Nvidia CUDA Paralelní programování na GPU
|
|
|
- Vendula Dostálová
- před 7 lety
- Počet zobrazení:
Transkript
1 Mendelova univerzita v Brně Provozně ekonomická fakulta Nvidia CUDA Paralelní programování na GPU 2017
2 O čem to bude... Trocha historie Shadery Unifikace GPGPU CUDA Využití GPGPU GPU a jeho Hardware Nvidia CUDA, OpenCL Jak na GPU programovat Podroběnjší pohled na architekturu CUDA Ukázky kódu a porovnání implementací
 Direct3D (cca 1995) RenderMorphics Microsoft 3dfx Voodoo")
3 Jak to začalo Nejznámější API pro 3D grafiku: Glide (cca 1990) OpenGL (cca 1992) Silicon Graphics Khronos Group 3dfx x Nvidia Vulkan (2016) Direct3D (cca 1995) RenderMorphics Microsoft 3dfx Voodoo (1996)
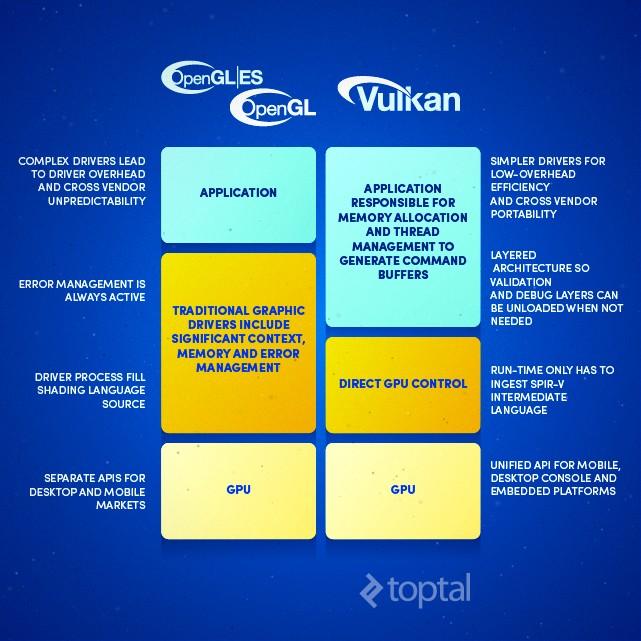
4 Vulkan:

5 Grafická pipeline: Vertex Shaders + Pixel (Fragment) Shaders Malé programy se specifickou sadou instrukcí pro výpočet změny geometrie, nebo modifikace barevnosti fragmentů
6 Shadery Dříve pevně daný počet Vertex a Pixel shaderů Unfied Shader Model Co největší sjednocení instrukčních sad pro shadery Unified Shading Architecture Každá shader jednotka je schopná provádět jakýkoliv výpočetní úkol Dynamické škálovaní dle potřeby mezi jednotlivými typy shaderů Dostupné na GPU od Nvidia GeForce 8 a ATI Radeon HD 2000

7 Shadery Unified Shading Architecture

8 Shadery Unified Shading Architecture

9 Shadery Unified Shading Architecture
10 GPGPU General-Purpose Computing on Graphics Processing Units Převedení algoritmů z CPU na GPU vysoce výkonná vícejádrová zařízení s velkou datovou propustností GPU poskytuje vývojáři paralelní procesory k obecnému použití programovatelné v jazyce C GPU nejčastěji zpracovává vektory (RGB, XYZ) a je pro tento typ práce uzpůsobená <R1, B1, G1> <R2, B2, G2> Od roku 2002 James Fung (University of Toronto) ve spolupráci s firmou Nvidia publikoval několik článků, které nakonec vedly k vydání Nvidia CUDA v roce 2006 (API které umožňuje pomocí jazyka C vytvářet a spouštět kód na grafikách Geforce 8 a novější) a konkurenčního OpenCL.
 Ageia zakoupena Nvidií v roce 2008 PPU výpočty realizovány pomocí GPGPU Nvidia")
11 Využití GPGPU PhysX Engine pro simulaci fyziky v reálném čase Dnes jeden z nejpoužívanějších enginů Vytvořený firmou Ageia spolu s vlastním HW řešením (PPU physics processing unit) Ageia zakoupena Nvidií v roce 2008 PPU výpočty realizovány pomocí GPGPU Nvidia CUDA
 Ageia zakoupena Nvidií v roce 2008 PPU výpočty realizovány pomocí GPGPU")
12 Ageia PhysX Engine pro simulaci fyziky v reálném čase Dnes jeden z nejpoužívanějších enginů Vytvořený firmou Ageia spolu s vlastním HW řešením (PPU physics processing unit) Ageia zakoupena Nvidií v roce 2008 PPU výpočty realizovány pomocí GPGPU Nvidia CUDA

13 Ageia PhysX
14 Ukázka simulace pomocí fyzikálního enginu Ks
15 Využití GPGPU Vědecké výpočty, simulace, Matlab Klasifikace neuronové sítě, KNN Zpracování videa a zvuku Bioinformatika, medicínské aplikace Počítačové vidění, zpracování obrazu, OpenCV Kryptografie
16 Mooreův zákon počet tranzistorů, které mohou být umístěny na integrovaný obvod se při zachování stejné ceny zhruba každých 18 měsíců zdvojnásobí. => Exponenciální růst? Nýní se počet tranzistorů zdvojnásobuje cca každé dva roky.
17 Mooreův zákon Column 1 Column 2 Column Row 1 Row 2 Row 3 Row 4
18 Jak získat vyšší výkon?
19 Jak získat vyšší výkon, pokud se počet tranzistorů stále zvyšuje? Zvýšením rychlost procesoru zvyšování frekvence Paralelizací vícevláknové aplikace

20 Jak získat vyšší výkon?

21 CPU vs GPU

22 CPU Architektura Intel Haswell (Core i7) Výrobní proces: 22nm 4 Jádra 1.4B tranzistorů
23 GPU Architektura Nvidia Kepler Geforce 7xx Geforce 8xx Nvidia GK110 Výrobní proces: 28nm 15 multiprocesorů (SMX) po 192 CUDA jádrech = 2880 CUDA jader 7.1B transistorů
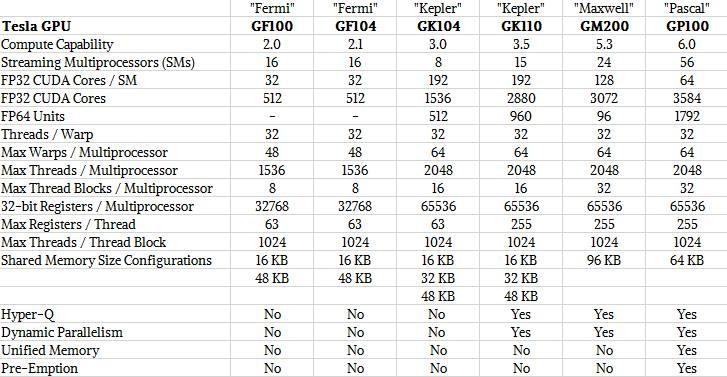
24 GPU Architektura
25 CPU GPU CPU minimální odezva s nízkým objemem práce za čas (low latency low throughput processors) GPU maximální objem práce za čas i s horší odezvou (high latency high throughput processors)
26 CPU GPU CPU disponuje velkou cache pamětí a instrukční jednotkou (Control). Zvládne tedy dobře optimalizovat vykonávání instrukcí GPU jde spíše o hrubou sílu. V rámci jednoho multiprocesoru je používána řídící jednotka pro několik ALU (nazývaných stream procesory) a velmi malá cache paměť, což téměř vylučuje jakékoliv optimalizace vykonávání instrukcí

27 Výhoda? "If you were plowing a field, which would you rather use: Two strong oxen or 1024 chickens?" Seymour Cray Odpověď?

28 Amdahlův zákon zrychlení = P: Paralelní část programu S: Sekvenční část programu

29 GPGPU API Nvidia CUDA OpenCL Compute Unified Device Architecture Open Computing Language Direct Compute
30 CUDA vs. OpenCL Pouze pro platformu Nvidia SDK verze 1.0 dostupné od února 2007 (Windows, Linux) První funkční balík na trhu Pokročilejší implementace množství funkcí, které usnadňují programátorům implementaci (High-level i Low-level API) Přehlednější implementace, debugging jádra a práce s pamětí Proprietární - Freeware Pro většinu platforem Nvidia, AMD, Intel Specifikace verze 1.0 v listopadu 2008 první implementace říjen 2009, IBM Inspirované Nvidia CUDA implementované podobně Spíše Low-level API Složitější debugging jádra a kompexnější práce s pamětí, ale obecnější Součást Khronos Group Royalty Free Open Standard
31 CUDA Compute Unified Device Architecture Platforma pro paralelizované výpočty na GPU CUDA SDK balík potřebných nástrojů pro vývoj verze balíku CUDA 8 Vlastní překladač nvcc pro GPU kód Zpětná binární kompatibilita Aktuálně dostupná verze 6.1 (compute capability) (Titan X, GeForce GTX 1080,...) Programy pro první G8x GPU by měly fungovat bez problémů i na moderních GPU Grafické karty řady Quadro pro pracovní nasazení, věda, grafika vysoký výkon, vysoká cena
32 Floating-Point Operations per Second for the CPU and GPU
33 Memory Bandwidth for the CPU and GPU
34 GPU Architektura Nvidia G80 (Tesla) Geforce 8600 Geforce 8800 Výrobní proces: 90nm 8 multiprocesorů (SMX) po 16 CUDA jádrech = 128 CUDA jader 681 milionu transistorů

35 GPU Opravy
36 SIMD processor (Single Instruction Multiple Data) Streaming processor Streaming multiprocessor
37 Column 1 Column Row 1 Row 2 Row 3 Row 4

38 GPU Archtektura Multiprocesor (G80) Rozložení na obrázku: Dva spárované multiprocesory složené každý z 8 stream procesorů MP = Multi procesor SP = Stream processor L1/L2 = Cache TF = Texture filtering unit

