Pokročilé architektury počítačů
|
|
|
- Jaroslava Urbanová
- před 6 lety
- Počet zobrazení:
Transkript
1 Pokročilé architektury počítačů Tutoriál 4 Superpočítače a paralelní počítání Martin Milata
2
3 Dvě třídy MIMD multiprocesorů Třídy se odvíjí od počtu procesorů, který v důsledku definuje organizaci paměti a propojovací strategii Architektura s centralizovanou sdílenou pamětí Menší počet procesorů (méně než 100) umožňuje sdílení jedné centralizované paměti Použití cache pamětí per procesor Sdílená paměť dělená do banků (větší propustnost) Pro všechny procesory zůstává zachována stejná (uniformní) přístupová doba Uniform Memory Access (UMA) se Symmetric (shared-memory) Multiprocessors (SMPs)
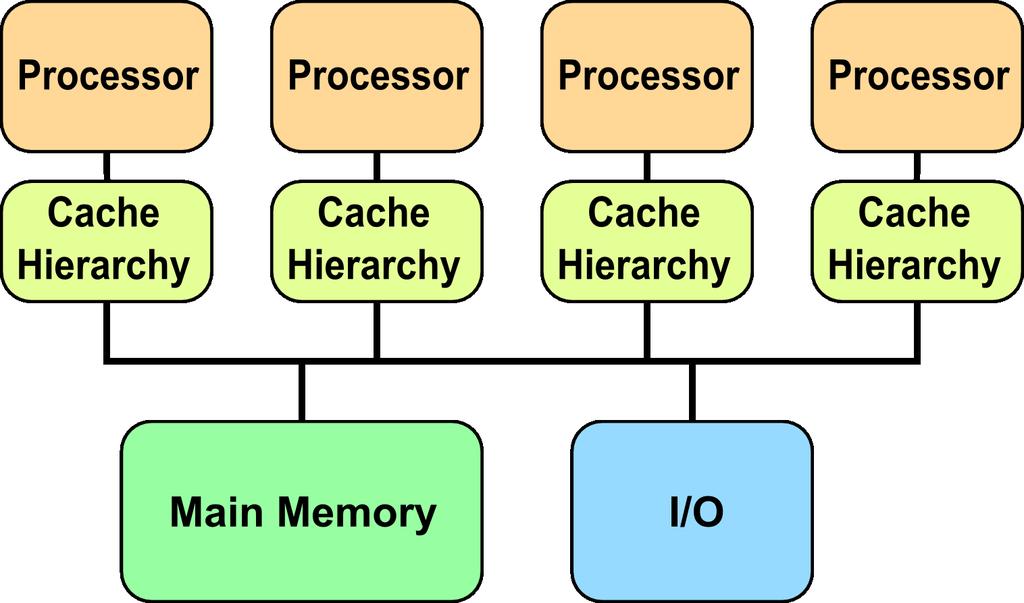

4 MIMD s centralizovanou sdílenou pamětí
5 Dvě třídy MIMD multiprocesorů Architektura multiprocesorů s fyzicky distribuovanou pamětí Umožňuje použití většího počtu procesoru v klasteru v porovnání s architekturou se sdílenou pamětí Lepší škálovatelnost - cenově dostupnější řešení složené z většího počtu levnějších pamětí Větší šířka pásma každý uzel přispívá šířkou lokální směrnice k její celkové velikosti Redukce latence přístupu do paměti - většina přístupu řešena lokálně v rámci jednoho uzlu Komplikovaný a pomalý přístup do pamětí jiných uzlů (vzdálený přístup) Jednotlivé uzly musejí být propojeny vhodnou propojovací sítí (obousměrná přepínaná síť, vedlejší multidimenzionální síť)


6 MIMD s fyzicky distribuovanou pamětí
7 Modely přístupu k paměti Na základě modelu adresního prostoru sdílené paměti rozlišujeme dva přístupy Sdílený adresní prostor Adresní prostor je rozprostřen přes všechny uzly resp. části distribuované paměti Vytváří tím jeden logický sdílený adresní prostor Pomocí něj může být adresována libovolná paměťová buňka kdekoliv v distribuované soustavě Model se nazývá Distributed shared-memory (DSM) Přístupová doba v rámci celého prostoru není jednotná Přístup k lokální částí distribuované paměti je výrazně kratší ve srovnání s latencí vzdáleného přístupu Nonuniform memory access (NUMAs) Stejná fyzická adresa vždy ukazuje na stejnou paměťovou buňku
8 Modely přístupu k paměti Per uzel privátní adresní prostor Každý uzel disponuje vlastním adresním prostorem Uzel lze chápat jako samostatný počítač (Obvykle je samostatným počítačem). Procesor nemá přímou možnost adresovat paměť jiného uzlu Stejná fyzická adresa na různých uzlech reprezentuje různé paměťové buňky Preferovaný paměťový model pro dnešní klasterová řešení Přístup k paměti cizích uzlů Sdílený adresní prostor Load a Store instrukce, jejichž implementace počítá s možným přístupem mimo lokální paměť Privátní adresní prostory Metoda explicitního zasílání zpráv mezi procesory

 tak sdílená data (sdílí se mezi")
9 Symetrická sdílená paměť Přístup do fyzické paměti realizován pomocí procesory společně sdílené sběrnice Použití cache pamětí pro redukci průměrné latence a potřebné šířky pásma do fyzické paměti Více úrovňová cache paměť s různým stupněm sdílení mezi procesory Cache ukládá jak privátní data (používaná pouze jedním procesorem) tak sdílená data (sdílí se mezi procesory)
10 Cache paměť a multi-procesory Uložení sdílených dat v cache paměti Redukuje přístupovou latenci a potřebnou šířku pásma pro přístup do fyzické paměti Způsobuje replikaci a dočasné uložení informace na více místech a to i v rámci stejného stupně cache hierarchie Cache přiřazená každému procesoru může obsahovat vlastní kopii dat Tím umožňuje paralelní přístup k datům bez vyvolání konfliktu na společné sběrnici Přináší problém cache koherence Potřeba zajistit, aby každé čtení datové položky obsažené v cache pamětích vrátilo pro něj aktuální zapsanou hodnotu Přináší problém konzistence Definice pořadí read a write požadavků na sdílenou datovou položku
11 Schémata zajištění koherence Pro multiprocesorové systémy s menším počtem procesorů je obvykle protokol zajištění cache koherence implementován v HW Jeho realizace je založena na sledování datových bloků na sdílené sběrnici mezi procesory a fyzickou pamětí Dvě základní třídy protokolu pro zajištění cache koherence Directory based - Stav sdílení bloku fyzické paměti je udržován na jednom místě (directory). Přináší vyšší implementační režii než sooping. Výhodou je možnost použití s větším počtem procesorů Snooping Stav bloků neuchovává centralizovaně. Podmínkou nasazení je možnost zaslání broadcast zprávy, kterou zaregistrují všechny cache kontroléry. Změny aktualizace obsahu bloků v cache se provádí na základně odposlouchávání komunikace jiných procesorů

12 MSI transakční diagram Popis událostí Obsluhovaná událost / Důsledek zasílán na sběrnici Události způsobené procesorem PrWr zápis hodnoty PrRd čtení hodnoty Transakce na sběrnici BusRd čtení hodnoty bez následné modifikace BusRdX čtení hodnoty s následnou modifikací (zpráva pro invalidaci ostatní cache)
13 Propojovací sítě paralelního počítače taxonomie Komponenty propojovací sítě Linka (drát, optika) Přepínač význam závislý na použité technologii Výpočetní uzel Topologie Statická síť spojení realizováno p2p pevnými linkami (přímé propojení) Dynamická síť propoj tvořen přepínanou sítí (nepřímé propojení přepínačem zprostředkované) Povaha sítě Blokující existují takové cesty mezi různými uzly p, q a r, s pro něž platí, že komunikace nemůže probíhat současně (konfliktní cesty) Neblokující plně nezávislé cesty mezi všemi propojenými uzly

