Informační systémy pro podporu rozhodování
|
|
|
- Adéla Jandová
- před 9 lety
- Počet zobrazení:
Transkript
1 Informační systémy pro podporu rozhodování 2 Jan Žižka, Naděžda Chalupová Ústav informatiky PEF Mendelova universita v Brně

2 Strojové učení, umělá inteligence, dolování z dat Strojové učení je moderní, rychle a neustále se rozvíjející technologie pro získávání ( dolování ) znalosti z dat. Umělá inteligence se zabývá technologiemi prohledávání libovolných (reálných a abstraktních) prostorů; cílem je nalezení optima (globálního maxima), což je nejlepší řešení nějakého zadaného problému. Dolování z dat je zaměřeno na odkrytí znalosti v datech ukryté: data informace znalost. Dolování z dat využívá veškeré vhodné technologie, zejména strojové učení, umělou inteligenci, logiku a matematiku.
, což je nejlepší řešení nějakého zadaného problému.")
3 Mezi vytvářením dat a jejich porozuměním neustále narůstá mezera. Souvisí to úměrně s narůstajícím množstvím dat. Data ukrývají informaci jako svou potenciálně užitečnou část pro řešení různých konkrétních úloh. Data obsahují skupiny vzájemně si podobných hodnot, které představují vzory, tj. vzor (něco společného a typického) je zobecněním určité skupiny dat: lovci sledují typické chování své kořisti, zemědělci sledují typické souvislosti při pěstování plodin, politici sledují typické vzory názorů voličů, milenci typické odezvy svých partnerů, apod.
 je zobecněním určité skupiny dat: lovci sledují typické chování své kořisti, zemědělci sledují typické")
4 Dolování z dat se zaměřuje na elektronicky uložená data, přičemž prohledávání dat je automatizované pomocí počítačů. Odhaduje se, že množství uložených dat na celém světě se zdvojnásobuje každých 20 měsíců. Obecně platí, že více dat obsahuje více informace, tj. více znalosti, která je stále složitější. Inteligentně analyzovaná data představují velmi cenný zdroj. Z komerčního hlediska může jít o zvyšování konkurenční schopnosti; z vědeckého hlediska např. o zvýšení znalosti o řešeném problému.

5 Dolování z dat se zabývá řešením problémů pomocí analýzy dat, která jsou v daném čase k dispozici. Odhalená znalost pak může účinně pomáhat při odhadu budoucích jevů. Užitečné vzory umožňují netriviální predikce o nových, v budoucnu se vyskytujících instancích. Data získaná libovolným způsobem nemají obecně nijak zřetelnou strukturu. Dolování z dat odhaluje různé skryté, avšak existující struktury vzory struktur, tj. něco obecného, typického, aplikovatelného na více či méně si podobné popisy objektů. Objekty pak lze kategorizovat do jim příslušných skupin (tříd), kde není rozhodující unikátní individualita, nýbrž společné vlastnosti definující typ, např.: červené, zelené, modré,... předměty (libovolného tvaru).
, kde není rozhodující unikátní individualita, nýbrž společné vlastnosti definující typ, např.")
6 Metody alternativní ke statistice umožňují nalézt skryté datové struktury, které statistika odhalí jen velice obtížně nebo vůbec ne. Ilustrace ukazuje čtyři jednoduché případy, kdy odhalení neznámé struktury statisticky do druhého řádu selhává, protože všechny čtyři ukázky mají stejný střed + i kovarianci, takže se jeví stejně ve skutečnosti by individuální případy měly být zařazeny do příslušných shluků či kategorií odlišně. Vícerozměrné případy jsou pak mnohem komplikovanější.

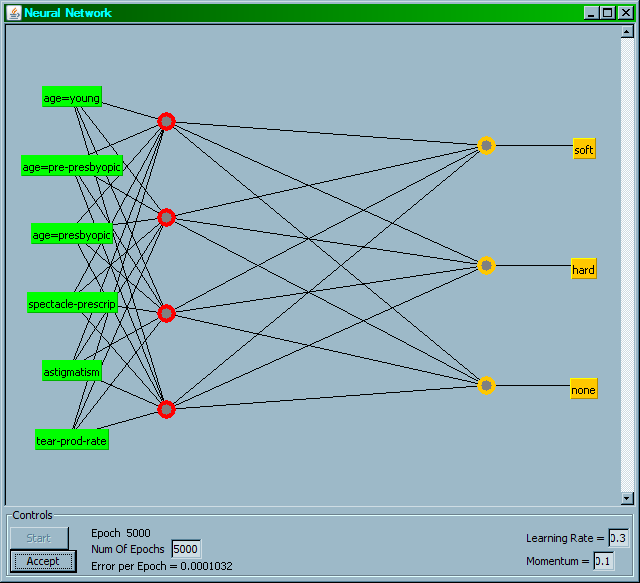
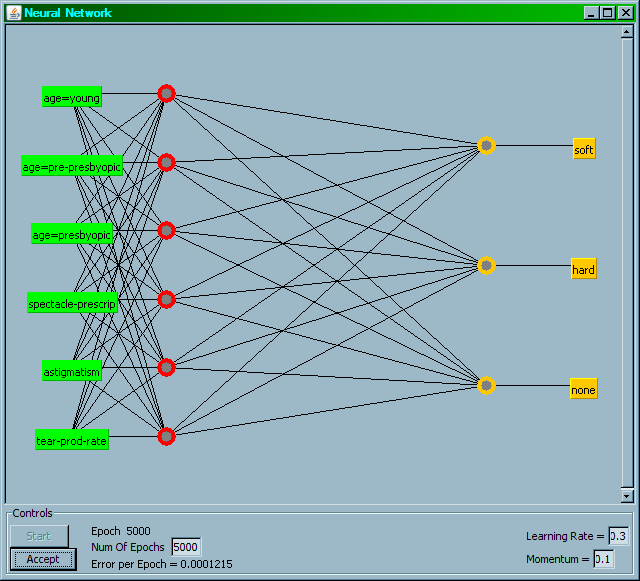
7 Příklad dolování z dat: Kontaktní čočky ID Age Spectacle prescription Astigmatism Tear production rate 1 young myope no reduced none 2 young myope no normal soft 3 young myope yes reduced none 4 young myope yes normal hard 5 young hypermetrope no reduced none 6 young hypermetrope no normal soft 7 young hypermetrope yes reduced none 8 young hypermetrope yes normal hard 9 pre-presbyopic myope no reduced none 10 pre-presbyopic myope no normal soft 11 pre-presbyopic myope yes reduced none 12 pre-presbyopic myope yes normal hard 13 pre-presbyopic hypermetrope no reduced none 14 pre-presbyopic hypermetrope no normal soft 15 pre-presbyopic hypermetrope yes reduced none 16 pre-presbyopic hypermetrope yes normal none 17 presbyopic myope no reduced none 18 presbyopic myope no normal none 19 presbyopic myope yes reduced none 20 presbyopic myope yes normal hard 21 presbyopic hypermetrope no reduced none 22 presbyopic hypermetrope no normal soft 23 presbyopic hypermetrope yes reduced none 24 presbyopic hypermetrope yes normal none Recommended lenses presbyopic: dalekozraký starší (pokles akomodace věkem) myope: krátkozraký hypermetrope: dalekozraký

8 Data kontaktní čočky popisují podmínky, kdy optik (ne)má předepsat určitý druh kontaktních čoček. Tabulka je mírně zjednodušená (nejsou v ní všechny atributy mající vliv na předpis čoček). Databáze popisuje všechny možné případy, které jsou bez chybějících hodnot a bez šumu. Dohromady je 24 instancí, popis čtyřmi atributy, které nabývají nominálních hodnot. Klasifikační třídy jsou tři. Data pocházejí ze srpna Jsou ve veřejně přístupném souboru různých dat UCI Repository Of Machine Learning Databases and Domain Theories (Univ. of California, Irvine, CA).

9 Je v datech nějaká struktura? Jsou tři třídy: none (žádné čočky), soft (měké) a hard (tuhé) čočky. Podle čeho lze každou kombinaci nominálních hodnot zařadit do jednotlivých tříd? young, myope, no, reduced: none presbyopic, hypermetrope, no, reduced: none pre-presbyopic, hypermetrope, yes, reduced: none presbyopic, myope, yes, reduced:? Z tabulky plyne, že když je tear-production-rate = reduced, tak je vždy třída none. Ale ne vždy je hodnota atributu tear-production-rate = reduced pro třídu none!

10 Například: pre-presbyopic, hypermetrope, yes, normal: none Takže nestačí se řídit pouze jedním atributem, relevantní jsou zjevně i další: v jaké kombinaci hodnot? Popis struktury dat z hlediska klasifikační třídy může být různý, například srozumitelně pomocí pravidel nebo rozhodovacího stromu (white-box), nebo nesrozumitelně pomocí natrénované umělé neuronové sítě (black-box). Příklad pravidel a stromu získaných strojovým učením z dat kontaktní čočky:
, nebo nesrozumitelně pomocí natrénované umělé neuronové sítě (black-box).")
11 If astigmatism = no and tear-prod-rate = normal and spectacle-prescrip = hypermetrope then soft If astigmatism = no and tear-prod-rate = normal and age = young then soft If age = pre-presbyopic and astigmatism = no and tear-prod-rate = normal then soft If astigmatism = yes and tear-prod-rate = normal and spectacle-prescrip = myope then hard If age = young and astigmatism = yes and tear-prod-rate = normal then hard If tear-prod-rate = reduced then none If age = presbyopic and tear-prod-rate = normal and spectacle-prescrip = myope and astigmatism = no then none If spectacle-prescrip = hypermetrope and astigmatism = yes and age = pre-presbyopic then none If age = presbyopic and spectacle-prescrip = hypermetrope and astigmatism = yes then none Celkem 9 pravidel popisuje kompletně problém předepsání kontaktních čoček. Pravidla vygenerována algoritmem PRISM.

12 tear-prod-rate = reduced: none tear-prod-rate = normal astigmatism = no age = young: soft age = pre-presbyopic: soft age = presbyopic spectacle-prescrip = myope: none spectacle-prescrip = hypermetrope: soft astigmatism = yes spectacle-prescrip = myope: hard spectacle-prescrip = hypermetrope age = young: hard age = pre-presbyopic: none age = presbyopic: none Rozhodovací strom vytvořený algoritmem ID3 popisuje problém rovněž zcela správně. Každá větev zároveň představuje jedno pravidlo.

13 reduced t-p-r normal none no astig yes age young pre-pre pre myope spect hyper soft soft spect hard myope hyper young age pre-pre pre none soft hard none none Překreslený rozhodovací strom ID3

14 Detailní popis demonstrovaných algoritmů: PRISM algoritmus: J. Cendrowska (1987). PRISM: An algorithm for inducing modular rules. International Journal of Man-Machine Studies. 27(4): ID3 algoritmus: R. Quinlan (1986). Induction of decision trees. Machine Learning. 1(1):
. Induction of decision trees.")
15 (Počet věcí, které mají vysvětlovat jevy, nemá být zbytečně násobený.) Machine Learning, Artificial Intelligence, Data Mining Alternativní algoritmus: Umělá neuronová síť se sigmoidálními přenosovými funkcemi neuronů (nelineární hranice oddělující třídy) trénovaná tzv. zpětným šířením chyb (backpropagation). Není zřejmé, jakou architekturu má síť mít. Lze zkusit různé architektury (pouze počet vstupních a výstupních jednotek je dán úlohou). Jako výsledek se vybere dle Occamova (resp. Ockhamova) pravidla architektura nejjednodušší, dává-li stejně dobré výsledky jako architektury složitější (tzv. Occamova břitva, Occam s / Ockham s razor): Entia non sunt multiplicanda praeter necessitatem.
. Jako výsledek se vybere dle Occamova (resp.")
16
17

18

19 Dolování z dat data mining Metody strojového učení jsou prakticky zaměřené, využívají všech vhodných teorií a postupů včetně exaktní matematiky, pravděpodobnosti, umělé inteligence, přibližného usuzování, logiky, apod. Strojové učení nepředpokládá žádný filosofický přístup k termínu učení jde o naučení se (zobecnění) znalosti z dat a informace, zejména induktivně, z příkladů. Algoritmy, metody, jejich kombinace, příprava dat, zpracování a interpretace výsledků většinou bývají dosti složité a vyžadují výkonné počítače (rychlý procesor, lépe více procesorů, a rozsáhlou paměť).