39 GPU Architektua celek (G80) 128 Stream procesorů 16MP x 8SP
40 GPU Architektura Nvidia G70 (2005) Geforce 7xxx Tesla (2006) GeForce 8, 9, 100, 200, 300 Series Fermi (2009) GeForce 400, GeForce 500 Kepler (2012) GeForce 600, 700, 800 series Maxwell (2014) GeForce 700, 800M, 900, Titan series Pascal (2016) GeForce 10xx (10) series. Volta (2018)???
 po 16 CUDA jádrech = 128 CUDA jader 681 milionu")
41 GPU Architektura Nvidia G80 (Tesla) Geforce 8600 Geforce 8800 Výrobní proces: 90nm 8 multiprocesorů (SM) po 16 CUDA jádrech = 128 CUDA jader 681 milionu transistorů
 po 32 CUDA jádrech = 512 CUDA jader 3 biliony")
42 GPU Architektura Nvidia Fermi Geforce 400, 500 Geforce Výrobní proces: 40nm 16 multiprocesorů (SM) po 32 CUDA jádrech = 512 CUDA jader 3 biliony transistorů
43 GPU Architektura Nvidia Kepler Geforce 700 Geforce 800 Nvidia GK110 Výrobní proces: 28nm Až 15 multiprocesorů (SMX) po 192 CUDA jádrech = 2880 CUDA jader 7.1B transistorů
 po 128 CUDA jádrech = 3072 CUDA jader 8.")
44 GPU Architektura Nvidia Maxwell Geforce 700 Geforce 800 Geforce 900 GM200 (GTX Titan) Výrobní proces: 28nm 24 multiprocesorů (SMM) po 128 CUDA jádrech = 3072 CUDA jader 8.3B transistorů
 Pascal SMP (Streaming")
45 GPU Architektura Kepler: SMX Maxwell SMM (Streaming Muptiproocessor Maxwell) Pascal SMP (Streaming Muptiprocessor Pascal)
 po 64 CUDA jádrech = 3840 CUDA jader 15.")
46 GPU Architektura Nvidia Pascal Geforce 10xx Výrobní proces: 14 nm a 16 nm 60 multiprocesorů (SMP) po 64 CUDA jádrech = 3840 CUDA jader 15.3B transistorů


47 GPU Architektura Nvidia Volta Geforce???? Výrobní proces: 12 nm GV100????
48

49 Nvidia CUDA princip práce Odeslání dat na GPU Spuštění výpočtu Vyčkání na dokončení výpočtu Stažení dat z GPU
50 CUDA heterogenní programování Rozlišujeme: Host zařízení kde běží hlavní program (CPU) Device zařízení které spouští vlákna (GPU) Host a device mají oddělené paměti Je nutné nahrát data ke zpracování z host na device a po výpočtu zkopírovat vypočtená data zpět Kvalifikátory funkcí device Vykonávaná a volaná pouze na device global Vykonávaná na device volaná z host host Vykonávaná a volaná pouze na host

51 CUDA paměti CPU Memory 6 -> 64 GB Memory Bandwidth 24 -> 32 GB/s L2 Cache 8 -> 15 MB L1 Cache 256 -> 512 kb GPU Memory 768MB -> 6 GB Memory Bandwidth 100 -> 200 GB/s L2 Cache 512 -> 768 kb L1 Cache 16 -> 48 kb
, nevhodná pro přístup z vláken Konstantní paměť readonly, rychlá odezva a velká")
52 CUDA paměti Registry extrémně rychlé, přístupné jednotlivými vlákny Sdílená paměť extrémně rychlá, vysoce paralelní, dostupná pro jednotlivé bloky Globální paměť dostupná pro všechny, pomalá ( cyklů), nevhodná pro přístup z vláken Konstantní paměť readonly, rychlá odezva a velká propustnost

53 CUDA Unified Memory (CUDA 6)

54 CUDA Unified Memory
55 CUDA: Mřížka Blok - Vlákno
56 CUDA bloky a vlákna Vlákna jsou sjednocovány do bloků Blok je spouštěn a na mutiprocesoru Bloky čekají ve frontě ke zpracování na dostupných multiprocesorech Blok možnost 1D, 2D, 3D indexace Bloky vykonávají stejný kernel

57 CUDA mřížka a bloky Bloky vláken jsou sjednoceny do mřížky Každá mřížka (Grid) může spouštět rozdílné kernely Mřížka > Blok > Vlákno Identifikace vlákna ve vícerozměrném bloku : threadidx.x threadidx.y threadidx.z Identifikace bloku: interní proměnná blockidx (blockidx.{x,y})
58 CUDA bloky a vlákna Identifikace vlákna: interní proměnná threadidx.x,y,z Identifikace bloku: interní proměnná blockidx.x,y,z Rozměr bloku: interní proměnná blockdim.x,y,z Rozměr mřížky: interní proměnná griddim.x,y,z
59 CUDA bloky a vlákna Pozice X Pozice Y = blockidx.y * blockdim.y + threadidx.y Počet vláken na ose X? = blockidx.x * blockdim.x + threadidx.x... blockdim.x * griddim.x

60 CUDA škálování Rozložení stejného výpočtu na různých GPU s různým počtem multiprocesorů automatické

61 CUDA vybrané specifikace
 Kolekce vláken stejného bloku, která provádí stejnou instrukci Pospuštění kernelu jsou při")
62 CUDA: Warp Warp size - 32 (verze ) Kolekce vláken stejného bloku, která provádí stejnou instrukci Pospuštění kernelu jsou při runtime alokovány warpy do SM podle potřeb jejich registrů a pamětí
63 CUDA příklad Zpracování obrázku 1024 x 1024 px Stanovíme rozměr Bloku na 16 x vláken Potřebujeme 4096 bloků ((1024x1024) / 256 ) dim3 threadsperblock(16, 16); Vytvoříme 2D mřížku (64 x 64 bloků) Potřebujeme vláken dim3 blockspergrid(imagewidth / threadsperblock.x, imageheight / threadsperblock.y); Spuštění kernelu gpukernel <<< threadsperblock, blockspergrid >>();
64 CUDA kernel void cpu_soucet() {float vys[], float c1[], float c2[]){ for(int i=0, i<size,i++) vys[i] = c1[i] + c2[i]; } global void gpu_soucet(float *vys, float *c1, float *c2){ int i = threadidx.x; vys[i] = c1[i] + c2[i]; } Překlad kernelu pomocí NVCC NVIDIA LLVM-based C/C++ překladače