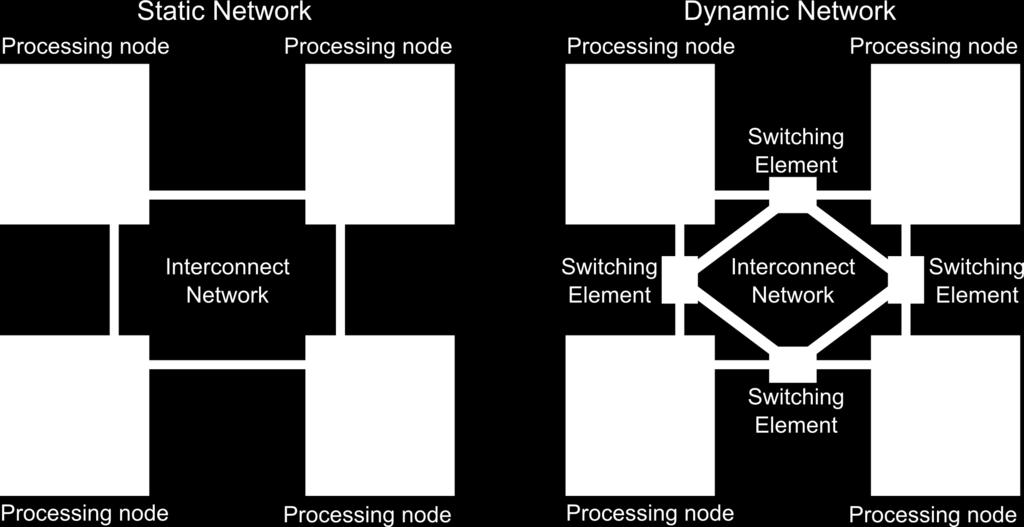
14 Statické a dynamické propojovací sítě
15 Vlastností propojovací sítě Síťové rozhraní Zodpovídá za přípravu paketů, výpočet směrovací informace (obvykle se nepohybujeme v prostředí IP sítí) a dočasné ukládání odesílaných resp. přijímaných dat (I/O buffering) Můžeme rozlišit na I/O Bus (karty různých technologií nepříklad pro PCI, PCI Expres sloty) Memory Bus (Intel QuickPath Interconnect, AMD HyperTransport) Síťová topologie Stupeň (uzlu) počet linek na uzel Diametr (sítě) nejkratší cesta mezi nejvzdálenějšími uzly sítě Bisekční šířka (Bisection Width) minimální počat hran dělící síť na dvě části Cena počet linek nebo přepínačů



16 Náhrada sběrnicové topologie v dnešních procesorech Intel QuickPath Interconnect Obrázky převzaty z:
17 Topologie propojovacích sítí paralelních počítačů Nepřímé propojovací sítě Sběrnice (Bus-Based Networks) Plně přepínaná síť (Crossbar Networks) Víceúrovňové sítě (Multistage Networks) Přímé propojovací sítě (modely) Plně propojená síť (Full Mesh Networks) Síť s hvězdicovou topologií (Star-Connected Networks) k-dimenzionální mesh sítě (k-dim mesh Networks) Sítě se stromovou strukturou

 3D torus je často používaná")
18 Model topologie propojovací sítě Statické toroidní sítě Statické topologie s toroidním uspořádáním n rozměrný torus (1 rozměrný torus resp. kruh, 2,3 rozměrný torus) 3D torus je často používaná topologie pro mnoha uzlové systémy
19 Fyzická versus logická topologie Fyzická organizace uzlů často nevyhovuje požadavkům na propojení prováděného výpočtu Nad fyzickou topologií se buduje logická s pomocí mapování výpočetních uzlů (vrcholů) logického uspořádání na fyzické Pomocí logického přemapování topologie je možné realizovat výpočet na superpočítačích s rozdílným fyzickým uspořádáním Metriky pro mapování mezi topologiemi G(V, E) na G'(V', E') Congestion (Zahlcení) Dilation (Roztažení) maximální počet hran z E mapovaný na hranu z E' maximální počet hran z E' mapovaný na jednu hranu z E Expansion (Rozšíření) Četnost množiny V / četnost množiny V'

20 Příklad mapování mřížky na hyperkrychli Požadovaná topologie Mřížka 2r x 2s Fyzická organizace 2r+s-dimensionalni hyperkrychle Congestion = Dilation = Expansion = 1

21 Typy propojení superpočítačů
22 Klastr Sestava vzájemně propojených počítačů (výpočetních uzlů) Většinou homogenní (uzly stejné HW konfigurace) Uzly dokáží efektivně řešit paralelní algoritmy s pomocí vzájemné spolupráce (nestačí počítače propojit, musejí být schopny na úloze spolupracovat) Spolupráce uzlů a tím i paralelizace založena na zasílání zpráv (message-passing MPI) Obtížnější paralelizace ve srovnání s MPP Potřeba propojů mezi uzly s nízkou latencí a vysokou propustností InfiniBand, kombinovaná a proprietární řešení Obtížnější správa Jedná se o samostatné počítače s více či méně nezávislými OS Distribuované souborové systémy,...




23 Klastr IBM Roadrunner Výpočetní uzel 4x PowerXCell 2x Opteron Interconnect InfiniBand 4x DDR Dvě úrovně InfiniBand přepínačů
24 Literatura John L. Hennessy, David A. Patterson, Computer Architecture: A Quantitative Approach (4th Edition) Ananth Grama, Anshul Gupta, George Karypis, Vipin Kumar: Introduction to Parallel Computing, 2003 Filip Staněk: Superpočítače dnes a zítra (aneb krátký náhled na SC) D. Goldenberg: InfiniBand Technology Overview J. M. Crummey: Parallel Computing Platforms (Routing, Network Embedding) T. Shanley, J. Winkles: InfiniBand network architecture Internetové zdroje
25 Superpočítání a plánovač Torque Skript pro stažení a automatický import hlavního a výpočetních uzlů clustery wget -O /tmp/cluster.sh Importují se dva virtuální počítače HeadNode řídící uzel klastru CN1 výpočetní uzel klastru Druhý výpočetní uzel lze importovat stažením souborů a jejich následným importem do VirtualBoxu wget -O /tmp/cn2.vmdk wget -O /tmp/cn2.ovf
26 Přístup k výpočetním uzlům Pro všechny uzly jsou platné dva přístupové účty root / pap pap / pap Práce s Torque Výpis stavu konfigurovaných uzlů pbsnodes -a Výpis konfigurace Torque na HeadNode cat /var/spool/torque/server_priv/nodes Výpis fronty úloh qstat Zařazení interaktivní úlohy (nelze jako root su pap) qsub -I
Pokročilé architektury počítačů
 Pokročilé architektury počítačů Přednáška 8 Multiprocesory vláknový paralelismus Martin Milata Obsah Paralelní architektury MIMD model Multi-jádrové a multi-vláknové procesory Klasterové řešení Sdílení
Pokročilé architektury počítačů Přednáška 8 Multiprocesory vláknový paralelismus Martin Milata Obsah Paralelní architektury MIMD model Multi-jádrové a multi-vláknové procesory Klasterové řešení Sdílení
Architektury paralelních počítačů I.
 Architektury paralelních počítačů I. Úvod, Koherence a konzistence u SMP Ing. Miloš Bečvář s použitím slajdů Prof. Ing. Pavla Tvrdíka, CSc. Osnova přednášky Typy paralelismu a jejich využití v arch. poč.
Architektury paralelních počítačů I. Úvod, Koherence a konzistence u SMP Ing. Miloš Bečvář s použitím slajdů Prof. Ing. Pavla Tvrdíka, CSc. Osnova přednášky Typy paralelismu a jejich využití v arch. poč.
IB109 Návrh a implementace paralelních systémů. Organizace kurzu a úvod. RNDr. Jiří Barnat, Ph.D.
