B0M33BDT Technologie pro velká data. Storage
|
|
|
- Tomáš Malý
- před 5 lety
- Počet zobrazení:
Transkript

1 B0M33BDT Technologie pro velká data Storage Milan Kratochvíl
2 Motivace Jak efektivně ukládat data v Hadoop ekosystému? formát ukládání dat a jejich komprese možnost paralelně zpracovávat na mnoha nodech Jak efektivně přistupovat k datům v Hadoop ekosystému? nástroje na dotazování/ukládání dat Jak efektivně spravovat data v Hadoop ekosystému? data lifecycle management 2
3 Osnova přednášky HDFS možnosti ukládání dat Formáty ukládání dat v Hadoop Komprese Hive/Impala Shrnutí 3
4 HDFS

5
6 HDFS opakování Distribuovaný file system Namenode vs Datanode Replikace (3 by default) Velké soubory fyzicky rozloženy do bloků (nemusí být na stejném nodu!) Co musíme řešit: Jak pracovat s velkými soubory? Jak pracovat s mnoha malými soubory? Jak modifikovat soubory? 6
7 HDFS API Java API Soubory jsou z pohledu API streamy Podporované operace create (zápis) [hadoop fs -put] open [hadoop fs -get] delete [hadoop fs -rm] append [hadoop fs -appendtofile] seek (je možno v otevřeném souboru skákat ) [N/A] 7
8 HDFS ukládání souborů Typy souborů vstupní data Binární exporty zdrojových systémů (CDRs - telco) videa, obrázky, zvukové záznamy Textové prostý text CSV (comma-separated values), TSV (tab-separated values) apod. XML JSON Komprese žádná zip, gzip 8
9 HDFS ukládání souborů Typy souborů interní formáty ukládání dat Binární beze změny Textové prostý text CSV (comma-separated values), TSV (tab-separated values) apod. Tabulární řádkově orientované úložiště CSV/TSV nenese informaci o schématu Avro ( ve skutečnosti nástroj na serializaci, obsahuje schéma Tabulární sloupcově orientované úložiště v metadatech obsaženo schéma RCfile ORC ( Parquet ( Ostatní SequenceFile 9

10 Řádkově a sloupcově orientované úložiště CSV, tradiční relační databáze řádkově orientované (většinou) Příklad ( Reprezentace úložiště řádkově sloupcově 10
 http://www.svds.")
11 Avro Řádkově orientované úložiště/formát pro serializaci Nese schéma, umožňuje appendovat data (stejné schéma) 11
12 Sloupcově orientované úložiště Výhody Možnost rychle číst jen sloupce, které potřebuji (omezení IO operací disků) Efektivnější komprese Nevýhody Práce s jedním záznamem a potřeba čtení celého záznamu je pomalá Nelze snadno modifikovat ale to v Hadoop stejně prakticky není možné (myšleno napřímo tedy nejedná se o nevýhodu!) Náročný pro zápis Vstupní data je třeba rozdělit do bloku řádků, až ty se ukládají sloupcově Velikost každého bloku řádků se musí vejít do bloku HDFS Shrnutí Výhodné použít pro OLAP Velmi nevhodné pro OLTP 12


13 Parquet 13
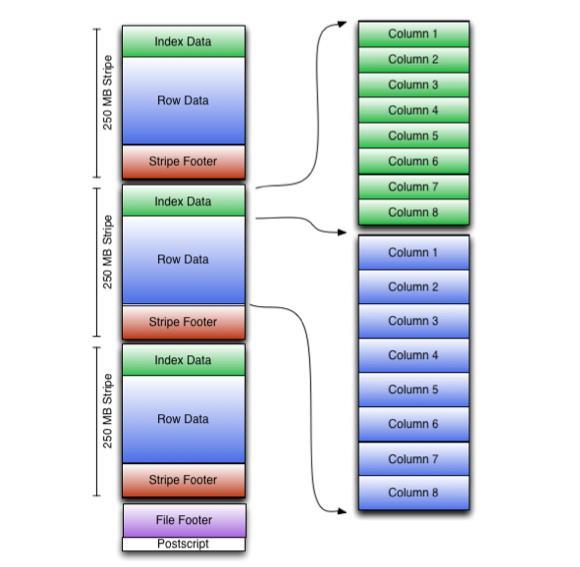
14 ORC 14
15 Sloupcově orientovaná úložiště RCFile jen historické aplikace ORC Optimized Row Columnar file format vše, co RCFile + něco navíc ukládá metadata/statistiky (average, max, count...) může obsahovat i indexy načítá jen potřebná data optimalizuje dotaz Parquet velmi podobné, jednoduší/lightweight Metadata na konci souboru, resp. bloku zapisují se, až když je soubor známý na jaké konkrétní místo souboru skočit 15
16 Odbočka malé soubory Mnoho malých souborů je problém malý soubor typicky stovky bajtů až stovky kilobajtů Typická situace když už potřebuji zpracovávat malé soubory, pak jich je skutečně mnoho Kolik je mnoho? Více než desítky milionů 1 záznam o bloku na HDFS cca 200bajtů v RAM na NameNode Příklad 1 soubor 10kB 10E6 souborů 100 GB dat cca 2 GB RAM na NameNode 1E9 souborů 10 TB dat cca 200 GB RAM Typické řešení na následujícím slajdu 16

17 SequenceFile Umožňuje ukládat data ve formátu key/value key název souboru value obsah souboru Umožňuje blokové rozdělení/blokovou kompresi Umožňuje data přidávat [append] Vhodné pro full scan 17
18 Komprese Výrazně zrychlí přístup k datům opakování nejpomalejší jsou IO operace Používané algoritmy Gzip základní formát, často vstupní soubory v Hadoop přímo se moc nepoužívá, relativně pomalý, ale účinný Bzip2 LZO Zlib typicky používaný ve spojení s ORC; stejný algoritmus jako Gzip Snappy typicky používaný ve spojení s Parquet (ale nejen to) nižší účinnost, ale nejrychlejší 18
19 Kompresní algoritmy - srovnání Algoritmus Rychlost Účinnost Splittable GZIP/ZLib BZip2 LZO Snappy Splitovatelnost kompresní algoritmus vytváří bloky, které lze samostatně dekomprimovat nutnost pro paralelní zpracování Kompatibilita Ne každý formát a každý nástroj podporuje libovolnou kompresi! (Např. v Impala nelze použít ORC) 19
20 Kdy použít jaký kompresní algoritmus? Častý přístup k datům hot data minimalizace doby přístupu k datům LZO, Snappy Archivace, řídký přístup k datům cold data minimalizace požadovaného diskového prostoru GZIP, BZip2 Kdy potřebuji splittable algoritmus? Možná nikdy... Obrovské CSV? Inteligentní souborové formáty obsahují bloky, které se komprimují; nekomprimuje se celý soubor 20
21 Hive a Impala

22
 Exekuce dotazů")
23 Hive Snaha přivést SQL do světa Hadoop Nástroj pro dotazování a manipulaci s daty Vlastní jazyk HQL (variace na SQL) Exekuce dotazů probíhá prostřednictvím klasických technologií Hadoop silná i slabá stránka zároveň Poměrně vyspělý a mocný nástroj 23

24 Hive architektura /bk_performance_tuning/content/ch_hive_architectural_overvi ew.html 24
25 Hive ukládání dat Přístup k datům je prostřednictvím klasických DB tabulek Data jsou ukládána v HDFS externí tabulky managed tabulky Jak je tabulka uložena? Tabulka je celý adresář Obsahuje více souborů, nebo i dalších podadresářů Data jsou ukládána ve vhodném formátu Parquet, Avro, CSV, ORC... Metadata jsou uložena v Metastore klasická relační DB MySQL, PostgreSQL umístění souborů statistiky práva 25
26 Hive HQL DDL (Data Definition Language) CREATE [EXTERNAL] TABLE DROP TABLE TRUNCATE TABLE ALTER TABLE DML (Data Manipulation Language) LOAD DATA INSERT INTO TABLE, INSERT OVERWRITE TABLE Query SELECT Nelze obecně UPDATE DELETE (až na specifické případy tabulek s podporou ACID) 26
