Architektura počítačů Paměťová hierarchie
|
|
|
- Vladimíra Fišerová
- před 6 lety
- Počet zobrazení:
Transkript
1 Architektura počítačů Paměťová hierarchie Lubomír Bulej CHARLES UNIVERSITY IN PRAGUE faculty of mathematics and physics


2 2/72 Paměťová zeď Výkon procesorů omezen výkonem pamětí Výkon procesorů roste rychleji než výkon pamětí Jednoduché operace trvají desetiny ns Přístup do paměti trvá desítky ns Nedosažitelný cíl kombinace: paměť stejně rychlá jako procesor, dostatečná kapacita, rozumná cena
3 Paměťová zeď (2) 3/72 Burks, Goldstine, von Neumann: Preliminary discussion of the logical design of an electronic computing instrument (1946) Ideally, one would desire an infinitely large memory capacity such that any particular word would be immmediately available [...] We are forced to recognize the possibility of constructing a hierarchy of memories, each of which has a greater capacity than the preceding but which is less quickly accessible.
4 Paměťová zeď (3) 4/72 Analogie: knihy a knihovna Knihovna Spousta knih, ale přístup k nim je pomalý (cesta do knihovny) Velikost knihovny (nějakou dobu trvá najít správnou knihu) Jak se vyhnout vysoké latenci? Půjčit si nějaké knihy domů Mohou ležet na polici nebo pracovním stole Často používané knihy mohou být po ruce (časová lokalita) Půjčíme si více knih na podobné téma (prostorová lokalita) Odhadneme, co budeme potřebovat příště (prefetching) Police a stůl mají omezenou kapacitu
5 5/72 Paměťová zeď (4) Jak překonat paměťovou zeď Princip lokality přístupu do paměti Vlastnost většiny reálných programů (instrukce i data) Časová lokalita (temporal locality) K nedávno použitým datům budeme velmi pravděpodobně přistupovat znovu Nedávná data uložíme v malé, velmi rychlé paměti Prostorová lokalita (spatial locality) S velkou pravděpodobností budeme přistupovat k datům poblíž těch, ke kterým jsme přistupovali nedávno Přistupovat k datům po větších blocích (zahrnující i okolní data)
6 6/72 Volatilní paměti Statická RAM Primární cíl: Rychlost Sekundární cíl: Kapacita 6 tranzistorů na bit, rychlost závisí na ploše (pro malé kapacity latence < 1 ns) Dobře se kombinuje s ostatní procesorovou logikou Obsah není nutné periodicky obnovovat
7 Statická RAM 7/72 Klopný obvod typu D 1 bit, ~ 4 hradla, ~ 9 tranzistorů D Q d q c
8 8/72 Buňka statické RAM Dvojice invertorů + řídící tranzistory 6 tranzistorů na 1 buňku bit line!bit line word line
9 Statická RAM v maticovém uspořádání 9/72 M N bitů: M řádků po N bitech Výběr řádku Dekodér 1 z M Přístup ve dvou krocích 1. Výběr řádku (word lines) 2. Čtení sloupců (bit lines) wl[0] wl[1] bl[0] bl[1] bl[2] wl[2]
10 Statická RAM (2) row decoder data 10/72 bit n-1 n-bit address X memory matrix Y... Y-gating bit 0
11 Volatilní paměti (2) Dynamická RAM Primární cíl: Hustota (cena za bit) 1 tranzistor a 1 kondenzátor na bit Vysoká latence 40 ns uvnitř samotné paměti 100 ns mezi obvody Obsah je nutné periodicky občerstvovat (číst a znovu zapisovat) Nelze snadno kombinovat s logikou procesoru Jiný výrobní postup 11/72
12 Buňka dynamické RAM Kondenzátor + řídící tranzistor Informace uložena jako elektrický náboj Kondenzátor se samovolně vybíjí/nabíjí v důsledku ztrát a obsahu sousedních buněk Čtení je destruktivní (přečtená hodnota se ihned zapisuje zpět) bl[0] bl[1] bit line wl[0] wl[1] word line sense amplifiers 12/72
13 Dynamická RAM control logic row decoder data 13/72 address memory matrix RAS... Sense amps... CAS Y Y-gating WE
14 Zvyšování výkonu DRAM Pozorování Nejdéle trvá čtení řádku DRAM Řádek obsahuje více dat než jen požadované slovo Amortizace ceny čtení řádku Použít více slov z jednoho přečteného řádku Pipelining výstupu dat a výběru nového řádku Přečtený řádek uložen do výstupního registru, zahájení čtení dat z jiného řádku současně s přenosem dat z paměti do procesoru po sběrnici 14/72
15 Využití lokality přístupu Hierarchie paměťových komponent Vyšší vrstvy: Rychlé, malé, drahé Nižší vrstvy: Pomalé, velké, levné Vzájemné propojení sběrnicemi Přidávají latenci, omezují propustnost Nejčastěji používaná data v M1 Druhá nejpoužívanější data v M2 atd. Přesun dat mezi vrstvami Optimalizace průměrné doby přístupu CPU M1 M2 Lat avg = Lat hit + Lat miss % miss M3 15/72
16 16/72 Hierarchie paměťových komponent M0: Registry CPU Data pro instrukce M1: Primární cache Oddělená instrukční a datová SRAM (kb) M2: Sekundární cache Regs D I spravuje překladač Nejlépe na čipu, určitě v pouzdře SRAM (MB) M3: Operační paměť SRAM (kb MB, embedded zařízení) DRAM (GB) M4: Odkládací paměť L2 spravuje hardware spravuje software Soubory, swap HDD, flash (TB) RAM Disk
17 Hierarchie paměťových komponent (2) Analogie s knihovnou Registry aktuálně otevřená stránka v knize Jen jedna stránka Primární cache knihy na stole Aktivně využívány, velmi rychlý přístup, malá kapacita Sekundární cache knihy na polici Aktivně využívány, poměrně rychlý přístup, střední kapacita Operační paměť knihovna Skoro veškerá data, pomalý přístup, velká kapacita Odkládací paměť meziknihovní výpůjčka Velmi pomalé, ale také velmi málo časté 17/72
18 Cache Iluze velké a rychlé paměti Přesun dat mezi vrstvami cache řídí hardware Automatické nalezení chybějících dat Řadič cache (cache controller) SRAM, integrovaná na čipu Software může dávat nápovědy Organizace cache (ABC) Asociativita, velikost bloku, kapacita Klasifikace výpadků cache 18/72
19 Přímé mapování paměti do cache Základní struktura Pole cache lines Např cache lines po 64 B 64 KB Hardwarová hashovací tabulka podle adresy Příklad konfigurace pro 32bitové adresy 64bajtové bloky spodních 6 bitů adresuje bajt v bloku (offset bits) 1024 bloků dalších 10 bitů představuje číslo bloku (index bits) Co dělat se zbývajícími 16 bity? 19/72
20 Přímé mapování paměti do cache (2) 20/72 h 2 index [31:16] [15:6] [5:0] offset MUX address data
21 Přímé mapování paměti do cache (3) Nalezení správných dat V každém řádku cache může být jeden z 2 16 bloků operační paměti (v případě vzorové konfiguraci pro 32bitové adresy) Kolize hashovací funkce Detekce správných dat Příznak platnosti řádky (valid bit) Tag se zbývajícími bity adresy (tag bits) Algoritmus 1. Přečteme řádek určený indexem 2. Pokud je nastaven valid bit a tag se shoduje s bity v adrese, jedná se o cache hit 3. Jinak se jedná o cache miss 21/72
22 Přímé mapování paměti do cache (4) 22/72 h 2 tag index offset = valid [31:16] [15:6] [5:0] MUX address data hit
23 Režie tagů a valid bitů Pro 64 KB cache s 1024 řádky po 64 B Pro 32bitové adresy (16 bitů na tag + 1 valid bit) 1024 řádků ~ 2,1 KB Režie 3,3 % Pro 64bitové adresy (48 bitů na tag + 1 valid bit) 1024 řádků ~ 6,1 KB Režie 9,6 % 23/72
24 Obsluha výpadku cache Načtení dat do cache Řadič cache Sekvenční obvod/stavový automat Vyžádá si data z následující úrovně hierarchie na základě adresy výpadku Zapíše data, tag a valid bit do řádku cache Výpadky cache zpožďují pipeline Analogie datového hazardu Zpožďovací logika je řízena signálem cache miss 24/72
25 Výkonnost cache Operace cache Přístup (čtení/zápis) do cache (access) Nalezení požadovaných dat (hit) Výpadek cache (miss) Načtení dat do cache (fill) Charakteristika cache % miss : Poměr výpadků a všech přístupů (miss rate) t hit : Doba přístupu do cache při hitu t miss : Doba potřebná k načtení dat do cache Výkonnostní metrika: Průměrný čas přístupu t avg = t hit + t miss % miss 25/72

26 Snížení miss rate Přímá cesta: zvyšování kapacity Miss rate klesá monotonně Zákon klesajících výnosů t hit roste s 2. odmocninou kapacity Složitější cesta Při konstantní kapacitě Změna organizace cache [1] 26/72
27 Organizace cache: Velikost řádku Zvětšení velikosti řádku Předpoklad: Využití prostorové lokality Změna poměru indexových/offsetových bitů (velikost tagu se nemění) Důsledky Snížení miss rate (do určité míry) Nižší režie na tagy Více potenciálně zbytečných přenosů dat Předčasná náhrada užitečných dat 27/72

28 Vliv velikosti řádku na miss rate Načítání okolních dat (spatial prefetching) Pro bloky se sousedními adresami mění miss/miss na miss/hit Rušení (interference) Pro bloky s nesousedními adresami v sousedních řádcích cache mění hit na miss Znemožňuje současný výskyt v cache Vždy oba efekty Ze začátku dominuje pozitivní efekt Limitní případ: Cache s jedním řádkem Obvyklá rozumná velikost řádku: B [1] 28/72
29 29/72 Vliv velikosti řádku na dobu plnění cache V principu Přečtení větších řádků by vždy mělo trvat déle V praxi Pro izolované výpadky se t miss nemění Critical Word First / Early Restart Z paměti se nejprve čte právě požadované slovo (pro minimalizaci zpoždění pipeline procesoru) Ostatní slova řádku cache se dočítají následně V případě skupin výpadků se t miss zvyšuje Nelze číst/přenášet/doplňovat více řádků současně Hromadění zpoždění Omezená přenosová kapacity mezi pamětí a procesorem
30 Asociativní mapování paměti do cache Množinová asociativita (set associativity) Skupiny řádků = množiny, řádek v množině = cesta Např.: 2-cestná množinově-asociativní cache (2-way set-associative) Limitní případy Pouze jedna cesta: Přímo mapovaná cache Pouze jedna množina: Plně asociativní cache Cíl: Omezení konfliktů Blok paměti může být ve různých řádcích jedné množiny Prodlužuje t hit Výběr dat z řádků v množině 30/72
31 Asociativní mapování paměti do cache (2) ways h 2 h 2 sets = valid = valid tag index offset [31:16] [15:6] [5:0] MUX address data hit 31/72
32 Asociativní mapování paměti do cache (3) Algoritmus 1. Pomocí index bitů adresy (set) najdeme množinu řádků 2. Přečteme současně všechna data a tagy ze všech řádků (ways) v množině 3. Porovnáme současně tagy řádků s tagem z adresy Vliv na tag/index bity Více cest méně množin Více tag bitů 32/72
![Vliv asociativity na miss rate Vyšší stupeň asociativity Snižuje miss rate Zákon klesajících výnosů Prodlužuje t hit [1] Dává smysl mít n-cestnou asociativitu, kde n není](/docs-images/101/151272880/images/33-3.jpg "mocnina dvojky Ničemu to nevadí, i když to není obvyklé Velikost řádku a počet množin by měly být mocninou dvojky Zjednodušuje to indexaci (lze jednoduše použít bity adresy)")
