Dobývání znalostí z textů text mining
|
|
|
- Anna Žáková
- před 6 lety
- Počet zobrazení:
Transkript
1 Dobývání znalostí z textů text mining Text mining - data mining na nestrukturovaných textových dokumentech 2 možné přístupy: Předzpracování dat + běžné algoritmy pro data mining Speciální algoritmy pro text mining 2 typy úloh: Vyhledávání informací (information retrieval) práce na úrovni celých dokumentů Extrakce informací (information extraction) analýza obsahu dokumentu P. Berka, /18
2 Reprezentace dokumentu (předzpracování) Nutnost převést volný text na řádek v datové matici: Lexikální analýza (nalezení jednotlivých slov) Lematizace (převedení slova na základní gramatický tvar) ignorování stop-slov (slov, která nenesou informaci o obsahu textu typicky spojky, předložky) řádek v datové matici - vektor který má tolik složek, kolik je možných termínů (bag-of-words). Termíny kódovány: binárně tedy výskyt/nevýskyt v dokumentu, počtem výskytů v a all also an and any are as at be Author 46,12,0,3,66,9,4,16,13,13,4,8,8,1,0,1,5,0,21,12,16,3,6,62,3,3,30,3,9,14,1,2,6,5,0,1 0,16,2,54,7,8,1,7,0,4,7,1,3,3,17,67,6,2,5,1,4,47,2,3,40,11,7,5,6,8,4,9,1,0,1,Austen P. Berka, /18
3 pomocí hodnoty TFIDF (term frequency inverse document frequency) TFIDF = n * log M m n je počet výskytů termínu v dokumentu m je počet výskytů termínu v celé kolekci M je počet dokumentů v kolekci Výhody: invariantní vůči pořadí termínů v dokumentu nevyžaduje předzpracování dat Nevýhody: nezachytí víceslovné fráze lze řešit tak, že se místo jednoho termínu kódují fráze, nebo použitím n-gramů např. Mistr Jan Hus: bigramy Mistr Jan, Jan Hus trigramy Mistr Jan Hus nevyužije strukturu dokumentů lze řešit pomocí vah termínů příliš veliká dimenze vektorů (~ ) - je třeba řešit metodami předzpracování selekce atributů metoda obálky = využití hrubé síly počítačů metoda filtru = vyhodnocení relevance jednotlivých termínů transformace atributů např. indexace latentní sémantiky: P. Berka, /18

4 reprezentace dokumentů pomocí menšího počtu konceptů př. předzpracování v SAS text mineru: text parsing P. Berka, /18


5 text filtering P. Berka, /18


6 text topic P. Berka, /18
7 Podobnost dokumentů Pro dva dokumenty x 1 ={x 11,x 12,, x 1m } x 2 ={x 21,x 22,, x 2m } Kosínová míra podobnosti sim C (x 1, x 2 ) = cos (x 1, x 2 ) = x 1 x 2 x 1 x 2 Míra symetrického překrytí sim S (x 1, x 2 ) = j min(x 1j,x 2j ) min( j x 1j, j x 2j ) Diceho míra podobnosti sim D (x 1, x 2 ) = 2 x 1 x 2 x 1 + x 2 = 2 x 1 x 2 j x 1j + j x 2j Jacardova míra podobnosti sim J (x 1, x 2 ) = x 1 x 2 x 1 x 2 = x 1 x 2 j x 1j + j x 2j - x z kde x 1 x 2 = m j=1 x 1j x 2j x = x x = m j=1 x j 2 P. Berka, /18
8 A) Úloha vyhledávání informací (information retrieval) dokument chápan jako celek Information retreival v klasickém smyslu: nalézt dokumenty, které nejlépe odpovídají zadanému dotazu 1. booleovský model = vyhledávací podmínka tvořena pomocí logických spojek AND, OR a NOT neumožňuje vzít do úvahy důležitost termínů v dokumentu neumožňuje vzít do úvahy důležitost termínů v dotazu nabízí jen hrubou škálu (dokument vyhovuje/nevyhovuje) 2. fuzzy rozšíření = využití více hodnot než TRUE, FALSE např. pro dotaz Q zadaný pomocí vážených termínů t j :v j a t k :v k a dokument D obsahující stejné termíny (s vahami w) t j :w j a t k :w k, bude míra relevance R(D,Q) dokumentu D vzhledem k dotazu Q pro dotaz D daný konjunkcí t j :v j AND t k :v k R(D,Q) = min (v j w j,v k w k ) a pro dotaz D daný disjunkcí t j :v j OR t k :v k R(D,Q) = max (v j w j,v k w k ). P. Berka, /18
9 3. vektorový model = využití výše uvedených měr podobnosti hodnocení výsledků vyhledávání přesnost (precision) a úplnost (recall) TP TP Přesnost = Úplnost = TP + FP TP + FN Vztah přesnosti a úplnosti úzké dotazy (AND) naleznou relativně malý počet dokumentů, které jsou většinou relevantní, široké dotazy (OR) naleznou relativně velký počet dokumentů, které ale nebývají většinou relevantní P. Berka, /18
 duplication detection hledání podobných dokumentů SAS Document duplication detection P.")
10 Text mining na úrovni dokumentů: text categorization klasifikace dokumentů do více tříd document clustering seskupování dokumentů na základě podobnosti document filtering klasifikace dokumentů do 2 tříd (zajímavé vs. nezajímavé, spam vs. ham) duplication detection hledání podobných dokumentů SAS Document duplication detection P. Berka, /18


11 sentiment analysis klasifikace dokumentů dle emočního obsahu (obvykle 3 třídy: pozitivní, negativní a neutrální emoce) SAS sentiment analysis P. Berka, /18
12 Systémy a algoritmy pro vyhledávání informací algoritmus SMART (System for Manipulating And Retrieving Text) vektorová reprezentace, TFIDF, kosínovou míru a míru symetrického překrytí (Salton, 1971) naivní bayesovský klasifikátor pro klasifikaci dokumentů model založený na pravděpodobnostech P(i-té_slovo_ je_ X dokument_patří_do_třídy) (Lewis, 1991), (Mitchell, 1997), (Grobelnik, Mladenic, 1998) Kohonenova neuronová síť SOM - geometrická interpretace Kohonenovy mapy se převádí na interpretaci pojmovou; čím více jsou dva shluky od sebe v Kohonenově mapě dále, tím rozdílnější obsah odpovídá příslušným dokumentům WebSOM (Honkela, 1996), (Kohonen, 1998) - kategorizace dokumentů na Internetu genetické algoritmy - dokumenty reprezentovány bitovými řetězci (chromozomem) kódujícími výskyt (1) nebo nevýskyt (0) určitého termínu, funkce fit bude odpovídat některé míře podobnosti (např. Jaccardově) mezi dokumentem a dotazem, rovněž reprezentovaným bitovým řetězcem (Gordon, 1988) P. Berka, /18


13 SAS Text Miner P. Berka, /18

14 P. Berka, /18

15 B) Úloha extrakce informací (information extraction) analýza nestrukturovaného textu za účelem nalezení určitého typu informace 1. text summarization: vytvoření souhrnu textu např: SAS Text Summarization Vybírá důležité věty z textu - důležitost je dána výskytem uživatelem definovaných konceptů, čím více konceptů ve větě je, tím je důležitější. Při definici konceptů je možné využít regulární výrazy a gramatická pravidla Možnosti shrnutí: Celý dokument, odstavce nebo sekce 2. named entity recognition: hledání atomických elementů typu jméno osoby, jméno organizace, místní název, časový údaj a pod.) např. (Labský, Svátek, 2007) v rámci projektu MedIEQ P. Berka, /18
 např.")

16 3. template mining: hledání sekvence slov (obvykle zadáno formou tzv. regulárního výrazu) např. SAS Content Categorization: klasifikační koncept definovaný seznamem slov nebo pomocí regulárních výrazů gramatický koncept definovaný lingvistickými pravidly definice gramatického konceptu nalezení gramatického konceptu P. Berka, /18
 - aplikace na zprávy o politických událostech (Feldman, Hirsh, 1997) {Iran,USA} Reagan Systém")
17 Hledání přídavných jmen: přesnost i úplnost je 13/17= hledání asociací: mezi výskytem různých frází v souboru dokumentů A S,.. píše-li se o A, píše se současně i o B Systém FACT (Finding Associations in Collections of Text) - aplikace na zprávy o politických událostech (Feldman, Hirsh, 1997) {Iran,USA} Reagan Systém Document Explorer - aplikace na ekonomické texty (Feldman a kol, 1998) america online inc, bertelsmann ag joint venture (13, 0.72) Rozhodující pro provádění automatické extrakce informací je dostatečné množství doménových znalostí. V případě systému FACT to byly geopolitické znalosti a znalosti linguistické (synonyma k vybraným termínům) v případě systému Document Explorer se jednalo o znalosti o firmách. P. Berka, /18
 http://www.sas.com/technologies/analytics/datamining/ textminer Po vhodném předzpracování textů do podoby relační tabulky lze použít i běžné systémy pro dobývání znalostí z databází. weka P.")
