Část 3 CUDA VS. OPENCL, OPENACC
|
|
|
- Vít Matoušek
- před 7 lety
- Počet zobrazení:
Transkript
1 Část 3 CUDA VS. OPENCL, OPENACC
2 Jazyky a API pro výpočty na GPU Jazyky pro programování shaderů HLSL DirectX GLSL OpenGL Cg překlad do OpenGL i DirectX Nadstavby rozšíření o proudové zpracování dat BrookGPU / Brook+ RapidMind PeakStream Jazyky pro obecné výpočty na GPU (GPGPU) CUDA OpenCL MS DirectCompute OpenACC 2
3 CUDA (Compute Unified Device Architecture) CUDA = API + runtime prostředí + podpora v HW Aplikační rozhraní (API) CUDA C rozšíření jazyka C CUDA driver (low-level) Runtime prostředí spouštění kernelů přesuny dat Přímá podpora v hardwaru Architektura SIMT (Single-Instruction, Multiple-Thread) Streaming Multiprocessor se sdílenou pamětí 3
4 OpenCL (Open Computing Language) Standard od Khronos Group pro paralelní výpočty nezávislost na konkrétní hardwarové platformě Založen na C99 obohacený o podporu pro paralelismus (datový i programový) Podpora heterogenních systémů (tj. multi-core CPU + GPU, další typy procesorů Xeon Phi, Cell, DSP) OpenCL framework se skládá ze 2 částí: OpenCL C rozšíření jazyka C OpenCL runtime API Implementace závislá na konkrétním výrobci grafických karet a procesorů: Překladač Runtime prostředí 4
5 MS Direct Compute Microsoft DirectCompute je API pro podporu GPGPU. Podporované OS jsou Microsoft Windows Vista a Windows 7 a novější. DirectCompute je součástí Microsoft DirectX API (verze 10 a 11). Rozhraní jsou shodná nebo obdobná jako OpenCL, OpenGL, CUDA. 5
6 OpenACC OpenACC (Open Accelerator): nový (představen 2012) standard pro práci s akcelerátory: GPU Nvidia GPU AMD/ATI Xeon Phi atd. Přístup podobný OpenMP => vyšší úroveň Optimalizace je přenechána kompilátoru => efektivita? Větší podpora jen v komerčních produktech: Portland Group (PGI), Accelerator Compiler CAPS, HMPP Workbench Cray Corporation, Compilation Environment Nekomerční podpora: Podpora v rámci LLVM Pracuje se na podpoře v rámci GNU GCC 6
7 C++ AMP (2012?) C++ Accelerated Massive Parallelism (C++ AMP) je programovací model pro datově paralelní úlohy C++ AMP je knihovna implementována na základě DirectX 11 a otevřené specifikace od fy Microsoft HCC kompilátor kompiluje kód do: OpenCL, Standard Portable Intermediate Representation (SPIR), HSA Intermediate Language (HSAIL)
8 CUDA (Compute Unified Device Architecture) CUDA je architektura pro provádění paralelních výpočtů, která definuje: Programming model vlákna (threads), blok (block) a mřížka (grid) Memory model registry, lokální, sdílená a globální paměť Execution model spouštění vláken a jejich mapování na HW Vývojové prostředí zahrnuje: Driver Runtime spouštění C funkcí na GPU Toolkit překladač, debugger, profiler Knihovny CUFFT, CUBLAS, SDK dokumentace + ukázky kódu CUDA je podporována na všech grafických procesorech NVIDIA (CUDA enabled-gpus) počínaje čipem G80 (Geforce 8800) CUDA programy je možno psát v jazyku C/C++ nebo Fortran.
9 CUDA základní pojmy CPU (označované jako host hostitel) Kernel = část kódu, kterou chceme provádět paralelně na GPU (def. jako funkce) Vlákno (thread) = instance kernelu GPU (označované jako device zařízení) je tvořeno multiprocesory. Streaming Multiprocesor (dále jen SM) se skládá z několika (např. 8 u G80) procesorů (jader = SP). SM provádějí bloky vláken. Warp je skupina vláken spouštěná najednou, např. 32 na GT200 GPU má SIMT architekturu = všechna vlákna v rámci warpu jsou ovládány jednou instrukční jednotkou = provádí stejnou instrukci (kromě podmíněných příkazů) Vlákna během výpočtu přistupují k různým druhům pamětí
10 CUDA capabilities Compute capability 1.0 (Tesla) G80 Compute capability 1.1 G86, G84, G98, G96, G96b, G94, G94b, G92, G92b Compute capability 1.2 GT218, GT216, GT215 Compute capability 1.3 GT200, GT200b Compute capability 2.0 (Fermi) GF100, GF110 Compute capability 2.1 GF108, GF106, GF104, GF114, GF116 Compute capability 3.0 (Keppler) GK104, GK106, GK107 Compute capability 3.5 GK110 Compute capability 5.0 (Maxwell) GM107 Výpis CUDA-enabled grafických karet a jejich CC možno nalézt na: 10
11 CUDA limity Platí stále: Velikost warpu je 32. Velikost konstantní paměti je 64 KB. Cache pro konstantní paměť na SM je 8 KB. Cache pro textury na SM je mezi 6 KB a 8 KB. 11
12 Compute capability 1.0 Maximální velikost sdílené paměti na jeden SM je 16 KB. Maximální počet vláken na blok je 512. Maximální počet rezidentních bloků na SM je 8. Maximální počet rezidentní warpů na SM je 24. Počet 32bitových registrů na SM je 8K (8*1024). Počet bank sdílené paměti je 16. Velikost lokální paměti na vlákno je 16 KB. Maximální počet instrukcí pro kernel = 2 millióny Compute capability 1.1 Atomické instrukce 32bit int v globální paměti 12
13 Compute capability 1.2 Atomické instrukce 64bit int v globální paměti Atomické instrukce 32bit int ve sdílené paměti Podpora volby v rámci warpu Maximální počet rezidentní warpů na SM je bitových registrů na SM je 16 K. Podpora typu double Compute capability
14 Compute capability 2.0 Fermi architektura Atomické přičtení float v globální paměti nebo ve sdílené paměti Podpora threadfence (paměťová synchronizace). Přístupy do globální paměti používají L2 (768KB), případně L1 cache (ale možno změnit 16/48KB). Maximální počet vláken na blok je Maximální počet rezidentní warpů na SM je 48. Počet 32bitových registrů na SM je 32K (32*1024). Počet bank sdílené paměti je 32. Velikost lokální paměti na vlákno je 512 KB. Maximální velikost sdílené paměti na jeden SM je možno zvětšit na 48 KB. Zvětšena texturovací cache na SM Maximální počet instrukcí pro kernel je 512 milliónů 14
15 Compute capability 3.0 Změna architektury (SMX), Keppler architektura Podpora pro instrukce výměny v rámci warpu. Maximální počet rezidentních bloků na SM je 16. Maximální počet rezidentní warpů na SM je 64. Počet 32bitových registrů na SM je 64K (64*1024). Zmenšena L2 cache (256/512KB) Compute capability 3.5 Možnost dynamického paralelismu Zvýšení výkonu pro dvojitou přesnost Zvětšena L2 cache (1536KB) 15
16 Compute capability 5.0 Maxwell architektura Maximální počet rezidentních bloků na SM je 32. Změna architektury (SMM). Maximální velikost sdílené paměti na jeden SM je možno zvětšit na 64 KB. Zvětšena texturovací cache na SM Zvětšena L2 cache (2048KB) 16
17 Maximální výkonnost SM(X,M) float add, mul, FMA double add, mul, FMA 32-bit integer add 32-bit integer mul 32-bit integer compare Compute Capability ,3.7 5.x / / ?? multiple
18 Maximální výkonnost SM(X,M) Compute Capability , bit integer shift /64 64 Logical operations population count?? bit int multiply 8 8 Multiple Multiple Multiple Multiple Multiple 32-bit FP reciprocal,
19 Maximální výkonnost SM(X,M) Compute Capability , Type conv. from 8- bit and 16-bit int to 32-bit Type conv. from and to 64-bit All other type conversions Multiple 1 4/ /
20 Budoucnost 2. Generace Maxwell Nepodstatné změny z hlediska CUDA Architektura Pascal (Volta) 3D memory. Unified memory spojení adresových prostorů CPU a GPU NVLink nova high-speed bus mezi CPU a GPU, nahrazující PCIe; udávaná propostnost 80 and 200 GB/s. 20
21 CUDA 1. příklad // definice kernelu global void HelloWorld() { //proveden kernelem = na GPU printf( Hello World!\n ); } Musí být void int main() { // volani kernelu z funkce main HelloWorld <<<1, 1>>>(); } Počet vláken v bloku Počet bloků
22 CUDA 2. příklad global void HelloWorld2() { //identifikační číslo vlákna int i = threadidx.x; printf( Hello World from thread %i!\n,i); } Číslo v rámci bloku int main() { // volání kernelu z funkce main HelloWorld2 <<<1, 10>>>(); } Počet vláken v bloku Počet bloků
23 CUDA 3. příklad global void PrintInt(int *vstup) { int i = threadidx.x; printf( Value at %i = %i\n,i, vstup[i]); } int main() { int i, a[n]; for(i=0;i<n;i++) a[i]=i; PrintInt <<<1, N>>>(a);!!! Ukazatel předán, ale chyba: kernelu je předána adresa v rámci CPU nikoliv v rámci GPU!!! } Počet vláken v bloku Počet bloků
24 CUDA 4. příklad I global void VecAdd(float* A, float* B, float* C) { int i = threadidx.x; C[i] = A[i] + B[i]; } int main() { N=A.size(); VecAdd<<<1, N>>>(A, B, C); Číslo v rámci bloku (každé vlákno sečte unikátní položky) } Počet vláken v bloku (omezeno!!!) Počet bloků
25 CUDA 4. příklad II int main( void ) { int N,i,j; float *hostc, *hosta,*hostb; float *devc,*deva,*devb; Deklarace ukazatelů V rámci CPU i GPU Alokace paměti na GPU cudamalloc( (void**)&deva, N * sizeof(float) ) ; cudamalloc( (void**)&devb, N * sizeof(float) ) ; cudamalloc( (void**)&devc, N * sizeof(float) ) ; cudahostalloc( (void**)&hosta, N * sizeof(float), cudahostallocdefault ) ; cudahostalloc( (void**)&hostb, N * sizeof(float), cudahostallocdefault ) ; cudahostalloc( (void**)&hostc, N * sizeof(float), cudahostallocdefault ) ; Alokace paměti na CPU, Možno I pomocí malloc nebo new
26 CUDA 4. příklad III Init(hostA); Init(hostB); Kopírování CPU -> GPU cudamemcpy(deva,hosta,sizeof(float)*n,cudamemcpyhosttodevice); cudamemcpy(devb,hostb,sizeof(float)*n,cudamemcpyhosttodevice); VecAdd<<<1,N>>>( deva, devb, devc); cudadevicesynchronize(); Volání kernelu Čekání na dokončení kernelu cudamemcpy(hostc,devc,sizeof(float)*n,cudamemcpydevicetohost); Kopírování GPU -> CPU
27 CUDA 4. příklad IV cudafreehost( hosta ) ; cudafreehost( hostb ) ; cudafreehost( hostc ) ; Uvolnění paměťových bloků na CPU cudafree( deva ) ; cudafree( devb ) ; cudafree( devc ) ; } Uvolnění paměťových bloků na GPU
28 Práce s globální pamětí cudaerror_t cudamemcpy (void *dst, const void *src, size_t count, enum cudamemcpykind kind ); kopírování dat mezi GPU CPU (cudamemcpyhosttohost, cudamemcpyhosttodevice, cudamemcpydevicetohost, cudamemcpydevicetodevice) cudaerror_t cudamalloc ( void **devptr, size_t size ); alokace paměti na GPU pro uložení dat data nejsou přímo přístupná na CPU kopírování dat pomocí cudamemcpy() cudaerror_t cudafree ( void *devptr ); GPU nemůže přistupovat do paměti CPU a opačně uvolnění alokované paměti na straně GPU
29 Zjištění dostupných zařízení cudaerror_t cudagetdevicecount ( int *count ); vrátí počet zařízení (tj. CUDA enabled GPU), pokud žádné neexistuje, pak vrátí cudaerrornodevice cudaerror_t cudagetdeviceproperties(struct cudadeviceprop *prop, int device ); vrátí informace (struktura cudadeviceprop) o zařízení s číslem device: jméno zařízení, Počet SM velikost globální paměti, max. počet vláken na blok, apod.
30 Nvidia GPU Device Složeno z několika Streaming multiprocessors (SMs) Multiprocessor N Multiprocessor 2 Multiprocessor 1 Dále části společné: Shared Memory L2 cache Rozhraní k paměti Registers Processor 1 Registers Processor 2 Registers Processor M Instruction Unit apod. Constant Cache Texture Cache Device memory 30
 Warp Scheduler Dispatch Unit Core Core Core Core Core Core Core Core Core Core Core Core Core Core Core Core Instruction Cache Register File 32768")
31 Streaming multiprocessor Streaming multiprocessor (SM) obsahuje: Instrukční cache Jednotky pro obsluhu instrukcí (fetchdispatch) Sdílená paměť Registrové pole Registry pro uložení kontextu vláken Daný počet SP Daný počet SFU (special function unit) Warp Scheduler Dispatch Unit Core Core Core Core Core Core Core Core Core Core Core Core Core Core Core Core Instruction Cache Register File x 32bit Core Core Core Core Core Core Core Core Core Core Core Core Core Core Core Core Warp Scheduler Dispatch Unit LDST LDST LDST LDST LDST LDST LDST LDST LDST LDST LDST LDST LDST LDST LDST LDST SFU SFU SFU SFU Interconnect Memory L1 Cache / 64kB Shared Memory L2 Cache 31
32 CUDA core Dispatch Port Operand Collector FP Unit Int Unit Result Queue 32
33 2D architektura = škálovatelnost Každý GPU se může lišit Frekvencí GPU Pamětí a velikostí GPU paměti Počtem SM Počtem jader na SM Schopnostmi (CUDA capabilities) Protože jednotlivé SM pracují víceméně nezávisle, je snadné zvyšovat výkon GPU zvýšením počtu SM GPU využívá masivní paralelismus na několika úrovních: V rámci GPU existuje několika procesorů (SM=Streaming Multiprocessor), které jsou pouze volně vázané. V rámci SM je prováděna paralelně jedna instrukce pro danou skupinu vláken (tzv. warp=32 vláken), SIMT přístup. V rámci SM se v provádění střídají jednotlivé skupiny vláken (prokládání warpů).
