UČENÍ BEZ UČITELE. Václav Hlaváč
|
|
|
- Blanka Krausová
- před 9 lety
- Počet zobrazení:
Transkript
1 UČENÍ BEZ UČITELE Václav Hlaváč Fakulta elektrotechnická ČVUT v Praze katedra kybernetiky, Centrum strojového vnímání hlavac@fel.cvut.cz, 1/22 OBSAH PŘEDNÁŠKY

2 ÚVOD Učení bez učitele se používá pro analýzu pozorování (nebo dat), když není k dispozici informace od učitele, tj. trénovací multimnožina. Pozorovaná data se mají vysvětlit pomocí matematického modelu. Statistický přístup učení statistického modelu z dat. Deterministický přístup podle jiných měr podobnosti dat, např. podle vzdálenosti. Neformálně: data patřící jedné třídě jsou si navzájem podobnější než data z různých tříd. Jiný název: shluková analýza. 2/22

3 MOTIVAČNÍ OBRÁZEK 3/22
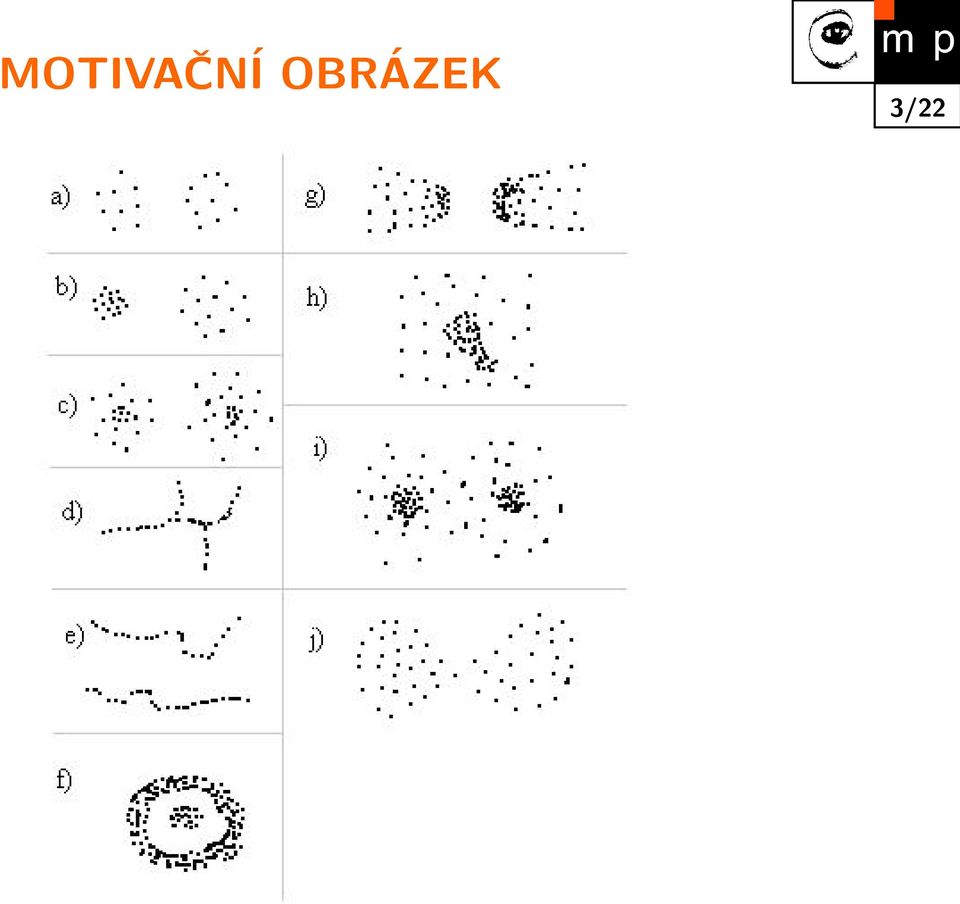
4 SHLUKOVÁ ANALÝZA, 2 PŘÍSTUPY 1. Hierarchické další shluky se hledají na základě předchozích shluků, a to metodou shora dolů nebo zdola nahoru. 4/22 2. Rozdělující najdou shluky najednou (těm se budeme v této přednášce především věnovat). Metoda k-průměrů (angl. k-means). EM algoritmus.

5 STATISTICKÝ PŘÍSTUP 5/22 Pozorování se obvykle chápou jako náhodné veličiny. Výsledkem učení je statistický model dovolující přiřadit pozorování x X ke třídě (skrytému stavu) k K, a to podle modelované sdružené hustoty pravděpodobnosti p(x, k). Ze statistického modelu p(x, k) se odvozují podmíněné pravděpodobnosti tříd p(x k) a mohou se použít pro (bayesovské) rozhodování (jako v případě učení s učitelem). Další důležitou aplikací statistického učení bez učitele je komprese dat.
 se odvozují podmíněné pravděpodobnosti tříd p(x k) a mohou se použít pro (bayesovské)")
6 POUŽÍVANÉ VELIČINY 6/22 x X - pozorování. k K - skrytý stav (výsledek rozpoznávání). q : X K - rozhodovací strategie (klasifikátor). x = (x1, x2,..., xn) - posloupnost pozorování (z trénovací multimnožiny). k = (k1, k2,..., kn) - posloupnost výsledků rozpoznávání (informace učitele z trénovací multimnožiny). Θ - parametr, na němž závisí rozhodovací strategie.
 - posloupnost výsledků rozpoznávání (informace učitele z trénovací multimnožiny).")
7 KLASIFIKÁTOR S PROMĚNNÝMI PARAMETRY 7/22 Dosud jsme se soustředili na návrh klasifikátoru, jehož rozhodovací funkce q závisela na parametru Θ. x q(x, Θ) k Θ k = q(x, Θ)

8 UČENÍ S UČITELEM 8/22 x q(x, Θ) Θ k trénovací data x k uèení Θ = učení(x, k) Rozhodovací pravidlo se naučí na základě trénovací multimnožiny.

9 UČENÍ BEZ UČITELE 9/22 x q(x, Θ) Θ k uèení bez uèitele Θ = učení(x, k) Pro (samo)učení se používá místo trénovací množiny výstup z klasifikátoru.

10 ALGORITMUS UČENÍ BEZ UČITELE 10/22 Inicializace, tj. počáteční volba parametru Θ t=0. Cyklus Rozpoznávání k = q(x, Θt) Učení Θt+1 = učení(x, k) Důležitou otázkou je konvergence algoritmu.
 Učení Θt+1 =")
11 PROČ JE UČENÍ BEZ UČITELE DŮLEŽITÉ? 11/22 Klasifikace dat není předem známá. Příklad: dolování v datech (angl. data mining). Klasifikace dat člověkem může být příliš drahá. Příklad: rozpoznávání řeči. Složitý skrytý markovský model posloupnost. Vyžaduje spoustu trénovacích dat. Rozsáhlé datové soubory je možné komprimovat tím, že se nahradí několika málo významnými reprezentanty. Lze použít jako metodu aproximující složitou hustotu pravděpodobnosti pomocí směsi (např. gaussovských) rozdělení.

12 PŘÍKLAD UČENÍ BEZ UČITELE ALGORITMUS n-průměrů 12/22 Předpokládejme statistický model p k (1) = p k (2) =... = p k ( K ) p(x k j, µ j ) jsou gaussovská rozdělení s jednotkovou kovarianční maticí. Parametry Θ = µ 1,..., µ K. Rozpoznávání podle bayesovské strategie k = argmax k p(k x) = argmin k x µ k odpovídá rozpoznávání podle nejbližšího souseda.

13 PŘÍKLAD UČENÍ BEZ UČITELE ALGORITMUS n-průměrů (2) 13/22 Učení maximálně věrohodný (ML) odhad parametrů Θ t+1 = argmax Θ = argmax µ 1,...,µ K = argmin µ 1,...,µ K = argmin 1 n log p xk (x i, k i ) i=1 n log i=1 ( ) 1 1 ( 2π) exp n 2 (x µ k i ) T (x µ ki ) n (x µ ki ) T (x µ ki ) i=1 µ j = 1 I j (x µ ki ) T (x µ ki ),..., argmin i I k 1 i I j x i, j = 1,... K i I k (x µ ki ) T (x µ ki )
 n (x µ ki ) T (x µ ki ) i=1 µ j = 1 I j (x µ ki ) T (x µ ki ),.")
14 VZTAH K ÚLOZE ODHADU HUSTOT PRAVDĚPODOBNOSTI 14/22 Již známe: Parametrické odhady maximálně věrohodný (ML) odhad. Neparametrické odhady metoda Parzenova okna (nebo metoda n-nejbližších sousedů). Alternativní metoda: modelování hustoty pomocí směsi gaussovských rozdělení.
.")
15 EM algoritmus EM ALGORITMUS, NEFORMÁLNĚ 15/22 je iterativní postup z rodiny maximálních věrohodných odhadů (MLE) pro případy, kde MLE řešení neexistuje nebo je velmi složité; se typicky používá při chybějících datech nebo informaci od učitele pro vytvoření trénovací množiny; převádí rozkládá jednu složitou MLE optimalizační úlohu na několik jednodušších optimalizačních úloh tím, že zavede chybějící parametr. používá gradientní optimalizaci (nejstrmější vzestup) pro nalezení MLE optima. Proto trpí neduhem uvíznutí v lokálních extrémech.
 pro nalezení MLE optima.")
