INTERAKTIVNÍ POČÍTAČOVÁ ANALÝZA DAT prof. RNDr. Milan Meloun, DrSc.
|
|
|
- Helena Tomanová
- před 8 lety
- Počet zobrazení:
Transkript


1 INTERAKTIVNÍ POČÍTAČOVÁ ANALÝZA DAT prof. RNDr. Milan Meloun, DrSc. studijní materiál ke kurzu Mezioborové dimenze vědy Fakulta informatiky a managementu Univerzity Hradec Králové Projekt Informační, kognitivní a interdisciplinární podpora výzkumu je spolufinancován Evropským sociálním fondem a státním rozpočtem České republiky.

2 Univerzita Hradec Králové Fakulta informatiky a managementu Rokitanského Hradec Králové Interaktivní statistická analýza dat Brožurka k repetitoriu znalostí v kurzu v rámci projektu INKOV na FIM UHK dne Prof. RNDr. Milan Meloun, DrSc. Katedra analytické chemie, Chemickotechnologická fakulta, Univerzita Pardubice, s. Legií 565, Pardubice, http: //meloun.upce.cz, milan.meloun@upce.cz, telefon: , fax: , 1
3 1.Interaktivní analýza jednorozměrných dat 1 Úvod Otázka spolehlivosti a správného vyhodnocení experimentálních dat se v době osobních počítačů ocitá u každého měření dat na prvním místě. V kontrolní laboratoři, ať už vodohospodářské, chemické, biologické, fyzikální či jakékoliv jiné, tvoří základ experimentální práce měření na přístroji. V laboratořích dnes představují instrumentální metody spojovací článek mezi přírodovědnými a technickými obory, protože moderní počítačem řízené přístroje používá každá laboratoř. Navíc na každém psacím stole laboratoře nacházíme počítač, většinou nejvyšší kvality, kapacity a rychlosti, vybavený moderním software. Je proto neomluvitelné vyhodnocovat naměřená data zjednodušenými, aproximativními postupy pozůstalými z dob kalkulaček. Kontrolní orgány, komisaři akreditačních komisí ale především konkurenční pracoviště v zahraničí se předhánějí při vyhodnocování dat v užívání špičkového software s rigorózními matematickými postupy, ve kterých není žádného zjednodušení či zanedbání nějakých statistických předpokladů. Výsledky dosažené těmito náročnějšími postupy se pak berou za validní a jedině správné a přijatelné třeba v okružním testu. Ukažme si zde proto jeden z novějších postupů interaktivní statistické analýzy dat, který je založen na diagnostikování v dialogu s osobním počítačem čili na interaktivní analýze a který nabízí uživateli hlubší pohled do všech tajemství, ukrytých v experimentálních datech. S tímto problémem souvisí obvykle i vhodný software, který zajistí bezproblémové a přátelské prostředí a nechá data promluvit. Nezapomeňme přitom na důležité pravidlo, že úroveň užívaného software dnes prozrazuje úroveň celého pracoviště. Postup interaktivní analýzy dat Obecný postup náročnější statistické analýzy jednorozměrných dat lze vyjádřit následujícím schématem. Interaktivní přístup uvedený postup ulehčuje, protože většina statistického software obsahuje uvedené statistické diagnostiky a testy. 1. Průzkumová (exploratorní) analýza dat (EDA) vyšetřuje především stupeň symetrie a špičatosti rozdělení, lokální koncentraci dat a odhaluje také vybočující a podezřelá data.. Ověření základních předpokladů o výběru dat se týká ověření normality, ověření nezávislosti, ověření homogenity a konečně i určení minimální četnosti analyzovaných dat. 3. Transformace dat následuje v případě porušení některého z předpokladů o výběru. Patří sem mocninná, exponenciální transformace a Boxova-Coxova transformace. 4. Vyčíslení nejlepších odhadů parametrů polohy, rozptýlení a tvaru se týká vyčíslení jednak klasických odhadů (aritmetický průměr a rozptyl), jednak robustních odhadů (medián, uřezané průměry, winsorizovaný rozptyl) a konečně i adaptivních M-odhadů. Retransformovaný průměr po transformaci dat se přesto obvykle jeví jako nejlepší odhad střední hodnoty. 3 Exploratorní diagnostiky v analýze jednorozměrných dat Prvním krokem v analýze jednorozměrných dat je průzkumová, exploratorní analýza. Jejím cílem je odhalit statistické zvláštnosti v datech a ověřit předpoklady o výběru pro následné rigorózní statistické zpracování. Jedině tak lze zabránit provádění numerických výpočtů bez hlubších statistických souvislostí. Obr. 1 Konstrukce barierově-číslicového schématu indikujícího vybočující hodnoty: a) diagram rozptýlení s mediánem M, kvartily F D (dolní) a F H (horní), vnitřní hradby B D (dolní) a B H (horní), vnější hradby V D (dolní) a V H (horní); b) oblast vybočujících hodnot: A přilehlé (B PD je blízké B D a B PH je blízké B H ), B značí oblast vnějších a C vzdálených bodů.
4 Z různých typů výběru se v laboratoři nejvíce uplatňuje reprezentativní náhodný výběr, {x i }, i = 1,..., n, který má čtyři základní vlastnosti: (1) Jednotlivé prvky výběru x i jsou vzájemně nezávislé. () Výběr je homogenní, tj. všechna x i pocházejí ze stejného rozdělení pravděpodobnosti s konstantním rozptylem. (3) Předpokládá se také, že jde o normální rozdělení pravděpodobnosti. (4) Všechny prvky souboru mají stejnou pravděpodobnost, že budou zařazeny do výběru. Před vlastní analýzou je vždy nezbytné ověřit platnost základních předpokladů, tj. nezávislost, homogenitu a normalitu výběru. Využívá se k tomu robustních kvantilových charakteristik, které umožňují sledování lokálního chování dat a které jsou vhodné pro malé nebo středně velké výběry. Vychází se z pořádkových statistik výběru x (1) # x () #... # x (n). Platí, že střední hodnota i-té pořádkové statistiky je rovna 100P i procentnímu kvantilu výběrového rozdělení F -1 (P i ) = Q(P i ), kde F(x) označuje distribuční funkci a Q(P i ) kvantilovou funkci výběru. Symbol P i = i/(n + 1) označuje pořadovou pravděpodobnost. Připomeňme, že 100P i procentní výběrový kvantil je hodnota, pod kterou leží 100P i procent prvků výběru. Optimální hodnoty P i závisí na předpokládaném rozdělení výběru. Pro normální rozdělení se doporučuje volba P i = (i - 3/8)/(n + 1/4). Vynesením hodnot x (i) proti P i, i = 1,..., n, se získá hrubý odhad kvantilové funkce Q(P). Ta je inverzní k funkci distribuční a jednoznačně charakterizuje rozdělení výběru. V průzkumové analýze se často používá speciálních kvantilů L pro pořadové pravděpodobnosti P i = -i, i = 1,,..., které se také nazývají písmenové hodnoty. Tabulka 1. Označení písmenových hodnot Pořadová pravděpodobnost P i i i-tý kvantil Symbol písmenové hodnoty L Hodnota kvantilu u Pj 1 Medián -1 = 1 / M 0 Kvantity - = 1 / 4 F Oktily -3 = 1 / 8 E Sedecily -4 = 1 / 16 D Symbol u Pi označuje kvantil normovaného normálního rozdělení N(0, 1). Kromě mediánu (i = 1) existují pro každé i > 1 dvojice kvantilů, a to dolní a horní písmenová hodnota L D a L H. Dolní písmenová hodnota je pro pořadovou pravděpodobnost P i = -i, zatímco horní je pro P i = 1 - -i. Počet písmenových hodnot závisí na rozsahu výběru. Pro velikost výběru n lze určit n L písmenových hodnot včetně mediánu dle vztahu n L = 1.44 ln (n + 1). Obr. Kvantilové grafy (robustní --- a klasické...) pro výběry z rozdělení (a) normálního, symetrického rozdělení Úlohy E.10, (b) asymetrického rozdělení Úlohy E.07. Kvantilový graf (osa x: pořadová pravděpodobnost P i, osa y: pořádková statistika x (i) ) umožňuje přehledně znázornit data a snadněji rozlišit tvar rozdělení, který může být symetrický, sešikmený k vyšším nebo nižším hodnotám. Ke snadnějšímu porovnání s normálním rozdělením se do tohoto grafu zakreslují i kvantilové funkce normálního rozdělení N = ˆ μ + ˆ σu, pro 0 1, a to: (1) klasických odhadů parametrů polohy a rozptýlení Pi ˆ μ = x a ˆ σ = s, a () robustních odhadů ˆ μ = x% 0.5 a ˆ σ = R F / Pi P i 3
5 Obr. 3 Konstrukce (a) diagramu rozptýlení a (b) rozmítnutého diagramu rozptýlení pro výběry z rozdělení (a) normálního, symetrického rozdělení, (b) asymetrického rozdělení. Diagram rozptýlení (osa x: hodnoty x, osa y: libovolná úroveň, obyčejně y = 0) představuje jednorozměrnou projekci kvantilového grafu do osy x, zatímco rozmítnutý diagram rozptýlení představuje týž graf ale body jsou vhodně rozmítnuté ve směru y-nové osy. I při své jednoduchosti tento diagram názorně ukazuje na lokální koncentraci dat a indikuje i podezřelá a vybočující měření. Obr. 4 Konstrukce (a) krabicového grafu, a (b) vrubového krabicového grafu z dat diagramu rozptýlení pro výběry z rozdělení (a) normálního, symetrického rozdělení, (b) asymetrického rozdělení. Prázdná kolečka indikují vybočující hodnoty. Krabicový graf (osa x: úměrná hodnotám x, osa y: libovolný interval) umožňuje vedle znázornění robustního odhadu polohy, mediánu M také posouzení symetrie v okolí kvantilů a posouzení symetrie u konců rozdělení a často i identifikaci odlehlých dat. Jde o obdélník délky RF = FH FD = x% 0.75 x% 0.5 s vhodně zvolenou šířkou, která je úměrná hodnotě n. V místě mediánu je vertikální čára. Od obou protilehlých stran tohoto obdélníku pokračují úsečky. Ty jsou ukončeny přilehlými hodnotami B PH a B PD, ležícími uvnitř vnitřních hradeb nejblíže k jejich hranicím B H, B D, tj. BH = FH + 1.5RF a BD = FD 1.5RF. Pro data pocházející z normálního rozdělení platí B H - B D = 4.. Prvky výběru mimo vnitřní hradby jsou považovány za podezřelá měření (kroužky). Obdobou je vrubový krabicový graf, který umožňuje i posouzení variability mediánu, vyjádřenou robustním intervalem spolehlivosti I D M IH. Obr. 5 Grafy polosum pro výběry z rozdělení (a) normálního, symetrického rozdělení, (b) asymetrického rozdělení. Graf polosum (osa x: pořádkové statistiky x (i), osa y: Zi = 0.5( x( 1 ) + x( 1) ) diagnostikuje tak, že pro symetrické n+ i rozdělení je grafem horizontální přímka, určená rovnicí x% 0.5 = M. 4
6 Obr. 6 Grafy symetrie pro výběry z rozdělení (a) normálního, symetrického rozdělení, (b) asymetrického rozdělení. Graf symetrie (osa x: u P i / pro Pi = i/( n+ 1), osa y: Zi = 0.5( x( 1 ) + x( )) je obdobou předešlého grafu, u n+ i i kterého symetrická rozdělení vykazují horizontální přímku y = x% 0.5 = M. Pokud tato přímka nemá nulovou směrnici, je směrnice odhadem parametru šikmosti, asymetrie. Obr. 7 Konstrukce grafu rozptýlení s kvantily pro výběry z rozdělení (a) normálního, symetrického rozdělení, (b) asymetrického rozdělení. Graf rozptýlení s kvantily (osa x: P i, osa y: x ()) představuje vlastně kvantilový graf, který se získá spojením i bodů {x (i), P i } lineárními úseky a pro symetrická rozdělení nabývá tato kvantilová funkce sigmoidálního tvaru. Pro rozdělení sešikmená k vyšším hodnotám je konvexně rostoucí a pro rozdělení sešikmená k nižším hodnotám konkávně rostoucí. Do kvantilového grafu se zakreslují tři obdélníky F, E a D: (1) Kvartilový obdélník F: na ose x pravděpodobnosti P = - = 0.5 a = () Oktilový obdélník E: na y oktily E D a E H a na ose x P 3 = -3 = 0.15 a = (3) Sedecilový obdélník D: na y sedecily D D, D H a na x P 4 = -4 = a = Tato pomůcka může diagnostikovat i určité anomálie: (a) Symetrické unimodální rozdělení výběru obsahuje obdélníky symetricky uvnitř sebe. (b) Nesymetrická rozdělení mají pro rozdělení sešikmené k vyšším hodnotám vzdálenosti mezi dolními hranami obdélníků F, E a D výrazně kratší než mezi jejich horními hranami. (c) Odlehlá pozorování jsou indikována tím, že na kvantilové funkci mimo obdélník F se objeví náhlý vzrůst. Obr. 8 Jádrové odhady hustoty pravděpodobnosti pro výběry z rozdělení (a) normálního, symetrického rozdělení, (b) asymetrického rozdělení. Čárkovaně je znázorněna hustota Gaussova rozdělení s parametry x a s a plnou čarou jádrový odhad hustoty pravděpodobnosti empirického rozdělení výběru. Jádrový odhad hustoty pravděpodobnosti (osa x: x, osa y: hustota pravděpodobnosti) a histogram patří k nejužívanějším pomůckám a histogram pak k nejstarším diagramům hustoty pravděpodobnosti. U histogramu jde o obrys sloupcového grafu, kde jsou na ose x jednotlivé třídy, definující šířky sloupců, a výšky sloupců odpovídají empirickým hustotám pravděpodobnosti. Kvalitu histogramu ovlivňuje ve značné míře volba počtu tříd L a všech délek intervalů Δ x j. Pro přibližně symetrická rozdělení výběru lze vyčíslit L podle vztahu 5
