Přednáška 12: Shlukování
|
|
|
- Renata Dagmar Vlčková
- před 5 lety
- Počet zobrazení:
Transkript



")

1 České vysoké učení technické v Praze Fakulta informačních technologií Katedra teoretické informatiky Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti MI-ADM Algoritmy data miningu (2010/2011) Přednáška 12: Shlukování Pavel Kordík, FIT, Czech Technical University in Prague
2 Osnova dnešní přednášky Metriky Hiearchické shlukování Algoritmy Dendrogramy K-means SOM Gaussovská směs MI-ADM Algoritmy data miningu (FIT CVUT)
3 Shluková analýza Máme data, neznáme kategorie (třídy) Chceme najít množiny podobných vzorů, které jsou zároveň nepodobné vzorům z ostatních množin. Řešíme optimalizační problém! Co jsou naše neznámé? počet shluků přiřazení dat (vzorů) do shluků MI-ADM Algoritmy data miningu (FIT CVUT)
4 Metrika, Euklidovská vzdálenost Je třeba nějak určit podobnost vzorů jejich vzdálenost Vzdálenost musí splňovat určité podmínky: 1. d(x,y) > d(x,y) = 0 iff x = y. 3. d(x,y) = d(y,x). 4. d(x,y) < d(x,z) + d(z,y) (trojúhelníková nerovnost ). Je Euklidovská vzdálenost metrika? Dva body v n-rozměrném prostoru: Euklidovská vzdálenost P a Q = MI-ADM Algoritmy data miningu (FIT CVUT)

 p n qn, Q = p1 q1 +")

5 Manhattonská vzdálenost Jak budeme počítat vzdálenost dvou cyklistů v Manhattonu? M ( P ) p n qn, Q = p1 q1 + p2 q MI-ADM Algoritmy data miningu (FIT CVUT)
6 Kosinová vzdálenost Je invariantní vůči natočení p θ p.q q q dist(p, q) = θ = arccos(p.q/ q p ) MI-ADM Algoritmy data miningu (FIT CVUT)
7 Editační vzdálenost Pro určení vzdálenosti např. dvou slov Počítá se jako počet smazání (vložení) písmene, potřebný k transformaci jednoho slova na druhé. MI-ADM Algoritmy data miningu (FIT CVUT)
8 Shluky, reprezentanti Výsledky ankety, proč lidé pijí alkohol Reprezentant shluku = typický představitel Tradice Sociální nutnost Individualita Úkolem shlukové analýzy je najít v datech shluky, případně jim přiřadit typické reprezentanty MI-ADM Algoritmy data miningu (FIT CVUT) Postavení
9 Shluková analýza III Klasická shluková analýza (Cluster Analysis) je nástroj pro disjunktní rozklad množiny vzorů ze vstupního prostoru R n do H > 1 tříd (shluků). Shluková analýza požaduje maximální podobnost vzorů v rámci jedné třídy a současně maximální nepodobnost vzorů různých tříd. MI-ADM Algoritmy data miningu (FIT CVUT)
10 Jak byste problém řešili vy? Jak najít shluky? spojujeme vždy 2 nejpodobnější vektory MI-ADM Algoritmy data miningu (FIT CVUT)
11 Metody vyhodnocení vzdálenosti shluků Metoda nejbližšího souseda single linkage vzdálenost shluků je určována vzdáleností dvou nejbližších objektů z různých shluků Metoda nejvzdálenějšího souseda complete linkage zdálenost shluků je určována naopak vzdáleností dvou nejvzdálenějších objektů z různých shluků Centroidní metoda centroid linkage vzdálenost shluků je určována vzdáleností jejich center Metoda průměrné vazby average linkage vzdálenost shluků je určována jako průměr vzdáleností všech párů objektů z různých shluků Wardova metoda Ward slinkage vzdálenost shluků se určí jako suma čtverců vzdáleností jejich center MI-ADM Algoritmy data miningu (FIT CVUT)
12 Single linkage Ze shluku vždy vybírám toho nejbližšího A B MI-ADM Algoritmy data miningu (FIT CVUT)
13 Complete linkage Ze shluku vždy vybírám toho nejvzdálenějšího A B MI-ADM Algoritmy data miningu (FIT CVUT)
14 Centroid linkage Reprezentantem shluku je centroid A B MI-ADM Algoritmy data miningu (FIT CVUT)
15 Kolik jsme našli shluků? Jiný pohled na náš algoritmus: Na začátku každý vektor shluk Spojování vektorů do shluků Na konci jeden velký shluk Počet shluků? Dendrogram => Algoritmus se jmenuje: Hierarchické shlukování Obrázek je ilustrační, neodpovídá přesně datům z minulého slajdu MI-ADM Algoritmy data miningu (FIT CVUT)
16 Záleží na tom, kde řízneme dendrogram Co se děje, když řežeme dendrogram na nižší/vyšší úrovni? Kam patří nový vektor? Problém? Musím počítat vzdálenosti ke všem vektorům! MI-ADM Algoritmy data miningu (FIT CVUT)
17 Obsahují data opravdu shluky? Vypočteme CPCC (Cophenetic Correlation Coeffitient) CPCC je normovaná kovariance vzdáleností v původním prostoru a v dendrogramu Pokud je hodnota CPCC menší než cca 0.8, všechny instance patří do jediného velkého shluku Obecně platí, že čím vyšší je kofenetický koeficient korelace, tím nižší je ztráta informací, vznikající v procesu slučování objektů do shluků MI-ADM Algoritmy data miningu (FIT CVUT)
18 Hierarchické shlukování Pseudokód algoritmu hierarchického shlukování c je požadovaný počet shluků 1. begin initialize c, c n, Di {xi} i=1,...,n 2. do c c vypočteme matici vzdáleností 4. najdeme nejbližší shluky Di a Dj 5. sloučíme shluky Di a Dj 6. until c=c 7. return c shluků 8. end procedura skončí, když je dosaženo požadovaného počtu shluků když c=1, dostaneme dendogram složitost O(cn 2 d) a typicky n>>c MI-ADM Algoritmy data miningu (FIT CVUT)
19 Algoritmus K-středů (K-means) Jak se vyhnout výpočtu všech vzájemných vzdáleností? Budu počítat vzdálenosti od reprezentantů shluků. Počet reprezentantů je výrazně menší než počet instancí. Nevýhoda: musím dopředu určit počet reprezentantů (K). MI-ADM Algoritmy data miningu (FIT CVUT)
20 K-means Reprezentanti - zde se jmenují středy (centroidy) Střed shluku c vypočteme: Co to znamená? Jak se sčítají vektory? r µ(c) 1 = c x r c r x x 1 x 1 + x 2 přeškálování x 2 Dejme tomu, že známe počet shluků (centroidů), jen hledáme jejich pozici. MI-ADM Algoritmy data miningu (FIT CVUT)

 http://www.")
21 K-means applet MI-ADM Algoritmy data miningu (FIT CVUT)
22 Jak K-means pracuje? Náhodně inicializuj k centroidů. Opakuj dokud algoritmus nezkonverguje: fáze přiřazení vektorů: každý vektor x přiřaď shluku X i, pro který vzdálenost x od µ r i (centroid X i ) je minimální fáze pohybu centroidů: oprav pozici centroidů podle aktuálních vektorů ve shlucích r 1 r µ = i(x i) x j X r i x j X i MI-ADM Algoritmy data miningu (FIT CVUT)
23 K-means vlastnosti Lokálně minimalizujeme energii Co to znamená? K l = 1 x X i i Pro K shluků sečti vzdálenost všech vektorů daného shluku od jeho centroidu Konverguje vždy do globálního minima energie? Ne, často do lokálních minim. Závislost na inicializaci centroidů. MI-ADM Algoritmy data miningu (FIT CVUT) l x µ l 2
24 Algoritmus k-středů Pseudokód algoritmu K-středů vstup: n vzorů a počet výsledných středů c výstup: výsledné středy µ 1,..., µ c algoritmus: 1. begin initialize n, c, µ1,..., µc 2. do klasifikuj n vzorů k jejich nejbližšímu µi 3. přepočti µi 4. until žádný µi se nezměnil 6. return µ1,..., µc 7. end složitost: O(ndcT) kde d je dimenze vzorů a T je počet iterací MI-ADM Algoritmy data miningu (FIT CVUT)
25 Dětský k-means pseudokód Once there was a land with N houses... One day K kings arrived to this land.. Each house was taken by the nearest king.. But the community wanted their king to be at the center of the village, so the throne was moved there. Then the kings realized that some houses were closer to them now, so they took those houses, but they lost some.. This went on and on..(2-3-4) Until one day they couldn't move anymore, so they settled down and lived happily ever after in their village... MI-ADM Algoritmy data miningu (FIT CVUT)
26 Počet středů (shluků) Pro K-means je třeba K určit předem to je těžké když o datech nic nevíme Vymyslete algoritmus, který bude počet shluků odvozovat automaticky z dat. Např. Leader-follower strategie Problém určit univerzální hodnotu prahu MI-ADM Algoritmy data miningu (FIT CVUT)
27 Jaké použít kritérium pro volbu K? Minimum energie? K x l = 1 x X i W ( K ) = µ l i l 2 Nevhodné, klesá k nule pro K=počet instancí. Lépe najít maximum funkce: H ( K ) = W ( K ) W W ( K ( K + 1) + 1) MI-ADM Algoritmy data miningu (FIT CVUT)
 e <-1,1> s( i) = b( i) a( i) max{ a( i), b( i)} kde a(i) je průměrná")

28 Silhouette graf obrysů shluků Iris data, pro každou instanci vypočti jistotu zařazení do shluku s(i) e <-1,1> s( i) = b( i) a( i) max{ a( i), b( i)} kde a(i) je průměrná vzdálenost instance i od instancí shluku, do kterého je zařazena b(i) je průměrná vzdálenost instance i od instancí nejbližšího shluku MI-ADM Algoritmy data miningu (FIT CVUT)


29 Hodnocení shluknutí pomocí Silhouette Který výstup K-means je lepší? Ten, který má lepší průměr hodnoty s(i) pro všechny instance. Ideálně na testovacích datech. MI-ADM Algoritmy data miningu (FIT CVUT)

