Dobývání a vizualizace znalostí
|
|
|
- Miloslav Pešan
- před 9 lety
- Počet zobrazení:
Transkript

1 Dobývání a vizualizace znalostí Olga Štěpánková et al. 1

2 Osnova předmětu 1. Dobývání znalostí - popis a metodika procesu a objasnění základních pojmů 2. Nástroje pro modelování klasifikovaných dat a jejich využití I 3. Vyhodnocení a využití modelů 4. Porozumnění datům a jejich příprava, vizualizace dat 5. Selekce a extrakce příznaků 6. Konstrukce asociačních pravidel (s využitím Apriori algoritmu). 7. Tvorba modelu kombinací více základních modelů 8. Neuronové sítě, volba parametrů a jejich aplikace. 9. Nástroje pro modelování neklasifikovaných dat a jejich využití 10. Práce s časovými řadami. 11. Zpracování přirozeného jazyka jako vstupu 12. Text mining a podpora kreativity 13. Prezentace semestrálních prací 14. Zajímavé aplikace Prerekvizity: Přehled základních pojmů ze statistiky 2

3 Doporučené zdroje P. Berka: Dobývání znalostí z databází, Academia 2003 M. Kubát: Strojové učení v Mařík et al. (eds) Umělá inteligence (1), Academia 1993 F.Železný, J.Kléma, O.Štěpánková: Strojové učení v dobývání dat v Mařík et al. (eds) Umělá inteligence (4), Academia 2003 S. Few: Simple Visualization Techniques for Quantitative Analysis Now you see it. Analytics Press 2009 Michael Berthold, David J. Hand: Intelligent Data Analysis, Springer 1999, 2003 Daniel T. Larose: Discovering Knowledge in Data, Wiley 2005 Daniel T. Larose: Data Mining: Methods and Models, Wiley 2006 Oded Maimon, Lior Rokach (eds): The Data Mining and Knowledge Discovery Handbook, Springer

4 Osnova Úvod: data a jejich rostoucí objem Vytěžování dat (Data Mining) & dobývání znalostí (Knowledge Discovery) a související pojmy Typické postupy DM metodika CRISP-DM Průzkumová analýza dat a její základní vizualizační techniky 4

5 Kde se bere současná záplava dat? Digitální data a archivace. Archivace a její meze. Oblasti: Obchodní transakce (obchodní řetězce, banky, pojišťovny...) Telekomunikace, internet a elektronický obchod Zdravotnictví Věda a výzkum: astronomie, biologie, genomika, Publikace: texty, časopisy a knihy 5
 Telekomunikace, internet a elektronický obchod Zdravotnictví Věda a")
6 Záplava dat? Prefix Násobek mega 10 6 giga 10 9 tera peta exa zetta yotta Ancestry.com má asi 600 terabytů genealogických dat zahrnující US Census data z let 1790 až Data předávaná přes Internet: v roce 1993 asi 100 terabytů. V r odhaduje Cisco, Inetrnetová výměna dat činí asi 160 terabytů/s (tedy asi 5 zettabytů za rok). AT&T zpracovává miliardy spojení za den Země: méně než 3x10 50 atomů. Vznikající objemy dat nelze skladovat ani prohlížet. Je nutné z nich vybírat jen to důležité! Role znalostí. 6
.")
7 Dobývání znalostí z dat Cíl: částečná automatizace procesu získání zajímavých vzorů chování z reálných dat: tvorba jejich modelů - pomocí nástrojů strojového učení, statistiky, databázových technologií, Nové slibné odvětví SW průmyslu, jehož cílem je využít existující data pro zlepšení rozhodovacích procesů a získání nových znalostí 7

8 Souvislosti Strojové učení Vizualizace Dobývání znalostí (Data Mining) Statistika Databázové technologie 8

9 Dobývání znalostí z dat Příklady aplikací: průmysl (diagnostika poruch, predikce spotřeby ) obchod (marketing, bankovnictví) věda (charakterizace karcinogenních látek) medicína (mapování lidského genomu) 9
 medicína (mapování lidského")
10 Definice dobývání znalostí Data Mining is the non-trivial process of identifying valid novel potentially useful and ultimately understandable patterns in data. from Advances in Knowledge Discovery and Data Mining, Fayyad, Piatetsky-Shapiro, Smyth, and Uthurusamy, (Chapter 1), AAAI/MIT Press

11 Terminologie Koncept: oblast zájmu co chceme předpověď počasí Instance(pozorování): - nezávislé pozorované jednotky data o počasí jednoho konkrétního dne Atributy(příznaky): - jednotlivé vlastnosti instance teplota, tlak, množství srážek Příznakový prostor: prostor, jehož dimenze jsou definovány jednotlivými příznaky pozorování jsou body v příznakovém prostoru Matice pozorování: řádky jsou instance a sloupce příznaky 11

12 Metodika CRISP-DM ( 12

13 Zadaní Business Understanding pochopení cílů úlohy náklady hodnotí se přínos stanovení předběžného plánu forma předání dat anonymizace dat formát dat 13

14 Problémy reálných dat? Data obsahují špatné údaje způsobené chybami měřicích přístrojů i lidské obsluhy Nevyplněné údaje Data jsou popsána pomocí příliš mnoha atributů - není zřejmé, které z nich jsou pro řešení zvolené úlohy relevantní. Úspěch modelování závisí na volbě vhodné množiny atributů (PAC učení) Data mají formu složitého relačního schématu, nikoliv jediné tabulky předpokládané atributovými metodami strojového učení POZOR na zpracování osobních údajů!!! 14
 Data mají formu složitého relačního schématu,")
15 Analýza dat Data Understanding získání základní představy o datech kvalita dat (chybějící údaje) descriptivní charakteristiky dat četnosti hodnot (histogramy) minima, maxima, průměry použití vizualizačních technik 15
 minima, maxima, průměry použití")
16 16 Metodika CRISP-DM
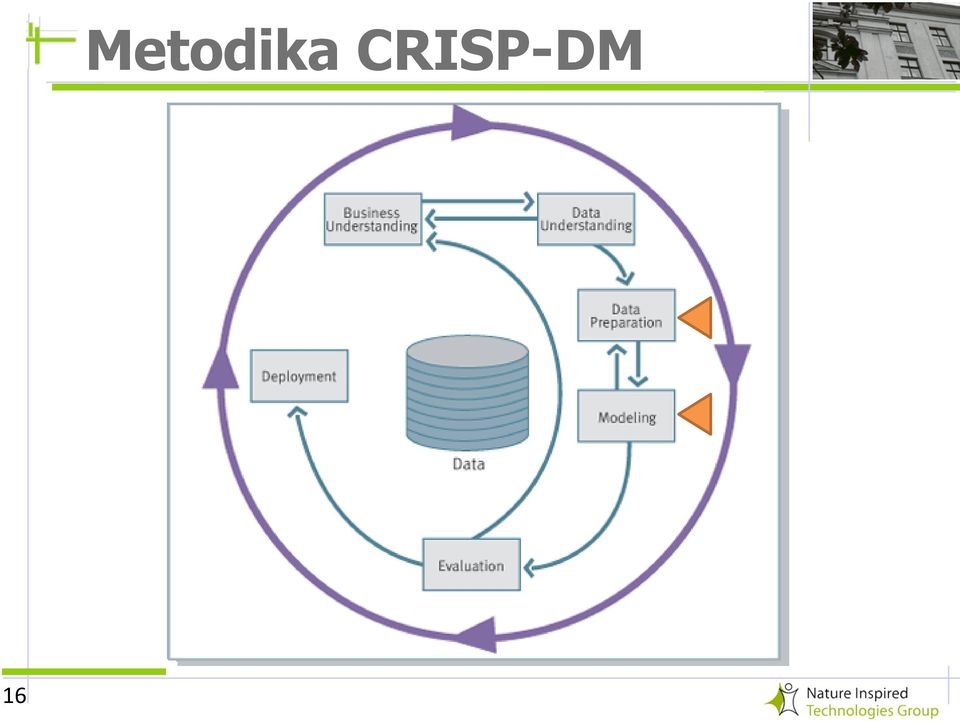
17 Příprava dat Data Preparation příprava dat pro modelování selekce atributů výběr relevantních atributů čištění dat získávání odvozených atributů převod typů dat transformace dat do jedné velké tabulky formátování pro jednotlivé modelovací techniky nejpracnější část celého procesu často se provádí opakovaně 17

18 Modelování - Modeling použití analytických metod (metody strojového učení) používá se více metod příklady metod rozhodovací stromy asociační pravidla shluková analýza statistické metody často návrat zpět k přípravě dat 18

19 Typy úloh Klasifikace: přiřazení třídy objektu Predikce: předpověď chování objektu v čase Asociace: hledání vazeb mezi objekty Shlukování: seskupování podobných objektů 19

