Tomáš Karel LS 2012/2013
|
|
|
- Božena Blažková
- před 9 lety
- Počet zobrazení:
Transkript

1 Tomáš Karel LS 2012/2013

2 Vypočítejte: ?? Tomáš Karel - 4ST201 2

3 n n! 8! k (n k)! k! (8 3)! 3! (5 4321) n n! 10! k (n k)! k! (10 9)! 9! (1) ( ) Tomáš Karel - 4ST
 (9 8 7 6 5 4 3 2 1) Tomáš Karel -")
4 V populárním seriálu The Big Bang Theory (Teorie velkého třesku) jedna z hlavních postav tohoto seriálu, Sheldon Cooper, uvádí rozšíření tradiční hry kámen nůžky papír o další dva symboly tapíra a Spocka (postava ze Star Treku) celkem na pětici symbolů kámen nůžky papír tapír Spock Kolik musí být ve hře s pěti symboly stanoveno pravidel, podle kterých se vůči sobě jednotlivé symboly chovají? Např. 1) Papír balí kámen, 2) nůžky stříhají papír Tomáš Karel - 4ST

! 2! 32121 6 pravidel, určujících jak se jednotlivé symboly vůči sobě chovají: Nůžky stříhají papír")

5 Ve hře s pěti symboly musí být udáno celkem n 5 5! k 2 (5 2)! 2! pravidel, určujících jak se jednotlivé symboly vůči sobě chovají: Nůžky stříhají papír Tapír balí kámen Kámen rozdrtí Tapíra Tapír otráví Spocka Spock zničí nůžky Nůžky ustřihnou hlavu Tapírovi Tapír sní papír Papír usvědčuje Spocka Spock nechá vypařit kámen A jak je tomu zvykem, kámen tupí nůžky Tomáš Karel - 4ST

6 Statistické znaky kvantitativní kvalitativní ordinální (pořadové) měřitelné alternativní (binomické) množné Tomáš Karel - 4ST201

7 absolutní četnosti n i, i 1,2,..., k relativní četnosti p i ni n kumulativní absolutní četnosti platí: k i1 n i kumulativní relativní četnosti n n p 1n2 1 p platí: k i1 p i Tomáš Karel - 4ST201 7

8 průměr (aritmetický, geometrický, harmonický, kvadratický) modus = hodnota s nejvyšší četností a%-ní kvantil = dělí soubor uspořádaný podle velikosti (od nejnižších hodnot po nejvyšší) na prvních a% hodnot a zbývajících (100-a)% medián = prostřední hodnota v souboru uspořádaném podle velikosti = 50% kvantil dolní kvartil = 25% kvantil horní kvartil = 75% kvantil Tomáš Karel - 4ST201

9 Tomáš Karel - 4ST201

10 Jaký je průměrný počet věk vybraných spolužáků? (vypočtěte dvojím způsobem - nejdříve ze základní tabulky a poté z tabulky rozdělení četností) ze základní tabulky (prostý aritmetický průměr) x n i 1 n x i z tabulky rozdělení četností (vážený aritmetický průměr) x k i1 k i1 x i n n i i Tomáš Karel - 4ST201 10
 x k i1 k i1 x i n n")
11 POZOR NA GRAFY!!!

12 Kombinační čísla Četnosti Absolutní Relativní Kumulativní Charakteristiky úrovně Průměr Prostý aritmetický Vážený aritmetický Harmonický/vážený harmonický Medián Kvartily n k n i, i 1,2,..., k x n! ( n k)! k! n i 1 x n n x i1 i n 1 x i ni n k n n... p p absolutní i1 n p i i n 1 2 -relativní x k i1 k i1 x n i n i i k i1 p i 1 medián 21; 21; 22; 22; 22; 23; kvartil 2.kvartil

13 Prostý aritmetický průměr Při zpracování studie o průměrné výši měsíčních příjmů v České republice jsme získali data celkem od 5-ti tazatelů. Každý z těchto pěti souborů dat obsahoval údaje o deseti statistických jednotkách (respondentech - těch, kteří odpověděli). x n i 1 soubor Počet respondentů Průměr v souboru (tis. Kč) 18,5 21,2 24, ,2 n x i Vypočítejte celkovou průměrnou hodnotu ze všech získaných dat.
. x n i 1 soubor 1. 2. 3. 4. 5. Počet respondentů 10 10 10 10 10 Průměr v souboru (tis.")
14 soubor Počet respondentů Průměr v souboru (tis. Kč) 18,5 21,2 24, ,2 Prostý aritmetický průměr n xi i1 18,5 21, 2 24, , 2 109,1 x 21,82 n 5 5
 18,5 21,2 24,2 19 26,2 Prostý aritmetický")
15 Vážený aritmetický průměr x k i1 k i1 x i n n i i Při zpracování studie o průměrné výši měsíčních příjmů v České republice jsme získali data celkem od 5-ti tazatelů. Každý z těchto pěti souborů dat obsahoval odlišný počet údajů o statistických jednotkách (respondentech - těch, kteří odpověděli). soubor Počet respondentů Průměr v souboru (tis. Kč) 18,5 21,2 24, ,2 Vypočítejte celkovou průměrnou hodnotu ze všech získaných dat.
. soubor 1. 2. 3. 4. 5. Počet respondentů 10 13 15 7 5 Průměr v souboru (tis.")
16 soubor Počet respondentů - n i Průměr v souboru x i (tis. Kč) 18,5 21,2 24, ,2 Vážený aritmetický průměr k xn i i i1 18,510 21, , , ,9 x 21, 75 k n i1 i
 18,5 21,2 24,2 19 26,2 Vážený aritmetický průměr k")
17 Jak je možné, že průměrná mzda v České republice je 24,5 tis Kč a více jak 60 % obyvatel ČR má plat nižší??? Datový soubor od prvního tazatele: respondent průměr příjem 10,5 11 9,5 11,5 15,5 16, , ,5 n xi i1 10,5 11 9,5 11,5 15,5 16, ,5 63 x 18,5 n 10 Odkaz 1 Odkaz2

18 1) Seřadit podle velikosti respondent průměr příjem 9,5 10, , , ,5 16, ,5 medián průměr 63, ,0 22,5 22,0 21,5 21,0 20,5 20,0 19,5 19,0 18,5 18,0 17,5 17,0 16,5 16,0 15,5 15,0 14,5 14,0 13,5 13,0 12,5 12,0 11,5 11,0 10,5 10,0 9,5 9,0 2) Určit prostřední hodnotu x x 15 15,5 2 2 (5) (6) x0,5 x 15, 25 90% hodnot menších než průměr!!!
 Určit prostřední hodnotu x x 15 15,5 2 2 (5)")
19 1) Seřadit podle velikosti respondent průměr příjem 9,5 10, , , ,5 16,5 63,1 18,5 medián průměr 63, ,0 22,5 22,0 21,5 21,0 20,5 20,0 19,5 19,0 18,5 18,0 17,5 17,0 16,5 16,0 15,5 15,0 14,5 14,0 13,5 13,0 12,5 12,0 11,5 11,0 10,5 10,0 9,5 9,0 2) Určit 1. kvartil x 0,25 3) Určit 3. kvartil x 0,75 p p n zp n 1 x0,25 x(3) p p n zp n 1 x0,75 x(8) 16, % hodnot menších než průměr!!!
 Určit 1. kvartil x 0,25 3) Určit 3.")

20 Modus (modální hodnota) je taková hodnota, která je v souboru nejčastěji zastoupena (má největší četnost) modus medián průměr 63, ,0 22,5 22,0 21,5 21,0 20,5 20,0 19,5 19,0 18,5 18,0 17,5 17,0 16,5 16,0 15,5 15,0 14,5 14,0 13,5 13,0 12,5 12,0 11,5 11,0 10,5 10,0 9,5 9,0 Průměr 18,5 tis Kč průměrná hodnota Modus 16,5 tis Kč nejčastěji zastoupená hodnota Medián 15,25 tis Kč prostřední hodnota

21 Rozptyl směrodatná odchylka variační koeficient variační rozpětí Rozklad rozptylu vnitroskupinový rozptyl meziskupinový rozptyl Vlastnosti rozptylu
22 Sociální nůžky Představme si dvě městečka v Jihočeském kraji* Levicov a Pravicov V obou městech bylo provedeno šetření o průměrném měsíčním příjmu obyvatel. Z výzkumu vyšlo, že v obou městech je průměrný měsíční příjem stejný a to 20 tis. Kč. Zdá se, že se v průměru se daří obyvatelům obou měst stejně. Pokud se však podíváme na bodový graf podrobněji v něčem se tato města liší. Přestože průměrný příjem jejich obyvatel je stejný. Jak to ale číselně vyjádřit? průměr Pravicov průměr x 20 tis Kč x 20 tis Kč Levicov
23 Na minulém cvičení jsme se zabývali měrami polohy (průměry, medián, modus), které charakterizovaly hodnotovou úroveň souboru, typickou hodnotu v souboru apod. Často je však zapotřebí kromě typické hodnotové úrovně poznat i to, jak moc se jednotlivé hodnoty souboru od sebe odlišují (tzv. variabilitu souboru Levicov vs. Pravicov). K tomuto účelu slouží právě míry variability. Abychom zachytili vzájemnou odlišnost hodnot souboru, můžeme studovat například to, jak se jednotlivé hodnoty liší od průměru. Abychom dokázali kvantifikovat (číselně vajádřit) tuto vlastnost (tj. odlišnost hodnot souboru od průměru) můžeme zvolit několik různých přístupů. Můžeme např. studovat průměrnou absolutní odchylku hodnot souboru od průměru, nebo průměrnou kvadratickou odchylku hodnot souboru od průměru apod. Právě průměrná kvadratická odchylka hodnot souboru od průměru je základem definice rozptylu jako jedné z nejvýznamnějších měr variability souboru. Existují však samozřejmě i jiné míry variability
24 Absolutní Rozptyl kvadratická odchylka od průměru (Klasický) rozptyl známe všechny hodnoty všech jednotek 1 s (x x) n 2 2 x i n i 1 (v každém městě je pouze 10 obyvatel) Výběrový rozptyl známe pouze některé hodnoty ze souboru (v každém městě je víc jak 10 obyvatel) n s x (xi x) n1 i 1 x x Směrodatná odchylka je druhá odmocnina z rozptylu Variační rozpětí - nejvyšší hodnota mínus nejnižší s nebo s R x x max min Relativní Variační koeficient směrodatná odchylka dělená průměrem s s x x x V x,nebo V x x
25 s (x x) ( ) ( )... n x i n 1 i Pravicov 1... ( ) ( ) ( 11000) ( 11000) ) Směrodatná odchylka: Variační koeficient: Variační rozpětí: 2 6 s x s s V 0, 689 x Rozptyl: x R x x max min x x Rozptyl: 1 1 s (x x) ( ) ( )... n x i n 1 i Levicov ( ) ( ) ( 2000) ( 1000) ) 1, Směrodatná odchylka: Variační koeficient: s s 1, Variační rozpětí: x 2 6 x R x x max min s 1154 x x V x 0, 058
26 Míra variability Pravicov Levicov Výběrový rozptyl 190x10 6 1,333x10 6 Výběrová směrodatná odchylka Variační rozpětí Variační koeficient 0,689 0,058 Míra úrovně (polohy) Pravicov Levicov Průměr Medián Modus
27 Co by se stalo s mírami variability v jednotlivých městech, pokud by Česká republika vstoupila do měnové unie se směným kurzem 26 Kč/EUR?
28 Míra variability Pravicov (CZK) Levicov (CZK) Pravicov (EUR) Levicov (EUR) absolutní Výběrový rozptyl 190x10 6 1,333x Výběrová směrodatná odchylka Variační rozpětí relativní Variační koeficient 0,689 0,058 0,689 0,058 Míra úrovně (polohy) Pravicov (CZK) Levicov (CZK) Pravicov (EUR) Levicov (EUR) Průměr Medián Modus
29 Vypočítejte míry variability (rozptyl, směrodatnou odchylku), jestliže jsou údaje z předešlého příkladu zadány v relativních četnostech a známy pro celé město (=základní rozptyl). Levicov 1/10 obyvatel má příjem Kč 2/10 obyvatel má příjem Kč 4/10 obyvatel má příjem Kč 2/10 obyvatel má příjem Kč zbytek obyvatel má příjem Kč
30 Příjem Kč má: Průměr z relativních četností n x xipi i1 k k Rozptyl z relativních četností sx x x xi pi xi pi i1 i , Směrodatná odchylka s s 1, x 2 6 x
31

32
33
34
35

36
37
38
39
40
41
42
43
44
45
46
47
48 Náhodný pokus pokus, jehož výsledek se i při dodržení podmínek mění, tj. jehož výsledek závisí na náhodě (např. hod kostkou). Náhodný jev výsledek náhodného pokusu (např. na kostce padla šestka). Náhodný jev budeme značit většinou velkými písmeny, např. A, B atd. Pravděpodobnost náhodného jevu A budeme označovat jako P(A). Jev jistý (označíme např. jako nebo E) Jev, jež nastane vždy, tj. při každém opakování náhod. pokusu (např. na kostce padne nějaké číslo z 1, 2, 3, 4, 5, 6), P( ) =1 Jev nemožný (označíme jako Ø) Jev, jež nikdy nenastane (např. na kostce padne číslo 7), P(Ø ) = 0 Elementární jev nelze vyjádřit jako sjednocení (viz. další slide) dvou jevů, jež jsou různé od tohoto jevu. Doplňkový (opačný) jev k jevu A (označíme A) Jev jež nastane právě, když nenastane jev A, P( A) = 1 - P( A )

