Náhodné vektory a matice. Katedra textilních materiálů Technická Universita Liberec,
|
|
|
- Jarmila Konečná
- před 6 lety
- Počet zobrazení:
Transkript




1 Náhodné vektory a matice Jiří Militký Katedra textilních materiálů Technická Universita Liberec,
2 Symbolika A B Jev jistý S (nastane vždy) P(S) = 1 Jev nemožný (nenastane nikdy ) P( ) =0 Doplňkový jev k jevu A (označení D) je D= S - A a tedy P(D) = 1 - P(A) Sjednocení jevů A a B (nastane A nebo B nebo oba současně) C = A B. To znamená, že C je jev, kdy nastane alespoň jeden z jevů A, B. Průnik jevů A a B (nastanou oba jevy současně) C = A B. To znamená, že C je jev, kdy nastanou právě oba jevy. Neslučitelné (vzájemně se vylučující resp. disjunktní ) jevy A a B (nemohou nastat současně) A B = Elementární jev ei.(.nelze ho vyjádřit sjednocením jiných jevů - není dále dělitelný). 0 P(e i ) 1
3 Pravidla I A B Pravděpodobnost sjednocení dvou jevů A a B je obecně P(A B) = P(A) + P(B) - P(A B) Vylučující se jevy A B = je P(A B) = P(A) + P(B) Pravidlo sčítání pravděpodobností p :Pravděpodobnost, p, že nastane alespoň jeden z neslučitelných jevů A i je rovna součtu pravděpodobností P(A i ). Podmíněná pravděpodobnost je pravděpodobnost P(A/B), že nastane jev A za podmínky, že nastal jev B P(A/B) = P(A B) / P(B) Pravděpodobnost P(A B) současného výskytu A a B P(A B) = P(A/B). P(B) = P(B/A). P(A),
4 Pravidla II Pro spojité náhodné veličiny platí analogické vztahy vta ypo pro hustoty ustotypavděpodob pravděpodobnosti. ost Tedy pro nezávislé veličiny f(x,y) = f(x)f(y), f(x y) = f(x), f(y x) = f(y) Nezávislé jevy A a B ( výskyt A není ovlivněn výskytem B) tedy P(A/B) = P(A) a pak P(A B) = P(A) P(B) Pravidlo násobení pravděpodobností: pravděpodobnost současného č výskytu nezávislých jevů. ů A i je rovna součinu pravděpodobností P(A i ) Pravděpodobnost výskytu jevu A,,pokud nastal jev B se označuje jako podmíněná pravděpodobnost P(A/B) a (pro P(B)>0): Bayesův vztah P ( A B ) = P( A B) P( B) P(B/A) = P(A/B) P(B) / P(A) P(B) apriorní informace, P(B/A) aposteriorní informace, P(A/B) informace z dat
5 Náhodný vektor Vícerozměrná náhodná veličina ξ je určena svou sdruženou distribuční funkcí F(x). Pravděpodobnost, že všechny složky ξi vektoru ξ budou menší než složky yxx i zadaného o( (nenáhodného) o)vektoru uxx F(x) = P( ξ x ξ x... ξ x ) 1 1 m m je logický součin (současná platnost uvedených podmínek). Sdružená distribuční funkce F(x) je neklesající funkcí svých argumentů, je nezáporná a maximálně rovna jedné. Marginální (okrajová) distribuční funkce F(x i )složkyξ i je zvláštním případem simultánní distribuční funkce F(x), u které jsou všechny ostatní složky náhodného vektoru na horní mezi svého definičního intervalu; obyčejněξ j = pro j i.
6 Podmíněná distribuční funkce Podmíněná distribuční funkce F(x/x i ), vyjadřuje pravděpodobnost, že všechny složky vektoru ξ kromě i- té budou menší než odpovídající složka vektoru x. Pro složku ξi platí, že je přibližně konstantní, tj. leží v nekonečně malém intervalu x i ξ i dx i + x i. F( x / x ) = P( ξ x... x ξ ( x + d x... ξ x ) i 1 1 i i i i m m Nezávislé složky vektoru ξ, podmíněné distribuční funkce nezávisí na podmínce. m F(x) = F( xi) Derivace distribučních funkcí jsou hustoty pravděpodobnosti f(x i ), f(x), resp. f(x/x i ) i=1
7 y Standard Gaussian density Normální rozdělení Pro spojitou náhodnou veličinu x, - < x <. Unimodální a symetrické. μ = střední hodnota σ = směrodatná odchylka Hustota pravděpodobnosti f(x) = 1 πσ e ( μ ) - x- Distribuční funkce t F(t) = f (x)dx s x
8 Vícerozměrné normální rozdělení I Zobecnění na p rozměrů: 1 f( x) = exp - x-μ Σ x - μ / p 1 π det Σ ( ) ( ) kde - x i, i = 1,,p. ( ( ) T -1 ( ) ) Čtverec zobecněné ě vzdálenosti mezi x a μ μ σ11 σ1 σ 1 1p μ σ σ σ Označení N p (μ, Σ) 1 p μ=, Σ = μ p σp1 σp σpp σ 11 =σ 1
9 Vícerozměrné normální rozdělení II Sdružená hustota pravděpodobnosti vícerozměrného normálního rozdělení / 1/ 1 T -p/ -1/ T -1 f(x) = ( π) (det C ) exp - (x - μ) C (x - μ) det(c)označuje determinant matice C a x T označuje transponovaný vektor x. Parametry tohoto rozdělení jsou vektor stěedních hodnot o μ a kovarianční č matice C s prvky pv yc ij = cov(ξ i, ξ j ) Koznačení vícerozměrného normálního rozdělení se používá symbol N(μ, C). Pokud vektor x pochází z rozdělení N(μ, C), platí, že veličina T -1 Q(x) = (x - μ (x - μ) ) C má χ rozdělení s m stupni volnosti
10 D normální rozdělení -1 1 Inverze kovarianční matice: Σ = σ σ -σ Kovariance: σ 1 = ρ1 σ11 σ σ σ - σ = σ σ 1-ρ 11 1 ( ) Determinant: σ -σ -σ σ T 1 σ -ρ1 σ11 σ x-μ = x1-μ 1 x-μ σσ ( ) x-μ 11 1-ρ 1 -ρ1 σ11 σ σ11 μ -1 ( x μ) Σ ( x μ) ( ) ( ) ( )( ) σ x-μ +σ x-μ -ρ σ σ x-μ x-μ = σσ 1-ρ ( ) 11 1 μ 1 x μ μ 1-μ 1 x-μ x1-μ 1 x-μ = + -ρ 1 1-ρ 1 σ 11 σ σ 11 σ
11 PDF pro D normální rozdělení 1 f( x)= exp - x-μ Σ x- μ / ( π) det ( Σ) 1 ( ) ( ) ( ) π σ11σ 1-ρ 1-ρ1 1 ( ( ) T -1 ( ) ) 1 1 x-μ 1 1 x-μ x-μ 1 1 x-μ exp + -ρ 1 σ 11 σ σ 11 σ =
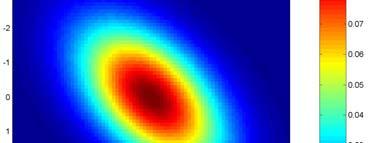
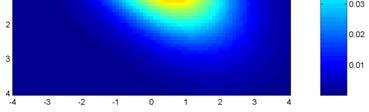
12 Graf pdf D normálního rozdělení f(x 1, X ) Linie úrovní X X 1 Všechny body stejné hustoty pravděpodobnosti se označují jako linie úrovní T -1 ( ) ( ) x μ Σ x μ = c
13 μ μ = μ Linie úrovní 1 μ linie konstantního c X f(x 1, X ) Koncentrické elipsoidy se středem μ a osami ±c λ e i ±c λ e i f(x 1, X ) ±c λ e 1 1 T ( x-μ ) Σ -1 ( x-μ ) χ α resp. χ ( ) ( ) p p,α X 1 T -1 ( ) ( ) ( ) Pr x μ Σ x μ χ α p = 1 - α
14 Speciální případ Pro stejné rozptyly (σ 11 = σ ): det ( Σ- λe) =0 resp. σ11-λ σ 0=det 1 = ( σ -λ) -σ σ1 σ11-λ ( ) ( ) = λ-σ -σ λ-σ +σ takže λ 1=σ 11+σ 1, λ =σ11-σ1




15 Speciální struktury Sféricita N(μ,Σ=σ E) Σ = σ σ Σ = 0 1 Σ = Σ = 1
16 Σ e Vlastní vektory ~ matice Σ i = λ e resp. i i σ11 σ1 e1 e =λ 1 σ 1 1 σ 11 e e ( ) nebo σ e+σ e = σ +σ e ( ) σ e+σ e = σ +σ e což znamená λ =σ + σ a e = 1 1 a λ =σ - σ podobně platí,že = e -1
17 Kladná kovariance linie T ( ) -1 ( ) c= x μ Σ x μ f(x 1, x ) X f(x 1, X ) - pro kladnou kovarianci σ 1, leží vlastní vektor na přímce pootočené o 45 0, která prochází středem μ: c σ -σ 11 1 c σ 11 + σ1 X 1
18 Záporná kovariance linie T ( μ) -1 ( μ) c= x Σ x X f(x 1, X ) - pro zápornou kovarianci i σ 1, leží druhý vlastní vektor v prvém úhlu k přímce pootočené o 45 0, která prochází středem μ: c σ11-σ 1 f(x 1, X ) c σ 11+σ 1 X 1
19 X 1 a X nekorelované 1 f( x)= exp x μ Σ x μ 1 π Σ ( ( ) T -1 ( )/ ) ( ) (r 1 = 0) 1 1 x 1-μμ 1 x -μμ x 1-μμ 1 x -μμ = exp ( ) ( ) + -ρ ( ) 1 π σσ 11 1-ρ 1-ρ 1 1 σ11 σ σ11 σ 1 1 x-μ 1 1 x-μ = exp + ( π ) σσ 11 σ11 σ f(x 1 ) f(x ) 1 ( ) / ( ) / 1 = exp( x 1 11 μ σ ) exp( 1 x μ σ ) π σ11 π σ
20 Vlastnosti vícerozměrného normálního rozdělení I Pro libovolný náhodný vektor x s normálním rozdělením platí, že pdf 1 f ( x ) = exp - x-μ Σ x - μ / p 1 π Σ ( ) ( ( μ ) T -1 ( μ ) ) má maximum v místě μ 1 μ μ = μ p Medián, modus a střední hodnota jsou totožné ~
21 Hustota pravděpodobnosti 1 f( x ) = exp x μ Σ x μ p 1 π ~ Σ ( ) ( ( ) T -1 ( ) /) Je symetrická se středem v μ Lineární kombinace složek vektoru X má normální rozdělení Všechny podmnožiny složek X mají (vícerozměrné) normální rozdělení Nulová kovariance znamená, že odpovídající složky vektoru X jsou nezávislé. Podmíněné rozdělení složek X je (vícerozměrné) normální
22 Vlastnosti vícerozměrného normálního rozdělení II Pokud X ~ N p (μ, Σ), pak všechny lineární kombinace T p = a ix i~n p T, T i=1 a X ( a μ a Σ a ) Pokud X ~ N p p(μ, (μ,σ), pak libovolná q lineární kombinace p a1ixi i=1 p Pokud d je vhodný T aixi T T ~N vektor konstant, pak AX= ( ) i=1 q Aμ, A ΣA X + d ~N p (μ + d, Σ) p aqixi i=1
23 Vlastnosti vícerozměrného normálního rozdělení III Pokud X ~ N p (μ, Σ), jsou všechny podmnožiny X normálně rozděleny X Σ11 Σ1 1 μ 1 ( qx1) ( qx1) ( qxq) ( qx( p-q) ) X =, μ =, Σ = px1 pxp X μ Σ1 Σ (( ) ) (( ) ) p-q x1 p-q x1 (( p-q ) xq ) (( p-q ) x( p-q )) ( px1) ( ) ( ) Pak X 1 ~ N q (μ 1, Σ 11 ) a X ~ N p-q (μ, Σ )
24 Vlastnosti vícerozměrného normálního rozdělení V Společná kovarianční matice Nechť X j ~ N p (μ j, Σ), j = 1,,n jsou vzájemně nezávislé. Pak ~ ~ n n n v 1 = cjxj~n p cjμ j, cj Σ ~ j=1 j=1 j=1 n n n v = b~ jxj~n p bjμ j, bj Σ j= 1 j= 1 j= 1 mají sdružené normální rozdělení s kovariační maticí n ( T c ) j Σ bc Σ V 1 and V jsou nezávislé, pokud n T b bc Σ bj Σ T c = 0! j=1 j=1 ( )
25 Souhrn Mezi důležité vlastnosti vícerozměrného normálního rozdělení patří: a) odpovídající marginální i podmíněná rozdělení jsou také normální, b) jsou-li všechny složky vektoru ξ vzájemně nekorelované (tj. všechny párové ékorelační č íkoeficienty i jsou nulové), znamená áto, že složky ξj, j = 1,..., m, jsou nezávislé, c) pokud má vektor ξ vícerozměrné normální rozdělení, mají libovolné lineární kombinace jeho složek ξ j také normální rozdělení. Z uvedeného plyne, že předpoklad normality usnadňuje analýzu aumožňuje poměrně jednoduché zpracování úloh souvisejících snáhodným áhdý vektorem ξ.
