INDEXY DIVERZITY. David Zelený Zpracování dat v ekologii společenstev
|
|
|
- Lenka Navrátilová
- před 5 lety
- Počet zobrazení:
Transkript
1 INDEXY DIVERZITY
 Cornel University Library 223 Jurasinski et al.")
2 ALFA, BETA A GAMA DIVERZITA Alfa diverzita druhová bohatost vzorku Beta diverzita (species turnover) změna v druhovém složení mezi vzorky Gama diverzita celková druhová bohatost regionu Robert Harding Whittaker ( ) Cornel University Library 223 Jurasinski et al. (2009)
3 ALFA, BETA A GAMA DIVERZITA 224
4 MÍRY ALFA DIVERZITY DRUHOVÁ BOHATOST VS VYROVNANOST druhová bohatost (species richness) vyjadřuje počet druhů ve vzorku vyrovnanost (evenness, equitability) vyjadřuje relativní zastoupení jednotlivých druhů ve vzorku (nejvyšších hodnot dosahuje při rovnoměrném relativním zastoupením všech druhů) jednotlivé indexy alfa diverzity (např. Shannonův nebo Simpsonův) se liší právě tím, jestli kladou větší důraz na bohatost (Shannon) nebo vyrovnanost (Simpson) alfa a gama diverzita se někdy označují jako inventární diverzita (inventory diversity) podstata je pro obě míry stejná (vyjádřené počty druhů, případně indexem diverzity), liší se ale škálou (alfa je diverzita na lokální škále, gama na regionální) beta diverzita je výrazně odlišný koncept jiná filozofie, jiné jednotky 225
5 MÍRY ALFA DIVERZITY SHANNONŮV INDEX n H = p i ln(p i ) i=1 označovaný také jako Shannon-Wiener index (nesprávně jako Shannon- Wiever) odvozen z informační teorie (entropie systému - s rostoucí entropií vzrůstá neuspořádanost systému, očekávatelná míra překvapení) vyjadřuje nejistotu, se kterou jsem schopen předpovědět, jakého druhu bude náhodně vybraný jedinec ze vzorku; nejistota klesá s klesajícím počtem druhů a s klesající vyrovnaností (více dominantních druhů) hodnoty v ekologických datech většinou v rozmezí 1,5 3,5 p i... relativní abundance druhu i n... počet druhů ve společenstvu maximální velikost indexu pro počet druhů S nastane, pokud mají všechny druhy stejnou relativní frekvenci: H max = ln (S) efektivní počet druhů (kolik druhů by se vyskytovalo ve vzorku s diverzitou H, pokud by se všechny druhy vyskytovaly se stejnou frekvencí): e H vyrovnanost odvozená ze Shannonova indexu (Shannon s evenness) J = H / H max = H / ln (S) 226
6 MÍRY ALFA DIVERZITY SIMPSONŮV INDEX vyjadřuje pravděpodobnost, že dva náhodně vybraní jedinci budou patřit ke stejnému druhu jeden z nejlepších (z hlediska interpretace) indexů diverzity se zvyšující se diverzitou hodnota indexu klesá proto se častěji používá komplementární (1-D) nebo reciproká forma indexu (1/D) zdůrazňuje dominanci druhu (při počtu druhů > 10 záleží jeho velikost prakticky už jen na dominanci druhů) efektivní počet druhů: 1/(1-S D ) = 1/D n D = p i 2 i=1 S D = 1 D p i... relativní abundance druhu i n... počet druhů ve společenstvu vyrovnanost odvozená ze Simpsona (Simpson s evenness): E = (1/D) / S (efektivní počet druhů/reálný počet druhů) 227
7 PŘÍKLAD EFEKTIVNÍ POČET DRUHŮ počet Simpson efektivní druhů index počet druhů Spol. 1: ,8 1) 5,0 3) Spol. 2: ,6 2) 2,5 4) Výpočet: 1) 1 p 2 = 1-5*(2/10) 2 = 1 5*0,04 = 1 0,2 = 0,8 2) 1 p 2 = 1 ((6/10) 2 + 4*(1/10) 2 ) = 1 (0,36 + 0,04) = 0,6 3) 1/(1-S D ) = 1/(1-0,8) = 5 4) 1/(1-S D ) = 1/(1-0,6) = 2,5 228
8 MÍRY ALFA DIVERZITY ad hoc doporučení: nemá smysl počítat velké množství indexů alfa diverzity a všechny je používat vhodnější je rozhodnout se hned na začátku, který z aspektů alfa diverzity (bohatost nebo vyrovnanost) mě zajímá, a podle toho vybrat index nejjednodušší volba je použítí druhové bohatosti (počtu druhů) Simpsonův index je intuitivně interpretovatelný, naopak interpretace Shannonova indexu je obtížná a je lépe ho nepoužívat (i když je populární) kde spočítat: EstimateS (R. Colwell, BioDiversityPro (Neil McAleece, 229
9 MÍRY BETA DIVERZITY popisuje rozdílnost v druhovém složení mezi vzorky Dva základní typy beta diverzity: 1. turnover (obrat druhů podél ekologického, prostorového nebo časového gradientu) Kolik nových druhů přibude a kolik jich ubude, když se pohybuji podél gradientu? 2. variation (variabilita v druhovém složení mezi vzorky, bez ohledu na směr nějakého gradientu) Opakují se v různých vzorcích pořád ty samé druhy? Jak moc celkový počet druhů v regionu přesahuje průměrnou druhovou bohatost vzorku? Anderson et al. (2011) 230
10 MÍRY BETA DIVERZITY KLASICKÉ INDEXY klasické indexy neberou v potaz druhové složení, ale jen počty druhů na lokální (alfa) a regionální (gamma) úrovni Whittakerova beta diverzita (multiplikativní míra): β w = (γ / α ) - 1 α... průměrná druhová bohatost vzorků kolikrát bohatost regionu přesahuje průměrnou bohatost vzorku Additivní míra beta diverzity: β Add = γ α průměrný počet druhů, které chybí v jednom náhodně vybraném vzorku/ploše výhodou je, že jednotkami jsou počty druhů Multiplikativní míra, která bere v potaz vyrovnanost: β Shannon = H γ / H α místo počtu druhů používá Shannonův index diverzity vypočtený pro regionální a lokální druhovou bohatost 231
11 MÍRY BETA DIVERZITY MNOHOROZMĚRNÉ INDEXY mnohorozměrné indexy pracují přímo s druhovým složením a hledají rozdíly v druhovém složení dvou a více vzorků/ploch používá indexy podobnosti (případně nepodobnosti) v druhovém složení mezi páry vzorků/ploch Bray-Curtis, Jaccard, Sorensen, Euclidovská vzdálenost atd. beta diverzita skupiny vzorků/ploch se spočte jako průměrná hodnota těchto podobností délka první osy DCA také vyjadřuje beta diverzitu (v jednotkách SD) 232
12 Anderson et al. (2011) MÍRY BETA DIVERZITY MNOHOROZMĚRNÉ INDEXY Rozdíly v interpretaci beta diverzity založené na Bray-Curtis indexu nepodobnosti a Euklidovské vzdálenosti na příkladu rozdílu v druhovém složení korálových útesů (Indonésie) v letech 1981, 1983 a 1985 (zásah El Nino v roce 1982) NMDS ordinace 233