65 CPU vs. GPU Prahování

66 CPU vs. GPU CPU Prahování

67 CPU vs. GPU GPU Prahování (CUDA)
68 CPU vs. GPU GPU Prahování (OpenCL)


69 CPU vs. GPU OpenCV OpenCV Open Source Computer Vision Knihovna sdružující funkce pro počítačové vidění a strojové učení GPU implementace
70 Porovnání implelemtací algoritmu prahování Doba provádění algoritmu prahování v závislosti na rozlišení obrázku a použité implementaci Oprimalizace > Akcelerace
71 Děkuji za pozornost...
Nvidia CUDA Paralelní programování na GPU
 Mendelova univerzita v Brně Provozně ekonomická fakulta Nvidia CUDA Paralelní programování na GPU 2014 O čem to bude... Trocha historie Shadery Unifikace GPGPU CUDA Využití GPGPU GPU a jeho Hardware Nvidia
Mendelova univerzita v Brně Provozně ekonomická fakulta Nvidia CUDA Paralelní programování na GPU 2014 O čem to bude... Trocha historie Shadery Unifikace GPGPU CUDA Využití GPGPU GPU a jeho Hardware Nvidia
GPU A CUDA HISTORIE GPU CO JE GPGPU? NVIDIA CUDA
 GPU A CUDA HISTORIE GPU CO JE GPGPU? NVIDIA CUDA HISTORIE GPU GPU = graphics processing unit jde o akcelerátory pro algoritmy v 3D grafice a vizualizaci mnoho z nich původně vzniklo pro účely počítačových
GPU A CUDA HISTORIE GPU CO JE GPGPU? NVIDIA CUDA HISTORIE GPU GPU = graphics processing unit jde o akcelerátory pro algoritmy v 3D grafice a vizualizaci mnoho z nich původně vzniklo pro účely počítačových
Úvod do GPGPU J. Sloup, I. Šimeček
 Úvod do GPGPU J. Sloup, I. Šimeček xsimecek@fit.cvut.cz Katedra počítačových systémů FIT České vysoké učení technické v Praze Ivan Šimeček, 2011 MI-PRC, LS2010/11, Predn.3 Příprava studijního programu
Úvod do GPGPU J. Sloup, I. Šimeček xsimecek@fit.cvut.cz Katedra počítačových systémů FIT České vysoké učení technické v Praze Ivan Šimeček, 2011 MI-PRC, LS2010/11, Predn.3 Příprava studijního programu
GPGPU. Jan Faigl. Gerstnerova Laboratoř pro inteligentní rozhodování a řízení České vysoké učení technické v Praze
 GPGPU Jan Faigl Gerstnerova Laboratoř pro inteligentní rozhodování a řízení České vysoké učení technické v Praze 8. cvičení katedra kybernetiky, FEL, ČVUT v Praze X33PTE - Programovací techniky GPGPU 1
GPGPU Jan Faigl Gerstnerova Laboratoř pro inteligentní rozhodování a řízení České vysoké učení technické v Praze 8. cvičení katedra kybernetiky, FEL, ČVUT v Praze X33PTE - Programovací techniky GPGPU 1
GPU a CUDA. Historie GPU. Co je GPGPU? Nvidia CUDA
 GPU a CUDA Historie GPU Co je GPGPU? Nvidia CUDA Historie GPU GPU = graphics processing unit jde o akcelerátory pro algoritmy v 3D grafice a vizualizaci mnoho z nich původně vzniklo pro účely počítačových
GPU a CUDA Historie GPU Co je GPGPU? Nvidia CUDA Historie GPU GPU = graphics processing unit jde o akcelerátory pro algoritmy v 3D grafice a vizualizaci mnoho z nich původně vzniklo pro účely počítačových
Pokročilé architektury počítačů
 Pokročilé architektury počítačů Tutoriál 3 CUDA - GPU Martin Milata Výpočetní model CUDA Organizace kódu Sériově organizovaný kód určený pro CPU Paralelní kód prováděný na GPU Označuje se jako kernel GPU
Pokročilé architektury počítačů Tutoriál 3 CUDA - GPU Martin Milata Výpočetní model CUDA Organizace kódu Sériově organizovaný kód určený pro CPU Paralelní kód prováděný na GPU Označuje se jako kernel GPU
Obecné výpočty na GPU v jazyce CUDA. Jiří Filipovič
 Obecné výpočty na GPU v jazyce CUDA Jiří Filipovič Obsah přednášky motivace architektura GPU CUDA programovací model jaké algoritmy urychlovat na GPU? optimalizace Motivace Moorův zákon stále platí pro
Obecné výpočty na GPU v jazyce CUDA Jiří Filipovič Obsah přednášky motivace architektura GPU CUDA programovací model jaké algoritmy urychlovat na GPU? optimalizace Motivace Moorův zákon stále platí pro
GPGPU Aplikace GPGPU. Obecné výpočty na grafických procesorech. Jan Vacata
 Obecné výpočty na grafických procesorech Motivace Úvod Motivace Technologie 3 GHz Intel Core 2 Extreme QX9650 Výkon: 96 GFLOPS Propustnost paměti: 21 GB/s Orientační cena: 1300 USD NVIDIA GeForce 9800
Obecné výpočty na grafických procesorech Motivace Úvod Motivace Technologie 3 GHz Intel Core 2 Extreme QX9650 Výkon: 96 GFLOPS Propustnost paměti: 21 GB/s Orientační cena: 1300 USD NVIDIA GeForce 9800
Co je grafický akcelerátor
 Co je grafický akcelerátor jednotka v osobním počítači či herní konzoli přebírá funkce hlavního procesoru pro grafické operace graphics renderer odlehčuje hlavnímu procesoru paralelní zpracování vybaven
Co je grafický akcelerátor jednotka v osobním počítači či herní konzoli přebírá funkce hlavního procesoru pro grafické operace graphics renderer odlehčuje hlavnímu procesoru paralelní zpracování vybaven
Pokročilé architektury počítačů
 Pokročilé architektury počítačů Přednáška 7 CUDA První paralelní aplikace Martin Milata Obsah SIMD versus SIMT Omezení a HW implementace Způsob zpracování warp skupiny vláken CUDA - pohled programátora
Pokročilé architektury počítačů Přednáška 7 CUDA První paralelní aplikace Martin Milata Obsah SIMD versus SIMT Omezení a HW implementace Způsob zpracování warp skupiny vláken CUDA - pohled programátora
GPU a CUDA. Historie GPU. Co je GPGPU? Nvidia CUDA
 GPU a CUDA Historie GPU Co je GPGPU? Nvidia CUDA Historie GPU GPU = graphics processing unit jde o akcelerátory pro algoritmy v 3D grafice a vizualizaci mnoho z nich původně vzniklo pro účely počítačových
GPU a CUDA Historie GPU Co je GPGPU? Nvidia CUDA Historie GPU GPU = graphics processing unit jde o akcelerátory pro algoritmy v 3D grafice a vizualizaci mnoho z nich původně vzniklo pro účely počítačových
Přehled paralelních architektur. Dělení paralelních architektur Flynnova taxonomie Komunikační modely paralelních architektur
 Přehled paralelních architektur Přehled paralelních architektur Dělení paralelních architektur Flynnova taxonomie Komunikační modely paralelních architektur Přehled I. paralelní počítače se konstruují
Přehled paralelních architektur Přehled paralelních architektur Dělení paralelních architektur Flynnova taxonomie Komunikační modely paralelních architektur Přehled I. paralelní počítače se konstruují
Pokročilé architektury počítačů
 Pokročilé architektury počítačů Přednáška 5 GPU - CUDA Martin Milata Obsah Obecné výpočty a GPU Grafické procesory NVIDIA Tesla Výpočetní model Paměťový model GT200 Zpracování instrukcí Vydávání instrukcí
Pokročilé architektury počítačů Přednáška 5 GPU - CUDA Martin Milata Obsah Obecné výpočty a GPU Grafické procesory NVIDIA Tesla Výpočetní model Paměťový model GT200 Zpracování instrukcí Vydávání instrukcí
PŘEDSTAVENÍ GRAFICKÉHO PROCESORU NVIDIA G200
 PŘEDSTAVENÍ GRAFICKÉHO PROCESORU NVIDIA G200 Bc.Adam Berger Ber 208 Historie a předchůdci G200 V červnu roku 2008 spatřila světlo světa nová grafická karta od společnosti Nvidia. Tato grafická karta opět
PŘEDSTAVENÍ GRAFICKÉHO PROCESORU NVIDIA G200 Bc.Adam Berger Ber 208 Historie a předchůdci G200 V červnu roku 2008 spatřila světlo světa nová grafická karta od společnosti Nvidia. Tato grafická karta opět
Paralelní a distribuované výpočty (B4B36PDV)
") Paralelní a distribuované výpočty (B4B36PDV) Branislav Bošanský, Michal Jakob bosansky@fel.cvut.cz Artificial Intelligence Center Department of Computer Science Faculty of Electrical Engineering Czech
Paralelní a distribuované výpočty (B4B36PDV) Branislav Bošanský, Michal Jakob bosansky@fel.cvut.cz Artificial Intelligence Center Department of Computer Science Faculty of Electrical Engineering Czech
Hlavní využití počítačů
 Úvod Hlavní využití počítačů Počítače jsou výkonné nástroje využívané pro zpracování dat. Provádějí: načtení a binární kódování dat provedení požadovaného výpočtu zobrazení výsledku Hlavní využití počítačů
Úvod Hlavní využití počítačů Počítače jsou výkonné nástroje využívané pro zpracování dat. Provádějí: načtení a binární kódování dat provedení požadovaného výpočtu zobrazení výsledku Hlavní využití počítačů
REALIZACE SUPERPOČÍTAČE POMOCÍ GRAFICKÉ KARTY
 VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ BRNO UNIVERSITY OF TECHNOLOGY FAKULTA ELEKTROTECHNIKY A KOMUNIKAČNÍCH TECHNOLOGIÍ ÚSTAV TELEKOMUNIKACÍ FACULTY OF ELECTRICAL ENGINEERING AND COMMUNICATION DEPARTMENT OF TELECOMMUNICATIONS
VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ BRNO UNIVERSITY OF TECHNOLOGY FAKULTA ELEKTROTECHNIKY A KOMUNIKAČNÍCH TECHNOLOGIÍ ÚSTAV TELEKOMUNIKACÍ FACULTY OF ELECTRICAL ENGINEERING AND COMMUNICATION DEPARTMENT OF TELECOMMUNICATIONS
CUDA J. Sloup a I. Šimeček
 CUDA J. Sloup a I. Šimeček xsimecek@fit.cvut.cz Katedra počítačových systémů FIT České vysoké učení technické v Praze Ivan Šimeček, 2011 MI-PAP, LS2010/11, Predn.6 Příprava studijního programu Informatika
CUDA J. Sloup a I. Šimeček xsimecek@fit.cvut.cz Katedra počítačových systémů FIT České vysoké učení technické v Praze Ivan Šimeček, 2011 MI-PAP, LS2010/11, Predn.6 Příprava studijního programu Informatika
Základní úrovně: Moorův zákon: multi-core mikroprocesory (CPU) hypertherading pipeline many-core Paralelní systém Instrukce iterace procedura Proces
 hypertherading pipeline many-core Paralelní systém Instrukce iterace procedura Proces") Základní úrovně: hardwarová (procesory, jádra) programová (procesy, vlákna) algoritmická (uf...) zvýšení výkonu, redundance, jiné cíle, ale podobné nástroje a problémy. Moorův zákon: Počet tranzistorů/komponent,
Základní úrovně: hardwarová (procesory, jádra) programová (procesy, vlákna) algoritmická (uf...) zvýšení výkonu, redundance, jiné cíle, ale podobné nástroje a problémy. Moorův zákon: Počet tranzistorů/komponent,
OPS Paralelní systémy, seznam pojmů, klasifikace
 Moorův zákon (polovina 60. let) : Výpočetní výkon a počet tranzistorů na jeden CPU chip integrovaného obvodu mikroprocesoru se každý jeden až dva roky zdvojnásobí; cena se zmenší na polovinu. Paralelismus
Moorův zákon (polovina 60. let) : Výpočetní výkon a počet tranzistorů na jeden CPU chip integrovaného obvodu mikroprocesoru se každý jeden až dva roky zdvojnásobí; cena se zmenší na polovinu. Paralelismus
Vyuºití GPGPU pro zpracování dat z magnetické rezonance
 Vyuºití pro zpracování dat z magnetické rezonance Katedra matematiky, Fakulta jaderná a fyzikáln inºenýrská, ƒeské vysoké u ení technické v Praze Bakalá ská práce 2007/2008 Cíle práce Zpracování dat z
Vyuºití pro zpracování dat z magnetické rezonance Katedra matematiky, Fakulta jaderná a fyzikáln inºenýrská, ƒeské vysoké u ení technické v Praze Bakalá ská práce 2007/2008 Cíle práce Zpracování dat z
Jiné výpočetní platformy J. Sloup, M. Skrbek, I. Šimeček
 Jiné výpočetní platformy J. Sloup, M. Skrbek, I. Šimeček xsimecek@fit.cvut.cz Katedra počítačových systémů FIT České vysoké učení technické v Praze Ivan Šimeček, 2011 BI-EIA, ZS2011/12, Predn.12 Příprava
Jiné výpočetní platformy J. Sloup, M. Skrbek, I. Šimeček xsimecek@fit.cvut.cz Katedra počítačových systémů FIT České vysoké učení technické v Praze Ivan Šimeček, 2011 BI-EIA, ZS2011/12, Predn.12 Příprava
Sběrnicová struktura PC Procesory PC funkce, vlastnosti Interní počítačové paměti PC
 Informační systémy 2 Obsah: Sběrnicová struktura PC Procesory PC funkce, vlastnosti Interní počítačové paměti PC ROM RAM Paměti typu CACHE IS2-4 1 Dnešní info: Informační systémy 2 03 Informační systémy
Informační systémy 2 Obsah: Sběrnicová struktura PC Procesory PC funkce, vlastnosti Interní počítačové paměti PC ROM RAM Paměti typu CACHE IS2-4 1 Dnešní info: Informační systémy 2 03 Informační systémy
Řešíme úlohu zpracování velkého množství dat. Data jsou symetrická, úloha je dobře paralelizovatelná. Propaganda výrobců grafických karet:
 GPGPU Motivace Řešíme úlohu zpracování velkého množství dat Data jsou symetrická, úloha je dobře paralelizovatelná Propaganda výrobců grafických karet: Vezměte váš C-čkový kód, zkompilujte a pusťte jej
GPGPU Motivace Řešíme úlohu zpracování velkého množství dat Data jsou symetrická, úloha je dobře paralelizovatelná Propaganda výrobců grafických karet: Vezměte váš C-čkový kód, zkompilujte a pusťte jej
Řešíme úlohu zpracování velkého množství dat. Data jsou symetrická, úloha je dobře paralelizovatelná
 GPGPU Motivace Řešíme úlohu zpracování velkého množství dat Data jsou symetrická, úloha je dobře paralelizovatelná Propaganda výrobců grafických karet: Vezměte váš C-čkový kód, zkompilujte a pusťte jej
GPGPU Motivace Řešíme úlohu zpracování velkého množství dat Data jsou symetrická, úloha je dobře paralelizovatelná Propaganda výrobců grafických karet: Vezměte váš C-čkový kód, zkompilujte a pusťte jej
Grafické karty s podporou DirectX 11 Quynh Trang Dao Dao007
 Pokročilé Architektury Počítačů 2009/2010 Semestrální projekt Grafické karty s podporou DirectX 11 Quynh Trang Dao Dao007 1. DirectX 11 V posledních pár letech se rozhraní DirectX dostalo do popředí a
Pokročilé Architektury Počítačů 2009/2010 Semestrální projekt Grafické karty s podporou DirectX 11 Quynh Trang Dao Dao007 1. DirectX 11 V posledních pár letech se rozhraní DirectX dostalo do popředí a
Pokročilé architektury počítačů
 Vysoká škola báňská Technická univerzita Ostrava Fakulta elektrotechniky a informatiky Pokročilé architektury počítačů Architektura Intel Larrabee 5.12.2009 Josef Stoklasa STO228 Obsah: 1. Úvod do tajů
Vysoká škola báňská Technická univerzita Ostrava Fakulta elektrotechniky a informatiky Pokročilé architektury počítačů Architektura Intel Larrabee 5.12.2009 Josef Stoklasa STO228 Obsah: 1. Úvod do tajů
Akcelerace výpočtů prostřednictvím GPU
 Mendelova univerzita v Brně Provozně ekonomická fakulta Akcelerace výpočtů prostřednictvím GPU Bakalářská práce Vedoucí práce: Ing. David Procházka, Ph.D. Karel Zídek Brno 2012 2 zadání práce 4 Děkuji
Mendelova univerzita v Brně Provozně ekonomická fakulta Akcelerace výpočtů prostřednictvím GPU Bakalářská práce Vedoucí práce: Ing. David Procházka, Ph.D. Karel Zídek Brno 2012 2 zadání práce 4 Děkuji
Geekovo Minimum. Počítačové Grafiky. Nadpis 1 Nadpis 2 Nadpis 3. Božetěchova 2, Brno
 Geekovo Minimum Nadpis 1 Nadpis 2 Nadpis 3 Počítačové Grafiky Jméno Adam Příjmení Herout Vysoké Vysoké učení technické učení technické v Brně, v Fakulta Brně, Fakulta informačních informačních technologií
Geekovo Minimum Nadpis 1 Nadpis 2 Nadpis 3 Počítačové Grafiky Jméno Adam Příjmení Herout Vysoké Vysoké učení technické učení technické v Brně, v Fakulta Brně, Fakulta informačních informačních technologií
GPU Computing.
 GPU Computing Motivace Procesory (CPU, Central Processing Units) jsou rychlé, paměť nestačí poskytovat data. Běžným lékem na latenční dobu (memory latency) paměti bývá užívání rychlých (ale malých) cache
GPU Computing Motivace Procesory (CPU, Central Processing Units) jsou rychlé, paměť nestačí poskytovat data. Běžným lékem na latenční dobu (memory latency) paměti bývá užívání rychlých (ale malých) cache
Pokročilá architektura počítačů
 Pokročilá architektura počítačů Technologie PhysX Jan Lukáč LUK145 Sony PlayStation 2 Emotion Engine První krok do světa akcelerované fyziky učinily pro mnohé velmi překvapivě herní konzole. Sony Playstation
Pokročilá architektura počítačů Technologie PhysX Jan Lukáč LUK145 Sony PlayStation 2 Emotion Engine První krok do světa akcelerované fyziky učinily pro mnohé velmi překvapivě herní konzole. Sony Playstation
PROCESOR. Typy procesorů
 PROCESOR Procesor je ústřední výkonnou jednotkou počítače, která čte z paměti instrukce a na jejich základě vykonává program. Primárním úkolem procesoru je řídit činnost ostatních částí počítače včetně
PROCESOR Procesor je ústřední výkonnou jednotkou počítače, která čte z paměti instrukce a na jejich základě vykonává program. Primárním úkolem procesoru je řídit činnost ostatních částí počítače včetně
Přednáška 1. Katedra počítačových systémů FIT, České vysoké učení technické v Praze Jan Trdlička, 2012
 Přednáška 1 Úvod do HW a OS. Katedra počítačových systémů FIT, České vysoké učení technické v Praze Jan Trdlička, 2012 Příprava studijního programu Informatika je podporována projektem financovaným z Evropského
Přednáška 1 Úvod do HW a OS. Katedra počítačových systémů FIT, České vysoké učení technické v Praze Jan Trdlička, 2012 Příprava studijního programu Informatika je podporována projektem financovaným z Evropského
Architektura grafických ip pro Xbox 360 a PS3
