Přednáška 10. Analýza závislosti
|
|
|
- Kateřina Tesařová
- před 9 lety
- Počet zobrazení:
Transkript
1 Přednáška 10 Analýza závislosti Analýza závislosti dvou kategoriálních proměnných Analýza závislosti v kontingečních tabulkách Analýza závislosti v asociačních tabulkách Simpsonův paradox Analýza závislosti dvou spojitých proměnných Pearsonův korelační koeficient, Spearmanův korelační koeficient

2 Analýza závislosti V praxi často u statistických jednotek (pozorovaných osob nebo jiných objektů) zjišťujeme současně řadu znaků. Například spotřeba, objem motoru, hmotnost a zrychlení automobilů, výše mzdy, velikost IQ, hmotnost a výška mužů, školní prospěch a pocit deprese u dětí, apod. Možnosti vyhodnocení: Analýza jednotlivých znaků (každý zvlášť) Analýza závislosti, tj. může zajímat, zda existuje závislost mezi spotřebou automobilu a jeho hmotností, výši mzdy a velikostí IQ, pocitem deprese u dětí a školním prospěchem.

3 Typ znaku X (příčina) Metody analýzy jednostranné závislosti Jednostranná závislost - znak X působí na znak Y, avšak znak Y již nepůsobí zpětně na znak X. kategoriální kvantitativní Typ znaku Y (důsledek) kategoriální kvantitativní analýza závislosti v kontingenčních, ANOVA resp. v asociačních tabulkách Diskriminační analýza, logistická regrese regresní a korelační analýza Není náplni základního kurzu Statistika!

4 Analýza závislosti dvou kategoriálních proměnných

5 Analýza závislosti v kontingenčních tabulkách

6 Motivační příklad Pro diferencovaný přístup v personální politice potřebuje vedení podniku vědět, zda spokojenost v práci závisí na tom, jedná-li se o pražský závod či závody mimopražské. Šetření se účastnilo 100 pracovníků z Prahy a 200 pracovníků z venkova. Výsledky šetření jsou v následující tabulce. místo/stupeň spokojenosti velmi spíše spíše velmi nespokojen nespokojen spokojen spokojen Praha Venkov Výsledky šetření analyzujte.

7 V jakém formátu obvykle získáváme tento typ dat? Místo Praha Praha Venkov Praha Venkov Venkov Stupeň spokojenosti velmi spokojen spíše spokojen spíše nespokojen spíše spokojen velmi spokojen spíše spokojen Tento převod lze provést pomocí většiny tabulkových procesorů i statistického software. Standardní datový formát místo/stupeň spokojenosti velmi spíše spíše velmi nespokojen nespokojen spokojen spokojen Praha Venkov Kontingenční tabulka

8 Základní terminologie Se základní terminologii a způsobem testování nezávislosti v kontingenční tabulce se seznamte v řešeném příkladu Analýza závislosti dvou kategoriálních veličin (flash animace).

9 Co je to kontingenční tabulka? X\Y y 1 y 2 y s Celkem x 1 n 11 n 12 n 1s n 1 x 2 n 21 n 22 n 2s n 2 x r n r1 n r2 n rs n r Celkem n 1 n 2 n s n Schéma rozšířené kontingenční tabulka Dvourozměrná tabulka četností, z jejichž hodnot můžeme usoudit na závislost či nezávislost mezi dvěma kategoriálními proměnnými.

10 Jak posoudit intenzitu závislosti mezi dvěma kategoriálními proměnnými pomoci explor. analýzy? Grafická analýza Shlukový sloupcový graf, kumulativní sloupcový graf, prostorový sloupcový graf (angl. sky chart), mozaikový graf, 100% skládaný pruhový graf Míry kontingence koeficient kontingence (počet variant obou proměnných je stejný) korigovaný koeficient kontingence, Cramerovo V Čím jsou tyto koeficienty blíže 1, tím je závislost mezi X a Y těsnější.
 korigovaný koeficient kontingence, Cramerovo V Čím jsou tyto koeficienty blíže 1, tím")
11 Míry kontingence Označme: r počet variant proměnné X, s počet variant proměnné Y, K = r i=1 s j=1 O ij E ij 2 E ij, kde O ij jsou pozorované sdružené četnosti zapsané v kontingenční tabulce a E ij jsou očekávané četnosti odpovídající součinu příslušných marginálních relativních četností. Koeficient kontingence ( r = s CC 0; 1 ) CC = K K+n

12 Míry kontingence Označme: r počet variant proměnné X, s počet variant proměnné Y, K = r i=1 s j=1 O ij E ij 2 E ij, kde O ij jsou pozorované sdružené četnosti zapsané v kontingenční tabulce a E ij jsou očekávané četnosti odpovídající součinu příslušných marginálních relativních četností. Korigovaný koeficient kontingence CC cor = CC CC max, kde CC max = min r;s 1 min r;s

13 Míry kontingence Označme: r počet variant proměnné X, s počet variant proměnné Y, K = r i=1 s j=1 O ij E ij 2 E ij, kde O ij jsou pozorované sdružené četnosti zapsané v kontingenční tabulce a E ij jsou očekávané četnosti odpovídající součinu příslušných marginálních relativních četností. Cramerovo V V = K n min r;s 1

14 Motivační příklad Pro diferencovaný přístup v personální politice potřebuje vedení podniku vědět, zda spokojenost v práci závisí na tom, jedná-li se o pražský závod či závody mimopražské. Šetření se účastnilo 100 pracovníků z Prahy a 200 pracovníků z venkova. Výsledky šetření jsou v následující tabulce. místo/stupeň spokojenosti velmi spíše spíše velmi nespokojen nespokojen spokojen spokojen Praha Venkov Výsledky šetření analyzujte.

15 Exploratorní analýza pomocí Statgraphicsu
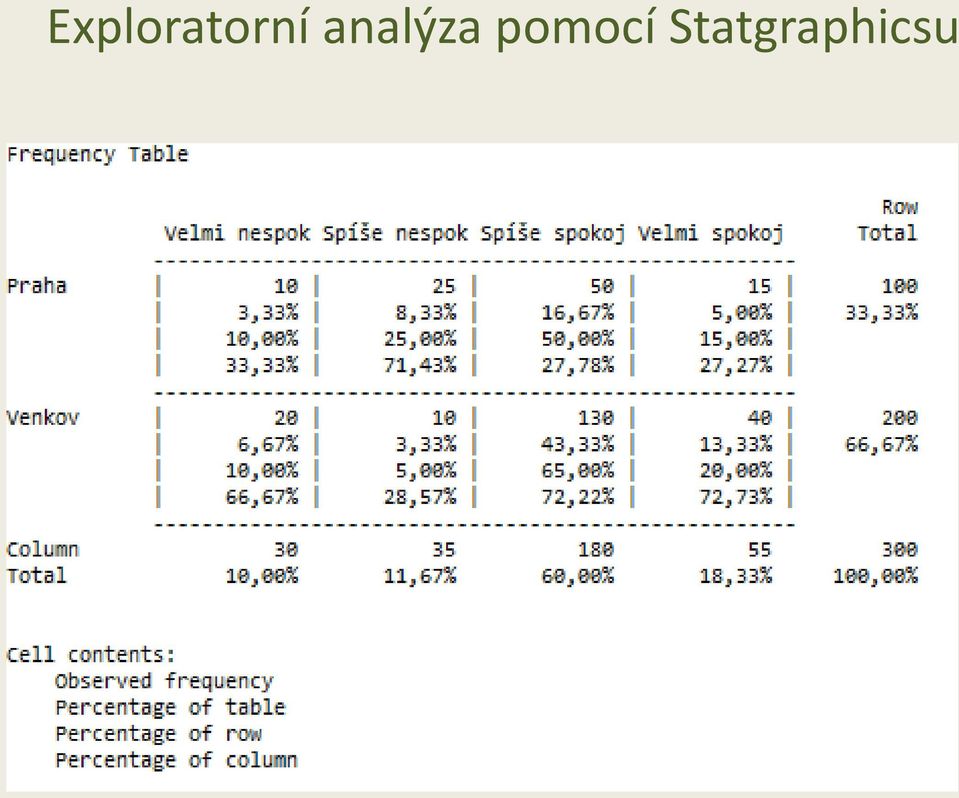
16 Exploratorní analýza pomocí Statgraphicsu Mosaic Plot Praha Velmi nespokojen Spíše nespokojen Spíše spokojen Velmi spokojen Venkov

17 Exploratorní analýza pomocí Statgraphicsu
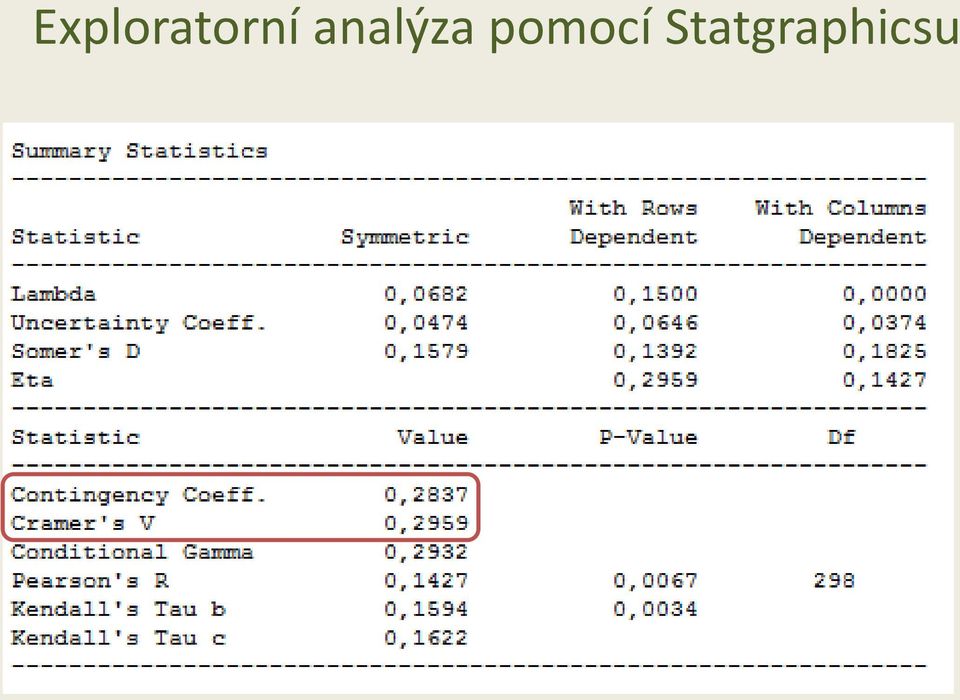
18 Exploratorní analýza pomocí Excelu Venkov Praha % 20% 40% 60% 80% 100% Praha Venkov Velmi nespokojen Spíše nespokojen Spíše spokojen Velmi spokojen 15 40

19 Metody statistické indukce vhodné pro analýzu závislosti dvou kategoriálních veličin Intervalové odhady vybraných pravděpodobností (viz Úvod do statistiky, kapitola 4) A to musím počítat intervalové odhady pro všechny pravděpodobnosti, které jsou v té tabulce???