33 Vliv asociativity na miss rate Vyšší stupeň asociativity Snižuje miss rate Zákon klesajících výnosů Prodlužuje t hit [1] Dává smysl mít n-cestnou asociativitu, kde n není mocnina dvojky Ničemu to nevadí, i když to není obvyklé Velikost řádku a počet množin by měly být mocninou dvojky Zjednodušuje to indexaci (lze jednoduše použít bity adresy) 33/72
34 Plně asociativní cache Množinově-asociativní mapování s 1 množinou (počet cest roven počtu bloků) Blok paměti může být v libovolném bloku/řádku cache (cache line) Všechny bity adresy (kromě offset bitů) představují tag Asociativní paměť Paměť adresovaná klíčem Klíč = tag 34/72
35 Plně asociativní cache (2)... = valid = valid tag offset... [31:6] [5:0] MUX... address data hit 35/72
36 3C Model Klasifikace výpadků cache Compulsory (cold) miss Tuhle adresu jsem nikdy neviděl K výpadku by došlo i v nekonečně velké cache Capacity miss Výpadek způsobený příliš malou kapacitou cache Opakovaný přístup k bloku paměti oddělený alespoň N přístupy do N jiných bloků (kde N je počet řádků cache) K výpadku by došlo i v plně asociativní cache Conflict miss Výpadek způsobený příliš malým stupněm asociativity Všechny ostatní výpadky 36/72
37 Miss rate: ABC Důsledky 3C modelu Pokud nevznikají konflikty, zvýšení asociativity nepomůže Asociativita (Associativity) Snižuje počet konfliktních výpadků Prodlužuje t hit Velikost bloku (Block size) Zvyšuje počet konfliktních/kapacitních výpadků (méně řádků) Snižuje počet studených/kapacitních výpadků (prostorová lokalita) Vesměs neovlivňuje t hit Kapacita (Capacity) Snižuje počet kapacitních výpadků Prodlužuje t hit 37/72
38 Čtení dat z cache Tag a (všechna) data lze číst současně Pokud tag nesouhlasí, data se nepoužijí (cache miss) Vygeneruje se požadavek na doplnění (fill) z nižší vrstvy Read miss: kam uložit data z nižší vstvy? Obsah některého řádků nutno nahradit novými daty Původní obsah je vyhozen (evicted) Přímo mapovaná cache Cílový řádek určen jednoznačně indexovými bity adresy (Množinově) asociativní cache Všechny cesty v množině jsou kandidáty, nutno vybrat oběť Ideálně: nezahodit data, která budou brzy potřeba Random LRU (Least Recently Used): Ideální vzhledem k časové lokalitě NMRU (Not Most Recently Used): Aproximace LRU 38/72
39 Zápis dat do cache (1) Write hit Data zapsána do příslušného řádku cache Při zápisu pouze do cache budou data v paměti a v cache nekonzistentní Write through Při každé operaci zápisu data uložena do cache i paměti/nižší vrstvy Problém: operace s pamětí (a tedy instrukce zápisu) trvají příliš dlouho Řešení: data zapsána do cache a write bufferu, odkud jsou zapsána do paměti Procesor musí čekat pouze pokud je write buffer plný (Kdy k tomu může dojít?) Při hledání dat v cache je nutné se podívat i do write bufferu Write-back Při operaci zápisu data uložena pouze do cache Vyžaduje dirty bit pro indikaci stavu řádku ve vztahu k paměti/nižší vrstvě Modifikovaný (dirty) řádek zapsán do nižší úrovně až když je nahrazen Zlepšuje výkon v situacích, kdy program generuje zápisy do paměti stejně rychle nebo rychleji, než je paměť schopna obsluhovat Složitější na implementaci 39/72
40 Zápis dat do cache (2) Write miss v případě write-through cache Je možné zároveň číst tag a zapisovat data Pokud dojde k přepsání špatných dat, správná data jsou ještě v paměti Write allocate Nejprve se do cache doplní data z nižší vrstvy Poté jako write hit: příslušná část řádku se přepíše zapisovanými daty Může zabránit výpadkům při příštím přístupu (lokalita) K tomu nemusí nutně dojit. Vyžaduje dodatečnou přenosovou kapacitu No write allocate Data se zapisují pouze do nižší vrstvy/paměti Eliminuje čtení z nižší vrstvy při write miss Vhodné pro data, která procesorem pouze prochází Např. nulování obsahu stránky, zápis bloku dat na disk, odeslání dat po síti... Některé procesory umožňují nastavit strategii zápisu na úrovni jednotlivých stránek 40/72
41 Zápis dat do cache (3) Write miss v případě write-back cache Není vždy možné zároveň číst tag a zapisovat data Změněný řádek/cesta musí být nejprve zapsán do paměti/nižší úrovně Zápis vyžaduje buď dva kroky... kontrola hit/miss a poté vlastní zápis nebo použití store bufferu kontrola hit/miss současně s odložením dat do bufferu při write hit data zapsána ze store bufferu do cache Zápis modifikovaného řádku (při nahrazení) Data nejprve přesunuta do write-back bufferu, později do paměti/nižší vrstvy Při hledání dat v cache opět nutno prohledávat i write-back buffer 41/72
42 Víceúrovňové cache (1) Cíl: snížení penalizace při výpadku 1-úrovňová cache: Total CPI = Memory stall cycles per instruction 4 GHz procesor, přístup do paměti 100 ns (400 taktů), 2% výpadků: Total CPI = % x 400 = 9 2-úrovňová cache: Total CPI = Primary stalls per instruction + Secondary stalls per instruction Přístupová doba 5 ns (20 taktů) pro hit/miss, sníží celkový počet výpadků na 0.5%: Total CPI = % x % x 400 = /72
43 43/72 Víceúrovňové cache (2) Různé úrovně cache mají různé role Umožňuje optimalizovat pro jiná (různá) kritéria než u jednoúrovňové cache Primární cache Mimimalizace hit time Umožňuje zvýšit taktovací frekvenci nebo snížit počet stupňů pipeline Typicky menší kapacita, menší velikost řádků (nižší penalizace za cache miss) Sekundární cache Mimimalizace miss rate Snižuje penalizaci za přístup do paměti Výrazně vyšší kapacita (přístupová doba není kritická), větší velikost řádků, vyšší stupeň asociativity (důraz na snížení počtu výpadků)
44 44/72 Proč je důležité o cache vědět? Quick Sort vs. Radix Sort LaMarca, Ladner (1996) O(n log n) vs. O(n) Teoreticky není co řešit Zdroj: P&H
45 Proč je důležité o cache vědět? (2) 45/72 Jenže: Quick Sort se pro větší množství dat ukázal rychlejší... Zdroj: P&H
46 46/72 Proč je důležité o cache vědět? (3) Důvod Způsob přístupu k datům v implementaci algoritmu Radix Sort způsoboval příliš mnoho výpadků cache Zdroj: P&H
47 47/72 Proč je důležité o cache vědět? (4) Řešení Úprava implementace algoritmu Radix Sort, aby pracoval s daty nejprve v rámci bloku paměti, který je již načtený v cache (řádku cache) Zdroj: P&H
48 48/72 Shrnutí: paměť dominuje výkonu CPU Paměťová zeď (the memory wall) výkonnost roste rychleji u procesorů než u paměti Neexistuje ideální paměťová technologie rychlá, velká, levná nelze mít vše najednou Lokalita přístupu do paměti časová + prostorová, vlastnost reálných programů Řešení: hierarchie pamětí optimalizace průměrné doby přístupu do paměti různé technologie v různých vrstvách mechanizmus pro přesun dat mezi vrstvami
49 Shrnutí: cache jako iluze ideální paměti 1-3 úrovně rychlé paměti mezi CPU a hlavní pamětí SRAM, kapacita L1 ~ 64KiB, L2/L3 ~ 256KiB-16MiB z pohledu programátora (i CPU) transparentní CPU (datová cesta) požaduje data pouze po cache přesun dat mezi cache a hlavní pamětí zajišťuje HW data uložena v řádcích odpovídajících blokům paměti tag část adresy, která činí mapování jednoznačné 3C model: klasifikace výpadků cache změna organizace cache s cílem odstranit výpadky ABC: základní parametry cache asociativita, velikost bloku, kapacita 49/72

50 Paralelismus a paměťová hierarchie Víceprocesorové systémy se sdílenou pamětí Procesory čtou a zapisují do sdílených proměnných Generují požadavky na čtení/zápis na konkrétní adresy v paměti Očekávané chování Čtení z nějaké adresy v paměti vždy vrátí hodnotu, která byla na tuto adresu naposledy zapsána libovolných procesorem [1] 50/72

51 51/72 Problém s koherencí dat v cache (1) Důsledek existence lokálního a globálního stavu Moderní procesory replikují obsah paměti v lokální cache V důsledku zápisů mohou mít procesory různé hodnoty pro stejnou adresu v paměti [1]

52 52/72 Problém s koherencí dat v cache (2) Existuje i u jednoprocesorových systémů DMA přenosy mezi IO zařízeními a pamětí Jak zařízení tak CPU může číst stará data Typická řešení Zápisy do paměti označené jako uncached Flush cache po skončení práce nad bufferem [1]
53 53/72 Problém s očekávaným chováním Očekávané chování Čtení z nějaké adresy v paměti vždy vrátí hodnotu, která byla na tuto adresu naposledy zapsána libovolných procesorem Co znamená poslední? Co když dva procesory zapisují současně? Co když po zápisu procesorem P1 následuje čtení procesorem P2 tak rychle, takže není možné uvědomit ostatní? V sekvenčním programu je poslední určeno pořadím v programu (nikoliv časem) Platí i v rámci vlákna v paralelním programu V případě více vláken pro určení pořadí nestačí.
54 54/72 Koherentní paměťový systém Procesor vidí vlastní zápisy v programovém pořadí Intuitivní požadavek pro jednoprocesorové systémy. Zápisy do paměti nakonec uvidí všechny procesory Definuje koherentní pohled na paměť. Pokud by procesor mohl neustále číst starou hodnotu, paměť by byla nekoherentní. Není určeno kdy přesně se informace o zápisu propaguje. Zápisy do stejného místa jsou serializované (uspořádané) Všechny procesory uvidí zápisy do stejného místa ve stejném pořadí.
55 Uspořádání (serializace) zápisů Zápisy do stejného místa jsou serializované (uspořádané) Dva zápisy do stejného místa libovolnými dvěma procesory musí ostatní procesory vidět ve stejném pořadí. Příklad P1 zapíše hodnotu a do X. Poté P2 zapíše hodnotu b do X. Pokud by každý procesor viděl zápisy v jiném pořadí P1 by nejprve viděl svůj zápis a do X a až poté cizí zápis b do X P2 by nejprve viděl svůj zápis b do X a až poté cizí zápis a do X V koherentním systému neexistuje globální uspořádání, které by takový výsledek paralelního programu umožnilo. 55/72
56 56/72 Koherence vs konzistence Koherence Určuje jaké hodnoty uvidíme při čtení Týká se čtení/zápisu do jednoho místa v paměti Konzistence Určuje kdy budou zápisy viditelné pro čtení Týká se čtení/zápisu do více míst v paměti Pro naše účely Pokud procesor zapíše na adresu X a potom na adresu Y, pak libovolný jiný procesor, který vidí výsledek zápisu do Y, uvidí také zápis do X.