20 Klasickým příkladem dolování znalosti je tzv. problém počasí a hry v tenis: Sledují se lidé, zda jdou či nejdou hrát tenis v závislosti na některých atributech popisujících počasí. Naměřené hodnoty a jejich kombinace nepokrývají veškeré možnosti. Idea je v zobecnění disponibilní informace tak, aby bylo možno předvídat, zda se půjde hrát či ne i pro kombinace hodnot, které během učení nebyly známy, a predikce má být co nejlepší, s minimální chybou. Disponibilní informaci ukazuje následující tabulka:

21 předpověď teplota vlhkost větrno hrát slunečno horko vysoká ne ne slunečno horko vysoká ne zataženo horko vysoká ne deštivo příjemně vysoká ne deštivo chladno normální ne deštivo chladno normální ne zataženo chladno normální slunečno příjemně vysoká ne ne slunečno chladno normální ne deštivo příjemně normální ne slunečno příjemně normální zataženo příjemně vysoká zataženo horko normální ne deštivo příjemně vysoká ne Počet možných kombinací hodnot je 36, známo je 14. zataženo, horko, normální, : hrát =? hrát = ne?

22 atribut teplota je pro trénovací data irelevantní vždy, když předpověď byla zataženo, se hrálo, takže na ostatních atributech nezáleželo zataženo, horko, normální, : hrát =? hrát = ne?
23 předpověď teplota vlhkost větrno hrát slunečno horko vysoká ne ne slunečno horko vysoká ne zataženo horko vysoká ne deštivo příjemně vysoká ne deštivo chladno? ne deštivo chladno normální ne zataženo chladno normální slunečno příjemně vysoká ne ne slunečno chladno normální ne deštivo příjemně normální ne slunečno příjemně normální zataženo příjemně vysoká zataženo horko normální ne deštivo příjemně vysoká ne Chybějící hodnota atributu vlhkost (původně = = normální).
: 7.")
24 Celkový počet instancí je opět 14: neznámá (chybějící) hodnota nahrazena dle výskytu hodnot v jiných instancích: (7.54/1.0): 7.54 zařazeno do třídy správně, 1 instance chybně strom je nyní odlišný: normální vysoká neúplná instance náleží částečně do více tříd
25 Instance s chybějícími hodnotami přinášejí méně informace do zpracování, takže výsledek klasifikace má obecně vyšší chybovost. Při dostatečném množství trénovacích instancí lze ty neúplné ze zpracování vyřadit; jinak je nutno chybějící hodnoty nahradit pomocí např. pravděpodobnostního výpočtu. Lze také zavést umělou hodnotu missing a strom pak ukáže, kam vede větev při výskytu chybějící hodnoty určitého atributu, což může napovědět, do jaké míry chybějící hodnoty ovlivňují výsledek. Někdy lze atribut s chybějícími hodnotami vyřadit jako irelevantní i za cenu zvýšení chyby klasifikace.
26 Entropie a rozhodovací stromy Odpovědi na dotazy v testovacích uzlech by měly dát co nejvíce informace, tj. odpovědi by měly být co nejužitečnější vzhledem k řešené úloze (např. rozdělení heterogenní množiny instancí na co nejhomogennější podmnožiny pro dosažení optimální klasifikace). Jedním z problémů při konstrukci rozhodovacího stromu je stvení vhodných dotazů. K dobrým a praktickým možnostem při hledání dotazů patří využití entropie. Entropie je definována v teorii informace a lze ji využít k mnoha účelům, nejen pro rozhodovací stromy.
27 Cílem klasifikace je přiřazení správné vlastnosti (tj. třídy) pro du instanci (vzorek). Pro trénovací data jsou jejich vlastnosti známy, takže jsou známy odpovědi na možné dotazy kvalitní dotazy mají odpovědi, které pro trénovací data vyvolají co nejmenší překvapení. Mírou překvapení je zde entropie, která ji měří pomocí pravděpodobnosti. S růstem pravděpodobnosti výskytu jevu klesá překvapení nad jeho výskytem, tj. je-li pravděpodobnost p = 1.0 pak lze daný jev očekávat zcela jistě. Podobně je tomu naopak pro p = 0.0, kdy také nevzniká překvapení. Překvapení (surprise) dvou nezávislých jevů s pravděpodobnostmi p a q: S(pq) = S(p) + S(q).
28 Teorie informace, jejíž základy položil zejména Shannon [Shannon C. E., Weaver W. (1949) The Mathematical Theory of Communication. Univ. of Illinois Press], definuje funkci typu S(p) vztahem S(p) = -log b p kde b je nějaký základ. Vyjadřujeme-li míru informace v jednotkách bit (binary digit), pak b = 2 (odpověď je buď nebo ne, např. zařazení instance do určité třídy). Entropie H(X) pro náhodnou proměnnou X je definována: H X = n p n S p n = n p n log 2 p n
29 H X = n p n log 2 p n 0, 0 p 1 Proměnná X má možné hodnoty x n s pravděpodobnostmi p n (kde n = 1, 2, 3,...). Záporné znaménko poskytuje kladné hodnoty entropie: logaritmy z hodnot pravděpodobností jsou záporné. Průběh funkce entropie ukazuje graf. Odpověď na dobrý dotaz je co nejblíže 0 nebo 1. Špatný dotaz bude zařazovat instance víceméně náhodně. H maximální entropie p
30 H(p) Entropie H(p) 0.8 H(p) = -p log 2 p - (1-p) log 2 (1-p) p
31 Při konstrukci rozhodovacího stromu se tedy hledají testy v uzlech tak, aby odpověď na test poskytla co nevíce informace, tj. aby byla co nejmenší entropie. Počáteční heterogenní množina trénovacích instancí je na základě odpovědí na test rozdělena na homogennější podmnožiny, snižuje se neuspořádst ( chaos ). Principem je výběr atributu, na jehož hodnoty se uzel ptá. Je nutno vyzkoušet všechny uvažované atributy, tj. zjistit, jakou poskytují entropii, a pak vybrat atribut s nejnižší entropií. Vznikne nová úroveň stromu (kořenem je počáteční množina trénovacích instancí), kterou lze rekursivně dále testovat. Konec generování stromu je dán nemožností dosažení nižší entropie (listy).
32 Příklad vytvoření rozhodovacího stromu pro výše uvedený problém počasí a hry v tenis: předpověď teplota vlhkost větrno hrát slunečno horko vysoká ne ne slunečno horko vysoká ne zataženo horko vysoká ne deštivo příjemně vysoká ne deštivo chladno normální ne deštivo chladno normální ne zataženo chladno normální slunečno příjemně vysoká ne ne slunečno chladno normální ne deštivo příjemně normální ne slunečno příjemně normální zataženo příjemně vysoká zataženo horko normální ne deštivo příjemně vysoká ne
33 Který atribut (předpověď, teplota, vlhkost, větrno) dá jako odpověď nejlepší rozdělení do homogennějších podmnožin? Postupně se spočítají entropie; např. pro předpověď: předpověď =? 9x se hrálo, 5x se nehrálo (9+5=14 trénovacích instancí). Pravděpodobnosti a posteriori pro jsou: slunečno ne ne ne zataženo deštivo ne ne 2/9 + 4/9 + 3/9 = 1.0, resp. pro ne: 3/5 + 0/5 + 2/5 = 1.0. Entropie je mírou neuspořádsti množiny (dokonalá uspořádst je dána hodnotou entropie = 1 nebo 0). Protože test zde rozdělí množinu na 3 podmnožiny, které obecně mohou mít různé neuspořádsti, tak se ství průměrná neuspořádst na konci větví vedoucích z testovacího uzlu. Neuspořádst množiny každé větve se váhuje rozměrem množiny relativně vzhledem k celkovému rozměru množin ve všech větvích. Váha je tedy počet příkladů n b ve větvi b ku celkovému počtu příkladů n t ve všech větvích: n b / n t.
34 Průměrná neuspořádst: H avg = b n b n t neuspořádst větveb H avg = [ b n b n t ] [ c n bc n b log 2 n bc n b ] kde n b n t... počet příkladů ve větvi b... celkový počet příkladů ve všech větvích n bc... celkový počet příkladů ve větvi b třídy c (Vzorec není posvátný, v praxi se osvědčil; lze samozřejmě použít i jiný vhodný, dává-li dobré výsledky.)
35 Zpátky k příkladu hrát tenis či ne? : slunečno předpověď =? Entropie pro předpověď: H avg = [- 5/14 (2/9 log 2 2/9 + 3/5 log 2 3/5)] + [- 4/14 (4/9 log 2 4/9 + 0/5 log 2 0/5)] + [- 5/14 (3/9 log 2 3/9 + 2/5 log 2 2/5)] = deštivo zataženo (Pozn.: 0 log b 0 = 0 [def.]; log b x = log 10 x / log 10 b) ne ne ne ne ne Z výsledku je vidět, že zvolený test předpověď snížil do určité míry původní neuspořádst (jedna ze vzniklých podmnožin, zataženo, je již zcela homogenní a není nutno ji už dále nijak dělit; podmnožiny ve větvi slunečno a deštivo jsou stále ještě heterogenní, takže se dále bude hledat možnost jejich rozdělení). Otázka nyní je, zda jiný atribut nemůže dát ještě lepší výsledek, bude-li použit jako test.
36 Další tři atributy včetně větvení a hodnot: teplota =? vlhkost =? větrno =? horko vysoká ne normální chladno příjemně ne ne ne ne ne ne ne ne ne ne ne ne ne ne ne
37 Spojité a diskrétní atributy Atributy popisující objekty mají velmi často číselný charakter (nejen binární či nominální). Obecně mohou být numerické atributy definovány na spojité reálné ose. Některé algoritmy jsou schopny zcela přirozeně pracovat i s číselnými atributy, část z nich pouze s numerickými hodnotami (např. metoda nejbližšího souseda k NN využívající Eukleidovy vzdálenosti, nebo algoritmy založené na regresních technikách, např. regresní strom M5P, kde i klasifikační třída je numerická). V takových případech je nutno převést data buď ze spojitého universa na diskrétní, resp. naopak.
38 Popisovaný typ rozhodovacích stromů vychází z původního algoritmu pro indukci rozhodovacího stromu ID3 (Interactive Dichotomizer No. 3), který umí zpracovat pouze nominální atributy. [Vysoká praktická úspěšnost aplikace ID3 vedla k rozšíření na atributy numerické. Nejznámější je c4.5 Rosse Quinlana, včetně následné komerční verze c5/see5 *) pro operační systémy Unix/Linux/Windows]. Princip rozšíření je v tzv. diskretizaci. Diskretizaci lze provést mnoha různými metodami, včetně zcela automatické (unsupervised) nebo řízené (supervised). Zpět k problému počasí a hry v tenis, tentokrát s atributy teplota avlhkost numerickými: *) Demonstrační, plně funkční verzi c5/see5 s omezením na počet příkladů lze získat zdarma na URL (2007):
39 předpověď teplota vlhkost větrno hrát slunečno ne ne slunečno ne zataženo ne deštivo ne deštivo ne deštivo ne zataženo slunečno ne ne slunečno ne deštivo ne slunečno zataženo zataženo ne deštivo ne Diskretizace musí rozdělit číselný interval, považovaný za spojitý, na soubor podintervalů. Každý vzniklý podinterval pak hraje roli nominální hodnoty. Pozn.: Teplota je ve stupních Farenheita: 32 F F odpovídá 0 C C. Vlhkost je relativní v %.
40 teplota: 85, 80, 83, 70, 68, 65, 64, 72, 69, 75, 75, 72, 81, 71 vlhkost: 85, 90, 86, 96, 80, 70, 65, 95, 70, 80, 70, 90, 75, 91 Některé z možných a používaných metod diskretizace: a) Rozdělení na určitý počet podintervalů stejné délky (nevýhoda může být ve velmi různém počtu hodnot v každém intervalu). b) Rozdělení na podintervaly, kde každý obsahuje (přibližně) stejný počet hodnot (v praxi se osvědčuje jako heuristika se pro stvení počtu intervalů často používá druhá odmocnina z celkového počtu hodnot daného atributu; intervaly ovšem mohou mít velmi různou délku). c) Rozdělení na podintervaly pomocí entropie, kde každý podinterval obsahuje (pokud možno) pouze hodnoty patřící do jediné třídy (diskretizace řízená tréninkovými daty).
41 a) b) c)
42 První krok diskretizace spočívá v seřazení hodnot: teplota: 64, 65, 68, 69, 70, 71, 72, 72, 75, 75, 80, 81, 83, 85 chladno příjemně horko vlhkost: 65, 70, 70, 70, 75, 80, 80, 85, 86, 90, 90, 91, 95, 96 normální vysoká Tento krok bývá z hlediska výpočetní složitosti obvykle nejnáročnější, ale jednou setříděné hodnoty se využijí i pro rekursivní generování podstromů na dalších úrovních stromu, takže stačí setřídit pouze jedenkrát. V dalším kroku se jednou z možných metod hledají dělící body mezi hodnotami, tj. hranice podintervalů.
43 Původní nominální a jim odpovídající numerická data: teplota vlhkost horko 85 vysoká 85 horko 80 vysoká 90 horko 83 vysoká 86 příjemně 70 vysoká 96 chladno 68 normální 80 chladno 65 normální 70 chladno 64 normální 65 příjemně 72 vysoká 95 chladno 69 normální 70 příjemně 75 normální 80 příjemně 75 normální 70 příjemně 72 vysoká 90 horko 81 normální 75 příjemně 71 vysoká 91 Postupně se musí (do značné míry hrubou silou ) zkoušet, která hranice mezi intervaly dá nejmenší entropii. Proto jsou úlohy s numerickými daty výpočetně složitější než úlohy s daty nominálními. V realitě však jsou numerické atributy poměrně běžné, obvykle doprovázeny atributy binárními i nominálními (smíšená reprezentace).
44 Výsledek entropické diskretizace atributu teplota: ne ne ne/ / ne ne / Je teoreticky dokázáno, že metoda minimalizace entropie při diskretizaci nikdy neumístí hranici mezi intervaly tak, aby byly odděleny dvě instance téže třídy (pozn.: zde mezi 72 a 75 je hranice, která odděluje /ne od /, tj. nikoliv dvě instance téže třídy). To vede k urychlení výpočtu: je třeba testovat hranice pouze mezi instancemi z různých tříd (takže ne 68/69, 69/70, apod.).