30 SOM SOM = Self Organizing Maps, Prof. Teuvo Kohonen, Finsko, TU Helsinki, 1981, od té doby se eviduje několik tisíc vědeckých literárních odkazů. Původní aplikace: fonetický psací stroj.
31 Kompetiční učení Jedinci (elementy, neurony) spolu soutěží Příklad bezdomovci a kontejnery Pamatuji si, kde byla dobrá kořist Vyhraje ten, kdo přijde dřív Musím být poblíž, aby mě někdo nepředběhl Když se dozvím o novém kontejneru, a mám šanci ho vybrat, musím se přesunout blíže k němu Kdo se to nenaučí, umře hlady Vede na teritoriální uspořádání, reflektující rozmístění kontejnerů a jejich využívanost
32 Kompetiční učení Přírodou inspirované Nepotřebuji žádného arbitra, který by jedincům stále říkal, kam mají jít učení bez učitele Jedinci se učí z příkladů Systém se v průběhu času organizuje sám samoorganizuje A teď to aplikujeme na shlukovou analýzu
33 Shluková analýza a kompetice Prozradí nám něco pozice bezdomovců o rozmístění kontejnerů? Co to je shluk? Množina bodů, které jsou si blízko a mají daleko k ostatním. Co to znamená daleko? Viz metriky Bezdomovec reprezentant shluku kontejnerů
34 Shluky, reprezentanti Obrázek si můžeme představit jako teritoria čtyř bezdomovců - veteránů Každý bezdomovec je reprezentant shluku kontejnerů Sever Západ Východ Jak simulovat pohyb bezdomovců? K-means? Jih
35 K-means
36 Jiný pohled na K-means Středy (reprezentanti) soutěží o data Používá strategii vítěz bere vše (Winner Takes All) Všechno jídlo zkonzumuje bezdomovec, který ke kontejneru dorazí první Chyba se počítá jako Nebo také E= 1 2 K N i= 1 j= 1 1 WTA K = 1 x l x X i E = µ, µ ) µ Kde funkce 1 WTA je 1, pokud je i tý střed nejblíže j tému vzoru, 0 jinak Tato chyba se také jmenuje kvantizační ( x j i x j i i l l 2
37 Co to je vektorová kvantizace? Cílem kvantizace vektorů (Vector Quantization) je aproximovat hustotu pravděpodobnosti p(x) rozložení reálných vstupních vektorů x є R n pomocí konečného počtu reprezentantů w i є R n. Tedy přesně to, o co se snažíme.
38 Problém se komplikuje Co se stane, když bezdomovec nestihne kontejner vybrat celý? Zbytek dostanou nejbližší Neplatí vítěz bere vše! Okolí = definuje vzdálenost, ze které se ještě vyplatí přijít. 2 nd 1 st Velmi malé okolí - vítěz bere vše Velmi velké okolí - komunismus 3 rd
39 Neuronový plyn (perestrojka ) Název berte z rezervou, nepracuje se s neurony, ale spíše s agenty (středy). Pseudokód: Náhodně inicializuj středy, zvol velké okolí Předlož vektor x j Pro všechny středy - Spočítej pořadí vzdáleností od vektoru - Uprav vzdálenosti (x j -µ i ) v závislosti na pořadí a velikosti okolí - (exp) - Přemísti středy opakuj (s menším okolím)
40 Neuronový plyn
41 Problém se stále komplikuje Co se stane, když se vítězný bezdomovec rozdělí jen s kamarády? Okolí již neudává vzdálenost v původním prostoru dat, ale v prostoru kamarádství. 1 st Velmi malé okolí - individualisté Velmi velké okolí - hippies 2 nd 3 rd

42 Samoorganiující se mapa (SOM) Kamarádství pro jednoduchost znázorněno mřížkou
43 Jak se liší od k-means? Existence okolí! g(x) x Používá se 1. při učení, 2. někdy k určování vítěze.
44 SOM inspirace Ne bezdomovci, ale mozek. Řídící centra souvisejících orgánů spolu sousedí.

45 SOM architektura 1/3 Representa nt Typicky: 2D pole reprezentantů (také se jim nepřesně říká neurony)
46 SOM architektura 2/3 2D- uspořádání (do mřížky) je nejtypičtější. Neurony lze ale uspořádat lineárně (1Ddost často), nebo prostorově (3D- velmi výjimečně). Uspořádání slouží k tomu, aby měl neuron definované sousedy ve svém okolí. Kohonenovo doporučení: obdélníková SOM!
47 SOM architektura 3/3 Každý neuron má vektor vah w, vektory se porovnávají se vstupním vektorem x, vybírá ten se nejpodobnější BMU Neuron, který nejlépe odpovídá (BMU) je reprezentant vektoru přiloženého na vstup

48 Timo Honkela (Description of Kohonen's Self-Organizing Map)
49 SOM neuron 1/2 Vyhodnocuje podobnost předloženého vstupní-ho vektoru od (ve vahách w i ) zapamatovaného, reprezentanta, referenčního vektoru. Podobnost = např. Eukleidovská vzdálenost: { } i * j = arg min x w, i SOM neuron je tedy reprezentantem shluku.
50 Učení Kohonenovy sítě 1/3 Nezapomeňte: učicí algoritmus uspořádává neurony v mřížce tak, aby reprezentovaly předložená vstupní data. Otázka k přemýšlení: co se děje s vahami neuronů v průběhu času?
51 Učení Kohonenovy sítě 2/3 1. Inicializace, 2. předložení vzoru, 3. výpočet vzdálenosti, 4. výběr nejpodobnějšího neuronu, 5. přizpůsobení vah, w ( t + 1) = w ( t) + η( t) x ( t) w ( t) 6. goto 2. [ ] ij ij i ij Rozumíte vzorci? Váhy jakých neuronů se přizpůsobují?
52 Příklad 0.52 X = W 1 = W 2 = 0.81 W 3 = d d d ( x1 w11 ) + ( x2 w21) = = ( ) + ( ) = ( x1 w12 ) + ( x2 w22 ) = = ( ) + ( ) = ( x1 w13 ) + ( x2 w23) = = ( ) + ( ) = Vyhrál třetí neuron je nejblíže
53 Příklad Přiblížím ho ke vzoru [ ] ( + 1) = ( ) + η( ) ( ) ( ) w t w t t x t w t ij ij i ij w13 = η (t) ( x1 w13 ) = 0.1( ) = 0.01 w23 = η (t)( x2 w23) = 0.1( ) = 0.01 W3 ( p + 1) = W3 ( p) + W3 ( p) = = Upravil jsem váhy pouze BMU vítěznému neuronu Zde tedy vítěz bere vše!

54 Takhle to vypadá, když updatuji také okolní neurony Slide by Johan Everts
55 Učení Kohonenovy sítě 3/3 Velkou roli při učení hraje okolí: topologické uspořádání, vzdálenost sousedů. Okolí se v čase mění: jeho průměr s časem klesá (až k nulovému). změna se realizuje sdruženým učicím parametrem η(t).
56 Příklad okolí: Gaussovské η ij * ( t) = α( t) r * j. exp 2 2 σ r i ( t) 2, Člen α(t) představuje učicí krok, druhý člen pak tvar okolí (v tomto případě Gaussova křivka s proměnným tvarem v čase).

57 Příklad okolí: Gaussovské Distance related learning Slide by Johan Everts
58 Visualizace: klasická SOM Problém jak zobrazit pozici neuronů (reprezentantů) Dimenze vah = dimenze vstupního vektoru Potřebuji zobrazit ve 2D, jak? U-matice, analýza hlavní komponenty (PCA), Sammonova nelineární projekce.
59 U-matice (Unified distance) Matice vzdáleností mezi váhovými vektory jednotlivých neuronů, typicky se vizualizuje, vzdáleností vyjádřeny barvou světlá barva = malá vzdálenost. Zobrazuje strukturu vzdáleností v prostoru dat. Poloha BMU odráží topologii dat. Barva neuronu je vzdálenost je váhového vektoru od všech ostatních váhových vektorů Tmavé váhové vektory jsou vzdáleny od ostatních datových vektorů ve vstupním prostoru. Světlé váhové vektory jsou obklopeny cizími vektory ve vstupním prostoru. Kopce oddělují clustery (údolí).


60 Příklad U-matice Data: Neurony Vzdálenosti mezi sousedními neurony
61 P-matrix (Pareto density estimation) Zobrazuje počet datových vektorů ze vstupního prostoru, které patří do koule kolem jeho váhového vektoru (s poloměrem nastaveným podle Paretova pravidla). Odráží hustotu dat. Neurony s velkou hodnotou jsou umístěny do hustých oblastí vstupního prostoru. Neurony s malou hodnotou jsou osamělé ve vstupním prostoru. údolí oddělují clustery ( náhorní plošiny ). Doplňuje informace získané z U-matice.
62 U*-Matrix Kombinace U-Matice a P-Matice Je to U-matice, korigovaná hodnotami v P- matici. Vzdálenosti mezi sousedními neurony (neurony a a b v mřížce) jsou vypočítány z U-matice a jsou váženy hustotou vektorů kolem neuronu a.
63 Nevýhody UMAT, PMAT, Zobrazují jen vzdálenosti mezi sousedy Při novém naučení sítě na stejných datech můžou vypadat jinak (můžou být např otočeny o 90 stupňů) Nejsou intuitivně interpretovatelné, pokud nevíte co přesně je barvou kódováno. Jak ale zobrazit n-rozměrná data ve 2D, abychom pokud možno zachovali originální vzdálenosti?
 špatná")
64 PCA nebo LDA Nové souřadnice vzniknou jako lineární kombinace původních dimenzí Algoritmus se jmenuje Analýza hlavní komponenty (Principal Component Analysis) špatná dobrá
65 Sammonova projekce Mějme N vektorů v L-dimenzionálním prostoru, které označme x i, i = 1,..., N. K nim nechť patří N dvoudimenzionálních vektorů označených y i, i = 1,..., N. Označme dále vzdálenost mezi vektory x i a x j v L-dimenzionálním prostoru D ij a vzdálenost odpovídajících si vektorů y i a y j symbolem d ij. Potom Sammonova projekce mapuje vstupní prostor na výstupní na základě minimalizace této chybové funkce: E sam = N 1 N i< j Dij i< j ( d D ) ij ij D ij 2..
66 Sammon leképezés Távolságtartó leképezés adatpontok közötti távolságok A Sammon stress célfüggvényt minimalizálja Nemlineáris optimalizálási feladat N(N-1)/2 távolság kiszámítása minden iterációs lépésben E = N 1 N i= 1 j= i+ 1 N 1 1 d( i, j) N i= 1 j= i+ 1 ( * d( i, j) d ( i, j) ) d( i, j) x 1 y 2 2 x 3 d( i, j) d * x 2 ( i, y 1 j)

