Regrese. 28. listopadu Pokud chceme daty proložit vhodnou regresní křivku, musíme obvykle splnit tři úkoly:
|
|
|
- Petra Valentová
- před 6 lety
- Počet zobrazení:
Transkript
1 Regrese 28. listopadu 2013 Pokud chceme daty proložit vhodnou regresní křivku, musíme obvykle splnit tři úkoly: 1. Ukázat, že data jsou opravdu závislá. 2. Provést regresi. 3. Ukázat, že zvolená křivka je pro data opravdu vhodná. Těmto třem úkolům se budeme postupně věnovat. Korelační koeficient Pro porozumění dalšímu textu musíme znát pojem regresní koeficient, který udává sílu lineární závislosti mezi dvěmi veličinami. Jak si příslušný vzorec snadno zapamatovat? Již na střední škole jsme se naučili vzorec pro výpočet úhlu mezi dvěma vektory: cos α = u v u v. Kosinus úhlu je jedna pro vektory ukazující stejným směrem, tj. v případě, že jeden vektor je kladným násobkem druhého. Kosinus úhlu je mínus jedna pro vektory ukazující směrem opačným, tj. v případě, že jeden vektor je záporným násobkem druhého. Tato skutečnost platí pro vektory o dvou, třech, nebo třeba tisíci položkách. Nyní stačí vzít za vektor u data x, od nichž odečtu jejich střední hodnotu a podobně pro vektor v. Tedy: u = x x, v = y y. Za korelační koeficient r mezi veličinami x a y pak prohlásíme právě onen kosinus úhlu. Tedy: r = u v u v = (x x) (y y). 2 (x x)2 (y y) Korelační koeficient tedy nabývá hodnot mezi 1 a -1. Na následujících obrázcích máme korelační koeficienty pro některé případy veličin x a y: 1
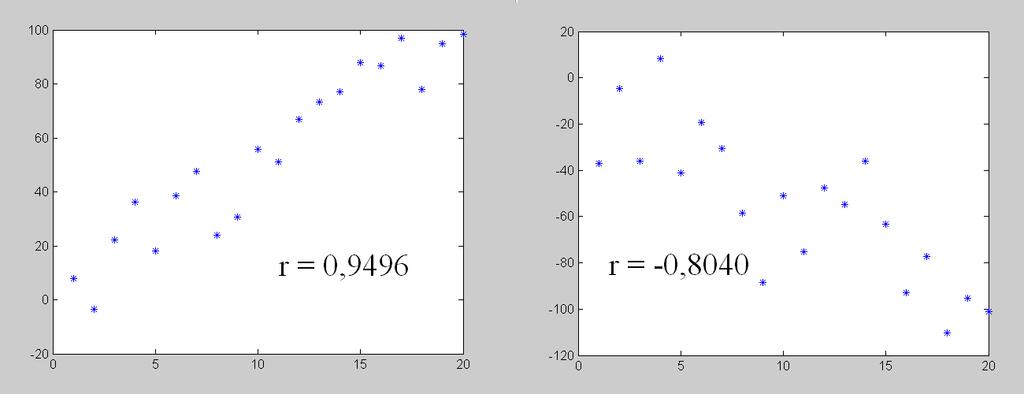
2 2
3 Závislost či nezávislost dat Prokládat daty jakoukoliv křivku má smysl pouze v případě, že jsou data závislá. My budeme daty prokládat přímku, proto budeme ověřovat závislost lineární. O té nám mnoho říká již korelační koeficient, ten ale nezohledňuje množství dat. Je něco jiného r = 0, 5 pro tři body a pro 1000 bodů. Proto provedeme test (ne)závislosti dat. Testů, které se k tomuto používají, je celá řada, my se naučíme test Pearsonův. Pearsonův test nezávislosti Nulová hypotéza: Data x a y jsou lineárně nezávislá. Směrování testu: Test je oboustranný. Testová statistika: t = r 1 r 2 n 2 kde r je regresní koeficient a n počet změřených bodů.. Rozdělení statistiky: Studentovo s n 2 stupni volnosti - St (n 2)., Příklad Naměřili jsme tato data: x y Jsou tato data lineárně závislá? Provedeme Pearsonův test na hladině významnosti α = 5%. Nejprve spočteme korelační koeficient: r = 0, Dosadíme do testové statistiky: t = r 1 r 2 n 2 = 0, , = 7, V tabulkách Studentova rozdělené se 4 stupni volnosti najdeme kvantily, které odříznou 2,5% vlevo a 2,5% vpravo: t 0,025 (4) = 2, 776, t 0,975 (4) = 2, 776. Obor přijetí je mezi těmito kvantily. Statistika ale padla do kritického oboru, proto nulovou hypotézu na hladině významnosti 5% zamítáme: Data x a y jsou lineárně lineárně závislá a pravděpodobnost, že se v tomto mýlíme, je menší než 5%. Příklad Testujte stejné zadání pomocí Matlabu. Hladinu významnosti volte α = 5%. 3
4 Je potřeba mít nainstalovaný statistický balíček. Pokud jej nemáte, najděte si na stránkách Ivana Nagyho ( v části PRP materiál Úvod do Matlabu a postupujte podle kapitolky 1.8. Pomocí příkazu hlp, volba 5, zjistíme, že test nezávislosti má tvar: struc=cor_test(x,y,alt,method). Dosadíme: struc=cor_test([3,5,8,9,11,14],[115,112,123,128,131,144], <>, p ) Zápis <> znamená, že se jedná o oboustranný test, volba p, že se jedná o Pearsonův test. Funkce nám vypíše kromě jiného hodnotu statistiky t = (mírně odlišná díky našemu zaokrouhlování) a zejména p-hodnotu P-hodnota je menší, než naše zvolená hladina významnosti 5%, proto nulovou hypotézu zamítáme: Data x a y jsou lineárně lineárně závislá a pravděpodobnost, že se v tomto mýlíme, je 0,22%. Poznámka Tento závěr testu je pro nás žádoucí. Ověříme tím totiž na příslušné hladině významnosti, resp. s příslušnou p-hodnotou, že data jsou opravdu lineárně závislá a že má smysl pokračovat lineární regresí. Metoda nejmenších čtverců Dříve, než s našimi daty provedeme lineární regresi, ukážeme si, jak se příslušné vzorce odvozují metodou nejmenších čtverců. Užitečné je to v tom, že stejnou metodou můžeme odvodit vzorce pro výpočet parametrů pro libovolnou křivku. Např. parabolu, exponencielu, logaritmus, nějakou s-křivku, atd. Myšlenka je následující: Body, které sedí na přímce, splňují rovnici: y n = A x n + B. Reálná data ale obvykle přesně na přímce nesedí, ale jsou rozmístěna v okolí přímky. To popíšeme tak, že y n vzniká nejen vlivem x n, ale i vlivem náhodné veličiny e n : y n = A x n + B + e n. Náhodné odchylky e n jsou na obrázku vyznačeny červeně: 4
5 Data (modré hvězdičky) známe, ale onu správnou přímku (modrá čára) neznáme. Z důvodů, které jsou skryty hlouběji v teorii, tipujeme, že ona správná přímka bude právě ta, pro niž bude součet čtverců odchylek e n nejmenší. 1 Odtud název metody metoda nejmenších čtverců. O tom, že to není hloupá myšlenka, nás přesvědčí další obrázek, kde jsme se pokusili proložit daty zcela špatnou přímku a vidíme, že chyby e n (a tudíž i jejich čtverce) jsou podstatně větší. Nyní z principu nejmenších čtverců odvodíme vzorce pro parametry A a B regresní přímky y n = A x n + B. Součet čtverců chyb e n si označíme S: S = e 2 n. Chyby e n si můžeme vyjádřit za pomoci dat takto: e n = y n A x n B. S je tedy funkcí dvou neznámých parametrů A a B. Hodnoty x n a y n známe z měření. S (A, B) = (y n A x n B) 2. S chceme mít co nejmenší. Minimum této funkce najdeme tak, že zjistíme, kde jsou obě parciální derivace nulové: Spočteme derivace: S A = 0, S B = 0. S A = 2 (y n A x n B) ( x n ) = = 2 x n y n + 2A x 2 n + 2B x n = 0, 1 Nebudeme tu řešit, proč zrovna druhá mocnina a ne třeba čtvrtá či proč ne absolutní hodnota. 5
6 S B = 2 (y n A x n B) ( 1) = = 2 y n + 2A x n + 2B 1 = = 2 y n + 2A x n + 2Bn = 0. Máme tedy dvě rovnice pro dvě neznámé: A x 2 n + B x n = x n y n, A x n + Bn = y n. Odtud již snadno vyjádříme A i B: A = B = xn yn n x n y n ( x n ) 2 n, x 2 n xn xn y n x 2 n ( x n ) 2 n x 2 n yn. Příklad Metodou nejmenších čtverců odvoďte vzorec pro bodový odhad pro parametr A, pokud víte, že veličiny x a y spolu souvisí přímou úměrností y n = A x n + e n. V tomto případě víme, že přímka musí procházet nulou. Nemůžeme tedy použít vzorec odvozený výše, kde je B obecné, ale musíme si vzorec odvodit: Součet čtverců chyb e n si označíme S: S = e 2 n. Chyby e n si můžeme vyjádřit za pomoci dat takto: e n = y n A x n. S je tedy funkcí neznámého parametru A. Hodnoty x n a y n známe z měření. S (A) = (y n A x n ) 2. S chceme mít co nejmenší. Minimum této funkce najdeme tak, že zjistíme, kde je derivace nulová: 2 2 Pokud máme více parametrů, používáme parciální derivace. Pokud je parametr jediný, použijeme derivaci obyčejnou. Spočteme derivaci: ds da = 0. ds da = 2 (y n A x n ) ( x n ) = = ( 2xn y n + 2Ax 2 n) = 6
