazu ve fázi indexování textů ukládaných do databáze. V tomto konkrétním případě to znamená, že každý text obsahující výraz jako např. dva kilogramy bude označen jako text obsahující potenciální odpověď na dotaz typu WEIGHT (HMOTNOST). Blok nadepsaný Question(WEIGHT) se uplatňuje při klasifikaci položených dotazů a následném vyhledávání skutečných odpovědí na konkrétní dotaz typu WEIGHT (HMOTNOST v textech předem vyhodnocených jako potenciálně relevantních k tomuto typu dotazu). Rozpoznávání dotazů daného typu je založeno na třech hlavních kategoriích formálních výrazů: Root(x) zastupuje libovolný tvar, případně odvozeninu slova x, kterou jako takovou rozpozná morfologický modul;

8 8 Wrd(x) slovní tvar x (přesně tak, jak je napsán to obecně zjednodušuje systému práci s neohebnými slovy, např. s předložkami nebo příslovci typu jak, ale někdy může být vhodné i pro rozpoznávání určitých ustálených frází, které se v určitých typech kontextů fakticky neohýbají);2 konstanty pojmenované určitým jménem (jako např. WeightNoun ) jsou definovány v pomocném souboru např. takto: Const WeightNoun = AnyRoot(hmotnost, hmota, "tíha", "váha", "zatížení"); Const WeightAdj = AnyRoot("těžký", "lehký"); Const WeightUnit1 = AnyRoot(mikrogram, miligram, centigram, decigram, gram, dekagram, hektogram, kilogram, kilo, cent, miligram, tuna, "karát", pond, kilopond, megapond, libra); Const WeightUnit2 = AnyWrd(mg, cg, dg, g, dag, deka, Dg, dkg, hg, kp, Mp, lb, "lb.", lbs, "lbs.", cwt, "cwt."); Const megagram, kg, q, Mg, t, p, WeightUnit = AnyConst(WeightUnit1, WeightUnit2); Výraz Cat(x) představuje (sám o sobě) jakékoli slovo, jemuž byla ve fázi morfologicko-lexikální analýzy přiřazena gramatická kategorie x (konkrétně např. V sloveso). Pomocný výraz Dist(a,b) vyjadřuje, že mezi jinými dílčími výrazy se může nacházet jistý počet (a až b) jiných slov. Za oddělovačem = je vždy uvedeno číslo vyjadřující relativní míru, v jaké text pokrytý daným vzorcem odpovídá danému typu dotazu. (To lze využít v případech, kdy určité obraty mohou vyjadřovat různé typy dotazů, ale některé pravděpodobněji.) Za oddělovači // jsou jako komentáře k formálním vzorcům uvedeny konkrétní příklady dotazů, které tyto vzorce pokrývají. Výrazy uzavřené ve složených závorkách { } v prostředním bloku, nadepsaném jen Answer, by měly představovat přesnou odpověď na daný dotaz (např. na dotaz typu HMOTNOST je to zpravidla výraz vyjadřující počet a jednotku hmotnosti). Výraz Definition With Pivot v témže bloku zastupuje jakoukoli jmennou frázi (rozpoznanou opět podle nějakých pravidel v pomocném souboru) obsahující alespoň jedno plnovýznamové slovo z dotazu. SintaGest je vlastně účelový editor a kompilátor definičních souborů naznačeného typu. Pomocí dalších programových nástrojů firem Priberam Informática a TiP jsou tyto soubory spolu s tabulkami definujícími morfologii (tvarosloví) a některými dalšími podpůrnými datovými soubory kompilovány do českého lingvistického modulu, spolupracujícího s indexovacím a vyhledávacím strojem systému MCAST. Problém volného slovosledu v češtině Čeština patří podle zavedené lingvistické typologie mezi tzv. jazyky s volným slovosledem. To sice neznamená, že by mohlo pořadí slov ve větě, která má vyjadřovat určité konkrétní sdělení, být úplně libovolné, nicméně dotaz na určitou věc a stejně tak odpověď na takový dotaz můžou být vyjádřeny určitými slovy v různém uspořádání. Tím se čeština (a jí podobné jazyky, jako např. polština, ruština aj.) dost výrazně liší od západoevropských jazyků typu angličtiny, francouzštiny nebo portugalštiny. Například otázka po vzdálenosti Brna může být formulována snad po řadě v klesající míře obvyklosti, ale stále gramaticky přípustně těmito způsoby: 2 Jak daleko je do Brna? Jak je daleko do Brna? Pokud bychom tímto způsobem chtěli například definovat frázi vzít nohy na ramena, mohli bychom asi použít formální výraz Root(vzít) Dist(0,3) Wrd(nohy) Wrd(na) Wrd(ramena).
; Const WeightAdj = AnyRoot(\"těžký\", \"lehký\"); Const WeightUnit1 = AnyRoot(mikrogram, miligram, centigram, decigram,")
9 9 Jak je do Brna daleko? Do Brna je jak daleko? Do Brna jak je daleko? Do Brna je daleko jak? Daleko je do Brna jak? Tento problém je prozatím řešen dvěma způsoby: 1) Některá slova, jako např. tvary sponového slovesa být, ale i některá jiná slovesa, která sama o sobě k rozpoznání typu dotazu/odpovědi nepřispívají, nejsou ve vzorcích uváděna vůbec (nahrazujeme je distančním operátorem ), anebo jsou uváděna paralelně na různých místech jako nepovinné prvky (s doplňujícím operátorem?, ve výše uvedené ukázce nepoužitým). 2) V souboru definic typů dotazů jsou uváděny některé zásadní slovosledné varianty jako samostatné vzorce. Morfologická analýza Nutným předpokladem fungování výše popsaných vzorců pro rozpoznávání typů dotazů a odpovědí je morfologická (tvaroslovná) analýza indexovaných textů a pokládaných dotazů. Obecným cílem morfologické analýzy je určit pro každý slovní tvar v každém textu, o jaký slovní druh a tvar jde a jak zní odpovídající základní (slovníkový) tvar. Ve stávajícím provedení vzorců pro rozpoznávání dotazů a odpovědí ovšem téměř nepoužíváme konkrétní hodnoty kategorií jako pád, číslo, osoba ap. Z výsledků morfologické analýzy vlastně využíváme prakticky jen údaje o slovním druhu a základním tvaru (lemmatu) slova. Možnost využití přesnějších morfologických kategorií však zůstává otevřená použitý formální jazyk rozpoznávacích vzorců to umožňuje, stejně jako morfologický analyzátor, který je součástí lingvistického modulu. (Srovnej ovšem následující oddíl Problém gramatické homonymie v češtině.) Morfologický analyzátor češtiny je založen na slovníku, ve kterém je každému slovu přiřazen jeden ze vzorů ohýbání, a systému tabulek definujících jednotlivé vzory ohýbání. (Z těchto dat je kompilována pracovní datová struktura efektivně uchovávající a rozpoznávající všechny tvary všech slov.) Tabulky definující vzory mají pochopitelně odlišnou strukturu podle slovních druhů. U českých podstatných jmen rozlišujeme 2 čísla a 7 pádů, takže např. tabulka definující vzor žena by na první pohled mohla vypadat následovně (symbol reprezentuje prázdnou koncovku): Pád Koncovka jednotného čísla 1. a 2. y 3. ě 4. u 5. o 6. ě 7. ou Koncovka množného čísla y ám y y ách ami Ve skutečnosti je však už jen skloňování českých podstatných jmen (resp. jeho exaktní popis, který potřebujeme) o něco složitější. U některých slov dochází v některých tvarech k určitým kmenovým změnám, které jsou poměrně snadno automaticky realizovatelné, nicméně musí být přesně popsány
 V souboru definic typů dotazů jsou uváděny některé zásadní slovosledné varianty jako samostatné vzorce.")
10 10 v tabulkách definujících vzory. Tak například pro slova jako babka potřebujeme vzor definovaný touto tabulkou: Pád Jednotné číslo Množné číslo kmen koncovka kmen koncovka 0 a 0 y 0 y +E +M0 e 0 ám 0 u 0 y 0 o 0 y +M0 e 0 ách 0 ou 0 ami Symboly v šedě vystínovaných sloupcích této tabulky reprezentují variantu kmene, ke které se má připojovat příslušná koncovka: 0 znamená základní kmen, +M0 jeden ze způsobů měkčení koncové souhlásky kmene (tak vznikne tvar babce, anebo podle stejného exaktního vzoru např. hře ),3 +E vložení písmena e mezi poslední dvě písmena kmene (tak vznikne tvar babek, nebo her ). Elementárních typů kmenových změn rozlišujeme v tomto pojetí asi deset, některé z nich se můžou vzájemně kombinovat.4 Za předpokladu, že chceme každému českému podstatnému jménu ve slovníku přiřadit nějaký vzor exaktně popisující jeho skloňování (i kdyby to měl být vzor právě jen pro toto jediné podstatné jméno), potřebujeme celkem přibližně 300 (!) vzorů jen pro skloňování podstatných jmen. Tyto vzory se ovšem ani zdaleka neuplatňují se srovnatelnou frekvencí. Při sestavování slovníku se na jedné straně ukázalo, že 19 nejfrekventovanějších vzorů stačí k popisu skloňování 95 % českých podstatných jmen a 56 vzorů pokrývá 99 % podstatných jmen. Na druhé straně zhruba 150 (tj. polovina) definovaných vzorů popisuje skloňování jen 1 3 podstatných jmen, přibližně 80 vzorů popisuje skloňování jediného podstatného jména.5 Vzory popisující ohýbání českých přídavných jmen a sloves v naznačeném pojetí mají ve srovnání se vzory pro podstatná jména výrazně složitější strukturu. Při popisu úplného schématu ohýbání přídavného jména je třeba vycházet z toho, že se tu základní počet 14 tvarů, rozlišitelných u podstatného jména (2 čísla 7 pádů), nejprve násobí čtyřmi, protože přídavné jméno (principiálně) rozlišuje tvary 4 rodů (mužského životného, mužského neživotného, ženského a středního), a dále ještě třemi, protože všechny dosud počítané tvary existují ve 3 stupních! Tím dostáváme celkem 168 (!) principiálně rozlišitelných tvarů přídavného jména. Je ovšem pravda, že mnohé z těchto tvarů systematicky splývají (např. rod mužský životný a neživotný se liší jedině ve 4. pádě jednotného čísla a v 1. pádě množného čísla, a rod střední se skoro stejně málo liší od rodu mužského neživotného) a některé tvary jsou vzájemně převeditelné jednoduchými formálními pravidly (např. tvar 3. stupně se 3 Exaktní realizace kmenové změny označené +M0 probíhá podle tohoto pravidla: g, h z; ch š; k c; r ř. Například k tomu, abychom správně nadefinovali tvar dvoře ke slovu dvůr, musíme specifikovat, že před koncovkou e se kmen mění hned dvěma způsoby: 1) krátí se kmenová samohláska (ů o); 2) měkčí se koncová souhláska (r ř). 5 Mezi takové speciální vzory patří mj. např. i vzor pro slovo člověk, jehož tvary množného čísla lidé, lidí atd. chápeme jako uplatnění ojedinělé kmenové změny formálně definované pravidlem člověk lid. Ale nejde zdaleka jen o takové případy, tradičně chápané jako absolutní nepravidelnosti. Ke vzorům, pro jejichž uplatnění jsme nenašli žádné jiné slovo, patří třeba i vzor pro slovo vůl (varianta tradičního vzoru pán s krácením kmenové samohlásky ve všech tvarech kromě 1. pádu jednotného čísla). Ostatně poněkud překvapivě se ukázalo, že velmi nízkou frekvenci v řádu několika jednotek vykazuje i samotný vzor pán v našem exaktním pojetí: krácení kmenové samohlásky jen v 5. pádě jednotného čísla ( pane! ) totiž podléhá pouze toto slovo a několik jeho odvozenin ( jemnostpán, milostpán, mocipán, zeměpán ap.)! Pro zhruba 800 dalších podstatných jmen, která se skloňují, jak se tradičně říká, podle vzoru pán, ale bez uvedené anomálie, musel být zaveden jiný vzor. 4
,3 +E vložení písmena e mezi poslední dvě písmena kmene (tak vznikne tvar babek, nebo her ).")
11 11 liší od tvaru 2. stupně vždy jen předponou nej-, bez ohledu na rod, číslo nebo pád). Kromě toho typy skloňování a stupňování českého přídavného jména jsou prakticky vzájemně nezávislé. V implementaci skloňování přídavných jmen vycházíme z následujícího schématu, rozlišujícího celkem 19 obecně odlišitelných tvarů (zde reprezentovaných očíslovanými koncovkami konkrétně pro tzv. tvrdá přídavná jména; šedě vystínovaná políčka této tabulky odkazují na jiné tvary, se kterými jsou dané tvary vždy shodné): Jednotné číslo Množné číslo muž. živ. muž. muž. živ. muž. stř. žen. žen. stř. neživ. neživ. 1. pád (1) ý (2) é (3) á (4) í (5) é (6) á 2. pád (7) ého (8) é (9) ých 3. pád (10) ému (11) é (12) ým 4. pád = (7) = (1) = (2) (13) ou = (5) = (6) 5. pád = (1) = (2) = (3) = (4) = (5) = (6) 6. pád (14) ém (15) é (16) ých 7. pád (17) ým (18) ou (19) ými Celkem čtyři tabulky tohoto typu (pro standardní tvrdé a měkké skloňování přídavných jmen, označené po řadě A1 a A2, a dále pro specifické skloňování přivlastňovacích přídavných jmen typu otcův a matčin, označené A3 a A4) se kombinují s jinak strukturovanými tabulkami definujícími stupňování zároveň s odvozováním a stupňováním příslovcí, což se jevilo jako výhodné řešení.6 Teprve tyto tabulky považujeme za vlastní vzory ohýbání přídavných jmen, protože v nich se projevuje mnohem větší variabilita tohoto slovního druhu v češtině. Následující tabulka je příkladem takového vzoru pro asi 2000 českých přídavných jmen typu divoký. Skupina tvarů Kmen Přípona M M2 ejš 4 +M0 e 5 +M2 eji Soubor koncovek A1 A2 Skupiny tvarů 1 a 2 v této tabulce představují dohromady soubor tvarů 1. stupně, přičemž skupina tvarů 2 tvoří ve skutečnosti jen jediný tvar, a to 1. pád množného čísla rodu mužského životného (s koncovkou č. 4 v tabulce skloňování přídavných jmen) ten totiž jako jediný u některých přídavných jmen vyžaduje změnu kmene; konkrétně tak od slova divoký vznikne tvar divocí. Tímto trikem se nám podařilo izolovat informace o potřebných kmenových změnách od skloňovacích tabulek A1 A4, což zjednodušuje celkový formát popisu ohýbání přídavných jmen.8 6 Četné úvahy o podstatě fungování gramatiky nejen v češtině, ale ve všech jazycích tradičně rozlišujících slovní druhy přídavných jmen a příslovcí vedou k závěru, že skutečná funkce příslovce odvozeného od přídavného jména není vlastně nic jiného než jakýsi (v češtině) 8. pád přídavného jména, který nerozlišuje číslo a používá se ve specifických syntaktických vazbách (zatímco přídavným jménem se rozvíjí podstatné jméno, příslovcem se rozvíjí sloveso nebo přídavné jméno). 7 Exaktní realizace kmenové změny označené +M2 probíhá podle tohoto pravidla: g, h ž; ch š; k č; r ř. 8 U přivlastňovacích přídavných jmen typu otcův jsme tento problém obešli tak, že celé sekvence -ův, -ova atd. definujeme technicky jako koncovky. Takové řešení sice není lingvisticky úplně čisté, ale přispívá k jednoduchosti datových struktur, na kterých je založen náš lingvistický modul.
