Základy bioinformatického zpracování dat v proteomice. Pavel Řehulka rehulka@pmfhk.cz
|
|
|
- Marian Brož
- před 8 lety
- Počet zobrazení:
Transkript
1 Základy bioinformatického zpracování dat v proteomice Pavel Řehulka rehulka@pmfhk.cz

2 Historie sekvencování DNA nepřímé metody určení sekvence bílkovin 1970: Ray Wu 12 nukleových bazí 3 roky práce 1975: Frederic Sanger & A. R. Coulson Sangerova sekvenační metoda 1977: Allan Maxam a Walter Gilbert Maxam-Gilbertova sekvenační metoda 1996: Pål Nyrén & Mostafa Ronaghi pyrosekvencování

3 Historie sekvencování DNA v dnešní době je rozvoj metod, jež jsou rychlé a pokud možno levné, například: 454 sekvencování paralelní sekvencování DNA na streptavidinových substrátech v pikolitrových reaktorech SMRT (Single molecule real-time) 1 molekula DNA, 1 molekula DNA-polymerázy 20 zeptolitrové nádobce, detekce záblesku po uvolnění fluorescenčního barviva při navázání značené báze detekce bazí el. proudem při průchodu DNA nanopóry

4 Maxam-Gilbertova metoda též chemické sekvencování vstupem je jednovláknová DNA značená radioaktivním 32 P na 5 (pomocí polynukleotid kinázy) nebo 3 konci rozdělení na 4 části, každá štěpena různými chemikáliem vzniklé různě dlouhé sekvence DNA ve všech směsích jsou separovány gelovou elektroforézou a detekovány autoradiografií

5 Maxam-Gilbertova metoda guanin: destrukce báze dimethylsulfátem, destrukce glykosidické vazby (zahřívání při neutrální ph), destrukce vazby (zahřívání při alkalickém ph) G A+G C+T C adenin + guanin: destrukce báze dimethylsulfátem, destrukce glykosidické vazby (zahřívání při neutrální ph), destrukce vazby (zahřívání při kyselém ph) cytosin a thymin: hydrazinolýza + štěpení piperidinem cytosin: hydrazinolýza v 2M NaCl + štěpení piperidinem 5 -TACCGCTTA-3
 cytosin a thymin: hydrazinolýza + štěpení piperidinem cytosin: hydrazinolýza v 2M NaCl + štěpení")
6 Sangerova metoda biochemická metoda, též dideoxy metoda nebo primed synthesis pro krátké sekvence jednovláknové DNA využívá se procesu replikace DNA v přítomnosti DNApolymerázy reakční směs: primer DNA-polymeráza radioaktivně značené ( 32 P) 2 -deoxyribonukleosidtrifosfáty 4 směsi obsahující navíc jednotlivé značené ( 32 P) 2,3 - dideoxyribonukleosidtrifosfáty (menší množství, asi 1%)
 2,3 - dideoxyribonukleosidtrifosfáty (menší")
7 Sangerova metoda DNA polymeráza při náhodném začlenění dideoxy analogu nemůže dále syntetizovat => vznik fragmentu separace těchto fragmentů na polyakrylamidovém gelu s následnou autoradiografickou detekcí ddatp ddttp ddctp ddgtp sekvenovaný úsek DNA 3 -GAATTCATTCGCCAT-5 5 -CTTAAGTAAGC primer syntetizovaný fragment reakce ve směsi s ddctp 5 -TAAGCGGTA-3 3 -ATTCGCCAT-5

8 Automatizovaná Sangerova metoda místo radioaktivního značení ( 32 P) použita fluorescenční detekce dnes nejpoužívanější metoda reakční směs: fluorescenčně značený primer (4 směsi => 4 značky) DNA-polymeráza 2 -deoxyribonukleosidtrifosfáty jednotlivé směsi obsahují navíc příslušné 2,3 -dideoxyribonukleosidtrifosfáty (menší množství, asi 1%) po reakci se směsi smíchají a probíhá separace kapilární elektroforézou s fluorescenční detekcí na konci kapiláry A T C G T A A G C G G T A

