Pravděpodobnost a matematická statistika
|
|
|
- Josef Macháček
- před 10 lety
- Počet zobrazení:
Transkript
1 Pravděpodobnost a matematická statistika Mirko Navara Centrum strojového vnímání katedra kybernetiky FEL ČVUT Karlovo náměstí, budova G, místnost 104a navara/mvt navara/psi 6. října 2010

2 1 O čem to je a o čem ne? Co mají následující výroky společného? 1. V loterii pravděpodobně nevyhraji. 2. Dálnici pravděpodobně projedu bez nehody. 3. Sněhové podmínky umožní příští mistrovství světa v lyžování. 4. Sněhové podmínky při příštím mistrovství světa v lyžování budou dobré. 5. Na 50. km dálnice pojedu rychlostí nejvýše 110 km/hod. V čem se toto výroky liší?

3 1. V loterii pravděpodobně nevyhraji.

4 1. V loterii pravděpodobně nevyhraji. Jasná pravidla. Lidé se účastní v naději, že budou jedním z miliónu. Výsledek nelze ovlivnit. 2. Dálnici pravděpodobně projedu bez nehody.

5 1. V loterii pravděpodobně nevyhraji. Jasná pravidla. Lidé se účastní v naději, že budou jedním z miliónu. Výsledek nelze ovlivnit. 2. Dálnici pravděpodobně projedu bez nehody. Nejasná pravidla. Lidé se účastní v naději, že nebudou jedním z miliónu. Výsledek lze ovlivnit. 3. Sněhové podmínky umožní příští mistrovství světa v lyžování.

6 1. V loterii pravděpodobně nevyhraji. Jasná pravidla. Lidé se účastní v naději, že budou jedním z miliónu. Výsledek nelze ovlivnit. 2. Dálnici pravděpodobně projedu bez nehody. Nejasná pravidla. Lidé se účastní v naději, že nebudou jedním z miliónu. Výsledek lze ovlivnit. 3. Sněhové podmínky umožní příští mistrovství světa v lyžování. Nejasná pravidla. Výsledek nelze ovlivnit. 4. Sněhové podmínky při příštím mistrovství světa v lyžování budou dobré.

7 1. V loterii pravděpodobně nevyhraji. Jasná pravidla. Lidé se účastní v naději, že budou jedním z miliónu. Výsledek nelze ovlivnit. 2. Dálnici pravděpodobně projedu bez nehody. Nejasná pravidla. Lidé se účastní v naději, že nebudou jedním z miliónu. Výsledek lze ovlivnit. 3. Sněhové podmínky umožní příští mistrovství světa v lyžování. Nejasná pravidla. Výsledek nelze ovlivnit. 4. Sněhové podmínky při příštím mistrovství světa v lyžování budou dobré. Nejasná pravidla i výsledek, který nelze ovlivnit. 5. Na 50. km dálnice pojedu rychlostí nejvýše 110 km/hod.

8 1. V loterii pravděpodobně nevyhraji. Jasná pravidla. Lidé se účastní v naději, že budou jedním z miliónu. Výsledek nelze ovlivnit. 2. Dálnici pravděpodobně projedu bez nehody. Nejasná pravidla. Lidé se účastní v naději, že nebudou jedním z miliónu. Výsledek lze ovlivnit. 3. Sněhové podmínky umožní příští mistrovství světa v lyžování. Nejasná pravidla. Výsledek nelze ovlivnit. 4. Sněhové podmínky při příštím mistrovství světa v lyžování budou dobré. Nejasná pravidla i výsledek, který nelze ovlivnit. 5. Na 50. km dálnice pojedu rychlostí nejvýše 110 km/hod. Jasná pravidla, výsledek lze ovlivnit, ale nelze jej teoreticky ověřit.

9 1.1 Teorie pravděpodobnosti je nástroj pro účelné rozhodování v systémech, kde budoucí pravdivost jevů závisí na okolnostech, které zcela neznáme.

10 1.1 Teorie pravděpodobnosti je nástroj pro účelné rozhodování v systémech, kde budoucí pravdivost jevů závisí na okolnostech, které zcela neznáme. Poskytuje model takových systémů a kvantifikaci výsledků.

11 1.1 Teorie pravděpodobnosti je nástroj pro účelné rozhodování v systémech, kde budoucí pravdivost jevů závisí na okolnostech, které zcela neznáme. Poskytuje model takových systémů a kvantifikaci výsledků. Pravděpodobnostní popis chování systému

12 1.1 Teorie pravděpodobnosti je nástroj pro účelné rozhodování v systémech, kde budoucí pravdivost jevů závisí na okolnostech, které zcela neznáme. Poskytuje model takových systémů a kvantifikaci výsledků. Pravděpodobnostní popis chování systému 1.2 Statistika je nástroj pro hledání a ověřování pravděpodobnostního popisu reálných systémů na základě jejich pozorování.

13 1.1 Teorie pravděpodobnosti je nástroj pro účelné rozhodování v systémech, kde budoucí pravdivost jevů závisí na okolnostech, které zcela neznáme. Poskytuje model takových systémů a kvantifikaci výsledků. Pravděpodobnostní popis chování systému 1.2 Statistika je nástroj pro hledání a ověřování pravděpodobnostního popisu reálných systémů na základě jejich pozorování. Chování systému pravděpodobnostní popis

14 1.1 Teorie pravděpodobnosti je nástroj pro účelné rozhodování v systémech, kde budoucí pravdivost jevů závisí na okolnostech, které zcela neznáme. Poskytuje model takových systémů a kvantifikaci výsledků. Pravděpodobnostní popis chování systému 1.2 Statistika je nástroj pro hledání a ověřování pravděpodobnostního popisu reálných systémů na základě jejich pozorování. Chování systému pravděpodobnostní popis Poskytuje daleko víc: nástroj pro zkoumání světa, pro hledání a ověřování závislostí, které nejsou zjevné.

15 2 Základní pojmy teorie pravděpodobnosti 2.1 Laplaceova (klasická) definice pravděpodobnosti Předpoklad: Náhodný pokus s n N různými, vzájemně se vylučujícími výsledky, které jsou stejně možné. Pravděpodobnost jevu, který nastává právě při k z těchto výsledků, je k/n.

16 2 Základní pojmy teorie pravděpodobnosti 2.1 Laplaceova (klasická) definice pravděpodobnosti Předpoklad: Náhodný pokus s n N různými, vzájemně se vylučujícími výsledky, které jsou stejně možné. Pravděpodobnost jevu, který nastává právě při k z těchto výsledků, je k/n. 1. problém: stejně možné = stejně pravděpodobné, ale co to znamená? (definice kruhem!)

17 2 Základní pojmy teorie pravděpodobnosti 2.1 Laplaceova (klasická) definice pravděpodobnosti Předpoklad: Náhodný pokus s n N různými, vzájemně se vylučujícími výsledky, které jsou stejně možné. Pravděpodobnost jevu, který nastává právě při k z těchto výsledků, je k/n. 1. problém: stejně možné = stejně pravděpodobné, ale co to znamená? (definice kruhem!) Elementární jevy jsou všechny stejně možné výsledky.

18 2 Základní pojmy teorie pravděpodobnosti 2.1 Laplaceova (klasická) definice pravděpodobnosti Předpoklad: Náhodný pokus s n N různými, vzájemně se vylučujícími výsledky, které jsou stejně možné. Pravděpodobnost jevu, který nastává právě při k z těchto výsledků, je k/n. 1. problém: stejně možné = stejně pravděpodobné, ale co to znamená? (definice kruhem!) Elementární jevy jsou všechny stejně možné výsledky. Množina všech elementárních jevů: Ω

19 2 Základní pojmy teorie pravděpodobnosti 2.1 Laplaceova (klasická) definice pravděpodobnosti Předpoklad: Náhodný pokus s n N různými, vzájemně se vylučujícími výsledky, které jsou stejně možné. Pravděpodobnost jevu, který nastává právě při k z těchto výsledků, je k/n. 1. problém: stejně možné = stejně pravděpodobné, ale co to znamená? (definice kruhem!) Elementární jevy jsou všechny stejně možné výsledky. Množina všech elementárních jevů: Ω Jev: A Ω