 IB109 Návrh a implementace paralelních systémů Organizace kurzu a úvod RNDr. Jiří Barnat, Ph.D. Sekce B109 Návrh a implementace paralelních systémů: Organizace kurzu a úvod str. 2/25 Organizace kurzu Organizace
IB109 Návrh a implementace paralelních systémů Organizace kurzu a úvod RNDr. Jiří Barnat, Ph.D. Sekce B109 Návrh a implementace paralelních systémů: Organizace kurzu a úvod str. 2/25 Organizace kurzu Organizace
Povídání na téma. SUPERPOČÍTAČE DNES A ZÍTRA (aneb krátký náhled na SC) 3. 12. 2009 Filip Staněk
 3. 12. 2009 Filip Staněk") Povídání na téma SUPERPOČÍTAČE DNES A ZÍTRA (aneb krátký náhled na SC) 3. 12. 2009 Filip Staněk Co je to vlastně SC? Výpočetní systém, který určuje hranici maximálního možného výpočetního výkonu......v
Povídání na téma SUPERPOČÍTAČE DNES A ZÍTRA (aneb krátký náhled na SC) 3. 12. 2009 Filip Staněk Co je to vlastně SC? Výpočetní systém, který určuje hranici maximálního možného výpočetního výkonu......v
Přednáška 1. Katedra počítačových systémů FIT, České vysoké učení technické v Praze Jan Trdlička, 2012
 Přednáška 1 Úvod do HW a OS. Katedra počítačových systémů FIT, České vysoké učení technické v Praze Jan Trdlička, 2012 Příprava studijního programu Informatika je podporována projektem financovaným z Evropského
Přednáška 1 Úvod do HW a OS. Katedra počítačových systémů FIT, České vysoké učení technické v Praze Jan Trdlička, 2012 Příprava studijního programu Informatika je podporována projektem financovaným z Evropského
Operační systémy. Přednáška 1: Úvod
 Operační systémy Přednáška 1: Úvod 1 Organizace předmětu Přednášky každé úterý 18:00-19:30 v K1 Přednášející Jan Trdlička email: trdlicka@fel.cvut.z kancelář: K324 Cvičení pondělí, úterý, středa Informace
Operační systémy Přednáška 1: Úvod 1 Organizace předmětu Přednášky každé úterý 18:00-19:30 v K1 Přednášející Jan Trdlička email: trdlicka@fel.cvut.z kancelář: K324 Cvičení pondělí, úterý, středa Informace
Přehled paralelních architektur. Dělení paralelních architektur Flynnova taxonomie Komunikační modely paralelních architektur
 Přehled paralelních architektur Přehled paralelních architektur Dělení paralelních architektur Flynnova taxonomie Komunikační modely paralelních architektur Přehled I. paralelní počítače se konstruují
Přehled paralelních architektur Přehled paralelních architektur Dělení paralelních architektur Flynnova taxonomie Komunikační modely paralelních architektur Přehled I. paralelní počítače se konstruují
architektura mostů severní / jižní most (angl. north / south bridge) 1. Čipové sady s architekturou severního / jižního mostu
 1. Čipové sady s architekturou severního / jižního mostu") Čipová sada Čipová sada (chipset) je hlavní logický integrovaný obvod základní desky. Jeho úkolem je řídit komunikaci mezi procesorem a ostatními zařízeními a obvody. V obvodech čipové sady jsou integrovány
Čipová sada Čipová sada (chipset) je hlavní logický integrovaný obvod základní desky. Jeho úkolem je řídit komunikaci mezi procesorem a ostatními zařízeními a obvody. V obvodech čipové sady jsou integrovány
Systémy pro sběr a přenos dat
 Systémy pro sběr a přenos dat Centralizované SPD VME, VXI Compact PCI, PXI, PXI Express Sběrnice VME 16/32/64 bitová paralelní sběrnice pro průmyslové aplikace Počátky v roce 1981 neustále se vyvíjí původní
Systémy pro sběr a přenos dat Centralizované SPD VME, VXI Compact PCI, PXI, PXI Express Sběrnice VME 16/32/64 bitová paralelní sběrnice pro průmyslové aplikace Počátky v roce 1981 neustále se vyvíjí původní
OPS Paralelní systémy, seznam pojmů, klasifikace
 Moorův zákon (polovina 60. let) : Výpočetní výkon a počet tranzistorů na jeden CPU chip integrovaného obvodu mikroprocesoru se každý jeden až dva roky zdvojnásobí; cena se zmenší na polovinu. Paralelismus
Moorův zákon (polovina 60. let) : Výpočetní výkon a počet tranzistorů na jeden CPU chip integrovaného obvodu mikroprocesoru se každý jeden až dva roky zdvojnásobí; cena se zmenší na polovinu. Paralelismus
Pokročilé architektury počítačů
 Pokročilé architektury počítačů Tutoriál 2 Virtualizace a její dopady Martin Milata Obsah Virtualizace Jak virtualizace funguje Typy HW podpora virtualizace Dopady virtualizace Jak virtualizace funguje?
Pokročilé architektury počítačů Tutoriál 2 Virtualizace a její dopady Martin Milata Obsah Virtualizace Jak virtualizace funguje Typy HW podpora virtualizace Dopady virtualizace Jak virtualizace funguje?
Přednáška #12: Úvod do paralelních počítačů. Paralelní počítače a architektury
 (36APS: Architektura počítačových systémů, posluchárna K1, Pon, 16/5/05, 9:15-10:45, přednáší Pavel Tvrdík) Přednáška #12: Úvod do paralelních počítačů Paralelní počítače a architektury Definice 1. (Almasi,
(36APS: Architektura počítačových systémů, posluchárna K1, Pon, 16/5/05, 9:15-10:45, přednáší Pavel Tvrdík) Přednáška #12: Úvod do paralelních počítačů Paralelní počítače a architektury Definice 1. (Almasi,
Mezipaměti počítače. L2 cache. L3 cache
 Mezipaměti počítače Cache paměť - mezipaměť Hlavní paměť procesoru je typu DRAM a je pomalá. Proto se mezi pomalou hlavní paměť a procesor vkládá menší, ale rychlá vyrovnávací (cache) paměť SRAM. Rychlost
Mezipaměti počítače Cache paměť - mezipaměť Hlavní paměť procesoru je typu DRAM a je pomalá. Proto se mezi pomalou hlavní paměť a procesor vkládá menší, ale rychlá vyrovnávací (cache) paměť SRAM. Rychlost
Profilová část maturitní zkoušky 2013/2014
 Střední průmyslová škola, Přerov, Havlíčkova 2 751 52 Přerov Profilová část maturitní zkoušky 2013/2014 TEMATICKÉ OKRUHY A HODNOTÍCÍ KRITÉRIA Studijní obor: 78-42-M/01 Technické lyceum Předmět: TECHNIKA
Střední průmyslová škola, Přerov, Havlíčkova 2 751 52 Přerov Profilová část maturitní zkoušky 2013/2014 TEMATICKÉ OKRUHY A HODNOTÍCÍ KRITÉRIA Studijní obor: 78-42-M/01 Technické lyceum Předmět: TECHNIKA
IB109 Návrh a implementace paralelních systémů. Organizace kurzu a úvod. Jiří Barnat
 IB109 Návrh a implementace paralelních systémů Organizace kurzu a úvod Jiří Barnat Sekce IB109 Návrh a implementace paralelních systémů: Organizace kurzu a úvod str. 2/32 Organizace kurzu Organizace kurzu
IB109 Návrh a implementace paralelních systémů Organizace kurzu a úvod Jiří Barnat Sekce IB109 Návrh a implementace paralelních systémů: Organizace kurzu a úvod str. 2/32 Organizace kurzu Organizace kurzu
MATURITNÍ OTÁZKY ELEKTROTECHNIKA - POČÍTAČOVÉ SYSTÉMY 2003/2004 TECHNICKÉ VYBAVENÍ POČÍTAČŮ
 MATURITNÍ OTÁZKY ELEKTROTECHNIKA - POČÍTAČOVÉ SYSTÉMY 2003/2004 TECHNICKÉ VYBAVENÍ POČÍTAČŮ 1) INFORMACE VE VÝPOČETNÍ TECHNICE 3 2) POČÍTAČOVÉ ARCHITEKTURY, POČÍTAČ JAKO ČÍSLICOVÝ STROJ 3 3) SIGNÁLY 3
MATURITNÍ OTÁZKY ELEKTROTECHNIKA - POČÍTAČOVÉ SYSTÉMY 2003/2004 TECHNICKÉ VYBAVENÍ POČÍTAČŮ 1) INFORMACE VE VÝPOČETNÍ TECHNICE 3 2) POČÍTAČOVÉ ARCHITEKTURY, POČÍTAČ JAKO ČÍSLICOVÝ STROJ 3 3) SIGNÁLY 3
Roman Výtisk, VYT027
 Roman Výtisk, VYT027 Ohlédnutí za architekturou AMD K8 Představení architektury procesoru AMD K10 Přínos Struktura cache IMC, HyperTransport sběrnice Použitá literatura Ohlášení x86-64 architektury 5.
Roman Výtisk, VYT027 Ohlédnutí za architekturou AMD K8 Představení architektury procesoru AMD K10 Přínos Struktura cache IMC, HyperTransport sběrnice Použitá literatura Ohlášení x86-64 architektury 5.