9 Pyrosekvencování syntéza nových sekvnencí DNA s různou detekcí nukleotidů bez elektroforézy přítomno spousta enzymů DNA polymeráza ATP sulfuryláza luciferáza apyráza substráty adenosinfosfosulfát luciferin přidávají se nukleotidy postupně datp, dgtp, dctp, dttp za sebou detekce uvolnění světla (i jeho intenzita) po uvolnění pyrofosfátu při začlenění konkrétního nukleotidu na konci spotřeba ATP luciferázou k oxidaci luciferinu a degradace přidaného nukleotidu Apyrase Ronaghi M, Genome Res Jan;11(1):3-11. datp (d)xmp Polymerase GATCACCTGAAGTCAGCCCTTG ACTTCAGTCGGGAAC PPi ATP Light ATPsulfurylase Luciferase
:3-11.")
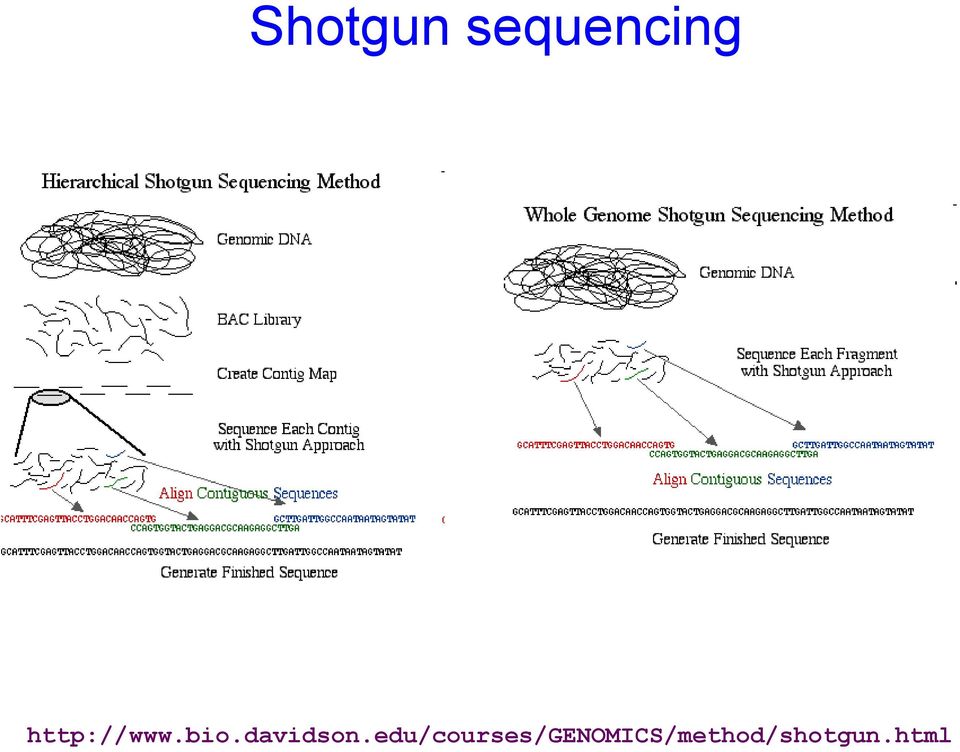
10 Shotgun sequencing též nazýváno shotgun cloning metoda sekvencování dlouhých DNA vláken delší sekvence DNA (> 800 bazí) fragmentovány na menší kousky restrikčními endonukleázami (nebo mechanicky) DNA-fragmenty jsou vloženy do plazmidů BAC knihovny (= bacterial artificial chromosome library) pro větší fragmenty DNA, ty se pak fragmentují na menší, které jsou vnášeny do bakterií v plazmidech plazmidy jsou vneseny do bakterií (obvykle E. coli) bakterie se namnoží a DNA obsahující analyzovaný fragment se po vyizolování osekvenuje

11 Shotgun sequencing tyto sekvenované kousky jsou pak reasemblovány zpět každá část sekvence musí být osekvenována 5-10x Strand Původní První shotgun sekvence Druhá shotgun sekvence Rekonstrukce Sekvence TGCAGATTGGCTGACTGAATGCCTG TGCAGATTGGCTGACT GAATGCCTG TGCAGATTG GCTGACTGAATGCCTG TGCAGATTGGCTGACTGAATGCCTG problém s repetitivními úseky

12 Shotgun sequencing
13 cdna knihovny a ESTs cdna = complementary DNA nebo též copy DNA cdna není přímo genomová DNA, ale pochází z přepisu mrna, tzn. kóduje exprimovaný gen (bílkovinu) tkáň -> lýza buněk -> izolace mrna hybridizace s poly-t primerem vytvoření kopie (= cdna) pomocí reverzní transkriptázy odbourání mrna alkalickým roztokem syntéza komplementárního řetězce DNA pomocí DNA-polymerázy (spárovaný 3 konec slouží jako primer) sekvencováním cdna dostáváme tzv. EST (expressed sequence tag) viz
 sekvencováním cdna dostáváme tzv. EST (expressed sequence tag) viz http://www.ncbi.nlm.nih.")
14 Sekvencování proteinů Určení N-koncové aminokyseliny Edmanova degradace sekvencování peptidů a proteinů pomocí hmotnostní spektrometrie

15 Určení koncové aminokyseliny provádí se pomocí reakce dansyl chloridu s N-koncovou aminoskupinou a po hydrolýze peptidu/proteinu se identifikovala N-koncová aminokyselina chromatograficky dříve se též provádělo pomocí 1-fluoro-2,4-dinitrobenzenu (F. Sanger, sekvenace insulinu) ph deg.c, 1 h 6M HCl deg.c, 16 h... n
 ph 8-10... 20 deg.")
16 Edmanova degradace N-koncová aminoskupina peptidu/proteinu reaguje s fenylisothiokyanátem v bazickém prostředí za zvýšené teploty (2,5 % PITC ve směsi pyridin/voda = 1:1, 30 min, 50 o C) Phenylisothiocyanate (PITC) N-terminus of the protein immobilized on a solid support PITC coupling Cleavage v kyselém prostředí (100 % TFA, 10 min, 50 o C) pak odštěpuje 5-thiozolinonový derivát N-koncové aminokyseliny, který je po konverzi (1M HCl, 10 min, 80 o C) na fenylthiohydantoinový derivát identifikován Phenylthiocarbamyl-derivatized protein 5-Thiozolinone derivative N-terminus of the degraded protein immobilized on a solid support Conversion zbytek peptidu/proteinu je podroben dalšímu identifikačnímu cyklu Phenylthiohydantoin derivative next degradation cycle

17 dnes plně automatizovaný proces Edmanova degradace nutná dostatečné množství čistého proteinu nebo alespoň izolovaného na membráně reagenty jsou dodávány v plynné fázi, peptid/protein je ukotven na pevném nosiči (kvarterní ammoniová sůl Polybren) citlivost: 1-5 pmol pro více než 20 cyklů (tj. stanovených aminokyselin) délka cyklu: ~ 45 min, tj. asi 3 vzorky/den blokovaný N-terminus proteinu => pracné odstraňování modifikace, ne vždy efektivně úspěšné přes spoustu nevýhod ve srovnání s hmotnostní spektrometrií je to stále alternativní metoda určování sekvence bílkovin

18 Hmotnostní spektrometrie (MS) separace nabitých částic na základě poměru jejich hmotnosti a náboje, tj. m/z výsledkem je tzv. hmotnostní spektrum, kde na ose x je vynesena hodnota m/z a na ose y intenzita odezvy detektoru, často normalizovaná na nejintenzivnější pík v zobrazovaném rozsahu m/z Ion Source Mass Analyzer Detector % Recorded Spectrum m/z