20 Učení s učitelem Úloha: Na základě učitelem klasifikovaných trénovacích dat nalezněte jednoduchou metodu, jak přiřadit třídu novým případům, pro které známe stejný soubor příznaků Postupy: statistika, Rozhodovací stromy, Neuronové sítě,...? 20

21 Učení bez učitele Úloha: Nalezněte přirozené shluky ve zpracovávaných datech, která nemají žádné značky 21
22 22 Metodika CRISP-DM
23 Vyhodnocení - Evaluation zhodnocení dosažených výsledků modelování zhodnocení výsledků z pohledu zadání použití vizualizačních technik často návrat zpět na začátek celého procesu a stanovení nových cílů (úprava zadaní) 23
24 Testování modelů Q: Jak dobře funguje (klasifikuje) model, který jsme vytvořili? Chyba, s jakou model klasifikuje na trénovacích datech není dobrým odhadem pro chování modelu na dosud neznámých datech Q: Proč? Nová data nebudou přesně stejná jako ta použitá pro učení! A navíc i náhodně vygenerovaný konečný soubor dat lze popsat nějakým modelem (třeba samotnou výchozí tabulkou). 24
25 Testování pro ROZSÁHLÁ data Máme-li hodně dat (tisíce instancí), které obsahují pro každou třídu dostatek vzorků (stovky instancí), pak stačí provést jednoduché testování: Rozděl výchozí data náhodně do 2 množin: trénovací (asi 2/3 dat) a testovací (zbytek, tedy asi 1/3 dat) Vytvoř klasifikační model nad trénovací množinou a proveď hodnocení (např.pomocí relativní chyby) na testovací množině Relativní chyba: procentuální podíl chybných instancí vůči mohutnosti celé uvažované množiny instancí 25
26 26 Metodika CRISP-DM
27 Použití - Deployment Úprava získaných znalostí do srozumitelné formy pro zadavatele Případně pomoc s implementací výsledků do praxe 27
28 Časové nároky procesu? Formulace problému Volba typu řešení Předpokládané využití Posouzení dat Potřebná čast času v rámci celého projektu (v %) Význam pro úspěch projektu (v %) Příprava dat Modelování 28
29 Shrnutí Co je dobývání znalostí? Co je koncept, pozorování(instance), příznak(atribut), příznakový prostor, matice pozorování? Co je metodika CRISP-DM a jaké jsou její jednotlivé fáze? Jaký je rozdíl mezi učením s učitelem a učením bez učitele? Proč při testování rozdělujeme data na trénovací a testovací množinu? 29
30 Analýza dat Data Understanding získání základní představy o datech počty instancí, atributů chybějící hodnoty descriptivní charakteristiky dat podle typu dat četnosti hodnot (histogramy) minima, maxima, průměry odlehlé hodnoty Vizualizace dat 30