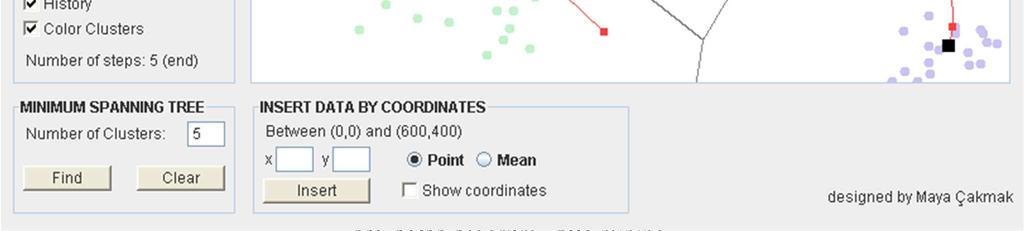
67 Aplikace SOMU

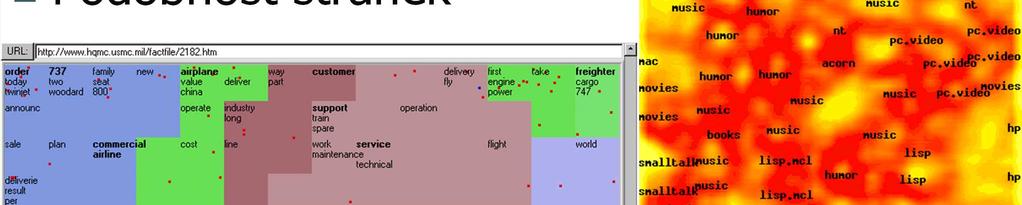

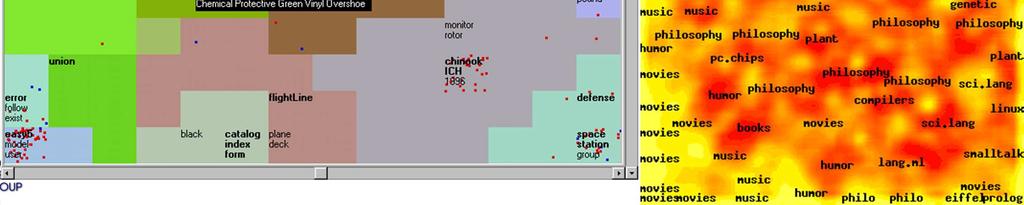
68 Websom Podobnost stránek


69 ReefSOM

70
71 SOM vlastnosti VQ vektorová kvantizace, více vektorů se mapuje do jednoho neuronu (jeho váhového vektoru), jak přesně? -> kvantizační chyba. Komprese dimenze vstupního prostoru. Zachování topologie dat sousední (ve vstupním prostoru) vektory se mapují do sousedních (v mřížce) neuronů, jak kvalitně? -> topografická chyba. SOM má energetickou funkci, kterou minimalizuje -> zkreslení. Y336VD Vytěžování dat
72 Zkreslení SOM Průměrná vzdálenost mezi každým datovým vektorem a jeho BMU. Určuje přesnost mapování (vektorové kvantizace) už známe c i je váhový vektor neuronu m j je vektor dat h bij je funkce okolí Y336VD Vytěžování dat
73 Topografická chyba SOM Počet vstupních vektorů, pro které vítězný neuron a druhý vítězný neuron nejsou sousedi v mřížce. u(ci) je 1, když sousedi nejsou, jinak 0 V procentech počet vzorků, u nichž nebyla zachována topologie. Y336VD Vytěžování dat
74 Software: Zajímavý a hlavně použitelný SW SOM_PAK: český návod na ovládání Matlab SOM toolbox SOMPAK addon Zooming SOM TKM, RSOM
75 Shlukování založené na modelech Např: Modelování hustoty pravděpodobnosti gaussovskou směsí (ukážeme si nyní) Model založený na samoorganizující se mapě (příští přednáška) MI-ADM Algoritmy data miningu (FIT CVUT)

76 Gaussovská směs Mnoharozměrná gaussovská hustota pravděpodobnosti 1D gaussovská funkce g ( x b) 2c ( x) = ae Vícedimenzionální směs 2 2 M a C? normalizace - pravděpodobnost MI-ADM Algoritmy data miningu (FIT CVUT) vážený průměr K gaussovek


77 Směs gausovských rozdělení M k a C k počítáme např. pomocí EM algoritmu Každá gaussovka jeden shluk předpokládá normální rozdělení dat ve shluku MI-ADM Algoritmy data miningu (FIT CVUT)
78 K-Means a EM algoritmus K-means je speciální případ obecnější procedury nazývané Expectation Maximization (EM) algoritmus. Expectation: Použij aktuální parametry (a data) k rekonstrukci černé skříňky Maximization: Použij černou skříňku a data ke zpřesnění parametrů MI-ADM Algoritmy data miningu (FIT CVUT)
79 Aplikační oblasti shlukové analýzy Hledání podobností v datech Určování významnosti proměnných Detekce odlehlých instancí Redukce dat MI-ADM Algoritmy data miningu (FIT CVUT)