57 Zajištění koherence Hardwarová řešení HW zajistí, že čtení nějakého místa v paměti libovolným procesorem vrátí poslední hodnotu zapsanou do tohoto místa Pro vhodnou/smysluplnou definici posledního Metadata udržují informace o stavu dat v cache ve vztahu k ostatním Řešení založena na zneplatnění (invalidaci) nebo aktualizaci (update) dat v cache Koherenční protokol: pravidla pro změny stavu (metadat) konkrétního bloku v cache v rámci celého systému 57/72
 Akce jednoho procesoru mohou přednačítat data pro jiné")
58 58/72 Snadné řešení: sdílená cache Problémy se škálovatelností Interference, contention Potenciální výhody Jemná granularita sdílení (překryv pracovních množin) Akce jednoho procesoru mohou přednačítat data pro jiné [1]
 paměťové operace Individuálně reagují tak, aby byla zajištěna koherence dat Musí reagovat jak na události jak ze strany procesoru (datové cesty), tak propojovacího média")
59 59/72 Řešení založená na snoopingu Procesory (řadiče cache) sdílejí projovovací médium Všechny události související s koherencí šířeny (broadcast) všem procesorům (řadičům cache) v systému Řadiče cache monitorují (snoop) paměťové operace Individuálně reagují tak, aby byla zajištěna koherence dat Musí reagovat jak na události jak ze strany procesoru (datové cesty), tak propojovacího média (aktivita ostatních procesorů) [1]

60 60/72 Jednoduchá implementace koherence Write-through cache Granularita koherence je cache line Při zápisu invaliduje cacheline ostatních procesorů Broadcast na sdíleném spoji Příští čtení stejné cache line na jiném procesoru bude cache miss Procesor načte aktuální hodnotu z paměti [1]
61 61/72 Základní Valid/Invalid (VI) protokol [1] A/B = radič cache vidí akci A, provede akci B Reakce na aktivitu na sdíleném spoji Reakce na požadavek procesoru Akce protokolu Processor Read (PrRd) Processor Write (PrWr) Bus Read (BusRd) Bus Write (BusWr) Požadavky na sdílený spoj Zápisové transakce viditelné pro všechny řadiče cache Zápisové transakce viditelné ve stejném pořadí Zjednodušující předpoklady WT cache používá strategii write no-allocate Paměťové transakce a transakce na sdíleném spoji jsou atomické Procesor čeká na dokončení paměťové operace předtím než zahájí novou Invalidace proběhne okamžitě, jako součást přijetí invalidační výzvy
62 62/72 Write-through strategie je neefektivní Každý zápis propagován do paměti Vysoké požadavky na přenosovou kapacitu Write-back cache absorbují většinu zápisů Výrazně nižší požadavky na přenosovou kapacitu Jak zajistit propagaci zápisů/uspořádání? Vyžaduje sofistikovanější protokol
63 63/72 Invalidační protokol pro write-back cache Cache line ve výhradním (exclusive) stavu možno modifikovat bez signalizace ostatním Ostatní cache ji nemají, takže ostatní procesory nemohou data z cache line číst aniž by vygenerovaly požadavek na čtení z paměti Zápis možný pouze do cache line ve výhradním stavu Pokud chce procesor zapisovat do cache line, která není ve výhradním stavu, řadič cache nejprve signalizuje výhradní čtení (read-exclusive) Požadavek na výhradní čtení informuje ostatní cache o nadcházejícím zápisu Požadavek na výhradní čtení je nutný i pro cache line, která už v cache je Dirty cache line je nutně výhradní (exclusive) Pokud řadič cache vidí požadavek na výhradní čtení Pokud se týká cache line, kterou má u sebe, musí ji invalidovat
![Základní invalidační protokol MSI [1] Hlavní cíle protokolu Získat výhradní přístup pro zápis Nalezení nejnovější kopie při](/docs-images/101/151272880/images/64-2.jpg "cache miss Stavy protokolu I: neplatná cache line S: clean cache line v jedné nebo více cache M: dirty cache line právě v")
 Čtení cache line s úmyslem ji modifikovat.")
64 Základní invalidační protokol MSI [1] Hlavní cíle protokolu Získat výhradní přístup pro zápis Nalezení nejnovější kopie při cache miss Stavy protokolu I: neplatná cache line S: clean cache line v jedné nebo více cache M: dirty cache line právě v jedné cache Akce protokolu Processor Read (PrRd) Processor Write (PrWr) Bus Read (BusRd) Čtení cache line bez úmyslu ji modifikovat Bus Read Exclusive (BusRdX) Čtení cache line s úmyslem ji modifikovat. Bus Write Back (BusWB) Zápis cache line do paměti 64/72
65 Uspokojí MSI požadavky na koherenci? Propagace zápisů V rámci invalidace. Uspořádání zápisů Zápisy, které se objeví na sběrnici, jsou uspořádány v pořadí, v jakém se objeví na sběrnici (BusRdX) Čtení, která se objeví na sběrnici, jsou uspořádány v pořadí, v jakém se objeví na sběrnici (BusRd) Zápisy do cache line ve výhradním (M) stavu se na sběrnici neobjeví Posloupnost zápisů do cache line se nachází mezi dvěma transakcemi na sběrnici. Všechny zápisy v posloupnosti provádí stejný procesor P, který je vidí ve správném pořadí. Všechny ostatní procesory uvidí tyto zápisy až po sběrnicové transakci pro danou cache line a všechny zápisy této transakci předchází. Všechny procesory vidí zápisy ve stejném pořadí. 65/72
66 66/72 Invalidační protokol MESI (1) MSI vyžaduje 2 transakce pro běžný případ čtení a následné modifikace dat 1. transakce: BusRd pro přesun ze stavu I do stavu S. 2. transakce: BusRdX pro přesun ze stavu S to stavu M. Nutné i v případě, kdy se cache line nikdy nesdílí Řešení: nový stav E (exclusive clean) Cache line není modifikovaná, ale existuje pouze v jedné cache Odděluje exkluzivitu cache line od vlastnictví (cache line není dirty, takže kopie dat v paměti je platnou kopií) Přesun ze stavu E do stavu M nevyžaduje sběrnicovou transakci
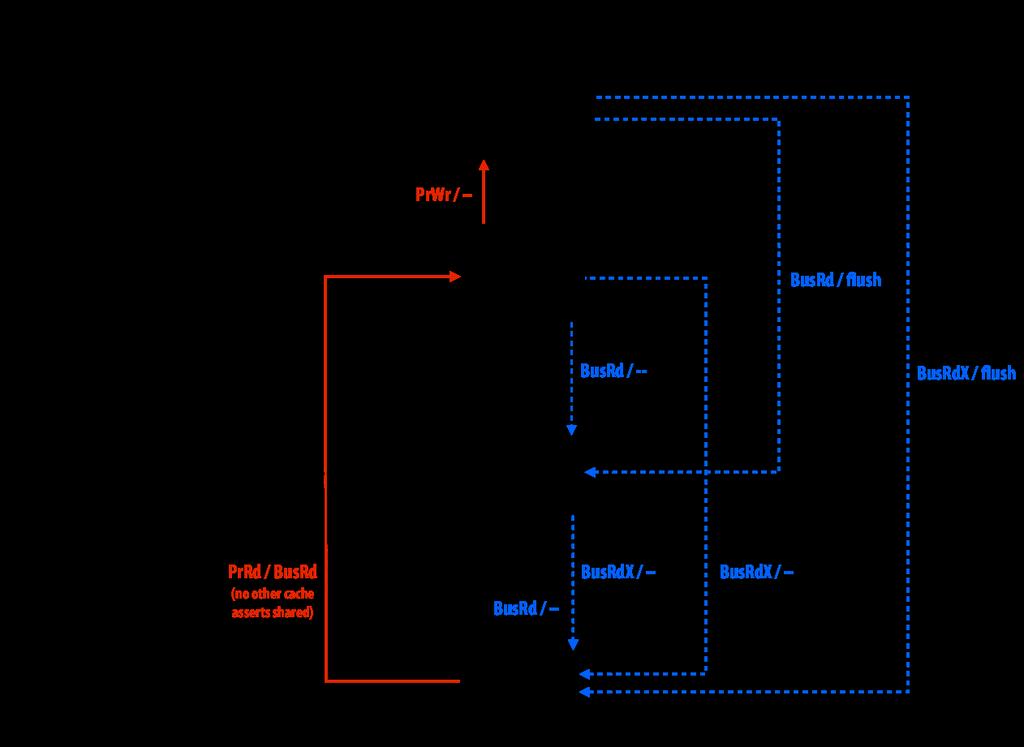

67 Invalidační protokol MESI (2) 67/72 [1]
68 Efektivnější (a složitější) protokoly MOESI (AMD Opteron) V protokolu MESI přesun ze stavu M do stavu S vyžaduje zápis dat do paměti MOESI přidává stav O (owned, not exclusive) bez zápisu dat (cache line zůstane dirty) Ostatní procesory mohou mít cache line ve stavu S, právě jeden procesor má cache line ve stavu O Data v paměti nejsou aktuální, takže cache obsahující cache line ve stavu O musí obsluhovat cache missy ostatních procesorů MESIF (Intel) Jako MESI, ale jedna cache drží sdílenou cache line ve stavu F (forward) místo ve stavu S Cache obsahující cache line ve stavu F obsluhuje cache miss Cache, která cache line četla naposled, ji načte ve stavu F Stav F migruje do poslední cache, která cache line načetla po read missu Předpokládá se, že tato cache tuto cache line hned nezahodí (a stav F se neztratí) Zjednodušuje rozhodování o tom, která cache má obsloužit cache miss 68/72
69 69/72 Důsledky implementace koherence Každá cache musí poslouchat a reagovat na koherenční události šířené po sdíleném spoji Nutno duplikovat tagy cache aby vyhledání tagu neinterferovalo s load/store požadavky procesoru Vyšší zatížení sdíleného spoje Může být významné/limitující pro velký počet jader GPU koherenci neimplementují vůbec nebo v omezené formě Příliš vysoká režie, malé uplatnění u grafických aplikací
70 Důsledky pro programátora Co je špatně na následujícím kódu? // allocate per-thread accumulators int counters [NUM_THREADS]; Lepší verze // allocate per-thread accumulators struct PerThreadState { int counter; char padding [64 sizeof (int)]; } PerThreadState counters [NUM_THREADS]; 70/72
71 71/72 Falešné sdílení (false sharing) Dvě vlákna zapisují do různých proměnných ve stejné cache line Cache line přeskakuje mezi cache zapisujících procesorů Koherenční protokol způsobuje velké množství komunikace přestože spolu vlákna vůbec nekomunikuji Veškerá komunikace je pouze nežádoucí produkt falešného sdílení Může výrazně ovlivnit výkonnost programu na architekturách implementujících koherenci Naprostá většina běžných CPU Bez ohledu na programovací jazyk
72 Reference 72/72 [1] Roth A., Martin M.: CIS 371 Computer Organization and Design, University of Pennsylvania, Dept. Of Computer and Information Science, 2009
Architektura počítačů Paměťová hierarchie
 Architektura počítačů Paměťová hierarchie http://d3s.mff.cuni.cz/teaching/computer_architecture/ Lubomír Bulej bulej@d3s.mff.cuni.cz CHARLES UNIVERSITY IN PRAGUE faculty of mathematics and physics Paměťová
Architektura počítačů Paměťová hierarchie http://d3s.mff.cuni.cz/teaching/computer_architecture/ Lubomír Bulej bulej@d3s.mff.cuni.cz CHARLES UNIVERSITY IN PRAGUE faculty of mathematics and physics Paměťová
Principy počítačů a operačních systémů
 Principy počítačů a operačních systémů Hierarchie paměti a cache Zimní semestr 2010/2011 Poděkování Při přípravě této prezentace jsem převzal a přeložil velké množství materiálu z prezentace Roth, A.,
Principy počítačů a operačních systémů Hierarchie paměti a cache Zimní semestr 2010/2011 Poděkování Při přípravě této prezentace jsem převzal a přeložil velké množství materiálu z prezentace Roth, A.,
Architektura počítačů Paměťová hierarchie
 Architektura počítačů Paměťová hierarchie http://d3s.mff.cuni.cz/teaching/computer_architecture/ Lubomír Bulej bulej@d3s.mff.cuni.cz CHARLES UNIVERSITY IN PRAGUE faculty of mathematcs and physics 2/72
Architektura počítačů Paměťová hierarchie http://d3s.mff.cuni.cz/teaching/computer_architecture/ Lubomír Bulej bulej@d3s.mff.cuni.cz CHARLES UNIVERSITY IN PRAGUE faculty of mathematcs and physics 2/72
Mezipaměti počítače. L2 cache. L3 cache
 Mezipaměti počítače Cache paměť - mezipaměť Hlavní paměť procesoru je typu DRAM a je pomalá. Proto se mezi pomalou hlavní paměť a procesor vkládá menší, ale rychlá vyrovnávací (cache) paměť SRAM. Rychlost
Mezipaměti počítače Cache paměť - mezipaměť Hlavní paměť procesoru je typu DRAM a je pomalá. Proto se mezi pomalou hlavní paměť a procesor vkládá menší, ale rychlá vyrovnávací (cache) paměť SRAM. Rychlost
Architektury paralelních počítačů I.
