B0M33BDT Stream processing. Milan Kratochvíl
|
|
|
- Vít Špringl
- před 5 lety
- Počet zobrazení:
Transkript
1 B0M33BDT Stream processing Milan Kratochvíl 13. prosinec 2017
2 Stream processing Průběžné zpracování trvalého toku zpráv Vstupní stream Message processor Stream processor Úložiště
3 Stream processing Hlavní komponenty Message processor vstup dat do streamového zpracování Stream processor jádro zpracování údajů Úložiště výstupů persistentní úložitě zpracovaných dat Životní cyklus zpráv 1. Příjem zpráv 2. Rozdělení zpráv do partitions 3. Zpracování zpráv (logika aplikace) 4. Uložení, notifikace výsledků atd.
4 Stream processing vs batch processing Batch processing Zpracování velkého množství dat najednou Pořadí nutno vyčíst z dat Zpracování s velkým zpožděním (denní, hodinové...) Výsledky z principu nelze poskytovat online Efektivní využití zdrojů (paměť, CPU) Zpracuje enormní množství libovolných dat (petabajty) Hadoop založen na batch zpracování Stream processing Zpracování záznam za záznamem Zaručené pořadí Zpracování ihned po příchodu zprávy nebo s malým zpožděním Výsledky jsou často dostupné online Náročnější na zdroje (paměť, CPU) Zpracování složitých dotazů na velkém množství dat nemusí být efektivní Pro Hadoop relativně nové 4
5 Messaging processor
 distribuovaný zajišťuje replikaci dat nevyžívá HDFS, má vlastní způsob ukládání dat schopnost řešit výpadky v clusteru škálovatelný lze snadno přidat nový node pro zvýšení")
6 Apache Kafka Distribuovaný systém pro zpracování datových streamů Typicky se používá jako messaging systém Transakční log Základní vlastnosti vysoce výkonný (zpracuje i miliony zpráv za sekundu) distribuovaný zajišťuje replikaci dat nevyžívá HDFS, má vlastní způsob ukládání dat schopnost řešit výpadky v clusteru škálovatelný lze snadno přidat nový node pro zvýšení propustnosti 6
7 Základní pojmy Topic pojmenovaná fronta zpráv Partition dělení topiku na menší části Offset aktuální pozice v topiku/paritition (orientace, kde se v topiku nacházíme) Consumer odběratel dat Consumer Group skupina odběratelů dat Producer tvůrce dat 7
8 Základní pojmy 8
9 Základní pojmy 9
10 Základní pojmy 10

11 Zápis a čtení broker 1 P1 P3 producer broker 2 P2 P3 broker 3 P2 P1 consumer Kafka cluster P1 P2 leader follower 11
12 12
13 Pořadí zpráv v Kafce Pořadí zpráv garance doručení zpráv v pořadí, v jakém byly zapsány per partition ale ne v rámci všech zpráv daného topiku! Standardně se zprávy rozdělují rovnoměrně mezi jednotlivé partitions (náhodně) Typicky ale potřebuji zajistit pořadí zpráv jen např. pro klienta, zařízení... možnost definovat vlastní pravidla partitioningu 13
14 Další možnosti Kafky Komprese zpráv Automatická retence zpráv staré zprávy automaticky maže po uplynutí definovaného období Obsahuje vlastní systém pro zpracování streamů Kafka Streams KSQL SQL-like jazyk pro přístup k datům Kafky Základní transakční zpracování consumer commituje poslední zpracovaný offset 14
15 Použití Kafky Všude tam, kde se komunikuje prostřednictvím zpráv, tj. skoro všude senzorická data finanční transakce burzovní informace logy Kappa architektura Kafka nabízí velkou propustnost a robustnost, ale někdy za cenu vyšších latencí obecně je třeba počítat s desítkami ms latencí jako minimum lze optimalizovat na úkor propustnosti a bezpečnosti (konzistence) dat 15
16 Stream processor
17 Charakteristiky streamového zpracování Stream je analogie ( nekonečné ) tabulky Streamy lze partitionovat paralelizace Streamy je možné číst zapisovat joinovat Často je potřeba udržovat stav (typicky agreace) např. suma obratů na účtu, průměrná hodnota konkrétního senzoru... Práce s časovými okny vyhodnocování úseků dat

18 Časová okna Délka okna Interval posunu jak často se okno posouvá Mohou se překrývat! Příklad délka okna 3s interval posunu 2s
19 Časová okna Většina transformací probíhá právě s oknem (typicky nás nezajímají libovolně stará data) Příklady akciové/bitcoinové trhy výpočty klouzavého průměru, např. délka okna 5min posun intervalu 1min detekce událostí zjišťuji, zda v intervalu nenastaly události společně, např. zjišťujeme, zda se průměr a medián liší v daném okně o více než 10% délka okna 5min posun intervalu 5min
20 Druhy streamového zpracování Podle doby zpracování Real time reakce na vstupní zprávu je typicky dokončena v řádu jednotek až stovek milisekund Near-real time reakce na vstupní zprávu je typicky dokončena v řádu jednotek až desítek sekund Podle technologie zpracování zpráv Real time streaming skutečné zpracování jednotlivých zpráv, jak přicházejí jedna za druhou Micro-batches sekvenční spouštění malých dávek, tj. nezpracovávají se zprávy ihned po příchodu, ale nejprve se nahromadí malá množina dat a ta se zpracuje jako celek
21 Real time streaming vs micro batches Real time streaming každá zpráva je zpracována nezávisle Micro batches zprávy jsou zpracovány v (malých) dávkách najednou
 neustále se zlepšuje Vyžaduje pro realtime zpracování")

22 Real time streaming vs micro batches Zpracování záznamu po záznamu Minimální latence Menší prostupnost (průměrný počet zpráv za sekundu) neustále se zlepšuje Vyžaduje pro realtime zpracování a batch zpracování samostatný kód Zpracování množství záznamů najednou Latence nejméně délka batch Typicky vyšší prostupnost Lze použít stejný kód pro streamové zpracování micro batches i pro velké batches 22
23 Streamové zpracování - architektura Vstup Enrich Výstup Obohacovací data (externí zdroj)
24 Streamové zpracování - architektura Vstup Enrich Výstup Obohacovací data Převádíme externí data na stream (tj. lokální cache) Obohacovací data (externí zdroj)
25 Sémantiky streamového zpracování Exactly once za každých okolností zajistíme, že zpráva bude doručena vyžaduje nějaký způsob checkpointování, aby se dalo zjistit, jaké zprávy byly zpracování, v případě, že dojde k havárii procesu At least once zpráva se může doručit více než jednou velmi častý kompromis At most once zprávu nikdy nedoručíme opakovaně, může také nastat, že zpráva bude zcela ztracena pouze pro nedůležitá data/data, která brzy ztrácejí cenu 25
26 Idempotence Nástroje pro stream zpracování obsahují možnosti, jak zajistit exactly once sémantiku v rámci jednoho procesu Ale je velmi složité zajistit toto v rámci více návazných procesů! Idempotence je takové chování, kdy opětovné doručení totožné zprávy nezmění stav systému Jak to řešit? Např. pokud jediný výstup je databáze (HBase) Doručení již existující zprávy způsobí uložení identických dat pod stejným klíčem (tj. systém není dotknut) 26
27 Používané nástroj Apache Spark Streaming pouze microbatche a velké batche Apache Flink real time streaming, podporuje i čistě batchové zpracování Apache Storm real time streaming Kafka Streams 27
28 Korektní průběh zpracování 28
29 Kumulace zpoždění 29

30 Úložiště - HBase
31 HBase NoSQL databáze dotazování de facto programaticky (Java), žádný vhodný SQL jazyk nemá Key/value storage vhodná konstrukce klíče je základ pro použití HBase! Ukládá data na HDFS Velmi rychlý přístup k datům podle klíče na rozdíl Impala a Hive random access! Velmi pomalý full scan Velmi dobrá horizontální škálovatelnost cca dotazů za sekundu per node Je třeba detailní znalost, při velkém množství dat je třeba správně nakonfigurovat Zajímavost: Využívá Facebook pro messaging 31
