Počítačová analýza vícerozměrných dat v oborech přírodních, technických a společenských věd
|
|
|
- Oldřich Stanislav Kolář
- před 8 lety
- Počet zobrazení:
Transkript
1 Počítačová analýza vícerozměrných dat v oborech přírodních, technických a společenských věd Prof. RNDr. Milan Meloun, DrSc. (Univerzita Pardubice, Pardubice) června 2011 Tato prezentace je spolufinancována Evropským sociálním fondem a státním rozpočtem České republiky
 2")
2 4.8 LOGISTICKÁ REGRESE (LR) 2
3 1. Zaměření metody LR Navržena v 60tých letech jako alternativní postup k MNC: závisle proměnná^ je binární (medicína) značí přítomnost (1) nebo nepřítomnost (0) choroby. Rozdíl od lineární regrese: predikuje pravděpodobnost události, která se buď stala (1) nebo nestala (0). 3
4 Logitová transformace Logitová transformace vede na sigmoidální vztah mezi závisle proměnnou y a nezávisle proměnnými x. Při nízkých x se pravděpodobnost proměnné y blíží k nule, při vysokých x se blíží k jedné. Logistická regrese používá kategorickou závisle proměnnou zatímco lineární regrese užívá pouze spojitou vysvětlovanou proměnnou. Logitová transformace vychází z poměru šancí či naděje. 4
5 Dle typu y se rozlišují: Binární logistická regrese: binární závisle proměnná nabývá pouze dvou hodnot, například přítomnost-absence, muž-žena. Vektor x obsahuje jednu či více spojitých proměnných (prediktory) nebo diskrétních, kategorických {faktory). Ordinální logistická regrese: ordinální závisle proměnná nabývá tři a více možných stavů, např. silný nesouhlas, nesouhlas, souhlas, silný souhlas. Vektor x nezávisle proměnných obsahuje jak prediktory tak i faktory. Nominální logistická regrese: nominální závisle proměnná o více než třech úrovních, např. mezi kterými je definována pouze odlišnost. Vektor x může obsahovat jak prediktory, tak i faktory. 5
6 2. Logistický regresní model Potřebujeme vědět, zda se událost stala (1) nebo nestala (0). Dichotomická hodnota 0-1 závisle proměnné^ predikuje odhad pravděpodobnosti, že se událost stala (1) či nestala (0). Je-li predikovaná pravděpodobnost větší než 0.50, pak se událost stala (1), jeli menší než 0.50, pak se nestala (0). LR porovnává pravděpodobnost události odehrané L (1) vůči pravděpodobnosti události neodehrané L (0) = 1 - L (1). Využijeme pravděpodobnostní poměr L (1) /L (0), ve kterém pravděpodobnost L (1) je vyjádřena logistickou funkcí 1 L (1) = 1 + exp C Z Pravděpodobnostní poměr (zvaný "poměr šancí") je vyjádřen L (1) L (0) = exp(a 0 + a 1 x 1 + a 2 x a p x p ), kde odhadované koeficienty a 0, a 2, a 2, a p jsou míry změny poměru pravděpodobností L (1) /L (0). 6
7 Poměr je lineární funkcí diskriminační funkce o p nezávisle proměnných Z = a 0 + a 1 x 1 + a 2 x a p x p Po zlogaritmování a úpravě vyjde C Z = ln L (0) L (1), kde C je absolutní člen a 0. Dle klasifikačního postupu je L (0) = P(G = 1 x) a L (1) = P G = 1 x a po úpravách bude = 1 P(G = 1 x) ln L (1) L (0) = b 0 + b 1 x 1 + b 2 x b p x p, kde b 0 = C + a 0, b i = a i pro i = 1,, p. Například: ve sportu řekneme, že tým má šanci 3:1. Tvrzení říká, že favorizovaný tým má pravděpodobnost vítězství pravděpodobnostní poměr L (1) L (0) = = = 3 4 = Platí tedy 7
8 Aposteriorní pravděpodobnost P(G = j x) zařazení do j-té kategorie: logistický model lze rozšířit na případ K tříd, a předpokládat, že aposteriorní pravděpodobnost P(G = j x) zařazení do j-té kategorie bude P(G = 1 x) ln P(G = K x) = b 1,0 + b T 1 x P(G = 2 x) ln P(G = K x) = b 2,0 + b T 2 x P(G = K 1 x) T ln = b P(G = K x) K 1,0 + b K 1 x Po zpětné transformaci vychází exp(b j,0 + b T j x) P G = j x = K l=1 exp(b l,0 + b T l x) a 1 P G = j x = K l=1 exp(b l,0 + b T l x) 8
9 Označíme pravděpodobnost P G = K x = p k (x, b) aby se zvýraznilo, že jde o funkci regresních parametrů b =,b 1,0, b 1, b 2,0, b 2, b K 1,0, b K 1 -. (Pro K = 2 přechází model na logistický model pro binární proměnnou y = G). 9
10 Odhady parametrů: Pro odhad parametrů logistických modelů se používá metoda maximální věrohodnosti. Přítomnost v první třídě y = 1 je pro G = 1. Nepřítomnost v první třídě y = 0 je pro G = 2 čili přítomnost ve druhé třídě. Výchozí data: vektor y rozměru n x 1 matice X rozměru n x m. Pro i-tý objekt má y i hodnotu buď 0, nebo 1 a x i T je i-tý řádek matice X. Označme p x, b = p 1 (x, b) a 1 p x, b =p 2 x, b a za předpokladu binomického rozdělení y lze zapsat logaritmus věrohodnostní funkce ve tvaru n ln L b = y i ln p x i, b i=1 + 1 y i ln 1 p x i, b = *y i b T x i ln(1 + exp(b T x i ))+ kde b T = *b 0, b 1 +a předpokládá se, že první sloupec matice X obsahuje pouze jedničky (absolutní člen). n i=1 10
11 Metoda odhadu parametrů: Pro maximalizaci lnl(b) se využívá nulity prvních derivací\ n d L b J = d b = x i(y i p(x i, b)) = 0 i=1 Jde o soustavu m + 1 nelineárních rovnic vzhledem k b. Řešení soustavy nelineárních rovnic využívá Newtonův-Raphsonovův algoritmus, který vyžaduje matici druhých derivací (hessiánu) H = d2 L b d b d b T = n i=1 x ix i T p(x i, b)(1 p(x i, b)) Newtonova-Raphsonova metoda je iterativní, takže výsledkem j-té iterace je zpřesněný odhad b (j+1) = b (j+1) H 1 (j) J j kde pro vektor pravděpodobnosti p rozměru n x 1 s prvky p(x i, b (j) ) a diagonální matici vah W rozměru n x m s prvky lze psát J (j) = X T (y p) a H = X T WX 11
12 Interpretace regresních koeficientů Předpoklady o x nejsou a x mohou být diskrétní (faktory) a spojité veličiny (prediktory). ln(l (1) /L (0) ) je lineární funkcí nezávisle proměnných a ln(l (1) /L (0) ) je nazván logit nebo-li logit transformace pravděpodobnosti. Model se nazývá vícenásobný logistický regresní model (krátce logit) a koeficienty b i jsou interpretovány jako regresní parametry b i. Logit lze dále upravit: dosazením za L (1) = (1 -L (0) ) dostaneme 1 L (0) = 1 + exp, (b 0 + b 1 x 1 + b 2 x b p x p )- Obecně: Kladné znaménko koeficientu b i zvyšuje pravděpodobnost L (0) a záporné znaménko tuto pravděpodobnost snižuje. 12
