StatSoft Jaký je mezi nimi rozdíl?
|
|
|
- Dana Jandová
- před 10 lety
- Počet zobrazení:
Transkript
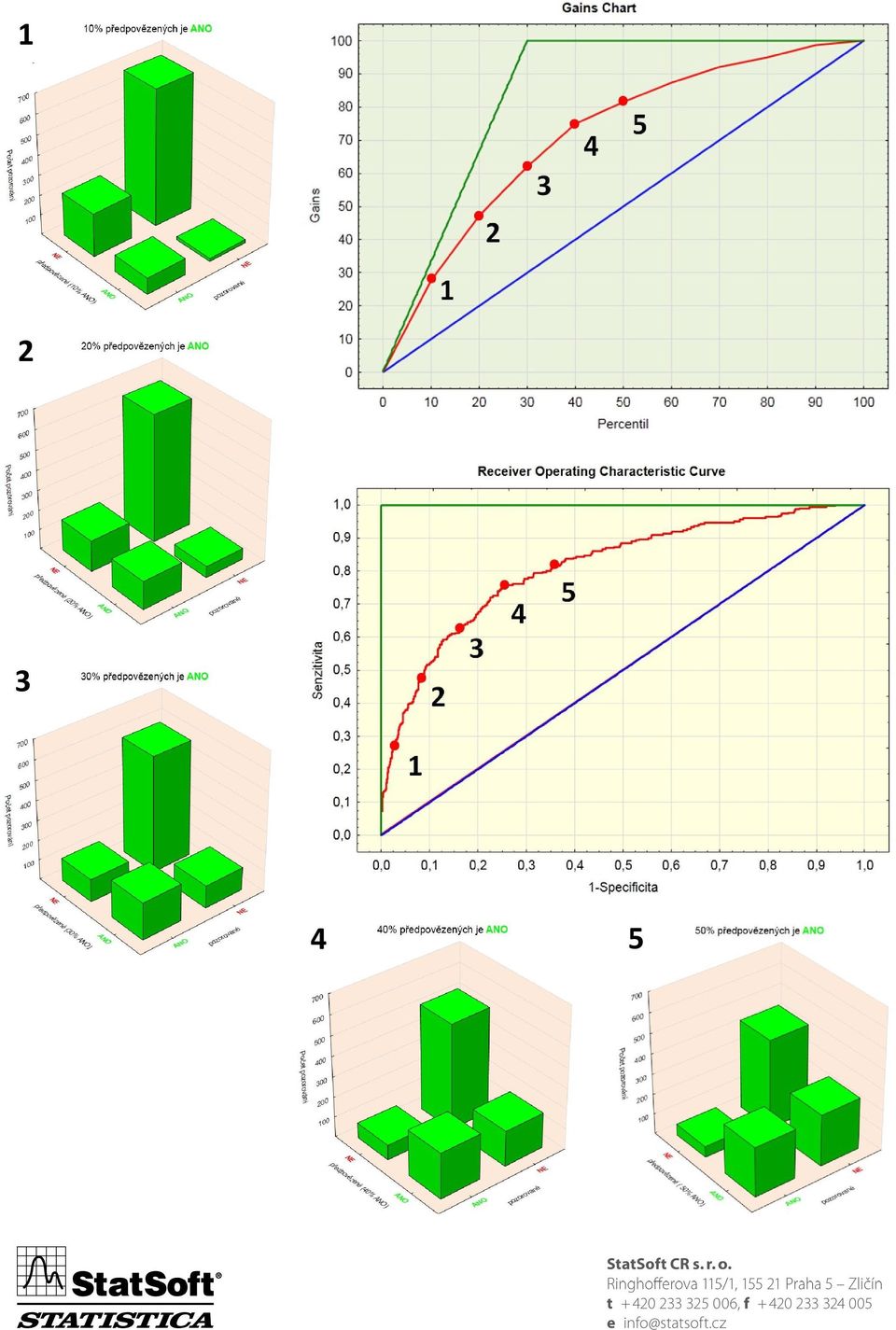
1 StatSoft Jaký je mezi nimi rozdíl? GAINS ROC X P okud se zabýváte klasifikačními úlohami, pak většinou potřebujete nějakým způsobem mezi sebou porovnat kvalitu vyprodukovaných modelů. Mezi základní pomůcky pro toto vyhodnocení patří Gains a ROC křivka. A právě těmito se budeme v tomto článku zabývat detailněji. Ačkoli jsou obě křivky známé a používané, je téměř nemožné dopátrat se, jaký je vlastně mezi nimi rozdíl. Proto jsme se rozhodli přijít této záhadě na kloub sami a ukázat Vám, jak to tedy je. Gains chart Nejdříve navodíme situaci a řekneme si, co je vlastně Gains chart (v angličtině také známo jako Cumulative Gains Chart, český ekvivalent se prakticky nepoužívá, dovolíme si alespoň přeložit a dále používat slovo křivka místo chart). Gains křivka se běžně vysvětluje na následujícím příkladu: Představme si, že děláme reklamní akci a oslovíme všechny naše stávající zákazníky, což je 1000 lidí, z nich 300 se na naši reklamní akci chytí a koupí si náš skvělý výrobek. Máme tedy úspěšnost 30%, přičemž jsme oslovili všech 1000 osob. Nicméně bychom byli rádi, kdybychom našli nějaký způsob, jak neoslovovat všechny, ale jen ty, kteří mají opravdu zájem. To by nám ušetřilo náklady na reklamní kampaň a zároveň ti, kteří nemají zájem a nebudou osloveni, by jistě uvítali, že je neobtěžujeme s něčím, o co vlastně nemají zájem. A právě s tímto úkolem nám přichází na pomoc statistika a její prediktivní klasifikační modely. Takových modelů je celá řada, ať už je to logistická regrese, klasifikační stromy, metody strojového učení nebo těžší kalibr v podobě neuronové sítě. Pokud máme nějaká historická data vhodná pro tento účel, můžeme sestavit modely, které nám předpoví, jestli si daný jedinec výrobek po reklamní akci koupí či nikoli. Výsledkem takového modelu je potom typicky tabulka pravděpodobností, jestli na danou akci jedinec zareaguje kladně či

2 nikoli. Pokud bychom tedy oslovovali osoby v pořadí podle velikosti pravděpodobnosti, že zareagují kladně, pak bychom měli být s dobrým modelem schopni lépe cílit v počáteční fázi oslovování, než kdybychom se ptali lidí náhodně. Gains křivka je poté vyjádřením tohoto principu. Na ose je procento oslovených z celkového počtu osob, na ose pak procento z těch, kteří odpověděli na naši kampaň pozitivně. Z tohoto obrázku můžete vše vyčíst. je Vezměme si například tento obrázek gains křivky, náš model představuje červená křivka: Co z něj můžeme například vyčíst - pokud se zeptáme na základě pravděpodobností z našeho modelu pouze 10% osob (v našem konkrétím příkladu to znamená tedy 100 osob), pak v nich bude 28% takových, kteří by odpověděli na naši nabídku kladně (28% ze 300, tedy 84 ze 100 odpoví kladně). Z hlediska statistické aplikace to znamená, ževybereme 10% osob s největší pravděpodobností na kladnou odpověď a tím, že je vybereme, jim vlastně předpovíme, že odpoví na naši kampaň kladně, ostatním pak logicky předpovíme, že kladně neodpoví a vůbec se jich ptát nemusíme (nechceme přece oslovovat ty, které to velmi pravděpodobně ani nezajímá). Při posunutí hranice a oslovení například 50% osob bychom již měli v oslovených přes 80% těch, kteří jsou nakloněni naší nabídce. Jinak řečeno, pokud oslovíme polovinu osob podle modelu z obrázku, pak ušetříme 50% nákladů a podaří se nám prodat více než 80% toho, co jsme vůbec schopni u všech 1000 osob prodat. Volba hranice pro rozhodovací mechanizmus, kolik procent oslovit, pak může vyplynout z konkrétní výše nákladů na reklamu a také ze zisku při kladné reakci. Gains křivka je pak jakési vyjádření závislosti na volbě hranice. Gains křivka pro popisovaný model je, jak už bylo řečeno, červená. Modrá křivka pak reprezentuje pro srovnání gains křivku modelu, kdy lidi vybíráme náhodně bez jakéhokoli schématu tedy zeptáme se 10% lidí a podařilo se nám oslovit přibližně 10% z celkového počtu těch, jež jsou nabídce nakloněni. Křivky se setkávají logicky v bodě (0;0) a (100;100). Tento druhý bod zmanená, že pokud se zeptáme všech osob, pak budeme mít také dotázáno i 100% těch, kteří by odpověděli kladně, nikdo další totiž už nezbývá. Je ale jasné, že ptát se všech v naší situaci trochu ztrácí smysl nač oslovovat lidi v nějakém sofistikovaném pořadí, když nakonec oslovíme stejně všechny. Zelená křivka je pak optimální model, kdy bychom oslovili nejdříve všechny, kteří budou na naši nabídku reagovat kladně a pak až ty ostatní směrnice vzestupu závisí tedy na poměru mezi kladně a záporně reagujícími (v tomto příkladě nám reagovalo kladně 300, což je 30% osob). Samozřejmě tento model je jen teoretický, v praxi jej dosáhne jen Chuck Norris.

