ZPRACOVÁNÍ DAT V EKOLOGII SPOLEČENSTEV
|
|
|
- Anežka Konečná
- před 7 lety
- Počet zobrazení:
Transkript
1 ZPRACOVÁNÍ DAT V EKOLOGII SPOLEČENSTEV
2 OSNOVA PŘEDNÁŠKY Příprava dat pro numerické analýzy typy sbíraných dat, čištění dat, odlehlé body, transformace, standardizace, EDA Ekologická podobnost indexy podobnosti a vzdálenosti mezi vzorky Ordinace lineární vs. unimodální, přímá vs. nepřímá, artefakty, ordinační diagramy, permutační testy, rozklad variance, parciální analýza, příkladové studie Klasifikace hierarchická vs. nehierarchická, aglomerativní vs. divisivní, řízená vs. neřízená Použití druhových atributů v analýzách funkční vlastnosti druhů (traits) vs. Ellenbergovy indikační hodnoty, vážený průměr, čtvrtý roh Indexy druhové bohatosti alfa, beta a gama diverzita, akumulační druhová křivka, rarefaction Design ekologických experimentů manipulativní experimenty vs. přírodní experimenty (pozorování) Případové studie na použití jednotlivých metod 2
3 LITERATURA Doporučená (najdete na bit.ly/zpradat v sekci Studijní materiály) Lepš J. & Šmilauer P. (2001) Mnohorozměrná analýza ekologických dat v anglické verzi vyšlo v nakladatelství Cambridge v roce 2003 jako Multivariate Analysis of Ecological Data using CANOCO (v roce 2014 vyšlo druhé vydání pro CANOCO 5) Herben T. & Münzbergová Z. (2003) Zpracování geobotanických dat v příkladech. Část 1. Data o druhovém složení Pro fajnšmekry Gotelli N.J. & Ellison A.M. (2004) A Primer of Ecological Statistics. Sinauer Associates. Oksanen J. (2004) Multivariate Analysis in Ecology, Lecture Notes. Palmer M. Ordination methods for ecologists, website Legendre P. & Legendre L. (2012) Numerical Ecology (Third English Edition). Elsevier. 3
4 SOFTWARE CANOCO 5 ordinační analýzy, kreslení ordinačních diagramů a odpovědních křivek druhů PC-ORD 5 numerické klasifikace, ordinační analýzy, analýza odlehlých bodů STATISTICA 12 korelace, ANOVA, regresní analýzy, klasifikace, ordinace Kde co sehnat: CANOCO 5 a PC-ORD 5 instalace z webových stránek předmětu ( záložka Software) STATISTICA licenci je třeba získat po přihlášení na v sekci Nabídka software 4
5 DALŠÍ INFORMACE Webové stránky předmětu: přednášky, software, příklady ke cvičení, studijní materiály některé sekce vyžadují přihlášení Cvičení probíhat bude v počítačové učebně blokově v dohodnutých termínech a zaměřené bude na analýzu dat a jejich vizualizaci v programu CANOCO 5 tři čtyřhodinové bloky v případě zájmu o program R je možné (v liché roky) zapsat si souběžně předmět Analýza dat v ekologii společenstev v programu R (Bi7550) Domácí úkol zadání bude sděleno v průběhu semestru Zkouška vypracování závěrečné práce (pokyny viz webové stránky předmětu, sekce Závěrečná práce) půlhodinová diskuze nad závěrečnou prací, doplněná o rozšiřující otázky týkající se probírané látky možné dělat zároveň se zkouškou z předmětu Bi7550 5
6 TYPY SBÍRANÝCH DAT PŘÍPRAVA DAT PRO ANALÝZY
7 DATA V EKOLOGII SPOLEČENSTEV popisují společenstvo, případně i jeho prostředí Společenstvo je skupina druhů, které se vyskytují společně v prostoru a v čase. (Begon 2007) ekologická data obsahují více proměnných (multivariate data) a dají se vyjádřit maticí dat (data matrix) společenstvo je typicky sledováno na určité ploše (v případě rostlin a některých málo mobilních živočichů) nebo např. inventarizací jedinců (např. ulovených v pastech v případě mobilních živočichů) složení živého společenstva je popsáno přítomností jednotlivých druhů daného typu organismů, na jedné ploše (v jedné pasti) se většinou vyskytuje více než jeden druh prostředí je popisováno jednou nebo více proměnnými, o kterých se předpokládá, že ovlivňují studovaný typ organismů 7
8 TYPY PROMĚNNÝCH Kategoriální (kvalitativní, nominální, prezenčně-absenční) např. geologický substrát, půdní typy, binární proměnné (přítomnost-absence druhu) kategorie jsou unikátní (každý jedinec/pozorování spadá právě do jedné z nich) a nelze je smysluplně seřadit Ordinální (semikvantitativní) např. Ellenbergovy indikační hodnoty pro druhy, Braun-Blanquetova stupnice pro odhad pokryvnosti druhů jednotlivé stupně (kategorie) lze seřadit, rozdíly mezi stupni jsou různě velké Kvantitativní diskrétní (počty jedinců, měření s malou přesností) x kontinuální (přesná měření) relativní stupnice (relative-scale) x intervalová stupnice (interval-scale) 0 30 relativní stupnice (relative scale) nula znamená, že charakteristika chybí 0 intervalová stupnice (interval scale) nula je stanovena arbitrárně 8
9 TYPY PROMĚNNÝCH ALTERNATIVNÍ TŘÍDĚNÍ Typ proměnné binární (dvoustavový, presence-absence) mnohostavový neseřazený seřazený semikvantitativní (ordinální) kvantitativní (měření) diskontinuální (počty, diskrétní) kontinuální Příklady přítomnost nebo absence druhu geologický substrát stupnice pokryvností druhy počet jedinců teplota, hloubka půdy Legendre & Legendre

10 PRIMÁRNÍ DATA 10

11 PRIMÁRNÍ DATA 11

 uložení dat ve veřejně dostupných elektronických repositoriích (např. Dryad Digital Repository, www.datadryad.org) nebo databázích (např.")
12 mgs/5152_tapes-small.jpg PRIMÁRNÍ DATA Zadávání primárních dat spreadsheet, metadata Uchování a zpřístupnění primárních dat problematika dlouhodobé archivace a nosičů dat (nejlepší je stále papír bez volných kyselin + laserová tiskárna) zpřístupnění primárních dat (některé časopisy, např. Ecological Monographs, Journal of Ecology aj., to mají jako podmínku zveřejnění článku) uložení dat ve veřejně dostupných elektronických repositoriích (např. Dryad Digital Repository, nebo databázích (např. Česká Národní Fytocenologická Databáze) 12 Programátorka Madeleine Carey s děrnými štítky, na kterých byl uložen program využívaný americkou leteckou obranou. Zdroj: Science 2013
 vyloučení proměnné nebo vzorku který má hodně chybějících hodnot odlehlé body (outliers) jejich detekce (outlier analysis) EDA exploratory data analysis")
13 PRIMÁRNÍ DATA Kontrola a čištění dat chyby (errors) někdy se chovají jako odlehlé body, je třeba zkontrolovat původní záznam a případně data z analýzy odstranit chybějící data (missing data, NA) možnosti jejich nahrazení (interpolace, model) vyloučení proměnné nebo vzorku který má hodně chybějících hodnot odlehlé body (outliers) jejich detekce (outlier analysis) EDA exploratory data analysis další úpravy: sloučení taxonomické nomenklatury někdy i vyloučení vzácných druhů (odstranění šumu v datech) 13
 průzkum dat a hledání hypotéz, které stojí za to testovat slouží také k tzv.")
14 KONFIRMAČNÍ VS. EXPLORAČNÍ ANALÝZA DAT (hypothesis-driven vs data-driven science) Konfirmační analýza dat (confirmatory data analysis, CDA) testuje hypotézy a generuje odhady parametrů např. regrese, ANOVA, testy signifikance Explorační analýza dat (exploratory data analysis, EDA) průzkum dat a hledání hypotéz, které stojí za to testovat slouží také k tzv. vytěžování dat (data mining, data dredging) grafická EDA slouží k odhalení odlehlých bodů (outlier analysis) distribuce dat (normalita) a nutnost transformace John Tukey ( ) 14
15 EDA EXPLORATORY DATA ANALYSIS ANALÝZA ODLEHLÝCH BODŮ BOX-PLOT & HISTOGRAM XERSSW potenciálně chybná hodnota Frequency Median 25%-75% Range Outliers XERSSW (head index) 15
 16 outlier (hodnota nižší než spodní kvartil + 1.")
16 DETAILY KE KRABICOVÝM GRAFŮM (BOXPLOT) Klasický boxplot (střední hodnota = medián) maximální hodnota Q3 horní kvartil Q2 - medián Q1 spodní kvartil minimální hodnota Definice odlehlých bodů a extrémů (STATISTICA) 16 outlier (hodnota nižší než spodní kvartil x interkvartilový rozsah)
17 EDA EXPLORATORY DATA ANALYSIS ANALÝZA ODLEHLÝCH BODŮ - SCATTERPLOT příliš vlivný vzorek XERSSW XERSW XERSSW XERSW 17
 statistické testy vyžadují, aby residuály měly")
18 PŘÍPRAVA DAT PRO NUMERICKÉ ANALÝZY TRANSFORMACE Transformace dat mění relativní vzdálenosti mezi jednotlivými hodnotami a tím i tvar jejich distribuce Proč data transformovat? protože škála měření je arbitrární a nemusí odpovídat ekologickému významu proměnné deset prstů => používání desítkové soustavy protože (některé) statistické testy vyžadují, aby residuály měly přibližně normální rozložení (normal distribution) homogenní varianci (homoskedasticita, mezi průměrem a směrodatnou odchylkou není žádný vztah) protože lineární vztahy se interpretují lépe než vztahy nelineární 18
19 PŘÍPRAVA DAT PRO NUMERICKÉ ANALÝZY TRANSFORMACE Na co si dát při transformaci pozor? aby transformace rozložení dat ještě nezhoršila a nevytvořila nové odlehlé body abychom při komentování výsledků používali netransformované hodnoty proměnných Typy transformace lineární přičtení konstanty nebo vynásobení konstantou nemění výsledky statistického testování nulových hypotéz např. převod teploty měřené ve stupních Celsia na stupně Fahrenheita nelineární log transformace, odmocninová transformace atd. může změnit výsledky statistického testování 19
20 ROZDĚLENÍ DAT (DATA DISTRIBUTION) symetrické (symetrical) pozitivně (doprava) zešikmené* (right skewed) negativně (doleva) zešikmené (left skewed) * ekologická data jsou často zešikmená pozitivně (doprava), protože jsou omezená nulou na začátku 20
21 PŘÍPRAVA DAT PRO NUMERICKÉ ANALÝZY TRANSFORMACE Logaritmická transformace (log transformation) zdroj: wikipedia.org pro data s výrazně pozitivně (doprava) šikmou distribucí (right skewed), u kterých existuje vztah mezi směrodatnou odchylkou a průměrem (lognormální rozložení) Y* = log (Y), případně Y* = log (a*y + c) na základě logaritmu nezáleží (10, 2, e) konstanta a = 1; pokud je Y z intervalu <0;1>, potom a > 1 konstanta c se přidává, pokud proměnná Y obsahuje nuly c může být např. 1, nebo arbitrárně zvolené malé číslo (0,001) na konstantě c může záležet výsledek analýz (ANOVA), a proto je dobré vybírat takové číslo, aby transformovaná proměnná byla co nejvíce symetrická 21
22 PŘÍPRAVA DAT PRO NUMERICKÉ ANALÝZY TRANSFORMACE Odmocninová transformace (square-root transformation) vhodná pro mírně doprava zešikmená data (right skewed), např. počty druhů (Poisson distribution) Y* = Y, případně Y* = (Y + c) konstanta c se přičítá, pokud soubor obsahuje nuly c může být např. 0,5, nebo 3/8 (0,325) třetí a vyšší odmocnina je účinnější na více zešikmená data (čtvrtá odmocnina se používá pro abundance druhů s mnoha nulami a několika vysokými hodnotami) Mocninná transformace (power transformation) vhodná pro data negativně (doleva) sešikmená (left skewed) Y* = Y p pokud p < 1 - odmocninová transformace (p = 0,5 druhá odmocnina, p = 0,25 čtvrtá odmocnina atd.) 22
23 PŘÍPRAVA DAT PRO NUMERICKÉ ANALÝZY TRANSFORMACE logaritmická odmocninová Legendre & Legendre (1998) 23

24 PŘÍPRAVA DAT PRO NUMERICKÉ ANALÝZY TRANSFORMACE 24 Münch. Med. Wschr. 124, 1982
25 PŘÍPRAVA DAT PRO NUMERICKÉ ANALÝZY TRANSFORMACE Transformace pomocí arcsin (angular transformation) vhodná pro procentické hodnoty (a obecně podíly) Y* = arcsin Y nebo Y* = arcsin Y použitelná pro hodnoty v intervalu <-1; 1> transformované hodnoty jsou v radiánech Reciproká transformace (reciprocal transformation) vhodná pro poměry (například výška/hmotnost, počet dětí v populaci na počet žen atd.) Y* = 1/Y 25
26 PŘÍPRAVA DAT PRO NUMERICKÉ ANALÝZY TRANSFORMACE Box-Cox transformace (zobecněná mocniná transformace) zobecněná parametrická transformace iterativní hledání parametru λ (lambda), pro které je rozdělení transformované proměnné nejblíže normálnímu rozdělení používá se v případě, že nemáme a priori představu, jakou transformaci použít Neparametrické metody transformace např. metoda Omnibus pro ordinální data Legendre & Legendre
27 MAJÍ DATA NORMÁLNÍ ROZDĚLENÍ? GRAFICKÁ ANALÝZA Histogram s křivkou normálního rozdělení Počet pozorování Soil depth vizuální zhodnocení normality dat Kolmogorovův-Smirnovův test Q-Q diagram (Quantile-Quantile plot) Oček. normál. hodnoty Pozorovaný kvantil porovnání rozdělení dvou proměnných, vynáší proti sobě kvantily jednotlivých proměnných jedna proměnná může být teoretická distribuce (v tomto případě normální rozdělení rankitový diagram) na stejném principu pracuje Shapiro-Wilk test 27
28 Theoretical quantiles Theoretical quantiles Theoretical quantiles Frequency Frequency Frequency MAJÍ DATA NORMÁLNÍ ROZDĚLENÍ? GRAFICKÁ ANALÝZA normální rozdělení pozitivně zešikmené negativně zešikmené variable variable variable Sample quantiles Sample quantiles Sample quantiles 28
29 Soil ph Soil ph Frequency Frequency BIMODÁLNÍ DATA transformace nepomůže, možnost rozdělit na dva podsoubory Soil ph Soil ph Annual precipitation [mm] Annual precipitation [mm]
30 PŘÍPRAVA DAT PRO NUMERICKÉ ANALÝZY STANDARDIZACE JEDNOTLIVÝCH PROMĚNNÝCH Centrování (centring) výsledná proměnná má průměr roven nule Y i * = Y i průměr (Y) Standardizace v úzkém slova smyslu výsledná proměnná má průměr roven nule a směrodatnou odchylku rovnu jedné synchronizuje proměnné měřené v různých jednotkách a na různých stupnicích Y i * = (Y i průměr (Y)) / směrodatná odchylka (Y) Změna rozsahu hodnot (ranging) výsledná proměnná je v rozsahu [0, 1] (a) Y i * = Y i / Y max nebo (b) Y i * = (Y i Y min ) / (Y max Y min ) a - proměnná na relativní škále (začíná nulou), b - obecná proměnná 30
31 PŘÍPRAVA DAT PRO NUMERICKÉ ANALÝZY STANDARDIZACE MATICE SPOLEČENSTVA Standardizace v případě matice společenstva (vzorky x druhy) standardizace po druzích (standardization by species) dává velkou váhu vzácným druhům ne vždy smysluplná (pokud se druh vyskytuje vzácně v jednom snímku, standardizace po druzích dá tomuto snímku velkou váhu bude velmi odlišný od ostatních) standardizace po vzorcích (standardization by samples) pokud je analýza zaměřená na relativní proporce mezi druhy, ne jejich absolutní abundance vhodné v případě, že výsledné abundance závisí na důkladnosti, s jakou sbíráme data (např. při odchytu živočichů doba strávená na ploše, počet pastí nebo vliv špatného počasí na mobilitu živočichů) 31
32 PŘÍPRAVA DAT PRO NUMERICKÉ ANALÝZY STANDARDIZACE MATICE SPOLEČENSTVA původní matice Druhy Vzorky druh 1 druh 2 druh 3 vzorek vzorek vzorek standardizace po druzích standardizace po vzorcích Druhy Druhy Vzorky druh 1 druh 2 druh 3 Vzorky druh 1 druh 2 druh 3 vzorek vzorek vzorek vzorek vzorek vzorek
33 PŘÍPRAVA DAT PRO NUMERICKÉ ANALÝZY TRANSFORMACE matematická funkce, jejíž argumenty nejsou odvozené z dat, na která je transformace aplikovaná (data independent) nejčastější důvod je změnit tvar rozložení proměnné, případně zajistit homoskedasticitu STANDARDIZACE mění data pomocí statistiky, která je spočtená na datech samotných, např. průměr, součet, rozsah aj. (data dependent) nejčastější důvod použití je vyrovnat rozdíly v relativním významu (váze) jednotlivých ekologických proměnných, druhů nebo vzorků ve své podstatě je to další typ transformace 33
34 PŘÍPRAVA DAT PRO NUMERICKÉ ANALÝZY KÓDOVÁNÍ DAT (DATA CODING) Dummy variables metoda, jak převést kvalitativní (kategoriální) proměnnou na kvantitativní (binární) proměnné použitelné v analýzách pokud má kategoriální proměnná n stavů (hodnot), pro její vyjádření stačí n-1 dummy proměnných (jedna z proměnných je vždy lineárně závislá na ostatních) hodnoty dummy proměnné KAMB LITO RANK FLUVI kambizem litozem ranker fluvizem
35 PŘÍPRAVA DAT PRO NUMERICKÉ ANALÝZY KÓDOVÁNÍ DAT (DATA CODING) např. nahrazení kódů u alfa-numerických stupnic, např. Braun- Blanquetovy stupnice dominance-abundance Braun-Blanquetova stupnice: r ordinální hodnoty*: střední hodnoty procent**: *) van der Maarel (2007), Table 1 **) Turboveg for Windows 2 35
36 SOUBORY S VELKÝM POČTEM NUL (ANEB VÝZNAM NULY V EKOLOGII) dva možné významy nuly: 1. hodnota může být ve skutečnosti nenulová, ale díky našim možnostem měření jsme ji naměřili jako nulovou (například koncentrace látky v roztoku) 2. hodnota je skutečná nula například absence druhu data obsahující pravé nuly obsahují dva typy informace: 1. druh chybí nebo je přítomen? 2. pokud je druh přítomen, jaká je jeho abundance? v datech obsahujících velké množství pravých nul je většina informace prvního typu problém pravých nul při logaritmické transformaci soubor s velkým počtem pravých nul není vhodné logaritmicky transformovat (přičítat k nim konstantu c), ale lépe ji nahradit binární proměnnou (prezence-absence) 36
![vzorky Zastoupení nul v matici [%] 97.0 97.5 98.0 98.5 99.](/docs-images/61/45577907/images/37-0.png "0 MATICE VZORKY DRUHY V EKOLOGII SPOLEČENSTEV (SPARSE MATRIX, ŘÍDKÁ MATICE) více než 90% hodnot tvoří nuly, u velkých souborů až")
37 vzorky Zastoupení nul v matici [%] MATICE VZORKY DRUHY V EKOLOGII SPOLEČENSTEV (SPARSE MATRIX, ŘÍDKÁ MATICE) více než 90% hodnot tvoří nuly, u velkých souborů až 99% Počet vegetačních snímků v matici 37 druhy
38 EKOLOGICKÁ PODOBNOST (ECOLOGICAL RESEMBLANCE)
39 EKOLOGICKÁ PODOBNOST jedinec společenstvo jedinci stejného druhu 39
40 EKOLOGICKÁ PODOBNOST 40
41 EKOLOGICKÁ PODOBNOST Q VS R ANALÝZA Druhy Vzorky druh 1 druh 2 druh 3 vzorek vzorek vzorek vztahy mezi vzorky Q analýza vztahy mezi druhy (nebo obecně mezi deskriptory) R analýza 41
42 PODOBNOSTI X VZDÁLENOSTI (Q ANALÝZA) Indexy podobnosti (similarity coefficients) slouží k vyjádření podobnosti mezi vzorky, ne k jejich umístění do mnohorozměrného prostoru (například ordinace) nejnižší hodnota 0 vzorky nesdílejí žádný druh nejvyšší hodnota (1 nebo jiná) vzorky jsou identické Vzdálenosti mezi vzorky (distance coefficients) slouží k umístění vzorků v mnohorozměrném prostoru nejnižší hodnota 0 vzorky jsou identické (ve stejné lokaci) hodnota se zvyšuje se zvyšující se nepodobností mezi vzorky 42
43 INDEXY PODOBNOSTI (SIMILARITY COEFFICIENTS) kvalitativní vs kvantitativní kvalitativní pro presenčně-absenční data kvantitativní pro data vyjadřující abundance, počty aj. symetrické vs asymetrické dvojité nepřítomnosti ( double-zero ) počet druhů, které chybí zároveň v obou vzorcích, v kontrastu s počtem druhů které se vyskytují zároveň v obou vzorcích symetrické dvojité nepřítomnosti hodnotí stejně jako dvojité přítomnosti (totiž že vyjadřují podobnost mezi vzorky); v ekologii se prakticky nepoužívají asymetrické dvojité nepřítomnosti ignorují; nejčastější typ indexů podobnosti v ekologii 43
44 PROBLÉM DVOJITÝCH NEPŘÍTOMNOSTÍ (DOUBLE-ZEROS) Skutečnost, že druh chybí zároveň v obou snímcích, může znamenat, že: vzorky leží mimo ekologickou niku druhu nemůžeme ale říci, zda oba vzorky leží na stejné straně ekologického gradientu mimo niku druhu (a jsou si tedy docela podobné) nebo na stranách opačných (a jsou pak úplně odlišné) vzorky leží uvnitř ekologické niky druhy, ale druh se ve vzorku nevyskytuje, protože se tam nedostal (dispersal limitation) jsme ho přehlédli a nezaznamenali (sampling bias) nachází se právě v dormantním stadiu a není proto vidět (jednoletky, geofyty) 44
45 vlhkomilný druh 1 vlhkomilný druh 2 mezický druh 1 mezický druh 2 suchomilný druh 1 suchomilný druh 2 PROBLÉM DVOJITÝCH NEPŘÍTOMNOSTÍ (DOUBLE-ZEROS PROBLEM) vzorek vzorek vzorek vzorky 1 až 3 jsou seřazeny podle vlhkosti stanoviště vzorek 1 je nejvlhčí, vzorek 3 nejsušší vzorek 1 a 3 neobsahují ani jeden mezický druh vzorek 1 je pro tyto druhy příliš vlhký, vzorek 3 příliš suchý symetrické indexy podobnosti: dvojitá nepřítomnost mezických druhů bude zvyšovat podobnost vzorků 1 a 3 asymetrické indexy: dvojité nepřítomnosti budou ignorovány 45
46 INDEXY PODOBNOSTI PRO KVALITATIVNÍ DATA druh je ve vzorku č. 1 a počet druhů přítomných v obou vzorcích b, c počet druhů přítomných jen v jednom vzorku přítomen d počet druhů, které chybí v obou vzorcích ( double zeros ) nepřítomen ve vzorku č. 2 přítomen a b Pokud nebereme v úvahu druhy nepřítomné v obou vzorcích (d), lze zobrazit i pomocí Vennova diagramu nepřítomen c d c a b 46 vzorek č. 1 vzorek č. 2
47 INDEXY PODOBNOSTI PRO KVALITATIVNÍ DATA Jaccardův koeficient J = a / (a + b + c) Sørensenův koeficient S = 2a / (2a + b + c) přítomnosti druhu v obou vzorcích (frakce [a]) přisuzuje dvojnásobnou váhu na rozdíl od Jaccarda je semimetrický Simpsonův koeficient Si = a / [a + min (b,c)] vhodný pro vzorky velmi odlišné počtem druhů c a b 47 vzorek č. 1 vzorek č. 2
48 INDEXY PODOBNOSTI PRO KVANTITATIVNÍ DATA zobecněný Sørensenův koeficient (procentická podobnost, percentage similarity) PS = [2 Σ min (x i, y i )] / Σ (x i + y i ) x i, y i... kvantita i-tého druhu ve srovnávaných vzorcích má rozsah od 0 do 1 pro presenčně absenční data přechází v 2a / (2a + b + c) velmi vhodný pro ekologická data percentage dissimilarity (PD, Bray-Curtis index) = 1 PS 48
49 VZDÁLENOSTI MEZI VZORKY (DISTANCE COEFFICIENTS) všechny indexy podobnosti (kvalitativní i kvantitativní) lze převést na distance D = 1 S, nebo D = (1 S) kde D je vzdálenost (distance) a S je podobnost (similarity) odmocninový převod se používá například pro Sørensenův koeficient neplatí obráceně - ne všechny vzdálenosti se dají převést na podobnosti (např. Euklidovská vzdálenost) 49
50 VZDÁLENOSTI MEZI VZORKY (DISTANCE MEASURES) Euklidovská vzdálenost (Euclidean distance) ED = Σ (x i y i ) 2 rozsah: od 0 (identické vzorky), horní mez není dána rozsah hodnot výrazně záleží na použitých jednotkách míra citlivá na odlehlé body - nevhodná pro ekologická data symetrická míra vzdálenosti trpí problémem dvojitých nul tětivová vzdálenost (chord distance, relativized Euclidean distance) Euklidovská vzdálenost použitá na datech standardizovaných přes vzorky (by sample norm) rozsah: od 0 (identické vzorky) do 2 (vzorky nesdílí žádný druh) Hellingerova vzdálenost (Hellinger distance) možno vypočíst jako Euklidovská vzdálenost aplikovaná na data po aplikaci Hellingerovy standardizace netrpí problémem dvojitých nul Chi-kvadrát vzdálenost (chi-square distance) málokdy se používá přímo na výpočet vzdálenosti mezi vzorky vyjadřuje vzdálenost mezi vzorky v unimodálních ordinačních metodách (např. v korespondenční analýze, CA) 50
51 EUKLIDOVSKÁ VZDÁLENOST PARADOX PŘI POUŽITÍ ABUNDANČNÍCH DAT při použití abundančních dat se může stát, že dva vzorky, které sdílí některé druhy (vzorky 1 a 3), budou mít větší vzdálenost než dva vzorky, které nesdílí ani jeden druh (vzorky 1 a 2) Vzorky Druhy druh 1 druh 2 druh 3 vzorek vzorek vzorek ,732 4,243 Eucl (vzorek 1, vzorek 2) = (0-1) 2 + (1-0) 2 + (1-0) 2 = 1,732 Eucl (vzorek 1, vzorek 3) = (0-0) 2 + (1-4) 2 + (1-4) 2 = 4,243 51
52 INDEXY PODOBNOSTI MEZI DRUHY (R ANALÝZA) V kolika vzorcích je... druh č. 1 přítomen nepřítomen druh č. 2 přítomen a b nepřítomen c d Diceův index Dice = 2a / (2a + b + c) stejný jako Sørensenův index pro podobnost mezi vzorky uveden dříve než Sørensen (Dice 1945 vs Sørensen 1948) Pearsonův korelační koeficient r není vhodný pro data s velkým počtem nul, ani po transformaci 52
53 MATICE PODOBNOSTÍ (VZDÁLENOSTÍ) MEZI VZORKY (NEBO DRUHY) je symetrická (podobnost mezi 2. a 3. snímkem = podobnost mezi 3. a 2. snímkem) diagonála obsahuje pouze nuly (matice vzdáleností) nebo pouze jedničky (matice podobností) matice Euklidovských vzdáleností mezi 10 vzorky 53
54 ORDINAČNÍ ANALÝZA
55 KONCEPCE MNOHOROZMĚRNÉHO PROSTORU Prostor může být definován: druhy (species space) vzorky (sample space) 55 Zuur et al. (2007)
56 ORDINACE RŮZNÉ FORMULACE PROBLÉMU 1) najdi skryté gradienty v druhovém složení (ordinační osy) 2) rozmísti vzorky v zobrazitelném prostoru (ordinační prostor) 56
57 vzorky vzorky vzorky NEPŘÍMÁ VS PŘÍMÁ ORDINACE UNCONSTRAINED VS CONSTRAINED ORD. Nepřímá ordinace pouze druhová matice druhy ordinační osy směry největší variability dat popisu dat a generování hypotéz Přímá ordinace druhová matice a matice proměnných prostředí ordinační osy variabilita dat vztažená k daným proměnným druhová matice druhy druhová matice + proměnné prostředí matice proměnných prostředí testování hypotéz 57
58 abundance abundance MODELY ODPOVĚDI DRUHŮ NA GRADIENT PROSTŘEDÍ lineární unimodální gradient gradient 58
59 abundance druhu abundance druhu LINEÁRNÍ MODEL ODPOVĚDI DRUHU JEN PŘI KRÁTKÉM EKOLOGICKÉM GRADIENTU krátký ekologický gradient dlouhý ekologický gradient gradient prostředí (ph, nadm. výška) gradient prostředí (ph, nadm. výška) 59 Lepš & Šmilauer (2003) Multivariate analysis of...
60 PŘEHLED METOD ORDINAČNÍ ANALÝZY raw-data-based (založené na primárních datech) linear (lineární) unimodal (unimodální) transformationbased (založené na transformovaných primárních datech) distancebased (založené na distanční matici) unconstrained (nepřímé) PCA (analýza hlavních komponent) CA, DCA (korespondenční a detrendovaná korespondenční analýza) tb-pca (analýza hlavních komponent na transformovaných primárních datech) PCoA (analýza hlavních koordinát) NMDS (nemetrické mnohorozměrné škálování) constrained (přímé) RDA (redundanční analýza) CCA (kanonická korespondenční analýza) tb-rda (redundanční analýza na transformovaných primárních datech) db-rda (redundanční analýza založená na distanční matici) 62
61 NEPŘÍMÁ ORDINAČNÍ ANALÝZA
62 PŘEHLED METOD ORDINAČNÍ ANALÝZY raw-data-based (založené na primárních datech) linear (lineární) unimodal (unimodální) transformationbased (založené na transformovaných primárních datech) distancebased (založené na distanční matici) unconstrained (nepřímé) PCA (analýza hlavních komponent) CA, DCA (korespondenční a detrendovaná korespondenční analýza) tb-pca (analýza hlavních komponent na transformovaných primárních datech) PCoA (analýza hlavních koordinát) NMDS (nemetrické mnohorozměrné škálování) constrained (přímé) RDA (redundanční analýza) CCA (kanonická korespondenční analýza) tb-rda (redundanční analýza na transformovaných primárních datech) db-rda (redundanční analýza založená na distanční matici) 64
63 NEPŘÍMÁ ORDINACE PRINCIP hledání skryté proměnné (gradientu), který nejlépe reprezentuje chování všech druhů podél tohoto gradientu první ordinační osa (ordination axis) a skóre vzorků na této ordinační ose (sample scores) odhad optima (odpovědi) jednotlivých druhů na této ose (species scores) druhá a vyšší ordinační osy musejí být lineárně nezávislé na všech nižších ordinačních osách 65
64 sp2 PCA PRINCIP VÝPOČTU (Principal Component Analysis, analýza hlavních komponent) sp1 sp2 samp1 2 1 samp4 samp2 3 4 samp3 5 0 samp4 7 6 samp5 9 2 a) rozmístění vzorků v prostoru definovaném druhy b) výpočet těžiště shluku c) centrování os d) rotace os samp2 samp1 samp3 sp1 samp5 66 Legendre & Legendre (1998)
 3D 2D 67 http://cnx.")
65 PCA PRINCIP VÝPOČTU (Principal Component Analysis, analýza hlavních komponent) 3D 2D 67
66 Příklad: rozeznávání písmen v analýze obrazu pomocí PCA a11 a12 a13 a14 a15 a21 a22 a23 a24 a25 a31 a32 a33 a34 a35 a41 a42 a43 a44 a45 a51 a52 a53 a54 a55 A B C D E F X Y Z Inspired by work of François Labelle (
67 PCA1 (O-X) PCA2 (H-I) vztah proměnných A11 a A12 výsledek PCA (1. a 2. PCA osa) 69
")