27 Loady a inserty dat Hive vytváří pro každou tabulku alespoň jeden soubor pokud je dat hodně, vytvoří se více souborů (konfigurovatelné) Ale pozor při každém INSERT se vytvoří vždy aspoň jeden nový soubor! Nedává tedy smysl INSERTovat záznam po záznamu jako v RDBMS Vždy INSERT z tabulky (např. pomocí externí tabulky) Cíl: můžeme mít mnoho souborů, ale měly by mít ideálně velikost cca 1 HDFS bloku (případně násobku) [typicky 128MB] 27
28 Partitioning (velmi důležité) Příklad: Data chodí s časovým razítkem a jejich velmi mnoho (např. tel. hovory) Typicky mě ale zajímají jen údaje za konkrétní den/měsíc... Jak se k těmto datům rychle dostat? Partitioning Logické rozdělení struktury tabulky do podadresářů 28
29 Hive další možnosti Partition s každou partition lze pracovat samostatně, např. DROP, LOAD, INSERT Indexy podpora pro indexy, možnost psát vlastní indexery defaultní indexer indexuje záznam k souboru v tabulce Bucketing rozděluje data do definovaného počtu kyblíčků podle zvoleného sloupce pro konkrétní hodnotu se spočítá hash (snaha o rovnoměrné rozdělení) a na ten se aplikuje modulo počtu kyblíků při dotazu na zvolený sloupec Hive šáhne přímo do správného kyblíku 29
30 Jak na partitioning a bucketing? Stále platí chceme mít soubory velikosti cca HDFS bloku Příliš mnoho partitions a bucketů může znamenat velmi malé soubory Např. při partioningu podle času je třeba zvážit, zda potřebuji skutečně partition podle jednotlivého dne, anebo stačí na celý měsíc Při návrhu partitions/buckets je třeba být uvážlivý. Prakticky nelze změnit! Změna = kompletní reload dat 30
31 Hive Execution engine Původně Hive využíval pouze klasický MapReduce pomalé intenzivní zápisy na disk ale paměťově nenáročné V současné době ale servery mají dostatek paměti má smysl hledat i jiné cesty Hive umožňuje nastavit execution engine MapReduce (Hive on MapReduce) Tez (Hive on Tez) Spark (Hive on Spark) Ve výsledku ale vždy trvá určitou dobu (cca desítky sekund) než se celý stroj rozběhne... 31
 vice versa Impala je ale rezidentní nemusí spouštět nové procesy, ale nepodporuje YARN na (některé) dotazy umí dát odpověď téměř ihned")
32 Impala Nástroj podobný Hive Velmi kompatibilní query language Sdílí Metastore, tj. tabulky vytvoření v Impala jsou viditelné v Hive a (téměř) vice versa Impala je ale rezidentní nemusí spouštět nové procesy, ale nepodporuje YARN na (některé) dotazy umí dát odpověď téměř ihned (velmi záleží na dotazu a na formátu souboru) ideální pro analytické dotazy (?) Omezenější v pestrosti řadu formátů umí jen číst, některé ani nečte nepodporuje bucketing, ani indexy 32
33 Hive vs Impala Hive je univerzálnější má bohatší sadu funkcí nahrávání dat je poměrně efektivní při práci s petabajty dat asi jediná varianta nové execution engines jsou výrazně rychlejší než MapReduce tlačí Hortonworks Impala uživatelsky přívětivější, rychlejší orientace spíše na výkon, než na feature set tj. můžeš si vybrat jakýkoli formát, pokud je to Parquet+Snappy tlačí Cloudera Jak se rozhodnout? na loady dat nejspíše Hive na analytiku podle použité distribuce... 33
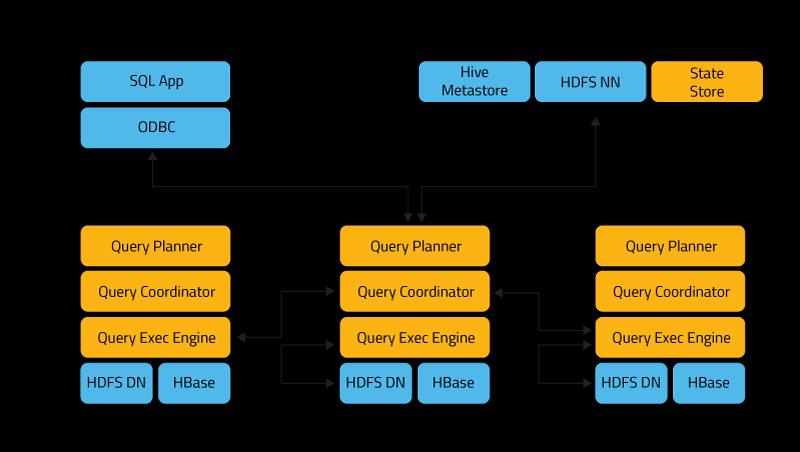
34 Impala - architektura 34
35 Hive příklad Extrakty (CSV) Dočasné tabulky Finální tabulky
36 Hive příklad Vytvoříme externí tabulku vázanou na zdrojové soubory CREATE EXTERNAL TABLE IF NOT EXISTS ap_temp ( ACC_KEY BIGINT, BUS_PROD_TP_ID VARCHAR(255), START_DATE TIMESTAMP, BUS_PROD_TP_DESCR VARCHAR(255) ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '~' LINES TERMINATED BY '\n' STORED AS TEXTFILE LOCATION /data/input/acc ;
37 Hive příklad Vytvoříme prázdnou optimalizovanou tabulku CREATE TABLE IF NOT EXISTS ap ( ACC_KEY BIGINT, BUS_PROD_TP_ID VARCHAR(255), START_DATE TIMESTAMP) PARTITIONED BY (BUS_PROD_TP_DESCR VARCHAR(255)) CLUSTERED BY (ACC_KEY) INTO 32 BUCKETS STORED AS ORC tblproperties ("orc.compress"="zlib");
38 Hive příklad Nahrajeme data do optimalizované tabulky INSERT OVERWRITE TABLE ap PARTITION (BUS_PROD_TP_DESCR) SELECT ACC_KEY, BUS_PROD_TP_ID, START_DATE, BUS_PROD_TP_DESCR FROM ap_temp; DROP TABLE ap_temp;

39 Shrnutí + Co se jinam nevešlo
40 Schema evolution Změna schématu souboru v průběhu života Typicky chceme přidat sloupec Někdy je i možné přejmenovat sloupec odstranit sloupec (zpravidla jen v metadatech) Podpora schema evolution záleží na formátu souboru i použitém nástroji vždy je třeba nastudovat Podporované formáty alespoň pro přidávání sloupců Avro ORC Parquet 40
41 Transakce Obecně v Hadoopu téměř není Otázka k diskusi: Je ale vůbec třeba při zpracování velkých dat? Limitovaná podpora (zatím): Lze řešit přegenerováním celé tabulky nebo partition ORC + Hive HBase ACID na úrovni řádku
42 Shrnutí Vždy se rozmýšlet, co je třeba, podle požadovaného použití každý nástroj nabízí jinou míru flexibility! Snažit se maximálně těžit ze sloupcově orientovaných úložišť např. analytické SQL-like úlohy Použít řádkově orientované úložiště tam, kde je nutný full scan Soubory v databázi Hive je třeba mít rozumně velké ideálně velikost HDFS bloku (po kompresi) Partitioning je základ optimalizace v Hive/Impala ale nepřehánět je dobré mít zhruba odhad velikosti partition Hive i Impala jsou dobré nástroje na loady dat Hive na analytiku se rozhodnu podle distribuce (Impala v případě Cloudery) HBase používat jen ve velmi specifických případech vyžaduje znalosti, zkušenosti a testování
43 Praxe Souborové formáty primárně Parquet, méně často pak Avro na vstupu CSV Komprese Parquet účinnost kolem 50% GZIP vstupní data Hive nahrávání dat, ETL Impala analytické dotazy Pracujeme s tabulkami obsahujícími cca 2-10 mld záznamů/jednotky TB složitý analytický dotaz běží cca 2min. na relační DB stejný dotaz trval 40min.