3 Graf správně a špatně zařazených Pokud nějakým modelem určíme, které osoby do kampaně zahrnout a které již ne, pak jsme schopni napočítat následující kontingenční tabulku (terminologie v buňkách typická jako u testování hypotéz): Ve skutečnosti ANO Ve skutečnosti NE Předpovíme ANO počet TP (správné rozhodnutí) počet FP (chyba druhého druhu) Předpovíme NE počet FN (chyba prvního druhu) počet (správné rozhodnutí) Samozřejmě se snažíme ideálně o model, aby správná rozhodnutí byla co nejčastější. I takováto tabulka je důležitou rozhodovací pomůckou při hodnocení kvality modelů a zkoumané křivky z ní vycházejí. Je důležité si uvědomit, že gains i ROC křivka vzniká vlastně vykreslením informací z většího počtu tabulek tohoto typu. Pro názornost a lepší orientaci v číslech je vhodné tuto tabulku vykreslovat do grafu, což se v praxi také běžně dělá. Z tohoto grafu jasně vidíme, kolikrát se model dopustil té které chyby a také hned vidíme, jak jsme se s předpovědí trefili. Čím lepší model, tím vyšší sloupce na diagonále (směrem k nám) a menší na krajích. FN TP Bod na gains křivce je tedy vlastně z tohoto pohledu vykreslení proti pocet FP. Dalšími pojmy, které se k tabulce správně a špatně zařazených váží, jsou pojmy spočítají následovně: FP specificita specificita pocet pocet pocet FP senzitivita a sensitivita, které se

4 ROC křivka ROC křivka (Receiver Operating Characteristics curve) je pak vykreslení specificity a sensitivity opět v závislosti na měnící se hranici pravděpodobnosti, pod kterou již předpovídáme, že osoba na reklamu nezareaguje (červená křivka zobrazuje stejný model, jako tomu bylo v příkladu gains křivky výše). Na osu se tedy vykresluje něco jako kvalita zařazení těch, co by ve skutečnosti odpověděli kladně, zatímco na osu vykresluje nekvalita zařazení těch, kteří ve skutečnosti kladně neodpoví. se Nejlepší možný model by zde byl takový, že senzitivita by stoupla na maximum, zatímco specificita by byla po celou dobu 1 (optimální model je naznačen v ROC grafu zelenou barvou). Čím blíže se ROC křivkou našeho modelu blížíme optimálnímu modelu, tím je náš model kvalitnější. Využití Gains a ROC křivka se používá jako shrnující charakteristika kvality modelu, průběh křivek napoví mnoho o vlastnostech modelu, je krásně vidět o kolik je náš model lepší než model, kde předpovídáme kategorie čistě náhodně, stejně jako je vidět, jak je model daleko od optimálního modelu. Pomocí těchto křivek je možné stanovit hranici klasifikátoru, která určí přes jakou pravděpodobnost je potřeba přelézt, abychom zařadili pozorování do dané skupiny (typicky volená hranice 0,5 totiž vůbec nemusí odpovídat nákladům či účelu modelu). Více gains či ROC křivek různých modelů v jednom grafu pak dává možnost porovnat kvalitu modelů. Je potřeba poznamenat, že gains i ROC křivka se vždy váže k jedné kategorii. My jsme se zabývali výhradně kategorií reagoval na nabídku ANO, protože to je objektem našeho zájmu. Mohli bychom si ale vykreslit i křivky ke kategorii reagoval na nabídku NE. Při existenci více kategorií bychom byli schopni vykreslit tolik křivek, kolik je kategorií závislé veličiny. Data pro křivku se pak počítají jako data z dané kategorie proti zbytku dat (ostatní kategorie se berou v tomto případě jako jedna sloučená kategorie).
.")
5 A jaký je tedy mezi nimi rozdíl? Obě křivky tedy vykreslují průběh správně zařazených osob kategorie, která nás zajímá (v našem příkladu: reagoval na nabídku ANO), v závislosti na měnícím se prahu zařazení do této kategorie. Rozdílem je tedy jen měřítko na ose tedy to, vůči čemu se se hodnota vynáší. Osa značí u obou grafů to stejné, jmenovitě tedy senzitivitu. Na ose je potom v jednom případě počet předpovězených pro danou skupinu (v tomto případě kategorie reagoval na nabídku ANO) nebo nekvalita zařazení druhé skupiny (tedy skupiny reagoval na nabídku NE). Kdo má rád vzorečky, jistě uvítá následující shrnutí rozdílu mezi křivkami: Gains osa : osa : ROC pocet FP pocet FP pocet pocet FP Pro propojení a jednodušší zapamatování všech zmíněných vykreslovaných veličin si ještě trochu pohrajeme s grafy a pokusíme se Vám ukázat, jak v nich jsou dané vzorce vidět (barvičky odpovídají barvám u vzorců): FN TP FP Na následující a zároveň poslední stránce našeho článku se můžete pokochat skupinou grafů, které se snaží osvětlit celý princip skrz propojení mezi gains křivkou, ROC křivkou a také tabulkami správných a špatných zařazení. Jistě uznáte, že další stránku bychom textem pouze znehodnotili, proto se loučíme již zde a přejeme mnoho kvalitních prediktivních modelů.
 nebo nekvalita zařazení druhé skupiny (tedy skupiny reagoval na nabídku NE).")
6
Diagnostika regrese pomocí grafu 7krát jinak
 StatSoft Diagnostika regrese pomocí grafu 7krát jinak V tomto článečku si uděláme exkurzi do teorie regresní analýzy a detailně se podíváme na jeden jediný diagnostický graf. Jedná se o graf Předpovědi
StatSoft Diagnostika regrese pomocí grafu 7krát jinak V tomto článečku si uděláme exkurzi do teorie regresní analýzy a detailně se podíváme na jeden jediný diagnostický graf. Jedná se o graf Předpovědi
Tvar dat a nástroj přeskupování
 StatSoft Tvar dat a nástroj přeskupování Chtěli jste někdy použít data v jistém tvaru a STATISTICA Vám to nedovolila? Jistě se najde někdo, kdo se v této situaci již ocitl. Není ale potřeba propadat panice,
StatSoft Tvar dat a nástroj přeskupování Chtěli jste někdy použít data v jistém tvaru a STATISTICA Vám to nedovolila? Jistě se najde někdo, kdo se v této situaci již ocitl. Není ale potřeba propadat panice,
StatSoft Jak vyzrát na datum
 StatSoft Jak vyzrát na datum Tento článek se věnuje podrobně možnostem práce s proměnnými, které jsou ve formě datumu. A že jich není málo. Pokud potřebujete pracovat s datumem, pak se Vám bude tento článek
StatSoft Jak vyzrát na datum Tento článek se věnuje podrobně možnostem práce s proměnnými, které jsou ve formě datumu. A že jich není málo. Pokud potřebujete pracovat s datumem, pak se Vám bude tento článek
StatSoft Jak se pozná normalita pomocí grafů?
 StatSoft Jak se pozná normalita pomocí grafů? Dnes se podíváme na zoubek speciální třídě grafů, podle názvu článku a případně i ilustračního obrázku vpravo jste jistě již odhadli, že půjde o třídu pravděpodobnostních
StatSoft Jak se pozná normalita pomocí grafů? Dnes se podíváme na zoubek speciální třídě grafů, podle názvu článku a případně i ilustračního obrázku vpravo jste jistě již odhadli, že půjde o třídu pravděpodobnostních
JEDNOVÝBĚROVÉ TESTY. Komentované řešení pomocí programu Statistica
 JEDNOVÝBĚROVÉ TESTY Komentované řešení pomocí programu Statistica Vstupní data Data umístěná v excelovském souboru překopírujeme do tabulky ve Statistice a pojmenujeme proměnné, viz prezentace k tématu
JEDNOVÝBĚROVÉ TESTY Komentované řešení pomocí programu Statistica Vstupní data Data umístěná v excelovském souboru překopírujeme do tabulky ve Statistice a pojmenujeme proměnné, viz prezentace k tématu
LINEÁRNÍ REGRESE Komentované řešení pomocí programu Statistica
 LINEÁRNÍ REGRESE Komentované řešení pomocí programu Statistica Vstupní data Data umístěná v excelovském souboru překopírujeme do tabulky ve Statistice a pojmenujeme proměnné, viz prezentace k tématu Popisná
LINEÁRNÍ REGRESE Komentované řešení pomocí programu Statistica Vstupní data Data umístěná v excelovském souboru překopírujeme do tabulky ve Statistice a pojmenujeme proměnné, viz prezentace k tématu Popisná
SEMESTRÁLNÍ PRÁCE Z PŘEDMĚTU STATISTIKY
 ČESKÉ VYSOKÉ UČENÍ TECHNICKÉ FAKULTA DOPRAVNÍ SEMESTRÁLNÍ PRÁCE Z PŘEDMĚTU STATISTIKY Facebook vs. studium Vypracovali: Martina Grivalská Nikola Karkošiaková Barbora Brůhová Obsah 1. Úvod 2. Dotazník 3.
