Katedra kybernetiky, FEL, ČVUT v Praze.
|
|
|
- František Havlíček
- před 6 lety
- Počet zobrazení:
Transkript

1 Symbolické metody učení z příkladů Jiří Kléma Katedra kybernetiky, FEL, ČVUT v Praze
2 pplán přednášky Zaměření 1: učení z příkladů motivace, formulace problému, prediktivní a deskriptivní modely, Zaměření 2: symbolické metody učení stromové prediktivní modely rozhodovací stromy TDIDT algoritmus, diskretizace, prořezávání, regresní stromy namísto rozhodnutí numerická předpověď, pravidlové prediktivní modely algoritmy AQ, CN2 další jednoduché klasifikátory naivní bayesův, logistická regrese, nejbližší soused, vícevrstvý perceptron. Y33ZUI


3 pučení z příkladů motivace Vytváření počítačových programů, které se zdokonalují se zkušeností Typicky na základě analýzy dat, tj. indukcí z příkladů ( X, Y ) s učitelem předpověz Y regrese, klasifikace X bez učitele najdi podobné příznakové vektory shlukování Příklad 1: microarray data najdi geny s podobnou expresí shlukování Příklad 2: digitalizované znaky rozlišuj rukou psaná čísla klasifikace Y33ZUI
4 ptypy učení Symbolické strojové učení znalost vyjádřena ve formě symbolických popisů učených konceptů, typicky algoritmy tvořící množiny pravidel zachycující vztah mezi atributy a třídou, tj. nezávislými proměnnými a proměnnou cílovou, propozicionální i relační (induktivní logické programování), konekcionistické učení znalost uchovávána ve formě sítě propojených neuronů s váženými synapsemi a prahovými hodnotami, pravděpodobnostní/statistické učení modelem je např. distribuční funkce nebo funkce pstní hustoty, statistické regresní modely (lineární, logistické), SVMs, další metody např. simulovaná evoluce a genetické algoritmy (analogie s přírodními procesy a darwinistickou teoríı přežití nejsilnějších). Y33ZUI
5 prozhodovací stromy Aproximují diskrétní cílovou veličinu Aproximace funkcí reprezentovanou stromem Rozhodovací strom je disjunktem konjunkcí mezi omezeními hodnot atributů Instance klasifikujeme dle hodnot atributů Reprezentace vnitřní uzly testují vlastnosti atributů, větve odpovídají možným hodnotám, listy přiřazují klasifikaci, tj. konkrétní hodnotu cílové veličiny. (Obloha = Slunečno Vlhkost = Normální) (Obloha = Zataženo) (Obloha = Déšť Vítr = Slabý) Y33ZUI
6 phrát tenis/golf? Trénovací příklady. Den Obloha Teplota Vlhkost Vítr Tenis/golf D1 Slunečno Vysoká Vysoká Slabý Ne D2 Slunečno Vysoká Vysoká Silný Ne D3 Zataženo Vysoká Vysoká Slabý Ano D4 Déšť Střední Vysoká Slabý Ano D5 Déšť Nízká Normální Slabý Ano D6 Déšť Nízká Normální Silný Ne D7 Zataženo Nízká Normální Silný Ano D8 Slunečno Střední Vysoká Slabý Ne D9 Slunečno Nízká Normální Slabý Ano D10 Déšť Střední Normální Slabý Ano D11 Slunečno Střední Normální Silný Ano D12 Zataženo Střední Vysoká Silný Ano D13 Zataženo Vysoká Normální Slabý Ano D14 Déšť Střední Vysoká Silný Ne Y33ZUI
7 ptdidt indukce shora dolů TDIDT = Top-Down Induction of Decision Trees, konkrétní algoritmus: ID3 (Quinlan, 1986) dáno: S - trénovací množina, A - množina atributů, C - množina tříd, if s S patří do stejné třídy c C then jde o list, označ jej třídou c else jde o uzel, vyber pro něj nejlepší rozhodovací atribut a A (s hodnotami v 1, v 2,..., v n ), rozděl trénovací množinu S na S 1,..., S n podle hodnot atributu a, rekurzivně vytvářej podstromy T 1,..., T n pro S 1,..., S n (přechodem na začátek algoritmu s S = S i ), výsledný strom T je tvořen podstromy T 1,..., T n. který atribut a je nejlepší? Y33ZUI
8 pentropie S vzorek trénovacích příkladů, p + (p ) je zastoupení pozitivních (negativních) příkladů v S zastoupení = relativní četnost pravděpodobnost, H(S) informační entropie trénovací množiny nejmenší průměrný počet bitů nutných k zakódování zprávy o třídě libovolného s S, teorie informace kód optimalní délky přiřazuje log 2 p bitů zprávě s pravděpodobností p průměrný počet bitů potřebný k zakódování + nebo náhodného prvku S H(S) = p log 2 p p + log 2 p + obecně pro c různých tříd: H(S) = c C p c log 2 p c Y33ZUI
9 pentropie Entropie jako funkce booleovské klasifikace vyjádřené relativní četností pozitivních příkladů četnost negativních příkladů je redundantní informací (p = 1 p + ), entropie je mírou neuspořádanosti v souboru příkladů, ideální rozhodovací nástroj (klasifikátor) minimalizuje neuspořádanost, tj. entropii. Y33ZUI
10 pinformační zisk Gain(S, a) nebo IG(S, a) heuristické kritérium očekávaná redukce entropie za předpokladu rozdělení množiny S dle atributu A, míra efektivity atributu pro klasifikaci trénovacích dat, přímé použití entropie, pouze přechod od minimalizačního k maximalizačnímu kritériu Gain(S, a) = Entropy(S) V alues(a) možné hodnoty atributu a, S v - podmnožina S, pro kterou a má hodnotu v, v V alues(a) S v S Entropy(S v) cílem je minimalizovat počet testů nutných k oddělení tříd (homogenizaci), a v důsledku generovat co nejmenší strom. Y33ZUI
11 phrát tenis? výpočet zisku V alues(v itr) = {Slaby, Silny} S = [9+, 5 ], E(S) = S slaby = [6+, 2 ], E(S slaby ) = S silny = [3+, 3 ], E(S silny ) = 1.0 Gain(S, V itr) = E(S) 8 14 E(S slaby) 6 14 E(S silny) = = V alues(obloha) = {Slunecno, Zatazeno, Dest} S = [9+, 5 ], E(S) = S slunecno = [2+, 3 ], E(S slunecno ) = S zatazeno = [4+, 0 ], E(S zatazeno ) = 0 S dest = [3+, 2 ], E(S dest ) = Gain(S, Obloha) = E(S) 5 14 E(S slunecno) 5 14 E(S dest) = = 0.246, Gain(S, V lhkost) = 0.151, Gain(S, T eplota) = Y33ZUI
12 pdalší heuristiky Informační zisk (Gain, IG) nezohledňuje jak široce a rovnoměrně atribut data děĺı (extrémní příklad: unikátní index), Poměrný zisk (Gain Ratio, GR) využívá doplňkovou informaci o dělení (split information) penalizuje tím atributy jako např. datum SI(S, a) = GR(S, a) = v V alues(a) S v S log 2 Gain(S, a) SI(S, a) další - Gini index, Mantarasova heuristika, heuristiky vážící cenu získání atributu (Nunez) S v S GainCost(S, A) = 2Gain(S,A) 1 (Cost(A) + 1) w w [0, 1] relativní důležitost Cost vs. Gain. Y33ZUI
13 pspojité atributy TDIDT založen na dělení do rozumného počtu větví, spojité atributy musí být diskretizovány, kategorizace diskretizačních přístupů s učitelem vs. bez učitele (supervised, unsupervised) využíváme znalost cílové veličiny? globální vs. lokální globální proveď diskretizaci před aplikací učícího se algoritmu na všech datech, lokální diskretizuj průběžně a pouze na aktuálních instancích, výhody a nevýhody: přímý kontext vs. citlivost na šum, práce s diskrétními atributy uvažuje algoritmus uspořádané hodnoty atributů? pokud ne, lze tomu přizpůsobit proces učení převeď každý diskretizovaný atribut (k hodnot) na množinu k-1 binárních atributů, i-tá hodnota diskretizované veličiny = i-1 binárních atr. 0, zbytek 1 TDIDT s učitelem, lokální, diskrétní atributy neuspořádané. Y33ZUI
 děl na intervaly o stejné")


 histogram, manuální, např.")