32 HBase data model Table Row pro každý jednoznačný klíč Column Family sloupce v jedné Column Family jsou vždy ukládány společně naopak, velká data (např. obrázky), která se načítají zřídka, lze dát do jiné Column Family a omezit tím množství čtených dat Column Version HBase neobsahuje datové typy! 32
33 Operace Get Put načtení záznamu podle klíče uložení záznamu Scan sekvenční načítání dat daného rozsahu klíčů nebo všech dat 33
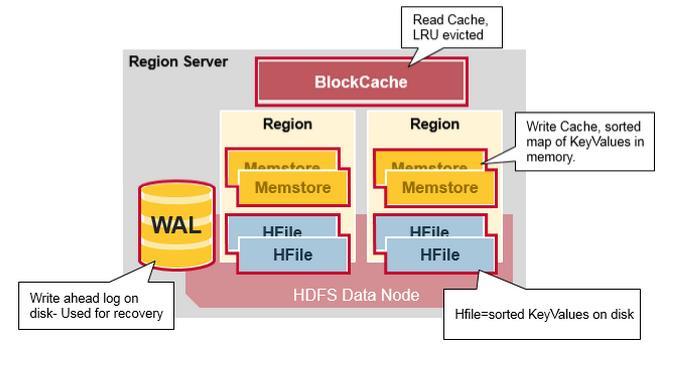
34 HBase architektura 34
35 HBase použití Vhodné použití jednoduché dotazy, hodně jednoduchých dotazů více se čte, než zapisuje odpověď je třeba velmi rychle (stovky ms) k datům se přistupuje jen podle klíče, příp. počáteční části klíče není třeba načítat velké množství dat sekvenčně Nevhodné analytické dotazy průchod daty/scan pouze zápisy (nebo nepoměrně mnoho zápisů vůči čtení) Základem je konstrukce klíče, podle kterého se dotazuje Lze použít tam, kde je jasně definovaný use-case na HBase nelze snadno stavět obecná/flexibilní řešení 35


36 HBase příklad Column family skupina sloupců, které spolu souvisí často se načítají společně zajištěno, že v HDFS jsou uloženy společně 36
37 HBase příklad public class RetriveData{ public static void main(string[] args) throws IOException, Exception{ // Instantiating Configuration class Configuration config = HBaseConfiguration.create(); // Instantiating HTable class HTable table = new HTable(config, "cli"); // Instantiating Get class Get g = new Get(Bytes.toBytes("stack@apache.org")); // Reading the data Result result = table.get(g); // Reading values from Result class object byte [] value = result.getvalue(bytes.tobytes("user_data"),bytes.tobytes("lname")); } } 37

38 Diskuze 38

39 Díky za pozornost Profinit EU, s.r.o. Tychonova 2, Praha 6 Telefon Web LinkedIn Twitter Facebook Youtube linkedin.com/company/profinit twitter.com/profinit_eu facebook.com/profinit.eu Profinit EU
B0M33BDT Technologie pro velká data. Storage
 B0M33BDT Technologie pro velká data Storage Milan Kratochvíl 25.10.2017 Motivace Jak efektivně ukládat data v Hadoop ekosystému? formát ukládání dat a jejich komprese možnost paralelně zpracovávat na mnoha
B0M33BDT Technologie pro velká data Storage Milan Kratochvíl 25.10.2017 Motivace Jak efektivně ukládat data v Hadoop ekosystému? formát ukládání dat a jejich komprese možnost paralelně zpracovávat na mnoha
B0M33BDT 7. přednáška Architektury a bezpečnost. Marek Sušický Milan Kratochvíl
 B0M33BDT 7. přednáška Architektury a bezpečnost Marek Sušický Milan Kratochvíl 5. prosinec 2018 Osnova Něco ze života Architektury Hadoop Lambda Kappa Zetta Security a dopady do architektury 2 Jak vypadá
B0M33BDT 7. přednáška Architektury a bezpečnost Marek Sušický Milan Kratochvíl 5. prosinec 2018 Osnova Něco ze života Architektury Hadoop Lambda Kappa Zetta Security a dopady do architektury 2 Jak vypadá
BigData. Marek Sušický
 BigData Marek Sušický 28. Únoru 2017 Osnova Big data a Hadoop Na jakém hardware + sizing Jak vypadá cluster - architektura HDFS Distribuce Komponenty YARN, správa zdrojů 2 Big data neznamená Hadoop 3 Apache
BigData Marek Sušický 28. Únoru 2017 Osnova Big data a Hadoop Na jakém hardware + sizing Jak vypadá cluster - architektura HDFS Distribuce Komponenty YARN, správa zdrojů 2 Big data neznamená Hadoop 3 Apache
Spark SQL, Spark Streaming. Jan Hučín
 Spark SQL, Spark Streaming Jan Hučín 21. listopadu 2018 Osnova 1. Spark SQL 2. Další rozšíření Sparku Spark streaming GraphX Spark ML 2 Spark SQL Spark SQL a DataFrames (DataSets) Rozšíření k tradičnímu
Spark SQL, Spark Streaming Jan Hučín 21. listopadu 2018 Osnova 1. Spark SQL 2. Další rozšíření Sparku Spark streaming GraphX Spark ML 2 Spark SQL Spark SQL a DataFrames (DataSets) Rozšíření k tradičnímu
Spark SQL, Spark Streaming. Jan Hučín
 Spark SQL, Spark Streaming Jan Hučín 22. listopadu 2017 Osnova 1. Spark SQL 2. Další rozšíření Sparku Spark streaming GraphX Spark ML 2 Spark SQL Spark SQL a DataFrames (DataSets) Rozšíření k tradičnímu
Spark SQL, Spark Streaming Jan Hučín 22. listopadu 2017 Osnova 1. Spark SQL 2. Další rozšíření Sparku Spark streaming GraphX Spark ML 2 Spark SQL Spark SQL a DataFrames (DataSets) Rozšíření k tradičnímu
Hadoop a HDFS. Bc. Milan Nikl
 3.12.2013 Hadoop a HDFS Bc. Milan Nikl Co je Hadoop: Open-Source Framework Vyvíjený Apache Software Foundation Pro ukládání a zpracovávání velkých objemů dat Big Data trojrozměrný růst dat (3V) Objem (Volume)
3.12.2013 Hadoop a HDFS Bc. Milan Nikl Co je Hadoop: Open-Source Framework Vyvíjený Apache Software Foundation Pro ukládání a zpracovávání velkých objemů dat Big Data trojrozměrný růst dat (3V) Objem (Volume)
B0M33BDT Technologie pro velká data. Storage
 B0M33BDT Technologie pro velká data Storage Milan Kratochvíl 24.10.2018 Motivace Jak efektivně ukládat data v Hadoop ekosystému? formát ukládání dat a jejich komprese možnost paralelně zpracovávat na mnoha
B0M33BDT Technologie pro velká data Storage Milan Kratochvíl 24.10.2018 Motivace Jak efektivně ukládat data v Hadoop ekosystému? formát ukládání dat a jejich komprese možnost paralelně zpracovávat na mnoha
B0M33BDT Technologie pro velká data. Supercvičení SQL, Python, Linux
 B0M33BDT Technologie pro velká data Supercvičení SQL, Python, Linux Sergej Stamenov, Jan Hučín 18. 10. 2017 Osnova cvičení Linux SQL Python 2 SQL pro uživatele aneb co potřebuje znát a umět bigdatový uživatel:
B0M33BDT Technologie pro velká data Supercvičení SQL, Python, Linux Sergej Stamenov, Jan Hučín 18. 10. 2017 Osnova cvičení Linux SQL Python 2 SQL pro uživatele aneb co potřebuje znát a umět bigdatový uživatel:
A4M33BDT Technologie pro velká data
 A4M33BDT Technologie pro velká data Milan Kratochvíl 22. března 2017 MapReduce 3 MapReduce Paradigma/framework/programovací model pro distribuované paralelní výpočty Princip: MAP vstupní data ve formátu
A4M33BDT Technologie pro velká data Milan Kratochvíl 22. března 2017 MapReduce 3 MapReduce Paradigma/framework/programovací model pro distribuované paralelní výpočty Princip: MAP vstupní data ve formátu
Návrh architektury škálovatelné cloudové služby aneb nespalte se v cloudu. Mgr. David Gešvindr MCSE: Data Platform MCT MSP
 Návrh architektury škálovatelné cloudové služby aneb nespalte se v cloudu Mgr. David Gešvindr MCSE: Data Platform MCT MSP david@wug.cz Motto Běžná webová aplikace navržená pro provoz na vlastním serveru
Návrh architektury škálovatelné cloudové služby aneb nespalte se v cloudu Mgr. David Gešvindr MCSE: Data Platform MCT MSP david@wug.cz Motto Běžná webová aplikace navržená pro provoz na vlastním serveru
Spark Jan Hučín 15. listopadu 2017
 Spark Jan Hučín 15. listopadu 2017 Osnova 1. Co to je a k čemu slouží 2. Jak se to naučit 3. Jak se s tím pracuje 4. Jak to funguje Logický a technický pohled Transformace, akce, kešování Příklady Architektura
Spark Jan Hučín 15. listopadu 2017 Osnova 1. Co to je a k čemu slouží 2. Jak se to naučit 3. Jak se s tím pracuje 4. Jak to funguje Logický a technický pohled Transformace, akce, kešování Příklady Architektura
