Pearsonův korelační koeficient
|
|
|
- Kristýna Marková
- před 8 lety
- Počet zobrazení:
Transkript

1 I I.I Pearsonův korelační koeficient Úvod Předpokládejme, že náhodně vybereme n objektů (nebo osob) ze zkoumané populace. Často se stává, že na každém z objektů měříme ne pouze jednu, ale několik kvantitativních proměnných. Uvažujme tedy pár takovýchto proměnných, mohlo by být zajímavé zjistit, zda mezi nimi existuje lineární vztah; tedy zjistit, jestli jsou korelované. Typy korelace bychom mohli kategorizovat podle toho, co se stane s první proměnou, když druhá poroste: Kladná korelace první proměnná má tendenci také růstů; Záporná korelace první proměnná má tendenci klesat; Nulová korelace první proměnná nemá tendenci ani růst, ani klesat. Začátkem každé takové analýzy by tedy měla být konstrukce a následné prozkoumání bodového grafu. Následují příklady záporné, nulové a kladné korelace. Motivační příklad. Podívejme se nyní na konkrétní příklad. Následující data obsahují úrovně hemoglobinu (Hb) a celkové objemy buněk (PCV) od 14 dárců krve ženského pohlaví. Zajímalo by nás, zda existuje nějaký vztah mezi proměnnými Hb a PCV v populaci žen. Hb PCV Hb PCV Bodový graf naznačuje vztah mezi PVC a Hb, kdy se vyšší hodnoty HB spojují s vyššími hodnotami PCV. Zdá se, že mezi těmito proměnnými existuje pozitivní korelace. Také si všimněme, že vztah mezi těmito proměnnými se zdá být lineární. Handout 1


2 I.II Korelační koeficient Pearsonův korelační koeficient je statistický ukazatel síly lineárního vztahu mezi párovými daty. Jedná se o výběrový korelační koeficient. Označme ho r, pro jeho hodnoty platí: 1 r 1 Poznámky: Kladné hodnoty r znamenají kladnou lineární korelaci; Záporné hodnoty r znamenají negativní lineární korelaci; Hodnota r nula znamená, že mezi proměnnými neexistuje lineární korelace; Čím je hodnota blíže 1 nebo -1, tím silnější lineární korelace je. Na schématu jsou ukázky vzorku dat a hodnoty jejich příslušných korelačních koeficientů. První tři reprezentují extrémní hodnoty korelací, a to -1, 0 a 1: Handout 2 Statistika 2


3 Jestliže r = ±1, potom řekneme, že máme dokonalou korelaci, kdy jsou body poskládané v dokonale rovné přímce. Nicméně výběrový soubor, se kterým většinou pracujeme vypadá spíše, jako následující soubory: Poznámky: Korelační koeficient nesouvisí se sklonem proložené přímky kromě znamínka + a - Korelační koeficient je měřítkem lineárního vztahu a tedy hodnota r = 0 neznamená, že mezi proměnnými není žádný vztah. Například následující bodový graf má r = 0, což značí nulovou korelaci, nicméně proměnné mají dokonale kvadratický vztah. Handout 3 Statistika 2
4 Korelace je míra souvislosti a tak je možné sílu korelace popsat i verbálně. Použijeme Evansovu (1996) příručku, kterou navrhl pro absolutní hodnotu r: 0,00-0,19 velmi slabá 0,20-0,39 slabá 0,40-0,59 střední 0,60-0,79 silná 0,80-1,00 velmi silná Například hodnota korelace r = 0,42 by byla slabá kladná korelace. I.III Předpoklady Výpočet Pearsonova korelačního koeficientu a další testy významnosti vyžadují následující předpoklady o datech: Intervalový nebo poměrový charakter; Lineární vztah; Dvojrozměrné normální rozložení. Pearsonův koeficient korelace je citlivý na zešikmení rozložení dat a na odlehlé hodnoty, při ověřování podmínek, bychom tedy měli dát důraz hlavně na tyto předpoklady. Pokud naše data nesplňují výše uvedené předpoklady, použijeme Spearmanův koeficient pořadové korelace! Příklad Orientační ověření prvních dvou předpokladů jsme provedli výše, nyní se zabývejme ověřením předpokladu dvourozměrné normality. Pro orientační posouzení dvojrozměrné normality datového souboru může sloužit například 95% konfidenční elipsa (pokud alespoň 95% hodnot našeho výběrového souboru leží uvnitř této elipsy budeme předpokládat, že předpoklad dvourozměrné normality není porušen). Podívejme se také na koeficienty šikmosti a zjistěme, zda naznačují zešikmení některé z proměnných. Obě proměnné mají koeficienty šikmosti skutečně kladné. Rychlým posouzením závažnosti problému je ověřit, jestli jsou absolutní hodnoty koeficientů zešikmení menší než dvojnásobek příslušné směrodatné odchylky. V obou případech je toto splněno, což je v souladu s předpokladem Handout 4 Statistika 2


5 normality dat. Nemáme tudíž žárné obavy ohledně normality dat a můžeme přistoupit ke korelační analýze. Pro data o Hemoglobinu/PCV, software STATISTICA poskytuje následující výstup: Hodnota Pearsonova korelačního koeficientu potvrzuje to, co bylo zřejmé z grafu, tedy že mezi těmito proměnnými se zdá být pozitivní korelace. Nicméně je nutné provést test významnosti, abychom rozhodli, jestli je možné na základě tohoto vzorku usuzovat na existenci lineární korelace v celé populaci. Abychom toho dosáhli, provedeme test s nulovou hypotézou H 0 : ρ = 0, že v populaci žádná korelace není, proti alternativní hypotéze, H 1 : ρ 0, která říká, že v populaci tato korelaci existuje. Na základě datového souboru zamítneme či nezamítneme nulovou hypotézu. Tedy nulová hypotéza říká, že v populaci lineární korelace neexistuje proti alternativní hypotéze, že lineární korelace v populaci existuje. STATISTICA vypočítala p-hodnotu tohoto testu jako 0,000 a tedy můžeme říct, že máme velmi silný důkaz ve prospěch H1, tedy máme silný důvod věřit, že Hb a PCV jsou v ženské populaci lineárně korelované. Významný Pearsonův koeficient s hodnotou potvrzuje to, co bylo zřejmé z grafu; zdá se, že mezi těmito proměnnými je velmi silná pozitivní korelace. Tedy vyšší hodnoty Hb se spojují s vyššími hodnotami PCV. Toto by mohlo být formálně zapsáno takto: Pearsonova korelace byla použita k určení vztahu mezi 14 hodnotami Hb a PCV měřených na ženách. Byla zjištěna velmi silná pozitivní korelace mezi Hb a PCV (r=0,88, N = 14, p< 0,001). Handout 5 Statistika 2
 a velikostí nohou (Foot lenght) u dětí.")

