PSY117/454 Statistická analýza dat v psychologii Přednáška 10
|
|
|
- Roman Procházka
- před 9 lety
- Počet zobrazení:
Transkript
1 PSY117/454 Statistická analýza dat v psychologii Přednáška 10 TESTY PRO NOMINÁLNÍ A ORDINÁLNÍ PROMĚNNÉ NEPARAMETRICKÉ METODY... a to mělo, jak sám vidíte, nedozírné následky. Smrť

2 Analýza četností hodnot nominální proměnné Výzkumné otázky Liší se významně preference nějakých politických stran? Liší se poměrné zastoupení kuřáků mezi ženami a muži? Souvisí nějak individuální volební preference s odhadem měsíčního příjmu respondenta? Otázky směřují Nominální proměnná buď k rozdílu četností různých jevů v rámci jedné proměnné (četnost různých jevů v jedné populaci), k rozdílu četností jevu mezi různými proměnnými (četnost jevu v různých populacích), Nebo k pravděpodobnosti výskytu dvou (či více) jevů současně. Též kategoriální, alternativní Zařazení jevu do určité kategorie Jednotlivé kategorie musí být vzájemně disjunktní metodologie & logika věci Kategorie mohou vzniknout i transformací z proměnné vyššího řádu kategorizace pořadí, známek ve škole, nižší úzkost x vyšší úzkost atd. Ordinální proměnné o málo opakujících se pořadích (k<10) mohou být analyzovány jako nominální Klíčová slova Četnost, relativní četnost, očekávaná četnost, rezidua, χ 2 (Chi-kvadrát) AJ: frequency, relative frequency, expected frequency, residuals, Chi-square
, Nebo k pravděpodobnosti výskytu dvou (či více) jevů současně.")
3 Rozdělení Chi 2
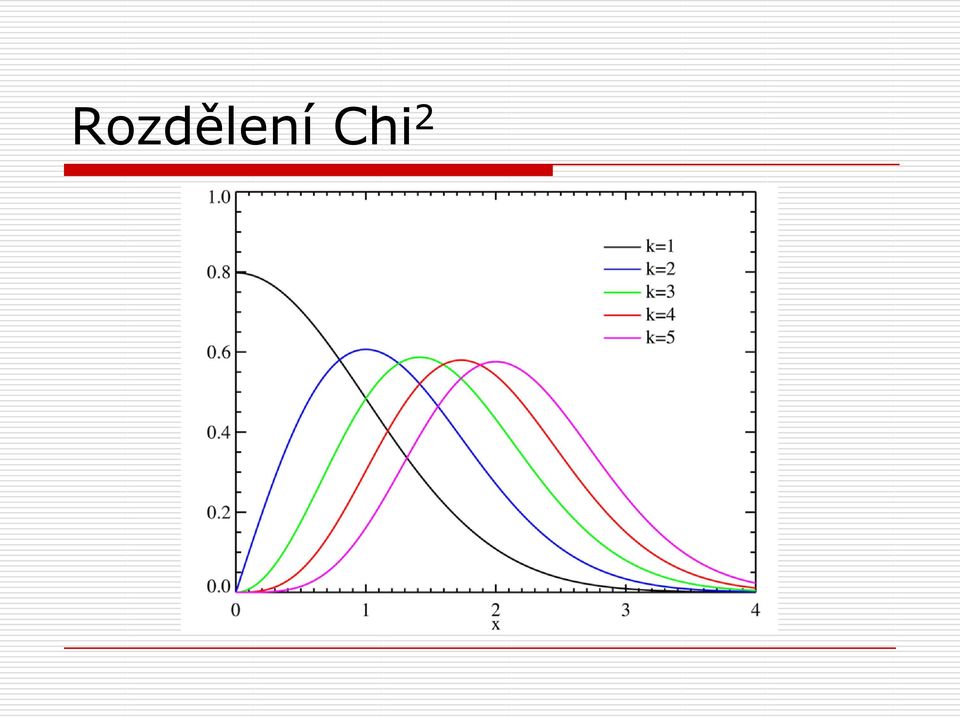
4 c 2 test dobré shody Liší se empirické četnosti nějakých jevů od teoreticky očekávaných četností? Házení kostkou kolikrát padne 1,2, Preference politických stran ve volbách Tedy jedna nominální proměnná, jeden výběr Testujeme pravděpodobnost daného rozdílu mezi empirickými a očekávanými hodnotami v rámci jednoho výběru k 2 2 ( n i npi ) c H 0 : F(x) = F 0 (x) vs. H 1 : F(x) F 0 (x) i1 npi k je počet kategorií, n velikost vzorku, n i pozorovaná četnost v kat. i, p i teoretická pravděpodnost jevu v kategorii (0 až 1); n i = np i Rozdělení c 2 ; stupně volnosti df = k-1 Překoná-li hodnota c 2 kritickou mez, H 0 zamítáme. Pro získání pravděpodobnosti c 2 CHIDIST(x,volnost); CHIINV(prst, volnost) Očekávané četnosti při uniformním rozložení 1:1:1 ; nebo libovolně teoreticky odvozené (10:24:32 ) N i i NP i vždy jako četnosti; nikdy ne procenta = relativní četnosti (ztráta informace o velikosti vzorku. AJ: Chi-square goodness-of-fit test, observed (empirical) frequency vs. expected frequency
; n i = np i Rozdělení c 2 ; stupně volnosti df = k-1 Překoná-li hodnota c 2 kritickou mez, H 0 zamítáme.")
5 Ve kterém měste by jste žili nejraději? Uniformní/náhodné rozdělení Kategorie n p np (n-np)^2/np Paříž 28 0, New York 28 0, Londýn 28 0, L.A. 28 0, Tokio 28 0, k ( n np ) c 2 i i np i1 i 2 Celkem Chi2 0 p 1,000
 c 2 i i np i1 i 2")
6 Ve kterém měste by jste žili nejraději? Empirické rozdělení Kategorie n p np (n-np)^2/np Paříž 38 0,2 28 3,57 New York 37 0,2 28 2,89 Londýn 22 0,2 28 1,29 L.A. 25 0,2 28 0,32 Tokio 18 0,2 28 3,57 k ( n np ) c 2 i i np i1 i 2 Celkem ,64 Chi2 11,64 p 0,02
 c 2 i i np i1 i 2")
7 Závislost kategoriálních proměnných Jaká je souvislost preference politické strany a úrovně hrubého příjmu voliče? Jaká je pravděpodobnost společného výskytu dvou jevů z x a y možných? Podmínka disjunkce! Kontingenční tabulka řádky x sloupce = r x s; i x j Ve těle tabulky jsou četnosti jednotlivých kombinací, v okrajích tzv. marginální četnosti sumy sloupců nebo řádků. Tedy n 12 znamená počet osob ve druhém sloupci prvního řádku; počet osob, u nichž nastal jev A 1 a současně B 2. Kategorie B 1 B 2... B s Řádkové součty A 1 n 11 n n 1s n 1. A 2 n 21 n n 2s n A r n i1 n i2... n ij n i. Sloupcové součty n.1 n.2... n. j n AJ: contingency table (crosstabulation, ctosstab), marginal frequencies

8 Závislost kategoriálních proměnných Postup analogický, jako u jednorozměrné verze testu dobré shody c 2 Očekávané četnosti: m ij (očekávaná četnost v i-j-té buňce)(i řádky, j sloupce) Testová statistika je c 2 Stupně volnosti: df = (i-1)*(j-1) m ij n i. n n. j r s ( n ij m 2 ij ) c m r1 j1 Kategorie B 1 B 2... B s Řádkové součty ij 2 A 1 n 11 n n 1s n 1. A 2 n 21 n n 2s n A r n i1 n i2... n ij n i. Sloupcové součty n.1 n.2... n. j n

9 Síla vztahu v kontingenční tabulce Koeficient kontingence (Pearson) C kor Cramerovo V Oba koeficienty v intervalu (0;1). Neindikují ovšem žádným způsobem směr vztahu. Směrů je v kontingenční tabulce mnoho :-) A proto jsou kontingenční tabulky mnohdy účelné i tehdy, máme-li k dispozici data na vyšší úrovni měření. Možnost odhalení nelineárních vztahů Skrze výpočet reziduí, tj. rozdílů mezi pozorovanou a očekávanou četností: n ij m ij = res i tyto zbytkové hodnoty lokalizují odchylky od pravděpodobnostního rozdělení Součet residuí v tabulce je vždy nula Standardizovaná rezidua (Pearsonova): R = (n ij m ij )/ m ij rozdělení standardizovaných reziduí je normální s průměrem 0 a sm. odchylkou 1; tedy R +- 1,96 jsou zajímavá pro interpretaci, významně přispívají k signifikanci χ 2. Analýza tabulky skrze χ 2 je nespolehlivá, je-li min(m ij ) < 5. I řídké jevy musí mít šanci Hendl str AJ: strength of association, contingency coefficient, standardized residuals

10 Testy středních hodnot pro ordinální proměnné neparametrické metody Metody užívající parametrů normálního rozložení nejsou dobře použitelné v případech, kdy Data nepochází z normálního rozložení Data mají ordinální charakter; nebo se jedná o krátké intervalové škály Jsou malé výběry Obecně parametry m, s nedávají dobrou informaci Neparametrické metody problém překonávají, jsou robustní vůči rozložení dat (nezávisí na parametrech norm. rozl.) Pro jeden výběr: znaménkový,... Pro párové srovnání: Marginal Homogeneity,... Pro 2 nezávislé výběry: Mann-Whitney U, Kolmogorov-Smirnov Z a mnoho dalších... na velkém vzorku je ale koneckonců robustní i t-test platnost centrální limitní věty; ovšem pozor na bimodalitu a další zvláštní jevy. Non-parametric, robust, data assumptions, sign test, sample distribution etc.