ČESKÉ VYSOKÉ UČENÍ TECHNICKÉ FAKULTA DOPRAVNÍ SEMESTRÁLNÍ PRÁCE Z PŘEDMĚTU STATISTIKY Facebook vs. studium Vypracovali: Martina Grivalská Nikola Karkošiaková Barbora Brůhová Obsah 1. Úvod 2. Dotazník 3.
prekrocena mez ukazatele kvality.
 Příklad efektivního využití dataminingových metod v oblasti kontroly kvality výroby Mgr. Petra Beranová Pokud hovoříme o data miningu (dolování dat), většina z nás si jako typické oblasti využití vybaví
Příklad efektivního využití dataminingových metod v oblasti kontroly kvality výroby Mgr. Petra Beranová Pokud hovoříme o data miningu (dolování dat), většina z nás si jako typické oblasti využití vybaví
Intervalový odhad. Interval spolehlivosti = intervalový odhad nějakého parametru s danou pravděpodobností = konfidenční interval pro daný parametr
 StatSoft Intervalový odhad Dnes se budeme zabývat neodmyslitelnou součástí statistiky a to intervaly v nejrůznějších podobách. Toto téma je také úzce spojeno s tématem testování hypotéz, a tedy plynule
StatSoft Intervalový odhad Dnes se budeme zabývat neodmyslitelnou součástí statistiky a to intervaly v nejrůznějších podobách. Toto téma je také úzce spojeno s tématem testování hypotéz, a tedy plynule
RNDr. Eva Janoušová doc. RNDr. Ladislav Dušek, Dr.
 Analýza dat pro Neurovědy RNDr. Eva Janoušová doc. RNDr. Ladislav Dušek, Dr. Jaro 2014 Institut biostatistiky Janoušová, a analýz Dušek: Analýza dat pro neurovědy Blok 6 Jak analyzovat kategoriální a binární
Analýza dat pro Neurovědy RNDr. Eva Janoušová doc. RNDr. Ladislav Dušek, Dr. Jaro 2014 Institut biostatistiky Janoušová, a analýz Dušek: Analýza dat pro neurovědy Blok 6 Jak analyzovat kategoriální a binární
RNDr. Eva Janoušová doc. RNDr. Ladislav Dušek, Dr.
 Analýza dat pro Neurovědy RNDr. Eva Janoušová doc. RNDr. Ladislav Dušek, Dr. Jaro 2014 Institut biostatistiky Janoušová, a analýz Dušek: Analýza dat pro neurovědy Blok 7 Jak hodnotit vztah spojitých proměnných
Analýza dat pro Neurovědy RNDr. Eva Janoušová doc. RNDr. Ladislav Dušek, Dr. Jaro 2014 Institut biostatistiky Janoušová, a analýz Dušek: Analýza dat pro neurovědy Blok 7 Jak hodnotit vztah spojitých proměnných
Jana Vránová, 3.lékařská fakulta UK, Praha. Hypotézy o populacích
 Jana Vránová, 3.lékařská fakulta UK, Praha Hypotézy o populacích Příklad IQ test: Předpokládejme, že z nějakého důvodu ministerstvo školství věří, že studenti absolventi středních škol v Hradci Králové
Jana Vránová, 3.lékařská fakulta UK, Praha Hypotézy o populacích Příklad IQ test: Předpokládejme, že z nějakého důvodu ministerstvo školství věří, že studenti absolventi středních škol v Hradci Králové
StatSoft Jak poznat vliv faktorů vizuálně
 StatSoft Jak poznat vliv faktorů vizuálně V tomto článku bychom se rádi věnovali otázce, jak poznat již z grafického náhledu vztahy a závislosti v analýze rozptylu. Pomocí následujících grafických zobrazení
StatSoft Jak poznat vliv faktorů vizuálně V tomto článku bychom se rádi věnovali otázce, jak poznat již z grafického náhledu vztahy a závislosti v analýze rozptylu. Pomocí následujících grafických zobrazení
KORELACE. Komentované řešení pomocí programu Statistica
 KORELACE Komentované řešení pomocí programu Statistica Vstupní data I Data umístěná v excelovském souboru překopírujeme do tabulky ve Statistice a pojmenujeme proměnné, viz prezentace k tématu Popisná
KORELACE Komentované řešení pomocí programu Statistica Vstupní data I Data umístěná v excelovském souboru překopírujeme do tabulky ve Statistice a pojmenujeme proměnné, viz prezentace k tématu Popisná
3. Optimalizace pomocí nástroje Řešitel
 3. Optimalizace pomocí nástroje Řešitel Rovnováha mechanické soustavy Uvažujme dvě různé nehmotné lineární pružiny P 1 a P 2 připevněné na pevné horizontální tyči splývající s osou x podle obrázku: (0,0)
3. Optimalizace pomocí nástroje Řešitel Rovnováha mechanické soustavy Uvažujme dvě různé nehmotné lineární pružiny P 1 a P 2 připevněné na pevné horizontální tyči splývající s osou x podle obrázku: (0,0)
Pravděpodobnostní rozdělení
 Náhodná proměnná Pravděpodobnostní rozdělení Základy logiky a matematiky, ISS FSV UK Martin Štrobl Tento pomocný materiál neobsahuje všechnu látku k danému tématu, pouze se zaměřuje na pochopení důležitých
Náhodná proměnná Pravděpodobnostní rozdělení Základy logiky a matematiky, ISS FSV UK Martin Štrobl Tento pomocný materiál neobsahuje všechnu látku k danému tématu, pouze se zaměřuje na pochopení důležitých
ANALÝZA A KLASIFIKACE DAT
 ANALÝZA A KLASIFIKACE DAT RNDr. Eva Janoušová INVESTICE DO ROZVOJE VZDĚLÁVÁNÍ HODNOCENÍ ÚSPĚŠNOSTI KLASIFIKACE A SROVNÁNÍ KLASIFIKÁTORŮ ÚVOD Vstupní data Subjekt Objem hipokampu Objem komor Skutečnost
ANALÝZA A KLASIFIKACE DAT RNDr. Eva Janoušová INVESTICE DO ROZVOJE VZDĚLÁVÁNÍ HODNOCENÍ ÚSPĚŠNOSTI KLASIFIKACE A SROVNÁNÍ KLASIFIKÁTORŮ ÚVOD Vstupní data Subjekt Objem hipokampu Objem komor Skutečnost
Odhady parametrů základního souboru. Cvičení 6 Statistické metody a zpracování dat 1 (podzim 2016) Brno, říjen listopad 2016 Ambrožová Klára
 Brno, říjen listopad 2016 Ambrožová Klára") Odhady parametrů základního souboru Cvičení 6 Statistické metody a zpracování dat 1 (podzim 2016) Brno, říjen listopad 2016 Ambrožová Klára Motivační příklad Mám průměrné roční teploty vzduchu z 8 stanic
Odhady parametrů základního souboru Cvičení 6 Statistické metody a zpracování dat 1 (podzim 2016) Brno, říjen listopad 2016 Ambrožová Klára Motivační příklad Mám průměrné roční teploty vzduchu z 8 stanic
10. Předpovídání - aplikace regresní úlohy
 10. Předpovídání - aplikace regresní úlohy Regresní úloha (analýza) je označení pro statistickou metodu, pomocí nichž odhadujeme hodnotu náhodné veličiny (tzv. závislé proměnné, cílové proměnné, regresandu
10. Předpovídání - aplikace regresní úlohy Regresní úloha (analýza) je označení pro statistickou metodu, pomocí nichž odhadujeme hodnotu náhodné veličiny (tzv. závislé proměnné, cílové proměnné, regresandu
Zpracování náhodného vektoru. Ing. Michal Dorda, Ph.D.
 Ing. Michal Dorda, Ph.D. 1 Př. 1: Cestující na vybraném spoji linky MHD byli dotazováni za účelem zjištění spokojenosti s kvalitou MHD. Legenda 1 Velmi spokojen Spokojen 3 Nespokojen 4 Velmi nespokojen
Ing. Michal Dorda, Ph.D. 1 Př. 1: Cestující na vybraném spoji linky MHD byli dotazováni za účelem zjištění spokojenosti s kvalitou MHD. Legenda 1 Velmi spokojen Spokojen 3 Nespokojen 4 Velmi nespokojen
Tabulka 1 Rizikové online zážitky v závislosti na místě přístupu k internetu N M SD Min Max. Přístup ve vlastním pokoji 10804 1,61 1,61 0,00 5,00
 Seminární úkol č. 4 Autoři: Klára Čapková (406803), Markéta Peschková (414906) Zdroj dat: EU Kids Online Survey Popis dat Analyzovaná data pocházejí z výzkumu online chování dětí z 25 evropských zemí.
Seminární úkol č. 4 Autoři: Klára Čapková (406803), Markéta Peschková (414906) Zdroj dat: EU Kids Online Survey Popis dat Analyzovaná data pocházejí z výzkumu online chování dětí z 25 evropských zemí.