20 Metody statistické indukce vhodné pro analýzu závislosti dvou kategoriálních veličin Intervalové odhady vybraných pravděpodobností (viz Úvod do statistiky, kapitola 4) NE!!! Vždy záleží na tom, co od výstupu analýzy očekáváš! Tohle je jen návrh analýz, které lze provést

21 Metody statistické indukce vhodné pro analýzu závislosti dvou kategoriálních veličin χ 2 test nezávislosti v kontingenční tabulce H 0 : Znaky X a Y v kontingenční tabulce jsou statisticky nezávislé H A : Znaky X a Y v kontingenční tabulce jsou statisticky závislé. Předpoklady testu: žádná z očekávaných četností E ij nesmí být menší než 2, alespoň 80% očekávaných četností E ij musí být větších než 5. Testové kritérium: K = r i=1 s j=1 O ij E ij 2 E ij p hodnota = 1 F 0 x OBS, kde F 0 x je distribuční funkce χ 2 rozdělení s r 1 s 1 stupni volnosti.
22 Metody statistické indukce vhodné pro analýzu závislosti dvou kategoriálních veličin Yatesova korekce χ 2 testu nezávislosti v kontingenční tabulce H 0 : Znaky X a Y v kontingenční tabulce jsou statisticky nezávislé H A : Znaky X a Y v kontingenční tabulce jsou statisticky závislé. Předpoklady testu: ---- Testové kritérium: K Yates = r i=1 s j=1 O ij E ij 0,5 2 E ij p hodnota = 1 F 0 x OBS, kde F 0 x je distribuční funkce χ 2 rozdělení s r 1 s 1 stupni volnosti. Poznámka: Test má menší sílu testu (oproti χ 2 testu nezávislosti).
23 Metody statistické indukce vhodné pro analýzu závislosti dvou kategoriálních veličin H 0 : Spokojenost v práci nesouvisí s umístěním závodu. H A : Spokojenost v práci souvisí s umístěním závodu. Ověření předpokladů testu: Všechny očekávané četnosti jsou větší než 5. Předpoklady testu lze považovat za splněné.
24 Metody statistické indukce vhodné pro analýzu závislosti dvou kategoriálních veličin H 0 : Spokojenost v práci nesouvisí s umístěním závodu. H A : Spokojenost v práci souvisí s umístěním závodu. Ověření předpokladů testu: A co když předpoklady splněny nebudou??? Všechny očekávané četnosti jsou větší než 5. Předpoklady testu lze považovat za splněné.
25 Metody statistické indukce vhodné pro analýzu závislosti dvou kategoriálních veličin H 0 : Spokojenost v práci nesouvisí s umístěním závodu. H A : Spokojenost v práci souvisí s umístěním závodu. Ověření předpokladů testu: Pokud lze některé varianty proměnné smysluplně sloučit, zkus to udělat. Pokud ne, nelze výsledky z výběrového šetření zobecnit na populaci. Na tento možný problém je vhodné myslet již před výběrovým šetřením (dostatečný rozsah výběru). Všechny očekávané četnosti jsou větší než 5. Předpoklady testu lze považovat za splněné.
26 Metody statistické indukce vhodné pro analýzu závislosti dvou kategoriálních veličin H 0 : Spokojenost v práci nesouvisí s umístěním závodu. H A : Spokojenost v práci souvisí s umístěním závodu. Ověření předpokladů testu: Všechny očekávané četnosti jsou větší než 5. Předpoklady testu lze považovat za splněné. Výstup ze Statgraphicsu (Nekopírovat do projektů, DP, článků!!!) Rozhodnutí: Na hladině významnosti 0,05 zamítáme nulovou hypotézu (χ 2 test nezávislosti v kontingenční tabulce, χ 2 = 26,27, DF = 3, p hodnota 0,001). Lze předpokládat, že spokojenost v práci souvisí s umístěním závodu (Cramerovo V = 0,296).
27 Takže stačí stáhnout něco z dotazníky vyhodnotit a mám projekt!!! No, když tam seženeš data, která lze považovat za náhodný výběr z populace, na níž chceš výsledky zobecnit, tak by to šlo. Bude hodně záležet na tom, jak to vyhodnocení provedeš
28 Analýza závislosti v asociačních tabulkách
29 Asociační tabulky speciální typ kontingenčních tabulek, které používáme k sledování závislosti dvou dichotomických znaků, tj. kategoriálních znaků nabývajících pouze dvou variant. (asociace = vztah dvou dichotomických znaků) X (okolnosti)\y(výskyt události) y 1 (úspěch) y 2 (neúspěch) Celkem x 1 (I.) a b a + b x 2 (II.) c d c + d Celkem a + c b + d n Schéma rozšířené asociační tabulky
30 Asociační tabulky speciální typ kontingenčních tabulek, které používáme k sledování závislosti dvou dichotomických znaků, tj. kategoriálních znaků nabývajících pouze dvou variant. (asociace = vztah dvou dichotomických znaků) X (sledovaný faktor)\y(výskyt onemocnění) D (ANO) D (NE) Celkem E (přítomnost faktoru) a b a + b E (nepřítomnost faktoru) c d c + d Celkem a + c b + d n Schéma rozšířené asociační tabulky (biomedicínská aplikace)
31 Asociační tabulky Na asociační tabulku lze sice nahlížet jako na speciální případ kontingenčních tabulek a při analýze používat jejich aparát, nicméně vhodnější je využít specifické metody a charakteristiky asociace. X (sledovaný faktor)\y(výskyt onemocnění) D (ANO) D (NE) Celkem E (přítomnost faktoru) a b a + b E (nepřítomnost faktoru) c d c + d Celkem a + c b + d n Schéma rozšířené asociační tabulky (biomedicínská aplikace)
32 Míry asociace Poměr šancí (angl. odds ratio ), nazýváno také křížový poměr (angl. cross product ratio ) Pozorovaný poměr počtu úspěchů k počtu neúspěchů (tzv. pozorovaná šance) za okolností I. je a, za okolností II. c. Odhad poměru šancí je pak b d OR = ad bc. X (okolnosti)\y(výskyt události) y 1 (úspěch) y 2 (neúspěch) Celkem x 1 (I.) a b a + b x 2 (II.) c d c + d Celkem a + c b + d n Schéma rozšířené asociační tabulky
33 Míry asociace Poměr šancí (angl. odds ratio ), nazýváno také křížový poměr (angl. cross product ratio ) Pozorovaný poměr počtu nemocných k počtu zdravých (tzv. pozorovaná šance) u exponované populace je a b, u neexponované populace c d. Odhad poměru šancí je pak OR = ad bc. X (sledovaný faktor)\y(výskyt onemocnění) D (ANO) D (NE) Celkem E (přítomnost faktoru) a b a + b E (nepřítomnost faktoru) c d c + d Celkem a + c b + d n Schéma rozšířené asociační tabulky (biomedicínská aplikace)
34 Závisí novorozenecká úmrtnost (do 7 dnů po porodu) na porodní váze? Data odpovídající situaci v New Yorku v roce 1974 jsou uvedena v následující tabulce. porodní váha\novorozenecká úmrtí ANO NE Celkem nízká normální Celkem Odhad šance novorozeneckého úmrtí u dětí s nízkou porodní váhou je a b = = 0,134, což odpovídá přibližně 134 novorozeneckým úmrtím na přeživších novorozenců s nízkou porodní váhou. Obdobně odhadneme šanci novorozeneckého úmrtí u dětí s normální porodní váhou. c d = = 0,006 Lze očekávat přibližně 6 novorozeneckých úmrtí na přeživších novorozenců s normální porodní hmotností.
35 Závisí novorozenecká úmrtnost (do 7 dnů po porodu) na porodní váze? Data odpovídající situaci v New Yorku v roce 1974 jsou uvedena v následující tabulce. porodní váha\novorozenecká úmrtí ANO NE Celkem nízká normální Celkem Odhad šance novorozeneckého úmrtí u dětí s nízkou porodní váhou je a b = = 0,134. Odhad šance novorozeneckého úmrtí u dětí s normální porodní váhou je c d = = 0,006 OR = ad bc = ,4 šance novorozeneckého úmrtí je 21,4 krát vyšší u novorozenců s nízkou porodní váhou než u novorozenců s normální porodní váhou.
36 Míry asociace Poměr šancí (angl. odds ratio ), nazýváno také křížový poměr (angl. cross product ratio ) OR = ad bc. 0R < 1 U exponované populace (populace vystavené sledovanému faktoru) je nižší šance výskytu nemoci. OR = 1 Šance výskytu onemocnění u exponované a neexponované populace jsou shodné. OR > 1 U exponované populace je vyšší šance výskytu nemoci. X (sledovaný faktor)\y(výskyt onemocnění) D (ANO) D (NE) Celkem E (přítomnost faktoru) a b a + b E (nepřítomnost faktoru) c d c + d Celkem a + c b + d n Schéma rozšířené asociační tabulky (biomedicínská aplikace)
37 Míry asociace Poměr šancí (angl. odds ratio ), nazýváno také křížový poměr (angl. cross product ratio ) OR = ad bc. 0R < 1 U exponované populace (populace vystavené sledovanému faktoru) je nižší šance výskytu nemoci. OR = 1 Šance výskytu onemocnění u exponované a neexponované populace jsou shodné. OR > 1 U exponované populace je vyšší šance výskytu nemoci. Je-li OR 1, potřebujeme zpravidla ještě rozhodnout, zda je indikována asociace statisticky významná. Woolfova metoda: α % intervalový odhad OR : OR e 1 a +1 b +1 c +1 d z 1 α 2; OR e 1 a +1 b +1 c +1 d z 1 α 2. Jestliže α % intervalový odhad OR nezahrnuje 1, pak zamítáme hypotézu o nezávislosti znaků X a Y.
38 Závisí novorozenecká úmrtnost (do 7 dnů po porodu) na porodní váze? Data odpovídající situaci v New Yorku v roce 1974 jsou uvedena v následující tabulce. porodní váha\novorozenecká úmrtí ANO NE Celkem nízká normální Celkem OR = ad bc = ,4 šance novorozeneckého úmrtí je 21,4 krát vyšší u novorozenců s nízkou porodní váhou než u novorozenců s normální porodní váhou. 95% intervalový odhad OR je dán vztahem OR e 1 a +1 b +1 c +1 d z 0,975 ; OR e 1 a +1 b +1 c +1 d z 0,975. z 0,975 = 1,64 (viz vybrana_rozdeleni.xls) Po dosazení: 95% intervalový odhad OR je 19,2; 23,8. Je zcela zřejmé, že šance novorozeneckého úmrtí závisí na porodní váze 1 19,2; 23,8.
39 Míry asociace Absolutní riziko (angl. absolute risk ) výskytu události (onemocnění, úmrtí, ) v závislosti na okolnostech (přítomnosti sledovaného faktoru) odhad absolutního rizika onemocnění u exponovaných respondentů je a a+b, odhad absolutního rizika onemocnění u neexponovaných respondentů je c c+d. Absolutní rizika mohou nabývat hodnot z intervalu 0; 1. X (sledovaný faktor)\y(výskyt onemocnění) D (ANO) D (NE) Celkem E (přítomnost faktoru) a b a + b E (nepřítomnost faktoru) c d c + d Celkem a + c b + d n Schéma rozšířené asociační tabulky (biomedicínská aplikace)
40 Míry asociace Relativní riziko (angl. relative risk ) poměr odhadů absolutních rizik vzniku onemocnění u exponovaných a neexponovaných osob, tj. RR = a c+d c a+b. X (sledovaný faktor)\y(výskyt onemocnění) D (ANO) D (NE) Celkem E (přítomnost faktoru) a b a + b E (nepřítomnost faktoru) c d c + d Celkem a + c b + d n Schéma rozšířené asociační tabulky (biomedicínská aplikace)
41 Závisí novorozenecká úmrtnost (do 7 dnů po porodu) na porodní váze? Data odpovídající situaci v New Yorku v roce 1974 jsou uvedena v následující tabulce. porodní váha\novorozenecká úmrtí ANO NE Celkem nízká normální Celkem Odhad absolutního rizika novorozeneckého úmrtí u dětí s nízkou porodní a hmotností je = 618 = 0,119, a+b tj. novorozenecké úmrtí lze očekávat u cca 119 z novorozenců s nízkou porodní váhou), u dětí s normální porodní hmotností je absolutní riziko: 0,006, c = 422 = c+d tj. novorozenecké úmrtí lze očekávat u cca 6 z novorozenců s normální porodní váhou.