7 L = int( n), kde funkce int(x) označuje celočíselnou část čísla x nebo je možné užít výraz L 0.4 = int(.46( n 1) ). Obr. 9 Grafy Q-Q pro porovnání rozdělení výběru normálního rozdělení s teoretickým rozdělením. Kvantil-kvantilový graf (graf Q-Q) (osa x: Q T (P i ), osa y: x (i) ) umožňuje posoudit shodu výběrového rozdělení, charakterizovaného kvantilovou funkcí Q E (P) s kvantilovou funkcí zvoleného teoretického rozdělení Q T (P). Za odhad kvantilové funkce výběru se užívají pořádkové statistiky x (i). Při shodě výběrového rozdělení se zvoleným teoretickým rozdělením musí platit přibližná rovnost kvantilů x (i) = Q T (P i ), kde P i je pořadová pravděpodobnost. Pokud je rozdělení výběru shodné se zvoleným teoretickým rozdělením, je závislost x (i) na Q T (P i ) lineární a výsledná závislost se nazývá graf Q-Q. Těsnost lineární závislosti experimentálními body lze posoudit korelačním koeficientem a využít ho jako rozhodčí kritérium při hledání typu rozdělení. 4 Mocninná a Boxova-Coxova transformace dat Pokud se na základě analýzy dat zjistí, že rozdělení výběru dat se systematicky odlišuje od rozdělení normálního, vzniká problém, jak data vůbec vyhodnotit. Často je pak nejlepším řešením vhodná transformace dat, která vede ke stabilizaci rozptylu, zesymetričtění rozdělení a někdy i k normalitě rozdělení. Zesymetričtění rozdělení výběru je možné provést užitím prosté mocninné transformace λ x ( λ > 0) ln x pro ( λ = 0) y = g( x) = λ x ( λ < 0) která však nezachovává měřítko a není vzhledem k exponentu λ všude spojitá a proto se hodí pouze pro kladná data. Optimální odhad exponentu λ se hledá s ohledem na optimalizaci charakteristik asymetrie (šikmosti) a špičatosti. Pro přiblížení rozdělení výběru k rozdělení normálnímu vzhledem k šikmosti a špičatosti je vhodná Boxova-Coxova transformace λ x 1 ( λ 0) y = g( x) = λ, pro ln x ( λ = 0) která je použitelná rovněž pouze pro kladná data. Rozšíření této transformace na oblast, kdy rozdělení dat začíná od prahové hodnoty x 0, spočívá v náhradě x rozdílem (x - x 0 ), který je vždy kladný. Graf logaritmu věrohodnostní funkce (osa x: λ, osa y: ln L). Pro odhad parametru λ v Boxově-Coxově transformaci lze užít metodu maximální věrohodnosti s tím, že pro λ = ˆ λ je rozdělení transformované veličiny y normální, N( μy, σ ( y)). Po úpravách bude logaritmus věrohodnostní funkce ve tvaru n ln ( ) ln n L λ = s ( y) + ( λ 1) ln x, i i = 1, 6
8 kde s ( y ) je výběrový rozptyl transformovaných dat y. Průběh věrohodnostní funkce ln L(λ) lze znázornit ve zvoleném intervalu, např. 3 λ 3, a identifikovat maximum křivky, jejíž souřadnice x indikuje odhad ˆλ. Dva průsečíky křivky ln L(λ) s rovnoběžkou s osou x indikují 100(1-α)% interval spolehlivosti parametru λ. Čím bude interval spolehlivosti +λ D, λ H, širší, tím je mocninná nebo Boxova-Coxova transformace méně výhodná. Pokud obsahuje interval +λ D, λ H, i hodnotu λ = 1, není transformace ze statistického hlediska přínosem. Zpětná transformace: Po vhodné transformaci se vyčíslí y, s ( y ) a potom pomocí zpětné transformace využitím Taylorova rozvoje v okolí y se odhadnou retransformované parametry polohy a rozptýlení x R a s ( x R ) původních dat. Uvedený postup vede vesměs k nejlepším odhadům polohy x R a rozptýlení s ( x R ) a je zvláště vhodný v případech asymetrického rozdělení výběru. 5 Intervalový odhad parametrů Představuje interval, ve kterém se bude se zadanou pravděpodobností či statistickou jistotou (1 - α) nacházet skutečná hodnota čili "pravda" daného parametru μ. Neznámý parametr μ odhadujeme dvěma číselnými hodnotami L D a L H, které tvoří meze tzv. intervalu spolehlivosti čili konfidenčního intervalu. Interval spolehlivosti pokryje parametr μ s předem zvolenou, statistickou jistotou čili dostatečně velikou pravděpodobností P = (1 - α), což lze vyjádřit vztahem P(L D < μ < L H ) = 1 - α, nazvanou koeficient spolehlivosti (čili konfidenční koeficient, statistická jistota). Je obyčejně roven 0.95 nebo Parametr α se nazývá hladina významnosti. Interval spolehlivosti vyjadřuje tvrzení: Statistická jistota, s jakou bude "pravda" μ ležet v náhodných mezích L D, L H je rovna právě 1 - α. Vlastnosti intervalu spolehlivosti: (1) Čím je rozsah výběru n větší, tím je interval spolehlivosti užší. () Čím je odhad přesnější a má menší rozptyl, tím je interval spolehlivosti užší. (3) Čím je vyšší statistická jistota (1 - α), tím je interval spolehlivosti širší. Konstrukce intervalových odhadů: Postup konstrukce intervalu spolehlivosti střední hodnoty μ normálního rozdělení N(μ, σ ): 1. Velký výběr n $ 30: Když nejlepším bodovým odhadem střední hodnoty μ je výběrový průměr x s rozdělením N( μσ, / n), pak v intervalu x ± 1.96 σ / n leží přibližně 95% hodnot náhodných veličin výběru o rozsahu n a 100(1-α)%ní interval spolehlivosti střední hodnoty μ bude vyčíslen vztahem σ σ x 1.96 μ x+ 1.96, n n kde hodnota 1.96 je 100(1-0.05/) = 97.5%ní kvantil normovaného normálního rozdělení u Malý výběr n # 30: v praxi obvykle neznáme směrodatnou odchylku σ ale pouze její odhad s a je-li t 1-α/ (n - 1) je 100(1 - α/)%ní kvantil Studentova rozdělení bude 100(1 - α)%ní interval spolehlivosti střední hodnoty μ roven s s x t ( n 1) μ x + t ( n 1) 1 α/ 1 α/ n n Meze intervalu spolehlivosti závisí vedle chyby s i na rozsahu výběru n. Pro větší rozsahy výběru (n > 30) lze použít místo kvantilu t 1-α/ kvantilu normovaného normálního rozdělení u 1-α/ a 100(1 - α)%ní oboustranný interval spolehlivosti rozptylu σ se vypočte dle ( n 1) s ( n 1) s σ, χ1 α/ ( n 1) χα/( n 1) kde ( n 1) χ1 α / je horní a χ ( n 1) α / dolní kvantil rozdělení přibližně vyčíslí 0.707s 0.707s x% 0.5 u1 α/ med x% u1 α/ n n χ. Robustní interval spolehlivosti mediánu se 7
9 6 Analýza malých výběrů Předem je třeba si uvědomit, že závěry z malých výběrů jsou vždy zatíženy značnou mírou nejistoty. Malých rozsahů proto užijeme jen tam, kde skutečně není možné zvýšit počet měření. Hornův postup pro malé výběry, 4 # n # 0 je založený na pořádkových statistikách. Nejprve se určí hloubka pivotu je H = (int((n + 1)/))/ nebo H = (int((n + 1)/ + 1)/, pak dolní pivot jako x D = x (H) a horní pivot dle x H = x (n+1-h). Odhadem parametru polohy je potom pivotová polosuma P L = (x D + x H )/ a a odhadem parametru rozptýlení je pivotové rozpětí R L = x H - x D. Lze definovat i náhodnou veličinu k testování T L = P L /R L, která má přibližně symetrické rozdělení, jehož vybrané kvantily jsou dostupné v tabulce [1]. Potom se 95%ní interval spolehlivosti střední hodnoty vypočte vztahem P R t ( n) μ P + R t ( n). L L L,0.975 L L L, Test správnosti výsledku Testy hypotéz o parametrech μ a σ normálního rozdělení: soubor s N(μ, σ ), výběr rozsahu n a vypočteme průměr x a směrodatnou odchylku s. Testy správnosti výsledku měření lze provést pomocí intervalu spolehlivosti dle pravidla: pokud 100(1 - α) %ní interval spolehlivosti parametru μ obsahuje zadanou hodnotu μ 0, nelze na hladině významnosti α zamítnout hypotézu H 0 : μ = μ 0. 8 Závěr analýzy jednorozměrných dat V postupu statistického vyhodnocení výsledků měření slouží průzkumová analýza dat EDA jako výhodná pomůcka k vyšetření zvláštností statistického chování dat. Z nejdůležitějších pomůcek jsou to vedle kvantilového grafu a grafu rozptýlení s kvantily i diagram rozptýlení a rozmítnutý diagram rozptýlení, krabicový graf, vrubový krabicový graf, graf polosum a symetrie, kvantil-kvantilový graf, jádrový odhad hustoty pravděpodobnosti a histogram k určení tvaru rozdělení. U malých výběrů 4 # n # 0 poskytuje správné odhady střední hodnoty Hornův postup pivotů. Pivotová polosuma a pivotové rozpětí umožňují vyčíslit i intervalový odhad střední hodnoty a navíc jsou oba odhady dostatečně robustní vůči asymetrii rozdělení malého výběru a i vůči odlehlým hodnotám. Studentův t-test správnosti analytického výsledku je ekvivalentní vůči intervalu spolehlivosti. Nachází-li se totiž hodnota μ 0 (tj. pravda, správná hodnota, norma, standard) v intervalu spolehlivosti [L D ; L H ], je stanovení správné. Exploratorní analýza předurčí volbu, zda k testu správnosti využijeme intervalový odhad aritmetického průměru v případě symetrického rozdělení nebo retransformovaného průměru v případě asymetrického rozdělení. Interaktivní statistická analýza při užití vhodného software umožňuje jednoznačně vyšetřit správnost analytického výsledku. 9 LITERATURA 1. M. Meloun, J. Militký: Statistické zpracování experimentálních dat, Plus Praha 1994 (1. vydání), East Publishing 1996 (. vydání), Academia Praha 004 (3. vydání).. M. Meloun, J. Militký: Kompendium statistického zpracování dat, Academia Praha ADSTAT, TriloByte Statistical Software s. r. o., Pardubice

10 . EDA 9

11 10
12 11
13 1
14 13
15 14
16 15
17 16
18 17
19 18
20 19
21 0
22 1
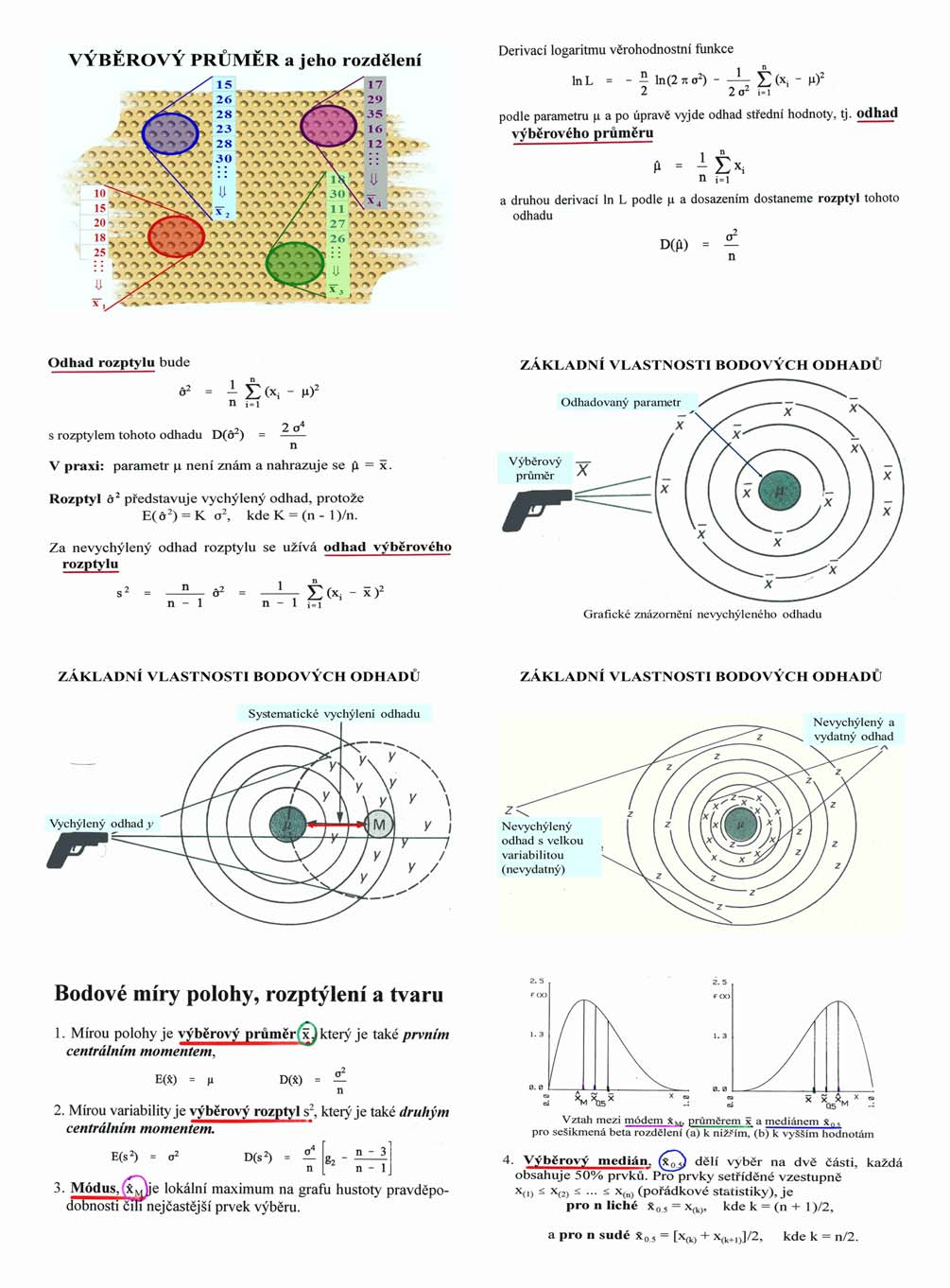
23 3. Odhady
24 3

25 4
26 5
27 6