UAI/612 - Cloudová Řešení. Technologie
 UAI/612 - Cloudová Řešení Technologie Rekapitulace Multitenance Bezestavovost Škálovatelnost Cachování Bezpečnost Způsoby nasazení Datová úložiště SQL databáze NoSQL databáze Cloudová datová úložiště (API)
UAI/612 - Cloudová Řešení Technologie Rekapitulace Multitenance Bezestavovost Škálovatelnost Cachování Bezpečnost Způsoby nasazení Datová úložiště SQL databáze NoSQL databáze Cloudová datová úložiště (API)
Hadoop, Hive a Spark: Využití pro data mining. Václav Zeman, KIZI VŠE
 Hadoop, Hive a Spark: Využití pro data mining Václav Zeman, KIZI VŠE VŠE: Katedra informačního a znalostního inženýrství Hlavní činnosti: Data Mining a Machine Learning Nástroje: LispMiner a EasyMiner
Hadoop, Hive a Spark: Využití pro data mining Václav Zeman, KIZI VŠE VŠE: Katedra informačního a znalostního inženýrství Hlavní činnosti: Data Mining a Machine Learning Nástroje: LispMiner a EasyMiner
Open Source projekty pro Big Data
 Open Source projekty pro Big Data Leo Galamboš LG@HQ.EGOTHOR.ORG Řešení pro velká data Oblasti 1. ukládání dat 2. zpracování dat 3. analýza dat (Dobrá zpráva) OSS řešení nyní pokrývají všechny oblasti
Open Source projekty pro Big Data Leo Galamboš LG@HQ.EGOTHOR.ORG Řešení pro velká data Oblasti 1. ukládání dat 2. zpracování dat 3. analýza dat (Dobrá zpráva) OSS řešení nyní pokrývají všechny oblasti
BIG DATA je oveľa viac ako Hadoop. Martin Pavlík
 BIG DATA je oveľa viac ako Hadoop Martin Pavlík Analýza všech dostupných dat? Big data =? = Buzzword? = Hadoop? Hadoop Jen ke zpracování nestrukturovaných dat? Mentální posun něco za něco 2 Big data =
BIG DATA je oveľa viac ako Hadoop Martin Pavlík Analýza všech dostupných dat? Big data =? = Buzzword? = Hadoop? Hadoop Jen ke zpracování nestrukturovaných dat? Mentální posun něco za něco 2 Big data =
Struktura pamětí a procesů v DB Oracle. Radek Strnad
 Struktura pamětí a procesů v DB Oracle Radek Strnad radek.strnad@gmail.com 1 Základní rozdělení paměti Software codes area Chráněná část spustitelného kódu samotné DB. System global area (SGA) Sdílená
Struktura pamětí a procesů v DB Oracle Radek Strnad radek.strnad@gmail.com 1 Základní rozdělení paměti Software codes area Chráněná část spustitelného kódu samotné DB. System global area (SGA) Sdílená
Novinky v Microsoft SQL Serveru RNDr. David Gešvindr MVP: Data Platform MCSE: Data Platform MCSD: Windows Store MCT
 Novinky v Microsoft SQL Serveru 2016 RNDr. David Gešvindr MVP: Data Platform MCSE: Data Platform MCSD: Windows Store MCT david@wug.cz @gesvindr Přehled hlavních novinek Výkon Query Store Temporal Tables
Novinky v Microsoft SQL Serveru 2016 RNDr. David Gešvindr MVP: Data Platform MCSE: Data Platform MCSD: Windows Store MCT david@wug.cz @gesvindr Přehled hlavních novinek Výkon Query Store Temporal Tables
Oracle XML DB. Tomáš Nykodým
 Oracle XML DB Tomáš Nykodým xnykodym@fi.muni.cz Osnova Oracle XML DB Architektura Oracle XML DB Hlavní rysy Oracle XML DB Hlavní rysy Oracle XML DB - pokračování XMLType XML Repository Využívání databázových
Oracle XML DB Tomáš Nykodým xnykodym@fi.muni.cz Osnova Oracle XML DB Architektura Oracle XML DB Hlavní rysy Oracle XML DB Hlavní rysy Oracle XML DB - pokračování XMLType XML Repository Využívání databázových
Architektura softwarových systémů
 Architektura softwarových systémů Ing. Jiří Mlejnek Katedra softwarového inženýrství Fakulta informačních technologií České vysoké učení technické v Praze Jiří Mlejnek, 2011 jiri.mlejnek@fit.cvut.cz Softwarové
Architektura softwarových systémů Ing. Jiří Mlejnek Katedra softwarového inženýrství Fakulta informačních technologií České vysoké učení technické v Praze Jiří Mlejnek, 2011 jiri.mlejnek@fit.cvut.cz Softwarové
Spark Jan Hučín 5. dubna 2017
 Spark Jan Hučín 5. dubna 2017 Osnova 1. Co to je a k čemu slouží 2. Jak se to naučit 3. Jak se s tím pracuje 4. Jak to funguje Logický a technický pohled Transformace, akce, kešování Příklady Nadstavby
Spark Jan Hučín 5. dubna 2017 Osnova 1. Co to je a k čemu slouží 2. Jak se to naučit 3. Jak se s tím pracuje 4. Jak to funguje Logický a technický pohled Transformace, akce, kešování Příklady Nadstavby
BIG DATA. Nové úlohy pro nástroje v oblasti BI. 27. listopadu 2012
 BIG DATA Nové úlohy pro nástroje v oblasti BI 27. listopadu 2012 AGENDA 1. Úvod 2. Jaké jsou potřeby? 3. Možné řešení 2 Jaké jsou potřeby? Dopady Analýza dat potřeba nového přístupu Jak na nestrukturovaná
BIG DATA Nové úlohy pro nástroje v oblasti BI 27. listopadu 2012 AGENDA 1. Úvod 2. Jaké jsou potřeby? 3. Možné řešení 2 Jaké jsou potřeby? Dopady Analýza dat potřeba nového přístupu Jak na nestrukturovaná
Healtcheck. databáze ORCL běžící na serveru db.tomas-solar.com pro
 Ukázka doporučení z health checku zaměřeného na PERFORMANCE. Neobsahuje veškeré podkladové materiály, proto i obsah píše špatné odkazy. Healtcheck databáze ORCL běžící na serveru db.tomas-solar.com pro
Ukázka doporučení z health checku zaměřeného na PERFORMANCE. Neobsahuje veškeré podkladové materiály, proto i obsah píše špatné odkazy. Healtcheck databáze ORCL běžící na serveru db.tomas-solar.com pro
Databázové systémy. Doc.Ing.Miloš Koch,CSc. koch@fbm.vutbr.cz
 Databázové systémy Doc.Ing.Miloš Koch,CSc. koch@fbm.vutbr.cz Vývoj databázových systémů Ukládání dat Aktualizace dat Vyhledávání dat Třídění dat Výpočty a agregace 60.-70. léta Program Komunikace Výpočty
Databázové systémy Doc.Ing.Miloš Koch,CSc. koch@fbm.vutbr.cz Vývoj databázových systémů Ukládání dat Aktualizace dat Vyhledávání dat Třídění dat Výpočty a agregace 60.-70. léta Program Komunikace Výpočty
RNDr. Michal Kopecký, Ph.D. Department of Software Engineering, Faculty of Mathematics and Physics, Charles University in Prague
 seminář: Administrace Oracle (NDBI013) LS2017/18 RNDr. Michal Kopecký, Ph.D. Department of Software Engineering, Faculty of Mathematics and Physics, Charles University in Prague Zvyšuje výkon databáze
seminář: Administrace Oracle (NDBI013) LS2017/18 RNDr. Michal Kopecký, Ph.D. Department of Software Engineering, Faculty of Mathematics and Physics, Charles University in Prague Zvyšuje výkon databáze
Využití ICT pro rozvoj klíčových kompetencí CZ.1.07/1.5.00/
 Střední odborná škola elektrotechnická, Centrum odborné přípravy Zvolenovská 537, Hluboká nad Vltavou Využití ICT pro rozvoj klíčových kompetencí CZ.1.07/1.5.00/34.0448 CZ.1.07/1.5.00/34.0448 1 Číslo projektu
Střední odborná škola elektrotechnická, Centrum odborné přípravy Zvolenovská 537, Hluboká nad Vltavou Využití ICT pro rozvoj klíčových kompetencí CZ.1.07/1.5.00/34.0448 CZ.1.07/1.5.00/34.0448 1 Číslo projektu
Enterprise funkce SQL Serveru 2016, které jsou od SP1 zdarma
 Enterprise funkce SQL Serveru 2016, které jsou od SP1 zdarma RNDr. David Gešvindr MVP: Data Platform MCSE: Data Platform MCSD: Windows Store MCT david@wug.cz @gesvindr SQL Server 2016 Service Pack 1 Vydán
Enterprise funkce SQL Serveru 2016, které jsou od SP1 zdarma RNDr. David Gešvindr MVP: Data Platform MCSE: Data Platform MCSD: Windows Store MCT david@wug.cz @gesvindr SQL Server 2016 Service Pack 1 Vydán
Replikace je proces kopírování a udržování databázových objektů, které tvoří distribuovaný databázový systém. Změny aplikované na jednu část jsou