11 Jeden výběr, znaménkový test Je průměrná známka z matematiky v nějaké třídě 2? Liší se empirická hodnota medianu od stanovené? H 0 : Md = Md 0 ; H 1 : Md Md 0... => H 0 : σ 2 = σ 2 0; H1: σ 2 σ 2 0 Pokud se hodnoty mediánů shodují, mělo by nad i pod teoretickým medianem být stejné množství případů Asymptotický test pomocí normálního rozdělení: rozdíly d i = x i Md 0 ; Z + je počet kladných rozdílů, analogicky Z -; d i = 0 ignorujeme. Platí-li H 0, Z + = Z -. Z + + Z - = n. Testovací statistika: z = (2Z + - n)/ n Padne-li statistika z do intervalu ±z α/2, H 0 nezamítáme. z má tvar asymptoticky normálního rozdělení, přesný test by využil binomického rozdělení. Jedná se tedy o alternativu t-testu pro jediný výběr; Pro závislé výběry (=párové srovnání) d i = x i y i ; znaménkovým testem zkoumáme, zda pro H 0 střední hodnota d = 0.
/ n Padne-li statistika z do intervalu ±z α/2, H 0 nezamítáme. z má tvar asymptoticky normálního rozdělení, přesný test by využil binomického rozdělení.")
12 Neparametrické testy pro nezávislé výběry Mediánový test Je li společný medián dvou výběrů shodný, leží na jedné straně Md 50% každého výběru. Určíme Md pro celý soubor; pokud platí H0, četnosti hodnot ležících nad i pod Md by měly být stejné pro x i y. Pokud H 0 neplatí, budou četnosti výrazně asymetrické, v diagonále. V asymptotické verzi testu je možné použít kvantily normálního rozložení pro: z ( a ( ad bc) b)( b d)( a n c)( c d) x y <Md a b a+b >Md c d c+d a+c b+d n Silnější alternativou je Wilcoxonův test pro nezávislé výběry nebo Mann-Whitney U, popřípadě další.
 b)( b d)( a n c)( c d) x y <Md a b a+b >Md c d c+d")
Statistické testování hypotéz II
 PSY117/454 Statistická analýza dat v psychologii Přednáška 9 Statistické testování hypotéz II Přehled testů, rozdíly průměrů, velikost účinku, síla testu Základní výzkumné otázky/hypotézy 1. Stanovení
PSY117/454 Statistická analýza dat v psychologii Přednáška 9 Statistické testování hypotéz II Přehled testů, rozdíly průměrů, velikost účinku, síla testu Základní výzkumné otázky/hypotézy 1. Stanovení
ADDS cvičení 7. Pavlína Kuráňová
 ADDS cvičení 7 Pavlína Kuráňová Analyzujte závislost věku obyvatel na místě kde nejčastěji tráví dovolenou. (dotazník dovolená, sloupce Jaký je Váš věk a Kde nejčastěji trávíte dovolenou) Analyzujte závislost
ADDS cvičení 7 Pavlína Kuráňová Analyzujte závislost věku obyvatel na místě kde nejčastěji tráví dovolenou. (dotazník dovolená, sloupce Jaký je Váš věk a Kde nejčastěji trávíte dovolenou) Analyzujte závislost
Analýza dat z dotazníkových šetření
 Analýza dat z dotazníkových šetření Cvičení 6. Rozsah výběru Př. Určete minimální rozsah výběru pro proměnnou věk v souboru dovolena, jestliže 95% interval spolehlivost průměru proměnné nemá být širší
Analýza dat z dotazníkových šetření Cvičení 6. Rozsah výběru Př. Určete minimální rozsah výběru pro proměnnou věk v souboru dovolena, jestliže 95% interval spolehlivost průměru proměnné nemá být širší
Jana Vránová, 3. lékařská fakulta UK
 Jana Vránová, 3. lékařská fakulta UK Vznikají při zkoumání vztahů kvalitativních resp. diskrétních znaků Jedná se o analogii s korelační analýzou spojitých znaků Přitom předpokládáme, že každý prvek populace
Jana Vránová, 3. lékařská fakulta UK Vznikají při zkoumání vztahů kvalitativních resp. diskrétních znaků Jedná se o analogii s korelační analýzou spojitých znaků Přitom předpokládáme, že každý prvek populace
Přednáška 9. Testy dobré shody. Grafická analýza pro ověření shody empirického a teoretického rozdělení
 Přednáška 9 Testy dobré shody Grafická analýza pro ověření shody empirického a teoretického rozdělení χ 2 test dobré shody ověření, zda jsou relativní četnosti jednotlivých variant rovny číslům π 01 ;
Přednáška 9 Testy dobré shody Grafická analýza pro ověření shody empirického a teoretického rozdělení χ 2 test dobré shody ověření, zda jsou relativní četnosti jednotlivých variant rovny číslům π 01 ;
5 Vícerozměrná data - kontingenční tabulky, testy nezávislosti, regresní analýza
 5 Vícerozměrná data - kontingenční tabulky, testy nezávislosti, regresní analýza 5.1 Vícerozměrná data a vícerozměrná rozdělení Při zpracování vícerozměrných dat se hledají souvislosti mezi dvěma, případně
5 Vícerozměrná data - kontingenční tabulky, testy nezávislosti, regresní analýza 5.1 Vícerozměrná data a vícerozměrná rozdělení Při zpracování vícerozměrných dat se hledají souvislosti mezi dvěma, případně
4ST201 STATISTIKA CVIČENÍ Č. 7
 4ST201 STATISTIKA CVIČENÍ Č. 7 testování hypotéz parametrické testy test hypotézy o střední hodnotě test hypotézy o relativní četnosti test o shodě středních hodnot testování hypotéz v MS Excel neparametrické
4ST201 STATISTIKA CVIČENÍ Č. 7 testování hypotéz parametrické testy test hypotézy o střední hodnotě test hypotézy o relativní četnosti test o shodě středních hodnot testování hypotéz v MS Excel neparametrické
Stav Svobodný Rozvedený Vdovec. Svobodná 37 10 6. Rozvedená 8 12 8. Vdova 5 8 6
 1. Příklad Byly sledovány rodinné stavy nevěst a ženichů při uzavírání sňatků a byla vytvořena následující tabulka četností. Stav Svobodný Rozvedený Vdovec Svobodná 37 10 6 Rozvedená 8 12 8 Vdova 5 8 6
1. Příklad Byly sledovány rodinné stavy nevěst a ženichů při uzavírání sňatků a byla vytvořena následující tabulka četností. Stav Svobodný Rozvedený Vdovec Svobodná 37 10 6 Rozvedená 8 12 8 Vdova 5 8 6
Název testu Předpoklady testu Testová statistika Nulové rozdělení. ( ) (p počet odhadovaných parametrů)
 (p počet odhadovaných parametrů)") VYBRANÉ TESTY NEPARAMETRICKÝCH HYPOTÉZ TESTY DOBRÉ SHODY Název testu Předpoklady testu Testová statistika Nulové rozdělení test dobré shody Očekávané četnosti, alespoň 80% očekávaných četností >5 ( ) (p
VYBRANÉ TESTY NEPARAMETRICKÝCH HYPOTÉZ TESTY DOBRÉ SHODY Název testu Předpoklady testu Testová statistika Nulové rozdělení test dobré shody Očekávané četnosti, alespoň 80% očekávaných četností >5 ( ) (p
Základy biostatistiky II. Veřejné zdravotnictví 3.LF UK - II
 Základy biostatistiky II Veřejné zdravotnictví 3.LF UK - II Teoretické rozložení-matematické modely rozložení Naměřená data Výběrové rozložení Teoretické rozložení 1 e 2 x 2 Teoretické rozložení-matematické
Základy biostatistiky II Veřejné zdravotnictví 3.LF UK - II Teoretické rozložení-matematické modely rozložení Naměřená data Výběrové rozložení Teoretické rozložení 1 e 2 x 2 Teoretické rozložení-matematické
Testy dobré shody Máme dvě veličiny, u kterých bychom chtěli prokázat závislost, TESTY DOBRÉ SHODY (angl. goodness-of-fit tests)
") Testy dobré shody Máme dvě veličiny, u kterých bychom chtěli prokázat závislost, např. hmotnost a pohlaví narozených dětí. Běžný statistický postup pro ověření závislosti dvou veličin je zamítnutí jejich
Testy dobré shody Máme dvě veličiny, u kterých bychom chtěli prokázat závislost, např. hmotnost a pohlaví narozených dětí. Běžný statistický postup pro ověření závislosti dvou veličin je zamítnutí jejich
Kategorická data METODOLOGICKÝ PROSEMINÁŘ II TÝDEN 7 4. DUBNA dubna 2018 Lukáš Hájek, Karel Höfer Metodologický proseminář II 1
 Kategorická data METODOLOGICKÝ PROSEMINÁŘ II TÝDEN 7 4. DUBNA 2018 4. dubna 2018 Lukáš Hájek, Karel Höfer Metodologický proseminář II 1 Typy proměnných nominální (nominal) o dvou hodnotách lze říci pouze
Kategorická data METODOLOGICKÝ PROSEMINÁŘ II TÝDEN 7 4. DUBNA 2018 4. dubna 2018 Lukáš Hájek, Karel Höfer Metodologický proseminář II 1 Typy proměnných nominální (nominal) o dvou hodnotách lze říci pouze
PSY117/454 Statistická analýza dat v psychologii seminář 9. Statistické testování hypotéz
 PSY117/454 Statistická analýza dat v psychologii seminář 9 Statistické testování hypotéz Základní výzkumné otázky/hypotézy 1. Stanovení hodnoty parametru =stanovení intervalu spolehlivosti na μ, σ, ρ,