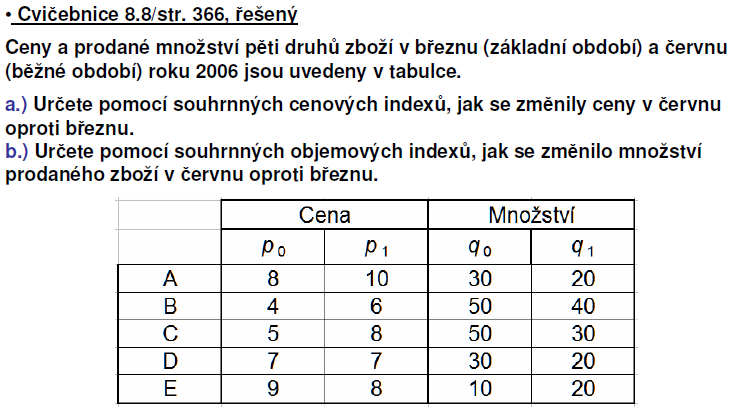
49
50 KLASICKÁ DEFINICE PRAVDĚPODOBNOSTI říká, že pravděpodobnost nějakého jevu je rovna podílu počtu výsledků, jež jsou danému jevu příznivé, ku celkovému (konečnému) počtu výsledků, jež jsou apriori stejně pravděpodobné. STATISTICKÁ DEFINICE PRAVDĚPODOBNOSTI říká, že pravděpodobnost nějakého jevu je relativní četností výskytu tohoto jevu v souboru o velké velikosti (v limitě blížící se k nekonečnu).
51
52
53 Příklad nezávislých jevů při hodu dvěma kostkami: A = na první kostce padne 1, B = na druhé kostce padne 1. Příklad závislých jevů při hodu dvěma kostkami: A = na první kostce padne 1, B = součet na obou kostkách bude 10. Jev je jevem nemožným (nemůže na první kostce padnou 1 a zároveň být součet 10), proto: ) ( ) ( ) ( B P A P B A P ) ( ) ( ) ( B P A P B A P ) ( ) ( ) ( 0 B P A P B A P
54 plocha průniku je při součtu P(A)+P(B) započítána 2x, proto jí musíme 1x odečíst pokud jevy A a B nemají průnik, nazýváme je neslučitelné (disjunktní) pokud jevy A a B jsou neslučitelné, přechází pravidlo o sčítání PP. na: ) ( ) ( ) ( ) ( B A P B P A P B A P ) ( ) ( ) ( B P A P B A P
55 Příklad neslučitelných jevů při hodu jednou kostkou: A = padne liché číslo B = padne sudé číslo 3 3 P(A B) P(A) P(B) Příklad jevů, které nejsou neslučitelné při hodu jednou kostkou: A = padne některé z čísel 1, 2, 3 nebo 4 B = padne 4, 5 nebo P(A B) P(A) P(B) P(A B)
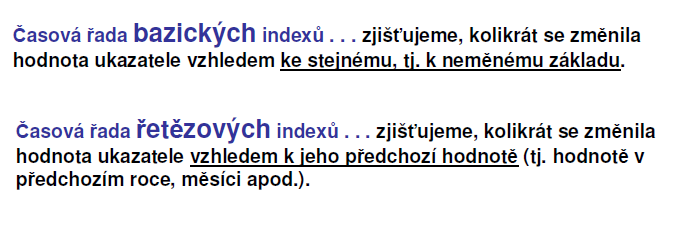
56 Jaká je pravděpodobnost, že při hodu dvěma kostkami padne: a) na obou kostkách šestka b) alespoň jedna šestka c) právě jedna šestka d) žádná šestka e) na obou kostkách sudé číslo Jev A... padla šestka na první kostce Jev B... padla šestka na druhé kostce Jev C... padlo sudé číslo na první kostce Jev D... padlo sudé číslo na druhé kostce

57

58

59

60

61
62 Z publikací Českého statistického úřadu byl převzat počet narozených chlapců a děvčat v letech Vypočítejte přibližnou pravděpodobnost, že narozené dítě bude chlapec a přibližnou pravděpodobnost, že narozené dítě bude děvče. Absolutní četnosti Rok Chlapci Děvčata Celkem Celkem
63 P(chlapec) P(chlapec) 0,514 P(celkem) P(dívka) P(dívka) 0, 486 P(celkem)
64 Na viděnou na příštím cvičení. Pokud jste něčemu nerozuměli, nebo Vám je něco nejasné, zastavte se v konzultačních hodinách nebo mi pošlete . Rád Vám nejasnosti vysvětlím. tomas.karel@vse.cz
65 Náhodný pokus pokus, jehož výsledek se i při dodržení podmínek mění, tj. jehož výsledek závisí na náhodě (např. hod kostkou). Náhodný jev výsledek náhodného pokusu (např. na kostce padla šestka). Náhodný jev budeme značit většinou velkými písmeny, např. A, B atd. Pravděpodobnost náhodného jevu A budeme označovat jako P(A). Jev jistý (označíme např. jako nebo E) Jev, jež nastane vždy, tj. při každém opakování náhod. pokusu (např. na kostce padne nějaké číslo z 1, 2, 3, 4, 5, 6), P( ) =1 Jev nemožný (označíme jako Ø) Jev, jež nikdy nenastane (např. na kostce padne číslo 7), P(Ø ) = 0 Elementární jev nelze vyjádřit jako sjednocení (viz. další slide) dvou jevů, jež jsou různé od tohoto jevu. Doplňkový (opačný) jev k jevu A (označíme ) Jev jež nastane právě, když nenastane jev A, P( A ) = 1 - P( A ) A
66 - proměnná, která v závislosti na náhodě nabývá různých hodnot - její hodnota je jednoznačně určena výsledkem náhodného pokusu, před provedením náhodného pokusu nelze určit její konkrétní hodnotu - podle typu dělíme náhodné veličiny na DISKRÉTNÍ náhodné veličiny SPOJITÉ náhodné veličiny
67 !!! Prosím rozlišujte mezi velkým X pro označení náhodné veličiny a malým x pro označení hodnoty, které veličina X nabyla!!! X = počet koupených piv v El Magicu náhodně vybraným studentem za dnešní večer (středa) (program) x = 0, 1, 2, 3, 4, 5, 6... ; diskrétní náhodná veličina X = počet pivních tácků ve stojánku, x = 2, 3, 4,.. diskrétní náhodná veličina X = počet hostů v plackárně na Blanici, x = 1, 2, 3,... ; diskrétní náhodná veličina X = počet SMS obdržených v průběhu téhle hodiny statistiky, x = 0, 1, 2, 3,... ; diskrétní náhodná veličina
68 Je pravidlo, které každé hodnotě nebo množině hodnot z každého intervalu přiřazuje pravděpodobnost, že NV nabude této hodnoty nebo hodnoty z určitého intervalu Distribuční funkce F(x) Udává pravděpodobnost, že náhodná veličina X nabude hodnoty menší nebo rovné hodnotě x F( x) P( X x) Pravděpodobnostní funkce P(x) Udává pravděpodobnost, že veličina X nabude hodnoty x. P( x) P( X x)
69 Podávají souhrnnou informaci o náhodné veličině Střední hodnota E ( X ) x P( x) x Rozptyl 2 2 D(X) EX E(X) x P(x) xp(x) x x 2 příslušné vztahy pro střední hodnotu a rozptyl náhodné veličiny též ve vzorcích z webu porovnejte s výpočtem rozptylu a průměru ze souboru dat za pomoci relativních četností Průměr x i x i p i Rozptyl s 2 x 2 xi pi xi pi i i 2
70 Nejmenovaný klub umístěný pod studentskou kolejí Vltava očekává v příštím roce čtyři možné zisky (před zdaněním) s následujícími pravděpodobnostmi: -1 mil. Kč s pravděpodobností 0,1 1 mil. Kč s pravděpodobností 0,4 2 mil. Kč s pravděpodobností 0,3 3 mil. Kč s pravděpodobností 0,2 a) Sestrojte pravděpodobnostní a distribuční funkci pro náhodnou veličinu zisk. b) Sestavte graf distribuční funkce. c) Jaká je střední hodnota zisku podniku? Co tato hodnota představuje? d) Jak byste ohodnotili nejistotu, že tento očekávaný zisk bude realizován?
71 Náhodnou veličinu zisk podniku v následujícím roce označme jako X Pravděpodobnostní funkce (zadaná tabulkou) x P(x) 0,1 0,4 0,3 0,2 F(x) 0,1 0,5 0,8 1 Distribuční funkce F(x) 0 x 1 F(x) 0,1 1 x 1 F(x) 0,5 1 x 2 F(x) 0,8 2 x 3 F(x) 1, 0 x 3
72 Distribuční funkce: Spojitá zprava Neklesající F(X) nabývá hodnot z intervalu <0;1>
73 Střední (očekávaná) hodnota zisku podniku E(X) x P(x) ( 1) 0,110, 4 20,3 30, 2 1,5 x Pokud by pravděpodobnosti jednotlivých zisků v zadání platily pro každý rok, a pokud bychom každý rok po mnoho let zaznamenávali zisky podniku, pak by se průměrný zisk za jeden rok blížil k hodnotě 1,5 mil. CZK. Neformálně řečeno: podnik je v průměru ziskový, v průměru očekáváme v dlouhodobém horizontu zisk 1,5 milion CZK za rok.
74 Nejistotu (riziko) spojené s podnikáním můžeme charakterizovat charakteristikami variability např. rozptylem D(X) náhodné veličiny X směrodatnou odchylkou s(x) náhodné veličiny X. Rozptyl D(X) můžeme počítat dvěma ekvivalentními tvary:
75 Po dosazení do druhého výpočetního tvaru získáváme D(X) E(X ) E(X) x P(x) xp(x) x x ( 1).0,1 (1).0, 4 (2).0,3 (3).0, 2 1,5 3,5 2, 25 1, 25 D(X) 1, 25 1,12 2 Pokud by pravděpodobnosti jednotlivých zisků v zadání platily pro každý rok, a pokud bychom každý rok po mnoho let zaznamenávali zisky podniku, a počítali směrodatnou odchylku těchto zisků, potom by se tato odchylka blížila 1,12 milionům CZK (s velmi velkou pravděpodobností). Řečeno jinak: očekávaná typická odchylka zisku od očekávaného zisku 1,5 milion CZK je 1,12 miliony CZK.


76 Výsledné známek z předmětu statistika byly v minulém semestru 2012/2013 popsány následující tabulkou. Výsledná známka celkem Počet studentů Určete přibližně pravděpodobnost, že náhodně vybraný student statistiky z minulého semestru získal výslednou známku: a) jedna b) lepší než tři c) prospěl d) neprospěl
77 Tabulka četností: Výsledná známka celkem Počet studentů => Tabulka rozdělení pravděpodobnosti Výsledná známka celkem pravděpodobnost 0,23 0,33 0,28 0,16 1 A) B) C) D) P(1) P(X 1) 0, 23 P(X 3) 0, 23 0,33 0,56 P(X 3) 0, 23 0,33 0, 28 0,84 P(X 4) 1 P(X 3) 10,84 0,16
78 některé náhodné veličiny mají jistý specifický tvar pravděpodobnostní funkce, resp. pravděpodobnostního rozdělení. Mezi nejznámější modelová pravděpodobnostní rozdělení náhodné veličiny patří např.: diskrétní náhodné veličiny: Alternativní Binomické Poissonovo Hypergeometrické
79 Pokus: Házíme jednou kostkou a potřebujeme, aby padla šestka. Náš pokus má tedy pouze dva výsledky (v jednom náhodném pokusu může nabýt pouze dvou hodnot) x = 1 jev nastane P(X=1)=p16 x = 0 jev nenastane P(X=0)=1-p 56 Pravděpodobnostní funkce střední hodnota rozptyl x 1 x ( x) p (1 p ) zvláštní případ binomického rozdělení pro n=1 (viz. dále) P E(X) p 1/ D(X) p(1 p) 1 0,
80 Udává pravděpodobnost úspěchu v sérii n nezávislých pokusů, z nichž každý pokus má stejnou pravděpodobnost úspěchu п (např. jaká je pravděpodobnost, že v deseti hodech kostkou padne 3x šestka) pravděpodobnostní funkce střední hodnota n 10 x 3 3 x n x 10 3 P(x) p (1 p) 1/ 6 (1 1/ 6) 0,155 E(X) np 101/ 6 1,666 rozptyl 1 1 D(X) n p(1 p) ,
81 Příklady, kdy ho použít: Obecně: výběr s vracením (z malého osudí) nebo výběr bez vracením z velkého osudí Počet úspěchů v sérii n nezávislých pokusů, z nichž každý pokus má stejnou pravděpodobnost úspěchu p. Např. jaká je pravděpodobnost, že z 15 hodů kostkou padne pětkrát trojka.
82 V osudí jsou míčky bílé barvy a míčky černé barvy. Pravděpodobnost vytažení míčku bílé barvy je 1/7. Z osudí vytáhneme náhodně jeden míček, zapíšeme si jeho barvu a míček do osudí vrátíme! Poté taháme znovu, zapíšeme si opět barvu vytaženého míčku, a míček opět do osudí vrátíme atd. Celkem takto vytáhneme s vracením 4 míčky. Určete pravděpodobnost, že a) žádný, b) Jeden c) dva z těchto 4 míčků budou bílé barvy. Poté nalezněte obecný vzorec udávající pravděpodobnost, že při vytažení celkem n míčků s vracením jich x bude bílých, pokud pravděpodobnost vytažení bílého míčku v jednom tahu je p.