44 Diskuze 44
45 Díky za pozornost Profinit EU, s.r.o. Tychonova 2, Praha 6 Telefon Web LinkedIn Twitter Facebook Youtube linkedin.com/company/profinit twitter.com/profinit_eu facebook.com/profinit.eu Profinit EU
B0M33BDT Technologie pro velká data. Storage
 B0M33BDT Technologie pro velká data Storage Milan Kratochvíl 25.10.2017 Motivace Jak efektivně ukládat data v Hadoop ekosystému? formát ukládání dat a jejich komprese možnost paralelně zpracovávat na mnoha
B0M33BDT Technologie pro velká data Storage Milan Kratochvíl 25.10.2017 Motivace Jak efektivně ukládat data v Hadoop ekosystému? formát ukládání dat a jejich komprese možnost paralelně zpracovávat na mnoha
B0M33BDT Technologie pro velká data. Supercvičení SQL, Python, Linux
 B0M33BDT Technologie pro velká data Supercvičení SQL, Python, Linux Sergej Stamenov, Jan Hučín 18. 10. 2017 Osnova cvičení Linux SQL Python 2 SQL pro uživatele aneb co potřebuje znát a umět bigdatový uživatel:
B0M33BDT Technologie pro velká data Supercvičení SQL, Python, Linux Sergej Stamenov, Jan Hučín 18. 10. 2017 Osnova cvičení Linux SQL Python 2 SQL pro uživatele aneb co potřebuje znát a umět bigdatový uživatel:
B0M33BDT Stream processing. Milan Kratochvíl
 B0M33BDT Stream processing Milan Kratochvíl 13. prosinec 2017 Stream processing Průběžné zpracování trvalého toku zpráv Vstupní stream Message processor Stream processor Úložiště Stream processing Hlavní
B0M33BDT Stream processing Milan Kratochvíl 13. prosinec 2017 Stream processing Průběžné zpracování trvalého toku zpráv Vstupní stream Message processor Stream processor Úložiště Stream processing Hlavní
BigData. Marek Sušický
 BigData Marek Sušický 28. Únoru 2017 Osnova Big data a Hadoop Na jakém hardware + sizing Jak vypadá cluster - architektura HDFS Distribuce Komponenty YARN, správa zdrojů 2 Big data neznamená Hadoop 3 Apache
BigData Marek Sušický 28. Únoru 2017 Osnova Big data a Hadoop Na jakém hardware + sizing Jak vypadá cluster - architektura HDFS Distribuce Komponenty YARN, správa zdrojů 2 Big data neznamená Hadoop 3 Apache
Hadoop a HDFS. Bc. Milan Nikl
 3.12.2013 Hadoop a HDFS Bc. Milan Nikl Co je Hadoop: Open-Source Framework Vyvíjený Apache Software Foundation Pro ukládání a zpracovávání velkých objemů dat Big Data trojrozměrný růst dat (3V) Objem (Volume)
3.12.2013 Hadoop a HDFS Bc. Milan Nikl Co je Hadoop: Open-Source Framework Vyvíjený Apache Software Foundation Pro ukládání a zpracovávání velkých objemů dat Big Data trojrozměrný růst dat (3V) Objem (Volume)
Spark SQL, Spark Streaming. Jan Hučín
 Spark SQL, Spark Streaming Jan Hučín 21. listopadu 2018 Osnova 1. Spark SQL 2. Další rozšíření Sparku Spark streaming GraphX Spark ML 2 Spark SQL Spark SQL a DataFrames (DataSets) Rozšíření k tradičnímu
Spark SQL, Spark Streaming Jan Hučín 21. listopadu 2018 Osnova 1. Spark SQL 2. Další rozšíření Sparku Spark streaming GraphX Spark ML 2 Spark SQL Spark SQL a DataFrames (DataSets) Rozšíření k tradičnímu
Spark SQL, Spark Streaming. Jan Hučín
 Spark SQL, Spark Streaming Jan Hučín 22. listopadu 2017 Osnova 1. Spark SQL 2. Další rozšíření Sparku Spark streaming GraphX Spark ML 2 Spark SQL Spark SQL a DataFrames (DataSets) Rozšíření k tradičnímu
Spark SQL, Spark Streaming Jan Hučín 22. listopadu 2017 Osnova 1. Spark SQL 2. Další rozšíření Sparku Spark streaming GraphX Spark ML 2 Spark SQL Spark SQL a DataFrames (DataSets) Rozšíření k tradičnímu
Úvod do databázových systémů
 Vysoká škola báňská Technická univerzita Ostrava Fakulta elektrotechniky a informatiky Úvod do databázových systémů Cvičení 8 Ing. Petr Lukáš petr.lukas@vsb.cz Ostrava, 2014 Opakování Entita Entitní typ
Vysoká škola báňská Technická univerzita Ostrava Fakulta elektrotechniky a informatiky Úvod do databázových systémů Cvičení 8 Ing. Petr Lukáš petr.lukas@vsb.cz Ostrava, 2014 Opakování Entita Entitní typ
O Apache Derby detailněji. Hynek Mlnařík
 O Apache Derby detailněji Hynek Mlnařík Agenda Historie Vlastnosti Architektura Budoucnost Historie 1997 Cloudscape Inc. - JBMS 1999 Informix Software, Inc. odkoupila Cloudscape, Inc. 2001 IBM odkoupila
O Apache Derby detailněji Hynek Mlnařík Agenda Historie Vlastnosti Architektura Budoucnost Historie 1997 Cloudscape Inc. - JBMS 1999 Informix Software, Inc. odkoupila Cloudscape, Inc. 2001 IBM odkoupila
DUM 12 téma: Příkazy pro tvorbu databáze
 DUM 12 téma: Příkazy pro tvorbu databáze ze sady: 3 tematický okruh sady: III. Databáze ze šablony: 7 Kancelářský software určeno pro: 4. ročník vzdělávací obor: 18-20-M/01 Informační technologie vzdělávací
DUM 12 téma: Příkazy pro tvorbu databáze ze sady: 3 tematický okruh sady: III. Databáze ze šablony: 7 Kancelářský software určeno pro: 4. ročník vzdělávací obor: 18-20-M/01 Informační technologie vzdělávací
TimescaleDB. Pavel Stěhule 2018
 TimescaleDB Pavel Stěhule 2018 O výkonu rozhodují Algoritmy Datové struktury 80-90 léta - vize univerzálních SQL databází Po roce 2000 - specializované databáze Relační SQL databáze Běžně optimalizována
TimescaleDB Pavel Stěhule 2018 O výkonu rozhodují Algoritmy Datové struktury 80-90 léta - vize univerzálních SQL databází Po roce 2000 - specializované databáze Relační SQL databáze Běžně optimalizována
04 - Databázové systémy
 04 - Databázové systémy Základní pojmy, principy, architektury Databáze (DB) je uspořádaná množina dat, se kterými můžeme dále pracovat. Správa databáze je realizována prostřednictvím Systému pro správu
04 - Databázové systémy Základní pojmy, principy, architektury Databáze (DB) je uspořádaná množina dat, se kterými můžeme dále pracovat. Správa databáze je realizována prostřednictvím Systému pro správu
Databázové systémy. Doc.Ing.Miloš Koch,CSc. koch@fbm.vutbr.cz
 Databázové systémy Doc.Ing.Miloš Koch,CSc. koch@fbm.vutbr.cz Vývoj databázových systémů Ukládání dat Aktualizace dat Vyhledávání dat Třídění dat Výpočty a agregace 60.-70. léta Program Komunikace Výpočty
Databázové systémy Doc.Ing.Miloš Koch,CSc. koch@fbm.vutbr.cz Vývoj databázových systémů Ukládání dat Aktualizace dat Vyhledávání dat Třídění dat Výpočty a agregace 60.-70. léta Program Komunikace Výpočty
B Organizace databáze na fyzické úrovni u serveru Oracle
 B Organizace databáze na fyzické úrovni u serveru Oracle B.1. Základní koncepty... 2 B.2. Možnosti rozšíření prostoru databáze... 9 B.3. Indexování a shlukování... 12 Literatura... 16 J. Zendulka: Databázové
B Organizace databáze na fyzické úrovni u serveru Oracle B.1. Základní koncepty... 2 B.2. Možnosti rozšíření prostoru databáze... 9 B.3. Indexování a shlukování... 12 Literatura... 16 J. Zendulka: Databázové
Stručně o XML (výhody, nevýhody) Proč komprimovat XML? Metody komprese XML XMill. Optimalizace komprese XML. Závěr
 Proč komprimovat XML? Metody komprese XML XMill. Optimalizace komprese XML. Závěr") Pavel Hruška Stručně o XML (výhody, nevýhody) Proč komprimovat XML? Metody komprese XML XMill Představení, princip, výsledky Analýza XML (možná úskalí) Optimalizace komprese XML Přeskládání kontejnerů
Pavel Hruška Stručně o XML (výhody, nevýhody) Proč komprimovat XML? Metody komprese XML XMill Představení, princip, výsledky Analýza XML (možná úskalí) Optimalizace komprese XML Přeskládání kontejnerů
Databáze SQL SELECT. David Hoksza http://siret.cz/hoksza
 Databáze SQL SELECT David Hoksza http://siret.cz/hoksza Osnova Úvod do SQL Základní dotazování v SQL Cvičení základní dotazování v SQL Structured Query Language (SQL) SQL napodobuje jednoduché anglické
Databáze SQL SELECT David Hoksza http://siret.cz/hoksza Osnova Úvod do SQL Základní dotazování v SQL Cvičení základní dotazování v SQL Structured Query Language (SQL) SQL napodobuje jednoduché anglické
5. POČÍTAČOVÉ CVIČENÍ
 5. POČÍTAČOVÉ CVIČENÍ Databáze Databázi si můžeme představit jako místo, kam se ukládají všechny potřebné údaje. Přístup k údajům uloženým v databázi obstarává program, kterému se říká Systém Řízení Báze
5. POČÍTAČOVÉ CVIČENÍ Databáze Databázi si můžeme představit jako místo, kam se ukládají všechny potřebné údaje. Přístup k údajům uloženým v databázi obstarává program, kterému se říká Systém Řízení Báze
RNDr. Michal Kopecký, Ph.D. Department of Software Engineering, Faculty of Mathematics and Physics, Charles University in Prague
 seminář: Administrace Oracle (NDBI013) LS2017/18 RNDr. Michal Kopecký, Ph.D. Department of Software Engineering, Faculty of Mathematics and Physics, Charles University in Prague Zvyšuje výkon databáze
seminář: Administrace Oracle (NDBI013) LS2017/18 RNDr. Michal Kopecký, Ph.D. Department of Software Engineering, Faculty of Mathematics and Physics, Charles University in Prague Zvyšuje výkon databáze
2. blok část B Základní syntaxe příkazů SELECT, INSERT, UPDATE, DELETE