PSY117/454 Statistická analýza dat v psychologii seminář 9 Statistické testování hypotéz Základní výzkumné otázky/hypotézy 1. Stanovení hodnoty parametru =stanovení intervalu spolehlivosti na μ, σ, ρ,
Příklad: Test nezávislosti kategoriálních znaků
 Příklad: Test nezávislosti kategoriálních znaků Určete na hladině významnosti 5 % na základě dat zjištěných v rámci dotazníkového šetření ve Šluknově, zda existuje závislost mezi pohlavím respondenta a
Příklad: Test nezávislosti kategoriálních znaků Určete na hladině významnosti 5 % na základě dat zjištěných v rámci dotazníkového šetření ve Šluknově, zda existuje závislost mezi pohlavím respondenta a
Seminář 6 statistické testy
 Seminář 6 statistické testy Část I. Volba správného testu Chceme zjistit, zda se středeční a čtvrteční seminární skupiny liší ve výsledcích v 1. průběžné písemce ze statistiky. Chceme zjistit, zda 1. průběžná
Seminář 6 statistické testy Část I. Volba správného testu Chceme zjistit, zda se středeční a čtvrteční seminární skupiny liší ve výsledcích v 1. průběžné písemce ze statistiky. Chceme zjistit, zda 1. průběžná
Seminář 6 statistické testy
 Seminář 6 statistické testy Část I. Volba správného testu Chceme zjistit, zda se Ježkovy a Širůčkovy seminární skupiny liší ve výsledcích v. průběžné písemce ze statistiky. Chceme zjistit, zda 1. průběžná
Seminář 6 statistické testy Část I. Volba správného testu Chceme zjistit, zda se Ježkovy a Širůčkovy seminární skupiny liší ve výsledcích v. průběžné písemce ze statistiky. Chceme zjistit, zda 1. průběžná
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz
 Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická
Mann-Whitney U-test. Znaménkový test. Vytvořil Institut biostatistiky a analýz, Masarykova univerzita J. Jarkovský, L. Dušek
 10. Neparametrické y Mann-Whitney U- Wilcoxonův Znaménkový Shrnutí statistických ů Typ srovnání Nulová hypotéza Parametrický Neparametrický 1 skupina dat vs. etalon Střední hodnota je rovna hodnotě etalonu.
10. Neparametrické y Mann-Whitney U- Wilcoxonův Znaménkový Shrnutí statistických ů Typ srovnání Nulová hypotéza Parametrický Neparametrický 1 skupina dat vs. etalon Střední hodnota je rovna hodnotě etalonu.
Mgr. Karla Hrbáčková, Ph.D. Základy kvantitativního výzkumu
 Mgr. Karla Hrbáčková, Ph.D. Základy kvantitativního výzkumu K čemu slouží statistika Popisuje velké soubory dat pomocí charakteristických čísel (popisná statistika). Hledá skryté zákonitosti v souborech
Mgr. Karla Hrbáčková, Ph.D. Základy kvantitativního výzkumu K čemu slouží statistika Popisuje velké soubory dat pomocí charakteristických čísel (popisná statistika). Hledá skryté zákonitosti v souborech
Přednáška X. Testování hypotéz o kvantitativních proměnných
 Přednáška X. Testování hypotéz o kvantitativních proměnných Testování hypotéz o podílech Kontingenční tabulka, čtyřpolní tabulka Testy nezávislosti, Fisherůvexaktní test, McNemarůvtest Testy dobré shody
Přednáška X. Testování hypotéz o kvantitativních proměnných Testování hypotéz o podílech Kontingenční tabulka, čtyřpolní tabulka Testy nezávislosti, Fisherůvexaktní test, McNemarůvtest Testy dobré shody
Obsah Úvod Kapitola 1 Než začneme Kapitola 2 Práce s hromadnými daty před analýzou
 Úvod.................................................................. 11 Kapitola 1 Než začneme.................................................................. 17 1.1 Logika kvantitativního výzkumu...........................................
Úvod.................................................................. 11 Kapitola 1 Než začneme.................................................................. 17 1.1 Logika kvantitativního výzkumu...........................................
PRAVDĚPODOBNOST A STATISTIKA. Neparametrické testy hypotéz čast 1
 PRAVDĚPODOBNOST A STATISTIKA Neparametrické testy hypotéz čast 1 Neparametrické testy hypotéz - úvod Neparametrické testy statistických hypotéz se používají v případech, kdy neznáme rozdělení pozorované
PRAVDĚPODOBNOST A STATISTIKA Neparametrické testy hypotéz čast 1 Neparametrické testy hypotéz - úvod Neparametrické testy statistických hypotéz se používají v případech, kdy neznáme rozdělení pozorované
UNIVERZITA OBRANY Fakulta ekonomiky a managementu. Aplikace STAT1. Výsledek řešení projektu PRO HORR2011 a PRO GRAM2011 3. 11.
 UNIVERZITA OBRANY Fakulta ekonomiky a managementu Aplikace STAT1 Výsledek řešení projektu PRO HORR2011 a PRO GRAM2011 Jiří Neubauer, Marek Sedlačík, Oldřich Kříž 3. 11. 2012 Popis a návod k použití aplikace
UNIVERZITA OBRANY Fakulta ekonomiky a managementu Aplikace STAT1 Výsledek řešení projektu PRO HORR2011 a PRO GRAM2011 Jiří Neubauer, Marek Sedlačík, Oldřich Kříž 3. 11. 2012 Popis a návod k použití aplikace
STATISTIKA A INFORMATIKA - bc studium OZW, 1.roč. (zkušební otázky)
") STATISTIKA A INFORMATIKA - bc studium OZW, 1.roč. (zkušební otázky) 1) Význam a využití statistiky v biologických vědách a veterinárním lékařství ) Rozdělení znaků (veličin) ve statistice 3) Základní a
STATISTIKA A INFORMATIKA - bc studium OZW, 1.roč. (zkušební otázky) 1) Význam a využití statistiky v biologických vědách a veterinárním lékařství ) Rozdělení znaků (veličin) ve statistice 3) Základní a
Rozhodnutí / Skutečnost platí neplatí Nezamítáme správně chyba 2. druhu Zamítáme chyba 1. druhu správně
 Testování hypotéz Nechť,, je náhodný výběr z nějakého rozdělení s neznámými parametry. Máme dvě navzájem si odporující hypotézy o parametrech daného rozdělení: Nulová hypotéza parametry (případně jediný
Testování hypotéz Nechť,, je náhodný výběr z nějakého rozdělení s neznámými parametry. Máme dvě navzájem si odporující hypotézy o parametrech daného rozdělení: Nulová hypotéza parametry (případně jediný
Přednáška 9. Testy dobré shody. Grafická analýza pro ověření shody empirického a teoretického rozdělení
 Přednáška 9 Testy dobré shody Grafická analýza pro ověření shody empirického a teoretického rozdělení χ 2 test dobré shody ověření, zda jsou relativní četnosti jednotlivých variant rovny číslům π 01 ;
Přednáška 9 Testy dobré shody Grafická analýza pro ověření shody empirického a teoretického rozdělení χ 2 test dobré shody ověření, zda jsou relativní četnosti jednotlivých variant rovny číslům π 01 ;
McNemarův test, Stuartův test, Test symetrie
 Tereza Burgetová McNemarův test, Stuartův test, Test symetrie 11. prosince 2017 McNemarův test - motivace Analýza kontingenčních tabulek, kdy není cílem provést klasický test nezávislosti. Příklad: Před
Tereza Burgetová McNemarův test, Stuartův test, Test symetrie 11. prosince 2017 McNemarův test - motivace Analýza kontingenčních tabulek, kdy není cílem provést klasický test nezávislosti. Příklad: Před
Testování hypotéz. Analýza dat z dotazníkových šetření. Kuranova Pavlina
 Testování hypotéz Analýza dat z dotazníkových šetření Kuranova Pavlina Statistická hypotéza Možné cíle výzkumu Srovnání účinnosti různých metod Srovnání výsledků různých skupin Tzn. prokázání rozdílů mezi
Testování hypotéz Analýza dat z dotazníkových šetření Kuranova Pavlina Statistická hypotéza Možné cíle výzkumu Srovnání účinnosti různých metod Srovnání výsledků různých skupin Tzn. prokázání rozdílů mezi
PSY117/454 Statistická analýza dat v psychologii. Zobrazení dvojrozměrných dat Bodový graf - Scatterplot Korelační koeficient
 PSY117/454 Statistická analýza dat v psychologii Zobrazení dvojrozměrných dat Bodový graf - Scatterplot Korelační koeficient Analýza vztahů mezi dvěma proměnnými Souvisí nějak? Výška a váha Známky u jednotlivých
PSY117/454 Statistická analýza dat v psychologii Zobrazení dvojrozměrných dat Bodový graf - Scatterplot Korelační koeficient Analýza vztahů mezi dvěma proměnnými Souvisí nějak? Výška a váha Známky u jednotlivých
PSY117/454 Statistická analýza dat v psychologii Přednáška 5 ZOBRAZENÍ DVOUROZMĚRNÝCH DAT KORELAČNÍ KOEFICIENT. Všichni žijeme v matrixu.