 Administrace Oracle Replikace je proces kopírování a udržování databázových objektů, které tvoří distribuovaný databázový systém. Změny aplikované na jednu část jsou zachyceny a uloženy lokálně před posláním
Administrace Oracle Replikace je proces kopírování a udržování databázových objektů, které tvoří distribuovaný databázový systém. Změny aplikované na jednu část jsou zachyceny a uloženy lokálně před posláním
Analytické systémy nad Hadoopom. Lukáš Antalov, Vedoucí týmu vývoje
 Analytické systémy nad Hadoopom Lukáš Antalov, Vedoucí týmu vývoje Outline Big Data Hadoop Štatistiky Sklik.cz Webová analytika Big Data Big Data sú všade 200 Londýnskych dopravných kamier 8 TB / deň Približný
Analytické systémy nad Hadoopom Lukáš Antalov, Vedoucí týmu vývoje Outline Big Data Hadoop Štatistiky Sklik.cz Webová analytika Big Data Big Data sú všade 200 Londýnskych dopravných kamier 8 TB / deň Približný
Databáze II. 1. přednáška. Helena Palovská palovska@vse.cz
 Databáze II 1. přednáška Helena Palovská palovska@vse.cz Program přednášky Úvod Třívrstvá architektura a O-R mapování Zabezpečení dat Role a přístupová práva Úvod Co je databáze Mnoho dat Organizovaných
Databáze II 1. přednáška Helena Palovská palovska@vse.cz Program přednášky Úvod Třívrstvá architektura a O-R mapování Zabezpečení dat Role a přístupová práva Úvod Co je databáze Mnoho dat Organizovaných
Analýza a modelování dat 6. přednáška. Helena Palovská
 Analýza a modelování dat 6. přednáška Helena Palovská Historie databázových modelů Jak je řešena temporalita? Temporalita v databázích Možnosti pro platnost faktu (valid time): platí nyní, je to aktuální
Analýza a modelování dat 6. přednáška Helena Palovská Historie databázových modelů Jak je řešena temporalita? Temporalita v databázích Možnosti pro platnost faktu (valid time): platí nyní, je to aktuální
TimescaleDB. Pavel Stěhule 2018
 TimescaleDB Pavel Stěhule 2018 O výkonu rozhodují Algoritmy Datové struktury 80-90 léta - vize univerzálních SQL databází Po roce 2000 - specializované databáze Relační SQL databáze Běžně optimalizována
TimescaleDB Pavel Stěhule 2018 O výkonu rozhodují Algoritmy Datové struktury 80-90 léta - vize univerzálních SQL databází Po roce 2000 - specializované databáze Relační SQL databáze Běžně optimalizována
Algoritmizace a programování
 Algoritmizace a programování Řídicí struktury jazyka Java Struktura programu Příkazy jazyka Blok příkazů Logické příkazy Ternární logický operátor Verze pro akademický rok 2012/2013 1 Struktura programu
Algoritmizace a programování Řídicí struktury jazyka Java Struktura programu Příkazy jazyka Blok příkazů Logické příkazy Ternární logický operátor Verze pro akademický rok 2012/2013 1 Struktura programu
Load Balancer. RNDr. Václav Petříček. Lukáš Hlůže Václav Nidrle Přemysl Volf Stanislav Živný
 Load Balancer RNDr. Václav Petříček Lukáš Hlůže Václav Nidrle Přemysl Volf Stanislav Živný 1.4.2005 Co je Load Balancer Nástroj pro zvýšení výkonnosti serverů Virtuální server skrývající farmu skutečných
Load Balancer RNDr. Václav Petříček Lukáš Hlůže Václav Nidrle Přemysl Volf Stanislav Živný 1.4.2005 Co je Load Balancer Nástroj pro zvýšení výkonnosti serverů Virtuální server skrývající farmu skutečných
Cílem kapitoly je seznámit studenta s pamětmi. Jejich minulostí, současností a hlavnímu parametry.
 Paměti Cílem kapitoly je seznámit studenta s pamětmi. Jejich minulostí, současností a hlavnímu parametry. Klíčové pojmy: paměť, RAM, rozdělení pamětí, ROM, vnitřní paměť, vnější paměť. Úvod Operační paměť
Paměti Cílem kapitoly je seznámit studenta s pamětmi. Jejich minulostí, současností a hlavnímu parametry. Klíčové pojmy: paměť, RAM, rozdělení pamětí, ROM, vnitřní paměť, vnější paměť. Úvod Operační paměť
SUPERPOČÍTAČE DANIEL LANGR ČVUT FIT / VZLÚ
 SUPERPOČÍTAČE DANIEL LANGR ČVUT FIT / VZLÚ TITAN / HOPPER / NOTEBOOK TITAN HOPPER NOTEBOOK Počet CPU jader 299 008 153 216 2 Operační paměť [GB] 598 016 217 000 8 Počet GPU (CUDA) jader 50 233 344 0 8
SUPERPOČÍTAČE DANIEL LANGR ČVUT FIT / VZLÚ TITAN / HOPPER / NOTEBOOK TITAN HOPPER NOTEBOOK Počet CPU jader 299 008 153 216 2 Operační paměť [GB] 598 016 217 000 8 Počet GPU (CUDA) jader 50 233 344 0 8
Bi-Direction Replication
 Bi-Direction Replication P2D2 2015 Petr Jelínek, 2ndQuadrant (petr@2ndquadrant.com) BDR Bi-Directional Replication Je možné zapisovat na všech serverech Asynchronní Nízká latence (zápisu) Tolerance ke
Bi-Direction Replication P2D2 2015 Petr Jelínek, 2ndQuadrant (petr@2ndquadrant.com) BDR Bi-Directional Replication Je možné zapisovat na všech serverech Asynchronní Nízká latence (zápisu) Tolerance ke
Paměti. Paměť je zařízení, které slouží k ukládání programů a dat, s nimiž počítač pracuje
 Paměti Paměť je zařízení, které slouží k ukládání programů a dat, s nimiž počítač pracuje Paměti počítače lze rozdělit do tří základních skupin: registry paměťová místa na čipu procesoru jsou používány
Paměti Paměť je zařízení, které slouží k ukládání programů a dat, s nimiž počítač pracuje Paměti počítače lze rozdělit do tří základních skupin: registry paměťová místa na čipu procesoru jsou používány
Webové služby a XML. Obsah přednášky. Co jsou to webové služby. Co jsou to webové služby. Webové služby a XML
 Obsah přednášky Webové služby a XML Miroslav Beneš Co jsou to webové služby Architektura webových služeb SOAP SOAP a Java SOAP a PHP SOAP a C# Webové služby a XML 2 Co jsou to webové služby rozhraní k
Obsah přednášky Webové služby a XML Miroslav Beneš Co jsou to webové služby Architektura webových služeb SOAP SOAP a Java SOAP a PHP SOAP a C# Webové služby a XML 2 Co jsou to webové služby rozhraní k
Java a XML. 10/26/09 1/7 Java a XML
 Java a XML Java i XML jsou přenositelné V javě existuje podpora pro práci s XML, nejčastější akce prováděné při zpracování XML: načítání XML elementů generování nových elementů nebo úprava starého zápis
Java a XML Java i XML jsou přenositelné V javě existuje podpora pro práci s XML, nejčastější akce prováděné při zpracování XML: načítání XML elementů generování nových elementů nebo úprava starého zápis
Základy databází. O autorech 17 PRVNÍ ČÁST. KAPITOLA 1 Začínáme 19
 3 Obsah Novinky v tomto vydání 10 Význam základních principů 11 Výuka principů nezávisle na databázových produktech 12 Klíčové pojmy, kontrolní otázky, cvičení, případové studie a projekty 12 Software,
3 Obsah Novinky v tomto vydání 10 Význam základních principů 11 Výuka principů nezávisle na databázových produktech 12 Klíčové pojmy, kontrolní otázky, cvičení, případové studie a projekty 12 Software,
Implementace dávkových operací
 Implementace dávkových operací Petr Steckovič 12. 5. 2011 Hradec Králové 1 Dávkové zpracování dat Procesy běžící na pozadí Spouštěné Časem Stavem (např. dochází místo) Ručně Obvykle se jedná o podpůrné
Implementace dávkových operací Petr Steckovič 12. 5. 2011 Hradec Králové 1 Dávkové zpracování dat Procesy běžící na pozadí Spouštěné Časem Stavem (např. dochází místo) Ručně Obvykle se jedná o podpůrné
Základy programovaní 3 - Java. Unit testy. Petr Krajča. Katedra informatiky Univerzita Palackého v Olomouci. 26.,27.