16 EM, STATISTICKÝ MODEL 16/22 Předpokládáme libovolný statistický model p(x, k; Θ) = p(k; Θ) p(x k; Θ) = p(k) p(x k; Θ k ) Θ = ( (p(k), Θ k ), k = 1,..., K )
 p(x k; Θ k ) Θ = ( (p(k), Θ k ),")
17 EM, OPAKOVÁNÍ DVOU KROKŮ E krok (rozpoznávání), Bayesovský odhad stavu k, tj. 17/22 α(i, k) = p(x k) = p(k) p(x; Θ k) p(k) p(x; Θ k ) Pozn. u k-means α(i, k) {0, 1}. Zde je odpovědí rozdělení pro stav k, tj. p(k x i ). M krok, (učení), maximálně věrohodný odhad z daného pozorování x a odhadnutých stavů k k Θ t+1 = argmax Θ Očekávaná věrohodnostní funkce L x,k (Θ) = n i=1 E p(k x) (L x,k (Θ)) log p(k) p(x; Θ k )
, maximálně věrohodný odhad z daného pozorování x a odhadnutých stavů k k Θ t+1 = argmax")
18 Inicializace Cyklus Rozpoznávání Učení EM ALGORITMUS Θ 0 = ( p 0 (k), Θ 0 k), k = 1,..., n. α t (i, k) = pt (k) p(x i ; Θ t k ) p t (k) p(x i ; Θ t k ) k 18/22 p t+1 (k) = n i=1 Θ t+1 k = argmax Θ k α t (i, k) n n i=1 α t (i, k) log p(x i, Θ i )
 = n i=1 Θ t+1 k = argmax Θ k α t (i, k) n n")
19 VLASTNOSTI EM ALGORITMU (1) 19/22 Maximalizuje věrohodnostní funkci L(Θ) = n log p(x i ; Θ) = n p(k) p(x i, Θ) i=1 i=1 log } k {{ } p(x i ;Θ) Obecně platí L(Θ0) L(Θ1)... L(Θt). Posloupnost L(Θt) konverguje pro t k L (L je shora omezená), které je buď lokálním minimem, sedlovým bodem nebo globálním minimem.
 konverguje pro t k L (L je shora omezená), které je buď")
20 VLASTNOSTI EM ALGORITMU (2) 20/22 Pokud je funkce Θt+1 = f (Θt) = L (x, R(x, Θt)) spojitá, pak posloupnost Θ 0, Θ 1,..., Θ t pro t konverguje k Θ. Pro speciální statistické modely, např. model podmíněné nezávislosti a dva stavy, konverguje EM algoritmus ke globálnímu maximu. Hypotéza: platí i pro více stavů.

21 ML ODHAD POMOCÍ EM 21/22 EM je pro ML odhady vhodný. Věrohodnostní funkce L(Θ) = p(x; Θ). Pokud lze rozložit pravděpodobnostní model p(x; Θ) = k p(x, k; Θ), k = 1,..., K, potom lze EM algoritmus použít pro ML odhad parametrů směsi. Příklad: odhad parametrů pro odhad konečných směsí, často gaussovských. ML odhad parametrů Θ = argmax Θ L(Θ). Pro jednoduché statistické modely je analytické řešení, L(Θ) Θ = 0.
22 EM MINIMALIZUJE DOLNÍ MEZ L EM začíná z nějakého odhadu Θ0. 22/22 Potom se v cyklu opakuje: E-krok: odhadne dolní mez funkce L(Θ) v bodě Θ t. M-krok: nalézá novou hodnotu parametru Θ t+1, která maximalizuje odhadnutou dolní mez. Ta se lépe optimalizuje. L( Θ) new estimate lower bound Θ t+1 Θ t Θ
Dobývání znalostí. Doc. RNDr. Iveta Mrázová, CSc. Katedra teoretické informatiky Matematicko-fyzikální fakulta Univerzity Karlovy v Praze
 Dobývání znalostí Doc. RNDr. Iveta Mrázová, CSc. Katedra teoretické informatiky Matematicko-fyzikální fakulta Univerzity Karlovy v Praze Dobývání znalostí Bayesovské modely Doc. RNDr. Iveta Mrázová, CSc.
Dobývání znalostí Doc. RNDr. Iveta Mrázová, CSc. Katedra teoretické informatiky Matematicko-fyzikální fakulta Univerzity Karlovy v Praze Dobývání znalostí Bayesovské modely Doc. RNDr. Iveta Mrázová, CSc.
Neparametrické odhady hustoty pravděpodobnosti
 Neparametrické odhady hustoty pravděpodobnosti Václav Hlaváč Elektrotechnická fakulta ČVUT Katedra kybernetiky Centrum strojového vnímání 121 35 Praha 2, Karlovo nám. 13 hlavac@fel.cvut.cz Statistické
Neparametrické odhady hustoty pravděpodobnosti Václav Hlaváč Elektrotechnická fakulta ČVUT Katedra kybernetiky Centrum strojového vnímání 121 35 Praha 2, Karlovo nám. 13 hlavac@fel.cvut.cz Statistické
Katedra kybernetiky laboratoř Inteligentní Datové Analýzy (IDA) Katedra počítačů, Computational Intelligence Group
 Katedra počítačů, Computational Intelligence Group") Vytěžování dat Miroslav Čepek, Filip Železný Katedra kybernetiky laboratoř Inteligentní Datové Analýzy (IDA) Katedra počítačů, Computational Intelligence Group Evropský sociální fond Praha & EU: Investujeme
Vytěžování dat Miroslav Čepek, Filip Železný Katedra kybernetiky laboratoř Inteligentní Datové Analýzy (IDA) Katedra počítačů, Computational Intelligence Group Evropský sociální fond Praha & EU: Investujeme
Statistická teorie učení
 Statistická teorie učení Petr Havel Marek Myslivec přednáška z 9. týdne 1 Úvod Představme si situaci výrobce a zákazníka, který si u výrobce objednal algoritmus rozpoznávání. Zákazník dodal experimentální
Statistická teorie učení Petr Havel Marek Myslivec přednáška z 9. týdne 1 Úvod Představme si situaci výrobce a zákazníka, který si u výrobce objednal algoritmus rozpoznávání. Zákazník dodal experimentální
EM algoritmus. Proč zahrnovat do modelu neznámé veličiny
 EM algoritmus používá se pro odhad nepozorovaných veličin. Jde o iterativní algoritmus opakující dva kroky: Estimate, který odhadne hodnoty nepozorovaných dat, a Maximize, který maximalizuje věrohodnost
EM algoritmus používá se pro odhad nepozorovaných veličin. Jde o iterativní algoritmus opakující dva kroky: Estimate, který odhadne hodnoty nepozorovaných dat, a Maximize, který maximalizuje věrohodnost
ROZPOZNÁVÁNÍ S MARKOVSKÝMI MODELY
 ROZPOZNÁVÁNÍ S MARKOVSKÝMI MODELY Václav Hlaváč Fakulta elektrotechnická ČVUT v Praze katedra kybernetiky, Centrum strojového vnímání hlavac@fel.cvut.cz, http://cmp.felk.cvut.cz/ hlavac 1/31 PLÁN PŘEDNÁŠKY
ROZPOZNÁVÁNÍ S MARKOVSKÝMI MODELY Václav Hlaváč Fakulta elektrotechnická ČVUT v Praze katedra kybernetiky, Centrum strojového vnímání hlavac@fel.cvut.cz, http://cmp.felk.cvut.cz/ hlavac 1/31 PLÁN PŘEDNÁŠKY
Klasifikace a rozpoznávání. Lineární klasifikátory
 Klasifikace a rozpoznávání Lineární klasifikátory Opakování - Skalární součin x = x1 x 2 w = w T x = w 1 w 2 x 1 x 2 w1 w 2 = w 1 x 1 + w 2 x 2 x. w w T x w Lineární klasifikátor y(x) = w T x + w 0 Vyber
Klasifikace a rozpoznávání Lineární klasifikátory Opakování - Skalární součin x = x1 x 2 w = w T x = w 1 w 2 x 1 x 2 w1 w 2 = w 1 x 1 + w 2 x 2 x. w w T x w Lineární klasifikátor y(x) = w T x + w 0 Vyber
Minikurz aplikované statistiky. Minikurz aplikované statistiky p.1
 Minikurz aplikované statistiky Marie Šimečková, Petr Šimeček Minikurz aplikované statistiky p.1 Program kurzu základy statistiky a pravděpodobnosti regrese (klasická, robustní, s náhodnými efekty, ev.
Minikurz aplikované statistiky Marie Šimečková, Petr Šimeček Minikurz aplikované statistiky p.1 Program kurzu základy statistiky a pravděpodobnosti regrese (klasická, robustní, s náhodnými efekty, ev.
Katedra kybernetiky, FEL, ČVUT v Praze.