68 PCA1 (O-X) PCA2 (H-I) vztah proměnných A11 a A12 výsledek PCA (1. a 2. PCA osa) 70
69 PC1 PC2 PC3 PC4 PC5 PC6 PC7 PC8 PC9 PC10 PC11 PC12 PC13 PC14 PC15 PC16 PC17 PC18 PC19 PC20 PC21 PC22 PC23 PC24 % variation KTERÉ OSY PCA JSOU DŮLEŽITÉ? Summary Table: Statistic Axis 1 Axis 2 Axis 3 Axis 4 Axis 5 Axis 6 Axis 7 Axis 8... Axis 23 Axis 24 Eigenvalues Explained variation (cumulative) % eigenvalue Broken stick model 0 71
70 PODSTATA MODELU ZLOMENÉ HOLE (BROKEN-STICK MODEL) hůl hůl se po pádu na zem rozpadne na 6 různě dlouhých částí 72
71 vektory = deskriptory body = vzorky PCA: circle of equilibrium contribution (kruh rovnovážného příspěvku proměnné) poloměr = d/p kde d = počet os v zobrazení, p = počet všech os v PCA (rovno počtu deskriptorů) Interpretace: deskriptory (druhy n. jiné proměnné) s vektory delšími než poloměr kruhu výrazně přispívají k interpretaci daných ordinačních os (v tomto případě první a druhé) Legendre P. & Legendre L. (2012) Numerical Ecology, p
72 CA - PRINCIP VÝPOČTU (Correspondence Analysis, korespondenční analýza) 5 výpočetních kroků 1. začni s arbitrárním (náhodným) skóre vzorků (x i ) 2. vypočti nové skóre pro jednotlivé druhy (species score, y i ) jako průměr skóre vzorků x i vážený abundancí druhu ve vzorcích 3. vypočti nové skóre pro jednotlivé vzorky (sample score, x i ) jako průměr skóre druhů y i vážený abundancí druhů ve vzorku 4. standardizuj skóre jednotlivých vzorků (natáhni osu) 5. pokud se skóre nemění, zastav, pokud ano, pokračuj krokem 2 74
73 CA - PRINCIP VÝPOČTU (Correspondence Analysis, korespondenční analýza) 75 Lepš & Šmilauer (2003) Multivariate analysis of...
74 CA - PRINCIP VÝPOČTU (Correspondence Analysis, korespondenční analýza) 76 Lepš & Šmilauer (2003) Multivariate analysis of...
75 CA - PRINCIP VÝPOČTU (Correspondence Analysis, korespondenční analýza) 77 Lepš & Šmilauer (2003) Multivariate analysis of...
76 CA - PRINCIP VÝPOČTU (Correspondence Analysis, korespondenční analýza) 78 Lepš & Šmilauer (2003) Multivariate analysis of...
77 CA - PRINCIP VÝPOČTU (Correspondence Analysis, korespondenční analýza) 79 Lepš & Šmilauer (2003) Multivariate analysis of...
78 CA2 CA2 CA2 CA2 CA1 CA1 náhodné rozložení bodů na začátku iterativního procesu pravidelné rozložení bodů na konci procesu CA1 CA1 80
79 SIMULOVANÁ DATA JEDEN EKOLOGICKÝ GRADIENT simulovaný gradient dlouhý 5000 jednotek 300 druhů s unimodální odpovědí, různými šířkami nik 500 vzorků náhodně rozmístěných podél gradientu 81
80 SIMULOVANÁ DATA ARTEFAKTY PCA - podkova CA - oblouk o vzorky + druhy 82
81 ARTEFAKTY V ORDINACÍCH PŘÍČINY důsledek algoritmu (lineární nezávislost všech os) důsledek projekce (nelineární vztahy mezi druhy -> lineární prostor) 83
82 ORDINAČNÍ DIAGRAMY lineární metoda unimodální metoda 84
83 DCA PRINCIP VÝPOČTU, ODSTRANĚNÍ TRENDU (Detrended Correspondence Analysis, detrendovaná korespondenční analýza) Krok 1 rozdělení první osy na několik segmentů Krok 2 vycentrování druhé osy každého segmentu kolem nuly 86
84 DCA PRINCIP VÝPOČTU, ODSTRANĚNÍ TRENDU (Detrended Correspondence Analysis, detrendovaná korespondenční analýza) Krok 3 nelineární přeškálování první osy Výsledek škálování: osy naškálované v jednotkách směrodatné odchylky (SD) celé druhové složení se obmění na 4 SD 87
85 CA DCA ROZDÍL MEZI CA A DCA NA STEJNÝCH DATECH CA DCA CA1 DCA1 Animace: 88
86 DCA DCA DCA DCA DCA ROZDÍLNÉ VÝSLEDKY PŘI POUŽITÍ RŮZNÉHO POČTU DETRENDOVACÍCH SEGMENTŮ 5 segmentů 16 segmentů DCA, # segments = 5 DCA, # segments = DCA1 DCA1 26 segmentů 40 segmentů DCA, # segments = 26 DCA, # segments = DCA DCA1
87 DCA NA SIMULOVANÝCH DATECH (JEDEN GRADIENT) o vzorky + druhy 90
88 VÝBĚR ORDINAČNÍ METODY NA ZÁKLADĚ DCA LINEÁRNÍ NEBO UNIMODÁLNÍ? Pokud je délka 1. osy DCA menší než 3 SD homogenní data - lineární metoda větší než 4 SD heterogenní data - unimodální metoda v rozmezí 3-4 SD obě techniky pracují rozumně Platí jen pro detrendování po segmentech a délku první osy! 91
89 92
90 TŘI ALTERNATIVNÍ PŘÍSTUPY K NEPŘÍMÉ ORDINAČNÍ ANALÝZE (a) Klasický přístup (b) Transformace dat (např. Hellingerova) (tb-pca) (c) Přes matici nepodobností (PCoA, NMDS) 93 Legendre & Legendre (2012)
91 PŘEHLED METOD ORDINAČNÍ ANALÝZY raw-data-based (založené na primárních datech) linear (lineární) unimodal (unimodální) transformationbased (založené na transformovaných primárních datech) distancebased (založené na distanční matici) unconstrained (nepřímé) PCA (analýza hlavních komponent) CA, DCA (korespondenční a detrendovaná korespondenční analýza) tb-pca (analýza hlavních komponent na transformovaných primárních datech) PCoA (analýza hlavních koordinát) NMDS (nemetrické mnohorozměrné škálování) constrained (přímé) RDA (redundanční analýza) CCA (kanonická korespondenční analýza) tb-rda (redundanční analýza na transformovaných primárních datech) db-rda (redundanční analýza založená na distanční matici) 94
92 PCOA PRINCIPAL COORDINATE ANALYSIS (analýza hlavních koordinát) metoda založená na distancích mezi vzorky vstupní data matice nepodobností mezi vzorky pokud zvolím Euklidovskou vzdálenost -> identické s PCA pokud zvolím Chi-kvadrát vzdálenost -> obdoba CA umístí objekty na základě jejich vzdáleností (distancí) do Euklidovského prostoru (tvořeného souřadnicemi skóre vzorků na osách) použití nemetrických distancí může způsobit výskyt os ze zápornou hodnotou eigenvalue synonymum MDS Metric Dimensional Scaling 95

93 PCoA PCOA PŘÍKLAD NA VZDÁLENOSTECH MEZI MĚSTY Vzdálenosti mezi městy (km) Stockholm Athens Barcelona Brussels... Athens 0 Barcelona Brussels Calais Cherbourg Cologne Copenhagen Geneva Gibraltar Hamburg Lisbon Gibraltar Madrid Copenhagen Hamburg Hook of Holland Calais Brussels Cologne Cherbourg Paris Munich Lyons Geneva Vienna Marseilles Milan Barcelona Rome Athens PCoA1 96
94 PCoA PCOA PŘÍKLAD NA VZDÁLENOSTECH MEZI MĚSTY Stockholm Lisbon Gibraltar Madrid Copenhagen Hamburg Hook of Holland Calais Brussels Cologne Cherbourg Paris Munich Lyons Geneva Vienna Marseilles Milan Barcelona Rome Athens PCoA1 97
95 NMDS - NON-METRIC MULTIDIMENSIONAL SCALING) ORDINACE ZALOŽENÁ NA DISTANCÍCH nemetrická varianta PCoA (nepracuje přímo s distancemi mezi vzorky, ale s jejich pořadím) vstupní data matice nepodobností mezi vzorky výpočet matice nepodobností jakýkoliv index nepodobnosti iterativní algoritmus, který nemusí pokaždé dojít ke stejnému výsledku (lokální optima) nutno určit počet dimenzí, se kterými bude metoda pracovat při větším množství dat VELMI časově náročná na rozdíl od PCoA optimalizuje výsledné vzdálenosti mezi vzorky do několika málo (dvě tři) dimenzí 98
96 NMDS NON-METRIC MULTIDIMENSIONAL SCALING náhodné rozmístění vzorků v prostoru rozmístění vzorků v prostoru respektuje jejich nepodobnost 99
:.- -... -.-. -....- 0 167 169 159 180 -... 167 0 96 79 163 -.-. 169 96 0 141 166 -.. 159 79 141 0 172. 180 163 166 172 0 -..-.. --. - ----.----- --. ---.----.--- -.-.--. --.----.. --...--.-. -.-.-.--..--- --... -...-...-..-..-. -...--..-......-...-...... -100-50 0 50 NMDS1 100")
97 NMDS Rothkopfův experiment s morseovkou 598 účastníkům byly přehrány všechny dvojice kódů a pokaždé měli rozhodnout, jestli jsou shodné nebo jiné matice nepodobností = počet odpovědí různé Ukázka datového souboru (kódy A,B,C,D,E): NMDS1 100
98 vzdálenost mezi vzorky v ordinačním diagramu NMDS SHEPARDŮV DIAGRAM stress-value = 0.18 Pro stress-value přibližně platí: < 0.05 vynikající < 0.1 výborný < 0.2 dobrý > 0.3 špatný (Clarke & Warwick 2001) nepodobnost mezi vzorky 101
99 POROVNÁNÍ METOD DCA A NMDS DCA NMDS 102 data z údolí Vltavy, klasifikace metodou TWINSPAN (Zelený & Chytrý 2007)
100 POROVNÁNÍ METOD DCA A NMDS DCA NMDS při větším počtu vzorků tvoří trojúhelník nebo pěticípou hvězdu (artefakt) má tendenci jakákoliv data zobrazit jako kouli 103
101 POROVNÁNÍ METOD DCA A NMDS SIMULOVANÁ DATA (JEDEN GRADIENT) DCA NMDS o vzorky + druhy 104

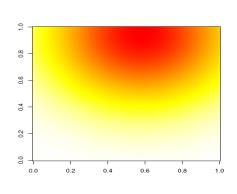
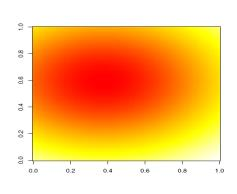
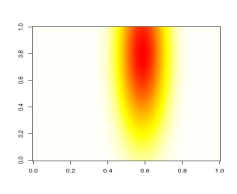
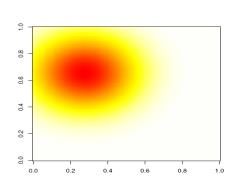


102 Gradient 2 (kratší) SIMULOVANÁ DATA DVA RŮZNĚ DLOUHÉ GRADIENTY Gradient 1 (delší) 105
103 SIMULOVANÁ DATA DVA RŮZNĚ DLOUHÉ GRADIENTY DCA NMDS PCA CA 106
104 SIMULOVANÁ DATA DVA STEJNĚ DLOUHÉ GRADIENTY DCA NMDS PCA CA 107
105 SIMULOVANÁ DATA DVA RŮZNĚ DLOUHÉ GRADIENTY krátké gradienty dlouhé gradienty 108
106 vzorky POUŽITÍ PROMĚNNÝCH PROSTŘEDÍ V ORDINACI ordinační osy vzorky DVA ALTERNATIVNÍ POSTUPY vzorky vzorky druhy druhy nepřímé srovnání korelace, regrese přímé srovnání přímá ordinace proměnné prostředí proměnné prostředí matice: Y druhové složení X proměnné prostředí oba přístupy jsou relevantní a navzájem se doplňují! 109 Legendre & Legendre (1998)
107 PASIVNĚ PROMÍTNUTÉ PROMĚNNÉ PROSTŘEDÍ V NEPŘÍMÉ ORDINACI KORELACE (REGRESE) S ORDINAČNÍMI OSAMI 110
108 PCA2 PH SOILDPT spe1 spe2 spe3 spe4... PCA 1 PCA 2 PH SOILDPT Korelace proměnných prostředí s ordinačními osami v nepřímé ordinaci (PCA) matice druhových dat skóre vzorků na první a druhé ose PCA proměnné prostředí sam1... PCA sam1 korelace sam1 sam2... sam2 sam2 sam3... sam3 sam3 sam4... sam4 sam PCA1 r 2 PCA 1 r 1 r 3 r 1 PCA 2 r 2 r 4 ordinační diagram PCA vztah proměnných prostředí (vektory) a ordinačních os korelace proměnných prostředí a ordinačních os 111
109 Náhodně generované proměnné (rand 1 až rand 9) pasivně promítnuté do ordinačního diagramu: náhodné proměnné reálné proměnné Data o druhovém složení: vegetace údolí Vltavy Analýza: NMDS s Bray-Curtis distancí rand 1 rand 9: náhodně generované proměnné ELEVATION, SOILDPT, - reálně měřené proměnné prostředí 112
110 PASIVNĚ PROMÍTNUTÉ PROMĚNNÉ PROSTŘEDÍ V NEPŘÍMÉ ORDINACI KORELACE (REGRESE) S ORDINAČNÍMI OSAMI Korelace mezi proměnnou prostředí a skóre vzorků na ordinačních osách pouze v ordinacích kde jsou skóre vzorků standardizované na jednotkovou varianci (PCA) v ostatních ordinacích, kde se variance os od sebe liší, je třeba použít (váženou) mnohonásobnou regresi: env ~ b0 + b1 * score1 + b2 * score2 b0 = 0 (všechny proměnné jsou centrované) b1, b2 regresní koeficienty 113
111 Možnost otestovat signifikanci vztahu proměnných prostředí k ordinačním osám náhodné proměnné reálné proměnné NMDS1 NMDS2 r2 Pr(>r) rand rand rand rand rand rand rand rand rand NMDS1 NMDS2 r2 Pr(>r) ELEVATION *** SLOPE *** ASPSSW *** HEAT.LOAD ** SURFSL *** SURFIS FLUVISOL *** SOILDPT *** ph *** (výstup z funkce envfit v knihovně vegan, testující regresi ordinačních os na proměnné prostředí) 114
112 PASIVNĚ PROMÍTNUTÉ PROMĚNNÉ PROSTŘEDÍ V NEPŘÍMÉ ORDINACI NELINEÁRNÍ VZTAH ZOBRAZENÝ JAKO VRSTEVNICE Data o druhovém složení: vegetace údolí Vltavy Analýza: DCA na log transformovaných datech ph měřené půdní ph vrstevnice jsou výsledkem GAM modelu 115
113 PŘÍMÁ ORDINAČNÍ ANALÝZA
114 PŘEHLED METOD ORDINAČNÍ ANALÝZY raw-data-based (založené na primárních datech) linear (lineární) unimodal (unimodální) transformationbased (založené na transformovaných primárních datech) distancebased (založené na distanční matici) unconstrained (nepřímé) PCA (analýza hlavních komponent) CA, DCA (korespondenční a detrendovaná korespondenční analýza) tb-pca (analýza hlavních komponent na transformovaných primárních datech) PCoA (analýza hlavních koordinát) NMDS (nemetrické mnohorozměrné škálování) constrained (přímé) RDA (redundanční analýza) CCA (kanonická korespondenční analýza) tb-rda (redundanční analýza na transformovaných primárních datech) db-rda (redundanční analýza založená na distanční matici) 117
115 species 1 (residual) env 1 env spe 1 spe 2 spe 3 species species 1 (predicted) spe 1 spe 2 spe spe 1 spe 2 spe 3 PRINCIP PŘÍMÉ ORDINAČNÍ ANALÝZY (RDA) matice vzorky druhy sam 1 sam 2 sam 3 sam 4 sam 5 sam 6 regrese abundance druhu na proměnné prostředí predikované hodnoty gradient sam 1 sam 2 sam 3 sam 4 sam 5 sam 6 sam 7 sam 7 sam 1 sam 2 sam gradient residuály sam 1 sam 2 sam 3 sam 4 sam 5 sam 4 sam 6 sam 5 sam 6 sam 7 matice s vysvětlujícími proměnnými gradient sam 7
116 spe 1 spe 2 spe 3 PCA2 RDA2 spe 1 spe 2 spe 3 Princip přímé ordinační analýzy - pokračování matice predikovaných hodnot ordinační osy s omezením (constrained axes) sam 1 sam 2 sam 3 sam 4 sam 5 sam 6 sam 7 PCA ordinace RDA1 počet ordinačních os s omezením = počet vysvětlujících proměnných (pokud je vysvětlující proměnná kategoriální, počet os je roven počtu kategorií minus 1) sam 1 sam 2 sam 3 PCA ordinace sam 4 sam 5 sam 6 sam 7 matice residuálů PCA1 ordinační osy bez omezení (unconstrained axes) 119
117 Nepřímá a přímá ordinační analýza PCA a RDA na datech z Vltavy (log + Hellinger) Method: PCA with supplementary variables Total variation is , supplementary variables account for 7.8% (adjusted explained variation is 5.8%) Summary Table: Statistic Axis 1 Axis 2 Axis 3 Axis 4 Eigenvalues Explained variation (cumulative) Pseudo-canonical correlation (suppl.) (modře označená pole v PCA se objeví jen pokud jsou do analýzy přidány pasivní proměnné prostředí a ukazují, kolik by tyto proměnné vysvětlily v přímé ordinační analýze) Method: RDA Total variation is , explanatory variables account for 7.8% (adjusted explained variation is 5.8%) Summary Table: Statistic Axis 1 Axis 2 Axis 3 Axis 4 Eigenvalues Explained variation (cumulative) Pseudo-canonical correlation Explained fitted variation (cumulative) Permutation Test Results: On All Axes pseudo-f=4.0, P=