34 Provádění GPU kódu I Vlákna jsou sdružována do bloků a bloky do mřížky (2D nebo 3D) Vlákna v rámci bloku: lze synchronizovat (pomocí bariéry) mohou sdílet data pomocí sdílené paměti Programátor zadá (téměř libovolně) počet bloků a počet vláken v bloku (2D z hlediska programátora) To jak přesně bude kód prováděn udává execution model. Ten se stará o korektní a efektivní mapování na dané HW. V HW totiž existuje daný počet SM a daný počet SP na jeden SM. (2D z hlediska HW)
35 Provádění GPU kódu II Každý blok vláken je prováděn na právě jednom SM. Na každý SM může být namapováno více bloků najednou (až 8 u GT200) Blok vláken je rozdělen do několika warpů (podle čísel vláken). Centrální distribuce bloků metodou round-robin. V každém časovém kroku plánovač (warp scheduler) každého SM (nezávisle na ostatních SM) naplánuje k provedení připravený warp (který má všechna data a neprovádí bariéru) z určité skupiny tzv. rezidentních warpů.
36 Provádění GPU kódu 1. Před vlastním provedením jedné instrukce dojde k přepnutí kontextu: pro všechna vlákna aktuálního warpu se provede nahrání obsahů patřičných registrů z registrového pole SM. 2. Vlákna warpu pak provedou paralelně jednu instrukci protože jde o SIMT architekturu. 3. Přepnutí kontextu II: pro všechna vlákna aktuálního warpu se provede uložení obsahů patřičných registrů do registrového pole SM. Toto plánování je akcelerováno pomocí hardware GPU proto má nulovou režii. GPU ale vždy vybírá z určité skupiny rezidentních warpů, jejíž velikost je hardwarově omezena. CC 1.0: maximálně 24 rezidentních warpů CC 1.2: maximálně 32 rezidentních warpů CC 2.0+: maximálně 48 rezidentních warpů
37 Provádění GPU kódu II CPU(1 core): 1. Ins. 0 Thr Ins. 1 Thr Ins. 2 Thr Ins. 3 Thr Ins Thr Ins. 0 Thr Ins. 1 Thr Ins. 2 Thr. 1 Přepnutí kontextu GPU(1 SM): 1. Ins. 0 Warp 0 2. Ins. 0 Warp 1 3. Ins. 0 Warp 2 4. Ins. 0 Warp Ins. 1 Warp Ins. 1 Warp Ins. 1 Warp Ins. 1 Warp 3
38 Provádění GPU kódu III Výhody Odstranění/ zmenšení vlivu latencí (cache misses, stalls) Není nutné implementovat Out-of-Order execution a jiné mechanismy Nevýhody: Nižší takt Velké registrové pole (+omezení reg. na vlákno) Velký počet pomocných registrů Komplikovanější přepínání kontextu vláken (registry/zásobník apod.)
39 Ukončení Pokud je kód pro dané vlákno ukončen, vlákno přestane vykonávat činnost. Pokud jsou ukončeny všechna vlákna ve warpu, je warp ukončen. Pokud jsou ukončeny všechny warpy v bloku, je blok ukončen. Pokud jsou ukončeny všechny bloky v kernelu, je kernel ukončen. 39
40 Modifikátory funkcí 1. global : 1. voláno z CPU kódu, 2. nemožno z GPU kódu 3. Návratový typ void 2. device : 1. Voláno z ostatních GPU funkcí, 2. Nemožno z CPU kódu 3. host : Prováděno na CPU, Voláno z CPU host a device mohou být kombinovány Kompilátor pak vytvoří jak CPU tak GPU kód
41 Bloky kontra vlákna I Je dobré mít velký počet vláken v bloku Synchronizace a předávání dat pomocí sdílené paměti je možno jen v rámci jednoho bloku! Díky přeplánování mohou být amortizovány velké latence. Ale: Blok může obsahovat maximálně 512 threadů pro CC 1.X 1024 threadů pro CC 2.0 Každý SM může (současně) provádět 8 bloků (16 pro CC 3.0, 32 pro CC 5.0), ale skutečný počet závisí na paměťových požadavcích na registry a sdílenou paměť = např. všechny bloky na SM mohou alokovat max. 16 kb sdílené paměti (pro CC 1.X), max. 48 kb sdílené paměti (pro CC 2.0), max. 112 kb sdílené paměti (pro CC 3.7) max. 64 kb sdílené paměti (pro CC 5.0), max. 96 kb sdílené paměti (pro CC 5.2). Stejně tak je limitován počet registrů pro vlákno. GPGPU II: Programování v CUDA
42 Bloky kontra vlákna II Omezení bloků: Bloky by měly být nezávislé Být navrženy tak, aby každé pořadí jejich vyhodnocení bylo korektní Mohou běžet paralelně nebo sekvenčně Data mohou být sdílena mezi bloky ale problém se synchronizací
43 Ošetření chyb static void HandleError( cudaerror_t err, const char *file, int line ) { if (err!= cudasuccess) { printf( "%s in %s at line %d\n", cudageterrorstring( err ), file, line ); exit( EXIT_FAILURE ); }} Makro pro zpracování chyb #define HANDLE_ERROR( err ) (HandleError( err, FILE, LINE )). HANDLE_ERROR( cudamalloc( (void**)&deva, N * sizeof(float) ) );. Výpis případné chyby
44 Zabudované vektorové typy Mohou být použity v GPU nebo CPU kódu [u]char[1..4], [u]short[1..4], [u]int[1..4], [u]long[1..4], float[1..4] Struktury přístupné nikoliv pomocí indexů ale pomocí položek x, y, z, w: Např. uint4 param; int y = param.y; Speciální typ dim3, založen na typu uint3 používán ke specifikaci dimenzí Defaultní hodnota (1,1,1)
45 Mřížka bloků Bloky mi mohou obecně tvořit maximálně 2D (pro CC 1.X) nebo 3D (pro CC 2.0) mřízku = grid Obdobně vlákna v rámci bloku mi mohou obecně tvořit (maximálně 3D) matici. Ale mřížka i matice jsou převedeny do 1D, takže nemají velký význam kromě vyššího komfortu pro programátora při přístupu do vícedimenzionálního pole.
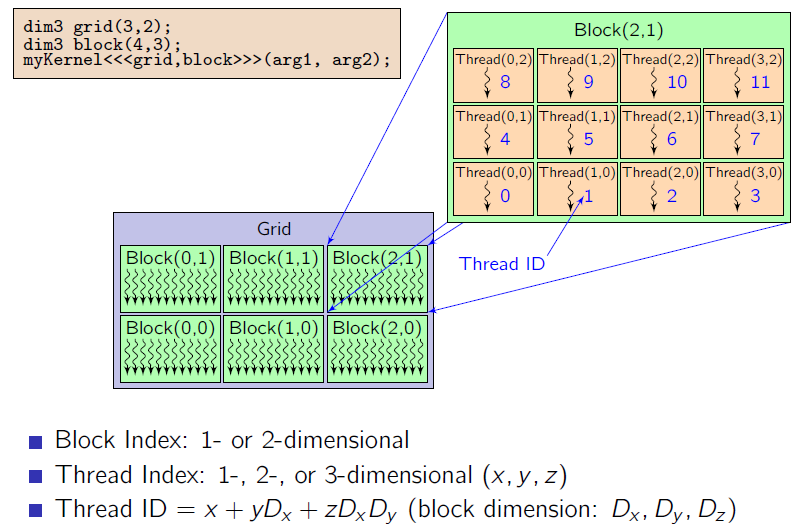
46 Mapování
47 Automaticky definované proměnné I Všechny global a device funkce mají přístup k těmto automaticky definovaným proměnným dim3 griddim; dimenze mřížky v blocích dim3 blockdim; Dimenze bloku ve vláknech dim3 blockidx; Index bloku v gridu dim3 threadidx; index vlákna v bloku Častý přepočet: int idx = blockdim.x * blockidx.x + threadidx.x;
48 Automaticky definované proměnné II Obsahují informace o konfiguraci mřížky a také jednoznačné identifikátory jednotlivých vláken v rámci bloku a bloků v rámci mřížky: griddim udává velikost mřížky, tj. počet bloků v jednotlivých dimenzích. Maximální velikost kterékoliv dimenze je 2^16-1 (pro CC ) nebo 2^31-1 (pro CC 3.0). blockdim určuje velikost bloku v jednotlivých dimenzích. Blok je chápán jako třírozměrné pole vláken, jejichž maximální počet v rámci bloku je omezen na 512 pro CC 1.X a 1024 pro CC 2.0, max. velikost z-dimenze je 64).
49 Automaticky definované proměnné III Každé vlákno je jednoznačně identifikováno pomocí: čísla bloku v rámci mřížky blockidx čísla vlákna v rámci bloku threadidx warpsize definuje počet vláken tvořících warp (velikost warpu je zatím rovna 32).
50 Mapování I global void MujKernel(int i) {// v tomto kernelu bude mit: // griddim.x stále hodnotu 5 // griddim.y stále hodnotu 7 // griddim.z stále hodnotu 1 // blockdim.x stále hodnotu 4 // blockdim.y stále hodnotu 3 // blockdim.z stále hodnotu 2 int parametr; dim3 gridres(5,7,1); ); //gridres mi určuje třírozměrnou mřížku bloků dim3 BlockRes(4,3,2); //blockres mi určuje třírozměrné pole vláken MujKernel<<<gridRes,blockRes>>>(parametr); 50
51 Mapování II global void MujKernel(int i) {// v tomto kernelu bude mit: // blockidx.x hodnotu mezi <0,gridDim.x) tj. mezi 0 a 4 // blockidx.y hodnotu mezi <0,gridDim.y) tj. mezi 0 a 6 // blockidx.z hodnotu mezi <0,gridDim.z) tj. 0 // threadidx.x hodnotu mezi <0,blockDim.x) tj. mezi 0 a 3 // threadidx.y hodnotu mezi <0,blockDim.y) tj. mezi 0 a 2 // threadidx.z hodnotu mezi <0,blockDim.z) tj. mezi 0 a 1 } int parametr; dim3 gridres(5,7,1); //gridres mi určuje třírozměrnou mřížku bloků dim3 BlockRes(4,3,2); //blockres mi určuje třírozměrné pole vláken MujKernel<<<gridRes,blockRes>>>(parametr); 51
52 Mapování III // převod 2D indexu vlákna na linearní index (v rámci bloku ) int idx = blockdim.x* threadidx.y + threadidx.x; // převod 3D indexu vlákna na lineární (v rámci bloku ) int idx = blockdim.x*( blockdim.y* threadidx.z + threadidx.y) + threadidx.x; // výpočet globálního indexu vlákna v rámci 2D mřížky int column = blockdim.x * blockidx.x + threadidx.x; int row = blockdim.y * blockidx.y + threadidx.y;
53 Součet vektorů I global void VecAdd2(float* A, float* B, float* C,int N) { int i; for(i=0;i<n;i++) C[i] = A[i] + B[i]; } int main() { VecAdd2<<<1, 1>>>(A, B, C, N); } Sekvenční!!!!
54 Součet vektorů II global void VecAdd(float* A, float* B, float* C) { int i = threadidx.x; C[i] = A[i] + B[i]; } int main() { Číslo v rámci bloku (každé vlákno sečte unikátní položky) } VecAdd2<<<1, N>>>(A, B, C); Počet vláken v bloku (omezeno N 1024) Počet bloků
55 Součet vektorů III global void VecAdd3(float* A, float* B, float* C, int N) { } int i = blockdim.x * blockidx.x + threadidx.x; if (i<n) C[i] = A[i] + B[i]; Přepočet na unikátní číslo v rámci mřížky (každé vlákno sečte unikátní položky) int main() { VecAdd3<<<round_up(N/1024), 1024>>>(A, B, C); } Celkový počet vláken N
56 Násobení matic global void Mul_IJ( float *ina, float *inb, float *outc, int N ) { int i=blockidx.x; int j=threadidx.x; int k; float s=0.0; Index bloku Index v rámci bloku for(k=0;k<n;k++) s+=ina[i*n+k]*inb[k*n+j]; outc[i*n+j]=s; } Provedení skalárního součinu Mul_IJ<<<N,N>>>( deva, devb, devc, N ); Volání kernelu
57 Trojúhelníková matice global void TrojMatice( float *A, int N ) { } int i=blockidx.x; int j=threadidx.x; if (j>i) return; A[i*n+j]*=2.0; Index bloku Index v rámci bloku Elegantní, ale trochu neefektivní TrojMatice<<<N,N>>>( deva, N ); Volání kernelu pro zpracování troj. matice
58 Synchronizace s hostitelem Spuštení kernelů je asynchronní operace Vrací řízení CPU ihned jak je to možné Pokud je třeba počkat na dokončení práce všech CUDA volání: cudathreadsynchronize() nebo spíše cudadevicesynchronize() kernel je spuštěn po dokončení všech předchozích CUDA voláních Např. operace kopírování cudamemcpy() je synchronní, je spuštěna po dokončení všech předchozích CUDA volání
59 Synchronní CUDA volání cudamalloc(void **pointer, size_t nbytes) cudamemset(void *pointer, int value, size_t count) cudafree(void *pointer) cudamemcpy(void *dst, void *src, size_t nbytes, enum cudamemcpykind direction);
60 Asynchronní CUDA volání Vzhledem k hostiteli: Spuštění kernelu v default streamu cudamemcpy*async cudamemset*async cudamemcpy v rámci stejného device HostToDevice cudamemcpy pro 64kB nebo menší blok Vzhledem k device: Pomocí více streamů (bude uvedeno později)
61 Synchronizace v rámci bloku I Většina vláken běží asynchronně pouze vlákna v rámci jednoho warpu musí běžet plně synchronně. Synchronizace (bariéra) v rámci celého bloku pomocí built-in funkce syncthreads() Žádné vlákno nemůže překročit bariéru, pokud ji nedosáhnou všechny vlákna bloku Časté použití: synchronizace přístupu ke sdílené paměti Předcházení RAW, WAR, WAW hazardů
62 Synchronizace v rámci bloku II Je třeba velké opatrnosti při použití např. v podmínce //dimblock.x = 256 if (threadidx.x < 128) { } syncthreads(); // CHYBA! Možno jen v podmínce, která je platná pro všechny vlákna v bloku: if (blockidx.x < 128) {... }!!! Jinak hrozí deadlock nebo jiné nepředvídatelné chování!!!
