Pokročilé architektury počítačů
|
|
|
- Matěj Beránek
- před 9 lety
- Počet zobrazení:
Transkript
1 Pokročilé architektury počítačů Přednáška 2 Instrukční paralelizmus a jeho limity Martin Milata

2 Obsah Instrukční hazardy a datové závislosti (připomenutí) Tomasulo algoritmus a dynamické plánování Základní myšlenka Přesná a nepřesná přerušení Spekulace Re-order buffer CPI < 1 Paralelní vydávání instrukcí Limity ILP Alternativní přístupy k dynamickému plánování VLIW a EPIC Vektorové procesory a vektorová rozšíření

3 Hazardy a jejich typy Brání efektivnímu využití zřetězení Strukturální hazardy Konflikty sdílených zdrojů procesoru Datové hazardy Datové konflikty typu RAW, WAR, WAW Řídící hazardy Neočekávané či nepredikovatelné změny vykonávání programu

4 Datové závislosti a hazardy Obojí je nedílnou součástí programů Závislost mezi instrukcemi indikuje možnou přítomnost hazardu. To jestli se a jak daný hazard projeví, je ovšem záležitostí hardwarového uzpůsobení instrukční linky a řazení instrukcí na ni. Problematika datových závislostí Indikace možné přítomnosti datových hazardů Nutnost stanovení pořadí v němž musí být dosaženo výsledků jednotlivých instrukcí Stanovení možných paralelismů pro optimální využití instrukční linky Dnes řešeno s podporou nebo přímo v HW Kontrolní závislosti Případné změny pořadí provádění instrukcí nesmí ovlivnit očekávané chování programu Musí být zachován datový tok. Instrukce vykonávané mimo pořadí nesmí neočekávaně změnit hodnoty datového toku

5 Dynamické plánování instrukcí Výhody dynamického plánování Nezávislost na platformě. Přináší její efektivní využití Jednoduchý kompilátor, mnoho závislostí řešeno až při provádění Klíčová myšlenka Dovolit vykonávání instrukcí mimo pořadí tak aby nezávislé instrukce nebyly omezovány předchozími hazardy Důsledky Instrukce jsou vydávány v pořadí Provádění instrukcí je umožněno mimo pořadí Dokončování instrukcí nastává mimo pořadí

6 První krok v dynamickém plánování Přináší možnost vykonávání instrukcí mimo pořadí při zachování jejich vydávání v pořadí Pro 5-ti stupňovou zřetězenou linku to znamená rozdělení DI fáze do dvou částí Vydání instrukce (II) její dekódování (in-order) Čtení operandů (RO) příprava požadovaných dat operandů pro další zpracování (out-of-order) Strukturální závislosti se řeší při vydávání instrukce Datové závislosti ve fázi čtení operandů v rámci vydaných instrukcí (issue window) Issue window reprezentuje plovoucí okénko, obvykle pevné délky, které se posouvá po vydávaných instrukcích. Instrukce, které se v něm nacházejí, jsou vydány, mohou být zpracovávány nebo čekají na operandy. K posunu okénka dojde až v okamžiku, kdy první vydaná instrukce zapíše svůj výsledek.

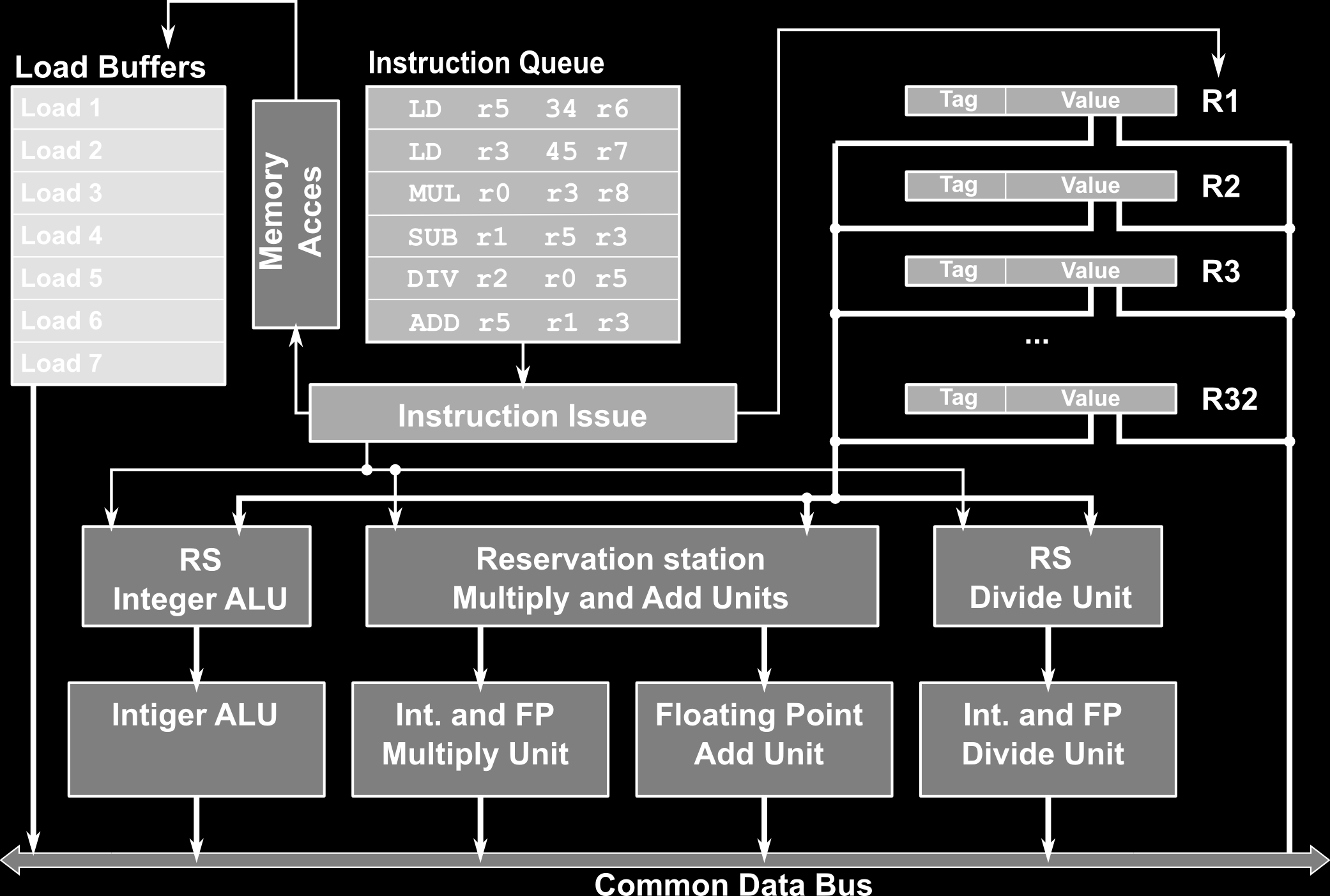
7 Tomasulo Algoritmus Klíčový algoritmus používaný při dynamickém plánování instrukcí Alpha 21264, MIPS10000/R12000, Pentium II/III/4, Core, Core2, Nehalem, AMD K5, K6, Athlon, Opteron, Phenom, PowerPC... Jak Tomasulo pracuje? (1) Reservační stanice (RS) přidružené k funkčním jednotkám (FU) Místo pro uložení omezeného počtu dekódovaných instrukcí určených pro danou FU V RS distribuováno řízení a dočasné ukládání (ukládá operandy i výsledky instrukcí) V instrukcích používané registry jsou nahrazeny ukazatelem nebo přímo jejich hodnotou v RS (register renaming) Předchází se tak WAR, WAW V RS může být uloženo více různých hodnot než je skutečný počet registrů. Program není možné optimalizovat při kompilaci
 V instrukcích používané registry jsou nahrazeny ukazatelem nebo přímo jejich hodnotou v RS (register renaming) Předchází")
8 Tomasulo Algoritmus Jak Tomasulo pracuje? (2) Common Data Bus (CDB) sběrnice propojující všechny RS zaslaná data obsahují navíc identifikátor zdroje (ID RS, která instrukci vydala) data jsou doručena na všechny RS (broadcast) kde jsou aktualizovány položky, které na data čekaly (plná asociativita v rámci RS je nutná) Každá instrukce se může nacházet v jednom z následujících stavů vydaná instrukce je načtená a dekódovaná (II) pokud je k dispozici místo v RS (strukturální hazardy) a jsou splněny kontrolní závislosti, pak je instrukce s dostupnými hodnotami operandů zaslána do RS provádí se probíhá vlastní výpočet nad operandy (EX) podmíněno dostupností všech zdrojových operandů, pokud dostupné nejsou vyčkává se a provádí se kontrola CDB ukládá se výsledek dokončení výpočtu (WB) výsledek je zaslán na CDB (tím je předán všem čekajícím položkám v RSs současně), použité místo v RS je uvolněno
 a jsou splněny kontrolní závislosti, pak je instrukce s dostupnými hodnotami operandů zaslána do RS provádí se probíhá vlastní výpočet nad operandy")
9 Tomasulo Algoritmus
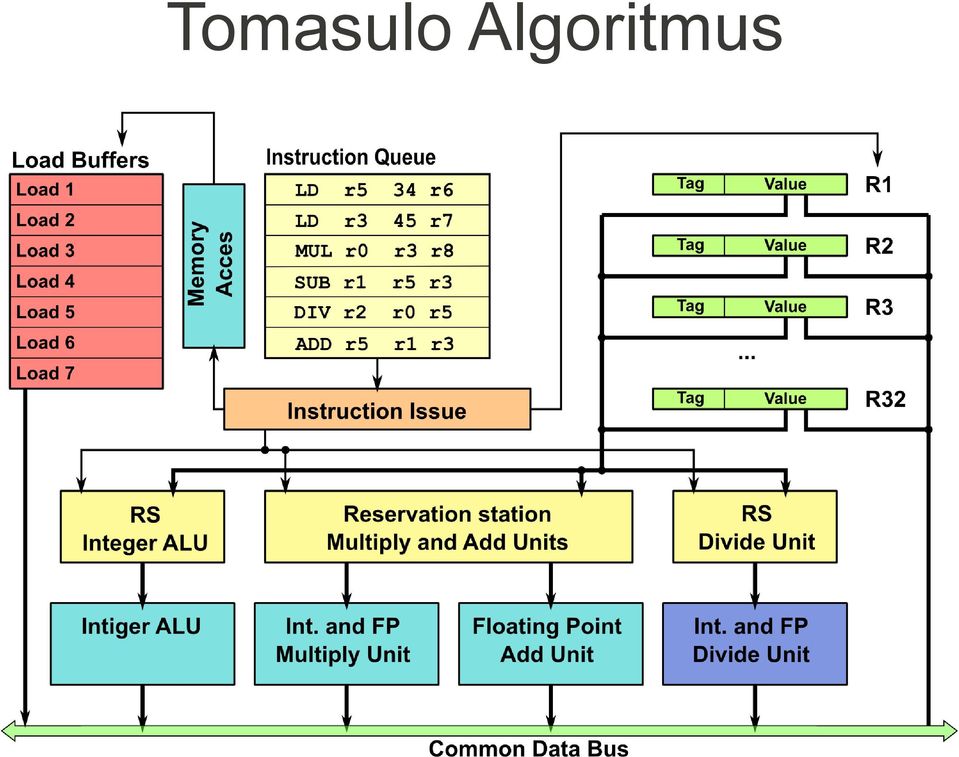
10 Tomasulo Algoritmus Vydávání instrukce instrukce jsou vydávány v pořadí vždy jsou stanoveny zdroje operandů a to buď registry nebo odkazy na RS, které se o výsledek produkující instrukce starají výsledek je doprovázen hodnotou tagu RS, která instrukci k výpočtu předala. Zápis výsledků instrukce budou pravděpodobně dokončovány mimo pořadí jejich výsledek je rozšiřován pomocí CDB spolu s výsledkem je zasílána informace o RS (tag), která se o instrukci starala RS a registry musí monitorovat CDB, na základě shody tagu aktualizovat hodnoty operandů instrukcí po aktualizaci hodnot se kompletní instrukce předají z RS funkční jednotce
, která se o instrukci starala RS a registry musí monitorovat CDB, na základě shody tagu aktualizovat hodnoty operandů instrukcí po aktualizaci hodnot se")

11 Rezervační stanice Rezervační stanice může být v procesoru zastoupena jen jednou jako společná pro všechny funkční jednoty několikrát s tím, že některé funkční jednotky RS sdílejí samostatně pro každou funkční jednotku Obsah RS je závislý na tom, zda obsahuje hodnoty operandů instrukcí nebo pouze ukazatele na zdrojové registry Op. - operační kód instrukce Vj, Vk hodnoty zdrojových operandů (případně ukazatelé na zdrojové registry) Qj, Qk ukazatele na RS,která se stará o instrukci, jenž má vypočíst požadovanou hodnotu (pokud je nastaveno na 0 pak je hodnota k dispozici) Busy Indikuje platnost pozice v RS (zpracovávání instrukce ještě nebylo dokončeno)
 Qj, Qk ukazatele na RS,která se stará o instrukci, jenž má")
12 Tomasulo Algoritmus Stav instrukcí Instrukce j k Ld r5 34 r6 Ld r3 45 r7 Mul r0 r3 r8 Sub r1 r5 r3 Div r2 r0 r5 Add r5 r1 r3 Rezervační stanice Dokon- Zápis Vydaná čeno výsled. Tok instrukcí Taktů na FU FU Busy Op. Vj Vk Qj Qk Počet taktů k dokončení instrukce Záznamy v rezervačních stanicích Časování událostí Přístup do paměti Load1 Load2 Load3 Registry r0 r1 r2 r3 r4 r5 r6 r7 r8 Busy Address Jednotky pro práci s pamětí Tag Hodnota

13 Tomasulo Algoritmus Stav instrukcí Instrukce j k Ld r5 34 r6 Ld r3 45 r7 Mul r0 r3 r8 Sub r1 r5 r3 Div r2 r0 r5 Add r5 r1 r3 Rezervační stanice Dokon- Zápis Vydaná čeno výsled. Taktů na FU FU Busy Op. Vj Vk Qj Qk 1 Přístup do paměti Busy Address Load1 Yes 34 + r6 Load2 Load3 Registry r0 r1 r2 r3 r4 r5 r6 r7 r8 Tag Hodnota Load1 Clock 1

14 Tomasulo Algoritmus Stav instrukcí Instrukce j k Ld r5 34 r6 Ld r3 45 r7 Mul r0 r3 r8 Sub r1 r5 r3 Div r2 r0 r5 Add r5 r1 r3 Rezervační stanice Dokon- Zápis Vydaná čeno výsled. Taktů na FU FU Busy Op. Vj Vk Qj Qk 1 2 Přístup do paměti Busy Address Load1 Yes 34 + r6 Load2 Yes 45 + r7 Load3 Registry r0 r1 r2 r3 r4 r5 r6 r7 r8 Tag Hodnota Load2 Load1 Clock 2

15 Tomasulo Algoritmus Stav instrukcí Instrukce j k Ld r5 34 r6 Ld r3 45 r7 Mul r0 r3 r8 Sub r1 r5 r3 Div r2 r0 r5 Add r5 r1 r3 Rezervační stanice Dokon- Zápis Vydaná čeno výsled. Taktů na FU FU Busy Op. Vj Vk Qj Qk mul1 yes Mul R(r8) Load2 Přístup do paměti Busy Address Load1 Yes 34 + r6 Load2 Yes 45 + r7 Load3 Registry r0 r1 r2 r3 r4 r5 r6 r7 r8 Tag Hodnota mul1 Load2 Load1 Clock 3