13 MÍRY BETA DIVERZITY MNOHOROZMĚRNÉ INDEXY Roleček et al. (2009) J. Veg. Sci. Whittakerova beta a Total inertia - indexy závislé na počtu vzorků Průměrná Jaccardova nebo Sorensenova nepodobnost mezi páry vzorkůindexy nezávislé na počtu vzorků 234
14 INDEXY FUNKČNÍ DIVERZITY funkční diverzita zohledňuje diverzitu funkčních typů (functional traits), které se ve vzorku vyskytují druhová bohatost se často považuje za odhad funkční diverzity, ale nepřesný dva různé druhy mohou ve společenstvu plnit stejnou funkci (mít stejnou kombinací funkčních typů) Rao index (Lepš et al Preslia) FD = i j d ij p i p j d ij... nepodobnost mezi druhem i a j p i, p j... relativní abundance druhu i a j zobecněná forma Simpsonova indexu diversity 235
15 AKUMULAČNÍ DRUHOVÁ KŘIVKA SPECIES ACCUMULATION CURVE vynáší kumulativní počet druhů S v závislosti na intenzitě vzorkování n (počet jedinců, počet ploch, čas) zvláštním typem je species-area curve (ale jen v případě, že plocha narůstá v rámci určitého území, neplatí pro ostrovy) čte se zleva doprava může být extrapolována (zvýší intenzita průzkumu celkový počet nalezených druhů?) 236
16 RAREFAKČNÍ KŘIVKA RAREFACTION CURVE cílem je zjistit, jaká by byla druhová bohatost, pokud bychom v daném společenstvu nasbírali menší počet jedinců/vzorků (to rarefy rozředit) porovnání druhové bohatosti mezi společenstvy s různým počtem jedinců/vzorků čte se zprava doleva rozdíl mezi sample based a individual based rarefaction 237 Michalcová et al. (2011) Journal of Vegetation Science
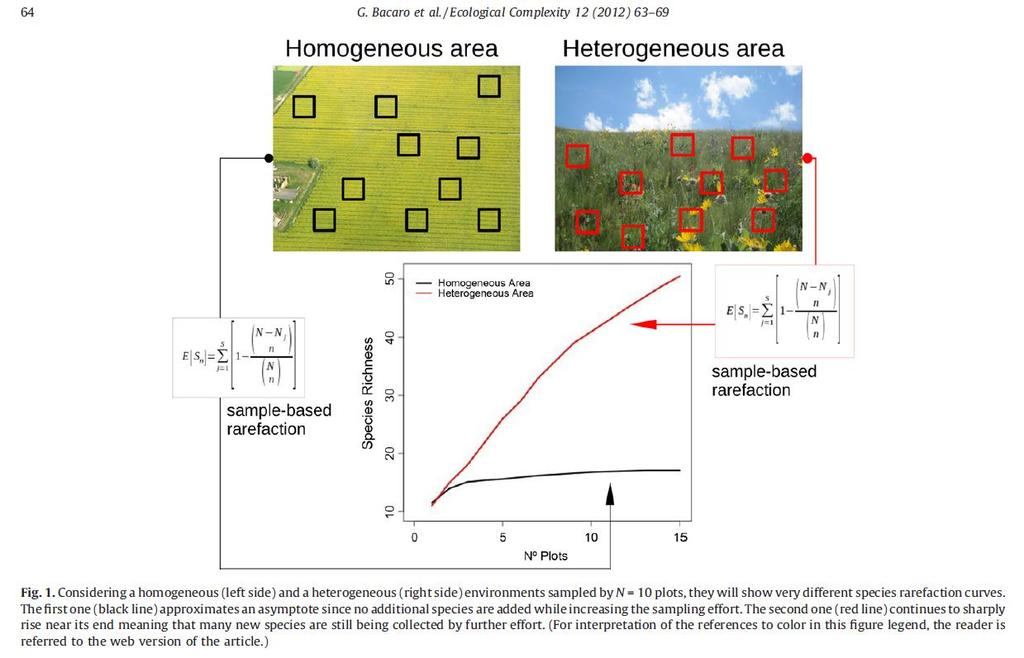
17 238
18 SOFTWARE (MIMO R, VE KTERÉM SPOČTETE VŠECHNO) indexy alfa diverzity (Shannon, Simpson atd.) a beta diverzity Biodiversity Pro (Neil McAleece, EstimateS (Robert Colwell, PC-ORD 5 JUICE species accumulation curve a rarefaction PC-ORD 5 EstimateS (Robert Colwell, 239
19 TESTOVÁNÍ PRŮKAZNOSTI A POUŽÍVÁNÍ HODNOTY P
20 ZÁKLADNÍ DEFINICE Hodnota P (P value) pravděpodobnost, že bychom získali stejně velkou nebo větší hodnotu testové statistiky za předpokladu platnosti nulové hypotézy čím menší je hodnota P, tím silnější je argument ukazující na neplatnost nulové hypotézy ale pozor vysoké hodnoty P nejsou důkazem, že nulová hypotéza je pravdivá! (např. pokud nemůžete najít statisticky signifikantní rozdíl mezi dvěma druhy, neznamená to, že můžete tvrdit, že oba druhy jsou stejné) V případe porovnání dvou výběrů (např. t-test) se hodnota P snižuje pokud se skutečný rozdíl mezi průměry výběrů zvýší snižuje se zvyšujícím se počtem opakování zvyšuje s variabilitou v datech 241

21 P HODNOTA DŮKAZ, KTERÝ EXISTUJE PROTI PLATNOSTI NULOVÉ HYPOTÉZY přesvědčivý středně silný P hodnota náznak důkazu, ale nepřesvědčivý máme důkaz proti platnosti nulové hypotézy? ne Ramsey & Schaffer (2002) 242
22 DOPORUČENÍ P hodnoty by měly být posuzovány jako důvěryhodnost důkazu, který máme proti platnosti nulové hypotézy (Dá se rozdílu věřit? Je důkaz důvěryhodný?) Neklást důraz na binární rozhodnutí (signifikantní vs nesignifikantní) Spolu s hodnotou P je třeba uvádět i tzv. velikost účinku (effect size), (např. R 2 u regrese, Pearsonův korelační koeficient r u korelace) Vhodné je testovaný vztah vizualizovat (boxploty pro porovnání výběrů, bodový diagram závislosti dvou proměnných aj.), a pokud není vztah z obrázku patrný, věc důkladně prošetřit (není třeba průkaznost způsobena výskytem jednoho odlehlého a vlivného pozorování?) Obecně platí, že k výsledkům by měly být dostupná i primární data (v elektronické podobě v příloze, případně na vyžádání), a detailní postup, jak byla analyzována (např. R skript). Sdílení dat a detailní popis metodiky je základem transparentního výzkumu a umožňuje zopakování analýz a případné odhalení chyb. 243
INDEXY DIVERZITY. David Zelený Zpracování dat v ekologii společenstev
 INDEXY DIVERZITY Jurasinski et al. (2009) ALFA, BETA A GAMA DIVERZITA Alfa diverzita druhová bohatost vzorku Beta diverzita (species turnover) změna v druhovém složení mezi vzorky Gama diverzita celková
INDEXY DIVERZITY Jurasinski et al. (2009) ALFA, BETA A GAMA DIVERZITA Alfa diverzita druhová bohatost vzorku Beta diverzita (species turnover) změna v druhovém složení mezi vzorky Gama diverzita celková
DIVERZITA. David Zelený Zpracování dat v ekologii společenstev
 DIVERZITA ALFA, BETA A GAMA DIVERZITA Alfa diverzita druhová bohatost vzorku Beta diverzita (species turnover) změna v druhovém složení mezi vzorky heterogenita druhového složení Gama diverzita celková
DIVERZITA ALFA, BETA A GAMA DIVERZITA Alfa diverzita druhová bohatost vzorku Beta diverzita (species turnover) změna v druhovém složení mezi vzorky heterogenita druhového složení Gama diverzita celková
EKOLOGICKÁ PODOBNOST (ECOLOGICAL RESEMBLANCE) David Zelený Zpracování dat v ekologii společenstev
 David Zelený Zpracování dat v ekologii společenstev") EKOLOGICKÁ PODOBNOST (ECOLOGICAL RESEMBLANCE) EKOLOGICKÁ PODOBNOST Q VS R ANALÝZA Vzorky Druhy druh 1 druh 2 druh 3 vzorek 1 0 1 1 vzorek 2 1 0 0 vzorek 3 0 4 4 vztahy mezi vzorky Q analýza vztahy mezi
EKOLOGICKÁ PODOBNOST (ECOLOGICAL RESEMBLANCE) EKOLOGICKÁ PODOBNOST Q VS R ANALÝZA Vzorky Druhy druh 1 druh 2 druh 3 vzorek 1 0 1 1 vzorek 2 1 0 0 vzorek 3 0 4 4 vztahy mezi vzorky Q analýza vztahy mezi
NUMERICKÁ KLASIFIKACE. David Zelený Zpracování dat v ekologii společenstev
 NUMERICKÁ KLASIFIKACE http://wfc3.gsfc.nasa.gov PROČ MÁ SMYSL VĚCI KLASIFIKOVAT? vlnová délka (~ ekologický gradient) 172 http://wfc3.gsfc.nasa.gov PROČ MÁ SMYSL VĚCI KLASIFIKOVAT? vlnová délka (~ ekologický
NUMERICKÁ KLASIFIKACE http://wfc3.gsfc.nasa.gov PROČ MÁ SMYSL VĚCI KLASIFIKOVAT? vlnová délka (~ ekologický gradient) 172 http://wfc3.gsfc.nasa.gov PROČ MÁ SMYSL VĚCI KLASIFIKOVAT? vlnová délka (~ ekologický
RNDr. Eva Janoušová doc. RNDr. Ladislav Dušek, Dr.
