Cvičení ze statistiky - 9. Filip Děchtěrenko
|
|
|
- Filip Špringl
- před 9 lety
- Počet zobrazení:
Transkript
1 Cvičení ze statistiky - 9 Filip Děchtěrenko

2 Minule bylo.. Dobrali jsme normální rozdělení Tyhle termíny by měly být známé: Inferenční statistika Konfidenční intervaly Z-test

3 Postup při testování hypotéz 1. Stanovíme si známé parametry 2. Stanovíme si nulovou a alternativní hypotézu 3. Stanovíme hladinu významnosti α a na jejím základě určíme kritickou hodnotu 4. Vypočítáme testovou statistiku (tohle je závislé na testu 5. Srovnáme testovou statistiku s kritickou hodnotou 6. Určíme p-hodnotu testu (= Jestliže H 0 platí, jaká je pst, že získáme vypočítanou hodnotu nebo ještě neobvyklejší? )

4 Druhy testů Celkem nás může potkat několik případů Budeme uvažovat, že data pocházejí z normálního rozdělení (jinak by se musely použít jiné metody) Zkoumáme μ základního souboru Známe σ základního souboru z-test Neznáme σ základního souboru t-test Porovnáváme μ 1 a μ 2 dvou základních souborů Výběry na sobě závisí Párový t-test Výběry na sobě nezávisí Dvouvýběrový t-test Zkoumáme-li σ základního souboru, používáme speciální testy pracující s χ 2 rozdělením (nebudeme testovat) či F-testy (nebudeme testovat)
 či F-testy (nebudeme")
5 Z-test Výpočet testovací statistiky: Z = X μ 0 n σ Pro alternativní znak p π 0 Z = π 0 (1 π 0 ) n
 n")
6 Příklad 2 Na minci nám padlo 22 orlů ze 40 hodů. Preferuje tato mince orly? (řešte pro α=0.01)? p=22/40=0.55, π 0 =0.5, n=40 H 0 : π = π 0 H A : π > π 0 (jednostranný test > ) α=0.01-> u 0.99 =2.33 Z= p π 0 π0(1 π0) n = (1 0.5) 40 =0.63 Abychom zamítli, musí platit Z>2.33, což neplatí (0.63 < 2.33), Hypotézu H 0 tedy nezamítáme P(Z>0.63)=1-P(Z 0.63)=1-0.74=0.26 (a to je více než α=0.01) Kolik potřebujeme hodů, abychom tato nevyváženost (55%) byla významná? Abychom mohli nulovou hypotézu zamítnout, musí platit, že Z>2.33, tedy (1 0.5) n > > n n>23.3 n> Potřebujeme tedy alespoň 543 hodů s 55% výběrovým poměrem, aby to bylo významné
 Kolik potřebujeme hodů, abychom tato nevyváženost (55%) byla významná? Abychom mohli nulovou hypotézu zamítnout, musí platit, že Z>2.33, tedy 0.55 0.5 0.5(1 0.5) n >2.")
7 t-rozdělení Co když ale neznáme σ základního souboru? -> tak to bývá ve většině případů Nahradíme-li sigma výběrovou směrodatnou odchylkou, nedává Z-transformace normální rozdělení, ale dostaneme jiné rozdělení Nazývá studentovo rozdělení (t-rozdělení) t n 1 = X μ, kde s s X = s2 X n Tvar tohoto rozdělení závisí na parametru označovaným jako stupně volnosti (df) df=n-1 Pro df se rozdělení blíží normálnímu rozdělení
 t n 1 = X μ, kde s s X = s2 X n Tvar tohoto rozdělení závisí na parametru označovaným jako")
8 Příklad Spotřeba téhož auta byla testována u 11 řidičů s výsledky 8.8,8.9, 9.0, 8.7, 9.3, 9.0, 8.7, 8.8, 9.4, 8.6, 8.9 (l/100 km). Je pravdivá výrobcem udávaná spotřeba 8,8 l/100 km? Předpokládejte normalitu dat n=11 -> df=10, x = s 2 = >s X = α=0.05 t 0.995,10 = t= X μ s X = =1.576 t< t 0.995,10, tudíž nezamítáme na hladině významnosti α=0.05 (p-hodnota je těžší na spočítání)

9 Dva výběry Máme-li dva výběry, můžeme testovat, zda se jejich průměry statisticky významně liší (tedy zda nejde o náhodu, že to nevyšlo podobně) Pokud jsou na sobě výběry nezávislé (tj. každý pochází z vlastní populace), použijeme dvouvýběrový t-test Pokud jsou na sobě závislé (např. měříme před a po experimentu, používáme párový t-test) Můžete je počítat v Excelu TTEST(pole1;pole2;strany;typ)
 Můžete je počítat v Excelu")

10 χ 2 -test dobré shody Hodili jsme 100 krát mincí, padla nám 60krát panna, 40 orel. Je mince falešná? Na tyto otázky se nám hodí χ 2 -test dobré shody Obecně ho používáme v případech, že chceme porovnat rozdělení vzorku se známým rozdělením základního souboru Používáme k tomu χ 2 rozdělení Opět má parametr stupeň volnosti Testovou charakteristiku spočítáme jako: 2 χ k 1 = PC OC 2 kde OC k je počet kategorií (u mince máme dvě) PC je pozorovaná četnost OC je očekávaná četnost Kritickou hodnotu opět hledám v tabulkách podle stupňů volnosti a hladiny významnosti Nepoužíváme oboustranný test, protože rozdělení je nesymetrické!
 PC je pozorovaná četnost OC je očekávaná četnost Kritickou hodnotu opět hledám v tabulkách podle stupňů volnosti a hladiny")
11 Příklad Řetezec cukráren, který nabízí 4 druhy zmrzliny otevřel provozovnu v nové lokalitě. Vyjádřete se pomocí statistického testu ke shodě či odlišnosti struktury prodeje v nové lokalitě oproti dosavadnímu řetězci. Prodej řetězce Vanilková 62% Čokoládová 18% Jahodová 12% Pistáciová 8% α=0.05, df=3 -> χ 3,0.975 χ 2 3 = Prodej nové prodejny Vanilková 120 ks Čokoládová 40 ks Jahodová 18 ks Pistáciová 22 ks 2 = = <7.815, tedy nulovou hypotézu nezamítáme na hladině významosti α=


12 Příklad ze života Zkoumali jsme množství násilných činů ve státech USA

13 Deskriptivní statistika Popisné charakteristiky Bodové grafy

14 Korelace Pearsonovy koeficienty korelace Hladiny významnosti

15 Regresní funkce Vypadá to, že mezi počet vražd a napadení je lineární závislost A vyšlo to významně

16 Hypotéza vraždy souvisí s volbou Výsledky voleb prezidenta

17 Zločiny a prezident

18 Hypotéza vraždy souvisí s bohatstvím
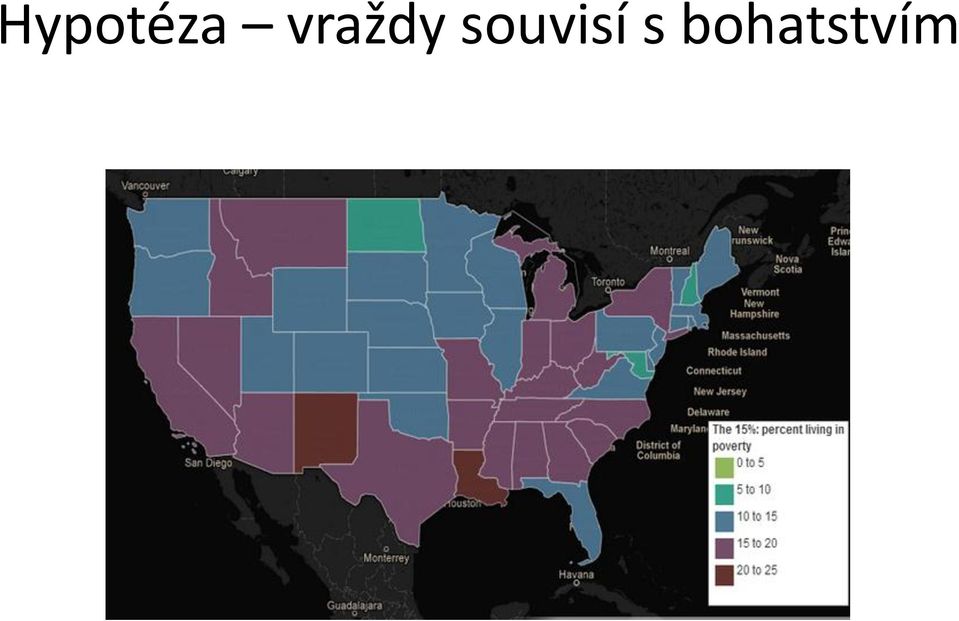
19 Chudoba vs. zločiny

20 A toť je vše Hodně štěstí u zkoušky

Cvičení ze statistiky - 8. Filip Děchtěrenko
 Cvičení ze statistiky - 8 Filip Děchtěrenko Minule bylo.. Dobrali jsme normální rozdělení Tyhle termíny by měly být známé: Centrální limitní věta Laplaceho věta (+ korekce na spojitost) Konfidenční intervaly
Cvičení ze statistiky - 8 Filip Děchtěrenko Minule bylo.. Dobrali jsme normální rozdělení Tyhle termíny by měly být známé: Centrální limitní věta Laplaceho věta (+ korekce na spojitost) Konfidenční intervaly
4ST201 STATISTIKA CVIČENÍ Č. 7
 4ST201 STATISTIKA CVIČENÍ Č. 7 testování hypotéz parametrické testy test hypotézy o střední hodnotě test hypotézy o relativní četnosti test o shodě středních hodnot testování hypotéz v MS Excel neparametrické
4ST201 STATISTIKA CVIČENÍ Č. 7 testování hypotéz parametrické testy test hypotézy o střední hodnotě test hypotézy o relativní četnosti test o shodě středních hodnot testování hypotéz v MS Excel neparametrické
676 + 4 + 100 + 196 + 0 + 484 + 196 + 324 + 64 + 324 = = 2368