31 31 Histogram

32 32 Scater plot = XY graf

33 Box graf B D F D M F H B H M medián F horní a dolní kvartil 1.5R F R F 1.5R F R B F D F F H D F D 1.5R F 33
34 Shrnutí Co je to kvartil? Jaký je rozdíl mezi výběrovým průměrem a mediánem? Co je to histogram? Jak se zobrazuje odlehlá hodnota v box grafu? 34
Dobývání a vizualizace znalostí
 Dobývání a vizualizace znalostí Olga Štěpánková et al. 1 Osnova předmětu 1. Dobývání znalostí - popis a metodika procesu a objasnění základních pojmů 2. Nástroje pro modelování klasifikovaných dat a jejich
Dobývání a vizualizace znalostí Olga Štěpánková et al. 1 Osnova předmětu 1. Dobývání znalostí - popis a metodika procesu a objasnění základních pojmů 2. Nástroje pro modelování klasifikovaných dat a jejich
Dobývání a vizualizace znalostí. Olga Štěpánková et al.
 Dobývání a vizualizace znalostí Olga Štěpánková et al. 1 Osnova předmětu Dobývání znalostí - popis a metodika procesu CRISP a objasnění základních pojmů Nástroje pro modelování klasifikovaných dat a jejich
Dobývání a vizualizace znalostí Olga Štěpánková et al. 1 Osnova předmětu Dobývání znalostí - popis a metodika procesu CRISP a objasnění základních pojmů Nástroje pro modelování klasifikovaných dat a jejich
Dobývání a vizualizace znalostí
 Dobývání a vizualizace znalostí Olga Štěpánková, Lenka Vysloužilová, et al. https://cw.fel.cvut.cz/wiki/courses/a6m33dvz/start 1 Osnova přednášky Úvod: data, objem, reprezentace a základní terminologie
Dobývání a vizualizace znalostí Olga Štěpánková, Lenka Vysloužilová, et al. https://cw.fel.cvut.cz/wiki/courses/a6m33dvz/start 1 Osnova přednášky Úvod: data, objem, reprezentace a základní terminologie
Získávání dat z databází 1 DMINA 2010
 Získávání dat z databází 1 DMINA 2010 Získávání dat z databází Motto Kde je moudrost? Ztracena ve znalostech. Kde jsou znalosti? Ztraceny v informacích. Kde jsou informace? Ztraceny v datech. Kde jsou
Získávání dat z databází 1 DMINA 2010 Získávání dat z databází Motto Kde je moudrost? Ztracena ve znalostech. Kde jsou znalosti? Ztraceny v informacích. Kde jsou informace? Ztraceny v datech. Kde jsou
Získávání znalostí z dat
 Získávání znalostí z dat Informační a komunikační technologie ve zdravotnictví Získávání znalostí z dat Definice: proces netriviálního získávání implicitní, dříve neznámé a potencionálně užitečné informace
Získávání znalostí z dat Informační a komunikační technologie ve zdravotnictví Získávání znalostí z dat Definice: proces netriviálního získávání implicitní, dříve neznámé a potencionálně užitečné informace
Dobývání znalostí z databází
 Dobývání znalostí z databází (Knowledge Discovery in Databases, Data Mining,..., Knowledge Destilery,...) Non-trivial process of identifying valid, novel, potentially useful and ultimately understandable
Dobývání znalostí z databází (Knowledge Discovery in Databases, Data Mining,..., Knowledge Destilery,...) Non-trivial process of identifying valid, novel, potentially useful and ultimately understandable
Ing. Petr Hájek, Ph.D. Podpora přednášky kurzu Aplikace umělé inteligence
 APLIKACE UMĚLÉ INTELIGENCE Ing. Petr Hájek, Ph.D. Podpora přednášky kurzu Aplikace umělé inteligence Aplikace umělé inteligence - seminář ING. PETR HÁJEK, PH.D. ÚSTAV SYSTÉMOVÉHO INŽENÝRSTVÍ A INFORMATIKY
APLIKACE UMĚLÉ INTELIGENCE Ing. Petr Hájek, Ph.D. Podpora přednášky kurzu Aplikace umělé inteligence Aplikace umělé inteligence - seminář ING. PETR HÁJEK, PH.D. ÚSTAV SYSTÉMOVÉHO INŽENÝRSTVÍ A INFORMATIKY
Katedra kybernetiky laboratoř Inteligentní Datové Analýzy (IDA) Katedra počítačů, Computational Intelligence Group
 Katedra počítačů, Computational Intelligence Group") Vytěžování dat Miroslav Čepek, Filip Železný Katedra kybernetiky laboratoř Inteligentní Datové Analýzy (IDA) Katedra počítačů, Computational Intelligence Group Evropský sociální fond Praha & EU: Investujeme
Vytěžování dat Miroslav Čepek, Filip Železný Katedra kybernetiky laboratoř Inteligentní Datové Analýzy (IDA) Katedra počítačů, Computational Intelligence Group Evropský sociální fond Praha & EU: Investujeme
ZÍSKÁVÁNÍ ZNALOSTÍ Z DATABÁZÍ
 metodický list č. 1 Dobývání znalostí z databází Cílem tohoto tematického celku je vysvětlení základních pojmů z oblasti dobývání znalostí z databází i východisek dobývání znalostí z databází inspirovaných
metodický list č. 1 Dobývání znalostí z databází Cílem tohoto tematického celku je vysvětlení základních pojmů z oblasti dobývání znalostí z databází i východisek dobývání znalostí z databází inspirovaných
ZÍSKÁVÁNÍ ZNALOSTÍ Z DATABÁZÍ
 Metodický list č. 1 Dobývání znalostí z databází Cílem tohoto tematického celku je vysvětlení základních pojmů z oblasti dobývání znalostí z databází i východisek dobývání znalostí z databází inspirovaných
Metodický list č. 1 Dobývání znalostí z databází Cílem tohoto tematického celku je vysvětlení základních pojmů z oblasti dobývání znalostí z databází i východisek dobývání znalostí z databází inspirovaných
Získávání znalostí z databází. Alois Kužela
 Získávání znalostí z databází Alois Kužela Obsah související pojmy datové sklady, získávání znalostí asocianí pravidla 2/37 Úvod získávání znalostí z dat, dolování (z) dat, data mining proces netriviálního
Získávání znalostí z databází Alois Kužela Obsah související pojmy datové sklady, získávání znalostí asocianí pravidla 2/37 Úvod získávání znalostí z dat, dolování (z) dat, data mining proces netriviálního
Moderní systémy pro získávání znalostí z informací a dat
 Moderní systémy pro získávání znalostí z informací a dat Jan Žižka IBA Institut biostatistiky a analýz PřF & LF, Masarykova universita Kamenice 126/3, 625 00 Brno Email: zizka@iba.muni.cz Bioinformatika:
Moderní systémy pro získávání znalostí z informací a dat Jan Žižka IBA Institut biostatistiky a analýz PřF & LF, Masarykova universita Kamenice 126/3, 625 00 Brno Email: zizka@iba.muni.cz Bioinformatika:
DOBÝVÁNÍ ZNALOSTÍ Z DATABÁZÍ
 DOBÝVÁNÍ ZNALOSTÍ Z DATABÁZÍ Úvod a oblasti aplikací Martin Plchút plchut@e-globals.net DEFINICE A POJMY Netriviální extrakce implicitních, ch, dříve d neznámých a potenciáln lně užitečných informací z
DOBÝVÁNÍ ZNALOSTÍ Z DATABÁZÍ Úvod a oblasti aplikací Martin Plchút plchut@e-globals.net DEFINICE A POJMY Netriviální extrakce implicitních, ch, dříve d neznámých a potenciáln lně užitečných informací z
Využití metod strojového učení v bioinformatice David Hoksza
 Využití metod strojového učení v bioinformatice David Hoksza SIRET Research Group Katedra softwarového inženýrství, Matematicko-fyzikální fakulta Karlova Univerzita v Praze Bioinformatika Biologické inspirace
Využití metod strojového učení v bioinformatice David Hoksza SIRET Research Group Katedra softwarového inženýrství, Matematicko-fyzikální fakulta Karlova Univerzita v Praze Bioinformatika Biologické inspirace
Obsah. Seznam obrázků. Seznam tabulek. Petr Berka, 2011
 Petr Berka, 2011 Obsah... 1... 1 1 Obsah 1... 1 Dobývání znalostí z databází 1 Dobývání znalostí z databází O dobývání znalostí z databází (Knowledge Discovery in Databases, KDD) se začíná ve vědeckých
Petr Berka, 2011 Obsah... 1... 1 1 Obsah 1... 1 Dobývání znalostí z databází 1 Dobývání znalostí z databází O dobývání znalostí z databází (Knowledge Discovery in Databases, KDD) se začíná ve vědeckých
znalostí z databází- mnohostranná interpretace dat
 Dobývání znalostí z databází- mnohostranná interpretace dat Petr Berka VŠE Praha berka@vse vse.cz Dobývání znalostí z databází Non-trivial process of identifying valid, novel, potentially useful and ultimately
Dobývání znalostí z databází- mnohostranná interpretace dat Petr Berka VŠE Praha berka@vse vse.cz Dobývání znalostí z databází Non-trivial process of identifying valid, novel, potentially useful and ultimately
Strojové učení Marta Vomlelová
 Strojové učení Marta Vomlelová marta@ktiml.mff.cuni.cz KTIML, S303 Literatura 1.T. Hastie, R. Tishirani, and J. Friedman. The Elements of Statistical Learning, Data Mining, Inference and Prediction. Springer