20 2 Základní pojmy teorie pravděpodobnosti 2.1 Laplaceova (klasická) definice pravděpodobnosti Předpoklad: Náhodný pokus s n N různými, vzájemně se vylučujícími výsledky, které jsou stejně možné. Pravděpodobnost jevu, který nastává právě při k z těchto výsledků, je k/n. 1. problém: stejně možné = stejně pravděpodobné, ale co to znamená? (definice kruhem!) Elementární jevy jsou všechny stejně možné výsledky. Množina všech elementárních jevů: Ω Jev: A Ω Úmluva. Nadále budeme jevy ztotožňovat s příslušnými množinami elementárních jevů a používat pro ně množinové operace (místo výrokových).
 Elementární jevy jsou všechny stejně možné výsledky.")
21 2.1.1 Základní pojmy Jev jistý: Ω, 1
22 2.1.1 Základní pojmy Jev jistý: Ω, 1 Jev nemožný:, 0
23 2.1.1 Základní pojmy Jev jistý: Ω, 1 Jev nemožný:, 0 Konjunkce jevů ( and ): A B
24 2.1.1 Základní pojmy Jev jistý: Ω, 1 Jev nemožný:, 0 Konjunkce jevů ( and ): A B Disjunkce jevů ( or ): A B
25 2.1.1 Základní pojmy Jev jistý: Ω, 1 Jev nemožný:, 0 Konjunkce jevů ( and ): A B Disjunkce jevů ( or ): A B Jev opačný k A: A = Ω \ A
26 2.1.1 Základní pojmy Jev jistý: Ω, 1 Jev nemožný:, 0 Konjunkce jevů ( and ): A B Disjunkce jevů ( or ): A B Jev opačný k A: A = Ω \ A A B: A B
27 2.1.1 Základní pojmy Jev jistý: Ω, 1 Jev nemožný:, 0 Konjunkce jevů ( and ): A B Disjunkce jevů ( or ): A B Jev opačný k A: A = Ω \ A A B: A B Jevy neslučitelné (=vzájemně se vylučující): A 1,..., A n : i n A i =
28 2.1.1 Základní pojmy Jev jistý: Ω, 1 Jev nemožný:, 0 Konjunkce jevů ( and ): A B Disjunkce jevů ( or ): A B Jev opačný k A: A = Ω \ A A B: A B Jevy neslučitelné (=vzájemně se vylučující): A 1,..., A n : i n A i = Jevy po dvou neslučitelné: A 1,..., A n : i, j {1,..., n}, i j : A i A j =
29 2.1.1 Základní pojmy Jev jistý: Ω, 1 Jev nemožný:, 0 Konjunkce jevů ( and ): A B Disjunkce jevů ( or ): A B Jev opačný k A: A = Ω \ A A B: A B Jevy neslučitelné (=vzájemně se vylučující): A 1,..., A n : i n A i = Jevy po dvou neslučitelné: A 1,..., A n : i, j {1,..., n}, i j : A i A j = Jevové pole: všechny jevy pozorovatelné v náhodném pokusu, zde exp Ω (=množina všech podmnožin množiny Ω)
30 2.1.2 Pravděpodobnost jevu A: kde. značí počet prvků množiny P (A) = A Ω,
31 2.1.3 Náhodná veličina je libovolná funkce X : Ω R
32 2.1.3 Náhodná veličina je libovolná funkce X : Ω R Střední hodnota: kde n = Ω. EX = 1 n ω Ω X (ω),
33 2.1.3 Náhodná veličina je libovolná funkce X : Ω R Střední hodnota: kde n = Ω. EX = 1 n ω Ω X (ω), Interpretace: Je-li hodnota náhodné veličiny hodnotou výhry ve hře, pak střední hodnota je spravedlivá cena za účast ve hře.
34 2.2 Vlastnosti pravděpodobnosti P (A) 0, 1
35 2.2 Vlastnosti pravděpodobnosti P (A) 0, 1 P (0) = 0, P (1) = 1
36 2.2 Vlastnosti pravděpodobnosti P (A) 0, 1 P (0) = 0, P (1) = 1 P (A) = 1 P (A)
37 2.2 Vlastnosti pravděpodobnosti P (A) 0, 1 P (0) = 0, P (1) = 1 P (A) = 1 P (A) A B P (A) P (B)
38 2.2 Vlastnosti pravděpodobnosti P (A) 0, 1 P (0) = 0, P (1) = 1 P (A) = 1 P (A) A B P (A) P (B) A B P (B \ A) = P (B) P (A)
39 2.2 Vlastnosti pravděpodobnosti P (A) 0, 1 P (0) = 0, P (1) = 1 P (A) = 1 P (A) A B P (A) P (B) A B P (B \ A) = P (B) P (A) A B = P (A B) = P (A) + P (B) (aditivita)
40 2.2 Vlastnosti pravděpodobnosti P (A) 0, 1 P (0) = 0, P (1) = 1 P (A) = 1 P (A) A B P (A) P (B) A B P (B \ A) = P (B) P (A) A B = P (A B) = P (A) + P (B) (aditivita) P (A B) = P (A) + P (B) P (A B)
41 2.2.1 Úplný systém jevů tvoří jevy B i, i I, jestliže jsou po dvou neslučitelné a i I B i = 1.
42 2.2.1 Úplný systém jevů tvoří jevy B i, i I, jestliže jsou po dvou neslučitelné a i I B i = 1. Speciální případ pro 2 jevy: {C, C}
43 2.2.1 Úplný systém jevů tvoří jevy B i, i I, jestliže jsou po dvou neslučitelné a i I B i = 1. Speciální případ pro 2 jevy: {C, C} Je-li {B 1,..., B n } úplný systém jevů, pak n i=1 P (B i ) = 1 a pro libovolný jev A Speciálně: P (A) = n i=1 P (A B i ). P (A) = P (A C) + P ( A C ).
44 2.3 Problémy Laplaceovy definice pravděpodobnosti
45 2.3 Problémy Laplaceovy definice pravděpodobnosti 2. problém: Nedovoluje nekonečné množiny jevů, geometrickou pravděpodobnost...
46 2.3 Problémy Laplaceovy definice pravděpodobnosti 2. problém: Nedovoluje nekonečné množiny jevů, geometrickou pravděpodobnost... Příklad: Podíl plochy pevniny k povrchu Země je pravděpodobnost, že náhodně vybraný bod na Zemi leží na pevnině (je-li výběr bodů prováděn rovnoměrně ).
47 2.3 Problémy Laplaceovy definice pravděpodobnosti 2. problém: Nedovoluje nekonečné množiny jevů, geometrickou pravděpodobnost... Příklad: Podíl plochy pevniny k povrchu Země je pravděpodobnost, že náhodně vybraný bod na Zemi leží na pevnině (je-li výběr bodů prováděn rovnoměrně ). Příklad: Na linkovaný papír hodíme jehlu, jejíž délka je rovna vzdálenosti mezi linkami. Jaká je pravděpodobnost, že jehla protne nějakou linku?
48 2.3 Problémy Laplaceovy definice pravděpodobnosti 2. problém: Nedovoluje nekonečné množiny jevů, geometrickou pravděpodobnost... Příklad: Podíl plochy pevniny k povrchu Země je pravděpodobnost, že náhodně vybraný bod na Zemi leží na pevnině (je-li výběr bodů prováděn rovnoměrně ). Příklad: Na linkovaný papír hodíme jehlu, jejíž délka je rovna vzdálenosti mezi linkami. Jaká je pravděpodobnost, že jehla protne nějakou linku? 3. problém: Nedovoluje iracionální hodnoty pravděpodobnosti.
49 2.3.1 Rozšíření Laplaceova modelu pravděpodobnosti Příklad: Místo hrací kostky házíme krabičkou od zápalek, jejíž strany jsou nestejně dlouhé. Jaká je pravděpodobnost možných výsledků?
50 2.3.1 Rozšíření Laplaceova modelu pravděpodobnosti Příklad: Místo hrací kostky házíme krabičkou od zápalek, jejíž strany jsou nestejně dlouhé. Jaká je pravděpodobnost možných výsledků? Připustíme, že elementární jevy nemusí být stejně pravděpodobné.
51 2.3.1 Rozšíření Laplaceova modelu pravděpodobnosti Příklad: Místo hrací kostky házíme krabičkou od zápalek, jejíž strany jsou nestejně dlouhé. Jaká je pravděpodobnost možných výsledků? Připustíme, že elementární jevy nemusí být stejně pravděpodobné. Ztrácíme návod, jak pravděpodobnost stanovit. Je to funkce, která jevům přiřazuje čísla z intervalu 0, 1 a splňuje jisté podmínky. Nemáme návod, jak z nich vybrat tu pravou.
52 2.3.1 Rozšíření Laplaceova modelu pravděpodobnosti Příklad: Místo hrací kostky házíme krabičkou od zápalek, jejíž strany jsou nestejně dlouhé. Jaká je pravděpodobnost možných výsledků? Připustíme, že elementární jevy nemusí být stejně pravděpodobné. Ztrácíme návod, jak pravděpodobnost stanovit. Je to funkce, která jevům přiřazuje čísla z intervalu 0, 1 a splňuje jisté podmínky. Nemáme návod, jak z nich vybrat tu pravou. Tato nevýhoda je neodstranitelná a je důvodem pro vznik statistiky, která k danému opakovatelnému pokusu hledá pravděpodobnostní model.
53 2.4 Kombinatorické pojmy a vzorce (Dle [Zvára, Štěpán].) V urně je n rozlišitelných objektů, postupně vytáhneme k.
54 2.4 Kombinatorické pojmy a vzorce (Dle [Zvára, Štěpán].) V urně je n rozlišitelných objektů, postupně vytáhneme k. výběr s vracením bez vracení uspořádaný neuspořádaný variace s opakováním n k kombinace s opakováním ( n+k 1 k ) variace bez opakování n! (n k)! kombinace bez opakování n! k! (n k)! = ( ) n k Z této tabulky pouze kombinace s opakováním nejsou všechny stejně pravděpodobné (odpovídají různému počtu variací s opakováním) a nedovolují proto použití Laplaceova modelu pravděpodobnosti. Permutace (pořadí) bez opakování: Tvoříme posloupnost z n hodnot, přičemž každá se vyskytne právě jednou. Počet permutací je n! (je to speciální případ variací bez opakování pro n = k).
55 Permutace s opakováním: Tvoříme posloupnost délky k z n hodnot, přičemž j-tá hodnota se opakuje k j -krát, n j=1 k j = k. Počet různých posloupností je k! k 1!... k n!. Speciálně pro n = 2 dostáváme k! k 1! k 2! = k! k 1! (k k 1 )! = ( k ), k 1 což je počet kombinací bez opakování (ovšem k 1 -prvkových z k prvků).
56 Věta. Pro dané k N a pro n se poměr počtů variací (resp. kombinací) bez opakování a s opakováním bĺıží jedné, tj. lim n n! (n k)! n k = 1, lim n ( n k) ( ) n+k 1 = 1. k Důkaz. n! n (n 1) (n (k 1)) = (n k)! nk n k = ( = ) ( 1 k 1 ) 1, n n ( n k) ( ) n+k 1 = k (počet činitelů k je konstantní). n (n 1) (n (k 1)) (n + (k 1)) (n + 1) n = = 1 ( 1 n 1 ) ( ) 1 k 1 n ( ) ( ) k 1 n n 1
57 Důsledek. Pro n k je počet variací (resp. kombinací) s opakováním přibližně n! (n k)!. = n k, ( n k ).= n k k!. Jednodušší bývá neuspořádaný výběr bez vracení nebo uspořádaný výběr s vracením.
58 2.5 Kolmogorovova definice pravděpodobnosti
59 2.5 Kolmogorovova definice pravděpodobnosti Elementárních jevů (=prvků množiny Ω) může být nekonečně mnoho, nemusí být stejně pravděpodobné.
60 2.5 Kolmogorovova definice pravděpodobnosti Elementárních jevů (=prvků množiny Ω) může být nekonečně mnoho, nemusí být stejně pravděpodobné. Jevy jsou podmnožiny množiny Ω, ale ne nutně všechny; tvoří podmnožinu A exp Ω, která splňuje následující podmínky:
61 2.5 Kolmogorovova definice pravděpodobnosti Elementárních jevů (=prvků množiny Ω) může být nekonečně mnoho, nemusí být stejně pravděpodobné. Jevy jsou podmnožiny množiny Ω, ale ne nutně všechny; tvoří podmnožinu A exp Ω, která splňuje následující podmínky: (A1) A. (A2) A A A A. (A3) ( n N : A n A) n N A n A.
62 2.5 Kolmogorovova definice pravděpodobnosti Elementárních jevů (=prvků množiny Ω) může být nekonečně mnoho, nemusí být stejně pravděpodobné. Jevy jsou podmnožiny množiny Ω, ale ne nutně všechny; tvoří podmnožinu A exp Ω, která splňuje následující podmínky: (A1) A. (A2) A A A A. (A3) ( n N : A n A) n N A n A. Systém A podmnožin nějaké množiny Ω, který splňuje podmínky (A1-3), se nazývá σ-algebra.
63 Důsledky: Ω = A, ( n N : A n A) A n = A n A. n N n N
64 Důsledky: Ω = A, ( n N : A n A) A n = A n A. n N n N Přirozený nápad A = exp Ω vede k nežádoucím paradoxům.
65 Důsledky: Ω = A, ( n N : A n A) A n = A n A. n N n N Přirozený nápad A = exp Ω vede k nežádoucím paradoxům. (A1) je uzavřenost na spočetná sjednocení.
66 Důsledky: Ω = A, ( n N : A n A) A n = A n A. n N n N Přirozený nápad A = exp Ω vede k nežádoucím paradoxům. (A1) je uzavřenost na spočetná sjednocení. Uzavřenost na jakákoli sjednocení se ukazuje jako příliš silný požadavek.
67 Důsledky: Ω = A, ( n N : A n A) A n = A n A. n N n N Přirozený nápad A = exp Ω vede k nežádoucím paradoxům. (A1) je uzavřenost na spočetná sjednocení. Uzavřenost na jakákoli sjednocení se ukazuje jako příliš silný požadavek. Uzavřenost na konečná sjednocení se ukazuje jako příliš slabý požadavek; nedovoluje např. vyjádřit kruh jako sjednocení obdélníků.
68 Důsledky: Ω = A, ( n N : A n A) A n = A n A. n N n N Přirozený nápad A = exp Ω vede k nežádoucím paradoxům. (A1) je uzavřenost na spočetná sjednocení. Uzavřenost na jakákoli sjednocení se ukazuje jako příliš silný požadavek. Uzavřenost na konečná sjednocení se ukazuje jako příliš slabý požadavek; nedovoluje např. vyjádřit kruh jako sjednocení obdélníků. A nemusí ani obsahovat všechny jednobodové množiny, v tom případě elementární jevy nemusí být jevy!
69 2.5.1 Borelova σ-algebra je nejmenší σ-algebra podmnožin R, která obsahuje všechny intervaly.
70 2.5.1 Borelova σ-algebra je nejmenší σ-algebra podmnožin R, která obsahuje všechny intervaly. Obsahuje všechny intervaly otevřené, uzavřené i polouzavřené, i jejich spočetná sjednocení, a některé další množiny, ale je menší než exp R. Její prvky nazýváme borelovské množiny.
71 2.5.2 Pravděpodobnost (=pravděpodobnostní míra) je funkce P : A 0, 1, splňující podmínky (P1) P (1) = 1, (P2) P ( ) A n n N neslučitelné. = n N P (A n ), pokud jsou množiny (=jevy) A n, n N, po dvou (spočetná aditivita)
72 2.5.2 Pravděpodobnost (=pravděpodobnostní míra) je funkce P : A 0, 1, splňující podmínky (P1) P (1) = 1, (P2) P ( ) A n n N neslučitelné. = n N P (A n ), pokud jsou množiny (=jevy) A n, n N, po dvou (spočetná aditivita) Pravděpodobnostní prostor je trojice (Ω, A, P ), kde Ω je neprázdná množina, A je σ-algebra podmnožin množiny Ω a P : A 0, 1 je pravděpodobnost.