7 = 2 x n y n + 2A x 2 n = 0. Vyjádříme A: A = xn y n x 2 n. Lineární regrese Nyní již máme vše připraveno. Ověřili jsme, že data jsou opravdu lineárně závislá, rozvážíme si, zda hledaná lineární závislost je přímá úměra y n = A x n nebo obecná přímka y n = A x n + B a dosadíme do příslušných vzorců. Vzorce, které jsme zde uvedli, jsou pro bodový odhad. To znamená, že nám dají tu nejpravděpodobnější hodnotu parametrů s tím, že ty skutečně správné hodnoty jsou nejspíše trošku jinde. Bodovým odhadem můžeme odhadovat i výstupní veličinu y. To uděláme velmi jednoduše tak, že dosadíme příslušné x do rovnice se spočtenými parametry, ale bez šumu. Kromě bodových odhadů můžeme mít i odhady intervalové, kdy pro parametry i výstup získáme příslušné intervaly spolehlivosti. Vzorce pro intervalový odhad ani jejich odvození zde uvádět nebudeme. Příklad Zjistěte bodové odhady parametrů přímky z následujících dat. Spočtěte i bodový odhad výstupu pro x = 10. x y Pro tato data jsme již ověřili lineární závislost, můžeme proto rovnou přistoupit k lineární regresi. Jako model volíme obecnou přímku y n = A x n + B + e n. Dosadíme do vzorce: A = B = xn yn n x n y n ( x n ) 2 n = 2, 8109, x 2 n xn xn y n x 2 n yn ( x n ) 2 n = 102, x 2 n Tyto výsledky jsem si poctivě spočetl dle těchto vzorců v Matlabu, mohl jsem ale rovnou použít funkci ze statistického balíčku lin_reg(x,y). Bodový odhad výstupu pro x = 10 spočtu dosazením: y = A x + B = A 10 + B = 130, Výsledky i regresní přímku jsem vykreslil: 7
8 Ověření vhodnosti regresní křivky Často jsme v situaci, kdy nevíme, jakou přesně křivkou máme data proložit. Pomoci nám může teorie, důležité je také data vykreslit a vidět. Zda byla vybraná křivka opravdu vhodná, můžeme zjistit pohledem, nebo můžeme provést test pořadové nezávislosti pro rezidua (chyby) e n. Test pořadové nezávislosti reziduí Následující obrázek nám ilustruje, že pokud křivku nezvolíme dobře, bude sérií reziduí se stejným znaménkem příliš málo a test pořadové nezávislosti neprojde. V tomto případě, pro 41 dat, máme jen tři série znamének. Kladnou, zápornou a kladnou. Dosadíme do příslušné statistiky: z = 2b (n 2) 2 3 (41 2) = = 5, n Test je levostranný, provedeme jej na hladině významnosti 1%. Příslušný kvantil najdeme v tabulce: z 0,01 = z 0,99 = 2, 326. Obor přijetí je tedy 2, 326, ). Statistika padla do kritického oboru, proto hypotézu, že data jsou pořadově nezávislá, respektive, že odchylky od přímky jsou pouze náhodné, respektive, že naše přímka je vhodnou regresní 8
9 křivkou, zamítáme. Pravděpodobnost, že se v tomto mýlíme, je menší než 1%. Příklad Ověřte, že přímka, kterou jste spočetli lineární regresí v minulém příkladě je pro data opravdu vhodnou křivkou. Nejsnazší je vyjít z obrázku a vyznačit si znaménka reziduí: Získáme tuto posloupnost znamének: +, -, -, +, -, +. Máme tedy pět sérií: b = 5. Počet dat je: n = 6. Dosadíme do příslušné statistiky pro test pořadové nezávislosti: z = 2b (n 2) n 1 = 2, Test je levostranný, provedeme jej na hladině významnosti 5%. Příslušný kvantil najdeme v tabulce: z 0,05 = z 0,95 = 1, 645. Obor přijetí je tedy 1, 645, ). Statistika padla do oboru přijetí, proto hypotézu, že data jsou pořadově nezávislá, respektive, že odchylky od přímky jsou pouze náhodné, respektive, že naše přímka je vhodnou regresní křivkou, nezamítáme. Převod nelineární regrese na lineární Často potřebujeme daty prokládat jinou křivku než přímku. Můžeme si pro ten či onen případ odvodit příslušné vzorce metodou nejmenších čtverců, často se ale volí jiný postup, a nelineární případ se převede na lineární: Příkladem může být nepřímá úměrnost: y = k x. Pokud místo dat x vezmu jejich převrácenou hodnotu X = 1 x, získávám rovnici přímé úměrnosti: y = k X. Nyní mohu použít vzorec, který jsme si již odvodili. 9
10 Jiným příkladem může být exponenciála: y = b e ax. Rovnici zlogaritmujeme: ln y = ln b e ax = ln b + ln e ax = ln b + ax ln e = ax + ln b. Pokud místo hodnot y vezmu Y = ln y a konstantu ln b si označím B, dostávám obecnou lineární závislost Y = ax + B. Použiji standardní vzorce a spočtu konstanty a a B. Konstantu malé b spočtu z velkého B snadno: ln b = B b = e B. 10
Testy. Pavel Provinský. 19. listopadu 2013
 Testy Pavel Provinský 19. listopadu 2013 Test a intervalový odhad Testy a intervalové odhady - jsou vlastně to samé. Jiný je jen úhel pohledu. Lze přecházet od jednoho k druhému. Například: Při odvozování
Testy Pavel Provinský 19. listopadu 2013 Test a intervalový odhad Testy a intervalové odhady - jsou vlastně to samé. Jiný je jen úhel pohledu. Lze přecházet od jednoho k druhému. Například: Při odvozování
INDUKTIVNÍ STATISTIKA
 10. SEMINÁŘ INDUKTIVNÍ STATISTIKA 3. HODNOCENÍ ZÁVISLOSTÍ HODNOCENÍ ZÁVISLOSTÍ KVALITATIVNÍ VELIČINY - Vychází se z kombinační (kontingenční) tabulky, která je výsledkem třídění druhého stupně KVANTITATIVNÍ
10. SEMINÁŘ INDUKTIVNÍ STATISTIKA 3. HODNOCENÍ ZÁVISLOSTÍ HODNOCENÍ ZÁVISLOSTÍ KVALITATIVNÍ VELIČINY - Vychází se z kombinační (kontingenční) tabulky, která je výsledkem třídění druhého stupně KVANTITATIVNÍ
Regresní a korelační analýza
 Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Testování hypotéz o parametrech regresního modelu
 Statistika II Katedra ekonometrie FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Lineární regresní model kde Y = Xβ + e, y 1 e 1 β y 2 Y =., e = e 2 x 11 x 1 1k., X =....... β 2,
Statistika II Katedra ekonometrie FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Lineární regresní model kde Y = Xβ + e, y 1 e 1 β y 2 Y =., e = e 2 x 11 x 1 1k., X =....... β 2,
Testování hypotéz o parametrech regresního modelu
 Testování hypotéz o parametrech regresního modelu Ekonometrie Jiří Neubauer Katedra kvantitativních metod FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Jiří Neubauer (Katedra UO
Testování hypotéz o parametrech regresního modelu Ekonometrie Jiří Neubauer Katedra kvantitativních metod FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Jiří Neubauer (Katedra UO
