STATISTICKÉ ŘÍZENÍ PROCESŮ SE SW PODPOROU
|
|
|
- Eduard Pospíšil
- před 9 lety
- Počet zobrazení:
Transkript
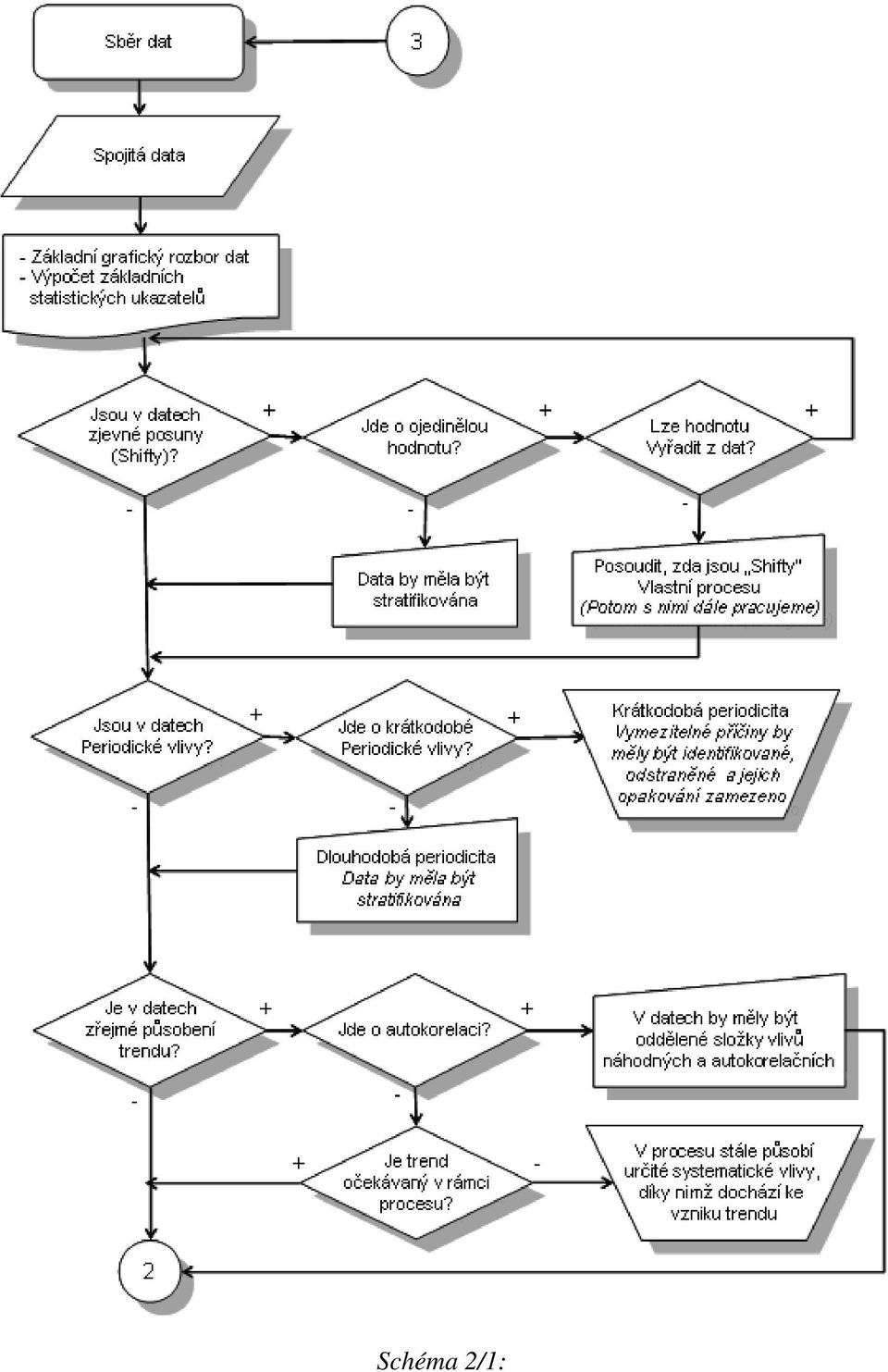
1 STATISTICKÉ ŘÍZENÍ PROCESŮ SE SW PODPOROU RNDr. Jiří Michálek, CSc. Centrum pro kvalitu a spolehlivost CQR při Ústavu teorie informace a automatizace AVČR michalek@utia.cas.cz Ing. Jan Král ISQ PRAHA s.r.o., Pechlátova 9, Praha 5, tel./fax: ; kral.jan@isq.cz Klíčová slova: SPC, regulační diagramy; metody statistické regulace; statisticky zvládnutý proces; rozšířené (modifikované) regulační meze. Metodická schémata pro aplikaci SPC Cílem těchto schémat je poskytnout lidem z praxe ověřené a teoreticky podložené postupy, kterých by se měli držet při používání statistických nástrojů pro řízení a sledování znaků jakosti na výrobku. Jde totiž o to, aby se grafické a numerické výsledky statistické analýzy skutečně vztahovaly k reálné situaci, která panuje ve výrobním procesu. Schéma ve formě vývojového diagramu ukazuje základní vztah mezi daty získanými při sledování výrobního procesu a možnostmi použití nástrojů pro SPC. Z procesu lze na výrobku získávat data dvojí povahy. Jednak jsou to data diskrétní povahy, která vyjadřují buď počet neshodných výrobků či počet neshod. Hovoříme taktéž o atributivních datech. Druhým typem dat jsou data spojitého charakteru, které obvykle nesou více informace o stavu procesu nežli data atributivní. Při analýze diskrétních dat se obvykle problémy nevyskytují, zde stačí použít binomické či Poissonovo rozdělení pro jejich analýzu, větší problémy nastávají u dat spojité povahy, neboť tam je nutno najít vhodný statistický model neboli rozdělení pravděpodobnosti obvykle ve formě hustoty, který nám pomůže s daty správně pracovat. Je tedy zapotřebí ověřit splnění základních požadavků pro správnou aplikaci nástrojů SPC, aby statistická analýza dávala relevantní výsledky, protože zcela formální postup bez ověření předpokladů, které matematická statistika vyžaduje, může přinést zcela nereálnou představu o stavu výrobního procesu. Prvním krokem je samozřejmě sběr dat (viz Schéma ). Bez nich se nelze nic dozvědět o stavu výrobního procesu. tento krok je velice důležitý, protože od kvality dat se vše ostatní odvíjí. Před vlastním odběrem dat z procesu je nutno rozhodnout, která data budeme získávat, jak je budeme měřit či zjišťovat, kdo bude sběr provádět, jak často, kam se data budou zapisovat či ukládat, jaké množství dat bude zapotřebí, aby data přinesla žádanou informaci, jaký problém chceme pomocí dat řešit či k čemu budeme data potřebovat. S tím úzce souvisí samozřejmě i analýza systému měření, především reprodukovatelnost a opakovatelnost, přesnost měření na dostatečný počet desetinných míst a též zaškolení pracovníků hlavně při využívání výpočetní techniky spolu s nějakým softwarem. Podle charakteru dat hovoříme o SPC měřením či SPC srovnáváním. Platí doporučení, pokud lze informaci získat měřením, je to vždy výhodnější především z pohledu počtu získávaných dat nežli při SPC srovnáváním, i když při srovnávání jsou data získávána obvykle snazším způsobem.

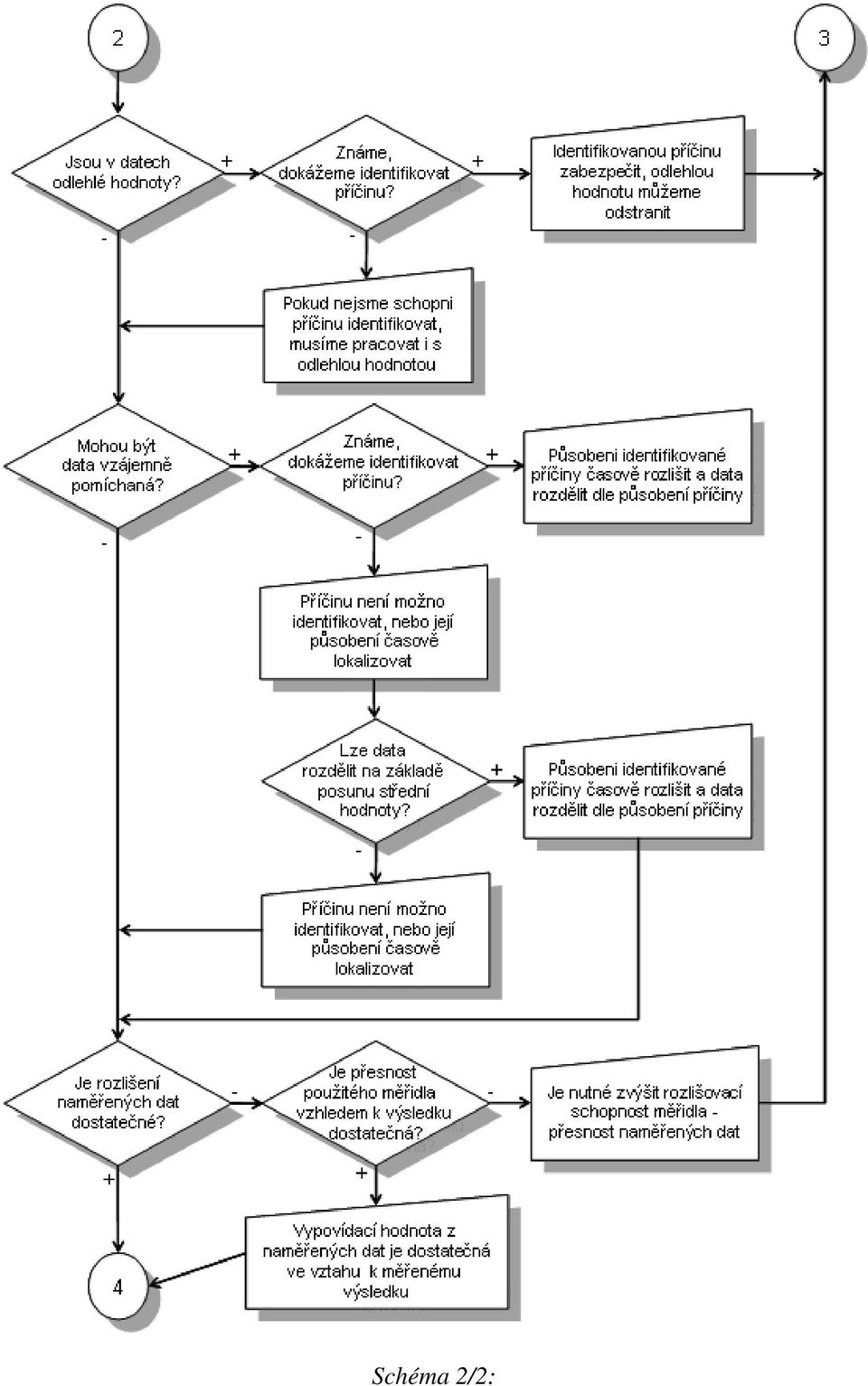
2 Schéma : Druhým krokem je základní statistická analýza dat spolu s ověřením možnosti aplikace Shewhartových regulačních diagramů. V tomto místě se postupy odlišují podstatně podle toho, o jaký typ dat se jedná: U dat diskrétního charakteru není obvykle nutné provádět ověřování předpokladů, pro volbu vhodného regulačního diagramu je pouze nutné si uvědomit, zdali sledujeme počet neshodných výrobků či počet neshod. U dat spojitého charakteru je situace komplikovanější, neboť musíme najít vhodný statistický model pro popis dat. Nejčastěji se jedná o model normálního rozdělení, ale není to pravidlem.

3 Schéma /:
4 Schéma /:
5 Začíná se grafickým rozborem dat s nástroji jako je histogram, bodový či krabicový diagram a průběhový diagram. Podle tvaru histogramu usuzujeme na vhodný model rozdělení pravděpodobnosti, jehož volbu ověříme pomocí testu dobré shody. Je nutno mít na paměti, že konstrukce klasických Shewhartových regulačních diagramů je založena na předpokladu normálně rozdělených dat. Tento předpoklad je nutno ověřit především při aplikaci regulačního diagramu I-MR pro individuální data, i když i v případě aplikace regulačních diagramů xbar-r či xbar-s se nemusejí aritmetické průměry z jednotlivých logických podskupin chovat jako normálně rozdělená data. Toto nebezpečí je akutní hlavně u podskupin s malým počtem dat a kde výchozí data vykazují silně asymetrické chování (histogram je silně vychýlený na jednu stranu). V těchto případech je nutno konstrukci regulačních diagramů založit na příslušných kvantilech vhodného rozdělení pravděpodobnosti, které popisuje chování individuálních dat u diagramu I-MR či aritmetických průměrů u xbar-r či xbar-s diagramů. Průběhový diagram slouží k identifikaci zjevných nenáhodných seskupení dat, případně odhalení kandidátů na odlehlá pozorování. Za nenáhodná seskupení se považují posuny, periodické chování apod. Každé takové seskupení je vyvoláno nějakou reálnou příčinou, která vyvolala změnu podmínek, za nichž byla data získána. Rovněž tak u dat podezřelých z odlehlosti zřejmě došlo ke změně podmínek, za nichž byla data získána. Tyto změny by měly být identifikovány a mělo by být zajištěno, aby se pokud možno neopakovaly Proto je vhodné či přímo nutné současně se sběrem dat vést poznámky, ve kterých bude zaznamenána jakákoliv změna či zásah týkající se výrobního procesu. Tyto poznámky pak slouží ke snazší identifikaci příčin vyvolávajících změny v procesu. Když se nepodaří odhalit příčinu v chování procesu, jedná se o nestabilitu v jeho průběhu a u takového procesu aplikace klasických regulačních diagramů Shewhartova typu obvykle selhává a je nutno použít modifikované typy diagramů, například s rozšířenými mezemi. Dalším jevem, který se může v praxi vyskytovat je závislost dat, která opět není u Shewhartových diagramů předpokládána. Je tedy vhodné u dat, která vykazují podezření na setrvačnost se přesvědčit, zdali nejsou mezi sebou jako časová řada korelována. Zvláště v případě kladné autokorelace by formální použití klasických regulačních diagramů mohlo vést ke zvýšenému počtu falešných poplachů. Shewhartovvy regulační diagramy Základním předpokladem pro aplikaci klasických Shewhartových diagramů je stabilita procesu, neboli jeho statistická zvládnutelnost, a normalita výchozích dat. Postup, jak tyto předpoklady ověřit, je popsán ve Schématu 3. Stabilita procesu znamená, že parametr polohy i úroveň variability u sledovaného znaku jakosti lze považovat za konstantní v čase. Je nutné si uvědomit na základě zkušeností z praxe, že takto se chová pouze malé procento reálných výrobních procesů. Budeme hovořit o zvládnutelnosti v užším slova smyslu. Nutným předpokladem pro dosažení takového stavu procesu je přítomnost pouze tzv. náhodných příčin, které nelze nikdy úplně z procesu eliminovat, které neumíme odhalit a každá působí pouze nepatrnou měrou na chování procesu. Jejich přítomnost vyvolává jistou úroveň tzv. inherentní variability, která je nejvhodněji odhadována pomocí odhadů variability uvnitř logických podskupin. Pokud nelze některé vymezitelné (speciální) příčiny, které vyvolávají změny v chování znaku jakosti z procesu odstranit, je nutno vlivy těchto změn zakomponovat do tvorby a používání regulačních diagramů. Toto je v praxi vcelku běžný stav. Jestliže se ale podaří dosáhnout takového stavu procesu, kdy jsou tyto změny pod kontrolou a zvládnuty, potom budeme hovořit o procesu stabilním v širším slova smyslu. Nejčastěji se jedná o změny v chování parametru polohy, tzn. trendy či posuny vůči požadované cílové hodnotě.