45 Další možné diskretizační metody: Nikoliv shora dolů, jak ukázáno, ale naopak zdola nahoru, tj. napřed každá jednotlivá instance je oddělena a pak se hledá, zda ji lze spojit se sousední. Počítání chyb, ke kterým dojde při predikci pro různé diskretizace (hrozí degenerace, že každá instance bude prohlášena za interval; je nutno předem omezit počet intervalů). Metoda hrubou silou vyzkoušet všechny možnosti je exponenciálně náročná (počet intervalů k je v exponentu). Dynamické programování (způsob optimalizace) rozdělí N instancí do k intervalů v čase úměrném kn 2.
46 Převod diskrétních atributů na numerické: Některé algoritmy vyžadují pouze numerické hodnoty, takže je zapotřebí opačný převod. Atributy s nominálními hodnotami předpokládají různost dvou nominálních hodnot jako nenulovou vzdálenost a stejnost jako vzdálenost nulovou. Je-li k různých nominálních hodnot, jsou uměle nahrazeny binárními hodnotami 0/1, např. atribut barva může nabývat tří hodnot (modrá, zelená, červená), takže tento atribut je převeden na tři binární atributy: modrý, zelený, červený, a modrý objekt pak má odpovídající hodnoty nových umělých atributů 1, 0, 0. Pak lze počítat např. vzdálenosti mezi objekty, kde nulová vzdálenost znamená identitu (dva stejné objekty), apod. Seřaditelné nominální hodnoty lze nahradit celými čísly.
47 Trénování a testování Pro odhad chyby klasifikátoru na budoucích datech, která nebyla k dispozici během trénování, je nutno klasifikátor otestovat. K tomu se buď použijí nějak vyčleněná data, která se tréninku nezúčastní (testovací data), nebo se dá využít části tréninkových dat tím, že se použijí jako testovací, což ale vede ke snížení počtu trénovacích příkladů a dále k vyřazení určitých příkladů; negativním důsledkem může být zhoršený trénink a nižší kvalita klasifikátoru. Existují metody, kdy lze použít pro trénink všechny příklady a zároveň klasifikátor týmiž daty otestovat. Rozšířená (ale ne jediná) je např. metoda krosvalidace.
48 Krosvalidace (cross-validation) Tato metoda rozdělí náhodným výběrem data na k pokud možno stejně velkých částí, např. na 10 podmnožin (k může záviset na celkovém množství trénovacích instancí). Pak proběhne 10 tréninků tak, že v každém z nich se použije 9 podmnožin jako trénovací a 1 jako testovací. Každý trénink používá pro testování různou z podmnožin, takže postupně všechna data jsou využita na trénování a testování. Každé testování zjistí chybu klasifikátoru, a výsledná očekávaná chyba je průměrem. Tato chyba je tzv. pesimistická, protože byla odhadnuta na menším počtu trénovacích příkladů (zde např. na 90 %). Výsledný klasifikátor se pak natrénuje pomocí všech příkladů.
49 Počet podmnožin může být i jiný, 10 je prakticky osvědčená heuristika. Extrémem je rozdělení trénovací množiny na počet podmnožin odpovídající počtu trénovacích příkladů n. Pak se jedná o tzv. krosvalidaci 1-z-n, která má výhodu v trénování téměř všemi instancemi v každém z n trénovacích kroků. Nevýhodou je úplná ztráta rozložení hodnot [které je při obyčejné krosvalidaci (náhodným výběrem) do určité míry v podmnožinách zachováno]. Pro odhad chyby lze také použít obě metody a výsledky porovnat jsou-li např. chyby všech jednotlivých kroků velmi podobné a navíc jsou podobné i mezi krosvalidací obyčejnou a 1-z-n, pak je systém datově robustní.
50 Protože výběr prvků do podmnožin se provádí náhodně, může být i výsledek náhodně velmi špatný nebo náhodně příliš dobrý. Generátor (pseudo)náhodných čísel potřebuje na začátek tzv. násadu, z níž odvozuje posloupnost generovaných čísel s rovnoměrným rozložením. Takových posloupností lze vytvořit mnoho a předem není jasné, která povede k jakému výsledku. Proto je velmi vhodné celý proces krosvalidace zopakovat vícekrát, pokaždé s jinak provedeným náhodným výběrem. Strojové učení má jako empirický standard tzv. desetinásobně opakovu krosvalidaci s dělením na 10 částí (10-times 10-fold crossvalidation). Lze ovšem použít i jiné hodnoty odpověď dají experimenty a jejich pečlivé vyhodnocení.
51 Bootstrap Bootstrap je statistická metoda založená na výběru s vracením. Znamená to, že tímto výběrem vzniklá sada příkladů může obsahovat některé příklady vícekrát (takže nelze hovořit o množině). Myšlenka vychází z toho, že když některé příklady jsou náhodně vybrány vícekrát, jiné nejsou vybrány nikdy a právě tyto nevybrané příklady pak vytvoří testovací množinu.
52 Data, mající n příkladů, jsou podrobena n výběrům s vracením. Šance, že nějaký příklad nebude vybrán v žádném z n pokusů (výběr musí být náhodný), je založena na tom, že pravděpodobnost být vybrán je 1/n a nebýt vybrán 1 1/n. Opakuje-li se výběr n-krát, pak vynásobením pravděpodobností vznikne pravděpodobnostní odhad, kolikrát nedojde k výběru:. (1 1/n) n = e -1 = (pro n ), kde e je základ přirozených logaritmů. Např. pro n = 1000 pokusů je (1 1/1000) = = %.
53 Odhad stvuje, že v testovací množině bude cca 36.8 % příkladů, zatímco v trénovací množině zůstane 63.2 %, takže originální data jsou statisticky oprávněně rozdělena přibližně na 2/3 trénovacích a 1/3 testovacích. Někdy se této metodě výběru říká bootstrap. Samozřejmě, že ani trénovací ani testovací množina pak neobsahují opakované příklady.
54 Vzhledem k náhodnosti výběru mohou být data rozdělena i příliš dobře nebo příliš špatně, takže testovací část vůči trénovací může poskytnout neoprávněně malou či velkou chybu [ale míra (ne)oprávněnosti není známá, pouze se statististicky odhaduje]. Aby bylo možno se vyhnout výsledkům ovlivněných náhodností negativně, je vhodné trénování a testování provést opakovaně několikát, pokaždé s novým náhodným rozdělením výchozí datové množiny. Je nutno dát pozor na to, aby generátor náhodných čísel, používaných k výběru, vždy vyprodukoval jinou posloupnost hodnot s rovnoměrným rozdělením. To zajišťuje tzv. násada (seed).
55 Každé testování pak dá obecně více či méně odlišnou odhadnutou budoucí chybu a výsledná očekávaná chyba se spočítá jako průměr (platí i pro krosvalidaci). Rozptyl průměrně očekávané chyby poskytuje informaci o stabilitě algoritmu vůči složení dat. Pro dosažení dobré stability (robustnosti algoritmu) je ideální co nejmenší rozptyl. To především ovlivňují samotná data, ale různé algoritmy mohou dát různé výsledky i z tohoto hlediska, přestože průměrná chyba může být téměř stejná. Výsledky testování jsou tedy dalším hlediskem pro výběr algoritmu i z hlediska robustnosti.
56 Prořezávání (pruning) Znalost je zobecněná informace, a strom je jednou z možných reprezentací znalosti. Proto by měl být dostatečně obecný, tj. ne být dokonalý na tréninkových datech velmi často může velice chybovat na testovacích datech, i když na tréninkových dosahuje nízkých chyb. Ukazuje se, že k lepším výsledkům na testovacích datech přispívá tzv. prořezávání po celkovém vytvoření stromu. Strom se nenechá tak rozkošatět. Jednou z metod je tzv. náhrada podstromu, kdy podstrom je nahrazen listem. Tato operace zvýší chybu na trénovacích datech, ale pro testovací data je chyba nižší než před náhradou.
57 Příčina je zřejmá např. z extrémního případu, kdy mohou tréninkem vzniknout listy obsahující jedinou instanci; to je špatná generalizace, protože ideální je, aby každý list pokrýval co nejvíce příkladů. Obsahují-li tréninkové příklady šum, pak jednoprvkové množiny v listech mohou vést k chybné klasifikaci řízené spíše šumem než zobecněním souboru hodnot relevantních atributů. Takové přetrénování hrozí nejen při entropické tvorbě rozhodovacích stromů, ale i pro mnoho jiných algoritmů. U stromů lze zabránit přetrénování prořezáváním.
58 Existují dva postupy prořezávání: Shora dolů (pre-pruning) Zdola nahoru (post-pruning) Pre-pruning zastaví růst větve, když začne poskytovat nespolehlivou informaci. Post-pruning nechá strom zcela vyrůst a rozkošatět, a pak zpět směrem od listů ruší nespolehlivé části. V praxi se dává přednost metodě post-pruning (zdola nahoru), protože pre-pruning mívá tendenci zastavit růst větve příliš brzo. Pre-pruning je ale výpočetně rychlejší metoda než post-pruning.
59 Pre-pruning využívá test statistického významu propojení atributu s klasifikační třídou pro konkrétní uzel. Pro testování se nejčastěji používá χ 2 (chí-kvadrát), což je test vycházející z frekvencí hodnot, zde vzhledem ke třídě. Předčasné zastavení růstu lze demonstrovat na klasickém případu parity (neboli XOR-problému): id x 1 x 2 c Ani jeden z individuálních atributů x 1 a x 2 nevykazuje žádný významný vztah ke třídě c. Struktura je vidět pouze na zcela vyrostlém stromě, avšak pre-pruning a χ 2 zastaví růst hned v kořeni zcela degenerovaný strom. Přesto ale lze pro XOR korektní strom vytvořit.
60 XOR-problém: id x 1 x 2 c Obrázek ukazuje dvě zcela správná řešení. XOR je pro řadu algoritmů obtížný typ problému. V praxi se však vyskytuje poměrně zřídka. XOR je typická ukázka případu, kdy jednotlivé atributy nemají prediktivní význam, ale jejich kombinace. 0 x x 2 1 x 2 x x 1 x
61 Post-pruning vychází z následujícího principu: zcela homogenní listy vzniklé ze společného uzlu se zpětně uměle sloučí s rodičovským uzlem a vytvoří se tak list, který už není homogenní (má entropii > 0). Tím se zvýší chyba stromu na trénovacích příkladech, ale ta není rozhodující. Zato však může lépe generalizovat, což je podstatné pro klasifikaci testovacích datových příkladů. Úvaha platí i pro listy pokrývající více příkladů, a nemusí být homogenní. Zda nahradit či nenahradit podstrom listem, na to odpoví odhad chyby na testovacích datech (vždy po náhradě je nutno překlasifikovat příklady použité pro vytvoření neprořezaného stromu). Je-li po prořezání chyba na testovacích datech nižší, pak je doporučena náhrada listem.
62 Následující příklad demonstruje post-pruning na reálných (veřejně přístupných) vzorcích z vyjednávání o kolektivních smlouvách a podmínkách v kanadském průmyslu (listopad 1998). Data jsou popsána 57 příklady a 16 atributy a jsou k dispozici (spolu s mnoha dalšími z nejrůznějších oborů) na URL (rok 2007): Následující obrázek ukazuje vygenerovaný strom (ne úplný), v němž lze postupně zkoušet náhradu podstromů listy. Každý pokus vyžaduje po stvení místa prořezání zjistit chybu na trénovacích i testovacích datech. Zvýšení trénovací chyby se snížením testovací chyby (ve srovnání se stromem bez náhrady podstromu) určí, že náhrada listem je správná.
63 Post-pruning pracuje tak, že napřed nechá strom zcela vyrůst, čímž jsou zachyceny i kombinace mezi atributy. Poté hledá, zda lze nějaké podstromy nahradit listem. bad bad
64 Dva podstromy (viz předchozí obrázek) byly postupně nahrazeny listem bad. Zeleně ohraničený podstrom listem bad, a pak modře ohraničený podstrom rovněž listem bad. Strom je značně zjednodušen, lépe generalizuje na testovacích datech (na trénovacích má o něco vyšší chybu).
65 Další obrázky ukazují výsledky dosažené algoritmem J48 (c4.8) systému WEKA (labor-negotiation data jsou součástí WEKA jako jeden z příkladů, labor.arff). Lze srovnat různé výsledky dosažené nad týmiž daty pro různé koeficienty CF (0.1, 0.25, 0.5,1.0), kde menší hodnota znamená větší prořezání stromu. Sleduje-li se chyba testování pomocí krosvalidace 10 (implicitně nabízená hodnota), tak lze pozorovat, že testovací chyba klesá až do CF = 0.5 (a platí to i pro chybu trénovací). Výsledný strom by měl být vybrán tak, aby dosahoval minimální předpovězené testovací chyby a aby nebyl příliš prořezán. Lepší je mít pro testování oddělená data, krosvalidace zde snižuje počet trénovacích.
 Faktor jistoty (confidence factor, CF ) je parametr ovlivňující prořezávání.")
66 CF = 0.1 CF = 0.25 (implicitní hodnota daná statistikou) Faktor jistoty (confidence factor, CF ) je parametr ovlivňující prořezávání. Nižší hodnota znamená větší prořezávání a naopak. Parametr zadává uživatel, implicitně platí CF = 0.25.
67 CF = 0.5
68 CF = 1.0 Maximální jistota poskytované informace vede k neprořezanému stromu. Může i nemusí snižovat generalizaci závisí na konkrétní aplikaci.