18 Systémy pro text mining Intelligent Miner for Text firmy IBM Text Analyst firmy Megaputer Intelligence Text Miner (SAS Institute Inc.) textminer Po vhodném předzpracování textů do podoby relační tabulky lze použít i běžné systémy pro dobývání znalostí z databází. weka P. Berka, /18
Text Mining: SAS Enterprise Miner versus Teragram. Petr Berka, Tomáš Kliegr VŠE Praha
 Text Mining: SAS Enterprise Miner versus Teragram Petr Berka, Tomáš Kliegr VŠE Praha Text mining vs. data mining Text mining = data mining na nestrukturovaných textových dokumentech otázka vhodné reprezentace
Text Mining: SAS Enterprise Miner versus Teragram Petr Berka, Tomáš Kliegr VŠE Praha Text mining vs. data mining Text mining = data mining na nestrukturovaných textových dokumentech otázka vhodné reprezentace
ZÍSKÁVÁNÍ ZNALOSTÍ Z DATABÁZÍ
 metodický list č. 1 Dobývání znalostí z databází Cílem tohoto tematického celku je vysvětlení základních pojmů z oblasti dobývání znalostí z databází i východisek dobývání znalostí z databází inspirovaných
metodický list č. 1 Dobývání znalostí z databází Cílem tohoto tematického celku je vysvětlení základních pojmů z oblasti dobývání znalostí z databází i východisek dobývání znalostí z databází inspirovaných
ZÍSKÁVÁNÍ ZNALOSTÍ Z DATABÁZÍ
 Metodický list č. 1 Dobývání znalostí z databází Cílem tohoto tematického celku je vysvětlení základních pojmů z oblasti dobývání znalostí z databází i východisek dobývání znalostí z databází inspirovaných
Metodický list č. 1 Dobývání znalostí z databází Cílem tohoto tematického celku je vysvětlení základních pojmů z oblasti dobývání znalostí z databází i východisek dobývání znalostí z databází inspirovaných
Dolování z textu. Martin Vítek
 Dolování z textu Martin Vítek Proč dolovat z textu Obrovské množství materiálu v nestrukturované textové podobě knihy časopisy vědeckéčlánky sborníky konferencí internetové diskuse Proč dolovat z textu
Dolování z textu Martin Vítek Proč dolovat z textu Obrovské množství materiálu v nestrukturované textové podobě knihy časopisy vědeckéčlánky sborníky konferencí internetové diskuse Proč dolovat z textu
Modely vyhledávání informací 4 podle technologie. 1) Booleovský model. George Boole 1815 1864. Aplikace booleovské logiky
 Booleovský model. George Boole 1815 1864. Aplikace booleovské logiky") Modely vyhledávání informací 4 podle technologie 1) Booleovský model 1) booleovský 2) vektorový 3) strukturní 4) pravděpodobnostní a další 1 dokumenty a dotazy jsou reprezentovány množinou indexových termů
Modely vyhledávání informací 4 podle technologie 1) Booleovský model 1) booleovský 2) vektorový 3) strukturní 4) pravděpodobnostní a další 1 dokumenty a dotazy jsou reprezentovány množinou indexových termů
Automatické vyhledávání informace a znalosti v elektronických textových datech
 Automatické vyhledávání informace a znalosti v elektronických textových datech Jan Žižka Ústav informatiky & SoNet RC PEF, Mendelova universita Brno (Text Mining) Data, informace, znalost Elektronická
Automatické vyhledávání informace a znalosti v elektronických textových datech Jan Žižka Ústav informatiky & SoNet RC PEF, Mendelova universita Brno (Text Mining) Data, informace, znalost Elektronická
Dobývání znalostí z webu web mining
 Dobývání znalostí z webu web mining Web Mining is is the application of data mining techniques to discover patterns from the Web (Wikipedia) Tři oblasti: Web content mining (web jako kolekce dokumentů)
Dobývání znalostí z webu web mining Web Mining is is the application of data mining techniques to discover patterns from the Web (Wikipedia) Tři oblasti: Web content mining (web jako kolekce dokumentů)
pomocí hodnoty TFIDF (term frequency inverse document frequency) 4
 4") 10. Nové směry V drtivé většině se databázemi ze kterých se dobývají znalosti myslí relační databáze (jedna nebo více). U těchto databází se předpokládá vzájemná nezávislost záznamů z hlediska pořadí v
10. Nové směry V drtivé většině se databázemi ze kterých se dobývají znalosti myslí relační databáze (jedna nebo více). U těchto databází se předpokládá vzájemná nezávislost záznamů z hlediska pořadí v
Dolování asociačních pravidel
 Dolování asociačních pravidel Miloš Trávníček UIFS FIT VUT v Brně Obsah přednášky 1. Proces získávání znalostí 2. Asociační pravidla 3. Dolování asociačních pravidel 4. Algoritmy pro dolování asociačních
Dolování asociačních pravidel Miloš Trávníček UIFS FIT VUT v Brně Obsah přednášky 1. Proces získávání znalostí 2. Asociační pravidla 3. Dolování asociačních pravidel 4. Algoritmy pro dolování asociačních
InternetovéTechnologie
 7 InternetovéTechnologie vyhledávání na internetu Ing. Michal Radecký, Ph.D. www.cs.vsb.cz/radecky Vyhledávání a vyhledávače - Jediný možný způsob, jak získat obecný přístup k informacím na Internetu -
7 InternetovéTechnologie vyhledávání na internetu Ing. Michal Radecký, Ph.D. www.cs.vsb.cz/radecky Vyhledávání a vyhledávače - Jediný možný způsob, jak získat obecný přístup k informacím na Internetu -
Obsah. Seznam obrázků. Seznam tabulek. Petr Berka, 2011
 Petr Berka, 2011 Obsah... 1... 1 1 Obsah 1... 1 Dobývání znalostí z databází 1 Dobývání znalostí z databází O dobývání znalostí z databází (Knowledge Discovery in Databases, KDD) se začíná ve vědeckých
Petr Berka, 2011 Obsah... 1... 1 1 Obsah 1... 1 Dobývání znalostí z databází 1 Dobývání znalostí z databází O dobývání znalostí z databází (Knowledge Discovery in Databases, KDD) se začíná ve vědeckých
Vizualizace v Information Retrieval
 Vizualizace v Information Retrieval Petr Kopka VŠB-TU Ostrava Fakulta elektrotechniky a informatiky Katedra informatiky Obsah Co je Information Retrieval, vizualizace, proces přístupu k informacím Způsoby
Vizualizace v Information Retrieval Petr Kopka VŠB-TU Ostrava Fakulta elektrotechniky a informatiky Katedra informatiky Obsah Co je Information Retrieval, vizualizace, proces přístupu k informacím Způsoby
InternetovéTechnologie
 4 InternetovéTechnologie vyhledávání na internetu Ing. Michal Radecký, Ph.D. www.cs.vsb.cz/radecky Vyhledávání a vyhledávače - Jediný možný způsob, jak získat obecný přístup k informacím na Internetu -
4 InternetovéTechnologie vyhledávání na internetu Ing. Michal Radecký, Ph.D. www.cs.vsb.cz/radecky Vyhledávání a vyhledávače - Jediný možný způsob, jak získat obecný přístup k informacím na Internetu -
Textmining a Redukce dimenzionality
 Vytěžování dat, cvičení 7: Textmining a Redukce dimenzionality Miroslav Čepek, Michael Anděl Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti Fakulta elektrotechnická, ČVUT 1 / 22 Textmining
Vytěžování dat, cvičení 7: Textmining a Redukce dimenzionality Miroslav Čepek, Michael Anděl Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti Fakulta elektrotechnická, ČVUT 1 / 22 Textmining
DOBÝVÁNÍ ZNALOSTÍ Z DATABÁZÍ
 DOBÝVÁNÍ ZNALOSTÍ Z DATABÁZÍ Úvod a oblasti aplikací Martin Plchút plchut@e-globals.net DEFINICE A POJMY Netriviální extrakce implicitních, ch, dříve d neznámých a potenciáln lně užitečných informací z
