Přednáška 10: Kombinování modelů
|
|
|
- Michaela Matoušková
- před 7 lety
- Počet zobrazení:
Transkript



")

1 České vysoké učení technické v Praze Fakulta informačních technologií Katedra teoretické informatiky Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti MI-ADM Algoritmy data miningu (2010/2011) Přednáška 10: Kombinování modelů Pavel Kordík, FIT, Czech Technical University in Prague
2 Osnova přednášky Netflix prize Teoretické aspekty kombinování modelů Skupina modelů Různorodost modelů Dekompozice chyb (rozptyl dat/systematická chyba modelu) Jaké modely kombinovat? Populární ensemble metody Bagging Boosting Stacking Algoritmus, co vyhrál milión $
, které udělili jednotlivým filmům.")
3 Vyrobte mi klasifikátor, který je o 10% lepší než to co mám, a dostanete milion dolarů! Učení s učitelem Trénovací data jsou množiny respondentů a jejich hodnocení (1,2,3,4,5 hvězdiček), které udělili jednotlivým filmům. Vytvoř klasifikátor, který dostane na vstup identifikaci uživatele a jím ještě nehodnocený film a vyprodukuje počet hvězdiček.

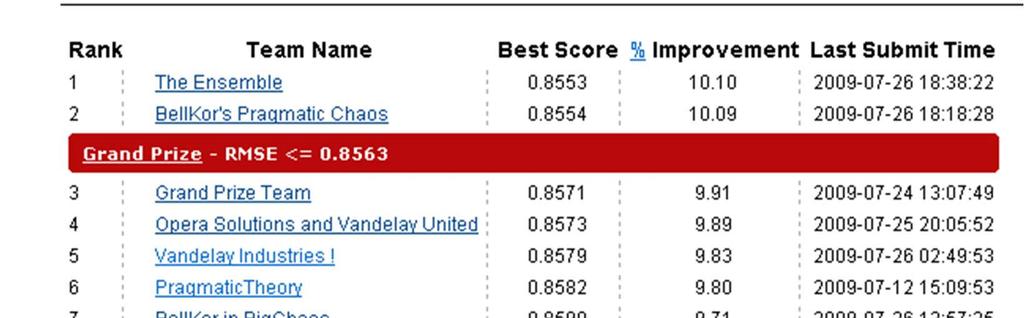
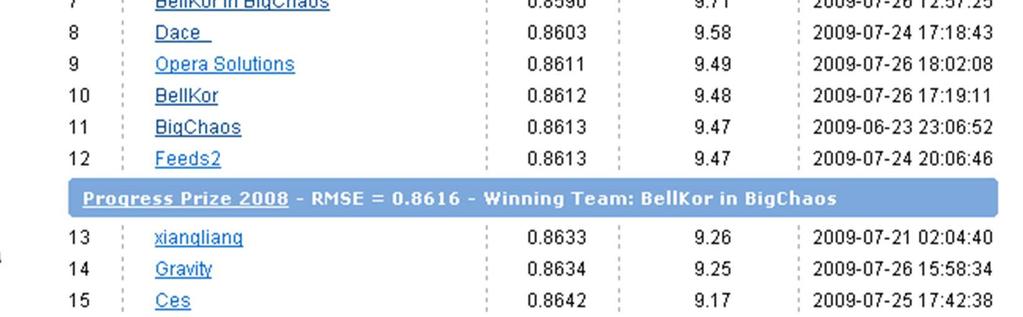
4 A kdo tedy vyhrál?
5 The Ensemble And lo, as if powered by gravity, Grand Prize Team and Vandelay Industries! began to draw in more and more members. And Vandelay went on to join forces with Opera Solutions, and then Vandelay and Opera united with Grand Prize Team, and then... and then... well, things got so complex we decided just to call ourselves The Ensemble. Ale i druhý vítěz BellKor s Pragmatic Chaos je vlastně ensemble!

6 Takhle to vypadalo v květnu 2009




7 Vývoj soutěže

8 Rookies Thanks to Paul Harrison's collaboration, a simple mix of our solutions improved our result from 6.31 to 6.75
9 Arek Paterek My approach is to combine the results of many methods (also twoway interactions between them) using linear regression on the test set. The best method in my ensemble is regularized SVD with biases, post processed with kernel ridge regression
10 U of Toronto When the predictions of multiple RBM models and multiplesvd models are linearly combined, we achieve an error rate that is well over 6% better than the score of Netflix s own system.
11 A co tahoun celé soutěže? BellKor / KorBell Our final solution (RMSE=0.8712) consists of blending 107 individual results. blendingem rozuměj kombinování modelů


12 Chyba klesá s počtem modelů BellKor in BigChaos Jak a jaké modely kombinovat?
13 Princip kombinování modelů Skupina modelů (např. rozhodovacích stromů) se naučí na stejný (podobný) úkol. Výstupy naučených modelů se kombinují. Vstupní proměnné Model 1 Model 2 Model 3 Model N Výstupní proměnná Kombinace Výstupní proměnná Skupinový (ensemble) výstup
14 Různorodost ensemble modelů Co se stane, když budou všechny modely totožné? => Degradace na jeden model. Jak zajistíme, aby byly modely různorodé? Různé množiny trénovacích dat (počáteční podmínky) Různé metody konstrukce modelů Jak se dá měřit různorodost modelů? Odchylky výstupů na jednotlivých testovacích datech. Strukturální odlišnosti
15 Funguje to vůbec? Chceme zjistit, za jakých předpokladů se vyplatí modely kombinovat. Zajímá nás proč ensembling funguje. Potřebujeme k tomu analyzovat, čím je chyba modelů způsobena
16 Příklad výška lidí Cíl: odhadnout výšku dospělého muže. Přesněji: Najít odhad ŷ který minimalizuje střední hodnotu chyby E y {(y-ŷ) 2 } přes celou populaci. p(y) hustota pravděpodobnosti 180 y
17 Jak by na to šel pan Bayes? Změřil by všechny dospělé muže v celé populaci, vypočetl střední hodnotu E y {y} a prohlásil ji za optimální odhad. Potlesk, úloha vyřešena, výsledek je: E y {y} = y= p ( y) y Ale v reálu je p(y) neznámá, její odhad je třeba zkonstruovat pomocí skupiny mužů LS={y 1,y 2,,y N }, jejichž výšku jsme změřili.
18 Výstup nějakého našeho modelu Protože skupina LS je náhodně zvolena, odhad ŷ bude také náhodná veličina. p LS (ŷ) Dobrý učicí algoritmus by měl fungovat dobře na libovolně zvolené skupině LS, tedy poskytnout minimální chybu v průměru pro různé LS: E=E LS {E y {(y-ŷ) 2 }} ŷ
19 Dekompozice bias/variance (1) var y {y} E y {y} y E = E y {(y-e y {y}) 2 } + E LS {(E y {y}-ŷ) 2 } = residuální chyba = minimální dosažitelná chyba = var y {y}
20 Dekompozice bias/variance (2) bias 2 E y {y} E LS {ŷ} ŷ E = var y {y} + (E y {y}-e LS {ŷ}) 2 + E LS {ŷ} = průměrný model (přes všechny LS) bias 2 = chyba průměrného modelu oproti modelu pana Bayese (optimálnímu) Náš algoritmus učení
21 Dekompozice bias/variance (3) var LS {ŷ} E LS {ŷ} ŷ E = var y {y} + bias 2 + E LS {(ŷ-e LS {ŷ}) 2 } var LS {ŷ} = variance našich modelů pro různé LS = důsledek přeučení
22 Dekompozice bias/variance (4) var y {y} bias 2 var LS {ŷ} E y {y} E LS {ŷ} ŷ E = var y {y} + bias 2 + var LS {ŷ}
23 Dekompozice bias/variance (5) E LS {E y x {(y-ŷ(x))^2}}=noise(x)+bias 2 (x)+variance(x) Šum(x) = E y x {(y-h B (x)) 2 } Kvantifikuje odchylku výstupu y od optimálního modelu h B (x) = E y x {y}. Bias 2 (x) = (h B (x)-e LS {ŷ(x)}) 2 : Chyba průměrného modelu vzhledem k optimálnímu. Variance(x) = E LS {(ŷ(x)-e LS {ŷ(x)) 2 } : Jak moc se predikce ŷ(x) liší pro různé učicí množiny LS.
24 Příklad (1) Najděte algoritmus produkující co nejlepší modely pro následující data: y x
25 Příklad (2) Optimální model: Vstup x, náhodná proměnná rovnoměrně rozložená v intervalu [0,1] y=h(x)+ε, kde ε N(0,1) je Bayesovský model y a šum y h(x)=e y x {y} x
26 Příklad algoritmus lineární regrese Modely mají malý rozptyl (variance), ale velké zaujetí (bias) nedoučení E LS {ŷ(x)}
27 Příklad algoritmus RBFN s počtem neuronů = mohutnost LS Nízké zaujetí (bias), velký rozptyl (variance) modelů přeučení E LS {ŷ(x)}
28 Zpět ke kombinování modelů Co se stane, když naučím 2 jednoduché modely na různých podmnožinách LS? y y=f1(x) y=f2(x) y= f1(x)+f2(x) 2 x
29 Ensembling snižujevarianci Trénovací data pro model 1 ensemble model Trénovací data pro model 2
30 Ensembling snižujebias model 2 model 1 ensemble model
31 Tedy:
32 Podobně pro klasifikaci? model 1 model 2 model 3 ensemble model třída 1 třída 1 a třída 2 b třída 2 Obrázky z TCD AI Course, 2005 hranice tříd Snižuje se bias nebo variance?
33 Jaké modely kombinovat? Co se stane, když zkombinují optimálně naučené modely? model 3 model 2 model 1 Výhodně se dají kombinovat jednoduché modely (tzv. weak learners). Modely musí být různorodé! Musejí redukujeme bias vykazovat různé chyby na jednotlivých trénovacích vzorech. ensemble model redukujeme varianci
34 Populární ensemble metody Bagging (Bootstrap Aggregating) Modely naučím nezávisle a jednoduše zkombinuji jejich výstup Boosting Modely se učí sekvenčně, trénovací data jsou závislá na chybách předchozích modelů Stacking Modely se učí nezávisle, kombinují naučením speciálního modelu
35 Bagging (1) E LS {Err(x)}=E y x {(y-h B (x)) 2 }+ (h B (x)-e LS {ŷ(x)}) 2 +E LS {(ŷ(x)-e LS {ŷ(x)) 2 } Myšlenka: průměrný model E LS {ŷ(x)} má stejný bias jako původní metoda, ale nulovou varianci Bagging (Bootstrap AGGregatING) : K vypočtení E LS {ŷ (x)}, potřebujeme nekonečně mnoho skupin LS (velikosti N) Máme však jen jednu skupinu LS, musíme si sami nějak pomoc



