Matematika pro geometrickou morfometrii (5)
|
|
|
- Bohumil Kopecký
- před 7 lety
- Počet zobrazení:
Transkript
 Laboratoř 3D zobrazovacích a")

1 Ján Dupej Laboratoř 3D zobrazovacích a analytických metod Katedra antropologie a genetiky člověka Přírodovědecká fakulta UK v Praze
2 Cíle GM 1. Popsat tvar čísly 2. Čísla statisticky vyhodnotit Měření Čísla Závěr Metoda Metoda 2
3 Doporučený software PAST Paleontological Statistics Tabulkový editor Nabídka Statistics základní testy Nabídka Multivar multivariační analýza Nabídka Model regresní analýza R, Matlab, Octave Psaní skriptů Cokoliv Excel Morphome3cs R in disguise 3
4 Analýza dat Visualizace hrubých naměřených dat Grafy Scatter plot 4
5 Analýza dat Souhrny Průměr Směrodatná odchylka Median Kvantily > q [1] > mean(q) [1] > sd(q) [1] > summary(q) Min. 1st Qu. Median Mean 3rd Qu. Max
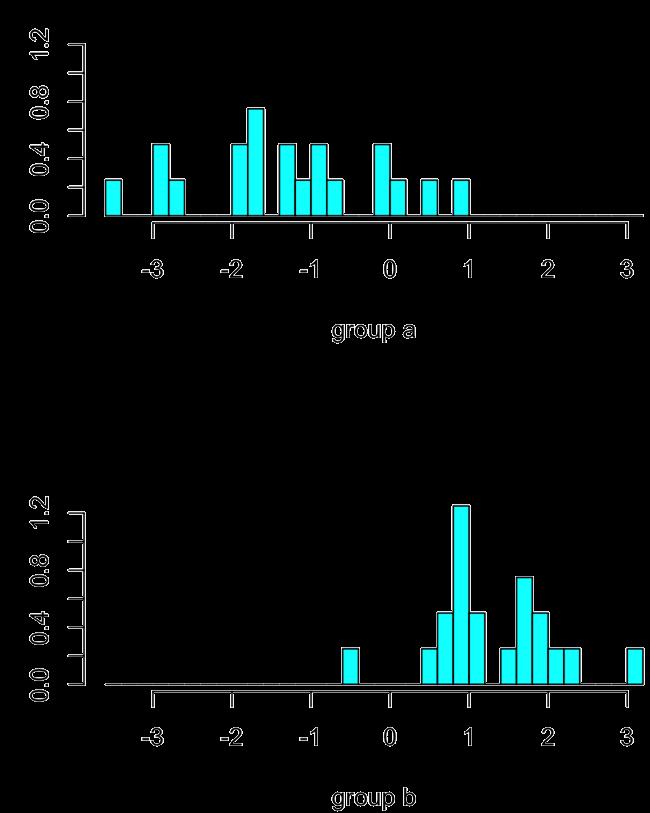
6 Frequency Matematika pro geometrickou Analýza dat Histogram Boxplot s kníry Histogram of q q 6
7 Pravděpodobnost Náhodný jev Výsledek pro: hod mincí, hod kostkou... Pravděpodobnost náhodného jevu Náhodná veličina Funkce na množině elementárních jevů Přirazení čísel jevům Rozdělení Popis náhodné veličiny Odpovídá histogramu pro mnoho opakování 7
8 Náhodná veličina Spojitá nebo diskrétní Popis tzv. momenty Střední hodnota EX = x f x dx Aritmetický průměr x = 1 N x i Rozptyl var X = E X EX 2 Výběrový rozptyl σ 2 = 1 N 1 x i x 2 Šikmost (skewness) Špičatost (curtosis) 8
9 f(t) f(t) Matematika pro geometrickou Hustota vs. Distribuční funkce Hustota f t P(X = t) Pst. že náhodná veličina X má hodnotu t Distr. funkce f t P(X t) Pst. že náhodná veličina X má hodnotu nanejvýš t X~N(0,1) X~N(0,1) t t
10 Normální rozdělení Velké odchylky od očekávání jsou málo pravděpodobné f X = 1 X X 2 0 2σ 2 2πσ 2 e Centrální limitní věta Komplexní děje se skládají z mnoha náhodných událostí normální rozdělení je všude Součty libovolného rozdělení se blíží normálnímu rozdělení Z-transformace Posunutí a zúžení rozdělení aby výsledá střední hodnota byla 0 a kvadratická chyba 1 Z = X μ σ(x) 10
11 Normální rozdělení Z-skóre Symetrie rozdělení, tabulky Celková ploch pod grafem = 1 11
12 Populace a vzorek Populace Vzorek Vzorek Vzorek Vzorek Vykopávky Sbírka Průměr P Rozptyl R Další vykopávky a sbírky Průměr p Rozptyl r Průměr p Rozptyl r Průměr p Rozptyl r Průměr p Rozptyl r Máme pouze toto Průměr P Rozptyl R Jaké je rozdělení tohoto? 12
13 Populace a vzorek Rozdělení pravděpodobnosti výběru Normální rozložení průměru pro velký vzorek, bez ohledu na rozdělení populace Střední hodnota odpovídá střední hodnotě populace Rozptyl nepřímo úměrný velikosti vzorku Větší vzorek = menší chyba odhadu 13
14 t - rozdělení Rozdělení pravděpodobnosti rozptylu při výběru vzorku z populace Vzorek je malý a neznáme rozptyl populace Použijeme výběrovou směrodatnou odchylku vzorku Parametrizované velikostí vzorku Vhodné pro GM kde se často pracuje s malými vzorky Komplikovaný výpočet distr. funkce Tabulka t-hodnota 14
15 Intervalové odhady Chceme určit výsledek s předem danou přesností Ptáme se na výsledek v celé populaci vzorek Skutočný výsledek se nalézá okolo průměru vzorku Rozptyl odhadu je dán rozptylem populace a velikostí vzorku Rozptyl v populaci nahradíme rozptylem ve vzorku K výpočtu intervalu použijeme tabulkové hodnoty Pro velké vzorky normální rozdělení Pro malé vzorky t-rozdělení 15
16 Test hypotézy Vyvrátit pravdivost nějakého tvrzení o datech Rovnost středních hodnot dvou vzorků Rovnost střední hodnoty konkrétní hodnotě Jediný důkaz pro vyvrácení je v datech Nevyvrátit potvrdit Postup Nulová hypotéza: X má střední hodnotu 0 Alternativní hypotéza: X nemá střední hodnotu 0 Určení skóre jevu popírajícího nulovou hypotézu Výpočet p-hodnoty, pravděpodobnosti že pozorovaný jev je dílem náhody Porovnání s hladinou významnosti (nejčastěji 0.05, 0.1) 16
17 Příklad jednovýberový t-test Data H0: Data mají střední hodnotu 0 Málo vzorků použij t-rozdělení a t-statistiku t = X μ 0 s N = = Porovnání t-statistiky s kritickou hodnotou n 1 stupňů volnosti, kvantil dle hladiny významnosti (Ne)Odmítnutí H0 t = 2.23 H0 neodmítáme 17
18 Statistická významnost p-value Nejnižší hladina na které ještě hypotézu nezamítáme Porovnání přímo s hladinou významnosti Hvězdičková konvence R, Morphome3cs Signif. codes: 0 `***' `**' 0.01 `*' 0.05 `.' 0.1 ` ' 1 18
19 Síla testu Chyba prvního typu Test odmítl pravdivou hypotézu False negative Míra chyby α Chyba druhého typu Test neodmítl neplatící hypotézu False positive Míra chyby β Síla testu 1 β 19
20 Typy testů Rovnost středních hodnot t-test, Hotelling T2, Wilcoxonův test Stejný rozptyl F-test Stejné rozdělení pravděpodobnosti Test normality Shapiro-Wilk, Kolmogorov-Smirnoff Test outlierů... 20
21 Porovnání dvou vzorků Nepárový t-test Dva vzorky z dvou populací významný rozdíl? Vzorek každé populace je náhodná veličina X 1, X 2 Rozdíl středních hodnot je také náhodná veličina μ 1 μ 2 Jaké je rozdělení, střední hodnota, rozptyl? Pro velké vzorky normální kritická hodnota Kritická hodnota výpočet intervalového odhadu stř. hodnoty 21
22 Porovnání dvou vzorků Směrodatná odchylka Za předpokladu normality a nezávislosti s = σ2 (X 1 ) n 1 + σ2 (X 2 ) n 2 Porovnání jako test hypotézy Vzorky mají stejnou střední hodnotu rozdíl je nulový z = X 1 X 2 μ 1 μ 2 s 22
23 Dvouvýběrový t-test Pro malé vzorky se používá statistika t-skóre Předpokládá se normalita a nezávislost Neznámý ale stejný rozptyl Pro odhad směrodatné odchylky kombinujeme rozptyly vzorků s = n 1 σ2 X 1 + m 1 σ 2 X 2 n+m+2 1 n + 1 m Porovnám s kvantilem t-rozdělení s n + m 2 stupni volnosti t = X 1 X 2 s 23
24 Neparametrické testy Co když data nejsou normálně rozdělená Příklad: málo dat, patologie,... Použití bootstrap simulace Wilcoxonův test Co když vzorky nemají stejný rozptyl Složený odhad pro směrodatnou odchylku nemá normální ani t- rozdělení Použití bootstrap simulace pro určení hladiny významnosti Monte Carlo, Jackknife 24
25 Permutační test Co když je rozdíl středních hodnot malý a rozptyl příliš velký t-test nemusí zamítnout hypotézu jen díky náhodě výběru Hledáme test s lepší rozlišovací schopností Počet případů kdy rozdíl středních hodnot B a A ku celkovému počtu opakování je pravděpodobnost že rozdíl B a A je pří H0 (rovnost A a B) náhoda. A = 1; 10; 11; 2; 7; 2; 14; 2; 8; 3; 12; 0 A = ; σ 2 = B = 3; 2; 10; 4; 2; 1; 9; 2; 0; 1; 13; 7 B = ; σ 2 = Permutace, Opakovat n-krát