28 . Metodologie počítačové analýzy rozptylu, ANOVA 1 Úvod Analýza rozptylu, označovaná ANOVA (z anglického Analysis of Variance), se v technické praxi používá buď jako samostatná technika nebo jako postup umožňující analýzu zdrojç variability u statistických modelç. ANOVA jako samostatná technika umožňuje posouzení významnosti zdrojç variability v datech, vlivu přípravy vzorků na výsledek analýzy, vlivu typu přístroje, lidského faktoru a obsluhy na výsledek měření. Podstatou analýzy rozptylu je rozklad celkového rozptylu dat na složky objasněné, jeñ představují známé zdroje variability a složku neobjasněnou, náhodnou čili šum. Následně se testují hypotézy o významnosti jednotlivých zdrojç variability. Podle konkrétního uspořádání experimentu existuje řada variant analýzy rozptylu. Přehled základních technik lze nalézt v Íad článků 1, a monografií 3-6. Často se ANOVA vyskytuje v technické praxi v souvislosti s technikami plánovaných experimentç. Omezíme se zde na jednodušší techniky, vhodné k řešení běžných vodohospodářských úloh. Základní pojmy Historicky se analýza rozptylu za ala rozvíjet zejména píi vyhodnocování dat v zem d lství. Její terminologie je proto poněkud speciální. Vedle kvalitativních faktorç se vyskytují také faktory kvantitativní, jako jsou fyzikální a chemické veličiny. Jednotlivé faktory se vyskytují na jistých úrovních Z 1, Z, Z 3, jeñ se označují jako zpracování. Tyto úrovně mohou být op t kvalitativní nebo kvantitativní. Zdrojem variability výsledků měření y ij jsou jednotlivé úrovně faktoru. Tomu odpovídá jednoduchý model y = μ + ε, kde μ ij i ij i je skutečná hodnota výsledků analýz a ε ij pak označuje náhodnou chybu. Veličina μ i se skládá ze složky odpovídající celkovému průměru μ ze všech úrovní faktoru a efektu i-té úrovně daného faktoru α i, tj. μ = μ + α, kde μ i i i je střední hodnota pro i-tou úroveň. Účelem analýzy rozptylu je testování shody jednotlivých úrovní, čili nulové hypotézy H 0 : μ 1 = μ = μ 3, nebo jinak vyjádřeno významnosti efektç α i čili nulové hypotézy H 0 : α 1 = α = α 3 = 0. Pokud jsou předmětem zájmu pouze rozdíly mezi danými úrovněmi, jde o modely s pevnými efekty. Pokud jsou jednotlivé úrovně pouze výběrem z konečného i nekonečného souboru, jde o modely s náhodnými efekty. Výběr mezi pevnými a náhodnými efekty závisí na vlastním záměru analýzy rozptylu a mçñe se podle n ho m nit. Je-li sledován pouze jeden faktor, jde o jednofaktorovou analýzu rozptylu, čili tříd ní dle jednoho faktoru. Často se však sleduje i vliv n kolika faktorç, kdy jde o vícefaktorovou analýzu rozptylu. Jako u jednofaktorové analýzy rozptylu, můžeme provést rozklad μ ij na celkovou střední hodnotu, složky α i odpovídající efektçm faktoru Z, složky β j odpovídající efektçm faktoru L a interakce τ ij, μ ij = μ + α i+ β j + τ ij. len τ ij označuje efekt interakce úrovní Z i a L j. Používá se v případech, kdy nelze objasnit variabilitu y ijk pouze aditivním působením jednotlivých faktorç. Pro vlastní zpracování modelů analýzy rozptylu je důležité, zda je píi všech kombinacích faktorç proveden stejný počet měření čili opakování. Kombinace úrovní jednotlivých faktorç, napí. Z i L j se pak označuje jako cela. Pro stejný počet opakování ve všech celách se experimenty označují jako vyvážené, zatímco pro nestejný počet opakování jako nevyvážené. Postupy analýzy nevyvážených experimentç jsou komplikovanější a navíc mçñe píi extrémních rozdílech mezi po ty opakování dojít píi malých odchylkách od základních předpokladç, napí. normality, ke značnému zkreslení výsledků testç 5. 3 Jednofaktorová analýza rozptylu PÍi třídění podle jednoho faktoru se zkoumá jeho vliv na výsledek experimentu. Pro případ dvou úrovní jde o porovnání dvou výběrç. Zajímavý bude obecnější případ, kdy daný faktor A má celkem K různých úrovní A 1,..., A K. Na každé úrovni A i je provedeno n i m Íení {y ij }, j = 1,..., n i. Celkový počet měření je Přehlednější je uspořádání dat v Tabulce 1. Tabulka 1. Uspořádání dat pro jednofaktorovou analýzu rozptylu Úroveň faktoru N = K i = 1 n i A 1 A... A i... A K Celek 7
29 y 11 y 1... y i1... y K1 y 1 y... y i... y K Opakování m Íení y 1n1 y n... y ini... y KnK Průměry ˆ μ 1 ˆ μ... ˆ μ... i ˆ μ K ˆμ Počet n 1 n... n i... n K N n 1 i Sloupcový průměr ˆi μ představuje součet prvků sloupce pro A i dělený po tem opakování n i, ˆ μ i = yij n. i j = 1 K 1 Celkový průměr ˆμ je součet všech hodnot dělený celkovým po tem dat ˆ μ = ˆ μ i. Pro výpočet odhadç K i = 1 efektç α i lze pak použít vztah ˆ α i = ˆ μ - ˆ μ. PÍi zavedení μ i vznikne přeurčený model, obsahující o jeden i parametr více. Proto se píi odhadu efektç α i používá ještě jedna omezující podmínka vyvážených experimentç lze použít zjednodušenou podmínku K i = 1 α i = K niα i i = 1 = 0. Pro případ 0. Vlastní analýza rozptylu, tj. rozklad celkového rozptylu, závisí také na tom, zda jde o modely s pevnými nebo náhodnými efekty. Základním předpokladem statistické analýzy je fakt, ñe náhodné chyby ε ij jsou nezávislé a náhodné veličiny s normálním rozdělením N(0, σ ). Střední hodnota chyb je rovna nule a rozptyl σ je konstantní. Součet čtverců K n i odchylek od celkového průměru ˆμ, definovaný vztahem S c = ( y - ˆ μ ij ) se rozloží s využitím μ i na dvě složky K n i c ij i i A R i = 1 j = 1 K S A i ˆ μ i i = 1 K n i S R = ( y ˆ ij - μ i ) i = 1 j = 1 S = [( y - ˆ μ ) + ( ˆ μ - ˆ μ )] = S + S jednotlivými úrovněmi daného faktoru jednotlivých úrovní, i = 1 j = 1, kde S A představuje součet čtverců odchylek mezi = n ( - ˆ μ ) a S R je reziduální součet čtverců odchylek uvnitř. Jednotlivé sou ty čtverců resp. složky rozptylu se zapisují do tabulky, která má pro jednofaktorovou analýzu rozptylu s pevnými efekty tvar Tabulky. Tabulka. Tabulka analýzy rozptylu pro jednoduché tříd ní u modelu s pevnými efekty Součet čtverců Počet stupňů volnosti Průměrný čtverec Očekávaná hodnota Mezi úrovněmi S A K - 1 S A K - 1 σ + K i = 1 e n i α K - 1 i Reziduální S R N - K σ e 8
30 S R N - K Celkový S c N Poslední sloupec tabulky obsahuje očekávanou hodnotu průměrného čtverce. Nevychýleným odhadem rozptylu S R chyb σ e je průměrný reziduální čtverec σ e =. Cílem je především testování, zda jsou efekty α i nulové, N - K tedy zda jednotlivé úrovně daného faktoru vedou ke statisticky nevýznamným rozdílçm ve výsledcích. Nulová hypotéza H 0 : α i = 0, i = 1,..., K, se ověřuje proti alternativní hypotéze H A : α i 0, i = 1,..., K. PÍi testování se využívá faktu, ñe veličina S A / σ e má χ -rozdělení s (K - 1) stupni volnosti a veličina S R / σ e má nezávislé χ - rozdělení s (N - K) stupni volnosti. Jejich podíl má pak F-rozdělení s (K - 1) a (N - K) stupni volnosti. Testovací S A (N - K) Fisherova statistika F e má tvar F e =. PÍi platnosti nulové hypotézy H 0 má F e statistika Fisherovo S R (K - 1) F-rozdělení s (K - 1) a (N - K) stupni volnosti. Vyjde-li F e větší neñ kvantil Fisherova rozd lení F 1-α (K - 1, N - K), je nutné nulovou hypotézu H 0 na hladin významnosti α zamítnout a efekty považovat za nenulové a statisticky významné. 3.1 Technika vícenásobného porovnání Pokud vyjde vliv jednotlivých efektç jako statisticky významný, jsou rozdíly mezi průměry μ i, μ j, i j rovněž významné. Pro hlubší analýzu se používá řady metod, například Scheffého metoda vícenásobného porovnání 5, pro kterou se zamítá hypotéza H 0 : μ i = μ j pro všechny dvojice (i, j), pro které platí 1 1 ˆ μ ˆ ˆ i- μ j (K - 1) σ F 1-α(K - 1, N - K) +, ni n j kde ˆ σ je reziduální rozptyl ˆ σ e. Tento vztah se používá pro všechny možné dvojice indexç (i, j). V n kterých případech je třeba testovat pouze zvolený lineární kontrast q definovaný vztahem konstantami C i, pro které platí q ˆ = K K K Ci 0 C i > 0 i = 1 i = 1 q = K C i μ i se známými i = 1 =,. Odhadem lineárního kontrastu q je veličina C i ˆ μ i. Mají-li výsledky měření y ij normální rozdělení N(μ i, σ ), lze testovat nulovovu hypotézu H 0 : q = 0 i = 1 pomocí statistiky F = qˆ q K i. PÍi platnosti nulové hypotézy H 0 má tato testovací statistika F-rozdělení s 1 C ˆ σ i= 1 ni a (N - K) stupni volnosti. Hypotéza H 0 se zamítá, pokud F q je větší neñ kvantil F 1 - α (1, N - K). Dosavadní postupy analýzy rozptylu jsou správné jen za předpokladu, kdyñ jednotlivé hodnoty y ij jsou vzájemně nezávislé, a kdyñ chyby ε ij mají normální rozdělení s konstantním rozptylem. V praxi však bývá důležité tyto předpoklady rovněž ověřit. 3. Ověření normality chyb Pro posouzení normality chyb lze použít především rankitové grafy. Výhodné je v těchto grafech užití eˆ ij standardizovaných reziduí eˆ Si =. V případ platnosti předpokladç klasické analýzy rozptylu mají 1 ˆ σ 1 - n i standardizovaná rezidua přibližně normální rozdělení N(0, 1). Pokud platí podmínka, ñe ε ij. N(0, σ ), vznikne v rankitovém grafu lineární závislost s nulovým úsekem a jednotkovou směrnicí. 9
31 Obr. 1. Rankitový graf pro Jacknife rezidua V Íad případç je možné zlepšit rozdělení dat ve smyslu přiblížení k normalit s využitím vhodné transformace. Častým případem je, ñe data jsou zešikmená směrem k vyšším hodnotám. Pak je vhodné použít napí. posunutou logaritmickou transformaci y * = ln (y + C). Optimální hodnota C se volí tak, aby rezidua byla přibližně symetrická se špičatostí blízkou hodnot Gaussova rozdělení tj. třem. Pro účely identifikace vybočujících hodnot je však výhodné použít Jackknife reziduí e Jij, která jsou definována vztahem eˆ = eˆ N - K - 1 N - K - eˆ Jij Sij Sij předpokladu normality vykazují tato rezidua Studentovo rozdělení s (N - K - 1) stupni volnosti. Orientačně platí, ñe pokud ê Jij > 10, lze danou hodnotu y ij považovat za velmi silně vybočující.. Za 3.3 Ověření konstantnosti rozptylu (homoskedasticity) Předpoklad konstantnosti rozptylu (homoskedasticity) lze ověřit stejnými metodami jako u lineárních regresních modelç. U nevyvážených plánç je třeba uvažovat s nekonstantností rozptylu klasických reziduí způsobem nestejného po tu měření na jednotlivých úrovních. Pokud je k dispozici dostatečný počet opakování píi jednotlivých úrovních daného faktoru, lze krom průměru ˆμ i počítat také výběrové rozptyly s i. Předpoklad konstantnosti rozptylu lze pak ověřit na základ grafu s i vs. ˆμ i. Pokud vznikne náhodný shluk bodç, lze považovat předpoklad shody rozptylç u všech úrovní za přijatelný. Jinak je možné použít vhodnou transformaci stabilizující rozptyl. 4 Dvoufaktorová analýza rozptylu PÍi dvoufaktorové analýze rozptylu se provádí experimenty na různých úrovních dvou faktorç A a B. Kombinace úrovní faktorç tvoří typickou mřížkovou strukturu, jejímñ elementem je tzv. cela. Platí, ñe (i, j)-tá cela odpovídá kombinaci úrovně A i faktoru A a B j faktoru B. Schematicky je mííñková struktura znázorněna v Tabulce 3: V každé cele je obecně n ij pozorování. Často se však setkáváme s případem bez opakování, kdy v každé cele je pouze jediné pozorování, n ij = 1. Pro případ analýzy rozptylu bez opakování dojde ke zjednodušení zápisu y = μ + ε, kde μ ij ij ij ij lze rozložit tak, ñe krom řádkových α i a sloupcových ß j efektç se zde vyskytuje také interakční len τ ij. Tento len je pak důsledkem různých kombinací sloupcových a řádkových efektç. Tabulka 3. Uspořádání dat pro dvoufaktorovou analýzu rozptylu B 1 B... B M A A cela A B A N