 Architektury paralelních počítačů I. Úvod, Koherence a konzistence u SMP Ing. Miloš Bečvář s použitím slajdů Prof. Ing. Pavla Tvrdíka, CSc. Osnova přednášky Typy paralelismu a jejich využití v arch. poč.
Architektury paralelních počítačů I. Úvod, Koherence a konzistence u SMP Ing. Miloš Bečvář s použitím slajdů Prof. Ing. Pavla Tvrdíka, CSc. Osnova přednášky Typy paralelismu a jejich využití v arch. poč.
Paměťový podsystém počítače
 Paměťový podsystém počítače typy pamětových systémů počítače virtuální paměť stránkování segmentace rychlá vyrovnávací paměť 30.1.2013 O. Novák: CIE6 1 Organizace paměťového systému počítače Paměťová hierarchie...
Paměťový podsystém počítače typy pamětových systémů počítače virtuální paměť stránkování segmentace rychlá vyrovnávací paměť 30.1.2013 O. Novák: CIE6 1 Organizace paměťového systému počítače Paměťová hierarchie...
Pamět ová hierarchie, návrh skryté paměti cache 2
 Architektura počítačových systémů Róbert Lórencz 8. přednáška Pamět ová hierarchie, návrh skryté paměti cache 2 http://service.felk.cvut.cz/courses/36aps lorencz@fel.cvut.cz Róbert Lórencz (ČVUT FEL, 2005)
Architektura počítačových systémů Róbert Lórencz 8. přednáška Pamět ová hierarchie, návrh skryté paměti cache 2 http://service.felk.cvut.cz/courses/36aps lorencz@fel.cvut.cz Róbert Lórencz (ČVUT FEL, 2005)
Paměti cache. Cache může být realizována softwarově nebo hardwarově.
 Paměti cache Cache je označení pro vyrovnávací paměť nacházející se mezi dvěma subsystémy s rozdílnou přenosovou rychlostí, a jak již její název vypovídá, tak tuto rychlost vyrovnává. Cache může být realizována
Paměti cache Cache je označení pro vyrovnávací paměť nacházející se mezi dvěma subsystémy s rozdílnou přenosovou rychlostí, a jak již její název vypovídá, tak tuto rychlost vyrovnává. Cache může být realizována
Pokročilé architektury počítačů
 Pokročilé architektury počítačů Architektura paměťového a periferního podsystému České vysoké učení technické, Fakulta elektrotechnická A4M36PAP Pokročílé architektury počítačů Ver.1.00 2010 1 Motivace
Pokročilé architektury počítačů Architektura paměťového a periferního podsystému České vysoké učení technické, Fakulta elektrotechnická A4M36PAP Pokročílé architektury počítačů Ver.1.00 2010 1 Motivace
Pamět ová hierarchie, návrh skryté paměti 2. doc. Ing. Róbert Lórencz, CSc.
 Architektura počítačových systémů Pamět ová hierarchie, návrh skryté paměti 2 doc. Ing. Róbert Lórencz, CSc. České vysoké učení technické v Praze Fakulta informačních technologií Katedra počítačových systémů
Architektura počítačových systémů Pamět ová hierarchie, návrh skryté paměti 2 doc. Ing. Róbert Lórencz, CSc. České vysoké učení technické v Praze Fakulta informačních technologií Katedra počítačových systémů
Struktura a architektura počítačů (BI-SAP) 10
 10") Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti Struktura a architektura počítačů (BI-SAP) 10 doc. Ing. Hana Kubátová, CSc. Katedra číslicového návrhu Fakulta informačních technologii
Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti Struktura a architektura počítačů (BI-SAP) 10 doc. Ing. Hana Kubátová, CSc. Katedra číslicového návrhu Fakulta informačních technologii
Struktura a architektura počítačů (BI-SAP) 11
 11") Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti Struktura a architektura počítačů (BI-SAP) 11 doc. Ing. Hana Kubátová, CSc. Katedra číslicového návrhu Fakulta informačních technologii
Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti Struktura a architektura počítačů (BI-SAP) 11 doc. Ing. Hana Kubátová, CSc. Katedra číslicového návrhu Fakulta informačních technologii
Paměti. Paměť je zařízení, které slouží k ukládání programů a dat, s nimiž počítač pracuje
 Paměti Paměť je zařízení, které slouží k ukládání programů a dat, s nimiž počítač pracuje Paměti počítače lze rozdělit do tří základních skupin: registry paměťová místa na čipu procesoru jsou používány
Paměti Paměť je zařízení, které slouží k ukládání programů a dat, s nimiž počítač pracuje Paměti počítače lze rozdělit do tří základních skupin: registry paměťová místa na čipu procesoru jsou používány
Paměti a jejich organizace
 Kapitola 5 Paměti a jejich organizace 5.1 Vnitřní a vnější paměti, vlastnosti jednotlivých typů Vnější paměti Jsou umístěny mimo základní jednotku. Lze je zařadit mezi periferní zařízení. Zápis a čtení
Kapitola 5 Paměti a jejich organizace 5.1 Vnitřní a vnější paměti, vlastnosti jednotlivých typů Vnější paměti Jsou umístěny mimo základní jednotku. Lze je zařadit mezi periferní zařízení. Zápis a čtení
PROCESOR. Typy procesorů
 PROCESOR Procesor je ústřední výkonnou jednotkou počítače, která čte z paměti instrukce a na jejich základě vykonává program. Primárním úkolem procesoru je řídit činnost ostatních částí počítače včetně
PROCESOR Procesor je ústřední výkonnou jednotkou počítače, která čte z paměti instrukce a na jejich základě vykonává program. Primárním úkolem procesoru je řídit činnost ostatních částí počítače včetně
Operační systémy. Jednoduché stránkování. Virtuální paměť. Příklad: jednoduché stránkování. Virtuální paměť se stránkování. Memory Management Unit
 Jednoduché stránkování Operační systémy Přednáška 8: Správa paměti II Hlavní paměť rozdělená na malé úseky stejné velikosti (např. 4kB) nazývané rámce (frames). Program rozdělen na malé úseky stejné velikosti
Jednoduché stránkování Operační systémy Přednáška 8: Správa paměti II Hlavní paměť rozdělená na malé úseky stejné velikosti (např. 4kB) nazývané rámce (frames). Program rozdělen na malé úseky stejné velikosti
Paměti EEPROM (1) Paměti EEPROM (2) Paměti Flash (1) Paměti EEPROM (3) Paměti Flash (2) Paměti Flash (3)
 Paměti EEPROM (2) Paměti Flash (1) Paměti EEPROM (3) Paměti Flash (2) Paměti Flash (3)") Paměti EEPROM (1) EEPROM Electrically EPROM Mají podobné chování jako paměti EPROM, tj. jedná se o statické, energeticky nezávislé paměti, které je možné naprogramovat a později z nich informace vymazat
Paměti EEPROM (1) EEPROM Electrically EPROM Mají podobné chování jako paměti EPROM, tj. jedná se o statické, energeticky nezávislé paměti, které je možné naprogramovat a později z nich informace vymazat
Miroslav Flídr Počítačové systémy LS 2006-1/21- Západočeská univerzita v Plzni
 Počítačové systémy Vnitřní paměti Miroslav Flídr Počítačové systémy LS 2006-1/21- Západočeská univerzita v Plzni Hierarchire pamětí Miroslav Flídr Počítačové systémy LS 2006-2/21- Západočeská univerzita
Počítačové systémy Vnitřní paměti Miroslav Flídr Počítačové systémy LS 2006-1/21- Západočeská univerzita v Plzni Hierarchire pamětí Miroslav Flídr Počítačové systémy LS 2006-2/21- Západočeská univerzita
Paměťová hierarchie. INP 2008 FIT VUT v Brně
 Paměťová hierarchie INP 2008 FIT VUT v Brně 000 Výkonová mezera mezi CPU a pamětí Moorův zákon CPU CPU 60% za rok (2X/.5roku) výkonnost 00 0 980 98 DRAM 982 983 984 985 986 987 988 989 990 99 992 993 994
Paměťová hierarchie INP 2008 FIT VUT v Brně 000 Výkonová mezera mezi CPU a pamětí Moorův zákon CPU CPU 60% za rok (2X/.5roku) výkonnost 00 0 980 98 DRAM 982 983 984 985 986 987 988 989 990 99 992 993 994
Pamět ová hierarchie, virtuální pamět. doc. Ing. Róbert Lórencz, CSc.
 Architektura počítačových systémů Pamět ová hierarchie, virtuální pamět doc. Ing. Róbert Lórencz, CSc. České vysoké učení technické v Praze Fakulta informačních technologií Katedra počítačových systémů
Architektura počítačových systémů Pamět ová hierarchie, virtuální pamět doc. Ing. Róbert Lórencz, CSc. České vysoké učení technické v Praze Fakulta informačních technologií Katedra počítačových systémů
Sběrnicová struktura PC Procesory PC funkce, vlastnosti Interní počítačové paměti PC
 Informační systémy 2 Obsah: Sběrnicová struktura PC Procesory PC funkce, vlastnosti Interní počítačové paměti PC ROM RAM Paměti typu CACHE IS2-4 1 Dnešní info: Informační systémy 2 03 Informační systémy
Informační systémy 2 Obsah: Sběrnicová struktura PC Procesory PC funkce, vlastnosti Interní počítačové paměti PC ROM RAM Paměti typu CACHE IS2-4 1 Dnešní info: Informační systémy 2 03 Informační systémy
Cílem kapitoly je seznámit studenta s pamětmi. Jejich minulostí, současností a hlavnímu parametry.