12. Virtuální sítě (VLAN) VLAN. Počítačové sítě I. 1 (7) KST/IPS1. Studijní cíl. Základní seznámení se sítěmi VLAN. Doba nutná k nastudování
 VLAN. Počítačové sítě I. 1 (7) KST/IPS1. Studijní cíl. Základní seznámení se sítěmi VLAN. Doba nutná k nastudování") 12. Virtuální sítě (VLAN) Studijní cíl Základní seznámení se sítěmi VLAN. Doba nutná k nastudování 1 hodina VLAN Virtuální síť bývá definována jako logický segment LAN, který spojuje koncové uzly, které
12. Virtuální sítě (VLAN) Studijní cíl Základní seznámení se sítěmi VLAN. Doba nutná k nastudování 1 hodina VLAN Virtuální síť bývá definována jako logický segment LAN, který spojuje koncové uzly, které
Povídání na téma SUPERPOČÍTAČE DNES A ZÍTRA
 Povídání na téma SUPERPOČÍTAČE DNES A ZÍTRA (aneb krátký náhled na SC) 29. 10. 2015 Filip Staněk Osnova Co jsou to Superpočítače? Výkon SC Architektura Software Algoritmy IT4Innovations Odkazy na další
Povídání na téma SUPERPOČÍTAČE DNES A ZÍTRA (aneb krátký náhled na SC) 29. 10. 2015 Filip Staněk Osnova Co jsou to Superpočítače? Výkon SC Architektura Software Algoritmy IT4Innovations Odkazy na další
Luděk Matyska. Jaro 2014
 IA039: Architektura superpočítačů a náročné výpočty Paralelní počítače Luděk Matyska Fakulta informatiky MU Jaro 2014 Luděk Matyska (FI MU) Paralelní počítače Jaro 2014 1 / 63 Paralelní počítače Small-scale
IA039: Architektura superpočítačů a náročné výpočty Paralelní počítače Luděk Matyska Fakulta informatiky MU Jaro 2014 Luděk Matyska (FI MU) Paralelní počítače Jaro 2014 1 / 63 Paralelní počítače Small-scale
Paralelní architektury se sdílenou pamětí typu NUMA. NUMA architektury
 Paralelní architektury se sdílenou pamětí typu NUMA NUMA architektury Multiprocesorové systémy s distribuovanou pamětí I. úzkým hrdlem multiprocesorů se sdílenou pamětí je datová komunikace s rostoucím
Paralelní architektury se sdílenou pamětí typu NUMA NUMA architektury Multiprocesorové systémy s distribuovanou pamětí I. úzkým hrdlem multiprocesorů se sdílenou pamětí je datová komunikace s rostoucím
Profilová část maturitní zkoušky 2017/2018
 Střední průmyslová škola, Přerov, Havlíčkova 2 751 52 Přerov Profilová část maturitní zkoušky 2017/2018 TEMATICKÉ OKRUHY A HODNOTÍCÍ KRITÉRIA Studijní obor: 78-42-M/01 Technické lyceum Předmět: TECHNIKA
Střední průmyslová škola, Přerov, Havlíčkova 2 751 52 Přerov Profilová část maturitní zkoušky 2017/2018 TEMATICKÉ OKRUHY A HODNOTÍCÍ KRITÉRIA Studijní obor: 78-42-M/01 Technické lyceum Předmět: TECHNIKA
Využití paralelních výpočtů v geodézii
 České vysoké učení technické v Praze Fakulta stavební Katedra mapování a kartografie Využití paralelních výpočtů v geodézii DOKTORSKÁ DISERTAČNÍ PRÁCE Ing. Martin Jeřábek Praha, září 2001 Doktorský studijní
České vysoké učení technické v Praze Fakulta stavební Katedra mapování a kartografie Využití paralelních výpočtů v geodézii DOKTORSKÁ DISERTAČNÍ PRÁCE Ing. Martin Jeřábek Praha, září 2001 Doktorský studijní
Pokročilé architektury počítačů
 Pokročilé architektury počítačů Architektura IO podsystému České vysoké učení technické, Fakulta elektrotechnická A4M36PAP Pokročílé architektury počítačů Ver.1.00 2010 1 Co je úkolem? Propojit jednotlivé
Pokročilé architektury počítačů Architektura IO podsystému České vysoké učení technické, Fakulta elektrotechnická A4M36PAP Pokročílé architektury počítačů Ver.1.00 2010 1 Co je úkolem? Propojit jednotlivé
Paralelní algoritmy --- Parallel Algorithms
 Paralelní algoritmy --- Parallel Algorithms Přemysl Šůcha suchap@fel.cvut.cz Motivace Nepopíratelnost trendu směřování k paralelním systémům i více-jádrový telefon je dnes samozřejmostí energetická efektivita
Paralelní algoritmy --- Parallel Algorithms Přemysl Šůcha suchap@fel.cvut.cz Motivace Nepopíratelnost trendu směřování k paralelním systémům i více-jádrový telefon je dnes samozřejmostí energetická efektivita
Přidělování paměti II Mgr. Josef Horálek
 Přidělování paměti II Mgr. Josef Horálek Techniky přidělování paměti = Přidělování jediné souvislé oblasti paměti = Přidělování paměti po sekcích = Dynamické přemisťování sekcí = Stránkování = Stránkování
Přidělování paměti II Mgr. Josef Horálek Techniky přidělování paměti = Přidělování jediné souvislé oblasti paměti = Přidělování paměti po sekcích = Dynamické přemisťování sekcí = Stránkování = Stránkování
Platforma Juniper QFabric
 Platforma Juniper QFabric Matěj Čenčík (CEN027) Abstrakt: Tématem článku je princip a architektura JuniperQFabric platformy. Klíčová slova: Juniper, QFabric, Platforma, Converged services, non-blocking
Platforma Juniper QFabric Matěj Čenčík (CEN027) Abstrakt: Tématem článku je princip a architektura JuniperQFabric platformy. Klíčová slova: Juniper, QFabric, Platforma, Converged services, non-blocking
Paměťový podsystém počítače
 Paměťový podsystém počítače typy pamětových systémů počítače virtuální paměť stránkování segmentace rychlá vyrovnávací paměť 30.1.2013 O. Novák: CIE6 1 Organizace paměťového systému počítače Paměťová hierarchie...
Paměťový podsystém počítače typy pamětových systémů počítače virtuální paměť stránkování segmentace rychlá vyrovnávací paměť 30.1.2013 O. Novák: CIE6 1 Organizace paměťového systému počítače Paměťová hierarchie...
Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti
 Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti MI-SOC: 8 SÍTĚ NAČIPU (NOC) doc. Ing. Hana Kubátová, CSc. Katedra číslicového návrhu Fakulta informačních technologii ČVUT v Praze Hana
Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti MI-SOC: 8 SÍTĚ NAČIPU (NOC) doc. Ing. Hana Kubátová, CSc. Katedra číslicového návrhu Fakulta informačních technologii ČVUT v Praze Hana
Paralelní výpočty ve finančnictví
 Paralelní výpočty ve finančnictví Jan Houška HUMUSOFT s.r.o. houska@humusoft.cz Výpočetně náročné úlohy distribuované úlohy mnoho relativně nezávislých úloh snížení zatížení klientské pracovní stanice
Paralelní výpočty ve finančnictví Jan Houška HUMUSOFT s.r.o. houska@humusoft.cz Výpočetně náročné úlohy distribuované úlohy mnoho relativně nezávislých úloh snížení zatížení klientské pracovní stanice
Hlavní využití počítačů
 Úvod Hlavní využití počítačů Počítače jsou výkonné nástroje využívané pro zpracování dat. Provádějí: načtení a binární kódování dat provedení požadovaného výpočtu zobrazení výsledku Hlavní využití počítačů
Úvod Hlavní využití počítačů Počítače jsou výkonné nástroje využívané pro zpracování dat. Provádějí: načtení a binární kódování dat provedení požadovaného výpočtu zobrazení výsledku Hlavní využití počítačů
Systém řízení sběrnice
 Systém řízení sběrnice Sběrnice je komunikační cesta, která spojuje dvě či více zařízení. V určitý okamžik je možné aby pouze jedno z připojených zařízení vložilo na sběrnici data. Vložená data pak mohou
Systém řízení sběrnice Sběrnice je komunikační cesta, která spojuje dvě či více zařízení. V určitý okamžik je možné aby pouze jedno z připojených zařízení vložilo na sběrnici data. Vložená data pak mohou
METACentrum Český národní gridovýprojekt. Projekt METACentrum. Jan Kmuníček ÚVT MU & CESNET. meta.cesnet.cz
 METACentrum Český národní gridovýprojekt Projekt METACentrum Jan Kmuníček ÚVT MU & CESNET meta.cesnet.cz Motivace Gridu METACentrum organizace technické zázemí aplikační vybavení poskytované služby podpora
METACentrum Český národní gridovýprojekt Projekt METACentrum Jan Kmuníček ÚVT MU & CESNET meta.cesnet.cz Motivace Gridu METACentrum organizace technické zázemí aplikační vybavení poskytované služby podpora
Procesy a vlákna (Processes and Threads)
") ÚVOD DO OPERAČNÍCH SYSTÉMŮ Ver.1.00 Procesy a vlákna (Processes and Threads) Správa procesů a vláken České vysoké učení technické Fakulta elektrotechnická 2012 Použitá literatura [1] Stallings, W.: Operating
