Závěrečná zpráva o výsledcích řešení výzkumného záměru v letech Předkládá. PhDr. Bohdana Stoklasová, hlavní řešitelka.
|
|
|
- Bohumír Kašpar
- před 8 lety
- Počet zobrazení:
Transkript

1 Budování vzájemně kompatibilních informačních systémů pro přístup k heterogenním informačním zdrojům a jejich zastřešení prostřednictvím Jednotné informační brány Závěrečná zpráva o výsledcích řešení výzkumného záměru v letech Předkládá PhDr. Bohdana Stoklasová, hlavní řešitelka Spolupracovali Mgr. Marie Balíková, Ing. Libor Coufal, Mgr. Jan Hutař, Mgr. Edita Lichtenbergová, PhDr. Jiří Polišenský, Mgr. Jindřiška Pospíšilová Národní knihovna České republiky Klementinum Praha ledna 2011
2 OBSAH A KONSTATAČNÍ ČÁST... 3 A.1 Rešerše... 4 A.2 Současný stav ve světě a v ČR... 5 A.3 Vstupní data a cíl... 7 B ANALYTICKÁ ČÁST B.1 Vlastní řešení B.2 Přínos řešitele B.3 Posun znalostí C NÁVRHOVÁ ČÁST C.1 Výsledky řešení C.2 Závěr C.3 Návrhy opatření D POUŽITÍ FINANČNÍCH PROSTŘEDKŮ D.1 Komentář a tabulky E RESUMÉ A KLÍČOVÁ SLOVA E.1 Resumé a klíčová slova v češtině E.2 Abstract and key words in English
3 A Konstatační část Úvodní poznámka vztahující se ke struktuře předkládané zprávy: Předmětem výzkumné činnosti realizované ve výzkumném záměru Budování vzájemně kompatibilních informačních systémů pro přístup k heterogenním informačním zdrojům a jejich zastřešení prostřednictvím Jednotné informační brány byl podle stanoveného cíle výzkum a vývoj směřující k vytvoření informačních systémů pro přístup k heterogenním informačním zdrojům, které budou navzájem kompatibilní do té míry, že bude možné je zastřešit tak, že se budou navenek (tj. pro koncového uživatele) prezentovat jako systém jediný. Jednalo se o komplexní výzkumný záměr, který v sobě integroval výzkumnou činnost v pěti vzájemně provázaných oblastech: 1. Zajištění trvalé dostupnosti heterogenních informačních zdrojů (domácích i zahraničních) včetně vyhodnocování a koordinace jejich využití. 2. Koordinace jmenného zpracování a zpřístupnění heterogenních informačních zdrojů s ohledem na mezinárodní kontext (metadata, formáty, katalogizační pravidla). 3. Optimalizace věcného zpřístupnění dokumentů s ohledem na integraci v mezinárodním kontextu (kombinace vyhledávání v plných textech a řízených slovnících, konkordance klasifikací, aplikace metody konspektu). 4. Optimalizace využití heterogenních informačních zdrojů prostřednictvím jejich integrace v rámci Jednotné informační brány (jednotné prostředí, jednotné kladení dotazů, jednotné výstupy, vlastní prostředí, přidané služby). 5. Budování digitálních depozitních knihoven s ohledem na možnost jejich integrace v rámci Jednotné informační brány a nadnárodních portálů. První čtyři oblasti byly obsahem výzkumného záměru od počátku, pátá byla přidána v závěrečných letech řešení, kdy byly naopak první dvě oblasti utlumeny. Původně velmi široce koncipovaný výzkumný záměr byl na základě doporučení hodnotitelské komise postupně zužován na okruhy, v nichž bylo možné dosáhnout kvalitních výsledků v oblasti výzkumu a vývoje a podpůrné okruhy spíše praktického zaměření byly utlumeny. Důraz kladený na určité oblasti v jednotlivých letech řešení koresponduje nejen s časovým rozložením rozvojových aktivit NK ČR v době řešení od roku 2004 až 2010, ale odráží i mezinárodní kontext. Na počátku řešení byla horkým tématem standardizace bibliografických dat v rovině jmenné i věcné, postupně zastřešení jednotlivých aplikací pomocí portálů. Metadata přestávají uživatelům stačit, vyžadují jejich nejrůznější obohacení (obálky, obsahy, geografické souřadnice) a přístup k primárním dokumentům, postupně nestačí pouhý náhled na obrazovou podobu dokumentu, je požadován plný text, probíhají experimenty s kladením dotazů v přirozeném jazyce. V závěrečné fázi řešení projektu se posouvá akcent na budování digitálních depozitních knihoven, neboť předpokladem trvalého zpřístupnění dokumentů v digitální podobě je jejich zachování a ochrana. Významnou složkou národního kulturního dědictví se stává český web, který je (stejně jako klasické dokumenty) nutné zachytit, ochránit a zpřístupnit. Takto lze velmi stručně charakterizovat vývoj výzkumného záměru v průběhu uplynulých sedmi let řešení. Podrobnější informace budou uvedeny v následujícím textu, i zde se ale jedná spíše o souhrnné informace. Podrobný popis výsledků řešení za jednotlivé roky uvádějí dílčí zprávy za jednotlivé roky řešení. 3
4 A.1 Rešerše Rešerše obsahuje výsledky publikační činnosti řešitelů a dalších pracovníků NK ČR vztahující se k řešenému tématu, které se staly uznanými výsledky řešení projektu. Výsledky řešení za rok 2010 budou do evidence RIV teprve nahlášeny. Jedná se o 3 monografie a 8 odborných článků, z nichž 4 byly publikovány v zahraničních periodikách. Soupis je uspořádán (stejně jako celá závěrečná zpráva na úrovni jednotlivých kapitol) chronologicky od nejstarších publikací po nejnovější. Další bohatá publikační činnost řešitelů výzkumného záměru doma i v zahraničí je uvedena v dílčích (ročních) zprávách STOKLASOVÁ, Bohdana. Conspectus method used for collections mapping and structuring of portals in Czech Libraries. In Signum : the Finnish Research Library Association, 2006, č. 3, s ISSN STOKLASOVÁ, Bohdana. Czech digital library. In Archiving 2006 : final program and proceedings. Ottawa : Society for Imaging Science and Technology, s ISBN STOKLASOVÁ, Bohdana. Perspektivy důvěryhodného digitálního úložiště v rámci Národní digitální knihovny. Knihovna. Praha, Národní knihovna ČR, 2006, roč. 17, č. 2, s ISSN NERGLOVÁ, Anna; HUTAŘ, Jan. Dlouhodobé uchování a zpřístupnění digitálních dokumentů v Evropě : výsledky dotazníkového průzkumu. Knihovna. Praha, Národní knihovna ČR, 2006, roč. 17, č. 2, s ISSN BALÍKOVÁ, Marie; STROSSA, Petr; VŘEŠŤÁLOVÁ, Dana. Dotazování v přirozeném jazyce : Zkušenosti s aplikací prototypu systému M-CAST v českém prostředí. Praha : Národní knihovna ČR, s. ISBN COUFAL, Libor; ŽABIČKA, Petr. Strategies and Approaches to Building Thematic Collections in WebArchiv. In INFuture 2007 : digital information and heritage. Zagreb : Odsjek za informacijske znanosti Filozofskog fakulteta u Zagrebu, 2007, s ISBN STOKLASOVÁ, Bohdana; HUTAŘ, Jan. Nové směry v dlouhodobém uchovávání dokumentů v mezinárodním kontextu. In Automatizace knihovnických procesů 11. Liberec Praha : ČVUT, s ISBN STOKLASOVÁ, Bohdana; HUTAŘ, Jan; KRBEC, Pavel. Preservation of digital cultural heritage in Europe and in Czech Republic [Ochrana digitálního kulturního dědictví v Evropě a v České republice]. In Communication of memory in archives, libraries and museums : the interaction of science, policy and practices, Vilnius, Vilnius: Vilnius University Press, 2008, s (ISBN ) 2009 POSPÍŠILOVÁ, Jindřiška; KOŠŤÁLOVÁ, Karolína; NEMEŠKALOVÁ, Hana. Katalogy nové generace : analýza vybraných systémů z pohledu uživatele. Praha : Národní knihovna ČR, s. ISBN (brož.) 4
5 2010 CUBR, Ladislav. Dlouhodobá ochrana digitálních dokumentů. Praha : Národní knihovna ČR, s. ISBN (brož). CUBR, Ladislav. Budování důvěryhodného systému trvalé identifikace digitálních dokumentů. Knihovna. 2010, roč. 21, č. 1, s ISSN A.2 Současný stav ve světě a v ČR Popis stavu ve světě a jeho porovnání se situací u nás je obsažen v jednotlivých ročních zprávách. V závěrečné zprávě se soustředíme na zhodnocení situace u nás v konfrontaci s mezinárodním kontextem. Hodnocení je rozděleno podle tematických okruhů řešených v průběhu projektu. 1. Zajištění trvalé dostupnosti heterogenních informačních zdrojů (domácích i zahraničních) včetně vyhodnocování a koordinace jejich využití Do této oblasti byla původně zařazena i archivace webu, která byla postupně integrována s dalšími souvisejícími aktivitami v rámci oblasti Budování digitálních depozitních knihoven s ohledem na možnost jejich integrace v rámci Jednotné informační brány a nadnárodních portálů, kde bude také zhodnocen současný stav v porovnání s mezinárodním kontextem. Dalším okruhem bylo zajištění elektronických informačních zdrojů a tvorba konsorcií tvořených v zájmu získání elektronických zdrojů pro řadu institucí za výhodných finančních podmínek. V průběhu řešení výzkumného záměru participovala NK ČR na řadě projektů zaměřených na získávání elektronických zdrojů, některé z nich vedla a stále vede. V současné době je situace v této oblasti v porovnání se zahraničím velmi dobrá, máme-li na mysli jejich sortiment a možnosti i menších a chudších knihoven tyto zdroje díky různým grantům získat. Pokud bychom však měli hodnotit statistiky využití těchto zdrojů, porovnání se zahraničím nevyznívá pro nás příznivě. Centrální financování je v budoucích letech nejisté a NK ČR bude muset (stejně jako řada dalších českých knihoven) modifikovat svoji akviziční politiku s ohledem na financování řady elektronických zdrojů z vlastního rozpočtu. Do této oblasti spadalo i analytické zpracování včetně kooperačního systému článkové bibliografie. Analytické zpracování se v NK ČR udrželo (v porovnání se zahraničními knihovnami) velmi dlouho a vznikl zde rozsáhlý kooperační systém. Až nyní dochází k jeho útlumu. 2. Koordinace jmenného zpracování a zpřístupnění heterogenních informačních zdrojů s ohledem na mezinárodní kontext (metadata, formáty, katalogizační pravidla) Jedná se o oblast, kde je NK ČR v mezinárodním kontextu velmi respektovanou institucí. Rychlá a úspěšná implementace mezinárodních standardů (MARC, AACR2R) bez zásadních modifikací nám umožnila po desetiletích izolace rychle navázat kontakt se zahraničím, stali jsme se první posttotalitní zemí, která byla schopna dodat své bibliografické záznamy do souborného katalogu WorldCat, velká pozornost věnovaná jmenným autoritám naši pozici ještě posílila a usnadnila naši mezinárodní kooperaci a integraci zdrojů. Stali jsme se jedním z prvních partnerů projektu VIAF. 5
6 3. Optimalizace věcného zpřístupnění dokumentů s ohledem na integraci v mezinárodním kontextu V oblasti věcného zpřístupnění patří NK ČR v mezinárodním kontextu k nejvyspělejším zemím. Podobně jako v oblasti jmenného zpracování, i zde došlo k rychlé implementaci mezinárodních standardů (MDT a konkordance na DDR, Konspekt, LCSH). Na požadavky uživatelů rychle reaguje obohacování bibliografických záznamů o obsahy, geografické souřadnice, dotazy v přirozeném jazyce atd. Výrazným trendem v mezinárodním kontextu je v poslední době hledání nových cest ke zkvalitnění a obohacení věcného zpřístupnění dokumentů. V souvislosti s integrovaným zpřístupněním digitálních objektů v různých paměťových institucích dochází stále více ke spolupráci nejen mezi knihovnami, ale napříč paměťovými institucemi. Významnou manifestací tohoto trendu je evropský projekt EUROPEANA. Prioritou věcného zpřístupnění je v posledních letech vývoj a rozvoj nástrojů pro spolupráci různých paměťových institucí na bázi národních věcných autorit. Naše výsledky dosažené v této oblasti se těší velkému celonárodnímu i mezinárodnímu zájmu a z ohlasu na naše prezentace vyplývá, že v mezinárodním kontextu velmi dobře obstojí. NK ČR byla a je zapojena do řady národních i mezinárodních projektů. Mnohé z nich vedla/vede. 4. Optimalizace využití heterogenních informačních zdrojů prostřednictvím jejich integrace v rámci Jednotné informační brány Integrace heterogenních informačních zdrojů v rámci Jednotné informační brány, vztah mezi univerzálním národním portálem a oborovými branami, i péče o rozvoj příslušných standardů řadí NK ČR stále na velmi dobré místo v mezinárodním kontextu. Situace se však vyvíjí velmi rychle. Aby knihovny a jejich služby mohly konkurovat nástrojům a službám dostupným na volném internetu a neztratily svoji pozici základních (primárních) poskytovatelů informací, přizpůsobují své katalogy a služby současným možnostem. Jedním z trendů je zpřístupnění všech relevantních zdrojů knihovny a vyhledávání pod jedním rozhraním, které je uživatelsky jednoduché, přehledné a názorné. JIB pracující na základě MetaLibu a SFX je dobrým příkladem integrace zdrojů, v současné době však knihovny ve světě implementují novou generaci portálů, která pracuje jako běžné komerční služby zobrazí relevantní výsledky bez ohledu na primární zdroj s nabídkou všech dostupných služeb. NK ČR disponuje rozsáhlými analýzami těchto služeb a je dobře připravena na implementaci některé z nich v rámci projektu Národní digitální knihovna (NDK). 5. Budování digitálních depozitních knihoven s ohledem na možnost jejich integrace v rámci Jednotné informační brány a nadnárodních portálů Do této oblasti spadá kromě budování digitálních depozitních knihoven i archivace webu. NK ČR začala s archivací českého webu již v roce 2000 a od počátku se zapojila jako platný a respektovaný člen do mezinárodní spolupráce. Problematika budování digitálních depozitních knihoven je problematikou relativně novou. I zde získala NK ČR velmi rychle potřebné znalosti a zapojila se do mezinárodní spolupráce. Problematika budování digitálních úložišť je jedním z klíčových témat řešených v paměťových institucích všech zemí, které již nashromáždily určité objemy digitálních dat. Česká republika je v této oblasti vysoce ceněna v rovině koncepční. Koncepce Národní digitální knihovny (NDK) včetně centrálního digitálního úložiště se těší trvalému mezinárodnímu zájmu a částečně se uplatnily i v rámci zahraničních koncepcí. 6
