CUDA J. Sloup a I. Šimeček
|
|
|
- Václav Navrátil
- před 8 lety
- Počet zobrazení:
Transkript
1 CUDA J. Sloup a I. Šimeček xsimecek@fit.cvut.cz Katedra počítačových systémů FIT České vysoké učení technické v Praze Ivan Šimeček, 2011 MI-PAP, LS2010/11, Predn.6 Příprava studijního programu Informatika je podporována projektem financovaným z Evropského sociálního fondu a rozpočtu hlavního města Prahy. Praha & EU: Investujeme do vaší budoucnosti
2 CUDA (Compute Unified Device Architecture) CUDA je architektura pro provádění paralelních výpočtů, která definuje: Programming model vlákna (threads), blok (block) a mřížka (grid) Memory model registry, lokální, sdílená a globální paměť Execution model spouštění vláken a jejich mapování na HW Vývojové prostředí zahrnuje: Driver Runtime spouštění C funkcí na GPU Toolkit překladač, debugger, profiler Libraries CUFFT, CUBLAS, SDK dokumentace + ukázky kódu CUDA je podporována na všech grafických procesorech NVIDIA (CUDA enabled-gpus) počínaje čipem G80 CUDA programy je možno psát v jazyku C/C++ nebo Fortran.
3 CUDA základní pojmy CPU (označované jako host hostitel) Kernel = část kódu, kterou chceme provádět paralelně na GPU (def. jako funkce) Vlákno (thread) = instance kernelu GPU (označované jako device zařízení) je tvořeno multiprocesory. Streaming Multiprocesor (dále jen SM) se skládá z několika (např. 8 u G80) procesorů (jader = SP). SM provádějí bloky vláken. Warp je skupina vláken spouštěná najednou, např. 32 na GT200 GPU má SIMT architekturu = všechna vlákna v rámci warpu jsou ovládány jednou instrukční jednotkou = provádí stejnou instrukci (kromě podmíněných příkazů) Vlákna během výpočtu přistupují k různým druhům pamětí
4 2D architektura = škálovatelnost Každý GPU se může lišit Frekvencí GPU Pamětí a velikostí GPU paměti Počtem SM Počtem jader na SM Schopnostmi (CUDA capabilities) Protože jednotlivé SM pracují víceméně nezávisle, je snadné zvyšovat výkon GPU zvýšením počtu SM
5 Provádění GPU kódu Vlákna jsou sdružována do bloků a bloky do mřížky (2D) Vlákna v rámci bloku: lze synchronizovat (pomocí bariéry) mohou sdílet data pomocí sdílené paměti Programátor zadá (téměř libovolně) počet bloků a počet vláken v bloku (2D z hlediska programátora) To jak přesně bude kód prováděn udává execution model. Ten se stará o korektní a efektivní mapování na dané HW. V HW totiž existuje daný počet SM a daný počet SP na jeden SM. (2D z hlediska HW)
6 Provádění GPU kódu Každý blok vláken je prováděn na právě jednom SM. Na každý SM může být namapováno více bloků najednou (až 8 u GT200) Blok vláken je rozdělen do několika warpů (podle čísel vláken). Centrální distribuce bloků metodou round-robin. V každém časovém kroku plánovač naplánuje (nulová režie!) k provedení připravený warp (který má všechna data a neprovádí bariéru). Vlákna warpu pak provedou paralelně jednu instrukci. Plánování je HW akcelerováno GeForce 8800: maximálně 24 rozpracovaných warpů GTX 280: maximálně 32 rozpracovaných warpů
7 Bloky kontra vlákna I Je dobré mít velký počet vláken v bloku Synchronizace a předávání dat pomocí sdílené paměti jen v rámci jednoho bloku! Díky přeplánování mohou být amortizovány velké latence. Ale: Blok může obsahovat maximálně 512 threadů Každý SM může (současně) provádět 8 bloků, ale skutečný počet závisí na paměťových požadavcích na registry a sdílenou paměť = např. všechny bloky na SM mohou alokovat max. 16 kb sdílené paměti. Stejně tak je limitován počet registrů pro vlákno
8 Bloky kontra vlákna II Bloky by měly být nezávislé Být navrženy tak, aby každé pořadí jejich vyhodnocení bylo korektní Mohou běžet paralelně nebo sekvenčně Data mohou být sdílena mezi bloky ale problém se synchronizací
9 Jednoduchý CUDA příklad // definice kernelu global void VecAdd(float* A, float* B, float* C) { //identifikacni cislo vlakna int i = threadidx.x; C[i] = A[i] + B[i]; } int main() { // volani kernelu z funkce main VecAdd<<<1, N>>>(A, B, C); Musí být void Číslo v rámci bloku } Počet vláken v bloku Počet bloků
10 Mřížka bloků Bloky mi mohou obecně tvořit (maximálně 2D) mřízku = grid Obdobně vlákna v rámci bloku mi mohou obecně tvořit (maximálně 3D) matici. Ale mřížka i matice jsou převedeny do 1D, takže nemají velký význam kromě vyššího komfortu pro programátora při přístupu do vícedimenzionálního pole.
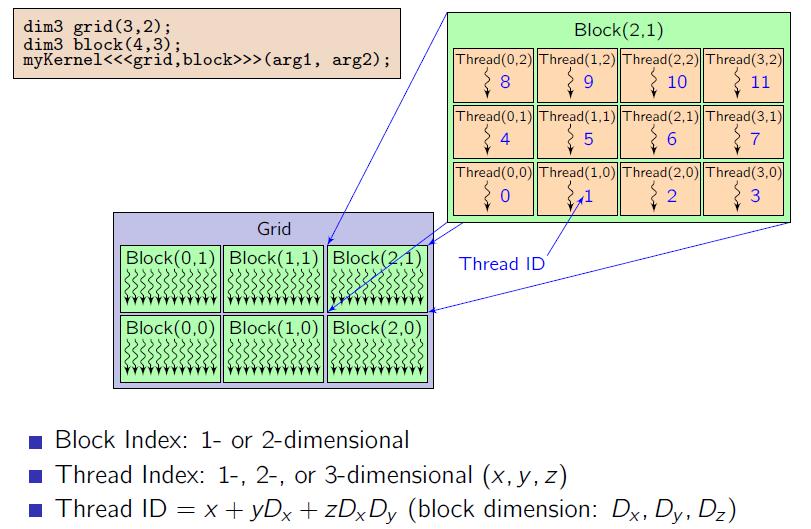
11 Mapování
12 Kompilace CUDA soubory mají příponu.cu Kompilátor nvcc (přesněji compiler driver). Ten má podobné parametry jako gcc. nvcc vezme zdrojový kód v.cu (nebo i.c/.cpp) souboru a za použití dalších aplikací, jako gcc, cl, apod. zkompiluje standardní c/c++ zdrojový kód do spustitelné podoby. Kód určený pro GPU, je přeložen do ptx (Parallel Thread Execution) virtual machine mezikódu. Podporuje i budoucí generace GPU PTX je následně zkompilován během spuštení (JIT pomocí ovladače grafické karty) do binárního kódu pro dané zařízení (pro danou verzi compute capability). Společně se spustitelným kódem se slinkují i knihovny cudart (CUDA runtime library) a cuda (CUDA core library), nutné k běhu aplikace
13 Synchronizace s hostitelem Spuštení kernelů je asynchronní operace Vrací řízení CPU ihned jak je to možné Pokud je třeba počkat na dokončení práce všech CUDA volání cudathreadsynchronize() kernel je spuštěn po dokončení všech předchozích CUDA voláních Operace kopírování cudamemcpy() je synchronní, je spuštěna po dokončení všech předchozích CUDA voláních
14 Násobení matic (CUDA v1) I global void Mul_IJ( float *ina, float *inb, float *outc, int N ) { int i=blockidx.x; int j=threadidx.x; int k; float s=0.0; Číslo bloku Číslo v rámci bloku } for(k=0;k<n;k++) s+=ina[i*n+k]*inb[k*n+j]; outc[i*n+j]=s; syncthreads(); Bariéra v rámci bloku
15 Násobení matic (CUDA v1) II static void HandleError( cudaerror_t err, const char *file, int line ) { if (err!= cudasuccess) { printf( "%s in %s at line %d\n", cudageterrorstring( err ), file, line ); exit( EXIT_FAILURE ); }} Zpracování chyb #define HANDLE_ERROR( err ) (HandleError( err, FILE, LINE )) int main( void ) { cudadeviceprop prop; int whichdevice,n,i,j; cudaevent_t start, stop; float elapsedtime; float *hostm, *hostm2,*hostx,*hosty; float *devm,*devx,*devy; Vlastnosti GPU CUDA události Ukazatele