26 Návrh experimentu Párový test Další možností je provést párový test/měření Jedinec se vyskytuje v obou populacích Randomizace Vzorky jsou vybrány náhodně při dělení do skupin Lokální kontrola Eliminace variability Rozdělení testované množiny do bloků Replikace Stejně velké skupiny náhodných jedinců, stejný postup opakovaného měření a stejné výchozí podmínky 26


27 Regresní anaýza Vztah závislosti mezi dvěma veličinami Závislá x a nezávislá y y = α + βx Jaký může být tzv. model Lineární Vyšší stupeň y i y i Myšlenka minimalizovat čtverec vzdálenosti vzorků v ose y n SSE = y i y i 2 i=1 27

28 Regresní analýza Koeficienty β = SSxy SSxx α = y βx Další míry SSxx = x i x 2 SSyy = y i y 2 SSyy = x i x y i y 28

29 Regresní analýza Čtverec korelace koeficient determinace Korelační koeficient Rostoucí/klesající regresní křivka Inferenční regresní analýza Parametry křivky jsou náhodné veličiny Vícerozměrná regresní analýza Více závislých proměnných, jedna nezávislá 29
30 Regresní analýa - R > data() > trees Girth Height Volume > a<-trees$girth > b<-trees$height > lm(a~b) Call: lm(formula = a ~ b) Coefficients: (Intercept) b > summary(lm(a~b)) Call: lm(formula = a ~ b) Residuals: Min 1Q Median 3Q Max Coefficients: Estimate Std. Error t value Pr(> t ) (Intercept) b ** --- Signif. codes: 0 *** ** 0.01 * Residual standard error: on 29 degrees of freedom Multiple R-squared: , Adjusted R-squared: F-statistic: on 1 and 29 DF, p-value:
31 ANOVA Analysis of variance Závislost veličiny popisující jedince na ostatních Zobecňuje t-test pro více skupin (nezávislé proměnné jsou diskrétní, popisují kategorii) Předpoklad normality a stejného rozptylu F-hodnota F = MS b MS e F-rozdělení Obtížné na výpočet Veličina Skupina 31
32 ANOVA - výpočet MS b = SS b K 1 = MS e = SS e N K = K n i i X i X 2 K 1 K i n i j X i,j X i N K 2 Střední hodnota vzorku (Grand mean) Střední hodnota skupiny P-hodnota se spočítá s využitím tabulky F-rozdělení Existuje statistický rozdíl mezi skupinami? 32
33 ANOVA interpretace ANOVA odhalí že existuje statisticky významný rozdíl, neřekne která skupina od které a jak moc Provádí se dodatečné testy každého s každým, podobně jako t-test Takových testů existuje víc, např. HSD-Tukey Předpoklad stejného počtu prvků v každé skupině n g Tukey HSD = X 1 X 2 MS e n g Koeficient se vyhodnotí např. pomocí tabulky Podobně jako t, F-hodnota 33
34 Density Matematika pro geometrickou ANOVA - R > d <- c(rnorm(100, mean=-0.5, sd=1), rnorm(100, mean=0.5, sd=1)) > cls <- c(rep(0,100), rep(1,100)) > summary(aov(d ~ cls)) Df Sum Sq Mean Sq F value Pr(>F) cls e-09 *** Residuals Signif. codes: 0 *** ** 0.01 * > plot(density(d), xlim=c(-4,4), ylim=c(0,0.5), type="n") > lines(density(d[1:100])) > lines(density(d[101:200])) density.default(x = d) N = 200 Bandwidth =
35 Two-way ANOVA Pokud máme dvě kategorizující funkce (faktor) Např. věkové skupiny a pohlaví Máme tři nulové hypotézy získáme 3 p-hodnoty Závislost veličiny na první kategorii, na druhé kategorii Závislost první kategorie na druhé kategorii (interakce) Stejný počet jedinců v kombinaci kategorií Jde i pokud není stejný počet, komplikovanější 35
36 MANOVA Zkoumáme případ více závislých proměnných na jedné nebo víc kategoriích Wilks lambda ukáže že existuje významný vztah nezávislých závislých proměnných Malá hodnota dobrá separabilita Pro další zkoumání, např. diskriminační analýza 36
37 Hotellingův T 2 -test Zobecnění t-testu pro multivariační analýzu (více proměnných) Je třeba z vektorových náhodných veličin získat skalární hodnotu (výsledek testu) t 2 = n x μ W 1 x μ Střední hodnota vzorku Testovaná střední hodnota Kovarianční matice vzorku t 2 má Hotellingovo t-kvadrát rozdělení (tabulka) Dvouvýběrová varianta 37
 f je lineární Dimenze dat je libovoln Rozšíření pro více")
38 Diskriminační analýza Dichotomie rozdělitelnost vzorku na dvě skupiny Hledání takové diskriminační funkce, která jedince x: f x > 0 příradí do první skupiny f x < 0 přiradí do druhé skupiny Lineární diskriminační analýza (LDA) f je lineární Dimenze dat je libovoln Rozšíření pro více skupin 38

39 LDA 39

40 Interpretace DA Oddělení skupin ve vzorku je optimální pro vzorek, ne celou populaci chceme výsledek zobecnit na populaci Cross-validation trénovací množina, testovací množina, počítá se úspěšnost na testovací množině Varianty: k-fold, leave-one-out 40
 maximum margin")
 SVM")
41 Modifikace DA Složitější podmínky Support vector machines (SVM) maximum margin criterion Složitější dělení prostoru Quadratic discriminant analysis (QDA) SVM kernels 41
 Libovolná dimenze Hierarchické shlukování Míra podobnosti Nehierarchické shlukování Znám počet")
42 Shluková analýza Co když nevím Kolik skupin data obsahují Do kterých skupín data patří (učení bez učitele) Jestli jsou shluky lineárně oddělitelné Hledání přirozených shluků (explorativní metoda) Libovolná dimenze Hierarchické shlukování Míra podobnosti Nehierarchické shlukování Znám počet shluků 42

43 Hierarchické shlukování Normalizace dat, použití vhodných metrik Aglomerativní, divizivní techniky 43
44 Hierarchické shlukování Vysvětlená variabilita je dána poměrem variability shluků k celkové variabilitě elbow criterion Nalezení optimálního počtu shluků 44
")

45 K-means shlukování Znám K počet shluků Umístím (náhodně) středy a shlukuji nejbližší sousedy Přepočítám středy a opakuji 45
46 Klasifikace - interpretace Úspěšnost klasifikace Počet správně zaklasifikovaných / počet celkem Posteriorní Nacvičit na všech, zjistit počet správně klasifikovaných Cross-validace Rozdělit data na foldy Nacvičit na k 1 a testovat zbytek, opakovat Víc restriktivní, lépe vypovídá o vhodnosti klasifikátoru 46
Matematika pro geometrickou morfometrii
 Matematika pro geometrickou morfometrii Václav Krajíček Vaclav.Krajicek@mff.cuni.cz Department of Software and Computer Science Education Faculty of Mathematics and Physics Charles University Přednáška
Matematika pro geometrickou morfometrii Václav Krajíček Vaclav.Krajicek@mff.cuni.cz Department of Software and Computer Science Education Faculty of Mathematics and Physics Charles University Přednáška
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz
 Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická
Úvodem Dříve les než stromy 3 Operace s maticemi
 Obsah 1 Úvodem 13 2 Dříve les než stromy 17 2.1 Nejednoznačnost terminologie 17 2.2 Volba metody analýzy dat 23 2.3 Přehled vybraných vícerozměrných metod 25 2.3.1 Metoda hlavních komponent 26 2.3.2 Faktorová
Obsah 1 Úvodem 13 2 Dříve les než stromy 17 2.1 Nejednoznačnost terminologie 17 2.2 Volba metody analýzy dat 23 2.3 Přehled vybraných vícerozměrných metod 25 2.3.1 Metoda hlavních komponent 26 2.3.2 Faktorová
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc.
 Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika 010 1.týden (0.09.-4.09. ) Data, typy dat, variabilita, frekvenční analýza
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika 010 1.týden (0.09.-4.09. ) Data, typy dat, variabilita, frekvenční analýza
Testování hypotéz. 1. vymezení základních pojmů 2. testování hypotéz o rozdílu průměrů 3. jednovýběrový t-test
 Testování hypotéz 1. vymezení základních pojmů 2. testování hypotéz o rozdílu průměrů 3. jednovýběrový t-test Testování hypotéz proces, kterým rozhodujeme, zda přijmeme nebo zamítneme nulovou hypotézu
Testování hypotéz 1. vymezení základních pojmů 2. testování hypotéz o rozdílu průměrů 3. jednovýběrový t-test Testování hypotéz proces, kterým rozhodujeme, zda přijmeme nebo zamítneme nulovou hypotézu
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc.
 Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika 2010 1.týden (20.09.-24.09. ) Data, typy dat, variabilita, frekvenční analýza
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika 2010 1.týden (20.09.-24.09. ) Data, typy dat, variabilita, frekvenční analýza
Intervalové odhady. Interval spolehlivosti pro střední hodnotu v N(µ, σ 2 ) Interpretace intervalu spolehlivosti. Interval spolehlivosti ilustrace
 Interpretace intervalu spolehlivosti. Interval spolehlivosti ilustrace") Intervalové odhady Interval spolehlivosti pro střední hodnotu v Nµ, σ 2 ) Situace: X 1,..., X n náhodný výběr z Nµ, σ 2 ), kde σ 2 > 0 známe měli jsme: bodové odhady odhadem charakteristiky je číslo) nevyjadřuje
Intervalové odhady Interval spolehlivosti pro střední hodnotu v Nµ, σ 2 ) Situace: X 1,..., X n náhodný výběr z Nµ, σ 2 ), kde σ 2 > 0 známe měli jsme: bodové odhady odhadem charakteristiky je číslo) nevyjadřuje
Testování statistických hypotéz
 Testování statistických hypotéz Na základě náhodného výběru, který je reprezentativním vzorkem základního souboru (který přesně neznáme, k němuž se ale daná statistická hypotéza váže), potřebujeme ověřit,
Testování statistických hypotéz Na základě náhodného výběru, který je reprezentativním vzorkem základního souboru (který přesně neznáme, k němuž se ale daná statistická hypotéza váže), potřebujeme ověřit,
Intervalové odhady. Interval spolehlivosti pro střední hodnotu v N(µ, σ 2 ) Interpretace intervalu spolehlivosti. Interval spolehlivosti ilustrace
 Interpretace intervalu spolehlivosti. Interval spolehlivosti ilustrace") Intervalové odhady Interval spolehlivosti pro střední hodnotu v Nµ, σ 2 ) Situace: X 1,..., X n náhodný výběr z Nµ, σ 2 ), kde σ 2 > 0 známe měli jsme: bodové odhady odhadem charakteristiky je číslo) nevyjadřuje
Intervalové odhady Interval spolehlivosti pro střední hodnotu v Nµ, σ 2 ) Situace: X 1,..., X n náhodný výběr z Nµ, σ 2 ), kde σ 2 > 0 známe měli jsme: bodové odhady odhadem charakteristiky je číslo) nevyjadřuje
Zápočtová práce STATISTIKA I
 Zápočtová práce STATISTIKA I Obsah: - úvodní stránka - charakteristika dat (původ dat, důvod zpracování,...) - výpis naměřených hodnot (v tabulce) - zpracování dat (buď bodové nebo intervalové, podle charakteru
Zápočtová práce STATISTIKA I Obsah: - úvodní stránka - charakteristika dat (původ dat, důvod zpracování,...) - výpis naměřených hodnot (v tabulce) - zpracování dat (buď bodové nebo intervalové, podle charakteru
Analýza rozptylu. Ekonometrie. Jiří Neubauer. Katedra kvantitativních metod FVL UO Brno kancelář 69a, tel
 Analýza rozptylu Ekonometrie Jiří Neubauer Katedra kvantitativních metod FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Jiří Neubauer (Katedra UO Brno) Analýza rozptylu 1 / 30 Analýza
Analýza rozptylu Ekonometrie Jiří Neubauer Katedra kvantitativních metod FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Jiří Neubauer (Katedra UO Brno) Analýza rozptylu 1 / 30 Analýza
Testy statistických hypotéz
 Testy statistických hypotéz Statistická hypotéza je jakýkoliv předpoklad o rozdělení pravděpodobnosti jedné nebo několika náhodných veličin. Na základě náhodného výběru, který je reprezentativním vzorkem
Testy statistických hypotéz Statistická hypotéza je jakýkoliv předpoklad o rozdělení pravděpodobnosti jedné nebo několika náhodných veličin. Na základě náhodného výběru, který je reprezentativním vzorkem
Stručný úvod do testování statistických hypotéz
 Stručný úvod do testování statistických hypotéz 1. Formulujeme hypotézu (předpokládáme, že pozorovaný jev je pouze náhodný). 2. Zvolíme hladinu významnosti testu a, tj. riziko, s nímž jsme ochotni se smířit.
Stručný úvod do testování statistických hypotéz 1. Formulujeme hypotézu (předpokládáme, že pozorovaný jev je pouze náhodný). 2. Zvolíme hladinu významnosti testu a, tj. riziko, s nímž jsme ochotni se smířit.
Testování hypotéz o parametrech regresního modelu
 Testování hypotéz o parametrech regresního modelu Ekonometrie Jiří Neubauer Katedra kvantitativních metod FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Jiří Neubauer (Katedra UO
Testování hypotéz o parametrech regresního modelu Ekonometrie Jiří Neubauer Katedra kvantitativních metod FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Jiří Neubauer (Katedra UO
STATISTIKA A INFORMATIKA - bc studium OZW, 1.roč. (zkušební otázky)
") STATISTIKA A INFORMATIKA - bc studium OZW, 1.roč. (zkušební otázky) 1) Význam a využití statistiky v biologických vědách a veterinárním lékařství ) Rozdělení znaků (veličin) ve statistice 3) Základní a
STATISTIKA A INFORMATIKA - bc studium OZW, 1.roč. (zkušební otázky) 1) Význam a využití statistiky v biologických vědách a veterinárním lékařství ) Rozdělení znaků (veličin) ve statistice 3) Základní a
Testování hypotéz o parametrech regresního modelu
 Statistika II Katedra ekonometrie FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Lineární regresní model kde Y = Xβ + e, y 1 e 1 β y 2 Y =., e = e 2 x 11 x 1 1k., X =....... β 2,
Statistika II Katedra ekonometrie FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Lineární regresní model kde Y = Xβ + e, y 1 e 1 β y 2 Y =., e = e 2 x 11 x 1 1k., X =....... β 2,
Cvičení ze statistiky - 9. Filip Děchtěrenko
 Cvičení ze statistiky - 9 Filip Děchtěrenko Minule bylo.. Dobrali jsme normální rozdělení Tyhle termíny by měly být známé: Inferenční statistika Konfidenční intervaly Z-test Postup při testování hypotéz
Cvičení ze statistiky - 9 Filip Děchtěrenko Minule bylo.. Dobrali jsme normální rozdělení Tyhle termíny by měly být známé: Inferenční statistika Konfidenční intervaly Z-test Postup při testování hypotéz
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc.
 Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika 2010 1.týden (20.09.-24.09. ) Data, typy dat, variabilita, frekvenční analýza
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika 2010 1.týden (20.09.-24.09. ) Data, typy dat, variabilita, frekvenční analýza
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc.
 Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika 2010 1.týden (20.09.-24.09. ) Data, typy dat, variabilita, frekvenční analýza
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika 2010 1.týden (20.09.-24.09. ) Data, typy dat, variabilita, frekvenční analýza
ANALÝZA A KLASIFIKACE DAT
 ANALÝZA A KLASIFIKACE DAT RNDr. Eva Janoušová INVESTICE DO ROZVOJE VZDĚLÁVÁNÍ HODNOCENÍ ÚSPĚŠNOSTI KLASIFIKACE A SROVNÁNÍ KLASIFIKÁTORŮ ÚVOD Vstupní data Subjekt Objem hipokampu Objem komor Skutečnost
ANALÝZA A KLASIFIKACE DAT RNDr. Eva Janoušová INVESTICE DO ROZVOJE VZDĚLÁVÁNÍ HODNOCENÍ ÚSPĚŠNOSTI KLASIFIKACE A SROVNÁNÍ KLASIFIKÁTORŮ ÚVOD Vstupní data Subjekt Objem hipokampu Objem komor Skutečnost
Opravená data Úloha (A) + (E) Úloha (C) Úloha (B) Úloha (D) Lineární regrese
 + (E) Úloha (C) Úloha (B) Úloha (D) Lineární regrese") - základní ukazatele Komentované řešení pomocí programu R Ústav matematiky Fakulta chemicko inženýrská Vysoká škola chemicko-technologická v Praze - základní ukazatele Načtení vstupních dat Vstupní data
- základní ukazatele Komentované řešení pomocí programu R Ústav matematiky Fakulta chemicko inženýrská Vysoká škola chemicko-technologická v Praze - základní ukazatele Načtení vstupních dat Vstupní data
UNIVERZITA OBRANY Fakulta ekonomiky a managementu. Aplikace STAT1. Výsledek řešení projektu PRO HORR2011 a PRO GRAM2011 3. 11.
 UNIVERZITA OBRANY Fakulta ekonomiky a managementu Aplikace STAT1 Výsledek řešení projektu PRO HORR2011 a PRO GRAM2011 Jiří Neubauer, Marek Sedlačík, Oldřich Kříž 3. 11. 2012 Popis a návod k použití aplikace
UNIVERZITA OBRANY Fakulta ekonomiky a managementu Aplikace STAT1 Výsledek řešení projektu PRO HORR2011 a PRO GRAM2011 Jiří Neubauer, Marek Sedlačík, Oldřich Kříž 3. 11. 2012 Popis a návod k použití aplikace
Testování hypotéz. Testování hypotéz o rozdílu průměrů t-test pro nezávislé výběry t-test pro závislé výběry
 Testování hypotéz Testování hypotéz o rozdílu průměrů t-test pro nezávislé výběry t-test pro závislé výběry Testování hypotéz Obecný postup 1. Určení statistické hypotézy 2. Určení hladiny chyby 3. Výpočet
Testování hypotéz Testování hypotéz o rozdílu průměrů t-test pro nezávislé výběry t-test pro závislé výběry Testování hypotéz Obecný postup 1. Určení statistické hypotézy 2. Určení hladiny chyby 3. Výpočet
Statistická analýza dat
 Statistická analýza dat Jméno: Podpis: Cvičení Zkouška (písemná + ústní) 25 Celkem 50 Známka Pokyny k vypracování: doba řešení je 120min, jasně zodpovězte pokud možno všechny otázky ze zadání, pracujte
Statistická analýza dat Jméno: Podpis: Cvičení Zkouška (písemná + ústní) 25 Celkem 50 Známka Pokyny k vypracování: doba řešení je 120min, jasně zodpovězte pokud možno všechny otázky ze zadání, pracujte
Výběrové charakteristiky a jejich rozdělení
 Katedra ekonometrie, FVL, UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Statistické šetření úplné (vyčerpávající) neúplné (výběrové) U výběrového šetření se snažíme o to, aby výběrový
Katedra ekonometrie, FVL, UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Statistické šetření úplné (vyčerpávající) neúplné (výběrové) U výběrového šetření se snažíme o to, aby výběrový
Regresní a korelační analýza
 Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Inovace bakalářského studijního oboru Aplikovaná chemie
 http://aplchem.upol.cz CZ.1.07/2.2.00/15.0247 Tento projekt je spolufinancován Evropským sociálním fondem a státním rozpočtem České republiky. Regrese Závislostproměnných funkční y= f(x) regresní y= f(x)
http://aplchem.upol.cz CZ.1.07/2.2.00/15.0247 Tento projekt je spolufinancován Evropským sociálním fondem a státním rozpočtem České republiky. Regrese Závislostproměnných funkční y= f(x) regresní y= f(x)
Dobývání znalostí. Doc. RNDr. Iveta Mrázová, CSc. Katedra teoretické informatiky Matematicko-fyzikální fakulta Univerzity Karlovy v Praze
 Dobývání znalostí Doc. RNDr. Iveta Mrázová, CSc. Katedra teoretické informatiky Matematicko-fyzikální fakulta Univerzity Karlovy v Praze Dobývání znalostí Pravděpodobnost a učení Doc. RNDr. Iveta Mrázová,
Dobývání znalostí Doc. RNDr. Iveta Mrázová, CSc. Katedra teoretické informatiky Matematicko-fyzikální fakulta Univerzity Karlovy v Praze Dobývání znalostí Pravděpodobnost a učení Doc. RNDr. Iveta Mrázová,
Normální (Gaussovo) rozdělení
 rozdělení") Normální (Gaussovo) rozdělení Normální (Gaussovo) rozdělení popisuje vlastnosti náhodné spojité veličiny, která vzniká složením různých náhodných vlivů, které jsou navzájem nezávislé, kterých je velký
Normální (Gaussovo) rozdělení Normální (Gaussovo) rozdělení popisuje vlastnosti náhodné spojité veličiny, která vzniká složením různých náhodných vlivů, které jsou navzájem nezávislé, kterých je velký
Základní statistické metody v rizikovém inženýrství
 Základní statistické metody v rizikovém inženýrství Petr Misák Ústav stavebního zkušebnictví Fakulta stavební, VUT v Brně misak.p@fce.vutbr.cz Základní pojmy Jev souhrn skutečností zobrazujících ucelenou
Základní statistické metody v rizikovém inženýrství Petr Misák Ústav stavebního zkušebnictví Fakulta stavební, VUT v Brně misak.p@fce.vutbr.cz Základní pojmy Jev souhrn skutečností zobrazujících ucelenou
Charakterizace rozdělení
 Charakterizace rozdělení Momenty f(x) f(x) f(x) μ >μ 1 σ 1 σ >σ 1 g 1 g σ μ 1 μ x μ x x N K MK = x f( x) dx 1 M K = x N CK = ( x M ) f( x) dx ( xi M 1 C = 1 K 1) N i= 1 K i K N i= 1 K μ = E ( X ) = xf
Charakterizace rozdělení Momenty f(x) f(x) f(x) μ >μ 1 σ 1 σ >σ 1 g 1 g σ μ 1 μ x μ x x N K MK = x f( x) dx 1 M K = x N CK = ( x M ) f( x) dx ( xi M 1 C = 1 K 1) N i= 1 K i K N i= 1 K μ = E ( X ) = xf
MATEMATICKÁ STATISTIKA - XP01MST
 MATEMATICKÁ STATISTIKA - XP01MST 1. Úvod. Matematická statistika (statistics) se zabývá vyšetřováním zákonitostí, které v sobě obsahují prvek náhody. Zpracováním hodnot, které jsou výstupem sledovaného
MATEMATICKÁ STATISTIKA - XP01MST 1. Úvod. Matematická statistika (statistics) se zabývá vyšetřováním zákonitostí, které v sobě obsahují prvek náhody. Zpracováním hodnot, které jsou výstupem sledovaného
1 Tyto materiály byly vytvořeny za pomoci grantu FRVŠ číslo 1145/2004.
 Vícenásobná regresní a korelační analýza 1 1 Tto materiál bl vtvořen za pomoci grantu FRVŠ číslo 1145/2004. O vícenásobné závislosti mluvíme tehd, jestliže je závisle proměnná závislá na více nezávislých
Vícenásobná regresní a korelační analýza 1 1 Tto materiál bl vtvořen za pomoci grantu FRVŠ číslo 1145/2004. O vícenásobné závislosti mluvíme tehd, jestliže je závisle proměnná závislá na více nezávislých
PRAVDĚPODOBNOST A STATISTIKA
 PRAVDĚPODOBNOST A STATISTIKA Testování hypotéz Nechť X je náhodná proměnná, která má distribuční funkci F(x, ϑ). Předpokládejme, že známe tvar distribuční funkce (víme jaké má rozdělení) a neznáme parametr
PRAVDĚPODOBNOST A STATISTIKA Testování hypotéz Nechť X je náhodná proměnná, která má distribuční funkci F(x, ϑ). Předpokládejme, že známe tvar distribuční funkce (víme jaké má rozdělení) a neznáme parametr
ADDS cviceni. Pavlina Kuranova
 ADDS cviceni Pavlina Kuranova Testy pro dva nezávislé výběry Mannův Whitneyho test - Založen na Wilcoxnově statistice W - založen na pořadí jednotlivých pozorování (oba výběry spojeny do jednoho celku)
ADDS cviceni Pavlina Kuranova Testy pro dva nezávislé výběry Mannův Whitneyho test - Založen na Wilcoxnově statistice W - založen na pořadí jednotlivých pozorování (oba výběry spojeny do jednoho celku)
Problematika analýzy rozptylu. Ing. Michael Rost, Ph.D.