7 Ministerstvo kultury a česká vláda přijaly Národní digitální knihovnu za strategickou prioritu, financování je schváleno a zajištěno v rámci Integrovaného Operačního Programu IOP (Smart Administration). NK ČR spolu s Moravskou zemskou knihovnu v Brně má v rámci projektu NDK tři hlavní cílové linie: urychlení digitalizace (dvě digitalizační centra v Praze a v Brně, nasazení masové digitalizace) dlouhodobá ochrana digitálních objektů (zdigitalizovaných i digital born dokumentů) - důvěryhodný digitální repozitář komfortní zpřístupnění a práce s dokumenty ze strany uživatele Řada výsledků řešení tohoto výzkumného záměru je důležitým základem a vstupem pro řešení projektu NDK. Země různých částí světa, které mají určité zkušenosti s výzkumem a vývojem v oblasti archivace webu, spojují své síly a usilují o spolupráci, zejména na vývoji softwarových nástrojů a standardů. K tomuto účelu bylo v roce 2003 založeno konsorcium IIPC (International Internet Preservation Consortium), jehož členem se od května 2007 stala i NK ČR. Naše mezinárodní aktivity a kontakty v této oblasti jsou velmi významné a naše výsledky snesou mezinárodní měřítka. A.3 Vstupní data a cíl Rekapitulace cílů uvedených v projektu pro jednotlivé oblasti a jejich zasazení do časového harmonogramu budou užitečnou pomůckou pro posouzení toho, které z vytčených cílů se podařilo/nepodařilo v průběhu sedmi let řešení výzkumného záměru realizovat. U jednotlivých oblastí je uvedeno, zda se zde podařilo/nepodařilo dosáhnout uznaných výsledků. Soupis všech uznaných výsledků za roky a výsledků, které budou nahlášeny za rok 2010, je uveden v kapitole C 1 Výsledky řešení. 1. Zajištění trvalé dostupnosti heterogenních informačních zdrojů (domácích i zahraničních) včetně vyhodnocování a koordinace jejich využití Domácí zdroje (WebArchiv): Další vývoj aplikačních softwarových nástrojů pro tvorbu metadat, jednoznačnou identifikaci dokumentů, stahování zdrojů a jejich ukládání do archivu a vyhledávacích nástrojů (průběžně ). Výzkum metod pro zajištění trvalého přístupu k dokumentům uloženým v digitálním archivu (průběžně ). Výzkum způsobů efektivního zpřístupnění archivovaných dokumentů pro badatelské účely. I efektivní zpřístupnění dokumentů uložených v digitálním archivu vyžaduje permanentní monitorování trendů rozvoje HW i SW a v návaznosti na tento vývoj takovou modifikaci způsobů zpřístupnění archivovaných dokumentů, aby byla pro uživatele-badatele příjemná a efektivní (průběžně ) a současně i v souladu s platnou legislativou. Všechny vytčené cíle byly splněny. V oblasti archivace webu se podařilo dosáhnout řady významných výsledků, které byly na základě nahlášení do RIV uznány. Jedná se o prototyp, poloprovoz a publikační činnost. Domácí zdroje (analytické zpracování): Vytvoření předpokladů pro zpracování a zpřístupnění dosud obtížně dostupných analytických dokumentů s částečným ohledem na elektronické publikování v této oblasti ( ). 7
8 Vývoj aplikace standardů pro zpracování a zpřístupnění analytických dokumentů včetně jejich vazby na plné texty primárních dokumentů (URN, SICI). Jednoznačné identifikátory URN a SICI zajistí snadnou a okamžitou dostupnost primárních dokumentů (plných textů). V rámci záměru bude probíhat výzkum jejich optimálního využití v rámci JIB ( ). Implementace souborů věcných autorit v oblasti analytického zpracování s ohledem na jeho plnou integraci v JIB (2004), výzkum v oblasti optimalizace využití řízeného slovníku ve vazbě na plné texty dokumentů (průběžně ). Zahraniční zdroje: Efektivní zpřístupňování a využívání plnotextových databází odborných zahraničních periodik a dalších informačních zdrojů sekundárního charakteru ( ). Strategie získávání zdrojů v návaznosti na statistické ukazatele jejich využití (průběžně ). Integrované zpřístupnění zahraničních časopisů ( ). Všechny vytčené cíle byly sice splněny, ale v této oblasti se nedařilo dosáhnout významných výsledků uznatelných jako výsledky řešení v oblasti VaV. Proto byla tato oblast na základě doporučení hodnotící komise, která ji pokládala spíše za oblast praktických aplikací než oblast výzkumu a vývoje, utlumena v roce Koordinace jmenného zpracování a zpřístupnění heterogenních informačních zdrojů s ohledem na mezinárodní kontext (metadata, formáty, katalogizační pravidla) Soustavné sledování vývoje existujících standardů pro jmenné zpracování (metadata, formáty, katalogizační pravidla) a vzniku a vývoje standardů nových (průběžně ). Vývoj aplikací mezinárodních standardů pro české knihovny (průběžně ). Jednotná implementace modifikovaných a nových standardů v českých knihovnách (průběžně ). Všechny vytčené cíle byly sice splněny, ale ani v této oblasti se nedařilo dosáhnout významných výsledků uznatelných jako výsledky řešení v oblasti VaV. Proto byla tato oblast na základě doporučení hodnotící komise, která ji pokládala spíše za oblast praktických aplikací než oblast výzkumu a vývoje, utlumena v roce Optimalizace věcného zpřístupnění dokumentů s ohledem na integraci v mezinárodním kontextu Soustavné sledování vývoje existujících standardů pro věcné zpřístupnění a vzniku a vývoje standardů nových (průběžně ). Vývoj aplikací mezinárodních standardů pro české knihovny (průběžně ). Jednotná implementace modifikovaných a nových standardů v českých knihovnách (průběžně ). Vývoj integrovaného nástroje pro indexaci a vyhledávaní informací ( ). Všechny vytčené cíle byly splněny. V oblasti věcného zpřístupnění dokumentů se podařilo dosáhnout řady výsledků, které byly na základě nahlášení do RIV uznány. Jedná se o prototyp, software a publikační činnost. 8
9 4. Optimalizace využití heterogenních informačních zdrojů prostřednictvím jejich integrace v rámci Jednotné informační brány Výzkum optimálního zpřístupnění heterogenních informačních zdrojů v rámci JIB a vývoj nových nástrojů korespondujících s rozvojem informačních technologií i uživatelských potřeb (průběžně ). Aplikace metody Konspektu v celonárodním měřítku ( ). Budování tematických bran (průběžně ). Všechny vytčené cíle byly splněny. V oblasti využití heterogenních informačních zdrojů se podařilo dosáhnout výsledků, které byly na základě nahlášení do RIV uznány. Jedná se o prototyp a publikační činnost. 5. Budování digitálních depozitních knihoven s ohledem na možnost jejich integrace v rámci Jednotné informační brány a nadnárodních portálů Analýza existujících a nově vznikajících metadatových standardů (rovina bibliografická, administrativní, technická i ochranná) a návrh českých národních standardů ( ). Analýza digitálních depozitních knihoven v mezinárodním kontextu ( ). Specifikace funkčních požadavků národního repozitáře s ohledem na jeho snadnou integraci v rámci portálů a Souborného katalogu ČR ( ). Všechny vytčené cíle byly splněny. V oblasti budování digitálních depozitních knihoven se podařilo dosáhnout řady výsledků, které byly na základě nahlášení do RIV uznány. Jedná se o prototyp a publikační činnost. 9
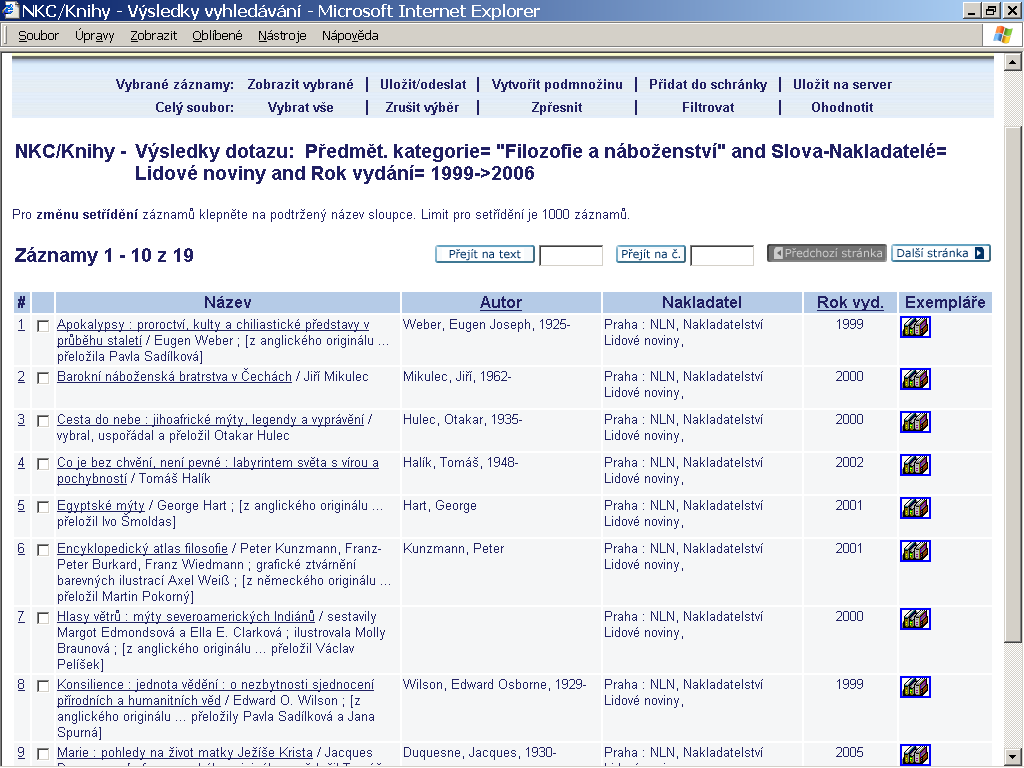
10 B Analytická část B.1 Vlastní řešení Výsledky řešení dosažené v jednotlivých letech jsou detailně popsány v příslušných ročních zprávách, proto budou v závěrečné zprávě zrekapitulovány pouze nejvýznamnější výsledky typu software, prototyp a poloprovoz dosažené v jednotlivých oblastech obsažené v evidenci RIV. Výsledky za rok 2010 budou do evidence teprve nahlášeny. Soupis všech uznaných výsledků (včetně publikační činnosti) za roky a výsledků, které budou nahlášeny za rok 2010, je uveden v kapitole C 1 Výsledky řešení. Soupis je uspořádán chronologicky od nejstarších výsledků po nejnovější. Popis výsledků je převzat z příslušných ročních zpráv, proto ilustrativní příklady (obrazovky) odpovídají době, kdy byl výsledek uplatněn. Rok 2006 Tematická mapa fondů (S prototyp) Aplikací schématu předmětové kategorizace pro potřeby Konspektu v bibliografických záznamech a připojením pořadového čísla předmětových kategorií u jednotlivých skupin Konspektu v bibliografických záznamech byl vytvořen základ pro vznik komplexní a srozumitelné tematické mapy knihovních fondů vytvořené na základě jednotné metodiky. Tematická mapa fondů poskytuje kvalitní popis obsahu fondů a přispívá tak ke komplexnímu zpřístupnění knihovních fondů a ke snadné navigaci uživatelů hledajících informace k určitému tématu. Výrazným způsobem též posiluje koordinaci v oblasti budování a využívání knihovních fondů v českých knihovnách. Cílem tematických map knihovních fondů je umožnit získání základní informace o tematickém profilu fondů jednotlivých institucí bez podrobných bibliografických informací vyhledávání dokumentů jednoduchým a uživatelsky vstřícným způsobem. Cílem tematické mapy fondů je umožnit vyhledávání informací o dokumentech jednoduchým a uživatelsky vstřícným způsobem. Pomocí jednoduchého formuláře, v němž lze podle jednotlivých kritérií pomocí logických operátorů a zadáním dalšího selekčního termínu vybraného z nabídky zpřesnit či zúžit dotaz a získat záznamy o dokumentech přesně odpovídající dotazu uživatele. Názorným dokladem tohoto postupu je ukázka vyhledávání informací o dokumentech v tematickém portálu NK ČR: např. nakladatel získá přehled o dokumentech v dané tematické oblasti a v určitém období, které v rámci plnění svých povinností vyplývajících ze zákonných ustanovení o povinném výtisku zaslal do knihovny, která je oprávněným příjemcem povinného výtisku. 10
11 11

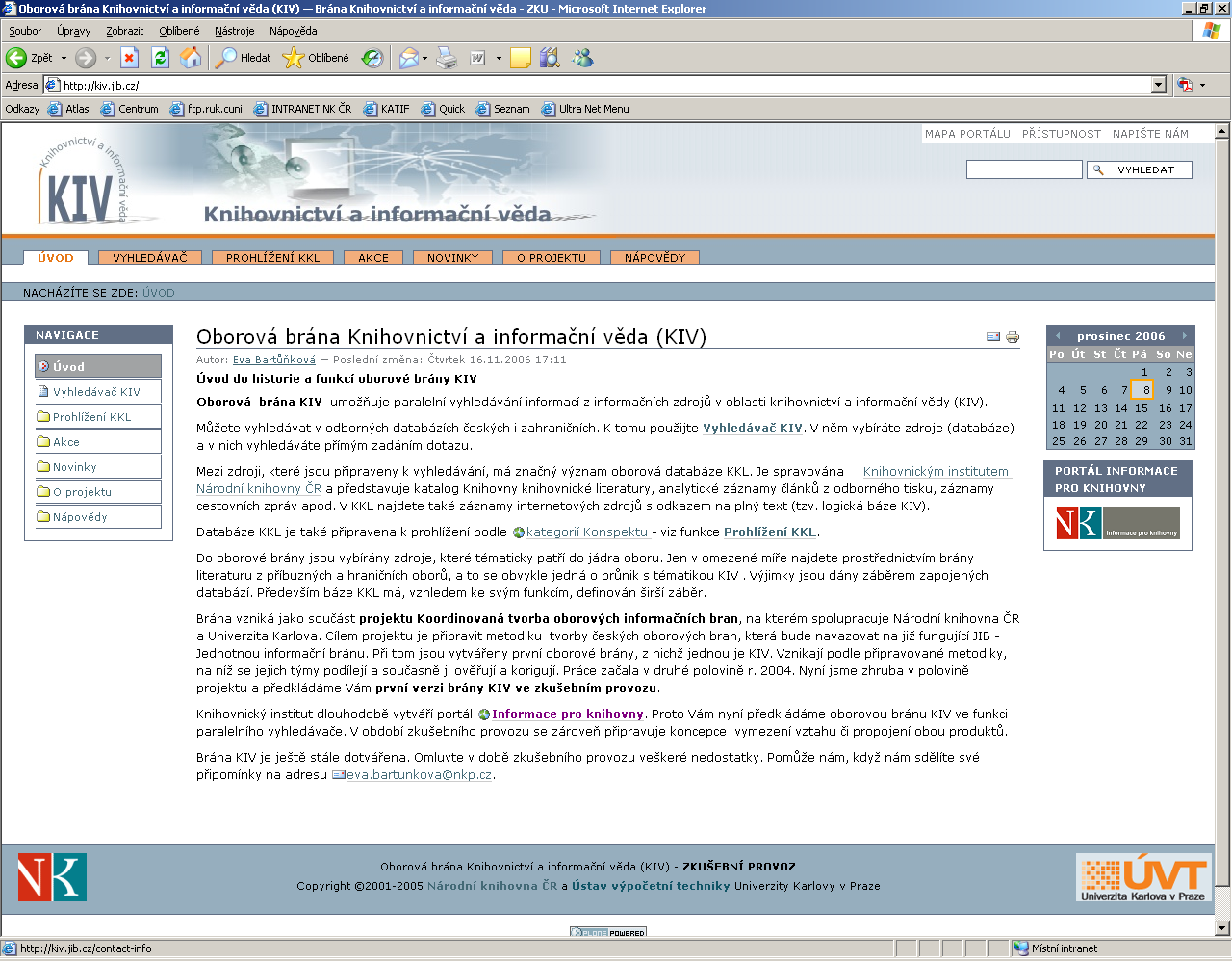
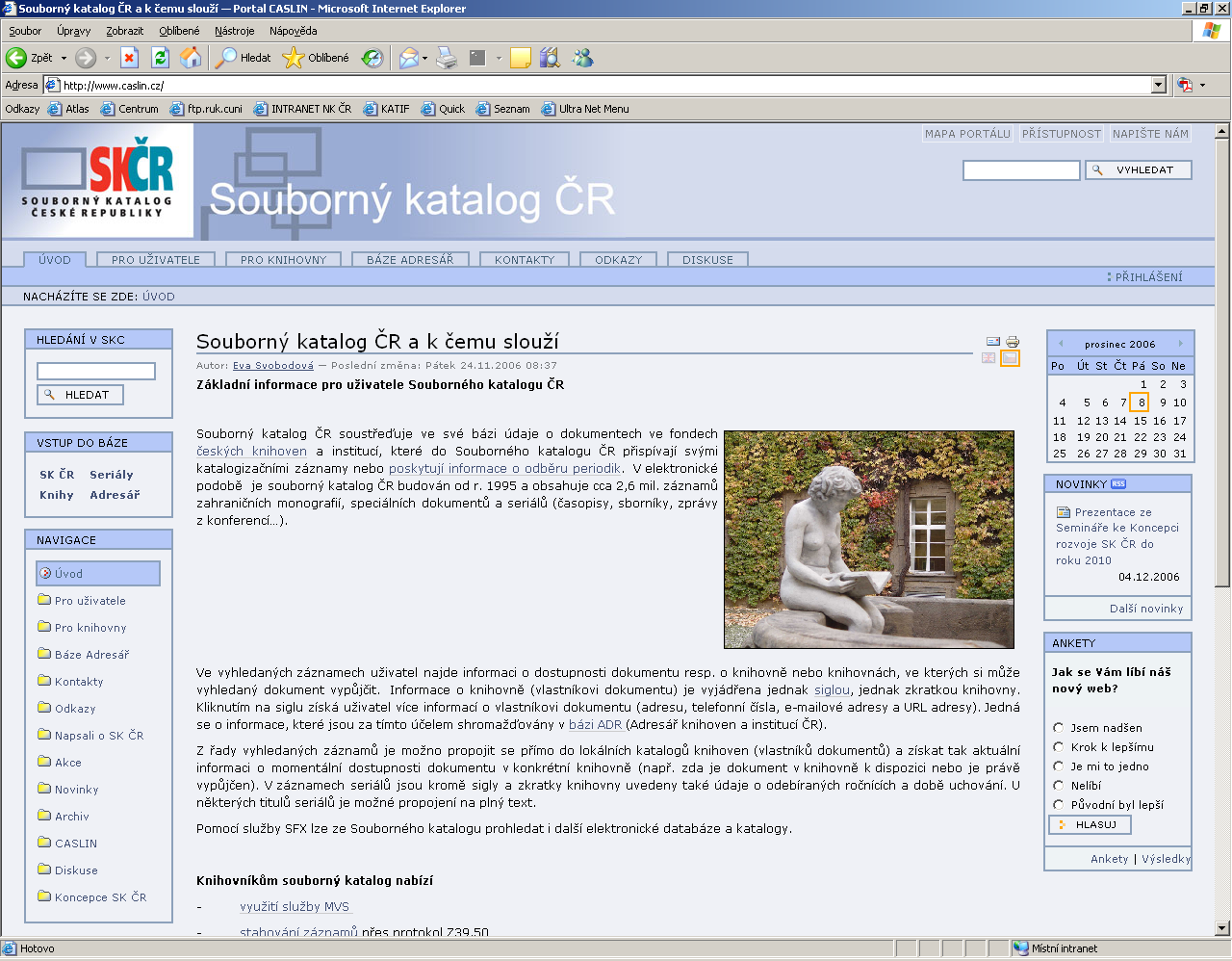
12 Rychlou informaci o tematickém profilu fondů lze zobrazit názorným způsobem pomocí jednoduchých grafů, které přinášejí nenáročnou formou cenné informace o složení a proporcionalitě knihovních fondů. Podávají spolehlivý obraz o tom, jak jednotlivé knihovní instituce plní své úkoly v informačním pokrytí jim svěřeného oboru. V konkrétní rovině poskytují účinnou zpětnou vazbu pro koncepční a kooperativní budování knihovních fondů a sbírek. Tematická mapa fondů NK ČR je dostupná na adrese Portálové řešení pro univerzální portály (S prototyp) V roce 2006 došlo k významnému posunu v oblasti budování portálů. S využitím volně dostupného základu Plone byl vyvinut jednotný základ nejen pro Jednotnou informační bránu a oborové brány KIV (knihovnictví a informační věda) a MUS (hudba), kde je využit MetaLib jako jednotný vyhledávač a SFX jako jednotný nástroj pro přidané služby, ale i pro Souborný katalog ČR a Národní digitální knihovnu. O využití (modifikaci) prototypu portálu již projevila zájem řada českých knihoven a oborových bran. 12
13 13
14 14
")
15 V následujících letech byl prototyp využit pro vytvoření oborové brány TECH (technika) 15
 V roce 2008 byly zahájeny testy s SRU/SRW rozhraním pro vyhledávání nad fulltextovým indexem a jeho integrací s")
16 a oborové brány IREL (mezinárodní vztahy). Rok 2008 SRU/SRW rozhraní pro vyhledávání nad fulltextovým indexem (G/A prototyp) V roce 2008 byly zahájeny testy s SRU/SRW rozhraním pro vyhledávání nad fulltextovým indexem a jeho integrací s metavyhledávacími portály typu Jednotné informační brány. Náš tým byl osloven Státní knihovnou v Berlíně, respektive správci Slavistik-Portalu, kteří měli zájem o zpřístupnění fulltextového indexu WebArchivu pomocí standardního SRU rozhraní, kde experimentovali s vyhledáváním nad více Lucene indexy (tj. v našem případě indexy vytvořenými pomocí nástroje Nutch, resp. NutchWAX). Do tohoto experimentu jsou nyní zapojeny i další knihovny např. z Polska nebo Ruska. Paralelně pak běží testování začlenění stejného indexu do rozhraní Jednotné informační brány (resp. systému MetaLib). Zkratka SRU znamená Search/Retrieval via URL tj. vyhledání a získání dokumentů je umožněno na základě URL. Veškeré parametry pro vyhledávání (např. operation, version, query, startrecord, ) se vkládají do URL. Výsledek dotazu je ve formátu XML, který se pomocí XLST transformuje v příslušném softwaru do HTML. Pro vyhledávání se používá Contextual Query Language. Jde o formální jazyk pro reprezentování dotazů nad informačními systémy, jako jsou webové indexy, bibliografické katalogy nebo různé datové kolekce. Velký důraz je kladen na to, aby schéma a vzhled dotazu byly co nejvíce intuitivní a čitelné, a tedy i snadné na zapamatování. Do dotazů mohou být přidány i další klauzule, např. zajišťující třídění dle daného pole v indexu. 16