26 Charakteristiky vícerozměrných rozdělení Náhodný vektor X 1 x = X m Střed rozdělení je vektor středních hodnot Míra variability je kovarianční matice: ( ) ( ) EX 1 μ = Ex = EX m var x1 cov x 1,x m Σ = cov( X) = cov( x 1) m,x var ( x m )
27 Pojmy Náhodný vektor vektor, jehož elementy jsou náhodné proměnné nebo jejich funkce. Náhodná matice matice, jejíž elementy jsou náhodné proměnné ě nebo jejich ji funkce. Střední hodnota E x 11 E x1 E x1m E x1 E x E xm E X = E xn1 E xn E xnm ( x ) xp ij ij ij all xij E x ij = ( ) xf ij ij xij dxij E(cX) =ce(x) E(X+Y) = E(X) + E(Y) E(AXB)= AE(X)B
28 Kovarianční matice Pozitivně semi definitní (všechny rozptyly jsou 0) ( x )( ) ( )( ) 1 μ1 x1 μ1 x1 μ1 xm μm Σ = cov( x ) = E = ( x )( ) ( )( ) d μm x1 μ1 xm μm x m μm = E( )( ) T Σ x μ x μ σ σ σ T Var c X = T σ σ σ ( )( ) = = 1 m E X -μ X - μ = T σm1 σm σmm c Σc m
29 Korelační matice Populační kovarianční matice Σ se snadno převede na korelační matici ρ. Platí = V 1 ρ V 1 σ σ V = σ 0 0 mm ρ= covik ρ ik = σ σ 1 ii kk ( V 1 ) ( V 1 ) 1
30 Kovariance I Mírou intenzity vztahu mezi složkami ξ i a ξ j, j # i je druhý smíšený centrální moment, nazývaný kovariance cov(ξ i, ξ j ), cov( ξ, ξ) = E( ξ ξ) - E( ξ) E( ξ) i j i j i j a) Kovariance je kladná resp. záporná resp.nulová. b) Kovariance je v absolutní hodnotě shora ohraničená součinem σ i σj, tj. tjabs(cov(ξ i, ξ j )) σ i σ j. c) Kovariance je symetrickou funkcí svých argumentů. d) Kovariance se nemění posunem počátku, ale změna měřítka se projeví úměrně jeho velikosti. Pro čísla a 1, a, b 1, b platí cov( a ξ + b, a ξ + b ) = a a cov( ξ, ξ) 1 i 1 j 1 i j
31 Kovariance II e) Pro nekorelované náhodné veličiny je cov(ξ i, ξ j ) = 0 a mohou nastat dva případy: 1. E(ξ i ξ j ) = 0 a zároveň E(ξ i ) = E(ξ j ) = 0, což je případ centrovaných ortogonálních náhodných veličin.. E(ξ i ξ j ) = E(ξ i ) E(ξ j ), což je případ nezávislých náhodných veličin. Je tedy patrné, že nekorelovanost neznamená vždy nezávislost. f) Kovariance je mírou intenzity lineární závislosti. Limitní it je případ, kdy jsou ξ i, ξ j lineárně ě závislé, takže ξ j = a ξ i + b, a cov(ξ i, ξ j ) = E(a ξ i+bξ ξ i ) - E(ξ i )E(aξ ξ i +b)=a σii σ
32 Korelace I Hodnoty kovariance závisí na měřítku, ve kterém jsou vyjádřeny ξ 1 a ξ. Její velikost lze hodnotit vzhledem k součinu σ i σ j. Proto je přirozené provést standardizaci dělením tímto součinem. Vzniklá veličina ρ ij = ρ(ξ i, ξ j ) se nazývá párový korelační koeficient cov( ξi, ξj) ρ( ξi, ξj) = ρij = σi σj Korelační koeficient ležívrozmezí -1 ρ ij 1. Pokud je ρij > 0jde 0, o pozitivně korelované náhodné veličiny, a pokud je ρij < 0, jde o negativně korelované náhodné veličiny a) abs(ρ ij ) = 1 znamená, že mezi ξ i a ξ j existuje přesně lineární vztah. b) Pro vzájemně nekorelované náhodné veličiny ξ i a ξ j, je ρ ij = 0.
33 Korelace II c) V případě, že ξ i a ξ j pocházejí z vícerozměrného normálního rozdělení a ρ ij = 0, znamená áto, že jsou vzájemně ě nezávislé. áilé d) I pro nelineárně závislé náhodné veličiny může být ρ ij = 0 e) Korelační koeficient ρ ii náhodné veličiny ξ i samotné se sebou je roven jedné. f) Korelační koeficient je invariantní vůči lineární transformaci náhodných proměnných ξ i, ξ j. Pro čísla a 1, a, b 1, b platí ρ(a ξ + b, a ξ + b ) = sign(a a ) ρ( ξ, ξ) 1 i 1 j 1 i j -1 pro x < 0 sign(x) = 0 pro x = 0 1 pro x > 1
34 Šikmost a špičatost Pro dva vektory, ξ 1 ξ, které jsou nezávislé a stejně rozdělené se střední hodnotou μ a kovarianční maticí Σ = C, je vícerozměrná šikmost g = 1m 1,m E[( ξ - μ ) ( - μ) ] a vícerozměrná špičatost T C ξ g =E[(,m ξ - μ ) ( - μ) ] T -1 1 C ξ1 Pokud m = 1, přecházejí tyto vztahy na šikmosti a špičatosti jednorozměrných dat,. K vyjádření funkcí g 1,m ag,m lze využít i vícerozměrných centrálních momentů. Pro případ vícerozměrného normálního rozdělení je 1,m = 0 g g =,m m (m + )
35 Vícerozměrná data Nestrukturovaná vícerozměrná data jsou běžně v maticovém uspořádání, kde pozorování (objekty) jsou v řádcích a proměnné (rysy) ve sloupcích proměnná 1 proměnná proměnná m pozorování 1 x11 x1 x1m pozorování x1 x xm pozorování n x x x n1 n nm Pokud se znaky rozdělují na skupinu vysvětlovaných proměnných Pokud se znaky rozdělují na skupinu vysvětlovaných proměnných (závisle proměnných) a proměnných vysvětlujících (nezávisle proměnných), označuje se submatice vysvětlovaných proměnných jako Y (n k) a matice Z rozměru n (m k) pak tvoří skupinu vysvětlujících proměnných.
36 Odhady parametrů I Z vícerozměrného výběru velikosti n, definovaného n-ticí m- rozměrných vektorů x = T i (x i1,..., x im ), i = 1,..., n, který lze vyjádřit maticí měřených hodnot X (n x m), je možno určit výběrový vektor středních hodnot μˆμ x1 S využitím matice X lze vyjádřit n 1 μˆ = x= = x výběrovou střední hodnotu jako i n i = 1 1 m x ˆ = T n μ X 1 n kde l n je vektor rozměru (n x 1), obsahující jako prvky samé jedničky. Pro vektor výběrových středních hodnot platí E( ˆ) = a D( ˆ) = / n μ μ μ Σ Odhad ˆμ je tedy nevychýlený.
37 Odhady parametrů II Pro odhad kovarianční matice S 0 platí rovnice n 0 1 T S = ( i - ˆ) ( ˆ i - ) n x μ x μ n i = 1 n ( x i1 x1) ( xi1 x1 )( xid xd ) i= 1 i= S = n n n ( xid xd )( xi1 x1) ( xid xd ) i= 1 i= 1 Pro odhad kovarianční matice platí E jednotková 0 1 T S = X UX 1 T n je ová U = n n n n E 1 1 matice řádu (n x n). n
38 Odhady parametrů III Pro odhad kovarianční matice platí, že 0 n -1 E( S ) = n Σ Jde tedy ovychýlený ýodhad. Proto se podobně jako u jednorozměrných dat používá výběrová korigovaná kovarianční matice S = n S n která je již nevychýleným odhadem kovarianční matice Σ = C. Matice S 0 je výběrová kovarianční matice. Odhady ˆμ a S 0 jsou maximálně věrohodné pro případ, že náhodný áhdývýběr charakterizovaný maticí íxx pochází z normálního rozdělení N(μ, C).
39 Zobecněný rozptyl Náhodný výběr X pochází z normálního rozdělení N(μ, C). Odhad μˆμ má rozdělení N(μ, C /n) n). n - 1 Veličina V = n S 0 T je rozdělená jako suma y y i i kde y i jsou nezávislé áilénáhodné áhdévektory s rozdělením N(0, C). Tento typ rozdělení se nazývá Wishartův Zobecněný rozptyl je definován jako det(c) a jeho výběrový odhad je det(s). Symbolem det(s) je označen determinant matice S. Asymptotické rozdělení výběrového zobecněného rozptylu det(s) je normální se střední hodnotou det(c) a rozptylem n - 1 det(s) m náhodná veličina U = - 1 D[det(S)] = [det(c)] m det(c) n - 1 má normální rozdělení N(0, 1). i = 1
40 James Steinův odhad James a Stein ukázali, že pro m 3 existuje odhad který má menší kvadratickou ztrátovou funkci a je ze statistického hlediska lepší než klasický výběrový průměr Kvadratická ztrátová funkce pro obecný odhad ΘˆΘ střední hodnoty ˆ T -1 L = n ( Θ - μ) C ( Θˆ - μ) Jde o čtverec Mahalanobisovy vzdálenosti mezi vektory ΘˆΘ a μ Jamesův-Steinův odhad střední hodnoty vícerozměrného normálního rozdělení N( μ,, C) (n - 1) (m - ) μˆ ˆ J = 1 - T -1 n (n - m + ) ˆ ˆ μ μ S μ Čím je μ blížeknulovému vektoru, tím je tento odhad lepší. Na druhé straně je tento odhad vychýlený. ˆμ J
41 Robustní odhady Podobně jako u jednorozměrných dat je výhodné použít robustních metod odhadu vektoru středních hodnot a kovarianční matice. Robustní odhady složek vektoru středních hodnot lze získat např. použitím 10%ních uřezaných průměrů. K určení robustního odhadu kovariance se dá přímo využít 1 robustních odhadů, rozptylů, protože 1 cov(x, x ) = [D(x + x ) - D(x - x )] Místo rozptylů py D(x) () se pak používá jejich jj robustních odhadů. Jiný postup určování robustních odhadů spočívá ve vícerozměrném uřezáníř ítk tak, aby byl blzachován tvar rozptylového tl diagramu bodů bdů v prostoru E m.
42 Robustifikace pomocí zobecněné vzdálenosti Vlastní proces je iterační a vychází z Mahalanobisovy vzdálenosti * T * -1 * i = ( i - ) ( ) ( i- ) d x μ S x μ * μ a S * jsou odhady vektoru středních hodnot a kovarianční matice, určené z předchozích iterací. Zvolený podíl γ (obyčejně γ = 0.1) bodů x i s největšími hodnotami d i je v každé iteraci vypuštěn z výpočtu. Není automaticky zajištěna pozitivní definitnost a nevychýlenost odhadu kovarianční matice S resp. korelační matice R.