 2. blok část B Základní syntaxe příkazů SELECT, INSERT, UPDATE, DELETE Studijní cíl Tento blok je věnován základní syntaxi příkazu SELECT, pojmům projekce a restrikce. Stručně zde budou představeny příkazy
2. blok část B Základní syntaxe příkazů SELECT, INSERT, UPDATE, DELETE Studijní cíl Tento blok je věnován základní syntaxi příkazu SELECT, pojmům projekce a restrikce. Stručně zde budou představeny příkazy
cstore_fdw column store pro PostgreSQL Prague PostgreSQL Developer Day 2015 Jan Holčapek
 cstore_fdw column store pro PostgreSQL Prague PostgreSQL Developer Day 2015 Jan Holčapek holcapek@gmail.com cstore_fdw > foreign data wrapper pro ORC* formát > ORC, Optimized Row Columnar > jeden z formátů,
cstore_fdw column store pro PostgreSQL Prague PostgreSQL Developer Day 2015 Jan Holčapek holcapek@gmail.com cstore_fdw > foreign data wrapper pro ORC* formát > ORC, Optimized Row Columnar > jeden z formátů,
Databázové systémy úvod
 Databázové systémy úvod Michal Valenta Katedra softwarového inženýrství Fakulta informačních technologií České vysoké učení technické v Praze c Michal Valenta, 2016 BI-DBS, LS 2015/16 https://edux.fit.cvut.cz/courses/bi-dbs/
Databázové systémy úvod Michal Valenta Katedra softwarového inženýrství Fakulta informačních technologií České vysoké učení technické v Praze c Michal Valenta, 2016 BI-DBS, LS 2015/16 https://edux.fit.cvut.cz/courses/bi-dbs/
CSPUG 2011-květen. GridSQL a pg-pool II. Vratislav Beneš benes@optisolutions.cz
 GridSQL a pg-pool II Vratislav Beneš benes@optisolutions.cz Agenda 1. Datové sklady a datová tržiště 2. pg-pool II 1. Infrastrukutra 2. Využití pro datové sklady 3. GridSQL 1. Infrastuktura 2. Vytvoření
GridSQL a pg-pool II Vratislav Beneš benes@optisolutions.cz Agenda 1. Datové sklady a datová tržiště 2. pg-pool II 1. Infrastrukutra 2. Využití pro datové sklady 3. GridSQL 1. Infrastuktura 2. Vytvoření
InnoDB transakce, cizí klíče, neumí fulltext (a nebo už ano?) CSV v textovém souboru ve formátu hodnot oddělených čárkou
 CSV v textovém souboru ve formátu hodnot oddělených čárkou") MySQL Typy tabulek Storage Engines MyISAM defaultní, neumí transakce, umí fulltext InnoDB transakce, cizí klíče, neumí fulltext (a nebo už ano?) MEMORY (HEAP) v paměti; neumí transakce ARCHIVE velké množství
MySQL Typy tabulek Storage Engines MyISAM defaultní, neumí transakce, umí fulltext InnoDB transakce, cizí klíče, neumí fulltext (a nebo už ano?) MEMORY (HEAP) v paměti; neumí transakce ARCHIVE velké množství
Obchodní akademie a Jazyková škola s právem státní jazykové zkoušky Jihlava
 Obchodní akademie a Jazyková škola s právem státní jazykové zkoušky Jihlava Šablona 32 VY_32_INOVACE_038.ICT.34 Tvorba webových stránek SQL stručné minimum OA a JŠ Jihlava, VY_32_INOVACE_038.ICT.34 Číslo
Obchodní akademie a Jazyková škola s právem státní jazykové zkoušky Jihlava Šablona 32 VY_32_INOVACE_038.ICT.34 Tvorba webových stránek SQL stručné minimum OA a JŠ Jihlava, VY_32_INOVACE_038.ICT.34 Číslo
BIG DATA je oveľa viac ako Hadoop. Martin Pavlík
 BIG DATA je oveľa viac ako Hadoop Martin Pavlík Analýza všech dostupných dat? Big data =? = Buzzword? = Hadoop? Hadoop Jen ke zpracování nestrukturovaných dat? Mentální posun něco za něco 2 Big data =
BIG DATA je oveľa viac ako Hadoop Martin Pavlík Analýza všech dostupných dat? Big data =? = Buzzword? = Hadoop? Hadoop Jen ke zpracování nestrukturovaných dat? Mentální posun něco za něco 2 Big data =
PostgreSQL. Podpora dědičnosti Rozšiřitelnost vlastní datové typy. Univerzální nasazení ve vědecké sféře
 PostgreSQL Vzniká jako akademický projekt Experimentální vlastnosti Podpora dědičnosti Rozšiřitelnost vlastní datové typy Univerzální nasazení ve vědecké sféře Obsahuje podporu polí (časové řady) Geotypy
PostgreSQL Vzniká jako akademický projekt Experimentální vlastnosti Podpora dědičnosti Rozšiřitelnost vlastní datové typy Univerzální nasazení ve vědecké sféře Obsahuje podporu polí (časové řady) Geotypy
B0M33BDT 7. přednáška Architektury a bezpečnost. Marek Sušický Milan Kratochvíl
 B0M33BDT 7. přednáška Architektury a bezpečnost Marek Sušický Milan Kratochvíl 5. prosinec 2018 Osnova Něco ze života Architektury Hadoop Lambda Kappa Zetta Security a dopady do architektury 2 Jak vypadá
B0M33BDT 7. přednáška Architektury a bezpečnost Marek Sušický Milan Kratochvíl 5. prosinec 2018 Osnova Něco ze života Architektury Hadoop Lambda Kappa Zetta Security a dopady do architektury 2 Jak vypadá
8.2 Používání a tvorba databází
 8.2 Používání a tvorba databází Slide 1 8.2.1 Základní pojmy z oblasti relačních databází Slide 2 Databáze ~ Evidence lidí peněz věcí... výběry, výpisy, početní úkony Slide 3 Pojmy tabulka, pole, záznam
8.2 Používání a tvorba databází Slide 1 8.2.1 Základní pojmy z oblasti relačních databází Slide 2 Databáze ~ Evidence lidí peněz věcí... výběry, výpisy, početní úkony Slide 3 Pojmy tabulka, pole, záznam
Databázové systémy. - SQL * definice dat * aktualizace * pohledy. Tomáš Skopal
 Databázové systémy - SQL * definice dat * aktualizace * pohledy Tomáš Skopal Osnova přednášky definice dat definice (schémat) tabulek a integritních omezení CREATE TABLE změna definice schématu ALTER TABLE
Databázové systémy - SQL * definice dat * aktualizace * pohledy Tomáš Skopal Osnova přednášky definice dat definice (schémat) tabulek a integritních omezení CREATE TABLE změna definice schématu ALTER TABLE
Úvod do databázových systémů
 Vysoká škola báňská Technická univerzita Ostrava Fakulta elektrotechniky a informatiky Úvod do databázových systémů Cvičení 3 Ing. Petr Lukáš petr.lukas@vsb.cz Ostrava, 2014 Opakování 4 fáze vytváření
Vysoká škola báňská Technická univerzita Ostrava Fakulta elektrotechniky a informatiky Úvod do databázových systémů Cvičení 3 Ing. Petr Lukáš petr.lukas@vsb.cz Ostrava, 2014 Opakování 4 fáze vytváření
Oracle XML DB. Tomáš Nykodým
 Oracle XML DB Tomáš Nykodým xnykodym@fi.muni.cz Osnova Oracle XML DB Architektura Oracle XML DB Hlavní rysy Oracle XML DB Hlavní rysy Oracle XML DB - pokračování XMLType XML Repository Využívání databázových
Oracle XML DB Tomáš Nykodým xnykodym@fi.muni.cz Osnova Oracle XML DB Architektura Oracle XML DB Hlavní rysy Oracle XML DB Hlavní rysy Oracle XML DB - pokračování XMLType XML Repository Využívání databázových
Použití databází na Webu
 4IZ228 tvorba webových stránek a aplikací Jirka Kosek Poslední modifikace: $Date: 2010/11/18 11:33:52 $ Obsah Co nás čeká... 3 Architektura webových databázových aplikací... 4 K čemu se používají databázové
4IZ228 tvorba webových stránek a aplikací Jirka Kosek Poslední modifikace: $Date: 2010/11/18 11:33:52 $ Obsah Co nás čeká... 3 Architektura webových databázových aplikací... 4 K čemu se používají databázové
Databáze I. 5. přednáška. Helena Palovská
 Databáze I 5. přednáška Helena Palovská palovska@vse.cz SQL jazyk definice dat - - DDL (data definition language) Základní databáze, schemata, tabulky, indexy, constraints, views DATA Databáze/schéma
Databáze I 5. přednáška Helena Palovská palovska@vse.cz SQL jazyk definice dat - - DDL (data definition language) Základní databáze, schemata, tabulky, indexy, constraints, views DATA Databáze/schéma
Základy informatiky. 08 Databázové systémy. Daniela Szturcová
 Základy informatiky 08 Databázové systémy Daniela Szturcová Problém zpracování dat Důvodem je potřeba zpracovat velké množství dat - evidovat údaje o nějaké skutečnosti. o skupině lidí (zaměstnanců, studentů,
Základy informatiky 08 Databázové systémy Daniela Szturcová Problém zpracování dat Důvodem je potřeba zpracovat velké množství dat - evidovat údaje o nějaké skutečnosti. o skupině lidí (zaměstnanců, studentů,
Novinky v Microsoft SQL Serveru RNDr. David Gešvindr MVP: Data Platform MCSE: Data Platform MCSD: Windows Store MCT
 Novinky v Microsoft SQL Serveru 2016 RNDr. David Gešvindr MVP: Data Platform MCSE: Data Platform MCSD: Windows Store MCT david@wug.cz @gesvindr Přehled hlavních novinek Výkon Query Store Temporal Tables
Novinky v Microsoft SQL Serveru 2016 RNDr. David Gešvindr MVP: Data Platform MCSE: Data Platform MCSD: Windows Store MCT david@wug.cz @gesvindr Přehled hlavních novinek Výkon Query Store Temporal Tables
Sada 1 - PHP. 14. Úvod do jazyka SQL
 S třední škola stavební Jihlava Sada 1 - PHP 14. Úvod do jazyka SQL Digitální učební materiál projektu: SŠS Jihlava šablony registrační číslo projektu:cz.1.09/1.5.00/34.0284 Šablona: III/2 - inovace a
S třední škola stavební Jihlava Sada 1 - PHP 14. Úvod do jazyka SQL Digitální učební materiál projektu: SŠS Jihlava šablony registrační číslo projektu:cz.1.09/1.5.00/34.0284 Šablona: III/2 - inovace a
Kurz Databáze. Obsah. Dotazy. Zpracování dat. Doc. Ing. Radim Farana, CSc.