 Základy programovaní 3 - Java Unit testy Petr Krajča Katedra informatiky Univerzita Palackého v Olomouci 26.,27. listopad, 2014 Petr Krajča (UP) Unit testy 26.,27. listopad, 2014 1 / 14 Testování zásadní
Základy programovaní 3 - Java Unit testy Petr Krajča Katedra informatiky Univerzita Palackého v Olomouci 26.,27. listopad, 2014 Petr Krajča (UP) Unit testy 26.,27. listopad, 2014 1 / 14 Testování zásadní
Použití databází na Webu
 4IZ228 tvorba webových stránek a aplikací Jirka Kosek Poslední modifikace: $Date: 2010/11/18 11:33:52 $ Obsah Co nás čeká... 3 Architektura webových databázových aplikací... 4 K čemu se používají databázové
4IZ228 tvorba webových stránek a aplikací Jirka Kosek Poslední modifikace: $Date: 2010/11/18 11:33:52 $ Obsah Co nás čeká... 3 Architektura webových databázových aplikací... 4 K čemu se používají databázové
Softwarový proces Martin Hlavatý 4. říjen 2018
 Softwarový proces Martin Hlavatý 4. říjen 2018 Úvod Základní pojmy Softwarový proces / Model životního cyklu vývoje software (SDLC, Software Development Lifecycle) Množina aktivit nutných k tomu, aby software
Softwarový proces Martin Hlavatý 4. říjen 2018 Úvod Základní pojmy Softwarový proces / Model životního cyklu vývoje software (SDLC, Software Development Lifecycle) Množina aktivit nutných k tomu, aby software
Anotace a Hibernate. Aleš Nosek Ondřej Vadinský Daniel Krátký
 Anotace a Hibernate Aleš Nosek Ondřej Vadinský Daniel Krátký Anotace v Javě novinka Javy 5 umožňují k Java kódu přidávat dodatečné informace (podobně jako JavaDoc) za předchůdce anotací je možné považovat
Anotace a Hibernate Aleš Nosek Ondřej Vadinský Daniel Krátký Anotace v Javě novinka Javy 5 umožňují k Java kódu přidávat dodatečné informace (podobně jako JavaDoc) za předchůdce anotací je možné považovat
Optimalizace dotazů a databázové transakce v Oracle
 Optimalizace dotazů a databázové transakce v Oracle Marek Rychlý Vysoké učení technické v Brně Fakulta informačních technologií Ústav informačních systémů Demo-cvičení pro IDS 22. dubna 2015 Marek Rychlý
Optimalizace dotazů a databázové transakce v Oracle Marek Rychlý Vysoké učení technické v Brně Fakulta informačních technologií Ústav informačních systémů Demo-cvičení pro IDS 22. dubna 2015 Marek Rychlý
George J. Klir. State University of New York (SUNY) Binghamton, New York 13902, USA gklir@binghamton.edu
 Binghamton, New York 13902, USA gklir@binghamton.edu") A Tutorial Advances in query languages for similarity-based databases George J. Klir Petr Krajča State University of New York (SUNY) Binghamton, New York 13902, USA gklir@binghamton.edu Palacky University,
A Tutorial Advances in query languages for similarity-based databases George J. Klir Petr Krajča State University of New York (SUNY) Binghamton, New York 13902, USA gklir@binghamton.edu Palacky University,
Informační systémy 2008/2009. Radim Farana. Obsah. Základní principy XML
 10 Vysoká škola báňská Technická univerzita Ostrava Fakulta strojní, Katedra automatizační techniky a řízení 2008/2009 Radim Farana 1 Obsah Export a import dat Formát XML a SQL server Zálohování a obnova
10 Vysoká škola báňská Technická univerzita Ostrava Fakulta strojní, Katedra automatizační techniky a řízení 2008/2009 Radim Farana 1 Obsah Export a import dat Formát XML a SQL server Zálohování a obnova
RadioBase 3 Databázový subsystém pro správu dat vysílačů plošného pokrytí
 Databázový subsystém pro správu dat vysílačů plošného pokrytí RadioBase je datový subsystém pro ukládání a správu dat vysílačů plošného pokrytí zejména pro služby analogové a digitální televize a rozhlasu.
Databázový subsystém pro správu dat vysílačů plošného pokrytí RadioBase je datový subsystém pro ukládání a správu dat vysílačů plošného pokrytí zejména pro služby analogové a digitální televize a rozhlasu.
Vhodnost nasazení jednotlivých webových architektur, sdílení dat, perzistence, webové služby a REST, asynchronnost, messaging
 Vhodnost nasazení jednotlivých webových architektur, sdílení dat, perzistence, webové služby a REST, asynchronnost, messaging 1. Vhodnost nasazení jednotlivých webových architektur - toto je podle Klímy
Vhodnost nasazení jednotlivých webových architektur, sdílení dat, perzistence, webové služby a REST, asynchronnost, messaging 1. Vhodnost nasazení jednotlivých webových architektur - toto je podle Klímy
PB002 Základy informačních technologií
 Operační systémy 25. září 2012 Struktura přednašky 1 Číselné soustavy 2 Reprezentace čísel 3 Operační systémy historie 4 OS - základní složky 5 Procesy Číselné soustavy 1 Dle základu: dvojková, osmičková,
Operační systémy 25. září 2012 Struktura přednašky 1 Číselné soustavy 2 Reprezentace čísel 3 Operační systémy historie 4 OS - základní složky 5 Procesy Číselné soustavy 1 Dle základu: dvojková, osmičková,
OPS Paralelní systémy, seznam pojmů, klasifikace
 Moorův zákon (polovina 60. let) : Výpočetní výkon a počet tranzistorů na jeden CPU chip integrovaného obvodu mikroprocesoru se každý jeden až dva roky zdvojnásobí; cena se zmenší na polovinu. Paralelismus
Moorův zákon (polovina 60. let) : Výpočetní výkon a počet tranzistorů na jeden CPU chip integrovaného obvodu mikroprocesoru se každý jeden až dva roky zdvojnásobí; cena se zmenší na polovinu. Paralelismus
Souborové systémy a práce s daty David Antoš
 Souborové systémy a práce s daty David Antoš antos@ics.muni.cz Úvod obecný úvod do síťových souborových systémů souborové systémy v MetaCentru jejich použití práce s nimi praktické poznámky kvóty efektivní
Souborové systémy a práce s daty David Antoš antos@ics.muni.cz Úvod obecný úvod do síťových souborových systémů souborové systémy v MetaCentru jejich použití práce s nimi praktické poznámky kvóty efektivní
B Organizace databáze na fyzické úrovni u serveru Oracle
 B Organizace databáze na fyzické úrovni u serveru Oracle B.1. Základní koncepty... 2 B.2. Možnosti rozšíření prostoru databáze... 9 B.3. Indexování a shlukování... 12 Literatura... 16 J. Zendulka: Databázové
B Organizace databáze na fyzické úrovni u serveru Oracle B.1. Základní koncepty... 2 B.2. Možnosti rozšíření prostoru databáze... 9 B.3. Indexování a shlukování... 12 Literatura... 16 J. Zendulka: Databázové
1 Osobní počítač Obecně o počítačích Technické a programové vybavení... 4
 1 Osobní počítač... 2 1.1 Architektura IBM PC... 2 2 Obecně o počítačích... 3 2.1 Co jsou počítače dnes... 3 3 Technické a programové vybavení... 4 3.1 Hardware... 4 3.1.1 Procesor... 4 3.1.2 Sběrnice...
1 Osobní počítač... 2 1.1 Architektura IBM PC... 2 2 Obecně o počítačích... 3 2.1 Co jsou počítače dnes... 3 3 Technické a programové vybavení... 4 3.1 Hardware... 4 3.1.1 Procesor... 4 3.1.2 Sběrnice...