42 Závisí novorozenecká úmrtnost (do 7 dnů po porodu) na porodní váze? Data odpovídající situaci v New Yorku v roce 1974 jsou uvedena v následující tabulce. porodní váha\novorozenecká úmrtí ANO NE Celkem nízká normální Celkem Odhad absolutního rizika novorozeneckého úmrtí u dětí s nízkou porodní a hmotností je = 618 = 0,119, a+b u dětí s normální porodní hmotností je absolutní riziko: 0,006, c = 422 = c+d Odhad relativního rizika novorozeneckého úmrtí RR = a c+d = 0,119 = 19,0. c a+b 0,006 Ve sledovaném období bylo u dětí s nízkou porodní váhou 19 krát vyšší riziko novorozeneckého úmrtí než u dětí s normální porodní váhou.
43 Míry asociace Relativní riziko (angl. relative risk ) poměr odhadů absolutních rizik vzniku onemocnění u exponovaných a neexponovaných osob, tj. RR = a c+d c a+b. RR < 1 RR = 1 RR > 1 Expozice snižuje riziko onemocnění. Mezi expozici a onemocněním neexistuje žádná asociace. Expozice zvyšuje riziko onemocnění. X (sledovaný faktor)\y(výskyt onemocnění) D (ANO) D (NE) Celkem E (přítomnost faktoru) a b a + b E (nepřítomnost faktoru) c d c + d Celkem a + c b + d n Schéma rozšířené asociační tabulky (biomedicínská aplikace)
44 Míry asociace Relativní riziko (angl. relative risk ) poměr odhadů absolutních rizik vzniku onemocnění u exponovaných a neexponovaných osob, tj. RR = a c+d c a+b. RR < 1 RR = 1 RR > 1 Expozice snižuje riziko onemocnění. Mezi expozici a onemocněním neexistuje žádná asociace. Expozice zvyšuje riziko onemocnění. Je-li RR 1, musíme rozhodnout, zda je indikována asociace statisticky významná. Katzova metoda: α % intervalový odhad RR: RR e b a a+b + d c c+d z 1 α 2; RR e b a a+b + d c c+d z 1 α 2. Jestliže α % intervalový odhad RR nezahrnuje 1, pak zamítáme hypotézu o nezávislosti znaků X a Y.
45 Závisí novorozenecká úmrtnost (do 7 dnů po porodu) na porodní váze? Data odpovídající situaci v New Yorku v roce 1974 jsou uvedena v následující tabulce. porodní váha\novorozenecká úmrtí ANO NE Celkem nízká normální Celkem Odhad relativního rizika novorozeneckého úmrtí RR = 19,0 ve sledovaném období bylo u dětí s nízkou porodní váhou 19 krát vyšší riziko novorozeneckého úmrtí než u dětí s normální porodní váhou. 95% intervalový odhad RR je dán vztahem RR e b a a+b + d c c+d z 1 α 2; RR e b a a+b + d c c+d z 1 α 2. z 0,975 = 1,64 (viz vybrana_rozdeleni.xls) Po dosazení: 95% intervalový odhad RR je 17,1; 21,0. Je zcela zřejmé, že riziko novorozeneckého úmrtí závisí na porodní váze 1 17,1; 21,0.
46 Simpsonův paradox aneb pozor na posuzování tabulek, které se skládají ze dvou či více skupin
47 V Horních Sádrovicích bylo hospitalizováno 600 lehkých pacientů, z nichž 10 (1,7%) zemřelo a 400 těžkých pacientů, z nichž zemřelo 190 (47,5%). Ve Staré Dláze bylo hospitalizováno 900 lehkých pacientů, z nichž 30 (3,2%) zemřelo a 100 těžkých pacientů, z nichž zemřelo 100 (10,0%). Horní Sádrovice stav pacienta při přijetí/úmrtnost ANO NE celkem lehký ,017 (10/600) 0,983 (590/600) těžký ,475 (190/400) 0,525 (210/400) celkem ,200 (200/1000) 0,800 (800/1000)
48 Horní Sádrovice stav pacienta při přijetí/úmrtnost ANO NE celkem lehký ,017 (10/600) 0,983 (590/600) těžký ,475 (190/400) 0,525 (210/400) celkem ,200 (200/1000) 0,800 (800/1000) Stará Dláha stav pacienta při přijetí/úmrtnost ANO NE celkem lehký ,033 (30/900) 0,967 (870/900) těžký , 700 (70/100) 0,300 (30/100) celkem , 100 (100/1000) 0,900 (900/1000) Kontingenční tabulky rozšířené o marginální četnosti a řádkové rel. četnosti
49 Horní Sádrovice stav pacienta při přijetí/úmrtnost ANO NE celkem lehký ,017 (10/600) 0,983 (590/600) těžký ,475 (190/400) 0,525 (210/400) celkem ,200 (200/1000) 0,800 (800/1000) Stará Dláha stav pacienta při přijetí/úmrtnost ANO NE celkem lehký ,033 (30/900) 0,967 (870/900) těžký , 700 (70/100) 0,300 (30/100) celkem , 100 (100/1000) 0,900 (900/1000) Ve kterém městě je u lehkých pacientů nižší riziko úmrtí?
50 Horní Sádrovice stav pacienta při přijetí/úmrtnost ANO NE celkem lehký ,017 (10/600) 0,983 (590/600) těžký ,475 (190/400) 0,525 (210/400) celkem ,200 (200/1000) 0,800 (800/1000) Stará Dláha stav pacienta při přijetí/úmrtnost ANO NE celkem lehký ,033 (30/900) 0,967 (870/900) těžký , 700 (70/100) 0,300 (30/100) celkem , 100 (100/1000) 0,900 (900/1000) Ve kterém městě je u lehkých pacientů nižší riziko úmrtí?
51 Horní Sádrovice stav pacienta při přijetí/úmrtnost ANO NE celkem lehký ,017 (10/600) 0,983 (590/600) těžký ,475 (190/400) 0,525 (210/400) celkem ,200 (200/1000) 0,800 (800/1000) Stará Dláha stav pacienta při přijetí/úmrtnost ANO NE celkem lehký ,033 (30/900) 0,967 (870/900) těžký , 700 (70/100) 0,300 (30/100) celkem , 100 (100/1000) 0,900 (900/1000) Ve kterém městě je u těžkých pacientů nižší riziko úmrtí?
52 Horní Sádrovice stav pacienta při přijetí/úmrtnost ANO NE celkem lehký ,017 (10/600) 0,983 (590/600) těžký ,475 (190/400) 0,525 (210/400) celkem ,200 (200/1000) 0,800 (800/1000) Stará Dláha stav pacienta při přijetí/úmrtnost ANO NE celkem lehký ,033 (30/900) 0,967 (870/900) těžký , 700 (70/100) 0,300 (30/100) celkem , 100 (100/1000) 0,900 (900/1000) Ve kterém městě je u lehkých pacientů nižší riziko úmrtí?
53 Horní Sádrovice stav pacienta při přijetí/úmrtnost ANO NE celkem lehký ,017 (10/600) 0,983 (590/600) těžký ,475 (190/400) 0,525 (210/400) celkem ,200 (200/1000) 0,800 (800/1000) Stará Dláha stav pacienta při přijetí/úmrtnost ANO NE celkem lehký ,033 (30/900) 0,967 (870/900) těžký , 700 (70/100) 0,300 (30/100) celkem , 100 (100/1000) 0,900 (900/1000) Ve kterém městě je nižší riziko úmrtí pacienta?
54 Horní Sádrovice stav pacienta při přijetí/úmrtnost ANO NE celkem lehký ,017 (10/600) 0,983 (590/600) těžký ,475 (190/400) 0,525 (210/400) celkem ,200 (200/1000) 0,800 (800/1000) Stará Dláha stav pacienta při přijetí/úmrtnost ANO NE celkem lehký ,033 (30/900) 0,967 (870/900) těžký , 700 (70/100) 0,300 (30/100) celkem , 100 (100/1000) 0,900 (900/1000) Ve kterém městě je nižší riziko úmrtí pacienta?
55 Horní Sádrovice stav pacienta při přijetí/úmrtnost ANO NE celkem lehký ,017 (10/600) 0,983 (590/600) těžký ,475 (190/400) 0,525 (210/400) celkem ,200 (200/1000) 0,800 (800/1000) Stará Dláha stav pacienta při přijetí/úmrtnost ANO NE celkem lehký ,033 (30/900) 0,967 (870/900) těžký , 700 (70/100) 0,300 (30/100) celkem , 100 (100/1000) 0,900 (900/1000)???
56 Horní Sádrovice stav pacienta při přijetí/úmrtnost ANO NE celkem lehký ,017 (10/600) 0,983 (590/600) těžký ,475 (190/400) 0,525 (210/400) celkem ,200 (200/1000) 0,800 (800/1000) Stará Dláha stav pacienta při přijetí/úmrtnost ANO NE celkem lehký ,033 (30/900) 0,967 (870/900) těžký , 700 (70/100) 0,300 (30/100) celkem , 100 (100/1000) 0,900 (900/1000) Simpsonův paradox
57 Simpsonův paradox Jedná se o situaci, kdy se závislost mezi dvěma znaky kvalitativně změní, jestliže uvážíme vliv znaku třetího (skrytého). (Např. vztah mezi úmrtnosti pacientů a místem léčby (Horní Sádrovice vs. Stará Dláha), vezmeme-li v úvahu stav pacienta při přijetí do nemocnice.) Důvodem je silná závislost mezi jedním z dvou analyzovaných znaků a znakem skrytým.
58 Simpsonův paradox Zajímavé odkazy: 1) 2) Agresti, A. (2002). Categorical Data Analysis, Second Edition. Hoboken: John Wiley and Sons. ISBN ) Blyth, C. R. (1972). On Simpson's paradox and the sure-thing principle. Journal of the American Statistical Association, 67, ) Davis, L. J. (1989). Intersection union tests for strictly collapsibility in three-dimensional contingency tables. Annals of Statistics, 17, ) Dong, J. (1998). Simpson's paradox. Pp in Encyclopedia of Biostatistics, vol. 5. Chichester: John Wiley and Sons. 6) Pavlides, M. G., Perlman, M. D. (2009). How likely is Simpson's paradox? The American Statistician, 63, ) Samuels, M. L. (1993). Simpson's paradox and related phenomena. Journal of the American Statistical Association, 88, ) Simpson, E. H. (1951). The interpretation of interaction in contingency tables. Journal of the Royal Statistical Society, Series B, 13, ) Wagner, C. H. (1982). Simpson's paradox in real life. The American Statistician, 36, ) Wardrop, R. L. (1995). Simpson's paradox and the hot hand in basketball. The American Statistician, 49,
59 Analýza závislosti dvou numerických proměnných
60 Malé opakování z pravděpodobnosti Co je to kovariance? Kovariance cov X, Y je definována jako smíšený centrální moment řádu cov X, Y = E X E X Y E Y Vlastnosti kovariance 1. cov X, Y = E X Y E X E Y (výpočetní vztah), 2. cov X, X = D X, 3. cov a 1 X + b 1, a 2 Y + b 2 = a 1 a 2 cov X, Y, 4. jsou-li X, Y jsou nezávislé náhodné veličiny, pak cov X, Y = 0.
61 Malé opakování z pravděpodobnosti Co je to korelační koeficient? Korelační koeficient ρ X, Y je mírou lineární závislosti dvou náh. veličin. ρ X, Y = cov X, Y, DX, DY 0, DX DY 0 jinak. Vlastnosti korelačního koeficientu 1. 1 ρ X, Y 1, 2. ρ X, Y = ρ Y, X, 3. ρ X, X = 1, 4. jsou-li X, Y nezávislé náhodné veličiny, pak ρ X, Y = 0, 5. je-li ρ X, Y = 0, říkáme, že X, Y jsou nekorelované náhodné veličiny, 6. je-li ρ X, Y = 1, pak existuje a, b R, a > 0 takové, že Y = ax + b s pravd je-li ρ X, Y = 1, pak existuje a, b R, a < 0 takové, že Y = ax + b s pravd je-li ρ X, Y > 0, říkáme, že X, Y jsou pozitivně korelované (s rostoucím X roste Y), 9. je-li ρ X, Y < 0, říkáme, že X, Y jsou negativně korelované (s rostoucím X klesá Y).
62 Malé opakování z pravděpodobnosti ρ X, Y =1,000 ρ X, Y = -1,000 ρ X, Y =0,000 ρ X, Y =0,934 ρ X, Y =0,967 ρ X, Y =0,857 ρ X, Y =-0,143 ρ X, Y =0,608 Ověřit si, zda máte představu o významu korelačního koeficientu, můžete ZDE (jar).
63 Malé opakování z pravděpodobnosti Pokud jsou dvě náhodné veličiny korelované, znamená to pouze to, že jsou lineárně závislé. Nelze z toho však ještě usoudit, že by jedna z nich musela být příčinou a druhá následkem. To samotná korelovanost nedovoluje rozhodnout. Silná korelace