16 Násobení matic (CUDA v1) III HANDLE_ERROR( cudagetdevice( &whichdevice ) ); HANDLE_ERROR( cudagetdeviceproperties( &prop, whichdevice ) ); HANDLE_ERROR( cudaeventcreate( &start ) ); HANDLE_ERROR( cudaeventcreate( &stop ) ); Inicializace HANDLE_ERROR( cudamalloc( (void**)&devx, N * N* sizeof(float) ) ); HANDLE_ERROR( cudamalloc( (void**)&devy, N * N *sizeof(float) ) ); HANDLE_ERROR( cudamalloc( (void**)&devm, N * N * sizeof(float) ) ); HANDLE_ERROR( cudahostalloc( (void**)&hostx, N * N* sizeof(float), cudahostallocdefault ) ); HANDLE_ERROR( cudahostalloc( (void**)&hosty, N * N *sizeof(float), cudahostallocdefault ) ); HANDLE_ERROR( cudahostalloc( (void**)&hostm, N * N *sizeof(float), cudahostallocdefault ) ); HANDLE_ERROR( cudahostalloc( (void**)&hostm2, N * N *sizeof(float), cudahostallocdefault ) ); Alokace paměti na GPU Alokace paměti na CPU
17 Násobení matic (CUDA v1) IV cudamemcpy(devx,hostx,sizeof(int)*n*n,cudamemcpyhosttodevice); cudamemcpy(devy,hosty,sizeof(int)*n*n,cudamemcpyhosttodevice); Kopírování CPU -> GPU HANDLE_ERROR( cudaeventrecord( start, 0 ) ); Volání kernelu Mul_I<<<N,N>>>( devx, devy, devm, N ); cudathreadsynchronize(); HANDLE_ERROR( cudaeventrecord( stop, 0 ) ); Zjištění času HANDLE_ERROR( cudaeventsynchronize( stop ) ); HANDLE_ERROR( cudaeventelapsedtime( &elapsedtime, start, stop ) ); printf( GPU time taken: %g ms\n", elapsedtime ); cudamemcpy(hostm,devm,sizeof(float)*n*n,cudamemcpydevicetohost); Kopírování GPU -> CPU
18 Násobení matic (CUDA v1) V HANDLE_ERROR( cudaeventdestroy( start ) ); HANDLE_ERROR( cudaeventdestroy( stop ) ); HANDLE_ERROR( cudafreehost( hostx ) ); HANDLE_ERROR( cudafreehost( hosty ) ); HANDLE_ERROR( cudafreehost( hostm ) ); HANDLE_ERROR( cudafreehost( hostm2 ) ); HANDLE_ERROR( cudafree( devx ) ); HANDLE_ERROR( cudafree( devy ) ); HANDLE_ERROR( cudafree( devm ) );
19 Literatura [1] J. Sloup: přednášky z předmětu GPGPU, KPGI FEL ČVUT. [2] CUDA Programming Guide for CUDA Toolkit [3] René Müller: Data Processing on GPUs and GPGPUs. Lecture in class :Data Processing on Modern Hardware. ETH Zurich. Fall [4]
Pokročilé architektury počítačů
 Pokročilé architektury počítačů Tutoriál 3 CUDA - GPU Martin Milata Výpočetní model CUDA Organizace kódu Sériově organizovaný kód určený pro CPU Paralelní kód prováděný na GPU Označuje se jako kernel GPU
Pokročilé architektury počítačů Tutoriál 3 CUDA - GPU Martin Milata Výpočetní model CUDA Organizace kódu Sériově organizovaný kód určený pro CPU Paralelní kód prováděný na GPU Označuje se jako kernel GPU
Úvod do GPGPU J. Sloup, I. Šimeček
 Úvod do GPGPU J. Sloup, I. Šimeček xsimecek@fit.cvut.cz Katedra počítačových systémů FIT České vysoké učení technické v Praze Ivan Šimeček, 2011 MI-PRC, LS2010/11, Predn.3 Příprava studijního programu
Úvod do GPGPU J. Sloup, I. Šimeček xsimecek@fit.cvut.cz Katedra počítačových systémů FIT České vysoké učení technické v Praze Ivan Šimeček, 2011 MI-PRC, LS2010/11, Predn.3 Příprava studijního programu
GPGPU. Jan Faigl. Gerstnerova Laboratoř pro inteligentní rozhodování a řízení České vysoké učení technické v Praze
 GPGPU Jan Faigl Gerstnerova Laboratoř pro inteligentní rozhodování a řízení České vysoké učení technické v Praze 8. cvičení katedra kybernetiky, FEL, ČVUT v Praze X33PTE - Programovací techniky GPGPU 1
GPGPU Jan Faigl Gerstnerova Laboratoř pro inteligentní rozhodování a řízení České vysoké učení technické v Praze 8. cvičení katedra kybernetiky, FEL, ČVUT v Praze X33PTE - Programovací techniky GPGPU 1
GPU A CUDA HISTORIE GPU CO JE GPGPU? NVIDIA CUDA
 GPU A CUDA HISTORIE GPU CO JE GPGPU? NVIDIA CUDA HISTORIE GPU GPU = graphics processing unit jde o akcelerátory pro algoritmy v 3D grafice a vizualizaci mnoho z nich původně vzniklo pro účely počítačových
GPU A CUDA HISTORIE GPU CO JE GPGPU? NVIDIA CUDA HISTORIE GPU GPU = graphics processing unit jde o akcelerátory pro algoritmy v 3D grafice a vizualizaci mnoho z nich původně vzniklo pro účely počítačových
Knihovny pro CUDA J. Sloup a I. Šimeček
 Knihovny pro CUDA J. Sloup a I. Šimeček xsimecek@fit.cvut.cz Katedra počítačových systémů FIT České vysoké učení technické v Praze Ivan Šimeček, 2011 MI-PRC, LS2010/11, Predn.10 Příprava studijního programu
Knihovny pro CUDA J. Sloup a I. Šimeček xsimecek@fit.cvut.cz Katedra počítačových systémů FIT České vysoké učení technické v Praze Ivan Šimeček, 2011 MI-PRC, LS2010/11, Predn.10 Příprava studijního programu
GPU a CUDA. Historie GPU. Co je GPGPU? Nvidia CUDA
 GPU a CUDA Historie GPU Co je GPGPU? Nvidia CUDA Historie GPU GPU = graphics processing unit jde o akcelerátory pro algoritmy v 3D grafice a vizualizaci mnoho z nich původně vzniklo pro účely počítačových
GPU a CUDA Historie GPU Co je GPGPU? Nvidia CUDA Historie GPU GPU = graphics processing unit jde o akcelerátory pro algoritmy v 3D grafice a vizualizaci mnoho z nich původně vzniklo pro účely počítačových
Pokročilé architektury počítačů
 Pokročilé architektury počítačů Přednáška 7 CUDA První paralelní aplikace Martin Milata Obsah SIMD versus SIMT Omezení a HW implementace Způsob zpracování warp skupiny vláken CUDA - pohled programátora
Pokročilé architektury počítačů Přednáška 7 CUDA První paralelní aplikace Martin Milata Obsah SIMD versus SIMT Omezení a HW implementace Způsob zpracování warp skupiny vláken CUDA - pohled programátora
Cvičení MI-PAP I. Šimeček, M. Skrbek, J. Trdlička
 Cvičení MI-PAP I. Šimeček, M. Skrbek, J. Trdlička xsimecek@fit.cvut.cz Katedra počítačových systémů FIT České vysoké učení technické v Praze Ivan Šimeček, 2011 MI-PAP, LS2010/11, Cvičení 1-6 Příprava studijního
Cvičení MI-PAP I. Šimeček, M. Skrbek, J. Trdlička xsimecek@fit.cvut.cz Katedra počítačových systémů FIT České vysoké učení technické v Praze Ivan Šimeček, 2011 MI-PAP, LS2010/11, Cvičení 1-6 Příprava studijního
Obecné výpočty na GPU v jazyce CUDA. Jiří Filipovič
 Obecné výpočty na GPU v jazyce CUDA Jiří Filipovič Obsah přednášky motivace architektura GPU CUDA programovací model jaké algoritmy urychlovat na GPU? optimalizace Motivace Moorův zákon stále platí pro
Obecné výpočty na GPU v jazyce CUDA Jiří Filipovič Obsah přednášky motivace architektura GPU CUDA programovací model jaké algoritmy urychlovat na GPU? optimalizace Motivace Moorův zákon stále platí pro
GPU a CUDA. Historie GPU. Co je GPGPU? Nvidia CUDA
 GPU a CUDA Historie GPU Co je GPGPU? Nvidia CUDA Historie GPU GPU = graphics processing unit jde o akcelerátory pro algoritmy v 3D grafice a vizualizaci mnoho z nich původně vzniklo pro účely počítačových
GPU a CUDA Historie GPU Co je GPGPU? Nvidia CUDA Historie GPU GPU = graphics processing unit jde o akcelerátory pro algoritmy v 3D grafice a vizualizaci mnoho z nich původně vzniklo pro účely počítačových
GPU Computing.