80 Demo Shlukování studentů FIT MI-ADM Algoritmy data miningu (FIT CVUT)
Vytěžování znalostí z dat
 Pavel Kordík (ČVUT FIT) Vytěžování znalostí z dat BI-VZD, 2012, Přednáška 10 1/50 Vytěžování znalostí z dat Pavel Kordík Department of Computer Systems Faculty of Information Technology Czech Technical
Pavel Kordík (ČVUT FIT) Vytěžování znalostí z dat BI-VZD, 2012, Přednáška 10 1/50 Vytěžování znalostí z dat Pavel Kordík Department of Computer Systems Faculty of Information Technology Czech Technical
Státnice odborné č. 20
 Státnice odborné č. 20 Shlukování dat Shlukování dat. Metoda k-středů, hierarchické (aglomerativní) shlukování, Kohonenova mapa SOM Shlukování dat Shluková analýza je snaha o seskupení objektů do skupin
Státnice odborné č. 20 Shlukování dat Shlukování dat. Metoda k-středů, hierarchické (aglomerativní) shlukování, Kohonenova mapa SOM Shlukování dat Shluková analýza je snaha o seskupení objektů do skupin
Miroslav Čepek
 Vytěžování Dat Přednáška 4 Shluková analýza Miroslav Čepek Katedra počítačů, Computational Intelligence Group Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti 14.10.2014 Miroslav Čepek
Vytěžování Dat Přednáška 4 Shluková analýza Miroslav Čepek Katedra počítačů, Computational Intelligence Group Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti 14.10.2014 Miroslav Čepek
Miroslav Čepek
 Vytěžování Dat Přednáška 5 Self Organizing Map Miroslav Čepek Katedra počítačů, Computational Intelligence Group Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti 21.10.2014 Miroslav Čepek
Vytěžování Dat Přednáška 5 Self Organizing Map Miroslav Čepek Katedra počítačů, Computational Intelligence Group Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti 21.10.2014 Miroslav Čepek
AVDAT Mnohorozměrné metody, metody klasifikace Shluková analýza
 AVDAT Mnohorozměrné metody, metody klasifikace Shluková analýza Josef Tvrdík Katedra informatiky Přírodovědecká fakulta Ostravská univerzita Shluková analýza Cílem shlukové analýzy je nalézt v datech podmnožiny
AVDAT Mnohorozměrné metody, metody klasifikace Shluková analýza Josef Tvrdík Katedra informatiky Přírodovědecká fakulta Ostravská univerzita Shluková analýza Cílem shlukové analýzy je nalézt v datech podmnožiny
Přednáška 13 Redukce dimenzionality
 Vytěžování Dat Přednáška 13 Redukce dimenzionality Miroslav Čepek Fakulta Elektrotechnická, ČVUT Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti ČVUT (FEL) Redukce dimenzionality 1 /
Vytěžování Dat Přednáška 13 Redukce dimenzionality Miroslav Čepek Fakulta Elektrotechnická, ČVUT Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti ČVUT (FEL) Redukce dimenzionality 1 /
Algoritmy a struktury neuropočítačů ASN P3
 Algoritmy a struktury neuropočítačů ASN P3 SOM algoritmus s učitelem i bez učitele U-matice Vektorová kvantizace Samoorganizující se mapy ( Self-Organizing Maps ) PROČ? Základní myšlenka: analogie s činností
Algoritmy a struktury neuropočítačů ASN P3 SOM algoritmus s učitelem i bez učitele U-matice Vektorová kvantizace Samoorganizující se mapy ( Self-Organizing Maps ) PROČ? Základní myšlenka: analogie s činností
ANALÝZA A KLASIFIKACE BIOMEDICÍNSKÝCH DAT. Institut biostatistiky a analýz
 ANALÝZA A KLASIFIKACE BIOMEDICÍNSKÝCH DAT prof. Ing. Jiří Holčík,, CSc. NEURONOVÉ SÍTĚ otázky a odpovědi 1 AKD_predn4, slide 8: Hodnota výstupu závisí na znaménku funkce net i, tedy na tom, zda bude suma
ANALÝZA A KLASIFIKACE BIOMEDICÍNSKÝCH DAT prof. Ing. Jiří Holčík,, CSc. NEURONOVÉ SÍTĚ otázky a odpovědi 1 AKD_predn4, slide 8: Hodnota výstupu závisí na znaménku funkce net i, tedy na tom, zda bude suma
Vícerozměrné statistické metody
 Vícerozměrné statistické metody Shluková analýza Jiří Jarkovský, Simona Littnerová FSTA: Pokročilé statistické metody Typy shlukových analýz Shluková analýza: cíle a postupy Shluková analýza se snaží o
Vícerozměrné statistické metody Shluková analýza Jiří Jarkovský, Simona Littnerová FSTA: Pokročilé statistické metody Typy shlukových analýz Shluková analýza: cíle a postupy Shluková analýza se snaží o
Vytěžování znalostí z dat
 Pavel Kordík, Jan Motl (ČVUT FIT) Vytěžování znalostí z dat BI-VZD, 2012, Přednáška 4 1/27 Vytěžování znalostí z dat Pavel Kordík, Jan Motl Department of Computer Systems Faculty of Information Technology
Pavel Kordík, Jan Motl (ČVUT FIT) Vytěžování znalostí z dat BI-VZD, 2012, Přednáška 4 1/27 Vytěžování znalostí z dat Pavel Kordík, Jan Motl Department of Computer Systems Faculty of Information Technology
Fakulta chemicko-technologická Katedra analytické chemie. 3.2 Metody s latentními proměnnými a klasifikační metody
 Fakulta chemicko-technologická Katedra analytické chemie 3.2 Metody s latentními proměnnými a klasifikační metody Vypracoval: Ing. Tomáš Nekola Studium: licenční Datum: 21. 1. 2008 Otázka 1. Vypočtěte
Fakulta chemicko-technologická Katedra analytické chemie 3.2 Metody s latentními proměnnými a klasifikační metody Vypracoval: Ing. Tomáš Nekola Studium: licenční Datum: 21. 1. 2008 Otázka 1. Vypočtěte
Vytěžování znalostí z dat
 Pavel Kordík, Josef Borkovec (ČVUT FIT) Vytěžování znalostí z dat BI-VZD, 2012, Přednáška 8 1/26 Vytěžování znalostí z dat Pavel Kordík, Josef Borkovec Department of Computer Systems Faculty of Information
Pavel Kordík, Josef Borkovec (ČVUT FIT) Vytěžování znalostí z dat BI-VZD, 2012, Přednáška 8 1/26 Vytěžování znalostí z dat Pavel Kordík, Josef Borkovec Department of Computer Systems Faculty of Information
Vytěžování znalostí z dat
 Pavel Kordík, Jan Motl (ČVUT FIT) Vytěžování znalostí z dat BI-VZD, 2012, Přednáška 1 1/32 Vytěžování znalostí z dat Pavel Kordík, Jan Motl Department of Computer Systems Faculty of Information Technology
Pavel Kordík, Jan Motl (ČVUT FIT) Vytěžování znalostí z dat BI-VZD, 2012, Přednáška 1 1/32 Vytěžování znalostí z dat Pavel Kordík, Jan Motl Department of Computer Systems Faculty of Information Technology
oddělení Inteligentní Datové Analýzy (IDA)
") Vytěžování dat Filip Železný Katedra počítačů oddělení Inteligentní Datové Analýzy (IDA) 22. září 2014 Filip Železný (ČVUT) Vytěžování dat 22. září 2014 1 / 25 Odhad rozdělení Úloha: Vstup: data D = {
Vytěžování dat Filip Železný Katedra počítačů oddělení Inteligentní Datové Analýzy (IDA) 22. září 2014 Filip Železný (ČVUT) Vytěžování dat 22. září 2014 1 / 25 Odhad rozdělení Úloha: Vstup: data D = {
Umělé neuronové sítě
 Umělé neuronové sítě 17. 3. 2018 5-1 Model umělého neuronu y výstup neuronu u vnitřní potenciál neuronu w i váhy neuronu x i vstupy neuronu Θ práh neuronu f neuronová aktivační funkce 5-2 Neuronové aktivační
Umělé neuronové sítě 17. 3. 2018 5-1 Model umělého neuronu y výstup neuronu u vnitřní potenciál neuronu w i váhy neuronu x i vstupy neuronu Θ práh neuronu f neuronová aktivační funkce 5-2 Neuronové aktivační
Samoučící se neuronová síť - SOM, Kohonenovy mapy
 Samoučící se neuronová síť - SOM, Kohonenovy mapy Antonín Vojáček, 14 Květen, 2006-10:33 Měření a regulace Samoorganizující neuronové sítě s učením bez učitele jsou stále více využívány pro rozlišení,
Samoučící se neuronová síť - SOM, Kohonenovy mapy Antonín Vojáček, 14 Květen, 2006-10:33 Měření a regulace Samoorganizující neuronové sítě s učením bez učitele jsou stále více využívány pro rozlišení,
Klasifikace a rozpoznávání. Lineární klasifikátory
 Klasifikace a rozpoznávání Lineární klasifikátory Opakování - Skalární součin x = x1 x 2 w = w T x = w 1 w 2 x 1 x 2 w1 w 2 = w 1 x 1 + w 2 x 2 x. w w T x w Lineární klasifikátor y(x) = w T x + w 0 Vyber
Klasifikace a rozpoznávání Lineární klasifikátory Opakování - Skalární součin x = x1 x 2 w = w T x = w 1 w 2 x 1 x 2 w1 w 2 = w 1 x 1 + w 2 x 2 x. w w T x w Lineární klasifikátor y(x) = w T x + w 0 Vyber
4. Učení bez učitele. Shlukování. K-means, EM. Hierarchické shlukování. Kompetitivní učení. Kohonenovy mapy.
 GoBack 4. Učení bez učitele. Shlukování., EM. Hierarchické.. Kohonenovy mapy. Petr Pošík Katedra kybernetiky ČVUT FEL P. Pošík c 29 Aplikace umělé inteligence 1 / 53 Obsah P. Pošík c 29 Aplikace umělé
GoBack 4. Učení bez učitele. Shlukování., EM. Hierarchické.. Kohonenovy mapy. Petr Pošík Katedra kybernetiky ČVUT FEL P. Pošík c 29 Aplikace umělé inteligence 1 / 53 Obsah P. Pošík c 29 Aplikace umělé
Úvod do optimalizace, metody hladké optimalizace
 Evropský sociální fond Investujeme do vaší budoucnosti Úvod do optimalizace, metody hladké optimalizace Matematika pro informatiky, FIT ČVUT Martin Holeňa, 13. týden LS 2010/2011 O čem to bude? Příklady
Evropský sociální fond Investujeme do vaší budoucnosti Úvod do optimalizace, metody hladké optimalizace Matematika pro informatiky, FIT ČVUT Martin Holeňa, 13. týden LS 2010/2011 O čem to bude? Příklady
Aplikovaná numerická matematika
 Aplikovaná numerická matematika 6. Metoda nejmenších čtverců doc. Ing. Róbert Lórencz, CSc. České vysoké učení technické v Praze Fakulta informačních technologií Katedra počítačových systémů Příprava studijních
Aplikovaná numerická matematika 6. Metoda nejmenších čtverců doc. Ing. Róbert Lórencz, CSc. České vysoké učení technické v Praze Fakulta informačních technologií Katedra počítačových systémů Příprava studijních
Úloha - rozpoznávání číslic
 Úloha - rozpoznávání číslic Vojtěch Franc, Tomáš Pajdla a Tomáš Svoboda http://cmp.felk.cvut.cz 27. listopadu 26 Abstrakt Podpůrný text pro cvičení předmětu X33KUI. Vysvětluje tři způsoby rozpoznávání