13 Diskuse koeficientu b i. 1) Je-li b i kladné, funkce exp je větší než 1 a pravděpodobnostní poměr (L (1) /L (0) ) se bude zvyšovat. Zvýšení se objeví, když predikovaná pravděpodobnost odehrané události L (1) se zvýší a predikovaná pravděpodobnost neodebrané události L (0) se sníží. Proto má model vyšší predikovanou pravděpodobnost odehrané události L (1). 2) Je-li b i záporné, je funkce exp menší než 1 a pravděpodobnostní poměr (L (1) /L (0) ) se bude snižovat. 3) Pro b i roven 0, vede funkce exp k hodnotě 1 čili k žádné změně pravděpodobnosti. L (1) se mění od 0 do 1 a pravděpodobnostní poměr L (1) /L (0) se mění od 0 do. Je-li L (1) = 0.5, je poměr L (1) /L (0) roven 1. Ve stupnicí pravděpodobnostního poměru odpovídají hodnoty od 0 do 1 hodnotám pravděpodobnosti L (1) od 0 do 0.5. Na druhé straně hodnoty pravděpodobnosti L (1) od 0.5 do 1 vedou k poměru L (1) /L (0) od 1 do. Po zlogaritmování poměru L (1) /L (0) bude tato asymetrie odstraněna, neboť pro pro L (1) = 0 je ln (L (1) /L (0) ) =, pro L (1) = 0.5 je ln (L (1) /L (0) ) = 0.0, pro L (1) = 1.0 je ln (I (1) /I (0) ) = -. 13
14 Test významnosti regresních koeficientů Logistická regrese umožňuje testovat významnost koeficientů čili ověřit, že regresní koeficient se liší od nuly. Nula zde značí, že pravděpodobnostní poměr L (1) /L (0) se nemění a pravděpodobnost tím pádem není ovlivněna. Studentův t-test k vyšetření statistické významnosti jednotlivých regresních koeficientů. Waldovo testační kritérium W a,i = b i s b i 2 vyčísluje statistickou významnost pro odhady regresních koeficientů stejně jako ve vícenásobné regresi. Pro kategorické proměnné má W a,i počet stupňů volnosti roven o 1 méně než je počet kategorií. Waldova statistika W a má nežádoucí vlastnost: pro velikou hodnotu regresního koeficientu b i a veliký odhad jeho směrodatné odchylky s(b i ) je výsledkem příliš malá hodnota testačního kritéria W a,i, která vede k selhání zamítnutí nulové hypotézy, že regresní koeficient je nulový. Proto, je -li regresní koeficient veliký, neužijeme Waldova kritéria. 14
15 Parciální korelace Je obtížné určit příspěvek jednotlivých proměnných. Příspěvek každé proměnné závisí také na ostatních proměnných v logistickém modelu. K vyšetření parciální korelace mezi závisle proměnnou a každou nezávisle proměnnou se užívá korelační koeficient R i (v intervalu od -1 do +1). 1) Kladné hodnoty R i. když roste hodnota R i, zvyšuje se pravděpodobnost objektu "v události" L (1) 2) Záporné hodnoty R i. naopak snižuje se pravděpodobnost objektů "v události" L (1). 3) Malé hodnoty R i : proměnná má malý vliv na model. Korelační koeficient R i se vyčíslí R i = ± ( W a,i 2df 2 ln L (0) ), kde 2df značí počet stupňů volnosti a týká se počtu odhadovaných parametrů. 2 ln L (0) je záporný dvojnásobek logaritmu pravděpodobnosti základního logistického modelu, který neobsahuje žádné proměnné kromě absolutního členu (úseku) b 0. Je-li Waldova statistika W a,i menší než 2df, je R i položeno definitoricky 0. 15
16 Kategorické proměnné Výhodou logistického modeluje možnost užívat i kategorické nezávisle proměnné x, zvané faktory. Za faktor lze použít numerickou, textovou nebo datumovou hodnotu, zvanou úroveň nebo referenční hladina. Nejjednodušší situace je jediný faktor x se dvěma možnými hodnotami. Pojmu šance se hodně využívá v biomedikálních aplikacích. Je mírou spojení binární proměnné, jako je faktor risku výskytu dané události, například nemoci. Kategorická proměnná čili faktor má dvě úrovně, tj. x = 0 značící muže a x = 1 značící ženy a logistickou rovnici pak budel (1) = 1 1+exp( a bx), odhad parametru a a odhad b. Odhad b představuje přirozený logaritmus pravděpodobnostního poměru žen a mužů. Odhad a je přirozený logaritmus pravděpodobnostního poměru mužů (x = 0). Existuje - li pouze jedna dichotomní proměnná, není potřebné provádět logistickou regresní analýzu. Přibližný interval spolehlivosti pro pravděpodobnostní poměr jako pro binární proměnnou se vypočte užitím odhadu směrnice b a odhaduje jí směrodatné odchylky. 16
17 3. Volba proměnných Například úloha logistické předpovědi infarktu: data jsou z dlouhodobého sledování z počátku zdravých pacientů, u kterých byla dlouhodobě provedena opakovaná měření. Několik jedinců bylo postiženo infarktem. Byl sledován výběr nezávisle proměnných, které by mohly odhalit blížící se infarkt. Výběr účinných nezávisle proměnných byl předem lékaři vytypován. Častěji však uživatel předem neví nic o nezávisle proměnných. Proměnné x jsou nejprve vyšetřovány, která je nejvíce spjata z dichotomní závisle proměnnou. Studentův t-test významnosti jednotlivých parametrů: užívá se dostatečně vysoká hladina významnosti, například α = 0.15, aby užitečná nezávisle proměnná nemohla být odstraněna. Vyšetření zredukuje počet nezávisle proměnných na 10 či ještě méně. 17
18 3. Volba proměnných Pak nastoupí kroková logistická regresní analýza: jde o test, zda proměnná jc. zlepší predikční schopnost modelu. Postupy a jejich kritéria jsou užita k rozhodování, kolik proměnných x i a které je třeba užít. Testy v dopředně krokové analýze jsou postaveny na χ 2 -statistice: velká hodnota χ 2 nebo malá spočtená hladina významnosti P ukazují, že nezávisle proměnná by měla být zařazena do proměnných. Nalezená velká hodnota χ 2 ukazuje, že proměnné jsou užitečné. 18
19 4. Těsnost proložení logistickým modelem Před analýzou je třeba posoudit, zda nejsou odlehlé hodnoty. Rozptylové diagramy snadno odhalí odlehlé body. Proměnné nemusí být normálně rozděleny. Regresní diagnostika s analýzou vlivných bodů odhalí O a E. Logistická křivka má esovitý tvar a vystihuje logistický model, který je vzhledem ke koeficientům b nelineární. Mírou těsnosti proložení navrženého modelu daty je hodnota pravděpodobnosti L (1), že se událost uskuteční. Místo veličiny L (1) se používá tzv. odchylka, deviance D = 2 ln L (1) čili D = 2LL, když D představuje míru těsnosti proložení dat logistickým modelem: 1) Dobrý model vede k vysoké pravděpodobnosti objektů v události L (1), což přetransformáno do veličiny -2 ln L (1) poskytne malou hodnotu blízkou nule. 2) Minimální hodnotou pro -2 ln L (1) je nula, při které je dosaženo naprosto perfektní těsnosti proložení. Rozdíl v odchylce je definován G = D(model bez proměnné) - D(model s proměnnou) Pravděpodobnost modelu bez proměnné Čili G = -2 ln pravděpodobnost modelu s proměnnou. Veličina G proto odpovídá věrohodnostnímu poměru, 19
20 Těsnost proložení: spočívá porovnání experimentálních hodnot E s vypočtenými V: Pearsonův test dobré shody χ 2 se užije, když model platí: Velká hodnota χ 2 indikuje špatné proložení modelu. Malé hodnoty vypočtené hladiny významnosti P indikují špatné proložení modelu. Nejužívanější způsoby posouzení těsnosti proložení: 20