6 Schéma 3:
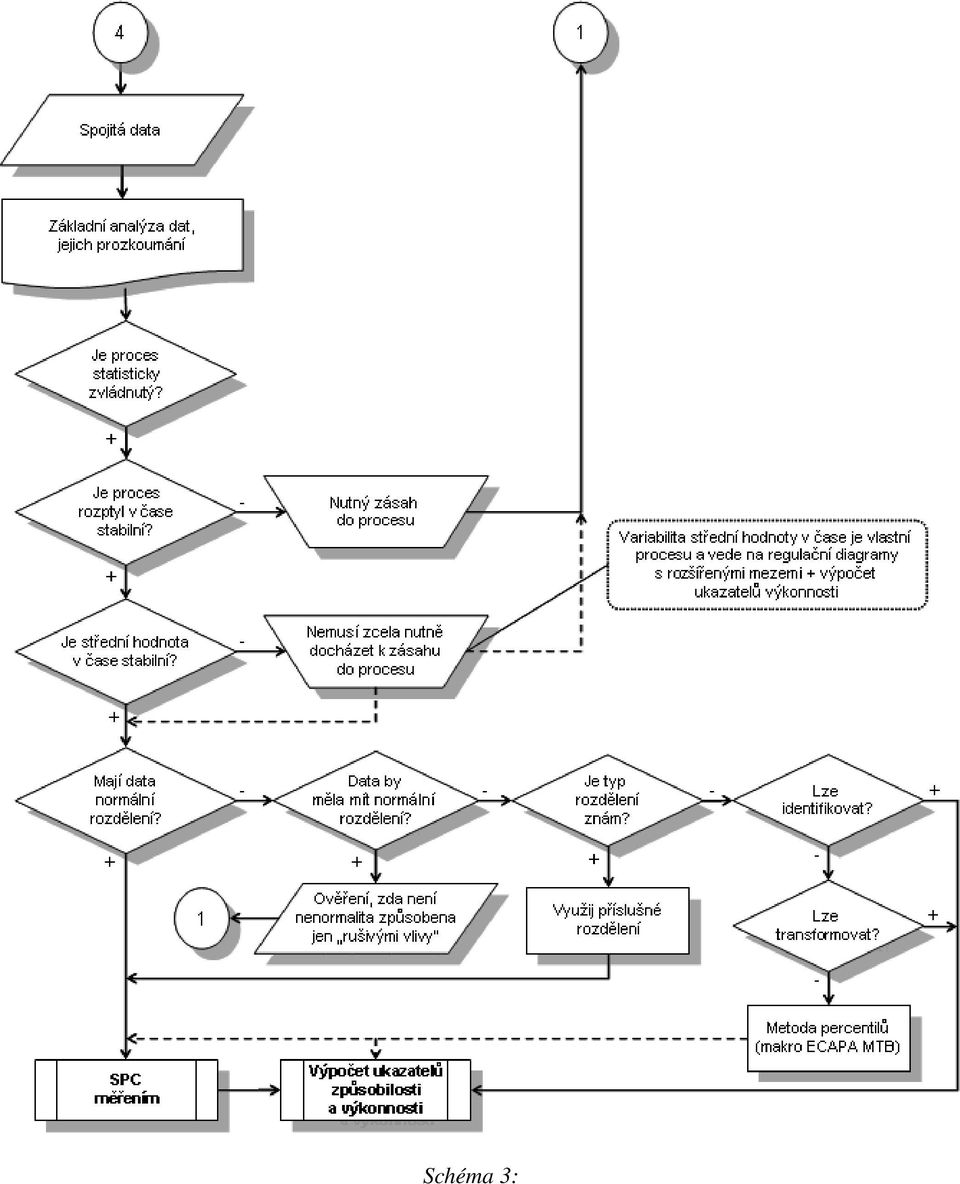
7 V takovém případě do chování sledovaného znaku jakosti vstupuje další forma variability, a to variabilita mezi logickými podskupinami vyvolaná právě změnami v procesu. Tato variabilita není pak zachycena klasickými regulačními diagramy, jejichž konstrukce stojí pouze na úrovni inherentní variability, a tím formální použití Shewhartových diagramů není možné, protože by vedlo k vysokému výskytu falešných poplachů, a je nutno se obrátit na regulační diagramy s rozšířenými mezemi. Stabilitu procesu posuzujeme jednak vůči parametru polohy, a jednak vůči úrovně variability u sledovaného znaku jakosti. Nejdříve posoudíme úroveň variability. Zde je nutné mít data sbírána ve formě podskupin, každá podskupina musí obsahovat alespoň dvě pozorování. Pokud jsou data pozorována individuálně, tj. podskupina je jednoprvková, je nutno si řadu pozorování rozdělit uměle do podskupin. Nulová hypotéza zní, že v podskupinách je úroveň variability stejná, proti alternativní hypotéze, že v alespoň jedné podskupině je úroveň variability odlišná. Lze použít Bartlettův či Leveneův test, první předpokládá normalitu dat, druhý test se hodí na jakákoliv spojitá data. Pokud je nulová hypotéza zamítnuta, znamená to, že se v procesu projevuje nějaká vymezitelná příčina, která s úroveň variability v čase mění. Pomocí analýzy rozptylu (ANOVA) lze za předpokladu nezamítnutí nulové hypotézy o úrovni variability rozhodnout o tom, zdali všechny logické podskupiny mají stejnou střední hodnotu, tj. nulová hypotéza, proti alternativě, že tomu tak není. Pokud obě nulové hypotézy nejsou zamítnuty a znak jakosti lze popsat normálním rozdělením, lze se obrátit k použití klasických regulačních diagramů popsaných např. v ČSN ISO normě 858. Pokud některá nulová hypotéza je zamítnuta, je nutno hledat příčinu, která tuto nestabilitu způsobuje a pokusit se ji odstranit z procesu. Pokud příčinu odhalíme, porozumíme, jak proces ovlivňuje, ale je trvalou součástí procesu, nelze obvykle klasické regulační diagramy použít a je nutno je modifikovat. Samozřejmě problémy nastávají, když data nelze popsat normálním rozdělením. Jak postupovat v takovém případě. První možnost je, že sledovaný znak jakosti se nedá popsat normálním rozdělením z nějakých často fyzikálních důvodů a tento rys se projevuje u tohoto znaku vždy. Zde je nutno hledat jiný typ rozdělení, který se hodí na popis chování dat. Často s jedná o logaritmicko-normální rozdělení, Weibullovo rozdělení, překlopené normální rozdělení, rozdělení maximálních či minimálních hodnot apod. Zde se bez vhodného softwaru neobejdeme. Další možnost je, že data jsou sice původně normálně rozdělena, ale pocházejí z různých zdrojů, jedná se vlastně o směs normálních rozdělení, která lze někdy od sebe oddělit (stratifikovat) podle nějakého příznaku (např. různé stroje, různí operátoři, různé dávky vstupního materiálu). Další možnost spočívá ve větším počtu dat nebo v přesnějším měření ( na více desetinných míst). I tímto způsobem lze v datech normalitu objevit. Pokud data stále odolávají, přichází další možnost založená na vhodné transformaci dat na nová data, která již budou normálně rozdělena. Tento postup se dá uplatnit i při statistické regulaci, kdy se proces řídí a sleduje přes transformovaná data, na něž lze použít klasické regulační diagramy. Nejčastěji přichází v úvahu Box-Coxova transformace či třída Johnsonových transformací. Opět se neobejdeme bez hodného statistického softwaru. Může se ale stát, že vhodná transformace nefunguje, pak de facto poslední možností jsou odhady požadovaných kvantilů získané numerickou cestou. Tento přístup má ale velké úskalí v tom, že pro spolehlivé odhady kvantilů potřebujeme poměrně velký počet dat ( jedná se o stovky), což nemusí být snadné vždy opatřit.

8 Ukazatele způsobilosti Základní myšlenkou definice ukazatelů způsobilosti a výkonnosti, je poměr mezi tolerančním rozmezím, tj. rozpětím mezi horní a dolní mezní hodnotou (USL LSL) a referenčním intervalem, tj. intervalem pokrývajícím 99,73 % sledovaného znaku jakosti v procesu (U 99,865% - L 0,35% ), vymezujícím přirozenou variabilitou jakostního znaku ve výrobním procesu. V případě normálně rozděleného znaku jakosti odpovídá tento interval šestinásobku směrodatné odchylky s znaku jakosti. Horní mezní hodnotu značíme USL, dolní mezní hodnotu značíme LSL; U 99,865% je horní percentil, pod kterým leží 99,865% a L 0,35% je dolní percentil, pod kterým leží 0,35% všech hodnot sledovaného znaku jakosti. (Hovoří se o kvantilech, pokud se místo procent uvažují podíly.) Je-li znak jakosti rozdělen normálně se střední hodnotou µ a směrodatnou odchylkou σ, potom interval U 99,865% - L 0,35% = 6 σ. Jestliže se proces nachází ve stabilním stavu v užším slova smyslu, lze vyhodnocovat jeho způsobilost pomocí ukazatelů C p a C pk. Z dat vypočteme jejich odhady, správně bychom měli rozlišovat mezi použitými odhady směrodatné odchylky inherentní variability, a tyto odhady pomocí metod matematické statistiky konfrontovat s požadovanými hodnotami ukazatelů způsobilosti, jak si přeje zákazník či konstruktér. Pouze porovnání těchto bodových odhadů s požadovanými nic neřeší, je nutno předepsané hodnoty ukazatelů porovnávat s konfidenčními mezemi. Odhady ukazatelů výkonnosti P p a P pk by se v těchto případech neměly prakticky lišit od odhadů ukazatelů způsobilosti. Je nutno opět zdůraznit, že data použitá k odhadům ukazatelů musí vyhovovat normalitě, aby bylo možno použít vzorce: C p = (USL-LSL)/6 σ C pk = min(usl- µ, µ -LSL)/3 σ. Běžně se proces považuje za způsobilý, pokud ukazatel C p je alespoň.33, tj. pokud toleranční rozmezí odpovídá nejméně osmi směrodatným odchylkám (USL LSL)= 8 σ. Pokud je C p <.0, považuje se proces za nezpůsobilý, v případě C p =.0 za přibližně způsobilý. Vzhledem k tomu, že ukazatel způsobilosti C p nezohledňuje nastavení procesu (parametr polohy mí ), budou jeho hodnoty stejné i v případě procesů, které nejsou centrovány. Když je proces zvládnut v širším slova smyslu, pak ukazatele C p a C pk je nutno nahradit ukazateli P p a P pk, neboť do hry vstupuje místo inherentní variability tzv. celková či totální variabilita, která v sobě obsahuje jak variabilitu inherentní, tak i variabilitu mezi podskupinami vyvolanou nestabilitou v parametru polohy. Opět je nutno se přesvědčit, zdali lze data považovat celkově za normálně rozdělená, aby byly použity správné vzorce pro odhady ukazatelů výkonnosti. Jestliže data nelze vysvětlit normálním rozdělením a i když ve proces v ustáleném stavu v užším slova smyslu, ukazatelé způsobilosti C p a C pk ztrácejí smysl, protože v odpovídajících vzorcích pro nenormální data nevystupuje směrodatná odchylka inherentní variability, ale kvantilové rozpětí a medián. Pak je nutno buď hledat jiný model rozdělení pravděpodobnosti, či data transformovat na data normálně rozdělená či numerickými metodami získat odhady požadovaných kvantilů pro odhad délky statistického pokryvného intervalu, která vystupuje místo 6 σ u normálně rozdělených dat. Zde se opět neobejdeme bez vhodného statistického softwaru.