14 pdiskretizace bez učitele stejná šíře intervalů (equal-width binning) děl na intervaly o stejné šířce, šířka=(max-min)/počet intervalů, distribuce instancí může být nerovnoměrná, stejná četnost instancí (equal-depth binning) založeno na rozložení hodnot atributu, někdy nazývána vyrovnáním histogramu uniformní (plochý) histogram, manuální, např. odvozené od histogramu. Y33ZUI
 nový booleovský atribut a c je true iff a > c, jediná otázka")

15 pdiskretizace s učitelem často založená na entropii např. binarizace definuj (dynamicky) nový booleovský atribut a c je true iff a > c, jediná otázka volba prahové hodnoty c, zvol práh optimalizující IG heuristiku setřiď všechny instance podle a, najdi sousedící příklady lišící se klasifikací, kandidát na c střed mezi příslušnými hodnotami a, zvol nejlepší c. Y33ZUI
16 pdiskretizace s učitelem generalizace binarizace = dělení do více intervalů R-binarizace a je použit vícekrát na stejné cestě od kořene k listu stromu. zobecněná binarizace najdi optimální dělení (IG je použit jako hodnotící fce), opakuj až do splnění ukončovací podmínky, ukončovací podmínka? princip minimální délky popisu (minimum description length MDL) nejlepší teorie je ta, která minimalizuje svoji délku současně s délkou zprávy nutnou k popsání výjimek z teorie, nejlepší generalizace je ta, která minimalizuje počet bitů nutných ke komunikaci generalizace a všech příkladů, z nichž je vytvořena. diskretizace založená na chybovosti (namísto entropie) minimalizuje počet chyb, snadno se počítá ale nelze dosáhnout sousedních intervalů se stejnou třídou (označením). Y33ZUI
17 ppoznámky k tvorbě DT a ID3 Jak obtížné je nalézt optimální strom? uvažujme m instancí popsaných n binárními atributy optimalita strom minimalizuje počet testů = uzlů jde o NP-úplný problém pro algoritmus bez orákula hypotézový prostor roste superexponenciálně s počtem atributů, nelze prohledávat úplně, je třeba řešit heuristicky/lokálním prohledáváním, Hladové prohledávání žádné zpětné řetězení při prohledávání, TDIDT/ID3 udržuje jedinou průběžnou hypotézu, nutně konverguje pouze k lokálnímu optimu, ID3 strategie upřednostňuje menší stromy před většími jak? atributy s vysokým IG jsou bĺıže ke kořeni, induktivní zaujetí Occamova břitva Plurality should not be assumed without necessity. or KISS: Keep it simple, stupid. nejjednodušší strom pravděpodobně nebude obsahovat neužitečná omezení, tj. testy. Y33ZUI
18 pprořezávání DT Přeučení (overfitting) DT složité stromy odrážející singularity v trénovacích datech, statistická volba atributů při stavbě stromu zajišťuje robustnost vůči šumům přesto může být omezující rozklad na zcela homogenní podmnožiny příkladů, řešení: prořezávání (pruning), prahové prořezávání jednoduše zdola nahoru definuj prahovou přesnost ac 0, if ac = 1 e/n > ac 0 then prune, (n = počet příkladů v uzlu, e = počet chyb = počet příkladů z minoritních tříd), prořezávání založené na očekávané chybě aproximuj očekávanou chybu pokud daný uzel N (pokrývající množinu příkladů S) prořízneme Laplaceův odhad chyby: E(S) =, T = počet tříd, e+t 1 n+t aproximuj záložní chybu v následnících N předpokládající, že prořezání neprovedeme BackedUpE(S) = l children(n) p le(s l ), je-li očekávaná chyba menší než záložní chyba prořež N. Y33ZUI
19 pvhodné problémy pro DT Instance jsou reprezentovány páry atribut-hodnota (tj. data mají tvar obdélníkové tabulky) ne vždy, viz multirelační data, cílová funkce je diskrétní pro spojité cílové funkce regresní stromy, disjunktivní hypotézy jsou přijatelným výstupem, srozumitelná klasifikace DT = white box, strom rozumné velikosti je přehledný pro lidi, šum a chybějící hodnoty data mohou obsahovat chybné klasifikace a hodnoty atributů, v datech se mohou vyskytnout chybějící hodnoty atributů. Y33ZUI
20 pregresní stromy učení se spojitou třídou CART (Breiman, Friedman) v listech hodnoty (namísto ID tříd u DT) standardní odchylka jako chybová míra míra její redukce určuje nejlepší atribut δ err = sd(s) S v v values(a) S sd(s v) CART model mapy ceny domů v Kalifornii, c Carnegie Mellon University, Course , Data Mining Y33ZUI
21 pregresní stromy M5 (Quinlan) v listech multivariační lineární modely schopnost extrapolace, model = stromový, po částech lineární další vylepšení nečistota = standardní odchylka z regresního odhadu, lineární model sestavený v uzlu zohledňuje pouze atributy použité v daném podstromu. zjednodušení eliminuj atributy málo vylepšující model prořezávání acc = n + λ 1 n λ n n i=1 f real i f pred i λ... počet parametrů v modelu, f i... hodnota cílové veličiny ve vzorku i, extrémní případ... pouze konstanta (pak shoda s CART), porovnej přesnost lineárního modelu s přesností podstromu, je-li model lepší pak prořež, vyhlazování hodnota predikovaná v listu je přizpůsobena dle odhadů v uzlech na cestě od kořene. Y33ZUI


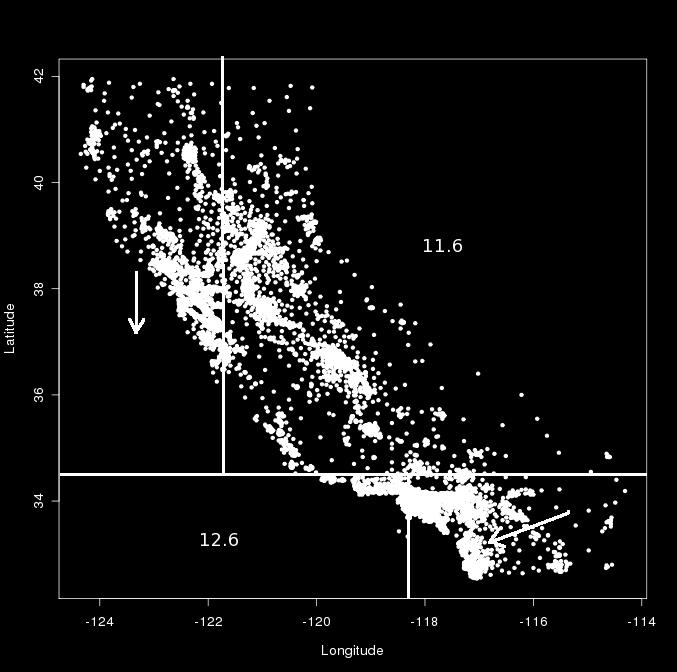
22 pregresní stromy M5 model mapy ceny domů v Kalifornii, WEKA Y33ZUI

 = konjunkce selektorů, pravidla mají stejnou expresivitu jako stromy")
23 prozhodovací pravidla další metoda aproximace diskrétních cílových veličin, aproximační fce ve tvaru množiny (seznamu) rozhodovacích pravidel, jestliže <podmínka> pak <třída> selektor = jednoduchý test hodnoty atributu, např. <Obloha=Slunečno>, {=,?, >,?} typicky relační operátory, podmínka (complex) = konjunkce selektorů, pravidla mají stejnou expresivitu jako stromy stromy - rozděl a panuj dělení, čistě shora dolů, pravidla - odděl a panuj pokrytí, konstrukce oběma směry. Y33ZUI
24 paq algoritmus Michalski algoritmus pro pokrytí množiny dáno: S - trénovací množina, C - množina tříd, c C opakuj S c = P c N c (pozitivní a negativní příklady) bázepravidel(c)={} opakuj {najdi množinu pravidel pro c} R=find-one-rule(P c N c ) (najdi pravidlo pokrývající nějaké pozitivní příklady a žádný negativní příklad) bázepravidel(c)+=r P c -=pokryto(r,p c ), dokud naplatí P c ={} find-one-rule procedura je kritickým krokem, přístup zdola-nahoru generalizace. Y33ZUI
25 paq algoritmus find-one-rule zvol náhodně pozitivní příklad (zrno) generuj všechny maximální generalizace zrna pokrývá co nejvíce pozitivních příkladů nepokrývá žádný negativní příklad vyber nejlepší generalizaci (preferenční heuristika) ID a1 a2 a3 Třída 1 x r m + 2 y r n + 3 y s n + 4 x s m - 5 z t n - 6 z r n - zrno 1: příklad 2 if (a1=y) & (a2=r) & (a3=n) then + g1: if (a1=y) then + zrno 2: příklad 1 if (a1=x) & (a2=r) & (a3=m) then + g1: if (a1=x) & (a2=r) then + g2: if (a2=r) & (a3=m) then + Y33ZUI
26 pripper algoritmus AQ je spíše modelový algoritmus závisí na volbě zrna je nedeterministický, není vhodný pro domény s chybami/šumem, příklad praktičtějšího algoritmu implementováného ve WEKA: RIPPER (JRip) RIPPER (Repeated Incremental Pruning to produce Error Reduction, Cohen 1995) dvě fáze: grow and prune náhodně rozděl data na trénovací (2/3) a validační (1/3), na trénovcích pravidla vytvářej (grow) pravidlo nesmí pokrýt žádný negativní příklad, kritériem výběru selektoru je informační zisk, na validačních pravidla zjednodušuj (prune reduced error pruning), odebírej selektory, které nezlepšují přesnost na validačních datech, maximalizuj funkci: v = p n p+n p... počet pozitivních validačních příkladů pokrytých pravidlem, n... počet negativních validačních příkladů pokrytých pravidlem. Y33ZUI
27 pirep algoritmus pseudokód dáno: S = Pos + Neg - množina klasifikovaných příkladů, Ruleset= while Pos (GrowPos,GrowNeg,PrunePos,PruneNeg)=split(Pos,Neg) Rule=GrowRule(GrowPos,GrowNeg) Rule=PruneRule(Rule,PrunePos,PruneNeg) if errorrate(rule,prunepos,puneneg)>0.5 then return Ruleset else add Rule to Ruleset remove examples covered by Rule from (Pos,Neg) endif endwhile return Ruleset Y33ZUI
28 pdoporučené doplňky zdroje přednášky Mařík & kol.: Umělá inteligence. díl I., kapitola Strojové učení, díl IV., kapitola 11., Strojové učení v dobývání znalostí, Berka: Dobývání znalostí z databází. kniha Academia, široký přehled, Quinlan: Induction of Decision Trees. starší článek (1986) s příkladem z přednášky, Quinlan.pdf, Cohen: Fast Effective Rule Induction. Ripper pravidlový klasifikátor, Y33ZUI
Katedra kybernetiky, FEL, ČVUT v Praze.