 Příklad 1 Je třeba prověřit, zda lze na 5% hladině významnosti pokládat za prokázanou hypotézu, že střední doba výroby výlisku je 30 sekund. Přitom 10 náhodně vybraných výlisků bylo vyráběno celkem 540
Příklad 1 Je třeba prověřit, zda lze na 5% hladině významnosti pokládat za prokázanou hypotézu, že střední doba výroby výlisku je 30 sekund. Přitom 10 náhodně vybraných výlisků bylo vyráběno celkem 540
Testování statistických hypotéz. Ing. Michal Dorda, Ph.D.
 Testování statistických hypotéz Ing. Michal Dorda, Ph.D. Testování normality Př. : Při simulaci provozu na křižovatce byla získána data o mezerách mezi přijíždějícími vozidly v [s]. Otestujte na hladině
Testování statistických hypotéz Ing. Michal Dorda, Ph.D. Testování normality Př. : Při simulaci provozu na křižovatce byla získána data o mezerách mezi přijíždějícími vozidly v [s]. Otestujte na hladině
Testování hypotéz. 1. vymezení základních pojmů 2. testování hypotéz o rozdílu průměrů 3. jednovýběrový t-test
 Testování hypotéz 1. vymezení základních pojmů 2. testování hypotéz o rozdílu průměrů 3. jednovýběrový t-test Testování hypotéz proces, kterým rozhodujeme, zda přijmeme nebo zamítneme nulovou hypotézu
Testování hypotéz 1. vymezení základních pojmů 2. testování hypotéz o rozdílu průměrů 3. jednovýběrový t-test Testování hypotéz proces, kterým rozhodujeme, zda přijmeme nebo zamítneme nulovou hypotézu
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz
 Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická
12. cvičení z PST. 20. prosince 2017
 1 cvičení z PST 0 prosince 017 11 test rozptylu normálního rozdělení Do laboratoře bylo odesláno n = 5 stejných vzorků krve ke stanovení obsahu alkoholu X v promilích alkoholu Výsledkem byla realizace
1 cvičení z PST 0 prosince 017 11 test rozptylu normálního rozdělení Do laboratoře bylo odesláno n = 5 stejných vzorků krve ke stanovení obsahu alkoholu X v promilích alkoholu Výsledkem byla realizace
Testování statistických hypotéz
 Testování statistických hypotéz Na základě náhodného výběru, který je reprezentativním vzorkem základního souboru (který přesně neznáme, k němuž se ale daná statistická hypotéza váže), potřebujeme ověřit,
Testování statistických hypotéz Na základě náhodného výběru, který je reprezentativním vzorkem základního souboru (který přesně neznáme, k němuž se ale daná statistická hypotéza váže), potřebujeme ověřit,
STATISTIKA A INFORMATIKA - bc studium OZW, 1.roč. (zkušební otázky)
") STATISTIKA A INFORMATIKA - bc studium OZW, 1.roč. (zkušební otázky) 1) Význam a využití statistiky v biologických vědách a veterinárním lékařství ) Rozdělení znaků (veličin) ve statistice 3) Základní a
STATISTIKA A INFORMATIKA - bc studium OZW, 1.roč. (zkušební otázky) 1) Význam a využití statistiky v biologických vědách a veterinárním lékařství ) Rozdělení znaků (veličin) ve statistice 3) Základní a
Pravděpodobnost a statistika, Biostatistika pro kombinované studium. Tutoriál č. 5: Bodové a intervalové odhady, testování hypotéz.
 Pravděpodobnost a statistika, Biostatistika pro kombinované studium Letní semestr 2015/2016 Tutoriál č. 5: Bodové a intervalové odhady, testování hypotéz Jan Kracík jan.kracik@vsb.cz Obsah: Výběrová rozdělení
Pravděpodobnost a statistika, Biostatistika pro kombinované studium Letní semestr 2015/2016 Tutoriál č. 5: Bodové a intervalové odhady, testování hypotéz Jan Kracík jan.kracik@vsb.cz Obsah: Výběrová rozdělení
Testování hypotéz. Testování hypotéz o rozdílu průměrů t-test pro nezávislé výběry t-test pro závislé výběry
 Testování hypotéz Testování hypotéz o rozdílu průměrů t-test pro nezávislé výběry t-test pro závislé výběry Testování hypotéz Obecný postup 1. Určení statistické hypotézy 2. Určení hladiny chyby 3. Výpočet
Testování hypotéz Testování hypotéz o rozdílu průměrů t-test pro nezávislé výběry t-test pro závislé výběry Testování hypotéz Obecný postup 1. Určení statistické hypotézy 2. Určení hladiny chyby 3. Výpočet
STATISTICKÉ TESTY VÝZNAMNOSTI
 STATISTICKÉ TESTY VÝZNAMNOSTI jsou statistické postupy, pomocí nichž ověřujeme, zda mezi proměnnými existuje vztah (závislost, rozdíl). Pokud je výsledek šetření statisticky významný (signifikantní), znamená
STATISTICKÉ TESTY VÝZNAMNOSTI jsou statistické postupy, pomocí nichž ověřujeme, zda mezi proměnnými existuje vztah (závislost, rozdíl). Pokud je výsledek šetření statisticky významný (signifikantní), znamená
Korelace. Komentované řešení pomocí MS Excel
 Korelace Komentované řešení pomocí MS Excel Vstupní data Tabulka se vstupními daty je umístěna v oblasti A2:B84 (viz. obrázek) Prvotní představu o tvaru a síle závislosti docházky a počtu bodů nám poskytne
Korelace Komentované řešení pomocí MS Excel Vstupní data Tabulka se vstupními daty je umístěna v oblasti A2:B84 (viz. obrázek) Prvotní představu o tvaru a síle závislosti docházky a počtu bodů nám poskytne
Intervalové odhady. Interval spolehlivosti pro střední hodnotu v N(µ, σ 2 ) Interpretace intervalu spolehlivosti. Interval spolehlivosti ilustrace
 Interpretace intervalu spolehlivosti. Interval spolehlivosti ilustrace") Intervalové odhady Interval spolehlivosti pro střední hodnotu v Nµ, σ 2 ) Situace: X 1,..., X n náhodný výběr z Nµ, σ 2 ), kde σ 2 > 0 známe měli jsme: bodové odhady odhadem charakteristiky je číslo) nevyjadřuje
Intervalové odhady Interval spolehlivosti pro střední hodnotu v Nµ, σ 2 ) Situace: X 1,..., X n náhodný výběr z Nµ, σ 2 ), kde σ 2 > 0 známe měli jsme: bodové odhady odhadem charakteristiky je číslo) nevyjadřuje
Intervalové odhady. Interval spolehlivosti pro střední hodnotu v N(µ, σ 2 ) Interpretace intervalu spolehlivosti. Interval spolehlivosti ilustrace
 Interpretace intervalu spolehlivosti. Interval spolehlivosti ilustrace") Intervalové odhady Interval spolehlivosti pro střední hodnotu v Nµ, σ 2 ) Situace: X 1,..., X n náhodný výběr z Nµ, σ 2 ), kde σ 2 > 0 známe měli jsme: bodové odhady odhadem charakteristiky je číslo) nevyjadřuje
Intervalové odhady Interval spolehlivosti pro střední hodnotu v Nµ, σ 2 ) Situace: X 1,..., X n náhodný výběr z Nµ, σ 2 ), kde σ 2 > 0 známe měli jsme: bodové odhady odhadem charakteristiky je číslo) nevyjadřuje
11. cvičení z PSI prosince hodnota pozorovaná četnost n i p X (i) = q i (1 q), i N 0.