 Load2 Přístup do paměti Busy Address Load1 Yes 34 + r6")
16 Tomasulo Algoritmus Stav instrukcí Instrukce j k Ld r5 34 r6 Ld r3 45 r7 Mul r0 r3 r8 Sub r1 r5 r3 Div r2 r0 r5 Add r5 r1 r3 Rezervační stanice Dokon- Zápis Vydaná čeno výsled Taktů na FU FU Busy Op. Vj Vk Qj Qk mul1 yes Mul R(r8) Load2 add1 yes Sub M(L1) Load2 Přístup do paměti Busy Address Load1 Load2 Yes 45 + r7 Load3 Registry r0 r1 r2 r3 r4 r5 r6 r7 r8 Tag Hodnota mul1 add1 Load2 Clock 4 M(L1)
 Load2 add1 yes Sub M(L1) Load2 Přístup do paměti Busy Address Load1")
17 Tomasulo Algoritmus Stav instrukcí Instrukce j k Ld r5 34 r6 Ld r3 45 r7 Mul r0 r3 r8 Sub r1 r5 r3 Div r2 r0 r5 Add r5 r1 r3 Rezervační stanice Dokon- Zápis Vydaná čeno výsled Taktů na FU FU Busy Op. Vj Vk Qj Qk 10 mul1 yes Mul M(L2) R(r8) 2 add1 yes Sub M(L1) M(L2) div1 yes Div M(L1) mul1 Přístup do paměti Load1 Load2 Load3 Registry r0 r1 r2 r3 r4 r5 r6 r7 r8 Busy Address Tag Hodnota mul1 add1 div1 Clock 5 M(L2) M(L1)
")
18 Tomasulo Algoritmus Stav instrukcí Instrukce j k Ld r5 34 r6 Ld r3 45 r7 Mul r0 r3 r8 Sub r1 r5 r3 Div r2 r0 r5 Add r5 r1 r3 Rezervační stanice Dokon- Zápis Vydaná čeno výsled Taktů na FU FU Busy Op. Vj Vk Qj Qk 9 mul1 yes Mul M(L2) R(r8) 1 add1 yes Sub M(L1) M(L2) div1 yes Div M(L1) mul1 add2 yes Add M(L2) add1 Přístup do paměti Load1 Load2 Load3 Registry r0 r1 r2 r3 r4 r5 r6 r7 r8 Busy Address Tag Hodnota mul1 add1 div1 add2 Clock 6 M(L2)

19 Tomasulo Algoritmus Stav instrukcí Instrukce j k Ld r5 34 r6 Ld r3 45 r7 Mul r0 r3 r8 Sub r1 r5 r3 Div r2 r0 r5 Add r5 r1 r3 Rezervační stanice Dokon- Zápis Vydaná čeno výsled Taktů na FU FU Busy Op. Vj Vk Qj Qk 8 mul1 yes Mul M(L2) R(r8) 0 add1 yes Sub M(L1) M(L2) div1 yes Div M(L1) mul1 add2 yes Add M(L2) add1 Přístup do paměti Load1 Load2 Load3 Registry r0 r1 r2 r3 r4 r5 r6 r7 r8 Busy Address Tag Hodnota mul1 add1 div1 add2 Clock 7 M(L2)

20 Tomasulo Algoritmus Stav instrukcí Instrukce j k Ld r5 34 r6 Ld r3 45 r7 Mul r0 r3 r8 Sub r1 r5 r3 Div r2 r0 r5 Add r5 r1 r3 Rezervační stanice Dokon- Zápis Vydaná čeno výsled Taktů na FU FU Busy Op. Vj Vk Qj Qk 7 mul1 yes Mul M(L2) R(r8) div1 yes Div M(L1) mul1 2 add2 yes Add sub M(L2) Přístup do paměti Load1 Load2 Load3 Registry r0 r1 r2 r3 r4 r5 r6 r7 r8 Busy Address Tag Hodnota mul1 div1 add2 Clock 8 sub M(L2)
 R(r8) div1 yes Div M(L1) mul1 2 add2 yes Add sub M(L2) Přístup do paměti")
21 Tomasulo Algoritmus Stav instrukcí Instrukce j k Ld r5 34 r6 Ld r3 45 r7 Mul r0 r3 r8 Sub r1 r5 r3 Div r2 r0 r5 Add r5 r1 r3 Rezervační stanice Dokon- Zápis Vydaná čeno výsled Taktů na FU FU Busy Op. Vj Vk Qj Qk 6 mul1 yes Mul M(L2) R(r8) div1 yes Div M(L1) mul1 1 add2 yes Add sub M(L2) Přístup do paměti Load1 Load2 Load3 Registry r0 r1 r2 r3 r4 r5 r6 r7 r8 Busy Address Tag Hodnota mul1 div1 add2 Clock 9 sub M(L2)
22 Tomasulo Algoritmus Stav instrukcí Instrukce j k Ld r5 34 r6 Ld r3 45 r7 Mul r0 r3 r8 Sub r1 r5 r3 Div r2 r0 r5 Add r5 r1 r3 Rezervační stanice Dokon- Zápis Vydaná čeno výsled Taktů na FU FU Busy Op. Vj Vk Qj Qk 5 mul1 yes Mul M(L2) R(r8) div1 yes Div M(L1) mul1 0 add2 yes Add sub M(L2) Přístup do paměti Load1 Load2 Load3 Registry r0 r1 r2 r3 r4 r5 r6 r7 r8 Busy Address Tag Hodnota mul1 div1 add2 Clock 10 sub M(L2)
23 Tomasulo Algoritmus Stav instrukcí Instrukce j k Ld r5 34 r6 Ld r3 45 r7 Mul r0 r3 r8 Sub r1 r5 r3 Div r2 r0 r5 Add r5 r1 r3 Rezervační stanice Dokon- Zápis Vydaná čeno výsled Taktů na FU FU Busy Op. Vj Vk Qj Qk 4 mul1 yes Mul M(L2) R(r8) div1 yes Div M(L1) mul1 Přístup do paměti Load1 Load2 Load3 Registry r0 r1 r2 r3 r4 r5 r6 r7 r8 Busy Address Tag Hodnota mul1 div1 Clock 11 sub M(L2) add
24 Tomasulo Algoritmus Stav instrukcí Instrukce j k Ld r5 34 r6 Ld r3 45 r7 Mul r0 r3 r8 Sub r1 r5 r3 Div r2 r0 r5 Add r5 r1 r3 Rezervační stanice Dokon- Zápis Vydaná čeno výsled Taktů na FU FU Busy Op. Vj Vk Qj Qk 3 mul1 yes Mul M(L2) R(r8) div1 yes Div M(L1) mul1 Přístup do paměti Load1 Load2 Load3 Registry r0 r1 r2 r3 r4 r5 r6 r7 r8 Busy Address Tag Hodnota mul1 div1 Clock 12 sub M(L2) add
25 Tomasulo Algoritmus Stav instrukcí Instrukce j k Ld r5 34 r6 Ld r3 45 r7 Mul r0 r3 r8 Sub r1 r5 r3 Div r2 r0 r5 Add r5 r1 r3 Rezervační stanice Dokon- Zápis Vydaná čeno výsled Taktů na FU FU Busy Op. Vj Vk Qj Qk 2 mul1 yes Mul M(L2) R(r8) div1 yes Div M(L1) mul1 Přístup do paměti Load1 Load2 Load3 Registry r0 r1 r2 r3 r4 r5 r6 r7 r8 Busy Address Tag Hodnota mul1 div1 Clock 13 sub M(L2) add
26 Tomasulo Algoritmus Stav instrukcí Instrukce j k Ld r5 34 r6 Ld r3 45 r7 Mul r0 r3 r8 Sub r1 r5 r3 Div r2 r0 r5 Add r5 r1 r3 Rezervační stanice Dokon- Zápis Vydaná čeno výsled Taktů na FU FU Busy Op. Vj Vk Qj Qk 1 mul1 yes Mul M(L2) R(r8) div1 yes Div M(L1) mul1 Přístup do paměti Load1 Load2 Load3 Registry r0 r1 r2 r3 r4 r5 r6 r7 r8 Busy Address Tag Hodnota mul1 div1 Clock 14 sub M(L2) add
27 Tomasulo Algoritmus Stav instrukcí Instrukce j k Ld r5 34 r6 Ld r3 45 r7 Mul r0 r3 r8 Sub r1 r5 r3 Div r2 r0 r5 Add r5 r1 r3 Rezervační stanice Dokon- Zápis Vydaná čeno výsled Taktů na FU FU Busy Op. Vj Vk Qj Qk 0 mul1 yes Mul M(L2) R(r8) div1 yes Div M(L1) mul1 Přístup do paměti Load1 Load2 Load3 Registry r0 r1 r2 r3 r4 r5 r6 r7 r8 Busy Address Tag Hodnota mul1 div1 Clock 15 sub M(L2) add
28 Tomasulo Algoritmus Stav instrukcí Instrukce j k Ld r5 34 r6 Ld r3 45 r7 Mul r0 r3 r8 Sub r1 r5 r3 Div r2 r0 r5 Add r5 r1 r3 Rezervační stanice Dokon- Zápis Vydaná čeno výsled Taktů na FU FU Busy Op. Vj Vk Qj Qk 40 div1 yes Div mul M(L1) Přístup do paměti Load1 Load2 Load3 Registry r0 r1 r2 r3 r4 r5 r6 r7 r8 Busy Address Tag Hodnota div1 Clock 16 mul sub M(L2) add
29 Tomasulo Algoritmus Stav instrukcí Instrukce j k Ld r5 34 r6 Ld r3 45 r7 Mul r0 r3 r8 Sub r1 r5 r3 Div r2 r0 r5 Add r5 r1 r3 Rezervační stanice Dokon- Zápis Vydaná čeno výsled Taktů na FU FU Busy Op. Vj Vk Qj Qk 1 div1 yes Div mul M(L1) Přístup do paměti Load1 Load2 Load3 Registry r0 r1 r2 r3 r4 r5 r6 r7 r8 Busy Address Tag Hodnota div1 Clock 55 mul sub M(L2) add
30 Tomasulo Algoritmus Stav instrukcí Instrukce j k Ld r5 34 r6 Ld r3 45 r7 Mul r0 r3 r8 Sub r1 r5 r3 Div r2 r0 r5 Add r5 r1 r3 Rezervační stanice Dokon- Zápis Vydaná čeno výsled Taktů na FU FU Busy Op. Vj Vk Qj Qk 0 div1 yes Div mul M(L1) Přístup do paměti Load1 Load2 Load3 Registry r0 r1 r2 r3 r4 r5 r6 r7 r8 Busy Address Tag Hodnota div1 Clock 56 mul sub M(L2) add
31 Tomasulo Algoritmus Stav instrukcí Instrukce j k Ld r5 34 r6 Ld r3 45 r7 Mul r0 r3 r8 Sub r1 r5 r3 Div r2 r0 r5 Add r5 r1 r3 Rezervační stanice Dokon- Zápis Vydaná čeno výsled. Taktů na FU FU Busy Op. Vj Vk Qj Qk Přístup do paměti Load1 Load2 Load3 Registry r0 r1 r2 r3 r4 r5 r6 r7 r8 Busy Clock 57 Address Tag Hodnota mul sub div M(L2) add
32 Tomasulo alg. - výhody Distribuovaná logika pro detekci a řešení hazardních stavů Distribuovanost v RS a CDB Hromadná aktualizace (dodání hodnoty) operandů všem instrukcím, které na něj čekají pomocí CDB Eliminace pozastavení linky z důvodu WAW a WAR Přejmenovávání registrů v RS Data nemusí vždy procházet cílovým registrem Použití CDB k distribuci výsledků (do registru je vždy uložena v data flow poslední hodnota správný výsledek) Automatické rozmotávání smyček Tomasulo dynamicky za běhu vytváří a sleduje plán datových závislostí. Překryv a vykonávání instrukcí mimo pořadí z rozdílných iterací smyček je řešen s pomocí přejmenovávání registrů a sledování toku dat mezi iteracemi, tak aby žádný z výsledků neporušil datový tok jiné iterace.