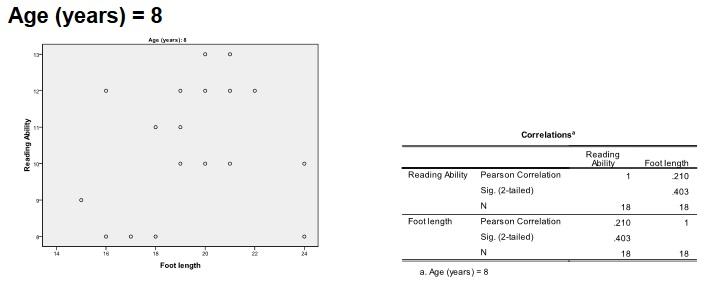
6 I.IV Upozornění Existence silné korelace neznamená kauzální vztah mezi proměnnými. Například nemůžeme předpokládat, že hodnoty Hb určují hodnoty PCV nebo naopak. Také bychom si měli být vědomi, že je možná existence skryté nebo intervenující proměnné. Například můžeme uvažovat vztah mezi schopností číst (Reading Ability) a velikostí nohou (Foot lenght) u dětí. Bodový graf a analýza korelace dat ukazují, že mezi nimi existuje velmi silná korelace (r= 0,88, N=54, p=0,003): Nicméně pokud vezmeme v úvahu věk dítěte, vidíme, že tato očividná korelace by mohla být jen zdánlivá. Pokud nyní znovu prozkoumáme data podle věkových skupin, skutečně zjistíme, že v každé skupině není viditelná žádná korelace mezi schopností číst a velikostí nohou u dětí (tento příklad byl zpracován v softwaru SPSS). Handout 6 Statistika 2

7 Handout 7 Statistika 2
Korelace. Komentované řešení pomocí MS Excel
 Korelace Komentované řešení pomocí MS Excel Vstupní data Tabulka se vstupními daty je umístěna v oblasti A2:B84 (viz. obrázek) Prvotní představu o tvaru a síle závislosti docházky a počtu bodů nám poskytne
Korelace Komentované řešení pomocí MS Excel Vstupní data Tabulka se vstupními daty je umístěna v oblasti A2:B84 (viz. obrázek) Prvotní představu o tvaru a síle závislosti docházky a počtu bodů nám poskytne
Testování statistických hypotéz
 Testování statistických hypotéz Na základě náhodného výběru, který je reprezentativním vzorkem základního souboru (který přesně neznáme, k němuž se ale daná statistická hypotéza váže), potřebujeme ověřit,
Testování statistických hypotéz Na základě náhodného výběru, který je reprezentativním vzorkem základního souboru (který přesně neznáme, k němuž se ale daná statistická hypotéza váže), potřebujeme ověřit,
MÍRY ZÁVISLOSTI (KORELACE A REGRESE)
") zhanel@fsps.muni.cz MÍRY ZÁVISLOSTI (KORELACE A REGRESE) 2.5 MÍRY ZÁVISLOSTI 2.5.1 ZÁVISLOST PEVNÁ, VOLNÁ, STATISTICKÁ A KORELAČNÍ Jednorozměrné soubory - charakterizovány jednotlivými statistickými znaky
zhanel@fsps.muni.cz MÍRY ZÁVISLOSTI (KORELACE A REGRESE) 2.5 MÍRY ZÁVISLOSTI 2.5.1 ZÁVISLOST PEVNÁ, VOLNÁ, STATISTICKÁ A KORELAČNÍ Jednorozměrné soubory - charakterizovány jednotlivými statistickými znaky
KORELACE. Komentované řešení pomocí programu Statistica
 KORELACE Komentované řešení pomocí programu Statistica Vstupní data I Data umístěná v excelovském souboru překopírujeme do tabulky ve Statistice a pojmenujeme proměnné, viz prezentace k tématu Popisná
KORELACE Komentované řešení pomocí programu Statistica Vstupní data I Data umístěná v excelovském souboru překopírujeme do tabulky ve Statistice a pojmenujeme proměnné, viz prezentace k tématu Popisná
Lineární regrese. Komentované řešení pomocí MS Excel
 Lineární regrese Komentované řešení pomocí MS Excel Vstupní data Tabulka se vstupními daty je umístěna v oblasti A1:B11 (viz. obrázek) na listu cela data Postup Základní výpočty - regrese Výpočet základních
Lineární regrese Komentované řešení pomocí MS Excel Vstupní data Tabulka se vstupními daty je umístěna v oblasti A1:B11 (viz. obrázek) na listu cela data Postup Základní výpočty - regrese Výpočet základních
Statistická analýza jednorozměrných dat
 Statistická analýza jednorozměrných dat Prof. RNDr. Milan Meloun, DrSc. Univerzita Pardubice, Pardubice 31.ledna 2011 Tato prezentace je spolufinancována Evropským sociálním fondem a státním rozpočtem
Statistická analýza jednorozměrných dat Prof. RNDr. Milan Meloun, DrSc. Univerzita Pardubice, Pardubice 31.ledna 2011 Tato prezentace je spolufinancována Evropským sociálním fondem a státním rozpočtem
Program Statistica Base 9. Mgr. Karla Hrbáčková, Ph.D.
 Program Statistica Base 9 Mgr. Karla Hrbáčková, Ph.D. OBSAH KURZU obsluha jednotlivých nástrojů, funkce pro import dat z jiných aplikací, práce s popisnou statistikou, vytváření grafů, analýza dat, výstupní
Program Statistica Base 9 Mgr. Karla Hrbáčková, Ph.D. OBSAH KURZU obsluha jednotlivých nástrojů, funkce pro import dat z jiných aplikací, práce s popisnou statistikou, vytváření grafů, analýza dat, výstupní
Mgr. Karla Hrbáčková, Ph.D. Základy kvantitativního výzkumu
 Mgr. Karla Hrbáčková, Ph.D. Základy kvantitativního výzkumu K čemu slouží statistika Popisuje velké soubory dat pomocí charakteristických čísel (popisná statistika). Hledá skryté zákonitosti v souborech
Mgr. Karla Hrbáčková, Ph.D. Základy kvantitativního výzkumu K čemu slouží statistika Popisuje velké soubory dat pomocí charakteristických čísel (popisná statistika). Hledá skryté zákonitosti v souborech
Náhodné veličiny jsou nekorelované, neexistuje mezi nimi korelační vztah. Když jsou X; Y nekorelované, nemusí být nezávislé.
 1. Korelační analýza V životě většinou nesledujeme pouze jeden statistický znak. Sledujeme více statistických znaků zároveň. Kromě vlastností statistických znaků nás zajímá také jejich těsnost (velikost,
1. Korelační analýza V životě většinou nesledujeme pouze jeden statistický znak. Sledujeme více statistických znaků zároveň. Kromě vlastností statistických znaků nás zajímá také jejich těsnost (velikost,
Jednofaktorová analýza rozptylu
 I I.I Jednofaktorová analýza rozptylu Úvod Jednofaktorová analýza rozptylu (ANOVA) se využívá při porovnání několika středních hodnot. Často se využívá ve vědeckých a lékařských experimentech, při kterých
I I.I Jednofaktorová analýza rozptylu Úvod Jednofaktorová analýza rozptylu (ANOVA) se využívá při porovnání několika středních hodnot. Často se využívá ve vědeckých a lékařských experimentech, při kterých
Testy statistických hypotéz
 Testy statistických hypotéz Statistická hypotéza je jakýkoliv předpoklad o rozdělení pravděpodobnosti jedné nebo několika náhodných veličin. Na základě náhodného výběru, který je reprezentativním vzorkem
Testy statistických hypotéz Statistická hypotéza je jakýkoliv předpoklad o rozdělení pravděpodobnosti jedné nebo několika náhodných veličin. Na základě náhodného výběru, který je reprezentativním vzorkem
Regresní a korelační analýza
 Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Regresní a korelační analýza
 Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
PSY117/454 Statistická analýza dat v psychologii. Zobrazení dvojrozměrných dat Bodový graf - Scatterplot Korelační koeficient
 PSY117/454 Statistická analýza dat v psychologii Zobrazení dvojrozměrných dat Bodový graf - Scatterplot Korelační koeficient Analýza vztahů mezi dvěma proměnnými Souvisí nějak? Výška a váha Známky u jednotlivých
PSY117/454 Statistická analýza dat v psychologii Zobrazení dvojrozměrných dat Bodový graf - Scatterplot Korelační koeficient Analýza vztahů mezi dvěma proměnnými Souvisí nějak? Výška a váha Známky u jednotlivých
RNDr. Eva Janoušová doc. RNDr. Ladislav Dušek, Dr.