19 Tandemová hmotnostní spektrometrie (MS/MS) spojení dvou hmotnostně spektrometrických analýz v prostoru nebo čase, oddělených od sebe procesem disociace iontů (většinou kolizí s neutrálním plynem) výsledkem je opět hmotnostní spektrum, popisující vztah rodičovského iontu a jeho fragmentů důležité pro získání strukturní informace rodičovského iontu ionization MS 1 precursor ion selection fragmentation of selected precursor MS 2 analysis of fragment ions

20 Trojitý kvadupól příklad MS/MS přístroje ion source detector + Q0 ion transmission Q1 precursor ion selection Q2 collision cell Q3 fragment ion analysis

21 Sekvenace proteinů pomocí MS izolace bílkovin, jejich separace (často gelovou elektroforézou) digesce vhodným enzymem (nebo chemicky) na peptidy směs peptidů buď přímo nebo po separaci (kapalinovou chromatografií) analyzujeme pomocí MS/MS vzniklé fragmentové ionty umožňují identifikaci/sekvenaci peptidů, a v důsledku i proteinů x 4 y 4 z 4 x 3 y 3 z 3 x 2 y 2 z 2 x 1 y 1 z 1 R1 O R2 O R3 O R4 O R5 H + H 2 N C C N C C N C C N C C N C COOH H H H H H H H H H a 1 b 1 c 1 a 2 b 2 c 2 a 3 b 3 c 3 a 4 b 4 c 4
22 Fragmentové ionty peptidů [N] hmotnost N- koncové skupiny peptidu [C] hmotnost C- koncové skupiny peptidu [M] součet hmotností aminokyselinových zbytků obsažených ve fragmentovém iontu [e] hmotnost elektronu Ion type Ion mass a [N] + [M] CO [e] b [N] + [M] [e] c [N] + [M] + NH 3 [e] x [C] + [M] + CO [e] y [C] + [M] + H 2 [e] z [C] + [M] NH [e] d [a-ion] [part of side chain] v [y-ion] [whole side chain] w [z-ion] [part of side chain] immonium ion [M] + H CO [e] internal y m a n [M] + H CO [e] internal y m b n [M] + H [e]
23 Struktura fragmentových iontů peptidů R1 O H 2 N C C N + C H H R2 H R3 O R4 O + C N C C N C C N C H H H H H H O R5 COOH R1 H 2 N C C N C H O H HC H R' H + a 2 x 3 d 2 R1 O H 2 N C C N C C H H R2 H O + R3 + H 3 N C C N C C H O H R4 H O N H R5 C H COOH HN C C N C C H O H R4 H O N H R5 C H H + COOH b 2 y 3 v 3 R1 O H 2 N C C N C C H H R2 O H NH 3 + R3 O R4 O C + C N C C H H H N H R5 C H COOH R' CH O R4 O C C N C C H H H N H R5 C H H + COOH c 2 z 3 w 3 R3 O R4 H 2 N C C N + C R3 O R4 H 2 N C C N C C O + R + H 2 N CH H H y 3 a 4 H H H y 3 b 4 H immonium ion
24 % Intensity Příklad MS/MS spektra peptidu interpretace MS/MS spektra vede k získání částečné nebo úplné sekvence peptidu Parent mass [M+H] y intepreted sequence: LPSEFDLSAFLR y1 20 y8 y10 b6 10 y3 y4 y5-nh3 b7 y2 y5 y7 y11 R y Mass (m/z)
25 Sekvenční databáze
26 Od DNA k proteinu (eukaryotní buňka) transkripcí z DNA vzniká primární RNA-transkript (exony + introny) modifikace konců primárního RNA-transkriptu (čepička RNA + poly(a) konec) vyštěpení intronů v enzymově katalyzovaném sestřihu RNA => vznik mrna transport mrna z jádra do cytoplasmy, kde dochází k translaci a vzniku bílkoviny některé procesy probíhají současně DNA cytoplasma exony primární RNA-transkript čepička RNA mrna mrna protein jádro gen introny transkripce přidání 5 -čepičky a poly(a) konce sestřih export do cytoplasmy translace AAAAA AAAAA AAAAA
27 Od DNA k proteinu (prokaryotní buňka) jednodušší proces (absence jádra) 5 -konec mrna vzniká iniciací transkripce, 3 -konec je určen místem terminace genu DNA gen transkripce translace může začít již před dokončením transkripce mrna translace protein
28 Sekvenční databáze Historie vzniku databází Primární a sekundární databáze Nukleotidové sekvenční databáze Struktura záznamu nukleotidové sekvence Proteinové sekvenční databáze
29 Historie vzniku databází snaha o zpřístupnění výsledků sekvenačních experimentů a vzájemnou výměnu informací 60. léta minulého století Margaret Dayhoff se spolupracovníky Protein Information Resource (PIR) sbírka proteinových sekvencí známých v té době vyšlo v tištěné podobě jako Atlas of Protein Sequence and Structure původně pouze sekvence proteinů z Edmanova sekvenování, později přidávány i nukleotidové sekvence byly přidávány i popisy sekvencí => první anotovaná databáze 1972 nutnost převést do el. podoby (nárůst rozsahu) distribuce na magn. pásku spolu s programy pro analýzu vzdálených evolučních příbuzností
30 Historie vzniku databází 1982: vzniká DNA sekvenční databáze na European Molecular Biology Laboratory (EMBL) v Heidelbergu krátce nato se připojuje GenBank při National Center for Biotechnology Information (NCBI) součást National Library of Medicine při National Institutes of Health o několik let později se připojuje i DNA Database of Japan (DDBJ) 1988: sjednocení formy spolupráce a formátu dat mezi EMBL, GenBank a DDBJ dnes: DDBJ / EMBL / GenBank konsorcium tvořené the National Institute of Genetics in Mishima, Japan the European Bioinformatics Institute (EBI) in Hinxton, UK NCBI in Bethesda, Maryland, USA