 Analýza dat pro Neurovědy RNDr. Eva Janoušová doc. RNDr. Ladislav Dušek, Dr. Jaro 2014 Institut biostatistiky Janoušová, a analýz Dušek: Analýza dat pro neurovědy Blok 7 Jak hodnotit vztah spojitých proměnných
Analýza dat pro Neurovědy RNDr. Eva Janoušová doc. RNDr. Ladislav Dušek, Dr. Jaro 2014 Institut biostatistiky Janoušová, a analýz Dušek: Analýza dat pro neurovědy Blok 7 Jak hodnotit vztah spojitých proměnných
STATISTICKÉ METODY; ZÍSKÁVÁNÍ INFORMACÍ Z DRUHOVÝCH A ENVIRONMENTÁLNÍCH DAT
 STATISTICKÉ METODY; ZÍSKÁVÁNÍ INFORMACÍ Z DRUHOVÝCH A ENVIRONMENTÁLNÍCH DAT (NE)VÝHODY STATISTIKY OTÁZKY si klást ještě před odběrem a podle nich naplánovat design, metodiku odběru (experimentální vs.
STATISTICKÉ METODY; ZÍSKÁVÁNÍ INFORMACÍ Z DRUHOVÝCH A ENVIRONMENTÁLNÍCH DAT (NE)VÝHODY STATISTIKY OTÁZKY si klást ještě před odběrem a podle nich naplánovat design, metodiku odběru (experimentální vs.
REGRESE VS KALIBRACE. David Zelený Zpracování dat v ekologii společenstev
 REGRESE VS KALIBRACE David Zelený METODY GRADIENTOVÉ ANALÝZY Data, která máme: počet charakteristik prostředí počet druhů Apriorní znalost vztahů mezi druhy a prostředím? Použijeme: Dostaneme: 1, n 1 ne
REGRESE VS KALIBRACE David Zelený METODY GRADIENTOVÉ ANALÝZY Data, která máme: počet charakteristik prostředí počet druhů Apriorní znalost vztahů mezi druhy a prostředím? Použijeme: Dostaneme: 1, n 1 ne
ZX510 Pokročilé statistické metody geografického výzkumu. Téma: Měření síly asociace mezi proměnnými (korelační analýza)
") ZX510 Pokročilé statistické metody geografického výzkumu Téma: Měření síly asociace mezi proměnnými (korelační analýza) Měření síly asociace (korelace) mezi proměnnými Vztah mezi dvěma proměnnými existuje,
ZX510 Pokročilé statistické metody geografického výzkumu Téma: Měření síly asociace mezi proměnnými (korelační analýza) Měření síly asociace (korelace) mezi proměnnými Vztah mezi dvěma proměnnými existuje,
Základy biostatistiky II. Veřejné zdravotnictví 3.LF UK - II
 Základy biostatistiky II Veřejné zdravotnictví 3.LF UK - II Teoretické rozložení-matematické modely rozložení Naměřená data Výběrové rozložení Teoretické rozložení 1 e 2 x 2 Teoretické rozložení-matematické
Základy biostatistiky II Veřejné zdravotnictví 3.LF UK - II Teoretické rozložení-matematické modely rozložení Naměřená data Výběrové rozložení Teoretické rozložení 1 e 2 x 2 Teoretické rozložení-matematické
Testování hypotéz. 1. vymezení základních pojmů 2. testování hypotéz o rozdílu průměrů 3. jednovýběrový t-test
 Testování hypotéz 1. vymezení základních pojmů 2. testování hypotéz o rozdílu průměrů 3. jednovýběrový t-test Testování hypotéz proces, kterým rozhodujeme, zda přijmeme nebo zamítneme nulovou hypotézu
Testování hypotéz 1. vymezení základních pojmů 2. testování hypotéz o rozdílu průměrů 3. jednovýběrový t-test Testování hypotéz proces, kterým rozhodujeme, zda přijmeme nebo zamítneme nulovou hypotézu
Testování hypotéz a měření asociace mezi proměnnými
 Testování hypotéz a měření asociace mezi proměnnými Testování hypotéz Nulová a alternativní hypotéza většina statistických analýz zahrnuje různá porovnání, hledání vztahů, efektů Tvrzení, že efekt je nulový,
Testování hypotéz a měření asociace mezi proměnnými Testování hypotéz Nulová a alternativní hypotéza většina statistických analýz zahrnuje různá porovnání, hledání vztahů, efektů Tvrzení, že efekt je nulový,
Statistické metody v medicíně II. - p-hodnota
 Statistické metody v medicíně II. - p-hodnota Martin Hynek Gennet, Centre for Fetal Medicine, Prague EuroMISE Centre, First Faculty of Medicine of Charles University in Prague p-hodnota p-value (p-level)
Statistické metody v medicíně II. - p-hodnota Martin Hynek Gennet, Centre for Fetal Medicine, Prague EuroMISE Centre, First Faculty of Medicine of Charles University in Prague p-hodnota p-value (p-level)
Korelační a regresní analýza. 1. Pearsonův korelační koeficient 2. jednoduchá regresní analýza 3. vícenásobná regresní analýza
 Korelační a regresní analýza 1. Pearsonův korelační koeficient 2. jednoduchá regresní analýza 3. vícenásobná regresní analýza Pearsonův korelační koeficient u intervalových a poměrových dat můžeme jako
Korelační a regresní analýza 1. Pearsonův korelační koeficient 2. jednoduchá regresní analýza 3. vícenásobná regresní analýza Pearsonův korelační koeficient u intervalových a poměrových dat můžeme jako
Úvodem Dříve les než stromy 3 Operace s maticemi
 Obsah 1 Úvodem 13 2 Dříve les než stromy 17 2.1 Nejednoznačnost terminologie 17 2.2 Volba metody analýzy dat 23 2.3 Přehled vybraných vícerozměrných metod 25 2.3.1 Metoda hlavních komponent 26 2.3.2 Faktorová
Obsah 1 Úvodem 13 2 Dříve les než stromy 17 2.1 Nejednoznačnost terminologie 17 2.2 Volba metody analýzy dat 23 2.3 Přehled vybraných vícerozměrných metod 25 2.3.1 Metoda hlavních komponent 26 2.3.2 Faktorová
ELLENBERGOVY INDIKAČNÍ HODNOTY. David Zelený Zpracování dat v ekologii společenstev
 3 2 6 6 5 2 ELLENBERGOVY INDIKAČNÍ HODNOTY ELLENBERGOVY INDIKAČNÍ HODNOTY (EIH) optima druhů rostlin na gradientu živin, vlhkosti, půdní reakce, kontinentality, teploty, světla a salinity (salinita se
3 2 6 6 5 2 ELLENBERGOVY INDIKAČNÍ HODNOTY ELLENBERGOVY INDIKAČNÍ HODNOTY (EIH) optima druhů rostlin na gradientu živin, vlhkosti, půdní reakce, kontinentality, teploty, světla a salinity (salinita se
MÍRY ZÁVISLOSTI (KORELACE A REGRESE)
") zhanel@fsps.muni.cz MÍRY ZÁVISLOSTI (KORELACE A REGRESE) 2.5 MÍRY ZÁVISLOSTI 2.5.1 ZÁVISLOST PEVNÁ, VOLNÁ, STATISTICKÁ A KORELAČNÍ Jednorozměrné soubory - charakterizovány jednotlivými statistickými znaky
zhanel@fsps.muni.cz MÍRY ZÁVISLOSTI (KORELACE A REGRESE) 2.5 MÍRY ZÁVISLOSTI 2.5.1 ZÁVISLOST PEVNÁ, VOLNÁ, STATISTICKÁ A KORELAČNÍ Jednorozměrné soubory - charakterizovány jednotlivými statistickými znaky