 Strojové učení a dolování dat přehled Jiří Kléma Katedra kybernetiky, FEL, ČVUT v Praze http://ida.felk.cvut.cz posnova přednášek Přednáška Učitel Obsah 1. J. Kléma Úvod do předmětu, učení s a bez učitele.
Strojové učení a dolování dat přehled Jiří Kléma Katedra kybernetiky, FEL, ČVUT v Praze http://ida.felk.cvut.cz posnova přednášek Přednáška Učitel Obsah 1. J. Kléma Úvod do předmětu, učení s a bez učitele.
Trénování sítě pomocí učení s učitelem
 Trénování sítě pomocí učení s učitelem! předpokládá se, že máme k dispozici trénovací množinu, tj. množinu P dvojic [vstup x p, požadovaný výstup u p ]! chceme nastavit váhy a prahy sítě tak, aby výstup
Trénování sítě pomocí učení s učitelem! předpokládá se, že máme k dispozici trénovací množinu, tj. množinu P dvojic [vstup x p, požadovaný výstup u p ]! chceme nastavit váhy a prahy sítě tak, aby výstup
ÚVOD DO ROZPOZNÁVÁNÍ
 ÚVOD DO ROZPOZNÁVÁNÍ 1/31 Václav Hlaváč Fakulta elektrotechnická ČVUT v Praze katedra kybernetiky, Centrum strojového vnímání hlavac@fel.cvut.cz, http://cmp.felk.cvut.cz/ hlavac Osnova přednášky Modelování
ÚVOD DO ROZPOZNÁVÁNÍ 1/31 Václav Hlaváč Fakulta elektrotechnická ČVUT v Praze katedra kybernetiky, Centrum strojového vnímání hlavac@fel.cvut.cz, http://cmp.felk.cvut.cz/ hlavac Osnova přednášky Modelování
Klasifikace a rozpoznávání. Bayesovská rozhodovací teorie
 Klasifikace a rozpoznávání Bayesovská rozhodovací teorie Extrakce p íznaků Granáty Četnost Jablka Váha [dkg] Pravděpodobnosti - diskrétní p íznaky Uvažujme diskrétní p íznaky váhové kategorie Nechť tabulka
Klasifikace a rozpoznávání Bayesovská rozhodovací teorie Extrakce p íznaků Granáty Četnost Jablka Váha [dkg] Pravděpodobnosti - diskrétní p íznaky Uvažujme diskrétní p íznaky váhové kategorie Nechť tabulka
Algoritmy a struktury neuropočítačů ASN P9 SVM Support vector machines Support vector networks (Algoritmus podpůrných vektorů)
") Algoritmy a struktury neuropočítačů ASN P9 SVM Support vector machines Support vector networks (Algoritmus podpůrných vektorů) Autor: Vladimir Vapnik Vapnik, V. The Nature of Statistical Learning Theory.
Algoritmy a struktury neuropočítačů ASN P9 SVM Support vector machines Support vector networks (Algoritmus podpůrných vektorů) Autor: Vladimir Vapnik Vapnik, V. The Nature of Statistical Learning Theory.
Lineární klasifikátory
 Lineární klasifikátory Lineární klasifikátory obsah: perceptronový algoritmus základní verze varianta perceptronového algoritmu přihrádkový algoritmus podpůrné vektorové stroje Lineární klasifikátor navrhnout
Lineární klasifikátory Lineární klasifikátory obsah: perceptronový algoritmus základní verze varianta perceptronového algoritmu přihrádkový algoritmus podpůrné vektorové stroje Lineární klasifikátor navrhnout
Markov Chain Monte Carlo. Jan Kracík.
 Markov Chain Monte Carlo Jan Kracík jan.kracik@vsb.cz Princip Monte Carlo integrace Cílem je (přibližný) výpočet integrálu I(g) = E f [g(x)] = g(x)f (x)dx. (1) Umíme-li generovat nezávislé vzorky x (1),
Markov Chain Monte Carlo Jan Kracík jan.kracik@vsb.cz Princip Monte Carlo integrace Cílem je (přibližný) výpočet integrálu I(g) = E f [g(x)] = g(x)f (x)dx. (1) Umíme-li generovat nezávislé vzorky x (1),
Dobývání znalostí. Doc. RNDr. Iveta Mrázová, CSc. Katedra teoretické informatiky Matematicko-fyzikální fakulta Univerzity Karlovy v Praze
 Dobývání znalostí Doc. RNDr. Iveta Mrázová, CSc. Katedra teoretické informatiky Matematicko-fyzikální fakulta Univerzity Karlovy v Praze Dobývání znalostí Pravděpodobnost a učení Doc. RNDr. Iveta Mrázová,
Dobývání znalostí Doc. RNDr. Iveta Mrázová, CSc. Katedra teoretické informatiky Matematicko-fyzikální fakulta Univerzity Karlovy v Praze Dobývání znalostí Pravděpodobnost a učení Doc. RNDr. Iveta Mrázová,
Úvod do optimalizace, metody hladké optimalizace
 Evropský sociální fond Investujeme do vaší budoucnosti Úvod do optimalizace, metody hladké optimalizace Matematika pro informatiky, FIT ČVUT Martin Holeňa, 13. týden LS 2010/2011 O čem to bude? Příklady
Evropský sociální fond Investujeme do vaší budoucnosti Úvod do optimalizace, metody hladké optimalizace Matematika pro informatiky, FIT ČVUT Martin Holeňa, 13. týden LS 2010/2011 O čem to bude? Příklady
oddělení Inteligentní Datové Analýzy (IDA)
") Vytěžování dat Filip Železný Katedra počítačů oddělení Inteligentní Datové Analýzy (IDA) 22. září 2014 Filip Železný (ČVUT) Vytěžování dat 22. září 2014 1 / 25 Odhad rozdělení Úloha: Vstup: data D = {
Vytěžování dat Filip Železný Katedra počítačů oddělení Inteligentní Datové Analýzy (IDA) 22. září 2014 Filip Železný (ČVUT) Vytěžování dat 22. září 2014 1 / 25 Odhad rozdělení Úloha: Vstup: data D = {
KOMPRESE OBRAZŮ. Václav Hlaváč. Fakulta elektrotechnická ČVUT v Praze katedra kybernetiky, Centrum strojového vnímání. hlavac@fel.cvut.
 1/24 KOMPRESE OBRAZŮ Václav Hlaváč Fakulta elektrotechnická ČVUT v Praze katedra kybernetiky, Centrum strojového vnímání hlavac@fel.cvut.cz http://cmp.felk.cvut.cz/ hlavac KOMPRESE OBRAZŮ, ÚVOD 2/24 Cíl:
1/24 KOMPRESE OBRAZŮ Václav Hlaváč Fakulta elektrotechnická ČVUT v Praze katedra kybernetiky, Centrum strojového vnímání hlavac@fel.cvut.cz http://cmp.felk.cvut.cz/ hlavac KOMPRESE OBRAZŮ, ÚVOD 2/24 Cíl:
Úvodem Dříve les než stromy 3 Operace s maticemi
 Obsah 1 Úvodem 13 2 Dříve les než stromy 17 2.1 Nejednoznačnost terminologie 17 2.2 Volba metody analýzy dat 23 2.3 Přehled vybraných vícerozměrných metod 25 2.3.1 Metoda hlavních komponent 26 2.3.2 Faktorová
Obsah 1 Úvodem 13 2 Dříve les než stromy 17 2.1 Nejednoznačnost terminologie 17 2.2 Volba metody analýzy dat 23 2.3 Přehled vybraných vícerozměrných metod 25 2.3.1 Metoda hlavních komponent 26 2.3.2 Faktorová
VZTAH MEZI STATISTICKÝM A STRUKTURNÍM ROZPOZNÁVÁNÍM
 VZTAH MEZI STATISTICKÝM A STRUKTURNÍM ROZPOZNÁVÁNÍM 1/46 Václav Hlaváč Fakulta elektrotechnická ČVUT v Praze katedra kybernetiky, Centrum strojového vnímání hlavac@fel.cvut.cz, http://cmp.felk.cvut.cz/
VZTAH MEZI STATISTICKÝM A STRUKTURNÍM ROZPOZNÁVÁNÍM 1/46 Václav Hlaváč Fakulta elektrotechnická ČVUT v Praze katedra kybernetiky, Centrum strojového vnímání hlavac@fel.cvut.cz, http://cmp.felk.cvut.cz/
Úloha - rozpoznávání číslic
 Úloha - rozpoznávání číslic Vojtěch Franc, Tomáš Pajdla a Tomáš Svoboda http://cmp.felk.cvut.cz 27. listopadu 26 Abstrakt Podpůrný text pro cvičení předmětu X33KUI. Vysvětluje tři způsoby rozpoznávání
Úloha - rozpoznávání číslic Vojtěch Franc, Tomáš Pajdla a Tomáš Svoboda http://cmp.felk.cvut.cz 27. listopadu 26 Abstrakt Podpůrný text pro cvičení předmětu X33KUI. Vysvětluje tři způsoby rozpoznávání
Implementace Bayesova kasifikátoru
 Implementace Bayesova kasifikátoru a diskriminačních funkcí v prostředí Matlab J. Havlík Katedra teorie obvodů Fakulta elektrotechnická České vysoké učení technické v Praze Technická 2, 166 27 Praha 6
Implementace Bayesova kasifikátoru a diskriminačních funkcí v prostředí Matlab J. Havlík Katedra teorie obvodů Fakulta elektrotechnická České vysoké učení technické v Praze Technická 2, 166 27 Praha 6