33 Tomasulo alg. - nevýhody Složitost a cena distribuovaná logika vykonávání a nároky na zpoždění RS musí být pro CDB plně asociativní (rychlá aktualizace výsledků) Výkon je kriticky ovlivňován šířkou CDB CDB obsluhuje všechny FU, tvoří jedinou cestu jak předat výsledek Počet CDB (šířka) limituje počat FU, které mohou současně předávat výsledek při paralelním dokončení výpočtu Více CDB přináší složitější logiku pří výběru jedné pro zápis a komplikují asociativní část používanou při aktualizaci Nepřesná přerušení (non-precise interrupts) Při přerušení provádění programu není jasné pořadí instrukcí, které té, jenž přerušení vyvolala, předcházely nebo byly počítány mimo pořadí. Bude probíráno později
34 Tomasulo Algoritmus - Smyčky Stav instrukcí Instrukce j k L: 1 Ld r0 0 r1 1 Mul r4 r0 r2 1 Sd r4 0 r1 Sub r1 r1 8 Bne r1 r2 L: 2 Ld r0 Iterace 0 r1 smyčky 2 Mul r4 r0 r2 2 Sd r4 0 r1 Rezervační stanice Dokon- Zápis Vydaná čeno výsled. Tok instrukcí Taktů na FU FU Busy Op. Vj Vk Qj Qk Počet taktů k dokončení instrukce Záznamy v rezervačních stanicích Časování událostí Přístup do paměti Load1 Load2 Load3 Store1 Store2 Store3 Registry Busy Address Fu Jednotky pro práci s pamětí r0 r1 r2 r3 r4 r5 r6 r7 r8 Tag Hodnota
35 Tomasulo Algoritmus - Smyčky Stav instrukcí Instrukce j k L: 1 Ld r0 0 r1 1 Mul r4 r0 r2 1 Sd r4 0 r1 Sub r1 r1 8 Bne r1 r2 L: 2 Ld r0 0 r1 2 Mul r4 r0 r2 2 Sd r4 0 r1 Rezervační stanice Dokon- Zápis Vydaná čeno výsled. Taktů na FU FU Busy Op. Vj Vk Qj Qk 1 Přístup do paměti Busy Address Fu Load1 Yes 80 Load2 Load3 Store1 Store2 Store3 Registry r0 r1 r2 r3 r4 r5 r6 r7 r8 Tag Hodnota load1 Clock 1
36 Tomasulo Algoritmus - Smyčky Stav instrukcí Instrukce j k L: 1 Ld r0 0 r1 1 Mul r4 r0 r2 1 Sd r4 0 r1 Sub r1 r1 8 Bne r1 r6 L: 2 Ld r0 0 r1 2 Mul r4 r0 r2 2 Sd r4 0 r1 Rezervační stanice Dokon- Zápis Vydaná čeno výsled. 1 2 Taktů na FU FU Busy Op. Vj Vk Qj Qk mul1 yes Mul R(r2) load1 Přístup do paměti Registry r0 r1 r2 r3 r4 r5 r6 r7 r8 Tag Hodnota load1 mul1 Clock 2 Busy Address Fu Load1 Yes 80 Load2 Load3 Store1 Store2 Store3
37 Tomasulo Algoritmus - Smyčky Stav instrukcí Instrukce j k L: 1 Ld r0 0 r1 1 Mul r4 r0 r2 1 Sd r4 0 r1 Sub r1 r1 8 Bne r1 r6 L: 2 Ld r0 0 r1 2 Mul r4 r0 r2 2 Sd r4 0 r1 Rezervační stanice Dokon- Zápis Vydaná čeno výsled Taktů na FU FU Busy Op. Vj Vk Qj Qk mul1 yes Mul R(r2) load1 Přístup do paměti Registry r0 r1 r2 r3 r4 r5 r6 r7 r8 Tag Hodnota load1 mul1 Clock 3 Busy Address Fu Load1 Yes 80 Load2 Load3 Store1 Yes 80 mul1 Store2 Store3
38 Tomasulo Algoritmus - Smyčky Stav instrukcí Instrukce j k L: 1 Ld r0 0 r1 1 Mul r4 r0 r2 1 Sd r4 0 r1 Sub r1 r1 8 Bne r1 r6 L: 2 Ld r0 0 r1 2 Mul r4 r0 r2 2 Sd r4 0 r1 Rezervační stanice Dokon- Zápis Vydaná čeno výsled. Taktů na FU FU Busy Op. Vj Vk Qj Qk mul1 yes Mul R(r2) load1 1 sub1 yes Sub R(r1) # Přístup do paměti Registry r0 r1 r2 r3 r4 r5 r6 r7 r8 Tag Hodnota load1 sub1 mul1 Clock 4 Busy Address Fu Load1 Yes 80 Load2 Load3 Store1 Yes 80 mul1 Store2 Store3
39 Tomasulo Algoritmus - Smyčky Stav instrukcí Instrukce j k L: 1 Ld r0 0 r1 1 Mul r4 r0 r2 1 Sd r4 0 r1 Sub r1 r1 8 Bne r1 r6 L: 2 Ld r0 0 r1 2 Mul r4 r0 r2 2 Sd r4 0 r1 Rezervační stanice Dokon- Zápis Vydaná čeno výsled Taktů na FU FU Busy Op. Vj Vk Qj Qk mul1 yes Mul R(r2) load1 0 sub1 yes Sub R(r1) #8 bne1 yes Bne R(r6) sub1 Přístup do paměti Registry r0 r1 r2 r3 r4 r5 r6 r7 r8 Tag Hodnota load1 sub1 mul1 Clock 5 Busy Address Fu Load1 Yes 80 Load2 Load3 Store1 Yes 80 mul1 Store2 Store3
40 Tomasulo Algoritmus - Smyčky Stav instrukcí Instrukce j k L: 1 Ld r0 0 r1 1 Mul r4 r0 r2 1 Sd r4 0 r1 Sub r1 r1 8 Bne r1 r6 L: 2 Ld r0 0 r1 2 Mul r4 r0 r2 2 Sd r4 0 r1 Rezervační stanice Dokon- Zápis Vydaná čeno výsled Taktů na FU FU Busy Op. Vj Vk Qj Qk mul1 yes Mul R(r2) load1 0 bne1 yes Bne sub1 R(r6) Přístup do paměti Registry r0 r1 r2 r3 r4 r5 r6 r7 r8 Tag Hodnota load1 mul1 Clock 6 Busy Address Fu Load1 Yes 80 Load2 Load3 Store1 Yes 80 mul1 Store2 Store3 sub1
41 Tomasulo Algoritmus - Smyčky Stav instrukcí Instrukce j k L: 1 Ld r0 0 r1 1 Mul r4 r0 r2 1 Sd r4 0 r1 Sub r1 r1 8 Bne r1 r6 L: 2 Ld r0 0 r1 2 Mul r4 r0 r2 2 Sd r4 0 r1 Rezervační stanice Dokon- Zápis Vydaná čeno výsled Taktů na FU FU Busy Op. Vj Vk Qj Qk mul1 yes Mul R(r2) load1 Přístup do paměti Registry r0 r1 r2 r3 r4 r5 r6 r7 r8 Tag Hodnota load2 mul1 Clock 7 Busy Address Fu Load1 Yes 80 Load2 Yes 72 Load3 Store1 Yes 80 mul1 Store2 Store3 sub1
42 Tomasulo Algoritmus - Smyčky Stav instrukcí Instrukce j k L: 1 Ld r0 0 r1 1 Mul r4 r0 r2 1 Sd r4 0 r1 Sub r1 r1 8 Bne r1 r6 L: 2 Ld r0 0 r1 2 Mul r4 r0 r2 2 Sd r4 0 r1 Rezervační stanice Dokon- Zápis Vydaná čeno výsled Taktů na FU FU Busy Op. Vj Vk Qj Qk mul1 yes Mul R(r2) load1 mul2 yes Mul R(r2) load2 Přístup do paměti Registry r0 r1 r2 r3 r4 r5 r6 r7 r8 Tag Hodnota load2 mul2 Clock 8 Busy Address Fu Load1 Yes 80 Load2 Yes 72 Load3 Store1 Yes 80 mul1 Store2 Store3 sub1
43 Tomasulo Algoritmus - Smyčky Stav instrukcí Instrukce j k L: 1 Ld r0 0 r1 1 Mul r4 r0 r2 1 Sd r4 0 r1 Sub r1 r1 8 Bne r1 r6 L: 2 Ld r0 0 r1 2 Mul r4 r0 r2 2 Sd r4 0 r1 Rezervační stanice Dokon- Zápis Vydaná čeno výsled Taktů na FU FU Busy Op. Vj Vk Qj Qk mul1 yes Mul R(r2) load1 mul2 yes Mul R(r2) load2 Přístup do paměti Registry r0 r1 r2 r3 r4 r5 r6 r7 r8 Tag Hodnota load2 mul2 Clock 9 Busy Address Fu Load1 Yes 80 Load2 Yes 72 Load3 Store1 Yes 80 mul1 Store2 Yes 72 mul2 Store3 sub1
44 Tomasulo Algoritmus - Smyčky Stav instrukcí Instrukce j k L: 1 Ld r0 0 r1 1 Mul r4 r0 r2 1 Sd r4 0 r1 Sub r1 r1 8 Bne r1 r6 L: 2 Ld r0 0 r1 2 Mul r4 r0 r2 2 Sd r4 0 r1 Rezervační stanice Dokon- Zápis Vydaná čeno výsled Taktů na FU FU Busy Op. Vj Vk Qj Qk 3 mul1 yes Mul load1 R(r2) mul2 yes Mul R(r2) load2 Přístup do paměti Registry r0 r1 r2 r3 r4 r5 r6 r7 r8 Tag Hodnota load2 mul2 Clock 10 Busy Address Fu Load1 Load2 Yes 72 Load3 Store1 Yes 80 mul1 Store2 Yes 72 mul2 Store3 sub1
45 Tomasulo Algoritmus - Smyčky Stav instrukcí Instrukce j k L: 1 Ld r0 0 r1 1 Mul r4 r0 r2 1 Sd r4 0 r1 Sub r1 r1 8 Bne r1 r6 L: 2 Ld r0 0 r1 2 Mul r4 r0 r2 2 Sd r4 0 r1 Rezervační stanice Dokon- Zápis Vydaná čeno výsled Taktů na FU FU Busy Op. Vj Vk Qj Qk 2 mul1 yes Mul load1 R(r2) 3 mul2 yes Mul load2 R(r2) Přístup do paměti Registry r0 r1 r2 r3 r4 r5 r6 r7 r8 Tag Hodnota mul2 Clock 11 Busy Address Fu Load1 Load2 Load3 Store1 Yes 80 mul1 Store2 Yes 72 mul2 Store3 load2 sub1
46 Tomasulo Algoritmus - Smyčky Stav instrukcí Instrukce j k L: 1 Ld r0 0 r1 1 Mul r4 r0 r2 1 Sd r4 0 r1 Sub r1 r1 8 Bne r1 r6 L: 2 Ld r0 0 r1 2 Mul r4 r0 r2 2 Sd r4 0 r1 Rezervační stanice Dokon- Zápis Vydaná čeno výsled Taktů na FU FU Busy Op. Vj Vk Qj Qk 1 mul1 yes Mul load1 R(r2) 2 mul2 yes Mul load2 R(r2) Přístup do paměti Registry r0 r1 r2 r3 r4 r5 r6 r7 r8 Tag Hodnota mul2 Clock 12 Busy Address Fu Load1 Load2 Load3 Store1 Yes 80 mul1 Store2 Yes 72 mul2 Store3 load2 sub1
47 Tomasulo Algoritmus - Smyčky Stav instrukcí Instrukce j k L: 1 Ld r0 0 r1 1 Mul r4 r0 r2 1 Sd r4 0 r1 Sub r1 r1 8 Bne r1 r6 L: 2 Ld r0 0 r1 2 Mul r4 r0 r2 2 Sd r4 0 r1 Rezervační stanice Dokon- Zápis Vydaná čeno výsled Taktů na FU FU Busy Op. Vj Vk Qj Qk 0 mul1 yes Mul load1 R(r2) 1 mul2 yes Mul load2 R(r2) Přístup do paměti Registry r0 r1 r2 r3 r4 r5 r6 r7 r8 Tag Hodnota mul2 Clock 13 Busy Address Fu Load1 Load2 Load3 Store1 Yes 80 mul1 Store2 Yes 72 mul2 Store3 load2 sub1
48 Tomasulo Algoritmus - Smyčky Stav instrukcí Instrukce j k L: 1 Ld r0 0 r1 1 Mul r4 r0 r2 1 Sd r4 0 r1 Sub r1 r1 8 Bne r1 r6 L: 2 Ld r0 0 r1 2 Mul r4 r0 r2 2 Sd r4 0 r1 Rezervační stanice Dokon- Zápis Vydaná čeno výsled Taktů na FU FU Busy Op. Vj Vk Qj Qk 0 mul2 yes Mul load2 R(r2) Přístup do paměti Registry r0 r1 r2 r3 r4 r5 r6 r7 r8 Tag Hodnota mul2 Clock 14 Busy Address Fu Load1 Load2 Load3 Store1 Yes 80 [mul1] Store2 Yes 72 mul2 Store3 load2 sub1
49 Tomasulo Algoritmus - Smyčky Stav instrukcí Instrukce j k L: 1 Ld r0 0 r1 1 Mul r4 r0 r2 1 Sd r4 0 r1 Sub r1 r1 8 Bne r1 r6 L: 2 Ld r0 0 r1 2 Mul r4 r0 r2 2 Sd r4 0 r1 Rezervační stanice Dokon- Zápis Vydaná čeno výsled. Taktů na FU FU Busy Op. Vj Vk Qj Qk Přístup do paměti Registry r0 r1 r2 r3 r4 r5 r6 r7 r8 Clock 15 Busy Address Fu Load1 Load2 Load3 Store1 Yes 80 [mul1] Store2 Yes 72 [mul2] Store3 Tag Hodnota load2 sub1 mul2
50 Tomasulo Algoritmus - Smyčky Stav instrukcí Instrukce j k L: 1 Ld r0 0 r1 1 Mul r4 r0 r2 1 Sd r4 0 r1 Sub r1 r1 8 Bne r1 r6 L: 2 Ld r0 0 r1 2 Mul r4 r0 r2 2 Sd r4 0 r1 Rezervační stanice Dokon- Zápis Vydaná čeno výsled. Taktů na FU FU Busy Op. Vj Vk Qj Qk Přístup do paměti Registry r0 r1 r2 r3 r4 r5 r6 r7 r8 Clock 16 Busy Address Fu Load1 Load2 Load3 Store1 Yes 80 [mul1] Store2 Yes 72 [mul2] Store3 Tag Hodnota load2 sub1 mul2
51 Tomasulo Algoritmus - Smyčky Stav instrukcí Instrukce j k L: 1 Ld r0 0 r1 1 Mul r4 r0 r2 1 Sd r4 0 r1 Sub r1 r1 8 Bne r1 r6 L: 2 Ld r0 0 r1 2 Mul r4 r0 r2 2 Sd r4 0 r1 Rezervační stanice Dokon- Zápis Vydaná čeno výsled. Taktů na FU FU Busy Op. Vj Vk Qj Qk Přístup do paměti Registry r0 r1 r2 r3 r4 r5 r6 r7 r8 Clock 17 Busy Address Fu Load1 Load2 Load3 Store1 Store2 Yes 72 [mul2] Store3 Tag Hodnota load2 sub1 mul2
52 Tomasulo Algoritmus - Smyčky Stav instrukcí Instrukce j k L: 1 Ld r0 0 r1 1 Mul r4 r0 r2 1 Sd r4 0 r1 Sub r1 r1 8 Bne r1 r6 L: 2 Ld r0 0 r1 2 Mul r4 r0 r2 2 Sd r4 0 r1 Rezervační stanice Dokon- Zápis Vydaná čeno výsled. Taktů na FU FU Busy Op. Vj Vk Qj Qk Přístup do paměti Load1 Load2 Load3 Store1 Store2 Store3 Registry r0 r1 r2 r3 r4 r5 r6 r7 r8 Clock 18 Busy Address Fu Tag Hodnota load2 sub1 mul2
53 Přesné přerušení Přesné přerušení (precise interrupt) Umožňuje přesné přerušení s tím, že všechny instrukce, které mu předcházely jsou vypočteny a výsledky, které by za ním následovaly, nejsou uloženy Dokončování instrukcí mimo pořadí přesné přerušení komplikuje Implementace dodatečných mechanizmů, které jej umožní (HW podpora) dokončování in-order nebo in-order commit výsledků Přerušení Co může způsobit přerušení Breakpoint (programová přerušení), porušení ochrany paměti, Page fault, požadavky na I/O zařízení, abnormality při aritmetických operacích (dělení 0), použití nedefinované instrukce, selhání HW nebo napájení, Typy přerušení synchronní versus asynchronní, uživatelská versus vynucená, maskovatelná versus nemaskovatelná, přerušení v instrukci versus mezi instrukcemi, přerušení se zotavením versus s ukončením programu
54 Přesné přerušení a spekulace Spekulace Spekulaci lze chápat jako formu hádání provádění instrukcí při běhu programu Dnes je klíčová při řešení větvení programu Spolu s komplexní predikcí větvení dnes hrají klíčovou úlohu při efektivním zpracování instrukcí větvení programu. Pokud dochází ke spekulativnímu vykonávání instrukcí, může dojít k jejich nechtěnému provádění. Vzniká potřeba mít možnost se vrátit (odstranit neplatné výsledky) a navázat na správný průchod programu, tedy jistá forma přerušení. Přesná přerušení jako řešení? Díky přesnému přerušení lze navázat na místo odkud bylo spekulativně provedeno chybné větvení programu.