36 Bootstrapping: trocha historie Rudolf Raspe, Baron Munchausen s Narrative of his Marvellous Travels and Campaings in Russia, 1785 He hauls himself and his horse out of the mud by lifting himself by his own hair. This term was also used to refer to doing something on your own, without the use of external help since 1860s Since 1950s it refers to the procedure of getting a computer to start (to boot, to reboot)
37 Co je Bootstrap? X=(3.12, 0, 1.57, 19.67, 0.22, 2.20) Mean=4.46 X1=(1.57,0.22,19.67, 0,0,2.2,3.12) Mean=4.13 X2=(0, 2.20, 2.20, 2.20, 19.67, 1.57) Mean=4.64 X3=(0.22, 3.12,1.57, 3.12, 2.20, 0.22) Mean=1.74 statistika: odhad intervalu spolehlivosti
38 Příklad bootstrap (Opitz, 1999) Trénovací vzory vzorek vzorek vzorek M
39 Bagging (2) LS LS 1 LS 2 LS T x ŷ 1 (x) ŷ 2 (x) ŷ T (x) Pro regresi: ŷ(x) = 1/k * (ŷ 1 (x)+ŷ 2 (x)+ +ŷ T (x)) Pro klasifikaci: ŷ(x) = majoritní třída z {ŷ 1 (x),,ŷ T (x)}
40 Bagging (Bootstrap agregating) Výběrem s opakováním utvořte M trénovacích souborů o n vzorech (místo jednoho původního souboru o n vzorech). Postavte model pro každý trénovací soubor. Zkombinujte modely. Bootstrap samples! výběr s opakováním vzorek 1 trénovací algoritmus Model 1 průměrování nebo hlasování Trénovací data vzorek 2 trénovací algoritmus Model 2 Ensemble model výstup... vzorek M trénovací algoritmus Model M vynálezce: Breiman (1996)
41 Bagging př. rozhodovací stromy Obvykle bagging podstatně sníží varianci a zachová zaujetí modelů. Podívejme se na příklad s rozhodovacími stromy: Metoda E Bias Variance 3 Test regr. Tree Bagged (T=25) Full regr. Tree Bagged (T=25) V tomto případě jsou pro učení rozhodovacích stromů použity všechny vstupní atributy a diverzita je způsobena proměnnou učicí množinou
42 Náhodné (rozhodovací) lesy random forests K baggingu se ještě přidá to, že náhodně vybíráme podmnožinu vstupních atributů Tedy: Postav rozhodovací strom z bootstrap vzorku Najdi best split mezi náhodnou podmnožinou k atributů, ne mezi všemi jako normálně (= bagging, když k je rovno počtu attributů) Odhadnete vliv k? Menší k redukuje varianci a zvyšuje bias
43 Boosting Iterativní procedura adaptivně měnící rozložení učicích dat zvýrazňujíce špatně klasifikované vzory Používá se zejména ke kombinaci slabých modelů (weak learners), které mají velké zaujetí Výrazně redukuje bias náchylnost k přeučení
44 Boosting (2) LS LS 1 LS 2 LS T x ŷ 1 (x) ŷ 2 (x) ŷ T (x) Pro regresi: ŷ(x) = β 1 *ŷ 1 (x)+ β 2 *ŷ 2 (x)+ + β T *ŷ T (x)) Pro klasifikaci: ŷ(x) = majorita tříd z {ŷ 1 (x),,ŷ T (x)} s použitím vah {β 1,β 2,,β T }
45 Boosting (3) Na počátku mají všechny vzory stejnou váhu Po naučení modelu zvýšíme váhu špatně klasifikovaným vzorům a snížíme ji dobře klasifikovaným Příklad: vzor 4 je špatně klasifikovatelný Postupně se zvyšuje jeho váha a tedy i pravděpodobnost zařazení do učicí množiny Original Data Boosting (Round 1) Boosting (Round 2) Boosting (Round 3)
46 Algoritmus AdaBoost (1) Klasifikátory: C 1, C 2,, C T Jejich chyby: ε i = 1 N w jδ N j= 1 i j ) ( C ( x y ) Důležitost klasifikátoru: j váha vzoru (chyby na zmnožených vzorech bolí více!) β i = ε i ln ε i
47 Algoritmus AdaBoost (2) Update vah: w ( j+ 1) i kde Z = j ( j) β j w exp if ( ) i C j xi = β j Z j exp if C j ( xi ) je normalizační konstanta y y i i Finální klasifikace: C *( x) = arg max β δ y T j= 1 j ( C ( x) = y) j
48 Příklad AdaBoost Počáteční inicializace vah Data vybraná do učicí množiny Špatně klasifikováno B1, váhy rostou.
49 Příklad AdaBoost

50 Při inicializaci jsou váhy vzorů stejné, puntíky mají stejnou velikost. Vzory se mají klasifikovat do modré a červené třídy. Po 1. iteraci AdaBoostu rostou váhy špatně klasifikovaných vzorů na pomezí tříd 3. iterace Po naučení 20 klasifikátorů jsou váhy vzorů mimo hranici tříd téměř nulové (nejsou vybírány do trénovací množiny) 20 iterace fromelder, John. From Trees to Forests and Rule Sets -A Unified Overview of Ensemble Methods
51 Stacking Používá meta model pro kombinaci výstupů ensemble modelů (oproti jednoduchému průměrování, nebo hlasování) Výstupy ensemble modelů jsou použity jako trénovací data pro meta model Ensemble modely jsou většinou naučeny různými algoritmy Teoretická analýza stackingu je obtížná, jedná se o black magic Slide from Ensembles of Classifiers by Evgueni Smirnov
52 Stacking BC 1 BC instance 1 BC n 1 meta instances instance 1 BC 1 BC 2 BC n Class 1 Slide from Ensembles of Classifiers by Evgueni Smirnov
53 Stacking BC 1 BC instance 2 BC n 0 meta instances instance 1 BC 1 BC 2 BC n Class instance Slide from Ensembles of Classifiers by Evgueni Smirnov
54 Stacking Meta Classifier meta instances BC 1 BC 2 BC n instance Class instance Slide from Ensembles of Classifiers by Evgueni Smirnov
55 Stacking BC instance BC 2 1 Meta Classifier BC n 1 meta instance instance BC 1 BC 2 BC n Slide from Ensembles of Classifiers by Evgueni Smirnov
56 Argumenty proti kombinování modelů? Okamova břitva v jednoduchosti je síla Je lepší mít jednoduchý optimální model, než kombinaci mnoha modelů ale jak najít optimální model? Domingos, P. Occam s two razors: the sharp and the blunt. KDD Kombinováním modelů se často kamufluje nedokonalost metod produkujících nedoučené nebo přeučené modely Kombinováním dostanu model s horšími výsledky na testovacích datech, než mají kombinované modely
57 Argumenty pro kombinování Většinou zlepším výsledky na testovacích datech Algoritmy jsou implicitně nastaveny, je třeba experimentovat s jejich konfigurací, aby produkované modely byly optimální konkrétních datech Dostanu povědomí o jistotě modelu když se pro jeden vstupní vektor jednotlivé modely hodně liší, zřejmě jsme mimo oblast trénovacích dat Netflix prize
58 Co přesně použil vítěz? Víceúrovňový Stacking pomocí MLP Gradient Boosting rozhodovacích stromů A samozřejmě výborné base-klasifikátory: KNN SVD RBM
59 Netflix prize a další aplikace Podrobný popis vítězných algoritmů _BPC_BellKor.pdf _BPC_BigChaos.pdf _BPC_PragmaticTheory.pdf Ještě něco zajímavého na ensemblech?
60 Příklady použití ensemble metod (klimatické modely) Skupinová předpověď (Ensemble forecast) Ensemble je soubor předpovědí, které kolektivně mapují pravděpodobné budoucí stavy, s ohledem na nejistotu provázející proces předpovědi. Předpovědi modelů s drobnými odlišnostmi v parametrech (v počátečních podmínkách) Interval vysoké pravděpodobnosti. Předpověď teploty Zdroj: prezentace J.P. Céron 2003 Aktuální čas Horizont předpovědi