 = q i (1 q), i N 0.") 11 cvičení z PSI 12-16 prosince 2016 111 (Test dobré shody - geometrické rozdělení Realizací náhodné veličiny X jsme dostali následující četnosti výsledků: hodnota 0 1 2 3 4 5 6 pozorovaná četnost 29 15
11 cvičení z PSI 12-16 prosince 2016 111 (Test dobré shody - geometrické rozdělení Realizací náhodné veličiny X jsme dostali následující četnosti výsledků: hodnota 0 1 2 3 4 5 6 pozorovaná četnost 29 15
Aplikovaná statistika v R - cvičení 2
 Aplikovaná statistika v R - cvičení 2 Filip Děchtěrenko Matematicko-fyzikální fakulta filip.dechterenko@gmail.com 5.6.2014 Filip Děchtěrenko (MFF UK) Aplikovaná statistika v R 5.6.2014 1 / 18 Přehled Rkových
Aplikovaná statistika v R - cvičení 2 Filip Děchtěrenko Matematicko-fyzikální fakulta filip.dechterenko@gmail.com 5.6.2014 Filip Děchtěrenko (MFF UK) Aplikovaná statistika v R 5.6.2014 1 / 18 Přehled Rkových
PARAMETRICKÉ TESTY. 1) Měření Etalonu. Dataset - mereni_etalonu.sta - 9 měření etalonu srovnáváme s PŘEDPOKLÁDANOU HODNOTOU 10.
 Měření Etalonu. Dataset - mereni_etalonu.sta - 9 měření etalonu srovnáváme s PŘEDPOKLÁDANOU HODNOTOU 10.") PARAMETRICKÉ TESTY Testujeme rovnost průměru - předpokladem normální rozdělení I) Jednovýběrový t-test 1) Měření Etalonu. Dataset - mereni_etalonu.sta - 9 měření etalonu srovnáváme s PŘEDPOKLÁDANOU HODNOTOU
PARAMETRICKÉ TESTY Testujeme rovnost průměru - předpokladem normální rozdělení I) Jednovýběrový t-test 1) Měření Etalonu. Dataset - mereni_etalonu.sta - 9 měření etalonu srovnáváme s PŘEDPOKLÁDANOU HODNOTOU
Kategorická data METODOLOGICKÝ PROSEMINÁŘ II TÝDEN 7 4. DUBNA dubna 2018 Lukáš Hájek, Karel Höfer Metodologický proseminář II 1
 Kategorická data METODOLOGICKÝ PROSEMINÁŘ II TÝDEN 7 4. DUBNA 2018 4. dubna 2018 Lukáš Hájek, Karel Höfer Metodologický proseminář II 1 Typy proměnných nominální (nominal) o dvou hodnotách lze říci pouze
Kategorická data METODOLOGICKÝ PROSEMINÁŘ II TÝDEN 7 4. DUBNA 2018 4. dubna 2018 Lukáš Hájek, Karel Höfer Metodologický proseminář II 1 Typy proměnných nominální (nominal) o dvou hodnotách lze říci pouze
Testování hypotéz. 1 Jednovýběrové testy. 90/2 odhad času
 Testování hypotéz 1 Jednovýběrové testy 90/ odhad času V podmínkách naprostého odloučení má voák prokázat schopnost orientace v čase. Úkolem voáka e provést odhad časového intervalu 1 hodiny bez hodinek
Testování hypotéz 1 Jednovýběrové testy 90/ odhad času V podmínkách naprostého odloučení má voák prokázat schopnost orientace v čase. Úkolem voáka e provést odhad časového intervalu 1 hodiny bez hodinek
Tomáš Karel LS 2012/2013
 Tomáš Karel LS 2012/2013 Doplňkový materiál ke cvičení z předmětu 4ST201. Na případné faktické chyby v této presentaci mě prosím upozorněte. Děkuji. Tyto slidy berte pouze jako doplňkový materiál není
Tomáš Karel LS 2012/2013 Doplňkový materiál ke cvičení z předmětu 4ST201. Na případné faktické chyby v této presentaci mě prosím upozorněte. Děkuji. Tyto slidy berte pouze jako doplňkový materiál není
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc.
 Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika 010 1.týden (0.09.-4.09. ) Data, typy dat, variabilita, frekvenční analýza
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika 010 1.týden (0.09.-4.09. ) Data, typy dat, variabilita, frekvenční analýza
Příklad 1. Korelační pole. Řešení 1 ŘEŠENÉ PŘÍKLADY Z MV2 ČÁST 13
 Příklad 1 Máme k dispozici výsledky prvního a druhého testu deseti sportovců. Na hladině významnosti 0,05 prověřte, zda jsou výsledky testů kladně korelované. 1.test : 7, 8, 10, 4, 14, 9, 6, 2, 13, 5 2.test
Příklad 1 Máme k dispozici výsledky prvního a druhého testu deseti sportovců. Na hladině významnosti 0,05 prověřte, zda jsou výsledky testů kladně korelované. 1.test : 7, 8, 10, 4, 14, 9, 6, 2, 13, 5 2.test
TESTOVÁNÍ HYPOTÉZ STATISTICKÁ HYPOTÉZA Statistické testy Testovací kritérium = B B > B < B B - B - B < 0 - B > 0 oboustranný test = B > B
 TESTOVÁNÍ HYPOTÉZ Od statistického šetření neočekáváme pouze elementární informace o velikosti některých statistických ukazatelů. Používáme je i k ověřování našich očekávání o výsledcích nějakého procesu,
TESTOVÁNÍ HYPOTÉZ Od statistického šetření neočekáváme pouze elementární informace o velikosti některých statistických ukazatelů. Používáme je i k ověřování našich očekávání o výsledcích nějakého procesu,
STATISTICA Téma 6. Testy na základě jednoho a dvou výběrů
 STATISTICA Téma 6. Testy na základě jednoho a dvou výběrů 1) Test na velikost rozptylu Test na velikost rozptylu STATISTICA nemá. 2) Test na velikost střední hodnoty V menu Statistika zvolíme nabídku Základní
STATISTICA Téma 6. Testy na základě jednoho a dvou výběrů 1) Test na velikost rozptylu Test na velikost rozptylu STATISTICA nemá. 2) Test na velikost střední hodnoty V menu Statistika zvolíme nabídku Základní
JEDNOVÝBĚROVÉ TESTY. Komentované řešení pomocí programu Statistica
 JEDNOVÝBĚROVÉ TESTY Komentované řešení pomocí programu Statistica Vstupní data Data umístěná v excelovském souboru překopírujeme do tabulky ve Statistice a pojmenujeme proměnné, viz prezentace k tématu
JEDNOVÝBĚROVÉ TESTY Komentované řešení pomocí programu Statistica Vstupní data Data umístěná v excelovském souboru překopírujeme do tabulky ve Statistice a pojmenujeme proměnné, viz prezentace k tématu
TESTOVÁNÍ STATISTICKÝCH HYPOTÉZ ZÁKLADNÍ POJMY
 TESTOVÁNÍ STATISTICKÝCH HYPOTÉZ ZÁKLADNÍ POJMY Statistická hypotéza je určitá domněnka (předpoklad) o vlastnostech ZÁKLADNÍHO SOUBORU. Test statistické hypotézy je pravidlo (kritérium), které na základě
TESTOVÁNÍ STATISTICKÝCH HYPOTÉZ ZÁKLADNÍ POJMY Statistická hypotéza je určitá domněnka (předpoklad) o vlastnostech ZÁKLADNÍHO SOUBORU. Test statistické hypotézy je pravidlo (kritérium), které na základě
INDUKTIVNÍ STATISTIKA
 10. SEMINÁŘ INDUKTIVNÍ STATISTIKA 3. HODNOCENÍ ZÁVISLOSTÍ HODNOCENÍ ZÁVISLOSTÍ KVALITATIVNÍ VELIČINY - Vychází se z kombinační (kontingenční) tabulky, která je výsledkem třídění druhého stupně KVANTITATIVNÍ
10. SEMINÁŘ INDUKTIVNÍ STATISTIKA 3. HODNOCENÍ ZÁVISLOSTÍ HODNOCENÍ ZÁVISLOSTÍ KVALITATIVNÍ VELIČINY - Vychází se z kombinační (kontingenční) tabulky, která je výsledkem třídění druhého stupně KVANTITATIVNÍ
Testy statistických hypotéz
 Testy statistických hypotéz Statistická hypotéza je jakýkoliv předpoklad o rozdělení pravděpodobnosti jedné nebo několika náhodných veličin. Na základě náhodného výběru, který je reprezentativním vzorkem
Testy statistických hypotéz Statistická hypotéza je jakýkoliv předpoklad o rozdělení pravděpodobnosti jedné nebo několika náhodných veličin. Na základě náhodného výběru, který je reprezentativním vzorkem
STATISTICKÉ TESTY VÝZNAMNOSTI
 STATISTICKÉ TESTY VÝZNAMNOSTI jsou statistické postupy, pomocí nichž ověřujeme, zda mezi proměnnými existuje vztah (závislost, rozdíl). Pokud je výsledek šetření statisticky významný (signifikantní), znamená
STATISTICKÉ TESTY VÝZNAMNOSTI jsou statistické postupy, pomocí nichž ověřujeme, zda mezi proměnnými existuje vztah (závislost, rozdíl). Pokud je výsledek šetření statisticky významný (signifikantní), znamená
Příklady na testy hypotéz o parametrech normálního rozdělení
 Příklady na testy hypotéz o parametrech normálního rozdělení. O životnosti 75W žárovky (v hodinách) je známo, že má normální rozdělení s = 5h. Pro náhodný výběr 0 žárovek byla stanovena průměrná životnost
Příklady na testy hypotéz o parametrech normálního rozdělení. O životnosti 75W žárovky (v hodinách) je známo, že má normální rozdělení s = 5h. Pro náhodný výběr 0 žárovek byla stanovena průměrná životnost
t-test, Studentův párový test Ing. Michael Rost, Ph.D.
 Testování hypotéz: dvouvýběrový t-test, Studentův párový test Ing. Michael Rost, Ph.D. Úvod do problému... Již známe jednovýběrový t-test, při kterém jsme měli k dispozici pouze jeden výběr. Můžeme se
Testování hypotéz: dvouvýběrový t-test, Studentův párový test Ing. Michael Rost, Ph.D. Úvod do problému... Již známe jednovýběrový t-test, při kterém jsme měli k dispozici pouze jeden výběr. Můžeme se
UNIVERZITA OBRANY Fakulta ekonomiky a managementu. Aplikace STAT1. Výsledek řešení projektu PRO HORR2011 a PRO GRAM2011 3. 11.
 UNIVERZITA OBRANY Fakulta ekonomiky a managementu Aplikace STAT1 Výsledek řešení projektu PRO HORR2011 a PRO GRAM2011 Jiří Neubauer, Marek Sedlačík, Oldřich Kříž 3. 11. 2012 Popis a návod k použití aplikace
UNIVERZITA OBRANY Fakulta ekonomiky a managementu Aplikace STAT1 Výsledek řešení projektu PRO HORR2011 a PRO GRAM2011 Jiří Neubauer, Marek Sedlačík, Oldřich Kříž 3. 11. 2012 Popis a návod k použití aplikace
Testování hypotéz. Analýza dat z dotazníkových šetření. Kuranova Pavlina
 Testování hypotéz Analýza dat z dotazníkových šetření Kuranova Pavlina Statistická hypotéza Možné cíle výzkumu Srovnání účinnosti různých metod Srovnání výsledků různých skupin Tzn. prokázání rozdílů mezi
Testování hypotéz Analýza dat z dotazníkových šetření Kuranova Pavlina Statistická hypotéza Možné cíle výzkumu Srovnání účinnosti různých metod Srovnání výsledků různých skupin Tzn. prokázání rozdílů mezi
Tomáš Karel LS 2012/2013
 Tomáš Karel LS 2012/2013 Doplňkový materiál ke cvičení z předmětu 4ST201. Na případné faktické chyby v této presentaci mě prosím upozorněte. Děkuji. Tyto slidy berte pouze jako doplňkový materiál není
Tomáš Karel LS 2012/2013 Doplňkový materiál ke cvičení z předmětu 4ST201. Na případné faktické chyby v této presentaci mě prosím upozorněte. Děkuji. Tyto slidy berte pouze jako doplňkový materiál není
Náhodné veličiny jsou nekorelované, neexistuje mezi nimi korelační vztah. Když jsou X; Y nekorelované, nemusí být nezávislé.