 GPU Computing Motivace Procesory (CPU, Central Processing Units) jsou rychlé, paměť nestačí poskytovat data. Běžným lékem na latenční dobu (memory latency) paměti bývá užívání rychlých (ale malých) cache
GPU Computing Motivace Procesory (CPU, Central Processing Units) jsou rychlé, paměť nestačí poskytovat data. Běžným lékem na latenční dobu (memory latency) paměti bývá užívání rychlých (ale malých) cache
Část 3 CUDA VS. OPENCL, OPENACC
 Část 3 CUDA VS. OPENCL, OPENACC Jazyky a API pro výpočty na GPU Jazyky pro programování shaderů HLSL DirectX GLSL OpenGL Cg překlad do OpenGL i DirectX Nadstavby rozšíření o proudové zpracování dat BrookGPU
Část 3 CUDA VS. OPENCL, OPENACC Jazyky a API pro výpočty na GPU Jazyky pro programování shaderů HLSL DirectX GLSL OpenGL Cg překlad do OpenGL i DirectX Nadstavby rozšíření o proudové zpracování dat BrookGPU
Nvidia CUDA Paralelní programování na GPU
 Mendelova univerzita v Brně Provozně ekonomická fakulta Nvidia CUDA Paralelní programování na GPU 2014 O čem to bude... Trocha historie Shadery Unifikace GPGPU CUDA Využití GPGPU GPU a jeho Hardware Nvidia
Mendelova univerzita v Brně Provozně ekonomická fakulta Nvidia CUDA Paralelní programování na GPU 2014 O čem to bude... Trocha historie Shadery Unifikace GPGPU CUDA Využití GPGPU GPU a jeho Hardware Nvidia
Pokročilé architektury počítačů
 Pokročilé architektury počítačů Přednáška 5 GPU - CUDA Martin Milata Obsah Obecné výpočty a GPU Grafické procesory NVIDIA Tesla Výpočetní model Paměťový model GT200 Zpracování instrukcí Vydávání instrukcí
Pokročilé architektury počítačů Přednáška 5 GPU - CUDA Martin Milata Obsah Obecné výpočty a GPU Grafické procesory NVIDIA Tesla Výpočetní model Paměťový model GT200 Zpracování instrukcí Vydávání instrukcí
REALIZACE SUPERPOČÍTAČE POMOCÍ GRAFICKÉ KARTY
 VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ BRNO UNIVERSITY OF TECHNOLOGY FAKULTA ELEKTROTECHNIKY A KOMUNIKAČNÍCH TECHNOLOGIÍ ÚSTAV TELEKOMUNIKACÍ FACULTY OF ELECTRICAL ENGINEERING AND COMMUNICATION DEPARTMENT OF TELECOMMUNICATIONS
VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ BRNO UNIVERSITY OF TECHNOLOGY FAKULTA ELEKTROTECHNIKY A KOMUNIKAČNÍCH TECHNOLOGIÍ ÚSTAV TELEKOMUNIKACÍ FACULTY OF ELECTRICAL ENGINEERING AND COMMUNICATION DEPARTMENT OF TELECOMMUNICATIONS
GPGPU Aplikace GPGPU. Obecné výpočty na grafických procesorech. Jan Vacata
 Obecné výpočty na grafických procesorech Motivace Úvod Motivace Technologie 3 GHz Intel Core 2 Extreme QX9650 Výkon: 96 GFLOPS Propustnost paměti: 21 GB/s Orientační cena: 1300 USD NVIDIA GeForce 9800
Obecné výpočty na grafických procesorech Motivace Úvod Motivace Technologie 3 GHz Intel Core 2 Extreme QX9650 Výkon: 96 GFLOPS Propustnost paměti: 21 GB/s Orientační cena: 1300 USD NVIDIA GeForce 9800
Nvidia CUDA Paralelní programování na GPU
 Mendelova univerzita v Brně Provozně ekonomická fakulta Nvidia CUDA Paralelní programování na GPU 2017 O čem to bude... Trocha historie Shadery Unifikace GPGPU CUDA Využití GPGPU GPU a jeho Hardware Nvidia
Mendelova univerzita v Brně Provozně ekonomická fakulta Nvidia CUDA Paralelní programování na GPU 2017 O čem to bude... Trocha historie Shadery Unifikace GPGPU CUDA Využití GPGPU GPU a jeho Hardware Nvidia
Procesy a vlákna (Processes and Threads)
") ÚVOD DO OPERAČNÍCH SYSTÉMŮ Ver.1.00 Procesy a vlákna (Processes and Threads) Správa procesů a vláken České vysoké učení technické Fakulta elektrotechnická 2012 Použitá literatura [1] Stallings, W.: Operating
ÚVOD DO OPERAČNÍCH SYSTÉMŮ Ver.1.00 Procesy a vlákna (Processes and Threads) Správa procesů a vláken České vysoké učení technické Fakulta elektrotechnická 2012 Použitá literatura [1] Stallings, W.: Operating
Přednáška. Vstup/Výstup. Katedra počítačových systémů FIT, České vysoké učení technické v Praze Jan Trdlička, 2012
 Přednáška Vstup/Výstup. Katedra počítačových systémů FIT, České vysoké učení technické v Praze Jan Trdlička, 2012 Příprava studijního programu Informatika je podporována projektem financovaným z Evropského
Přednáška Vstup/Výstup. Katedra počítačových systémů FIT, České vysoké učení technické v Praze Jan Trdlička, 2012 Příprava studijního programu Informatika je podporována projektem financovaným z Evropského
Vícevláknové programování na CPU: POSIX vlákna a OpenMP I. Šimeček
 Vícevláknové programování na CPU: POSIX vlákna a OpenMP I. Šimeček xsimecek@fit.cvut.cz Katedra počítačových systémů FIT České vysoké učení technické v Praze Ivan Šimeček, 2011 MI-PRC, LS2010/11, Predn.2
Vícevláknové programování na CPU: POSIX vlákna a OpenMP I. Šimeček xsimecek@fit.cvut.cz Katedra počítačových systémů FIT České vysoké učení technické v Praze Ivan Šimeček, 2011 MI-PRC, LS2010/11, Predn.2
Paralelní a distribuované výpočty (B4B36PDV)
") Paralelní a distribuované výpočty (B4B36PDV) Branislav Bošanský, Michal Jakob bosansky@fel.cvut.cz Artificial Intelligence Center Department of Computer Science Faculty of Electrical Engineering Czech
Paralelní a distribuované výpočty (B4B36PDV) Branislav Bošanský, Michal Jakob bosansky@fel.cvut.cz Artificial Intelligence Center Department of Computer Science Faculty of Electrical Engineering Czech
Optimalizace pro GPU hardware
 Optimalizace pro GPU hardware Jiří Filipovič jaro 2015 Jiří Filipovič Optimalizace pro GPU hardware 1 / 52 Paralelismus GPU Paralelní algoritmy je nutno navrhovat vzhledem k paralelismu, který poskytuje
Optimalizace pro GPU hardware Jiří Filipovič jaro 2015 Jiří Filipovič Optimalizace pro GPU hardware 1 / 52 Paralelismus GPU Paralelní algoritmy je nutno navrhovat vzhledem k paralelismu, který poskytuje
OPS Paralelní systémy, seznam pojmů, klasifikace
 Moorův zákon (polovina 60. let) : Výpočetní výkon a počet tranzistorů na jeden CPU chip integrovaného obvodu mikroprocesoru se každý jeden až dva roky zdvojnásobí; cena se zmenší na polovinu. Paralelismus
Moorův zákon (polovina 60. let) : Výpočetní výkon a počet tranzistorů na jeden CPU chip integrovaného obvodu mikroprocesoru se každý jeden až dva roky zdvojnásobí; cena se zmenší na polovinu. Paralelismus
Architektury VLIW M. Skrbek a I. Šimeček
 Architektury VLIW M. Skrbek a I. Šimeček xsimecek@fit.cvut.cz Katedra počítačových systémů FIT České vysoké učení technické v Praze Ivan Šimeček, 2011 MI-PAP, LS2010/11, Predn.3 Příprava studijního programu
Architektury VLIW M. Skrbek a I. Šimeček xsimecek@fit.cvut.cz Katedra počítačových systémů FIT České vysoké učení technické v Praze Ivan Šimeček, 2011 MI-PAP, LS2010/11, Predn.3 Příprava studijního programu
Jiné výpočetní platformy J. Sloup, M. Skrbek, I. Šimeček
 Jiné výpočetní platformy J. Sloup, M. Skrbek, I. Šimeček xsimecek@fit.cvut.cz Katedra počítačových systémů FIT České vysoké učení technické v Praze Ivan Šimeček, 2011 BI-EIA, ZS2011/12, Predn.12 Příprava
Jiné výpočetní platformy J. Sloup, M. Skrbek, I. Šimeček xsimecek@fit.cvut.cz Katedra počítačových systémů FIT České vysoké učení technické v Praze Ivan Šimeček, 2011 BI-EIA, ZS2011/12, Predn.12 Příprava
Přednáška. Správa paměti II. Katedra počítačových systémů FIT, České vysoké učení technické v Praze Jan Trdlička, 2012
 Přednáška Správa paměti II. Katedra počítačových systémů FIT, České vysoké učení technické v Praze Jan Trdlička, 2012 Příprava studijního programu Informatika je podporována projektem financovaným z Evropského
Přednáška Správa paměti II. Katedra počítačových systémů FIT, České vysoké učení technické v Praze Jan Trdlička, 2012 Příprava studijního programu Informatika je podporována projektem financovaným z Evropského
11. Přehled prog. jazyků
 Jiří Vokřínek, 2016 B6B36ZAL - Přednáška 11 1 Základy algoritmizace 11. Přehled prog. jazyků doc. Ing. Jiří Vokřínek, Ph.D. Katedra počítačů Fakulta elektrotechnická České vysoké učení technické v Praze