 PSY117/454 Statistická analýza dat v psychologii Přednáška 5 ZOBRAZENÍ DVOUROZMĚRNÝCH DAT KORELAČNÍ KOEFICIENT Všichni žijeme v matrixu. V minulých dílech jsme viděli/y: Frekvence = četnosti Procenta =
PSY117/454 Statistická analýza dat v psychologii Přednáška 5 ZOBRAZENÍ DVOUROZMĚRNÝCH DAT KORELAČNÍ KOEFICIENT Všichni žijeme v matrixu. V minulých dílech jsme viděli/y: Frekvence = četnosti Procenta =
Příklad 1. Řešení 1 ŘEŠENÉ PŘÍKLADY Z MV2 ČÁST 11
 Příklad 1 Vyhláška Ministerstva zdravotnictví předpokládala, že doba dojezdu k pacientovi od nahlášení požadavku nepřekročí 17 minut. Hodnoty deseti náhodně vybraných dob příjezdu sanitky k nemocnému byly:
Příklad 1 Vyhláška Ministerstva zdravotnictví předpokládala, že doba dojezdu k pacientovi od nahlášení požadavku nepřekročí 17 minut. Hodnoty deseti náhodně vybraných dob příjezdu sanitky k nemocnému byly:
Kontingenční tabulky, korelační koeficienty
 Statistika II Katedra ekonometrie FVL UO Brno kancelář 69a, tel 973 442029 email:jirineubauer@unobcz Budeme předpokládat, že X a Y jsou kvalitativní náhodné veličiny, obor hodnot X obsahuje r hodnot (kategorií,
Statistika II Katedra ekonometrie FVL UO Brno kancelář 69a, tel 973 442029 email:jirineubauer@unobcz Budeme předpokládat, že X a Y jsou kvalitativní náhodné veličiny, obor hodnot X obsahuje r hodnot (kategorií,
Statgraphics v. 5.0 STATISTICKÁ INDUKCE PRO JEDNOROZMĚRNÁ DATA. Martina Litschmannová 1. Typ proměnné. Požadovaný typ analýzy
 Dichotomická proměnná (0-1) Spojitá proměnná STATISTICKÁ INDUKCE PRO JEDNOROZMĚRNÁ DATA Typ proměnné Požadovaný typ analýzy Ověření variability Předpoklady Testy, resp. intervalové odhad Test o rozptylu
Dichotomická proměnná (0-1) Spojitá proměnná STATISTICKÁ INDUKCE PRO JEDNOROZMĚRNÁ DATA Typ proměnné Požadovaný typ analýzy Ověření variability Předpoklady Testy, resp. intervalové odhad Test o rozptylu
PSY117/454 Statistická analýza dat v psychologii přednáška 8. Statistické usuzování, odhady
 PSY117/454 Statistická analýza dat v psychologii přednáška 8 Statistické usuzování, odhady Výběr od deskripce k indukci Deskripce dat, odhad parametrů Usuzování = inference = indukce Počítá se s náhodným
PSY117/454 Statistická analýza dat v psychologii přednáška 8 Statistické usuzování, odhady Výběr od deskripce k indukci Deskripce dat, odhad parametrů Usuzování = inference = indukce Počítá se s náhodným
ANALÝZA DAT V R 7. KONTINGENČNÍ TABULKA. Mgr. Markéta Pavlíková Katedra pravděpodobnosti a matematické statistiky MFF UK.
 ANALÝZA DAT V R 7. KONTINGENČNÍ TABULKA Mgr. Markéta Pavlíková Katedra pravděpodobnosti a matematické statistiky MFF UK www.biostatisticka.cz PŘEHLED TESTŮ rozdělení normální spojité alternativní / diskrétní
ANALÝZA DAT V R 7. KONTINGENČNÍ TABULKA Mgr. Markéta Pavlíková Katedra pravděpodobnosti a matematické statistiky MFF UK www.biostatisticka.cz PŘEHLED TESTŮ rozdělení normální spojité alternativní / diskrétní
2 ) 4, Φ 1 (1 0,005)
 4, Φ 1 (1 0,005)") Příklad 1 Ze zásilky velkého rozsahu byl náhodně vybrán soubor obsahující 1000 kusů. V tomto souboru bylo zjištěno 26 kusů nekvalitních. Rozhodněte, zda je možné s 99% jistotou tvrdit, že zásilka obsahuje
Příklad 1 Ze zásilky velkého rozsahu byl náhodně vybrán soubor obsahující 1000 kusů. V tomto souboru bylo zjištěno 26 kusů nekvalitních. Rozhodněte, zda je možné s 99% jistotou tvrdit, že zásilka obsahuje
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc.
 Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika 010 1.týden (0.09.-4.09. ) Data, typy dat, variabilita, frekvenční analýza
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika 010 1.týden (0.09.-4.09. ) Data, typy dat, variabilita, frekvenční analýza
Testování statistických hypotéz. Ing. Michal Dorda, Ph.D. 1
 Testování statistických hypotéz Ing. Michal Dorda, Ph.D. 1 Úvodní poznámky Statistickou hypotézou rozumíme hypotézu o populaci (základním souboru) např.: Střední hodnota základního souboru je rovna 100.
Testování statistických hypotéz Ing. Michal Dorda, Ph.D. 1 Úvodní poznámky Statistickou hypotézou rozumíme hypotézu o populaci (základním souboru) např.: Střední hodnota základního souboru je rovna 100.
Počet pravděpodobnosti
 PSY117/454 Statistická analýza dat v psychologii Přednáška 4 Počet pravděpodobnosti Je známo, že když muž použije jeden z okrajových pisoárů, sníží se pravděpodobnost, že bude pomočen o 50%. anonym Pravděpodobnost
PSY117/454 Statistická analýza dat v psychologii Přednáška 4 Počet pravděpodobnosti Je známo, že když muž použije jeden z okrajových pisoárů, sníží se pravděpodobnost, že bude pomočen o 50%. anonym Pravděpodobnost
KGG/STG Statistika pro geografy
 KGG/STG Statistika pro geografy 9. Korelační analýza Mgr. David Fiedor 20. dubna 2015 Analýza závislostí v řadě geografických disciplín studujeme jevy, u kterých vyšetřujeme nikoliv pouze jednu vlastnost
KGG/STG Statistika pro geografy 9. Korelační analýza Mgr. David Fiedor 20. dubna 2015 Analýza závislostí v řadě geografických disciplín studujeme jevy, u kterých vyšetřujeme nikoliv pouze jednu vlastnost
Statistické metody uţívané při ověřování platnosti hypotéz
 Statistické metody uţívané při ověřování platnosti hypotéz Hypotéza Domněnka, předpoklad Nejčastěji o rozdělení, středních hodnotách, závislostech, Hypotézy ve vědeckém výzkumu pracovní, věcné hypotézy
Statistické metody uţívané při ověřování platnosti hypotéz Hypotéza Domněnka, předpoklad Nejčastěji o rozdělení, středních hodnotách, závislostech, Hypotézy ve vědeckém výzkumu pracovní, věcné hypotézy
Analýza dat na PC I.