21 a) Klasický Pearsonův přístup začíná s identifikováním různých kombinací hodnot proměnných v regresním modelu, tj. vzorů. Například dvě dichotomní proměnné,(pohlaví a zaměstnán) vedou na 4 kombinace: muž zaměstnán, muž nezaměstnán, žena zaměstnána, žena nezaměstnána. Pro každou kombinaci vyčíslíme počet E experimentálních hodnot jednotlivců (objektů) ve třídě I a II. Podobně pro každého jednotlivce vypočteme pravděpodobnost, že se nachází ve třídě I a ve třídě II logistickou regresní analýzou. Suma těchto pravděpodobností pro daný vzor se označí V. Testační statistika testu dobré shody χ 2 2 se vyčíslí jakoχ exp = 2E(ln E i=1 ) V, kde suma se provede přes všechny odlišné vzory. Rezidua se sledují právě pro tyto odlišné vzory 21
22 b) Hosmerův-Lemeshowův test dobré shody byl navržen v Pearsonův χ 2 -test dobré shody k redukci v logaritmech hodnoty pravděpodobnosti je mírou sledování zlepšení těsnosti zavedením jedné či více nezávisle proměnných. Základní model, který je podobný výpočtu sumy čtverců při použití pouze průměrů, poskytuje nulovou linii k porovnání. Vedle χ 2 -testu existuje několik R 2 -podobných měr k posouzení těsnosti proložení, obdoba koeficientu determinace ve vícenásobné regresi. "Pseudo R 2 v logistické regresi pro logitový model se vypočte dle 2 R logit = 2 ln L nul ( 2 ln L model ) = D model + D nul 2 ln L nul D nul 22
23 c) Metoda klasifikačních matic, vyvinutých v diskriminační analýze slouží k vyhodnocení predikční schopnosti v pojmech zařazení do třídy. Pravděpodobnost zařazení do třídy I je vypočtena pro každého jednotlivce (objekt) ve výběru a výsledný počet je uspořádán vzestupně. Pravděpodobnosti jsou pak rozděleny do 10 skupin (decily). Pro každý naměřený počet jednotlivců ve třídě I je vyčíslen počet E. Užitím logické regrese jsou pro jedince v každém decilu vypočteny počty V. Pak se vyčíslí Pearsonova χ 2 - statistika testu dobré shody χ2 exp = E V 2 kde sumace se provede přes obě třídy a 10 decilů. Velká hodnota χ 2 nebo malá hodnota P indikují, že proložení není dobré. n i=1 V 23
24 5. Kvalita vyhodnocení logistickou regresí Třídíme objekty do tříd, musíme nalézt prahový bod pravděpodobnosti P c : objekt je "v události", když pravděpodobnost události větší nebo rovna hodnotě P c. Graf prahové operační charakteristiky ROC k detekci signálu, když signál nebylo vždy možné správně přijmout. Na ose y je procento správně zařazených objektů "v události" nazvané pozitivní podíl (a v lékařském výzkumu nazývané citlivost). Na ose x je procento nesprávně zařazených objektů nazvané falešný podíl nebo v lékařském výzkumu "1 minus specificita" (v lékařském výzkumu nazývané senzitivita zařazených krys pro správně zařazené krysy a specificita krys pro falešně zařazené krysy). 1) Horní křivka v grafu ROC představu je výtečnou predikci: i pro malé podíly nesprávně zařazených objektů se získá vysoké procento správně zařazených objektů, které skutečně jsou "v události". 2) Střední křivka je skutečná křivka při uvažování malého počtu nezávisle proměnných, třeba dvou. Vysoké procento (80 %) objektů správně zařazených v události je v poměru k 65 % chybně zařazených v události na nepřijatelné hladině. 3) Dolní hypotetická křivka, (přímka) odpovídá nahodilým výsledkům, například házení mincí. Blízkost střední křivky k dolní ukazuje, že je potřeba buď volit jinou, anebo přidat ještě další nezávisle proměnnou, abychom získali lepší model, i když je ale tento model statisticky významný na spočtené hladině P =
25 5. Kvalita vyhodnocení logistickou regresí (a) Vybereme prahový bod na dolní části křivky grafu ROC a nechceme mít příliš mnoho objektů, zařazených jako "v události", bude se nazývat přísný práh. Nevýhoda: je ztráta mnoha objektů, které jsou "v události". (b) Vybereme prahový bod na horní části křivky grafu ROC a chceme mít hodně objektů zařazených jako "v události", bude se nazývat nedbalý práh. Nevýhoda: sice velmi málo objektů "v události" bude ztraceno ale mnoho objektů "v neudálosti" bude chybně označeno jako "v události". Křivky v grafu ROC musí procházet body (0, 0) a (1,1). 25
26 5. Kvalita vyhodnocení logistickou regresí Maximální plocha pod křivkou je je dna čili 100%. Numerická hodnota velikosti plochy bude blízká 1, když predikce modelu bude výtečná. Když bude plocha blízká hodnotě 0,5, bude predikce modelu špatná. Křivka ROC je proto užitečná při rozhodování, který ze dvou logistických modelů vybrat: lepší model dosáhne větší plochy pod křivkou ROC ale také větší výšky prahového bodu na křivce ROC. Většina programů vybírá logistický model podle kritéria největší plochy pod křivkou ROC. 26
27 6. Aplikace logistické regrese Modelu vícenásobné logistické regrese se často užívá k odhadu pravděpodobnosti jisté události, která se přihodí danému objektu. Výběr dat může být uskutečněn dvojím způsobem: 1. Výběr cross-validation: je získán náhodným způsobem a pozorování provedeno v uvedeném časovém období. Z tohoto výběru se vyčlení dva podvýběry: první podvýběr, který obsahuje hodně zkušenosti o události, a druhý podvýběr, který obsahuje zbylé údaje. Na datech prvního podvýběru se vyčíslí logistický regresní model, který pak může být aplikován na člena druhého podvýběru. 2. Případ řídícího výběru: spočívá v získání dvou náhodných výběrů: první výběr, ve kterém se událost objeví, a druhý výběr, ve kterém se událost neobjeví. Hodnoty predikovaných proměnných se musí získat retrospektivním způsobem, z minulých záznamů nebo ze vzpomínek. Konstanta a musí být nastavena tak, aby vyjadřovala pravý poměr objektu v události. 27
28 Existují důležité požadavky: 1. Model předpokládá, že logaritmus pravděpodobnostního poměru je lineárně závislý na nezávislých proměnných. Nesplnění by mělo být předem prověřeno buď užitím měr těsnosti proložení, nebo jinými způsoby. To může vyžadovat transformaci dat. 2. Výpočty jsou často časově náročné, a proto by měl uživatel rozumně redukovat počet proměnných. 3. Logistická regrese by se neměla užívat k vyhodnocení faktorů risku v dlouhodobých studiích, ve kterých jsou jednotlivé studie rozličné délky. 4. Regresní koeficienty pro nezávisle proměnnou v logistickém regresním modelu závisí na ostatních proměnných, zařazených do logistického modelu. Koeficienty pro stejnou nezávisle proměnnou, když se použijí různé výběry proměnných, mohou být zcela odlišné. 5. Je - li užita sehraná analýza, kterákoliv proměnná pro sehrání nemůže být použita jako nezávisle proměnná. 6. Jsou okolnosti, kde metoda maximální věrohodnosti odhadovaných regresních koeficientů neposkytne odhady, tj. nekonverguje. 28