 ý (2) é (3) á (4) í (5) é (6) á 2. pád (7) ého (8) é (9) ých 3. pád (10) ému (11) é (12) ým 4. pád = (7) = (1) = (2) (13) ou = (5) = (6) 5. pád = (1) = (2) = (3) = (4) = (5) = (6) 6.")
12 12 Skupina tvarů 3 představuje tvary 2. stupně ( divočejší a další odpovídající pády), a zároveň pomocí přípony nej- odvozené odpovídající tvary 3. stupně. Skupina tvarů 4 je opět ve skutečnosti jediný tvar příslovce v 1. stupni ( divoce ); skupina tvarů 5 představuje tvary 2. a 3. stupně příslovce ( divočeji, nejdivočeji ). Vzorů tohoto typu zahrnuje český morfologický modul systému M-CAST celkem asi 50. Z toho ovšem tři nejfrekventovanější pokrývají ohýbání 78 % všech přídavných jmen, a jen 14 vzorů popisuje ohýbání alespoň 10 různých slov.9 Rovněž formát potřebný pro úplný a exaktní popis časování sloves vykazuje složitost srovnatelnou se zde uvedeným formátem pro přídavná jména.10 Zde už jen uvedeme, že v českém lingvistickém modulu systému M-CAST je použito zhruba 150 vzorů pro slovesa, přičemž ovšem asi pro 60 % českých sloves by postačovaly dva vzory dělat a kupovat. I další statistika by tu byla podobná jako u podstatných a přídavných jmen. Otázka objektivní existence a správnosti některých tvarů v české morfologii V některých tabulkách definujících komplexní vzory ohýbání českých přídavných jmen jsou některé ze skupin tvarů 3 5 prázdné, což znamená, že se přídavná jména ohýbaná podle těchto tabulek nestupňují, resp. neodvozují se od nich příslovce. Tuto možnost však (opět pro maximální jednoduchost celého systému) využíváme jen u kategorií přídavných jmen, kde tato zvláštnost souvisí s jinými morfologickými specifiky. Například pro přídavná jména odvozená od sloves příponou -ací platí všeobecně, že se nestupňují a neodvozují se od nich příslovce, a navíc můžeme říci, že normální rodilý uživatel češtiny by ani nevěděl, jak by se od nich takové útvary daly odvodit. Proto takovým přídavným jménům přiřazujeme vzor nepřipouštějící ani stupňování, ani odvozování příslovcí. Na druhé straně přídavná jména odvozená od podstatných jmen příponou -ový obecně, čistě morfologicky nahlíženo, lze stupňovat a lze od nich odvozovat příslovce, i když u mnoha z nich to z hlediska sémantického či pragmatického nemá smysl, a proto se to prostě nedělá. (Jaký smysl by měl např. 2. stupeň morovější nebo příslovce morově?) Takové jemnosti náš lingvistický modul nerozlišuje, přídavným jménům odvozeným příponou -ový je pro jednoduchost přiřazen jediný vzor, který připouští stupňování i odvozování příslovcí. Jinými slovy, náš lingvistický modul rozpoznává všechny tvary, které podle obecných formálních pravidel lze utvořit, i když se v praxi nepoužívají. To nepovažujeme za chybu, protože jako hlavní úkol našeho lingvistického modulu vidíme rozpoznání slov, která někdo použil v dobré víře, že mu bude porozuměno. Uvedený princip, kterým jsme se obecně řídili při návrhu českého lingvistického modulu, se netýká jen vzorů pro přídavná jména, a také se netýká jen otázky existence či neexistence některých tvarů (např. tvarů 2. stupně) jako takových. Ze stejného důvodu naše vzory všeobecně připouštějí i některé způsoby tvoření některých tvarů, které např. Pravidla českého pravopisu prohlašují za nesprávné, nicméně víme, že je lidé (a nehodláme se zabývat otázkou, kolik je takových lidí a zda představují vývojový trend nebo ne) používají. Speciálně například pro některé skupiny cizích vlastních jmen (jako Goethe, Nietzsche, Tódžó nebo Jacques ) jsme zavedli vzory skloňování, ve kterých bylo naším hlavním cílem, aby nechyběla žádná koncovka, kterou by někoho mohlo napadnout u takových jmen použít bez ohledu na to, co o tom říkají naše příliš často se měnící, rozporuplně zdůvodňované a především nepříliš ve veřejnosti vžité normy. Na druhé straně jsme si výše uvedeným principem zjednodušovali práci všude tam, kde se nám jevilo příliš namáhavé nebo neefektivní kategorizovat slova podle mnoha různých gramaticko-sémantických charakteristik, ze kterých by vyplývala praktická možnost nebo nemožnost výskytu některých tvarů. Například tvary přechodníku přítomného (resp. budoucího?) i minulého formálně připouštíme u všech 9 Pro zajímavost: tradiční na školách vyučovaný vzor mladý, zde ovšem chápaný komplexně, tedy včetně stupňování mladší, nejmladší, je v uspořádání podle klesající slovníkové frekvence až na 13. místě. 10 Je třeba si uvědomit, že do slovesné morfologie v širším pojetí patří vedle elementárních tvarů neurčitého, oznamovacího a rozkazovacího způsobu, minulých a trpných příčestí a přechodníků také (běžně používaná) příčestí činná, jako např. dělající od dělat ale ta se opět skloňují ve všech rodech jako přídavná jména!

13 13 sloves, přestože je zřejmé, že v reálných textech v moderní češtině, pokud se vůbec na nějaké přechodníky narazí, půjde nejspíš jen o přítomné přechodníky nedokonavých sloves ( dělaje ap.) nebo o minulé přechodníky sloves dokonavých ( udělav ap.). Formální schopnost rozpoznat i tvary, které neexistují (jako dělav a udělaje ), nepokládáme za chybu, zejména když je spojená se zmenšením počtu vzorů zhruba o polovinu (zde tím, že principiálně nerozlišujeme vzory pro dokonavá a nedokonavá slovesa). Problém gramatické homonymie v češtině K typickým vlastnostem doprovázejícím jiné charakteristiky české morfologie (i morfologie blízce příbuzných jazyků, např. polštiny) patří poměrně velmi častá a široká homonymie (nejednoznačnost) gramatických tvarů slov. Uvažme například, jaké možné tvaroslovné interpretace má slovo kovové, pokud ho posuzujeme samostatně, nezávisle na kontextu. Ze zmiňovaných 168 v češtině obecně existujících tvaroslovných interpretací stupňovatelného přídavného jména zde můžeme okamžitě vyloučit všechny tvary 2. a 3. stupně. Ovšem ze zbývajících 56 tvarů se může jednat o tyto: 1., 4. nebo 5. pád jednotného čísla středního rodu; 1., 4. nebo 5. pád množného čísla mužského rodu neživotného; 1., 4. nebo 5. pád množného čísla ženského rodu; 2., 3. nebo 6. pád jednotného čísla ženského rodu; 4. pád množného čísla mužského rodu životného. To je celkem 13 skutečně možných interpretací! V této souvislosti se projevil jeden koncepční nedostatek původních verzí portugalských lingvistických technologií ve vztahu ke slovanským jazykům. Představme si, že budeme během procesu analýzy zaznamenávat u každého rozpoznaného přídavného jména čtyři samostatné morfologické parametry: PÁD, ČÍSLO, ROD a STUPEŇ. Pro naše slovo kovové bude samozřejmě jednoznačně stanovitelná pouze hodnota parametru STUPEŇ ( 1. ). Podívejme se však pozorněji, co může být zapsáno do zbývajících tří parametrů: Za předpokladu, že neznáme hodnoty parametrů ČÍSLO a ROD, může parametr PÁD nabývat hodnot 1., 2., 3., 4., 5. i 6.. Za předpokladu, že neznáme hodnoty parametrů PÁD a ROD (resp. s upřesněním pro danou situaci irelevantním že PÁD může mít jakoukoli hodnotu kromě 7., viz výše), může parametr ČÍSLO nabývat hodnot jednotné i množné. Konečně za předpokladu, že neznáme hodnoty parametrů PÁD a ČÍSLO (resp. pro PÁD víme stále jen, že není 7. ), může parametr ROD nabývat hodnot mužský životný, mužský neživotný, ženský i střední. Samostatné parametry PÁD, ČÍSLO a ROD tedy v češtině naprosto nejsou schopné vzájemně upřesnit své hodnoty a celkový počet možných interpretací reprezentovaných touto trojicí parametrů pro slovo kovové vychází nikoli 13, ale = 48 téměř čtyřikrát vyšší, než skutečně je! Takovým způsobem reprezentovanou morfologickou interpretaci slova prakticky nelze použít k následnému testování nějakých prvků syntaktických struktur např. požadavku, aby celá jmenná fráze byla v 2. pádě: budou-li v textu za sebou následovat slova kovové lešení, pak pro slovo kovové i pro slovo lešení hodnota PÁD = 2. přichází v úvahu (je mezi možnými), a tedy interpretaci celé fráze kovové lešení jako fráze v 2. pádě nelze formálně vyloučit! Z tohoto důvodu se také zdá, že uvádění požadavků na určitý pád nebo číslo určitých slov ve vzorcích pro rozpoznávání typů dotazů a odpovědí na ně (viz předchozí oddíl Vzorce pro rozpoznávání typů dotazů a potenciálních odpovědí) by prakticky nevedlo k žádnému zlepšení přesnosti rozpoznávání ledaže

14 14 by byl v celém lingvistickém modulu použit jiný způsob vnitřního kódování morfologických informací o slovech, na kterém zatím zahájili společné práce naši polští a portugalští partneři v projektu. Inherentní gramatická nejednoznačnost českých slovních tvarů ostatně může spolu s volným slovosledem v extrémních případech vést i k objektivní nejednoznačnosti celých vět bez ohledu na to, jak dobře nebo špatně máme zakódované morfologické informace o jednotlivých rozpoznaných slovech. Oblíbeným příkladem tohoto jevu je věta: Ženu holí stroj. V této větě můžeme každé ze slov interpretovat jako určitý slovesný tvar, tedy přísudek, a tomu přizpůsobit interpretaci ostatních slov. Gramaticky správná jednoduchá věta v češtině přirozeně nemůže obsahovat dva určité slovesné tvary, ale protože všechna slova této věty jsou vhodným způsobem homonymní, můžeme větu objektivně chápat jako složenou z těchto trojic slov (v základních slovníkových tvarech): hnát(i), hůl, stroj, žena, holit, stroj, nebo konečně žena, hůl, strojit. Pro první a třetí lexikální trojici navíc přichází v úvahu různé možnosti zapojení podstatného jména hůl do struktury věty protože jeho tvar holí stále ještě připouští dvě gramatické interpretace, které se obě formálně hodí do daného kontextu: 7. pád jednotného čísla a 2. pád množného čísla. Celkově tedy existuje minimálně pět různých interpretací věty ženu holí stroj, z nichž některé vypadají v různé míře nesmyslně, ale čistě gramaticky jsou všechny korektní. Výše uvedený příklad snad může vypadat poněkud vykonstruovaně. Proto uvedeme ještě jeden příklad objektivní homonymie slov v českých větách (i při zohlednění větného kontextu), o jehož reálnosti nemůže být pochyb. Navíc jde o příklad jednoduchého faktografického dotazu, čili jazykového útvaru, na jehož zpracování je specificky zaměřen systém M-CAST. Příklad zní: Jaký je plat Petra Hanka? Problém této tázací věty spočívá v tom, že ačkoli je člověku na první pohled jasné (a dokonce i počítač může na základě jednoduchých formálních pravidel rozpoznat), že se tazatel zajímá o nějakého člověka jménem X a příjmením Y, není zdaleka jednoznačné, jak zní základní tvar jména X a příjmení Y. Uvážíme-li pravidla, podle kterých se v češtině můžou skloňovat osobní jména českého, slovenského, německého, anglického a jihoslovanského původu, spolu s tím, jaká podobně začínající jména opravdu existují, vyjde nám, že základní tvar jména X by mohl být Petr, Peter nebo Petar. Podobně pro příjmení Y přichází v úvahu základní tvary Hanek, Hank, Hanke a Hanko (mimochodem všechny existující v pražském telefonním seznamu). Ve výše uvedeném příkladu je však zvláště kuriózní, které dvě interpretace jmen X a Y z hlediska zdravého rozumu nepřicházejí v úvahu: totiž že X = Petra a Y = Hanka přestože obě tato jména v češtině existují (a druhé z nich dokonce prokazatelně i jako příjmení)! To se ovšem dá formálně zdůvodnit jedině na základě rozpoznání syntaktické struktury celého dotazu: podmětem věty je slovo plat, za ním následuje vlastní jméno jako jeho přívlastek vyjadřující přináležitost ( čí plat ), čili toto vlastní jméno je nutně v 2. pádě. Proto musí jít o některé z existujících jmen, jejichž 2. pád může znít Petra, resp. Hanka. V této poloze jde o další problém, který západoevropské jazyky neznají. Jeho na uživatele inteligentně působící řešení by vyžadovalo: 1) předem zahrnout do slovníku všechna existující vlastní jména (což je přístup jistě možný, nicméně odlišný od koncepce všech dřívějších západoevropských jazykových modulů systému M-CAST, a podle našeho odhadu by to znamenalo několikanásobné zvětšení slovníku);

15 15 2) zpřesnit vzorce pro rozpoznávání typů dotazů a odpovědí na ně v míře, s jakou v projektech předcházejících projektu M-CAST ani v tomto projektu od začátku nikdo nepočítal.11 V každém případě musíme konstatovat, že současná verze českého lingvistického modulu systému M-CAST nedokáže ve formulaci typu jaký je plat Hanka rozpoznat, že nemůže jít o osobu jménem Hanka. To samozřejmě může uživateli připadat hloupé, a také v konečném důsledku snižovat celkovou přesnost nabízených odpovědí na dotaz. Z uvedených údajů by ovšem zároveň mělo být patrné, že snížení přesnosti samotným tímto detailem ve skutečnosti vůbec nemusí být rozhodující. Přitom úplné odstranění problému homonymie asi zvláště u tvarů vlastních jmen v češtině nikdy nebude možné jinak než pomocí funkce interaktivního upřesnění dotazu ( Myslíte jméno: 1. Hanek; 2. Hank; ). Možnosti vyhledávání v systému M-CAST Systém M-CAST podporuje dva typy vyhledávání: jednoduché a pokročilé. Při jednoduchém vyhledávání se zapíše do vyhledávacího boxu dotaz, kterým může být skupina termínů, nebo otázka v přirozeném jazyce. Systém M-CAST odpoví vytvořením stránky s výsledky, tj. nabídne přesnou odpověď na dotaz a seznam úryvků odpovědí. Nejvíce relevantní odpovědi jsou umístěny jako první. Kromě jednoduchého vyhledávání umožňuje M-CAST provádět pokročilé vyhledávání, při kterém je možné zúžit oblast vyhledávání podle tří úrovní kategorií klasifikačního systému MDT. První úroveň: 0 Všeobecnosti. Informatika a informační vědy 1 Filozofie. Psychologie 2 Náboženství. Teologie 3 Společenské vědy. Statistika. Politika. Vláda. Ekonomie. Správa. Vojenství. Folkloristika 4 Neobsazeno 5 Přírodní vědy. Matematika 6 Aplikované vědy. Lékařství. Technika 7 Umění. Rekreace. Zábava. Hudba. Sport 8 Jazyky. Lingvistika. Literatura 9 Geografie. Biografie. Dějiny Kategorie MDT si lze vybrat ze seznamu v prvním řádku kliknutím na rozbalovací šipku vpravo, ve druhém a třetím řádku se po kliknutí na šipku objeví nabídka kategorie nižší úrovně. 11 Bylo by asi skutečně nutné rozpoznávat celou syntaktickou strukturu každého dotazu, nejen jeho prvky charakterizující jednotlivé typy dotazů a odpovědi na ně. Stačí například uvážit tento dotaz: Jaký plat Hanka dává svým zaměstnancům? Zde jde o jméno (resp. příjmení) Hanka v základním tvaru, a navíc nikoli o přímé rozvití slova plat nejde o plat Hanky, jde o plat zaměstnanců Hanky. V širším pohledu tento problém opět významně souvisí i s problémem volného slovosledu jde tu mimo jiné i o to, nakolik je uvedená formulace (a) běžná a (b) ekvivalentní formulaci: Jaký plat dává Hanka svým zaměstnancům? Srovnej oddíl Problém volného slovosledu v češtině.