 1 Kurz Databáze Zpracování dat Doc. Ing. Radim Farana, CSc. Obsah Druhy dotazů, tvorba dotazu, prostředí QBE (Query by Example). Realizace základních relačních operací selekce, projekce a spojení. Agregace
1 Kurz Databáze Zpracování dat Doc. Ing. Radim Farana, CSc. Obsah Druhy dotazů, tvorba dotazu, prostředí QBE (Query by Example). Realizace základních relačních operací selekce, projekce a spojení. Agregace
Administrace Oracle. Práva a role, audit
 Administrace Oracle Práva a role, audit Filip Řepka 2010 Práva (privileges) Objekty (tabulky, pohledy, procedury,...) jsou v databázi logicky rozděleny do schémat. Každý uživatel má přiděleno svoje schéma
Administrace Oracle Práva a role, audit Filip Řepka 2010 Práva (privileges) Objekty (tabulky, pohledy, procedury,...) jsou v databázi logicky rozděleny do schémat. Každý uživatel má přiděleno svoje schéma
10. Datové sklady (Data Warehouses) Datový sklad
 Datový sklad") 10. Datové sklady (Data Warehouses) Datový sklad komplexní data uložená ve struktuře, která umožňuje efektivní analýzu a dotazování data čerpána z primárních informačních systémů a dalších zdrojů OLAP
10. Datové sklady (Data Warehouses) Datový sklad komplexní data uložená ve struktuře, která umožňuje efektivní analýzu a dotazování data čerpána z primárních informačních systémů a dalších zdrojů OLAP
Přehled systému Microsoft SQL Server. Komu je kniha určena Struktura knihy Nejvhodnější výchozí bod pro čtení knihy Konvence a struktura knihy
 Komu je kniha určena Struktura knihy Nejvhodnější výchozí bod pro čtení knihy Konvence a struktura knihy Konvence Další prvky Požadavky na systém Ukázkové databáze Ukázky kódu Použití ukázek kódu Další
Komu je kniha určena Struktura knihy Nejvhodnější výchozí bod pro čtení knihy Konvence a struktura knihy Konvence Další prvky Požadavky na systém Ukázkové databáze Ukázky kódu Použití ukázek kódu Další
Operátory ROLLUP a CUBE
 Operátory ROLLUP a CUBE Dotazovací jazyky, 2009 Marek Polák Martin Chytil Osnova přednášky o Analýza dat o Agregační funkce o GROUP BY a jeho problémy o Speciální hodnotový typ ALL o Operátor CUBE o Operátor
Operátory ROLLUP a CUBE Dotazovací jazyky, 2009 Marek Polák Martin Chytil Osnova přednášky o Analýza dat o Agregační funkce o GROUP BY a jeho problémy o Speciální hodnotový typ ALL o Operátor CUBE o Operátor
Databázové systémy Cvičení 5.2
 Databázové systémy Cvičení 5.2 SQL jako jazyk pro definici dat Detaily zápisu integritních omezení tabulek Integritní omezení tabulek kromě integritních omezení sloupců lze zadat integritní omezení jako
Databázové systémy Cvičení 5.2 SQL jako jazyk pro definici dat Detaily zápisu integritních omezení tabulek Integritní omezení tabulek kromě integritních omezení sloupců lze zadat integritní omezení jako
Analytické systémy nad Hadoopom. Lukáš Antalov, Vedoucí týmu vývoje
 Analytické systémy nad Hadoopom Lukáš Antalov, Vedoucí týmu vývoje Outline Big Data Hadoop Štatistiky Sklik.cz Webová analytika Big Data Big Data sú všade 200 Londýnskych dopravných kamier 8 TB / deň Približný
Analytické systémy nad Hadoopom Lukáš Antalov, Vedoucí týmu vývoje Outline Big Data Hadoop Štatistiky Sklik.cz Webová analytika Big Data Big Data sú všade 200 Londýnskych dopravných kamier 8 TB / deň Približný
Databázové systémy a SQL
 Databázové systémy a SQL Daniel Klimeš Autor, Název akce 1 About me Daniel Klimeš Vzdělání: Obecná biologie PGS: onkologie Specializace: klinické databáze Databáze ORACLE klimes@iba.muni.cz Kotlářská 2,
Databázové systémy a SQL Daniel Klimeš Autor, Název akce 1 About me Daniel Klimeš Vzdělání: Obecná biologie PGS: onkologie Specializace: klinické databáze Databáze ORACLE klimes@iba.muni.cz Kotlářská 2,
Jazyk SQL databáze SQLite. připravil ing. petr polách
 Jazyk SQL databáze SQLite připravil ing. petr polách SQL - úvod Structured Query Language (strukturovaný dotazovací jazyk 70. léta min. století) Standardizovaný dotazovací jazyk používaný pro práci s daty
Jazyk SQL databáze SQLite připravil ing. petr polách SQL - úvod Structured Query Language (strukturovaný dotazovací jazyk 70. léta min. století) Standardizovaný dotazovací jazyk používaný pro práci s daty
Spark Jan Hučín 15. listopadu 2017
 Spark Jan Hučín 15. listopadu 2017 Osnova 1. Co to je a k čemu slouží 2. Jak se to naučit 3. Jak se s tím pracuje 4. Jak to funguje Logický a technický pohled Transformace, akce, kešování Příklady Architektura
Spark Jan Hučín 15. listopadu 2017 Osnova 1. Co to je a k čemu slouží 2. Jak se to naučit 3. Jak se s tím pracuje 4. Jak to funguje Logický a technický pohled Transformace, akce, kešování Příklady Architektura
SQL - trigger, Databázové modelování
 6. přednáška z předmětu Datové struktury a databáze (DSD) Ústav nových technologií a aplikované informatiky Fakulta mechatroniky, informatiky a mezioborových studií Technická univerzita v Liberci jan.lisal@tul.cz
6. přednáška z předmětu Datové struktury a databáze (DSD) Ústav nových technologií a aplikované informatiky Fakulta mechatroniky, informatiky a mezioborových studií Technická univerzita v Liberci jan.lisal@tul.cz
Michal Krátký, Miroslav Beneš
 Databázové a informační systémy Michal Krátký, Miroslav Beneš Katedra informatiky VŠB Technická univerzita Ostrava 5.12.2005 2005 Michal Krátký, Miroslav Beneš Databázové a informační systémy 1/24 Obsah
Databázové a informační systémy Michal Krátký, Miroslav Beneš Katedra informatiky VŠB Technická univerzita Ostrava 5.12.2005 2005 Michal Krátký, Miroslav Beneš Databázové a informační systémy 1/24 Obsah
Databáze Bc. Veronika Tomsová
 Databáze Bc. Veronika Tomsová Databázové schéma Mapování konceptuálního modelu do (relačního) databázového schématu. 2/21 Fyzické ik schéma databáze Určuje č jakým způsobem ů jsou data v databázi ukládána
Databáze Bc. Veronika Tomsová Databázové schéma Mapování konceptuálního modelu do (relačního) databázového schématu. 2/21 Fyzické ik schéma databáze Určuje č jakým způsobem ů jsou data v databázi ukládána
Návrh a tvorba WWW stránek 1/14. PHP a databáze
 Návrh a tvorba WWW stránek 1/14 PHP a databáze nejčastěji MySQL součástí balíčků PHP navíc podporuje standard ODBC PHP nemá žádné šablony pro práci s databází princip práce s databází je stále stejný opakované
Návrh a tvorba WWW stránek 1/14 PHP a databáze nejčastěji MySQL součástí balíčků PHP navíc podporuje standard ODBC PHP nemá žádné šablony pro práci s databází princip práce s databází je stále stejný opakované
Informační systémy 2008/2009. Radim Farana. Obsah. Jazyk SQL
 4 Vysoká škola báňská Technická univerzita Ostrava Fakulta strojní, Katedra automatizační techniky a řízení 2008/2009 Radim Farana 1 Obsah Jazyk SQL, datové typy, klauzule SELECT, WHERE, a ORDER BY. Doporučená
4 Vysoká škola báňská Technická univerzita Ostrava Fakulta strojní, Katedra automatizační techniky a řízení 2008/2009 Radim Farana 1 Obsah Jazyk SQL, datové typy, klauzule SELECT, WHERE, a ORDER BY. Doporučená
DATABÁZOVÉ SYSTÉMY. Metodický list č. 1
 Metodický list č. 1 Cíl: Cílem předmětu je získat přehled o možnostech a principech databázového zpracování, získat v tomto směru znalosti potřebné pro informačního manažera. Databázové systémy, databázové
Metodický list č. 1 Cíl: Cílem předmětu je získat přehled o možnostech a principech databázového zpracování, získat v tomto směru znalosti potřebné pro informačního manažera. Databázové systémy, databázové
Kapitola 1: Úvod. Systém pro správu databáze (Database Management Systém DBMS) Účel databázových systémů