1 Tyto materiály byly vytvořeny za pomoci grantu FRVŠ číslo 1145/2004.
 Prostá regresní a korelační analýza 1 1 Tyto materiály byly vytvořeny za pomoci grantu FRVŠ číslo 1145/2004. Problematika závislosti V podstatě lze rozlišovat mezi závislostí nepodstatnou, čili náhodnou
Prostá regresní a korelační analýza 1 1 Tyto materiály byly vytvořeny za pomoci grantu FRVŠ číslo 1145/2004. Problematika závislosti V podstatě lze rozlišovat mezi závislostí nepodstatnou, čili náhodnou
Regresní a korelační analýza
 Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
PŘÍKLADY POUŽITÍ ORDINAČNÍCH METOD
 PŘÍKLADY POUŽITÍ ORDINAČNÍCH METOD 1 PŘÍKLAD NA ROZKLAD VARIANCE SPOLEČENSTVA MĚKKÝŠŮ NA PRAMENIŠTÍCH druhové složení společenstev měkkýšů druhové složení slatiništní vegetace ph Ca cond Mg Na měřené proměnné
PŘÍKLADY POUŽITÍ ORDINAČNÍCH METOD 1 PŘÍKLAD NA ROZKLAD VARIANCE SPOLEČENSTVA MĚKKÝŠŮ NA PRAMENIŠTÍCH druhové složení společenstev měkkýšů druhové složení slatiništní vegetace ph Ca cond Mg Na měřené proměnné
Kategorická data METODOLOGICKÝ PROSEMINÁŘ II TÝDEN 7 4. DUBNA dubna 2018 Lukáš Hájek, Karel Höfer Metodologický proseminář II 1
 Kategorická data METODOLOGICKÝ PROSEMINÁŘ II TÝDEN 7 4. DUBNA 2018 4. dubna 2018 Lukáš Hájek, Karel Höfer Metodologický proseminář II 1 Typy proměnných nominální (nominal) o dvou hodnotách lze říci pouze
Kategorická data METODOLOGICKÝ PROSEMINÁŘ II TÝDEN 7 4. DUBNA 2018 4. dubna 2018 Lukáš Hájek, Karel Höfer Metodologický proseminář II 1 Typy proměnných nominální (nominal) o dvou hodnotách lze říci pouze
Aplikovaná statistika v R - cvičení 2
 Aplikovaná statistika v R - cvičení 2 Filip Děchtěrenko Matematicko-fyzikální fakulta filip.dechterenko@gmail.com 5.6.2014 Filip Děchtěrenko (MFF UK) Aplikovaná statistika v R 5.6.2014 1 / 18 Přehled Rkových
Aplikovaná statistika v R - cvičení 2 Filip Děchtěrenko Matematicko-fyzikální fakulta filip.dechterenko@gmail.com 5.6.2014 Filip Děchtěrenko (MFF UK) Aplikovaná statistika v R 5.6.2014 1 / 18 Přehled Rkových
Tomáš Karel LS 2012/2013
 Tomáš Karel LS 2012/2013 Doplňkový materiál ke cvičení z předmětu 4ST201. Na případné faktické chyby v této presentaci mě prosím upozorněte. Děkuji. Tyto slidy berte pouze jako doplňkový materiál není
Tomáš Karel LS 2012/2013 Doplňkový materiál ke cvičení z předmětu 4ST201. Na případné faktické chyby v této presentaci mě prosím upozorněte. Děkuji. Tyto slidy berte pouze jako doplňkový materiál není
Testování statistických hypotéz
 Testování statistických hypotéz 1 Testování statistických hypotéz 1 Statistická hypotéza a její test V praxi jsme nuceni rozhodnout, zda nějaké tvrzeni o parametrech náhodných veličin nebo o veličině samotné
Testování statistických hypotéz 1 Testování statistických hypotéz 1 Statistická hypotéza a její test V praxi jsme nuceni rozhodnout, zda nějaké tvrzeni o parametrech náhodných veličin nebo o veličině samotné
Testování statistických hypotéz
 Testování statistických hypotéz Na základě náhodného výběru, který je reprezentativním vzorkem základního souboru (který přesně neznáme, k němuž se ale daná statistická hypotéza váže), potřebujeme ověřit,
Testování statistických hypotéz Na základě náhodného výběru, který je reprezentativním vzorkem základního souboru (který přesně neznáme, k němuž se ale daná statistická hypotéza váže), potřebujeme ověřit,
You created this PDF from an application that is not licensed to print to novapdf printer (http://www.novapdf.com)
") Závislost náhodných veličin Úvod Předchozí přednášky: - statistické charakteristiky jednoho výběrového nebo základního souboru - vztahy mezi výběrovým a základním souborem - vztahy statistických charakteristik
Závislost náhodných veličin Úvod Předchozí přednášky: - statistické charakteristiky jednoho výběrového nebo základního souboru - vztahy mezi výběrovým a základním souborem - vztahy statistických charakteristik
Pravděpodobnost a aplikovaná statistika
 Pravděpodobnost a aplikovaná statistika MGR. JANA SEKNIČKOVÁ, PH.D. 8. KAPITOLA STATISTICKÉ TESTOVÁNÍ HYPOTÉZ 22.11.2016 Opakování: CLV příklad 1 Zadání: Před volbami je v populaci státu 52 % příznivců
Pravděpodobnost a aplikovaná statistika MGR. JANA SEKNIČKOVÁ, PH.D. 8. KAPITOLA STATISTICKÉ TESTOVÁNÍ HYPOTÉZ 22.11.2016 Opakování: CLV příklad 1 Zadání: Před volbami je v populaci státu 52 % příznivců
Tomáš Karel LS 2012/2013
 Tomáš Karel LS 2012/2013 Doplňkový materiál ke cvičení z předmětu 4ST201. Na případné faktické chyby v této presentaci mě prosím upozorněte. Děkuji. Tyto slidy berte pouze jako doplňkový materiál není
Tomáš Karel LS 2012/2013 Doplňkový materiál ke cvičení z předmětu 4ST201. Na případné faktické chyby v této presentaci mě prosím upozorněte. Děkuji. Tyto slidy berte pouze jako doplňkový materiál není
Pravděpodobnost a statistika, Biostatistika pro kombinované studium. Tutoriál č. 5: Bodové a intervalové odhady, testování hypotéz.
 Pravděpodobnost a statistika, Biostatistika pro kombinované studium Letní semestr 2015/2016 Tutoriál č. 5: Bodové a intervalové odhady, testování hypotéz Jan Kracík jan.kracik@vsb.cz Obsah: Výběrová rozdělení
Pravděpodobnost a statistika, Biostatistika pro kombinované studium Letní semestr 2015/2016 Tutoriál č. 5: Bodové a intervalové odhady, testování hypotéz Jan Kracík jan.kracik@vsb.cz Obsah: Výběrová rozdělení
Statistická analýza jednorozměrných dat
 Statistická analýza jednorozměrných dat Prof. RNDr. Milan Meloun, DrSc. Univerzita Pardubice, Pardubice 31.ledna 2011 Tato prezentace je spolufinancována Evropským sociálním fondem a státním rozpočtem
Statistická analýza jednorozměrných dat Prof. RNDr. Milan Meloun, DrSc. Univerzita Pardubice, Pardubice 31.ledna 2011 Tato prezentace je spolufinancována Evropským sociálním fondem a státním rozpočtem
Regresní a korelační analýza
 Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Vícerozměrné statistické metody
 Vícerozměrné statistické metody Podobnosti a vzdálenosti ve vícerozměrném prostoru, asociační matice II Jiří Jarkovský, Simona Littnerová Vícerozměrné statistické metody Práce s asociační maticí Vzdálenosti
Vícerozměrné statistické metody Podobnosti a vzdálenosti ve vícerozměrném prostoru, asociační matice II Jiří Jarkovský, Simona Littnerová Vícerozměrné statistické metody Práce s asociační maticí Vzdálenosti
Grafický a číselný popis rozložení dat 3.1 Způsoby zobrazení dat Metody zobrazení kvalitativních a ordinálních dat Metody zobrazení kvan
 1 Úvod 1.1 Empirický výzkum a jeho etapy 1.2 Význam teorie pro výzkum 1.2.1 Konstrukty a jejich operacionalizace 1.2.2 Role teorie ve výzkumu 1.2.3 Proces ověření hypotéz a teorií 1.3 Etika vědecké práce
1 Úvod 1.1 Empirický výzkum a jeho etapy 1.2 Význam teorie pro výzkum 1.2.1 Konstrukty a jejich operacionalizace 1.2.2 Role teorie ve výzkumu 1.2.3 Proces ověření hypotéz a teorií 1.3 Etika vědecké práce
Pokročilé neparametrické metody. Klára Kubošová
 Klára Kubošová Další typy stromů CHAID, PRIM, MARS CHAID - Chi-squared Automatic Interaction Detector G.V.Kass (1980) nebinární strom pro kategoriální proměnné. Jako kriteriální statistika pro větvení
Klára Kubošová Další typy stromů CHAID, PRIM, MARS CHAID - Chi-squared Automatic Interaction Detector G.V.Kass (1980) nebinární strom pro kategoriální proměnné. Jako kriteriální statistika pro větvení
Regresní a korelační analýza
 Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Regresní a korelační analýza
 Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Číselné charakteristiky
 . Číselné charakteristiky statistických dat Průměrný statistik se během svého života ožení s 1,75 ženami, které se ho snaží vytáhnout večer do společnosti,5 x týdně, ale pouze s 50% úspěchem. W. F. Miksch
. Číselné charakteristiky statistických dat Průměrný statistik se během svého života ožení s 1,75 ženami, které se ho snaží vytáhnout večer do společnosti,5 x týdně, ale pouze s 50% úspěchem. W. F. Miksch
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz
 Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická
Tématické okruhy pro státní závěrečné zkoušky. bakalářské studium. studijní obor "Management jakosti"
 Tématické okruhy pro státní závěrečné zkoušky bakalářské studium studijní obor "Management jakosti" školní rok 2013/2014 Management jakosti A 1. Pojem jakosti a význam managementu jakosti v současném období.