 Problematika analýzy rozptylu Ing. Michael Rost, Ph.D. Úvod do problému Již umíte testovat shodu dvou středních hodnot prostřednictvím t-testů. Otázka: Jaké předpoklady musí být splněny, abyste mohli použít
Problematika analýzy rozptylu Ing. Michael Rost, Ph.D. Úvod do problému Již umíte testovat shodu dvou středních hodnot prostřednictvím t-testů. Otázka: Jaké předpoklady musí být splněny, abyste mohli použít
Aplikovaná statistika v R - cvičení 2
 Aplikovaná statistika v R - cvičení 2 Filip Děchtěrenko Matematicko-fyzikální fakulta filip.dechterenko@gmail.com 5.6.2014 Filip Děchtěrenko (MFF UK) Aplikovaná statistika v R 5.6.2014 1 / 18 Přehled Rkových
Aplikovaná statistika v R - cvičení 2 Filip Děchtěrenko Matematicko-fyzikální fakulta filip.dechterenko@gmail.com 5.6.2014 Filip Děchtěrenko (MFF UK) Aplikovaná statistika v R 5.6.2014 1 / 18 Přehled Rkových
Statistická analýza jednorozměrných dat
 Statistická analýza jednorozměrných dat Prof. RNDr. Milan Meloun, DrSc. Univerzita Pardubice, Pardubice 31.ledna 2011 Tato prezentace je spolufinancována Evropským sociálním fondem a státním rozpočtem
Statistická analýza jednorozměrných dat Prof. RNDr. Milan Meloun, DrSc. Univerzita Pardubice, Pardubice 31.ledna 2011 Tato prezentace je spolufinancována Evropským sociálním fondem a státním rozpočtem
pravděpodobnosti, popisné statistiky
 8. Modelová rozdělení pravděpodobnosti, popisné statistiky Rozdělení pravděpodobnosti Normální rozdělení jako statistický model Přehled a aplikace modelových rozdělení Popisné statistiky Anotace Klasickým
8. Modelová rozdělení pravděpodobnosti, popisné statistiky Rozdělení pravděpodobnosti Normální rozdělení jako statistický model Přehled a aplikace modelových rozdělení Popisné statistiky Anotace Klasickým
Grafický a číselný popis rozložení dat 3.1 Způsoby zobrazení dat Metody zobrazení kvalitativních a ordinálních dat Metody zobrazení kvan
 1 Úvod 1.1 Empirický výzkum a jeho etapy 1.2 Význam teorie pro výzkum 1.2.1 Konstrukty a jejich operacionalizace 1.2.2 Role teorie ve výzkumu 1.2.3 Proces ověření hypotéz a teorií 1.3 Etika vědecké práce
1 Úvod 1.1 Empirický výzkum a jeho etapy 1.2 Význam teorie pro výzkum 1.2.1 Konstrukty a jejich operacionalizace 1.2.2 Role teorie ve výzkumu 1.2.3 Proces ověření hypotéz a teorií 1.3 Etika vědecké práce
JAK MODELOVAT VÝSLEDKY NÁH. POKUSŮ? Martina Litschmannová
 JAK MODELOVAT VÝSLEDKY NÁH. POKUSŮ? Martina Litschmannová Opakování Základní pojmy z teorie pravděpodobnosti Co je to náhodný pokus? Děj, jehož výsledek není předem jednoznačně určen podmínkami, za nichž
JAK MODELOVAT VÝSLEDKY NÁH. POKUSŮ? Martina Litschmannová Opakování Základní pojmy z teorie pravděpodobnosti Co je to náhodný pokus? Děj, jehož výsledek není předem jednoznačně určen podmínkami, za nichž
Regresní analýza 1. Regresní analýza
 Regresní analýza 1 1 Regresní funkce Regresní analýza Důležitou statistickou úlohou je hledání a zkoumání závislostí proměnných, jejichž hodnoty získáme při realizaci experimentů Vzhledem k jejich náhodnému
Regresní analýza 1 1 Regresní funkce Regresní analýza Důležitou statistickou úlohou je hledání a zkoumání závislostí proměnných, jejichž hodnoty získáme při realizaci experimentů Vzhledem k jejich náhodnému
AVDAT Náhodný vektor, mnohorozměrné rozdělení
 AVDAT Náhodný vektor, mnohorozměrné rozdělení Josef Tvrdík Katedra informatiky Přírodovědecká fakulta Ostravská univerzita Opakování, náhodná veličina, rozdělení Náhodná veličina zobrazuje elementární
AVDAT Náhodný vektor, mnohorozměrné rozdělení Josef Tvrdík Katedra informatiky Přírodovědecká fakulta Ostravská univerzita Opakování, náhodná veličina, rozdělení Náhodná veličina zobrazuje elementární
Obsah přednášky Jaká asi bude chyba modelu na nových datech?
 Obsah přednášky Jaká asi bude chyba modelu na nových datech? Chyba modelu Bootstrap Cross Validation Vapnik-Chervonenkisova dimenze 2 Chyba skutečná a trénovací Máme 30 záznamů, rozhodli jsme se na jejich
Obsah přednášky Jaká asi bude chyba modelu na nových datech? Chyba modelu Bootstrap Cross Validation Vapnik-Chervonenkisova dimenze 2 Chyba skutečná a trénovací Máme 30 záznamů, rozhodli jsme se na jejich
Pravděpodobnost a statistika, Biostatistika pro kombinované studium. Tutoriál č. 5: Bodové a intervalové odhady, testování hypotéz.
 Pravděpodobnost a statistika, Biostatistika pro kombinované studium Letní semestr 2015/2016 Tutoriál č. 5: Bodové a intervalové odhady, testování hypotéz Jan Kracík jan.kracik@vsb.cz Obsah: Výběrová rozdělení
Pravděpodobnost a statistika, Biostatistika pro kombinované studium Letní semestr 2015/2016 Tutoriál č. 5: Bodové a intervalové odhady, testování hypotéz Jan Kracík jan.kracik@vsb.cz Obsah: Výběrová rozdělení
Charakteristika datového souboru
 Zápočtová práce z předmětu Statistika Vypracoval: 10. 11. 2014 Charakteristika datového souboru Zadání: Při kontrole dodržování hygienických norem v kuchyni se prováděl odběr vzduchu a pomocí filtru Pallflex
Zápočtová práce z předmětu Statistika Vypracoval: 10. 11. 2014 Charakteristika datového souboru Zadání: Při kontrole dodržování hygienických norem v kuchyni se prováděl odběr vzduchu a pomocí filtru Pallflex
Praktická statistika. Petr Ponížil Eva Kutálková
 Praktická statistika Petr Ponížil Eva Kutálková Zápis výsledků měření Předpokládejme, že známe hodnotu napětí U = 238,9 V i její chybu 3,3 V. Hodnotu veličiny zapíšeme na tolik míst, aby až poslední bylo
Praktická statistika Petr Ponížil Eva Kutálková Zápis výsledků měření Předpokládejme, že známe hodnotu napětí U = 238,9 V i její chybu 3,3 V. Hodnotu veličiny zapíšeme na tolik míst, aby až poslední bylo
Mann-Whitney U-test. Znaménkový test. Vytvořil Institut biostatistiky a analýz, Masarykova univerzita J. Jarkovský, L. Dušek
 10. Neparametrické y Mann-Whitney U- Wilcoxonův Znaménkový Shrnutí statistických ů Typ srovnání Nulová hypotéza Parametrický Neparametrický 1 skupina dat vs. etalon Střední hodnota je rovna hodnotě etalonu.
10. Neparametrické y Mann-Whitney U- Wilcoxonův Znaménkový Shrnutí statistických ů Typ srovnání Nulová hypotéza Parametrický Neparametrický 1 skupina dat vs. etalon Střední hodnota je rovna hodnotě etalonu.
Testování hypotéz. Testování hypotéz o rozdílu průměrů t-test pro nezávislé výběry t-test pro závislé výběry
 Testování hypotéz Testování hypotéz o rozdílu průměrů t-test pro nezávislé výběry t-test pro závislé výběry Testování hypotéz Obecný postup 1. Určení statistické hypotézy 2. Určení hladiny chyby 3. Výpočet
Testování hypotéz Testování hypotéz o rozdílu průměrů t-test pro nezávislé výběry t-test pro závislé výběry Testování hypotéz Obecný postup 1. Určení statistické hypotézy 2. Určení hladiny chyby 3. Výpočet
RNDr. Eva Janoušová doc. RNDr. Ladislav Dušek, Dr.