 Účel databázových systémů") - 1.1 - Kapitola 1: Úvod Účel databázových systémů Pohled na data Modely dat Jazyk pro definici dat (Data Definition Language; DDL) Jazyk pro manipulaci s daty (Data Manipulation Language; DML) Správa
- 1.1 - Kapitola 1: Úvod Účel databázových systémů Pohled na data Modely dat Jazyk pro definici dat (Data Definition Language; DDL) Jazyk pro manipulaci s daty (Data Manipulation Language; DML) Správa
Databázové a informační systémy
 Databázové a informační systémy doc. Ing. Miroslav Beneš, Ph.D. katedra informatiky FEI VŠB-TUO A-1007 / 597 324 213 http://www.cs.vsb.cz/benes Miroslav.Benes@vsb.cz Obsah Jak ukládat a efektivně zpracovávat
Databázové a informační systémy doc. Ing. Miroslav Beneš, Ph.D. katedra informatiky FEI VŠB-TUO A-1007 / 597 324 213 http://www.cs.vsb.cz/benes Miroslav.Benes@vsb.cz Obsah Jak ukládat a efektivně zpracovávat
Databázové systémy. Cvičení 6: SQL
 Databázové systémy Cvičení 6: SQL Co je SQL? SQL = Structured Query Language SQL je standardním (ANSI, ISO) textovým počítačovým jazykem SQL umožňuje jednoduchým způsobem přistupovat k datům v databázi
Databázové systémy Cvičení 6: SQL Co je SQL? SQL = Structured Query Language SQL je standardním (ANSI, ISO) textovým počítačovým jazykem SQL umožňuje jednoduchým způsobem přistupovat k datům v databázi
Úvod do databází. Modelování v řízení. Ing. Petr Kalčev
 Úvod do databází Modelování v řízení Ing. Petr Kalčev Co je databáze? Množina záznamů a souborů, které jsou organizovány za určitým účelem. Jaké má mít přínosy? Rychlost Spolehlivost Přesnost Bezpečnost
Úvod do databází Modelování v řízení Ing. Petr Kalčev Co je databáze? Množina záznamů a souborů, které jsou organizovány za určitým účelem. Jaké má mít přínosy? Rychlost Spolehlivost Přesnost Bezpečnost
Databáze. Velmi stručný a zjednodušený úvod do problematiky databází pro programátory v Pythonu. Bedřich Košata
 Databáze Velmi stručný a zjednodušený úvod do problematiky databází pro programátory v Pythonu Bedřich Košata K čemu jsou databáze Ukládání dat ve strukturované podobě Možnost ukládat velké množství dat
Databáze Velmi stručný a zjednodušený úvod do problematiky databází pro programátory v Pythonu Bedřich Košata K čemu jsou databáze Ukládání dat ve strukturované podobě Možnost ukládat velké množství dat
A4M33BDT Technologie pro velká data
 A4M33BDT Technologie pro velká data Milan Kratochvíl 22. března 2017 MapReduce 3 MapReduce Paradigma/framework/programovací model pro distribuované paralelní výpočty Princip: MAP vstupní data ve formátu
A4M33BDT Technologie pro velká data Milan Kratochvíl 22. března 2017 MapReduce 3 MapReduce Paradigma/framework/programovací model pro distribuované paralelní výpočty Princip: MAP vstupní data ve formátu
Vhodnost nasazení jednotlivých webových architektur, sdílení dat, perzistence, webové služby a REST, asynchronnost, messaging
 Vhodnost nasazení jednotlivých webových architektur, sdílení dat, perzistence, webové služby a REST, asynchronnost, messaging 1. Vhodnost nasazení jednotlivých webových architektur - toto je podle Klímy
Vhodnost nasazení jednotlivých webových architektur, sdílení dat, perzistence, webové služby a REST, asynchronnost, messaging 1. Vhodnost nasazení jednotlivých webových architektur - toto je podle Klímy
Relační DB struktury sloužící k optimalizaci dotazů - indexy, clustery, indexem organizované tabulky
 Otázka 20 A7B36DBS Zadání... 1 Slovníček pojmů... 1 Relační DB struktury sloužící k optimalizaci dotazů - indexy, clustery, indexem organizované tabulky... 1 Zadání Relační DB struktury sloužící k optimalizaci
Otázka 20 A7B36DBS Zadání... 1 Slovníček pojmů... 1 Relační DB struktury sloužící k optimalizaci dotazů - indexy, clustery, indexem organizované tabulky... 1 Zadání Relační DB struktury sloužící k optimalizaci
INDEXY JSOU GRUNT. Pavel Stěhule
 INDEXY JSOU GRUNT Pavel Stěhule Indexy bez indexu čteme vše a zahazujeme nechtěné s indexem čteme pouze to co nás zajímá POZOR - indexy vedou k random IO, navíc se čtou dvě databázové relace (index a heap)
INDEXY JSOU GRUNT Pavel Stěhule Indexy bez indexu čteme vše a zahazujeme nechtěné s indexem čteme pouze to co nás zajímá POZOR - indexy vedou k random IO, navíc se čtou dvě databázové relace (index a heap)
Stěhování aplikací. Michal Tomek, Sales Manager
 Stěhování aplikací Michal Tomek, Sales Manager Agenda Co míníme stěhováním Typické situace Role InterSystems Příležitosti Migrace Stěhování informačního systému Nová budova. HW a OS Získáme nové vlastnosti
Stěhování aplikací Michal Tomek, Sales Manager Agenda Co míníme stěhováním Typické situace Role InterSystems Příležitosti Migrace Stěhování informačního systému Nová budova. HW a OS Získáme nové vlastnosti
Databáze II. 1. přednáška. Helena Palovská palovska@vse.cz
 Databáze II 1. přednáška Helena Palovská palovska@vse.cz Program přednášky Úvod Třívrstvá architektura a O-R mapování Zabezpečení dat Role a přístupová práva Úvod Co je databáze Mnoho dat Organizovaných
Databáze II 1. přednáška Helena Palovská palovska@vse.cz Program přednášky Úvod Třívrstvá architektura a O-R mapování Zabezpečení dat Role a přístupová práva Úvod Co je databáze Mnoho dat Organizovaných
Obsah. Kapitola 1. Kapitola 2. Kapitola 3. Kapitola 4. Úvod 11. Stručný úvod do relačních databází 13. Platforma 10g 23
 Stručný obsah 1. Stručný úvod do relačních databází 13 2. Platforma 10g 23 3. Instalace, první přihlášení, start a zastavení databázového serveru 33 4. Nástroje pro administraci a práci s daty 69 5. Úvod
Stručný obsah 1. Stručný úvod do relačních databází 13 2. Platforma 10g 23 3. Instalace, první přihlášení, start a zastavení databázového serveru 33 4. Nástroje pro administraci a práci s daty 69 5. Úvod
Hadoop, Hive a Spark: Využití pro data mining. Václav Zeman, KIZI VŠE
 Hadoop, Hive a Spark: Využití pro data mining Václav Zeman, KIZI VŠE VŠE: Katedra informačního a znalostního inženýrství Hlavní činnosti: Data Mining a Machine Learning Nástroje: LispMiner a EasyMiner
Hadoop, Hive a Spark: Využití pro data mining Václav Zeman, KIZI VŠE VŠE: Katedra informačního a znalostního inženýrství Hlavní činnosti: Data Mining a Machine Learning Nástroje: LispMiner a EasyMiner
Spark Jan Hučín 5. dubna 2017
 Spark Jan Hučín 5. dubna 2017 Osnova 1. Co to je a k čemu slouží 2. Jak se to naučit 3. Jak se s tím pracuje 4. Jak to funguje Logický a technický pohled Transformace, akce, kešování Příklady Nadstavby
Spark Jan Hučín 5. dubna 2017 Osnova 1. Co to je a k čemu slouží 2. Jak se to naučit 3. Jak se s tím pracuje 4. Jak to funguje Logický a technický pohled Transformace, akce, kešování Příklady Nadstavby
Databáze 2011/2012 SQL DDL (CREATE/ALTER/DROP TABLE), DML (INSERT/UPDATE/DELETE) RNDr.David Hoksza, Ph.D. http://siret.cz/hoksza
, DML (INSERT/UPDATE/DELETE) RNDr.David Hoksza, Ph.D. http://siret.cz/hoksza") Databáze 2011/2012 SQL DDL (CREATE/ALTER/DROP TABLE), DML (INSERT/UPDATE/DELETE) RNDr.David Hksza, Ph.D. http://siret.cz/hksza Osnva Seznámení s SQL Server Management Studiem (SSMS) Základní architektura
Databáze 2011/2012 SQL DDL (CREATE/ALTER/DROP TABLE), DML (INSERT/UPDATE/DELETE) RNDr.David Hksza, Ph.D. http://siret.cz/hksza Osnva Seznámení s SQL Server Management Studiem (SSMS) Základní architektura
Enterprise funkce SQL Serveru 2016, které jsou od SP1 zdarma
 Enterprise funkce SQL Serveru 2016, které jsou od SP1 zdarma RNDr. David Gešvindr MVP: Data Platform MCSE: Data Platform MCSD: Windows Store MCT david@wug.cz @gesvindr SQL Server 2016 Service Pack 1 Vydán
Enterprise funkce SQL Serveru 2016, které jsou od SP1 zdarma RNDr. David Gešvindr MVP: Data Platform MCSE: Data Platform MCSD: Windows Store MCT david@wug.cz @gesvindr SQL Server 2016 Service Pack 1 Vydán