 Analýza dat pro Neurovědy RNDr. Eva Janoušová doc. RNDr. Ladislav Dušek, Dr. Jaro 2014 Institut biostatistiky Janoušová, a analýz Dušek: Analýza dat pro neurovědy Blok 7 Jak hodnotit vztah spojitých proměnných
Analýza dat pro Neurovědy RNDr. Eva Janoušová doc. RNDr. Ladislav Dušek, Dr. Jaro 2014 Institut biostatistiky Janoušová, a analýz Dušek: Analýza dat pro neurovědy Blok 7 Jak hodnotit vztah spojitých proměnných
INDUKTIVNÍ STATISTIKA
 10. SEMINÁŘ INDUKTIVNÍ STATISTIKA 3. HODNOCENÍ ZÁVISLOSTÍ HODNOCENÍ ZÁVISLOSTÍ KVALITATIVNÍ VELIČINY - Vychází se z kombinační (kontingenční) tabulky, která je výsledkem třídění druhého stupně KVANTITATIVNÍ
10. SEMINÁŘ INDUKTIVNÍ STATISTIKA 3. HODNOCENÍ ZÁVISLOSTÍ HODNOCENÍ ZÁVISLOSTÍ KVALITATIVNÍ VELIČINY - Vychází se z kombinační (kontingenční) tabulky, která je výsledkem třídění druhého stupně KVANTITATIVNÍ
Regresní a korelační analýza
 Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Regresní a korelační analýza
 Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
KGG/STG Statistika pro geografy
 KGG/STG Statistika pro geografy 9. Korelační analýza Mgr. David Fiedor 20. dubna 2015 Analýza závislostí v řadě geografických disciplín studujeme jevy, u kterých vyšetřujeme nikoliv pouze jednu vlastnost
KGG/STG Statistika pro geografy 9. Korelační analýza Mgr. David Fiedor 20. dubna 2015 Analýza závislostí v řadě geografických disciplín studujeme jevy, u kterých vyšetřujeme nikoliv pouze jednu vlastnost
JEDNOVÝBĚROVÉ TESTY. Komentované řešení pomocí programu Statistica
 JEDNOVÝBĚROVÉ TESTY Komentované řešení pomocí programu Statistica Vstupní data Data umístěná v excelovském souboru překopírujeme do tabulky ve Statistice a pojmenujeme proměnné, viz prezentace k tématu
JEDNOVÝBĚROVÉ TESTY Komentované řešení pomocí programu Statistica Vstupní data Data umístěná v excelovském souboru překopírujeme do tabulky ve Statistice a pojmenujeme proměnné, viz prezentace k tématu
Testování hypotéz. 1. vymezení základních pojmů 2. testování hypotéz o rozdílu průměrů 3. jednovýběrový t-test
 Testování hypotéz 1. vymezení základních pojmů 2. testování hypotéz o rozdílu průměrů 3. jednovýběrový t-test Testování hypotéz proces, kterým rozhodujeme, zda přijmeme nebo zamítneme nulovou hypotézu
Testování hypotéz 1. vymezení základních pojmů 2. testování hypotéz o rozdílu průměrů 3. jednovýběrový t-test Testování hypotéz proces, kterým rozhodujeme, zda přijmeme nebo zamítneme nulovou hypotézu
Aplikovaná statistika v R - cvičení 2
 Aplikovaná statistika v R - cvičení 2 Filip Děchtěrenko Matematicko-fyzikální fakulta filip.dechterenko@gmail.com 5.6.2014 Filip Děchtěrenko (MFF UK) Aplikovaná statistika v R 5.6.2014 1 / 18 Přehled Rkových
Aplikovaná statistika v R - cvičení 2 Filip Děchtěrenko Matematicko-fyzikální fakulta filip.dechterenko@gmail.com 5.6.2014 Filip Děchtěrenko (MFF UK) Aplikovaná statistika v R 5.6.2014 1 / 18 Přehled Rkových
Regresní a korelační analýza
 Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Testy nezávislosti kardinálních veličin
 Testy nezávislosti kardinálních veličin Komentované řešení pomocí programu R Ústav matematiky Fakulta chemicko inženýrská Vysoká škola chemicko-technologická v Praze Načtení vstupních dat Vstupní data
Testy nezávislosti kardinálních veličin Komentované řešení pomocí programu R Ústav matematiky Fakulta chemicko inženýrská Vysoká škola chemicko-technologická v Praze Načtení vstupních dat Vstupní data
DVOUVÝBĚROVÉ A PÁROVÉ TESTY Komentované řešení pomocí programu Statistica
 DVOUVÝBĚROVÉ A PÁROVÉ TESTY Komentované řešení pomocí programu Statistica Úloha A) koncentrace glukózy v krvi V této části posoudíme pomocí párového testu, zda nový lék prokazatelně snižuje koncentraci
DVOUVÝBĚROVÉ A PÁROVÉ TESTY Komentované řešení pomocí programu Statistica Úloha A) koncentrace glukózy v krvi V této části posoudíme pomocí párového testu, zda nový lék prokazatelně snižuje koncentraci
TESTOVÁNÍ HYPOTÉZ STATISTICKÁ HYPOTÉZA Statistické testy Testovací kritérium = B B > B < B B - B - B < 0 - B > 0 oboustranný test = B > B
 TESTOVÁNÍ HYPOTÉZ Od statistického šetření neočekáváme pouze elementární informace o velikosti některých statistických ukazatelů. Používáme je i k ověřování našich očekávání o výsledcích nějakého procesu,
TESTOVÁNÍ HYPOTÉZ Od statistického šetření neočekáváme pouze elementární informace o velikosti některých statistických ukazatelů. Používáme je i k ověřování našich očekávání o výsledcích nějakého procesu,
Popisná statistika. Komentované řešení pomocí MS Excel
 Popisná statistika Komentované řešení pomocí MS Excel Vstupní data Máme k dispozici data o počtech bodů z 1. a 2. zápočtového testu z Matematiky I v zimním semestru 2015/2016 a to za všech 762 studentů,
Popisná statistika Komentované řešení pomocí MS Excel Vstupní data Máme k dispozici data o počtech bodů z 1. a 2. zápočtového testu z Matematiky I v zimním semestru 2015/2016 a to za všech 762 studentů,
Jana Vránová, 3. lékařská fakulta UK
 Jana Vránová, 3. lékařská fakulta UK Vznikají při zkoumání vztahů kvalitativních resp. diskrétních znaků Jedná se o analogii s korelační analýzou spojitých znaků Přitom předpokládáme, že každý prvek populace
Jana Vránová, 3. lékařská fakulta UK Vznikají při zkoumání vztahů kvalitativních resp. diskrétních znaků Jedná se o analogii s korelační analýzou spojitých znaků Přitom předpokládáme, že každý prvek populace
LINEÁRNÍ REGRESE Komentované řešení pomocí programu Statistica
 LINEÁRNÍ REGRESE Komentované řešení pomocí programu Statistica Vstupní data Data umístěná v excelovském souboru překopírujeme do tabulky ve Statistice a pojmenujeme proměnné, viz prezentace k tématu Popisná
LINEÁRNÍ REGRESE Komentované řešení pomocí programu Statistica Vstupní data Data umístěná v excelovském souboru překopírujeme do tabulky ve Statistice a pojmenujeme proměnné, viz prezentace k tématu Popisná
MĚŘENÍ STATISTICKÝCH ZÁVISLOSTÍ
 MĚŘENÍ STATISTICKÝCH ZÁVISLOSTÍ v praxi u jednoho prvku souboru se často zkoumá více veličin, které mohou na sobě různě záviset jednorozměrný výběrový soubor VSS X vícerozměrným výběrovým souborem VSS
MĚŘENÍ STATISTICKÝCH ZÁVISLOSTÍ v praxi u jednoho prvku souboru se často zkoumá více veličin, které mohou na sobě různě záviset jednorozměrný výběrový soubor VSS X vícerozměrným výběrovým souborem VSS
Testování hypotéz a měření asociace mezi proměnnými
 Testování hypotéz a měření asociace mezi proměnnými Testování hypotéz Nulová a alternativní hypotéza většina statistických analýz zahrnuje různá porovnání, hledání vztahů, efektů Tvrzení, že efekt je nulový,
Testování hypotéz a měření asociace mezi proměnnými Testování hypotéz Nulová a alternativní hypotéza většina statistických analýz zahrnuje různá porovnání, hledání vztahů, efektů Tvrzení, že efekt je nulový,
Korelační a regresní analýza
 Korelační a regresní analýza Analýza závislosti v normálním rozdělení Pearsonův (výběrový) korelační koeficient: r = s XY s X s Y, kde s XY = 1 n (x n 1 i=0 i x )(y i y ), s X (s Y ) je výběrová směrodatná
Korelační a regresní analýza Analýza závislosti v normálním rozdělení Pearsonův (výběrový) korelační koeficient: r = s XY s X s Y, kde s XY = 1 n (x n 1 i=0 i x )(y i y ), s X (s Y ) je výběrová směrodatná
Dvouvýběrové a párové testy. Komentované řešení pomocí MS Excel
 Dvouvýběrové a párové testy Komentované řešení pomocí MS Excel Úloha A) koncentrace glukózy v krvi V této části posoudíme pomocí párového testu, zda nový lék prokazatelně snižuje koncentraci glukózy v
Dvouvýběrové a párové testy Komentované řešení pomocí MS Excel Úloha A) koncentrace glukózy v krvi V této části posoudíme pomocí párového testu, zda nový lék prokazatelně snižuje koncentraci glukózy v
RNDr. Eva Janoušová doc. RNDr. Ladislav Dušek, Dr.