 Analýza dat pro Neurovědy RNDr. Eva Janoušová doc. RNDr. Ladislav Dušek, Dr. Jaro 2014 Institut biostatistiky Janoušová, a analýz Dušek: Analýza dat pro neurovědy Blok 3 Jak a kdy použít parametrické a
Analýza dat pro Neurovědy RNDr. Eva Janoušová doc. RNDr. Ladislav Dušek, Dr. Jaro 2014 Institut biostatistiky Janoušová, a analýz Dušek: Analýza dat pro neurovědy Blok 3 Jak a kdy použít parametrické a
MÍRY ZÁVISLOSTI (KORELACE A REGRESE)
") zhanel@fsps.muni.cz MÍRY ZÁVISLOSTI (KORELACE A REGRESE) 2.5 MÍRY ZÁVISLOSTI 2.5.1 ZÁVISLOST PEVNÁ, VOLNÁ, STATISTICKÁ A KORELAČNÍ Jednorozměrné soubory - charakterizovány jednotlivými statistickými znaky
zhanel@fsps.muni.cz MÍRY ZÁVISLOSTI (KORELACE A REGRESE) 2.5 MÍRY ZÁVISLOSTI 2.5.1 ZÁVISLOST PEVNÁ, VOLNÁ, STATISTICKÁ A KORELAČNÍ Jednorozměrné soubory - charakterizovány jednotlivými statistickými znaky
Co je to statistika? Úvod statistické myšlení. Základy statistického hodnocení výsledků zkoušek. Petr Misák
 Základy statistického hodnocení výsledků zkoušek Petr Misák misak.p@fce.vutbr.cz Co je to statistika? Statistika je jako bikiny. Odhalí téměř vše, ale to nejdůležitější nám zůstane skryto. (autor neznámý)
Základy statistického hodnocení výsledků zkoušek Petr Misák misak.p@fce.vutbr.cz Co je to statistika? Statistika je jako bikiny. Odhalí téměř vše, ale to nejdůležitější nám zůstane skryto. (autor neznámý)
Jednofaktorová analýza rozptylu
 I I.I Jednofaktorová analýza rozptylu Úvod Jednofaktorová analýza rozptylu (ANOVA) se využívá při porovnání několika středních hodnot. Často se využívá ve vědeckých a lékařských experimentech, při kterých
I I.I Jednofaktorová analýza rozptylu Úvod Jednofaktorová analýza rozptylu (ANOVA) se využívá při porovnání několika středních hodnot. Často se využívá ve vědeckých a lékařských experimentech, při kterých
PSY117/454 Statistická analýza dat v psychologii seminář 9. Statistické testování hypotéz
 PSY117/454 Statistická analýza dat v psychologii seminář 9 Statistické testování hypotéz Základní výzkumné otázky/hypotézy 1. Stanovení hodnoty parametru =stanovení intervalu spolehlivosti na μ, σ, ρ,
PSY117/454 Statistická analýza dat v psychologii seminář 9 Statistické testování hypotéz Základní výzkumné otázky/hypotézy 1. Stanovení hodnoty parametru =stanovení intervalu spolehlivosti na μ, σ, ρ,
Regresní a korelační analýza
 Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Pravděpodobnost, náhoda, kostky
 Pravděpodobnost, náhoda, kostky Radek Pelánek IV122 Výhled pravděpodobnost náhodná čísla lineární regrese detekce shluků Dnes lehce nesourodá směs úloh souvisejících s pravděpodobností připomenutí, souvislosti
Pravděpodobnost, náhoda, kostky Radek Pelánek IV122 Výhled pravděpodobnost náhodná čísla lineární regrese detekce shluků Dnes lehce nesourodá směs úloh souvisejících s pravděpodobností připomenutí, souvislosti
Přednáška IX. Analýza rozptylu (ANOVA)
") Přednáška IX. Analýza rozptylu (ANOVA) Princip a metodika výpočtu Předpoklady analýzy rozptylu a jejich ověření Rozbor rozdílů jednotlivých skupin násobné testování hypotéz Analýza rozptylu jako lineární
Přednáška IX. Analýza rozptylu (ANOVA) Princip a metodika výpočtu Předpoklady analýzy rozptylu a jejich ověření Rozbor rozdílů jednotlivých skupin násobné testování hypotéz Analýza rozptylu jako lineární
Pravděpodobnost a aplikovaná statistika
 Pravděpodobnost a aplikovaná statistika MGR. JANA SEKNIČKOVÁ, PH.D. 8. KAPITOLA STATISTICKÉ TESTOVÁNÍ HYPOTÉZ 22.11.2016 Opakování: CLV příklad 1 Zadání: Před volbami je v populaci státu 52 % příznivců
Pravděpodobnost a aplikovaná statistika MGR. JANA SEKNIČKOVÁ, PH.D. 8. KAPITOLA STATISTICKÉ TESTOVÁNÍ HYPOTÉZ 22.11.2016 Opakování: CLV příklad 1 Zadání: Před volbami je v populaci státu 52 % příznivců
Vybraná rozdělení náhodné veličiny
 3.3 Vybraná rozdělení náhodné veličiny 0,16 0,14 0,12 0,1 0,08 0,06 0,04 0,02 0 Rozdělení Z 3 4 5 6 7 8 9 10 11 12 13 14 15 Život je umění vytvářet uspokojivé závěry na základě nedostatečných předpokladů.
3.3 Vybraná rozdělení náhodné veličiny 0,16 0,14 0,12 0,1 0,08 0,06 0,04 0,02 0 Rozdělení Z 3 4 5 6 7 8 9 10 11 12 13 14 15 Život je umění vytvářet uspokojivé závěry na základě nedostatečných předpokladů.
Regresní analýza. Eva Jarošová
 Regresní analýza Eva Jarošová 1 Obsah 1. Regresní přímka 2. Možnosti zlepšení modelu 3. Testy v regresním modelu 4. Regresní diagnostika 5. Speciální využití Lineární model 2 1. Regresní přímka 3 nosnost
Regresní analýza Eva Jarošová 1 Obsah 1. Regresní přímka 2. Možnosti zlepšení modelu 3. Testy v regresním modelu 4. Regresní diagnostika 5. Speciální využití Lineární model 2 1. Regresní přímka 3 nosnost
12. cvičení z PST. 20. prosince 2017
 1 cvičení z PST 0 prosince 017 11 test rozptylu normálního rozdělení Do laboratoře bylo odesláno n = 5 stejných vzorků krve ke stanovení obsahu alkoholu X v promilích alkoholu Výsledkem byla realizace
1 cvičení z PST 0 prosince 017 11 test rozptylu normálního rozdělení Do laboratoře bylo odesláno n = 5 stejných vzorků krve ke stanovení obsahu alkoholu X v promilích alkoholu Výsledkem byla realizace
Normální (Gaussovo) rozdělení
 rozdělení") Normální (Gaussovo) rozdělení f x = 1 2 exp x 2 2 2 f(x) je funkce hustoty pravděpodobnosti, symetrická vůči poloze maxima x = μ μ střední hodnota σ směrodatná odchylka (tzv. pološířka křivky mezi inflexními
Normální (Gaussovo) rozdělení f x = 1 2 exp x 2 2 2 f(x) je funkce hustoty pravděpodobnosti, symetrická vůči poloze maxima x = μ μ střední hodnota σ směrodatná odchylka (tzv. pološířka křivky mezi inflexními
Me neˇ nezˇ minimum ze statistiky Michaela S ˇ edova KPMS MFF UK Principy medicı ny zalozˇene na du kazech a za klady veˇdecke prˇı pravy 1 / 33
 1 / 33 Méně než minimum ze statistiky Michaela Šedová KPMS MFF UK Principy medicíny založené na důkazech a základy vědecké přípravy Příklad Studie syndromu náhodného úmrtí dětí. Dvě skupiny: Děti, které
1 / 33 Méně než minimum ze statistiky Michaela Šedová KPMS MFF UK Principy medicíny založené na důkazech a základy vědecké přípravy Příklad Studie syndromu náhodného úmrtí dětí. Dvě skupiny: Děti, které
Všechno, co jste chtěli vědět z teorie pravděpodobnosti, z teorie informace a
 Všechno, co jste chtěli vědět z teorie pravděpodobnosti, z teorie informace a báli jste se zeptat Jedinečnou funkcí statistiky je, že umožňuje vědci číselně vyjádřit nejistotu v jeho závěrech. (G. W. Snedecor)
Všechno, co jste chtěli vědět z teorie pravděpodobnosti, z teorie informace a báli jste se zeptat Jedinečnou funkcí statistiky je, že umožňuje vědci číselně vyjádřit nejistotu v jeho závěrech. (G. W. Snedecor)
letní semestr 2012 Katedra pravděpodobnosti a matematické statistiky Matematicko-fyzikální fakulta Univerzity Karlovy Matematická statistika
 Šárka Hudecová Katedra pravděpodobnosti a matematické statistiky Matematicko-fyzikální fakulta Univerzity Karlovy letní semestr 2012 Opakování t- vs. neparametrické Wilcoxonův jednovýběrový test Opakování
Šárka Hudecová Katedra pravděpodobnosti a matematické statistiky Matematicko-fyzikální fakulta Univerzity Karlovy letní semestr 2012 Opakování t- vs. neparametrické Wilcoxonův jednovýběrový test Opakování
Testování hypotéz. Analýza dat z dotazníkových šetření. Kuranova Pavlina
 Testování hypotéz Analýza dat z dotazníkových šetření Kuranova Pavlina Statistická hypotéza Možné cíle výzkumu Srovnání účinnosti různých metod Srovnání výsledků různých skupin Tzn. prokázání rozdílů mezi
Testování hypotéz Analýza dat z dotazníkových šetření Kuranova Pavlina Statistická hypotéza Možné cíle výzkumu Srovnání účinnosti různých metod Srovnání výsledků různých skupin Tzn. prokázání rozdílů mezi