64 Malé opakování z pravděpodobnosti Pokud jsou dvě náhodné veličiny korelované, znamená to pouze to, že jsou lineárně závislé. Nelze z toho však ještě usoudit, že by jedna z nich musela být příčinou a druhá následkem. To samotná korelovanost nedovoluje rozhodnout. Silná korelace
65 Pearsonův korelační koeficient Korelační koeficient ρ dokážeme určit pouze tehdy, známe-li sdružené rozdělení náhodného vektoru X; Y. Nechť X 1 ; Y 1,, X n ; Y n je výběr z dvourozměrného normálního rozdělení, tj. z rozdělení, jehož sdružená hustota pravděpodobnosti je dána vztahem f x; y = 1 2πσ X σ Y 1 ρ 2 e 2 1 x μ X 2 1 ρ 2 2ρ x μ X y μ Y σ X σ X σ Y + y μ 2 Y σ Y. Pak lze odhad korelačního koeficientu ρ určit jako r = kde S XY = 1 n 1 n S XY S X 2 S Y 2, S X 2, S Y 2 0, 0 jinak, i=1 X i X Y i Y = n i=1 X i Y i nxy n X 2 i=1 i nx 2 n Y 2 i i=1 ny 2.
66 Pearsonův korelační koeficient Nechť X 1 ; Y 1,, X n ; Y n je výběr z dvourozměrného normálního rozdělení. Zjistíme-li, že výběrový korelační koeficient r 0, zpravidla nás zajímá, zda je indikovaná korelace statisticky významná. Chceme testovat nulovou hypotézu H 0 : ρ = 0 vůči alternativě H A : ρ 0, resp. ρ < 0, resp. ρ > 0. Testová statistika: T = r n 2 1 r 2 má za předpokladu platnosti H 0 Studentovo rozdělení s n 2 stupni volnosti. Poznámka: Jsou-li složky náhodného vektoru X; Y s dvourozměrným normálním rozdělením nekorelované, jsou nezávislé. (POZOR! Obecně to neplatí.)
67 Spearmanův korelační koeficient Mějme náhodný výběr X 1 ; Y 1,, X n ; Y n z dvourozměrného rozdělení. Nechť R X1,, R Xn jsou pořadí veličin X 1,, X n a nechť R Y1,, R Yn jsou pořadí veličin Y 1,, Y n. r S = 1 6 n n 2 1 n i=1 R X1 R Y1 2 Pokud se v náhodných výběrech, z nichž je r S počítán, vyskytuje mnoho shod (tj. stejně velkých pozorování), doporučuje se používat korigovaný Spearmanův korelační koeficient r Skorig. r Skorig = 1 6 n 2 R n 3 n T X T i=1 X1 R Y1 Y
68 Spearmanův korelační koeficient Mějme náhodný výběr X 1 ; Y 1,, X n ; Y n z dvourozměrného rozdělení. Nechť R X1,, R Xn jsou pořadí veličin X 1,, X n a nechť R Y1,, R Yn jsou pořadí veličin Y 1,, Y n. Pokud se v náhodných výběrech, z nichž je r S počítán, vyskytuje mnoho shod (tj. stejně velkých pozorování), doporučuje se používat korigovaný Spearmanův korelační koeficient r Skorig. r Skorig = 1 6 n 2 R n 3 n T X T i=1 X1 R Y1, Y kde T X = 1 2 t X 3 t X, T Y = 1 2 t Y 3 t Y, kde t X jsou rozsahy skupin stejně velkých X-ových hodnot. Obdobně definujeme t Y.
69 Spearmanův korelační koeficient Je-li hodnota Spearmanova korelačního koeficientu r S blízká nule, chceme zpravidla testovat, zda je odchylka koeficientu r S od nuly náhodná či statisticky významná. H 0 : X, Y jsou nezávislé náhodné veličiny. H A : X, Y jsou závislé náhodné veličiny. Testová statistika: r S Nulovou hypotézu zamítáme pokud r S r S α, kde r S α je kritická hodnota Spearmanova korelačního koeficientu. Pro rozsah výběru n 30 a hladiny významnosti 0,05, resp. 0,01 jsou kritické hodnoty r S α; n tabelovány (tabulka T16). Je-li rozsah výběru n > 30, pak r S α; n = z 1 α 2 n 1, kde z 1 α 2 je 1 α 2 kvantil normovaného normálního rozdělení.
70 Na základě datového souboru biometrie.sf3 analyzujte míru závislosti mezi výškou a váhou respondentů. Describe/Numeric Data/Multiple Variable Analysis