DOBÝVÁNÍ ZNALOSTÍ Z DATABÁZÍ Úvod a oblasti aplikací Martin Plchút plchut@e-globals.net DEFINICE A POJMY Netriviální extrakce implicitních, ch, dříve d neznámých a potenciáln lně užitečných informací z
Katedra kybernetiky laboratoř Inteligentní Datové Analýzy (IDA) Katedra počítačů, Computational Intelligence Group
 Katedra počítačů, Computational Intelligence Group") Vytěžování dat Miroslav Čepek, Filip Železný Katedra kybernetiky laboratoř Inteligentní Datové Analýzy (IDA) Katedra počítačů, Computational Intelligence Group Evropský sociální fond Praha & EU: Investujeme
Vytěžování dat Miroslav Čepek, Filip Železný Katedra kybernetiky laboratoř Inteligentní Datové Analýzy (IDA) Katedra počítačů, Computational Intelligence Group Evropský sociální fond Praha & EU: Investujeme
InternetovéTechnologie
 7 InternetovéTechnologie vyhledávání na internetu Ing. Michal Radecký, Ph.D. www.cs.vsb.cz/radecky Vyhledávání a vyhledávače - Jediný možný způsob, jak získat obecný přístup k informacím na Internetu -
7 InternetovéTechnologie vyhledávání na internetu Ing. Michal Radecký, Ph.D. www.cs.vsb.cz/radecky Vyhledávání a vyhledávače - Jediný možný způsob, jak získat obecný přístup k informacím na Internetu -
Moderní systémy pro získávání znalostí z informací a dat
 Moderní systémy pro získávání znalostí z informací a dat Jan Žižka IBA Institut biostatistiky a analýz PřF & LF, Masarykova universita Kamenice 126/3, 625 00 Brno Email: zizka@iba.muni.cz Bioinformatika:
Moderní systémy pro získávání znalostí z informací a dat Jan Žižka IBA Institut biostatistiky a analýz PřF & LF, Masarykova universita Kamenice 126/3, 625 00 Brno Email: zizka@iba.muni.cz Bioinformatika:
Získávání dat z databází 1 DMINA 2010
 Získávání dat z databází 1 DMINA 2010 Získávání dat z databází Motto Kde je moudrost? Ztracena ve znalostech. Kde jsou znalosti? Ztraceny v informacích. Kde jsou informace? Ztraceny v datech. Kde jsou
Získávání dat z databází 1 DMINA 2010 Získávání dat z databází Motto Kde je moudrost? Ztracena ve znalostech. Kde jsou znalosti? Ztraceny v informacích. Kde jsou informace? Ztraceny v datech. Kde jsou
Modely a sémantika. Petr Šaloun VŠB-Technická univerzita Ostrava FEI, katedra informatiky
 Modely a sémantika Petr Šaloun VŠB-Technická univerzita Ostrava FEI, katedra informatiky Úvod Existující problémy Prudký nárůst množství informací na webu Kognitivní přetížení Ztráta v informačním prostoru
Modely a sémantika Petr Šaloun VŠB-Technická univerzita Ostrava FEI, katedra informatiky Úvod Existující problémy Prudký nárůst množství informací na webu Kognitivní přetížení Ztráta v informačním prostoru
Databázové systémy. * relační kalkuly. Tomáš Skopal. - relační model
 Databázové systémy Tomáš Skopal - relační model * relační kalkuly Osnova přednášky relační kalkuly doménový n-ticový Relační kalkuly využití aparátu predikátové logiky 1. řádu pro dotazování rozšíření
Databázové systémy Tomáš Skopal - relační model * relační kalkuly Osnova přednášky relační kalkuly doménový n-ticový Relační kalkuly využití aparátu predikátové logiky 1. řádu pro dotazování rozšíření
Strojové učení se zaměřením na vliv vstupních dat
 Strojové učení se zaměřením na vliv vstupních dat Irina Perfilieva, Petr Hurtík, Marek Vajgl Centre of excellence IT4Innovations Division of the University of Ostrava Institute for Research and Applications
Strojové učení se zaměřením na vliv vstupních dat Irina Perfilieva, Petr Hurtík, Marek Vajgl Centre of excellence IT4Innovations Division of the University of Ostrava Institute for Research and Applications
EXTRAKCE STRUKTUROVANÝCH DAT O PRODUKTOVÝCH A PRACOVNÍCH NABÍDKÁCH POMOCÍ EXTRAKČNÍCH ONTOLOGIÍ ALEŠ POUZAR
 EXTRAKCE STRUKTUROVANÝCH DAT O PRODUKTOVÝCH A PRACOVNÍCH NABÍDKÁCH POMOCÍ EXTRAKČNÍCH ONTOLOGIÍ ALEŠ POUZAR PŘEDMĚT PRÁCE Popis extrakce strukturovaných dat ve vybraných doménách ze semistrukturovaných
EXTRAKCE STRUKTUROVANÝCH DAT O PRODUKTOVÝCH A PRACOVNÍCH NABÍDKÁCH POMOCÍ EXTRAKČNÍCH ONTOLOGIÍ ALEŠ POUZAR PŘEDMĚT PRÁCE Popis extrakce strukturovaných dat ve vybraných doménách ze semistrukturovaných
Úvod do dobývání. znalostí z databází
 POROZUMĚNÍ 4iz260 Úvod do DZD Úvod do dobývání DOMÉNOVÉ OBLASTI znalostí z databází VYUŽITÍ VÝSLEDKŮ POROZUMĚNÍ DATŮM DATA VYHODNO- CENÍ VÝSLEDKŮ MODELOVÁNÍ (ANALYTICKÉ PROCEDURY) PŘÍPRAVA DAT Ukázka slidů
POROZUMĚNÍ 4iz260 Úvod do DZD Úvod do dobývání DOMÉNOVÉ OBLASTI znalostí z databází VYUŽITÍ VÝSLEDKŮ POROZUMĚNÍ DATŮM DATA VYHODNO- CENÍ VÝSLEDKŮ MODELOVÁNÍ (ANALYTICKÉ PROCEDURY) PŘÍPRAVA DAT Ukázka slidů
Ontologie. Otakar Trunda
 Ontologie Otakar Trunda Definice Mnoho různých definic: Formální specifikace sdílené konceptualizace Hierarchicky strukturovaná množina termínů popisujících určitou věcnou oblast Strukturovaná slovní zásoba
Ontologie Otakar Trunda Definice Mnoho různých definic: Formální specifikace sdílené konceptualizace Hierarchicky strukturovaná množina termínů popisujících určitou věcnou oblast Strukturovaná slovní zásoba
Korpusová lingvistika a počítačové zpracování přirozeného jazyka
 Korpusová lingvistika a počítačové zpracování přirozeného jazyka Vladimír Petkevič & Alexandr Rosen Ústav teoretické a komputační lingvistiky Filozofické fakulty Univerzity Karlovy v Praze Korpusový seminář
Korpusová lingvistika a počítačové zpracování přirozeného jazyka Vladimír Petkevič & Alexandr Rosen Ústav teoretické a komputační lingvistiky Filozofické fakulty Univerzity Karlovy v Praze Korpusový seminář
METODY DOLOVÁNÍ V DATECH DATOVÉ SKLADY TEREZA HYNČICOVÁ H2IGE1
 METODY DOLOVÁNÍ V DATECH DATOVÉ SKLADY TEREZA HYNČICOVÁ H2IGE1 DOLOVÁNÍ V DATECH (DATA MINING) OBJEVUJE SE JIŽ OD 60. LET 20. ST. S ROZVOJEM POČÍTAČOVÉ TECHNIKY DEFINICE PROCES VÝBĚRU, PROHLEDÁVÁNÍ A MODELOVÁNÍ
METODY DOLOVÁNÍ V DATECH DATOVÉ SKLADY TEREZA HYNČICOVÁ H2IGE1 DOLOVÁNÍ V DATECH (DATA MINING) OBJEVUJE SE JIŽ OD 60. LET 20. ST. S ROZVOJEM POČÍTAČOVÉ TECHNIKY DEFINICE PROCES VÝBĚRU, PROHLEDÁVÁNÍ A MODELOVÁNÍ
Jak vytvářet poznatkovou bázi pro konkurenční zpravodajství. ing. Tomáš Vejlupek
 Jak vytvářet poznatkovou bázi pro konkurenční zpravodajství ing. Tomáš Vejlupek Informace tvořící konkurenční výhodu K rozhodování nestačí jen informace. K rozhodování je nutná také znalost umožňující
Jak vytvářet poznatkovou bázi pro konkurenční zpravodajství ing. Tomáš Vejlupek Informace tvořící konkurenční výhodu K rozhodování nestačí jen informace. K rozhodování je nutná také znalost umožňující
Textová data a dobývání znalostí
 Textová data a dobývání znalostí Obsah prezentace Co je to dobývání znalostí z textových dat (TM: text data mining) a proč je užitečné? Hlavní cíle a úlohy TM. Co je specifické pro práci s textovými daty?
Textová data a dobývání znalostí Obsah prezentace Co je to dobývání znalostí z textových dat (TM: text data mining) a proč je užitečné? Hlavní cíle a úlohy TM. Co je specifické pro práci s textovými daty?