Konzistentnost. Přednášky z distribuovaných systémů
 Konzistentnost Přednášky z distribuovaných systémů Pro a proti replikaci 1. Zvýšení spolehlivosti. 2. Zvýšení výkonnosti. 3. Nutnost zachování škálovatelnosti systému co do počtu komponent i geografické
Konzistentnost Přednášky z distribuovaných systémů Pro a proti replikaci 1. Zvýšení spolehlivosti. 2. Zvýšení výkonnosti. 3. Nutnost zachování škálovatelnosti systému co do počtu komponent i geografické
Microsoft Azure Workshop
 Miroslav Holec Developer Evangelist Microsoft MVP: Microsoft Azure, MCSD Microsoft Student Partner Lead miroslavholec.cz @miroslavholec Microsoft Azure Workshop Software Engineer HAVIT, s.r.o. Agenda ODKAZY
Miroslav Holec Developer Evangelist Microsoft MVP: Microsoft Azure, MCSD Microsoft Student Partner Lead miroslavholec.cz @miroslavholec Microsoft Azure Workshop Software Engineer HAVIT, s.r.o. Agenda ODKAZY
Netezza. Martin Pavlík. 2. Února 2011. to pravé řešení pro analytický datový sklad
 Netezza to pravé řešení pro analytický datový sklad Martin Pavlík 2. Února 2011 Co je Netezza? Napříč odvětvími Retail Telekomunikace Co Netezza dodává Vysoce výkonné appliance Firma Špičková technologie
Netezza to pravé řešení pro analytický datový sklad Martin Pavlík 2. Února 2011 Co je Netezza? Napříč odvětvími Retail Telekomunikace Co Netezza dodává Vysoce výkonné appliance Firma Špičková technologie
Informační systémy 2008/2009. Radim Farana. Obsah. Obsah předmětu. Požadavky kreditového systému. Relační datový model, Architektury databází
 1 Vysoká škola báňská Technická univerzita Ostrava Fakulta strojní, Katedra automatizační techniky a řízení 2008/2009 Radim Farana 1 Obsah Požadavky kreditového systému. Relační datový model, relace, atributy,
1 Vysoká škola báňská Technická univerzita Ostrava Fakulta strojní, Katedra automatizační techniky a řízení 2008/2009 Radim Farana 1 Obsah Požadavky kreditového systému. Relační datový model, relace, atributy,
CSPUG 2011-květen. GridSQL a pg-pool II. Vratislav Beneš benes@optisolutions.cz
 GridSQL a pg-pool II Vratislav Beneš benes@optisolutions.cz Agenda 1. Datové sklady a datová tržiště 2. pg-pool II 1. Infrastrukutra 2. Využití pro datové sklady 3. GridSQL 1. Infrastuktura 2. Vytvoření
GridSQL a pg-pool II Vratislav Beneš benes@optisolutions.cz Agenda 1. Datové sklady a datová tržiště 2. pg-pool II 1. Infrastrukutra 2. Využití pro datové sklady 3. GridSQL 1. Infrastuktura 2. Vytvoření
DataDomain pod drobnohledem
 DataDomain pod drobnohledem Lukáš Slabihoudek Petr Rada 1 Agenda Popis deduplikačního procesu Stream Informed Segment Layout Ochrana dat proti poškození DD BOOST Replikace Popis důležitých HW součástí
DataDomain pod drobnohledem Lukáš Slabihoudek Petr Rada 1 Agenda Popis deduplikačního procesu Stream Informed Segment Layout Ochrana dat proti poškození DD BOOST Replikace Popis důležitých HW součástí
Operační systémy. Jednoduché stránkování. Virtuální paměť. Příklad: jednoduché stránkování. Virtuální paměť se stránkování. Memory Management Unit
 Jednoduché stránkování Operační systémy Přednáška 8: Správa paměti II Hlavní paměť rozdělená na malé úseky stejné velikosti (např. 4kB) nazývané rámce (frames). Program rozdělen na malé úseky stejné velikosti
Jednoduché stránkování Operační systémy Přednáška 8: Správa paměti II Hlavní paměť rozdělená na malé úseky stejné velikosti (např. 4kB) nazývané rámce (frames). Program rozdělen na malé úseky stejné velikosti
Michal Krátký. Úvod do programovacích jazyků (Java), 2006/2007
, 2006/2007") Úvod do programovacích jazyků (Java) Michal Krátký Katedra informatiky VŠB Technická univerzita Ostrava Úvod do programovacích jazyků (Java), 2006/2007 c 2006 Michal Krátký Úvod do programovacích jazyků
Úvod do programovacích jazyků (Java) Michal Krátký Katedra informatiky VŠB Technická univerzita Ostrava Úvod do programovacích jazyků (Java), 2006/2007 c 2006 Michal Krátký Úvod do programovacích jazyků
UAI/612 - Cloudová Řešení. Návrh aplikací pro cloud
 UAI/612 - Cloudová Řešení Návrh aplikací pro cloud Rekapitulace Cloud computing Virtualizace IaaS, PaaS, SaaS Veřejný, Privátní, Komunitní, Hybridní Motivace Návrh aplikací pro cloud Software as a Service
UAI/612 - Cloudová Řešení Návrh aplikací pro cloud Rekapitulace Cloud computing Virtualizace IaaS, PaaS, SaaS Veřejný, Privátní, Komunitní, Hybridní Motivace Návrh aplikací pro cloud Software as a Service
Jak správně navrhnout moderní a efektivní řešení pro ukládání dat
 Moderní a spolehlivá řešení pro ukládání dat Jak správně navrhnout moderní a efektivní řešení pro ukládání dat Petr Dvořák GAPP System, spol. s r.o. 2. dubna 2014 Architektura ukládání aktivních dat Typ
Moderní a spolehlivá řešení pro ukládání dat Jak správně navrhnout moderní a efektivní řešení pro ukládání dat Petr Dvořák GAPP System, spol. s r.o. 2. dubna 2014 Architektura ukládání aktivních dat Typ
MBI - technologická realizace modelu
 MBI - technologická realizace modelu 22.1.2015 MBI, Management byznys informatiky Snímek 1 Agenda Technická realizace portálu MBI. Cíle a principy technického řešení. 1.Obsah portálu - objekty v hierarchiích,
MBI - technologická realizace modelu 22.1.2015 MBI, Management byznys informatiky Snímek 1 Agenda Technická realizace portálu MBI. Cíle a principy technického řešení. 1.Obsah portálu - objekty v hierarchiích,
Databázové a informační systémy
 Databázové a informační systémy doc. Ing. Miroslav Beneš, Ph.D. katedra informatiky FEI VŠB-TUO A-1007 / 597 324 213 http://www.cs.vsb.cz/benes Miroslav.Benes@vsb.cz Obsah Jak ukládat a efektivně zpracovávat
Databázové a informační systémy doc. Ing. Miroslav Beneš, Ph.D. katedra informatiky FEI VŠB-TUO A-1007 / 597 324 213 http://www.cs.vsb.cz/benes Miroslav.Benes@vsb.cz Obsah Jak ukládat a efektivně zpracovávat
Přednášky o výpočetní technice. Hardware teoreticky. Adam Dominec 2010
 Přednášky o výpočetní technice Hardware teoreticky Adam Dominec 2010 Rozvržení Historie Procesor Paměť Základní deska přednášky o výpočetní technice Počítací stroje Mechanické počítačky se rozvíjely už
Přednášky o výpočetní technice Hardware teoreticky Adam Dominec 2010 Rozvržení Historie Procesor Paměť Základní deska přednášky o výpočetní technice Počítací stroje Mechanické počítačky se rozvíjely už
Platforma Juniper QFabric
 Platforma Juniper QFabric Matěj Čenčík (CEN027) Abstrakt: Tématem článku je princip a architektura JuniperQFabric platformy. Klíčová slova: Juniper, QFabric, Platforma, Converged services, non-blocking
Platforma Juniper QFabric Matěj Čenčík (CEN027) Abstrakt: Tématem článku je princip a architektura JuniperQFabric platformy. Klíčová slova: Juniper, QFabric, Platforma, Converged services, non-blocking
Soubor jako posloupnost bytů
 Soubory Soubor je množina údajů uložená ve vnější paměti počítače, obvykle na disku Pro soubor jsou typické tyto operace. otevření souboru čtení údaje zápis údaje uzavření souboru Přístup k údajům (čtení
Soubory Soubor je množina údajů uložená ve vnější paměti počítače, obvykle na disku Pro soubor jsou typické tyto operace. otevření souboru čtení údaje zápis údaje uzavření souboru Přístup k údajům (čtení
Pokročilé techniky tvorby sestav v Caché. ZENové Reporty