9 Schéma 4/:
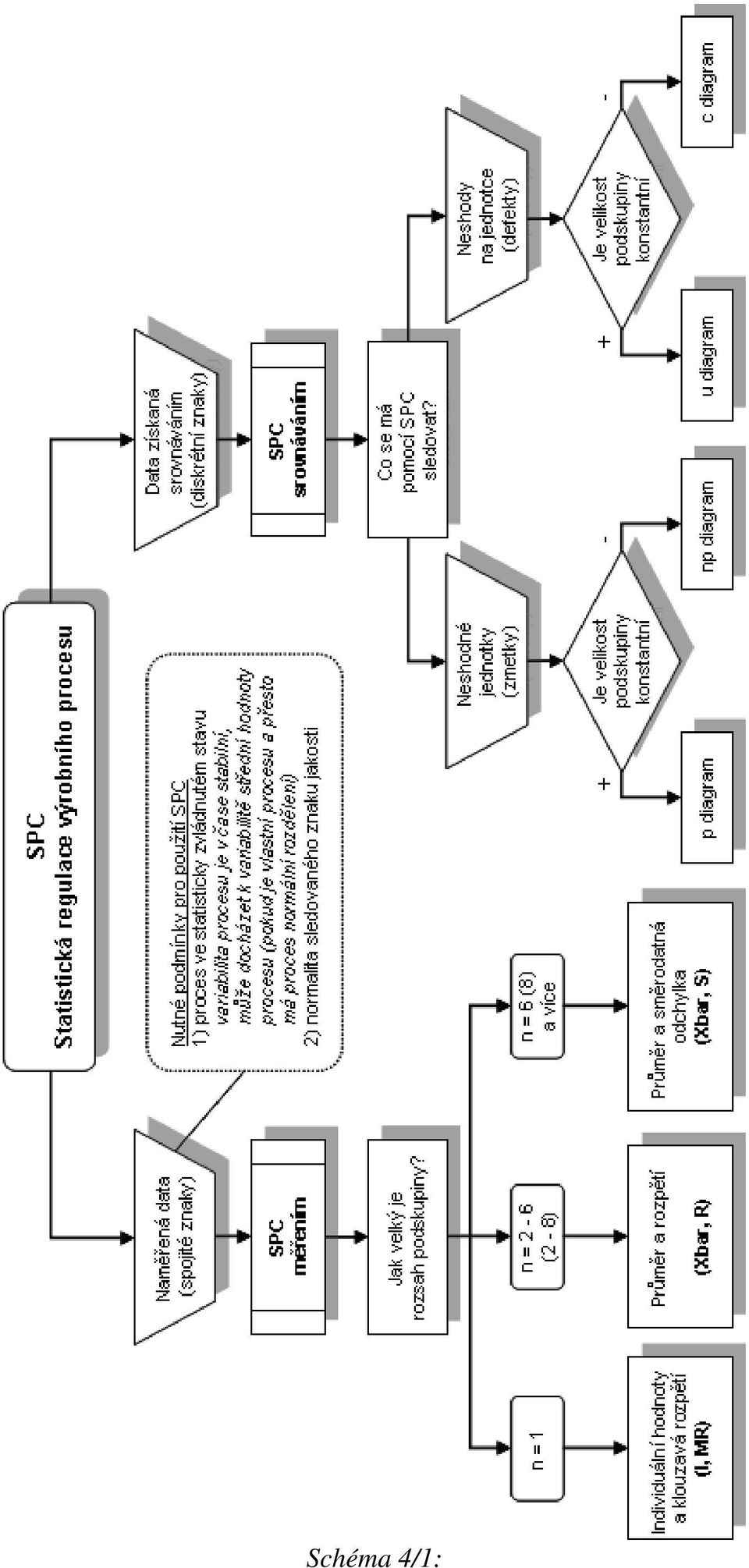
10 Schéma 4/:
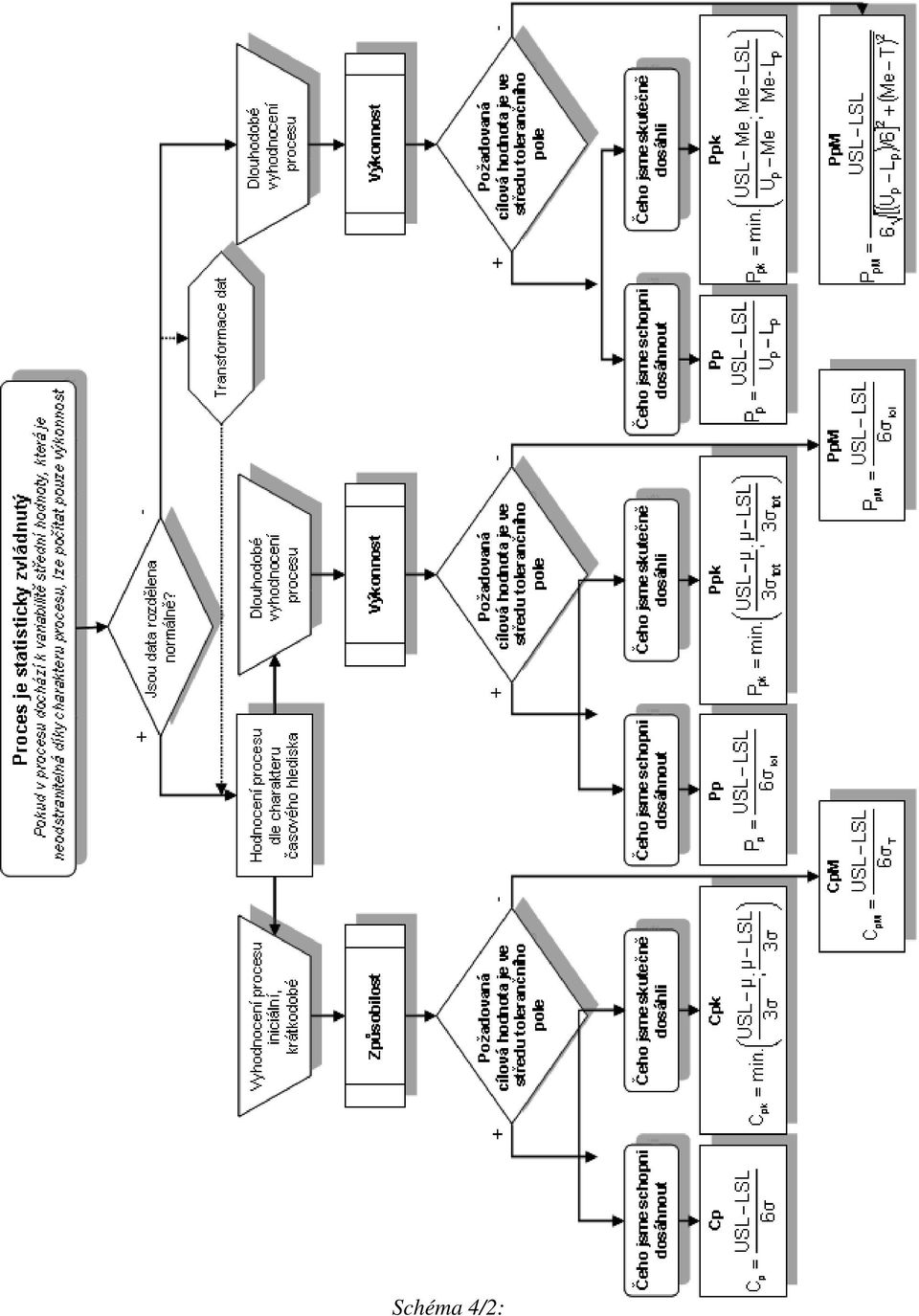
11 Ukazatele výkonnosti Výkonnost procesu je definována na základě celkové (totální) variability procesu, charakterizované směrodatnou odchylkou s TOT, tj. variability vyvolané náhodnými příčinami a případnými neodstranitelnými zvláštními příčinami za předpokladu, že proces je statisticky zvládnut v širším slova smyslu, takže se v čase mění známým a odůvodněným, ale neodstranitelným způsobem střední hodnota procesu. Jedná se např. o trend vyvolaný opotřebováním nástroje, o nemožnost udržet proces přesně centrovaný vlivem vstupního materiálu apod. Postupu při volbě vhodného regulačního diagramu Schéma 4 je věnováno postupu při volbě vhodného regulačního diagramu podle typu znaku jakosti, zdali se jedná o spojitá či atributivní data. Dále rozhodujícím faktorem je i velikost podskupiny, která má být u spojitých dat konstantní, u atributivních dat se může velikost podskupiny měnit. Nevýhodou klasických regulačních diagramů je jejich poměrně dlouhá doba odezvy na změnu v chování znaku jakosti. Pro zkrácení průměrné doby odezvy na změnu neboli zmenšení chyby. druhu, pokud se na regulační diagram díváme jako na sekvenční test, je vhodné zvláště u procesů citlivých na změny použít modernější typy regulačních diagramů jako jsou diagramy EWMA či CUSUM. Příklad vyhodnocení procesních dat Příspěvek je zakončen příkladem zaměřeným na data, která nejsou normálně rozdělena a je nutno vyhodnotit výkonnost sledovaného procesu. Zpracování dat je provedeno pomocí softwaru Minitab 5. Uvažujeme případ, kdy znak jakosti v procesu není rozdělen normálně. Ze znalosti procesu a z dřívějších měření je patrno, že data jsou rozdělena asymetricky. Dolní mezní hodnota byla stanovena LSL = 0,5 a horní mezní hodnota USL = 5. Požaduje se ověřit typ rozdělení znaku jakosti a odhadnout jeho parametry; vyhodnotit výkonnost procesu a navrhnout regulační diagram pro individuální hodnoty. Z procesu bylo odebráno během několika pracovních dnů v přibližně stejných intervalech celkem 00 jednotek (počet podskupin k = 00 rozsahu n = ). Byl sledován znak jakosti, o kterém se předpokládá, že v čase nedochází ke změně střední hodnoty ani variability (proces je statisticky zvládnut). Úkolem je ověřit, typ rozdělení znaku jakosti, odhadnout jeho parametry a ověřit předpoklad, že proces je statisticky zvládnut. Dále vyhodnotit výkonnost procesu a vypočítat na základě napozorovaných dat parametry regulačního diagramu pro individuální hodnoty x i a klouzavá rozpětí dvou sousedních hodnot MR. ) První informace o napozorovaných datech základní výběrové charakteristiky, histogram s proloženou křivkou hustoty hypotetického normálního rozdělení pravděpodobnosti a 95%-ní konfidenční intervaly pro střední hodnotu µ a směrodatnou odchylku σ - je získána pomocí funkce Graphical Summary (Stat > Basic Statistic > Graphical Summary).

12 Summary for Data 00 Anderson-Darling Normality Test A -Squared 4,86 P-V alue < 0,005 Mean,564 StDev 0,548 V ariance 0,754 Skew ness,3688 Kurtosis,49 N 00 0,8,,6,0,4,8 3, Minimum 0,785 st Quartile,483 Median,3877 3rd Q uartile,800 Maximum 3, % C onfidence Interv al for Mean,453, % C onfidence Interv al for Median,34,493 95% Confidence Intervals 95% Confidence Interval for StDev 0,4779 0,580 Mean Median,30,35,40,45,50,55,60 Z histogramu s proloženou hustotou pravděpodobnosti normálního rozdělení je patrno, že studovaný znak jakosti není normálně rozdělen. To potvrzuje i p-hodnota Anderson- Darlingova testu normality (p-value < 0,005) která je hluboko pod obvykle používanou hladinou významnosti α = 0,05. Asymetričnost rozdělení ke patrna i z box-plot diagramu. ) Minitab umožňuje a) identifikovat vhodný typ rozdělení pravděpodobnosti; b) transformovat původní nenormálně rozdělená data pomocí Box-Coxovy transformace; c) transformovat původní nenormálně rozdělená data pomocí Johnsonovy transformace. V Minitabu (Stat > Quality Tools > Individual Distribution Identification) zvolíme typy rozdělení, která chceme pro napozorovaná data ve sloupci C Data 00 odzkoušet (Např. normální, Weibullovo, logaritmicko-normální, gama). Percent Percent Normal - 95% CI 99, , 0 3 Data 00 3-Parameter Lognormal - 95% CI 99, Percent Percent 99, , 0, 99, , 0, 0,,0 0,0 Data 00 - Threshold Probability Plot for Data Weibull - 95% C I,0 Data 00 Gamma - 95% CI Data 00 0 Goodness of Fit Test Normal A D = 4,864 P-Value < 0,005 Weibull A D = 4,635 P-Value < 0,00 3-Parameter Lognormal A D = 0,0 P-V alue = * Gamma A D =,98 P-Value < 0,005
 která je hluboko pod obvykle používanou hladinou významnosti α = 0,05.")
13 Z pravděpodobnostních grafů je patrno, že nejlépe napozorovaná data vystihuje model 3-parametrického log-normálního rozdělení. V okně Session jsou zobrazeny v tabulce číselné výsledky parametry modelu a tabulka zadaných percentilů: Z pravděpodobnostního grafu plyne, že je dobrá shoda empirických dat s identifikovaným modelem 3-parametrického log-normálního rozdělení s parametry Loc = -0,0995; Scale = 0,5004; Thresh = 0,50. Naměřené hodnoty leží v 95%-ním konfidenčním intervalu a p-hodnota Anderson-Darlingova testu je větší než 0,50.

14 Probability Plot of Data 00 3-Parameter Lognormal - 95% CI Percent 99, Loc -0,0995 Scale 0,5004 Thresh 0,50 N 00 AD 0,0 P-Value >0,50 0, 0,,0 Data 00 - Threshold 0,0 Do histogramu z napozorovaných hodnot můžeme zakreslit hustotu pravděpodobnosti identifikovaného modelu, červeně mezní hodnoty LSL = 0,5; USL = 5,0 a modře vypočítané percentily pro 0,35 %; 50 %; 99,865 %. Histogram of Data 00 3-Parameter Lognormal 0,704,408 4,565 0, Loc -0,0995 Scale 0,5004 Thresh 0,50 N 00 Frequency ,6,,8,4 3,0 Data 00 3,6 4, 4,8 V případech, kdy se nepodaří identifikovat rozdělení studovaného znaku jakosti nebo si navrženým modelem nejsme jisti (nízká p-hodnota), můžeme použít obě výše zmíněné transformace Box-Coxovu a Johnsonovu. V tomto případě necháme transformované hodnoty zapsat např. do sloupců C a C3. V Minitabu (Stat > Quality Tools > Individual Distribution Identification) zvolíme Box-Cox transformation a Johnson transformation pro napozorovaná data ve sloupci C Data 00. Výstupem jsou pravděpodobnostní grafy transformovaných dat, které ukazují na velmi dobrou shodu transformovaných dat s modelem normálního rozdělení, p-hodnoty jsou relativně vysoké 0,558 a 0,95. Nejlepší výsledek se jeví při Johnsonově transformaci, kde p-hodnota je velmi vysoká 0,95. Zdá se vhodné využít takto transformovaných dat pro další výpočty.

15 99, Probability Plot for Data 00 Normal - 95% CI Normal - 95% CI 99, Goodness of Fit Test Box-Cox Transformation A D = 0,308 P-V alue = 0,558 Johnson Transformation A D = 0,80 P-V alue = 0,95 Percent 50 Percent , 0, 0,50 0,75,00,5-4 0 Data 00 Data 00 After Box-Cox transformation (lambda = -0,5) After Johnson transformation 4 V okně Session jsou zobrazeny v tabulce číselné výsledky obou transformací a tabulka zadaných percentilů:

16 Napozorovaná data můžeme v programu Minitab transformovat následujícím postupem: (Stat > Quality Tools > Johnson Transformation) >...). Výstupem je tabulka obsahující pravděpodobnostní grafy původních a transformovaných dat a transformační rovnice: Johnson Transformation for Data 00 Percent Probability Plot for Original Data 99,9 N AD 4,864 P-Value <0, , 0 3 P-Value for AD test Select a Transformation 0,8 0,8 0,6 0,4 0, 0,0 0, 0,4 0,6 0,8,0 Z Value (P-Value = means <= 0.005), Ref P Percent Probability Plot for T ransformed Data 99,9 N AD 0,80 P-Value 0, P-Value for Best Fit: 0,9543 Z for Best Fit: 0,8 Best Transformation Ty pe: SB Transformation function equals 4,6567 +,70066 * Ln( ( X - 0, ) / ( 0, X ) ) 0, Histogram transformovaných dat můžeme porovnat s odpovídajícím normálním rozdělením. V grafu jsou čárkovaně modře zakresleny zvolené percentily odpovídající 035 %; 50 %; 99,865 %. Červeně čárkovaně je zakreslena transformovaná horní mezní hodnota. Dolní mezní hodnota je již mimo rámec transformace (ve výraze se vyskytne záporný argument v přirozeném logaritmu). Transformace mezních hodnot se provedí pomocí kalkulátoru (Calc > Calculator) Histogram of Johnson Normal 3,67-3,69-0,006 3,56 Mean -0,00688 StDev,054 N 00 Frequency Johnson 3 3) Abychom mohli ověřit, že v čase nedochází ke změně variability (rozptylu), rozdělíme pozorování do několika (v našem případě do osmi) za sebou jdoucích úseků. Úseky jsou uvedeny ve sloupci C4. Na základě Leveneova testu rovnosti rozptylů, vhodného v případě spojitého rozdělení (Stat > ANOVA > Test for Equal Variances), není důvod pochybovat, že podskupiny pocházejí ze základních souborů se stejnými rozptyly; p- hodnota (0,6) tohoto testu je nad obvykle volenou hladinou významnosti α = 0,05. Je možno akceptovat předpoklad, že v čase se nemění variabilita sledovaného znaku jakosti.