 Symbolické metody učení z příkladů Jiří Kléma Katedra kybernetiky, FEL, ČVUT v Praze http://ida.felk.cvut.cz pplán přednášky Zaměření 1: učení z příkladů motivace, formulace problému, prediktivní a deskriptivní
Symbolické metody učení z příkladů Jiří Kléma Katedra kybernetiky, FEL, ČVUT v Praze http://ida.felk.cvut.cz pplán přednášky Zaměření 1: učení z příkladů motivace, formulace problému, prediktivní a deskriptivní
Dobývání znalostí. Doc. RNDr. Iveta Mrázová, CSc. Katedra teoretické informatiky Matematicko-fyzikální fakulta Univerzity Karlovy v Praze
 Dobývání znalostí Doc. RNDr. Iveta Mrázová, CSc. Katedra teoretické informatiky Matematicko-fyzikální fakulta Univerzity Karlovy v Praze Dobývání znalostí Rozhodovací stromy Doc. RNDr. Iveta Mrázová, CSc.
Dobývání znalostí Doc. RNDr. Iveta Mrázová, CSc. Katedra teoretické informatiky Matematicko-fyzikální fakulta Univerzity Karlovy v Praze Dobývání znalostí Rozhodovací stromy Doc. RNDr. Iveta Mrázová, CSc.
Rozhodovací pravidla
 Rozhodovací pravidla Úloha klasifikace příkladů do tříd. pravidlo Ant C, kde Ant je konjunkce hodnot atributů a C je cílový atribut A. Algoritmus pokrývání množin metoda separate and conquer (odděl a panuj)
Rozhodovací pravidla Úloha klasifikace příkladů do tříd. pravidlo Ant C, kde Ant je konjunkce hodnot atributů a C je cílový atribut A. Algoritmus pokrývání množin metoda separate and conquer (odděl a panuj)
DATA MINING KLASIFIKACE DMINA LS 2009/2010
 DATA MINING KLASIFIKACE DMINA LS 2009/2010 Osnova co je to klasifikace typy klasifikátoru typy výstupu jednoduchý klasifikátor (1R) rozhodovací stromy Klasifikace (ohodnocení) zařazuje data do předdefinovaných
DATA MINING KLASIFIKACE DMINA LS 2009/2010 Osnova co je to klasifikace typy klasifikátoru typy výstupu jednoduchý klasifikátor (1R) rozhodovací stromy Klasifikace (ohodnocení) zařazuje data do předdefinovaných
Katedra kybernetiky laboratoř Inteligentní Datové Analýzy (IDA) Katedra počítačů, Computational Intelligence Group
 Katedra počítačů, Computational Intelligence Group") Vytěžování dat Miroslav Čepek, Filip Železný Katedra kybernetiky laboratoř Inteligentní Datové Analýzy (IDA) Katedra počítačů, Computational Intelligence Group Evropský sociální fond Praha & EU: Investujeme
Vytěžování dat Miroslav Čepek, Filip Železný Katedra kybernetiky laboratoř Inteligentní Datové Analýzy (IDA) Katedra počítačů, Computational Intelligence Group Evropský sociální fond Praha & EU: Investujeme
ZÍSKÁVÁNÍ ZNALOSTÍ Z DATABÁZÍ
 metodický list č. 1 Dobývání znalostí z databází Cílem tohoto tematického celku je vysvětlení základních pojmů z oblasti dobývání znalostí z databází i východisek dobývání znalostí z databází inspirovaných
metodický list č. 1 Dobývání znalostí z databází Cílem tohoto tematického celku je vysvětlení základních pojmů z oblasti dobývání znalostí z databází i východisek dobývání znalostí z databází inspirovaných
ZÍSKÁVÁNÍ ZNALOSTÍ Z DATABÁZÍ
 Metodický list č. 1 Dobývání znalostí z databází Cílem tohoto tematického celku je vysvětlení základních pojmů z oblasti dobývání znalostí z databází i východisek dobývání znalostí z databází inspirovaných
Metodický list č. 1 Dobývání znalostí z databází Cílem tohoto tematického celku je vysvětlení základních pojmů z oblasti dobývání znalostí z databází i východisek dobývání znalostí z databází inspirovaných
5.1 Rozhodovací stromy
 5.1 Rozhodovací stromy 5.1.1 Základní algoritmus Způsob reprezentování znalostí v podobě rozhodovacích stromů je dobře znám z řady oblastí. Vzpomeňme jen nejrůznějších klíčů k určování různých živočichů
5.1 Rozhodovací stromy 5.1.1 Základní algoritmus Způsob reprezentování znalostí v podobě rozhodovacích stromů je dobře znám z řady oblastí. Vzpomeňme jen nejrůznějších klíčů k určování různých živočichů
Přednáška 13 Redukce dimenzionality
 Vytěžování Dat Přednáška 13 Redukce dimenzionality Miroslav Čepek Fakulta Elektrotechnická, ČVUT Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti ČVUT (FEL) Redukce dimenzionality 1 /
Vytěžování Dat Přednáška 13 Redukce dimenzionality Miroslav Čepek Fakulta Elektrotechnická, ČVUT Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti ČVUT (FEL) Redukce dimenzionality 1 /
Pravděpodobně skoro správné. PAC učení 1
 Pravděpodobně skoro správné (PAC) učení PAC učení 1 Výpočetní teorie strojového učení Věta o ošklivém kačátku. Nechť E je klasifikovaná trénovací množina pro koncept K, který tvoří podmnožinu konečného
Pravděpodobně skoro správné (PAC) učení PAC učení 1 Výpočetní teorie strojového učení Věta o ošklivém kačátku. Nechť E je klasifikovaná trénovací množina pro koncept K, který tvoří podmnožinu konečného
Dobývání znalostí. Doc. RNDr. Iveta Mrázová, CSc. Katedra teoretické informatiky Matematicko-fyzikální fakulta Univerzity Karlovy v Praze
 Dobývání znalostí Doc. RNDr. Iveta Mrázová, CSc. Katedra teoretické informatiky Matematicko-fyzikální fakulta Univerzity Karlovy v Praze Dobývání znalostí Pravděpodobnost a učení Doc. RNDr. Iveta Mrázová,
Dobývání znalostí Doc. RNDr. Iveta Mrázová, CSc. Katedra teoretické informatiky Matematicko-fyzikální fakulta Univerzity Karlovy v Praze Dobývání znalostí Pravděpodobnost a učení Doc. RNDr. Iveta Mrázová,
Asociační pravidla. Informační a komunikační technologie ve zdravotnictví. Biomedical Data Processing G r o u p
 Asociační pravidla Informační a komunikační technologie ve zdravotnictví Definice pojmů Stavový prostor S je množina uzlů(stavů), kde cílem je najít stav splňující danou podmínku g. Formálně je problém
Asociační pravidla Informační a komunikační technologie ve zdravotnictví Definice pojmů Stavový prostor S je množina uzlů(stavů), kde cílem je najít stav splňující danou podmínku g. Formálně je problém
Projekční algoritmus. Urychlení evolučních algoritmů pomocí regresních stromů a jejich zobecnění. Jan Klíma
 Urychlení evolučních algoritmů pomocí regresních stromů a jejich zobecnění Jan Klíma Obsah Motivace & cíle práce Evoluční algoritmy Náhradní modelování Stromové regresní metody Implementace a výsledky
Urychlení evolučních algoritmů pomocí regresních stromů a jejich zobecnění Jan Klíma Obsah Motivace & cíle práce Evoluční algoritmy Náhradní modelování Stromové regresní metody Implementace a výsledky
přetrénování = ztráta schopnosti generalizovat vlivem přílišného zaměření klasifikátorů na rozeznávání pouze konkrétních trénovacích dat
 Zkouška ISR 2013 přetrénování = ztráta schopnosti generalizovat vlivem přílišného zaměření klasifikátorů na rozeznávání pouze konkrétních trénovacích dat 1. Rozdílné principy u induktivního a deduktivního
Zkouška ISR 2013 přetrénování = ztráta schopnosti generalizovat vlivem přílišného zaměření klasifikátorů na rozeznávání pouze konkrétních trénovacích dat 1. Rozdílné principy u induktivního a deduktivního
Pokročilé neparametrické metody. Klára Kubošová
 Klára Kubošová Další typy stromů CHAID, PRIM, MARS CHAID - Chi-squared Automatic Interaction Detector G.V.Kass (1980) nebinární strom pro kategoriální proměnné. Jako kriteriální statistika pro větvení
Klára Kubošová Další typy stromů CHAID, PRIM, MARS CHAID - Chi-squared Automatic Interaction Detector G.V.Kass (1980) nebinární strom pro kategoriální proměnné. Jako kriteriální statistika pro větvení
Moderní systémy pro získávání znalostí z informací a dat
 Moderní systémy pro získávání znalostí z informací a dat Jan Žižka IBA Institut biostatistiky a analýz PřF & LF, Masarykova universita Kamenice 126/3, 625 00 Brno Email: zizka@iba.muni.cz Bioinformatika:
Moderní systémy pro získávání znalostí z informací a dat Jan Žižka IBA Institut biostatistiky a analýz PřF & LF, Masarykova universita Kamenice 126/3, 625 00 Brno Email: zizka@iba.muni.cz Bioinformatika:
8. Strojové učení. Strojové učení. 16. prosince 2014. Václav Matoušek. 8-1 Úvod do znalostního inženýrství, ZS 2014/15
 Strojové učení 16. prosince 2014 8-1 Klasifikace metod strojového učení podle vynaloženého úsilí na získání nových znalostí Učení zapamatováním (rote learning, biflování) Pouhé zaznamenání dat nebo znalostí.
Strojové učení 16. prosince 2014 8-1 Klasifikace metod strojového učení podle vynaloženého úsilí na získání nových znalostí Učení zapamatováním (rote learning, biflování) Pouhé zaznamenání dat nebo znalostí.