31 Historie vzniku databází 80. léta minulého století: Amos Bairoch (Ženeva) převedl PIR Atlas do formátu podobného EMBL formátu pro nukleotidové sekvence a přidal anotace k proteinovým sekvencím => PIR+ 1986: distribuce PIR+ na síti US Bionet (předchůdce Internetu) tehdy obsahovala 3900 sekvencí později vzniká SwissProt
32 Typy databází hlavní úkol databází zpřístupnit obsažené sekvence primární databáze archivní funkce obsahují experimentální výsledky s částečnou interpretací neobsahují však odborně doplněné popisy mnoha vlastností vztahujících se k dané sekvenci sekundární databáze administrované experty někdy též nazývané databáze vzorů (pattern databases) obsahují výsledky analýzy sekvencí z primárních databází kompozitní databáze kombinují různé zdroje primárních databází není nutno procházet každou primární databázi zvlášť
33 Příklady databází primární sekundární kompozitní DDBJ PROSITE NRDB EMBL Profiles OWL GenBank PRINTS PIR Pfam SwissProt BLOCKS TrEMBL IDENTIFY
34 Nukleotidové sekvenční databáze hlavním zdrojem nukleotidových sekvenčních databází je International Nucleotide Sequence Database Collaboration DDBJ / EMBL / GenBank nové sekvence lze zadávat do kterékoliv z těchto databází každá databáze si spravuje pouze sekvence do ní vložené jednou za 24 hodin si databáze navzájem vymění nová data a celkový obsah konsorcia je synchronizován (umožněno společným formátem dat) primární zdroj sekvenční a biologické informace => mnoho databází závisí na správnosti údajů v DDBJ / EMBL / GenBank
35 Konsorcium DDBJ / EMBL / GenBank Entrez NIH NCBI submissions updates GenBank NIG submissions updates CIB DDBJ EMBL EBI SRS submissions updates getentry EMBL
36 Vlastnosti databází DDBJ / EMBL / GenBank pokud pro danou nukleotidovou sekvenci není indikována kódující sekvence, tak není vytvořen odpovídající záznam v proteinové databázi příslušné porovnávání sekvencí vycházející z proteinových sekvencí může některé dostupné informace ztratit pokud záznam obsahující kódující sekvenci obsahuje chybu, tak tato chyba může být dále propagována mezi databázemi (i pomocí odvození dalších sekvencí na základě podobnosti) pokud důležitá vlastnost o proteinové sekvenci není na správném místě, tak programy navržené pro jejich získávání ji mohou ztratit
37 FASTA formát Formáty dat jednoduchý formát pro sekvence flatfile základní jednotka pro informaci o konkrétní sekvenci konkrétní formáty pro jednotlivé databáze se od sebe částečně liší ale jeho struktura přesto umožňuje vzájemnou výměnu vložených sekvencí mezi databázemi
38 FASTA formát začátek nového záznamu zdrojová databáze (SwissProt) přístupové číslo UniProt ideintifikátor krátký popis definiční řádek >sp P48598 IF4E_DROME Eukaryotic translation initiation factor 4E OS=Drosophila melanogaster GN=eIF-4E PE=1 SV=1 MQSDFHRMKNFANPKSMFKTSAPSTEQGRPEPPTSAAAPAEAKDVKPKEDPQETGEPAGN TATTTAPAGDDAVRTEHLYKHPLMNVWTLWYLENDRSKSWEDMQNEITSFDTVEDFWSLY NHIKPPSEIKLGSDYSLFKKNIRPMWEDAANKQGGRWVITLNKSSKTDLDNLWLDVLLCL IGEAFDHSDQICGAVINIRGKSNKISIWTADGNNEEAALEIGHKLRDALRLGRNNSLQYQ LHKDTMVKQGSNVKSIYTL sekvence proteinu (obvykle 60 znaků na řádek)
39 FASTA formát více záznamů >sp Q55D85 CAS1_DICDI Cycloartenol synthase OS=Dictyostelium discoideum GN=cas1 PE=1 SV=1 MTTTNWSLKVDRGRQTWEYSQEKKEATDVDIHLLRLKEPGTHCPEGCDLNRAKTPQQAIK KAFQYFSKVQTEDGHWAGDYGGPMFLLPGLVITCYVTGYQLPESTQREIIRYLFNRQNPV DGGWGLHIEAHSDIFGTTLQYVSLRLLGVPADHPSVVKARTFLLQNGGATGIPSWGKFWL ATLNAYDWNGLNPIPIEFWLLPYNLPIAPGRWWCHCRMVYLPMSYIYAKKTTGPLTDLVK DLRREIYCQEYEKINWSEQRNNISKLDMYYEHTSLLNVINGSLNAYEKVHSKWLRDKAID YTFDHIRYEDEQTKYIDIGPVNKTVNMLCVWDREGKSPAFYKHADRLKDYLWLSFDGMKM QGYNGSQLWDTAFTIQAFMESGIANQFQDCMKLAGHYLDISQVPEDARDMKHYHRHYSKG AWPFSTVDHGWPISDCTAEGIKSALALRSLPFIEPISLDRIADGINVLLTLQNGDGGWAS YENTRGPKWLEKFNPSEVFQNIMIDYSYVECSAACIQAMSAFRKHAPNHPRIKEINRSIA RGVKFIKSIQRQDGSWLGSWGICFTYGTWFGIEGLVASGEPLTSPSIVKACKFLASKQRA DGGWGESFKSNVTKEYVQHETSQVVNTGWALLSLMSAKYPDRECIERGIKFLIQRQYPNG DFPQESIIGVFNFNCMISYSNYKNIFPLWALSRYNQLYLKSKI >sp Q05581 CAS1_STRCL Clavaminate synthase 1 OS=Streptomyces clavuligerus GN=cs1 PE=1 SV=3 MTSVDCTAYGPELRALAARLPRTPRADLYAFLDAAHTAAASLPGALATALDTFNAEGSED GHLLLRGLPVEADADLPTTPSSTPAPEDRSLLTMEAMLGLVGRRLGLHTGYRELRSGTVY HDVYPSPGAHHLSSETSETLLEFHTEMAYHRLQPNYVMLACSRADHERTAATLVASVRKA LPLLDERTRARLLDRRMPCCVDVAFRGGVDDPGAIAQVKPLYGDADDPFLGYDRELLAPE DPADKEAVAALSKALDEVTEAVYLEPGDLLIVDNFRTTHARTPFSPRWDGKDRWLHRVYI RTDRNGQLSGGERAGDVVAFTPRG >sp P18503 CAS4_EPHMU Short-chain collagen C4 (Fragment) OS=Ephydatia muelleri PE=2 SV=1 DTGPQGPQGVAGPPGIDGAKGDKGECFYPPPPTCPTCPAGPPGAPGPQGAPGAPGAPGLP GPAGPQGPKGDKGLPGNDGQPGAPGAPGYDGAKGDKGDTGAPGPQGPKGDQGPKGDQGYK GDAGLPGQPGQTGAPGKDGQDGAKGDKGDQGPAGTPGAPGKDGAQGPAGPAGPAGPAGPV GPTGPQGPQGPKGDVGPQGPQGAPGSNGAVVYIRWGNNVCPAGETNVYSGHIVESSNAND ANGDYLCLPDTHNAYPPQTQNPLLNLKDVTDSYGKTVPCVACLASGRSTVFTFPDNTVCP YGWTTEYVGYEAANPKWPGQNLCVDTYFGDKLSQTPCNNLAVIAKGPLNAYSYQPQDVVS