Úloha - rozpoznávání číslic Vojtěch Franc, Tomáš Pajdla a Tomáš Svoboda http://cmp.felk.cvut.cz 27. listopadu 26 Abstrakt Podpůrný text pro cvičení předmětu X33KUI. Vysvětluje tři způsoby rozpoznávání
ANALÝZA A KLASIFIKACE DAT
 ANALÝZA A KLASIFIKACE DAT prof. Ing. Jiří Holčík, CSc. INVESTICE Institut DO biostatistiky ROZVOJE VZDĚLÁVÁNÍ a analýz IV. LINEÁRNÍ KLASIFIKACE PRINCIPY KLASIFIKACE pomocí diskriminačních funkcí funkcí,
ANALÝZA A KLASIFIKACE DAT prof. Ing. Jiří Holčík, CSc. INVESTICE Institut DO biostatistiky ROZVOJE VZDĚLÁVÁNÍ a analýz IV. LINEÁRNÍ KLASIFIKACE PRINCIPY KLASIFIKACE pomocí diskriminačních funkcí funkcí,
Matematika pro geometrickou morfometrii
 Matematika pro geometrickou morfometrii Václav Krajíček Vaclav.Krajicek@mff.cuni.cz Department of Software and Computer Science Education Faculty of Mathematics and Physics Charles University Přednáška
Matematika pro geometrickou morfometrii Václav Krajíček Vaclav.Krajicek@mff.cuni.cz Department of Software and Computer Science Education Faculty of Mathematics and Physics Charles University Přednáška
5. Umělé neuronové sítě. neuronové sítě. Umělé Ondřej Valenta, Václav Matoušek. 5-1 Umělá inteligence a rozpoznávání, LS 2015
 Umělé neuronové sítě 5. 4. 205 _ 5- Model umělého neuronu y výstup neuronu u vnitřní potenciál neuronu w i váhy neuronu x i vstupy neuronu Θ práh neuronu f neuronová aktivační funkce _ 5-2 Neuronové aktivační
Umělé neuronové sítě 5. 4. 205 _ 5- Model umělého neuronu y výstup neuronu u vnitřní potenciál neuronu w i váhy neuronu x i vstupy neuronu Θ práh neuronu f neuronová aktivační funkce _ 5-2 Neuronové aktivační
UČENÍ BEZ UČITELE. Václav Hlaváč
 UČENÍ BEZ UČITELE Václav Hlaváč Fakulta elektrotechnická ČVUT v Praze katedra kybernetiky, Centrum strojového vnímání hlavac@fel.cvut.cz, http://cmp.felk.cvut.cz/~hlavac 1/22 OBSAH PŘEDNÁŠKY ÚVOD Učení
UČENÍ BEZ UČITELE Václav Hlaváč Fakulta elektrotechnická ČVUT v Praze katedra kybernetiky, Centrum strojového vnímání hlavac@fel.cvut.cz, http://cmp.felk.cvut.cz/~hlavac 1/22 OBSAH PŘEDNÁŠKY ÚVOD Učení
LDA, logistická regrese
 Vytěžování Dat Přednáška 9 Lineární klasifikátor, rozšíření báze, LDA, logistická regrese Miroslav Čepek Fakulta Elektrotechnická, ČVUT Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti
Vytěžování Dat Přednáška 9 Lineární klasifikátor, rozšíření báze, LDA, logistická regrese Miroslav Čepek Fakulta Elektrotechnická, ČVUT Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti
Metody analýzy dat I. Míry a metriky - pokračování
 Metody analýzy dat I Míry a metriky - pokračování Literatura Newman, M. (2010). Networks: an introduction. Oxford University Press. [168-193] Zaki, M. J., Meira Jr, W. (2014). Data Mining and Analysis:
Metody analýzy dat I Míry a metriky - pokračování Literatura Newman, M. (2010). Networks: an introduction. Oxford University Press. [168-193] Zaki, M. J., Meira Jr, W. (2014). Data Mining and Analysis:
Zpracování digitalizovaného obrazu (ZDO) - Popisy III
 - Popisy III") Zpracování digitalizovaného obrazu (ZDO) - Popisy III Statistické popisy tvaru a vzhledu Ing. Zdeněk Krňoul, Ph.D. Katedra Kybernetiky Fakulta aplikovaných věd Západočeská univerzita v Plzni Zpracování
Zpracování digitalizovaného obrazu (ZDO) - Popisy III Statistické popisy tvaru a vzhledu Ing. Zdeněk Krňoul, Ph.D. Katedra Kybernetiky Fakulta aplikovaných věd Západočeská univerzita v Plzni Zpracování
Shluková analýza dat a stanovení počtu shluků
 Shluková analýza dat a stanovení počtu shluků Autor: Tomáš Löster Vysoká škola ekonomická v Praze Ostrava, červen 2017 Osnova prezentace Úvod a teorie shlukové analýzy Podrobný popis shlukování na příkladu
Shluková analýza dat a stanovení počtu shluků Autor: Tomáš Löster Vysoká škola ekonomická v Praze Ostrava, červen 2017 Osnova prezentace Úvod a teorie shlukové analýzy Podrobný popis shlukování na příkladu
Rosenblattův perceptron
 Perceptron Přenosové funkce Rosenblattův perceptron Rosenblatt r. 1958. Inspirace lidským okem Podle fyziologického vzoru je třívrstvá: Vstupní vrstva rozvětvovací jejím úkolem je mapování dvourozměrného
Perceptron Přenosové funkce Rosenblattův perceptron Rosenblatt r. 1958. Inspirace lidským okem Podle fyziologického vzoru je třívrstvá: Vstupní vrstva rozvětvovací jejím úkolem je mapování dvourozměrného
Klasifikace a rozpoznávání
 Klasifikace a rozpoznávání Prezentace přednášek M. Španěl, 2009 Ústav počítačové grafiky a multimédií Téma přednášky Unsupervised techniky Obsah: Literatura Úvod do shlukování Metriky, základní přístupy,
Klasifikace a rozpoznávání Prezentace přednášek M. Španěl, 2009 Ústav počítačové grafiky a multimédií Téma přednášky Unsupervised techniky Obsah: Literatura Úvod do shlukování Metriky, základní přístupy,
Vytěžování znalostí z dat
 Pavel Kordík, Josef Borkovec (ČVUT FIT) Vytěžování znalostí z dat BI-VZD, 2011, Cvičení 10 1/21 Vytěžování znalostí z dat Pavel Kordík, Josef Borkovec Department of Computer Systems Faculty of Information
Pavel Kordík, Josef Borkovec (ČVUT FIT) Vytěžování znalostí z dat BI-VZD, 2011, Cvičení 10 1/21 Vytěžování znalostí z dat Pavel Kordík, Josef Borkovec Department of Computer Systems Faculty of Information
Aplikovaná numerická matematika - ANM
 Aplikovaná numerická matematika - ANM 3 Řešení soustav lineárních rovnic iterační metody doc Ing Róbert Lórencz, CSc České vysoké učení technické v Praze Fakulta informačních technologií Katedra počítačových
Aplikovaná numerická matematika - ANM 3 Řešení soustav lineárních rovnic iterační metody doc Ing Róbert Lórencz, CSc České vysoké učení technické v Praze Fakulta informačních technologií Katedra počítačových
Algoritmy a struktury neuropočítačů ASN - P2. Topologie neuronových sítí, principy učení Samoorganizující se neuronové sítě Kohonenovy mapy
 Algoritmy a struktury neuropočítačů ASN - P2 Topologie neuronových sítí, principy učení Samoorganizující se neuronové sítě Kohonenovy mapy Topologie neuronových sítí (struktura, geometrie, architektura)
Algoritmy a struktury neuropočítačů ASN - P2 Topologie neuronových sítí, principy učení Samoorganizující se neuronové sítě Kohonenovy mapy Topologie neuronových sítí (struktura, geometrie, architektura)
Instance based learning
 Učení založené na instancích Instance based learning Charakteristika IBL (nejbližších sousedů) Tyto metody nepředpokládají určitý model nejsou strukturované a typicky nejsou příliš užitečné pro porozumění
Učení založené na instancích Instance based learning Charakteristika IBL (nejbližších sousedů) Tyto metody nepředpokládají určitý model nejsou strukturované a typicky nejsou příliš užitečné pro porozumění
Cvičná bakalářská zkouška, 1. varianta
 jméno: studijní obor: PřF BIMAT počet listů(včetně tohoto): 1 2 3 4 5 celkem Cvičná bakalářská zkouška, 1. varianta 1. Matematická analýza Najdětelokálníextrémyfunkce f(x,y)=e 4(x y) x2 y 2. 2. Lineární
jméno: studijní obor: PřF BIMAT počet listů(včetně tohoto): 1 2 3 4 5 celkem Cvičná bakalářská zkouška, 1. varianta 1. Matematická analýza Najdětelokálníextrémyfunkce f(x,y)=e 4(x y) x2 y 2. 2. Lineární
Základy vytěžování dat
 Základy vytěžování dat předmět A7Bb36vyd Vytěžování dat Filip Železný, Miroslav Čepek, Radomír Černoch, Jan Hrdlička katedra kybernetiky a katedra počítačů ČVUT v Praze, FEL Evropský sociální fond Praha
Základy vytěžování dat předmět A7Bb36vyd Vytěžování dat Filip Železný, Miroslav Čepek, Radomír Černoch, Jan Hrdlička katedra kybernetiky a katedra počítačů ČVUT v Praze, FEL Evropský sociální fond Praha
AVDAT Mnohorozměrné metody, metody klasifikace
 AVDAT Mnohorozměrné metody, metody klasifikace Josef Tvrdík Katedra informatiky Přírodovědecká fakulta Ostravská univerzita Mnohorozměrné metody Regrese jedna náhodná veličina je vysvětlována pomocí jiných
AVDAT Mnohorozměrné metody, metody klasifikace Josef Tvrdík Katedra informatiky Přírodovědecká fakulta Ostravská univerzita Mnohorozměrné metody Regrese jedna náhodná veličina je vysvětlována pomocí jiných
Moderní systémy pro získávání znalostí z informací a dat
 Moderní systémy pro získávání znalostí z informací a dat Jan Žižka IBA Institut biostatistiky a analýz PřF & LF, Masarykova universita Kamenice 126/3, 625 00 Brno Email: zizka@iba.muni.cz Bioinformatika:
Moderní systémy pro získávání znalostí z informací a dat Jan Žižka IBA Institut biostatistiky a analýz PřF & LF, Masarykova universita Kamenice 126/3, 625 00 Brno Email: zizka@iba.muni.cz Bioinformatika:
Asociativní sítě (paměti) Asociace známého vstupního vzoru s daným výstupním vzorem. Typická funkce 1 / 44
 Asociace známého vstupního vzoru s daným výstupním vzorem. Typická funkce 1 / 44") Asociativní paměti Asociativní sítě (paměti) Cíl učení Asociace známého vstupního vzoru s daným výstupním vzorem Okoĺı známého vstupního vzoru x by se mělo také zobrazit na výstup y odpovídající x správný
Asociativní paměti Asociativní sítě (paměti) Cíl učení Asociace známého vstupního vzoru s daným výstupním vzorem Okoĺı známého vstupního vzoru x by se mělo také zobrazit na výstup y odpovídající x správný
Profilování vzorků heroinu s využitím vícerozměrné statistické analýzy
 Profilování vzorků heroinu s využitím vícerozměrné statistické analýzy Autor práce : RNDr. Ivo Beroun,CSc. Vedoucí práce: prof. RNDr. Milan Meloun, DrSc. PROFILOVÁNÍ Profilování = klasifikace a rozlišování