 CENTRUM BIOSTATISTIKY A ANALÝZ Lékařská a Přírodovědecká fakulta, Masarykova univerzita Analýza dat na PC I. Popisná analýza v programu Statistica IBA výuka Základní popisná statistika Popisná statistika
CENTRUM BIOSTATISTIKY A ANALÝZ Lékařská a Přírodovědecká fakulta, Masarykova univerzita Analýza dat na PC I. Popisná analýza v programu Statistica IBA výuka Základní popisná statistika Popisná statistika
Test dobré shody v KONTINGENČNÍCH TABULKÁCH
 Test dobré shody v KONTINGENČNÍCH TABULKÁCH Opakování: Mějme náhodné veličiny X a Y uspořádané do kontingenční tabulky. Řekli jsme, že nulovou hypotézu H 0 : veličiny X, Y jsou nezávislé zamítneme, když
Test dobré shody v KONTINGENČNÍCH TABULKÁCH Opakování: Mějme náhodné veličiny X a Y uspořádané do kontingenční tabulky. Řekli jsme, že nulovou hypotézu H 0 : veličiny X, Y jsou nezávislé zamítneme, když
Testy. Pavel Provinský. 19. listopadu 2013
 Testy Pavel Provinský 19. listopadu 2013 Test a intervalový odhad Testy a intervalové odhady - jsou vlastně to samé. Jiný je jen úhel pohledu. Lze přecházet od jednoho k druhému. Například: Při odvozování
Testy Pavel Provinský 19. listopadu 2013 Test a intervalový odhad Testy a intervalové odhady - jsou vlastně to samé. Jiný je jen úhel pohledu. Lze přecházet od jednoho k druhému. Například: Při odvozování
Testy dobré shody TESTY DOBRÉ SHODY (angl. goodness-of-fit tests), : veličiny X, Y jsou nezávislé nij eij
, : veličiny X, Y jsou nezávislé nij eij") Testy dobré shody Máme dvě veličiny a předpokládáme, že jsou nezávislé (platí nulová hypotéza nezávislosti). Často chceme naopak prokázat jejich závislost. K tomu slouží: TESTY DOBRÉ SHODY (angl. goodness-of-fit
Testy dobré shody Máme dvě veličiny a předpokládáme, že jsou nezávislé (platí nulová hypotéza nezávislosti). Často chceme naopak prokázat jejich závislost. K tomu slouží: TESTY DOBRÉ SHODY (angl. goodness-of-fit
Statistická analýza dat v psychologii. Věci, které můžeme přímo pozorovat, jsou téměř vždy pouze vzorky. Alfred North Whitehead
 PSY117/454 Statistická analýza dat v psychologii Přednáška 8 Statistické usuzování, odhady Věci, které můžeme přímo pozorovat, jsou téměř vždy pouze vzorky. Alfred North Whitehead Barevná srdíčka kolegyně
PSY117/454 Statistická analýza dat v psychologii Přednáška 8 Statistické usuzování, odhady Věci, které můžeme přímo pozorovat, jsou téměř vždy pouze vzorky. Alfred North Whitehead Barevná srdíčka kolegyně
Kontingenční tabulky, korelační koeficienty
 Statistika II Katedra ekonometrie FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Mějme kategoriální proměnné X a Y. Vytvoříme tzv. kontingenční tabulku. Budeme tedy testovat hypotézu
Statistika II Katedra ekonometrie FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Mějme kategoriální proměnné X a Y. Vytvoříme tzv. kontingenční tabulku. Budeme tedy testovat hypotézu
Stručný úvod do vybraných zredukovaných základů statistické analýzy dat
 Stručný úvod do vybraných zredukovaných základů statistické analýzy dat Statistika nuda je, má však cenné údaje. Neklesejme na mysli, ona nám to vyčíslí. Z pohádky Princové jsou na draka Populace (základní
Stručný úvod do vybraných zredukovaných základů statistické analýzy dat Statistika nuda je, má však cenné údaje. Neklesejme na mysli, ona nám to vyčíslí. Z pohádky Princové jsou na draka Populace (základní
15. T e s t o v á n í h y p o t é z
 15. T e s t o v á n í h y p o t é z Na základě hodnot náhodného výběru činíme rozhodnutí o platnosti hypotézy o hodnotách parametrů rozdělení nebo o jeho vlastnostech. Rozeznáváme dva základní typy testů:
15. T e s t o v á n í h y p o t é z Na základě hodnot náhodného výběru činíme rozhodnutí o platnosti hypotézy o hodnotách parametrů rozdělení nebo o jeho vlastnostech. Rozeznáváme dva základní typy testů:
příklad: předvolební průzkum Statistika (MD360P03Z, MD360P03U) ak. rok 2007/2008 příklad: souvisí plánované těhotenství se vzděláním?
 ak. rok 2007/2008 příklad: souvisí plánované těhotenství se vzděláním?") Statistika (MD360P03Z, MD360P03U) ak. rok 2007/2008 Karel Zvára karel.zvara@mff.cuni.cz http://www.karlin.mff.cuni.cz/ zvara (naposledy upraveno 17. prosince 2007) 1(249) závislost kvalitativních znaků
Statistika (MD360P03Z, MD360P03U) ak. rok 2007/2008 Karel Zvára karel.zvara@mff.cuni.cz http://www.karlin.mff.cuni.cz/ zvara (naposledy upraveno 17. prosince 2007) 1(249) závislost kvalitativních znaků
Zpracování studie týkající se průzkumu vlastností statistických proměnných a vztahů mezi nimi.
 SEMINÁRNÍ PRÁCE Zadání: Data: Statistické metody: Zpracování studie týkající se průzkumu vlastností statistických proměnných a vztahů mezi nimi. Minimálně 6 proměnných o 30 pozorováních (z toho 2 proměnné
SEMINÁRNÍ PRÁCE Zadání: Data: Statistické metody: Zpracování studie týkající se průzkumu vlastností statistických proměnných a vztahů mezi nimi. Minimálně 6 proměnných o 30 pozorováních (z toho 2 proměnné
INDUKTIVNÍ STATISTIKA
 10. SEMINÁŘ INDUKTIVNÍ STATISTIKA 3. HODNOCENÍ ZÁVISLOSTÍ HODNOCENÍ ZÁVISLOSTÍ KVALITATIVNÍ VELIČINY - Vychází se z kombinační (kontingenční) tabulky, která je výsledkem třídění druhého stupně KVANTITATIVNÍ
10. SEMINÁŘ INDUKTIVNÍ STATISTIKA 3. HODNOCENÍ ZÁVISLOSTÍ HODNOCENÍ ZÁVISLOSTÍ KVALITATIVNÍ VELIČINY - Vychází se z kombinační (kontingenční) tabulky, která je výsledkem třídění druhého stupně KVANTITATIVNÍ
15. T e s t o v á n í h y p o t é z
 15. T e s t o v á n í h y p o t é z Na základě hodnot náhodného výběru činíme rozhodnutí o platnosti hypotézy o hodnotách parametrů rozdělení nebo o jeho vlastnostech. Rozeznáváme dva základní typy testů:
15. T e s t o v á n í h y p o t é z Na základě hodnot náhodného výběru činíme rozhodnutí o platnosti hypotézy o hodnotách parametrů rozdělení nebo o jeho vlastnostech. Rozeznáváme dva základní typy testů:
Cvičení 12: Binární logistická regrese
 Cvičení 12: Binární logistická regrese Příklad: V roce 2014 konalo státní závěrečné zkoušky bakalářského studia na jisté fakultě 167 studentů. U každého studenta bylo zaznamenáno jeho pohlaví (0 žena,
Cvičení 12: Binární logistická regrese Příklad: V roce 2014 konalo státní závěrečné zkoušky bakalářského studia na jisté fakultě 167 studentů. U každého studenta bylo zaznamenáno jeho pohlaví (0 žena,
ADDS cviceni. Pavlina Kuranova
 ADDS cviceni Pavlina Kuranova Testy pro dva nezávislé výběry Mannův Whitneyho test - Založen na Wilcoxnově statistice W - založen na pořadí jednotlivých pozorování (oba výběry spojeny do jednoho celku)
ADDS cviceni Pavlina Kuranova Testy pro dva nezávislé výběry Mannův Whitneyho test - Založen na Wilcoxnově statistice W - založen na pořadí jednotlivých pozorování (oba výběry spojeny do jednoho celku)
TESTOVÁNÍ HYPOTÉZ STATISTICKÁ HYPOTÉZA Statistické testy Testovací kritérium = B B > B < B B - B - B < 0 - B > 0 oboustranný test = B > B
 TESTOVÁNÍ HYPOTÉZ Od statistického šetření neočekáváme pouze elementární informace o velikosti některých statistických ukazatelů. Používáme je i k ověřování našich očekávání o výsledcích nějakého procesu,
TESTOVÁNÍ HYPOTÉZ Od statistického šetření neočekáváme pouze elementární informace o velikosti některých statistických ukazatelů. Používáme je i k ověřování našich očekávání o výsledcích nějakého procesu,
6. T e s t o v á n í h y p o t é z
 6. T e s t o v á n í h y p o t é z Na základě hodnot z realizace náhodného výběru činíme rozhodnutí o platnosti hypotézy o hodnotách parametrů rozdělení nebo o jeho vlastnostech. Používáme k tomu vhodně
6. T e s t o v á n í h y p o t é z Na základě hodnot z realizace náhodného výběru činíme rozhodnutí o platnosti hypotézy o hodnotách parametrů rozdělení nebo o jeho vlastnostech. Používáme k tomu vhodně
Statistické metody v ekonomii. Ing. Michael Rost, Ph.D.