73 2.5.2 Pravděpodobnost (=pravděpodobnostní míra) je funkce P : A 0, 1, splňující podmínky (P1) P (1) = 1, (P2) P ( ) A n n N neslučitelné. = n N P (A n ), pokud jsou množiny (=jevy) A n, n N, po dvou (spočetná aditivita) Pravděpodobnostní prostor je trojice (Ω, A, P ), kde Ω je neprázdná množina, A je σ-algebra podmnožin množiny Ω a P : A 0, 1 je pravděpodobnost. Dříve uvedené vlastnosti pravděpodobnosti jsou důsledkem (P1), (P2).
74 (Konečná) aditivita by byla příliš slabá, nedovoluje např. přechod od obsahu obdélníka k obsahu kruhu.
75 (Konečná) aditivita by byla příliš slabá, nedovoluje např. přechod od obsahu obdélníka k obsahu kruhu. Úplná aditivita (pro jakékoli soubory po dvou neslučitelných jevů) by byla příliš silným požadavkem. Pak bychom nepřipouštěli ani rovnoměrné rozdělení na intervalu nebo na ploše.
76 (Konečná) aditivita by byla příliš slabá, nedovoluje např. přechod od obsahu obdélníka k obsahu kruhu. Úplná aditivita (pro jakékoli soubory po dvou neslučitelných jevů) by byla příliš silným požadavkem. Pak bychom nepřipouštěli ani rovnoměrné rozdělení na intervalu nebo na ploše. Pravděpodobnost zachovává limity monotónních posloupností jevů (množin): Necht (A n ) n N je posloupnost jevů. A 1 A 2... P A 1 A 2... P ( ( n N n N A n ) = lim n P (A n), A n ) = lim n P (A n).
77 Laplaceův model konečně mnoho jevů p-sti jen racionální P (A) = 0 A = 0 p-sti určeny strukturou jevů Kolmogorovův model i nekonečně mnoho jevů p-sti i iracionální možné jevy s nulovou p-stí p-sti neurčeny strukturou jevů
78 3 Nezávislost a podmíněná pravděpodobnost 3.1 Nezávislé jevy Motivace: Dva jevy spolu nesouvisí
79 3 Nezávislost a podmíněná pravděpodobnost 3.1 Nezávislé jevy Motivace: Dva jevy spolu nesouvisí Definice: P (A B) = P (A) P (B).
80 3 Nezávislost a podmíněná pravděpodobnost 3.1 Nezávislé jevy Motivace: Dva jevy spolu nesouvisí Definice: P (A B) = P (A) P (B). To je ovšem jen náhražka, která říká mnohem méně, než jsme chtěli! (Podobně jako P (A B) = 0 neznamená, že jevy A, B jsou neslučitelné.)
81 3 Nezávislost a podmíněná pravděpodobnost 3.1 Nezávislé jevy Motivace: Dva jevy spolu nesouvisí Definice: P (A B) = P (A) P (B). To je ovšem jen náhražka, která říká mnohem méně, než jsme chtěli! (Podobně jako P (A B) = 0 neznamená, že jevy A, B jsou neslučitelné.) Pro nezávislé jevy A, B P (A B) = P (A) + P (B) P (A) P (B).
82 3 Nezávislost a podmíněná pravděpodobnost 3.1 Nezávislé jevy Motivace: Dva jevy spolu nesouvisí Definice: P (A B) = P (A) P (B). To je ovšem jen náhražka, která říká mnohem méně, než jsme chtěli! (Podobně jako P (A B) = 0 neznamená, že jevy A, B jsou neslučitelné.) Pro nezávislé jevy A, B P (A B) = P (A) + P (B) P (A) P (B). Důkaz: P (A B) = P (A) + P (B) P (A) P (B) = P (A) + P (B) P (A) P (B).
83 Jsou-li jevy A, B nezávislé, pak jsou nezávislé také jevy A, B (a též dvojice jevů A, B a A, B).
84 Jsou-li jevy A, B nezávislé, pak jsou nezávislé také jevy A, B (a též dvojice jevů A, B a A, B). Důkaz: P (A B) = P (A) P (A B) = P (A) P (A) P (B) = = P (A) (1 P (B)) = P (A) P (B).
85 Jsou-li jevy A, B nezávislé, pak jsou nezávislé také jevy A, B (a též dvojice jevů A, B a A, B). Důkaz: P (A B) = P (A) P (A B) = P (A) P (A) P (B) = = P (A) (1 P (B)) = P (A) P (B). Jevy A 1,..., A n se nazývají po dvou nezávislé, jestliže každé dva z nich jsou nezávislé.
86 Jsou-li jevy A, B nezávislé, pak jsou nezávislé také jevy A, B (a též dvojice jevů A, B a A, B). Důkaz: P (A B) = P (A) P (A B) = P (A) P (A) P (B) = = P (A) (1 P (B)) = P (A) P (B). Jevy A 1,..., A n se nazývají po dvou nezávislé, jestliže každé dva z nich jsou nezávislé. To je málo.
87 Jsou-li jevy A, B nezávislé, pak jsou nezávislé také jevy A, B (a též dvojice jevů A, B a A, B). Důkaz: P (A B) = P (A) P (A B) = P (A) P (A) P (B) = = P (A) (1 P (B)) = P (A) P (B). Jevy A 1,..., A n se nazývají po dvou nezávislé, jestliže každé dva z nich jsou nezávislé. To je málo. Množina jevů M se nazývá nezávislá, jestliže P ( A ) = A K A K pro všechny konečné podmnožiny K M. P (A)
88 3.2 Podmíněná pravděpodobnost Příklad: Fotbalová družstva mohla mít před zápasem rovné šance na vítězství. Je-li však stav zápasu 5 minut před koncem 3 : 0, pravděpodobnosti výhry jsou jiné.
89 3.2 Podmíněná pravděpodobnost Příklad: Fotbalová družstva mohla mít před zápasem rovné šance na vítězství. Je-li však stav zápasu 5 minut před koncem 3 : 0, pravděpodobnosti výhry jsou jiné. Máme pravděpodobnostní popis systému. Dostaneme-li dodatečnou informaci, že nastal jev B, aktualizujeme naši znalost o pravděpodobnosti jevu A na P (A B) = P (A B) P (B) což je podmíněná pravděpodobnost jevu A za podmínky B. Je definována pouze pro P (B) 0. (To předpokládáme i nadále.),
90 3.2 Podmíněná pravděpodobnost Příklad: Fotbalová družstva mohla mít před zápasem rovné šance na vítězství. Je-li však stav zápasu 5 minut před koncem 3 : 0, pravděpodobnosti výhry jsou jiné. Máme pravděpodobnostní popis systému. Dostaneme-li dodatečnou informaci, že nastal jev B, aktualizujeme naši znalost o pravděpodobnosti jevu A na P (A B) = P (A B) P (B) což je podmíněná pravděpodobnost jevu A za podmínky B. Je definována pouze pro P (B) 0. (To předpokládáme i nadále.), V novém modelu je P (B B) = 0, což odráží naši znalost, že jev B nenastal.
91 3.2 Podmíněná pravděpodobnost Příklad: Fotbalová družstva mohla mít před zápasem rovné šance na vítězství. Je-li však stav zápasu 5 minut před koncem 3 : 0, pravděpodobnosti výhry jsou jiné. Máme pravděpodobnostní popis systému. Dostaneme-li dodatečnou informaci, že nastal jev B, aktualizujeme naši znalost o pravděpodobnosti jevu A na P (A B) = P (A B) P (B) což je podmíněná pravděpodobnost jevu A za podmínky B. Je definována pouze pro P (B) 0. (To předpokládáme i nadále.), V novém modelu je P (B B) = 0, což odráží naši znalost, že jev B nenastal. Podmíněná pravděpodobnost je chápána též jako funkce P (. B): A 0, 1, A a je to pravděpodobnost v původním smyslu. P (A B) P (B)
92 Vlastnosti podmíněné pravděpodobnosti: P (1 B) = 1, P (0 B) = 0. Jsou-li jevy A 1, A 2,... jsou po dvou neslučitelné, pak P ( n N A n B ) = n N P (A n B). Je-li P (A B) definována, jsou jevy A, B nezávislé, právě když P (A B) = P (A). B A P (A B) = 1, P (A B) = 0 P (A B) = 0.
93 Věta o úplné pravděpodobnosti: Necht B i, i I, je (spočetný) úplný systém jevů a i I : P (B i ) 0. Pak pro každý jev A platí P (A) = i I P (B i ) P (A B i ).
94 Věta o úplné pravděpodobnosti: Necht B i, i I, je (spočetný) úplný systém jevů a i I : P (B i ) 0. Pak pro každý jev A platí P (A) = i I P (B i ) P (A B i ). Důkaz: P (A) = P = i I (( j I ) ) B j A = P ( j I ( Bj A )) = P (B i A) = i I P (B i ) P (A B i ).
95 Věta o úplné pravděpodobnosti: Necht B i, i I, je (spočetný) úplný systém jevů a i I : P (B i ) 0. Pak pro každý jev A platí P (A) = i I P (B i ) P (A B i ). Důkaz: P (A) = P = i I (( j I ) ) B j A = P ( j I ( Bj A )) = P (B i A) = i I P (B i ) P (A B i ). Příklad: Test nemoci je u 1% zdravých falešně pozitivní a u 10% nemocných falešně negativní. Nemocných je v populaci Jaká je pravděpodobnost, že pacient s pozitivním testem je nemocný?
96 Bayesova věta: Necht B i, i I, je (spočetný) úplný systém jevů a i I : P (B i ) 0. Pak pro každý jev A splňující P (A) 0 platí P (B i A) = P (B i) P (A B i ) P (B j ) P (A B j ). j I
97 Bayesova věta: Necht B i, i I, je (spočetný) úplný systém jevů a i I : P (B i ) 0. Pak pro každý jev A splňující P (A) 0 platí P (B i A) = P (B i) P (A B i ) P (B j ) P (A B j ). j I Důkaz (s využitím věty o úplné pravděpodobnosti): P (B i A) = P (B i A) P (A) = P (B i) P (A B i ) P (B j ) P (A B j ). j I
98 Bayesova věta: Necht B i, i I, je (spočetný) úplný systém jevů a i I : P (B i ) 0. Pak pro každý jev A splňující P (A) 0 platí P (B i A) = P (B i) P (A B i ) P (B j ) P (A B j ). j I Důkaz (s využitím věty o úplné pravděpodobnosti): P (B i A) = P (B i A) P (A) = P (B i) P (A B i ) P (B j ) P (A B j ). j I Význam: Pravděpodobnosti P (A B i ) odhadneme z pokusů nebo z modelu, pomocí nich určíme pravděpodobnosti P (B i A), které slouží k optimálnímu odhadu, který z jevů B i nastal.
99 Bayesova věta: Necht B i, i I, je (spočetný) úplný systém jevů a i I : P (B i ) 0. Pak pro každý jev A splňující P (A) 0 platí P (B i A) = P (B i) P (A B i ) P (B j ) P (A B j ). j I Důkaz (s využitím věty o úplné pravděpodobnosti): P (B i A) = P (B i A) P (A) = P (B i) P (A B i ) P (B j ) P (A B j ). j I Význam: Pravděpodobnosti P (A B i ) odhadneme z pokusů nebo z modelu, pomocí nich určíme pravděpodobnosti P (B i A), které slouží k optimálnímu odhadu, který z jevů B i nastal. Problém: Ke stanovení aposteriorní pravděpodobnosti P (B i A) potřebujeme znát i apriorní pravděpodobnost P (B i ).
100 Příklad: Na vstupu informačního kanálu mohou být znaky 1,..., m, výskyt znaku j označujeme jako jev B j. Na výstupu mohou být znaky 1,..., k, výskyt znaku i označujeme jako jev A i. (Obykle k = m, ale není to nutné.) Obvykle lze odhadnout podmíněné pravděpoděpodobnosti P ( A i B j ), že znak j bude přijat jako i. Pokud známe apriorní pravděpodobnosti (vyslání znaku j) P ( B j ), můžeme pravděpodobnosti příjmu znaků vypočítat maticovým násobením: [ P (A1 ) P (A 2 ) P (A k ) ] = = [ P (B 1 ) P (B 2 ) P (B m ) ] P (A 1 B 1 ) P (A 2 B 1 ) P (A k B 1 ) P (A 1 B 2 ) P (A 2 B 2 ) P (A k B 2 ) P (A 1 B m ) P (A 2 B m ) P (A k B m ) Všechny matice v tomto vzorci mají jednotkové součty řádků (takové matice nazýváme stochastické). Podmíněné rozdělení pravděpodobnosti, pokud byl přijat znak i, je P ( ) P ( A i B j B j A i = P (A i ) ) P ( Bj )..
101 Rozdělení pravděpodobností vyslaných znaků je [ P (B1 ) P (B 2 ) P (B m ) ] = = [ P (A 1 ) P (A 2 ) P (A k ) ] pokud k = m a příslušná inverzní matice existuje. P (A 1 B 1 ) P (A 2 B 1 ) P (A k B 1 ) P (A 1 B 2 ) P (A 2 B 2 ) P (A k B 2 ) P (A 1 B m ) P (A 2 B m ) P (A k B m ) 1,
102 Rozdělení pravděpodobností vyslaných znaků je [ P (B1 ) P (B 2 ) P (B m ) ] = = [ P (A 1 ) P (A 2 ) P (A k ) ] pokud k = m a příslušná inverzní matice existuje. P (A 1 B 1 ) P (A 2 B 1 ) P (A k B 1 ) P (A 1 B 2 ) P (A 2 B 2 ) P (A k B 2 ) P (A 1 B m ) P (A 2 B m ) P (A k B m ) 1, Podmíněná nezávislost Náhodné jevy A, B jsou podmíněně nezávislé za podmínky C, jestliže P (A B C) = P (A C) P (B C). Podobně definujeme podmíněnou nezávislost více jevů.
103 4 Náhodné veličiny a vektory 4.1 Náhodná veličina na pravděpodobnostním prostoru (Ω, A, P ) je měřitelná funkce X : Ω R, tj. taková, že pro každý interval I platí X 1 (I) = {ω Ω X(ω) I} A
104 4 Náhodné veličiny a vektory 4.1 Náhodná veličina na pravděpodobnostním prostoru (Ω, A, P ) je měřitelná funkce X : Ω R, tj. taková, že pro každý interval I platí X 1 (I) = {ω Ω X(ω) I} A Je popsaná pravděpodobnostmi P X (I) = P [X I] = P ({ω Ω X (ω) I}), definovanými pro libovolný interval I (a tedy i pro libovolné sjednocení spočetně mnoha intervalů a pro libovolnou borelovskou množinu). P X je pravděpodobnostní míra na Borelově σ-algebře určující rozdělení náhodné veličiny X. K tomu, aby stačila znalost P X na intervalech, se potřebujeme omezit na tzv. perfektní míry; s jinými se v praxi nesetkáme.
105 Pravděpodobnostní míra P X splňuje podmínky: P X (R) = 1, ( ) P X I n n N = P X (I n ), pokud jsou množiny I n, n N, navzájem disjunktní. n N
106 Pravděpodobnostní míra P X splňuje podmínky: P X (R) = 1, ( ) P X I n n N = P X (I n ), pokud jsou množiny I n, n N, navzájem disjunktní. n N Z toho vyplývá: P X ( ) = 0, P X (R \ I) = 1 P X (I), jestliže I J, pak P X (I) P X (J) a P X (J \ I) = P X (J) P X (I).
107 Úspornější reprezentace: omezíme se na intervaly tvaru I = (, t, t R, P [X (, t ] = P [X t] = P X ((, t ) = F X (t). F X : R 0, 1 je distribuční funkce náhodné veličiny X. Ta stačí, nebot (a, b = (, b \ (, a, P X ((a, b ) = P [a < X b] = F X (b) F X (a), (a, ) = R \ (, a, P X ((a, )) = 1 F X (a), (, a) = (, b, P X ((, a)) = P [X < a] = lim F X(b) = F X (a ) b: b<a b a {a} = (, a \ (, a), P X ({a}) = P [X = a] = F X (a) F X (a ),......
108 Vlastnosti distribuční funkce: neklesající, zprava spojitá, lim t F X(t) = 0, lim t F X(t) = 1. Věta: Tyto podmínky jsou nejen nutné, ale i postačující.