1 Tyto materiály byly vytvořeny za pomoci grantu FRVŠ číslo 1145/2004.
 Prostá regresní a korelační analýza 1 1 Tyto materiály byly vytvořeny za pomoci grantu FRVŠ číslo 1145/2004. Problematika závislosti V podstatě lze rozlišovat mezi závislostí nepodstatnou, čili náhodnou
Prostá regresní a korelační analýza 1 1 Tyto materiály byly vytvořeny za pomoci grantu FRVŠ číslo 1145/2004. Problematika závislosti V podstatě lze rozlišovat mezi závislostí nepodstatnou, čili náhodnou
Regresní a korelační analýza
 Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Stavový model a Kalmanův filtr
 Stavový model a Kalmanův filtr 2 prosince 23 Stav je veličina, kterou neznáme, ale chtěli bychom znát Dozvídáme se o ní zprostředkovaně prostřednictvím výstupů Příkladem může býapř nějaký zašuměný signál,
Stavový model a Kalmanův filtr 2 prosince 23 Stav je veličina, kterou neznáme, ale chtěli bychom znát Dozvídáme se o ní zprostředkovaně prostřednictvím výstupů Příkladem může býapř nějaký zašuměný signál,
LINEÁRNÍ REGRESE. Lineární regresní model
 LINEÁRNÍ REGRESE Chemometrie I, David MILDE Lineární regresní model 1 Typy závislosti 2 proměnných FUNKČNÍ VZTAH: 2 závisle proměnné: určité hodnotě x odpovídá jediná hodnota y. KORELACE: 2 náhodné (nezávislé)
LINEÁRNÍ REGRESE Chemometrie I, David MILDE Lineární regresní model 1 Typy závislosti 2 proměnných FUNKČNÍ VZTAH: 2 závisle proměnné: určité hodnotě x odpovídá jediná hodnota y. KORELACE: 2 náhodné (nezávislé)
Regresní a korelační analýza
 Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Regresní analýza 1. Regresní analýza
 Regresní analýza 1 1 Regresní funkce Regresní analýza Důležitou statistickou úlohou je hledání a zkoumání závislostí proměnných, jejichž hodnoty získáme při realizaci experimentů Vzhledem k jejich náhodnému
Regresní analýza 1 1 Regresní funkce Regresní analýza Důležitou statistickou úlohou je hledání a zkoumání závislostí proměnných, jejichž hodnoty získáme při realizaci experimentů Vzhledem k jejich náhodnému
676 + 4 + 100 + 196 + 0 + 484 + 196 + 324 + 64 + 324 = = 2368
 Příklad 1 Je třeba prověřit, zda lze na 5% hladině významnosti pokládat za prokázanou hypotézu, že střední doba výroby výlisku je 30 sekund. Přitom 10 náhodně vybraných výlisků bylo vyráběno celkem 540
Příklad 1 Je třeba prověřit, zda lze na 5% hladině významnosti pokládat za prokázanou hypotézu, že střední doba výroby výlisku je 30 sekund. Přitom 10 náhodně vybraných výlisků bylo vyráběno celkem 540
Regresní a korelační analýza
 Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
12. cvičení z PST. 20. prosince 2017
 1 cvičení z PST 0 prosince 017 11 test rozptylu normálního rozdělení Do laboratoře bylo odesláno n = 5 stejných vzorků krve ke stanovení obsahu alkoholu X v promilích alkoholu Výsledkem byla realizace
1 cvičení z PST 0 prosince 017 11 test rozptylu normálního rozdělení Do laboratoře bylo odesláno n = 5 stejných vzorků krve ke stanovení obsahu alkoholu X v promilích alkoholu Výsledkem byla realizace
Regresní a korelační analýza
 Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
11. cvičení z PSI prosince hodnota pozorovaná četnost n i p X (i) = q i (1 q), i N 0.
 = q i (1 q), i N 0.") 11 cvičení z PSI 12-16 prosince 2016 111 (Test dobré shody - geometrické rozdělení Realizací náhodné veličiny X jsme dostali následující četnosti výsledků: hodnota 0 1 2 3 4 5 6 pozorovaná četnost 29 15
11 cvičení z PSI 12-16 prosince 2016 111 (Test dobré shody - geometrické rozdělení Realizací náhodné veličiny X jsme dostali následující četnosti výsledků: hodnota 0 1 2 3 4 5 6 pozorovaná četnost 29 15
Odhady - Sdružené rozdělení pravděpodobnosti
 Odhady - Sdružené rozdělení pravděpodobnosti 4. listopadu 203 Kdybych chtěl znát maximum informací o náhodné veličině, musel bych znát všechny hodnoty, které mohou padnout, a jejich pravděpodobnosti. Tedy
Odhady - Sdružené rozdělení pravděpodobnosti 4. listopadu 203 Kdybych chtěl znát maximum informací o náhodné veličině, musel bych znát všechny hodnoty, které mohou padnout, a jejich pravděpodobnosti. Tedy
Testování statistických hypotéz
 Testování statistických hypotéz 1 Testování statistických hypotéz 1 Statistická hypotéza a její test V praxi jsme nuceni rozhodnout, zda nějaké tvrzeni o parametrech náhodných veličin nebo o veličině samotné
Testování statistických hypotéz 1 Testování statistických hypotéz 1 Statistická hypotéza a její test V praxi jsme nuceni rozhodnout, zda nějaké tvrzeni o parametrech náhodných veličin nebo o veličině samotné
Bodové odhady parametrů a výstupů
 Bodové odhady parametrů a výstupů 26. listopadu 2013 Máme rozdělení s neznámými parametry a chceme odhadnout jeden nebo několik příštích výstupů. Již víme, že úplnou informaci v této situaci nese sdružené
Bodové odhady parametrů a výstupů 26. listopadu 2013 Máme rozdělení s neznámými parametry a chceme odhadnout jeden nebo několik příštích výstupů. Již víme, že úplnou informaci v této situaci nese sdružené
TECHNICKÁ UNIVERZITA V LIBERCI
 TECHNICKÁ UNIVERZITA V LIBERCI Ekonomická fakulta Semestrální práce z předmětu Statistický rozbor dat z dotazníkového šetření Jméno: Lucie Krechlerová, Karel Kozma, René Dubský, David Drobík Ročník: 2015/2016
TECHNICKÁ UNIVERZITA V LIBERCI Ekonomická fakulta Semestrální práce z předmětu Statistický rozbor dat z dotazníkového šetření Jméno: Lucie Krechlerová, Karel Kozma, René Dubský, David Drobík Ročník: 2015/2016
Odhad parametrů N(µ, σ 2 )
") Odhad parametrů N(µ, σ 2 ) Mějme statistický soubor x 1, x 2,, x n modelovaný jako realizaci náhodného výběru z normálního rozdělení N(µ, σ 2 ) s neznámými parametry µ a σ. Jaký je maximální věrohodný
Odhad parametrů N(µ, σ 2 ) Mějme statistický soubor x 1, x 2,, x n modelovaný jako realizaci náhodného výběru z normálního rozdělení N(µ, σ 2 ) s neznámými parametry µ a σ. Jaký je maximální věrohodný
Tomáš Karel LS 2012/2013
 Tomáš Karel LS 2012/2013 Doplňkový materiál ke cvičení z předmětu 4ST201. Na případné faktické chyby v této presentaci mě prosím upozorněte. Děkuji. Tyto slidy berte pouze jako doplňkový materiál není
Tomáš Karel LS 2012/2013 Doplňkový materiál ke cvičení z předmětu 4ST201. Na případné faktické chyby v této presentaci mě prosím upozorněte. Děkuji. Tyto slidy berte pouze jako doplňkový materiál není
PRAVDĚPODOBNOST A STATISTIKA
 PRAVDĚPODOBNOST A STATISTIKA Testování hypotéz Nechť X je náhodná proměnná, která má distribuční funkci F(x, ϑ). Předpokládejme, že známe tvar distribuční funkce (víme jaké má rozdělení) a neznáme parametr
PRAVDĚPODOBNOST A STATISTIKA Testování hypotéz Nechť X je náhodná proměnná, která má distribuční funkci F(x, ϑ). Předpokládejme, že známe tvar distribuční funkce (víme jaké má rozdělení) a neznáme parametr
Náhodné veličiny jsou nekorelované, neexistuje mezi nimi korelační vztah. Když jsou X; Y nekorelované, nemusí být nezávislé.