 Analýza dat pro Neurovědy RNDr. Eva Janoušová doc. RNDr. Ladislav Dušek, Dr. Jaro 2014 Institut biostatistiky Janoušová, a analýz Dušek: Analýza dat pro neurovědy Blok 3 Jak a kdy použít parametrické a
Analýza dat pro Neurovědy RNDr. Eva Janoušová doc. RNDr. Ladislav Dušek, Dr. Jaro 2014 Institut biostatistiky Janoušová, a analýz Dušek: Analýza dat pro neurovědy Blok 3 Jak a kdy použít parametrické a
Stručný úvod do testování statistických hypotéz
 Stručný úvod do testování statistických hypotéz 1. Formulujeme hypotézu (předpokládáme, že pozorovaný jev je pouze náhodný). 2. Zvolíme hladinu významnosti testu a, tj. riziko, s nímž jsme ochotni se smířit.
Stručný úvod do testování statistických hypotéz 1. Formulujeme hypotézu (předpokládáme, že pozorovaný jev je pouze náhodný). 2. Zvolíme hladinu významnosti testu a, tj. riziko, s nímž jsme ochotni se smířit.
ZX510 Pokročilé statistické metody geografického výzkumu. Téma: Měření síly asociace mezi proměnnými (korelační analýza)
") ZX510 Pokročilé statistické metody geografického výzkumu Téma: Měření síly asociace mezi proměnnými (korelační analýza) Měření síly asociace (korelace) mezi proměnnými Vztah mezi dvěma proměnnými existuje,
ZX510 Pokročilé statistické metody geografického výzkumu Téma: Měření síly asociace mezi proměnnými (korelační analýza) Měření síly asociace (korelace) mezi proměnnými Vztah mezi dvěma proměnnými existuje,
Návrhy dalších možností statistického zpracování aktualizovaných dat
 Návrhy dalších možností statistického zpracování aktualizovaných dat Při zjišťování disparit ve fyzické dostupnosti bydlení navrhuji použití těchto statistických metod: Bag plot; Krabicové grafy a jejich
Návrhy dalších možností statistického zpracování aktualizovaných dat Při zjišťování disparit ve fyzické dostupnosti bydlení navrhuji použití těchto statistických metod: Bag plot; Krabicové grafy a jejich
Neparametrické metody
 Neparametrické metody Dosud jsme se zabývali statistickými metodami, které zahrnovaly předpoklady o rozdělení dat. Zpravidla jsme předpokládali normální rozdělení. Např. Grubbsův test odlehlých hodnot
Neparametrické metody Dosud jsme se zabývali statistickými metodami, které zahrnovaly předpoklady o rozdělení dat. Zpravidla jsme předpokládali normální rozdělení. Např. Grubbsův test odlehlých hodnot
Testování hypotéz o parametrech regresního modelu
 Testování hypotéz o parametrech regresního modelu Ekonometrie Jiří Neubauer Katedra kvantitativních metod FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Jiří Neubauer (Katedra UO
Testování hypotéz o parametrech regresního modelu Ekonometrie Jiří Neubauer Katedra kvantitativních metod FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Jiří Neubauer (Katedra UO
Regresní analýza 1. Regresní analýza
 Regresní analýza 1 1 Regresní funkce Regresní analýza Důležitou statistickou úlohou je hledání a zkoumání závislostí proměnných, jejichž hodnoty získáme při realizaci experimentů Vzhledem k jejich náhodnému
Regresní analýza 1 1 Regresní funkce Regresní analýza Důležitou statistickou úlohou je hledání a zkoumání závislostí proměnných, jejichž hodnoty získáme při realizaci experimentů Vzhledem k jejich náhodnému
4EK211 Základy ekonometrie
 4EK211 Základy ekonometrie ZS 2015/16 Cvičení 1: Opakování ze statistiky LENKA FIŘTOVÁ KATEDRA EKONOMETRIE, FAKULTA INFORMATIKY A STATISTIKY VYSOKÁ ŠKOLA EKONOMICKÁ V PRAZE Z čeho studovat 1) Z KNIHY Krkošková,
4EK211 Základy ekonometrie ZS 2015/16 Cvičení 1: Opakování ze statistiky LENKA FIŘTOVÁ KATEDRA EKONOMETRIE, FAKULTA INFORMATIKY A STATISTIKY VYSOKÁ ŠKOLA EKONOMICKÁ V PRAZE Z čeho studovat 1) Z KNIHY Krkošková,
Testování statistických hypotéz. Ing. Michal Dorda, Ph.D.
 Testování statistických hypotéz Ing. Michal Dorda, Ph.D. Testování normality Př. : Při simulaci provozu na křižovatce byla získána data o mezerách mezi přijíždějícími vozidly v [s]. Otestujte na hladině
Testování statistických hypotéz Ing. Michal Dorda, Ph.D. Testování normality Př. : Při simulaci provozu na křižovatce byla získána data o mezerách mezi přijíždějícími vozidly v [s]. Otestujte na hladině
676 + 4 + 100 + 196 + 0 + 484 + 196 + 324 + 64 + 324 = = 2368
 Příklad 1 Je třeba prověřit, zda lze na 5% hladině významnosti pokládat za prokázanou hypotézu, že střední doba výroby výlisku je 30 sekund. Přitom 10 náhodně vybraných výlisků bylo vyráběno celkem 540
Příklad 1 Je třeba prověřit, zda lze na 5% hladině významnosti pokládat za prokázanou hypotézu, že střední doba výroby výlisku je 30 sekund. Přitom 10 náhodně vybraných výlisků bylo vyráběno celkem 540
Cvičení ze statistiky - 9. Filip Děchtěrenko
 Cvičení ze statistiky - 9 Filip Děchtěrenko Minule bylo.. Dobrali jsme normální rozdělení Tyhle termíny by měly být známé: Inferenční statistika Konfidenční intervaly Z-test Postup při testování hypotéz
Cvičení ze statistiky - 9 Filip Děchtěrenko Minule bylo.. Dobrali jsme normální rozdělení Tyhle termíny by měly být známé: Inferenční statistika Konfidenční intervaly Z-test Postup při testování hypotéz
PSY117/454 Statistická analýza dat v psychologii Přednáška 5 ZOBRAZENÍ DVOUROZMĚRNÝCH DAT KORELAČNÍ KOEFICIENT. Všichni žijeme v matrixu.