 Pokročilé techniky tvorby sestav v Caché ZENové Reporty Úvodem Jednoduché sestavy Pokročilé sestavy Ladění Historie ZEN reporty sdílejí podobný princip definování obsahu jako ZENové stránky Byly uvedeny
Pokročilé techniky tvorby sestav v Caché ZENové Reporty Úvodem Jednoduché sestavy Pokročilé sestavy Ladění Historie ZEN reporty sdílejí podobný princip definování obsahu jako ZENové stránky Byly uvedeny
Softwarový proces. Bohumír Zoubek, Tomáš Krátký
 Softwarový proces Bohumír Zoubek, Tomáš Krátký 1 Úvod Základní pojmy Softwarový proces / Model životního cyklu vývoje software (SDLC, Software Development Lifecycle) Množina aktivit nutných k tomu, aby
Softwarový proces Bohumír Zoubek, Tomáš Krátký 1 Úvod Základní pojmy Softwarový proces / Model životního cyklu vývoje software (SDLC, Software Development Lifecycle) Množina aktivit nutných k tomu, aby
8.2 Používání a tvorba databází
 8.2 Používání a tvorba databází Slide 1 8.2.1 Základní pojmy z oblasti relačních databází Slide 2 Databáze ~ Evidence lidí peněz věcí... výběry, výpisy, početní úkony Slide 3 Pojmy tabulka, pole, záznam
8.2 Používání a tvorba databází Slide 1 8.2.1 Základní pojmy z oblasti relačních databází Slide 2 Databáze ~ Evidence lidí peněz věcí... výběry, výpisy, početní úkony Slide 3 Pojmy tabulka, pole, záznam
Datová úložiště. Zdroj: IBM
 Datová úložiště Zdroj: IBM Malé ohlédnutí Malé ohlédnutí Malé ohlédnutí (?) Ukládání dat domácí Uložení na pevný disk počítače Použití pro malé objemy Typicky domácí a kancelářské použití Když záloha,
Datová úložiště Zdroj: IBM Malé ohlédnutí Malé ohlédnutí Malé ohlédnutí (?) Ukládání dat domácí Uložení na pevný disk počítače Použití pro malé objemy Typicky domácí a kancelářské použití Když záloha,
Portfolio úložišť WD pro datová centra Kapacitní úložiště prošlo vývojem
 Kapacitní úložiště, které posune váš výkon k inovacím. WD a logo WD jsou registrované ochranné známky společnosti Western Digital Technologies, Inc. v USA a dalších zemích; WD Ae, WD Re+, WD Re, WD Se,
Kapacitní úložiště, které posune váš výkon k inovacím. WD a logo WD jsou registrované ochranné známky společnosti Western Digital Technologies, Inc. v USA a dalších zemích; WD Ae, WD Re+, WD Re, WD Se,
Obecné výpočty na GPU v jazyce CUDA. Jiří Filipovič
 Obecné výpočty na GPU v jazyce CUDA Jiří Filipovič Obsah přednášky motivace architektura GPU CUDA programovací model jaké algoritmy urychlovat na GPU? optimalizace Motivace Moorův zákon stále platí pro
Obecné výpočty na GPU v jazyce CUDA Jiří Filipovič Obsah přednášky motivace architektura GPU CUDA programovací model jaké algoritmy urychlovat na GPU? optimalizace Motivace Moorův zákon stále platí pro
Aplikace. vliv na to, jakou mají strukturu i na to, jak pracné je je vyvinout. Bylo vypozorováno, že aplikace je možné rozdělit do skupin
 Aplikace Aplikace se liší tím, k jakému účelu jsou tvořeny. To má vliv na to, jakou mají strukturu i na to, jak pracné je je vyvinout. Bylo vypozorováno, že aplikace je možné rozdělit do skupin s podobnou
Aplikace Aplikace se liší tím, k jakému účelu jsou tvořeny. To má vliv na to, jakou mají strukturu i na to, jak pracné je je vyvinout. Bylo vypozorováno, že aplikace je možné rozdělit do skupin s podobnou
Tvorba informačních systémů
 Tvorba informačních systémů Michal Krátký 1, Miroslav Beneš 1 1 Katedra informatiky VŠB Technická univerzita Ostrava Tvorba informačních systémů, 2005/2006 c 2006 Michal Krátký, Miroslav Beneš Tvorba informačních
Tvorba informačních systémů Michal Krátký 1, Miroslav Beneš 1 1 Katedra informatiky VŠB Technická univerzita Ostrava Tvorba informačních systémů, 2005/2006 c 2006 Michal Krátký, Miroslav Beneš Tvorba informačních
Wonderware Historian. Příklady vícevrstvých architektur. Jiří Nikl, Tomáš Mandys Pantek (CS) s.r.o.
 s.r.o.") Wonderware Historian Příklady vícevrstvých architektur Jiří Nikl, Tomáš Mandys Pantek (CS) s.r.o. Strana 2 Wonderware Historian Server využití vícevrstvé architektury Historizační databáze Wonderware Historian
Wonderware Historian Příklady vícevrstvých architektur Jiří Nikl, Tomáš Mandys Pantek (CS) s.r.o. Strana 2 Wonderware Historian Server využití vícevrstvé architektury Historizační databáze Wonderware Historian
Základy business intelligence. Jaroslav Šmarda
 Základy business intelligence Jaroslav Šmarda Základy business intelligence Business intelligence Datový sklad On-line Analytical Processing (OLAP) Kontingenční tabulky v MS Excelu jako příklad OLAP Dolování
Základy business intelligence Jaroslav Šmarda Základy business intelligence Business intelligence Datový sklad On-line Analytical Processing (OLAP) Kontingenční tabulky v MS Excelu jako příklad OLAP Dolování
Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti
 Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti MI-SOC: 7 ČASOVÁNÍ A SYNCHRONIZACE TECHNICKÉHO VYBAVENÍ doc. Ing. Hana Kubátová, CSc. Katedra číslicového návrhu Fakulta informačních
Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti MI-SOC: 7 ČASOVÁNÍ A SYNCHRONIZACE TECHNICKÉHO VYBAVENÍ doc. Ing. Hana Kubátová, CSc. Katedra číslicového návrhu Fakulta informačních
Správy cache. Martin Žádník. Vysoké učení technické v Brně, Fakulta informačních technologií v Brně Božetěchova 2, Brno
 Správy cache Martin Žádník Vysoké učení technické v Brně, Fakulta informačních technologií v Brně Božetěchova 2, 612 66 Brno ant@fit.vutbr.cz Hierarchie Cílem cache je dostat data co nejblíže výpočetnímu
Správy cache Martin Žádník Vysoké učení technické v Brně, Fakulta informačních technologií v Brně Božetěchova 2, 612 66 Brno ant@fit.vutbr.cz Hierarchie Cílem cache je dostat data co nejblíže výpočetnímu
Vývoj multiplatformní aplikace v Qt
 Vývoj multiplatformní aplikace v Qt z pohledu vývoje Datovky Karel Slaný karel.slany@nic.cz 13. 11. 2015 Obsah Co je Qt Nástroje Qt Koncepty Qt Problémy při vývoji Datovky Balíčkování aplikace Datovka
Vývoj multiplatformní aplikace v Qt z pohledu vývoje Datovky Karel Slaný karel.slany@nic.cz 13. 11. 2015 Obsah Co je Qt Nástroje Qt Koncepty Qt Problémy při vývoji Datovky Balíčkování aplikace Datovka
FIREBIRD relační databázový systém. Tomáš Svoboda
 FIREBIRD relační databázový systém Tomáš Svoboda xsvobo13@fi.muni.cz Firebird historie 80. léta - Jim Starkey (DEC) InterBase 1994 - odkoupila firma Borland 2000 - Borland uvolnil zdrojové texty InterBase
FIREBIRD relační databázový systém Tomáš Svoboda xsvobo13@fi.muni.cz Firebird historie 80. léta - Jim Starkey (DEC) InterBase 1994 - odkoupila firma Borland 2000 - Borland uvolnil zdrojové texty InterBase
GTL GENERATOR NÁSTROJ PRO GENEROVÁNÍ OBJEKTŮ OBJEKTY PRO INFORMATICA POWERCENTER. váš partner na cestě od dat k informacím
 GTL GENERATOR NÁSTROJ PRO GENEROVÁNÍ OBJEKTŮ OBJEKTY PRO INFORMATICA POWERCENTER váš partner na cestě od dat k informacím globtech spol. s r.o. karlovo náměstí 17 c, praha 2 tel.: +420 221 986 390 info@globtech.cz
GTL GENERATOR NÁSTROJ PRO GENEROVÁNÍ OBJEKTŮ OBJEKTY PRO INFORMATICA POWERCENTER váš partner na cestě od dat k informacím globtech spol. s r.o. karlovo náměstí 17 c, praha 2 tel.: +420 221 986 390 info@globtech.cz
TSM for Virtual Environments Data Protection for VMware v6.3. Ondřej Bláha CEE+R Tivoli Storage Team Leader. TSM architektura. 2012 IBM Corporation