Jiří Vokřínek, 2016 B6B36ZAL - Přednáška 11 1 Základy algoritmizace 11. Přehled prog. jazyků doc. Ing. Jiří Vokřínek, Ph.D. Katedra počítačů Fakulta elektrotechnická České vysoké učení technické v Praze
VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ BRNO UNIVERSITY OF TECHNOLOGY
 VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ BRNO UNIVERSITY OF TECHNOLOGY FAKULTA INFORMAČNÍCH TECHNOLOGIÍ ÚSTAV POČÍTAČOVÉ GRAFIKY A MULTIMÉDIÍ FACULTY OF INFORMATION TECHNOLOGY DEPARTMENT OF COMPUTER GRAPHICS AND
VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ BRNO UNIVERSITY OF TECHNOLOGY FAKULTA INFORMAČNÍCH TECHNOLOGIÍ ÚSTAV POČÍTAČOVÉ GRAFIKY A MULTIMÉDIÍ FACULTY OF INFORMATION TECHNOLOGY DEPARTMENT OF COMPUTER GRAPHICS AND
Paralení programování pro vícejádrové stroje s použitím OpenMP. B4B36PDV Paralelní a distribuované výpočty
 Paralení programování pro vícejádrové stroje s použitím OpenMP B4B36PDV Paralelní a distribuované výpočty Minulé cvičení: Vlákna a jejich synchronizace v C++ 11... 1 Minulé cvičení: Vlákna a jejich synchronizace
Paralení programování pro vícejádrové stroje s použitím OpenMP B4B36PDV Paralelní a distribuované výpočty Minulé cvičení: Vlákna a jejich synchronizace v C++ 11... 1 Minulé cvičení: Vlákna a jejich synchronizace
Řešíme úlohu zpracování velkého množství dat. Data jsou symetrická, úloha je dobře paralelizovatelná. Propaganda výrobců grafických karet:
 GPGPU Motivace Řešíme úlohu zpracování velkého množství dat Data jsou symetrická, úloha je dobře paralelizovatelná Propaganda výrobců grafických karet: Vezměte váš C-čkový kód, zkompilujte a pusťte jej
GPGPU Motivace Řešíme úlohu zpracování velkého množství dat Data jsou symetrická, úloha je dobře paralelizovatelná Propaganda výrobců grafických karet: Vezměte váš C-čkový kód, zkompilujte a pusťte jej
Matematika v programovacích
 Matematika v programovacích jazycích Pavla Kabelíková am.vsb.cz/kabelikova pavla.kabelikova@vsb.cz Úvodní diskuze Otázky: Jaké programovací jazyky znáte? S jakými programovacími jazyky jste již pracovali?
Matematika v programovacích jazycích Pavla Kabelíková am.vsb.cz/kabelikova pavla.kabelikova@vsb.cz Úvodní diskuze Otázky: Jaké programovací jazyky znáte? S jakými programovacími jazyky jste již pracovali?
Vyuºití GPGPU pro zpracování dat z magnetické rezonance
 Vyuºití pro zpracování dat z magnetické rezonance Katedra matematiky, Fakulta jaderná a fyzikáln inºenýrská, ƒeské vysoké u ení technické v Praze Bakalá ská práce 2007/2008 Cíle práce Zpracování dat z
Vyuºití pro zpracování dat z magnetické rezonance Katedra matematiky, Fakulta jaderná a fyzikáln inºenýrská, ƒeské vysoké u ení technické v Praze Bakalá ská práce 2007/2008 Cíle práce Zpracování dat z
PŘEDSTAVENÍ GRAFICKÉHO PROCESORU NVIDIA G200
 PŘEDSTAVENÍ GRAFICKÉHO PROCESORU NVIDIA G200 Bc.Adam Berger Ber 208 Historie a předchůdci G200 V červnu roku 2008 spatřila světlo světa nová grafická karta od společnosti Nvidia. Tato grafická karta opět
PŘEDSTAVENÍ GRAFICKÉHO PROCESORU NVIDIA G200 Bc.Adam Berger Ber 208 Historie a předchůdci G200 V červnu roku 2008 spatřila světlo světa nová grafická karta od společnosti Nvidia. Tato grafická karta opět
Struktura programu v době běhu
 Struktura programu v době běhu Miroslav Beneš Dušan Kolář Struktura programu v době běhu Vztah mezi zdrojovým programem a činností přeloženého programu reprezentace dat správa paměti aktivace podprogramů
Struktura programu v době běhu Miroslav Beneš Dušan Kolář Struktura programu v době běhu Vztah mezi zdrojovým programem a činností přeloženého programu reprezentace dat správa paměti aktivace podprogramů
Řešíme úlohu zpracování velkého množství dat. Data jsou symetrická, úloha je dobře paralelizovatelná
 GPGPU Motivace Řešíme úlohu zpracování velkého množství dat Data jsou symetrická, úloha je dobře paralelizovatelná Propaganda výrobců grafických karet: Vezměte váš C-čkový kód, zkompilujte a pusťte jej
GPGPU Motivace Řešíme úlohu zpracování velkého množství dat Data jsou symetrická, úloha je dobře paralelizovatelná Propaganda výrobců grafických karet: Vezměte váš C-čkový kód, zkompilujte a pusťte jej
Základní operace. Prefix sum. Segmentovaný prefix-sum
 Základní operace Paralelní redukce Paralelní redukce na architekturách se sdílenou pamětí Paralelní redukce na architekturách s distribuovanou pamětí Paralelní redukce na GPU v CUDA Prefix sum Segmentovaný
Základní operace Paralelní redukce Paralelní redukce na architekturách se sdílenou pamětí Paralelní redukce na architekturách s distribuovanou pamětí Paralelní redukce na GPU v CUDA Prefix sum Segmentovaný
CUDA OpenCL PhysX Literatura NPGR019. Úvod do architektury CUDA. MFF UK Praha. Jan Horáček CUDA 1 / 53
 Hardware pro počítačovou grafiku NPGR019 do architektury Jan Horáček http://cgg.mff.cuni.cz/ MFF UK Praha 2012 Jan Horáček 1 / 53 Obsah Historie Vícejádrové zpracování CPU vs GPU 1 2 3 4 5 Jan Horáček
Hardware pro počítačovou grafiku NPGR019 do architektury Jan Horáček http://cgg.mff.cuni.cz/ MFF UK Praha 2012 Jan Horáček 1 / 53 Obsah Historie Vícejádrové zpracování CPU vs GPU 1 2 3 4 5 Jan Horáček
Část 2 POROVNÁNÍ VÝKONNOSTI A POUŽITELNOSTI ARCHITEKTUR V TYPICKÝCH APLIKACÍCH
 Část 2 POROVNÁNÍ VÝKONNOSTI A POUŽITELNOSTI ARCHITEKTUR V TYPICKÝCH APLIKACÍCH Paralelizace kódu Rozdíl v přístupu k paralelizaci kódu si ukážeme na operaci násobení matice maticí: Mějme tři čtvercové
Část 2 POROVNÁNÍ VÝKONNOSTI A POUŽITELNOSTI ARCHITEKTUR V TYPICKÝCH APLIKACÍCH Paralelizace kódu Rozdíl v přístupu k paralelizaci kódu si ukážeme na operaci násobení matice maticí: Mějme tři čtvercové
IUJCE 07/08 Přednáška č. 6
 Správa paměti Motivace a úvod v C (skoro vždy) ručně statické proměnné o datový typ, počet znám v době překladu o zabírají paměť po celou dobu běhu programu problém velikosti definovaných proměnných jak
Správa paměti Motivace a úvod v C (skoro vždy) ručně statické proměnné o datový typ, počet znám v době překladu o zabírají paměť po celou dobu běhu programu problém velikosti definovaných proměnných jak
Přehled paralelních architektur. Dělení paralelních architektur Flynnova taxonomie Komunikační modely paralelních architektur
 Přehled paralelních architektur Přehled paralelních architektur Dělení paralelních architektur Flynnova taxonomie Komunikační modely paralelních architektur Přehled I. paralelní počítače se konstruují
Přehled paralelních architektur Přehled paralelních architektur Dělení paralelních architektur Flynnova taxonomie Komunikační modely paralelních architektur Přehled I. paralelní počítače se konstruují
Mělká a hluboká kopie
 Karel Müller, Josef Vogel (ČVUT FIT) Mělká a hluboká kopie BI-PA2, 2011, Přednáška 5 1/28 Mělká a hluboká kopie Ing. Josef Vogel, CSc Katedra softwarového inženýrství Katedra teoretické informatiky, Fakulta
Karel Müller, Josef Vogel (ČVUT FIT) Mělká a hluboká kopie BI-PA2, 2011, Přednáška 5 1/28 Mělká a hluboká kopie Ing. Josef Vogel, CSc Katedra softwarového inženýrství Katedra teoretické informatiky, Fakulta
VYUŽITÍ GRAFICKÉHO ADAPTÉRU PRO OBECNÉ VÝPOČTY GENERAL-PURPOSE COMPUTATION USING GRAPHICS CARD
 VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ BRNO UNIVERSITY OF TECHNOLOGY FAKULTA INFORMAČNÍCH TECHNOLOGIÍ ÚSTAV POČÍTAČOVÝCH SYSTÉMŮ FACULTY OF INFORMATION TECHNOLOGY DEPARTMENT OF COMPUTER SYSTEMS VYUŽITÍ GRAFICKÉHO
VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ BRNO UNIVERSITY OF TECHNOLOGY FAKULTA INFORMAČNÍCH TECHNOLOGIÍ ÚSTAV POČÍTAČOVÝCH SYSTÉMŮ FACULTY OF INFORMATION TECHNOLOGY DEPARTMENT OF COMPUTER SYSTEMS VYUŽITÍ GRAFICKÉHO
Paralelní architektury se sdílenou pamětí typu NUMA. NUMA architektury