UČENÍ BEZ UČITELE. Václav Hlaváč
 UČENÍ BEZ UČITELE Václav Hlaváč Fakulta elektrotechnická ČVUT v Praze katedra kybernetiky, Centrum strojového vnímání hlavac@fel.cvut.cz, http://cmp.felk.cvut.cz/~hlavac 1/22 OBSAH PŘEDNÁŠKY ÚVOD Učení
UČENÍ BEZ UČITELE Václav Hlaváč Fakulta elektrotechnická ČVUT v Praze katedra kybernetiky, Centrum strojového vnímání hlavac@fel.cvut.cz, http://cmp.felk.cvut.cz/~hlavac 1/22 OBSAH PŘEDNÁŠKY ÚVOD Učení
Kybernetika a umělá inteligence, cvičení 10/11
 Kybernetika a umělá inteligence, cvičení 10/11 Program 1. seminární cvičení: základní typy klasifikátorů a jejich princip 2. počítačové cvičení: procvičení na problému rozpoznávání číslic... body za aktivitu
Kybernetika a umělá inteligence, cvičení 10/11 Program 1. seminární cvičení: základní typy klasifikátorů a jejich princip 2. počítačové cvičení: procvičení na problému rozpoznávání číslic... body za aktivitu
Rozdělování dat do trénovacích a testovacích množin
 Rozdělování dat do trénovacích a testovacích množin Marcel Jiřina Rozpoznávání je důležitou metodou při zpracování reálných úloh. Rozpoznávání je definováno dvěma kroky a to pořízením dat o reálném rozpoznávaném
Rozdělování dat do trénovacích a testovacích množin Marcel Jiřina Rozpoznávání je důležitou metodou při zpracování reálných úloh. Rozpoznávání je definováno dvěma kroky a to pořízením dat o reálném rozpoznávaném
Obsah přednášky Jaká asi bude chyba modelu na nových datech?
 Obsah přednášky Jaká asi bude chyba modelu na nových datech? Chyba modelu Bootstrap Cross Validation Vapnik-Chervonenkisova dimenze 2 Chyba skutečná a trénovací Máme 30 záznamů, rozhodli jsme se na jejich
Obsah přednášky Jaká asi bude chyba modelu na nových datech? Chyba modelu Bootstrap Cross Validation Vapnik-Chervonenkisova dimenze 2 Chyba skutečná a trénovací Máme 30 záznamů, rozhodli jsme se na jejich
Dobývání znalostí. Doc. RNDr. Iveta Mrázová, CSc. Katedra teoretické informatiky Matematicko-fyzikální fakulta Univerzity Karlovy v Praze
 Dobývání znalostí Doc. RNDr. Iveta Mrázová, CSc. Katedra teoretické informatiky Matematicko-fyzikální fakulta Univerzity Karlovy v Praze Dobývání znalostí Bayesovské modely Doc. RNDr. Iveta Mrázová, CSc.
Dobývání znalostí Doc. RNDr. Iveta Mrázová, CSc. Katedra teoretické informatiky Matematicko-fyzikální fakulta Univerzity Karlovy v Praze Dobývání znalostí Bayesovské modely Doc. RNDr. Iveta Mrázová, CSc.
Ing. Petr Hájek, Ph.D. Podpora přednášky kurzu Aplikace umělé inteligence
 APLIKACE UMĚLÉ INTELIGENCE Ing. Petr Hájek, Ph.D. Podpora přednášky kurzu Aplikace umělé inteligence Aplikace umělé inteligence - seminář ING. PETR HÁJEK, PH.D. ÚSTAV SYSTÉMOVÉHO INŽENÝRSTVÍ A INFORMATIKY
APLIKACE UMĚLÉ INTELIGENCE Ing. Petr Hájek, Ph.D. Podpora přednášky kurzu Aplikace umělé inteligence Aplikace umělé inteligence - seminář ING. PETR HÁJEK, PH.D. ÚSTAV SYSTÉMOVÉHO INŽENÝRSTVÍ A INFORMATIKY
12. Globální metody MI-PAA
 Jan Schmidt 2011 Katedra číslicového návrhu Fakulta informačních technologií České vysoké učení technické v Praze Zimní semestr 2011/12 MI-PAA EVROPSKÝ SOCIÁLNÍ FOND PRAHA & EU: INVESTUJENE DO VAŠÍ BUDOUCNOSTI
Jan Schmidt 2011 Katedra číslicového návrhu Fakulta informačních technologií České vysoké učení technické v Praze Zimní semestr 2011/12 MI-PAA EVROPSKÝ SOCIÁLNÍ FOND PRAHA & EU: INVESTUJENE DO VAŠÍ BUDOUCNOSTI
Stromy, haldy, prioritní fronty
 Stromy, haldy, prioritní fronty prof. Ing. Pavel Tvrdík CSc. Katedra počítačů FEL České vysoké učení technické DSA, ZS 2008/9, Přednáška 6 http://service.felk.cvut.cz/courses/x36dsa/ prof. Pavel Tvrdík
Stromy, haldy, prioritní fronty prof. Ing. Pavel Tvrdík CSc. Katedra počítačů FEL České vysoké učení technické DSA, ZS 2008/9, Přednáška 6 http://service.felk.cvut.cz/courses/x36dsa/ prof. Pavel Tvrdík
Pokročilé neparametrické metody. Klára Kubošová
 Pokročilé neparametrické metody Klára Kubošová Pokročilé neparametrické metody Výuka 13 přednášek doplněných o praktické cvičení v SW Úvod do neparametrických metod + princip rozhodovacích stromů Klasifikační
Pokročilé neparametrické metody Klára Kubošová Pokročilé neparametrické metody Výuka 13 přednášek doplněných o praktické cvičení v SW Úvod do neparametrických metod + princip rozhodovacích stromů Klasifikační
Vytěžování znalostí z dat
 Pavel Kordík, Josef Borkovec (ČVUT FIT) Vytěžování znalostí z dat BI-VZD, 2012, Přednáška 8 1/26 Vytěžování znalostí z dat Pavel Kordík, Josef Borkovec Department of Computer Systems Faculty of Information
Pavel Kordík, Josef Borkovec (ČVUT FIT) Vytěžování znalostí z dat BI-VZD, 2012, Přednáška 8 1/26 Vytěžování znalostí z dat Pavel Kordík, Josef Borkovec Department of Computer Systems Faculty of Information
Připomeň: Shluková analýza
 Připomeň: Shluková analýza Data Návrh kategorií X Y= 1, 2,..., K resp. i jejich počet K = co je s čím blízké + jak moc Neposkytne pravidlo pro zařazování Připomeň: Klasifikace Data (X,Y) X... prediktory
Připomeň: Shluková analýza Data Návrh kategorií X Y= 1, 2,..., K resp. i jejich počet K = co je s čím blízké + jak moc Neposkytne pravidlo pro zařazování Připomeň: Klasifikace Data (X,Y) X... prediktory
Rozhodovací stromy a jejich konstrukce z dat
 Rozhodovací stromy a jejich konstrukce z dat Příklad počítačová hra. Můžeme počítač naučit rozlišovat přátelské a nepřátelské roboty? Učení s učitelem: u některých už víme, jakou mají povahu (klasifikace)
Rozhodovací stromy a jejich konstrukce z dat Příklad počítačová hra. Můžeme počítač naučit rozlišovat přátelské a nepřátelské roboty? Učení s učitelem: u některých už víme, jakou mají povahu (klasifikace)
ČVUT FEL X36PAA - Problémy a algoritmy. 5. úloha - Seznámení se se zvolenou pokročilou iterativní metodou na problému batohu
 ČVUT FEL X36PAA - Problémy a algoritmy 5. úloha - Seznámení se se zvolenou pokročilou iterativní metodou na problému batohu Jméno: Marek Handl Datum: 4. 2. 2009 Cvičení: Pondělí 9:00 Zadání Zvolte si heuristiku,
ČVUT FEL X36PAA - Problémy a algoritmy 5. úloha - Seznámení se se zvolenou pokročilou iterativní metodou na problému batohu Jméno: Marek Handl Datum: 4. 2. 2009 Cvičení: Pondělí 9:00 Zadání Zvolte si heuristiku,
Rozhodovací stromy a jejich konstrukce z dat
 Příklad počítačová hra. Můžeme počítač naučit rozlišovat přátelské a přátelské roboty? Rozhodovací stromy a jejich konstruk z dat Učení s učitelem: u některých už víme, jakou mají povahu (klasifika) Neparametrická
Příklad počítačová hra. Můžeme počítač naučit rozlišovat přátelské a přátelské roboty? Rozhodovací stromy a jejich konstruk z dat Učení s učitelem: u některých už víme, jakou mají povahu (klasifika) Neparametrická
Asociační i jiná. Pravidla. (Ch )
") Asociační i jiná Pravidla (Ch. 14 +...) Učení bez učitele Nemáme cílovou třídu Y, G; máme N pozorování což jsou p-dimenzionální vektory se sdruženou pravděpodobností chceme odvozovat vlastnosti. Pro málo
Asociační i jiná Pravidla (Ch. 14 +...) Učení bez učitele Nemáme cílovou třídu Y, G; máme N pozorování což jsou p-dimenzionální vektory se sdruženou pravděpodobností chceme odvozovat vlastnosti. Pro málo
Vytěžování znalostí z dat
 Pavel Kordík, Josef Borkovec (ČVUT FIT) Vytěžování znalostí z dat BI-VZD, 2012, Přednáška 3 1/29 Vytěžování znalostí z dat Pavel Kordík, Josef Borkovec Department of Computer Systems Faculty of Information
Pavel Kordík, Josef Borkovec (ČVUT FIT) Vytěžování znalostí z dat BI-VZD, 2012, Přednáška 3 1/29 Vytěžování znalostí z dat Pavel Kordík, Josef Borkovec Department of Computer Systems Faculty of Information
Úloha - rozpoznávání číslic
 Úloha - rozpoznávání číslic Vojtěch Franc, Tomáš Pajdla a Tomáš Svoboda http://cmp.felk.cvut.cz 27. listopadu 26 Abstrakt Podpůrný text pro cvičení předmětu X33KUI. Vysvětluje tři způsoby rozpoznávání
Úloha - rozpoznávání číslic Vojtěch Franc, Tomáš Pajdla a Tomáš Svoboda http://cmp.felk.cvut.cz 27. listopadu 26 Abstrakt Podpůrný text pro cvičení předmětu X33KUI. Vysvětluje tři způsoby rozpoznávání
Předzpracování dat. Lenka Vysloužilová
 Předzpracování dat Lenka Vysloužilová 1 Metodika CRISP-DM (www.crisp-dm.org) Příprava dat Data Preparation příprava dat pro modelování selekce příznaků výběr relevantních příznaků čištění dat získávání