118 KOEFICIENT DETERMINACE V REGRESI celková suma čtverců residuální suma čtverců 122
119 vysvětlená variabilita VYSVĚTLENÁ VARIABILITA (R 2 ) R 2 R 2 Adj počet vysvětlujících proměnných počet vzorků v datovém souboru vysvětlená variabilita stoupá s počtem vysvětlujících proměnných (i když jsou náhodné) a klesá s počtem vzorků v datovém souboru platí pro přímou (kanonickou) ordinační analýzu i mnohonásobnou regresi Peres-Neto et al. (2006) Ecology 123
120 vysvětlená variabilita VYSVĚTLENÁ VARIABILITA (R 2 ) A ADJUSTOVANÝ R 2 R 2 R 2 Adj počet vysvětlujících proměnných počet vzorků v datovém souboru adjustovaný R2 se nemění s počtem vysvětlujících proměnných a počtem vzorků v souboru 124 Peres-Neto et al. (2006) Ecology
121 Výpočet adjustovaného R 2 pomocí Ezekielovy formule (RDA) n... počet vzorků p... počet vysvětlujících proměnných R 2 Y X... vysvětlená variabilita bez adjustace Výpočet adjustovaného R 2 permutačním modelem (RDA, CCA) 2 R perm variabilita vysvětlená proměnnými prostředí po jejich znáhodnění R 2 variabilita vysvětlená proměnnými prostředí R 2 R 2 adj o kolik variability vysvětlí proměnné prostředí víc než by vysvětlily náhodné proměnné? 2 R adj 1 = R 2 1 R perm 125
122 VYSVĚTLENÁ VARIABILITA A ADJUSTOVANÝ R 2 nelze srovnávat vysvětlenou variabilitu v analýzách založených na různém počtu vzorků a druhů i náhodná proměnná vysvětlí nenulové množství variability (při následném testování signifikance ale bude neprůkazná) množství vysvětlené variability stoupá s počtem vysvětlujících proměnných (i když tyto jsou třeba úplně náhodné) nelze srovnávat variabilitu vysvětlenou modelem s různým počtem vysvětlujících proměnných (čím víc proměnných, tím víc vysvětlené variability) možné řešení použití tzv. adjustovaného R 2, tzn. vysvětlené variability ošetřené o variabilitu, kterou by vysvětlil stejný počet náhodných proměnných adjustovaný R 2 je možné spočítat pro lineární ordinační metody, pro unimodální je třeba použít metody založené na permutacích CANOCO umí adjr2 pro lineární i unimodální metody (CCA i RDA), erko (vegan) jen pro lineární (RDA) 126
 testová statistika F data (pseudo-f) P")
123 PŘÍMÁ ORDINAČNÍ ANALÝZA MONTE-CARLO PERMUTAČNÍ TEST testuje nulovou hypotézu, že druhové složení je nezávislé na jedné nebo více vysvětlujících proměnných test první kanonické osy vliv jen jedné kvantitativní proměnné test všech kanonických os vliv všech proměnných, nebo vliv jedné kategoriální proměnné s více kategoriemi (počet os = počet kategorií 1) testová statistika F data (pseudo-f) P hladina signifikance n x počet permutací, kde F perm >= F data N celkový počet permutací 127

124 PŘÍMÁ ORDINAČNÍ ANALÝZA MONTE-CARLO PERMUTAČNÍ TEST 128 Herben & Münzbergová (2001)

")
125 PŘÍMÁ ORDINAČNÍ ANALÝZA MONTE-CARLO PERMUTAČNÍ TEST randomizace ploch bez omezení (unrestricted randomization) randomizace ploch v blocích (randomization within blocks defined by covariables) 129 Herben & Münzbergová 2001
126 POSTUPNÝ VÝBĚR VYSVĚTLUJÍCÍCH PROMĚNNÝCH FORWARD SELECTION ze souboru vysvětlujících proměnných umožňuje vybrat jen ty, které mají průkazný vliv v každém kroku testuje zvlášť vliv jednotlivých proměnných (Monte- Carlo permutační test) vybere tu proměnnou, která vysvětlí nejvíce variability a zároveň je signifikantní; tuto proměnnou pak do modelu zahrne jako kovariátu v dalším kroku znovu testuje vliv jednotlivých proměnných na druhová data (s odstraněním vlivu kovariát) a opakuje předchozí kroky testy signifikance jsou zatíženy mnohonásobným porovnáním, a jsou proto poměrně liberální (počet signifikantních proměnných je často nerealisticky vysoký a vyžaduje např. Bonferroniho korekci) 130
 průkazné korelace (p < 0.")
127 PROBLÉM MNOHONÁSOBNÉHO POROVNÁNÍ Simulace: 25 náhodně vygenerovaných proměnných otestování průkaznosti korelace každé proměnné s každou (čtvercová matice) průkazné korelace (p < 0.05) jsou označeny červeně dohromady 300 analýz, z nich je 16 průkazných 131
128 PARCIÁLNÍ ORDINACE PARTIAL ORDINATION odstraňuje část variability vysvětlené proměnnými, které jsou pro nás nezajímavé (například vliv umístění ploch do bloků) následně se přímou nebo nepřímou ordinací analyzuje zbytková variabilita nezajímavé proměnné se definují jako kovariáty pokud následuje přímá ordinace ordinační osy představují čistý vliv ostatních vysvětlujících proměnných bez vlivu kovariát pokud následuje nepřímá ordinace ordinační osy zachycují zbytkovou variabilitu v druhových datech po odstranění vlivu kovariát 132
129 ROZKLAD VARIANCE VARIANCE PARTITIONING zbytková variabilita variabilita vysvětlená proměnnou 1 variabilita vysvětlená proměnnou 2 vysvětlená variabilita sdílená proměnnou 1 a proměnnou 2 Borcard et al. 1992, Ecology 73:
130 ROZKLAD VARIANCE VARIANCE PARTITIONING vysvětlující proměnná kovariáta vysvětlená variabilita 1 a 2 není [a]+[b]+[c] 1 2 [a] 2 1 [c] sdílená variabilita [b] = ([a]+[b]+[c]) [a] [c] nevysvětlená variabilita [d] = Total inertia ([a]+[b]+[c]) [d] [a] [b] [c] proměnná 1 proměnná 2 [a]+[b] celkový (marginal) vliv proměnné 1 [a] čistý (partial, conditional) vliv proměnné 1 (bez vlivu prom. 2) 134 Borcard et al. 1992, Ecology 73:
131 NEVYSVĚTLENÁ VARIABILITA [d] ordinační metody jsou založené na modelu (lineární nebo unimodální) odpovědi druhu na gradient prostředí, který je velkým zjednodušením skutečnosti variance nevysvětlená modelem (složka D) ve skutečnosti obsahuje variabilitu, která by mohla být vysvětlena některou z proměnných, pokud by se data chovala podle teoretického modelu varianci nevysvětlenou modelem tedy nelze interpretovat jen jako zbytkovou variabilitu, která je dána šumem v datech a tím, že ne všechny proměnné prostředí byly měřeny Total inertia proto není měřítkem celkové variability v druhových datech, ale variability, kterou je možné zachytit pomocí zvoleného modelu (lineárního nebo unimodálního) variabilita vysvětlená danou proměnnou prostředí a vypočtená jako eigenvalue / total inertia je proto podhodnocená Økland (1999) J. Veg.Sci. 10: vedle procenta vysvětlené variability (eigenvalue / total inertia) uvádějte také relativní množství variability, kterou daná proměnná vysvětlí z celkové variability vysvětlené všemi proměnnými prostředí 135




132 PŘÍKLAD NA ROZKLAD VARIANCE SPOLEČENSTVA MĚKKÝŠŮ NA PRAMENIŠTÍCH druhové složení společenstev měkkýšů ph Ca cond Mg Na druhové složení slatiništní vegetace měřené proměnné prostředí (ve vodě) Otázka: Je druhové složení společenstev měkkýšů na slatiništích ovlivněno více druhovým složením vegetace, nebo stanovištními podmínkami? Horsák M. & Hájek M. (2003) 137
133 PŘÍKLAD NA ROZKLAD VARIANCE SPOLEČENSTVA MĚKKÝŠŮ NA PRAMENIŠTÍCH druhové složení měkkýšů (Hellingerova transformace) -> RDA druhové složení vegetace > DCA (krátký gradient) -> PCA postupný výběr proměnných (RDA) na měkkýších mezi PCA osami reprezentujícími vegetaci mezi proměnnými prostředí reprezentujícími stanovištní podmínky výsledek z vegetačních dat nejlépe vysvětlí měkkýše první dvě osy PCA z proměnných prostředí je nejlepší obsah vápníku a konduktivita slatiništní vody rozklad variance mezi vegetaci a proměnné prostředí test marginálních a parciálních frakcí vysvětlené variability 138
134 PŘÍKLAD NA ROZKLAD VARIANCE SPOLEČENSTVA MĚKKÝŠŮ NA PRAMENIŠTÍCH vegetace [PC1 + PC2] 6% p < 0.01 proměnné prostředí [Ca + conduct] 20% 2% p = [d] = 72% 139

135 ROZKLAD VARIANCE MEZI PROMĚNNÉ PROSTŘEDÍ A PROMĚNNÉ POPISUJÍCÍ PROSTOROVÉ VZTAHY 140


136 ROZKLAD VARIANCE MEZI PROMĚNNÉ PROSTŘEDÍ A PROMĚNNÉ POPISUJÍCÍ PROSTOROVÉ VZTAHY 141
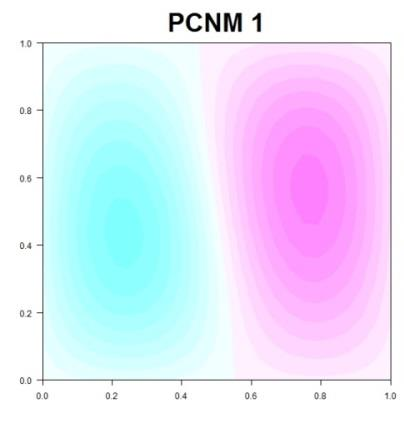

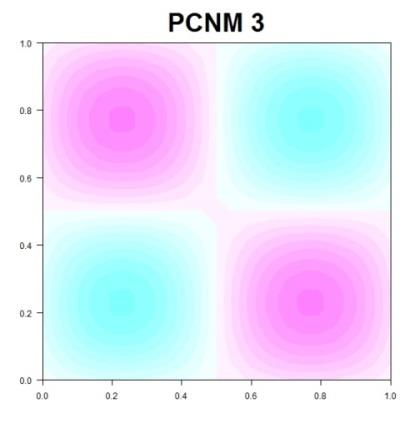
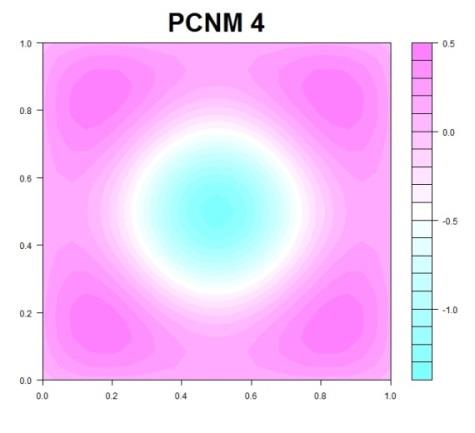
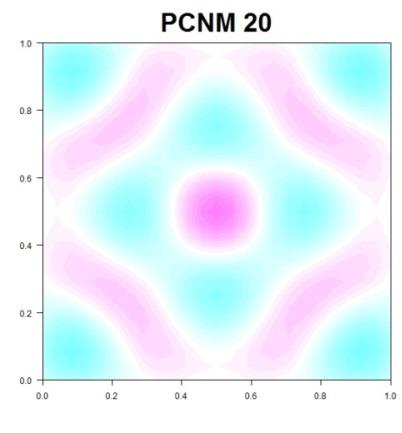
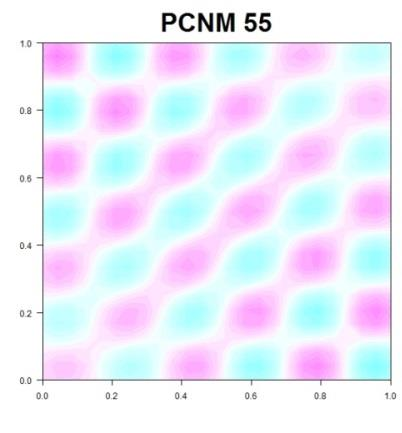
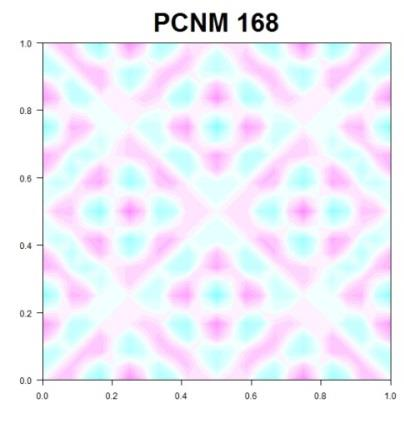

137 PCNM (PRINCIPAL COORDINATES OF NEIGHBOUR MATRICES)

138 ROZKLAD VARIANCE MEZI PROMĚNNÉ PROSTŘEDÍ A PROMĚNNÉ POPISUJÍCÍ PROSTOROVÉ VZTAHY 143

139 ROZKLAD VARIANCE MEZI PROMĚNNÉ PROSTŘEDÍ A PROMĚNNÉ POPISUJÍCÍ PROSTOROVÉ VZTAHY 144
140 JAK ČÍST VÝSLEDKY ORDINAČNÍCH METOD? procento variability vysvětlené hlavními osami CANOCO: cummulative percentage variance of species data vypočte se také jako eigenvalue / total variance ukazuje, jak úspěšný byl celý proces ordinace čím více jsou jednotlivé druhy korelované, tím více variability bude vysvětleno několika málo hlavními osami má smysl srovnávat vysvětlenou variabilitu hlavních os různými ordinačními technikami na stejných datech nemá smysl srovnávat vysvětlenou variabilitu hlavních os stejnými ordinačními technikami na různých datech (eigenvalues jsou závislé na počtu hráčů ve hře druhů, vzorků) skóre (souřadnice) závisle proměnných (druhů) na osách u lineárních technik skóre = regresní koeficient, v ordinačních diagramech zobrazeny jako šipky u unimodálních technik skóre = optimum druhu, v ordinačních diagramech zobrazeny jako body 145
141 JAK ČÍST VÝSLEDKY ORDINAČNÍCH METOD? skóry vzorků (snímků) na osách v ordinačních diagramech vzorky zobrazeny jako body (lineární i unimodální techniky) vzdálenost mezi body v ordinačním prostoru odpovídá nepodobnosti mezi vzorky (ne ale nepodobnosti celého floristického složení, ale jenom té části, která je vyjádřena zobrazenými ordinačními osami) skóry nezávislých (vysvětlujících proměnných) * regresní koeficienty, důležitá jsou jejich znaménka test signifikance (Monte-Carlo permutační test) * ukazuje na statistickou významnost použitých vysvětlujících proměnných 146 * jen přímé ordinační techniky
142 JEDNOTLIVÉ PROMĚNNÉ TERMINOLOGIE vysvětlované / závislé proměnné CANOCO: druhy (species) vysvětlující / nezávislé proměnné, prediktory * CANOCO: proměnné prostředí (environmental variables) měřené nebo odhadované proměnné vzorky, objekty, případy (cases) CANOCO: snímky (samples) kovariáty, nezajímavé vysvětlující / nezávislé proměnné * CANOCO: kovariáty (covariables) proměnné, jejichž vliv nás nezajímá a chceme ho z analýzy odstranit 147 * jen přímé ordinační techniky
143 Nepřímá a přímá ordinační analýza PCA a RDA na datech z Vltavy (log + Hellinger) PCA s pasivně promítnutými proměnnými prostředí RDA s vysvětlujícími proměnnými prostředí 149
144 ORDINAČNÍ DIAGRAMY KONVENCE zobrazení vzorků -> body zobrazení druhů -> šipky (lineární metody) -> body, centroidy (unimodální metody) zobrazení ordinačních os vodorovná bývá osa vyššího řádu (např. první) orientace os je arbitrární zobrazení proměnných prostředí šipky (kvantitativní proměnné) centroidy (kategoriální proměnné) typ ordinačního diagramu: Lepš & Šmilauer (2003) Multivariate analysis of... scatterplot - 1 typ dat (vzorky nebo druhy) biplot - 2 typy dat (např. vzorky a druhy) triplot - 3 typy dat (např. vzorky, druhy a proměnné prostředí) 150
145 ORDINAČNÍ DIAGRAMY nepřímá ordinace přímá ordinace lineární metoda unimodální metoda Lepš & Šmilauer (2003) Multivariate analysis of
: An ordination of the upland forest communities of Southern Wisconsin.")
146 HISTORICKÉ ORDINAČNÍ DIAGRAMY BRAY & CURTIS NEPŘÍMÁ GRADIENTOVÁ ANALÝZA 152 Bray & Curtis (1957): An ordination of the upland forest communities of Southern Wisconsin. Ecological Monographs 27:
 153")
147 MODERNÍ ANALOGIE (DCA V KNIHOVNĚ VEGAN) 153
148 TŘI ALTERNATIVNÍ PŘÍSTUPY K PŘÍMÉ ORDINAČNÍ ANALÝZE (a) Klasický přístup: RDA zachovává euklidovské distance, CCA chi-kvadrát distance (b) Transformace dat (tb-rda): používá distance vzniklé transformací dat (např. Hellingerova distance) (c) Přes matici nepodobností (db-rda): zachovává distance použité ve vstupní distanční matici 154 Legendre & Legendre (2012) podle Legendre & Gallagher (2001)
149 PŘEHLED METOD ORDINAČNÍ ANALÝZY raw-data-based (založené na primárních datech) linear (lineární) unimodal (unimodální) transformationbased (založené na transformovaných primárních datech) distancebased (založené na distanční matici) unconstrained (nepřímé) PCA (analýza hlavních komponent) CA, DCA (korespondenční a detrendovaná korespondenční analýza) tb-pca (analýza hlavních komponent na transformovaných primárních datech) PCoA (analýza hlavních koordinát) NMDS (nemetrické mnohorozměrné škálování) constrained (přímé) RDA (redundanční analýza) CCA (kanonická korespondenční analýza) tb-rda (redundanční analýza na transformovaných primárních datech) db-rda (redundanční analýza založená na distanční matici) 155
150 MANTEL TEST KORELACE MEZI MATICEMI NEPODOBNOSTÍ 156 Legendre & Legendre 1998
151 MANTEL TEST proměnná prostředí ph D e druhová data sp1 sp (eucl.) D sp D e D sp r = p =
152 SHRNUTÍ 158 Legendre & Legendre 1998


153 POUŽÍVÁNÍ ORDINAČNÍCH METOD A SOFTWARE (VEGETAČNÍ STUDIE) 159 von Wehrden et al. (2009) JVS
154 PCA PŘÍKLAD TRENDY V NÁZVECH ČLÁNKŮ V EKOLOGICKÝCH ČASOPISECH 160 Nobis & Wohlgemuth (2004) Oikos
155 161 Nobis & Wohlgemuth (2004) Oikos

 byly promítnuty do síťové mapy Chytrý")
156 DCA PŘÍKLAD FLORISTICKÁ DATA Z NP PODYJÍ skóre pro jednotlivé kvadráty z 1. a 2. osy DCA (na základě jejich floristického složení) byly promítnuty do síťové mapy Chytrý et al. (1999) Preslia 162
157 PCA PŘÍKLAD ZMĚNY V DRUHOVÉM SLOŽENÍ PÁLAVSKÝCH DUBOHABŘIN (R. HEDL 2005, DISERTAČNÍ PRÁCE) Výrazný úbytek druhové bohatosti bylinného (E1) a keřového (E2) patra v posledních 50ti letech. Data jsou založená na zopakování fytocenologických snímků na plochách snímkovaných Jaroslavem Horákem v šedesátých letech. Změna v druhovém složení vegetace v průběhu 50ti let samovolné sukcese (PCA diagram). 163