69 Přehled rozložení hodnot pro atributy dat labor-negotiation
70 Výše popisovaný problém XOR dává při použití J48/c4.8 degenerovaný strom pro každou hodnotu CF (první z následujících tří obrázků). Modernější (avšak komerční) verze c5/see5 pro vhodné nastavení parametrů vygeneruje správný strom. Je nutno zadat minimální pruning (pro c5 je to hodnota 99 % což odpovídá 1.0 či 0.99 pro J48/c4.8). Vzhledem k aplikaci je nutno povolit, aby v listech mohl být i pouze jeden příklad (implicitně je nastaveno minimální množství instancí pokrytých listem na 2). Implicitní hodnoty c5/see5 zde dávají špatný výsledek.
 pro XOR problém list (kořen) pokrývá všechny 4 případy, z toho")
71 Zdegenerovaný strom J48 (c4.8) pro XOR problém list (kořen) pokrývá všechny 4 případy, z toho 2 chybně: 4/2, výsledná chyba je 50 %

72 Komerční verze c4.5/c4.8 pod názvem c5/see5 může dát správný výsledek, má-li nastaveny správně parametry: Je nutno omezit pruning a povolit jedinou instanci na list (dáno konkrétním problémem).
73 Implicitní parametry dávají ovšem chybný výsledek:
přetrénování = ztráta schopnosti generalizovat vlivem přílišného zaměření klasifikátorů na rozeznávání pouze konkrétních trénovacích dat
 Zkouška ISR 2013 přetrénování = ztráta schopnosti generalizovat vlivem přílišného zaměření klasifikátorů na rozeznávání pouze konkrétních trénovacích dat 1. Rozdílné principy u induktivního a deduktivního
Zkouška ISR 2013 přetrénování = ztráta schopnosti generalizovat vlivem přílišného zaměření klasifikátorů na rozeznávání pouze konkrétních trénovacích dat 1. Rozdílné principy u induktivního a deduktivního
Moderní systémy pro získávání znalostí z informací a dat
 Moderní systémy pro získávání znalostí z informací a dat Jan Žižka IBA Institut biostatistiky a analýz PřF & LF, Masarykova universita Kamenice 126/3, 625 00 Brno Email: zizka@iba.muni.cz Bioinformatika:
Moderní systémy pro získávání znalostí z informací a dat Jan Žižka IBA Institut biostatistiky a analýz PřF & LF, Masarykova universita Kamenice 126/3, 625 00 Brno Email: zizka@iba.muni.cz Bioinformatika:
DATA MINING KLASIFIKACE DMINA LS 2009/2010
 DATA MINING KLASIFIKACE DMINA LS 2009/2010 Osnova co je to klasifikace typy klasifikátoru typy výstupu jednoduchý klasifikátor (1R) rozhodovací stromy Klasifikace (ohodnocení) zařazuje data do předdefinovaných
DATA MINING KLASIFIKACE DMINA LS 2009/2010 Osnova co je to klasifikace typy klasifikátoru typy výstupu jednoduchý klasifikátor (1R) rozhodovací stromy Klasifikace (ohodnocení) zařazuje data do předdefinovaných
Velmi stručný úvod do použití systému WEKA pro Data Mining (Jan Žižka, ÚI PEF)
") Velmi stručný úvod do použití systému WEKA pro Data Mining (Jan Žižka, ÚI PEF) Systém WEKA, implementovaný v jazyce Java, lze získat nejlépe z následující URL: . Dále
Velmi stručný úvod do použití systému WEKA pro Data Mining (Jan Žižka, ÚI PEF) Systém WEKA, implementovaný v jazyce Java, lze získat nejlépe z následující URL: . Dále
Projekční algoritmus. Urychlení evolučních algoritmů pomocí regresních stromů a jejich zobecnění. Jan Klíma
 Urychlení evolučních algoritmů pomocí regresních stromů a jejich zobecnění Jan Klíma Obsah Motivace & cíle práce Evoluční algoritmy Náhradní modelování Stromové regresní metody Implementace a výsledky
Urychlení evolučních algoritmů pomocí regresních stromů a jejich zobecnění Jan Klíma Obsah Motivace & cíle práce Evoluční algoritmy Náhradní modelování Stromové regresní metody Implementace a výsledky
Katedra kybernetiky laboratoř Inteligentní Datové Analýzy (IDA) Katedra počítačů, Computational Intelligence Group
 Katedra počítačů, Computational Intelligence Group") Vytěžování dat Miroslav Čepek, Filip Železný Katedra kybernetiky laboratoř Inteligentní Datové Analýzy (IDA) Katedra počítačů, Computational Intelligence Group Evropský sociální fond Praha & EU: Investujeme
Vytěžování dat Miroslav Čepek, Filip Železný Katedra kybernetiky laboratoř Inteligentní Datové Analýzy (IDA) Katedra počítačů, Computational Intelligence Group Evropský sociální fond Praha & EU: Investujeme
Obsah přednášky Jaká asi bude chyba modelu na nových datech?
 Obsah přednášky Jaká asi bude chyba modelu na nových datech? Chyba modelu Bootstrap Cross Validation Vapnik-Chervonenkisova dimenze 2 Chyba skutečná a trénovací Máme 30 záznamů, rozhodli jsme se na jejich
Obsah přednášky Jaká asi bude chyba modelu na nových datech? Chyba modelu Bootstrap Cross Validation Vapnik-Chervonenkisova dimenze 2 Chyba skutečná a trénovací Máme 30 záznamů, rozhodli jsme se na jejich
K možnostem krátkodobé předpovědi úrovně znečištění ovzduší statistickými metodami. Josef Keder
 K možnostem krátkodobé předpovědi úrovně znečištění ovzduší statistickými metodami Josef Keder Motivace Předpověď budoucí úrovně znečištění ovzduší s předstihem v řádu alespoň několika hodin má význam
K možnostem krátkodobé předpovědi úrovně znečištění ovzduší statistickými metodami Josef Keder Motivace Předpověď budoucí úrovně znečištění ovzduší s předstihem v řádu alespoň několika hodin má význam
Dobývání znalostí. Doc. RNDr. Iveta Mrázová, CSc. Katedra teoretické informatiky Matematicko-fyzikální fakulta Univerzity Karlovy v Praze
 Dobývání znalostí Doc. RNDr. Iveta Mrázová, CSc. Katedra teoretické informatiky Matematicko-fyzikální fakulta Univerzity Karlovy v Praze Dobývání znalostí Pravděpodobnost a učení Doc. RNDr. Iveta Mrázová,
Dobývání znalostí Doc. RNDr. Iveta Mrázová, CSc. Katedra teoretické informatiky Matematicko-fyzikální fakulta Univerzity Karlovy v Praze Dobývání znalostí Pravděpodobnost a učení Doc. RNDr. Iveta Mrázová,
UČENÍ BEZ UČITELE. Václav Hlaváč
 UČENÍ BEZ UČITELE Václav Hlaváč Fakulta elektrotechnická ČVUT v Praze katedra kybernetiky, Centrum strojového vnímání hlavac@fel.cvut.cz, http://cmp.felk.cvut.cz/~hlavac 1/22 OBSAH PŘEDNÁŠKY ÚVOD Učení
UČENÍ BEZ UČITELE Václav Hlaváč Fakulta elektrotechnická ČVUT v Praze katedra kybernetiky, Centrum strojového vnímání hlavac@fel.cvut.cz, http://cmp.felk.cvut.cz/~hlavac 1/22 OBSAH PŘEDNÁŠKY ÚVOD Učení
Dobývání znalostí. Doc. RNDr. Iveta Mrázová, CSc. Katedra teoretické informatiky Matematicko-fyzikální fakulta Univerzity Karlovy v Praze
 Dobývání znalostí Doc. RNDr. Iveta Mrázová, CSc. Katedra teoretické informatiky Matematicko-fyzikální fakulta Univerzity Karlovy v Praze Dobývání znalostí Rozhodovací stromy Doc. RNDr. Iveta Mrázová, CSc.
Dobývání znalostí Doc. RNDr. Iveta Mrázová, CSc. Katedra teoretické informatiky Matematicko-fyzikální fakulta Univerzity Karlovy v Praze Dobývání znalostí Rozhodovací stromy Doc. RNDr. Iveta Mrázová, CSc.
Dobývání znalostí. Doc. RNDr. Iveta Mrázová, CSc. Katedra teoretické informatiky Matematicko-fyzikální fakulta Univerzity Karlovy v Praze
 Dobývání znalostí Doc. RNDr. Iveta Mrázová, CSc. Katedra teoretické informatiky Matematicko-fyzikální fakulta Univerzity Karlovy v Praze Dobývání znalostí Bayesovské modely Doc. RNDr. Iveta Mrázová, CSc.
Dobývání znalostí Doc. RNDr. Iveta Mrázová, CSc. Katedra teoretické informatiky Matematicko-fyzikální fakulta Univerzity Karlovy v Praze Dobývání znalostí Bayesovské modely Doc. RNDr. Iveta Mrázová, CSc.
Analýza dat pomocí systému Weka, Rapid miner a Enterprise miner
 Vysoká škola ekonomická v Praze Analýza dat pomocí systému Weka, Rapid miner a Enterprise miner Dobývání znalostí z databází 4IZ450 XXXXXXXXXXX Přidělená data a jejich popis Data určená pro zpracování
Vysoká škola ekonomická v Praze Analýza dat pomocí systému Weka, Rapid miner a Enterprise miner Dobývání znalostí z databází 4IZ450 XXXXXXXXXXX Přidělená data a jejich popis Data určená pro zpracování
Ing. Petr Hájek, Ph.D. Podpora přednášky kurzu Aplikace umělé inteligence
 APLIKACE UMĚLÉ INTELIGENCE Ing. Petr Hájek, Ph.D. Podpora přednášky kurzu Aplikace umělé inteligence Aplikace umělé inteligence - seminář ING. PETR HÁJEK, PH.D. ÚSTAV SYSTÉMOVÉHO INŽENÝRSTVÍ A INFORMATIKY
APLIKACE UMĚLÉ INTELIGENCE Ing. Petr Hájek, Ph.D. Podpora přednášky kurzu Aplikace umělé inteligence Aplikace umělé inteligence - seminář ING. PETR HÁJEK, PH.D. ÚSTAV SYSTÉMOVÉHO INŽENÝRSTVÍ A INFORMATIKY
Neuronové časové řady (ANN-TS)
") Neuronové časové řady (ANN-TS) Menu: QCExpert Prediktivní metody Neuronové časové řady Tento modul (Artificial Neural Network Time Series ANN-TS) využívá modelovacího potenciálu neuronové sítě k predikci
Neuronové časové řady (ANN-TS) Menu: QCExpert Prediktivní metody Neuronové časové řady Tento modul (Artificial Neural Network Time Series ANN-TS) využívá modelovacího potenciálu neuronové sítě k predikci
7. Rozdělení pravděpodobnosti ve statistice
 7. Rozdělení pravděpodobnosti ve statistice Statistika nuda je, má však cenné údaje, neklesejte na mysli, ona nám to vyčíslí Jednou z úloh statistiky je odhad (výpočet) hodnot statistického znaku x i,
7. Rozdělení pravděpodobnosti ve statistice Statistika nuda je, má však cenné údaje, neklesejte na mysli, ona nám to vyčíslí Jednou z úloh statistiky je odhad (výpočet) hodnot statistického znaku x i,
Automatické vyhledávání informace a znalosti v elektronických textových datech
 Automatické vyhledávání informace a znalosti v elektronických textových datech Jan Žižka Ústav informatiky & SoNet RC PEF, Mendelova universita Brno (Text Mining) Data, informace, znalost Elektronická
Automatické vyhledávání informace a znalosti v elektronických textových datech Jan Žižka Ústav informatiky & SoNet RC PEF, Mendelova universita Brno (Text Mining) Data, informace, znalost Elektronická
Pokročilé neparametrické metody. Klára Kubošová
 Klára Kubošová Další typy stromů CHAID, PRIM, MARS CHAID - Chi-squared Automatic Interaction Detector G.V.Kass (1980) nebinární strom pro kategoriální proměnné. Jako kriteriální statistika pro větvení