71 Na základě datového souboru biometrie.sf3 analyzujte míru závislosti mezi výškou a váhou respondentů. Describe/Numeric Data/Multiple Variable Analysis
72 Na základě datového souboru biometrie.sf3 analyzujte míru závislosti mezi výškou a váhou respondentů. Pro výpočty jsou brány v úvahu pouze statistické jednotky neobsahující chybějící hodnoty (angl. missing values) pro žádnou z analyzovaných proměnných. (Lze nastavit v Analysis Options.) Rozptylogram Pearsonův korelační koeficient Describe/Numeric Data/Multiple Variable Posuzovat Analysis hodnotu Pearsonova korelačního koeficientu bez vizuálního posouzení rozptylogramu nemá smysl!!!
 pro žádnou z analyzovaných proměnných. (Lze nastavit v Analysis Options.) Rozptylogram Pearsonův korelační koeficient Je to správný korelační koeficient?")
73 Na základě datového souboru biometrie.sf3 analyzujte míru závislosti mezi výškou a váhou respondentů. Pro výpočty jsou brány v úvahu pouze statistické jednotky neobsahující chybějící hodnoty (angl. missing values) pro žádnou z analyzovaných proměnných. (Lze nastavit v Analysis Options.) Rozptylogram Pearsonův korelační koeficient Je to správný korelační koeficient??? Describe/Numeric Data/Multiple Variable Posuzovat Analysis hodnotu Pearsonova korelačního koeficientu bez vizuálního posouzení rozptylogramu nemá smysl!!!
74 Na základě datového souboru biometrie.sf3 analyzujte míru závislosti mezi výškou a váhou respondentů. H 0 : Data jsou výběrem z normálního rozdělení. H A : Data nejsou výběrem z normálního rozdělení. Proměnná Váha 0,178 Výška 0,021 P-hodnota (χ 2 test dobré shody) Na hladině významnosti 0,05 zamítáme předpoklad normality pro proměnnou výška. předpoklady pro použití Pearsonova korelačního koeficientu byly zamítnuty, je nutno použít např. Spearmanův korelační koeficient. Nutno ověřit normalitu proměnných!!!
75 Na základě datového souboru biometrie.sf3 analyzujte míru závislosti mezi výškou a váhou respondentů. H 0 : Data jsou výběrem z normálního rozdělení. H A : Data nejsou výběrem z normálního rozdělení. Proměnná Váha 0,178 Výška 0,021 P-hodnota (χ 2 test dobré shody) Na hladině významnosti 0,05 zamítáme předpoklad normality pro proměnnou výška. předpoklady pro použití Pearsonova korelačního koeficientu byly zamítnuty, je nutno použít např. Spearmanův korelační koeficient. Statgraphics: Tabular Options (žlutá ikona), Rank Correlations
76 Na základě datového souboru biometrie.sf3 analyzujte míru závislosti mezi výškou a váhou respondentů. korigovaný Spearmanův korelační koeficient
 použit korigovaný Spearmanův korelační koeficient.")
77 Na základě datového souboru biometrie.sf3 analyzujte míru závislosti mezi výškou a váhou respondentů. Pro posouzení korelace mezi váhou a výškou byl z důvodů porušení normality u proměnné výška (χ 2 test dobré shody, p hodnota = 0,021) použit korigovaný Spearmanův korelační koeficient. Pozorovanou hodnotu korelace (0,519) lze na hladině významnosti 0,05 označit za statisticky významnou (p hodnota 0,001).
78 Děkuji za pozornost!
ANALÝZA ZÁVISLOSTI. Martina Litschmannová
 ANALÝZA ZÁVISLOSTI Martina Litschmannová Obsah přednášky Analýza závislosti dvou kategoriálních proměnných Analýza závislosti v kontingečních tabulkách Analýza závislosti v asociačních tabulkách Simpsonův
ANALÝZA ZÁVISLOSTI Martina Litschmannová Obsah přednášky Analýza závislosti dvou kategoriálních proměnných Analýza závislosti v kontingečních tabulkách Analýza závislosti v asociačních tabulkách Simpsonův
Dokážete si vybrat správnou nemocnici? aneb Ministr zdravotnictví ML varuje Martina Litschmannová
 Dokážete si vybrat správnou nemocnici? aneb Ministr zdravotnictví ML varuje Martina Litschmannová ŠKOMAM 2013 Pán Úzkostný onemocněl chorobou Moribundus. V blízkosti jeho bydliště jsou dvě nemocnice Dolní
Dokážete si vybrat správnou nemocnici? aneb Ministr zdravotnictví ML varuje Martina Litschmannová ŠKOMAM 2013 Pán Úzkostný onemocněl chorobou Moribundus. V blízkosti jeho bydliště jsou dvě nemocnice Dolní
Název testu Předpoklady testu Testová statistika Nulové rozdělení. ( ) (p počet odhadovaných parametrů)
 (p počet odhadovaných parametrů)") VYBRANÉ TESTY NEPARAMETRICKÝCH HYPOTÉZ TESTY DOBRÉ SHODY Název testu Předpoklady testu Testová statistika Nulové rozdělení test dobré shody Očekávané četnosti, alespoň 80% očekávaných četností >5 ( ) (p
VYBRANÉ TESTY NEPARAMETRICKÝCH HYPOTÉZ TESTY DOBRÉ SHODY Název testu Předpoklady testu Testová statistika Nulové rozdělení test dobré shody Očekávané četnosti, alespoň 80% očekávaných četností >5 ( ) (p
Základy biostatistiky II. Veřejné zdravotnictví 3.LF UK - II
 Základy biostatistiky II Veřejné zdravotnictví 3.LF UK - II Teoretické rozložení-matematické modely rozložení Naměřená data Výběrové rozložení Teoretické rozložení 1 e 2 x 2 Teoretické rozložení-matematické
Základy biostatistiky II Veřejné zdravotnictví 3.LF UK - II Teoretické rozložení-matematické modely rozložení Naměřená data Výběrové rozložení Teoretické rozložení 1 e 2 x 2 Teoretické rozložení-matematické
Zpracování náhodného vektoru. Ing. Michal Dorda, Ph.D.
 Ing. Michal Dorda, Ph.D. 1 Př. 1: Cestující na vybraném spoji linky MHD byli dotazováni za účelem zjištění spokojenosti s kvalitou MHD. Legenda 1 Velmi spokojen Spokojen 3 Nespokojen 4 Velmi nespokojen
Ing. Michal Dorda, Ph.D. 1 Př. 1: Cestující na vybraném spoji linky MHD byli dotazováni za účelem zjištění spokojenosti s kvalitou MHD. Legenda 1 Velmi spokojen Spokojen 3 Nespokojen 4 Velmi nespokojen
Statgraphics v. 5.0 STATISTICKÁ INDUKCE PRO JEDNOROZMĚRNÁ DATA. Martina Litschmannová 1. Typ proměnné. Požadovaný typ analýzy
 Dichotomická proměnná (0-1) Spojitá proměnná STATISTICKÁ INDUKCE PRO JEDNOROZMĚRNÁ DATA Typ proměnné Požadovaný typ analýzy Ověření variability Předpoklady Testy, resp. intervalové odhad Test o rozptylu
Dichotomická proměnná (0-1) Spojitá proměnná STATISTICKÁ INDUKCE PRO JEDNOROZMĚRNÁ DATA Typ proměnné Požadovaný typ analýzy Ověření variability Předpoklady Testy, resp. intervalové odhad Test o rozptylu
Jana Vránová, 3. lékařská fakulta UK
 Jana Vránová, 3. lékařská fakulta UK Vznikají při zkoumání vztahů kvalitativních resp. diskrétních znaků Jedná se o analogii s korelační analýzou spojitých znaků Přitom předpokládáme, že každý prvek populace
Jana Vránová, 3. lékařská fakulta UK Vznikají při zkoumání vztahů kvalitativních resp. diskrétních znaků Jedná se o analogii s korelační analýzou spojitých znaků Přitom předpokládáme, že každý prvek populace
Testy dobré shody Máme dvě veličiny, u kterých bychom chtěli prokázat závislost, TESTY DOBRÉ SHODY (angl. goodness-of-fit tests)
") Testy dobré shody Máme dvě veličiny, u kterých bychom chtěli prokázat závislost, např. hmotnost a pohlaví narozených dětí. Běžný statistický postup pro ověření závislosti dvou veličin je zamítnutí jejich
Testy dobré shody Máme dvě veličiny, u kterých bychom chtěli prokázat závislost, např. hmotnost a pohlaví narozených dětí. Běžný statistický postup pro ověření závislosti dvou veličin je zamítnutí jejich
Kontingenční tabulky, korelační koeficienty
 Statistika II Katedra ekonometrie FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Mějme kategoriální proměnné X a Y. Vytvoříme tzv. kontingenční tabulku. Budeme tedy testovat hypotézu
Statistika II Katedra ekonometrie FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Mějme kategoriální proměnné X a Y. Vytvoříme tzv. kontingenční tabulku. Budeme tedy testovat hypotézu
5 Vícerozměrná data - kontingenční tabulky, testy nezávislosti, regresní analýza
 5 Vícerozměrná data - kontingenční tabulky, testy nezávislosti, regresní analýza 5.1 Vícerozměrná data a vícerozměrná rozdělení Při zpracování vícerozměrných dat se hledají souvislosti mezi dvěma, případně
5 Vícerozměrná data - kontingenční tabulky, testy nezávislosti, regresní analýza 5.1 Vícerozměrná data a vícerozměrná rozdělení Při zpracování vícerozměrných dat se hledají souvislosti mezi dvěma, případně
Kontingenční tabulky, korelační koeficienty
 Statistika II Katedra ekonometrie FVL UO Brno kancelář 69a, tel 973 442029 email:jirineubauer@unobcz Budeme předpokládat, že X a Y jsou kvalitativní náhodné veličiny, obor hodnot X obsahuje r hodnot (kategorií,
Statistika II Katedra ekonometrie FVL UO Brno kancelář 69a, tel 973 442029 email:jirineubauer@unobcz Budeme předpokládat, že X a Y jsou kvalitativní náhodné veličiny, obor hodnot X obsahuje r hodnot (kategorií,
Přednáška XI. Asociace ve čtyřpolní tabulce a základy korelační analýzy
 Přednáška XI. Asociace ve čtyřpolní tabulce a základy korelační analýzy Relativní riziko a poměr šancí Princip korelace dvou náhodných veličin Korelační koeficienty Pearsonůva Spearmanův Korelace a kauzalita
Přednáška XI. Asociace ve čtyřpolní tabulce a základy korelační analýzy Relativní riziko a poměr šancí Princip korelace dvou náhodných veličin Korelační koeficienty Pearsonůva Spearmanův Korelace a kauzalita
Příklad 1. Korelační pole. Řešení 1 ŘEŠENÉ PŘÍKLADY Z MV2 ČÁST 13
 Příklad 1 Máme k dispozici výsledky prvního a druhého testu deseti sportovců. Na hladině významnosti 0,05 prověřte, zda jsou výsledky testů kladně korelované. 1.test : 7, 8, 10, 4, 14, 9, 6, 2, 13, 5 2.test
Příklad 1 Máme k dispozici výsledky prvního a druhého testu deseti sportovců. Na hladině významnosti 0,05 prověřte, zda jsou výsledky testů kladně korelované. 1.test : 7, 8, 10, 4, 14, 9, 6, 2, 13, 5 2.test
Korelační a regresní analýza
 Korelační a regresní analýza Analýza závislosti v normálním rozdělení Pearsonův (výběrový) korelační koeficient: r = s XY s X s Y, kde s XY = 1 n (x n 1 i=0 i x )(y i y ), s X (s Y ) je výběrová směrodatná
Korelační a regresní analýza Analýza závislosti v normálním rozdělení Pearsonův (výběrový) korelační koeficient: r = s XY s X s Y, kde s XY = 1 n (x n 1 i=0 i x )(y i y ), s X (s Y ) je výběrová směrodatná
ANALÝZA DAT V R 7. KONTINGENČNÍ TABULKA. Mgr. Markéta Pavlíková Katedra pravděpodobnosti a matematické statistiky MFF UK.
 ANALÝZA DAT V R 7. KONTINGENČNÍ TABULKA Mgr. Markéta Pavlíková Katedra pravděpodobnosti a matematické statistiky MFF UK www.biostatisticka.cz PŘEHLED TESTŮ rozdělení normální spojité alternativní / diskrétní
ANALÝZA DAT V R 7. KONTINGENČNÍ TABULKA Mgr. Markéta Pavlíková Katedra pravděpodobnosti a matematické statistiky MFF UK www.biostatisticka.cz PŘEHLED TESTŮ rozdělení normální spojité alternativní / diskrétní
Analýza dat z dotazníkových šetření
 Analýza dat z dotazníkových šetření Cvičení 6. Rozsah výběru Př. Určete minimální rozsah výběru pro proměnnou věk v souboru dovolena, jestliže 95% interval spolehlivost průměru proměnné nemá být širší
Analýza dat z dotazníkových šetření Cvičení 6. Rozsah výběru Př. Určete minimální rozsah výběru pro proměnnou věk v souboru dovolena, jestliže 95% interval spolehlivost průměru proměnné nemá být širší
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz
 Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická
KGG/STG Statistika pro geografy
 KGG/STG Statistika pro geografy 9. Korelační analýza Mgr. David Fiedor 20. dubna 2015 Analýza závislostí v řadě geografických disciplín studujeme jevy, u kterých vyšetřujeme nikoliv pouze jednu vlastnost
KGG/STG Statistika pro geografy 9. Korelační analýza Mgr. David Fiedor 20. dubna 2015 Analýza závislostí v řadě geografických disciplín studujeme jevy, u kterých vyšetřujeme nikoliv pouze jednu vlastnost
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc.
 Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika 010 1.týden (0.09.-4.09. ) Data, typy dat, variabilita, frekvenční analýza
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika 010 1.týden (0.09.-4.09. ) Data, typy dat, variabilita, frekvenční analýza
Vysoká škola báňská technická univerzita Ostrava. Fakulta elektrotechniky a informatiky
 Vysoká škola báňská technická univerzita Ostrava Fakulta elektrotechniky a informatiky Bankovní účty (semestrální projekt statistika) Tomáš Hejret (hej124) 18.5.2013 Úvod Cílem tohoto projektu, zadaného