158 NMDS PŘÍKLAD VLIV SUCHA NA SLOŽENÍ SPOLEČENSTEV V EXPERIMENTÁLNÍ STUDII 164 Chase (2007) PNAS

 Skóre ploch v 3D NMDS ordinačním diagramu")
159 NMDS PŘÍKLAD ZOBRAZENÍ ZMĚN V DRUHOVÉM SLOŽENÍ V PROSTORU NA PŘÍKLADU TRVALÝCH PLOCH V TROPICKÉM LESE Baldeck et al. (2013) Skóre ploch v 3D NMDS ordinačním diagramu vyjádřené pomocí RGB barev 166
 Preslia")
160 CCA PŘÍKLAD ROZDÍL MEZI PRADÁVNÝMI A DRUHOTNÝMI LESY Vojta (2007) Preslia 169
161 CCA PŘÍKLAD STANOVENÍ EKOLOGICKÉHO OPTIMA JEDNOTLIVÝCH DRUHŮ MĚKKÝŠŮ PODÉL EKOLOGICKÝCH GRADIENTŮ 170 Horsák et al. (2007) Acta Oecologica
162 NUMERICKÁ KLASIFIKACE
163 PROČ MÁ SMYSL VĚCI KLASIFIKOVAT? vlnová délka (~ ekologický gradient) 172

164 PROČ MÁ SMYSL VĚCI KLASIFIKOVAT? vlnová délka (~ ekologický gradient) 173


165 PROČ MÁ SMYSL VĚCI KLASIFIKOVAT? Knihovna Ústavu botaniky a zoologie, PřF MU v Brně. Knihy rozklasifikované podle velikosti hřbetu. 174
166 KLASIFIKACE O klasifikaci obecně platí: smyslem je najít diskontinuity v jinak kontinuální realitě, které můžeme pojmenovat například proto, abychom si usnadnili komunikaci cílem je seskupit podobné objekty (vzorky, druhy) do skupin, které jsou vnitřně homogenní, dobře popsatelné a zároveň dobře odlišitelné od ostatních skupin O klasifikaci ekologických dat platí: pokud analyzuji vzorky daná skupina obsahuje vzorky s podobným druhovým složením (např. podobná stanoviště) pokud analyzuji druhy daná skupina obsahuje druhy s podobným ekologickým chováním 175
167 KLASIFIKACE OBECNÉ ROZDĚLENÍ neřízená (unsupervised, bez učitele) cílem je vytvořit novou klasifikaci pomocí datového souboru výslednou klasifikaci můžeme ovlivnit pouze výběrem metody (kombinace klasifikačního algoritmu a míry podobnosti), případně požadovaného počtu shluků numerické metody klasifikace (cluster analysis, TWINSPAN) řízená (supervised, s učitelem) cílem je aplikovat již existující klasifikaci ( danou učitelem ) na datový soubor klasifikační systém musíme nejdříve naučit, jak má vypadat výsledná klasifikace (training), a systém ji pak reprodukuje na dalších vzorcích ANN artificial neural networks, klasifikační stromy, náhodné lesy (random forests), COCKTAIL 177
168 KLASIFIKACE OBECNÉ ROZDĚLENÍ subjektivní vs objektivní v době rozkvětu metod numerické klasifikace se věřilo, že numerické metody přinášejí klasifikaci založenou na objektivních kritériích, tedy tu která skutečně existuje (narozdíl od té subjektivní, která je výmyslem badatele ) všechny klasifikace jsou ale z principu subjektivní v případě, že Bůh není, pak není nikdo, kdo by řekl, která klasifikace je jediná správná neformalizovaná vs formalizovaná formalizovaná klasifikace je taková, která je provedena na základě jasných kritérií a díky tomu je možné ji znovu reprodukovat opakem je klasifikace založená na neformálních kritériích (například pocitu), kterou pak není snadné zopakovat 178
169 OTÁZKY, KTERÉ BYCH SI MĚL POLOŽIT PŘED TÍM, NEŽ ZAČNU NĚCO KLASIFIKOVAT Pro jaký účel klasifikaci dělám? chci klasifikovat můj datový soubor (srovnat knihy v mojí domácí knihovničce) chci vytvořit obecný klasifikační systém, který bude použitelný i na další soubory (vytvořit knihovnický systém kategorizace knih, používaný i v jiných knihovnách) Podle jakých kritérií budu objekty klasifikovat? kritérium, podle kterého budu posuzovat, jestli si jsou objekty více či méně podobné (knihy budu třídit podle obsahové podobnosti nebo např. podle velikosti) odpovídá výběru indexu podobnosti mezi vzorky Jak stanovím hranice mezi jednotlivými skupinami? pravidla, podle kterých budu přiřazovat objekty do skupin odpovídá výběru klasifikačního algoritmu 179
170 KLASIFIKACE klasifikační metody nehierarchické (K-means clustering) divisivní (TWINSPAN) hierarchické aglomerativní (klasická cluster analysis) 180
171 KLASIFIKACE klasifikační metody nehierarchické (K-means clustering) divisivní (TWINSPAN) hierarchické aglomerativní (klasická cluster analysis) 181
172 KLASIFIKACE HIERARCHICKÁ A AGLOMERATIVNÍ Shluková analýza (cluster analysis ) hierarchická metoda shluky jsou hierarchicky uspořádány aglomerativní metoda shluky jsou tvořeny odspodu, tzn. postupným shlukováním jednotlivých vzorků do větších skupin základní volby: míra nepodobnosti mezi vzorky (distance measure) shlukovací (klastrovací) algoritmus (clustering algorithm) 182
173 SHLUKOVÁ ANALÝZA (CLUSTER ANALYSIS) Výsledek shlukové analýzy je ovlivněn celou řadou rozhodnutí, které provádíme na různých úrovních zpracování dat sběr dat volba důležitostní hodnoty (pokryvnost, početnost) primární data transformace strandardizace míra nepodobnosti (Euklidovská, Bray-Curtis atd.) matice nepodobností výběr klastrovacího algoritmu (single linkage, complete linkage atd.) výsledná klasifikace 183
174 SHLUKOVÁ ANALÝZA (CLUSTER ANALYSIS) SHLUKOVACÍ ALGORITMY Metoda jednospojná (single linkage) páry vzorků seřazené podle podobností matice podobností Legendre & Legendre 1998 výsledný dendrogram 184
175 SHLUKOVÁ ANALÝZA (CLUSTER ANALYSIS) SHLUKOVACÍ ALGORITMY Metoda jednospojná (single linkage, nearest neighbour) vzorky se pojí ke shluku, ve kterém je jim nejpodobnější vzorek přidám se ke skupině, ve které je ten, kdo je mí nejvíc sympatický Metoda všespojná (complete linkage, farthest neighbour) vzorky se připojí ke shluku až v okamžiku, kdy shluk obsahuje všechny podobné vzorky přidám se ke skupině ve které je ten, kdo je mi nejmíň nesympatický single linkage complete linkage 185
176 distance SHLUKOVÁ ANALÝZA (CLUSTER ANALYSIS) DENDROGRAM záleží na tom, které vzorky jsou spojeny na které úrovni nezáleží na tom, který vzorek (skupina) je vpravo a který vlevo 186
177 METODA JEDNOSPOJNÁ VS VŠESPOJNÁ Bray-Curtis distance / Single linkage Bray-Curtis distance / Complete linkage metoda jednospojná se výrazně řetězí 187
178 METODA JEDNOSPOJNÁ VLIV TRANSFORMACE DRUHOVÝCH DAT Single linkage / Euclidean distance / no transformation Single linkage / Euclidean distance / LOG transformation transformace dat (např. logaritmická) může výrazně ovlivnit výsledný dendrogram v případě euklidovských vzdáleností a jednospojné metody obzvlášť 188
179 SHLUKOVÁ ANALÝZA (CLUSTER ANALYSIS) SHLUKOVACÍ ALGORITMY Average linkage (např. UPGMA) zahrnuje řadu metod, které stojí mezi single a complete linkage a v ekologii jsou smysluplnější UPGMA (unweighted pair-group method using arithmetic averages) vzorek se připojí ke shluku, ke kterému má největší (neváženou) průměrnou podobnost se všemi jeho vzorky přidám se ke skupině, ve které jsou mi všichni v průměru nejvíc sympatičtí Euclidean distance / UPGMA 189
180 SHLUKOVÁ ANALÝZA (CLUSTER ANALYSIS) SHLUKOVACÍ ALGORITMY Wardova metoda (Ward s minimum variance method) Euclidean distance / Ward's method ke shluku se připojí vzorek, jehož vzdálenost od centroidu shluku je nejmenší (počítáno přes čtverce vzdáleností mezi vzorky a centroidy shluků) neměla by se kombinovat se Sørensenovým (Bray-Curtis) indexem podobnosti 190
181 SHLUKOVÁ ANALÝZA (CLUSTER ANALYSIS) Flexible clustering (beta flexible) nastavení parametru β ovlivňuje řetězení dendrogramu nejvíc se řetězí pro β ~ 1, nejméně pro β = -1 SHLUKOVACÍ ALGORITMY optimální reprezentace vzdáleností mezi vzorky je při β = -0,25 Legendre & Legendre
182 KLASIFIKACE klasifikační metody nehierarchické (K-means clustering) divisivní (TWINSPAN) hierarchické aglomerativní (klasická cluster analysis) 192
183 KLASIFIKACE HIERARCHICKÁ A DIVISIVNÍ TWINSPAN (Two Way INdicator Species ANalysis) divisivní metoda začíná dělením celého souboru vzorků a postupuje směrem dolů polytetická metoda každé dělení závisí na několika (indikačních) druzích (x monotetická metoda dělení ovlivňuje jediný druh) metoda velmi oblíbená mezi vegetačními ekology ale algoritmus je poměrně složitý, s řadou arbitrárních kroků, a proto má také řadu zarytých odpůrců vzorky jsou uspořádány podle první osy korespondenční analýzy (CA, DCA) a podle ní jsou rozděleny do dvou shluků (vzorky s pozitivním skóre a negativním skóre) metoda ošetří vzorky, které leží blízko středu osy, a které tak mají velkou pravděpodobnost, že budou špatně klasifikovány 193
184 KLASIFIKACE HIERARCHICKÁ A DIVISIVNÍ TWINSPAN (Two Way INdicator Species ANalysis) pseudospecies metoda primárně funguje pro kvalitativní data kvantitativní informace se dodává rozdělením druhů na pseudospecies podle abundance (cut levels) 194 Lepš & Šmilauer (2003)
185 KLASIFIKACE HIERARCHICKÁ A DIVISIVNÍ TWINSPAN (Two Way INdicator Species ANalysis) pseudospecies metoda primárně funguje pro kvalitativní data kvantitativní informace se dodává rozdělením druhů na pseudospecies podle abundance (cut levels) výsledkem je (mimo jiné) tabulka podobná fytocenologické snímky z určitých klastrů a druhy s vysokou fidelitou k dané skupině jsou seskupeny dohromady metoda vhodná v případě, že jsou data strukturovaná podle jednoho výrazného gradientu vhodné na hledání (několika málo) ekologicky interpretovatelných skupin v datech PC-ORD, JUICE 195
186 TWINSPAN 196
187 MODIFIKOVANÝ TWINSPAN (ROLEČEK ET AL. 2009) na rozdíl od původního algoritmu (a) umožňuje modifikovaný TWINSPAN (b) dopředu stanovit cílový počet skupin algoritmus se po každém dělení na dvě skupiny rozhoduje, kterou ze skupin bude dále dělit vybere tu, která je více heterogenní na základě její betadiverzity míru betadiverzity je nutné zvolit (např. Jaccardův index podobnosti) JUICE 197
")

188 KLASIFIKACE klasifikační metody nehierarchické (K-means clustering) divisivní (TWINSPAN) hierarchické aglomerativní (klasická cluster analysis) 198
189 KLASIFIKACE NEHIERARCHICKÁ K-means clustering (shlukování metodou K-průměrů) Legendre & Legendre 1998 nehierarchická metoda všechny shluky jsou si rovny analogie Wardovy metody - minimalizuje sumy čtverců vzdáleností vzorků od centroidů shluku na začátku uživatel zvolí počet shluků (k) iterativní metoda, začne od náhodného přiřazení vzorků do shluků, postupně přehazuje vzorky mezi shluky a hledá optimální řešení výsledek do určité míry záleží na počátečním rozmístění shluků do vzorků a je proto dobré proces mnohokrát zopakovat (najít stabilní řešení), protože metoda má tendenci nacházet lokální minima STATISTICA, SYN-TAX 2000, R 199
190 INTERPRETACE VÝSLEDKŮ NUMERICKÉ KLASIFIKACE promítnutí výsledků do ordinačního diagramu porovnání skupin na základě externích kritérií (např. měřených proměnných prostředí) porovnání skupin na základě druhového složení stanovení charakteristických druhů 200
191 PROMÍTNUTÍ VÝSLEDKŮ NUMERICKÉ KLASIFIKACE DO ORDINAČNÍHO DIAGRAMU DCA + TWINSPAN NMDS (Bray-Curtis) + TWINSPAN Je vhodné, aby míra nepodobnosti mezi vzorky byla v obou metodách (numerické klasifikaci i ordinační analýze) stejná (ze zvolených příkladů ten vlevo je vhodné řešení, vpravo nevhodné) 201 data z údolí Vltavy, klasifikace metodou TWINSPAN (Zelený & Chytrý 2007)
 202 Borcard et al.")
192 SILHOUETTE DIAGRAM hodnotí stupeň podobnosti daného vzorku ke klastru, do kterého byl zařazen, a srovnává ho s jeho podobností k nejbližšímu jinému klastru negativní hodnoty tyto vzorky byly s velkou pravděpodobností špatně klasifikovány (ve skutečnosti patří jinam) 202 Borcard et al. (2011) Numerical Ecology with R
 203 Borcard et al.")
193 HEAT MAP (intenzita barvy se zvyšuje s abundancí druhu ve vzorku) 203 Borcard et al. (2011) Numerical Ecology with R
 Numerical Ecology with")
194 HEAT MAP 204 Borcard et al. (2011) Numerical Ecology with R



195 205
196 STANOVENÍ DRUHŮ TYPICKÝCH PRO JEDNOTLIVÉ SHLUKY Analýza indikačních druhů (Dufrêne & Legendre 1997) - IndVal bere v potaz dva parametry: specificita kj = průměrná abundance druhu j uvnitř shluku k součet průměrných abundancí druhu j uvnitř ostatních shluků fidelita kj = počet vzorků ve shluku k obsahující druh j celkový počet vzorků ve shluku k IndVal kj = specificita kj * fidelita kj (pro druh j ve shluku k) IndVal j = max (IndVal kj ) (pro druh j celkově) možnost testování signifikance Monte-Carlo permutačním testem dostupné v PC-ORD 206
197 STANOVENÍ DRUHŮ TYPICKÝCH PRO JEDNOTLIVÉ SHLUKY Analýza indikačních druhů (Dufrêne & Legendre 1997) - IndVal (příklad z knihy Legendre & Legendre 2013) 207
198 STANOVENÍ DRUHŮ TYPICKÝCH PRO JEDNOTLIVÉ SHLUKY Fidelita (věrnost) druhu ke vzorku (Chytrý et al. 2002) Phi koeficient asociace (analogie Pearsonova korelačního koeficientu r) ϕ = (ad bc) / (a + b)(c + d)(a + c)(b + d) Počet vzorků ve shluku A mimo shluk A obsahující daný druh a b neobsahující daný druh c d rozsah <-1, 1>, 0 při shodné frekvenci uvnitř a vně shluku v JUICE možnost standardizace na velikost skupiny exaktní Fisherův test pro testování signifikance dostupné v programu JUICE 208
199 TESTOVÁNÍ PRŮKAZNOSTI A POUŽÍVÁNÍ HODNOTY P
200 ZÁKLADNÍ DEFINICE Hodnota P (P value) pravděpodobnost, že bychom získali stejně velkou nebo větší hodnotu testové statistiky za předpokladu platnosti nulové hypotézy čím menší je hodnota P, tím silnější je argument ukazující na neplatnost nulové hypotézy ale pozor vysoké hodnoty P nejsou důkazem, že nulová hypotéza je pravdivá! (např. pokud nemůžete najít statisticky signifikantní rozdíl mezi dvěma druhy, neznamená to, že můžete tvrdit, že oba druhy jsou stejné) V případě porovnání dvou výběrů (např. t-test) se hodnota P snižuje pokud se skutečný rozdíl mezi průměry výběrů zvýší snižuje se zvyšujícím se počtem opakování zvyšuje s variabilitou v datech 210

201 P HODNOTA DŮKAZ, KTERÝ EXISTUJE PROTI PLATNOSTI NULOVÉ HYPOTÉZY přesvědčivý středně silný P hodnota náznak důkazu, ale nepřesvědčivý máme důkaz proti platnosti nulové hypotézy? ne Ramsey & Schaffer (2002) 211
202 DOPORUČENÍ P hodnoty by měly být posuzovány jako důvěryhodnost důkazu, který máme proti platnosti nulové hypotézy (Dá se rozdílu věřit? Je důkaz důvěryhodný?) Neklást důraz na binární rozhodnutí (signifikantní vs nesignifikantní) Spolu s hodnotou P je třeba uvádět i tzv. velikost účinku (effect size), (např. R 2 u regrese, Pearsonův korelační koeficient r u korelace) Vhodné je testovaný vztah vizualizovat (boxploty pro porovnání výběrů, bodový diagram závislosti dvou proměnných aj.), a pokud není vztah z obrázku patrný, věc důkladně prošetřit (není třeba průkaznost způsobena výskytem jednoho odlehlého a vlivného pozorování?) Obecně platí, že k výsledkům by měly být dostupná i primární data (v elektronické podobě v příloze, případně na vyžádání), a detailní postup, jak byla analyzována (např. R skript). Sdílení dat a detailní popis metodiky je základem transparentního výzkumu a umožňuje zopakování analýz a případné odhalení chyb. 213
203 REGRESE VS KALIBRACE
204 METODY GRADIENTOVÉ ANALÝZY Data, která máme: počet charakteristik prostředí počet druhů Apriorní znalost vztahů mezi druhy a prostředím? Použijeme: Dostaneme: 1, n 1 ne regrese závislost druhu na prostředí žádné n ano kalibrace odhady hodnot charakteristik prostředí žádné n ne nepřímá ordinace 1, n n ne přímá ordinace osy variability v druhovém složení variabilita ve druhovém složení vysvětlená charakteristikami prostředí Lepš & Šmilauer (2003) Multivariate analysis of
205 REGRESE VS KALIBRACE lineární model regrese odhad směrnice regresní přímky metoda nejmenších čtverců kalibrace odhad hodnoty proměnné prostředí metoda váženého průměrování (váhy = směrnice regresních přímek) nepoužívá se unimodální model odhad optima druhu na gradientu prostředí metoda váženého průměrování odhad hodnoty proměnné prostředí metoda váženého průměrování (váhy = abundance druhu ve vzorku) používá se často 216
206 abundance druhu REGRESE UNIMODÁLNÍ ODPOVĚĎ DRUHU Odhad optima druhu váženým průměrováním WA Sp = n j=1 n j=1 Env j Abund j Abund j Env j hodnota gradientu prostředí ve vzorku j Abund j abundance druhu ve vzorku j n celkový počet vzorků v souboru abundance druhu v jednotlivých vzorcích vypočtený vážený průměr gradient prostředí 217
207 abundance druhu KALIBRACE UNIMODÁLNÍ ODPOVĚĎ DRUHU odhad hodnoty gradientu pro vzorek je stanoven průměrem optim jednotlivých druhů, vážených jejich abundancí ignoruje toleranci druhu Druh 3 Druh 4 Druh 2 Druh 1 WA Samp = s i=1 s i=1 IV i Abund i Abund i IV i indikační hodnota druhu i Abund j abundance druhu i ve vzorku s celkový počet druhů ve vzorku 219 gradient prostředí
208 KALIBRACE UNIMODÁLNÍ ODPOVĚĎ DRUHU Příklady použití: saprobní index v limnologii (založený na rozsivkách) použití v paleoekologii k rekonstrukci ekologických poměrů v minulosti na základě fosilních nálezů Ellenbergovy (nebo jiné) indikační hodnoty pro rostlinné druhy (viz dále) CWM (community-weighted mean) počítá vážený průměr funkčních vlastností druhů pro vzorek (functional traits) 220
209 SPECIES ATTRIBUTES IN ANALYSIS OF COMMUNITY ECOLOGY DATA
210 HOW TO ANALYSE RELATIONSHIP BETWEEN SAMPLE ATTRIBUTES AND SPECIES ATTRIBUTES VIA SPECIES COMPOSITION? species sample attributes samples L R 222 species attributes Q combining (L & Q) and relate to R - community-weighted mean approach combining (L & R) and relate to Q - species centroid approach relating R to Q via L - fourth-corner approach
211 THE FOURTH-CORNER PROBLEM (LEGENDRE ET AL. 1997) Fig. 1 from Dray & Legendre (2008)
212 Legendre & Legendre (2012) The fourth-corner problem: testing the significance

213 The fourth-corner problem Dray et al. (2014)

214 The fourth-corner problem Dray et al. (2014)
215 RLQ ordination analysis Dray et al. (2014)
216 COMMUNITY-WEIGHTED MEAN OF SPECIES ATTRIBUTES species weighted mean of species attr. sample attributes samples L s M = L s Q n M ~ R 228 m n = a np t p species attributes Q p=1 R... matrix of sample attributes (e.g. environmental variables) L... matrix of species composition (L s... standardized by sample totals) Q... matrix of species attributes (e.g. traits, species indicator values) M... matrix of weighted means of species attributes (e.g. CWM, meiv)
217 COMMUNITY-WEIGHTED MEAN OF SPECIES ATTRIBUTES Vegetation ecology: mean Ellenberg indicator values (e.g. for nutrients) mean species trait values (e.g. mean SLA) mean species specialization index (CMS, Clavero & Brotons 2010) mean plant height as estimation of stand biomass (Axmanová et al. 2012) 229 Limnology: diatom index (mean diatom indicator values weighted by species tolerances) Paleoecology: transfer functions for reconstruction of past environment from fossil diatom (or other organism type) records
218 weighted mean of SLA (herbs) Community-weighted mean approach r 2 = 0.123, P < cover of trees and shrubs [%] Vltava data, Zelený (unpubl.)
![SLA [mm2/mg] 0 20 40 60 80 Weighted-mean vs fourth-corner approach FC: r = 0.151, n = 5506 WM: r = 0.](/docs-images/61/45577907/images/219-0.png "427, n = 97 + + + ++ + ++ + ++ + ++ + +++ ++ + ++ + ++ + + ++ + ++ ++ + + + + + + +++ + + ++ ++ + + + ++ ++ + +++ + ++ ++ + ++ + ++")