83 a) b) c)
84 d)
85 Pravděpodobnost, že se narodí chlapec je 0,515. Jaká je pravděpodobnost, že mezi 7 po sobě narozenými dětmi v porodnici budou: a) první 3 děvčata a další 4 chlapci b) právě 3 děvčata?
86 a) první 3 jsou děvčata a další 4 chlapci 3 x n x 7 3 P(x) p (1 p) 0, 485 (1 0, 485) 0,008 b) právě 3 děvčata n 7 x 3 3 x n x 7 3 P(x) p (1 p) 0, 485 (1 0, 485) 0, 281
87 Udává pravděpodobnost výskytu náhodného jevu v určitém časovém intervalu Mají ho například Veličiny, které představují výskyt x událostí v pevném časovém intervalu, přičemž události musejí nastávat nezávisle od okamžiku poslední události veličiny, které mají rozdělení binomické a zároveň počet pozorování velký (n>30) a п je malé (п<0,1) pravděpodobnostní funkce P( x) x x! e střední hodnota E(X) rozptyl D(X)
88 Poissonovo rozdělení mají např. následující 2 typy náhodných veličin: 1.) Veličiny, které mají rozdělení binomické a zároveň parametr n tohoto binomického rozdělení je velký (n>30) a parametr p tohoto binomického rozdělení je malý (p<0,1). Takováto binomická veličina má přibližně také Poissonovo rozdělení, přičemž pro parametr l tohoto Poissonova rozdělení platí = np. 2.) Veličiny, jež představují výskyt x událostí v pevném časovém (případně plošném, prostorovém) intervalu, pokud známe průměrný počet událostí l, které v tomto intervalu nastávají. Navíc události musejí nastávat nezávisle od okamžiku (případně místa výskytu) poslední události. P( x) x x! e E(X) D(X)
89 Při kontrole účetních dokladů v určitém velkém průmyslovém podniku auditor, že zkušenosti ví, že lze předpokládat formální chyby u 2 % účetních dokladů. Jestliže ze souboru účetních dokladů jich auditor vybere 100, jaká je pravděpodobnost, že a) mezi nimi budou právě 2 chybné? b) ani jeden chybný? c) maximálně dva chybné? Učebnice (2.6 / str. 102, neřešený)
90
91
92
93 Student ze zkušenosti ví, že v době od 15:00 do 19:00 obdrží v průměru 3 SMSky od svých kamarádů. Dnes měl v době od 16:00 do 18:00 rozbitý mobil. a.) Jaká je pravděpodobnost, že mu kamarádi během těchto dvou hodin neposlali žádnou SMS? b.) Jaká je střední hodnota a rozptyl počtu náhodné veličiny počet příchozích SMSek v době od 16:00 do 18:00? Modifikace příkladu z učebnice (2.7 / str. 103, neřešený)
94
95 Na povrchu skla se v průměru vyskytuje 5 kazů na metr čtvereční. Jaká je pravděpodobnost, že na skleněné desce o ploše 2 metry čtvereční bude přesně 7 kazů?
96 Pravděpodobnost, že na 2 m 2 bude přesně 7 kazů je 0,09.
97 máme-li soubor N jednotek, z nichž M má určitou vlastnost a ze souboru vybíráme bez vracení n jednotek ( x výběr s vracením binomické rozdělení) pravděpodobnostní funkce střední hodnota P ( x) M E(X) n N M x N M n x N n rozptyl M M N n D(X) n 1 N N N 1
98 V osudí je 30 míčků modrých a 20 červených. Náhodně vybereme 10 míčků. Jaká je pravděpodobnost, že mezi vybranými míčky bude právě 6 červených, jestliže: a) vybíráme s vracením b) vybíráme bez vracení?
99 a) vybíráme s vracením (-> binomické rozdělení) n x x nx P(x) p (1 p) 1 0,111 b) vybíráme bez vracení? (-> hypergeometrické rozdělení) Výběr bez vracení z malého (!!) osudí. V osudí je M prvků s danou vlastností a N M prvků bez této vlastnosti. Vybíráme celkem n objektů a ptáme se, jaká je pravděpodobnost, že prvků s danou vlastností jsme vybrali právě x. n = 10; N = 50; M = 20; x = 6 M N M x n x P(x) 0,103 N 50 n 10
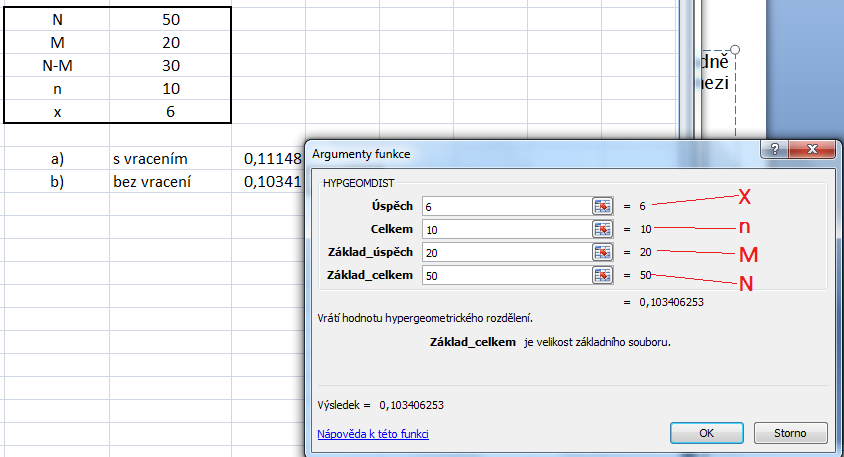
100
101 Určitý typ součástek je dodáván v sériích po 100 kusech. Při přejímací kontrole je z každé série náhodně vybráno 10 výrobků. Série je přijata, jestliže mezi kontrolovanými výrobky je maximálně 1 zmetek. Jaká je pravděpodobnost, že série bude přijata, jestliže obsahuje 8 zmetků. Kontrola je přitom prováděna tak, že kontrolovaný výrobek je podroben destrukční zkoušce. Jedná se o příklad typu výběr bez vracení z malého osudí => hypergeometrické rozdělení
102
103
104 Příklady spojitých náhodných veličin: X = výška náhodně vybraného studenta, 100 cm < x < 220 cm; X = čas, který náhodně vybraný student stráví denně na facebooku, 0 x 24 hodin; X = doba, kterou musíme čekat na obsluhu u baru v El magicu X = maximální rychlost automobilu, kterou automobil dosáhne na dálnici Jednotlivé náhodné veličiny mají různá pravděpodobnostní rozdělení Jak popsat rozdělení pravděpodobnosti pro spojitou náhodnou veličinu?
105 Distribuční funkce F(x) Distribuční funkce F(x) udává pravděpodobnost, že náhodná veličina X nabude hodnoty menší nebo rovné hodnotě x Hustota pravděpodobnosti f(x) b a f (x)dx P(a X b) F(b) F(a) Hustota pravděpodobnosti f(x) je taková funkce, že pro libovolné a < b platí:
106 Sumace byla u spojité NV zaměněna za integraci, pravděpodobnostní funkce za hustotu pravděpodobnosti Střední hodnota Rozptyl Kvantily (pouze pro spojité NV) 100p% kvantil pravd. rozdělení spojité NV je takové číslo xp pro které platí: p x p P(X x ) f (x)dx F(x ) p p
107 Normální rozdělení Normované normální rozdělení Logaritmicko normální rozdělení Chí-kvadrát Studentovo Fisherovo
108 významné rozdělení v teorii pravděpodobnosti a matematické statistiky, mnohé NV v ekonomii, technice a přírodních vědách mají přibližně normální rozdělení (zákon chyb) aproximují (nahrazují) se jím některá nespojitá rozdělení hustota pravděpodobnosti: střední hodnota: E(X ) f ( x) ( x) e 2p 2 x rozptyl: kvantily: 2 D( X ) x p u p
109 Příklady využití: tělesná výška, teplota, hmotnost chyby měření velikost chodidla
110
111 Jaká je pravděpodobnost, že náhodně vybraný muž bude mít výšku v rozmezí 170 až 185 cm? Předpokládejme přitom, že výška mužů má normální rozdělení s parametry: μ = 180 σ 2 =49 =>

112
113
114
115 Pro výpočet využijeme transformaci na normované normální rozdělení Takto transformovaná veličina se označuje jako U a má normální rozdělení s parametry μ = 0 a σ 2 =1. N(0;1) -> NORMOVANÉ NORMÁLNÍ ROZDĚLENÍ
116
 resp. na http://statistika.vse.")
117 hodnoty kvantilů normovaného normálního rozdělení jsou tabelovány v tabulkách (např. příloha učebnice Hindls a kol.) resp. na
118

119
120
121 Jaká je pravděpodobnost, že náhodně vybraná žena bude mít výšku v rozmezí 160 a 175 cm? Předpokládejme přitom, že výška žen má normální rozdělení s parametry μ = 170 a σ 2 = 36.
122
123
124 Náhodná veličina X má normální rozdělení s parametry μ = 10 a σ 2 = 25. Určete následující pravděpodobnosti a kvantily: a) P(X < 5) b) P(8<X<12) c) P(X >18) d) P(X = 5) e) X 0,975 f) X 0,05
125 Bylo zjištěno, že pevnost v tahu určitého druhu výrobku má normální rozdělení se střední hodnotou 200 jednotek a směrodatnou odchylkou 40 jednotek. Každý výrobek je před expedicí testován a ty výrobky, jejichž pevnost v tahu je větší než 220 jednotek, jsou označovány za velmi kvalitní. Jaká je pravděpodobnost vyrobení velmi kvalitního výrobku?
126 Odchylka rozměru výrobku od požadované hodnoty má normální rozdělení se střední hodnotou 0 mm a se směrodatnou odchylkou 5mm. Jaká musí být šířka intervalu normy (symetrického kolem požadované hodnoty) pro velikost výrobku, aby rozměr výrobku nepřekročil interval s pravděpodobností 0,95?
127 Statistické odhady - metody odhadování neznámých parametrů základního souboru na základě informací o charakteristikách náhodného výběru Testování statistických hypotéz induktivní postupy, které vedou k zamítnutí nebo potvrzení určitých tvrzení (hypotéz) o základním souboru
128 Biolog, matematik, informatik a statistik jsou na safari. Zastaví džíp a pozorují dalekohledem. Biolog: Podívejte se! Stádo zeber! A mezi nimi bílá zebra! To je fantastické! Existují bílé zebry! Budeme slavní! Matematik: Ve skutečnosti pouze víme, že existuje zebra, která je na jedné straně bílá. Informatik: Ale kdepak! To je výjimka! Statistik: To mě nezajímá, to není významné. Hypotézu, že bílé zebry neexistují nemůžeme na rozumné hladině významnosti zamítnout!
, rozptyl těchto výdajů (σ 2 ) apod. Velká zásilka konzerv. Zkoumaným znakem muže být např. kvalita konzerv.")
129 Základním souborem mohou být např.: Domácnosti v ČR. Zkoumaným znakem mohou být např. finanční výdaje domácností za říjen 09. Některými z parametrů tohoto základního souboru mohou být průměrné výdaje (μ ), rozptyl těchto výdajů (σ 2 ) apod. Velká zásilka konzerv. Zkoumaným znakem muže být např. kvalita konzerv. Jedním z parametrů tohoto základního souboru může být relativní četnost zkažených konzerv (p ) apod. Velký (příp. nekonečný) soubor hodnot pocházející z jistého pravděpodobnostního rozdělení se střední hodnotou μ a rozptylem σ 2 atd.
, výběrový rozptyl těchto výdajů ( ) v tomto výběrovémsouboru apod. Rozsah výběru je n = 1000. 100 konzerv náhodně vybraných z celé zásilky.")
130 Výběrovým souborem k základním souborům z předchozího slajdu může být : 1000 náhodně vybraných domácnosti v ČR. Parametry tohoto výběrového souboru jsou průměrné výdaje ( ), výběrový rozptyl těchto výdajů ( ) v tomto výběrovémsouboru apod. Rozsah výběru je n = konzerv náhodně vybraných z celé zásilky. Jedním z parametrů tohoto výběrového souboru je relativní četnost zkažených konzerv (p) v tomto výběrové m souboru. Rozsah výběru je n = 100 Několik hodnot tažených z jistého pravděpodobnostního rozdělení. Parametrem tohoto výběrového souboru je průměr, rozptyl tohoto výběrového souboru apod.
131 Bodový odhad pomocí vhodné výběrové statistiky odhadujeme skutečnou hodnotu parametru rozdělení, ze kterého hodnoty pocházejí Intervalový odhad konstruujeme co nejužší interval, který se zvolenou spolehlivostí obsahuje odhadovaný parametr

132
133
134 interval, který s předem danou spolehlivostí bude obsahovat skutečnou hodnotu některého z parametrů základního souboru
135 Sestrojme nyní interval, ve kterém bude s předem danou pravděpodobností ležet námi hledaný parametr Výběrový průměr (z normálního rozdělení) má následující rozdělení.
136
137 Interval je náhodný! Jeho význam je takový, že v (1 α).100 % případů konstrukce tohoto intervalu (pokud bychom jeho konstrukci mnohokrát opakovali z více výběrů), tento interval v sobě bude zahrnovat skutečnou hodnotu μ. Jeden konkrétní interval skutečnou hodnotu μ buď zahrnuje anebo nezahrnuje. Snižuji-li α, zvyšuji spolehlivost odhadu (pravděpodobnost, že teoretická hodnota bude v intervalu ležet), ale snižuji přesnost odhadu (neboť dostanu širší interval spolehlivosti).
138 Byla změřena výška 6 žen s následujícími výsledky 163 cm, 175 cm, 177 cm, 165 cm, 171 cm, 174 cm a.) Nalezněte bodový odhad průměrné výšky žen v celé republice. b.) Sestrojte 95% oboustranný interval spolehlivosti pro odhad průměrné výšky žen v celé republice. c.) Výšku kolika žen bychom museli změřit, abychom přiíustnou chybu intervalového odhadu průměrné výšky žen v celé republice snížili pod 1 cm. Předpokládejte, že výška jedné náhodně vybrané ženy má normální rozdělení s neznámou střední hodnotou (tu právě odhadujeme) a s rozptylem stejným jako byl rozptyl výšky jednoho náhodně vybraného muže (z 5. 2 cvičení), neboli = 49..
139 Bodový odhad průměrné výšky žen v celé republice je 170,83 cm.
140
141 Pokud budeme chtít přípustnou chybu odhadu snížit pod 1 cm (s předem zvolenou pravděpodobností 0,95),museli bychom změřit výšku alespoň 189 žen.
142 Z velké zásilky balení brambůrků Bohemia Chips bylo vybráno 5 balení a byla zjištěna jejich hmotnost. Výsledky jsou: 163 g, 159 g, 161 g, 157 g, 158 g a) nalezněte bodový odhad pro průměrnou hmotnost jednoho balení v celé zásilce b) sestrojte 99% oboustranný interval spolehlivosti pro průměrnou hmotnost jednoho balení v celé zásilce c) odhadněte, kolik váží celá zásilka, pokud víte, že obsahuje 90 balení. Předpokládejme, že rozdělení hmotnosti balení v zásilce je normální, se známým rozptylem 25.
143 Z velké zásilky balení s kukuřičnými vločkami jsme vybrali celkem 5 balení a zjistili jsme jejich hmotnost. Zde jsou výsledky: 460 gramů, 520 gramů, 490 gramů, 560 gramů, 510 gramů. a.) Nalezněte bodový odhad pro průměrnou hmotnost jednoho balení v celé zásilce. b.) Sestrojte 99% oboustranný interval spolehlivosti pro průměrnou hmotnost jednoho balení v celé zásilce. c.) Odhadněte, kolik váží celá zásilka pokud víte, že obsahuje celkem 2400 balení. Předpokládejme přitom, že rozdělení hmotností balení v zásilce je normální.
144 Bodový odhad průměrné hmotnosti zásilky s čokoládovými kuličkami je 508 g.
145