 Paměti Cílem kapitoly je seznámit studenta s pamětmi. Jejich minulostí, současností a hlavnímu parametry. Klíčové pojmy: paměť, RAM, rozdělení pamětí, ROM, vnitřní paměť, vnější paměť. Úvod Operační paměť
Paměti Cílem kapitoly je seznámit studenta s pamětmi. Jejich minulostí, současností a hlavnímu parametry. Klíčové pojmy: paměť, RAM, rozdělení pamětí, ROM, vnitřní paměť, vnější paměť. Úvod Operační paměť
Systém adresace paměti
 Systém adresace paměti Základní pojmy Adresa fyzická - adresa, která je přenesena na adresní sběrnici a fyzicky adresuje hlavní paměť logická - adresa, kterou má k dispozici proces k adresaci přiděleného
Systém adresace paměti Základní pojmy Adresa fyzická - adresa, která je přenesena na adresní sběrnici a fyzicky adresuje hlavní paměť logická - adresa, kterou má k dispozici proces k adresaci přiděleného
Pohled do nitra mikroprocesoru Josef Horálek
 Pohled do nitra mikroprocesoru Josef Horálek Z čeho vycházíme = Vycházíme z Von Neumannovy architektury = Celý počítač se tak skládá z pěti koncepčních bloků: = Operační paměť = Programový řadič = Aritmeticko-logická
Pohled do nitra mikroprocesoru Josef Horálek Z čeho vycházíme = Vycházíme z Von Neumannovy architektury = Celý počítač se tak skládá z pěti koncepčních bloků: = Operační paměť = Programový řadič = Aritmeticko-logická
ÚVOD DO OPERAČNÍCH SYSTÉMŮ. Správa paměti. Přímý přístup k fyzické paměti, abstrakce: adresový prostor, virtualizace, segmentace
 ÚVOD DO OPERAČNÍCH SYSTÉMŮ Správa paměti Přímý přístup k fyzické paměti, abstrakce: adresový prostor, virtualizace, segmentace České vysoké učení technické Fakulta elektrotechnická Y38ÚOS Úvod do operačních
ÚVOD DO OPERAČNÍCH SYSTÉMŮ Správa paměti Přímý přístup k fyzické paměti, abstrakce: adresový prostor, virtualizace, segmentace České vysoké učení technické Fakulta elektrotechnická Y38ÚOS Úvod do operačních
Přednášky o výpočetní technice. Hardware teoreticky. Adam Dominec 2010
 Přednášky o výpočetní technice Hardware teoreticky Adam Dominec 2010 Rozvržení Historie Procesor Paměť Základní deska přednášky o výpočetní technice Počítací stroje Mechanické počítačky se rozvíjely už
Přednášky o výpočetní technice Hardware teoreticky Adam Dominec 2010 Rozvržení Historie Procesor Paměť Základní deska přednášky o výpočetní technice Počítací stroje Mechanické počítačky se rozvíjely už
Rychlá vyrovnávací paměť v architektuře PC
 Rychlá vyrovnávací paměť v architektuře PC 1 Cíl přednášky Prezentovat důvody, které vedly k zavedení rychlé vyrovnávací paměti (RVP) do architektury počítače. Vysvětlit principy činnosti RVP. Ukázat vývoj
Rychlá vyrovnávací paměť v architektuře PC 1 Cíl přednášky Prezentovat důvody, které vedly k zavedení rychlé vyrovnávací paměti (RVP) do architektury počítače. Vysvětlit principy činnosti RVP. Ukázat vývoj
Přednáška. Správa paměti II. Katedra počítačových systémů FIT, České vysoké učení technické v Praze Jan Trdlička, 2012
 Přednáška Správa paměti II. Katedra počítačových systémů FIT, České vysoké učení technické v Praze Jan Trdlička, 2012 Příprava studijního programu Informatika je podporována projektem financovaným z Evropského
Přednáška Správa paměti II. Katedra počítačových systémů FIT, České vysoké učení technické v Praze Jan Trdlička, 2012 Příprava studijního programu Informatika je podporována projektem financovaným z Evropského
Sběrnicová struktura PC Procesory PC funkce, vlastnosti Interní počítačové paměti PC
 Informatika 2 Technické prostředky počítačové techniky - 2 Přednáší: doc. Ing. Jan Skrbek, Dr. - KIN Přednášky: středa 14 20 15 55 Spojení: e-mail: jan.skrbek@tul.cz 16 10 17 45 tel.: 48 535 2442 Obsah:
Informatika 2 Technické prostředky počítačové techniky - 2 Přednáší: doc. Ing. Jan Skrbek, Dr. - KIN Přednášky: středa 14 20 15 55 Spojení: e-mail: jan.skrbek@tul.cz 16 10 17 45 tel.: 48 535 2442 Obsah:
Cache paměť - mezipaměť
 Cache paměť - mezipaměť 10.přednáška Urychlení přenosu mezi procesorem a hlavní pamětí Hlavní paměť procesoru je typu DRAM a je pomalá. Proto se mezi pomalou hlavní paměť a procesor vkládá menší, ale rychlá
Cache paměť - mezipaměť 10.přednáška Urychlení přenosu mezi procesorem a hlavní pamětí Hlavní paměť procesoru je typu DRAM a je pomalá. Proto se mezi pomalou hlavní paměť a procesor vkládá menší, ale rychlá
Technické prostředky počítačové techniky
 Počítač - stroj, který podle předem připravených instrukcí zpracovává data Základní části: centrální procesorová jednotka (schopná řídit se posloupností instrukcí a ovládat další části počítače) zařízení
Počítač - stroj, který podle předem připravených instrukcí zpracovává data Základní části: centrální procesorová jednotka (schopná řídit se posloupností instrukcí a ovládat další části počítače) zařízení
Paměť počítače. 0 (neprochází proud) 1 (prochází proud)
 1 (prochází proud)") Paměť počítače Paměť je nezbytnou součástí jakéhokoli počítače. Slouží k uložení základních informací počítače, operačního systému, aplikačních programů a dat uživatele. Počítače jsou vybudovány z bistabilních
Paměť počítače Paměť je nezbytnou součástí jakéhokoli počítače. Slouží k uložení základních informací počítače, operačního systému, aplikačních programů a dat uživatele. Počítače jsou vybudovány z bistabilních
Dělení pamětí Volatilní paměti Nevolatilní paměti. Miroslav Flídr Počítačové systémy LS /11- Západočeská univerzita v Plzni
 ělení pamětí Volatilní paměti Nevolatilní paměti Počítačové systémy Vnitřní paměti Miroslav Flídr Počítačové systémy LS 2006-1/11- Západočeská univerzita v Plzni ělení pamětí Volatilní paměti Nevolatilní
ělení pamětí Volatilní paměti Nevolatilní paměti Počítačové systémy Vnitřní paměti Miroslav Flídr Počítačové systémy LS 2006-1/11- Západočeská univerzita v Plzni ělení pamětí Volatilní paměti Nevolatilní
Procesor. Procesor FPU ALU. Řadič mikrokód
 Procesor Procesor Integrovaný obvod zajišťující funkce CPU Tvoří srdce a mozek celého počítače a do značné míry ovlivňuje výkon celého počítače (čím rychlejší procesor, tím rychlejší počítač) Provádí jednotlivé
Procesor Procesor Integrovaný obvod zajišťující funkce CPU Tvoří srdce a mozek celého počítače a do značné míry ovlivňuje výkon celého počítače (čím rychlejší procesor, tím rychlejší počítač) Provádí jednotlivé
Paměti Josef Horálek
 Paměti Josef Horálek Paměť = Paměť je pro počítač životní nutností = mikroprocesor z ní čte programy, kterými je řízen a také do ní ukládá výsledky své práce = Paměti v zásadě můžeme rozdělit na: = Primární
Paměti Josef Horálek Paměť = Paměť je pro počítač životní nutností = mikroprocesor z ní čte programy, kterými je řízen a také do ní ukládá výsledky své práce = Paměti v zásadě můžeme rozdělit na: = Primární
Pokročilé architektury počítačů
 Pokročilé architektury počítačů Přednáška 8 Multiprocesory vláknový paralelismus Martin Milata Obsah Paralelní architektury MIMD model Multi-jádrové a multi-vláknové procesory Klasterové řešení Sdílení
Pokročilé architektury počítačů Přednáška 8 Multiprocesory vláknový paralelismus Martin Milata Obsah Paralelní architektury MIMD model Multi-jádrové a multi-vláknové procesory Klasterové řešení Sdílení
Sběrnicová struktura PC Procesory PC funkce, vlastnosti Interní počítačové paměti PC
 Informatika 2 Technické prostředky počítačové techniky - 2 Přednáší: doc. Ing. Jan Skrbek, Dr. - KIN Přednášky: středa 14 20 15 55 Spojení: e-mail: jan.skrbek@tul.cz 16 10 17 45 tel.: 48 535 2442 Obsah:
Informatika 2 Technické prostředky počítačové techniky - 2 Přednáší: doc. Ing. Jan Skrbek, Dr. - KIN Přednášky: středa 14 20 15 55 Spojení: e-mail: jan.skrbek@tul.cz 16 10 17 45 tel.: 48 535 2442 Obsah:
architektura mostů severní / jižní most (angl. north / south bridge) 1. Čipové sady s architekturou severního / jižního mostu
 1. Čipové sady s architekturou severního / jižního mostu") Čipová sada Čipová sada (chipset) je hlavní logický integrovaný obvod základní desky. Jeho úkolem je řídit komunikaci mezi procesorem a ostatními zařízeními a obvody. V obvodech čipové sady jsou integrovány
Čipová sada Čipová sada (chipset) je hlavní logický integrovaný obvod základní desky. Jeho úkolem je řídit komunikaci mezi procesorem a ostatními zařízeními a obvody. V obvodech čipové sady jsou integrovány
Využití ICT pro rozvoj klíčových kompetencí CZ.1.07/1.5.00/
 Střední odborná škola elektrotechnická, Centrum odborné přípravy Zvolenovská 537, Hluboká nad Vltavou Využití ICT pro rozvoj klíčových kompetencí CZ.1.07/1.5.00/34.0448 CZ.1.07/1.5.00/34.0448 1 Číslo projektu
Střední odborná škola elektrotechnická, Centrum odborné přípravy Zvolenovská 537, Hluboká nad Vltavou Využití ICT pro rozvoj klíčových kompetencí CZ.1.07/1.5.00/34.0448 CZ.1.07/1.5.00/34.0448 1 Číslo projektu
Kapitola 10: Diskové a souborové struktury. Klasifikace fyzických médií. Fyzická média
 - 10.1 - Kapitola 10: Diskové a souborové struktury Přehled fyzických ukládacích médií Magnetické disky RAID (Redundant Array of Inexpensive Disks) Terciární úložiště Přístup k médiu Souborové organizace
- 10.1 - Kapitola 10: Diskové a souborové struktury Přehled fyzických ukládacích médií Magnetické disky RAID (Redundant Array of Inexpensive Disks) Terciární úložiště Přístup k médiu Souborové organizace
Paměti počítače ROM, RAM
 Paměti počítače ROM, RAM Paměť je zařízení, které slouží k ukládání programů a dat, s nimiž počítač pracuje. Paměti počítače lze rozdělit do tří základních skupin: registry paměťová místa na čipu procesoru
Paměti počítače ROM, RAM Paměť je zařízení, které slouží k ukládání programů a dat, s nimiž počítač pracuje. Paměti počítače lze rozdělit do tří základních skupin: registry paměťová místa na čipu procesoru
Architektura počítačů Logické obvody
 Architektura počítačů Logické obvody http://d3s.mff.cuni.cz/teaching/computer_architecture/ Lubomír Bulej bulej@d3s.mff.cuni.cz CHARLES UNIVERSITY IN PRAGUE faculty of mathematics and physics Digitální
Architektura počítačů Logické obvody http://d3s.mff.cuni.cz/teaching/computer_architecture/ Lubomír Bulej bulej@d3s.mff.cuni.cz CHARLES UNIVERSITY IN PRAGUE faculty of mathematics and physics Digitální
Paměťové prvky. ITP Technika personálních počítačů. Zdeněk Kotásek Marcela Šimková Pavel Bartoš
 Paměťové prvky ITP Technika personálních počítačů Zdeněk Kotásek Marcela Šimková Pavel Bartoš Vysoké učení technické v Brně, Fakulta informačních technologií v Brně Božetěchova 2, 612 66 Brno Osnova Typy
Paměťové prvky ITP Technika personálních počítačů Zdeněk Kotásek Marcela Šimková Pavel Bartoš Vysoké učení technické v Brně, Fakulta informačních technologií v Brně Božetěchova 2, 612 66 Brno Osnova Typy
Paměti Flash. Paměti Flash. Základní charakteristiky
 Paměti Flash K.D. - přednášky 1 Základní charakteristiky (Flash EEPROM): Přepis dat bez mazání: ne. Mazání: po blocích nebo celý čip. Zápis: po slovech nebo po blocích. Typická životnost: 100 000 1 000
Paměti Flash K.D. - přednášky 1 Základní charakteristiky (Flash EEPROM): Přepis dat bez mazání: ne. Mazání: po blocích nebo celý čip. Zápis: po slovech nebo po blocích. Typická životnost: 100 000 1 000
Princip funkce počítače
 Princip funkce počítače Princip funkce počítače prvotní úlohou počítačů bylo zrychlit provádění matematických výpočtů první počítače kopírovaly obvyklý postup manuálního provádění výpočtů pokyny pro zpracování
Princip funkce počítače Princip funkce počítače prvotní úlohou počítačů bylo zrychlit provádění matematických výpočtů první počítače kopírovaly obvyklý postup manuálního provádění výpočtů pokyny pro zpracování
Architektura počítače
 Architektura počítače Výpočetní systém HIERARCHICKÁ STRUKTURA Úroveň aplikačních programů Úroveň obecných funkčních programů Úroveň vyšších programovacích jazyků a prostředí Úroveň základních programovacích
Architektura počítače Výpočetní systém HIERARCHICKÁ STRUKTURA Úroveň aplikačních programů Úroveň obecných funkčních programů Úroveň vyšších programovacích jazyků a prostředí Úroveň základních programovacích
Architektury paralelních počítačů II.