29 Příklad 4.26 Volba proměnných kpopisu leukemie Lee (1980) publikoval data o leukemii pacientů. Závisle proměnnou je binární proměnná REMISS, zda se objeví ústup leukemiey (1) či neobjeví (0). Nezávisle proměnnými x jsou: CELL celulirita, buněčnost sraženiny kostní dřeně, SMEAR skvrna diferenčního procenta napadení, INF1L procento infiltrátu kostní dřeně buňkou leukemie, LI procento označeného indexu leukemických buněk kostní dřeně, BLAST absolutní počet napadení v periferní krvi, TEMP nejvyšší teplota před začátkem léčby. Otázkou je, které nezávisle proměnné jsou statisticky významné v navrženém logistickém regresním modelu. 29
30 Data Data: n = 2i,p = 6, 30
31 Data 31
32 Řešení: Byl užit program NCSS Odhad regresních koeficientů. χ 2 udává Pearsonovo testační kritérium χ 2 pro 1 stupeň volnosti k testu H 0 : β i = 0 vs. H A : β i 0. Vyčíslí se Waldovo kritériumw 2 a,i = b 2 i. s b i Test významnosti b i : je-li spočtená hladina P menší než předvolená α = 0.05, je parametr b i statisticky významný. Všechny prediktory se jeví jako statisticky nevýznamné. Poslední R 2 udává hodnotu, která se přičte k celkové R 2 když se tato nezávisle proměnná přidá do logistického regresního modelu. Vypočte se dle R 2 = χ 2 df,χ 2 df + n p
33 Řešení: Byl užit program NCSS Nalezený model v transformované formě. Nalezený logistický regresní model: *CELL *SMEAR *INFIL *LI *BLAST *TEMP. 3. Přehled modelu. R 2 modelu df Odchylka D Spočtená hladina významnosti P Odchylka D testuje, zda všechny regresní koeficienty β i, kromě úseku β 0 jsou rovny nule. Protože je spočtená P menší než α = 0.05, je regresní model statisticky významný. 33
34 Řešení: Byl užit program NCSS Klasifikační tabulka. Tabulka přináší četnosti, řádková procenta a sloupcová procenta predikovaných objektů a nakonec je procento správně klasifikovaných objektů. Jde o procento z celkového počtu, které padne na diagonálu tabulky. 34
35 5. Predikovaná klasifikace. 35
36 5. Predikovaná klasifikace. Daná třída určuje zadanou skutečnou třídu. Nalezená třída představuje nalezenou třídu na základě logistického regresního modelu. Logistické skóre je odhad pravděpodobnosti, že objekt patří do třídy Ne. Reziduum představuje to rozdíl mezi Logistickým skóre a indexem skutečné třídy. Index třídy Ne je 0 a index třídy Ano jel. 36
37 6. Chybně klasifikované objekty. Jsou zde zobrazeny pouze chybně zařazené řádky. 37
38 CVIČENÍ V PROGRAMU STATISTICA 38
39 Úloha: Predikce počtu samečků kraba usilujících o samičku logistickou regresí 39
40 Úloha: Predikce počtu samečků kraba usilujících o samičku logistickou regresí Samice kraba obecného může být oplozena pouze v určitou, omezenou dobu, která nastává krátce po svlékání, dokud je její krunýř ještě měkký. Jakmile se samice kraba obecného zbaví starého krunýře, samec ihned vystříkne semeno do jejího těla, kde zůstává uchováno, dokud se v těle samice nevytvoří vajíčka. Teprve pak dochází k oplodnění. Oplozená vajíčka pak visí přichycena zvláštní lepkavou hmotou pod zadečkem samice. Po určitém čase se z vajíček vylíhnou průhledné, malým garnátům podobné larvy, které mají mezi očima dlouhý výrůstek. Larvy žijí po několik týdnů jako součást planktonu. Z těch, které se navzájem nepožerou, vyrostou larvy, které se již částečně podobají dospělým krabům. Ty klesnou na mořské dno, kde se krmí a rostou. Průměrná doba inkubace, než se z vajíček vylíhnou aktivně larvy trvá přibližně 12 až 18 týdnů. 40
41 Úloha: Predikce počtu samečků kraba usilujících o samičku logistickou regresí Samičce kraba se dvoří řada samců, přibližujících se k samičce a jejímu hnízdu a které zde označíme satelity. Počet samičkou lákaných satelitů je řízen barvou samičky (Color), stavem hřbetu (Spine), šířkou těla v cm (Width) a její hmotností v kg (Weight) samičky. Logitem čili závisle proměnnou y (Satellite) je počet samečků kraba, dvořících se jedné samičce, který může být nulový (y = 0) nebo nenulový (y = 1). Kategorické (nespojité) nezávisle proměnné čili faktory jsou dva, Color o 4 hodnotách barvy a Spine o třech hodnotách kvality hřbetu. Spojité nezávisle proměnné čili prediktory jsou také dva, Width (šířka těla samičky) a Weight (hmotnost samičky). 41
42 Cíl úlohy: Cíl úlohy: Cestou logitu (satellit) y = 0 či 1 budeme hledat minimální počet nezávisle proměnných (faktorů a prediktorů), které budou spolehlivě predikovat, zda jsou samci-sateliti vedle jednoho samce-partnera ve svém dvoření jedné samičce úspěšní. 42

43

44

45
46

47
48
49
50
51
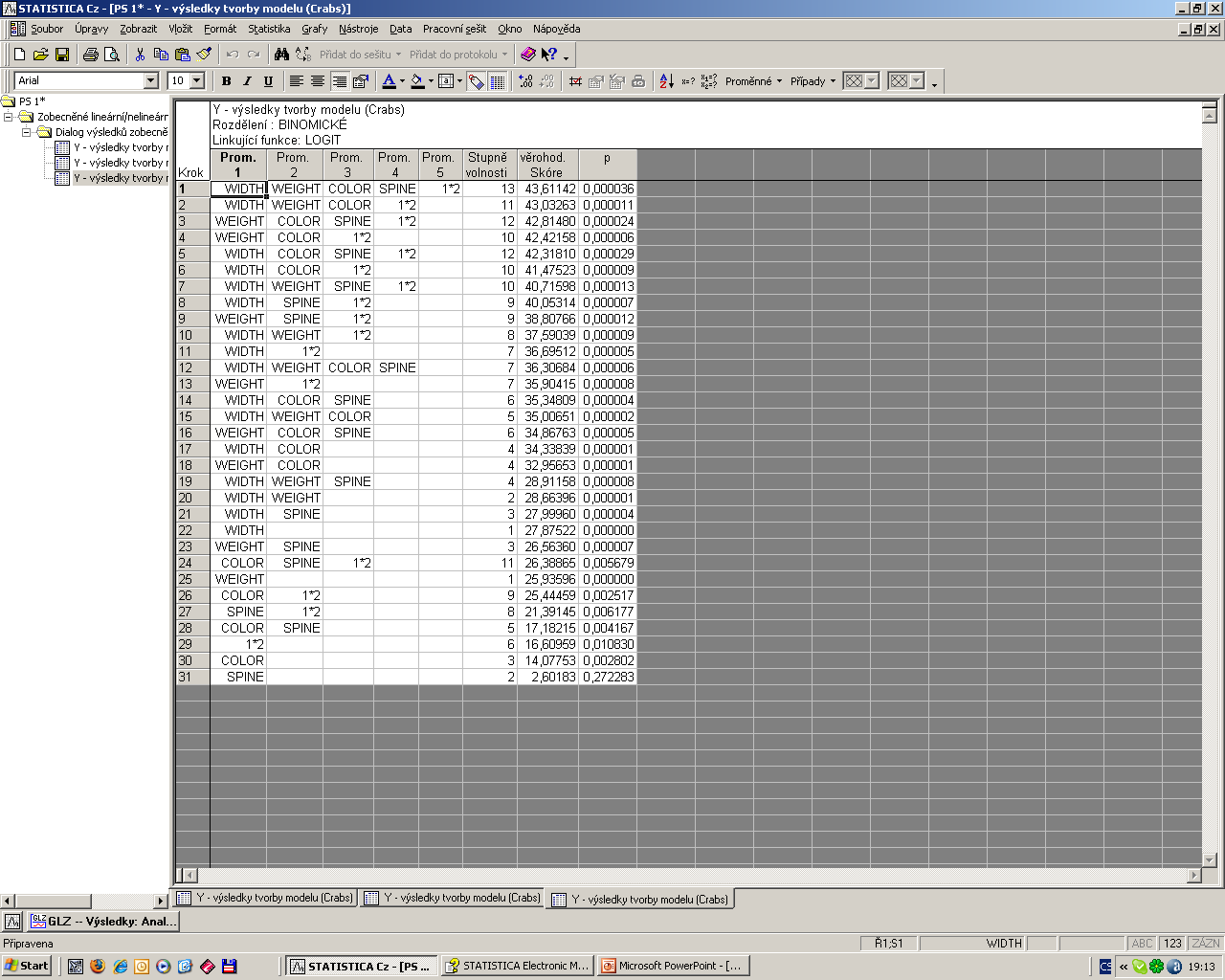

52
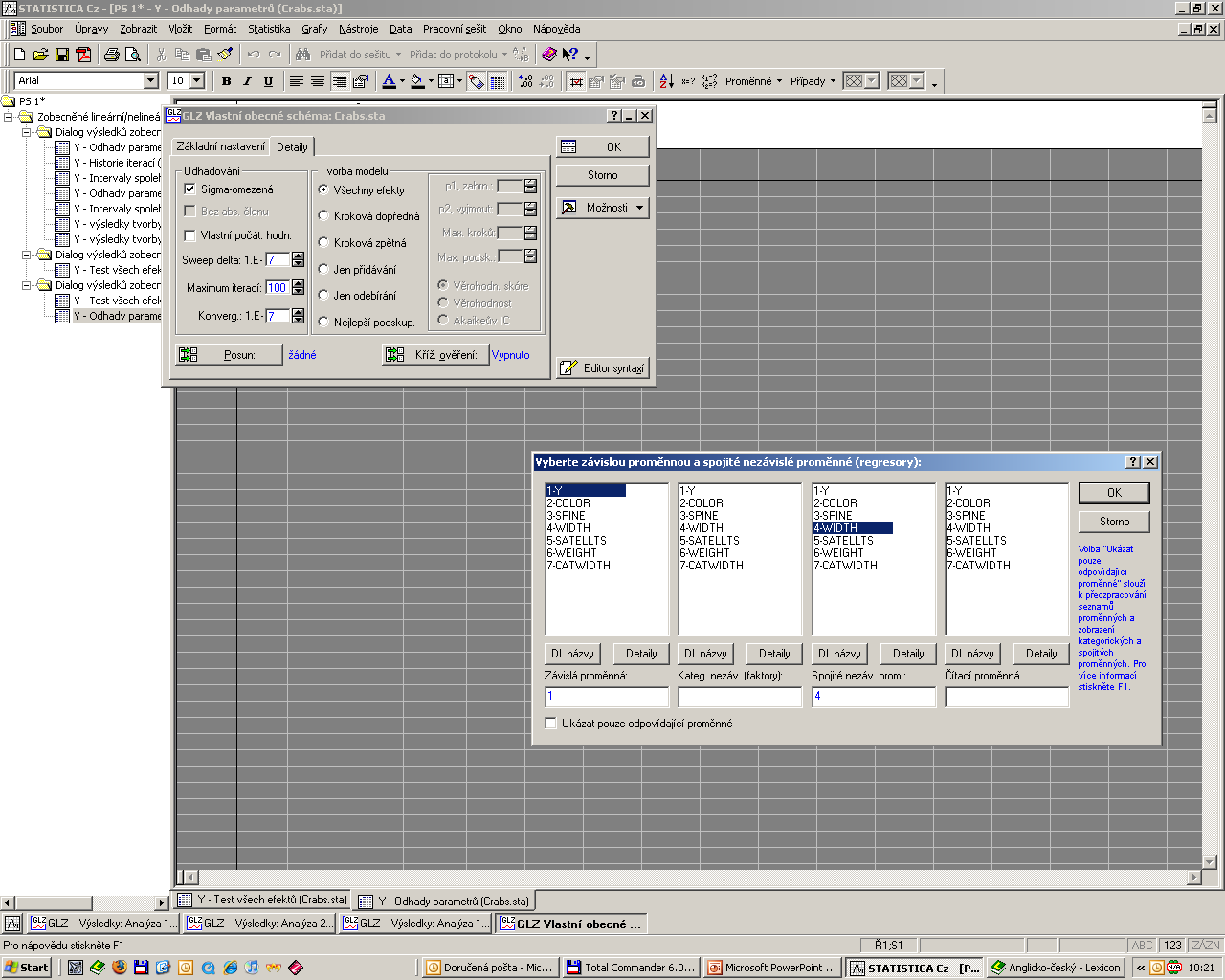

53
54
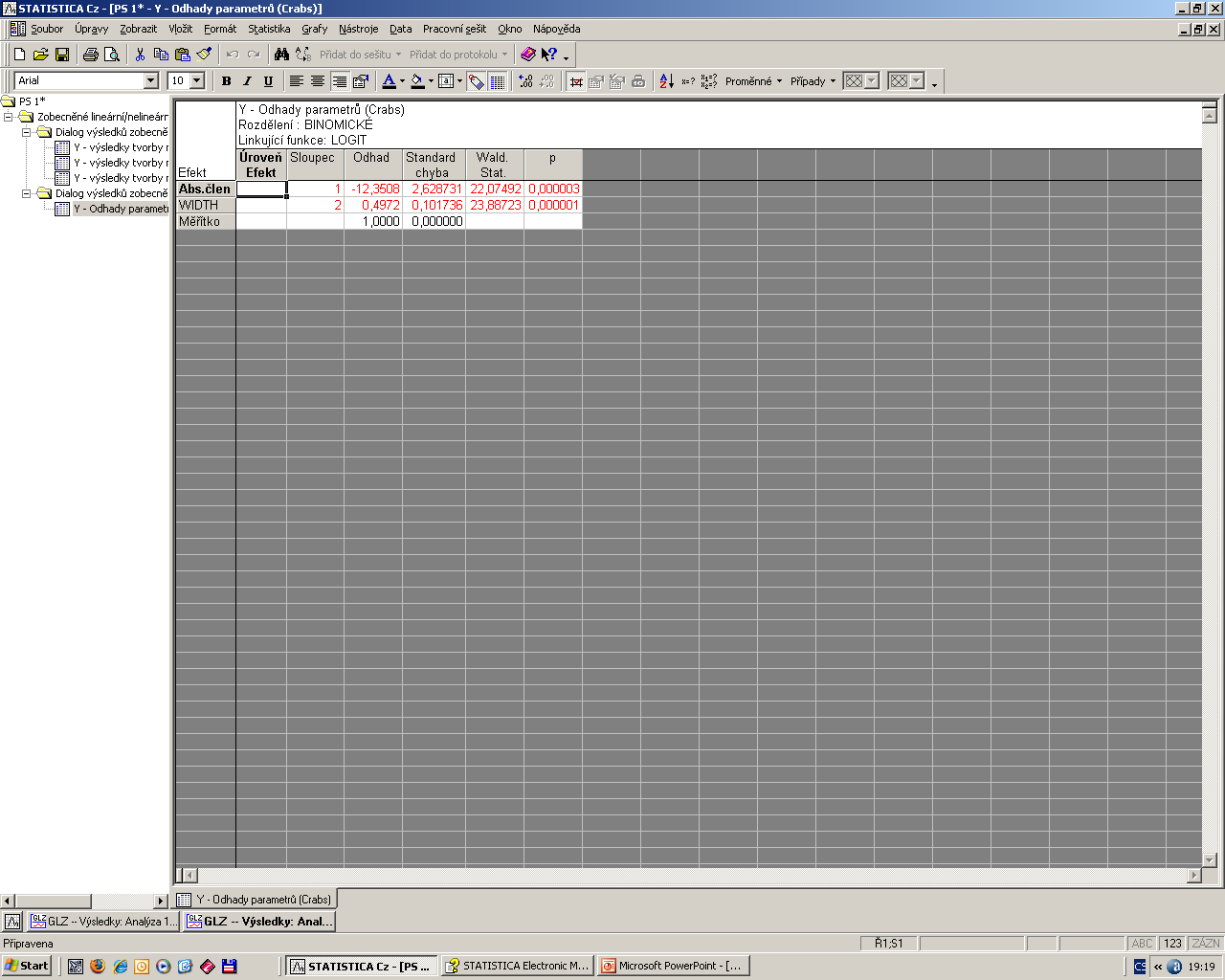

55
56

57
58
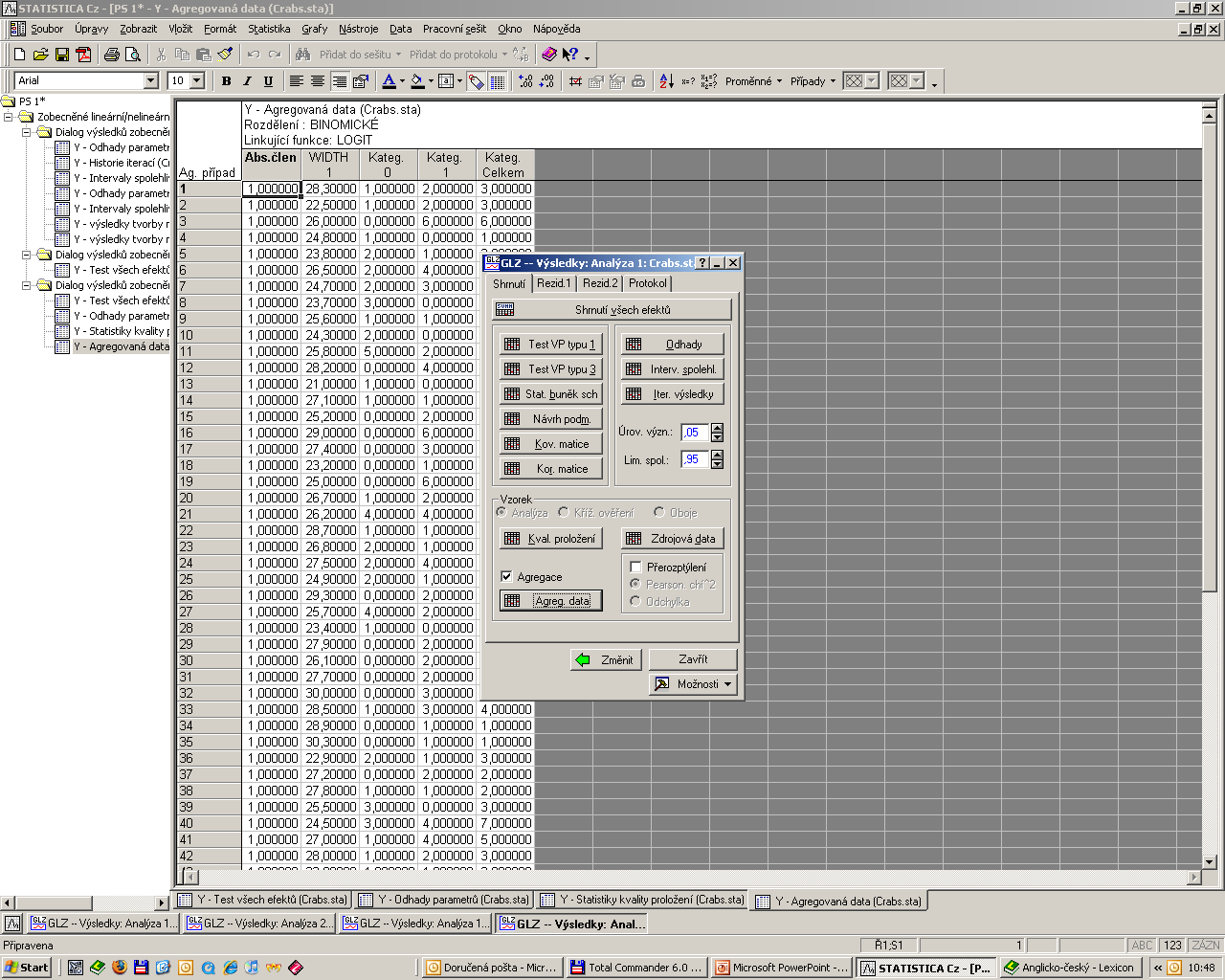
59
60
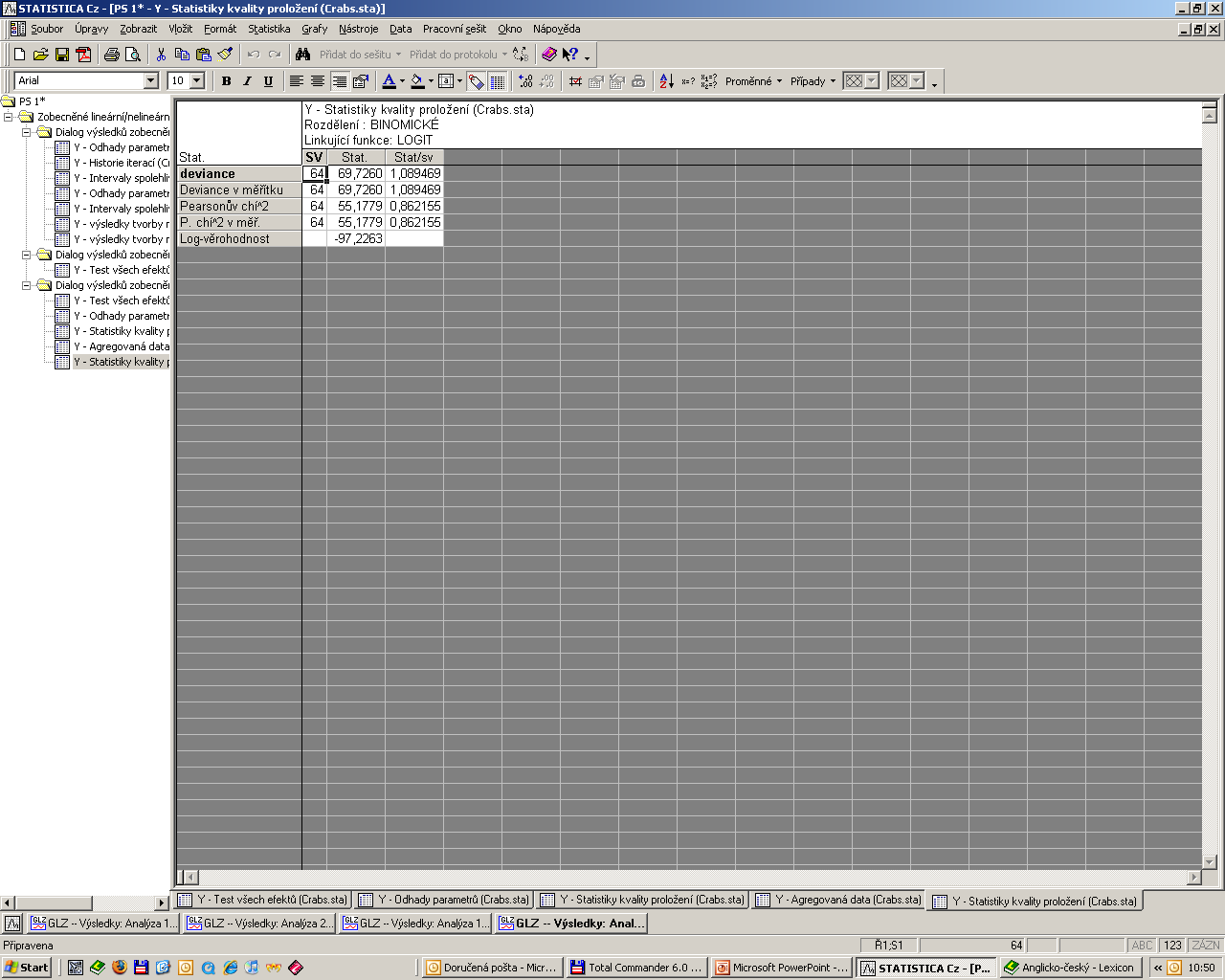

61
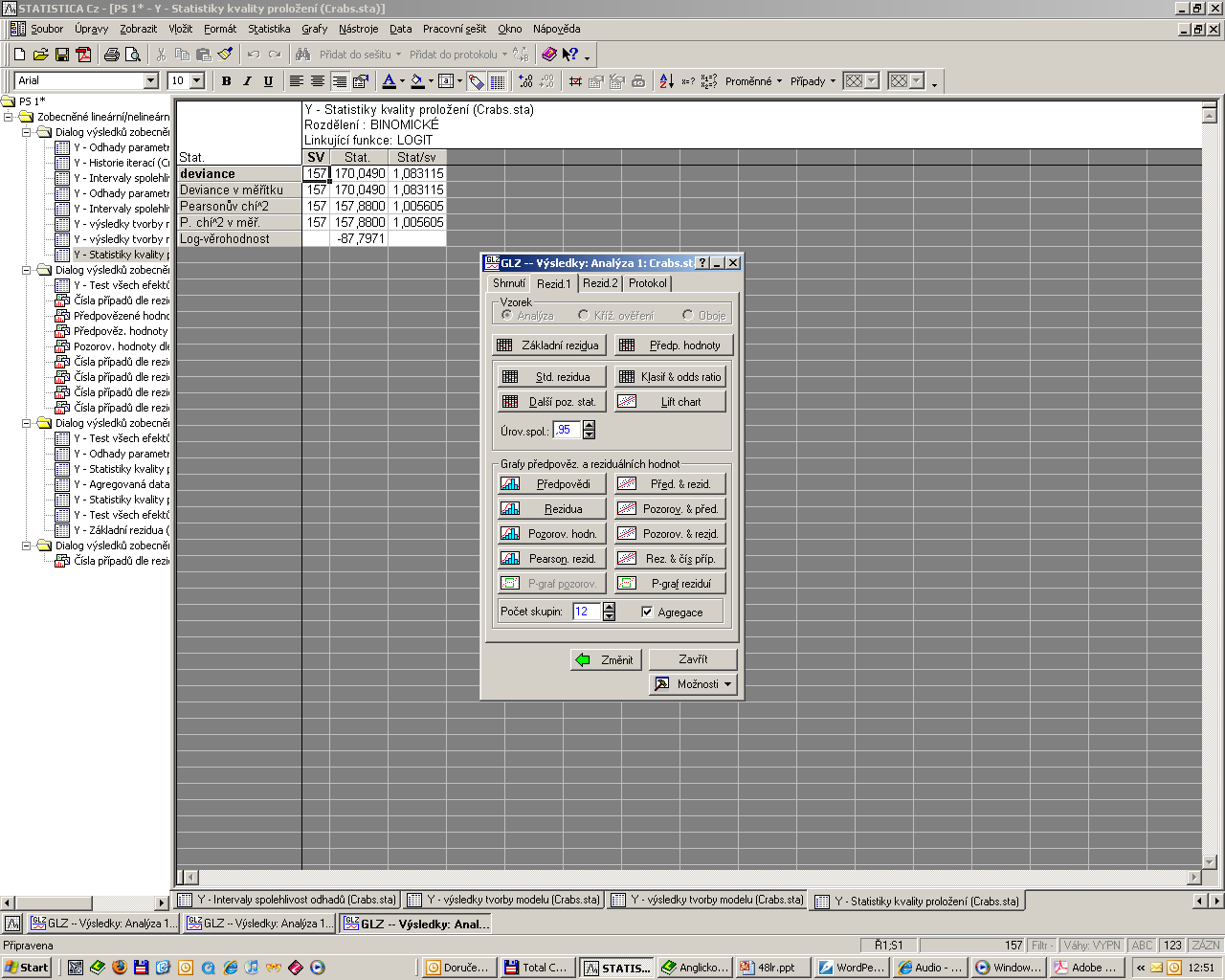
62
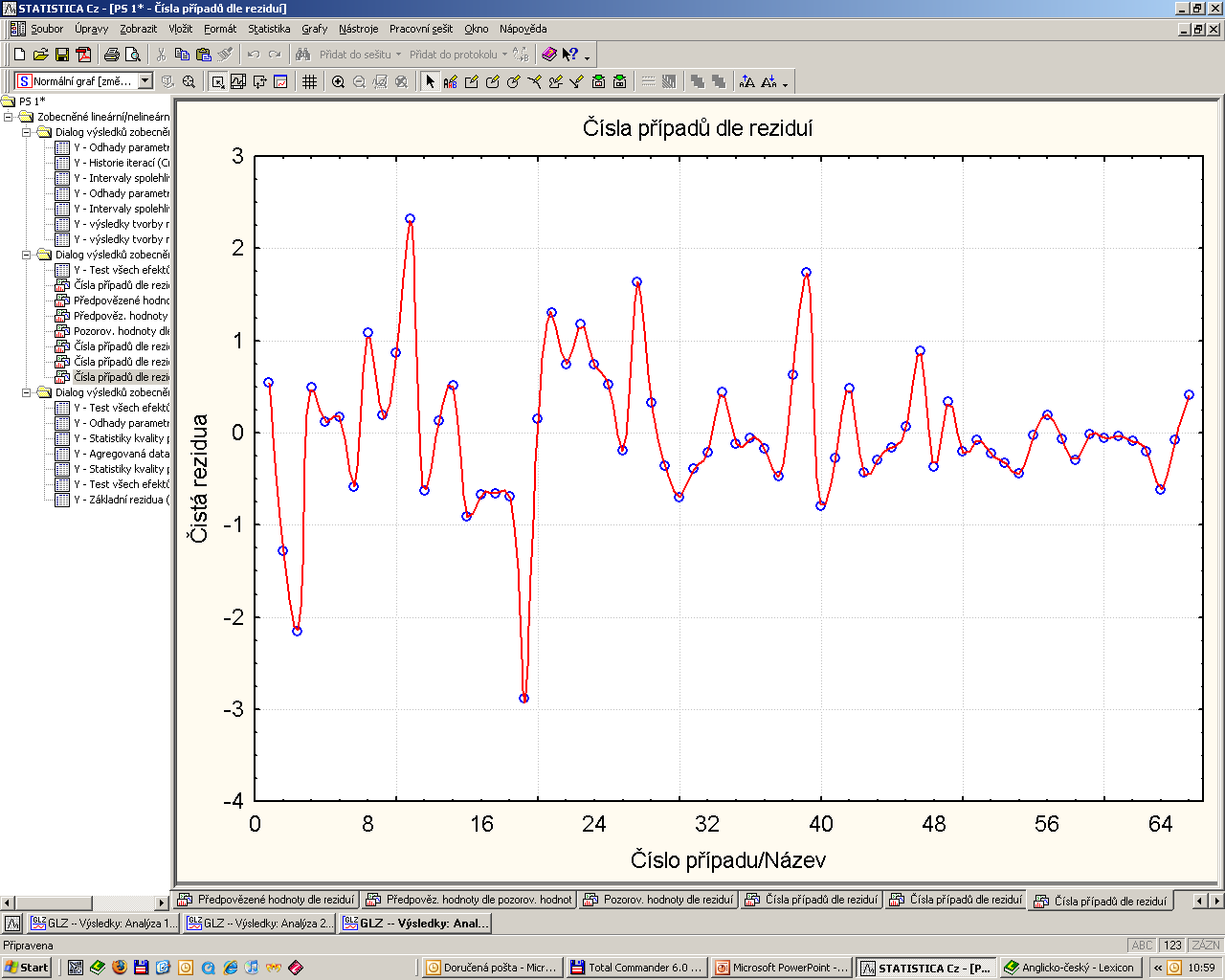
63
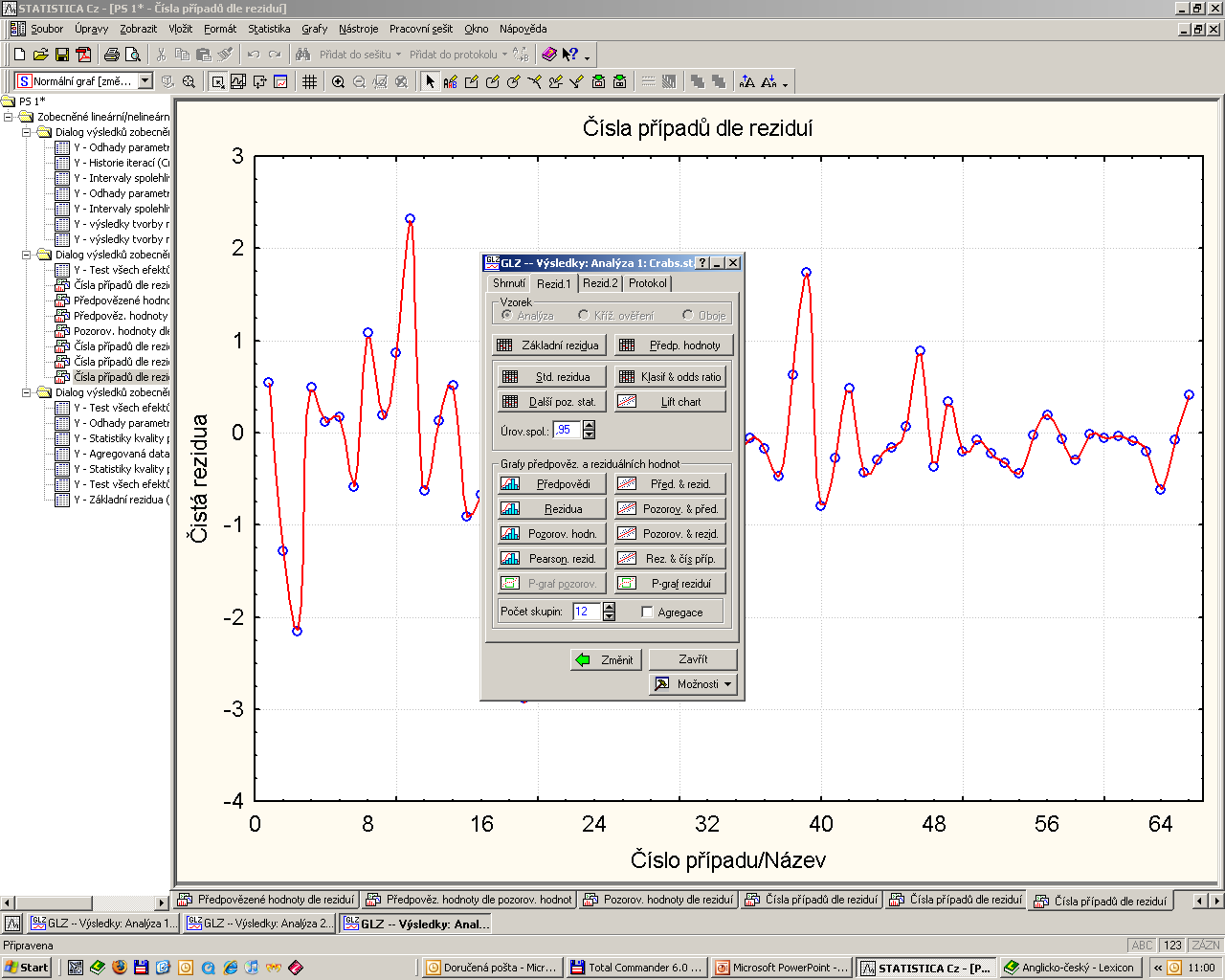
64
65
66 Příklad 8.7/str. 261 Data PCS.sta
67
68
69 Příklad 8.8/str. 264 Data Meexp.sta
70
71 Příklad 8.6/str. 259 Data Lowbwt.sta
72
73 Příklad 8.5/str. 253 Data ICU.sta
74
75
76 Příklad 8.4/str. 249 Data Phyrynx.sta
77
78
79 Příklad 8.3/str. 243 Data Phyrynx.sta
80
Pravděpodobnost v závislosti na proměnné x je zde modelován pomocí logistického modelu. exp x. x x x. log 1
 Logistická regrese Menu: QCExpert Regrese Logistická Modul Logistická regrese umožňuje analýzu dat, kdy odezva je binární, nebo frekvenční veličina vyjádřená hodnotami 0 nebo 1, případně poměry v intervalu
Logistická regrese Menu: QCExpert Regrese Logistická Modul Logistická regrese umožňuje analýzu dat, kdy odezva je binární, nebo frekvenční veličina vyjádřená hodnotami 0 nebo 1, případně poměry v intervalu
Jana Vránová, 3. lékařská fakulta, UK Praha
 Jana Vránová, 3. lékařská fakulta, UK Praha Byla navržena v 60tých letech jako alternativa k metodě nejmenších čtverců pro případ, že vysvětlovaná proměnná je binární Byla především používaná v medicíně
Jana Vránová, 3. lékařská fakulta, UK Praha Byla navržena v 60tých letech jako alternativa k metodě nejmenších čtverců pro případ, že vysvětlovaná proměnná je binární Byla především používaná v medicíně