Evoluční algoritmy. Podmínka zastavení počet iterací kvalita nejlepšího jedince v populaci změna kvality nejlepšího jedince mezi iteracemi
 Evoluční algoritmy Použítí evoluční principů, založených na metodách optimalizace funkcí a umělé inteligenci, pro hledání řešení nějaké úlohy. Populace množina jedinců, potenciálních řešení Fitness function
Evoluční algoritmy Použítí evoluční principů, založených na metodách optimalizace funkcí a umělé inteligenci, pro hledání řešení nějaké úlohy. Populace množina jedinců, potenciálních řešení Fitness function
Analýzou dat k efektivnějšímu rozhodování
 Analýzou dat k efektivnějšímu rozhodování Chytrá řešení pro veřejnou správu Václav Bahník, ECM Solution Consultant Marek Šoule, ECM Software Sales Representative 8.4.2013 Řízení efektivního poskytování
Analýzou dat k efektivnějšímu rozhodování Chytrá řešení pro veřejnou správu Václav Bahník, ECM Solution Consultant Marek Šoule, ECM Software Sales Representative 8.4.2013 Řízení efektivního poskytování
PRODUKTY Tovek Server 6
 Tovek Server je serverová aplikace určená pro efektivní zpracování velkého objemu sdílených strukturovaných i nestrukturovaných dat. Umožňuje automaticky indexovat data z různých informačních zdrojů, intuitivně
Tovek Server je serverová aplikace určená pro efektivní zpracování velkého objemu sdílených strukturovaných i nestrukturovaných dat. Umožňuje automaticky indexovat data z různých informačních zdrojů, intuitivně
Automatická oprava textu v různých jazycích
 Automatická oprava textu v různých jazycích Bc. Petr Semrád, doc. Ing. František Dařena Ph.D., Ústav informatiky, Provozně ekonomická fakulta, Mendelova univerzita v Brně, xsemrad@mendelu.cz, frantisek.darena@mendelu.cz
Automatická oprava textu v různých jazycích Bc. Petr Semrád, doc. Ing. František Dařena Ph.D., Ústav informatiky, Provozně ekonomická fakulta, Mendelova univerzita v Brně, xsemrad@mendelu.cz, frantisek.darena@mendelu.cz
Formální systém výrokové logiky
 Formální systém výrokové logiky 1.Jazyk výrokové logiky Nechť P = {p,q,r, } je neprázdná množina symbolů, které nazýváme prvotní formule. Symboly jazyka L P výrokové logiky jsou : a) prvky množiny P, b)
Formální systém výrokové logiky 1.Jazyk výrokové logiky Nechť P = {p,q,r, } je neprázdná množina symbolů, které nazýváme prvotní formule. Symboly jazyka L P výrokové logiky jsou : a) prvky množiny P, b)
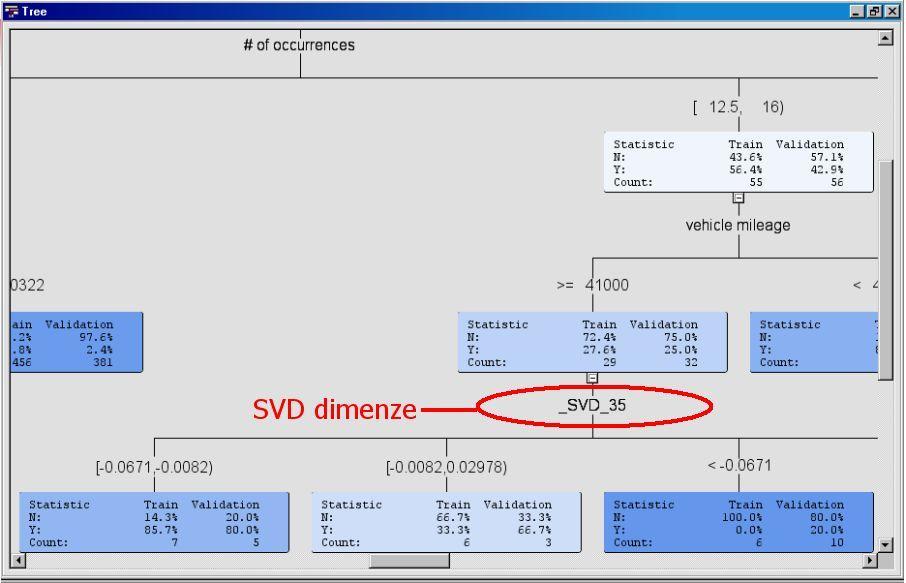
Přednáška 13 Redukce dimenzionality
 Vytěžování Dat Přednáška 13 Redukce dimenzionality Miroslav Čepek Fakulta Elektrotechnická, ČVUT Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti ČVUT (FEL) Redukce dimenzionality 1 /
Vytěžování Dat Přednáška 13 Redukce dimenzionality Miroslav Čepek Fakulta Elektrotechnická, ČVUT Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti ČVUT (FEL) Redukce dimenzionality 1 /
Aplikace metod předzpracování při dolování znalostí z textových dat
 Mendelova univerzita v Brně Provozně ekonomická fakulta Aplikace metod předzpracování při dolování znalostí z textových dat Diplomová práce Vedoucí práce: doc. Ing. František Dařena, Ph.D. Bc. Michaela
Mendelova univerzita v Brně Provozně ekonomická fakulta Aplikace metod předzpracování při dolování znalostí z textových dat Diplomová práce Vedoucí práce: doc. Ing. František Dařena, Ph.D. Bc. Michaela
Vojtěch Franc. Biometrie ZS Poděkování Janu Šochmanovi za slajdy vysvětlující AdaBoost
 Rozpoznávání tváří I Vojtěch Franc Centrum strojového vnímání, ČVUT FEL Praha Biometrie ZS 2013 Poděkování Janu Šochmanovi za slajdy vysvětlující AdaBoost Úlohy rozpoznávání tváří: Detekce Cíl: lokalizovat
Rozpoznávání tváří I Vojtěch Franc Centrum strojového vnímání, ČVUT FEL Praha Biometrie ZS 2013 Poděkování Janu Šochmanovi za slajdy vysvětlující AdaBoost Úlohy rozpoznávání tváří: Detekce Cíl: lokalizovat
Autor: Jan Hošek
 Úvod STC Závěr Autor: Jan Hošek Školitel: RNDr. Radim Řehůřek Fakulta jaderná a fyzikálně inženýrzká České vysoké učení technické v Praze 25. 5. 2009 Osnova Úvod STC Závěr 1 Úvod Motivace Ukázka technologie
Úvod STC Závěr Autor: Jan Hošek Školitel: RNDr. Radim Řehůřek Fakulta jaderná a fyzikálně inženýrzká České vysoké učení technické v Praze 25. 5. 2009 Osnova Úvod STC Závěr 1 Úvod Motivace Ukázka technologie
Dolování dat z multimediálních databází. Ing. Igor Szöke Speech group ÚPGM, FIT, VUT
 Dolování dat z multimediálních databází Ing. Igor Szöke Speech group ÚPGM, FIT, VUT Obsah prezentace Co jsou multimediální databáze Možnosti dolování dat v multimediálních databázích Vyhledávání fotografií
Dolování dat z multimediálních databází Ing. Igor Szöke Speech group ÚPGM, FIT, VUT Obsah prezentace Co jsou multimediální databáze Možnosti dolování dat v multimediálních databázích Vyhledávání fotografií
Vytěžování znalostí z dat
 Vytěžování znalostí z dat Department of Computer Systems Faculty of Information Technology Czech Technical University in Prague Přednáška 5: Hodnocení kvality modelu BI-VZD, 09/2011 MI-POA Evropský sociální
Vytěžování znalostí z dat Department of Computer Systems Faculty of Information Technology Czech Technical University in Prague Přednáška 5: Hodnocení kvality modelu BI-VZD, 09/2011 MI-POA Evropský sociální
DATABÁZOVÉ SYSTÉMY. Metodický list č. 1
 Metodický list č. 1 Cíl: Cílem předmětu je získat přehled o možnostech a principech databázového zpracování, získat v tomto směru znalosti potřebné pro informačního manažera. Databázové systémy, databázové
Metodický list č. 1 Cíl: Cílem předmětu je získat přehled o možnostech a principech databázového zpracování, získat v tomto směru znalosti potřebné pro informačního manažera. Databázové systémy, databázové
Business Intelligence
 Business Intelligence Skorkovský KAMI, ESF MU Principy BI zpracování velkých objemů dat tak, aby výsledek této akce manažerům pomohl k rozhodování při řízení procesů výsledkem zpracování musí být relevantní