CVVCSI >sp P02662 CASA1_BOVIN Alpha-S1-casein OS=Bos taurus GN=CSN1S1 PE=1 SV=2 MKLLILTCLVAVALARPKHPIKHQGLPQEVLNENLLRFFVAPFPEVFGKEKVNELSKDIG SESTEDQAMEDIKQMEAESISSSEEIVPNSVEQKHIQKEDVPSERYLGYLEQLLRLKKYK VPQLEIVPNSAEERLHSMKEGIHAQQKEPMIGVNQELAYFYPELFRQFYQLDAYPSGAWY YVPLGTQYTDAPSFSDIPNPIGSENSEKTTMPLW počet záznamů souhrnné informace o databázi UniProt/SwissProt verze databáze Time files compressed : Tue Feb 02 19:18: Time files compressed (int) : Time / date of fasta file : Thu Jan 21 06:55: Time of fasta files (int) : Number of residues : Number of sequences : Number with invalid residues: 0 Number of sequences too long: 0 Length of longest sequence : Maximum Accession Length : 11 ftp://ftp.expasy.org/databases/uniprot/knowledgebase/uniprot_sprot.fasta.gz
40 Flatfile v DDBJ / EMBL / GenBank DDBJ a GenBank flatfiles jsou téměř shodné; používají slovní označení oddílů (lépe srozumitelnější) EMBL používá dvojpísmenné prefixy pro jednotlivé řádky obsahují 3 hlavní oddíly: hlavička (header) informace o celém záznamu vlastnosti (features) anotace záznamu nukleotidová sekvence poslední řádek končí znaky //
41 LOCUS DMU bp DNA linear INV 22-FEB-1998 DEFINITION Drosophila melanogaster eukaryotic initiation factor 4E (eif4e) gene, alternative splice products, complete cds. ACCESSION U54469 VERSION U GI: KEYWORDS. SOURCE Drosophila melanogaster (fruit fly) ORGANISM Drosophila melanogaster Eukaryota; Metazoa; Arthropoda; Hexapoda; Insecta; Pterygota; Neoptera; Endopterygota; Diptera; Brachycera; Muscomorpha; Ephydroidea; Drosophilidae; Drosophila; Sophophora. REFERENCE 1 (bases 1 to 2881) AUTHORS Lavoie,C.A., Lachance,P.E., Sonenberg,N. and Lasko,P. TITLE Alternatively spliced transcripts from the Drosophila eif4e gene produce two different Cap-binding proteins JOURNAL J. Biol. Chem. 271 (27), (1996) PUBMED REFERENCE 2 (bases 1 to 2881) AUTHORS Lasko,P.F. TITLE Direct Submission JOURNAL Submitted (09-APR-1996) Paul F. Lasko, Biology, McGill University, 1205 Avenue Docteur Penfield, Montreal, QC H3A 1B1, Canada FEATURES Location/Qualifiers source /organism="drosophila melanogaster" /mol_type="genomic DNA" /db_xref="taxon:7227" /chromosome="3" /map="67a8-b2" gene /gene="eif4e" mrna join( , , , , , ) /gene="eif4e" /product="eukaryotic initiation factor 4E-I" mrna join( , , , , , ) /gene="eif4e" /product="eukaryotic initiation factor 4E-I" mrna join( , , , , ) /gene="eif4e" /product="eukaryotic initiation factor 4E-II" CDS join( , , , , ) /gene="eif4e" /note="method: conceptual translation with partial peptide sequencing" /codon_start=1 /product="eukaryotic initiation factor 4E-II" /protein_id="aac " /db_xref="gi: " /translation="mvvletektsapsteqgrpepptsaaapaeakdvkpkedpqetg EPAGNTATTTAPAGDDAVRTEHLYKHPLMNVWTLWYLENDRSKSWEDMQNEITSFDTV EDFWSLYNHIKPPSEIKLGSDYSLFKKNIRPMWEDAANKQGGRWVITLNKSSKTDLDN LWLDVLLCLIGEAFDHSDQICGAVINIRGKSNKISIWTADGNNEEAALEIGHKLRDAL RLGRNNSLQYQLHKDTMVKQGSNVKSIYTL" CDS join( , , , , ) /gene="eif4e" /note="method: conceptual translation with partial peptide sequencing; two alternatively spliced transcripts both encode 4E-I" /codon_start=1 /product="eukaryotic initiation factor 4E-I" /protein_id="aac " /db_xref="gi: " /translation="mqsdfhrmknfanpksmfktsapsteqgrpepptsaaapaeakd VKPKEDPQETGEPAGNTATTTAPAGDDAVRTEHLYKHPLMNVWTLWYLENDRSKSWED MQNEITSFDTVEDFWSLYNHIKPPSEIKLGSDYSLFKKNIRPMWEDAANKQGGRWVIT LNKSSKTDLDNLWLDVLLCLIGEAFDHSDQICGAVINIRGKSNKISIWTADGNNEEAA LEIGHKLRDALRLGRNNSLQYQLHKDTMVKQGSNVKSIYTL" ORIGIN 1 cggttgcttg ggttttataa catcagtcag tgacaggcat ttccagagtt gccctgttca 61 acaatcgata gctgcctttg gccaccaaaa tcccaaactt aattaaagaa ttaaataatt 121 cgaataataa ttaagcccag taacctacgc agcttgagtg cgtaaccgat atctagtata Flatfile v GenBank a EMBL - příklad ID U54469; SV 1; linear; genomic DNA; STD; INV; 2881 BP. XX AC U54469; XX DT 19-MAY-1996 (Rel. 47, Created) DT 17-APR-2005 (Rel. 83, Last updated, Version 4) XX DE Drosophila melanogaster eukaryotic initiation factor 4E (eif4e) gene, DE alternative splice products, complete cds. XX KW. XX OS Drosophila melanogaster (fruit fly) OC Eukaryota; Metazoa; Arthropoda; Hexapoda; Insecta; Pterygota; Neoptera; OC Endopterygota; Diptera; Brachycera; Muscomorpha; Ephydroidea; OC Drosophilidae; Drosophila; Sophophora. XX RN [1] RP RX DOI; /jbc RX PUBMED; RA Lavoie C.A., Lachance P.E.D., Sonenberg N., Lasko P.; RT "Alternatively spliced transcripts from the Drosophila eif4e gene produce RT two different Cap-binding proteins"; RL J. Biol. Chem. 271(27): (1996). XX RN [2] RP RA Lasko P.F.; RT ; RL Submitted (09-APR-1996) to the EMBL/GenBank/DDBJ databases. RL Paul F. Lasko, Biology, McGill University, 1205 Avenue Docteur Penfield, RL Montreal, QC H3A 1B1, Canada XX FH Key Location/Qualifiers FH FT source FT /organism="drosophila melanogaster" FT /chromosome="3" FT /map="67a8-b2" FT /mol_type="genomic DNA" FT /db_xref="taxon:7227" FT mrna join( , , , , , FT ) FT /gene="eif4e" FT /product="eukaryotic initiation factor 4E-I" FT mrna join( , , , , , FT ) FT /gene="eif4e" FT /product="eukaryotic initiation factor 4E-I" FT mrna join( , , , , ) FT /gene="eif4e" FT /product="eukaryotic initiation factor 4E-II" FT CDS join( , , , , ) FT /codon_start=1 FT /gene="eif4e" FT /product="eukaryotic initiation factor 4E-II" FT /note="method: conceptual translation with partial peptide FT sequencing." FT /db_xref="flybase:fbgn " FT /db_xref="goa:p48598" FT /db_xref="interpro:ipr001040" FT /db_xref="interpro:ipr019770" FT /db_xref="uniprotkb/swiss-prot:p48598" FT /protein_id="aac " FT /translation="mvvletektsapsteqgrpepptsaaapaeakdvkpkedpqetge
42 Příklad: Eukaryotic translation initiation factor 4E ?report=genbank entry?accnumber=u54469
43 Third party annotation (TPA) databáze navržená pro doplnění experimentálních / odvozených informací doplňující / potvrzující informace poskytnuté zadavatelem sekvence vhodné pro ostatní vědce nemající přímý přístup k databázové položce TPA dataset obsahuje reanotace existujících položek kombinace nových sekvencí a existujících primárních položek anotace archivu a celých genomových shotgun dat př.:
44 RefSeq projekt administrovaná sekundární databáze s cílem poskytnout souhrnný, integrovaný a neredundantní soubor sekvencí jak z genomické, tak transkripční a proteinové úrovně pro stále se zvyšující počet organismů důvodem vzniku byla redundance sekvencí a nejasnost původu záznamu (experiment vs. počítačové odvození) referenční sekvenci pro každou molekulu (DNA, mrna, protein) opět vyžaduje hodně práce biologických odborníků 2+6 formát přístupového kódu experimentální data genomická anotace genomický úsek (DNA) NT_ mrna NM_ XM_ modelová mrna protein NP_ XP_ modelový protein
45 EMBL Genome Reviews přechází na Ensembl Genomes opět důvodem překlenutí nedovoleného přístupu pro ostatní sekundární databáze pro administrované verze kompletních genomových sekvencí v DDBJ / EMBL / GenBank přidané další informace např. z UniProt knowledgebase, Gene Ontology Annotation (GOA), InterPro a pod. synchronizace s databází UniProt
46 Proteinové sekvenční databáze vznikly hlavně z důvodu analýzy proteinů kódovaných v genomech důležité obzvláště s příchodem aplikací hmotnostní spektrometrie v analýze proteinů (mj. analýza posttranslačních modifikací) z větší části jsou to sekundární databáze protože obsahují sekvence odvozené z DNA databází
47 Proteinové sekvenční databáze příklady GenPept jen pro proteinové sekvence odvozené translací nukleotidových sekvencí dnes součástí NCBI Protein - RefSeq obsahuje též proteinové sekvence (pro vybrané organismy) UniProt administrovaná databáze; kompozit SwissProt, TrEMBL a PIR-PSD UniProt Archive (UniParc) vkládání nových sekvencí UniProt Knowledgebase rozšíření práce původně prováděné se SwissProt, TrEMBL a PIR-PSD s cílem poskytnout expertní administrovanou databázi UniRef UniProt nonredundant reference database poskytuje neredundantní pohled na data v UniParc a UniProt Knowledgebase
48 UniProt Archive (UniParc) podstatná část sekvenčních dat proteinů pochází z přímé sekvenace proteinů SwissProt, TrEMBL, PIR-PSD patentové aplikace, PDB IPI, RefSeq, FlyBase, WormBase UniParc dává dohromady tyto zdroje (spolu s přímým zadáváním sekvencí) každá sekvence reprezentována pouze jednou svým jedinečným identifikačním číslem křížové referencování se zdrojovými databázemi (včetně verze vložené sekvence) spolu s označením stavu sekvence UniParc nemá žádné anotace sekvencí ty jsou dostupné přes původní databáze UniParc slouží k párovému přikládání sekvencí UniProt NREF 100, UniProt NREF 90, UniProt NREF 50 (UniRef klastry) seskupovány sekvence bez ohledu na druh
49 UniProt Knowledgebase SwissProt manuálně anotované záznamy založené na informaci z literatury + administrátorem vyhodnocené počítačové analýzy sekvencí TrEMBL počítačové anotované záznamy čekající na manuální anotaci (CDS z EMBL, které nejsou ve SwissProt) také PIR-PSD záznamy, které nejsou ve SwissProt/TrEMBL
50 UniProt Knowledgebase Knowledgebase je také neredundantní snaha popsat produkty odvozené z jednoho genu (nebo genů) jednoho druhu organismu jedno přístupové číslo spolu s identifikátorama isoforem (alternativní sestřihy, proteolytické štěpy, post-translační modifikace) rozsáhlé křížové reference => rozbočovač pro biomolekulární informace např. link k SWISS-2DPAGE
51 UniProt tok dat z primárních zdrojů UniProt NREF 50 UniProt NREF 90 UniProt NREF 100 Proteome Sets UniProt Knowledgebase SwissProt + TrEMBL IPI UniProt Archive Sub/ Peptide Data DDBJ/ EMBL/ GenBank VEGA PDB Patent Data WGS EnsEMBL RefSeq FlyBase WormBase Database sources