55 HW podpora pro přesná přerušení Re-order buffer (ROB) Paměť dočasně uchovávající výsledky před jejich uložením do registrů Obvykle pole označující pořadí, cílový registr, hodnotu k uložení, platnost položky, přítomnost výjimky či přerušení, a hodnotu PC Položky jsou vkládány v okamžiku zápisu výsledku instrukce, tedy out-oforder Zápis do registrů je prováděn nespekulativně a in-order Snadné rušení instrukcí neuložením jejich výsledků do registrů Commit fáze vykonávání instrukce Provádí se zápis výsledků z ROB do registrů a to vždy v pořadí vydávání instrukcí (in-order) Pokud dojde k chybné spekulaci či jiné formě přerušení, pak je v pořadí dokončen zápis výsledků všech přerušení předešlých instrukcí. Zbylý obsah je zahozen (graduation).
56 Re-order buffer a Tomasulo algoritmus Vydávání instrukcí Postup vydávání instrukcí se liší pouze v nutnosti alokovat pro každou z nich záznam v ROB záznam obsahuje cílový registr, tag označení zdrojové FU, pořadí záznamů reprezentuje pořadí instrukcí Zápis výsledků Výsledek je pomoci CDB propagován mezi ostatní FU (ROB nemá vliv na out-of-order zpracovávání instrukcí) a aktualizován u záznamu v ROB Často dvojí pohled na sadu registrů. pohled na registry s perspektivy vydávaných instrukcí, který je aktualizován mimo pořadí pohled na registry ze strany ROB resp. commit jednotky, jenž je aktualizován vždy v pořadí
57 Re-order buffer a Tomasulo algoritmus Commit výsledků Z ROB jsou commit jednotkou v pořadí vložení záznamu zpracovávány vypočtené výsledky. V případě chybné spekulace či přerušení jsou nežádoucí výsledky v ROB stornovány a stav registrů z pohledu vydávání obnoven hodnotami z commit pohledu. v případě chybné spekulace se program vydává správnou cestou v případech přerušení vlivem výjimky, zotavení nemusí být možné (záleží na druhu výjimky) rozpracované instrukce (v ostatních FU) musejí být obvykle dopočteny. Není možné je z FU stornovat. Na jejich výsledek vlivem změny provádění programu však nikdo nečeká.

58 Architektura Tomasulo + ROB
59 Složitost ROB řešení Problém vyhledávání aktuálních hodnot ROB může sloužit jako zdroj dalšího paměťového prostoru Vyhledávání musí být extrémně rychlé (úroveň práce s registry) mnohonásobně asociativní, počet cest do ROB by měl být teoreticky roven počtu registrů Rozhodnutí co je pro danou instrukci, která data požaduje, aktuální informace (nepotvrzená hodnota nebo potvrzený stav registrů) Provádění Store instrukcí Provedení zápisu do paměti musí být pozastaveno až do okamžiku potvrzení dané instrukce Load instrukce mířící na neuloženou adresu musí být obslouženy hodnotou z ROB Paralelní vydávání více instrukcí Větší propustnost ROB, vyšší asociativita,...
60 Jak zvýšit počet instrukcí za cyklus? CPI < 1 Cílem je dosáhnout zvýšení průměrného počtu v jednom cyklu dokončených instrukcí na hodnotu větší než jedna. Vektorové procesory a vektorové instrukce multimediální vektorové instrukce jsou dnes zastoupeny na mnoha typech procesorech Superskalární procesory s dynamickým plánováním počet vydávaných instrukcí na cyklus je obvykle v mezích 1 až 8, je proměnný Superskalární procesory s převážně statickým plánováním obvykle fixní počet vydávaných instrukcí (4 až 16), jsou plánovány kompilátorem Intel Architecture-64 (IA-64) Explicitly Parallel Instruction Computer (EPIC)
61 Paralelní vydávání více instrukcí Dynamické řešení přineslo jako první vydávání dvou instrukcí paralelně pro 5-ti stupňovou pipeline instrukce musely být jedna celočíselná a jedna s řádovou čárkou eliminace závislostí až na instrukce čtení a zápisu do paměti (výpočet adres je prováděn na čísti procesoru určené pro celočíselnou aritmetiku) Dopady paralelního vydávání více instrukcí Balíčkování instrukcí v podobě skupin instrukcí, které mohou být vydány v jednom cyklu vydávání může omezit přítomnost strukturních a datových hazardů na dříve vydané instrukce (nemusí být vydána ani jedna instrukce) Náročné vyhledávání nezávislých instrukcí z balíčku Je potřeba provést velké množství komparací (složitost O(n 2 -n)) Přináší limity na rychlost CPU (pomalý clock) Vlivem toho často dělení fáze vydávání instrukcí: 1. stanovení počtu paralelně proveditelných instrukcí, 2. prohledávání na hazardy
62 Důsledky paralelního vydávání Pokud chceme dosáhnout dokončování dvou instrukcí v jednom cyklu, pak musí být v kódu rovnoměrně rozloženy celočíselné a FP instrukce. Paralelní vydávání přináší značnou složitost a HW náročnost Paralelní přístup do instrukční cache Možnost 6-ti přístupů do pole registrů v jednom taktu (4x read, 2x write) Rychlé a účinné rozhodování o možném počtu vydávaných instrukcí se značnou složitostí vzhledem k nutnému počtu srovnání (O(n 2 n)) Nutnost přejmenování až dvou registrů v jednom cyklu pro předcházení WAR a WAW. Větší šířka sběrnic pro zápis výsledků (CDB), častěji se schází požadavky na paralelní zápisy
63 Virtuální registry a ROB Virtuální registry lze chápat jako rozsáhlou kolekci registrů na něž jsou při vydávání instrukce původní přejmenovávány Slouží spolu s procesem přejmenovávání jako náhrada ROB Musejí uchovávat dvojí hodnoty - architekturní a dočasné pohledy (spekulativní vykonávání instrukcí) Jednoznačný proces mapování registrů ve fázi vydávání instrukcí Zjednodušení fáze commit uložení spekulativního dočasného pohledu do architekturního Nutnost dostatečného množství registrové paměti na čipu CPU přináší limity (40 80 registrů navíc) použito např. v procesorech Pentium nebo Alpha
64 Limity instrukčního paralelizmu S čím srovnávat aneb ideální procesor Dopady přítomnosti HW limitů reálných procesorů budou srovnávány s ideálním procesorem, který má vždy dostatek virtuálních registrů pro realizaci přejmenování a tím předcházení WAW a WAR konfliktů (Register Renaming) má dokonalou predikci skoků a větvení programů tím, že se při predikci nikdy nesplete (Branch and Jump Prediction) dovede vždy dokonale analyzovat přístupy do paměti tak, že je vždy zřejmé pořadí provádění operací čtení a zápisu (Memory address alias analysis) přístup do datové a instrukční cache realizuje s zpožděním jednoho cyklu Procesor není reálné zkonstruovat Jakým způsobem bude dopad limitů měřen? Sledování průměrného počtu vydaných instrukcí pro 6 SPEC testů výkonnosti (benchmarks)
65 Ideální procesor výsledky testů Prováděných 6 testů lze rozdělit do dvou skupin 160 Testy gcc, espresso, li zaměřeny na práci v celočíselné aritmetice Testy fpppp, doduc, tomcatv zaměřeny na operace s plovoucí řádovou čárkou Dále uvedené výsledky vždy reprezentují dopad konkrétního omezení s kumulativní aplikací předešlých omezení. Instruction issues per cycle gcc espresso li fpppp doduc tomcatv Uváděná data převzata z knihy: John L. Hennessy & David A. Patterson, Computer Architecture - A Quantitative Approach - 4th Edition SPEC benchmarks
66 Omezení velikosti vydávacího okénka (window size) Patrný dopad velikosti vydávacího okénka 160 S jeho zmenšující se velikostí se srovnává počet nalezených paralelismů přes všechny testy Pro dnešní procesory není jeho velikost přímo rozhodující (ostatní limity mají tvrdší dopad) Dnes velikost 64 až ~250 instrukcí Velikost vydávacího okna také nepřímo ovlivní výpadky cache. Instruction issues per cycle Infinita 2k Při výpadku cache je potřeba držet instrukci ve vydávacím okně 40 Obsazená pozice instrukcí blokovanou čekáním na paměť 20 Dále je předpokládána velikost okna 2000 záznamů s maximálně 64 vydanými instrukcemi 0 gcc espresso li fpppp doduc tomcatv SPEC benchmarks
67 Realistická predikce větvení a skoků Vzhledem k množství instrukcí větvení a skoků přináší další významný dopad jejich predikce nejlepší výsledek přináší kombinovaná predikce tournamentovým prediktorem nejvýznamnější dopad na int testech způsobený množstvím špatně predikovatelných větvení (nedostatek cyklů) Perfect Tournament predictor 2-bit predictor Profile-based ne Pro další výsledky předpokládáme dvouúrovňový tournament prediktor s 8k záznamy 10 0 gcc espresso li fpppp doduc tomcatv
68 Omezení počtu virtuálních registrů Počet virtuálních registrů má drastický dopad především na výpočty se silnou spekulací nebo překryvy prováděných smyček (FP testy) dnešní procesory běžně disponují 128 až 256 registry Infinite 256 int FP 128 int FP 64 int + 64 FP 32 int + 32 FP ne Dále se bude předpokládat přítomnost dvou sad registru (int a FP registry), každá o 256 registrech gcc espresso li fpppp doduc tomcatv
69 Analýza konfliktů při přístupu do paměti Cílem je analyzovat přístupy do paměti a umožnit co nejefektivnější uspořádání load a store instrukcí z hlediska možných paralelismů Perfektní analýza přístupů ke globálním proměnným a na stack dnes dosažitelná s pomocí kompilátoru Další schémata můžou vylučovat konflikty na základě analýzy offsetu a bázového registru Perfect Global-stack perfect Inspection ne 0 gcc espresso li fpppp doduc tomcatv
70 Instrukční paralelizmus na realistickém procesoru Předpoklady pro měření 60 vydání až 64 instrukcí za takt (řádově více než dnešní CPU) tournamentův prediktor s 1k položkami a 16 záznamy pro návratovou predikci téměř perfektní analýza závislostí přístupu do paměti dvě nezávisle sady registru (int a FP) o 64 registrech pro přejmenovávání Uvedený graf reprezentuje potenciální množství vydaných instrukci za takt vzhledem k uvedené velikosti vydávacího okna gcc espresso li fpppp doduc tomcatv Infinite
71 Alternativní přístupy Statické plánování Přesun zodpovědnosti za ILP z HW procesoru na stranu kompilátoru Přináší zjednodušení procesoru a tím jeho potenciálně rychlejší strojový cyklus Použití VLIW instrukcí HW neprování explicitní kontroly hazardů mezi dílčími instrukcemi v VLIW Více prostoru pro registry na čipu procesoru Možnost provádění spekulací na základě celkového chování programu Silně závislé na použité platformě Obtížnější predikce větvení Nárůst velikosti kódu
72 VLIW a problémy první generace Nárůst velikosti kódu Nezvládnuté náročné rozmotávání smyček často vedlo k neefektivnímu kódu (přímočaré vykonávání plně rozmotané smyčky) VLIW instrukce často nevyužívaly všechny jednotky procesoru. Nepoužitá jednotka nemohla být z VLIW instrukce vyřazena (pevná poloha dílčích částí instrukce pro FU) Problém procesoru bez detekce hazardů Zastavení jedné jednotky vlivem závislostí vede k zastavení celého procesoru (ostatní jednotky nemohou pokračovat synchronizace na jedné VLIW instrukci) Řazení instrukcí kompilátorem nezohledňuje délku výpočtu na různých FU Binární kompatibilita Každá verze procesoru vyžaduje vlastní kompilát kódu
73 VLIW a EPIC procesory Více procesorové systémy Multiflow TRACE /500, Cydrome Cydra 5, IBM Yorktown VLIW Computer (výzkumný procesor) Jednočipové procesory Intel iwarp Multimediální jednočipy Trimedia, Chromatic, Micro-Unity, DSP procesory Hybridní architektury Intel/HP EPIC IA-64 (Explicitly Parallel Instruction Computer)
74 Intel/HP EPIC IA-64 Je považováno za VLIW druhé generace Intel Itanium první implementace IA-64 vysoce paralelní deseti stupňová instrukční linka průměrný výkon, nepříliš úspěšný Intel Itanium 2 zaznamenalo 7 vývojových cyklů, končí v roce 2010 na procesoru Itanium 9300 (Tukwila) přejímá odzkoušené technologie z jiných procesorů 2 až 4 jádra na čipu (propoje QPI představeno v Nehalem) 30 funkčních jednotek na každé jádro dvě sady registrů pro int a FP, každá 128 registrů (64/82 bit registry) použití v serverových řešeních
75 IA-64 Itanium 2 Optimalizace provádění kódu v HW Predikce průchodu výpočtu kódem Podpora spekulací, non-faulting čtení Softwarově asistovaná predikce větvení Softwarově asistovaná hierarchická organizace paměti Instrukční skupiny Skupinu instrukcí tvoří nezávislé instrukce, které mohou být prováděny paralelně za předpokladu volných HW prostředků Skupiny jsou tvořeny obvykle několika slovy, která jsou 128 bitů dlouhá. Nepoužití jednotky nemusí být zastoupeny úspora místa.