 1. Korelační analýza V životě většinou nesledujeme pouze jeden statistický znak. Sledujeme více statistických znaků zároveň. Kromě vlastností statistických znaků nás zajímá také jejich těsnost (velikost,
1. Korelační analýza V životě většinou nesledujeme pouze jeden statistický znak. Sledujeme více statistických znaků zároveň. Kromě vlastností statistických znaků nás zajímá také jejich těsnost (velikost,
Jednostranné intervaly spolehlivosti
 Jednostranné intervaly spolehlivosti hledáme jen jednu z obou mezí Princip: dle zadání úlohy hledáme jen dolní či jen horní mez podle oboustranného vzorce s tou změnou, že výraz 1-α/2 ve vzorci nahradíme
Jednostranné intervaly spolehlivosti hledáme jen jednu z obou mezí Princip: dle zadání úlohy hledáme jen dolní či jen horní mez podle oboustranného vzorce s tou změnou, že výraz 1-α/2 ve vzorci nahradíme
Testy. Pavel Provinský. 19. listopadu 2013
 Testy Pavel Provinský 19. listopadu 2013 Test a intervalový odhad Testy a intervalové odhady - jsou vlastně to samé. Jiný je jen úhel pohledu. Lze přecházet od jednoho k druhému. Například: Při odvozování
Testy Pavel Provinský 19. listopadu 2013 Test a intervalový odhad Testy a intervalové odhady - jsou vlastně to samé. Jiný je jen úhel pohledu. Lze přecházet od jednoho k druhému. Například: Při odvozování
Jana Vránová, 3.lékařská fakulta UK, Praha. Hypotézy o populacích
 Jana Vránová, 3.lékařská fakulta UK, Praha Hypotézy o populacích Příklad IQ test: Předpokládejme, že z nějakého důvodu ministerstvo školství věří, že studenti absolventi středních škol v Hradci Králové
Jana Vránová, 3.lékařská fakulta UK, Praha Hypotézy o populacích Příklad IQ test: Předpokládejme, že z nějakého důvodu ministerstvo školství věří, že studenti absolventi středních škol v Hradci Králové
Testování hypotéz. Testování hypotéz o rozdílu průměrů t-test pro nezávislé výběry t-test pro závislé výběry
 Testování hypotéz Testování hypotéz o rozdílu průměrů t-test pro nezávislé výběry t-test pro závislé výběry Testování hypotéz Obecný postup 1. Určení statistické hypotézy 2. Určení hladiny chyby 3. Výpočet
Testování hypotéz Testování hypotéz o rozdílu průměrů t-test pro nezávislé výběry t-test pro závislé výběry Testování hypotéz Obecný postup 1. Určení statistické hypotézy 2. Určení hladiny chyby 3. Výpočet
Testování hypotéz. 4. přednáška 6. 3. 2010
 Testování hypotéz 4. přednáška 6. 3. 2010 Základní pojmy Statistická hypotéza Je tvrzení o vlastnostech základního souboru, o jehož pravdivosti se chceme přesvědčit. Předem nevíme, zda je pravdivé nebo
Testování hypotéz 4. přednáška 6. 3. 2010 Základní pojmy Statistická hypotéza Je tvrzení o vlastnostech základního souboru, o jehož pravdivosti se chceme přesvědčit. Předem nevíme, zda je pravdivé nebo
Intervalový odhad. Interval spolehlivosti = intervalový odhad nějakého parametru s danou pravděpodobností = konfidenční interval pro daný parametr
 StatSoft Intervalový odhad Dnes se budeme zabývat neodmyslitelnou součástí statistiky a to intervaly v nejrůznějších podobách. Toto téma je také úzce spojeno s tématem testování hypotéz, a tedy plynule
StatSoft Intervalový odhad Dnes se budeme zabývat neodmyslitelnou součástí statistiky a to intervaly v nejrůznějších podobách. Toto téma je také úzce spojeno s tématem testování hypotéz, a tedy plynule
Rozhodnutí / Skutečnost platí neplatí Nezamítáme správně chyba 2. druhu Zamítáme chyba 1. druhu správně
 Testování hypotéz Nechť,, je náhodný výběr z nějakého rozdělení s neznámými parametry. Máme dvě navzájem si odporující hypotézy o parametrech daného rozdělení: Nulová hypotéza parametry (případně jediný
Testování hypotéz Nechť,, je náhodný výběr z nějakého rozdělení s neznámými parametry. Máme dvě navzájem si odporující hypotézy o parametrech daného rozdělení: Nulová hypotéza parametry (případně jediný
Statistické metody uţívané při ověřování platnosti hypotéz
 Statistické metody uţívané při ověřování platnosti hypotéz Hypotéza Domněnka, předpoklad Nejčastěji o rozdělení, středních hodnotách, závislostech, Hypotézy ve vědeckém výzkumu pracovní, věcné hypotézy
Statistické metody uţívané při ověřování platnosti hypotéz Hypotéza Domněnka, předpoklad Nejčastěji o rozdělení, středních hodnotách, závislostech, Hypotézy ve vědeckém výzkumu pracovní, věcné hypotézy
Cvičení ze statistiky - 7. Filip Děchtěrenko
 Cvičení ze statistiky - 7 Filip Děchtěrenko Minule bylo.. Probrali jsme spojité modely Tyhle termíny by měly být známé: Rovnoměrné rozdělení Střední hodnota Mccalova transformace Normální rozdělení Přehled
Cvičení ze statistiky - 7 Filip Děchtěrenko Minule bylo.. Probrali jsme spojité modely Tyhle termíny by měly být známé: Rovnoměrné rozdělení Střední hodnota Mccalova transformace Normální rozdělení Přehled
You created this PDF from an application that is not licensed to print to novapdf printer (http://www.novapdf.com)
") Testování statistických hypotéz Testování statistických hypotéz Princip: Ověřování určitého předpokladu zjišťujeme, zda zkoumaný výběr pochází ze základního souboru, který má určité rozdělení zjišťujeme,
Testování statistických hypotéz Testování statistických hypotéz Princip: Ověřování určitého předpokladu zjišťujeme, zda zkoumaný výběr pochází ze základního souboru, který má určité rozdělení zjišťujeme,
II. Statistické metody vyhodnocení kvantitativních dat Gejza Dohnal
 Základy navrhování průmyslových experimentů DOE II. Statistické metody vyhodnocení kvantitativních dat Gejza Dohnal! Testování statistických hypotéz kvalitativní odezva kvantitativní chí-kvadrát test homogenity,
Základy navrhování průmyslových experimentů DOE II. Statistické metody vyhodnocení kvantitativních dat Gejza Dohnal! Testování statistických hypotéz kvalitativní odezva kvantitativní chí-kvadrát test homogenity,
31. 3. 2014, Brno Hanuš Vavrčík Základy statistiky ve vědě
 31. 3. 2014, Brno Hanuš Vavrčík Základy statistiky ve vědě Motto Statistika nuda je, má však cenné údaje. strana 3 Statistické charakteristiky Charakteristiky polohy jsou kolem ní seskupeny ostatní hodnoty
31. 3. 2014, Brno Hanuš Vavrčík Základy statistiky ve vědě Motto Statistika nuda je, má však cenné údaje. strana 3 Statistické charakteristiky Charakteristiky polohy jsou kolem ní seskupeny ostatní hodnoty
diskriminaci žen letní semestr 2012 1 = výrok, o jehož pravdivosti chceme rozhodnout tvrzení o populaci, o jehož platnosti rozhodujeme
 motivační příklad Párový Párový Příklad (Platová diskriminace) firma provedla šetření s cílem zjistit, zda dochází k platové diskriminaci žen Šárka Hudecová Katedra pravděpodobnosti a matematické statistiky
motivační příklad Párový Párový Příklad (Platová diskriminace) firma provedla šetření s cílem zjistit, zda dochází k platové diskriminaci žen Šárka Hudecová Katedra pravděpodobnosti a matematické statistiky
Základy biostatistiky II. Veřejné zdravotnictví 3.LF UK - II
 Základy biostatistiky II Veřejné zdravotnictví 3.LF UK - II Teoretické rozložení-matematické modely rozložení Naměřená data Výběrové rozložení Teoretické rozložení 1 e 2 x 2 Teoretické rozložení-matematické
Základy biostatistiky II Veřejné zdravotnictví 3.LF UK - II Teoretické rozložení-matematické modely rozložení Naměřená data Výběrové rozložení Teoretické rozložení 1 e 2 x 2 Teoretické rozložení-matematické
Testování statistických hypotéz. Obecný postup
 poznámky k MIII, Tomečková I., poslední aktualizace 9. listopadu 016 9 Testování statistických hypotéz Obecný postup (I) Vyslovení hypotézy O datech vyslovíme doměnku, kterou chceme ověřit statistickým
poznámky k MIII, Tomečková I., poslední aktualizace 9. listopadu 016 9 Testování statistických hypotéz Obecný postup (I) Vyslovení hypotézy O datech vyslovíme doměnku, kterou chceme ověřit statistickým
12. cvičení z PSI prosince (Test střední hodnoty dvou normálních rozdělení se stejným neznámým rozptylem)
") cvičení z PSI 0-4 prosince 06 Test střední hodnoty dvou normálních rozdělení se stejným neznámým rozptylem) Z realizací náhodných veličin X a Y s normálním rozdělením) jsme z výběrů daného rozsahu obdrželi
cvičení z PSI 0-4 prosince 06 Test střední hodnoty dvou normálních rozdělení se stejným neznámým rozptylem) Z realizací náhodných veličin X a Y s normálním rozdělením) jsme z výběrů daného rozsahu obdrželi
Regresní a korelační analýza
 Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Příklad 1. Řešení 1 ŘEŠENÉ PŘÍKLADY Z MV2 ČÁST 11
 Příklad 1 Vyhláška Ministerstva zdravotnictví předpokládala, že doba dojezdu k pacientovi od nahlášení požadavku nepřekročí 17 minut. Hodnoty deseti náhodně vybraných dob příjezdu sanitky k nemocnému byly:
Příklad 1 Vyhláška Ministerstva zdravotnictví předpokládala, že doba dojezdu k pacientovi od nahlášení požadavku nepřekročí 17 minut. Hodnoty deseti náhodně vybraných dob příjezdu sanitky k nemocnému byly:
Jednofaktorová analýza rozptylu
 I I.I Jednofaktorová analýza rozptylu Úvod Jednofaktorová analýza rozptylu (ANOVA) se využívá při porovnání několika středních hodnot. Často se využívá ve vědeckých a lékařských experimentech, při kterých
I I.I Jednofaktorová analýza rozptylu Úvod Jednofaktorová analýza rozptylu (ANOVA) se využívá při porovnání několika středních hodnot. Často se využívá ve vědeckých a lékařských experimentech, při kterých
Regresní a korelační analýza
 Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Neparametrické metody
 Neparametrické metody Dosud jsme se zabývali statistickými metodami, které zahrnovaly předpoklady o rozdělení dat. Zpravidla jsme předpokládali normální rozdělení. Např. Grubbsův test odlehlých hodnot
Neparametrické metody Dosud jsme se zabývali statistickými metodami, které zahrnovaly předpoklady o rozdělení dat. Zpravidla jsme předpokládali normální rozdělení. Např. Grubbsův test odlehlých hodnot
Regresní analýza 1. Regresní analýza
 Regresní analýza 1 1 Regresní funkce Regresní analýza Důležitou statistickou úlohou je hledání a zkoumání závislostí proměnných, jejichž hodnoty získáme při realizaci experimentů Vzhledem k jejich náhodnému
Regresní analýza 1 1 Regresní funkce Regresní analýza Důležitou statistickou úlohou je hledání a zkoumání závislostí proměnných, jejichž hodnoty získáme při realizaci experimentů Vzhledem k jejich náhodnému
Regresní a korelační analýza
 Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Testování statistických hypotéz. Ing. Michal Dorda, Ph.D. 1
 Testování statistických hypotéz Ing. Michal Dorda, Ph.D. 1 Úvodní poznámky Statistickou hypotézou rozumíme hypotézu o populaci (základním souboru) např.: Střední hodnota základního souboru je rovna 100.