109
 = { 0 pro r / I, 1 pro r I, F r (t) = { 0 pro t < r, 1 pro t r.")
110 Příklad: Reálnému číslu r odpovídá náhodná veličina (značená též r) s Diracovým rozdělením v r: P r (I) = { 0 pro r / I, 1 pro r I, F r (t) = { 0 pro t < r, 1 pro t r. (F r je posunutá Heavisideova funkce.)
111 4.2 n-rozměrný náhodný vektor (n-rozměrná náhodná veličina) na pravděpodobnostním prostoru (Ω, A, P ) je měřitelná funkce X : Ω R n, tj. taková, že pro každý n-rozměrný interval I platí Lze psát X 1 (I) = {ω Ω X(ω) I} A. X (ω) = (X 1 (ω),..., X n (ω)), kde zobrazení X k : Ω R, k = 1,..., n, jsou náhodné veličiny. Náhodný vektor lze považovat za vektor náhodných veličin X = (X 1,..., X n ).
112 Je popsaný pravděpodobnostmi P X (I 1... I n ) = P [X 1 I 1,..., X n I n ] = = P ({ω Ω X 1 (ω) I 1,..., X n (ω) I n }), kde I 1,..., I n jsou intervaly v R. Z těch vyplývají pravděpodobnosti P X (I) = P [X I] = P ({ω Ω X (ω) I}), definované pro libovolnou borelovskou množinu I v R n (speciálně pro libovolné sjednocení spočetně mnoha n-rozměrných intervalů) a určující rozdělení náhodného vektoru X.
113 Úspornější reprezentace: Stačí intervaly tvaru I k = (, t k, t k R, P [X 1 (, t 1,..., X n (, t n ] = P [X 1 t 1,..., X n t n ] = = P X ((, t 1... (, t n ) = = F X (t 1,..., t n ). F X : R n 0, 1 je distribuční funkce náhodného vektoru X. Je neklesající (ve všech proměnných), zprava spojitá (ve všech proměnných), lim t 1,...,t n F X (t 1,..., t n ) = 1, k {1,..., n} t 1,..., t k 1, t k+1,..., t n : lim t k F X (t 1,..., t n ) = 0.
114 Úspornější reprezentace: Stačí intervaly tvaru I k = (, t k, t k R, P [X 1 (, t 1,..., X n (, t n ] = P [X 1 t 1,..., X n t n ] = = P X ((, t 1... (, t n ) = = F X (t 1,..., t n ). F X : R n 0, 1 je distribuční funkce náhodného vektoru X. Je neklesající (ve všech proměnných), zprava spojitá (ve všech proměnných), lim t 1,...,t n F X (t 1,..., t n ) = 1, k {1,..., n} t 1,..., t k 1, t k+1,..., t n : lim t k F X (t 1,..., t n ) = 0. Věta: Tyto podmínky jsou nutné, nikoli postačující.
115 Úspornější reprezentace: Stačí intervaly tvaru I k = (, t k, t k R, P [X 1 (, t 1,..., X n (, t n ] = P [X 1 t 1,..., X n t n ] = = P X ((, t 1... (, t n ) = = F X (t 1,..., t n ). F X : R n 0, 1 je distribuční funkce náhodného vektoru X. Je neklesající (ve všech proměnných), zprava spojitá (ve všech proměnných), lim t 1,...,t n F X (t 1,..., t n ) = 1, k {1,..., n} t 1,..., t k 1, t k+1,..., t n : lim t k F X (t 1,..., t n ) = 0. Věta: Tyto podmínky jsou nutné, nikoli postačující. Nestačí znát marginální rozdělení náhodných veličin X 1,..., X n, nebot ta neobsahují informace o závislosti.
116 4.3 Nezávislost náhodných veličin Náhodné veličiny X 1, X 2 jsou nezávislé, pokud pro všechny intervaly I 1, I 2 jsou jevy X 1 I 1, X 2 I 2 nezávislé, tj. P [X 1 I 1, X 2 I 2 ] = P [X 1 I 1 ] P [X 2 I 2 ]. Stačí se omezit na intervaly tvaru (, t, tj. neboli pro všechna t 1, t 2 R. P [X 1 t 1, X 2 t 2 ] = P [X 1 t 1 ] P [X 2 t 2 ], F X1,X 2 (t 1, t 2 ) = F X1 (t 1 ) F X2 (t 2 ) Náhodné veličiny X 1,..., X n jsou nezávislé, pokud pro libovolné intevaly I 1,..., I n platí P [X 1 I 1,..., X n I n ] = n i=1 P [X i I i ].
117 Na rozdíl od definice nezávislosti více než 2 jevů, zde není třeba požadovat nezávislost pro libovolnou podmnožinu náhodných veličin X 1,..., X n. Ta vyplývá z toho, že libovolnou náhodnou veličinu X i lze vynechat tak, že zvoĺıme příslušný interval I i = R. Pak P [X i I i ] = 1 a v součinu se tento činitel neprojeví. Ekvivalentně stačí požadovat P [X 1 t 1,..., X n t n ] = n i=1 P [X i t i ] pro všechna t 1,..., t n R, což pro sdruženou distribuční funkci nezávislých náhodných veličin znamená F X (t 1,..., t n ) = n k=1 F Xk (t k ). Náhodné veličiny X 1,..., X n jsou po dvou nezávislé, pokud každé dvě (různé) z nich jsou nezávislé. To je slabší podmínka než nezávislost veličin X 1,..., X n.
118 4.4 Obecnější náhodné veličiny Komplexní náhodná veličina je náhodný vektor se dvěma složkami interpretovanými jako reálná a imaginární část. Někdy připouštíme i náhodné veličiny, jejichž hodnoty jsou jiné než numerické. Mohou to být např. náhodné množiny. Jindy nabývají konečně mnoha hodnot, kterým ponecháme jejich přirozené označení, např. rub, ĺıc, kámen, nůžky, papír apod. Na těchto hodnotách nemusí být definovaná žádná aritmetika ani uspořádání. Mohli bychom všechny hodnoty očíslovat, ale není žádný důvod, proč bychom to měli udělat právě určitým způsobem (který by ovlivnil následné numerické výpočty). (Příklad: Číslování politických stran ve volbách.)
119 4.5 Směs náhodných veličin Příklad: Náhodné veličiny U, V jsou výsledky studenta při odpovědích na dvě zkouškové otázky. Učitel vybere náhodně jednu z otázek a podle odpovědi na ni uděĺı známku. Jaké rozdělení má výsledná známka?
120 4.5 Směs náhodných veličin Příklad: Náhodné veličiny U, V jsou výsledky studenta při odpovědích na dvě zkouškové otázky. Učitel vybere náhodně jednu z otázek a podle odpovědi na ni uděĺı známku. Jaké rozdělení má výsledná známka? Necht U, resp. V je náhodná veličina na pravděpodobnostním prostoru (Ω 1, A 1, P 1 ), resp. (Ω 2, A 2, P 2 ), přičemž Ω 1 Ω 2. Necht c 0, 1. Definujeme nový pravděpodobnostní prostor (Ω, A, P ), kde Ω = Ω 1 Ω 2, A = {A 1 A 2 A 1 A 1, A 2 A 2 }, P (A 1 A 2 ) = c P 1 (A 1 ) + (1 c) P 2 (A 2 ) pro A 1 A 1, A 2 A 2. Definujeme funkci X : Ω R: X (ω) = { U (ω) pro ω Ω1, V (ω) pro ω Ω 2. X je náhodná veličina na (Ω, A, P ); nazýváme ji směs náhodných veličin U, V koeficientem c (angl. mixture) a značíme Mix c (U, V ). s
121 X = Mix c (U, V ) má pravděpodobnostní míru P X = c P U + (1 c) P V a distribuční funkci F X = c F U + (1 c) F V, F X (t) = c F U (t) + (1 c) F V (t).
122 Podobně definujeme obecněji směs náhodných veličin U 1,..., U n s koeficienty c 1,..., c n 0, 1, n i=1 c i = 1, značíme Mix (c1,..., c n ) (U 1,..., U n ) = Mix c (U 1,..., U n ), kde c = (c 1,..., c n ). Má pravděpodobnostní míru n i=1 n i=1 c i F Ui. (Lze zobecnit i na spočetně mnoho náhodných veličin.) c i P Ui a distribuční funkci Podíl jednotlivých složek je určen vektorem koeficientů c = (c 1,..., c n ). Jejich počet je stejný jako počet náhodných veličin ve směsi. Jelikož c n = 1 n 1 c i, poslední koeficient někdy vynecháváme. i=1 Speciálně pro dvě náhodné veličiny Mix (c,1 c) (U, V ) = Mix c (U, V ) (kde c je číslo, nikoli vektor).
123 Příklad: Směsí reálných čísel r 1,..., r n s koeficienty c 1,..., c n je náhodná veličina X = Mix (c1,..., c n ) (r 1,..., r n ), P X (I) = P [X I] = i:r i I c i, F X (t) = i:r i t Lze ji popsat též pravděpodobnostní funkcí p X : R 0, 1, { ci pro t = r i, p X (t) = P X ({t}) = P [X = t] = 0 jinak (pokud jsou r 1,..., r n navzájem různá). Možno zobecnit i na spočetně mnoho reálných čísel. c i.
124 4.6 Druhy náhodných veličin 1. Diskrétní: (z předchozího příkladu) Existuje spočetná množina O X, pro kterou P X (R \ O X ) = P [X / O X ] = 0. Nejmenší taková množina (pokud existuje) je Ω X = {t R : P X ({t}) 0} = {t R : P [X = t] 0}. Diskrétní náhodnou veličinu lze popsat pravděpodobnostní funkcí p X (t) = P X ({t}) = P [X = t]. Splňuje t R p X (t) = (Absolutně) spojitá: F X (t) = t f X(u) du pro nějakou nezápornou funkci f X : R 0, ), zvanou hustota náhodné veličiny X. Splňuje f X (u) du = 1.
125 Není určena jednoznačně, ale dvě hustoty f X, g X téže náhodné veličiny splňují I (f X(x) g X (x)) dx = 0 pro všechny intervaly I. Lze volit f X (t) = df X(t) dt, pokud derivace existuje. P X ({t}) = 0 pro všechna t. 3. Smíšená: Směs předchozích dvou případů; Ω X, P X (R \ Ω X ) = P [X / Ω X ] 0. Nejde popsat ani pravděpodobnostní funkcí (existuje, ale neurčuje celé rozdělení) ani hustotou (neexistuje, nebot nevychází konečná). 4. Další možné případy: Např. náhodná veličina se spojitou distribuční funkcí, kterou nelze vyjádřit jako integrál. Tyto případy dále neuvažujeme.
126 4.7 Popis smíšené náhodné veličiny Náhodnou veličinu X se smíšeným rozdělením lze jednoznačně vyjádřit ve tvaru X = Mix c (U, V ), kde U je diskrétní, V je spojitá a c (0, 1): c P U ({t}) + (1 c) P V ({t}) } {{ } 0 c = P X (Ω X ) = P X ({t R : P X ({t}) 0}), = c P U ({t}) = P X ({t}), p U (t) = P U ({t}) = P X({t}), c Ω U = Ω X, c P U (I) + (1 c) P V (I) = P X (I), P V (I) = P X(I) c P U (I), 1 c F V (t) = F X(t) c F U (t). 1 c
127 Alternativa bez použití pravděpodobnostní míry: c = t R P [X = t], c P [U = t] = P [X = t], P [X = t] p U (t) = P [U = t] =, c c P [U I] + (1 c) P [V I] = P [X I], P [X I] c P [U I] P [V I] =, 1 c F V (t) = F X(t) c F U (t). 1 c (Lze ještě pokračovat rozkladem diskrétní části na směs Diracových rozdělení.) 4.8 Kvantilová funkce náhodné veličiny α (0, 1) t R : P [X < t] α P [X t].
128 Pokud je takových čísel víc, tvoří omezený interval a vezmeme z něj (obvykle) střed, přesněji tedy q X (α) = 1 (sup {t R P [X < t] α} + inf {t R P [X t] α}). 2
129 2 q(a) a 1 2 Číslo q X (α) se nazývá α-kvantil náhodné veličiny X a funkce q X : (0, 1) R je kvantilová funkce náhodné veličiny X. Speciálně q X ( 2 1 ) je medián, další kvantily
130 mají také svá jména tercil, kvartil (dolní q X ( 4 1 ), horní q X( 3 4 ))... decil... centil neboli percentil... Vlastnosti kvantilové funkce: neklesající, q X (α) = 1 2 (q X(α ) + q X (α+)). Věta: Tyto podmínky jsou nutné i postačující. Můžeme mluvit o vertikální reprezentaci náhodné veličiny pomocí distribuční funkce F X : R [0, 1] a horizontální reprezentaci pomocí kvantilové funkce q X : (0, 1) R. Obrácený převod: F X (t) = inf{α (0, 1) q X (α) > t} = sup{α (0, 1) q X (α) t}. Funkce F X, q X jsou navzájem inverzní tam, kde jsou spojité a rostoucí (tyto podmínky stačí ověřit pro jednu z nich).
131 4.9 Jak reprezentovat náhodnou veličinu v počítači 1. Diskrétní: Nabývá-li pouze konečného počtu hodnot t k, k = 1,..., n, stačí k reprezentaci tyto hodnoty a jejich pravděpodobnosti p X (t k ) = P X ({t k }) = P [X = t k ], čímž je plně popsána pravděpodobnostní funkce 2n čísly (až na nepřesnost zobrazení reálných čísel v počítači).
132 Pokud diskrétní náhodná veličina nabývá (spočetně) nekonečně mnoha hodnot, musíme některé vynechat, zejména ty, které jsou málo pravděpodobné. Pro každé ε > 0 lze vybrat konečně mnoho hodnot t k, k = 1,..., n, tak, že P X (R {t 1,..., t n }) = P [X / {t 1,..., t n }] ε. Zbývá však problém, jakou hodnotu přiřadit zbývajícím (byt málo pravděpodobným) případům. 2. (Absolutně) spojitá: Hustotu můžeme přibližně popsat hodnotami f(t k ) v dostatečně mnoha bodech t k, k = 1,..., n, ale jen za předpokladu, že je dostatečně hladká. Zajímají nás z ní spíše integrály typu F X (t k+1 ) F X (t k ) = tk+1 t k f X (u) du, z nichž lze přibližně zkonstruovat distribuční funkci. Můžeme pro reprezentaci použít přímo hodnoty distribuční funkce F X (t k ). Tam, kde je hustota velká, potřebujeme volit body hustě. Můžeme volit body t k, k = 1,..., n, tak, aby přírůstky F X (t k+1 ) F X (t k ) měly zvolenou velikost. Zvoĺıme tedy α k (0, 1), k = 1,..., n, a k nim najdeme čísla t k = q X (α k ).
133 Pamět ová náročnost je velká, závisí na jemnosti škály hodnot náhodné veličiny, resp. její distribuční funkce. Často je rozdělení známého typu a stačí doplnit několik parametrů, aby bylo plně určeno. Mnohé obecnější případy se snažíme vyjádřit alespoň jako směsi náhodných veličin s rozděleními známého typu, abychom vystačili s konečně mnoha parametry. 3. Smíšená: Jako u spojité náhodné veličiny. Tento popis je však pro diskrétní část zbytečně nepřesný. Můžeme použít rozklad na diskrétní a spojitou část.
 = P X (I), P X+r (J) = P X (J r), F X+r (t + r) = F X (t), F")
134 4.10 Operace s náhodnými veličinami Zde I, J R jsou intervaly nebo spočetná sjednocení intervalů. Přičtení konstanty r odpovídá posunutí ve směru vodorovné osy: P X+r (I + r) = P X (I), P X+r (J) = P X (J r), F X+r (t + r) = F X (t), F X+r (u) = F X (u r), q X+r (α) = q X (α) + r.
 = F X (t), F rx (u) = F X ( ur ), qrx (α) = r q X (α),")
135 Vynásobení nenulovou konstantou r odpovídá podobnost ve směru vodorovné osy: P rx (ri) = P X (I), P rx (J) = P X ( Jr ). Pro distribuční funkci musíme rozlišit případy: r > 0: F rx (rt) = F X (t), F rx (u) = F X ( ur ), qrx (α) = r q X (α),
![r = 1: F X ( t) = P X ((, t ) = P X ( t, )) = 1 P X ((, t)), v bodech spojitosti distribuční funkce F X ( t) = 1 P X ((, t)) = 1 P [X < t] = 1 P [X t] = 1 P X ((, t )](/docs-images/13/15563/images/136-0.jpg "= 1 F X (t), F X (u) = 1 F X ( u), v bodech nespojitosti limita zprava (středová symetrie grafu podle bodu ( 0, 1 2) s opravou na spojitost zprava), q X (α) = q X (1")
136 r = 1: F X ( t) = P X ((, t ) = P X ( t, )) = 1 P X ((, t)), v bodech spojitosti distribuční funkce F X ( t) = 1 P X ((, t)) = 1 P [X < t] = 1 P [X t] = 1 P X ((, t ) = 1 F X (t), F X (u) = 1 F X ( u), v bodech nespojitosti limita zprava (středová symetrie grafu podle bodu ( 0, 1 2) s opravou na spojitost zprava), q X (α) = q X (1 α),
 (h(i)) = P X (I), F h(x) (h(t)) = F X (t), F h(x) (u) = F X (h")
137 r < 0: kombinace předchozích případů. Zobrazení spojitou rostoucí funkcí h: P h(x) (h(i)) = P X (I), F h(x) (h(t)) = F X (t), F h(x) (u) = F X (h 1 (u)), q h(x) (α) = h(q X (α)) v bodech spojitosti kvantilové funkce.
138 Zobrazení neklesající, zleva spojitou funkcí h: F h(x) (u) = sup{f X (t) h(t) u}. Zobrazení po částech monotonní, zleva spojitou funkcí h: Můžeme vyjádřit h = h + h, kde h +, h jsou neklesající. X vyjádříme jako směs X = Mix c (U, V ), kde U nabývá pouze hodnot, v nichž je h neklesající, V pouze hodnot, v nichž je h nerostoucí. Výsledek dostaneme jako směs dvou náhodných veličin, vzniklých zobrazením funkcemi h +, h. Funkci h lze aplikovat na směs po složkách, tj. h(mix c (U, V )) = Mix c (h(u), h(v )). Součet náhodných veličin není jednoznačně určen, jedině za předpokladu nezávislosti. Ani pak není vztah jednoduchý. Směs náhodných veličin viz výše. Na rozdíl od součtu je plně určena (marginálními) rozděleními vstupních náhodných veličin a koeficienty směsi.
139 4.11 Jak realizovat náhodnou veličinu na počítači 1. Vytvoříme náhodný (nebo pseudonáhodný) generátor náhodné veličiny X s rovnoměrným rozdělením na 0, Náhodná veličina q Y (X) má stejné rozdělení jako Y. (Stačí tedy na každou realizaci náhodné veličiny X aplikovat funkci q Y.) Všechna rozdělení spojitých náhodných veličin jsou stejná až na (nelineární) změnu měřítka Střední hodnota Značení: E. nebo µ. Je definována zvlášt pro
140 diskrétní náhodnou veličinu U: EU = µ U = t p U (t) = t p U (t), t R t Ω U spojitou náhodnou veličinu V : EV = µ V = t f V (t) dt, směs náhodných veličin X = Mix c (U, V ), kde U je diskrétní, V je spojitá: (To není linearita střední hodnoty!) EX = c EU + (1 c) EV. Lze vyjít z definice pro diskrétní náhodnou veličinu a ostatní případy dostat jako limitu pro aproximaci jiných rozdělení diskrétním.
141 Všechny tři případy pokrývá univerzální vzorec s použitím kvantilové funkce EX = 1 q X (α) dα. 0 Ten lze navíc jednoduše zobecnit na střední hodnotu jakékoli funkce náhodné veličiny: E (h(x)) = 1 h (q X (α)) dα. Speciálně pro diskrétní náhodnou veličinu 0 E (h(u)) = t Ω U h (t) p U (t), pro spojitou náhodnou veličinu by obdobný vzorec platil jen za omezujících předpokladů, protože spojitost náhodné veličiny se nemusí zachovávat. Střední hodnota je vodorovnou souřadnicí těžiště grafu distribuční funkce, jsou-li jeho elementy váženy přírůstkem distribuční funkce:

142 Pokud pracujeme se střední hodnotou, automaticky předpokládáme, že existuje (což není vždy splněno).
143 Vlastnosti střední hodnoty Er = r, spec. E(EX) = EX, E (X + Y ) = EX + EY, spec. E (X + r) = EX + r, E (X Y ) = EX EY, E (r X) = r EX, obecněji E (r X + s Y ) = r EX + s EY. (To je linearita střední hodnoty.) E (Mix c (U, V )) = c EU + (1 c) EV. (To není linearita střední hodnoty.) Pouze pro nezávislé náhodné veličiny E (X Y ) = EX EY.
144 4.13 Rozptyl (disperze) Značení: σ 2., D., var. DX = E ( (X EX) 2) = E ( X 2) (EX) 2, E ( X 2) = (EX) 2 + DX. (1) Vlastnosti: DX = 1 0 (q X (α) EX) 2 dα. DX 0, Dr = 0, D (X + r) = DX, D (r X) = r 2 DX.
145 D (Mix c (U, V )) = E ( Mix c (U, V ) 2) (E (Mix c (U, V ))) 2 = c E ( U 2) + (1 c) E ( V 2) (c EU + (1 c) EV ) 2 = c ( DU + (EU) 2) + (1 c) ( DV + (EV ) 2) ( c 2 (EU) c (1 c) EU EV + (1 c) 2 (EV ) 2) = c DU + (1 c) DV + c (1 c) (EU) 2 2 c (1 c) EU EV + c (1 c) (EV ) 2 = c DU + (1 c) DV + c (1 c) (EU EV ) 2. Pouze pro nezávislé náhodné veličiny D (X + Y ) = DX + DY, D (X Y ) = DX + DY Směrodatná odchylka Značení: σ.
146 σ X = DX = E ( (X EX) 2) Na rozdíl od rozptylu má stejný fyzikální rozměr jako původní náhodná veličina. Vlastnosti: σ X = 1 0 (q X (α) EX) 2 dα. σ X 0, σ r = 0, σ X+r = σ X, σ r X = r σ X. Pouze pro nezávislé náhodné veličiny σ X+Y = DX + DY = σ 2 X + σ2 Y.
147 4.15 Obecné momenty k N k-tý obecný moment (značení nezavádíme): E ( X k), speciálně: pro k = 1: EX, pro k = 2: E ( X 2) = (EX) 2 + DX. Alternativní značení: m k, µ k. k-tý centrální moment (značení nezavádíme): E ( (X EX) k), speciálně: pro k = 1: 0, pro k = 2: DX.
148 Alternativní značení: µ k. Pomocí kvantilové funkce: E ( X k) = E ( (X EX) k) = (q X (α)) k dα. (q X (α) EX) k dα.
149 4.16 Normovaná náhodná veličina je taková, která má nulovou střední hodnotu a jednotkový rozptyl: norm X = X EX σ X (pokud má vzorec smysl). Zpětná transformace je X = EX + σ X norm X. (2)
150 4.17 Základní typy diskrétních rozdělení Diracovo Je jediný možný výsledek r R. p X (r) = 1, EX = r, DX = 0. Všechna diskrétní rozdělení jsou směsi Diracových rozdělení.
151 Rovnoměrné Je m možných výsledků stejně pravděpodobných. Speciálně pro obor hodnot {1, 2,..., m} dostáváme p X (k) = 1, m k {1, 2,..., m}, EX = m + 1, 2 DX = 1 (m + 1) (m 1). 12
152 Alternativní (Bernoulliovo) Jsou 2 možné výsledky. (Směs dvou Diracových rozdělení.) Pokud výsledky jsou 0, 1, kde 1 má pravděpodobnost p (0, 1), dostáváme p X (1) = p, p X (0) = 1 p, EX = p, DX = p(1 p).
153 Binomické Bi(m, p) Počet úspěchů z m nezávislých pokusů, je-li v každém stejná pravděpodobnost úspěchu p 0, 1. (Součet m nezávislých alternativních rozdělení.) p X (k) = ( ) m k p k (1 p) m k, k {0, 1, 2,..., m}, EX = mp, DX = mp(1 p). Výpočetní složitost výpočtu p X (k) je O(k), celého rozdělení O(m 2 ).
154 Poissonovo Po(λ) Limitní případ binomického rozdělení pro m při konstantním mp = λ > 0 (tedy p 0). p X (k) = λk k! e λ, k {0, 1, 2,...}. Jednotlivé pravděpodobnosti se počítají snáze než u binomického rozdělení (ovšem všechny nevypočítáme, protože jich je nekonečně mnoho). EX = λ, DX = λ. Střední hodnota se rovná rozptylu; jedná se vždy o bezrozměrné celočíselné náhodné veličiny (počet výskytů).
155 Pro m při kon- Poissonovo rozdělení jako limitní případ binomického stantním mp = λ, tj. p = m λ : p X (k) = ( ) m k p k (1 p) m k m (m 1)... (m (k 1)) = k! = λk ( k! ) ( 1 k 1 m m ( ) λ k ( m ) ( } {{ } 1 λk k! e λ. 1 λ m 1 λ m ) k ( } {{ } 1 ) m k 1 λ m ) m } {{ } e λ
156 Geometrické Počet úspěchů do prvního neúspěchu, je-li v každém pokusu stejná pravděpodobnost úspěchu p (0, 1). p X (k) = p k (1 p), k {0, 1, 2,...}, EX = p 1 p, DX = p (1 p) 2.
157 Hypergeometrické Počet výskytů v m vzorcích, vybraných z M objektů, v nichž je K výskytů (1 m K M). p X (k) = ( )( ) K M K k m k ( M m), k {0, 1, 2,..., m}, EX = mk M, DX = mk (M K) (M m) M 2 (M 1). Výpočetní složitost výpočtu p X (k) je O(m), celého rozdělení O(m 2 ).
158 Binomické rozdělení jako limitní případ hypergeometrického Lemma: Pro m, M N, m < M, je ( lim ) M m! M m M m = 1. Důkaz: ( M m) m! M (M 1) (M (m 1)) = M m M m = 1 ( 1 1 ) ( M 1 m 1 M ) 1. Důsledek: Pro M m můžeme ( ) M m počítat přibližně jako M m m!. Hypergeometrické rozdělení pro M při konstantním M K (s využitím předchozího lemmatu): p X (k) = = ( )( ) K M K k m k ( M m) K k k! (M K)m k (m k)! M m m! m! k! (m k)! Kk (M K)m k M k M m k = p, tj. M K M = ( ) m k p k (1 p) m k. = 1 p
159 4.18 Základní typy spojitých rozdělení Rovnoměrné R(a, b) f X (t) = { 1 b a EX = a + b 2 pro t a, b, 0 jinak,, DX = 1 12 (b a)2.
160 Normální (Gaussovo) N(µ, σ 2 ) A. Normované N(0, 1): f N(0,1) (t) = 1 2π exp ( t 2 Distribuční funkce je transcendentní (Gaussův integrál) Φ, ( u 1 t 2 Φ(u) = F N(0,1) (u) = exp 2π 2 kvantilová funkce Φ 1 je inverzní k Φ. 2 ) ) dt, B. Obecné N(µ, σ 2 ): f N(µ,σ 2 ) (t) = 1 σ 2π exp ( (t µ) 2 2 σ 2 ), EX = µ, DX = σ 2.
161 Logaritmickonormální LN(µ, σ 2 ) je rozdělení náhodné veličiny X = exp(y ), kde Y má N(µ, σ 2 ) f X (t) = EX = exp ( 1 u σ 2 π exp ) (ln u µ)2 2 σ 2 pro t > 0, 0 jinak, ( µ + σ2 2 ), DX = ( exp ( 2 µ + σ 2)) ( exp ( σ 2) 1 ).
162 Exponenciální Ex(τ) Např. rozdělení času do první poruchy, jestliže (podmíněná) pravděpodobnost poruchy za časový interval t, t + δ závisí jen na δ, nikoli na t: { 1τ exp ( t ) f X (t) = τ pro t > 0, 0 jinak, EX = τ, DX = τ 2.
163 4.19 Náhodné vektory 2 Náhodný vektor X = (X 1,..., X n ) je popsaný sdruženou distribuční funkcí F X : R n 0, 1 F X (t 1,..., t n ) = P [X 1 t 1,..., X n t n ].
164 Diskrétní náhodný vektor má všechny složky diskrétní. Lze jej popsat též sdruženou pravděpodobnostní funkcí p X : R n 0, 1 p X (t 1,..., t n ) = P [X 1 = t 1,..., X n = t n ], která je nenulová jen ve spočetně mnoha bodech. Diskrétní náhodné veličiny X 1,..., X n jsou nezávislé, právě když P [X 1 = t 1,..., X n = t n ] = n i=1 pro všechna t 1,..., t n R. Ekvivalentní formulace: P [X i = t i ] p X (t 1,..., t n ) = n i=1 p Xi (t i ).
165 Spojitý náhodný vektor má všechny složky spojité. Lze jej popsat též sdruženou hustotou pravděpodobnosti což je (každá) nezáporná funkce f X : R n 0, ) taková, že F X (t 1,..., t n ) = pro všechna t 1,..., t n R. t1... tn f X (u 1,..., u n ) du 1... du n, Speciálně pro intervaly a i, b i dostáváme P [X 1 a 1, b 1,..., X n a n, b n ] = P X ( a 1, b 1... a n, b n ) = b1 a 1... bn a n f X (u 1,..., u n ) du 1... du n Spojité náhodné veličiny X 1,..., X n jsou nezávislé, právě když pro skoro všechna t 1,..., t n R. f X (t 1,..., t n ) = n i=1 f Xi (t i ).
166 4.20 Číselné charakteristiky náhodného vektoru Střední hodnota náhodného vektoru X = (X 1,..., X n ): EX = (EX 1,..., EX n ) komplexní náhodné veličiny: X = R(X)+i I(X): EX = ER(X)+i EI(X) nenumerické náhodné veličiny: nemá smysl
167 Rozptyl náhodného vektoru X = (X 1,..., X n ): DX = (DX 1,..., DX n ) Je-li U náhodná veličina, a, b R, pak a U + b má charakteristiky E (a U + b) = a EU + b, D (a U + b) = a 2 DU. Na rozdíl od jednorozměrné náhodné veličiny, střední hodnota a rozptyl náhodného vektoru nedávají dostatečnou informaci pro výpočet rozptylu jeho lineárních funkcí. Proto zavádíme další charakteristiky. Např. E (X + Y ) = EX + EY, D (X + Y ) = E ( (X + Y ) 2) (E (X + Y )) 2 = E ( X 2 + Y X Y ) (EX + EY ) 2 = E ( X 2) + E ( Y 2) + 2 E (X Y ) ( (EX) 2 + (EY ) EX EY ) = E ( X 2) (EX) 2 + E ( Y 2) (EY ) 2 } {{ } } {{ } DX DY = DX + DY + 2 cov(x, Y ), +2 (E (X Y ) EX EY } {{ } cov(x,y ) kde cov(x, Y ) = E (X Y ) EX EY je kovariance náhodných veličin X, Y. Ekvivalentně ji lze definovat cov(x, Y ) = E ((X EX) (Y EY )), )
168 nebot E ((X EX) (Y EY )) = E (X Y X EY Y EX + EX EY ) (První vzorec je vhodnější pro výpočet.) = E (X Y ) EX EY EX EY + EX EY } {{ } 0. Pro existenci kovariance je postačující existence rozptylů DX, DY.
169 Vlastnosti kovariance: cov(x, X) = DX, cov(y, X) = cov(x, Y ), cov(a X + b, c Y + d) = a c cov(x, Y ) (a, b, c, d R) (srovnejte s vlastnostmi rozptylu jako speciálního případu), speciálně cov(x, X) = DX. Pro nezávislé náhodné veličiny X, Y je cov(x, Y ) = 0. Použitím kovariance pro normované náhodné veličiny vyjde korelace: ϱ(x, Y ) = cov(norm X, norm Y ) = cov(x, Y ) σ X σ Y = E (norm X norm Y ) (předpokládáme, že směrodatné odchylky ve jmenovateli jsou nenulové). Speciálně ϱ(x, X) = 1.
170 Vlastnosti korelace: ϱ(x, X) = 1, ϱ(x, X) = 1, ϱ(x, Y ) 1, 1, ϱ(y, X) = ϱ(x, Y ), ϱ(ax + b, cy + d) = sign (ac) ϱ(x, Y ) (a, b, c, d R, a 0 c) (až na znaménko nezáleží na prosté lineární transformaci). Důsledek: ϱ(ax + b, X) = sign (a). Jsou-li náhodné veličiny X, Y nezávislé, je ϱ(x, Y ) = 0. Obrácená implikace však neplatí (není to postačující podmínka pro nezávislost). Náhodné veličiny X, Y splňující ϱ(x, Y ) = 0 nazýváme nekorelované.
171 Pro náhodný vektor X = (X 1,..., X n ) je definována kovarianční matice Σ X = = cov(x 1, X 1 ) cov(x 1, X 2 ) cov(x 1, X n ) cov(x 2, X 1 ) cov(x 2, X 2 ) cov(x 2, X n ) cov(x n, X 1 ) cov(x n, X 2 ) cov(x n, X n ) DX 1 cov(x 1, X 2 ) cov(x 1, X n ) cov(x 1, X 2 ) DX 2 cov(x 2, X n ) cov(x 1, X n ) cov(x 2, X n ) DX n Je symetrická pozitivně semidefinitní, na diagonále má rozptyly.. Podobně je definována korelační matice ϱ X = Je symetrická pozitivně semidefinitní. 1 ϱ(x 1, X 2 ) ϱ(x 1, X n ) ϱ(x 1, X 2 ) 1 ϱ(x 2, X n ) ϱ(x 1, X n ) ϱ(x 2, X n ) 1.
172 Vícerozměrné normální rozdělení N( µ, Σ) popisuje speciální případ náhodného vektoru, jehož složky mají normální rozdělení a nemusí být nekorelované. Má hustotu ( 1 f N( µ,σ) ( t) = (2 π) n det Σ exp 1 ( t µ ) T Σ 1 ( t µ )), 2 kde t = (t 1,..., t n ) R n, µ = (µ 1,..., µ n ) R n je vektor středních hodnot, Σ R n n je symetrická pozitivně definitní kovarianční matice a Σ 1 je matice k ní inverzní. Marginální rozdělení i-té složky je N(µ i, Σ ii ).
173 4.21 Lineární prostor náhodných veličin Zvolme pevně pravděpodobnostní prostor (Ω, A, P ). Označme L množinu všech náhodných veličin na (Ω, A, P ), tj. A-měřitelných funkcí Ω R. Operacím sčítání náhodných veličin a jejich násobení reálným číslem odpovídají příslušné operace s funkcemi (prováděné na Ω bod po bodu). Stejně jako funkce, tvoří i náhodné veličiny z L lineární prostor. Dále se omezíme na prostor L 2 všech náhodných veličin z L, které mají rozptyl (L 2 je lineární podprostor prostoru L). Na něm lze definovat binární operaci : L 2 L 2 R X Y = E (X Y ).
174 Ta je bilineární (tj. lineární v obou argumentech) a komutativní. Pokud ztotožníme náhodné veličiny, které se liší jen na množině nulové míry, pak je skalární součin. (Po ztotožnění náhodných veličin X, Y, pro které P [X Y ] = 0 považujeme za prvky prostoru třídy ekvivalence místo jednotlivých náhodných veličin.) Skalární součin definuje normu X = X X = E ( X 2) a metriku (vzdálenost) d(x, Y ) = X Y = E ( (X Y ) 2). (Bez předchozího ztotožnění by toto byla jen pseudometrika, mohla by vyjít nulová i pro X Y.)
175 V L 2 rozlišíme 2 důležité podprostory: R = jednodimenzionální prostor všech konstatních náhodných veličin (tj. s Diracovým rozdělením), N = prostor všech náhodných veličin s nulovou střední hodnotou. N je ortogonální doplněk podprostoru R, tj. N = {X L 2 ( Y R : X Y = 0)}. EX je kolmý průmět X do R (pokud ztotožňujeme toto reálné číslo s příslušnou konstantní náhodnou veličinou, jinak souřadnice ve směru R), X EX je kolmý průmět X do N, norm X = X EX σ je jednotkový vektor ve směru kolmého průmětu X do N, X σ X = X EX je vzdálenost X od R. Z kolmosti vektorů X EX N, EX R a Pythagorovy věty plyne X X = X 2 = X EX 2 + EX 2, E ( X 2) = DX + (EX) 2.
176 Lineární podprostor náhodných veličin s nulovými středními hodnotami Speciálně pro náhodné veličiny z N vychází σ 2 X = X X, σ X = X, cov(x, Y ) = X Y, ϱ(x, Y ) = cov(x, Y ) σ X σ Y = X Y X Y, takže korelace ϱ(x, Y ) je kosinus úhlu vektorů X, Y N. Důsledek: Náhodné veličiny X, Y s nulovými středními hodnotami jsou ortogonální, právě když jsou nekorelované.
177 Obecně v L 2 ϱ(x, Y ) je kosinus úhlu průmětů X, Y do N, cov(x, Y ) = X Y EX EY je skalární součin průmětů X, Y do N Lineární regrese Úloha: Je dán náhodný vektor X = (X 1,..., X n ) a náhodná veličina Y. (Předpokládáme, že všechny náhodné veličiny jsou z L 2 ). Máme najít takové koeficienty c 1,..., c n, aby lineární kombinace c i X i byla co nejlepší aproximací i náhodné veličiny Y ve smyslu kritéria k c k X k Y.
178 Řešení: K vektoru Y hledáme nejbližší bod v lineárním podprostoru, který je lineárním obalem vektorů X 1,..., X n ; řešením je kolmý průmět. Ten je charakterizován tím, že vektor c i X i Y je kolmý na X j, j = 1,..., n, i ( i k c k X k Y ) X j = 0, c i ( Xi X j ) = Y Xj. To je soustava lineárních rovnic pro neznámé koeficienty c 1,..., c n (soustava normálních rovnic). Speciálně pro náhodné veličiny s nulovými středními hodnotami: i takže matice soustavy je Σ X. c i cov ( X i, X j ) = cov ( Y, Xj ),
179 4.22 Reprezentace náhodných vektorů v počítači Obdobná jako u náhodných veličin, avšak s rostoucí dimenzí rychle roste pamět ová náročnost. To by se nestalo, kdyby náhodné veličiny byly nezávislé; pak by stačilo znát marginální rozdělení. Proto velkou úsporu může přinést i podmíněná nezávislost. Pokud najdeme úplný systém jevů, které zajišt ují podmíněnou nezávislost dvou náhodných veličin, pak můžeme jejich rozdělení popsat jako směs rozdělení nezávislých náhodných veličin (a tedy úsporněji).
180 4.23 Čebyševova nerovnost Věta: kde norm X = X EX σ X δ > 0 : P [ norm X < δ] 1 1 δ 2, (pokud má výraz smysl). Důkaz pomocí kvantilové funkce: D (norm X) } {{ } 1 = E ( (norm X) 2) (E (norm X)) 2, } {{ } 0 1 = E ( (norm X) 2) = EY, kde Y = (norm X) 2. Odhad pravděpodobnosti β = P [ norm X < δ] = P [Y < δ 2 ] = F Y (δ 2 ): 1 = EY = 1 0 q Y (α) dα = β 0 q Y (α) } {{ } 0 dα + 1 β q Y (α) } {{ } δ 2 dα (1 β) δ 2, β 1 1 δ 2.
181 Důkaz pomocí směsi: Vyjádříme Y = (norm X) 2 = Mix β (L, U), kde L nabývá pouze hodnot z 0, δ 2 ), U nabývá pouze hodnot z δ 2, ), takže EU δ 2, β = F Y (δ 2 ). 1 = EY = β EL }{{} 0 + (1 β) EU }{{} δ 2 (1 β) δ 2. Rovnost nastává pro U = δ 2, L = 0, tj. pro diskrétní rozdělení {(EX δ σ X, 1 β 2 ), (EX, β), (EX + δ σ X, 1 β 2 )}. Ekvivalentní tvary (ε = δ σ X ): δ > 0 : P [ X EX δ σ X ] 1 δ 2, ε > 0 : P [ X EX ε] σ2 X ε 2 = DX ε 2.