76 IA-64 Itanium 2
77 Vektorové procesory Cílem návrhu vektorových procesorů je zefektivnit provádění výpočtů nad lineárními poli čísel původně provádění ve smyčce vektorová instrukce zastoupí smyčku (cyklus) Vlastnosti vektorových instrukcí nezávislost dílčích výsledků zvýšení rychlosti provádění, lepší zřetězení přístup do paměti se známým vzorem (známá vzdálenost mezi jednotlivými prvky) méně výpadků cache, snadnější predikce přístupu a příprava dat, datová cache není potřeba redukuje se počet větvení (tím také problém s jeho predikci) v instrukční lince jedna vektorová instrukce vykoná práci mnoho instrukcí nevektorového cyklu vydávání méně instrukcí (menší pravděpodobnost výpadku cache)
78 Vektorové procesory Vektorové operace nejsou prováděny v jednom cyklu po inicializaci výpočtu následuje N cyklů pro získání výsledků N prvkového vektoru Typy vektorových procesorů memory-memory vector processors operace jsou prováděny přímo nad pamětí (bez použití registrů) vectore-register processors vektorové operace jsou prováděny nad vektorovými registry (kromě load and store)
79 Komponenty vektorových procesorů Vektorová část vektorové registry pevné délky (vector registers VR) typická délka bitových prvků, 8-32 registrů limitován počet portů pro čtení a zápis (2x r + 1x w) Vektorové FU FU pro provádění add, mul, reciprocal (1/x) operací FU pro práci s pamětí (Load-Store Units LSU) všechny jednotky jsou zřetězené Skalární část skalární registry FU pro celočíselné operace a operace v plovoucí řádové čárce
80 Přístupy do paměti Využívá se vektorových instrukcí Load a Store slouží k přesunu bloku dat mezi pamětí a vektorovým registrem Vzhledem k adresování jednotlivých prvků rozlišujeme tři přístupy prvky jsou v paměti uloženy jeden za druhým (Unit stride) nejrychlejší možný přístup sekvenční čtení bloků paměti mezi prvky je vždy konstantní úsek paměti, který s čtenými daty nesouvisí (non-unit constant stride) práce se sloupci matice (mezi prvky vektoru jsou vždy data ostatních sloupců) indexovaný přístup nepřímý přístup k vektoru používá se při práci s řídkými poli vektorová komprese a expanze
81 Jak na dlouhé vektory Použití registru délky vektoru (vector-length register VLR) Řídí všechny vektorové operace Hodnota slouží k omezení délky vektoru na jeho skutečnou délku Délka vektoru často nemůže být stanovena při překladu programu - dynamická velikost vektoru. Dlouhé vektory Výpočet je prováděn ve více krocích (vždy takový úsek, aby jej bylo možno do vektorového registru uložit) Postupné provádění nad délkami VR ve smyčce low = 0 VL = n mod MVL for ( j=0; j<=(n/mvl); j++ ){ for (i=low, i<low+vl) { Y(i) = X(i) + Y(i) } low = low + VL VL = MVL } obalovací smyčka s minimálním počtem opakování efektivnější než práce bez vektorové instrukce
82 Výběr prvků a vektorová maska Maska vektoru má stejný počet prvků jako vektorové registry definuje pro které prvky se provádí vektorová operace (dovoluje ponechat prvek cílového vektoru nezměněn) obvykle pro každou pozici vektoru uložen 1bit (0 neaktualizuj, 1 aktualizuj) instrukce, která provádí srovnání prvků a aktualizaci masky podle zadané podmínky Použití vektorové masky využívá se v případech, kdy vektorově zpracovávána smyčka obsahuje podmínku neprovádění aktualizace neznamená ušetření cyklu (operace se provede, výsledek se neuloží) for (i=0; i<n; i++) { if (Y(i) < m) { Y(i) = a * Y(i) } }

83 Řetězení vektorových operací Vektorové instrukce je možno provádět bez překryvu dokončení jedné operace předá celý modifikovaný vektor ke zpracovávání další instrukci s překryvem instrukce jsou vzájemně překryty s tím, že nedochází k předání celého vektoru ale již dílčích výsledků
84 Metriky pro srovnávání vektorových procesorů Srovnávání výkonu pro referenční vektory R výkon procesoru pro nekonečně dlouhé vektory idealizovaný vektor nekonečně dlouhý vektor nezohledňuje inicializační čas potřebný při startu výpočtu doprovází se reálnějším srovnáním R n výkonem procesoru pro vektory délky n N 1/2 poloviční velikost vektorů využívá se při sledování dopadu inicializačního času N V délka vektorů, při které je vektorová instrukce již rychlejší než klasická skalární smyčka sleduje výkon vektorových operací jak ve vztahu k inicializačnímu času tak k vlastnímu výkonu vektorové jednotky
85 Vektorové operace pro multimédia Rozšíření instrukčního soubory Intel MMX/SSE nejedná se o vektorové instrukce ve předchozím prezentovaném smyslu podobná rozšíření potkaly instrukční soubor většiny procesorů Cílem je provést požadovanou operaci nad skupinou krátkých operandů a zrychlit tak multimediální operace 128bit registr je dělen na 2x 64bits, 4x 32bits, 8x 16bits, 16x 8bits Provádí se obvykle ve specializované aritmetice právě pro multimediální operace saturovaná aritmetika
86 Závěr Představení Tomasulo algoritmu a princip jeho použití v moderních porocesorech Problematika paralelního vydávání instrukcí Dopady nedokonalostí dnešních procesorů na úroveň ILP Alternativy k dynamickému plánování Vývoj VLIW procesorů Vektorové procesory a princip jejich činnosti
87 Dotazy?
88 Literatura John L. Hennessy, David A. Patterson, Computer Architecture: A Quantitative Approach (4th Edition) Paul H. J. Kelly, Advanced Computer Architecture Lecture notes 332 Andrew S. Tanenbaum, Operating Systems: Design and Implementation 88
Architektury VLIW M. Skrbek a I. Šimeček
 Architektury VLIW M. Skrbek a I. Šimeček xsimecek@fit.cvut.cz Katedra počítačových systémů FIT České vysoké učení technické v Praze Ivan Šimeček, 2011 MI-PAP, LS2010/11, Predn.3 Příprava studijního programu
Architektury VLIW M. Skrbek a I. Šimeček xsimecek@fit.cvut.cz Katedra počítačových systémů FIT České vysoké učení technické v Praze Ivan Šimeček, 2011 MI-PAP, LS2010/11, Predn.3 Příprava studijního programu
Pohled do nitra mikroprocesoru Josef Horálek
 Pohled do nitra mikroprocesoru Josef Horálek Z čeho vycházíme = Vycházíme z Von Neumannovy architektury = Celý počítač se tak skládá z pěti koncepčních bloků: = Operační paměť = Programový řadič = Aritmeticko-logická
Pohled do nitra mikroprocesoru Josef Horálek Z čeho vycházíme = Vycházíme z Von Neumannovy architektury = Celý počítač se tak skládá z pěti koncepčních bloků: = Operační paměť = Programový řadič = Aritmeticko-logická
Paměťový podsystém počítače
 Paměťový podsystém počítače typy pamětových systémů počítače virtuální paměť stránkování segmentace rychlá vyrovnávací paměť 30.1.2013 O. Novák: CIE6 1 Organizace paměťového systému počítače Paměťová hierarchie...
Paměťový podsystém počítače typy pamětových systémů počítače virtuální paměť stránkování segmentace rychlá vyrovnávací paměť 30.1.2013 O. Novák: CIE6 1 Organizace paměťového systému počítače Paměťová hierarchie...
Architektura procesorů PC shrnutí pojmů
 Architektura procesorů PC shrnutí pojmů 1 Co je to superskalární architektura? Minimálně dvě fronty instrukcí. Provádění instrukcí je možné iniciovat současně, instrukce se pak provádějí paralelně. Realizovatelné
Architektura procesorů PC shrnutí pojmů 1 Co je to superskalární architektura? Minimálně dvě fronty instrukcí. Provádění instrukcí je možné iniciovat současně, instrukce se pak provádějí paralelně. Realizovatelné
Princip funkce počítače
 Princip funkce počítače Princip funkce počítače prvotní úlohou počítačů bylo zrychlit provádění matematických výpočtů první počítače kopírovaly obvyklý postup manuálního provádění výpočtů pokyny pro zpracování
Princip funkce počítače Princip funkce počítače prvotní úlohou počítačů bylo zrychlit provádění matematických výpočtů první počítače kopírovaly obvyklý postup manuálního provádění výpočtů pokyny pro zpracování
Procesor Intel Pentium (1) Procesor Intel Pentium (3) Procesor Intel Pentium Pro (1) Procesor Intel Pentium (2)
 Procesor Intel Pentium (3) Procesor Intel Pentium Pro (1) Procesor Intel Pentium (2)") Procesor Intel Pentium (1) 32-bitová vnitřní architektura s 64-bitovou datovou sběrnicí Superskalární procesor: obsahuje více než jednu (dvě) frontu pro zřetězené zpracování instrukcí (značeny u, v) poskytuje
Procesor Intel Pentium (1) 32-bitová vnitřní architektura s 64-bitovou datovou sběrnicí Superskalární procesor: obsahuje více než jednu (dvě) frontu pro zřetězené zpracování instrukcí (značeny u, v) poskytuje
NSWI /2011 ZS. Principy cpypočítačůčů aoperačních systémů ARCHITEKTURA
 Principy cpypočítačůčů aoperačních systémů ARCHITEKTURA Literatura W.Stallings: Computer Organization & Architecture J.L.Hennessy, P.A.Patterson: Patterson: Computer Architecture: a Quantitative Approach
Principy cpypočítačůčů aoperačních systémů ARCHITEKTURA Literatura W.Stallings: Computer Organization & Architecture J.L.Hennessy, P.A.Patterson: Patterson: Computer Architecture: a Quantitative Approach
Představení a vývoj architektur vektorových procesorů
 Představení a vývoj architektur vektorových procesorů Drong Lukáš Dro098 1 Obsah Úvod 3 Historie, současnost 3 Architektura 4 - pipelining 4 - Operace scatter a gather 4 - vektorové registry 4 - Řetězení
Představení a vývoj architektur vektorových procesorů Drong Lukáš Dro098 1 Obsah Úvod 3 Historie, současnost 3 Architektura 4 - pipelining 4 - Operace scatter a gather 4 - vektorové registry 4 - Řetězení
Strojový kód k d a asembler procesoru MIPS SPIM. MIPS - prostředí NMS NMS. 32 ks 32bitových registrů ( adresa registru = 5 bitů).
.") Strojový kód k d a asembler procesoru MIPS Použit ití simulátoru SPIM K.D. - cvičení ÚPA 1 MIPS - prostředí 32 ks 32bitových registrů ( adresa registru = 5 bitů). Registr $0 je zero čte se jako 0x0, zápis
Strojový kód k d a asembler procesoru MIPS Použit ití simulátoru SPIM K.D. - cvičení ÚPA 1 MIPS - prostředí 32 ks 32bitových registrů ( adresa registru = 5 bitů). Registr $0 je zero čte se jako 0x0, zápis
Architektura Intel Atom
 Architektura Intel Atom Štěpán Sojka 5. prosince 2008 1 Úvod Hlavní rysem Atomu je podpora platformy x86, která umožňuje spouštět a běžně používat řadu let vyvíjené aplikace, na které jsou uživatelé zvyklí
Architektura Intel Atom Štěpán Sojka 5. prosince 2008 1 Úvod Hlavní rysem Atomu je podpora platformy x86, která umožňuje spouštět a běžně používat řadu let vyvíjené aplikace, na které jsou uživatelé zvyklí
Architektura Pentia úvod
 Architektura Pentia úvod 1 Co je to superskalární architektura? Minimálně dvě fronty instrukcí. Provádění instrukcí je možné iniciovat současně, instrukce se pak provádějí paralelně. Realizovatelné jak
Architektura Pentia úvod 1 Co je to superskalární architektura? Minimálně dvě fronty instrukcí. Provádění instrukcí je možné iniciovat současně, instrukce se pak provádějí paralelně. Realizovatelné jak
CHARAKTERISTIKA MODERNÍCH PENTIÍ. Flynnova klasifikace paralelních systémů
 Úvod: CHARAKTERISTIKA MODERNÍCH PENTIÍ Flynnova klasifikace paralelních systémů Paralelní systémy lze třídit z hlediska počtu toků instrukcí a počtu toků dat: SI systém s jedním tokem instrukcí (Single
Úvod: CHARAKTERISTIKA MODERNÍCH PENTIÍ Flynnova klasifikace paralelních systémů Paralelní systémy lze třídit z hlediska počtu toků instrukcí a počtu toků dat: SI systém s jedním tokem instrukcí (Single
Činnost CPU. IMTEE Přednáška č. 2. Několik úrovní abstrakce od obvodů CPU: Hodinový cyklus fáze strojový cyklus instrukční cyklus
 Činnost CPU Několik úrovní abstrakce od obvodů CPU: Hodinový cyklus fáze strojový cyklus instrukční cyklus Hodinový cyklus CPU je synchronní obvod nutné hodiny (f CLK ) Instrukční cyklus IF = doba potřebná
Činnost CPU Několik úrovní abstrakce od obvodů CPU: Hodinový cyklus fáze strojový cyklus instrukční cyklus Hodinový cyklus CPU je synchronní obvod nutné hodiny (f CLK ) Instrukční cyklus IF = doba potřebná
Řízení IO přenosů DMA řadičem
 Řízení IO přenosů DMA řadičem Doplňující text pro POT K. D. 2001 DMA řadič Při přímém řízení IO operací procesorem i při použití přerušovacího systému je rychlost přenosu dat mezi IO řadičem a pamětí limitována