Profilování vzorků heroinu s využitím vícerozměrné statistické analýzy Autor práce : RNDr. Ivo Beroun,CSc. Vedoucí práce: prof. RNDr. Milan Meloun, DrSc. PROFILOVÁNÍ Profilování = klasifikace a rozlišování
Optimální rozdělující nadplocha 4. Support vector machine. Adaboost.
 Optimální rozdělující nadplocha. Support vector machine. Adaboost. Petr Pošík Czech Technical University in Prague Faculty of Electrical Engineering Dept. of Cybernetics Opakování Lineární diskriminační
Optimální rozdělující nadplocha. Support vector machine. Adaboost. Petr Pošík Czech Technical University in Prague Faculty of Electrical Engineering Dept. of Cybernetics Opakování Lineární diskriminační
Algoritmy pro shlukování prostorových dat
 Algoritmy pro shlukování prostorových dat Marta Žambochová Katedra matematiky a informatiky Fakulta sociálně ekonomická Univerzita J. E. Purkyně v Ústí nad Labem ROBUST 21. 26. leden 2018 Rybník - Hostouň
Algoritmy pro shlukování prostorových dat Marta Žambochová Katedra matematiky a informatiky Fakulta sociálně ekonomická Univerzita J. E. Purkyně v Ústí nad Labem ROBUST 21. 26. leden 2018 Rybník - Hostouň
Shlukování. Zpracováno s využitím skvělého tutoriálu autorů Eamonn Keogh, Ziv Bar-Joseph a Andrew Moore
 Shlukování Zpracováno s využitím skvělého tutoriálu autorů Eamonn Keogh, Ziv Bar-Joseph a Andrew Moore Motivace Míra vzdálenosti Osnova přednášky Hierarchické shlukování Hodnocení kvality rozkladu Shlukování
Shlukování Zpracováno s využitím skvělého tutoriálu autorů Eamonn Keogh, Ziv Bar-Joseph a Andrew Moore Motivace Míra vzdálenosti Osnova přednášky Hierarchické shlukování Hodnocení kvality rozkladu Shlukování
Algoritmy a struktury neuropočítačů ASN - P11
 Aplikace UNS při rozpoznání obrazů Základní úloha segmentace obrazu rozdělení obrazu do několika významných oblastí klasifikační úloha, clusterová analýza target Metody Kohonenova metoda KSOM Kohonenova
Aplikace UNS při rozpoznání obrazů Základní úloha segmentace obrazu rozdělení obrazu do několika významných oblastí klasifikační úloha, clusterová analýza target Metody Kohonenova metoda KSOM Kohonenova
STATISTICKÉ NÁSTROJE A JEJICH VYUŽITÍ PŘI SEGMENTACI TRHU STATISTICAL TOOLS AND THEIR UTILIZATION DURING THE PROCESS OF MARKETING SEGMENTATION
 STATISTICKÉ NÁSTROJE A JEJICH VYUŽITÍ PŘI SEGMENTACI TRHU STATISTICAL TOOLS AND THEIR UTILIZATION DURING THE PROCESS OF MARKETING SEGMENTATION Anna Čermáková Michael Rost Abstrakt Cílem příspěvku bylo
STATISTICKÉ NÁSTROJE A JEJICH VYUŽITÍ PŘI SEGMENTACI TRHU STATISTICAL TOOLS AND THEIR UTILIZATION DURING THE PROCESS OF MARKETING SEGMENTATION Anna Čermáková Michael Rost Abstrakt Cílem příspěvku bylo
Mgr. Rudolf Blažek, Ph.D. prof. RNDr. Roman Kotecký Dr.Sc.
 Náhodné veličiny III Mgr. Rudolf Blažek, Ph.D. prof. RNDr. Roman Kotecký Dr.Sc. Katedra teoretické informatiky Fakulta informačních technologií České vysoké učení technické v Praze c Rudolf Blažek, Roman
Náhodné veličiny III Mgr. Rudolf Blažek, Ph.D. prof. RNDr. Roman Kotecký Dr.Sc. Katedra teoretické informatiky Fakulta informačních technologií České vysoké učení technické v Praze c Rudolf Blažek, Roman
Klasifikace a rozpoznávání. Extrakce příznaků
 Klasifikace a rozpoznávání Extrakce příznaků Extrakce příznaků - parametrizace Poté co jsme ze snímače obdržely data která jsou relevantní pro naši klasifikační úlohu, je potřeba je přizpůsobit potřebám
Klasifikace a rozpoznávání Extrakce příznaků Extrakce příznaků - parametrizace Poté co jsme ze snímače obdržely data která jsou relevantní pro naši klasifikační úlohu, je potřeba je přizpůsobit potřebám
1. Vlastnosti diskretních a číslicových metod zpracování signálů... 15
 Úvodní poznámky... 11 1. Vlastnosti diskretních a číslicových metod zpracování signálů... 15 1.1 Základní pojmy... 15 1.2 Aplikační oblasti a etapy zpracování signálů... 17 1.3 Klasifikace diskretních
Úvodní poznámky... 11 1. Vlastnosti diskretních a číslicových metod zpracování signálů... 15 1.1 Základní pojmy... 15 1.2 Aplikační oblasti a etapy zpracování signálů... 17 1.3 Klasifikace diskretních
Dobývání znalostí. Doc. RNDr. Iveta Mrázová, CSc. Katedra teoretické informatiky Matematicko-fyzikální fakulta Univerzity Karlovy v Praze
 Dobývání znalostí Doc. RNDr. Iveta Mrázová, CSc. Katedra teoretické informatiky Matematicko-fyzikální fakulta Univerzity Karlovy v Praze Dobývání znalostí Pravděpodobnost a učení Doc. RNDr. Iveta Mrázová,
Dobývání znalostí Doc. RNDr. Iveta Mrázová, CSc. Katedra teoretické informatiky Matematicko-fyzikální fakulta Univerzity Karlovy v Praze Dobývání znalostí Pravděpodobnost a učení Doc. RNDr. Iveta Mrázová,
Vytěžování znalostí z dat
 Pavel Kordík, Jan Motl (ČVUT FIT) Vytěžování znalostí z dat BI-VZD, 2012, Přednáška 7 1/27 Vytěžování znalostí z dat Pavel Kordík, Jan Motl Department of Computer Systems Faculty of Information Technology
Pavel Kordík, Jan Motl (ČVUT FIT) Vytěžování znalostí z dat BI-VZD, 2012, Přednáška 7 1/27 Vytěžování znalostí z dat Pavel Kordík, Jan Motl Department of Computer Systems Faculty of Information Technology
AVDAT Nelineární regresní model
 AVDAT Nelineární regresní model Josef Tvrdík Katedra informatiky Přírodovědecká fakulta Ostravská univerzita Nelineární regresní model Ey i = f (x i, β) kde x i je k-členný vektor vysvětlujících proměnných
AVDAT Nelineární regresní model Josef Tvrdík Katedra informatiky Přírodovědecká fakulta Ostravská univerzita Nelineární regresní model Ey i = f (x i, β) kde x i je k-členný vektor vysvětlujících proměnných
ZÁPOČTOVÁ PRÁCE Informace a neurčitost. SOMPak
 UNIVERZITA PALACKÉHO V OLOMOUCI KATEDRA MATEMATICKÉ INFORMATIKY ZÁPOČTOVÁ PRÁCE Informace a neurčitost SOMPak Říjen 2005 Pavel Kubát Informatika V. ročník Abstrakt The objective of this work is describe
UNIVERZITA PALACKÉHO V OLOMOUCI KATEDRA MATEMATICKÉ INFORMATIKY ZÁPOČTOVÁ PRÁCE Informace a neurčitost SOMPak Říjen 2005 Pavel Kubát Informatika V. ročník Abstrakt The objective of this work is describe
Numerické metody a programování. Lekce 8
 Numerické metody a programování Lekce 8 Optimalizace hledáme bod x, ve kterém funkce jedné nebo více proměnných f x má minimum (maximum) maximalizace f x je totéž jako minimalizace f x Minimum funkce lokální:
Numerické metody a programování Lekce 8 Optimalizace hledáme bod x, ve kterém funkce jedné nebo více proměnných f x má minimum (maximum) maximalizace f x je totéž jako minimalizace f x Minimum funkce lokální:
Neuronové sítě Ladislav Horký Karel Břinda
 Neuronové sítě Ladislav Horký Karel Břinda Obsah Úvod, historie Modely neuronu, aktivační funkce Topologie sítí Principy učení Konkrétní typy sítí s ukázkami v prostředí Wolfram Mathematica Praktické aplikace
Neuronové sítě Ladislav Horký Karel Břinda Obsah Úvod, historie Modely neuronu, aktivační funkce Topologie sítí Principy učení Konkrétní typy sítí s ukázkami v prostředí Wolfram Mathematica Praktické aplikace
Faculty of Nuclear Sciences and Physical Engineering Czech Technical University in Prague
 1 / 40 regula Faculty of Nuclear Sciences and Physical Engineering Czech Technical University in Prague regula 1 2 3 4 5 regula 6 7 8 2 / 40 2 / 40 regula Iterační pro nelineární e Bud f reálná funkce
1 / 40 regula Faculty of Nuclear Sciences and Physical Engineering Czech Technical University in Prague regula 1 2 3 4 5 regula 6 7 8 2 / 40 2 / 40 regula Iterační pro nelineární e Bud f reálná funkce
Shluková analýza. Jiří Militky. Analýza experimentálních dat V. Červeně označené slide jsou jen pro doplnění informací a nezkouší se.
 Červeně označené slide jsou jen pro doplnění informací a nezkouší se. Shluková analýza Jiří Militky Analýza experimentálních dat V Klasifikace objektů Rozdělení objektů do shluků dle jejich podobnosti
Červeně označené slide jsou jen pro doplnění informací a nezkouší se. Shluková analýza Jiří Militky Analýza experimentálních dat V Klasifikace objektů Rozdělení objektů do shluků dle jejich podobnosti
Stavový model a Kalmanův filtr
 Stavový model a Kalmanův filtr 2 prosince 23 Stav je veličina, kterou neznáme, ale chtěli bychom znát Dozvídáme se o ní zprostředkovaně prostřednictvím výstupů Příkladem může býapř nějaký zašuměný signál,
Stavový model a Kalmanův filtr 2 prosince 23 Stav je veličina, kterou neznáme, ale chtěli bychom znát Dozvídáme se o ní zprostředkovaně prostřednictvím výstupů Příkladem může býapř nějaký zašuměný signál,
Kybernetika a umělá inteligence, cvičení 10/11
 Kybernetika a umělá inteligence, cvičení 10/11 Program 1. seminární cvičení: základní typy klasifikátorů a jejich princip 2. počítačové cvičení: procvičení na problému rozpoznávání číslic... body za aktivitu
Kybernetika a umělá inteligence, cvičení 10/11 Program 1. seminární cvičení: základní typy klasifikátorů a jejich princip 2. počítačové cvičení: procvičení na problému rozpoznávání číslic... body za aktivitu
odlehlých hodnot pomocí algoritmu k-means
 Chybějící a odlehlé hodnoty; odstranění odlehlých hodnot pomocí algoritmu k-means Návod ke druhému cvičení Matěj Holec, holecmat@fel.cvut.cz ZS 2011/2012 Úvod Cílem cvičení je připomenout důležitost předzpracování
Chybějící a odlehlé hodnoty; odstranění odlehlých hodnot pomocí algoritmu k-means Návod ke druhému cvičení Matěj Holec, holecmat@fel.cvut.cz ZS 2011/2012 Úvod Cílem cvičení je připomenout důležitost předzpracování
ZÍSKÁVÁNÍ ZNALOSTÍ Z DATABÁZÍ