ÚVOD DO OPERAČNÍCH SYSTÉMŮ Ver.1.00 Procesy a vlákna (Processes and Threads) Správa procesů a vláken České vysoké učení technické Fakulta elektrotechnická 2012 Použitá literatura [1] Stallings, W.: Operating
Ro R dina procesor pr ů Int In e t l Nehalem Šmída Mojmír, SMI108 PAP PA 2009
 Rodina procesorů Intel Nehalem Šmída Mojmír, SMI108 PAP 2009 Obsah: Úvod Nejpodstatnější prvky Nehalemu (i7 900) Nehalem ve střední třídě (i7 800, i5 700) Výkon Závěr Úvod Nhl Nehalem staví na úspěšné
Rodina procesorů Intel Nehalem Šmída Mojmír, SMI108 PAP 2009 Obsah: Úvod Nejpodstatnější prvky Nehalemu (i7 900) Nehalem ve střední třídě (i7 800, i5 700) Výkon Závěr Úvod Nhl Nehalem staví na úspěšné
Základy počítačových sítí Model počítačové sítě, protokoly
 Základy počítačových sítí Model počítačové sítě, protokoly Základy počítačových sítí Lekce Ing. Jiří ledvina, CSc Úvod - protokoly pravidla podle kterých síťové komponenty vzájemně komunikují představují
Základy počítačových sítí Model počítačové sítě, protokoly Základy počítačových sítí Lekce Ing. Jiří ledvina, CSc Úvod - protokoly pravidla podle kterých síťové komponenty vzájemně komunikují představují
Řízení IO přenosů DMA řadičem
 Řízení IO přenosů DMA řadičem Doplňující text pro POT K. D. 2001 DMA řadič Při přímém řízení IO operací procesorem i při použití přerušovacího systému je rychlost přenosu dat mezi IO řadičem a pamětí limitována
Řízení IO přenosů DMA řadičem Doplňující text pro POT K. D. 2001 DMA řadič Při přímém řízení IO operací procesorem i při použití přerušovacího systému je rychlost přenosu dat mezi IO řadičem a pamětí limitována
Pokročilé architektury počítačů
 Pokročilé architektury počítačů Přednáška 5 GPU - CUDA Martin Milata Obsah Obecné výpočty a GPU Grafické procesory NVIDIA Tesla Výpočetní model Paměťový model GT200 Zpracování instrukcí Vydávání instrukcí
Pokročilé architektury počítačů Přednáška 5 GPU - CUDA Martin Milata Obsah Obecné výpočty a GPU Grafické procesory NVIDIA Tesla Výpočetní model Paměťový model GT200 Zpracování instrukcí Vydávání instrukcí
5. Směrování v počítačových sítích a směrovací protokoly
 5. Směrování v počítačových sítích a směrovací protokoly Studijní cíl V této kapitole si představíme proces směrování IP.. Seznámení s procesem směrování na IP vrstvě a s protokoly RIP, RIPv2, EIGRP a
5. Směrování v počítačových sítích a směrovací protokoly Studijní cíl V této kapitole si představíme proces směrování IP.. Seznámení s procesem směrování na IP vrstvě a s protokoly RIP, RIPv2, EIGRP a
MetaCentrum - Virtualizace a její použití
 MetaCentrum - Virtualizace a její použití Miroslav Ruda,... Cesnet Brno, 2009 M. Ruda (Cesnet) Virtualizace Brno, 2009 1 / 18 Obsah Motivace co je virtualizace kde ji lze využít Stávající využití na výpočetních
MetaCentrum - Virtualizace a její použití Miroslav Ruda,... Cesnet Brno, 2009 M. Ruda (Cesnet) Virtualizace Brno, 2009 1 / 18 Obsah Motivace co je virtualizace kde ji lze využít Stávající využití na výpočetních
Architektura počítačů
 Architektura počítačů Studijní materiál pro předmět Architektury počítačů Ing. Petr Olivka katedra informatiky FEI VŠB-TU Ostrava email: petr.olivka@vsb.cz Ostrava, 2010 1 1 Architektura počítačů Pojem
Architektura počítačů Studijní materiál pro předmět Architektury počítačů Ing. Petr Olivka katedra informatiky FEI VŠB-TU Ostrava email: petr.olivka@vsb.cz Ostrava, 2010 1 1 Architektura počítačů Pojem
Struktura a architektura počítačů (BI-SAP) 11
 11") Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti Struktura a architektura počítačů (BI-SAP) 11 doc. Ing. Hana Kubátová, CSc. Katedra číslicového návrhu Fakulta informačních technologii
Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti Struktura a architektura počítačů (BI-SAP) 11 doc. Ing. Hana Kubátová, CSc. Katedra číslicového návrhu Fakulta informačních technologii
Novinky z vývoje v MetaCentru
 Novinky z vývoje v MetaCentru Miroslav Ruda miroslav.ruda@cesnet.cz CESNET Brno, 2011 Novinky z vývoje MetaCentra otázky a odpovědi, čím více otázek, tím lépe přechod na plánovací systém Torque úpravy
Novinky z vývoje v MetaCentru Miroslav Ruda miroslav.ruda@cesnet.cz CESNET Brno, 2011 Novinky z vývoje MetaCentra otázky a odpovědi, čím více otázek, tím lépe přechod na plánovací systém Torque úpravy
4. Úvod do paralelismu, metody paralelizace
 4. Úvod do paralelismu, metody paralelizace algoritmů Ing. Michal Bližňák, Ph.D. Ústav informatiky a umělé inteligence Fakulta aplikované informatiky UTB Zĺın Paralelní procesy a programování, Zĺın, 26.
4. Úvod do paralelismu, metody paralelizace algoritmů Ing. Michal Bližňák, Ph.D. Ústav informatiky a umělé inteligence Fakulta aplikované informatiky UTB Zĺın Paralelní procesy a programování, Zĺın, 26.
Představení a vývoj architektur vektorových procesorů
 Představení a vývoj architektur vektorových procesorů Drong Lukáš Dro098 1 Obsah Úvod 3 Historie, současnost 3 Architektura 4 - pipelining 4 - Operace scatter a gather 4 - vektorové registry 4 - Řetězení
Představení a vývoj architektur vektorových procesorů Drong Lukáš Dro098 1 Obsah Úvod 3 Historie, současnost 3 Architektura 4 - pipelining 4 - Operace scatter a gather 4 - vektorové registry 4 - Řetězení
Referát (pokročilé architektury počítačů)
") Referát (pokročilé architektury počítačů) Představení architektury procesoru AMD K10 Roman Výtisk, VYT027 1 AMD K8 Nejprve bych zmínil, co této architektuře předcházelo a co tato architektura přinesla
Referát (pokročilé architektury počítačů) Představení architektury procesoru AMD K10 Roman Výtisk, VYT027 1 AMD K8 Nejprve bych zmínil, co této architektuře předcházelo a co tato architektura přinesla
Systém adresace paměti
 Systém adresace paměti Základní pojmy Adresa fyzická - adresa, která je přenesena na adresní sběrnici a fyzicky adresuje hlavní paměť logická - adresa, kterou má k dispozici proces k adresaci přiděleného
Systém adresace paměti Základní pojmy Adresa fyzická - adresa, která je přenesena na adresní sběrnici a fyzicky adresuje hlavní paměť logická - adresa, kterou má k dispozici proces k adresaci přiděleného
Distribuovaný systém je takový systém propojení množiny nezávislých počítačů, který poskytuje uživateli dojem jednotného systému.
 1. B4. Počítačové sítě a decentralizované systémy Jakub MÍŠA (2006) Decentralizace a distribuovanost v architekturách počítačových sítí. Centralizovaná a distribuovaná správa prostředků, bezpečnostní politika
1. B4. Počítačové sítě a decentralizované systémy Jakub MÍŠA (2006) Decentralizace a distribuovanost v architekturách počítačových sítí. Centralizovaná a distribuovaná správa prostředků, bezpečnostní politika
Martin Lísal. Úvod do MPI
 Martin Lísal září 2003 PARALELNÍ POČÍTÁNÍ Úvod do MPI 1 1 Co je to paralelní počítání? Paralelní počítání je počítání na paralelních počítačích či jinak řečeno využití více než jednoho procesoru při výpočtu
Martin Lísal září 2003 PARALELNÍ POČÍTÁNÍ Úvod do MPI 1 1 Co je to paralelní počítání? Paralelní počítání je počítání na paralelních počítačích či jinak řečeno využití více než jednoho procesoru při výpočtu
Propojování sítí,, aktivní prvky a jejich principy
 Propojování sítí,, aktivní prvky a jejich principy Petr Grygárek 1 Důvody propojování/rozdělování sítí zvětšení rozsahu: překonání fyzikálních omezení dosahu technologie lokální sítě propojení původně
Propojování sítí,, aktivní prvky a jejich principy Petr Grygárek 1 Důvody propojování/rozdělování sítí zvětšení rozsahu: překonání fyzikálních omezení dosahu technologie lokální sítě propojení původně