 Statistické metody v ekonomii Ing. Michael Rost, Ph.D. Jihočeská univerzita v Českých Budějovicích Test χ 2 v kontingenční tabulce typu 2 2 Jde vlastně o speciální případ χ 2 testu pro čtyřpolní tabulku.
Statistické metody v ekonomii Ing. Michael Rost, Ph.D. Jihočeská univerzita v Českých Budějovicích Test χ 2 v kontingenční tabulce typu 2 2 Jde vlastně o speciální případ χ 2 testu pro čtyřpolní tabulku.
Kontingenční tabulky. (Analýza kategoriálních dat)
") Kontingenční tabulky (Analýza kategoriálních dat) Agenda Standardní analýzy dat v kontingenčních tabulkách úvod, KT, míry diverzity nominálních veličin, některá rozdělení chí kvadrát testy, analýza reziduí,
Kontingenční tabulky (Analýza kategoriálních dat) Agenda Standardní analýzy dat v kontingenčních tabulkách úvod, KT, míry diverzity nominálních veličin, některá rozdělení chí kvadrát testy, analýza reziduí,
Cvičení ze statistiky - 9. Filip Děchtěrenko
 Cvičení ze statistiky - 9 Filip Děchtěrenko Minule bylo.. Dobrali jsme normální rozdělení Tyhle termíny by měly být známé: Inferenční statistika Konfidenční intervaly Z-test Postup při testování hypotéz
Cvičení ze statistiky - 9 Filip Děchtěrenko Minule bylo.. Dobrali jsme normální rozdělení Tyhle termíny by měly být známé: Inferenční statistika Konfidenční intervaly Z-test Postup při testování hypotéz
Měření závislosti statistických dat
 5.1 Měření závislosti statistických dat Každý pořádný astronom je schopen vám předpovědět, kde se bude nacházet daná hvězda půl hodiny před půlnocí. Ne každý je však téhož schopen předpovědět v případě
5.1 Měření závislosti statistických dat Každý pořádný astronom je schopen vám předpovědět, kde se bude nacházet daná hvězda půl hodiny před půlnocí. Ne každý je však téhož schopen předpovědět v případě
Epidemiologické ukazatele. lních dat. analýza kategoriáln. Prof. RNDr. Jana Zvárová, DrSc. Záznam epidemiologických dat. a I E
 Testování statistických hypotéz z a analýza kategoriáln lních dat Prof. RNDr. Jana Zvárová, DrSc. Epidemiologické ukazatele Rizikový faktor Populace Přítomen Nepřítomen Celkem Nemocní a b a+b Kontroly
Testování statistických hypotéz z a analýza kategoriáln lních dat Prof. RNDr. Jana Zvárová, DrSc. Epidemiologické ukazatele Rizikový faktor Populace Přítomen Nepřítomen Celkem Nemocní a b a+b Kontroly
PSY117. Přednáška VZTAHY MEZI PROMĚNNÝMI KORELAČNÍ KOEFICIENT
 PSY117 Statistická analýza dat v psychologii Přednáška 5 2016 VZTAHY MEZI PROMĚNNÝMI KORELAČNÍ KOEFICIENT Sloupcový diagram s tříděním - vztah mezi dvěma kategorickými proměnnými (c) Stanislav Ježek, Jan
PSY117 Statistická analýza dat v psychologii Přednáška 5 2016 VZTAHY MEZI PROMĚNNÝMI KORELAČNÍ KOEFICIENT Sloupcový diagram s tříděním - vztah mezi dvěma kategorickými proměnnými (c) Stanislav Ježek, Jan
Pravděpodobnost a aplikovaná statistika
 Pravděpodobnost a aplikovaná statistika MGR. JANA SEKNIČKOVÁ, PH.D. 8. KAPITOLA STATISTICKÉ TESTOVÁNÍ HYPOTÉZ 22.11.2016 Opakování: CLV příklad 1 Zadání: Před volbami je v populaci státu 52 % příznivců
Pravděpodobnost a aplikovaná statistika MGR. JANA SEKNIČKOVÁ, PH.D. 8. KAPITOLA STATISTICKÉ TESTOVÁNÍ HYPOTÉZ 22.11.2016 Opakování: CLV příklad 1 Zadání: Před volbami je v populaci státu 52 % příznivců
Grafický a číselný popis rozložení dat 3.1 Způsoby zobrazení dat Metody zobrazení kvalitativních a ordinálních dat Metody zobrazení kvan
 1 Úvod 1.1 Empirický výzkum a jeho etapy 1.2 Význam teorie pro výzkum 1.2.1 Konstrukty a jejich operacionalizace 1.2.2 Role teorie ve výzkumu 1.2.3 Proces ověření hypotéz a teorií 1.3 Etika vědecké práce
1 Úvod 1.1 Empirický výzkum a jeho etapy 1.2 Význam teorie pro výzkum 1.2.1 Konstrukty a jejich operacionalizace 1.2.2 Role teorie ve výzkumu 1.2.3 Proces ověření hypotéz a teorií 1.3 Etika vědecké práce
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc.
 Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika 2010 1.týden (20.09.-24.09. ) Data, typy dat, variabilita, frekvenční analýza
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika 2010 1.týden (20.09.-24.09. ) Data, typy dat, variabilita, frekvenční analýza
KGG/STG Statistika pro geografy
 KGG/STG Statistika pro geografy 4. Teoretická rozdělení Mgr. David Fiedor 9. března 2015 Osnova Úvod 1 Úvod 2 3 4 5 Vybraná rozdělení náhodných proměnných normální rozdělení normované normální rozdělení
KGG/STG Statistika pro geografy 4. Teoretická rozdělení Mgr. David Fiedor 9. března 2015 Osnova Úvod 1 Úvod 2 3 4 5 Vybraná rozdělení náhodných proměnných normální rozdělení normované normální rozdělení
Tomáš Karel LS 2012/2013
 Tomáš Karel LS 2012/2013 Doplňkový materiál ke cvičení z předmětu 4ST201. Na případné faktické chyby v této presentaci mě prosím upozorněte. Děkuji. Tyto slidy berte pouze jako doplňkový materiál není
Tomáš Karel LS 2012/2013 Doplňkový materiál ke cvičení z předmětu 4ST201. Na případné faktické chyby v této presentaci mě prosím upozorněte. Děkuji. Tyto slidy berte pouze jako doplňkový materiál není
11. cvičení z PSI prosince hodnota pozorovaná četnost n i p X (i) = q i (1 q), i N 0.
 = q i (1 q), i N 0.") 11 cvičení z PSI 12-16 prosince 2016 111 (Test dobré shody - geometrické rozdělení Realizací náhodné veličiny X jsme dostali následující četnosti výsledků: hodnota 0 1 2 3 4 5 6 pozorovaná četnost 29 15
11 cvičení z PSI 12-16 prosince 2016 111 (Test dobré shody - geometrické rozdělení Realizací náhodné veličiny X jsme dostali následující četnosti výsledků: hodnota 0 1 2 3 4 5 6 pozorovaná četnost 29 15
Program Statistica Base 9. Mgr. Karla Hrbáčková, Ph.D.
 Program Statistica Base 9 Mgr. Karla Hrbáčková, Ph.D. OBSAH KURZU obsluha jednotlivých nástrojů, funkce pro import dat z jiných aplikací, práce s popisnou statistikou, vytváření grafů, analýza dat, výstupní
Program Statistica Base 9 Mgr. Karla Hrbáčková, Ph.D. OBSAH KURZU obsluha jednotlivých nástrojů, funkce pro import dat z jiných aplikací, práce s popisnou statistikou, vytváření grafů, analýza dat, výstupní
You created this PDF from an application that is not licensed to print to novapdf printer (http://www.novapdf.com)
") Testování statistických hypotéz Testování statistických hypotéz Princip: Ověřování určitého předpokladu zjišťujeme, zda zkoumaný výběr pochází ze základního souboru, který má určité rozdělení zjišťujeme,
Testování statistických hypotéz Testování statistických hypotéz Princip: Ověřování určitého předpokladu zjišťujeme, zda zkoumaný výběr pochází ze základního souboru, který má určité rozdělení zjišťujeme,
Intervalové odhady. Interval spolehlivosti pro střední hodnotu v N(µ, σ 2 ) Interpretace intervalu spolehlivosti. Interval spolehlivosti ilustrace
 Interpretace intervalu spolehlivosti. Interval spolehlivosti ilustrace") Intervalové odhady Interval spolehlivosti pro střední hodnotu v Nµ, σ 2 ) Situace: X 1,..., X n náhodný výběr z Nµ, σ 2 ), kde σ 2 > 0 známe měli jsme: bodové odhady odhadem charakteristiky je číslo) nevyjadřuje
Intervalové odhady Interval spolehlivosti pro střední hodnotu v Nµ, σ 2 ) Situace: X 1,..., X n náhodný výběr z Nµ, σ 2 ), kde σ 2 > 0 známe měli jsme: bodové odhady odhadem charakteristiky je číslo) nevyjadřuje
Zpracování náhodného vektoru. Ing. Michal Dorda, Ph.D.