146

147 99% interval spolehlivosti pro hmotnost celé zásilky
148 Dne 25. a 26. ledna 2013 se v České republice konalo druhé kolo prezidentské volby. V závěrečném duelu se utkal Karel Schwarzenberg se pozdějším vítězem volby Milošem Zemanem. Představme si hypotetickou situaci. 200 náhodně vybraných voličů, po té co vhodilo svůj hlas do urny, bylo dotázáno, koho volilo. 110 z nich odpovědělo, že Miloše Zemana. Předpokládejme, že odpovědi jsou pravdivé, že vybraný vzorek dotázaných voličů je reprezentativním vzorkem voličů ČR a že k dispozici nejsou žádné jiné dodatečné průzkumy nebo indicie nasvědčující vítězství M. Zemana případně K. Schwarzenberga v daném místě. a.) Bodově odhadněte podíl voličů Miloše Zemana v kraji Vysočina. b.) Nalezněte 95% oboustranný interval spolehlivosti pro podíl voličů Miloše Zemana v kraji Vysočina.
149 Bodový odhad procentuelního zastoupení voličů, kteří volí M. Zemana v kraji Vysočina je 55%.
150
151 Zdroj: idnes.cz
152 statistická hypotéza je určitý předpoklad o parametrech nebo tvaru určitého rozdělení. test statistické hypotézy = postup, kterým na základě výběrových dat ověřujeme platnost dané hypotézy
153
154 Chceme otestovat, zda je mince symetrická (tj. zda orel i hlava padají se stejnou pravděpodobností). Při 150 hodech touto mincí padl 90-krát orel. Proveďte test hypotézy o symetrii mince na hladině významnosti 1 %.
155
156
157
158
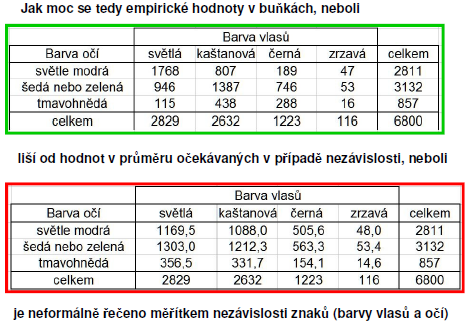
159 Mediálně známý ředitel velkého podniku tvrdí, že průměrná mzda v jeho zaměstnanců je korun. Chceme ověřit toto ředitelovo tvrzení, neboť ho podezíráme, že průměrnou mzdu nadhodnocuje. Zjistili jsme tedy mzdy 49 náhodně vybraných zaměstnanců podniku, a napočetli průměr těchto 49 mezd: korun, a výběrovou směrodatnou odchylku těchto 49 mezd: 5500 korun. Na 5 % hladině významnosti ověřte, zda je možné na základě těchto údajů zamítnout hypotézu o průměrně mzdě korun v celém podniku (tj. řečeno neformálně: vyvrátit tvrzení ředitele.)
160
161
 byly 5,3875 tun na hektar a výběrový rozptyl (výnosů napočtený z 38 polí pohnojených novým hnojivem) byl 0,2698.")
162 Bylo vybráno 73 polí stejné kvality. Na 38 z nich se zkoušel nový způsob hnojení, zbývajících 35 bylo ošetřeno běžným způsobem. Průměrné výnosy pšenice při novém způsobu hnojení (tzn. průměrné výnosy napočtené z 38 polí pohnojených novým hnojivem) byly 5,3875 tun na hektar a výběrový rozptyl (výnosů napočtený z 38 polí pohnojených novým hnojivem) byl 0,2698. Průměrné výnosy pšenice při běžném způsobu hnojení (tzn. průměrné výnosy napočtené z 35 polí pohnojených běžným hnojivem) byly 4,7 tun na hektar a výběrový rozptyl (výnosů napočtený z 35 polí pohnojených běžným hnojivem) byl 0,24. Je třeba zjistit, zda nový způsob hnojení má vliv na výnosy pšenice. MODIFIKACE příkladu z: Anděl, J: Statistické metody, 1998, matfyzpress, Vydavatelství Matematicko-fyzikální fakulty UK
163 Čím více se budou lišit výběrové průměry výnosů u nového a běžného způsobu hnojení, tím větší je šance, že nový způsob hnojení má vliv na výnosy.

164
165 ROVNOST STŘEDNÍCH HODNOT DVOU ROZDĚLENÍ
166
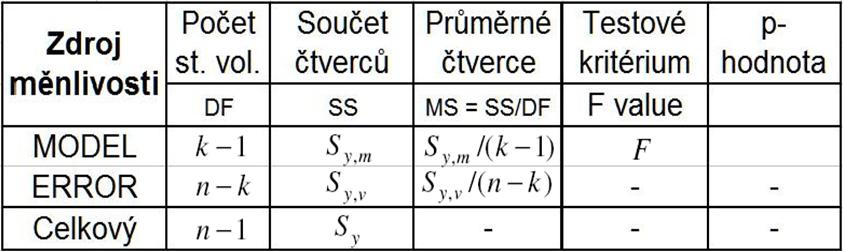
167
168 Při sledování životnosti nových baterií VTEC 3000 bylo ze souboru baterií vybráno 30 a u nich byl vypočten průměr 195 dnů. Směrodatná odchylka v základním souboru je známá a její hodnota je 20. Předpokládáme, že životnost baterií se řídí normálním rozdělením. a) sestrojte 95% oboustranný interval spolehlivosti (IS) b) Vypočtěte, jak se změní IS, pokud zvýšíme rozsah výběru na 100 baterií c) Jak se změní IS, pokud nebudeme požadovat spolehlivost 95 %, ale 99 %?

169 Prodejna potravin odebírá uzenářské výrobky od dvou dodavatelů a za důležitou považuje dobu, která uplyne od předání objednávky dodavatelům do okamžiku dodání objednaného zboží. První dodavatel byl testován ve 14 případech, průměrná doba čekání na objednané zboží byla 58 hodin při rozptylu 8,5. U druhého dodavatele uzenin bylo provedeno 11 pozorování, s průměrnou dobou 56 hodin s rozptylem 5. Na hladině významnosti 5 % ověřte hypotézu, zda mezi oběma dodavateli existuje takový rozdíl v rychlosti dodávek uzenin, který by byl pro vedení prodejny potravin podstatný.
170
171 dosud jsme se zabývali testy o parametrech nějakého rozdělení předpokládali jsme tedy, že náhodný výběr pochází z určitého rozdělení ale i tento předpoklad musíme ověřit testy o tvaru rozdělení testy dobré shody testovaná hypotéza: test shody mezi teoretickým a empirickým rozdělením četností
172 hlavní podmínky použití: nezávislost jevů velký rozsah výběrového souboru G k 2 ( n 0, ) 2 i n p i [ k np i1 0, i 1]
173 Předpokládá se, že v České republice má: 41 % obyvatel krevní skupinu A 14 % obyvatel krevní skupinu B 7 % obyvatel krevní skupinu AB 38 % obyvatel krevní skupinu 0 V jistém týdnu darovalo krev celkem 215 dárců, kteří měli následující krevní skupiny: 82 mělo krevní skupinu A 38 mělo krevní skupinu B 26 mělo krevní skupinu AB 69 mělo krevní skupinu 0 Na 1% hladině významnosti rozhodněte, zda tyto zjištěné údaje jsou v souladu s předpokladem o poměrném zastoupení krevních skupin v České republice.
174 G k 2 ( n 0, ) 2 i n p i [ k np i1 0, i 1]
175
176
177 kontingence = závislost 2 kvalitativních proměnných zkoumá závislost mezi kvalitativními znaky k ověření závislosti se používá Chí-kvadrát test nezávislosti, založený na porovnání empirických teoretických četností 1) stanovení hypotézy H 0 : X a Y jsou nezávislé H 1 : non H 0 2) výpočet testového kritéria
178 U 6800 osob byla zjišťována barva očí a vlasů. Výsledky jsou zaneseny v tabulce. Barva vlasů Barva očí světlá kaštanová černá zrzavá celkem světle modrá šedá nebo zelená tmavohnědá celkem Rozhodněte, zda barva očí a barva vlasů jsou závislé znaky.
179 kontingenční tabulka Barva vlasů Barva očí světlá kaštanová černá zrzavá celkem světle modrá n11 n12 n13 n14 n1 šedá nebo zelená n21 n22 n23 n24 n2 tmavohnědá n31 n32 n33 n34 n3 celkem n 1 n 2 n 3 n 4 n 3 obměny prvního kvalitativního znaku(barvy očí) 4 obměny druhého kvalitativního znaku(barvy vlasů)

180 pokud by znaky byly nezávislé, potom bychom v průměru očekávali následující hodnoty: Barva vlasů Barva očí světlá kaštanová černá zrzavá celkem světle modrá 1169, ,02 505,57 47, šedá nebo zelená 1303, ,27 563,30 53, tmavohnědá 356,54 331,71 154,13 14, celkem
181
182
183
184 sílu závislosti dvou kvalitativních proměnných můžeme vyjádřit pomocí: Pearsonova koeficientu kontingence: Cramérova koeficientu kontingence: pro zcela nezávislé veličiny: jsou C i V =0
185 1. vytvoření kontingenční tabulky karta Vložení kontingenční tabulka 2. očekávané relativní četnosti v případě nezávislosti 3. testová statistika G 4. Pearsonův koeficient kontingence 5. Cramérův koeficient kontingence
186 Z provedeného průzkumu máme informace o pohlaví a preferenci bydliště. Na základě těchto údajů rozhodněte, zda závisí preference trvalého bydlení na pohlaví. Bydliště Pohlaví Město Venkov Muž Žena 82 56
187 závislost kvalitativní (slovní) a kvantitativní (číselné) proměnné nejčastější případ potřebujeme posoudit, zda má na určitou kvantitativní veličinu vliv kvalitativní nebo kvantitativní faktor metoda vychází z rozkladu rozptylu (součtu čtvercových odchylek) na vnitroskupinovou a meziskupinovou variabilitu je-li uvažovaná numerická proměnná nezávislá na zmíněné kategoriální proměnné, platí, že:
188 Je třeba rozhodnout, zda varianty testu (označíme je jako A, B, C) jsou stejně náročné. Každou variantu si napsali 4 náhodně vybraní studenti. Jejich výsledky jsou zaneseny v tabulce. Rozhodněte, zda se průměrný počet bodů získaný za různé varianty testu významně liší. (Řešte ručně a v Excelu) Varianta testu Dosažené body A B C

189
190
191
192
193
194 2 P R-square 0, 2178
 proměnná jako následek regresní funkce = idealizující matematická funkce, která co nejlépe vyjadřuje charakter")
195 slouží k popisu jednostranné závislosti dvou číselných proměnných, kdy proti sobě stojí vysvětlující (nezávislá) proměnná jako pří-čina a vysvětlovaná (závislá) proměnná jako následek regresní funkce = idealizující matematická funkce, která co nejlépe vyjadřuje charakter závislosti
196 V tabulce jsou uvedeny roční náklady na údržbu (v dolarech) a cena domu (v tisících dolarů): Náklady Cena a) modelujte závislost nákladů na údržbu na ceně regresní přímkou b) zhodnoťte kvalitu modelu pomocí koeficientu determinace c) interpretujte věcně hodnotu regresního koeficientu b1 d) odhadněte střední hodnotu nákladů u domů za 80. tisíc dolarů e) ověřte pomocí testu, zda se jedná o významnou závislost
197
198
199
200
201
202 Výpočet pomocí EXCELU a metody nejmenších čtverců i y i x i x i y i x i suma průměr 425,1 77, ,3 7508,5

203 závislost nákladů na údržbu na ceně můžeme modelovat následující přímkou:
204
205 MS excel: 1) data analýza dat regrese 2) Vstupní oblast y sloupec Náklady 3) Vstupní oblast x sloupec Cena 4) Nic jiného neupravovat (max. popisky)- OK b o - konstanta b 1 směrnice přímky, regresní koeficient
206 b) zhodnoťte kvalitu modelu pomocí koeficientu determinace vztah je tím silnější a regresní funkce je tím lepší, čím více jsou empirické hodnoty vysvětlované proměnné soustředěné kolem odhadnuté regresní funkce, a naopak tím slabší, čím více jsou vzdálené od odhadnuté regresní funkce závislost y a x bude tím silnější, čím větší bude podíl rozptylu vyrovnaných hodnot na celkovém rozptylu
207

208
209 i y i x i Yi yi-yi (yi-yi)2 (yi-y_) ,68-34, , , ,42 41, , , ,49 6,51 42, , ,69 82, , , ,75 26,25 689, , ,32 47, , , ,09-34, , , ,47 15,53 241, , ,65-106, , , ,45-44, , ,01 suma , ,90 S R S y
210

211 R 2 = I 2 Index determinace Upravený index determinace
212
213 c) interpretujte věcně hodnotu regresního koeficientu b1
214 d) odhadněte střední hodnotu nákladů u domů za 80. tisíc dolarů
215 e.) Ověřte pomocí testu, zda se jedná o významnou závislost. Výběrový regresní koeficient b 1 je náhodná veličina v tom smyslu, že jeho hodnota závisí na konkrétním výběru (tj. na konkrétních datech, jimiž jsme prokládali přímku). V našem případě vyšla hodnota Teoretický regresní koeficient β 1, který neznáme (a je konstantou), může být přesto roven nule. V tom případě by mezi cenou a náklady neexistovala lineární závislost. Otestujme proto hypotézu o nulové hodnotě teoretického regresního koeficientu β 1.