Měření dat Filtrace dat, Kalmanův filtr
 Měření dat Filtrace dat, Matematické metody pro ITS (11MAMY) Jan Přikryl Ústav aplikované matematiky ČVUT v Praze, Fakulta dopravní 3. přednáška 11MAMY čtvrtek 28. února 2018 verze: 2018-03-21 16:45 Obsah
Měření dat Filtrace dat, Matematické metody pro ITS (11MAMY) Jan Přikryl Ústav aplikované matematiky ČVUT v Praze, Fakulta dopravní 3. přednáška 11MAMY čtvrtek 28. února 2018 verze: 2018-03-21 16:45 Obsah
Pravděpodobnost, náhoda, kostky
 Pravděpodobnost, náhoda, kostky Radek Pelánek IV122 Výhled pravděpodobnost náhodná čísla lineární regrese detekce shluků Dnes lehce nesourodá směs úloh souvisejících s pravděpodobností připomenutí, souvislosti
Pravděpodobnost, náhoda, kostky Radek Pelánek IV122 Výhled pravděpodobnost náhodná čísla lineární regrese detekce shluků Dnes lehce nesourodá směs úloh souvisejících s pravděpodobností připomenutí, souvislosti
Moderní systémy pro získávání znalostí z informací a dat
 Moderní systémy pro získávání znalostí z informací a dat Jan Žižka IBA Institut biostatistiky a analýz PřF & LF, Masarykova universita Kamenice 126/3, 625 00 Brno Email: zizka@iba.muni.cz Bioinformatika:
Moderní systémy pro získávání znalostí z informací a dat Jan Žižka IBA Institut biostatistiky a analýz PřF & LF, Masarykova universita Kamenice 126/3, 625 00 Brno Email: zizka@iba.muni.cz Bioinformatika:
Pravděpodobnost, náhoda, kostky
 Pravděpodobnost, náhoda, kostky Radek Pelánek IV122, jaro 2015 Výhled pravděpodobnost náhodná čísla lineární regrese detekce shluků Dnes lehce nesourodá směs úloh souvisejících s pravděpodobností krátké
Pravděpodobnost, náhoda, kostky Radek Pelánek IV122, jaro 2015 Výhled pravděpodobnost náhodná čísla lineární regrese detekce shluků Dnes lehce nesourodá směs úloh souvisejících s pravděpodobností krátké
Bayesovská klasifikace
 Bayesovská klasifikace založeno na Bayesově větě P(H E) = P(E H) P(H) P(E) použití pro klasifikaci: hypotéza s maximální aposteriorní pravděpodobností H MAP = H J právě když P(H J E) = max i P(E H i) P(H
Bayesovská klasifikace založeno na Bayesově větě P(H E) = P(E H) P(H) P(E) použití pro klasifikaci: hypotéza s maximální aposteriorní pravděpodobností H MAP = H J právě když P(H J E) = max i P(E H i) P(H
TECHNICKÁ UNIVERZITA V LIBERCI
 TECHNICKÁ UNIVERZITA V LIBERCI Fakulta mechatroniky, informatiky a mezioborových studií Základní pojmy diagnostiky a statistických metod vyhodnocení Učební text Ivan Jaksch Liberec 2012 Materiál vznikl
TECHNICKÁ UNIVERZITA V LIBERCI Fakulta mechatroniky, informatiky a mezioborových studií Základní pojmy diagnostiky a statistických metod vyhodnocení Učební text Ivan Jaksch Liberec 2012 Materiál vznikl
1. Vlastnosti diskretních a číslicových metod zpracování signálů... 15
 Úvodní poznámky... 11 1. Vlastnosti diskretních a číslicových metod zpracování signálů... 15 1.1 Základní pojmy... 15 1.2 Aplikační oblasti a etapy zpracování signálů... 17 1.3 Klasifikace diskretních
Úvodní poznámky... 11 1. Vlastnosti diskretních a číslicových metod zpracování signálů... 15 1.1 Základní pojmy... 15 1.2 Aplikační oblasti a etapy zpracování signálů... 17 1.3 Klasifikace diskretních
Aktivní detekce chyb
 Fakulta aplikovaných věd, Katedra kybernetiky a Výzkumné centrum Data - Algoritmy - Rozhodování Západočeská univerzita v Plzni Prezentace v rámci odborného semináře Katedry kybernetiky Obsah Motivační
Fakulta aplikovaných věd, Katedra kybernetiky a Výzkumné centrum Data - Algoritmy - Rozhodování Západočeská univerzita v Plzni Prezentace v rámci odborného semináře Katedry kybernetiky Obsah Motivační
AVDAT Mnohorozměrné metody, metody klasifikace Shluková analýza
 AVDAT Mnohorozměrné metody, metody klasifikace Shluková analýza Josef Tvrdík Katedra informatiky Přírodovědecká fakulta Ostravská univerzita Shluková analýza Cílem shlukové analýzy je nalézt v datech podmnožiny
AVDAT Mnohorozměrné metody, metody klasifikace Shluková analýza Josef Tvrdík Katedra informatiky Přírodovědecká fakulta Ostravská univerzita Shluková analýza Cílem shlukové analýzy je nalézt v datech podmnožiny
Projekční algoritmus. Urychlení evolučních algoritmů pomocí regresních stromů a jejich zobecnění. Jan Klíma
 Urychlení evolučních algoritmů pomocí regresních stromů a jejich zobecnění Jan Klíma Obsah Motivace & cíle práce Evoluční algoritmy Náhradní modelování Stromové regresní metody Implementace a výsledky
Urychlení evolučních algoritmů pomocí regresních stromů a jejich zobecnění Jan Klíma Obsah Motivace & cíle práce Evoluční algoritmy Náhradní modelování Stromové regresní metody Implementace a výsledky
Kybernetika a umělá inteligence, cvičení 10/11
 Kybernetika a umělá inteligence, cvičení 10/11 Program 1. seminární cvičení: základní typy klasifikátorů a jejich princip 2. počítačové cvičení: procvičení na problému rozpoznávání číslic... body za aktivitu
Kybernetika a umělá inteligence, cvičení 10/11 Program 1. seminární cvičení: základní typy klasifikátorů a jejich princip 2. počítačové cvičení: procvičení na problému rozpoznávání číslic... body za aktivitu
Teorie rozhodování (decision theory)
") Umělá inteligence II Roman Barták, KTIML roman.bartak@mff.cuni.cz http://ktiml.mff.cuni.cz/~bartak Teorie pravděpodobnosti (probability theory) popisuje v co má agent věřit na základě pozorování. Teorie
Umělá inteligence II Roman Barták, KTIML roman.bartak@mff.cuni.cz http://ktiml.mff.cuni.cz/~bartak Teorie pravděpodobnosti (probability theory) popisuje v co má agent věřit na základě pozorování. Teorie
Měření dat Filtrace dat, Kalmanův filtr
 Měření dat Filtrace dat, Matematické metody pro ITS (11MAMY) Jan Přikryl Ústav aplikované matematiky ČVUT v Praze, Fakulta dopravní 3. přednáška 11MAMY čtvrtek 28. února 2018 verze: 2018-02-28 12:20 Obsah
Měření dat Filtrace dat, Matematické metody pro ITS (11MAMY) Jan Přikryl Ústav aplikované matematiky ČVUT v Praze, Fakulta dopravní 3. přednáška 11MAMY čtvrtek 28. února 2018 verze: 2018-02-28 12:20 Obsah
1. Číselné posloupnosti - Definice posloupnosti, základní vlastnosti, operace s posloupnostmi, limita posloupnosti, vlastnosti limit posloupností,
 KMA/SZZS1 Matematika 1. Číselné posloupnosti - Definice posloupnosti, základní vlastnosti, operace s posloupnostmi, limita posloupnosti, vlastnosti limit posloupností, operace s limitami. 2. Limita funkce
KMA/SZZS1 Matematika 1. Číselné posloupnosti - Definice posloupnosti, základní vlastnosti, operace s posloupnostmi, limita posloupnosti, vlastnosti limit posloupností, operace s limitami. 2. Limita funkce
Obr. 1: Vizualizace dat pacientů, kontrolních subjektů a testovacího subjektu.
 Řešení příkladu - klasifikace testovacího subjektu pomocí Bayesova klasifikátoru: ata si vizualizujeme (Obr. ). Objem mozkových komor 9 8 7 6 5 pacienti kontroly testovací subjekt 5 6 Objem hipokampu Obr.
Řešení příkladu - klasifikace testovacího subjektu pomocí Bayesova klasifikátoru: ata si vizualizujeme (Obr. ). Objem mozkových komor 9 8 7 6 5 pacienti kontroly testovací subjekt 5 6 Objem hipokampu Obr.