 Architektura grafických ip pro Xbox 360 a PS3 Jakub Stoszek sto171 VŠB TU Ostrava 12.12.2008 Obsah Grafická karta ATI Xenox (Xbox 360)...3 ip grafické karty ATI Xenos (Xbox 360)...3 Pam grafické karty
Architektura grafických ip pro Xbox 360 a PS3 Jakub Stoszek sto171 VŠB TU Ostrava 12.12.2008 Obsah Grafická karta ATI Xenox (Xbox 360)...3 ip grafické karty ATI Xenos (Xbox 360)...3 Pam grafické karty
PV109: Historie a vývojové trendy ve VT
 PV109: Historie a vývojové trendy ve VT Vývojové trendy Luděk Matyska Fakulta informatiky Masarykovy univerzity podzim 2014 Luděk Matyska (FI MU) PV109: Historie a vývojové trendy ve VT podzim 2014 1 /
PV109: Historie a vývojové trendy ve VT Vývojové trendy Luděk Matyska Fakulta informatiky Masarykovy univerzity podzim 2014 Luděk Matyska (FI MU) PV109: Historie a vývojové trendy ve VT podzim 2014 1 /
VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ BRNO UNIVERSITY OF TECHNOLOGY
 VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ BRNO UNIVERSITY OF TECHNOLOGY FAKULTA INFORMAČNÍCH TECHNOLOGIÍ ÚSTAV POČÍTAČOVÉ GRAFIKY A MULTIMÉDIÍ FACULTY OF INFORMATION TECHNOLOGY DEPARTMENT OF COMPUTER GRAPHICS AND
VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ BRNO UNIVERSITY OF TECHNOLOGY FAKULTA INFORMAČNÍCH TECHNOLOGIÍ ÚSTAV POČÍTAČOVÉ GRAFIKY A MULTIMÉDIÍ FACULTY OF INFORMATION TECHNOLOGY DEPARTMENT OF COMPUTER GRAPHICS AND
FAKULTA INFORMAČNÍCH TECHNOLOGIÍ
 VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ BRNO UNIVERSITY OF TECHNOLOGY FAKULTA INFORMAČNÍCH TECHNOLOGIÍ ÚSTAV POČÍTAČOVÝCH SYSTÉMŮ FACULTY OF INFORMATION TECHNOLOGY DEPARTMENT OF COMPUTER SYSTEMS POUŽITÍ OPENCL V
VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ BRNO UNIVERSITY OF TECHNOLOGY FAKULTA INFORMAČNÍCH TECHNOLOGIÍ ÚSTAV POČÍTAČOVÝCH SYSTÉMŮ FACULTY OF INFORMATION TECHNOLOGY DEPARTMENT OF COMPUTER SYSTEMS POUŽITÍ OPENCL V
Základy informatiky. 2. Přednáška HW. Lenka Carr Motyčková. February 22, 2011 Základy informatiky 2
 Základy informatiky 2. Přednáška HW Lenka Carr Motyčková February 22, 2011 Základy informatiky 1 February 22, 2011 Základy informatiky 2 February 22, 2011 Základy informatiky 3 February 22, 2011 Základy
Základy informatiky 2. Přednáška HW Lenka Carr Motyčková February 22, 2011 Základy informatiky 1 February 22, 2011 Základy informatiky 2 February 22, 2011 Základy informatiky 3 February 22, 2011 Základy
GRAFICKÉ ADAPTÉRY. Pracovní režimy grafické karty
 GRAFICKÉ ADAPTÉRY Grafický adaptér (též videokarta, grafická karta, grafický akcelerátor) je rozhraní, které zabezpečuje výstup obrazových dat z počítače na zobrazovací jednotku (monitor, displej, dataprojektor,
GRAFICKÉ ADAPTÉRY Grafický adaptér (též videokarta, grafická karta, grafický akcelerátor) je rozhraní, které zabezpečuje výstup obrazových dat z počítače na zobrazovací jednotku (monitor, displej, dataprojektor,
Grafické karty. Autor: Kulhánek Zdeněk
 Grafické karty Autor: Kulhánek Zdeněk Škola: Hotelová škola, Obchodní akademie a Střední průmyslová škola Teplice, Benešovo náměstí 1, příspěvková organizace Kód: VY_32_INOVACE_ICT_826 1.11.2012 1 1. Grafická
Grafické karty Autor: Kulhánek Zdeněk Škola: Hotelová škola, Obchodní akademie a Střední průmyslová škola Teplice, Benešovo náměstí 1, příspěvková organizace Kód: VY_32_INOVACE_ICT_826 1.11.2012 1 1. Grafická
Procesy a vlákna (Processes and Threads)
") ÚVOD DO OPERAČNÍCH SYSTÉMŮ Ver.1.00 Procesy a vlákna (Processes and Threads) Správa procesů a vláken České vysoké učení technické Fakulta elektrotechnická 2012 Použitá literatura [1] Stallings, W.: Operating
ÚVOD DO OPERAČNÍCH SYSTÉMŮ Ver.1.00 Procesy a vlákna (Processes and Threads) Správa procesů a vláken České vysoké učení technické Fakulta elektrotechnická 2012 Použitá literatura [1] Stallings, W.: Operating
Představení a srovnání grafických procesorů ATI RV770 a NVIDIA G(T)200
200") Představení a srovnání grafických procesorů ATI RV770 a NVIDIA G(T)200 Adam Količ, kol400 NVIDIA G(T)200 Technické info: 65nm (G200b - 55nm) 1,4 mld. tranzistorů 240 stream procesorů 32 ROP/RBE 80 texturovacích
Představení a srovnání grafických procesorů ATI RV770 a NVIDIA G(T)200 Adam Količ, kol400 NVIDIA G(T)200 Technické info: 65nm (G200b - 55nm) 1,4 mld. tranzistorů 240 stream procesorů 32 ROP/RBE 80 texturovacích
Matematika v programovacích
 Matematika v programovacích jazycích Pavla Kabelíková am.vsb.cz/kabelikova pavla.kabelikova@vsb.cz Úvodní diskuze Otázky: Jaké programovací jazyky znáte? S jakými programovacími jazyky jste již pracovali?
Matematika v programovacích jazycích Pavla Kabelíková am.vsb.cz/kabelikova pavla.kabelikova@vsb.cz Úvodní diskuze Otázky: Jaké programovací jazyky znáte? S jakými programovacími jazyky jste již pracovali?
2.8 Procesory. Střední průmyslová škola strojnická Vsetín. Ing. Martin Baričák. Název šablony Název DUMu. Předmět Druh učebního materiálu
 Název školy Číslo projektu Autor Název šablony Název DUMu Tematická oblast Předmět Druh učebního materiálu Anotace Vybavení, pomůcky Ověřeno ve výuce dne, třída Střední průmyslová škola strojnická Vsetín
Název školy Číslo projektu Autor Název šablony Název DUMu Tematická oblast Předmět Druh učebního materiálu Anotace Vybavení, pomůcky Ověřeno ve výuce dne, třída Střední průmyslová škola strojnická Vsetín
vlastnosti, praktické zkušenosti
 Obecné výpočty na grafických kartách použitelnost, vlastnosti, praktické zkušenosti Martin Kruliš, Jakub Yaghob KSI MFF UK Malostranské nám. 25, Praha {krulis,yaghob}@ksi.mff.cuni.cz Abstrakt. Nedávný
Obecné výpočty na grafických kartách použitelnost, vlastnosti, praktické zkušenosti Martin Kruliš, Jakub Yaghob KSI MFF UK Malostranské nám. 25, Praha {krulis,yaghob}@ksi.mff.cuni.cz Abstrakt. Nedávný
ARCHITEKTURA AMD PUMA
 VŠB-TU Ostrava Fakulta elektrotechniky a informatiky Katedra informačných technológií ARCHITEKTURA AMD PUMA Martin Raichl, RAI033 21. listopadu 2009 Ján Podracký, POD123 Obsah Architektura AMD PUMA nová
VŠB-TU Ostrava Fakulta elektrotechniky a informatiky Katedra informačných technológií ARCHITEKTURA AMD PUMA Martin Raichl, RAI033 21. listopadu 2009 Ján Podracký, POD123 Obsah Architektura AMD PUMA nová
Optimalizace pro GPU hardware
 Optimalizace pro GPU hardware Jiří Filipovič jaro 2015 Jiří Filipovič Optimalizace pro GPU hardware 1 / 52 Paralelismus GPU Paralelní algoritmy je nutno navrhovat vzhledem k paralelismu, který poskytuje
Optimalizace pro GPU hardware Jiří Filipovič jaro 2015 Jiří Filipovič Optimalizace pro GPU hardware 1 / 52 Paralelismus GPU Paralelní algoritmy je nutno navrhovat vzhledem k paralelismu, který poskytuje
Paralelní výpočty ve finančnictví
 Paralelní výpočty ve finančnictví Jan Houška HUMUSOFT s.r.o. houska@humusoft.cz Výpočetně náročné úlohy distribuované úlohy mnoho relativně nezávislých úloh snížení zatížení klientské pracovní stanice
Paralelní výpočty ve finančnictví Jan Houška HUMUSOFT s.r.o. houska@humusoft.cz Výpočetně náročné úlohy distribuované úlohy mnoho relativně nezávislých úloh snížení zatížení klientské pracovní stanice
FAKULTA INFORMAČNÍCH TECHNOLOGIÍ
 VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ BRNO UNIVERSITY OF TECHNOLOGY FAKULTA INFORMAČNÍCH TECHNOLOGIÍ ÚSTAV POČÍTAČOVÝCH SYSTÉMŮ FACULTY OF INFORMATION TECHNOLOGY DEPARTMENT OF COMPUTER SYSTEMS NUMERICKÁ SIMULACE
VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ BRNO UNIVERSITY OF TECHNOLOGY FAKULTA INFORMAČNÍCH TECHNOLOGIÍ ÚSTAV POČÍTAČOVÝCH SYSTÉMŮ FACULTY OF INFORMATION TECHNOLOGY DEPARTMENT OF COMPUTER SYSTEMS NUMERICKÁ SIMULACE
IB109 Návrh a implementace paralelních systémů. Organizace kurzu a úvod. RNDr. Jiří Barnat, Ph.D.
 IB109 Návrh a implementace paralelních systémů Organizace kurzu a úvod RNDr. Jiří Barnat, Ph.D. Sekce B109 Návrh a implementace paralelních systémů: Organizace kurzu a úvod str. 2/25 Organizace kurzu Organizace
IB109 Návrh a implementace paralelních systémů Organizace kurzu a úvod RNDr. Jiří Barnat, Ph.D. Sekce B109 Návrh a implementace paralelních systémů: Organizace kurzu a úvod str. 2/25 Organizace kurzu Organizace
Část 2 POROVNÁNÍ VÝKONNOSTI A POUŽITELNOSTI ARCHITEKTUR V TYPICKÝCH APLIKACÍCH