 Ing. Michal Dorda, Ph.D. 1 Př. 1: Cestující na vybraném spoji linky MHD byli dotazováni za účelem zjištění spokojenosti s kvalitou MHD. Legenda 1 Velmi spokojen Spokojen 3 Nespokojen 4 Velmi nespokojen
Ing. Michal Dorda, Ph.D. 1 Př. 1: Cestující na vybraném spoji linky MHD byli dotazováni za účelem zjištění spokojenosti s kvalitou MHD. Legenda 1 Velmi spokojen Spokojen 3 Nespokojen 4 Velmi nespokojen
Intervalové odhady. Interval spolehlivosti pro střední hodnotu v N(µ, σ 2 ) Interpretace intervalu spolehlivosti. Interval spolehlivosti ilustrace
 Interpretace intervalu spolehlivosti. Interval spolehlivosti ilustrace") Intervalové odhady Interval spolehlivosti pro střední hodnotu v Nµ, σ 2 ) Situace: X 1,..., X n náhodný výběr z Nµ, σ 2 ), kde σ 2 > 0 známe měli jsme: bodové odhady odhadem charakteristiky je číslo) nevyjadřuje
Intervalové odhady Interval spolehlivosti pro střední hodnotu v Nµ, σ 2 ) Situace: X 1,..., X n náhodný výběr z Nµ, σ 2 ), kde σ 2 > 0 známe měli jsme: bodové odhady odhadem charakteristiky je číslo) nevyjadřuje
ÚVOD DO TEORIE ODHADU. Martina Litschmannová
 ÚVOD DO TEORIE ODHADU Martina Litschmannová Obsah lekce Výběrové charakteristiky parametry populace vs. výběrové charakteristiky limitní věty další rozdělení pravděpodobnosti (Chí-kvadrát (Pearsonovo),
ÚVOD DO TEORIE ODHADU Martina Litschmannová Obsah lekce Výběrové charakteristiky parametry populace vs. výběrové charakteristiky limitní věty další rozdělení pravděpodobnosti (Chí-kvadrát (Pearsonovo),
Statistika, Biostatistika pro kombinované studium Letní semestr 2011/2012. Tutoriál č. 4: Exploratorní analýza. Jan Kracík
 Statistika, Biostatistika pro kombinované studium Letní semestr 2011/2012 Tutoriál č. 4: Exploratorní analýza Jan Kracík jan.kracik@vsb.cz Statistika věda o získávání znalostí z empirických dat empirická
Statistika, Biostatistika pro kombinované studium Letní semestr 2011/2012 Tutoriál č. 4: Exploratorní analýza Jan Kracík jan.kracik@vsb.cz Statistika věda o získávání znalostí z empirických dat empirická
PSY Statistická analýza dat v psychologii Přednáška 3. Transformace skórů a kvantily normálního rozložení
 PSY117 2016 Statistická analýza dat v psychologii Přednáška 3 Transformace skórů a kvantily normálního rozložení Transformace skórů (dat) Pro usnadnění porozumění a možnost dalších analýz často přepočítáváme
PSY117 2016 Statistická analýza dat v psychologii Přednáška 3 Transformace skórů a kvantily normálního rozložení Transformace skórů (dat) Pro usnadnění porozumění a možnost dalších analýz často přepočítáváme
PRAVDĚPODOBNOST A STATISTIKA. Testování hypotéz o rozdělení
 PRAVDĚPODOBNOST A STATISTIKA Testování hypotéz o rozdělení Testování hypotéz o rozdělení Nechť X e náhodná proměnná, která má distribuční funkci F(x, ϑ). Předpokládeme, že neznáme tvar distribuční funkce
PRAVDĚPODOBNOST A STATISTIKA Testování hypotéz o rozdělení Testování hypotéz o rozdělení Nechť X e náhodná proměnná, která má distribuční funkci F(x, ϑ). Předpokládeme, že neznáme tvar distribuční funkce
JEDNOVÝBĚROVÉ TESTY. Komentované řešení pomocí programu Statistica
 JEDNOVÝBĚROVÉ TESTY Komentované řešení pomocí programu Statistica Vstupní data Data umístěná v excelovském souboru překopírujeme do tabulky ve Statistice a pojmenujeme proměnné, viz prezentace k tématu
JEDNOVÝBĚROVÉ TESTY Komentované řešení pomocí programu Statistica Vstupní data Data umístěná v excelovském souboru překopírujeme do tabulky ve Statistice a pojmenujeme proměnné, viz prezentace k tématu
PSY117/454 Statistická analýza dat v psychologii Přednáška 5 ZOBRAZENÍ DVOUROZMĚRNÝCH DAT KORELAČNÍ KOEFICIENT. Všichni žijeme v matrixu.
 PSY117/454 Statistická analýza dat v psychologii Přednáška 5 ZOBRAZENÍ DVOUROZMĚRNÝCH DAT KORELAČNÍ KOEFICIENT Všichni žijeme v matrixu. Výzkumné otázky Hypotézy o vzájemné souvislosti jevů: Predikuje
PSY117/454 Statistická analýza dat v psychologii Přednáška 5 ZOBRAZENÍ DVOUROZMĚRNÝCH DAT KORELAČNÍ KOEFICIENT Všichni žijeme v matrixu. Výzkumné otázky Hypotézy o vzájemné souvislosti jevů: Predikuje
12. cvičení z PST. 20. prosince 2017
 1 cvičení z PST 0 prosince 017 11 test rozptylu normálního rozdělení Do laboratoře bylo odesláno n = 5 stejných vzorků krve ke stanovení obsahu alkoholu X v promilích alkoholu Výsledkem byla realizace
1 cvičení z PST 0 prosince 017 11 test rozptylu normálního rozdělení Do laboratoře bylo odesláno n = 5 stejných vzorků krve ke stanovení obsahu alkoholu X v promilích alkoholu Výsledkem byla realizace
Vybraná rozdělení náhodné veličiny
 3.3 Vybraná rozdělení náhodné veličiny 0,16 0,14 0,12 0,1 0,08 0,06 0,04 0,02 0 Rozdělení Z 3 4 5 6 7 8 9 10 11 12 13 14 15 Život je umění vytvářet uspokojivé závěry na základě nedostatečných předpokladů.
3.3 Vybraná rozdělení náhodné veličiny 0,16 0,14 0,12 0,1 0,08 0,06 0,04 0,02 0 Rozdělení Z 3 4 5 6 7 8 9 10 11 12 13 14 15 Život je umění vytvářet uspokojivé závěry na základě nedostatečných předpokladů.
ROZDĚLENÍ NÁHODNÝCH VELIČIN
 ROZDĚLENÍ NÁHODNÝCH VELIČIN 1 Vytvořeno s podporou projektu Průřezová inovace studijních programů Lesnické a dřevařské fakulty MENDELU v Brně (LDF) s ohledem na discipliny společného základu (reg. č. CZ.1.07/2.2.00/28.0021)
ROZDĚLENÍ NÁHODNÝCH VELIČIN 1 Vytvořeno s podporou projektu Průřezová inovace studijních programů Lesnické a dřevařské fakulty MENDELU v Brně (LDF) s ohledem na discipliny společného základu (reg. č. CZ.1.07/2.2.00/28.0021)
Přednáška XI. Asociace ve čtyřpolní tabulce a základy korelační analýzy
 Přednáška XI. Asociace ve čtyřpolní tabulce a základy korelační analýzy Relativní riziko a poměr šancí Princip korelace dvou náhodných veličin Korelační koeficienty Pearsonůva Spearmanův Korelace a kauzalita
Přednáška XI. Asociace ve čtyřpolní tabulce a základy korelační analýzy Relativní riziko a poměr šancí Princip korelace dvou náhodných veličin Korelační koeficienty Pearsonůva Spearmanův Korelace a kauzalita
Porovnání dvou výběrů
 Porovnání dvou výběrů Menu: QCExpert Porovnání dvou výběrů Tento modul je určen pro podrobnou analýzu dvou datových souborů (výběrů). Modul poskytuje dva postupy analýzy: porovnání dvou nezávislých výběrů
Porovnání dvou výběrů Menu: QCExpert Porovnání dvou výběrů Tento modul je určen pro podrobnou analýzu dvou datových souborů (výběrů). Modul poskytuje dva postupy analýzy: porovnání dvou nezávislých výběrů
Z mých cvičení dostalo jedničku 6 studentů, dvojku 8 studentů, trojku 16 studentů a čtyřku nebo omluveno 10 studentů.