17 Protokol umožňuje tři základní typy operací (tzv. parametr operation): 1. explain získání informací o databázi umístěné na vyhledávacím serveru (její umístění, její popis, přístupové body nebo podporované vlastnosti) 2. searchretrieve umožňuje vyhledávání pomocí CQL jazyka (formát výsledků je možné získat pomocí předchozí operace explain, např. Doublin Core, MODS, Marc) 3. scan slouží k získávání termínů z indexu databáze pro procházení rejstříku K zajištění přístupu k našemu fulltextovému indexu byl použit nástroj SRW FRED LOM Web Service (viz implementující SRW Search/Retrieve standard. Jako další vhodný nástroj se jeví OCLC Research SRW Server 2.0, který však není již nějakou dobu dostupný a není tedy možné jej vyzkoušet (viz Aplikace běží pod javovským kontejnerem Apache Tomcat 5.5 a pro svou konfiguraci používá dvou konfiguračních souborů: SRWDatabase.props mezi nejdůležitější nastavení patří přiřazení xsl souborů k jednotlivým druhům operací (xsl soubory slouží pro XSLT transformaci výsledků operací do HTML výstupu), dalším důležitým nastavením tohoto soboru je namapování jednotlivých polí indexu na standardní pole. Např. používáme dva různé indexy, v jednom indexu je URL zaznamenáno v poli local.url a ve druhém indexu v poli lucene.url. Namapování potom znamená, že pro obě pole použijeme zástupné jméno, např. url. Umožní to, že jeden dotaz je možný klást nad více indexy a nemusíme měnit pro každý index název daného pole. SRWServer.props zde se nastavují jména databází pro vyhledávání nad různými indexy a cesty k těmto indexům. Implementaci je možné vyzkoušet na následujícím URL Jak je vidět, naše databáze (pojem databáze je zde značně zavádějící) se jmenuje LuceneDemoDB. Ke každé takové databázi se přiřazuje cesta k indexu a lze tedy prohledávat více indexů, pokud není možné inkrementální indexování. Z webového rozhraní je patrné, na co vše je možné se dotazovat. Je ovšem nutno podotknout, že tato implementace neumožňuje vyhledávání ve všech polích ani používání zástupných znaků v dotazech. Jako ukázku dotazu lze použít následující URL: on+%3d+%22serials%22+and+local.content+%3d+%22brod%22+and+local.title+%3 D+%22brod%22&version=1.1&operation=searchRetrieve&recordSchema=info%3Asrw% 2Fschema%2F1%2FLuceneDocument&maximumRecords=10&startRecord=1&resultSetTT L=300&recordPacking=xml&recordXPath=&sortKeys=. Zde jsme vyhledávali všechny dokumenty, které obsahují slovo brod a mající stejné slovo ve svém názvu (pole local.title). Dále jsme výsledek omezili jen na kolekci serials. Dále je patrná verze protokolu (1.1), jméno operace (searchretrieve). Pro automatické zpracování nebo i k jiným účelům se jeví jako lepší použití webové služby. Předchozí příklad dotazu by vypadal následovně (používání webových služeb jako prostředek je popsán níže) <SOAP:Envelope xmlns:soap=" <SOAP:Body> <SRW:searchRetrieveRequest xmlns:srw=" <SRW:version>1.1</SRW:version> 17
18 <SRW:query>(local.collection = "serials" and local.title = "brod" and local.content = "brod")</srw:query> <SRW:startRecord>1</SRW:startRecord> <SRW:maximumRecords>10</SRW:maximumRecords> <SRW:recordSchema> </SRW:searchRetreiveRequest> </SOAP:Body> </SOAP:Envelope> Kromě standardního SRU vyhledávání (standardizace je zajištěna specifikací SRU v současné době verze 1.2) podporuje i SRW Search/Retrieve Web Service. Tedy vyhledávání a získání dokumentů prostřednictvím webovým služeb. SRW si jako svůj vzor vzalo protokol Z39.50 (klient-server protokol pro vyhledávání a obdržení informací ze vzdálených počítačových systémů/databází). Ve své podstatě SRW není tak komplexní, a proto jeho implementace je značně ulehčena. Je použito jen běžných webových protokolů a nástrojů jako WSDL, SOAP, HTTP a XML. Podobně jako SRU používá pro dotazy CQL jazyk. Námi používaná implementace zatím stále vykazuje problémy s kódováním znaků v dokumentech, na odstranění tohoto problému se pracuje. Dalším úkolem, který zbývá k vyřešení, je vyhledávání nad všemi poli indexu, což by umožnilo vyhledávat dokumenty i na základě polí jako je např. local.date, local.arcdate, local.host nebo local.exacturl. S využitím možností jazyka CQL by pak bylo snadné vyhledávat dokumenty také na základě času a url. Takový dotaz by pak vypadal přibližně takto: <SRW:query>(local.date >= " " and local.date < " " and local.exacturl = " Obohacení geografických autorit o kódované kartografické matematické údaje (R software) Cílem aplikace je obohacení autoritních geografických termínů o konkrétní lokalizaci geografické entity na mapě a doplnění poznámkového aparátu o informace požadované uživateli; jednotlivé geografické entity jsou propojeny s veřejně dostupnými mapovými službami. Práci na vývoji aplikace předcházela analýza dostupných mapových služeb. V současné době je k dispozici celá řada mapových portálů, tj. internetových mapových služeb. Při výběru nejvhodnějšího kandidáta jsme se zaměřili na licenční podmínky, technologické možnosti nabízené služby, nabízené mapové podklady, rozsah a dostupnost dokumentace dané služby. Na základě těchto kritérií byly vybrány dvě mapové internetové služby: Mapy Google (Google Maps) pro lokalizaci a zpřístupnění oblastí, měst, obcí a jejich částí a mapový portál Mapy.cz pro lokalizaci a zpřístupnění přírodních, geomorfologických i umělých útvarů, např. pohoří, hor, rybníků, přehrad apod. Mapový portál Google Maps byl vybrán zejména pro univerzální platnost, protože pokrývá celý svět, nezaměřuje se pouze na Evropu. Tato služba také zveřejnila API a umožnila tak vývoj vlastního webového rozhraní: Google Maps API podporuje vlastní mapové podklady, ovládací prvky a značky. Navíc stránka používající Google Maps API nemá prakticky žádné omezení týkající se počtu zobrazení této stránky za den (umožňuje půl milionu zobrazení stránky denně); stránky musejí používat nejnovější verzi API. Dostupná dokumentace je komplexní a obsahuje všechny potřebné informace. K nedostatkům portálu Google Maps patří především prozatímní nedostatečné pokrytí 18
19 území Česka, portál také nenabízí všechny verze mapových podkladů, např. turistickou mapu, satelitní mapu poskytuje v menším rozlišení. Internetová mapová služba Mapy.cz se zaměřuje pouze na Evropu, funkčnost mapového řešení je ve srovnání s portálem Google.Maps méně dokonalé, tvorba složitějších aplikací není umožněna. Maximální počet zobrazení stránky za den je 1000, API je možné využívat pouze pro nekomerční účely. K výhodám portálu Mapy.cz patří kvalita satelitních map a detailní mapy měst, obcí a jejich částí, ulic (až na popisné číslo). V rámci přípravy byly definovány základní cíle aplikace: uvádět souřadnice ve tvaru požadovaném formátem MARC 21 (zapsání hodnot zeměpisné šířky a délky v desetinném formátu, což vyžadují všechny API pro práci s mapami) a zároveň ve formě vstřícné i pro uživatele, tedy pomocí obvyklých jednotek stupňů, minut a vteřin generovat link do mapy umožňující zobrazení lokality na mapě zachovat základní funkčnost map, tj. podporovat možnost přibližování a vzdalování se, neomezený pohyb po mapě Dílčí postupy: Aplikace umožňuje (pomocí speciální pomůcky): propojení z autoritního záznamu na zvolenou internetovou mapovou službu zápis GEO termínu do vyhledávacího pole, zobrazení lokality na mapě a odečtení/zpřístupnění hodnoty metadatových geoinformací souřadnic připojení souřadnic do speciálního pole GPS Při uložení záznamu dochází k úpravě údajů v poli GPS do standardního tvaru (odstranění interpunkce, mezer atd.), zaokrouhlení údajů na desetiny úhlové vteřiny k převedení hodnot vyjádřených ve stupních, minutách, vteřinách na hodnoty desetinné a vytvoření pole 034 Pokud je v záznamu odkaz na mapový portál Mapy.cz, další odkazy se nevytvářejí. V opačném případě se na základě údajů v poli GPS vytvoří standardní odkaz do vlastního webového rozhraní odkaz je vždy aktuální a stejně jako pole 034 odpovídá hodnotám v poli GPS. Realizace těchto úkolů předpokládala: implementovat pole pro zápis kódovaných kartografických matematických informací (pole 034) do autoritních záznamů porovnat světovou databázi Geonames s bází geografických autorit u jednoznačných geografických názvů generovat link do mapy; asi 4200 názvů měst, obcí a jejich částí bylo možno propojit, 3750 geografických názvů je nutné posoudit jednotlivě. 19

20 Ukázka záznamu GEO autority s propojením na mapový portál Mapy.cz Ukázka záznamu GEO autority s propojením na mapový portál Gogole Maps 20

21 Informační portál Kramerius (G/A prototyp) Připravili a zpřístupnili jsme prototyp portálu Kramerius, který bude soustřeďovat informace o digitalizaci novodobých fondů v ČR i v zahraničí i souvisejících technologiích, standardech a projektech. Rok 2009 SRU/SRW rozhraní pro vyhledávání nad fulltextovým indexem (Z/A poloprovoz) Fulltextovou indexaci archivu provádíme pomocí systému NutchWAX (Nutch -Web Archive Extension). Jde o rozšíření webového vyhledávacího rozhraní Nutch, založeného na indexovací a vyhledávací technologii Lucene. V současné době indexujeme pouze veřejnou část WebArchivu. Rozhraní fulltextového systému NutchWAX je provozováno na adrese docno bed9a segment tar digest df26b5f3b8fb741da1c4a boost 1.0 date arcdate encoding windows-1250 collection Serials arcname IAH harvester.nkp.cz 21
22 arcoffset primarytype text subtype html url title Zařazení druhů do rodů a čeledí Výše uvedený příklad ukazuje data uložená v Lucene o jednotlivých souborech z archivu. Zapojení do portálů pomocí protokolu SRU/SRWU V loňské zprávě jsme podrobněji popsali mechanismus SRU/SRW. SRU protokol jsme zvolili pro zapojení fulltextového indexu, generovaného systémem NutchWAX. Díky tomu, že index z NutchWAX je založen na Lucene, byla pro napojení zvolena aplikace OCLC, která zpřístupnění Lucene indexu přímo podporuje. Rozhraní SRU je provozováno na adrese Zároveň vzniklo druhé, alternativní připojení, na kterém je možno testovat vyvíjenou verzi SRU serveru bez ohrožení ostrého provozu. Výhodou této aplikace je to, že díky odkázaným stylesheetům lze při diagnostice s použitím browseru generovat z přijatého XML přímo dotazovací formulář nebo zobrazit výsledky v přehledné tabulce. Při zapojování fulltextového indexu do JIB bylo nutné překonat některé překážky. MetaLib sám rozhraní SRU podporuje jen díky skriptům v Perlu, vyvinutým původně ve finské národní knihovně. Tyto skripty zajišťují komunikaci přes SRU pro dva formáty: MARCXML a Dublin Core. SRU aplikace nad Lucene indexem generuje automaticky jen XML záznam poplatný struktuře dat uložených v indexu. Není tedy bez úprav na jedné či druhé straně možné přímé propojení obou systémů. Přistoupili jsme proto k takové úpravě SRU serveru, která by umožňovala rozpoznat příchozí vyhledávací dotazy kódované ve formátu Dublin Core a vracela výsledky opět v tomto formátu. SRW Lucene na dotaz od MetaLibu vrací odpověď v SRW DC, kterou už MetaLib (resp. dodaný konektor po nakonfigurovaní - zejména vynucení si schématu Dublin Core místo defaultního MARCXML) je schopen zpracovat a předložit uživateli. Mapovaní dotazu je zajištěno těmito pravidly: qualifier.cql.serverchoice=content qualifier.dc.creator=url qualifier.dc.title=title qualifier.dc.subject=content qualifier.dc.identifier=url qualifier.dc.date=arcdate 22

23 V rozhraní JIB lze tento zdroj nalézt pod názvem WebArchiv - fulltext. Integrace s Wayback Machine Nutch jsme upravili tak, aby jím indexované dokumenty byly uživateli přímo dostupné prostřednictvím aplikace Wayback z archivu WebArchiv. Výsledný seznam hitů tak pro každý záznam obsahuje mimo názvu dokumentu ještě odkaz na živý web, odkaz na konkrétní dokument do aplikace Wayback a také odkaz do rozhraní Waybacku, zpřístupňující všechny časové verze daného dokumentu. Výsledek vyhledávání v plných textech WebArchivu prostřednictvím JIB 23

24 Zobrazení konkrétního výsledku s odkazy na Wayback a živý web Zobrazení konkrétní časové verze výsledku ve Waybacku 24
25 Rok 2010 SRU/SRW rozhraní pro vyhledávání nad fulltextovým indexem (Z/A poloprovoz) Pro fulltextovou indexaci WebArchivu používáme nástroj NutchWAX 1 vyvinutý organizací Internet Archive 2, který rozšiřuje funkcionalitu open source internetového vyhledávače Nutch 3 o indexaci ARC souborů a ukládání specifických metadat pro WebArchiv. Fulltextová indexace se skládá z následujících fází: 1. Import obsahu dokumentů z ARC souborů - z každého textového dokumentu jsou extrahována metadata, text a v případě HTML stránek ještě navíc odkazy. Výsledky jsou ukládány do tzv. segmentů. 2. Aktualizace databáze crawleru - tato část je sice z našeho pohledu zbytečná, neboť používáme pro sklízení Heritirix a ne crawler Nutche, ale z jistých technických důvodů ji nelze vynechat. 3. Invertování odkazů - každému dokumentu je přiřazen seznam stránek, které na něj odkazují. 4. Vygenerování pageranku pro hodnocení relavance stránek - je vygenerován textový soubor obsahující na každém řádku URL dokumentu, podle kterého je lexikograficky setříděn a počet externích odkazů (tzn. odkazů z jiných domén), které na daný dokument odkazují. 5. Indexace - ze segmentů, které byly vytvořeny v první fázi, se generuje invertovaný soubor a ke každému dokumentu se navíc ukládá hodnota pageranku. Seznam metadat ukládaných do indexu je v následující tabulce: pole popis příklad segment title content Národní knihovna segment, má význam pouze pro nuchwax titulek stránky (z obsahu elementu title) textový obsah dokumentu pro generování úryvků url URL dokumentu digest collection sha1:no2wdxitso6mdwubnk3bxzapzcslqge6 otisk (hash) z obsahu dokumentu jméno kolekce (nepovinné, nepoužíváme) date čas sklizně dokumentu type text/html MIME typ dokumentu length velikost dokumentu v bytech boost 5.0 relevance dokumentu pro řazení výsledků, hodnota je rovna log 10 N, kde N je počet externích odkazů na tento dokument Fulltextová indexace probíhá po částech, výsledné indexy je třeba sloučit do jednoho a následně odstranit z indexu duplicitní dokumenty, které rozlišujeme podle MD5 haše