Předzpracování dat Lenka Vysloužilová 1 Metodika CRISP-DM (www.crisp-dm.org) Příprava dat Data Preparation příprava dat pro modelování selekce příznaků výběr relevantních příznaků čištění dat získávání
Výpočetní teorie strojového učení a pravděpodobně skoro správné (PAC) učení. PAC učení 1
 učení. PAC učení 1") Výpočetní teorie strojového učení a pravděpodobně skoro správné (PAC) učení PAC učení 1 Cíl induktivního strojového učení Na základě omezeného vzorku příkladů E + a E -, charakterizovat (popsat) zamýšlenou
Výpočetní teorie strojového učení a pravděpodobně skoro správné (PAC) učení PAC učení 1 Cíl induktivního strojového učení Na základě omezeného vzorku příkladů E + a E -, charakterizovat (popsat) zamýšlenou
Rozhodovací stromy a lesy
 Rozhodovací stromy a lesy Klára Komprdová Leden 2012 Příprava a vydání této publikace byly podporovány projektem ESF č. CZ.1.07/2.2.00/07.0318 Víceoborová inovace studia Matematické biologie a státním
Rozhodovací stromy a lesy Klára Komprdová Leden 2012 Příprava a vydání této publikace byly podporovány projektem ESF č. CZ.1.07/2.2.00/07.0318 Víceoborová inovace studia Matematické biologie a státním
Jasové transformace. Karel Horák. Rozvrh přednášky:
 1 / 23 Jasové transformace Karel Horák Rozvrh přednášky: 1. Úvod. 2. Histogram obrazu. 3. Globální jasová transformace. 4. Lokální jasová transformace. 5. Bodová jasová transformace. 2 / 23 Jasové transformace
1 / 23 Jasové transformace Karel Horák Rozvrh přednášky: 1. Úvod. 2. Histogram obrazu. 3. Globální jasová transformace. 4. Lokální jasová transformace. 5. Bodová jasová transformace. 2 / 23 Jasové transformace
Základní datové struktury III: Stromy, haldy
 Základní datové struktury III: Stromy, haldy prof. Ing. Pavel Tvrdík CSc. Katedra počítačových systémů Fakulta informačních technologií České vysoké učení technické v Praze c Pavel Tvrdík, 2010 Efektivní
Základní datové struktury III: Stromy, haldy prof. Ing. Pavel Tvrdík CSc. Katedra počítačových systémů Fakulta informačních technologií České vysoké učení technické v Praze c Pavel Tvrdík, 2010 Efektivní
Strukturální regresní modely. určitý nadhled nad rozličnými typy modelů
 Strukturální regresní modely určitý nadhled nad rozličnými typy modelů Jde zlepšit odhad k-nn? Odhad k-nn konverguje pro slušné k očekávané hodnotě. ALE POMALU! Jiné přístupy přidají předpoklad o funkci
Strukturální regresní modely určitý nadhled nad rozličnými typy modelů Jde zlepšit odhad k-nn? Odhad k-nn konverguje pro slušné k očekávané hodnotě. ALE POMALU! Jiné přístupy přidají předpoklad o funkci
Algoritmizace Dynamické programování. Jiří Vyskočil, Marko Genyg-Berezovskyj 2010
 Dynamické programování Jiří Vyskočil, Marko Genyg-Berezovskyj 2010 Rozděl a panuj (divide-and-conquer) Rozděl (Divide): Rozděl problém na několik podproblémů tak, aby tyto podproblémy odpovídaly původnímu
Dynamické programování Jiří Vyskočil, Marko Genyg-Berezovskyj 2010 Rozděl a panuj (divide-and-conquer) Rozděl (Divide): Rozděl problém na několik podproblémů tak, aby tyto podproblémy odpovídaly původnímu
Úvod do optimalizace, metody hladké optimalizace
 Evropský sociální fond Investujeme do vaší budoucnosti Úvod do optimalizace, metody hladké optimalizace Matematika pro informatiky, FIT ČVUT Martin Holeňa, 13. týden LS 2010/2011 O čem to bude? Příklady
Evropský sociální fond Investujeme do vaší budoucnosti Úvod do optimalizace, metody hladké optimalizace Matematika pro informatiky, FIT ČVUT Martin Holeňa, 13. týden LS 2010/2011 O čem to bude? Příklady
Strojové učení Marta Vomlelová
 Strojové učení Marta Vomlelová marta@ktiml.mff.cuni.cz KTIML, S303 Literatura 1.T. Hastie, R. Tishirani, and J. Friedman. The Elements of Statistical Learning, Data Mining, Inference and Prediction. Springer
Strojové učení Marta Vomlelová marta@ktiml.mff.cuni.cz KTIML, S303 Literatura 1.T. Hastie, R. Tishirani, and J. Friedman. The Elements of Statistical Learning, Data Mining, Inference and Prediction. Springer
Vytěžování znalostí z dat
 Pavel Kordík, Jan Motl (ČVUT FIT) Vytěžování znalostí z dat BI-VZD, 2012, Přednáška 7 1/27 Vytěžování znalostí z dat Pavel Kordík, Jan Motl Department of Computer Systems Faculty of Information Technology
Pavel Kordík, Jan Motl (ČVUT FIT) Vytěžování znalostí z dat BI-VZD, 2012, Přednáška 7 1/27 Vytěžování znalostí z dat Pavel Kordík, Jan Motl Department of Computer Systems Faculty of Information Technology
Dobývání dat a strojové učení
 Dobývání dat a strojové učení Dobývání znalostí z databází (Knowledge discovery in databases) Non-trivial process of identifying valid, novel, potentially useful and ultimately understandable patterns
Dobývání dat a strojové učení Dobývání znalostí z databází (Knowledge discovery in databases) Non-trivial process of identifying valid, novel, potentially useful and ultimately understandable patterns
Evoluční algoritmy. Podmínka zastavení počet iterací kvalita nejlepšího jedince v populaci změna kvality nejlepšího jedince mezi iteracemi
 Evoluční algoritmy Použítí evoluční principů, založených na metodách optimalizace funkcí a umělé inteligenci, pro hledání řešení nějaké úlohy. Populace množina jedinců, potenciálních řešení Fitness function
Evoluční algoritmy Použítí evoluční principů, založených na metodách optimalizace funkcí a umělé inteligenci, pro hledání řešení nějaké úlohy. Populace množina jedinců, potenciálních řešení Fitness function
Genetické programování
 Genetické programování Vyvinuto v USA v 90. letech J. Kozou Typické problémy: Predikce, klasifikace, aproximace, tvorba programů Vlastnosti Soupeří s neuronovými sítěmi apod. Potřebuje značně velké populace
Genetické programování Vyvinuto v USA v 90. letech J. Kozou Typické problémy: Predikce, klasifikace, aproximace, tvorba programů Vlastnosti Soupeří s neuronovými sítěmi apod. Potřebuje značně velké populace
Lineární klasifikátory
 Lineární klasifikátory Lineární klasifikátory obsah: perceptronový algoritmus základní verze varianta perceptronového algoritmu přihrádkový algoritmus podpůrné vektorové stroje Lineární klasifikátor navrhnout
Lineární klasifikátory Lineární klasifikátory obsah: perceptronový algoritmus základní verze varianta perceptronového algoritmu přihrádkový algoritmus podpůrné vektorové stroje Lineární klasifikátor navrhnout
Vytěžování znalostí z dat
 Vytěžování znalostí z dat Department of Computer Systems Faculty of Information Technology Czech Technical University in Prague Přednáška 5: Hodnocení kvality modelu BI-VZD, 09/2011 MI-POA Evropský sociální
Vytěžování znalostí z dat Department of Computer Systems Faculty of Information Technology Czech Technical University in Prague Přednáška 5: Hodnocení kvality modelu BI-VZD, 09/2011 MI-POA Evropský sociální
Usuzování za neurčitosti
 Usuzování za neurčitosti 25.11.2014 8-1 Usuzování za neurčitosti Hypotetické usuzování a zpětná indukce Míry postačitelnosti a nezbytnosti Kombinace důkazů Šíření pravděpodobnosti v inferenčních sítích
Usuzování za neurčitosti 25.11.2014 8-1 Usuzování za neurčitosti Hypotetické usuzování a zpětná indukce Míry postačitelnosti a nezbytnosti Kombinace důkazů Šíření pravděpodobnosti v inferenčních sítích
Učení z klasifikovaných dat
 Učení z klasifikovaných dat Příklad počítačová hra. Můžeme počítač naučit rozlišovat přátelské a nepřátelské roboty? Učení s učitelem: u některých objektů už víme, jakou mají povahu (klasifikace) Neparametrická
Učení z klasifikovaných dat Příklad počítačová hra. Můžeme počítač naučit rozlišovat přátelské a nepřátelské roboty? Učení s učitelem: u některých objektů už víme, jakou mají povahu (klasifikace) Neparametrická
Informační systémy pro podporu rozhodování
 Informační systémy pro podporu rozhodování 2 Jan Žižka, Naděžda Chalupová Ústav informatiky PEF Mendelova universita v Brně Strojové učení, umělá inteligence, dolování z dat Strojové učení je moderní,
Informační systémy pro podporu rozhodování 2 Jan Žižka, Naděžda Chalupová Ústav informatiky PEF Mendelova universita v Brně Strojové učení, umělá inteligence, dolování z dat Strojové učení je moderní,
Vyhledávání. doc. Mgr. Jiří Dvorský, Ph.D. Katedra informatiky Fakulta elektrotechniky a informatiky VŠB TU Ostrava. Prezentace ke dni 21.