Vysoká škola báňská technická univerzita Ostrava Fakulta elektrotechniky a informatiky Bankovní účty (semestrální projekt statistika) Tomáš Hejret (hej124) 18.5.2013 Úvod Cílem tohoto projektu, zadaného
Náhodné veličiny jsou nekorelované, neexistuje mezi nimi korelační vztah. Když jsou X; Y nekorelované, nemusí být nezávislé.
 1. Korelační analýza V životě většinou nesledujeme pouze jeden statistický znak. Sledujeme více statistických znaků zároveň. Kromě vlastností statistických znaků nás zajímá také jejich těsnost (velikost,
1. Korelační analýza V životě většinou nesledujeme pouze jeden statistický znak. Sledujeme více statistických znaků zároveň. Kromě vlastností statistických znaků nás zajímá také jejich těsnost (velikost,
Statistické metody v ekonomii. Ing. Michael Rost, Ph.D.
 Statistické metody v ekonomii Ing. Michael Rost, Ph.D. Jihočeská univerzita v Českých Budějovicích Test χ 2 v kontingenční tabulce typu 2 2 Jde vlastně o speciální případ χ 2 testu pro čtyřpolní tabulku.
Statistické metody v ekonomii Ing. Michael Rost, Ph.D. Jihočeská univerzita v Českých Budějovicích Test χ 2 v kontingenční tabulce typu 2 2 Jde vlastně o speciální případ χ 2 testu pro čtyřpolní tabulku.
Epidemiologické ukazatele. lních dat. analýza kategoriáln. Prof. RNDr. Jana Zvárová, DrSc. Záznam epidemiologických dat. a I E
 Testování statistických hypotéz z a analýza kategoriáln lních dat Prof. RNDr. Jana Zvárová, DrSc. Epidemiologické ukazatele Rizikový faktor Populace Přítomen Nepřítomen Celkem Nemocní a b a+b Kontroly
Testování statistických hypotéz z a analýza kategoriáln lních dat Prof. RNDr. Jana Zvárová, DrSc. Epidemiologické ukazatele Rizikový faktor Populace Přítomen Nepřítomen Celkem Nemocní a b a+b Kontroly
Přednáška 9. Testy dobré shody. Grafická analýza pro ověření shody empirického a teoretického rozdělení
 Přednáška 9 Testy dobré shody Grafická analýza pro ověření shody empirického a teoretického rozdělení χ 2 test dobré shody ověření, zda jsou relativní četnosti jednotlivých variant rovny číslům π 01 ;
Přednáška 9 Testy dobré shody Grafická analýza pro ověření shody empirického a teoretického rozdělení χ 2 test dobré shody ověření, zda jsou relativní četnosti jednotlivých variant rovny číslům π 01 ;
PSY117/454 Statistická analýza dat v psychologii Přednáška 10
 PSY117/454 Statistická analýza dat v psychologii Přednáška 10 TESTY PRO NOMINÁLNÍ A ORDINÁLNÍ PROMĚNNÉ NEPARAMETRICKÉ METODY... a to mělo, jak sám vidíte, nedozírné následky. Smrť Analýza četností hodnot
PSY117/454 Statistická analýza dat v psychologii Přednáška 10 TESTY PRO NOMINÁLNÍ A ORDINÁLNÍ PROMĚNNÉ NEPARAMETRICKÉ METODY... a to mělo, jak sám vidíte, nedozírné následky. Smrť Analýza četností hodnot
Regresní a korelační analýza
 Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
{ } ( 2) Příklad: Test nezávislosti kategoriálních znaků
 Příklad: Test nezávislosti kategoriálních znaků") Příklad: Test nezávislosti kategoriálních znaků Určete na hladině významnosti 5 % na základě dat zjištěných v rámci dotazníkového šetření ve Šluknově, zda existuje závislost mezi pohlavím respondenta a
Příklad: Test nezávislosti kategoriálních znaků Určete na hladině významnosti 5 % na základě dat zjištěných v rámci dotazníkového šetření ve Šluknově, zda existuje závislost mezi pohlavím respondenta a
Test dobré shody v KONTINGENČNÍCH TABULKÁCH
 Test dobré shody v KONTINGENČNÍCH TABULKÁCH Opakování: Mějme náhodné veličiny X a Y uspořádané do kontingenční tabulky. Řekli jsme, že nulovou hypotézu H 0 : veličiny X, Y jsou nezávislé zamítneme, když
Test dobré shody v KONTINGENČNÍCH TABULKÁCH Opakování: Mějme náhodné veličiny X a Y uspořádané do kontingenční tabulky. Řekli jsme, že nulovou hypotézu H 0 : veličiny X, Y jsou nezávislé zamítneme, když
INDUKTIVNÍ STATISTIKA
 10. SEMINÁŘ INDUKTIVNÍ STATISTIKA 3. HODNOCENÍ ZÁVISLOSTÍ HODNOCENÍ ZÁVISLOSTÍ KVALITATIVNÍ VELIČINY - Vychází se z kombinační (kontingenční) tabulky, která je výsledkem třídění druhého stupně KVANTITATIVNÍ
10. SEMINÁŘ INDUKTIVNÍ STATISTIKA 3. HODNOCENÍ ZÁVISLOSTÍ HODNOCENÍ ZÁVISLOSTÍ KVALITATIVNÍ VELIČINY - Vychází se z kombinační (kontingenční) tabulky, která je výsledkem třídění druhého stupně KVANTITATIVNÍ
NÁHODNÝ VEKTOR. 4. cvičení
 NÁHODNÝ VEKTOR 4. cvičení Náhodný vektor Náhodným vektorem rozumíme sloupcový vektor X=(X, X,, X n ) složený z náhodných veličin X, X,, X n, který je charakterizován sdruženým rozdělením pravděpodobnosti.
NÁHODNÝ VEKTOR 4. cvičení Náhodný vektor Náhodným vektorem rozumíme sloupcový vektor X=(X, X,, X n ) složený z náhodných veličin X, X,, X n, který je charakterizován sdruženým rozdělením pravděpodobnosti.
analýza kategoriáln lních dat Prof. RNDr. Jana Zvárová, DrSc. Záznam epidemiologických dat Epidemiologické ukazatele
 Testování statistických hypotéz z a analýza kategoriáln lních dat Prof. RNDr. Jana Zvárová, DrSc. 1 Záznam epidemiologických dat Rizikový faktor Populace Přítomen Nepřítomen Celkem Nemocní a b a+b Kontroly
Testování statistických hypotéz z a analýza kategoriáln lních dat Prof. RNDr. Jana Zvárová, DrSc. 1 Záznam epidemiologických dat Rizikový faktor Populace Přítomen Nepřítomen Celkem Nemocní a b a+b Kontroly
Statistická analýza jednorozměrných dat
 Statistická analýza jednorozměrných dat Prof. RNDr. Milan Meloun, DrSc. Univerzita Pardubice, Pardubice 31.ledna 2011 Tato prezentace je spolufinancována Evropským sociálním fondem a státním rozpočtem
Statistická analýza jednorozměrných dat Prof. RNDr. Milan Meloun, DrSc. Univerzita Pardubice, Pardubice 31.ledna 2011 Tato prezentace je spolufinancována Evropským sociálním fondem a státním rozpočtem
MÍRY ZÁVISLOSTI (KORELACE A REGRESE)
") zhanel@fsps.muni.cz MÍRY ZÁVISLOSTI (KORELACE A REGRESE) 2.5 MÍRY ZÁVISLOSTI 2.5.1 ZÁVISLOST PEVNÁ, VOLNÁ, STATISTICKÁ A KORELAČNÍ Jednorozměrné soubory - charakterizovány jednotlivými statistickými znaky
zhanel@fsps.muni.cz MÍRY ZÁVISLOSTI (KORELACE A REGRESE) 2.5 MÍRY ZÁVISLOSTI 2.5.1 ZÁVISLOST PEVNÁ, VOLNÁ, STATISTICKÁ A KORELAČNÍ Jednorozměrné soubory - charakterizovány jednotlivými statistickými znaky
PRAVDĚPODOBNOST A STATISTIKA
 PRAVDĚPODOBNOST A STATISTIKA Testování hypotéz Nechť X je náhodná proměnná, která má distribuční funkci F(x, ϑ). Předpokládejme, že známe tvar distribuční funkce (víme jaké má rozdělení) a neznáme parametr
PRAVDĚPODOBNOST A STATISTIKA Testování hypotéz Nechť X je náhodná proměnná, která má distribuční funkci F(x, ϑ). Předpokládejme, že známe tvar distribuční funkce (víme jaké má rozdělení) a neznáme parametr
6. Lineární regresní modely
 6. Lineární regresní modely 6.1 Jednoduchá regrese a validace 6.2 Testy hypotéz v lineární regresi 6.3 Kritika dat v regresním tripletu 6.4 Multikolinearita a polynomy 6.5 Kritika modelu v regresním tripletu
6. Lineární regresní modely 6.1 Jednoduchá regrese a validace 6.2 Testy hypotéz v lineární regresi 6.3 Kritika dat v regresním tripletu 6.4 Multikolinearita a polynomy 6.5 Kritika modelu v regresním tripletu
Tomáš Karel LS 2012/2013
 Tomáš Karel LS 2012/2013 Doplňkový materiál ke cvičení z předmětu 4ST201. Na případné faktické chyby v této presentaci mě prosím upozorněte. Děkuji. Tyto slidy berte pouze jako doplňkový materiál není
Tomáš Karel LS 2012/2013 Doplňkový materiál ke cvičení z předmětu 4ST201. Na případné faktické chyby v této presentaci mě prosím upozorněte. Děkuji. Tyto slidy berte pouze jako doplňkový materiál není
Testování statistických hypotéz
 Testování statistických hypotéz Na základě náhodného výběru, který je reprezentativním vzorkem základního souboru (který přesně neznáme, k němuž se ale daná statistická hypotéza váže), potřebujeme ověřit,
Testování statistických hypotéz Na základě náhodného výběru, který je reprezentativním vzorkem základního souboru (který přesně neznáme, k němuž se ale daná statistická hypotéza váže), potřebujeme ověřit,
STATISTIKA A INFORMATIKA - bc studium OZW, 1.roč. (zkušební otázky)
") STATISTIKA A INFORMATIKA - bc studium OZW, 1.roč. (zkušební otázky) 1) Význam a využití statistiky v biologických vědách a veterinárním lékařství ) Rozdělení znaků (veličin) ve statistice 3) Základní a
STATISTIKA A INFORMATIKA - bc studium OZW, 1.roč. (zkušební otázky) 1) Význam a využití statistiky v biologických vědách a veterinárním lékařství ) Rozdělení znaků (veličin) ve statistice 3) Základní a
Pravděpodobnost a statistika, Biostatistika pro kombinované studium. Tutoriál č. 5: Bodové a intervalové odhady, testování hypotéz.
 Pravděpodobnost a statistika, Biostatistika pro kombinované studium Letní semestr 2015/2016 Tutoriál č. 5: Bodové a intervalové odhady, testování hypotéz Jan Kracík jan.kracik@vsb.cz Obsah: Výběrová rozdělení
Pravděpodobnost a statistika, Biostatistika pro kombinované studium Letní semestr 2015/2016 Tutoriál č. 5: Bodové a intervalové odhady, testování hypotéz Jan Kracík jan.kracik@vsb.cz Obsah: Výběrová rozdělení
Regresní a korelační analýza
 Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
ADDS cvičení 7. Pavlína Kuráňová
 ADDS cvičení 7 Pavlína Kuráňová Analyzujte závislost věku obyvatel na místě kde nejčastěji tráví dovolenou. (dotazník dovolená, sloupce Jaký je Váš věk a Kde nejčastěji trávíte dovolenou) Analyzujte závislost
ADDS cvičení 7 Pavlína Kuráňová Analyzujte závislost věku obyvatel na místě kde nejčastěji tráví dovolenou. (dotazník dovolená, sloupce Jaký je Váš věk a Kde nejčastěji trávíte dovolenou) Analyzujte závislost
Pracovní adresář. Nápověda. Instalování a načtení nového balíčku. Importování datového souboru. Práce s datovým souborem
 Pracovní adresář getwd() # výpis pracovního adresáře setwd("c:/moje/pracovni") # nastavení pracovního adresáře setwd("c:\\moje\\pracovni") # nastavení pracovního adresáře Nápověda?funkce # nápověda pro
Pracovní adresář getwd() # výpis pracovního adresáře setwd("c:/moje/pracovni") # nastavení pracovního adresáře setwd("c:\\moje\\pracovni") # nastavení pracovního adresáře Nápověda?funkce # nápověda pro
11. cvičení z PSI prosince hodnota pozorovaná četnost n i p X (i) = q i (1 q), i N 0.
 = q i (1 q), i N 0.") 11 cvičení z PSI 12-16 prosince 2016 111 (Test dobré shody - geometrické rozdělení Realizací náhodné veličiny X jsme dostali následující četnosti výsledků: hodnota 0 1 2 3 4 5 6 pozorovaná četnost 29 15
11 cvičení z PSI 12-16 prosince 2016 111 (Test dobré shody - geometrické rozdělení Realizací náhodné veličiny X jsme dostali následující četnosti výsledků: hodnota 0 1 2 3 4 5 6 pozorovaná četnost 29 15
12. cvičení z PST. 20. prosince 2017
 1 cvičení z PST 0 prosince 017 11 test rozptylu normálního rozdělení Do laboratoře bylo odesláno n = 5 stejných vzorků krve ke stanovení obsahu alkoholu X v promilích alkoholu Výsledkem byla realizace
1 cvičení z PST 0 prosince 017 11 test rozptylu normálního rozdělení Do laboratoře bylo odesláno n = 5 stejných vzorků krve ke stanovení obsahu alkoholu X v promilích alkoholu Výsledkem byla realizace
Úvodem Dříve les než stromy 3 Operace s maticemi
 Obsah 1 Úvodem 13 2 Dříve les než stromy 17 2.1 Nejednoznačnost terminologie 17 2.2 Volba metody analýzy dat 23 2.3 Přehled vybraných vícerozměrných metod 25 2.3.1 Metoda hlavních komponent 26 2.3.2 Faktorová
Obsah 1 Úvodem 13 2 Dříve les než stromy 17 2.1 Nejednoznačnost terminologie 17 2.2 Volba metody analýzy dat 23 2.3 Přehled vybraných vícerozměrných metod 25 2.3.1 Metoda hlavních komponent 26 2.3.2 Faktorová
UNIVERZITA OBRANY Fakulta ekonomiky a managementu. Aplikace STAT1. Výsledek řešení projektu PRO HORR2011 a PRO GRAM2011 3. 11.
 UNIVERZITA OBRANY Fakulta ekonomiky a managementu Aplikace STAT1 Výsledek řešení projektu PRO HORR2011 a PRO GRAM2011 Jiří Neubauer, Marek Sedlačík, Oldřich Kříž 3. 11. 2012 Popis a návod k použití aplikace
UNIVERZITA OBRANY Fakulta ekonomiky a managementu Aplikace STAT1 Výsledek řešení projektu PRO HORR2011 a PRO GRAM2011 Jiří Neubauer, Marek Sedlačík, Oldřich Kříž 3. 11. 2012 Popis a návod k použití aplikace