Strojové učení Marta Vomlelová marta@ktiml.mff.cuni.cz KTIML, S303 Literatura 1.T. Hastie, R. Tishirani, and J. Friedman. The Elements of Statistical Learning, Data Mining, Inference and Prediction. Springer
Předzpracování dat. Lenka Vysloužilová
 Předzpracování dat Lenka Vysloužilová 1 Metodika CRISP-DM (www.crisp-dm.org) Příprava dat Data Preparation příprava dat pro modelování selekce příznaků výběr relevantních příznaků čištění dat získávání
Předzpracování dat Lenka Vysloužilová 1 Metodika CRISP-DM (www.crisp-dm.org) Příprava dat Data Preparation příprava dat pro modelování selekce příznaků výběr relevantních příznaků čištění dat získávání
Pravděpodobně skoro správné. PAC učení 1
 Pravděpodobně skoro správné (PAC) učení PAC učení 1 Výpočetní teorie strojového učení Věta o ošklivém kačátku. Nechť E je klasifikovaná trénovací množina pro koncept K, který tvoří podmnožinu konečného
Pravděpodobně skoro správné (PAC) učení PAC učení 1 Výpočetní teorie strojového učení Věta o ošklivém kačátku. Nechť E je klasifikovaná trénovací množina pro koncept K, který tvoří podmnožinu konečného
Příprava dat v softwaru Statistica
 Příprava dat v softwaru Statistica Software Statistica obsahuje pokročilé nástroje pro přípravu dat a tvorbu nových proměnných. Tyto funkcionality přinášejí značnou úsporu času při přípravě datového souboru,
Příprava dat v softwaru Statistica Software Statistica obsahuje pokročilé nástroje pro přípravu dat a tvorbu nových proměnných. Tyto funkcionality přinášejí značnou úsporu času při přípravě datového souboru,
ANALÝZA A KLASIFIKACE DAT
 ANALÝZA A KLASIFIKACE DAT prof. Ing. Jiří Holčík, CSc. INVESTICE Institut DO biostatistiky ROZVOJE VZDĚLÁVÁNÍ a analýz LITERATURA Holčík, J.: přednáškové prezentace Holčík, J.: Analýza a klasifikace signálů.
ANALÝZA A KLASIFIKACE DAT prof. Ing. Jiří Holčík, CSc. INVESTICE Institut DO biostatistiky ROZVOJE VZDĚLÁVÁNÍ a analýz LITERATURA Holčík, J.: přednáškové prezentace Holčík, J.: Analýza a klasifikace signálů.
ANALÝZA NÁKUPNÍHO KOŠÍKU SEMINÁŘ
 ANALÝZA NÁKUPNÍHO KOŠÍKU SEMINÁŘ 18.11.2012 Radim Tvardek, Petr Bulava, Daniel Mašek U&SLUNO a.s. I Sadová 28 I 702 00 Ostrava I Czech Republic PŘEDPOKLADY PRO ANALÝZU NÁKUPNÍHO KOŠÍKU 18.11.2012 Daniel
ANALÝZA NÁKUPNÍHO KOŠÍKU SEMINÁŘ 18.11.2012 Radim Tvardek, Petr Bulava, Daniel Mašek U&SLUNO a.s. I Sadová 28 I 702 00 Ostrava I Czech Republic PŘEDPOKLADY PRO ANALÝZU NÁKUPNÍHO KOŠÍKU 18.11.2012 Daniel
Statistika, Biostatistika pro kombinované studium Letní semestr 2011/2012. Tutoriál č. 4: Exploratorní analýza. Jan Kracík
 Statistika, Biostatistika pro kombinované studium Letní semestr 2011/2012 Tutoriál č. 4: Exploratorní analýza Jan Kracík jan.kracik@vsb.cz Statistika věda o získávání znalostí z empirických dat empirická
Statistika, Biostatistika pro kombinované studium Letní semestr 2011/2012 Tutoriál č. 4: Exploratorní analýza Jan Kracík jan.kracik@vsb.cz Statistika věda o získávání znalostí z empirických dat empirická
Projekční algoritmus. Urychlení evolučních algoritmů pomocí regresních stromů a jejich zobecnění. Jan Klíma
 Urychlení evolučních algoritmů pomocí regresních stromů a jejich zobecnění Jan Klíma Obsah Motivace & cíle práce Evoluční algoritmy Náhradní modelování Stromové regresní metody Implementace a výsledky
Urychlení evolučních algoritmů pomocí regresních stromů a jejich zobecnění Jan Klíma Obsah Motivace & cíle práce Evoluční algoritmy Náhradní modelování Stromové regresní metody Implementace a výsledky
Dolování z textu. Martin Vítek
 Dolování z textu Martin Vítek Proč dolovat z textu Obrovské množství materiálu v nestrukturované textové podobě knihy časopisy vědeckéčlánky sborníky konferencí internetové diskuse Proč dolovat z textu
Dolování z textu Martin Vítek Proč dolovat z textu Obrovské množství materiálu v nestrukturované textové podobě knihy časopisy vědeckéčlánky sborníky konferencí internetové diskuse Proč dolovat z textu
Datová věda (Data Science) akademický navazující magisterský program
 akademický navazující magisterský program") Datová věda () akademický navazující magisterský program Reaguje na potřebu, kterou vyvolala rychle rostoucí produkce komplexních, obvykle rozsáhlých dat ve vědě, v průmyslu a obecně v hospodářských činnostech.
Datová věda () akademický navazující magisterský program Reaguje na potřebu, kterou vyvolala rychle rostoucí produkce komplexních, obvykle rozsáhlých dat ve vědě, v průmyslu a obecně v hospodářských činnostech.
Algoritmy a struktury neuropočítačů ASN P9 SVM Support vector machines Support vector networks (Algoritmus podpůrných vektorů)
") Algoritmy a struktury neuropočítačů ASN P9 SVM Support vector machines Support vector networks (Algoritmus podpůrných vektorů) Autor: Vladimir Vapnik Vapnik, V. The Nature of Statistical Learning Theory.
Algoritmy a struktury neuropočítačů ASN P9 SVM Support vector machines Support vector networks (Algoritmus podpůrných vektorů) Autor: Vladimir Vapnik Vapnik, V. The Nature of Statistical Learning Theory.
Kybernetika a umělá inteligence, cvičení 10/11
 Kybernetika a umělá inteligence, cvičení 10/11 Program 1. seminární cvičení: základní typy klasifikátorů a jejich princip 2. počítačové cvičení: procvičení na problému rozpoznávání číslic... body za aktivitu
Kybernetika a umělá inteligence, cvičení 10/11 Program 1. seminární cvičení: základní typy klasifikátorů a jejich princip 2. počítačové cvičení: procvičení na problému rozpoznávání číslic... body za aktivitu
K možnostem krátkodobé předpovědi úrovně znečištění ovzduší statistickými metodami. Josef Keder
 K možnostem krátkodobé předpovědi úrovně znečištění ovzduší statistickými metodami Josef Keder Motivace Předpověď budoucí úrovně znečištění ovzduší s předstihem v řádu alespoň několika hodin má význam
K možnostem krátkodobé předpovědi úrovně znečištění ovzduší statistickými metodami Josef Keder Motivace Předpověď budoucí úrovně znečištění ovzduší s předstihem v řádu alespoň několika hodin má význam
Dobývání znalostí. Doc. RNDr. Iveta Mrázová, CSc. Katedra teoretické informatiky Matematicko-fyzikální fakulta Univerzity Karlovy v Praze
 Dobývání znalostí Doc. RNDr. Iveta Mrázová, CSc. Katedra teoretické informatiky Matematicko-fyzikální fakulta Univerzity Karlovy v Praze Dobývání znalostí Úvod do problematiky Doc. RNDr. Iveta Mrázová,
Dobývání znalostí Doc. RNDr. Iveta Mrázová, CSc. Katedra teoretické informatiky Matematicko-fyzikální fakulta Univerzity Karlovy v Praze Dobývání znalostí Úvod do problematiky Doc. RNDr. Iveta Mrázová,
Zadání semestrální práce IKTZ 2 letní semestr 2009/2010
 Zadání semestrální práce IKTZ 2 letní semestr 2009/2010 Obecné zadání Dle zadání zpracujte data ze studie STULONG (soubory Entry a Contr). Práce je rozdělena do tří částí, které se řeší odděleně. Výstupem
Zadání semestrální práce IKTZ 2 letní semestr 2009/2010 Obecné zadání Dle zadání zpracujte data ze studie STULONG (soubory Entry a Contr). Práce je rozdělena do tří částí, které se řeší odděleně. Výstupem
Obsah přednášky Jaká asi bude chyba modelu na nových datech?
 Obsah přednášky Jaká asi bude chyba modelu na nových datech? Chyba modelu Bootstrap Cross Validation Vapnik-Chervonenkisova dimenze 2 Chyba skutečná a trénovací Máme 30 záznamů, rozhodli jsme se na jejich
Obsah přednášky Jaká asi bude chyba modelu na nových datech? Chyba modelu Bootstrap Cross Validation Vapnik-Chervonenkisova dimenze 2 Chyba skutečná a trénovací Máme 30 záznamů, rozhodli jsme se na jejich
METODY DOLOVÁNÍ V DATECH DATOVÉ SKLADY TEREZA HYNČICOVÁ H2IGE1
 METODY DOLOVÁNÍ V DATECH DATOVÉ SKLADY TEREZA HYNČICOVÁ H2IGE1 DOLOVÁNÍ V DATECH (DATA MINING) OBJEVUJE SE JIŽ OD 60. LET 20. ST. S ROZVOJEM POČÍTAČOVÉ TECHNIKY DEFINICE PROCES VÝBĚRU, PROHLEDÁVÁNÍ A MODELOVÁNÍ
METODY DOLOVÁNÍ V DATECH DATOVÉ SKLADY TEREZA HYNČICOVÁ H2IGE1 DOLOVÁNÍ V DATECH (DATA MINING) OBJEVUJE SE JIŽ OD 60. LET 20. ST. S ROZVOJEM POČÍTAČOVÉ TECHNIKY DEFINICE PROCES VÝBĚRU, PROHLEDÁVÁNÍ A MODELOVÁNÍ
