mezi studenty. Dále bychom rádi posoudili, zda dobrý výsledek v prvním testu bývá doprovázen dobrým výsledkem i v druhém testu.
|
|
|
- Štěpánka Musilová
- před 6 lety
- Počet zobrazení:
Transkript
1 Popisná statistika Slovní popis problému Naším cílem v této úloze bude stručně a přehledně charakterizovat rozsáhlý soubor dat - v našem případě počty bodů z prvního a druhého zápočtového testu z matematiky. Chceme získat představu o středním počtu získaných bodů v jednotlivých písemkách (poloha), jejich variabilitě a rozdělení mezi studenty. Dále bychom rádi posoudili, zda dobrý výsledek v prvním testu bývá doprovázen dobrým výsledkem i v druhém testu. Data Máme k dispozici počty získaných bodů z první a druhé paralelkové písemky z předmětu Matematika I (zimní semestr 2015/2016) a to za 762 studentů (všichni studenti, kteří psali první i druhou zápočtovou písemku). Pro spravedlivější porovnání výsledků obou písemek jsme vyloučili ze zkoumání studenty, kteří psali pouze první písemku. Následuje ukázka tabulky s body z písemek. Student(ka) 1.PP 2.PP Řešení - teorie Než představíme jednotlivé charakteristiky, je potřeba si uvědomit, že půjde o charakteristiky populační, nikoliv výběrové. Vycházíme totiž z toho, že známe celý základní soubor (výsledky všech studentů) a můžeme tedy dané charakteristiky spočítat přesně. Naopak výběrové charakteristiky se používají v situacích, kdy máme k dispozici pouze malou část základního souboru (získanou náhodným výběrem), a pomocí těchto výběrových charakteristik se snažíme (co možná nejlépe) odhadnout charakteristiky celého základního souboru, které neznáme. Výběrové charakteristiky bychom tedy použili např. v situaci, kdy bychom neměli přístup k databázi dosažených bodů a tak bychom náhodně vybrali 20 studentů a zeptali se jich na jejich výsledky ze zápočtových písemek. Míry polohy 1. Aritmetický průměr Jde o nejčastěji používanou míru polohy. Jsou-li x i (i = 1...n) jednotlivá pozorování (v našem případě počty bodů), aritmetický průměr definujeme takto: x = 1 n n x i. i=1 1
2 Mezi výhody průměru patří, že je srozumitelný široké veřejnosti (i bez znalosti statistiky) a že jde o hodnotu, která v jistém smyslu nejlépe vystihuje daný soubor dat (minimalizuje součet čtverců odchylek jednotlivých pozorování od této hodnoty). Nevýhodou může být obtížnější interpretovatelnost (hodnota průměru nemusí být v oboru přípustných hodnot pro x - např. průměrný počet bodů nemusí být celočíselný) a vyšší citlivost na odlehlá pozorování (např. když se někdo při zadávání bodů do počítače splete a zapíše třímístné číslo, vychýlí to průměr a tím přestane dobře charakterizovat polohu dat). Poznamenejme, že vedle aritmetického průměru existují i jiné průměry (např. geometrický, harmonický atd.), ty se však používají ve specifických situacích (např. při výpočtu průměrného tempa růstu, kdy nelze počítat celkový růst za několik období pomocí součtu, nýbrž pomocí součinu růstů v jednotlivých obdobích). 2. Medián Další oblíbenou charakteristikou polohy je medián. Je to, zhruba řečeno, prostřední hodnota ze všech hodnot v souboru, tedy 50 % hodnot by mělo být menších než medián a 50 % hodnot větších než medián. Jedná se tedy o 50% kvantil. Jednotlivá pozorování x i v souboru dat uspořádejme vzestupně podle velikosti, tj. x (1) x (2) x (3)... x (n). (1) Potom medián x spočítáme takto { x( n+1 x = 2 ) pro n liché, (x ( n 2 ) + x ( n 2 +1) )/2 pro n sudé. Výhodou mediánu je, že není citlivý na odlehlá pozorování (chybně zadaná hodnota neovlivní medián, nebo jej ovlivní jen velmi nepatrně). Použití mediánu naopak není výhodné v případech, kdy sledovaný znak nabývá jen malého počtu různých hodnot (např. pouze 0 nebo 1), v takovém případě je totiž medián příliš hrubý ukazatel s nízkou vypovídací hodnotou o poloze dat a může být i dosti citlivý na malé změny v datech, jsou-li četnosti jednotlivých hodnot vyrovnané. Míry varibility 1. Rozptyl, Směrodatná odchylka Nejběžněji používanou mírou variability je rozptyl, potažmo směrodatná odchylka. Rozptyl je definován takto: σ 2 = 1 n (x i x) 2. n i=1 Jedná se tedy o průměr druhých mocnin vzdáleností jednotlivých pozorování od průměru. Toto číslo je poněkud obtížněji interpretovatelné (je vyjádřeno v druhé mocnině jednotek, ve kterých měříme x i ), proto se dále definuje směrodatná odchylka jako odmocnina z rozptylu: σ = σ 2. 2
3 Směrodatná odchylka tedy vyjadřuje průměrnou vzdálenost jednotlivých pozorování od průměru. Čím větší je variabilita dat, těm větší je samozřejmě tato vzdálenost. 2. Rozpětí Rozpětí je vlastně rozdílem dvou kvantilů a udává šířku intervalu, ve kterém je koncentrována předem daná část celého souboru. Čím větší je rozptýlenost dat, tím větší jsou šířky těchto intervalů. 100α% kvantil (značíme x α ) je taková hodnota, která rozděluje daný soubor dat na dvě části - 100α % dat je menších nebo rovna dané hodnotě a 100(1 α) % dat je větších než daná hodnota. Pokud by tato hodnota vycházela někde mezi dvěma pozorováními, používají se různé interpolace nebo zaokrouhlování (různé softwary k tomu přistupují různě) - viz. např. výpočet mediánu pro n sudé výše. Variační rozpětí R = x max x min Jde o rozdíl největší a nejmenší hodnoty, tedy šířku intervalu, ve kterém se nachází všechna pozorování. Decilové rozpětí R d = x 0,9 x 0,1 Decilové rozpětí je rozdíl posledního a prvního decilu a odpovídá šířce intervalu, ve kterém se nachází 80 % hodnot. Kvartilové rozpětí R q = x 0,75 x 0,25 Kvartilové rozpětí je rozdíl horního a dolního kvartilu a představuje šířku intervalu, ve kterém se nachází 50 % dat. Jelikož jsou rozpětí odvozená od kvantilů, nejsou citlivá na extrémní hodnoty (kromě variačního rozpětí). Nevýhodou oproti momentovým charakteristikám (rozptyl, směrodatná odchylka) je fakt, že nevyužívají veškerou číselnou informaci v datech obsaženou, ale pouze uspořádání dat. 3. Variační koeficient Na rozdíl od předchozích charakteristik variability je variační koeficient relativní (nikoliv absolutní) mírou variabilitu. Proměnlivost hodnot totiž vztahuje k velikosti těchto hodnot, přesněji směrodatnou odchylku vztahuje k průměru. Je tedy definován takto: V = σ x. Tento ukazatel vychází z empirického pravidla, že čím větších hodnot sledovaná proměnná nabývá, tím větší bývá její rozptýlení. Pro potřeby srovnání variability různých proměnných nebo souborů se tedy variační koeficient snaží tento jev eliminovat. Míry (lineární) závisloti 3