Business Intelligence Skorkovský KAMI, ESF MU Principy BI zpracování velkých objemů dat tak, aby výsledek této akce manažerům pomohl k rozhodování při řízení procesů výsledkem zpracování musí být relevantní
KMA/PDB. Karel Janečka. Tvorba materiálů byla podpořena z prostředků projektu FRVŠ č. F0584/2011/F1d
 KMA/PDB Prostorové databáze Karel Janečka Tvorba materiálů byla podpořena z prostředků projektu FRVŠ č. F0584/2011/F1d Sylabus předmětu KMA/PDB Úvodní přednáška Základní terminologie Motivace rozdíl klasické
KMA/PDB Prostorové databáze Karel Janečka Tvorba materiálů byla podpořena z prostředků projektu FRVŠ č. F0584/2011/F1d Sylabus předmětu KMA/PDB Úvodní přednáška Základní terminologie Motivace rozdíl klasické
Úvod do databázových systémů
 Vysoká škola báňská Technická univerzita Ostrava Fakulta elektrotechniky a informatiky Katedra informatiky Database Research Group Úvod do databázových systémů Cvičení 3 Ing. Petr Lukáš petr.lukas@vsb.cz
Vysoká škola báňská Technická univerzita Ostrava Fakulta elektrotechniky a informatiky Katedra informatiky Database Research Group Úvod do databázových systémů Cvičení 3 Ing. Petr Lukáš petr.lukas@vsb.cz
ANALÝZA A KLASIFIKACE DAT. Institut biostatistiky a analýz
 ANALÝZA A KLASIFIKACE DAT prof. Ing. Jiří Holčík,, CSc. VII. VOLBA A VÝBĚR PŘÍZNAKŮ ZAČÍNÁME kolik a jaké příznaky? málo příznaků možná chyba klasifikace; moc příznaků možná nepřiměřená pracnost, vysoké
ANALÝZA A KLASIFIKACE DAT prof. Ing. Jiří Holčík,, CSc. VII. VOLBA A VÝBĚR PŘÍZNAKŮ ZAČÍNÁME kolik a jaké příznaky? málo příznaků možná chyba klasifikace; moc příznaků možná nepřiměřená pracnost, vysoké
Dobývání a vizualizace znalostí
 Dobývání a vizualizace znalostí Olga Štěpánková et al. 1 Osnova předmětu 1. Dobývání znalostí - popis a metodika procesu a objasnění základních pojmů 2. Nástroje pro modelování klasifikovaných dat a jejich
Dobývání a vizualizace znalostí Olga Štěpánková et al. 1 Osnova předmětu 1. Dobývání znalostí - popis a metodika procesu a objasnění základních pojmů 2. Nástroje pro modelování klasifikovaných dat a jejich
Texto t vá v á d at a a t a dobývání znalostí
 Textová data a dobývání znalostí Obsah prezentace Co je to dobývání znalostí z dat (TM: text mining) a proč je užitečné? Hlavní cíle a úlohy TM. Čím se liší práce s textovými daty např. od práce se senzorickými
Textová data a dobývání znalostí Obsah prezentace Co je to dobývání znalostí z dat (TM: text mining) a proč je užitečné? Hlavní cíle a úlohy TM. Čím se liší práce s textovými daty např. od práce se senzorickými
Komunikace člověk počítač v přirozeném jazyce
 Komunikace člověk počítač v přirozeném jazyce 16. 5. 2012 10-1 Principy komunikace člověk - počítač v přirozeném jazyce 2 1 3 5 Technischer Dienst 4 Telefonischer Dienst Vertriebs-Dienst 10-2 Sensorické
Komunikace člověk počítač v přirozeném jazyce 16. 5. 2012 10-1 Principy komunikace člověk - počítač v přirozeném jazyce 2 1 3 5 Technischer Dienst 4 Telefonischer Dienst Vertriebs-Dienst 10-2 Sensorické
Algoritmizace prostorových úloh
 Algoritmizace prostorových úloh Vektorová data Daniela Szturcová Prostorová data Geoobjekt entita definovaná v prostoru. Znalost jeho identifikace, lokalizace umístění v prostoru, vlastností vlastních
Algoritmizace prostorových úloh Vektorová data Daniela Szturcová Prostorová data Geoobjekt entita definovaná v prostoru. Znalost jeho identifikace, lokalizace umístění v prostoru, vlastností vlastních
RELACE, OPERACE. Relace
 RELACE, OPERACE Relace Užití: 1. K popisu (evidenci) nějaké množiny objektů či jevů, které lze charakterizovat pomocí jejich vlastnostmi. Entita je popsána pomocí atributů. Ty se vybírají z domén. Různé
RELACE, OPERACE Relace Užití: 1. K popisu (evidenci) nějaké množiny objektů či jevů, které lze charakterizovat pomocí jejich vlastnostmi. Entita je popsána pomocí atributů. Ty se vybírají z domén. Různé
teorie logických spojek chápaných jako pravdivostní funkce
 Výroková logika teorie logických spojek chápaných jako pravdivostní funkce zabývá se způsoby tvoření výroků pomocí spojek a vztahy mezi pravdivostí různých výroků používá specifický jazyk složený z výrokových
Výroková logika teorie logických spojek chápaných jako pravdivostní funkce zabývá se způsoby tvoření výroků pomocí spojek a vztahy mezi pravdivostí různých výroků používá specifický jazyk složený z výrokových
Popis zobrazení pomocí fuzzy logiky
 Popis zobrazení pomocí fuzzy logiky diplomová práce Ján Fröhlich KM, FJFI, ČVUT 23. dubna 2009 Ján Fröhlich ( KM, FJFI, ČVUT ) Popis zobrazení pomocí fuzzy logiky 23. dubna 2009 1 / 25 Obsah 1 Úvod Základy
Popis zobrazení pomocí fuzzy logiky diplomová práce Ján Fröhlich KM, FJFI, ČVUT 23. dubna 2009 Ján Fröhlich ( KM, FJFI, ČVUT ) Popis zobrazení pomocí fuzzy logiky 23. dubna 2009 1 / 25 Obsah 1 Úvod Základy
MANAŽERSKÉ ROZHODOVÁNÍ ZA VYUŽITÍ METOD PRO ZPRACOVÁNÍ DOKUMENTŮ
 MANAŽERSKÉ ROZHODOVÁNÍ ZA VYUŽITÍ METOD PRO ZPRACOVÁNÍ DOKUMENTŮ Hana Kopáčková, Renáta Máchová Ústav systémového inženýrství a informatiky, Fakulta ekonomicko-správní, UPA Abstrakt: Tento příspěvek se
MANAŽERSKÉ ROZHODOVÁNÍ ZA VYUŽITÍ METOD PRO ZPRACOVÁNÍ DOKUMENTŮ Hana Kopáčková, Renáta Máchová Ústav systémového inženýrství a informatiky, Fakulta ekonomicko-správní, UPA Abstrakt: Tento příspěvek se
Obsah. Kapitola 1. Kapitola 2. Kapitola 3. Úvod 9
 Obsah Úvod 9 Kapitola 1 Business Intelligence, datové sklady 11 Přechod od transakčních databází k analytickým..................... 13 Kvalita údajů pro analýzy................................................
Obsah Úvod 9 Kapitola 1 Business Intelligence, datové sklady 11 Přechod od transakčních databází k analytickým..................... 13 Kvalita údajů pro analýzy................................................