43 Odlehlé body I Robustní varianta Mahalanobisovy vzdálenosti MD( x ) = ( x - R( x) R( S ( x - R( x)) T -1 i i ) ) i R( x ) R( S ) kde je robustní verze výběrových ýhprůměrů ů ě ů a je robustní verze kovarianční matice. Poměrně dobré robustní vlastnosti (asymptoticky může být téměř polovina dat vybočujících) má odhad, založený na elipsoidu minimálního objemu (MVE), což je nejmenší elipsoid, pokrývající alespoň polovinu bodů. Elipsoid je definován rovnicí T -1 ( x - R( x) ) R( S) ( x - R( x)) = m Objem tohoto elipsoidu je det(r(s)), kde det(.) je determinant. Pro robustní odhady polohy a kovarianční matice se bere podmnožina h bodů x, i = 1..h kde h = int (n + m + 1)/) * i
44 Odlehlé body II Robustní odhady jsou speciálně vážené odhady z podmnožiny h bodůç, počítané ze vztahç h * * i xi i=1 R( x ) = w * * T ( - R( ))( - R( )) h * RS ) = w i x i x x i x i=1 (0) wi = 1/h, i = 1,..., h V první iteraci se volí váhy Pokud vyjde pro všechny robustní Mahalanobisovy vzdálenosti že MD( xi) m pokrývá elipsoid všechny body. Pokud však vyjde že MD( xi ) je pro některá xi větší mež m, je třeba provést úpravu vah w = w (MD( x )/m) (k+1) (k) i i i a znovu určit opravené robustní odhady
45 Odlehlé body III T -1 T H X X X X = ( ) * Určení podmnožiny x i, i = 1..haby jí odpovídající elipsoid měl minimální objem. Použití všech možných podmnožin může být časově velmi náročné. Pro sestavení vhodné podmnožiny dat je možné použít postup, p, založený na vektoru EID (i-tý ýprvek odpovídá příspěvku i-tého bodu ke všem vlastním číslům informační matice). Postup je shodný s výpočtem prvků H ii projekční matice H Pokud se vypustí z dat i-tý bod, dojde ke změně determinantu matic X T X, vyjádřené vztahem T T det( (-i) X(-i) ) = (1 - EID i) det( X X) X ProtožejeMVE úměrné determinantu kovarianční matice, stačí místo Protože je MVE úměrné determinantu kovarianční matice, stačí místo X použít centrované matice X C a postupně vypouštět body s maximálním EID i až do nalezení podmnožiny h všech bodů.
46 Výběrové šikmosti a špičatosti I Pro vyjádření výběrových vícerozměrných šikmostí a špičatostí se vychází z veličin T -1 wij = ( xi - μˆ ) V ( xj - μˆ ) μ kde V = S n je výběrová kovarianční matice a ˆμ je výběrový průměr w ii je čtverec zobecněné Mahalanobisovy vzdálenosti. Odhad výběrové šikmosti a špičatosti gˆ = n 1,m n n n 3 wij gˆ,m = n i = 1 j = 1 i = 1 w m (m +) E( gˆ 1,m) = [(n + 1) (m + 1) - 6] (n + 1) (n + 3) 8m(m+)(n (n - 3) E( gˆ,m) = (n - m - 1) (n - m + 1) (n + 1 ) (n + 3) (n + 5) ii
47 Výběrové šikmosti a špičatosti II 1 w w w d = ( + - ) Snadno lze určit, že ij ii jj ij Lze také definovat tzv. Mahalanobisovy úhly θ ij mezi vektory x i - μˆ a ˆ x μ a x - = j μ pro které platí cos θij wij / w ii w jj n n 1 Pro výběrovou šikmost pak platí g ˆ 1,m = ( Wii Wjj cos θij) n i=1 i=1 Pokud jsou jednotlivé znaky x i rovnoměrně rozděleny na m-rozměrné kouli je gˆ 1,m = 0 To samé platí pro všechna kulově symetrická rozdělení. Pokud však dojde k narušení sférické symetrie, např. shlukováním části dat, vyjde ĝg 1,m vysoké.
48 Rozdělení šikmosti a špičatosti ˆμ Pro případ, že a S jsou určeny na základě náhodného výběru velikosti n z m-rozměrného normálního rozdělení N(μ, C) s pozitivně definitní kovarianční maticí C, platí, že náhodná veličina U 1 = n gˆ 1,m 6 má asymptoticky χ -rozdělení sm(m + 1)(m + )/6 stupni volnosti. Náhodná veličina U U = gˆ - g,m,m 8 m m + n má pak asymptoticky standardizované normální rozdělení N(0, 1)
49 Ověření normality U vícerozměrných výběrů hraje hlavní roli předpoklad, že data pocházejí z vícerozměrného normálního rozdělení.tentopředpoklad usnadňuje zejména statistickou analýzu vektoru středních hodnot nebo kovarianční matice. Problém testování vícerozměrné normality spočívá ve faktu, že m-rozměrný náhodný vektor x má normální rozdělení jen tehdy, když pro všechny možné nenulové vektory a platí, že a T x je náhodná veličina s jednorozměrným normálním rozdělením. Pokud oudvšechny yso složky x j vektoru x mají normální rozdělení, nelze e ještě tvrdit, že vektor x má vícerozměrné normální rozdělení. Podobně jako v jednorozměrném případě, existuje i zde řada testů, které jsou více či méně citlivé vůči různým typům narušení normality.
50 Grafické techniky I Grafické techniky ověřování vícerozměrné normality využívají normalizační transformace -1/ y ˆ i = S ( xi - μ) V případě, že výběr pochází z vícerozměrného normálního rozdělení, mají y i přibližně normované normální rozdělení N(0, E). Skalární T součin d i = yy i i má přibližně χ - rozdělení s m stupni volnosti Tento součin je vlastně čtverec Mahalanobisovy vzdálenosti. Pro větší rozsahy výběru lze vynášet nebo proti odpovídajícím pořádkovým statistikám χ -rozdělení. Jde o případ Q-Q grafu pro teoretické rozdělení di χ m /3 di Přibližně lineární závislost zde indikuje vícerozměrnou normalitu.
51 Grafické techniky II n di Výhodné je použití veličiny Zi = (n - 1) která má beta-rozdělení rozděleníb[05m B[0.5 m, (n - m - 1)]. Při konstrukci Q-Q grafu se pak vynášejí pořádkové statistiky Z (i), pro které platí Z (i) Z (i+1), i= 1,..., n - 1 proti hodnotám * i - α 0.5 m (n - m - 1) - 1 Z i = kde α = a β = m n - m - 1 n - α - β + 1 Pro rozsah výběru n > 50 lze také použít přibližné rovnosti platné pro případ, že data pocházejí z vícerozměrného normálního rozdělení i n Z(i) log (n - m - 1) log 1 - n (n - 1) vícerozměrná * i (i) * n Z yi = log 1 - proti x i = log 1 - normalita n (n - 1)
52 Testy normality I Na základě hlavních komponent Y = X V lze počítat koeficienty vícerozměrné šikmosti respektive špičatosti 1 g y ) m m n -3/ 3 ˆ = 1s, m L ii ( ij- y / n i j=1 i=1 m n 1-4 gˆ = s, m Lii ( y ij - y ) i n m j=1 i=1 L ii jsou vlastní čísla kovarianční matice S. Za předpokladu 6 vícerozměrné normality platí, že E( gˆ ˆ 1s, m) 0, D( g1s, m) n m Statistika n m Q ˆ má přibližně rozdělení 1s = g áp ě χ odě s m 1s, m stupni volnosti. 6
53 Testy normality II E( gˆ ) 3, D( gˆ ) 4 n m Platí, že s, m s, m Q n m = g ˆ Statistika s s, m 4 má normované normální rozdělení N(0, 1). Jestliže nebyla prokázána vícerozměrná normalita, může to znamenat, že v datech jsou vybočující skupiny bodů respektive jejich rozdělení se liší tvarem od vícerozměrného normálního rozdělení. Pokud lze vyloučit přítomnost t vybočujících č í bodů a skupin je možné použít ke zlepšení rozdělení dat mocninné transformace. Je vhodné provést nejdříve mocninné transformace všech znaků, tj. sloupců zdrojové matice X a přesvědčit se testem, zda je již vícerozměrná normalita akceptována.
54 Box Coxova transformace I Účelem je nalézt vektor parametrů λ = (λ 1,..., λ m ), pro které bude přibližně platit, že matice X vboxcoxově Box-Coxově transformaci ( λ) ( λ1) ( λm) X = ( X1,..., Xm ) x(λ) = ( x λ -1)/λ resp. bude mít normální rozdělení N(μ, C) x(λ) = ln x označuje Box- Coxovu transformaci Logaritmus věrohodnostní funkce a je až na konstantu vyjádřitelný ve tvaru n ( λ), T ( λ) n ( λ) Lmax ( x ) = - ln det ( Z T Z ) - ln det ( S ) V této rovnici je S(λ) kovarianční matice odpovídající matici X (λ) znaků v mocninné transformaci a transformační matice je T Τ = En - ln ln /n E n je jednotková matice řádu n a 1 n je vektor rozměru (n x 1), obsahující samé jedničky.
55 Box Coxova transformace II Matice Z(λ) má prvky Z ( λj) ( ) ij -1/n λj = J( λ j) (j) xij, i = 1,..., n, j = 1,..., p Symbol J označuje složky Jakobiánu transformace, pro který platí, že J ( λ ) j (j) = n Π i=1 x ij ( λ - 1) Maximálně věrohodný odhad vektoru parametrů λ = (λ..., λ m T 1, m) pak tedy vede k minimalizaci determinantu matice S(λ) respektive matice Z(λ) T T Z(λ). Při minimalizaci je v tomto případě výhodné m m využít rozkladu ( λ) T ( λ) ( λ) T ( λ) det ( Z T Z ) = Π Z k T Z k ) Π (1 - r k ) k=1 k=1 kde Z (λk) k je k-tý ýsloupec matice Z (λ), r 1 = 0 a r k pro k =,..., m je vícenásobný korelační koeficient regrese Z (λk) k na proměnných (Z (λ1) 1,..., Z (λm) m. j
56 Box Coxova transformace III Protože se v průběhu optimalizace korelační koeficienty příliš nemění, je obyčejně vektor λ blízký vektoru λ M, jehož složky jsou určeny použitím jednoduché Box-Coxovy transformace pro jednotlivé sloupce zdrojové matice X zvlášť. Při náhradě matice S(λ) vhodným robustním odhadem lze získat parametry robustní Box.Coxovy transformace. Jak je patrné, lze pro účely zlepšení rozdělení ídat tčasto t pracovat s jednotlivými i znaky izolovaně. S výhodou se dá i zde použít místo původních dat X transformace do hlavních komponent Y = X V. Pro tento případ již bude korelační matice S diagonální a všechny korelační č íkoeficienty i r 0tkž bd ˆ ˆ k = 0, takže bude možné psát λ = λm Pak zcela postačí Box-Coxovy transformace jednotlivých znaků
57 Hypotézy o střední hodnotě Testování nulové hypotézy H 0 : μ = μ 0 proti alternativní H 1 : μ μ 0. Vychází se z předpokladu, žedatax x i, i = 1,..., n, jsou náhodným výběrem z m-rozměrného normálního rozdělení N(μ, C). Parametry μ a C jsou neznámé a odhadují duj se pomocí oc výběrových charakteristik ˆμ a S Hotellingova T T -1 statistika T = n ( μ ˆ - μ ˆ 0) S ( μ - μ0) Statistika T má tzv. Hotellingovo rozdělení s kvantilovou funkcí T (α). Vyjde-li testováním, že T T (1 - α / ), je na hladině významnosti α hypotéza H 0 přijata. Za předpokladu platnosti hypotézy H 0 má veličina C = (n - m) T / (m (n - 1)) F-rozdělení s m a (n - m) stupni volnosti. Pokud je H 0 neplatná, ltámá veličina C necentrální F-rozdělení.