 1. Korelační analýza V životě většinou nesledujeme pouze jeden statistický znak. Sledujeme více statistických znaků zároveň. Kromě vlastností statistických znaků nás zajímá také jejich těsnost (velikost,
1. Korelační analýza V životě většinou nesledujeme pouze jeden statistický znak. Sledujeme více statistických znaků zároveň. Kromě vlastností statistických znaků nás zajímá také jejich těsnost (velikost,
Pravděpodobnost a matematická statistika
 Pravděpodobnost a matematická statistika Příklady k přijímacím zkouškám na doktorské studium 1 Popisná statistika Určete aritmetický průměr dat, zadaných tabulkou hodnot x i a četností n i x i 1 2 3 n
Pravděpodobnost a matematická statistika Příklady k přijímacím zkouškám na doktorské studium 1 Popisná statistika Určete aritmetický průměr dat, zadaných tabulkou hodnot x i a četností n i x i 1 2 3 n
MÍRY ZÁVISLOSTI (KORELACE A REGRESE)
") zhanel@fsps.muni.cz MÍRY ZÁVISLOSTI (KORELACE A REGRESE) 2.5 MÍRY ZÁVISLOSTI 2.5.1 ZÁVISLOST PEVNÁ, VOLNÁ, STATISTICKÁ A KORELAČNÍ Jednorozměrné soubory - charakterizovány jednotlivými statistickými znaky
zhanel@fsps.muni.cz MÍRY ZÁVISLOSTI (KORELACE A REGRESE) 2.5 MÍRY ZÁVISLOSTI 2.5.1 ZÁVISLOST PEVNÁ, VOLNÁ, STATISTICKÁ A KORELAČNÍ Jednorozměrné soubory - charakterizovány jednotlivými statistickými znaky
5 Parametrické testy hypotéz
 5 Parametrické testy hypotéz 5.1 Pojem parametrického testu (Skripta str. 95-96) Na základě výběru srovnáváme dvě tvrzení o hodnotě určitého parametru θ rozdělení f(x, θ). První tvrzení (které většinou
5 Parametrické testy hypotéz 5.1 Pojem parametrického testu (Skripta str. 95-96) Na základě výběru srovnáváme dvě tvrzení o hodnotě určitého parametru θ rozdělení f(x, θ). První tvrzení (které většinou
2 ) 4, Φ 1 (1 0,005)
 4, Φ 1 (1 0,005)") Příklad 1 Ze zásilky velkého rozsahu byl náhodně vybrán soubor obsahující 1000 kusů. V tomto souboru bylo zjištěno 26 kusů nekvalitních. Rozhodněte, zda je možné s 99% jistotou tvrdit, že zásilka obsahuje
Příklad 1 Ze zásilky velkého rozsahu byl náhodně vybrán soubor obsahující 1000 kusů. V tomto souboru bylo zjištěno 26 kusů nekvalitních. Rozhodněte, zda je možné s 99% jistotou tvrdit, že zásilka obsahuje
Vícerozměrná rozdělení
 Vícerozměrná rozdělení 7. září 0 Učivo: Práce s vícerozměrnými rozděleními. Sdružené, marginální, podmíněné rozdělení pravděpodobnosti. Vektorová střední hodnota. Kovariance, korelace, kovarianční matice.
Vícerozměrná rozdělení 7. září 0 Učivo: Práce s vícerozměrnými rozděleními. Sdružené, marginální, podmíněné rozdělení pravděpodobnosti. Vektorová střední hodnota. Kovariance, korelace, kovarianční matice.
PRAVDĚPODOBNOST A STATISTIKA
 PRAVDĚPODOBNOS A SAISIKA Regresní analýza - motivace Základní úlohou regresní analýzy je nalezení vhodného modelu studované závislosti. Je nutné věnovat velkou pozornost tomu aby byla modelována REÁLNÁ
PRAVDĚPODOBNOS A SAISIKA Regresní analýza - motivace Základní úlohou regresní analýzy je nalezení vhodného modelu studované závislosti. Je nutné věnovat velkou pozornost tomu aby byla modelována REÁLNÁ
Téma 9: Vícenásobná regrese
 Téma 9: Vícenásobná regrese 1) Vytvoření modelu V menu Statistika zvolíme nabídku Vícerozměrná regrese. Aktivujeme kartu Detailní nastavení viz obr.1. Nastavíme Proměnné tak, že v příslušném okně viz.
Téma 9: Vícenásobná regrese 1) Vytvoření modelu V menu Statistika zvolíme nabídku Vícerozměrná regrese. Aktivujeme kartu Detailní nastavení viz obr.1. Nastavíme Proměnné tak, že v příslušném okně viz.
LINEÁRNÍ REGRESE Komentované řešení pomocí programu Statistica
 LINEÁRNÍ REGRESE Komentované řešení pomocí programu Statistica Vstupní data Data umístěná v excelovském souboru překopírujeme do tabulky ve Statistice a pojmenujeme proměnné, viz prezentace k tématu Popisná
LINEÁRNÍ REGRESE Komentované řešení pomocí programu Statistica Vstupní data Data umístěná v excelovském souboru překopírujeme do tabulky ve Statistice a pojmenujeme proměnné, viz prezentace k tématu Popisná
Matematické modelování Náhled do ekonometrie. Lukáš Frýd
 Matematické modelování Náhled do ekonometrie Lukáš Frýd Výnos akcie vs. Výnos celého trhu - CAPM model r it = r ft + β 1. (r mt r ft ) r it r ft = α 0 + β 1. (r mt r ft ) + ε it Ekonomický (finanční model)
Matematické modelování Náhled do ekonometrie Lukáš Frýd Výnos akcie vs. Výnos celého trhu - CAPM model r it = r ft + β 1. (r mt r ft ) r it r ft = α 0 + β 1. (r mt r ft ) + ε it Ekonomický (finanční model)
RNDr. Eva Janoušová doc. RNDr. Ladislav Dušek, Dr.
 Analýza dat pro Neurovědy RNDr. Eva Janoušová doc. RNDr. Ladislav Dušek, Dr. Jaro 2014 Institut biostatistiky Janoušová, a analýz Dušek: Analýza dat pro neurovědy Blok 7 Jak hodnotit vztah spojitých proměnných
Analýza dat pro Neurovědy RNDr. Eva Janoušová doc. RNDr. Ladislav Dušek, Dr. Jaro 2014 Institut biostatistiky Janoušová, a analýz Dušek: Analýza dat pro neurovědy Blok 7 Jak hodnotit vztah spojitých proměnných
Korelační a regresní analýza
 Korelační a regresní analýza Analýza závislosti v normálním rozdělení Pearsonův (výběrový) korelační koeficient: r = s XY s X s Y, kde s XY = 1 n (x n 1 i=0 i x )(y i y ), s X (s Y ) je výběrová směrodatná
Korelační a regresní analýza Analýza závislosti v normálním rozdělení Pearsonův (výběrový) korelační koeficient: r = s XY s X s Y, kde s XY = 1 n (x n 1 i=0 i x )(y i y ), s X (s Y ) je výběrová směrodatná
Testování hypotéz. 1. vymezení základních pojmů 2. testování hypotéz o rozdílu průměrů 3. jednovýběrový t-test
 Testování hypotéz 1. vymezení základních pojmů 2. testování hypotéz o rozdílu průměrů 3. jednovýběrový t-test Testování hypotéz proces, kterým rozhodujeme, zda přijmeme nebo zamítneme nulovou hypotézu
Testování hypotéz 1. vymezení základních pojmů 2. testování hypotéz o rozdílu průměrů 3. jednovýběrový t-test Testování hypotéz proces, kterým rozhodujeme, zda přijmeme nebo zamítneme nulovou hypotézu
Lineární regrese. Komentované řešení pomocí MS Excel
 Lineární regrese Komentované řešení pomocí MS Excel Vstupní data Tabulka se vstupními daty je umístěna v oblasti A1:B11 (viz. obrázek) na listu cela data Postup Základní výpočty - regrese Výpočet základních
Lineární regrese Komentované řešení pomocí MS Excel Vstupní data Tabulka se vstupními daty je umístěna v oblasti A1:B11 (viz. obrázek) na listu cela data Postup Základní výpočty - regrese Výpočet základních
Bodové a intervalové odhady parametrů v regresním modelu
 Statistika II Katedra ekonometrie FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Lineární regresní model Mějme lineární regresní model (LRM) Y = Xβ + e, kde y 1 e 1 β y 2 Y =., e
Statistika II Katedra ekonometrie FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Lineární regresní model Mějme lineární regresní model (LRM) Y = Xβ + e, kde y 1 e 1 β y 2 Y =., e
Odhad parametrů N(µ, σ 2 )
") Odhad parametrů N(µ, σ 2 ) Mějme statistický soubor x 1, x 2,, x n modelovaný jako realizaci náhodného výběru z normálního rozdělení N(µ, σ 2 ) s neznámými parametry µ a σ. Jaký je maximální věrohodný
Odhad parametrů N(µ, σ 2 ) Mějme statistický soubor x 1, x 2,, x n modelovaný jako realizaci náhodného výběru z normálního rozdělení N(µ, σ 2 ) s neznámými parametry µ a σ. Jaký je maximální věrohodný
ANALYTICKÁ GEOMETRIE V ROVINĚ
 ANALYTICKÁ GEOMETRIE V ROVINĚ Analytická geometrie vyšetřuje geometrické objekty (body, přímky, kuželosečky apod.) analytickými metodami. Podle prostoru, ve kterém pracujeme, můžeme analytickou geometrii
ANALYTICKÁ GEOMETRIE V ROVINĚ Analytická geometrie vyšetřuje geometrické objekty (body, přímky, kuželosečky apod.) analytickými metodami. Podle prostoru, ve kterém pracujeme, můžeme analytickou geometrii
SEMESTRÁLNÍ PRÁCE. Leptání plasmou. Ing. Pavel Bouchalík
 SEMESTRÁLNÍ PRÁCE Leptání plasmou Ing. Pavel Bouchalík 1. ÚVOD Tato semestrální práce obsahuje písemné vypracování řešení příkladu Leptání plasmou. Jde o praktickou zkoušku znalostí získaných při přednáškách
SEMESTRÁLNÍ PRÁCE Leptání plasmou Ing. Pavel Bouchalík 1. ÚVOD Tato semestrální práce obsahuje písemné vypracování řešení příkladu Leptání plasmou. Jde o praktickou zkoušku znalostí získaných při přednáškách
VZOROVÝ TEST PRO 3. ROČNÍK (3. A, 5. C)
") VZOROVÝ TEST PRO 3. ROČNÍK (3. A, 5. C) max. 3 body 1 Zjistěte, zda vektor u je lineární kombinací vektorů a, b, je-li u = ( 8; 4; 3), a = ( 1; 2; 3), b = (2; 0; 1). Pokud ano, zapište tuto lineární kombinaci.