32 Nejjednodušším je Tukeyův model interakce, vyjádřený tvarem τ ij = C α i β j, kde C je konstanta. Složitější jsou řádkov lineární modely interakcí, vyjádřené tvarem τ ij = γ iβ jc R nebo sloupcově lineární modely interakcí ve tvaru τ ij = α i C K δ j. Kompletnější je aditivně-multiplikativní model interakcí τ ij = γ i δ j C W. Uvedené vztahy obsahují krom sloupcových a řádkových konstant δ j a γ i i obecné konstanty C R, C K, C W. Omezme se zde pouze na nejjednodušší Tukeyçv model interakce. Vzhledem ke své speciální definici obsahuje tento model pouze jeden parametr C, a proto se označuje jako model neaditivity s jedním stupněm volnosti. Pouñití Tukeyova modelu interakce je výhodné zejména v případech, kdy je v každé cele pouze jedno pozorování, obr.. Obr.. Model dvojného třídění μij = μ+ αi + β j + εij, kde α i je řádkový efekt a odpovídá poloměru kolečka. β j sloupcový efekt a náhodná chyba U modelç bez opakování měření obsahuje každá cela práv jednu hodnotu y ij. O chybách ε ij se předpokládá, ñe jsou to nezávislé a shodně rozdělené náhodné veličiny s nulovou střední hodnotou a konstantním rozptylem. PÍi testování se navíc předpokládá, ñe rozdělení chyb je normální. Pokud v ANOVA modelu provedeme rozklad, je model analýzy rozptylu přeurčený. Proto se definují omezující podmínky N M N M α = 0; β = 0; τ = 0; τ = 0. V případ pouze aditivního působení jednotlivých faktorç je i j ij ij i= 1 j= 1 i= 1 j= 1 τ ij = 0 pro všechna i = 1,..., N a j = 1,..., M. Odhady parametrç μ, α i, β j lze pak určit ze vztahç N M M N 1 ˆ μ = yij N M, α 1 i = y ˆ ij μ, ˆ 1 β = ˆ j yij - μ. Pro rezidua e ˆij platí e ˆ ˆij = y ˆ ij - μ - ˆ α i - β. K j i = 1 j = 1 M j= 1 N i = 1 určení interakcí můžeme využít skutečnosti, ñe τ ij = E( yij ) - μ - αi - β j a pro odhad interakcí platí přibližně ˆ τ ij eˆij. Lze snadno identifikovat Tukeyův model interakce. Platí-li tento model, vyjde na grafu ê ij vs. ˆ α i ˆ β j lineární trend. Ze směrnice odpovídající regresní přímky se odhadne parametr C. Platí pro n j výraz C ˆ = N M e ˆ i = 1 j = 1 N M i = 1 j = 1 ij ˆ α i ˆ α i ˆ β ˆ β j j. Graf ê ij vs. ˆ α ˆ i β / ˆ μ se označuje jako graf neaditivity. Pokud vyjde v tomto grafu j nenáhodný trend, znamená to, ñe je třeba uvažovat interakce. Tabulka 4. Tabulka analýzy rozptylu pro dvojné tříd ní s interakcí Tukeyova typu Součet čtverců pro Stupně volnosti Průměrný čtverec Kritérium F ε ij N - 1 M A =S A /(N-1) F A = M A /M AB 31
33 Faktor A, S A = M N i = 1 α i Faktor B, M M - 1 M B =S B /(M-1) F B = M B /M AB S B = N ß j j = 1 Interakce (Tukey) S T 1 M T = S T F T = M T /M E Reziduální S R = S AB -S T N M - N - M M E = S R /(NM-N-M) - Celkový S C = ( ˆ μ - y ) (i) (j) ij N M V tabulce 4 představuje S T součet čtverců odchylek odpovídající Tukeyově interakci 3 S N M y ij i = 1 j = 1 T = N M i = 1 j = 1 ˆ α i ˆ α i ˆ β j Symbol S AB označuje reziduální součet čtverců pro případ bez interakcí β j. N M a ij j i = 1 j = 1 S ˆ ˆ ˆ AB = ( y - μ - α i - β ) S AB průměrný čtverec je M AB = (N - 1) (M - 1). Hodnota M AB je nevychýleným odhadem rozptylu σ. Pomocí F- kritéria lze op t provádět statistické testy. Začíná se testováním nulové hypotézy H 0 : "Tukeyova interakce je nevýznamná", pro kterou lze použít testovací statistiku F T z tabulky 4. Za předpokladu platnosti nulové hypotézy H 0 má tato testovací statistika F-rozdělení s 1 a (N M - N - M) stupni volnosti. Pokud nelze tuto hypotézu zamítnout, testuje se nulová hypotéza H 0 : α i = 0, i = 1,..., N (efekty řádků, čili faktoru A, jsou nevýznamné) pomocí statistiky F A nebo nulová hypotéza H 0 : β j = 0, j = 1,..., M (efekty sloupců, čili faktoru B, jsou nevýznamné) pomocí statistiky F B. Ob tyto testovací statistiky jsou uvedeny v Tabulce 4. Za předpokladu platnosti hypotézy H 0 má statistika F A F-rozdělení s (N - 1) a (N - 1)(M - 1) stupni volnosti a statistika F B také F- rozdělení s (M - 1) a (N - 1)(M - 1) stupni volnosti. Pokud však vyjde F T vyšší neñ odpovídající kvantil F- rozdělení, je efekt Tukeyovy interakce významný. V n kterých případech je výhodné provést eliminaci neaditivity s využitím mocninné transformace λ ( y ij + K ) - 1 * pro λ 0 yij = λ, ln ( yij + K) pro λ = 0 kde K je vhodně volená konstanta zajišťující, aby platilo (y ij + K) > 0, a kde λ je parametr transformace. 4.1 Vyvážené modely Pro vyvážené modely platí, ñe v každé cele je n ij = n pozorování. Odhadem μ ij jsou aritmetické průměry n 1 ˆ μ ij = yijk. Pro odhady ostatních parametrç se použijí vztahy n k = 1 N M M N 1 ˆ μ = ˆ μ ij N M, ˆ 1 α ˆ ˆ i = μ ij - μ M, ˆ 1 β = ˆ μ ij - ˆ μ j N. i = 1 j = 1 j = 1 i = 1 3
34 Rezidua vyjádříme vztahem e ˆ ˆ ˆ ˆijk = y ijk - μ - α i - β j. Podobně lze i v tomto případ definovat odhad interakcí ˆij τ = ˆ μ ij - ˆ μ - ˆ α i - β j. Povšimněme si, ñe tento vztah se liší jen tím, ñe se místo veličin y ij používá průměrů ˆμ ij. Pro ověření Tukeyova modelu interakce neaditivity lze vynášet graf ˆ τ ij vs. ˆ α i ˆ β. Náhodný obrazec bodç zde dokazuje aditivní působení obou faktorç. Sou ty čtverců modelu analýzy rozptylu pro obecný případ interakcí jsou uvedeny v Tabulce 5. Odpovídající průměrné hodnoty (očekávané hodnoty) průměrných čtverců jsou N n M α i i = 1 σ E( M A ) = σ + = + n M σ A, (N - 1) σ a M n N β j j = 1 σ E( M B ) = σ + = + n N σ (M - 1) σ N M n τ ij i = 1 j= 1 E( M AB ) = σ + = σ + n σ AB (N - 1) (M - 1) σ Očekávaná hodnota E(M R ) = σ ukazuje, ñe rozptyl M R je nevychýleným odhadem σ rozptylu chyb. Rozptyly σ A, σ Ba σ AB odpovídají efektçm řádků, sloupců a interakcí.. j B Tabulka 5. Tabulka analýzy rozptylu pro dvojné tííd ní a vyváñený experiment Součet čtverců pro Stupně volnosti Průměrný čtverec Kritérium F Faktor A, S A = n M N ˆ α i i = 1 N - 1 M A = S A N - 1 F A = M M A R Faktor B, S B M = n N ˆ β j j = 1 M - 1 M B = S B M - 1 F B = M M B R Interakce AB, S AB N = n ˆ τ ij i = 1 j = 1 (N - 1)(M - 1) M AB S AB = (N - 1) (M - 1) F AB M = M AB R Reziduální S R N M n = ( y - ˆ μ ) i = 1 j = 1 k = 1 ijk ij M N (n - 1) M R = S R M N (n - 1) - Celkový S C N M n = ( y ˆ μ ) i = 1 j = 1 k = 1 ijk M N n
35 Těchto vztahç lze využít i v případech, kdy se hledají odhady rozptylç příslušející faktorçm a interakcím. Pak se místo středních hodnot E(.) dosazují přímo průměrné čtverce a místo rozptylu σ reziduální rozptyl ˆ σ. Důležité je, ñe průměrné čtverce nejsou přímo odhady odpovídajících rozptylç. Také v případ analýzy rozptylu definované Tabulkou 5 se využitím statistik F AB, F B a F A testuje, zda je možné považovat sloupcové a řádkové efekty, resp. interakce, za nevýznamné. Pro test nulové hypotézy H 0 : τ ij = 0, i = 1,..., N a j = 1,..., M, lze použít testační statistiku F AB, která má za předpokladu platnosti hypotézy H 0 F-rozdělení s {(N - 1)(M - 1)} a {M N (n - 1)} stupni volnosti. PÍi testování významnosti řádkových efektç faktoru A je H 0 : α i = 0, i =1,..., N. Pokud nulová hypotéza platí, má testovací F A statistika F-rozdělení s (N - 1) a {M N (n - 1)} stupni volnosti. Analogicky píi testování významnosti sloupcových efektç faktoru B je H 0 : β j = 0, j = 1,..., M. Pokud nulová hypotéza platí, má testovací F B statistika F-rozdělení s (M - 1) a {M N (n - 1)} stupni volnosti. Nevychýleným odhadem rozptylu je M R. Výhodou vyvážených experimentç je fakt, ñe jednotlivé složky modelç analýzy rozptylu jsou vzájemně nezávislé. Proto je možno sčítat jednotlivé díl í sou ty čtverců v tabulce 5 a 4, coñ umožňuje současné testování n kolika hypotéz. V podstat lze tímto jednoduchým postupem ověřovat platnost různých submodelů analýzy rozptylu od nejjednoduššího y = + ijk μ ε ijk píes všechny díl í (obsahující jen n které z parametrç α, β a τ). Sčítání součtů čtverců se doporučuje i v případech, kdy se vliv n kterých faktorç i interakcí prokáže jako nevýznamný. Pak se příslušný součet čtverců přičte k reziduálnímu a v modelu se odpovídající členy vypustí. 5 Souhrn: Postup píi analýze rozptylu Obecně lze postup analýzy rozptylu rozdělit do těchto krokç: 1. Provede se odhad parametrů základního modelu ANOVA.. Provede se testování jeho významnosti a konstrukce různých submodelů u modelů s pevnými efekty. 3. Provede se ověření předpokladů normality, homogenity rozptylů a přítomnosti silně vybočujících pozorování. Ne vždy se pro tyto účely hodí klasicky definovaná rezidua a využívají se proto i jiné typy reziduí. 4. Provede se interpretace výsledků s ohledem na zadání dat a jejich případné úpravy. 6 Doporu ená literatura: [1] Searle S. R.: Biometrics 7, 1 (1971). [] Bartlett M. S., Kendall D. G.: J. Roy. Stat. Soc. B8, 18 (1946). [3] Scheffé H.: The Analysis of Variance. J. Wiley, New York [4] Searle S. R.: Linear Models. J. Wiley, New York [5] Miller P. G.: Beyond ANOVA, Basics of Applied Statistics. J. Wiley, New York [6] Speed T. P.: Annals of Statist. 15, 885 (1987). [7] Emerson J. D., Hoaglin D. C., Kempthorne P. I.: J. Amer. Statist. Assoc. 79, 39 (1984). [8] Bradu D., Hawkins D. M.: Technometrics 4, 103 (198). [9] Bloomfield P., Steiger W.: Least Absolute Deviations: Theory, Applications and Algorithms. Birkhäuser, Boston, [10] Gabriel K. R.: J. R. Stat. Soc. B40, 186 (1978). [11] Cressie N. A. C.: Biometrics 34, 505 (1978). [1] Potocký R a kol.: Zbierka úloh z pravdepodobnosti a matematickej štatistiky, ALFA-SNTL Bratislava [13] Anderson R. L.: Practical Statistics for Analytical Chemists, van Nostrand Reinhold Comp., New York [14] Miller J. C., Miller J. N.: Statistics for Analytical Chemistry, Ellis Horwood Chichester [15] Liteanu C., Rica I.: Statistical Theory and Methodology of Trace Analysis, Ellis Horwood Chichester [16] Rice J. A.: Mathematical Statistics and Data Analysis, Wadsworth & Brooks, California 1988, str [17] Meloun M., Militký J.: Statistické zpracování experimentálních dat, Plus Praha 1994, resp. East Publishing Praha 1998, Academia Praha 004. [18] Meloun M., Militký J.: Kompendium statistického zpracování dat, Academia Praha 00, Academia Praha 006. [19] ADSTAT 1.5,.0 a verze 3.0, TriloByte Statistical Software Pardubice, 199, 1993,
36 35
37 36
38 37
39 38
40 Doporučená literatura ke kurzu (1) M. Meloun, J. Militký: Statistické zpracování experimentálních dat, Plus Praha 1994, (1. vydání), East Publishing Praha 1998 (. vydání), Academia Praha 004 (3. vydání). () M. Meloun, J. Militký: Statistické zpracování experimentálních dat - Sbírka úloh, Univerzita Pardubice (3) ADSTAT 1.5,.0 a verze 3.0, TriloByte Statistical Software Pardubice, 199, 1993, (4) M. Meloun, J. Militký: Kompendium statistického zpracování experimentálních dat, Academia Praha 00 (1. vydání), Academia Praha 006 (. rozšířené vydání). 39
Statistická analýza jednorozměrných dat
 Statistická analýza jednorozměrných dat Prof. RNDr. Milan Meloun, DrSc. Univerzita Pardubice, Pardubice 31.ledna 2011 Tato prezentace je spolufinancována Evropským sociálním fondem a státním rozpočtem
Statistická analýza jednorozměrných dat Prof. RNDr. Milan Meloun, DrSc. Univerzita Pardubice, Pardubice 31.ledna 2011 Tato prezentace je spolufinancována Evropským sociálním fondem a státním rozpočtem
Kvantily a písmenové hodnoty E E E E-02