63 CUDA typy pamětí I Registry Jen pro jedno vlákno Umístěna na čipu, velmi rychlá Počet použitých registrů pro každé vlákno je dán kernelem Počet použitých registrů omezuje počet rezidentních warpů a bloků na jednom SM (všechny se musí vejít do reg. pole daného SM)
64 CUDA typy pamětí II Globální Přístupná i pro hostitele Přístupná pro všechny bloky Umístěna mimo čip a pro CC 1.X nemá cache => velká latence CC 2.0 při přístupu využívána cache Pro maximální využití přenosové rychlosti je nutný sdružený přístup (coalesced access) Paralelní přístupy serializovány Pro implementaci není nutný žádný koherenční protokol
65 CUDA typy pamětí III Sdílená (shared) Přístupná pro všechny vlákna ale jen uvnitř jednoho bloku Umístěna na čipu, velmi rychlá, neobsahuje cache Rozdělena na: Pro CC 1.X 16 bank (prokládaně po 32b) Pro CC bank (prokládaně po 32b) Současný přístup k různým adresám v jedné bance vede k serializaci Při čtení ze stejné adresy je hodnota distribuována pomocí operace broadcast Její velikost omezuje počet rezidentních bloků na jednom SM (všechny se musí vejít do sdílené paměti daného SM)
66 CUDA typy pamětí IV Lokální (lokální) Přístupná pro jedno vlákno Část globální paměti (rychlost?) Jako možné rozšíření registrového pole (tzv. register spilling)
67 CUDA typy pamětí V Pro konstanty (constant) Přístupná pro všechny vlákna Umístěna mimo čip, ale obsahuje vlastní cache => rychlost? Část globální paměti určená jen pro čtení Pro implementaci není nutný žádný koherenční protokol (jen pro čtení) Speciální operace cudamemcpytosymbol pro načtení dat do konstantní paměti
68 CUDA typy pamětí VI Texturovací (texture) Přístupná pro všechny vlákna Umístěna mimo čip, ale obsahuje vlastní cache => rychlost? Část globální paměti určená jen pro čtení (speciální 2D kešování) Pro implementaci není nutný žádný koherenční protokol (jen pro čtení)
69 CUDA typy pamětí VII Pamět jen pro čtení Od CC 3.0 Přístupná pro všechny vlákna Část globální paměti určená jen pro čtení Umístěna mimo čip, ale používá texturovou cache i pro jiné datové objekty než textury Přistupované proměnné musí být deklarována s modifikátory const a restrict Pro implementaci není nutný žádný koherenční protokol (jen pro čtení)
70 CUDA typy pamětí Druh paměti Přístup Umístění Operace Kešovaná Registry 1 vlákno Na čipu R+W NE Lokální 1 vlákno DRAM R+W NE/ANO Sdílená Globální Texturovací Pro konstanty Jen pro čtení Všechny vlákna bloku Všechna vlákna a host Všechna vlákna a host Všechna vlákna a host Všechna vlákna a host Na čipu R+W NE DRAM R+W NE/ANO DRAM R ANO DRAM R ANO DRAM R ANO
71 Jak specifikovat umístění proměnných (GPU kód) device Uloženo v globální paměti Alokováno pomocí cudamalloc Přístupná pro všechny vlákna shared Ve sdílené paměti Alokováno pomocí execution configuration nebo v době kompilace constant V paměti konstant Neoznačené proměnné: Skaláry a zabudované vektorové typy jsou uloženy v registrech Pole v lokální paměti (registry nejsou adresovatelné)
72 Použití sdílené paměti V čase kompilace global void kernel( ) { shared float sdata[256]; } int main(void) { kernel<<<nblocks,blocksize>>>( ); } Až při spuštění kernelu global void kernel( ) { extern shared float sdata[]; } int main(void) { smbytes = blocksize*sizeof(float); kernel<<<nblocks, blocksize,smbytes>>>( ); }
73 Konstantní paměť Proměnné s modifikátorem constant Automaticky alokováno potřebné místo. Musíme pouze zajistit nakopírování příslušných dat z hlavní paměti do paměti konstant pomocí cudamemcpytosymbol. Př. constant float constdata[256]; // pole v konstantní paměti float data[256]; // pole v paměti hostitele // kopírování pole z hlavní paměti do konstantní paměti cudamemcpytosymbol(constdata, data, sizeof(data));
74 Dynamicky alokovaná paměť I void* malloc (size t size); free (void* ptr); Paměť je kernelem dynamicky alokována resp. vrácena zpět z haldy pevné velikosti vytvořené v globální paměti adresa paměťového bloku velkého nejméně size bytů je zarovnána na 16 bytů v případě neúspěchu vrací NULL Může být používána či dealokována i jinými vláknem, než která jí původně vytvořilo.
75 Dynamicky alokovaná paměť II Standardní velikost haldy je 8 MB, ale jsou k dispozici funkce, které umožňují zjistit její aktuální velikost a tuto velikost změnit: void* cudadevicegetlimit (size t *size, cudalimitmallocheapsize); cudadevicesetlimit (cudalimitmallocheapsize, size t size); Možno měnit i: cudalimitstacksize: max. velikost zásobníku pro GPU vlákno cudalimitprintffifosize: velikost FIFO pro printf() a fprintf().
76 Násobení matic (CUDA v1) I static void HandleError( cudaerror_t err, const char *file, int line ) { if (err!= cudasuccess) { printf( "%s in %s at line %d\n", cudageterrorstring( err ), file, line ); exit( EXIT_FAILURE ); }} Zpracování chyb #define HANDLE_ERROR( err ) (HandleError( err, FILE, LINE )) int main( void ) { int N,i,j; float *hostc, *hosta,*hostb; float *devc,*deva,*devb; Ukazatele
77 Násobení matic (CUDA v1) II global void Mul_IJ( float *ina, float *inb, float *outc, int N ) { int i=blockidx.x; int j=threadidx.x; int k; float s=0.0; Index bloku Index v rámci bloku for(k=0;k<n;k++) s+=ina[i*n+k]*inb[k*n+j]; outc[i*n+j]=s; syncthreads(); } Bariéra v rámci bloku
78 Násobení matic (CUDA v1) III static void HandleError( cudaerror_t err, const char *file, int line ) { if (err!= cudasuccess) { printf( "%s in %s at line %d\n", cudageterrorstring( err ), file, line ); exit( EXIT_FAILURE ); }} Makro pro zpracování chyb #define HANDLE_ERROR( err ) (HandleError( err, FILE, LINE )) int main( void ) { cudadeviceprop prop; int whichdevice,n,i,j; cudaevent_t start, stop; float elapsedtime; float *hosta,*hostb,*hostc; float *deva,*devb,*devc; Vlastnosti GPU CUDA události Ukazatele
79 Násobení matic (CUDA v1) IV HANDLE_ERROR( cudagetdevice( &whichdevice ) ); HANDLE_ERROR( cudagetdeviceproperties( &prop, whichdevice ) ); cudaeventcreate( &start ) ; cudaeventcreate( &stop ) ; cudamalloc( (void**)&deva, N * N* sizeof(float) ) ; cudamalloc( (void**)&devb, N * N *sizeof(float) ) ; cudamalloc( (void**)&devc, N * N * sizeof(float) ) ; cudahostalloc( (void**)&hosta, N * N* sizeof(float), cudahostallocdefault ) ; cudahostalloc( (void**)&hostb, N * N *sizeof(float), cudahostallocdefault ) ; cudahostalloc( (void**)&hostc, N * N *sizeof(float), cudahostallocdefault ) ; Inicializace Alokace paměti na GPU Alokace paměti na CPU
80 Násobení matic (CUDA v1) V cudamemcpy(deva,hosta,sizeof(float)*n*n,cudamemcpyhosttodevice); cudamemcpy(devb,hostb,sizeof(float)*n*n,cudamemcpyhosttodevice); Kopírování CPU -> GPU cudaeventrecord( start, 0 ) ; Volání kernelu Mul_IJ<<<N,N>>>( deva, devb, devc, N ); cudathreadsynchronize(); cudaeventrecord( stop, 0 ) ; Zjištění času cudaeventsynchronize( stop ) ; cudaeventelapsedtime( &elapsedtime, start, stop )); printf( GPU time taken: %g ms\n", elapsedtime ); cudamemcpy(hostc,devc,sizeof(float)*n*n,cudamemcpydevicetohost); Kopírování GPU -> CPU
81 Násobení matic (CUDA v1) VI cudaeventdestroy( start ) ; cudaeventdestroy( stop ) ; cudafreehost( hosta ) ; cudafreehost( hostb ); cudafreehost( hostc ) ; cudafree( deva ) ; cudafree( devb ) ; cudafree( devc ) ; }
82 Rozdělení (Diverging) warpu I Nastává při podmíněném skoku (důsledek SIMT přístupu) Vlákna ve stejném warpu mohou vykonávat různé větve výpočtu. Příklad: if (threadidx.x < 11) { branch1(); } else { branch2(); }
83 Rozdělení (Diverging) warpu II Warp musí provést obě větve Warp se rozdělí v podmínce, vlákna dělají všechna stejnou instrukci (ale ty které jsou ve špatné větvi nevykonávají instrukce) Při víceúrovňovém větvení může dojít k extrému: každé vlákno ve warpu je vlastně prováděno sekvenčně Pokud počet aktivních vláken ve warpu klesne na nulu, je ukončeno provádění tohoto warpu
84 Rozdělení (Diverging) warpu III Rozdělení (diverging) warpu nastává, pokud: if/else s různou hodnotou podmínky v rámci warpu Vlákna provádí různý počet iterací cyklu Pokud počet vláken v bloku není násobek 32 (velikosti warpu) Rozdělení (diverging) warpu nenastává, pokud: Jsou aktivní všechna vlákna v rámci warpu Jsou neaktivní všechna vlákna v rámci warpu
85 Rozdělení (Diverging) warpu IV Problém s efektivitou může nastat při provádění tohoto kódu for(i=0;i<n;i++){ } if (podminka1(i)) continue; if (podminka2(i)) continue; if (podminka3(i)) continue; Každá podmínka omezí počet aktivních vláken ve warpu, klesá paralelismus! Ale nevadí, pokud je pravděpodobnost splnění podmínek nízká nebo vysoká (vypadávají celé warpy)
86 Rozdělení (Diverging) warpu V Předchozí kód možno nahradit takto: for(i=0;i<n;i++) if (!podminka1(i)) ulož1(i) // počet uložení je v proměnné pocet1 bariera(); for(i=0;i<pocet1;i++) if (!podminka2(i)) ulož2(i) // počet uložení je v proměnné pocet2 bariera(); for(i=0;i<pocet2;i++) if (!podminka3(i)) ulož3(i) // počet uložení je v proměnné pocet3 Nevhodné, pokud jsou podmínky jednoduché => režie operací ulož1, ulož2, ulož3 Nutnost opakovaného průchodu datovými strukturami
87 GPU Atomic Integer Operations Podpora atomických operací pro typ integer v globální paměti CUDA capabilities >= 1.1 ve sdílené paměti CUDA capabilities >= 1.2 Týká se těchto operací atomicmin(), atomicmax(), atomicadd(), atomicsub(), atomicinc(), atomicdec(), exchange ( atomicexch() ), compare and swap ( atomiccas() ) atomicand(), atomicor(), atomicxor() Např. shared totalsum; atomicadd(&totalsum, 1);
88 OpenCL (Open Computing Language) Standard od Khronos Group pro paralelní výpočty nezávislost na konkrétní hardwarové platformě Založen na C99 obohacený o podporu pro paralelismus (datový i programový) Podpora heterogenních systémů (tj. multi-core CPU + GPU, další typy procesorů Cell, DSP) OpenCL framework se skládá ze 2 částí: OpenCL C rozšíření jazyka C OpenCL runtime API Implementace závislá na konkrétním výrobci grafických karet a procesorů: Překladač Runtime prostředí Převzato z [1]
89 Programovací jazyk OpenCL C Založen na C99, rozšíření: Vektorové datové typy. Datové typy a funkce podporující práci s obrázky a jejích filtrování. Kvalifikátory adresního prostoru. Kvalifikátory přístupových práv. Kernelové funkce. Přesnost čísel v plovoucí desetinné čárce dle standardu IEEE 754.
90 Programovací jazyk OpenCL C Omezení: Ukazatele na funkce, pole proměnné délky a bitová pole jsou zakázaná. Mnoho hlavičkových souborů standardní knihovny jazyka C je nedostupná. Rekurzivní funkce nejsou povolené. Kernelové funkce nesmějí deklarovat argumenty typu ukazatel na ukazatel ani nic vracet. Zápisy na pole číselných typů menších než 32 bitů jsou zakázané.
91 Novinky I Profil embedded profil pro mobilní či vestavěná zařízení, která jsou schopná podporovat modely architektury OpenCL, ale nedisponují dostatečným výkonem pro zajištění plného rozsahu funkčnosti. některé části standardu nepovinné (podpora 3D obrazu) Nebo odstraněné úplně (striktní konformita s IEEE- 754, 64bitové číselné typy).