Obsah. Kapitola 1 Hardware, procesory a vlákna Prohlídka útrob počítače...20 Motivace pro vícejádrové procesory...21
 Stručný obsah 1. Hardware, procesory a vlákna... 19 2. Programování s ohledemna výkon... 45 3. Identifikování příležitostí pro paralelizmus... 93 4. Synchronizace a sdílení dat... 123 5. Vlákna v rozhraní
Stručný obsah 1. Hardware, procesory a vlákna... 19 2. Programování s ohledemna výkon... 45 3. Identifikování příležitostí pro paralelizmus... 93 4. Synchronizace a sdílení dat... 123 5. Vlákna v rozhraní
Profilová část maturitní zkoušky 2014/2015
 Střední průmyslová škola, Přerov, Havlíčkova 2 751 52 Přerov Profilová část maturitní zkoušky 2014/2015 TEMATICKÉ OKRUHY A HODNOTÍCÍ KRITÉRIA Studijní obor: 26-41-M/01 Elektrotechnika Zaměření: technika
Střední průmyslová škola, Přerov, Havlíčkova 2 751 52 Přerov Profilová část maturitní zkoušky 2014/2015 TEMATICKÉ OKRUHY A HODNOTÍCÍ KRITÉRIA Studijní obor: 26-41-M/01 Elektrotechnika Zaměření: technika
Paralelní a distribuované výpočty (B4B36PDV)
") Paralelní a distribuované výpočty (B4B36PDV) Branislav Bošanský, Michal Jakob bosansky@fel.cvut.cz Artificial Intelligence Center Department of Computer Science Faculty of Electrical Engineering Czech
Paralelní a distribuované výpočty (B4B36PDV) Branislav Bošanský, Michal Jakob bosansky@fel.cvut.cz Artificial Intelligence Center Department of Computer Science Faculty of Electrical Engineering Czech
Systémy pro sběr a přenos dat
 Systémy pro sběr a přenos dat propojování distribuovaných systémů modely Klient/Server, Producent/Konzument koncept VFD (Virtual Field Device) Propojování distribuovaných systémů Používá se pojem internetworking
Systémy pro sběr a přenos dat propojování distribuovaných systémů modely Klient/Server, Producent/Konzument koncept VFD (Virtual Field Device) Propojování distribuovaných systémů Používá se pojem internetworking
SUPERPOČÍTAČE DANIEL LANGR ČVUT FIT / VZLÚ
 SUPERPOČÍTAČE DANIEL LANGR ČVUT FIT / VZLÚ TITAN / HOPPER / NOTEBOOK TITAN HOPPER NOTEBOOK Počet CPU jader 299 008 153 216 2 Operační paměť [GB] 598 016 217 000 8 Počet GPU (CUDA) jader 50 233 344 0 8
SUPERPOČÍTAČE DANIEL LANGR ČVUT FIT / VZLÚ TITAN / HOPPER / NOTEBOOK TITAN HOPPER NOTEBOOK Počet CPU jader 299 008 153 216 2 Operační paměť [GB] 598 016 217 000 8 Počet GPU (CUDA) jader 50 233 344 0 8
Komunikační sítě paralelních architektur
 Komunikační sítě paralelních architektur Komunikační sítě - úvod Topologie komunikačních sítí Nepřímé komunikační sítě Sběrnice (bus) Sítě s přepínači - crossbar networks Víceúrovňové sítě Přímé komunikační
Komunikační sítě paralelních architektur Komunikační sítě - úvod Topologie komunikačních sítí Nepřímé komunikační sítě Sběrnice (bus) Sítě s přepínači - crossbar networks Víceúrovňové sítě Přímé komunikační
NSWI /2011 ZS. Principy cpypočítačůčů aoperačních systémů ARCHITEKTURA
 Principy cpypočítačůčů aoperačních systémů ARCHITEKTURA Literatura W.Stallings: Computer Organization & Architecture J.L.Hennessy, P.A.Patterson: Patterson: Computer Architecture: a Quantitative Approach
Principy cpypočítačůčů aoperačních systémů ARCHITEKTURA Literatura W.Stallings: Computer Organization & Architecture J.L.Hennessy, P.A.Patterson: Patterson: Computer Architecture: a Quantitative Approach
PRINCIPY OPERAČNÍCH SYSTÉMŮ
 Metodický list č. 1 Název tématického celku: Přehled operačních systémů a jejich funkcí Základním cílem tohoto tematického celku je seznámení se s předmětem (vědním oborem) Operační systémy (OS) a se základními
Metodický list č. 1 Název tématického celku: Přehled operačních systémů a jejich funkcí Základním cílem tohoto tematického celku je seznámení se s předmětem (vědním oborem) Operační systémy (OS) a se základními
Petr Holášek / 1 of 21
 "Klidně to přeruš!" aneb pojednání o zpracovávání HW přerušení na OS Linux Petr Holášek / pholasek@redhat.com 1 of 21 Koho by měly zajímat přerušení? Administrátory Systémové inženýry Uživatele, které
"Klidně to přeruš!" aneb pojednání o zpracovávání HW přerušení na OS Linux Petr Holášek / pholasek@redhat.com 1 of 21 Koho by měly zajímat přerušení? Administrátory Systémové inženýry Uživatele, které
C2115 Praktický úvod do superpočítání
 C2115 Praktický úvod do superpočítání IX. lekce Petr Kulhánek, Tomáš Bouchal kulhanek@chemi.muni.cz Národní centrum pro výzkum biomolekul, Přírodovědecká fakulta, Masarykova univerzita, Kotlářská 2, CZ-61137
C2115 Praktický úvod do superpočítání IX. lekce Petr Kulhánek, Tomáš Bouchal kulhanek@chemi.muni.cz Národní centrum pro výzkum biomolekul, Přírodovědecká fakulta, Masarykova univerzita, Kotlářská 2, CZ-61137
Operační systémy. Jednoduché stránkování. Virtuální paměť. Příklad: jednoduché stránkování. Virtuální paměť se stránkování. Memory Management Unit
 Jednoduché stránkování Operační systémy Přednáška 8: Správa paměti II Hlavní paměť rozdělená na malé úseky stejné velikosti (např. 4kB) nazývané rámce (frames). Program rozdělen na malé úseky stejné velikosti
Jednoduché stránkování Operační systémy Přednáška 8: Správa paměti II Hlavní paměť rozdělená na malé úseky stejné velikosti (např. 4kB) nazývané rámce (frames). Program rozdělen na malé úseky stejné velikosti
Počítačové síťě (computer network) Realizují propojení mezi PC z důvodu sdílení SW (informací, programů) a HW(disky, tiskárny..)
 Realizují propojení mezi PC z důvodu sdílení SW (informací, programů) a HW(disky, tiskárny..)") Počítačové síťě (computer network) Realizují propojení mezi PC z důvodu sdílení SW (informací, programů) a HW(disky, tiskárny..) Důvody propojení počítačů do sítě Sdílení HW (disky, tiskárny) Sdílení SW
Počítačové síťě (computer network) Realizují propojení mezi PC z důvodu sdílení SW (informací, programů) a HW(disky, tiskárny..) Důvody propojení počítačů do sítě Sdílení HW (disky, tiskárny) Sdílení SW
Sbě b r ě n r i n ce
 Sběrnice Sběrnice paralelní & sériové PCI, PCI-X PCI Express, USB Typ přenosu dat počet vodičů & způsob přenosu interní & externí ISA, PCI, PCI express & USB, FireWare Lokální & universální VL Bus PCI
Sběrnice Sběrnice paralelní & sériové PCI, PCI-X PCI Express, USB Typ přenosu dat počet vodičů & způsob přenosu interní & externí ISA, PCI, PCI express & USB, FireWare Lokální & universální VL Bus PCI
Příloha č. 1 zadávací dokumentace. Technická dokumentace, specifikace požadovaného plnění a popis hodnocení
 Příloha č. 1 zadávací dokumentace Dodávka komponent výpočetního clusteru národní gridové infrastruktury pro projekt Velká infrastruktura CESNET Technická dokumentace, specifikace požadovaného plnění a
Příloha č. 1 zadávací dokumentace Dodávka komponent výpočetního clusteru národní gridové infrastruktury pro projekt Velká infrastruktura CESNET Technická dokumentace, specifikace požadovaného plnění a
Pamět ová hierarchie, návrh skryté paměti 2. doc. Ing. Róbert Lórencz, CSc.
 Architektura počítačových systémů Pamět ová hierarchie, návrh skryté paměti 2 doc. Ing. Róbert Lórencz, CSc. České vysoké učení technické v Praze Fakulta informačních technologií Katedra počítačových systémů
Architektura počítačových systémů Pamět ová hierarchie, návrh skryté paměti 2 doc. Ing. Róbert Lórencz, CSc. České vysoké učení technické v Praze Fakulta informačních technologií Katedra počítačových systémů
X.25 Frame Relay. Frame Relay
 X.25 Frame Relay Frame Relay 1 Předmět: Téma hodiny: Třída: Počítačové sítě a systémy X.25, Frame relay _ 3. a 4. ročník SŠ technické Autor: Ing. Fales Alexandr Software: SMART Notebook 11.0.583.0 Obr.
X.25 Frame Relay Frame Relay 1 Předmět: Téma hodiny: Třída: Počítačové sítě a systémy X.25, Frame relay _ 3. a 4. ročník SŠ technické Autor: Ing. Fales Alexandr Software: SMART Notebook 11.0.583.0 Obr.