 Metodický list č. 1 Dobývání znalostí z databází Cílem tohoto tematického celku je vysvětlení základních pojmů z oblasti dobývání znalostí z databází i východisek dobývání znalostí z databází inspirovaných
Metodický list č. 1 Dobývání znalostí z databází Cílem tohoto tematického celku je vysvětlení základních pojmů z oblasti dobývání znalostí z databází i východisek dobývání znalostí z databází inspirovaných
Intervalové Odhady Parametrů
 Parametrů Mgr. Rudolf B. Blažek, Ph.D. prof. RNDr. Roman Kotecký, DrSc. Katedra počítačových systémů Katedra teoretické informatiky Fakulta informačních technologií České vysoké učení technické v Praze
Parametrů Mgr. Rudolf B. Blažek, Ph.D. prof. RNDr. Roman Kotecký, DrSc. Katedra počítačových systémů Katedra teoretické informatiky Fakulta informačních technologií České vysoké učení technické v Praze
Hledání optimální polohy stanic a zastávek na tratích regionálního významu
 Hledání optimální polohy stanic a zastávek na tratích regionálního významu Václav Novotný 31. 10. 2018 Anotace 1. Dopravní obsluha území tratěmi regionálního významu 2. Cíle výzkumu a algoritmus práce
Hledání optimální polohy stanic a zastávek na tratích regionálního významu Václav Novotný 31. 10. 2018 Anotace 1. Dopravní obsluha území tratěmi regionálního významu 2. Cíle výzkumu a algoritmus práce
Katedra kybernetiky, FEL, ČVUT v Praze.
 Strojové učení a dolování dat přehled Jiří Kléma Katedra kybernetiky, FEL, ČVUT v Praze http://ida.felk.cvut.cz posnova přednášek Přednáška Učitel Obsah 1. J. Kléma Úvod do předmětu, učení s a bez učitele.
Strojové učení a dolování dat přehled Jiří Kléma Katedra kybernetiky, FEL, ČVUT v Praze http://ida.felk.cvut.cz posnova přednášek Přednáška Učitel Obsah 1. J. Kléma Úvod do předmětu, učení s a bez učitele.
NG C Implementace plně rekurentní
 NG C Implementace plně rekurentní neuronové sítě v systému Mathematica Zdeněk Buk, Miroslav Šnorek {bukz1 snorek}@fel.cvut.cz Neural Computing Group Department of Computer Science and Engineering, Faculty
NG C Implementace plně rekurentní neuronové sítě v systému Mathematica Zdeněk Buk, Miroslav Šnorek {bukz1 snorek}@fel.cvut.cz Neural Computing Group Department of Computer Science and Engineering, Faculty
Už bylo: Učení bez učitele (unsupervised learning) Kompetitivní modely
 Kompetitivní modely") Učení bez učitele Už bylo: Učení bez učitele (unsupervised learning) Kompetitivní modely Klastrování Kohonenovy mapy LVQ (Učení vektorové kvantizace) Zbývá: Hybridní modely (kombinace učení bez učitele
Učení bez učitele Už bylo: Učení bez učitele (unsupervised learning) Kompetitivní modely Klastrování Kohonenovy mapy LVQ (Učení vektorové kvantizace) Zbývá: Hybridní modely (kombinace učení bez učitele
Neuronové časové řady (ANN-TS)
") Neuronové časové řady (ANN-TS) Menu: QCExpert Prediktivní metody Neuronové časové řady Tento modul (Artificial Neural Network Time Series ANN-TS) využívá modelovacího potenciálu neuronové sítě k predikci
Neuronové časové řady (ANN-TS) Menu: QCExpert Prediktivní metody Neuronové časové řady Tento modul (Artificial Neural Network Time Series ANN-TS) využívá modelovacího potenciálu neuronové sítě k predikci
Statistické metody v ekonomii. Ing. Michael Rost, Ph.D.
 Statistické metody v ekonomii Ing. Michael Rost, Ph.D. Jihočeská univerzita v Českých Budějovicích Shluková analýza Shluková analýza je souhrnným názvem pro celou řadu výpočetních algoritmů, jejichž cílem
Statistické metody v ekonomii Ing. Michael Rost, Ph.D. Jihočeská univerzita v Českých Budějovicích Shluková analýza Shluková analýza je souhrnným názvem pro celou řadu výpočetních algoritmů, jejichž cílem
Kartografické modelování. VIII Modelování vzdálenosti
 VIII Modelování vzdálenosti jaro 2015 Petr Kubíček kubicek@geogr.muni.cz Laboratory on Geoinformatics and Cartography (LGC) Institute of Geography Masaryk University Czech Republic Vzdálenostní funkce
VIII Modelování vzdálenosti jaro 2015 Petr Kubíček kubicek@geogr.muni.cz Laboratory on Geoinformatics and Cartography (LGC) Institute of Geography Masaryk University Czech Republic Vzdálenostní funkce
Asociační i jiná. Pravidla. (Ch )
") Asociační i jiná Pravidla (Ch. 14 +...) Učení bez učitele Nemáme cílovou třídu Y, G; máme N pozorování což jsou p-dimenzionální vektory se sdruženou pravděpodobností chceme odvozovat vlastnosti. Pro málo
Asociační i jiná Pravidla (Ch. 14 +...) Učení bez učitele Nemáme cílovou třídu Y, G; máme N pozorování což jsou p-dimenzionální vektory se sdruženou pravděpodobností chceme odvozovat vlastnosti. Pro málo
Interpolace, ortogonální polynomy, Gaussova kvadratura
 Interpolace, ortogonální polynomy, Gaussova kvadratura Petr Tichý 20. listopadu 2013 1 Úloha Lagrangeovy interpolace Dán omezený uzavřený interval [a, b] a v něm n + 1 různých bodů x 0, x 1,..., x n. Nechť
Interpolace, ortogonální polynomy, Gaussova kvadratura Petr Tichý 20. listopadu 2013 1 Úloha Lagrangeovy interpolace Dán omezený uzavřený interval [a, b] a v něm n + 1 různých bodů x 0, x 1,..., x n. Nechť
1. Soutěživé sítě. 1.1 Základní informace. 1.2 Výstupy z učení. 1.3 Jednoduchá soutěživá síť MAXNET
 Obsah 1. Soutěživé sítě... 2 1.1 Základní informace... 2 1.2 Výstupy z učení... 2 1.3 Jednoduchá soutěživá síť MAXNET... 2 1.3.1 Organizační dynamika... 2 1.3.2 Adaptační dynamika... 4 1.3.3 Aktivní dynamika...
Obsah 1. Soutěživé sítě... 2 1.1 Základní informace... 2 1.2 Výstupy z učení... 2 1.3 Jednoduchá soutěživá síť MAXNET... 2 1.3.1 Organizační dynamika... 2 1.3.2 Adaptační dynamika... 4 1.3.3 Aktivní dynamika...
Odhad parametrů N(µ, σ 2 )
") Odhad parametrů N(µ, σ 2 ) Mějme statistický soubor x 1, x 2,, x n modelovaný jako realizaci náhodného výběru z normálního rozdělení N(µ, σ 2 ) s neznámými parametry µ a σ. Jaký je maximální věrohodný
Odhad parametrů N(µ, σ 2 ) Mějme statistický soubor x 1, x 2,, x n modelovaný jako realizaci náhodného výběru z normálního rozdělení N(µ, σ 2 ) s neznámými parametry µ a σ. Jaký je maximální věrohodný
Dynamické programování
 Dynamické programování prof. Ing. Pavel Tvrdík CSc. Katedra počítačových systémů Fakulta informačních technologií České vysoké učení technické v Praze c Pavel Tvrdík, 2010 Efektivní algoritmy (BI-EFA)
Dynamické programování prof. Ing. Pavel Tvrdík CSc. Katedra počítačových systémů Fakulta informačních technologií České vysoké učení technické v Praze c Pavel Tvrdík, 2010 Efektivní algoritmy (BI-EFA)
Automatická detekce anomálií při geofyzikálním průzkumu. Lenka Kosková Třísková NTI TUL Doktorandský seminář, 8. 6. 2011
 Automatická detekce anomálií při geofyzikálním průzkumu Lenka Kosková Třísková NTI TUL Doktorandský seminář, 8. 6. 2011 Cíle doktorandské práce Seminář 10. 11. 2010 Najít, implementovat, ověřit a do praxe
Automatická detekce anomálií při geofyzikálním průzkumu Lenka Kosková Třísková NTI TUL Doktorandský seminář, 8. 6. 2011 Cíle doktorandské práce Seminář 10. 11. 2010 Najít, implementovat, ověřit a do praxe
Algoritmy a struktury neuropočítačů ASN - P10. Aplikace UNS v biomedicíně
 Aplikace UNS v biomedicíně aplikace v medicíně postup při zpracování úloh Aplikace UNS v medicíně Důvod: nalezení exaktnějších, levnějších a snadnějších metod určování diagnóz pro lékaře nalezení šetrnějších
Aplikace UNS v biomedicíně aplikace v medicíně postup při zpracování úloh Aplikace UNS v medicíně Důvod: nalezení exaktnějších, levnějších a snadnějších metod určování diagnóz pro lékaře nalezení šetrnějších
Shluková analýza, Hierarchické, Nehierarchické, Optimum, Dodatek. Učení bez učitele
 1 Obsah přednášy 1. Shluová analýza 2. Podobnost objetů 3. Hierarchicé shluování 4. Nehierarchicé shluování 5. Optimální počet shluů 6. Další metody 2 Učení bez učitele není dána výstupní lasifiace (veličina
1 Obsah přednášy 1. Shluová analýza 2. Podobnost objetů 3. Hierarchicé shluování 4. Nehierarchicé shluování 5. Optimální počet shluů 6. Další metody 2 Učení bez učitele není dána výstupní lasifiace (veličina
prof. RNDr. Čestmír Burdík DrCs. prof. Ing. Edita Pelantová CSc. BI-ZMA ZS 2009/2010
 Věty o přírustku funkce prof. RNDr. Čestmír Burdík DrCs. prof. Ing. Edita Pelantová CSc. Katedra matematiky České vysoké učení technické v Praze c Čestmír Burdík, Edita Pelantová 2009 Základy matematické
Věty o přírustku funkce prof. RNDr. Čestmír Burdík DrCs. prof. Ing. Edita Pelantová CSc. Katedra matematiky České vysoké učení technické v Praze c Čestmír Burdík, Edita Pelantová 2009 Základy matematické
OPTIMALIZACE. (přehled metod)
") OPTIMALIZACE (přehled metod) Typy optimalizačních úloh Optimalizace bez omezení Nederivační metody Derivační metody Optimalizace s omezeními Lineární programování Nelineární programování Globální optimalizace
OPTIMALIZACE (přehled metod) Typy optimalizačních úloh Optimalizace bez omezení Nederivační metody Derivační metody Optimalizace s omezeními Lineární programování Nelineární programování Globální optimalizace
Katedra kybernetiky laboratoř Inteligentní Datové Analýzy (IDA) Katedra počítačů, Computational Intelligence Group
 Katedra počítačů, Computational Intelligence Group") Vytěžování dat Miroslav Čepek, Filip Železný Katedra kybernetiky laboratoř Inteligentní Datové Analýzy (IDA) Katedra počítačů, Computational Intelligence Group Evropský sociální fond Praha & EU: Investujeme
Vytěžování dat Miroslav Čepek, Filip Železný Katedra kybernetiky laboratoř Inteligentní Datové Analýzy (IDA) Katedra počítačů, Computational Intelligence Group Evropský sociální fond Praha & EU: Investujeme