Testování statistických hypotéz Ing. Michal Dorda, Ph.D. 1 Úvodní poznámky Statistickou hypotézou rozumíme hypotézu o populaci (základním souboru) např.: Střední hodnota základního souboru je rovna 100.
TECHNICKÁ UNIVERZITA V LIBERCI
 TECHNICKÁ UNIVERZITA V LIBERCI Ekonomická fakulta Semestrální práce z předmětu Statistický rozbor dat z dotazníkového šetření Jméno: Lucie Krechlerová, Karel Kozma, René Dubský, David Drobík Ročník: 2015/2016
TECHNICKÁ UNIVERZITA V LIBERCI Ekonomická fakulta Semestrální práce z předmětu Statistický rozbor dat z dotazníkového šetření Jméno: Lucie Krechlerová, Karel Kozma, René Dubský, David Drobík Ročník: 2015/2016
PRAVDĚPODOBNOST A STATISTIKA
 PRAVDĚPODOBNOST A STATISTIKA Testování hypotéz Nechť X je náhodná proměnná, která má distribuční funkci F(x, ϑ). Předpokládejme, že známe tvar distribuční funkce (víme jaké má rozdělení) a neznáme parametr
PRAVDĚPODOBNOST A STATISTIKA Testování hypotéz Nechť X je náhodná proměnná, která má distribuční funkci F(x, ϑ). Předpokládejme, že známe tvar distribuční funkce (víme jaké má rozdělení) a neznáme parametr
4EK211 Základy ekonometrie
 4EK211 Základy ekonometrie ZS 2015/16 Cvičení 1: Opakování ze statistiky LENKA FIŘTOVÁ KATEDRA EKONOMETRIE, FAKULTA INFORMATIKY A STATISTIKY VYSOKÁ ŠKOLA EKONOMICKÁ V PRAZE Z čeho studovat 1) Z KNIHY Krkošková,
4EK211 Základy ekonometrie ZS 2015/16 Cvičení 1: Opakování ze statistiky LENKA FIŘTOVÁ KATEDRA EKONOMETRIE, FAKULTA INFORMATIKY A STATISTIKY VYSOKÁ ŠKOLA EKONOMICKÁ V PRAZE Z čeho studovat 1) Z KNIHY Krkošková,
Regresní a korelační analýza
 Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
ADDS cviceni. Pavlina Kuranova
 ADDS cviceni Pavlina Kuranova Testy pro dva nezávislé výběry Mannův Whitneyho test - Založen na Wilcoxnově statistice W - založen na pořadí jednotlivých pozorování (oba výběry spojeny do jednoho celku)
ADDS cviceni Pavlina Kuranova Testy pro dva nezávislé výběry Mannův Whitneyho test - Založen na Wilcoxnově statistice W - založen na pořadí jednotlivých pozorování (oba výběry spojeny do jednoho celku)
12. prosince n pro n = n = 30 = S X
 11 cvičení z PSI 1 prosince 018 111 test střední hodnoty normálního rozdělení při známém rozptylu Teploměrem o jehož chybě předpokládáme že má normální rozdělení se směrodatnou odchylkou σ = 3 jsme provedli
11 cvičení z PSI 1 prosince 018 111 test střední hodnoty normálního rozdělení při známém rozptylu Teploměrem o jehož chybě předpokládáme že má normální rozdělení se směrodatnou odchylkou σ = 3 jsme provedli
Porovnání dvou výběrů
 Porovnání dvou výběrů Menu: QCExpert Porovnání dvou výběrů Tento modul je určen pro podrobnou analýzu dvou datových souborů (výběrů). Modul poskytuje dva postupy analýzy: porovnání dvou nezávislých výběrů
Porovnání dvou výběrů Menu: QCExpert Porovnání dvou výběrů Tento modul je určen pro podrobnou analýzu dvou datových souborů (výběrů). Modul poskytuje dva postupy analýzy: porovnání dvou nezávislých výběrů
MATEMATIKA III V PŘÍKLADECH
 VYSOKÁ ŠKOLA BÁŇSKÁ TECHNICKÁ UNIVERZITA OSTRAVA FAKULTA STROJNÍ MATEMATIKA III V PŘÍKLADECH Cvičení 12 Testování hypotéz Mgr. Petr Otipka Ostrava 2013 Mgr. Petr Otipka Vysoká škola báňská Technická univerzita
VYSOKÁ ŠKOLA BÁŇSKÁ TECHNICKÁ UNIVERZITA OSTRAVA FAKULTA STROJNÍ MATEMATIKA III V PŘÍKLADECH Cvičení 12 Testování hypotéz Mgr. Petr Otipka Ostrava 2013 Mgr. Petr Otipka Vysoká škola báňská Technická univerzita
Název testu Předpoklady testu Testová statistika Nulové rozdělení. ( ) (p počet odhadovaných parametrů)
 (p počet odhadovaných parametrů)") VYBRANÉ TESTY NEPARAMETRICKÝCH HYPOTÉZ TESTY DOBRÉ SHODY Název testu Předpoklady testu Testová statistika Nulové rozdělení test dobré shody Očekávané četnosti, alespoň 80% očekávaných četností >5 ( ) (p
VYBRANÉ TESTY NEPARAMETRICKÝCH HYPOTÉZ TESTY DOBRÉ SHODY Název testu Předpoklady testu Testová statistika Nulové rozdělení test dobré shody Očekávané četnosti, alespoň 80% očekávaných četností >5 ( ) (p
Lineární regrese. Komentované řešení pomocí MS Excel
 Lineární regrese Komentované řešení pomocí MS Excel Vstupní data Tabulka se vstupními daty je umístěna v oblasti A1:B11 (viz. obrázek) na listu cela data Postup Základní výpočty - regrese Výpočet základních
Lineární regrese Komentované řešení pomocí MS Excel Vstupní data Tabulka se vstupními daty je umístěna v oblasti A1:B11 (viz. obrázek) na listu cela data Postup Základní výpočty - regrese Výpočet základních
KORELACE. Komentované řešení pomocí programu Statistica
 KORELACE Komentované řešení pomocí programu Statistica Vstupní data I Data umístěná v excelovském souboru překopírujeme do tabulky ve Statistice a pojmenujeme proměnné, viz prezentace k tématu Popisná
KORELACE Komentované řešení pomocí programu Statistica Vstupní data I Data umístěná v excelovském souboru překopírujeme do tabulky ve Statistice a pojmenujeme proměnné, viz prezentace k tématu Popisná
Korelační a regresní analýza
 Korelační a regresní analýza Analýza závislosti v normálním rozdělení Pearsonův (výběrový) korelační koeficient: r = s XY s X s Y, kde s XY = 1 n (x n 1 i=0 i x )(y i y ), s X (s Y ) je výběrová směrodatná
Korelační a regresní analýza Analýza závislosti v normálním rozdělení Pearsonův (výběrový) korelační koeficient: r = s XY s X s Y, kde s XY = 1 n (x n 1 i=0 i x )(y i y ), s X (s Y ) je výběrová směrodatná
NÁHODNÁ ČÍSLA. F(x) = 1 pro x 1. Náhodná čísla lze generovat některým z následujících generátorů náhodných čísel:
 = 1 pro x 1. Náhodná čísla lze generovat některým z následujících generátorů náhodných čísel:") NÁHODNÁ ČÍSLA TYPY GENERÁTORŮ, LINEÁRNÍ KONGRUENČNÍ GENERÁTORY, TESTY NÁHODNOSTI, VYUŽITÍ HODNOT NÁHODNÝCH VELIČIN V SIMULACI CO JE TO NÁHODNÉ ČÍSLO? Náhodné číslo definujeme jako nezávislé hodnoty z rovnoměrného