 Architektury paralelních počítačů II. Sekvenční konzistence paměti Implementace synchronizačních událostí Ing. Miloš Bečvář s použitím slajdů Prof. Ing. Pavla Tvrdíka, CSc. Osnova přednášky Opakování definice
Architektury paralelních počítačů II. Sekvenční konzistence paměti Implementace synchronizačních událostí Ing. Miloš Bečvář s použitím slajdů Prof. Ing. Pavla Tvrdíka, CSc. Osnova přednášky Opakování definice
Cílem kapitoly je seznámit studenta s pamětmi. Jejich minulostí, současností, budoucností a hlavními parametry.
 Paměti Cílem kapitoly je seznámit studenta s pamětmi. Jejich minulostí, současností, budoucností a hlavními parametry. Klíčové pojmy: paměť, RAM, rozdělení pamětí, ROM, vnitřní paměť, vnější paměť. Úvod
Paměti Cílem kapitoly je seznámit studenta s pamětmi. Jejich minulostí, současností, budoucností a hlavními parametry. Klíčové pojmy: paměť, RAM, rozdělení pamětí, ROM, vnitřní paměť, vnější paměť. Úvod
Principy operačních systémů. Lekce 3: Virtualizace paměti
 Principy operačních systémů Lekce 3: Virtualizace paměti Virtuální paměť Adresní prostor paměti je uspořádán logicky jinak, nebo je dokonce větší než je fyzická operační paměť RAM Rozšíření vnitřní paměti
Principy operačních systémů Lekce 3: Virtualizace paměti Virtuální paměť Adresní prostor paměti je uspořádán logicky jinak, nebo je dokonce větší než je fyzická operační paměť RAM Rozšíření vnitřní paměti
Základy informatiky. 2. Přednáška HW. Lenka Carr Motyčková. February 22, 2011 Základy informatiky 2
 Základy informatiky 2. Přednáška HW Lenka Carr Motyčková February 22, 2011 Základy informatiky 1 February 22, 2011 Základy informatiky 2 February 22, 2011 Základy informatiky 3 February 22, 2011 Základy
Základy informatiky 2. Přednáška HW Lenka Carr Motyčková February 22, 2011 Základy informatiky 1 February 22, 2011 Základy informatiky 2 February 22, 2011 Základy informatiky 3 February 22, 2011 Základy
Cache paměti (1) Cache paměť: V dnešních počítačích se běžně používají dva, popř. tři druhy cache pamětí:
 Cache paměť: V dnešních počítačích se běžně používají dva, popř. tři druhy cache pamětí:") Cache paměti (1) Cache paměť: rychlá vyrovnávací paměť mezi rychlým zařízením (např. procesor) a pomalejším zařízením (např. operační paměť) vyrobena z obvodů SRAM s přístupovou dobou 1-20 ns V dnešních
Cache paměti (1) Cache paměť: rychlá vyrovnávací paměť mezi rychlým zařízením (např. procesor) a pomalejším zařízením (např. operační paměť) vyrobena z obvodů SRAM s přístupovou dobou 1-20 ns V dnešních
DUM č. 10 v sadě. 31. Inf-7 Technické vybavení počítačů
 projekt GML Brno Docens DUM č. 10 v sadě 31. Inf-7 Technické vybavení počítačů Autor: Roman Hrdlička Datum: 04.12.2013 Ročník: 1A, 1B, 1C Anotace DUMu: jak fungují vnitřní paměti, typy ROM a RAM pamětí,
projekt GML Brno Docens DUM č. 10 v sadě 31. Inf-7 Technické vybavení počítačů Autor: Roman Hrdlička Datum: 04.12.2013 Ročník: 1A, 1B, 1C Anotace DUMu: jak fungují vnitřní paměti, typy ROM a RAM pamětí,
NSWI /2011 ZS. Principy cpypočítačůčů aoperačních systémů ARCHITEKTURA
 Principy cpypočítačůčů aoperačních systémů ARCHITEKTURA Literatura W.Stallings: Computer Organization & Architecture J.L.Hennessy, P.A.Patterson: Patterson: Computer Architecture: a Quantitative Approach
Principy cpypočítačůčů aoperačních systémů ARCHITEKTURA Literatura W.Stallings: Computer Organization & Architecture J.L.Hennessy, P.A.Patterson: Patterson: Computer Architecture: a Quantitative Approach
Pokročilé architektury počítačů
 Pokročilé architektury počítačů Přednáška 3 Hierarchické uspořádání pamětí počítače Martin Milata Obsah Paměťový subsystém Obvyklé chování programů při přístupu do paměti Cache paměti princip činnosti
Pokročilé architektury počítačů Přednáška 3 Hierarchické uspořádání pamětí počítače Martin Milata Obsah Paměťový subsystém Obvyklé chování programů při přístupu do paměti Cache paměti princip činnosti
Architektura počítačů Logické obvody
 Architektura počítačů Logické obvody http://d3s.mff.cuni.cz/teaching/computer_architecture/ Lubomír Bulej bulej@d3s.mff.cuni.cz CHARLES UNIVERSITY IN PRAGUE faculty of mathematics and physics 2/36 Digitální
Architektura počítačů Logické obvody http://d3s.mff.cuni.cz/teaching/computer_architecture/ Lubomír Bulej bulej@d3s.mff.cuni.cz CHARLES UNIVERSITY IN PRAGUE faculty of mathematics and physics 2/36 Digitální
asociativní paměti Ing. Jakub Št astný, Ph.D. 1 Katedra teorie obvodů FEL ČVUT Technická 2, Praha 6,
 Pamět ové obvody, řadiče a implementace, asociativní paměti AČS Ing. Jakub Št astný, Ph.D. 1 1 FPGA Laboratoř Katedra teorie obvodů FEL ČVUT Technická 2, Praha 6, 166 27 http://amber.feld.cvut.cz/fpga
Pamět ové obvody, řadiče a implementace, asociativní paměti AČS Ing. Jakub Št astný, Ph.D. 1 1 FPGA Laboratoř Katedra teorie obvodů FEL ČVUT Technická 2, Praha 6, 166 27 http://amber.feld.cvut.cz/fpga
Roman Výtisk, VYT027
 Roman Výtisk, VYT027 Ohlédnutí za architekturou AMD K8 Představení architektury procesoru AMD K10 Přínos Struktura cache IMC, HyperTransport sběrnice Použitá literatura Ohlášení x86-64 architektury 5.
Roman Výtisk, VYT027 Ohlédnutí za architekturou AMD K8 Představení architektury procesoru AMD K10 Přínos Struktura cache IMC, HyperTransport sběrnice Použitá literatura Ohlášení x86-64 architektury 5.