Řízení IO přenosů DMA řadičem Doplňující text pro POT K. D. 2001 DMA řadič Při přímém řízení IO operací procesorem i při použití přerušovacího systému je rychlost přenosu dat mezi IO řadičem a pamětí limitována
2.8 Procesory. Střední průmyslová škola strojnická Vsetín. Ing. Martin Baričák. Název šablony Název DUMu. Předmět Druh učebního materiálu
 Název školy Číslo projektu Autor Název šablony Název DUMu Tematická oblast Předmět Druh učebního materiálu Anotace Vybavení, pomůcky Ověřeno ve výuce dne, třída Střední průmyslová škola strojnická Vsetín
Název školy Číslo projektu Autor Název šablony Název DUMu Tematická oblast Předmět Druh učebního materiálu Anotace Vybavení, pomůcky Ověřeno ve výuce dne, třída Střední průmyslová škola strojnická Vsetín
Architektury CISC a RISC, uplatnění v personálních počítačích
 Architektury CISC a RISC, uplatnění v personálních počítačích 1 Cíl přednášky Vysvětlit, jak pracují architektury CISC a RISC, upozornit na rozdíly. Zdůraznit, jak se typické rysy obou typů architektur
Architektury CISC a RISC, uplatnění v personálních počítačích 1 Cíl přednášky Vysvětlit, jak pracují architektury CISC a RISC, upozornit na rozdíly. Zdůraznit, jak se typické rysy obou typů architektur
Procesor. Procesor FPU ALU. Řadič mikrokód
 Procesor Procesor Integrovaný obvod zajišťující funkce CPU Tvoří srdce a mozek celého počítače a do značné míry ovlivňuje výkon celého počítače (čím rychlejší procesor, tím rychlejší počítač) Provádí jednotlivé
Procesor Procesor Integrovaný obvod zajišťující funkce CPU Tvoří srdce a mozek celého počítače a do značné míry ovlivňuje výkon celého počítače (čím rychlejší procesor, tím rychlejší počítač) Provádí jednotlivé
Sběrnicová struktura PC Procesory PC funkce, vlastnosti Interní počítačové paměti PC
 Informační systémy 2 Obsah: Sběrnicová struktura PC Procesory PC funkce, vlastnosti Interní počítačové paměti PC ROM RAM Paměti typu CACHE IS2-4 1 Dnešní info: Informační systémy 2 03 Informační systémy
Informační systémy 2 Obsah: Sběrnicová struktura PC Procesory PC funkce, vlastnosti Interní počítačové paměti PC ROM RAM Paměti typu CACHE IS2-4 1 Dnešní info: Informační systémy 2 03 Informační systémy
Charakteristika dalších verzí procesorů v PC
 Charakteristika dalších verzí procesorů v PC 1 Cíl přednášky Poukázat na principy tvorby architektur nových verzí personálních počítačů. Prezentovat aktuální pojmy. 2 Úvod Zvyšování výkonu cestou paralelizace
Charakteristika dalších verzí procesorů v PC 1 Cíl přednášky Poukázat na principy tvorby architektur nových verzí personálních počítačů. Prezentovat aktuální pojmy. 2 Úvod Zvyšování výkonu cestou paralelizace
Techniky zvýšení výkonnosti procesoru, RISC a CISC procesory
 Techniky zvýšení výkonnosti procesoru, RISC a CISC procesory Kategorizace architektur počítačů Co popisuje architektura počítačů: (CPU = ALU + řadič + paměť + Vstupy/Výstupy) Subskalární architektura (von
Techniky zvýšení výkonnosti procesoru, RISC a CISC procesory Kategorizace architektur počítačů Co popisuje architektura počítačů: (CPU = ALU + řadič + paměť + Vstupy/Výstupy) Subskalární architektura (von
Operační systémy. Jednoduché stránkování. Virtuální paměť. Příklad: jednoduché stránkování. Virtuální paměť se stránkování. Memory Management Unit
 Jednoduché stránkování Operační systémy Přednáška 8: Správa paměti II Hlavní paměť rozdělená na malé úseky stejné velikosti (např. 4kB) nazývané rámce (frames). Program rozdělen na malé úseky stejné velikosti
Jednoduché stránkování Operační systémy Přednáška 8: Správa paměti II Hlavní paměť rozdělená na malé úseky stejné velikosti (např. 4kB) nazývané rámce (frames). Program rozdělen na malé úseky stejné velikosti
Systém adresace paměti
 Systém adresace paměti Základní pojmy Adresa fyzická - adresa, která je přenesena na adresní sběrnici a fyzicky adresuje hlavní paměť logická - adresa, kterou má k dispozici proces k adresaci přiděleného
Systém adresace paměti Základní pojmy Adresa fyzická - adresa, která je přenesena na adresní sběrnici a fyzicky adresuje hlavní paměť logická - adresa, kterou má k dispozici proces k adresaci přiděleného
Strojový kód. Instrukce počítače
 Strojový kód Strojový kód (Machine code) je program vyjádřený v počítači jako posloupnost instrukcí procesoru (posloupnost bajtů, resp. bitů). Z hlediska uživatele je strojový kód nesrozumitelný, z hlediska
Strojový kód Strojový kód (Machine code) je program vyjádřený v počítači jako posloupnost instrukcí procesoru (posloupnost bajtů, resp. bitů). Z hlediska uživatele je strojový kód nesrozumitelný, z hlediska
Přednáška. Správa paměti II. Katedra počítačových systémů FIT, České vysoké učení technické v Praze Jan Trdlička, 2012
 Přednáška Správa paměti II. Katedra počítačových systémů FIT, České vysoké učení technické v Praze Jan Trdlička, 2012 Příprava studijního programu Informatika je podporována projektem financovaným z Evropského
Přednáška Správa paměti II. Katedra počítačových systémů FIT, České vysoké učení technické v Praze Jan Trdlička, 2012 Příprava studijního programu Informatika je podporována projektem financovaným z Evropského
Struktura a architektura počítačů (BI-SAP) 11
 11") Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti Struktura a architektura počítačů (BI-SAP) 11 doc. Ing. Hana Kubátová, CSc. Katedra číslicového návrhu Fakulta informačních technologii
Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti Struktura a architektura počítačů (BI-SAP) 11 doc. Ing. Hana Kubátová, CSc. Katedra číslicového návrhu Fakulta informačních technologii
Architektury počítačů a procesorů
 Kapitola 3 Architektury počítačů a procesorů 3.1 Von Neumannova (a harvardská) architektura Von Neumann 1. počítač se skládá z funkčních jednotek - paměť, řadič, aritmetická jednotka, vstupní a výstupní
Kapitola 3 Architektury počítačů a procesorů 3.1 Von Neumannova (a harvardská) architektura Von Neumann 1. počítač se skládá z funkčních jednotek - paměť, řadič, aritmetická jednotka, vstupní a výstupní
Architektura procesoru ARM
 Architektura procesoru ARM Bc. Jan Grygerek GRY095 Obsah ARM...3 Historie...3 Charakteristika procesoru ARM...4 Architektura procesoru ARM...5 Specifikace procesoru...6 Instrukční soubor procesoru...6
Architektura procesoru ARM Bc. Jan Grygerek GRY095 Obsah ARM...3 Historie...3 Charakteristika procesoru ARM...4 Architektura procesoru ARM...5 Specifikace procesoru...6 Instrukční soubor procesoru...6
Procesor z pohledu programátora
 Procesor z pohledu programátora Terminologie Procesor (CPU) = řadič + ALU. Mikroprocesor = procesor vyrobený monolitickou technologií na čipu. Mikropočítač = počítač postavený na bázi mikroprocesoru. Mikrokontrolér
Procesor z pohledu programátora Terminologie Procesor (CPU) = řadič + ALU. Mikroprocesor = procesor vyrobený monolitickou technologií na čipu. Mikropočítač = počítač postavený na bázi mikroprocesoru. Mikrokontrolér
Pokročilé architektury počítačů
 Pokročilé architektury počítačů Přednáška 5 GPU - CUDA Martin Milata Obsah Obecné výpočty a GPU Grafické procesory NVIDIA Tesla Výpočetní model Paměťový model GT200 Zpracování instrukcí Vydávání instrukcí
Pokročilé architektury počítačů Přednáška 5 GPU - CUDA Martin Milata Obsah Obecné výpočty a GPU Grafické procesory NVIDIA Tesla Výpočetní model Paměťový model GT200 Zpracování instrukcí Vydávání instrukcí
Pokročilé architektury počítačů
 Pokročilé architektury počítačů Tutoriál 3 CUDA - GPU Martin Milata Výpočetní model CUDA Organizace kódu Sériově organizovaný kód určený pro CPU Paralelní kód prováděný na GPU Označuje se jako kernel GPU
Pokročilé architektury počítačů Tutoriál 3 CUDA - GPU Martin Milata Výpočetní model CUDA Organizace kódu Sériově organizovaný kód určený pro CPU Paralelní kód prováděný na GPU Označuje se jako kernel GPU
Intel 80486 (2) Intel 80486 (1) Intel 80486 (3) Intel 80486 (4) Intel 80486 (6) Intel 80486 (5) Nezřetězené zpracování instrukcí:
 Intel 80486 (1) Intel 80486 (3) Intel 80486 (4) Intel 80486 (6) Intel 80486 (5) Nezřetězené zpracování instrukcí:") Intel 80486 (1) Vyroben v roce 1989 Prodáván pod oficiálním názvem 80486DX Plně 32bitový procesor Na svém čipu má integrován: - zmodernizovaný procesor 80386 - numerický koprocesor 80387 - L1 (interní)
Intel 80486 (1) Vyroben v roce 1989 Prodáván pod oficiálním názvem 80486DX Plně 32bitový procesor Na svém čipu má integrován: - zmodernizovaný procesor 80386 - numerický koprocesor 80387 - L1 (interní)
Další aspekty architektur CISC a RISC Aktuálnost obsahu registru
 Cíl přednášky: Vysvětlit principy práce s registry v architekturách RISC a CISC, upozornit na rozdíly. Vysvětlit možnosti využívání sad registrů. Zabývat se principy využívanými v procesorech Intel. Zabývat
Cíl přednášky: Vysvětlit principy práce s registry v architekturách RISC a CISC, upozornit na rozdíly. Vysvětlit možnosti využívání sad registrů. Zabývat se principy využívanými v procesorech Intel. Zabývat
Pokročilé architektury počítačů
 Pokročilé architektury počítačů Tutoriál 2 Virtualizace a její dopady Martin Milata Obsah Virtualizace Jak virtualizace funguje Typy HW podpora virtualizace Dopady virtualizace Jak virtualizace funguje?
Pokročilé architektury počítačů Tutoriál 2 Virtualizace a její dopady Martin Milata Obsah Virtualizace Jak virtualizace funguje Typy HW podpora virtualizace Dopady virtualizace Jak virtualizace funguje?
Obecné výpočty na GPU v jazyce CUDA. Jiří Filipovič
 Obecné výpočty na GPU v jazyce CUDA Jiří Filipovič Obsah přednášky motivace architektura GPU CUDA programovací model jaké algoritmy urychlovat na GPU? optimalizace Motivace Moorův zákon stále platí pro
Obecné výpočty na GPU v jazyce CUDA Jiří Filipovič Obsah přednášky motivace architektura GPU CUDA programovací model jaké algoritmy urychlovat na GPU? optimalizace Motivace Moorův zákon stále platí pro
Jan Nekvapil ČESKÉ VYSOKÉ UČENÍ TECHNICKÉ V PRAZE Fakulta elektrotechnická
 Jan Nekvapil jan.nekvapil@tiscali.cz ČESKÉ VYSOKÉ UČENÍ TECHNICKÉ V PRAZE Fakulta elektrotechnická Motivace MMX, EMMX, MMX+ 3DNow!, 3DNow!+ SSE SSE2 SSE3 SSSE3 SSE4.2 Závěr 2 Efektivní práce s vektory
Jan Nekvapil jan.nekvapil@tiscali.cz ČESKÉ VYSOKÉ UČENÍ TECHNICKÉ V PRAZE Fakulta elektrotechnická Motivace MMX, EMMX, MMX+ 3DNow!, 3DNow!+ SSE SSE2 SSE3 SSSE3 SSE4.2 Závěr 2 Efektivní práce s vektory
Procesor. Základní prvky procesoru Instrukční sada Metody zvýšení výkonu procesoru
 Počítačové systémy Procesor Miroslav Flídr Počítačové systémy LS 2006-1/17- Západočeská univerzita v Plzni Víceúrovňová organizace počítače Digital logic level Microarchitecture level Processor Instruction
Počítačové systémy Procesor Miroslav Flídr Počítačové systémy LS 2006-1/17- Západočeská univerzita v Plzni Víceúrovňová organizace počítače Digital logic level Microarchitecture level Processor Instruction
Základy informatiky. 2. Přednáška HW. Lenka Carr Motyčková. February 22, 2011 Základy informatiky 2
 Základy informatiky 2. Přednáška HW Lenka Carr Motyčková February 22, 2011 Základy informatiky 1 February 22, 2011 Základy informatiky 2 February 22, 2011 Základy informatiky 3 February 22, 2011 Základy
Základy informatiky 2. Přednáška HW Lenka Carr Motyčková February 22, 2011 Základy informatiky 1 February 22, 2011 Základy informatiky 2 February 22, 2011 Základy informatiky 3 February 22, 2011 Základy
Roman Výtisk, VYT027
 Roman Výtisk, VYT027 Ohlédnutí za architekturou AMD K8 Představení architektury procesoru AMD K10 Přínos Struktura cache IMC, HyperTransport sběrnice Použitá literatura Ohlášení x86-64 architektury 5.
Roman Výtisk, VYT027 Ohlédnutí za architekturou AMD K8 Představení architektury procesoru AMD K10 Přínos Struktura cache IMC, HyperTransport sběrnice Použitá literatura Ohlášení x86-64 architektury 5.