Algoritmizace prostorových úloh
 INOVACE BAKALÁŘSKÝCH A MAGISTERSKÝCH STUDIJNÍCH OBORŮ NA HORNICKO-GEOLOGICKÉ FAKULTĚ VYSOKÉ ŠKOLY BÁŇSKÉ - TECHNICKÉ UNIVERZITY OSTRAVA Algoritmizace prostorových úloh Datové struktury Daniela Szturcová
INOVACE BAKALÁŘSKÝCH A MAGISTERSKÝCH STUDIJNÍCH OBORŮ NA HORNICKO-GEOLOGICKÉ FAKULTĚ VYSOKÉ ŠKOLY BÁŇSKÉ - TECHNICKÉ UNIVERZITY OSTRAVA Algoritmizace prostorových úloh Datové struktury Daniela Szturcová
Aplikace algoritmů umělé inteligence pro data mining v prostředí realitního trhu
 Jihočeská univerzita v Českých Budějovicích Přírodovědecká fakulta Aplikace algoritmů umělé inteligence pro data mining v prostředí realitního trhu Diplomová práce Bc. Miloslav Thon Školitel: Ing. Jan
Jihočeská univerzita v Českých Budějovicích Přírodovědecká fakulta Aplikace algoritmů umělé inteligence pro data mining v prostředí realitního trhu Diplomová práce Bc. Miloslav Thon Školitel: Ing. Jan
Algoritmy pro shlukování prostorových dat
 Algoritmy pro shlukování prostorových dat Marta Žambochová Katedra matematiky a informatiky Fakulta sociálně ekonomická Univerzita J. E. Purkyně v Ústí nad Labem ROBUST 21. 26. leden 2018 Rybník - Hostouň
Algoritmy pro shlukování prostorových dat Marta Žambochová Katedra matematiky a informatiky Fakulta sociálně ekonomická Univerzita J. E. Purkyně v Ústí nad Labem ROBUST 21. 26. leden 2018 Rybník - Hostouň
Výroková logika. Teoretická informatika Tomáš Foltýnek
 Výroková logika Teoretická informatika Tomáš Foltýnek foltynek@pef.mendelu.cz Teoretická informatika strana 2 Opakování z minulé přednášky Co je to formalismus a co je jeho cílem? Formulujte Russelův paradox
Výroková logika Teoretická informatika Tomáš Foltýnek foltynek@pef.mendelu.cz Teoretická informatika strana 2 Opakování z minulé přednášky Co je to formalismus a co je jeho cílem? Formulujte Russelův paradox
Okruhy ke státní závěrečné zkoušce z vedlejší specializace Informatika v řízení podniku
 Okruhy ke státní závěrečné zkoušce z vedlejší specializace Informatika v řízení podniku Aplikace auditních postupů Vyberte si jeden typ auditu (útvaru, projektu, aplikace, procesu, ) a na něm demonstrujte
Okruhy ke státní závěrečné zkoušce z vedlejší specializace Informatika v řízení podniku Aplikace auditních postupů Vyberte si jeden typ auditu (útvaru, projektu, aplikace, procesu, ) a na něm demonstrujte
Úvod do databázových systémů
 Vysoká škola báňská Technická univerzita Ostrava Fakulta elektrotechniky a informatiky Úvod do databázových systémů Cvičení 3 Ing. Petr Lukáš petr.lukas@vsb.cz Ostrava, 2014 Opakování 4 fáze vytváření
Vysoká škola báňská Technická univerzita Ostrava Fakulta elektrotechniky a informatiky Úvod do databázových systémů Cvičení 3 Ing. Petr Lukáš petr.lukas@vsb.cz Ostrava, 2014 Opakování 4 fáze vytváření
Následující text je součástí učebních textů předmětu Bi0034 Analýza a klasifikace dat a je určen
 11. Klasifikace V této kapitole se seznámíme s účelem, principy a jednotlivými metodami klasifikace dat, jež tvoří samostatnou rozsáhlou oblast analýzy dat. Klasifikace umožňuje určit, do které skupiny
11. Klasifikace V této kapitole se seznámíme s účelem, principy a jednotlivými metodami klasifikace dat, jež tvoří samostatnou rozsáhlou oblast analýzy dat. Klasifikace umožňuje určit, do které skupiny
Využití metod strojového učení v bioinformatice David Hoksza
 Využití metod strojového učení v bioinformatice David Hoksza SIRET Research Group Katedra softwarového inženýrství, Matematicko-fyzikální fakulta Karlova Univerzita v Praze Bioinformatika Biologické inspirace
Využití metod strojového učení v bioinformatice David Hoksza SIRET Research Group Katedra softwarového inženýrství, Matematicko-fyzikální fakulta Karlova Univerzita v Praze Bioinformatika Biologické inspirace
SQL tříhodnotová logika
 SQL tříhodnotová logika Jmeno Prijmeni Student Jaroslav Novák true Josef Novotný false Jiří Brabenec SELECT * FROM OSOBA WHERE Student!= true Jaký bude výsledek? SQL tříhodnotová logika Jmeno Prijmeni
SQL tříhodnotová logika Jmeno Prijmeni Student Jaroslav Novák true Josef Novotný false Jiří Brabenec SELECT * FROM OSOBA WHERE Student!= true Jaký bude výsledek? SQL tříhodnotová logika Jmeno Prijmeni
Využití SVD pro indexování latentní sémantiky
 Využití SVD pro indexování latentní sémantiky Michal Krátký 1 Department of Computer Science, VŠB-Technical University of Ostrava, Czech Republic michal.kratky@vsb.cz Abstrakt Zpracováváním velkého množství
Využití SVD pro indexování latentní sémantiky Michal Krátký 1 Department of Computer Science, VŠB-Technical University of Ostrava, Czech Republic michal.kratky@vsb.cz Abstrakt Zpracováváním velkého množství
Diplomová práce Sumarizace rozdílů v recenzních textech
 Západočeská univerzita v Plzni Fakulta aplikovaných věd Katedra informatiky a výpočetní techniky Diplomová práce Sumarizace rozdílů v recenzních textech Plzeň 2018 Michal Veverka Místo této strany bude
Západočeská univerzita v Plzni Fakulta aplikovaných věd Katedra informatiky a výpočetní techniky Diplomová práce Sumarizace rozdílů v recenzních textech Plzeň 2018 Michal Veverka Místo této strany bude
Databáze Bc. Veronika Tomsová
 Databáze Bc. Veronika Tomsová Databázové schéma Mapování konceptuálního modelu do (relačního) databázového schématu. 2/21 Fyzické ik schéma databáze Určuje č jakým způsobem ů jsou data v databázi ukládána
Databáze Bc. Veronika Tomsová Databázové schéma Mapování konceptuálního modelu do (relačního) databázového schématu. 2/21 Fyzické ik schéma databáze Určuje č jakým způsobem ů jsou data v databázi ukládána
Předzpracování dat. Lenka Vysloužilová
 Předzpracování dat Lenka Vysloužilová 1 Metodika CRISP-DM (www.crisp-dm.org) Příprava dat Data Preparation příprava dat pro modelování selekce příznaků výběr relevantních příznaků čištění dat získávání
Předzpracování dat Lenka Vysloužilová 1 Metodika CRISP-DM (www.crisp-dm.org) Příprava dat Data Preparation příprava dat pro modelování selekce příznaků výběr relevantních příznaků čištění dat získávání
Metody tvorby ontologií a sémantický web. Martin Malčík, Rostislav Miarka
 Metody tvorby ontologií a sémantický web Martin Malčík, Rostislav Miarka Obsah Reprezentace znalostí Ontologie a sémantický web Tvorba ontologií Hierarchie znalostí (D.R.Tobin) Data jakékoliv znakové řetězce
Metody tvorby ontologií a sémantický web Martin Malčík, Rostislav Miarka Obsah Reprezentace znalostí Ontologie a sémantický web Tvorba ontologií Hierarchie znalostí (D.R.Tobin) Data jakékoliv znakové řetězce
Wichterlovo gymnázium, Ostrava-Poruba, příspěvková organizace. Maturitní otázky z předmětu INFORMATIKA A VÝPOČETNÍ TECHNIKA
 Wichterlovo gymnázium, Ostrava-Poruba, příspěvková organizace Maturitní otázky z předmětu INFORMATIKA A VÝPOČETNÍ TECHNIKA 1. Algoritmus a jeho vlastnosti algoritmus a jeho vlastnosti, formy zápisu algoritmu
Wichterlovo gymnázium, Ostrava-Poruba, příspěvková organizace Maturitní otázky z předmětu INFORMATIKA A VÝPOČETNÍ TECHNIKA 1. Algoritmus a jeho vlastnosti algoritmus a jeho vlastnosti, formy zápisu algoritmu
Mgr. Petr Šmejkal.