NÁHODNÁ ČÍSLA TYPY GENERÁTORŮ, LINEÁRNÍ KONGRUENČNÍ GENERÁTORY, TESTY NÁHODNOSTI, VYUŽITÍ HODNOT NÁHODNÝCH VELIČIN V SIMULACI CO JE TO NÁHODNÉ ČÍSLO? Náhodné číslo definujeme jako nezávislé hodnoty z rovnoměrného
KGG/STG Statistika pro geografy
 KGG/STG Statistika pro geografy 9. Korelační analýza Mgr. David Fiedor 20. dubna 2015 Analýza závislostí v řadě geografických disciplín studujeme jevy, u kterých vyšetřujeme nikoliv pouze jednu vlastnost
KGG/STG Statistika pro geografy 9. Korelační analýza Mgr. David Fiedor 20. dubna 2015 Analýza závislostí v řadě geografických disciplín studujeme jevy, u kterých vyšetřujeme nikoliv pouze jednu vlastnost
Regresní a korelační analýza
 Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
letní semestr 2012 Katedra pravděpodobnosti a matematické statistiky Matematicko-fyzikální fakulta Univerzity Karlovy Matematická statistika t-test
 Párový Šárka Hudecová Katedra pravděpodobnosti a matematické statistiky Matematicko-fyzikální fakulta Univerzity Karlovy letní semestr 2012 motivační příklad Párový Příklad (Platová diskriminace) firma
Párový Šárka Hudecová Katedra pravděpodobnosti a matematické statistiky Matematicko-fyzikální fakulta Univerzity Karlovy letní semestr 2012 motivační příklad Párový Příklad (Platová diskriminace) firma
a) Základní informace o souboru Statistika: Základní statistika a tabulky: Popisné statistiky: Detaily
 Základní informace o souboru Statistika: Základní statistika a tabulky: Popisné statistiky: Detaily") Testování hypotéz Testování hypotéz jsou klasické statistické úsudky založené na nějakém apriorním předpokladu. Vyslovíme-li předpoklad o hodnotě neznámého parametru nebo o zákonu rozdělení sledované náhodné
Testování hypotéz Testování hypotéz jsou klasické statistické úsudky založené na nějakém apriorním předpokladu. Vyslovíme-li předpoklad o hodnotě neznámého parametru nebo o zákonu rozdělení sledované náhodné
Testování statistických hypotéz
 Testování statistických hypotéz Michal Fusek Ústav matematiky FEKT VUT, fusekmi@feec.vutbr.cz 11. přednáška z ESMAT Michal Fusek (fusekmi@feec.vutbr.cz) 1 / 27 Obsah 1 Testování statistických hypotéz 2
Testování statistických hypotéz Michal Fusek Ústav matematiky FEKT VUT, fusekmi@feec.vutbr.cz 11. přednáška z ESMAT Michal Fusek (fusekmi@feec.vutbr.cz) 1 / 27 Obsah 1 Testování statistických hypotéz 2
Cvičení 10. Přednášející: Mgr. Rudolf B. Blažek, Ph.D. prof. RNDr. Roman Kotecký, DrSc.
 10 Přednášející: Mgr. Rudolf B. Blažek, Ph.D. prof. RNDr. Roman Kotecký, DrSc. Katedra počítačových systémů Katedra teoretické informatiky Fakulta informačních technologií České vysoké učení technické
10 Přednášející: Mgr. Rudolf B. Blažek, Ph.D. prof. RNDr. Roman Kotecký, DrSc. Katedra počítačových systémů Katedra teoretické informatiky Fakulta informačních technologií České vysoké učení technické
Cvičení 9: Neparametrické úlohy o mediánech
 Cvičení 9: Neparametrické úlohy o mediánech Úkol 1.: Párový znaménkový test a párový Wilcoxonův test Při zjišťování kvality jedné složky půdy se používají dvě metody označené A a B. Výsledky: Vzorek 1
Cvičení 9: Neparametrické úlohy o mediánech Úkol 1.: Párový znaménkový test a párový Wilcoxonův test Při zjišťování kvality jedné složky půdy se používají dvě metody označené A a B. Výsledky: Vzorek 1
Úvod do analýzy rozptylu
 Úvod do analýzy rozptylu Párovým t-testem se podařilo prokázat, že úprava režimu stravování a fyzické aktivity ve vybrané škole měla vliv na zlepšené hodnoty HDLcholesterolu u školáků. Pro otestování jsme
Úvod do analýzy rozptylu Párovým t-testem se podařilo prokázat, že úprava režimu stravování a fyzické aktivity ve vybrané škole měla vliv na zlepšené hodnoty HDLcholesterolu u školáků. Pro otestování jsme
MÍRY ZÁVISLOSTI (KORELACE A REGRESE)
") zhanel@fsps.muni.cz MÍRY ZÁVISLOSTI (KORELACE A REGRESE) 2.5 MÍRY ZÁVISLOSTI 2.5.1 ZÁVISLOST PEVNÁ, VOLNÁ, STATISTICKÁ A KORELAČNÍ Jednorozměrné soubory - charakterizovány jednotlivými statistickými znaky
zhanel@fsps.muni.cz MÍRY ZÁVISLOSTI (KORELACE A REGRESE) 2.5 MÍRY ZÁVISLOSTI 2.5.1 ZÁVISLOST PEVNÁ, VOLNÁ, STATISTICKÁ A KORELAČNÍ Jednorozměrné soubory - charakterizovány jednotlivými statistickými znaky
VYBRANÉ DVOUVÝBĚROVÉ TESTY. Martina Litschmannová
 VYBRANÉ DVOUVÝBĚROVÉ TESTY Martina Litschmannová Obsah přednášky Vybrané dvouvýběrové testy par. hypotéz test o shodě rozptylů (F-test), testy o shodě středních hodnot (t-test, Aspinové-Welchův test),
VYBRANÉ DVOUVÝBĚROVÉ TESTY Martina Litschmannová Obsah přednášky Vybrané dvouvýběrové testy par. hypotéz test o shodě rozptylů (F-test), testy o shodě středních hodnot (t-test, Aspinové-Welchův test),
Náhodné veličiny, náhodné chyby
 Náhodné veličiny, náhodné chyby Máme náhodnou veličinu X, jejíž vlastnosti zkoumáme. Pokud známe její rozložení (např. z nějaké dřívější studie) nebo alespoň předpokládáme znalost rozložení, můžeme ji
Náhodné veličiny, náhodné chyby Máme náhodnou veličinu X, jejíž vlastnosti zkoumáme. Pokud známe její rozložení (např. z nějaké dřívější studie) nebo alespoň předpokládáme znalost rozložení, můžeme ji
Základní statistické metody v rizikovém inženýrství
 Základní statistické metody v rizikovém inženýrství Petr Misák Ústav stavebního zkušebnictví Fakulta stavební, VUT v Brně misak.p@fce.vutbr.cz Základní pojmy Jev souhrn skutečností zobrazujících ucelenou
Základní statistické metody v rizikovém inženýrství Petr Misák Ústav stavebního zkušebnictví Fakulta stavební, VUT v Brně misak.p@fce.vutbr.cz Základní pojmy Jev souhrn skutečností zobrazujících ucelenou