VZOROVÝ TEST PRO 3. ROČNÍK (3. A, 5. C) max. 3 body 1 Zjistěte, zda vektor u je lineární kombinací vektorů a, b, je-li u = ( 8; 4; 3), a = ( 1; 2; 3), b = (2; 0; 1). Pokud ano, zapište tuto lineární kombinaci.
Lingebraické kapitolky - Analytická geometrie
 Lingebraické kapitolky - Analytická geometrie Jaroslav Horáček KAM MFF UK 2013 Co je to vektor? Šipička na tabuli? Ehm? Množina orientovaných úseček majících stejný směr. Prvek vektorového prostoru. V
Lingebraické kapitolky - Analytická geometrie Jaroslav Horáček KAM MFF UK 2013 Co je to vektor? Šipička na tabuli? Ehm? Množina orientovaných úseček majících stejný směr. Prvek vektorového prostoru. V
10. cvičení z PST. 5. prosince T = (n 1) S2 X. (n 1) s2 x σ 2 q χ 2 (n 1) (1 α 2 ). q χ 2 (n 1) 2. 2 x. (n 1) s. x = 1 6. x i = 457.
 S2 X. (n 1) s2 x σ 2 q χ 2 (n 1) (1 α 2 ). q χ 2 (n 1) 2. 2 x. (n 1) s. x = 1 6. x i = 457.") 0 cvičení z PST 5 prosince 208 0 (intervalový odhad pro rozptyl) Soubor (70, 84, 89, 70, 74, 70) je náhodným výběrem z normálního rozdělení N(µ, σ 2 ) Určete oboustranný symetrický 95% interval spolehlivosti
0 cvičení z PST 5 prosince 208 0 (intervalový odhad pro rozptyl) Soubor (70, 84, 89, 70, 74, 70) je náhodným výběrem z normálního rozdělení N(µ, σ 2 ) Určete oboustranný symetrický 95% interval spolehlivosti
Charakteristika datového souboru
 Zápočtová práce z předmětu Statistika Vypracoval: 10. 11. 2014 Charakteristika datového souboru Zadání: Při kontrole dodržování hygienických norem v kuchyni se prováděl odběr vzduchu a pomocí filtru Pallflex
Zápočtová práce z předmětu Statistika Vypracoval: 10. 11. 2014 Charakteristika datového souboru Zadání: Při kontrole dodržování hygienických norem v kuchyni se prováděl odběr vzduchu a pomocí filtru Pallflex
4EK211 Základy ekonometrie
 4EK211 Základy ekonometrie LS 2014/15 Cvičení 7: Autokorelace LENKA FIŘTOVÁ KATEDRA EKONOMETRIE, FAKULTA INFORMATIKY A STATISTIKY VYSOKÁ ŠKOLA EKONOMICKÁ V PRAZE 1. Autokorelace - teorie Zopakujte si G-M
4EK211 Základy ekonometrie LS 2014/15 Cvičení 7: Autokorelace LENKA FIŘTOVÁ KATEDRA EKONOMETRIE, FAKULTA INFORMATIKY A STATISTIKY VYSOKÁ ŠKOLA EKONOMICKÁ V PRAZE 1. Autokorelace - teorie Zopakujte si G-M
Příklad 1. Řešení 1a. Řešení 1b ŘEŠENÉ PŘÍKLADY Z M1B ČÁST 5
 Příklad 1 Najděte totální diferenciál d (h) pro h=(h,h ) v příslušných bodech pro následující funkce: a) (,)= cos, =1; b) (,)=ln( + ), =2; 0 c) (,)=arctg(), =1; 0 1 d) (,)= +, =1; 1 Řešení 1a Máme nalézt
Příklad 1 Najděte totální diferenciál d (h) pro h=(h,h ) v příslušných bodech pro následující funkce: a) (,)= cos, =1; b) (,)=ln( + ), =2; 0 c) (,)=arctg(), =1; 0 1 d) (,)= +, =1; 1 Řešení 1a Máme nalézt
Cvičení ze statistiky - 8. Filip Děchtěrenko
 Cvičení ze statistiky - 8 Filip Děchtěrenko Minule bylo.. Dobrali jsme normální rozdělení Tyhle termíny by měly být známé: Centrální limitní věta Laplaceho věta (+ korekce na spojitost) Konfidenční intervaly
Cvičení ze statistiky - 8 Filip Děchtěrenko Minule bylo.. Dobrali jsme normální rozdělení Tyhle termíny by měly být známé: Centrální limitní věta Laplaceho věta (+ korekce na spojitost) Konfidenční intervaly
4EK211 Základy ekonometrie
 4EK211 Základy ekonometrie ZS 2015/16 Cvičení 7: Časově řady, autokorelace LENKA FIŘTOVÁ KATEDRA EKONOMETRIE, FAKULTA INFORMATIKY A STATISTIKY VYSOKÁ ŠKOLA EKONOMICKÁ V PRAZE 1. Časové řady Data: HDP.wf1
4EK211 Základy ekonometrie ZS 2015/16 Cvičení 7: Časově řady, autokorelace LENKA FIŘTOVÁ KATEDRA EKONOMETRIE, FAKULTA INFORMATIKY A STATISTIKY VYSOKÁ ŠKOLA EKONOMICKÁ V PRAZE 1. Časové řady Data: HDP.wf1
Pravděpodobnost v závislosti na proměnné x je zde modelován pomocí logistického modelu. exp x. x x x. log 1
 Logistická regrese Menu: QCExpert Regrese Logistická Modul Logistická regrese umožňuje analýzu dat, kdy odezva je binární, nebo frekvenční veličina vyjádřená hodnotami 0 nebo 1, případně poměry v intervalu
Logistická regrese Menu: QCExpert Regrese Logistická Modul Logistická regrese umožňuje analýzu dat, kdy odezva je binární, nebo frekvenční veličina vyjádřená hodnotami 0 nebo 1, případně poměry v intervalu
Parametrická rovnice přímky v rovině
 Parametrická rovnice přímky v rovině Nechť je v kartézské soustavě souřadnic dána přímka AB. Nechť vektor u = B - A. Pak libovolný bod X[x; y] leží na přímce AB právě tehdy, když vektory u a X - A jsou
Parametrická rovnice přímky v rovině Nechť je v kartézské soustavě souřadnic dána přímka AB. Nechť vektor u = B - A. Pak libovolný bod X[x; y] leží na přímce AB právě tehdy, když vektory u a X - A jsou
Regrese. používáme tehdy, jestliže je vysvětlující proměnná kontinuální pokud je kategoriální, jde o ANOVA
 Regrese používáme tehd, jestliže je vsvětlující proměnná kontinuální pokud je kategoriální, jde o ANOVA Specifikace modelu = a + bx a závisle proměnná b x vsvětlující proměnná Cíl analýz Odhadnout hodnot
Regrese používáme tehd, jestliže je vsvětlující proměnná kontinuální pokud je kategoriální, jde o ANOVA Specifikace modelu = a + bx a závisle proměnná b x vsvětlující proměnná Cíl analýz Odhadnout hodnot
Interpolace pomocí splajnu
 Interpolace pomocí splajnu Interpolace pomocí splajnu Připomenutí U interpolace požadujeme, aby graf aproximující funkce procházel všemi uzlovými body. Interpolační polynom aproximující funkce je polynom
Interpolace pomocí splajnu Interpolace pomocí splajnu Připomenutí U interpolace požadujeme, aby graf aproximující funkce procházel všemi uzlovými body. Interpolační polynom aproximující funkce je polynom
Intervalový odhad. Interval spolehlivosti = intervalový odhad nějakého parametru s danou pravděpodobností = konfidenční interval pro daný parametr
 StatSoft Intervalový odhad Dnes se budeme zabývat neodmyslitelnou součástí statistiky a to intervaly v nejrůznějších podobách. Toto téma je také úzce spojeno s tématem testování hypotéz, a tedy plynule
StatSoft Intervalový odhad Dnes se budeme zabývat neodmyslitelnou součástí statistiky a to intervaly v nejrůznějších podobách. Toto téma je také úzce spojeno s tématem testování hypotéz, a tedy plynule
Testování statistických hypotéz. Ing. Michal Dorda, Ph.D.