 Rešeršní činnost Mgr. Petr Šmejkal 43262@mail.muni.cz Rešeršní strategie možnosti, jak postupovat při vyhledávání výzkum práce referenčních knihovníků a rešeršérů 1. strategie stavebních kamenů 2. vyhledávání
Rešeršní činnost Mgr. Petr Šmejkal 43262@mail.muni.cz Rešeršní strategie možnosti, jak postupovat při vyhledávání výzkum práce referenčních knihovníků a rešeršérů 1. strategie stavebních kamenů 2. vyhledávání
Univerzita Pardubice Fakulta ekonomicko správní. Srovnávací studie text miningových nástrojů. Lukáš Hrdlička
 Univerzita Pardubice Fakulta ekonomicko správní Srovnávací studie text miningových nástrojů Lukáš Hrdlička Diplomová práce 2009 Prohlašuji: Tuto práci jsem vypracoval samostatně. Veškeré literární prameny
Univerzita Pardubice Fakulta ekonomicko správní Srovnávací studie text miningových nástrojů Lukáš Hrdlička Diplomová práce 2009 Prohlašuji: Tuto práci jsem vypracoval samostatně. Veškeré literární prameny
NPRG030 Programování I, 2010/11
 Podmínka = něco, co JE, nebo NENÍ splněno typ Boolean hodnoty: TRUE pravda FALSE lež domluva (optimistická): FALSE < TRUE když X, Y jsou (číselné) výrazy, potom X = Y X Y X < Y X > Y X = Y jsou
Podmínka = něco, co JE, nebo NENÍ splněno typ Boolean hodnoty: TRUE pravda FALSE lež domluva (optimistická): FALSE < TRUE když X, Y jsou (číselné) výrazy, potom X = Y X Y X < Y X > Y X = Y jsou
ANALÝZA BIOLOGICKÝCH A KLINICKÝCH DAT V MEZIOBOROVÉM POJETÍ
 ANALÝZA BIOLOGICKÝCH A KLINICKÝCH DAT V MEZIOBOROVÉM POJETÍ INVESTICE Institut DO biostatistiky ROZVOJE VZDĚLÁVÁNÍ a analýz 5. LETNÍ ŠKOLA MATEMATICKÉ BIOLOGIE ANALÝZA BIOLOGICKÝCH A KLINICKÝCH DAT V MEZIOBOROVÉM
ANALÝZA BIOLOGICKÝCH A KLINICKÝCH DAT V MEZIOBOROVÉM POJETÍ INVESTICE Institut DO biostatistiky ROZVOJE VZDĚLÁVÁNÍ a analýz 5. LETNÍ ŠKOLA MATEMATICKÉ BIOLOGIE ANALÝZA BIOLOGICKÝCH A KLINICKÝCH DAT V MEZIOBOROVÉM
Úvodem Dříve les než stromy 3 Operace s maticemi
 Obsah 1 Úvodem 13 2 Dříve les než stromy 17 2.1 Nejednoznačnost terminologie 17 2.2 Volba metody analýzy dat 23 2.3 Přehled vybraných vícerozměrných metod 25 2.3.1 Metoda hlavních komponent 26 2.3.2 Faktorová
Obsah 1 Úvodem 13 2 Dříve les než stromy 17 2.1 Nejednoznačnost terminologie 17 2.2 Volba metody analýzy dat 23 2.3 Přehled vybraných vícerozměrných metod 25 2.3.1 Metoda hlavních komponent 26 2.3.2 Faktorová
Logika a logické programování
 Logika a logické programování témata ke zkoušce Poslední aktualizace: 16. prosince 2009 Zkouška je písemná, skládá se obvykle ze sedmi otázek (může být více nebo méně, podle náročnosti otázek), z toho
Logika a logické programování témata ke zkoušce Poslední aktualizace: 16. prosince 2009 Zkouška je písemná, skládá se obvykle ze sedmi otázek (může být více nebo méně, podle náročnosti otázek), z toho
Inteligentní systémy (TIL) Marie Duží
 Marie Duží") Inteligentní systémy (TIL) Marie Duží http://www.cs.vsb.cz/duzi/ /d Přednáška 3 Sémantické schéma Výraz vyjadřuje označuje Význam (konstrukce konstrukce) k ) konstruuje denotát Ontologie TIL: rozvětvená
Inteligentní systémy (TIL) Marie Duží http://www.cs.vsb.cz/duzi/ /d Přednáška 3 Sémantické schéma Výraz vyjadřuje označuje Význam (konstrukce konstrukce) k ) konstruuje denotát Ontologie TIL: rozvětvená
Dobývání a vizualizace znalostí. Olga Štěpánková et al.
 Dobývání a vizualizace znalostí Olga Štěpánková et al. 1 Osnova předmětu Dobývání znalostí - popis a metodika procesu CRISP a objasnění základních pojmů Nástroje pro modelování klasifikovaných dat a jejich
Dobývání a vizualizace znalostí Olga Štěpánková et al. 1 Osnova předmětu Dobývání znalostí - popis a metodika procesu CRISP a objasnění základních pojmů Nástroje pro modelování klasifikovaných dat a jejich
Multidimenzionální pohled na zdravotnické prostředí. INMED Petr Tůma
 Multidimenzionální pohled na zdravotnické prostředí INMED - 21.11.2003 Petr Tůma Koncepce multid pohledu Poskytování péče probíhá v multidimenzionálním světě; dimenze tento svět mapují podobně jako souřadnice
Multidimenzionální pohled na zdravotnické prostředí INMED - 21.11.2003 Petr Tůma Koncepce multid pohledu Poskytování péče probíhá v multidimenzionálním světě; dimenze tento svět mapují podobně jako souřadnice
Uživatelská podpora v prostředí WWW
 Uživatelská podpora v prostředí WWW Jiří Jelínek Katedra managementu informací Fakulta managementu Jindřichův Hradec Vysoká škola ekonomická Praha Úvod WWW obsáhlost obsahová i formátová pestrost dokumenty,
Uživatelská podpora v prostředí WWW Jiří Jelínek Katedra managementu informací Fakulta managementu Jindřichův Hradec Vysoká škola ekonomická Praha Úvod WWW obsáhlost obsahová i formátová pestrost dokumenty,
Klasifikace webových stránek na základě vizuální podoby a odkazů mezi dokumenty
 Klasifikace webových stránek na základě vizuální podoby a odkazů mezi dokumenty Petr Loukota, Vladimír Bartík Ústav informačních systémů, Fakulta informačních technologií VUT v Brně, Česká republika iloukota@fit.vutbr.cz,
Klasifikace webových stránek na základě vizuální podoby a odkazů mezi dokumenty Petr Loukota, Vladimír Bartík Ústav informačních systémů, Fakulta informačních technologií VUT v Brně, Česká republika iloukota@fit.vutbr.cz,
Vojtěch Franc Centrum strojového vnímání, Katedra kybernetiky, FEL ČVUT v Praze Eyedea Recognition s.r.o MLMU 29.4.2015
 Příklady použití metod strojového učení v rozpoznávání tváří Vojtěch Franc Centrum strojového vnímání, Katedra kybernetiky, FEL ČVUT v Praze Eyedea Recognition s.r.o MLMU 29.4.2015 Stavební bloky systému
Příklady použití metod strojového učení v rozpoznávání tváří Vojtěch Franc Centrum strojového vnímání, Katedra kybernetiky, FEL ČVUT v Praze Eyedea Recognition s.r.o MLMU 29.4.2015 Stavební bloky systému
Teorie informace a kódování (KMI/TIK) Reed-Mullerovy kódy
 Reed-Mullerovy kódy") Teorie informace a kódování (KMI/TIK) Reed-Mullerovy kódy Lukáš Havrlant Univerzita Palackého 10. ledna 2014 Primární zdroj Jiří Adámek: Foundations of Coding. Strany 137 160. Na webu ke stažení, heslo:
Teorie informace a kódování (KMI/TIK) Reed-Mullerovy kódy Lukáš Havrlant Univerzita Palackého 10. ledna 2014 Primární zdroj Jiří Adámek: Foundations of Coding. Strany 137 160. Na webu ke stažení, heslo:
VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ BRNO UNIVERSITY OF TECHNOLOGY
 VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ BRNO UNIVERSITY OF TECHNOLOGY FAKULTA INFORMAČNÍCH TECHNOLOGIÍ ÚSTAV INFORMAČNÍCH SYSTÉMŮ FACULTY OF INFORMATION TECHNOLOGY DEPARTMENT OF INFORMATION SYSTEMS VYHLEDÁVÁNÍ INFORMACÍ
VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ BRNO UNIVERSITY OF TECHNOLOGY FAKULTA INFORMAČNÍCH TECHNOLOGIÍ ÚSTAV INFORMAČNÍCH SYSTÉMŮ FACULTY OF INFORMATION TECHNOLOGY DEPARTMENT OF INFORMATION SYSTEMS VYHLEDÁVÁNÍ INFORMACÍ
NPRG030 Programování I, 2016/17 1 / :58:13
 NPRG030 Programování I, 2016/17 1 / 31 10. 10. 2016 10:58:13 Podmínka = něco, co JE, nebo NENÍ splněno typ Boolean hodnoty: TRUE pravda FALSE lež domluva (optimistická): FALSE < TRUE NPRG030 Programování
NPRG030 Programování I, 2016/17 1 / 31 10. 10. 2016 10:58:13 Podmínka = něco, co JE, nebo NENÍ splněno typ Boolean hodnoty: TRUE pravda FALSE lež domluva (optimistická): FALSE < TRUE NPRG030 Programování
VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ
 VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ BRNO UNIVERSITY OF TECHNOLOGY FAKULTA ELEKTROTECHNIKY A KOMUNIKAČNÍCH TECHNOLOGIÍ ÚSTAV TELEKOMUNIKACÍ FACULTY OF ELECTRICAL ENGINEERING AND COMMUNICATION DEPARTMENT OF TELECOMMUNICATIONS
VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ BRNO UNIVERSITY OF TECHNOLOGY FAKULTA ELEKTROTECHNIKY A KOMUNIKAČNÍCH TECHNOLOGIÍ ÚSTAV TELEKOMUNIKACÍ FACULTY OF ELECTRICAL ENGINEERING AND COMMUNICATION DEPARTMENT OF TELECOMMUNICATIONS
TEORIE ZPRACOVÁNÍ DAT
 Vysoká škola báňská - Technická univerzita Ostrava Fakulta elektrotechniky a informatiky TEORIE ZPRACOVÁNÍ DAT pro kombinované a distanční studium Jana Šarmanová Ostrava 2003 Jana Šarmanová, 2003 Fakulta
Vysoká škola báňská - Technická univerzita Ostrava Fakulta elektrotechniky a informatiky TEORIE ZPRACOVÁNÍ DAT pro kombinované a distanční studium Jana Šarmanová Ostrava 2003 Jana Šarmanová, 2003 Fakulta
Algoritmy a struktury neuropočítačů ASN - P11
 Aplikace UNS při rozpoznání obrazů Základní úloha segmentace obrazu rozdělení obrazu do několika významných oblastí klasifikační úloha, clusterová analýza target Metody Kohonenova metoda KSOM Kohonenova
Aplikace UNS při rozpoznání obrazů Základní úloha segmentace obrazu rozdělení obrazu do několika významných oblastí klasifikační úloha, clusterová analýza target Metody Kohonenova metoda KSOM Kohonenova
PRODUKTY. Tovek Tools
 Analyst Pack je desktopovou aplikací určenou k vyhledávání informací, tvorbě různých typů analýz a vytváření přehledů a rešerší. Jsou vhodné pro práci i s velkým objemem textových dat z různorodých informačních
Analyst Pack je desktopovou aplikací určenou k vyhledávání informací, tvorbě různých typů analýz a vytváření přehledů a rešerší. Jsou vhodné pro práci i s velkým objemem textových dat z různorodých informačních
Moderní metody vyhledávání dokumentů v rozsáhlých plnotextových databázích : příklad vektorového modelu
 Moderní metody vyhledávání dokumentů v rozsáhlých plnotextových databázích : příklad vektorového modelu Petr Houdek 1, Josef Schwarz 2, Václav Snášel 3 1 Parlamentní knihovna, Sněmovní 4, Praha houdek@psp.cz
Moderní metody vyhledávání dokumentů v rozsáhlých plnotextových databázích : příklad vektorového modelu Petr Houdek 1, Josef Schwarz 2, Václav Snášel 3 1 Parlamentní knihovna, Sněmovní 4, Praha houdek@psp.cz
GIS Geografické informační systémy
 GIS Geografické informační systémy Obsah přednášky Prostorové vektorové modely Špagetový model Topologický model Převody geometrií Vektorový model Reprezentuje reálný svět po jednotlivých složkách popisu
GIS Geografické informační systémy Obsah přednášky Prostorové vektorové modely Špagetový model Topologický model Převody geometrií Vektorový model Reprezentuje reálný svět po jednotlivých složkách popisu
Algoritmy a struktury neuropočítačů ASN - P10. Aplikace UNS v biomedicíně
 Aplikace UNS v biomedicíně aplikace v medicíně postup při zpracování úloh Aplikace UNS v medicíně Důvod: nalezení exaktnějších, levnějších a snadnějších metod určování diagnóz pro lékaře nalezení šetrnějších
Aplikace UNS v biomedicíně aplikace v medicíně postup při zpracování úloh Aplikace UNS v medicíně Důvod: nalezení exaktnějších, levnějších a snadnějších metod určování diagnóz pro lékaře nalezení šetrnějších
GRR. získávání znalostí v geografických datech Autoři. Knowledge Discovery Group Faculty of Informatics Masaryk Univerzity Brno, Czech Republic
 GRR získávání znalostí v geografických datech Autoři Knowledge Discovery Group Faculty of Informatics Masaryk Univerzity Brno, Czech Republic GRR cílet 2 GRR - Popis systému - cíle systém pro dolování
GRR získávání znalostí v geografických datech Autoři Knowledge Discovery Group Faculty of Informatics Masaryk Univerzity Brno, Czech Republic GRR cílet 2 GRR - Popis systému - cíle systém pro dolování
PRODUKTY. Tovek Tools
 jsou desktopovou aplikací určenou k vyhledávání informací, tvorbě různých typů analýz a vytváření přehledů a rešerší. Jsou vhodné pro práci i s velkým objemem textových dat z různorodých informačních zdrojů.
jsou desktopovou aplikací určenou k vyhledávání informací, tvorbě různých typů analýz a vytváření přehledů a rešerší. Jsou vhodné pro práci i s velkým objemem textových dat z různorodých informačních zdrojů.
Výroková logika syntaxe a sémantika
 syntaxe a sémantika Jiří Velebil: AD0B01LGR 2015 Handout 01: & sémantika VL 1/16 1 Proč formální jazyk? 1 Přirozené jazyky jsou složité a často nejednoznačné. 2 Komunikace s formálními nástroji musí být
syntaxe a sémantika Jiří Velebil: AD0B01LGR 2015 Handout 01: & sémantika VL 1/16 1 Proč formální jazyk? 1 Přirozené jazyky jsou složité a často nejednoznačné. 2 Komunikace s formálními nástroji musí být
Vyhledávání podle klíčových slov v relačních databázích. Dotazovací jazyky I ZS 2010/11 Karel Poledna
 Vyhledávání podle klíčových slov v relačních databázích Dotazovací jazyky I ZS 2010/11 Karel Poledna Vyhledávání podle klíčových slov Uživatel zadá jedno nebo více slov a jsou mu zobrazeny výsledky. Uživatel
Vyhledávání podle klíčových slov v relačních databázích Dotazovací jazyky I ZS 2010/11 Karel Poledna Vyhledávání podle klíčových slov Uživatel zadá jedno nebo více slov a jsou mu zobrazeny výsledky. Uživatel
Dobývání znalostí z databází
 Dobývání znalostí z databází (Knowledge Discovery in Databases, Data Mining,..., Knowledge Destilery,...) Non-trivial process of identifying valid, novel, potentially useful and ultimately understandable
Dobývání znalostí z databází (Knowledge Discovery in Databases, Data Mining,..., Knowledge Destilery,...) Non-trivial process of identifying valid, novel, potentially useful and ultimately understandable
Obsah. Předmluva 13. O autorovi 15. Poděkování 16. O odborných korektorech 17. Úvod 19
 Předmluva 13 O autorovi 15 Poděkování 16 O odborných korektorech 17 Úvod 19 Co kniha popisuje 19 Co budete potřebovat 20 Komu je kniha určena 20 Styly 21 Zpětná vazba od čtenářů 22 Errata 22 KAPITOLA 1
Předmluva 13 O autorovi 15 Poděkování 16 O odborných korektorech 17 Úvod 19 Co kniha popisuje 19 Co budete potřebovat 20 Komu je kniha určena 20 Styly 21 Zpětná vazba od čtenářů 22 Errata 22 KAPITOLA 1
Petr Křemen. Katedra kybernetiky, FEL ČVUT. Petr Křemen (Katedra kybernetiky, FEL ČVUT) Sémantické sítě a rámce 1 / 112
 Sémantické sítě a rámce 1 / 112") Sémantické sítě a rámce Petr Křemen Katedra kybernetiky, FEL ČVUT Petr Křemen (Katedra kybernetiky, FEL ČVUT) Sémantické sítě a rámce 1 / 112 Co nás čeká 1 Úvod do reprezentace znalostí 2 Sémantické sítě
Sémantické sítě a rámce Petr Křemen Katedra kybernetiky, FEL ČVUT Petr Křemen (Katedra kybernetiky, FEL ČVUT) Sémantické sítě a rámce 1 / 112 Co nás čeká 1 Úvod do reprezentace znalostí 2 Sémantické sítě
Extrakce a selekce příznaků
 Extrakce a selekce příznaků Based on slides Martina Bachlera martin.bachler@igi.tugraz.at, Makoto Miwa And paper Isabelle Guyon, André Elisseeff: An Introduction to variable and feature selection. JMLR,
Extrakce a selekce příznaků Based on slides Martina Bachlera martin.bachler@igi.tugraz.at, Makoto Miwa And paper Isabelle Guyon, André Elisseeff: An Introduction to variable and feature selection. JMLR,
Kartografické modelování V Topologické překrytí - Overlay
 Kartografické modelování V Topologické překrytí - Overlay jaro 2017 Petr Kubíček kubicek@geogr.muni.cz Laboratory on Geoinformatics and Cartography (LGC) Institute of Geography Masaryk University Czech
Kartografické modelování V Topologické překrytí - Overlay jaro 2017 Petr Kubíček kubicek@geogr.muni.cz Laboratory on Geoinformatics and Cartography (LGC) Institute of Geography Masaryk University Czech