92 OpenCL 2.0 Updates and additions: Shared virtual memory Nested parallelism Generic address space Images C11 atomics Pipes Android installable client driver extension
93 OpenCL 2.1 November 16, the OpenCL C kernel language is replaced with OpenCL C++, a subset of C++14 Copying of kernel objects and states Low-latency device timer queries Ingestion of SPIR-V code by runtime Execution priority hints for queues Zero-sized dispatches from host
94 Firmy na OpenCL AMD/ATI, IBM, Intel nvidia Apple Nový standard 2.1 je podporován: AMD, ARM, Intel, HPC, YetiWare
95 Srovnání s CUDA OpenCL má obecnější model, díky tomu je ukecanější Je těžké napsat kód, který bude efektivní na všech OpenCL platformách OpenCL kvůli obecnosti nedokáže plně využít všechny HW features architektury OpenCL má vyšší režii, kód kernelu je kompilován až za běhu programu
96 Základní pojmy I Host (CUDA: host) = CPU. Device (CUDA: device) výpočetní zařízení CPU nebo GPU. Platform: systém (host + devices) spravovaný pomocí OpenCL Context: definuje celé prostředí OpenCL Kernel (CUDA: kernel) fce volaná z hosta, vykonávaná na device. Kompilované až při spuštění Program: množina kernelů a dalších fcí
97 Základní pojmy II Work-item (CUDA: thread), každý své ID. Work-group (CUDA: thread block) skupina work-items které mohou kooperovat a komunikovat, každý své ID. Je to N- dimensional grid of work-groups, N = 1, 2 or 3). ND-Range: popisuje velikosti dimenzí work-groups (jako N- dimensional grid of work-groups, N = 1, 2 or 3). Compute Unit (CUDA: Streaming Multiprocessor) Processing Element (CUDA: Streaming processor, core)
98 Identifikace WI Jednotlivé WI jsou jednoznačně dány: global id (unikátní v rámci index space) work-group ID a local ID v rámci work-group
99 Identifikace Pro identifikaci vláken v každé dimenzi: get_global_id(dim) get_global_size(dim) Nebo zjištění work-group ID and ID v rámci WG get_group_id(dim) get_num_groups(dim) get_local_id(dim) get_local_size(dim) get_global_id(0) = column, get_global_id(1) = row get_num_groups(0) * get_local_size(0) == get_global_size(0)
100 OpenCL Je definováno několik modelů Platform Model Execution Model Memory Model Programming Model Jejich účel je obdobný jako v CUDA, navíc je platform, který CUDA nepotřebuje
101 Platform Model Každá OpenCL implementace definuje platformu, která umožnuje hostisteli využívat OpenCL zařízení OpenCL používá Installable Client Driver model Umožňuje více platforem (od každého výrobce jednu) na jednom systému, ale mohou zde být různá omezení souběžného provozu více platforem
102 Platform Model Hostitel je připojen na několik OpenCL zařízení (device) Jedno zřízení je rozděleno na několik compute units (CU) Každé CU je rozdělenona několik processing elements (PE) Každý PE má vlastní program counter
103 Memory Model Každá pracovní jednotka (work item) má přístup do následujících pamětí: Global Memory (CUDA: globální paměť) hlavní paměť, která je přístupná všem pracovním jednotkám jak pro čtení, tak pro zápis Constant Memory (CUDA: paměť pro konstanty) oblast globální paměti jejíž obsah zůstává během spuštění kernelu konstantní Local Memory (CUDA: sdílená paměť) paměť sdílená všemi pracovními jednotkami v rámci pracovní skupiny (work-groups) Private Memory (CUDA: lokální paměť a registry) privátní paměť přístupná pouze jednotlivým pracovním jednotkám (work-items) Private to a work-item
104 Paměťové objekty Buffers Souvislé kusy paměti Přímý přístup (arrays, pointers, structs) Read/write Images Objekty se souřadnicemi(2d nebo 3D) Přístup pomocí read_image() and write_image() Buď jen pro čtení nebo jen pro zápis
105 Programming model Work-groups jsou prováděny na CU( computeunits) Není zaručena komunikace/koherence mezi různými work-groups (není obsaženo v OpenCL specifikaci) Synchronizace Mezi WI v rámci WG Mezi příkazy v kontextu příkazové fronty
106 Program Program (jedná se o objekt) je kolekce OpenCL kernelů Může to být zdrojový kód v textové formě nebo překompilovaný binární kód Může obsahovat konstantní data a pomocné funkce Vytváření programu vyžaduje načtení zdrojového kódu v textové formě nebo překompilovaného binárního kódu ke zkompilování programu je nutno: Specifikovat cílové zařízení Program je zkompilován zvlášť pro každé zařízení Zahrnutí volitelných nastavení kompilátoru Zjištění případných chyb při kompilaci
107 Mapování na HW Pro AMD (Intel?) vícejádrové CPU všechny CPU tvoří jedno zařízení (device) každé jádro je jedna CU a jeden PE pro GPU každé GPU tvoří zvláštní zařízení (device) jedno VLIW jádro tvoří jeden Processing element (PE) Jeden SIMD Engine tvoří jednu compute unit (CU)

108 Nvidia GPU Instruction Cache Warp Scheduler Dispatch Unit Warp Scheduler Dispatch Unit Register File x 32bit Core Core Core Core Core Core Core Core Core Core Core Core Core Core Core Core LDST LDST LDST LDST LDST LDST LDST LDST SFU SFU Core Core Core Core Core Core Core Core Core Core Core Core Core Core Core Core LDST LDST LDST LDST LDST LDST LDST LDST SFU SFU Interconnect Memory L1 Cache / 64kB Shared Memory L2 Cache

109 CUDA core Jeden SP = jedno jádro v CUDA je tvoří pouze ALU a FPU Dispatch Port Operand Collector FP Unit Int Unit Result Queue
110 AMD GPU HW Architecture AMD 5870 Cypress 20 SIMD engines 16 SIMD units per core 5 multiply-adds per functional unit (VLIW processing) 2.72 Teraflops Single Precision 544 Gigaflops Double Precision
111 SIMD Engine A SIMD engine consists of a set of Stream Cores Stream cores arranged as a five way Very Long Instruction Word (VLIW) processor Up to five scalar operations can be issued in a VLIW instruction Scalar operations executed on each processing element Stream cores within compute unit execute same VLIW instruction The block of work-items that are executed together is called a wavefront. 64 work items for 5870 One SIMD Engine One Stream Core Instruction and Control Flow General Purpose Registers Source: AMD Accelerated Parallel Processing OpenCL Programming Guide
112 Architektura AMD/ATI VLIW4 nebo VLIW5 Jedno GPU je složeno z Compute Units (CU) = SIMD engines. Každá Compute Units z proudových jader (Stream Core, SC). Každé SC obsahuje: 3 nebo 4 Procesních elementů, T-Procesního element, jednotku vykonávající větvení programu (Branch Execution Unit). Jednotlivé PE a T-PE (=ALU) provádějí samotný výpočet. Každý PE a T-PE umožňuje vykonávat integer operace a FP operace v jednoduché přesností. FP operace ve dvojnásobné přesnosti lze vykonávat při spojení dvou až čtyř PE. T-PE umožňuje navíc vykonávat matematické operace jako je sinus, cosinus, logaritmus, atd.
113 Architektura AMD/ATI VLIW4 nebo VLIW5 SC = čtyř- nebo pěti-cestný very long instruction word (VLIW) procesor, který vykonává až čtyři (VLIW4) nebo pět (VLIW5) skalárních operací současně v jedné VLIW instrukci. Blok vláken vykonávaných paralelně nazývá Wave-Front (velikost v současné generaci je 64). Zhruba odpovídá CUDA warpu.
114 Architektura GCN GCN (Graphics Core Next} AMD/ATI opustila koncept VLIW, nová technologie Southern Islands. První zástupci jsou karty s technologií GCN, v současné době jsou to karty Radeon HD 77xx-79xx. Každá GCN karta je složena z několika CU. Každá CU obsahuje: jednotka vykonávající větvení programu (Branch Execution Unit), plánovač(e), 4 vektorových (SIMD) jednotek (Vector Units=VU), skalární jednotky (Scalar Unit), registrové pole (jak pro skalární tak pro vektorové jednotky).
115 OpenCL kompilace LLVM - Low Level Virtual Machine Kernely jsou zkomiplovány do LLVM IR Open Source Compiler Platform, OS independent Multiple back ends
116 Fáze v OpenCL Fáze v CUDA 1. zjištění dostupných platforem 2. výběr vhodného zařízení 3. vytvoření kontextu 4. vytvoření fronty příkazů 5. vytvoření paměťových objektů pro uložení dat 6. načtení kernelů ze souboru (případně definice pomocí stringu) 7. vytvoření objektu pro uložení programu (program object) 8. vytvoření spustitelné verze programu (překlad a linkování) 9. vytvoření objektu kernelu (kernel object) 10. nastavení parametrů kernelu 11. překopírování dat do zařízení 12. spuštění kernelu 13. překopírování výsledků ze zařízení 14. uvolnění alokovaných prostředků (objektů) 1. výběr vhodného zařízení 2. alokace paměťových objektů pro uložení dat 3. překopírování dat do zařízení 4. spuštění kernelu 5. překopírování výsledků ze zařízení 6. uvolnění alokovaných prostředků (objektů)
117 Příkazová fronta (Command-Queue) Objekt, kam jsou uloženy OpenCL příkazy. Více těchto front umožnuje zařízení provádět (paralelně) více příkazů bez potřeby synchronizace. Typy příkazů: spuštění kernelu na výpočetních elementech zařízení datové přenosy z/do paměťových objektů a přenosy mezi paměťovými objekty, mapovaní paměťových objektů do paměti hosta synchronizační příkazy Příkazy ve frontách se mohou provádět dvěma způsoby: In-order Execution sériové provádění příkazů ve frontě (předchozí příkaz musí být dokončen než je spuštěn další) Out-of-order Execution nečeká se na dokončení předchozích příkazů, ale obvykle vyžaduje synchronizační příkazy (bariera, události)
118 Kód kernelu kernel void vector_add_gpu ( global const float* src_a, global const float* src_b, Vstupní parametry global float* res, const int num) { Číslo work-item const int idx = get_global_id(0); if (idx < num) res[idx] = src_a[idx] + src_b[idx]; } Návratový typ kernelu je vždy void. Všechny kernely musí být v souborech ".cl" files, které obsahují jen OpenCL kód.
119 Fáze 1) cl_int error = 0; cl_platform_id platform; error = oclgetplatformid(&platform); if (error!= CL_SUCCESS) { cout << "Error getting platform id: " << errormessage(error) << endl; exit(error); } Zjistí identifikátory dostupných platforem Informace o konkrétní platformě (jméno, podporovaná verze OpenCL, výrobce, podporované extenze) mohou být zjištěny pomocí příkazu clgetplatforminfo( )
120 Fáze 2) cl_device_id device; error = clgetdeviceids(platform, CL_DEVICE_TYPE_GPU, 1, &device, NULL); if (err!= CL_SUCCESS) { cout << "Error getting device ids: " << errormessage(error) << endl; exit(error); } Typ zřízení může být CL_DEVICE_TYPE_CPU, CL_DEVICE_TYPE_GPU, CL_DEVICE_TYPE_DEFAULT, CL_DEVICE_TYPE_ALL informace o konkrétním zařízení (typ, počet výpočetních jednotek, max.velikost pracovní skupiny, ) mohou být zjištěny pomocí příkazu clgetdeviceinfo( )
121 Fáze 3) cl_context context; context = clcreatecontext(0, 1, &device, NULL, NULL, &error); if (error!= CL_SUCCESS) { cout << "Error creating context: " << errormessage(error) << endl; exit(error); } Kontext může zahrnovat jedno nebo více zařízení
122 Fáze 4) cl_command_queue queue; queue = clcreatecommandqueue(context, device, 0, &error); if (error!= CL_SUCCESS) { cout << "Error creating command queue: " << errormessage(error) << endl; exit(error); } 3. parametr je požadované vlastnosti fronty je logický součet hodnot CL_QUEUE_OUT_OF_ORDER_EXEC_MODE_ENABLE a CL_QUEUE_PROFILING_ENABLE
123 Fáze 5) a 11) const int size = ; float* src_a_h = new float[size]; float* src_b_h = new float[size]; float* res_h = new float[size]; for (int i = 0; i < size; i++) { src_a_h = src_b_h = (float) i; } const int mem_size = sizeof(float)*size; cl_mem src_a_d = clcreatebuffer(context, CL_MEM_READ_ONLY CL_MEM_COPY_HOST_PTR, mem_size, src_a_h, &error); cl_mem src_b_d = clcreatebuffer(context, CL_MEM_READ_ONLY CL_MEM_COPY_HOST_PTR, mem_size, src_b_h, &error); cl_mem res_d = clcreatebuffer(context, CL_MEM_WRITE_ONLY, mem_size, NULL, &error);
124 Vytvoření bufferu cl_mem clcreatebuffer (cl_context context, cl_mem_flags flags, size_t size, void *host_ptr, cl_int *errcode_ret) Velikost v B V kterém kontextu vrací objekt typu cl_mem odkazující na paměť alokovanou na zařízení položka flags obsahuje bitově zapsané tyto možnosti: CL_MEM_READ_WRITE CL_MEM_WRITE_ONLY CL_MEM_READ_ONLY CL_MEM_USE_HOST_PTR CL_MEM_ALLOC_HOST_PTR CL_MEM_COPY_HOST_PTR kopíruje paměť z host_ptr
125 Fáze 6), 7), 8) // Uses NVIDIA helper functions to get the code string and it's size (in bytes) size_t src_size = 0; const char* path = shrfindfilepath("vector_add_gpu.cl", NULL); const char* source = oclloadprogsource(path, "", &src_size); cl_program program = clcreateprogramwithsource(context, 1, &source, &src_size, &error); assert(error == CL_SUCCESS); // Builds the program error = clbuildprogram(program, 1, &device, NULL, NULL, NULL); assert(error == CL_SUCCESS); kernel lze definovat v programu jako string nebo je nutno kód kernelu načíst ze souboru (buď jako zdrojový kód nebo jeho binární verzi) spustitelná verze programu je vytvořena voláním OpenCL překladače (kompilace + slinkování)
126 Fáze 9) char* build_log; size_t log_size; // First call to know the proper size clgetprogrambuildinfo(program, device, CL_PROGRAM_BUILD_LOG, 0, NULL, &log_size); build_log = new char[log_size+1]; // Second call to get the log clgetprogrambuildinfo(program, device, CL_PROGRAM_BUILD_LOG, log_size, build_log, NULL); build_log[log_size] = '\0'; cout << build_log << endl; delete[] build_log; // Extracting the kernel cl_kernel vector_add_kernel = clcreatekernel(program, "vector_add_gpu", &error); assert(error == CL_SUCCESS); spustitelná verze programu může obsahovat více kernelů, musíme pro každý kernel, který chceme spouštět, vytvořit jeden objekt kernelu (obsahuje jméno spouštěné funkce a popis jejích parametrů)
127 Fáze 10 // Enqueuing parameters // Note that we inform the size of the cl_mem object, not the size of the memory pointed by it error = clsetkernelarg(vector_add_k, 0, sizeof(cl_mem), &src_a_d); error = clsetkernelarg(vector_add_k, 1, sizeof(cl_mem), &src_b_d); error = clsetkernelarg(vector_add_k, 2, sizeof(cl_mem), &res_d); error = clsetkernelarg(vector_add_k, 3, sizeof(size_t), &size); assert(error == CL_SUCCESS); // Launching kernel před spuštěním kernelu je nutné nastavit hodnotu každého parametru
128 Fáze 12), const size_t local_ws = 512; // Number of work-items per work-group // shrroundup returns the smallest multiple of local_ws bigger than size const size_t global_ws = shrroundup(local_ws, size); // Total number of work-items error = clenqueuendrangekernel(queue, vector_add_k, 1, NULL, &global_ws, &local_ws, 0, NULL, NULL); assert(error == CL_SUCCESS); 5.parametr je celkový počet pracovních jednotek (pole obsahující počet pracovních jednotek v jednotlivých dimenzích) 6.parametr je dimenze pracovní skupiny (pole obsahující počet pracovních jednotek v jednotlivých dimenzích)
129 Fáze 13) // Reading back float* check = new float[size]; clenqueuereadbuffer(queue, res_d, CL_TRUE, 0, mem_size, check, 0, NULL, NULL); CL_TRUE = blokující synchronní čtení (čeká se na jeho dokončení)
130 Fáze 14) // Cleaning up delete[] src_a_h; delete[] src_b_h; delete[] res_h; delete[] check; clreleasekernel(vector_add_k); clreleasecommandqueue(queue); clreleasecontext(context); clreleasememobject(src_a_d); clreleasememobject(src_b_d); clreleasememobject(res_d);
131 OpenMP 4.0 Introduced in 2013, standardization was done by: AMD, Cray, Fujitsu, HP, IBM, Intel, Nvidia, etc. Similar to, but not the same as OpenACC directives. Support for more than just loops Not GPU specific suitable for Xeon Phi or DSPs, for example Fully integrated into the rest of OpenMP Supported compilers: GCC: GCC 4.9 supports OpenMP 4.0 for C/C++, GCC also for Fortran. GCC 5 adds support for Offloading LLVM 3.8 Intel C++ Composer XE
132 What is new in OpenMP 4.0 Support for accelerators (or heterogeneous devices) Thread affinity support SIMD support for vectorization Thread cancellation Fortran 2003 support Extended support for Tasking (groups, dependencies, abort) Reductions (i.e. User Defined Reductions) Atomics (sequential consistency)
133 Basic model for accelerators One host device and multiple target devices of the same type. Device = a logical execution engine device data environment = a data environment associated with a target data or target region. Keyword target constructs control how data and code is offloaded to a device. Data is mapped from a host data environment to a device data environment.