Základy biostatistiky II. Veřejné zdravotnictví 3.LF UK - II
 Základy biostatistiky II Veřejné zdravotnictví 3.LF UK - II Teoretické rozložení-matematické modely rozložení Naměřená data Výběrové rozložení Teoretické rozložení 1 e 2 x 2 Teoretické rozložení-matematické
Základy biostatistiky II Veřejné zdravotnictví 3.LF UK - II Teoretické rozložení-matematické modely rozložení Naměřená data Výběrové rozložení Teoretické rozložení 1 e 2 x 2 Teoretické rozložení-matematické
Statistika, Biostatistika pro kombinované studium. Jan Kracík
 Statistika, Biostatistika pro kombinované studium Letní semestr 2014/2015 Tutoriál č. 6: ANOVA Jan Kracík jan.kracik@vsb.cz Obsah: Testování hypotéz opakování ANOVA Testování hypotéz (opakování) Testování
Statistika, Biostatistika pro kombinované studium Letní semestr 2014/2015 Tutoriál č. 6: ANOVA Jan Kracík jan.kracik@vsb.cz Obsah: Testování hypotéz opakování ANOVA Testování hypotéz (opakování) Testování
ANALÝZA DAT V R 3. POPISNÉ STATISTIKY, NÁHODNÁ VELIČINA. Mgr. Markéta Pavlíková Katedra pravděpodobnosti a matematické statistiky MFF UK
 ANALÝZA DAT V R 3. POPISNÉ STATISTIKY, NÁHODNÁ VELIČINA Mgr. Markéta Pavlíková Katedra pravděpodobnosti a matematické statistiky MFF UK www.biostatisticka.cz POPISNÉ STATISTIKY - OPAKOVÁNÍ jedna kvalitativní
ANALÝZA DAT V R 3. POPISNÉ STATISTIKY, NÁHODNÁ VELIČINA Mgr. Markéta Pavlíková Katedra pravděpodobnosti a matematické statistiky MFF UK www.biostatisticka.cz POPISNÉ STATISTIKY - OPAKOVÁNÍ jedna kvalitativní
Jednofaktorová analýza rozptylu
 Jednofaktorová analýza rozptylu David Hampel Ústav statistiky a operačního výzkumu, Mendelova univerzita v Brně Kurz pokročilých statistických metod Global Change Research Centre AS CR, 5 7 8 2015 Tato
Jednofaktorová analýza rozptylu David Hampel Ústav statistiky a operačního výzkumu, Mendelova univerzita v Brně Kurz pokročilých statistických metod Global Change Research Centre AS CR, 5 7 8 2015 Tato
VYBRANÉ DVOUVÝBĚROVÉ TESTY. Martina Litschmannová
 VYBRANÉ DVOUVÝBĚROVÉ TESTY Martina Litschmannová Obsah přednášky Vybrané dvouvýběrové testy par. hypotéz test o shodě rozptylů (F-test), testy o shodě středních hodnot (t-test, Aspinové-Welchův test),
VYBRANÉ DVOUVÝBĚROVÉ TESTY Martina Litschmannová Obsah přednášky Vybrané dvouvýběrové testy par. hypotéz test o shodě rozptylů (F-test), testy o shodě středních hodnot (t-test, Aspinové-Welchův test),
Tomáš Karel LS 2012/2013
 Tomáš Karel LS 2012/2013 Doplňkový materiál ke cvičení z předmětu 4ST201. Na případné faktické chyby v této presentaci mě prosím upozorněte. Děkuji. Tyto slidy berte pouze jako doplňkový materiál není
Tomáš Karel LS 2012/2013 Doplňkový materiál ke cvičení z předmětu 4ST201. Na případné faktické chyby v této presentaci mě prosím upozorněte. Děkuji. Tyto slidy berte pouze jako doplňkový materiál není
PRAVDĚPODOBNOST A STATISTIKA
 PRAVDĚPODOBNOST A STATISTIKA Definice lineárního normálního regresního modelu Lineární normální regresní model Y β ε Matice n,k je matice realizací. Předpoklad: n > k, h() k - tj. matice je plné hodnosti
PRAVDĚPODOBNOST A STATISTIKA Definice lineárního normálního regresního modelu Lineární normální regresní model Y β ε Matice n,k je matice realizací. Předpoklad: n > k, h() k - tj. matice je plné hodnosti
Design Experimentu a Statistika - AGA46E
 Design Experimentu a Statistika - AGA46E Czech University of Life Sciences in Prague Department of Genetics and Breeding Summer Term 2015 Matúš Maciak (@ A 211) Office Hours: T 9:00 10:30 or by appointment
Design Experimentu a Statistika - AGA46E Czech University of Life Sciences in Prague Department of Genetics and Breeding Summer Term 2015 Matúš Maciak (@ A 211) Office Hours: T 9:00 10:30 or by appointment
Vymezení důležitých pojmů. nulová hypotéza, alternativní hypotéza testování hypotézy hladina významnosti (alfa) chyba I. druhu, chyba II.
 chyba I. druhu, chyba II.") Testování hypotéz 1. vymezení důležitých pojmů 2. testování hypotéz o rozdílu průměrů 3. jednovýběrový t-test 4. t-test pro nezávislé výběry 5. t-test pro závislé výběry Vymezení důležitých pojmů nulová
Testování hypotéz 1. vymezení důležitých pojmů 2. testování hypotéz o rozdílu průměrů 3. jednovýběrový t-test 4. t-test pro nezávislé výběry 5. t-test pro závislé výběry Vymezení důležitých pojmů nulová
Korelační a regresní analýza. 1. Pearsonův korelační koeficient 2. jednoduchá regresní analýza 3. vícenásobná regresní analýza
 Korelační a regresní analýza 1. Pearsonův korelační koeficient 2. jednoduchá regresní analýza 3. vícenásobná regresní analýza Pearsonův korelační koeficient u intervalových a poměrových dat můžeme jako
Korelační a regresní analýza 1. Pearsonův korelační koeficient 2. jednoduchá regresní analýza 3. vícenásobná regresní analýza Pearsonův korelační koeficient u intervalových a poměrových dat můžeme jako
Bakalářské studium na MFF UK v Praze Obecná matematika Zaměření: Stochastika. 1 Úvodní poznámky. Verze: 13. června 2013
 Bakalářské studium na MFF UK v Praze Obecná matematika Zaměření: Stochastika Podrobnější rozpis okruhů otázek pro třetí část SZZ Verze: 13. června 2013 1 Úvodní poznámky 6 Smyslem SZZ by nemělo být toliko
Bakalářské studium na MFF UK v Praze Obecná matematika Zaměření: Stochastika Podrobnější rozpis okruhů otázek pro třetí část SZZ Verze: 13. června 2013 1 Úvodní poznámky 6 Smyslem SZZ by nemělo být toliko
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc.
 Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika 2010 1.týden (20.09.-24.09. ) Data, typy dat, variabilita, frekvenční analýza
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika 2010 1.týden (20.09.-24.09. ) Data, typy dat, variabilita, frekvenční analýza
Určujeme neznámé hodnoty parametru základního souboru. Pomocí výběrové charakteristiky vypočtené z náhodného výběru.
 1 Statistické odhady Určujeme neznámé hodnoty parametru základního souboru. Pomocí výběrové charakteristiky vypočtené z náhodného výběru. Odhad lze provést jako: Bodový odhad o Jedna číselná hodnota Intervalový
1 Statistické odhady Určujeme neznámé hodnoty parametru základního souboru. Pomocí výběrové charakteristiky vypočtené z náhodného výběru. Odhad lze provést jako: Bodový odhad o Jedna číselná hodnota Intervalový
PSY117/454 Statistická analýza dat v psychologii přednáška 8. Statistické usuzování, odhady
 PSY117/454 Statistická analýza dat v psychologii přednáška 8 Statistické usuzování, odhady Výběr od deskripce k indukci Deskripce dat, odhad parametrů Usuzování = inference = indukce Počítá se s náhodným
PSY117/454 Statistická analýza dat v psychologii přednáška 8 Statistické usuzování, odhady Výběr od deskripce k indukci Deskripce dat, odhad parametrů Usuzování = inference = indukce Počítá se s náhodným
Úvod do analýzy rozptylu
 Úvod do analýzy rozptylu Párovým t-testem se podařilo prokázat, že úprava režimu stravování a fyzické aktivity ve vybrané škole měla vliv na zlepšené hodnoty HDLcholesterolu u školáků. Pro otestování jsme
Úvod do analýzy rozptylu Párovým t-testem se podařilo prokázat, že úprava režimu stravování a fyzické aktivity ve vybrané škole měla vliv na zlepšené hodnoty HDLcholesterolu u školáků. Pro otestování jsme
Obsah Úvod Kapitola 1 Než začneme Kapitola 2 Práce s hromadnými daty před analýzou
 Úvod.................................................................. 11 Kapitola 1 Než začneme.................................................................. 17 1.1 Logika kvantitativního výzkumu...........................................