OPS Paralelní systémy, seznam pojmů, klasifikace
 Moorův zákon (polovina 60. let) : Výpočetní výkon a počet tranzistorů na jeden CPU chip integrovaného obvodu mikroprocesoru se každý jeden až dva roky zdvojnásobí; cena se zmenší na polovinu. Paralelismus
Moorův zákon (polovina 60. let) : Výpočetní výkon a počet tranzistorů na jeden CPU chip integrovaného obvodu mikroprocesoru se každý jeden až dva roky zdvojnásobí; cena se zmenší na polovinu. Paralelismus
Počítač jako prostředek řízení. Struktura a organizace počítače
 Řídicí počítače - pro řízení technologických procesů. Specielní přídavná zařízení - I/O, přerušovací systém, reálný čas, Č/A a A/Č převodníky a j. s obsluhou - operátorské periferie bez obsluhy - operátorský
Řídicí počítače - pro řízení technologických procesů. Specielní přídavná zařízení - I/O, přerušovací systém, reálný čas, Č/A a A/Č převodníky a j. s obsluhou - operátorské periferie bez obsluhy - operátorský
Architektura počítačů
 Architektura počítačů Studijní materiál pro předmět Architektury počítačů Ing. Petr Olivka katedra informatiky FEI VŠB-TU Ostrava email: petr.olivka@vsb.cz Ostrava, 2010 1 1 Architektura počítačů Pojem
Architektura počítačů Studijní materiál pro předmět Architektury počítačů Ing. Petr Olivka katedra informatiky FEI VŠB-TU Ostrava email: petr.olivka@vsb.cz Ostrava, 2010 1 1 Architektura počítačů Pojem
Procesy a vlákna (Processes and Threads)
") ÚVOD DO OPERAČNÍCH SYSTÉMŮ Ver.1.00 Procesy a vlákna (Processes and Threads) Správa procesů a vláken České vysoké učení technické Fakulta elektrotechnická 2012 Použitá literatura [1] Stallings, W.: Operating
ÚVOD DO OPERAČNÍCH SYSTÉMŮ Ver.1.00 Procesy a vlákna (Processes and Threads) Správa procesů a vláken České vysoké učení technické Fakulta elektrotechnická 2012 Použitá literatura [1] Stallings, W.: Operating
Vstupně - výstupní moduly
 Vstupně - výstupní moduly Přídavná zařízení sloužící ke vstupu a výstupu dat bo k uchovávání a archivaci dat Nejsou připojována ke sběrnici přímo, ale prostřednictvím vstupně-výstupních modulů ( ů ). Hlavní
Vstupně - výstupní moduly Přídavná zařízení sloužící ke vstupu a výstupu dat bo k uchovávání a archivaci dat Nejsou připojována ke sběrnici přímo, ale prostřednictvím vstupně-výstupních modulů ( ů ). Hlavní
Přerušovací systém s prioritním řetězem
 Přerušovací systém s prioritním řetězem Doplňující text pro přednášky z POT Úvod Přerušovací systém mikropočítače může být koncipován několika způsoby. Jednou z možností je přerušovací systém s prioritním
Přerušovací systém s prioritním řetězem Doplňující text pro přednášky z POT Úvod Přerušovací systém mikropočítače může být koncipován několika způsoby. Jednou z možností je přerušovací systém s prioritním
Operační systémy. Správa paměti (SP) Požadavky na SP. Spojování a zavedení programu. Spojování programu (linking) Zavádění programu (loading)
 Požadavky na SP. Spojování a zavedení programu. Spojování programu (linking) Zavádění programu (loading)") Správa paměti (SP) Operační systémy Přednáška 7: Správa paměti I Memory Management Unit (MMU) hardware umístěný na CPU čipu např. překládá logické adresy na fyzické adresy, Memory Manager software, který
Správa paměti (SP) Operační systémy Přednáška 7: Správa paměti I Memory Management Unit (MMU) hardware umístěný na CPU čipu např. překládá logické adresy na fyzické adresy, Memory Manager software, který
Přidělování paměti II Mgr. Josef Horálek
 Přidělování paměti II Mgr. Josef Horálek Techniky přidělování paměti = Přidělování jediné souvislé oblasti paměti = Přidělování paměti po sekcích = Dynamické přemisťování sekcí = Stránkování = Stránkování
Přidělování paměti II Mgr. Josef Horálek Techniky přidělování paměti = Přidělování jediné souvislé oblasti paměti = Přidělování paměti po sekcích = Dynamické přemisťování sekcí = Stránkování = Stránkování
PB002 Základy informačních technologií
 Počítačové systémy 21. září 2015 Základní informace 1 Přednášky nejsou povinné 2 Poku účast klesne pod pět studentů, přednáška se nekoná 3 Slidy z přednášky budou vystaveny 4 Zkouška bude pouze písemná
Počítačové systémy 21. září 2015 Základní informace 1 Přednášky nejsou povinné 2 Poku účast klesne pod pět studentů, přednáška se nekoná 3 Slidy z přednášky budou vystaveny 4 Zkouška bude pouze písemná
Intel Itanium. Referát. Vysoká škola báňská Technická univerzita Ostrava Fakulta elektrotechniky a informatiky Katedra informatiky
 Vysoká škola báňská Technická univerzita Ostrava Fakulta elektrotechniky a informatiky Katedra informatiky Pokročilé architektury počítačů Intel Itanium Referát Tomáš Vojtas (voj209) 2.12.2009 Úvod Itanium
Vysoká škola báňská Technická univerzita Ostrava Fakulta elektrotechniky a informatiky Katedra informatiky Pokročilé architektury počítačů Intel Itanium Referát Tomáš Vojtas (voj209) 2.12.2009 Úvod Itanium
Sběrnicová struktura PC Procesory PC funkce, vlastnosti Interní počítačové paměti PC
 Informatika 2 Technické prostředky počítačové techniky - 2 Přednáší: doc. Ing. Jan Skrbek, Dr. - KIN Přednášky: středa 14 20 15 55 Spojení: e-mail: jan.skrbek@tul.cz 16 10 17 45 tel.: 48 535 2442 Obsah:
Informatika 2 Technické prostředky počítačové techniky - 2 Přednáší: doc. Ing. Jan Skrbek, Dr. - KIN Přednášky: středa 14 20 15 55 Spojení: e-mail: jan.skrbek@tul.cz 16 10 17 45 tel.: 48 535 2442 Obsah:
Vícejádrový procesor. Dvě nebo více nezávislých jader Pro plné využití. podporovat multihreading
 Vývoj Jan Smuda, Petr Zajíc Procesor ALU (aritmeticko logická jednotka) Registry Řadič Jednotky pro práci s plovoucí čárkou Cache Vývoj procesorů Predikce skoku Plánování instrukcí Naráží na fyzická omezení
Vývoj Jan Smuda, Petr Zajíc Procesor ALU (aritmeticko logická jednotka) Registry Řadič Jednotky pro práci s plovoucí čárkou Cache Vývoj procesorů Predikce skoku Plánování instrukcí Naráží na fyzická omezení
Charakteristika dalších verzí procesorů Pentium
 Charakteristika dalších verzí procesorů Pentium 1 Cíl přednášky Poukázat na principy architektur nových verzí typů Pentií. Prezentovat aktuální pojmy. 2 Úvod Paralelní systémy lze třídit z hlediska počtu
Charakteristika dalších verzí procesorů Pentium 1 Cíl přednášky Poukázat na principy architektur nových verzí typů Pentií. Prezentovat aktuální pojmy. 2 Úvod Paralelní systémy lze třídit z hlediska počtu
Adresní mody procesoru
 Adresní mody procesoru K.D. - přednášky 1 Obecně o adresování Různé typy procesorů mohou mít v instrukci 1, 2 nebo více adres. Operandy mohou ležet v registrech nebo v paměti. Adresní mechanismus procesoru
Adresní mody procesoru K.D. - přednášky 1 Obecně o adresování Různé typy procesorů mohou mít v instrukci 1, 2 nebo více adres. Operandy mohou ležet v registrech nebo v paměti. Adresní mechanismus procesoru
Metody připojování periferií BI-MPP Přednáška 2
 Metody připojování periferií BI-MPP Přednáška 2 Ing. Miroslav Skrbek, Ph.D. Katedra počítačových systémů Fakulta informačních technologií České vysoké učení technické v Praze Miroslav Skrbek 2010,2011
Metody připojování periferií BI-MPP Přednáška 2 Ing. Miroslav Skrbek, Ph.D. Katedra počítačových systémů Fakulta informačních technologií České vysoké učení technické v Praze Miroslav Skrbek 2010,2011
ZÁKLADY PROGRAMOVÁNÍ. Mgr. Vladislav BEDNÁŘ 2013 1.3 2/14
 ZÁKLADY PROGRAMOVÁNÍ Mgr. Vladislav BEDNÁŘ 2013 1.3 2/14 Co je vhodné vědět, než si vybereme programovací jazyk a začneme programovat roboty. 1 / 14 0:40 1.3. Vliv hardware počítače na programování Vliv
ZÁKLADY PROGRAMOVÁNÍ Mgr. Vladislav BEDNÁŘ 2013 1.3 2/14 Co je vhodné vědět, než si vybereme programovací jazyk a začneme programovat roboty. 1 / 14 0:40 1.3. Vliv hardware počítače na programování Vliv
Operační systémy. Přednáška 7: Správa paměti I
 Operační systémy Přednáška 7: Správa paměti I 1 Správa paměti (SP) Memory Management Unit (MMU) hardware umístěný na CPU čipu např. překládá logické adresy na fyzické adresy, Memory Manager software, který
Operační systémy Přednáška 7: Správa paměti I 1 Správa paměti (SP) Memory Management Unit (MMU) hardware umístěný na CPU čipu např. překládá logické adresy na fyzické adresy, Memory Manager software, který
Principy počítačů I - Procesory
 Principy počítačů I - Procesory snímek 1 VJJ Principy počítačů Část V Procesory 1 snímek 2 Struktura procesoru musí umožnit změnu stavu stroje v libovolném kroku uvolnění nebo znemožnění pohybu dat po
Principy počítačů I - Procesory snímek 1 VJJ Principy počítačů Část V Procesory 1 snímek 2 Struktura procesoru musí umožnit změnu stavu stroje v libovolném kroku uvolnění nebo znemožnění pohybu dat po
Disková pole (RAID) 1
 1") Disková pole (RAID) 1 Architektury RAID Základní myšlenka: snaha o zpracování dat paralelně. Pozice diskové paměti v klasickém personálním počítači vyhovuje pro aplikace s jedním uživatelem. Řešení: data
Disková pole (RAID) 1 Architektury RAID Základní myšlenka: snaha o zpracování dat paralelně. Pozice diskové paměti v klasickém personálním počítači vyhovuje pro aplikace s jedním uživatelem. Řešení: data
Pokročilé architektury počítačů
 Pokročilé architektury počítačů Přednáška 3 Hierarchické uspořádání pamětí počítače Martin Milata Obsah Paměťový subsystém Obvyklé chování programů při přístupu do paměti Cache paměti princip činnosti
Pokročilé architektury počítačů Přednáška 3 Hierarchické uspořádání pamětí počítače Martin Milata Obsah Paměťový subsystém Obvyklé chování programů při přístupu do paměti Cache paměti princip činnosti
PROCESOR. Typy procesorů
 PROCESOR Procesor je ústřední výkonnou jednotkou počítače, která čte z paměti instrukce a na jejich základě vykonává program. Primárním úkolem procesoru je řídit činnost ostatních částí počítače včetně
PROCESOR Procesor je ústřední výkonnou jednotkou počítače, která čte z paměti instrukce a na jejich základě vykonává program. Primárním úkolem procesoru je řídit činnost ostatních částí počítače včetně
Gymnázium Vysoké Mýto nám. Vaňorného 163, 566 01 Vysoké Mýto
 Gymnázium Vysoké Mýto nám. Vaňorného 163, 566 01 Vysoké Mýto Registrační číslo projektu Šablona Autor Název materiálu CZ.1.07/1.5.00/34.0951 III/2 INOVACE A ZKVALITNĚNÍ VÝUKY PROSTŘEDNICTVÍM ICT Mgr. Petr
Gymnázium Vysoké Mýto nám. Vaňorného 163, 566 01 Vysoké Mýto Registrační číslo projektu Šablona Autor Název materiálu CZ.1.07/1.5.00/34.0951 III/2 INOVACE A ZKVALITNĚNÍ VÝUKY PROSTŘEDNICTVÍM ICT Mgr. Petr
Cache paměť - mezipaměť
 Cache paměť - mezipaměť 10.přednáška Urychlení přenosu mezi procesorem a hlavní pamětí Hlavní paměť procesoru je typu DRAM a je pomalá. Proto se mezi pomalou hlavní paměť a procesor vkládá menší, ale rychlá
Cache paměť - mezipaměť 10.přednáška Urychlení přenosu mezi procesorem a hlavní pamětí Hlavní paměť procesoru je typu DRAM a je pomalá. Proto se mezi pomalou hlavní paměť a procesor vkládá menší, ale rychlá
Přednáška. Správa paměti I. Katedra počítačových systémů FIT, České vysoké učení technické v Praze Jan Trdlička, 2012
 Přednáška Správa paměti I. Katedra počítačových systémů FIT, České vysoké učení technické v Praze Jan Trdlička, 2012 Příprava studijního programu Informatika je podporována projektem financovaným z Evropského
Přednáška Správa paměti I. Katedra počítačových systémů FIT, České vysoké učení technické v Praze Jan Trdlička, 2012 Příprava studijního programu Informatika je podporována projektem financovaným z Evropského
V 70. letech výzkumy četnosti výskytu instrukcí ukázaly, že programátoři a
 1 Počítače CISC a RISC V dnešní době se ustálilo dělení počítačů do dvou základních kategorií podle typu použitého procesoru: CISC - počítač se složitým souborem instrukcí (Complex Instruction Set Computer)
1 Počítače CISC a RISC V dnešní době se ustálilo dělení počítačů do dvou základních kategorií podle typu použitého procesoru: CISC - počítač se složitým souborem instrukcí (Complex Instruction Set Computer)
Základní uspořádání pamětí MCU
 Základní uspořádání pamětí MCU Harwardská architektura. Oddělený adresní prostor kódové a datové. Používané u malých MCU a signálových procesorů. Von Neumannova architektura (Princetonská). Kódová i jsou
Základní uspořádání pamětí MCU Harwardská architektura. Oddělený adresní prostor kódové a datové. Používané u malých MCU a signálových procesorů. Von Neumannova architektura (Princetonská). Kódová i jsou
Systém řízení sběrnice
 Systém řízení sběrnice Sběrnice je komunikační cesta, která spojuje dvě či více zařízení. V určitý okamžik je možné aby pouze jedno z připojených zařízení vložilo na sběrnici data. Vložená data pak mohou
Systém řízení sběrnice Sběrnice je komunikační cesta, která spojuje dvě či více zařízení. V určitý okamžik je možné aby pouze jedno z připojených zařízení vložilo na sběrnici data. Vložená data pak mohou
Faculty of Nuclear Sciences and Physical Engineering Czech Technical University in Prague
 Tomáš Faculty of Nuclear Sciences and Physical Engineering Czech Technical University in Prague Zjednodušené schéma systému z základ hardware pro mainframe tvoří: operační pamět - MAIN / REAL STORAGE jeden
Tomáš Faculty of Nuclear Sciences and Physical Engineering Czech Technical University in Prague Zjednodušené schéma systému z základ hardware pro mainframe tvoří: operační pamět - MAIN / REAL STORAGE jeden
Řetězené zpracování. INP 2008 FIT VUT v Brně
 Řetězené zpracování INP 2008 FIT VUT v Brně 1 Techniky urychlování výpočtu v HW Lze realizovat speciální kódování dle potřeby dané úlohy Příklad: aritmetické operace v kódu zbytkových tříd jsou extrémně
Řetězené zpracování INP 2008 FIT VUT v Brně 1 Techniky urychlování výpočtu v HW Lze realizovat speciální kódování dle potřeby dané úlohy Příklad: aritmetické operace v kódu zbytkových tříd jsou extrémně
Pokročilé architektury počítačů
 Pokročilé architektury počítačů Architektura IO podsystému České vysoké učení technické, Fakulta elektrotechnická A4M36PAP Pokročílé architektury počítačů Ver.1.00 2010 1 Co je úkolem? Propojit jednotlivé
Pokročilé architektury počítačů Architektura IO podsystému České vysoké učení technické, Fakulta elektrotechnická A4M36PAP Pokročílé architektury počítačů Ver.1.00 2010 1 Co je úkolem? Propojit jednotlivé
Obsah. Kapitola 1 Hardware, procesory a vlákna Prohlídka útrob počítače...20 Motivace pro vícejádrové procesory...21
 Stručný obsah 1. Hardware, procesory a vlákna... 19 2. Programování s ohledemna výkon... 45 3. Identifikování příležitostí pro paralelizmus... 93 4. Synchronizace a sdílení dat... 123 5. Vlákna v rozhraní
Stručný obsah 1. Hardware, procesory a vlákna... 19 2. Programování s ohledemna výkon... 45 3. Identifikování příležitostí pro paralelizmus... 93 4. Synchronizace a sdílení dat... 123 5. Vlákna v rozhraní
Principy počítačů a operačních systémů
 Principy počítačů a operačních systémů Zvyšování výkonnosti procesorů Zimní semestr 2/22 Co nám omezuje výkonnost procesoru? Jednocyklové zpracování insn.fetch, dec, exec Vícecyklové zpracování insn.fetch
Principy počítačů a operačních systémů Zvyšování výkonnosti procesorů Zimní semestr 2/22 Co nám omezuje výkonnost procesoru? Jednocyklové zpracování insn.fetch, dec, exec Vícecyklové zpracování insn.fetch
Úvod do architektur personálních počítačů
 Úvod do architektur personálních počítačů 1 Cíl přednášky Popsat principy proudového zpracování informace. Popsat principy zřetězeného zpracování instrukcí. Zabývat se způsoby uplatnění tohoto principu
Úvod do architektur personálních počítačů 1 Cíl přednášky Popsat principy proudového zpracování informace. Popsat principy zřetězeného zpracování instrukcí. Zabývat se způsoby uplatnění tohoto principu
Referát (pokročilé architektury počítačů)
") Referát (pokročilé architektury počítačů) Představení architektury procesoru AMD K10 Roman Výtisk, VYT027 1 AMD K8 Nejprve bych zmínil, co této architektuře předcházelo a co tato architektura přinesla
Referát (pokročilé architektury počítačů) Představení architektury procesoru AMD K10 Roman Výtisk, VYT027 1 AMD K8 Nejprve bych zmínil, co této architektuře předcházelo a co tato architektura přinesla
Pokročilé architektury počítačů
 Pokročilé architektury počítačů 05 Superskalární techniky Tok dat z/do paměti (Memory Data Flow) a Procesory VLIW a EPIC České vysoké učení technické, Fakulta elektrotechnická A4M36PAP Pokročilé architektury
Pokročilé architektury počítačů 05 Superskalární techniky Tok dat z/do paměti (Memory Data Flow) a Procesory VLIW a EPIC České vysoké učení technické, Fakulta elektrotechnická A4M36PAP Pokročilé architektury
Kubatova 19.4.2007 Y36SAP - 13. procesor - control unit obvodový a mikroprogramový řadič RISC. 19.4.2007 Y36SAP-control unit 1
 Y36SAP - 13 procesor - control unit obvodový a mikroprogramový řadič RISC 19.4.2007 Y36SAP-control unit 1 Von Neumannova architektura (UPS1) Instrukce a data jsou uloženy v téže paměti. Paměť je organizována
Y36SAP - 13 procesor - control unit obvodový a mikroprogramový řadič RISC 19.4.2007 Y36SAP-control unit 1 Von Neumannova architektura (UPS1) Instrukce a data jsou uloženy v téže paměti. Paměť je organizována
Profilová část maturitní zkoušky 2014/2015
 Střední průmyslová škola, Přerov, Havlíčkova 2 751 52 Přerov Profilová část maturitní zkoušky 2014/2015 TEMATICKÉ OKRUHY A HODNOTÍCÍ KRITÉRIA Studijní obor: 26-41-M/01 Elektrotechnika Zaměření: technika
Střední průmyslová škola, Přerov, Havlíčkova 2 751 52 Přerov Profilová část maturitní zkoušky 2014/2015 TEMATICKÉ OKRUHY A HODNOTÍCÍ KRITÉRIA Studijní obor: 26-41-M/01 Elektrotechnika Zaměření: technika
Disková pole (RAID) 1
 1") Disková pole (RAID) 1 Architektury RAID Důvod zavedení RAID: reakce na zvyšující se rychlost procesoru. Pozice diskové paměti v klasickém personálním počítači vyhovuje pro aplikace s jedním uživatelem.