134 Targets I Code inside target region is executed on the device (default is sequential execution) Parallel execution by other OpenMP directives Clauses to control data movement. Can specify which device to use. #pragma omp target map(to:b,c), map(tofrom:sum) #pragma omp parallel for reduction(+:sum) for (int i=0;i<n;i++){sum += B[i] + C[i];} Mapping of variables TO the memory of device For the result of reduction
135 Targets II target data construct just moves data and does not execute code can have multiple target regions inside a target data region allows data to persist on device between target regions target update construct updates data during a target data region. declare target compiles a version of function/subroutine that can be called on the device.
CUDA J. Sloup a I. Šimeček
 CUDA J. Sloup a I. Šimeček xsimecek@fit.cvut.cz Katedra počítačových systémů FIT České vysoké učení technické v Praze Ivan Šimeček, 2011 MI-PAP, LS2010/11, Predn.6 Příprava studijního programu Informatika
CUDA J. Sloup a I. Šimeček xsimecek@fit.cvut.cz Katedra počítačových systémů FIT České vysoké učení technické v Praze Ivan Šimeček, 2011 MI-PAP, LS2010/11, Predn.6 Příprava studijního programu Informatika
Pokročilé architektury počítačů
 Pokročilé architektury počítačů Tutoriál 3 CUDA - GPU Martin Milata Výpočetní model CUDA Organizace kódu Sériově organizovaný kód určený pro CPU Paralelní kód prováděný na GPU Označuje se jako kernel GPU
Pokročilé architektury počítačů Tutoriál 3 CUDA - GPU Martin Milata Výpočetní model CUDA Organizace kódu Sériově organizovaný kód určený pro CPU Paralelní kód prováděný na GPU Označuje se jako kernel GPU
Úvod do GPGPU J. Sloup, I. Šimeček
 Úvod do GPGPU J. Sloup, I. Šimeček xsimecek@fit.cvut.cz Katedra počítačových systémů FIT České vysoké učení technické v Praze Ivan Šimeček, 2011 MI-PRC, LS2010/11, Predn.3 Příprava studijního programu
Úvod do GPGPU J. Sloup, I. Šimeček xsimecek@fit.cvut.cz Katedra počítačových systémů FIT České vysoké učení technické v Praze Ivan Šimeček, 2011 MI-PRC, LS2010/11, Predn.3 Příprava studijního programu
GPGPU. Jan Faigl. Gerstnerova Laboratoř pro inteligentní rozhodování a řízení České vysoké učení technické v Praze
 GPGPU Jan Faigl Gerstnerova Laboratoř pro inteligentní rozhodování a řízení České vysoké učení technické v Praze 8. cvičení katedra kybernetiky, FEL, ČVUT v Praze X33PTE - Programovací techniky GPGPU 1
GPGPU Jan Faigl Gerstnerova Laboratoř pro inteligentní rozhodování a řízení České vysoké učení technické v Praze 8. cvičení katedra kybernetiky, FEL, ČVUT v Praze X33PTE - Programovací techniky GPGPU 1
GPU A CUDA HISTORIE GPU CO JE GPGPU? NVIDIA CUDA
 GPU A CUDA HISTORIE GPU CO JE GPGPU? NVIDIA CUDA HISTORIE GPU GPU = graphics processing unit jde o akcelerátory pro algoritmy v 3D grafice a vizualizaci mnoho z nich původně vzniklo pro účely počítačových
GPU A CUDA HISTORIE GPU CO JE GPGPU? NVIDIA CUDA HISTORIE GPU GPU = graphics processing unit jde o akcelerátory pro algoritmy v 3D grafice a vizualizaci mnoho z nich původně vzniklo pro účely počítačových
Nvidia CUDA Paralelní programování na GPU
 Mendelova univerzita v Brně Provozně ekonomická fakulta Nvidia CUDA Paralelní programování na GPU 2014 O čem to bude... Trocha historie Shadery Unifikace GPGPU CUDA Využití GPGPU GPU a jeho Hardware Nvidia
Mendelova univerzita v Brně Provozně ekonomická fakulta Nvidia CUDA Paralelní programování na GPU 2014 O čem to bude... Trocha historie Shadery Unifikace GPGPU CUDA Využití GPGPU GPU a jeho Hardware Nvidia
Nvidia CUDA Paralelní programování na GPU
 Mendelova univerzita v Brně Provozně ekonomická fakulta Nvidia CUDA Paralelní programování na GPU 2017 O čem to bude... Trocha historie Shadery Unifikace GPGPU CUDA Využití GPGPU GPU a jeho Hardware Nvidia
Mendelova univerzita v Brně Provozně ekonomická fakulta Nvidia CUDA Paralelní programování na GPU 2017 O čem to bude... Trocha historie Shadery Unifikace GPGPU CUDA Využití GPGPU GPU a jeho Hardware Nvidia
GPU a CUDA. Historie GPU. Co je GPGPU? Nvidia CUDA
 GPU a CUDA Historie GPU Co je GPGPU? Nvidia CUDA Historie GPU GPU = graphics processing unit jde o akcelerátory pro algoritmy v 3D grafice a vizualizaci mnoho z nich původně vzniklo pro účely počítačových
GPU a CUDA Historie GPU Co je GPGPU? Nvidia CUDA Historie GPU GPU = graphics processing unit jde o akcelerátory pro algoritmy v 3D grafice a vizualizaci mnoho z nich původně vzniklo pro účely počítačových
Pokročilé architektury počítačů
 Pokročilé architektury počítačů Přednáška 7 CUDA První paralelní aplikace Martin Milata Obsah SIMD versus SIMT Omezení a HW implementace Způsob zpracování warp skupiny vláken CUDA - pohled programátora
Pokročilé architektury počítačů Přednáška 7 CUDA První paralelní aplikace Martin Milata Obsah SIMD versus SIMT Omezení a HW implementace Způsob zpracování warp skupiny vláken CUDA - pohled programátora
GPU Computing.
 GPU Computing Motivace Procesory (CPU, Central Processing Units) jsou rychlé, paměť nestačí poskytovat data. Běžným lékem na latenční dobu (memory latency) paměti bývá užívání rychlých (ale malých) cache
GPU Computing Motivace Procesory (CPU, Central Processing Units) jsou rychlé, paměť nestačí poskytovat data. Běžným lékem na latenční dobu (memory latency) paměti bývá užívání rychlých (ale malých) cache
Pokročilé architektury počítačů
 Pokročilé architektury počítačů Přednáška 5 GPU - CUDA Martin Milata Obsah Obecné výpočty a GPU Grafické procesory NVIDIA Tesla Výpočetní model Paměťový model GT200 Zpracování instrukcí Vydávání instrukcí
Pokročilé architektury počítačů Přednáška 5 GPU - CUDA Martin Milata Obsah Obecné výpočty a GPU Grafické procesory NVIDIA Tesla Výpočetní model Paměťový model GT200 Zpracování instrukcí Vydávání instrukcí
GPU a CUDA. Historie GPU. Co je GPGPU? Nvidia CUDA
 GPU a CUDA Historie GPU Co je GPGPU? Nvidia CUDA Historie GPU GPU = graphics processing unit jde o akcelerátory pro algoritmy v 3D grafice a vizualizaci mnoho z nich původně vzniklo pro účely počítačových
GPU a CUDA Historie GPU Co je GPGPU? Nvidia CUDA Historie GPU GPU = graphics processing unit jde o akcelerátory pro algoritmy v 3D grafice a vizualizaci mnoho z nich původně vzniklo pro účely počítačových
Obecné výpočty na GPU v jazyce CUDA. Jiří Filipovič
 Obecné výpočty na GPU v jazyce CUDA Jiří Filipovič Obsah přednášky motivace architektura GPU CUDA programovací model jaké algoritmy urychlovat na GPU? optimalizace Motivace Moorův zákon stále platí pro
Obecné výpočty na GPU v jazyce CUDA Jiří Filipovič Obsah přednášky motivace architektura GPU CUDA programovací model jaké algoritmy urychlovat na GPU? optimalizace Motivace Moorův zákon stále platí pro
Řešíme úlohu zpracování velkého množství dat. Data jsou symetrická, úloha je dobře paralelizovatelná
 GPGPU Motivace Řešíme úlohu zpracování velkého množství dat Data jsou symetrická, úloha je dobře paralelizovatelná Propaganda výrobců grafických karet: Vezměte váš C-čkový kód, zkompilujte a pusťte jej
GPGPU Motivace Řešíme úlohu zpracování velkého množství dat Data jsou symetrická, úloha je dobře paralelizovatelná Propaganda výrobců grafických karet: Vezměte váš C-čkový kód, zkompilujte a pusťte jej
Řešíme úlohu zpracování velkého množství dat. Data jsou symetrická, úloha je dobře paralelizovatelná. Propaganda výrobců grafických karet:
 GPGPU Motivace Řešíme úlohu zpracování velkého množství dat Data jsou symetrická, úloha je dobře paralelizovatelná Propaganda výrobců grafických karet: Vezměte váš C-čkový kód, zkompilujte a pusťte jej
GPGPU Motivace Řešíme úlohu zpracování velkého množství dat Data jsou symetrická, úloha je dobře paralelizovatelná Propaganda výrobců grafických karet: Vezměte váš C-čkový kód, zkompilujte a pusťte jej
Procesy a vlákna (Processes and Threads)
") ÚVOD DO OPERAČNÍCH SYSTÉMŮ Ver.1.00 Procesy a vlákna (Processes and Threads) Správa procesů a vláken České vysoké učení technické Fakulta elektrotechnická 2012 Použitá literatura [1] Stallings, W.: Operating
ÚVOD DO OPERAČNÍCH SYSTÉMŮ Ver.1.00 Procesy a vlákna (Processes and Threads) Správa procesů a vláken České vysoké učení technické Fakulta elektrotechnická 2012 Použitá literatura [1] Stallings, W.: Operating
Architektury VLIW M. Skrbek a I. Šimeček
 Architektury VLIW M. Skrbek a I. Šimeček xsimecek@fit.cvut.cz Katedra počítačových systémů FIT České vysoké učení technické v Praze Ivan Šimeček, 2011 MI-PAP, LS2010/11, Predn.3 Příprava studijního programu
Architektury VLIW M. Skrbek a I. Šimeček xsimecek@fit.cvut.cz Katedra počítačových systémů FIT České vysoké učení technické v Praze Ivan Šimeček, 2011 MI-PAP, LS2010/11, Predn.3 Příprava studijního programu
Jiné výpočetní platformy J. Sloup, M. Skrbek, I. Šimeček
 Jiné výpočetní platformy J. Sloup, M. Skrbek, I. Šimeček xsimecek@fit.cvut.cz Katedra počítačových systémů FIT České vysoké učení technické v Praze Ivan Šimeček, 2011 BI-EIA, ZS2011/12, Predn.12 Příprava
Jiné výpočetní platformy J. Sloup, M. Skrbek, I. Šimeček xsimecek@fit.cvut.cz Katedra počítačových systémů FIT České vysoké učení technické v Praze Ivan Šimeček, 2011 BI-EIA, ZS2011/12, Predn.12 Příprava
Představení a vývoj architektur vektorových procesorů
 Představení a vývoj architektur vektorových procesorů Drong Lukáš Dro098 1 Obsah Úvod 3 Historie, současnost 3 Architektura 4 - pipelining 4 - Operace scatter a gather 4 - vektorové registry 4 - Řetězení
Představení a vývoj architektur vektorových procesorů Drong Lukáš Dro098 1 Obsah Úvod 3 Historie, současnost 3 Architektura 4 - pipelining 4 - Operace scatter a gather 4 - vektorové registry 4 - Řetězení
REALIZACE SUPERPOČÍTAČE POMOCÍ GRAFICKÉ KARTY
 VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ BRNO UNIVERSITY OF TECHNOLOGY FAKULTA ELEKTROTECHNIKY A KOMUNIKAČNÍCH TECHNOLOGIÍ ÚSTAV TELEKOMUNIKACÍ FACULTY OF ELECTRICAL ENGINEERING AND COMMUNICATION DEPARTMENT OF TELECOMMUNICATIONS
VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ BRNO UNIVERSITY OF TECHNOLOGY FAKULTA ELEKTROTECHNIKY A KOMUNIKAČNÍCH TECHNOLOGIÍ ÚSTAV TELEKOMUNIKACÍ FACULTY OF ELECTRICAL ENGINEERING AND COMMUNICATION DEPARTMENT OF TELECOMMUNICATIONS
OPS Paralelní systémy, seznam pojmů, klasifikace
 Moorův zákon (polovina 60. let) : Výpočetní výkon a počet tranzistorů na jeden CPU chip integrovaného obvodu mikroprocesoru se každý jeden až dva roky zdvojnásobí; cena se zmenší na polovinu. Paralelismus
Moorův zákon (polovina 60. let) : Výpočetní výkon a počet tranzistorů na jeden CPU chip integrovaného obvodu mikroprocesoru se každý jeden až dva roky zdvojnásobí; cena se zmenší na polovinu. Paralelismus
Management procesu I Mgr. Josef Horálek
 Management procesu I Mgr. Josef Horálek Procesy = Starší počítače umožňovaly spouštět pouze jeden program. Tento program plně využíval OS i všechny systémové zdroje. Současné počítače umožňují běh více
Management procesu I Mgr. Josef Horálek Procesy = Starší počítače umožňovaly spouštět pouze jeden program. Tento program plně využíval OS i všechny systémové zdroje. Současné počítače umožňují běh více