Klára Kubošová Další typy stromů CHAID, PRIM, MARS CHAID - Chi-squared Automatic Interaction Detector G.V.Kass (1980) nebinární strom pro kategoriální proměnné. Jako kriteriální statistika pro větvení
Chyby měření 210DPSM
 Chyby měření 210DPSM Jan Zatloukal Stručný přehled Zdroje a druhy chyb Systematické chyby měření Náhodné chyby měření Spojité a diskrétní náhodné veličiny Normální rozdělení a jeho vlastnosti Odhad parametrů
Chyby měření 210DPSM Jan Zatloukal Stručný přehled Zdroje a druhy chyb Systematické chyby měření Náhodné chyby měření Spojité a diskrétní náhodné veličiny Normální rozdělení a jeho vlastnosti Odhad parametrů
Algoritmy a struktury neuropočítačů ASN P9 SVM Support vector machines Support vector networks (Algoritmus podpůrných vektorů)
") Algoritmy a struktury neuropočítačů ASN P9 SVM Support vector machines Support vector networks (Algoritmus podpůrných vektorů) Autor: Vladimir Vapnik Vapnik, V. The Nature of Statistical Learning Theory.
Algoritmy a struktury neuropočítačů ASN P9 SVM Support vector machines Support vector networks (Algoritmus podpůrných vektorů) Autor: Vladimir Vapnik Vapnik, V. The Nature of Statistical Learning Theory.
STATISTICKÝ SOUBOR. je množina sledovaných objektů - statistických jednotek, které mají z hlediska statistického zkoumání společné vlastnosti
 ZÁKLADNÍ STATISTICKÉ POJMY HROMADNÝ JEV Statistika pracuje s tzv. HROMADNÝMI JEVY cílem statistického zpracování dat je podání informace o vlastnostech a zákonitostech hromadných jevů: velkého počtu jedinců
ZÁKLADNÍ STATISTICKÉ POJMY HROMADNÝ JEV Statistika pracuje s tzv. HROMADNÝMI JEVY cílem statistického zpracování dat je podání informace o vlastnostech a zákonitostech hromadných jevů: velkého počtu jedinců
Pravděpodobně skoro správné. PAC učení 1
 Pravděpodobně skoro správné (PAC) učení PAC učení 1 Výpočetní teorie strojového učení Věta o ošklivém kačátku. Nechť E je klasifikovaná trénovací množina pro koncept K, který tvoří podmnožinu konečného
Pravděpodobně skoro správné (PAC) učení PAC učení 1 Výpočetní teorie strojového učení Věta o ošklivém kačátku. Nechť E je klasifikovaná trénovací množina pro koncept K, který tvoří podmnožinu konečného
Trénování sítě pomocí učení s učitelem
 Trénování sítě pomocí učení s učitelem! předpokládá se, že máme k dispozici trénovací množinu, tj. množinu P dvojic [vstup x p, požadovaný výstup u p ]! chceme nastavit váhy a prahy sítě tak, aby výstup
Trénování sítě pomocí učení s učitelem! předpokládá se, že máme k dispozici trénovací množinu, tj. množinu P dvojic [vstup x p, požadovaný výstup u p ]! chceme nastavit váhy a prahy sítě tak, aby výstup
Usuzování za neurčitosti
 Usuzování za neurčitosti 25.11.2014 8-1 Usuzování za neurčitosti Hypotetické usuzování a zpětná indukce Míry postačitelnosti a nezbytnosti Kombinace důkazů Šíření pravděpodobnosti v inferenčních sítích
Usuzování za neurčitosti 25.11.2014 8-1 Usuzování za neurčitosti Hypotetické usuzování a zpětná indukce Míry postačitelnosti a nezbytnosti Kombinace důkazů Šíření pravděpodobnosti v inferenčních sítích
Státnice odborné č. 20
 Státnice odborné č. 20 Shlukování dat Shlukování dat. Metoda k-středů, hierarchické (aglomerativní) shlukování, Kohonenova mapa SOM Shlukování dat Shluková analýza je snaha o seskupení objektů do skupin
Státnice odborné č. 20 Shlukování dat Shlukování dat. Metoda k-středů, hierarchické (aglomerativní) shlukování, Kohonenova mapa SOM Shlukování dat Shluková analýza je snaha o seskupení objektů do skupin
Pokročilé neparametrické metody. Klára Kubošová
 Pokročilé neparametrické metody Klára Kubošová Pokročilé neparametrické metody Výuka 13 přednášek doplněných o praktické cvičení v SW Úvod do neparametrických metod + princip rozhodovacích stromů Klasifikační
Pokročilé neparametrické metody Klára Kubošová Pokročilé neparametrické metody Výuka 13 přednášek doplněných o praktické cvičení v SW Úvod do neparametrických metod + princip rozhodovacích stromů Klasifikační
Rozdělování dat do trénovacích a testovacích množin
 Rozdělování dat do trénovacích a testovacích množin Marcel Jiřina Rozpoznávání je důležitou metodou při zpracování reálných úloh. Rozpoznávání je definováno dvěma kroky a to pořízením dat o reálném rozpoznávaném
Rozdělování dat do trénovacích a testovacích množin Marcel Jiřina Rozpoznávání je důležitou metodou při zpracování reálných úloh. Rozpoznávání je definováno dvěma kroky a to pořízením dat o reálném rozpoznávaném
Pravděpodobnost, náhoda, kostky
 Pravděpodobnost, náhoda, kostky Radek Pelánek IV122 Výhled pravděpodobnost náhodná čísla lineární regrese detekce shluků Dnes lehce nesourodá směs úloh souvisejících s pravděpodobností připomenutí, souvislosti
Pravděpodobnost, náhoda, kostky Radek Pelánek IV122 Výhled pravděpodobnost náhodná čísla lineární regrese detekce shluků Dnes lehce nesourodá směs úloh souvisejících s pravděpodobností připomenutí, souvislosti
Základy popisné statistiky
 Základy popisné statistiky Michal Fusek Ústav matematiky FEKT VUT, fusekmi@feec.vutbr.cz 8. přednáška z ESMAT Michal Fusek (fusekmi@feec.vutbr.cz) 1 / 26 Obsah 1 Základy statistického zpracování dat 2
Základy popisné statistiky Michal Fusek Ústav matematiky FEKT VUT, fusekmi@feec.vutbr.cz 8. přednáška z ESMAT Michal Fusek (fusekmi@feec.vutbr.cz) 1 / 26 Obsah 1 Základy statistického zpracování dat 2
Pravděpodobnost, náhoda, kostky
 Pravděpodobnost, náhoda, kostky Radek Pelánek IV122, jaro 2015 Výhled pravděpodobnost náhodná čísla lineární regrese detekce shluků Dnes lehce nesourodá směs úloh souvisejících s pravděpodobností krátké
Pravděpodobnost, náhoda, kostky Radek Pelánek IV122, jaro 2015 Výhled pravděpodobnost náhodná čísla lineární regrese detekce shluků Dnes lehce nesourodá směs úloh souvisejících s pravděpodobností krátké
10. Předpovídání - aplikace regresní úlohy
 10. Předpovídání - aplikace regresní úlohy Regresní úloha (analýza) je označení pro statistickou metodu, pomocí nichž odhadujeme hodnotu náhodné veličiny (tzv. závislé proměnné, cílové proměnné, regresandu
10. Předpovídání - aplikace regresní úlohy Regresní úloha (analýza) je označení pro statistickou metodu, pomocí nichž odhadujeme hodnotu náhodné veličiny (tzv. závislé proměnné, cílové proměnné, regresandu
Úloha - rozpoznávání číslic
 Úloha - rozpoznávání číslic Vojtěch Franc, Tomáš Pajdla a Tomáš Svoboda http://cmp.felk.cvut.cz 27. listopadu 26 Abstrakt Podpůrný text pro cvičení předmětu X33KUI. Vysvětluje tři způsoby rozpoznávání
Úloha - rozpoznávání číslic Vojtěch Franc, Tomáš Pajdla a Tomáš Svoboda http://cmp.felk.cvut.cz 27. listopadu 26 Abstrakt Podpůrný text pro cvičení předmětu X33KUI. Vysvětluje tři způsoby rozpoznávání
Dolování asociačních pravidel
 Dolování asociačních pravidel Miloš Trávníček UIFS FIT VUT v Brně Obsah přednášky 1. Proces získávání znalostí 2. Asociační pravidla 3. Dolování asociačních pravidel 4. Algoritmy pro dolování asociačních
Dolování asociačních pravidel Miloš Trávníček UIFS FIT VUT v Brně Obsah přednášky 1. Proces získávání znalostí 2. Asociační pravidla 3. Dolování asociačních pravidel 4. Algoritmy pro dolování asociačních
NÁHODNÁ ČÍSLA. F(x) = 1 pro x 1. Náhodná čísla lze generovat některým z následujících generátorů náhodných čísel:
 = 1 pro x 1. Náhodná čísla lze generovat některým z následujících generátorů náhodných čísel:") NÁHODNÁ ČÍSLA TYPY GENERÁTORŮ, LINEÁRNÍ KONGRUENČNÍ GENERÁTORY, TESTY NÁHODNOSTI, VYUŽITÍ HODNOT NÁHODNÝCH VELIČIN V SIMULACI CO JE TO NÁHODNÉ ČÍSLO? Náhodné číslo definujeme jako nezávislé hodnoty z rovnoměrného
NÁHODNÁ ČÍSLA TYPY GENERÁTORŮ, LINEÁRNÍ KONGRUENČNÍ GENERÁTORY, TESTY NÁHODNOSTI, VYUŽITÍ HODNOT NÁHODNÝCH VELIČIN V SIMULACI CO JE TO NÁHODNÉ ČÍSLO? Náhodné číslo definujeme jako nezávislé hodnoty z rovnoměrného
Lineární klasifikátory
 Lineární klasifikátory Lineární klasifikátory obsah: perceptronový algoritmus základní verze varianta perceptronového algoritmu přihrádkový algoritmus podpůrné vektorové stroje Lineární klasifikátor navrhnout
Lineární klasifikátory Lineární klasifikátory obsah: perceptronový algoritmus základní verze varianta perceptronového algoritmu přihrádkový algoritmus podpůrné vektorové stroje Lineární klasifikátor navrhnout
Pravděpodobnost v závislosti na proměnné x je zde modelován pomocí logistického modelu. exp x. x x x. log 1
 Logistická regrese Menu: QCExpert Regrese Logistická Modul Logistická regrese umožňuje analýzu dat, kdy odezva je binární, nebo frekvenční veličina vyjádřená hodnotami 0 nebo 1, případně poměry v intervalu
Logistická regrese Menu: QCExpert Regrese Logistická Modul Logistická regrese umožňuje analýzu dat, kdy odezva je binární, nebo frekvenční veličina vyjádřená hodnotami 0 nebo 1, případně poměry v intervalu
Statistika. Regresní a korelační analýza Úvod do problému. Roman Biskup
 Statistika Regresní a korelační analýza Úvod do problému Roman Biskup Jihočeská univerzita v Českých Budějovicích Ekonomická fakulta (Zemědělská fakulta) Katedra aplikované matematiky a informatiky 2008/2009
Statistika Regresní a korelační analýza Úvod do problému Roman Biskup Jihočeská univerzita v Českých Budějovicích Ekonomická fakulta (Zemědělská fakulta) Katedra aplikované matematiky a informatiky 2008/2009
Změkčování hranic v klasifikačních stromech
 Změkčování hranic v klasifikačních stromech Jakub Dvořák Seminář strojového učení a modelování 24.5.2012 Obsah Klasifikační stromy Změkčování hran Ranking, ROC křivka a AUC Metody změkčování Experiment
Změkčování hranic v klasifikačních stromech Jakub Dvořák Seminář strojového učení a modelování 24.5.2012 Obsah Klasifikační stromy Změkčování hran Ranking, ROC křivka a AUC Metody změkčování Experiment
Rozhodovací stromy a jejich konstrukce z dat