219 SLA [mm2/mg] Weighted-mean vs fourth-corner approach FC: r = 0.151, n = 5506 WM: r = 0.427, n = cover of canopy [%] Zelený (unpubl.)
220 ELLENBERGOVY INDIKAČNÍ HODNOTY
221 ELLENBERGOVY INDIKAČNÍ HODNOTY (EIH) optima druhů rostlin na gradientu živin, vlhkosti, půdní reakce, kontinentality, teploty, světla a salinity (salinita se ve Střední Evropě nepoužívá) hodnoty na ordinální škále (1-9, případně 1-12 pro vlhkost) optima stanovená na základě terénních pozorování, v některých případech upřesněna experimentálně hodnoty tabelované původně pro Německo, ale používané i v okolních zemích, pro vzdálenější státy (Anglie, Itálie, Řecko) byly tyto hodnoty překalibrovány, jinde (Maďarsko, Švýcarsko) se používají alternativní hodnoty od jiných autorů (Borhidi, resp. Landolt) tabulky obsahují pouze údaje o druhových optimech, ne o šířkách druhové niky v případě, že nemám měřená data o proměnných prostředí, průměrné EIH nabízejí ekologicky intuitivní odhad stanovištních podmínek 233
222 Lawesson Systémy indikačních hodnot druhů cévnatých rostlin používané v Evropě Hill Ellenberg Landolt Frank & Klotz Zarzycki Didukh Böhling 234 : Use of mean Ellenberg inidicator values revisited (again)
223 ELLENBERGOVY INDIKAČNÍ HODNOTY (EIH) POUŽITÍ PRO KALIBRACI EIV pro půdní reakci Mycelis muralis Moehringia trinervia Mercurialis perennis Lathyrus vernus Myosotis sylvatica Milium effusum Melica nutans Melampyrum pratense Myosotis ramosissima Lychnis viscaria Melittis melissophyllum průměr 235
224 ELLENBERGOVY INDIKAČNÍ HODNOTY (EIH) POUŽITÍ PRO KALIBRACI EIV pro půdní reakci Mycelis muralis Moehringia trinervia Mercurialis perennis Lathyrus vernus Myosotis sylvatica Milium effusum Melica nutans Melampyrum pratense Myosotis ramosissima Lychnis viscaria Melittis melissophyllum průměrná hodnota:
225 VÝPOČET PRŮMĚRNÝCH EIH H. Ellenberg Empirická zkušenost s ekologií druhů průměrné Ellenbergovy indikační hodnoty Data o druhovém složení průměrná EIH pro daný vegetační snímek obsahuje dvojí informaci: 1. ekologicky relevantní informaci o charakteru stanoviště, a to díky použití tabelovaných druhových EIH, které jsou založeny na empirických pozorování ekologických nároků druhů v terénu 2. informaci o podobnosti druhového složení daného snímku k ostatním snímkům v datovém souboru, která je v nich uložena díky způsobu, jak jsou průměrné EIH počítány 238
226 VÝPOČET PRŮMĚRNÝCH EIH H. Ellenberg Empirická zkušenost s ekologií druhů průměrné Ellenbergovy indikační hodnoty Data o druhovém složení díky způsobu jak jsou počítány, obsahují průměrné EIH informaci o podobnosti v druhovém složení mezi vegetačními snímky vegetační snímky s úplně stejným druhovým složením budou mít přesně stejné průměrné EIH pro měřené faktory toto ale neplatí malý rozdíl v druhovém složení mezi vegetačními snímky povede jen k malému rozdílu v jejich průměrných EIH 239


227 VÝPOČET PRŮMĚRNÝCH EIH H. Ellenberg Empirická zkušenost s ekologií druhů průměrné Ellenbergovy indikační hodnoty!! Data o druhovém složení problém nastává v okamžiku, kdy jsou průměrné EIH analyzovány současně s daty o druhovém složení, ze kterých jsou vypočteny 240
228 VYTVOŘENÍ PRŮMĚRNÝCH EIH, KTERÉ NEOBSAHUJÍ EKOLOGICKOU INFORMACI průměrné reálné EIH pro půdní reakci: průměrné znáhodněné EIH pro půdní reakci: průměrné reálné EIH obsahují ekologicky relevantní informaci a informaci o podobnosti v druhovém složení průměrné znáhodněné EIH obsahují pouze informaci o podobnosti v druhovém složení (ekologicky relevantní informace byla zničena promícháním druhových EIH mezi druhy) 241

229 KORELACE PRŮMĚRNÝCH EIH SE SKÓRY SNÍMKŮ NA OSÁCH DCA průměrná EIH bude s velkou pravděpodobností signifikantně korelovaná s DCA, i když neobsahuje ekologickou informaci! Počet signifikantních korelací mezí osami DCA a průměrnými znáhodněnými EIH (šedé sloupečky) nebo náhodnými čísly (bílé sloupečky) 1000 opakování 242
230 PRŮMĚRNÉ EIH V NEPŘÍMÉ ORDINACI DCA1 DCA2 R 2 P orig P modif Světlo 0,477 0,879 0,600 < 0,001 0,004 Teplota 0,350 0,937 0,471 < 0,001 0,011 Kontinentalita 0,726 0,688 0,148 0,004 0,452 Vlhkost -0,925 0,381 0,897 < 0,001 < 0,001 Živiny -0,998 0,066 0,831 < 0,001 < 0,001 Půdní reakce -0,653 0,757 0,429 < 0,001 0,
231 průměrná Mean EIH Ellenberg pro reaction půdní reakci vysvětlená Explained variability variabilita [%] [%] měřené ph náhodná čísla průměrné reálné EIH průměrné znáhodnéné EIH náhodná čísla POROVNÁNÍ MĚŘENÉHO PŮDNÍHO PH A VYPOČTENÉ PRŮMĚRNÉ EIH PRO PŮDNÍ REAKCI VYSVĚTLUJÍCÍ PROMĚNNÉ V CCA měřené ph Measured soil ph real ph měřené ph Ellenberg reaction EIH pro půdní reakci Průměrná EIH pro půdní reakci vysvětlí víc variability než měřené ph, i když obě proměnné jsou spolu těsně korelované 244
232 PRŮMĚRNÉ ELLENBERGOVY INDIKAČNÍ HODNOTY PRAVIDLA POUŽITÍ použití průměrných EIH v analýze spolu s jinými proměnnými vypočtenými z těchto dat může vést k závěrům, které jsou optimističtější, než by ve skutečnosti měly být pokud jsou k dispozici relevantní měřené faktory prostředí, není třeba používat zároveň i průměrné EIH jen proto, že je tak snadné je vypočíst průkaznost jejich vztahu s jinými proměnnými, které jsou odvozeny ze stejných druhových dat, by měla být testována modifikovaným permutačním testem, který bere v potaz skutečnost, že testované proměnné na sobě nejsou nezávislé průměrné EIH by neměly být bez dalšího statistického ošetření srovnávány s analogickými měřenými faktory prostředí, protože se oproti nim mohou neoprávněně jevit lepšími, než ve skutečnosti jsou (například tím, že jsou lépe korelované nebo častěji a více průkazné) 246


233 MOPET: (ERKOVÝ) PROGRAM PRO VÝPOČET MODIFIKOVANÉHO PERMUTAČNÍHO TESTU 247


234 PŘÍKLADY NA POUŽÍTÍ PRŮMĚRNÝCH EIH Použití na floristická data z NP Podyjí ekologické gradienty v krajině (Chytrý et al. 1999, Preslia) 248



235 Ekologická kalibrace vegetačních jednotek v přehledu Vegetace ČR (Chytrý [ed.] 2007) 249
236 DIVERZITA
 Robert H. Whittaker Cornel University Library Jurasinski et al.")
237 ALFA, BETA A GAMA DIVERZITA Alfa diverzita druhová bohatost vzorku Beta diverzita (species turnover) změna v druhovém složení mezi vzorky heterogenita druhového složení Gama diverzita celková druhová bohatost regionu Robert Harding Whittaker ( ) Robert H. Whittaker Cornel University Library Jurasinski et al. (2009) 251
238 ALFA, BETA A GAMA DIVERZITA 252

239 DRUHOVÁ BOHATOST SPOLEČENSTVA VS RELATIVNÍ ABUNDANCE DRUHŮ VE SPOLEČENSTVU Gotelli & Chao (2013) 253
240 DRUHOVÁ BOHATOST SPOLEČENSTVA VS RELATIVNÍ ABUNDANCE DRUHŮ VE SPOLEČENSTVU Dva komponenty druhové diverzity: druhová bohatost (species richness) vyjadřuje počet druhů ve vzorku vyrovnanost (evenness, equitability) vyjadřuje relativní zastoupení jednotlivých druhů ve vzorku (nejvyšších hodnot dosahuje při rovnoměrném relativním zastoupením všech druhů) jednotlivé indexy alfa diverzity (např. Shannonův nebo Simpsonův) se liší právě tím, jestli kladou větší důraz na bohatost (Shannon) nebo vyrovnanost (Simpson) 254 Hubbel (2001)
241 MÍRY ALFA DIVERZITY SHANNONŮV INDEX n H = p i ln(p i ) i=1 označovaný také jako Shannon-Wiener index (nesprávně jako Shannon- Weaver nebo omylem jako Shannon-Weiner) odvozen z informační teorie (entropie systému - s rostoucí entropií vzrůstá neuspořádanost systému, očekávatelná míra překvapení) vyjadřuje nejistotu, se kterou jsem schopen předpovědět, jakého druhu bude náhodně vybraný jedinec ze vzorku; nejistota klesá s klesajícím počtem druhů a s klesající vyrovnaností (více dominantních druhů) hodnoty v ekologických datech většinou v rozmezí 1,5 3,5 p i... relativní abundance druhu i n... počet druhů ve společenstvu maximální velikost indexu pro počet druhů S nastane, pokud mají všechny druhy stejnou relativní frekvenci: H max = ln (S) efektivní počet druhů (kolik druhů by se vyskytovalo ve vzorku s diverzitou H, pokud by se všechny druhy vyskytovaly se stejnou frekvencí): e H vyrovnanost odvozená ze Shannonova indexu (Shannon s evenness) J = H / H max = H / ln (S) 255
242 MÍRY ALFA DIVERZITY SIMPSONŮV INDEX (D) GINI-SIMPSON INDEX (S D ) vyjadřuje pravděpodobnost, že dva náhodně vybraní jedinci budou patřit ke stejnému druhu jeden z nejlepších (z hlediska interpretace) indexů diverzity se zvyšující se diverzitou hodnota indexu klesá proto se častěji používá komplementární (1-D) nebo reciproká forma indexu (1/D) zdůrazňuje dominanci druhu (při počtu druhů > 10 záleží jeho velikost prakticky už jen na dominanci druhů) efektivní počet druhů: 1/(1-S D ) = 1/D n D = p i 2 i=1 S D = 1 D p i... relativní abundance druhu i n... počet druhů ve společenstvu vyrovnanost odvozená ze Simpsona (Simpson s evenness): E = (1/D) / S (efektivní počet druhů/reálný počet druhů) 256
243 PŘÍKLAD EFEKTIVNÍ POČET DRUHŮ počet Simpson efektivní druhů index počet druhů Spol. 1: ,8 1) 5,0 3) Spol. 2: ,6 2) 2,5 4) Výpočet: 1) 1 p 2 = 1-5*(2/10) 2 = 1 5*0,04 = 1 0,2 = 0,8 2) 1 p 2 = 1 ((6/10) 2 + 4*(1/10) 2 ) = 1 (0,36 + 0,04) = 0,6 3) 1/(1-S D ) = 1/(1-0,8) = 5 4) 1/(1-S D ) = 1/(1-0,6) = 2,5 257
244 HILLOVA ČÍSLA HILL NUMBERS zavedl Mark Hill (1973), rodina indexů diverzity, které kombinují použití druhové bohatosti, Shannonova indexu a Gini-Simpsonova indexu jednotlivá Hillova čísla se liší řádem : q D Hillovo číslo řádu q q - reálné číslo, nejčastěji 0, 1, 2 S celkový počet druhů p i relativní abundance druhu i 0 D druhová bohatost celkový počet druhů ve vzorku bez ohledu na relativní abundance druhů (v principu je to v podstatě počet vzácných druhů) 1 D Shannon-Wienerův index (resp. jeho exponenciální podoba) počet typických druhů druhy váženy proporčně jejich frekvenci ve společenstvu 2 D Gini-Simpsonův index počet velmi početných druhů, vzácně se vyskytující druhy jsou potlačeny 258
245 HILLOVA ČÍSLA HILL NUMBERS Příklad: každé společenstvo má přesně 100 druhů a 500 jedinců, ale liší se vyrovnaností od perfektně vyrovnaného (completely even) se všemi druhy zastoupenými stejným počtem jedinců, po velmi nevyrovnané (highly uneven), kde dominuje několik málo druhů Gotelli & Chao (2013) 259
246 MÍRY ALFA DIVERZITY ad hoc doporučení: nemá smysl počítat velké množství indexů alfa diverzity a všechny je používat vhodnější je rozhodnout se hned na začátku, který z aspektů alfa diverzity (bohatost nebo vyrovnanost) mě zajímá, a podle toho vybrat index nejjednodušší volba je použítí druhové bohatosti (počtu druhů) Simpsonův index je intuitivně interpretovatelný, naopak interpretace Shannonova indexu je obtížná a je lépe ho nepoužívat (i když je populární) kde spočítat: EstimateS (R. Colwell, BioDiversityPro (Neil McAleece, 260
247 VZTAH DRUHOVÉ BOHATOSTI A INTENZITY PRŮZKUMU (SPECIES RICHNESS ~ SAMPLING INTENSITY) druhová bohatost vzorku odráží druhovou bohatosti společenstva jen pokud je vzorek reprezentativní dostatečně velký počet jedinců nutnost standardizace vzorků na intenzitu průzkumu (počet jedinců, velikost vzorkované plochy) sample completeness do jaké míry je druhová bohatost vzorku kompletní, tzn. kolik druhů z celkového počtu druhů ve společenstvu bylo zachyceno Community Completeness Index (sensu Partel et al. 2013) CCI = ln počet druhů ve vzorku počet nerealizovaných druhů počet nerealizovaných druhů = celkový počet druhů ve společenstvu (species pool) počet druhů ve vzorku Sample coverage (sensu Chao & Jost 2012) koncept vyvinutý během 2. světové války při dešifrování německého kódu Enigma proporce celkového počtu jedinců ve sledovaném společenstvu, kteří náležejí druhům ve vzorku 261

 (Isidore")
248 GOOD-TURING THEOREM ESTIMATION OF UNSEEN SPECIES Alan Turing ( ) I.J. Good ( ) (Isidore Jacob Gudak) 262
249 AKUMULAČNÍ DRUHOVÁ KŘIVKA SPECIES ACCUMULATION CURVE vynáší kumulativní počet druhů S v závislosti na intenzitě vzorkování n (počet jedinců, počet ploch, čas) zvláštním typem je species-area curve (ale jen v případě, že plocha narůstá v rámci určitého území, neplatí pro ostrovy) čte se zleva doprava může být extrapolována (zvýší intenzita průzkumu celkový počet nalezených druhů?) 263
250 RAREFAKČNÍ KŘIVKA RAREFACTION CURVE cílem je zjistit, jaká by byla druhová bohatost, pokud bychom v daném společenstvu nasbírali menší počet jedinců/vzorků (to rarefy rozředit) porovnání druhové bohatosti mezi společenstvy s různým počtem jedinců/vzorků čte se zprava doleva rozdíl mezi sample based a individual based rarefaction 264 Michalcová et al. (2011) Journal of Vegetation Science
251 MÍRY BETA DIVERZITY popisuje rozdílnost v druhovém složení mezi vzorky Dva základní typy beta diverzity: 1. turnover (obrat druhů podél ekologického, prostorového nebo časového gradientu) Kolik nových druhů přibude a kolik jich ubude, když se pohybuji podél gradientu? 2. variation (variabilita v druhovém složení mezi vzorky, bez ohledu na směr nějakého gradientu) Opakují se v různých vzorcích pořád ty samé druhy? Jak moc celkový počet druhů v regionu přesahuje průměrnou druhovou bohatost vzorku? Anderson et al. (2011) 265
252 MÍRY BETA DIVERZITY KLASICKÉ INDEXY klasické indexy neberou v potaz druhové složení, ale jen počty druhů na lokální (alfa) a regionální (gamma) úrovni Whittakerova beta diverzita (multiplikativní míra): β w = (γ / α ) - 1 α... průměrná druhová bohatost vzorků kolikrát bohatost regionu přesahuje průměrnou bohatost vzorku Additivní míra beta diverzity: β Add = γ α průměrný počet druhů, které chybí v jednom náhodně vybraném vzorku/ploše výhodou je, že jednotkami jsou počty druhů Multiplikativní míra, která bere v potaz vyrovnanost: β Shannon = H γ / H α místo počtu druhů používá Shannonův index diverzity vypočtený pro regionální a lokální druhovou bohatost 266
253 MÍRY BETA DIVERZITY MNOHOROZMĚRNÉ INDEXY mnohorozměrné indexy pracují přímo s druhovým složením a hledají rozdíly v druhovém složení dvou a více vzorků/ploch používá indexy podobnosti (případně nepodobnosti) v druhovém složení mezi páry vzorků/ploch Bray-Curtis, Jaccard, Sorensen, Euclidovská vzdálenost atd. beta diverzita skupiny vzorků/ploch se spočte jako průměrná hodnota těchto podobností délka první osy DCA také vyjadřuje beta diverzitu (v jednotkách SD) 267
254 Anderson et al. (2011) MÍRY BETA DIVERZITY MNOHOROZMĚRNÉ INDEXY Rozdíly v interpretaci beta diverzity založené na Bray-Curtis indexu nepodobnosti a Euklidovské vzdálenosti na příkladu rozdílu v druhovém složení korálových útesů (Indonésie) v letech 1981, 1983 a 1985 (zásah El Nino v roce 1982) NMDS ordinace 268
255 INDEXY FUNKČNÍ DIVERZITY funkční diverzita zohledňuje diverzitu funkčních typů (functional traits), které se ve vzorku vyskytují druhová bohatost se často považuje za odhad funkční diverzity, ale nepřesný dva různé druhy mohou ve společenstvu plnit stejnou funkci (mít stejnou kombinací funkčních typů) Rao index (Lepš et al Preslia) FD = i j d ij p i p j d ij... nepodobnost mezi druhem i a j p i, p j... relativní abundance druhu i a j zobecněná forma Simpsonova indexu diversity 270
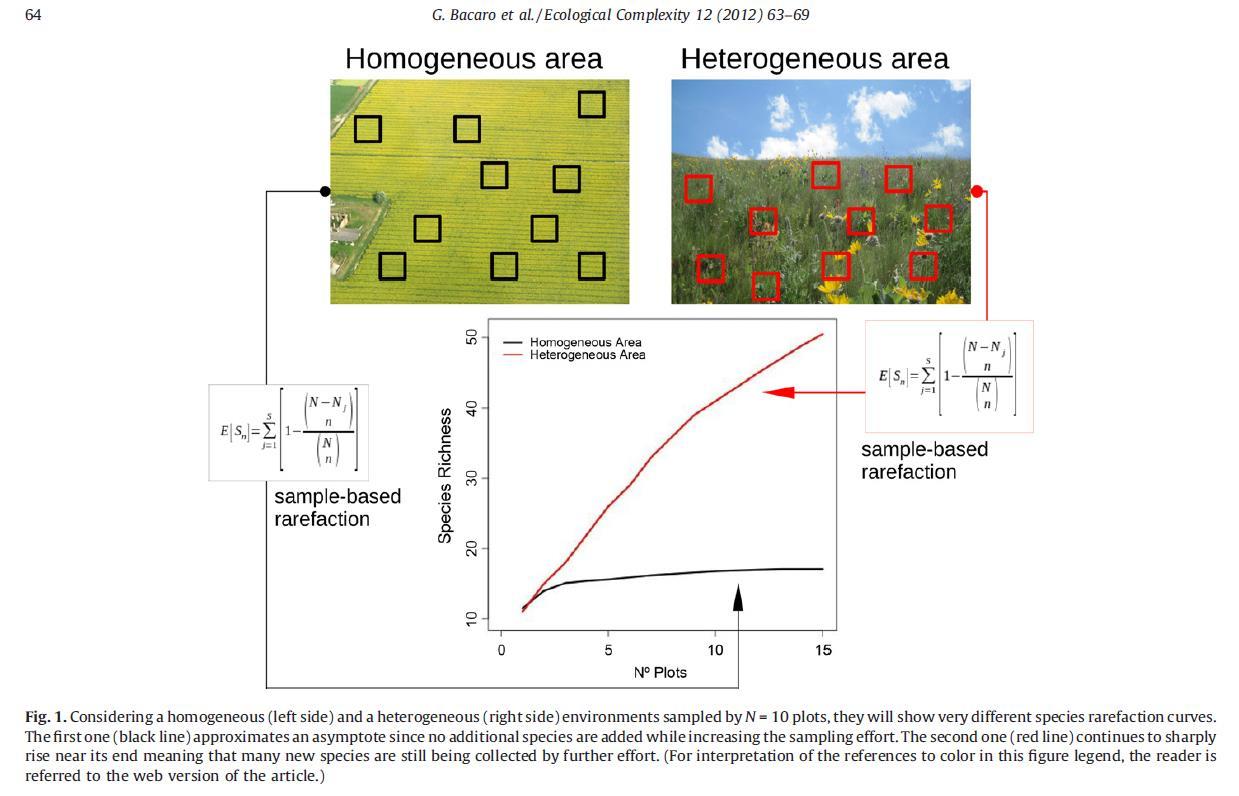
256 271
257 SOFTWARE (MIMO R, VE KTERÉM SPOČTETE VŠECHNO) indexy alfa diverzity (Shannon, Simpson atd.) a beta diverzity Biodiversity Pro (Neil McAleece, EstimateS (Robert Colwell, PC-ORD 5 JUICE species accumulation curve a rarefaction PC-ORD 5 EstimateS (Robert Colwell, 272
258 DESIGN EKOLOGICKÝCH EXPERIMENTŮ To call in the statistician after the experiment is done may be no more than asking him to perform a post mortem examination: he may be able to say what the experiment died of. Sir Ronald Fisher, Indian Statistical Congress, Sankhya 1939
259 ZÁKLADNÍ OTÁZKA: CO CHCI EXPERIMENTEM ZJISTIT? Jaká je variabilita proměnné Y v čase nebo prostoru? pattern description nejčastější otázka v ekologických observačních studiích Má faktor X vliv na proměnnou Y? hypothesis testing, otázka pro manipulativní experiment může platit i pro některé přírodní experimenty, ale výsledky těchto testů jsou podstatně slabší (nemáme kontrolu nad vlivem ostatních faktorů, které mohou výsledky ovlivnit) Chová se proměnná Y tak, jak předpovídá hypotéza H? klasická konfrontace mezi teorií a reálnými daty platí pro data získaná jak manipulativním tak přírodním experimentem ne vždy je snadné najít správnou hypotézu Jaký model nejlépe vystihuje vztah mezi faktorem X a proměnnou Y? experimentem sbíráme podklady pro matematické modelování 274
260 MANIPULATIVNÍ VS PŘÍRODNÍ EXPERIMENTY Manipulativní experimenty uměle manipulujeme vysvětlující proměnnou (X) a sledujeme reakci vysvětlované proměnné (Y) umožňuje přímé testování hypotéz známe směr vztahu mezi příčinou a důsledkem - kauzalita Přírodní experimenty (pozorování, observační studie) vysvětlující proměnnou manipuluje sama příroda slouží spíše ke generování než testování hypotéz neznáme směr vztahu mezi příčinou a důsledkem - korelace 275
261 MANIPULATIVNÍ VS PŘÍRODNÍ EXPERIMENTY SROVNÁNÍ TESTOVANÝCH HYPOTÉZ Příklad: na ostrovech v Karibiku sledujeme vztah mezi počtem ještěrek na určité ploše a počtem pavouků (Gotelli & Ellison 2004) Manipulativní experiment Provedení: v jednotlivých plochách (klecích) je uměle ovlivněn počet ještěrek a sledováno množství pavouků Nulová hypotéza: počet ještěrek nemá vliv na počet pavouků v klecích Alternativní hypotéza: se vzrůstající hustotou ještěrek klesá počet pavouků (ještěrky žerou pavouky) 276
262 MANIPULATIVNÍ VS PŘÍRODNÍ EXPERIMENTY Přírodní experiment (pozorování, observační studie) Provedení: SROVNÁNÍ TESTOVANÝCH HYPOTÉZ na vybraných plochách je sledován počet ještěrek a počet pavouků. Vybíráme plochy (nebo ostrovy) s různou hustotou ještěrek (hustota ještěrek tedy není přímo manipulována, ale záleží na jiných faktorech). Možné hypotézy vysvětlující negativní vztah mezi ještěrkami a pavouky: 1. počet ještěrek (negativně) ovlivňuje počet pavouků (ještěrky žerou pavouky) 2. počet pavouků má vliv na počet ještěrek (draví pavouci napadají mláďata ještěrek) 3. počet ještěrek i pavouků je ovlivňován neměřeným faktorem prostředí (třeba vlhkostí) 4. některý faktor prostředí ovlivňuje sílu vztahu mezi ještěrkami a pavouky (třeba zase vlhkost) Možná řešení: 1. vybírat plochy tak, aby se omezila variabilita vlhkosti (sledovat třeba jen vlhké plochy, které se liší hustotou ještěrek) 2. dodatečně měřit faktory, které mohou ovlivňovat vztah (např. onu vlhkost) 277
263 závisle proměnná závisle proměnná MANIPULATIVNÍ EXPERIMENT PRESS VS PULSE EXPERIMENT Press experiment (experiment pod stálým tlakem ) zásah je proveden na začátku experimentu a pak znovu v pravidelných intervalech měří resistenci systému na experimentální zásah jak je systém (společenstvo) schopné odolávat, případně se přizpůsobit změnám v podmínkách prostředí Pulse experiment (pulzní experiment, jednou a dost ) zásah je proveden jen jednou, obvykle na začátku experimentu měří resilienci systému jak pružně je systém (společenstvo) schopné reagovat na experimentální zásah čas čas 278
264 PŘÍRODNÍ EXPERIMENT (POZOROVÁNÍ) SNAPSHOT VS TRAJECTORY EXPERIMENT Snapshot experiment (momentka) opakuje se v prostoru, ale ne v čase sběr vzorků provedu na několika (mnoha) lokalitách v relativně krátkém čase (týden, sezóna, dva roky sběru dat pro diplomku...) představuje většinu přírodních experimentů v ekologii zahrnuje i sukcesní studie, kdy sledujeme zároveň různá sukcesní stadia Trajectory experiment (sledujeme trajektorii procesu v čase) opakuje se v čase (a případně i v prostoru) sběr vzorků se na daných (většinou pevně vymezených plochách) opakuje několikrát za sebou sukcesní studie prováděné několik let, trvalé plochy v lesních porostech opakovaně měřené jednou za x let 279
265 MANIPULATIVNÍ EXPERIMENT ZÁKLADNÍ TYPY ROZMÍSTĚNÍ PLOCH kompletně znáhodněný design nebere v úvahu heterogenitu prostředí ne vždy je nejvhodnější znáhodněné bloky vlastní bloky jsou vnitřně homogenní (pokud možno) počet bloků = počet opakování bloky jsou umístěné podle gradientu prostředí v každém bloku je právě jedna replikace každého zásahu gradient prostředí 280
266 MANIPULATIVNÍ EXPERIMENT ZÁKLADNÍ TYPY ROZMÍSTĚNÍ PLOCH latinský čtverec předpokládá přítomnost dvou gradientů v prostředí každý sloupec a každý řádek obsahuje právě jednu variantu zásahu možno použít i několik latinských čtverců gradient 1 gradient 2 281
267 MANIPULATIVNÍ EXPERIMENT NEJČASTĚJŠÍ CHYBY pseudoreplikace testovat lze jen rozdíly v průměrech jednotlivých bloků plochy se stejným zásahem jsou umístěny blízko sebe, a mají proto větší pravděpodobnost, že si budou podobné i bez vlivu vlastního zásahu neúplně znáhodněný design v podstatě pseudoreplikace, jen méně zřejmá gradient prostředí gradient prostředí 282
268 gradient prostředí gradient prostředí gradient prostředí MANIPULATIVNÍ EXPERIMENT NEJČASTĚJŠÍ CHYBY design se znáhodněnými bloky špatná orientace bloků správně špatně špatně 283
269 MANIPULATIVNÍ EXPERIMENT S VÍCE NEŽ JEDNÍM TYPEM ZÁSAHU faktoriální design každá hladina prvního faktoru je kombinovaná s každou hladinou druhého faktoru (případně třetího atd.) například kombinace koseno vs nekoseno hnojeno vs nehnojeno jednotlivé kombinace mohou být rozmístěny v prostoru např. v rámci latinského čtverce ano ne koseno hnojeno 284
270 MANIPULATIVNÍ EXPERIMENT S VÍCE NEŽ JEDNÍM TYPEM ZÁSAHU split-plot design faktory jsou strukturovány hierarchicky (nested) například plochy hnojené různými hnojivy (C, N, P) v rámci bloků umístěných na vápenci (modrá) a žule (červená barva) N N P C C P N C P C P N P P N C C N 285