Regresní a korelační analýza
 Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Statistická analýza jednorozměrných dat
 Statistická analýza jednorozměrných dat Prof. RNDr. Milan Meloun, DrSc. Univerzita Pardubice, Pardubice 31.ledna 2011 Tato prezentace je spolufinancována Evropským sociálním fondem a státním rozpočtem
Statistická analýza jednorozměrných dat Prof. RNDr. Milan Meloun, DrSc. Univerzita Pardubice, Pardubice 31.ledna 2011 Tato prezentace je spolufinancována Evropským sociálním fondem a státním rozpočtem
UNIVERZITA PARDUBICE Fakulta chemicko-technologická Katedra analytické chemie Nám. Čs. Legií 565, Pardubice
 UNIVERZITA PARDUBICE Fakulta chemicko-technologická Katedra analytické chemie Nám. Čs. Legií 565, 532 10 Pardubice 10. licenční studium chemometrie STATISTICKÉ ZPRACOVÁNÍ DAT Semestrální práce KALIBRACE
UNIVERZITA PARDUBICE Fakulta chemicko-technologická Katedra analytické chemie Nám. Čs. Legií 565, 532 10 Pardubice 10. licenční studium chemometrie STATISTICKÉ ZPRACOVÁNÍ DAT Semestrální práce KALIBRACE
Univerzita Pardubice Fakulta chemicko technologická Katedra analytické chemie Licenční studium Management systému jakosti
 Univerzita Pardubice Fakulta chemicko technologická Katedra analytické chemie Licenční studium Management systému jakosti 3.3 v analýze dat Autor práce: Přednášející: Prof. RNDr. Milan Meloun, DrSc Pro
Univerzita Pardubice Fakulta chemicko technologická Katedra analytické chemie Licenční studium Management systému jakosti 3.3 v analýze dat Autor práce: Přednášející: Prof. RNDr. Milan Meloun, DrSc Pro
Regresní a korelační analýza
 Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Stanovení manganu a míry přesnosti kalibrace ( Lineární kalibrace )
") Příklad č. 1 Stanovení manganu a míry přesnosti kalibrace ( Lineární kalibrace ) Zadání : Stanovení manganu ve vodách se provádí oxidací jodistanem v kyselém prostředí až na manganistan. (1) Sestrojte
Příklad č. 1 Stanovení manganu a míry přesnosti kalibrace ( Lineární kalibrace ) Zadání : Stanovení manganu ve vodách se provádí oxidací jodistanem v kyselém prostředí až na manganistan. (1) Sestrojte
Korelační a regresní analýza
 Korelační a regresní analýza Analýza závislosti v normálním rozdělení Pearsonův (výběrový) korelační koeficient: r = s XY s X s Y, kde s XY = 1 n (x n 1 i=0 i x )(y i y ), s X (s Y ) je výběrová směrodatná
Korelační a regresní analýza Analýza závislosti v normálním rozdělení Pearsonův (výběrový) korelační koeficient: r = s XY s X s Y, kde s XY = 1 n (x n 1 i=0 i x )(y i y ), s X (s Y ) je výběrová směrodatná
RNDr. Eva Janoušová doc. RNDr. Ladislav Dušek, Dr.
 Analýza dat pro Neurovědy RNDr. Eva Janoušová doc. RNDr. Ladislav Dušek, Dr. Jaro 2014 Institut biostatistiky Janoušová, a analýz Dušek: Analýza dat pro neurovědy Blok 7 Jak hodnotit vztah spojitých proměnných
Analýza dat pro Neurovědy RNDr. Eva Janoušová doc. RNDr. Ladislav Dušek, Dr. Jaro 2014 Institut biostatistiky Janoušová, a analýz Dušek: Analýza dat pro neurovědy Blok 7 Jak hodnotit vztah spojitých proměnných
Kalibrace a limity její přesnosti
 Univerzita Pardubice Fakulta chemicko-technologická Katedra analytické chemie Kalibrace a limity její přesnosti Semestrální práce Licenční studium GALILEO Interaktivní statistická analýza dat Brno, 2015
Univerzita Pardubice Fakulta chemicko-technologická Katedra analytické chemie Kalibrace a limity její přesnosti Semestrální práce Licenční studium GALILEO Interaktivní statistická analýza dat Brno, 2015
6. Lineární regresní modely
 6. Lineární regresní modely 6.1 Jednoduchá regrese a validace 6.2 Testy hypotéz v lineární regresi 6.3 Kritika dat v regresním tripletu 6.4 Multikolinearita a polynomy 6.5 Kritika modelu v regresním tripletu
6. Lineární regresní modely 6.1 Jednoduchá regrese a validace 6.2 Testy hypotéz v lineární regresi 6.3 Kritika dat v regresním tripletu 6.4 Multikolinearita a polynomy 6.5 Kritika modelu v regresním tripletu
5 Vícerozměrná data - kontingenční tabulky, testy nezávislosti, regresní analýza
 5 Vícerozměrná data - kontingenční tabulky, testy nezávislosti, regresní analýza 5.1 Vícerozměrná data a vícerozměrná rozdělení Při zpracování vícerozměrných dat se hledají souvislosti mezi dvěma, případně
5 Vícerozměrná data - kontingenční tabulky, testy nezávislosti, regresní analýza 5.1 Vícerozměrná data a vícerozměrná rozdělení Při zpracování vícerozměrných dat se hledají souvislosti mezi dvěma, případně
PRAVDĚPODOBNOST A STATISTIKA
 PRAVDĚPODOBNOST A STATISTIKA Definice lineárního normálního regresního modelu Lineární normální regresní model Y β ε Matice n,k je matice realizací. Předpoklad: n > k, h() k - tj. matice je plné hodnosti
PRAVDĚPODOBNOST A STATISTIKA Definice lineárního normálního regresního modelu Lineární normální regresní model Y β ε Matice n,k je matice realizací. Předpoklad: n > k, h() k - tj. matice je plné hodnosti
http: //meloun.upce.cz,
 Porovnání rozlišovací schopnosti regresní analýzy spekter a spolehlivosti Prof. RNDr. Milan Meloun, DrSc. Katedra analytické chemie, Chemickotechnologická fakulta, Univerzita Pardubice, nám. s. Legií 565,
Porovnání rozlišovací schopnosti regresní analýzy spekter a spolehlivosti Prof. RNDr. Milan Meloun, DrSc. Katedra analytické chemie, Chemickotechnologická fakulta, Univerzita Pardubice, nám. s. Legií 565,
1 Tyto materiály byly vytvořeny za pomoci grantu FRVŠ číslo 1145/2004.
 Prostá regresní a korelační analýza 1 1 Tyto materiály byly vytvořeny za pomoci grantu FRVŠ číslo 1145/2004. Problematika závislosti V podstatě lze rozlišovat mezi závislostí nepodstatnou, čili náhodnou
Prostá regresní a korelační analýza 1 1 Tyto materiály byly vytvořeny za pomoci grantu FRVŠ číslo 1145/2004. Problematika závislosti V podstatě lze rozlišovat mezi závislostí nepodstatnou, čili náhodnou
UNIVERZITA PARDUBICE
 UNIVERZITA PARDUBICE Fakulta chemicko technologická Katedra analytické chemie Licenční studium chemometrie na téma Tvorba nelineárních regresních modelů v analýze dat Vedoucí licenčního studia Prof. RNDr.
UNIVERZITA PARDUBICE Fakulta chemicko technologická Katedra analytické chemie Licenční studium chemometrie na téma Tvorba nelineárních regresních modelů v analýze dat Vedoucí licenčního studia Prof. RNDr.