Princip funkce počítače
 Princip funkce počítače Princip funkce počítače prvotní úlohou počítačů bylo zrychlit provádění matematických výpočtů první počítače kopírovaly obvyklý postup manuálního provádění výpočtů pokyny pro zpracování
Princip funkce počítače Princip funkce počítače prvotní úlohou počítačů bylo zrychlit provádění matematických výpočtů první počítače kopírovaly obvyklý postup manuálního provádění výpočtů pokyny pro zpracování
Pohled do nitra mikroprocesoru Josef Horálek
 Pohled do nitra mikroprocesoru Josef Horálek Z čeho vycházíme = Vycházíme z Von Neumannovy architektury = Celý počítač se tak skládá z pěti koncepčních bloků: = Operační paměť = Programový řadič = Aritmeticko-logická
Pohled do nitra mikroprocesoru Josef Horálek Z čeho vycházíme = Vycházíme z Von Neumannovy architektury = Celý počítač se tak skládá z pěti koncepčních bloků: = Operační paměť = Programový řadič = Aritmeticko-logická
UAI/612 - Cloudová Řešení. Návrh aplikací pro cloud
 UAI/612 - Cloudová Řešení Návrh aplikací pro cloud Rekapitulace Cloud computing Virtualizace IaaS, PaaS, SaaS Veřejný, Privátní, Komunitní, Hybridní Motivace Návrh aplikací pro cloud Software as a Service
UAI/612 - Cloudová Řešení Návrh aplikací pro cloud Rekapitulace Cloud computing Virtualizace IaaS, PaaS, SaaS Veřejný, Privátní, Komunitní, Hybridní Motivace Návrh aplikací pro cloud Software as a Service
TOPOLOGIE DATOVÝCH SÍTÍ
 TOPOLOGIE DATOVÝCH SÍTÍ Topologie sítě charakterizuje strukturu datové sítě. Popisuje způsob, jakým jsou mezi sebou propojeny jednotlivá koncová zařízení (stanice) a toky dat mezi nimi. Topologii datových
TOPOLOGIE DATOVÝCH SÍTÍ Topologie sítě charakterizuje strukturu datové sítě. Popisuje způsob, jakým jsou mezi sebou propojeny jednotlivá koncová zařízení (stanice) a toky dat mezi nimi. Topologii datových
Úvod Úrovňová architektura sítě Prvky síťové architektury Historie Příklady
 Úvod Úrovňová architektura sítě Prvky síťové architektury Historie Příklady 1 Pracovní stanice modem Pracovní stanice Směrovač sítě Směrovač sítě Pracovní stanice Aplikační server Směrovač sítě 2 Soubor
Úvod Úrovňová architektura sítě Prvky síťové architektury Historie Příklady 1 Pracovní stanice modem Pracovní stanice Směrovač sítě Směrovač sítě Pracovní stanice Aplikační server Směrovač sítě 2 Soubor
Paralelní architektury - úvod
 Paralelní architektury - úvod Úvod do paralelních architektur Příklady paralelních architektur Processor arrays Multiprocesory Multiprocesory se sdílenou pamětí Multiprocesory s distribuovanou pamětí Multipočítače
Paralelní architektury - úvod Úvod do paralelních architektur Příklady paralelních architektur Processor arrays Multiprocesory Multiprocesory se sdílenou pamětí Multiprocesory s distribuovanou pamětí Multipočítače
Profilová část maturitní zkoušky 2015/2016
 Střední průmyslová škola, Přerov, Havlíčkova 2 751 52 Přerov Profilová část maturitní zkoušky 2015/2016 TEMATICKÉ OKRUHY A HODNOTÍCÍ KRITÉRIA Studijní obor: 26-41-M/01 Elektrotechnika Zaměření: technika
Střední průmyslová škola, Přerov, Havlíčkova 2 751 52 Přerov Profilová část maturitní zkoušky 2015/2016 TEMATICKÉ OKRUHY A HODNOTÍCÍ KRITÉRIA Studijní obor: 26-41-M/01 Elektrotechnika Zaměření: technika
Informační a komunikační technologie
 Informační a komunikační technologie 4. www.isspolygr.cz Vytvořil: Ing. David Adamovský Strana: 1 Škola Integrovaná střední škola polygrafická Ročník Název projektu 1. ročník SOŠ Interaktivní metody zdokonalující
Informační a komunikační technologie 4. www.isspolygr.cz Vytvořil: Ing. David Adamovský Strana: 1 Škola Integrovaná střední škola polygrafická Ročník Název projektu 1. ročník SOŠ Interaktivní metody zdokonalující
AGP - Accelerated Graphics Port
 AGP - Accelerated Graphics Port Grafiku 3D a video bylo možné v jisté vývojové etapě techniky pracovních stanic provozovat pouze na kvalitních pracovních stanicích (cena 20 000 USD a více) - AGP představuje
AGP - Accelerated Graphics Port Grafiku 3D a video bylo možné v jisté vývojové etapě techniky pracovních stanic provozovat pouze na kvalitních pracovních stanicích (cena 20 000 USD a více) - AGP představuje
1. Směrovače směrového protokolu směrovací tabulku 1.1 TTL
 1. Směrovače Směrovače (routery) jsou síťové prvky zahrnující vrstvy fyzickou, linkovou a síťovou. Jejich hlavním úkolem je směrování paketů jednotlivými sítěmi ležícími na cestě mezi zdrojovou a cílovou
1. Směrovače Směrovače (routery) jsou síťové prvky zahrnující vrstvy fyzickou, linkovou a síťovou. Jejich hlavním úkolem je směrování paketů jednotlivými sítěmi ležícími na cestě mezi zdrojovou a cílovou
PRINCIPY POČÍTAČŮ Metodický list číslo 1
 Metodický list číslo 1 Téma č.1: Historie, vývoj počítačů, architektura počítače. historický přehled, předpoklady pro vývin a rozvoj počítačů nejvýznamnější osoby, vynálezy a stroje von Neumannova architektura
Metodický list číslo 1 Téma č.1: Historie, vývoj počítačů, architektura počítače. historický přehled, předpoklady pro vývin a rozvoj počítačů nejvýznamnější osoby, vynálezy a stroje von Neumannova architektura
METACentrum zastřešení českých gridových aktivit
 METACentrum Český národní gridovýprojekt METACentrum zastřešení českých gridových aktivit Jan Kmuníček, Miroslav Ruda Masarykova univerzita & CESNET meta.cesnet.cz Motivace Gridu METACentrum technické
METACentrum Český národní gridovýprojekt METACentrum zastřešení českých gridových aktivit Jan Kmuníček, Miroslav Ruda Masarykova univerzita & CESNET meta.cesnet.cz Motivace Gridu METACentrum technické
Informační technologie. Název oboru: Školní rok: jarní i podzimní zkušební období 2017/2018
 Název oboru: Kód oboru: Druh zkoušky: Forma zkoušky: ta profilové maturitní zkoušky z předmětu Souborná zkouška z odborných předmětů informačních technologii (Technické vybavení, Operační systémy, Programové
Název oboru: Kód oboru: Druh zkoušky: Forma zkoušky: ta profilové maturitní zkoušky z předmětu Souborná zkouška z odborných předmětů informačních technologii (Technické vybavení, Operační systémy, Programové
Metody připojování periferií BI-MPP Přednáška 1
 Metody připojování periferií BI-MPP Přednáška 1 Ing. Miroslav Skrbek, Ph.D. Katedra počítačových systémů Fakulta informačních technologií České vysoké učení technické v Praze Miroslav Skrbek 2010,2011
Metody připojování periferií BI-MPP Přednáška 1 Ing. Miroslav Skrbek, Ph.D. Katedra počítačových systémů Fakulta informačních technologií České vysoké učení technické v Praze Miroslav Skrbek 2010,2011
Virtualizace MetaCentra
 Virtualizace MetaCentra David Antoš antos@ics.muni.cz SCB ÚVT MU a CESNET, z. s. p. o. Přehled současný stav virtualizace výpočty na cizím clusteru virtualizace počítačů připravujeme virtuální clustery
Virtualizace MetaCentra David Antoš antos@ics.muni.cz SCB ÚVT MU a CESNET, z. s. p. o. Přehled současný stav virtualizace výpočty na cizím clusteru virtualizace počítačů připravujeme virtuální clustery
Paralelní architektury - úvod
 Paralelní architektury - úvod Úvod do paralelních architektur Příklady paralelních architektur Processor arrays Multiprocesory Multiprocesory se sdílenou pamětí Multiprocesory s distribuovanou pamětí Multipočítače
Paralelní architektury - úvod Úvod do paralelních architektur Příklady paralelních architektur Processor arrays Multiprocesory Multiprocesory se sdílenou pamětí Multiprocesory s distribuovanou pamětí Multipočítače
Cloudy a gridy v národní einfrastruktuře
 Cloudy a gridy v národní einfrastruktuře Tomáš Rebok MetaCentrum, CESNET z.s.p.o. CERIT-SC, Masarykova Univerzita (rebok@ics.muni.cz) Ostrava, 5. 4. 2012 PRACE a IT4Innovations Workshop Cestovní mapa národních
Cloudy a gridy v národní einfrastruktuře Tomáš Rebok MetaCentrum, CESNET z.s.p.o. CERIT-SC, Masarykova Univerzita (rebok@ics.muni.cz) Ostrava, 5. 4. 2012 PRACE a IT4Innovations Workshop Cestovní mapa národních