58 Konfidenční oblast S využitím statistiky T lze konstruovat konfidenční oblasti pro vektor μ. Platí,že 100(1 - α)%ní oblast m-rozměrného vektoru je ohraničena povrchem T -1 m (n - 1) ( μˆ - μ ) S ( μˆ - μ ) = Fm,n-m(1- α ) n (n - m) kde F m,n-m (1 - α) je kvantil F- rozdělení s man-m stupni volnosti. Jde o m-rozměrný elipsoid se středem v místě μˆμ
59 Shoda více středních hodnot Úlohou je testovat shodu celkem r středních hodnot μ i. Nulová hypotéza H 0 : μ 1 = μ =... μ r proti alternativní H A : μ i μ j. Vychází se z r-tice náhodných výběrů x (j)i, i = 1,...n j, j = 1,..., r, o kterých se předpokládá, ř že pocházejí zrozdělení N(μ i, C), lišících í se pouze středními hodnotami. Z těchto výběrů jsou vypočteny odhady ˆμ r r j a S j = V j / n j -1. μ V, n = = V n j j j S j j r j = 1 j = 1 r = n i μ ˆ i V C ni μˆ μ ˆ μ i μ i i = 1 n i = 1 = ( - ) ( - ) Wilcoxovo λ kritérium λ =det(v S )/det(v S + V C ) T
60 Testy kovariančních matic I Při analýze kovariančních matic se vychází z výběru (x i ), i = 1,..., n, o kterém se předpokládá, že pochází z m-rozměrného normálního rozdělení N(μ, C). Test sféricity -testuje se nulová hypotéza H 0: C = σ E proti alternativě H A : C σ E, kde σ > 0 je rozptyl a E je jednotková matice. -m + m + tr ( V) m TS = det ( V) ST = - n - ln ( TS) m 6 m S T má χ -rozdělení s {m (m + 1) / - 1} stupni volnosti. Test nezávislost složek vícerozměrného normálního rozdělení. Nulová hypotéza H 0 : R = E, alternativní H A : R E. m + 11 Q = - n - ln (det( )) 6 R má χ -rozdělení s {m (m - 1) / } stupni volnosti.
61 Testy kovariančních matic II Testování nulové hypotézy H 0 : C = C 0 proti alternativní H A : C C 0. Lc = (n - 1) ln (det( C0)) - (n - 1) m - (n - 1) ln (det( S)) + T + (n + 1) tr ( SC ) Platí, žel= L )mápřibližně c (1 - D 1 χ -rozdělení s {m (m + 1) / } stupni volnosti. Pro parametr D 1 platí D 1 m+1- = m (n - 1) Analogicky lze testovat i hypotézu, že korelační matice R se rovná známé korelační matici R 0 0
62 Shoda kovariančních matic 1 1 m + 3 m - 1 b = j = 1 n j - 1 6( (m +1) ( n j - 1) j = 1 Test shody dvou kovariančních matic, C 1 = C. Vychází se ze dvou výběrů (x i ), i = 1,..., n 1, a (y i ), i = 1,..., n, o kterých se předpokládá, že pocházejí z normálních rozdělení x N( μ, C) a y N( μ, C ) 1 1 Používá se opět odhadů S 1, S a společné kovarianční matice S p, ( n1-1) S1 + ( n- 1) S S p = n1+ n- K testování hypotézy H0: C 1 = C (HA: C 1 C ) lze použít testovací statistiku 1 LU= ( nj- 1) ln (det ( Sp)) - ( nj- 1) ln (det ( Sj)) b j = 1 j = 1 Rozdělení L U je přibližně χ s {(m + 1) m / } stupni volnosti
Náhodné vektory a matice
 Náhodné vektory a matice Jiří Militký Katedra textilních materiálů Technická Universita Liberec, Červeně označené slide jsou jen pro doplnění informací a nezkouší se. Symbolika A B Jev jistý S (nastane
Náhodné vektory a matice Jiří Militký Katedra textilních materiálů Technická Universita Liberec, Červeně označené slide jsou jen pro doplnění informací a nezkouší se. Symbolika A B Jev jistý S (nastane
Charakterizace rozdělení
 Charakterizace rozdělení Momenty f(x) f(x) f(x) μ >μ 1 σ 1 σ >σ 1 g 1 g σ μ 1 μ x μ x x N K MK = x f( x) dx 1 M K = x N CK = ( x M ) f( x) dx ( xi M 1 C = 1 K 1) N i= 1 K i K N i= 1 K μ = E ( X ) = xf
Charakterizace rozdělení Momenty f(x) f(x) f(x) μ >μ 1 σ 1 σ >σ 1 g 1 g σ μ 1 μ x μ x x N K MK = x f( x) dx 1 M K = x N CK = ( x M ) f( x) dx ( xi M 1 C = 1 K 1) N i= 1 K i K N i= 1 K μ = E ( X ) = xf
AVDAT Náhodný vektor, mnohorozměrné rozdělení
 AVDAT Náhodný vektor, mnohorozměrné rozdělení Josef Tvrdík Katedra informatiky Přírodovědecká fakulta Ostravská univerzita Opakování, náhodná veličina, rozdělení Náhodná veličina zobrazuje elementární
AVDAT Náhodný vektor, mnohorozměrné rozdělení Josef Tvrdík Katedra informatiky Přírodovědecká fakulta Ostravská univerzita Opakování, náhodná veličina, rozdělení Náhodná veličina zobrazuje elementární
4 STATISTICKÁ ANALÝZA VÍCEROZMĚRNÝCH DAT
 4 SAISICKÁ ANALÝZA VÍCEROZMĚRNÝCH DA V technické biologické ale také lékařské praxi se často vedle informací obsažených v náhodném skaláru ξ vyskytují i informace obsažené v náhodném vektoru ξ s m složkami
4 SAISICKÁ ANALÝZA VÍCEROZMĚRNÝCH DA V technické biologické ale také lékařské praxi se často vedle informací obsažených v náhodném skaláru ξ vyskytují i informace obsažené v náhodném vektoru ξ s m složkami
Statistická analýza jednorozměrných dat
 Statistická analýza jednorozměrných dat Prof. RNDr. Milan Meloun, DrSc. Univerzita Pardubice, Pardubice 31.ledna 2011 Tato prezentace je spolufinancována Evropským sociálním fondem a státním rozpočtem
Statistická analýza jednorozměrných dat Prof. RNDr. Milan Meloun, DrSc. Univerzita Pardubice, Pardubice 31.ledna 2011 Tato prezentace je spolufinancována Evropským sociálním fondem a státním rozpočtem
Pravděpodobnost a aplikovaná statistika
 Pravděpodobnost a aplikovaná statistika MGR. JANA SEKNIČKOVÁ, PH.D. 2. KAPITOLA PODMÍNĚNÁ PRAVDĚPODOBNOST 3. KAPITOLA NÁHODNÁ VELIČINA 9.11.2017 Opakování Uveďte příklad aplikace geometrické definice pravděpodobnosti
Pravděpodobnost a aplikovaná statistika MGR. JANA SEKNIČKOVÁ, PH.D. 2. KAPITOLA PODMÍNĚNÁ PRAVDĚPODOBNOST 3. KAPITOLA NÁHODNÁ VELIČINA 9.11.2017 Opakování Uveďte příklad aplikace geometrické definice pravděpodobnosti
Úloha E301 Čistota vody v řece testem BSK 5 ( Statistická analýza jednorozměrných dat )
") Úloha E301 Čistota vody v řece testem BSK 5 ( Statistická analýza jednorozměrných dat ) Zadání : Čistota vody v řece byla denně sledována v průběhu 10 dní dle biologické spotřeby kyslíku BSK 5. Jsou v
Úloha E301 Čistota vody v řece testem BSK 5 ( Statistická analýza jednorozměrných dat ) Zadání : Čistota vody v řece byla denně sledována v průběhu 10 dní dle biologické spotřeby kyslíku BSK 5. Jsou v
Definice 7.1 Nechť je dán pravděpodobnostní prostor (Ω, A, P). Zobrazení. nebo ekvivalentně
. Zobrazení. nebo ekvivalentně") 7 Náhodný vektor Nezávislost náhodných veličin Definice 7 Nechť je dán pravděpodobnostní prostor (Ω, A, P) Zobrazení X : Ω R n, které je A-měřitelné, se nazývá (n-rozměrný) náhodný vektor Měřitelností
7 Náhodný vektor Nezávislost náhodných veličin Definice 7 Nechť je dán pravděpodobnostní prostor (Ω, A, P) Zobrazení X : Ω R n, které je A-měřitelné, se nazývá (n-rozměrný) náhodný vektor Měřitelností
Téma 22. Ondřej Nývlt
 Téma 22 Ondřej Nývlt nyvlto1@fel.cvut.cz Náhodná veličina a náhodný vektor. Distribuční funkce, hustota a pravděpodobnostní funkce náhodné veličiny. Střední hodnota a rozptyl náhodné veličiny. Sdružené
Téma 22 Ondřej Nývlt nyvlto1@fel.cvut.cz Náhodná veličina a náhodný vektor. Distribuční funkce, hustota a pravděpodobnostní funkce náhodné veličiny. Střední hodnota a rozptyl náhodné veličiny. Sdružené
Pravděpodobnost a statistika, Biostatistika pro kombinované studium. Jan Kracík
 Pravděpodobnost a statistika, Biostatistika pro kombinované studium Letní semestr 2017/2018 Tutoriál č. 2:, náhodný vektor Jan Kracík jan.kracik@vsb.cz náhodná veličina rozdělení pravděpodobnosti náhodné
Pravděpodobnost a statistika, Biostatistika pro kombinované studium Letní semestr 2017/2018 Tutoriál č. 2:, náhodný vektor Jan Kracík jan.kracik@vsb.cz náhodná veličina rozdělení pravděpodobnosti náhodné
Statistická analýza jednorozměrných dat
 Statistická analýza jednorozměrných dat Prof. RNDr. Milan Meloun, DrSc. Univerzita Pardubice, Pardubice 31.ledna 2011 Tato prezentace je spolufinancována Evropským sociálním fondem a státním rozpočtem
Statistická analýza jednorozměrných dat Prof. RNDr. Milan Meloun, DrSc. Univerzita Pardubice, Pardubice 31.ledna 2011 Tato prezentace je spolufinancována Evropským sociálním fondem a státním rozpočtem
Náhodné veličiny jsou nekorelované, neexistuje mezi nimi korelační vztah. Když jsou X; Y nekorelované, nemusí být nezávislé.
 1. Korelační analýza V životě většinou nesledujeme pouze jeden statistický znak. Sledujeme více statistických znaků zároveň. Kromě vlastností statistických znaků nás zajímá také jejich těsnost (velikost,
1. Korelační analýza V životě většinou nesledujeme pouze jeden statistický znak. Sledujeme více statistických znaků zároveň. Kromě vlastností statistických znaků nás zajímá také jejich těsnost (velikost,
Regresní analýza 1. Regresní analýza
 Regresní analýza 1 1 Regresní funkce Regresní analýza Důležitou statistickou úlohou je hledání a zkoumání závislostí proměnných, jejichž hodnoty získáme při realizaci experimentů Vzhledem k jejich náhodnému
Regresní analýza 1 1 Regresní funkce Regresní analýza Důležitou statistickou úlohou je hledání a zkoumání závislostí proměnných, jejichž hodnoty získáme při realizaci experimentů Vzhledem k jejich náhodnému
Pojmy z kombinatoriky, pravděpodobnosti, znalosti z kapitoly náhodná veličina, znalost parciálních derivací, dvojného integrálu.