Předzpracování dat pro data mining: metody a nástroje
 Předzpracování dat pro data mining: metody a nástroje Olga Štěpánková, Zdeněk Kouba, P. Mikšovský, P. Aubrecht Gerstnerova laboratoř pro inteligentní rozhodování a řízení České vysoké učení technické v
Předzpracování dat pro data mining: metody a nástroje Olga Štěpánková, Zdeněk Kouba, P. Mikšovský, P. Aubrecht Gerstnerova laboratoř pro inteligentní rozhodování a řízení České vysoké učení technické v
GRR. získávání znalostí v geografických datech Autoři. Knowledge Discovery Group Faculty of Informatics Masaryk Univerzity Brno, Czech Republic
 GRR získávání znalostí v geografických datech Autoři Knowledge Discovery Group Faculty of Informatics Masaryk Univerzity Brno, Czech Republic GRR cílet 2 GRR - Popis systému - cíle systém pro dolování
GRR získávání znalostí v geografických datech Autoři Knowledge Discovery Group Faculty of Informatics Masaryk Univerzity Brno, Czech Republic GRR cílet 2 GRR - Popis systému - cíle systém pro dolování
1. Dobývání znalostí z databází
 1. Dobývání znalostí z databází O dobývání znalostí z databází (Knowledge Discovery in Databases, KDD) se začíná ve vědeckých kruzích mluvit počátkem 90. let. První impuls přišel z Ameriky, kde se na konferencích
1. Dobývání znalostí z databází O dobývání znalostí z databází (Knowledge Discovery in Databases, KDD) se začíná ve vědeckých kruzích mluvit počátkem 90. let. První impuls přišel z Ameriky, kde se na konferencích
Dobývání znalostí. Doc. RNDr. Iveta Mrázová, CSc. Katedra teoretické informatiky Matematicko-fyzikální fakulta Univerzity Karlovy v Praze
 Dobývání znalostí Doc. RNDr. Iveta Mrázová, CSc. Katedra teoretické informatiky Matematicko-fyzikální fakulta Univerzity Karlovy v Praze Dobývání znalostí Pravděpodobnost a učení Doc. RNDr. Iveta Mrázová,
Dobývání znalostí Doc. RNDr. Iveta Mrázová, CSc. Katedra teoretické informatiky Matematicko-fyzikální fakulta Univerzity Karlovy v Praze Dobývání znalostí Pravděpodobnost a učení Doc. RNDr. Iveta Mrázová,
Umělá inteligence a rozpoznávání
 Václav Matoušek KIV e-mail: matousek@kiv.zcu.cz 0-1 Sylabus předmětu: Datum Náplň přednášky 11. 2. Úvod, historie a vývoj UI, základní problémové oblasti a typy úloh, aplikace UI, příklady inteligentních
Václav Matoušek KIV e-mail: matousek@kiv.zcu.cz 0-1 Sylabus předmětu: Datum Náplň přednášky 11. 2. Úvod, historie a vývoj UI, základní problémové oblasti a typy úloh, aplikace UI, příklady inteligentních
UČENÍ BEZ UČITELE. Václav Hlaváč
 UČENÍ BEZ UČITELE Václav Hlaváč Fakulta elektrotechnická ČVUT v Praze katedra kybernetiky, Centrum strojového vnímání hlavac@fel.cvut.cz, http://cmp.felk.cvut.cz/~hlavac 1/22 OBSAH PŘEDNÁŠKY ÚVOD Učení
UČENÍ BEZ UČITELE Václav Hlaváč Fakulta elektrotechnická ČVUT v Praze katedra kybernetiky, Centrum strojového vnímání hlavac@fel.cvut.cz, http://cmp.felk.cvut.cz/~hlavac 1/22 OBSAH PŘEDNÁŠKY ÚVOD Učení
BA_EM Electronic Marketing. Pavel
 BA_EM Electronic Marketing Pavel Kotyza @VŠFS Agenda Efektivní data mining jako zdroj relevantních dat o potřebách zákazníků Co je data mining? Je absolutní Je předem neznámý Je užitečný Co jsou data?
BA_EM Electronic Marketing Pavel Kotyza @VŠFS Agenda Efektivní data mining jako zdroj relevantních dat o potřebách zákazníků Co je data mining? Je absolutní Je předem neznámý Je užitečný Co jsou data?
Dobývání dat a strojové učení
 Dobývání dat a strojové učení Dobývání znalostí z databází (Knowledge discovery in databases) Non-trivial process of identifying valid, novel, potentially useful and ultimately understandable patterns
Dobývání dat a strojové učení Dobývání znalostí z databází (Knowledge discovery in databases) Non-trivial process of identifying valid, novel, potentially useful and ultimately understandable patterns
Václav Matoušek KIV. Umělá inteligence a rozpoznávání. Václav Matoušek / KIV
 Umělá inteligence a rozpoznávání Václav Matoušek KIV e-mail: matousek@kiv.zcu.cz 0-1 Sylabus předmětu: Datum Náplň přednášky 16. 2. (3h) 2. 3. (4h) 17. 3. (5h) 14. 4. (3h) Úvod, historie a vývoj UI, základní
Umělá inteligence a rozpoznávání Václav Matoušek KIV e-mail: matousek@kiv.zcu.cz 0-1 Sylabus předmětu: Datum Náplň přednášky 16. 2. (3h) 2. 3. (4h) 17. 3. (5h) 14. 4. (3h) Úvod, historie a vývoj UI, základní
Chybějící atributy a postupy pro jejich náhradu
 Chybějící atributy a postupy pro jejich náhradu Jedná se o součást čištění dat Čistota dat je velmi důležitá, neboť kvalita dat zásadně ovlivňuje kvalitu výsledků, které DM vyprodukuje, neboť platí Garbage
Chybějící atributy a postupy pro jejich náhradu Jedná se o součást čištění dat Čistota dat je velmi důležitá, neboť kvalita dat zásadně ovlivňuje kvalitu výsledků, které DM vyprodukuje, neboť platí Garbage
Otevřená data ČSSZ: Přehledné informace dostupné všem, snadno a zdarma. Ing. Jiří Šunka Ing. Michaela Hendrychová. ISSS Hradec Králové, 5. 4.
 Otevřená data ČSSZ: Přehledné informace dostupné všem, snadno a zdarma ISSS Hradec Králové, 5. 4. 2016 Ing. Jiří Šunka Ing. Michaela Hendrychová Obsah 1. Představení ČSSZ 2. Proces publikace otevřených
Otevřená data ČSSZ: Přehledné informace dostupné všem, snadno a zdarma ISSS Hradec Králové, 5. 4. 2016 Ing. Jiří Šunka Ing. Michaela Hendrychová Obsah 1. Představení ČSSZ 2. Proces publikace otevřených
Algoritmy a struktury neuropočítačů ASN - P10. Aplikace UNS v biomedicíně
 Aplikace UNS v biomedicíně aplikace v medicíně postup při zpracování úloh Aplikace UNS v medicíně Důvod: nalezení exaktnějších, levnějších a snadnějších metod určování diagnóz pro lékaře nalezení šetrnějších
Aplikace UNS v biomedicíně aplikace v medicíně postup při zpracování úloh Aplikace UNS v medicíně Důvod: nalezení exaktnějších, levnějších a snadnějších metod určování diagnóz pro lékaře nalezení šetrnějších
2. Modelovací jazyk UML 2.1 Struktura UML 2.1.1 Diagram tříd 2.1.1.1 Asociace 2.1.2 OCL. 3. Smalltalk 3.1 Jazyk 3.1.1 Pojmenování
 1. Teoretické základy modelování na počítačích 1.1 Lambda-kalkul 1.1.1 Formální zápis, beta-redukce, alfa-konverze 1.1.2 Lambda-výraz jako data 1.1.3 Příklad alfa-konverze 1.1.4 Eta-redukce 1.2 Základy
1. Teoretické základy modelování na počítačích 1.1 Lambda-kalkul 1.1.1 Formální zápis, beta-redukce, alfa-konverze 1.1.2 Lambda-výraz jako data 1.1.3 Příklad alfa-konverze 1.1.4 Eta-redukce 1.2 Základy
Segmentace bankovních zákazníků algoritmem k- means
 Segmentace bankovních zákazníků algoritmem k- means LS 2014/2015 Michal Heřmanský xherm22 Obsah 1 Úvod... 3 1.1 CRISP- DM... 3 2 Porozumění problematice a datům... 4 3 Příprava dat... 5 4 Modelování...
Segmentace bankovních zákazníků algoritmem k- means LS 2014/2015 Michal Heřmanský xherm22 Obsah 1 Úvod... 3 1.1 CRISP- DM... 3 2 Porozumění problematice a datům... 4 3 Příprava dat... 5 4 Modelování...
Návrh datového skladu z hlediska zdrojů
 Návrh datového skladu Návrh datového skladu OLTP ETL OLAP, DM Operativní data Datové sklady Zdroje dat Transformace zdroj - cíl Etapy realizace 1 Návrh datového skladu Hlavní úskalí analýzy a návrhu spočívá
Návrh datového skladu Návrh datového skladu OLTP ETL OLAP, DM Operativní data Datové sklady Zdroje dat Transformace zdroj - cíl Etapy realizace 1 Návrh datového skladu Hlavní úskalí analýzy a návrhu spočívá
Datové modelování II
 Datové modelování II Atributy Převod DM do schématu SŘBD Dotazovací jazyk SQL Multidimenzionální modelování Principy Doc. Miniberger, BIVŠ Atributy Atributem entity budeme rozumět název záznamu či informace,
Datové modelování II Atributy Převod DM do schématu SŘBD Dotazovací jazyk SQL Multidimenzionální modelování Principy Doc. Miniberger, BIVŠ Atributy Atributem entity budeme rozumět název záznamu či informace,
Úvod do dobývání. znalostí z databází
 POROZUMĚNÍ 4iz260 Úvod do DZD Úvod do dobývání DOMÉNOVÉ OBLASTI znalostí z databází VYUŽITÍ VÝSLEDKŮ POROZUMĚNÍ DATŮM DATA VYHODNO- CENÍ VÝSLEDKŮ MODELOVÁNÍ (ANALYTICKÉ PROCEDURY) PŘÍPRAVA DAT Ukázka slidů