4 1. Korelační koeficient (Pearsonův) Jednou z nejužívanějších (ovšem zdaleka ne jedinou) mírou závislosti (či podobnosti) dvou veličin je korelační koeficient. Uvažujme, že u každého objektu (v našem případě student) sledujeme dvě proměnné (v našem případě počty bodů v prvním a druhém testu) x, y. Sílu (a také směr) lineární závislosti mezi těmito proměnnými lze vyjádřit pomocí korelačního koeficientu, který je definován takto: r(x, y) = cov(x, y) S x S y = n i=1 (x i x)(y i ȳ) n i=1 (x i x) 2 n i=1 (y i ȳ) 2. Dá se ukázat, že 1 r(x, y) 1, přičemž hodnoty blízké -1 indikují silnou negativní závislost (s rostoucím x klesá y), hodnoty blízké 1 indikují silnou pozitivní závislost (s rostoucím x roste i y) a hodnoty blízké nule znamenají absenci lineární závislosti. Vizualizace dat Velmi užitečným nástrojem pro pochopení a prezentaci dat jsou grafy. V literatuře existuje nepřeberné množství různých typů grafů zaměřených na zobrazení různých aspektů či vlastností datového souboru. My se zaměříme na zobrazení polohy, variability a rozdělení počtu bodů v jednotlivých testech a na zobrazení souvislosti mezi počtem bodů v prvním a v druhém testu. 1. Krabicový graf (Box plot) Hlavním cílem krabicového grafu je znázornit polohu a variabilitu datového souboru a to vykreslením vybraných kvantilů (mediánu, kvartilů). V omezené míře také vypovídá něco o rozdělení dat a napomáhá identifikovat odlehlé hodnoty. Krabicový diagram budeme kreslit na výšku a to tímto postupem (pro ilustraci viz. obr. níže): (a) Vykreslí se základní obdélník (krabice), jehož dolní a horní strana odpovídají dolnímu a hornímu kvartilu (x 0,25, x 0,75 ). Výška krabice tedy odpovídá kvartilovému rozpětí. (b) Uvnitř krabice se udělá vodorovná čára ve výšce mediánu ( x = x 0,5 ). Tím jsme rozdělili soubor dat na čtyři stejně velké (co do četnosti) části. (c) Ze spodní části krabice se pak vede svislá úsečka směrem dolů (dolní fous), přičemž její dolní mez odpovídá takové nejmenší hodnotě ze souboru, která leží pod krabicí ve vzdálenosti nejvýše 1,5 násobku výšky krabice. Podobným způsobem se sestrojí horní fous krabice. (d) Hodnoty ze základního souboru, které leží mimo tyto fousy (bud nad nebo pod nimi) se zobrazí v grafu individuálně (každá zvlášt ) a odpovídají odlehlým pozorováním. Poznamenejme, že chceme-li porovnat polohu a variabilitu více různých datových souborů (popř. více proměnných v jednom souboru), bývá výhodné nakreslit všechny krabicové grafy do jednoho obrázku. 4
5 2. Histogram Podobně jako krabicový graf i histogram dokáže do určité míry znázornit polohu a variabilitu dat. Jeho hlavním cílem je však přehledně zobrazit rozdělení dat v souboru. Prvním (a nejdůležitějším) krokem je rozdělit jednotlivá pozorování do intervalů dle zjištěných hodnot. Intervaly jsou zpravidla ekvidistantní (mají stejnou šířku), musí pokrývat celý obor hodnot sledované proměnné a v každém intervalu by měl být dostatečný počet pozorování. Finální volba intervalů je více méně arbitrární, protože neexistuje žádné univerzální pravidlo pro jejich konstruování. V literatuře se takových (zpravidla empirických) pravidel dá najít více a žádné z nich není to jediné nejlepší. Vzhledem k tomu, že vzhled výsledného grafu může být dosti citlivý na volbě intervalů, bývá někdy dobré s hranicemi intervalů trochu experimentovat a nakonec vybrat tu možnost, která nejlépe zobrazí rozdělení dat. Jakmile máme zvolené intervaly, zjistíme, kolik hodnot z datového souboru leží v jednotlivých intervalech. Tím získáme tabulku četností. Z tabulky četností pak vytvoříme sloupcový graf a to tak, aby šířka jednotlivých sloupců odpovídala šířce intervalu a aby se sloupce svými stranami dotýkaly. V případě ekvidistantních intervalů výška sloupce odpovídá četnosti hodnot v daném intervalu. Pozor, pokud však intervaly nejsou ekvidistantní, je třeba výšky sloupců volit tak, aby obsahy (nikoliv výšky) jednotlivých sloupců odpovídaly příslušným četnostem. Pro ilustraci uvádíme příklad histogramu níže. 5
 sledujeme dvě vlastnosti, které kvantifikujeme pomocí dvou proměnných (v našem případě počet bodů z prvního testu a počet bodů z druhého")
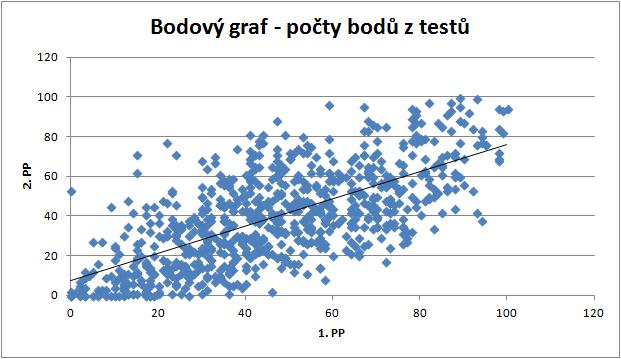
6 3. Bodový graf (Scatter plot) Bodový graf (též nazývaný korelační diagram) je velmi jednoduchý grafický nástroj pro znázornění vzájemné závislosti (či podobnosti) dvou proměnných. Uvažujme, že u každého objektu (v našem případě student) sledujeme dvě vlastnosti, které kvantifikujeme pomocí dvou proměnných (v našem případě počet bodů z prvního testu a počet bodů z druhého testu). Každému objektu tak odpovídá dvojice čísel a můžeme jej tedy znázornit jako bod v rovině (x-ová souřadnice daného bodu bude opovídat hodnotě první proměnné - např. počet bodů v prvním testu, zatímco y-ová souřadnice bude odpovídat hodnotě druhé proměnné - počet bodů z druhého testu). Podle rozložení jednotlivých bodů v rovině poznáme, zda vyšším hodnotám jedné proměnné odpovídají i vyšší hodnoty druhé proměnné, či nižší hodnoty druhé proměnné, popř. zda je závislost složitější (nemonotónní). Může se také ukázat, že žádná zjevná souvislost mezi proměnnými není. Pro větší názornost se často do bodového diagramu přidává regresní přímka (přímka, která na základě kritéria nejmenších čtverců nejlépe aproximuje zakreslené body). Ukázka bodového grafu s regresní přímkou viz. níže. 6
7 7
Popisná statistika. Komentované řešení pomocí MS Excel
 Popisná statistika Komentované řešení pomocí MS Excel Vstupní data Máme k dispozici data o počtech bodů z 1. a 2. zápočtového testu z Matematiky I v zimním semestru 2015/2016 a to za všech 762 studentů,
Popisná statistika Komentované řešení pomocí MS Excel Vstupní data Máme k dispozici data o počtech bodů z 1. a 2. zápočtového testu z Matematiky I v zimním semestru 2015/2016 a to za všech 762 studentů,
POPISNÁ STATISTIKA Komentované řešení pomocí programu Statistica
 POPISNÁ STATISTIKA Komentované řešení pomocí programu Statistica Program Statistica I Statistica je velmi podobná Excelu. Na základní úrovni je to klikací program určený ke statistickému zpracování dat.
POPISNÁ STATISTIKA Komentované řešení pomocí programu Statistica Program Statistica I Statistica je velmi podobná Excelu. Na základní úrovni je to klikací program určený ke statistickému zpracování dat.
Zpracování náhodného výběru. Ing. Michal Dorda, Ph.D.
 Zpracování náhodného výběru popisná statistika Ing. Michal Dorda, Ph.D. Základní pojmy Úkolem statistiky je na základě vlastností výběrového souboru usuzovat o vlastnostech celé populace. Populace(základní
Zpracování náhodného výběru popisná statistika Ing. Michal Dorda, Ph.D. Základní pojmy Úkolem statistiky je na základě vlastností výběrového souboru usuzovat o vlastnostech celé populace. Populace(základní
veličin, deskriptivní statistika Ing. Michael Rost, Ph.D.