Regresní a korelační analýza
 Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Neuronové časové řady (ANN-TS)
") Neuronové časové řady (ANN-TS) Menu: QCExpert Prediktivní metody Neuronové časové řady Tento modul (Artificial Neural Network Time Series ANN-TS) využívá modelovacího potenciálu neuronové sítě k predikci
Neuronové časové řady (ANN-TS) Menu: QCExpert Prediktivní metody Neuronové časové řady Tento modul (Artificial Neural Network Time Series ANN-TS) využívá modelovacího potenciálu neuronové sítě k predikci
Vytěžování znalostí z dat
 Vytěžování znalostí z dat Department of Computer Systems Faculty of Information Technology Czech Technical University in Prague Přednáška 5: Hodnocení kvality modelu BI-VZD, 09/2011 MI-POA Evropský sociální
Vytěžování znalostí z dat Department of Computer Systems Faculty of Information Technology Czech Technical University in Prague Přednáška 5: Hodnocení kvality modelu BI-VZD, 09/2011 MI-POA Evropský sociální
Cvičení 12: Binární logistická regrese
 Cvičení 12: Binární logistická regrese Příklad: V roce 2014 konalo státní závěrečné zkoušky bakalářského studia na jisté fakultě 167 studentů. U každého studenta bylo zaznamenáno jeho pohlaví (0 žena,
Cvičení 12: Binární logistická regrese Příklad: V roce 2014 konalo státní závěrečné zkoušky bakalářského studia na jisté fakultě 167 studentů. U každého studenta bylo zaznamenáno jeho pohlaví (0 žena,
PROJEKT DO STATISTIKY PRŮZKUM V TECHNICKÉ MENZE
 PROJEKT DO STATISTIKY PRŮZKUM V TECHNICKÉ MENZE Náplní tohoto projektu byl prvotní průzkum, následné statistické zpracování dat a vyhodnocení. Data jsme získaly skrze internetový dotazník, který jsme rozeslaly
PROJEKT DO STATISTIKY PRŮZKUM V TECHNICKÉ MENZE Náplní tohoto projektu byl prvotní průzkum, následné statistické zpracování dat a vyhodnocení. Data jsme získaly skrze internetový dotazník, který jsme rozeslaly
Rozhodnutí / Skutečnost platí neplatí Nezamítáme správně chyba 2. druhu Zamítáme chyba 1. druhu správně
 Testování hypotéz Nechť,, je náhodný výběr z nějakého rozdělení s neznámými parametry. Máme dvě navzájem si odporující hypotézy o parametrech daného rozdělení: Nulová hypotéza parametry (případně jediný
Testování hypotéz Nechť,, je náhodný výběr z nějakého rozdělení s neznámými parametry. Máme dvě navzájem si odporující hypotézy o parametrech daného rozdělení: Nulová hypotéza parametry (případně jediný
Předpovídejte snadno a rychle
 Předpovídejte snadno a rychle Newsletter Statistica ACADEMY Téma: Časové řady, exponenciální vyrovnávání Typ článku: Příklad Dnes se budeme zabývat situací, kdy chceme předpovídat, jak se bude v čase vyvíjet
Předpovídejte snadno a rychle Newsletter Statistica ACADEMY Téma: Časové řady, exponenciální vyrovnávání Typ článku: Příklad Dnes se budeme zabývat situací, kdy chceme předpovídat, jak se bude v čase vyvíjet
Testy dobré shody Máme dvě veličiny, u kterých bychom chtěli prokázat závislost, TESTY DOBRÉ SHODY (angl. goodness-of-fit tests)
") Testy dobré shody Máme dvě veličiny, u kterých bychom chtěli prokázat závislost, např. hmotnost a pohlaví narozených dětí. Běžný statistický postup pro ověření závislosti dvou veličin je zamítnutí jejich
Testy dobré shody Máme dvě veličiny, u kterých bychom chtěli prokázat závislost, např. hmotnost a pohlaví narozených dětí. Běžný statistický postup pro ověření závislosti dvou veličin je zamítnutí jejich
Kategorická data METODOLOGICKÝ PROSEMINÁŘ II TÝDEN 7 4. DUBNA dubna 2018 Lukáš Hájek, Karel Höfer Metodologický proseminář II 1
 Kategorická data METODOLOGICKÝ PROSEMINÁŘ II TÝDEN 7 4. DUBNA 2018 4. dubna 2018 Lukáš Hájek, Karel Höfer Metodologický proseminář II 1 Typy proměnných nominální (nominal) o dvou hodnotách lze říci pouze
Kategorická data METODOLOGICKÝ PROSEMINÁŘ II TÝDEN 7 4. DUBNA 2018 4. dubna 2018 Lukáš Hájek, Karel Höfer Metodologický proseminář II 1 Typy proměnných nominální (nominal) o dvou hodnotách lze říci pouze
StatSoft Odkud tak asi je?
 StatSoft Odkud tak asi je? Ukážeme si, jak bychom mohli vypočítat pravděpodobnosti, na které jsme se ptali v minulém newsletteru Úkolem bylo zjistit, z kterého kraje nejpravděpodobněji pochází náš výherce
StatSoft Odkud tak asi je? Ukážeme si, jak bychom mohli vypočítat pravděpodobnosti, na které jsme se ptali v minulém newsletteru Úkolem bylo zjistit, z kterého kraje nejpravděpodobněji pochází náš výherce
GRAF FUNKCE NEPŘÍMÁ ÚMĚRNOST
 GRAF FUNKCE NEPŘÍMÁ ÚMĚRNOST Úloha: Sestrojte graf funkce nepřímé úměrnosti a zjistěte její vlastnosti. Popis funkcí modelu: Sestrojit graf funkce nepřímá úměrnost Najít průsečíky grafu se souřadnými osami
GRAF FUNKCE NEPŘÍMÁ ÚMĚRNOST Úloha: Sestrojte graf funkce nepřímé úměrnosti a zjistěte její vlastnosti. Popis funkcí modelu: Sestrojit graf funkce nepřímá úměrnost Najít průsečíky grafu se souřadnými osami
Máte rádi kávu? Statistický výzkum o množství vypité kávy napříč věkovým spektrem.
 Máte rádi kávu? Statistický výzkum o množství vypité kávy napříč věkovým spektrem. SEMESTRÁLNÍ PRÁCE STATISTIKA VYPRACOVALA: IRENA VALÁŠKOVÁ A BARBORA SLAVÍKOVÁ DNE: 29. 12. 2012 SKUPINA: 2 36 Obsah Pár
Máte rádi kávu? Statistický výzkum o množství vypité kávy napříč věkovým spektrem. SEMESTRÁLNÍ PRÁCE STATISTIKA VYPRACOVALA: IRENA VALÁŠKOVÁ A BARBORA SLAVÍKOVÁ DNE: 29. 12. 2012 SKUPINA: 2 36 Obsah Pár
Lineární regrese. Komentované řešení pomocí MS Excel
 Lineární regrese Komentované řešení pomocí MS Excel Vstupní data Tabulka se vstupními daty je umístěna v oblasti A1:B11 (viz. obrázek) na listu cela data Postup Základní výpočty - regrese Výpočet základních
Lineární regrese Komentované řešení pomocí MS Excel Vstupní data Tabulka se vstupními daty je umístěna v oblasti A1:B11 (viz. obrázek) na listu cela data Postup Základní výpočty - regrese Výpočet základních
ČESKÉ VYSOKÉ UČENÍ TECHNICKÉ V PRAZE
 ČESKÉ VYSOKÉ UČENÍ TECHNICKÉ V PRAZE FAKULTA DOPRAVNÍ Statistický projekt STATISTIKA SLEDOVÁNÍ SERIÁLŮ A ZÁBAVNÍCH POŘADŮ Autoři: Jakub Volek, Zuzana Zapletalová Skupina: 240 Školní rok: 2011/2012 Oponenti:
ČESKÉ VYSOKÉ UČENÍ TECHNICKÉ V PRAZE FAKULTA DOPRAVNÍ Statistický projekt STATISTIKA SLEDOVÁNÍ SERIÁLŮ A ZÁBAVNÍCH POŘADŮ Autoři: Jakub Volek, Zuzana Zapletalová Skupina: 240 Školní rok: 2011/2012 Oponenti:
7.1.3 Vzdálenost bodů
 7.. Vzdálenost bodů Předpoklady: 70 Př. : Urči vzdálenost bodů A [ ;] a B [ 5;] obecný vzorec pro vzdálenost bodů A[ a ; a ] a [ ; ]. Na základě řešení příkladu se pokus sestavit B b b. y A[;] B[5;] Z
7.. Vzdálenost bodů Předpoklady: 70 Př. : Urči vzdálenost bodů A [ ;] a B [ 5;] obecný vzorec pro vzdálenost bodů A[ a ; a ] a [ ; ]. Na základě řešení příkladu se pokus sestavit B b b. y A[;] B[5;] Z
Fyzikální korespondenční seminář MFF UK
 Úloha I.S... náhodná 10 bodů; průměr 7,04; řešilo 45 studentů a) Zkuste vlastními slovy popsat, co je to náhodná veličina a jaké má vlastnosti (postačí vlastními slovy objasnit následující pojmy: náhodná
Úloha I.S... náhodná 10 bodů; průměr 7,04; řešilo 45 studentů a) Zkuste vlastními slovy popsat, co je to náhodná veličina a jaké má vlastnosti (postačí vlastními slovy objasnit následující pojmy: náhodná
Metody analýzy modelů. Radek Pelánek
 Metody analýzy modelů Radek Pelánek Fáze modelování 1 Formulace problému 2 Základní návrh modelu 3 Budování modelu 4 Verifikace a validace 5 Simulace a analýza 6 Sumarizace výsledků Simulace a analýza
Metody analýzy modelů Radek Pelánek Fáze modelování 1 Formulace problému 2 Základní návrh modelu 3 Budování modelu 4 Verifikace a validace 5 Simulace a analýza 6 Sumarizace výsledků Simulace a analýza
Regresní a korelační analýza
 Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
UNIVERZITA OBRANY Fakulta ekonomiky a managementu. Aplikace STAT1. Výsledek řešení projektu PRO HORR2011 a PRO GRAM2011 3. 11.