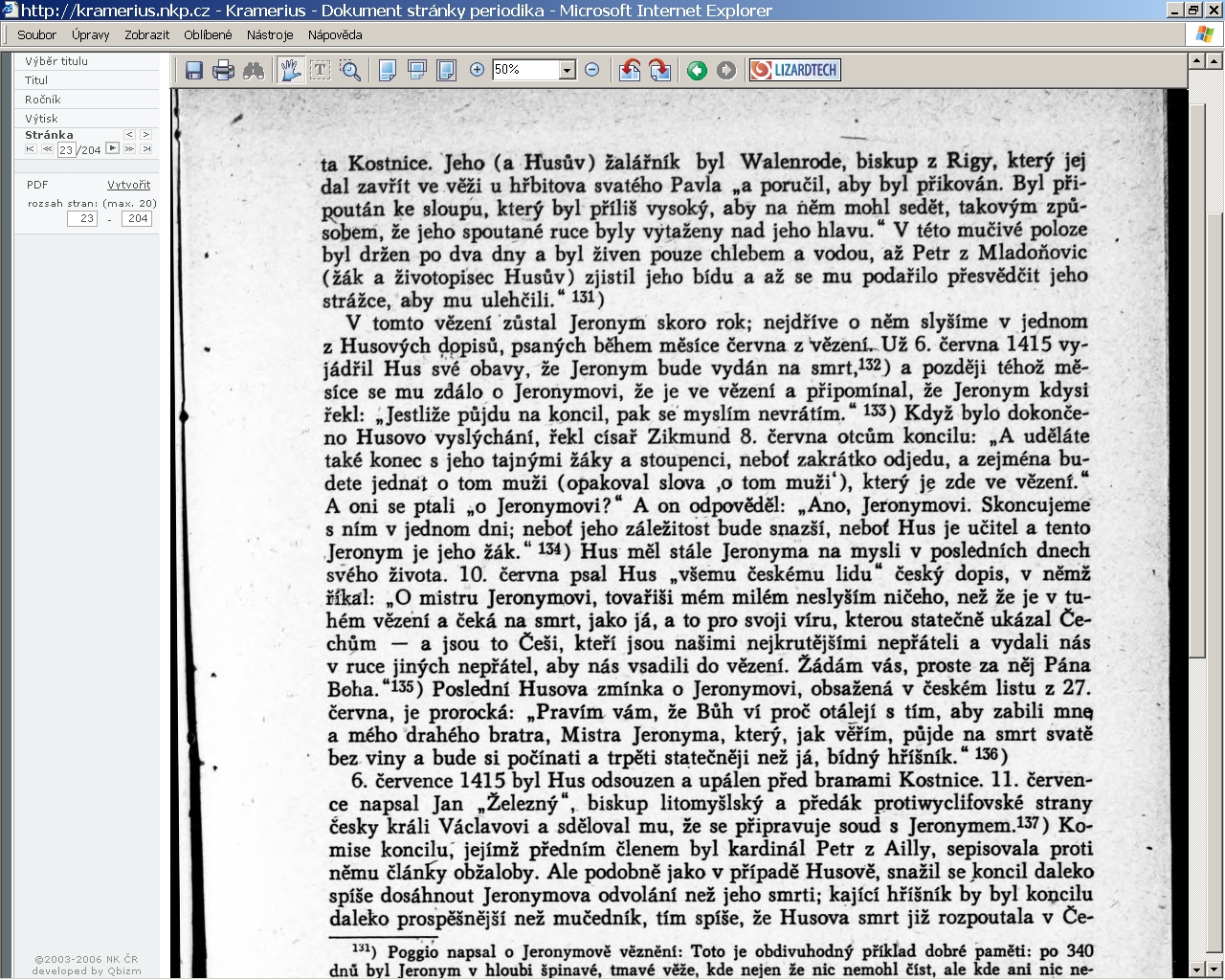
16 16 M-CAST v NK ČR Databáze indexovaných dokumentů NK ČR nemá k dispozici bohaté reprezentativní sbírky digitálních či digitalizovaných dokumentů, jejichž existence je základním předpokladem a podmínkou úspěšné aplikace metody dotazování v přirozeném jazyce. Proto bylo zvoleno náhradní řešení. Pro testovací fázi systému M-CAST zpřístupnila NK ČR tyto databáze: Kramerius (kramerius.nkp.cz), která obsahuje sbírku digitalizovaných periodik a monografií; vyhledává se v plných textech, výsledkem hledání může být každá strana dokumentu, slouží k testování českého modulu; MEMORIA ( obsahující sbírku historických dokumentů; vyhledává se v popisných údajích, výsledkem hledání jsou metadatové záznamy, slouží k testování českého modulu; ALEPH (sigma.nkp.cz), tj. elektronický katalog Národní knihovny České republiky; vyhledává se v popisných údajích, výsledkem hledání jsou metadatové záznamy, slouží k testování českého modulu; EU Constitution (europa.eu/constitution/) Evropská ústava obsahuje texty ve všech jazycích M-CASTu, slouží tedy k testování vícejazyčného modulu. Jak bylo uvedeno výše, NK ČR v současné době nevlastní rozsáhlé soubory vícejazyčných dat soudobých dokumentů, proto byla tato fáze testování v NK ČR zaměřena na ověření funkčnosti systému M-CAST při vyhledávání informací ve sbírce indexovaných historických textů. Při testování bylo nutné vyřešit problémy spojené s dotazováním v přirozeném jazyce aplikovaném při dotazování ve sbírce historických dokumentů, protože vzorové otázky pro M-CAP NK ČR byly původně
 obsahující sbírku historických dokumentů; vyhledává se v popisných údajích, výsledkem hledání jsou metadatové záznamy, slouží k testování českého modulu; ALEPH (sigma.nkp.cz), tj.")
17 17 definovány pro vyhledávání ve sbírkách současných textů. Bylo tedy nutné překonat problémy s dobově podmíněným pravopisem, s historickým slovníkem a složitostí historické syntaxe. Kvalita OCR textů Navíc výsledky testování byly výrazně ovlivněny kvalitou OCR textů. Původním cílem databáze Kramerius byla záchrana a zpřístupnění bohemikálních dokumentů tištěných na kyselém papíru, jejichž existence je ohrožena rozpadem (křehnutím) papírového nosiče. Špatný fyzický stav především starších novin a časopisů ovlivnil kvalitu výsledných obrazových souborů a výstup konverze OCR. Horší kvalita obrazových souborů se pak mnohdy negativně promítla do chybovosti při rozpoznávání během procesu konverze OCR do textové podoby. Při skenování textu z novin obvykle dochází k problémům při segmentaci znaků, k chybám při rozpoznávání textu z nekvalitní předlohy. OCR texty obsažené v databázi Kramerius byly indexovány pro potřeby M-CASTu bez předchozích úprav: nebyly odstraněny nepřesnosti při segmentaci textu a chybějící nerozpoznané znaky, proto mnohdy některá slova, případně fráze nebyly identifikovány správně a docházelo tak k významovým posunům, případně výsledek dotazu nedával smysl. Metoda dotazování v přirozeném jazyce aplikovaná v systému M-CAST Z pozice uživatele zpracovává systém M-CAST dotazy položené v přirozeném jazyce a nabízí přesné a jednoznačné odpovědi podpořené úryvky odpovědí, které jsou extrahovány z obsáhlé databáze indexovaných dokumentů. Jednou z nejdůležitějších podmínek úspěšnosti vyhledávání pomocí této metody je soubor dobře formulovaných otázek. Dotazy aplikované v systému M-CAST mají být faktografické, jednoduché, jasně a přesně formulované. Všechny informace, které jsou předmětem dotazu, musejí být obsaženy v databázi indexovaných dokumentů. Délka dotazů Dotazy používané při aplikaci metody dotazování v přirozeném jazyce jsou obvykle krátké, skládají se ze tří, čtyř slov. Dotaz formulovaný jako celá věta vede však automaticky k jeho prodlužování. Dlouhá otázka obsahující více klíčových významových prvků, pivotů, může mít za následek, že při vyhledávání dokumentů jsou relevantní dokumenty odfiltrovány a nabídnuty dokumenty méně relevantní, obsahující více klíčových slov, avšak nerelevantních pro daný dotaz. Např. dotaz "Který umělecký soubor vystoupí na zahájení výstavy Velká Morava v Berlíně?" je příliš dlouhý, obsahuje 6 významových prvků; přímá odpověď, ani úryvek obsahující přímou odpověď na tento dotaz nebyly získány.

. Např.")
18 18 Odpovědi v systému M-CAST Systém M-CAST generuje na uživatelův dotaz celý soubor, blok odpovědí, který se skládá z: přímé odpovědi; úryvku obsahujícího/podporujícího přímou odpověď; možnosti vizualizace zdrojového dokumentu. Přímá odpověď Přímé odpovědi jsou většinou jmenné entity (jméno, místo, chronologický údaj, jmenné a slovesné fráze). Např. přímá odpověď na otázku "Co držel Zeus v pravé ruce?" je "bohyni vítězství". Úryvek odpovědi Systém M-CAST generuje spolu s přímou odpovědí i odpovídající úryvek zdrojového dokumentu, který zasazuje přímou odpověď do potřebného minimálního kontextu. Úryvek obsahující přímou odpověď na výše uvedenou otázku je tedy: "V pravé ruce držel Zeus bohyni vítězství, jak se právě k němu sklání, chtíc hlavu jeho věncem ozdobiti; v levé držel žezlo." Vizualizace zdrojového dokumentu Poslední část bloku odpovědi představuje potenciální vizualizace zdrojového dokumentu, tedy hypertextový odkaz vedoucí k příslušné stránce zdrojového dokumentu.