Inovace výuky prostřednictvím ICT v SPŠ Zlín, CZ.1.07/1.5.00/ Vzdělávání v informačních a komunikačních technologií
 VY_32_INOVACE_31_09 Škola Název projektu, reg. č. Vzdělávací oblast Vzdělávací obor Tematický okruh Téma Tematická oblast Název Autor Vytvořeno, pro obor, ročník Anotace Přínos/cílové kompetence Střední
VY_32_INOVACE_31_09 Škola Název projektu, reg. č. Vzdělávací oblast Vzdělávací obor Tematický okruh Téma Tematická oblast Název Autor Vytvořeno, pro obor, ročník Anotace Přínos/cílové kompetence Střední
Cache paměti (1) Cache paměť: V dnešních počítačích se běžně používají dva, popř. tři druhy cache pamětí:
 Cache paměť: V dnešních počítačích se běžně používají dva, popř. tři druhy cache pamětí:") Cache paměti (1) Cache paměť: rychlá vyrovnávací paměť mezi rychlým zařízením (např. procesor) a pomalejším zařízením (např. operační paměť) vyrobena z obvodů SRAM s přístupovou dobou 1-20 ns V dnešních
Cache paměti (1) Cache paměť: rychlá vyrovnávací paměť mezi rychlým zařízením (např. procesor) a pomalejším zařízením (např. operační paměť) vyrobena z obvodů SRAM s přístupovou dobou 1-20 ns V dnešních
Principy počítačů I Netradiční stroje
 Principy počítačů I Netradiční stroje snímek 1 Principy počítačů Část X Netradiční stroje VJJ 1 snímek 2 Netradiční procesory architektury a organizace počítačů, které se vymykají struktuře popsané Johnem
Principy počítačů I Netradiční stroje snímek 1 Principy počítačů Část X Netradiční stroje VJJ 1 snímek 2 Netradiční procesory architektury a organizace počítačů, které se vymykají struktuře popsané Johnem
Přednáška. Správa paměti II. Katedra počítačových systémů FIT, České vysoké učení technické v Praze Jan Trdlička, 2012
 Přednáška Správa paměti II. Katedra počítačových systémů FIT, České vysoké učení technické v Praze Jan Trdlička, 2012 Příprava studijního programu Informatika je podporována projektem financovaným z Evropského
Přednáška Správa paměti II. Katedra počítačových systémů FIT, České vysoké učení technické v Praze Jan Trdlička, 2012 Příprava studijního programu Informatika je podporována projektem financovaným z Evropského
Pokročilé architektury počítačů
 Pokročilé architektury počítačů Multiprocesorové systémy SMP a problém koherence České vysoké učení technické, Fakulta elektrotechnická A4M36PAP Pokročílé architektury počítačů Ver.1.00 1 Osnova Co je
Pokročilé architektury počítačů Multiprocesorové systémy SMP a problém koherence České vysoké učení technické, Fakulta elektrotechnická A4M36PAP Pokročílé architektury počítačů Ver.1.00 1 Osnova Co je
Identifikátor materiálu: ICT-1-08
 Identifikátor materiálu: ICT-1-08 Předmět Informační a komunikační technologie Téma materiálu Motherboard, CPU a RAM Autor Ing. Bohuslav Nepovím Anotace Student si procvičí / osvojí základní desku počítače.
Identifikátor materiálu: ICT-1-08 Předmět Informační a komunikační technologie Téma materiálu Motherboard, CPU a RAM Autor Ing. Bohuslav Nepovím Anotace Student si procvičí / osvojí základní desku počítače.
Server je v informatice obecné označení pro počítač, který poskytuje nějaké služby nebo počítačový program, který tyto služby realizuje.
 Server je v informatice obecné označení pro počítač, který poskytuje nějaké služby nebo počítačový program, který tyto služby realizuje. Servery jsou buď umístěny volně nebo ve speciální místnosti, kterou
Server je v informatice obecné označení pro počítač, který poskytuje nějaké služby nebo počítačový program, který tyto služby realizuje. Servery jsou buď umístěny volně nebo ve speciální místnosti, kterou
C2115 Praktický úvod do superpočítání
 C2115 Praktický úvod do superpočítání II. lekce Petr Kulhánek, Tomáš Bouchal kulhanek@chemi.muni.cz Národní centrum pro výzkum biomolekul, Přírodovědecká fakulta, Masarykova univerzita, Kotlářská 2, CZ-61137
C2115 Praktický úvod do superpočítání II. lekce Petr Kulhánek, Tomáš Bouchal kulhanek@chemi.muni.cz Národní centrum pro výzkum biomolekul, Přírodovědecká fakulta, Masarykova univerzita, Kotlářská 2, CZ-61137
Pokročilé architektury počítačů
 Pokročilé architektury počítačů Přednáška 5 Virtualizace Martin Milata Obsah Typy virtualizace (připomenutí) Tři třídy virtualizace VM s vlastním OS Softwarová úplná virtualizace Paravirtualizace Úplná
Pokročilé architektury počítačů Přednáška 5 Virtualizace Martin Milata Obsah Typy virtualizace (připomenutí) Tři třídy virtualizace VM s vlastním OS Softwarová úplná virtualizace Paravirtualizace Úplná
Souborové služby. Richard Biječek
 Souborové služby Richard Biječek Sdílení složky Instalace role Doplňkové služby a nástroje DFS FSRM Role souborových služeb Dialog rozšířené sdílení Název sdílení Omezení počtu uživatelů Oprávnění Soubory
Souborové služby Richard Biječek Sdílení složky Instalace role Doplňkové služby a nástroje DFS FSRM Role souborových služeb Dialog rozšířené sdílení Název sdílení Omezení počtu uživatelů Oprávnění Soubory
Směrování. static routing statické Při statickém směrování administrátor manuálně vloží směrovací informace do směrovací tabulky.
 Směrování Ve větších sítích již není možné propojit všechny počítače přímo. Limitujícím faktorem je zde množství paketů všesměrového vysílání broadcast, omezené množství IP adres atd. Jednotlivé sítě se
Směrování Ve větších sítích již není možné propojit všechny počítače přímo. Limitujícím faktorem je zde množství paketů všesměrového vysílání broadcast, omezené množství IP adres atd. Jednotlivé sítě se
Obecné výpočty na GPU v jazyce CUDA. Jiří Filipovič
 Obecné výpočty na GPU v jazyce CUDA Jiří Filipovič Obsah přednášky motivace architektura GPU CUDA programovací model jaké algoritmy urychlovat na GPU? optimalizace Motivace Moorův zákon stále platí pro
Obecné výpočty na GPU v jazyce CUDA Jiří Filipovič Obsah přednášky motivace architektura GPU CUDA programovací model jaké algoritmy urychlovat na GPU? optimalizace Motivace Moorův zákon stále platí pro
Vstupně - výstupní moduly
 Vstupně - výstupní moduly Přídavná zařízení sloužící ke vstupu a výstupu dat bo k uchovávání a archivaci dat Nejsou připojována ke sběrnici přímo, ale prostřednictvím vstupně-výstupních modulů ( ů ). Hlavní
Vstupně - výstupní moduly Přídavná zařízení sloužící ke vstupu a výstupu dat bo k uchovávání a archivaci dat Nejsou připojována ke sběrnici přímo, ale prostřednictvím vstupně-výstupních modulů ( ů ). Hlavní
Síťová vrstva. RNDr. Ing. Vladimir Smotlacha, Ph.D.
 Síťová vrstva RNDr. Ing. Vladimir Smotlacha, Ph.D. Katedra počítačových systémů Fakulta informačních technologií České vysoké učení technické v Praze Vladimír Smotlacha, 2011 Počítačové sít ě BI-PSI LS
Síťová vrstva RNDr. Ing. Vladimir Smotlacha, Ph.D. Katedra počítačových systémů Fakulta informačních technologií České vysoké učení technické v Praze Vladimír Smotlacha, 2011 Počítačové sít ě BI-PSI LS
Pokročilé architektury počítačů
 Pokročilé architektury počítačů Tutoriál 3 CUDA - GPU Martin Milata Výpočetní model CUDA Organizace kódu Sériově organizovaný kód určený pro CPU Paralelní kód prováděný na GPU Označuje se jako kernel GPU
Pokročilé architektury počítačů Tutoriál 3 CUDA - GPU Martin Milata Výpočetní model CUDA Organizace kódu Sériově organizovaný kód určený pro CPU Paralelní kód prováděný na GPU Označuje se jako kernel GPU
Cache paměti (2) Cache paměti (1) Cache paměti (3) Cache paměti (4) Cache paměti (6) Cache paměti (5) Cache paměť:
 Cache paměti (1) Cache paměti (3) Cache paměti (4) Cache paměti (6) Cache paměti (5) Cache paměť:") Cache paměti (1) Cache paměť: rychlá vyrovnávací paměť mezi rychlým zařízením (např. procesor) a pomalejším zařízením (např. operační paměť) vyrobena z obvodů SRAM s přístupovou dobou 1 20 ns V dnešních
Cache paměti (1) Cache paměť: rychlá vyrovnávací paměť mezi rychlým zařízením (např. procesor) a pomalejším zařízením (např. operační paměť) vyrobena z obvodů SRAM s přístupovou dobou 1 20 ns V dnešních