 Na úloze ukážeme postup průzkumové analýzy dat. Při výrobě calciferolu se provádí kontrola meziproduktu 3,5 DNB esteru calciferolu metodou HPLC. Sleduje se také obsah přítomného ergosterinu jako nečistoty,
Na úloze ukážeme postup průzkumové analýzy dat. Při výrobě calciferolu se provádí kontrola meziproduktu 3,5 DNB esteru calciferolu metodou HPLC. Sleduje se také obsah přítomného ergosterinu jako nečistoty,
PRŮZKUMOVÁ ANALÝZA JEDNOROZMĚRNÝCH DAT Exploratory Data Analysis (EDA)
") PRŮZKUMOVÁ ANALÝZA JEDNOROZMĚRNÝCH DAT Exploratory Data Analysis (EDA) Reprezentativní náhodný výběr: 1. Prvky výběru x i jsou vzájemně nezávislé. 2. Výběr je homogenní, tj. všechna x i jsou ze stejného
PRŮZKUMOVÁ ANALÝZA JEDNOROZMĚRNÝCH DAT Exploratory Data Analysis (EDA) Reprezentativní náhodný výběr: 1. Prvky výběru x i jsou vzájemně nezávislé. 2. Výběr je homogenní, tj. všechna x i jsou ze stejného
Statistická analýza jednorozměrných dat
 Statistická analýza jednorozměrných dat Prof. RNDr. Milan Meloun, DrSc. Univerzita Pardubice, Pardubice 31.ledna 2011 Tato prezentace je spolufinancována Evropským sociálním fondem a státním rozpočtem
Statistická analýza jednorozměrných dat Prof. RNDr. Milan Meloun, DrSc. Univerzita Pardubice, Pardubice 31.ledna 2011 Tato prezentace je spolufinancována Evropským sociálním fondem a státním rozpočtem
Statistická analýza jednorozměrných dat
 Statistická analýza jednorozměrných dat Prof. RNDr. Milan Meloun, DrSc. Univerzita Pardubice, Pardubice 31.ledna 2011 Tato prezentace je spolufinancována Evropským sociálním fondem a státním rozpočtem
Statistická analýza jednorozměrných dat Prof. RNDr. Milan Meloun, DrSc. Univerzita Pardubice, Pardubice 31.ledna 2011 Tato prezentace je spolufinancována Evropským sociálním fondem a státním rozpočtem
UNIVERZITA PARDUBICE Fakulta chemicko-technologická Katedra analytické chemie Nám. Čs. Legií 565, Pardubice
 UNIVERZITA PARDUBICE Fakulta chemicko-technologická Katedra analytické chemie Nám. Čs. Legií 565, 532 10 Pardubice 10. licenční studium chemometrie STATISTICKÉ ZPRACOVÁNÍ DAT Semestrální práce STATISTICKÁ
UNIVERZITA PARDUBICE Fakulta chemicko-technologická Katedra analytické chemie Nám. Čs. Legií 565, 532 10 Pardubice 10. licenční studium chemometrie STATISTICKÉ ZPRACOVÁNÍ DAT Semestrální práce STATISTICKÁ
S E M E S T R Á L N Í
 Univerzita Pardubice Fakulta chemicko-technologická Katedra analytické chemie S E M E S T R Á L N Í P R Á C E Licenční studium Statistické zpracování dat při managementu jakosti Předmět ANOVA analýza rozptylu
Univerzita Pardubice Fakulta chemicko-technologická Katedra analytické chemie S E M E S T R Á L N Í P R Á C E Licenční studium Statistické zpracování dat při managementu jakosti Předmět ANOVA analýza rozptylu
Úloha E301 Čistota vody v řece testem BSK 5 ( Statistická analýza jednorozměrných dat )
") Úloha E301 Čistota vody v řece testem BSK 5 ( Statistická analýza jednorozměrných dat ) Zadání : Čistota vody v řece byla denně sledována v průběhu 10 dní dle biologické spotřeby kyslíku BSK 5. Jsou v
Úloha E301 Čistota vody v řece testem BSK 5 ( Statistická analýza jednorozměrných dat ) Zadání : Čistota vody v řece byla denně sledována v průběhu 10 dní dle biologické spotřeby kyslíku BSK 5. Jsou v
Předpoklad o normalitě rozdělení je zamítnut, protože hodnota testovacího kritéria χ exp je vyšší než tabulkový 2
 Na úloze ukážeme postup analýzy velkého výběru s odlehlými prvky pro určení typu rozdělení koncentrace kyseliny močové u 50 dárců krve. Jaká je míra polohy a rozptýlení uvedeného výběru? Z grafických diagnostik
Na úloze ukážeme postup analýzy velkého výběru s odlehlými prvky pro určení typu rozdělení koncentrace kyseliny močové u 50 dárců krve. Jaká je míra polohy a rozptýlení uvedeného výběru? Z grafických diagnostik
UNIVERZITA PARDUBICE
 UNIVERZITA PARDUBICE Fakulta chemicko-technologická Katedra analytické chemie Vedoucí studia a odborný garant: Prof. RNDr. Milan Meloun, DrSc. Vyučující: Prof. RNDr. Milan Meloun, DrSc. Autor práce: ANDRII
UNIVERZITA PARDUBICE Fakulta chemicko-technologická Katedra analytické chemie Vedoucí studia a odborný garant: Prof. RNDr. Milan Meloun, DrSc. Vyučující: Prof. RNDr. Milan Meloun, DrSc. Autor práce: ANDRII
Statistická analýza. jednorozměrných dat
 Univerzita Pardubice Fakulta chemicko technologická Katedra analytické chemie icenční studium chemometrie Statistické zpracování dat Statistická analýza jednorozměrných dat Zdravotní ústav se sídlem v
Univerzita Pardubice Fakulta chemicko technologická Katedra analytické chemie icenční studium chemometrie Statistické zpracování dat Statistická analýza jednorozměrných dat Zdravotní ústav se sídlem v
Nejlepší odhady polohy a rozptýlení chemických dat
 Nejlepší odhady polohy a rozptýlení chemických dat Prof. RNDr. Milan Meloun, DrSc., Katedra analytické chemie, Univerzita Pardubice, 532 10 Pardubice email: milan.meloun@upce.cz, http://meloun.upce.cz
Nejlepší odhady polohy a rozptýlení chemických dat Prof. RNDr. Milan Meloun, DrSc., Katedra analytické chemie, Univerzita Pardubice, 532 10 Pardubice email: milan.meloun@upce.cz, http://meloun.upce.cz
UNIVERZITA PARDUBICE Fakulta chemicko-technologická Katedra analytické chemie. Nám. Čs. Legií 565, Pardubice. Semestrální práce ANOVA 2015
 UNIVERZITA PARDUBICE Fakulta chemicko-technologická Katedra analytické chemie Nám. Čs. Legií 565, 532 10 Pardubice 15. licenční studium INTERAKTIVNÍ STATISTICKÁ ANALÝZA DAT Semestrální práce ANOVA 2015
UNIVERZITA PARDUBICE Fakulta chemicko-technologická Katedra analytické chemie Nám. Čs. Legií 565, 532 10 Pardubice 15. licenční studium INTERAKTIVNÍ STATISTICKÁ ANALÝZA DAT Semestrální práce ANOVA 2015
Univerzita Pardubice Fakulta chemicko-technologická Katedra analytické chemie STATISTICKÉ ZPRACOVÁNÍ EXPERIMENTÁLNÍCH DAT
 Univerzita Pardubice Fakulta chemicko-technologická Katedra analytické chemie STATISTICKÉ ZPRACOVÁNÍ EXPERIMENTÁLNÍCH DAT STATISTICKÁ ANALÝZA JEDNOROZMĚRNÝCH DAT Seminární práce 1 Brno, 2002 Ing. Pavel
Univerzita Pardubice Fakulta chemicko-technologická Katedra analytické chemie STATISTICKÉ ZPRACOVÁNÍ EXPERIMENTÁLNÍCH DAT STATISTICKÁ ANALÝZA JEDNOROZMĚRNÝCH DAT Seminární práce 1 Brno, 2002 Ing. Pavel
UNIVERZITA PARDUBICE Fakulta chemicko-technologická Katedra analytické chemie Nám. Čs. Legií 565, Pardubice
 UNIVERZITA PARDUBICE Fakulta chemicko-technologická Katedra analytické chemie Nám. Čs. Legií 565, 532 10 Pardubice 10. licenční studium chemometrie STATISTICKÉ ZPRACOVÁNÍ DAT Semestrální práce ANALÝZA
UNIVERZITA PARDUBICE Fakulta chemicko-technologická Katedra analytické chemie Nám. Čs. Legií 565, 532 10 Pardubice 10. licenční studium chemometrie STATISTICKÉ ZPRACOVÁNÍ DAT Semestrální práce ANALÝZA
1 Tyto materiály byly vytvořeny za pomoci grantu FRVŠ číslo 1145/2004.
 Testy hypotéz na základě více než 2 výběrů 1 1 Tyto materiály byly vytvořeny za pomoci grantu FRVŠ číslo 1145/2004. Testy hypotéz na základě více než 2 výběrů Na analýzu rozptylu lze pohlížet v podstatě
Testy hypotéz na základě více než 2 výběrů 1 1 Tyto materiály byly vytvořeny za pomoci grantu FRVŠ číslo 1145/2004. Testy hypotéz na základě více než 2 výběrů Na analýzu rozptylu lze pohlížet v podstatě
ANOVA. Semestrální práce UNIVERZITA PARDUBICE. Fakulta chemicko-technologická Katedra analytické chemie
 UNIVERZITA PARDUBICE Fakulta chemicko-technologická Katedra analytické chemie ANOVA Semestrální práce Licenční studium Galileo Interaktivní statistická analýza dat Brno 2015 Ing. Petra Hlaváčková, Ph.D.
UNIVERZITA PARDUBICE Fakulta chemicko-technologická Katedra analytické chemie ANOVA Semestrální práce Licenční studium Galileo Interaktivní statistická analýza dat Brno 2015 Ing. Petra Hlaváčková, Ph.D.
S E M E S T R Á L N Í
 Univerzita Pardubice Fakulta chemicko-technologická Katedra analytické chemie S E M E S T R Á L N Í P R Á C E Licenční studium Statistické zpracování dat při managementu jakosti Předmět Statistická analýza
Univerzita Pardubice Fakulta chemicko-technologická Katedra analytické chemie S E M E S T R Á L N Í P R Á C E Licenční studium Statistické zpracování dat při managementu jakosti Předmět Statistická analýza
Jednofaktorová analýza rozptylu
 Jednofaktorová analýza rozptylu David Hampel Ústav statistiky a operačního výzkumu, Mendelova univerzita v Brně Kurz pokročilých statistických metod Global Change Research Centre AS CR, 5 7 8 2015 Tato
Jednofaktorová analýza rozptylu David Hampel Ústav statistiky a operačního výzkumu, Mendelova univerzita v Brně Kurz pokročilých statistických metod Global Change Research Centre AS CR, 5 7 8 2015 Tato
Statistická analýza jednorozměrných dat
 Statistická analýza jednorozměrných dat Prof. RNDr. Milan Meloun, DrSc. Univerzita Pardubice, Pardubice 31.ledna 2011 Tato prezentace je spolufinancována Evropským sociálním fondem a státním rozpočtem
Statistická analýza jednorozměrných dat Prof. RNDr. Milan Meloun, DrSc. Univerzita Pardubice, Pardubice 31.ledna 2011 Tato prezentace je spolufinancována Evropským sociálním fondem a státním rozpočtem
Porovnání dvou reaktorů
 Porovnání dvou reaktorů Zadání: Chemické reakce při kontinuální výrobě probíhají ve dvou identických reaktorech. Konstanty potřebné pro regulaci průběhu reakce jsou nastaveny pro každý reaktor samostatně.
Porovnání dvou reaktorů Zadání: Chemické reakce při kontinuální výrobě probíhají ve dvou identických reaktorech. Konstanty potřebné pro regulaci průběhu reakce jsou nastaveny pro každý reaktor samostatně.
UNIVERZITA PARDUBICE Fakulta chemicko-technologická Katedra analytické chemie
 UNIVERZITA PARDUBICE Fakulta chemicko-technologická Katedra analytické chemie Licenční studium Pythagoras Statistické zpracování experimentálních dat Semestrální práce ANOVA vypracoval: Ing. David Dušek
UNIVERZITA PARDUBICE Fakulta chemicko-technologická Katedra analytické chemie Licenční studium Pythagoras Statistické zpracování experimentálních dat Semestrální práce ANOVA vypracoval: Ing. David Dušek
UNIVERZITA PARDUBICE CHEMICKO-TECHNOLOGICKÁ FAKULTA KATEDRA ANALYTICKÉ CHEMIE
 UNIVERZITA PARDUBICE CHEMICKO-TECHNOLOGICKÁ FAKULTA KATEDRA ANALYTICKÉ CHEMIE STATISTICKÁ ANALÝZA JEDNOROZMĚRNÝCH DAT V OSTRAVĚ 20.3.2006 MAREK MOČKOŘ PŘÍKLAD Č.1 : ANALÝZA VELKÝCH VÝBĚRŮ Zadání: Pro kontrolu
UNIVERZITA PARDUBICE CHEMICKO-TECHNOLOGICKÁ FAKULTA KATEDRA ANALYTICKÉ CHEMIE STATISTICKÁ ANALÝZA JEDNOROZMĚRNÝCH DAT V OSTRAVĚ 20.3.2006 MAREK MOČKOŘ PŘÍKLAD Č.1 : ANALÝZA VELKÝCH VÝBĚRŮ Zadání: Pro kontrolu
Univerzita Pardubice Fakulta chemicko-technologická Katedra analytické chemie ANOVA. Semestrální práce
 Univerzita Pardubice Fakulta chemicko-technologická Katedra analytické chemie ANOVA Semestrální práce Licenční studium GALILEO Interaktivní statistická analýza dat Brno, 2015 Doc. Mgr. Jan Muselík, Ph.D.