Disková pole (RAID) 1 Architektury RAID Důvod zavedení RAID: reakce na zvyšující se rychlost procesoru. Pozice diskové paměti v klasickém personálním počítači vyhovuje pro aplikace s jedním uživatelem.
RISC a CISC architektura
 RISC a CISC architektura = dva rozdílné přístupy ke konstrukci CPU CISC (Complex Instruction Set Computer) vývojově starší přístup: pomoci konstrukci překladače z VPP co nejpodobnějšími instrukcemi s příkazy
RISC a CISC architektura = dva rozdílné přístupy ke konstrukci CPU CISC (Complex Instruction Set Computer) vývojově starší přístup: pomoci konstrukci překladače z VPP co nejpodobnějšími instrukcemi s příkazy
Přehled paralelních architektur. Dělení paralelních architektur Flynnova taxonomie Komunikační modely paralelních architektur
 Přehled paralelních architektur Přehled paralelních architektur Dělení paralelních architektur Flynnova taxonomie Komunikační modely paralelních architektur Přehled I. paralelní počítače se konstruují
Přehled paralelních architektur Přehled paralelních architektur Dělení paralelních architektur Flynnova taxonomie Komunikační modely paralelních architektur Přehled I. paralelní počítače se konstruují
Vstupně výstupní moduly. 13.přednáška
 Vstupně výstupní moduly 13.přednáška Vstupně-výstupn výstupní modul (I/O modul) Přídavná zařízení sloužící ke vstupu a výstupu dat nebo k uchovávání a archivaci dat Nejsou připojována ke sběrnici přímo,
Vstupně výstupní moduly 13.přednáška Vstupně-výstupn výstupní modul (I/O modul) Přídavná zařízení sloužící ke vstupu a výstupu dat nebo k uchovávání a archivaci dat Nejsou připojována ke sběrnici přímo,
Koncepce DMA POT POT. Při vstupu nebo výstupu dat se opakují jednoduché činnosti. Jednotlivé kroky lze realizovat pomocí speciálního HW.
 p 1 Koncepce DMA Při vstupu nebo výstupu dat se opakují jednoduché činnosti. Jednotlivé kroky lze realizovat pomocí speciálního HW. Čekání na připravenost V/V Přenos paměť V/V nebo V/V paměť Posun pointeru
p 1 Koncepce DMA Při vstupu nebo výstupu dat se opakují jednoduché činnosti. Jednotlivé kroky lze realizovat pomocí speciálního HW. Čekání na připravenost V/V Přenos paměť V/V nebo V/V paměť Posun pointeru
Základní principy konstrukce systémové sběrnice - shrnutí. Shrnout základní principy konstrukce a fungování systémových sběrnic.
 Základní principy konstrukce systémové sběrnice - shrnutí Shrnout základní principy konstrukce a fungování systémových sběrnic. 1 Co je to systémová sběrnice? Systémová sběrnice je prostředek sloužící
Základní principy konstrukce systémové sběrnice - shrnutí Shrnout základní principy konstrukce a fungování systémových sběrnic. 1 Co je to systémová sběrnice? Systémová sběrnice je prostředek sloužící
Mikrokontroléry. Doplňující text pro POS K. D. 2001
 Mikrokontroléry Doplňující text pro POS K. D. 2001 Úvod Mikrokontroléry, jinak též označované jako jednočipové mikropočítače, obsahují v jediném pouzdře všechny podstatné části mikropočítače: Řadič a aritmetickou
Mikrokontroléry Doplňující text pro POS K. D. 2001 Úvod Mikrokontroléry, jinak též označované jako jednočipové mikropočítače, obsahují v jediném pouzdře všechny podstatné části mikropočítače: Řadič a aritmetickou
Xbox 360 Cpu = IBM Xenon
 Xbox 360 Cpu = IBM Xenon VŠB TUO Ostrava 7.11.2008 Zdeněk Dubnický Architektura procesoru IBM Xenon a její přínosy -architektura -CPU -FSB -testování a ladění IBM Xenon Vývoj tohoto procesoru začal v roce
Xbox 360 Cpu = IBM Xenon VŠB TUO Ostrava 7.11.2008 Zdeněk Dubnický Architektura procesoru IBM Xenon a její přínosy -architektura -CPU -FSB -testování a ladění IBM Xenon Vývoj tohoto procesoru začal v roce
Mezipaměti počítače. L2 cache. L3 cache
 Mezipaměti počítače Cache paměť - mezipaměť Hlavní paměť procesoru je typu DRAM a je pomalá. Proto se mezi pomalou hlavní paměť a procesor vkládá menší, ale rychlá vyrovnávací (cache) paměť SRAM. Rychlost
Mezipaměti počítače Cache paměť - mezipaměť Hlavní paměť procesoru je typu DRAM a je pomalá. Proto se mezi pomalou hlavní paměť a procesor vkládá menší, ale rychlá vyrovnávací (cache) paměť SRAM. Rychlost
Semestrální práce z předmětu Speciální číslicové systémy X31SCS
 Semestrální práce z předmětu Speciální číslicové systémy X31SCS Katedra obvodů DSP16411 ZPRACOVAL: Roman Holubec Školní rok: 2006/2007 Úvod DSP16411 patří do rodiny DSP16411 rozšiřuje DSP16410 o vyšší
Semestrální práce z předmětu Speciální číslicové systémy X31SCS Katedra obvodů DSP16411 ZPRACOVAL: Roman Holubec Školní rok: 2006/2007 Úvod DSP16411 patří do rodiny DSP16411 rozšiřuje DSP16410 o vyšší
Procesory, mikroprocesory, procesory na FPGA. 30.1.2013 O. Novák, CIE 11 1
 Procesory, mikroprocesory, procesory na FPGA 30.1.2013 O. Novák, CIE 11 1 Od sekvenčních automatů k mikroprocesorům 30.1.2013 O. Novák, CIE 11 2 30.1.2013 O. Novák, CIE 11 3 Architektura počítačů Von Neumannovská,
Procesory, mikroprocesory, procesory na FPGA 30.1.2013 O. Novák, CIE 11 1 Od sekvenčních automatů k mikroprocesorům 30.1.2013 O. Novák, CIE 11 2 30.1.2013 O. Novák, CIE 11 3 Architektura počítačů Von Neumannovská,
4-1 4. Přednáška. Strojový kód a data. 4. Přednáška ISA. 2004-2007 J. Buček, R. Lórencz
 4-4. Přednáška 4. Přednáška ISA J. Buček, R. Lórencz 24-27 J. Buček, R. Lórencz 4-2 4. Přednáška Obsah přednášky Násobení a dělení v počítači Základní cyklus počítače Charakteristika třech základní typů
4-4. Přednáška 4. Přednáška ISA J. Buček, R. Lórencz 24-27 J. Buček, R. Lórencz 4-2 4. Přednáška Obsah přednášky Násobení a dělení v počítači Základní cyklus počítače Charakteristika třech základní typů
Assembler RISC RISC MIPS. T.Mainzer, kiv.zcu.cz
 Assembler RISC T.Mainzer, kiv.zcu.cz RISC RISC, neboli Reduced Instruction Set Computer - koncepce procesorů s redukovaným souborem instrukcí (vs. CISC, neboli Complex Instruction Set Computer, "bohatý"
Assembler RISC T.Mainzer, kiv.zcu.cz RISC RISC, neboli Reduced Instruction Set Computer - koncepce procesorů s redukovaným souborem instrukcí (vs. CISC, neboli Complex Instruction Set Computer, "bohatý"
Sběrnicová struktura PC Procesory PC funkce, vlastnosti Interní počítačové paměti PC
 Informatika 2 Technické prostředky počítačové techniky - 2 Přednáší: doc. Ing. Jan Skrbek, Dr. - KIN Přednášky: středa 14 20 15 55 Spojení: e-mail: jan.skrbek@tul.cz 16 10 17 45 tel.: 48 535 2442 Obsah:
Informatika 2 Technické prostředky počítačové techniky - 2 Přednáší: doc. Ing. Jan Skrbek, Dr. - KIN Přednášky: středa 14 20 15 55 Spojení: e-mail: jan.skrbek@tul.cz 16 10 17 45 tel.: 48 535 2442 Obsah:
Pokročilé architektury počítačů
 Vysoká škola báňská Technická univerzita Ostrava Fakulta elektrotechniky a informatiky Pokročilé architektury počítačů Architektura Intel Larrabee 5.12.2009 Josef Stoklasa STO228 Obsah: 1. Úvod do tajů
Vysoká škola báňská Technická univerzita Ostrava Fakulta elektrotechniky a informatiky Pokročilé architektury počítačů Architektura Intel Larrabee 5.12.2009 Josef Stoklasa STO228 Obsah: 1. Úvod do tajů
Architektury CISC a RISC, uplatnění v personálních počítačích - pokračování
 Architektury CISC a RISC, uplatnění v personálních počítačích - pokračování 1 Cíl přednášky Vysvětlit, jak pracují architektury CISC a RISC, upozornit na rozdíly. Upozornit, jak se typické rysy obou typů
Architektury CISC a RISC, uplatnění v personálních počítačích - pokračování 1 Cíl přednášky Vysvětlit, jak pracují architektury CISC a RISC, upozornit na rozdíly. Upozornit, jak se typické rysy obou typů
Linux a 64 bitů. SUSE Labs. Michal Ludvig Vojtěch Pavlík
 1 Linux a 64 bitů Michal Ludvig Vojtěch Pavlík SUSE Labs 02.04.04 Linux a 64 bitů, Michal Ludvig+Vojtěch Pavlík, SUSE Labs, 02.04.04, Strana 1 64 čeho? 2 bitovost procesoru
1 Linux a 64 bitů Michal Ludvig Vojtěch Pavlík SUSE Labs 02.04.04 Linux a 64 bitů, Michal Ludvig+Vojtěch Pavlík, SUSE Labs, 02.04.04, Strana 1 64 čeho? 2 bitovost procesoru
Architektura počítače
 Architektura počítače Výpočetní systém HIERARCHICKÁ STRUKTURA Úroveň aplikačních programů Úroveň obecných funkčních programů Úroveň vyšších programovacích jazyků a prostředí Úroveň základních programovacích
Architektura počítače Výpočetní systém HIERARCHICKÁ STRUKTURA Úroveň aplikačních programů Úroveň obecných funkčních programů Úroveň vyšších programovacích jazyků a prostředí Úroveň základních programovacích
Architektury CISC a RISC, uplatnění rysů architektur RISC v personálních počítačích - pokračování
 Architektury CISC a RISC, uplatnění rysů architektur RISC v personálních počítačích - pokračování 1 Cíl přednášky Vysvětlit další rysy architektur CISC a RISC, upozornit na rozdíly. Upozornit, jak se typické
Architektury CISC a RISC, uplatnění rysů architektur RISC v personálních počítačích - pokračování 1 Cíl přednášky Vysvětlit další rysy architektur CISC a RISC, upozornit na rozdíly. Upozornit, jak se typické
ARCHITEKTURA PROCESORŮ
 ARCHITEKTURA PROCESORŮ Základními jednotkami, které tvoří vnitřní strukturu procesorů, jsou: řadič, který má za úkol číst operandy (data, čísla) a instrukce z operační paměti, dekódovat je a na základě
ARCHITEKTURA PROCESORŮ Základními jednotkami, které tvoří vnitřní strukturu procesorů, jsou: řadič, který má za úkol číst operandy (data, čísla) a instrukce z operační paměti, dekódovat je a na základě
Akademický rok: 2004/05 Datum: Příjmení: Křestní jméno: Osobní číslo: Obor:
 Západočeská univerzita v Plzni Písemná zkouška z předmětu: Zkoušející: Katedra informatiky a výpočetní techniky Počítačová technika KIV/POT Dr. Ing. Karel Dudáček Akademický rok: 2004/05 Datum: Příjmení:
Západočeská univerzita v Plzni Písemná zkouška z předmětu: Zkoušející: Katedra informatiky a výpočetní techniky Počítačová technika KIV/POT Dr. Ing. Karel Dudáček Akademický rok: 2004/05 Datum: Příjmení:
Principy počítačů I ZVYŠOVÁNÍ VÝKONU PROCESORŮ. Sériové zpracování. Pipeline. Úspora při použití pipeline. Problém 1: přístup k datům.
 Principy počítačů I Sériové zpracování ZVYŠOVÁNÍ VÝKONU PROCESORŮ Copak je po jméně? Co růží zvou i zváno jinak vonělo by stejně. William Shakespeare Pipeline Úspora při použití pipeline Pipeline s k kroky,
Principy počítačů I Sériové zpracování ZVYŠOVÁNÍ VÝKONU PROCESORŮ Copak je po jméně? Co růží zvou i zváno jinak vonělo by stejně. William Shakespeare Pipeline Úspora při použití pipeline Pipeline s k kroky,
Přerušení POT POT. Přerušovací systém. Přerušovací systém. skok do obslužného programu. vykonávaný program. asynchronní událost. obslužný.
 1 Přerušení Při výskytu určité události procesor přeruší vykonávání hlavního programu a začne vykonávat obslužnou proceduru pro danou událost. Po dokončení obslužné procedury pokračuje výpočet hlavního
1 Přerušení Při výskytu určité události procesor přeruší vykonávání hlavního programu a začne vykonávat obslužnou proceduru pro danou událost. Po dokončení obslužné procedury pokračuje výpočet hlavního
Technické prostředky počítačové techniky
 Počítač - stroj, který podle předem připravených instrukcí zpracovává data Základní části: centrální procesorová jednotka (schopná řídit se posloupností instrukcí a ovládat další části počítače) zařízení
Počítač - stroj, který podle předem připravených instrukcí zpracovává data Základní části: centrální procesorová jednotka (schopná řídit se posloupností instrukcí a ovládat další části počítače) zařízení