61 Ensemble modely pro předpověď počasí vizualizace předpovědi zdroj: J.P. Céron
 modelů, které se liší složitostí, počátečními podmínkami a parametry. Dr. Thomas Stocker, Climate and Environmental Physics University of Bern, Switzerland www.")
62 Ensemble modely a globální oteplování Knutti et al. (2002) Pouze jeden model ignoruje neodmyslitelné mezery v našich znalostech a limity předvídatelnosti vývoje Země. Potřebujeme celou skupinu (ensemble) modelů, které se liší složitostí, počátečními podmínkami a parametry. Dr. Thomas Stocker, Climate and Environmental Physics University of Bern, Switzerland MI-ADM Algoritmy 2003 data miningu
63 Otázky Jakou novou informaci získáme použitím skupiny modelů oproti použití pouze jednoho modelu? Může ensemble zpřesnit předpověď, pro jaké modely? Jaké jsou nevýhody ensemble předpovědi?
64 Další vylepšení Hierarchické kombinování modelů Meta-learning templates Šlechtění topologie ensemblu na konkrétních datech více v MI-MVI

65 Meta-learning Templates Submitted to KDD 2011 (Kordík, Černý)
66 The template can be executed
67 to produce a model



68

69

70



71




72
Vytěžování znalostí z dat
 Pavel Kordík (ČVUT FIT) Vytěžování znalostí z dat BI-VZD, 2012, Přednáška 11 1/31 Vytěžování znalostí z dat Pavel Kordík Department of Computer Systems Faculty of Information Technology Czech Technical
Pavel Kordík (ČVUT FIT) Vytěžování znalostí z dat BI-VZD, 2012, Přednáška 11 1/31 Vytěžování znalostí z dat Pavel Kordík Department of Computer Systems Faculty of Information Technology Czech Technical
Miroslav Čepek. Fakulta Elektrotechnická, ČVUT. Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti
 Vytěžování Dat Přednáška 12 Kombinování modelů Miroslav Čepek Pavel Kordík a Jan Černý (FIT) Fakulta Elektrotechnická, ČVUT Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti ČVUT (FEL)
Vytěžování Dat Přednáška 12 Kombinování modelů Miroslav Čepek Pavel Kordík a Jan Černý (FIT) Fakulta Elektrotechnická, ČVUT Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti ČVUT (FEL)
Vytěžování znalostí z dat
 Pavel Kordík, Jan Motl (ČVUT FIT) Vytěžování znalostí z dat BI-VZD, 2012, Přednáška 7 1/27 Vytěžování znalostí z dat Pavel Kordík, Jan Motl Department of Computer Systems Faculty of Information Technology
Pavel Kordík, Jan Motl (ČVUT FIT) Vytěžování znalostí z dat BI-VZD, 2012, Přednáška 7 1/27 Vytěžování znalostí z dat Pavel Kordík, Jan Motl Department of Computer Systems Faculty of Information Technology
Obsah přednášky Jaká asi bude chyba modelu na nových datech?
 Obsah přednášky Jaká asi bude chyba modelu na nových datech? Chyba modelu Bootstrap Cross Validation Vapnik-Chervonenkisova dimenze 2 Chyba skutečná a trénovací Máme 30 záznamů, rozhodli jsme se na jejich
Obsah přednášky Jaká asi bude chyba modelu na nových datech? Chyba modelu Bootstrap Cross Validation Vapnik-Chervonenkisova dimenze 2 Chyba skutečná a trénovací Máme 30 záznamů, rozhodli jsme se na jejich
Kombinování klasifikátorů Ensamble based systems
 Kombinování klasifikátorů Ensamble based systems Rozhodování z více hledisek V běžném životě se často snažíme získat názor více expertů, než přijmeme závažné rozhodnutí: Před operací se radíme s více lékaři
Kombinování klasifikátorů Ensamble based systems Rozhodování z více hledisek V běžném životě se často snažíme získat názor více expertů, než přijmeme závažné rozhodnutí: Před operací se radíme s více lékaři
Projekční algoritmus. Urychlení evolučních algoritmů pomocí regresních stromů a jejich zobecnění. Jan Klíma
 Urychlení evolučních algoritmů pomocí regresních stromů a jejich zobecnění Jan Klíma Obsah Motivace & cíle práce Evoluční algoritmy Náhradní modelování Stromové regresní metody Implementace a výsledky
Urychlení evolučních algoritmů pomocí regresních stromů a jejich zobecnění Jan Klíma Obsah Motivace & cíle práce Evoluční algoritmy Náhradní modelování Stromové regresní metody Implementace a výsledky
Dobývání znalostí. Doc. RNDr. Iveta Mrázová, CSc. Katedra teoretické informatiky Matematicko-fyzikální fakulta Univerzity Karlovy v Praze
 Dobývání znalostí Doc. RNDr. Iveta Mrázová, CSc. Katedra teoretické informatiky Matematicko-fyzikální fakulta Univerzity Karlovy v Praze Dobývání znalostí Pravděpodobnost a učení Doc. RNDr. Iveta Mrázová,
Dobývání znalostí Doc. RNDr. Iveta Mrázová, CSc. Katedra teoretické informatiky Matematicko-fyzikální fakulta Univerzity Karlovy v Praze Dobývání znalostí Pravděpodobnost a učení Doc. RNDr. Iveta Mrázová,
Kybernetika a umělá inteligence, cvičení 10/11
 Kybernetika a umělá inteligence, cvičení 10/11 Program 1. seminární cvičení: základní typy klasifikátorů a jejich princip 2. počítačové cvičení: procvičení na problému rozpoznávání číslic... body za aktivitu
Kybernetika a umělá inteligence, cvičení 10/11 Program 1. seminární cvičení: základní typy klasifikátorů a jejich princip 2. počítačové cvičení: procvičení na problému rozpoznávání číslic... body za aktivitu
Statistická analýza dat
 Statistická analýza dat Jméno: Podpis: Cvičení Zkouška (písemná + ústní) 25 Celkem 50 Známka Pokyny k vypracování: doba řešení je 120min, jasně zodpovězte pokud možno všechny otázky ze zadání, pracujte
Statistická analýza dat Jméno: Podpis: Cvičení Zkouška (písemná + ústní) 25 Celkem 50 Známka Pokyny k vypracování: doba řešení je 120min, jasně zodpovězte pokud možno všechny otázky ze zadání, pracujte
Odhady Parametrů Lineární Regrese
 Odhady Parametrů Lineární Regrese Mgr. Rudolf B. Blažek, Ph.D. prof. RNDr. Roman Kotecký, DrSc. Katedra počítačových systémů Katedra teoretické informatiky Fakulta informačních technologií České vysoké
Odhady Parametrů Lineární Regrese Mgr. Rudolf B. Blažek, Ph.D. prof. RNDr. Roman Kotecký, DrSc. Katedra počítačových systémů Katedra teoretické informatiky Fakulta informačních technologií České vysoké
Optimální rozdělující nadplocha 4. Support vector machine. Adaboost.
 Optimální rozdělující nadplocha. Support vector machine. Adaboost. Petr Pošík Czech Technical University in Prague Faculty of Electrical Engineering Dept. of Cybernetics Opakování Lineární diskriminační
Optimální rozdělující nadplocha. Support vector machine. Adaboost. Petr Pošík Czech Technical University in Prague Faculty of Electrical Engineering Dept. of Cybernetics Opakování Lineární diskriminační
Vytěžování znalostí z dat
 Vytěžování znalostí z dat Department of Computer Systems Faculty of Information Technology Czech Technical University in Prague Přednáška 5: Hodnocení kvality modelu BI-VZD, 09/2011 MI-POA Evropský sociální
Vytěžování znalostí z dat Department of Computer Systems Faculty of Information Technology Czech Technical University in Prague Přednáška 5: Hodnocení kvality modelu BI-VZD, 09/2011 MI-POA Evropský sociální
Miroslav Čepek 16.12.2014
 Vytěžování Dat Přednáška 12 Kombinování modelů Miroslav Čepek Pavel Kordík a Jan Černý (FIT) Fakulta Elektrotechnická, ČVUT Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti 16.12.2014
Vytěžování Dat Přednáška 12 Kombinování modelů Miroslav Čepek Pavel Kordík a Jan Černý (FIT) Fakulta Elektrotechnická, ČVUT Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti 16.12.2014
Obsah přednášky. 1. Principy Meta-learningu 2. Bumping 3. Bagging 4. Stacking 5. Boosting 6. Shrnutí
 1 Obsah přednášy 1. Principy Meta-learningu 2. Bumping 3. Bagging 4. Stacing 5. Boosting 6. Shrnutí 2 Meta learning = Ensemble methods Cíl použít predici ombinaci více různých modelů Meta learning (meta
1 Obsah přednášy 1. Principy Meta-learningu 2. Bumping 3. Bagging 4. Stacing 5. Boosting 6. Shrnutí 2 Meta learning = Ensemble methods Cíl použít predici ombinaci více různých modelů Meta learning (meta
Katedra kybernetiky laboratoř Inteligentní Datové Analýzy (IDA) Katedra počítačů, Computational Intelligence Group
 Katedra počítačů, Computational Intelligence Group") Vytěžování dat Miroslav Čepek, Filip Železný Katedra kybernetiky laboratoř Inteligentní Datové Analýzy (IDA) Katedra počítačů, Computational Intelligence Group Evropský sociální fond Praha & EU: Investujeme