19 19 NK ČR je jedním z testovacích pracovišť systému M-CAST. Naším úkolem bylo ověřit funkcionalitu sytému M-CAST v plném provozu, prověřit odezvu systému, provést různé zátěžové testy a svými praktickými zkušenostmi přispět k odstranění všech případných nedostatků. Na testování se podílelo 40 účastníků: všichni měli zkušenosti s vyhledáváním v online katalozích, faktografických databázích, v prostředí internet, avšak pouze 5 účastníků mělo dílčí zkušenosti s kladením dotazů v přirozeném

20 20 jazyce. Měli jsme tak možnost ověřit, je-li vyhledávání v systému M-CAST komplikované, nebo naopak snadné a intuitivní, jak proklamovali naši kolegové, producenti systému. Na základě získaných zkušeností můžeme potvrdit, že vyhledávání v systému M-CAST je intuitivní a snadné i pro méně zkušeného či nezkušeného uživatele. Hodnocení evaluace systému M-CAST Odezva systému Jedním z důležitých kritérií hodnocení kvality systému je dosažená odezva. Průměrná odezva prototypu systému M-CAST byla v době testování 4,9 s. Správnost odpovědí Proces hodnocení byl ztížen tím, že systém M-CAST nabízí soubor/blok odpovědí, přičemž je všeobecně známo, že evaluace komplexu odpovědí generovaných systémem je obtížnější než evaluace jednotlivých typů odpovědí. Proto byla pro potřeby hodnocení systému vypracována tato speciální kategorizace opovědí: Přímá odpověď správná, tj. přesná krátká odpověď nesprávná, tj. chybná krátká odpověď nepřesná, tj. krátká odpověď obsahující méně či více informací, než vyžadoval dotaz žádná odpověď Úryvek odpovědi správná odpověď obsažená v úryvku správná odpověď obsažená v úryvcích na dalších pozicích nesprávná + žádná odpověď, tj. úryvek obsahoval nesprávnou odpověď, případně systém negeneroval žádný úryvek jako odpověď na položený dotaz Optimální počet odpovědí V průběhu testování se ukázalo, že optimální počet získaných odpovědí je 5. Někteří účastníci, obeznámení s vyhledávaným tématem, by se spokojili se 2 odpověďmi, zatímco větší počet odpovědí požadovali uživatelé, kteří nebyli podrobněji seznámeni s předmětem svého zájmu. Frekvence výskytu správných přímých odpovědí i úryvků odpovědí byla ovlivněna menší kvalitou OCR textů (vysvětlení výše). Výsledná statistika Přímá odpověď správná nesprávná nepřesná žádná celkem 10 % 6% 31 % 53 % 100 %

21 21 Úryvek odpovědi správná odpověď, úryvek správná odpověď, ostatní nesprávná + žádná odpověď celkem 73 % 15 % 12 % 100 % Závěr Výsledky projektu M-CAST jsou v souladu s cíli evropského programu econtent v oblasti vícejazyčného vyhledávání. Prokázaly možnosti uplatnění systému dotazů v přirozeném jazyce v prostředí hybridních i digitálních knihoven. Technologie zpracování přirozeného jazyka (natural language processing) se úspěšně uplatňují v oblasti analýzy dotazů, indexování dokumentů a extrakce otázek i ve vícejazyčném prostředí. Budoucím záměrem je rozvíjet a zlepšovat systém M-CAST v několika směrech. V současné době dokáže systém zodpovědět zhruba 70 % faktografických otázek a % nefaktografických otázek, a to ve francouzštině a portugalštině. Nyní je potřeba soustředit se na to, aby i ostatní jazyky dosáhly stejného procenta zodpovězených faktografických otázek, a současně zvýšit výrazně poměr zodpovězených nefaktografických otázek ve všech jazycích. V neposlední řadě je třeba zapojit do systému další jazyky (uvažuje se o němčině), včetně jazyků nelatinkového písma (arabština, čínština). Bibliografie Amaral, Carlos. Laurent, Dominique (2006) Implementation of a QA system in a real context [Paper Presented at TEL-ME-MOR/M-CAST Seminar On Subject Access, Prague, November 24, 2006] Available at Balíková, Marie (2006) M-CAST in libraries [Paper Presented at TEL-ME-MOR/M-CAST Seminar On Subject Access, Prague, November 24, 2006] Available at Czerniejewski, Borys (2006) Multilingual Content Aggregation System based on TRUST Search Engine (M-CAST) [Paper Presented at TEL-ME-MOR/M-CAST Seminar On Subject Access, Prague, November 24, 2006] Available at Lisek, Sebastian (2006) P2P networks for distributed queries [Paper Presented at TEL-MEMOR/ M-CAST Seminar On Subject Access, Prague, November 24, 2006] Available at Strossa, Petr (2006) Information Query Formulation in a Slavonic Language and its Automatic Processing : Experience from Polish and Czech in comparison to Western European Languages [Paper Presented at TEL-ME-MOR/M-CAST Seminar On Subject Access, Prague, November 24, 2006] Available at
22 22 Příloha 1: Příklady Otázka: Kdy byla Karlova univerzita zpřístupněna ženám? Odpověď se skládá z přímé odpovědi, úryvku odpovědi a propojení na stránku zdrojového dokumentu přímá odpověď: "od roku 1897" úryvek odpovědi: "Od roku 1897 byla ženám zpřístupněna Karlova univerzita"


23 23 vizualizace stránky zdrojového dokumentu Otázka: Co držel Zeus v levé ruce? Odpověď: žezlo

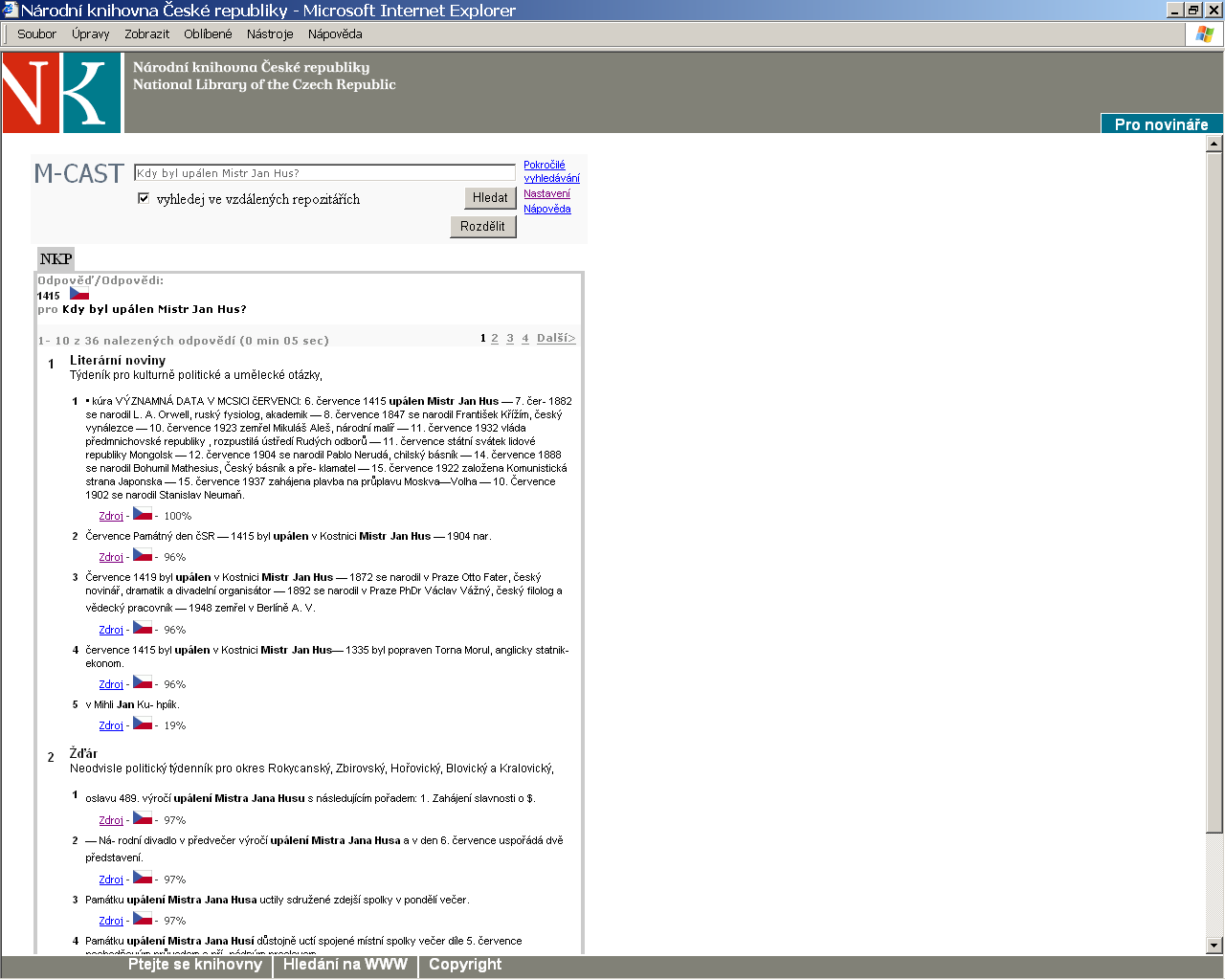
24 24 Otázka: Kdy byl upálen Mistr Jan Hus
25 25
26 26

27 27 Vícejazyčné vyhledávání: Otázka v angličtině, odpověď v polštině Otázka v češtině, odpověď v polštině

28 28 Otázka v polštině, odpověď v češtině Otázka ve francouzštině, odpověď v portugalštině
Systém M-CAST Multilingual Content Aggregation System Vícejazyčný systém agregace informací
 Systém M-CAST Multilingual Content Aggregation System Vícejazyčný systém agregace informací Marie Balíková Marie.Balikova@nkp.cz Petr Strossa Kizips@vse.cz 1 M-CAST v reálném světě Kdy byla Karlova univerzita
Systém M-CAST Multilingual Content Aggregation System Vícejazyčný systém agregace informací Marie Balíková Marie.Balikova@nkp.cz Petr Strossa Kizips@vse.cz 1 M-CAST v reálném světě Kdy byla Karlova univerzita
SYSTÉM M-CAST V HYBRIDNÍCH KNIHOVNÁCH?
 SYSTÉM M-CAST V HYBRIDNÍCH KNIHOVNÁCH? Marie Balíková, Národní knihovna ČR M-CAST Multilingual Content Aggregation System Vícejazyčný systém agregace informací je vícejazyčný vyhledávací systém založený
SYSTÉM M-CAST V HYBRIDNÍCH KNIHOVNÁCH? Marie Balíková, Národní knihovna ČR M-CAST Multilingual Content Aggregation System Vícejazyčný systém agregace informací je vícejazyčný vyhledávací systém založený
M-CAST v knihovnách. Osnova. Obecně o projektu M-CAST. Ontologie. Typy dotazů a odpovědí. Český lingvistický modul. Dotazy, odpovědi, vyhledávání
 M-CAST v knihovnách Marie.Bal Balíková @nkp.cz Osnova Obecně o projektu M-CAST Ontologie Typy dotazů a odpovědí Český lingvistický modul Dotazy, odpovědi, vyhledávání Aplikace v knihovnách Ukázky M. Balíková
M-CAST v knihovnách Marie.Bal Balíková @nkp.cz Osnova Obecně o projektu M-CAST Ontologie Typy dotazů a odpovědí Český lingvistický modul Dotazy, odpovědi, vyhledávání Aplikace v knihovnách Ukázky M. Balíková
Systém M-CAST v českém kontextu
 038 Systém M-CAST v českém kontextu Marie Balíková / Národní knihovna ČR / e-mail: marie.balikova@nkp.cz Abstrakt: Vícejazyčný systém agregace informací (M-CAST, Multilingual Content Aggregation System)
038 Systém M-CAST v českém kontextu Marie Balíková / Národní knihovna ČR / e-mail: marie.balikova@nkp.cz Abstrakt: Vícejazyčný systém agregace informací (M-CAST, Multilingual Content Aggregation System)
Dataprojektor, kodifikační příručky
 Předmět: Náplň: Třída: Počet hodin: Pomůcky: Český jazyk (CEJ) Jazyková výchova Prima 2 hodiny týdně Dataprojektor, kodifikační příručky Slovní druhy Objasní motivaci pojmenování slovních druhů Vysvětlí
Předmět: Náplň: Třída: Počet hodin: Pomůcky: Český jazyk (CEJ) Jazyková výchova Prima 2 hodiny týdně Dataprojektor, kodifikační příručky Slovní druhy Objasní motivaci pojmenování slovních druhů Vysvětlí
Český jazyk - Jazyková výchova
 Prima Zvuková stránka jazyka Stavba slova a pravopis rozlišuje spisovný jazyk, nářečí a obecnou češtinu Jazyk a jeho útvary seznamuje se s jazykovou normou spisovně vyslovuje česká a běžně užívaná cizí
Prima Zvuková stránka jazyka Stavba slova a pravopis rozlišuje spisovný jazyk, nářečí a obecnou češtinu Jazyk a jeho útvary seznamuje se s jazykovou normou spisovně vyslovuje česká a běžně užívaná cizí
Vývoj moderních technologií při vyhledávání. Patrik Plachý SEFIRA spol. s.r.o. plachy@sefira.cz
 Vývoj moderních technologií při vyhledávání Patrik Plachý SEFIRA spol. s.r.o. plachy@sefira.cz INFORUM 2007: 13. konference o profesionálních informačních zdrojích Praha, 22. - 24.5. 2007 Abstrakt Vzhledem
Vývoj moderních technologií při vyhledávání Patrik Plachý SEFIRA spol. s.r.o. plachy@sefira.cz INFORUM 2007: 13. konference o profesionálních informačních zdrojích Praha, 22. - 24.5. 2007 Abstrakt Vzhledem
Dataprojektor, jazykové příručky, pracovní listy
 Předmět: Náplň: Třída: Počet hodin: Pomůcky: Tvarosloví *) Český jazyk (CEJ) Jazyková výchova Sekunda 2 hodiny týdně Dataprojektor, jazykové příručky, pracovní listy Určuje slovní druhy, své tvrzení vždy
Předmět: Náplň: Třída: Počet hodin: Pomůcky: Tvarosloví *) Český jazyk (CEJ) Jazyková výchova Sekunda 2 hodiny týdně Dataprojektor, jazykové příručky, pracovní listy Určuje slovní druhy, své tvrzení vždy
Příloha č. 4 ČESKÝ JAZYK JAZYKOVÁ VÝCHOVA
 Žák porovnává významy slov, zvláště slova podobného nebo stejného významu a slova vícevýznamová O jazyce Opakování učiva 3. ročníku Národní jazyk Naše vlast a národní jazyk Nauka o slově Slova a pojmy,
Žák porovnává významy slov, zvláště slova podobného nebo stejného významu a slova vícevýznamová O jazyce Opakování učiva 3. ročníku Národní jazyk Naše vlast a národní jazyk Nauka o slově Slova a pojmy,
SADA VY_32_INOVACE_CJ1
 SADA VY_32_INOVACE_CJ1 Přehled anotačních tabulek k dvaceti výukovým materiálům vytvořených Mgr. Bronislavou Zezulovou a Mgr. Šárkou Adamcovou. Kontakt na tvůrce těchto DUM: zezulova@szesro.cz a adamcova@szesro.cz
SADA VY_32_INOVACE_CJ1 Přehled anotačních tabulek k dvaceti výukovým materiálům vytvořených Mgr. Bronislavou Zezulovou a Mgr. Šárkou Adamcovou. Kontakt na tvůrce těchto DUM: zezulova@szesro.cz a adamcova@szesro.cz
VĚCNÝ POPIS DOKUMENTŮ (VĚCNÁ KATALOGIZACE) Mgr. Dagmar Smékalová
 Mgr. Dagmar Smékalová") VĚCNÝ POPIS DOKUMENTŮ (VĚCNÁ KATALOGIZACE) Mgr. Dagmar Smékalová smekalova@svkos.cz ZÁKLADNÍ POJMY 1 POŘÁDÁNÍ INFORMACÍ (IDENTIFIKAČNÍ A VĚCNÉ POŘÁDÁNÍ) VĚCNÁ KATALOGIZACE OBSAHOVÁ ANALÝZA DOKUMENTŮ SELEKČNÍ
VĚCNÝ POPIS DOKUMENTŮ (VĚCNÁ KATALOGIZACE) Mgr. Dagmar Smékalová smekalova@svkos.cz ZÁKLADNÍ POJMY 1 POŘÁDÁNÍ INFORMACÍ (IDENTIFIKAČNÍ A VĚCNÉ POŘÁDÁNÍ) VĚCNÁ KATALOGIZACE OBSAHOVÁ ANALÝZA DOKUMENTŮ SELEKČNÍ
Příklad z učebnice matematiky pro základní školu:
 Příklad z učebnice matematiky pro základní školu: Součet trojnásobku neznámého čísla zvětšeného o dva a dvojnásobku neznámého čísla zmenšeného o pět se rovná čtyřnásobku neznámého čísla zvětšeného o jedna.