Tématické okruhy pro státní závěrečné zkoušky bakalářské studium studijní obor "Management jakosti" školní rok 2013/2014 Management jakosti A 1. Pojem jakosti a význam managementu jakosti v současném období.
Statistika, Biostatistika pro kombinované studium. Jan Kracík
 Statistika, Biostatistika pro kombinované studium Letní semestr 2014/2015 Tutoriál č. 6: ANOVA Jan Kracík jan.kracik@vsb.cz Obsah: Testování hypotéz opakování ANOVA Testování hypotéz (opakování) Testování
Statistika, Biostatistika pro kombinované studium Letní semestr 2014/2015 Tutoriál č. 6: ANOVA Jan Kracík jan.kracik@vsb.cz Obsah: Testování hypotéz opakování ANOVA Testování hypotéz (opakování) Testování
Testy statistických hypotéz
 Testy statistických hypotéz Statistická hypotéza je jakýkoliv předpoklad o rozdělení pravděpodobnosti jedné nebo několika náhodných veličin. Na základě náhodného výběru, který je reprezentativním vzorkem
Testy statistických hypotéz Statistická hypotéza je jakýkoliv předpoklad o rozdělení pravděpodobnosti jedné nebo několika náhodných veličin. Na základě náhodného výběru, který je reprezentativním vzorkem
6. Lineární regresní modely
 6. Lineární regresní modely 6.1 Jednoduchá regrese a validace 6.2 Testy hypotéz v lineární regresi 6.3 Kritika dat v regresním tripletu 6.4 Multikolinearita a polynomy 6.5 Kritika modelu v regresním tripletu
6. Lineární regresní modely 6.1 Jednoduchá regrese a validace 6.2 Testy hypotéz v lineární regresi 6.3 Kritika dat v regresním tripletu 6.4 Multikolinearita a polynomy 6.5 Kritika modelu v regresním tripletu
Statistika. Testování hypotéz statistická indukce Úvod do problému. Roman Biskup
 Statistika Testování hypotéz statistická indukce Úvod do problému Roman Biskup (zapálený) statistik ve výslužbě, aktuálně analytik v praxi ;-) roman.biskup(at)email.cz 21. února 2012 Statistika by Birom
Statistika Testování hypotéz statistická indukce Úvod do problému Roman Biskup (zapálený) statistik ve výslužbě, aktuálně analytik v praxi ;-) roman.biskup(at)email.cz 21. února 2012 Statistika by Birom
Obsah Úvod Kapitola 1 Než začneme Kapitola 2 Práce s hromadnými daty před analýzou
 Úvod.................................................................. 11 Kapitola 1 Než začneme.................................................................. 17 1.1 Logika kvantitativního výzkumu...........................................
Úvod.................................................................. 11 Kapitola 1 Než začneme.................................................................. 17 1.1 Logika kvantitativního výzkumu...........................................
KGG/STG Statistika pro geografy
 KGG/STG Statistika pro geografy 9. Korelační analýza Mgr. David Fiedor 20. dubna 2015 Analýza závislostí v řadě geografických disciplín studujeme jevy, u kterých vyšetřujeme nikoliv pouze jednu vlastnost
KGG/STG Statistika pro geografy 9. Korelační analýza Mgr. David Fiedor 20. dubna 2015 Analýza závislostí v řadě geografických disciplín studujeme jevy, u kterých vyšetřujeme nikoliv pouze jednu vlastnost
TLOUŠŤKOVÁ A VÝŠKOVÁ STRUKTURA A JEJÍ MODELOVÁNÍ
 TLOUŠŤKOVÁ A VÝŠKOVÁ STRUKTURA A JEJÍ MODELOVÁNÍ 1 Vlastnosti tloušťkové struktury porostu tloušťky mají vyšší variabilitu než výšky světlomilné dřeviny mají křivku početností tlouštěk špičatější a s menší
TLOUŠŤKOVÁ A VÝŠKOVÁ STRUKTURA A JEJÍ MODELOVÁNÍ 1 Vlastnosti tloušťkové struktury porostu tloušťky mají vyšší variabilitu než výšky světlomilné dřeviny mají křivku početností tlouštěk špičatější a s menší
Epidemiologické ukazatele. lních dat. analýza kategoriáln. Prof. RNDr. Jana Zvárová, DrSc. Záznam epidemiologických dat. a I E
 Testování statistických hypotéz z a analýza kategoriáln lních dat Prof. RNDr. Jana Zvárová, DrSc. Epidemiologické ukazatele Rizikový faktor Populace Přítomen Nepřítomen Celkem Nemocní a b a+b Kontroly
Testování statistických hypotéz z a analýza kategoriáln lních dat Prof. RNDr. Jana Zvárová, DrSc. Epidemiologické ukazatele Rizikový faktor Populace Přítomen Nepřítomen Celkem Nemocní a b a+b Kontroly
Analýza rozptylu. PSY117/454 Statistická analýza dat v psychologii Přednáška 12. Srovnávání více než dvou průměrů
 PSY117/454 Statistická analýza dat v psychologii Přednáška 12 Analýza rozptylu Srovnávání více než dvou průměrů If your experiment needs statistics, you ought to have done a better experiment. Ernest Rutherford
PSY117/454 Statistická analýza dat v psychologii Přednáška 12 Analýza rozptylu Srovnávání více než dvou průměrů If your experiment needs statistics, you ought to have done a better experiment. Ernest Rutherford
Základy počtu pravděpodobnosti a metod matematické statistiky
 Errata ke skriptu Základy počtu pravděpodobnosti a metod matematické statistiky K. Hron a P. Kunderová Autoři prosí čtenáře uvedeného studijního textu, aby případné další odhalené chyby nad rámec tohoto
Errata ke skriptu Základy počtu pravděpodobnosti a metod matematické statistiky K. Hron a P. Kunderová Autoři prosí čtenáře uvedeného studijního textu, aby případné další odhalené chyby nad rámec tohoto
PCA BIPLOT ŠKÁLOVÁNÍ OS (1)
") PCA BIPLOT ŠKÁLOVÁNÍ OS (1) 1 (sites) o zaměření na odlišnosti mezi lokalitami zachovány euklidovské vzdálenosti mezi vzorky úhly mezi šipkami neodpovídají kovariancím (korelacím) proměnných variance skóre
PCA BIPLOT ŠKÁLOVÁNÍ OS (1) 1 (sites) o zaměření na odlišnosti mezi lokalitami zachovány euklidovské vzdálenosti mezi vzorky úhly mezi šipkami neodpovídají kovariancím (korelacím) proměnných variance skóre
Regresní a korelační analýza
 Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Statistika (KMI/PSTAT)
") Statistika (KMI/PSTAT) Cvičení dvanácté aneb Regrese a korelace Statistika (KMI/PSTAT) 1 / 18 V souboru 25 jedinců jsme měřili jejich výšku a hmotnost. Výsledky jsou v tabulce a grafu. Statistika (KMI/PSTAT)
Statistika (KMI/PSTAT) Cvičení dvanácté aneb Regrese a korelace Statistika (KMI/PSTAT) 1 / 18 V souboru 25 jedinců jsme měřili jejich výšku a hmotnost. Výsledky jsou v tabulce a grafu. Statistika (KMI/PSTAT)
JEDNOVÝBĚROVÉ TESTY. Komentované řešení pomocí programu Statistica
 JEDNOVÝBĚROVÉ TESTY Komentované řešení pomocí programu Statistica Vstupní data Data umístěná v excelovském souboru překopírujeme do tabulky ve Statistice a pojmenujeme proměnné, viz prezentace k tématu
JEDNOVÝBĚROVÉ TESTY Komentované řešení pomocí programu Statistica Vstupní data Data umístěná v excelovském souboru překopírujeme do tabulky ve Statistice a pojmenujeme proměnné, viz prezentace k tématu
Jednofaktorová analýza rozptylu
 I I.I Jednofaktorová analýza rozptylu Úvod Jednofaktorová analýza rozptylu (ANOVA) se využívá při porovnání několika středních hodnot. Často se využívá ve vědeckých a lékařských experimentech, při kterých
I I.I Jednofaktorová analýza rozptylu Úvod Jednofaktorová analýza rozptylu (ANOVA) se využívá při porovnání několika středních hodnot. Často se využívá ve vědeckých a lékařských experimentech, při kterých
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc.
 Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika 010 1.týden (0.09.-4.09. ) Data, typy dat, variabilita, frekvenční analýza
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika 010 1.týden (0.09.-4.09. ) Data, typy dat, variabilita, frekvenční analýza
Pearsonův korelační koeficient
 I I.I Pearsonův korelační koeficient Úvod Předpokládejme, že náhodně vybereme n objektů (nebo osob) ze zkoumané populace. Často se stává, že na každém z objektů měříme ne pouze jednu, ale několik kvantitativních
I I.I Pearsonův korelační koeficient Úvod Předpokládejme, že náhodně vybereme n objektů (nebo osob) ze zkoumané populace. Často se stává, že na každém z objektů měříme ne pouze jednu, ale několik kvantitativních
Matematické modelování Náhled do ekonometrie. Lukáš Frýd
 Matematické modelování Náhled do ekonometrie Lukáš Frýd Výnos akcie vs. Výnos celého trhu - CAPM model r it = r ft + β 1. (r mt r ft ) r it r ft = α 0 + β 1. (r mt r ft ) + ε it Ekonomický (finanční model)
Matematické modelování Náhled do ekonometrie Lukáš Frýd Výnos akcie vs. Výnos celého trhu - CAPM model r it = r ft + β 1. (r mt r ft ) r it r ft = α 0 + β 1. (r mt r ft ) + ε it Ekonomický (finanční model)
PSY117/454 Statistická analýza dat v psychologii přednáška 8. Statistické usuzování, odhady
 PSY117/454 Statistická analýza dat v psychologii přednáška 8 Statistické usuzování, odhady Výběr od deskripce k indukci Deskripce dat, odhad parametrů Usuzování = inference = indukce Počítá se s náhodným
PSY117/454 Statistická analýza dat v psychologii přednáška 8 Statistické usuzování, odhady Výběr od deskripce k indukci Deskripce dat, odhad parametrů Usuzování = inference = indukce Počítá se s náhodným
TECHNICKÁ UNIVERZITA V LIBERCI
 TECHNICKÁ UNIVERZITA V LIBERCI Ekonomická fakulta Semestrální práce z předmětu Statistický rozbor dat z dotazníkového šetření Jméno: Lucie Krechlerová, Karel Kozma, René Dubský, David Drobík Ročník: 2015/2016
TECHNICKÁ UNIVERZITA V LIBERCI Ekonomická fakulta Semestrální práce z předmětu Statistický rozbor dat z dotazníkového šetření Jméno: Lucie Krechlerová, Karel Kozma, René Dubský, David Drobík Ročník: 2015/2016
Normální (Gaussovo) rozdělení
 rozdělení") Normální (Gaussovo) rozdělení Normální (Gaussovo) rozdělení popisuje vlastnosti náhodné spojité veličiny, která vzniká složením různých náhodných vlivů, které jsou navzájem nezávislé, kterých je velký
Normální (Gaussovo) rozdělení Normální (Gaussovo) rozdělení popisuje vlastnosti náhodné spojité veličiny, která vzniká složením různých náhodných vlivů, které jsou navzájem nezávislé, kterých je velký
Měření závislosti statistických dat
 5.1 Měření závislosti statistických dat Každý pořádný astronom je schopen vám předpovědět, kde se bude nacházet daná hvězda půl hodiny před půlnocí. Ne každý je však téhož schopen předpovědět v případě
5.1 Měření závislosti statistických dat Každý pořádný astronom je schopen vám předpovědět, kde se bude nacházet daná hvězda půl hodiny před půlnocí. Ne každý je však téhož schopen předpovědět v případě
Téma 9: Vícenásobná regrese
 Téma 9: Vícenásobná regrese 1) Vytvoření modelu V menu Statistika zvolíme nabídku Vícerozměrná regrese. Aktivujeme kartu Detailní nastavení viz obr.1. Nastavíme Proměnné tak, že v příslušném okně viz.
Téma 9: Vícenásobná regrese 1) Vytvoření modelu V menu Statistika zvolíme nabídku Vícerozměrná regrese. Aktivujeme kartu Detailní nastavení viz obr.1. Nastavíme Proměnné tak, že v příslušném okně viz.
Regrese. používáme tehdy, jestliže je vysvětlující proměnná kontinuální pokud je kategoriální, jde o ANOVA
 Regrese používáme tehd, jestliže je vsvětlující proměnná kontinuální pokud je kategoriální, jde o ANOVA Specifikace modelu = a + bx a závisle proměnná b x vsvětlující proměnná Cíl analýz Odhadnout hodnot
Regrese používáme tehd, jestliže je vsvětlující proměnná kontinuální pokud je kategoriální, jde o ANOVA Specifikace modelu = a + bx a závisle proměnná b x vsvětlující proměnná Cíl analýz Odhadnout hodnot
Analýza rozptylu. Ekonometrie. Jiří Neubauer. Katedra kvantitativních metod FVL UO Brno kancelář 69a, tel
 Analýza rozptylu Ekonometrie Jiří Neubauer Katedra kvantitativních metod FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Jiří Neubauer (Katedra UO Brno) Analýza rozptylu 1 / 30 Analýza
Analýza rozptylu Ekonometrie Jiří Neubauer Katedra kvantitativních metod FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Jiří Neubauer (Katedra UO Brno) Analýza rozptylu 1 / 30 Analýza
INDUKTIVNÍ STATISTIKA
 10. SEMINÁŘ INDUKTIVNÍ STATISTIKA 3. HODNOCENÍ ZÁVISLOSTÍ HODNOCENÍ ZÁVISLOSTÍ KVALITATIVNÍ VELIČINY - Vychází se z kombinační (kontingenční) tabulky, která je výsledkem třídění druhého stupně KVANTITATIVNÍ
10. SEMINÁŘ INDUKTIVNÍ STATISTIKA 3. HODNOCENÍ ZÁVISLOSTÍ HODNOCENÍ ZÁVISLOSTÍ KVALITATIVNÍ VELIČINY - Vychází se z kombinační (kontingenční) tabulky, která je výsledkem třídění druhého stupně KVANTITATIVNÍ
Jarqueův a Beryho test normality (Jarque-Bera Test, JB test)
") Jarqueův a Beryho test normality (Jarque-Bera Test, JB test) Autoři: Carlos M. Jarque and Anil K. Bera Předpoklady: - Výběrová data mohou obsahovat chybějící pozorování (chybějící hodnoty) vhodné zejména
Jarqueův a Beryho test normality (Jarque-Bera Test, JB test) Autoři: Carlos M. Jarque and Anil K. Bera Předpoklady: - Výběrová data mohou obsahovat chybějící pozorování (chybějící hodnoty) vhodné zejména
Tématické okruhy pro státní závěrečné zkoušky. bakalářské studium. studijní obor "Management jakosti"
 Tématické okruhy pro státní závěrečné zkoušky bakalářské studium studijní obor "Management jakosti" školní rok 2010/2011 Management jakosti A 1. Pojem jakosti a význam managementu jakosti v současném období.
Tématické okruhy pro státní závěrečné zkoušky bakalářské studium studijní obor "Management jakosti" školní rok 2010/2011 Management jakosti A 1. Pojem jakosti a význam managementu jakosti v současném období.