 TSM for Virtual Environments Data Protection for VMware v6.3 Ondřej Bláha CEE+R Tivoli Storage Team Leader TSM architektura 2012 IBM Corporation Tradiční zálohování a obnova dat ze strany virtuálního stroje
TSM for Virtual Environments Data Protection for VMware v6.3 Ondřej Bláha CEE+R Tivoli Storage Team Leader TSM architektura 2012 IBM Corporation Tradiční zálohování a obnova dat ze strany virtuálního stroje
Technické informace. PA152,Implementace databázových systémů 4 / 25. Projekty. pary/pa152/ Pavel Rychlý
 Technické informace PA152 Implementace databázových systémů Pavel Rychlý pary@fi.muni.cz Laboratoř zpracování přirozeného jazyka http://www.fi.muni.cz/nlp/ http://www.fi.muni.cz/ pary/pa152/ přednáška
Technické informace PA152 Implementace databázových systémů Pavel Rychlý pary@fi.muni.cz Laboratoř zpracování přirozeného jazyka http://www.fi.muni.cz/nlp/ http://www.fi.muni.cz/ pary/pa152/ přednáška
Přednáška. Správa paměti II. Katedra počítačových systémů FIT, České vysoké učení technické v Praze Jan Trdlička, 2012
 Přednáška Správa paměti II. Katedra počítačových systémů FIT, České vysoké učení technické v Praze Jan Trdlička, 2012 Příprava studijního programu Informatika je podporována projektem financovaným z Evropského
Přednáška Správa paměti II. Katedra počítačových systémů FIT, České vysoké učení technické v Praze Jan Trdlička, 2012 Příprava studijního programu Informatika je podporována projektem financovaným z Evropského
Bc. David Gešvindr MSP MCSA MCTS MCITP MCPD
 Bc. David Gešvindr MSP MCSA MCTS MCITP MCPD 1. Návrh strategie zálohování 2. Zálohování uživatelských databází 3. Obnova uživatelských databází 4. Obnova z databázového snapshotu 5. Automatizace záloh
Bc. David Gešvindr MSP MCSA MCTS MCITP MCPD 1. Návrh strategie zálohování 2. Zálohování uživatelských databází 3. Obnova uživatelských databází 4. Obnova z databázového snapshotu 5. Automatizace záloh
C# - Databáze úvod, ADO.NET. Centrum pro virtuální a moderní metody a formy vzdělávání na Obchodní akademii T.G. Masaryka, Kostelec nad Orlicí
 C# - Databáze úvod, ADO.NET Centrum pro virtuální a moderní metody a formy vzdělávání na Obchodní akademii T.G. Masaryka, Kostelec nad Orlicí Co je to databáze? Databáze je určitá uspořádaná množina informací
C# - Databáze úvod, ADO.NET Centrum pro virtuální a moderní metody a formy vzdělávání na Obchodní akademii T.G. Masaryka, Kostelec nad Orlicí Co je to databáze? Databáze je určitá uspořádaná množina informací
Systém adresace paměti
 Systém adresace paměti Základní pojmy Adresa fyzická - adresa, která je přenesena na adresní sběrnici a fyzicky adresuje hlavní paměť logická - adresa, kterou má k dispozici proces k adresaci přiděleného
Systém adresace paměti Základní pojmy Adresa fyzická - adresa, která je přenesena na adresní sběrnici a fyzicky adresuje hlavní paměť logická - adresa, kterou má k dispozici proces k adresaci přiděleného
DOPLNĚK. Projekt Informační systém základních registrů je spolufinancován Evropskou unií z Evropského fondu pro regionální rozvoj.
 GLOBÁLNÍ ARCHITEKTURA ZÁKLADNÍCH REGISTRŮ DOPLNĚK Projekt Informační systém základních registrů je spolufinancován Evropskou unií z Evropského fondu pro regionální rozvoj. Obsah 1 Cíle dokumentu...3 2
GLOBÁLNÍ ARCHITEKTURA ZÁKLADNÍCH REGISTRŮ DOPLNĚK Projekt Informační systém základních registrů je spolufinancován Evropskou unií z Evropského fondu pro regionální rozvoj. Obsah 1 Cíle dokumentu...3 2
Databázové systémy úvod
 Databázové systémy úvod Michal Valenta Katedra softwarového inženýrství Fakulta informačních technologií České vysoké učení technické v Praze c Michal Valenta, 2016 BI-DBS, LS 2015/16 https://edux.fit.cvut.cz/courses/bi-dbs/
Databázové systémy úvod Michal Valenta Katedra softwarového inženýrství Fakulta informačních technologií České vysoké učení technické v Praze c Michal Valenta, 2016 BI-DBS, LS 2015/16 https://edux.fit.cvut.cz/courses/bi-dbs/
Disková pole (RAID) 1
 1") Disková pole (RAID) 1 Architektury RAID Důvod zavedení RAID: reakce na zvyšující se rychlost procesoru. Pozice diskové paměti v klasickém personálním počítači vyhovuje pro aplikace s jedním uživatelem.
Disková pole (RAID) 1 Architektury RAID Důvod zavedení RAID: reakce na zvyšující se rychlost procesoru. Pozice diskové paměti v klasickém personálním počítači vyhovuje pro aplikace s jedním uživatelem.
Ro R dina procesor pr ů Int In e t l Nehalem Šmída Mojmír, SMI108 PAP PA 2009
 Rodina procesorů Intel Nehalem Šmída Mojmír, SMI108 PAP 2009 Obsah: Úvod Nejpodstatnější prvky Nehalemu (i7 900) Nehalem ve střední třídě (i7 800, i5 700) Výkon Závěr Úvod Nhl Nehalem staví na úspěšné
Rodina procesorů Intel Nehalem Šmída Mojmír, SMI108 PAP 2009 Obsah: Úvod Nejpodstatnější prvky Nehalemu (i7 900) Nehalem ve střední třídě (i7 800, i5 700) Výkon Závěr Úvod Nhl Nehalem staví na úspěšné
IW3 MS SQL SERVER 2014
 Zálohování a obnova IW3 MS SQL SERVER 2014 Ing. Peter Solár, MCITP EA solar@pocitacoveskoleni.cz 1 OSNOVA 1. Návrh strategie zálohování 2. Zálohování uživatelských databází 3. Obnova uživatelských databází
Zálohování a obnova IW3 MS SQL SERVER 2014 Ing. Peter Solár, MCITP EA solar@pocitacoveskoleni.cz 1 OSNOVA 1. Návrh strategie zálohování 2. Zálohování uživatelských databází 3. Obnova uživatelských databází
Michal Krátký, Miroslav Beneš
 Databázové a informační systémy Michal Krátký, Miroslav Beneš Katedra informatiky VŠB Technická univerzita Ostrava 5.12.2005 2005 Michal Krátký, Miroslav Beneš Databázové a informační systémy 1/24 Obsah
Databázové a informační systémy Michal Krátký, Miroslav Beneš Katedra informatiky VŠB Technická univerzita Ostrava 5.12.2005 2005 Michal Krátký, Miroslav Beneš Databázové a informační systémy 1/24 Obsah
Diagnostika webových aplikací v Azure
 Miroslav Holec Software Engineer Microsoft MVP: Microsoft Azure MCSD, MCSA, MSP Lead miroslavholec.cz @miroslavholec Diagnostika webových aplikací v Azure 18. 03. 10. 03. Brno Diagnostic tools in Microsoft
Miroslav Holec Software Engineer Microsoft MVP: Microsoft Azure MCSD, MCSA, MSP Lead miroslavholec.cz @miroslavholec Diagnostika webových aplikací v Azure 18. 03. 10. 03. Brno Diagnostic tools in Microsoft
7. přednáška - třídy, objekty třídy objekty atributy tříd metody tříd
 7. přednáška - třídy, objekty třídy objekty atributy tříd metody tříd Algoritmizace (Y36ALG), Šumperk - 7. přednáška 1 Třída jako zdroj funkcionality Třída v jazyku Java je programová jednotka tvořená
7. přednáška - třídy, objekty třídy objekty atributy tříd metody tříd Algoritmizace (Y36ALG), Šumperk - 7. přednáška 1 Třída jako zdroj funkcionality Třída v jazyku Java je programová jednotka tvořená
SSD akcelerátor v PCIe slotu. Až 25 SSD/SAS/NL-SAS disků na jeden server
 AC Privátní Cloud Popis funkcí 1. Základní stavební jednotka - x86 server Základní stavební jednotkou systému jsou 2U x86 servery, které slouží zároveň pro ukládání dat (storage cluster) i jako HW vrstva
AC Privátní Cloud Popis funkcí 1. Základní stavební jednotka - x86 server Základní stavební jednotkou systému jsou 2U x86 servery, které slouží zároveň pro ukládání dat (storage cluster) i jako HW vrstva