 Vybraná rozdělení spojitých náhodných veličin, deskriptivní statistika Ing. Michael Rost, Ph.D. Třídění Základním zpracováním dat je jejich třídění. Jde o uspořádání získaných dat, kde volba třídícího
Vybraná rozdělení spojitých náhodných veličin, deskriptivní statistika Ing. Michael Rost, Ph.D. Třídění Základním zpracováním dat je jejich třídění. Jde o uspořádání získaných dat, kde volba třídícího
Statistika, Biostatistika pro kombinované studium Letní semestr 2011/2012. Tutoriál č. 4: Exploratorní analýza. Jan Kracík
 Statistika, Biostatistika pro kombinované studium Letní semestr 2011/2012 Tutoriál č. 4: Exploratorní analýza Jan Kracík jan.kracik@vsb.cz Statistika věda o získávání znalostí z empirických dat empirická
Statistika, Biostatistika pro kombinované studium Letní semestr 2011/2012 Tutoriál č. 4: Exploratorní analýza Jan Kracík jan.kracik@vsb.cz Statistika věda o získávání znalostí z empirických dat empirická
Základy popisné statistiky. Vytvořil Institut biostatistiky a analýz, Masarykova univerzita J. Jarkovský, L. Dušek
 Základy popisné statistiky Anotace Realitu můžeme popisovat různými typy dat, každý z nich se specifickými vlastnostmi, výhodami, nevýhodami a vlastní sadou využitelných statistických metod -od binárních
Základy popisné statistiky Anotace Realitu můžeme popisovat různými typy dat, každý z nich se specifickými vlastnostmi, výhodami, nevýhodami a vlastní sadou využitelných statistických metod -od binárních
Popisná statistika. Statistika pro sociology
 Popisná statistika Jitka Kühnová Statistika pro sociology 24. září 2014 Jitka Kühnová (GSTAT) Popisná statistika 24. září 2014 1 / 31 Outline 1 Základní pojmy 2 Typy statistických dat 3 Výběrové charakteristiky
Popisná statistika Jitka Kühnová Statistika pro sociology 24. září 2014 Jitka Kühnová (GSTAT) Popisná statistika 24. září 2014 1 / 31 Outline 1 Základní pojmy 2 Typy statistických dat 3 Výběrové charakteristiky
Statistika pro geografy
 Statistika pro geografy 2. Popisná statistika Mgr. David Fiedor 23. února 2015 Osnova 1 2 3 Pojmy - Bodové rozdělení četností Absolutní četnost Absolutní četností hodnoty x j znaku x rozumíme počet statistických
Statistika pro geografy 2. Popisná statistika Mgr. David Fiedor 23. února 2015 Osnova 1 2 3 Pojmy - Bodové rozdělení četností Absolutní četnost Absolutní četností hodnoty x j znaku x rozumíme počet statistických
Matematika III. 27. listopadu Vysoká škola báňská - Technická univerzita Ostrava. Matematika III
 Vysoká škola báňská - Technická univerzita Ostrava 27. listopadu 2017 Typy statistických znaků (proměnných) Typy proměnných: Kvalitativní proměnná (kategoriální, slovní,... ) Kvantitativní proměnná (numerická,
Vysoká škola báňská - Technická univerzita Ostrava 27. listopadu 2017 Typy statistických znaků (proměnných) Typy proměnných: Kvalitativní proměnná (kategoriální, slovní,... ) Kvantitativní proměnná (numerická,
Číselné charakteristiky a jejich výpočet
 Katedra ekonometrie, FVL, UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz charakteristiky polohy charakteristiky variability charakteristiky koncetrace charakteristiky polohy charakteristiky
Katedra ekonometrie, FVL, UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz charakteristiky polohy charakteristiky variability charakteristiky koncetrace charakteristiky polohy charakteristiky
Zápočtová práce STATISTIKA I
 Zápočtová práce STATISTIKA I Obsah: - úvodní stránka - charakteristika dat (původ dat, důvod zpracování,...) - výpis naměřených hodnot (v tabulce) - zpracování dat (buď bodové nebo intervalové, podle charakteru
Zápočtová práce STATISTIKA I Obsah: - úvodní stránka - charakteristika dat (původ dat, důvod zpracování,...) - výpis naměřených hodnot (v tabulce) - zpracování dat (buď bodové nebo intervalové, podle charakteru
STATISTICKÉ CHARAKTERISTIKY
 STATISTICKÉ CHARAKTERISTIKY 1 Vytvořeno s podporou projektu Průřezová inovace studijních programů Lesnické a dřevařské fakulty MENDELU v Brně (LDF) s ohledem na discipliny společného základu (reg. č. CZ.1.07/2.2.00/28.0021)
STATISTICKÉ CHARAKTERISTIKY 1 Vytvořeno s podporou projektu Průřezová inovace studijních programů Lesnické a dřevařské fakulty MENDELU v Brně (LDF) s ohledem na discipliny společného základu (reg. č. CZ.1.07/2.2.00/28.0021)
Základy popisné statistiky
 Základy popisné statistiky Michal Fusek Ústav matematiky FEKT VUT, fusekmi@feec.vutbr.cz 8. přednáška z ESMAT Michal Fusek (fusekmi@feec.vutbr.cz) 1 / 26 Obsah 1 Základy statistického zpracování dat 2
Základy popisné statistiky Michal Fusek Ústav matematiky FEKT VUT, fusekmi@feec.vutbr.cz 8. přednáška z ESMAT Michal Fusek (fusekmi@feec.vutbr.cz) 1 / 26 Obsah 1 Základy statistického zpracování dat 2
Informační technologie a statistika 1
 Informační technologie a statistika 1 přednášející: konzul. hodiny: e-mail: Martin Schindler KAP, tel. 48 535 2836, budova G po dohodě martin.schindler@tul.cz naposledy upraveno: 21. září 2015, 1/33 Požadavek
Informační technologie a statistika 1 přednášející: konzul. hodiny: e-mail: Martin Schindler KAP, tel. 48 535 2836, budova G po dohodě martin.schindler@tul.cz naposledy upraveno: 21. září 2015, 1/33 Požadavek
Číselné charakteristiky
 . Číselné charakteristiky statistických dat Průměrný statistik se během svého života ožení s 1,75 ženami, které se ho snaží vytáhnout večer do společnosti,5 x týdně, ale pouze s 50% úspěchem. W. F. Miksch
. Číselné charakteristiky statistických dat Průměrný statistik se během svého života ožení s 1,75 ženami, které se ho snaží vytáhnout večer do společnosti,5 x týdně, ale pouze s 50% úspěchem. W. F. Miksch
1 Tyto materiály byly vytvořeny za pomoci grantu FRVŠ číslo 1145/2004.
 Prostá regresní a korelační analýza 1 1 Tyto materiály byly vytvořeny za pomoci grantu FRVŠ číslo 1145/2004. Problematika závislosti V podstatě lze rozlišovat mezi závislostí nepodstatnou, čili náhodnou
Prostá regresní a korelační analýza 1 1 Tyto materiály byly vytvořeny za pomoci grantu FRVŠ číslo 1145/2004. Problematika závislosti V podstatě lze rozlišovat mezi závislostí nepodstatnou, čili náhodnou
Charakteristika datového souboru
 Zápočtová práce z předmětu Statistika Vypracoval: 10. 11. 2014 Charakteristika datového souboru Zadání: Při kontrole dodržování hygienických norem v kuchyni se prováděl odběr vzduchu a pomocí filtru Pallflex
Zápočtová práce z předmětu Statistika Vypracoval: 10. 11. 2014 Charakteristika datového souboru Zadání: Při kontrole dodržování hygienických norem v kuchyni se prováděl odběr vzduchu a pomocí filtru Pallflex
Popisná statistika kvantitativní veličiny
 StatSoft Popisná statistika kvantitativní veličiny Protože nám surová data obvykle žádnou smysluplnou informaci neposkytnou, je žádoucí vyjádřit tyto ve zhuštěnější formě. V předchozím dílu jsme začali
StatSoft Popisná statistika kvantitativní veličiny Protože nám surová data obvykle žádnou smysluplnou informaci neposkytnou, je žádoucí vyjádřit tyto ve zhuštěnější formě. V předchozím dílu jsme začali
23. Matematická statistika
 Projekt: Inovace oboru Mechatronik pro Zlínský kraj Registrační číslo: CZ.1.07/1.1.08/03.0009 23. Matematická statistika Statistika je věda, která se snaží zkoumat reálná data a s pomocí teorii pravděpodobnosti
Projekt: Inovace oboru Mechatronik pro Zlínský kraj Registrační číslo: CZ.1.07/1.1.08/03.0009 23. Matematická statistika Statistika je věda, která se snaží zkoumat reálná data a s pomocí teorii pravděpodobnosti
Renáta Bednárová STATISTIKA PRO EKONOMY
 Renáta Bednárová STATISTIKA PRO EKONOMY ZÁKLADNÍ STATISTICKÉ POJMY Statistika Statistický soubor Statistická jednotky Statistický znak STATISTIKA Vědní obor, který se zabývá hromadnými jevy Hromadné jevy
Renáta Bednárová STATISTIKA PRO EKONOMY ZÁKLADNÍ STATISTICKÉ POJMY Statistika Statistický soubor Statistická jednotky Statistický znak STATISTIKA Vědní obor, který se zabývá hromadnými jevy Hromadné jevy
Statistika s Excelem aneb Máme data. A co dál? Martina Litschmannová Katedra aplikované matematiky, FEI, VŠB-TU Ostrava
 Statistika s Excelem aneb Máme data. A co dál? Martina Litschmannová Katedra aplikované matematiky, FEI, VŠB-TU Ostrava ŠKOMAM 2016 Jak získat data? Primární zdroje dat Vlastní měření (fyzika, biologie,
Statistika s Excelem aneb Máme data. A co dál? Martina Litschmannová Katedra aplikované matematiky, FEI, VŠB-TU Ostrava ŠKOMAM 2016 Jak získat data? Primární zdroje dat Vlastní měření (fyzika, biologie,
MATEMATICKÁ STATISTIKA. Katedra matematiky a didaktiky matematiky Technická univerzita v Liberci
 MATEMATICKÁ STATISTIKA Dana Černá http://www.fp.tul.cz/kmd/ Katedra matematiky a didaktiky matematiky Technická univerzita v Liberci Matematická statistika Matematická statistika se zabývá matematickým
MATEMATICKÁ STATISTIKA Dana Černá http://www.fp.tul.cz/kmd/ Katedra matematiky a didaktiky matematiky Technická univerzita v Liberci Matematická statistika Matematická statistika se zabývá matematickým
Metodologie pro ISK II
 Metodologie pro ISK II Všechny hodnoty z daného intervalu Zjišťujeme: Centrální míry Variabilitu Šikmost, špičatost Percentily (decily, kvantily ) Zobrazení: histogram MODUS je hodnota, která se v datech
Metodologie pro ISK II Všechny hodnoty z daného intervalu Zjišťujeme: Centrální míry Variabilitu Šikmost, špičatost Percentily (decily, kvantily ) Zobrazení: histogram MODUS je hodnota, která se v datech
Statistické metody. Martin Schindler KAP, tel , budova G. naposledy upraveno: 9.