 6. NÁHODNÝ VEKTOR Průvodce studiem V počtu pravděpodobnosti i v matematické statistice se setkáváme nejen s náhodnými veličinami, jejichž hodnotami jsou reálná čísla, ale i s takovými, jejichž hodnotami
6. NÁHODNÝ VEKTOR Průvodce studiem V počtu pravděpodobnosti i v matematické statistice se setkáváme nejen s náhodnými veličinami, jejichž hodnotami jsou reálná čísla, ale i s takovými, jejichž hodnotami
AVDAT Klasický lineární model, metoda nejmenších
 AVDAT Klasický lineární model, metoda nejmenších čtverců Josef Tvrdík Katedra informatiky Přírodovědecká fakulta Ostravská univerzita Lineární model y i = β 0 + β 1 x i1 + + β k x ik + ε i (1) kde y i
AVDAT Klasický lineární model, metoda nejmenších čtverců Josef Tvrdík Katedra informatiky Přírodovědecká fakulta Ostravská univerzita Lineární model y i = β 0 + β 1 x i1 + + β k x ik + ε i (1) kde y i
správně - A, jeden celý příklad správně - B, jinak - C. Pro postup k ústní části zkoušky je potřeba dosáhnout stupně A nebo B.
 Zkouška z předmětu KMA/PST. Anotace předmětu Náhodné jevy, pravděpodobnost, podmíněná pravděpodobnost. Nezávislé náhodné jevy. Náhodná veličina, distribuční funkce. Diskrétní a absolutně spojitá náhodná
Zkouška z předmětu KMA/PST. Anotace předmětu Náhodné jevy, pravděpodobnost, podmíněná pravděpodobnost. Nezávislé náhodné jevy. Náhodná veličina, distribuční funkce. Diskrétní a absolutně spojitá náhodná
Regresní a korelační analýza
 Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
MATEMATICKÁ STATISTIKA. Katedra matematiky a didaktiky matematiky Technická univerzita v Liberci
 MATEMATICKÁ STATISTIKA Dana Černá http://www.fp.tul.cz/kmd/ Katedra matematiky a didaktiky matematiky Technická univerzita v Liberci Matematická statistika Matematická statistika se zabývá matematickým
MATEMATICKÁ STATISTIKA Dana Černá http://www.fp.tul.cz/kmd/ Katedra matematiky a didaktiky matematiky Technická univerzita v Liberci Matematická statistika Matematická statistika se zabývá matematickým
Testování hypotéz o parametrech regresního modelu
 Testování hypotéz o parametrech regresního modelu Ekonometrie Jiří Neubauer Katedra kvantitativních metod FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Jiří Neubauer (Katedra UO
Testování hypotéz o parametrech regresního modelu Ekonometrie Jiří Neubauer Katedra kvantitativních metod FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Jiří Neubauer (Katedra UO
Testování hypotéz o parametrech regresního modelu
 Statistika II Katedra ekonometrie FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Lineární regresní model kde Y = Xβ + e, y 1 e 1 β y 2 Y =., e = e 2 x 11 x 1 1k., X =....... β 2,
Statistika II Katedra ekonometrie FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Lineární regresní model kde Y = Xβ + e, y 1 e 1 β y 2 Y =., e = e 2 x 11 x 1 1k., X =....... β 2,
Úvodem Dříve les než stromy 3 Operace s maticemi
 Obsah 1 Úvodem 13 2 Dříve les než stromy 17 2.1 Nejednoznačnost terminologie 17 2.2 Volba metody analýzy dat 23 2.3 Přehled vybraných vícerozměrných metod 25 2.3.1 Metoda hlavních komponent 26 2.3.2 Faktorová
Obsah 1 Úvodem 13 2 Dříve les než stromy 17 2.1 Nejednoznačnost terminologie 17 2.2 Volba metody analýzy dat 23 2.3 Přehled vybraných vícerozměrných metod 25 2.3.1 Metoda hlavních komponent 26 2.3.2 Faktorová
n = 2 Sdružená distribuční funkce (joint d.f.) n. vektoru F (x, y) = P (X x, Y y)
 n. vektoru F (x, y) = P (X x, Y y)") 5. NÁHODNÝ VEKTOR 5.1. Rozdělení náhodného vektoru Náhodný vektor X = (X 1, X 2,..., X n ) T n-rozměrný vektor, složky X i, i = 1,..., n náhodné veličiny. Vícerozměrná (n-rozměrná) náhodná veličina n =
5. NÁHODNÝ VEKTOR 5.1. Rozdělení náhodného vektoru Náhodný vektor X = (X 1, X 2,..., X n ) T n-rozměrný vektor, složky X i, i = 1,..., n náhodné veličiny. Vícerozměrná (n-rozměrná) náhodná veličina n =
Regresní a korelační analýza
 Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Výběrové charakteristiky a jejich rozdělení
 Katedra ekonometrie, FVL, UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Statistické šetření úplné (vyčerpávající) neúplné (výběrové) U výběrového šetření se snažíme o to, aby výběrový
Katedra ekonometrie, FVL, UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Statistické šetření úplné (vyčerpávající) neúplné (výběrové) U výběrového šetření se snažíme o to, aby výběrový
PRAVDĚPODOBNOST A STATISTIKA. Bayesovské odhady
 PRAVDĚPODOBNOST A STATISTIKA Bayesovské odhady Bayesovské odhady - úvod Klasický bayesovský přístup: Klasický přístup je založen na opakování pokusech sledujeme rekvenci nastoupení zvolených jevů Bayesovský
PRAVDĚPODOBNOST A STATISTIKA Bayesovské odhady Bayesovské odhady - úvod Klasický bayesovský přístup: Klasický přístup je založen na opakování pokusech sledujeme rekvenci nastoupení zvolených jevů Bayesovský
PRAVDĚPODOBNOST A STATISTIKA
 PRAVDĚPODOBNOST A STATISTIKA Definice lineárního normálního regresního modelu Lineární normální regresní model Y β ε Matice n,k je matice realizací. Předpoklad: n > k, h() k - tj. matice je plné hodnosti
PRAVDĚPODOBNOST A STATISTIKA Definice lineárního normálního regresního modelu Lineární normální regresní model Y β ε Matice n,k je matice realizací. Předpoklad: n > k, h() k - tj. matice je plné hodnosti
1. Náhodný vektor (X, Y ) má diskrétní rozdělení s pravděpodobnostní funkcí p, kde. p(x, y) = a(x + y + 1), x, y {0, 1, 2}.
 má diskrétní rozdělení s pravděpodobnostní funkcí p, kde. p(x, y) = a(x + y + 1), x, y {0, 1, 2}.") VIII. Náhodný vektor. Náhodný vektor (X, Y má diskrétní rozdělení s pravděpodobnostní funkcí p, kde p(x, y a(x + y +, x, y {,, }. a Určete číslo a a napište tabulku pravděpodobnostní funkce p. Řešení:
VIII. Náhodný vektor. Náhodný vektor (X, Y má diskrétní rozdělení s pravděpodobnostní funkcí p, kde p(x, y a(x + y +, x, y {,, }. a Určete číslo a a napište tabulku pravděpodobnostní funkce p. Řešení:
MATEMATICKÉ PRINCIPY VÍCEROZMĚRNÉ ANALÝZY DAT
 8. licenční studium Univerzita Pardubice Fakulta chemicko-technologická Katedra analytické chemie MATEMATICKÉ PRINCIPY VÍCEROZMĚRNÉ ANALÝZY DAT Příklady: ) Najděte vlastní (charakteristická) čísla a vlastní
8. licenční studium Univerzita Pardubice Fakulta chemicko-technologická Katedra analytické chemie MATEMATICKÉ PRINCIPY VÍCEROZMĚRNÉ ANALÝZY DAT Příklady: ) Najděte vlastní (charakteristická) čísla a vlastní
I. D i s k r é t n í r o z d ě l e n í
 6. T y p y r o z d ě l e n í Poznámka: V odst. 5.5-5.10 jsme uvedli příklady náhodných veličin a jejich distribučních funkcí. Poznali jsme, že se od sebe liší svým typem. V příkladech 5.5, 5.6 a 5.8 jsme
6. T y p y r o z d ě l e n í Poznámka: V odst. 5.5-5.10 jsme uvedli příklady náhodných veličin a jejich distribučních funkcí. Poznali jsme, že se od sebe liší svým typem. V příkladech 5.5, 5.6 a 5.8 jsme
MATEMATICKÁ STATISTIKA - XP01MST
 MATEMATICKÁ STATISTIKA - XP01MST 1. Úvod. Matematická statistika (statistics) se zabývá vyšetřováním zákonitostí, které v sobě obsahují prvek náhody. Zpracováním hodnot, které jsou výstupem sledovaného
MATEMATICKÁ STATISTIKA - XP01MST 1. Úvod. Matematická statistika (statistics) se zabývá vyšetřováním zákonitostí, které v sobě obsahují prvek náhody. Zpracováním hodnot, které jsou výstupem sledovaného
p(x) = P (X = x), x R,
 = P (X = x), x R,") 6. T y p y r o z d ě l e n í Poznámka: V odst. 5.5-5.10 jsme uvedli příklady náhodných veličin a jejich distribučních funkcí. Poznali jsme, že se od sebe liší svým typem. V příkladech 5.5, 5.6 a 5.8 jsme
6. T y p y r o z d ě l e n í Poznámka: V odst. 5.5-5.10 jsme uvedli příklady náhodných veličin a jejich distribučních funkcí. Poznali jsme, že se od sebe liší svým typem. V příkladech 5.5, 5.6 a 5.8 jsme
Vícerozměrná rozdělení
 Vícerozměrná rozdělení 7. září 0 Učivo: Práce s vícerozměrnými rozděleními. Sdružené, marginální, podmíněné rozdělení pravděpodobnosti. Vektorová střední hodnota. Kovariance, korelace, kovarianční matice.
Vícerozměrná rozdělení 7. září 0 Učivo: Práce s vícerozměrnými rozděleními. Sdružené, marginální, podmíněné rozdělení pravděpodobnosti. Vektorová střední hodnota. Kovariance, korelace, kovarianční matice.
Statistika II. Jiří Neubauer
 Statistika II Katedra ekonometrie FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Zaměříme se především na popis dvourozměrných náhodných veličin (vektorů). Definice Nechť X a Y jsou
Statistika II Katedra ekonometrie FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Zaměříme se především na popis dvourozměrných náhodných veličin (vektorů). Definice Nechť X a Y jsou
Matematika III 10. týden Číselné charakteristiky střední hodnota, rozptyl, kovariance, korelace
 Matematika III 10. týden Číselné charakteristiky střední hodnota, rozptyl, kovariance, korelace Jan Slovák Masarykova univerzita Fakulta informatiky 28. 11 2. 12. 2016 Obsah přednášky 1 Literatura 2 Střední
Matematika III 10. týden Číselné charakteristiky střední hodnota, rozptyl, kovariance, korelace Jan Slovák Masarykova univerzita Fakulta informatiky 28. 11 2. 12. 2016 Obsah přednášky 1 Literatura 2 Střední
NMAI059 Pravděpodobnost a statistika
 NMAI059 Pravděpodobnost a statistika podle přednášky Daniela Hlubinky (hlubinka@karlin.mff.cuni.cz) zapsal Pavel Obdržálek (pobdr@matfyz.cz) 205/20 poslední změna: 4. prosince 205 . přednáška. 0. 205 )
NMAI059 Pravděpodobnost a statistika podle přednášky Daniela Hlubinky (hlubinka@karlin.mff.cuni.cz) zapsal Pavel Obdržálek (pobdr@matfyz.cz) 205/20 poslední změna: 4. prosince 205 . přednáška. 0. 205 )
Předpoklad o normalitě rozdělení je zamítnut, protože hodnota testovacího kritéria χ exp je vyšší než tabulkový 2
 Na úloze ukážeme postup analýzy velkého výběru s odlehlými prvky pro určení typu rozdělení koncentrace kyseliny močové u 50 dárců krve. Jaká je míra polohy a rozptýlení uvedeného výběru? Z grafických diagnostik
Na úloze ukážeme postup analýzy velkého výběru s odlehlými prvky pro určení typu rozdělení koncentrace kyseliny močové u 50 dárců krve. Jaká je míra polohy a rozptýlení uvedeného výběru? Z grafických diagnostik
Definice spojité náhodné veličiny zjednodušená verze
 Definice spojité náhodné veličiny zjednodušená verze Náhodná veličina X se nazývá spojitá, jestliže existuje nezáporná funkce f : R R taková, že pro každé a, b R { }, a < b, platí P(a < X < b) = b a f
Definice spojité náhodné veličiny zjednodušená verze Náhodná veličina X se nazývá spojitá, jestliže existuje nezáporná funkce f : R R taková, že pro každé a, b R { }, a < b, platí P(a < X < b) = b a f
z Matematické statistiky 1 1 Konvergence posloupnosti náhodných veličin
 Příklady k procvičení z Matematické statistiky Poslední úprava. listopadu 207. Konvergence posloupnosti náhodných veličin. Necht X, X 2... jsou nezávislé veličiny s rovnoměrným rozdělením na [0, ]. Definujme
Příklady k procvičení z Matematické statistiky Poslední úprava. listopadu 207. Konvergence posloupnosti náhodných veličin. Necht X, X 2... jsou nezávislé veličiny s rovnoměrným rozdělením na [0, ]. Definujme
Minikurz aplikované statistiky. Minikurz aplikované statistiky p.1
 Minikurz aplikované statistiky Marie Šimečková, Petr Šimeček Minikurz aplikované statistiky p.1 Program kurzu základy statistiky a pravděpodobnosti regrese (klasická, robustní, s náhodnými efekty, ev.