POROZUMĚNÍ 4iz260 Úvod do DZD Úvod do dobývání DOMÉNOVÉ OBLASTI znalostí z databází VYUŽITÍ VÝSLEDKŮ POROZUMĚNÍ DATŮM DATA VYHODNO- CENÍ VÝSLEDKŮ MODELOVÁNÍ (ANALYTICKÉ PROCEDURY) PŘÍPRAVA DAT Ukázka slidů
Učící se klasifikátory obrazu v průmyslu
 Učící se klasifikátory obrazu v průmyslu FCC průmyslové systémy s.r.o. FCC průmyslové systémy je technicko obchodní společností, působící v oblasti průmyslové automatizace. Tvoří ji dvě základní divize:
Učící se klasifikátory obrazu v průmyslu FCC průmyslové systémy s.r.o. FCC průmyslové systémy je technicko obchodní společností, působící v oblasti průmyslové automatizace. Tvoří ji dvě základní divize:
Neuronové časové řady (ANN-TS)
") Neuronové časové řady (ANN-TS) Menu: QCExpert Prediktivní metody Neuronové časové řady Tento modul (Artificial Neural Network Time Series ANN-TS) využívá modelovacího potenciálu neuronové sítě k predikci
Neuronové časové řady (ANN-TS) Menu: QCExpert Prediktivní metody Neuronové časové řady Tento modul (Artificial Neural Network Time Series ANN-TS) využívá modelovacího potenciálu neuronové sítě k predikci
PRŮZKUMOVÁ ANALÝZA JEDNOROZMĚRNÝCH DAT Exploratory Data Analysis (EDA)
") PRŮZKUMOVÁ ANALÝZA JEDNOROZMĚRNÝCH DAT Exploratory Data Analysis (EDA) Reprezentativní náhodný výběr: 1. Prvky výběru x i jsou vzájemně nezávislé. 2. Výběr je homogenní, tj. všechna x i jsou ze stejného
PRŮZKUMOVÁ ANALÝZA JEDNOROZMĚRNÝCH DAT Exploratory Data Analysis (EDA) Reprezentativní náhodný výběr: 1. Prvky výběru x i jsou vzájemně nezávislé. 2. Výběr je homogenní, tj. všechna x i jsou ze stejného
Diabetická asociace České republiky. Závěrečná zpráva pilotního projektu
 . Titulní strana Centra edukace pro diabetiky v okresních městech Diabetická asociace České republiky Závěrečná zpráva pilotního projektu Zdůvodnění zprávy: Zkoušející nebo koordinující zkoušející: Vyhodnocení
. Titulní strana Centra edukace pro diabetiky v okresních městech Diabetická asociace České republiky Závěrečná zpráva pilotního projektu Zdůvodnění zprávy: Zkoušející nebo koordinující zkoušející: Vyhodnocení
Státnice odborné č. 20
 Státnice odborné č. 20 Shlukování dat Shlukování dat. Metoda k-středů, hierarchické (aglomerativní) shlukování, Kohonenova mapa SOM Shlukování dat Shluková analýza je snaha o seskupení objektů do skupin
Státnice odborné č. 20 Shlukování dat Shlukování dat. Metoda k-středů, hierarchické (aglomerativní) shlukování, Kohonenova mapa SOM Shlukování dat Shluková analýza je snaha o seskupení objektů do skupin
Trénování sítě pomocí učení s učitelem
 Trénování sítě pomocí učení s učitelem! předpokládá se, že máme k dispozici trénovací množinu, tj. množinu P dvojic [vstup x p, požadovaný výstup u p ]! chceme nastavit váhy a prahy sítě tak, aby výstup
Trénování sítě pomocí učení s učitelem! předpokládá se, že máme k dispozici trénovací množinu, tj. množinu P dvojic [vstup x p, požadovaný výstup u p ]! chceme nastavit váhy a prahy sítě tak, aby výstup
Vytěžování dat přednáška I
 České vysoké učení technické v Praze Fakulta elektrotechnická Katedra kybernetiky Katedra počítačů Vytěžování dat přednáška I Úvod do vytěžování dat Filip Železný: zelezny@fel.cvut.cz Pavel Kordík: kordikp@fel.cvut.cz
České vysoké učení technické v Praze Fakulta elektrotechnická Katedra kybernetiky Katedra počítačů Vytěžování dat přednáška I Úvod do vytěžování dat Filip Železný: zelezny@fel.cvut.cz Pavel Kordík: kordikp@fel.cvut.cz
5. Umělé neuronové sítě. Neuronové sítě
 Neuronové sítě Přesný algoritmus práce přírodních neuronových systémů není doposud znám. Přesto experimentální výsledky na modelech těchto systémů dávají dnes velmi slibné výsledky. Tyto systémy, včetně
Neuronové sítě Přesný algoritmus práce přírodních neuronových systémů není doposud znám. Přesto experimentální výsledky na modelech těchto systémů dávají dnes velmi slibné výsledky. Tyto systémy, včetně
Text Mining: SAS Enterprise Miner versus Teragram. Petr Berka, Tomáš Kliegr VŠE Praha
 Text Mining: SAS Enterprise Miner versus Teragram Petr Berka, Tomáš Kliegr VŠE Praha Text mining vs. data mining Text mining = data mining na nestrukturovaných textových dokumentech otázka vhodné reprezentace
Text Mining: SAS Enterprise Miner versus Teragram Petr Berka, Tomáš Kliegr VŠE Praha Text mining vs. data mining Text mining = data mining na nestrukturovaných textových dokumentech otázka vhodné reprezentace
Automatizační a měřicí technika (B-AMT)
") Ústav automatizace a měřicí techniky Bakalářský studijní program Automatizační a měřicí technika () Specializace oboru Řídicí technika Měřicí technika Průmyslová automatizace Robotika a umělá inteligence
Ústav automatizace a měřicí techniky Bakalářský studijní program Automatizační a měřicí technika () Specializace oboru Řídicí technika Měřicí technika Průmyslová automatizace Robotika a umělá inteligence
Katedra kybernetiky, FEL, ČVUT v Praze.
 Strojové učení a dolování dat přehled Jiří Kléma Katedra kybernetiky, FEL, ČVUT v Praze http://ida.felk.cvut.cz posnova přednášek Přednáška Učitel Obsah 1. J. Kléma Úvod do předmětu, učení s a bez učitele.
Strojové učení a dolování dat přehled Jiří Kléma Katedra kybernetiky, FEL, ČVUT v Praze http://ida.felk.cvut.cz posnova přednášek Přednáška Učitel Obsah 1. J. Kléma Úvod do předmětu, učení s a bez učitele.
KMI/ZZD Získávání znalostí z dat
 KMI/ZZD Získávání znalostí z dat Úvod, motivace, modely KPD, úlohy DM Jan Konečný 17. února 2015 Rozvrh a sylabus http://phoenix.inf.upol.cz/~konecnyj/vyuka/zzd.html Rozvrh: Úterý: 8:00 10:15 (v tom je
KMI/ZZD Získávání znalostí z dat Úvod, motivace, modely KPD, úlohy DM Jan Konečný 17. února 2015 Rozvrh a sylabus http://phoenix.inf.upol.cz/~konecnyj/vyuka/zzd.html Rozvrh: Úterý: 8:00 10:15 (v tom je
Cíle supervizovaného učení Ondřej Háva
 Cíle supervizovaného učení Ondřej Háva ACREA CR Využíváme více než 40 let zkušeností IBM s hlavním cílem: řízení rozhodovacích procesů Akvizice SPSS společností IBM v říjnu 2009 Přejmenování SPSS CR na
Cíle supervizovaného učení Ondřej Háva ACREA CR Využíváme více než 40 let zkušeností IBM s hlavním cílem: řízení rozhodovacích procesů Akvizice SPSS společností IBM v říjnu 2009 Přejmenování SPSS CR na
INFORMATIKA. Libovolná učebnice k MS OFFICE 200x (samostatné učebnice k textovému procesoru MS Word 200x, tabulkovému procesoru MS Excel 200x).
.") Cíl předmětu: Cílem předmětu je prohloubit znalosti studentů ze základních aplikačních programů. Jedná se především o pokročilejší nástroje z aplikací MS Word a MS Excel. Jednotlivé semináře se zaměřují
Cíl předmětu: Cílem předmětu je prohloubit znalosti studentů ze základních aplikačních programů. Jedná se především o pokročilejší nástroje z aplikací MS Word a MS Excel. Jednotlivé semináře se zaměřují
Pracovní celky 3.2, 3.3 a 3.4 Sémantická harmonizace - Srovnání a přiřazení datových modelů
 Pracovní celky 3.2, 3.3 a 3.4 Sémantická harmonizace - Srovnání a datových modelů Obsah Seznam tabulek... 1 Seznam obrázků... 1 1 Úvod... 2 2 Metody sémantické harmonizace... 2 3 Dvojjazyčné katalogy objektů
Pracovní celky 3.2, 3.3 a 3.4 Sémantická harmonizace - Srovnání a datových modelů Obsah Seznam tabulek... 1 Seznam obrázků... 1 1 Úvod... 2 2 Metody sémantické harmonizace... 2 3 Dvojjazyčné katalogy objektů
Analytické procedury v systému LISp-Miner
 Dobývání znalostí z databází MI-KDD ZS 2011 Přednáška 8 Analytické procedury v systému LISp-Miner Část II. (c) 2011 Ing. M. Šimůnek, Ph.D. KIZI, Fakulta informatiky a statistiky, VŠE Praha Evropský sociální
Dobývání znalostí z databází MI-KDD ZS 2011 Přednáška 8 Analytické procedury v systému LISp-Miner Část II. (c) 2011 Ing. M. Šimůnek, Ph.D. KIZI, Fakulta informatiky a statistiky, VŠE Praha Evropský sociální
Okruhy ke státní závěrečné zkoušce z vedlejší specializace Informatika v řízení podniku