17 Test for Equal Variances for Data 00 3 Bartlett's Test Test Statistic 5,5 P-Value 0,030 Levene's Test Test Statistic,5 P-Value 0,6 Úseky , 0,3 0,4 0,5 0,6 0,7 0,8 0,9,0, 95% Bonferroni Confidence Intervals for StDevs 4) Na základě výsledku analýzy rozptylu (Stat > ANOVA > One Way), kde p-hodnota (0,00) je menší než obvykle volená hladina významnosti, máme důvod zamítnout předpoklad, že data v podskupinách pocházejí ze základních souborů se stejnými středními hodnotami. Tento výsledek je však třeba brát pouze orientačně, protože ANOVA předpokládá normální rozdělení analyzovaných dat. Jako vhodnější se nabízí použití neparametrického testu o rovnosti mediánů, např. test Kruskal-Wallisův (viz Poznámka na konci tohoto příkladu).

18 Tento výsledek dokumentuje i příslušný diagram Boxplot. 3,5 Boxplot of Data 00 3,0,5 Data 00,0,5,0 3 4 Úseky Srovnatelný výsledek dostaneme i v případě analýzy transformovaných dat: 3 Boxplot of Johnson Johnson Úseky

19 5) Výkonnost procesu ve vztahu k mezním hodnotám USL = 5,0 a LSL = 0,5 je možno vyhodnotit jedním z následujících postupů. a) Vycházíme z identifikovaného rozdělení pravděpodobnosti, v našem případě se jedná o 3- parametrické log-normální rozdělení, pro které jsme dostatečně přesně stanovili percentily (kvantily) pro 0,35 %; 50 %; 99,865 %, které označíme L p = 0,704; Me =,408; U p = 4,565. Potom odhady ukazatelů výkonnosti počítáme ze vztahů V našem příkladě se jedná o odhady: a tedy Pˆpk =, 38. Pˆ Pˆ P p = USL LSL U p L p P pk = min{ P, P pu pl} = min USL Me Me LSL,. Up Me Me L p Pˆ USL LSL 5,0 0,5 4,5 = = =,66, U L 4,565 0,704 3,86 = p p p USL Me 5,0,408 3,59 = = =,38, U Me 4,565,408 3,57 = pu p Me LSL,408 0,5 0,908 = = =,90, Me L,408 0,704 0,704 = pl p ; b) Minitab počítá ukazatele výkonnosti v případě nenormálně rozdělených dat postupem (Stat > Quality Tools > Capability Analysis > Nonnormal). Je-li identifikován typ rozdělení pravděpodobnosti (tj. 3-parametrické log-normální), Minitab po jeho zadání vyhodnotí příslušné ukazatele výkonnosti a očekávaný počet ppm mimo aktuální mezní hodnoty. V tomto příkladě vychází odhady P p =,7; PPL (P pl ) =,9; PPU (P pu ) =,4 a P pk =,4 (stejně jako výše) a očekávaný počet mimo USL je 679 ppm; mimo LSL je 0 ppm; celkem 679 ppm. Process Capability of Data 00 Calculations Based on Lognormal Distribution Model Process Data LSL 0,5 Target * USL 5 Sample Mean,5643 Sample N 00 Location -0, Scale 0,50049 Threshold 0,504 O bserved Performance PPM < LSL 0,00 PPM > USL 0,00 PPM Total 0,00 LSL USL O verall Capability Pp,7 PPL,9 PPU,4 Ppk,4 Exp. O verall Performance PPM < LSL 0,00 PPM > USL 678,99 PPM Total 678,99 0,6,,8,4 3,0 3,6 4, 4,8

20 c) Minitab počítá ukazatele výkonnosti v případě nenormálně rozdělených dat rovněž pomocí Johnsonovy transformace postupem (Stat > Quality Tools > Capability Analysis > Nonnormal). Není-li identifikován typ rozdělení pravděpodobnosti (což je častý případ), Minitab nabízí volit metodu na základě Johnsonovy transformace. V tomto případě je umožněno počítat i konfidenční intervaly aktuálních ukazatelů výkonnosti. Ty není možno počítat v předešlém případě při zadání konkrétného modelu. Tento postup někdy může selhat, jako v tomto případě, kdy dolní mezní hodnota LSL = 0,5 je mimo definiční obor transformace. Potom program nevyhodnotí ukazatele P p a PPL (P pl ). Transformovaná data, která jsou uložena ve sloupci C3 Johnson, je možno použít k různým výpočtům, například k výpočtu kvantilů, regulačních mezí pro individuální hodnoty a pod. Do původních hodnot se zpět můžeme dostat pomocí zpětné transformace (viz soubor Zpětná transformace.xls ), kam je třeba vložit koeficienty transformační rovnice 4,6567 +,70066 * Ln((x 0,588679) / (0,9047 x)). Process Data LSL 0,5 Target * USL 5 Sample Mean,5643 Sample N 00 StDev 0,5480 Shape 4,6567 Shape,70066 Location 0, Scale 0,36 After Transformation LSL* * Target* * USL* 3,66979 Sample Mean* -0, StDev*,0549 Observed Performance PPM < LSL 0,00 PPM > USL 0,00 PPM Total 0,00 Process Capability of Data 00 Johnson Transformation with SB Distribution Type 4,66 +,70 * Ln( ( X - 0,589 ) / ( 0,905 - X ) ) (using 95,0% confidence) transformed data USL* Overall Capability Pp * Lower CL * Upper CL * PPL * PPU,6 Ppk,6 Lower CL * Upper CL * Exp. Overall Performance PPM < LSL * PPM > USL 44,3 PPM Total 44, d) Minitab umožňuje počítat ukazatele výkonnosti rovněž na základě Box-Coxovy transformace (Stat > Quality Tools > Capability Analysis > Normal). To přichází v úvahu např. není-li identifikován typ rozdělení pravděpodobnosti a nepodařilo-li se najít Johnsonovu transformaci. V dialogovém okně použijeme tlačítko Box-Cox a zvolíme Use optimal lambda. Process Capability of Data 00 Using Box-Cox Transformation With Lambda = -0,5 (using 95,0% confidence) Process Data LSL 0,5 Target * USL 4,5 Sample Mean,5643 Sample N 00 StDev (Within) 0, StDev (O v erall) 0,5480 A fter Transformation LSL*,44 Target* * USL* 0,47405 Sample Mean* 0,8454 StDev (Within)* 0,3643 StDev (O v erall)* 0,3087 O bserved Performance PPM < LSL 0,00 PPM > USL 0,00 PPM Total 0,00 USL* 0,60 Exp. Within Performance PPM > LSL*,8 PPM < USL* 378,6 PPM Total 380,44 0,75 transformed data 0,90,05 Exp. O verall Performance PPM > LSL* 6,5 PPM < USL* 374,50 PPM Total 380,75,0,35 LSL* Within O v erall Potential (Within) C apability C p,7 Lower C L,5 Upper C L,40 C PL,54 C PU,00 C pk,00 Lower C L 0,89 Upper C L, O verall C apability Pp,0 Lower C L,08 Upper C L,3 PPL,46 PPU 0,94 Ppk 0,94 Lower C L 0,84 Upper C L,04 C pm * Lower C L *
.")
21 e) Počítat ukazatele výkonnosti pro znak jakosti, který není normálně rozdělen jako kdyby normálně rozdělen byl, je v praxi poměrně časté a vede to k nemalým chybám. Postup (Stat > Quality Tools > Capability Analysis > Normal) bez volby Box-Coxovy transformace vede k následujícímu výsledku: hodnoty odhadů ukazatelů výkonnosti P a zejména ukazatelů C se v tomto případě výrazně liší od realitě odpovídajícím hodnotám. Process Capability of Data 00 (using 95,0% confidence) Process Data LSL 0,5 Target * USL 4,5 Sample Mean,5643 Sample N 00 StDev (Within) 0, StDev (O v erall) 0,5480 O bserved Performance PPM < LSL 0,00 PPM > USL 0,00 PPM Total 0,00 LSL 0,6, Exp. Within Performance PPM < LSL 4477,4 PPM > USL 0,00 PPM Total 4477,4,8,4 3,0 3,6 Exp. O verall Performance PPM < LSL 54, PPM > USL 0,0 PPM Total 54,3 4, USL Within Overall Potential (Within) Capability C p,4 Lower C L,8 Upper C L,56 C PL 0,73 C PU, C pk 0,73 Lower C L 0,64 Upper C L 0,8 O v erall C apability Pp,7 Lower C L,5 Upper C L,39 PPL 0,65 PPU,89 Ppk 0,65 Lower C L 0,57 Upper C L 0,73 C pm * Lower C L * 6) Vzhledem k tomu, že sledovaný znak jakosti není normálně rozdělen, nabízí software možnost navrhnout regulační diagram s využitím Box-Coxovy transformace. Stat > Control Charts > Variables Charts for Individuals > I-MR Chart a v nabídce I-MR Options > Box-Cox zvolit Optimal lamda. I-MR Chart of Data 00 Using Box-Cox Transformation With Lambda = -0,50,5 5 UCL=,5 Individual Value,00 0,75 6 _ X=0,845 0,50 LCL=0, Observation ,45 UCL=0,4557 Moving Range 0,30 0,5 0,00 MR=0,395 LCL= Observation Parametry tohoto regulačního diagramu pro individuální hodnoty jsou CL = 0,845; UCL =,5; LCL = 0,4706 a pro výběrová rozpětí jsou CL = 0,395; UCL = 0,4557; LCL = 0.
22 Tento přístup má ovšem ten nedostatek, že do regulačního diagramu je třeba zakreslovat transformované a nikoliv přímo naměřené hodnoty. Další možnost je využít již dříve vypočítané kvantily identifikovaného rozdělení (3- parametrické log-normální rozdělení ) K 0,35 = L p = 0,704, K 50 = Me =,408; a K 99,865 = U p = 4,565 a použít je jako regulační meze zásahové (zakresleny čárkovaně modře do diagramu netransformovaných hodnot (meze zakreslené plně červeně jsou běžné Shewhartovy regulační meze vypočítané programem za předpokladu normálního rozdělení znaku jakosti). I-MR Chart of Data 00 4,565 Individual Value UC L=,936 _ X=,56,408 0,704 0 LC L=0, Observation Moving Range,0,5,0 0,5 UC L=,73 MR=0,530 0,0 LC L= Observation V tomto případě červeně zvýrazněné výběrové body obvykle signalizující přítomnost nenáhodné příčiny variability ztrácejí smysl, neboť jejich poloha je konfrontována se Shewhartovými mezemi. 7) Uvedeme postup, který se v tomto případě jeví jako optimální, i když pracnější, respektující i tu skutečnost, že proces není striktně statisticky zvládnut a zahrnuje i variabilitu ve střední hodnotě (viz výsledky ANOVA). Ve sloupci C3 Worksheetu Data jsou původní data po Johnsonově transformaci, která jsou normálně rozdělena. Softwarem vybraná transformační rovnice je: 4,6567 +,70066 * Ln((x 0,588679) / (0,9047 x)). Pravděpodobnostní graf a Anderson-Darlingův test dobré shody (p-hodnota = 0,95) potvrzuje, že nemáme důvod pochybovat o normálním rozdělení dat ve sloupci C3:
23 Probability Plot of Johnson Normal - 95% CI Percent 99, Mean -0,00688 StDev,054 N 00 AD 0,80 P-Value 0,95 0, Johnson 3 4 Můžeme tedy pro tato data vytvořit běžný Shewhartův graf pro individuální hodnoty. I Chart of Johnson 3 UCL=,96 Individual Value _ X=-0,006-3 LCL=-, Observation Vzhledem k tomu, že proces není statisticky zvládnut v užším slova smyslu, je třeba použít rozšířených regulačních mezí, v tomto případě s použitím celkové směrodatné odchylky, na místo směrodatné odchylky odvozené z krátkodobé variability, tj. klouzavého rozpětí dvou sousedních hodnot. Informace o transformovaných datech základní výběrové charakteristiky, histogram s proloženou křivkou hustoty hypotetického normálního rozdělení pravděpodobnosti a 95% konfidenční intervaly pro střední hodnotu µ a směrodatnou odchylku σ - získáme běžně pomocí funkce Graphical Summary (Stat > Basic Statistic > Graphical Summary).
24 Summary for Johnson Anderson-Darling Normality Test A -Squared 0,8 P-V alue 0,95 Mean -0,0069 StDev,0549 V ariance,3 Skewness -0,0877 Kurtosis -0, N Minimum -3,549 st Q uartile -0,69555 Median -0,0477 3rd Q uartile 0,73694 Maximum, % Confidence Interval for Mean -0,538 0,408 95% Confidence Interval for Median -0,50 0, % Confidence Intervals 95% Confidence Interval for StDev 0,9600,690 Mean Median -0, -0, 0,0 0, 0, Vidíme, že celkový (totální) průměr x TOT = -0,0069 a s TOT =,0549. Potom regulační meze v diagramu individuálních hodnot lze rozšířit: LCL = -3,688 ; CL = -0,0069 ; UCL = 3,564. Tyto meze zakreslíme čárkovaně modře do regulačního diagramu transformovaných hodnot (uvedeného výše). I Chart of Johnson 4 3 3,56 UCL=,96 Individual Value 0 - _ X=-0, Observation LCL=-,973-3,69 Aby se v praxi každá naměřená hodnota nemusela transformovat, provedeme zpětnou transformaci vypočtených rozšířených regulačních mezí. Oba postupy dávají téměř stejné regulační meze.
25 I Chart of Data ,59 Individual Value 3 5 UCL=,936 _ X=,56,406 0,75 0 LCL=0, Observation Pro zakreslení prázdného formuláře výsledného regulačního diagramu pro další období můžeme použít makra BLANKCH.MAC : Zvolíme Editor > Enable Commands a v okně Session za příkaz MTB> zapíšeme %BLANKCH a potvrdíme ENTER. Výstupem v okně Session jsou instrukce a dotazy (zadání). Po jejich vyplnění je výstupem požadovaný regulační diagram se zakreslenými již zadanými regulačními mezemi. 4,64 4,590 UC L=4,59 3,9056 3,55 3,988,8454,490,386,785,438 Mu=,406,0784 0,750 LC L=0,75 0,

26 Poznámka Instalace makra BLANKCH.MAC. V adresáři BLANKCH je zapsáno makro BLANKCH.MAC ve formátu Poznámkový blok. Tento soubor je třeba uložit pro verzi Minitab 5 na adresu: Program Files > Minitab 5 > English > Macros. Pro verzi Minitab 4 na adresu: Program Files > Minitab 4 > Macros. Knihovna dalších uživatelských maker pro Minitab je dostupná na adrese Makra mohou být prováděna buď z okna Session tak, že se vybere: nebo se vybere Editor > Enable Commands > kde se zobrazí MTB > zapíše se příslušné Macro > Enter ; Edit > Command Line Editor > zapíše se příslušné Macro > Submit Commands. U jednotlivých maker jsou uvedeny specifické pokyny pro jejich provedení. Poznámka Kruskal-Wallisův test je neparametrickou alternativou jednocestné ANOVA. Nevyžaduje, aby data byla rozdělena normálně, stačí předpokládat spojité rozdělení sledovaného znaku jakosti. Pro analýzu využívá pořadí dat namísto jejich aktuálních hodnot. Lze použít k ověření, zda dva nebo více nezávislých výběrů pochází ze základních souborů se stejným mediánem. V softwaru Minitab postupujeme následovně: Stat > Nonparametrics > Kruskal Wallis > vyplníme dialogové okno a potvrdíme OK.