 Paralelní architektury se sdílenou pamětí typu NUMA NUMA architektury Multiprocesorové systémy s distribuovanou pamětí I. úzkým hrdlem multiprocesorů se sdílenou pamětí je datová komunikace s rostoucím
Paralelní architektury se sdílenou pamětí typu NUMA NUMA architektury Multiprocesorové systémy s distribuovanou pamětí I. úzkým hrdlem multiprocesorů se sdílenou pamětí je datová komunikace s rostoucím
Semestrální práce z předmětu Speciální číslicové systémy X31SCS
 Semestrální práce z předmětu Speciální číslicové systémy X31SCS Katedra obvodů DSP16411 ZPRACOVAL: Roman Holubec Školní rok: 2006/2007 Úvod DSP16411 patří do rodiny DSP16411 rozšiřuje DSP16410 o vyšší
Semestrální práce z předmětu Speciální číslicové systémy X31SCS Katedra obvodů DSP16411 ZPRACOVAL: Roman Holubec Školní rok: 2006/2007 Úvod DSP16411 patří do rodiny DSP16411 rozšiřuje DSP16410 o vyšší
Metody připojování periferií
 Metody připojování periferií BI-MPP Přednáška 13 Ing. Miroslav Skrbek, Ph.D. Katedra počítačových systémů Fakulta informačních technologií České vysoké učení technické v Praze Miroslav Skrbek 2010,2011
Metody připojování periferií BI-MPP Přednáška 13 Ing. Miroslav Skrbek, Ph.D. Katedra počítačových systémů Fakulta informačních technologií České vysoké učení technické v Praze Miroslav Skrbek 2010,2011
Úvod Seznámení s předmětem Co je.net Vlastnosti.NET Konec. Programování v C# Úvodní slovo 1 / 25
 Programování v C# Úvodní slovo 1 / 25 Obsah přednášky Seznámení s předmětem Co je.net Vlastnosti.NET 2 / 25 Kdo je kdo Petr Vaněček vanecek@pf.jcu.cz J 502 Václav Novák vacnovak@pf.jcu.cz?? Při komunikaci
Programování v C# Úvodní slovo 1 / 25 Obsah přednášky Seznámení s předmětem Co je.net Vlastnosti.NET 2 / 25 Kdo je kdo Petr Vaněček vanecek@pf.jcu.cz J 502 Václav Novák vacnovak@pf.jcu.cz?? Při komunikaci
Přednáška 1. Katedra počítačových systémů FIT, České vysoké učení technické v Praze Jan Trdlička, 2012
 Přednáška 1 Úvod do HW a OS. Katedra počítačových systémů FIT, České vysoké učení technické v Praze Jan Trdlička, 2012 Příprava studijního programu Informatika je podporována projektem financovaným z Evropského
Přednáška 1 Úvod do HW a OS. Katedra počítačových systémů FIT, České vysoké učení technické v Praze Jan Trdlička, 2012 Příprava studijního programu Informatika je podporována projektem financovaným z Evropského
8 Třídy, objekty, metody, předávání argumentů metod
 8 Třídy, objekty, metody, předávání argumentů metod Studijní cíl Tento studijní blok má za cíl pokračovat v základních prvcích jazyka Java. Konkrétně bude věnována pozornost třídám a objektům, instančním
8 Třídy, objekty, metody, předávání argumentů metod Studijní cíl Tento studijní blok má za cíl pokračovat v základních prvcích jazyka Java. Konkrétně bude věnována pozornost třídám a objektům, instančním
Vláknové programování část I
 Vláknové programování část I Lukáš Hejmánek, Petr Holub {xhejtman,hopet}@ics.muni.cz Laboratoř pokročilých síťových technologií PV192 2015 04 07 1/27 Vláknové programování v C/C++ 1. Procesy, vlákna, přepínání
Vláknové programování část I Lukáš Hejmánek, Petr Holub {xhejtman,hopet}@ics.muni.cz Laboratoř pokročilých síťových technologií PV192 2015 04 07 1/27 Vláknové programování v C/C++ 1. Procesy, vlákna, přepínání
Generátor efektivního kódu fúzovaných CUDA kernelů
 MASARYKOVA UNIVERZITA FAKULTA INFORMATIKY Generátor efektivního kódu fúzovaných CUDA kernelů Diplomová práce Bedřich Lakomý Brno, 2012 Prohlášení Prohlašuji, že tato práce je mým původním autorským dílem,
MASARYKOVA UNIVERZITA FAKULTA INFORMATIKY Generátor efektivního kódu fúzovaných CUDA kernelů Diplomová práce Bedřich Lakomý Brno, 2012 Prohlášení Prohlašuji, že tato práce je mým původním autorským dílem,
Management procesu I Mgr. Josef Horálek
 Management procesu I Mgr. Josef Horálek Procesy = Starší počítače umožňovaly spouštět pouze jeden program. Tento program plně využíval OS i všechny systémové zdroje. Současné počítače umožňují běh více
Management procesu I Mgr. Josef Horálek Procesy = Starší počítače umožňovaly spouštět pouze jeden program. Tento program plně využíval OS i všechny systémové zdroje. Současné počítače umožňují běh více
Architektury paralelních počítačů II.
 Architektury paralelních počítačů II. Sekvenční konzistence paměti Implementace synchronizačních událostí Ing. Miloš Bečvář s použitím slajdů Prof. Ing. Pavla Tvrdíka, CSc. Osnova přednášky Opakování definice
Architektury paralelních počítačů II. Sekvenční konzistence paměti Implementace synchronizačních událostí Ing. Miloš Bečvář s použitím slajdů Prof. Ing. Pavla Tvrdíka, CSc. Osnova přednášky Opakování definice
PB161 Programování v jazyce C++ Přednáška 4
 PB161 Programování v jazyce C++ Přednáška 4 Přetěžování funkcí Konstruktory a destruktory Nikola Beneš 9. října 2017 PB161 přednáška 4: přetěžování funkcí, konstruktory, destruktory 9. října 2017 1 / 20
PB161 Programování v jazyce C++ Přednáška 4 Přetěžování funkcí Konstruktory a destruktory Nikola Beneš 9. října 2017 PB161 přednáška 4: přetěžování funkcí, konstruktory, destruktory 9. října 2017 1 / 20
Přednáška. Správa paměti I. Katedra počítačových systémů FIT, České vysoké učení technické v Praze Jan Trdlička, 2012
 Přednáška Správa paměti I. Katedra počítačových systémů FIT, České vysoké učení technické v Praze Jan Trdlička, 2012 Příprava studijního programu Informatika je podporována projektem financovaným z Evropského
Přednáška Správa paměti I. Katedra počítačových systémů FIT, České vysoké učení technické v Praze Jan Trdlička, 2012 Příprava studijního programu Informatika je podporována projektem financovaným z Evropského
Opakování programování
 Opakování programování HW návaznost - procesor sběrnice, instrukční sada, optimalizace rychlosti, datové typy, operace (matematické, logické, podmínky, skoky, podprogram ) - paměti a periferie - adresování
Opakování programování HW návaznost - procesor sběrnice, instrukční sada, optimalizace rychlosti, datové typy, operace (matematické, logické, podmínky, skoky, podprogram ) - paměti a periferie - adresování
Michal Krátký. Úvod do programovacích jazyků (Java), 2006/2007
, 2006/2007") Úvod do programovacích jazyků (Java) Michal Krátký 1 Katedra informatiky VŠB Technická univerzita Ostrava Úvod do programovacích jazyků (Java), 2006/2007 c 2006 Michal Krátký Úvod do programovacích jazyků
Úvod do programovacích jazyků (Java) Michal Krátký 1 Katedra informatiky VŠB Technická univerzita Ostrava Úvod do programovacích jazyků (Java), 2006/2007 c 2006 Michal Krátký Úvod do programovacích jazyků
Úvod do jazyka C. Ing. Jan Fikejz (KST, FEI) Fakulta elektrotechniky a informatiky Katedra softwarových technologií
 Fakulta elektrotechniky a informatiky Katedra softwarových technologií") 1 Fakulta elektrotechniky a informatiky Katedra softwarových technologií 12. října 2009 Organizace výuky Přednášky Teoretické základy dle normy jazyka C Cvičení Praktické úlohy odpřednášené látky Prostřední
1 Fakulta elektrotechniky a informatiky Katedra softwarových technologií 12. října 2009 Organizace výuky Přednášky Teoretické základy dle normy jazyka C Cvičení Praktické úlohy odpřednášené látky Prostřední
Michal Krátký. Úvod do programovacích jazyků (Java), 2006/2007
, 2006/2007") Úvod do programovacích jazyků (Java) Michal Krátký 1 Katedra informatiky VŠB Technická univerzita Ostrava Úvod do programovacích jazyků (Java), 2006/2007 c 2006 Michal Krátký Úvod do programovacích jazyků
Úvod do programovacích jazyků (Java) Michal Krátký 1 Katedra informatiky VŠB Technická univerzita Ostrava Úvod do programovacích jazyků (Java), 2006/2007 c 2006 Michal Krátký Úvod do programovacích jazyků
Real Time programování v LabView. Ing. Martin Bušek, Ph.D.