 Vyhledávání doc. Mgr. Jiří Dvorský, Ph.D. Katedra informatiky Fakulta elektrotechniky a informatiky VŠB TU Ostrava Prezentace ke dni 21. září 2018 Jiří Dvorský (VŠB TUO) Vyhledávání 242 / 433 Osnova přednášky
Vyhledávání doc. Mgr. Jiří Dvorský, Ph.D. Katedra informatiky Fakulta elektrotechniky a informatiky VŠB TU Ostrava Prezentace ke dni 21. září 2018 Jiří Dvorský (VŠB TUO) Vyhledávání 242 / 433 Osnova přednášky
8. Strojové učení Strojové učení
 Strojové učení 5. prosince 2017 8-1 Strojové učení je podoblastí umělé inteligence, zabývající se algoritmy a technikami, které umožňují počítačovému systému 'učit se'. Učením v daném kontextu rozumíme
Strojové učení 5. prosince 2017 8-1 Strojové učení je podoblastí umělé inteligence, zabývající se algoritmy a technikami, které umožňují počítačovému systému 'učit se'. Učením v daném kontextu rozumíme
Rekurzivní algoritmy
 Rekurzivní algoritmy prof. Ing. Pavel Tvrdík CSc. Katedra počítačových systémů Fakulta informačních technologií České vysoké učení technické v Praze c Pavel Tvrdík, 2010 Efektivní algoritmy (BI-EFA) ZS
Rekurzivní algoritmy prof. Ing. Pavel Tvrdík CSc. Katedra počítačových systémů Fakulta informačních technologií České vysoké učení technické v Praze c Pavel Tvrdík, 2010 Efektivní algoritmy (BI-EFA) ZS
Katedra kybernetiky, FEL, ČVUT v Praze.
 Strojové učení a dolování dat přehled Jiří Kléma Katedra kybernetiky, FEL, ČVUT v Praze http://ida.felk.cvut.cz posnova přednášek Přednáška Učitel Obsah 1. J. Kléma Úvod do předmětu, učení s a bez učitele.
Strojové učení a dolování dat přehled Jiří Kléma Katedra kybernetiky, FEL, ČVUT v Praze http://ida.felk.cvut.cz posnova přednášek Přednáška Učitel Obsah 1. J. Kléma Úvod do předmětu, učení s a bez učitele.
Aproximativní algoritmy UIN009 Efektivní algoritmy 1
 Aproximativní algoritmy. 14.4.2005 UIN009 Efektivní algoritmy 1 Jak nakládat s NP-těžkými úlohami? Speciální případy Aproximativní algoritmy Pravděpodobnostní algoritmy Exponenciální algoritmy pro data
Aproximativní algoritmy. 14.4.2005 UIN009 Efektivní algoritmy 1 Jak nakládat s NP-těžkými úlohami? Speciální případy Aproximativní algoritmy Pravděpodobnostní algoritmy Exponenciální algoritmy pro data
Základy umělé inteligence
 Základy umělé inteligence Automatické řešení úloh Základy umělé inteligence - prohledávání. Vlasta Radová, ZČU, katedra kybernetiky 1 Formalizace úlohy UI chápe řešení úloh jako proces hledání řešení v
Základy umělé inteligence Automatické řešení úloh Základy umělé inteligence - prohledávání. Vlasta Radová, ZČU, katedra kybernetiky 1 Formalizace úlohy UI chápe řešení úloh jako proces hledání řešení v
u odpovědí typu A, B, C, D, E: Obsah: jako 0) CLP Constraint Logic Programming
 CLP Constraint Logic Programming") Průběžná písemná práce Průběžná písemná práce Obsah: Průběžná písemná práce Aleš Horák E-mail: hales@fi.muni.cz http://nlp.fi.muni.cz/uui/ délka pro vypracování: 25 minut nejsou povoleny žádné materiály
Průběžná písemná práce Průběžná písemná práce Obsah: Průběžná písemná práce Aleš Horák E-mail: hales@fi.muni.cz http://nlp.fi.muni.cz/uui/ délka pro vypracování: 25 minut nejsou povoleny žádné materiály
Intervalová data a výpočet některých statistik
 Intervalová data a výpočet některých statistik Milan Hladík 1 Michal Černý 2 1 Katedra aplikované matematiky Matematicko-fyzikální fakulta Univerzita Karlova 2 Katedra ekonometrie Fakulta informatiky a
Intervalová data a výpočet některých statistik Milan Hladík 1 Michal Černý 2 1 Katedra aplikované matematiky Matematicko-fyzikální fakulta Univerzita Karlova 2 Katedra ekonometrie Fakulta informatiky a
KOMPRESE OBRAZŮ. Václav Hlaváč, Jan Kybic. Fakulta elektrotechnická ČVUT v Praze katedra kybernetiky, Centrum strojového vnímání.
 1/25 KOMPRESE OBRAZŮ Václav Hlaváč, Jan Kybic Fakulta elektrotechnická ČVUT v Praze katedra kybernetiky, Centrum strojového vnímání hlavac@fel.cvut.cz http://cmp.felk.cvut.cz/ hlavac KOMPRESE OBRAZŮ, ÚVOD
1/25 KOMPRESE OBRAZŮ Václav Hlaváč, Jan Kybic Fakulta elektrotechnická ČVUT v Praze katedra kybernetiky, Centrum strojového vnímání hlavac@fel.cvut.cz http://cmp.felk.cvut.cz/ hlavac KOMPRESE OBRAZŮ, ÚVOD
Testování modelů a jejich výsledků. Jak moc můžeme věřit tomu, co jsme se naučili?
 Testování modelů a jejich výsledků Jak moc můžeme věřit tomu, co jsme se naučili? Osnova Úvod Trénovací, Testovací a Validační datové soubory Práce s nebalancovanými daty; ladění parametrů Křížová validace
Testování modelů a jejich výsledků Jak moc můžeme věřit tomu, co jsme se naučili? Osnova Úvod Trénovací, Testovací a Validační datové soubory Práce s nebalancovanými daty; ladění parametrů Křížová validace
Neparametrické odhady hustoty pravděpodobnosti
 Neparametrické odhady hustoty pravděpodobnosti Václav Hlaváč Elektrotechnická fakulta ČVUT Katedra kybernetiky Centrum strojového vnímání 121 35 Praha 2, Karlovo nám. 13 hlavac@fel.cvut.cz Statistické
Neparametrické odhady hustoty pravděpodobnosti Václav Hlaváč Elektrotechnická fakulta ČVUT Katedra kybernetiky Centrum strojového vnímání 121 35 Praha 2, Karlovo nám. 13 hlavac@fel.cvut.cz Statistické
Miroslav Čepek. Fakulta Elektrotechnická, ČVUT. Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti
 Vytěžování Dat Přednáška 12 Kombinování modelů Miroslav Čepek Pavel Kordík a Jan Černý (FIT) Fakulta Elektrotechnická, ČVUT Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti ČVUT (FEL)
Vytěžování Dat Přednáška 12 Kombinování modelů Miroslav Čepek Pavel Kordík a Jan Černý (FIT) Fakulta Elektrotechnická, ČVUT Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti ČVUT (FEL)
Trénování sítě pomocí učení s učitelem
 Trénování sítě pomocí učení s učitelem! předpokládá se, že máme k dispozici trénovací množinu, tj. množinu P dvojic [vstup x p, požadovaný výstup u p ]! chceme nastavit váhy a prahy sítě tak, aby výstup
Trénování sítě pomocí učení s učitelem! předpokládá se, že máme k dispozici trénovací množinu, tj. množinu P dvojic [vstup x p, požadovaný výstup u p ]! chceme nastavit váhy a prahy sítě tak, aby výstup
ANALÝZA A KLASIFIKACE DAT
 ANALÝZA A KLASIFIKACE DAT RNDr. Eva Janoušová INVESTICE DO ROZVOJE VZDĚLÁVÁNÍ HODNOCENÍ ÚSPĚŠNOSTI KLASIFIKACE A SROVNÁNÍ KLASIFIKÁTORŮ ÚVOD Vstupní data Subjekt Objem hipokampu Objem komor Skutečnost
ANALÝZA A KLASIFIKACE DAT RNDr. Eva Janoušová INVESTICE DO ROZVOJE VZDĚLÁVÁNÍ HODNOCENÍ ÚSPĚŠNOSTI KLASIFIKACE A SROVNÁNÍ KLASIFIKÁTORŮ ÚVOD Vstupní data Subjekt Objem hipokampu Objem komor Skutečnost
AVDAT Mnohorozměrné metody, metody klasifikace
 AVDAT Mnohorozměrné metody, metody klasifikace Josef Tvrdík Katedra informatiky Přírodovědecká fakulta Ostravská univerzita Mnohorozměrné metody Regrese jedna náhodná veličina je vysvětlována pomocí jiných
AVDAT Mnohorozměrné metody, metody klasifikace Josef Tvrdík Katedra informatiky Přírodovědecká fakulta Ostravská univerzita Mnohorozměrné metody Regrese jedna náhodná veličina je vysvětlována pomocí jiných
Vytěžování znalostí z dat
 Pavel Kordík, Jan Motl (ČVUT FIT) Vytěžování znalostí z dat BI-VZD, 2012, Přednáška 6 1/25 Vytěžování znalostí z dat Pavel Kordík, Jan Motl Department of Computer Systems Faculty of Information Technology
Pavel Kordík, Jan Motl (ČVUT FIT) Vytěžování znalostí z dat BI-VZD, 2012, Přednáška 6 1/25 Vytěžování znalostí z dat Pavel Kordík, Jan Motl Department of Computer Systems Faculty of Information Technology
Úvodem Dříve les než stromy 3 Operace s maticemi
 Obsah 1 Úvodem 13 2 Dříve les než stromy 17 2.1 Nejednoznačnost terminologie 17 2.2 Volba metody analýzy dat 23 2.3 Přehled vybraných vícerozměrných metod 25 2.3.1 Metoda hlavních komponent 26 2.3.2 Faktorová
Obsah 1 Úvodem 13 2 Dříve les než stromy 17 2.1 Nejednoznačnost terminologie 17 2.2 Volba metody analýzy dat 23 2.3 Přehled vybraných vícerozměrných metod 25 2.3.1 Metoda hlavních komponent 26 2.3.2 Faktorová
Změkčování hranic v klasifikačních stromech
 Změkčování hranic v klasifikačních stromech Jakub Dvořák Seminář strojového učení a modelování 24.5.2012 Obsah Klasifikační stromy Změkčování hran Ranking, ROC křivka a AUC Metody změkčování Experiment
Změkčování hranic v klasifikačních stromech Jakub Dvořák Seminář strojového učení a modelování 24.5.2012 Obsah Klasifikační stromy Změkčování hran Ranking, ROC křivka a AUC Metody změkčování Experiment
Testování modelů a jejich výsledků. tomu, co jsme se naučili?