Operační systémy. Jednoduché stránkování. Virtuální paměť. Příklad: jednoduché stránkování. Virtuální paměť se stránkování. Memory Management Unit
 Jednoduché stránkování Operační systémy Přednáška 8: Správa paměti II Hlavní paměť rozdělená na malé úseky stejné velikosti (např. 4kB) nazývané rámce (frames). Program rozdělen na malé úseky stejné velikosti
Jednoduché stránkování Operační systémy Přednáška 8: Správa paměti II Hlavní paměť rozdělená na malé úseky stejné velikosti (např. 4kB) nazývané rámce (frames). Program rozdělen na malé úseky stejné velikosti
Vláknové programování část I
 Vláknové programování část I Lukáš Hejmánek, Petr Holub {xhejtman,hopet}@ics.muni.cz Laboratoř pokročilých síťových technologií PV192 2015 04 07 1/27 Vláknové programování v C/C++ 1. Procesy, vlákna, přepínání
Vláknové programování část I Lukáš Hejmánek, Petr Holub {xhejtman,hopet}@ics.muni.cz Laboratoř pokročilých síťových technologií PV192 2015 04 07 1/27 Vláknové programování v C/C++ 1. Procesy, vlákna, přepínání
GPGPU Aplikace GPGPU. Obecné výpočty na grafických procesorech. Jan Vacata
 Obecné výpočty na grafických procesorech Motivace Úvod Motivace Technologie 3 GHz Intel Core 2 Extreme QX9650 Výkon: 96 GFLOPS Propustnost paměti: 21 GB/s Orientační cena: 1300 USD NVIDIA GeForce 9800
Obecné výpočty na grafických procesorech Motivace Úvod Motivace Technologie 3 GHz Intel Core 2 Extreme QX9650 Výkon: 96 GFLOPS Propustnost paměti: 21 GB/s Orientační cena: 1300 USD NVIDIA GeForce 9800
Přednáška. Správa paměti II. Katedra počítačových systémů FIT, České vysoké učení technické v Praze Jan Trdlička, 2012
 Přednáška Správa paměti II. Katedra počítačových systémů FIT, České vysoké učení technické v Praze Jan Trdlička, 2012 Příprava studijního programu Informatika je podporována projektem financovaným z Evropského
Přednáška Správa paměti II. Katedra počítačových systémů FIT, České vysoké učení technické v Praze Jan Trdlička, 2012 Příprava studijního programu Informatika je podporována projektem financovaným z Evropského
Procesor Intel Pentium (1) Procesor Intel Pentium (3) Procesor Intel Pentium Pro (1) Procesor Intel Pentium (2)
 Procesor Intel Pentium (3) Procesor Intel Pentium Pro (1) Procesor Intel Pentium (2)") Procesor Intel Pentium (1) 32-bitová vnitřní architektura s 64-bitovou datovou sběrnicí Superskalární procesor: obsahuje více než jednu (dvě) frontu pro zřetězené zpracování instrukcí (značeny u, v) poskytuje
Procesor Intel Pentium (1) 32-bitová vnitřní architektura s 64-bitovou datovou sběrnicí Superskalární procesor: obsahuje více než jednu (dvě) frontu pro zřetězené zpracování instrukcí (značeny u, v) poskytuje
Paralelní a distribuované výpočty (B4B36PDV)
") Paralelní a distribuované výpočty (B4B36PDV) Branislav Bošanský, Michal Jakob bosansky@fel.cvut.cz Artificial Intelligence Center Department of Computer Science Faculty of Electrical Engineering Czech
Paralelní a distribuované výpočty (B4B36PDV) Branislav Bošanský, Michal Jakob bosansky@fel.cvut.cz Artificial Intelligence Center Department of Computer Science Faculty of Electrical Engineering Czech
Paralelní programování
 Paralelní programování přednášky Jan Outrata únor květen 2011 Jan Outrata (KI UP) Paralelní programování únor květen 2011 1 / 15 Simulátor konkurence abstrakce = libovolné proložení atom. akcí sekvenčních
Paralelní programování přednášky Jan Outrata únor květen 2011 Jan Outrata (KI UP) Paralelní programování únor květen 2011 1 / 15 Simulátor konkurence abstrakce = libovolné proložení atom. akcí sekvenčních
IUJCE 07/08 Přednáška č. 6
 Správa paměti Motivace a úvod v C (skoro vždy) ručně statické proměnné o datový typ, počet znám v době překladu o zabírají paměť po celou dobu běhu programu problém velikosti definovaných proměnných jak
Správa paměti Motivace a úvod v C (skoro vždy) ručně statické proměnné o datový typ, počet znám v době překladu o zabírají paměť po celou dobu běhu programu problém velikosti definovaných proměnných jak
Co je grafický akcelerátor
 Co je grafický akcelerátor jednotka v osobním počítači či herní konzoli přebírá funkce hlavního procesoru pro grafické operace graphics renderer odlehčuje hlavnímu procesoru paralelní zpracování vybaven
Co je grafický akcelerátor jednotka v osobním počítači či herní konzoli přebírá funkce hlavního procesoru pro grafické operace graphics renderer odlehčuje hlavnímu procesoru paralelní zpracování vybaven
VYUŽITÍ GRAFICKÉHO ADAPTÉRU PRO OBECNÉ VÝPOČTY GENERAL-PURPOSE COMPUTATION USING GRAPHICS CARD
 VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ BRNO UNIVERSITY OF TECHNOLOGY FAKULTA INFORMAČNÍCH TECHNOLOGIÍ ÚSTAV POČÍTAČOVÝCH SYSTÉMŮ FACULTY OF INFORMATION TECHNOLOGY DEPARTMENT OF COMPUTER SYSTEMS VYUŽITÍ GRAFICKÉHO
VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ BRNO UNIVERSITY OF TECHNOLOGY FAKULTA INFORMAČNÍCH TECHNOLOGIÍ ÚSTAV POČÍTAČOVÝCH SYSTÉMŮ FACULTY OF INFORMATION TECHNOLOGY DEPARTMENT OF COMPUTER SYSTEMS VYUŽITÍ GRAFICKÉHO
8 Třídy, objekty, metody, předávání argumentů metod
 8 Třídy, objekty, metody, předávání argumentů metod Studijní cíl Tento studijní blok má za cíl pokračovat v základních prvcích jazyka Java. Konkrétně bude věnována pozornost třídám a objektům, instančním
8 Třídy, objekty, metody, předávání argumentů metod Studijní cíl Tento studijní blok má za cíl pokračovat v základních prvcích jazyka Java. Konkrétně bude věnována pozornost třídám a objektům, instančním
Obsah. Předmluva 13 Zpětná vazba od čtenářů 14 Zdrojové kódy ke knize 15 Errata 15
 Předmluva 13 Zpětná vazba od čtenářů 14 Zdrojové kódy ke knize 15 Errata 15 KAPITOLA 1 Úvod do programo vání v jazyce C++ 17 Základní pojmy 17 Proměnné a konstanty 18 Typy příkazů 18 IDE integrované vývojové
Předmluva 13 Zpětná vazba od čtenářů 14 Zdrojové kódy ke knize 15 Errata 15 KAPITOLA 1 Úvod do programo vání v jazyce C++ 17 Základní pojmy 17 Proměnné a konstanty 18 Typy příkazů 18 IDE integrované vývojové
Intel 80486 (2) Intel 80486 (1) Intel 80486 (3) Intel 80486 (4) Intel 80486 (6) Intel 80486 (5) Nezřetězené zpracování instrukcí:
 Intel 80486 (1) Intel 80486 (3) Intel 80486 (4) Intel 80486 (6) Intel 80486 (5) Nezřetězené zpracování instrukcí:") Intel 80486 (1) Vyroben v roce 1989 Prodáván pod oficiálním názvem 80486DX Plně 32bitový procesor Na svém čipu má integrován: - zmodernizovaný procesor 80386 - numerický koprocesor 80387 - L1 (interní)
Intel 80486 (1) Vyroben v roce 1989 Prodáván pod oficiálním názvem 80486DX Plně 32bitový procesor Na svém čipu má integrován: - zmodernizovaný procesor 80386 - numerický koprocesor 80387 - L1 (interní)
Optimalizace pro GPU hardware
 Optimalizace pro GPU hardware Jiří Filipovič jaro 2015 Jiří Filipovič Optimalizace pro GPU hardware 1 / 52 Paralelismus GPU Paralelní algoritmy je nutno navrhovat vzhledem k paralelismu, který poskytuje
Optimalizace pro GPU hardware Jiří Filipovič jaro 2015 Jiří Filipovič Optimalizace pro GPU hardware 1 / 52 Paralelismus GPU Paralelní algoritmy je nutno navrhovat vzhledem k paralelismu, který poskytuje
PŘEDSTAVENÍ GRAFICKÉHO PROCESORU NVIDIA G200
 PŘEDSTAVENÍ GRAFICKÉHO PROCESORU NVIDIA G200 Bc.Adam Berger Ber 208 Historie a předchůdci G200 V červnu roku 2008 spatřila světlo světa nová grafická karta od společnosti Nvidia. Tato grafická karta opět
PŘEDSTAVENÍ GRAFICKÉHO PROCESORU NVIDIA G200 Bc.Adam Berger Ber 208 Historie a předchůdci G200 V červnu roku 2008 spatřila světlo světa nová grafická karta od společnosti Nvidia. Tato grafická karta opět
Vícevláknové programování na CPU: POSIX vlákna a OpenMP I. Šimeček
 Vícevláknové programování na CPU: POSIX vlákna a OpenMP I. Šimeček xsimecek@fit.cvut.cz Katedra počítačových systémů FIT České vysoké učení technické v Praze Ivan Šimeček, 2011 MI-PRC, LS2010/11, Predn.2
Vícevláknové programování na CPU: POSIX vlákna a OpenMP I. Šimeček xsimecek@fit.cvut.cz Katedra počítačových systémů FIT České vysoké učení technické v Praze Ivan Šimeček, 2011 MI-PRC, LS2010/11, Predn.2
Paralelní programování
 Paralelní programování přednáška 5 Michal Krupka 15. března 2011 Michal Krupka (KI UP) Paralelní programování 15. března 2011 1 / 13 Ještě ke kritickým sekcím Použití v praxi obvykle pomocí zámků (locks)
Paralelní programování přednáška 5 Michal Krupka 15. března 2011 Michal Krupka (KI UP) Paralelní programování 15. března 2011 1 / 13 Ještě ke kritickým sekcím Použití v praxi obvykle pomocí zámků (locks)
Část 2 POROVNÁNÍ VÝKONNOSTI A POUŽITELNOSTI ARCHITEKTUR V TYPICKÝCH APLIKACÍCH
 Část 2 POROVNÁNÍ VÝKONNOSTI A POUŽITELNOSTI ARCHITEKTUR V TYPICKÝCH APLIKACÍCH Paralelizace kódu Rozdíl v přístupu k paralelizaci kódu si ukážeme na operaci násobení matice maticí: Mějme tři čtvercové
Část 2 POROVNÁNÍ VÝKONNOSTI A POUŽITELNOSTI ARCHITEKTUR V TYPICKÝCH APLIKACÍCH Paralelizace kódu Rozdíl v přístupu k paralelizaci kódu si ukážeme na operaci násobení matice maticí: Mějme tři čtvercové
Jan Nekvapil ČESKÉ VYSOKÉ UČENÍ TECHNICKÉ V PRAZE Fakulta elektrotechnická
 Jan Nekvapil jan.nekvapil@tiscali.cz ČESKÉ VYSOKÉ UČENÍ TECHNICKÉ V PRAZE Fakulta elektrotechnická Motivace MMX, EMMX, MMX+ 3DNow!, 3DNow!+ SSE SSE2 SSE3 SSSE3 SSE4.2 Závěr 2 Efektivní práce s vektory
Jan Nekvapil jan.nekvapil@tiscali.cz ČESKÉ VYSOKÉ UČENÍ TECHNICKÉ V PRAZE Fakulta elektrotechnická Motivace MMX, EMMX, MMX+ 3DNow!, 3DNow!+ SSE SSE2 SSE3 SSSE3 SSE4.2 Závěr 2 Efektivní práce s vektory
Charakteristika dalších verzí procesorů v PC
 Charakteristika dalších verzí procesorů v PC 1 Cíl přednášky Poukázat na principy tvorby architektur nových verzí personálních počítačů. Prezentovat aktuální pojmy. 2 Úvod Zvyšování výkonu cestou paralelizace
Charakteristika dalších verzí procesorů v PC 1 Cíl přednášky Poukázat na principy tvorby architektur nových verzí personálních počítačů. Prezentovat aktuální pojmy. 2 Úvod Zvyšování výkonu cestou paralelizace
Paralení programování pro vícejádrové stroje s použitím OpenMP. B4B36PDV Paralelní a distribuované výpočty
 Paralení programování pro vícejádrové stroje s použitím OpenMP B4B36PDV Paralelní a distribuované výpočty Minulé cvičení: Vlákna a jejich synchronizace v C++ 11... 1 Minulé cvičení: Vlákna a jejich synchronizace
Paralení programování pro vícejádrové stroje s použitím OpenMP B4B36PDV Paralelní a distribuované výpočty Minulé cvičení: Vlákna a jejich synchronizace v C++ 11... 1 Minulé cvičení: Vlákna a jejich synchronizace
Základní operace. Prefix sum. Segmentovaný prefix-sum
 Základní operace Paralelní redukce Paralelní redukce na architekturách se sdílenou pamětí Paralelní redukce na architekturách s distribuovanou pamětí Paralelní redukce na GPU v CUDA Prefix sum Segmentovaný
Základní operace Paralelní redukce Paralelní redukce na architekturách se sdílenou pamětí Paralelní redukce na architekturách s distribuovanou pamětí Paralelní redukce na GPU v CUDA Prefix sum Segmentovaný
14.4.2010. Obsah přednášky 7. Základy programování (IZAPR) Přednáška 7. Parametry metod. Parametry, argumenty. Parametry metod.