182
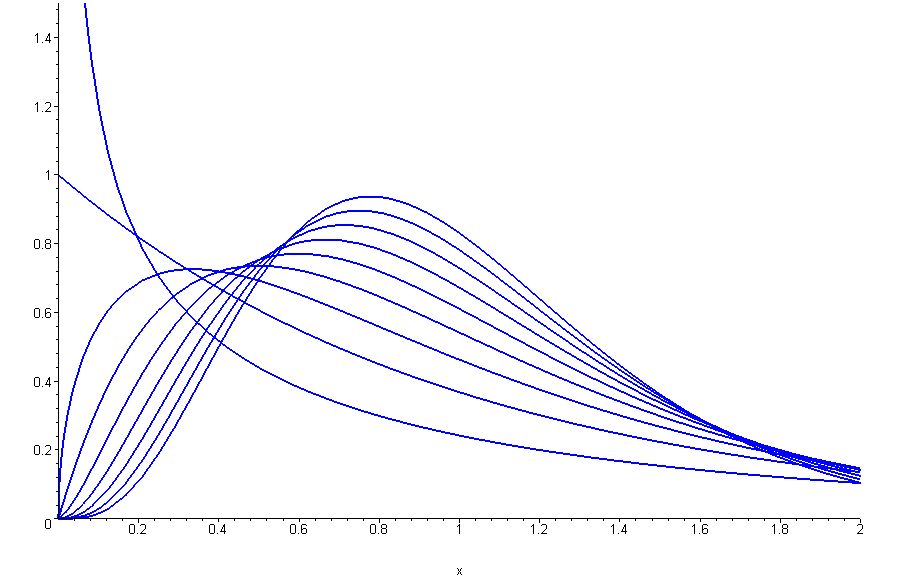
183

184
185 5 Základní pojmy statistiky 5.1 K čemu potřebujeme statistiku Zkoumání společných vlastností velkého počtu obdobných jevů. Přitom nezkoumáme všechny, ale jen vybraný vzorek (kvůli ceně testů, jejich destruktivnosti apod.). Odhady parametrů pravděpodobnostního modelu Testování hypotéz Potíže statistického výzkumu viz [Rogalewicz].
186 5.2 Pojem náhodného výběru, odhady Soubor základní (=populace) výběrový Náhodný výběr jednoho prvku základního souboru (s rovnoměrným rozdělením) a stanovení určitého parametru tohoto prvku určuje rozdělení náhodné veličiny. Opakovaným výběrem dostaneme náhodný vektor, jehož složky mají stejné rozdělení a jsou nezávislé. Takto vytvoříme výběrový soubor rozsahu n, obvykle však vyloučíme vícenásobný výběr stejného prvku (výběr bez vracení). Jeho rozdělení se může poněkud lišit od původního. Tento rozdíl se obvykle zanedbává, nebot
187 1. pro velký rozsah základního souboru to není podstatné, 2. rozsah základního souboru někdy není znám, 3. výpočty se značně zjednoduší. Přesnost odhadu je dána velikostí výběrového souboru, nikoli populace. Náhodný výběr X = (X 1,..., X n ) je vektor náhodných veličin, které jsou nezávislé a mají stejné rozdělení. (Vynecháváme indexy, např. F X místo F Xk.) Provedením pokusu dostaneme realizaci náhodného výběru, x = (x 1,..., x n ) R n, kde n je rozsah výběru.
188 Statistika je (každá) měritelná funkce G, definovaná na náhodném výběru libovolného rozsahu. (Počítá se z náhodných veličin výběru, nikoli z parametrů rozdělení.) Měřitelná znamená, že pro každé t R je definována pravděpodobnost P [G(X 1,..., X n ) t] = F G(X1,...,X n ) (t). Statistika jako funkce náhodných veličin je rovněž náhodná veličina. Obvykle se používá jako odhad parametrů rozdělení (které nám zůstávají skryté). Značení: ϑ... skutečný parametr (reálné číslo), Θ, Θ n... jeho odhad založený na náhodném výběru rozsahu n (náhodná veličina) ϑ, ϑ n... realizace odhadu (obvykle reálné číslo)
189 Žádoucí vlastnosti odhadů: E Θ n = ϑ nestranný (opak: vychýlený) lim n E Θ n = ϑ asymptoticky nestranný eficientní = s malým rozptylem, což posuzujeme podle E ( ( Θ n ϑ) 2) = D Θ n + ( E( Θ n ϑ) ) 2, pro nestranný odhad se redukuje na D Θ n nejlepší nestranný odhad je ze všech nestranných ten, který je nejvíce eficientní (mohou však existovat více eficientní vychýlené odhady) lim n E Θ n = ϑ, lim n σ Θn = 0 konzistentní robustní, tj. odolný vůči šumu ( i při zašuměných datech dostáváme dobrý výsledek ) zde už přesné kritérium chybí, zato je to velmi praktická vlastnost
190 5.3 Výběrový průměr z náhodného výběru X = (X 1,..., X n ) je X = 1 n n X j j=1 Alternativní značení: X n (pokud potřebujeme zdůraznit rozsah výběru) Jeho realizaci značíme malým písmenem: x = 1 n n j=1 x j.
191 Věta: EX n = 1 n n j=1 EX = EX, DX n = 1 n 2 n j=1 DX = 1 n DX, σ Xn = pokud existují. (Zde EX = EX j atd.) 1 n DX = 1 n σ X, Důsledek: Výběrový průměr je nestranný konzistentní odhad střední hodnoty. (Nezávisle na typu rozdělení.) Čebyševova nerovnost pro X n dává P [ Xn EX ε ] DX n ε 2 = DX n ε 2 0 pro n. To platí i za obecnějších předpokladů (X j nemusí mít stejné rozdělení) slabý zákon velkých čísel.
192 Lidově se hovoří o přesném součtu nepřesných čísel, což je chyba, nebot součet nj=1 X j má rozptyl n DX. Relativní chyba součtu klesá, absolutní roste. Rozdělení výběrového průměru může být podstatně složitější než původní, jen ve speciálních případech je jednoduchá odpověd. Věta: Výběrový průměr z normálního rozdělení N(µ, σ 2 ) má normální rozdělení N ( µ, 1 n σ2) a je nejlepším nestranným odhadem střední hodnoty. Podobná věta platí i pro jiná rozdělení alespoň asymptoticky: Centrální limitní věta: Necht X j, j N, jsou nezávislé stejně rozdělené náhodné veličiny se střední hodnotou EX a směrodatnou odchylkou σ X 0. Pak normované náhodné veličiny n Y n = norm X n = (X n EX) σ X konvergují k normovanému normálnímu rozdělení v následujícím smyslu: t R : lim n F Y n (t) = lim n F norm X n (t) = Φ(t).
193 5.4 Výběrový rozptyl náhodného výběru X = (X 1,..., X n ) je statistika S 2 X = 1 n 1 n j=1 (X j X n ) 2. Alternativní značení: S 2 (Dvojka v horním indexu zde neznamená kvadrát!) Jeho realizaci značíme malým písmenem: s 2 X = 1 n 1 Praktičtější jednoprůchodový vzorec: n j=1 (x j x n ) 2. S 2 X = 1 n 1 n j=1 X 2 j n n 1 X2 n = 1 n 1 n j=1 X 2 j 1 n (n 1) ( n j=1 X j ) 2. Věta: ES 2 X = DX.
194 Důkaz: Z jednoprůchodového vzorce pro SX 2 dostáváme ESX 2 = n n 1 EX2 n n 1 EX2 n = n (DX + (EX) 2 DX n ( ) ) 2 EX n = n 1 = n (DX + (EX) 2 1n ) n 1 DX (EX)2 = DX. Věta: Výběrový rozptyl je nestranný konzistentní odhad rozptylu (pokud původní rozdělení má rozptyl a 4. centrální moment). Rozdělení výběrového rozptylu může být podstatně složitější. Speciálně pro rozdělení N(0, 1) a n = 2: X = X 1 + X 2 2, X 1 X = (X 2 X) = X 1 X 2 2 má rozdělení N ( 0, 1 2), S 2 X = (X 1 X) 2 + (X 2 X) 2 = 2 kde U = X 1 X 2 2 má rozdělení N (0, 1). ( X1 X 2 2 ) 2 = ( X1 X 2 2 ) 2 = U 2, Tomu říkáme rozdělení χ 2 s 1 stupněm volnosti.
195 5.4.1 Rozdělení χ 2 s η stupni volnosti je definováno jako rozdělení náhodné veličiny Y = η j=1 U 2 j, kde U j jsou nezávislé náhodné veličiny s normovaným normálním rozdělením N(0, 1). Značení: χ 2 (η). Jeho hustota je pro x > 0 f Y (y) = c(η) = Γ(z) = { c(η) y η 2 1 e y 2 pro y > 0, 0 jinak, 1 2 η 2 Γ ( η 0 2 ), t z 1 e t dt, speciálně Γ(m + 1) = m! pro všechna m N. Speciálně pro η = 2 je c(η) = 1/2 a dostáváme exponenciální rozdělení.