Příklad z učebnice matematiky pro základní školu: Součet trojnásobku neznámého čísla zvětšeného o dva a dvojnásobku neznámého čísla zmenšeného o pět se rovná čtyřnásobku neznámého čísla zvětšeného o jedna.
PRODUKTY. Tovek Tools
 jsou desktopovou aplikací určenou k vyhledávání informací, tvorbě různých typů analýz a vytváření přehledů a rešerší. Jsou vhodné pro práci i s velkým objemem textových dat z různorodých informačních zdrojů.
jsou desktopovou aplikací určenou k vyhledávání informací, tvorbě různých typů analýz a vytváření přehledů a rešerší. Jsou vhodné pro práci i s velkým objemem textových dat z různorodých informačních zdrojů.
Český jazyk a literatura - jazyková výchova
 Využívá znalostí získaných v předešlých ročnících. OPAKOVÁNÍ OPAKOVÁNÍ Vysvětlí pojmy: sl.nadřazené, podřazené a slova souřadná.uvede příklady. Rozpozná sl. jednoznač.a mnohoznačná. V textu vyhledá synonyma,
Využívá znalostí získaných v předešlých ročnících. OPAKOVÁNÍ OPAKOVÁNÍ Vysvětlí pojmy: sl.nadřazené, podřazené a slova souřadná.uvede příklady. Rozpozná sl. jednoznač.a mnohoznačná. V textu vyhledá synonyma,
Pracovní celky 3.2, 3.3 a 3.4 Sémantická harmonizace - Srovnání a přiřazení datových modelů
 Pracovní celky 3.2, 3.3 a 3.4 Sémantická harmonizace - Srovnání a datových modelů Obsah Seznam tabulek... 1 Seznam obrázků... 1 1 Úvod... 2 2 Metody sémantické harmonizace... 2 3 Dvojjazyčné katalogy objektů
Pracovní celky 3.2, 3.3 a 3.4 Sémantická harmonizace - Srovnání a datových modelů Obsah Seznam tabulek... 1 Seznam obrázků... 1 1 Úvod... 2 2 Metody sémantické harmonizace... 2 3 Dvojjazyčné katalogy objektů
Příloha č. 4 ČESKÝ JAZYK JAZYKOVÁ VÝCHOVA
 září Žák porovnává významy slov, zvláště slova podobného nebo stejného významu a slova vícevýznamová. Žák dokáže rozlišit mluvnické kategorie podstatných jmen (pád, číslo, rod), rozliší větu jednoduchou
září Žák porovnává významy slov, zvláště slova podobného nebo stejného významu a slova vícevýznamová. Žák dokáže rozlišit mluvnické kategorie podstatných jmen (pád, číslo, rod), rozliší větu jednoduchou
Olympiáda v českém jazyce 45. ročník, 2018/2019
 Národní institut pro další vzdělávání MŠMT Senovážné náměstí 25, 110 00 Praha 1 Olympiáda v českém jazyce 45. ročník, 2018/2019 Krajské kolo zadání II. kategorie přidělené soutěžní číslo body gramatika
Národní institut pro další vzdělávání MŠMT Senovážné náměstí 25, 110 00 Praha 1 Olympiáda v českém jazyce 45. ročník, 2018/2019 Krajské kolo zadání II. kategorie přidělené soutěžní číslo body gramatika
Olympiáda v českém jazyce 45. ročník 2018/2019
 Národní institut pro další vzdělávání MŠMT Senovážné náměstí 25, 110 00 Praha 1 Olympiáda v českém jazyce 45. ročník 2018/2019 Krajské kolo zadání I. kategorie přidělené soutěžní číslo body gramatika sloh
Národní institut pro další vzdělávání MŠMT Senovážné náměstí 25, 110 00 Praha 1 Olympiáda v českém jazyce 45. ročník 2018/2019 Krajské kolo zadání I. kategorie přidělené soutěžní číslo body gramatika sloh
Vyučovací předmět: Český jazyk a literatura Ročník: 6. Jazyková výchova
 Vyučovací předmět: Český jazyk a literatura Ročník: 6. Vzdělávací obsah Očekávané výstupy z RVP ZV Školní výstupy Učivo Přesahy a vazby, průřezová témata rozlišuje spisovný jazyk, nářečí a obecnou češtinu
Vyučovací předmět: Český jazyk a literatura Ročník: 6. Vzdělávací obsah Očekávané výstupy z RVP ZV Školní výstupy Učivo Přesahy a vazby, průřezová témata rozlišuje spisovný jazyk, nářečí a obecnou češtinu
Tematický plán pro školní rok 2015/16 Předmět: Český jazyk Vyučující: Mgr. Iveta Jedličková Týdenní dotace hodin: 8 hodin Ročník: pátý
 ČASOVÉ OBDOBÍ Září Říjen KONKRÉTNÍ VÝSTUPY KONKRÉTNÍ UČIVO PRŮŘEZOVÁ TÉMATA Umí vyznačit ve slově kořen, předponu, příponu, koncovku Umí vytvořit tvar slova a slovo příbuzné Umí odvodit slova pomocí přípony
ČASOVÉ OBDOBÍ Září Říjen KONKRÉTNÍ VÝSTUPY KONKRÉTNÍ UČIVO PRŮŘEZOVÁ TÉMATA Umí vyznačit ve slově kořen, předponu, příponu, koncovku Umí vytvořit tvar slova a slovo příbuzné Umí odvodit slova pomocí přípony
Ontologie. Otakar Trunda
 Ontologie Otakar Trunda Definice Mnoho různých definic: Formální specifikace sdílené konceptualizace Hierarchicky strukturovaná množina termínů popisujících určitou věcnou oblast Strukturovaná slovní zásoba
Ontologie Otakar Trunda Definice Mnoho různých definic: Formální specifikace sdílené konceptualizace Hierarchicky strukturovaná množina termínů popisujících určitou věcnou oblast Strukturovaná slovní zásoba
Obsah. Úvodní poznámka 11 Německý jazyk, spisovná řeč a nářečí 13 Pomůcky ke studiu němčiny 15
 Obsah Úvodní poznámka 11 Německý jazyk, spisovná řeč a nářečí 13 Pomůcky ke studiu němčiny 15 VÝSLOVNOST A PRAVOPIS Německá výslovnost 18 Hlavni rozdíly mezi českou a německou výslovnosti 19 Přízvuk 20
Obsah Úvodní poznámka 11 Německý jazyk, spisovná řeč a nářečí 13 Pomůcky ke studiu němčiny 15 VÝSLOVNOST A PRAVOPIS Německá výslovnost 18 Hlavni rozdíly mezi českou a německou výslovnosti 19 Přízvuk 20
Metody tvorby ontologií a sémantický web. Martin Malčík, Rostislav Miarka
 Metody tvorby ontologií a sémantický web Martin Malčík, Rostislav Miarka Obsah Reprezentace znalostí Ontologie a sémantický web Tvorba ontologií Hierarchie znalostí (D.R.Tobin) Data jakékoliv znakové řetězce
Metody tvorby ontologií a sémantický web Martin Malčík, Rostislav Miarka Obsah Reprezentace znalostí Ontologie a sémantický web Tvorba ontologií Hierarchie znalostí (D.R.Tobin) Data jakékoliv znakové řetězce
Obohacování bibliografických záznamů o věcné selekční prvky postup NKČR
 Obohacování bibliografických záznamů o věcné selekční prvky postup NKČR Bod programu: Věcné zpracování (možnosti obohacování dříve dodaných záznamů) Marie.Balikova@nkp.cz Pracovní skupina pro SK, 7.3.
Obohacování bibliografických záznamů o věcné selekční prvky postup NKČR Bod programu: Věcné zpracování (možnosti obohacování dříve dodaných záznamů) Marie.Balikova@nkp.cz Pracovní skupina pro SK, 7.3.
Reálné gymnázium a základní škola města Prostějova Školní vzdělávací program pro ZV Ruku v ruce
 1 JAZYK A JAZYKOVÁ KOMUNIKACE UČEBNÍ OSNOVY 1. 2 Cvičení z českého jazyka Cvičení z českého jazyka 7. ročník 1 hodina 8. ročník 1 hodina 9. ročník 1 hodina Charakteristika Žáci si tento předmět vybírají
1 JAZYK A JAZYKOVÁ KOMUNIKACE UČEBNÍ OSNOVY 1. 2 Cvičení z českého jazyka Cvičení z českého jazyka 7. ročník 1 hodina 8. ročník 1 hodina 9. ročník 1 hodina Charakteristika Žáci si tento předmět vybírají
DIGITÁLNÍ ARCHIV VZDĚLÁVACÍCH MATERIÁLŮ
 DIGITÁLNÍ ARCHIV VZDĚLÁVACÍCH MATERIÁLŮ Číslo projektu Číslo a název šablony klíčové aktivity Tématická oblast CZ.1.07/1.5.00/34.0963 II/2 Inovace a zkvalitnění výuky směřující k rozvoji čtenářské a informační
DIGITÁLNÍ ARCHIV VZDĚLÁVACÍCH MATERIÁLŮ Číslo projektu Číslo a název šablony klíčové aktivity Tématická oblast CZ.1.07/1.5.00/34.0963 II/2 Inovace a zkvalitnění výuky směřující k rozvoji čtenářské a informační
Vyhledávání na portálu Knihovny.cz
 Inforum 2017 Vyhledávání na portálu Knihovny.cz Petr Žabička, Václav Rosecký, Petra Žabičková Moravská zemská knihovna v Brně Obsah Co indexuje portál Knihovny.cz Rozšíření o centrální index Hledání v
Inforum 2017 Vyhledávání na portálu Knihovny.cz Petr Žabička, Václav Rosecký, Petra Žabičková Moravská zemská knihovna v Brně Obsah Co indexuje portál Knihovny.cz Rozšíření o centrální index Hledání v
Tovek Server. Tovek Server nabízí následující základní a servisní funkce: Bezpečnost Statistiky Locale
 je serverová aplikace určená pro efektivní zpracování velkého objemu sdílených nestrukturovaných dat. Umožňuje automaticky indexovat data z různých informačních zdrojů, intuitivně vyhledávat informace,
je serverová aplikace určená pro efektivní zpracování velkého objemu sdílených nestrukturovaných dat. Umožňuje automaticky indexovat data z různých informačních zdrojů, intuitivně vyhledávat informace,
PRODUKTY Tovek Server 6
 Tovek Server je serverová aplikace určená pro efektivní zpracování velkého objemu sdílených strukturovaných i nestrukturovaných dat. Umožňuje automaticky indexovat data z různých informačních zdrojů, intuitivně
Tovek Server je serverová aplikace určená pro efektivní zpracování velkého objemu sdílených strukturovaných i nestrukturovaných dat. Umožňuje automaticky indexovat data z různých informačních zdrojů, intuitivně
Ročník: 5. Časová dotace: 7 hodin týdně učivo, téma očekávané výstupy klíčové kompetence, mezipředmětové vazby
 Ročník: 5. Časová dotace: 7 hodin týdně Komunikační a slohová Zážitkové čtení a naslouchání klíčová slova vyhledávací čtení aktivní naslouchání se záznamem slyšeného Žák při hlasitém čtení vhodně využívá
Ročník: 5. Časová dotace: 7 hodin týdně Komunikační a slohová Zážitkové čtení a naslouchání klíčová slova vyhledávací čtení aktivní naslouchání se záznamem slyšeného Žák při hlasitém čtení vhodně využívá
VĚCNÝ POPIS DOKUMENTŮ (VĚCNÁ KATALOGIZACE) s m e k a l o v a @ s v k o s. c z
 s m e k a l o v a @ s v k o s. c z") VĚCNÝ POPIS DOKUMENTŮ (VĚCNÁ KATALOGIZACE) M g r. D a g m a r S m é k a l o v á s m e k a l o v a @ s v k o s. c z ZÁKLADNÍ POJMY 1 POŘÁDÁNÍ INFORMACÍ (IDENTIFIKAČNÍ A VĚCNÉ POŘÁDÁNÍ) VĚCNÁ KATALOGIZACE
VĚCNÝ POPIS DOKUMENTŮ (VĚCNÁ KATALOGIZACE) M g r. D a g m a r S m é k a l o v á s m e k a l o v a @ s v k o s. c z ZÁKLADNÍ POJMY 1 POŘÁDÁNÍ INFORMACÍ (IDENTIFIKAČNÍ A VĚCNÉ POŘÁDÁNÍ) VĚCNÁ KATALOGIZACE
MBI - technologická realizace modelu
 MBI - technologická realizace modelu 22.1.2015 MBI, Management byznys informatiky Snímek 1 Agenda Technická realizace portálu MBI. Cíle a principy technického řešení. 1.Obsah portálu - objekty v hierarchiích,
MBI - technologická realizace modelu 22.1.2015 MBI, Management byznys informatiky Snímek 1 Agenda Technická realizace portálu MBI. Cíle a principy technického řešení. 1.Obsah portálu - objekty v hierarchiích,
E K O G Y M N Á Z I U M B R N O o.p.s. přidružená škola UNESCO