 Část 2 POROVNÁNÍ VÝKONNOSTI A POUŽITELNOSTI ARCHITEKTUR V TYPICKÝCH APLIKACÍCH Paralelizace kódu Rozdíl v přístupu k paralelizaci kódu si ukážeme na operaci násobení matice maticí: Mějme tři čtvercové
Část 2 POROVNÁNÍ VÝKONNOSTI A POUŽITELNOSTI ARCHITEKTUR V TYPICKÝCH APLIKACÍCH Paralelizace kódu Rozdíl v přístupu k paralelizaci kódu si ukážeme na operaci násobení matice maticí: Mějme tři čtvercové
Architektura Intel Atom
 Architektura Intel Atom Štěpán Sojka 5. prosince 2008 1 Úvod Hlavní rysem Atomu je podpora platformy x86, která umožňuje spouštět a běžně používat řadu let vyvíjené aplikace, na které jsou uživatelé zvyklí
Architektura Intel Atom Štěpán Sojka 5. prosince 2008 1 Úvod Hlavní rysem Atomu je podpora platformy x86, která umožňuje spouštět a běžně používat řadu let vyvíjené aplikace, na které jsou uživatelé zvyklí
GPU jako levný výpočetní akcelerátor pro obrazovou JPEG2000 kompresi. ORS 2011 Karviná,
 GPU jako levný výpočetní akcelerátor pro obrazovou JPEG2000 kompresi Jiří Matela ORS 2011 Karviná, 2011 10 21 PROPOJENÍ 3 UltraGrid nízkolatenční, nízkolatenční, vysoké rozlišení, nízkolatenční, vysoké
GPU jako levný výpočetní akcelerátor pro obrazovou JPEG2000 kompresi Jiří Matela ORS 2011 Karviná, 2011 10 21 PROPOJENÍ 3 UltraGrid nízkolatenční, nízkolatenční, vysoké rozlišení, nízkolatenční, vysoké
Xbox 360 Cpu = IBM Xenon
 Xbox 360 Cpu = IBM Xenon VŠB TUO Ostrava 7.11.2008 Zdeněk Dubnický Architektura procesoru IBM Xenon a její přínosy -architektura -CPU -FSB -testování a ladění IBM Xenon Vývoj tohoto procesoru začal v roce
Xbox 360 Cpu = IBM Xenon VŠB TUO Ostrava 7.11.2008 Zdeněk Dubnický Architektura procesoru IBM Xenon a její přínosy -architektura -CPU -FSB -testování a ladění IBM Xenon Vývoj tohoto procesoru začal v roce
Paralelní programování
 Paralelní programování přednášky Jan Outrata únor květen 2011 Jan Outrata (KI UP) Paralelní programování únor květen 2011 1 / 15 Simulátor konkurence abstrakce = libovolné proložení atom. akcí sekvenčních
Paralelní programování přednášky Jan Outrata únor květen 2011 Jan Outrata (KI UP) Paralelní programování únor květen 2011 1 / 15 Simulátor konkurence abstrakce = libovolné proložení atom. akcí sekvenčních
SUPERPOČÍTAČE DANIEL LANGR ČVUT FIT / VZLÚ
 SUPERPOČÍTAČE DANIEL LANGR ČVUT FIT / VZLÚ TITAN / HOPPER / NOTEBOOK TITAN HOPPER NOTEBOOK Počet CPU jader 299 008 153 216 2 Operační paměť [GB] 598 016 217 000 8 Počet GPU (CUDA) jader 50 233 344 0 8
SUPERPOČÍTAČE DANIEL LANGR ČVUT FIT / VZLÚ TITAN / HOPPER / NOTEBOOK TITAN HOPPER NOTEBOOK Počet CPU jader 299 008 153 216 2 Operační paměť [GB] 598 016 217 000 8 Počet GPU (CUDA) jader 50 233 344 0 8
CUDA OpenCL PhysX Literatura NPGR019. Úvod do architektury CUDA. MFF UK Praha. Jan Horáček CUDA 1 / 53
 Hardware pro počítačovou grafiku NPGR019 do architektury Jan Horáček http://cgg.mff.cuni.cz/ MFF UK Praha 2012 Jan Horáček 1 / 53 Obsah Historie Vícejádrové zpracování CPU vs GPU 1 2 3 4 5 Jan Horáček
Hardware pro počítačovou grafiku NPGR019 do architektury Jan Horáček http://cgg.mff.cuni.cz/ MFF UK Praha 2012 Jan Horáček 1 / 53 Obsah Historie Vícejádrové zpracování CPU vs GPU 1 2 3 4 5 Jan Horáček
Metoda sledování paprsku na grafických akcelerátorech. Martin Zlatuška
 České vysoké učení technické v Praze Fakulta elektrotechnická Diplomová práce Metoda sledování paprsku na grafických akcelerátorech Martin Zlatuška Vedoucí práce: Ing. Vlastimil Havran, Ph.D. Studijní
České vysoké učení technické v Praze Fakulta elektrotechnická Diplomová práce Metoda sledování paprsku na grafických akcelerátorech Martin Zlatuška Vedoucí práce: Ing. Vlastimil Havran, Ph.D. Studijní
Masivně paralelní zpracování obrazu v prostředí systému VisionLab. 25. 9. 2013 Liberec Roman Cagaš, rc@mii.cz
 Masivně paralelní zpracování obrazu v prostředí systému VisionLab 25. 9. 2013 Liberec Roman Cagaš, rc@mii.cz Moravské přístroje a.s. - oblasti vývoje a výroby Prostředí pro vývoj aplikací Software pro
Masivně paralelní zpracování obrazu v prostředí systému VisionLab 25. 9. 2013 Liberec Roman Cagaš, rc@mii.cz Moravské přístroje a.s. - oblasti vývoje a výroby Prostředí pro vývoj aplikací Software pro
Procesor Intel Pentium (1) Procesor Intel Pentium (3) Procesor Intel Pentium Pro (1) Procesor Intel Pentium (2)
 Procesor Intel Pentium (3) Procesor Intel Pentium Pro (1) Procesor Intel Pentium (2)") Procesor Intel Pentium (1) 32-bitová vnitřní architektura s 64-bitovou datovou sběrnicí Superskalární procesor: obsahuje více než jednu (dvě) frontu pro zřetězené zpracování instrukcí (značeny u, v) poskytuje
Procesor Intel Pentium (1) 32-bitová vnitřní architektura s 64-bitovou datovou sběrnicí Superskalární procesor: obsahuje více než jednu (dvě) frontu pro zřetězené zpracování instrukcí (značeny u, v) poskytuje
Základní operace. Prefix sum. Segmentovaný prefix-sum
 Základní operace Paralelní redukce Paralelní redukce na architekturách se sdílenou pamětí Paralelní redukce na architekturách s distribuovanou pamětí Paralelní redukce na GPU v CUDA Prefix sum Segmentovaný
Základní operace Paralelní redukce Paralelní redukce na architekturách se sdílenou pamětí Paralelní redukce na architekturách s distribuovanou pamětí Paralelní redukce na GPU v CUDA Prefix sum Segmentovaný
Návrhy elektromagnetických zení
 Návrhy elektromagnetických součástek stek a zařízen zení Zuzana Záhorová zuzanaz@humusoft.cz Karel Bittner bittner@humusoft.cz www.humusoft.cz www.comsol comsol.com tel.: 284 011 730 fax: 284 011 740 Program
Návrhy elektromagnetických součástek stek a zařízen zení Zuzana Záhorová zuzanaz@humusoft.cz Karel Bittner bittner@humusoft.cz www.humusoft.cz www.comsol comsol.com tel.: 284 011 730 fax: 284 011 740 Program
VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ BRNO UNIVERSITY OF TECHNOLOGY
 VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ BRNO UNIVERSITY OF TECHNOLOGY FAKULTA ELEKTROTECHNIKY A KOMUNIKAČNÍCH TECHNOLOGIÍ ÚSTAV AUTOMATIZACE A MĚŘÍCÍ TECHNIKY FACULTY OF ELECTRICAL ENGINEERING AND COMMUNICATION
VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ BRNO UNIVERSITY OF TECHNOLOGY FAKULTA ELEKTROTECHNIKY A KOMUNIKAČNÍCH TECHNOLOGIÍ ÚSTAV AUTOMATIZACE A MĚŘÍCÍ TECHNIKY FACULTY OF ELECTRICAL ENGINEERING AND COMMUNICATION
Představení a vývoj architektur vektorových procesorů
 Představení a vývoj architektur vektorových procesorů Drong Lukáš Dro098 1 Obsah Úvod 3 Historie, současnost 3 Architektura 4 - pipelining 4 - Operace scatter a gather 4 - vektorové registry 4 - Řetězení
Představení a vývoj architektur vektorových procesorů Drong Lukáš Dro098 1 Obsah Úvod 3 Historie, současnost 3 Architektura 4 - pipelining 4 - Operace scatter a gather 4 - vektorové registry 4 - Řetězení
Pohled do nitra mikroprocesoru Josef Horálek
 Pohled do nitra mikroprocesoru Josef Horálek Z čeho vycházíme = Vycházíme z Von Neumannovy architektury = Celý počítač se tak skládá z pěti koncepčních bloků: = Operační paměť = Programový řadič = Aritmeticko-logická
Pohled do nitra mikroprocesoru Josef Horálek Z čeho vycházíme = Vycházíme z Von Neumannovy architektury = Celý počítač se tak skládá z pěti koncepčních bloků: = Operační paměť = Programový řadič = Aritmeticko-logická
Přednášky o výpočetní technice. Hardware teoreticky. Adam Dominec 2010
 Přednášky o výpočetní technice Hardware teoreticky Adam Dominec 2010 Rozvržení Historie Procesor Paměť Základní deska přednášky o výpočetní technice Počítací stroje Mechanické počítačky se rozvíjely už
Přednášky o výpočetní technice Hardware teoreticky Adam Dominec 2010 Rozvržení Historie Procesor Paměť Základní deska přednášky o výpočetní technice Počítací stroje Mechanické počítačky se rozvíjely už
Intel Itanium. Referát. Vysoká škola báňská Technická univerzita Ostrava Fakulta elektrotechniky a informatiky Katedra informatiky
 Vysoká škola báňská Technická univerzita Ostrava Fakulta elektrotechniky a informatiky Katedra informatiky Pokročilé architektury počítačů Intel Itanium Referát Tomáš Vojtas (voj209) 2.12.2009 Úvod Itanium
Vysoká škola báňská Technická univerzita Ostrava Fakulta elektrotechniky a informatiky Katedra informatiky Pokročilé architektury počítačů Intel Itanium Referát Tomáš Vojtas (voj209) 2.12.2009 Úvod Itanium