 PSY117/454 Statistická analýza dat v psychologii Přednáška 5 ZOBRAZENÍ DVOUROZMĚRNÝCH DAT KORELAČNÍ KOEFICIENT Všichni žijeme v matrixu. V minulých dílech jsme viděli/y: Frekvence = četnosti Procenta =
PSY117/454 Statistická analýza dat v psychologii Přednáška 5 ZOBRAZENÍ DVOUROZMĚRNÝCH DAT KORELAČNÍ KOEFICIENT Všichni žijeme v matrixu. V minulých dílech jsme viděli/y: Frekvence = četnosti Procenta =
1 Tyto materiály byly vytvořeny za pomoci grantu FRVŠ číslo 1145/2004.
 Prostá regresní a korelační analýza 1 1 Tyto materiály byly vytvořeny za pomoci grantu FRVŠ číslo 1145/2004. Problematika závislosti V podstatě lze rozlišovat mezi závislostí nepodstatnou, čili náhodnou
Prostá regresní a korelační analýza 1 1 Tyto materiály byly vytvořeny za pomoci grantu FRVŠ číslo 1145/2004. Problematika závislosti V podstatě lze rozlišovat mezi závislostí nepodstatnou, čili náhodnou
UNIVERZITA OBRANY Fakulta ekonomiky a managementu. Aplikace STAT1. Výsledek řešení projektu PRO HORR2011 a PRO GRAM2011 3. 11.
 UNIVERZITA OBRANY Fakulta ekonomiky a managementu Aplikace STAT1 Výsledek řešení projektu PRO HORR2011 a PRO GRAM2011 Jiří Neubauer, Marek Sedlačík, Oldřich Kříž 3. 11. 2012 Popis a návod k použití aplikace
UNIVERZITA OBRANY Fakulta ekonomiky a managementu Aplikace STAT1 Výsledek řešení projektu PRO HORR2011 a PRO GRAM2011 Jiří Neubauer, Marek Sedlačík, Oldřich Kříž 3. 11. 2012 Popis a návod k použití aplikace
Testování hypotéz o parametrech regresního modelu
 Statistika II Katedra ekonometrie FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Lineární regresní model kde Y = Xβ + e, y 1 e 1 β y 2 Y =., e = e 2 x 11 x 1 1k., X =....... β 2,
Statistika II Katedra ekonometrie FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Lineární regresní model kde Y = Xβ + e, y 1 e 1 β y 2 Y =., e = e 2 x 11 x 1 1k., X =....... β 2,
{ } ( 2) Příklad: Test nezávislosti kategoriálních znaků
 Příklad: Test nezávislosti kategoriálních znaků") Příklad: Test nezávislosti kategoriálních znaků Určete na hladině významnosti 5 % na základě dat zjištěných v rámci dotazníkového šetření ve Šluknově, zda existuje závislost mezi pohlavím respondenta a
Příklad: Test nezávislosti kategoriálních znaků Určete na hladině významnosti 5 % na základě dat zjištěných v rámci dotazníkového šetření ve Šluknově, zda existuje závislost mezi pohlavím respondenta a
POPISNÁ STATISTIKA Komentované řešení pomocí programu Statistica
 POPISNÁ STATISTIKA Komentované řešení pomocí programu Statistica Program Statistica I Statistica je velmi podobná Excelu. Na základní úrovni je to klikací program určený ke statistickému zpracování dat.
POPISNÁ STATISTIKA Komentované řešení pomocí programu Statistica Program Statistica I Statistica je velmi podobná Excelu. Na základní úrovni je to klikací program určený ke statistickému zpracování dat.
Kontingenční tabulky, korelační koeficienty
 Statistika II Katedra ekonometrie FVL UO Brno kancelář 69a, tel 973 442029 email:jirineubauer@unobcz Budeme předpokládat, že X a Y jsou kvalitativní náhodné veličiny, obor hodnot X obsahuje r hodnot (kategorií,
Statistika II Katedra ekonometrie FVL UO Brno kancelář 69a, tel 973 442029 email:jirineubauer@unobcz Budeme předpokládat, že X a Y jsou kvalitativní náhodné veličiny, obor hodnot X obsahuje r hodnot (kategorií,
Cvičení ze statistiky - 8. Filip Děchtěrenko
 Cvičení ze statistiky - 8 Filip Děchtěrenko Minule bylo.. Dobrali jsme normální rozdělení Tyhle termíny by měly být známé: Centrální limitní věta Laplaceho věta (+ korekce na spojitost) Konfidenční intervaly
Cvičení ze statistiky - 8 Filip Děchtěrenko Minule bylo.. Dobrali jsme normální rozdělení Tyhle termíny by měly být známé: Centrální limitní věta Laplaceho věta (+ korekce na spojitost) Konfidenční intervaly
Kontingenční tabulky, korelační koeficienty
 Statistika II Katedra ekonometrie FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Mějme kategoriální proměnné X a Y. Vytvoříme tzv. kontingenční tabulku. Budeme tedy testovat hypotézu
Statistika II Katedra ekonometrie FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Mějme kategoriální proměnné X a Y. Vytvoříme tzv. kontingenční tabulku. Budeme tedy testovat hypotézu
Normální rozložení a odvozená rozložení
 I Normální rozložení a odvozená rozložení I.I Normální rozložení Data, se kterými pracujeme, pocházejí z různých rozložení. Mohou být vychýlena (doleva popř. doprava, nebo v nich není na první pohled vidět
I Normální rozložení a odvozená rozložení I.I Normální rozložení Data, se kterými pracujeme, pocházejí z různých rozložení. Mohou být vychýlena (doleva popř. doprava, nebo v nich není na první pohled vidět
Charakteristika datového souboru
 Zápočtová práce z předmětu Statistika Vypracoval: 10. 11. 2014 Charakteristika datového souboru Zadání: Při kontrole dodržování hygienických norem v kuchyni se prováděl odběr vzduchu a pomocí filtru Pallflex
Zápočtová práce z předmětu Statistika Vypracoval: 10. 11. 2014 Charakteristika datového souboru Zadání: Při kontrole dodržování hygienických norem v kuchyni se prováděl odběr vzduchu a pomocí filtru Pallflex
Mnohorozměrná statistická data
 Statistika II Katedra ekonometrie FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Statistický znak, statistický soubor Jednotlivé objekty nebo subjekty, které jsou při statistickém
Statistika II Katedra ekonometrie FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Statistický znak, statistický soubor Jednotlivé objekty nebo subjekty, které jsou při statistickém
UNIVERZITA PARDUBICE Fakulta chemicko-technologická Katedra analytické chemie Nám. Čs. Legií 565, Pardubice
 UNIVERZITA PARDUBICE Fakulta chemicko-technologická Katedra analytické chemie Nám. Čs. Legií 565, 532 10 Pardubice 10. licenční studium chemometrie STATISTICKÉ ZPRACOVÁNÍ DAT Semestrální práce STATISTICKÁ
UNIVERZITA PARDUBICE Fakulta chemicko-technologická Katedra analytické chemie Nám. Čs. Legií 565, 532 10 Pardubice 10. licenční studium chemometrie STATISTICKÉ ZPRACOVÁNÍ DAT Semestrální práce STATISTICKÁ
Úvodem Dříve les než stromy 3 Operace s maticemi
 Obsah 1 Úvodem 13 2 Dříve les než stromy 17 2.1 Nejednoznačnost terminologie 17 2.2 Volba metody analýzy dat 23 2.3 Přehled vybraných vícerozměrných metod 25 2.3.1 Metoda hlavních komponent 26 2.3.2 Faktorová
Obsah 1 Úvodem 13 2 Dříve les než stromy 17 2.1 Nejednoznačnost terminologie 17 2.2 Volba metody analýzy dat 23 2.3 Přehled vybraných vícerozměrných metod 25 2.3.1 Metoda hlavních komponent 26 2.3.2 Faktorová
Popisná statistika kvantitativní veličiny
 StatSoft Popisná statistika kvantitativní veličiny Protože nám surová data obvykle žádnou smysluplnou informaci neposkytnou, je žádoucí vyjádřit tyto ve zhuštěnější formě. V předchozím dílu jsme začali
StatSoft Popisná statistika kvantitativní veličiny Protože nám surová data obvykle žádnou smysluplnou informaci neposkytnou, je žádoucí vyjádřit tyto ve zhuštěnější formě. V předchozím dílu jsme začali
6. Lineární regresní modely
 6. Lineární regresní modely 6.1 Jednoduchá regrese a validace 6.2 Testy hypotéz v lineární regresi 6.3 Kritika dat v regresním tripletu 6.4 Multikolinearita a polynomy 6.5 Kritika modelu v regresním tripletu
6. Lineární regresní modely 6.1 Jednoduchá regrese a validace 6.2 Testy hypotéz v lineární regresi 6.3 Kritika dat v regresním tripletu 6.4 Multikolinearita a polynomy 6.5 Kritika modelu v regresním tripletu
Analýza dat na PC I.