 Seznam výukových materiálů III/2 Inovace a zkvalitnění výuky prostřednictvím ICT Tematická oblast: Předmět: Vytvořil: Současný český jazyk upevňování a procvičování obtížných gramatických jevů Český jazyk
Seznam výukových materiálů III/2 Inovace a zkvalitnění výuky prostřednictvím ICT Tematická oblast: Předmět: Vytvořil: Současný český jazyk upevňování a procvičování obtížných gramatických jevů Český jazyk
Slohový útvar Výklad hypotézy Požadavky:
 Jan Vožen enílek Gymnázium F. X. Šaldy Slohový útvar Výklad je útvar, který přináší čtenáři odborné poučení, neboť podává a vysvětluje vědecké poznatky. (Ne tedy názory, domněnky, city, přesvědčení ) Ve
Jan Vožen enílek Gymnázium F. X. Šaldy Slohový útvar Výklad je útvar, který přináší čtenáři odborné poučení, neboť podává a vysvětluje vědecké poznatky. (Ne tedy názory, domněnky, city, přesvědčení ) Ve
Všestranný jazykový rozbor (VJR)
") Všestranný jazykový rozbor (VJR) VJR by měl tvořit součást téměř každé vyučovací hodiny a můžeme jej zařadit do kterékoli její části. Nejčastěji se používá při opakovaní a vyvozování nového učiva. Pokud
Všestranný jazykový rozbor (VJR) VJR by měl tvořit součást téměř každé vyučovací hodiny a můžeme jej zařadit do kterékoli její části. Nejčastěji se používá při opakovaní a vyvozování nového učiva. Pokud
Nové orgány na postupu
 Nové orgány na postupu Pěstování celých orgánů z kmenových buněk je v současnosti oblíbené. Základní postup, který biologové používají, je vesměs podobný. Aby se kmenová buňka změnila ve správný buněčný
Nové orgány na postupu Pěstování celých orgánů z kmenových buněk je v současnosti oblíbené. Základní postup, který biologové používají, je vesměs podobný. Aby se kmenová buňka změnila ve správný buněčný
PRODUKTY. Tovek Tools
 Analyst Pack je desktopovou aplikací určenou k vyhledávání informací, tvorbě různých typů analýz a vytváření přehledů a rešerší. Jsou vhodné pro práci i s velkým objemem textových dat z různorodých informačních
Analyst Pack je desktopovou aplikací určenou k vyhledávání informací, tvorbě různých typů analýz a vytváření přehledů a rešerší. Jsou vhodné pro práci i s velkým objemem textových dat z různorodých informačních
Národní institut pro další vzdělávání MŠMT Senovážné náměstí 25, Praha 1. Olympiáda v českém jazyce, 42. ročník, 2015/2016 okresní kolo
 Národní institut pro další vzdělávání MŠMT Senovážné náměstí 25, 110 00 Praha 1 Olympiáda v českém jazyce, 42. ročník, 2015/2016 okresní kolo I. kategorie Počet bodů:... Jméno:... Škola:... 1. Od některých
Národní institut pro další vzdělávání MŠMT Senovážné náměstí 25, 110 00 Praha 1 Olympiáda v českém jazyce, 42. ročník, 2015/2016 okresní kolo I. kategorie Počet bodů:... Jméno:... Škola:... 1. Od některých
Projekt IMPLEMENTACE ŠVP
 Střední škola umělecká a řemeslná Evropský sociální fond "Praha a EU: Investujeme do vaší budoucnosti" Projekt IMPLEMENTACE ŠVP Evaluace a aktualizace metodiky předmětu Německý jazyk Obory nástavbového
Střední škola umělecká a řemeslná Evropský sociální fond "Praha a EU: Investujeme do vaší budoucnosti" Projekt IMPLEMENTACE ŠVP Evaluace a aktualizace metodiky předmětu Německý jazyk Obory nástavbového
Programovací jazyk Pascal
 Programovací jazyk Pascal Syntaktická pravidla (syntaxe jazyka) přesná pravidla pro zápis příkazů Sémantická pravidla (sémantika jazyka) pravidla, která každému příkazu přiřadí přesný význam Všechny konstrukce
Programovací jazyk Pascal Syntaktická pravidla (syntaxe jazyka) přesná pravidla pro zápis příkazů Sémantická pravidla (sémantika jazyka) pravidla, která každému příkazu přiřadí přesný význam Všechny konstrukce
Tovek Tools. Tovek Tools jsou standardně dodávány ve dvou variantách: Tovek Tools Search Pack Tovek Tools Analyst Pack. Připojené informační zdroje
 jsou souborem klientských desktopových aplikací určených k indexování dat, vyhledávání informací, tvorbě různých typů analýz a vytváření přehledů a rešerší. Jsou vhodné pro práci s velkým objemem textových
jsou souborem klientských desktopových aplikací určených k indexování dat, vyhledávání informací, tvorbě různých typů analýz a vytváření přehledů a rešerší. Jsou vhodné pro práci s velkým objemem textových
Jak vypadá opravdová discovery služba
 Jak vypadá opravdová discovery služba K čemu Summon? Chybí jasné a přitažlivé místo pro vyhledávání Potíže s určením vhodných zdrojů Současné nástroje neodpovídají očekáváním uživatelů Nejlepší místo,
Jak vypadá opravdová discovery služba K čemu Summon? Chybí jasné a přitažlivé místo pro vyhledávání Potíže s určením vhodných zdrojů Současné nástroje neodpovídají očekáváním uživatelů Nejlepší místo,
Roční úvodní kurs českého jazyka pro nově příchozí žáky - cizince
 Roční úvodní kurs českého jazyka pro nově příchozí žáky - cizince Cíl kursu: 1/rychlé osvojení češtiny na komunikační úrovni - rozvoj slovní zásoby 2/ pochopení základních pravidel systému jazyka druhy
Roční úvodní kurs českého jazyka pro nově příchozí žáky - cizince Cíl kursu: 1/rychlé osvojení češtiny na komunikační úrovni - rozvoj slovní zásoby 2/ pochopení základních pravidel systému jazyka druhy
Relační DB struktury sloužící k optimalizaci dotazů - indexy, clustery, indexem organizované tabulky
 Otázka 20 A7B36DBS Zadání... 1 Slovníček pojmů... 1 Relační DB struktury sloužící k optimalizaci dotazů - indexy, clustery, indexem organizované tabulky... 1 Zadání Relační DB struktury sloužící k optimalizaci
Otázka 20 A7B36DBS Zadání... 1 Slovníček pojmů... 1 Relační DB struktury sloužící k optimalizaci dotazů - indexy, clustery, indexem organizované tabulky... 1 Zadání Relační DB struktury sloužící k optimalizaci
Přídavná jména Střední průmyslová škola a Obchodní akademie Uherský Brod Český jazyk a literatura
 Přídavná jména Název školy: Střední průmyslová škola a Obchodní akademie Uherský Brod Adresa: Nivnická 1781, 688 01 Uherský Brod Předmět: Český jazyk a literatura Vyučující: Balaštíková Andrea Přídavná
Přídavná jména Název školy: Střední průmyslová škola a Obchodní akademie Uherský Brod Adresa: Nivnická 1781, 688 01 Uherský Brod Předmět: Český jazyk a literatura Vyučující: Balaštíková Andrea Přídavná
ZŠ ÚnO, Bratří Čapků 1332
 TS Český jazyk 1 (Pravopis) Terasoft Vyjmenovaná slova doplňování i(í) nebo y(ý), chybné odpovědi jsou vypsány s uvedením správného pravopisu před vlastním testem je možné zvolit písmena, po kterých budou
TS Český jazyk 1 (Pravopis) Terasoft Vyjmenovaná slova doplňování i(í) nebo y(ý), chybné odpovědi jsou vypsány s uvedením správného pravopisu před vlastním testem je možné zvolit písmena, po kterých budou
Anglický jazyk. Anglický jazyk. žák: TÉMATA. Fonetika: abeceda, výslovnost odlišných hlásek, zvuková podoba slova a její zvláštnosti
 Prima jednoduše mluví o sobě Slovní zásoba: elementární slovní 1 B/ 26, 27, 29, 30 tvoří jednoduché otázky a aktivně je používá zásoba pro zvolené tematické okruhy odpovídá na jednoduché otázky obsahující
Prima jednoduše mluví o sobě Slovní zásoba: elementární slovní 1 B/ 26, 27, 29, 30 tvoří jednoduché otázky a aktivně je používá zásoba pro zvolené tematické okruhy odpovídá na jednoduché otázky obsahující
Pracovní skupina pro věcné zpracování
 Pracovní skupina pro věcné 13.12. 2011 Marie.Balikova@nkp.cz 1 Program 10:00-11:15 úvodní informace problematika věcného zpřístupnění úprava Konspektového schématu 11:15-12:00 přestávka 12:00-13:15 integrace
Pracovní skupina pro věcné 13.12. 2011 Marie.Balikova@nkp.cz 1 Program 10:00-11:15 úvodní informace problematika věcného zpřístupnění úprava Konspektového schématu 11:15-12:00 přestávka 12:00-13:15 integrace
Stonožka jak se z výsledků dozvědět co nejvíce
 Stonožka jak se z výsledků dozvědět co nejvíce Vytvoření Map učebního pokroku umožňuje vyhodnotit v testování Stonožka i dílčí oblasti učiva. Mapy učebního pokroku sledují individuální pokrok žáka a nabízejí
Stonožka jak se z výsledků dozvědět co nejvíce Vytvoření Map učebního pokroku umožňuje vyhodnotit v testování Stonožka i dílčí oblasti učiva. Mapy učebního pokroku sledují individuální pokrok žáka a nabízejí
JAK PRACOVAT S INFORMACEMI TAK, ABY ONY PRACOVALY PRO NÁS? Přednáška kurzu Informační a databázové systémy v rostlinolékařství
 JAK PRACOVAT S INFORMACEMI TAK, ABY ONY PRACOVALY PRO NÁS? Přednáška kurzu Informační a databázové systémy v rostlinolékařství Co jsme si slíbili Co je to databáze? Co je to rešerše? Jak správně zadat
JAK PRACOVAT S INFORMACEMI TAK, ABY ONY PRACOVALY PRO NÁS? Přednáška kurzu Informační a databázové systémy v rostlinolékařství Co jsme si slíbili Co je to databáze? Co je to rešerše? Jak správně zadat
Český jazyk a literatura
 Vyučovací předmět: Období ročník: Učební texty: Český jazyk a literatura 2. období 5. ročník Český jazyk pro 4. ročník I. část (Fortuna), Český jazyk pro 4. ročník II. část (Fortuna) Český jazyk pro 5.
Vyučovací předmět: Období ročník: Učební texty: Český jazyk a literatura 2. období 5. ročník Český jazyk pro 4. ročník I. část (Fortuna), Český jazyk pro 4. ročník II. část (Fortuna) Český jazyk pro 5.
Microsoft SharePoint Portal Server 2003. Zvýšená týmová produktivita a úspora času při správě dokumentů ve společnosti Makro Cash & Carry ČR
 Microsoft SharePoint Portal Server 2003 Zvýšená týmová produktivita a úspora času při správě dokumentů ve společnosti Makro Cash & Carry ČR Přehled Země: Česká republika Odvětví: Velkoobchod Profil zákazníka
Microsoft SharePoint Portal Server 2003 Zvýšená týmová produktivita a úspora času při správě dokumentů ve společnosti Makro Cash & Carry ČR Přehled Země: Česká republika Odvětví: Velkoobchod Profil zákazníka
Inovace CRM systémů využitím internetových zdrojů dat pro malé a střední podniky. Ing. Jan Ministr, Ph.D.
 Inovace CRM systémů využitím internetových zdrojů dat pro malé a střední podniky Ing. Jan Ministr, Ph.D. I. Úvod Agenda II. Customer Intelligence (CI),zpracování dat z Internetu III. Analýza obsahu IV.
Inovace CRM systémů využitím internetových zdrojů dat pro malé a střední podniky Ing. Jan Ministr, Ph.D. I. Úvod Agenda II. Customer Intelligence (CI),zpracování dat z Internetu III. Analýza obsahu IV.