52 UniProt
53 ID IF4E_DROME Reviewed; 259 AA. AC P48598; A4V1Q6; Q95SV3; Q9VSX8; Q9VSX9; DT 01-FEB-1996, integrated into UniProtKB/Swiss-Prot. DT 01-FEB-1996, sequence version 1. DT 20-APR-2010, entry version 89. DE RecName: Full=Eukaryotic translation initiation factor 4E; DE Short=eIF-4E; DE Short=eIF4E; DE AltName: Full=mRNA cap-binding protein; DE AltName: Full=eIF-4F 25 kda subunit; GN Name=eIF-4E; Synonyms=Eif4e, EIF4F; ORFNames=CG4035; OS Drosophila melanogaster (Fruit fly). OC Eukaryota; Metazoa; Arthropoda; Hexapoda; Insecta; Pterygota; OC Neoptera; Endopterygota; Diptera; Brachycera; Muscomorpha; OC Ephydroidea; Drosophilidae; Drosophila; Sophophora. OX NCBI_TaxID=7227; RN [1] RP NUCLEOTIDE SEQUENCE [MRNA] (ISOFORM I), AND DEVELOPMENTAL STAGE. RX MEDLINE= ; PubMed= ; RA Hernandez G., Sierra J.M.; RT "Translation initiation factor eif-4e from Drosophila: cdna sequence RT and expression of the gene."; RL Biochim. Biophys. Acta 1261: (1995). RN [2] RP NUCLEOTIDE SEQUENCE [GENOMIC DNA] (ISOFORMS I AND II), AND FUNCTION. RX MEDLINE= ; PubMed= ; DOI= /jbc ; RA Lavoie C.A., Lachance P.E.D., Sonenberg N., Lasko P.; RT "Alternatively spliced transcripts from the Drosophila eif4e gene RT produce two different Cap-binding proteins."; RL J. Biol. Chem. 271: (1996). RN [3] RP NUCLEOTIDE SEQUENCE [GENOMIC DNA] (ISOFORMS I AND II), TISSUE RP SPECIFICITY, AND DEVELOPMENTAL STAGE. RC STRAIN=Canton-S; RX MEDLINE= ; PubMed= ; DOI= /s ; RA Hernandez G., del Corral R., Santoyo J., Campuzano S., Sierra J.M.; RT "Localization, structure and expression of the gene for translation RT initiation factor eif-4e from Drosophila melanogaster."; RL Mol. Gen. Genet. 253: (1997). RN [4] RP NUCLEOTIDE SEQUENCE [LARGE SCALE GENOMIC DNA]. RC STRAIN=Berkeley; RX MEDLINE= ; PubMed= ; DOI= /science ; RA Adams M.D., Celniker S.E., Holt R.A., Evans C.A., Gocayne J.D., RA Amanatides P.G., Scherer S.E., Li P.W., Hoskins R.A., Galle R.F., RA George R.A., Lewis S.E., Richards S., Ashburner M., Henderson S.N., RA Sutton G.G., Wortman J.R., Yandell M.D., Zhang Q., Chen L.X., RA Brandon R.C., Rogers Y.-H.C., Blazej R.G., Champe M., Pfeiffer B.D., RA Wan K.H., Doyle C., Baxter E.G., Helt G., Nelson C.R., Miklos G.L.G., RA Abril J.F., Agbayani A., An H.-J., Andrews-Pfannkoch C., Baldwin D., RA Ballew R.M., Basu A., Baxendale J., Bayraktaroglu L., Beasley E.M., RA Beeson K.Y., Benos P.V., Berman B.P., Bhandari D., Bolshakov S., RA Borkova D., Botchan M.R., Bouck J., Brokstein P., Brottier P., RA Burtis K.C., Busam D.A., Butler H., Cadieu E., Center A., Chandra I., RA Cherry J.M., Cawley S., Dahlke C., Davenport L.B., Davies P., Flatfile v UniProtu - příklad