Minikurz aplikované statistiky Marie Šimečková, Petr Šimeček Minikurz aplikované statistiky p.1 Program kurzu základy statistiky a pravděpodobnosti regrese (klasická, robustní, s náhodnými efekty, ev.
1 Klasická pravděpodobnost. Bayesův vzorec. Poslední změna (oprava): 11. května 2018 ( 6 4)( 43 2 ) ( 49 6 ) 3. = (a) 1 1 2! + 1 3!
: 11. května 2018 ( 6 4)( 43 2 ) ( 49 6 ) 3. = (a) 1 1 2! + 1 3!") Výsledky příkladů na procvičení z NMSA0 Klasická pravděpodobnost. 5. ( 4( 43 ( 49 3. 8! 3! 0! = 5 Poslední změna (oprava:. května 08 4. (a! + 3! + ( n+ n! = n k= ( k+ /k! = n k=0 ( k /k!; (b n k=0 ( k
Výsledky příkladů na procvičení z NMSA0 Klasická pravděpodobnost. 5. ( 4( 43 ( 49 3. 8! 3! 0! = 5 Poslední změna (oprava:. května 08 4. (a! + 3! + ( n+ n! = n k= ( k+ /k! = n k=0 ( k /k!; (b n k=0 ( k
UNIVERZITA PARDUBICE
 UNIVERZITA PARDUBICE Fakulta chemicko-technologická Katedra analytické chemie Vedoucí studia a odborný garant: Prof. RNDr. Milan Meloun, DrSc. Vyučující: Prof. RNDr. Milan Meloun, DrSc. Autor práce: ANDRII
UNIVERZITA PARDUBICE Fakulta chemicko-technologická Katedra analytické chemie Vedoucí studia a odborný garant: Prof. RNDr. Milan Meloun, DrSc. Vyučující: Prof. RNDr. Milan Meloun, DrSc. Autor práce: ANDRII
Pravděpodobnost a matematická statistika
 Pravděpodobnost a matematická statistika Příklady k přijímacím zkouškám na doktorské studium 1 Popisná statistika Určete aritmetický průměr dat, zadaných tabulkou hodnot x i a četností n i x i 1 2 3 n
Pravděpodobnost a matematická statistika Příklady k přijímacím zkouškám na doktorské studium 1 Popisná statistika Určete aritmetický průměr dat, zadaných tabulkou hodnot x i a četností n i x i 1 2 3 n
Statistická analýza jednorozměrných dat
 Statistická analýza jednorozměrných dat Prof. RNDr. Milan Meloun, DrSc. Univerzita Pardubice, Pardubice 31.ledna 2011 Tato prezentace je spolufinancována Evropským sociálním fondem a státním rozpočtem
Statistická analýza jednorozměrných dat Prof. RNDr. Milan Meloun, DrSc. Univerzita Pardubice, Pardubice 31.ledna 2011 Tato prezentace je spolufinancována Evropským sociálním fondem a státním rozpočtem
Základy maticového počtu Matice, determinant, definitnost
 Základy maticového počtu Matice, determinant, definitnost Petr Liška Masarykova univerzita 18.9.2014 Matice a vektory Matice Matice typu m n je pravoúhlé (nebo obdélníkové) schéma, které má m řádků a n
Základy maticového počtu Matice, determinant, definitnost Petr Liška Masarykova univerzita 18.9.2014 Matice a vektory Matice Matice typu m n je pravoúhlé (nebo obdélníkové) schéma, které má m řádků a n
Úvod do lineární algebry
 Úvod do lineární algebry 1 Aritmetické vektory Definice 11 Mějme n N a utvořme kartézský součin R n R R R Každou uspořádanou n tici x 1 x 2 x, x n budeme nazývat n rozměrným aritmetickým vektorem Prvky
Úvod do lineární algebry 1 Aritmetické vektory Definice 11 Mějme n N a utvořme kartézský součin R n R R R Každou uspořádanou n tici x 1 x 2 x, x n budeme nazývat n rozměrným aritmetickým vektorem Prvky
PRAVDĚPODOBNOST A STATISTIKA
 PRAVDĚPODOBNOST A STATISTIKA Testování hypotéz Nechť X je náhodná proměnná, která má distribuční funkci F(x, ϑ). Předpokládejme, že známe tvar distribuční funkce (víme jaké má rozdělení) a neznáme parametr
PRAVDĚPODOBNOST A STATISTIKA Testování hypotéz Nechť X je náhodná proměnná, která má distribuční funkci F(x, ϑ). Předpokládejme, že známe tvar distribuční funkce (víme jaké má rozdělení) a neznáme parametr
1 Tyto materiály byly vytvořeny za pomoci grantu FRVŠ číslo 1145/2004.
 Prostá regresní a korelační analýza 1 1 Tyto materiály byly vytvořeny za pomoci grantu FRVŠ číslo 1145/2004. Problematika závislosti V podstatě lze rozlišovat mezi závislostí nepodstatnou, čili náhodnou
Prostá regresní a korelační analýza 1 1 Tyto materiály byly vytvořeny za pomoci grantu FRVŠ číslo 1145/2004. Problematika závislosti V podstatě lze rozlišovat mezi závislostí nepodstatnou, čili náhodnou
15. T e s t o v á n í h y p o t é z
 15. T e s t o v á n í h y p o t é z Na základě hodnot náhodného výběru činíme rozhodnutí o platnosti hypotézy o hodnotách parametrů rozdělení nebo o jeho vlastnostech. Rozeznáváme dva základní typy testů:
15. T e s t o v á n í h y p o t é z Na základě hodnot náhodného výběru činíme rozhodnutí o platnosti hypotézy o hodnotách parametrů rozdělení nebo o jeho vlastnostech. Rozeznáváme dva základní typy testů:
Univerzita Pardubice Fakulta chemicko-technologická Katedra analytické chemie STATISTICKÉ ZPRACOVÁNÍ EXPERIMENTÁLNÍCH DAT
 Univerzita Pardubice Fakulta chemicko-technologická Katedra analytické chemie STATISTICKÉ ZPRACOVÁNÍ EXPERIMENTÁLNÍCH DAT STATISTICKÁ ANALÝZA JEDNOROZMĚRNÝCH DAT Seminární práce 1 Brno, 2002 Ing. Pavel
Univerzita Pardubice Fakulta chemicko-technologická Katedra analytické chemie STATISTICKÉ ZPRACOVÁNÍ EXPERIMENTÁLNÍCH DAT STATISTICKÁ ANALÝZA JEDNOROZMĚRNÝCH DAT Seminární práce 1 Brno, 2002 Ing. Pavel
ANOVA. Semestrální práce UNIVERZITA PARDUBICE. Fakulta chemicko-technologická Katedra analytické chemie
 UNIVERZITA PARDUBICE Fakulta chemicko-technologická Katedra analytické chemie ANOVA Semestrální práce Licenční studium Galileo Interaktivní statistická analýza dat Brno 2015 Ing. Petra Hlaváčková, Ph.D.
UNIVERZITA PARDUBICE Fakulta chemicko-technologická Katedra analytické chemie ANOVA Semestrální práce Licenční studium Galileo Interaktivní statistická analýza dat Brno 2015 Ing. Petra Hlaváčková, Ph.D.
IDENTIFIKACE BIMODALITY V DATECH
 IDETIFIKACE BIMODALITY V DATECH Jiří Militky Technická universita v Liberci e- mail: jiri.miliky@vslib.cz Milan Meloun Universita Pardubice, Pardubice Motto: Je normální předpokládat normální data? Zvláštnosti
IDETIFIKACE BIMODALITY V DATECH Jiří Militky Technická universita v Liberci e- mail: jiri.miliky@vslib.cz Milan Meloun Universita Pardubice, Pardubice Motto: Je normální předpokládat normální data? Zvláštnosti
NÁHODNÝ VEKTOR. 4. cvičení
 NÁHODNÝ VEKTOR 4. cvičení Náhodný vektor Náhodným vektorem rozumíme sloupcový vektor X=(X, X,, X n ) složený z náhodných veličin X, X,, X n, který je charakterizován sdruženým rozdělením pravděpodobnosti.
NÁHODNÝ VEKTOR 4. cvičení Náhodný vektor Náhodným vektorem rozumíme sloupcový vektor X=(X, X,, X n ) složený z náhodných veličin X, X,, X n, který je charakterizován sdruženým rozdělením pravděpodobnosti.