Vytěžování dat Miroslav Čepek, Filip Železný Katedra kybernetiky laboratoř Inteligentní Datové Analýzy (IDA) Katedra počítačů, Computational Intelligence Group Evropský sociální fond Praha & EU: Investujeme
Vytěžování znalostí z dat
 Pavel Kordík, Josef Borkovec (ČVUT FIT) Vytěžování znalostí z dat BI-VZD, 2012, Přednáška 8 1/26 Vytěžování znalostí z dat Pavel Kordík, Josef Borkovec Department of Computer Systems Faculty of Information
Pavel Kordík, Josef Borkovec (ČVUT FIT) Vytěžování znalostí z dat BI-VZD, 2012, Přednáška 8 1/26 Vytěžování znalostí z dat Pavel Kordík, Josef Borkovec Department of Computer Systems Faculty of Information
AVDAT Mnohorozměrné metody, metody klasifikace
 AVDAT Mnohorozměrné metody, metody klasifikace Josef Tvrdík Katedra informatiky Přírodovědecká fakulta Ostravská univerzita Mnohorozměrné metody Regrese jedna náhodná veličina je vysvětlována pomocí jiných
AVDAT Mnohorozměrné metody, metody klasifikace Josef Tvrdík Katedra informatiky Přírodovědecká fakulta Ostravská univerzita Mnohorozměrné metody Regrese jedna náhodná veličina je vysvětlována pomocí jiných
Zadání Máme data hdp.wf1, která najdete zde: Bodová předpověď: Intervalová předpověď:
 Predikce Text o predikci pro upřesnění pro ty, které zajímá, kde se v EViews všechna ta čísla berou. Ruční výpočty u průběžného testu nebudou potřeba. Co bude v závěrečném testu, to nevím. Ale přečíst
Predikce Text o predikci pro upřesnění pro ty, které zajímá, kde se v EViews všechna ta čísla berou. Ruční výpočty u průběžného testu nebudou potřeba. Co bude v závěrečném testu, to nevím. Ale přečíst
AVDAT Nelineární regresní model
 AVDAT Nelineární regresní model Josef Tvrdík Katedra informatiky Přírodovědecká fakulta Ostravská univerzita Nelineární regresní model Ey i = f (x i, β) kde x i je k-členný vektor vysvětlujících proměnných
AVDAT Nelineární regresní model Josef Tvrdík Katedra informatiky Přírodovědecká fakulta Ostravská univerzita Nelineární regresní model Ey i = f (x i, β) kde x i je k-členný vektor vysvětlujících proměnných
Pravděpodobně skoro správné. PAC učení 1
 Pravděpodobně skoro správné (PAC) učení PAC učení 1 Výpočetní teorie strojového učení Věta o ošklivém kačátku. Nechť E je klasifikovaná trénovací množina pro koncept K, který tvoří podmnožinu konečného
Pravděpodobně skoro správné (PAC) učení PAC učení 1 Výpočetní teorie strojového učení Věta o ošklivém kačátku. Nechť E je klasifikovaná trénovací množina pro koncept K, který tvoří podmnožinu konečného
Strojové učení Marta Vomlelová
 Strojové učení Marta Vomlelová marta@ktiml.mff.cuni.cz KTIML, S303 Literatura 1.T. Hastie, R. Tishirani, and J. Friedman. The Elements of Statistical Learning, Data Mining, Inference and Prediction. Springer
Strojové učení Marta Vomlelová marta@ktiml.mff.cuni.cz KTIML, S303 Literatura 1.T. Hastie, R. Tishirani, and J. Friedman. The Elements of Statistical Learning, Data Mining, Inference and Prediction. Springer
Stavový model a Kalmanův filtr
 Stavový model a Kalmanův filtr 2 prosince 23 Stav je veličina, kterou neznáme, ale chtěli bychom znát Dozvídáme se o ní zprostředkovaně prostřednictvím výstupů Příkladem může býapř nějaký zašuměný signál,
Stavový model a Kalmanův filtr 2 prosince 23 Stav je veličina, kterou neznáme, ale chtěli bychom znát Dozvídáme se o ní zprostředkovaně prostřednictvím výstupů Příkladem může býapř nějaký zašuměný signál,
Vytěžování znalostí z dat
 Pavel Kordík, Josef Borkovec (ČVUT FIT) Vytěžování znalostí z dat BI-VZD, 2011, Cvičení 9 1/16 Vytěžování znalostí z dat Pavel Kordík, Josef Borkovec Department of Computer Systems Faculty of Information
Pavel Kordík, Josef Borkovec (ČVUT FIT) Vytěžování znalostí z dat BI-VZD, 2011, Cvičení 9 1/16 Vytěžování znalostí z dat Pavel Kordík, Josef Borkovec Department of Computer Systems Faculty of Information
Klasifikace a rozpoznávání
 Klasifikace a rozpoznávání Prezentace přednášek Ústav počítačové grafiky a multimédií Téma přednášky Boosting Michal Hradiš UPGM FIT Brno University of Technology Obsah: Co je to boosting? Algoritmus AdaBoost
Klasifikace a rozpoznávání Prezentace přednášek Ústav počítačové grafiky a multimédií Téma přednášky Boosting Michal Hradiš UPGM FIT Brno University of Technology Obsah: Co je to boosting? Algoritmus AdaBoost
oddělení Inteligentní Datové Analýzy (IDA)
") Vytěžování dat Filip Železný Katedra počítačů oddělení Inteligentní Datové Analýzy (IDA) 22. září 2014 Filip Železný (ČVUT) Vytěžování dat 22. září 2014 1 / 25 Odhad rozdělení Úloha: Vstup: data D = {
Vytěžování dat Filip Železný Katedra počítačů oddělení Inteligentní Datové Analýzy (IDA) 22. září 2014 Filip Železný (ČVUT) Vytěžování dat 22. září 2014 1 / 25 Odhad rozdělení Úloha: Vstup: data D = {
Pokročilé neparametrické metody. Klára Kubošová
 Pokročilé neparametrické metody Klára Kubošová Klasifikační a regresní lesy Pokročilé neparametrické metody Klasifikační a regresní lesy Klasifikační les Klasifikační les je klasifikační model vytvořený
Pokročilé neparametrické metody Klára Kubošová Klasifikační a regresní lesy Pokročilé neparametrické metody Klasifikační a regresní lesy Klasifikační les Klasifikační les je klasifikační model vytvořený
Měření dat Filtrace dat, Kalmanův filtr
 Měření dat Filtrace dat, Matematické metody pro ITS (11MAMY) Jan Přikryl Ústav aplikované matematiky ČVUT v Praze, Fakulta dopravní 3. přednáška 11MAMY čtvrtek 28. února 2018 verze: 2018-02-28 12:20 Obsah
Měření dat Filtrace dat, Matematické metody pro ITS (11MAMY) Jan Přikryl Ústav aplikované matematiky ČVUT v Praze, Fakulta dopravní 3. přednáška 11MAMY čtvrtek 28. února 2018 verze: 2018-02-28 12:20 Obsah
Základy vytěžování dat
 Základy vytěžování dat předmět A7Bb36vyd Vytěžování dat Filip Železný, Miroslav Čepek, Radomír Černoch, Jan Hrdlička katedra kybernetiky a katedra počítačů ČVUT v Praze, FEL Evropský sociální fond Praha
Základy vytěžování dat předmět A7Bb36vyd Vytěžování dat Filip Železný, Miroslav Čepek, Radomír Černoch, Jan Hrdlička katedra kybernetiky a katedra počítačů ČVUT v Praze, FEL Evropský sociální fond Praha
Některé potíže s klasifikačními modely v praxi. Nikola Kaspříková KMAT FIS VŠE v Praze
 Některé potíže s klasifikačními modely v praxi Nikola Kaspříková KMAT FIS VŠE v Praze Literatura J. M. Chambers: Greater or Lesser Statistics: A Choice for Future Research. Statistics and Computation 3,
Některé potíže s klasifikačními modely v praxi Nikola Kaspříková KMAT FIS VŠE v Praze Literatura J. M. Chambers: Greater or Lesser Statistics: A Choice for Future Research. Statistics and Computation 3,
ZÍSKÁVÁNÍ ZNALOSTÍ Z DATABÁZÍ
 Metodický list č. 1 Dobývání znalostí z databází Cílem tohoto tematického celku je vysvětlení základních pojmů z oblasti dobývání znalostí z databází i východisek dobývání znalostí z databází inspirovaných
Metodický list č. 1 Dobývání znalostí z databází Cílem tohoto tematického celku je vysvětlení základních pojmů z oblasti dobývání znalostí z databází i východisek dobývání znalostí z databází inspirovaných
AVDAT Klasický lineární model, metoda nejmenších
 AVDAT Klasický lineární model, metoda nejmenších čtverců Josef Tvrdík Katedra informatiky Přírodovědecká fakulta Ostravská univerzita Lineární model y i = β 0 + β 1 x i1 + + β k x ik + ε i (1) kde y i
AVDAT Klasický lineární model, metoda nejmenších čtverců Josef Tvrdík Katedra informatiky Přírodovědecká fakulta Ostravská univerzita Lineární model y i = β 0 + β 1 x i1 + + β k x ik + ε i (1) kde y i
přetrénování = ztráta schopnosti generalizovat vlivem přílišného zaměření klasifikátorů na rozeznávání pouze konkrétních trénovacích dat
 Zkouška ISR 2013 přetrénování = ztráta schopnosti generalizovat vlivem přílišného zaměření klasifikátorů na rozeznávání pouze konkrétních trénovacích dat 1. Rozdílné principy u induktivního a deduktivního