27 Výsledek testu je zapsán v okně Session: Výsledná p-hodnota < 0,05 signalizuje důvod zamítnout hypotézu, že náhodné výběry (podskupiny) pocházejí ze základních souborů se stejným mediánem. Použitá literatura: [] Michálek J. aj. Statistické metody řízení jakosti, Česká společnost pro jakost. Praha 007 [] Montgomery D.C.: Introduction to Statistical Quality Control. John Wiley. N.Y. 000 (4.vydání) [3] Daimler Chrysler Corporation, Ford Motor Company, General Motrors Corporation: Statistická regulace procesů (SPC), Česká společnost pro jakost, Praha 005 [4] Michálek J.: Vyhodnocování způsobilosti a výkonnosti výrobního procesu, Centrum pro jakost a spolehlivost ve výrobě (CQR), Praha 009
Národní informační středisko pro podporu kvality
 Národní informační středisko pro podporu kvality STATISTICKÁ REGULACE POMOCÍ VÝBĚROVÝCH PRŮMĚRŮ Z NENORMÁLNĚ ROZDĚLENÝCH DAT Ing. Jan Král, RNDr. Jiří Michálek, CSc., Ing. Josef Křepela Duben, 20 Co je
Národní informační středisko pro podporu kvality STATISTICKÁ REGULACE POMOCÍ VÝBĚROVÝCH PRŮMĚRŮ Z NENORMÁLNĚ ROZDĚLENÝCH DAT Ing. Jan Král, RNDr. Jiří Michálek, CSc., Ing. Josef Křepela Duben, 20 Co je
SW podpora při řešení projektů s aplikací statistických metod
 SW podpora při řešení projektů s aplikací statistických metod Jan Král, Josef Křepela Úvod Uplatňování statistických metod vyžaduje počítačovou podporu. V současné době je rozšiřována řada vynikajících
SW podpora při řešení projektů s aplikací statistických metod Jan Král, Josef Křepela Úvod Uplatňování statistických metod vyžaduje počítačovou podporu. V současné době je rozšiřována řada vynikajících
HODNOCENÍ VÝKONNOSTI ATRIBUTIVNÍCH ZNAKŮ JAKOSTI. Josef Křepela, Jiří Michálek. OSSM při ČSJ
 HODNOCENÍ VÝKONNOSTI ATRIBUTIVNÍCH ZNAKŮ JAKOSTI Josef Křepela, Jiří Michálek OSSM při ČSJ Červen 009 Hodnocení způsobilosti atributivních znaků jakosti (počet neshodných jednotek) Nechť p je pravděpodobnost
HODNOCENÍ VÝKONNOSTI ATRIBUTIVNÍCH ZNAKŮ JAKOSTI Josef Křepela, Jiří Michálek OSSM při ČSJ Červen 009 Hodnocení způsobilosti atributivních znaků jakosti (počet neshodných jednotek) Nechť p je pravděpodobnost
SPC v případě autokorelovaných dat. Jiří Michálek, Jan Král OSSM,
 SPC v případě autokorelovaných dat Jiří Michálek, Jan Král OSSM, 2.6.202 Pojem korelace Statistická vazba mezi veličinami Korelace vs. stochastická nezávislost Koeficient korelace = míra lineární vazby
SPC v případě autokorelovaných dat Jiří Michálek, Jan Král OSSM, 2.6.202 Pojem korelace Statistická vazba mezi veličinami Korelace vs. stochastická nezávislost Koeficient korelace = míra lineární vazby
Výkonnost procesů v případě nenormálně rozděleného znaku kvality. Jiří Michálek
 Výkonnost procesů v případě nenormálně rozděleného znaku kvality Jiří Michálek 1 Hodnocení způsobilosti a výkonnosti výrobních procesů je prováděno především u dodavatelů do automobilového průmyslu, kde
Výkonnost procesů v případě nenormálně rozděleného znaku kvality Jiří Michálek 1 Hodnocení způsobilosti a výkonnosti výrobních procesů je prováděno především u dodavatelů do automobilového průmyslu, kde
Národní informační středisko pro podporu kvality
 Národní informační středisko pro podporu kvality Nestandardní regulační diagramy J.Křepela, J.Michálek REGULAČNÍ DIAGRAM PRO VŠECHNY INDIVIDUÁLNÍ HODNOTY xi V PODSKUPINĚ V praxi se někdy setkáváme s požadavkem
Národní informační středisko pro podporu kvality Nestandardní regulační diagramy J.Křepela, J.Michálek REGULAČNÍ DIAGRAM PRO VŠECHNY INDIVIDUÁLNÍ HODNOTY xi V PODSKUPINĚ V praxi se někdy setkáváme s požadavkem
Jak správně interpretovat ukazatele způsobilosti a výkonnosti výrobního procesu
 Jak správně interpretovat ukazatele způsobilosti a výkonnosti výrobního procesu Jiří Michálek Ukazatele způsobilosti a výkonnosti C p, C pk, P p, P pk byly zavedeny ve snaze popsat stav výrobního procesu,
Jak správně interpretovat ukazatele způsobilosti a výkonnosti výrobního procesu Jiří Michálek Ukazatele způsobilosti a výkonnosti C p, C pk, P p, P pk byly zavedeny ve snaze popsat stav výrobního procesu,
Národníinformačnístředisko pro podporu jakosti
 Národníinformačnístředisko pro podporu jakosti OVĚŘOVÁNÍ PŘEDPOKLADU NORMALITY Doc. Ing. Eva Jarošová, CSc. Ing. Jan Král Používané metody statistické testy: Chí-kvadrát test dobré shody Kolmogorov -Smirnov
Národníinformačnístředisko pro podporu jakosti OVĚŘOVÁNÍ PŘEDPOKLADU NORMALITY Doc. Ing. Eva Jarošová, CSc. Ing. Jan Král Používané metody statistické testy: Chí-kvadrát test dobré shody Kolmogorov -Smirnov
Národní informační středisko pro podporu kvality
 Národní informační středisko pro podporu kvality Využití metody bootstrapping při analýze dat II.část Doc. Ing. Olga TŮMOVÁ, CSc. Obsah Klasické procedury a statistické SW - metody výpočtů konfidenčních
Národní informační středisko pro podporu kvality Využití metody bootstrapping při analýze dat II.část Doc. Ing. Olga TŮMOVÁ, CSc. Obsah Klasické procedury a statistické SW - metody výpočtů konfidenčních
Statistické řízení jakosti - regulace procesu měřením a srovnáváním
 Statistické řízení jakosti - regulace procesu měřením a srovnáváním Statistická regulace výrobního procesu (SPC) SPC = Statistical Process Control preventivní nástroj řízení jakosti, který na základě včasného
Statistické řízení jakosti - regulace procesu měřením a srovnáváním Statistická regulace výrobního procesu (SPC) SPC = Statistical Process Control preventivní nástroj řízení jakosti, který na základě včasného
Národní informační středisko pro podporu jakosti
 Národní informační středisko pro podporu jakosti 1 METODA KUMULOVANÝCH SOUČTŮ C U S U M metoda: tabulkový (lineární) CUSUM RNDr. Jiří Michálek, CSc., Ing. Antonie Poskočilová 2 Základem SPC jsou Shewhartovy
Národní informační středisko pro podporu jakosti 1 METODA KUMULOVANÝCH SOUČTŮ C U S U M metoda: tabulkový (lineární) CUSUM RNDr. Jiří Michálek, CSc., Ing. Antonie Poskočilová 2 Základem SPC jsou Shewhartovy
Přehled metod regulace procesů při různých typech chování procesu
 Přehled metod regulace procesů při různých typech chování procesu Eva Jarošová, Darja Noskievičová Škoda Auto Vysoká škola, VŠB Ostrava ČSJ 7.9.205 Typy procesů (ČSN ISO 2747) Procesy typu A Výsledné rozdělení
Přehled metod regulace procesů při různých typech chování procesu Eva Jarošová, Darja Noskievičová Škoda Auto Vysoká škola, VŠB Ostrava ČSJ 7.9.205 Typy procesů (ČSN ISO 2747) Procesy typu A Výsledné rozdělení
Regulační diagramy (RD)
") Regulační diagramy (RD) Control Charts Patří k základním nástrojům vnitřní QC laboratoře či výrobního procesu (grafická pomůcka). Pomocí RD lze dlouhodobě sledovat stabilitu (chemického) měřícího systému.
Regulační diagramy (RD) Control Charts Patří k základním nástrojům vnitřní QC laboratoře či výrobního procesu (grafická pomůcka). Pomocí RD lze dlouhodobě sledovat stabilitu (chemického) měřícího systému.
Q-diagramy. Jiří Michálek ÚTIA AVČR
 Q-diagramy Jiří Michálek ÚTIA AVČR Proč Q-diagramy? Nevýhody Shewhartových diagramů velikost regulačních mezí závisí na rozsahu logické podskupiny nehodí se pro krátké výrobní série normálně rozdělená
Q-diagramy Jiří Michálek ÚTIA AVČR Proč Q-diagramy? Nevýhody Shewhartových diagramů velikost regulačních mezí závisí na rozsahu logické podskupiny nehodí se pro krátké výrobní série normálně rozdělená
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz
 Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická
Statistické řízení jakosti. Deming: Klíč k jakosti je v pochopení variability procesu.
 Statistické řízení jakosti Deming: Klíč k jakosti je v pochopení variability procesu. SŘJ Statistická regulace výrobního procesu Statistická přejímka jakosti měřením srovnáváním měřením srovnáváním - X
Statistické řízení jakosti Deming: Klíč k jakosti je v pochopení variability procesu. SŘJ Statistická regulace výrobního procesu Statistická přejímka jakosti měřením srovnáváním měřením srovnáváním - X
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc.
 Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika 010 1.týden (0.09.-4.09. ) Data, typy dat, variabilita, frekvenční analýza
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika 010 1.týden (0.09.-4.09. ) Data, typy dat, variabilita, frekvenční analýza
MSA-Analýza systému měření
 MSA-Analýza systému měření Josef Bednář Abstrakt: V příspěvku je popsáno provedení analýzy systému měření v technické praxi pro spojitá data. Je zde popsáno provedení R&R studie pomocí analýzy rozptylu
MSA-Analýza systému měření Josef Bednář Abstrakt: V příspěvku je popsáno provedení analýzy systému měření v technické praxi pro spojitá data. Je zde popsáno provedení R&R studie pomocí analýzy rozptylu
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc.
 Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika 2010 1.týden (20.09.-24.09. ) Data, typy dat, variabilita, frekvenční analýza
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika 2010 1.týden (20.09.-24.09. ) Data, typy dat, variabilita, frekvenční analýza
Normy ČSN a ČSN ISO z oblasti aplikované statistiky (stav aktualizovaný k 1.1.2008)
") Normy ČSN a ČSN ISO z oblasti aplikované statistiky (stav aktualizovaný k 1.1.2008) Ing. Vratislav Horálek, DrSc., předseda TNK 4 při ČNI 1 Terminologické normy [1] ČSN ISO 3534-1:1994 Statistika Slovník
Normy ČSN a ČSN ISO z oblasti aplikované statistiky (stav aktualizovaný k 1.1.2008) Ing. Vratislav Horálek, DrSc., předseda TNK 4 při ČNI 1 Terminologické normy [1] ČSN ISO 3534-1:1994 Statistika Slovník
Inovace bakalářského studijního oboru Aplikovaná chemie http://aplchem.upol.cz
 http://aplchem.upol.cz CZ.1.07/2.2.00/15.0247 Tento projekt je spolufinancován Evropským sociálním fondem a státním rozpočtem České republiky. Sedm základních nástrojů řízení kvality Doc. RNDr. Jiří Šimek,
http://aplchem.upol.cz CZ.1.07/2.2.00/15.0247 Tento projekt je spolufinancován Evropským sociálním fondem a státním rozpočtem České republiky. Sedm základních nástrojů řízení kvality Doc. RNDr. Jiří Šimek,
Průzkumová analýza dat
 Průzkumová analýza dat Proč zkoumat data? Základ průzkumové analýzy dat položil John Tukey ve svém díle Exploratory Data Analysis (odtud zkratka EDA). Často se stává, že data, se kterými pracujeme, se
Průzkumová analýza dat Proč zkoumat data? Základ průzkumové analýzy dat položil John Tukey ve svém díle Exploratory Data Analysis (odtud zkratka EDA). Často se stává, že data, se kterými pracujeme, se
Lineární regrese. Komentované řešení pomocí MS Excel
 Lineární regrese Komentované řešení pomocí MS Excel Vstupní data Tabulka se vstupními daty je umístěna v oblasti A1:B11 (viz. obrázek) na listu cela data Postup Základní výpočty - regrese Výpočet základních
Lineární regrese Komentované řešení pomocí MS Excel Vstupní data Tabulka se vstupními daty je umístěna v oblasti A1:B11 (viz. obrázek) na listu cela data Postup Základní výpočty - regrese Výpočet základních
Jednofaktorová analýza rozptylu
 Jednofaktorová analýza rozptylu David Hampel Ústav statistiky a operačního výzkumu, Mendelova univerzita v Brně Kurz pokročilých statistických metod Global Change Research Centre AS CR, 5 7 8 2015 Tato
Jednofaktorová analýza rozptylu David Hampel Ústav statistiky a operačního výzkumu, Mendelova univerzita v Brně Kurz pokročilých statistických metod Global Change Research Centre AS CR, 5 7 8 2015 Tato
Rozdíl rizik zbytečného signálu v regulačním diagramu (I,MR) a (xbar,r)
 a (xbar,r)") Rozdíl rizik zbytečného signálu v regulačním diagramu (I,MR) a (xbar,r) Bohumil Maroš 1. Úvod Regulační diagram je nejefektivnější nástroj pro identifikaci stability, resp. nestability procesu. Vhodně
Rozdíl rizik zbytečného signálu v regulačním diagramu (I,MR) a (xbar,r) Bohumil Maroš 1. Úvod Regulační diagram je nejefektivnější nástroj pro identifikaci stability, resp. nestability procesu. Vhodně
y = 0, ,19716x.