 Testování statistických hypotéz Ing. Michal Dorda, Ph.D. Testování normality Př. : Při simulaci provozu na křižovatce byla získána data o mezerách mezi přijíždějícími vozidly v [s]. Otestujte na hladině
Testování statistických hypotéz Ing. Michal Dorda, Ph.D. Testování normality Př. : Při simulaci provozu na křižovatce byla získána data o mezerách mezi přijíždějícími vozidly v [s]. Otestujte na hladině
12. cvičení z PSI prosince (Test střední hodnoty dvou normálních rozdělení se stejným neznámým rozptylem)
") cvičení z PSI 0-4 prosince 06 Test střední hodnoty dvou normálních rozdělení se stejným neznámým rozptylem) Z realizací náhodných veličin X a Y s normálním rozdělením) jsme z výběrů daného rozsahu obdrželi
cvičení z PSI 0-4 prosince 06 Test střední hodnoty dvou normálních rozdělení se stejným neznámým rozptylem) Z realizací náhodných veličin X a Y s normálním rozdělením) jsme z výběrů daného rozsahu obdrželi
Testování hypotéz. 1 Jednovýběrové testy. 90/2 odhad času
 Testování hypotéz 1 Jednovýběrové testy 90/ odhad času V podmínkách naprostého odloučení má voák prokázat schopnost orientace v čase. Úkolem voáka e provést odhad časového intervalu 1 hodiny bez hodinek
Testování hypotéz 1 Jednovýběrové testy 90/ odhad času V podmínkách naprostého odloučení má voák prokázat schopnost orientace v čase. Úkolem voáka e provést odhad časového intervalu 1 hodiny bez hodinek
Příklad 1. Řešení 1 ŘEŠENÉ PŘÍKLADY Z MV2 ČÁST 11
 Příklad 1 Vyhláška Ministerstva zdravotnictví předpokládala, že doba dojezdu k pacientovi od nahlášení požadavku nepřekročí 17 minut. Hodnoty deseti náhodně vybraných dob příjezdu sanitky k nemocnému byly:
Příklad 1 Vyhláška Ministerstva zdravotnictví předpokládala, že doba dojezdu k pacientovi od nahlášení požadavku nepřekročí 17 minut. Hodnoty deseti náhodně vybraných dob příjezdu sanitky k nemocnému byly:
ANALYTICKÁ GEOMETRIE LINEÁRNÍCH ÚTVARŮ V ROVINĚ
 ANALYTICKÁ GEOMETRIE LINEÁRNÍCH ÚTVARŮ V ROVINĚ Parametrické vyjádření přímky v rovině Máme přímku p v rovině určenou body A, B. Sestrojíme vektor u = B A. Pro bod B tím pádem platí: B = A + u. Je zřejmé,
ANALYTICKÁ GEOMETRIE LINEÁRNÍCH ÚTVARŮ V ROVINĚ Parametrické vyjádření přímky v rovině Máme přímku p v rovině určenou body A, B. Sestrojíme vektor u = B A. Pro bod B tím pádem platí: B = A + u. Je zřejmé,
Regresní analýza. Ekonometrie. Jiří Neubauer. Katedra ekonometrie FVL UO Brno kancelář 69a, tel
 Regresní analýza Ekonometrie Jiří Neubauer Katedra ekonometrie FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Jiří Neubauer (Katedra ekonometrie UO Brno) Regresní analýza 1 / 23
Regresní analýza Ekonometrie Jiří Neubauer Katedra ekonometrie FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Jiří Neubauer (Katedra ekonometrie UO Brno) Regresní analýza 1 / 23
9. T r a n s f o r m a c e n á h o d n é v e l i č i n y
 9. T r a n s f o r m a c e n á h o d n é v e l i č i n y Při popisu procesů zpracováváme vstupní údaj, hodnotu x tak, že výstupní hodnota y závisí nějakým způsobem na vstupní, je její funkcí y = f(x).
9. T r a n s f o r m a c e n á h o d n é v e l i č i n y Při popisu procesů zpracováváme vstupní údaj, hodnotu x tak, že výstupní hodnota y závisí nějakým způsobem na vstupní, je její funkcí y = f(x).
Konvexnost, konkávnost
 20. srpna 2007 1. f = x 3 12x 2. f = x 2 e x 3. f = x ln x Příklad 1. Určete intervaly, na kterých je funkce konvexní a konkávní a určete inflexní body f = x 3 12x Příklad 1. f = x 3 12x Řešení: Df = R
20. srpna 2007 1. f = x 3 12x 2. f = x 2 e x 3. f = x ln x Příklad 1. Určete intervaly, na kterých je funkce konvexní a konkávní a určete inflexní body f = x 3 12x Příklad 1. f = x 3 12x Řešení: Df = R
Jednovýběrový Wilcoxonův test a jeho asymptotická varianta (neparametrická obdoba jednovýběrového t-testu)
") Jednovýběrový Wilcoxonův test a jeho asymptotická varianta (neparametrická obdoba jednovýběrového t-testu) Frank Wilcoxon (1892 1965): Americký statistik a chemik Nechť X 1,..., X n je náhodný výběr ze
Jednovýběrový Wilcoxonův test a jeho asymptotická varianta (neparametrická obdoba jednovýběrového t-testu) Frank Wilcoxon (1892 1965): Americký statistik a chemik Nechť X 1,..., X n je náhodný výběr ze
Parametry hledáme tak, aby součet čtverců odchylek byl minimální. Řešením podle teorie je =
 Příklad 1 Metodou nejmenších čtverců nalezněte odhad lineární regresní funkce popisující závislost mezi výnosy pšenice a množstvím použitého hnojiva na základě hodnot výběrového souboru uvedeného v tabulce.
Příklad 1 Metodou nejmenších čtverců nalezněte odhad lineární regresní funkce popisující závislost mezi výnosy pšenice a množstvím použitého hnojiva na základě hodnot výběrového souboru uvedeného v tabulce.
Sever Jih Západ Plechovka Točené Sever Jih Západ Součty Plechovka Točené Součty
 Neparametrické testy (motto: Hypotézy jsou lešením, které se staví před budovu a pak se strhává, je-li budova postavena. Jsou nutné pro vědeckou práci, avšak skutečný vědec nepokládá hypotézy za předmětnou
Neparametrické testy (motto: Hypotézy jsou lešením, které se staví před budovu a pak se strhává, je-li budova postavena. Jsou nutné pro vědeckou práci, avšak skutečný vědec nepokládá hypotézy za předmětnou
JEDNOVÝBĚROVÉ TESTY. Komentované řešení pomocí programu Statistica
 JEDNOVÝBĚROVÉ TESTY Komentované řešení pomocí programu Statistica Vstupní data Data umístěná v excelovském souboru překopírujeme do tabulky ve Statistice a pojmenujeme proměnné, viz prezentace k tématu
JEDNOVÝBĚROVÉ TESTY Komentované řešení pomocí programu Statistica Vstupní data Data umístěná v excelovském souboru překopírujeme do tabulky ve Statistice a pojmenujeme proměnné, viz prezentace k tématu
10. cvičení - LS 2017
 10. cvičení - LS 2017 Michal Outrata Příklad 1 Spočtěte následující itu daných posloupností: (a) (b) (c) n 3 +5n 2 n 3 6n 2 +3 n ; n 4 3n 2 6 n 4 + 3n 2 + 6; n 2 15n+2(1 n). 2(n 2) 3 2n 3 Příklad 2 Pro
10. cvičení - LS 2017 Michal Outrata Příklad 1 Spočtěte následující itu daných posloupností: (a) (b) (c) n 3 +5n 2 n 3 6n 2 +3 n ; n 4 3n 2 6 n 4 + 3n 2 + 6; n 2 15n+2(1 n). 2(n 2) 3 2n 3 Příklad 2 Pro
Příklady na testy hypotéz o parametrech normálního rozdělení
 Příklady na testy hypotéz o parametrech normálního rozdělení. O životnosti 75W žárovky (v hodinách) je známo, že má normální rozdělení s = 5h. Pro náhodný výběr 0 žárovek byla stanovena průměrná životnost
Příklady na testy hypotéz o parametrech normálního rozdělení. O životnosti 75W žárovky (v hodinách) je známo, že má normální rozdělení s = 5h. Pro náhodný výběr 0 žárovek byla stanovena průměrná životnost
2 Zpracování naměřených dat. 2.1 Gaussův zákon chyb. 2.2 Náhodná veličina a její rozdělení
 2 Zpracování naměřených dat Důležitou součástí každé experimentální práce je statistické zpracování naměřených dat. V této krátké kapitole se budeme věnovat určení intervalů spolehlivosti získaných výsledků
2 Zpracování naměřených dat Důležitou součástí každé experimentální práce je statistické zpracování naměřených dat. V této krátké kapitole se budeme věnovat určení intervalů spolehlivosti získaných výsledků
Příklad 1. Korelační pole. Řešení 1 ŘEŠENÉ PŘÍKLADY Z MV2 ČÁST 13
 Příklad 1 Máme k dispozici výsledky prvního a druhého testu deseti sportovců. Na hladině významnosti 0,05 prověřte, zda jsou výsledky testů kladně korelované. 1.test : 7, 8, 10, 4, 14, 9, 6, 2, 13, 5 2.test
Příklad 1 Máme k dispozici výsledky prvního a druhého testu deseti sportovců. Na hladině významnosti 0,05 prověřte, zda jsou výsledky testů kladně korelované. 1.test : 7, 8, 10, 4, 14, 9, 6, 2, 13, 5 2.test
Inovace bakalářského studijního oboru Aplikovaná chemie
 http://aplchem.upol.cz CZ.1.07/2.2.00/15.0247 Tento projekt je spolufinancován Evropským sociálním fondem a státním rozpočtem České republiky. Regrese Závislostproměnných funkční y= f(x) regresní y= f(x)