 Statistické metody Matematika pro přírodní vědy přednášející: konzul. hodiny: e-mail: Martin Schindler KAP, tel. 48 535 2836, budova G po dohodě martin.schindler@tul.cz naposledy upraveno: 9. ledna 2015,
Statistické metody Matematika pro přírodní vědy přednášející: konzul. hodiny: e-mail: Martin Schindler KAP, tel. 48 535 2836, budova G po dohodě martin.schindler@tul.cz naposledy upraveno: 9. ledna 2015,
Základní statistické charakteristiky
 Základní statistické charakteristiky Základní statistické charakteristiky slouží pro vzájemné porovnávání statistických souborů charakteristiky = čísla, pomocí kterých porovnáváme Základní statistické
Základní statistické charakteristiky Základní statistické charakteristiky slouží pro vzájemné porovnávání statistických souborů charakteristiky = čísla, pomocí kterých porovnáváme Základní statistické
TECHNICKÁ UNIVERZITA V LIBERCI SEMESTRÁLNÍ PRÁCE
 TECHNICKÁ UNIVERZITA V LIBERCI Ekonomická fakulta Studentská 2 461 17 Liberec 1 SEMESTRÁLNÍ PRÁCE STATISTICKÝ ROZBOR DAT Z DOTAZNÍKOVÝCH ŠETŘENÍ Gabriela Dlasková, Veronika Bukovinská Sára Kroupová, Dagmar
TECHNICKÁ UNIVERZITA V LIBERCI Ekonomická fakulta Studentská 2 461 17 Liberec 1 SEMESTRÁLNÍ PRÁCE STATISTICKÝ ROZBOR DAT Z DOTAZNÍKOVÝCH ŠETŘENÍ Gabriela Dlasková, Veronika Bukovinská Sára Kroupová, Dagmar
Úloha č. 2 - Kvantil a typická hodnota. (bodově tříděná data): (intervalově tříděná data): Zadání úlohy: Zadání úlohy:
: (intervalově tříděná data): Zadání úlohy: Zadání úlohy:") Úloha č. 1 - Kvantily a typická hodnota (bodově tříděná data): Určete typickou hodnotu, 40% a 80% kvantil. Tabulka hodnot: Varianta Četnost 0 4 1 14 2 17 3 37 4 20 5 14 6 7 7 11 8 20 Typická hodnota je
Úloha č. 1 - Kvantily a typická hodnota (bodově tříděná data): Určete typickou hodnotu, 40% a 80% kvantil. Tabulka hodnot: Varianta Četnost 0 4 1 14 2 17 3 37 4 20 5 14 6 7 7 11 8 20 Typická hodnota je
Úvod do kurzu. Moodle kurz. (a) https://dl1.cuni.cz/course/view.php?id=2022 (b) heslo pro hosty: statistika (c) skripta na pravděpodobnost
 https://dl1.cuni.cz/course/view.php?id=2022 (b) heslo pro hosty: statistika (c) skripta na pravděpodobnost") Úvod do kurzu Moodle kurz (a) https://dl1.cuni.cz/course/view.php?id=2022 (b) heslo pro hosty: statistika (c) skripta na pravděpodobnost Výpočty online: www.statisticsonweb.tf.czu.cz Začátek výuky posunut
Úvod do kurzu Moodle kurz (a) https://dl1.cuni.cz/course/view.php?id=2022 (b) heslo pro hosty: statistika (c) skripta na pravděpodobnost Výpočty online: www.statisticsonweb.tf.czu.cz Začátek výuky posunut
Analýza dat na PC I.
 CENTRUM BIOSTATISTIKY A ANALÝZ Lékařská a Přírodovědecká fakulta, Masarykova univerzita Analýza dat na PC I. Popisná analýza v programu Statistica IBA výuka Základní popisná statistika Popisná statistika
CENTRUM BIOSTATISTIKY A ANALÝZ Lékařská a Přírodovědecká fakulta, Masarykova univerzita Analýza dat na PC I. Popisná analýza v programu Statistica IBA výuka Základní popisná statistika Popisná statistika
Obecné momenty prosté tvary
 Obecné momenty prosté tvary První obecný moment: (Σy i )/n, i=1 n aritmetický průměr, těžiště dat y Druhý obecný moment: (Σy i2 )/n, i=1 n y 2 Obecné momenty prosté tvary Příklad 1 pokračování: y = (3+4+2+3+2+3+3+3)/8
Obecné momenty prosté tvary První obecný moment: (Σy i )/n, i=1 n aritmetický průměr, těžiště dat y Druhý obecný moment: (Σy i2 )/n, i=1 n y 2 Obecné momenty prosté tvary Příklad 1 pokračování: y = (3+4+2+3+2+3+3+3)/8
KGG/STG Statistika pro geografy
 KGG/STG Statistika pro geografy 5. Odhady parametrů základního souboru Mgr. David Fiedor 16. března 2015 Vztahy mezi výběrovým a základním souborem Osnova 1 Úvod, pojmy Vztahy mezi výběrovým a základním
KGG/STG Statistika pro geografy 5. Odhady parametrů základního souboru Mgr. David Fiedor 16. března 2015 Vztahy mezi výběrovým a základním souborem Osnova 1 Úvod, pojmy Vztahy mezi výběrovým a základním
marek.pomp@vsb.cz http://homel.vsb.cz/~pom68
 Statistika B (151-0303) Marek Pomp ZS 2014 marek.pomp@vsb.cz http://homel.vsb.cz/~pom68 Cvičení: Pavlína Kuráňová & Marek Pomp Podmínky pro úspěšné ukončení zápočet 45 bodů, min. 23 bodů, dvě zápočtové
Statistika B (151-0303) Marek Pomp ZS 2014 marek.pomp@vsb.cz http://homel.vsb.cz/~pom68 Cvičení: Pavlína Kuráňová & Marek Pomp Podmínky pro úspěšné ukončení zápočet 45 bodů, min. 23 bodů, dvě zápočtové
Popisná statistika. Komentované řešení pomocí programu R. Ústav matematiky Fakulta chemicko inženýrská Vysoká škola chemicko-technologická v Praze
 Komentované řešení pomocí programu R Ústav matematiky Fakulta chemicko inženýrská Vysoká škola chemicko-technologická v Praze Načtení vstupních dat Máme k dispozici data o počtech bodů z 1. a 2. zápočtového
Komentované řešení pomocí programu R Ústav matematiky Fakulta chemicko inženýrská Vysoká škola chemicko-technologická v Praze Načtení vstupních dat Máme k dispozici data o počtech bodů z 1. a 2. zápočtového
Statistika. cílem je zjednodušit nějaká data tak, abychom se v nich lépe vyznali důsledkem je ztráta informací!