26 Úskalí při fulltextové indexaci: 1. Špatné či chybějící deklarované kódování dokumentu - nástroj NutchWAX byl modifikován tak, že identifikuje kódování dokumentu stejným způsobem jako wayback, u kterého je již odladěné. Pokud deklarace kódování chybí, použije se heurisitika. Úprava spočívala v ukládání HTTP hlavičky s kodováním při importu segmentů, kterou sám o sobě NutchWAX zahazuje, a využitím této informace při indexaci. Toto řešení lze využít i v distribuované verzi. 2. Problém s občasnými pády byl vyřešen přechodem na Javu od IBM. 3. Extrakce textu z některých nekorektně vytvořených PDF dokumentů je stále problémem, protože z některých dokumentů po extrakci vypadne "čínský čaj" a získat původní text není schopen ani Acrobat Reader. 4. Spam Při detekci znakové sady se postupuje následovně (při prvním pozitivním výsledku se nepokračuje): 1. Deklarace znakové sady v HTTP hlavičce odpovědi serveru 2. Deklarace znakové sady v prologu HTML dokumentu 3. Jednoduchá heuristika, pro každou českou znakovou sadu (UTF-8, ISO , CP-1250) se spočítá celkový počet českých znaků s diakritikou ze začátku dokumentu a jako výsledek se bere znaková sada s nejvyšším dosaženým počtem. Možnosti omezení vyhledávání dokumentů na volně dostupné: 1. Mít dva indexy, jeden úplný a druhý jen s volně dostupnými dokumenty vygenerovány jednou za čas z úplného indexu stejným způsobem, jakým odstraňujeme duplikáty. 2. Odlišit ve výsledcích hledání volné a nedostupné dokumenty, např. ikonou či poznámku. 3. Modifikace indexu je problematická, změnit metadata dokumentu lze jen tak, že ho odstraníme a přidáme znovu do indexu. Odstraňování dokumentů z indexu je poněkud komplikované, protože index v Lucene nelze upravit na místě ("in place") a je tudíž náročnější na místo na disku (potřebujeme až M dodatečného volného místa, kde M je velikost původního indexu): 1. Nejprve je vygenerována bitmapa, kde každý bit reprezentuje jeden dokument a jeho hodnota indikuje, zda má či nemá být ponechán. 2. Při slučování indexů se přečte bitmapa každého indexu a do výsledného indexu jsou přidány jen dokumenty, které nebyly označeny jako smazané. Sloučit lze jeden či více dokumentů. Statistika fulltextu Rychlost indexace se pohybovala v rozmezí 1000 až 1500 ARC souborů za den, statistiky za jednotlivé roky lze najít v následující tabulce: java IBM JRE procesor 4 x Intel(R) Xeon(R) CPU E5420@2.50GHz operační paměť 8 GB diskové pole 10 TB 26
27 rok zaindexované ARC soubory počet dokumentů v tisících do roku celkem Vyhledávání ve fulltextu Vyhledávání ve fulltextu je dostupné na zvýrazňování výsledků ve waybacku zajišťuje javascript, který hledaná slova získá z redirectu a funkčnost není garantována u všech stránek. Aktuálně (k ) jsou zaindexované nasmlouvané zdroje od roku 2003 do března Postupně se bude index rozšiřovat o nové sklizně. Formát dotazu: Výsledek obsahuje pouze stránky, které obsahují všechna slova v dotazu. Lze vyhledávat i fráze, hledanou frázi je třeba uzavřít do dvojitých uvozovek, např. "Národní knihovna". U dotazů nezáleží na velikosti písmen. Určitý výraz můžete z vyhledávání vyřadit vložením znaménka mínus před něj, např. vyhledávání football -NFL najde všechny stránky týkající se fotbalu, ale neobsahující slovo "NFL". Dokumenty lze vyhledavát i podle času, např. dotaz "Národní knihovna" date:2005. Čas je porovnávan prefixově, tzn. pro dotaz "date:2005" najde všechny dokumenty z roku 2005, pro dotaz "date:200512" všechny dokumenty z prosince Lze vyhledávat i podle intervalu, např. "Národní knihovna" date: Pokud nás zajímají pouze výsledky z domény použijeme pole site, např. site: "Národní knihovna". Vyhledávat lze i podle mime typu, např. dotaz "Národní knihovna" type:application/pdf najde všechny PDF dokumenty, které obsahují frázi "Národní knihovna". Poznámky k hledání: Vyhledávat lze i dlouhé fráze skládající se z několika vět, takže není problém vzít pár vět z odstavce nějakého článku a hledat, kde všude byl článek převzat. Šlo by to využít i pro detekci podobných dokumentů. Nutch neumí detekovat podobné dokumenty při zobrazování výsledků, proto se často stává, že podobné dokumenty mají shodnou relevanci a tudíž jsou ve výsledcích u sebe. Detekce znakové sady Nutchem u některých dokumentů není optimální, na řešení se pracuje. U některých PDF vypadne při převodu na text "čínský" čaj. Původně chyběla možnost stránkování výsledků jako u Googlu, řešením je použít XSL šablonu distribuovanou s NutchWAXem, která transformuje výsledky z Open Search do HTML a podporuje stránkování. 27

28 Oficiální dokumentace k vyhledávání je na Vyhledávání ve fulltextu je dostupné na: Webové rozhraní na které využívá OpenSearch a výsledky z XML transformuje do HTML za pomocí XSL šablony. OpenSearch rozhraní na Jednotná informační brána, název zdroje je WebArchiv vyhledávání v plných textech. MetaLib Masarykovy univerzity pod názvem WebArchiv. Obr. Úplné zobrazení nalezeného výsledku fulltextového vyhledávání v JIB SRU/SRW protokol, zapojení do JIB Jednotná informační brána podporuje protokol SRU/SRW díky skriptům napsaných v Perlu vyvinutých finskou národní knihovnou, které transformují dotazy a odpovědi do (z) protokolu SRW/U a zpřístupňují je tak jádru systému MetaLib, který je srdcem JIB. Veškeré parametry dotazu jsou v případě SRU součástí URL, v případě SRW se pro volání a vracení výsledku používají webové služby. Dotazy jsou vyjádřené v jazyce CQL (Contextual/Common Query Language), což je poměrně silný a lidsky čitelný jazyk pro dotazování nad vyhledávacími stroji. CQL podporuje: booleovské operátory (AND, NOT, OR). Příkladem dotazu je "'auto' OR 'motocykl'". relační operátory (=, >, <,...). Příklad dotazu je "year > 2000". dotazy na příslušný klíč, např. "dc.autor='božena Němcová'". podrobnější popis a příklady dotazů lze najít v A Gentle Introduction to CQL 4. OpenSearch 5 je jednoduchý protokol pro vyhledávání na webu, základem je jednoduchý XML dokument, který popisuje syntaxi URL pro volání a seznam podporovaných formátů (JSON, RSS, HTML). Příklad takového XML dokumentu je: <?xml version="1.0" encoding="utf-8"?> <OpenSearchDescription xmlns="
29 <ShortName>Web Search</ShortName> <Description>Use Example.com to search the Web.</Description> <Tags>example web</tags> <Url type="application/rss+xml" template=" </OpenSearchDescription> Každý OpenSearch deskriptor obsahuje jeden či více elementů Url, které obsahují v atributu type vrácený formát (RSS, JSON, HTML) a v atributu template syntaxi URL pro volání, která obsahuje následující parametry, které jsou při dotazu nahrazeny za příslušnou hodnotu parametru: parametr povinný význam {searchterms} ano dotaz, hledaný výraz {startpage?} ne číslo požadované stránky (umožňuje stránkování výsledků) {count?} ne počet vrácených výsledků {startindex?} ne zobraz výsledky od (umožňuje stránkování výsledků) Příklad volání, které vrátí prvních pět výsledků pro dotaz MZK ve formátu RSS je: &format=rss Markantní rozdíl mezi OpenSearch a SRU/SRW je, že OpenSearch nepředepisuje na dotaz žádná omezení a může jím být prakticky cokoliv. V SRU/SRW formu dotazu předepisuje jazyk CQL. Příklad dotazu v CQL, a jeho ekvivalentu pro Nutch ilustrujeme v následující tabulce, Nutch podporuje "googlovské" výrazy: dotaz v CQL dc.title="hello" AND dc.date=2008 "příklad dlouhé fráze" "první fráze" AND "druhá fráze" "obsahuje" NOT "neobsahuje" cql.serverchoice="studená válka" dc.author="novak" "auto" OR "motocykl" ekvivalent dotazu pro Nutch title:"ahoj" date:2008 "příklad dlouhé fráze" "první fráze" "druhá fráze" "obsahuje" -"neobsahuje" "studená válka" - (nelze přeložit) "auto" "motocykl" (není ekvivalentní) Předposlední dotaz nelze přeložit, neboť pole autor z Dublin Core nelze namapovat na odpovídající pole v Nutch a v takových případech vrátíme chybu. Poslední dotaz není ekvivalentní dotazu v CQL, protože Nutch nepodporuje operátor OR a výsledný dotaz najde všechny dokumenty, ve kterých se vyskytují zároveň slova auto a motocykl, zatímco dotaz v CQL najde dokumenty, které obsahují slova auto nebo motocykl. Při implementaci rozhraní mezi OpenSearch a SRU/SRW musíme počítat s tím, že ne veškeré dotazy v CQL půjdou přeložit do OpenSearch. Mapování polí z Dulin Core, na které se dotazuje MetaLib, na pole Nutche je přitom následující: formulář v MetaLibu pole v CQL Nutch všechna pole cql.serverchoice implicitní pole název dc.title title 29
30 rok dc.date date předmět dc.subject chyba, ekvivalent neexistuje autor dc.author chyba, ekvivalent neexistuje ISSN dc.identifier chyba, ekvivalent neexistuje ISBN dc.identifier chyba, ekvivalent neexistuje Příklad výsledku dotazu SRU/SRW ve formátu Dublin Core: <?xml version="1.0" encoding="utf-8"?> <srw xmlns="info:srw/schema/1/dc-v1.1"> <title>mzk Brno</title> <publisher> <date> </date> <description>uryvky</description> <identifier>odkaz na živou verzi/</identifier> <identifier>odkaz do waybacku</identifier> <identifier>všechny časové verze</identifier> <format>text/html</format> </srw> Vyvinuli jsme tedy překladač z jazyka CQL na ekvivalentní dotaz v OpenSearch pro NutchWAX, který lze ovšem využít i pro jiné zdroje s podobnou syntaxí (otestovali jsme ho i na Google Books) a který bere v potaz výše uvedená úskalí překladu. Dále jsme vyvinuli konfigurovatelnou bránu mezi SRU/SRW a OpenSearch, do které jsme začlenili tento překladač a XSL šablonu, která konvertuje RSS výsledky NutchWAXe do formátu Dublin Core. Zdrojové kódy rozhraní mezi OpenSearch a SRU/SRW jsou dostupné na adrese Konfigurace brány Brána se konfiguruje v textovém souboru ve formátu java properties, který definuje URL s OpenSearch deskriptorem, XSL šablonu pro transformaci výsledku, definici jmenných prostorů, XPath výraz pro separaci jednotlivých výsledků a XPath výraz, který vrátí počet celkových výsledků. V XPath výrazech se můžeme odvolávat na definované jmenné prostory. Pro tranformaci dotazu musíme definovat podporované logické operátory (AND, OR, NOT) a mapování polí z CQL na odpovídající OpenSearch ekvivalent. Většina vyhledáváčů totiž podporuje výrazy ve tvaru klíč:hodnota. opensearch.url= opensearch.xsl_template=/home/app/opensearch/googlebooks.xsl opensearch.namespace.opensearch= opensearch.namespace.atom= opensearch.records_xpath=//atom:entry opensearch.total_records_xpath=//opensearch:totalresults/text() operator.and=and operator.or=or operator.not=key.srw.serverchoice= key.cql.serverchoice= key.cql.any= key.title=intitle #dublin core elements key.dc.creator=inauthor key.dc.title=intitle 30
31 key.dc.publisher=inpublisher key.dc.identifier=isbn Příklad konfigurace pro Google Books Při psaní XSL šablony musíme dávat pozor na definici jmenných prostorů, Google Books vrací Dublin Core ve jmenném prostoru s URI MetaLib je ovšem vyžaduje ve jmenném prostoru info:srw/schema/1/dc-v1.1, Google Books vrací výsledky ve formátu DC, stačí u všech elementů DB změnit jmenný prostor. <?xml version="1.0" encoding="utf-8"?> <xsl:stylesheet version="1.0" xmlns:xsl=" xmlns:dc_google=" xmlns:dc=" xmlns:srw_dc="info:srw/schema/1/dc-v1.1" xmlns:atom=" exclude-result-prefixes="atom dc_google"> <xsl:output method="xml" encoding="utf-8" indent="yes" /> <xsl:template match="/"> <srw_dc:dc> <xsl:apply-templates/> </srw_dc:dc> </xsl:template> <xsl:template match="//dc_google:*"> <xsl:variable name="element" select="name()"/> <xsl:element name="{$element}"> <xsl:value-of select="text()"/> </xsl:element> </xsl:template> <xsl:template match="text()"/> </xsl:stylesheet> XSL šablona pro Google Books Loňským výsledkem tohoto záměru byl poloprovoz SRU/SRW rozhraní pro vyhledávání nad fulltextovým indexem a jeho integraci s metavyhledávacími portály. V letošním roce jsme se v této oblasti posunuli na úroveň provozu, který bude nahlášen jako jeden z výsledků řešení za rok Resolver URN:NBN (Z/A poloprovoz) Cílem v roce 2010 bylo připravit prostředí a základní SW aplikaci pro pilotní test systému pro využití URN:NBN v NK ČR. Aplikace umožní přiřazování globálně jedinečného identifikátoru odpovídajícího pravidlům URN:NBN, dále jeho správu (administrátorský modul), vyhledávání dle identifikátoru a bude spolupracovat s již běžícími systémy NK, které jsou potřeba pro pilotní projekt. V první pilotní fázi (do poloviny roku 2011) je aplikace určena pro využití v NK ČR, pro přidělování a zpřístupňování identifikátorů dokumentů projektu Kramerius, VISK7 a Norských fondů. Identifikátory budou přiřazeny všem digitalizovaným dokumentům 31
32 z těchto projektů evidovaným v RD.CZ. V dalších fázích (mimo tento výzkumný záměr) bude služba poskytována i ostatním paměťovým institucím za předem určených podmínek. Dokumenty, které v pilotní fázi dostanou URN:NBN musí být v současné době uloženy v repozitáři NK ČR nebo tam musí být uloženy později. Pilotní aplikace byla funkční a otestovaná do konce roku 2010, s případnými úpravami se počítá na rok Pilotní fáze se vědomě vyhýbá digital born dokumentům. Velmi intenzivně probíhaly debaty s Odborem zpracování fondů, zejména kvůli číslu národní bibliografie a návaznostech na systém URN:NBN. Obr. výchozí rozhraní aplikace Obecná funkcionalita Návrh našeho pilotního řešení umožnil vytvoření nástroje, který dokáže přidělovat jedinečné identifikátory postavené na syntaxi URN:NBN pro digitální dokumenty (logické entity). Během implementace návrhu a vývoje nástroje resolver se potvrdila námi deklarovaná skutečnost 6, že je velmi komplikované a nelogické vytvářet aplikaci resolveru dříve, než bezpečně víme, jak bude vypadat životní cyklus digitálních dokumentů, kterým URN:NBN chceme přidělovat. Vzhledem k výše zmíněnému je logika pilotního řešení zatím omezena na dokumenty, které jsou registrovány v jednom balíčku jako zakázka v systému RD.CZ, a to pouze ty z nich, které jsou již reálně zdigitalizovány a budou trvale archivovány v digitálním repozitáři Národní knihovny ČR. Nástroj resolver umožňuje rozeznávat na základě podřízených jmenných prostorů různé digitalizující subjekty (instituce) a přidělovat jim globálně jedinečné identifikátory, 6 viz CUBR, Ladislav; HUTAŘ, Jan; MELICHAR, Marek. Kontrolní seznam pro strategii zajištění perzistence identifikátorů. Knihovna. 2009, roč. 20, č. 2. s Přístupné z WWW: < 32