Úloha 1: Lineární kalibrace
 Úloha 1: Lineární kalibrace U pacientů s podezřením na rakovinu prostaty byl metodou GC/MS měřen obsah sarkosinu v moči. Pro kvantitativní stanovení bylo nutné změřit řadu kalibračních roztoků o různé
Úloha 1: Lineární kalibrace U pacientů s podezřením na rakovinu prostaty byl metodou GC/MS měřen obsah sarkosinu v moči. Pro kvantitativní stanovení bylo nutné změřit řadu kalibračních roztoků o různé
Kanonická korelační analýza
 Kanonická korelační analýza Kanonická korelační analýza je vícerozměrná metoda, která se používá ke zkoumání závislosti mezi dvěma skupinami proměnných. První ze skupin se považuje za soubor nezávisle
Kanonická korelační analýza Kanonická korelační analýza je vícerozměrná metoda, která se používá ke zkoumání závislosti mezi dvěma skupinami proměnných. První ze skupin se považuje za soubor nezávisle
MÍRY ZÁVISLOSTI (KORELACE A REGRESE)
") zhanel@fsps.muni.cz MÍRY ZÁVISLOSTI (KORELACE A REGRESE) 2.5 MÍRY ZÁVISLOSTI 2.5.1 ZÁVISLOST PEVNÁ, VOLNÁ, STATISTICKÁ A KORELAČNÍ Jednorozměrné soubory - charakterizovány jednotlivými statistickými znaky
zhanel@fsps.muni.cz MÍRY ZÁVISLOSTI (KORELACE A REGRESE) 2.5 MÍRY ZÁVISLOSTI 2.5.1 ZÁVISLOST PEVNÁ, VOLNÁ, STATISTICKÁ A KORELAČNÍ Jednorozměrné soubory - charakterizovány jednotlivými statistickými znaky
Kontingenční tabulky, korelační koeficienty
 Statistika II Katedra ekonometrie FVL UO Brno kancelář 69a, tel 973 442029 email:jirineubauer@unobcz Budeme předpokládat, že X a Y jsou kvalitativní náhodné veličiny, obor hodnot X obsahuje r hodnot (kategorií,
Statistika II Katedra ekonometrie FVL UO Brno kancelář 69a, tel 973 442029 email:jirineubauer@unobcz Budeme předpokládat, že X a Y jsou kvalitativní náhodné veličiny, obor hodnot X obsahuje r hodnot (kategorií,
Závislost obsahu lipoproteinu v krevním séru na třech faktorech ( Lineární regresní modely )
") Úloha M608 Závislost obsahu lipoproteinu v krevním séru na třech faktorech ( Lineární regresní modely ) Zadání : Při kvantitativní analýze lidského krevního séra ovlivňují hodnotu obsahu vysokohustotního
Úloha M608 Závislost obsahu lipoproteinu v krevním séru na třech faktorech ( Lineární regresní modely ) Zadání : Při kvantitativní analýze lidského krevního séra ovlivňují hodnotu obsahu vysokohustotního
Semestrální práce. 2. semestr
 Licenční studium č. 89002 Semestrální práce 2. semestr Tvorba lineárních regresních modelů při analýze dat Příklad 1 Porovnání dvou regresních přímek u jednoduchého lineárního regresního modelu. Počet
Licenční studium č. 89002 Semestrální práce 2. semestr Tvorba lineárních regresních modelů při analýze dat Příklad 1 Porovnání dvou regresních přímek u jednoduchého lineárního regresního modelu. Počet
Tvorba nelineárních regresních
 Univerzita Pardubice Fakulta chemicko technologická Katedra analytické chemie Licenční studium chemometrie Statistické zpracování dat Tvorba nelineárních regresních modelů v analýze dat Zdravotní ústav
Univerzita Pardubice Fakulta chemicko technologická Katedra analytické chemie Licenční studium chemometrie Statistické zpracování dat Tvorba nelineárních regresních modelů v analýze dat Zdravotní ústav
Statistická analýza jednorozměrných dat
 Statistická analýza jednorozměrných dat Prof. RNDr. Milan Meloun, DrSc. Univerzita Pardubice, Pardubice 31.ledna 2011 Tato prezentace je spolufinancována Evropským sociálním fondem a státním rozpočtem
Statistická analýza jednorozměrných dat Prof. RNDr. Milan Meloun, DrSc. Univerzita Pardubice, Pardubice 31.ledna 2011 Tato prezentace je spolufinancována Evropským sociálním fondem a státním rozpočtem
PRAVDĚPODOBNOST A STATISTIKA
 PRAVDĚPODOBNOST A STATISTIKA Definice lineárního normálního regresního modelu Lineární normální regresní model Y Xβ ε Předpoklady: Matice X X n,k je matice realizací. Předpoklad: n > k, h(x) k - tj. matice
PRAVDĚPODOBNOST A STATISTIKA Definice lineárního normálního regresního modelu Lineární normální regresní model Y Xβ ε Předpoklady: Matice X X n,k je matice realizací. Předpoklad: n > k, h(x) k - tj. matice
AVDAT Klasický lineární model, metoda nejmenších
 AVDAT Klasický lineární model, metoda nejmenších čtverců Josef Tvrdík Katedra informatiky Přírodovědecká fakulta Ostravská univerzita Lineární model y i = β 0 + β 1 x i1 + + β k x ik + ε i (1) kde y i
AVDAT Klasický lineární model, metoda nejmenších čtverců Josef Tvrdík Katedra informatiky Přírodovědecká fakulta Ostravská univerzita Lineární model y i = β 0 + β 1 x i1 + + β k x ik + ε i (1) kde y i
Kalibrace a limity její přesnosti
 Univerzita Pardubice Fakulta chemicko technologická Katedra analytické chemie Licenční studium chemometrie Statistické zpracování dat Kalibrace a limity její přesnosti Zdravotní ústav se sídlem v Ostravě
Univerzita Pardubice Fakulta chemicko technologická Katedra analytické chemie Licenční studium chemometrie Statistické zpracování dat Kalibrace a limity její přesnosti Zdravotní ústav se sídlem v Ostravě
Diskriminační analýza hodnocení rozdílů mezi 2 nebo více skupinami objektů charakterizovanými více znaky
 Diskriminační analýza hodnocení rozdílů mezi 2 nebo více skupinami objektů charakterizovanými více znaky Interpretují rozdíly mezi předem stanovenými třídami Cílem je klasifikace objektů do skupin Hledáme
Diskriminační analýza hodnocení rozdílů mezi 2 nebo více skupinami objektů charakterizovanými více znaky Interpretují rozdíly mezi předem stanovenými třídami Cílem je klasifikace objektů do skupin Hledáme
LINEÁRNÍ REGRESE. Lineární regresní model
 LINEÁRNÍ REGRESE Chemometrie I, David MILDE Lineární regresní model 1 Typy závislosti 2 proměnných FUNKČNÍ VZTAH: 2 závisle proměnné: určité hodnotě x odpovídá jediná hodnota y. KORELACE: 2 náhodné (nezávislé)
LINEÁRNÍ REGRESE Chemometrie I, David MILDE Lineární regresní model 1 Typy závislosti 2 proměnných FUNKČNÍ VZTAH: 2 závisle proměnné: určité hodnotě x odpovídá jediná hodnota y. KORELACE: 2 náhodné (nezávislé)
Korelační a regresní analýza. 1. Pearsonův korelační koeficient 2. jednoduchá regresní analýza 3. vícenásobná regresní analýza
 Korelační a regresní analýza 1. Pearsonův korelační koeficient 2. jednoduchá regresní analýza 3. vícenásobná regresní analýza Pearsonův korelační koeficient u intervalových a poměrových dat můžeme jako
Korelační a regresní analýza 1. Pearsonův korelační koeficient 2. jednoduchá regresní analýza 3. vícenásobná regresní analýza Pearsonův korelační koeficient u intervalových a poměrových dat můžeme jako
KALIBRACE A LIMITY JEJÍ PŘESNOSTI. Semestrální práce UNIVERZITA PARDUBICE. Fakulta chemicko-technologická Katedra analytické chemie
 UNIVERZITA PARDUBICE Fakulta chemicko-technologická Katedra analytické chemie KALIBRACE A LIMITY JEJÍ PŘESNOSTI Semestrální práce Licenční studium Galileo Interaktivní statistická analýza dat Brno 2016
UNIVERZITA PARDUBICE Fakulta chemicko-technologická Katedra analytické chemie KALIBRACE A LIMITY JEJÍ PŘESNOSTI Semestrální práce Licenční studium Galileo Interaktivní statistická analýza dat Brno 2016
POLYNOMICKÁ REGRESE. Jedná se o regresní model, který je lineární v parametrech, ale popisuje nelineární závislost mezi proměnnými.
 POLYNOMICKÁ REGRESE Jedná se o regresní model, který je lineární v parametrech, ale popisuje nelineární závislost mezi proměnnými. y = b 0 + b 1 x + b 2 x 2 + + b n x n kde b i jsou neznámé parametry,
POLYNOMICKÁ REGRESE Jedná se o regresní model, který je lineární v parametrech, ale popisuje nelineární závislost mezi proměnnými. y = b 0 + b 1 x + b 2 x 2 + + b n x n kde b i jsou neznámé parametry,
Tomáš Karel LS 2012/2013
 Tomáš Karel LS 2012/2013 Doplňkový materiál ke cvičení z předmětu 4ST201. Na případné faktické chyby v této presentaci mě prosím upozorněte. Děkuji. Tyto slidy berte pouze jako doplňkový materiál není
Tomáš Karel LS 2012/2013 Doplňkový materiál ke cvičení z předmětu 4ST201. Na případné faktické chyby v této presentaci mě prosím upozorněte. Děkuji. Tyto slidy berte pouze jako doplňkový materiál není
4EK211 Základy ekonometrie
 4EK Základy ekonometrie Odhad klasického lineárního regresního modelu II Cvičení 3 Zuzana Dlouhá Klasický lineární regresní model - zadání příkladu Soubor: CV3_PR.xls Data: y = maloobchodní obrat potřeb
4EK Základy ekonometrie Odhad klasického lineárního regresního modelu II Cvičení 3 Zuzana Dlouhá Klasický lineární regresní model - zadání příkladu Soubor: CV3_PR.xls Data: y = maloobchodní obrat potřeb
KGG/STG Statistika pro geografy
 KGG/STG Statistika pro geografy 9. Korelační analýza Mgr. David Fiedor 20. dubna 2015 Analýza závislostí v řadě geografických disciplín studujeme jevy, u kterých vyšetřujeme nikoliv pouze jednu vlastnost
KGG/STG Statistika pro geografy 9. Korelační analýza Mgr. David Fiedor 20. dubna 2015 Analýza závislostí v řadě geografických disciplín studujeme jevy, u kterých vyšetřujeme nikoliv pouze jednu vlastnost
Inovace bakalářského studijního oboru Aplikovaná chemie
 http://aplchem.upol.cz CZ.1.07/2.2.00/15.0247 Tento projekt je spolufinancován Evropským sociálním fondem a státním rozpočtem České republiky. Regrese Závislostproměnných funkční y= f(x) regresní y= f(x)
http://aplchem.upol.cz CZ.1.07/2.2.00/15.0247 Tento projekt je spolufinancován Evropským sociálním fondem a státním rozpočtem České republiky. Regrese Závislostproměnných funkční y= f(x) regresní y= f(x)
Lineární regrese. Komentované řešení pomocí MS Excel
 Lineární regrese Komentované řešení pomocí MS Excel Vstupní data Tabulka se vstupními daty je umístěna v oblasti A1:B11 (viz. obrázek) na listu cela data Postup Základní výpočty - regrese Výpočet základních
Lineární regrese Komentované řešení pomocí MS Excel Vstupní data Tabulka se vstupními daty je umístěna v oblasti A1:B11 (viz. obrázek) na listu cela data Postup Základní výpočty - regrese Výpočet základních
Základy biostatistiky II. Veřejné zdravotnictví 3.LF UK - II
 Základy biostatistiky II Veřejné zdravotnictví 3.LF UK - II Teoretické rozložení-matematické modely rozložení Naměřená data Výběrové rozložení Teoretické rozložení 1 e 2 x 2 Teoretické rozložení-matematické
Základy biostatistiky II Veřejné zdravotnictví 3.LF UK - II Teoretické rozložení-matematické modely rozložení Naměřená data Výběrové rozložení Teoretické rozložení 1 e 2 x 2 Teoretické rozložení-matematické
UNIVERZITA PARDUBICE
 UNIVERZITA PARDUBICE Fakulta chemicko technologická Katedra analytické chemie Licenční studium chemometrie na téma Kalibrace a limity její přesnosti Vedoucí licenčního studia Prof. RNDr. Milan Meloun,
UNIVERZITA PARDUBICE Fakulta chemicko technologická Katedra analytické chemie Licenční studium chemometrie na téma Kalibrace a limity její přesnosti Vedoucí licenčního studia Prof. RNDr. Milan Meloun,
Kalibrace a limity její přesnosti
 Univerzita Pardubice Fakulta chemicko-technologická Katedra analytické chemie Licenční studium GALILEO a limity její přesnosti Seminární práce Monika Vejpustková leden 2016 OBSAH Úloha 1. Lineární kalibrace...
Univerzita Pardubice Fakulta chemicko-technologická Katedra analytické chemie Licenční studium GALILEO a limity její přesnosti Seminární práce Monika Vejpustková leden 2016 OBSAH Úloha 1. Lineární kalibrace...
TVORBA LINEÁRNÍCH REGRESNÍCH MODELŮ PŘI ANALÝZE DAT. Semestrální práce UNIVERZITA PARDUBICE. Fakulta chemicko-technologická Katedra analytické chemie
 UNIVERZITA PARDUBICE Fakulta chemicko-technologická Katedra analytické chemie TVORBA LINEÁRNÍCH REGRESNÍCH MODELŮ PŘI ANALÝZE DAT Semestrální práce Licenční studium Galileo Interaktivní statistická analýza
UNIVERZITA PARDUBICE Fakulta chemicko-technologická Katedra analytické chemie TVORBA LINEÁRNÍCH REGRESNÍCH MODELŮ PŘI ANALÝZE DAT Semestrální práce Licenční studium Galileo Interaktivní statistická analýza
Přednáška XI. Asociace ve čtyřpolní tabulce a základy korelační analýzy
 Přednáška XI. Asociace ve čtyřpolní tabulce a základy korelační analýzy Relativní riziko a poměr šancí Princip korelace dvou náhodných veličin Korelační koeficienty Pearsonůva Spearmanův Korelace a kauzalita
Přednáška XI. Asociace ve čtyřpolní tabulce a základy korelační analýzy Relativní riziko a poměr šancí Princip korelace dvou náhodných veličin Korelační koeficienty Pearsonůva Spearmanův Korelace a kauzalita
Testování hypotéz o parametrech regresního modelu
 Statistika II Katedra ekonometrie FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Lineární regresní model kde Y = Xβ + e, y 1 e 1 β y 2 Y =., e = e 2 x 11 x 1 1k., X =....... β 2,
Statistika II Katedra ekonometrie FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Lineární regresní model kde Y = Xβ + e, y 1 e 1 β y 2 Y =., e = e 2 x 11 x 1 1k., X =....... β 2,
Plánování experimentu
 Fakulta chemicko technologická Katedra analytické chemie licenční studium Management systému jakosti Autor: Ing. Radek Růčka Přednášející: Prof. Ing. Jiří Militký, CSc. 1. LEPTÁNÍ PLAZMOU 1.1 Zadání Proces
Fakulta chemicko technologická Katedra analytické chemie licenční studium Management systému jakosti Autor: Ing. Radek Růčka Přednášející: Prof. Ing. Jiří Militký, CSc. 1. LEPTÁNÍ PLAZMOU 1.1 Zadání Proces
Regresní a korelační analýza
 Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Regresní a korelační analýza
 Přednáška STATISTIKA II - EKONOMETRIE Katedra ekonometrie FEM UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Regresní analýza Cíl regresní analýzy: stanovení formy (trendu, tvaru, průběhu)
Přednáška STATISTIKA II - EKONOMETRIE Katedra ekonometrie FEM UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Regresní analýza Cíl regresní analýzy: stanovení formy (trendu, tvaru, průběhu)
INDUKTIVNÍ STATISTIKA
 10. SEMINÁŘ INDUKTIVNÍ STATISTIKA 3. HODNOCENÍ ZÁVISLOSTÍ HODNOCENÍ ZÁVISLOSTÍ KVALITATIVNÍ VELIČINY - Vychází se z kombinační (kontingenční) tabulky, která je výsledkem třídění druhého stupně KVANTITATIVNÍ
10. SEMINÁŘ INDUKTIVNÍ STATISTIKA 3. HODNOCENÍ ZÁVISLOSTÍ HODNOCENÍ ZÁVISLOSTÍ KVALITATIVNÍ VELIČINY - Vychází se z kombinační (kontingenční) tabulky, která je výsledkem třídění druhého stupně KVANTITATIVNÍ
Regresní analýza 1. Regresní analýza
 Regresní analýza 1 1 Regresní funkce Regresní analýza Důležitou statistickou úlohou je hledání a zkoumání závislostí proměnných, jejichž hodnoty získáme při realizaci experimentů Vzhledem k jejich náhodnému
Regresní analýza 1 1 Regresní funkce Regresní analýza Důležitou statistickou úlohou je hledání a zkoumání závislostí proměnných, jejichž hodnoty získáme při realizaci experimentů Vzhledem k jejich náhodnému
UNIVERZITA PARDUBICE Fakulta chemicko-technologická Katedra analytické chemie Nám. Čs. Legií 565, Pardubice
 UNIVERZITA PARDUBICE Fakulta chemicko-technologická Katedra analytické chemie Nám. Čs. Legií 565, 532 10 Pardubice 10. licenční studium chemometrie STATISTICKÉ ZPRACOVÁNÍ DAT Semestrální práce ANALÝZA
UNIVERZITA PARDUBICE Fakulta chemicko-technologická Katedra analytické chemie Nám. Čs. Legií 565, 532 10 Pardubice 10. licenční studium chemometrie STATISTICKÉ ZPRACOVÁNÍ DAT Semestrální práce ANALÝZA
Cvičení 12: Binární logistická regrese
 Cvičení 12: Binární logistická regrese Příklad: V roce 2014 konalo státní závěrečné zkoušky bakalářského studia na jisté fakultě 167 studentů. U každého studenta bylo zaznamenáno jeho pohlaví (0 žena,
Cvičení 12: Binární logistická regrese Příklad: V roce 2014 konalo státní závěrečné zkoušky bakalářského studia na jisté fakultě 167 studentů. U každého studenta bylo zaznamenáno jeho pohlaví (0 žena,
SEMESTRÁLNÍ PRÁCE. Leptání plasmou. Ing. Pavel Bouchalík
 SEMESTRÁLNÍ PRÁCE Leptání plasmou Ing. Pavel Bouchalík 1. ÚVOD Tato semestrální práce obsahuje písemné vypracování řešení příkladu Leptání plasmou. Jde o praktickou zkoušku znalostí získaných při přednáškách
SEMESTRÁLNÍ PRÁCE Leptání plasmou Ing. Pavel Bouchalík 1. ÚVOD Tato semestrální práce obsahuje písemné vypracování řešení příkladu Leptání plasmou. Jde o praktickou zkoušku znalostí získaných při přednáškách
Regresní a korelační analýza
 Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Semestrální práce. 3.3 Tvorba nelineárních regresních modelů v analýze dat
 Semestrální práce 1 3.3 Tvorba nelineárních regresních modelů v analýze dat Ing. Ján Lengyel, CSc. Centrální analytická laboratoř Ústav jaderného výzkumu Řež, a. s. Husinec Řež 130 250 68 Řež V Řeži, únor
Semestrální práce 1 3.3 Tvorba nelineárních regresních modelů v analýze dat Ing. Ján Lengyel, CSc. Centrální analytická laboratoř Ústav jaderného výzkumu Řež, a. s. Husinec Řež 130 250 68 Řež V Řeži, únor
Mann-Whitney U-test. Znaménkový test. Vytvořil Institut biostatistiky a analýz, Masarykova univerzita J. Jarkovský, L. Dušek
 10. Neparametrické y Mann-Whitney U- Wilcoxonův Znaménkový Shrnutí statistických ů Typ srovnání Nulová hypotéza Parametrický Neparametrický 1 skupina dat vs. etalon Střední hodnota je rovna hodnotě etalonu.