 Okruhy ke státní závěrečné zkoušce z vedlejší specializace Informatika v řízení podniku Aplikace auditních postupů Vyberte si jeden typ auditu (útvaru, projektu, aplikace, procesu, ) a na něm demonstrujte
Okruhy ke státní závěrečné zkoušce z vedlejší specializace Informatika v řízení podniku Aplikace auditních postupů Vyberte si jeden typ auditu (útvaru, projektu, aplikace, procesu, ) a na něm demonstrujte
analýzy dat v oboru Matematická biologie
 INSTITUT BIOSTATISTIKY A ANALÝZ Lékařská a Přírodovědecká fakulta, Masarykova univerzita Komplexní přístup k výuce analýzy dat v oboru Matematická biologie Tomáš Pavlík, Daniel Schwarz, Jiří Jarkovský,
INSTITUT BIOSTATISTIKY A ANALÝZ Lékařská a Přírodovědecká fakulta, Masarykova univerzita Komplexní přístup k výuce analýzy dat v oboru Matematická biologie Tomáš Pavlík, Daniel Schwarz, Jiří Jarkovský,
POPISNÁ STATISTIKA Komentované řešení pomocí programu Statistica
 POPISNÁ STATISTIKA Komentované řešení pomocí programu Statistica Program Statistica I Statistica je velmi podobná Excelu. Na základní úrovni je to klikací program určený ke statistickému zpracování dat.
POPISNÁ STATISTIKA Komentované řešení pomocí programu Statistica Program Statistica I Statistica je velmi podobná Excelu. Na základní úrovni je to klikací program určený ke statistickému zpracování dat.
Vizualizace v Information Retrieval
 Vizualizace v Information Retrieval Petr Kopka VŠB-TU Ostrava Fakulta elektrotechniky a informatiky Katedra informatiky Obsah Co je Information Retrieval, vizualizace, proces přístupu k informacím Způsoby
Vizualizace v Information Retrieval Petr Kopka VŠB-TU Ostrava Fakulta elektrotechniky a informatiky Katedra informatiky Obsah Co je Information Retrieval, vizualizace, proces přístupu k informacím Způsoby
Profitabilita klienta v kontextu Performance management
 IBM Technical specialist team Pre Sale 26/10/2010 Profitabilita klienta v kontextu Performance management Co všechno řadíme do PM? Automatická data Běžný reporting Pokročilé statistické modely Včera What
IBM Technical specialist team Pre Sale 26/10/2010 Profitabilita klienta v kontextu Performance management Co všechno řadíme do PM? Automatická data Běžný reporting Pokročilé statistické modely Včera What
DOBÝVÁNÍ ZNALOSTÍ Z DATABÁZÍ PŘÍKLADY APLIKACÍ V KARDIOLOGICKÝCH DATECH Jan Rauch
 DOBÝVÁNÍ ZNALOSTÍ Z DATABÁZÍ PŘÍKLADY APLIKACÍ V KARDIOLOGICKÝCH DATECH Jan Rauch Anotace: Příspěvek obsahuje základní informace o dobývání znalostí jakožto důležité disciplíně informatiky a ukazuje příklady
DOBÝVÁNÍ ZNALOSTÍ Z DATABÁZÍ PŘÍKLADY APLIKACÍ V KARDIOLOGICKÝCH DATECH Jan Rauch Anotace: Příspěvek obsahuje základní informace o dobývání znalostí jakožto důležité disciplíně informatiky a ukazuje příklady
Obsah. Kapitola 1. Kapitola 2. Kapitola 3. Úvod 9
 Obsah Úvod 9 Kapitola 1 Business Intelligence, datové sklady 11 Přechod od transakčních databází k analytickým..................... 13 Kvalita údajů pro analýzy................................................
Obsah Úvod 9 Kapitola 1 Business Intelligence, datové sklady 11 Přechod od transakčních databází k analytickým..................... 13 Kvalita údajů pro analýzy................................................
RNDr. Eva Janoušová doc. RNDr. Ladislav Dušek, Dr.
 Analýza dat pro Neurovědy RNDr. Eva Janoušová doc. RNDr. Ladislav Dušek, Dr. Jaro 2014 Institut biostatistiky Janoušová, a analýz Dušek: Analýza dat pro neurovědy Blok 7 Jak hodnotit vztah spojitých proměnných
Analýza dat pro Neurovědy RNDr. Eva Janoušová doc. RNDr. Ladislav Dušek, Dr. Jaro 2014 Institut biostatistiky Janoušová, a analýz Dušek: Analýza dat pro neurovědy Blok 7 Jak hodnotit vztah spojitých proměnných
Ústav automatizace a měřicí techniky.
 www.feec.vutbr.cz Specializace studijního oboru Automatizační a Měřicí Technika: Řídicí technika Moderní algoritmy řízení, teorie řízení Modelování a identifikace parametrů řízených systémů Pokročilé metody
www.feec.vutbr.cz Specializace studijního oboru Automatizační a Měřicí Technika: Řídicí technika Moderní algoritmy řízení, teorie řízení Modelování a identifikace parametrů řízených systémů Pokročilé metody
Proces marketingového výzkumu - jednotlivé fáze, význam, stručná charakteristika. Výběr a formulace výzkumného problému. Vztahy mezi proměnnými.
 Proces marketingového výzkumu - jednotlivé fáze, význam, stručná charakteristika. Výběr a formulace výzkumného problému. Projekt. Jednotky analýzy. Proměnné. Vztahy mezi proměnnými. Téma č. 2 Cíle marketingového
Proces marketingového výzkumu - jednotlivé fáze, význam, stručná charakteristika. Výběr a formulace výzkumného problému. Projekt. Jednotky analýzy. Proměnné. Vztahy mezi proměnnými. Téma č. 2 Cíle marketingového
Úvod do principů objektově orientovaného programování
 OBSAH DISTANČNÍHO E-LEARNINGOVÉHO KURZU PROFESNÍ RŮST ANALYTIKA OD ZÁKLADŮ (BASE) ÚVOD DO TECHNOLOGIÍ INFORMAČNÍCH SYSTÉMŮ Jak funguje počítač na základní úrovni Základy HTML Skripty ve webovských technologiích
OBSAH DISTANČNÍHO E-LEARNINGOVÉHO KURZU PROFESNÍ RŮST ANALYTIKA OD ZÁKLADŮ (BASE) ÚVOD DO TECHNOLOGIÍ INFORMAČNÍCH SYSTÉMŮ Jak funguje počítač na základní úrovni Základy HTML Skripty ve webovských technologiích
Analýza dat pomocí systému Weka, Rapid miner a Enterprise miner
 Vysoká škola ekonomická v Praze Analýza dat pomocí systému Weka, Rapid miner a Enterprise miner Dobývání znalostí z databází 4IZ450 XXXXXXXXXXX Přidělená data a jejich popis Data určená pro zpracování
Vysoká škola ekonomická v Praze Analýza dat pomocí systému Weka, Rapid miner a Enterprise miner Dobývání znalostí z databází 4IZ450 XXXXXXXXXXX Přidělená data a jejich popis Data určená pro zpracování
Uživatelská podpora v prostředí WWW
 Uživatelská podpora v prostředí WWW Jiří Jelínek Katedra managementu informací Fakulta managementu Jindřichův Hradec Vysoká škola ekonomická Praha Úvod WWW obsáhlost obsahová i formátová pestrost dokumenty,
Uživatelská podpora v prostředí WWW Jiří Jelínek Katedra managementu informací Fakulta managementu Jindřichův Hradec Vysoká škola ekonomická Praha Úvod WWW obsáhlost obsahová i formátová pestrost dokumenty,
Profilování vzorků heroinu s využitím vícerozměrné statistické analýzy
 Profilování vzorků heroinu s využitím vícerozměrné statistické analýzy Autor práce : RNDr. Ivo Beroun,CSc. Vedoucí práce: prof. RNDr. Milan Meloun, DrSc. PROFILOVÁNÍ Profilování = klasifikace a rozlišování
Profilování vzorků heroinu s využitím vícerozměrné statistické analýzy Autor práce : RNDr. Ivo Beroun,CSc. Vedoucí práce: prof. RNDr. Milan Meloun, DrSc. PROFILOVÁNÍ Profilování = klasifikace a rozlišování
Predikce roční spotřeby zemního plynu po ceníkových pásmech
 Predikce roční spotřeby zemního plynu po ceníkových pásmech Ondřej Konár, Marek Brabec, Ivan Kasanický, Marek Malý, Emil Pelikán Ústav informatiky AV ČR, v.v.i. ROBUST 2014 Jetřichovice 20. ledna 2014
Predikce roční spotřeby zemního plynu po ceníkových pásmech Ondřej Konár, Marek Brabec, Ivan Kasanický, Marek Malý, Emil Pelikán Ústav informatiky AV ČR, v.v.i. ROBUST 2014 Jetřichovice 20. ledna 2014
STATISTIKA S EXCELEM. Martina Litschmannová MODAM,
 STATISTIKA S EXCELEM Martina Litschmannová MODAM, 8. 4. 216 Obsah Motivace aneb Máme data a co dál? Základní terminologie Analýza kvalitativního znaku rozdělení četnosti, vizualizace Analýza kvantitativního
STATISTIKA S EXCELEM Martina Litschmannová MODAM, 8. 4. 216 Obsah Motivace aneb Máme data a co dál? Základní terminologie Analýza kvalitativního znaku rozdělení četnosti, vizualizace Analýza kvantitativního
8.2 Používání a tvorba databází
 8.2 Používání a tvorba databází Slide 1 8.2.1 Základní pojmy z oblasti relačních databází Slide 2 Databáze ~ Evidence lidí peněz věcí... výběry, výpisy, početní úkony Slide 3 Pojmy tabulka, pole, záznam
8.2 Používání a tvorba databází Slide 1 8.2.1 Základní pojmy z oblasti relačních databází Slide 2 Databáze ~ Evidence lidí peněz věcí... výběry, výpisy, početní úkony Slide 3 Pojmy tabulka, pole, záznam