Zkouška ISR 2013 přetrénování = ztráta schopnosti generalizovat vlivem přílišného zaměření klasifikátorů na rozeznávání pouze konkrétních trénovacích dat 1. Rozdílné principy u induktivního a deduktivního
4EK211 Základy ekonometrie
 4EK211 Základy ekonometrie ZS 2015/16 Cvičení 7: Časově řady, autokorelace LENKA FIŘTOVÁ KATEDRA EKONOMETRIE, FAKULTA INFORMATIKY A STATISTIKY VYSOKÁ ŠKOLA EKONOMICKÁ V PRAZE 1. Časové řady Data: HDP.wf1
4EK211 Základy ekonometrie ZS 2015/16 Cvičení 7: Časově řady, autokorelace LENKA FIŘTOVÁ KATEDRA EKONOMETRIE, FAKULTA INFORMATIKY A STATISTIKY VYSOKÁ ŠKOLA EKONOMICKÁ V PRAZE 1. Časové řady Data: HDP.wf1
Strojové učení Marta Vomlelová
 Strojové učení Marta Vomlelová marta@ktiml.mff.cuni.cz KTIML, S303 Literatura T. Hastie, R. Tishirani, and J. Friedman. The Elements of Statistical Learning, Data Mining, Inference and Prediction. Springer
Strojové učení Marta Vomlelová marta@ktiml.mff.cuni.cz KTIML, S303 Literatura T. Hastie, R. Tishirani, and J. Friedman. The Elements of Statistical Learning, Data Mining, Inference and Prediction. Springer
Evoluční algoritmy. Podmínka zastavení počet iterací kvalita nejlepšího jedince v populaci změna kvality nejlepšího jedince mezi iteracemi
 Evoluční algoritmy Použítí evoluční principů, založených na metodách optimalizace funkcí a umělé inteligenci, pro hledání řešení nějaké úlohy. Populace množina jedinců, potenciálních řešení Fitness function
Evoluční algoritmy Použítí evoluční principů, založených na metodách optimalizace funkcí a umělé inteligenci, pro hledání řešení nějaké úlohy. Populace množina jedinců, potenciálních řešení Fitness function
Odhad stavu matematického modelu křižovatek
 Odhad stavu matematického modelu křižovatek Miroslav Šimandl, Miroslav Flídr a Jindřich Duník Katedra kybernetiky & Výzkumné centrum Data-Algoritmy-Rozhodování Fakulta aplikovaných věd Západočeská univerzita
Odhad stavu matematického modelu křižovatek Miroslav Šimandl, Miroslav Flídr a Jindřich Duník Katedra kybernetiky & Výzkumné centrum Data-Algoritmy-Rozhodování Fakulta aplikovaných věd Západočeská univerzita
Extrakce a selekce příznaků
 Extrakce a selekce příznaků Based on slides Martina Bachlera martin.bachler@igi.tugraz.at, Makoto Miwa And paper Isabelle Guyon, André Elisseeff: An Introduction to variable and feature selection. JMLR,
Extrakce a selekce příznaků Based on slides Martina Bachlera martin.bachler@igi.tugraz.at, Makoto Miwa And paper Isabelle Guyon, André Elisseeff: An Introduction to variable and feature selection. JMLR,
DATA MINING KLASIFIKACE DMINA LS 2009/2010
 DATA MINING KLASIFIKACE DMINA LS 2009/2010 Osnova co je to klasifikace typy klasifikátoru typy výstupu jednoduchý klasifikátor (1R) rozhodovací stromy Klasifikace (ohodnocení) zařazuje data do předdefinovaných
DATA MINING KLASIFIKACE DMINA LS 2009/2010 Osnova co je to klasifikace typy klasifikátoru typy výstupu jednoduchý klasifikátor (1R) rozhodovací stromy Klasifikace (ohodnocení) zařazuje data do předdefinovaných
Strukturální regresní modely. určitý nadhled nad rozličnými typy modelů
 Strukturální regresní modely určitý nadhled nad rozličnými typy modelů Jde zlepšit odhad k-nn? Odhad k-nn konverguje pro slušné k očekávané hodnotě. ALE POMALU! Jiné přístupy přidají předpoklad o funkci
Strukturální regresní modely určitý nadhled nad rozličnými typy modelů Jde zlepšit odhad k-nn? Odhad k-nn konverguje pro slušné k očekávané hodnotě. ALE POMALU! Jiné přístupy přidají předpoklad o funkci
Matematické modelování Náhled do ekonometrie. Lukáš Frýd
 Matematické modelování Náhled do ekonometrie Lukáš Frýd Výnos akcie vs. Výnos celého trhu - CAPM model r it = r ft + β 1. (r mt r ft ) r it r ft = α 0 + β 1. (r mt r ft ) + ε it Ekonomický (finanční model)
Matematické modelování Náhled do ekonometrie Lukáš Frýd Výnos akcie vs. Výnos celého trhu - CAPM model r it = r ft + β 1. (r mt r ft ) r it r ft = α 0 + β 1. (r mt r ft ) + ε it Ekonomický (finanční model)
Přednáška 13 Redukce dimenzionality
 Vytěžování Dat Přednáška 13 Redukce dimenzionality Miroslav Čepek Fakulta Elektrotechnická, ČVUT Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti ČVUT (FEL) Redukce dimenzionality 1 /
Vytěžování Dat Přednáška 13 Redukce dimenzionality Miroslav Čepek Fakulta Elektrotechnická, ČVUT Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti ČVUT (FEL) Redukce dimenzionality 1 /
ZÍSKÁVÁNÍ ZNALOSTÍ Z DATABÁZÍ
 metodický list č. 1 Dobývání znalostí z databází Cílem tohoto tematického celku je vysvětlení základních pojmů z oblasti dobývání znalostí z databází i východisek dobývání znalostí z databází inspirovaných
metodický list č. 1 Dobývání znalostí z databází Cílem tohoto tematického celku je vysvětlení základních pojmů z oblasti dobývání znalostí z databází i východisek dobývání znalostí z databází inspirovaných
Pokročilé neparametrické metody. Klára Kubošová
 Pokročilé neparametrické metody Klára Kubošová Pokročilé neparametrické metody Výuka 13 přednášek doplněných o praktické cvičení v SW Úvod do neparametrických metod + princip rozhodovacích stromů Klasifikační
Pokročilé neparametrické metody Klára Kubošová Pokročilé neparametrické metody Výuka 13 přednášek doplněných o praktické cvičení v SW Úvod do neparametrických metod + princip rozhodovacích stromů Klasifikační
Ing. Petr Hájek, Ph.D. Podpora přednášky kurzu Aplikace umělé inteligence
 APLIKACE UMĚLÉ INTELIGENCE Ing. Petr Hájek, Ph.D. Podpora přednášky kurzu Aplikace umělé inteligence Aplikace umělé inteligence - seminář ING. PETR HÁJEK, PH.D. ÚSTAV SYSTÉMOVÉHO INŽENÝRSTVÍ A INFORMATIKY
APLIKACE UMĚLÉ INTELIGENCE Ing. Petr Hájek, Ph.D. Podpora přednášky kurzu Aplikace umělé inteligence Aplikace umělé inteligence - seminář ING. PETR HÁJEK, PH.D. ÚSTAV SYSTÉMOVÉHO INŽENÝRSTVÍ A INFORMATIKY
Testování modelů a jejich výsledků. Jak moc můžeme věřit tomu, co jsme se naučili?
 Testování modelů a jejich výsledků Jak moc můžeme věřit tomu, co jsme se naučili? 2 Osnova Úvod různé klasifikační modely a jejich kvalita Hodnotící míry (kriteria kvality) pro zvolený model. Postup vyhodnocování
Testování modelů a jejich výsledků Jak moc můžeme věřit tomu, co jsme se naučili? 2 Osnova Úvod různé klasifikační modely a jejich kvalita Hodnotící míry (kriteria kvality) pro zvolený model. Postup vyhodnocování
PSY117/454 Statistická analýza dat v psychologii přednáška 8. Statistické usuzování, odhady
 PSY117/454 Statistická analýza dat v psychologii přednáška 8 Statistické usuzování, odhady Výběr od deskripce k indukci Deskripce dat, odhad parametrů Usuzování = inference = indukce Počítá se s náhodným
PSY117/454 Statistická analýza dat v psychologii přednáška 8 Statistické usuzování, odhady Výběr od deskripce k indukci Deskripce dat, odhad parametrů Usuzování = inference = indukce Počítá se s náhodným
Instance based learning
 Učení založené na instancích Instance based learning Charakteristika IBL (nejbližších sousedů) Tyto metody nepředpokládají určitý model nejsou strukturované a typicky nejsou příliš užitečné pro porozumění
Učení založené na instancích Instance based learning Charakteristika IBL (nejbližších sousedů) Tyto metody nepředpokládají určitý model nejsou strukturované a typicky nejsou příliš užitečné pro porozumění
Markovovy modely v Bioinformatice
 Markovovy modely v Bioinformatice Outline Markovovy modely obecně Profilové HMM Další použití HMM v Bioinformatice Analýza biologických sekvencí Biologické sekvence: DNA,RNA,protein prim.str. Sekvenování
Markovovy modely v Bioinformatice Outline Markovovy modely obecně Profilové HMM Další použití HMM v Bioinformatice Analýza biologických sekvencí Biologické sekvence: DNA,RNA,protein prim.str. Sekvenování
Analýza rozptylu. PSY117/454 Statistická analýza dat v psychologii Přednáška 12. Srovnávání více než dvou průměrů
 PSY117/454 Statistická analýza dat v psychologii Přednáška 12 Analýza rozptylu Srovnávání více než dvou průměrů If your experiment needs statistics, you ought to have done a better experiment. Ernest Rutherford