 UNIVERZITA OBRANY Fakulta ekonomiky a managementu Aplikace STAT1 Výsledek řešení projektu PRO HORR2011 a PRO GRAM2011 Jiří Neubauer, Marek Sedlačík, Oldřich Kříž 3. 11. 2012 Popis a návod k použití aplikace
UNIVERZITA OBRANY Fakulta ekonomiky a managementu Aplikace STAT1 Výsledek řešení projektu PRO HORR2011 a PRO GRAM2011 Jiří Neubauer, Marek Sedlačík, Oldřich Kříž 3. 11. 2012 Popis a návod k použití aplikace
Pearsonův korelační koeficient
 I I.I Pearsonův korelační koeficient Úvod Předpokládejme, že náhodně vybereme n objektů (nebo osob) ze zkoumané populace. Často se stává, že na každém z objektů měříme ne pouze jednu, ale několik kvantitativních
I I.I Pearsonův korelační koeficient Úvod Předpokládejme, že náhodně vybereme n objektů (nebo osob) ze zkoumané populace. Často se stává, že na každém z objektů měříme ne pouze jednu, ale několik kvantitativních
Vybraná rozdělení náhodné veličiny
 3.3 Vybraná rozdělení náhodné veličiny 0,16 0,14 0,12 0,1 0,08 0,06 0,04 0,02 0 Rozdělení Z 3 4 5 6 7 8 9 10 11 12 13 14 15 Život je umění vytvářet uspokojivé závěry na základě nedostatečných předpokladů.
3.3 Vybraná rozdělení náhodné veličiny 0,16 0,14 0,12 0,1 0,08 0,06 0,04 0,02 0 Rozdělení Z 3 4 5 6 7 8 9 10 11 12 13 14 15 Život je umění vytvářet uspokojivé závěry na základě nedostatečných předpokladů.
Testy do hodin - souhrnný test - 6. ročník
 Kolik procent škol jste předstihli Škola: Název: Obec: BCEH ZŠ a MŠ, Slezská 316 Slavkov - 6. ročník ČESKÝ JAZYK Máte lepší výsledky než 7 % zúčastněných škol. MATEMATIKA Máte lepší výsledky než 7 % zúčastněných
Kolik procent škol jste předstihli Škola: Název: Obec: BCEH ZŠ a MŠ, Slezská 316 Slavkov - 6. ročník ČESKÝ JAZYK Máte lepší výsledky než 7 % zúčastněných škol. MATEMATIKA Máte lepší výsledky než 7 % zúčastněných
Analýza dat na PC I.
 CENTRUM BIOSTATISTIKY A ANALÝZ Lékařská a Přírodovědecká fakulta, Masarykova univerzita Analýza dat na PC I. Popisná analýza v programu Statistica IBA výuka Základní popisná statistika Popisná statistika
CENTRUM BIOSTATISTIKY A ANALÝZ Lékařská a Přírodovědecká fakulta, Masarykova univerzita Analýza dat na PC I. Popisná analýza v programu Statistica IBA výuka Základní popisná statistika Popisná statistika
Analýza rozptylu dvojného třídění
 StatSoft Analýza rozptylu dvojného třídění V tomto příspěvku si ukážeme konkrétní práci v softwaru STATISTICA a to sice při detekci vlivu jednotlivých faktorů na chování laboratorních krys v bludišti.
StatSoft Analýza rozptylu dvojného třídění V tomto příspěvku si ukážeme konkrétní práci v softwaru STATISTICA a to sice při detekci vlivu jednotlivých faktorů na chování laboratorních krys v bludišti.
PORUCHY CHOVÁNÍ V ZÁKLADNÍM ŠKOLSTVÍ V DATECH
 PORUCHY CHOVÁNÍ V ZÁKLADNÍM ŠKOLSTVÍ V DATECH HLAVNÍ ZJIŠTĚNÍ Ve školním roce 2016/2017 se v základních školách vzdělávalo 9 225 dětí s diagnózou závažné poruchy chování (dále jen poruchy chování). 1 Většina
PORUCHY CHOVÁNÍ V ZÁKLADNÍM ŠKOLSTVÍ V DATECH HLAVNÍ ZJIŠTĚNÍ Ve školním roce 2016/2017 se v základních školách vzdělávalo 9 225 dětí s diagnózou závažné poruchy chování (dále jen poruchy chování). 1 Většina
Korelace. Komentované řešení pomocí MS Excel
 Korelace Komentované řešení pomocí MS Excel Vstupní data Tabulka se vstupními daty je umístěna v oblasti A2:B84 (viz. obrázek) Prvotní představu o tvaru a síle závislosti docházky a počtu bodů nám poskytne
Korelace Komentované řešení pomocí MS Excel Vstupní data Tabulka se vstupními daty je umístěna v oblasti A2:B84 (viz. obrázek) Prvotní představu o tvaru a síle závislosti docházky a počtu bodů nám poskytne
{ 3;4;5;6 } pravděpodobnost je zřejmě 4 = 2.
 9..3 Pravděpodobnosti jevů I Předpoklady: 90 Opět se vrátíme k hodu kostkou. Pokus má šest stejně pravděpodobných náhodných výsledků pravděpodobnost každého z nich je 6. Do domečku nám chybí tři políčka.
9..3 Pravděpodobnosti jevů I Předpoklady: 90 Opět se vrátíme k hodu kostkou. Pokus má šest stejně pravděpodobných náhodných výsledků pravděpodobnost každého z nich je 6. Do domečku nám chybí tři políčka.
PRAVDĚPODOBNOST A STATISTIKA. Testování hypotéz o rozdělení
 PRAVDĚPODOBNOST A STATISTIKA Testování hypotéz o rozdělení Testování hypotéz o rozdělení Nechť X e náhodná proměnná, která má distribuční funkci F(x, ϑ). Předpokládeme, že neznáme tvar distribuční funkce
PRAVDĚPODOBNOST A STATISTIKA Testování hypotéz o rozdělení Testování hypotéz o rozdělení Nechť X e náhodná proměnná, která má distribuční funkci F(x, ϑ). Předpokládeme, že neznáme tvar distribuční funkce
StatSoft Úvod do data miningu
 StatSoft Úvod do data miningu Tento článek je úvodním povídáním o data miningu, jeho vzniku, účelu a využití. Historie data miningu Rozvoj počítačů, výpočetní techniky a zavedení elektronického sběru dat
StatSoft Úvod do data miningu Tento článek je úvodním povídáním o data miningu, jeho vzniku, účelu a využití. Historie data miningu Rozvoj počítačů, výpočetní techniky a zavedení elektronického sběru dat
Jednofaktorová analýza rozptylu
 I I.I Jednofaktorová analýza rozptylu Úvod Jednofaktorová analýza rozptylu (ANOVA) se využívá při porovnání několika středních hodnot. Často se využívá ve vědeckých a lékařských experimentech, při kterých
I I.I Jednofaktorová analýza rozptylu Úvod Jednofaktorová analýza rozptylu (ANOVA) se využívá při porovnání několika středních hodnot. Často se využívá ve vědeckých a lékařských experimentech, při kterých
KGG/STG Statistika pro geografy
 KGG/STG Statistika pro geografy 9. Korelační analýza Mgr. David Fiedor 20. dubna 2015 Analýza závislostí v řadě geografických disciplín studujeme jevy, u kterých vyšetřujeme nikoliv pouze jednu vlastnost
KGG/STG Statistika pro geografy 9. Korelační analýza Mgr. David Fiedor 20. dubna 2015 Analýza závislostí v řadě geografických disciplín studujeme jevy, u kterých vyšetřujeme nikoliv pouze jednu vlastnost
TECHNICKÁ UNIVERZITA V LIBERCI
 TECHNICKÁ UNIVERZITA V LIBERCI Ekonomická fakulta Semestrální práce z předmětu Statistický rozbor dat z dotazníkového šetření Jméno: Lucie Krechlerová, Karel Kozma, René Dubský, David Drobík Ročník: 2015/2016
TECHNICKÁ UNIVERZITA V LIBERCI Ekonomická fakulta Semestrální práce z předmětu Statistický rozbor dat z dotazníkového šetření Jméno: Lucie Krechlerová, Karel Kozma, René Dubský, David Drobík Ročník: 2015/2016
Zadání Máme data hdp.wf1, která najdete zde: Bodová předpověď: Intervalová předpověď:
 Predikce Text o predikci pro upřesnění pro ty, které zajímá, kde se v EViews všechna ta čísla berou. Ruční výpočty u průběžného testu nebudou potřeba. Co bude v závěrečném testu, to nevím. Ale přečíst
Predikce Text o predikci pro upřesnění pro ty, které zajímá, kde se v EViews všechna ta čísla berou. Ruční výpočty u průběžného testu nebudou potřeba. Co bude v závěrečném testu, to nevím. Ale přečíst
VYUŽITÍ PRAVDĚPODOBNOSTNÍ METODY MONTE CARLO V SOUDNÍM INŽENÝRSTVÍ
 VYUŽITÍ PRAVDĚPODOBNOSTNÍ METODY MONTE CARLO V SOUDNÍM INŽENÝRSTVÍ Michal Kořenář 1 Abstrakt Rozvoj výpočetní techniky v poslední době umožnil také rozvoj výpočetních metod, které nejsou založeny na bázi
VYUŽITÍ PRAVDĚPODOBNOSTNÍ METODY MONTE CARLO V SOUDNÍM INŽENÝRSTVÍ Michal Kořenář 1 Abstrakt Rozvoj výpočetní techniky v poslední době umožnil také rozvoj výpočetních metod, které nejsou založeny na bázi
You created this PDF from an application that is not licensed to print to novapdf printer (http://www.novapdf.com)
") Závislost náhodných veličin Úvod Předchozí přednášky: - statistické charakteristiky jednoho výběrového nebo základního souboru - vztahy mezi výběrovým a základním souborem - vztahy statistických charakteristik