 Neparametricke testy (motto: Hypotézy jsou lešením, které se staví před budovu a pak se strhává, je-li budova postavena. Jsou nutné pro vědeckou práci, avšak skutečný vědec nepokládá hypotézy za předmětnou
Neparametricke testy (motto: Hypotézy jsou lešením, které se staví před budovu a pak se strhává, je-li budova postavena. Jsou nutné pro vědeckou práci, avšak skutečný vědec nepokládá hypotézy za předmětnou
ROZDĚLENÍ SPOJITÝCH NÁHODNÝCH VELIČIN
 ROZDĚLENÍ SPOJITÝCH NÁHODNÝCH VELIČIN Rovnoměrné rozdělení R(a,b) rozdělení s konstantní hustotou pravděpodobnosti v intervalu (a,b) f( x) distribuční funkce 0 x a F( x) a x b b a 1 x b b 1 a x a a x b
ROZDĚLENÍ SPOJITÝCH NÁHODNÝCH VELIČIN Rovnoměrné rozdělení R(a,b) rozdělení s konstantní hustotou pravděpodobnosti v intervalu (a,b) f( x) distribuční funkce 0 x a F( x) a x b b a 1 x b b 1 a x a a x b
Pracovní adresář. Nápověda. Instalování a načtení nového balíčku. Importování datového souboru. Práce s datovým souborem
 Pracovní adresář getwd() # výpis pracovního adresáře setwd("c:/moje/pracovni") # nastavení pracovního adresáře setwd("c:\\moje\\pracovni") # nastavení pracovního adresáře Nápověda?funkce # nápověda pro
Pracovní adresář getwd() # výpis pracovního adresáře setwd("c:/moje/pracovni") # nastavení pracovního adresáře setwd("c:\\moje\\pracovni") # nastavení pracovního adresáře Nápověda?funkce # nápověda pro
analýza kategoriáln lních dat Prof. RNDr. Jana Zvárová, DrSc. Záznam epidemiologických dat Epidemiologické ukazatele
 Testování statistických hypotéz z a analýza kategoriáln lních dat Prof. RNDr. Jana Zvárová, DrSc. 1 Záznam epidemiologických dat Rizikový faktor Populace Přítomen Nepřítomen Celkem Nemocní a b a+b Kontroly
Testování statistických hypotéz z a analýza kategoriáln lních dat Prof. RNDr. Jana Zvárová, DrSc. 1 Záznam epidemiologických dat Rizikový faktor Populace Přítomen Nepřítomen Celkem Nemocní a b a+b Kontroly
{ } ( 2) Příklad: Test nezávislosti kategoriálních znaků
 Příklad: Test nezávislosti kategoriálních znaků") Příklad: Test nezávislosti kategoriálních znaků Určete na hladině významnosti 5 % na základě dat zjištěných v rámci dotazníkového šetření ve Šluknově, zda existuje závislost mezi pohlavím respondenta a
Příklad: Test nezávislosti kategoriálních znaků Určete na hladině významnosti 5 % na základě dat zjištěných v rámci dotazníkového šetření ve Šluknově, zda existuje závislost mezi pohlavím respondenta a
5. T e s t o v á n í h y p o t é z
 5. T e s t o v á n í h y p o t é z Na základě hodnot náhodného výběru činíme rozhodnutí o platnosti hypotézy o hodnotách parametrů rozdělení nebo o jeho vlastnostech. Rozeznáváme dva základní typy testů:
5. T e s t o v á n í h y p o t é z Na základě hodnot náhodného výběru činíme rozhodnutí o platnosti hypotézy o hodnotách parametrů rozdělení nebo o jeho vlastnostech. Rozeznáváme dva základní typy testů:
Pravděpodobnost a statistika, Biostatistika pro kombinované studium. Tutoriál č. 5: Bodové a intervalové odhady, testování hypotéz.
 Pravděpodobnost a statistika, Biostatistika pro kombinované studium Letní semestr 2015/2016 Tutoriál č. 5: Bodové a intervalové odhady, testování hypotéz Jan Kracík jan.kracik@vsb.cz Obsah: Výběrová rozdělení
Pravděpodobnost a statistika, Biostatistika pro kombinované studium Letní semestr 2015/2016 Tutoriál č. 5: Bodové a intervalové odhady, testování hypotéz Jan Kracík jan.kracik@vsb.cz Obsah: Výběrová rozdělení
Příklad 1. Korelační pole. Řešení 1 ŘEŠENÉ PŘÍKLADY Z MV2 ČÁST 13
 Příklad 1 Máme k dispozici výsledky prvního a druhého testu deseti sportovců. Na hladině významnosti 0,05 prověřte, zda jsou výsledky testů kladně korelované. 1.test : 7, 8, 10, 4, 14, 9, 6, 2, 13, 5 2.test
Příklad 1 Máme k dispozici výsledky prvního a druhého testu deseti sportovců. Na hladině významnosti 0,05 prověřte, zda jsou výsledky testů kladně korelované. 1.test : 7, 8, 10, 4, 14, 9, 6, 2, 13, 5 2.test
Náhodná veličina a rozdělení pravděpodobnosti
 3.2 Náhodná veličina a rozdělení pravděpodobnosti Bůh hraje se světem hru v kostky. Jsou to ale falešné kostky. Naším hlavním úkolem je zjistit, podle jakých pravidel byly označeny, a pak toho využít pro
3.2 Náhodná veličina a rozdělení pravděpodobnosti Bůh hraje se světem hru v kostky. Jsou to ale falešné kostky. Naším hlavním úkolem je zjistit, podle jakých pravidel byly označeny, a pak toho využít pro
ANALÝZA DAT V R 5. ZÁKLADNÍ STATISTICKÉ TESTY. Mgr. Markéta Pavlíková Katedra pravděpodobnosti a matematické statistiky MFF UK.
 ANALÝZA DAT V R 5. ZÁKLADNÍ STATISTICKÉ TESTY Mgr. Markéta Pavlíková Katedra pravděpodobnosti a matematické statistiky MFF UK www.biostatisticka.cz PRINCIPY STATISTICKÉ INFERENCE identifikace závisle proměnné
ANALÝZA DAT V R 5. ZÁKLADNÍ STATISTICKÉ TESTY Mgr. Markéta Pavlíková Katedra pravděpodobnosti a matematické statistiky MFF UK www.biostatisticka.cz PRINCIPY STATISTICKÉ INFERENCE identifikace závisle proměnné
Modul Analýza síly testu Váš pomocník při analýze dat.
 6..0 Modul Analýza síly testu Váš pomocník při analýze dat. Power Analysis and Interval Estimation Analýza síly testu Odhad velikosti vzorku Pokročilé techniky pro odhad intervalu spolehlivosti Rozdělení
6..0 Modul Analýza síly testu Váš pomocník při analýze dat. Power Analysis and Interval Estimation Analýza síly testu Odhad velikosti vzorku Pokročilé techniky pro odhad intervalu spolehlivosti Rozdělení
II. Statistické metody vyhodnocení kvantitativních dat Gejza Dohnal
 Základy navrhování průmyslových experimentů DOE II. Statistické metody vyhodnocení kvantitativních dat Gejza Dohnal! Testování statistických hypotéz kvalitativní odezva kvantitativní chí-kvadrát test homogenity,
Základy navrhování průmyslových experimentů DOE II. Statistické metody vyhodnocení kvantitativních dat Gejza Dohnal! Testování statistických hypotéz kvalitativní odezva kvantitativní chí-kvadrát test homogenity,
2. Základní typy dat Spojitá a kategoriální data Základní popisné statistiky Frekvenční tabulky Grafický popis dat
 2. Základní typy dat Spojitá a kategoriální data Základní popisné statistiky Frekvenční tabulky Grafický popis dat Anotace Realitu můžeme popisovat různými typy dat, každý z nich se specifickými vlastnostmi,
2. Základní typy dat Spojitá a kategoriální data Základní popisné statistiky Frekvenční tabulky Grafický popis dat Anotace Realitu můžeme popisovat různými typy dat, každý z nich se specifickými vlastnostmi,
Jednovýběrové testy. Komentované řešení pomocí MS Excel
 Jednovýběrové testy Komentované řešení pomocí MS Excel Vstupní data V dalším budeme předpokládat, že tabulka se vstupními daty je umístěna v oblasti A1:C23 (viz. obrázek) Základní statistiky vložíme vzorce
Jednovýběrové testy Komentované řešení pomocí MS Excel Vstupní data V dalším budeme předpokládat, že tabulka se vstupními daty je umístěna v oblasti A1:C23 (viz. obrázek) Základní statistiky vložíme vzorce
IBM SPSS Exact Tests. Přesné analýzy malých datových souborů. Nejdůležitější. IBM SPSS Statistics
 IBM Software IBM SPSS Exact Tests Přesné analýzy malých datových souborů Při rozhodování o existenci vztahu mezi proměnnými v kontingenčních tabulkách a při používání neparametrických ů analytici zpravidla
IBM Software IBM SPSS Exact Tests Přesné analýzy malých datových souborů Při rozhodování o existenci vztahu mezi proměnnými v kontingenčních tabulkách a při používání neparametrických ů analytici zpravidla