Databázové systémy trocha teorie
 Databázové systémy trocha teorie Základní pojmy Historie vývoje zpracování dat: 50. Léta vše v programu nevýhody poměrně jasné Aplikace1 alg.1 Aplikace2 alg.2 typy1 data1 typy2 data2 vytvoření systémů
Databázové systémy trocha teorie Základní pojmy Historie vývoje zpracování dat: 50. Léta vše v programu nevýhody poměrně jasné Aplikace1 alg.1 Aplikace2 alg.2 typy1 data1 typy2 data2 vytvoření systémů
Healtcheck. databáze ORCL běžící na serveru db.tomas-solar.com pro
 Ukázka doporučení z health checku zaměřeného na PERFORMANCE. Neobsahuje veškeré podkladové materiály, proto i obsah píše špatné odkazy. Healtcheck databáze ORCL běžící na serveru db.tomas-solar.com pro
Ukázka doporučení z health checku zaměřeného na PERFORMANCE. Neobsahuje veškeré podkladové materiály, proto i obsah píše špatné odkazy. Healtcheck databáze ORCL běžící na serveru db.tomas-solar.com pro
RELAČNÍ DATABÁZOVÉ SYSTÉMY
 RELAČNÍ DATABÁZOVÉ SYSTÉMY VÝPIS KONTROLNÍCH OTÁZEK S ODPOVĚDMI: Základní pojmy databázové technologie: 1. Uveďte základní aspekty pro vymezení jednotlivých přístupů ke zpracování hromadných dat: Pro vymezení
RELAČNÍ DATABÁZOVÉ SYSTÉMY VÝPIS KONTROLNÍCH OTÁZEK S ODPOVĚDMI: Základní pojmy databázové technologie: 1. Uveďte základní aspekty pro vymezení jednotlivých přístupů ke zpracování hromadných dat: Pro vymezení
Optimalizace dotazů a databázové transakce v Oracle
 Optimalizace dotazů a databázové transakce v Oracle Marek Rychlý Vysoké učení technické v Brně Fakulta informačních technologií Ústav informačních systémů Demo-cvičení pro IDS 22. dubna 2015 Marek Rychlý
Optimalizace dotazů a databázové transakce v Oracle Marek Rychlý Vysoké učení technické v Brně Fakulta informačních technologií Ústav informačních systémů Demo-cvičení pro IDS 22. dubna 2015 Marek Rychlý
Základy informatiky. 06 Databázové systémy. Kačmařík/Szturcová/Děrgel/Rapant
 Základy informatiky 06 Databázové systémy Kačmařík/Szturcová/Děrgel/Rapant Problém zpracování dat důvodem je potřeba zpracovat velké množství dat, evidovat údaje o nějaké skutečnosti: o skupině lidí (zaměstnanců,
Základy informatiky 06 Databázové systémy Kačmařík/Szturcová/Děrgel/Rapant Problém zpracování dat důvodem je potřeba zpracovat velké množství dat, evidovat údaje o nějaké skutečnosti: o skupině lidí (zaměstnanců,
Úvod do databázových systémů
 Vysoká škola báňská Technická univerzita Ostrava Fakulta elektrotechniky a informatiky Katedra informatiky Database Research Group Úvod do databázových systémů Cvičení 3 Ing. Petr Lukáš petr.lukas@vsb.cz
Vysoká škola báňská Technická univerzita Ostrava Fakulta elektrotechniky a informatiky Katedra informatiky Database Research Group Úvod do databázových systémů Cvičení 3 Ing. Petr Lukáš petr.lukas@vsb.cz
MetaCentrum. datové služby. Miroslav Ruda, Zdeněk Šustr
 MetaCentrum datové služby Miroslav Ruda, Zdeněk Šustr Agenda Národní gridová infrastruktura přehled služeb MetaCentra aktuální stav výpočetní grid cloudové prostředí MapReduce výpočty Národní gridová infrastruktura
MetaCentrum datové služby Miroslav Ruda, Zdeněk Šustr Agenda Národní gridová infrastruktura přehled služeb MetaCentra aktuální stav výpočetní grid cloudové prostředí MapReduce výpočty Národní gridová infrastruktura
Migrace CIDUG. Ing. Pavel Krutina
 d-prog s.r.o. Migrace Ing. Pavel Krutina 11.9.2008 Osnova Migrace Typy migrace Postupy migrace Problémy migrace Paralelizace Co lze paralelizovat Postup paralelizace Rizika paralelizace 2 Co je migrace?
d-prog s.r.o. Migrace Ing. Pavel Krutina 11.9.2008 Osnova Migrace Typy migrace Postupy migrace Problémy migrace Paralelizace Co lze paralelizovat Postup paralelizace Rizika paralelizace 2 Co je migrace?
Archivace relačních databází
 Archivace relačních databází Možnosti, formát SIARD, nástroje, tvorba, prohlížení, datové výstupy Martin Rechtorik 30.11.2018 Archivace relačních databází 1. Možnosti archivace relačních databází 2. Formát
Archivace relačních databází Možnosti, formát SIARD, nástroje, tvorba, prohlížení, datové výstupy Martin Rechtorik 30.11.2018 Archivace relačních databází 1. Možnosti archivace relačních databází 2. Formát
Technické informace. PA152,Implementace databázových systémů 4 / 25. Projekty. pary/pa152/ Pavel Rychlý
 Technické informace PA152 Implementace databázových systémů Pavel Rychlý pary@fi.muni.cz Laboratoř zpracování přirozeného jazyka http://www.fi.muni.cz/nlp/ http://www.fi.muni.cz/ pary/pa152/ přednáška
Technické informace PA152 Implementace databázových systémů Pavel Rychlý pary@fi.muni.cz Laboratoř zpracování přirozeného jazyka http://www.fi.muni.cz/nlp/ http://www.fi.muni.cz/ pary/pa152/ přednáška
MBI - technologická realizace modelu
 MBI - technologická realizace modelu 22.1.2015 MBI, Management byznys informatiky Snímek 1 Agenda Technická realizace portálu MBI. Cíle a principy technického řešení. 1.Obsah portálu - objekty v hierarchiích,
MBI - technologická realizace modelu 22.1.2015 MBI, Management byznys informatiky Snímek 1 Agenda Technická realizace portálu MBI. Cíle a principy technického řešení. 1.Obsah portálu - objekty v hierarchiích,
Vladimír Mach. @vladimirmach 2. 1. 2013
 Vladimír Mach @vladimirmach 2. 1. 2013 SQL Server Compact Edition Jednoduchá relační databáze Použití i v malých zařízeních s omezenými zdroji Dříve pod názvem SQL Server Mobile Časté využití při programování
Vladimír Mach @vladimirmach 2. 1. 2013 SQL Server Compact Edition Jednoduchá relační databáze Použití i v malých zařízeních s omezenými zdroji Dříve pod názvem SQL Server Mobile Časté využití při programování
Novinky v PostgreSQL 9.4. Tomáš Vondra, 2ndQuadrant
 Novinky v PostgreSQL 9.4 Tomáš Vondra, 2ndQuadrant (tomas@2ndquadrant.com) http://blog.pgaddict.com (tomas@pgaddict.com) vývojáři JSONB aggregate expressions (FILTER) SELECT a, SUM(CASE WHEN b < 10 THEN
Novinky v PostgreSQL 9.4 Tomáš Vondra, 2ndQuadrant (tomas@2ndquadrant.com) http://blog.pgaddict.com (tomas@pgaddict.com) vývojáři JSONB aggregate expressions (FILTER) SELECT a, SUM(CASE WHEN b < 10 THEN
GTL GENERATOR NÁSTROJ PRO GENEROVÁNÍ OBJEKTŮ OBJEKTY PRO INFORMATICA POWERCENTER. váš partner na cestě od dat k informacím
 GTL GENERATOR NÁSTROJ PRO GENEROVÁNÍ OBJEKTŮ OBJEKTY PRO INFORMATICA POWERCENTER váš partner na cestě od dat k informacím globtech spol. s r.o. karlovo náměstí 17 c, praha 2 tel.: +420 221 986 390 info@globtech.cz
GTL GENERATOR NÁSTROJ PRO GENEROVÁNÍ OBJEKTŮ OBJEKTY PRO INFORMATICA POWERCENTER váš partner na cestě od dat k informacím globtech spol. s r.o. karlovo náměstí 17 c, praha 2 tel.: +420 221 986 390 info@globtech.cz
Obsah přednášky. Představení webu ASP.NET frameworky Relační databáze Objektově-relační mapování Entity framework
 Web Jaroslav Nečas Obsah přednášky Představení webu ASP.NET frameworky Relační databáze Objektově-relační mapování Entity framework Co to je web HTTP protokol bezstavový GET POST HEAD Cookies Session HTTPS
Web Jaroslav Nečas Obsah přednášky Představení webu ASP.NET frameworky Relační databáze Objektově-relační mapování Entity framework Co to je web HTTP protokol bezstavový GET POST HEAD Cookies Session HTTPS
Optimalizace plnění a aktualizace velkých tabulek. Milan Rafaj, IBM
 Optimalizace plnění a aktualizace velkých tabulek Milan Rafaj, IBM Agenda OLTP vs DSS zpracování Optimalizace INSERT operací Optimalizace DELETE operací Optimalizace UPDATE operací Zdroje Dotazy OLTP vs