196

197 Hustoty rozdělení χ 2 s 1, 2,..., 10 stupni volnosti a jeho odmocniny ( vzdálenost od středu terče ).
198 Věta: Necht X, Y jsou nezávislé náhodné veličiny s rozdělením χ 2 (ξ), resp. χ 2 (η). Pak X + Y má rozdělení χ 2 (ξ + η). Věta: Pro náhodnou veličinu Y s rozdělením χ 2 s η stupni volnosti platí (Toto rozdělení není zvykem normovat.) EY = η, DY = 2 η Výběrový rozptyl z normálního rozdělení N(EX, DX) splňuje: (n 1) S 2 X DX má rozdělení χ 2 (n 1).
199 3
 je DS 2 X = 2 n 1 (DX)2.")
200 Rozdělení odhadu rozptylu pomocí vyběrového rozptylu SX 2 pro rozsah výběru 2, 3,..., 10 a 3 = , ,..., = 129. Důsledek: Rozptyl výběrového rozptylu z normálního rozdělení N(EX, DX) je DS 2 X = 2 n 1 (DX)2.
201 Věta: Pro náhodný výběr X = (X 1,..., X n ) z normálního rozdělení je X nejlepší nestranný odhad střední hodnoty, SX 2 je nejlepší nestranný odhad rozptylu a statistiky X, SX 2 jsou konzistentní a nezávislé. Existuje však vychýlený odhad rozptylu, který je eficientnější: Alternativní odhad rozptylu DX = 1 n n j=1 (X j X n ) 2 = n 1 n S2 X. Věta: DX je vychýlený konzistentní odhad rozptylu. Důkaz: E DX = n 1 n DX DX,
202 DX má rozptyl menší než SX 2, a to v poměru ( ) n 1 2. n Eficienci nemůžeme porovnat obecně; aspoň pro normální rozdělení: 1. eficience odhadu S 2 X : DS 2 X = 2 n 1 (DX)2. 2. eficience odhadu DX (DX je konstanta): E( DX DX) 2 = D ( DX DX ) + ( E ( DX DX )) 2 = a protože ( 1 ) 2 = = D ( DX ) + n DX ( ) n = n n 1 (DX)2 + 1 n 2 (DX)2 = 2n 1 n 2 (DX) 2, je odhad DX více eficientní než S 2 X 2n 1 n 2 < 2 n < 2 n 1, (který je nejlepší nestranný!).
203 5.5 Výběrová směrodatná odchylka náhodného výběru X = (X 1,..., X n ) je statistika Alternativní značení: S S X = S 2 X = 1 n 1 n j=1 (X j X n ) 2. Její realizaci značíme malým písmenem: s X = 1 n 1 n j=1 (x j x n ) 2. Věta: ES X σ X. Rovnost obecně nenastává, takže to není nestranný odhad směrodatné odchylky!
204 Důkaz: DX = ESX 2 = (ES X) 2 + DS } {{ X } 0 σ X ES X. (ES X ) 2, Věta: Výběrová směrodatná odchylka je konzistentní odhad směrodatné odchylky (pokud původní rozdělení má rozptyl a 4. centrální moment). 5.6 Výběrový k-tý obecný moment náhodného výběru X = (X 1,..., X n ) je statistika M X k = 1 n n j=1 X k j. Alternativní značení: M k
205 Jeho realizaci značíme malým písmenem: m X k = 1 n n j=1 x k j. Věta: EM X k = EX k. (Tj. je to nestranný odhad k-tého obecného momentu.) Věta: Výběrový k-tý obecný moment je konzistentní odhad k-tého obecného momentu (pokud X má k-tý a 2 k-tý obecný moment). Důkaz: DM X k = 1 n 2 n DXk = 1 n DXk = 1 n ( E(X k ) 2 (EX k ) 2) = 1 n ( EX 2 k (EX k ) 2).
206 5.7 Histogram a empirické rozdělení V (nenáhodném) vektoru x = (x 1,..., x n ) R n (získaném např. jako realizace náhodného výběru) nezáleží na pořadí složek (ale záleží na jejich opakování). Úsporněji je popsán množinou hodnot H = {x 1,..., x n } (ta má nejvýše n prvků, obvykle méně) a jejich četnostmi n t, t H. Tato data obvykle znázorňujeme tabulkou četností nebo grafem zvaným histogram. Normováním dostaneme relativní četnosti r t = n t n, t H. Jelikož t H r t = 1, definují relativní četnosti pravděpodobnostní funkci p Emp(x) (t) = r t tzv. empirického rozdělení Emp(x). Je to diskrétní rozdělení s nejvýše n hodnotami charakterizující vektor x Vlastnosti empirického rozdělení (Indexem Emp(x) označujeme parametry jakékoli náhodné veličiny, která má toto rozdělení.)
207 E Emp(x) = t H E (Emp(x)) k = t H t r t = 1 n t k r t = 1 n t H t H t n t = 1 n t k n t = 1 n n i=1 n x i = x, i=1 x k i. D Emp(x) = = 1 n t H n i=1 (t E Emp(x)) 2 r t = 1 n (x i x) 2 = n 1 n s2 X. t H (t x) 2 n t Obecné momenty empirického rozdělení se rovnají výběrovým momentům původního rozdělení. Výpočet z histogramu (z empirického rozdělení) může být jednodušší než z původní realizace náhodného výběru (pokud se opakují stejné hodnoty). Rozptyl empirického rozdělení odpovídá odhadu DX = n 1 n rozdělení, odlišnému od SX 2. S2 X rozptylu původního
208 5.8 Výběrový medián je medián empirického rozdělení, q Emp(x) ( 1 2 ). Poskytuje jinou informaci než výběrový průměr, mnohdy užitečnější (mj. robustnější odolnější vůči vlivu vychýlených hodnot, outliers). Navíc víme, jak se změní monotonní funkcí. Proč se používá méně než výběrový průměr: Výpočetní náročnost je vyšší; seřazení hodnot má pracnost úměrnou n ln n, zatímco výběrový průměr n. Pamět ová náročnost je vyšší potřebujeme zapamatovat všechna data, u výběrového průměru stačí 2 registry. Možnosti decentralizace a paralelizace výpočtu výběrového mediánu jsou velmi omezené.
209 5.9 Intervalové odhady Dosud jsme skutečnou hodnotu parametru ϑ nahrazovali bodovým odhadem Θ (což je náhodná veličina). Nyní místo toho hledáme intervalový odhad, tzv. interval spolehlivosti I, což je minimální interval takový, že P [ϑ I] 1 α, kde α (0, 2 1 ) je pravděpodobnost, že meze intervalu I budou překročeny; 1 α je koeficient spolehlivosti. Obvykle hledáme horní, resp. dolní jednostranný odhad, kdy I = (, q Θ(1 α), resp. I = q Θ(α), ), nebo (symetrický) oboustranný odhad, I = ( ) α, q Θ q Θ 2 ( 1 α ) 2. K tomu potřebujeme znát rozdělení odhadu Θ.
210 5.10 Intervalové odhady parametrů normálního rozdělení N(µ, σ 2 ) Odhad střední hodnoty při známém rozptylu σ 2 µ odhadneme výběrovým průměrem X s rozdělením N Normovaná náhodná veličina norm X = n σ [ n P σ (X µ) (, Φ 1 (1 α) = 1 α [ ] n = P σ (X µ) Φ 1 (1 α) = P = P [ [ µ X + σ n Φ 1 (1 α) µ ( ( µ, σ2 n ). (X µ) má rozdělení N(0, 1);, X + σ n Φ 1 (1 α) ] ] ].
211 Obdobně dostaneme i další intervalové odhady (, X + σ n Φ 1 (1 α) X σ n Φ 1 (1 α), X σ n Φ 1 ( 1 α 2 kde X σ n Φ 1 (1 α) = X + σ n Φ 1 (α) ) ),,, X + σ n Φ 1 ( 1 α 2 ), (Φ 1 (α) = Φ 1 (1 α) ovšem nebývá v tabulkách). Při výpočtu nahradíme výběrový průměr X jeho realizací x Odhad střední hodnoty při neznámém rozptylu µ odhadneme výběrovým průměrem X s rozdělením N ( µ, σ2 n ),
212 σ 2 odhadneme výběrovým rozptylem S 2 X ; (n 1) S2 X σ 2 má rozdělení χ 2 (n 1). Testujeme analogicky náhodnou veličinu normální, ačkoli X, S X jsou nezávislé. n S X (X µ), její rozdělení však není Studentovo t-rozdělení (autor: Gossett) s η stupni volnosti je rozdělení náhodné veličiny U V η, kde U má rozdělení N(0, 1), V má rozdělení χ 2 (η), U, V jsou nezávislé.
213 Značení: t(η). Hustota: ( f t(η) (x) = c (η) 1 + x2 η c (η) = Γ ( ) 1+η 2 ( ) ηπ Γ n2. )1 η 2, Symetrie kolem nuly q t(η) (1 α) = q t(η) (α). Pro velký počet stupňů volnosti se nahrazuje normálním rozdělením.
214