 Testování modelů a jejich výsledků Jak moc můžeme věřit tomu, co jsme se naučili? Osnova Úvod Trénovací, Testovací a Validační datové soubory Práce s nebalancovanými daty; ladění parametrů Křížová validace
Testování modelů a jejich výsledků Jak moc můžeme věřit tomu, co jsme se naučili? Osnova Úvod Trénovací, Testovací a Validační datové soubory Práce s nebalancovanými daty; ladění parametrů Křížová validace
Markov Chain Monte Carlo. Jan Kracík.
 Markov Chain Monte Carlo Jan Kracík jan.kracik@vsb.cz Princip Monte Carlo integrace Cílem je (přibližný) výpočet integrálu I(g) = E f [g(x)] = g(x)f (x)dx. (1) Umíme-li generovat nezávislé vzorky x (1),
Markov Chain Monte Carlo Jan Kracík jan.kracik@vsb.cz Princip Monte Carlo integrace Cílem je (přibližný) výpočet integrálu I(g) = E f [g(x)] = g(x)f (x)dx. (1) Umíme-li generovat nezávislé vzorky x (1),
jedna hrana pro každou možnou hodnotu tohoto atributu; listy jsou označeny předpokládanou hodnotou cílového atributu Atribut Outlook
 Rozhodovací stromy Outlook Sunny Overcast Rain Humidity Yes Wind High Normal Strong Weak Atribut hodnota cílového atributu Hodnota atributu No Yes No Yes Rozhodovací strom pro daný cílový atribut G je
Rozhodovací stromy Outlook Sunny Overcast Rain Humidity Yes Wind High Normal Strong Weak Atribut hodnota cílového atributu Hodnota atributu No Yes No Yes Rozhodovací strom pro daný cílový atribut G je
Statistická teorie učení
 Statistická teorie učení Petr Havel Marek Myslivec přednáška z 9. týdne 1 Úvod Představme si situaci výrobce a zákazníka, který si u výrobce objednal algoritmus rozpoznávání. Zákazník dodal experimentální
Statistická teorie učení Petr Havel Marek Myslivec přednáška z 9. týdne 1 Úvod Představme si situaci výrobce a zákazníka, který si u výrobce objednal algoritmus rozpoznávání. Zákazník dodal experimentální
Dynamické programování
 Dynamické programování prof. Ing. Pavel Tvrdík CSc. Katedra počítačových systémů Fakulta informačních technologií České vysoké učení technické v Praze c Pavel Tvrdík, 2010 Efektivní algoritmy (BI-EFA)
Dynamické programování prof. Ing. Pavel Tvrdík CSc. Katedra počítačových systémů Fakulta informačních technologií České vysoké učení technické v Praze c Pavel Tvrdík, 2010 Efektivní algoritmy (BI-EFA)
REGRESNÍ ANALÝZA V PROSTŘEDÍ MATLAB
 62 REGRESNÍ ANALÝZA V PROSTŘEDÍ MATLAB BEZOUŠKA VLADISLAV Abstrakt: Text se zabývá jednoduchým řešením metody nejmenších čtverců v prostředí Matlab pro obecné víceparametrové aproximační funkce. Celý postup
62 REGRESNÍ ANALÝZA V PROSTŘEDÍ MATLAB BEZOUŠKA VLADISLAV Abstrakt: Text se zabývá jednoduchým řešením metody nejmenších čtverců v prostředí Matlab pro obecné víceparametrové aproximační funkce. Celý postup
Rozhodovací stromy. Úloha klasifikace objektů do tříd. Top down induction of decision trees (TDIDT) - metoda divide and conquer (rozděl a panuj)
 - metoda divide and conquer (rozděl a panuj)") Rozhodovací stromy Úloha klasifikace objektů do tříd. Top dow iductio of decisio trees (TDIDT) - metoda divide ad coquer (rozděl a pauj) metoda specializace v prostoru hypotéz stromů (postup shora dolů,
Rozhodovací stromy Úloha klasifikace objektů do tříd. Top dow iductio of decisio trees (TDIDT) - metoda divide ad coquer (rozděl a pauj) metoda specializace v prostoru hypotéz stromů (postup shora dolů,
Rekonstrukce diskrétního rozdělení psti metodou maximální entropie
 Rekonstrukce diskrétního rozdělení psti metodou maximální entropie Příklad Lze nalézt četnosti nepozorovaných stavů tak, abychom si vymýšleli co nejméně? Nechť n i, i = 1, 2,..., N jsou známé (absolutní)
Rekonstrukce diskrétního rozdělení psti metodou maximální entropie Příklad Lze nalézt četnosti nepozorovaných stavů tak, abychom si vymýšleli co nejméně? Nechť n i, i = 1, 2,..., N jsou známé (absolutní)
Dolování asociačních pravidel
 Dolování asociačních pravidel Miloš Trávníček UIFS FIT VUT v Brně Obsah přednášky 1. Proces získávání znalostí 2. Asociační pravidla 3. Dolování asociačních pravidel 4. Algoritmy pro dolování asociačních
Dolování asociačních pravidel Miloš Trávníček UIFS FIT VUT v Brně Obsah přednášky 1. Proces získávání znalostí 2. Asociační pravidla 3. Dolování asociačních pravidel 4. Algoritmy pro dolování asociačních
Algoritmy pro shlukování prostorových dat
 Algoritmy pro shlukování prostorových dat Marta Žambochová Katedra matematiky a informatiky Fakulta sociálně ekonomická Univerzita J. E. Purkyně v Ústí nad Labem ROBUST 21. 26. leden 2018 Rybník - Hostouň
Algoritmy pro shlukování prostorových dat Marta Žambochová Katedra matematiky a informatiky Fakulta sociálně ekonomická Univerzita J. E. Purkyně v Ústí nad Labem ROBUST 21. 26. leden 2018 Rybník - Hostouň
Algoritmy výpočetní geometrie
 Algoritmy výpočetní geometrie prof. Ing. Pavel Tvrdík CSc. Katedra počítačových systémů Fakulta informačních technologií České vysoké učení technické v Praze c Pavel Tvrdík, 2010 Efektivní algoritmy (BI-EFA)
Algoritmy výpočetní geometrie prof. Ing. Pavel Tvrdík CSc. Katedra počítačových systémů Fakulta informačních technologií České vysoké učení technické v Praze c Pavel Tvrdík, 2010 Efektivní algoritmy (BI-EFA)
Instance based learning
 Učení založené na instancích Instance based learning Charakteristika IBL (nejbližších sousedů) Tyto metody nepředpokládají určitý model nejsou strukturované a typicky nejsou příliš užitečné pro porozumění
Učení založené na instancích Instance based learning Charakteristika IBL (nejbližších sousedů) Tyto metody nepředpokládají určitý model nejsou strukturované a typicky nejsou příliš užitečné pro porozumění
OSA. maximalizace minimalizace 1/22
 OSA Systémová analýza metodika používaná k navrhování a racionalizaci systémů v podmínkách neurčitosti vyšší stupeň operační analýzy Operační analýza (výzkum) soubor metod umožňující řešit rozhodovací,
OSA Systémová analýza metodika používaná k navrhování a racionalizaci systémů v podmínkách neurčitosti vyšší stupeň operační analýzy Operační analýza (výzkum) soubor metod umožňující řešit rozhodovací,
1. Vlastnosti diskretních a číslicových metod zpracování signálů... 15
 Úvodní poznámky... 11 1. Vlastnosti diskretních a číslicových metod zpracování signálů... 15 1.1 Základní pojmy... 15 1.2 Aplikační oblasti a etapy zpracování signálů... 17 1.3 Klasifikace diskretních
Úvodní poznámky... 11 1. Vlastnosti diskretních a číslicových metod zpracování signálů... 15 1.1 Základní pojmy... 15 1.2 Aplikační oblasti a etapy zpracování signálů... 17 1.3 Klasifikace diskretních
Testování modelů a jejich výsledků. Jak moc můžeme věřit tomu, co jsme se naučili?