Odhad stavu matematického modelu křižovatek
 Odhad stavu matematického modelu křižovatek Miroslav Šimandl, Miroslav Flídr a Jindřich Duník Katedra kybernetiky & Výzkumné centrum Data-Algoritmy-Rozhodování Fakulta aplikovaných věd Západočeská univerzita
Odhad stavu matematického modelu křižovatek Miroslav Šimandl, Miroslav Flídr a Jindřich Duník Katedra kybernetiky & Výzkumné centrum Data-Algoritmy-Rozhodování Fakulta aplikovaných věd Západočeská univerzita
Přednáška 13 Redukce dimenzionality
 Vytěžování Dat Přednáška 13 Redukce dimenzionality Miroslav Čepek Fakulta Elektrotechnická, ČVUT Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti ČVUT (FEL) Redukce dimenzionality 1 /
Vytěžování Dat Přednáška 13 Redukce dimenzionality Miroslav Čepek Fakulta Elektrotechnická, ČVUT Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti ČVUT (FEL) Redukce dimenzionality 1 /
KOMPRESE OBRAZŮ. Václav Hlaváč, Jan Kybic. Fakulta elektrotechnická ČVUT v Praze katedra kybernetiky, Centrum strojového vnímání.
 1/25 KOMPRESE OBRAZŮ Václav Hlaváč, Jan Kybic Fakulta elektrotechnická ČVUT v Praze katedra kybernetiky, Centrum strojového vnímání hlavac@fel.cvut.cz http://cmp.felk.cvut.cz/ hlavac KOMPRESE OBRAZŮ, ÚVOD
1/25 KOMPRESE OBRAZŮ Václav Hlaváč, Jan Kybic Fakulta elektrotechnická ČVUT v Praze katedra kybernetiky, Centrum strojového vnímání hlavac@fel.cvut.cz http://cmp.felk.cvut.cz/ hlavac KOMPRESE OBRAZŮ, ÚVOD
Státnice odborné č. 20
 Státnice odborné č. 20 Shlukování dat Shlukování dat. Metoda k-středů, hierarchické (aglomerativní) shlukování, Kohonenova mapa SOM Shlukování dat Shluková analýza je snaha o seskupení objektů do skupin
Státnice odborné č. 20 Shlukování dat Shlukování dat. Metoda k-středů, hierarchické (aglomerativní) shlukování, Kohonenova mapa SOM Shlukování dat Shluková analýza je snaha o seskupení objektů do skupin
PRAVDĚPODOBNOST A STATISTIKA
 PRAVDĚPODOBNOST A STATISTIKA Náhodný výběr Nechť X je náhodná proměnná, která má distribuční funkci F(x, ϑ). Předpokládejme, že známe tvar distribuční funkce (víme jaké má rozdělení) a neznáme parametr
PRAVDĚPODOBNOST A STATISTIKA Náhodný výběr Nechť X je náhodná proměnná, která má distribuční funkci F(x, ϑ). Předpokládejme, že známe tvar distribuční funkce (víme jaké má rozdělení) a neznáme parametr
Pokročilé neparametrické metody. Klára Kubošová
 Pokročilé neparametrické metody Klára Kubošová Pokročilé neparametrické metody Výuka 13 přednášek doplněných o praktické cvičení v SW Úvod do neparametrických metod + princip rozhodovacích stromů Klasifikační
Pokročilé neparametrické metody Klára Kubošová Pokročilé neparametrické metody Výuka 13 přednášek doplněných o praktické cvičení v SW Úvod do neparametrických metod + princip rozhodovacích stromů Klasifikační
Pravděpodobnost a statistika (BI-PST) Cvičení č. 9
 Cvičení č. 9") Pravděpodobnost a statistika (BI-PST) Cvičení č. 9 R. Blažek, M. Jiřina, J. Hrabáková, I. Petr, F. Štampach, D. Vašata Katedra aplikované matematiky Fakulta informačních technologií České vysoké učení
Pravděpodobnost a statistika (BI-PST) Cvičení č. 9 R. Blažek, M. Jiřina, J. Hrabáková, I. Petr, F. Štampach, D. Vašata Katedra aplikované matematiky Fakulta informačních technologií České vysoké učení
Vytěžování znalostí z dat
 Pavel Kordík, Jan Motl (ČVUT FIT) Vytěžování znalostí z dat BI-VZD, 2012, Přednáška 7 1/27 Vytěžování znalostí z dat Pavel Kordík, Jan Motl Department of Computer Systems Faculty of Information Technology
Pavel Kordík, Jan Motl (ČVUT FIT) Vytěžování znalostí z dat BI-VZD, 2012, Přednáška 7 1/27 Vytěžování znalostí z dat Pavel Kordík, Jan Motl Department of Computer Systems Faculty of Information Technology
Učící se klasifikátory obrazu v průmyslu
 Učící se klasifikátory obrazu v průmyslu FCC průmyslové systémy s.r.o. FCC průmyslové systémy je technicko obchodní společností, působící v oblasti průmyslové automatizace. Tvoří ji dvě základní divize:
Učící se klasifikátory obrazu v průmyslu FCC průmyslové systémy s.r.o. FCC průmyslové systémy je technicko obchodní společností, působící v oblasti průmyslové automatizace. Tvoří ji dvě základní divize:
SRE 03 - Statistické rozpoznávání
 SRE 03 - Statistické rozpoznávání vzorů II Lukáš Burget ÚPGM FIT VUT Brno, burget@fit.vutbr.cz FIT VUT Brno SRE 03 - Statistické rozpoznávání vzorů II Lukáš Burget, ÚPGM FIT VUT Brno, 2006/07 1/29 Opakování
SRE 03 - Statistické rozpoznávání vzorů II Lukáš Burget ÚPGM FIT VUT Brno, burget@fit.vutbr.cz FIT VUT Brno SRE 03 - Statistické rozpoznávání vzorů II Lukáš Burget, ÚPGM FIT VUT Brno, 2006/07 1/29 Opakování
Odhady Parametrů Lineární Regrese
 Odhady Parametrů Lineární Regrese Mgr. Rudolf B. Blažek, Ph.D. prof. RNDr. Roman Kotecký, DrSc. Katedra počítačových systémů Katedra teoretické informatiky Fakulta informačních technologií České vysoké
Odhady Parametrů Lineární Regrese Mgr. Rudolf B. Blažek, Ph.D. prof. RNDr. Roman Kotecký, DrSc. Katedra počítačových systémů Katedra teoretické informatiky Fakulta informačních technologií České vysoké
Pravděpodobnostní (Markovské) metody plánování, MDP - obsah
 metody plánování, MDP - obsah") Pravděpodobnostní (Markovské) metody plánování, MDP - obsah Pravděpodobnostní plánování - motivace. Nejistota ve výběr akce Markovské rozhodovací procesy Strategie plán (control policy) Částečně pozorovatelné
Pravděpodobnostní (Markovské) metody plánování, MDP - obsah Pravděpodobnostní plánování - motivace. Nejistota ve výběr akce Markovské rozhodovací procesy Strategie plán (control policy) Částečně pozorovatelné
Agent pracující v částečně pozorovatelném prostředí udržuje na základě senzorického modelu odhaduje, jak se svět může vyvíjet.