 Přednáška 7. Parametry metod. Parametry, argumenty. Parametry metod.") Základy programování (IZAPR) Přednáška 7 Ing. Michael Bažant, Ph.D. Katedra softwarových technologií Kancelář č. 229, Náměstí Čs. legií Michael.Bazant@upce.cz Obsah přednášky 7 Parametry metod, předávání
Základy programování (IZAPR) Přednáška 7 Ing. Michael Bažant, Ph.D. Katedra softwarových technologií Kancelář č. 229, Náměstí Čs. legií Michael.Bazant@upce.cz Obsah přednášky 7 Parametry metod, předávání
Další aspekty architektur CISC a RISC Aktuálnost obsahu registru
 Cíl přednášky: Vysvětlit principy práce s registry v architekturách RISC a CISC, upozornit na rozdíly. Vysvětlit možnosti využívání sad registrů. Zabývat se principy využívanými v procesorech Intel. Zabývat
Cíl přednášky: Vysvětlit principy práce s registry v architekturách RISC a CISC, upozornit na rozdíly. Vysvětlit možnosti využívání sad registrů. Zabývat se principy využívanými v procesorech Intel. Zabývat
Přednáška. Vstup/Výstup. Katedra počítačových systémů FIT, České vysoké učení technické v Praze Jan Trdlička, 2012
 Přednáška Vstup/Výstup. Katedra počítačových systémů FIT, České vysoké učení technické v Praze Jan Trdlička, 2012 Příprava studijního programu Informatika je podporována projektem financovaným z Evropského
Přednáška Vstup/Výstup. Katedra počítačových systémů FIT, České vysoké učení technické v Praze Jan Trdlička, 2012 Příprava studijního programu Informatika je podporována projektem financovaným z Evropského
Opakování programování
 Opakování programování HW návaznost - procesor sběrnice, instrukční sada, optimalizace rychlosti, datové typy, operace (matematické, logické, podmínky, skoky, podprogram ) - paměti a periferie - adresování
Opakování programování HW návaznost - procesor sběrnice, instrukční sada, optimalizace rychlosti, datové typy, operace (matematické, logické, podmínky, skoky, podprogram ) - paměti a periferie - adresování
Ústav technické matematiky FS ( Ústav technické matematiky FS ) / 35
 / 35") Úvod do paralelního programování 2 MPI Jakub Šístek Ústav technické matematiky FS 9.1.2007 ( Ústav technické matematiky FS ) 9.1.2007 1 / 35 Osnova 1 Opakování 2 Představení Message Passing Interface (MPI)
Úvod do paralelního programování 2 MPI Jakub Šístek Ústav technické matematiky FS 9.1.2007 ( Ústav technické matematiky FS ) 9.1.2007 1 / 35 Osnova 1 Opakování 2 Představení Message Passing Interface (MPI)
IUJCE 07/08 Přednáška č. 1
 Úvod do předmětu Literatura Záznamy přednášek a vaše poznámky Harbison, S. P., Steele, G. L.: Referenční příručka jazyka C Herout, P.: Učebnice jazyka C Kernighan, B. W., Ritchie, D. M.: The C Programming
Úvod do předmětu Literatura Záznamy přednášek a vaše poznámky Harbison, S. P., Steele, G. L.: Referenční příručka jazyka C Herout, P.: Učebnice jazyka C Kernighan, B. W., Ritchie, D. M.: The C Programming
Činnost CPU. IMTEE Přednáška č. 2. Několik úrovní abstrakce od obvodů CPU: Hodinový cyklus fáze strojový cyklus instrukční cyklus
 Činnost CPU Několik úrovní abstrakce od obvodů CPU: Hodinový cyklus fáze strojový cyklus instrukční cyklus Hodinový cyklus CPU je synchronní obvod nutné hodiny (f CLK ) Instrukční cyklus IF = doba potřebná
Činnost CPU Několik úrovní abstrakce od obvodů CPU: Hodinový cyklus fáze strojový cyklus instrukční cyklus Hodinový cyklus CPU je synchronní obvod nutné hodiny (f CLK ) Instrukční cyklus IF = doba potřebná
Matematika v programovacích
 Matematika v programovacích jazycích Pavla Kabelíková am.vsb.cz/kabelikova pavla.kabelikova@vsb.cz Úvodní diskuze Otázky: Jaké programovací jazyky znáte? S jakými programovacími jazyky jste již pracovali?
Matematika v programovacích jazycích Pavla Kabelíková am.vsb.cz/kabelikova pavla.kabelikova@vsb.cz Úvodní diskuze Otázky: Jaké programovací jazyky znáte? S jakými programovacími jazyky jste již pracovali?
Základy informatiky. 2. Přednáška HW. Lenka Carr Motyčková. February 22, 2011 Základy informatiky 2
 Základy informatiky 2. Přednáška HW Lenka Carr Motyčková February 22, 2011 Základy informatiky 1 February 22, 2011 Základy informatiky 2 February 22, 2011 Základy informatiky 3 February 22, 2011 Základy
Základy informatiky 2. Přednáška HW Lenka Carr Motyčková February 22, 2011 Základy informatiky 1 February 22, 2011 Základy informatiky 2 February 22, 2011 Základy informatiky 3 February 22, 2011 Základy
FAKULTA INFORMAČNÍCH TECHNOLOGIÍ
 VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ BRNO UNIVERSITY OF TECHNOLOGY FAKULTA INFORMAČNÍCH TECHNOLOGIÍ ÚSTAV POČÍTAČOVÝCH SYSTÉMŮ FACULTY OF INFORMATION TECHNOLOGY DEPARTMENT OF COMPUTER SYSTEMS POUŽITÍ OPENCL V
VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ BRNO UNIVERSITY OF TECHNOLOGY FAKULTA INFORMAČNÍCH TECHNOLOGIÍ ÚSTAV POČÍTAČOVÝCH SYSTÉMŮ FACULTY OF INFORMATION TECHNOLOGY DEPARTMENT OF COMPUTER SYSTEMS POUŽITÍ OPENCL V
Přehled paralelních architektur. Dělení paralelních architektur Flynnova taxonomie Komunikační modely paralelních architektur
 Přehled paralelních architektur Přehled paralelních architektur Dělení paralelních architektur Flynnova taxonomie Komunikační modely paralelních architektur Přehled I. paralelní počítače se konstruují
Přehled paralelních architektur Přehled paralelních architektur Dělení paralelních architektur Flynnova taxonomie Komunikační modely paralelních architektur Přehled I. paralelní počítače se konstruují
Obsah. Kapitola 1 Hardware, procesory a vlákna Prohlídka útrob počítače...20 Motivace pro vícejádrové procesory...21
 Stručný obsah 1. Hardware, procesory a vlákna... 19 2. Programování s ohledemna výkon... 45 3. Identifikování příležitostí pro paralelizmus... 93 4. Synchronizace a sdílení dat... 123 5. Vlákna v rozhraní
Stručný obsah 1. Hardware, procesory a vlákna... 19 2. Programování s ohledemna výkon... 45 3. Identifikování příležitostí pro paralelizmus... 93 4. Synchronizace a sdílení dat... 123 5. Vlákna v rozhraní
Úvod Seznámení s předmětem Co je.net Vlastnosti.NET Konec. Programování v C# Úvodní slovo 1 / 25
 Programování v C# Úvodní slovo 1 / 25 Obsah přednášky Seznámení s předmětem Co je.net Vlastnosti.NET 2 / 25 Kdo je kdo Petr Vaněček vanecek@pf.jcu.cz J 502 Václav Novák vacnovak@pf.jcu.cz?? Při komunikaci
Programování v C# Úvodní slovo 1 / 25 Obsah přednášky Seznámení s předmětem Co je.net Vlastnosti.NET 2 / 25 Kdo je kdo Petr Vaněček vanecek@pf.jcu.cz J 502 Václav Novák vacnovak@pf.jcu.cz?? Při komunikaci
CUDA OpenCL PhysX Literatura NPGR019. Úvod do architektury CUDA. MFF UK Praha. Jan Horáček CUDA 1 / 53
 Hardware pro počítačovou grafiku NPGR019 do architektury Jan Horáček http://cgg.mff.cuni.cz/ MFF UK Praha 2012 Jan Horáček 1 / 53 Obsah Historie Vícejádrové zpracování CPU vs GPU 1 2 3 4 5 Jan Horáček
Hardware pro počítačovou grafiku NPGR019 do architektury Jan Horáček http://cgg.mff.cuni.cz/ MFF UK Praha 2012 Jan Horáček 1 / 53 Obsah Historie Vícejádrové zpracování CPU vs GPU 1 2 3 4 5 Jan Horáček
Pohled do nitra mikroprocesoru Josef Horálek
 Pohled do nitra mikroprocesoru Josef Horálek Z čeho vycházíme = Vycházíme z Von Neumannovy architektury = Celý počítač se tak skládá z pěti koncepčních bloků: = Operační paměť = Programový řadič = Aritmeticko-logická
Pohled do nitra mikroprocesoru Josef Horálek Z čeho vycházíme = Vycházíme z Von Neumannovy architektury = Celý počítač se tak skládá z pěti koncepčních bloků: = Operační paměť = Programový řadič = Aritmeticko-logická
Real Time programování v LabView. Ing. Martin Bušek, Ph.D.
 Real Time programování v LabView Ing. Martin Bušek, Ph.D. Úvod - související komponenty LabVIEW development Konkrétní RT hardware - cíl Použití LabVIEW RT module - Pharlap ETS, RTX, VxWorks Možnost užití
Real Time programování v LabView Ing. Martin Bušek, Ph.D. Úvod - související komponenty LabVIEW development Konkrétní RT hardware - cíl Použití LabVIEW RT module - Pharlap ETS, RTX, VxWorks Možnost užití
Strojový kód k d a asembler procesoru MIPS SPIM. MIPS - prostředí NMS NMS. 32 ks 32bitových registrů ( adresa registru = 5 bitů).
.") Strojový kód k d a asembler procesoru MIPS Použit ití simulátoru SPIM K.D. - cvičení ÚPA 1 MIPS - prostředí 32 ks 32bitových registrů ( adresa registru = 5 bitů). Registr $0 je zero čte se jako 0x0, zápis
Strojový kód k d a asembler procesoru MIPS Použit ití simulátoru SPIM K.D. - cvičení ÚPA 1 MIPS - prostředí 32 ks 32bitových registrů ( adresa registru = 5 bitů). Registr $0 je zero čte se jako 0x0, zápis
Cvičení MI-PAP I. Šimeček, M. Skrbek, J. Trdlička
 Cvičení MI-PAP I. Šimeček, M. Skrbek, J. Trdlička xsimecek@fit.cvut.cz Katedra počítačových systémů FIT České vysoké učení technické v Praze Ivan Šimeček, 2011 MI-PAP, LS2010/11, Cvičení 1-6 Příprava studijního
Cvičení MI-PAP I. Šimeček, M. Skrbek, J. Trdlička xsimecek@fit.cvut.cz Katedra počítačových systémů FIT České vysoké učení technické v Praze Ivan Šimeček, 2011 MI-PAP, LS2010/11, Cvičení 1-6 Příprava studijního
Čipové karty Lekařská informatika
 Čipové karty Lekařská informatika Následující kód je jednoduchou aplikací pro čipové karty, která po překladu vytváří prostor na kartě, nad kterým jsou prováděny jednotlivé operace a do kterého jsou ukládány
Čipové karty Lekařská informatika Následující kód je jednoduchou aplikací pro čipové karty, která po překladu vytváří prostor na kartě, nad kterým jsou prováděny jednotlivé operace a do kterého jsou ukládány
Sběrnicová struktura PC Procesory PC funkce, vlastnosti Interní počítačové paměti PC
 Informační systémy 2 Obsah: Sběrnicová struktura PC Procesory PC funkce, vlastnosti Interní počítačové paměti PC ROM RAM Paměti typu CACHE IS2-4 1 Dnešní info: Informační systémy 2 03 Informační systémy
Informační systémy 2 Obsah: Sběrnicová struktura PC Procesory PC funkce, vlastnosti Interní počítačové paměti PC ROM RAM Paměti typu CACHE IS2-4 1 Dnešní info: Informační systémy 2 03 Informační systémy
Princip funkce počítače
 Princip funkce počítače Princip funkce počítače prvotní úlohou počítačů bylo zrychlit provádění matematických výpočtů první počítače kopírovaly obvyklý postup manuálního provádění výpočtů pokyny pro zpracování
Princip funkce počítače Princip funkce počítače prvotní úlohou počítačů bylo zrychlit provádění matematických výpočtů první počítače kopírovaly obvyklý postup manuálního provádění výpočtů pokyny pro zpracování
Programování výpočtů na grafických kartách
 Jihočeská univerzita v Českých Budějovicích Přírodovědecká fakulta Bakalářská práce Programování výpočtů na grafických kartách Autor: Tomáš Krejsa Vedoucí práce: RNDr. Milan Předota, Ph.D. Studijní obor:
Jihočeská univerzita v Českých Budějovicích Přírodovědecká fakulta Bakalářská práce Programování výpočtů na grafických kartách Autor: Tomáš Krejsa Vedoucí práce: RNDr. Milan Předota, Ph.D. Studijní obor:
Paralelní architektury se sdílenou pamětí typu NUMA. NUMA architektury
 Paralelní architektury se sdílenou pamětí typu NUMA NUMA architektury Multiprocesorové systémy s distribuovanou pamětí I. úzkým hrdlem multiprocesorů se sdílenou pamětí je datová komunikace s rostoucím
Paralelní architektury se sdílenou pamětí typu NUMA NUMA architektury Multiprocesorové systémy s distribuovanou pamětí I. úzkým hrdlem multiprocesorů se sdílenou pamětí je datová komunikace s rostoucím
Programování v C++ 1, 1. cvičení
 Programování v C++ 1, 1. cvičení opakování látky ze základů programování 1 1 Fakulta jaderná a fyzikálně inženýrská České vysoké učení technické v Praze Zimní semestr 2018/2019 Přehled 1 2 Shrnutí procvičených
Programování v C++ 1, 1. cvičení opakování látky ze základů programování 1 1 Fakulta jaderná a fyzikálně inženýrská České vysoké učení technické v Praze Zimní semestr 2018/2019 Přehled 1 2 Shrnutí procvičených
x86 assembler and inline assembler in GCC
 x86 assembler and inline assembler in GCC Michal Sojka sojkam1@fel.cvut.cz ČVUT, FEL License: CC-BY-SA 4.0 Useful instructions mov moves data between registers and memory mov $1,%eax # move 1 to register
x86 assembler and inline assembler in GCC Michal Sojka sojkam1@fel.cvut.cz ČVUT, FEL License: CC-BY-SA 4.0 Useful instructions mov moves data between registers and memory mov $1,%eax # move 1 to register
Sdílení dat mezi podprogramy
 Sdílení dat mezi podprogramy Datové objekty mohou být mezi podprogramy sdíleny pomocí ne-lokálních referenčních prostředí, která jsou vytvářena na základě æ explicitních modifikací (formální parametry
Sdílení dat mezi podprogramy Datové objekty mohou být mezi podprogramy sdíleny pomocí ne-lokálních referenčních prostředí, která jsou vytvářena na základě æ explicitních modifikací (formální parametry
ADT/ADS = abstraktní datové typy / struktury
 DT = datové typy obor hodnot, které může proměnná nabývat, s operacemi na tomto oboru určen: obor hodnot + výpočetní operace např. INT = { 2 147 483 648 až +2 147 483 647} + {+,,*,/,} ADT/ADS = abstraktní
DT = datové typy obor hodnot, které může proměnná nabývat, s operacemi na tomto oboru určen: obor hodnot + výpočetní operace např. INT = { 2 147 483 648 až +2 147 483 647} + {+,,*,/,} ADT/ADS = abstraktní
Paralelní výpočetní jádro matematického modelu elektrostatického zvlákňování
 Paralelní výpočetní jádro matematického modelu elektrostatického zvlákňování Milan Šimko Technická univerzita v Liberci Interní odborný seminář KO MIX 19. prosince 2011 Obsah prezentace 1 MOTIVACE 2 VLÁKNOVÝ
Paralelní výpočetní jádro matematického modelu elektrostatického zvlákňování Milan Šimko Technická univerzita v Liberci Interní odborný seminář KO MIX 19. prosince 2011 Obsah prezentace 1 MOTIVACE 2 VLÁKNOVÝ
Preprocesor. Karel Richta a kol. katedra počítačů FEL ČVUT v Praze. Karel Richta, Martin Hořeňovský, Aleš Hrabalík, 2016
 Preprocesor Karel Richta a kol. katedra počítačů FEL ČVUT v Praze Karel Richta, Martin Hořeňovský, Aleš Hrabalík, 2016 Programování v C++, A7B36PJC 4/2016, Lekce 9b https://cw.fel.cvut.cz/wiki/courses/a7b36pjc/start
Preprocesor Karel Richta a kol. katedra počítačů FEL ČVUT v Praze Karel Richta, Martin Hořeňovský, Aleš Hrabalík, 2016 Programování v C++, A7B36PJC 4/2016, Lekce 9b https://cw.fel.cvut.cz/wiki/courses/a7b36pjc/start
09. Memory management. ZOS 2006, L.Pešička
 09. Memory management ZOS 2006, L.Pešička Správa paměti paměťová pyramida absolutní adresa relativní adresa počet bytů od absolutní adresy fyzický prostor adres fyzicky k dispozici výpočetnímu systému
09. Memory management ZOS 2006, L.Pešička Správa paměti paměťová pyramida absolutní adresa relativní adresa počet bytů od absolutní adresy fyzický prostor adres fyzicky k dispozici výpočetnímu systému
ZPRO v "C" Ing. Vít Hanousek. verze 0.3
 verze 0.3 Hello World Nejjednoduší program ukazující vypsání textu. #include using namespace std; int main(void) { cout
verze 0.3 Hello World Nejjednoduší program ukazující vypsání textu. #include using namespace std; int main(void) { cout
Přednáška 1. Katedra počítačových systémů FIT, České vysoké učení technické v Praze Jan Trdlička, 2012
 Přednáška 1 Úvod do HW a OS. Katedra počítačových systémů FIT, České vysoké učení technické v Praze Jan Trdlička, 2012 Příprava studijního programu Informatika je podporována projektem financovaným z Evropského
Přednáška 1 Úvod do HW a OS. Katedra počítačových systémů FIT, České vysoké učení technické v Praze Jan Trdlička, 2012 Příprava studijního programu Informatika je podporována projektem financovaným z Evropského
Struktura programu v době běhu
 Struktura programu v době běhu Miroslav Beneš Dušan Kolář Struktura programu v době běhu Vztah mezi zdrojovým programem a činností přeloženého programu reprezentace dat správa paměti aktivace podprogramů
Struktura programu v době běhu Miroslav Beneš Dušan Kolář Struktura programu v době běhu Vztah mezi zdrojovým programem a činností přeloženého programu reprezentace dat správa paměti aktivace podprogramů
Algoritmizace a programování
 Algoritmizace a programování Řídicí struktury jazyka Java Struktura programu Příkazy jazyka Blok příkazů Logické příkazy Ternární logický operátor Verze pro akademický rok 2012/2013 1 Struktura programu
Algoritmizace a programování Řídicí struktury jazyka Java Struktura programu Příkazy jazyka Blok příkazů Logické příkazy Ternární logický operátor Verze pro akademický rok 2012/2013 1 Struktura programu
Více o konstruktorech a destruktorech
 Více o konstruktorech a destruktorech Více o konstruktorech a o přiřazení... inicializovat objekt lze i pomocí jiného objektu lze provést přiřazení mezi objekty v původním C nebylo možné provést přiřazení
Více o konstruktorech a destruktorech Více o konstruktorech a o přiřazení... inicializovat objekt lze i pomocí jiného objektu lze provést přiřazení mezi objekty v původním C nebylo možné provést přiřazení
1. lekce. do souboru main.c uložíme následující kód a pomocí F9 ho zkompilujeme a spustíme:
 1. lekce 1. Minimální program do souboru main.c uložíme následující kód a pomocí F9 ho zkompilujeme a spustíme: #include #include int main() { printf("hello world!\n"); return 0; 2.