 Testování modelů a jejich výsledků Jak moc můžeme věřit tomu, co jsme se naučili? 2 Osnova Úvod různé klasifikační modely a jejich kvalita Hodnotící míry (kriteria kvality) pro zvolený model. Postup vyhodnocování
Testování modelů a jejich výsledků Jak moc můžeme věřit tomu, co jsme se naučili? 2 Osnova Úvod různé klasifikační modely a jejich kvalita Hodnotící míry (kriteria kvality) pro zvolený model. Postup vyhodnocování
Algoritmy a struktury neuropočítačů ASN P9 SVM Support vector machines Support vector networks (Algoritmus podpůrných vektorů)
") Algoritmy a struktury neuropočítačů ASN P9 SVM Support vector machines Support vector networks (Algoritmus podpůrných vektorů) Autor: Vladimir Vapnik Vapnik, V. The Nature of Statistical Learning Theory.
Algoritmy a struktury neuropočítačů ASN P9 SVM Support vector machines Support vector networks (Algoritmus podpůrných vektorů) Autor: Vladimir Vapnik Vapnik, V. The Nature of Statistical Learning Theory.
Kombinatorická minimalizace
 Kombinatorická minimalizace Cílem je nalézt globální minimum ve velké diskrétní množině, kde může být mnoho lokálních minim. Úloha obchodního cestujícího Cílem je najít nejkratší cestu, která spojuje všechny
Kombinatorická minimalizace Cílem je nalézt globální minimum ve velké diskrétní množině, kde může být mnoho lokálních minim. Úloha obchodního cestujícího Cílem je najít nejkratší cestu, která spojuje všechny
Obsah: CLP Constraint Logic Programming. u odpovědí typu A, B, C, D, E: jako 0)
") Aleš Horák E-mail: hales@fi.muni.cz http://nlp.fi.muni.cz/uui/ Obsah: Průběžná písemná práce Úvod do umělé inteligence 6/12 1 / 17 Průběžná písemná práce Průběžná písemná práce délka pro vypracování: 25
Aleš Horák E-mail: hales@fi.muni.cz http://nlp.fi.muni.cz/uui/ Obsah: Průběžná písemná práce Úvod do umělé inteligence 6/12 1 / 17 Průběžná písemná práce Průběžná písemná práce délka pro vypracování: 25
KOMPRESE OBRAZŮ. Václav Hlaváč. Fakulta elektrotechnická ČVUT v Praze katedra kybernetiky, Centrum strojového vnímání. hlavac@fel.cvut.
 1/24 KOMPRESE OBRAZŮ Václav Hlaváč Fakulta elektrotechnická ČVUT v Praze katedra kybernetiky, Centrum strojového vnímání hlavac@fel.cvut.cz http://cmp.felk.cvut.cz/ hlavac KOMPRESE OBRAZŮ, ÚVOD 2/24 Cíl:
1/24 KOMPRESE OBRAZŮ Václav Hlaváč Fakulta elektrotechnická ČVUT v Praze katedra kybernetiky, Centrum strojového vnímání hlavac@fel.cvut.cz http://cmp.felk.cvut.cz/ hlavac KOMPRESE OBRAZŮ, ÚVOD 2/24 Cíl:
Hodnocení klasifikátoru Test nezávislosti. 14. prosinec Rozvoj aplikačního potenciálu (RAPlus) CZ.1.07/2.4.00/
 CZ.1.07/2.4.00/") Čtyřpolní tabulky Čtyřpolní tabulky 14. prosinec 2012 Rozvoj aplikačního potenciálu (RAPlus) CZ.1.07/2.4.00/17.0117 O čem se bude mluvit? Čtyřpolní tabulky Osnova prezentace Čtyřpolní tabulky 1. přístupy
Čtyřpolní tabulky Čtyřpolní tabulky 14. prosinec 2012 Rozvoj aplikačního potenciálu (RAPlus) CZ.1.07/2.4.00/17.0117 O čem se bude mluvit? Čtyřpolní tabulky Osnova prezentace Čtyřpolní tabulky 1. přístupy
Analýza dat pomocí systému Weka, Rapid miner a Enterprise miner
 Vysoká škola ekonomická v Praze Analýza dat pomocí systému Weka, Rapid miner a Enterprise miner Dobývání znalostí z databází 4IZ450 XXXXXXXXXXX Přidělená data a jejich popis Data určená pro zpracování
Vysoká škola ekonomická v Praze Analýza dat pomocí systému Weka, Rapid miner a Enterprise miner Dobývání znalostí z databází 4IZ450 XXXXXXXXXXX Přidělená data a jejich popis Data určená pro zpracování
Binární vyhledávací stromy pokročilé partie
 Binární vyhledávací stromy pokročilé partie KMI/ALS lekce Jan Konečný 30.9.204 Literatura Cormen Thomas H., Introduction to Algorithms, 2nd edition MIT Press, 200. ISBN 0-262-5396-8 6, 3, A Knuth Donald
Binární vyhledávací stromy pokročilé partie KMI/ALS lekce Jan Konečný 30.9.204 Literatura Cormen Thomas H., Introduction to Algorithms, 2nd edition MIT Press, 200. ISBN 0-262-5396-8 6, 3, A Knuth Donald
Učící se klasifikátory obrazu v průmyslu
 Učící se klasifikátory obrazu v průmyslu FCC průmyslové systémy s.r.o. FCC průmyslové systémy je technicko obchodní společností, působící v oblasti průmyslové automatizace. Tvoří ji dvě základní divize:
Učící se klasifikátory obrazu v průmyslu FCC průmyslové systémy s.r.o. FCC průmyslové systémy je technicko obchodní společností, působící v oblasti průmyslové automatizace. Tvoří ji dvě základní divize:
Otázky ke státní závěrečné zkoušce
 Otázky ke státní závěrečné zkoušce obor Ekonometrie a operační výzkum a) Diskrétní modely, Simulace, Nelineární programování. b) Teorie rozhodování, Teorie her. c) Ekonometrie. Otázka č. 1 a) Úlohy konvexního
Otázky ke státní závěrečné zkoušce obor Ekonometrie a operační výzkum a) Diskrétní modely, Simulace, Nelineární programování. b) Teorie rozhodování, Teorie her. c) Ekonometrie. Otázka č. 1 a) Úlohy konvexního
Vyhledávání. doc. Mgr. Jiří Dvorský, Ph.D. Katedra informatiky Fakulta elektrotechniky a informatiky VŠB TU Ostrava. Prezentace ke dni 12.
 Vyhledávání doc. Mgr. Jiří Dvorský, Ph.D. Katedra informatiky Fakulta elektrotechniky a informatiky VŠB TU Ostrava Prezentace ke dni 12. září 2016 Jiří Dvorský (VŠB TUO) Vyhledávání 201 / 344 Osnova přednášky
Vyhledávání doc. Mgr. Jiří Dvorský, Ph.D. Katedra informatiky Fakulta elektrotechniky a informatiky VŠB TU Ostrava Prezentace ke dni 12. září 2016 Jiří Dvorský (VŠB TUO) Vyhledávání 201 / 344 Osnova přednášky
UNIVERZITA PARDUBICE. 4.4 Aproximace křivek a vyhlazování křivek
 UNIVERZITA PARDUBICE Licenční Studium Archimedes Statistické zpracování dat a informatika 4.4 Aproximace křivek a vyhlazování křivek Mgr. Jana Kubátová Endokrinologický ústav V Praze, leden 2012 Obsah
UNIVERZITA PARDUBICE Licenční Studium Archimedes Statistické zpracování dat a informatika 4.4 Aproximace křivek a vyhlazování křivek Mgr. Jana Kubátová Endokrinologický ústav V Praze, leden 2012 Obsah
7. Rozdělení pravděpodobnosti ve statistice
 7. Rozdělení pravděpodobnosti ve statistice Statistika nuda je, má však cenné údaje, neklesejte na mysli, ona nám to vyčíslí Jednou z úloh statistiky je odhad (výpočet) hodnot statistického znaku x i,
7. Rozdělení pravděpodobnosti ve statistice Statistika nuda je, má však cenné údaje, neklesejte na mysli, ona nám to vyčíslí Jednou z úloh statistiky je odhad (výpočet) hodnot statistického znaku x i,
Dynamické datové struktury III.
 Dynamické datové struktury III. Halda. Tomáš Bayer bayertom@natur.cuni.cz Katedra aplikované geoinformatiky a kartografie, Přírodovědecká fakulta UK. Tomáš Bayer bayertom@natur.cuni.cz (Katedra aplikované
Dynamické datové struktury III. Halda. Tomáš Bayer bayertom@natur.cuni.cz Katedra aplikované geoinformatiky a kartografie, Přírodovědecká fakulta UK. Tomáš Bayer bayertom@natur.cuni.cz (Katedra aplikované
NPRG030 Programování I, 2018/19 1 / :03:07
 NPRG030 Programování I, 2018/19 1 / 20 3. 12. 2018 09:03:07 Vnitřní třídění Zadání: Uspořádejte pole délky N podle hodnot prvků Měřítko efektivity: * počet porovnání * počet přesunů NPRG030 Programování
NPRG030 Programování I, 2018/19 1 / 20 3. 12. 2018 09:03:07 Vnitřní třídění Zadání: Uspořádejte pole délky N podle hodnot prvků Měřítko efektivity: * počet porovnání * počet přesunů NPRG030 Programování
Projekt LISp-Miner. M. Šimůnek
 Projekt LISp-Miner http://lispminer.vse.cz M. Šimůnek Obsah Systém LISp-Miner Vývoj systému v dlouhém období ETree-Miner Project LISp-Miner 2 Systém LISp-Miner Metoda GUHA (od roku 1966) předchozí implementace
Projekt LISp-Miner http://lispminer.vse.cz M. Šimůnek Obsah Systém LISp-Miner Vývoj systému v dlouhém období ETree-Miner Project LISp-Miner 2 Systém LISp-Miner Metoda GUHA (od roku 1966) předchozí implementace