ELLENBERGOVY INDIKAČNÍ HODNOTY. David Zelený Zpracování dat v ekologii společenstev
 3 2 6 6 5 2 ELLENBERGOVY INDIKAČNÍ HODNOTY ELLENBERGOVY INDIKAČNÍ HODNOTY (EIH) optima druhů rostlin na gradientu ţivin, vlhkosti, půdní reakce, kontinentality, teploty, světla a salinity (salinita se
3 2 6 6 5 2 ELLENBERGOVY INDIKAČNÍ HODNOTY ELLENBERGOVY INDIKAČNÍ HODNOTY (EIH) optima druhů rostlin na gradientu ţivin, vlhkosti, půdní reakce, kontinentality, teploty, světla a salinity (salinita se
analýza kategoriáln lních dat Prof. RNDr. Jana Zvárová, DrSc. Záznam epidemiologických dat Epidemiologické ukazatele
 Testování statistických hypotéz z a analýza kategoriáln lních dat Prof. RNDr. Jana Zvárová, DrSc. 1 Záznam epidemiologických dat Rizikový faktor Populace Přítomen Nepřítomen Celkem Nemocní a b a+b Kontroly
Testování statistických hypotéz z a analýza kategoriáln lních dat Prof. RNDr. Jana Zvárová, DrSc. 1 Záznam epidemiologických dat Rizikový faktor Populace Přítomen Nepřítomen Celkem Nemocní a b a+b Kontroly
Neparametrické metody
 Neparametrické metody Dosud jsme se zabývali statistickými metodami, které zahrnovaly předpoklady o rozdělení dat. Zpravidla jsme předpokládali normální rozdělení. Např. Grubbsův test odlehlých hodnot
Neparametrické metody Dosud jsme se zabývali statistickými metodami, které zahrnovaly předpoklady o rozdělení dat. Zpravidla jsme předpokládali normální rozdělení. Např. Grubbsův test odlehlých hodnot
4ST201 STATISTIKA CVIČENÍ Č. 10
 4ST201 STATISTIKA CVIČENÍ Č. 10 regresní analýza - vícenásobná lineární regrese korelační analýza Př. 10.1 Máte zadaný výstup regresní analýzy závislosti závisle proměnné Y na nezávisle proměnné X. Doplňte
4ST201 STATISTIKA CVIČENÍ Č. 10 regresní analýza - vícenásobná lineární regrese korelační analýza Př. 10.1 Máte zadaný výstup regresní analýzy závislosti závisle proměnné Y na nezávisle proměnné X. Doplňte
4EK211 Základy ekonometrie
 4EK Základy ekonometrie Odhad klasického lineárního regresního modelu II Cvičení 3 Zuzana Dlouhá Klasický lineární regresní model - zadání příkladu Soubor: CV3_PR.xls Data: y = maloobchodní obrat potřeb
4EK Základy ekonometrie Odhad klasického lineárního regresního modelu II Cvičení 3 Zuzana Dlouhá Klasický lineární regresní model - zadání příkladu Soubor: CV3_PR.xls Data: y = maloobchodní obrat potřeb
=10 =80 - =
 Protokol č. DĚDIČNOST KVALITATIVNÍCH VLASTNOSTÍ ) Jednorozměrné rozdělení fenotypové charakteristiky (hodnoty) populace ) Vícerozměrné rozdělení korelační a regresní počet pro dvě sledované vlastnosti
Protokol č. DĚDIČNOST KVALITATIVNÍCH VLASTNOSTÍ ) Jednorozměrné rozdělení fenotypové charakteristiky (hodnoty) populace ) Vícerozměrné rozdělení korelační a regresní počet pro dvě sledované vlastnosti
Statistické testování hypotéz II
 PSY117/454 Statistická analýza dat v psychologii Přednáška 9 Statistické testování hypotéz II Přehled testů, rozdíly průměrů, velikost účinku, síla testu Základní výzkumné otázky/hypotézy 1. Stanovení
PSY117/454 Statistická analýza dat v psychologii Přednáška 9 Statistické testování hypotéz II Přehled testů, rozdíly průměrů, velikost účinku, síla testu Základní výzkumné otázky/hypotézy 1. Stanovení
10. Předpovídání - aplikace regresní úlohy
 10. Předpovídání - aplikace regresní úlohy Regresní úloha (analýza) je označení pro statistickou metodu, pomocí nichž odhadujeme hodnotu náhodné veličiny (tzv. závislé proměnné, cílové proměnné, regresandu
10. Předpovídání - aplikace regresní úlohy Regresní úloha (analýza) je označení pro statistickou metodu, pomocí nichž odhadujeme hodnotu náhodné veličiny (tzv. závislé proměnné, cílové proměnné, regresandu
Kanonická korelační analýza
 Kanonická korelační analýza Kanonická korelační analýza je vícerozměrná metoda, která se používá ke zkoumání závislosti mezi dvěma skupinami proměnných. První ze skupin se považuje za soubor nezávisle
Kanonická korelační analýza Kanonická korelační analýza je vícerozměrná metoda, která se používá ke zkoumání závislosti mezi dvěma skupinami proměnných. První ze skupin se považuje za soubor nezávisle
8 Coxův model proporcionálních rizik I
 8 Coxův model proporcionálních rizik I Předpokládané výstupy z výuky: 1. Student umí formulovat Coxův model proporcionálních rizik 2. Student rozumí významu regresních koeficientů modelu 3. Student zná
8 Coxův model proporcionálních rizik I Předpokládané výstupy z výuky: 1. Student umí formulovat Coxův model proporcionálních rizik 2. Student rozumí významu regresních koeficientů modelu 3. Student zná
Statistická a věcná významnost. Statistická významnost. Historie hypotézy a testů. Hypotézy a statistické testy.
 Statistická a věcná významnost Statistická významnost Petr Soukup 5.11.2009 Fisher (1925) Historie hypotézy a testů Null and alternative hypothesis (NHST) (Neyman&Pearson, 1937) Dnes běžná praxe a součást
Statistická a věcná významnost Statistická významnost Petr Soukup 5.11.2009 Fisher (1925) Historie hypotézy a testů Null and alternative hypothesis (NHST) (Neyman&Pearson, 1937) Dnes běžná praxe a součást
Tématické okruhy pro státní závěrečné zkoušky. bakalářské studium. studijní obor "Management jakosti"
 Tématické okruhy pro státní závěrečné zkoušky bakalářské studium studijní obor "Management jakosti" školní rok 2009/2010 Management jakosti A 1. Pojem jakosti a význam managementu jakosti v současném období.
Tématické okruhy pro státní závěrečné zkoušky bakalářské studium studijní obor "Management jakosti" školní rok 2009/2010 Management jakosti A 1. Pojem jakosti a význam managementu jakosti v současném období.
DVOUVÝBĚROVÉ A PÁROVÉ TESTY Komentované řešení pomocí programu Statistica
 DVOUVÝBĚROVÉ A PÁROVÉ TESTY Komentované řešení pomocí programu Statistica Úloha A) koncentrace glukózy v krvi V této části posoudíme pomocí párového testu, zda nový lék prokazatelně snižuje koncentraci
DVOUVÝBĚROVÉ A PÁROVÉ TESTY Komentované řešení pomocí programu Statistica Úloha A) koncentrace glukózy v krvi V této části posoudíme pomocí párového testu, zda nový lék prokazatelně snižuje koncentraci
UNIVERZITA PARDUBICE Fakulta chemicko-technologická Katedra analytické chemie
 UNIVERZITA PARDUBICE Fakulta chemicko-technologická Katedra analytické chemie Licenční studium Pythagoras Statistické zpracování experimentálních dat Semestrální práce ANOVA vypracoval: Ing. David Dušek
UNIVERZITA PARDUBICE Fakulta chemicko-technologická Katedra analytické chemie Licenční studium Pythagoras Statistické zpracování experimentálních dat Semestrální práce ANOVA vypracoval: Ing. David Dušek
Kompetice a mortalita
 Kompetice a mortalita Nauka o růstu lesa Michal Kneifl Tento projekt je spolufinancován Evropským sociálním fondem a Státním rozpočtem ČR InoBio CZ.1.07/2.2.00/28.0018 Úvod vnitrodruhové a mezidruhové
Kompetice a mortalita Nauka o růstu lesa Michal Kneifl Tento projekt je spolufinancován Evropským sociálním fondem a Státním rozpočtem ČR InoBio CZ.1.07/2.2.00/28.0018 Úvod vnitrodruhové a mezidruhové
PRAVDĚPODOBNOST A STATISTIKA. Bayesovské odhady
 PRAVDĚPODOBNOST A STATISTIKA Bayesovské odhady Bayesovské odhady - úvod Klasický bayesovský přístup: Klasický přístup je založen na opakování pokusech sledujeme rekvenci nastoupení zvolených jevů Bayesovský
PRAVDĚPODOBNOST A STATISTIKA Bayesovské odhady Bayesovské odhady - úvod Klasický bayesovský přístup: Klasický přístup je založen na opakování pokusech sledujeme rekvenci nastoupení zvolených jevů Bayesovský
ANALÝZA DAT V R 3. POPISNÉ STATISTIKY, NÁHODNÁ VELIČINA. Mgr. Markéta Pavlíková Katedra pravděpodobnosti a matematické statistiky MFF UK
 ANALÝZA DAT V R 3. POPISNÉ STATISTIKY, NÁHODNÁ VELIČINA Mgr. Markéta Pavlíková Katedra pravděpodobnosti a matematické statistiky MFF UK www.biostatisticka.cz POPISNÉ STATISTIKY - OPAKOVÁNÍ jedna kvalitativní