 Statistika aneb známe tři druhy lži: úmyslná neúmyslná statistika Statistika je metoda, jak vyjádřit nejistá data s přesností na setinu procenta. den..00..00 3..00..00..00..00..00..00..00..00..00..00 3..00..00..00..00..00..00..00
Statistika aneb známe tři druhy lži: úmyslná neúmyslná statistika Statistika je metoda, jak vyjádřit nejistá data s přesností na setinu procenta. den..00..00 3..00..00..00..00..00..00..00..00..00..00 3..00..00..00..00..00..00..00
Praktická statistika. Petr Ponížil Eva Kutálková
 Praktická statistika Petr Ponížil Eva Kutálková Zápis výsledků měření Předpokládejme, že známe hodnotu napětí U = 238,9 V i její chybu 3,3 V. Hodnotu veličiny zapíšeme na tolik míst, aby až poslední bylo
Praktická statistika Petr Ponížil Eva Kutálková Zápis výsledků měření Předpokládejme, že známe hodnotu napětí U = 238,9 V i její chybu 3,3 V. Hodnotu veličiny zapíšeme na tolik míst, aby až poslední bylo
Regresní a korelační analýza
 Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
31. 3. 2014, Brno Hanuš Vavrčík Základy statistiky ve vědě
 31. 3. 2014, Brno Hanuš Vavrčík Základy statistiky ve vědě Motto Statistika nuda je, má však cenné údaje. strana 3 Statistické charakteristiky Charakteristiky polohy jsou kolem ní seskupeny ostatní hodnoty
31. 3. 2014, Brno Hanuš Vavrčík Základy statistiky ve vědě Motto Statistika nuda je, má však cenné údaje. strana 3 Statistické charakteristiky Charakteristiky polohy jsou kolem ní seskupeny ostatní hodnoty
Výrobní produkce divizí Ice Cream Po lo ha plane t Rozložený výse ový 3D graf Bublinový graf Histogram t s tn e ídy
 Výrobní produkce divizí Ice Cream Polo ha planet Rozložený výsečový 3D graf Bublinový graf Ice Cream 1 15% Ice Cream 2 12% Ice Cream 3 18% Ice Cream 4 20% Statistika 40 30 20 Ice Cream 6 19% Ice Cream
Výrobní produkce divizí Ice Cream Polo ha planet Rozložený výsečový 3D graf Bublinový graf Ice Cream 1 15% Ice Cream 2 12% Ice Cream 3 18% Ice Cream 4 20% Statistika 40 30 20 Ice Cream 6 19% Ice Cream
Regresní a korelační analýza
 Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Popisná statistika. Jaroslav MAREK. Univerzita Palackého
 Popisná statistika Jaroslav MAREK Univerzita Palackého Přírodovědecká fakulta Katedra matematické analýzy a aplikací matematiky Tomkova 40, 779 00 Olomouc Hejčín tel. 585634606 marek@inf.upol.cz pondělí
Popisná statistika Jaroslav MAREK Univerzita Palackého Přírodovědecká fakulta Katedra matematické analýzy a aplikací matematiky Tomkova 40, 779 00 Olomouc Hejčín tel. 585634606 marek@inf.upol.cz pondělí
Popisná statistika. úvod rozdělení hodnot míry centrální tendence míry variability míry šikmosti a špičatosti grafy
 Popisná statistika úvod rozdělení hodnot míry centrální tendence míry variability míry šikmosti a špičatosti grafy Úvod užívá se k popisu základních vlastností dat poskytuje jednoduché shrnutí hodnot proměnných
Popisná statistika úvod rozdělení hodnot míry centrální tendence míry variability míry šikmosti a špičatosti grafy Úvod užívá se k popisu základních vlastností dat poskytuje jednoduché shrnutí hodnot proměnných
MATEMATIKA III V PŘÍKLADECH
 VYSOKÁ ŠKOLA BÁŇSKÁ TECHNICKÁ UNIVERZITA OSTRAVA FAKULTA STROJNÍ MATEMATIKA III V PŘÍKLADECH Cvičení 8 Statistický soubor s jedním argumentem Mgr. Petr Otipka Ostrava 2013 Mgr. Petr Otipka Vysoká škola
VYSOKÁ ŠKOLA BÁŇSKÁ TECHNICKÁ UNIVERZITA OSTRAVA FAKULTA STROJNÍ MATEMATIKA III V PŘÍKLADECH Cvičení 8 Statistický soubor s jedním argumentem Mgr. Petr Otipka Ostrava 2013 Mgr. Petr Otipka Vysoká škola
Základy pravděpodobnosti a statistiky. Popisná statistika
 Základy pravděpodobnosti a statistiky Popisná statistika Josef Tvrdík Přírodovědecká fakulta, katedra informatiky josef.tvrdik@osu.cz konzultace v úterý 14.10 až 15.40 hod. Příklad ze života Cimrman, Smoljak/Svěrák,
Základy pravděpodobnosti a statistiky Popisná statistika Josef Tvrdík Přírodovědecká fakulta, katedra informatiky josef.tvrdik@osu.cz konzultace v úterý 14.10 až 15.40 hod. Příklad ze života Cimrman, Smoljak/Svěrák,
TECHNICKÁ UNIVERZITA V LIBERCI. Ekonomická fakulta. Semestrální práce. Statistický rozbor dat z dotazníkového šetření školní zadání
 TECHNICKÁ UNIVERZITA V LIBERCI Ekonomická fakulta Semestrální práce Statistický rozbor dat z dotazníkového šetření školní zadání Skupina: 51 Vypracovaly: Pavlína Horná, Nikola Loumová, Petra Mikešová,
TECHNICKÁ UNIVERZITA V LIBERCI Ekonomická fakulta Semestrální práce Statistický rozbor dat z dotazníkového šetření školní zadání Skupina: 51 Vypracovaly: Pavlína Horná, Nikola Loumová, Petra Mikešová,
Regresní a korelační analýza
 Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
ZÁKLADNÍ STATISTICKÉ CHARAKTERISTIKY
 zhanel@fsps.muni.cz ZÁKLADNÍ STATISTICKÉ CHARAKTERISTIKY METODY DESKRIPTIVNÍ STATISTIKY 1. URČENÍ TYPU ŠKÁLY (nominální, ordinální, metrické) a) nominální + ordinální neparametrické stat. metody b) metrické
zhanel@fsps.muni.cz ZÁKLADNÍ STATISTICKÉ CHARAKTERISTIKY METODY DESKRIPTIVNÍ STATISTIKY 1. URČENÍ TYPU ŠKÁLY (nominální, ordinální, metrické) a) nominální + ordinální neparametrické stat. metody b) metrické
Mnohorozměrná statistická data
 Mnohorozměrná statistická data Ekonometrie Jiří Neubauer Katedra ekonometrie FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Jiří Neubauer (Katedra ekonometrie UO Brno) Mnohorozměrná
Mnohorozměrná statistická data Ekonometrie Jiří Neubauer Katedra ekonometrie FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Jiří Neubauer (Katedra ekonometrie UO Brno) Mnohorozměrná
Mnohorozměrná statistická data
 Statistika II Katedra ekonometrie FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Statistický znak, statistický soubor Jednotlivé objekty nebo subjekty, které jsou při statistickém
Statistika II Katedra ekonometrie FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Statistický znak, statistický soubor Jednotlivé objekty nebo subjekty, které jsou při statistickém
Příloha podrobný výklad vybraných pojmů
 Příloha podrobný výklad vybraných pojmů 1.1 Parametry (popisné charakteristiky) základního souboru 1.1.1 Míry polohy (střední hodnoty) Aritmetický průměr představuje pravděpodobně nejznámější střední hodnotou,
Příloha podrobný výklad vybraných pojmů 1.1 Parametry (popisné charakteristiky) základního souboru 1.1.1 Míry polohy (střední hodnoty) Aritmetický průměr představuje pravděpodobně nejznámější střední hodnotou,
Náhodná proměnná. Náhodná proměnná může mít rozdělení diskrétní (x 1. , x 2. ; x 2. spojité (<x 1
 Náhodná proměnná Náhodná proměnná může mít rozdělení diskrétní (x 1, x 2,,x n ) spojité () Poznámky: 1. Fyzikální veličiny jsou zpravidla spojité, ale změřené hodnoty jsou diskrétní. 2. Pokud
Náhodná proměnná Náhodná proměnná může mít rozdělení diskrétní (x 1, x 2,,x n ) spojité () Poznámky: 1. Fyzikální veličiny jsou zpravidla spojité, ale změřené hodnoty jsou diskrétní. 2. Pokud
Jevy a náhodná veličina
 Jevy a náhodná veličina Výsledky některých jevů jsou vyjádřeny číselně -na hrací kostce padne číslo 1, 4, 6.., jiným jevům můžeme čísla přiřadit (stupeň školního vzdělání: ZŠ, SŠ, VŠ) Data jsme rozdělili
Jevy a náhodná veličina Výsledky některých jevů jsou vyjádřeny číselně -na hrací kostce padne číslo 1, 4, 6.., jiným jevům můžeme čísla přiřadit (stupeň školního vzdělání: ZŠ, SŠ, VŠ) Data jsme rozdělili
Komplexní čísla, Kombinatorika, pravděpodobnost a statistika, Posloupnosti a řady
 Předmět: Náplň: Třída: Počet hodin: Pomůcky: Matematika Komplexní čísla, Kombinatorika, pravděpodobnost a statistika, Posloupnosti a řady 4. ročník a oktáva 3 hodiny týdně PC a dataprojektor, učebnice
Předmět: Náplň: Třída: Počet hodin: Pomůcky: Matematika Komplexní čísla, Kombinatorika, pravděpodobnost a statistika, Posloupnosti a řady 4. ročník a oktáva 3 hodiny týdně PC a dataprojektor, učebnice
3. Základní statistické charakteristiky. KGG/STG Zimní semestr Základní statistické charakteristiky 1
 3. charakteristiky charakteristiky 1 charakteristiky slouží pro vzájemné porovnávání statistických souborů charakteristiky = čísla, pomocí kterých porovnáváme charakteristiky 2 charakteristiky Dva hlavní
3. charakteristiky charakteristiky 1 charakteristiky slouží pro vzájemné porovnávání statistických souborů charakteristiky = čísla, pomocí kterých porovnáváme charakteristiky 2 charakteristiky Dva hlavní
Zpracování náhodného výběru. Ing. Michal Dorda, Ph.D.