 Real Time programování v LabView Ing. Martin Bušek, Ph.D. Úvod - související komponenty LabVIEW development Konkrétní RT hardware - cíl Použití LabVIEW RT module - Pharlap ETS, RTX, VxWorks Možnost užití
Real Time programování v LabView Ing. Martin Bušek, Ph.D. Úvod - související komponenty LabVIEW development Konkrétní RT hardware - cíl Použití LabVIEW RT module - Pharlap ETS, RTX, VxWorks Možnost užití
Preprocesor. Karel Richta a kol. katedra počítačů FEL ČVUT v Praze. Karel Richta, Martin Hořeňovský, Aleš Hrabalík, 2016
 Preprocesor Karel Richta a kol. katedra počítačů FEL ČVUT v Praze Karel Richta, Martin Hořeňovský, Aleš Hrabalík, 2016 Programování v C++, A7B36PJC 4/2016, Lekce 9b https://cw.fel.cvut.cz/wiki/courses/a7b36pjc/start
Preprocesor Karel Richta a kol. katedra počítačů FEL ČVUT v Praze Karel Richta, Martin Hořeňovský, Aleš Hrabalík, 2016 Programování v C++, A7B36PJC 4/2016, Lekce 9b https://cw.fel.cvut.cz/wiki/courses/a7b36pjc/start
VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ BRNO UNIVERSITY OF TECHNOLOGY
 VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ BRNO UNIVERSITY OF TECHNOLOGY FAKULTA INFORMAČNÍCH TECHNOLOGIÍ ÚSTAV POČÍTAČOVÉ GRAFIKY A MULTIMÉDIÍ FACULTY OF INFORMATION TECHNOLOGY DEPARTMENT OF COMPUTER GRAPHICS AND
VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ BRNO UNIVERSITY OF TECHNOLOGY FAKULTA INFORMAČNÍCH TECHNOLOGIÍ ÚSTAV POČÍTAČOVÉ GRAFIKY A MULTIMÉDIÍ FACULTY OF INFORMATION TECHNOLOGY DEPARTMENT OF COMPUTER GRAPHICS AND
Paralelní programování
 Paralelní programování přednášky Jan Outrata únor květen 2011 Jan Outrata (KI UP) Paralelní programování únor květen 2011 1 / 15 Simulátor konkurence abstrakce = libovolné proložení atom. akcí sekvenčních
Paralelní programování přednášky Jan Outrata únor květen 2011 Jan Outrata (KI UP) Paralelní programování únor květen 2011 1 / 15 Simulátor konkurence abstrakce = libovolné proložení atom. akcí sekvenčních
Správa paměti. doc. Ing. Miroslav Beneš, Ph.D. katedra informatiky FEI VŠB-TUO A-1007 /
 Správa paměti doc. Ing. Miroslav Beneš, Ph.D. katedra informatiky FEI VŠB-TUO A-1007 / 597 324 213 http://www.cs.vsb.cz/benes Miroslav.Benes@vsb.cz Obsah přednášky Motivace Úrovně správy paměti. Manuální
Správa paměti doc. Ing. Miroslav Beneš, Ph.D. katedra informatiky FEI VŠB-TUO A-1007 / 597 324 213 http://www.cs.vsb.cz/benes Miroslav.Benes@vsb.cz Obsah přednášky Motivace Úrovně správy paměti. Manuální
VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ BRNO UNIVERSITY OF TECHNOLOGY
 VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ BRNO UNIVERSITY OF TECHNOLOGY FAKULTA ELEKTROTECHNIKY A KOMUNIKAČNÍCH TECHNOLOGIÍ ÚSTAV AUTOMATIZACE A MĚŘÍCÍ TECHNIKY FACULTY OF ELECTRICAL ENGINEERING AND COMMUNICATION
VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ BRNO UNIVERSITY OF TECHNOLOGY FAKULTA ELEKTROTECHNIKY A KOMUNIKAČNÍCH TECHNOLOGIÍ ÚSTAV AUTOMATIZACE A MĚŘÍCÍ TECHNIKY FACULTY OF ELECTRICAL ENGINEERING AND COMMUNICATION
Vlákno (anglicky: thread) v informatice označuje vlákno výpočtu neboli samostatný výpočetní tok, tedy posloupnost po sobě jdoucích operací.
 v informatice označuje vlákno výpočtu neboli samostatný výpočetní tok, tedy posloupnost po sobě jdoucích operací.") Trochu teorie Vlákno (anglicky: thread) v informatice označuje vlákno výpočtu neboli samostatný výpočetní tok, tedy posloupnost po sobě jdoucích operací. Každá spuštěná aplikace má alespoň jeden proces
Trochu teorie Vlákno (anglicky: thread) v informatice označuje vlákno výpočtu neboli samostatný výpočetní tok, tedy posloupnost po sobě jdoucích operací. Každá spuštěná aplikace má alespoň jeden proces
Architektura Intel Atom
 Architektura Intel Atom Štěpán Sojka 5. prosince 2008 1 Úvod Hlavní rysem Atomu je podpora platformy x86, která umožňuje spouštět a běžně používat řadu let vyvíjené aplikace, na které jsou uživatelé zvyklí
Architektura Intel Atom Štěpán Sojka 5. prosince 2008 1 Úvod Hlavní rysem Atomu je podpora platformy x86, která umožňuje spouštět a běžně používat řadu let vyvíjené aplikace, na které jsou uživatelé zvyklí
Algoritmizace a programování
 Algoritmizace a programování Strukturované proměnné Struktura, union Jazyk C České vysoké učení technické Fakulta elektrotechnická A8B14ADP Jazyk C - Strukturované proměnné Ver.1.10 J. Zděnek 20151 Struktura
Algoritmizace a programování Strukturované proměnné Struktura, union Jazyk C České vysoké učení technické Fakulta elektrotechnická A8B14ADP Jazyk C - Strukturované proměnné Ver.1.10 J. Zděnek 20151 Struktura
SUPERPOČÍTAČE DANIEL LANGR ČVUT FIT / VZLÚ
 SUPERPOČÍTAČE DANIEL LANGR ČVUT FIT / VZLÚ TITAN / HOPPER / NOTEBOOK TITAN HOPPER NOTEBOOK Počet CPU jader 299 008 153 216 2 Operační paměť [GB] 598 016 217 000 8 Počet GPU (CUDA) jader 50 233 344 0 8
SUPERPOČÍTAČE DANIEL LANGR ČVUT FIT / VZLÚ TITAN / HOPPER / NOTEBOOK TITAN HOPPER NOTEBOOK Počet CPU jader 299 008 153 216 2 Operační paměť [GB] 598 016 217 000 8 Počet GPU (CUDA) jader 50 233 344 0 8
INDIVIDUÁLNÍ PROJEKT 1 - ZPRACOVÁNÍ GNSS SIGNÁLU V GPU
 V O J T Ě C H T E R Š 27.1.2013 INDIVIDUÁLNÍ PROJEKT 1 - ZPRACOVÁNÍ GNSS SIGNÁLU V GPU Ú K O L P R O J E K T U: Přeprogramování rychlé diskrétní Furierovy Transformace (FFT) do jazyka Open CL. V Y B R
V O J T Ě C H T E R Š 27.1.2013 INDIVIDUÁLNÍ PROJEKT 1 - ZPRACOVÁNÍ GNSS SIGNÁLU V GPU Ú K O L P R O J E K T U: Přeprogramování rychlé diskrétní Furierovy Transformace (FFT) do jazyka Open CL. V Y B R
Algoritmizace a programování
 Algoritmizace a programování Řídicí struktury jazyka Java Struktura programu Příkazy jazyka Blok příkazů Logické příkazy Ternární logický operátor Verze pro akademický rok 2012/2013 1 Struktura programu
Algoritmizace a programování Řídicí struktury jazyka Java Struktura programu Příkazy jazyka Blok příkazů Logické příkazy Ternární logický operátor Verze pro akademický rok 2012/2013 1 Struktura programu
Osobní počítač. Zpracoval: ict Aktualizace: 10. 11. 2011
 Osobní počítač Zpracoval: ict Aktualizace: 10. 11. 2011 Charakteristika PC Osobní počítač (personal computer - PC) je nástroj člověka pro zpracovávání informací Vyznačuje se schopností samostatně pracovat
Osobní počítač Zpracoval: ict Aktualizace: 10. 11. 2011 Charakteristika PC Osobní počítač (personal computer - PC) je nástroj člověka pro zpracovávání informací Vyznačuje se schopností samostatně pracovat
MSP 430F1611. Jiří Kašpar. Charakteristika
 MSP 430F1611 Charakteristika Mikroprocesor MSP430F1611 je 16 bitový, RISC struktura s von-neumannovou architekturou. Na mikroprocesor má neuvěřitelně velkou RAM paměť 10KB, 48KB + 256B FLASH paměť. Takže
MSP 430F1611 Charakteristika Mikroprocesor MSP430F1611 je 16 bitový, RISC struktura s von-neumannovou architekturou. Na mikroprocesor má neuvěřitelně velkou RAM paměť 10KB, 48KB + 256B FLASH paměť. Takže