 CENTRUM BIOSTATISTIKY A ANALÝZ Lékařská a Přírodovědecká fakulta, Masarykova univerzita Analýza dat na PC I. Popisná analýza v programu Statistica IBA výuka Základní popisná statistika Popisná statistika
CENTRUM BIOSTATISTIKY A ANALÝZ Lékařská a Přírodovědecká fakulta, Masarykova univerzita Analýza dat na PC I. Popisná analýza v programu Statistica IBA výuka Základní popisná statistika Popisná statistika
MATEMATICKÁ STATISTIKA. Katedra matematiky a didaktiky matematiky Technická univerzita v Liberci
 MATEMATICKÁ STATISTIKA Dana Černá http://www.fp.tul.cz/kmd/ Katedra matematiky a didaktiky matematiky Technická univerzita v Liberci Matematická statistika Matematická statistika se zabývá matematickým
MATEMATICKÁ STATISTIKA Dana Černá http://www.fp.tul.cz/kmd/ Katedra matematiky a didaktiky matematiky Technická univerzita v Liberci Matematická statistika Matematická statistika se zabývá matematickým
LEKCE 5 STATISTICKÁ INFERENCE ANEB ZOBECŇOVÁNÍ VÝSLEDKŮ Z VÝBĚROVÉHO NA ZÁKLADNÍ SOUBOR
 LEKCE 5 STATISTICKÁ INFERENCE ANEB ZOBECŇOVÁNÍ VÝSLEDKŮ Z VÝBĚROVÉHO NA ZÁKLADNÍ SOUBOR Ve většině případů pracujeme s výběrovým souborem a výběrové výsledky zobecňujeme na základní soubor. Smysluplné
LEKCE 5 STATISTICKÁ INFERENCE ANEB ZOBECŇOVÁNÍ VÝSLEDKŮ Z VÝBĚROVÉHO NA ZÁKLADNÍ SOUBOR Ve většině případů pracujeme s výběrovým souborem a výběrové výsledky zobecňujeme na základní soubor. Smysluplné
UNIVERZITA PARDUBICE Fakulta chemicko-technologická Katedra analytické chemie Nám. Čs. Legií 565, Pardubice
 UNIVERZITA PARDUBICE Fakulta chemicko-technologická Katedra analytické chemie Nám. Čs. Legií 565, 532 10 Pardubice 10. licenční studium chemometrie STATISTICKÉ ZPRACOVÁNÍ DAT Semestrální práce ANALÝZA
UNIVERZITA PARDUBICE Fakulta chemicko-technologická Katedra analytické chemie Nám. Čs. Legií 565, 532 10 Pardubice 10. licenční studium chemometrie STATISTICKÉ ZPRACOVÁNÍ DAT Semestrální práce ANALÝZA
Mnohorozměrná statistická data
 Mnohorozměrná statistická data Ekonometrie Jiří Neubauer Katedra ekonometrie FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Jiří Neubauer (Katedra ekonometrie UO Brno) Mnohorozměrná
Mnohorozměrná statistická data Ekonometrie Jiří Neubauer Katedra ekonometrie FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Jiří Neubauer (Katedra ekonometrie UO Brno) Mnohorozměrná
Jana Vránová, 3.lékařská fakulta UK, Praha. Hypotézy o populacích
 Jana Vránová, 3.lékařská fakulta UK, Praha Hypotézy o populacích Příklad IQ test: Předpokládejme, že z nějakého důvodu ministerstvo školství věří, že studenti absolventi středních škol v Hradci Králové
Jana Vránová, 3.lékařská fakulta UK, Praha Hypotézy o populacích Příklad IQ test: Předpokládejme, že z nějakého důvodu ministerstvo školství věří, že studenti absolventi středních škol v Hradci Králové
Normální (Gaussovo) rozdělení
 rozdělení") Normální (Gaussovo) rozdělení Normální (Gaussovo) rozdělení popisuje vlastnosti náhodné spojité veličiny, která vzniká složením různých náhodných vlivů, které jsou navzájem nezávislé, kterých je velký
Normální (Gaussovo) rozdělení Normální (Gaussovo) rozdělení popisuje vlastnosti náhodné spojité veličiny, která vzniká složením různých náhodných vlivů, které jsou navzájem nezávislé, kterých je velký
Pravděpodobnost v závislosti na proměnné x je zde modelován pomocí logistického modelu. exp x. x x x. log 1
 Logistická regrese Menu: QCExpert Regrese Logistická Modul Logistická regrese umožňuje analýzu dat, kdy odezva je binární, nebo frekvenční veličina vyjádřená hodnotami 0 nebo 1, případně poměry v intervalu
Logistická regrese Menu: QCExpert Regrese Logistická Modul Logistická regrese umožňuje analýzu dat, kdy odezva je binární, nebo frekvenční veličina vyjádřená hodnotami 0 nebo 1, případně poměry v intervalu
Diagnostika regrese pomocí grafu 7krát jinak
 StatSoft Diagnostika regrese pomocí grafu 7krát jinak V tomto článečku si uděláme exkurzi do teorie regresní analýzy a detailně se podíváme na jeden jediný diagnostický graf. Jedná se o graf Předpovědi
StatSoft Diagnostika regrese pomocí grafu 7krát jinak V tomto článečku si uděláme exkurzi do teorie regresní analýzy a detailně se podíváme na jeden jediný diagnostický graf. Jedná se o graf Předpovědi
Průzkumová analýza dat
 Průzkumová analýza dat Proč zkoumat data? Základ průzkumové analýzy dat položil John Tukey ve svém díle Exploratory Data Analysis (odtud zkratka EDA). Často se stává, že data, se kterými pracujeme, se
Průzkumová analýza dat Proč zkoumat data? Základ průzkumové analýzy dat položil John Tukey ve svém díle Exploratory Data Analysis (odtud zkratka EDA). Často se stává, že data, se kterými pracujeme, se
Korelační a regresní analýza. 1. Pearsonův korelační koeficient 2. jednoduchá regresní analýza 3. vícenásobná regresní analýza
 Korelační a regresní analýza 1. Pearsonův korelační koeficient 2. jednoduchá regresní analýza 3. vícenásobná regresní analýza Pearsonův korelační koeficient u intervalových a poměrových dat můžeme jako
Korelační a regresní analýza 1. Pearsonův korelační koeficient 2. jednoduchá regresní analýza 3. vícenásobná regresní analýza Pearsonův korelační koeficient u intervalových a poměrových dat můžeme jako
Příklad 1. Korelační pole. Řešení 1 ŘEŠENÉ PŘÍKLADY Z MV2 ČÁST 13
 Příklad 1 Máme k dispozici výsledky prvního a druhého testu deseti sportovců. Na hladině významnosti 0,05 prověřte, zda jsou výsledky testů kladně korelované. 1.test : 7, 8, 10, 4, 14, 9, 6, 2, 13, 5 2.test
Příklad 1 Máme k dispozici výsledky prvního a druhého testu deseti sportovců. Na hladině významnosti 0,05 prověřte, zda jsou výsledky testů kladně korelované. 1.test : 7, 8, 10, 4, 14, 9, 6, 2, 13, 5 2.test
Normální (Gaussovo) rozdělení
 rozdělení") Normální (Gaussovo) rozdělení f x = 1 2 exp x 2 2 2 f(x) je funkce hustoty pravděpodobnosti, symetrická vůči poloze maxima x = μ μ střední hodnota σ směrodatná odchylka (tzv. pološířka křivky mezi inflexními
Normální (Gaussovo) rozdělení f x = 1 2 exp x 2 2 2 f(x) je funkce hustoty pravděpodobnosti, symetrická vůči poloze maxima x = μ μ střední hodnota σ směrodatná odchylka (tzv. pološířka křivky mezi inflexními
Máte rádi kávu? Statistický výzkum o množství vypité kávy napříč věkovým spektrem.