Paralelní architektury se sdílenou pamětí typu NUMA. NUMA architektury
 Paralelní architektury se sdílenou pamětí typu NUMA NUMA architektury Multiprocesorové systémy s distribuovanou pamětí I. úzkým hrdlem multiprocesorů se sdílenou pamětí je datová komunikace s rostoucím
Paralelní architektury se sdílenou pamětí typu NUMA NUMA architektury Multiprocesorové systémy s distribuovanou pamětí I. úzkým hrdlem multiprocesorů se sdílenou pamětí je datová komunikace s rostoucím
Paměti EEPROM (1) 25/07/2006 1
 25/07/2006 1") Paměti EEPROM (1) EEPROM - Electrically EPROM Mají podobné chování jako paměti EPROM, tj. jedná se o statické, energeticky nezávislé paměti, které je možné naprogramovat a později z nich informace vymazat
Paměti EEPROM (1) EEPROM - Electrically EPROM Mají podobné chování jako paměti EPROM, tj. jedná se o statické, energeticky nezávislé paměti, které je možné naprogramovat a později z nich informace vymazat
Architektura Intel Atom
 Architektura Intel Atom Štěpán Sojka 5. prosince 2008 1 Úvod Hlavní rysem Atomu je podpora platformy x86, která umožňuje spouštět a běžně používat řadu let vyvíjené aplikace, na které jsou uživatelé zvyklí
Architektura Intel Atom Štěpán Sojka 5. prosince 2008 1 Úvod Hlavní rysem Atomu je podpora platformy x86, která umožňuje spouštět a běžně používat řadu let vyvíjené aplikace, na které jsou uživatelé zvyklí
Přidělování paměti II Mgr. Josef Horálek
 Přidělování paměti II Mgr. Josef Horálek Techniky přidělování paměti = Přidělování jediné souvislé oblasti paměti = Přidělování paměti po sekcích = Dynamické přemisťování sekcí = Stránkování = Stránkování
Přidělování paměti II Mgr. Josef Horálek Techniky přidělování paměti = Přidělování jediné souvislé oblasti paměti = Přidělování paměti po sekcích = Dynamické přemisťování sekcí = Stránkování = Stránkování
Operační systémy. Přednáška 8: Správa paměti II
 Operační systémy Přednáška 8: Správa paměti II 1 Jednoduché stránkování Hlavní paměť rozdělená na malé úseky stejné velikosti (např. 4kB) nazývané rámce (frames). Program rozdělen na malé úseky stejné
Operační systémy Přednáška 8: Správa paměti II 1 Jednoduché stránkování Hlavní paměť rozdělená na malé úseky stejné velikosti (např. 4kB) nazývané rámce (frames). Program rozdělen na malé úseky stejné
Řízení IO přenosů DMA řadičem
 Řízení IO přenosů DMA řadičem Doplňující text pro POT K. D. 2001 DMA řadič Při přímém řízení IO operací procesorem i při použití přerušovacího systému je rychlost přenosu dat mezi IO řadičem a pamětí limitována
Řízení IO přenosů DMA řadičem Doplňující text pro POT K. D. 2001 DMA řadič Při přímém řízení IO operací procesorem i při použití přerušovacího systému je rychlost přenosu dat mezi IO řadičem a pamětí limitována
Vstupně - výstupní moduly
 Vstupně - výstupní moduly Přídavná zařízení sloužící ke vstupu a výstupu dat bo k uchovávání a archivaci dat Nejsou připojována ke sběrnici přímo, ale prostřednictvím vstupně-výstupních modulů ( ů ). Hlavní
Vstupně - výstupní moduly Přídavná zařízení sloužící ke vstupu a výstupu dat bo k uchovávání a archivaci dat Nejsou připojována ke sběrnici přímo, ale prostřednictvím vstupně-výstupních modulů ( ů ). Hlavní
Osobní počítač. Zpracoval: ict Aktualizace: 10. 11. 2011
 Osobní počítač Zpracoval: ict Aktualizace: 10. 11. 2011 Charakteristika PC Osobní počítač (personal computer - PC) je nástroj člověka pro zpracovávání informací Vyznačuje se schopností samostatně pracovat
Osobní počítač Zpracoval: ict Aktualizace: 10. 11. 2011 Charakteristika PC Osobní počítač (personal computer - PC) je nástroj člověka pro zpracovávání informací Vyznačuje se schopností samostatně pracovat
Paměti počítače 9.přednáška
 Paměti počíta tače 9.přednáška Paměť Paměť je zařízení, které slouží k ukládání programů a dat, s nimiž počítač pracuje Paměti počítače lze rozdělit do tří základních skupin: registry paměťová místa na
Paměti počíta tače 9.přednáška Paměť Paměť je zařízení, které slouží k ukládání programů a dat, s nimiž počítač pracuje Paměti počítače lze rozdělit do tří základních skupin: registry paměťová místa na
2.9 Vnitřní paměti. Střední průmyslová škola strojnická Vsetín. Ing. Martin Baričák. Název šablony Název DUMu. Předmět Druh učebního materiálu
 Název školy Číslo projektu Autor Název šablony Název DUMu Tematická oblast Předmět Druh učebního materiálu Anotace Vybavení, pomůcky Ověřeno ve výuce dne, třída Střední průmyslová škola strojnická Vsetín
Název školy Číslo projektu Autor Název šablony Název DUMu Tematická oblast Předmět Druh učebního materiálu Anotace Vybavení, pomůcky Ověřeno ve výuce dne, třída Střední průmyslová škola strojnická Vsetín
Procesor. Základní prvky procesoru Instrukční sada Metody zvýšení výkonu procesoru
 Počítačové systémy Procesor Miroslav Flídr Počítačové systémy LS 2006-1/17- Západočeská univerzita v Plzni Víceúrovňová organizace počítače Digital logic level Microarchitecture level Processor Instruction
Počítačové systémy Procesor Miroslav Flídr Počítačové systémy LS 2006-1/17- Západočeská univerzita v Plzni Víceúrovňová organizace počítače Digital logic level Microarchitecture level Processor Instruction
Cache paměti (2) Cache paměti (1) Cache paměti (3) Cache paměti (4) Cache paměti (6) Cache paměti (5) Cache paměť:
 Cache paměti (1) Cache paměti (3) Cache paměti (4) Cache paměti (6) Cache paměti (5) Cache paměť:") Cache paměti (1) Cache paměť: rychlá vyrovnávací paměť mezi rychlým zařízením (např. procesor) a pomalejším zařízením (např. operační paměť) vyrobena z obvodů SRAM s přístupovou dobou 1 20 ns V dnešních
Cache paměti (1) Cache paměť: rychlá vyrovnávací paměť mezi rychlým zařízením (např. procesor) a pomalejším zařízením (např. operační paměť) vyrobena z obvodů SRAM s přístupovou dobou 1 20 ns V dnešních
Architektura počítačů
 Architektura počítačů Studijní materiál pro předmět Architektury počítačů Ing. Petr Olivka katedra informatiky FEI VŠB-TU Ostrava email: petr.olivka@vsb.cz Ostrava, 2010 1 1 Architektura počítačů Pojem
Architektura počítačů Studijní materiál pro předmět Architektury počítačů Ing. Petr Olivka katedra informatiky FEI VŠB-TU Ostrava email: petr.olivka@vsb.cz Ostrava, 2010 1 1 Architektura počítačů Pojem
Z{kladní struktura počítače
 Z{kladní struktura počítače Cílem této kapitoly je sezn{mit se s různými strukturami počítače, které využív{ výpočetní technika v současnosti. Klíčové pojmy: Von Neumannova struktura počítače, Harvardská
Z{kladní struktura počítače Cílem této kapitoly je sezn{mit se s různými strukturami počítače, které využív{ výpočetní technika v současnosti. Klíčové pojmy: Von Neumannova struktura počítače, Harvardská
PAMĚŤOVÝ SUBSYSTÉM. Principy počítačů I. Literatura. Parametry paměti. Parametry paměti. Dělení pamětí podle funkce. Kritéria dělení pamětí
 Principy počítačů I PAMĚŤOVÝ SUBSYSTÉM Literatura http://www.tomshardware.com http://www.play-hookey.com/digital/ 6 kb ought to be enough for anybody. Bill Gates, 98 Parametry paměti kapacita objem informace,
Principy počítačů I PAMĚŤOVÝ SUBSYSTÉM Literatura http://www.tomshardware.com http://www.play-hookey.com/digital/ 6 kb ought to be enough for anybody. Bill Gates, 98 Parametry paměti kapacita objem informace,
2010/2011 ZS P i r i nc č py po ít č čů a PAMĚŤOVÝ ĚŤ SUBSYSTÉM z pohledu OS OS
 Pi Principy i počítačů čů PAMĚŤOVÝ SUBSYSTÉM z pohledu OS Správa paměti OS je správcem prostředků, tedy i paměti přidělování procesům zajištění ochrany systému i procesů zajištění požadavků aniž by došlo
Pi Principy i počítačů čů PAMĚŤOVÝ SUBSYSTÉM z pohledu OS Správa paměti OS je správcem prostředků, tedy i paměti přidělování procesům zajištění ochrany systému i procesů zajištění požadavků aniž by došlo
Obecné výpočty na GPU v jazyce CUDA. Jiří Filipovič
 Obecné výpočty na GPU v jazyce CUDA Jiří Filipovič Obsah přednášky motivace architektura GPU CUDA programovací model jaké algoritmy urychlovat na GPU? optimalizace Motivace Moorův zákon stále platí pro
Obecné výpočty na GPU v jazyce CUDA Jiří Filipovič Obsah přednášky motivace architektura GPU CUDA programovací model jaké algoritmy urychlovat na GPU? optimalizace Motivace Moorův zákon stále platí pro
ODBORNÝ VÝCVIK VE 3. TISÍCILETÍ. MEIII Paměti konstant
 Projekt: ODBORNÝ VÝCVIK VE 3. TISÍCILETÍ Téma: MEIII - 1.5 Paměti konstant Obor: Mechanik elektronik Ročník: 3. Zpracoval(a): Jiří Kolář Střední průmyslová škola Uherský Brod, 2010 Projekt je spolufinancován
Projekt: ODBORNÝ VÝCVIK VE 3. TISÍCILETÍ Téma: MEIII - 1.5 Paměti konstant Obor: Mechanik elektronik Ročník: 3. Zpracoval(a): Jiří Kolář Střední průmyslová škola Uherský Brod, 2010 Projekt je spolufinancován
Základní deska (1) Parametry procesoru (2) Parametry procesoru (1) Označována také jako mainboard, motherboard
 Parametry procesoru (2) Parametry procesoru (1) Označována také jako mainboard, motherboard") Základní deska (1) Označována také jako mainboard, motherboard Deska plošného spoje tvořící základ celého počítače Zpravidla obsahuje: procesor (mikroprocesor) patici pro numerický koprocesor (resp. osazený
Základní deska (1) Označována také jako mainboard, motherboard Deska plošného spoje tvořící základ celého počítače Zpravidla obsahuje: procesor (mikroprocesor) patici pro numerický koprocesor (resp. osazený
Kapitola 13: Transakce. Koncept transakce. ACID vlastnosti
 - 13.1 - Kapitola 13: Transakce Koncept transakce Stavy transakce Implementace atomičnosti a trvanlivosti Souběžné spouštění Serializovatelnost Koncept transakce Transakce je posloupnost operací (část
- 13.1 - Kapitola 13: Transakce Koncept transakce Stavy transakce Implementace atomičnosti a trvanlivosti Souběžné spouštění Serializovatelnost Koncept transakce Transakce je posloupnost operací (část
Operační systémy. Přednáška 7: Správa paměti I
 Operační systémy Přednáška 7: Správa paměti I 1 Správa paměti (SP) Memory Management Unit (MMU) hardware umístěný na CPU čipu např. překládá logické adresy na fyzické adresy, Memory Manager software, který
Operační systémy Přednáška 7: Správa paměti I 1 Správa paměti (SP) Memory Management Unit (MMU) hardware umístěný na CPU čipu např. překládá logické adresy na fyzické adresy, Memory Manager software, který
Přednáška. Správa paměti I. Katedra počítačových systémů FIT, České vysoké učení technické v Praze Jan Trdlička, 2012
 Přednáška Správa paměti I. Katedra počítačových systémů FIT, České vysoké učení technické v Praze Jan Trdlička, 2012 Příprava studijního programu Informatika je podporována projektem financovaným z Evropského
Přednáška Správa paměti I. Katedra počítačových systémů FIT, České vysoké učení technické v Praze Jan Trdlička, 2012 Příprava studijního programu Informatika je podporována projektem financovaným z Evropského
Základní principy konstrukce systémové sběrnice - shrnutí. Shrnout základní principy konstrukce a fungování systémových sběrnic.