Závislost náhodných veličin Úvod Předchozí přednášky: - statistické charakteristiky jednoho výběrového nebo základního souboru - vztahy mezi výběrovým a základním souborem - vztahy statistických charakteristik
Motivace. Náhodný pokus, náhodný n jev. Pravděpodobnostn. podobnostní charakteristiky diagnostických testů, Bayesův vzorec
 Pravděpodobnostn podobnostní charakteristiky diagnostických testů, Bayesův vzorec Prof.RND.Jana Zvárov rová,, DrSc. Motivace V medicíně má mnoho problémů pravěpodobnostní charakter prognóza diagnoza účinnost
Pravděpodobnostn podobnostní charakteristiky diagnostických testů, Bayesův vzorec Prof.RND.Jana Zvárov rová,, DrSc. Motivace V medicíně má mnoho problémů pravěpodobnostní charakter prognóza diagnoza účinnost
Časové řady - Cvičení
 Časové řady - Cvičení Příklad 2: Zobrazte měsíční časovou řadu míry nezaměstnanosti v obci Rybitví za roky 2005-2010. Příslušná data naleznete v souboru cas_rada.xlsx. Řešení: 1. Pro transformaci dat do
Časové řady - Cvičení Příklad 2: Zobrazte měsíční časovou řadu míry nezaměstnanosti v obci Rybitví za roky 2005-2010. Příslušná data naleznete v souboru cas_rada.xlsx. Řešení: 1. Pro transformaci dat do
Vliv reklamy na studenty
 Vliv reklamy na studenty Tématem našeho statistického průzkumu byla reklama. Rozhodli jsme se vytvořit několik jednoduchých otázek a prostřednictvím internetové ankety získat kýžené odpovědi z řad studentů.
Vliv reklamy na studenty Tématem našeho statistického průzkumu byla reklama. Rozhodli jsme se vytvořit několik jednoduchých otázek a prostřednictvím internetové ankety získat kýžené odpovědi z řad studentů.
VÝBĚR A JEHO REPREZENTATIVNOST
 VÝBĚR A JEHO REPREZENTATIVNOST Induktivní, analytická statistika se snaží odhadnout charakteristiky populace pomocí malého vzorku, který se nazývá VÝBĚR neboli VÝBĚROVÝ SOUBOR. REPREZENTATIVNOST VÝBĚRU:
VÝBĚR A JEHO REPREZENTATIVNOST Induktivní, analytická statistika se snaží odhadnout charakteristiky populace pomocí malého vzorku, který se nazývá VÝBĚR neboli VÝBĚROVÝ SOUBOR. REPREZENTATIVNOST VÝBĚRU:
Jana Vránová, 3. lékařská fakulta UK
 Jana Vránová, 3. lékařská fakulta UK Vznikají při zkoumání vztahů kvalitativních resp. diskrétních znaků Jedná se o analogii s korelační analýzou spojitých znaků Přitom předpokládáme, že každý prvek populace
Jana Vránová, 3. lékařská fakulta UK Vznikají při zkoumání vztahů kvalitativních resp. diskrétních znaků Jedná se o analogii s korelační analýzou spojitých znaků Přitom předpokládáme, že každý prvek populace
Manuální kroková regrese Newsletter Statistica ACADEMY
 Manuální kroková regrese Newsletter Statistica ACADEMY Téma: Logistická regrese Typ článku: Novinka verze 12, návody Dnes si popíšeme funkcionalitu, která Vám pomůže při tvorbě regresního modelu (v našem
Manuální kroková regrese Newsletter Statistica ACADEMY Téma: Logistická regrese Typ článku: Novinka verze 12, návody Dnes si popíšeme funkcionalitu, která Vám pomůže při tvorbě regresního modelu (v našem
ANALÝZA DAT V R 2. POPISNÉ STATISTIKY. Mgr. Markéta Pavlíková Katedra pravděpodobnosti a matematické statistiky MFF UK.
 ANALÝZA DAT V R 2. POPISNÉ STATISTIKY Mgr. Markéta Pavlíková Katedra pravděpodobnosti a matematické statistiky MFF UK www.biostatisticka.cz CO SE SKRÝVÁ V DATECH data sbíráme proto, abychom porozuměli
ANALÝZA DAT V R 2. POPISNÉ STATISTIKY Mgr. Markéta Pavlíková Katedra pravděpodobnosti a matematické statistiky MFF UK www.biostatisticka.cz CO SE SKRÝVÁ V DATECH data sbíráme proto, abychom porozuměli
Statistické metody v ekonomii. Ing. Michael Rost, Ph.D.
 Statistické metody v ekonomii Ing. Michael Rost, Ph.D. Jihočeská univerzita v Českých Budějovicích Test χ 2 v kontingenční tabulce typu 2 2 Jde vlastně o speciální případ χ 2 testu pro čtyřpolní tabulku.
Statistické metody v ekonomii Ing. Michael Rost, Ph.D. Jihočeská univerzita v Českých Budějovicích Test χ 2 v kontingenční tabulce typu 2 2 Jde vlastně o speciální případ χ 2 testu pro čtyřpolní tabulku.
Statistické zkoumání faktorů výšky obyvatel ČR
 ČESKÉ VYSOKÉ UČENÍ TECHNICKÉ V PRAZE Fakulta dopravní 1. blok studia Statistické zkoumání faktorů výšky obyvatel ČR Statistika 2012/2013 Semestrální práce Studijní skupina: 2_37 Vedoucí práce: Ing. Tomáš
ČESKÉ VYSOKÉ UČENÍ TECHNICKÉ V PRAZE Fakulta dopravní 1. blok studia Statistické zkoumání faktorů výšky obyvatel ČR Statistika 2012/2013 Semestrální práce Studijní skupina: 2_37 Vedoucí práce: Ing. Tomáš
Statistická teorie učení
 Statistická teorie učení Petr Havel Marek Myslivec přednáška z 9. týdne 1 Úvod Představme si situaci výrobce a zákazníka, který si u výrobce objednal algoritmus rozpoznávání. Zákazník dodal experimentální
Statistická teorie učení Petr Havel Marek Myslivec přednáška z 9. týdne 1 Úvod Představme si situaci výrobce a zákazníka, který si u výrobce objednal algoritmus rozpoznávání. Zákazník dodal experimentální
Vysoká škola báňská technická univerzita Ostrava. Fakulta elektrotechniky a informatiky
 Vysoká škola báňská technická univerzita Ostrava Fakulta elektrotechniky a informatiky Bankovní účty (semestrální projekt statistika) Tomáš Hejret (hej124) 18.5.2013 Úvod Cílem tohoto projektu, zadaného
Vysoká škola báňská technická univerzita Ostrava Fakulta elektrotechniky a informatiky Bankovní účty (semestrální projekt statistika) Tomáš Hejret (hej124) 18.5.2013 Úvod Cílem tohoto projektu, zadaného
INDUKTIVNÍ STATISTIKA
 10. SEMINÁŘ INDUKTIVNÍ STATISTIKA 3. HODNOCENÍ ZÁVISLOSTÍ HODNOCENÍ ZÁVISLOSTÍ KVALITATIVNÍ VELIČINY - Vychází se z kombinační (kontingenční) tabulky, která je výsledkem třídění druhého stupně KVANTITATIVNÍ
10. SEMINÁŘ INDUKTIVNÍ STATISTIKA 3. HODNOCENÍ ZÁVISLOSTÍ HODNOCENÍ ZÁVISLOSTÍ KVALITATIVNÍ VELIČINY - Vychází se z kombinační (kontingenční) tabulky, která je výsledkem třídění druhého stupně KVANTITATIVNÍ
Hodnocení klasifikátoru Test nezávislosti. 14. prosinec Rozvoj aplikačního potenciálu (RAPlus) CZ.1.07/2.4.00/
 CZ.1.07/2.4.00/") Čtyřpolní tabulky Čtyřpolní tabulky 14. prosinec 2012 Rozvoj aplikačního potenciálu (RAPlus) CZ.1.07/2.4.00/17.0117 O čem se bude mluvit? Čtyřpolní tabulky Osnova prezentace Čtyřpolní tabulky 1. přístupy
Čtyřpolní tabulky Čtyřpolní tabulky 14. prosinec 2012 Rozvoj aplikačního potenciálu (RAPlus) CZ.1.07/2.4.00/17.0117 O čem se bude mluvit? Čtyřpolní tabulky Osnova prezentace Čtyřpolní tabulky 1. přístupy
Nerovnice. Vypracovala: Ing. Stanislava Kaděrková
 Nerovnice Vypracovala: Ing. Stanislava Kaděrková Název školy Název a číslo projektu Název modulu Obchodní akademie a Střední odborné učiliště, Veselí nad Moravou Motivace žáků ke studiu technických předmětů
Nerovnice Vypracovala: Ing. Stanislava Kaděrková Název školy Název a číslo projektu Název modulu Obchodní akademie a Střední odborné učiliště, Veselí nad Moravou Motivace žáků ke studiu technických předmětů
Základy vytěžování dat
 Základy vytěžování dat předmět A7Bb36vyd Vytěžování dat Filip Železný, Miroslav Čepek, Radomír Černoch, Jan Hrdlička katedra kybernetiky a katedra počítačů ČVUT v Praze, FEL Evropský sociální fond Praha
Základy vytěžování dat předmět A7Bb36vyd Vytěžování dat Filip Železný, Miroslav Čepek, Radomír Černoch, Jan Hrdlička katedra kybernetiky a katedra počítačů ČVUT v Praze, FEL Evropský sociální fond Praha
5 Informace o aspiračních úrovních kritérií
 5 Informace o aspiračních úrovních kritérií Aspirační úroveň kritérií je minimální (maximální) hodnota, které musí varianta pro dané maximalizační (minimalizační) kritérium dosáhnout, aby byla akceptovatelná.