 Máte rádi kávu? Statistický výzkum o množství vypité kávy napříč věkovým spektrem. SEMESTRÁLNÍ PRÁCE STATISTIKA VYPRACOVALA: IRENA VALÁŠKOVÁ A BARBORA SLAVÍKOVÁ DNE: 29. 12. 2012 SKUPINA: 2 36 Obsah Pár
Máte rádi kávu? Statistický výzkum o množství vypité kávy napříč věkovým spektrem. SEMESTRÁLNÍ PRÁCE STATISTIKA VYPRACOVALA: IRENA VALÁŠKOVÁ A BARBORA SLAVÍKOVÁ DNE: 29. 12. 2012 SKUPINA: 2 36 Obsah Pár
STATISTICKÉ ODHADY Odhady populačních charakteristik
 STATISTICKÉ ODHADY Odhady populačních charakteristik Jak stanovit charakteristiky rozložení sledované veličiny v základní populaci? Populaci většinou nemáme celou k dispozici, musíme se spokojit jen s
STATISTICKÉ ODHADY Odhady populačních charakteristik Jak stanovit charakteristiky rozložení sledované veličiny v základní populaci? Populaci většinou nemáme celou k dispozici, musíme se spokojit jen s
STATISTIKA A INFORMATIKA - bc studium OZW, 1.roč. (zkušební otázky)
") STATISTIKA A INFORMATIKA - bc studium OZW, 1.roč. (zkušební otázky) 1) Význam a využití statistiky v biologických vědách a veterinárním lékařství ) Rozdělení znaků (veličin) ve statistice 3) Základní a
STATISTIKA A INFORMATIKA - bc studium OZW, 1.roč. (zkušební otázky) 1) Význam a využití statistiky v biologických vědách a veterinárním lékařství ) Rozdělení znaků (veličin) ve statistice 3) Základní a
KONTINGENČNÍ TABULKY Komentované řešení pomocí programu Statistica
 KONTINGENČNÍ TABULKY Komentované řešení pomocí programu Statistica Vstupní data transformace před vložením Než data vložíme do tabulky ve Statistice, musíme si je předpřipravit. Označme si P Prahu, S Šumperk
KONTINGENČNÍ TABULKY Komentované řešení pomocí programu Statistica Vstupní data transformace před vložením Než data vložíme do tabulky ve Statistice, musíme si je předpřipravit. Označme si P Prahu, S Šumperk
Metodologie pro Informační studia a knihovnictví 2
 Metodologie pro Informační studia a knihovnictví 2 Modul 5: Popis nekategorizovaných dat Co se dozvíte v tomto modulu? Kdy používat modus, průměr a medián. Co je to směrodatná odchylka. Jak popsat distribuci
Metodologie pro Informační studia a knihovnictví 2 Modul 5: Popis nekategorizovaných dat Co se dozvíte v tomto modulu? Kdy používat modus, průměr a medián. Co je to směrodatná odchylka. Jak popsat distribuci
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc.
 Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika 2010 1.týden (20.09.-24.09. ) Data, typy dat, variabilita, frekvenční analýza
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika 2010 1.týden (20.09.-24.09. ) Data, typy dat, variabilita, frekvenční analýza
Jarqueův a Beryho test normality (Jarque-Bera Test, JB test)
") Jarqueův a Beryho test normality (Jarque-Bera Test, JB test) Autoři: Carlos M. Jarque and Anil K. Bera Předpoklady: - Výběrová data mohou obsahovat chybějící pozorování (chybějící hodnoty) vhodné zejména
Jarqueův a Beryho test normality (Jarque-Bera Test, JB test) Autoři: Carlos M. Jarque and Anil K. Bera Předpoklady: - Výběrová data mohou obsahovat chybějící pozorování (chybějící hodnoty) vhodné zejména
Souběžná validita testů SAT a OSP
 Souběžná validita testů SAT a OSP www.scio.cz 15. ledna 2013 Souběžná validita testů SAT a OSP Abstrakt Pro testování obecných studijních dovedností existuje mnoho testů. Některé jsou všeobecně známé a
Souběžná validita testů SAT a OSP www.scio.cz 15. ledna 2013 Souběžná validita testů SAT a OSP Abstrakt Pro testování obecných studijních dovedností existuje mnoho testů. Některé jsou všeobecně známé a
Obsah Úvod Kapitola 1 Než začneme Kapitola 2 Práce s hromadnými daty před analýzou
 Úvod.................................................................. 11 Kapitola 1 Než začneme.................................................................. 17 1.1 Logika kvantitativního výzkumu...........................................
Úvod.................................................................. 11 Kapitola 1 Než začneme.................................................................. 17 1.1 Logika kvantitativního výzkumu...........................................