 Grafické ověřování a testování vybraných modelů 1 Grafické ověřování empirického rozdělení Při grafické analýze empirického rozdělení vycházíme z empirické distribuční funkce F n (x) příslušné k náhodnému
Grafické ověřování a testování vybraných modelů 1 Grafické ověřování empirického rozdělení Při grafické analýze empirického rozdělení vycházíme z empirické distribuční funkce F n (x) příslušné k náhodnému
VŠB Technická univerzita Ostrava Fakulta elektrotechniky a informatiky SMAD
 VŠB Technická univerzita Ostrava Fakulta elektrotechniky a informatiky JMÉNO STUDENTKY/STUDENTA: OSOBNÍ ČÍSLO: JMÉNO CVIČÍCÍ/CVIČÍCÍHO: SMAD Cvičení Ostrava, AR 2016/2017 Popis datového souboru Pro dlouhodobý
VŠB Technická univerzita Ostrava Fakulta elektrotechniky a informatiky JMÉNO STUDENTKY/STUDENTA: OSOBNÍ ČÍSLO: JMÉNO CVIČÍCÍ/CVIČÍCÍHO: SMAD Cvičení Ostrava, AR 2016/2017 Popis datového souboru Pro dlouhodobý
Intervalové odhady. Interval spolehlivosti pro střední hodnotu v N(µ, σ 2 ) Interpretace intervalu spolehlivosti. Interval spolehlivosti ilustrace
 Interpretace intervalu spolehlivosti. Interval spolehlivosti ilustrace") Intervalové odhady Interval spolehlivosti pro střední hodnotu v Nµ, σ 2 ) Situace: X 1,..., X n náhodný výběr z Nµ, σ 2 ), kde σ 2 > 0 známe měli jsme: bodové odhady odhadem charakteristiky je číslo) nevyjadřuje
Intervalové odhady Interval spolehlivosti pro střední hodnotu v Nµ, σ 2 ) Situace: X 1,..., X n náhodný výběr z Nµ, σ 2 ), kde σ 2 > 0 známe měli jsme: bodové odhady odhadem charakteristiky je číslo) nevyjadřuje
DVOUVÝBĚROVÉ A PÁROVÉ TESTY Komentované řešení pomocí programu Statistica
 DVOUVÝBĚROVÉ A PÁROVÉ TESTY Komentované řešení pomocí programu Statistica Úloha A) koncentrace glukózy v krvi V této části posoudíme pomocí párového testu, zda nový lék prokazatelně snižuje koncentraci
DVOUVÝBĚROVÉ A PÁROVÉ TESTY Komentované řešení pomocí programu Statistica Úloha A) koncentrace glukózy v krvi V této části posoudíme pomocí párového testu, zda nový lék prokazatelně snižuje koncentraci
JEDNOVÝBĚROVÉ TESTY. Komentované řešení pomocí programu Statistica
 JEDNOVÝBĚROVÉ TESTY Komentované řešení pomocí programu Statistica Vstupní data Data umístěná v excelovském souboru překopírujeme do tabulky ve Statistice a pojmenujeme proměnné, viz prezentace k tématu
JEDNOVÝBĚROVÉ TESTY Komentované řešení pomocí programu Statistica Vstupní data Data umístěná v excelovském souboru překopírujeme do tabulky ve Statistice a pojmenujeme proměnné, viz prezentace k tématu
Intervalové odhady. Interval spolehlivosti pro střední hodnotu v N(µ, σ 2 ) Interpretace intervalu spolehlivosti. Interval spolehlivosti ilustrace
 Interpretace intervalu spolehlivosti. Interval spolehlivosti ilustrace") Intervalové odhady Interval spolehlivosti pro střední hodnotu v Nµ, σ 2 ) Situace: X 1,..., X n náhodný výběr z Nµ, σ 2 ), kde σ 2 > 0 známe měli jsme: bodové odhady odhadem charakteristiky je číslo) nevyjadřuje
Intervalové odhady Interval spolehlivosti pro střední hodnotu v Nµ, σ 2 ) Situace: X 1,..., X n náhodný výběr z Nµ, σ 2 ), kde σ 2 > 0 známe měli jsme: bodové odhady odhadem charakteristiky je číslo) nevyjadřuje
Analýza dat na PC I.
 CENTRUM BIOSTATISTIKY A ANALÝZ Lékařská a Přírodovědecká fakulta, Masarykova univerzita Analýza dat na PC I. Popisná analýza v programu Statistica IBA výuka Základní popisná statistika Popisná statistika
CENTRUM BIOSTATISTIKY A ANALÝZ Lékařská a Přírodovědecká fakulta, Masarykova univerzita Analýza dat na PC I. Popisná analýza v programu Statistica IBA výuka Základní popisná statistika Popisná statistika
UNIVERZITA OBRANY Fakulta ekonomiky a managementu. Aplikace STAT1. Výsledek řešení projektu PRO HORR2011 a PRO GRAM2011 3. 11.
 UNIVERZITA OBRANY Fakulta ekonomiky a managementu Aplikace STAT1 Výsledek řešení projektu PRO HORR2011 a PRO GRAM2011 Jiří Neubauer, Marek Sedlačík, Oldřich Kříž 3. 11. 2012 Popis a návod k použití aplikace
UNIVERZITA OBRANY Fakulta ekonomiky a managementu Aplikace STAT1 Výsledek řešení projektu PRO HORR2011 a PRO GRAM2011 Jiří Neubauer, Marek Sedlačík, Oldřich Kříž 3. 11. 2012 Popis a návod k použití aplikace
VŠB Technická univerzita Ostrava Fakulta elektrotechniky a informatiky
 VŠB Technická univerzita Ostrava Fakulta elektrotechniky a informatiky PRAVDĚPODOBNOST A STATISTIKA Zadání 1 JMÉNO STUDENTKY/STUDENTA: OSOBNÍ ČÍSLO: JMÉNO CVIČÍCÍ/CVIČÍCÍHO: DATUM ODEVZDÁNÍ DOMÁCÍ ÚKOL
VŠB Technická univerzita Ostrava Fakulta elektrotechniky a informatiky PRAVDĚPODOBNOST A STATISTIKA Zadání 1 JMÉNO STUDENTKY/STUDENTA: OSOBNÍ ČÍSLO: JMÉNO CVIČÍCÍ/CVIČÍCÍHO: DATUM ODEVZDÁNÍ DOMÁCÍ ÚKOL
RNDr. Eva Janoušová doc. RNDr. Ladislav Dušek, Dr.
 Analýza dat pro Neurovědy RNDr. Eva Janoušová doc. RNDr. Ladislav Dušek, Dr. Jaro 2014 Institut biostatistiky Janoušová, a analýz Dušek: Analýza dat pro neurovědy Blok 3 Jak a kdy použít parametrické a
Analýza dat pro Neurovědy RNDr. Eva Janoušová doc. RNDr. Ladislav Dušek, Dr. Jaro 2014 Institut biostatistiky Janoušová, a analýz Dušek: Analýza dat pro neurovědy Blok 3 Jak a kdy použít parametrické a
Vyhodnocování způsobilosti a výkonnosti výrobního procesu
 Vyhodnocování způsobilosti a výkonnosti výrobního procesu Jiří Michálek CQR 2009 Vyhodnocování způsobilosti a výkonnosti výrobního procesu Jiří Michálek Centrum pro jakost a spolehlivost ve výrobě CQR
Vyhodnocování způsobilosti a výkonnosti výrobního procesu Jiří Michálek CQR 2009 Vyhodnocování způsobilosti a výkonnosti výrobního procesu Jiří Michálek Centrum pro jakost a spolehlivost ve výrobě CQR
Různé metody manažerství kvality. Práce č.12: Výpočet PPM a způsobilost procesů
 - Různé metody manažerství kvality - Práce č.12: Výpočet PPM a způsobilost procesů Datum: 02-12-2018 Martin Bažant Obsah Obsah... 2 1 Úvod... 3 2 Způsobilost procesů... 3 3 Výpočet PPM... 7 3.1 Základní
- Různé metody manažerství kvality - Práce č.12: Výpočet PPM a způsobilost procesů Datum: 02-12-2018 Martin Bažant Obsah Obsah... 2 1 Úvod... 3 2 Způsobilost procesů... 3 3 Výpočet PPM... 7 3.1 Základní
VYSOKÁ ŠKOLA BÁŇSKÁ TECHNICKÁ UNIVERZITA OSTRAVA FAKULTA METALURGIE A MATERIÁLOVÉHO INŽENÝRSTVÍ KATEDRA KONTROLY A ŘÍZENÍ JAKOSTI
 VYSOKÁ ŠKOLA BÁŇSKÁ TECHNICKÁ UNIVERZITA OSTRAVA FAKULTA METALURGIE A MATERIÁLOVÉHO INŽENÝRSTVÍ KATEDRA KONTROLY A ŘÍZENÍ JAKOSTI Elektronická sbírka příkladů k předmětům zaměřeným na aplikovanou statistiku
VYSOKÁ ŠKOLA BÁŇSKÁ TECHNICKÁ UNIVERZITA OSTRAVA FAKULTA METALURGIE A MATERIÁLOVÉHO INŽENÝRSTVÍ KATEDRA KONTROLY A ŘÍZENÍ JAKOSTI Elektronická sbírka příkladů k předmětům zaměřeným na aplikovanou statistiku
ROBUST 2012 Němčičky 9.9. - 14.9. 2012. Metodika komplexního návrhu regulačního diagramu. Ing. Jan Král. ISQ PRAHA s.r.o. kral.jan@isq.
 ROBUST 2012 Němčičky 9.9. - 14.9. 2012 Metodika komplexního návrhu regulačního diagramu Ing. Jan Král ISQ PRAHA s.r.o. kral.jan@isq.cz Cíl práce Prezentovaná práce si klade za cíl vytvořit ucelenou systematickou
ROBUST 2012 Němčičky 9.9. - 14.9. 2012 Metodika komplexního návrhu regulačního diagramu Ing. Jan Král ISQ PRAHA s.r.o. kral.jan@isq.cz Cíl práce Prezentovaná práce si klade za cíl vytvořit ucelenou systematickou
POPISNÁ STATISTIKA Komentované řešení pomocí programu Statistica
 POPISNÁ STATISTIKA Komentované řešení pomocí programu Statistica Program Statistica I Statistica je velmi podobná Excelu. Na základní úrovni je to klikací program určený ke statistickému zpracování dat.
POPISNÁ STATISTIKA Komentované řešení pomocí programu Statistica Program Statistica I Statistica je velmi podobná Excelu. Na základní úrovni je to klikací program určený ke statistickému zpracování dat.
Ekonomické aspekty statistické regulace pro vysoce způsobilé procesy. Kateřina Brodecká
 Ekonomické aspekty statistické regulace pro vysoce způsobilé procesy Kateřina Brodecká Vysoce způsobilé procesy s rozvojem technologií a důrazem kladeným na aktivity neustálého zlepšování a zeštíhlování
Ekonomické aspekty statistické regulace pro vysoce způsobilé procesy Kateřina Brodecká Vysoce způsobilé procesy s rozvojem technologií a důrazem kladeným na aktivity neustálého zlepšování a zeštíhlování
Ústav teorie informace a automatizace RESEARCH REPORT. Nestandardní regulační diagramy pro SPC. No. 2311 December 2011
 kademie věd České republiky Ústav teorie informace a automatizace cademy of Sciences of the Czech Republic Institute of Information Theory and utomation RESERCH REPORT Josef Křepela, Jiří Michálek: Nestandardní
kademie věd České republiky Ústav teorie informace a automatizace cademy of Sciences of the Czech Republic Institute of Information Theory and utomation RESERCH REPORT Josef Křepela, Jiří Michálek: Nestandardní
Pravděpodobnost v závislosti na proměnné x je zde modelován pomocí logistického modelu. exp x. x x x. log 1
 Logistická regrese Menu: QCExpert Regrese Logistická Modul Logistická regrese umožňuje analýzu dat, kdy odezva je binární, nebo frekvenční veličina vyjádřená hodnotami 0 nebo 1, případně poměry v intervalu
Logistická regrese Menu: QCExpert Regrese Logistická Modul Logistická regrese umožňuje analýzu dat, kdy odezva je binární, nebo frekvenční veličina vyjádřená hodnotami 0 nebo 1, případně poměry v intervalu
PRINCIPY ZABEZPEČENÍ KVALITY
 (c) David MILDE, 2013 PRINCIPY ZABEZPEČENÍ KVALITY POUŽÍVANÁ OPATŘENÍ QA/QC Interní opatření (uvnitř laboratoře): pravidelná analýza kontrolních vzorků a CRM, sledování slepých postupů a možných kontaminací,
(c) David MILDE, 2013 PRINCIPY ZABEZPEČENÍ KVALITY POUŽÍVANÁ OPATŘENÍ QA/QC Interní opatření (uvnitř laboratoře): pravidelná analýza kontrolních vzorků a CRM, sledování slepých postupů a možných kontaminací,
Testy nezávislosti kardinálních veličin
 Testy nezávislosti kardinálních veličin Komentované řešení pomocí programu R Ústav matematiky Fakulta chemicko inženýrská Vysoká škola chemicko-technologická v Praze Načtení vstupních dat Vstupní data
Testy nezávislosti kardinálních veličin Komentované řešení pomocí programu R Ústav matematiky Fakulta chemicko inženýrská Vysoká škola chemicko-technologická v Praze Načtení vstupních dat Vstupní data
Charakteristika datového souboru
 Zápočtová práce z předmětu Statistika Vypracoval: 10. 11. 2014 Charakteristika datového souboru Zadání: Při kontrole dodržování hygienických norem v kuchyni se prováděl odběr vzduchu a pomocí filtru Pallflex
Zápočtová práce z předmětu Statistika Vypracoval: 10. 11. 2014 Charakteristika datového souboru Zadání: Při kontrole dodržování hygienických norem v kuchyni se prováděl odběr vzduchu a pomocí filtru Pallflex
LINEÁRNÍ REGRESE Komentované řešení pomocí programu Statistica
 LINEÁRNÍ REGRESE Komentované řešení pomocí programu Statistica Vstupní data Data umístěná v excelovském souboru překopírujeme do tabulky ve Statistice a pojmenujeme proměnné, viz prezentace k tématu Popisná
LINEÁRNÍ REGRESE Komentované řešení pomocí programu Statistica Vstupní data Data umístěná v excelovském souboru překopírujeme do tabulky ve Statistice a pojmenujeme proměnné, viz prezentace k tématu Popisná
VYUŽITÍ PRAVDĚPODOBNOSTNÍ METODY MONTE CARLO V SOUDNÍM INŽENÝRSTVÍ
 VYUŽITÍ PRAVDĚPODOBNOSTNÍ METODY MONTE CARLO V SOUDNÍM INŽENÝRSTVÍ Michal Kořenář 1 Abstrakt Rozvoj výpočetní techniky v poslední době umožnil také rozvoj výpočetních metod, které nejsou založeny na bázi
VYUŽITÍ PRAVDĚPODOBNOSTNÍ METODY MONTE CARLO V SOUDNÍM INŽENÝRSTVÍ Michal Kořenář 1 Abstrakt Rozvoj výpočetní techniky v poslední době umožnil také rozvoj výpočetních metod, které nejsou založeny na bázi
VŠB Technická univerzita Ostrava BIOSTATISTIKA
 VŠB Technická univerzita Ostrava Fakulta elektrotechniky a informatiky JMÉNO STUDENTKY/STUDENTA: OSOBNÍ ČÍSLO: JMÉNO CVIČÍCÍ/CVIČÍCÍHO: BIOSTATISTIKA Domácí úkoly Zadání 5 DATUM ODEVZDÁNÍ DOMÁCÍ ÚKOL 1:
VŠB Technická univerzita Ostrava Fakulta elektrotechniky a informatiky JMÉNO STUDENTKY/STUDENTA: OSOBNÍ ČÍSLO: JMÉNO CVIČÍCÍ/CVIČÍCÍHO: BIOSTATISTIKA Domácí úkoly Zadání 5 DATUM ODEVZDÁNÍ DOMÁCÍ ÚKOL 1:
Jednofaktorová analýza rozptylu
 I I.I Jednofaktorová analýza rozptylu Úvod Jednofaktorová analýza rozptylu (ANOVA) se využívá při porovnání několika středních hodnot. Často se využívá ve vědeckých a lékařských experimentech, při kterých
I I.I Jednofaktorová analýza rozptylu Úvod Jednofaktorová analýza rozptylu (ANOVA) se využívá při porovnání několika středních hodnot. Často se využívá ve vědeckých a lékařských experimentech, při kterých
KORELACE. Komentované řešení pomocí programu Statistica
 KORELACE Komentované řešení pomocí programu Statistica Vstupní data I Data umístěná v excelovském souboru překopírujeme do tabulky ve Statistice a pojmenujeme proměnné, viz prezentace k tématu Popisná
KORELACE Komentované řešení pomocí programu Statistica Vstupní data I Data umístěná v excelovském souboru překopírujeme do tabulky ve Statistice a pojmenujeme proměnné, viz prezentace k tématu Popisná