Univerzita Pardubice Fakulta chemicko-technologická Katedra analytické chemie ANOVA Semestrální práce Licenční studium GALILEO Interaktivní statistická analýza dat Brno, 2015 Doc. Mgr. Jan Muselík, Ph.D.
Univerzita Pardubice Fakulta chemicko technologická Katedra analytické chemie Licenční studium chemometrie
 Univerzita Pardubice Fakulta chemicko technologická Katedra analytické chemie Licenční studium chemometrie Statistické zpracování dat ANOVA Zdravotní ústav se sídlem v Ostravě Odbor hygienických laboratoří
Univerzita Pardubice Fakulta chemicko technologická Katedra analytické chemie Licenční studium chemometrie Statistické zpracování dat ANOVA Zdravotní ústav se sídlem v Ostravě Odbor hygienických laboratoří
Dva případy chybného rozhodnutí při testování: a) Testační statistika padne mimo obor přijetí nulové H hypotézy O, tj.
 Testační statistika padne mimo obor přijetí nulové H hypotézy O, tj.") Uvedeme obecný postup statistického testování:. Formulace nulové H 0a alternativní hpotéz H A.. Volba hladin významnosti α.. Volba testační statistik např... Určení kritického oboru testové charakteristik.
Uvedeme obecný postup statistického testování:. Formulace nulové H 0a alternativní hpotéz H A.. Volba hladin významnosti α.. Volba testační statistik např... Určení kritického oboru testové charakteristik.
Statistická analýza jednorozměrných dat
 Univerzita Pardubice Fakulta chemicko-technologická, Katedra analytické chemie Licenční studium GALILEO Interaktivní statistická analýza dat Semestrální práce z předmětu Statistická analýza jednorozměrných
Univerzita Pardubice Fakulta chemicko-technologická, Katedra analytické chemie Licenční studium GALILEO Interaktivní statistická analýza dat Semestrální práce z předmětu Statistická analýza jednorozměrných
Průzkumová analýza dat
 Průzkumová analýza dat Proč zkoumat data? Základ průzkumové analýzy dat položil John Tukey ve svém díle Exploratory Data Analysis (odtud zkratka EDA). Často se stává, že data, se kterými pracujeme, se
Průzkumová analýza dat Proč zkoumat data? Základ průzkumové analýzy dat položil John Tukey ve svém díle Exploratory Data Analysis (odtud zkratka EDA). Často se stává, že data, se kterými pracujeme, se
IDENTIFIKACE BIMODALITY V DATECH
 IDETIFIKACE BIMODALITY V DATECH Jiří Militky Technická universita v Liberci e- mail: jiri.miliky@vslib.cz Milan Meloun Universita Pardubice, Pardubice Motto: Je normální předpokládat normální data? Zvláštnosti
IDETIFIKACE BIMODALITY V DATECH Jiří Militky Technická universita v Liberci e- mail: jiri.miliky@vslib.cz Milan Meloun Universita Pardubice, Pardubice Motto: Je normální předpokládat normální data? Zvláštnosti
PRAVDĚPODOBNOST A STATISTIKA
 PRAVDĚPODOBNOST A STATISTIKA Definice lineárního normálního regresního modelu Lineární normální regresní model Y β ε Matice n,k je matice realizací. Předpoklad: n > k, h() k - tj. matice je plné hodnosti
PRAVDĚPODOBNOST A STATISTIKA Definice lineárního normálního regresního modelu Lineární normální regresní model Y β ε Matice n,k je matice realizací. Předpoklad: n > k, h() k - tj. matice je plné hodnosti
Analýza rozptylu. Ekonometrie. Jiří Neubauer. Katedra kvantitativních metod FVL UO Brno kancelář 69a, tel
 Analýza rozptylu Ekonometrie Jiří Neubauer Katedra kvantitativních metod FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Jiří Neubauer (Katedra UO Brno) Analýza rozptylu 1 / 30 Analýza
Analýza rozptylu Ekonometrie Jiří Neubauer Katedra kvantitativních metod FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Jiří Neubauer (Katedra UO Brno) Analýza rozptylu 1 / 30 Analýza
Problematika analýzy rozptylu. Ing. Michael Rost, Ph.D.
 Problematika analýzy rozptylu Ing. Michael Rost, Ph.D. Úvod do problému Již umíte testovat shodu dvou středních hodnot prostřednictvím t-testů. Otázka: Jaké předpoklady musí být splněny, abyste mohli použít
Problematika analýzy rozptylu Ing. Michael Rost, Ph.D. Úvod do problému Již umíte testovat shodu dvou středních hodnot prostřednictvím t-testů. Otázka: Jaké předpoklady musí být splněny, abyste mohli použít
Analýza rozptylu ANOVA
 Licenční studium Galileo: Statistické zpracování dat ANOVA ANOVA B ANOVA P Analýza rozptylu ANOVA Semestrální práce Lenka Husáková Pardubice 05 Obsah Jednofaktorová ANOVA... 3. Zadání... 3. Data... 3.3
Licenční studium Galileo: Statistické zpracování dat ANOVA ANOVA B ANOVA P Analýza rozptylu ANOVA Semestrální práce Lenka Husáková Pardubice 05 Obsah Jednofaktorová ANOVA... 3. Zadání... 3. Data... 3.3
Charakteristika datového souboru
 Zápočtová práce z předmětu Statistika Vypracoval: 10. 11. 2014 Charakteristika datového souboru Zadání: Při kontrole dodržování hygienických norem v kuchyni se prováděl odběr vzduchu a pomocí filtru Pallflex
Zápočtová práce z předmětu Statistika Vypracoval: 10. 11. 2014 Charakteristika datového souboru Zadání: Při kontrole dodržování hygienických norem v kuchyni se prováděl odběr vzduchu a pomocí filtru Pallflex
Statistická analýza jednorozměrných dat
 Licenční studium Galileo: Statistické zpracování dat Analýza velkých výběrů Hornův postup analýzy malých výběrů Statistické testování Statistická analýza jednorozměrných dat Semestrální práce Lenka Husáková
Licenční studium Galileo: Statistické zpracování dat Analýza velkých výběrů Hornův postup analýzy malých výběrů Statistické testování Statistická analýza jednorozměrných dat Semestrální práce Lenka Husáková
Porovnání dvou výběrů
 Porovnání dvou výběrů Menu: QCExpert Porovnání dvou výběrů Tento modul je určen pro podrobnou analýzu dvou datových souborů (výběrů). Modul poskytuje dva postupy analýzy: porovnání dvou nezávislých výběrů
Porovnání dvou výběrů Menu: QCExpert Porovnání dvou výběrů Tento modul je určen pro podrobnou analýzu dvou datových souborů (výběrů). Modul poskytuje dva postupy analýzy: porovnání dvou nezávislých výběrů
http: //meloun.upce.cz,
 Porovnání rozlišovací schopnosti regresní analýzy spekter a spolehlivosti Prof. RNDr. Milan Meloun, DrSc. Katedra analytické chemie, Chemickotechnologická fakulta, Univerzita Pardubice, nám. s. Legií 565,
Porovnání rozlišovací schopnosti regresní analýzy spekter a spolehlivosti Prof. RNDr. Milan Meloun, DrSc. Katedra analytické chemie, Chemickotechnologická fakulta, Univerzita Pardubice, nám. s. Legií 565,
Analýza rozptylu. Podle počtu analyzovaných faktorů rozlišujeme jednofaktorovou, dvoufaktorovou a vícefaktorovou analýzu rozptylu.
 Analýza rozptylu Analýza rozptylu umožňuje ověřit významnost rozdílu mezi výběrovými průměry většího počtu náhodných výběrů, umožňuje posoudit vliv různých faktorů. Podle počtu analyzovaných faktorů rozlišujeme
Analýza rozptylu Analýza rozptylu umožňuje ověřit významnost rozdílu mezi výběrovými průměry většího počtu náhodných výběrů, umožňuje posoudit vliv různých faktorů. Podle počtu analyzovaných faktorů rozlišujeme
Zápočtová práce STATISTIKA I
 Zápočtová práce STATISTIKA I Obsah: - úvodní stránka - charakteristika dat (původ dat, důvod zpracování,...) - výpis naměřených hodnot (v tabulce) - zpracování dat (buď bodové nebo intervalové, podle charakteru
Zápočtová práce STATISTIKA I Obsah: - úvodní stránka - charakteristika dat (původ dat, důvod zpracování,...) - výpis naměřených hodnot (v tabulce) - zpracování dat (buď bodové nebo intervalové, podle charakteru
UNIVERZITA OBRANY Fakulta ekonomiky a managementu. Aplikace STAT1. Výsledek řešení projektu PRO HORR2011 a PRO GRAM2011 3. 11.
 UNIVERZITA OBRANY Fakulta ekonomiky a managementu Aplikace STAT1 Výsledek řešení projektu PRO HORR2011 a PRO GRAM2011 Jiří Neubauer, Marek Sedlačík, Oldřich Kříž 3. 11. 2012 Popis a návod k použití aplikace
UNIVERZITA OBRANY Fakulta ekonomiky a managementu Aplikace STAT1 Výsledek řešení projektu PRO HORR2011 a PRO GRAM2011 Jiří Neubauer, Marek Sedlačík, Oldřich Kříž 3. 11. 2012 Popis a návod k použití aplikace
UNIVERZITA PARDUBICE Fakulta chemicko-technologická Katedra analytické chemie Nám. Čs. Legií 565, Pardubice
 UNIVERZITA PARDUBICE Fakulta chemicko-technologická Katedra analytické chemie Nám. Čs. Legií 565, 532 10 Pardubice 10. licenční studium chemometrie STATISTICKÉ ZPRACOVÁNÍ DAT Semestrální práce KALIBRACE
UNIVERZITA PARDUBICE Fakulta chemicko-technologická Katedra analytické chemie Nám. Čs. Legií 565, 532 10 Pardubice 10. licenční studium chemometrie STATISTICKÉ ZPRACOVÁNÍ DAT Semestrální práce KALIBRACE
PRAVDĚPODOBNOST A STATISTIKA
 PRAVDĚPODOBNOST A STATISTIKA Definice lineárního normálního regresního modelu Lineární normální regresní model Y Xβ ε Předpoklady: Matice X X n,k je matice realizací. Předpoklad: n > k, h(x) k - tj. matice
PRAVDĚPODOBNOST A STATISTIKA Definice lineárního normálního regresního modelu Lineární normální regresní model Y Xβ ε Předpoklady: Matice X X n,k je matice realizací. Předpoklad: n > k, h(x) k - tj. matice
VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ. FAKULTA STROJNÍHO INŽENÝRSTVÍ Ústav materiálového inženýrství - odbor slévárenství
 1 PŘÍLOHA KE KAPITOLE 11 2 Seznam příloh ke kapitole 11 Podkapitola 11.2. Přilité tyče: Graf 1 Graf 2 Graf 3 Graf 4 Graf 5 Graf 6 Graf 7 Graf 8 Graf 9 Graf 1 Graf 11 Rychlost šíření ultrazvuku vs. pořadí
1 PŘÍLOHA KE KAPITOLE 11 2 Seznam příloh ke kapitole 11 Podkapitola 11.2. Přilité tyče: Graf 1 Graf 2 Graf 3 Graf 4 Graf 5 Graf 6 Graf 7 Graf 8 Graf 9 Graf 1 Graf 11 Rychlost šíření ultrazvuku vs. pořadí
Kalibrace a limity její přesnosti
 Univerzita Pardubice Fakulta chemicko technologická Katedra analytické chemie Licenční studium chemometrie Statistické zpracování dat Kalibrace a limity její přesnosti Zdravotní ústav se sídlem v Ostravě
Univerzita Pardubice Fakulta chemicko technologická Katedra analytické chemie Licenční studium chemometrie Statistické zpracování dat Kalibrace a limity její přesnosti Zdravotní ústav se sídlem v Ostravě
Statistika, Biostatistika pro kombinované studium. Jan Kracík
 Statistika, Biostatistika pro kombinované studium Letní semestr 2014/2015 Tutoriál č. 6: ANOVA Jan Kracík jan.kracik@vsb.cz Obsah: Testování hypotéz opakování ANOVA Testování hypotéz (opakování) Testování
Statistika, Biostatistika pro kombinované studium Letní semestr 2014/2015 Tutoriál č. 6: ANOVA Jan Kracík jan.kracik@vsb.cz Obsah: Testování hypotéz opakování ANOVA Testování hypotéz (opakování) Testování
Regresní analýza 1. Regresní analýza
 Regresní analýza 1 1 Regresní funkce Regresní analýza Důležitou statistickou úlohou je hledání a zkoumání závislostí proměnných, jejichž hodnoty získáme při realizaci experimentů Vzhledem k jejich náhodnému
Regresní analýza 1 1 Regresní funkce Regresní analýza Důležitou statistickou úlohou je hledání a zkoumání závislostí proměnných, jejichž hodnoty získáme při realizaci experimentů Vzhledem k jejich náhodnému
Charakterizace rozdělení
 Charakterizace rozdělení Momenty f(x) f(x) f(x) μ >μ 1 σ 1 σ >σ 1 g 1 g σ μ 1 μ x μ x x N K MK = x f( x) dx 1 M K = x N CK = ( x M ) f( x) dx ( xi M 1 C = 1 K 1) N i= 1 K i K N i= 1 K μ = E ( X ) = xf
Charakterizace rozdělení Momenty f(x) f(x) f(x) μ >μ 1 σ 1 σ >σ 1 g 1 g σ μ 1 μ x μ x x N K MK = x f( x) dx 1 M K = x N CK = ( x M ) f( x) dx ( xi M 1 C = 1 K 1) N i= 1 K i K N i= 1 K μ = E ( X ) = xf
Univerzita Pardubice Fakulta chemicko technologická Katedra analytické chemie Licenční studium Management systému jakosti
 Univerzita Pardubice Fakulta chemicko technologická Katedra analytické chemie Licenční studium Management systému jakosti 3.3 v analýze dat Autor práce: Přednášející: Prof. RNDr. Milan Meloun, DrSc Pro
Univerzita Pardubice Fakulta chemicko technologická Katedra analytické chemie Licenční studium Management systému jakosti 3.3 v analýze dat Autor práce: Přednášející: Prof. RNDr. Milan Meloun, DrSc Pro
Kalibrace a limity její přesnosti
 Univerzita Pardubice Fakulta chemicko-technologická Katedra analytické chemie Kalibrace a limity její přesnosti Semestrální práce Licenční studium GALILEO Interaktivní statistická analýza dat Brno, 2015
Univerzita Pardubice Fakulta chemicko-technologická Katedra analytické chemie Kalibrace a limity její přesnosti Semestrální práce Licenční studium GALILEO Interaktivní statistická analýza dat Brno, 2015
y = 0, ,19716x.