5 Informace o aspiračních úrovních kritérií Aspirační úroveň kritérií je minimální (maximální) hodnota, které musí varianta pro dané maximalizační (minimalizační) kritérium dosáhnout, aby byla akceptovatelná.
Pravděpodobnost, náhoda, kostky
 Pravděpodobnost, náhoda, kostky Radek Pelánek IV122 Výhled pravděpodobnost náhodná čísla lineární regrese detekce shluků Dnes lehce nesourodá směs úloh souvisejících s pravděpodobností připomenutí, souvislosti
Pravděpodobnost, náhoda, kostky Radek Pelánek IV122 Výhled pravděpodobnost náhodná čísla lineární regrese detekce shluků Dnes lehce nesourodá směs úloh souvisejících s pravděpodobností připomenutí, souvislosti
Že tuto definici znáte, ale stále přesně nevíte, jak funkci chápat? Ukážeme si konkrétní příklad. 1 2 3 4 5 Definiční obor (množina A)
") Funkce úvod Co je funkce Funkce je předpis, který číslu z množiny A přiřazuje právě jedno číslo z množiny B. Množina A je definiční obor funkce a množina B je obor hodnot funkce. Že tuto definici znáte,
Funkce úvod Co je funkce Funkce je předpis, který číslu z množiny A přiřazuje právě jedno číslo z množiny B. Množina A je definiční obor funkce a množina B je obor hodnot funkce. Že tuto definici znáte,
Metodologie pro ISK 2, jaro Ladislava Z. Suchá
 Metodologie pro ISK 2, jaro 2014. Ladislava Z. Suchá Metodologie pro Informační studia a knihovnictví 2 Modul 7: Třídění druhého stupně. Kontingenční tabulky Co se dozvíte v tomto modulu? Co je třídění
Metodologie pro ISK 2, jaro 2014. Ladislava Z. Suchá Metodologie pro Informační studia a knihovnictví 2 Modul 7: Třídění druhého stupně. Kontingenční tabulky Co se dozvíte v tomto modulu? Co je třídění
Vícekriteriální hodnocení variant úvod
 Vícekriteriální hodnocení variant úvod Jana Klicnarová Katedra aplikované matematiky a informatiky Jihočeská Univerzita v Českých Budějovicích, Ekonomická fakulta 2010 Vícekriteriální hodnocení variant
Vícekriteriální hodnocení variant úvod Jana Klicnarová Katedra aplikované matematiky a informatiky Jihočeská Univerzita v Českých Budějovicích, Ekonomická fakulta 2010 Vícekriteriální hodnocení variant
Tomáš Karel LS 2012/2013
 Tomáš Karel LS 2012/2013 Doplňkový materiál ke cvičení z předmětu 4ST201. Na případné faktické chyby v této presentaci mě prosím upozorněte. Děkuji. Tyto slidy berte pouze jako doplňkový materiál není
Tomáš Karel LS 2012/2013 Doplňkový materiál ke cvičení z předmětu 4ST201. Na případné faktické chyby v této presentaci mě prosím upozorněte. Děkuji. Tyto slidy berte pouze jako doplňkový materiál není
You created this PDF from an application that is not licensed to print to novapdf printer (http://www.novapdf.com)
") Testování statistických hypotéz Testování statistických hypotéz Princip: Ověřování určitého předpokladu zjišťujeme, zda zkoumaný výběr pochází ze základního souboru, který má určité rozdělení zjišťujeme,
Testování statistických hypotéz Testování statistických hypotéz Princip: Ověřování určitého předpokladu zjišťujeme, zda zkoumaný výběr pochází ze základního souboru, který má určité rozdělení zjišťujeme,
1 Tyto materiály byly vytvořeny za pomoci grantu FRVŠ číslo 1145/2004.
 Prostá regresní a korelační analýza 1 1 Tyto materiály byly vytvořeny za pomoci grantu FRVŠ číslo 1145/2004. Problematika závislosti V podstatě lze rozlišovat mezi závislostí nepodstatnou, čili náhodnou
Prostá regresní a korelační analýza 1 1 Tyto materiály byly vytvořeny za pomoci grantu FRVŠ číslo 1145/2004. Problematika závislosti V podstatě lze rozlišovat mezi závislostí nepodstatnou, čili náhodnou
Národní informační středisko pro podporu kvality
 Národní informační středisko pro podporu kvality 1 STATISTICKÉ PŘEJÍMKY CHYBY PŘI APLIKACI A JEJICH DŮSLEDKY Ing. Vratislav Horálek, DrSc. 2 A. NEPOCHOPENÍ VLASTNÍHO CÍLE STATISTICKÉ PŘEJÍMKY (STP) STP
Národní informační středisko pro podporu kvality 1 STATISTICKÉ PŘEJÍMKY CHYBY PŘI APLIKACI A JEJICH DŮSLEDKY Ing. Vratislav Horálek, DrSc. 2 A. NEPOCHOPENÍ VLASTNÍHO CÍLE STATISTICKÉ PŘEJÍMKY (STP) STP
Jak definovat pravidlo pro více buněk naráz
 Podmíněné formátování s pomocí vzorce je tématem pro pokročilejší uživatele. Zatímco začátky necháváme na průvodcích, jako je Zvýraznit pravidla buněk a další nástroje (pruhy, škály, ikony), komplikovanější
Podmíněné formátování s pomocí vzorce je tématem pro pokročilejší uživatele. Zatímco začátky necháváme na průvodcích, jako je Zvýraznit pravidla buněk a další nástroje (pruhy, škály, ikony), komplikovanější
Pravděpodobnost, náhoda, kostky
 Pravděpodobnost, náhoda, kostky Radek Pelánek IV122, jaro 2015 Výhled pravděpodobnost náhodná čísla lineární regrese detekce shluků Dnes lehce nesourodá směs úloh souvisejících s pravděpodobností krátké
Pravděpodobnost, náhoda, kostky Radek Pelánek IV122, jaro 2015 Výhled pravděpodobnost náhodná čísla lineární regrese detekce shluků Dnes lehce nesourodá směs úloh souvisejících s pravděpodobností krátké
676 + 4 + 100 + 196 + 0 + 484 + 196 + 324 + 64 + 324 = = 2368
 Příklad 1 Je třeba prověřit, zda lze na 5% hladině významnosti pokládat za prokázanou hypotézu, že střední doba výroby výlisku je 30 sekund. Přitom 10 náhodně vybraných výlisků bylo vyráběno celkem 540
Příklad 1 Je třeba prověřit, zda lze na 5% hladině významnosti pokládat za prokázanou hypotézu, že střední doba výroby výlisku je 30 sekund. Přitom 10 náhodně vybraných výlisků bylo vyráběno celkem 540
Stupnice geomagnetické aktivity
 AKADEMIE VĚD ČESKÉ REPUBLIKY Geofyzikální ústav Stupnice geomagnetické aktivity Petr Kubašta Rozbor a zhodnocení předpovědí geomagnetické aktivity Praha, 2011 Abstrakt Tento článek poskytuje kvantitativní
AKADEMIE VĚD ČESKÉ REPUBLIKY Geofyzikální ústav Stupnice geomagnetické aktivity Petr Kubašta Rozbor a zhodnocení předpovědí geomagnetické aktivity Praha, 2011 Abstrakt Tento článek poskytuje kvantitativní
K možnostem krátkodobé předpovědi úrovně znečištění ovzduší statistickými metodami. Josef Keder
 K možnostem krátkodobé předpovědi úrovně znečištění ovzduší statistickými metodami Josef Keder Motivace Předpověď budoucí úrovně znečištění ovzduší s předstihem v řádu alespoň několika hodin má význam
K možnostem krátkodobé předpovědi úrovně znečištění ovzduší statistickými metodami Josef Keder Motivace Předpověď budoucí úrovně znečištění ovzduší s předstihem v řádu alespoň několika hodin má význam
Souhrnné výsledky za školu
 XYZ třída počet žáků percentil skupinový percentil (G4) čistá úspěšnost skóre směrodatná odchylka skóre x geometrie funkce algebra třída počet žáků percentil skupinový percentil (G4) čistá úspěšnost skóre
XYZ třída počet žáků percentil skupinový percentil (G4) čistá úspěšnost skóre směrodatná odchylka skóre x geometrie funkce algebra třída počet žáků percentil skupinový percentil (G4) čistá úspěšnost skóre
veličin, deskriptivní statistika Ing. Michael Rost, Ph.D.