 286 Silvertown et al.")
271 letecký pohled plán zásahů MANIPULATIVNÍ EXPERIMENTY PŘÍPADOVÉ STUDIE ROTHAMSTED (ENGLAND) PARK GRASSLAND EXPERIMENT (ZALOŽEN 1843) 286 Silvertown et al. (2006) J. Ecol.
 (http://www.rothamsted.ac.")
272 MANIPULATIVNÍ EXPERIMENTY PŘÍPADOVÉ STUDIE ROTHAMSTED (ENGLAND) PARK GRASSLAND EXP. 287 Třídění bylinné biomasy do druhů (kolem roku 1930) (


273 MANIPULATIVNÍ EXPERIMENTY PŘÍPADOVÉ STUDIE KOMPETICE O SVĚTLO V EXPERIMENTÁLNÍM PROSTŘEDÍ Při vyšším přísunu živin rostou rostliny rychleji a začnou si konkurovat o světlo tak proč jim trochu nepřisvítit? Hautier et al. (2009) Science 324:
274 MANIPULATIVNÍ EXPERIMENTY PŘÍPADOVÉ STUDIE KOMPETICE O SVĚTLO V EXPERIMENTÁLNÍM PROSTŘEDÍ 289 Hautier et al. (2009) Science 324:


275 MANIPULATIVNÍ EXPERIMENTY PŘÍPADOVÉ STUDIE STANOVENÍ POTENCIÁLNÍ STANOVIŠTNÍ PRODUKTIVITY V DOUBRAVÁCH PĚSTOVÁNÍM ŘEDKVIČEK VE SKLENÍKU 290 Veselá et. al (2008): Bioassay experiment for assessment of site productivity in oak forests. - 17th International Workshop European Vegetation Survey, Brno, Czech Republic,



276 MANIPULATIVNÍ EXPERIMENTY PŘÍPADOVÉ STUDIE MEZOKOSMOVÝ EXPERIMENT S HMYZEM A PREDÁTORY Kádě, které samy o sobě nejsou obsazeny predátory (larvy vážek a pstruzi), ale jsou v blízkosti kádí s predátory, jsou pro létající hmyz kladoucí vajíčka stejně neatraktivní jako vlastní kádě s predátory. na začátku experimentu Wesner et al. (2012) Ecology 93:





277 MANIPULATIVNÍ EXPERIMENTY PŘÍPADOVÉ STUDIE VLIV HERBIVORNÍCH RYB NA DRUHOVÉ SLOŽENÍ KORÁLOVÝCH ÚTESŮ hustá klec zabrání všem rybám na začátku experimentu... řídká klec zabrání jen velkým rybám... a po čtyřech měsících pod klecí Atol Agatti (Lakedivy, Indie) 292 Autor: Nicole Černohorská (v rámci disertační práce)

278 detailní pohled na korálový útes s nárostem řas (autor: Nicole Černohorská) 293
279 PŘÍRODNÍ EXPERIMENT (OBSERVAČNÍ STUDIE) ROZMÍSTĚNÍ VZORKOVACÍCH PLOCH Preferenční 294
280 PŘÍRODNÍ EXPERIMENT (OBSERVAČNÍ STUDIE) ROZMÍSTĚNÍ VZORKOVACÍCH PLOCH Systematické rozmístění v síti (lattice) 295
281 PŘÍRODNÍ EXPERIMENT (OBSERVAČNÍ STUDIE) ROZMÍSTĚNÍ VZORKOVACÍCH PLOCH Systematické rozmístění v síti (grid) 296
282 PŘÍRODNÍ EXPERIMENT (OBSERVAČNÍ STUDIE) ROZMÍSTĚNÍ VZORKOVACÍCH PLOCH Systematické rozmístění na transektu 297
283 PŘÍRODNÍ EXPERIMENT (OBSERVAČNÍ STUDIE) ROZMÍSTĚNÍ VZORKOVACÍCH PLOCH Náhodné rozmístění 298
284 PŘÍRODNÍ EXPERIMENT (OBSERVAČNÍ STUDIE) ROZMÍSTĚNÍ VZORKOVACÍCH PLOCH Preferenční rozmístění statistické hledisko: snímky nejsou náhodným výběrem, což limituje jejich použití při statistických analýzách (Lajer 2007, Folia Geobotanica) hledisko vegetačního ekologa: popisují maximální variabilitu vegetace praktické důsledky: snímky bývají druhově bohatší, obsahují větší počet diagnostických nebo vzácných druhů Náhodné (a systematické) rozmístění statistické hledisko: snímky jsou náhodným výběrem v reálném prostoru (ne ale v ekologickém hyperprostoru) hledisko veg. ekologa: nezachytí celou variabilitu vegetace - chybí maloplošné a vzácné vegetační typy, převládají velkoplošné a běžné typy, zahrnují řadu špatně klasifikovatelných vegetačních přechodů praktické důsledky: snímky odrážejí reálnou strukturu a bohatost vegetace v krajině, ale metoda je neúměrně pracná 299
285 PŘÍRODNÍ EXPERIMENT (OBSERVAČNÍ STUDIE) ROZMÍSTĚNÍ VZORKOVACÍCH PLOCH Stratifikované náhodné rozmístění 300