1 Tyto materiály byly vytvořeny za pomoci grantu FRVŠ číslo 1145/2004.
 Testy hypotéz na základě více než 2 výběrů 1 1 Tyto materiály byly vytvořeny za pomoci grantu FRVŠ číslo 1145/2004. Testy hypotéz na základě více než 2 výběrů Na analýzu rozptylu lze pohlížet v podstatě
Testy hypotéz na základě více než 2 výběrů 1 1 Tyto materiály byly vytvořeny za pomoci grantu FRVŠ číslo 1145/2004. Testy hypotéz na základě více než 2 výběrů Na analýzu rozptylu lze pohlížet v podstatě
Testování hypotéz. 1 Jednovýběrové testy. 90/2 odhad času
 Testování hypotéz 1 Jednovýběrové testy 90/ odhad času V podmínkách naprostého odloučení má voák prokázat schopnost orientace v čase. Úkolem voáka e provést odhad časového intervalu 1 hodiny bez hodinek
Testování hypotéz 1 Jednovýběrové testy 90/ odhad času V podmínkách naprostého odloučení má voák prokázat schopnost orientace v čase. Úkolem voáka e provést odhad časového intervalu 1 hodiny bez hodinek
Testování statistických hypotéz. Ing. Michal Dorda, Ph.D.
 Testování statistických hypotéz Ing. Michal Dorda, Ph.D. Testování normality Př. : Při simulaci provozu na křižovatce byla získána data o mezerách mezi přijíždějícími vozidly v [s]. Otestujte na hladině
Testování statistických hypotéz Ing. Michal Dorda, Ph.D. Testování normality Př. : Při simulaci provozu na křižovatce byla získána data o mezerách mezi přijíždějícími vozidly v [s]. Otestujte na hladině
Předpoklad o normalitě rozdělení je zamítnut, protože hodnota testovacího kritéria χ exp je vyšší než tabulkový 2
 Na úloze ukážeme postup analýzy velkého výběru s odlehlými prvky pro určení typu rozdělení koncentrace kyseliny močové u 50 dárců krve. Jaká je míra polohy a rozptýlení uvedeného výběru? Z grafických diagnostik
Na úloze ukážeme postup analýzy velkého výběru s odlehlými prvky pro určení typu rozdělení koncentrace kyseliny močové u 50 dárců krve. Jaká je míra polohy a rozptýlení uvedeného výběru? Z grafických diagnostik
ANALÝZA DAT V R 3. POPISNÉ STATISTIKY, NÁHODNÁ VELIČINA. Mgr. Markéta Pavlíková Katedra pravděpodobnosti a matematické statistiky MFF UK
 ANALÝZA DAT V R 3. POPISNÉ STATISTIKY, NÁHODNÁ VELIČINA Mgr. Markéta Pavlíková Katedra pravděpodobnosti a matematické statistiky MFF UK www.biostatisticka.cz POPISNÉ STATISTIKY - OPAKOVÁNÍ jedna kvalitativní
ANALÝZA DAT V R 3. POPISNÉ STATISTIKY, NÁHODNÁ VELIČINA Mgr. Markéta Pavlíková Katedra pravděpodobnosti a matematické statistiky MFF UK www.biostatisticka.cz POPISNÉ STATISTIKY - OPAKOVÁNÍ jedna kvalitativní
Přednáška 9. Testy dobré shody. Grafická analýza pro ověření shody empirického a teoretického rozdělení
 Přednáška 9 Testy dobré shody Grafická analýza pro ověření shody empirického a teoretického rozdělení χ 2 test dobré shody ověření, zda jsou relativní četnosti jednotlivých variant rovny číslům π 01 ;
Přednáška 9 Testy dobré shody Grafická analýza pro ověření shody empirického a teoretického rozdělení χ 2 test dobré shody ověření, zda jsou relativní četnosti jednotlivých variant rovny číslům π 01 ;
PRŮZKUMOVÁ ANALÝZA JEDNOROZMĚRNÝCH DAT Exploratory Data Analysis (EDA)
") PRŮZKUMOVÁ ANALÝZA JEDNOROZMĚRNÝCH DAT Exploratory Data Analysis (EDA) Reprezentativní náhodný výběr: 1. Prvky výběru x i jsou vzájemně nezávislé. 2. Výběr je homogenní, tj. všechna x i jsou ze stejného
PRŮZKUMOVÁ ANALÝZA JEDNOROZMĚRNÝCH DAT Exploratory Data Analysis (EDA) Reprezentativní náhodný výběr: 1. Prvky výběru x i jsou vzájemně nezávislé. 2. Výběr je homogenní, tj. všechna x i jsou ze stejného
Vlastnosti odhadů ukazatelů způsobilosti
 Vlastnosti odhadů ukazatelů způsobilosti Jiří Michálek CQR při Ústavu teorie informace a automatizace AV ČR v Praze Úvod Ve výzkumné zprávě č 06 Odhady koeficientů způsobilosti a jejich vlastnosti viz
Vlastnosti odhadů ukazatelů způsobilosti Jiří Michálek CQR při Ústavu teorie informace a automatizace AV ČR v Praze Úvod Ve výzkumné zprávě č 06 Odhady koeficientů způsobilosti a jejich vlastnosti viz
Normální (Gaussovo) rozdělení
 rozdělení") Normální (Gaussovo) rozdělení Normální (Gaussovo) rozdělení popisuje vlastnosti náhodné spojité veličiny, která vzniká složením různých náhodných vlivů, které jsou navzájem nezávislé, kterých je velký
Normální (Gaussovo) rozdělení Normální (Gaussovo) rozdělení popisuje vlastnosti náhodné spojité veličiny, která vzniká složením různých náhodných vlivů, které jsou navzájem nezávislé, kterých je velký
KGG/STG Statistika pro geografy
 KGG/STG Statistika pro geografy 5. Odhady parametrů základního souboru Mgr. David Fiedor 16. března 2015 Vztahy mezi výběrovým a základním souborem Osnova 1 Úvod, pojmy Vztahy mezi výběrovým a základním
KGG/STG Statistika pro geografy 5. Odhady parametrů základního souboru Mgr. David Fiedor 16. března 2015 Vztahy mezi výběrovým a základním souborem Osnova 1 Úvod, pojmy Vztahy mezi výběrovým a základním
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc.
 Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika 2010 1.týden (20.09.-24.09. ) Data, typy dat, variabilita, frekvenční analýza
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika 2010 1.týden (20.09.-24.09. ) Data, typy dat, variabilita, frekvenční analýza
Simulace. Simulace dat. Parametry
 Simulace Simulace dat Menu: QCExpert Simulace Simulace dat Tento modul je určen pro generování pseudonáhodných dat s danými statistickými vlastnostmi. Nabízí čtyři typy rozdělení: normální, logaritmicko-normální,
Simulace Simulace dat Menu: QCExpert Simulace Simulace dat Tento modul je určen pro generování pseudonáhodných dat s danými statistickými vlastnostmi. Nabízí čtyři typy rozdělení: normální, logaritmicko-normální,
Metodologie pro Informační studia a knihovnictví 2
 Metodologie pro Informační studia a knihovnictví 2 Modul 5: Popis nekategorizovaných dat Co se dozvíte v tomto modulu? Kdy používat modus, průměr a medián. Co je to směrodatná odchylka. Jak popsat distribuci
Metodologie pro Informační studia a knihovnictví 2 Modul 5: Popis nekategorizovaných dat Co se dozvíte v tomto modulu? Kdy používat modus, průměr a medián. Co je to směrodatná odchylka. Jak popsat distribuci
letní semestr 2012 Katedra pravděpodobnosti a matematické statistiky Matematicko-fyzikální fakulta Univerzity Karlovy Matematická statistika
 Šárka Hudecová Katedra pravděpodobnosti a matematické statistiky Matematicko-fyzikální fakulta Univerzity Karlovy letní semestr 2012 Opakování t- vs. neparametrické Wilcoxonův jednovýběrový test Opakování
Šárka Hudecová Katedra pravděpodobnosti a matematické statistiky Matematicko-fyzikální fakulta Univerzity Karlovy letní semestr 2012 Opakování t- vs. neparametrické Wilcoxonův jednovýběrový test Opakování
Národní informační středisko pro podporu jakosti
 Národní informační středisko pro podporu jakosti Stanovení měr opakovatelnosti a reprodukovatelnosti při kontrole měřením a srovnáváním Ing. Jan Král Úvodní teze Zásah do procesu se děje na základě měření.
Národní informační středisko pro podporu jakosti Stanovení měr opakovatelnosti a reprodukovatelnosti při kontrole měřením a srovnáváním Ing. Jan Král Úvodní teze Zásah do procesu se děje na základě měření.
Zápočtová práce STATISTIKA I
 Zápočtová práce STATISTIKA I Obsah: - úvodní stránka - charakteristika dat (původ dat, důvod zpracování,...) - výpis naměřených hodnot (v tabulce) - zpracování dat (buď bodové nebo intervalové, podle charakteru
Zápočtová práce STATISTIKA I Obsah: - úvodní stránka - charakteristika dat (původ dat, důvod zpracování,...) - výpis naměřených hodnot (v tabulce) - zpracování dat (buď bodové nebo intervalové, podle charakteru
Vybrané praktické aplikace statistické regulace procesu
 ČSJ, OSSM Praha, 19. 4. 2012 Vybrané praktické aplikace statistické regulace procesu Prof. Ing. Darja Noskievičová, CSc. Katedra kontroly a řízení jakosti Fakulta metalurgie a materiálového inženýrství
ČSJ, OSSM Praha, 19. 4. 2012 Vybrané praktické aplikace statistické regulace procesu Prof. Ing. Darja Noskievičová, CSc. Katedra kontroly a řízení jakosti Fakulta metalurgie a materiálového inženýrství
Univerzita Pardubice Fakulta chemicko-technologická Katedra analytické chemie STATISTICKÉ ZPRACOVÁNÍ EXPERIMENTÁLNÍCH DAT
 Univerzita Pardubice Fakulta chemicko-technologická Katedra analytické chemie STATISTICKÉ ZPRACOVÁNÍ EXPERIMENTÁLNÍCH DAT STATISTICKÁ ANALÝZA JEDNOROZMĚRNÝCH DAT Seminární práce 1 Brno, 2002 Ing. Pavel
Univerzita Pardubice Fakulta chemicko-technologická Katedra analytické chemie STATISTICKÉ ZPRACOVÁNÍ EXPERIMENTÁLNÍCH DAT STATISTICKÁ ANALÝZA JEDNOROZMĚRNÝCH DAT Seminární práce 1 Brno, 2002 Ing. Pavel
676 + 4 + 100 + 196 + 0 + 484 + 196 + 324 + 64 + 324 = = 2368
 Příklad 1 Je třeba prověřit, zda lze na 5% hladině významnosti pokládat za prokázanou hypotézu, že střední doba výroby výlisku je 30 sekund. Přitom 10 náhodně vybraných výlisků bylo vyráběno celkem 540
Příklad 1 Je třeba prověřit, zda lze na 5% hladině významnosti pokládat za prokázanou hypotézu, že střední doba výroby výlisku je 30 sekund. Přitom 10 náhodně vybraných výlisků bylo vyráběno celkem 540
Semestrální práce z předmětu Pravděpodobnost, statistika a teorie informace
 České vysoké učení technické v Praze Fakulta elektrotechnická Semestrální práce z předmětu Pravděpodobnost, statistika a teorie informace Životnost LED diod Autor: Joel Matějka Praha, 2012 Obsah 1 Úvod
České vysoké učení technické v Praze Fakulta elektrotechnická Semestrální práce z předmětu Pravděpodobnost, statistika a teorie informace Životnost LED diod Autor: Joel Matějka Praha, 2012 Obsah 1 Úvod
UNIVERZITA PARDUBICE Fakulta chemicko-technologická Katedra analytické chemie Nám. Čs. Legií 565, Pardubice
 UNIVERZITA PARDUBICE Fakulta chemicko-technologická Katedra analytické chemie Nám. Čs. Legií 565, 532 10 Pardubice 10. licenční studium chemometrie STATISTICKÉ ZPRACOVÁNÍ DAT Semestrální práce STATISTICKÁ
UNIVERZITA PARDUBICE Fakulta chemicko-technologická Katedra analytické chemie Nám. Čs. Legií 565, 532 10 Pardubice 10. licenční studium chemometrie STATISTICKÉ ZPRACOVÁNÍ DAT Semestrální práce STATISTICKÁ
MATEMATICKO STATISTICKÉ PARAMETRY ANALYTICKÝCH VÝSLEDKŮ
 MATEMATICKO STATISTICKÉ PARAMETRY ANALYTICKÝCH VÝSLEDKŮ Má-li analytický výsledek objektivně vypovídat o chemickém složení vzorku, musí splňovat určitá kriteria: Mezinárodní metrologický slovník (VIM 3),
MATEMATICKO STATISTICKÉ PARAMETRY ANALYTICKÝCH VÝSLEDKŮ Má-li analytický výsledek objektivně vypovídat o chemickém složení vzorku, musí splňovat určitá kriteria: Mezinárodní metrologický slovník (VIM 3),
Ilustrační příklad odhadu LRM v SW Gretl
 Ilustrační příklad odhadu LRM v SW Gretl Podkladové údaje Korelační matice Odhad lineárního regresního modelu (LRM) Verifikace modelu PEF ČZU Praha Určeno pro posluchače předmětu Ekonometrie Needitovaná
Ilustrační příklad odhadu LRM v SW Gretl Podkladové údaje Korelační matice Odhad lineárního regresního modelu (LRM) Verifikace modelu PEF ČZU Praha Určeno pro posluchače předmětu Ekonometrie Needitovaná
Kvantily a písmenové hodnoty E E E E-02
 Na úloze ukážeme postup průzkumové analýzy dat. Při výrobě calciferolu se provádí kontrola meziproduktu 3,5 DNB esteru calciferolu metodou HPLC. Sleduje se také obsah přítomného ergosterinu jako nečistoty,
Na úloze ukážeme postup průzkumové analýzy dat. Při výrobě calciferolu se provádí kontrola meziproduktu 3,5 DNB esteru calciferolu metodou HPLC. Sleduje se také obsah přítomného ergosterinu jako nečistoty,
Jednostranné intervaly spolehlivosti
 Jednostranné intervaly spolehlivosti hledáme jen jednu z obou mezí Princip: dle zadání úlohy hledáme jen dolní či jen horní mez podle oboustranného vzorce s tou změnou, že výraz 1-α/2 ve vzorci nahradíme
Jednostranné intervaly spolehlivosti hledáme jen jednu z obou mezí Princip: dle zadání úlohy hledáme jen dolní či jen horní mez podle oboustranného vzorce s tou změnou, že výraz 1-α/2 ve vzorci nahradíme
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc.
 Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika 2010 1.týden (20.09.-24.09. ) Data, typy dat, variabilita, frekvenční analýza
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika 2010 1.týden (20.09.-24.09. ) Data, typy dat, variabilita, frekvenční analýza
Testování statistických hypotéz
 Testování statistických hypotéz Na základě náhodného výběru, který je reprezentativním vzorkem základního souboru (který přesně neznáme, k němuž se ale daná statistická hypotéza váže), potřebujeme ověřit,
Testování statistických hypotéz Na základě náhodného výběru, který je reprezentativním vzorkem základního souboru (který přesně neznáme, k němuž se ale daná statistická hypotéza váže), potřebujeme ověřit,
Statistické metody - nástroj poznání a rozhodování anebo zdroj omylů a lží
 Statistické metody - nástroj poznání a rozhodování anebo zdroj omylů a lží Zdeněk Karpíšek Jsou tři druhy lží: lži, odsouzeníhodné lži a statistiky. Statistika je logická a přesná metoda, jak nepřesně
Statistické metody - nástroj poznání a rozhodování anebo zdroj omylů a lží Zdeněk Karpíšek Jsou tři druhy lží: lži, odsouzeníhodné lži a statistiky. Statistika je logická a přesná metoda, jak nepřesně
You created this PDF from an application that is not licensed to print to novapdf printer (http://www.novapdf.com)
") Testování statistických hypotéz Testování statistických hypotéz Princip: Ověřování určitého předpokladu zjišťujeme, zda zkoumaný výběr pochází ze základního souboru, který má určité rozdělení zjišťujeme,
Testování statistických hypotéz Testování statistických hypotéz Princip: Ověřování určitého předpokladu zjišťujeme, zda zkoumaný výběr pochází ze základního souboru, který má určité rozdělení zjišťujeme,
RNDr. Eva Janoušová doc. RNDr. Ladislav Dušek, Dr.
 Analýza dat pro Neurovědy RNDr. Eva Janoušová doc. RNDr. Ladislav Dušek, Dr. Jaro 2014 Institut biostatistiky Janoušová, a analýz Dušek: Analýza dat pro neurovědy Blok 4 Jak a kdy použít parametrické a
Analýza dat pro Neurovědy RNDr. Eva Janoušová doc. RNDr. Ladislav Dušek, Dr. Jaro 2014 Institut biostatistiky Janoušová, a analýz Dušek: Analýza dat pro neurovědy Blok 4 Jak a kdy použít parametrické a
Metodologie pro Informační studia a knihovnictví 2
 Metodologie pro Informační studia a knihovnictví 2 Modul V: Nekategorizovaná data Metodologie pro ISK 2, jaro 2014. Ladislava Z. Suchá Metodologie pro Informační studia a knihovnictví 2 Modul 5: Popis
Metodologie pro Informační studia a knihovnictví 2 Modul V: Nekategorizovaná data Metodologie pro ISK 2, jaro 2014. Ladislava Z. Suchá Metodologie pro Informační studia a knihovnictví 2 Modul 5: Popis
Analýza způsobilosti procesů. Studijní opory
 Operační program Vzdělávání pro konkurenceschopnost PROJEKT Integrovaný systém modulární počítačové podpory výuky ekonomicko-technického zaměření CZ.1.07/2.2.00/28.0300 Analýza způsobilosti procesů Studijní
Operační program Vzdělávání pro konkurenceschopnost PROJEKT Integrovaný systém modulární počítačové podpory výuky ekonomicko-technického zaměření CZ.1.07/2.2.00/28.0300 Analýza způsobilosti procesů Studijní
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc.
 Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika 2010 1.týden (20.09.-24.09. ) Data, typy dat, variabilita, frekvenční analýza
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika 2010 1.týden (20.09.-24.09. ) Data, typy dat, variabilita, frekvenční analýza
Statistická analýza jednorozměrných dat
 Statistická analýza jednorozměrných dat Prof. RNDr. Milan Meloun, DrSc. Univerzita Pardubice, Pardubice 31.ledna 2011 Tato prezentace je spolufinancována Evropským sociálním fondem a státním rozpočtem
Statistická analýza jednorozměrných dat Prof. RNDr. Milan Meloun, DrSc. Univerzita Pardubice, Pardubice 31.ledna 2011 Tato prezentace je spolufinancována Evropským sociálním fondem a státním rozpočtem
VYUŽITÍ MATLAB WEB SERVERU PRO INTERNETOVOU VÝUKU ANALÝZY DAT A ŘÍZENÍ JAKOSTI
 VYUŽITÍ MATLAB WEB SERVERU PRO INTERNETOVOU VÝUKU ANALÝZY DAT A ŘÍZENÍ JAKOSTI Aleš Linka 1, Petr Volf 2 1 Katedra textilních materiálů, FT TUL, 2 Katedra aplikované matematiky, FP TUL ABSTRAKT. Internetové
VYUŽITÍ MATLAB WEB SERVERU PRO INTERNETOVOU VÝUKU ANALÝZY DAT A ŘÍZENÍ JAKOSTI Aleš Linka 1, Petr Volf 2 1 Katedra textilních materiálů, FT TUL, 2 Katedra aplikované matematiky, FP TUL ABSTRAKT. Internetové
31. 3. 2014, Brno Hanuš Vavrčík Základy statistiky ve vědě
 31. 3. 2014, Brno Hanuš Vavrčík Základy statistiky ve vědě Motto Statistika nuda je, má však cenné údaje. strana 3 Statistické charakteristiky Charakteristiky polohy jsou kolem ní seskupeny ostatní hodnoty
31. 3. 2014, Brno Hanuš Vavrčík Základy statistiky ve vědě Motto Statistika nuda je, má však cenné údaje. strana 3 Statistické charakteristiky Charakteristiky polohy jsou kolem ní seskupeny ostatní hodnoty
TECHNICKÁ UNIVERZITA V LIBERCI. Ekonomická fakulta. Semestrální práce. Statistický rozbor dat z dotazníkového šetření školní zadání
 TECHNICKÁ UNIVERZITA V LIBERCI Ekonomická fakulta Semestrální práce Statistický rozbor dat z dotazníkového šetření školní zadání Skupina: 51 Vypracovaly: Pavlína Horná, Nikola Loumová, Petra Mikešová,
TECHNICKÁ UNIVERZITA V LIBERCI Ekonomická fakulta Semestrální práce Statistický rozbor dat z dotazníkového šetření školní zadání Skupina: 51 Vypracovaly: Pavlína Horná, Nikola Loumová, Petra Mikešová,
Základní statistické metody v rizikovém inženýrství
 Základní statistické metody v rizikovém inženýrství Petr Misák Ústav stavebního zkušebnictví Fakulta stavební, VUT v Brně misak.p@fce.vutbr.cz Základní pojmy Jev souhrn skutečností zobrazujících ucelenou
Základní statistické metody v rizikovém inženýrství Petr Misák Ústav stavebního zkušebnictví Fakulta stavební, VUT v Brně misak.p@fce.vutbr.cz Základní pojmy Jev souhrn skutečností zobrazujících ucelenou
Tématické okruhy pro státní závěrečné zkoušky. bakalářské studium. studijní obor "Management jakosti"
 Tématické okruhy pro státní závěrečné zkoušky bakalářské studium studijní obor "Management jakosti" školní rok 2010/2011 Management jakosti A 1. Pojem jakosti a význam managementu jakosti v současném období.
Tématické okruhy pro státní závěrečné zkoušky bakalářské studium studijní obor "Management jakosti" školní rok 2010/2011 Management jakosti A 1. Pojem jakosti a význam managementu jakosti v současném období.
Testování hypotéz testy o tvaru rozdělení. Jiří Neubauer. Katedra ekonometrie, FVL, UO Brno kancelář 69a, tel
 Katedra ekonometrie, FVL, UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Statistickou hypotézou se rozumí určité tvrzení o parametrech rozdělení zkoumané náhodné veličiny (µ, σ 2, π,
Katedra ekonometrie, FVL, UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Statistickou hypotézou se rozumí určité tvrzení o parametrech rozdělení zkoumané náhodné veličiny (µ, σ 2, π,
Statistika, Biostatistika pro kombinované studium Letní semestr 2011/2012. Tutoriál č. 4: Exploratorní analýza. Jan Kracík
 Statistika, Biostatistika pro kombinované studium Letní semestr 2011/2012 Tutoriál č. 4: Exploratorní analýza Jan Kracík jan.kracik@vsb.cz Statistika věda o získávání znalostí z empirických dat empirická
Statistika, Biostatistika pro kombinované studium Letní semestr 2011/2012 Tutoriál č. 4: Exploratorní analýza Jan Kracík jan.kracik@vsb.cz Statistika věda o získávání znalostí z empirických dat empirická
Tématické okruhy pro státní závěrečné zkoušky. bakalářské studium. studijní obor "Management jakosti"
 Tématické okruhy pro státní závěrečné zkoušky bakalářské studium studijní obor "Management jakosti" školní rok 2013/2014 Management jakosti A 1. Pojem jakosti a význam managementu jakosti v současném období.
Tématické okruhy pro státní závěrečné zkoušky bakalářské studium studijní obor "Management jakosti" školní rok 2013/2014 Management jakosti A 1. Pojem jakosti a význam managementu jakosti v současném období.
Regulační diagramy CUSUM pro atributivní znaky. Eva Jarošová
 Regulační diagramy CUSUM pro atributivní znaky Eva Jarošová Obsah. Klasické diagramy pro atributivní znaky, omezení a nevýhody jejich aplikace 2. Přístup založený na transformaci sledované veličiny 3.
Regulační diagramy CUSUM pro atributivní znaky Eva Jarošová Obsah. Klasické diagramy pro atributivní znaky, omezení a nevýhody jejich aplikace 2. Přístup založený na transformaci sledované veličiny 3.
Vícerozměrné regulační diagramy. Josef Křepela, Jiří Michálek OSSM
 Vícerozměrné regulační diagramy Josef Křepela, Jiří Michálek OSSM..0 Monitorování a řízení procesu s více proměnnými Obvykle se uvažuje pouze jeden znak jakosti (proměnná, náhodná veličina) na výstupu
Vícerozměrné regulační diagramy Josef Křepela, Jiří Michálek OSSM..0 Monitorování a řízení procesu s více proměnnými Obvykle se uvažuje pouze jeden znak jakosti (proměnná, náhodná veličina) na výstupu
NÁHODNÁ ČÍSLA. F(x) = 1 pro x 1. Náhodná čísla lze generovat některým z následujících generátorů náhodných čísel:
 = 1 pro x 1. Náhodná čísla lze generovat některým z následujících generátorů náhodných čísel:") NÁHODNÁ ČÍSLA TYPY GENERÁTORŮ, LINEÁRNÍ KONGRUENČNÍ GENERÁTORY, TESTY NÁHODNOSTI, VYUŽITÍ HODNOT NÁHODNÝCH VELIČIN V SIMULACI CO JE TO NÁHODNÉ ČÍSLO? Náhodné číslo definujeme jako nezávislé hodnoty z rovnoměrného
NÁHODNÁ ČÍSLA TYPY GENERÁTORŮ, LINEÁRNÍ KONGRUENČNÍ GENERÁTORY, TESTY NÁHODNOSTI, VYUŽITÍ HODNOT NÁHODNÝCH VELIČIN V SIMULACI CO JE TO NÁHODNÉ ČÍSLO? Náhodné číslo definujeme jako nezávislé hodnoty z rovnoměrného
STATISTICKÉ ODHADY Odhady populačních charakteristik
 STATISTICKÉ ODHADY Odhady populačních charakteristik Jak stanovit charakteristiky rozložení sledované veličiny v základní populaci? Populaci většinou nemáme celou k dispozici, musíme se spokojit jen s
STATISTICKÉ ODHADY Odhady populačních charakteristik Jak stanovit charakteristiky rozložení sledované veličiny v základní populaci? Populaci většinou nemáme celou k dispozici, musíme se spokojit jen s
4ST201 STATISTIKA CVIČENÍ Č. 7
 4ST201 STATISTIKA CVIČENÍ Č. 7 testování hypotéz parametrické testy test hypotézy o střední hodnotě test hypotézy o relativní četnosti test o shodě středních hodnot testování hypotéz v MS Excel neparametrické
4ST201 STATISTIKA CVIČENÍ Č. 7 testování hypotéz parametrické testy test hypotézy o střední hodnotě test hypotézy o relativní četnosti test o shodě středních hodnot testování hypotéz v MS Excel neparametrické
Normy ČSN,ČSN ISO a ČSN EN
 Normy ČSN,ČSN ISO a ČSN EN z oblasti aplikované statistiky (stav aktualizovaný k 1.1.2013) Ing. Vratislav Horálek, DrSc. předseda TNK 4 při ÚNMZ 1 A Terminologické normy 2 [1] ČSN ISO 3534-1:2010 Statistika
Normy ČSN,ČSN ISO a ČSN EN z oblasti aplikované statistiky (stav aktualizovaný k 1.1.2013) Ing. Vratislav Horálek, DrSc. předseda TNK 4 při ÚNMZ 1 A Terminologické normy 2 [1] ČSN ISO 3534-1:2010 Statistika