PSY117/454 Statistická analýza dat v psychologii Přednáška 12 Analýza rozptylu Srovnávání více než dvou průměrů If your experiment needs statistics, you ought to have done a better experiment. Ernest Rutherford
Úloha - rozpoznávání číslic
 Úloha - rozpoznávání číslic Vojtěch Franc, Tomáš Pajdla a Tomáš Svoboda http://cmp.felk.cvut.cz 27. listopadu 26 Abstrakt Podpůrný text pro cvičení předmětu X33KUI. Vysvětluje tři způsoby rozpoznávání
Úloha - rozpoznávání číslic Vojtěch Franc, Tomáš Pajdla a Tomáš Svoboda http://cmp.felk.cvut.cz 27. listopadu 26 Abstrakt Podpůrný text pro cvičení předmětu X33KUI. Vysvětluje tři způsoby rozpoznávání
WORKSHEET 1: LINEAR EQUATION 1
 WORKSHEET 1: LINEAR EQUATION 1 1. Write down the arithmetical problem according the dictation: 2. Translate the English words, you can use a dictionary: equations to solve solve inverse operation variable
WORKSHEET 1: LINEAR EQUATION 1 1. Write down the arithmetical problem according the dictation: 2. Translate the English words, you can use a dictionary: equations to solve solve inverse operation variable
Statistická teorie učení
 Statistická teorie učení Petr Havel Marek Myslivec přednáška z 9. týdne 1 Úvod Představme si situaci výrobce a zákazníka, který si u výrobce objednal algoritmus rozpoznávání. Zákazník dodal experimentální
Statistická teorie učení Petr Havel Marek Myslivec přednáška z 9. týdne 1 Úvod Představme si situaci výrobce a zákazníka, který si u výrobce objednal algoritmus rozpoznávání. Zákazník dodal experimentální
Cvičení 3. Přednášející: Mgr. Rudolf B. Blažek, Ph.D. prof. RNDr. Roman Kotecký, DrSc.
 Cvičení 3 Přednášející: Mgr. Rudolf B. Blažek, Ph.D. prof. RNDr. Roman Kotecký, DrSc. Katedra počítačových systémů Katedra teoretické informatiky Fakulta informačních technologií České vysoké učení technické
Cvičení 3 Přednášející: Mgr. Rudolf B. Blažek, Ph.D. prof. RNDr. Roman Kotecký, DrSc. Katedra počítačových systémů Katedra teoretické informatiky Fakulta informačních technologií České vysoké učení technické
Algoritmy a struktury neuropočítačů ASN P9 SVM Support vector machines Support vector networks (Algoritmus podpůrných vektorů)
") Algoritmy a struktury neuropočítačů ASN P9 SVM Support vector machines Support vector networks (Algoritmus podpůrných vektorů) Autor: Vladimir Vapnik Vapnik, V. The Nature of Statistical Learning Theory.
Algoritmy a struktury neuropočítačů ASN P9 SVM Support vector machines Support vector networks (Algoritmus podpůrných vektorů) Autor: Vladimir Vapnik Vapnik, V. The Nature of Statistical Learning Theory.
Lineární diskriminační funkce. Perceptronový algoritmus.
 Lineární. Perceptronový algoritmus. Petr Pošík Czech Technical University in Prague Faculty of Electrical Engineering Dept. of Cybernetics P. Pošík c 2012 Artificial Intelligence 1 / 12 Binární klasifikace
Lineární. Perceptronový algoritmus. Petr Pošík Czech Technical University in Prague Faculty of Electrical Engineering Dept. of Cybernetics P. Pošík c 2012 Artificial Intelligence 1 / 12 Binární klasifikace
Dobývání znalostí. Doc. RNDr. Iveta Mrázová, CSc. Katedra teoretické informatiky Matematicko-fyzikální fakulta Univerzity Karlovy v Praze
 Dobývání znalostí Doc. RNDr. Iveta Mrázová, CSc. Katedra teoretické informatiky Matematicko-fyzikální fakulta Univerzity Karlovy v Praze Dobývání znalostí Bayesovské modely Doc. RNDr. Iveta Mrázová, CSc.
Dobývání znalostí Doc. RNDr. Iveta Mrázová, CSc. Katedra teoretické informatiky Matematicko-fyzikální fakulta Univerzity Karlovy v Praze Dobývání znalostí Bayesovské modely Doc. RNDr. Iveta Mrázová, CSc.
Klasifikace a rozpoznávání. Lineární klasifikátory
 Klasifikace a rozpoznávání Lineární klasifikátory Opakování - Skalární součin x = x1 x 2 w = w T x = w 1 w 2 x 1 x 2 w1 w 2 = w 1 x 1 + w 2 x 2 x. w w T x w Lineární klasifikátor y(x) = w T x + w 0 Vyber
Klasifikace a rozpoznávání Lineární klasifikátory Opakování - Skalární součin x = x1 x 2 w = w T x = w 1 w 2 x 1 x 2 w1 w 2 = w 1 x 1 + w 2 x 2 x. w w T x w Lineární klasifikátor y(x) = w T x + w 0 Vyber
Pokročilé neparametrické metody. Klára Kubošová
 Klára Kubošová Další typy stromů CHAID, PRIM, MARS CHAID - Chi-squared Automatic Interaction Detector G.V.Kass (1980) nebinární strom pro kategoriální proměnné. Jako kriteriální statistika pro větvení
Klára Kubošová Další typy stromů CHAID, PRIM, MARS CHAID - Chi-squared Automatic Interaction Detector G.V.Kass (1980) nebinární strom pro kategoriální proměnné. Jako kriteriální statistika pro větvení
Moderní systémy pro získávání znalostí z informací a dat
 Moderní systémy pro získávání znalostí z informací a dat Jan Žižka IBA Institut biostatistiky a analýz PřF & LF, Masarykova universita Kamenice 126/3, 625 00 Brno Email: zizka@iba.muni.cz Bioinformatika:
Moderní systémy pro získávání znalostí z informací a dat Jan Žižka IBA Institut biostatistiky a analýz PřF & LF, Masarykova universita Kamenice 126/3, 625 00 Brno Email: zizka@iba.muni.cz Bioinformatika:
Všechno, co jste chtěli vědět z teorie pravděpodobnosti, z teorie informace a
 Všechno, co jste chtěli vědět z teorie pravděpodobnosti, z teorie informace a báli jste se zeptat Jedinečnou funkcí statistiky je, že umožňuje vědci číselně vyjádřit nejistotu v jeho závěrech. (G. W. Snedecor)
Všechno, co jste chtěli vědět z teorie pravděpodobnosti, z teorie informace a báli jste se zeptat Jedinečnou funkcí statistiky je, že umožňuje vědci číselně vyjádřit nejistotu v jeho závěrech. (G. W. Snedecor)
Vytěžování znalostí z dat
 Pavel Kordík, Jan Motl (ČVUT FIT) Vytěžování znalostí z dat BI-VZD, 2012, Přednáška 1 1/32 Vytěžování znalostí z dat Pavel Kordík, Jan Motl Department of Computer Systems Faculty of Information Technology
Pavel Kordík, Jan Motl (ČVUT FIT) Vytěžování znalostí z dat BI-VZD, 2012, Přednáška 1 1/32 Vytěžování znalostí z dat Pavel Kordík, Jan Motl Department of Computer Systems Faculty of Information Technology
O kurzu MSTU Témata probíraná v MSTU
 O kurzu MSTU Témata probíraná v MSTU 1.: Úvod do STU. Základní dělení, paradigmata. 2.: Základy statistiky. Charakteristiky, rozložení, testy. 3.: Modely: rozhodovací stromy. 4.: Modely: učení založené
O kurzu MSTU Témata probíraná v MSTU 1.: Úvod do STU. Základní dělení, paradigmata. 2.: Základy statistiky. Charakteristiky, rozložení, testy. 3.: Modely: rozhodovací stromy. 4.: Modely: učení založené
KLASIFIKAČNÍ A REGRESNÍ LESY
 ROBUST 2004 c JČMF 2004 KLASIFIKAČNÍ A REGRESNÍ LESY Jan Klaschka, Emil Kotrč Klíčová slova: Klasifikační stromy, klasifikační lesy, bagging, boosting, arcing, Random Forests. Abstrakt: Klasifikační les
ROBUST 2004 c JČMF 2004 KLASIFIKAČNÍ A REGRESNÍ LESY Jan Klaschka, Emil Kotrč Klíčová slova: Klasifikační stromy, klasifikační lesy, bagging, boosting, arcing, Random Forests. Abstrakt: Klasifikační les
Dobývání dat a strojové učení
 Dobývání dat a strojové učení Dobývání znalostí z databází (Knowledge discovery in databases) Non-trivial process of identifying valid, novel, potentially useful and ultimately understandable patterns
Dobývání dat a strojové učení Dobývání znalostí z databází (Knowledge discovery in databases) Non-trivial process of identifying valid, novel, potentially useful and ultimately understandable patterns
UČENÍ BEZ UČITELE. Václav Hlaváč
 UČENÍ BEZ UČITELE Václav Hlaváč Fakulta elektrotechnická ČVUT v Praze katedra kybernetiky, Centrum strojového vnímání hlavac@fel.cvut.cz, http://cmp.felk.cvut.cz/~hlavac 1/22 OBSAH PŘEDNÁŠKY ÚVOD Učení
UČENÍ BEZ UČITELE Václav Hlaváč Fakulta elektrotechnická ČVUT v Praze katedra kybernetiky, Centrum strojového vnímání hlavac@fel.cvut.cz, http://cmp.felk.cvut.cz/~hlavac 1/22 OBSAH PŘEDNÁŠKY ÚVOD Učení
Předzpracování dat. Lenka Vysloužilová
 Předzpracování dat Lenka Vysloužilová 1 Metodika CRISP-DM (www.crisp-dm.org) Příprava dat Data Preparation příprava dat pro modelování selekce příznaků výběr relevantních příznaků čištění dat získávání