INTLIB. Osnova. Projekt (TA02010182/Inteligentní knihovna) je řešen s finanční podporou TA ČR. ! Legislativní doména
 je řešen s finanční podporou TA ČR. ! Legislativní doména") INTLIB Projekt (TA02010182/Inteligentní knihovna) je řešen s finanční podporou TA ČR. Osnova! O projektu! Postupy prací podle oblastí! Legislativní doména " Judikatura " Účetní poddoména! Environmentální
INTLIB Projekt (TA02010182/Inteligentní knihovna) je řešen s finanční podporou TA ČR. Osnova! O projektu! Postupy prací podle oblastí! Legislativní doména " Judikatura " Účetní poddoména! Environmentální
E K O G Y M N Á Z I U M B R N O o.p.s. přidružená škola UNESCO
 Seznam výukových materiálů III/2 Inovace a zkvalitnění výuky prostřednictvím ICT Tematická oblast: Předmět: Vytvořil: Rozvoj řečových dovedností Ruský jazyk Helena Malášková 01 O spánku a váze - prezentace
Seznam výukových materiálů III/2 Inovace a zkvalitnění výuky prostřednictvím ICT Tematická oblast: Předmět: Vytvořil: Rozvoj řečových dovedností Ruský jazyk Helena Malášková 01 O spánku a váze - prezentace
Zpráva o zhotoveném plnění
 Zpráva o zhotoveném plnění Aplikace byla vytvořena v souladu se Smlouvou a na základě průběžných konzultací s pověřenými pracovníky referátu Manuscriptorium. Toto je zpráva o zhotoveném plnění. Autor:
Zpráva o zhotoveném plnění Aplikace byla vytvořena v souladu se Smlouvou a na základě průběžných konzultací s pověřenými pracovníky referátu Manuscriptorium. Toto je zpráva o zhotoveném plnění. Autor:
Vzdělávací oblast: Jazyk a jazyková komunikace Vzdělávací obor (předmět): Český jazyk: jazyková výchova - ročník: PRIMA
: Český jazyk: jazyková výchova - ročník: PRIMA") Vzdělávací oblast: Jazyk a jazyková komunikace Vzdělávací obor (předmět): Český jazyk: jazyková výchova - ročník: PRIMA Téma Učivo Výstupy Kódy Dle RVP Školní (ročníkové) PT KK Podstatná jména: - konkrétní
Vzdělávací oblast: Jazyk a jazyková komunikace Vzdělávací obor (předmět): Český jazyk: jazyková výchova - ročník: PRIMA Téma Učivo Výstupy Kódy Dle RVP Školní (ročníkové) PT KK Podstatná jména: - konkrétní
ČESKÝ JAZYK A LITERATURA 4.ROČNÍK
 VZDĚLÁVACÍ OBLAST: VZDĚLÁVACÍ OBOR: PŘEDMĚT: JAZYK A JAZYKOVÁ KOMUNIKACE ČESKÝ JAZYK A LITERATURA ČESKÝ JAZYK A LITERATURA 4.ROČNÍK Téma, učivo Rozvíjené kompetence, očekávané výstupy Mezipředmětové vztahy
VZDĚLÁVACÍ OBLAST: VZDĚLÁVACÍ OBOR: PŘEDMĚT: JAZYK A JAZYKOVÁ KOMUNIKACE ČESKÝ JAZYK A LITERATURA ČESKÝ JAZYK A LITERATURA 4.ROČNÍK Téma, učivo Rozvíjené kompetence, očekávané výstupy Mezipředmětové vztahy
Informační média a služby
 Informační média a služby Výuka informatiky má na Fakultě informatiky a statistiky VŠE v Praze dlouholetou tradici. Ke dvěma již zavedeným oborům ( Aplikovaná informatika a Multimédia v ekonomické praxi
Informační média a služby Výuka informatiky má na Fakultě informatiky a statistiky VŠE v Praze dlouholetou tradici. Ke dvěma již zavedeným oborům ( Aplikovaná informatika a Multimédia v ekonomické praxi
Olympiáda v českém jazyce 45. ročník, 2018/2019
 Národní institut pro další vzdělávání MŠMT Senovážné náměstí 25, 110 00 Praha 1 Olympiáda v českém jazyce 45. ročník, 2018/2019 Okresní kolo zadání I. kategorie přidělené soutěžní číslo body gramatika
Národní institut pro další vzdělávání MŠMT Senovážné náměstí 25, 110 00 Praha 1 Olympiáda v českém jazyce 45. ročník, 2018/2019 Okresní kolo zadání I. kategorie přidělené soutěžní číslo body gramatika
Vzdělávací obsah vyučovacího předmětu
 Vzdělávací obsah vyučovacího předmětu Český jazyk a literatura 5. ročník Zpracovala: Mgr. Helena Ryčlová Komunikační a slohová výchova čte s porozuměním přiměřeně náročné texty potichu i nahlas vymyslí
Vzdělávací obsah vyučovacího předmětu Český jazyk a literatura 5. ročník Zpracovala: Mgr. Helena Ryčlová Komunikační a slohová výchova čte s porozuměním přiměřeně náročné texty potichu i nahlas vymyslí
Dolování z textu. Martin Vítek
 Dolování z textu Martin Vítek Proč dolovat z textu Obrovské množství materiálu v nestrukturované textové podobě knihy časopisy vědeckéčlánky sborníky konferencí internetové diskuse Proč dolovat z textu
Dolování z textu Martin Vítek Proč dolovat z textu Obrovské množství materiálu v nestrukturované textové podobě knihy časopisy vědeckéčlánky sborníky konferencí internetové diskuse Proč dolovat z textu
III/2 - Inovace a zkvalitnění výuky prostřednictvím ICT. Žák se seznámí se základními pojmy morfologie tvarosloví, ohebnost, význam slov.
 Název školy: Číslo a název projektu: Číslo a název šablony klíčové aktivity: Označení materiálu: Typ materiálu: Předmět, ročník, obor: Číslo a název sady: Téma: Jméno a příjmení autora: STŘEDNÍ ODBORNÁ
Název školy: Číslo a název projektu: Číslo a název šablony klíčové aktivity: Označení materiálu: Typ materiálu: Předmět, ročník, obor: Číslo a název sady: Téma: Jméno a příjmení autora: STŘEDNÍ ODBORNÁ
Nápověda 360 Search. Co je 360 Search? Tipy pro vyhledávání
 1 z 5 Nápověda 360 Search Co je 360 Search? 360 Search je metavyhledávač, který slouží k paralelnímu prohledávání všech dostupných informačních zdrojů prostřednictvím jednotného rozhraní. Nástroj 360 Search
1 z 5 Nápověda 360 Search Co je 360 Search? 360 Search je metavyhledávač, který slouží k paralelnímu prohledávání všech dostupných informačních zdrojů prostřednictvím jednotného rozhraní. Nástroj 360 Search
1. KRITÉRIA HODNOCENÍ ZKOUŠEK A DÍLČÍCH ZKOUŠEK SPOLEČNÉ ČÁSTI MATURITNÍ ZKOUŠKY
 V Praze dne 11. března 2015 Č. j.: MSMT-6626/2015-1 SDĚLENÍ V souladu s 22, odst. 1 vyhlášky č. 177/2009 Sb., o bližších podmínkách ukončování vzdělávání ve středních školách maturitní zkouškou, ve znění
V Praze dne 11. března 2015 Č. j.: MSMT-6626/2015-1 SDĚLENÍ V souladu s 22, odst. 1 vyhlášky č. 177/2009 Sb., o bližších podmínkách ukončování vzdělávání ve středních školách maturitní zkouškou, ve znění
Webinář GEOBIBLINE. Mgr. Michaela Alijonov Hametová Knihovna geografie PřF UK
 Webinář GEOBIBLINE Mgr. Michaela Alijonov Hametová Knihovna geografie PřF UK 12. 8. 2015 Struktura webináře Co Vám může GEOBIBLINE nabídnout a pro jaké účely je skutečně vhodná. Vyhledávání v rámci GEOBIBLINE
Webinář GEOBIBLINE Mgr. Michaela Alijonov Hametová Knihovna geografie PřF UK 12. 8. 2015 Struktura webináře Co Vám může GEOBIBLINE nabídnout a pro jaké účely je skutečně vhodná. Vyhledávání v rámci GEOBIBLINE
WEBOVÉ KORPUSY ARANEA A VÍCEJAZYČNÉ KOLOKAČNÍ PROFILY
 WEBOVÉ KORPUSY ARANEA A VÍCEJAZYČNÉ KOLOKAČNÍ PROFILY Datum konání: 11. dubna 2014 Místo konání: Filozofická fakulta Masarykovy univerzity (učebna G13) Název přednášky: Přednášející: Webové korpusy Aranea
WEBOVÉ KORPUSY ARANEA A VÍCEJAZYČNÉ KOLOKAČNÍ PROFILY Datum konání: 11. dubna 2014 Místo konání: Filozofická fakulta Masarykovy univerzity (učebna G13) Název přednášky: Přednášející: Webové korpusy Aranea
Vzdělávací obor Německý jazyk
 7. ročník Hlavní okruhy Očekávané výstupy dle RVP ZV Metody práce (praktická cvičeni) obor navázání na již zvládnuté 1. POSLECH S Kompetence komunikativní Témata: POROZUMĚNÍM Žák rozumí jednoduchým otázkám
7. ročník Hlavní okruhy Očekávané výstupy dle RVP ZV Metody práce (praktická cvičeni) obor navázání na již zvládnuté 1. POSLECH S Kompetence komunikativní Témata: POROZUMĚNÍM Žák rozumí jednoduchým otázkám
Autor: JUDr. Lukáš Bohuslav Redakce: JUDr. Petr Flášar
 Autor: JUDr. Lukáš Bohuslav Redakce: JUDr. Petr Flášar Cíl přednášky Ukázat základní parametry práce s jednotlivými právními informačními systémy (základ pro pozdější oddělenou práci s PIS) Získávání informací
Autor: JUDr. Lukáš Bohuslav Redakce: JUDr. Petr Flášar Cíl přednášky Ukázat základní parametry práce s jednotlivými právními informačními systémy (základ pro pozdější oddělenou práci s PIS) Získávání informací
Základní informace o modulu
 12 12.1 Výuka modulu Vyučující Jméno Telefon E-mail VEDOUCÍ MODULU Doc. Ing. Jiří Rybička, Dr. 545 13 22 23 rybicka@mendelu.cz Cíl výuky v modulu Získání základního přehledu o principech funkce a možnostech
12 12.1 Výuka modulu Vyučující Jméno Telefon E-mail VEDOUCÍ MODULU Doc. Ing. Jiří Rybička, Dr. 545 13 22 23 rybicka@mendelu.cz Cíl výuky v modulu Získání základního přehledu o principech funkce a možnostech
České internetové medicínské zdroje v Národní lékařské knihovně
 České internetové medicínské zdroje v Národní lékařské knihovně Kateřina Štěchovská Národní lékařská knihovna, Praha stechovs@nlk.cz INFORUM 2005: 11. konference o profesionálních informačních zdrojích
České internetové medicínské zdroje v Národní lékařské knihovně Kateřina Štěchovská Národní lékařská knihovna, Praha stechovs@nlk.cz INFORUM 2005: 11. konference o profesionálních informačních zdrojích
MODUL BIBLIOGRAFIE ASPI, a. s. 2006
 MODUL BIBLIOGRAFIE ASPI, a. s. 2006 OBSAH OBSAH 1. ÚVOD............................................................... 4 2. ZADÁNÍ DOTAZU...................................................... 6 Pole Forma
MODUL BIBLIOGRAFIE ASPI, a. s. 2006 OBSAH OBSAH 1. ÚVOD............................................................... 4 2. ZADÁNÍ DOTAZU...................................................... 6 Pole Forma
Příklad rozpracování minimální doporučené úrovně pro úpravu. očekávaných výstupů v rámci podpůrných opatření. do učebních osnov vyučovacího předmětu
 Příklad rozpracování minimální doporučené úrovně pro úpravu očekávaných výstupů v rámci podpůrných opatření do učebních osnov vyučovacího předmětu ČESKÝ JAZYK A LITERATURA Ukázka byla zpracována s využitím
Příklad rozpracování minimální doporučené úrovně pro úpravu očekávaných výstupů v rámci podpůrných opatření do učebních osnov vyučovacího předmětu ČESKÝ JAZYK A LITERATURA Ukázka byla zpracována s využitím
Tematický plán pro školní rok 2015/2016 Předmět: Český jazyk Vyučující: Mgr. Jitka Vlčková Týdenní dotace hodin: 8 hodin Ročník: čtvrtý
 ČASOVÉ OBDOBÍ Září KONKRÉTNÍ VÝSTUPY KONKRÉTNÍ UČIVO PRŮŘEZOVÁ TÉMATA rozliší větu jednoduchou a souvětí ví, co znamená věta, slovo rozlišuje slova nespisovná a nahradí je spisovnými zná pravidla pro psaní
ČASOVÉ OBDOBÍ Září KONKRÉTNÍ VÝSTUPY KONKRÉTNÍ UČIVO PRŮŘEZOVÁ TÉMATA rozliší větu jednoduchou a souvětí ví, co znamená věta, slovo rozlišuje slova nespisovná a nahradí je spisovnými zná pravidla pro psaní
Inovace výuky prostřednictvím ICT v SPŠ Zlín, CZ.1.07/1.5.00/34.0333 Vzdělávání v informačních a komunikačních technologií
 VY_32_INOVACE_33_05 Škola Střední průmyslová škola Zlín Název projektu, reg. č. Inovace výuky prostřednictvím ICT v SPŠ Zlín, CZ.1.07/1.5.00/34.0333 Vzdělávací oblast Vzdělávání v informačních a komunikačních
VY_32_INOVACE_33_05 Škola Střední průmyslová škola Zlín Název projektu, reg. č. Inovace výuky prostřednictvím ICT v SPŠ Zlín, CZ.1.07/1.5.00/34.0333 Vzdělávací oblast Vzdělávání v informačních a komunikačních
Olympiáda v českém jazyce 44. ročník, 2017/2018
 Národní institut pro další vzdělávání MŠMT Senovážné náměstí 25, 110 00 Praha 1 Olympiáda v českém jazyce 44. ročník, 2017/2018 Okresní kolo řešení I. kategorie 1. a) Kdo jinému jámu kopá, sám do ní padá.
Národní institut pro další vzdělávání MŠMT Senovážné náměstí 25, 110 00 Praha 1 Olympiáda v českém jazyce 44. ročník, 2017/2018 Okresní kolo řešení I. kategorie 1. a) Kdo jinému jámu kopá, sám do ní padá.
KOMUNIKAČNÍ A SLOHOVÁ VÝCHOVA - čtení - praktické plynulé čtení. - naslouchání praktické naslouchání; věcné a pozorné naslouchání.