Ovladače pro Windows. Ovladače Windows A4M38KRP. Str. 1
 Ovladače Windows A4M38KRP Str. 1 Struktura OS Windows Str. 2 Typy ovladačů Str. 3 Typy ovladačů Virtual Device Driver User mode ovladač Virtualizace HW pro DOS aplikace Legacy Driver Pro zařízení nepodporující
Ovladače Windows A4M38KRP Str. 1 Struktura OS Windows Str. 2 Typy ovladačů Str. 3 Typy ovladačů Virtual Device Driver User mode ovladač Virtualizace HW pro DOS aplikace Legacy Driver Pro zařízení nepodporující
Paralelní programování
 Paralelní programování přednášky Jan Outrata únor duben 2011 Jan Outrata (KI UP) Paralelní programování únor duben 2011 1 / 11 Literatura Ben-Ari M.: Principles of concurrent and distributed programming.
Paralelní programování přednášky Jan Outrata únor duben 2011 Jan Outrata (KI UP) Paralelní programování únor duben 2011 1 / 11 Literatura Ben-Ari M.: Principles of concurrent and distributed programming.
Představení a vývoj architektur vektorových procesorů
 Představení a vývoj architektur vektorových procesorů Drong Lukáš Dro098 1 Obsah Úvod 3 Historie, současnost 3 Architektura 4 - pipelining 4 - Operace scatter a gather 4 - vektorové registry 4 - Řetězení
Představení a vývoj architektur vektorových procesorů Drong Lukáš Dro098 1 Obsah Úvod 3 Historie, současnost 3 Architektura 4 - pipelining 4 - Operace scatter a gather 4 - vektorové registry 4 - Řetězení
VYUŽITÍ KNIHOVNY SWING PROGRAMOVACÍHO JAZYKU JAVA PŘI TVORBĚ UŽIVATELSKÉHO ROZHRANÍ SYSTÉMU "HOST PC - TARGET PC" PRO ŘÍZENÍ POLOVODIČOVÝCH MĚNIČŮ
 VYUŽITÍ KNIHOVNY SWING PROGRAMOVACÍHO JAZYKU JAVA PŘI TVORBĚ UŽIVATELSKÉHO ROZHRANÍ SYSTÉMU "HOST PC - TARGET PC" PRO ŘÍZENÍ POLOVODIČOVÝCH MĚNIČŮ Stanislav Flígl Katedra elektrických pohonů a trakce (K13114),
VYUŽITÍ KNIHOVNY SWING PROGRAMOVACÍHO JAZYKU JAVA PŘI TVORBĚ UŽIVATELSKÉHO ROZHRANÍ SYSTÉMU "HOST PC - TARGET PC" PRO ŘÍZENÍ POLOVODIČOVÝCH MĚNIČŮ Stanislav Flígl Katedra elektrických pohonů a trakce (K13114),
Obsah. Kapitola 1 Hardware, procesory a vlákna Prohlídka útrob počítače...20 Motivace pro vícejádrové procesory...21
 Stručný obsah 1. Hardware, procesory a vlákna... 19 2. Programování s ohledemna výkon... 45 3. Identifikování příležitostí pro paralelizmus... 93 4. Synchronizace a sdílení dat... 123 5. Vlákna v rozhraní
Stručný obsah 1. Hardware, procesory a vlákna... 19 2. Programování s ohledemna výkon... 45 3. Identifikování příležitostí pro paralelizmus... 93 4. Synchronizace a sdílení dat... 123 5. Vlákna v rozhraní
Profilování paralelních aplikací Profiling of Parallel Applications
 VŠB Technická univerzita Ostrava Fakulta elektrotechniky a informatiky Katedra informatiky Profilování paralelních aplikací Profiling of Parallel Applications 2018 Bc. Jakub Beránek Chtěl bych poděkovat
VŠB Technická univerzita Ostrava Fakulta elektrotechniky a informatiky Katedra informatiky Profilování paralelních aplikací Profiling of Parallel Applications 2018 Bc. Jakub Beránek Chtěl bych poděkovat
Operační systémy. Jednoduché stránkování. Virtuální paměť. Příklad: jednoduché stránkování. Virtuální paměť se stránkování. Memory Management Unit
 Jednoduché stránkování Operační systémy Přednáška 8: Správa paměti II Hlavní paměť rozdělená na malé úseky stejné velikosti (např. 4kB) nazývané rámce (frames). Program rozdělen na malé úseky stejné velikosti
Jednoduché stránkování Operační systémy Přednáška 8: Správa paměti II Hlavní paměť rozdělená na malé úseky stejné velikosti (např. 4kB) nazývané rámce (frames). Program rozdělen na malé úseky stejné velikosti
Závěrečná zpráva projektu Experimentální výpočetní grid pro numerickou lineární algebru
 Závěrečná zpráva projektu Experimentální výpočetní grid pro numerickou lineární algebru Ing. Ivan Šimeček Ph.D., Zdeněk Buk xsimecek@fit.cvut.cz, bukz1fel.cvut.cz Červen, 2012 1 Zadání Paralelní zpracování
Závěrečná zpráva projektu Experimentální výpočetní grid pro numerickou lineární algebru Ing. Ivan Šimeček Ph.D., Zdeněk Buk xsimecek@fit.cvut.cz, bukz1fel.cvut.cz Červen, 2012 1 Zadání Paralelní zpracování
Cvičení MI-PRC I. Šimeček
 Cvičení MI-PRC I. Šimeček xsimecek@fit.cvut.cz Katedra počítačových systémů FIT České vysoké učení technické v Praze Ivan Šimeček, 2011 MI-PRC, LS2010/11, Cv.1-6 Příprava studijního programu Informatika
Cvičení MI-PRC I. Šimeček xsimecek@fit.cvut.cz Katedra počítačových systémů FIT České vysoké učení technické v Praze Ivan Šimeček, 2011 MI-PRC, LS2010/11, Cv.1-6 Příprava studijního programu Informatika
Paralelní výpočetní jádro matematického modelu elektrostatického zvlákňování
 Paralelní výpočetní jádro matematického modelu elektrostatického zvlákňování Milan Šimko Technická univerzita v Liberci Interní odborný seminář KO MIX 19. prosince 2011 Obsah prezentace 1 MOTIVACE 2 VLÁKNOVÝ
Paralelní výpočetní jádro matematického modelu elektrostatického zvlákňování Milan Šimko Technická univerzita v Liberci Interní odborný seminář KO MIX 19. prosince 2011 Obsah prezentace 1 MOTIVACE 2 VLÁKNOVÝ
AKCELERACE EVOLUCE PRAVIDEL CELULÁRNÍCH AUTOMATŮ NA GPU
 AKCELERACE EVOLUCE PRAVIDEL CELULÁRNÍCH AUTOMATŮ NA GPU Luděk Žaloudek Výpočetní technika a informatika, 2. ročník, prezenční studium Školitel: Lukáš Sekanina Fakulta informačních technologií, Vysoké učení
AKCELERACE EVOLUCE PRAVIDEL CELULÁRNÍCH AUTOMATŮ NA GPU Luděk Žaloudek Výpočetní technika a informatika, 2. ročník, prezenční studium Školitel: Lukáš Sekanina Fakulta informačních technologií, Vysoké učení
Virtualizace. Lukáš Krahulec, KRA556
 Virtualizace Lukáš Krahulec, KRA556 Co je vitualizace Způsob jak přistupovat ke zdrojům systému jako k univerzálnímu výkonu a nezajímat se o železo Způsob jak využít silný HW a rozložit ho mezi uživatele,
Virtualizace Lukáš Krahulec, KRA556 Co je vitualizace Způsob jak přistupovat ke zdrojům systému jako k univerzálnímu výkonu a nezajímat se o železo Způsob jak využít silný HW a rozložit ho mezi uživatele,
Paralelní a distribuované výpočty (B4B36PDV)
") Paralelní a distribuované výpočty (B4B36PDV) Branislav Bošanský, Michal Jakob bosansky@fel.cvut.cz Artificial Intelligence Center Department of Computer Science Faculty of Electrical Engineering Czech
Paralelní a distribuované výpočty (B4B36PDV) Branislav Bošanský, Michal Jakob bosansky@fel.cvut.cz Artificial Intelligence Center Department of Computer Science Faculty of Electrical Engineering Czech
Ústav technické matematiky FS ( Ústav technické matematiky FS ) / 35
 / 35") Úvod do paralelního programování 2 MPI Jakub Šístek Ústav technické matematiky FS 9.1.2007 ( Ústav technické matematiky FS ) 9.1.2007 1 / 35 Osnova 1 Opakování 2 Představení Message Passing Interface (MPI)
Úvod do paralelního programování 2 MPI Jakub Šístek Ústav technické matematiky FS 9.1.2007 ( Ústav technické matematiky FS ) 9.1.2007 1 / 35 Osnova 1 Opakování 2 Představení Message Passing Interface (MPI)
a co je operační systém?