Vysoká škola báňská technická univerzita Ostrava. Fakulta elektrotechniky a informatiky
 Vysoká škola báňská technická univerzita Ostrava Fakulta elektrotechniky a informatiky Bankovní účty (semestrální projekt statistika) Tomáš Hejret (hej124) 18.5.2013 Úvod Cílem tohoto projektu, zadaného
Vysoká škola báňská technická univerzita Ostrava Fakulta elektrotechniky a informatiky Bankovní účty (semestrální projekt statistika) Tomáš Hejret (hej124) 18.5.2013 Úvod Cílem tohoto projektu, zadaného
Přednáška 13 Redukce dimenzionality
 Vytěžování Dat Přednáška 13 Redukce dimenzionality Miroslav Čepek Fakulta Elektrotechnická, ČVUT Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti ČVUT (FEL) Redukce dimenzionality 1 /
Vytěžování Dat Přednáška 13 Redukce dimenzionality Miroslav Čepek Fakulta Elektrotechnická, ČVUT Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti ČVUT (FEL) Redukce dimenzionality 1 /
Hodnocení klasifikátoru Test nezávislosti. 14. prosinec Rozvoj aplikačního potenciálu (RAPlus) CZ.1.07/2.4.00/
 CZ.1.07/2.4.00/") Čtyřpolní tabulky Čtyřpolní tabulky 14. prosinec 2012 Rozvoj aplikačního potenciálu (RAPlus) CZ.1.07/2.4.00/17.0117 O čem se bude mluvit? Čtyřpolní tabulky Osnova prezentace Čtyřpolní tabulky 1. přístupy
Čtyřpolní tabulky Čtyřpolní tabulky 14. prosinec 2012 Rozvoj aplikačního potenciálu (RAPlus) CZ.1.07/2.4.00/17.0117 O čem se bude mluvit? Čtyřpolní tabulky Osnova prezentace Čtyřpolní tabulky 1. přístupy
Statistická teorie učení
 Statistická teorie učení Petr Havel Marek Myslivec přednáška z 9. týdne 1 Úvod Představme si situaci výrobce a zákazníka, který si u výrobce objednal algoritmus rozpoznávání. Zákazník dodal experimentální
Statistická teorie učení Petr Havel Marek Myslivec přednáška z 9. týdne 1 Úvod Představme si situaci výrobce a zákazníka, který si u výrobce objednal algoritmus rozpoznávání. Zákazník dodal experimentální
1. Data mining. Strojové učení. Základní úlohy.
 1... Základní úlohy. Učení s učitelem a bez učitele. Petr Pošík Katedra kybernetiky ČVUT FEL P. Pošík c 2010 Aplikace umělé inteligence 1 / 36 Obsah P. Pošík c 2010 Aplikace umělé inteligence 2 / 36 Co
1... Základní úlohy. Učení s učitelem a bez učitele. Petr Pošík Katedra kybernetiky ČVUT FEL P. Pošík c 2010 Aplikace umělé inteligence 1 / 36 Obsah P. Pošík c 2010 Aplikace umělé inteligence 2 / 36 Co
Analytické metody v motorsportu
 Analytické metody v motorsportu Bronislav Růžička Ústav konstruování Odbor konstruování strojů Fakulta strojního inženýrství Vysoké učení technické v Brně 26. června 2013, FSI VUT v Brně, Česká republika
Analytické metody v motorsportu Bronislav Růžička Ústav konstruování Odbor konstruování strojů Fakulta strojního inženýrství Vysoké učení technické v Brně 26. června 2013, FSI VUT v Brně, Česká republika
Zpracování náhodného výběru. Ing. Michal Dorda, Ph.D.
 Zpracování náhodného výběru popisná statistika Ing. Michal Dorda, Ph.D. Základní pojmy Úkolem statistiky je na základě vlastností výběrového souboru usuzovat o vlastnostech celé populace. Populace(základní
Zpracování náhodného výběru popisná statistika Ing. Michal Dorda, Ph.D. Základní pojmy Úkolem statistiky je na základě vlastností výběrového souboru usuzovat o vlastnostech celé populace. Populace(základní
Insolvenční řízení - očekávání, realita, budoucnost. Reorganizace vs. sanační konkurz"
 Insolvenční řízení - očekávání, realita, budoucnost Reorganizace vs. sanační konkurz" Ing. Jaroslav SCHŐNFELD, Ph.D., 7.12.2015, Senát parlamentu České republiky, Praha Obsah 1) Výsledky statistického
Insolvenční řízení - očekávání, realita, budoucnost Reorganizace vs. sanační konkurz" Ing. Jaroslav SCHŐNFELD, Ph.D., 7.12.2015, Senát parlamentu České republiky, Praha Obsah 1) Výsledky statistického
EKONOMICKÉ MODELOVÁNÍ
 Metodický list č. 1 Podnikové procesy v řízení podniku Cílem tohoto tematického celku je vysvětlení základních pojmů z oblasti podnikových procesů a úvod do Business Process Reengineeringu i východisek
Metodický list č. 1 Podnikové procesy v řízení podniku Cílem tohoto tematického celku je vysvětlení základních pojmů z oblasti podnikových procesů a úvod do Business Process Reengineeringu i východisek
Analýza dat na PC I.
 CENTRUM BIOSTATISTIKY A ANALÝZ Lékařská a Přírodovědecká fakulta, Masarykova univerzita Analýza dat na PC I. Popisná analýza v programu Statistica IBA výuka Základní popisná statistika Popisná statistika
CENTRUM BIOSTATISTIKY A ANALÝZ Lékařská a Přírodovědecká fakulta, Masarykova univerzita Analýza dat na PC I. Popisná analýza v programu Statistica IBA výuka Základní popisná statistika Popisná statistika
Big Data a oficiální statistika. Unicorn College Open 24. dubna 2015 Doc. Ing. Marie Bohatá, CSc.
 Big Data a oficiální statistika Unicorn College Open 24. dubna 2015 Doc. Ing. Marie Bohatá, CSc. Obsah příspěvku Charakteristiky Big Data Výzvy a úskalí z perspektivy statistiky Výzvy z perspektivy computing
Big Data a oficiální statistika Unicorn College Open 24. dubna 2015 Doc. Ing. Marie Bohatá, CSc. Obsah příspěvku Charakteristiky Big Data Výzvy a úskalí z perspektivy statistiky Výzvy z perspektivy computing
7. Rozdělení pravděpodobnosti ve statistice
 7. Rozdělení pravděpodobnosti ve statistice Statistika nuda je, má však cenné údaje, neklesejte na mysli, ona nám to vyčíslí Jednou z úloh statistiky je odhad (výpočet) hodnot statistického znaku x i,
7. Rozdělení pravděpodobnosti ve statistice Statistika nuda je, má však cenné údaje, neklesejte na mysli, ona nám to vyčíslí Jednou z úloh statistiky je odhad (výpočet) hodnot statistického znaku x i,
Testování modelů a jejich výsledků. tomu, co jsme se naučili?
 Testování modelů a jejich výsledků Jak moc můžeme věřit tomu, co jsme se naučili? Osnova Úvod Trénovací, Testovací a Validační datové soubory Práce s nebalancovanými daty; ladění parametrů Křížová validace
Testování modelů a jejich výsledků Jak moc můžeme věřit tomu, co jsme se naučili? Osnova Úvod Trénovací, Testovací a Validační datové soubory Práce s nebalancovanými daty; ladění parametrů Křížová validace
Ontologie. Otakar Trunda
 Ontologie Otakar Trunda Definice Mnoho různých definic: Formální specifikace sdílené konceptualizace Hierarchicky strukturovaná množina termínů popisujících určitou věcnou oblast Strukturovaná slovní zásoba
Ontologie Otakar Trunda Definice Mnoho různých definic: Formální specifikace sdílené konceptualizace Hierarchicky strukturovaná množina termínů popisujících určitou věcnou oblast Strukturovaná slovní zásoba
IDENTIFIKACE AUTOMATICKÝCH PŘÍSTUPŮ INTERNETOVÝCH OBCHODŮ S VYUŽÍTÍM METOD WEB USAGE MININGU
 IDENTIFIKACE AUTOMATICKÝCH PŘÍSTUPŮ INTERNETOVÝCH OBCHODŮ S VYUŽÍTÍM METOD WEB USAGE MININGU Jana Filipová, Karel Michálek, Pavel Petr Ústav systémového inženýrství a informatiky, Fakulta ekonomicko-správní,
IDENTIFIKACE AUTOMATICKÝCH PŘÍSTUPŮ INTERNETOVÝCH OBCHODŮ S VYUŽÍTÍM METOD WEB USAGE MININGU Jana Filipová, Karel Michálek, Pavel Petr Ústav systémového inženýrství a informatiky, Fakulta ekonomicko-správní,
Informační systémy 2006/2007
 13 Vysoká škola báňská Technická univerzita Ostrava Fakulta strojní, Katedra automatizační techniky a řízení Informační systémy 2006/2007 Ivan Kedroň 1 Obsah Analytické nástroje SQL serveru. OLAP analýza
13 Vysoká škola báňská Technická univerzita Ostrava Fakulta strojní, Katedra automatizační techniky a řízení Informační systémy 2006/2007 Ivan Kedroň 1 Obsah Analytické nástroje SQL serveru. OLAP analýza
1 Úvod 1.1 Vlastnosti programového vybavení (SW)
") 1 Úvod 1.1 Vlastnosti programového vybavení (SW) - dávkové zpracování - omezená distribuce - zakázkový SW - distribuované systémy - vestavěná inteligence - laciný HW - vliv zákazníka 1950 1960 1970 1980
1 Úvod 1.1 Vlastnosti programového vybavení (SW) - dávkové zpracování - omezená distribuce - zakázkový SW - distribuované systémy - vestavěná inteligence - laciný HW - vliv zákazníka 1950 1960 1970 1980