215 Hustota normovaného normálního rozdělení a Studentova rozdělení s 5 stupni volnosti (původního a normovaného).
Numerické metody pro nalezení
 Masarykova univerzita Brno Fakulta přírodovědecká Katedra aplikované matematiky Numerické metody pro nalezení vlastních čísel matic Diplomová práce květen 006 Alena Baštincová Poděkování V úvodu bych ráda
Masarykova univerzita Brno Fakulta přírodovědecká Katedra aplikované matematiky Numerické metody pro nalezení vlastních čísel matic Diplomová práce květen 006 Alena Baštincová Poděkování V úvodu bych ráda
FAKULTA STAVEBNÍ GEODÉZIE, KARTOGRAFIE A GEOINFORMATIKA
 ČESKÉ VYSOKÉ UČENÍ TECHNICKÉ FAKULTA STAVEBNÍ OBOR GEODÉZIE, KARTOGRAFIE A GEOINFORMATIKA BAKALÁŘSKÁ PRÁCE MATICOVÉ ROZKLADY PRO KALMANŮV FILTR Vedoucí práce: doc. RNDr. Milada Kočandrlová, CSc. Katedra
ČESKÉ VYSOKÉ UČENÍ TECHNICKÉ FAKULTA STAVEBNÍ OBOR GEODÉZIE, KARTOGRAFIE A GEOINFORMATIKA BAKALÁŘSKÁ PRÁCE MATICOVÉ ROZKLADY PRO KALMANŮV FILTR Vedoucí práce: doc. RNDr. Milada Kočandrlová, CSc. Katedra
Úvod do statistiky (interaktivní učební text) - Řešené příklady. Martina Litschmannová
 - Řešené příklady. Martina Litschmannová") Vysoká škola báňská Technická univerzita Ostrava Západočeská univerzita v Plzni Úvod do statistiky (interaktivní učební text) - Řešené příklady Martina Litschmannová 1. strana ze 159 1 Explorační analýza
Vysoká škola báňská Technická univerzita Ostrava Západočeská univerzita v Plzni Úvod do statistiky (interaktivní učební text) - Řešené příklady Martina Litschmannová 1. strana ze 159 1 Explorační analýza
Ω = 6 6 3 = 1 36 = 0.0277,
 Příklad : Házíme třemi kostkami. Jaká je pravděpodobnost, že součet bude roven 5? Jev A značí příznivé možnosti: {,, 3}; {,, }; {, 3, }; {,, }; {,, }; {3,, }; P (A) = A Ω = 6 6 3 = 36 = 0.077, kde. značí
Příklad : Házíme třemi kostkami. Jaká je pravděpodobnost, že součet bude roven 5? Jev A značí příznivé možnosti: {,, 3}; {,, }; {, 3, }; {,, }; {,, }; {3,, }; P (A) = A Ω = 6 6 3 = 36 = 0.077, kde. značí
JIHOČESKÁ UNIVERZITA, PEDAGOGICKÁ FAKULTA ÚVOD DO STATISTIKY. Tomáš MRKVIČKA, Vladimíra PETRÁŠKOVÁ
 JIHOČESKÁ UNIVERZITA, PEDAGOGICKÁ FAKULTA ÚVOD DO STATISTIKY Tomáš MRKVIČKA, Vladimíra PETRÁŠKOVÁ ČESKÉ BUDĚJOVICE 2006 Recenzenti: prof. RNDr. Jindřich Klůfa, CSc., doc. RNDr. Pavel Tlustý, CSc. c Tomáš
JIHOČESKÁ UNIVERZITA, PEDAGOGICKÁ FAKULTA ÚVOD DO STATISTIKY Tomáš MRKVIČKA, Vladimíra PETRÁŠKOVÁ ČESKÉ BUDĚJOVICE 2006 Recenzenti: prof. RNDr. Jindřich Klůfa, CSc., doc. RNDr. Pavel Tlustý, CSc. c Tomáš
DYNAMICKÉ SYSTÉMY I. Marek Lampart Michaela Mlíchová Lenka Obadalová
 DYNAMICKÉ SYSTÉMY I Jana Dvořáková Marek Lampart Michaela Mlíchová Lenka Obadalová Předmluva Tento učební text vznikl v rámci projektu FRVŠ č. 2644/2008. Jde o učební text určený pro první semestr předmětu
DYNAMICKÉ SYSTÉMY I Jana Dvořáková Marek Lampart Michaela Mlíchová Lenka Obadalová Předmluva Tento učební text vznikl v rámci projektu FRVŠ č. 2644/2008. Jde o učební text určený pro první semestr předmětu
FAKULTA ELEKTROTECHNICKÁ
 ČESKÉ VYSOKÉ UČENÍ TECHNICKÉ FAKULTA ELEKTROTECHNICKÁ Měření zpoždění mezi signály EEG Ondřej Drbal Vedoucí diplomové práce: Doc. Ing. Roman katedra Teorie obvodů rok obhajoby 24 Čmejla, CSc. Zadání diplomové
ČESKÉ VYSOKÉ UČENÍ TECHNICKÉ FAKULTA ELEKTROTECHNICKÁ Měření zpoždění mezi signály EEG Ondřej Drbal Vedoucí diplomové práce: Doc. Ing. Roman katedra Teorie obvodů rok obhajoby 24 Čmejla, CSc. Zadání diplomové
Základní pojmy a úvod do teorie pravděpodobnosti. Ing. Michael Rost, Ph.D.
 Základní pojmy a úvod do teorie pravděpodobnosti Ing. Michael Rost, Ph.D. Co je to Statistika? Statistiku lze definovat jako vědní obor, zabývající se hromadnými jevy a procesy. Statistika zahrnuje jak
Základní pojmy a úvod do teorie pravděpodobnosti Ing. Michael Rost, Ph.D. Co je to Statistika? Statistiku lze definovat jako vědní obor, zabývající se hromadnými jevy a procesy. Statistika zahrnuje jak
Základní pojmy termodynamiky
 Kapitola 1 Základní pojmy termodynamiky 1.1 Úvod Moderní přírodní vědy a fyzika jsou postaveny na experimentu a pozorování. Poznávání zákonitostí neživé přírody je založeno na indukční vědecké metodě Francise
Kapitola 1 Základní pojmy termodynamiky 1.1 Úvod Moderní přírodní vědy a fyzika jsou postaveny na experimentu a pozorování. Poznávání zákonitostí neživé přírody je založeno na indukční vědecké metodě Francise
MASARYKOVA UNIVERZITA. Moduly nad okruhy hlavních ideálů JANA MEDKOVÁ
 MASARYKOVA UNIVERZITA Přírodovědecká fakulta Moduly nad okruhy hlavních ideálů JANA MEDKOVÁ Bakalářská práce Vedoucí práce: prof. RNDr. Radan Kučera, DSc. Studijní program: matematika Studijní obor: obecná
MASARYKOVA UNIVERZITA Přírodovědecká fakulta Moduly nad okruhy hlavních ideálů JANA MEDKOVÁ Bakalářská práce Vedoucí práce: prof. RNDr. Radan Kučera, DSc. Studijní program: matematika Studijní obor: obecná
Srovnatelnost skupin pacientů v observačních a klinických studiích Bakalářská práce
 MASARYKOVA UNIVERZITA PŘÍRODOVĚDECKÁ FAKULTA STUDIJNÍ PROGRAM: EXPERIMENTÁLNÍ BIOLOGIE Srovnatelnost skupin pacientů v observačních a klinických studiích Bakalářská práce Adéla Šenková VEDOUCÍ PRÁCE: RND
MASARYKOVA UNIVERZITA PŘÍRODOVĚDECKÁ FAKULTA STUDIJNÍ PROGRAM: EXPERIMENTÁLNÍ BIOLOGIE Srovnatelnost skupin pacientů v observačních a klinických studiích Bakalářská práce Adéla Šenková VEDOUCÍ PRÁCE: RND
Uvažování o počtech, množstvích a číslech
 Uvažování o počtech, množstvích a číslech Adam Nohejl 27. ledna 2010 Ne náhodou sdílí počítání se čtením příznačný praslovanský základ čit- s původním významem rozeznávat (podle [6]). Číst (psát) a počítat
Uvažování o počtech, množstvích a číslech Adam Nohejl 27. ledna 2010 Ne náhodou sdílí počítání se čtením příznačný praslovanský základ čit- s původním významem rozeznávat (podle [6]). Číst (psát) a počítat
Celá a necelá část reálného čísla
 UNIVERZITA KARLOVA V PRAZE PEDAGOGICKÁ FAKULTA Katedra matematiky a didaktiky matematiky Celá a necelá část reálného čísla Bakalářská práce Autor: Vedoucí práce: Vladimír Bílek Prof. RNDr. Jarmila Novotná,
UNIVERZITA KARLOVA V PRAZE PEDAGOGICKÁ FAKULTA Katedra matematiky a didaktiky matematiky Celá a necelá část reálného čísla Bakalářská práce Autor: Vedoucí práce: Vladimír Bílek Prof. RNDr. Jarmila Novotná,
Nesprávná užívání statistické významnosti a jejich možná řešení*
 Nesprávná užívání statistické významnosti a jejich možná řešení* Petr Soukup** Institut sociologických studií Fakulta sociálních věd, Univerzita Karlova v Praze Improper Use of Statistical Significance
Nesprávná užívání statistické významnosti a jejich možná řešení* Petr Soukup** Institut sociologických studií Fakulta sociálních věd, Univerzita Karlova v Praze Improper Use of Statistical Significance
Obsah. 1 ÚVOD 2 1.1 Vektorové operace... 2 1.2 Moment síly k bodu a ose... 4 1.3 Statické ekvivalence silových soustav... 10 2 TĚŽIŠTĚ TĚLES 21
 Obsah 1 ÚVOD 1.1 Vektorové operace................................... 1. Moment síly k bodu a ose.............................. 4 1.3 Statické ekvivalence silových soustav........................ 1 TĚŽIŠTĚ
Obsah 1 ÚVOD 1.1 Vektorové operace................................... 1. Moment síly k bodu a ose.............................. 4 1.3 Statické ekvivalence silových soustav........................ 1 TĚŽIŠTĚ
Open Access Repository eprint
 Open Access Repository eprint Terms and Conditions: Users may access, download, store, search and print a hard copy of the article. Copying must be limited to making a single printed copy or electronic
Open Access Repository eprint Terms and Conditions: Users may access, download, store, search and print a hard copy of the article. Copying must be limited to making a single printed copy or electronic
8 Střední hodnota a rozptyl
 Břetislav Fajmon, UMAT FEKT, VUT Brno Této přednášce odpovídá kapitola 10 ze skript [1]. Také je k dispozici sbírka úloh [2], kde si můžete procvičit příklady z kapitol 2, 3 a 4. K samostatnému procvičení
Břetislav Fajmon, UMAT FEKT, VUT Brno Této přednášce odpovídá kapitola 10 ze skript [1]. Také je k dispozici sbírka úloh [2], kde si můžete procvičit příklady z kapitol 2, 3 a 4. K samostatnému procvičení
Střední hodnota a rozptyl náhodné. kvantilu. Ing. Michael Rost, Ph.D.
 Střední hodnota a rozptyl náhodné veličiny, vybraná rozdělení diskrétních a spojitých náhodných veličin, pojem kvantilu Ing. Michael Rost, Ph.D. Príklad Předpokládejme že máme náhodnou veličinu X která
Střední hodnota a rozptyl náhodné veličiny, vybraná rozdělení diskrétních a spojitých náhodných veličin, pojem kvantilu Ing. Michael Rost, Ph.D. Príklad Předpokládejme že máme náhodnou veličinu X která
EFEKTIVNÍ TERMOMECHANICKÉ VLASTNOSTI ZDIVA
 EFEKTIVNÍ TERMOMECHANICKÉ VLASTNOSTI ZDIVA Vypracoval: Vedoucí diplomové práce: Prof. Ing. Jiří Šejnoha, DrSc. Datum: 20. 12. 2005 PODĚKOVÁNÍ Na tomto místě bych rád poděkoval všem, kteří se zasloužili
EFEKTIVNÍ TERMOMECHANICKÉ VLASTNOSTI ZDIVA Vypracoval: Vedoucí diplomové práce: Prof. Ing. Jiří Šejnoha, DrSc. Datum: 20. 12. 2005 PODĚKOVÁNÍ Na tomto místě bych rád poděkoval všem, kteří se zasloužili
1 Linearní prostory nad komplexními čísly
 1 Linearní prostory nad komplexními čísly V této přednášce budeme hledat kořeny polynomů, které se dále budou moci vyskytovat jako složky vektorů nebo matic Vzhledem k tomu, že kořeny polynomu (i reálného)
1 Linearní prostory nad komplexními čísly V této přednášce budeme hledat kořeny polynomů, které se dále budou moci vyskytovat jako složky vektorů nebo matic Vzhledem k tomu, že kořeny polynomu (i reálného)
E(X) = np D(X) = np(1 p) 1 2p np(1 p) (n + 1)p 1 ˆx (n + 1)p. A 3 (X) =
 = np D(X) = np(1 p) 1 2p np(1 p) (n + 1)p 1 ˆx (n + 1)p. A 3 (X) =") Základní rozdělení pravděpodobnosti Diskrétní rozdělení pravděpodobnosti. Pojem Náhodná veličina s Binomickým rozdělením Bi(n, p), kde n je přirozené číslo, p je reálné číslo, < p < má pravděpodobnostní
Základní rozdělení pravděpodobnosti Diskrétní rozdělení pravděpodobnosti. Pojem Náhodná veličina s Binomickým rozdělením Bi(n, p), kde n je přirozené číslo, p je reálné číslo, < p < má pravděpodobnostní
ČÁST IX - M A K R O S K O P I C K É S Y S T É M Y
 ČÁST IX - M A K R O S K O P I C K É S Y S T É M Y 38 Struktura makroskopických systémů 39 Mechanické vlastnosti 40 Tepelné vlastnosti 41 Elektrické vlastnosti 42 Magnetické vlastnosti 43 Termoelektrické
ČÁST IX - M A K R O S K O P I C K É S Y S T É M Y 38 Struktura makroskopických systémů 39 Mechanické vlastnosti 40 Tepelné vlastnosti 41 Elektrické vlastnosti 42 Magnetické vlastnosti 43 Termoelektrické
4. Topologické vlastnosti množiny reálných
 Matematická analýza I přednášky M. Málka cvičení A. Hakové a R. Otáhalové Zimní semestr 2004/05 4. Topologické vlastnosti množiny reálných čísel V této kapitole definujeme přirozenou topologii na množině
Matematická analýza I přednášky M. Málka cvičení A. Hakové a R. Otáhalové Zimní semestr 2004/05 4. Topologické vlastnosti množiny reálných čísel V této kapitole definujeme přirozenou topologii na množině
1 Nástroje používané v mikroekonomii
 1 Nástroje používané v mikroekonomii 1.1 Předmět zkoumání Ekonomie se podle tradiční definice zabývá zkoumáním alokace vzácných zdrojů mezi různá alternativní užití tak, aby byly uspokojeny lidské potřeby.
1 Nástroje používané v mikroekonomii 1.1 Předmět zkoumání Ekonomie se podle tradiční definice zabývá zkoumáním alokace vzácných zdrojů mezi různá alternativní užití tak, aby byly uspokojeny lidské potřeby.
D A T A B Á Z O V É S Y S T É M Y
 1(22) Konceptuální úroveň - vytvářím první model reality - ER-model jednoduchý grafický aparát, dá se jednoduše identifikovat - entita skládá se z vlastností, které chci zpracovávat - Chenovo pojetí -
1(22) Konceptuální úroveň - vytvářím první model reality - ER-model jednoduchý grafický aparát, dá se jednoduše identifikovat - entita skládá se z vlastností, které chci zpracovávat - Chenovo pojetí -
Dendrometrie Garant předmětu : Doc.Ing.Josef Sequens, Csc.
 Dendrometrie Garant předmětu : Doc.Ing.Josef Sequens, Csc. POUŽITÁ LITERATURA : Korf, V.: Dendrometrie, Praha 1953 Assman, E.: Waldertragslehre, Mnichov 1961 Prodan, M.: Holzmeslehre, Franfurkt 1965 Korf,
Dendrometrie Garant předmětu : Doc.Ing.Josef Sequens, Csc. POUŽITÁ LITERATURA : Korf, V.: Dendrometrie, Praha 1953 Assman, E.: Waldertragslehre, Mnichov 1961 Prodan, M.: Holzmeslehre, Franfurkt 1965 Korf,
Spektrální vlastnosti rodin planetek podle přehlídky Sloan Digital Sky Survey
 Univerzita Hradec Králové Pedagogická fakulta Katedra Fyziky Spektrální vlastnosti rodin planetek podle přehlídky Sloan Digital Sky Survey Bakalářská práce Autor: Lenka Trojanová Studijní program: M 7530
Univerzita Hradec Králové Pedagogická fakulta Katedra Fyziky Spektrální vlastnosti rodin planetek podle přehlídky Sloan Digital Sky Survey Bakalářská práce Autor: Lenka Trojanová Studijní program: M 7530
STROJÍRENSKÁ METROLOGIE část 1
 Vysoká škola báňská Technická univerzita Ostrava FS STROJÍRENSKÁ METROLOGIE část 1 Šárka Tichá Ostrava 004 Obsah Předmluva... 6 1. Význam metrologie... 7. Základní pojmy... 7.1 Některé základní pojmy (ČSN
Vysoká škola báňská Technická univerzita Ostrava FS STROJÍRENSKÁ METROLOGIE část 1 Šárka Tichá Ostrava 004 Obsah Předmluva... 6 1. Význam metrologie... 7. Základní pojmy... 7.1 Některé základní pojmy (ČSN
Základy programování v GNU Octave pro předmět PPAŘ
 Základy programování v GNU Octave pro předmět PPAŘ Introduction to programing in Octave for subject denoted as Computer Aires Automation Control Jaroslav Popelka Bakalářská práce 2008 UTB ve Zlíně, Fakulta
Základy programování v GNU Octave pro předmět PPAŘ Introduction to programing in Octave for subject denoted as Computer Aires Automation Control Jaroslav Popelka Bakalářská práce 2008 UTB ve Zlíně, Fakulta
1. 1 V Z N I K A V Ý V O J A T O M O V É T E O R I E
 1. Atomová fyzika 9 1. 1 V Z N I K A V Ý V O J A T O M O V É T E O R I E V této kapitole se dozvíte: které experimentální skutečnosti si vynutily vznik atomové teorie; o historii vývoje modelů atomů. Budete
1. Atomová fyzika 9 1. 1 V Z N I K A V Ý V O J A T O M O V É T E O R I E V této kapitole se dozvíte: které experimentální skutečnosti si vynutily vznik atomové teorie; o historii vývoje modelů atomů. Budete