Paralelní programování
 Paralelní programování přednáška 5 Michal Krupka 15. března 2011 Michal Krupka (KI UP) Paralelní programování 15. března 2011 1 / 13 Ještě ke kritickým sekcím Použití v praxi obvykle pomocí zámků (locks)
Paralelní programování přednáška 5 Michal Krupka 15. března 2011 Michal Krupka (KI UP) Paralelní programování 15. března 2011 1 / 13 Ještě ke kritickým sekcím Použití v praxi obvykle pomocí zámků (locks)
HW počítače co se nalézá uvnitř počítačové skříně
 ZVT HW počítače co se nalézá uvnitř počítačové skříně HW vybavení PC Hardware Vnitřní (uvnitř počítačové skříně) Vnější ( ) Základní HW základní jednotka + zobrazovací zařízení + klávesnice + (myš) Vnější
ZVT HW počítače co se nalézá uvnitř počítačové skříně HW vybavení PC Hardware Vnitřní (uvnitř počítačové skříně) Vnější ( ) Základní HW základní jednotka + zobrazovací zařízení + klávesnice + (myš) Vnější
Sem vložte zadání Vaší práce.
 Sem vložte zadání Vaší práce. České vysoké učení technické v Praze Fakulta informačních technologií Katedra počítačových systémů Diplomová práce Distribuované prolamování hesel v PDF na svazku GPU Bc.
Sem vložte zadání Vaší práce. České vysoké učení technické v Praze Fakulta informačních technologií Katedra počítačových systémů Diplomová práce Distribuované prolamování hesel v PDF na svazku GPU Bc.
Procesor. Hardware - komponenty počítačů Procesory
 Procesor Jedna z nejdůležitějších součástek počítače = mozek počítače, bez něhož není počítač schopen vykonávat žádné operace. Procesor v počítači plní funkci centrální jednotky (CPU - Central Processing
Procesor Jedna z nejdůležitějších součástek počítače = mozek počítače, bez něhož není počítač schopen vykonávat žádné operace. Procesor v počítači plní funkci centrální jednotky (CPU - Central Processing
Architektura počítače
 Architektura počítače Výpočetní systém HIERARCHICKÁ STRUKTURA Úroveň aplikačních programů Úroveň obecných funkčních programů Úroveň vyšších programovacích jazyků a prostředí Úroveň základních programovacích
Architektura počítače Výpočetní systém HIERARCHICKÁ STRUKTURA Úroveň aplikačních programů Úroveň obecných funkčních programů Úroveň vyšších programovacích jazyků a prostředí Úroveň základních programovacích
VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ BRNO UNIVERSITY OF TECHNOLOGY
 VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ BRNO UNIVERSITY OF TECHNOLOGY FAKULTA INFORMAČNÍCH TECHNOLOGIÍ ÚSTAV POČÍTAČOVÝCH SYSTÉMŮ FACULTY OF INFORMATION TECHNOLOGY DEPARTMENT OF COMPUTER SYSTEMS SIMULACE ŠÍŘENÍ
VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ BRNO UNIVERSITY OF TECHNOLOGY FAKULTA INFORMAČNÍCH TECHNOLOGIÍ ÚSTAV POČÍTAČOVÝCH SYSTÉMŮ FACULTY OF INFORMATION TECHNOLOGY DEPARTMENT OF COMPUTER SYSTEMS SIMULACE ŠÍŘENÍ
České vysoké učení technické v Praze
 České vysoké učení technické v Praze Fakulta stavební Katedra mechaniky BAKALÁŘSKÁ PRÁCE Efektivní algoritmy pro vyhodnocení statistických deskriptorů Vedoucí práce: Ing. Jan Sýkora, Ph.D. Praha 2012 Jan
České vysoké učení technické v Praze Fakulta stavební Katedra mechaniky BAKALÁŘSKÁ PRÁCE Efektivní algoritmy pro vyhodnocení statistických deskriptorů Vedoucí práce: Ing. Jan Sýkora, Ph.D. Praha 2012 Jan
Ing. Jan Buriánek. Katedra softwarového inženýrství Fakulta informačních technologií České vysoké učení technické v Praze Jan Buriánek, 2010
 Ing. Jan Buriánek (ČVUT FIT) GPU a GTC BI-MGA, 2010, Přednáška 11 1/29 Ing. Jan Buriánek Katedra softwarového inženýrství Fakulta informačních technologií České vysoké učení technické v Praze Jan Buriánek,
Ing. Jan Buriánek (ČVUT FIT) GPU a GTC BI-MGA, 2010, Přednáška 11 1/29 Ing. Jan Buriánek Katedra softwarového inženýrství Fakulta informačních technologií České vysoké učení technické v Praze Jan Buriánek,
Sběrnicová struktura PC Procesory PC funkce, vlastnosti Interní počítačové paměti PC
 Informatika 2 Technické prostředky počítačové techniky - 2 Přednáší: doc. Ing. Jan Skrbek, Dr. - KIN Přednášky: středa 14 20 15 55 Spojení: e-mail: jan.skrbek@tul.cz 16 10 17 45 tel.: 48 535 2442 Obsah:
Informatika 2 Technické prostředky počítačové techniky - 2 Přednáší: doc. Ing. Jan Skrbek, Dr. - KIN Přednášky: středa 14 20 15 55 Spojení: e-mail: jan.skrbek@tul.cz 16 10 17 45 tel.: 48 535 2442 Obsah:
Gymnázium Vysoké Mýto nám. Vaňorného 163, 566 01 Vysoké Mýto
 Gymnázium Vysoké Mýto nám. Vaňorného 163, 566 01 Vysoké Mýto Registrační číslo projektu Šablona Autor CZ.1.07/1.5.00/34.0951 III/2 INOVACE A ZKVALITNĚNÍ VÝUKY PROSTŘEDNICTVÍM ICT Mgr. Jana Kubcová Název
Gymnázium Vysoké Mýto nám. Vaňorného 163, 566 01 Vysoké Mýto Registrační číslo projektu Šablona Autor CZ.1.07/1.5.00/34.0951 III/2 INOVACE A ZKVALITNĚNÍ VÝUKY PROSTŘEDNICTVÍM ICT Mgr. Jana Kubcová Název
Úvod do problematiky návrhu počítačových systémů. INP 2008 FIT VUT v Brně
 Úvod do problematiky návrhu počítačových systémů INP 2008 FIT VUT v Brně Čím se budeme zabývat Budou nás zejména zajímat jednoprocesorové číslicové počítače: Funkce počítače Struktura propojení funkčních
Úvod do problematiky návrhu počítačových systémů INP 2008 FIT VUT v Brně Čím se budeme zabývat Budou nás zejména zajímat jednoprocesorové číslicové počítače: Funkce počítače Struktura propojení funkčních
Gymnázium a Střední odborná škola, Rokycany, Mládežníků 1115
 Gymnázium a Střední odborná škola, Rokycany, Mládežníků 1115 Číslo projektu: Číslo šablony: 3 CZ.1.07/1.5.00/34.0410 Název materiálu: Ročník: Identifikace materiálu: Jméno autora: Předmět: Tématický celek:
Gymnázium a Střední odborná škola, Rokycany, Mládežníků 1115 Číslo projektu: Číslo šablony: 3 CZ.1.07/1.5.00/34.0410 Název materiálu: Ročník: Identifikace materiálu: Jméno autora: Předmět: Tématický celek:
VYUŽITÍ GRAFICKÉHO ADAPTÉRU PRO OBECNÉ VÝPOČTY GENERAL-PURPOSE COMPUTATION USING GRAPHICS CARD
 VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ BRNO UNIVERSITY OF TECHNOLOGY FAKULTA INFORMAČNÍCH TECHNOLOGIÍ ÚSTAV POČÍTAČOVÝCH SYSTÉMŮ FACULTY OF INFORMATION TECHNOLOGY DEPARTMENT OF COMPUTER SYSTEMS VYUŽITÍ GRAFICKÉHO
VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ BRNO UNIVERSITY OF TECHNOLOGY FAKULTA INFORMAČNÍCH TECHNOLOGIÍ ÚSTAV POČÍTAČOVÝCH SYSTÉMŮ FACULTY OF INFORMATION TECHNOLOGY DEPARTMENT OF COMPUTER SYSTEMS VYUŽITÍ GRAFICKÉHO
Obsah. Kapitola 1 Hardware, procesory a vlákna Prohlídka útrob počítače...20 Motivace pro vícejádrové procesory...21
 Stručný obsah 1. Hardware, procesory a vlákna... 19 2. Programování s ohledemna výkon... 45 3. Identifikování příležitostí pro paralelizmus... 93 4. Synchronizace a sdílení dat... 123 5. Vlákna v rozhraní
Stručný obsah 1. Hardware, procesory a vlákna... 19 2. Programování s ohledemna výkon... 45 3. Identifikování příležitostí pro paralelizmus... 93 4. Synchronizace a sdílení dat... 123 5. Vlákna v rozhraní
Využití ICT pro rozvoj klíčových kompetencí CZ.1.07/1.5.00/
 Střední odborná škola elektrotechnická, Centrum odborné přípravy Zvolenovská 537, Hluboká nad Vltavou Využití ICT pro rozvoj klíčových kompetencí CZ.1.07/1.5.00/34.0448 CZ.1.07/1.5.00/34.0448 1 Číslo projektu
Střední odborná škola elektrotechnická, Centrum odborné přípravy Zvolenovská 537, Hluboká nad Vltavou Využití ICT pro rozvoj klíčových kompetencí CZ.1.07/1.5.00/34.0448 CZ.1.07/1.5.00/34.0448 1 Číslo projektu
OBRAZU FAKULTA INFORMAČNÍCH TECHNOLOGIÍ BRNO UNIVERSITY OF TECHNOLOGY FACULTY OF INFORMATION TECHNOLOGY DEPARTMENT OF COMPUTER GRAPHICS AND MULTIMEDIA
 VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ BRNO UNIVERSITY OF TECHNOLOGY FAKULTA INFORMAČNÍCH TECHNOLOGIÍ ÚSTAV POČÍTAČOVÉ GRAFIKY A MULTIMÉDIÍ FACULTY OF INFORMATION TECHNOLOGY DEPARTMENT OF COMPUTER GRAPHICS AND
VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ BRNO UNIVERSITY OF TECHNOLOGY FAKULTA INFORMAČNÍCH TECHNOLOGIÍ ÚSTAV POČÍTAČOVÉ GRAFIKY A MULTIMÉDIÍ FACULTY OF INFORMATION TECHNOLOGY DEPARTMENT OF COMPUTER GRAPHICS AND
Intel 80486 (2) Intel 80486 (1) Intel 80486 (3) Intel 80486 (4) Intel 80486 (6) Intel 80486 (5) Nezřetězené zpracování instrukcí:
 Intel 80486 (1) Intel 80486 (3) Intel 80486 (4) Intel 80486 (6) Intel 80486 (5) Nezřetězené zpracování instrukcí:") Intel 80486 (1) Vyroben v roce 1989 Prodáván pod oficiálním názvem 80486DX Plně 32bitový procesor Na svém čipu má integrován: - zmodernizovaný procesor 80386 - numerický koprocesor 80387 - L1 (interní)
Intel 80486 (1) Vyroben v roce 1989 Prodáván pod oficiálním názvem 80486DX Plně 32bitový procesor Na svém čipu má integrován: - zmodernizovaný procesor 80386 - numerický koprocesor 80387 - L1 (interní)
Blue Gene 24. 11. 2009. Vysoká škola báňská-technická univerzita Ostrava. Blue Gene. Karel Chrastina. Úvod. Blue Gene L. Blue Gene P.
 Blue Gene Vysoká škola báňská-technická univerzita Ostrava 24. 11. 2009 Obsah prezentace 1 2 3 4 5 Trocha pojmů a historie FLOPS FLoating point Operations Per Second. Někdy se zapisuje jako flop, flop/s.
Blue Gene Vysoká škola báňská-technická univerzita Ostrava 24. 11. 2009 Obsah prezentace 1 2 3 4 5 Trocha pojmů a historie FLOPS FLoating point Operations Per Second. Někdy se zapisuje jako flop, flop/s.
PROCESORY. Typy procesorů
 PROCESORY Procesor (CPU Central Processing Unit) je ústřední výkonnou jednotkou počítače, která čte z paměti instrukce a na jejich základě vykonává program. Primárním úkolem procesoru je řídit činnost
PROCESORY Procesor (CPU Central Processing Unit) je ústřední výkonnou jednotkou počítače, která čte z paměti instrukce a na jejich základě vykonává program. Primárním úkolem procesoru je řídit činnost
Nová architektura od ATI (Radeon HD 4800) Datum: 26.11.2008 Vypracoval: Bc. Radek Stromský
 Datum: 26.11.2008 Vypracoval: Bc. Radek Stromský") Nová architektura od ATI (Radeon HD 4800) Datum: 26.11.2008 Vypracoval: Bc. Radek Stromský Použité zkratky GDDR5 - Graphics Double Data Rate, verze 5 GPU - Graphic Processing Unit ALU - Arithmetic Logic
Nová architektura od ATI (Radeon HD 4800) Datum: 26.11.2008 Vypracoval: Bc. Radek Stromský Použité zkratky GDDR5 - Graphics Double Data Rate, verze 5 GPU - Graphic Processing Unit ALU - Arithmetic Logic
IB109 Návrh a implementace paralelních systémů. Organizace kurzu a úvod. Jiří Barnat
 IB109 Návrh a implementace paralelních systémů Organizace kurzu a úvod Jiří Barnat Sekce IB109 Návrh a implementace paralelních systémů: Organizace kurzu a úvod str. 2/32 Organizace kurzu Organizace kurzu
IB109 Návrh a implementace paralelních systémů Organizace kurzu a úvod Jiří Barnat Sekce IB109 Návrh a implementace paralelních systémů: Organizace kurzu a úvod str. 2/32 Organizace kurzu Organizace kurzu
FAKULTA INFORMAČNÍCH TECHNOLOGIÍ
 VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ BRNO UNIVERSITY OF TECHNOLOGY FAKULTA INFORMAČNÍCH TECHNOLOGIÍ ÚSTAV POČÍTAČOVÉ GRAFIKY A MULTIMÉDIÍ FACULTY OF INFORMATION TECHNOLOGY DEPARTMENT OF COMPUTER GRAPHICS AND
VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ BRNO UNIVERSITY OF TECHNOLOGY FAKULTA INFORMAČNÍCH TECHNOLOGIÍ ÚSTAV POČÍTAČOVÉ GRAFIKY A MULTIMÉDIÍ FACULTY OF INFORMATION TECHNOLOGY DEPARTMENT OF COMPUTER GRAPHICS AND
4. Úvod do paralelismu, metody paralelizace
 4. Úvod do paralelismu, metody paralelizace algoritmů Ing. Michal Bližňák, Ph.D. Ústav informatiky a umělé inteligence Fakulta aplikované informatiky UTB Zĺın Paralelní procesy a programování, Zĺın, 26.
4. Úvod do paralelismu, metody paralelizace algoritmů Ing. Michal Bližňák, Ph.D. Ústav informatiky a umělé inteligence Fakulta aplikované informatiky UTB Zĺın Paralelní procesy a programování, Zĺın, 26.
Paralení programování pro vícejádrové stroje s použitím OpenMP. B4B36PDV Paralelní a distribuované výpočty
 Paralení programování pro vícejádrové stroje s použitím OpenMP B4B36PDV Paralelní a distribuované výpočty Minulé cvičení: Vlákna a jejich synchronizace v C++ 11... 1 Minulé cvičení: Vlákna a jejich synchronizace
Paralení programování pro vícejádrové stroje s použitím OpenMP B4B36PDV Paralelní a distribuované výpočty Minulé cvičení: Vlákna a jejich synchronizace v C++ 11... 1 Minulé cvičení: Vlákna a jejich synchronizace
Procesory nvidia Tegra
 VŠB-TU Ostrava Fakulta elektrotechniky a informatiky Procesory nvidia Tegra Petr Dostalík, DOS140 Pokročilé architektury počítačů Představení nvidia Tegra V únoru roku 2008 představila společnost nvidia
VŠB-TU Ostrava Fakulta elektrotechniky a informatiky Procesory nvidia Tegra Petr Dostalík, DOS140 Pokročilé architektury počítačů Představení nvidia Tegra V únoru roku 2008 představila společnost nvidia
Paralelní a distribuované výpočty (B4B36PDV)
") Paralelní a distribuované výpočty (B4B36PDV) Branislav Bošanský, Michal Jakob bosansky@fel.cvut.cz Artificial Intelligence Center Department of Computer Science Faculty of Electrical Engineering Czech
Paralelní a distribuované výpočty (B4B36PDV) Branislav Bošanský, Michal Jakob bosansky@fel.cvut.cz Artificial Intelligence Center Department of Computer Science Faculty of Electrical Engineering Czech
Paralelní výpočetní jádro matematického modelu elektrostatického zvlákňování
 Paralelní výpočetní jádro matematického modelu elektrostatického zvlákňování Milan Šimko Technická univerzita v Liberci Interní odborný seminář KO MIX 19. prosince 2011 Obsah prezentace 1 MOTIVACE 2 VLÁKNOVÝ
Paralelní výpočetní jádro matematického modelu elektrostatického zvlákňování Milan Šimko Technická univerzita v Liberci Interní odborný seminář KO MIX 19. prosince 2011 Obsah prezentace 1 MOTIVACE 2 VLÁKNOVÝ
Operační systémy. Přednáška 1: Úvod
 Operační systémy Přednáška 1: Úvod 1 Organizace předmětu Přednášky každé úterý 18:00-19:30 v K1 Přednášející Jan Trdlička email: trdlicka@fel.cvut.z kancelář: K324 Cvičení pondělí, úterý, středa Informace
Operační systémy Přednáška 1: Úvod 1 Organizace předmětu Přednášky každé úterý 18:00-19:30 v K1 Přednášející Jan Trdlička email: trdlicka@fel.cvut.z kancelář: K324 Cvičení pondělí, úterý, středa Informace
Závěrečná zpráva projektu Experimentální výpočetní grid pro numerickou lineární algebru
 Závěrečná zpráva projektu Experimentální výpočetní grid pro numerickou lineární algebru Ing. Ivan Šimeček Ph.D., Zdeněk Buk xsimecek@fit.cvut.cz, bukz1fel.cvut.cz Červen, 2012 1 Zadání Paralelní zpracování
Závěrečná zpráva projektu Experimentální výpočetní grid pro numerickou lineární algebru Ing. Ivan Šimeček Ph.D., Zdeněk Buk xsimecek@fit.cvut.cz, bukz1fel.cvut.cz Červen, 2012 1 Zadání Paralelní zpracování
Roman Výtisk, VYT027
 Roman Výtisk, VYT027 Ohlédnutí za architekturou AMD K8 Představení architektury procesoru AMD K10 Přínos Struktura cache IMC, HyperTransport sběrnice Použitá literatura Ohlášení x86-64 architektury 5.
Roman Výtisk, VYT027 Ohlédnutí za architekturou AMD K8 Představení architektury procesoru AMD K10 Přínos Struktura cache IMC, HyperTransport sběrnice Použitá literatura Ohlášení x86-64 architektury 5.
Úvod do architektur personálních počítačů
 Úvod do architektur personálních počítačů 1 Cíl přednášky Popsat principy proudového zpracování informace. Popsat principy zřetězeného zpracování instrukcí. Zabývat se způsoby uplatnění tohoto principu
Úvod do architektur personálních počítačů 1 Cíl přednášky Popsat principy proudového zpracování informace. Popsat principy zřetězeného zpracování instrukcí. Zabývat se způsoby uplatnění tohoto principu
Cvičení MI-PAP I. Šimeček, M. Skrbek, J. Trdlička
 Cvičení MI-PAP I. Šimeček, M. Skrbek, J. Trdlička xsimecek@fit.cvut.cz Katedra počítačových systémů FIT České vysoké učení technické v Praze Ivan Šimeček, 2011 MI-PAP, LS2010/11, Cvičení 1-6 Příprava studijního
Cvičení MI-PAP I. Šimeček, M. Skrbek, J. Trdlička xsimecek@fit.cvut.cz Katedra počítačových systémů FIT České vysoké učení technické v Praze Ivan Šimeček, 2011 MI-PAP, LS2010/11, Cvičení 1-6 Příprava studijního
VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ
 VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ BRNO UNIVERSITY OF TECHNOLOGY FAKULTA ELEKTROTECHNIKY A KOMUNIKAČNÍCH TECHNOLOGIÍ FACULTY OF ELECTRICAL ENGINEERING AND COMMUNICATION ÚSTAV RADIOELEKTRONIKY DEPARTMENT OF
VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ BRNO UNIVERSITY OF TECHNOLOGY FAKULTA ELEKTROTECHNIKY A KOMUNIKAČNÍCH TECHNOLOGIÍ FACULTY OF ELECTRICAL ENGINEERING AND COMMUNICATION ÚSTAV RADIOELEKTRONIKY DEPARTMENT OF