ANALÝZA DAT V R 3. POPISNÉ STATISTIKY, NÁHODNÁ VELIČINA Mgr. Markéta Pavlíková Katedra pravděpodobnosti a matematické statistiky MFF UK www.biostatisticka.cz POPISNÉ STATISTIKY - OPAKOVÁNÍ jedna kvalitativní
Kalkulace závažnosti komorbidit a komplikací pro CZ-DRG
 Kalkulace závažnosti komorbidit a komplikací pro CZ-DRG Michal Uher a analytický tým projektu DRG Restart Ústav zdravotnických informací a statistiky ČR, Praha Institut biostatistiky a analýzy, Lékařská
Kalkulace závažnosti komorbidit a komplikací pro CZ-DRG Michal Uher a analytický tým projektu DRG Restart Ústav zdravotnických informací a statistiky ČR, Praha Institut biostatistiky a analýzy, Lékařská
Pravděpodobnost v závislosti na proměnné x je zde modelován pomocí logistického modelu. exp x. x x x. log 1
 Logistická regrese Menu: QCExpert Regrese Logistická Modul Logistická regrese umožňuje analýzu dat, kdy odezva je binární, nebo frekvenční veličina vyjádřená hodnotami 0 nebo 1, případně poměry v intervalu
Logistická regrese Menu: QCExpert Regrese Logistická Modul Logistická regrese umožňuje analýzu dat, kdy odezva je binární, nebo frekvenční veličina vyjádřená hodnotami 0 nebo 1, případně poměry v intervalu
Pokročilejší metody: výběr. Začínáme otázkami na povahu vysvětlované proměnné a končíme otázkami na povahu vysvětlujících proměnných
 Výběr metody Jak vybrat správnou statistickou metodu pro moje data a pro otázku, kterou si kladu Neexistuje žádná náhražka za zkušenost nejlepší metoda, jak vědět co dělat, je použít stejnou správnou metodu
Výběr metody Jak vybrat správnou statistickou metodu pro moje data a pro otázku, kterou si kladu Neexistuje žádná náhražka za zkušenost nejlepší metoda, jak vědět co dělat, je použít stejnou správnou metodu
Korelační a regresní analýza
 Korelační a regresní analýza Analýza závislosti v normálním rozdělení Pearsonův (výběrový) korelační koeficient: r = s XY s X s Y, kde s XY = 1 n (x n 1 i=0 i x )(y i y ), s X (s Y ) je výběrová směrodatná
Korelační a regresní analýza Analýza závislosti v normálním rozdělení Pearsonův (výběrový) korelační koeficient: r = s XY s X s Y, kde s XY = 1 n (x n 1 i=0 i x )(y i y ), s X (s Y ) je výběrová směrodatná
KORELACE. Komentované řešení pomocí programu Statistica
 KORELACE Komentované řešení pomocí programu Statistica Vstupní data I Data umístěná v excelovském souboru překopírujeme do tabulky ve Statistice a pojmenujeme proměnné, viz prezentace k tématu Popisná
KORELACE Komentované řešení pomocí programu Statistica Vstupní data I Data umístěná v excelovském souboru překopírujeme do tabulky ve Statistice a pojmenujeme proměnné, viz prezentace k tématu Popisná
Normální (Gaussovo) rozdělení
 rozdělení") Normální (Gaussovo) rozdělení f x = 1 2 exp x 2 2 2 f(x) je funkce hustoty pravděpodobnosti, symetrická vůči poloze maxima x = μ μ střední hodnota σ směrodatná odchylka (tzv. pološířka křivky mezi inflexními
Normální (Gaussovo) rozdělení f x = 1 2 exp x 2 2 2 f(x) je funkce hustoty pravděpodobnosti, symetrická vůči poloze maxima x = μ μ střední hodnota σ směrodatná odchylka (tzv. pološířka křivky mezi inflexními
Prostorová variabilita
 Prostorová variabilita prostorová závislost (autokorelace) reprezentuje korelaci mezi hodnotami určité náhodné proměnné v místě i a hodnotami téže proměnné v jiném místě j; prostorová heterogenita je strukturální
Prostorová variabilita prostorová závislost (autokorelace) reprezentuje korelaci mezi hodnotami určité náhodné proměnné v místě i a hodnotami téže proměnné v jiném místě j; prostorová heterogenita je strukturální
Neparametrické testy
 Neparametrické testy Dosud jsme se zabývali statistickými metodami, které zahrnovaly předpoklady o rozdělení dat. Zpravidla jsme předpokládali normální (Gaussovo) rozdělení. Například: Grubbsův test odlehlých
Neparametrické testy Dosud jsme se zabývali statistickými metodami, které zahrnovaly předpoklady o rozdělení dat. Zpravidla jsme předpokládali normální (Gaussovo) rozdělení. Například: Grubbsův test odlehlých
Náhodný vektor. Náhodný vektor. Hustota náhodného vektoru. Hustota náhodného vektoru. Náhodný vektor je dvojice náhodných veličin (X, Y ) T = ( X
 T = ( X") Náhodný vektor Náhodný vektor zatím jsme sledovali jednu náhodnou veličinu, její rozdělení a charakteristiky často potřebujeme vyšetřovat vzájemný vztah několika náhodných veličin musíme sledovat jejich
Náhodný vektor Náhodný vektor zatím jsme sledovali jednu náhodnou veličinu, její rozdělení a charakteristiky často potřebujeme vyšetřovat vzájemný vztah několika náhodných veličin musíme sledovat jejich
PSY117/454 Statistická analýza dat v psychologii Přednáška 10
 PSY117/454 Statistická analýza dat v psychologii Přednáška 10 TESTY PRO NOMINÁLNÍ A ORDINÁLNÍ PROMĚNNÉ NEPARAMETRICKÉ METODY... a to mělo, jak sám vidíte, nedozírné následky. Smrť Analýza četností hodnot
PSY117/454 Statistická analýza dat v psychologii Přednáška 10 TESTY PRO NOMINÁLNÍ A ORDINÁLNÍ PROMĚNNÉ NEPARAMETRICKÉ METODY... a to mělo, jak sám vidíte, nedozírné následky. Smrť Analýza četností hodnot
Protokol č. 5. Vytyčovací údaje zkusných ploch
 Protokol č. 5 Vytyčovací údaje zkusných ploch Zadání: Ve vybraném porostu bylo prováděno zjišťování zásob za použití reprezentativní metody kruhových zkusných ploch. Na těchto zkusných plochách byl zjišťován
Protokol č. 5 Vytyčovací údaje zkusných ploch Zadání: Ve vybraném porostu bylo prováděno zjišťování zásob za použití reprezentativní metody kruhových zkusných ploch. Na těchto zkusných plochách byl zjišťován
4EK211 Základy ekonometrie
 4EK211 Základy ekonometrie Predikce Multikolinearita Cvičení 4 Zuzana Dlouhá Aplikace EM predikce obecně ekonomické prognózování, předpověď, předvídání hlavním cílem je odhad hodnot vysvětlované proměnné
4EK211 Základy ekonometrie Predikce Multikolinearita Cvičení 4 Zuzana Dlouhá Aplikace EM predikce obecně ekonomické prognózování, předpověď, předvídání hlavním cílem je odhad hodnot vysvětlované proměnné
Statistické metody uţívané při ověřování platnosti hypotéz
 Statistické metody uţívané při ověřování platnosti hypotéz Hypotéza Domněnka, předpoklad Nejčastěji o rozdělení, středních hodnotách, závislostech, Hypotézy ve vědeckém výzkumu pracovní, věcné hypotézy
Statistické metody uţívané při ověřování platnosti hypotéz Hypotéza Domněnka, předpoklad Nejčastěji o rozdělení, středních hodnotách, závislostech, Hypotézy ve vědeckém výzkumu pracovní, věcné hypotézy
Profilování vzorků heroinu s využitím vícerozměrné statistické analýzy
 Profilování vzorků heroinu s využitím vícerozměrné statistické analýzy Autor práce : RNDr. Ivo Beroun,CSc. Vedoucí práce: prof. RNDr. Milan Meloun, DrSc. PROFILOVÁNÍ Profilování = klasifikace a rozlišování
Profilování vzorků heroinu s využitím vícerozměrné statistické analýzy Autor práce : RNDr. Ivo Beroun,CSc. Vedoucí práce: prof. RNDr. Milan Meloun, DrSc. PROFILOVÁNÍ Profilování = klasifikace a rozlišování
676 + 4 + 100 + 196 + 0 + 484 + 196 + 324 + 64 + 324 = = 2368
 Příklad 1 Je třeba prověřit, zda lze na 5% hladině významnosti pokládat za prokázanou hypotézu, že střední doba výroby výlisku je 30 sekund. Přitom 10 náhodně vybraných výlisků bylo vyráběno celkem 540
Příklad 1 Je třeba prověřit, zda lze na 5% hladině významnosti pokládat za prokázanou hypotézu, že střední doba výroby výlisku je 30 sekund. Přitom 10 náhodně vybraných výlisků bylo vyráběno celkem 540
Univerzita Pardubice Fakulta chemicko-technologická Katedra analytické chemie STATISTICKÉ ZPRACOVÁNÍ EXPERIMENTÁLNÍCH DAT
 Univerzita Pardubice Fakulta chemicko-technologická Katedra analytické chemie STATISTICKÉ ZPRACOVÁNÍ EXPERIMENTÁLNÍCH DAT STATISTICKÁ ANALÝZA JEDNOROZMĚRNÝCH DAT Seminární práce 1 Brno, 2002 Ing. Pavel
Univerzita Pardubice Fakulta chemicko-technologická Katedra analytické chemie STATISTICKÉ ZPRACOVÁNÍ EXPERIMENTÁLNÍCH DAT STATISTICKÁ ANALÝZA JEDNOROZMĚRNÝCH DAT Seminární práce 1 Brno, 2002 Ing. Pavel