 Umělá inteligence II Roman Barták, KTIML roman.bartak@mff.cuni.cz http://ktiml.mff.cuni.cz/~bartak Dnešní program Agent pracující v částečně pozorovatelném prostředí udržuje na základě senzorického modelu
Umělá inteligence II Roman Barták, KTIML roman.bartak@mff.cuni.cz http://ktiml.mff.cuni.cz/~bartak Dnešní program Agent pracující v částečně pozorovatelném prostředí udržuje na základě senzorického modelu
Statistická analýza dat
 Statistická analýza dat Jméno: Podpis: Cvičení Zkouška (písemná + ústní) 25 Celkem 50 Známka Pokyny k vypracování: doba řešení je 120min, jasně zodpovězte pokud možno všechny otázky ze zadání, pracujte
Statistická analýza dat Jméno: Podpis: Cvičení Zkouška (písemná + ústní) 25 Celkem 50 Známka Pokyny k vypracování: doba řešení je 120min, jasně zodpovězte pokud možno všechny otázky ze zadání, pracujte
ZÍSKÁVÁNÍ ZNALOSTÍ Z DATABÁZÍ
 Metodický list č. 1 Dobývání znalostí z databází Cílem tohoto tematického celku je vysvětlení základních pojmů z oblasti dobývání znalostí z databází i východisek dobývání znalostí z databází inspirovaných
Metodický list č. 1 Dobývání znalostí z databází Cílem tohoto tematického celku je vysvětlení základních pojmů z oblasti dobývání znalostí z databází i východisek dobývání znalostí z databází inspirovaných
ZÍSKÁVÁNÍ ZNALOSTÍ Z DATABÁZÍ
 metodický list č. 1 Dobývání znalostí z databází Cílem tohoto tematického celku je vysvětlení základních pojmů z oblasti dobývání znalostí z databází i východisek dobývání znalostí z databází inspirovaných
metodický list č. 1 Dobývání znalostí z databází Cílem tohoto tematického celku je vysvětlení základních pojmů z oblasti dobývání znalostí z databází i východisek dobývání znalostí z databází inspirovaných
MATEMATICKÁ STATISTIKA. Katedra matematiky a didaktiky matematiky Technická univerzita v Liberci
 MATEMATICKÁ STATISTIKA Dana Černá http://www.fp.tul.cz/kmd/ Katedra matematiky a didaktiky matematiky Technická univerzita v Liberci Matematická statistika Matematická statistika se zabývá matematickým
MATEMATICKÁ STATISTIKA Dana Černá http://www.fp.tul.cz/kmd/ Katedra matematiky a didaktiky matematiky Technická univerzita v Liberci Matematická statistika Matematická statistika se zabývá matematickým
Strojové učení Marta Vomlelová
 Strojové učení Marta Vomlelová marta@ktiml.mff.cuni.cz KTIML, S303 Literatura 1.T. Hastie, R. Tishirani, and J. Friedman. The Elements of Statistical Learning, Data Mining, Inference and Prediction. Springer
Strojové učení Marta Vomlelová marta@ktiml.mff.cuni.cz KTIML, S303 Literatura 1.T. Hastie, R. Tishirani, and J. Friedman. The Elements of Statistical Learning, Data Mining, Inference and Prediction. Springer
Přijímací zkouška na navazující magisterské studium 2014
 Přijímací zkouška na navazující magisterské studium 24 Příklad (25 bodů) Spočtěte Studijní program: Studijní obor: Matematika Finanční a pojistná matematika Varianta A M x 2 dxdy, kde M = {(x, y) R 2 ;
Přijímací zkouška na navazující magisterské studium 24 Příklad (25 bodů) Spočtěte Studijní program: Studijní obor: Matematika Finanční a pojistná matematika Varianta A M x 2 dxdy, kde M = {(x, y) R 2 ;
aneb jiný úhel pohledu na prvák
 Účelná matematika aneb jiný úhel pohledu na prvák Jan Hejtmánek FEL, ČVUT v Praze 24. června 2015 Jan Hejtmánek (FEL, ČVUT v Praze) Technokrati 2015 24. června 2015 1 / 18 Outline 1 Motivace 2 Proč tolik
Účelná matematika aneb jiný úhel pohledu na prvák Jan Hejtmánek FEL, ČVUT v Praze 24. června 2015 Jan Hejtmánek (FEL, ČVUT v Praze) Technokrati 2015 24. června 2015 1 / 18 Outline 1 Motivace 2 Proč tolik
PRAVDĚPODOBNOST A STATISTIKA. Bayesovské odhady
 PRAVDĚPODOBNOST A STATISTIKA Bayesovské odhady Bayesovské odhady - úvod Klasický bayesovský přístup: Klasický přístup je založen na opakování pokusech sledujeme rekvenci nastoupení zvolených jevů Bayesovský
PRAVDĚPODOBNOST A STATISTIKA Bayesovské odhady Bayesovské odhady - úvod Klasický bayesovský přístup: Klasický přístup je založen na opakování pokusech sledujeme rekvenci nastoupení zvolených jevů Bayesovský
AVDAT Náhodný vektor, mnohorozměrné rozdělení
 AVDAT Náhodný vektor, mnohorozměrné rozdělení Josef Tvrdík Katedra informatiky Přírodovědecká fakulta Ostravská univerzita Opakování, náhodná veličina, rozdělení Náhodná veličina zobrazuje elementární
AVDAT Náhodný vektor, mnohorozměrné rozdělení Josef Tvrdík Katedra informatiky Přírodovědecká fakulta Ostravská univerzita Opakování, náhodná veličina, rozdělení Náhodná veličina zobrazuje elementární
Numerické metody optimalizace - úvod
 Numerické metody optimalizace - úvod Petr Tichý 16. února 2015 1 Organizace přednášek a cvičení 13 přednášek a cvičení. Zápočet: úloha programování a testování úloh v Matlabu. Další informace na blogu
Numerické metody optimalizace - úvod Petr Tichý 16. února 2015 1 Organizace přednášek a cvičení 13 přednášek a cvičení. Zápočet: úloha programování a testování úloh v Matlabu. Další informace na blogu
Umělá inteligence II
 Umělá inteligence II 11 http://ktiml.mff.cuni.cz/~bartak Roman Barták, KTIML roman.bartak@mff.cuni.cz Dnešní program! V reálném prostředí převládá neurčitost.! Neurčitost umíme zpracovávat pravděpodobnostními
Umělá inteligence II 11 http://ktiml.mff.cuni.cz/~bartak Roman Barták, KTIML roman.bartak@mff.cuni.cz Dnešní program! V reálném prostředí převládá neurčitost.! Neurčitost umíme zpracovávat pravděpodobnostními
Markovské metody pro modelování pravděpodobnosti
 Markovské metody pro modelování pravděpodobnosti rizikových stavů 1 Markovský řetězec Budeme uvažovat náhodný proces s diskrétním časem (náhodnou posloupnost) X(t), t T {0, 1, 2,... } s konečnou množinou
Markovské metody pro modelování pravděpodobnosti rizikových stavů 1 Markovský řetězec Budeme uvažovat náhodný proces s diskrétním časem (náhodnou posloupnost) X(t), t T {0, 1, 2,... } s konečnou množinou
Algoritmy a struktury neuropočítačů ASN P4. Vícevrstvé sítě dopředné a Elmanovy MLNN s učením zpětného šíření chyby
 Algoritmy a struktury neuropočítačů ASN P4 Vícevrstvé sítě dopředné a Elmanovy MLNN s učením zpětného šíření chyby Vrstevnatá struktura - vícevrstvé NN (Multilayer NN, MLNN) vstupní vrstva (input layer)
Algoritmy a struktury neuropočítačů ASN P4 Vícevrstvé sítě dopředné a Elmanovy MLNN s učením zpětného šíření chyby Vrstevnatá struktura - vícevrstvé NN (Multilayer NN, MLNN) vstupní vrstva (input layer)
Asociační i jiná. Pravidla. (Ch )
") Asociační i jiná Pravidla (Ch. 14 +...) Učení bez učitele Nemáme cílovou třídu Y, G; máme N pozorování což jsou p-dimenzionální vektory se sdruženou pravděpodobností chceme odvozovat vlastnosti. Pro málo
Asociační i jiná Pravidla (Ch. 14 +...) Učení bez učitele Nemáme cílovou třídu Y, G; máme N pozorování což jsou p-dimenzionální vektory se sdruženou pravděpodobností chceme odvozovat vlastnosti. Pro málo
Bayesovské rozhodování - kritétium minimální střední ztráty
 Bayesovské rozhodování - kritétium imální střední ztráty Lukáš Slánský, Ivana Čapková 6. června 2001 1 Formulace úlohy JE DÁNO: X množina možných pozorování (příznaků) x K množina hodnot skrytého parametru
Bayesovské rozhodování - kritétium imální střední ztráty Lukáš Slánský, Ivana Čapková 6. června 2001 1 Formulace úlohy JE DÁNO: X množina možných pozorování (příznaků) x K množina hodnot skrytého parametru
Statistika a spolehlivost v lékařství Charakteristiky spolehlivosti prvků I
 Statistika a spolehlivost v lékařství Charakteristiky spolehlivosti prvků I Příklad Tahová síla papíru používaného pro výrobu potravinových sáčků je důležitá charakteristika kvality. Je známo, že síla
Statistika a spolehlivost v lékařství Charakteristiky spolehlivosti prvků I Příklad Tahová síla papíru používaného pro výrobu potravinových sáčků je důležitá charakteristika kvality. Je známo, že síla
Uvod Modely n-tic Vyhodnocov an ı Vyhlazov an ı a stahov an ı Rozˇ s ıˇ ren ı model u n-tic Jazykov e modelov an ı Pavel Smrˇ z 27.
 Jazykové modelování Pavel Smrž 27. listopadu 2006 Osnova 1 Úvod motivace, základní pojmy 2 Modely n-tic 3 Způsob vyhodnocování 4 Vyhlazování a stahování 5 Rozšíření modelů n-tic 6 Lingvisticky motivované
Jazykové modelování Pavel Smrž 27. listopadu 2006 Osnova 1 Úvod motivace, základní pojmy 2 Modely n-tic 3 Způsob vyhodnocování 4 Vyhlazování a stahování 5 Rozšíření modelů n-tic 6 Lingvisticky motivované
Cvičení 5. Přednášející: Mgr. Rudolf B. Blažek, Ph.D. prof. RNDr. Roman Kotecký, DrSc.