286 STRATIFIKACE KRAJINY V GIS Teplota Srážky Půdní typy Stratifikované jednotky Austin et al

287 PROSTOROVÁ AUTOKORELACE bližší plochy jsou si podobnější 302


288 PROSTOROVÁ AUTOKORELACE vlastnosti určitého pozorování (vzorku) mohou být do určité míry odvozeny z pozorování v jeho okolí jednotlivá pozorování na sobě nejsou nezávislá běžná vlastnost prakticky všech reálných ekologických dat příroda se nechová podle zákonů statistiky může být pozitivní (bližší vzorky jsou si podobnější než by odpovídalo jejich náhodnému výběru) nebo negativní (sousední vzorky jsou si méně podobné než kdyby byly vybrány náhodou, např. v důsledku tzv. Janzen-Connellovy hypotézy) Vše souvisí se vším, ale bližší věci spolu souvisejí více než ty vzdálené Waldo Tobler (1969), První zákon geografie 303
289 PROSTOROVÁ AUTOKORELACE Co způsobuje prostorovou autokorelaci biologických dat? omezené možnosti disperze, genetický tok nebo klonální růst sousedé jsou si podobnější organismy jsou omezeny ekologickými faktory (například vlhkost nebo teplota), které jsou samy o sobě prostorově autokorelovány Jak se prostorová autokorelace projevuje při analýze dat? pozitivní PA zvyšuje pravděpodobnost chyby prvního druhy (Type I error), totiž že zamítneme nulovou hypotézu, která platí (statistické testy vycházejí průkazněji než by měly) negativní PA způsobuje opačný efekt problém je v počtu stupňů volnosti (degrees of freedom): pokud si stupně volnosti představíme jako množství informace, kterou každý nový vzorek přináší, pak každý nový nezávislý vzorek přináší jeden stupeň volnosti, ale prostorově autokorelovaný vzorek přináší méně 304
290 PROSTOROVÁ AUTOKORELACE Příklad: Vliv nadmořské výšky na vegetaci, studovaný pomocí transektů vedených podél nadmořské výšky prostorově neautokorelované transekty (každý transekt na různé hoře) prostorově autokorelované transekty (paralelně vedle sebe na jedné hoře) 305
291 PROBLÉM PROSTOROVÉ ŠKÁLY (SCALE OF THE STUDY) zrno (grain size) velikost nejmenší studované jednotky, zpravidla vzorkované plochy, dána vlastností a velikostí studovaných organismů rozsah (extent) velikost studovaného území, zachycení různých ekologických faktorů interval vzdálenost mezi vzorkovanými plochami Platí pravidlo, že studie malého rozsahu jsou hůře zobecnitelné 306 Legendre & Legendre (1998)
292 TVAR PLOCHY čtvercová obdélníková kruhová čtverec obdélník kruh celková plocha 100 m m m 2 rozměr tvaru m 20 5 m poloměr 5,64 m obvod 40 m 50 m ~ 35 m 307
293 gradient prostředí VLIV TVARU A ORIENTACE PLOCHY NA ZAZNAMENANOU DRUHOVOU BOHATOST obdélníkové plochy mohou mít vyšší druhovou bohatost než čtvercové plochy (o stejné ploše) 309 Stohlgren et al. (1995) Vegetatio 117: ; Condit et al. (1996) J.Ecol. 84: ; Keeley & Fotheringham (2005) J.Veg.Sci. 16:
294 VELIKOST PLOCHY STUDIUM VEGETACE NA VÍCE MĚŘÍTCÍCH SOUČASNĚ 310
: Louky Bílých Karpat.")
295 VELIKOST PLOCHY STUDIUM VEGETACE NA VÍCE MĚŘÍTCÍCH SOUČASNĚ Vztah mezi velikostí snímku a počtem druhů ve snímku bělokarpatské louky ve srovnání s jinými typy travinné vegetace Jongepierová [ed.](2008): Louky Bílých Karpat. 311
EKOLOGICKÁ PODOBNOST (ECOLOGICAL RESEMBLANCE) David Zelený Zpracování dat v ekologii společenstev
 David Zelený Zpracování dat v ekologii společenstev") EKOLOGICKÁ PODOBNOST (ECOLOGICAL RESEMBLANCE) EKOLOGICKÁ PODOBNOST Q VS R ANALÝZA Vzorky Druhy druh 1 druh 2 druh 3 vzorek 1 0 1 1 vzorek 2 1 0 0 vzorek 3 0 4 4 vztahy mezi vzorky Q analýza vztahy mezi
EKOLOGICKÁ PODOBNOST (ECOLOGICAL RESEMBLANCE) EKOLOGICKÁ PODOBNOST Q VS R ANALÝZA Vzorky Druhy druh 1 druh 2 druh 3 vzorek 1 0 1 1 vzorek 2 1 0 0 vzorek 3 0 4 4 vztahy mezi vzorky Q analýza vztahy mezi
PCA BIPLOT ŠKÁLOVÁNÍ OS (1)
") PCA BIPLOT ŠKÁLOVÁNÍ OS (1) 1 (sites) o zaměření na odlišnosti mezi lokalitami zachovány euklidovské vzdálenosti mezi vzorky úhly mezi šipkami neodpovídají kovariancím (korelacím) proměnných variance skóre
PCA BIPLOT ŠKÁLOVÁNÍ OS (1) 1 (sites) o zaměření na odlišnosti mezi lokalitami zachovány euklidovské vzdálenosti mezi vzorky úhly mezi šipkami neodpovídají kovariancím (korelacím) proměnných variance skóre
ZPRACOVÁNÍ DAT V EKOLOGII SPOLEČENSTEV
 ZPRACOVÁNÍ DAT V EKOLOGII SPOLEČENSTEV OSNOVA PŘEDNÁŠKY Typy sbíraných dat kategoriální vs kvantitativní, pokryvnosti, frekvence Příprava dat pro numerické analýzy čištění dat, odlehlé body, transformace,
ZPRACOVÁNÍ DAT V EKOLOGII SPOLEČENSTEV OSNOVA PŘEDNÁŠKY Typy sbíraných dat kategoriální vs kvantitativní, pokryvnosti, frekvence Příprava dat pro numerické analýzy čištění dat, odlehlé body, transformace,
PŘÍKLADY POUŽITÍ ORDINAČNÍCH METOD
 PŘÍKLADY POUŽITÍ ORDINAČNÍCH METOD 1 PŘÍKLAD NA ROZKLAD VARIANCE SPOLEČENSTVA MĚKKÝŠŮ NA PRAMENIŠTÍCH druhové složení společenstev měkkýšů druhové složení slatiništní vegetace ph Ca cond Mg Na měřené proměnné
PŘÍKLADY POUŽITÍ ORDINAČNÍCH METOD 1 PŘÍKLAD NA ROZKLAD VARIANCE SPOLEČENSTVA MĚKKÝŠŮ NA PRAMENIŠTÍCH druhové složení společenstev měkkýšů druhové složení slatiništní vegetace ph Ca cond Mg Na měřené proměnné
ZPRACOVÁNÍ DAT V EKOLOGII SPOLEČENSTEV
 ZPRACOVÁNÍ DAT V EKOLOGII SPOLEČENSTEV OSNOVA PŘEDNÁŠKY Příprava dat pro numerické analýzy typy sbíraných dat, čištění dat, odlehlé body, transformace, standardizace, EDA Ekologická podobnost indexy podobnosti
ZPRACOVÁNÍ DAT V EKOLOGII SPOLEČENSTEV OSNOVA PŘEDNÁŠKY Příprava dat pro numerické analýzy typy sbíraných dat, čištění dat, odlehlé body, transformace, standardizace, EDA Ekologická podobnost indexy podobnosti
ZPRACOVÁNÍ DAT V EKOLOGII
 ZPRACOVÁNÍ DAT V EKOLOGII SPOLEČENSTEV VÍT SYROVÁTKA OSNOVA PŘEDNÁŠKY o Příprava dat pro numerické analýzy typy sbíraných dat, čištění dat, odlehlé body, transformace, standardizace, EDA o Ekologická podobnost
ZPRACOVÁNÍ DAT V EKOLOGII SPOLEČENSTEV VÍT SYROVÁTKA OSNOVA PŘEDNÁŠKY o Příprava dat pro numerické analýzy typy sbíraných dat, čištění dat, odlehlé body, transformace, standardizace, EDA o Ekologická podobnost
ZPRACOVÁNÍ DAT V EKOLOGII SPOLEČENSTEV
 ZPRACOVÁNÍ DAT V EKOLOGII SPOLEČENSTEV OSNOVA PŘEDNÁŠKY Typy sbíraných dat kategoriální vs kvantitativní, pokryvnosti, frekvence Příprava dat pro numerické analýzy čištění dat, odlehlé body, transformace,
ZPRACOVÁNÍ DAT V EKOLOGII SPOLEČENSTEV OSNOVA PŘEDNÁŠKY Typy sbíraných dat kategoriální vs kvantitativní, pokryvnosti, frekvence Příprava dat pro numerické analýzy čištění dat, odlehlé body, transformace,
David Zelený GRADIENTOVÁ ANALÝZA
 David Zelený Zpracování dat v ekologii společenstev G GRADIENTOVÁ ANALÝZA HISTORIE WHITTAKER 1956 - PŘÍMÁ GRADIENTOVÁ ANALÝZA Zpracování dat v ekologii společenstev 108 Whittaker (1956): Vegetation of
David Zelený Zpracování dat v ekologii společenstev G GRADIENTOVÁ ANALÝZA HISTORIE WHITTAKER 1956 - PŘÍMÁ GRADIENTOVÁ ANALÝZA Zpracování dat v ekologii společenstev 108 Whittaker (1956): Vegetation of
ZPRACOVÁNÍ DAT V EKOLOGII
 ZPRACOVÁNÍ DAT V EKOLOGII SPOLEČENSTEV VÍT SYROVÁTKA OSNOVA PŘEDNÁŠKY o Příprava dat pro numerické analýzy typy sbíraných dat, čištění dat, odlehlé body, transformace, standardizace, EDA o Ekologická podobnost
ZPRACOVÁNÍ DAT V EKOLOGII SPOLEČENSTEV VÍT SYROVÁTKA OSNOVA PŘEDNÁŠKY o Příprava dat pro numerické analýzy typy sbíraných dat, čištění dat, odlehlé body, transformace, standardizace, EDA o Ekologická podobnost
ZPRACOVÁNÍ DAT V EKOLOGII SPOLEČENSTEV
 ZPRACOVÁNÍ DAT V EKOLOGII SPOLEČENSTEV OSNOVA PŘEDNÁŠKY Příprava dat pro numerické analýzy čištění dat, odlehlé body, transformace, standardizace, EDA Design ekologických experimentů manipulativní experimenty
ZPRACOVÁNÍ DAT V EKOLOGII SPOLEČENSTEV OSNOVA PŘEDNÁŠKY Příprava dat pro numerické analýzy čištění dat, odlehlé body, transformace, standardizace, EDA Design ekologických experimentů manipulativní experimenty
ZPRACOVÁNÍ DAT V EKOLOGII SPOLEČENSTEV
 ZPRACOVÁNÍ DAT V EKOLOGII SPOLEČENSTEV OSNOVA PŘEDNÁŠKY Příprava dat pro numerické analýzy čištění dat, odlehlé body, transformace, standardizace, EDA Design ekologických experimentů manipulativní experimenty
ZPRACOVÁNÍ DAT V EKOLOGII SPOLEČENSTEV OSNOVA PŘEDNÁŠKY Příprava dat pro numerické analýzy čištění dat, odlehlé body, transformace, standardizace, EDA Design ekologických experimentů manipulativní experimenty
ELLENBERGOVY INDIKAČNÍ HODNOTY. David Zelený Zpracování dat v ekologii společenstev
 3 2 6 6 5 2 ELLENBERGOVY INDIKAČNÍ HODNOTY ELLENBERGOVY INDIKAČNÍ HODNOTY (EIH) optima druhů rostlin na gradientu živin, vlhkosti, půdní reakce, kontinentality, teploty, světla a salinity (salinita se
3 2 6 6 5 2 ELLENBERGOVY INDIKAČNÍ HODNOTY ELLENBERGOVY INDIKAČNÍ HODNOTY (EIH) optima druhů rostlin na gradientu živin, vlhkosti, půdní reakce, kontinentality, teploty, světla a salinity (salinita se
STATISTICKÉ METODY; ZÍSKÁVÁNÍ INFORMACÍ Z DRUHOVÝCH A ENVIRONMENTÁLNÍCH DAT
 STATISTICKÉ METODY; ZÍSKÁVÁNÍ INFORMACÍ Z DRUHOVÝCH A ENVIRONMENTÁLNÍCH DAT (NE)VÝHODY STATISTIKY OTÁZKY si klást ještě před odběrem a podle nich naplánovat design, metodiku odběru (experimentální vs.
STATISTICKÉ METODY; ZÍSKÁVÁNÍ INFORMACÍ Z DRUHOVÝCH A ENVIRONMENTÁLNÍCH DAT (NE)VÝHODY STATISTIKY OTÁZKY si klást ještě před odběrem a podle nich naplánovat design, metodiku odběru (experimentální vs.
Úvodem Dříve les než stromy 3 Operace s maticemi
 Obsah 1 Úvodem 13 2 Dříve les než stromy 17 2.1 Nejednoznačnost terminologie 17 2.2 Volba metody analýzy dat 23 2.3 Přehled vybraných vícerozměrných metod 25 2.3.1 Metoda hlavních komponent 26 2.3.2 Faktorová
Obsah 1 Úvodem 13 2 Dříve les než stromy 17 2.1 Nejednoznačnost terminologie 17 2.2 Volba metody analýzy dat 23 2.3 Přehled vybraných vícerozměrných metod 25 2.3.1 Metoda hlavních komponent 26 2.3.2 Faktorová
ZPRACOVÁNÍ DAT V EKOLOGII SPOLEČENSTEV
 ZPRACOVÁNÍ DAT V EKOLOGII SPOLEČENSTEV OSNOVA PŘEDNÁŠKY Příprava dat pro numerické analýzy čištění dat, odlehlé body, transformace, standardizace, EDA Design ekologických experimentů manipulativní experimenty
ZPRACOVÁNÍ DAT V EKOLOGII SPOLEČENSTEV OSNOVA PŘEDNÁŠKY Příprava dat pro numerické analýzy čištění dat, odlehlé body, transformace, standardizace, EDA Design ekologických experimentů manipulativní experimenty
ELLENBERGOVY INDIKAČNÍ HODNOTY. David Zelený Zpracování dat v ekologii společenstev
 3 2 6 6 5 2 ELLENBERGOVY INDIKAČNÍ HODNOTY ELLENBERGOVY INDIKAČNÍ HODNOTY (EIH) optima druhů rostlin na gradientu ţivin, vlhkosti, půdní reakce, kontinentality, teploty, světla a salinity (salinita se
3 2 6 6 5 2 ELLENBERGOVY INDIKAČNÍ HODNOTY ELLENBERGOVY INDIKAČNÍ HODNOTY (EIH) optima druhů rostlin na gradientu ţivin, vlhkosti, půdní reakce, kontinentality, teploty, světla a salinity (salinita se
Analýza dat na PC I.
 CENTRUM BIOSTATISTIKY A ANALÝZ Lékařská a Přírodovědecká fakulta, Masarykova univerzita Analýza dat na PC I. Popisná analýza v programu Statistica IBA výuka Základní popisná statistika Popisná statistika
CENTRUM BIOSTATISTIKY A ANALÝZ Lékařská a Přírodovědecká fakulta, Masarykova univerzita Analýza dat na PC I. Popisná analýza v programu Statistica IBA výuka Základní popisná statistika Popisná statistika
Vícerozměrné statistické metody
 Vícerozměrné statistické metody Ordinační analýzy principy redukce dimenzionality Jiří Jarkovský, Simona Littnerová FSTA: Pokročilé statistické metody Ordinační analýza a její cíle Cíle ordinační analýzy
Vícerozměrné statistické metody Ordinační analýzy principy redukce dimenzionality Jiří Jarkovský, Simona Littnerová FSTA: Pokročilé statistické metody Ordinační analýza a její cíle Cíle ordinační analýzy
Hluboká říční údolí jako objekt pro modelování vztahů vegetace a proměnných prostředí?
 David Zelený Biologická fakulta JčU v Českých Budějovicích školitel: Milan Chytrý (PřF MU Brno) Hluboká říční údolí jako objekt pro modelování vztahů vegetace a proměnných prostředí? Vltava pod Dívčím
David Zelený Biologická fakulta JčU v Českých Budějovicích školitel: Milan Chytrý (PřF MU Brno) Hluboká říční údolí jako objekt pro modelování vztahů vegetace a proměnných prostředí? Vltava pod Dívčím
Korelační a regresní analýza. 1. Pearsonův korelační koeficient 2. jednoduchá regresní analýza 3. vícenásobná regresní analýza
 Korelační a regresní analýza 1. Pearsonův korelační koeficient 2. jednoduchá regresní analýza 3. vícenásobná regresní analýza Pearsonův korelační koeficient u intervalových a poměrových dat můžeme jako
Korelační a regresní analýza 1. Pearsonův korelační koeficient 2. jednoduchá regresní analýza 3. vícenásobná regresní analýza Pearsonův korelační koeficient u intervalových a poměrových dat můžeme jako
INDEXY DIVERZITY. David Zelený Zpracování dat v ekologii společenstev
 INDEXY DIVERZITY Jurasinski et al. (2009) ALFA, BETA A GAMA DIVERZITA Alfa diverzita druhová bohatost vzorku Beta diverzita (species turnover) změna v druhovém složení mezi vzorky Gama diverzita celková
INDEXY DIVERZITY Jurasinski et al. (2009) ALFA, BETA A GAMA DIVERZITA Alfa diverzita druhová bohatost vzorku Beta diverzita (species turnover) změna v druhovém složení mezi vzorky Gama diverzita celková
Vícerozměrné statistické metody
 Vícerozměrné statistické metody Podobnosti a vzdálenosti ve vícerozměrném prostoru, asociační matice II Jiří Jarkovský, Simona Littnerová Vícerozměrné statistické metody Práce s asociační maticí Vzdálenosti
Vícerozměrné statistické metody Podobnosti a vzdálenosti ve vícerozměrném prostoru, asociační matice II Jiří Jarkovský, Simona Littnerová Vícerozměrné statistické metody Práce s asociační maticí Vzdálenosti
Obsah Úvod Kapitola 1 Než začneme Kapitola 2 Práce s hromadnými daty před analýzou
 Úvod.................................................................. 11 Kapitola 1 Než začneme.................................................................. 17 1.1 Logika kvantitativního výzkumu...........................................
Úvod.................................................................. 11 Kapitola 1 Než začneme.................................................................. 17 1.1 Logika kvantitativního výzkumu...........................................
RNDr. Eva Janoušová doc. RNDr. Ladislav Dušek, Dr.
 Analýza dat pro Neurovědy RNDr. Eva Janoušová doc. RNDr. Ladislav Dušek, Dr. Jaro 2014 Institut biostatistiky Janoušová, a analýz Dušek: Analýza dat pro neurovědy Blok 7 Jak hodnotit vztah spojitých proměnných
Analýza dat pro Neurovědy RNDr. Eva Janoušová doc. RNDr. Ladislav Dušek, Dr. Jaro 2014 Institut biostatistiky Janoušová, a analýz Dušek: Analýza dat pro neurovědy Blok 7 Jak hodnotit vztah spojitých proměnných
INDEXY DIVERZITY. David Zelený Zpracování dat v ekologii společenstev
 INDEXY DIVERZITY ALFA, BETA A GAMA DIVERZITA Alfa diverzita druhová bohatost vzorku Beta diverzita (species turnover) změna v druhovém složení mezi vzorky Gama diverzita celková druhová bohatost regionu
INDEXY DIVERZITY ALFA, BETA A GAMA DIVERZITA Alfa diverzita druhová bohatost vzorku Beta diverzita (species turnover) změna v druhovém složení mezi vzorky Gama diverzita celková druhová bohatost regionu
NUMERICKÁ KLASIFIKACE. David Zelený Zpracování dat v ekologii společenstev
 NUMERICKÁ KLASIFIKACE http://wfc3.gsfc.nasa.gov PROČ MÁ SMYSL VĚCI KLASIFIKOVAT? vlnová délka (~ ekologický gradient) 172 http://wfc3.gsfc.nasa.gov PROČ MÁ SMYSL VĚCI KLASIFIKOVAT? vlnová délka (~ ekologický
NUMERICKÁ KLASIFIKACE http://wfc3.gsfc.nasa.gov PROČ MÁ SMYSL VĚCI KLASIFIKOVAT? vlnová délka (~ ekologický gradient) 172 http://wfc3.gsfc.nasa.gov PROČ MÁ SMYSL VĚCI KLASIFIKOVAT? vlnová délka (~ ekologický
Grafický a číselný popis rozložení dat 3.1 Způsoby zobrazení dat Metody zobrazení kvalitativních a ordinálních dat Metody zobrazení kvan
 1 Úvod 1.1 Empirický výzkum a jeho etapy 1.2 Význam teorie pro výzkum 1.2.1 Konstrukty a jejich operacionalizace 1.2.2 Role teorie ve výzkumu 1.2.3 Proces ověření hypotéz a teorií 1.3 Etika vědecké práce
1 Úvod 1.1 Empirický výzkum a jeho etapy 1.2 Význam teorie pro výzkum 1.2.1 Konstrukty a jejich operacionalizace 1.2.2 Role teorie ve výzkumu 1.2.3 Proces ověření hypotéz a teorií 1.3 Etika vědecké práce
Pokud data zadáme přes "Commands" okno: SDF1$X1<-c(1:15) //vytvoření řady čísel od 1 do 15 SDF1$Y1<-c(1.5,3,4.5,5,6,8,9,11,13,14,15,16,18.
 //vytvoření řady čísel od 1 do 15 SDF1$Y1<-c(1.5,3,4.5,5,6,8,9,11,13,14,15,16,18.") Regresní analýza; transformace dat Pro řešení vztahů mezi proměnnými kontinuálního typu používáme korelační a regresní analýzy. Korelace se používá pokud nelze určit "kauzalitu". Regresní analýza je určena
Regresní analýza; transformace dat Pro řešení vztahů mezi proměnnými kontinuálního typu používáme korelační a regresní analýzy. Korelace se používá pokud nelze určit "kauzalitu". Regresní analýza je určena
PRŮZKUMOVÁ ANALÝZA JEDNOROZMĚRNÝCH DAT Exploratory Data Analysis (EDA)
") PRŮZKUMOVÁ ANALÝZA JEDNOROZMĚRNÝCH DAT Exploratory Data Analysis (EDA) Reprezentativní náhodný výběr: 1. Prvky výběru x i jsou vzájemně nezávislé. 2. Výběr je homogenní, tj. všechna x i jsou ze stejného
PRŮZKUMOVÁ ANALÝZA JEDNOROZMĚRNÝCH DAT Exploratory Data Analysis (EDA) Reprezentativní náhodný výběr: 1. Prvky výběru x i jsou vzájemně nezávislé. 2. Výběr je homogenní, tj. všechna x i jsou ze stejného
KORELACE. Komentované řešení pomocí programu Statistica
 KORELACE Komentované řešení pomocí programu Statistica Vstupní data I Data umístěná v excelovském souboru překopírujeme do tabulky ve Statistice a pojmenujeme proměnné, viz prezentace k tématu Popisná
KORELACE Komentované řešení pomocí programu Statistica Vstupní data I Data umístěná v excelovském souboru překopírujeme do tabulky ve Statistice a pojmenujeme proměnné, viz prezentace k tématu Popisná
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz
 Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická
Popisná statistika. Statistika pro sociology
 Popisná statistika Jitka Kühnová Statistika pro sociology 24. září 2014 Jitka Kühnová (GSTAT) Popisná statistika 24. září 2014 1 / 31 Outline 1 Základní pojmy 2 Typy statistických dat 3 Výběrové charakteristiky
Popisná statistika Jitka Kühnová Statistika pro sociology 24. září 2014 Jitka Kühnová (GSTAT) Popisná statistika 24. září 2014 1 / 31 Outline 1 Základní pojmy 2 Typy statistických dat 3 Výběrové charakteristiky
Matematika III. 27. listopadu Vysoká škola báňská - Technická univerzita Ostrava. Matematika III
 Vysoká škola báňská - Technická univerzita Ostrava 27. listopadu 2017 Typy statistických znaků (proměnných) Typy proměnných: Kvalitativní proměnná (kategoriální, slovní,... ) Kvantitativní proměnná (numerická,
Vysoká škola báňská - Technická univerzita Ostrava 27. listopadu 2017 Typy statistických znaků (proměnných) Typy proměnných: Kvalitativní proměnná (kategoriální, slovní,... ) Kvantitativní proměnná (numerická,
Cronbachův koeficient α nová adaptovaná metoda uvedení vlastností položkové analýzy deskriptivní induktivní parametrické
 Československá psychologie 0009-062X Metodologické požadavky na výzkumné studie METODOLOGICKÉ POŽADAVKY NA VÝZKUMNÉ STUDIE Výzkumné studie mají přinášet nová konkrétní zjištění získaná specifickými výzkumnými
Československá psychologie 0009-062X Metodologické požadavky na výzkumné studie METODOLOGICKÉ POŽADAVKY NA VÝZKUMNÉ STUDIE Výzkumné studie mají přinášet nová konkrétní zjištění získaná specifickými výzkumnými
Regresní analýza. Eva Jarošová
 Regresní analýza Eva Jarošová 1 Obsah 1. Regresní přímka 2. Možnosti zlepšení modelu 3. Testy v regresním modelu 4. Regresní diagnostika 5. Speciální využití Lineární model 2 1. Regresní přímka 3 nosnost
Regresní analýza Eva Jarošová 1 Obsah 1. Regresní přímka 2. Možnosti zlepšení modelu 3. Testy v regresním modelu 4. Regresní diagnostika 5. Speciální využití Lineární model 2 1. Regresní přímka 3 nosnost
RNDr. Eva Janoušová doc. RNDr. Ladislav Dušek, Dr.
 Analýza dat pro Neurovědy RNDr. Eva Janoušová doc. RNDr. Ladislav Dušek, Dr. Jaro 2014 Institut biostatistiky Janoušová, a analýz Dušek: Analýza dat pro neurovědy Blok 3 Jak a kdy použít parametrické a
Analýza dat pro Neurovědy RNDr. Eva Janoušová doc. RNDr. Ladislav Dušek, Dr. Jaro 2014 Institut biostatistiky Janoušová, a analýz Dušek: Analýza dat pro neurovědy Blok 3 Jak a kdy použít parametrické a
Statistika, Biostatistika pro kombinované studium Letní semestr 2011/2012. Tutoriál č. 4: Exploratorní analýza. Jan Kracík
 Statistika, Biostatistika pro kombinované studium Letní semestr 2011/2012 Tutoriál č. 4: Exploratorní analýza Jan Kracík jan.kracik@vsb.cz Statistika věda o získávání znalostí z empirických dat empirická
Statistika, Biostatistika pro kombinované studium Letní semestr 2011/2012 Tutoriál č. 4: Exploratorní analýza Jan Kracík jan.kracik@vsb.cz Statistika věda o získávání znalostí z empirických dat empirická
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc.
 Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika 010 1.týden (0.09.-4.09. ) Data, typy dat, variabilita, frekvenční analýza
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika 010 1.týden (0.09.-4.09. ) Data, typy dat, variabilita, frekvenční analýza
Mann-Whitney U-test. Znaménkový test. Vytvořil Institut biostatistiky a analýz, Masarykova univerzita J. Jarkovský, L. Dušek
 10. Neparametrické y Mann-Whitney U- Wilcoxonův Znaménkový Shrnutí statistických ů Typ srovnání Nulová hypotéza Parametrický Neparametrický 1 skupina dat vs. etalon Střední hodnota je rovna hodnotě etalonu.
10. Neparametrické y Mann-Whitney U- Wilcoxonův Znaménkový Shrnutí statistických ů Typ srovnání Nulová hypotéza Parametrický Neparametrický 1 skupina dat vs. etalon Střední hodnota je rovna hodnotě etalonu.
Zpracování studie týkající se průzkumu vlastností statistických proměnných a vztahů mezi nimi.
 SEMINÁRNÍ PRÁCE Zadání: Data: Statistické metody: Zpracování studie týkající se průzkumu vlastností statistických proměnných a vztahů mezi nimi. Minimálně 6 proměnných o 30 pozorováních (z toho 2 proměnné
SEMINÁRNÍ PRÁCE Zadání: Data: Statistické metody: Zpracování studie týkající se průzkumu vlastností statistických proměnných a vztahů mezi nimi. Minimálně 6 proměnných o 30 pozorováních (z toho 2 proměnné
Pravděpodobnost v závislosti na proměnné x je zde modelován pomocí logistického modelu. exp x. x x x. log 1
 Logistická regrese Menu: QCExpert Regrese Logistická Modul Logistická regrese umožňuje analýzu dat, kdy odezva je binární, nebo frekvenční veličina vyjádřená hodnotami 0 nebo 1, případně poměry v intervalu
Logistická regrese Menu: QCExpert Regrese Logistická Modul Logistická regrese umožňuje analýzu dat, kdy odezva je binární, nebo frekvenční veličina vyjádřená hodnotami 0 nebo 1, případně poměry v intervalu
Základy popisné statistiky. Vytvořil Institut biostatistiky a analýz, Masarykova univerzita J. Jarkovský, L. Dušek
 Základy popisné statistiky Anotace Realitu můžeme popisovat různými typy dat, každý z nich se specifickými vlastnostmi, výhodami, nevýhodami a vlastní sadou využitelných statistických metod -od binárních
Základy popisné statistiky Anotace Realitu můžeme popisovat různými typy dat, každý z nich se specifickými vlastnostmi, výhodami, nevýhodami a vlastní sadou využitelných statistických metod -od binárních
2019/03/31 17:38 1/2 Klasifikační a regresní stromy
 2019/03/31 17:38 1/2 Klasifikační a regresní stromy Table of Contents Klasifikační a regresní stromy... 1 rpart (library rpart)... 1 draw.tree (library maptree)... 3 plotcp a rsq.rpart (library rpart)...
2019/03/31 17:38 1/2 Klasifikační a regresní stromy Table of Contents Klasifikační a regresní stromy... 1 rpart (library rpart)... 1 draw.tree (library maptree)... 3 plotcp a rsq.rpart (library rpart)...
Fakulta chemicko-technologická Katedra analytické chemie. 3.2 Metody s latentními proměnnými a klasifikační metody
 Fakulta chemicko-technologická Katedra analytické chemie 3.2 Metody s latentními proměnnými a klasifikační metody Vypracoval: Ing. Tomáš Nekola Studium: licenční Datum: 21. 1. 2008 Otázka 1. Vypočtěte
Fakulta chemicko-technologická Katedra analytické chemie 3.2 Metody s latentními proměnnými a klasifikační metody Vypracoval: Ing. Tomáš Nekola Studium: licenční Datum: 21. 1. 2008 Otázka 1. Vypočtěte
Regresní a korelační analýza
 Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
6. Lineární regresní modely
 6. Lineární regresní modely 6.1 Jednoduchá regrese a validace 6.2 Testy hypotéz v lineární regresi 6.3 Kritika dat v regresním tripletu 6.4 Multikolinearita a polynomy 6.5 Kritika modelu v regresním tripletu
6. Lineární regresní modely 6.1 Jednoduchá regrese a validace 6.2 Testy hypotéz v lineární regresi 6.3 Kritika dat v regresním tripletu 6.4 Multikolinearita a polynomy 6.5 Kritika modelu v regresním tripletu