216 e) ověřte pomocí testu, zda se jedná o významnou závislost
217
218
219
220
221 Test. kritérium P- hodnota Teoretický součet čtverců Reziduální součet čtverců P-hodnota 0,00 je menší než hladina významnosti (α=0,05). Zamítáme tedy nulovou hypotézu. Lineární závislost je statisticky významná. Celkový součet čtverců Na 5% hladině významnosti můžeme na základě testu o modelu zamítnout hypotézu o nulové hodnotě regresního parametru β 1. Lineární závislost je tedy statisticky významná
222 U automobilu byla měřena spotřeba benzínu v závislosti na rychlosti. Údaje jsou uvedeny v následující tabulce: Rychlost Spotřeba 5,7 5,4 5,2 5,2 5,8 6,0 7,5 8,1 a) vyrovnejte data regresní parabolou b) charakterizujte těsnost závislosti c) ověřte význam kvadratického členu v modelu d) proveďte bodový odhad spotřeby při rychlosti 80 km/h


223 Y = b o + b 1 x + b 2 x 2 = = 9,752 0,151x + 0,001x 2
224 Pro těsnost závislosti charakterizovanou indexem determinace a upraveným indexem determinace platí, že modelem bylo vysvětleno 96, 83 % veškeré variability
225
226
227 Y b b x b x 9, 752 0,151x 0, 001x ,752 0, , ,072
 zkonstruujte regresní model závislosti ceny auta na jeho stáří a počtu najetých km 2) posuďte jeho kvalitu 3) a použijte jej k odhadu")
228 Tabulka obsahuje údaje o stáří, počtu najetých km a ceně 20 ojetých aut značky Octavia Combi. 1) zkonstruujte regresní model závislosti ceny auta na jeho stáří a počtu najetých km 2) posuďte jeho kvalitu 3) a použijte jej k odhadu ceny auta starého 6 let, které má najeto 60 tis.km
229
230
231 Hodnota testového kritéria F Hladina významnosti
232
233
234
Tomáš Karel LS 2012/2013
 Tomáš Karel LS 2012/2013 Doplňkový materiál ke cvičení z předmětu 4ST201. Na případné faktické chyby v této presentaci mě prosím upozorněte. Děkuji. Tyto slidy berte pouze jako doplňkový materiál není
Tomáš Karel LS 2012/2013 Doplňkový materiál ke cvičení z předmětu 4ST201. Na případné faktické chyby v této presentaci mě prosím upozorněte. Děkuji. Tyto slidy berte pouze jako doplňkový materiál není
Doporučené příklady k procvičení k 2. Průběžnému testu
 Doporučené příklady k procvičení k 2. Průběžnému testu - Statistika v příkladech Marek a kol. (2013) - kapitola 2.3, 9 řešené příklady 2.52-2.53, 2.58a,b - kapitola 3.1 o řešené příklady: 3.1, 3.2, 3.4
Doporučené příklady k procvičení k 2. Průběžnému testu - Statistika v příkladech Marek a kol. (2013) - kapitola 2.3, 9 řešené příklady 2.52-2.53, 2.58a,b - kapitola 3.1 o řešené příklady: 3.1, 3.2, 3.4
Tomáš Karel LS 2013/2014
 Tomáš Karel LS 2013/2014 Vypočítejte: 8 3 10 9?? 1.12.2014 Tomáš Karel - 4ST201 2 n n! 8! 87654321 40320 k (n k)! k! (8 3)! 3! (5 4321) 321 1206 56 n n! 10! 109 8 7 6 5 4 3 2 1 10 k (n k)! k! (10 9)! 9!
Tomáš Karel LS 2013/2014 Vypočítejte: 8 3 10 9?? 1.12.2014 Tomáš Karel - 4ST201 2 n n! 8! 87654321 40320 k (n k)! k! (8 3)! 3! (5 4321) 321 1206 56 n n! 10! 109 8 7 6 5 4 3 2 1 10 k (n k)! k! (10 9)! 9!
Tomáš Karel LS 2012/2013
 Tomáš Karel LS 2012/2013 Doplňkový materiál ke cvičení z předmětu 4ST201. Na případné faktické chyby v této presentaci mě prosím upozorněte. Děkuji. Tyto slidy berte pouze jako doplňkový materiál není
Tomáš Karel LS 2012/2013 Doplňkový materiál ke cvičení z předmětu 4ST201. Na případné faktické chyby v této presentaci mě prosím upozorněte. Děkuji. Tyto slidy berte pouze jako doplňkový materiál není
Tomáš Karel LS 2012/2013
 Tomáš Karel LS 2012/2013 Doplňkový materiál ke cvičení z předmětu 4ST201. Na případné faktické chyby v této presentaci mě prosím upozorněte. Děkuji. Tyto slidy berte pouze jako doplňkový materiál není
Tomáš Karel LS 2012/2013 Doplňkový materiál ke cvičení z předmětu 4ST201. Na případné faktické chyby v této presentaci mě prosím upozorněte. Děkuji. Tyto slidy berte pouze jako doplňkový materiál není
Tomáš Karel LS 2012/2013
 Tomáš Karel LS 2012/2013 Doplňkový materiál ke cvičení z předmětu 4ST201. Na případné faktické chyby v této presentaci mě prosím upozorněte. Děkuji. Tyto slidy berte pouze jako doplňkový materiál není
Tomáš Karel LS 2012/2013 Doplňkový materiál ke cvičení z předmětu 4ST201. Na případné faktické chyby v této presentaci mě prosím upozorněte. Děkuji. Tyto slidy berte pouze jako doplňkový materiál není
Tomáš Karel LS 2012/2013
 Tomáš Karel LS 2012/2013 Doplňkový materiál ke cvičení z předmětu 4ST201. Na případné faktické chyby v této presentaci mě prosím upozorněte. Děkuji. Tyto slidy berte pouze jako doplňkový materiál není
Tomáš Karel LS 2012/2013 Doplňkový materiál ke cvičení z předmětu 4ST201. Na případné faktické chyby v této presentaci mě prosím upozorněte. Děkuji. Tyto slidy berte pouze jako doplňkový materiál není
Tomáš Karel LS 2012/2013
 Tomáš Karel LS 2012/2013 Doplňkový materiál ke cvičení z předmětu 4ST201. Na případné faktické chyby v této presentaci mě prosím upozorněte. Děkuji. Tyto slidy berte pouze jako doplňkový materiál není
Tomáš Karel LS 2012/2013 Doplňkový materiál ke cvičení z předmětu 4ST201. Na případné faktické chyby v této presentaci mě prosím upozorněte. Děkuji. Tyto slidy berte pouze jako doplňkový materiál není
Tomáš Karel LS 2012/2013
 Tomáš Karel LS 2012/2013 Doplňkový materiál ke cvičení ze 4ST201. Na případné faktické chyby v této prezentaci mě prosím upozorněte. Děkuji Tyto slidy berte pouze jako doplňkový materiál není v nich obsaženo
Tomáš Karel LS 2012/2013 Doplňkový materiál ke cvičení ze 4ST201. Na případné faktické chyby v této prezentaci mě prosím upozorněte. Děkuji Tyto slidy berte pouze jako doplňkový materiál není v nich obsaženo
Tomáš Karel LS 2012/2013
 Tomáš Karel LS 2012/2013 Doplňkový materiál ke cvičení z předmětu 4ST201. Na případné faktické chyby v této presentaci mě prosím upozorněte. Děkuji. Tyto slidy berte pouze jako doplňkový materiál není
Tomáš Karel LS 2012/2013 Doplňkový materiál ke cvičení z předmětu 4ST201. Na případné faktické chyby v této presentaci mě prosím upozorněte. Děkuji. Tyto slidy berte pouze jako doplňkový materiál není
tazatel 1 2 3 4 5 6 7 8 Průměr ve 15 250 18 745 21 645 25 754 28 455 32 254 21 675 35 500 Počet 110 125 100 175 200 215 200 55 respondentů Rozptyl ve
 Příklady k procvičení k průběžnému testu: 1) Při zpracování studie o průměrné výši měsíčních příjmů v České republice jsme získali data celkem od 8 tazatelů. Každý z těchto pěti souborů dat obsahoval odlišný
Příklady k procvičení k průběžnému testu: 1) Při zpracování studie o průměrné výši měsíčních příjmů v České republice jsme získali data celkem od 8 tazatelů. Každý z těchto pěti souborů dat obsahoval odlišný
Pravděpodobnost a statistika
 Pravděpodobnost a statistika Teorie pravděpodobnosti popisuje vznik náhodných dat, zatímco matematická statistika usuzuje z dat na charakter procesů, jimiž data vznikla. NÁHODNOST - forma existence látky,
Pravděpodobnost a statistika Teorie pravděpodobnosti popisuje vznik náhodných dat, zatímco matematická statistika usuzuje z dat na charakter procesů, jimiž data vznikla. NÁHODNOST - forma existence látky,
Náhodná veličina a rozdělení pravděpodobnosti
 3.2 Náhodná veličina a rozdělení pravděpodobnosti Bůh hraje se světem hru v kostky. Jsou to ale falešné kostky. Naším hlavním úkolem je zjistit, podle jakých pravidel byly označeny, a pak toho využít pro
3.2 Náhodná veličina a rozdělení pravděpodobnosti Bůh hraje se světem hru v kostky. Jsou to ale falešné kostky. Naším hlavním úkolem je zjistit, podle jakých pravidel byly označeny, a pak toho využít pro
Základy popisné statistiky
 Základy popisné statistiky Michal Fusek Ústav matematiky FEKT VUT, fusekmi@feec.vutbr.cz 8. přednáška z ESMAT Michal Fusek (fusekmi@feec.vutbr.cz) 1 / 26 Obsah 1 Základy statistického zpracování dat 2
Základy popisné statistiky Michal Fusek Ústav matematiky FEKT VUT, fusekmi@feec.vutbr.cz 8. přednáška z ESMAT Michal Fusek (fusekmi@feec.vutbr.cz) 1 / 26 Obsah 1 Základy statistického zpracování dat 2
Jiří Neubauer. Katedra ekonometrie, FVL, UO Brno kancelář 69a, tel
 Katedra ekonometrie, FVL, UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Výsledky některých náhodných pokusů jsou přímo vyjádřeny číselně (např. při hodu kostkou padne 6). Náhodnou veličinou
Katedra ekonometrie, FVL, UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Výsledky některých náhodných pokusů jsou přímo vyjádřeny číselně (např. při hodu kostkou padne 6). Náhodnou veličinou
Sever Jih Západ Plechovka Točené Sever Jih Západ Součty Plechovka Točené Součty
 Neparametrické testy (motto: Hypotézy jsou lešením, které se staví před budovu a pak se strhává, je-li budova postavena. Jsou nutné pro vědeckou práci, avšak skutečný vědec nepokládá hypotézy za předmětnou
Neparametrické testy (motto: Hypotézy jsou lešením, které se staví před budovu a pak se strhává, je-li budova postavena. Jsou nutné pro vědeckou práci, avšak skutečný vědec nepokládá hypotézy za předmětnou
Název testu Předpoklady testu Testová statistika Nulové rozdělení. ( ) (p počet odhadovaných parametrů)
 (p počet odhadovaných parametrů)") VYBRANÉ TESTY NEPARAMETRICKÝCH HYPOTÉZ TESTY DOBRÉ SHODY Název testu Předpoklady testu Testová statistika Nulové rozdělení test dobré shody Očekávané četnosti, alespoň 80% očekávaných četností >5 ( ) (p
VYBRANÉ TESTY NEPARAMETRICKÝCH HYPOTÉZ TESTY DOBRÉ SHODY Název testu Předpoklady testu Testová statistika Nulové rozdělení test dobré shody Očekávané četnosti, alespoň 80% očekávaných četností >5 ( ) (p
Matematika III. 4. října Vysoká škola báňská - Technická univerzita Ostrava. Matematika III
 Vysoká škola báňská - Technická univerzita Ostrava 4. října 2018 Podmíněná pravděpodobnost Při počítání pravděpodobnosti můžeme k náhodnému pokusu přidat i nějakou dodatečnou podmínku. Podmíněná pravděpodobnost
Vysoká škola báňská - Technická univerzita Ostrava 4. října 2018 Podmíněná pravděpodobnost Při počítání pravděpodobnosti můžeme k náhodnému pokusu přidat i nějakou dodatečnou podmínku. Podmíněná pravděpodobnost
KGG/STG Statistika pro geografy
 KGG/STG Statistika pro geografy 4. Teoretická rozdělení Mgr. David Fiedor 9. března 2015 Osnova Úvod 1 Úvod 2 3 4 5 Vybraná rozdělení náhodných proměnných normální rozdělení normované normální rozdělení
KGG/STG Statistika pro geografy 4. Teoretická rozdělení Mgr. David Fiedor 9. března 2015 Osnova Úvod 1 Úvod 2 3 4 5 Vybraná rozdělení náhodných proměnných normální rozdělení normované normální rozdělení
4ST201 STATISTIKA CVIČENÍ Č. 7
 4ST201 STATISTIKA CVIČENÍ Č. 7 testování hypotéz parametrické testy test hypotézy o střední hodnotě test hypotézy o relativní četnosti test o shodě středních hodnot testování hypotéz v MS Excel neparametrické
4ST201 STATISTIKA CVIČENÍ Č. 7 testování hypotéz parametrické testy test hypotézy o střední hodnotě test hypotézy o relativní četnosti test o shodě středních hodnot testování hypotéz v MS Excel neparametrické
Lékařská biofyzika, výpočetní technika I. Biostatistika Josef Tvrdík (doc. Ing. CSc.)
") Lékařská biofyzika, výpočetní technika I Biostatistika Josef Tvrdík (doc. Ing. CSc.) Přírodovědecká fakulta, katedra informatiky josef.tvrdik@osu.cz konzultace úterý 14.10 až 15.40 hod. http://www1.osu.cz/~tvrdik
Lékařská biofyzika, výpočetní technika I Biostatistika Josef Tvrdík (doc. Ing. CSc.) Přírodovědecká fakulta, katedra informatiky josef.tvrdik@osu.cz konzultace úterý 14.10 až 15.40 hod. http://www1.osu.cz/~tvrdik
ROZDĚLENÍ NÁHODNÝCH VELIČIN
 ROZDĚLENÍ NÁHODNÝCH VELIČIN 1 Vytvořeno s podporou projektu Průřezová inovace studijních programů Lesnické a dřevařské fakulty MENDELU v Brně (LDF) s ohledem na discipliny společného základu (reg. č. CZ.1.07/2.2.00/28.0021)
ROZDĚLENÍ NÁHODNÝCH VELIČIN 1 Vytvořeno s podporou projektu Průřezová inovace studijních programů Lesnické a dřevařské fakulty MENDELU v Brně (LDF) s ohledem na discipliny společného základu (reg. č. CZ.1.07/2.2.00/28.0021)