http://aplchem.upol.cz CZ.1.07/2.2.00/15.0247 Tento projekt je spolufinancován Evropským sociálním fondem a státním rozpočtem České republiky. Regrese Závislostproměnných funkční y= f(x) regresní y= f(x)
You created this PDF from an application that is not licensed to print to novapdf printer (http://www.novapdf.com)
") Závislost náhodných veličin Úvod Předchozí přednášky: - statistické charakteristiky jednoho výběrového nebo základního souboru - vztahy mezi výběrovým a základním souborem - vztahy statistických charakteristik
Závislost náhodných veličin Úvod Předchozí přednášky: - statistické charakteristiky jednoho výběrového nebo základního souboru - vztahy mezi výběrovým a základním souborem - vztahy statistických charakteristik
Bodové a intervalové odhady parametrů v regresním modelu
 Bodové a intervalové odhady parametrů v regresním modelu 1 Odhady parametrů 11 Bodové odhady Mějme lineární regresní model (LRM) kde Y = y 1 y 2 y n, e = e 1 e 2 e n Y = Xβ + e, x 11 x 1k, X =, β = x n1
Bodové a intervalové odhady parametrů v regresním modelu 1 Odhady parametrů 11 Bodové odhady Mějme lineární regresní model (LRM) kde Y = y 1 y 2 y n, e = e 1 e 2 e n Y = Xβ + e, x 11 x 1k, X =, β = x n1
Plánování experimentu
 Fakulta chemicko technologická Katedra analytické chemie licenční studium Management systému jakosti Autor: Ing. Radek Růčka Přednášející: Prof. Ing. Jiří Militký, CSc. 1. LEPTÁNÍ PLAZMOU 1.1 Zadání Proces
Fakulta chemicko technologická Katedra analytické chemie licenční studium Management systému jakosti Autor: Ing. Radek Růčka Přednášející: Prof. Ing. Jiří Militký, CSc. 1. LEPTÁNÍ PLAZMOU 1.1 Zadání Proces
CVIČNÝ TEST 5. OBSAH I. Cvičný test 2. Mgr. Václav Zemek. II. Autorské řešení 6 III. Klíč 17 IV. Záznamový list 19
 CVIČNÝ TEST 5 Mgr. Václav Zemek OBSAH I. Cvičný test 2 II. Autorské řešení 6 III. Klíč 17 IV. Záznamový list 19 I. CVIČNÝ TEST 1 Zjednodušte výraz (2x 5) 2 (2x 5) (2x + 5) + 20x. 2 Určete nejmenší trojciferné
CVIČNÝ TEST 5 Mgr. Václav Zemek OBSAH I. Cvičný test 2 II. Autorské řešení 6 III. Klíč 17 IV. Záznamový list 19 I. CVIČNÝ TEST 1 Zjednodušte výraz (2x 5) 2 (2x 5) (2x + 5) + 20x. 2 Určete nejmenší trojciferné
Univerzita Pardubice Fakulta chemicko technologická Katedra analytické chemie Licenční studium Management systému jakosti
 Univerzita Pardubice Fakulta chemicko technologická Katedra analytické chemie Licenční studium Management systému jakosti 3.3 v analýze dat Autor práce: Přednášející: Prof. RNDr. Milan Meloun, DrSc Pro
Univerzita Pardubice Fakulta chemicko technologická Katedra analytické chemie Licenční studium Management systému jakosti 3.3 v analýze dat Autor práce: Přednášející: Prof. RNDr. Milan Meloun, DrSc Pro
Funkce jedné reálné proměnné. lineární kvadratická racionální exponenciální logaritmická s absolutní hodnotou
 Funkce jedné reálné proměnné lineární kvadratická racionální exponenciální logaritmická s absolutní hodnotou lineární y = ax + b Průsečíky s osami: Px [-b/a; 0] Py [0; b] grafem je přímka (získá se pomocí
Funkce jedné reálné proměnné lineární kvadratická racionální exponenciální logaritmická s absolutní hodnotou lineární y = ax + b Průsečíky s osami: Px [-b/a; 0] Py [0; b] grafem je přímka (získá se pomocí
8.3). S ohledem na jednoduchost a názornost je výhodné seznámit se s touto Základní pojmy a vztahy. Definice
. S ohledem na jednoduchost a názornost je výhodné seznámit se s touto Základní pojmy a vztahy. Definice") 9. Lineární diferenciální rovnice 2. řádu Cíle Diferenciální rovnice, v nichž hledaná funkce vystupuje ve druhé či vyšší derivaci, nazýváme diferenciálními rovnicemi druhého a vyššího řádu. Analogicky
9. Lineární diferenciální rovnice 2. řádu Cíle Diferenciální rovnice, v nichž hledaná funkce vystupuje ve druhé či vyšší derivaci, nazýváme diferenciálními rovnicemi druhého a vyššího řádu. Analogicky
VYBRANÉ DVOUVÝBĚROVÉ TESTY. Martina Litschmannová
 VYBRANÉ DVOUVÝBĚROVÉ TESTY Martina Litschmannová Obsah přednášky Vybrané dvouvýběrové testy par. hypotéz test o shodě rozptylů (F-test), testy o shodě středních hodnot (t-test, Aspinové-Welchův test),
VYBRANÉ DVOUVÝBĚROVÉ TESTY Martina Litschmannová Obsah přednášky Vybrané dvouvýběrové testy par. hypotéz test o shodě rozptylů (F-test), testy o shodě středních hodnot (t-test, Aspinové-Welchův test),
STATISTICA Téma 6. Testy na základě jednoho a dvou výběrů
 STATISTICA Téma 6. Testy na základě jednoho a dvou výběrů 1) Test na velikost rozptylu Test na velikost rozptylu STATISTICA nemá. 2) Test na velikost střední hodnoty V menu Statistika zvolíme nabídku Základní
STATISTICA Téma 6. Testy na základě jednoho a dvou výběrů 1) Test na velikost rozptylu Test na velikost rozptylu STATISTICA nemá. 2) Test na velikost střední hodnoty V menu Statistika zvolíme nabídku Základní
13.1. Úvod Cílem regresní analýzy je popsat závislost hodnot znaku Y na hodnotách
 13 Regrese 13.1. Úvod Cílem regresní analýzy je popsat závislost hodnot znaku Y na hodnotách znaku X. Přitom je třeba vyřešit jednak volbu funkcí k vystižení dané závislosti a dále stanovení konkrétních
13 Regrese 13.1. Úvod Cílem regresní analýzy je popsat závislost hodnot znaku Y na hodnotách znaku X. Přitom je třeba vyřešit jednak volbu funkcí k vystižení dané závislosti a dále stanovení konkrétních
Věta 12.3 : Věta 12.4 (princip superpozice) : [MA1-18:P12.7] rovnice typu y (n) + p n 1 (x)y (n 1) p 1 (x)y + p 0 (x)y = q(x) (6)
![Věta 12.3 : Věta 12.4 (princip superpozice) : [MA1-18:P12.7] rovnice typu y (n) + p n 1 (x)y (n 1) p 1 (x)y + p 0 (x)y = q(x) (6)](/thumbs/96/128965676.jpg "Věta 12.3 : Věta 12.4 (princip superpozice) : [MA1-18:P12.7] rovnice typu y (n) + p n 1 (x)y (n 1) p 1 (x)y + p 0 (x)y = q(x) (6)") 1. Lineární diferenciální rovnice řádu n [MA1-18:P1.7] rovnice typu y n) + p n 1 )y n 1) +... + p 1 )y + p 0 )y = q) 6) počáteční podmínky: y 0 ) = y 0 y 0 ) = y 1 y n 1) 0 ) = y n 1. 7) Věta 1.3 : Necht
1. Lineární diferenciální rovnice řádu n [MA1-18:P1.7] rovnice typu y n) + p n 1 )y n 1) +... + p 1 )y + p 0 )y = q) 6) počáteční podmínky: y 0 ) = y 0 y 0 ) = y 1 y n 1) 0 ) = y n 1. 7) Věta 1.3 : Necht
Tomáš Karel LS 2012/2013
 Tomáš Karel LS 2012/2013 Doplňkový materiál ke cvičení z předmětu 4ST201. Na případné faktické chyby v této presentaci mě prosím upozorněte. Děkuji. Tyto slidy berte pouze jako doplňkový materiál není
Tomáš Karel LS 2012/2013 Doplňkový materiál ke cvičení z předmětu 4ST201. Na případné faktické chyby v této presentaci mě prosím upozorněte. Děkuji. Tyto slidy berte pouze jako doplňkový materiál není
PRAVDĚPODOBNOST A STATISTIKA. Neparametrické testy hypotéz čast 1
 PRAVDĚPODOBNOST A STATISTIKA Neparametrické testy hypotéz čast 1 Neparametrické testy hypotéz - úvod Neparametrické testy statistických hypotéz se používají v případech, kdy neznáme rozdělení pozorované
PRAVDĚPODOBNOST A STATISTIKA Neparametrické testy hypotéz čast 1 Neparametrické testy hypotéz - úvod Neparametrické testy statistických hypotéz se používají v případech, kdy neznáme rozdělení pozorované
Testy nezávislosti kardinálních veličin
 Testy nezávislosti kardinálních veličin Komentované řešení pomocí programu R Ústav matematiky Fakulta chemicko inženýrská Vysoká škola chemicko-technologická v Praze Načtení vstupních dat Vstupní data
Testy nezávislosti kardinálních veličin Komentované řešení pomocí programu R Ústav matematiky Fakulta chemicko inženýrská Vysoká škola chemicko-technologická v Praze Načtení vstupních dat Vstupní data
Lineární funkce, rovnice a nerovnice
 Lineární funkce, rovnice a nerovnice 1. Lineární funkce 1.1 Základní pojmy Pojem lineární funkce Funkce je předpis, který každému číslu x z definičního oboru funkce přiřadí právě jedno číslo y Obecně je
Lineární funkce, rovnice a nerovnice 1. Lineární funkce 1.1 Základní pojmy Pojem lineární funkce Funkce je předpis, který každému číslu x z definičního oboru funkce přiřadí právě jedno číslo y Obecně je