1. Číselné posloupnosti - Definice posloupnosti, základní vlastnosti, operace s posloupnostmi, limita posloupnosti, vlastnosti limit posloupností,
 KMA/SZZS1 Matematika 1. Číselné posloupnosti - Definice posloupnosti, základní vlastnosti, operace s posloupnostmi, limita posloupnosti, vlastnosti limit posloupností, operace s limitami. 2. Limita funkce
KMA/SZZS1 Matematika 1. Číselné posloupnosti - Definice posloupnosti, základní vlastnosti, operace s posloupnostmi, limita posloupnosti, vlastnosti limit posloupností, operace s limitami. 2. Limita funkce
PSY117/454 Statistická analýza dat v psychologii seminář 9. Statistické testování hypotéz
 PSY117/454 Statistická analýza dat v psychologii seminář 9 Statistické testování hypotéz Základní výzkumné otázky/hypotézy 1. Stanovení hodnoty parametru =stanovení intervalu spolehlivosti na μ, σ, ρ,
PSY117/454 Statistická analýza dat v psychologii seminář 9 Statistické testování hypotéz Základní výzkumné otázky/hypotézy 1. Stanovení hodnoty parametru =stanovení intervalu spolehlivosti na μ, σ, ρ,
Ordinační analýzy v programu JUICE
 Ordinační analýzy v programu JUICE Martina Nejezchlebová, Blansko, 30. 8. 2011 1.1 Ordinační analýzy Jsou nedílnou součástí mnoha vegetačních a ekologických analýz. V programu JUICE (Tichý 2002) v kombinaci
Ordinační analýzy v programu JUICE Martina Nejezchlebová, Blansko, 30. 8. 2011 1.1 Ordinační analýzy Jsou nedílnou součástí mnoha vegetačních a ekologických analýz. V programu JUICE (Tichý 2002) v kombinaci
Regresní a korelační analýza
 Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
POPISNÁ STATISTIKA Komentované řešení pomocí programu Statistica
 POPISNÁ STATISTIKA Komentované řešení pomocí programu Statistica Program Statistica I Statistica je velmi podobná Excelu. Na základní úrovni je to klikací program určený ke statistickému zpracování dat.
POPISNÁ STATISTIKA Komentované řešení pomocí programu Statistica Program Statistica I Statistica je velmi podobná Excelu. Na základní úrovni je to klikací program určený ke statistickému zpracování dat.
Popisná statistika. Komentované řešení pomocí MS Excel
 Popisná statistika Komentované řešení pomocí MS Excel Vstupní data Máme k dispozici data o počtech bodů z 1. a 2. zápočtového testu z Matematiky I v zimním semestru 2015/2016 a to za všech 762 studentů,
Popisná statistika Komentované řešení pomocí MS Excel Vstupní data Máme k dispozici data o počtech bodů z 1. a 2. zápočtového testu z Matematiky I v zimním semestru 2015/2016 a to za všech 762 studentů,
INDUKTIVNÍ STATISTIKA
 10. SEMINÁŘ INDUKTIVNÍ STATISTIKA 3. HODNOCENÍ ZÁVISLOSTÍ HODNOCENÍ ZÁVISLOSTÍ KVALITATIVNÍ VELIČINY - Vychází se z kombinační (kontingenční) tabulky, která je výsledkem třídění druhého stupně KVANTITATIVNÍ
10. SEMINÁŘ INDUKTIVNÍ STATISTIKA 3. HODNOCENÍ ZÁVISLOSTÍ HODNOCENÍ ZÁVISLOSTÍ KVALITATIVNÍ VELIČINY - Vychází se z kombinační (kontingenční) tabulky, která je výsledkem třídění druhého stupně KVANTITATIVNÍ
ANALÝZA DAT V R 3. POPISNÉ STATISTIKY, NÁHODNÁ VELIČINA. Mgr. Markéta Pavlíková Katedra pravděpodobnosti a matematické statistiky MFF UK
 ANALÝZA DAT V R 3. POPISNÉ STATISTIKY, NÁHODNÁ VELIČINA Mgr. Markéta Pavlíková Katedra pravděpodobnosti a matematické statistiky MFF UK www.biostatisticka.cz POPISNÉ STATISTIKY - OPAKOVÁNÍ jedna kvalitativní
ANALÝZA DAT V R 3. POPISNÉ STATISTIKY, NÁHODNÁ VELIČINA Mgr. Markéta Pavlíková Katedra pravděpodobnosti a matematické statistiky MFF UK www.biostatisticka.cz POPISNÉ STATISTIKY - OPAKOVÁNÍ jedna kvalitativní
Korelace. Komentované řešení pomocí MS Excel
 Korelace Komentované řešení pomocí MS Excel Vstupní data Tabulka se vstupními daty je umístěna v oblasti A2:B84 (viz. obrázek) Prvotní představu o tvaru a síle závislosti docházky a počtu bodů nám poskytne
Korelace Komentované řešení pomocí MS Excel Vstupní data Tabulka se vstupními daty je umístěna v oblasti A2:B84 (viz. obrázek) Prvotní představu o tvaru a síle závislosti docházky a počtu bodů nám poskytne
Vytěžování znalostí z dat
 Pavel Kordík, Jan Motl (ČVUT FIT) Vytěžování znalostí z dat BI-VZD, 2012, Přednáška 1 1/32 Vytěžování znalostí z dat Pavel Kordík, Jan Motl Department of Computer Systems Faculty of Information Technology
Pavel Kordík, Jan Motl (ČVUT FIT) Vytěžování znalostí z dat BI-VZD, 2012, Přednáška 1 1/32 Vytěžování znalostí z dat Pavel Kordík, Jan Motl Department of Computer Systems Faculty of Information Technology
Přednáška XI. Asociace ve čtyřpolní tabulce a základy korelační analýzy
 Přednáška XI. Asociace ve čtyřpolní tabulce a základy korelační analýzy Relativní riziko a poměr šancí Princip korelace dvou náhodných veličin Korelační koeficienty Pearsonůva Spearmanův Korelace a kauzalita
Přednáška XI. Asociace ve čtyřpolní tabulce a základy korelační analýzy Relativní riziko a poměr šancí Princip korelace dvou náhodných veličin Korelační koeficienty Pearsonůva Spearmanův Korelace a kauzalita
PSY117/454 Statistická analýza dat v psychologii Přednáška 10
 PSY117/454 Statistická analýza dat v psychologii Přednáška 10 TESTY PRO NOMINÁLNÍ A ORDINÁLNÍ PROMĚNNÉ NEPARAMETRICKÉ METODY... a to mělo, jak sám vidíte, nedozírné následky. Smrť Analýza četností hodnot
PSY117/454 Statistická analýza dat v psychologii Přednáška 10 TESTY PRO NOMINÁLNÍ A ORDINÁLNÍ PROMĚNNÉ NEPARAMETRICKÉ METODY... a to mělo, jak sám vidíte, nedozírné následky. Smrť Analýza četností hodnot
Pokročilé neparametrické metody. Klára Kubošová
 Pokročilé neparametrické metody Klára Kubošová Pokročilé neparametrické metody Výuka 13 přednášek doplněných o praktické cvičení v SW Úvod do neparametrických metod + princip rozhodovacích stromů Klasifikační
Pokročilé neparametrické metody Klára Kubošová Pokročilé neparametrické metody Výuka 13 přednášek doplněných o praktické cvičení v SW Úvod do neparametrických metod + princip rozhodovacích stromů Klasifikační
DIVERZITA. David Zelený Zpracování dat v ekologii společenstev
 DIVERZITA ALFA, BETA A GAMA DIVERZITA Alfa diverzita druhová bohatost vzorku Beta diverzita (species turnover) změna v druhovém složení mezi vzorky heterogenita druhového složení Gama diverzita celková
DIVERZITA ALFA, BETA A GAMA DIVERZITA Alfa diverzita druhová bohatost vzorku Beta diverzita (species turnover) změna v druhovém složení mezi vzorky heterogenita druhového složení Gama diverzita celková
Statistika. cílem je zjednodušit nějaká data tak, abychom se v nich lépe vyznali důsledkem je ztráta informací!
 Statistika aneb známe tři druhy lži: úmyslná neúmyslná statistika Statistika je metoda, jak vyjádřit nejistá data s přesností na setinu procenta. den..00..00 3..00..00..00..00..00..00..00..00..00..00 3..00..00..00..00..00..00..00
Statistika aneb známe tři druhy lži: úmyslná neúmyslná statistika Statistika je metoda, jak vyjádřit nejistá data s přesností na setinu procenta. den..00..00 3..00..00..00..00..00..00..00..00..00..00 3..00..00..00..00..00..00..00
Kategorická data METODOLOGICKÝ PROSEMINÁŘ II TÝDEN 7 4. DUBNA dubna 2018 Lukáš Hájek, Karel Höfer Metodologický proseminář II 1
 Kategorická data METODOLOGICKÝ PROSEMINÁŘ II TÝDEN 7 4. DUBNA 2018 4. dubna 2018 Lukáš Hájek, Karel Höfer Metodologický proseminář II 1 Typy proměnných nominální (nominal) o dvou hodnotách lze říci pouze
Kategorická data METODOLOGICKÝ PROSEMINÁŘ II TÝDEN 7 4. DUBNA 2018 4. dubna 2018 Lukáš Hájek, Karel Höfer Metodologický proseminář II 1 Typy proměnných nominální (nominal) o dvou hodnotách lze říci pouze
Karta předmětu prezenční studium
 Karta předmětu prezenční studium Název předmětu: Číslo předmětu: 545-0250 Garantující institut: Garant předmětu: Ekonomická statistika Institut ekonomiky a systémů řízení RNDr. Radmila Sousedíková, Ph.D.
Karta předmětu prezenční studium Název předmětu: Číslo předmětu: 545-0250 Garantující institut: Garant předmětu: Ekonomická statistika Institut ekonomiky a systémů řízení RNDr. Radmila Sousedíková, Ph.D.
Statistická analýza jednorozměrných dat
 Statistická analýza jednorozměrných dat Prof. RNDr. Milan Meloun, DrSc. Univerzita Pardubice, Pardubice 31.ledna 2011 Tato prezentace je spolufinancována Evropským sociálním fondem a státním rozpočtem
Statistická analýza jednorozměrných dat Prof. RNDr. Milan Meloun, DrSc. Univerzita Pardubice, Pardubice 31.ledna 2011 Tato prezentace je spolufinancována Evropským sociálním fondem a státním rozpočtem
Statistika pro geografy
 Statistika pro geografy 2. Popisná statistika Mgr. David Fiedor 23. února 2015 Osnova 1 2 3 Pojmy - Bodové rozdělení četností Absolutní četnost Absolutní četností hodnoty x j znaku x rozumíme počet statistických
Statistika pro geografy 2. Popisná statistika Mgr. David Fiedor 23. února 2015 Osnova 1 2 3 Pojmy - Bodové rozdělení četností Absolutní četnost Absolutní četností hodnoty x j znaku x rozumíme počet statistických
ZÁKLADNÍ STATISTICKÉ CHARAKTERISTIKY
 zhanel@fsps.muni.cz ZÁKLADNÍ STATISTICKÉ CHARAKTERISTIKY METODY DESKRIPTIVNÍ STATISTIKY 1. URČENÍ TYPU ŠKÁLY (nominální, ordinální, metrické) a) nominální + ordinální neparametrické stat. metody b) metrické
zhanel@fsps.muni.cz ZÁKLADNÍ STATISTICKÉ CHARAKTERISTIKY METODY DESKRIPTIVNÍ STATISTIKY 1. URČENÍ TYPU ŠKÁLY (nominální, ordinální, metrické) a) nominální + ordinální neparametrické stat. metody b) metrické
Tomáš Karel LS 2012/2013
 Tomáš Karel LS 2012/2013 Doplňkový materiál ke cvičení z předmětu 4ST201. Na případné faktické chyby v této presentaci mě prosím upozorněte. Děkuji. Tyto slidy berte pouze jako doplňkový materiál není
Tomáš Karel LS 2012/2013 Doplňkový materiál ke cvičení z předmětu 4ST201. Na případné faktické chyby v této presentaci mě prosím upozorněte. Děkuji. Tyto slidy berte pouze jako doplňkový materiál není
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc.
 Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika 2010 1.týden (20.09.-24.09. ) Data, typy dat, variabilita, frekvenční analýza
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika 2010 1.týden (20.09.-24.09. ) Data, typy dat, variabilita, frekvenční analýza
PRAVDĚPODOBNOST A STATISTIKA
 PRAVDĚPODOBNOST A STATISTIKA Definice lineárního normálního regresního modelu Lineární normální regresní model Y β ε Matice n,k je matice realizací. Předpoklad: n > k, h() k - tj. matice je plné hodnosti
PRAVDĚPODOBNOST A STATISTIKA Definice lineárního normálního regresního modelu Lineární normální regresní model Y β ε Matice n,k je matice realizací. Předpoklad: n > k, h() k - tj. matice je plné hodnosti
KGG/STG Statistika pro geografy
 KGG/STG Statistika pro geografy 9. Korelační analýza Mgr. David Fiedor 20. dubna 2015 Analýza závislostí v řadě geografických disciplín studujeme jevy, u kterých vyšetřujeme nikoliv pouze jednu vlastnost
KGG/STG Statistika pro geografy 9. Korelační analýza Mgr. David Fiedor 20. dubna 2015 Analýza závislostí v řadě geografických disciplín studujeme jevy, u kterých vyšetřujeme nikoliv pouze jednu vlastnost
Vícerozměrné statistické metody
 Vícerozměrné statistické metody Shluková analýza Jiří Jarkovský, Simona Littnerová FSTA: Pokročilé statistické metody Typy shlukových analýz Shluková analýza: cíle a postupy Shluková analýza se snaží o
Vícerozměrné statistické metody Shluková analýza Jiří Jarkovský, Simona Littnerová FSTA: Pokročilé statistické metody Typy shlukových analýz Shluková analýza: cíle a postupy Shluková analýza se snaží o
Metodologie pro ISK II
 Metodologie pro ISK II Všechny hodnoty z daného intervalu Zjišťujeme: Centrální míry Variabilitu Šikmost, špičatost Percentily (decily, kvantily ) Zobrazení: histogram MODUS je hodnota, která se v datech
Metodologie pro ISK II Všechny hodnoty z daného intervalu Zjišťujeme: Centrální míry Variabilitu Šikmost, špičatost Percentily (decily, kvantily ) Zobrazení: histogram MODUS je hodnota, která se v datech
UNIVERZITA PARDUBICE Fakulta chemicko-technologická Katedra analytické chemie
 UNIVERZITA PARDUBICE Fakulta chemicko-technologická Katedra analytické chemie Licenční studium Pythagoras Statistické zpracování experimentálních dat Semestrální práce ANOVA vypracoval: Ing. David Dušek
UNIVERZITA PARDUBICE Fakulta chemicko-technologická Katedra analytické chemie Licenční studium Pythagoras Statistické zpracování experimentálních dat Semestrální práce ANOVA vypracoval: Ing. David Dušek
Testy nezávislosti kardinálních veličin
 Testy nezávislosti kardinálních veličin Komentované řešení pomocí programu R Ústav matematiky Fakulta chemicko inženýrská Vysoká škola chemicko-technologická v Praze Načtení vstupních dat Vstupní data
Testy nezávislosti kardinálních veličin Komentované řešení pomocí programu R Ústav matematiky Fakulta chemicko inženýrská Vysoká škola chemicko-technologická v Praze Načtení vstupních dat Vstupní data
Univerzita Pardubice 8. licenční studium chemometrie
 Univerzita Pardubice 8. licenční studium chemometrie Statistické zpracování dat při managementu jakosti Semestrální práce Metody s latentními proměnnými a klasifikační metody Ing. Jan Balcárek, Ph.D. vedoucí
Univerzita Pardubice 8. licenční studium chemometrie Statistické zpracování dat při managementu jakosti Semestrální práce Metody s latentními proměnnými a klasifikační metody Ing. Jan Balcárek, Ph.D. vedoucí
ANALÝZA DAT V R 2. POPISNÉ STATISTIKY. Mgr. Markéta Pavlíková Katedra pravděpodobnosti a matematické statistiky MFF UK.
 ANALÝZA DAT V R 2. POPISNÉ STATISTIKY Mgr. Markéta Pavlíková Katedra pravděpodobnosti a matematické statistiky MFF UK www.biostatisticka.cz CO SE SKRÝVÁ V DATECH data sbíráme proto, abychom porozuměli
ANALÝZA DAT V R 2. POPISNÉ STATISTIKY Mgr. Markéta Pavlíková Katedra pravděpodobnosti a matematické statistiky MFF UK www.biostatisticka.cz CO SE SKRÝVÁ V DATECH data sbíráme proto, abychom porozuměli
1 Tyto materiály byly vytvořeny za pomoci grantu FRVŠ číslo 1145/2004.
 Prostá regresní a korelační analýza 1 1 Tyto materiály byly vytvořeny za pomoci grantu FRVŠ číslo 1145/2004. Problematika závislosti V podstatě lze rozlišovat mezi závislostí nepodstatnou, čili náhodnou
Prostá regresní a korelační analýza 1 1 Tyto materiály byly vytvořeny za pomoci grantu FRVŠ číslo 1145/2004. Problematika závislosti V podstatě lze rozlišovat mezi závislostí nepodstatnou, čili náhodnou
STATISTICKÉ CHARAKTERISTIKY
 STATISTICKÉ CHARAKTERISTIKY 1 Vytvořeno s podporou projektu Průřezová inovace studijních programů Lesnické a dřevařské fakulty MENDELU v Brně (LDF) s ohledem na discipliny společného základu (reg. č. CZ.1.07/2.2.00/28.0021)
STATISTICKÉ CHARAKTERISTIKY 1 Vytvořeno s podporou projektu Průřezová inovace studijních programů Lesnické a dřevařské fakulty MENDELU v Brně (LDF) s ohledem na discipliny společného základu (reg. č. CZ.1.07/2.2.00/28.0021)
Korelační a regresní analýza
 Korelační a regresní analýza Analýza závislosti v normálním rozdělení Pearsonův (výběrový) korelační koeficient: r = s XY s X s Y, kde s XY = 1 n (x n 1 i=0 i x )(y i y ), s X (s Y ) je výběrová směrodatná
Korelační a regresní analýza Analýza závislosti v normálním rozdělení Pearsonův (výběrový) korelační koeficient: r = s XY s X s Y, kde s XY = 1 n (x n 1 i=0 i x )(y i y ), s X (s Y ) je výběrová směrodatná
Tomáš Karel LS 2012/2013
 Tomáš Karel LS 2012/2013 Doplňkový materiál ke cvičení z předmětu 4ST201. Na případné faktické chyby v této presentaci mě prosím upozorněte. Děkuji. Tyto slidy berte pouze jako doplňkový materiál není
Tomáš Karel LS 2012/2013 Doplňkový materiál ke cvičení z předmětu 4ST201. Na případné faktické chyby v této presentaci mě prosím upozorněte. Děkuji. Tyto slidy berte pouze jako doplňkový materiál není
Eva Fišerová a Karel Hron. Katedra matematické analýzy a aplikací matematiky Přírodovědecká fakulta Univerzity Palackého v Olomouci.
 Ortogonální regrese pro 3-složkové kompoziční data využitím lineárních modelů Eva Fišerová a Karel Hron Katedra matematické analýzy a aplikací matematiky Přírodovědecká fakulta Univerzity Palackého v Olomouci
Ortogonální regrese pro 3-složkové kompoziční data využitím lineárních modelů Eva Fišerová a Karel Hron Katedra matematické analýzy a aplikací matematiky Přírodovědecká fakulta Univerzity Palackého v Olomouci
31. 3. 2014, Brno Hanuš Vavrčík Základy statistiky ve vědě
 31. 3. 2014, Brno Hanuš Vavrčík Základy statistiky ve vědě Motto Statistika nuda je, má však cenné údaje. strana 3 Statistické charakteristiky Charakteristiky polohy jsou kolem ní seskupeny ostatní hodnoty
31. 3. 2014, Brno Hanuš Vavrčík Základy statistiky ve vědě Motto Statistika nuda je, má však cenné údaje. strana 3 Statistické charakteristiky Charakteristiky polohy jsou kolem ní seskupeny ostatní hodnoty
Statgraphics v. 5.0 STATISTICKÁ INDUKCE PRO JEDNOROZMĚRNÁ DATA. Martina Litschmannová 1. Typ proměnné. Požadovaný typ analýzy
 Dichotomická proměnná (0-1) Spojitá proměnná STATISTICKÁ INDUKCE PRO JEDNOROZMĚRNÁ DATA Typ proměnné Požadovaný typ analýzy Ověření variability Předpoklady Testy, resp. intervalové odhad Test o rozptylu
Dichotomická proměnná (0-1) Spojitá proměnná STATISTICKÁ INDUKCE PRO JEDNOROZMĚRNÁ DATA Typ proměnné Požadovaný typ analýzy Ověření variability Předpoklady Testy, resp. intervalové odhad Test o rozptylu
Ilustrační příklad odhadu LRM v SW Gretl
 Ilustrační příklad odhadu LRM v SW Gretl Podkladové údaje Korelační matice Odhad lineárního regresního modelu (LRM) Verifikace modelu PEF ČZU Praha Určeno pro posluchače předmětu Ekonometrie Needitovaná
Ilustrační příklad odhadu LRM v SW Gretl Podkladové údaje Korelační matice Odhad lineárního regresního modelu (LRM) Verifikace modelu PEF ČZU Praha Určeno pro posluchače předmětu Ekonometrie Needitovaná
Gradient. Gradient změna některého faktoru prostředí
 Gradientová analýza Gradient Gradient změna některého faktoru prostředí Historické zdroje Teorie vegetačního kontinua (Gleason 1917, Ramenskij 1924) Wisconsinská škola (50. léta): Curtis, McIntosh, Bray
Gradientová analýza Gradient Gradient změna některého faktoru prostředí Historické zdroje Teorie vegetačního kontinua (Gleason 1917, Ramenskij 1924) Wisconsinská škola (50. léta): Curtis, McIntosh, Bray
DVOUVÝBĚROVÉ A PÁROVÉ TESTY Komentované řešení pomocí programu Statistica
 DVOUVÝBĚROVÉ A PÁROVÉ TESTY Komentované řešení pomocí programu Statistica Úloha A) koncentrace glukózy v krvi V této části posoudíme pomocí párového testu, zda nový lék prokazatelně snižuje koncentraci
DVOUVÝBĚROVÉ A PÁROVÉ TESTY Komentované řešení pomocí programu Statistica Úloha A) koncentrace glukózy v krvi V této části posoudíme pomocí párového testu, zda nový lék prokazatelně snižuje koncentraci
Mgr. Karla Hrbáčková, Ph.D. Základy kvantitativního výzkumu
 Mgr. Karla Hrbáčková, Ph.D. Základy kvantitativního výzkumu K čemu slouží statistika Popisuje velké soubory dat pomocí charakteristických čísel (popisná statistika). Hledá skryté zákonitosti v souborech
Mgr. Karla Hrbáčková, Ph.D. Základy kvantitativního výzkumu K čemu slouží statistika Popisuje velké soubory dat pomocí charakteristických čísel (popisná statistika). Hledá skryté zákonitosti v souborech
JEDNOVÝBĚROVÉ TESTY. Komentované řešení pomocí programu Statistica
 JEDNOVÝBĚROVÉ TESTY Komentované řešení pomocí programu Statistica Vstupní data Data umístěná v excelovském souboru překopírujeme do tabulky ve Statistice a pojmenujeme proměnné, viz prezentace k tématu
JEDNOVÝBĚROVÉ TESTY Komentované řešení pomocí programu Statistica Vstupní data Data umístěná v excelovském souboru překopírujeme do tabulky ve Statistice a pojmenujeme proměnné, viz prezentace k tématu
Testování hypotéz a měření asociace mezi proměnnými
 Testování hypotéz a měření asociace mezi proměnnými Testování hypotéz Nulová a alternativní hypotéza většina statistických analýz zahrnuje různá porovnání, hledání vztahů, efektů Tvrzení, že efekt je nulový,
Testování hypotéz a měření asociace mezi proměnnými Testování hypotéz Nulová a alternativní hypotéza většina statistických analýz zahrnuje různá porovnání, hledání vztahů, efektů Tvrzení, že efekt je nulový,
Matematika pro geometrickou morfometrii
 Matematika pro geometrickou morfometrii Václav Krajíček Vaclav.Krajicek@mff.cuni.cz Department of Software and Computer Science Education Faculty of Mathematics and Physics Charles University Přednáška
Matematika pro geometrickou morfometrii Václav Krajíček Vaclav.Krajicek@mff.cuni.cz Department of Software and Computer Science Education Faculty of Mathematics and Physics Charles University Přednáška
3.4 Určení vnitřní struktury analýzou vícerozměrných dat
 3. Určení vnitřní struktury analýzou vícerozměrných dat. Metoda hlavních komponent PCA Zadání: Byly provedeny analýzy chladící vody pro odběrové místa. Byly stanoveny parametry - ph, vodivost, celková
3. Určení vnitřní struktury analýzou vícerozměrných dat. Metoda hlavních komponent PCA Zadání: Byly provedeny analýzy chladící vody pro odběrové místa. Byly stanoveny parametry - ph, vodivost, celková
MĚŘENÍ, TYPY VELIČIN a TYPY ŠKÁL
 MĚŘENÍ, TYPY VELIČIN a TYPY ŠKÁL Matematika a stejně i matematická statistika a biometrie s námi hovoří řečí čísel. Musíme tedy vlastnosti nebo intenzitu vlastností jedinců změřit kvantifikovat. Měřením
MĚŘENÍ, TYPY VELIČIN a TYPY ŠKÁL Matematika a stejně i matematická statistika a biometrie s námi hovoří řečí čísel. Musíme tedy vlastnosti nebo intenzitu vlastností jedinců změřit kvantifikovat. Měřením
REGRESE VS KALIBRACE. David Zelený Zpracování dat v ekologii společenstev
 REGRESE VS KALIBRACE David Zelený METODY GRADIENTOVÉ ANALÝZY Data, která máme: počet charakteristik prostředí počet druhů Apriorní znalost vztahů mezi druhy a prostředím? Použijeme: Dostaneme: 1, n 1 ne
REGRESE VS KALIBRACE David Zelený METODY GRADIENTOVÉ ANALÝZY Data, která máme: počet charakteristik prostředí počet druhů Apriorní znalost vztahů mezi druhy a prostředím? Použijeme: Dostaneme: 1, n 1 ne
Popisná statistika kvantitativní veličiny
 StatSoft Popisná statistika kvantitativní veličiny Protože nám surová data obvykle žádnou smysluplnou informaci neposkytnou, je žádoucí vyjádřit tyto ve zhuštěnější formě. V předchozím dílu jsme začali
StatSoft Popisná statistika kvantitativní veličiny Protože nám surová data obvykle žádnou smysluplnou informaci neposkytnou, je žádoucí vyjádřit tyto ve zhuštěnější formě. V předchozím dílu jsme začali
Testování hypotéz o parametrech regresního modelu
 Testování hypotéz o parametrech regresního modelu Ekonometrie Jiří Neubauer Katedra kvantitativních metod FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Jiří Neubauer (Katedra UO
Testování hypotéz o parametrech regresního modelu Ekonometrie Jiří Neubauer Katedra kvantitativních metod FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Jiří Neubauer (Katedra UO
Statistické testování hypotéz II
 PSY117/454 Statistická analýza dat v psychologii Přednáška 9 Statistické testování hypotéz II Přehled testů, rozdíly průměrů, velikost účinku, síla testu Základní výzkumné otázky/hypotézy 1. Stanovení
PSY117/454 Statistická analýza dat v psychologii Přednáška 9 Statistické testování hypotéz II Přehled testů, rozdíly průměrů, velikost účinku, síla testu Základní výzkumné otázky/hypotézy 1. Stanovení
Profilování vzorků heroinu s využitím vícerozměrné statistické analýzy
 Profilování vzorků heroinu s využitím vícerozměrné statistické analýzy Autor práce : RNDr. Ivo Beroun,CSc. Vedoucí práce: prof. RNDr. Milan Meloun, DrSc. PROFILOVÁNÍ Profilování = klasifikace a rozlišování
Profilování vzorků heroinu s využitím vícerozměrné statistické analýzy Autor práce : RNDr. Ivo Beroun,CSc. Vedoucí práce: prof. RNDr. Milan Meloun, DrSc. PROFILOVÁNÍ Profilování = klasifikace a rozlišování
Cvičná bakalářská zkouška, 1. varianta
 jméno: studijní obor: PřF BIMAT počet listů(včetně tohoto): 1 2 3 4 5 celkem Cvičná bakalářská zkouška, 1. varianta 1. Matematická analýza Najdětelokálníextrémyfunkce f(x,y)=e 4(x y) x2 y 2. 2. Lineární
jméno: studijní obor: PřF BIMAT počet listů(včetně tohoto): 1 2 3 4 5 celkem Cvičná bakalářská zkouška, 1. varianta 1. Matematická analýza Najdětelokálníextrémyfunkce f(x,y)=e 4(x y) x2 y 2. 2. Lineární
Aplikovaná statistika v R - cvičení 2
 Aplikovaná statistika v R - cvičení 2 Filip Děchtěrenko Matematicko-fyzikální fakulta filip.dechterenko@gmail.com 5.6.2014 Filip Děchtěrenko (MFF UK) Aplikovaná statistika v R 5.6.2014 1 / 18 Přehled Rkových
Aplikovaná statistika v R - cvičení 2 Filip Děchtěrenko Matematicko-fyzikální fakulta filip.dechterenko@gmail.com 5.6.2014 Filip Děchtěrenko (MFF UK) Aplikovaná statistika v R 5.6.2014 1 / 18 Přehled Rkových