UNIVERZITA OBRANY Fakulta ekonomiky a managementu. Aplikace STAT1. Výsledek řešení projektu PRO HORR2011 a PRO GRAM2011 3. 11.
 UNIVERZITA OBRANY Fakulta ekonomiky a managementu Aplikace STAT1 Výsledek řešení projektu PRO HORR2011 a PRO GRAM2011 Jiří Neubauer, Marek Sedlačík, Oldřich Kříž 3. 11. 2012 Popis a návod k použití aplikace
UNIVERZITA OBRANY Fakulta ekonomiky a managementu Aplikace STAT1 Výsledek řešení projektu PRO HORR2011 a PRO GRAM2011 Jiří Neubauer, Marek Sedlačík, Oldřich Kříž 3. 11. 2012 Popis a návod k použití aplikace
Diskrétní náhodná veličina
 Lekce Diskrétní náhodná veličina Výsledek náhodného pokusu může být vyjádřen slovně to vede k zavedení pojmu náhodného jevu Výsledek náhodného pokusu můžeme někdy vyjádřit i číselně, což vede k pojmu náhodné
Lekce Diskrétní náhodná veličina Výsledek náhodného pokusu může být vyjádřen slovně to vede k zavedení pojmu náhodného jevu Výsledek náhodného pokusu můžeme někdy vyjádřit i číselně, což vede k pojmu náhodné
PRAVDĚPODOBNOST A STATISTIKA
 PRAVDĚPODOBNOST A STATISTIKA Testování hypotéz Nechť X je náhodná proměnná, která má distribuční funkci F(x, ϑ). Předpokládejme, že známe tvar distribuční funkce (víme jaké má rozdělení) a neznáme parametr
PRAVDĚPODOBNOST A STATISTIKA Testování hypotéz Nechť X je náhodná proměnná, která má distribuční funkci F(x, ϑ). Předpokládejme, že známe tvar distribuční funkce (víme jaké má rozdělení) a neznáme parametr
TECHNICKÁ UNIVERZITA V LIBERCI. Ekonomická fakulta. Semestrální práce. Statistický rozbor dat z dotazníkového šetření školní zadání
 TECHNICKÁ UNIVERZITA V LIBERCI Ekonomická fakulta Semestrální práce Statistický rozbor dat z dotazníkového šetření školní zadání Skupina: 51 Vypracovaly: Pavlína Horná, Nikola Loumová, Petra Mikešová,
TECHNICKÁ UNIVERZITA V LIBERCI Ekonomická fakulta Semestrální práce Statistický rozbor dat z dotazníkového šetření školní zadání Skupina: 51 Vypracovaly: Pavlína Horná, Nikola Loumová, Petra Mikešová,
Pravděpodobnost a aplikovaná statistika
 Pravděpodobnost a aplikovaná statistika MGR. JANA SEKNIČKOVÁ, PH.D. 2. KAPITOLA PODMÍNĚNÁ PRAVDĚPODOBNOST 3. KAPITOLA NÁHODNÁ VELIČINA 9.11.2017 Opakování Uveďte příklad aplikace geometrické definice pravděpodobnosti
Pravděpodobnost a aplikovaná statistika MGR. JANA SEKNIČKOVÁ, PH.D. 2. KAPITOLA PODMÍNĚNÁ PRAVDĚPODOBNOST 3. KAPITOLA NÁHODNÁ VELIČINA 9.11.2017 Opakování Uveďte příklad aplikace geometrické definice pravděpodobnosti
INDUKTIVNÍ STATISTIKA
 10. SEMINÁŘ INDUKTIVNÍ STATISTIKA 3. HODNOCENÍ ZÁVISLOSTÍ HODNOCENÍ ZÁVISLOSTÍ KVALITATIVNÍ VELIČINY - Vychází se z kombinační (kontingenční) tabulky, která je výsledkem třídění druhého stupně KVANTITATIVNÍ
10. SEMINÁŘ INDUKTIVNÍ STATISTIKA 3. HODNOCENÍ ZÁVISLOSTÍ HODNOCENÍ ZÁVISLOSTÍ KVALITATIVNÍ VELIČINY - Vychází se z kombinační (kontingenční) tabulky, která je výsledkem třídění druhého stupně KVANTITATIVNÍ
Určujeme neznámé hodnoty parametru základního souboru. Pomocí výběrové charakteristiky vypočtené z náhodného výběru.
 1 Statistické odhady Určujeme neznámé hodnoty parametru základního souboru. Pomocí výběrové charakteristiky vypočtené z náhodného výběru. Odhad lze provést jako: Bodový odhad o Jedna číselná hodnota Intervalový
1 Statistické odhady Určujeme neznámé hodnoty parametru základního souboru. Pomocí výběrové charakteristiky vypočtené z náhodného výběru. Odhad lze provést jako: Bodový odhad o Jedna číselná hodnota Intervalový
Základy biostatistiky II. Veřejné zdravotnictví 3.LF UK - II
 Základy biostatistiky II Veřejné zdravotnictví 3.LF UK - II Teoretické rozložení-matematické modely rozložení Naměřená data Výběrové rozložení Teoretické rozložení 1 e 2 x 2 Teoretické rozložení-matematické
Základy biostatistiky II Veřejné zdravotnictví 3.LF UK - II Teoretické rozložení-matematické modely rozložení Naměřená data Výběrové rozložení Teoretické rozložení 1 e 2 x 2 Teoretické rozložení-matematické
Pravděpodobnost a matematická statistika
 Pravděpodobnost a matematická statistika Příklady k přijímacím zkouškám na doktorské studium 1 Popisná statistika Určete aritmetický průměr dat, zadaných tabulkou hodnot x i a četností n i x i 1 2 3 n
Pravděpodobnost a matematická statistika Příklady k přijímacím zkouškám na doktorské studium 1 Popisná statistika Určete aritmetický průměr dat, zadaných tabulkou hodnot x i a četností n i x i 1 2 3 n
Statistika, Biostatistika pro kombinované studium Letní semestr 2011/2012. Tutoriál č. 4: Exploratorní analýza. Jan Kracík
 Statistika, Biostatistika pro kombinované studium Letní semestr 2011/2012 Tutoriál č. 4: Exploratorní analýza Jan Kracík jan.kracik@vsb.cz Statistika věda o získávání znalostí z empirických dat empirická
Statistika, Biostatistika pro kombinované studium Letní semestr 2011/2012 Tutoriál č. 4: Exploratorní analýza Jan Kracík jan.kracik@vsb.cz Statistika věda o získávání znalostí z empirických dat empirická
Náhodné (statistické) chyby přímých měření
 chyby přímých měření") Náhodné (statistické) chyby přímých měření Hodnoty náhodných chyb se nedají stanovit předem, ale na základě počtu pravděpodobnosti lze zjistit, která z možných naměřených hodnot je více a která je méně
Náhodné (statistické) chyby přímých měření Hodnoty náhodných chyb se nedají stanovit předem, ale na základě počtu pravděpodobnosti lze zjistit, která z možných naměřených hodnot je více a která je méně
Testování hypotéz o parametrech regresního modelu
 Testování hypotéz o parametrech regresního modelu Ekonometrie Jiří Neubauer Katedra kvantitativních metod FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Jiří Neubauer (Katedra UO
Testování hypotéz o parametrech regresního modelu Ekonometrie Jiří Neubauer Katedra kvantitativních metod FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Jiří Neubauer (Katedra UO
E(X) = np D(X) = np(1 p) 1 2p np(1 p) (n + 1)p 1 ˆx (n + 1)p. A 3 (X) =
 = np D(X) = np(1 p) 1 2p np(1 p) (n + 1)p 1 ˆx (n + 1)p. A 3 (X) =") Základní rozdělení pravděpodobnosti Diskrétní rozdělení pravděpodobnosti. Pojem Náhodná veličina s Binomickým rozdělením Bi(n, p), kde n je přirozené číslo, p je reálné číslo, < p < má pravděpodobnostní
Základní rozdělení pravděpodobnosti Diskrétní rozdělení pravděpodobnosti. Pojem Náhodná veličina s Binomickým rozdělením Bi(n, p), kde n je přirozené číslo, p je reálné číslo, < p < má pravděpodobnostní
Zápočtová práce STATISTIKA I
 Zápočtová práce STATISTIKA I Obsah: - úvodní stránka - charakteristika dat (původ dat, důvod zpracování,...) - výpis naměřených hodnot (v tabulce) - zpracování dat (buď bodové nebo intervalové, podle charakteru
Zápočtová práce STATISTIKA I Obsah: - úvodní stránka - charakteristika dat (původ dat, důvod zpracování,...) - výpis naměřených hodnot (v tabulce) - zpracování dat (buď bodové nebo intervalové, podle charakteru
Pojem a úkoly statistiky
 Katedra ekonometrie FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Pojem a úkoly statistiky Statistika je věda, která se zabývá získáváním, zpracováním a analýzou dat pro potřeby
Katedra ekonometrie FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Pojem a úkoly statistiky Statistika je věda, která se zabývá získáváním, zpracováním a analýzou dat pro potřeby
10. cvičení z PST. 5. prosince T = (n 1) S2 X. (n 1) s2 x σ 2 q χ 2 (n 1) (1 α 2 ). q χ 2 (n 1) 2. 2 x. (n 1) s. x = 1 6. x i = 457.
 S2 X. (n 1) s2 x σ 2 q χ 2 (n 1) (1 α 2 ). q χ 2 (n 1) 2. 2 x. (n 1) s. x = 1 6. x i = 457.") 0 cvičení z PST 5 prosince 208 0 (intervalový odhad pro rozptyl) Soubor (70, 84, 89, 70, 74, 70) je náhodným výběrem z normálního rozdělení N(µ, σ 2 ) Určete oboustranný symetrický 95% interval spolehlivosti
0 cvičení z PST 5 prosince 208 0 (intervalový odhad pro rozptyl) Soubor (70, 84, 89, 70, 74, 70) je náhodným výběrem z normálního rozdělení N(µ, σ 2 ) Určete oboustranný symetrický 95% interval spolehlivosti
Testování hypotéz o parametrech regresního modelu
 Statistika II Katedra ekonometrie FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Lineární regresní model kde Y = Xβ + e, y 1 e 1 β y 2 Y =., e = e 2 x 11 x 1 1k., X =....... β 2,
Statistika II Katedra ekonometrie FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Lineární regresní model kde Y = Xβ + e, y 1 e 1 β y 2 Y =., e = e 2 x 11 x 1 1k., X =....... β 2,
(motto: An unsophisticated forecaster uses statistics as a drunken man uses lamp-posts - for support rather than for illumination.
 Neparametricke testy (motto: An unsophisticated forecaster uses statistics as a drunken man uses lamp-posts - for support rather than for illumination. Andrew Lang) 1. Příklad V následující tabulce jsou
Neparametricke testy (motto: An unsophisticated forecaster uses statistics as a drunken man uses lamp-posts - for support rather than for illumination. Andrew Lang) 1. Příklad V následující tabulce jsou
MÍRY ZÁVISLOSTI (KORELACE A REGRESE)
") zhanel@fsps.muni.cz MÍRY ZÁVISLOSTI (KORELACE A REGRESE) 2.5 MÍRY ZÁVISLOSTI 2.5.1 ZÁVISLOST PEVNÁ, VOLNÁ, STATISTICKÁ A KORELAČNÍ Jednorozměrné soubory - charakterizovány jednotlivými statistickými znaky
zhanel@fsps.muni.cz MÍRY ZÁVISLOSTI (KORELACE A REGRESE) 2.5 MÍRY ZÁVISLOSTI 2.5.1 ZÁVISLOST PEVNÁ, VOLNÁ, STATISTICKÁ A KORELAČNÍ Jednorozměrné soubory - charakterizovány jednotlivými statistickými znaky
NÁHODNÁ VELIČINA. 3. cvičení
 NÁHODNÁ VELIČINA 3. cvičení Náhodná veličina Náhodná veličina funkce, která každému výsledku náhodného pokusu přiřadí reálné číslo. Je to matematický model popisující více či méně dobře realitu, který
NÁHODNÁ VELIČINA 3. cvičení Náhodná veličina Náhodná veličina funkce, která každému výsledku náhodného pokusu přiřadí reálné číslo. Je to matematický model popisující více či méně dobře realitu, který
MATEMATICKÁ STATISTIKA. Katedra matematiky a didaktiky matematiky Technická univerzita v Liberci
 MATEMATICKÁ STATISTIKA Dana Černá http://www.fp.tul.cz/kmd/ Katedra matematiky a didaktiky matematiky Technická univerzita v Liberci Matematická statistika Matematická statistika se zabývá matematickým
MATEMATICKÁ STATISTIKA Dana Černá http://www.fp.tul.cz/kmd/ Katedra matematiky a didaktiky matematiky Technická univerzita v Liberci Matematická statistika Matematická statistika se zabývá matematickým
ÚSTAV MATEMATIKY A DESKRIPTIVNÍ GEOMETRIE. Matematika 0A4. Cvičení, letní semestr DOMÁCÍ ÚLOHY. Jan Šafařík
 Vysoké učení technické v Brně Stavební fakulta ÚSTAV MATEMATIKY A DESKRIPTIVNÍ GEOMETRIE Matematika 0A4 Cvičení, letní semestr DOMÁCÍ ÚLOHY Jan Šafařík Brno c 200 (1) 120 krát jsme házeli hrací kostkou.
Vysoké učení technické v Brně Stavební fakulta ÚSTAV MATEMATIKY A DESKRIPTIVNÍ GEOMETRIE Matematika 0A4 Cvičení, letní semestr DOMÁCÍ ÚLOHY Jan Šafařík Brno c 200 (1) 120 krát jsme házeli hrací kostkou.
Vybraná rozdělení náhodné veličiny
 3.3 Vybraná rozdělení náhodné veličiny 0,16 0,14 0,12 0,1 0,08 0,06 0,04 0,02 0 Rozdělení Z 3 4 5 6 7 8 9 10 11 12 13 14 15 Život je umění vytvářet uspokojivé závěry na základě nedostatečných předpokladů.
3.3 Vybraná rozdělení náhodné veličiny 0,16 0,14 0,12 0,1 0,08 0,06 0,04 0,02 0 Rozdělení Z 3 4 5 6 7 8 9 10 11 12 13 14 15 Život je umění vytvářet uspokojivé závěry na základě nedostatečných předpokladů.
AKM CVIČENÍ. Opakování maticové algebry. Mějme matice A, B regulární, potom : ( AB) = B A
 = B A") AKM - 1-2 CVIČENÍ Opakování maticové algebry Mějme matice A, B regulární, potom : ( AB) = B A 1 1 ( A ) = ( A ) ( A ) = A ( A + B) = A + B 1 1 1 ( AB) = B A, kde A je řádu mxn a B nxk Čtvercová matice
AKM - 1-2 CVIČENÍ Opakování maticové algebry Mějme matice A, B regulární, potom : ( AB) = B A 1 1 ( A ) = ( A ) ( A ) = A ( A + B) = A + B 1 1 1 ( AB) = B A, kde A je řádu mxn a B nxk Čtvercová matice
7. Rozdělení pravděpodobnosti ve statistice
 7. Rozdělení pravděpodobnosti ve statistice Statistika nuda je, má však cenné údaje, neklesejte na mysli, ona nám to vyčíslí Jednou z úloh statistiky je odhad (výpočet) hodnot statistického znaku x i,