Zeptali jsme se 10 osob, kolik minut provolají měsíčně s rodinou a jejich odpovědi jsme zaznamenali do tabulky:
 Cvičení 10 Opakování probraných testů 1 Příklad z-test V souvislosti s rozsáhlou rekonstrukci tramvajových tratí dopravní podnik provádí průzkum, zda neklesl počet cestujících autobusovou linkou č.87689
Cvičení 10 Opakování probraných testů 1 Příklad z-test V souvislosti s rozsáhlou rekonstrukci tramvajových tratí dopravní podnik provádí průzkum, zda neklesl počet cestujících autobusovou linkou č.87689
Charakteristika datového souboru
 Zápočtová práce z předmětu Statistika Vypracoval: 10. 11. 2014 Charakteristika datového souboru Zadání: Při kontrole dodržování hygienických norem v kuchyni se prováděl odběr vzduchu a pomocí filtru Pallflex
Zápočtová práce z předmětu Statistika Vypracoval: 10. 11. 2014 Charakteristika datového souboru Zadání: Při kontrole dodržování hygienických norem v kuchyni se prováděl odběr vzduchu a pomocí filtru Pallflex
Bodové a intervalové odhady parametrů v regresním modelu
 Statistika II Katedra ekonometrie FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Lineární regresní model Mějme lineární regresní model (LRM) Y = Xβ + e, kde y 1 e 1 β y 2 Y =., e
Statistika II Katedra ekonometrie FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Lineární regresní model Mějme lineární regresní model (LRM) Y = Xβ + e, kde y 1 e 1 β y 2 Y =., e
Testování hypotéz Biolog Statistik: Matematik: Informatik:
 Testování hypotéz Biolog, Statistik, Matematik a Informatik na safari. Zastaví džíp a pozorují dalekohledem. Biolog "Podívejte se! Stádo zeber! A mezi nimi bílá zebra! To je fantastické! " "Existují bílé
Testování hypotéz Biolog, Statistik, Matematik a Informatik na safari. Zastaví džíp a pozorují dalekohledem. Biolog "Podívejte se! Stádo zeber! A mezi nimi bílá zebra! To je fantastické! " "Existují bílé
TECHNICKÁ UNIVERZITA V LIBERCI. Ekonomická fakulta. Semestrální práce. Statistický rozbor dat z dotazníkového šetření školní zadání
 TECHNICKÁ UNIVERZITA V LIBERCI Ekonomická fakulta Semestrální práce Statistický rozbor dat z dotazníkového šetření školní zadání Skupina: 51 Vypracovaly: Pavlína Horná, Nikola Loumová, Petra Mikešová,
TECHNICKÁ UNIVERZITA V LIBERCI Ekonomická fakulta Semestrální práce Statistický rozbor dat z dotazníkového šetření školní zadání Skupina: 51 Vypracovaly: Pavlína Horná, Nikola Loumová, Petra Mikešová,
Parametry hledáme tak, aby součet čtverců odchylek byl minimální. Řešením podle teorie je =
 Příklad 1 Metodou nejmenších čtverců nalezněte odhad lineární regresní funkce popisující závislost mezi výnosy pšenice a množstvím použitého hnojiva na základě hodnot výběrového souboru uvedeného v tabulce.
Příklad 1 Metodou nejmenších čtverců nalezněte odhad lineární regresní funkce popisující závislost mezi výnosy pšenice a množstvím použitého hnojiva na základě hodnot výběrového souboru uvedeného v tabulce.
Pearsonův korelační koeficient
 I I.I Pearsonův korelační koeficient Úvod Předpokládejme, že náhodně vybereme n objektů (nebo osob) ze zkoumané populace. Často se stává, že na každém z objektů měříme ne pouze jednu, ale několik kvantitativních
I I.I Pearsonův korelační koeficient Úvod Předpokládejme, že náhodně vybereme n objektů (nebo osob) ze zkoumané populace. Často se stává, že na každém z objektů měříme ne pouze jednu, ale několik kvantitativních
Test dobré shody v KONTINGENČNÍCH TABULKÁCH
 Test dobré shody v KONTINGENČNÍCH TABULKÁCH Opakování: Mějme náhodné veličiny X a Y uspořádané do kontingenční tabulky. Řekli jsme, že nulovou hypotézu H 0 : veličiny X, Y jsou nezávislé zamítneme, když
Test dobré shody v KONTINGENČNÍCH TABULKÁCH Opakování: Mějme náhodné veličiny X a Y uspořádané do kontingenční tabulky. Řekli jsme, že nulovou hypotézu H 0 : veličiny X, Y jsou nezávislé zamítneme, když
ÚVOD DO TEORIE ODHADU. Martina Litschmannová
 ÚVOD DO TEORIE ODHADU Martina Litschmannová Obsah lekce Výběrové charakteristiky parametry populace vs. výběrové charakteristiky limitní věty další rozdělení pravděpodobnosti (Chí-kvadrát (Pearsonovo),
ÚVOD DO TEORIE ODHADU Martina Litschmannová Obsah lekce Výběrové charakteristiky parametry populace vs. výběrové charakteristiky limitní věty další rozdělení pravděpodobnosti (Chí-kvadrát (Pearsonovo),
2 ) 4, Φ 1 (1 0,005)
 4, Φ 1 (1 0,005)") Příklad 1 Ze zásilky velkého rozsahu byl náhodně vybrán soubor obsahující 1000 kusů. V tomto souboru bylo zjištěno 26 kusů nekvalitních. Rozhodněte, zda je možné s 99% jistotou tvrdit, že zásilka obsahuje
Příklad 1 Ze zásilky velkého rozsahu byl náhodně vybrán soubor obsahující 1000 kusů. V tomto souboru bylo zjištěno 26 kusů nekvalitních. Rozhodněte, zda je možné s 99% jistotou tvrdit, že zásilka obsahuje
Jana Vránová, 3. lékařská fakulta UK
 Jana Vránová, 3. lékařská fakulta UK Vznikají při zkoumání vztahů kvalitativních resp. diskrétních znaků Jedná se o analogii s korelační analýzou spojitých znaků Přitom předpokládáme, že každý prvek populace
Jana Vránová, 3. lékařská fakulta UK Vznikají při zkoumání vztahů kvalitativních resp. diskrétních znaků Jedná se o analogii s korelační analýzou spojitých znaků Přitom předpokládáme, že každý prvek populace
Testy dobré shody Máme dvě veličiny, u kterých bychom chtěli prokázat závislost, TESTY DOBRÉ SHODY (angl. goodness-of-fit tests)
") Testy dobré shody Máme dvě veličiny, u kterých bychom chtěli prokázat závislost, např. hmotnost a pohlaví narozených dětí. Běžný statistický postup pro ověření závislosti dvou veličin je zamítnutí jejich
Testy dobré shody Máme dvě veličiny, u kterých bychom chtěli prokázat závislost, např. hmotnost a pohlaví narozených dětí. Běžný statistický postup pro ověření závislosti dvou veličin je zamítnutí jejich