Předzpracování dat Lenka Vysloužilová 1 Metodika CRISP-DM (www.crisp-dm.org) Příprava dat Data Preparation příprava dat pro modelování selekce příznaků výběr relevantních příznaků čištění dat získávání
BAYESOVSKÉ ODHADY. Michal Friesl V NĚKTERÝCH MODELECH. Katedra matematiky Fakulta aplikovaných věd Západočeská univerzita v Plzni
 BAYESOVSKÉ ODHADY V NĚKTERÝCH MODELECH Michal Friesl Katedra matematiky Fakulta aplikovaných věd Západočeská univerzita v Plzni Slunce Řidiči IQ Regrese Přežití Obvyklý model Pozorování X = (X 1,..., X
BAYESOVSKÉ ODHADY V NĚKTERÝCH MODELECH Michal Friesl Katedra matematiky Fakulta aplikovaných věd Západočeská univerzita v Plzni Slunce Řidiči IQ Regrese Přežití Obvyklý model Pozorování X = (X 1,..., X
Určujeme neznámé hodnoty parametru základního souboru. Pomocí výběrové charakteristiky vypočtené z náhodného výběru.
 1 Statistické odhady Určujeme neznámé hodnoty parametru základního souboru. Pomocí výběrové charakteristiky vypočtené z náhodného výběru. Odhad lze provést jako: Bodový odhad o Jedna číselná hodnota Intervalový
1 Statistické odhady Určujeme neznámé hodnoty parametru základního souboru. Pomocí výběrové charakteristiky vypočtené z náhodného výběru. Odhad lze provést jako: Bodový odhad o Jedna číselná hodnota Intervalový
Statistická analýza dat v psychologii. Věci, které můžeme přímo pozorovat, jsou téměř vždy pouze vzorky. Alfred North Whitehead
 PSY117/454 Statistická analýza dat v psychologii Přednáška 8 Statistické usuzování, odhady Věci, které můžeme přímo pozorovat, jsou téměř vždy pouze vzorky. Alfred North Whitehead Barevná srdíčka kolegyně
PSY117/454 Statistická analýza dat v psychologii Přednáška 8 Statistické usuzování, odhady Věci, které můžeme přímo pozorovat, jsou téměř vždy pouze vzorky. Alfred North Whitehead Barevná srdíčka kolegyně
Testování modelů a jejich výsledků. Jak moc můžeme věřit tomu, co jsme se naučili?
 Testování modelů a jejich výsledků Jak moc můžeme věřit tomu, co jsme se naučili? Osnova Úvod Trénovací, Testovací a Validační datové soubory Práce s nebalancovanými daty; ladění parametrů Křížová validace
Testování modelů a jejich výsledků Jak moc můžeme věřit tomu, co jsme se naučili? Osnova Úvod Trénovací, Testovací a Validační datové soubory Práce s nebalancovanými daty; ladění parametrů Křížová validace
Vytěžování znalostí z dat
 Pavel Kordík, Jan Motl (ČVUT FIT) Vytěžování znalostí z dat BI-VZD, 2012, Přednáška 4 1/27 Vytěžování znalostí z dat Pavel Kordík, Jan Motl Department of Computer Systems Faculty of Information Technology
Pavel Kordík, Jan Motl (ČVUT FIT) Vytěžování znalostí z dat BI-VZD, 2012, Přednáška 4 1/27 Vytěžování znalostí z dat Pavel Kordík, Jan Motl Department of Computer Systems Faculty of Information Technology
LDA, logistická regrese
 Vytěžování Dat Přednáška 9 Lineární klasifikátor, rozšíření báze, LDA, logistická regrese Miroslav Čepek Fakulta Elektrotechnická, ČVUT Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti
Vytěžování Dat Přednáška 9 Lineární klasifikátor, rozšíření báze, LDA, logistická regrese Miroslav Čepek Fakulta Elektrotechnická, ČVUT Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti
Aplikovaná numerická matematika
 Aplikovaná numerická matematika 6. Metoda nejmenších čtverců doc. Ing. Róbert Lórencz, CSc. České vysoké učení technické v Praze Fakulta informačních technologií Katedra počítačových systémů Příprava studijních
Aplikovaná numerická matematika 6. Metoda nejmenších čtverců doc. Ing. Róbert Lórencz, CSc. České vysoké učení technické v Praze Fakulta informačních technologií Katedra počítačových systémů Příprava studijních
Neuronové sítě (11. přednáška)
") Neuronové sítě (11. přednáška) Machine Learning Naučit stroje se učit O co jde? Máme model výpočtu (t.j. výpočetní postup jednoznačně daný vstupy a nějakými parametry), chceme najít vhodné nastavení parametrů,
Neuronové sítě (11. přednáška) Machine Learning Naučit stroje se učit O co jde? Máme model výpočtu (t.j. výpočetní postup jednoznačně daný vstupy a nějakými parametry), chceme najít vhodné nastavení parametrů,
Intervalová data a výpočet některých statistik
 Intervalová data a výpočet některých statistik Milan Hladík 1 Michal Černý 2 1 Katedra aplikované matematiky Matematicko-fyzikální fakulta Univerzita Karlova 2 Katedra ekonometrie Fakulta informatiky a
Intervalová data a výpočet některých statistik Milan Hladík 1 Michal Černý 2 1 Katedra aplikované matematiky Matematicko-fyzikální fakulta Univerzita Karlova 2 Katedra ekonometrie Fakulta informatiky a
Analýza dat pomocí systému Weka, Rapid miner a Enterprise miner
 Vysoká škola ekonomická v Praze Analýza dat pomocí systému Weka, Rapid miner a Enterprise miner Dobývání znalostí z databází 4IZ450 XXXXXXXXXXX Přidělená data a jejich popis Data určená pro zpracování
Vysoká škola ekonomická v Praze Analýza dat pomocí systému Weka, Rapid miner a Enterprise miner Dobývání znalostí z databází 4IZ450 XXXXXXXXXXX Přidělená data a jejich popis Data určená pro zpracování
Uni- and multi-dimensional parametric tests for comparison of sample results
 Uni- and multi-dimensional parametric tests for comparison of sample results Jedno- a více-rozměrné parametrické testy k porovnání výsledků Prof. RNDr. Milan Meloun, DrSc. Katedra analytické chemie, Universita
Uni- and multi-dimensional parametric tests for comparison of sample results Jedno- a více-rozměrné parametrické testy k porovnání výsledků Prof. RNDr. Milan Meloun, DrSc. Katedra analytické chemie, Universita
Algoritmy a struktury neuropočítačů ASN P3
 Algoritmy a struktury neuropočítačů ASN P3 SOM algoritmus s učitelem i bez učitele U-matice Vektorová kvantizace Samoorganizující se mapy ( Self-Organizing Maps ) PROČ? Základní myšlenka: analogie s činností
Algoritmy a struktury neuropočítačů ASN P3 SOM algoritmus s učitelem i bez učitele U-matice Vektorová kvantizace Samoorganizující se mapy ( Self-Organizing Maps ) PROČ? Základní myšlenka: analogie s činností
Kombinatorická minimalizace
 Kombinatorická minimalizace Cílem je nalézt globální minimum ve velké diskrétní množině, kde může být mnoho lokálních minim. Úloha obchodního cestujícího Cílem je najít nejkratší cestu, která spojuje všechny
Kombinatorická minimalizace Cílem je nalézt globální minimum ve velké diskrétní množině, kde může být mnoho lokálních minim. Úloha obchodního cestujícího Cílem je najít nejkratší cestu, která spojuje všechny
Eva Fišerová a Karel Hron. Katedra matematické analýzy a aplikací matematiky Přírodovědecká fakulta Univerzity Palackého v Olomouci.
 Ortogonální regrese pro 3-složkové kompoziční data využitím lineárních modelů Eva Fišerová a Karel Hron Katedra matematické analýzy a aplikací matematiky Přírodovědecká fakulta Univerzity Palackého v Olomouci
Ortogonální regrese pro 3-složkové kompoziční data využitím lineárních modelů Eva Fišerová a Karel Hron Katedra matematické analýzy a aplikací matematiky Přírodovědecká fakulta Univerzity Palackého v Olomouci
Intervalové Odhady Parametrů
 Parametrů Mgr. Rudolf B. Blažek, Ph.D. prof. RNDr. Roman Kotecký, DrSc. Katedra počítačových systémů Katedra teoretické informatiky Fakulta informačních technologií České vysoké učení technické v Praze
Parametrů Mgr. Rudolf B. Blažek, Ph.D. prof. RNDr. Roman Kotecký, DrSc. Katedra počítačových systémů Katedra teoretické informatiky Fakulta informačních technologií České vysoké učení technické v Praze
Testování modelů a jejich výsledků. tomu, co jsme se naučili?
 Testování modelů a jejich výsledků Jak moc můžeme věřit tomu, co jsme se naučili? Osnova Úvod Trénovací, Testovací a Validační datové soubory Práce s nebalancovanými daty; ladění parametrů Křížová validace
Testování modelů a jejich výsledků Jak moc můžeme věřit tomu, co jsme se naučili? Osnova Úvod Trénovací, Testovací a Validační datové soubory Práce s nebalancovanými daty; ladění parametrů Křížová validace