 - plynule čte v porozuměním text přiměřeného rozsahu a náročnosti KOMUNIKAČNÍ A SLOHOVÁ VÝCHOVA - čtení - praktické plynulé čtení. - porozumí písemným nebo mluveným pokynům přiměřené složitosti - respektuje
- plynule čte v porozuměním text přiměřeného rozsahu a náročnosti KOMUNIKAČNÍ A SLOHOVÁ VÝCHOVA - čtení - praktické plynulé čtení. - porozumí písemným nebo mluveným pokynům přiměřené složitosti - respektuje
E K O G Y M N Á Z I U M B R N O o.p.s. přidružená škola UNESCO
 Seznam výukových materiálů III/2 Inovace a zkvalitnění výuky prostřednictvím ICT Tematická oblast: Předmět: Vytvořil: Uplatnění jazyka v jednotlivých funkčních stylech Český jazyk a literatura Pavla Jamborová
Seznam výukových materiálů III/2 Inovace a zkvalitnění výuky prostřednictvím ICT Tematická oblast: Předmět: Vytvořil: Uplatnění jazyka v jednotlivých funkčních stylech Český jazyk a literatura Pavla Jamborová
Předmět - Český jazyk a literatura Ročník: 5. RVP - ZV Výstup Učivo Průřezová témata
 Předmět - Český jazyk a literatura Ročník: 5. čte s porozuměním přiměřeně náročné texty potichu i nahlas rozlišuje podstatné a okrajové informace v textu vhodném pro daný věk, podstatné informace zaznamenává
Předmět - Český jazyk a literatura Ročník: 5. čte s porozuměním přiměřeně náročné texty potichu i nahlas rozlišuje podstatné a okrajové informace v textu vhodném pro daný věk, podstatné informace zaznamenává
Pracovní skupina pro věcné zpracování
 Pracovní skupina pro věcné zpracování Prosinec 2014 Marie.Balikova@nkp.cz Program Věcné údaje v bibliografickém záznamu Požadavky uživatelů Význam Kvalita Schválení Doporučeného záznamu rozšířeného minimálně
Pracovní skupina pro věcné zpracování Prosinec 2014 Marie.Balikova@nkp.cz Program Věcné údaje v bibliografickém záznamu Požadavky uživatelů Význam Kvalita Schválení Doporučeného záznamu rozšířeného minimálně
- naslouchání praktické naslouchání; věcné a pozorné naslouchání. - respektování základních forem společenského styku.
 - plynule čte s porozuměním text přiměřeného rozsahu a náročnosti KOMUNIKAČNÍ A SLOHOVÁ VÝCHOVA - čtení - praktické plynulé čtení. OSV (komunikace)- specifické komunikační dovednosti - porozumí písemným
- plynule čte s porozuměním text přiměřeného rozsahu a náročnosti KOMUNIKAČNÍ A SLOHOVÁ VÝCHOVA - čtení - praktické plynulé čtení. OSV (komunikace)- specifické komunikační dovednosti - porozumí písemným
Příručka pro vyhledávání v digitálním archivu Aip Safe III
 Příručka pro vyhledávání v digitálním archivu Aip Safe III OBSAH PŘÍRUČKA PRO VYHLEDÁVÁNÍ V DIGITÁLNÍM ARCHIVU AIP SAFE III OBSAH 1. UŽIVATELSKÉ ROZHRANÍ 1.1. HLAVNÍ STRÁNKA 1.2. HORIZONTÁLNÍ MENU 1.3.
Příručka pro vyhledávání v digitálním archivu Aip Safe III OBSAH PŘÍRUČKA PRO VYHLEDÁVÁNÍ V DIGITÁLNÍM ARCHIVU AIP SAFE III OBSAH 1. UŽIVATELSKÉ ROZHRANÍ 1.1. HLAVNÍ STRÁNKA 1.2. HORIZONTÁLNÍ MENU 1.3.
Vzdělávací oblast: JAZYK A JAZYKOVÁ KOMUNIKACE Vyučovací předmět: Český jazyk a literatura Ročník: 6.
 Vzdělávací oblast: JAZYK A JAZYKOVÁ KOMUNIKACE Vyučovací předmět: Český jazyk a literatura Ročník: 6. Jazyková výchova - zná pojem mateřský jazyk 1. Čeština jako mateřský jazyk MKV 4.4 - zná základní složky
Vzdělávací oblast: JAZYK A JAZYKOVÁ KOMUNIKACE Vyučovací předmět: Český jazyk a literatura Ročník: 6. Jazyková výchova - zná pojem mateřský jazyk 1. Čeština jako mateřský jazyk MKV 4.4 - zná základní složky
PŘÍLOHA C Požadavky na Dokumentaci
 PŘÍLOHA C Požadavky na Dokumentaci Příloha C Požadavky na Dokumentaci Stránka 1 z 5 1. Obecné požadavky Dodavatel dokumentaci zpracuje a bude dokumentaci v celém rozsahu průběžně aktualizovat při každé
PŘÍLOHA C Požadavky na Dokumentaci Příloha C Požadavky na Dokumentaci Stránka 1 z 5 1. Obecné požadavky Dodavatel dokumentaci zpracuje a bude dokumentaci v celém rozsahu průběžně aktualizovat při každé
Sémantický web a extrakce
 Sémantický web a extrakce informací Martin Kavalec kavalec@vse.cz Katedra informačního a znalostního inženýrství FIS VŠE Seminář KEG, 11. 11. 2004 p.1 Přehled témat Vize sémantického webu Extrakce informací
Sémantický web a extrakce informací Martin Kavalec kavalec@vse.cz Katedra informačního a znalostního inženýrství FIS VŠE Seminář KEG, 11. 11. 2004 p.1 Přehled témat Vize sémantického webu Extrakce informací
Vyučovací předmět Ruský jazyk druhý cizí jazyk je součástí vzdělávací oblasti Jazyk a jazyková komunikace, vzdělávací obor Další cizí jazyk dle RVP.
 DALŠÍ CIZÍ JAZYK - RUSKÝ JAZYK Charakteristika vyučovacího předmětu Vyučovací předmět Ruský jazyk druhý cizí jazyk je součástí vzdělávací oblasti Jazyk a jazyková komunikace, vzdělávací obor Další cizí
DALŠÍ CIZÍ JAZYK - RUSKÝ JAZYK Charakteristika vyučovacího předmětu Vyučovací předmět Ruský jazyk druhý cizí jazyk je součástí vzdělávací oblasti Jazyk a jazyková komunikace, vzdělávací obor Další cizí
Počítač, dataprojektor, interaktivní tabule, smartphone, plány měst, mapy, slovníky
 Předmět: Náplň: Třída: Počet hodin: Pomůcky: Německý jazyk Výstupy odpovídající úrovni A2 podle SERR 2. ročník 4 hodiny týdně Počítač, dataprojektor, interaktivní tabule, smartphone, plány měst, mapy,
Předmět: Náplň: Třída: Počet hodin: Pomůcky: Německý jazyk Výstupy odpovídající úrovni A2 podle SERR 2. ročník 4 hodiny týdně Počítač, dataprojektor, interaktivní tabule, smartphone, plány měst, mapy,
5. Abstraktní podstatná jména se často tvoří odvozováním od přídavných jmen různými příponami. Utvořte:
 Vzorové zadání 1. Užijte předložkové spojení bez peněz ve čtyřech větách nebo slovních spojeních tak, aby pokaždé mělo funkci jiného větného členu (napište kterého). (Příslovečná určení různého druhu započítávejte
Vzorové zadání 1. Užijte předložkové spojení bez peněz ve čtyřech větách nebo slovních spojeních tak, aby pokaždé mělo funkci jiného větného členu (napište kterého). (Příslovečná určení různého druhu započítávejte
S D Ě L E N Í 1. KRITÉRIA HODNOCENÍ ZKOUŠEK A DÍLČÍCH ZKOUŠEK SPOLEČNÉ ČÁSTI MATURITNÍ ZKOUŠKY
 V Praze dne 19. března 2013 Č. j.: MSMT-10139/2013-211 S D Ě L E N Í V souladu s 22, odst. 1 vyhlášky č. 177/2009 Sb., o bližších podmínkách ukončování vzdělávání ve středních školách maturitní zkouškou,
V Praze dne 19. března 2013 Č. j.: MSMT-10139/2013-211 S D Ě L E N Í V souladu s 22, odst. 1 vyhlášky č. 177/2009 Sb., o bližších podmínkách ukončování vzdělávání ve středních školách maturitní zkouškou,
učivo, téma očekávané výstupy klíčové kompetence, mezipředmětové vazby Umí komunikovat se spolužáky a s dospělými.
 Ročník: 3. Časová dotace: 8 hodin týdně Komunikační a slohová Čtení praktické čtení pozorné, plynulé čtení vět a souvětí přednes básní vypravování dramatizace četba uměleckých a naučných textů Žák získává
Ročník: 3. Časová dotace: 8 hodin týdně Komunikační a slohová Čtení praktické čtení pozorné, plynulé čtení vět a souvětí přednes básní vypravování dramatizace četba uměleckých a naučných textů Žák získává
7. ročník. Český jazyk a literatura. Komunikační a slohová výchova. Vypravování uspořádání dějových prvků
 list 1 / 8 Čj časová dotace: 4 hod / týden Český jazyk a literatura 7. ročník (ČJL 9 1 09) sestaví vypravování v časové posloupnosti s využitím názorných jazykových prostředků sestaví vypravování s využitím
list 1 / 8 Čj časová dotace: 4 hod / týden Český jazyk a literatura 7. ročník (ČJL 9 1 09) sestaví vypravování v časové posloupnosti s využitím názorných jazykových prostředků sestaví vypravování s využitím
1. KRITÉRIA HODNOCENÍ ZKOUŠEK A DÍLČÍCH ZKOUŠEK SPOLEČNÉ ČÁSTI 1.1 ZPŮSOB VÝPOČTU A VYJÁDŘENÍ VÝSLEDKU HODNOCENÍ ZKOUŠEK SPOLEČNÉ ČÁSTI
 Praha dne 28. března 2017 Č. j.: MSMT-7337/2017-1 SDĚLENÍ V souladu s 22 odst. 1 vyhlášky č. 177/2009 Sb., o bližších podmínkách ukončování vzdělávání ve středních školách maturitní zkouškou, ve znění
Praha dne 28. března 2017 Č. j.: MSMT-7337/2017-1 SDĚLENÍ V souladu s 22 odst. 1 vyhlášky č. 177/2009 Sb., o bližších podmínkách ukončování vzdělávání ve středních školách maturitní zkouškou, ve znění
VY_32_INOVACE_ / IQ cesta
 1/6 3.2.07.08 Pravidla hry: 1. Hra je určena minimálně pro 2 hráče. 2. Jeden hráč (může se účastnit i hry) bude kontrolovat správnost odpovědí na Listině odpovědí. 3. Každý si vybere figurku jiné barvy
1/6 3.2.07.08 Pravidla hry: 1. Hra je určena minimálně pro 2 hráče. 2. Jeden hráč (může se účastnit i hry) bude kontrolovat správnost odpovědí na Listině odpovědí. 3. Každý si vybere figurku jiné barvy
ZEMĚMĚŘICKÝ ÚŘAD. Výzkum a vývoj programového aparátu pro generalizaci státního mapového díla. Ing. Přemysl JINDRÁK
 ZEMĚMĚŘICKÝ ÚŘAD Výzkum a vývoj programového aparátu pro generalizaci státního mapového díla Představení projektu Technologická Agentura ČR Praha, 31. 7. 2018 Ing. Přemysl JINDRÁK Základní vymezení Projekt
ZEMĚMĚŘICKÝ ÚŘAD Výzkum a vývoj programového aparátu pro generalizaci státního mapového díla Představení projektu Technologická Agentura ČR Praha, 31. 7. 2018 Ing. Přemysl JINDRÁK Základní vymezení Projekt
The bridge to knowledge 28/05/09
 The bridge to knowledge DigiTool umožňuje knihovnám vytvářet, administrovat, dlouhodobě uchovávat a sdílet digitální sbírky. DigiTool je možno využít pro institucionální repozitáře, sbírky výukových materiálu
The bridge to knowledge DigiTool umožňuje knihovnám vytvářet, administrovat, dlouhodobě uchovávat a sdílet digitální sbírky. DigiTool je možno využít pro institucionální repozitáře, sbírky výukových materiálu
Microsoft Office. Excel vyhledávací funkce
 Microsoft Office Excel vyhledávací funkce Karel Dvořák 2011 Vyhledávání v tabulkách Vzhledem ke skutečnosti, že Excel je na mnoha pracovištích používán i jako nástroj pro správu jednoduchých databází,
Microsoft Office Excel vyhledávací funkce Karel Dvořák 2011 Vyhledávání v tabulkách Vzhledem ke skutečnosti, že Excel je na mnoha pracovištích používán i jako nástroj pro správu jednoduchých databází,
III/2 - Inovace a zkvalitnění výuky prostřednictvím ICT
 Název školy: Číslo a název projektu: STŘEDNÍ ODBORNÁ ŠKOLA a STŘEDNÍ ODBORNÉ UČILIŠTĚ, Česká Lípa, 28. října 2707, příspěvková organizace CZ.1.07/1.5.00/34.0880 Digitální učební materiály www.skolalipa.cz
Název školy: Číslo a název projektu: STŘEDNÍ ODBORNÁ ŠKOLA a STŘEDNÍ ODBORNÉ UČILIŠTĚ, Česká Lípa, 28. října 2707, příspěvková organizace CZ.1.07/1.5.00/34.0880 Digitální učební materiály www.skolalipa.cz
Znalostní systém nad ontologií ve formátu Topic Maps
 Znalostní systém nad ontologií ve formátu Topic Maps Ladislav Buřita, Petr Do ladislav.burita@unob.cz; petr.do@unob.cz Univerzita obrany, Fakulta vojenských technologií Kounicova 65, 662 10 Brno Abstrakt:
Znalostní systém nad ontologií ve formátu Topic Maps Ladislav Buřita, Petr Do ladislav.burita@unob.cz; petr.do@unob.cz Univerzita obrany, Fakulta vojenských technologií Kounicova 65, 662 10 Brno Abstrakt:
Informační technologie
 1 Počet vyučovacích hodin za týden Celkem 1. ročník 2. ročník 3. ročník 4. ročník 5. ročník 6. ročník 7. ročník 8. ročník 9. ročník 0 0 0 1 1 1 0 0 0 3 Povinný Povinný Povinný Název předmětu Oblast Charakteristika
1 Počet vyučovacích hodin za týden Celkem 1. ročník 2. ročník 3. ročník 4. ročník 5. ročník 6. ročník 7. ročník 8. ročník 9. ročník 0 0 0 1 1 1 0 0 0 3 Povinný Povinný Povinný Název předmětu Oblast Charakteristika