 Př. : Stanovte jednotlivé četnosti a číselné charakteristiky zadaného statistického souboru a nakreslete krabicový graf:, 8, 7, 43, 9, 47, 4, 34, 34, 4, 35. Statistický soubor seřadíme vzestupně podle
Př. : Stanovte jednotlivé četnosti a číselné charakteristiky zadaného statistického souboru a nakreslete krabicový graf:, 8, 7, 43, 9, 47, 4, 34, 34, 4, 35. Statistický soubor seřadíme vzestupně podle
Základy popisné statistiky
 Základy popisné statistiky V této kapitole se seznámíme se základy popisné statistiky, představíme si základní pojmy a budeme si je ilustrovat na praktických příkladech. Kapitola je psána formou volného
Základy popisné statistiky V této kapitole se seznámíme se základy popisné statistiky, představíme si základní pojmy a budeme si je ilustrovat na praktických příkladech. Kapitola je psána formou volného
TEST Z TEORIE EXPLORAČNÍ ANALÝZA DAT
 EXPLORAČNÍ ANALÝZA DAT TEST Z TEORIE 1. Test ze Statistiky píše velké množství studentů. Představte si, že každý z nich odpoví správně přesně na polovinu otázek. V tomto případě bude směrodatná odchylka
EXPLORAČNÍ ANALÝZA DAT TEST Z TEORIE 1. Test ze Statistiky píše velké množství studentů. Představte si, že každý z nich odpoví správně přesně na polovinu otázek. V tomto případě bude směrodatná odchylka
2. Základní typy dat Spojitá a kategoriální data Základní popisné statistiky Frekvenční tabulky Grafický popis dat
 2. Základní typy dat Spojitá a kategoriální data Základní popisné statistiky Frekvenční tabulky Grafický popis dat Anotace Realitu můžeme popisovat různými typy dat, každý z nich se specifickými vlastnostmi,
2. Základní typy dat Spojitá a kategoriální data Základní popisné statistiky Frekvenční tabulky Grafický popis dat Anotace Realitu můžeme popisovat různými typy dat, každý z nich se specifickými vlastnostmi,
Lineární regrese. Komentované řešení pomocí MS Excel
 Lineární regrese Komentované řešení pomocí MS Excel Vstupní data Tabulka se vstupními daty je umístěna v oblasti A1:B11 (viz. obrázek) na listu cela data Postup Základní výpočty - regrese Výpočet základních
Lineární regrese Komentované řešení pomocí MS Excel Vstupní data Tabulka se vstupními daty je umístěna v oblasti A1:B11 (viz. obrázek) na listu cela data Postup Základní výpočty - regrese Výpočet základních
Pravděpodobnost a statistika
 Pravděpodobnost a statistika Teorie pravděpodobnosti popisuje vznik náhodných dat, zatímco matematická statistika usuzuje z dat na charakter procesů, jimiž data vznikla. NÁHODNOST - forma existence látky,
Pravděpodobnost a statistika Teorie pravděpodobnosti popisuje vznik náhodných dat, zatímco matematická statistika usuzuje z dat na charakter procesů, jimiž data vznikla. NÁHODNOST - forma existence látky,
INDUKTIVNÍ STATISTIKA
 10. SEMINÁŘ INDUKTIVNÍ STATISTIKA 3. HODNOCENÍ ZÁVISLOSTÍ HODNOCENÍ ZÁVISLOSTÍ KVALITATIVNÍ VELIČINY - Vychází se z kombinační (kontingenční) tabulky, která je výsledkem třídění druhého stupně KVANTITATIVNÍ
10. SEMINÁŘ INDUKTIVNÍ STATISTIKA 3. HODNOCENÍ ZÁVISLOSTÍ HODNOCENÍ ZÁVISLOSTÍ KVALITATIVNÍ VELIČINY - Vychází se z kombinační (kontingenční) tabulky, která je výsledkem třídění druhého stupně KVANTITATIVNÍ
Regresní a korelační analýza
 Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Regresní a korelační analýza
 Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Metoda Monte Carlo a její aplikace v problematice oceňování technologií. Manuál k programu
 Metoda Monte Carlo a její aplikace v problematice oceňování technologií Manuál k programu This software was created under the state subsidy of the Czech Republic within the research and development project
Metoda Monte Carlo a její aplikace v problematice oceňování technologií Manuál k programu This software was created under the state subsidy of the Czech Republic within the research and development project
STATISTIKA S EXCELEM. Martina Litschmannová MODAM,
 STATISTIKA S EXCELEM Martina Litschmannová MODAM, 8. 4. 216 Obsah Motivace aneb Máme data a co dál? Základní terminologie Analýza kvalitativního znaku rozdělení četnosti, vizualizace Analýza kvantitativního
STATISTIKA S EXCELEM Martina Litschmannová MODAM, 8. 4. 216 Obsah Motivace aneb Máme data a co dál? Základní terminologie Analýza kvalitativního znaku rozdělení četnosti, vizualizace Analýza kvantitativního
Požadavky k opravným zkouškám z matematiky školní rok 2013-2014
 Požadavky k opravným zkouškám z matematiky školní rok 2013-2014 1. ročník (první pololetí, druhé pololetí) 1) Množiny. Číselné obory N, Z, Q, I, R. 2) Absolutní hodnota reálného čísla, intervaly. 3) Procenta,
Požadavky k opravným zkouškám z matematiky školní rok 2013-2014 1. ročník (první pololetí, druhé pololetí) 1) Množiny. Číselné obory N, Z, Q, I, R. 2) Absolutní hodnota reálného čísla, intervaly. 3) Procenta,
letní semestr Katedra pravděpodobnosti a matematické statistiky Matematicko-fyzikální fakulta Univerzity Karlovy Matematická statistika
 Šárka Hudecová Katedra pravděpodobnosti a matematické Matematicko-fyzikální fakulta Univerzity Karlovy letní semestr 2012 1 1 Založeno na materiálech doc. Michala Kulicha Opakování populace a výběr z populace
Šárka Hudecová Katedra pravděpodobnosti a matematické Matematicko-fyzikální fakulta Univerzity Karlovy letní semestr 2012 1 1 Založeno na materiálech doc. Michala Kulicha Opakování populace a výběr z populace
KORELACE. Komentované řešení pomocí programu Statistica
 KORELACE Komentované řešení pomocí programu Statistica Vstupní data I Data umístěná v excelovském souboru překopírujeme do tabulky ve Statistice a pojmenujeme proměnné, viz prezentace k tématu Popisná
KORELACE Komentované řešení pomocí programu Statistica Vstupní data I Data umístěná v excelovském souboru překopírujeme do tabulky ve Statistice a pojmenujeme proměnné, viz prezentace k tématu Popisná
Popisná statistika. úvod rozdělení hodnot míry centrální tendence míry variability míry šikmosti a špičatosti grafy
 Popisná statistika úvod rozdělení hodnot míry centrální tendence míry variability míry šikmosti a špičatosti grafy Úvod užívá se k popisu základních vlastností dat poskytuje jednoduché shrnutí hodnot proměnných
Popisná statistika úvod rozdělení hodnot míry centrální tendence míry variability míry šikmosti a špičatosti grafy Úvod užívá se k popisu základních vlastností dat poskytuje jednoduché shrnutí hodnot proměnných
UNIVERZITA OBRANY Fakulta ekonomiky a managementu. Aplikace STAT1. Výsledek řešení projektu PRO HORR2011 a PRO GRAM2011 3. 11.