 Grafické ověřování a testování vybraných modelů 1 Grafické ověřování empirického rozdělení Při grafické analýze empirického rozdělení vycházíme z empirické distribuční funkce F n (x) příslušné k náhodnému
Grafické ověřování a testování vybraných modelů 1 Grafické ověřování empirického rozdělení Při grafické analýze empirického rozdělení vycházíme z empirické distribuční funkce F n (x) příslušné k náhodnému
Odhad parametrů N(µ, σ 2 )
") Odhad parametrů N(µ, σ 2 ) Mějme statistický soubor x 1, x 2,, x n modelovaný jako realizaci náhodného výběru z normálního rozdělení N(µ, σ 2 ) s neznámými parametry µ a σ. Jaký je maximální věrohodný
Odhad parametrů N(µ, σ 2 ) Mějme statistický soubor x 1, x 2,, x n modelovaný jako realizaci náhodného výběru z normálního rozdělení N(µ, σ 2 ) s neznámými parametry µ a σ. Jaký je maximální věrohodný
Testování hypotéz testy o tvaru rozdělení. Jiří Neubauer. Katedra ekonometrie, FVL, UO Brno kancelář 69a, tel
 Katedra ekonometrie, FVL, UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Statistickou hypotézou se rozumí určité tvrzení o parametrech rozdělení zkoumané náhodné veličiny (µ, σ 2, π,
Katedra ekonometrie, FVL, UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Statistickou hypotézou se rozumí určité tvrzení o parametrech rozdělení zkoumané náhodné veličiny (µ, σ 2, π,
Plánování experimentu
 Fakulta chemicko technologická Katedra analytické chemie licenční studium Management systému jakosti Autor: Ing. Radek Růčka Přednášející: Prof. Ing. Jiří Militký, CSc. 1. LEPTÁNÍ PLAZMOU 1.1 Zadání Proces
Fakulta chemicko technologická Katedra analytické chemie licenční studium Management systému jakosti Autor: Ing. Radek Růčka Přednášející: Prof. Ing. Jiří Militký, CSc. 1. LEPTÁNÍ PLAZMOU 1.1 Zadání Proces
STATISTICKÁ ANALÝZA JEDNOROZMĚRNÝCH DAT. Semestrální práce UNIVERZITA PARDUBICE. Fakulta chemicko-technologická Katedra analytické chemie
 UNIVERZITA PARDUBICE Fakulta chemicko-technologická Katedra analytické chemie STATISTICKÁ ANALÝZA JEDNOROZMĚRNÝCH DAT Semestrální práce Licenční studium Galileo Interaktivní statistická analýza dat Brno
UNIVERZITA PARDUBICE Fakulta chemicko-technologická Katedra analytické chemie STATISTICKÁ ANALÝZA JEDNOROZMĚRNÝCH DAT Semestrální práce Licenční studium Galileo Interaktivní statistická analýza dat Brno
Pravděpodobnost a matematická statistika
 Pravděpodobnost a matematická statistika Příklady k přijímacím zkouškám na doktorské studium 1 Popisná statistika Určete aritmetický průměr dat, zadaných tabulkou hodnot x i a četností n i x i 1 2 3 n
Pravděpodobnost a matematická statistika Příklady k přijímacím zkouškám na doktorské studium 1 Popisná statistika Určete aritmetický průměr dat, zadaných tabulkou hodnot x i a četností n i x i 1 2 3 n
8. Normální rozdělení
 8. Normální rozdělení 8.. Definice: Normální (Gaussovo) rozdělení N(µ, 2 ) s parametry µ a > 0 je rozdělení určené hustotou ( ) f(x) = (x µ) 2 e 2 2, x (, ). Rozdělení N(0; ) s parametry µ = 0 a = se nazývá
8. Normální rozdělení 8.. Definice: Normální (Gaussovo) rozdělení N(µ, 2 ) s parametry µ a > 0 je rozdělení určené hustotou ( ) f(x) = (x µ) 2 e 2 2, x (, ). Rozdělení N(0; ) s parametry µ = 0 a = se nazývá
Matematika III. 27. listopadu Vysoká škola báňská - Technická univerzita Ostrava. Matematika III
 Vysoká škola báňská - Technická univerzita Ostrava 27. listopadu 2017 Typy statistických znaků (proměnných) Typy proměnných: Kvalitativní proměnná (kategoriální, slovní,... ) Kvantitativní proměnná (numerická,
Vysoká škola báňská - Technická univerzita Ostrava 27. listopadu 2017 Typy statistických znaků (proměnných) Typy proměnných: Kvalitativní proměnná (kategoriální, slovní,... ) Kvantitativní proměnná (numerická,
Statistická analýza jednorozměrných dat
 Statistická analýza jednorozměrných dat Prof. RNDr. Milan Meloun, DrSc. Univerzita Pardubice, Pardubice 31.ledna 2011 Tato prezentace je spolufinancována Evropským sociálním fondem a státním rozpočtem
Statistická analýza jednorozměrných dat Prof. RNDr. Milan Meloun, DrSc. Univerzita Pardubice, Pardubice 31.ledna 2011 Tato prezentace je spolufinancována Evropským sociálním fondem a státním rozpočtem
Exploratorní analýza dat
 2. kapitola Exploratorní analýza dat Řešení praktických úloh z Kompendia, str. 81. Načtení dat po F3. Načtená data úlohy B201 je možné v editoru ještě opravovat. Volba statistické metody v červeném menu.
2. kapitola Exploratorní analýza dat Řešení praktických úloh z Kompendia, str. 81. Načtení dat po F3. Načtená data úlohy B201 je možné v editoru ještě opravovat. Volba statistické metody v červeném menu.
Normální (Gaussovo) rozdělení
 rozdělení") Normální (Gaussovo) rozdělení Normální (Gaussovo) rozdělení popisuje vlastnosti náhodné spojité veličiny, která vzniká složením různých náhodných vlivů, které jsou navzájem nezávislé, kterých je velký
Normální (Gaussovo) rozdělení Normální (Gaussovo) rozdělení popisuje vlastnosti náhodné spojité veličiny, která vzniká složením různých náhodných vlivů, které jsou navzájem nezávislé, kterých je velký
UNIVERZITA PARDUBICE
 UNIVERZITA PARDUBICE Fakulta chemicko technologická Katedra analytické chemie Licenční studium chemometrie na téma Tvorba nelineárních regresních modelů v analýze dat Vedoucí licenčního studia Prof. RNDr.
UNIVERZITA PARDUBICE Fakulta chemicko technologická Katedra analytické chemie Licenční studium chemometrie na téma Tvorba nelineárních regresních modelů v analýze dat Vedoucí licenčního studia Prof. RNDr.
Regresní a korelační analýza
 Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Určujeme neznámé hodnoty parametru základního souboru. Pomocí výběrové charakteristiky vypočtené z náhodného výběru.
 1 Statistické odhady Určujeme neznámé hodnoty parametru základního souboru. Pomocí výběrové charakteristiky vypočtené z náhodného výběru. Odhad lze provést jako: Bodový odhad o Jedna číselná hodnota Intervalový
1 Statistické odhady Určujeme neznámé hodnoty parametru základního souboru. Pomocí výběrové charakteristiky vypočtené z náhodného výběru. Odhad lze provést jako: Bodový odhad o Jedna číselná hodnota Intervalový
STATISTIKA A INFORMATIKA - bc studium OZW, 1.roč. (zkušební otázky)
") STATISTIKA A INFORMATIKA - bc studium OZW, 1.roč. (zkušební otázky) 1) Význam a využití statistiky v biologických vědách a veterinárním lékařství ) Rozdělení znaků (veličin) ve statistice 3) Základní a
STATISTIKA A INFORMATIKA - bc studium OZW, 1.roč. (zkušební otázky) 1) Význam a využití statistiky v biologických vědách a veterinárním lékařství ) Rozdělení znaků (veličin) ve statistice 3) Základní a
Základní statistické metody v rizikovém inženýrství
 Základní statistické metody v rizikovém inženýrství Petr Misák Ústav stavebního zkušebnictví Fakulta stavební, VUT v Brně misak.p@fce.vutbr.cz Základní pojmy Jev souhrn skutečností zobrazujících ucelenou
Základní statistické metody v rizikovém inženýrství Petr Misák Ústav stavebního zkušebnictví Fakulta stavební, VUT v Brně misak.p@fce.vutbr.cz Základní pojmy Jev souhrn skutečností zobrazujících ucelenou
7. Rozdělení pravděpodobnosti ve statistice
 7. Rozdělení pravděpodobnosti ve statistice Statistika nuda je, má však cenné údaje, neklesejte na mysli, ona nám to vyčíslí Jednou z úloh statistiky je odhad (výpočet) hodnot statistického znaku x i,
7. Rozdělení pravděpodobnosti ve statistice Statistika nuda je, má však cenné údaje, neklesejte na mysli, ona nám to vyčíslí Jednou z úloh statistiky je odhad (výpočet) hodnot statistického znaku x i,
Stanovení manganu a míry přesnosti kalibrace ( Lineární kalibrace )
") Příklad č. 1 Stanovení manganu a míry přesnosti kalibrace ( Lineární kalibrace ) Zadání : Stanovení manganu ve vodách se provádí oxidací jodistanem v kyselém prostředí až na manganistan. (1) Sestrojte
Příklad č. 1 Stanovení manganu a míry přesnosti kalibrace ( Lineární kalibrace ) Zadání : Stanovení manganu ve vodách se provádí oxidací jodistanem v kyselém prostředí až na manganistan. (1) Sestrojte
Postup statistického zpracování výsledků stopové analýzy při použití transformace dat
 Postup statistického zpracování výsledků stopové analýzy při použití transformace dat Milan Meloun Katedra analytické chemie, Univerzita Pardubice, 53 10 Pardubice milan.meloun@upce.cz a Jiří Militký Katedra
Postup statistického zpracování výsledků stopové analýzy při použití transformace dat Milan Meloun Katedra analytické chemie, Univerzita Pardubice, 53 10 Pardubice milan.meloun@upce.cz a Jiří Militký Katedra
Lineární regrese. Komentované řešení pomocí MS Excel
 Lineární regrese Komentované řešení pomocí MS Excel Vstupní data Tabulka se vstupními daty je umístěna v oblasti A1:B11 (viz. obrázek) na listu cela data Postup Základní výpočty - regrese Výpočet základních
Lineární regrese Komentované řešení pomocí MS Excel Vstupní data Tabulka se vstupními daty je umístěna v oblasti A1:B11 (viz. obrázek) na listu cela data Postup Základní výpočty - regrese Výpočet základních
VŠB Technická univerzita Ostrava Fakulta elektrotechniky a informatiky SMAD
 VŠB Technická univerzita Ostrava Fakulta elektrotechniky a informatiky JMÉNO STUDENTKY/STUDENTA: OSOBNÍ ČÍSLO: JMÉNO CVIČÍCÍ/CVIČÍCÍHO: SMAD Cvičení Ostrava, AR 2016/2017 Popis datového souboru Pro dlouhodobý
VŠB Technická univerzita Ostrava Fakulta elektrotechniky a informatiky JMÉNO STUDENTKY/STUDENTA: OSOBNÍ ČÍSLO: JMÉNO CVIČÍCÍ/CVIČÍCÍHO: SMAD Cvičení Ostrava, AR 2016/2017 Popis datového souboru Pro dlouhodobý
Testy statistických hypotéz
 Testy statistických hypotéz Statistická hypotéza je jakýkoliv předpoklad o rozdělení pravděpodobnosti jedné nebo několika náhodných veličin. Na základě náhodného výběru, který je reprezentativním vzorkem
Testy statistických hypotéz Statistická hypotéza je jakýkoliv předpoklad o rozdělení pravděpodobnosti jedné nebo několika náhodných veličin. Na základě náhodného výběru, který je reprezentativním vzorkem
1 Tyto materiály byly vytvořeny za pomoci grantu FRVŠ číslo 1145/2004.
 Prostá regresní a korelační analýza 1 1 Tyto materiály byly vytvořeny za pomoci grantu FRVŠ číslo 1145/2004. Problematika závislosti V podstatě lze rozlišovat mezi závislostí nepodstatnou, čili náhodnou
Prostá regresní a korelační analýza 1 1 Tyto materiály byly vytvořeny za pomoci grantu FRVŠ číslo 1145/2004. Problematika závislosti V podstatě lze rozlišovat mezi závislostí nepodstatnou, čili náhodnou
Praktická statistika. Petr Ponížil Eva Kutálková
 Praktická statistika Petr Ponížil Eva Kutálková Zápis výsledků měření Předpokládejme, že známe hodnotu napětí U = 238,9 V i její chybu 3,3 V. Hodnotu veličiny zapíšeme na tolik míst, aby až poslední bylo
Praktická statistika Petr Ponížil Eva Kutálková Zápis výsledků měření Předpokládejme, že známe hodnotu napětí U = 238,9 V i její chybu 3,3 V. Hodnotu veličiny zapíšeme na tolik míst, aby až poslední bylo
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc.
 Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika 2010 1.týden (20.09.-24.09. ) Data, typy dat, variabilita, frekvenční analýza
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika 2010 1.týden (20.09.-24.09. ) Data, typy dat, variabilita, frekvenční analýza
Normální (Gaussovo) rozdělení
 rozdělení") Normální (Gaussovo) rozdělení f x = 1 2 exp x 2 2 2 f(x) je funkce hustoty pravděpodobnosti, symetrická vůči poloze maxima x = μ μ střední hodnota σ směrodatná odchylka (tzv. pološířka křivky mezi inflexními
Normální (Gaussovo) rozdělení f x = 1 2 exp x 2 2 2 f(x) je funkce hustoty pravděpodobnosti, symetrická vůči poloze maxima x = μ μ střední hodnota σ směrodatná odchylka (tzv. pološířka křivky mezi inflexními
PYTHAGORAS Statistické zpracování experimentálních dat
 UNIVERZITA PARDUBICE Fakulta chemicko-technologická, Katedra analytické chemie SEMESTRÁLNÍ PRÁCE Květen 2008 Licenční studium PYTHAGORAS Statistické zpracování experimentálních dat Předmět 1.4 ANOVA a
UNIVERZITA PARDUBICE Fakulta chemicko-technologická, Katedra analytické chemie SEMESTRÁLNÍ PRÁCE Květen 2008 Licenční studium PYTHAGORAS Statistické zpracování experimentálních dat Předmět 1.4 ANOVA a
VŠB Technická univerzita Ostrava Fakulta elektrotechniky a informatiky
 VŠB Technická univerzita Ostrava Fakulta elektrotechniky a informatiky PRAVDĚPODOBNOST A STATISTIKA Zadání 1 JMÉNO STUDENTKY/STUDENTA: OSOBNÍ ČÍSLO: JMÉNO CVIČÍCÍ/CVIČÍCÍHO: DATUM ODEVZDÁNÍ DOMÁCÍ ÚKOL
VŠB Technická univerzita Ostrava Fakulta elektrotechniky a informatiky PRAVDĚPODOBNOST A STATISTIKA Zadání 1 JMÉNO STUDENTKY/STUDENTA: OSOBNÍ ČÍSLO: JMÉNO CVIČÍCÍ/CVIČÍCÍHO: DATUM ODEVZDÁNÍ DOMÁCÍ ÚKOL
Modul Základní statistika
 Modul Základní statistika Menu: QCExpert Základní statistika Základní statistika slouží k předběžné analýze a diagnostice dat, testování předpokladů (vlastností dat), jejichž splnění je nutné pro použití
Modul Základní statistika Menu: QCExpert Základní statistika Základní statistika slouží k předběžné analýze a diagnostice dat, testování předpokladů (vlastností dat), jejichž splnění je nutné pro použití
2 Zpracování naměřených dat. 2.1 Gaussův zákon chyb. 2.2 Náhodná veličina a její rozdělení
 2 Zpracování naměřených dat Důležitou součástí každé experimentální práce je statistické zpracování naměřených dat. V této krátké kapitole se budeme věnovat určení intervalů spolehlivosti získaných výsledků
2 Zpracování naměřených dat Důležitou součástí každé experimentální práce je statistické zpracování naměřených dat. V této krátké kapitole se budeme věnovat určení intervalů spolehlivosti získaných výsledků
Úvod do problematiky měření
 1/18 Lord Kelvin: "Když to, o čem mluvíte, můžete změřit, a vyjádřit to pomocí čísel, něco o tom víte. Ale když to nemůžete vyjádřit číselně, je vaše znalost hubená a nedostatečná. Může to být začátek
1/18 Lord Kelvin: "Když to, o čem mluvíte, můžete změřit, a vyjádřit to pomocí čísel, něco o tom víte. Ale když to nemůžete vyjádřit číselně, je vaše znalost hubená a nedostatečná. Může to být začátek
Jednofaktorová analýza rozptylu
 I I.I Jednofaktorová analýza rozptylu Úvod Jednofaktorová analýza rozptylu (ANOVA) se využívá při porovnání několika středních hodnot. Často se využívá ve vědeckých a lékařských experimentech, při kterých
I I.I Jednofaktorová analýza rozptylu Úvod Jednofaktorová analýza rozptylu (ANOVA) se využívá při porovnání několika středních hodnot. Často se využívá ve vědeckých a lékařských experimentech, při kterých
Testování hypotéz o parametrech regresního modelu
 Testování hypotéz o parametrech regresního modelu Ekonometrie Jiří Neubauer Katedra kvantitativních metod FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Jiří Neubauer (Katedra UO
Testování hypotéz o parametrech regresního modelu Ekonometrie Jiří Neubauer Katedra kvantitativních metod FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Jiří Neubauer (Katedra UO
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc.
 Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika 2010 1.týden (20.09.-24.09. ) Data, typy dat, variabilita, frekvenční analýza
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika 2010 1.týden (20.09.-24.09. ) Data, typy dat, variabilita, frekvenční analýza
UNIVERZITA PARDUBICE
 UNIVERZITA PARDUBICE Fakulta chemicko technologická Katedra analytické chemie Licenční studium chemometrie na téma Kalibrace a limity její přesnosti Vedoucí licenčního studia Prof. RNDr. Milan Meloun,
UNIVERZITA PARDUBICE Fakulta chemicko technologická Katedra analytické chemie Licenční studium chemometrie na téma Kalibrace a limity její přesnosti Vedoucí licenčního studia Prof. RNDr. Milan Meloun,
Návrh a vyhodnocení experimentu
 Návrh a vyhodnocení experimentu Návrh a vyhodnocení experimentů v procesech vývoje a řízení kvality vozidel Ing. Bohumil Kovář, Ph.D. FD ČVUT Ústav aplikované matematiky kovar@utia.cas.cz Mladá Boleslav
Návrh a vyhodnocení experimentu Návrh a vyhodnocení experimentů v procesech vývoje a řízení kvality vozidel Ing. Bohumil Kovář, Ph.D. FD ČVUT Ústav aplikované matematiky kovar@utia.cas.cz Mladá Boleslav
Uni- and multi-dimensional parametric tests for comparison of sample results
 Uni- and multi-dimensional parametric tests for comparison of sample results Jedno- a více-rozměrné parametrické testy k porovnání výsledků Prof. RNDr. Milan Meloun, DrSc. Katedra analytické chemie, Universita
Uni- and multi-dimensional parametric tests for comparison of sample results Jedno- a více-rozměrné parametrické testy k porovnání výsledků Prof. RNDr. Milan Meloun, DrSc. Katedra analytické chemie, Universita
INDUKTIVNÍ STATISTIKA
 10. SEMINÁŘ INDUKTIVNÍ STATISTIKA 3. HODNOCENÍ ZÁVISLOSTÍ HODNOCENÍ ZÁVISLOSTÍ KVALITATIVNÍ VELIČINY - Vychází se z kombinační (kontingenční) tabulky, která je výsledkem třídění druhého stupně KVANTITATIVNÍ
10. SEMINÁŘ INDUKTIVNÍ STATISTIKA 3. HODNOCENÍ ZÁVISLOSTÍ HODNOCENÍ ZÁVISLOSTÍ KVALITATIVNÍ VELIČINY - Vychází se z kombinační (kontingenční) tabulky, která je výsledkem třídění druhého stupně KVANTITATIVNÍ
Závislost obsahu lipoproteinu v krevním séru na třech faktorech ( Lineární regresní modely )
") Úloha M608 Závislost obsahu lipoproteinu v krevním séru na třech faktorech ( Lineární regresní modely ) Zadání : Při kvantitativní analýze lidského krevního séra ovlivňují hodnotu obsahu vysokohustotního
Úloha M608 Závislost obsahu lipoproteinu v krevním séru na třech faktorech ( Lineární regresní modely ) Zadání : Při kvantitativní analýze lidského krevního séra ovlivňují hodnotu obsahu vysokohustotního
8.1. Definice: Normální (Gaussovo) rozdělení N(µ, σ 2 ) s parametry µ a. ( ) ϕ(x) = 1. označovat písmenem U. Její hustota je pak.
 rozdělení N(µ, σ 2 ) s parametry µ a. ( ) ϕ(x) = 1. označovat písmenem U. Její hustota je pak.") 8. Normální rozdělení 8.. Definice: Normální (Gaussovo) rozdělení N(µ, ) s parametry µ a > 0 je rozdělení určené hustotou ( ) f(x) = (x µ) e, x (, ). Rozdělení N(0; ) s parametry µ = 0 a = se nazývá normované
8. Normální rozdělení 8.. Definice: Normální (Gaussovo) rozdělení N(µ, ) s parametry µ a > 0 je rozdělení určené hustotou ( ) f(x) = (x µ) e, x (, ). Rozdělení N(0; ) s parametry µ = 0 a = se nazývá normované
Regresní a korelační analýza
 Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
10. cvičení z PST. 5. prosince T = (n 1) S2 X. (n 1) s2 x σ 2 q χ 2 (n 1) (1 α 2 ). q χ 2 (n 1) 2. 2 x. (n 1) s. x = 1 6. x i = 457.
 S2 X. (n 1) s2 x σ 2 q χ 2 (n 1) (1 α 2 ). q χ 2 (n 1) 2. 2 x. (n 1) s. x = 1 6. x i = 457.") 0 cvičení z PST 5 prosince 208 0 (intervalový odhad pro rozptyl) Soubor (70, 84, 89, 70, 74, 70) je náhodným výběrem z normálního rozdělení N(µ, σ 2 ) Určete oboustranný symetrický 95% interval spolehlivosti
0 cvičení z PST 5 prosince 208 0 (intervalový odhad pro rozptyl) Soubor (70, 84, 89, 70, 74, 70) je náhodným výběrem z normálního rozdělení N(µ, σ 2 ) Určete oboustranný symetrický 95% interval spolehlivosti
Pravděpodobnost v závislosti na proměnné x je zde modelován pomocí logistického modelu. exp x. x x x. log 1
 Logistická regrese Menu: QCExpert Regrese Logistická Modul Logistická regrese umožňuje analýzu dat, kdy odezva je binární, nebo frekvenční veličina vyjádřená hodnotami 0 nebo 1, případně poměry v intervalu
Logistická regrese Menu: QCExpert Regrese Logistická Modul Logistická regrese umožňuje analýzu dat, kdy odezva je binární, nebo frekvenční veličina vyjádřená hodnotami 0 nebo 1, případně poměry v intervalu
SEMESTRÁLNÍ PRÁCE. Leptání plasmou. Ing. Pavel Bouchalík
 SEMESTRÁLNÍ PRÁCE Leptání plasmou Ing. Pavel Bouchalík 1. ÚVOD Tato semestrální práce obsahuje písemné vypracování řešení příkladu Leptání plasmou. Jde o praktickou zkoušku znalostí získaných při přednáškách
SEMESTRÁLNÍ PRÁCE Leptání plasmou Ing. Pavel Bouchalík 1. ÚVOD Tato semestrální práce obsahuje písemné vypracování řešení příkladu Leptání plasmou. Jde o praktickou zkoušku znalostí získaných při přednáškách
Testování hypotéz o parametrech regresního modelu
 Statistika II Katedra ekonometrie FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Lineární regresní model kde Y = Xβ + e, y 1 e 1 β y 2 Y =., e = e 2 x 11 x 1 1k., X =....... β 2,
Statistika II Katedra ekonometrie FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Lineární regresní model kde Y = Xβ + e, y 1 e 1 β y 2 Y =., e = e 2 x 11 x 1 1k., X =....... β 2,
Odhad parametrů N(µ, σ 2 )
") Odhad parametrů N(µ, σ 2 ) Mějme statistický soubor x 1, x 2,, x n modelovaný jako realizaci náhodného výběru z normálního rozdělení N(µ, σ 2 ) s neznámými parametry µ a σ. Jaký je maximální věrohodný
Odhad parametrů N(µ, σ 2 ) Mějme statistický soubor x 1, x 2,, x n modelovaný jako realizaci náhodného výběru z normálního rozdělení N(µ, σ 2 ) s neznámými parametry µ a σ. Jaký je maximální věrohodný
5 Vícerozměrná data - kontingenční tabulky, testy nezávislosti, regresní analýza
 5 Vícerozměrná data - kontingenční tabulky, testy nezávislosti, regresní analýza 5.1 Vícerozměrná data a vícerozměrná rozdělení Při zpracování vícerozměrných dat se hledají souvislosti mezi dvěma, případně
5 Vícerozměrná data - kontingenční tabulky, testy nezávislosti, regresní analýza 5.1 Vícerozměrná data a vícerozměrná rozdělení Při zpracování vícerozměrných dat se hledají souvislosti mezi dvěma, případně
Kalibrace a limity její přesnosti
 Univerzita Pardubice Fakulta chemicko-technologická Katedra analytické chemie Licenční studium GALILEO a limity její přesnosti Seminární práce Monika Vejpustková leden 2016 OBSAH Úloha 1. Lineární kalibrace...
Univerzita Pardubice Fakulta chemicko-technologická Katedra analytické chemie Licenční studium GALILEO a limity její přesnosti Seminární práce Monika Vejpustková leden 2016 OBSAH Úloha 1. Lineární kalibrace...
UNIVERZITA PARDUBICE
 UNIVERZITA PARDUBICE Fakulta chemicko-technologická Katedra analytické chemie Licenční studium chemometrie na téma Statistické zpracování dat Semestrální práce ze 6. soustředění Předmět: 3.3 Tvorba nelineárních
UNIVERZITA PARDUBICE Fakulta chemicko-technologická Katedra analytické chemie Licenční studium chemometrie na téma Statistické zpracování dat Semestrální práce ze 6. soustředění Předmět: 3.3 Tvorba nelineárních