 Příklad počítačová hra. Můžeme počítač naučit rozlišovat přátelské a přátelské roboty? Rozhodovací stromy a jejich konstruk z dat Učení s učitelem: u některých už víme, jakou mají povahu (klasifika) Neparametrická
Příklad počítačová hra. Můžeme počítač naučit rozlišovat přátelské a přátelské roboty? Rozhodovací stromy a jejich konstruk z dat Učení s učitelem: u některých už víme, jakou mají povahu (klasifika) Neparametrická
Statistická teorie učení
 Statistická teorie učení Petr Havel Marek Myslivec přednáška z 9. týdne 1 Úvod Představme si situaci výrobce a zákazníka, který si u výrobce objednal algoritmus rozpoznávání. Zákazník dodal experimentální
Statistická teorie učení Petr Havel Marek Myslivec přednáška z 9. týdne 1 Úvod Představme si situaci výrobce a zákazníka, který si u výrobce objednal algoritmus rozpoznávání. Zákazník dodal experimentální
Kybernetika a umělá inteligence, cvičení 10/11
 Kybernetika a umělá inteligence, cvičení 10/11 Program 1. seminární cvičení: základní typy klasifikátorů a jejich princip 2. počítačové cvičení: procvičení na problému rozpoznávání číslic... body za aktivitu
Kybernetika a umělá inteligence, cvičení 10/11 Program 1. seminární cvičení: základní typy klasifikátorů a jejich princip 2. počítačové cvičení: procvičení na problému rozpoznávání číslic... body za aktivitu
Umělé neuronové sítě
 Umělé neuronové sítě 17. 3. 2018 5-1 Model umělého neuronu y výstup neuronu u vnitřní potenciál neuronu w i váhy neuronu x i vstupy neuronu Θ práh neuronu f neuronová aktivační funkce 5-2 Neuronové aktivační
Umělé neuronové sítě 17. 3. 2018 5-1 Model umělého neuronu y výstup neuronu u vnitřní potenciál neuronu w i váhy neuronu x i vstupy neuronu Θ práh neuronu f neuronová aktivační funkce 5-2 Neuronové aktivační
Generování pseudonáhodných. Ing. Michal Dorda, Ph.D.
 Generování pseudonáhodných čísel při simulaci Ing. Michal Dorda, Ph.D. 1 Úvodní poznámky V simulačních modelech se velice často vyskytují náhodné proměnné. Proto se budeme zabývat otázkou, jak při simulaci
Generování pseudonáhodných čísel při simulaci Ing. Michal Dorda, Ph.D. 1 Úvodní poznámky V simulačních modelech se velice často vyskytují náhodné proměnné. Proto se budeme zabývat otázkou, jak při simulaci
Algoritmizace Dynamické programování. Jiří Vyskočil, Marko Genyg-Berezovskyj 2010
 Dynamické programování Jiří Vyskočil, Marko Genyg-Berezovskyj 2010 Rozděl a panuj (divide-and-conquer) Rozděl (Divide): Rozděl problém na několik podproblémů tak, aby tyto podproblémy odpovídaly původnímu
Dynamické programování Jiří Vyskočil, Marko Genyg-Berezovskyj 2010 Rozděl a panuj (divide-and-conquer) Rozděl (Divide): Rozděl problém na několik podproblémů tak, aby tyto podproblémy odpovídaly původnímu
Analytické procedury v systému LISp-Miner
 Dobývání znalostí z databází MI-KDD ZS 2011 Přednáška 8 Analytické procedury v systému LISp-Miner Část II. (c) 2011 Ing. M. Šimůnek, Ph.D. KIZI, Fakulta informatiky a statistiky, VŠE Praha Evropský sociální
Dobývání znalostí z databází MI-KDD ZS 2011 Přednáška 8 Analytické procedury v systému LISp-Miner Část II. (c) 2011 Ing. M. Šimůnek, Ph.D. KIZI, Fakulta informatiky a statistiky, VŠE Praha Evropský sociální
1. Základy teorie přenosu informací
 1. Základy teorie přenosu informací Úvodem citát o pojmu informace Informace je název pro obsah toho, co se vymění s vnějším světem, když se mu přizpůsobujeme a působíme na něj svým přizpůsobováním. N.
1. Základy teorie přenosu informací Úvodem citát o pojmu informace Informace je název pro obsah toho, co se vymění s vnějším světem, když se mu přizpůsobujeme a působíme na něj svým přizpůsobováním. N.
Automatická detekce anomálií při geofyzikálním průzkumu. Lenka Kosková Třísková NTI TUL Doktorandský seminář, 8. 6. 2011
 Automatická detekce anomálií při geofyzikálním průzkumu Lenka Kosková Třísková NTI TUL Doktorandský seminář, 8. 6. 2011 Cíle doktorandské práce Seminář 10. 11. 2010 Najít, implementovat, ověřit a do praxe
Automatická detekce anomálií při geofyzikálním průzkumu Lenka Kosková Třísková NTI TUL Doktorandský seminář, 8. 6. 2011 Cíle doktorandské práce Seminář 10. 11. 2010 Najít, implementovat, ověřit a do praxe
1 Tyto materiály byly vytvořeny za pomoci grantu FRVŠ číslo 1145/2004.
 Prostá regresní a korelační analýza 1 1 Tyto materiály byly vytvořeny za pomoci grantu FRVŠ číslo 1145/2004. Problematika závislosti V podstatě lze rozlišovat mezi závislostí nepodstatnou, čili náhodnou
Prostá regresní a korelační analýza 1 1 Tyto materiály byly vytvořeny za pomoci grantu FRVŠ číslo 1145/2004. Problematika závislosti V podstatě lze rozlišovat mezi závislostí nepodstatnou, čili náhodnou
Algoritmy a struktury neuropočítačů ASN - P11
 Aplikace UNS při rozpoznání obrazů Základní úloha segmentace obrazu rozdělení obrazu do několika významných oblastí klasifikační úloha, clusterová analýza target Metody Kohonenova metoda KSOM Kohonenova
Aplikace UNS při rozpoznání obrazů Základní úloha segmentace obrazu rozdělení obrazu do několika významných oblastí klasifikační úloha, clusterová analýza target Metody Kohonenova metoda KSOM Kohonenova
Náhodné (statistické) chyby přímých měření
 chyby přímých měření") Náhodné (statistické) chyby přímých měření Hodnoty náhodných chyb se nedají stanovit předem, ale na základě počtu pravděpodobnosti lze zjistit, která z možných naměřených hodnot je více a která je méně
Náhodné (statistické) chyby přímých měření Hodnoty náhodných chyb se nedají stanovit předem, ale na základě počtu pravděpodobnosti lze zjistit, která z možných naměřených hodnot je více a která je méně
Otázky ke státní závěrečné zkoušce
 Otázky ke státní závěrečné zkoušce obor Ekonometrie a operační výzkum a) Diskrétní modely, Simulace, Nelineární programování. b) Teorie rozhodování, Teorie her. c) Ekonometrie. Otázka č. 1 a) Úlohy konvexního
Otázky ke státní závěrečné zkoušce obor Ekonometrie a operační výzkum a) Diskrétní modely, Simulace, Nelineární programování. b) Teorie rozhodování, Teorie her. c) Ekonometrie. Otázka č. 1 a) Úlohy konvexního
Přednáška 13 Redukce dimenzionality
 Vytěžování Dat Přednáška 13 Redukce dimenzionality Miroslav Čepek Fakulta Elektrotechnická, ČVUT Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti ČVUT (FEL) Redukce dimenzionality 1 /
Vytěžování Dat Přednáška 13 Redukce dimenzionality Miroslav Čepek Fakulta Elektrotechnická, ČVUT Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti ČVUT (FEL) Redukce dimenzionality 1 /
5. Umělé neuronové sítě. Neuronové sítě
 Neuronové sítě Přesný algoritmus práce přírodních neuronových systémů není doposud znám. Přesto experimentální výsledky na modelech těchto systémů dávají dnes velmi slibné výsledky. Tyto systémy, včetně
Neuronové sítě Přesný algoritmus práce přírodních neuronových systémů není doposud znám. Přesto experimentální výsledky na modelech těchto systémů dávají dnes velmi slibné výsledky. Tyto systémy, včetně
Úvod do zpracování signálů
 1 / 25 Úvod do zpracování signálů Karel Horák Rozvrh přednášky: 1. Spojitý a diskrétní signál. 2. Spektrum signálu. 3. Vzorkovací věta. 4. Konvoluce signálů. 5. Korelace signálů. 2 / 25 Úvod do zpracování
1 / 25 Úvod do zpracování signálů Karel Horák Rozvrh přednášky: 1. Spojitý a diskrétní signál. 2. Spektrum signálu. 3. Vzorkovací věta. 4. Konvoluce signálů. 5. Korelace signálů. 2 / 25 Úvod do zpracování
2 Zpracování naměřených dat. 2.1 Gaussův zákon chyb. 2.2 Náhodná veličina a její rozdělení
 2 Zpracování naměřených dat Důležitou součástí každé experimentální práce je statistické zpracování naměřených dat. V této krátké kapitole se budeme věnovat určení intervalů spolehlivosti získaných výsledků
2 Zpracování naměřených dat Důležitou součástí každé experimentální práce je statistické zpracování naměřených dat. V této krátké kapitole se budeme věnovat určení intervalů spolehlivosti získaných výsledků
Úvodem Dříve les než stromy 3 Operace s maticemi
 Obsah 1 Úvodem 13 2 Dříve les než stromy 17 2.1 Nejednoznačnost terminologie 17 2.2 Volba metody analýzy dat 23 2.3 Přehled vybraných vícerozměrných metod 25 2.3.1 Metoda hlavních komponent 26 2.3.2 Faktorová
Obsah 1 Úvodem 13 2 Dříve les než stromy 17 2.1 Nejednoznačnost terminologie 17 2.2 Volba metody analýzy dat 23 2.3 Přehled vybraných vícerozměrných metod 25 2.3.1 Metoda hlavních komponent 26 2.3.2 Faktorová
Binární vyhledávací stromy pokročilé partie
 Binární vyhledávací stromy pokročilé partie KMI/ALS lekce Jan Konečný 30.9.204 Literatura Cormen Thomas H., Introduction to Algorithms, 2nd edition MIT Press, 200. ISBN 0-262-5396-8 6, 3, A Knuth Donald
Binární vyhledávací stromy pokročilé partie KMI/ALS lekce Jan Konečný 30.9.204 Literatura Cormen Thomas H., Introduction to Algorithms, 2nd edition MIT Press, 200. ISBN 0-262-5396-8 6, 3, A Knuth Donald
Dolování z textu. Martin Vítek
 Dolování z textu Martin Vítek Proč dolovat z textu Obrovské množství materiálu v nestrukturované textové podobě knihy časopisy vědeckéčlánky sborníky konferencí internetové diskuse Proč dolovat z textu
Dolování z textu Martin Vítek Proč dolovat z textu Obrovské množství materiálu v nestrukturované textové podobě knihy časopisy vědeckéčlánky sborníky konferencí internetové diskuse Proč dolovat z textu
ČVUT FEL X36PAA - Problémy a algoritmy. 4. úloha - Experimentální hodnocení algoritmů pro řešení problému batohu
 ČVUT FEL X36PAA - Problémy a algoritmy 4. úloha - Experimentální hodnocení algoritmů pro řešení problému batohu Jméno: Marek Handl Datum: 3. 2. 29 Cvičení: Pondělí 9: Zadání Prozkoumejte citlivost metod
ČVUT FEL X36PAA - Problémy a algoritmy 4. úloha - Experimentální hodnocení algoritmů pro řešení problému batohu Jméno: Marek Handl Datum: 3. 2. 29 Cvičení: Pondělí 9: Zadání Prozkoumejte citlivost metod