33 a zajistit, že žádný identifikátor nebude přidělen znovu. Tj. pokud dvě instituce zdigitalizují stejnou knihu, oba takto vzniklé digitální dokumenty budou mít různé URN:NBN, i kdyby byly naprosto shodné. Nástroj umožňuje rovněž vyhledávat identifikované digitální dokumenty, a to nejen podle identifikátoru URN:NBN podle kterého vyhledává primárně, ale také podle dalších užívaných identifikátorů, a sice ISSN, ISBN a ččnb (číslo České národní bibliografie). Po vyhledání dostane uživatel relevantní metadata k vyhledávanému dokumentu, vidí, zda a kým byl zdigitalizován a kde je zpřístupněn, včetně URL linku do konkrétní digitální knihovny. Obr. výsledek hledání dle URN:NBN - výřez Resolver je schopen přijmout a nadále udržovat URN:NBN přidělená jinými systémy, např. SW pro workflow digitalizace na konkrétním pracovišti (např. DocWorks nebo Sirius aj.). Druhou možností je, že workflow digitalizace bude volat resolver, ten přidělí URN:NBN. Syntax identifikátoru Syntax byla navržena takto - URN:NBN:CZ:XXX:12345A, kde: - XXX - kód vlastníka /původce / vydavatele (v pilotní fázi odpovídá údajům v RD.cz) A - šest alfanumerických znaků - pro čísla a písmena (10 číslic + 26 znaků latinky) máme 36 na 6 kombinací, tedy cca 2,1 miliardy kombinací - ve všech částech identifikátoru půjde o náhodná čísla, tj. nebudou označovat konkrétní číslo ročníku ani čísla (u periodik) apod. Současné řešení V pilotní fázi je resolver napojen na systém Registr Digitalizace (dále RD.CZ) a využívá jeho databáze. Do RD.CZ přicházejí data ve formě zakázek, které zpravidla reflektují způsob uložení dokumentů v depozitářích knihoven. Digitalizace probíhá obyčejně podle svazků monografií ovšem i periodik, které jsou svázány do svazků (dodatečně po akvizici) podle toho, jak se to vazačům hodilo, tj. bez obecně platných pravidel a jsou takto i digitalizovány. Jeden svazek tak může obsahovat různé množství čísel i ročníků, nebo naopak jen půl ročníku apod.). Ovšem metadata např. k číslu periodika v katalogu a ani v RD.cz neexistují. Do RD.CZ přichází takto digitalizované svazky jako zakázky a tedy jako celky (tj. digitální objekty), které v pilotní fázi dostanou přiděleno URN:NBN. Je 33
34 jasné, že tato situace není konsistentní, např. pro uživatele, který hledá konkrétní číslo periodika a to konkrétní číslo by mělo mít své číslo URN:NBN, stejně jako např. celý ročník nebo i titul periodika. Takto má URN:NBN digitální objekt (celek) vzniklý digitalizací svazku, jehož obsah jako intelektuální entity je proměnlivý (velmi často celý ročník, dále půlročníky, dva nebo více ročníků apod.). To působí problémy hlavně u periodik, u monografií méně (často svazek=číslo zakázky). Vyjmenované logické nekonzistence pilotního řešení nejsou problémem samotného resolveru, ten je již i v pilotní verzi schopen přidělit URN:NBN jakémukoliv digitálnímu objektu, který jako celek bude zaregistrován v RD.CZ nebo požádá o přidělení URN:NBN externě. Tj. pokud bude workflow digitalizace v NK nastaveno tak, že budou digitalizována periodika tzv. na čísla, každé číslo bude mít svůj metadatový záznam, pak tato číslo mohou dostat URN:NBN. Stejně se to děje již nyní, pokud digitální objekt v RD.CZ je číslo, pak URN:NBN je přiděleno pro číslo. Tj. resolver je připraven na budoucí změny ve workflow digitalizace (opuštění čísel zakázek a zrušení fixace digitálního objektu na fyzický svazek dokumentů). To čemu se bude URN:NBN přidělovat, musí být jasné již během procesu digitalizace, jejíž workflow tak musí být nastaveno. Obr.- výsledek hledání dle ISSN, lze vidět různé ročníky Lidových novin a jejich URN:NBN identifikátory (výřez) 34
 Obr.")
35 Obr.- rozhranní administrace (výřez) Obr. definice struktury dat 35
Zpráva o zhotoveném plnění
 Zpráva o zhotoveném plnění Aplikace byla vytvořena v souladu se Smlouvou a na základě průběžných konzultací s pověřenými pracovníky referátu Manuscriptorium. Toto je zpráva o zhotoveném plnění. Autor:
Zpráva o zhotoveném plnění Aplikace byla vytvořena v souladu se Smlouvou a na základě průběžných konzultací s pověřenými pracovníky referátu Manuscriptorium. Toto je zpráva o zhotoveném plnění. Autor:
Velká data v knihovnách Open source tools and their use in Czech libraries
 Velká data v knihovnách Open source tools and their use in Czech libraries Petr Žabička www.mzk.cz Obsah 1. Úvod 2. Souborný katalog 3. Obálky knih 4. Digitalizace 5. Digital born dokumenty 6. WebArchiv
Velká data v knihovnách Open source tools and their use in Czech libraries Petr Žabička www.mzk.cz Obsah 1. Úvod 2. Souborný katalog 3. Obálky knih 4. Digitalizace 5. Digital born dokumenty 6. WebArchiv
Obohacování bibliografických záznamů o věcné selekční prvky postup NKČR
 Obohacování bibliografických záznamů o věcné selekční prvky postup NKČR Bod programu: Věcné zpracování (možnosti obohacování dříve dodaných záznamů) Marie.Balikova@nkp.cz Pracovní skupina pro SK, 7.3.
Obohacování bibliografických záznamů o věcné selekční prvky postup NKČR Bod programu: Věcné zpracování (možnosti obohacování dříve dodaných záznamů) Marie.Balikova@nkp.cz Pracovní skupina pro SK, 7.3.
Zpráva o výsledcích řešení výzkumného záměru v roce 2010. PhDr. Bohdana Stoklasová, hlavní řešitelka Ing. Libor Coufal, Mgr.
 Budování vzájemně kompatibilních informačních systémů pro přístup k heterogenním informačním zdrojům a jejich zastřešení prostřednictvím Jednotné informační brány Zpráva o výsledcích řešení výzkumného
Budování vzájemně kompatibilních informačních systémů pro přístup k heterogenním informačním zdrojům a jejich zastřešení prostřednictvím Jednotné informační brány Zpráva o výsledcích řešení výzkumného
MBI - technologická realizace modelu
 MBI - technologická realizace modelu 22.1.2015 MBI, Management byznys informatiky Snímek 1 Agenda Technická realizace portálu MBI. Cíle a principy technického řešení. 1.Obsah portálu - objekty v hierarchiích,
MBI - technologická realizace modelu 22.1.2015 MBI, Management byznys informatiky Snímek 1 Agenda Technická realizace portálu MBI. Cíle a principy technického řešení. 1.Obsah portálu - objekty v hierarchiích,
The bridge to knowledge 28/05/09
 The bridge to knowledge DigiTool umožňuje knihovnám vytvářet, administrovat, dlouhodobě uchovávat a sdílet digitální sbírky. DigiTool je možno využít pro institucionální repozitáře, sbírky výukových materiálu
The bridge to knowledge DigiTool umožňuje knihovnám vytvářet, administrovat, dlouhodobě uchovávat a sdílet digitální sbírky. DigiTool je možno využít pro institucionální repozitáře, sbírky výukových materiálu
Vyhledávání na portálu Knihovny.cz
 Inforum 2017 Vyhledávání na portálu Knihovny.cz Petr Žabička, Václav Rosecký, Petra Žabičková Moravská zemská knihovna v Brně Obsah Co indexuje portál Knihovny.cz Rozšíření o centrální index Hledání v
Inforum 2017 Vyhledávání na portálu Knihovny.cz Petr Žabička, Václav Rosecký, Petra Žabičková Moravská zemská knihovna v Brně Obsah Co indexuje portál Knihovny.cz Rozšíření o centrální index Hledání v
Pracovní skupina pro věcné zpracování
 Pracovní skupina pro věcné 13.12. 2011 Marie.Balikova@nkp.cz 1 Program 10:00-11:15 úvodní informace problematika věcného zpřístupnění úprava Konspektového schématu 11:15-12:00 přestávka 12:00-13:15 integrace
Pracovní skupina pro věcné 13.12. 2011 Marie.Balikova@nkp.cz 1 Program 10:00-11:15 úvodní informace problematika věcného zpřístupnění úprava Konspektového schématu 11:15-12:00 přestávka 12:00-13:15 integrace
Co je (staro)nového v DSpace
nového v DSpace") Ústav výpočetní techniky, Masarykova univerzita, Brno CZDSUG 2011, Ostrava Obsah přednášky I Delegování práv. Autentizace přes IP adresy. Omezení viditelnosti, skrytí metadat. Export (CSV). Rozšířená konfigurace
Ústav výpočetní techniky, Masarykova univerzita, Brno CZDSUG 2011, Ostrava Obsah přednášky I Delegování práv. Autentizace přes IP adresy. Omezení viditelnosti, skrytí metadat. Export (CSV). Rozšířená konfigurace
Digitální knihovny v České republice
 Digitální knihovny v České republice PhDr. Martina Machátová Moravská zemská knihovna v Brně Tel.: 541 646 170 E-mail: machat@mzk.cz Aktualizace: 19. května 2019 Digitální knihovna Definice 1,,Integrovaný
Digitální knihovny v České republice PhDr. Martina Machátová Moravská zemská knihovna v Brně Tel.: 541 646 170 E-mail: machat@mzk.cz Aktualizace: 19. května 2019 Digitální knihovna Definice 1,,Integrovaný
Máte to? Summon jako základní vyhledávací nástroj NTK
 Máte to? Summon jako základní vyhledávací nástroj NTK Milan Janíček milan.janicek at techlib.cz odd. rozvoje elektronických služeb Národní technická knihovna Praha Obsah 1) Proč další systém? 2) Metavyhledávač
Máte to? Summon jako základní vyhledávací nástroj NTK Milan Janíček milan.janicek at techlib.cz odd. rozvoje elektronických služeb Národní technická knihovna Praha Obsah 1) Proč další systém? 2) Metavyhledávač
Projekt NUŠL a další projekty v ČR
 Projekt NUŠL a další projekty v ČR Petra Pejšová Státní technická knihovna p.pejsova@stk.cz, Osnova Základní informace o projektu Projektový tým Harmonogram Výstupy Vymezení NUŠL Dotazníkové šetření Metadata
Projekt NUŠL a další projekty v ČR Petra Pejšová Státní technická knihovna p.pejsova@stk.cz, Osnova Základní informace o projektu Projektový tým Harmonogram Výstupy Vymezení NUŠL Dotazníkové šetření Metadata
Digitální knihovny v České republice
 Digitální knihovny v České republice PhDr. Martina Machátová Moravská zemská knihovna v Brně Tel.: 541 646 170 E-mail: machat@mzk.cz Aktualizace: 19. prosince 2016 Digitální knihovna Definice 1 Integrovaný
Digitální knihovny v České republice PhDr. Martina Machátová Moravská zemská knihovna v Brně Tel.: 541 646 170 E-mail: machat@mzk.cz Aktualizace: 19. prosince 2016 Digitální knihovna Definice 1 Integrovaný
Strategie budování sbírky Webarchiv u
 Strategie budování sbírky Webarchiv u aktualizované znění Autoři: Datum: Mgr. Jaroslav Kvasnica, Mgr. Barbora Rudišinová, Mgr. Marie Haškovcová, Mgr. Monika Holoubková, Mgr. Markéta Hrdličková září 2017
Strategie budování sbírky Webarchiv u aktualizované znění Autoři: Datum: Mgr. Jaroslav Kvasnica, Mgr. Barbora Rudišinová, Mgr. Marie Haškovcová, Mgr. Monika Holoubková, Mgr. Markéta Hrdličková září 2017
Jan Pokorný MULTIDATA Praha PRIMO. od čtenářského OPAC ke čtenářskému portálu
 Jan Pokorný MULTIDATA Praha PRIMO od čtenářského OPAC ke čtenářskému portálu Knihovny současnosti 2007 Obsah prezentace Co je systém PRIMO Příklad fungování systému Komponenty systému Princip fungování
Jan Pokorný MULTIDATA Praha PRIMO od čtenářského OPAC ke čtenářskému portálu Knihovny současnosti 2007 Obsah prezentace Co je systém PRIMO Příklad fungování systému Komponenty systému Princip fungování
ANL+ Veronika Ševčíková Národní knihovna ČR
 ANL+ Veronika Ševčíková Národní knihovna ČR Obsah dnešní přednášky Představení ANL+ Co v bázi ANL+ naleznete Zajištění ANL+ v knihovnách ANL+ v rozhraní Primo ANL+ v rozhraní JIB Dotazy Co je ANL+ Zdroj
ANL+ Veronika Ševčíková Národní knihovna ČR Obsah dnešní přednášky Představení ANL+ Co v bázi ANL+ naleznete Zajištění ANL+ v knihovnách ANL+ v rozhraní Primo ANL+ v rozhraní JIB Dotazy Co je ANL+ Zdroj
Silný portál. Jindřiška Pospíšilová. Pracovní skupina pro silný portál. Národní knihovna ČR
 Silný portál Jindřiška Pospíšilová Pracovní skupina pro silný portál Národní knihovna ČR Koncepci rozvoje knihoven ČR na léta 2011-2014 Základní vize: Klient říká: V krásné, přívětivé a pohodlné knihovně
Silný portál Jindřiška Pospíšilová Pracovní skupina pro silný portál Národní knihovna ČR Koncepci rozvoje knihoven ČR na léta 2011-2014 Základní vize: Klient říká: V krásné, přívětivé a pohodlné knihovně
2008 Dostupný z Licence Creative Commons Uveďte autora-zachovejte licenci 3.0 Česko
 Tento dokument byl stažen z Národního úložiště šedé literatury (NUŠL). Datum stažení: 18.01.2017 Projekt NUŠL a další projekty v ČR Pejšová, Petra 2008 Dostupný z http://www.nusl.cz/ntk/nusl-41957 Dílo
Tento dokument byl stažen z Národního úložiště šedé literatury (NUŠL). Datum stažení: 18.01.2017 Projekt NUŠL a další projekty v ČR Pejšová, Petra 2008 Dostupný z http://www.nusl.cz/ntk/nusl-41957 Dílo
Metodika budování sbírky Webarchivu
 Metodika budování sbírky Webarchivu Autoři: Bjačková Barbora, Kvasnica Jaroslav Datum vytvoření: 4. 2. 2015 Terminologie: archivace webu proces sběru, ukládání, trvalého uchovávání a zpřístupňování webových
Metodika budování sbírky Webarchivu Autoři: Bjačková Barbora, Kvasnica Jaroslav Datum vytvoření: 4. 2. 2015 Terminologie: archivace webu proces sběru, ukládání, trvalého uchovávání a zpřístupňování webových
Budování virtuální depozitní knihovny. Tomáš Foltýn