PRAVDĚPODOBNOST A STATISTIKA
 PRAVDĚPODOBNOST A STATISTIKA Definice lineárního normálního regresního modelu Lineární normální regresní model Y Xβ ε Předpoklady: Matice X X n,k je matice realizací. Předpoklad: n > k, h(x) k - tj. matice
PRAVDĚPODOBNOST A STATISTIKA Definice lineárního normálního regresního modelu Lineární normální regresní model Y Xβ ε Předpoklady: Matice X X n,k je matice realizací. Předpoklad: n > k, h(x) k - tj. matice
Statistická analýza jednorozměrných dat
 Statistická analýza jednorozměrných dat Prof. RNDr. Milan Meloun, DrSc. Univerzita Pardubice, Pardubice 31.ledna 2011 Tato prezentace je spolufinancována Evropským sociálním fondem a státním rozpočtem
Statistická analýza jednorozměrných dat Prof. RNDr. Milan Meloun, DrSc. Univerzita Pardubice, Pardubice 31.ledna 2011 Tato prezentace je spolufinancována Evropským sociálním fondem a státním rozpočtem
Kvantily a písmenové hodnoty E E E E-02
 Na úloze ukážeme postup průzkumové analýzy dat. Při výrobě calciferolu se provádí kontrola meziproduktu 3,5 DNB esteru calciferolu metodou HPLC. Sleduje se také obsah přítomného ergosterinu jako nečistoty,
Na úloze ukážeme postup průzkumové analýzy dat. Při výrobě calciferolu se provádí kontrola meziproduktu 3,5 DNB esteru calciferolu metodou HPLC. Sleduje se také obsah přítomného ergosterinu jako nečistoty,
Statistická analýza. jednorozměrných dat
 Univerzita Pardubice Fakulta chemicko technologická Katedra analytické chemie icenční studium chemometrie Statistické zpracování dat Statistická analýza jednorozměrných dat Zdravotní ústav se sídlem v
Univerzita Pardubice Fakulta chemicko technologická Katedra analytické chemie icenční studium chemometrie Statistické zpracování dat Statistická analýza jednorozměrných dat Zdravotní ústav se sídlem v
6. Lineární regresní modely
 6. Lineární regresní modely 6.1 Jednoduchá regrese a validace 6.2 Testy hypotéz v lineární regresi 6.3 Kritika dat v regresním tripletu 6.4 Multikolinearita a polynomy 6.5 Kritika modelu v regresním tripletu
6. Lineární regresní modely 6.1 Jednoduchá regrese a validace 6.2 Testy hypotéz v lineární regresi 6.3 Kritika dat v regresním tripletu 6.4 Multikolinearita a polynomy 6.5 Kritika modelu v regresním tripletu
Příklady ke čtvrtému testu - Pravděpodobnost
 Příklady ke čtvrtému testu - Pravděpodobnost 6. dubna 0 Instrukce: Projděte si všechny příklady. Každý příklad se snažte pochopit. Pak vymyslete a vyřešte příklad podobný. Tím se ujistíte, že příkladu
Příklady ke čtvrtému testu - Pravděpodobnost 6. dubna 0 Instrukce: Projděte si všechny příklady. Každý příklad se snažte pochopit. Pak vymyslete a vyřešte příklad podobný. Tím se ujistíte, že příkladu
odpovídá jedna a jen jedna hodnota jiných
 8. Regresní a korelační analýza Problém: hledání, zkoumání a hodnocení souvislostí, závislostí mezi dvěma a více statistickými znaky (veličinami). Typy závislostí: pevné a volné Pevná závislost každé hodnotě
8. Regresní a korelační analýza Problém: hledání, zkoumání a hodnocení souvislostí, závislostí mezi dvěma a více statistickými znaky (veličinami). Typy závislostí: pevné a volné Pevná závislost každé hodnotě
Intervalové Odhady Parametrů
 Parametrů Mgr. Rudolf B. Blažek, Ph.D. prof. RNDr. Roman Kotecký, DrSc. Katedra počítačových systémů Katedra teoretické informatiky Fakulta informačních technologií České vysoké učení technické v Praze
Parametrů Mgr. Rudolf B. Blažek, Ph.D. prof. RNDr. Roman Kotecký, DrSc. Katedra počítačových systémů Katedra teoretické informatiky Fakulta informačních technologií České vysoké učení technické v Praze
Jiří Neubauer. Katedra ekonometrie, FVL, UO Brno kancelář 69a, tel
 Katedra ekonometrie, FVL, UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Výsledky některých náhodných pokusů jsou přímo vyjádřeny číselně (např. při hodu kostkou padne 6). Náhodnou veličinou
Katedra ekonometrie, FVL, UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Výsledky některých náhodných pokusů jsou přímo vyjádřeny číselně (např. při hodu kostkou padne 6). Náhodnou veličinou
Základy teorie odhadu parametrů bodový odhad
 Katedra ekonometrie, FVL, UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Odhady parametrů Úkolem výběrového šetření je podat informaci o neznámé hodnotě charakteristiky základního souboru
Katedra ekonometrie, FVL, UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Odhady parametrů Úkolem výběrového šetření je podat informaci o neznámé hodnotě charakteristiky základního souboru
Odhady Parametrů Lineární Regrese
 Odhady Parametrů Lineární Regrese Mgr. Rudolf B. Blažek, Ph.D. prof. RNDr. Roman Kotecký, DrSc. Katedra počítačových systémů Katedra teoretické informatiky Fakulta informačních technologií České vysoké
Odhady Parametrů Lineární Regrese Mgr. Rudolf B. Blažek, Ph.D. prof. RNDr. Roman Kotecký, DrSc. Katedra počítačových systémů Katedra teoretické informatiky Fakulta informačních technologií České vysoké
Střední hodnota a rozptyl náhodné. kvantilu. Ing. Michael Rost, Ph.D.
 Střední hodnota a rozptyl náhodné veličiny, vybraná rozdělení diskrétních a spojitých náhodných veličin, pojem kvantilu Ing. Michael Rost, Ph.D. Príklad Předpokládejme že máme náhodnou veličinu X která
Střední hodnota a rozptyl náhodné veličiny, vybraná rozdělení diskrétních a spojitých náhodných veličin, pojem kvantilu Ing. Michael Rost, Ph.D. Príklad Předpokládejme že máme náhodnou veličinu X která
Porovnání dvou výběrů
 Porovnání dvou výběrů Menu: QCExpert Porovnání dvou výběrů Tento modul je určen pro podrobnou analýzu dvou datových souborů (výběrů). Modul poskytuje dva postupy analýzy: porovnání dvou nezávislých výběrů
Porovnání dvou výběrů Menu: QCExpert Porovnání dvou výběrů Tento modul je určen pro podrobnou analýzu dvou datových souborů (výběrů). Modul poskytuje dva postupy analýzy: porovnání dvou nezávislých výběrů
15. T e s t o v á n í h y p o t é z
 15. T e s t o v á n í h y p o t é z Na základě hodnot náhodného výběru činíme rozhodnutí o platnosti hypotézy o hodnotách parametrů rozdělení nebo o jeho vlastnostech. Rozeznáváme dva základní typy testů:
15. T e s t o v á n í h y p o t é z Na základě hodnot náhodného výběru činíme rozhodnutí o platnosti hypotézy o hodnotách parametrů rozdělení nebo o jeho vlastnostech. Rozeznáváme dva základní typy testů:
UNIVERZITA PARDUBICE CHEMICKO-TECHNOLOGICKÁ FAKULTA KATEDRA ANALYTICKÉ CHEMIE
 UNIVERZITA PARDUBICE CHEMICKO-TECHNOLOGICKÁ FAKULTA KATEDRA ANALYTICKÉ CHEMIE STATISTICKÁ ANALÝZA JEDNOROZMĚRNÝCH DAT V OSTRAVĚ 20.3.2006 MAREK MOČKOŘ PŘÍKLAD Č.1 : ANALÝZA VELKÝCH VÝBĚRŮ Zadání: Pro kontrolu
UNIVERZITA PARDUBICE CHEMICKO-TECHNOLOGICKÁ FAKULTA KATEDRA ANALYTICKÉ CHEMIE STATISTICKÁ ANALÝZA JEDNOROZMĚRNÝCH DAT V OSTRAVĚ 20.3.2006 MAREK MOČKOŘ PŘÍKLAD Č.1 : ANALÝZA VELKÝCH VÝBĚRŮ Zadání: Pro kontrolu
Normální rozložení a odvozená rozložení
 I Normální rozložení a odvozená rozložení I.I Normální rozložení Data, se kterými pracujeme, pocházejí z různých rozložení. Mohou být vychýlena (doleva popř. doprava, nebo v nich není na první pohled vidět
I Normální rozložení a odvozená rozložení I.I Normální rozložení Data, se kterými pracujeme, pocházejí z různých rozložení. Mohou být vychýlena (doleva popř. doprava, nebo v nich není na první pohled vidět
AVDAT Mnohorozměrné metody, metody klasifikace
 AVDAT Mnohorozměrné metody, metody klasifikace Josef Tvrdík Katedra informatiky Přírodovědecká fakulta Ostravská univerzita Mnohorozměrné metody Regrese jedna náhodná veličina je vysvětlována pomocí jiných
AVDAT Mnohorozměrné metody, metody klasifikace Josef Tvrdík Katedra informatiky Přírodovědecká fakulta Ostravská univerzita Mnohorozměrné metody Regrese jedna náhodná veličina je vysvětlována pomocí jiných
Zpracování náhodného vektoru. Ing. Michal Dorda, Ph.D.
 Ing. Michal Dorda, Ph.D. 1 Př. 1: Cestující na vybraném spoji linky MHD byli dotazováni za účelem zjištění spokojenosti s kvalitou MHD. Legenda 1 Velmi spokojen Spokojen 3 Nespokojen 4 Velmi nespokojen
Ing. Michal Dorda, Ph.D. 1 Př. 1: Cestující na vybraném spoji linky MHD byli dotazováni za účelem zjištění spokojenosti s kvalitou MHD. Legenda 1 Velmi spokojen Spokojen 3 Nespokojen 4 Velmi nespokojen
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc.
 Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika 010 1.týden (0.09.-4.09. ) Data, typy dat, variabilita, frekvenční analýza
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika 010 1.týden (0.09.-4.09. ) Data, typy dat, variabilita, frekvenční analýza
BAYESOVSKÉ ODHADY. Michal Friesl V NĚKTERÝCH MODELECH. Katedra matematiky Fakulta aplikovaných věd Západočeská univerzita v Plzni
 BAYESOVSKÉ ODHADY V NĚKTERÝCH MODELECH Michal Friesl Katedra matematiky Fakulta aplikovaných věd Západočeská univerzita v Plzni Slunce Řidiči IQ Regrese Přežití Obvyklý model Pozorování X = (X 1,..., X
BAYESOVSKÉ ODHADY V NĚKTERÝCH MODELECH Michal Friesl Katedra matematiky Fakulta aplikovaných věd Západočeská univerzita v Plzni Slunce Řidiči IQ Regrese Přežití Obvyklý model Pozorování X = (X 1,..., X
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc.
 Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika 2010 1.týden (20.09.-24.09. ) Data, typy dat, variabilita, frekvenční analýza
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika 2010 1.týden (20.09.-24.09. ) Data, typy dat, variabilita, frekvenční analýza
8.1. Definice: Normální (Gaussovo) rozdělení N(µ, σ 2 ) s parametry µ a. ( ) ϕ(x) = 1. označovat písmenem U. Její hustota je pak.
 rozdělení N(µ, σ 2 ) s parametry µ a. ( ) ϕ(x) = 1. označovat písmenem U. Její hustota je pak.") 8. Normální rozdělení 8.. Definice: Normální (Gaussovo) rozdělení N(µ, ) s parametry µ a > 0 je rozdělení určené hustotou ( ) f(x) = (x µ) e, x (, ). Rozdělení N(0; ) s parametry µ = 0 a = se nazývá normované
8. Normální rozdělení 8.. Definice: Normální (Gaussovo) rozdělení N(µ, ) s parametry µ a > 0 je rozdělení určené hustotou ( ) f(x) = (x µ) e, x (, ). Rozdělení N(0; ) s parametry µ = 0 a = se nazývá normované
Dva případy chybného rozhodnutí při testování: a) Testační statistika padne mimo obor přijetí nulové H hypotézy O, tj.
 Testační statistika padne mimo obor přijetí nulové H hypotézy O, tj.") Uvedeme obecný postup statistického testování:. Formulace nulové H 0a alternativní hpotéz H A.. Volba hladin významnosti α.. Volba testační statistik např... Určení kritického oboru testové charakteristik.
Uvedeme obecný postup statistického testování:. Formulace nulové H 0a alternativní hpotéz H A.. Volba hladin významnosti α.. Volba testační statistik např... Určení kritického oboru testové charakteristik.