7. Rozdělení pravděpodobnosti ve statistice Statistika nuda je, má však cenné údaje, neklesejte na mysli, ona nám to vyčíslí Jednou z úloh statistiky je odhad (výpočet) hodnot statistického znaku x i,
31. 3. 2014, Brno Hanuš Vavrčík Základy statistiky ve vědě
 31. 3. 2014, Brno Hanuš Vavrčík Základy statistiky ve vědě Motto Statistika nuda je, má však cenné údaje. strana 3 Statistické charakteristiky Charakteristiky polohy jsou kolem ní seskupeny ostatní hodnoty
31. 3. 2014, Brno Hanuš Vavrčík Základy statistiky ve vědě Motto Statistika nuda je, má však cenné údaje. strana 3 Statistické charakteristiky Charakteristiky polohy jsou kolem ní seskupeny ostatní hodnoty
676 + 4 + 100 + 196 + 0 + 484 + 196 + 324 + 64 + 324 = = 2368
 Příklad 1 Je třeba prověřit, zda lze na 5% hladině významnosti pokládat za prokázanou hypotézu, že střední doba výroby výlisku je 30 sekund. Přitom 10 náhodně vybraných výlisků bylo vyráběno celkem 540
Příklad 1 Je třeba prověřit, zda lze na 5% hladině významnosti pokládat za prokázanou hypotézu, že střední doba výroby výlisku je 30 sekund. Přitom 10 náhodně vybraných výlisků bylo vyráběno celkem 540
Úloha č. 2 - Kvantil a typická hodnota. (bodově tříděná data): (intervalově tříděná data): Zadání úlohy: Zadání úlohy:
: (intervalově tříděná data): Zadání úlohy: Zadání úlohy:") Úloha č. 1 - Kvantily a typická hodnota (bodově tříděná data): Určete typickou hodnotu, 40% a 80% kvantil. Tabulka hodnot: Varianta Četnost 0 4 1 14 2 17 3 37 4 20 5 14 6 7 7 11 8 20 Typická hodnota je
Úloha č. 1 - Kvantily a typická hodnota (bodově tříděná data): Určete typickou hodnotu, 40% a 80% kvantil. Tabulka hodnot: Varianta Četnost 0 4 1 14 2 17 3 37 4 20 5 14 6 7 7 11 8 20 Typická hodnota je
Náhodný jev a definice pravděpodobnosti
 Náhodný jev a definice pravděpodobnosti Obsah kapitoly Náhodný jev. Vztahy mezi náhodnými jevy. Pravidla pro počítání s pravděpodobnostmi. Formule úplné pravděpodobnosti a Bayesův vzorec. Studijní cíle
Náhodný jev a definice pravděpodobnosti Obsah kapitoly Náhodný jev. Vztahy mezi náhodnými jevy. Pravidla pro počítání s pravděpodobnostmi. Formule úplné pravděpodobnosti a Bayesův vzorec. Studijní cíle
Náhodné jevy. Teorie pravděpodobnosti. Náhodné jevy. Operace s náhodnými jevy
 Teorie pravděpodobnosti Náhodný pokus skončí jedním z řady možných výsledků předem nevíme, jak skončí (náhoda) příklad: hod kostkou, zítřejší počasí,... Pravděpodobnost zkoumá náhodné jevy (mohou, ale
Teorie pravděpodobnosti Náhodný pokus skončí jedním z řady možných výsledků předem nevíme, jak skončí (náhoda) příklad: hod kostkou, zítřejší počasí,... Pravděpodobnost zkoumá náhodné jevy (mohou, ale
Diskrétní náhodná veličina. November 12, 2008
 Diskrétní náhodná veličina November 12, 2008 (Náhodná veličina (náhodná proměnná)) Náhodná veličina (nebo též náhodná proměnná) je veličina X, jejíž hodnota je jednoznačně určena výsledkem náhodného pokusu.
Diskrétní náhodná veličina November 12, 2008 (Náhodná veličina (náhodná proměnná)) Náhodná veličina (nebo též náhodná proměnná) je veličina X, jejíž hodnota je jednoznačně určena výsledkem náhodného pokusu.
TECHNICKÁ UNIVERZITA V LIBERCI
 TECHNICKÁ UNIVERZITA V LIBERCI Ekonomická fakulta Semestrální práce Statistický rozbor dat z dotazníkového šetření Počet stran: 10 Datum odevzdání: 13. 5. 2016 Pavel Kubát Obsah Úvod... 3 1 Charakterizujte
TECHNICKÁ UNIVERZITA V LIBERCI Ekonomická fakulta Semestrální práce Statistický rozbor dat z dotazníkového šetření Počet stran: 10 Datum odevzdání: 13. 5. 2016 Pavel Kubát Obsah Úvod... 3 1 Charakterizujte
Diskrétní matematika. DiM /01, zimní semestr 2016/2017
 Diskrétní matematika Petr Kovář petr.kovar@vsb.cz Vysoká škola báňská Technická univerzita Ostrava DiM 470-2301/01, zimní semestr 2016/2017 O tomto souboru Tento soubor je zamýšlen především jako pomůcka
Diskrétní matematika Petr Kovář petr.kovar@vsb.cz Vysoká škola báňská Technická univerzita Ostrava DiM 470-2301/01, zimní semestr 2016/2017 O tomto souboru Tento soubor je zamýšlen především jako pomůcka
8 Střední hodnota a rozptyl
 Břetislav Fajmon, UMAT FEKT, VUT Brno Této přednášce odpovídá kapitola 10 ze skript [1]. Také je k dispozici sbírka úloh [2], kde si můžete procvičit příklady z kapitol 2, 3 a 4. K samostatnému procvičení
Břetislav Fajmon, UMAT FEKT, VUT Brno Této přednášce odpovídá kapitola 10 ze skript [1]. Také je k dispozici sbírka úloh [2], kde si můžete procvičit příklady z kapitol 2, 3 a 4. K samostatnému procvičení
Statistické metody - nástroj poznání a rozhodování anebo zdroj omylů a lží
 Statistické metody - nástroj poznání a rozhodování anebo zdroj omylů a lží Zdeněk Karpíšek Jsou tři druhy lží: lži, odsouzeníhodné lži a statistiky. Statistika je logická a přesná metoda, jak nepřesně
Statistické metody - nástroj poznání a rozhodování anebo zdroj omylů a lží Zdeněk Karpíšek Jsou tři druhy lží: lži, odsouzeníhodné lži a statistiky. Statistika je logická a přesná metoda, jak nepřesně
STATISTIKA. Inovace předmětu. Obsah. 1. Inovace předmětu STATISTIKA... 2 2. Sylabus pro předmět STATISTIKA... 3 3. Pomůcky... 7
 Inovace předmětu STATISTIKA Obsah 1. Inovace předmětu STATISTIKA... 2 2. Sylabus pro předmět STATISTIKA... 3 3. Pomůcky... 7 1 1. Inovace předmětu STATISTIKA Předmět Statistika se na bakalářském oboru
Inovace předmětu STATISTIKA Obsah 1. Inovace předmětu STATISTIKA... 2 2. Sylabus pro předmět STATISTIKA... 3 3. Pomůcky... 7 1 1. Inovace předmětu STATISTIKA Předmět Statistika se na bakalářském oboru
Základy teorie pravděpodobnosti
 Základy teorie pravděpodobnosti Náhodná veličina Roman Biskup (zapálený) statistik ve výslužbě, aktuálně analytik v praxi ;-) roman.biskup(at)email.cz 12. února 2012 Statistika by Birom Základy teorie
Základy teorie pravděpodobnosti Náhodná veličina Roman Biskup (zapálený) statistik ve výslužbě, aktuálně analytik v praxi ;-) roman.biskup(at)email.cz 12. února 2012 Statistika by Birom Základy teorie
Statistika. Regresní a korelační analýza Úvod do problému. Roman Biskup
 Statistika Regresní a korelační analýza Úvod do problému Roman Biskup Jihočeská univerzita v Českých Budějovicích Ekonomická fakulta (Zemědělská fakulta) Katedra aplikované matematiky a informatiky 2008/2009
Statistika Regresní a korelační analýza Úvod do problému Roman Biskup Jihočeská univerzita v Českých Budějovicích Ekonomická fakulta (Zemědělská fakulta) Katedra aplikované matematiky a informatiky 2008/2009
2 ) 4, Φ 1 (1 0,005)
 4, Φ 1 (1 0,005)") Příklad 1 Ze zásilky velkého rozsahu byl náhodně vybrán soubor obsahující 1000 kusů. V tomto souboru bylo zjištěno 26 kusů nekvalitních. Rozhodněte, zda je možné s 99% jistotou tvrdit, že zásilka obsahuje
Příklad 1 Ze zásilky velkého rozsahu byl náhodně vybrán soubor obsahující 1000 kusů. V tomto souboru bylo zjištěno 26 kusů nekvalitních. Rozhodněte, zda je možné s 99% jistotou tvrdit, že zásilka obsahuje
Informační a znalostní systémy
 Informační a znalostní systémy Teorie pravděpodobnosti není v podstatě nic jiného než vyjádření obecného povědomí počítáním. P. S. de Laplace Pravděpodobnost a relativní četnost Pokusy, výsledky nejsou
Informační a znalostní systémy Teorie pravděpodobnosti není v podstatě nic jiného než vyjádření obecného povědomí počítáním. P. S. de Laplace Pravděpodobnost a relativní četnost Pokusy, výsledky nejsou
Charakteristika datového souboru
 Zápočtová práce z předmětu Statistika Vypracoval: 10. 11. 2014 Charakteristika datového souboru Zadání: Při kontrole dodržování hygienických norem v kuchyni se prováděl odběr vzduchu a pomocí filtru Pallflex
Zápočtová práce z předmětu Statistika Vypracoval: 10. 11. 2014 Charakteristika datového souboru Zadání: Při kontrole dodržování hygienických norem v kuchyni se prováděl odběr vzduchu a pomocí filtru Pallflex
pravděpodobnosti Pravděpodobnost je teorií statistiky a statistika je praxí teorie pravděpodobnosti.
 3.1 Základy teorie pravděpodobnosti Pravděpodobnost je teorií statistiky a statistika je praxí teorie pravděpodobnosti. Co se dozvíte Náhodný pokus a náhodný jev. Pravděpodobnost, počítání s pravděpodobnostmi.
3.1 Základy teorie pravděpodobnosti Pravděpodobnost je teorií statistiky a statistika je praxí teorie pravděpodobnosti. Co se dozvíte Náhodný pokus a náhodný jev. Pravděpodobnost, počítání s pravděpodobnostmi.
Mnohorozměrná statistická data
 Mnohorozměrná statistická data Ekonometrie Jiří Neubauer Katedra ekonometrie FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Jiří Neubauer (Katedra ekonometrie UO Brno) Mnohorozměrná
Mnohorozměrná statistická data Ekonometrie Jiří Neubauer Katedra ekonometrie FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Jiří Neubauer (Katedra ekonometrie UO Brno) Mnohorozměrná
Inženýrská statistika pak představuje soubor postupů a aplikací teoretických principů v oblasti inženýrské činnosti.
 Přednáška č. 1 Úvod do statistiky a počtu pravděpodobnosti Statistika Statistika je věda a postup jak rozvíjet lidské znalosti použitím empirických dat. Je založena na matematické statistice, která je
Přednáška č. 1 Úvod do statistiky a počtu pravděpodobnosti Statistika Statistika je věda a postup jak rozvíjet lidské znalosti použitím empirických dat. Je založena na matematické statistice, která je
Kontingenční tabulky, korelační koeficienty
 Statistika II Katedra ekonometrie FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Mějme kategoriální proměnné X a Y. Vytvoříme tzv. kontingenční tabulku. Budeme tedy testovat hypotézu
Statistika II Katedra ekonometrie FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Mějme kategoriální proměnné X a Y. Vytvoříme tzv. kontingenční tabulku. Budeme tedy testovat hypotézu
veličin, deskriptivní statistika Ing. Michael Rost, Ph.D.
 Vybraná rozdělení spojitých náhodných veličin, deskriptivní statistika Ing. Michael Rost, Ph.D. Třídění Základním zpracováním dat je jejich třídění. Jde o uspořádání získaných dat, kde volba třídícího
Vybraná rozdělení spojitých náhodných veličin, deskriptivní statistika Ing. Michael Rost, Ph.D. Třídění Základním zpracováním dat je jejich třídění. Jde o uspořádání získaných dat, kde volba třídícího
Náhodné chyby přímých měření
 Náhodné chyby přímých měření Hodnoty náhodných chyb se nedají stanovit předem, ale na základě počtu pravděpodobnosti lze zjistit, která z možných naměřených hodnot je více a která je méně pravděpodobná.
Náhodné chyby přímých měření Hodnoty náhodných chyb se nedají stanovit předem, ale na základě počtu pravděpodobnosti lze zjistit, která z možných naměřených hodnot je více a která je méně pravděpodobná.
Cvičící Kuba Kubina Kubinčák Body u závěrečného testu
 1. Příklad U 12 studentů jsme sledovali počet dosažených bodů na závěrečném testu (od 0 do 60). Vždy 4 z těchto studentů chodili k jednomu ze 3 cvičících panu Kubovi, panu Kubinovi, nebo panu Kubinčákovi.
1. Příklad U 12 studentů jsme sledovali počet dosažených bodů na závěrečném testu (od 0 do 60). Vždy 4 z těchto studentů chodili k jednomu ze 3 cvičících panu Kubovi, panu Kubinovi, nebo panu Kubinčákovi.
PRAVDĚPODOBNOST A JEJÍ UŽITÍ
 PRAVDĚPODOBNOST A JEJÍ UŽITÍ Základním pojmem teorie pravděpodobnosti je náhodný jev. náhodný jev : výsledek nějaké činnosti nebo pokusu, o němž má smysl prohlásit že nastal nebo ne. Náhodné jevy se označují
PRAVDĚPODOBNOST A JEJÍ UŽITÍ Základním pojmem teorie pravděpodobnosti je náhodný jev. náhodný jev : výsledek nějaké činnosti nebo pokusu, o němž má smysl prohlásit že nastal nebo ne. Náhodné jevy se označují
Technická univerzita v Liberci
 Technická univerzita v Liberci Ekonomická fakulta Analýza výsledků z dotazníkového šetření Jména studentů: Adam Pavlíček Michal Karlas Tomáš Vávra Anna Votavová Ročník: 2015/2016 Datum odevzdání: 13/05/2016