 Budování virtuální depozitní knihovny Tomáš Foltýn Motivace: platná legislativa ČR předepisuje knihovnám trvale uchovávat knižní sbírky garance trvalého uchování knižního dědictví ANO či NE? NE! Není přesný
Budování virtuální depozitní knihovny Tomáš Foltýn Motivace: platná legislativa ČR předepisuje knihovnám trvale uchovávat knižní sbírky garance trvalého uchování knižního dědictví ANO či NE? NE! Není přesný
Seminář pro vedoucí knihoven asviústavů AV ČR ASEP
 Seminář pro vedoucí knihoven asviústavů AV ČR ASEP 5. 5. 2016 ASEP bibliografická databáze repozitář Online katalog Repozitář Analytika ASEP Novinky ASEP Evidence výsledků vědecké práce ústavů AV ČR od
Seminář pro vedoucí knihoven asviústavů AV ČR ASEP 5. 5. 2016 ASEP bibliografická databáze repozitář Online katalog Repozitář Analytika ASEP Novinky ASEP Evidence výsledků vědecké práce ústavů AV ČR od
NTK Discovery. Od katalogu k centralizovanému vyhledávání
 NTK Discovery Od katalogu k centralizovanému vyhledávání Strategie NTK v oblasti zpřístupňování fondů Strategická priorita 3.4.2: Optimalizace uživatelské přívětivosti všech knihovních služeb NTK Implementace
NTK Discovery Od katalogu k centralizovanému vyhledávání Strategie NTK v oblasti zpřístupňování fondů Strategická priorita 3.4.2: Optimalizace uživatelské přívětivosti všech knihovních služeb NTK Implementace
Federativní autentizace v portálu Knihovny.cz, mojeid, IdP sociálních služeb, požadované atributy u Knihovny.cz
 Federativní autentizace v portálu Knihovny.cz, mojeid, IdP sociálních služeb, požadované atributy u Knihovny.cz Ing. Petr Žabička Moravská zemská knihovna v Brně 30.1.2019 - Konference e-infrastruktury
Federativní autentizace v portálu Knihovny.cz, mojeid, IdP sociálních služeb, požadované atributy u Knihovny.cz Ing. Petr Žabička Moravská zemská knihovna v Brně 30.1.2019 - Konference e-infrastruktury
webových zdrojů Mgr. Jan HUTAŘ Bc.. Lukáš JKA Mgr. Ludmila CELBOVÁ http://www.webarchiv.cz
 Vyhledávání v archivu českých webových zdrojů Mgr. Jan HUTAŘ Bc.. Lukáš MATĚJKA JKA Mgr. Ludmila CELBOVÁ Proč vznikl WebArchiv? archivace elektronických online zdrojů je celosvětovým trendem Potřeba zachránit
Vyhledávání v archivu českých webových zdrojů Mgr. Jan HUTAŘ Bc.. Lukáš MATĚJKA JKA Mgr. Ludmila CELBOVÁ Proč vznikl WebArchiv? archivace elektronických online zdrojů je celosvětovým trendem Potřeba zachránit
Digitalizace a digitální knihovny v České republice
 Digitalizace a digitální knihovny v České republice Ing. Martin Lhoták Knihovna AV ČR, v. v. i. Královéhradecká knihovnická konference 21. 11. 2017, Hradec Králové 20 let digitalizace v ČR Novodobé dokumenty
Digitalizace a digitální knihovny v České republice Ing. Martin Lhoták Knihovna AV ČR, v. v. i. Královéhradecká knihovnická konference 21. 11. 2017, Hradec Králové 20 let digitalizace v ČR Novodobé dokumenty
Nápověda 360 Search. Co je 360 Search? Tipy pro vyhledávání
 1 z 5 Nápověda 360 Search Co je 360 Search? 360 Search je metavyhledávač, který slouží k paralelnímu prohledávání všech dostupných informačních zdrojů prostřednictvím jednotného rozhraní. Nástroj 360 Search
1 z 5 Nápověda 360 Search Co je 360 Search? 360 Search je metavyhledávač, který slouží k paralelnímu prohledávání všech dostupných informačních zdrojů prostřednictvím jednotného rozhraní. Nástroj 360 Search
INFORMAČNÍ ZDROJE A VYHLEDÁVÁNÍ NA PORTÁLU KNIHOVNY.CZ. Ing. Petr Žabička, PhDr. Iva Zadražilová Moravská zemská knihovna v Brně
 INFORMAČNÍ ZDROJE A VYHLEDÁVÁNÍ NA PORTÁLU KNIHOVNY.CZ Ing. Petr Žabička, PhDr. Iva Zadražilová Moravská zemská knihovna v Brně Informační zdroje Národní zdroje (lokální) vs. zahraniční zdroje: lokální
INFORMAČNÍ ZDROJE A VYHLEDÁVÁNÍ NA PORTÁLU KNIHOVNY.CZ Ing. Petr Žabička, PhDr. Iva Zadražilová Moravská zemská knihovna v Brně Informační zdroje Národní zdroje (lokální) vs. zahraniční zdroje: lokální
RD.CZ : EVIDENCE DIGITALIZOVANÝCH DOKUMENTŮ A SLEDOVÁNÍ PROCESU ZPRACOVÁNÍ
 RD.CZ : EVIDENCE DIGITALIZOVANÝCH DOKUMENTŮ A SLEDOVÁNÍ PROCESU ZPRACOVÁNÍ Pavel Kocourek, Incad Praha Přestože mnohé knihovny v České republice digitalizují své dokumenty a další se na to chystají, neprobíhá
RD.CZ : EVIDENCE DIGITALIZOVANÝCH DOKUMENTŮ A SLEDOVÁNÍ PROCESU ZPRACOVÁNÍ Pavel Kocourek, Incad Praha Přestože mnohé knihovny v České republice digitalizují své dokumenty a další se na to chystají, neprobíhá
Projekt Digitální knihovna pro šedou literaturu po prvním roce řešení
 Projekt Digitální knihovna pro šedou literaturu po prvním roce řešení Petra Pejšová Státní technická knihovna, Osnova Trochu historie Základní informace o projektu Harmonogram Výstupy Návaznosti na další
Projekt Digitální knihovna pro šedou literaturu po prvním roce řešení Petra Pejšová Státní technická knihovna, Osnova Trochu historie Základní informace o projektu Harmonogram Výstupy Návaznosti na další
PRODUKTY. Tovek Tools
 jsou desktopovou aplikací určenou k vyhledávání informací, tvorbě různých typů analýz a vytváření přehledů a rešerší. Jsou vhodné pro práci i s velkým objemem textových dat z různorodých informačních zdrojů.
jsou desktopovou aplikací určenou k vyhledávání informací, tvorbě různých typů analýz a vytváření přehledů a rešerší. Jsou vhodné pro práci i s velkým objemem textových dat z různorodých informačních zdrojů.
Stav implementace perzistentních identifikátorů v NK ČR a výhled do budoucna. Jan Hutař Marek Melichar Ladislav Cubr
 Stav implementace perzistentních identifikátorů v NK ČR a výhled do budoucna Jan Hutař Marek Melichar Ladislav Cubr Osnova 1. Perzistentní identifikátory (PID) obecně 2. PID v digitálním světě 3. Současná
Stav implementace perzistentních identifikátorů v NK ČR a výhled do budoucna Jan Hutař Marek Melichar Ladislav Cubr Osnova 1. Perzistentní identifikátory (PID) obecně 2. PID v digitálním světě 3. Současná
PRODUKTY Tovek Server 6
 Tovek Server je serverová aplikace určená pro efektivní zpracování velkého objemu sdílených strukturovaných i nestrukturovaných dat. Umožňuje automaticky indexovat data z různých informačních zdrojů, intuitivně
Tovek Server je serverová aplikace určená pro efektivní zpracování velkého objemu sdílených strukturovaných i nestrukturovaných dat. Umožňuje automaticky indexovat data z různých informačních zdrojů, intuitivně
Certifikace Národní digitální knihovny podle ISO normy 16363. Jan Mottl AiP Safe s.r.o.
 Certifikace Národní digitální knihovny podle ISO normy 16363 Jan Mottl AiP Safe s.r.o. Proč? Ve smlouvě na dodávku NDK je certifikace požadována v Příloze č.1 Specifikace plnění smlouvy, v kapitole 1.10.
Certifikace Národní digitální knihovny podle ISO normy 16363 Jan Mottl AiP Safe s.r.o. Proč? Ve smlouvě na dodávku NDK je certifikace požadována v Příloze č.1 Specifikace plnění smlouvy, v kapitole 1.10.
RD.CZ EVIDENCE DIGITALIZOVANÝCH DOKUMENTŮ A SLEDOVÁNÍ PROCESU ZPRACOVÁNÍ
 Pomáháme vám využívat vaše informace RD.CZ EVIDENCE DIGITALIZOVANÝCH DOKUMENTŮ A SLEDOVÁNÍ PROCESU ZPRACOVÁNÍ Colloquium of Library Information Employees of the V4+ Countries 6 8 July 2008, Brno, Czech
Pomáháme vám využívat vaše informace RD.CZ EVIDENCE DIGITALIZOVANÝCH DOKUMENTŮ A SLEDOVÁNÍ PROCESU ZPRACOVÁNÍ Colloquium of Library Information Employees of the V4+ Countries 6 8 July 2008, Brno, Czech
ProArc. open source řešení pro produkci a archivaci digitálních dokumentů. Martina NEZBEDOVÁ Knihovna AV ČR, v. v. i., Praha nezbedova@knav.
 ProArc open source řešení pro produkci a archivaci digitálních dokumentů Martina NEZBEDOVÁ Knihovna AV ČR, v. v. i., Praha nezbedova@knav.cz INFORUM 2015: 21. ročník konference o profesionálních informačních
ProArc open source řešení pro produkci a archivaci digitálních dokumentů Martina NEZBEDOVÁ Knihovna AV ČR, v. v. i., Praha nezbedova@knav.cz INFORUM 2015: 21. ročník konference o profesionálních informačních
Bc. Martin Majer, AiP Beroun s.r.o.
 REGISTR DIGITALIZACE HISTORICKÝCH FONDŮ (RDHF) A DIGITÁLNÍCH KONKORDANCÍ (DK) Návrh uživatelského rozhraní klientských aplikací verze 1.0 Bc. Martin Majer, AiP Beroun s.r.o. 28.11.2016-1 - Obsah 1 Seznam
REGISTR DIGITALIZACE HISTORICKÝCH FONDŮ (RDHF) A DIGITÁLNÍCH KONKORDANCÍ (DK) Návrh uživatelského rozhraní klientských aplikací verze 1.0 Bc. Martin Majer, AiP Beroun s.r.o. 28.11.2016-1 - Obsah 1 Seznam
Nové nástroje pro staré mapy
 Nové nástroje pro staré mapy Petr Žabička Moravská zemská knihovna v Brně Projekt TEMAP www.temap.cz Archivy, knihovny a muzea v digitálním světě 30. 11. 2011 Obsah O projektu TEMAP Zpracování a zpřístupnění
Nové nástroje pro staré mapy Petr Žabička Moravská zemská knihovna v Brně Projekt TEMAP www.temap.cz Archivy, knihovny a muzea v digitálním světě 30. 11. 2011 Obsah O projektu TEMAP Zpracování a zpřístupnění
FUNKCE A VYHLEDÁVÁNÍ NA PORTÁLE KNIHOVNY.CZ PhDr. Iva Zadražilová, Moravská zemská knihovna
 FUNKCE A VYHLEDÁVÁNÍ NA PORTÁLE KNIHOVNY.CZ PhDr. Iva Zadražilová, Moravská zemská knihovna ZÁKLADNÍ MYŠLENKA Umožnit přístup ke službám, fondům a informacím o českých knihovnách z jednoho místa KOMUKOLIV
FUNKCE A VYHLEDÁVÁNÍ NA PORTÁLE KNIHOVNY.CZ PhDr. Iva Zadražilová, Moravská zemská knihovna ZÁKLADNÍ MYŠLENKA Umožnit přístup ke službám, fondům a informacím o českých knihovnách z jednoho místa KOMUKOLIV
Tovek Tools. Tovek Tools jsou standardně dodávány ve dvou variantách: Tovek Tools Search Pack Tovek Tools Analyst Pack. Připojené informační zdroje
 jsou souborem klientských desktopových aplikací určených k indexování dat, vyhledávání informací, tvorbě různých typů analýz a vytváření přehledů a rešerší. Jsou vhodné pro práci s velkým objemem textových
jsou souborem klientských desktopových aplikací určených k indexování dat, vyhledávání informací, tvorbě různých typů analýz a vytváření přehledů a rešerší. Jsou vhodné pro práci s velkým objemem textových
Využití nástrojů z projektu Česká digitální knihovna při digitalizaci a zpřístupnění digitálních dokumentů
 Využití nástrojů z projektu Česká digitální knihovna při digitalizaci a zpřístupnění digitálních dokumentů Martin Lhoták Knihovna AV ČR, v. v. i. Archivy, knihovny, muzea v digitálním světě 2013 Výzkumný
Využití nástrojů z projektu Česká digitální knihovna při digitalizaci a zpřístupnění digitálních dokumentů Martin Lhoták Knihovna AV ČR, v. v. i. Archivy, knihovny, muzea v digitálním světě 2013 Výzkumný
TECHNICKÁ SPECIFIKACE VEŘEJNÉ ZAKÁZKY
 Příloha č. 3 k č.j. MV-159754-3/VZ-2013 Počet listů: 7 TECHNICKÁ SPECIFIKACE VEŘEJNÉ ZAKÁZKY Nové funkcionality Czech POINT 2012 Popis rozhraní egon Service Bus Centrální Místo Služeb 2.0 (dále jen CMS
Příloha č. 3 k č.j. MV-159754-3/VZ-2013 Počet listů: 7 TECHNICKÁ SPECIFIKACE VEŘEJNÉ ZAKÁZKY Nové funkcionality Czech POINT 2012 Popis rozhraní egon Service Bus Centrální Místo Služeb 2.0 (dále jen CMS
local content in a Europeana cloud
 local content in a Europeana cloud Evropský projekt LoCloud jako inspirace pro informační systémy památkové péče Irena Blažková Národní památkový ústav Archivy, knihovny, muzea v digitálním světě, 26.-27.11.2014
local content in a Europeana cloud Evropský projekt LoCloud jako inspirace pro informační systémy památkové péče Irena Blažková Národní památkový ústav Archivy, knihovny, muzea v digitálním světě, 26.-27.11.2014
Formy komunikace s knihovnami
 Formy komunikace s knihovnami Současné moderní prostředky Jiří Šilha a Jiří Tobiáš, Tritius Solutions a.s., Brno Osnova Základní požadavky na komunikaci s knihovnami Historie komunikace s knihovnami Confluence
Formy komunikace s knihovnami Současné moderní prostředky Jiří Šilha a Jiří Tobiáš, Tritius Solutions a.s., Brno Osnova Základní požadavky na komunikaci s knihovnami Historie komunikace s knihovnami Confluence
ZPŘÍSTUPNĚNÍ A ARCHIVACE PLNÝCH
 ZPŘÍSTUPNĚNÍ A ARCHIVACE PLNÝCH TEXTŮ ČESKÝCH LÉKAŘSKÝCH A ZDRAVOTNICKÝCH ČASOPISŮ Konference Knihovny současnosti 2010 Lenka Maixnerová, Filip Kříž, Ondřej Horsák Úvod V roce 2004 zapojení do programu
ZPŘÍSTUPNĚNÍ A ARCHIVACE PLNÝCH TEXTŮ ČESKÝCH LÉKAŘSKÝCH A ZDRAVOTNICKÝCH ČASOPISŮ Konference Knihovny současnosti 2010 Lenka Maixnerová, Filip Kříž, Ondřej Horsák Úvod V roce 2004 zapojení do programu
Tzv. životní cyklus dokumentů u původce (Tematický blok č. 4) 1. Správa podnikového obsahu 2. Spisová služba
 1. Správa podnikového obsahu 2. Spisová služba") Tzv. životní cyklus dokumentů u původce (Tematický blok č. 4) 1. Správa podnikového obsahu 2. Spisová služba 1. 1. Správa podnikového obsahu (Enterprise Content Management ECM) Strategie, metody a nástroje
Tzv. životní cyklus dokumentů u původce (Tematický blok č. 4) 1. Správa podnikového obsahu 2. Spisová služba 1. 1. Správa podnikového obsahu (Enterprise Content Management ECM) Strategie, metody a nástroje
Vývoj moderních technologií při vyhledávání. Patrik Plachý SEFIRA spol. s.r.o. plachy@sefira.cz
 Vývoj moderních technologií při vyhledávání Patrik Plachý SEFIRA spol. s.r.o. plachy@sefira.cz INFORUM 2007: 13. konference o profesionálních informačních zdrojích Praha, 22. - 24.5. 2007 Abstrakt Vzhledem
Vývoj moderních technologií při vyhledávání Patrik Plachý SEFIRA spol. s.r.o. plachy@sefira.cz INFORUM 2007: 13. konference o profesionálních informačních zdrojích Praha, 22. - 24.5. 2007 Abstrakt Vzhledem
Osobní archivy publikovaných odborných prací v medicíně jako součást Digitální knihovny NLK