 Vybraná rozdělení spojitých náhodných veličin, deskriptivní statistika Ing. Michael Rost, Ph.D. Třídění Základním zpracováním dat je jejich třídění. Jde o uspořádání získaných dat, kde volba třídícího
Vybraná rozdělení spojitých náhodných veličin, deskriptivní statistika Ing. Michael Rost, Ph.D. Třídění Základním zpracováním dat je jejich třídění. Jde o uspořádání získaných dat, kde volba třídícího
Česká veřejnost o tzv. Islámském státu a o dění na Ukrajině leden 2016
 pm0 TISKOVÁ ZPRÁVA Centrum pro výzkum veřejného mínění Sociologický ústav AV ČR, v.v.i. Jilská, Praha Tel.: +0 0 E-mail: jan.cervenka@soc.cas.cz Česká veřejnost o tzv. Islámském státu a o dění na Ukrajině
pm0 TISKOVÁ ZPRÁVA Centrum pro výzkum veřejného mínění Sociologický ústav AV ČR, v.v.i. Jilská, Praha Tel.: +0 0 E-mail: jan.cervenka@soc.cas.cz Česká veřejnost o tzv. Islámském státu a o dění na Ukrajině
Testy. Pavel Provinský. 19. listopadu 2013
 Testy Pavel Provinský 19. listopadu 2013 Test a intervalový odhad Testy a intervalové odhady - jsou vlastně to samé. Jiný je jen úhel pohledu. Lze přecházet od jednoho k druhému. Například: Při odvozování
Testy Pavel Provinský 19. listopadu 2013 Test a intervalový odhad Testy a intervalové odhady - jsou vlastně to samé. Jiný je jen úhel pohledu. Lze přecházet od jednoho k druhému. Například: Při odvozování
coachpage.cz MARKETINGOVÝ VÝZKUM Faktory ovlivňující nákupní chování ve vztahu ke koupi automobilu TOOLS for SUCCESS in TODAY s BUSINESS
 coachpage.cz TOOLS for SUCCESS in TODAY s BUSINESS MARKETINGOVÝ VÝZKUM Faktory ovlivňující nákupní chování Faktory ovlivňující nákupní chování Hlavní cíl výzkumného projektu Výzkumný projekt si klade za
coachpage.cz TOOLS for SUCCESS in TODAY s BUSINESS MARKETINGOVÝ VÝZKUM Faktory ovlivňující nákupní chování Faktory ovlivňující nákupní chování Hlavní cíl výzkumného projektu Výzkumný projekt si klade za
Analytické znaky laboratorní metody Interní kontrola kvality Externí kontrola kvality
 Analytické znaky laboratorní metody Interní kontrola kvality Externí kontrola kvality RNDr. Alena Mikušková FN Brno Pracoviště dětské medicíny, OKB amikuskova@fnbrno.cz Analytické znaky laboratorní metody
Analytické znaky laboratorní metody Interní kontrola kvality Externí kontrola kvality RNDr. Alena Mikušková FN Brno Pracoviště dětské medicíny, OKB amikuskova@fnbrno.cz Analytické znaky laboratorní metody
Názor na rozšířenost a míru korupce u veřejných činitelů a institucí březen 2017
 Tisková zpráva Názor na rozšířenost a míru korupce u veřejných činitelů a institucí březen 0 Pouze % respondentů se domnívá, že velice málo veřejných činitelů je zkorumpováno. O zapojení téměř všech těchto
Tisková zpráva Názor na rozšířenost a míru korupce u veřejných činitelů a institucí březen 0 Pouze % respondentů se domnívá, že velice málo veřejných činitelů je zkorumpováno. O zapojení téměř všech těchto
Funkce, funkční závislosti Lineární funkce
 Funkce, funkční závislosti Lineární funkce Obsah: Definice funkce Grafické znázornění funkce Konstantní funkce Lineární funkce Vlastnosti lineárních funkcí Lineární funkce - příklady Zdroje Z Návrat na
Funkce, funkční závislosti Lineární funkce Obsah: Definice funkce Grafické znázornění funkce Konstantní funkce Lineární funkce Vlastnosti lineárních funkcí Lineární funkce - příklady Zdroje Z Návrat na
III/2 Inovace a zkvalitnění výuky prostřednictvím ICT
 Název školy Gymnázium, Šternberk, Horní nám. 5 Číslo projektu CZ.1.07/1.5.00/34.0218 Šablona III/2 Inovace a zkvalitnění výuky prostřednictvím ICT Označení materiálu VY_32_INOVACE_Hor017 Vypracoval(a),
Název školy Gymnázium, Šternberk, Horní nám. 5 Číslo projektu CZ.1.07/1.5.00/34.0218 Šablona III/2 Inovace a zkvalitnění výuky prostřednictvím ICT Označení materiálu VY_32_INOVACE_Hor017 Vypracoval(a),
ANALÝZA DAT V R 3. POPISNÉ STATISTIKY, NÁHODNÁ VELIČINA. Mgr. Markéta Pavlíková Katedra pravděpodobnosti a matematické statistiky MFF UK
 ANALÝZA DAT V R 3. POPISNÉ STATISTIKY, NÁHODNÁ VELIČINA Mgr. Markéta Pavlíková Katedra pravděpodobnosti a matematické statistiky MFF UK www.biostatisticka.cz POPISNÉ STATISTIKY - OPAKOVÁNÍ jedna kvalitativní
ANALÝZA DAT V R 3. POPISNÉ STATISTIKY, NÁHODNÁ VELIČINA Mgr. Markéta Pavlíková Katedra pravděpodobnosti a matematické statistiky MFF UK www.biostatisticka.cz POPISNÉ STATISTIKY - OPAKOVÁNÍ jedna kvalitativní
PRŮZKUMOVÁ ANALÝZA JEDNOROZMĚRNÝCH DAT Exploratory Data Analysis (EDA)
") PRŮZKUMOVÁ ANALÝZA JEDNOROZMĚRNÝCH DAT Exploratory Data Analysis (EDA) Reprezentativní náhodný výběr: 1. Prvky výběru x i jsou vzájemně nezávislé. 2. Výběr je homogenní, tj. všechna x i jsou ze stejného
PRŮZKUMOVÁ ANALÝZA JEDNOROZMĚRNÝCH DAT Exploratory Data Analysis (EDA) Reprezentativní náhodný výběr: 1. Prvky výběru x i jsou vzájemně nezávislé. 2. Výběr je homogenní, tj. všechna x i jsou ze stejného
pracovní list studenta Elektrický proud v kovech Voltampérová charakteristika spotřebiče Eva Bochníčková
 pracovní list studenta Elektrický proud v kovech Eva Bochníčková Výstup RVP: Klíčová slova: žák měří vybrané veličiny vhodnými metodami, zpracuje získaná data formou grafu; porovná získanou závislost s
pracovní list studenta Elektrický proud v kovech Eva Bochníčková Výstup RVP: Klíčová slova: žák měří vybrané veličiny vhodnými metodami, zpracuje získaná data formou grafu; porovná získanou závislost s
Popisná statistika kvantitativní veličiny
 StatSoft Popisná statistika kvantitativní veličiny Protože nám surová data obvykle žádnou smysluplnou informaci neposkytnou, je žádoucí vyjádřit tyto ve zhuštěnější formě. V předchozím dílu jsme začali
StatSoft Popisná statistika kvantitativní veličiny Protože nám surová data obvykle žádnou smysluplnou informaci neposkytnou, je žádoucí vyjádřit tyto ve zhuštěnější formě. V předchozím dílu jsme začali
Statistická zpráva zkoušek leteckých motorů
 Statistická zpráva zkoušek leteckých motorů Zpráva o zkoumání reakcí parametrů motorů na prováděné změny GE AVIATION CHZECH May, Autor: Milan Zapach Problematika zkoušek motorů Po smontování je zapotřebí
Statistická zpráva zkoušek leteckých motorů Zpráva o zkoumání reakcí parametrů motorů na prováděné změny GE AVIATION CHZECH May, Autor: Milan Zapach Problematika zkoušek motorů Po smontování je zapotřebí