Testování hypotéz. Analýza dat z dotazníkových šetření. Kuranova Pavlina
 Testování hypotéz Analýza dat z dotazníkových šetření Kuranova Pavlina Statistická hypotéza Možné cíle výzkumu Srovnání účinnosti různých metod Srovnání výsledků různých skupin Tzn. prokázání rozdílů mezi
Testování hypotéz Analýza dat z dotazníkových šetření Kuranova Pavlina Statistická hypotéza Možné cíle výzkumu Srovnání účinnosti různých metod Srovnání výsledků různých skupin Tzn. prokázání rozdílů mezi
ANALÝZA DAT V R 3. POPISNÉ STATISTIKY, NÁHODNÁ VELIČINA. Mgr. Markéta Pavlíková Katedra pravděpodobnosti a matematické statistiky MFF UK
 ANALÝZA DAT V R 3. POPISNÉ STATISTIKY, NÁHODNÁ VELIČINA Mgr. Markéta Pavlíková Katedra pravděpodobnosti a matematické statistiky MFF UK www.biostatisticka.cz POPISNÉ STATISTIKY - OPAKOVÁNÍ jedna kvalitativní
ANALÝZA DAT V R 3. POPISNÉ STATISTIKY, NÁHODNÁ VELIČINA Mgr. Markéta Pavlíková Katedra pravděpodobnosti a matematické statistiky MFF UK www.biostatisticka.cz POPISNÉ STATISTIKY - OPAKOVÁNÍ jedna kvalitativní
RNDr. Eva Janoušová doc. RNDr. Ladislav Dušek, Dr.
 Analýza dat pro Neurovědy RNDr. Eva Janoušová doc. RNDr. Ladislav Dušek, Dr. Jaro 2014 Institut biostatistiky Janoušová, a analýz Dušek: Analýza dat pro neurovědy Blok 7 Jak hodnotit vztah spojitých proměnných
Analýza dat pro Neurovědy RNDr. Eva Janoušová doc. RNDr. Ladislav Dušek, Dr. Jaro 2014 Institut biostatistiky Janoušová, a analýz Dušek: Analýza dat pro neurovědy Blok 7 Jak hodnotit vztah spojitých proměnných
Příklad: Test nezávislosti kategoriálních znaků
 Příklad: Test nezávislosti kategoriálních znaků Určete na hladině významnosti 5 % na základě dat zjištěných v rámci dotazníkového šetření ve Šluknově, zda existuje závislost mezi pohlavím respondenta a
Příklad: Test nezávislosti kategoriálních znaků Určete na hladině významnosti 5 % na základě dat zjištěných v rámci dotazníkového šetření ve Šluknově, zda existuje závislost mezi pohlavím respondenta a
Náhodný vektor. Náhodný vektor. Hustota náhodného vektoru. Hustota náhodného vektoru. Náhodný vektor je dvojice náhodných veličin (X, Y ) T = ( X
 T = ( X") Náhodný vektor Náhodný vektor zatím jsme sledovali jednu náhodnou veličinu, její rozdělení a charakteristiky často potřebujeme vyšetřovat vzájemný vztah několika náhodných veličin musíme sledovat jejich
Náhodný vektor Náhodný vektor zatím jsme sledovali jednu náhodnou veličinu, její rozdělení a charakteristiky často potřebujeme vyšetřovat vzájemný vztah několika náhodných veličin musíme sledovat jejich
Program Statistica Base 9. Mgr. Karla Hrbáčková, Ph.D.
 Program Statistica Base 9 Mgr. Karla Hrbáčková, Ph.D. OBSAH KURZU obsluha jednotlivých nástrojů, funkce pro import dat z jiných aplikací, práce s popisnou statistikou, vytváření grafů, analýza dat, výstupní
Program Statistica Base 9 Mgr. Karla Hrbáčková, Ph.D. OBSAH KURZU obsluha jednotlivých nástrojů, funkce pro import dat z jiných aplikací, práce s popisnou statistikou, vytváření grafů, analýza dat, výstupní
n = 2 Sdružená distribuční funkce (joint d.f.) n. vektoru F (x, y) = P (X x, Y y)
 n. vektoru F (x, y) = P (X x, Y y)") 5. NÁHODNÝ VEKTOR 5.1. Rozdělení náhodného vektoru Náhodný vektor X = (X 1, X 2,..., X n ) T n-rozměrný vektor, složky X i, i = 1,..., n náhodné veličiny. Vícerozměrná (n-rozměrná) náhodná veličina n =
5. NÁHODNÝ VEKTOR 5.1. Rozdělení náhodného vektoru Náhodný vektor X = (X 1, X 2,..., X n ) T n-rozměrný vektor, složky X i, i = 1,..., n náhodné veličiny. Vícerozměrná (n-rozměrná) náhodná veličina n =
Porovnání dvou výběrů
 Porovnání dvou výběrů Menu: QCExpert Porovnání dvou výběrů Tento modul je určen pro podrobnou analýzu dvou datových souborů (výběrů). Modul poskytuje dva postupy analýzy: porovnání dvou nezávislých výběrů
Porovnání dvou výběrů Menu: QCExpert Porovnání dvou výběrů Tento modul je určen pro podrobnou analýzu dvou datových souborů (výběrů). Modul poskytuje dva postupy analýzy: porovnání dvou nezávislých výběrů
Aplikovaná statistika v R - cvičení 2
 Aplikovaná statistika v R - cvičení 2 Filip Děchtěrenko Matematicko-fyzikální fakulta filip.dechterenko@gmail.com 5.6.2014 Filip Děchtěrenko (MFF UK) Aplikovaná statistika v R 5.6.2014 1 / 18 Přehled Rkových
Aplikovaná statistika v R - cvičení 2 Filip Děchtěrenko Matematicko-fyzikální fakulta filip.dechterenko@gmail.com 5.6.2014 Filip Děchtěrenko (MFF UK) Aplikovaná statistika v R 5.6.2014 1 / 18 Přehled Rkových
Intervalové odhady. Interval spolehlivosti pro střední hodnotu v N(µ, σ 2 ) Interpretace intervalu spolehlivosti. Interval spolehlivosti ilustrace
 Interpretace intervalu spolehlivosti. Interval spolehlivosti ilustrace") Intervalové odhady Interval spolehlivosti pro střední hodnotu v Nµ, σ 2 ) Situace: X 1,..., X n náhodný výběr z Nµ, σ 2 ), kde σ 2 > 0 známe měli jsme: bodové odhady odhadem charakteristiky je číslo) nevyjadřuje
Intervalové odhady Interval spolehlivosti pro střední hodnotu v Nµ, σ 2 ) Situace: X 1,..., X n náhodný výběr z Nµ, σ 2 ), kde σ 2 > 0 známe měli jsme: bodové odhady odhadem charakteristiky je číslo) nevyjadřuje
Regresní a korelační analýza
 Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
II. Statistické metody vyhodnocení kvantitativních dat Gejza Dohnal
 Základy navrhování průmyslových experimentů DOE II. Statistické metody vyhodnocení kvantitativních dat Gejza Dohnal! Testování statistických hypotéz kvalitativní odezva kvantitativní chí-kvadrát test homogenity,
Základy navrhování průmyslových experimentů DOE II. Statistické metody vyhodnocení kvantitativních dat Gejza Dohnal! Testování statistických hypotéz kvalitativní odezva kvantitativní chí-kvadrát test homogenity,
Technická univerzita v Liberci
 Technická univerzita v Liberci Ekonomická fakulta Analýza výsledků z dotazníkového šetření Jména studentů: Adam Pavlíček Michal Karlas Tomáš Vávra Anna Votavová Ročník: 2015/2016 Datum odevzdání: 13/05/2016
Technická univerzita v Liberci Ekonomická fakulta Analýza výsledků z dotazníkového šetření Jména studentů: Adam Pavlíček Michal Karlas Tomáš Vávra Anna Votavová Ročník: 2015/2016 Datum odevzdání: 13/05/2016
VYBRANÉ DVOUVÝBĚROVÉ TESTY. Martina Litschmannová
 VYBRANÉ DVOUVÝBĚROVÉ TESTY Martina Litschmannová Obsah přednášky Vybrané dvouvýběrové testy par. hypotéz test o shodě rozptylů (F-test), testy o shodě středních hodnot (t-test, Aspinové-Welchův test),
VYBRANÉ DVOUVÝBĚROVÉ TESTY Martina Litschmannová Obsah přednášky Vybrané dvouvýběrové testy par. hypotéz test o shodě rozptylů (F-test), testy o shodě středních hodnot (t-test, Aspinové-Welchův test),
Mnohorozměrná statistická data
 Mnohorozměrná statistická data Ekonometrie Jiří Neubauer Katedra ekonometrie FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Jiří Neubauer (Katedra ekonometrie UO Brno) Mnohorozměrná
Mnohorozměrná statistická data Ekonometrie Jiří Neubauer Katedra ekonometrie FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Jiří Neubauer (Katedra ekonometrie UO Brno) Mnohorozměrná
Stav Svobodný Rozvedený Vdovec. Svobodná 37 10 6. Rozvedená 8 12 8. Vdova 5 8 6
 1. Příklad Byly sledovány rodinné stavy nevěst a ženichů při uzavírání sňatků a byla vytvořena následující tabulka četností. Stav Svobodný Rozvedený Vdovec Svobodná 37 10 6 Rozvedená 8 12 8 Vdova 5 8 6
1. Příklad Byly sledovány rodinné stavy nevěst a ženichů při uzavírání sňatků a byla vytvořena následující tabulka četností. Stav Svobodný Rozvedený Vdovec Svobodná 37 10 6 Rozvedená 8 12 8 Vdova 5 8 6
Testování hypotéz o parametrech regresního modelu
 Testování hypotéz o parametrech regresního modelu Ekonometrie Jiří Neubauer Katedra kvantitativních metod FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Jiří Neubauer (Katedra UO
Testování hypotéz o parametrech regresního modelu Ekonometrie Jiří Neubauer Katedra kvantitativních metod FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Jiří Neubauer (Katedra UO
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc.
 Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika 2010 1.týden (20.09.-24.09. ) Data, typy dat, variabilita, frekvenční analýza
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika 2010 1.týden (20.09.-24.09. ) Data, typy dat, variabilita, frekvenční analýza
Tomáš Karel LS 2012/2013
 Tomáš Karel LS 2012/2013 Doplňkový materiál ke cvičení z předmětu 4ST201. Na případné faktické chyby v této presentaci mě prosím upozorněte. Děkuji. Tyto slidy berte pouze jako doplňkový materiál není
Tomáš Karel LS 2012/2013 Doplňkový materiál ke cvičení z předmětu 4ST201. Na případné faktické chyby v této presentaci mě prosím upozorněte. Děkuji. Tyto slidy berte pouze jako doplňkový materiál není
Pearsonův korelační koeficient
 I I.I Pearsonův korelační koeficient Úvod Předpokládejme, že náhodně vybereme n objektů (nebo osob) ze zkoumané populace. Často se stává, že na každém z objektů měříme ne pouze jednu, ale několik kvantitativních
I I.I Pearsonův korelační koeficient Úvod Předpokládejme, že náhodně vybereme n objektů (nebo osob) ze zkoumané populace. Často se stává, že na každém z objektů měříme ne pouze jednu, ale několik kvantitativních
Intervalové odhady. Interval spolehlivosti pro střední hodnotu v N(µ, σ 2 ) Interpretace intervalu spolehlivosti. Interval spolehlivosti ilustrace
 Interpretace intervalu spolehlivosti. Interval spolehlivosti ilustrace") Intervalové odhady Interval spolehlivosti pro střední hodnotu v Nµ, σ 2 ) Situace: X 1,..., X n náhodný výběr z Nµ, σ 2 ), kde σ 2 > 0 známe měli jsme: bodové odhady odhadem charakteristiky je číslo) nevyjadřuje
Intervalové odhady Interval spolehlivosti pro střední hodnotu v Nµ, σ 2 ) Situace: X 1,..., X n náhodný výběr z Nµ, σ 2 ), kde σ 2 > 0 známe měli jsme: bodové odhady odhadem charakteristiky je číslo) nevyjadřuje
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc.
 Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika 2010 1.týden (20.09.-24.09. ) Data, typy dat, variabilita, frekvenční analýza
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika 2010 1.týden (20.09.-24.09. ) Data, typy dat, variabilita, frekvenční analýza
4ST201 STATISTIKA CVIČENÍ Č. 7
 4ST201 STATISTIKA CVIČENÍ Č. 7 testování hypotéz parametrické testy test hypotézy o střední hodnotě test hypotézy o relativní četnosti test o shodě středních hodnot testování hypotéz v MS Excel neparametrické
4ST201 STATISTIKA CVIČENÍ Č. 7 testování hypotéz parametrické testy test hypotézy o střední hodnotě test hypotézy o relativní četnosti test o shodě středních hodnot testování hypotéz v MS Excel neparametrické
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc.
 Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika 2010 1.týden (20.09.-24.09. ) Data, typy dat, variabilita, frekvenční analýza
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika 2010 1.týden (20.09.-24.09. ) Data, typy dat, variabilita, frekvenční analýza
Přednáška 9. Testy dobré shody. Grafická analýza pro ověření shody empirického a teoretického rozdělení
 Přednáška 9 Testy dobré shody Grafická analýza pro ověření shody empirického a teoretického rozdělení χ 2 test dobré shody ověření, zda jsou relativní četnosti jednotlivých variant rovny číslům π 01 ;
Přednáška 9 Testy dobré shody Grafická analýza pro ověření shody empirického a teoretického rozdělení χ 2 test dobré shody ověření, zda jsou relativní četnosti jednotlivých variant rovny číslům π 01 ;
Testování hypotéz o parametrech regresního modelu
 Statistika II Katedra ekonometrie FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Lineární regresní model kde Y = Xβ + e, y 1 e 1 β y 2 Y =., e = e 2 x 11 x 1 1k., X =....... β 2,
Statistika II Katedra ekonometrie FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Lineární regresní model kde Y = Xβ + e, y 1 e 1 β y 2 Y =., e = e 2 x 11 x 1 1k., X =....... β 2,
Grafický a číselný popis rozložení dat 3.1 Způsoby zobrazení dat Metody zobrazení kvalitativních a ordinálních dat Metody zobrazení kvan