Mgr. Rudolf Blažek, Ph.D. prof. RNDr. Roman Kotecký Dr.Sc.
 Náhodné veličiny III Mgr. Rudolf Blažek, Ph.D. prof. RNDr. Roman Kotecký Dr.Sc. Katedra teoretické informatiky Fakulta informačních technologií České vysoké učení technické v Praze c Rudolf Blažek, Roman
Náhodné veličiny III Mgr. Rudolf Blažek, Ph.D. prof. RNDr. Roman Kotecký Dr.Sc. Katedra teoretické informatiky Fakulta informačních technologií České vysoké učení technické v Praze c Rudolf Blažek, Roman
Bodové a intervalové odhady parametrů v regresním modelu
 Statistika II Katedra ekonometrie FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Lineární regresní model Mějme lineární regresní model (LRM) Y = Xβ + e, kde y 1 e 1 β y 2 Y =., e
Statistika II Katedra ekonometrie FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Lineární regresní model Mějme lineární regresní model (LRM) Y = Xβ + e, kde y 1 e 1 β y 2 Y =., e
Lineární klasifikátory
 Lineární klasifikátory Lineární klasifikátory obsah: perceptronový algoritmus základní verze varianta perceptronového algoritmu přihrádkový algoritmus podpůrné vektorové stroje Lineární klasifikátor navrhnout
Lineární klasifikátory Lineární klasifikátory obsah: perceptronový algoritmus základní verze varianta perceptronového algoritmu přihrádkový algoritmus podpůrné vektorové stroje Lineární klasifikátor navrhnout
5EN306 Aplikované kvantitativní metody I
 5EN306 Aplikované kvantitativní metody I Přednáška 5 Zuzana Dlouhá Předmět a struktura kurzu 1. Úvod: struktura empirických výzkumů 2. Tvorba ekonomických modelů: teorie 3. Data: zdroje a typy dat, význam
5EN306 Aplikované kvantitativní metody I Přednáška 5 Zuzana Dlouhá Předmět a struktura kurzu 1. Úvod: struktura empirických výzkumů 2. Tvorba ekonomických modelů: teorie 3. Data: zdroje a typy dat, význam
PRODEJNÍ EAUKCE A JEJICH ROSTOUCÍ SEX-APPEAL SELLING EAUCTIONS AND THEIR GROWING APPEAL
 PRODEJNÍ EAUKCE A JEJICH ROSTOUCÍ SEX-APPEAL SELLING EAUCTIONS AND THEIR GROWING APPEAL Ing. Jan HAVLÍK, MPA tajemník Městského úřadu Žďár nad Sázavou Chief Executive Municipality of Žďár nad Sázavou CO
PRODEJNÍ EAUKCE A JEJICH ROSTOUCÍ SEX-APPEAL SELLING EAUCTIONS AND THEIR GROWING APPEAL Ing. Jan HAVLÍK, MPA tajemník Městského úřadu Žďár nad Sázavou Chief Executive Municipality of Žďár nad Sázavou CO
Získávání znalostí z dat
 Získávání znalostí z dat Informační a komunikační technologie ve zdravotnictví Získávání znalostí z dat Definice: proces netriviálního získávání implicitní, dříve neznámé a potencionálně užitečné informace
Získávání znalostí z dat Informační a komunikační technologie ve zdravotnictví Získávání znalostí z dat Definice: proces netriviálního získávání implicitní, dříve neznámé a potencionálně užitečné informace
PRAVDĚPODOBNOST A STATISTIKA
 PRAVDĚPODOBNOST A STATISTIKA Náhodný výběr Nechť X je náhodná proměnná, která má distribuční funkci F(x, ϑ). Předpokládejme, že známe tvar distribuční funkce (víme jaké má rozdělení) a neznáme parametr
PRAVDĚPODOBNOST A STATISTIKA Náhodný výběr Nechť X je náhodná proměnná, která má distribuční funkci F(x, ϑ). Předpokládejme, že známe tvar distribuční funkce (víme jaké má rozdělení) a neznáme parametr
Dyson s Coulomb gas on a circle and intermediate eigenvalue statistics
 Dyson s Coulomb gas on a circle and intermediate eigenvalue statistics Rainer Scharf, Félix M. Izrailev, 1990 rešerše: Pavla Cimrová, 28. 2. 2012 1 Náhodné matice Náhodné matice v současnosti nacházejí
Dyson s Coulomb gas on a circle and intermediate eigenvalue statistics Rainer Scharf, Félix M. Izrailev, 1990 rešerše: Pavla Cimrová, 28. 2. 2012 1 Náhodné matice Náhodné matice v současnosti nacházejí
Změkčování hranic v klasifikačních stromech
 Změkčování hranic v klasifikačních stromech Jakub Dvořák Seminář strojového učení a modelování 24.5.2012 Obsah Klasifikační stromy Změkčování hran Ranking, ROC křivka a AUC Metody změkčování Experiment
Změkčování hranic v klasifikačních stromech Jakub Dvořák Seminář strojového učení a modelování 24.5.2012 Obsah Klasifikační stromy Změkčování hran Ranking, ROC křivka a AUC Metody změkčování Experiment
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz
 Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická
Úvod do problematiky měření
 1/18 Lord Kelvin: "Když to, o čem mluvíte, můžete změřit, a vyjádřit to pomocí čísel, něco o tom víte. Ale když to nemůžete vyjádřit číselně, je vaše znalost hubená a nedostatečná. Může to být začátek
1/18 Lord Kelvin: "Když to, o čem mluvíte, můžete změřit, a vyjádřit to pomocí čísel, něco o tom víte. Ale když to nemůžete vyjádřit číselně, je vaše znalost hubená a nedostatečná. Může to být začátek
1. Přednáška. Ing. Miroslav Šulai, MBA
 N_OFI_2 1. Přednáška Počet pravděpodobnosti Statistický aparát používaný ve financích Ing. Miroslav Šulai, MBA 1 Počet pravděpodobnosti -náhodné veličiny 2 Počet pravděpodobnosti -náhodné veličiny 3 Jevy
N_OFI_2 1. Přednáška Počet pravděpodobnosti Statistický aparát používaný ve financích Ing. Miroslav Šulai, MBA 1 Počet pravděpodobnosti -náhodné veličiny 2 Počet pravděpodobnosti -náhodné veličiny 3 Jevy
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc.
 Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika 010 1.týden (0.09.-4.09. ) Data, typy dat, variabilita, frekvenční analýza
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika 010 1.týden (0.09.-4.09. ) Data, typy dat, variabilita, frekvenční analýza
logistická regrese Miroslav Čepek Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti
 Vytěžování Dat Přednáška 9 Lineární klasifikátor, rozšíření báze, LDA, logistická regrese Miroslav Čepek Fakulta Elektrotechnická, ČVUT Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti
Vytěžování Dat Přednáška 9 Lineární klasifikátor, rozšíření báze, LDA, logistická regrese Miroslav Čepek Fakulta Elektrotechnická, ČVUT Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti
VY_32_INOVACE_06_Předpřítomný čas_03. Škola: Základní škola Slušovice, okres Zlín, příspěvková organizace
 VY_32_INOVACE_06_Předpřítomný čas_03 Autor: Růžena Krupičková Škola: Základní škola Slušovice, okres Zlín, příspěvková organizace Název projektu: Zkvalitnění ICT ve slušovské škole Číslo projektu: CZ.1.07/1.4.00/21.2400
VY_32_INOVACE_06_Předpřítomný čas_03 Autor: Růžena Krupičková Škola: Základní škola Slušovice, okres Zlín, příspěvková organizace Název projektu: Zkvalitnění ICT ve slušovské škole Číslo projektu: CZ.1.07/1.4.00/21.2400
4EK211 Základy ekonometrie
 4EK211 Základy ekonometrie ZS 2016/17 Cvičení 3: Lineární regresní model LENKA FIŘTOVÁ KATEDRA EKONOMETRIE, FAKULTA INFORMATIKY A STATISTIKY VYSOKÁ ŠKOLA EKONOMICKÁ V PRAZE 1. Seznámení s EViews Upřesnění
4EK211 Základy ekonometrie ZS 2016/17 Cvičení 3: Lineární regresní model LENKA FIŘTOVÁ KATEDRA EKONOMETRIE, FAKULTA INFORMATIKY A STATISTIKY VYSOKÁ ŠKOLA EKONOMICKÁ V PRAZE 1. Seznámení s EViews Upřesnění
Vojtěch Franc. Biometrie ZS Poděkování Janu Šochmanovi za slajdy vysvětlující AdaBoost
 Rozpoznávání tváří I Vojtěch Franc Centrum strojového vnímání, ČVUT FEL Praha Biometrie ZS 2013 Poděkování Janu Šochmanovi za slajdy vysvětlující AdaBoost Úlohy rozpoznávání tváří: Detekce Cíl: lokalizovat
Rozpoznávání tváří I Vojtěch Franc Centrum strojového vnímání, ČVUT FEL Praha Biometrie ZS 2013 Poděkování Janu Šochmanovi za slajdy vysvětlující AdaBoost Úlohy rozpoznávání tváří: Detekce Cíl: lokalizovat
Využití metod strojového učení v bioinformatice David Hoksza
 Využití metod strojového učení v bioinformatice David Hoksza SIRET Research Group Katedra softwarového inženýrství, Matematicko-fyzikální fakulta Karlova Univerzita v Praze Bioinformatika Biologické inspirace
Využití metod strojového učení v bioinformatice David Hoksza SIRET Research Group Katedra softwarového inženýrství, Matematicko-fyzikální fakulta Karlova Univerzita v Praze Bioinformatika Biologické inspirace