 Osobní archivy publikovaných odborných prací v medicíně jako součást Digitální knihovny NLK Adéla Jarolímková, Národní lékařská knihovna Toto dílo dílo podléhá licenci Creative Commons Uveďte autora- Zachovejte
Osobní archivy publikovaných odborných prací v medicíně jako součást Digitální knihovny NLK Adéla Jarolímková, Národní lékařská knihovna Toto dílo dílo podléhá licenci Creative Commons Uveďte autora- Zachovejte
Bibliografické databáze umění vyhledávat v záplavě pramenů relevantní informace
 Bibliografické databáze umění vyhledávat v záplavě pramenů relevantní informace Jitka Stejskalová Ústav vědeckých informací 1. LF UK Jak si obstarám informace? informační exploze mnoho informací a jak
Bibliografické databáze umění vyhledávat v záplavě pramenů relevantní informace Jitka Stejskalová Ústav vědeckých informací 1. LF UK Jak si obstarám informace? informační exploze mnoho informací a jak
Digitalizace a Digitální archiv Státního oblastního archivu v Třeboni po čtyřech letech. Výsledky a perspektivy dalšího vývoje
 Digitalizace a Digitální archiv Státního oblastního archivu v Třeboni po čtyřech letech Výsledky a perspektivy dalšího vývoje Struktura příspěvku Definice projektu Základní data z historie projektu Základní
Digitalizace a Digitální archiv Státního oblastního archivu v Třeboni po čtyřech letech Výsledky a perspektivy dalšího vývoje Struktura příspěvku Definice projektu Základní data z historie projektu Základní
PRODUKTY. Tovek Tools
 Analyst Pack je desktopovou aplikací určenou k vyhledávání informací, tvorbě různých typů analýz a vytváření přehledů a rešerší. Jsou vhodné pro práci i s velkým objemem textových dat z různorodých informačních
Analyst Pack je desktopovou aplikací určenou k vyhledávání informací, tvorbě různých typů analýz a vytváření přehledů a rešerší. Jsou vhodné pro práci i s velkým objemem textových dat z různorodých informačních
SCOPUS a WEB OF SCIENCE
 SCOPUS a WEB OF SCIENCE 7. února 2012 Osnova 1. Typy ve vyhledávání v databázi SCOPUS 2. Typy ve vyhledávání v databázi Web of Science 3. Nástroje pro vyhledávání v jednom vyhledávacím prostředí: Metavyhledávače
SCOPUS a WEB OF SCIENCE 7. února 2012 Osnova 1. Typy ve vyhledávání v databázi SCOPUS 2. Typy ve vyhledávání v databázi Web of Science 3. Nástroje pro vyhledávání v jednom vyhledávacím prostředí: Metavyhledávače
Zpřístupnění kulturního dědictví v digitální podobě v ČR prostřednictvím knihoven
 Zpřístupnění kulturního dědictví v digitální podobě v ČR prostřednictvím knihoven současný stav, trendy, problémy Vít Richter 3.11.2015 Konference Kultura 2016 SKIP ČR Kulturní dědictví v digitální podobě
Zpřístupnění kulturního dědictví v digitální podobě v ČR prostřednictvím knihoven současný stav, trendy, problémy Vít Richter 3.11.2015 Konference Kultura 2016 SKIP ČR Kulturní dědictví v digitální podobě
Projekt NAKI e-deposit
 Projekt NAKI e-deposit Správa elektronických publikací v síti knihoven ČR Mgr. Martin Žížala Národní knihovna ČR Základní info 4-letý projekt (2012-2015), grantová podpora MK ČR (program aplikovaného výzkumu
Projekt NAKI e-deposit Správa elektronických publikací v síti knihoven ČR Mgr. Martin Žížala Národní knihovna ČR Základní info 4-letý projekt (2012-2015), grantová podpora MK ČR (program aplikovaného výzkumu
ZPŘÍSTUPNĚNÍ KARTOGRAFICKÝCH MATERIÁLŮ A DALŠÍ VÝSLEDKY PROJEKTU TEMAP
 ZPŘÍSTUPNĚNÍ KARTOGRAFICKÝCH MATERIÁLŮ A DALŠÍ VÝSLEDKY PROJEKTU TEMAP Petr Žabička, Moravská zemská knihovna v Brně Eva Novotná, Přírodovědecká fakulta Univerzity Karlovy TEMAP Technologie pro zpřístupnění
ZPŘÍSTUPNĚNÍ KARTOGRAFICKÝCH MATERIÁLŮ A DALŠÍ VÝSLEDKY PROJEKTU TEMAP Petr Žabička, Moravská zemská knihovna v Brně Eva Novotná, Přírodovědecká fakulta Univerzity Karlovy TEMAP Technologie pro zpřístupnění
Tovek Server. Tovek Server nabízí následující základní a servisní funkce: Bezpečnost Statistiky Locale
 je serverová aplikace určená pro efektivní zpracování velkého objemu sdílených nestrukturovaných dat. Umožňuje automaticky indexovat data z různých informačních zdrojů, intuitivně vyhledávat informace,
je serverová aplikace určená pro efektivní zpracování velkého objemu sdílených nestrukturovaných dat. Umožňuje automaticky indexovat data z různých informačních zdrojů, intuitivně vyhledávat informace,
FUNKCE A VYHLEDÁVÁNÍ NA PORTÁLE KNIHOVNY.CZ. PhDr. Iva Zadražilová, Moravská zemská knihovna
 FUNKCE A VYHLEDÁVÁNÍ NA PORTÁLE KNIHOVNY.CZ PhDr. Iva Zadražilová, Moravská zemská knihovna ZÁKLADNÍ MYŠLENKA Umožnit přístup ke službám, fondům a informacím o českých knihovnách z jednoho místa KOMUKOLIV
FUNKCE A VYHLEDÁVÁNÍ NA PORTÁLE KNIHOVNY.CZ PhDr. Iva Zadražilová, Moravská zemská knihovna ZÁKLADNÍ MYŠLENKA Umožnit přístup ke službám, fondům a informacím o českých knihovnách z jednoho místa KOMUKOLIV
1. Integrační koncept
 Příloha č. 2: Technický popis integrace 1. Integrační koncept Z hlediska koncepčního budování Smart Administration na Magistrátu města Mostu je možno hovořit o potřebě integrace tří úrovní systémové architektury
Příloha č. 2: Technický popis integrace 1. Integrační koncept Z hlediska koncepčního budování Smart Administration na Magistrátu města Mostu je možno hovořit o potřebě integrace tří úrovní systémové architektury
Vyhledávání v souborných katalozích
 Vyhledávání v souborných katalozích Jiskra Jindrová jiskra.jindrova@nkp.cz Souborný katalog ČR CASLIN česká a slovenská informační síť» budován od roku 1995» více než 6 mil. záznamů Funkce» Sdílená katalogizace»
Vyhledávání v souborných katalozích Jiskra Jindrová jiskra.jindrova@nkp.cz Souborný katalog ČR CASLIN česká a slovenská informační síť» budován od roku 1995» více než 6 mil. záznamů Funkce» Sdílená katalogizace»
Anotace. Klíčová slova. 1. Úvod
 SLUŽBA TYPU GOOGLE V NÁRODNÍ LÉKAŘSKÉ KNIHOVNĚ. Adéla Jarolímková, Eva Lesenková, Filip Kříž, Vladimíra Solová Anotace Národní lékařská knihovna zpřístupňuje pomocí internetových technologií medicínské
SLUŽBA TYPU GOOGLE V NÁRODNÍ LÉKAŘSKÉ KNIHOVNĚ. Adéla Jarolímková, Eva Lesenková, Filip Kříž, Vladimíra Solová Anotace Národní lékařská knihovna zpřístupňuje pomocí internetových technologií medicínské
Zapojování knihoven do Centrálního portálu knihoven. Petr Žabička, Moravská zemská knihovna v Brně
 Zapojování knihoven do Centrálního portálu knihoven Petr Žabička, v Brně Obsah 1. CPK a lokální index 2. Agregace metadat 3. Fasety 4. Exempláře 5. Identity uživatelů 6. Online platby CPK a lokální index
Zapojování knihoven do Centrálního portálu knihoven Petr Žabička, v Brně Obsah 1. CPK a lokální index 2. Agregace metadat 3. Fasety 4. Exempláře 5. Identity uživatelů 6. Online platby CPK a lokální index
Digitální konkordance a Registr digitalizace v Manuscriptoriu,
 Digitální konkordance a Registr digitalizace v Manuscriptoriu, aneb, Jak identifikovat a trvale zpřístupnit digitální kopie fyzických exemplářů historických dokumentů Olga Čiperová, AiP Beroun s.r.o. 25.5.2016
Digitální konkordance a Registr digitalizace v Manuscriptoriu, aneb, Jak identifikovat a trvale zpřístupnit digitální kopie fyzických exemplářů historických dokumentů Olga Čiperová, AiP Beroun s.r.o. 25.5.2016
Manuscriptorium v roce 2013
 Manuscriptorium v roce 2013 změny v uživatelském prostředí Olga Čiperová, AiP Beroun s.r.o. 22.5.2013 Změny pracovního a vyhledávacího prostředí podněty a připomínky od uživatelů Manuscriptoria (MNS) nová
Manuscriptorium v roce 2013 změny v uživatelském prostředí Olga Čiperová, AiP Beroun s.r.o. 22.5.2013 Změny pracovního a vyhledávacího prostředí podněty a připomínky od uživatelů Manuscriptoria (MNS) nová
Pracovní skupina pro věcné zpracování
 Pracovní skupina pro věcné zpracování Prosinec 2014 Marie.Balikova@nkp.cz Program Věcné údaje v bibliografickém záznamu Požadavky uživatelů Význam Kvalita Schválení Doporučeného záznamu rozšířeného minimálně
Pracovní skupina pro věcné zpracování Prosinec 2014 Marie.Balikova@nkp.cz Program Věcné údaje v bibliografickém záznamu Požadavky uživatelů Význam Kvalita Schválení Doporučeného záznamu rozšířeného minimálně
Lenka Maixnerová, Filip Kříž, Ondřej Horsák, Helena Bouzková
 Lenka Maixnerová, Filip Kříž, Ondřej Horsák, Helena Bouzková 1. Hrozba ztráty tištěných dokumentů způsobená degradací kyselého papíru, který se používal téměř 150 let a poškozením dokumentů častým používáním
Lenka Maixnerová, Filip Kříž, Ondřej Horsák, Helena Bouzková 1. Hrozba ztráty tištěných dokumentů způsobená degradací kyselého papíru, který se používal téměř 150 let a poškozením dokumentů častým používáním
Primo Central. Martin Vojnar MULTIDATA Praha s.r.o.
 Primo Central Martin Vojnar MULTIDATA Praha s.r.o. www.multidata.cz Kapitola 1: místo činu V roli knihovny sbírá dokumenty zpřístupňuje je uživatelům pečuje o své uživatele stejně jako o své sbírky? co
Primo Central Martin Vojnar MULTIDATA Praha s.r.o. www.multidata.cz Kapitola 1: místo činu V roli knihovny sbírá dokumenty zpřístupňuje je uživatelům pečuje o své uživatele stejně jako o své sbírky? co
Koncepce rozvoje knihoven ČR na léta 2011-2015. Priorita 2: Trvalé uchování digitálních dokumentů
 Koncepce rozvoje knihoven ČR na léta 2011-2015 Priorita 2: Trvalé uchování Koncepce rozvoje knihoven ČR na léta 2011-2015 Priorita 2: Trvalé uchování 1. Vytvořit národní koncepci dlouhodobé ochrany digitálních
Koncepce rozvoje knihoven ČR na léta 2011-2015 Priorita 2: Trvalé uchování Koncepce rozvoje knihoven ČR na léta 2011-2015 Priorita 2: Trvalé uchování 1. Vytvořit národní koncepci dlouhodobé ochrany digitálních
Česká digitální knihovna agregace digitálního obsahu českých knihoven
 Česká digitální knihovna agregace digitálního obsahu českých knihoven Martin Lhoták Knihovna AV ČR, v. v. i. Národní agregátor ve světě eculture, Praha, 14. 7. 2015 Výzkumný projekt financovaný z programu
Česká digitální knihovna agregace digitálního obsahu českých knihoven Martin Lhoták Knihovna AV ČR, v. v. i. Národní agregátor ve světě eculture, Praha, 14. 7. 2015 Výzkumný projekt financovaný z programu
Linked Heritage. Koordinace standardů a technologií za účelem obohacení Europeany. Alena Součková
 Linked Heritage Koordinace standardů a technologií za účelem obohacení Europeany Alena Součková Základní cíle Získat pro Europeanu velký objem nových dat, a to nejen z veřejného, ale i ze soukromého sektoru
Linked Heritage Koordinace standardů a technologií za účelem obohacení Europeany Alena Součková Základní cíle Získat pro Europeanu velký objem nových dat, a to nejen z veřejného, ale i ze soukromého sektoru
Systémy pro tvorbu digitálních knihoven
 Systémy pro tvorbu digitálních knihoven Vlastimil Krejčíř, krejcir@ics.muni.cz Ústav výpočetní techniky, Masarykova univerzita, Brno INFORUM 2006, Praha Obsah přednášky Úvod Fedora DSpace EPrints CDSware
Systémy pro tvorbu digitálních knihoven Vlastimil Krejčíř, krejcir@ics.muni.cz Ústav výpočetní techniky, Masarykova univerzita, Brno INFORUM 2006, Praha Obsah přednášky Úvod Fedora DSpace EPrints CDSware
Portál Knihovny.cz. Ing. Petr Žabička Moravská zemská knihovna v Brně. Bibliotheca academica, Plzeň
 Portál Knihovny.cz Ing. Petr Žabička Moravská zemská knihovna v Brně Bibliotheca academica, 31.10.2018 Plzeň ZÁKLADNÍ MYŠLENKA Umožnit přístup ke službám, fondům a informacím o českých knihovnách z jednoho
Portál Knihovny.cz Ing. Petr Žabička Moravská zemská knihovna v Brně Bibliotheca academica, 31.10.2018 Plzeň ZÁKLADNÍ MYŠLENKA Umožnit přístup ke službám, fondům a informacím o českých knihovnách z jednoho
Vyhledávání a georeferencování map
 Vyhledávání a georeferencování map Petr Žabička petr.zabicka@mzk.cz Petr Přidal petr.pridal@mzk.cz Obsah Co nového jsme vyvinuli Geografické hledání map Online georeferencování map Obsah Co nového jsme
Vyhledávání a georeferencování map Petr Žabička petr.zabicka@mzk.cz Petr Přidal petr.pridal@mzk.cz Obsah Co nového jsme vyvinuli Geografické hledání map Online georeferencování map Obsah Co nového jsme
Evropská digitální knihovna. < Prezentace k eseji pro předmět PV070 Digitální knihovny. Tomáš Drusa
 Prezentace k eseji pro předmět PV070 Digitální knihovny Evropská digitální knihovna Tomáš Drusa (256167@mail.muni.cz) 9. 12. 2009 Co je Europeana? Projekt Evropské unie Webový
Prezentace k eseji pro předmět PV070 Digitální knihovny Evropská digitální knihovna Tomáš Drusa (256167@mail.muni.cz) 9. 12. 2009 Co je Europeana? Projekt Evropské unie Webový
Pilotní řešení. AiP Beroun, autor Mgr. Olga Čiperová 28.11.2011-1 -
 ZDOKONALENÍ VIRTUÁLNÍHO BADATELSKÉHO PROSTŘEDÍ MANUSCRIPTORIA - VYUŽITÍ TEZAURŮ A DATABÁZÍ AUTORIT AGREGOVANÝCH CERL PRO VYHLEDÁVÁNÍ V MANUSCRIPTORIU Pilotní řešení Zpráva AiP Beroun, autor Mgr. Olga Čiperová
ZDOKONALENÍ VIRTUÁLNÍHO BADATELSKÉHO PROSTŘEDÍ MANUSCRIPTORIA - VYUŽITÍ TEZAURŮ A DATABÁZÍ AUTORIT AGREGOVANÝCH CERL PRO VYHLEDÁVÁNÍ V MANUSCRIPTORIU Pilotní řešení Zpráva AiP Beroun, autor Mgr. Olga Čiperová
Požadavky na systém pro automatizaci muzejní knihovny
 Požadavky na systém pro automatizaci muzejní knihovny aneb Pohled zvenčí Petr Žabička Moravská zemská knihovna v Brně zabak@mzk.cz Obsah Knihovny muzeí a galerií Katalogy knihoven Standardizace Výběr knihovního
Požadavky na systém pro automatizaci muzejní knihovny aneb Pohled zvenčí Petr Žabička Moravská zemská knihovna v Brně zabak@mzk.cz Obsah Knihovny muzeí a galerií Katalogy knihoven Standardizace Výběr knihovního
Ředitel odboru archivní správy a spisové služby PhDr. Jiří ÚLOVEC v. r.