1. lekce 1. Minimální program do souboru main.c uložíme následující kód a pomocí F9 ho zkompilujeme a spustíme: #include #include int main() { printf("hello world!\n"); return 0; 2.
11. Přehled prog. jazyků
 Jiří Vokřínek, 2016 B6B36ZAL - Přednáška 11 1 Základy algoritmizace 11. Přehled prog. jazyků doc. Ing. Jiří Vokřínek, Ph.D. Katedra počítačů Fakulta elektrotechnická České vysoké učení technické v Praze
Jiří Vokřínek, 2016 B6B36ZAL - Přednáška 11 1 Základy algoritmizace 11. Přehled prog. jazyků doc. Ing. Jiří Vokřínek, Ph.D. Katedra počítačů Fakulta elektrotechnická České vysoké učení technické v Praze
NA GPU FAKULTA INFORMAČNÍCH TECHNOLOGIÍ MICHAL KULA BRNO UNIVERSITY OF TECHNOLOGY FACULTY OF INFORMATION TECHNOLOGY DEPARTMENT OF COMPUTER SYSTEMS
 VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ BRNO UNIVERSITY OF TECHNOLOGY FAKULTA INFORMAČNÍCH TECHNOLOGIÍ ÚSTAV POČÍTAČOVÝCH SYSTÉMŮ FACULTY OF INFORMATION TECHNOLOGY DEPARTMENT OF COMPUTER SYSTEMS POROVNÁNÍ VÝKONNOSTI
VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ BRNO UNIVERSITY OF TECHNOLOGY FAKULTA INFORMAČNÍCH TECHNOLOGIÍ ÚSTAV POČÍTAČOVÝCH SYSTÉMŮ FACULTY OF INFORMATION TECHNOLOGY DEPARTMENT OF COMPUTER SYSTEMS POROVNÁNÍ VÝKONNOSTI
Operační systémy. Cvičení 4: Programování v C pod Unixem
 Operační systémy Cvičení 4: Programování v C pod Unixem 1 Obsah cvičení Řídící struktury Funkce Dynamická alokace paměti Ladění programu Kde najít další informace Poznámka: uvedené příklady jsou dostupné
Operační systémy Cvičení 4: Programování v C pod Unixem 1 Obsah cvičení Řídící struktury Funkce Dynamická alokace paměti Ladění programu Kde najít další informace Poznámka: uvedené příklady jsou dostupné
for (i = 0, j = 5; i < 10; i++) { // tělo cyklu }
 { // tělo cyklu }") 5. Operátor čárka, - slouží k jistému určení pořadí vykonání dvou příkazů - oddělím-li čárkou dva příkazy, je jisté, že ten první bude vykonán dříve než příkaz druhý. Např.: i = 5; j = 8; - po překladu
5. Operátor čárka, - slouží k jistému určení pořadí vykonání dvou příkazů - oddělím-li čárkou dva příkazy, je jisté, že ten první bude vykonán dříve než příkaz druhý. Např.: i = 5; j = 8; - po překladu
Semestrální práce z předmětu. Jan Bařtipán / A03043 bartipan@studentes.zcu.cz
 Semestrální práce z předmětu KIV/UPA Jan Bařtipán / A03043 bartipan@studentes.zcu.cz Zadání Program přečte ze vstupu dvě čísla v hexadecimálním tvaru a vypíše jejich součet (opět v hexadecimální tvaru).
Semestrální práce z předmětu KIV/UPA Jan Bařtipán / A03043 bartipan@studentes.zcu.cz Zadání Program přečte ze vstupu dvě čísla v hexadecimálním tvaru a vypíše jejich součet (opět v hexadecimální tvaru).
Zápis programu v jazyce C#
 Zápis programu v jazyce C# Základní syntaktická pravidla C# = case sensitive jazyk rozlišuje velikost písmen Tzv. bílé znaky (Enter, mezera, tab ) ve ZK překladač ignoruje každý příkaz končí ; oddělovač
Zápis programu v jazyce C# Základní syntaktická pravidla C# = case sensitive jazyk rozlišuje velikost písmen Tzv. bílé znaky (Enter, mezera, tab ) ve ZK překladač ignoruje každý příkaz končí ; oddělovač
Statické proměnné a metody. Tomáš Pitner, upravil Marek Šabo
 Statické proměnné a metody Tomáš Pitner, upravil Marek Šabo Úvod Se statickou metodou jsme se setkali už u úplně prvního programu - Hello, world! public class Demo { public static void main(string[] args)
Statické proměnné a metody Tomáš Pitner, upravil Marek Šabo Úvod Se statickou metodou jsme se setkali už u úplně prvního programu - Hello, world! public class Demo { public static void main(string[] args)
Paralelní výpočty ve finančnictví
 Paralelní výpočty ve finančnictví Jan Houška HUMUSOFT s.r.o. houska@humusoft.cz Výpočetně náročné úlohy distribuované úlohy mnoho relativně nezávislých úloh snížení zatížení klientské pracovní stanice
Paralelní výpočty ve finančnictví Jan Houška HUMUSOFT s.r.o. houska@humusoft.cz Výpočetně náročné úlohy distribuované úlohy mnoho relativně nezávislých úloh snížení zatížení klientské pracovní stanice
Operační systémy. Přednáška 7: Správa paměti I
 Operační systémy Přednáška 7: Správa paměti I 1 Správa paměti (SP) Memory Management Unit (MMU) hardware umístěný na CPU čipu např. překládá logické adresy na fyzické adresy, Memory Manager software, který
Operační systémy Přednáška 7: Správa paměti I 1 Správa paměti (SP) Memory Management Unit (MMU) hardware umístěný na CPU čipu např. překládá logické adresy na fyzické adresy, Memory Manager software, který
TG Motion verze 4 Modul Virtuální PLC návod k obsluze
 TG Motion verze 4 Modul Virtuální PLC návod k obsluze Olomoucká 1290/79-1 - Fax: +420 548 141 890 Historie revizí datum verze popis 10. 1. 2017 1.0 31. 7. 2017 1.1 upravena typografie Olomoucká 1290/79-2
TG Motion verze 4 Modul Virtuální PLC návod k obsluze Olomoucká 1290/79-1 - Fax: +420 548 141 890 Historie revizí datum verze popis 10. 1. 2017 1.0 31. 7. 2017 1.1 upravena typografie Olomoucká 1290/79-2
Operační systémy. Přednáška 4: Komunikace mezi procesy
 Operační systémy Přednáška 4: Komunikace mezi procesy 1 Časově závislé chyby Dva nebo několik procesů používá (čte/zapisuje) společné sdílené prostředky (např. sdílená paměť, sdílení proměnné, sdílené
Operační systémy Přednáška 4: Komunikace mezi procesy 1 Časově závislé chyby Dva nebo několik procesů používá (čte/zapisuje) společné sdílené prostředky (např. sdílená paměť, sdílení proměnné, sdílené
Algoritmizace a programování
 Algoritmizace a programování Struktura počítače - pokračování České vysoké učení technické Fakulta elektrotechnická Ver.1.10 J. Zděnek 2015 Systémová struktura počítače pokrač. Systém přerušení A8B14ADP
Algoritmizace a programování Struktura počítače - pokračování České vysoké učení technické Fakulta elektrotechnická Ver.1.10 J. Zděnek 2015 Systémová struktura počítače pokrač. Systém přerušení A8B14ADP
VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ BRNO UNIVERSITY OF TECHNOLOGY
 VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ BRNO UNIVERSITY OF TECHNOLOGY FAKULTA INFORMAČNÍCH TECHNOLOGIÍ ÚSTAV POČÍTAČOVÉ GRAFIKY A MULTIMÉDIÍ FACULTY OF INFORMATION TECHNOLOGY DEPARTMENT OF COMPUTER GRAPHICS AND
VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ BRNO UNIVERSITY OF TECHNOLOGY FAKULTA INFORMAČNÍCH TECHNOLOGIÍ ÚSTAV POČÍTAČOVÉ GRAFIKY A MULTIMÉDIÍ FACULTY OF INFORMATION TECHNOLOGY DEPARTMENT OF COMPUTER GRAPHICS AND
PROCESOR. Typy procesorů
 PROCESOR Procesor je ústřední výkonnou jednotkou počítače, která čte z paměti instrukce a na jejich základě vykonává program. Primárním úkolem procesoru je řídit činnost ostatních částí počítače včetně
PROCESOR Procesor je ústřední výkonnou jednotkou počítače, která čte z paměti instrukce a na jejich základě vykonává program. Primárním úkolem procesoru je řídit činnost ostatních částí počítače včetně
Vyuºití GPGPU pro zpracování dat z magnetické rezonance
 Vyuºití pro zpracování dat z magnetické rezonance Katedra matematiky, Fakulta jaderná a fyzikáln inºenýrská, ƒeské vysoké u ení technické v Praze Bakalá ská práce 2007/2008 Cíle práce Zpracování dat z
Vyuºití pro zpracování dat z magnetické rezonance Katedra matematiky, Fakulta jaderná a fyzikáln inºenýrská, ƒeské vysoké u ení technické v Praze Bakalá ská práce 2007/2008 Cíle práce Zpracování dat z
Čtvrtek 8. prosince. Pascal - opakování základů. Struktura programu:
 Čtvrtek 8 prosince Pascal - opakování základů Struktura programu: 1 hlavička obsahuje název programu, použité programové jednotky (knihovny), definice konstant, deklarace proměnných, všechny použité procedury
Čtvrtek 8 prosince Pascal - opakování základů Struktura programu: 1 hlavička obsahuje název programu, použité programové jednotky (knihovny), definice konstant, deklarace proměnných, všechny použité procedury
Úvod do OpenMP. Jiří Fürst
 Úvod do OpenMP Jiří Fürst Osnova: Úvod do paralelního programování Počítače se sdílenou pamětí Základy OpenMP Sdílené a soukromé proměnné Paralelizace cyklů Příklady Úvod do paralelního programování Počítač
Úvod do OpenMP Jiří Fürst Osnova: Úvod do paralelního programování Počítače se sdílenou pamětí Základy OpenMP Sdílené a soukromé proměnné Paralelizace cyklů Příklady Úvod do paralelního programování Počítač
1. lekce. do souboru main.c uložíme následující kód a pomocí F9 ho zkompilujeme a spustíme:
 1. lekce 1. Minimální program do souboru main.c uložíme následující kód a pomocí F9 ho zkompilujeme a spustíme: #include #include int main() { printf("hello world!\n"); return 0; 2.
1. lekce 1. Minimální program do souboru main.c uložíme následující kód a pomocí F9 ho zkompilujeme a spustíme: #include #include int main() { printf("hello world!\n"); return 0; 2.
Implementace numerických metod v jazyce C a Python
 Fakulta elektrotechnická Katedra matematiky Dokumentace k semestrální práci Implementace numerických metod v jazyce C a Python 2013/14 Michal Horáček a Petr Zemek Vyučující: Mgr. Zbyněk Vastl Předmět:
Fakulta elektrotechnická Katedra matematiky Dokumentace k semestrální práci Implementace numerických metod v jazyce C a Python 2013/14 Michal Horáček a Petr Zemek Vyučující: Mgr. Zbyněk Vastl Předmět:
Programování bez vláken. OpenMP
 Programování bez vláken Tradiční přístup je vytvoření vícevláknového programu, kde se řekne, co má které vlákno dělat Ale jde to i jinak, lze vytvořit program tak, že se řekne, co se má udělat paralelně
Programování bez vláken Tradiční přístup je vytvoření vícevláknového programu, kde se řekne, co má které vlákno dělat Ale jde to i jinak, lze vytvořit program tak, že se řekne, co se má udělat paralelně