 UNIVERZITA OBRANY Fakulta ekonomiky a managementu Aplikace STAT1 Výsledek řešení projektu PRO HORR2011 a PRO GRAM2011 Jiří Neubauer, Marek Sedlačík, Oldřich Kříž 3. 11. 2012 Popis a návod k použití aplikace
UNIVERZITA OBRANY Fakulta ekonomiky a managementu Aplikace STAT1 Výsledek řešení projektu PRO HORR2011 a PRO GRAM2011 Jiří Neubauer, Marek Sedlačík, Oldřich Kříž 3. 11. 2012 Popis a návod k použití aplikace
Regresní analýza 1. Regresní analýza
 Regresní analýza 1 1 Regresní funkce Regresní analýza Důležitou statistickou úlohou je hledání a zkoumání závislostí proměnných, jejichž hodnoty získáme při realizaci experimentů Vzhledem k jejich náhodnému
Regresní analýza 1 1 Regresní funkce Regresní analýza Důležitou statistickou úlohou je hledání a zkoumání závislostí proměnných, jejichž hodnoty získáme při realizaci experimentů Vzhledem k jejich náhodnému
UKAZATELÉ VARIABILITY
 UKAZATELÉ VARIABILITY VÝZNAM Porovnejte známky dvou studentek ze stejného předmětu: Studentka A: Studentka B: Oba soubory mají stejný rozsah hodnoty, ale liší se známky studentky A jsou vyrovnanější, jsou
UKAZATELÉ VARIABILITY VÝZNAM Porovnejte známky dvou studentek ze stejného předmětu: Studentka A: Studentka B: Oba soubory mají stejný rozsah hodnoty, ale liší se známky studentky A jsou vyrovnanější, jsou
Otázky k měření centrální tendence. 1. Je dáno rozložení, ve kterém průměr = medián. Co musí být pravdivé o tvaru tohoto rozložení?
 Otázky k měření centrální tendence 1. Je dáno rozložení, ve kterém průměr = medián. Co musí být pravdivé o tvaru tohoto rozložení? 2. Určete průměr, medián a modus u prvních čtyř rozložení (sad dat): a.
Otázky k měření centrální tendence 1. Je dáno rozložení, ve kterém průměr = medián. Co musí být pravdivé o tvaru tohoto rozložení? 2. Určete průměr, medián a modus u prvních čtyř rozložení (sad dat): a.
Statistika. Diskrétní data. Spojitá data. Charakteristiky polohy. Charakteristiky variability
 I Přednáška Statistika Diskrétní data Spojitá data Charakteristiky polohy Charakteristiky variability Statistika deskriptivní statistika ˆ induktivní statistika populace (základní soubor) ˆ výběr parametry
I Přednáška Statistika Diskrétní data Spojitá data Charakteristiky polohy Charakteristiky variability Statistika deskriptivní statistika ˆ induktivní statistika populace (základní soubor) ˆ výběr parametry
Deskriptivní statistika (kategorizované proměnné)
") Deskriptivní statistika (kategorizované proměnné) Nejprve malé opakování: - Deskriptivní statistika se zabývá popisem dat, jejich sumarizaci a prezentací. - Kategorizované proměnné jsou všechny proměnné,
Deskriptivní statistika (kategorizované proměnné) Nejprve malé opakování: - Deskriptivní statistika se zabývá popisem dat, jejich sumarizaci a prezentací. - Kategorizované proměnné jsou všechny proměnné,
Porovnání dvou výběrů
 Porovnání dvou výběrů Menu: QCExpert Porovnání dvou výběrů Tento modul je určen pro podrobnou analýzu dvou datových souborů (výběrů). Modul poskytuje dva postupy analýzy: porovnání dvou nezávislých výběrů
Porovnání dvou výběrů Menu: QCExpert Porovnání dvou výběrů Tento modul je určen pro podrobnou analýzu dvou datových souborů (výběrů). Modul poskytuje dva postupy analýzy: porovnání dvou nezávislých výběrů
Statistika I (KMI/PSTAT)
") Statistika I (KMI/PSTAT) Cvičení druhé aneb Kvantily, distribuční funkce Statistika I (KMI/PSTAT) 1 / 1 Co se dnes naučíme Po absolvování této hodiny byste měli být schopni: rozumět pojmu modus (modální
Statistika I (KMI/PSTAT) Cvičení druhé aneb Kvantily, distribuční funkce Statistika I (KMI/PSTAT) 1 / 1 Co se dnes naučíme Po absolvování této hodiny byste měli být schopni: rozumět pojmu modus (modální
Kontingenční tabulky v Excelu. Představení programu Statistica
 ASTAc/01 Biostatistika 2. cvičení Kontingenční tabulky v Excelu Základní popisné statistiky Představení programu Statistica Import a základní popis dat ve Statistice, M. Cvanová I. Kontingenční tabulky
ASTAc/01 Biostatistika 2. cvičení Kontingenční tabulky v Excelu Základní popisné statistiky Představení programu Statistica Import a základní popis dat ve Statistice, M. Cvanová I. Kontingenční tabulky
4. Zpracování číselných dat
 4. Zpracování číselných dat 4.1 Jednoduché hodnocení dat 4.2 Začlenění dat do písemné práce Zásady zpracování vědecké práce pro obory BOZO, PÚPN, LS 2011 4.1 Hodnocení číselných dat Popisná data: střední
4. Zpracování číselných dat 4.1 Jednoduché hodnocení dat 4.2 Začlenění dat do písemné práce Zásady zpracování vědecké práce pro obory BOZO, PÚPN, LS 2011 4.1 Hodnocení číselných dat Popisná data: střední
Metodologie pro Informační studia a knihovnictví 2
 Metodologie pro Informační studia a knihovnictví 2 Modul 5: Popis nekategorizovaných dat Co se dozvíte v tomto modulu? Kdy používat modus, průměr a medián. Co je to směrodatná odchylka. Jak popsat distribuci
Metodologie pro Informační studia a knihovnictví 2 Modul 5: Popis nekategorizovaných dat Co se dozvíte v tomto modulu? Kdy používat modus, průměr a medián. Co je to směrodatná odchylka. Jak popsat distribuci
KGG/STG Statistika pro geografy
 KGG/STG Statistika pro geografy 9. Korelační analýza Mgr. David Fiedor 20. dubna 2015 Analýza závislostí v řadě geografických disciplín studujeme jevy, u kterých vyšetřujeme nikoliv pouze jednu vlastnost
KGG/STG Statistika pro geografy 9. Korelační analýza Mgr. David Fiedor 20. dubna 2015 Analýza závislostí v řadě geografických disciplín studujeme jevy, u kterých vyšetřujeme nikoliv pouze jednu vlastnost
Normální (Gaussovo) rozdělení
 rozdělení") Normální (Gaussovo) rozdělení Normální (Gaussovo) rozdělení popisuje vlastnosti náhodné spojité veličiny, která vzniká složením různých náhodných vlivů, které jsou navzájem nezávislé, kterých je velký
Normální (Gaussovo) rozdělení Normální (Gaussovo) rozdělení popisuje vlastnosti náhodné spojité veličiny, která vzniká složením různých náhodných vlivů, které jsou navzájem nezávislé, kterých je velký
Statistika pro gymnázia
 Statistika pro gymnázia Pracovní verze učebního textu ZÁKLADNÍ POJMY Statistika zkoumá jevy (společenské, přírodní, technické) ve velkých statistických souborech. Prvky statistických souborů se nazývají
Statistika pro gymnázia Pracovní verze učebního textu ZÁKLADNÍ POJMY Statistika zkoumá jevy (společenské, přírodní, technické) ve velkých statistických souborech. Prvky statistických souborů se nazývají
Aplikovaná statistika v R
 Aplikovaná statistika v R Filip Děchtěrenko Matematicko-fyzikální fakulta filip.dechterenko@gmail.com 15.5.2014 Filip Děchtěrenko (MFF UK) Aplikovaná statistika v R 15.5.2014 1 / 15 Co bude náplní našich
Aplikovaná statistika v R Filip Děchtěrenko Matematicko-fyzikální fakulta filip.dechterenko@gmail.com 15.5.2014 Filip Děchtěrenko (MFF UK) Aplikovaná statistika v R 15.5.2014 1 / 15 Co bude náplní našich
Zaokrouhlování: Směrodatná odchylka se zaokrouhluje nahoru na stanovený počet platných cifer. Míry
 Červenou barvou jsou poznámky, věci na které máte při vypracovávání úkolu myslet. Úkol 1 a) Pomocí nástrojů explorační analýzy analyzujte kapacity akumulátorů výrobce A po 5 a po 100 nabíjecích cyklech.