Algoritmy výpočetní geometrie
 Algoritmy výpočetní geometrie prof. Ing. Pavel Tvrdík CSc. Katedra počítačových systémů Fakulta informačních technologií České vysoké učení technické v Praze c Pavel Tvrdík, 2010 Efektivní algoritmy (BI-EFA)
Algoritmy výpočetní geometrie prof. Ing. Pavel Tvrdík CSc. Katedra počítačových systémů Fakulta informačních technologií České vysoké učení technické v Praze c Pavel Tvrdík, 2010 Efektivní algoritmy (BI-EFA)
Statistické modely tvaru a vzhledu
 Kapitola 1 Statistické modely tvaru a vzhledu V této kapitole nastíním problematiku statistických modelů tvaru, jejich využití a metod potřebných pro jejich výpočet a použití. Existují dvě hlavní metody;
Kapitola 1 Statistické modely tvaru a vzhledu V této kapitole nastíním problematiku statistických modelů tvaru, jejich využití a metod potřebných pro jejich výpočet a použití. Existují dvě hlavní metody;
Projekční algoritmus. Urychlení evolučních algoritmů pomocí regresních stromů a jejich zobecnění. Jan Klíma
 Urychlení evolučních algoritmů pomocí regresních stromů a jejich zobecnění Jan Klíma Obsah Motivace & cíle práce Evoluční algoritmy Náhradní modelování Stromové regresní metody Implementace a výsledky
Urychlení evolučních algoritmů pomocí regresních stromů a jejich zobecnění Jan Klíma Obsah Motivace & cíle práce Evoluční algoritmy Náhradní modelování Stromové regresní metody Implementace a výsledky
Četba: Texty o lineární algebře (odkazy na webových stránkách přednášejícího).
.") Předmět: MA 4 Dnešní látka Vektorový (lineární) prostor (připomenutí) Normovaný lineární prostor Normy matic a vektorů Symetrické matice, pozitivně definitní matice Gaussova eliminační metoda, podmíněnost
Předmět: MA 4 Dnešní látka Vektorový (lineární) prostor (připomenutí) Normovaný lineární prostor Normy matic a vektorů Symetrické matice, pozitivně definitní matice Gaussova eliminační metoda, podmíněnost
13. Lineární programování
 Jan Schmidt 2011 Katedra číslicového návrhu Fakulta informačních technologií České vysoké učení technické v Praze Zimní semestr 2011/12 MI-PAA EVROPSKÝ SOCIÁLNÍ FOND PRAHA & EU: INVESTUJENE DO VAŠÍ BUDOUCNOSTI
Jan Schmidt 2011 Katedra číslicového návrhu Fakulta informačních technologií České vysoké učení technické v Praze Zimní semestr 2011/12 MI-PAA EVROPSKÝ SOCIÁLNÍ FOND PRAHA & EU: INVESTUJENE DO VAŠÍ BUDOUCNOSTI
Odhady Parametrů Lineární Regrese
 Odhady Parametrů Lineární Regrese Mgr. Rudolf B. Blažek, Ph.D. prof. RNDr. Roman Kotecký, DrSc. Katedra počítačových systémů Katedra teoretické informatiky Fakulta informačních technologií České vysoké
Odhady Parametrů Lineární Regrese Mgr. Rudolf B. Blažek, Ph.D. prof. RNDr. Roman Kotecký, DrSc. Katedra počítačových systémů Katedra teoretické informatiky Fakulta informačních technologií České vysoké
1 0 0 u 22 u 23 l 31. l u11
 LU dekompozice Jedná se o rozklad matice A na dvě trojúhelníkové matice L a U, A=LU. Matice L je dolní trojúhelníková s jedničkami na diagonále a matice U je horní trojúhelníková. a a2 a3 a 2 a 22 a 23
LU dekompozice Jedná se o rozklad matice A na dvě trojúhelníkové matice L a U, A=LU. Matice L je dolní trojúhelníková s jedničkami na diagonále a matice U je horní trojúhelníková. a a2 a3 a 2 a 22 a 23
Normální (Gaussovo) rozdělení
 rozdělení") Normální (Gaussovo) rozdělení Normální (Gaussovo) rozdělení popisuje vlastnosti náhodné spojité veličiny, která vzniká složením různých náhodných vlivů, které jsou navzájem nezávislé, kterých je velký
Normální (Gaussovo) rozdělení Normální (Gaussovo) rozdělení popisuje vlastnosti náhodné spojité veličiny, která vzniká složením různých náhodných vlivů, které jsou navzájem nezávislé, kterých je velký
Lineární klasifikátory
 Lineární klasifikátory Lineární klasifikátory obsah: perceptronový algoritmus základní verze varianta perceptronového algoritmu přihrádkový algoritmus podpůrné vektorové stroje Lineární klasifikátor navrhnout
Lineární klasifikátory Lineární klasifikátory obsah: perceptronový algoritmus základní verze varianta perceptronového algoritmu přihrádkový algoritmus podpůrné vektorové stroje Lineární klasifikátor navrhnout
NADSTAVBOVÝ MODUL MOHSA V1
 NADSTAVBOVÝ MODUL MOHSA V1 Nadstavbový modul pro hierarchické shlukování se jmenuje Mod_Sh_Hier (MOHSA V1) je součástí souboru Shluk_Hier.xls. Tento soubor je přístupný na http://jonasova.upce.cz, a je
NADSTAVBOVÝ MODUL MOHSA V1 Nadstavbový modul pro hierarchické shlukování se jmenuje Mod_Sh_Hier (MOHSA V1) je součástí souboru Shluk_Hier.xls. Tento soubor je přístupný na http://jonasova.upce.cz, a je
logistická regrese Miroslav Čepek Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti
 Vytěžování Dat Přednáška 9 Lineární klasifikátor, rozšíření báze, LDA, logistická regrese Miroslav Čepek Fakulta Elektrotechnická, ČVUT Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti
Vytěžování Dat Přednáška 9 Lineární klasifikátor, rozšíření báze, LDA, logistická regrese Miroslav Čepek Fakulta Elektrotechnická, ČVUT Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti
(Cramerovo pravidlo, determinanty, inverzní matice)
") KMA/MAT1 Přednáška a cvičení, Lineární algebra 2 Řešení soustav lineárních rovnic se čtvercovou maticí soustavy (Cramerovo pravidlo, determinanty, inverzní matice) 16 a 21 října 2014 V dnešní přednášce
KMA/MAT1 Přednáška a cvičení, Lineární algebra 2 Řešení soustav lineárních rovnic se čtvercovou maticí soustavy (Cramerovo pravidlo, determinanty, inverzní matice) 16 a 21 října 2014 V dnešní přednášce
Vícerozměrné statistické metody
 Vícerozměrné statistické metody Vícerozměrné statistické rozdělení a testy, operace s vektory a maticemi Jiří Jarkovský, Simona Littnerová FSTA: Pokročilé statistické metody Vícerozměrné statistické rozdělení
Vícerozměrné statistické metody Vícerozměrné statistické rozdělení a testy, operace s vektory a maticemi Jiří Jarkovský, Simona Littnerová FSTA: Pokročilé statistické metody Vícerozměrné statistické rozdělení
Úvod do mobilní robotiky AIL028
 SLAM - souběžná lokalizace a mapování {md zw} at robotika.cz http://robotika.cz/guide/umor07/cs 10. ledna 2008 1 2 3 SLAM intro Obsah SLAM = Simultaneous Localization And Mapping problém typu slepice-vejce
SLAM - souběžná lokalizace a mapování {md zw} at robotika.cz http://robotika.cz/guide/umor07/cs 10. ledna 2008 1 2 3 SLAM intro Obsah SLAM = Simultaneous Localization And Mapping problém typu slepice-vejce
Statistická teorie učení
 Statistická teorie učení Petr Havel Marek Myslivec přednáška z 9. týdne 1 Úvod Představme si situaci výrobce a zákazníka, který si u výrobce objednal algoritmus rozpoznávání. Zákazník dodal experimentální
Statistická teorie učení Petr Havel Marek Myslivec přednáška z 9. týdne 1 Úvod Představme si situaci výrobce a zákazníka, který si u výrobce objednal algoritmus rozpoznávání. Zákazník dodal experimentální
Úvodem Dříve les než stromy 3 Operace s maticemi
 Obsah 1 Úvodem 13 2 Dříve les než stromy 17 2.1 Nejednoznačnost terminologie 17 2.2 Volba metody analýzy dat 23 2.3 Přehled vybraných vícerozměrných metod 25 2.3.1 Metoda hlavních komponent 26 2.3.2 Faktorová
Obsah 1 Úvodem 13 2 Dříve les než stromy 17 2.1 Nejednoznačnost terminologie 17 2.2 Volba metody analýzy dat 23 2.3 Přehled vybraných vícerozměrných metod 25 2.3.1 Metoda hlavních komponent 26 2.3.2 Faktorová
Odhad stavu matematického modelu křižovatek
 Odhad stavu matematického modelu křižovatek Miroslav Šimandl, Miroslav Flídr a Jindřich Duník Katedra kybernetiky & Výzkumné centrum Data-Algoritmy-Rozhodování Fakulta aplikovaných věd Západočeská univerzita
Odhad stavu matematického modelu křižovatek Miroslav Šimandl, Miroslav Flídr a Jindřich Duník Katedra kybernetiky & Výzkumné centrum Data-Algoritmy-Rozhodování Fakulta aplikovaných věd Západočeská univerzita
Algoritmy a struktury neuropočítačů ASN P9 SVM Support vector machines Support vector networks (Algoritmus podpůrných vektorů)
") Algoritmy a struktury neuropočítačů ASN P9 SVM Support vector machines Support vector networks (Algoritmus podpůrných vektorů) Autor: Vladimir Vapnik Vapnik, V. The Nature of Statistical Learning Theory.
Algoritmy a struktury neuropočítačů ASN P9 SVM Support vector machines Support vector networks (Algoritmus podpůrných vektorů) Autor: Vladimir Vapnik Vapnik, V. The Nature of Statistical Learning Theory.
Matematika I 12a Euklidovská geometrie
 Matematika I 12a Euklidovská geometrie Jan Slovák Masarykova univerzita Fakulta informatiky 3. 12. 2012 Obsah přednášky 1 Euklidovské prostory 2 Odchylky podprostorů 3 Standardní úlohy 4 Objemy Plán přednášky
Matematika I 12a Euklidovská geometrie Jan Slovák Masarykova univerzita Fakulta informatiky 3. 12. 2012 Obsah přednášky 1 Euklidovské prostory 2 Odchylky podprostorů 3 Standardní úlohy 4 Objemy Plán přednášky
Příklad 2: Určení cihlářských surovin na základě chemické silikátové analýzy
 Příklad 2: Určení cihlářských surovin na základě chemické silikátové analýzy Zadání: Deponie nadložních jílových sedimentů SHP byla testována za účelem využití v cihlářské výrobě. Z deponie bylo odebráno
Příklad 2: Určení cihlářských surovin na základě chemické silikátové analýzy Zadání: Deponie nadložních jílových sedimentů SHP byla testována za účelem využití v cihlářské výrobě. Z deponie bylo odebráno