 a co je operační systém? Funkce vylepšení HW sjednocení různosti zařízení ulehčení programování (např. časové závislosti) přiblížení k potřebám aplikací o soubory namísto diskových bloků o více procesorů
a co je operační systém? Funkce vylepšení HW sjednocení různosti zařízení ulehčení programování (např. časové závislosti) přiblížení k potřebám aplikací o soubory namísto diskových bloků o více procesorů
Úvod do programování - Java. Cvičení č.4
 Úvod do programování - Java Cvičení č.4 1 Sekvence (posloupnost) Sekvence je tvořena posloupností jednoho nebo více příkazů, které se provádějí v pevně daném pořadí. Příkaz se začne provádět až po ukončení
Úvod do programování - Java Cvičení č.4 1 Sekvence (posloupnost) Sekvence je tvořena posloupností jednoho nebo více příkazů, které se provádějí v pevně daném pořadí. Příkaz se začne provádět až po ukončení
FAKULTA INFORMAČNÍCH TECHNOLOGIÍ
 VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ BRNO UNIVERSITY OF TECHNOLOGY FAKULTA INFORMAČNÍCH TECHNOLOGIÍ ÚSTAV POČÍTAČOVÝCH SYSTÉMŮ FACULTY OF INFORMATION TECHNOLOGY DEPARTMENT OF COMPUTER SYSTEMS NUMERICKÁ SIMULACE
VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ BRNO UNIVERSITY OF TECHNOLOGY FAKULTA INFORMAČNÍCH TECHNOLOGIÍ ÚSTAV POČÍTAČOVÝCH SYSTÉMŮ FACULTY OF INFORMATION TECHNOLOGY DEPARTMENT OF COMPUTER SYSTEMS NUMERICKÁ SIMULACE
Programování v C++ 1, 1. cvičení
 Programování v C++ 1, 1. cvičení opakování látky ze základů programování 1 1 Fakulta jaderná a fyzikálně inženýrská České vysoké učení technické v Praze Zimní semestr 2018/2019 Přehled 1 2 Shrnutí procvičených
Programování v C++ 1, 1. cvičení opakování látky ze základů programování 1 1 Fakulta jaderná a fyzikálně inženýrská České vysoké učení technické v Praze Zimní semestr 2018/2019 Přehled 1 2 Shrnutí procvičených
FAKULTA INFORMAČNÍCH TECHNOLOGIÍ
 VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ BRNO UNIVERSITY OF TECHNOLOGY FAKULTA INFORMAČNÍCH TECHNOLOGIÍ ÚSTAV POČÍTAČOVÉ GRAFIKY A MULTIMÉDIÍ FACULTY OF INFORMATION TECHNOLOGY DEPARTMENT OF COMPUTER GRAPHICS AND
VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ BRNO UNIVERSITY OF TECHNOLOGY FAKULTA INFORMAČNÍCH TECHNOLOGIÍ ÚSTAV POČÍTAČOVÉ GRAFIKY A MULTIMÉDIÍ FACULTY OF INFORMATION TECHNOLOGY DEPARTMENT OF COMPUTER GRAPHICS AND
vlastnosti, praktické zkušenosti
 Obecné výpočty na grafických kartách použitelnost, vlastnosti, praktické zkušenosti Martin Kruliš, Jakub Yaghob KSI MFF UK Malostranské nám. 25, Praha {krulis,yaghob}@ksi.mff.cuni.cz Abstrakt. Nedávný
Obecné výpočty na grafických kartách použitelnost, vlastnosti, praktické zkušenosti Martin Kruliš, Jakub Yaghob KSI MFF UK Malostranské nám. 25, Praha {krulis,yaghob}@ksi.mff.cuni.cz Abstrakt. Nedávný
VÝUKOVÝ MATERIÁL. 3. ročník učebního oboru Elektrikář Přílohy. bez příloh. Identifikační údaje školy
 VÝUKOVÝ MATERIÁL Identifikační údaje školy Číslo projektu Název projektu Číslo a název šablony Autor Tematická oblast Číslo a název materiálu Anotace Vyšší odborná škola a Střední škola, Varnsdorf, příspěvková
VÝUKOVÝ MATERIÁL Identifikační údaje školy Číslo projektu Název projektu Číslo a název šablony Autor Tematická oblast Číslo a název materiálu Anotace Vyšší odborná škola a Střední škola, Varnsdorf, příspěvková
Základy informatiky. 2. Přednáška HW. Lenka Carr Motyčková. February 22, 2011 Základy informatiky 2
 Základy informatiky 2. Přednáška HW Lenka Carr Motyčková February 22, 2011 Základy informatiky 1 February 22, 2011 Základy informatiky 2 February 22, 2011 Základy informatiky 3 February 22, 2011 Základy
Základy informatiky 2. Přednáška HW Lenka Carr Motyčková February 22, 2011 Základy informatiky 1 February 22, 2011 Základy informatiky 2 February 22, 2011 Základy informatiky 3 February 22, 2011 Základy
Operační systémy. Přednáška 7: Správa paměti I
 Operační systémy Přednáška 7: Správa paměti I 1 Správa paměti (SP) Memory Management Unit (MMU) hardware umístěný na CPU čipu např. překládá logické adresy na fyzické adresy, Memory Manager software, který
Operační systémy Přednáška 7: Správa paměti I 1 Správa paměti (SP) Memory Management Unit (MMU) hardware umístěný na CPU čipu např. překládá logické adresy na fyzické adresy, Memory Manager software, který
ČÁST 1. Základy 32bitového programování ve Windows
 Obsah Úvod 13 ČÁST 1 Základy 32bitového programování ve Windows Kapitola 1 Nástroje pro programování ve Windows 19 První program v Assembleru a jeho kompilace 19 Objektové soubory 23 Direktiva INVOKE 25
Obsah Úvod 13 ČÁST 1 Základy 32bitového programování ve Windows Kapitola 1 Nástroje pro programování ve Windows 19 První program v Assembleru a jeho kompilace 19 Objektové soubory 23 Direktiva INVOKE 25
Metody připojování periferií
 Metody připojování periferií BI-MPP Přednáška 10 Ing. Miroslav Skrbek, Ph.D. Katedra počítačových systémů Fakulta informačních technologií České vysoké učení technické v Praze Miroslav Skrbek 2010,2011
Metody připojování periferií BI-MPP Přednáška 10 Ing. Miroslav Skrbek, Ph.D. Katedra počítačových systémů Fakulta informačních technologií České vysoké učení technické v Praze Miroslav Skrbek 2010,2011
Správa paměti. Karel Richta a kol. Katedra počítačů Fakulta elektrotechnická České vysoké učení technické v Praze Karel Richta, 2016
 Správa paměti Karel Richta a kol. Katedra počítačů Fakulta elektrotechnická České vysoké učení technické v Praze Karel Richta, 2016 Objektové modelování, B36OMO 10/2016, Lekce 2 https://cw.fel.cvut.cz/wiki/courses/xxb36omo/start
Správa paměti Karel Richta a kol. Katedra počítačů Fakulta elektrotechnická České vysoké učení technické v Praze Karel Richta, 2016 Objektové modelování, B36OMO 10/2016, Lekce 2 https://cw.fel.cvut.cz/wiki/courses/xxb36omo/start