 1 Úvod 1.1 Empirický výzkum a jeho etapy 1.2 Význam teorie pro výzkum 1.2.1 Konstrukty a jejich operacionalizace 1.2.2 Role teorie ve výzkumu 1.2.3 Proces ověření hypotéz a teorií 1.3 Etika vědecké práce
1 Úvod 1.1 Empirický výzkum a jeho etapy 1.2 Význam teorie pro výzkum 1.2.1 Konstrukty a jejich operacionalizace 1.2.2 Role teorie ve výzkumu 1.2.3 Proces ověření hypotéz a teorií 1.3 Etika vědecké práce
1.1 Úvod... 1 1.2 Data... 1. 3 Statistická analýza dotazníkových dat 8. Literatura 10
 MÍRY STATISTICKÉ VAZBY, VÝBĚROVÁ ŠETŘENÍ, STATISTICKÁ ANALÝZA DOTAZNÍKOVÝCH DAT Obsah 1 Statistická data 1 1.1 Úvod.......................................... 1 1. Data...........................................
MÍRY STATISTICKÉ VAZBY, VÝBĚROVÁ ŠETŘENÍ, STATISTICKÁ ANALÝZA DOTAZNÍKOVÝCH DAT Obsah 1 Statistická data 1 1.1 Úvod.......................................... 1 1. Data...........................................
Regresní a korelační analýza
 Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Mannův-Whitneyův(Wilcoxonův) test pořadová obdoba dvouvýběrového t-testu. Statistika (MD360P03Z, MD360P03U) ak. rok 2007/2008
 test pořadová obdoba dvouvýběrového t-testu. Statistika (MD360P03Z, MD360P03U) ak. rok 2007/2008") Statistika (MD30P03Z, MD30P03U) ak. rok 007/008 Karel Zvára karel.zvara@mff.cuni.cz http://www.karlin.mff.cuni.cz/ zvara (naposledy upraveno. listopadu 007) 1(4) Mann-Whitney párový Wilcoxon párový znaménkový
Statistika (MD30P03Z, MD30P03U) ak. rok 007/008 Karel Zvára karel.zvara@mff.cuni.cz http://www.karlin.mff.cuni.cz/ zvara (naposledy upraveno. listopadu 007) 1(4) Mann-Whitney párový Wilcoxon párový znaménkový
Kategorická data METODOLOGICKÝ PROSEMINÁŘ II TÝDEN 7 4. DUBNA dubna 2018 Lukáš Hájek, Karel Höfer Metodologický proseminář II 1
 Kategorická data METODOLOGICKÝ PROSEMINÁŘ II TÝDEN 7 4. DUBNA 2018 4. dubna 2018 Lukáš Hájek, Karel Höfer Metodologický proseminář II 1 Typy proměnných nominální (nominal) o dvou hodnotách lze říci pouze
Kategorická data METODOLOGICKÝ PROSEMINÁŘ II TÝDEN 7 4. DUBNA 2018 4. dubna 2018 Lukáš Hájek, Karel Höfer Metodologický proseminář II 1 Typy proměnných nominální (nominal) o dvou hodnotách lze říci pouze
Měření závislosti statistických dat
 5.1 Měření závislosti statistických dat Každý pořádný astronom je schopen vám předpovědět, kde se bude nacházet daná hvězda půl hodiny před půlnocí. Ne každý je však téhož schopen předpovědět v případě
5.1 Měření závislosti statistických dat Každý pořádný astronom je schopen vám předpovědět, kde se bude nacházet daná hvězda půl hodiny před půlnocí. Ne každý je však téhož schopen předpovědět v případě
Statistika, Biostatistika pro kombinované studium Letní semestr 2011/2012. Tutoriál č. 4: Exploratorní analýza. Jan Kracík
 Statistika, Biostatistika pro kombinované studium Letní semestr 2011/2012 Tutoriál č. 4: Exploratorní analýza Jan Kracík jan.kracik@vsb.cz Statistika věda o získávání znalostí z empirických dat empirická
Statistika, Biostatistika pro kombinované studium Letní semestr 2011/2012 Tutoriál č. 4: Exploratorní analýza Jan Kracík jan.kracik@vsb.cz Statistika věda o získávání znalostí z empirických dat empirická
Cvičení 12: Binární logistická regrese
 Cvičení 12: Binární logistická regrese Příklad: V roce 2014 konalo státní závěrečné zkoušky bakalářského studia na jisté fakultě 167 studentů. U každého studenta bylo zaznamenáno jeho pohlaví (0 žena,
Cvičení 12: Binární logistická regrese Příklad: V roce 2014 konalo státní závěrečné zkoušky bakalářského studia na jisté fakultě 167 studentů. U každého studenta bylo zaznamenáno jeho pohlaví (0 žena,
Testování hypotéz testy o tvaru rozdělení. Jiří Neubauer. Katedra ekonometrie, FVL, UO Brno kancelář 69a, tel
 Katedra ekonometrie, FVL, UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Statistickou hypotézou se rozumí určité tvrzení o parametrech rozdělení zkoumané náhodné veličiny (µ, σ 2, π,
Katedra ekonometrie, FVL, UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Statistickou hypotézou se rozumí určité tvrzení o parametrech rozdělení zkoumané náhodné veličiny (µ, σ 2, π,
Pojmy z kombinatoriky, pravděpodobnosti, znalosti z kapitoly náhodná veličina, znalost parciálních derivací, dvojného integrálu.
 6. NÁHODNÝ VEKTOR Průvodce studiem V počtu pravděpodobnosti i v matematické statistice se setkáváme nejen s náhodnými veličinami, jejichž hodnotami jsou reálná čísla, ale i s takovými, jejichž hodnotami
6. NÁHODNÝ VEKTOR Průvodce studiem V počtu pravděpodobnosti i v matematické statistice se setkáváme nejen s náhodnými veličinami, jejichž hodnotami jsou reálná čísla, ale i s takovými, jejichž hodnotami
Poznámky k předmětu Aplikovaná statistika, 4. téma
 Poznámky k předmětu Aplikovaná statistika, 4. téma 4. Náhodné vektory V praxi se nám může hodit postihnout více vlastností jednoho objektu najednou, např. výšku, váhu a pohlaví člověka; rychlost chemické
Poznámky k předmětu Aplikovaná statistika, 4. téma 4. Náhodné vektory V praxi se nám může hodit postihnout více vlastností jednoho objektu najednou, např. výšku, váhu a pohlaví člověka; rychlost chemické
Obsah Úvod Kapitola 1 Než začneme Kapitola 2 Práce s hromadnými daty před analýzou
 Úvod.................................................................. 11 Kapitola 1 Než začneme.................................................................. 17 1.1 Logika kvantitativního výzkumu...........................................
Úvod.................................................................. 11 Kapitola 1 Než začneme.................................................................. 17 1.1 Logika kvantitativního výzkumu...........................................
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc.
 Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika 2010 1.týden (20.09.-24.09. ) Data, typy dat, variabilita, frekvenční analýza
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika 2010 1.týden (20.09.-24.09. ) Data, typy dat, variabilita, frekvenční analýza
Testy statistických hypotéz
 Testy statistických hypotéz Statistická hypotéza je jakýkoliv předpoklad o rozdělení pravděpodobnosti jedné nebo několika náhodných veličin. Na základě náhodného výběru, který je reprezentativním vzorkem
Testy statistických hypotéz Statistická hypotéza je jakýkoliv předpoklad o rozdělení pravděpodobnosti jedné nebo několika náhodných veličin. Na základě náhodného výběru, který je reprezentativním vzorkem
Regresní a korelační analýza
 Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Poznámky k předmětu Aplikovaná statistika, 4. téma
 Poznámky k předmětu Aplikovaná statistika, 4. téma 4. Náhodné vektory V praxi se nám může hodit postihnout více vlastností jednoho objektu najednou, např. výšku, váhu a pohlaví člověka; rychlost chemické
Poznámky k předmětu Aplikovaná statistika, 4. téma 4. Náhodné vektory V praxi se nám může hodit postihnout více vlastností jednoho objektu najednou, např. výšku, váhu a pohlaví člověka; rychlost chemické
Náhodný vektor. Náhodný vektor. Hustota náhodného vektoru. Hustota náhodného vektoru. Náhodný vektor je dvojice náhodných veličin (X, Y ) T = ( X
 T = ( X") Náhodný vektor Náhodný vektor zatím jsme sledovali jednu náhodnou veličinu, její rozdělení a charakteristik často potřebujeme všetřovat vzájemný vztah několika náhodných veličin musíme sledovat jejich
Náhodný vektor Náhodný vektor zatím jsme sledovali jednu náhodnou veličinu, její rozdělení a charakteristik často potřebujeme všetřovat vzájemný vztah několika náhodných veličin musíme sledovat jejich
Návod na vypracování semestrálního projektu
 Návod na vypracování semestrálního projektu Následující dokument má charakter doporučení. Není závazný, je pouze návodem pro studenty, kteří si nejsou jisti výběrem dat, volbou metod a formou zpracování
Návod na vypracování semestrálního projektu Následující dokument má charakter doporučení. Není závazný, je pouze návodem pro studenty, kteří si nejsou jisti výběrem dat, volbou metod a formou zpracování
SOFTWARE STAT1 A R. Literatura 4. kontrolní skupině (viz obr. 4). Proto budeme testovat shodu středních hodnot µ 1 = µ 2 proti alternativní
. Proto budeme testovat shodu středních hodnot µ 1 = µ 2 proti alternativní") ŘEŠENÍ PRAKTICKÝCH ÚLOH UŽITÍM SOFTWARE STAT1 A R Obsah 1 Užití software STAT1 1 2 Užití software R 3 Literatura 4 Příklady k procvičení 6 1 Užití software STAT1 Praktické užití aplikace STAT1 si ukažme
ŘEŠENÍ PRAKTICKÝCH ÚLOH UŽITÍM SOFTWARE STAT1 A R Obsah 1 Užití software STAT1 1 2 Užití software R 3 Literatura 4 Příklady k procvičení 6 1 Užití software STAT1 Praktické užití aplikace STAT1 si ukažme
Korelace. Komentované řešení pomocí MS Excel
 Korelace Komentované řešení pomocí MS Excel Vstupní data Tabulka se vstupními daty je umístěna v oblasti A2:B84 (viz. obrázek) Prvotní představu o tvaru a síle závislosti docházky a počtu bodů nám poskytne
Korelace Komentované řešení pomocí MS Excel Vstupní data Tabulka se vstupními daty je umístěna v oblasti A2:B84 (viz. obrázek) Prvotní představu o tvaru a síle závislosti docházky a počtu bodů nám poskytne
Cvičení ze statistiky - 9. Filip Děchtěrenko
 Cvičení ze statistiky - 9 Filip Děchtěrenko Minule bylo.. Dobrali jsme normální rozdělení Tyhle termíny by měly být známé: Inferenční statistika Konfidenční intervaly Z-test Postup při testování hypotéz
Cvičení ze statistiky - 9 Filip Děchtěrenko Minule bylo.. Dobrali jsme normální rozdělení Tyhle termíny by měly být známé: Inferenční statistika Konfidenční intervaly Z-test Postup při testování hypotéz
Pravděpodobnost a aplikovaná statistika
 Pravděpodobnost a aplikovaná statistika MGR. JANA SEKNIČKOVÁ, PH.D. 2. KAPITOLA PODMÍNĚNÁ PRAVDĚPODOBNOST 3. KAPITOLA NÁHODNÁ VELIČINA 9.11.2017 Opakování Uveďte příklad aplikace geometrické definice pravděpodobnosti
Pravděpodobnost a aplikovaná statistika MGR. JANA SEKNIČKOVÁ, PH.D. 2. KAPITOLA PODMÍNĚNÁ PRAVDĚPODOBNOST 3. KAPITOLA NÁHODNÁ VELIČINA 9.11.2017 Opakování Uveďte příklad aplikace geometrické definice pravděpodobnosti
Ilustrační příklad odhadu LRM v SW Gretl
 Ilustrační příklad odhadu LRM v SW Gretl Podkladové údaje Korelační matice Odhad lineárního regresního modelu (LRM) Verifikace modelu PEF ČZU Praha Určeno pro posluchače předmětu Ekonometrie Needitovaná
Ilustrační příklad odhadu LRM v SW Gretl Podkladové údaje Korelační matice Odhad lineárního regresního modelu (LRM) Verifikace modelu PEF ČZU Praha Určeno pro posluchače předmětu Ekonometrie Needitovaná
letní semestr Katedra pravděpodobnosti a matematické statistiky Matematicko-fyzikální fakulta Univerzity Karlovy Matematická statistika vektory
 Šárka Hudecová Katedra pravděpodobnosti a matematické statistiky Matematicko-fyzikální fakulta Univerzity Karlovy letní semestr 202 Založeno na materiálech doc. Michala Kulicha Náhodný vektor často potřebujeme
Šárka Hudecová Katedra pravděpodobnosti a matematické statistiky Matematicko-fyzikální fakulta Univerzity Karlovy letní semestr 202 Založeno na materiálech doc. Michala Kulicha Náhodný vektor často potřebujeme
Fisherův exaktní test
 Katedra pravděpodobnosti a matematické statistiky Karel Kozmík Fisherův exaktní test 4. prosince 2017 Motivace Máme kontingenční tabulku 2x2 a předpokládáme, že četnosti vznikly z pozorování s multinomickým
Katedra pravděpodobnosti a matematické statistiky Karel Kozmík Fisherův exaktní test 4. prosince 2017 Motivace Máme kontingenční tabulku 2x2 a předpokládáme, že četnosti vznikly z pozorování s multinomickým
Přednáška X. Testování hypotéz o kvantitativních proměnných
 Přednáška X. Testování hypotéz o kvantitativních proměnných Testování hypotéz o podílech Kontingenční tabulka, čtyřpolní tabulka Testy nezávislosti, Fisherůvexaktní test, McNemarůvtest Testy dobré shody
Přednáška X. Testování hypotéz o kvantitativních proměnných Testování hypotéz o podílech Kontingenční tabulka, čtyřpolní tabulka Testy nezávislosti, Fisherůvexaktní test, McNemarůvtest Testy dobré shody