Využití neuronové sítě pro identifikaci realného systému
 1 Portál pre odborné publikovanie ISSN 1338-0087 Využití neuronové sítě pro identifikaci realného systému Pišan Radim Elektrotechnika 20.06.2011 Identifikace systémů je proces, kdy z naměřených dat můžeme
1 Portál pre odborné publikovanie ISSN 1338-0087 Využití neuronové sítě pro identifikaci realného systému Pišan Radim Elektrotechnika 20.06.2011 Identifikace systémů je proces, kdy z naměřených dat můžeme
1 Analytické metody durace a konvexita aktiva (dluhopisu) $)*
 $)*") Modely analýzy a syntézy plánů MAF/KIV) Přednáška 10 itlivostní analýza 1 Analytické metody durace a konvexita aktiva dluhopisu) Budeme uvažovat následující tvar cenové rovnice =, 1) kde jsou současná
Modely analýzy a syntézy plánů MAF/KIV) Přednáška 10 itlivostní analýza 1 Analytické metody durace a konvexita aktiva dluhopisu) Budeme uvažovat následující tvar cenové rovnice =, 1) kde jsou současná
Téma 2: Pravděpodobnostní vyjádření náhodných veličin
 0.025 0.02 0.015 0.01 0.005 Nominální napětí v pásnici Std Mean 140 160 180 200 220 240 260 Std Téma 2: Pravděpodobnostní vyjádření náhodných veličin Přednáška z předmětu: Pravděpodobnostní posuzování
0.025 0.02 0.015 0.01 0.005 Nominální napětí v pásnici Std Mean 140 160 180 200 220 240 260 Std Téma 2: Pravděpodobnostní vyjádření náhodných veličin Přednáška z předmětu: Pravděpodobnostní posuzování
E(X) = np D(X) = np(1 p) 1 2p np(1 p) (n + 1)p 1 ˆx (n + 1)p. A 3 (X) =
 = np D(X) = np(1 p) 1 2p np(1 p) (n + 1)p 1 ˆx (n + 1)p. A 3 (X) =") Základní rozdělení pravděpodobnosti Diskrétní rozdělení pravděpodobnosti. Pojem Náhodná veličina s Binomickým rozdělením Bi(n, p), kde n je přirozené číslo, p je reálné číslo, < p < má pravděpodobnostní
Základní rozdělení pravděpodobnosti Diskrétní rozdělení pravděpodobnosti. Pojem Náhodná veličina s Binomickým rozdělením Bi(n, p), kde n je přirozené číslo, p je reálné číslo, < p < má pravděpodobnostní
odlehlých hodnot pomocí algoritmu k-means
 Chybějící a odlehlé hodnoty; odstranění odlehlých hodnot pomocí algoritmu k-means Návod ke druhému cvičení Matěj Holec, holecmat@fel.cvut.cz ZS 2011/2012 Úvod Cílem cvičení je připomenout důležitost předzpracování
Chybějící a odlehlé hodnoty; odstranění odlehlých hodnot pomocí algoritmu k-means Návod ke druhému cvičení Matěj Holec, holecmat@fel.cvut.cz ZS 2011/2012 Úvod Cílem cvičení je připomenout důležitost předzpracování
Kombinatorická minimalizace
 Kombinatorická minimalizace Cílem je nalézt globální minimum ve velké diskrétní množině, kde může být mnoho lokálních minim. Úloha obchodního cestujícího Cílem je najít nejkratší cestu, která spojuje všechny
Kombinatorická minimalizace Cílem je nalézt globální minimum ve velké diskrétní množině, kde může být mnoho lokálních minim. Úloha obchodního cestujícího Cílem je najít nejkratší cestu, která spojuje všechny
UNIVERZITA OBRANY Fakulta ekonomiky a managementu. Aplikace STAT1. Výsledek řešení projektu PRO HORR2011 a PRO GRAM2011 3. 11.
 UNIVERZITA OBRANY Fakulta ekonomiky a managementu Aplikace STAT1 Výsledek řešení projektu PRO HORR2011 a PRO GRAM2011 Jiří Neubauer, Marek Sedlačík, Oldřich Kříž 3. 11. 2012 Popis a návod k použití aplikace
UNIVERZITA OBRANY Fakulta ekonomiky a managementu Aplikace STAT1 Výsledek řešení projektu PRO HORR2011 a PRO GRAM2011 Jiří Neubauer, Marek Sedlačík, Oldřich Kříž 3. 11. 2012 Popis a návod k použití aplikace
1. Statistická analýza dat Jak vznikají informace Rozložení dat
 1. Statistická analýza dat Jak vznikají informace Rozložení dat J. Jarkovský, L. Dušek, S. Littnerová, J. Kalina Význam statistické analýzy dat Sběr a vyhodnocování dat je způsobem k uchopení a pochopení
1. Statistická analýza dat Jak vznikají informace Rozložení dat J. Jarkovský, L. Dušek, S. Littnerová, J. Kalina Význam statistické analýzy dat Sběr a vyhodnocování dat je způsobem k uchopení a pochopení
Pracovní celky 3.2, 3.3 a 3.4 Sémantická harmonizace - Srovnání a přiřazení datových modelů
 Pracovní celky 3.2, 3.3 a 3.4 Sémantická harmonizace - Srovnání a datových modelů Obsah Seznam tabulek... 1 Seznam obrázků... 1 1 Úvod... 2 2 Metody sémantické harmonizace... 2 3 Dvojjazyčné katalogy objektů
Pracovní celky 3.2, 3.3 a 3.4 Sémantická harmonizace - Srovnání a datových modelů Obsah Seznam tabulek... 1 Seznam obrázků... 1 1 Úvod... 2 2 Metody sémantické harmonizace... 2 3 Dvojjazyčné katalogy objektů
Algoritmy a struktury neuropočítačů ASN - P10. Aplikace UNS v biomedicíně
 Aplikace UNS v biomedicíně aplikace v medicíně postup při zpracování úloh Aplikace UNS v medicíně Důvod: nalezení exaktnějších, levnějších a snadnějších metod určování diagnóz pro lékaře nalezení šetrnějších
Aplikace UNS v biomedicíně aplikace v medicíně postup při zpracování úloh Aplikace UNS v medicíně Důvod: nalezení exaktnějších, levnějších a snadnějších metod určování diagnóz pro lékaře nalezení šetrnějších
2. Základní typy dat Spojitá a kategoriální data Základní popisné statistiky Frekvenční tabulky Grafický popis dat
 2. Základní typy dat Spojitá a kategoriální data Základní popisné statistiky Frekvenční tabulky Grafický popis dat Anotace Realitu můžeme popisovat různými typy dat, každý z nich se specifickými vlastnostmi,
2. Základní typy dat Spojitá a kategoriální data Základní popisné statistiky Frekvenční tabulky Grafický popis dat Anotace Realitu můžeme popisovat různými typy dat, každý z nich se specifickými vlastnostmi,
Dynamické programování
 Dynamické programování prof. Ing. Pavel Tvrdík CSc. Katedra počítačových systémů Fakulta informačních technologií České vysoké učení technické v Praze c Pavel Tvrdík, 2010 Efektivní algoritmy (BI-EFA)
Dynamické programování prof. Ing. Pavel Tvrdík CSc. Katedra počítačových systémů Fakulta informačních technologií České vysoké učení technické v Praze c Pavel Tvrdík, 2010 Efektivní algoritmy (BI-EFA)
Testování prvočíselnosti
 Dokumentace zápočtového programu z Programování II (NPRG031) Testování prvočíselnosti David Pěgřímek http://davpe.net Úvodem V různých oborech (například v kryptografii) je potřeba zjistit, zda je číslo
Dokumentace zápočtového programu z Programování II (NPRG031) Testování prvočíselnosti David Pěgřímek http://davpe.net Úvodem V různých oborech (například v kryptografii) je potřeba zjistit, zda je číslo
2019/03/31 17:38 1/2 Klasifikační a regresní stromy
 2019/03/31 17:38 1/2 Klasifikační a regresní stromy Table of Contents Klasifikační a regresní stromy... 1 rpart (library rpart)... 1 draw.tree (library maptree)... 3 plotcp a rsq.rpart (library rpart)...
2019/03/31 17:38 1/2 Klasifikační a regresní stromy Table of Contents Klasifikační a regresní stromy... 1 rpart (library rpart)... 1 draw.tree (library maptree)... 3 plotcp a rsq.rpart (library rpart)...
Chybějící atributy a postupy pro jejich náhradu
 Chybějící atributy a postupy pro jejich náhradu Jedná se o součást čištění dat Čistota dat je velmi důležitá, neboť kvalita dat zásadně ovlivňuje kvalitu výsledků, které DM vyprodukuje, neboť platí Garbage
Chybějící atributy a postupy pro jejich náhradu Jedná se o součást čištění dat Čistota dat je velmi důležitá, neboť kvalita dat zásadně ovlivňuje kvalitu výsledků, které DM vyprodukuje, neboť platí Garbage
Připomeň: Shluková analýza
 Připomeň: Shluková analýza Data Návrh kategorií X Y= 1, 2,..., K resp. i jejich počet K = co je s čím blízké + jak moc Neposkytne pravidlo pro zařazování Připomeň: Klasifikace Data (X,Y) X... prediktory
Připomeň: Shluková analýza Data Návrh kategorií X Y= 1, 2,..., K resp. i jejich počet K = co je s čím blízké + jak moc Neposkytne pravidlo pro zařazování Připomeň: Klasifikace Data (X,Y) X... prediktory
Číselné charakteristiky
 . Číselné charakteristiky statistických dat Průměrný statistik se během svého života ožení s 1,75 ženami, které se ho snaží vytáhnout večer do společnosti,5 x týdně, ale pouze s 50% úspěchem. W. F. Miksch
. Číselné charakteristiky statistických dat Průměrný statistik se během svého života ožení s 1,75 ženami, které se ho snaží vytáhnout večer do společnosti,5 x týdně, ale pouze s 50% úspěchem. W. F. Miksch
Rozhodovací stromy a jejich konstrukce z dat
 Rozhodovací stromy a jejich konstrukce z dat Příklad počítačová hra. Můžeme počítač naučit rozlišovat přátelské a nepřátelské roboty? Učení s učitelem: u některých už víme, jakou mají povahu (klasifikace)
Rozhodovací stromy a jejich konstrukce z dat Příklad počítačová hra. Můžeme počítač naučit rozlišovat přátelské a nepřátelské roboty? Učení s učitelem: u některých už víme, jakou mají povahu (klasifikace)
Měření dat Filtrace dat, Kalmanův filtr
 Měření dat Filtrace dat, Matematické metody pro ITS (11MAMY) Jan Přikryl Ústav aplikované matematiky ČVUT v Praze, Fakulta dopravní 3. přednáška 11MAMY čtvrtek 28. února 2018 verze: 2018-03-21 16:45 Obsah
Měření dat Filtrace dat, Matematické metody pro ITS (11MAMY) Jan Přikryl Ústav aplikované matematiky ČVUT v Praze, Fakulta dopravní 3. přednáška 11MAMY čtvrtek 28. února 2018 verze: 2018-03-21 16:45 Obsah
Strojové učení Marta Vomlelová
 Strojové učení Marta Vomlelová marta@ktiml.mff.cuni.cz KTIML, S303 Literatura 1.T. Hastie, R. Tishirani, and J. Friedman. The Elements of Statistical Learning, Data Mining, Inference and Prediction. Springer
Strojové učení Marta Vomlelová marta@ktiml.mff.cuni.cz KTIML, S303 Literatura 1.T. Hastie, R. Tishirani, and J. Friedman. The Elements of Statistical Learning, Data Mining, Inference and Prediction. Springer
Rozpoznávání písmen. Jiří Šejnoha Rudolf Kadlec (c) 2005
 2005") Rozpoznávání písmen Jiří Šejnoha Rudolf Kadlec (c) 2005 Osnova Motivace Popis problému Povaha dat Neuronová síť Architektura Výsledky Zhodnocení a závěr Popis problému Jedná se o praktický problém, kdy