 Základní principy konstrukce systémové sběrnice - shrnutí Shrnout základní principy konstrukce a fungování systémových sběrnic. 1 Co je to systémová sběrnice? Systémová sběrnice je prostředek sloužící
Základní principy konstrukce systémové sběrnice - shrnutí Shrnout základní principy konstrukce a fungování systémových sběrnic. 1 Co je to systémová sběrnice? Systémová sběrnice je prostředek sloužící
Úvod do architektur personálních počítačů
 Úvod do architektur personálních počítačů 1 Cíl přednášky Popsat principy proudového zpracování informace. Popsat principy zřetězeného zpracování instrukcí. Zabývat se způsoby uplatnění tohoto principu
Úvod do architektur personálních počítačů 1 Cíl přednášky Popsat principy proudového zpracování informace. Popsat principy zřetězeného zpracování instrukcí. Zabývat se způsoby uplatnění tohoto principu
Uspořádání cache pamětí procesorů historie a současný stav
 Uspořádání cache pamětí procesorů historie a současný stav Stránka: 1 / 17 Obsah 1Úvod...3 2Hierarchie pamětí počítače...4 2.1Pracovní registry procesoru...4 2.2L1 cache...4 2.3L2 cache...5 2.4Operační
Uspořádání cache pamětí procesorů historie a současný stav Stránka: 1 / 17 Obsah 1Úvod...3 2Hierarchie pamětí počítače...4 2.1Pracovní registry procesoru...4 2.2L1 cache...4 2.3L2 cache...5 2.4Operační
Přehled paralelních architektur. Dělení paralelních architektur Flynnova taxonomie Komunikační modely paralelních architektur
 Přehled paralelních architektur Přehled paralelních architektur Dělení paralelních architektur Flynnova taxonomie Komunikační modely paralelních architektur Přehled I. paralelní počítače se konstruují
Přehled paralelních architektur Přehled paralelních architektur Dělení paralelních architektur Flynnova taxonomie Komunikační modely paralelních architektur Přehled I. paralelní počítače se konstruují
HW počítače co se nalézá uvnitř počítačové skříně
 ZVT HW počítače co se nalézá uvnitř počítačové skříně HW vybavení PC Hardware Vnitřní (uvnitř počítačové skříně) Vnější ( ) Základní HW základní jednotka + zobrazovací zařízení + klávesnice + (myš) Vnější
ZVT HW počítače co se nalézá uvnitř počítačové skříně HW vybavení PC Hardware Vnitřní (uvnitř počítačové skříně) Vnější ( ) Základní HW základní jednotka + zobrazovací zařízení + klávesnice + (myš) Vnější
Paměti operační paměti
 Paměti operační paměti Autor: Kulhánek Zdeněk Škola: Hotelová škola, Obchodní akademie a Střední průmyslová škola Teplice, Benešovo náměstí 1, příspěvková organizace Kód: VY_32_INOVACE_ICT_828 1.11.2012
Paměti operační paměti Autor: Kulhánek Zdeněk Škola: Hotelová škola, Obchodní akademie a Střední průmyslová škola Teplice, Benešovo náměstí 1, příspěvková organizace Kód: VY_32_INOVACE_ICT_828 1.11.2012
Témata profilové maturitní zkoušky
 Obor: 18-20-M/01 Informační technologie Předmět: Databázové systémy Forma: praktická 1. Datový model. 2. Dotazovací jazyk SQL. 3. Aplikační logika v PL/SQL. 4. Webová aplikace. Obor vzdělání: 18-20-M/01
Obor: 18-20-M/01 Informační technologie Předmět: Databázové systémy Forma: praktická 1. Datový model. 2. Dotazovací jazyk SQL. 3. Aplikační logika v PL/SQL. 4. Webová aplikace. Obor vzdělání: 18-20-M/01
Počítačová sestava paměti, operační paměť RAM
 Pavel Dvořák Gymnázium Velké Meziříčí Počítačová sestava paměti, operační paměť RAM Registrační číslo projektu: CZ.1.07/1.5.00/34.0948 Jazyk: čestina Datum vytvoření: 17. 10. 2012 Cílová skupina: studenti
Pavel Dvořák Gymnázium Velké Meziříčí Počítačová sestava paměti, operační paměť RAM Registrační číslo projektu: CZ.1.07/1.5.00/34.0948 Jazyk: čestina Datum vytvoření: 17. 10. 2012 Cílová skupina: studenti
Hardware počítačů. Architektura počítačů Paměti počítačů Aritmetika - ALU Řadič
 Hardware počítačů Architektura počítačů Paměti počítačů Aritmetika - ALU Řadič 5. Paměťový systém počítače Paměť je důležitou součástí počítače, procesor si s ní neustále vyměňuje data. vnitřní paměť =
Hardware počítačů Architektura počítačů Paměti počítačů Aritmetika - ALU Řadič 5. Paměťový systém počítače Paměť je důležitou součástí počítače, procesor si s ní neustále vyměňuje data. vnitřní paměť =
Integrovaná střední škola, Sokolnice 496
 Integrovaná střední škola, Sokolnice 496 Název projektu: Moderní škola Registrační číslo: CZ.1.07/1.5.00/34.0467 Název klíčové aktivity: III/2 - Inovace a zkvalitnění výuky prostřednictvím ICT Kód výstupu:
Integrovaná střední škola, Sokolnice 496 Název projektu: Moderní škola Registrační číslo: CZ.1.07/1.5.00/34.0467 Název klíčové aktivity: III/2 - Inovace a zkvalitnění výuky prostřednictvím ICT Kód výstupu:
PROGRAMOVATELNÉ LOGICKÉ OBVODY
 PROGRAMOVATELNÉ LOGICKÉ OBVODY (PROGRAMMABLE LOGIC DEVICE PLD) Programovatelné logické obvody jsou číslicové obvody, jejichž logická funkce může být programována uživatelem. Výhody: snížení počtu integrovaných
PROGRAMOVATELNÉ LOGICKÉ OBVODY (PROGRAMMABLE LOGIC DEVICE PLD) Programovatelné logické obvody jsou číslicové obvody, jejichž logická funkce může být programována uživatelem. Výhody: snížení počtu integrovaných
Vstupně výstupní moduly. 13.přednáška
 Vstupně výstupní moduly 13.přednáška Vstupně-výstupn výstupní modul (I/O modul) Přídavná zařízení sloužící ke vstupu a výstupu dat nebo k uchovávání a archivaci dat Nejsou připojována ke sběrnici přímo,
Vstupně výstupní moduly 13.přednáška Vstupně-výstupn výstupní modul (I/O modul) Přídavná zařízení sloužící ke vstupu a výstupu dat nebo k uchovávání a archivaci dat Nejsou připojována ke sběrnici přímo,
Intel 80486 (2) Intel 80486 (1) Intel 80486 (3) Intel 80486 (4) Intel 80486 (6) Intel 80486 (5) Nezřetězené zpracování instrukcí:
 Intel 80486 (1) Intel 80486 (3) Intel 80486 (4) Intel 80486 (6) Intel 80486 (5) Nezřetězené zpracování instrukcí:") Intel 80486 (1) Vyroben v roce 1989 Prodáván pod oficiálním názvem 80486DX Plně 32bitový procesor Na svém čipu má integrován: - zmodernizovaný procesor 80386 - numerický koprocesor 80387 - L1 (interní)
Intel 80486 (1) Vyroben v roce 1989 Prodáván pod oficiálním názvem 80486DX Plně 32bitový procesor Na svém čipu má integrován: - zmodernizovaný procesor 80386 - numerický koprocesor 80387 - L1 (interní)
Procesy a vlákna (Processes and Threads)
") ÚVOD DO OPERAČNÍCH SYSTÉMŮ Ver.1.00 Procesy a vlákna (Processes and Threads) Správa procesů a vláken České vysoké učení technické Fakulta elektrotechnická 2012 Použitá literatura [1] Stallings, W.: Operating
ÚVOD DO OPERAČNÍCH SYSTÉMŮ Ver.1.00 Procesy a vlákna (Processes and Threads) Správa procesů a vláken České vysoké učení technické Fakulta elektrotechnická 2012 Použitá literatura [1] Stallings, W.: Operating
Další aspekty architektur CISC a RISC Aktuálnost obsahu registru
 Cíl přednášky: Vysvětlit principy práce s registry v architekturách RISC a CISC, upozornit na rozdíly. Vysvětlit možnosti využívání sad registrů. Zabývat se principy využívanými v procesorech Intel. Zabývat
Cíl přednášky: Vysvětlit principy práce s registry v architekturách RISC a CISC, upozornit na rozdíly. Vysvětlit možnosti využívání sad registrů. Zabývat se principy využívanými v procesorech Intel. Zabývat
Operační paměti počítačů PC
 Operační paměti počítačů PC Dynamické paměti RAM operační č paměť je realizována čipy dynamických pamětí RAM DRAM informace uchovávána jako náboj na kondenzátoru nutnost náboj pravidelně obnovovat (refresh)
Operační paměti počítačů PC Dynamické paměti RAM operační č paměť je realizována čipy dynamických pamětí RAM DRAM informace uchovávána jako náboj na kondenzátoru nutnost náboj pravidelně obnovovat (refresh)
Přidělování zdrojů (prostředků)
") Přidělování zdrojů (prostředků) Proces potřebuje zdroje (prostředky) hardware (I/O zařízení, paměť) software (data, programy) Klasifikace zdrojů (z hlediska multitaskingového režimu) Násobně použitelné
Přidělování zdrojů (prostředků) Proces potřebuje zdroje (prostředky) hardware (I/O zařízení, paměť) software (data, programy) Klasifikace zdrojů (z hlediska multitaskingového režimu) Násobně použitelné
Operační systémy. Správa paměti (SP) Požadavky na SP. Spojování a zavedení programu. Spojování programu (linking) Zavádění programu (loading)
 Požadavky na SP. Spojování a zavedení programu. Spojování programu (linking) Zavádění programu (loading)") Správa paměti (SP) Operační systémy Přednáška 7: Správa paměti I Memory Management Unit (MMU) hardware umístěný na CPU čipu např. překládá logické adresy na fyzické adresy, Memory Manager software, který
Správa paměti (SP) Operační systémy Přednáška 7: Správa paměti I Memory Management Unit (MMU) hardware umístěný na CPU čipu např. překládá logické adresy na fyzické adresy, Memory Manager software, který
Pokročilé architektury počítačů
 Pokročilé architektury počítačů Tutoriál 3 CUDA - GPU Martin Milata Výpočetní model CUDA Organizace kódu Sériově organizovaný kód určený pro CPU Paralelní kód prováděný na GPU Označuje se jako kernel GPU
Pokročilé architektury počítačů Tutoriál 3 CUDA - GPU Martin Milata Výpočetní model CUDA Organizace kódu Sériově organizovaný kód určený pro CPU Paralelní kód prováděný na GPU Označuje se jako kernel GPU
Disková pole (RAID) 1
 1") Disková pole (RAID) 1 Architektury RAID Důvod zavedení RAID: reakce na zvyšující se rychlost procesoru. Pozice diskové paměti v klasickém personálním počítači vyhovuje pro aplikace s jedním uživatelem.
Disková pole (RAID) 1 Architektury RAID Důvod zavedení RAID: reakce na zvyšující se rychlost procesoru. Pozice diskové paměti v klasickém personálním počítači vyhovuje pro aplikace s jedním uživatelem.