10. Neparametrické y Mann-Whitney U- Wilcoxonův Znaménkový Shrnutí statistických ů Typ srovnání Nulová hypotéza Parametrický Neparametrický 1 skupina dat vs. etalon Střední hodnota je rovna hodnotě etalonu.
Úvodem Dříve les než stromy 3 Operace s maticemi
 Obsah 1 Úvodem 13 2 Dříve les než stromy 17 2.1 Nejednoznačnost terminologie 17 2.2 Volba metody analýzy dat 23 2.3 Přehled vybraných vícerozměrných metod 25 2.3.1 Metoda hlavních komponent 26 2.3.2 Faktorová
Obsah 1 Úvodem 13 2 Dříve les než stromy 17 2.1 Nejednoznačnost terminologie 17 2.2 Volba metody analýzy dat 23 2.3 Přehled vybraných vícerozměrných metod 25 2.3.1 Metoda hlavních komponent 26 2.3.2 Faktorová
Regresní a korelační analýza
 Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Testování hypotéz o parametrech regresního modelu
 Testování hypotéz o parametrech regresního modelu Ekonometrie Jiří Neubauer Katedra kvantitativních metod FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Jiří Neubauer (Katedra UO
Testování hypotéz o parametrech regresního modelu Ekonometrie Jiří Neubauer Katedra kvantitativních metod FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Jiří Neubauer (Katedra UO
Kontingenční tabulky, korelační koeficienty
 Statistika II Katedra ekonometrie FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Mějme kategoriální proměnné X a Y. Vytvoříme tzv. kontingenční tabulku. Budeme tedy testovat hypotézu
Statistika II Katedra ekonometrie FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Mějme kategoriální proměnné X a Y. Vytvoříme tzv. kontingenční tabulku. Budeme tedy testovat hypotézu
Univerzita Pardubice SEMESTRÁLNÍ PRÁCE. Tvorba nelineárních regresních modelů v analýze dat. 2015/2016 RNDr. Mgr. Leona Svobodová, Ph.D.
 Univerzita Pardubice SEMESTRÁLNÍ PRÁCE Tvorba nelineárních regresních modelů v analýze dat 2015/2016 RNDr. Mgr. Leona Svobodová, Ph.D. Úloha Nalezení vhodného modelu pro popis reakce TaqMan real-time PCR
Univerzita Pardubice SEMESTRÁLNÍ PRÁCE Tvorba nelineárních regresních modelů v analýze dat 2015/2016 RNDr. Mgr. Leona Svobodová, Ph.D. Úloha Nalezení vhodného modelu pro popis reakce TaqMan real-time PCR
10. cvičení z PST. 5. prosince T = (n 1) S2 X. (n 1) s2 x σ 2 q χ 2 (n 1) (1 α 2 ). q χ 2 (n 1) 2. 2 x. (n 1) s. x = 1 6. x i = 457.
 S2 X. (n 1) s2 x σ 2 q χ 2 (n 1) (1 α 2 ). q χ 2 (n 1) 2. 2 x. (n 1) s. x = 1 6. x i = 457.") 0 cvičení z PST 5 prosince 208 0 (intervalový odhad pro rozptyl) Soubor (70, 84, 89, 70, 74, 70) je náhodným výběrem z normálního rozdělení N(µ, σ 2 ) Určete oboustranný symetrický 95% interval spolehlivosti
0 cvičení z PST 5 prosince 208 0 (intervalový odhad pro rozptyl) Soubor (70, 84, 89, 70, 74, 70) je náhodným výběrem z normálního rozdělení N(µ, σ 2 ) Určete oboustranný symetrický 95% interval spolehlivosti
Statistika (KMI/PSTAT)
") Statistika (KMI/PSTAT) Cvičení dvanácté aneb Regrese a korelace Statistika (KMI/PSTAT) 1 / 18 V souboru 25 jedinců jsme měřili jejich výšku a hmotnost. Výsledky jsou v tabulce a grafu. Statistika (KMI/PSTAT)
Statistika (KMI/PSTAT) Cvičení dvanácté aneb Regrese a korelace Statistika (KMI/PSTAT) 1 / 18 V souboru 25 jedinců jsme měřili jejich výšku a hmotnost. Výsledky jsou v tabulce a grafu. Statistika (KMI/PSTAT)
UNIVERZITA PARDUBICE. 4.4 Aproximace křivek a vyhlazování křivek
 UNIVERZITA PARDUBICE Licenční Studium Archimedes Statistické zpracování dat a informatika 4.4 Aproximace křivek a vyhlazování křivek Mgr. Jana Kubátová Endokrinologický ústav V Praze, leden 2012 Obsah
UNIVERZITA PARDUBICE Licenční Studium Archimedes Statistické zpracování dat a informatika 4.4 Aproximace křivek a vyhlazování křivek Mgr. Jana Kubátová Endokrinologický ústav V Praze, leden 2012 Obsah
6. Lineární regresní modely
 6. Lineární regresní modely 6.1 Jednoduchá regrese a validace 6.2 Testy hypotéz v lineární regresi 6.3 Kritika dat v regresním tripletu 6.4 Multikolinearita a polynomy 6.5 Kritika modelu v regresním tripletu
6. Lineární regresní modely 6.1 Jednoduchá regrese a validace 6.2 Testy hypotéz v lineární regresi 6.3 Kritika dat v regresním tripletu 6.4 Multikolinearita a polynomy 6.5 Kritika modelu v regresním tripletu
Faktorová analýza (FACT)
") Faktorová analýza (FAC) Podobně jako metoda hlavních komponent patří také faktorová analýza mezi metody redukce počtu původních proměnných. Ve faktorové analýze předpokládáme, že každou vstupující proměnnou
Faktorová analýza (FAC) Podobně jako metoda hlavních komponent patří také faktorová analýza mezi metody redukce počtu původních proměnných. Ve faktorové analýze předpokládáme, že každou vstupující proměnnou
6. Lineární regresní modely
 6. Lineární regresní modely 6.1 Jednoduchá regrese a validace 6.2 Testy hypotéz v lineární regresi 6.3 Kritika dat v regresním tripletu 6.4 Multikolinearita a polynomy 6.5 Kritika modelu v regresním tripletu
6. Lineární regresní modely 6.1 Jednoduchá regrese a validace 6.2 Testy hypotéz v lineární regresi 6.3 Kritika dat v regresním tripletu 6.4 Multikolinearita a polynomy 6.5 Kritika modelu v regresním tripletu
ANOVA. Semestrální práce UNIVERZITA PARDUBICE. Fakulta chemicko-technologická Katedra analytické chemie
 UNIVERZITA PARDUBICE Fakulta chemicko-technologická Katedra analytické chemie ANOVA Semestrální práce Licenční studium Galileo Interaktivní statistická analýza dat Brno 2015 Ing. Petra Hlaváčková, Ph.D.
UNIVERZITA PARDUBICE Fakulta chemicko-technologická Katedra analytické chemie ANOVA Semestrální práce Licenční studium Galileo Interaktivní statistická analýza dat Brno 2015 Ing. Petra Hlaváčková, Ph.D.
Statistika. Regresní a korelační analýza Úvod do problému. Roman Biskup
 Statistika Regresní a korelační analýza Úvod do problému Roman Biskup Jihočeská univerzita v Českých Budějovicích Ekonomická fakulta (Zemědělská fakulta) Katedra aplikované matematiky a informatiky 2008/2009
Statistika Regresní a korelační analýza Úvod do problému Roman Biskup Jihočeská univerzita v Českých Budějovicích Ekonomická fakulta (Zemědělská fakulta) Katedra aplikované matematiky a informatiky 2008/2009
Stavový model a Kalmanův filtr
 Stavový model a Kalmanův filtr 2 prosince 23 Stav je veličina, kterou neznáme, ale chtěli bychom znát Dozvídáme se o ní zprostředkovaně prostřednictvím výstupů Příkladem může býapř nějaký zašuměný signál,
Stavový model a Kalmanův filtr 2 prosince 23 Stav je veličina, kterou neznáme, ale chtěli bychom znát Dozvídáme se o ní zprostředkovaně prostřednictvím výstupů Příkladem může býapř nějaký zašuměný signál,
You created this PDF from an application that is not licensed to print to novapdf printer (http://www.novapdf.com)
") Závislost náhodných veličin Úvod Předchozí přednášky: - statistické charakteristiky jednoho výběrového nebo základního souboru - vztahy mezi výběrovým a základním souborem - vztahy statistických charakteristik
Závislost náhodných veličin Úvod Předchozí přednášky: - statistické charakteristiky jednoho výběrového nebo základního souboru - vztahy mezi výběrovým a základním souborem - vztahy statistických charakteristik
Grafický a číselný popis rozložení dat 3.1 Způsoby zobrazení dat Metody zobrazení kvalitativních a ordinálních dat Metody zobrazení kvan
 1 Úvod 1.1 Empirický výzkum a jeho etapy 1.2 Význam teorie pro výzkum 1.2.1 Konstrukty a jejich operacionalizace 1.2.2 Role teorie ve výzkumu 1.2.3 Proces ověření hypotéz a teorií 1.3 Etika vědecké práce
1 Úvod 1.1 Empirický výzkum a jeho etapy 1.2 Význam teorie pro výzkum 1.2.1 Konstrukty a jejich operacionalizace 1.2.2 Role teorie ve výzkumu 1.2.3 Proces ověření hypotéz a teorií 1.3 Etika vědecké práce
KALIBRACE A LIMITY JEJÍ PŘESNOSTI 2015
 UNIVERZITA PARDUBICE Fakulta chemicko-technologická Katedra analytické chemie Nám. Čs. Legií 565, 532 10 Pardubice 15. licenční studium INTERAKTIVNÍ STATISTICKÁ ANALÝZA DAT Semestrální práce KALIBRACE
UNIVERZITA PARDUBICE Fakulta chemicko-technologická Katedra analytické chemie Nám. Čs. Legií 565, 532 10 Pardubice 15. licenční studium INTERAKTIVNÍ STATISTICKÁ ANALÝZA DAT Semestrální práce KALIBRACE
Porovnání dvou výběrů
 Porovnání dvou výběrů Menu: QCExpert Porovnání dvou výběrů Tento modul je určen pro podrobnou analýzu dvou datových souborů (výběrů). Modul poskytuje dva postupy analýzy: porovnání dvou nezávislých výběrů
Porovnání dvou výběrů Menu: QCExpert Porovnání dvou výběrů Tento modul je určen pro podrobnou analýzu dvou datových souborů (výběrů). Modul poskytuje dva postupy analýzy: porovnání dvou nezávislých výběrů
Univerzita Pardubice Fakulta chemicko technologická Katedra analytické chemie Licenční studium chemometrie
 Univerzita Pardubice Fakulta chemicko technologická Katedra analytické chemie Licenční studium chemometrie Statistické zpracování dat ANOVA Zdravotní ústav se sídlem v Ostravě Odbor hygienických laboratoří
Univerzita Pardubice Fakulta chemicko technologická Katedra analytické chemie Licenční studium chemometrie Statistické zpracování dat ANOVA Zdravotní ústav se sídlem v Ostravě Odbor hygienických laboratoří
6. Lineární regresní modely
 6. Lineární regresní modely 6.1 Jednoduchá regrese a validace 6.2 Testy hypotéz v lineární regresi 6.3 Kritika dat v regresním tripletu 6.4 Multikolinearita a polynomy 6.5 Kritika modelu v regresním tripletu
6. Lineární regresní modely 6.1 Jednoduchá regrese a validace 6.2 Testy hypotéz v lineární regresi 6.3 Kritika dat v regresním tripletu 6.4 Multikolinearita a polynomy 6.5 Kritika modelu v regresním tripletu
UNIVERZITA PARDUBICE Fakulta chemicko-technologická Katedra analytické chemie. Nám. Čs. Legií 565, Pardubice. Semestrální práce ANOVA 2015
 UNIVERZITA PARDUBICE Fakulta chemicko-technologická Katedra analytické chemie Nám. Čs. Legií 565, 532 10 Pardubice 15. licenční studium INTERAKTIVNÍ STATISTICKÁ ANALÝZA DAT Semestrální práce ANOVA 2015
UNIVERZITA PARDUBICE Fakulta chemicko-technologická Katedra analytické chemie Nám. Čs. Legií 565, 532 10 Pardubice 15. licenční studium INTERAKTIVNÍ STATISTICKÁ ANALÝZA DAT Semestrální práce ANOVA 2015
Tvorba nelineárních regresních modelů v analýze dat
 Univerzita Pardubice Fakulta chemicko-technologická Katedra analytické chemie Tvorba nelineárních regresních modelů v analýze dat Semestrální práce Licenční studium GALILEO Interaktivní statistická analýza
Univerzita Pardubice Fakulta chemicko-technologická Katedra analytické chemie Tvorba nelineárních regresních modelů v analýze dat Semestrální práce Licenční studium GALILEO Interaktivní statistická analýza
Statistická analýza jednorozměrných dat
 Statistická analýza jednorozměrných dat Prof. RNDr. Milan Meloun, DrSc. Univerzita Pardubice, Pardubice 31.ledna 2011 Tato prezentace je spolufinancována Evropským sociálním fondem a státním rozpočtem
Statistická analýza jednorozměrných dat Prof. RNDr. Milan Meloun, DrSc. Univerzita Pardubice, Pardubice 31.ledna 2011 Tato prezentace je spolufinancována Evropským sociálním fondem a státním rozpočtem
Univerzita Pardubice SEMESTRÁLNÍ PRÁCE. Tvorba lineárních regresních modelů. 2015/2016 RNDr. Mgr. Leona Svobodová, Ph.D.