1 Tyto materiály byly vytvořeny za pomoci grantu FRVŠ číslo 1145/2004.
 Vícenásobná regresní a korelační analýza 1 1 Tto materiál bl vtvořen za pomoci grantu FRVŠ číslo 1145/2004. O vícenásobné závislosti mluvíme tehd, jestliže je závisle proměnná závislá na více nezávislých
Vícenásobná regresní a korelační analýza 1 1 Tto materiál bl vtvořen za pomoci grantu FRVŠ číslo 1145/2004. O vícenásobné závislosti mluvíme tehd, jestliže je závisle proměnná závislá na více nezávislých
KGG/STG Statistika pro geografy
 KGG/STG Statistika pro geografy 9. Korelační analýza Mgr. David Fiedor 20. dubna 2015 Analýza závislostí v řadě geografických disciplín studujeme jevy, u kterých vyšetřujeme nikoliv pouze jednu vlastnost
KGG/STG Statistika pro geografy 9. Korelační analýza Mgr. David Fiedor 20. dubna 2015 Analýza závislostí v řadě geografických disciplín studujeme jevy, u kterých vyšetřujeme nikoliv pouze jednu vlastnost
jevu, čas vyjmutí ze sledování byl T j, T j < X j a T j je náhodná veličina.
 Parametrické metody odhadů z neúplných výběrů 2 1 Metoda maximální věrohodnosti pro cenzorované výběry 11 Náhodné cenzorování Při sledování složitých reálných systémů často nemáme možnost uspořádat experiment
Parametrické metody odhadů z neúplných výběrů 2 1 Metoda maximální věrohodnosti pro cenzorované výběry 11 Náhodné cenzorování Při sledování složitých reálných systémů často nemáme možnost uspořádat experiment
Metoda nejmenších čtverců Michal Čihák 26. listopadu 2012
 Metoda nejmenších čtverců Michal Čihák 26. listopadu 2012 Metoda nejmenších čtverců Matematicko-statistická metoda používaná zejména při zpracování nepřesných dat (typicky experimentálních empirických
Metoda nejmenších čtverců Michal Čihák 26. listopadu 2012 Metoda nejmenších čtverců Matematicko-statistická metoda používaná zejména při zpracování nepřesných dat (typicky experimentálních empirických
MĚŘENÍ STATISTICKÝCH ZÁVISLOSTÍ
 MĚŘENÍ STATISTICKÝCH ZÁVISLOSTÍ v praxi u jednoho prvku souboru se často zkoumá více veličin, které mohou na sobě různě záviset jednorozměrný výběrový soubor VSS X vícerozměrným výběrovým souborem VSS
MĚŘENÍ STATISTICKÝCH ZÁVISLOSTÍ v praxi u jednoho prvku souboru se často zkoumá více veličin, které mohou na sobě různě záviset jednorozměrný výběrový soubor VSS X vícerozměrným výběrovým souborem VSS
8 Střední hodnota a rozptyl
 Břetislav Fajmon, UMAT FEKT, VUT Brno Této přednášce odpovídá kapitola 10 ze skript [1]. Také je k dispozici sbírka úloh [2], kde si můžete procvičit příklady z kapitol 2, 3 a 4. K samostatnému procvičení
Břetislav Fajmon, UMAT FEKT, VUT Brno Této přednášce odpovídá kapitola 10 ze skript [1]. Také je k dispozici sbírka úloh [2], kde si můžete procvičit příklady z kapitol 2, 3 a 4. K samostatnému procvičení
Statistická analýza jednorozměrných dat
 Statistická analýza jednorozměrných dat Prof. RNDr. Milan Meloun, DrSc. Univerzita Pardubice, Pardubice 31.ledna 2011 Tato prezentace je spolufinancována Evropským sociálním fondem a státním rozpočtem
Statistická analýza jednorozměrných dat Prof. RNDr. Milan Meloun, DrSc. Univerzita Pardubice, Pardubice 31.ledna 2011 Tato prezentace je spolufinancována Evropským sociálním fondem a státním rozpočtem
Hledáme lokální extrémy funkce vzhledem k množině, která je popsána jednou či několika rovnicemi, vazebními podmínkami. Pokud jsou podmínky
 6. Vázané a absolutní extrémy. 01-a3b/6abs.tex Hledáme lokální extrémy funkce vzhledem k množině, která je popsána jednou či několika rovnicemi, vazebními podmínkami. Pokud jsou podmínky jednoduché, vyřešíme
6. Vázané a absolutní extrémy. 01-a3b/6abs.tex Hledáme lokální extrémy funkce vzhledem k množině, která je popsána jednou či několika rovnicemi, vazebními podmínkami. Pokud jsou podmínky jednoduché, vyřešíme
Neparametrické metody
 Neparametrické metody Dosud jsme se zabývali statistickými metodami, které zahrnovaly předpoklady o rozdělení dat. Zpravidla jsme předpokládali normální rozdělení. Např. Grubbsův test odlehlých hodnot
Neparametrické metody Dosud jsme se zabývali statistickými metodami, které zahrnovaly předpoklady o rozdělení dat. Zpravidla jsme předpokládali normální rozdělení. Např. Grubbsův test odlehlých hodnot
Normální (Gaussovo) rozdělení
 rozdělení") Normální (Gaussovo) rozdělení f x = 1 2 exp x 2 2 2 f(x) je funkce hustoty pravděpodobnosti, symetrická vůči poloze maxima x = μ μ střední hodnota σ směrodatná odchylka (tzv. pološířka křivky mezi inflexními
Normální (Gaussovo) rozdělení f x = 1 2 exp x 2 2 2 f(x) je funkce hustoty pravděpodobnosti, symetrická vůči poloze maxima x = μ μ střední hodnota σ směrodatná odchylka (tzv. pološířka křivky mezi inflexními
9. T r a n s f o r m a c e n á h o d n é v e l i č i n y
 9. T r a n s f o r m a c e n á h o d n é v e l i č i n Při popisu procesů zpracováváme vstupní údaj, hodnotu x tak, že výstupní hodnota závisí nějakým způsobem na vstupní, je její funkcí = f(x). Pokud
9. T r a n s f o r m a c e n á h o d n é v e l i č i n Při popisu procesů zpracováváme vstupní údaj, hodnotu x tak, že výstupní hodnota závisí nějakým způsobem na vstupní, je její funkcí = f(x). Pokud
Úvod do teorie odhadu. Ing. Michael Rost, Ph.D.
 Úvod do teorie odhadu Ing. Michael Rost, Ph.D. Náhodný výběr Náhodným výběrem ze základního souboru populace, která je popsána prostřednictvím hustoty pravděpodobnosti f(x, θ), budeme nazývat posloupnost
Úvod do teorie odhadu Ing. Michael Rost, Ph.D. Náhodný výběr Náhodným výběrem ze základního souboru populace, která je popsána prostřednictvím hustoty pravděpodobnosti f(x, θ), budeme nazývat posloupnost