 VMV čá. 65/2012 (část II) Oznámení Ministerstva vnitra, kterým se zveřejňuje vzorový provozní řád archivu oprávněného k ukládání archiválií v digitální podobě Ministerstvo vnitra zveřejňuje na základě
VMV čá. 65/2012 (část II) Oznámení Ministerstva vnitra, kterým se zveřejňuje vzorový provozní řád archivu oprávněného k ukládání archiválií v digitální podobě Ministerstvo vnitra zveřejňuje na základě
Kde hledat odborné články?
 Kde hledat odborné články? Martina Machátová E-mail: machat@mzk.cz Tel.: 541 646 170 Poslední aktualizace: 8. června 2015 The Free Library http://www.thefreelibrary.com/ Obsahuje skoro 25 milionů článků
Kde hledat odborné články? Martina Machátová E-mail: machat@mzk.cz Tel.: 541 646 170 Poslední aktualizace: 8. června 2015 The Free Library http://www.thefreelibrary.com/ Obsahuje skoro 25 milionů článků
Novinky IPAC 3.0. Libor Nesvadba Karel Pavelka
 Novinky IPAC 3.0 Libor Nesvadba Karel Pavelka Webové technologie Držíme laťku na vysoké úrovni Validní, sémantický, strukturovaný, přístupný, znovupoužitelný a jednoduchý XHTML kód. Komprimované JavaScripty
Novinky IPAC 3.0 Libor Nesvadba Karel Pavelka Webové technologie Držíme laťku na vysoké úrovni Validní, sémantický, strukturovaný, přístupný, znovupoužitelný a jednoduchý XHTML kód. Komprimované JavaScripty
Digitalizace knihovních dokumentů. Jiří Polišenský
 Digitalizace knihovních dokumentů Jiří Polišenský Obsah prezentace Základní prvky digitalizace Formáty a standardy Skenery Digitalizační work flow Systémy pro prezentaci a evidenci digitalizovaných dokumentů
Digitalizace knihovních dokumentů Jiří Polišenský Obsah prezentace Základní prvky digitalizace Formáty a standardy Skenery Digitalizační work flow Systémy pro prezentaci a evidenci digitalizovaných dokumentů
Paralelní vyhledávač MetaLib verze 3. Martin Ledínský Univerzita Karlova v Praze Ústav výpočetní techniky
 Paralelní vyhledávač MetaLib verze 3 Martin Ledínský Univerzita Karlova v Praze Ústav výpočetní techniky OBSAH Krátké představení MetaLibu Současné problémy s informačními zdroji Jak problémy řešit MetaLib
Paralelní vyhledávač MetaLib verze 3 Martin Ledínský Univerzita Karlova v Praze Ústav výpočetní techniky OBSAH Krátké představení MetaLibu Současné problémy s informačními zdroji Jak problémy řešit MetaLib
Manuscriptorium - 10 let
 manuscriptorium Manuscriptorium - 10 let 12. konference Archivy, knihovny, muzea v digitálním světě 2011 Tomáš Psohlavec, AIP Beroun s.r.o. 30.11.2011 návaznosti na Memoria Mundi 1993 UNESCO projekt Memory
manuscriptorium Manuscriptorium - 10 let 12. konference Archivy, knihovny, muzea v digitálním světě 2011 Tomáš Psohlavec, AIP Beroun s.r.o. 30.11.2011 návaznosti na Memoria Mundi 1993 UNESCO projekt Memory
Od portálu Jednotná informační brána k portálu Knihovny.cz
 Knihovnicko-informační zpravodaj U Nás Vyšlo: 20. 9. 2018 Číslo: Ročník 28 (2018), Číslo 3 Sekce: Naše téma Název článku: Od portálu Jednotná informační brána k portálu Knihovny.cz Autor: Bohdana Stoklasová
Knihovnicko-informační zpravodaj U Nás Vyšlo: 20. 9. 2018 Číslo: Ročník 28 (2018), Číslo 3 Sekce: Naše téma Název článku: Od portálu Jednotná informační brána k portálu Knihovny.cz Autor: Bohdana Stoklasová
FUNKCE A VYHLEDÁVÁNÍ NA PORTÁLE KNIHOVNY.CZ PhDr. Iva Zadražilová, Moravská zemská knihovna
 FUNKCE A VYHLEDÁVÁNÍ NA PORTÁLE KNIHOVNY.CZ PhDr. Iva Zadražilová, Moravská zemská knihovna ZÁKLADNÍ MYŠLENKA JE STÁLE PLATNÁ Umožnit přístup ke službám, fondům a informacím o českých knihovnách z jednoho
FUNKCE A VYHLEDÁVÁNÍ NA PORTÁLE KNIHOVNY.CZ PhDr. Iva Zadražilová, Moravská zemská knihovna ZÁKLADNÍ MYŠLENKA JE STÁLE PLATNÁ Umožnit přístup ke službám, fondům a informacím o českých knihovnách z jednoho
Seminář pro vedoucí knihoven a SVI ústavů AV ČR. Aleph
 Seminář pro vedoucí knihoven a SVI ústavů AV ČR Aleph 9.5.2012 Program Co je nového v Alephu Změny v bázi autorit Elektronické knihy a Vufind Aleph a Google Přechod na vyšší verzi Alephu Aleph základní
Seminář pro vedoucí knihoven a SVI ústavů AV ČR Aleph 9.5.2012 Program Co je nového v Alephu Změny v bázi autorit Elektronické knihy a Vufind Aleph a Google Přechod na vyšší verzi Alephu Aleph základní
Odevzdávání a příjem e-publikací
 Odevzdávání a příjem e-publikací v rámci projektu NAKI Správa elektronických publikací v síti knihoven ČR Mgr. Martin Žížala Oddělení doplňování domácích dokumentů NK ČR Elektronické publikace Vývoj počtu
Odevzdávání a příjem e-publikací v rámci projektu NAKI Správa elektronických publikací v síti knihoven ČR Mgr. Martin Žížala Oddělení doplňování domácích dokumentů NK ČR Elektronické publikace Vývoj počtu
Jindřiška Pospíšilová Karolína Košťálová Hana Nemeškalová, Národní knihovna ČR
 http://www.knihovny.cz Jindřiška Pospíšilová Karolína Košťálová Hana Nemeškalová, Národní knihovna ČR Na základě zkušeností a zpětné vazby z referenčních služeb poskytovaných i v rámci služby Ptejte se
http://www.knihovny.cz Jindřiška Pospíšilová Karolína Košťálová Hana Nemeškalová, Národní knihovna ČR Na základě zkušeností a zpětné vazby z referenčních služeb poskytovaných i v rámci služby Ptejte se
Digitální knihovny některých zemí
 Digitální knihovny některých zemí PhDr. Martina Machátová Moravská zemská knihovna v Brně Tel.: 541 646 170 E-mail: machat@mzk.cz Poslední aktualizace: 13. prosince 2018 Deutsche digitale Bibliothek https://www.deutsche-digitalebibliothek.de/?lang=en
Digitální knihovny některých zemí PhDr. Martina Machátová Moravská zemská knihovna v Brně Tel.: 541 646 170 E-mail: machat@mzk.cz Poslední aktualizace: 13. prosince 2018 Deutsche digitale Bibliothek https://www.deutsche-digitalebibliothek.de/?lang=en
Začínáme s Tovek Tools
 NAJÍT POCHOPIT VYUŽÍT Úvodní seznámení s produktem Tovek Tools JAK SI TOVEK TOOLS NAINSTALUJI?... 2 JAK SI PŘIPOJÍM INFORMAČNÍ ZDROJE, VE KTERÝCH CHCI VYHLEDÁVAT?... 2 JAK MOHU VYHLEDÁVAT V INFORMAČNÍCH
NAJÍT POCHOPIT VYUŽÍT Úvodní seznámení s produktem Tovek Tools JAK SI TOVEK TOOLS NAINSTALUJI?... 2 JAK SI PŘIPOJÍM INFORMAČNÍ ZDROJE, VE KTERÝCH CHCI VYHLEDÁVAT?... 2 JAK MOHU VYHLEDÁVAT V INFORMAČNÍCH
ebadatelna Zlínského kraje
 ebadatelna Zlínského kraje Portál pro zpřístupnění digitálního obsahu paměťových institucí Zlínského kraje Ing. Vítězslav Mach, Krajský úřad Zlínského kraje, oddělení informatiky PhDr. Blanka Rašticová,
ebadatelna Zlínského kraje Portál pro zpřístupnění digitálního obsahu paměťových institucí Zlínského kraje Ing. Vítězslav Mach, Krajský úřad Zlínského kraje, oddělení informatiky PhDr. Blanka Rašticová,
Technologie digitálních knihoven
 Technologie digitálních knihoven Miroslav Bartošek ÚVT MU Brno bartosek@ics.muni.cz Úvod Computers in Libraries (Washington, 2006) Millenials Informace k dispozici OKAMŽITĚ, KDEKOLIV, KDYKOLIV a nejlépe
Technologie digitálních knihoven Miroslav Bartošek ÚVT MU Brno bartosek@ics.muni.cz Úvod Computers in Libraries (Washington, 2006) Millenials Informace k dispozici OKAMŽITĚ, KDEKOLIV, KDYKOLIV a nejlépe
Sto tisíc e-dokumentů na dosah. Hana Nová Jindřiška Pospíšilová
 Sto tisíc e-dokumentů na dosah Hana Nová Jindřiška Pospíšilová Inforum 2011, 25.5.2011 Informační zdroje pro výzkum (INFOZ) navazuje na předchozí projekty MŠMT zajišťující přístup k EIZ LI2000 (2000-2003)
Sto tisíc e-dokumentů na dosah Hana Nová Jindřiška Pospíšilová Inforum 2011, 25.5.2011 Informační zdroje pro výzkum (INFOZ) navazuje na předchozí projekty MŠMT zajišťující přístup k EIZ LI2000 (2000-2003)
Příručka pro vyhledávání v digitálním archivu Aip Safe III
 Příručka pro vyhledávání v digitálním archivu Aip Safe III OBSAH PŘÍRUČKA PRO VYHLEDÁVÁNÍ V DIGITÁLNÍM ARCHIVU AIP SAFE III OBSAH 1. UŽIVATELSKÉ ROZHRANÍ 1.1. HLAVNÍ STRÁNKA 1.2. HORIZONTÁLNÍ MENU 1.3.
Příručka pro vyhledávání v digitálním archivu Aip Safe III OBSAH PŘÍRUČKA PRO VYHLEDÁVÁNÍ V DIGITÁLNÍM ARCHIVU AIP SAFE III OBSAH 1. UŽIVATELSKÉ ROZHRANÍ 1.1. HLAVNÍ STRÁNKA 1.2. HORIZONTÁLNÍ MENU 1.3.
ROZHRANÍ PRO ZPŘÍSTUPNĚNÍ A PREZENTACI ZNALOSTNÍ DATABÁZE INTERPI UŽIVATELSKÁ PŘÍRUČKA
 ROZHRANÍ PRO ZPŘÍSTUPNĚNÍ A PREZENTACI ZNALOSTNÍ DATABÁZE INTERPI UŽIVATELSKÁ PŘÍRUČKA INTERPI Interoperabilita v paměťových institucích Program aplikovaného výzkumu a vývoje národní kulturní identity
ROZHRANÍ PRO ZPŘÍSTUPNĚNÍ A PREZENTACI ZNALOSTNÍ DATABÁZE INTERPI UŽIVATELSKÁ PŘÍRUČKA INTERPI Interoperabilita v paměťových institucích Program aplikovaného výzkumu a vývoje národní kulturní identity
Knihovny.cz: spuštění se blíží
 Knihovny.cz: spuštění se blíží Petr ŽABIČKA, Petra ŽABIČKOVÁ, Martin KRAVEC Moravská zemská knihovna v Brně petr.zabicka@mzk.cz, petra.zabickova@mzk.cz, martin.kravec@mzk.cz INFORUM 2016: 22. ročník konference
Knihovny.cz: spuštění se blíží Petr ŽABIČKA, Petra ŽABIČKOVÁ, Martin KRAVEC Moravská zemská knihovna v Brně petr.zabicka@mzk.cz, petra.zabickova@mzk.cz, martin.kravec@mzk.cz INFORUM 2016: 22. ročník konference
Ukládání a vyhledávání XML dat
 XML teorie a praxe značkovacích jazyků (4IZ238) Jirka Kosek Poslední modifikace: $Date: 2014/12/04 19:41:24 $ Obsah Ukládání XML dokumentů... 3 Ukládání XML do souborů... 4 Nativní XML databáze... 5 Ukládání
XML teorie a praxe značkovacích jazyků (4IZ238) Jirka Kosek Poslední modifikace: $Date: 2014/12/04 19:41:24 $ Obsah Ukládání XML dokumentů... 3 Ukládání XML do souborů... 4 Nativní XML databáze... 5 Ukládání
Jak vypadá opravdová discovery služba
 Jak vypadá opravdová discovery služba K čemu Summon? Chybí jasné a přitažlivé místo pro vyhledávání Potíže s určením vhodných zdrojů Současné nástroje neodpovídají očekáváním uživatelů Nejlepší místo,
Jak vypadá opravdová discovery služba K čemu Summon? Chybí jasné a přitažlivé místo pro vyhledávání Potíže s určením vhodných zdrojů Současné nástroje neodpovídají očekáváním uživatelů Nejlepší místo,
Novinky v e-zdrojích NLK. Adéla Jarolímková, NLK
 Novinky v e-zdrojích NLK Adéla Jarolímková, NLK E-knihy EBSCO ebook 3 tituly, trvalý nákup Přístup pro jednoho uživatele (současně) Možnost online prohlížení i off-line stažení do počítače, čtečky či jiného
Novinky v e-zdrojích NLK Adéla Jarolímková, NLK E-knihy EBSCO ebook 3 tituly, trvalý nákup Přístup pro jednoho uživatele (současně) Možnost online prohlížení i off-line stažení do počítače, čtečky či jiného
Seznámení s přípravou platformy pro zajištění služeb dodávaní dokumentů včetně MVS: ZÍSKEJ - I
 Seznámení s přípravou platformy pro zajištění služeb dodávaní dokumentů včetně MVS: ZÍSKEJ - I Nové trendy v meziknihovních výpůjčních službách (MVS), platformě Získej - I Luboš Chára, NTK lubos.chara@techlib.cz
Seznámení s přípravou platformy pro zajištění služeb dodávaní dokumentů včetně MVS: ZÍSKEJ - I Nové trendy v meziknihovních výpůjčních službách (MVS), platformě Získej - I Luboš Chára, NTK lubos.chara@techlib.cz
IntraVUE 2.0.3 Co je nového
 IntraVUE 2.0.3 Co je nového Michal Tauchman Pantek (CS) s.r.o. Červen 2008 Strana 2/8 Úvod IntraVUE je diagnostický a podpůrný softwarový nástroj pro řešení komunikačních problémů, vizualizaci a dokumentaci
IntraVUE 2.0.3 Co je nového Michal Tauchman Pantek (CS) s.r.o. Červen 2008 Strana 2/8 Úvod IntraVUE je diagnostický a podpůrný softwarový nástroj pro řešení komunikačních problémů, vizualizaci a dokumentaci
Virtuální depozitní knihovna Nástroj pro doplňování bohemikálních konzervačních sbírek. Tomáš Foltýn & Jiří Polišenský & Radek Nepraš
 Virtuální depozitní knihovna Nástroj pro doplňování bohemikálních konzervačních sbírek Tomáš Foltýn & Jiří Polišenský & Radek Nepraš Projekt NAKI DF12P01OVV007 Vytvoření kooperativního systému pro budování
Virtuální depozitní knihovna Nástroj pro doplňování bohemikálních konzervačních sbírek Tomáš Foltýn & Jiří Polišenský & Radek Nepraš Projekt NAKI DF12P01OVV007 Vytvoření kooperativního systému pro budování
Aplikace. prostorového navázání nehod v silničním provozu na přilehlou pozemní komunikaci s využitím prostorových a popisných dat
 Aplikace prostorového navázání nehod v silničním provozu na přilehlou pozemní komunikaci s využitím prostorových a popisných dat METODIKA PRÁCE S TOUTO APLIKACÍ červen 13 Obsah ÚVOD 3 UŽIVATELÉ 4 OPERÁTOR
Aplikace prostorového navázání nehod v silničním provozu na přilehlou pozemní komunikaci s využitím prostorových a popisných dat METODIKA PRÁCE S TOUTO APLIKACÍ červen 13 Obsah ÚVOD 3 UŽIVATELÉ 4 OPERÁTOR