Poznámky k předmětu Aplikovaná statistika, 4. téma
 Poznámky k předmětu Aplikovaná statistika, 4. téma 4. Náhodné vektory V praxi se nám může hodit postihnout více vlastností jednoho objektu najednou, např. výšku, váhu a pohlaví člověka; rychlost chemické
Poznámky k předmětu Aplikovaná statistika, 4. téma 4. Náhodné vektory V praxi se nám může hodit postihnout více vlastností jednoho objektu najednou, např. výšku, váhu a pohlaví člověka; rychlost chemické
MATEMATICKÁ STATISTIKA
 MATEMATICKÁ STATISTIKA 1. Úvod. Matematická statistika se zabývá vyšetřováním zákonitostí, které v sobě obsahují prvek náhody. Zpracováním hodnot, které jsou výstupem sledovaného procesu, se snažíme popsat
MATEMATICKÁ STATISTIKA 1. Úvod. Matematická statistika se zabývá vyšetřováním zákonitostí, které v sobě obsahují prvek náhody. Zpracováním hodnot, které jsou výstupem sledovaného procesu, se snažíme popsat
Pravděpodobnost a statistika (BI-PST) Cvičení č. 7
 Cvičení č. 7") Pravděpodobnost a statistika (BI-PST) Cvičení č. 7 R. Blažek, M. Jiřina, J. Hrabáková, I. Petr, F. Štampach, D. Vašata Katedra aplikované matematiky Fakulta informačních technologií České vysoké učení
Pravděpodobnost a statistika (BI-PST) Cvičení č. 7 R. Blažek, M. Jiřina, J. Hrabáková, I. Petr, F. Štampach, D. Vašata Katedra aplikované matematiky Fakulta informačních technologií České vysoké učení
PRAVDĚPODOBNOST A STATISTIKA
 PRAVDĚPODOBNOS A SAISIKA Regresní analýza - motivace Základní úlohou regresní analýzy je nalezení vhodného modelu studované závislosti. Je nutné věnovat velkou pozornost tomu aby byla modelována REÁLNÁ
PRAVDĚPODOBNOS A SAISIKA Regresní analýza - motivace Základní úlohou regresní analýzy je nalezení vhodného modelu studované závislosti. Je nutné věnovat velkou pozornost tomu aby byla modelována REÁLNÁ
Vlastnosti odhadů ukazatelů způsobilosti
 Vlastnosti odhadů ukazatelů způsobilosti Jiří Michálek CQR při Ústavu teorie informace a automatizace AV ČR v Praze Úvod Ve výzkumné zprávě č 06 Odhady koeficientů způsobilosti a jejich vlastnosti viz
Vlastnosti odhadů ukazatelů způsobilosti Jiří Michálek CQR při Ústavu teorie informace a automatizace AV ČR v Praze Úvod Ve výzkumné zprávě č 06 Odhady koeficientů způsobilosti a jejich vlastnosti viz
5. T e s t o v á n í h y p o t é z
 5. T e s t o v á n í h y p o t é z Na základě hodnot náhodného výběru činíme rozhodnutí o platnosti hypotézy o hodnotách parametrů rozdělení nebo o jeho vlastnostech. Rozeznáváme dva základní typy testů:
5. T e s t o v á n í h y p o t é z Na základě hodnot náhodného výběru činíme rozhodnutí o platnosti hypotézy o hodnotách parametrů rozdělení nebo o jeho vlastnostech. Rozeznáváme dva základní typy testů:
Odhad parametrů N(µ, σ 2 )
") Odhad parametrů N(µ, σ 2 ) Mějme statistický soubor x 1, x 2,, x n modelovaný jako realizaci náhodného výběru z normálního rozdělení N(µ, σ 2 ) s neznámými parametry µ a σ. Jaký je maximální věrohodný
Odhad parametrů N(µ, σ 2 ) Mějme statistický soubor x 1, x 2,, x n modelovaný jako realizaci náhodného výběru z normálního rozdělení N(µ, σ 2 ) s neznámými parametry µ a σ. Jaký je maximální věrohodný
12. cvičení z PST. 20. prosince 2017
 1 cvičení z PST 0 prosince 017 11 test rozptylu normálního rozdělení Do laboratoře bylo odesláno n = 5 stejných vzorků krve ke stanovení obsahu alkoholu X v promilích alkoholu Výsledkem byla realizace
1 cvičení z PST 0 prosince 017 11 test rozptylu normálního rozdělení Do laboratoře bylo odesláno n = 5 stejných vzorků krve ke stanovení obsahu alkoholu X v promilích alkoholu Výsledkem byla realizace
Pravděpodobnost v závislosti na proměnné x je zde modelován pomocí logistického modelu. exp x. x x x. log 1
 Logistická regrese Menu: QCExpert Regrese Logistická Modul Logistická regrese umožňuje analýzu dat, kdy odezva je binární, nebo frekvenční veličina vyjádřená hodnotami 0 nebo 1, případně poměry v intervalu
Logistická regrese Menu: QCExpert Regrese Logistická Modul Logistická regrese umožňuje analýzu dat, kdy odezva je binární, nebo frekvenční veličina vyjádřená hodnotami 0 nebo 1, případně poměry v intervalu
Statistika. Regresní a korelační analýza Úvod do problému. Roman Biskup
 Statistika Regresní a korelační analýza Úvod do problému Roman Biskup Jihočeská univerzita v Českých Budějovicích Ekonomická fakulta (Zemědělská fakulta) Katedra aplikované matematiky a informatiky 2008/2009
Statistika Regresní a korelační analýza Úvod do problému Roman Biskup Jihočeská univerzita v Českých Budějovicích Ekonomická fakulta (Zemědělská fakulta) Katedra aplikované matematiky a informatiky 2008/2009
Odhad parametrů N(µ, σ 2 )
") Odhad parametrů N(µ, σ 2 ) Mějme statistický soubor x 1, x 2,, x n modelovaný jako realizaci náhodného výběru z normálního rozdělení N(µ, σ 2 ) s neznámými parametry µ a σ. Jaký je maximální věrohodný
Odhad parametrů N(µ, σ 2 ) Mějme statistický soubor x 1, x 2,, x n modelovaný jako realizaci náhodného výběru z normálního rozdělení N(µ, σ 2 ) s neznámými parametry µ a σ. Jaký je maximální věrohodný
Dobývání znalostí. Doc. RNDr. Iveta Mrázová, CSc. Katedra teoretické informatiky Matematicko-fyzikální fakulta Univerzity Karlovy v Praze
 Dobývání znalostí Doc. RNDr. Iveta Mrázová, CSc. Katedra teoretické informatiky Matematicko-fyzikální fakulta Univerzity Karlovy v Praze Dobývání znalostí Pravděpodobnost a učení Doc. RNDr. Iveta Mrázová,
Dobývání znalostí Doc. RNDr. Iveta Mrázová, CSc. Katedra teoretické informatiky Matematicko-fyzikální fakulta Univerzity Karlovy v Praze Dobývání znalostí Pravděpodobnost a učení Doc. RNDr. Iveta Mrázová,
Závislost obsahu lipoproteinu v krevním séru na třech faktorech ( Lineární regresní modely )
") Úloha M608 Závislost obsahu lipoproteinu v krevním séru na třech faktorech ( Lineární regresní modely ) Zadání : Při kvantitativní analýze lidského krevního séra ovlivňují hodnotu obsahu vysokohustotního
Úloha M608 Závislost obsahu lipoproteinu v krevním séru na třech faktorech ( Lineární regresní modely ) Zadání : Při kvantitativní analýze lidského krevního séra ovlivňují hodnotu obsahu vysokohustotního
5 Vícerozměrná data - kontingenční tabulky, testy nezávislosti, regresní analýza
 5 Vícerozměrná data - kontingenční tabulky, testy nezávislosti, regresní analýza 5.1 Vícerozměrná data a vícerozměrná rozdělení Při zpracování vícerozměrných dat se hledají souvislosti mezi dvěma, případně
5 Vícerozměrná data - kontingenční tabulky, testy nezávislosti, regresní analýza 5.1 Vícerozměrná data a vícerozměrná rozdělení Při zpracování vícerozměrných dat se hledají souvislosti mezi dvěma, případně
X = x, y = h(x) Y = y. hodnotám x a jedné hodnotě y. Dostaneme tabulku hodnot pravděpodobnostní
 Y = y. hodnotám x a jedné hodnotě y. Dostaneme tabulku hodnot pravděpodobnostní") ..08 8cv7.tex 7. cvičení - transformace náhodné veličiny Definice pojmů a základní vzorce Je-li X náhodná veličina a h : R R je měřitelná funkce, pak náhodnou veličinu Y, která je definovaná vztahem X
..08 8cv7.tex 7. cvičení - transformace náhodné veličiny Definice pojmů a základní vzorce Je-li X náhodná veličina a h : R R je měřitelná funkce, pak náhodnou veličinu Y, která je definovaná vztahem X
Charakteristika datového souboru
 Zápočtová práce z předmětu Statistika Vypracoval: 10. 11. 2014 Charakteristika datového souboru Zadání: Při kontrole dodržování hygienických norem v kuchyni se prováděl odběr vzduchu a pomocí filtru Pallflex
Zápočtová práce z předmětu Statistika Vypracoval: 10. 11. 2014 Charakteristika datového souboru Zadání: Při kontrole dodržování hygienických norem v kuchyni se prováděl odběr vzduchu a pomocí filtru Pallflex
Jarqueův a Beryho test normality (Jarque-Bera Test, JB test)
") Jarqueův a Beryho test normality (Jarque-Bera Test, JB test) Autoři: Carlos M. Jarque and Anil K. Bera Předpoklady: - Výběrová data mohou obsahovat chybějící pozorování (chybějící hodnoty) vhodné zejména
Jarqueův a Beryho test normality (Jarque-Bera Test, JB test) Autoři: Carlos M. Jarque and Anil K. Bera Předpoklady: - Výběrová data mohou obsahovat chybějící pozorování (chybějící hodnoty) vhodné zejména
Faktorová analýza. Ekonometrie. Jiří Neubauer. Katedra ekonometrie FVL UO Brno kancelář 69a, tel
 Ekonometrie Jiří Neubauer Katedra ekonometrie FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz J. Neubauer, J. Michálek (Katedra ekonometrie UO) 1 / 27 úvod Na sledovaných objektech
Ekonometrie Jiří Neubauer Katedra ekonometrie FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz J. Neubauer, J. Michálek (Katedra ekonometrie UO) 1 / 27 úvod Na sledovaných objektech
Poznámky k předmětu Aplikovaná statistika, 4. téma
 Poznámky k předmětu Aplikovaná statistika, 4. téma 4. Náhodné vektory V praxi se nám může hodit postihnout více vlastností jednoho objektu najednou, např. výšku, váhu a pohlaví člověka; rychlost chemické
Poznámky k předmětu Aplikovaná statistika, 4. téma 4. Náhodné vektory V praxi se nám může hodit postihnout více vlastností jednoho objektu najednou, např. výšku, váhu a pohlaví člověka; rychlost chemické
Testování statistických hypotéz
 Testování statistických hypotéz 1 Testování statistických hypotéz 1 Statistická hypotéza a její test V praxi jsme nuceni rozhodnout, zda nějaké tvrzeni o parametrech náhodných veličin nebo o veličině samotné
Testování statistických hypotéz 1 Testování statistických hypotéz 1 Statistická hypotéza a její test V praxi jsme nuceni rozhodnout, zda nějaké tvrzeni o parametrech náhodných veličin nebo o veličině samotné
AVDAT Geometrie metody nejmenších čtverců
 AVDAT Geometrie metody nejmenších čtverců Josef Tvrdík Katedra informatiky Přírodovědecká fakulta Ostravská univerzita Lineární model klasický lineární regresní model odhad parametrů MNČ y = Xβ + ε, ε
AVDAT Geometrie metody nejmenších čtverců Josef Tvrdík Katedra informatiky Přírodovědecká fakulta Ostravská univerzita Lineární model klasický lineární regresní model odhad parametrů MNČ y = Xβ + ε, ε
PRŮZKUMOVÁ ANALÝZA JEDNOROZMĚRNÝCH DAT Exploratory Data Analysis (EDA)
") PRŮZKUMOVÁ ANALÝZA JEDNOROZMĚRNÝCH DAT Exploratory Data Analysis (EDA) Reprezentativní náhodný výběr: 1. Prvky výběru x i jsou vzájemně nezávislé. 2. Výběr je homogenní, tj. všechna x i jsou ze stejného
PRŮZKUMOVÁ ANALÝZA JEDNOROZMĚRNÝCH DAT Exploratory Data Analysis (EDA) Reprezentativní náhodný výběr: 1. Prvky výběru x i jsou vzájemně nezávislé. 2. Výběr je homogenní, tj. všechna x i jsou ze stejného
S E M E S T R Á L N Í
 Univerzita Pardubice Fakulta chemicko-technologická Katedra analytické chemie S E M E S T R Á L N Í P R Á C E Licenční studium Statistické zpracování dat při managementu jakosti Předmět ANOVA analýza rozptylu
Univerzita Pardubice Fakulta chemicko-technologická Katedra analytické chemie S E M E S T R Á L N Í P R Á C E Licenční studium Statistické zpracování dat při managementu jakosti Předmět ANOVA analýza rozptylu
Náhodná veličina Číselné charakteristiky diskrétních náhodných veličin Spojitá náhodná veličina. Pravděpodobnost
 Pravděpodobnost Náhodné veličiny a jejich číselné charakteristiky Petr Liška Masarykova univerzita 19.9.2014 Představme si, že provádíme pokus, jehož výsledek dokážeme ohodnotit číslem. Před provedením
Pravděpodobnost Náhodné veličiny a jejich číselné charakteristiky Petr Liška Masarykova univerzita 19.9.2014 Představme si, že provádíme pokus, jehož výsledek dokážeme ohodnotit číslem. Před provedením