Technická univerzita v Liberci Ekonomická fakulta Analýza výsledků z dotazníkového šetření Jména studentů: Adam Pavlíček Michal Karlas Tomáš Vávra Anna Votavová Ročník: 2015/2016 Datum odevzdání: 13/05/2016
JEDNOVÝBĚROVÉ TESTY. Komentované řešení pomocí programu Statistica
 JEDNOVÝBĚROVÉ TESTY Komentované řešení pomocí programu Statistica Vstupní data Data umístěná v excelovském souboru překopírujeme do tabulky ve Statistice a pojmenujeme proměnné, viz prezentace k tématu
JEDNOVÝBĚROVÉ TESTY Komentované řešení pomocí programu Statistica Vstupní data Data umístěná v excelovském souboru překopírujeme do tabulky ve Statistice a pojmenujeme proměnné, viz prezentace k tématu
Praktická statistika. Petr Ponížil Eva Kutálková
 Praktická statistika Petr Ponížil Eva Kutálková Zápis výsledků měření Předpokládejme, že známe hodnotu napětí U = 238,9 V i její chybu 3,3 V. Hodnotu veličiny zapíšeme na tolik míst, aby až poslední bylo
Praktická statistika Petr Ponížil Eva Kutálková Zápis výsledků měření Předpokládejme, že známe hodnotu napětí U = 238,9 V i její chybu 3,3 V. Hodnotu veličiny zapíšeme na tolik míst, aby až poslední bylo
Statistika pro geografy
 Statistika pro geografy 2. Popisná statistika Mgr. David Fiedor 23. února 2015 Osnova 1 2 3 Pojmy - Bodové rozdělení četností Absolutní četnost Absolutní četností hodnoty x j znaku x rozumíme počet statistických
Statistika pro geografy 2. Popisná statistika Mgr. David Fiedor 23. února 2015 Osnova 1 2 3 Pojmy - Bodové rozdělení četností Absolutní četnost Absolutní četností hodnoty x j znaku x rozumíme počet statistických
You created this PDF from an application that is not licensed to print to novapdf printer (http://www.novapdf.com)
") Testování statistických hypotéz Testování statistických hypotéz Princip: Ověřování určitého předpokladu zjišťujeme, zda zkoumaný výběr pochází ze základního souboru, který má určité rozdělení zjišťujeme,
Testování statistických hypotéz Testování statistických hypotéz Princip: Ověřování určitého předpokladu zjišťujeme, zda zkoumaný výběr pochází ze základního souboru, který má určité rozdělení zjišťujeme,
Kontingenční tabulky, korelační koeficienty
 Statistika II Katedra ekonometrie FVL UO Brno kancelář 69a, tel 973 442029 email:jirineubauer@unobcz Budeme předpokládat, že X a Y jsou kvalitativní náhodné veličiny, obor hodnot X obsahuje r hodnot (kategorií,
Statistika II Katedra ekonometrie FVL UO Brno kancelář 69a, tel 973 442029 email:jirineubauer@unobcz Budeme předpokládat, že X a Y jsou kvalitativní náhodné veličiny, obor hodnot X obsahuje r hodnot (kategorií,
5 Vícerozměrná data - kontingenční tabulky, testy nezávislosti, regresní analýza
 5 Vícerozměrná data - kontingenční tabulky, testy nezávislosti, regresní analýza 5.1 Vícerozměrná data a vícerozměrná rozdělení Při zpracování vícerozměrných dat se hledají souvislosti mezi dvěma, případně
5 Vícerozměrná data - kontingenční tabulky, testy nezávislosti, regresní analýza 5.1 Vícerozměrná data a vícerozměrná rozdělení Při zpracování vícerozměrných dat se hledají souvislosti mezi dvěma, případně
Statistika (KMI/PSTAT)
") Statistika (KMI/PSTAT) Cvičení dvanácté aneb Regrese a korelace Statistika (KMI/PSTAT) 1 / 18 V souboru 25 jedinců jsme měřili jejich výšku a hmotnost. Výsledky jsou v tabulce a grafu. Statistika (KMI/PSTAT)
Statistika (KMI/PSTAT) Cvičení dvanácté aneb Regrese a korelace Statistika (KMI/PSTAT) 1 / 18 V souboru 25 jedinců jsme měřili jejich výšku a hmotnost. Výsledky jsou v tabulce a grafu. Statistika (KMI/PSTAT)
Matematika III. 27. listopadu Vysoká škola báňská - Technická univerzita Ostrava. Matematika III
 Vysoká škola báňská - Technická univerzita Ostrava 27. listopadu 2017 Typy statistických znaků (proměnných) Typy proměnných: Kvalitativní proměnná (kategoriální, slovní,... ) Kvantitativní proměnná (numerická,
Vysoká škola báňská - Technická univerzita Ostrava 27. listopadu 2017 Typy statistických znaků (proměnných) Typy proměnných: Kvalitativní proměnná (kategoriální, slovní,... ) Kvantitativní proměnná (numerická,
Mnohorozměrná statistická data
 Statistika II Katedra ekonometrie FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Statistický znak, statistický soubor Jednotlivé objekty nebo subjekty, které jsou při statistickém
Statistika II Katedra ekonometrie FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Statistický znak, statistický soubor Jednotlivé objekty nebo subjekty, které jsou při statistickém
PRAVDĚPODOBNOST A STATISTIKA 1 Metodický list č 1.
 Metodický list č 1. Název tématického celku: Elementární statistické zpracování 1 - Kolekce a interpretace statistických dat, základní pojmy deskriptivní statistiky. Cíl: Základním cílem tohoto tematického
Metodický list č 1. Název tématického celku: Elementární statistické zpracování 1 - Kolekce a interpretace statistických dat, základní pojmy deskriptivní statistiky. Cíl: Základním cílem tohoto tematického
Střední hodnota a rozptyl náhodné. kvantilu. Ing. Michael Rost, Ph.D.
 Střední hodnota a rozptyl náhodné veličiny, vybraná rozdělení diskrétních a spojitých náhodných veličin, pojem kvantilu Ing. Michael Rost, Ph.D. Príklad Předpokládejme že máme náhodnou veličinu X která
Střední hodnota a rozptyl náhodné veličiny, vybraná rozdělení diskrétních a spojitých náhodných veličin, pojem kvantilu Ing. Michael Rost, Ph.D. Príklad Předpokládejme že máme náhodnou veličinu X která
Testování statistických hypotéz
 Testování statistických hypotéz 1 Testování statistických hypotéz 1 Statistická hypotéza a její test V praxi jsme nuceni rozhodnout, zda nějaké tvrzeni o parametrech náhodných veličin nebo o veličině samotné
Testování statistických hypotéz 1 Testování statistických hypotéz 1 Statistická hypotéza a její test V praxi jsme nuceni rozhodnout, zda nějaké tvrzeni o parametrech náhodných veličin nebo o veličině samotné
ANALÝZA DAT V R 3. POPISNÉ STATISTIKY, NÁHODNÁ VELIČINA. Mgr. Markéta Pavlíková Katedra pravděpodobnosti a matematické statistiky MFF UK
 ANALÝZA DAT V R 3. POPISNÉ STATISTIKY, NÁHODNÁ VELIČINA Mgr. Markéta Pavlíková Katedra pravděpodobnosti a matematické statistiky MFF UK www.biostatisticka.cz POPISNÉ STATISTIKY - OPAKOVÁNÍ jedna kvalitativní
ANALÝZA DAT V R 3. POPISNÉ STATISTIKY, NÁHODNÁ VELIČINA Mgr. Markéta Pavlíková Katedra pravděpodobnosti a matematické statistiky MFF UK www.biostatisticka.cz POPISNÉ STATISTIKY - OPAKOVÁNÍ jedna kvalitativní
22. Pravděpodobnost a statistika
 22. Pravděpodobnost a statistika Pravděpodobnost náhodných jevů. Klasická pravděpodobnost. Statistický soubor, statistické jednotky, statistické znaky. Četnosti, jejich rozdělení a grafické znázornění.
22. Pravděpodobnost a statistika Pravděpodobnost náhodných jevů. Klasická pravděpodobnost. Statistický soubor, statistické jednotky, statistické znaky. Četnosti, jejich rozdělení a grafické znázornění.
Testování statistických hypotéz
 Testování statistických hypotéz Na základě náhodného výběru, který je reprezentativním vzorkem základního souboru (který přesně neznáme, k němuž se ale daná statistická hypotéza váže), potřebujeme ověřit,
Testování statistických hypotéz Na základě náhodného výběru, který je reprezentativním vzorkem základního souboru (který přesně neznáme, k němuž se ale daná statistická hypotéza váže), potřebujeme ověřit,
Cvičení ze statistiky - 5. Filip Děchtěrenko
 Cvičení ze statistiky - 5 Filip Děchtěrenko Minule bylo.. Začali jsme pravděpodobnost Klasická a statistická definice pravděpodobnosti Náhodný jev Doplněk, průnik, sjednocení Podmíněná pravděpodobnost
Cvičení ze statistiky - 5 Filip Děchtěrenko Minule bylo.. Začali jsme pravděpodobnost Klasická a statistická definice pravděpodobnosti Náhodný jev Doplněk, průnik, sjednocení Podmíněná pravděpodobnost
Všechno, co jste chtěli vědět z teorie pravděpodobnosti, z teorie informace a
 Všechno, co jste chtěli vědět z teorie pravděpodobnosti, z teorie informace a báli jste se zeptat Jedinečnou funkcí statistiky je, že umožňuje vědci číselně vyjádřit nejistotu v jeho závěrech. (G. W. Snedecor)
Všechno, co jste chtěli vědět z teorie pravděpodobnosti, z teorie informace a báli jste se zeptat Jedinečnou funkcí statistiky je, že umožňuje vědci číselně vyjádřit nejistotu v jeho závěrech. (G. W. Snedecor)
12. cvičení z PST. 20. prosince 2017
 1 cvičení z PST 0 prosince 017 11 test rozptylu normálního rozdělení Do laboratoře bylo odesláno n = 5 stejných vzorků krve ke stanovení obsahu alkoholu X v promilích alkoholu Výsledkem byla realizace
1 cvičení z PST 0 prosince 017 11 test rozptylu normálního rozdělení Do laboratoře bylo odesláno n = 5 stejných vzorků krve ke stanovení obsahu alkoholu X v promilích alkoholu Výsledkem byla realizace
Příklad 1. Řešení 1 ŘEŠENÉ PŘÍKLADY Z MV2 ČÁST 11
 Příklad 1 Vyhláška Ministerstva zdravotnictví předpokládala, že doba dojezdu k pacientovi od nahlášení požadavku nepřekročí 17 minut. Hodnoty deseti náhodně vybraných dob příjezdu sanitky k nemocnému byly:
Příklad 1 Vyhláška Ministerstva zdravotnictví předpokládala, že doba dojezdu k pacientovi od nahlášení požadavku nepřekročí 17 minut. Hodnoty deseti náhodně vybraných dob příjezdu sanitky k nemocnému byly:
{ } ( 2) Příklad: Test nezávislosti kategoriálních znaků
 Příklad: Test nezávislosti kategoriálních znaků") Příklad: Test nezávislosti kategoriálních znaků Určete na hladině významnosti 5 % na základě dat zjištěných v rámci dotazníkového šetření ve Šluknově, zda existuje závislost mezi pohlavím respondenta a
Příklad: Test nezávislosti kategoriálních znaků Určete na hladině významnosti 5 % na základě dat zjištěných v rámci dotazníkového šetření ve Šluknově, zda existuje závislost mezi pohlavím respondenta a
Pravděpodobnost a její vlastnosti
 Pravděpodobnost a její vlastnosti 1 Pravděpodobnost a její vlastnosti Náhodné jevy Náhodný jev je výsledek pokusu (tj. realizace určitého systému podmínek) a jeho charakteristickým rysem je, že může, ale
Pravděpodobnost a její vlastnosti 1 Pravděpodobnost a její vlastnosti Náhodné jevy Náhodný jev je výsledek pokusu (tj. realizace určitého systému podmínek) a jeho charakteristickým rysem je, že může, ale
Pracovní list č. 3 Charakteristiky variability
 1. Při zjišťování počtu nezletilých dětí ve třiceti vybraných rodinách byly získány tyto výsledky: 1, 1, 0, 2, 3, 4, 2, 2, 3, 0, 1, 2, 2, 4, 3, 3, 0, 1, 1, 1, 2, 2, 0, 2, 1, 1, 2, 3, 3, 2. Uspořádejte
1. Při zjišťování počtu nezletilých dětí ve třiceti vybraných rodinách byly získány tyto výsledky: 1, 1, 0, 2, 3, 4, 2, 2, 3, 0, 1, 2, 2, 4, 3, 3, 0, 1, 1, 1, 2, 2, 0, 2, 1, 1, 2, 3, 3, 2. Uspořádejte
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc.
 Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika 2010 1.týden (20.09.-24.09. ) Data, typy dat, variabilita, frekvenční analýza
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika 2010 1.týden (20.09.-24.09. ) Data, typy dat, variabilita, frekvenční analýza
Číselné charakteristiky
 . Číselné charakteristiky statistických dat Průměrný statistik se během svého života ožení s 1,75 ženami, které se ho snaží vytáhnout večer do společnosti,5 x týdně, ale pouze s 50% úspěchem. W. F. Miksch
. Číselné charakteristiky statistických dat Průměrný statistik se během svého života ožení s 1,75 ženami, které se ho snaží vytáhnout večer do společnosti,5 x týdně, ale pouze s 50% úspěchem. W. F. Miksch
4. ZÁKLADNÍ TYPY ROZDĚLENÍ PRAVDĚPODOBNOSTI DISKRÉTNÍ NÁHODNÉ VELIČINY
 4. ZÁKLADNÍ TYPY ROZDĚLENÍ PRAVDĚPODOBNOSTI DISKRÉTNÍ NÁHODNÉ VELIČINY Průvodce studiem V této kapitole se seznámíte se základními typy rozložení diskrétní náhodné veličiny. Vašim úkolem by neměla být
4. ZÁKLADNÍ TYPY ROZDĚLENÍ PRAVDĚPODOBNOSTI DISKRÉTNÍ NÁHODNÉ VELIČINY Průvodce studiem V této kapitole se seznámíte se základními typy rozložení diskrétní náhodné veličiny. Vašim úkolem by neměla být