Červenou barvou jsou poznámky, věci na které máte při vypracovávání úkolu myslet. Úkol 1 a) Pomocí nástrojů explorační analýzy analyzujte kapacity akumulátorů výrobce A po 5 a po 100 nabíjecích cyklech.
STATISTICKÉ ODHADY Odhady populačních charakteristik
 STATISTICKÉ ODHADY Odhady populačních charakteristik Jak stanovit charakteristiky rozložení sledované veličiny v základní populaci? Populaci většinou nemáme celou k dispozici, musíme se spokojit jen s
STATISTICKÉ ODHADY Odhady populačních charakteristik Jak stanovit charakteristiky rozložení sledované veličiny v základní populaci? Populaci většinou nemáme celou k dispozici, musíme se spokojit jen s
Pojem a úkoly statistiky
 Katedra ekonometrie FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Pojem a úkoly statistiky Statistika je věda, která se zabývá získáváním, zpracováním a analýzou dat pro potřeby
Katedra ekonometrie FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Pojem a úkoly statistiky Statistika je věda, která se zabývá získáváním, zpracováním a analýzou dat pro potřeby
Kombinatorika, pravděpodobnost a statistika, Posloupnosti a řady
 Předmět: Náplň: Třída: Počet hodin: Pomůcky: Matematika Kombinatorika, pravděpodobnost a statistika, Posloupnosti a řady 4. ročník 3 hodiny týdně PC a dataprojektor Kombinatorika Řeší jednoduché úlohy
Předmět: Náplň: Třída: Počet hodin: Pomůcky: Matematika Kombinatorika, pravděpodobnost a statistika, Posloupnosti a řady 4. ročník 3 hodiny týdně PC a dataprojektor Kombinatorika Řeší jednoduché úlohy
VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ. FAKULTA STROJNÍHO INŽENÝRSTVÍ Ústav materiálového inženýrství - odbor slévárenství
 1 PŘÍLOHA KE KAPITOLE 11 2 Seznam příloh ke kapitole 11 Podkapitola 11.2. Přilité tyče: Graf 1 Graf 2 Graf 3 Graf 4 Graf 5 Graf 6 Graf 7 Graf 8 Graf 9 Graf 1 Graf 11 Rychlost šíření ultrazvuku vs. pořadí
1 PŘÍLOHA KE KAPITOLE 11 2 Seznam příloh ke kapitole 11 Podkapitola 11.2. Přilité tyče: Graf 1 Graf 2 Graf 3 Graf 4 Graf 5 Graf 6 Graf 7 Graf 8 Graf 9 Graf 1 Graf 11 Rychlost šíření ultrazvuku vs. pořadí
10. cvičení z PST. 5. prosince T = (n 1) S2 X. (n 1) s2 x σ 2 q χ 2 (n 1) (1 α 2 ). q χ 2 (n 1) 2. 2 x. (n 1) s. x = 1 6. x i = 457.
 S2 X. (n 1) s2 x σ 2 q χ 2 (n 1) (1 α 2 ). q χ 2 (n 1) 2. 2 x. (n 1) s. x = 1 6. x i = 457.") 0 cvičení z PST 5 prosince 208 0 (intervalový odhad pro rozptyl) Soubor (70, 84, 89, 70, 74, 70) je náhodným výběrem z normálního rozdělení N(µ, σ 2 ) Určete oboustranný symetrický 95% interval spolehlivosti
0 cvičení z PST 5 prosince 208 0 (intervalový odhad pro rozptyl) Soubor (70, 84, 89, 70, 74, 70) je náhodným výběrem z normálního rozdělení N(µ, σ 2 ) Určete oboustranný symetrický 95% interval spolehlivosti
Nejčastější chyby v explorační analýze
 Nejčastější chyby v explorační analýze Obecně doporučuju přečíst přednášku 5: Výběrová šetření, Exploratorní analýza http://homel.vsb.cz/~lit40/sta1/materialy/io.pptx Použití nesprávných charakteristik
Nejčastější chyby v explorační analýze Obecně doporučuju přečíst přednášku 5: Výběrová šetření, Exploratorní analýza http://homel.vsb.cz/~lit40/sta1/materialy/io.pptx Použití nesprávných charakteristik
Zákony hromadění chyb.
 Zákony hromadění chyb. Zákon hromadění skutečných chyb. Zákon hromadění středních chyb. Tomáš Bayer bayertom@natur.cuni.cz Přírodovědecká fakulta Univerzity Karlovy v Praze, Katedra aplikované geoinformatiky
Zákony hromadění chyb. Zákon hromadění skutečných chyb. Zákon hromadění středních chyb. Tomáš Bayer bayertom@natur.cuni.cz Přírodovědecká fakulta Univerzity Karlovy v Praze, Katedra aplikované geoinformatiky
Metodologie pro Informační studia a knihovnictví 2
 Metodologie pro Informační studia a knihovnictví 2 Modul V: Nekategorizovaná data Metodologie pro ISK 2, jaro 2014. Ladislava Z. Suchá Metodologie pro Informační studia a knihovnictví 2 Modul 5: Popis
Metodologie pro Informační studia a knihovnictví 2 Modul V: Nekategorizovaná data Metodologie pro ISK 2, jaro 2014. Ladislava Z. Suchá Metodologie pro Informační studia a knihovnictví 2 Modul 5: Popis
Kartografické stupnice. Přednáška z předmětu Tematická kartografie (KMA/TKA) Otakar Čerba Západočeská univerzita
 Otakar Čerba Západočeská univerzita") Kartografické stupnice Přednáška z předmětu Tematická kartografie (KMA/TKA) Otakar Čerba Západočeská univerzita Datum vytvoření dokumentu: 20. 9. 2004 Datum poslední aktualizace: 16. 10. 2012 Stupnice
Kartografické stupnice Přednáška z předmětu Tematická kartografie (KMA/TKA) Otakar Čerba Západočeská univerzita Datum vytvoření dokumentu: 20. 9. 2004 Datum poslední aktualizace: 16. 10. 2012 Stupnice
Me neˇ nezˇ minimum ze statistiky Michaela S ˇ edova KPMS MFF UK Principy medicı ny zalozˇene na du kazech a za klady veˇdecke prˇı pravy 1 / 33
 1 / 33 Méně než minimum ze statistiky Michaela Šedová KPMS MFF UK Principy medicíny založené na důkazech a základy vědecké přípravy Příklad Studie syndromu náhodného úmrtí dětí. Dvě skupiny: Děti, které
1 / 33 Méně než minimum ze statistiky Michaela Šedová KPMS MFF UK Principy medicíny založené na důkazech a základy vědecké přípravy Příklad Studie syndromu náhodného úmrtí dětí. Dvě skupiny: Děti, které
Matematika III. 29. října Vysoká škola báňská - Technická univerzita Ostrava. Matematika III
 Vysoká škola báňská - Technická univerzita Ostrava 29. října 2018 Statistika Statistika Statistika je jako bikini. Co odhaluje, je zajímavé, co skrývá, je podstatné. Aaron Levenstein Statistika Statistika
Vysoká škola báňská - Technická univerzita Ostrava 29. října 2018 Statistika Statistika Statistika je jako bikini. Co odhaluje, je zajímavé, co skrývá, je podstatné. Aaron Levenstein Statistika Statistika
Diskrétní náhodná veličina
 Lekce Diskrétní náhodná veličina Výsledek náhodného pokusu může být vyjádřen slovně to vede k zavedení pojmu náhodného jevu Výsledek náhodného pokusu můžeme někdy vyjádřit i číselně, což vede k pojmu náhodné
Lekce Diskrétní náhodná veličina Výsledek náhodného pokusu může být vyjádřen slovně to vede k zavedení pojmu náhodného jevu Výsledek náhodného pokusu můžeme někdy vyjádřit i číselně, což vede k pojmu náhodné
Pravděpodobnost a statistika, Biostatistika pro kombinované studium. Jan Kracík
 Pravděpodobnost a statistika, Biostatistika pro kombinované studium Letní semestr 2017/2018 Tutoriál č. 2:, náhodný vektor Jan Kracík jan.kracik@vsb.cz náhodná veličina rozdělení pravděpodobnosti náhodné
Pravděpodobnost a statistika, Biostatistika pro kombinované studium Letní semestr 2017/2018 Tutoriál č. 2:, náhodný vektor Jan Kracík jan.kracik@vsb.cz náhodná veličina rozdělení pravděpodobnosti náhodné