 5 Přednášející: Mgr. Rudolf B. Blažek, Ph.D. prof. RNDr. Roman Kotecký, DrSc. Katedra počítačových systémů Katedra teoretické informatiky Fakulta informačních technologií České vysoké učení technické v
5 Přednášející: Mgr. Rudolf B. Blažek, Ph.D. prof. RNDr. Roman Kotecký, DrSc. Katedra počítačových systémů Katedra teoretické informatiky Fakulta informačních technologií České vysoké učení technické v
Cvičná bakalářská zkouška, 1. varianta
 jméno: studijní obor: PřF BIMAT počet listů(včetně tohoto): 1 2 3 4 5 celkem Cvičná bakalářská zkouška, 1. varianta 1. Matematická analýza Najdětelokálníextrémyfunkce f(x,y)=e 4(x y) x2 y 2. 2. Lineární
jméno: studijní obor: PřF BIMAT počet listů(včetně tohoto): 1 2 3 4 5 celkem Cvičná bakalářská zkouška, 1. varianta 1. Matematická analýza Najdětelokálníextrémyfunkce f(x,y)=e 4(x y) x2 y 2. 2. Lineární
Algoritmy a struktury neuropočítačů ASN P3
 Algoritmy a struktury neuropočítačů ASN P3 SOM algoritmus s učitelem i bez učitele U-matice Vektorová kvantizace Samoorganizující se mapy ( Self-Organizing Maps ) PROČ? Základní myšlenka: analogie s činností
Algoritmy a struktury neuropočítačů ASN P3 SOM algoritmus s učitelem i bez učitele U-matice Vektorová kvantizace Samoorganizující se mapy ( Self-Organizing Maps ) PROČ? Základní myšlenka: analogie s činností
Klasifikace podle nejbližších sousedů Nearest Neighbour Classification [k-nn]
![Klasifikace podle nejbližších sousedů Nearest Neighbour Classification [k-nn]](/thumbs/93/111339850.jpg "Klasifikace podle nejbližších sousedů Nearest Neighbour Classification [k-nn]") Klasifikace podle nejbližších sousedů Nearest Neighbour Classification [k-nn] Michal Houdek, Tomáš Svoboda, Tomáš Procházka 6. června 2001 1 Obsah 1 Úvod 3 2 Definice a postup klasifikace 3 3 Příklady
Klasifikace podle nejbližších sousedů Nearest Neighbour Classification [k-nn] Michal Houdek, Tomáš Svoboda, Tomáš Procházka 6. června 2001 1 Obsah 1 Úvod 3 2 Definice a postup klasifikace 3 3 Příklady
ANALÝZA A KLASIFIKACE DAT
 ANALÝZA A KLASIFIKACE DAT prof. Ing. Jiří Holčík, CSc. INVESTICE Institut DO biostatistiky ROZVOJE VZDĚLÁVÁNÍ a analýz LITERATURA Holčík, J.: přednáškové prezentace Holčík, J.: Analýza a klasifikace signálů.
ANALÝZA A KLASIFIKACE DAT prof. Ing. Jiří Holčík, CSc. INVESTICE Institut DO biostatistiky ROZVOJE VZDĚLÁVÁNÍ a analýz LITERATURA Holčík, J.: přednáškové prezentace Holčík, J.: Analýza a klasifikace signálů.
4. Na obrázku je rozdělovací funkce (hustota pravděpodobnosti) náhodné veličiny X. Jakou hodnotu musí mít parametr k?
 náhodné veličiny X. Jakou hodnotu musí mít parametr k?") A 1. Stanovte pravděpodobnost, že náhodná veličina X nabyde hodnoty menší než 6: P( X 6). Veličina X má rozdělení se střední hodnotou 6 a směrodatnou odchylkou 5: N(6,5). a) 0 b) 1/3 c) ½ 2. Je možné,
A 1. Stanovte pravděpodobnost, že náhodná veličina X nabyde hodnoty menší než 6: P( X 6). Veličina X má rozdělení se střední hodnotou 6 a směrodatnou odchylkou 5: N(6,5). a) 0 b) 1/3 c) ½ 2. Je možné,
Fakulta chemicko-technologická Katedra analytické chemie. 3.2 Metody s latentními proměnnými a klasifikační metody
 Fakulta chemicko-technologická Katedra analytické chemie 3.2 Metody s latentními proměnnými a klasifikační metody Vypracoval: Ing. Tomáš Nekola Studium: licenční Datum: 21. 1. 2008 Otázka 1. Vypočtěte
Fakulta chemicko-technologická Katedra analytické chemie 3.2 Metody s latentními proměnnými a klasifikační metody Vypracoval: Ing. Tomáš Nekola Studium: licenční Datum: 21. 1. 2008 Otázka 1. Vypočtěte
Řízení a optimalizace Stavové modely a model-prediktivní řízení
 Řízení a optimalizace Stavové modely a model-prediktivní řízení Matematické metody pro ITS (11MAMY) Jan Přikryl Ústav aplikované matematiky ČVUT v Praze, Fakulta dopravní 2. přednáška 11MAMY středa 22.
Řízení a optimalizace Stavové modely a model-prediktivní řízení Matematické metody pro ITS (11MAMY) Jan Přikryl Ústav aplikované matematiky ČVUT v Praze, Fakulta dopravní 2. přednáška 11MAMY středa 22.
Pravděpodobnost v závislosti na proměnné x je zde modelován pomocí logistického modelu. exp x. x x x. log 1
 Logistická regrese Menu: QCExpert Regrese Logistická Modul Logistická regrese umožňuje analýzu dat, kdy odezva je binární, nebo frekvenční veličina vyjádřená hodnotami 0 nebo 1, případně poměry v intervalu
Logistická regrese Menu: QCExpert Regrese Logistická Modul Logistická regrese umožňuje analýzu dat, kdy odezva je binární, nebo frekvenční veličina vyjádřená hodnotami 0 nebo 1, případně poměry v intervalu
Výběrové charakteristiky a jejich rozdělení
 Katedra ekonometrie, FVL, UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Statistické šetření úplné (vyčerpávající) neúplné (výběrové) U výběrového šetření se snažíme o to, aby výběrový
Katedra ekonometrie, FVL, UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Statistické šetření úplné (vyčerpávající) neúplné (výběrové) U výběrového šetření se snažíme o to, aby výběrový
Základy teorie odhadu parametrů bodový odhad
 Katedra ekonometrie, FVL, UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Odhady parametrů Úkolem výběrového šetření je podat informaci o neznámé hodnotě charakteristiky základního souboru
Katedra ekonometrie, FVL, UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Odhady parametrů Úkolem výběrového šetření je podat informaci o neznámé hodnotě charakteristiky základního souboru
Vytěžování znalostí z dat
 Pavel Kordík, Jan Motl (ČVUT FIT) Vytěžování znalostí z dat BI-VZD, 2012, Přednáška 1 1/32 Vytěžování znalostí z dat Pavel Kordík, Jan Motl Department of Computer Systems Faculty of Information Technology
Pavel Kordík, Jan Motl (ČVUT FIT) Vytěžování znalostí z dat BI-VZD, 2012, Přednáška 1 1/32 Vytěžování znalostí z dat Pavel Kordík, Jan Motl Department of Computer Systems Faculty of Information Technology
Základy matematiky pro FEK
 Základy matematiky pro FEK 4. přednáška Blanka Šedivá KMA zimní semestr 2016/2017 Blanka Šedivá (KMA) Základy matematiky pro FEK zimní semestr 2016/2017 1 / 27 Množiny Zavedení pojmu množina je velice
Základy matematiky pro FEK 4. přednáška Blanka Šedivá KMA zimní semestr 2016/2017 Blanka Šedivá (KMA) Základy matematiky pro FEK zimní semestr 2016/2017 1 / 27 Množiny Zavedení pojmu množina je velice
jevu, čas vyjmutí ze sledování byl T j, T j < X j a T j je náhodná veličina.
 Parametrické metody odhadů z neúplných výběrů 2 1 Metoda maximální věrohodnosti pro cenzorované výběry 11 Náhodné cenzorování Při sledování složitých reálných systémů často nemáme možnost uspořádat experiment
Parametrické metody odhadů z neúplných výběrů 2 1 Metoda maximální věrohodnosti pro cenzorované výběry 11 Náhodné cenzorování Při sledování složitých reálných systémů často nemáme možnost uspořádat experiment
PC: Identifikace struktury zobecněného dynamického systému
 PC: Identifikace struktury zobecněného dynamického systému Důležitý problém v obecné teorii systémů. 1. Podsystém a nadsystém. 2. Definice dekompozice systému. 3. Problém rekonstrukce systému: a. lokální
PC: Identifikace struktury zobecněného dynamického systému Důležitý problém v obecné teorii systémů. 1. Podsystém a nadsystém. 2. Definice dekompozice systému. 3. Problém rekonstrukce systému: a. lokální
Algoritmy pro spojitou optimalizaci
 Algoritmy pro spojitou optimalizaci Vladimír Bičík Katedra počítačů Fakulta elektrotechnická České vysoké učení technické v Praze 10.6.2010 Vladimír Bičík (ČVUT Praha) Algoritmy pro spojitou optimalizaci
Algoritmy pro spojitou optimalizaci Vladimír Bičík Katedra počítačů Fakulta elektrotechnická České vysoké učení technické v Praze 10.6.2010 Vladimír Bičík (ČVUT Praha) Algoritmy pro spojitou optimalizaci
Simulační modely. Kdy použít simulaci?