Tomáš Karel LS 2012/2013
 Tomáš Karel LS 2012/2013 Doplňkový materiál ke cvičení z předmětu 4ST201. Na případné faktické chyby v této presentaci mě prosím upozorněte. Děkuji. Tyto slidy berte pouze jako doplňkový materiál není
Tomáš Karel LS 2012/2013 Doplňkový materiál ke cvičení z předmětu 4ST201. Na případné faktické chyby v této presentaci mě prosím upozorněte. Děkuji. Tyto slidy berte pouze jako doplňkový materiál není
Základy biostatistiky II. Veřejné zdravotnictví 3.LF UK - II
 Základy biostatistiky II Veřejné zdravotnictví 3.LF UK - II Teoretické rozložení-matematické modely rozložení Naměřená data Výběrové rozložení Teoretické rozložení 1 e 2 x 2 Teoretické rozložení-matematické
Základy biostatistiky II Veřejné zdravotnictví 3.LF UK - II Teoretické rozložení-matematické modely rozložení Naměřená data Výběrové rozložení Teoretické rozložení 1 e 2 x 2 Teoretické rozložení-matematické
Statistické testování hypotéz II
 PSY117/454 Statistická analýza dat v psychologii Přednáška 9 Statistické testování hypotéz II Přehled testů, rozdíly průměrů, velikost účinku, síla testu Základní výzkumné otázky/hypotézy 1. Stanovení
PSY117/454 Statistická analýza dat v psychologii Přednáška 9 Statistické testování hypotéz II Přehled testů, rozdíly průměrů, velikost účinku, síla testu Základní výzkumné otázky/hypotézy 1. Stanovení
Testování hypotéz. 1 Jednovýběrové testy. 90/2 odhad času
 Testování hypotéz 1 Jednovýběrové testy 90/ odhad času V podmínkách naprostého odloučení má voák prokázat schopnost orientace v čase. Úkolem voáka e provést odhad časového intervalu 1 hodiny bez hodinek
Testování hypotéz 1 Jednovýběrové testy 90/ odhad času V podmínkách naprostého odloučení má voák prokázat schopnost orientace v čase. Úkolem voáka e provést odhad časového intervalu 1 hodiny bez hodinek
Vysoká škola báňská technická univerzita Ostrava. Fakulta elektrotechniky a informatiky
 Vysoká škola báňská technická univerzita Ostrava Fakulta elektrotechniky a informatiky Bankovní účty (semestrální projekt statistika) Tomáš Hejret (hej124) 18.5.2013 Úvod Cílem tohoto projektu, zadaného
Vysoká škola báňská technická univerzita Ostrava Fakulta elektrotechniky a informatiky Bankovní účty (semestrální projekt statistika) Tomáš Hejret (hej124) 18.5.2013 Úvod Cílem tohoto projektu, zadaného
LINEÁRNÍ REGRESE. Lineární regresní model
 LINEÁRNÍ REGRESE Chemometrie I, David MILDE Lineární regresní model 1 Typy závislosti 2 proměnných FUNKČNÍ VZTAH: 2 závisle proměnné: určité hodnotě x odpovídá jediná hodnota y. KORELACE: 2 náhodné (nezávislé)
LINEÁRNÍ REGRESE Chemometrie I, David MILDE Lineární regresní model 1 Typy závislosti 2 proměnných FUNKČNÍ VZTAH: 2 závisle proměnné: určité hodnotě x odpovídá jediná hodnota y. KORELACE: 2 náhodné (nezávislé)
Rozhodnutí / Skutečnost platí neplatí Nezamítáme správně chyba 2. druhu Zamítáme chyba 1. druhu správně
 Testování hypotéz Nechť,, je náhodný výběr z nějakého rozdělení s neznámými parametry. Máme dvě navzájem si odporující hypotézy o parametrech daného rozdělení: Nulová hypotéza parametry (případně jediný
Testování hypotéz Nechť,, je náhodný výběr z nějakého rozdělení s neznámými parametry. Máme dvě navzájem si odporující hypotézy o parametrech daného rozdělení: Nulová hypotéza parametry (případně jediný
Neparametrické testy
 Neparametrické testy Dosud jsme se zabývali statistickými metodami, které zahrnovaly předpoklady o rozdělení dat. Zpravidla jsme předpokládali normální (Gaussovo) rozdělení. Například: Grubbsův test odlehlých
Neparametrické testy Dosud jsme se zabývali statistickými metodami, které zahrnovaly předpoklady o rozdělení dat. Zpravidla jsme předpokládali normální (Gaussovo) rozdělení. Například: Grubbsův test odlehlých
Přednáška XI. Asociace ve čtyřpolní tabulce a základy korelační analýzy
 Přednáška XI. Asociace ve čtyřpolní tabulce a základy korelační analýzy Relativní riziko a poměr šancí Princip korelace dvou náhodných veličin Korelační koeficienty Pearsonůva Spearmanův Korelace a kauzalita
Přednáška XI. Asociace ve čtyřpolní tabulce a základy korelační analýzy Relativní riziko a poměr šancí Princip korelace dvou náhodných veličin Korelační koeficienty Pearsonůva Spearmanův Korelace a kauzalita
Zápočtová práce STATISTIKA I
 Zápočtová práce STATISTIKA I Obsah: - úvodní stránka - charakteristika dat (původ dat, důvod zpracování,...) - výpis naměřených hodnot (v tabulce) - zpracování dat (buď bodové nebo intervalové, podle charakteru
Zápočtová práce STATISTIKA I Obsah: - úvodní stránka - charakteristika dat (původ dat, důvod zpracování,...) - výpis naměřených hodnot (v tabulce) - zpracování dat (buď bodové nebo intervalové, podle charakteru
TECHNICKÁ UNIVERZITA V LIBERCI
 TECHNICKÁ UNIVERZITA V LIBERCI Ekonomická fakulta Semestrální práce z předmětu Statistický rozbor dat z dotazníkového šetření Jméno: Lucie Krechlerová, Karel Kozma, René Dubský, David Drobík Ročník: 2015/2016
TECHNICKÁ UNIVERZITA V LIBERCI Ekonomická fakulta Semestrální práce z předmětu Statistický rozbor dat z dotazníkového šetření Jméno: Lucie Krechlerová, Karel Kozma, René Dubský, David Drobík Ročník: 2015/2016
Testování hypotéz. Testování hypotéz o rozdílu průměrů t-test pro nezávislé výběry t-test pro závislé výběry
 Testování hypotéz Testování hypotéz o rozdílu průměrů t-test pro nezávislé výběry t-test pro závislé výběry Testování hypotéz Obecný postup 1. Určení statistické hypotézy 2. Určení hladiny chyby 3. Výpočet
Testování hypotéz Testování hypotéz o rozdílu průměrů t-test pro nezávislé výběry t-test pro závislé výběry Testování hypotéz Obecný postup 1. Určení statistické hypotézy 2. Určení hladiny chyby 3. Výpočet
1. Přednáška. Ing. Miroslav Šulai, MBA
 N_OFI_2 1. Přednáška Počet pravděpodobnosti Statistický aparát používaný ve financích Ing. Miroslav Šulai, MBA 1 Počet pravděpodobnosti -náhodné veličiny 2 Počet pravděpodobnosti -náhodné veličiny 3 Jevy
N_OFI_2 1. Přednáška Počet pravděpodobnosti Statistický aparát používaný ve financích Ing. Miroslav Šulai, MBA 1 Počet pravděpodobnosti -náhodné veličiny 2 Počet pravděpodobnosti -náhodné veličiny 3 Jevy
Testování hypotéz. Analýza dat z dotazníkových šetření. Kuranova Pavlina
 Testování hypotéz Analýza dat z dotazníkových šetření Kuranova Pavlina Statistická hypotéza Možné cíle výzkumu Srovnání účinnosti různých metod Srovnání výsledků různých skupin Tzn. prokázání rozdílů mezi
Testování hypotéz Analýza dat z dotazníkových šetření Kuranova Pavlina Statistická hypotéza Možné cíle výzkumu Srovnání účinnosti různých metod Srovnání výsledků různých skupin Tzn. prokázání rozdílů mezi
Porovnání dvou výběrů
 Porovnání dvou výběrů Menu: QCExpert Porovnání dvou výběrů Tento modul je určen pro podrobnou analýzu dvou datových souborů (výběrů). Modul poskytuje dva postupy analýzy: porovnání dvou nezávislých výběrů
Porovnání dvou výběrů Menu: QCExpert Porovnání dvou výběrů Tento modul je určen pro podrobnou analýzu dvou datových souborů (výběrů). Modul poskytuje dva postupy analýzy: porovnání dvou nezávislých výběrů