Optimalizace plnění a aktualizace velkých tabulek Milan Rafaj, IBM Agenda OLTP vs DSS zpracování Optimalizace INSERT operací Optimalizace DELETE operací Optimalizace UPDATE operací Zdroje Dotazy OLTP vs
Inovace a zkvalitnění výuky prostřednictvím ICT Databázové systémy MySQL základní pojmy, motivace Ing. Kotásek Jaroslav
 Střední průmyslová škola a Vyšší odborná škola technická Brno, Sokolská 1 Šablona: Název: Téma: Autor: Číslo: Anotace: Inovace a zkvalitnění výuky prostřednictvím ICT Databázové systémy MySQL základní
Střední průmyslová škola a Vyšší odborná škola technická Brno, Sokolská 1 Šablona: Název: Téma: Autor: Číslo: Anotace: Inovace a zkvalitnění výuky prostřednictvím ICT Databázové systémy MySQL základní
Petr Nevrlý
 Fulltextové vyhledávání Petr Nevrlý Vyhledávání Cíl vyhledávání Architektura Vyhledávání Robot Údaje z provozu Obsah přednášky Novinky ve fulltextu za rok 2010 Robot v3.0
Fulltextové vyhledávání Petr Nevrlý Vyhledávání Cíl vyhledávání Architektura Vyhledávání Robot Údaje z provozu Obsah přednášky Novinky ve fulltextu za rok 2010 Robot v3.0
Paralelní dotazy v PostgreSQL 9.6 (a 10.0)
") Paralelní dotazy v PostgreSQL 9.6 (a 10.0) Tomáš Vondra tomas.vondra@2ndquadrant.com Prague PostgreSQL Developer Day 16. února, 2017 Agenda spojení vs. procesy v PostgreSQL využití zdrojů výhody, nevýhody,
Paralelní dotazy v PostgreSQL 9.6 (a 10.0) Tomáš Vondra tomas.vondra@2ndquadrant.com Prague PostgreSQL Developer Day 16. února, 2017 Agenda spojení vs. procesy v PostgreSQL využití zdrojů výhody, nevýhody,
FIREBIRD relační databázový systém. Tomáš Svoboda
 FIREBIRD relační databázový systém Tomáš Svoboda xsvobo13@fi.muni.cz Firebird historie 80. léta - Jim Starkey (DEC) InterBase 1994 - odkoupila firma Borland 2000 - Borland uvolnil zdrojové texty InterBase
FIREBIRD relační databázový systém Tomáš Svoboda xsvobo13@fi.muni.cz Firebird historie 80. léta - Jim Starkey (DEC) InterBase 1994 - odkoupila firma Borland 2000 - Borland uvolnil zdrojové texty InterBase
Marketingová komunikace. 3. soustředění. Mgr. Pavel Vávra 9103@mail.vsfs.cz. Kombinované studium Skupina N9KMK3PH (vm3bph)
") Marketingová komunikace Kombinované studium Skupina N9KMK3PH (vm3bph) 3. soustředění Mgr. Pavel Vávra 9103@mail.vsfs.cz http://vavra.webzdarma.cz/home/index.htm Zdroje Studijní materiály Heleny Palovské
Marketingová komunikace Kombinované studium Skupina N9KMK3PH (vm3bph) 3. soustředění Mgr. Pavel Vávra 9103@mail.vsfs.cz http://vavra.webzdarma.cz/home/index.htm Zdroje Studijní materiály Heleny Palovské
DUM 15 téma: Příkazy pro řízení přístupu
 DUM 15 téma: Příkazy pro řízení přístupu ze sady: 3 tematický okruh sady: III. Databáze ze šablony: 7 Kancelářský software určeno pro: 4. ročník vzdělávací obor: 18-20-M/01 Informační technologie vzdělávací
DUM 15 téma: Příkazy pro řízení přístupu ze sady: 3 tematický okruh sady: III. Databáze ze šablony: 7 Kancelářský software určeno pro: 4. ročník vzdělávací obor: 18-20-M/01 Informační technologie vzdělávací
SQL v14. 4D Developer konference. 4D Developer conference 2015 Prague, CZ Celebrating 30 years
 SQL v14 4D Developer konference Obsah části SQL Porovnání 4D a SQL Nové příkazy SQL Upravené příkazy SQL Optimalizace SQL SQL v14 porovnání Definice dat - struktury Manipulace s daty Definice dat Vytvoření
SQL v14 4D Developer konference Obsah části SQL Porovnání 4D a SQL Nové příkazy SQL Upravené příkazy SQL Optimalizace SQL SQL v14 porovnání Definice dat - struktury Manipulace s daty Definice dat Vytvoření
Využití XML v DB aplikacích
 Využití XML v DB aplikacích Michal Kopecký Výběr ze slajdů k 7. přednášce předmětu Databázové Aplikace (DBI026) na MFF UK Komunikace aplikace s okolím Databázová aplikace potřebuje často komunikovat s
Využití XML v DB aplikacích Michal Kopecký Výběr ze slajdů k 7. přednášce předmětu Databázové Aplikace (DBI026) na MFF UK Komunikace aplikace s okolím Databázová aplikace potřebuje často komunikovat s
Databáze I. Přednáška 4
 Databáze I Přednáška 4 Definice dat v SQL Definice tabulek CREATE TABLE jméno_tab (jm_atributu typ [integr. omez.], jm_atributu typ [integr. omez.], ); integritní omezení lze dodefinovat později Definice
Databáze I Přednáška 4 Definice dat v SQL Definice tabulek CREATE TABLE jméno_tab (jm_atributu typ [integr. omez.], jm_atributu typ [integr. omez.], ); integritní omezení lze dodefinovat později Definice
Databázové systémy úvod
 Databázové systémy úvod Michal Valenta Katedra softwarového inženýrství FIT České vysoké učení technické v Praze c Michal Valenta, 2012 BI-DBS, ZS 2012/13 https://edux.fit.cvut.cz/courses/bi-dbs/ Michal
Databázové systémy úvod Michal Valenta Katedra softwarového inženýrství FIT České vysoké učení technické v Praze c Michal Valenta, 2012 BI-DBS, ZS 2012/13 https://edux.fit.cvut.cz/courses/bi-dbs/ Michal
Souborové systémy a logická struktura dat (principy, porovnání, příklady).
.") $TECH 13 Str. 1/5 Souborové systémy a logická struktura dat (principy, porovnání, příklady). Vymezení základních pojmů Soubor První definice: označuje pojmenovanou posloupnost bytů uloženou na nějakém
$TECH 13 Str. 1/5 Souborové systémy a logická struktura dat (principy, porovnání, příklady). Vymezení základních pojmů Soubor První definice: označuje pojmenovanou posloupnost bytů uloženou na nějakém
Jalapeño: pekelně ostrá Java persistence v Caché. Daniel Kutáč Senior Sales Engineer
 Jalapeño: pekelně ostrá Java persistence v Caché Daniel Kutáč Senior Sales Engineer Co je Jalapeño Pár slov ředitele vývoje software Klikni! Tak tedy, o čem dnes budeme mluvit Architektura Instalace Anotace
Jalapeño: pekelně ostrá Java persistence v Caché Daniel Kutáč Senior Sales Engineer Co je Jalapeño Pár slov ředitele vývoje software Klikni! Tak tedy, o čem dnes budeme mluvit Architektura Instalace Anotace
Portfolio úložišť WD pro datová centra Kapacitní úložiště prošlo vývojem
 Kapacitní úložiště, které posune váš výkon k inovacím. WD a logo WD jsou registrované ochranné známky společnosti Western Digital Technologies, Inc. v USA a dalších zemích; WD Ae, WD Re+, WD Re, WD Se,
Kapacitní úložiště, které posune váš výkon k inovacím. WD a logo WD jsou registrované ochranné známky společnosti Western Digital Technologies, Inc. v USA a dalších zemích; WD Ae, WD Re+, WD Re, WD Se,
Manipulace a restrukturalizace dat
 Manipulace a restrukturalizace dat Atributová data Editace Polohová data Konverze mezi softwarově specifickými formáty Editování Spojování a členění prostorových reprezentací Změna mapové projekce Transformace
Manipulace a restrukturalizace dat Atributová data Editace Polohová data Konverze mezi softwarově specifickými formáty Editování Spojování a členění prostorových reprezentací Změna mapové projekce Transformace
Jak ušetřit místo a zároveň mít data snadno dostupná. David Turoň
 Jak ušetřit místo a zároveň mít data snadno dostupná David Turoň david.turon@linuxbox.cz 16.2.2017 Proč: šetří místo na disku automatické mazání starých nepotřebných dat nad staršími daty rychlejší čtení/agregace
Jak ušetřit místo a zároveň mít data snadno dostupná David Turoň david.turon@linuxbox.cz 16.2.2017 Proč: šetří místo na disku automatické mazání starých nepotřebných dat nad staršími daty rychlejší čtení/agregace
Disková pole (RAID) 1
 1") Disková pole (RAID) 1 Architektury RAID Základní myšlenka: snaha o zpracování dat paralelně. Pozice diskové paměti v klasickém personálním počítači vyhovuje pro aplikace s jedním uživatelem. Řešení: data
Disková pole (RAID) 1 Architektury RAID Základní myšlenka: snaha o zpracování dat paralelně. Pozice diskové paměti v klasickém personálním počítači vyhovuje pro aplikace s jedním uživatelem. Řešení: data