 Simulační modely Simulace z lat. Simulare (napodobení). Princip simulace spočívá v sestavení modelu reálného systému a provádění opakovaných experimentů s tímto modelem. Simulaci je nutno považovat za
Simulační modely Simulace z lat. Simulare (napodobení). Princip simulace spočívá v sestavení modelu reálného systému a provádění opakovaných experimentů s tímto modelem. Simulaci je nutno považovat za
Restaurace (obnovení) obrazu při známé degradaci
 obrazu při známé degradaci") Restaurace (obnovení) obrazu při známé degradaci Václav Hlaváč České vysoké učení technické v Praze Centrum strojového vnímání (přemosťuje skupiny z) Český institut informatiky, robotiky a kybernetiky
Restaurace (obnovení) obrazu při známé degradaci Václav Hlaváč České vysoké učení technické v Praze Centrum strojového vnímání (přemosťuje skupiny z) Český institut informatiky, robotiky a kybernetiky
Hledání optimální polohy stanic a zastávek na tratích regionálního významu
 Hledání optimální polohy stanic a zastávek na tratích regionálního významu Václav Novotný 31. 10. 2018 Anotace 1. Dopravní obsluha území tratěmi regionálního významu 2. Cíle výzkumu a algoritmus práce
Hledání optimální polohy stanic a zastávek na tratích regionálního významu Václav Novotný 31. 10. 2018 Anotace 1. Dopravní obsluha území tratěmi regionálního významu 2. Cíle výzkumu a algoritmus práce
Detekce interakčních sil v proudu vozidel
 Detekce interakčních sil v proudu vozidel (ANEB OBECNĚJŠÍ POHLED NA POJEM VZDÁLENOSTI V MATEMATICE) Doc. Mgr. Milan Krbálek, Ph.D. Katedra matematiky Fakulta jaderná a fyzikálně inženýrská České vysoké
Detekce interakčních sil v proudu vozidel (ANEB OBECNĚJŠÍ POHLED NA POJEM VZDÁLENOSTI V MATEMATICE) Doc. Mgr. Milan Krbálek, Ph.D. Katedra matematiky Fakulta jaderná a fyzikálně inženýrská České vysoké
Algoritmy pro shlukování prostorových dat
 Algoritmy pro shlukování prostorových dat Marta Žambochová Katedra matematiky a informatiky Fakulta sociálně ekonomická Univerzita J. E. Purkyně v Ústí nad Labem ROBUST 21. 26. leden 2018 Rybník - Hostouň
Algoritmy pro shlukování prostorových dat Marta Žambochová Katedra matematiky a informatiky Fakulta sociálně ekonomická Univerzita J. E. Purkyně v Ústí nad Labem ROBUST 21. 26. leden 2018 Rybník - Hostouň
Cvičení z optimalizace Markowitzův model
 Cvičení z optimalizace Markowitzův model Vojtěch Franc, 29 1 Úvod V tomto cvičení se budeme zabývat aplikací kvadratického programování v ekonomii a sice v úloze, jejímž cílem bude optimalizovat portfolio
Cvičení z optimalizace Markowitzův model Vojtěch Franc, 29 1 Úvod V tomto cvičení se budeme zabývat aplikací kvadratického programování v ekonomii a sice v úloze, jejímž cílem bude optimalizovat portfolio
Řízení a optimalizace Stavové modely a model-prediktivní řízení
 Řízení a optimalizace Stavové modely a model-prediktivní řízení Matematické metody pro ITS (11MAMY) Jan Přikryl Ústav aplikované matematiky ČVUT v Praze, Fakulta dopravní 2. přednáška 11MAMY úterý 27.
Řízení a optimalizace Stavové modely a model-prediktivní řízení Matematické metody pro ITS (11MAMY) Jan Přikryl Ústav aplikované matematiky ČVUT v Praze, Fakulta dopravní 2. přednáška 11MAMY úterý 27.
Následující text je součástí učebních textů předmětu Bi0034 Analýza a klasifikace dat a je určen
 11. Klasifikace V této kapitole se seznámíme s účelem, principy a jednotlivými metodami klasifikace dat, jež tvoří samostatnou rozsáhlou oblast analýzy dat. Klasifikace umožňuje určit, do které skupiny
11. Klasifikace V této kapitole se seznámíme s účelem, principy a jednotlivými metodami klasifikace dat, jež tvoří samostatnou rozsáhlou oblast analýzy dat. Klasifikace umožňuje určit, do které skupiny
BAYESOVSKÉ ODHADY. Michal Friesl V NĚKTERÝCH MODELECH. Katedra matematiky Fakulta aplikovaných věd Západočeská univerzita v Plzni
 BAYESOVSKÉ ODHADY V NĚKTERÝCH MODELECH Michal Friesl Katedra matematiky Fakulta aplikovaných věd Západočeská univerzita v Plzni Slunce Řidiči IQ Regrese Přežití Obvyklý model Pozorování X = (X 1,..., X
BAYESOVSKÉ ODHADY V NĚKTERÝCH MODELECH Michal Friesl Katedra matematiky Fakulta aplikovaných věd Západočeská univerzita v Plzni Slunce Řidiči IQ Regrese Přežití Obvyklý model Pozorování X = (X 1,..., X
Státnicová otázka 6, okruh 1
 Státnicová otázka 6, okruh 1 Vojtěch Franc, xfrancv@electra.felk.cvut.cz 7. února 2000 1 Zadání Statické optimalizace. Lineární a nelineární programování. Optimální řízení a rozhodování v dynamických systémech,
Státnicová otázka 6, okruh 1 Vojtěch Franc, xfrancv@electra.felk.cvut.cz 7. února 2000 1 Zadání Statické optimalizace. Lineární a nelineární programování. Optimální řízení a rozhodování v dynamických systémech,
6. ZÁKLADY STATIST. ODHADOVÁNÍ. Θ parametrický prostor. Dva základní způsoby odhadu neznámého vektoru parametrů bodový a intervalový.
 6. ZÁKLADY STATIST. ODHADOVÁNÍ X={X 1, X 2,..., X n } výběr z rozdělení s F (x, θ), θ={θ 1,..., θ r } - vektor reálných neznámých param. θ Θ R k. Θ parametrický prostor. Dva základní způsoby odhadu neznámého
6. ZÁKLADY STATIST. ODHADOVÁNÍ X={X 1, X 2,..., X n } výběr z rozdělení s F (x, θ), θ={θ 1,..., θ r } - vektor reálných neznámých param. θ Θ R k. Θ parametrický prostor. Dva základní způsoby odhadu neznámého
AVDAT Klasický lineární model, metoda nejmenších
 AVDAT Klasický lineární model, metoda nejmenších čtverců Josef Tvrdík Katedra informatiky Přírodovědecká fakulta Ostravská univerzita Lineární model y i = β 0 + β 1 x i1 + + β k x ik + ε i (1) kde y i
AVDAT Klasický lineární model, metoda nejmenších čtverců Josef Tvrdík Katedra informatiky Přírodovědecká fakulta Ostravská univerzita Lineární model y i = β 0 + β 1 x i1 + + β k x ik + ε i (1) kde y i
Teorie náhodných matic aneb tak trochu jiná statistika
 Teorie náhodných matic aneb tak trochu jiná statistika B. Vlková 1, M.Berg 2, B. Martínek 3, O. Švec 4, M. Neumann 5 Gymnázium Uničov 1, Gymnázium Václava Hraběte Hořovice 2, Mendelovo gymnázium Opava
Teorie náhodných matic aneb tak trochu jiná statistika B. Vlková 1, M.Berg 2, B. Martínek 3, O. Švec 4, M. Neumann 5 Gymnázium Uničov 1, Gymnázium Václava Hraběte Hořovice 2, Mendelovo gymnázium Opava
Schéma identifikační procedury
 Schéma identifikační procedury systém S generátor rekonstrukčních hypotéz G a S nejsou porovnatelné nelze srovnat kvalitu G a S S a S jsou porovnatelné kvalita dekompozice S? S : (S,S ) = G dekompozice
Schéma identifikační procedury systém S generátor rekonstrukčních hypotéz G a S nejsou porovnatelné nelze srovnat kvalitu G a S S a S jsou porovnatelné kvalita dekompozice S? S : (S,S ) = G dekompozice
Aplikovaná numerická matematika
 Aplikovaná numerická matematika 6. Metoda nejmenších čtverců doc. Ing. Róbert Lórencz, CSc. České vysoké učení technické v Praze Fakulta informačních technologií Katedra počítačových systémů Příprava studijních
Aplikovaná numerická matematika 6. Metoda nejmenších čtverců doc. Ing. Róbert Lórencz, CSc. České vysoké učení technické v Praze Fakulta informačních technologií Katedra počítačových systémů Příprava studijních
Prohledávání svazu zjemnění
 Prohledávání svazu zjemnění Rekonstrukční chyba je monotonně neklesající podél každé cesty svazu zjemnění: Je-li G i G k G j potom (G i ) (G k ) (G j ) Rekonstrukční chyba je aditivní podél každé cesty
Prohledávání svazu zjemnění Rekonstrukční chyba je monotonně neklesající podél každé cesty svazu zjemnění: Je-li G i G k G j potom (G i ) (G k ) (G j ) Rekonstrukční chyba je aditivní podél každé cesty