Úvod.................................................................. 11 Kapitola 1 Než začneme.................................................................. 17 1.1 Logika kvantitativního výzkumu...........................................
Pokud data zadáme přes "Commands" okno: SDF1$X1<-c(1:15) //vytvoření řady čísel od 1 do 15 SDF1$Y1<-c(1.5,3,4.5,5,6,8,9,11,13,14,15,16,18.
 //vytvoření řady čísel od 1 do 15 SDF1$Y1<-c(1.5,3,4.5,5,6,8,9,11,13,14,15,16,18.") Regresní analýza; transformace dat Pro řešení vztahů mezi proměnnými kontinuálního typu používáme korelační a regresní analýzy. Korelace se používá pokud nelze určit "kauzalitu". Regresní analýza je určena
Regresní analýza; transformace dat Pro řešení vztahů mezi proměnnými kontinuálního typu používáme korelační a regresní analýzy. Korelace se používá pokud nelze určit "kauzalitu". Regresní analýza je určena
ANALÝZA DAT V R 7. KONTINGENČNÍ TABULKA. Mgr. Markéta Pavlíková Katedra pravděpodobnosti a matematické statistiky MFF UK.
 ANALÝZA DAT V R 7. KONTINGENČNÍ TABULKA Mgr. Markéta Pavlíková Katedra pravděpodobnosti a matematické statistiky MFF UK www.biostatisticka.cz PŘEHLED TESTŮ rozdělení normální spojité alternativní / diskrétní
ANALÝZA DAT V R 7. KONTINGENČNÍ TABULKA Mgr. Markéta Pavlíková Katedra pravděpodobnosti a matematické statistiky MFF UK www.biostatisticka.cz PŘEHLED TESTŮ rozdělení normální spojité alternativní / diskrétní
Průzkumová analýza dat
 Průzkumová analýza dat Proč zkoumat data? Základ průzkumové analýzy dat položil John Tukey ve svém díle Exploratory Data Analysis (odtud zkratka EDA). Často se stává, že data, se kterými pracujeme, se
Průzkumová analýza dat Proč zkoumat data? Základ průzkumové analýzy dat položil John Tukey ve svém díle Exploratory Data Analysis (odtud zkratka EDA). Často se stává, že data, se kterými pracujeme, se
Návrh a vyhodnocení experimentu
 Návrh a vyhodnocení experimentu Návrh a vyhodnocení experimentů v procesech vývoje a řízení kvality vozidel Ing. Bohumil Kovář, Ph.D. FD ČVUT Ústav aplikované matematiky kovar@utia.cas.cz Mladá Boleslav
Návrh a vyhodnocení experimentu Návrh a vyhodnocení experimentů v procesech vývoje a řízení kvality vozidel Ing. Bohumil Kovář, Ph.D. FD ČVUT Ústav aplikované matematiky kovar@utia.cas.cz Mladá Boleslav
II. Statistické metody vyhodnocení kvantitativních dat Gejza Dohnal
 Základy navrhování průmyslových experimentů DOE II. Statistické metody vyhodnocení kvantitativních dat Gejza Dohnal! Testování statistických hypotéz kvalitativní odezva kvantitativní chí-kvadrát test homogenity,
Základy navrhování průmyslových experimentů DOE II. Statistické metody vyhodnocení kvantitativních dat Gejza Dohnal! Testování statistických hypotéz kvalitativní odezva kvantitativní chí-kvadrát test homogenity,
Číselné charakteristiky
 . Číselné charakteristiky statistických dat Průměrný statistik se během svého života ožení s 1,75 ženami, které se ho snaží vytáhnout večer do společnosti,5 x týdně, ale pouze s 50% úspěchem. W. F. Miksch
. Číselné charakteristiky statistických dat Průměrný statistik se během svého života ožení s 1,75 ženami, které se ho snaží vytáhnout večer do společnosti,5 x týdně, ale pouze s 50% úspěchem. W. F. Miksch
KGG/STG Statistika pro geografy
 KGG/STG Statistika pro geografy 4. Teoretická rozdělení Mgr. David Fiedor 9. března 2015 Osnova Úvod 1 Úvod 2 3 4 5 Vybraná rozdělení náhodných proměnných normální rozdělení normované normální rozdělení
KGG/STG Statistika pro geografy 4. Teoretická rozdělení Mgr. David Fiedor 9. března 2015 Osnova Úvod 1 Úvod 2 3 4 5 Vybraná rozdělení náhodných proměnných normální rozdělení normované normální rozdělení
(motto: An unsophisticated forecaster uses statistics as a drunken man uses lamp-posts - for support rather than for illumination.
 Neparametricke testy (motto: An unsophisticated forecaster uses statistics as a drunken man uses lamp-posts - for support rather than for illumination. Andrew Lang) 1. Příklad V následující tabulce jsou
Neparametricke testy (motto: An unsophisticated forecaster uses statistics as a drunken man uses lamp-posts - for support rather than for illumination. Andrew Lang) 1. Příklad V následující tabulce jsou
Pravděpodobnost a statistika, Biostatistika pro kombinované studium. Jan Kracík
 Pravděpodobnost a statistika, Biostatistika pro kombinované studium Letní semestr 2017/2018 Tutoriál č. 2:, náhodný vektor Jan Kracík jan.kracik@vsb.cz náhodná veličina rozdělení pravděpodobnosti náhodné
Pravděpodobnost a statistika, Biostatistika pro kombinované studium Letní semestr 2017/2018 Tutoriál č. 2:, náhodný vektor Jan Kracík jan.kracik@vsb.cz náhodná veličina rozdělení pravděpodobnosti náhodné
Kategorická data METODOLOGICKÝ PROSEMINÁŘ II TÝDEN 7 4. DUBNA dubna 2018 Lukáš Hájek, Karel Höfer Metodologický proseminář II 1
 Kategorická data METODOLOGICKÝ PROSEMINÁŘ II TÝDEN 7 4. DUBNA 2018 4. dubna 2018 Lukáš Hájek, Karel Höfer Metodologický proseminář II 1 Typy proměnných nominální (nominal) o dvou hodnotách lze říci pouze
Kategorická data METODOLOGICKÝ PROSEMINÁŘ II TÝDEN 7 4. DUBNA 2018 4. dubna 2018 Lukáš Hájek, Karel Höfer Metodologický proseminář II 1 Typy proměnných nominální (nominal) o dvou hodnotách lze říci pouze
Analýza rozptylu. PSY117/454 Statistická analýza dat v psychologii Přednáška 12. Srovnávání více než dvou průměrů
 PSY117/454 Statistická analýza dat v psychologii Přednáška 12 Analýza rozptylu Srovnávání více než dvou průměrů If your experiment needs statistics, you ought to have done a better experiment. Ernest Rutherford
PSY117/454 Statistická analýza dat v psychologii Přednáška 12 Analýza rozptylu Srovnávání více než dvou průměrů If your experiment needs statistics, you ought to have done a better experiment. Ernest Rutherford
1. Číselné posloupnosti - Definice posloupnosti, základní vlastnosti, operace s posloupnostmi, limita posloupnosti, vlastnosti limit posloupností,
 KMA/SZZS1 Matematika 1. Číselné posloupnosti - Definice posloupnosti, základní vlastnosti, operace s posloupnostmi, limita posloupnosti, vlastnosti limit posloupností, operace s limitami. 2. Limita funkce
KMA/SZZS1 Matematika 1. Číselné posloupnosti - Definice posloupnosti, základní vlastnosti, operace s posloupnostmi, limita posloupnosti, vlastnosti limit posloupností, operace s limitami. 2. Limita funkce
Plánování experimentu
 Fakulta chemicko technologická Katedra analytické chemie licenční studium Management systému jakosti Autor: Ing. Radek Růčka Přednášející: Prof. Ing. Jiří Militký, CSc. 1. LEPTÁNÍ PLAZMOU 1.1 Zadání Proces
Fakulta chemicko technologická Katedra analytické chemie licenční studium Management systému jakosti Autor: Ing. Radek Růčka Přednášející: Prof. Ing. Jiří Militký, CSc. 1. LEPTÁNÍ PLAZMOU 1.1 Zadání Proces