 Univerzita Pardubice SEMESTRÁLNÍ PRÁCE Tvorba lineárních regresních modelů 2015/2016 RNDr. Mgr. Leona Svobodová, Ph.D. Úloha 1 Porovnání regresních přímek u jednoduchého lineárního regresního modelu Porovnání
Univerzita Pardubice SEMESTRÁLNÍ PRÁCE Tvorba lineárních regresních modelů 2015/2016 RNDr. Mgr. Leona Svobodová, Ph.D. Úloha 1 Porovnání regresních přímek u jednoduchého lineárního regresního modelu Porovnání
Profilování vzorků heroinu s využitím vícerozměrné statistické analýzy
 Profilování vzorků heroinu s využitím vícerozměrné statistické analýzy Autor práce : RNDr. Ivo Beroun,CSc. Vedoucí práce: prof. RNDr. Milan Meloun, DrSc. PROFILOVÁNÍ Profilování = klasifikace a rozlišování
Profilování vzorků heroinu s využitím vícerozměrné statistické analýzy Autor práce : RNDr. Ivo Beroun,CSc. Vedoucí práce: prof. RNDr. Milan Meloun, DrSc. PROFILOVÁNÍ Profilování = klasifikace a rozlišování
2.2 Kalibrace a limity její p esnosti
 UNIVERZITA PARDUBICE Òkolní rok 000/001 Fakulta chemicko-technologická, Katedra analytické chemie LICEN NÍ STUDIUM STATISTICKÉ ZPRACOVÁNÍ DAT PÌI MANAGEMENTU JAKOSTI P EDM T:. Kalibrace a limity její p
UNIVERZITA PARDUBICE Òkolní rok 000/001 Fakulta chemicko-technologická, Katedra analytické chemie LICEN NÍ STUDIUM STATISTICKÉ ZPRACOVÁNÍ DAT PÌI MANAGEMENTU JAKOSTI P EDM T:. Kalibrace a limity její p
Tvorba lineárních regresních modelů
 Univerzita Pardubice Fakulta chemicko technologická Katedra analytické chemie Licenční studium chemometrie Statistické zpracování dat Tvorba lineárních regresních modelů při analýze dat Zdravotní ústav
Univerzita Pardubice Fakulta chemicko technologická Katedra analytické chemie Licenční studium chemometrie Statistické zpracování dat Tvorba lineárních regresních modelů při analýze dat Zdravotní ústav
4EK211 Základy ekonometrie
 4EK211 Základy ekonometrie ZS 2015/16 Cvičení 7: Časově řady, autokorelace LENKA FIŘTOVÁ KATEDRA EKONOMETRIE, FAKULTA INFORMATIKY A STATISTIKY VYSOKÁ ŠKOLA EKONOMICKÁ V PRAZE 1. Časové řady Data: HDP.wf1
4EK211 Základy ekonometrie ZS 2015/16 Cvičení 7: Časově řady, autokorelace LENKA FIŘTOVÁ KATEDRA EKONOMETRIE, FAKULTA INFORMATIKY A STATISTIKY VYSOKÁ ŠKOLA EKONOMICKÁ V PRAZE 1. Časové řady Data: HDP.wf1
Ilustrační příklad odhadu LRM v SW Gretl
 Ilustrační příklad odhadu LRM v SW Gretl Podkladové údaje Korelační matice Odhad lineárního regresního modelu (LRM) Verifikace modelu PEF ČZU Praha Určeno pro posluchače předmětu Ekonometrie Needitovaná
Ilustrační příklad odhadu LRM v SW Gretl Podkladové údaje Korelační matice Odhad lineárního regresního modelu (LRM) Verifikace modelu PEF ČZU Praha Určeno pro posluchače předmětu Ekonometrie Needitovaná
Tvorba modelu sorpce a desorpce 85 Sr na krystalických horninách za dynamických podmínek metodou nelineární regrese
 Tvorba modelu sorpce a desorpce 85 Sr na krystalických horninách za dynamických podmínek metodou nelineární regrese Závěrečná práce 12. licenčního studia Pythagoras Fakulta chemicko-technologická, katedra
Tvorba modelu sorpce a desorpce 85 Sr na krystalických horninách za dynamických podmínek metodou nelineární regrese Závěrečná práce 12. licenčního studia Pythagoras Fakulta chemicko-technologická, katedra
8 Coxův model proporcionálních rizik I
 8 Coxův model proporcionálních rizik I Předpokládané výstupy z výuky: 1. Student umí formulovat Coxův model proporcionálních rizik 2. Student rozumí významu regresních koeficientů modelu 3. Student zná
8 Coxův model proporcionálních rizik I Předpokládané výstupy z výuky: 1. Student umí formulovat Coxův model proporcionálních rizik 2. Student rozumí významu regresních koeficientů modelu 3. Student zná
Statistické metody v marketingu. Ing. Michael Rost, Ph.D.
 Statistické metody v marketingu Ing. Michael Rost, Ph.D. Jihočeská univerzita v Českých Budějovicích Úvodem Modelování vztahů mezi vysvětlující a vysvětlovanou (závisle) proměnnou patří mezi základní aktivity,
Statistické metody v marketingu Ing. Michael Rost, Ph.D. Jihočeská univerzita v Českých Budějovicích Úvodem Modelování vztahů mezi vysvětlující a vysvětlovanou (závisle) proměnnou patří mezi základní aktivity,
Bodové a intervalové odhady parametrů v regresním modelu
 Statistika II Katedra ekonometrie FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Lineární regresní model Mějme lineární regresní model (LRM) Y = Xβ + e, kde y 1 e 1 β y 2 Y =., e
Statistika II Katedra ekonometrie FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Lineární regresní model Mějme lineární regresní model (LRM) Y = Xβ + e, kde y 1 e 1 β y 2 Y =., e
Aplikovaná statistika v R - cvičení 3
 Aplikovaná statistika v R - cvičení 3 Filip Děchtěrenko Matematicko-fyzikální fakulta filip.dechterenko@gmail.com 5.8.2014 Filip Děchtěrenko (MFF UK) Aplikovaná statistika v R 5.8.2014 1 / 10 Lineární
Aplikovaná statistika v R - cvičení 3 Filip Děchtěrenko Matematicko-fyzikální fakulta filip.dechterenko@gmail.com 5.8.2014 Filip Děchtěrenko (MFF UK) Aplikovaná statistika v R 5.8.2014 1 / 10 Lineární
Pravděpodobnost a matematická statistika
 Pravděpodobnost a matematická statistika Příklady k přijímacím zkouškám na doktorské studium 1 Popisná statistika Určete aritmetický průměr dat, zadaných tabulkou hodnot x i a četností n i x i 1 2 3 n
Pravděpodobnost a matematická statistika Příklady k přijímacím zkouškám na doktorské studium 1 Popisná statistika Určete aritmetický průměr dat, zadaných tabulkou hodnot x i a četností n i x i 1 2 3 n
Příloha č. 1 Grafy a protokoly výstupy z adstatu
 1 Příklad 3. Stanovení Si metodou OES Byly porovnávány naměřené hodnoty Si na automatickém analyzátoru OES s atestovanými hodnotami. Na základě testování statistické významnosti regresních parametrů (úseku
1 Příklad 3. Stanovení Si metodou OES Byly porovnávány naměřené hodnoty Si na automatickém analyzátoru OES s atestovanými hodnotami. Na základě testování statistické významnosti regresních parametrů (úseku
Regresní analýza. Eva Jarošová
 Regresní analýza Eva Jarošová 1 Obsah 1. Regresní přímka 2. Možnosti zlepšení modelu 3. Testy v regresním modelu 4. Regresní diagnostika 5. Speciální využití Lineární model 2 1. Regresní přímka 3 nosnost
Regresní analýza Eva Jarošová 1 Obsah 1. Regresní přímka 2. Možnosti zlepšení modelu 3. Testy v regresním modelu 4. Regresní diagnostika 5. Speciální využití Lineární model 2 1. Regresní přímka 3 nosnost
KGG/STG Statistika pro geografy
 KGG/STG Statistika pro geografy 10. Mgr. David Fiedor 27. dubna 2015 Nelineární závislost - korelační poměr užití v případě, kdy regresní čára není přímka, ale je vyjádřena složitější matematickou funkcí
KGG/STG Statistika pro geografy 10. Mgr. David Fiedor 27. dubna 2015 Nelineární závislost - korelační poměr užití v případě, kdy regresní čára není přímka, ale je vyjádřena složitější matematickou funkcí
Statistická analýza jednorozměrných dat
 Statistická analýza jednorozměrných dat Prof. RNDr. Milan Meloun, DrSc. Univerzita Pardubice, Pardubice 31.ledna 2011 Tato prezentace je spolufinancována Evropským sociálním fondem a státním rozpočtem
Statistická analýza jednorozměrných dat Prof. RNDr. Milan Meloun, DrSc. Univerzita Pardubice, Pardubice 31.ledna 2011 Tato prezentace je spolufinancována Evropským sociálním fondem a státním rozpočtem
Téma 9: Vícenásobná regrese
 Téma 9: Vícenásobná regrese 1) Vytvoření modelu V menu Statistika zvolíme nabídku Vícerozměrná regrese. Aktivujeme kartu Detailní nastavení viz obr.1. Nastavíme Proměnné tak, že v příslušném okně viz.
Téma 9: Vícenásobná regrese 1) Vytvoření modelu V menu Statistika zvolíme nabídku Vícerozměrná regrese. Aktivujeme kartu Detailní nastavení viz obr.1. Nastavíme Proměnné tak, že v příslušném okně viz.
EKONOMETRIE 7. přednáška Fáze ekonometrické analýzy
 EKONOMETRIE 7. přednáška Fáze ekonometrické analýzy Ekonometrická analýza proces, skládající se z následujících fází: a) specifikace b) kvantifikace c) verifikace d) aplikace Postupné zpřesňování jednotlivých
EKONOMETRIE 7. přednáška Fáze ekonometrické analýzy Ekonometrická analýza proces, skládající se z následujících fází: a) specifikace b) kvantifikace c) verifikace d) aplikace Postupné zpřesňování jednotlivých
Diagnostika regrese pomocí grafu 7krát jinak
 StatSoft Diagnostika regrese pomocí grafu 7krát jinak V tomto článečku si uděláme exkurzi do teorie regresní analýzy a detailně se podíváme na jeden jediný diagnostický graf. Jedná se o graf Předpovědi
StatSoft Diagnostika regrese pomocí grafu 7krát jinak V tomto článečku si uděláme exkurzi do teorie regresní analýzy a detailně se podíváme na jeden jediný diagnostický graf. Jedná se o graf Předpovědi
Cvičení ze statistiky - 3. Filip Děchtěrenko
 Cvičení ze statistiky - 3 Filip Děchtěrenko Minule bylo.. Dokončili jsme základní statistiky, typy proměnných a začali analýzu kvalitativních dat Tyhle termíny by měly být známé: Histogram, krabicový graf
Cvičení ze statistiky - 3 Filip Děchtěrenko Minule bylo.. Dokončili jsme základní statistiky, typy proměnných a začali analýzu kvalitativních dat Tyhle termíny by měly být známé: Histogram, krabicový graf
Předpoklad o normalitě rozdělení je zamítnut, protože hodnota testovacího kritéria χ exp je vyšší než tabulkový 2
 Na úloze ukážeme postup analýzy velkého výběru s odlehlými prvky pro určení typu rozdělení koncentrace kyseliny močové u 50 dárců krve. Jaká je míra polohy a rozptýlení uvedeného výběru? Z grafických diagnostik
Na úloze ukážeme postup analýzy velkého výběru s odlehlými prvky pro určení typu rozdělení koncentrace kyseliny močové u 50 dárců krve. Jaká je míra polohy a rozptýlení uvedeného výběru? Z grafických diagnostik