Rozpoznávání písmen Jiří Šejnoha Rudolf Kadlec (c) 2005 Osnova Motivace Popis problému Povaha dat Neuronová síť Architektura Výsledky Zhodnocení a závěr Popis problému Jedná se o praktický problém, kdy
Téma 2: Pravděpodobnostní vyjádření náhodných veličin
 0.05 0.0 0.05 0.0 0.005 Nominální napětí v pásnici Std Mean 40 60 80 00 0 40 60 Std Téma : Pravděpodobnostní vyjádření náhodných veličin Přednáška z předmětu: Spolehlivost a bezpečnost staveb 4. ročník
0.05 0.0 0.05 0.0 0.005 Nominální napětí v pásnici Std Mean 40 60 80 00 0 40 60 Std Téma : Pravděpodobnostní vyjádření náhodných veličin Přednáška z předmětu: Spolehlivost a bezpečnost staveb 4. ročník
Simulace. Simulace dat. Parametry
 Simulace Simulace dat Menu: QCExpert Simulace Simulace dat Tento modul je určen pro generování pseudonáhodných dat s danými statistickými vlastnostmi. Nabízí čtyři typy rozdělení: normální, logaritmicko-normální,
Simulace Simulace dat Menu: QCExpert Simulace Simulace dat Tento modul je určen pro generování pseudonáhodných dat s danými statistickými vlastnostmi. Nabízí čtyři typy rozdělení: normální, logaritmicko-normální,
Učící se klasifikátory obrazu v průmyslu
 Učící se klasifikátory obrazu v průmyslu FCC průmyslové systémy s.r.o. FCC průmyslové systémy je technicko obchodní společností, působící v oblasti průmyslové automatizace. Tvoří ji dvě základní divize:
Učící se klasifikátory obrazu v průmyslu FCC průmyslové systémy s.r.o. FCC průmyslové systémy je technicko obchodní společností, působící v oblasti průmyslové automatizace. Tvoří ji dvě základní divize:
EKONOMETRIE 7. přednáška Fáze ekonometrické analýzy
 EKONOMETRIE 7. přednáška Fáze ekonometrické analýzy Ekonometrická analýza proces, skládající se z následujících fází: a) specifikace b) kvantifikace c) verifikace d) aplikace Postupné zpřesňování jednotlivých
EKONOMETRIE 7. přednáška Fáze ekonometrické analýzy Ekonometrická analýza proces, skládající se z následujících fází: a) specifikace b) kvantifikace c) verifikace d) aplikace Postupné zpřesňování jednotlivých
Modely teorie grafů, min.kostra, max.tok, CPM, MPM, PERT
 PEF ČZU Modely teorie grafů, min.kostra, max.tok, CPM, MPM, PERT Okruhy SZB č. 5 Zdroje: Demel, J., Operační výzkum Jablonský J., Operační výzkum Šubrt, T., Langrová, P., Projektové řízení I. a různá internetová
PEF ČZU Modely teorie grafů, min.kostra, max.tok, CPM, MPM, PERT Okruhy SZB č. 5 Zdroje: Demel, J., Operační výzkum Jablonský J., Operační výzkum Šubrt, T., Langrová, P., Projektové řízení I. a různá internetová
Negativní informace. Petr Štěpánek. S použitím materiálu M.Gelfonda a V. Lifschitze. Logické programování 15 1
 Negativní informace Petr Štěpánek S použitím materiálu M.Gelfonda a V. Lifschitze 2009 Logické programování 15 1 Negace jako neúspěch Motivace: Tvrzení p (atomická formule) neplatí, jestliže nelze odvodit
Negativní informace Petr Štěpánek S použitím materiálu M.Gelfonda a V. Lifschitze 2009 Logické programování 15 1 Negace jako neúspěch Motivace: Tvrzení p (atomická formule) neplatí, jestliže nelze odvodit
12. Globální metody MI-PAA
 Jan Schmidt 2011 Katedra číslicového návrhu Fakulta informačních technologií České vysoké učení technické v Praze Zimní semestr 2011/12 MI-PAA EVROPSKÝ SOCIÁLNÍ FOND PRAHA & EU: INVESTUJENE DO VAŠÍ BUDOUCNOSTI
Jan Schmidt 2011 Katedra číslicového návrhu Fakulta informačních technologií České vysoké učení technické v Praze Zimní semestr 2011/12 MI-PAA EVROPSKÝ SOCIÁLNÍ FOND PRAHA & EU: INVESTUJENE DO VAŠÍ BUDOUCNOSTI
Fyzikální korespondenční seminář MFF UK
 Úloha I.S... náhodná 10 bodů; průměr 7,04; řešilo 45 studentů a) Zkuste vlastními slovy popsat, co je to náhodná veličina a jaké má vlastnosti (postačí vlastními slovy objasnit následující pojmy: náhodná
Úloha I.S... náhodná 10 bodů; průměr 7,04; řešilo 45 studentů a) Zkuste vlastními slovy popsat, co je to náhodná veličina a jaké má vlastnosti (postačí vlastními slovy objasnit následující pojmy: náhodná
Algoritmy pro shlukování prostorových dat
 Algoritmy pro shlukování prostorových dat Marta Žambochová Katedra matematiky a informatiky Fakulta sociálně ekonomická Univerzita J. E. Purkyně v Ústí nad Labem ROBUST 21. 26. leden 2018 Rybník - Hostouň
Algoritmy pro shlukování prostorových dat Marta Žambochová Katedra matematiky a informatiky Fakulta sociálně ekonomická Univerzita J. E. Purkyně v Ústí nad Labem ROBUST 21. 26. leden 2018 Rybník - Hostouň
Vyhledávání. doc. Mgr. Jiří Dvorský, Ph.D. Katedra informatiky Fakulta elektrotechniky a informatiky VŠB TU Ostrava. Prezentace ke dni 21.
 Vyhledávání doc. Mgr. Jiří Dvorský, Ph.D. Katedra informatiky Fakulta elektrotechniky a informatiky VŠB TU Ostrava Prezentace ke dni 21. září 2018 Jiří Dvorský (VŠB TUO) Vyhledávání 242 / 433 Osnova přednášky
Vyhledávání doc. Mgr. Jiří Dvorský, Ph.D. Katedra informatiky Fakulta elektrotechniky a informatiky VŠB TU Ostrava Prezentace ke dni 21. září 2018 Jiří Dvorský (VŠB TUO) Vyhledávání 242 / 433 Osnova přednášky
Vytěžování znalostí z dat
 Pavel Kordík, Josef Borkovec (ČVUT FIT) Vytěžování znalostí z dat BI-VZD, 2012, Přednáška 8 1/26 Vytěžování znalostí z dat Pavel Kordík, Josef Borkovec Department of Computer Systems Faculty of Information
Pavel Kordík, Josef Borkovec (ČVUT FIT) Vytěžování znalostí z dat BI-VZD, 2012, Přednáška 8 1/26 Vytěžování znalostí z dat Pavel Kordík, Josef Borkovec Department of Computer Systems Faculty of Information
Rosenblattův perceptron
 Perceptron Přenosové funkce Rosenblattův perceptron Rosenblatt r. 1958. Inspirace lidským okem Podle fyziologického vzoru je třívrstvá: Vstupní vrstva rozvětvovací jejím úkolem je mapování dvourozměrného
Perceptron Přenosové funkce Rosenblattův perceptron Rosenblatt r. 1958. Inspirace lidským okem Podle fyziologického vzoru je třívrstvá: Vstupní vrstva rozvětvovací jejím úkolem je mapování dvourozměrného
Časová a prostorová složitost algoritmů
 .. Časová a prostorová složitost algoritmů Programovací techniky doc. Ing. Jiří Rybička, Dr. ústav informatiky PEF MENDELU v Brně rybicka@mendelu.cz Hodnocení algoritmů Programovací techniky Časová a prostorová
.. Časová a prostorová složitost algoritmů Programovací techniky doc. Ing. Jiří Rybička, Dr. ústav informatiky PEF MENDELU v Brně rybicka@mendelu.cz Hodnocení algoritmů Programovací techniky Časová a prostorová
Kapacita jako náhodná veličina a její měření. Ing. Igor Mikolášek, Ing. Martin Bambušek Centrum dopravního výzkumu, v. v. i.
 Kapacita jako náhodná veličina a její měření Ing. Igor Mikolášek, Ing. Martin Bambušek Centrum dopravního výzkumu, v. v. i. Obsah Kapacita pozemních komunikací Funkce přežití Kaplan-Meier a parametrické
Kapacita jako náhodná veličina a její měření Ing. Igor Mikolášek, Ing. Martin Bambušek Centrum dopravního výzkumu, v. v. i. Obsah Kapacita pozemních komunikací Funkce přežití Kaplan-Meier a parametrické
Manažerská ekonomika KM IT
 KVANTITATIVNÍ METODY INFORMAČNÍ TECHNOLOGIE (zkouška č. 3) Cíl předmětu Získat základní znalosti v oblasti práce s ekonomickými ukazateli a daty, osvojit si znalosti finanční a pojistné matematiky, zvládnout
KVANTITATIVNÍ METODY INFORMAČNÍ TECHNOLOGIE (zkouška č. 3) Cíl předmětu Získat základní znalosti v oblasti práce s ekonomickými ukazateli a daty, osvojit si znalosti finanční a pojistné matematiky, zvládnout
Miroslav Čepek. Fakulta Elektrotechnická, ČVUT. Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti
 Vytěžování Dat Přednáška 12 Kombinování modelů Miroslav Čepek Pavel Kordík a Jan Černý (FIT) Fakulta Elektrotechnická, ČVUT Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti ČVUT (FEL)
Vytěžování Dat Přednáška 12 Kombinování modelů Miroslav Čepek Pavel Kordík a Jan Černý (FIT) Fakulta Elektrotechnická, ČVUT Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti ČVUT (FEL)
Inženýrská statistika pak představuje soubor postupů a aplikací teoretických principů v oblasti inženýrské činnosti.
 Přednáška č. 1 Úvod do statistiky a počtu pravděpodobnosti Statistika Statistika je věda a postup jak rozvíjet lidské znalosti použitím empirických dat. Je založena na matematické statistice, která je
Přednáška č. 1 Úvod do statistiky a počtu pravděpodobnosti Statistika Statistika je věda a postup jak rozvíjet lidské znalosti použitím empirických dat. Je založena na matematické statistice, která je
Stanovení nejistot při výpočtu kontaminace zasaženého území
 Stanovení nejistot při výpočtu kontaminace zasaženého území Michal Balatka Abstrakt Hodnocení ekologického rizika kontaminovaných území představuje komplexní úlohu, která vyžaduje celou řadu vstupních
Stanovení nejistot při výpočtu kontaminace zasaženého území Michal Balatka Abstrakt Hodnocení ekologického rizika kontaminovaných území představuje komplexní úlohu, která vyžaduje celou řadu vstupních
2. úkol MI-PAA. Jan Jůna (junajan) 3.11.2013
 3.11.2013") 2. úkol MI-PAA Jan Jůna (junajan) 3.11.2013 Specifikaci úlohy Problém batohu je jedním z nejjednodušších NP-těžkých problémů. V literatuře najdeme množství jeho variant, které mají obecně různé nároky
2. úkol MI-PAA Jan Jůna (junajan) 3.11.2013 Specifikaci úlohy Problém batohu je jedním z nejjednodušších NP-těžkých problémů. V literatuře najdeme množství jeho variant, které mají obecně různé nároky
ZÍSKÁVÁNÍ ZNALOSTÍ Z DATABÁZÍ
 Metodický list č. 1 Dobývání znalostí z databází Cílem tohoto tematického celku je vysvětlení základních pojmů z oblasti dobývání znalostí z databází i východisek dobývání znalostí z databází inspirovaných
Metodický list č. 1 Dobývání znalostí z databází Cílem tohoto tematického celku je vysvětlení základních pojmů z oblasti dobývání znalostí z databází i východisek dobývání znalostí z databází inspirovaných