54 EMBL-EBI

55 NCBI Natinal Center for Biotechnology Information
56 Nástroje pro práci se sekvenčními databázemi
57 Databázové nástroje ExPASy, UniProt, NCBI nástroje Mascot identifikace proteinů BLAST (pro nukleové kyseliny a proteiny)
58 ExPASy Expert Protein Analysis Server odkazy na databáze užitečné programy a nástroje zdroje informací pro výuku a návody k použití

59 rozebereme podrobněji ExPASy

60 UniProt
 Sequence Clusters (UniRef)")
61 UniProt vyhledávání (Search) vyhledávání v základních datech Protein Knowledgebase (UniProtKB) Sequence Clusters (UniRef) Sequence Archive (UniParc) doplňující data různé informace

62 Protein Knowledgebase UniProtKB

63 Sequence Clusters (UniRef) reprezentativní sekvence 64 bílkovin v klastru

64 UniProt další nástroje BLAST párové přiložení sekvencí Align vícenásobné přiložení sekvencí (ClustalW algoritmus) Retrieve dávkové získání sekvencí na základě identifikátorů sekvencí ID Mapping mapování identifikátorů v jednotlivých databázích

65 UniProt BLAST zadaná sekvence výsledky párového přiložení detail
66 UniProt BLAST (detail) informace o párovém přiložení (ID sekvence, skóre, atd.) zadaná sekvence přiřazená sekvence z databáze informace o totožnosti, resp. podobnosti residuí

67 UniProt Align (ClustalW) zadání a výsledek

68 UniProt Retrieve zadané identifikátory sekvencí různé formáty výstupních dat

69 UniProt ID Mapping zadané identifikátory sekvencí identifikační čísla v databázi EMBL/GenBank/DDBJ zadaných čísel
 databáze glykanů (GlycoSuiteDB)")
70 ExPASy databáze mezi dalšími např. databáze obrazů 2D gelů (SWISS- 2DPAGE) databáze glykanů (GlycoSuiteDB)
71 ExPASy nástroje mnoho nástrojů, jak na ExPASy serveru, tak mimo, rozdělených do několika kategorií: identifikace a charakterizace proteinů identifikace a charakterizace proteinů pomocí peptidového mapování identifikace a charakterizace proteinů pomocí tandemové hmotnostni spektrometrie idetifikace pomocí pi, MW nebo aminokyselinového složení ostatní predikční a charakterizační nástroje ostatní proteomické nástroje vyhodnocování MS dat (vizualizace, kvantifikace atd.) analýza dat z 2D gelové elektroforézy překlad DNA sekvencí na proteinové sekvence podobnostní vyhledávání vyhledávání vzorů a profilů predikce post-translačních modifikací, topologií analýza primární, sekundární, terciární a kvarterní struktury proteinů přiložení sekvencí (párové, násobné) fylogenetická analýza aj.

72 návrh teoretických struktur glykanů/glykopept idů na základě experimentálně zjištěné molekulové hmotnosti ExPASy GlycoMod vložení experimentálních hodnot nastavení parametrů

73 ExPASy GlycoMod (příklad výsledku) identifikovaný N-glykan odkaz do databáze GlycoSuiteDB
74 ExPASy predikční proteomické nástroje ProtParam fyzikálně-chemické parametry proteinové sekvence (aminokyselinové složení, elementární složení, izoelektrický bod, extinkční koeficient) Compute pi/mw spočítá hodnotu pi a molekulové hmotnosti jak pro sekvence v UniProt (pomocí ID sekvence), tak pro uževatelem zadanou sekvenci GlycanMass spočítá hmotnost oligosacharidové struktury PeptideCutter predikce štěpných míst v proteinové sekvenci PeptideMass spočítá teoretické hmotnosti peptidů (spolu s posttranslačními modifikacemi uvedenými v databázi) po digesci proteinu IsotopIdent predikce teoretické isotopové distribuce peptidy, proteinu polynukleotidu nebo jiné chem látky
75 ExPASy ProtParam vložení ID proteinu nebo sekvence část výpisu výsledných hodnot pro výpočet hodnot pi/mw lze analogicky použít program Compute pi/mw (
76 ExPASy PeptideMass vložení ID proteinu nebo sekvence část výpisu výsledných hodnot zadání parametrů teoretického štěpení
77 Nástroje pro identifikaci proteinů pomocí MS dat Mascot databázové vyhledávaní a identifikace proteinů s MS a/nebo MSMS daty (Matrix Science Ltd., London) ProFound databázové vyhledávaní a identifikace proteinů s MS daty (MSMS data program X! Tandem a X! Hunter); též predikční nástroje (The Rockefeller University, New York) ProteinProspector databázové vyhledávání + predikční nástroje pro identifikaci proteinů z MS a MSMS dat (University of California, San Francisco)
 Sequence Query vyhledávání na")
78 Mascot tři nástroje pro vyhledávání: Peptide Mass Fingerprinting nástroj pro prohledávání databáze na základě metody otisku prstu (MS data) Sequence Query vyhledávání na základě MSMS dat nebo jejich částečné interpretace MS/MS Ion Search prohledávání databází s MSMS daty (vetší soubory)
79 % Intensity Typické MS spektrum peptidové směsi po digesci v gelu E Mass (m/z)

80
81
82
83 % Intensity Typické MSMS spektrum vybraného peptidového prekurzoru Mass (m/z)

84
85
86
 porovnávání na úrovni nukleových kyselin porovnání na základě sekvencí proteinů další")
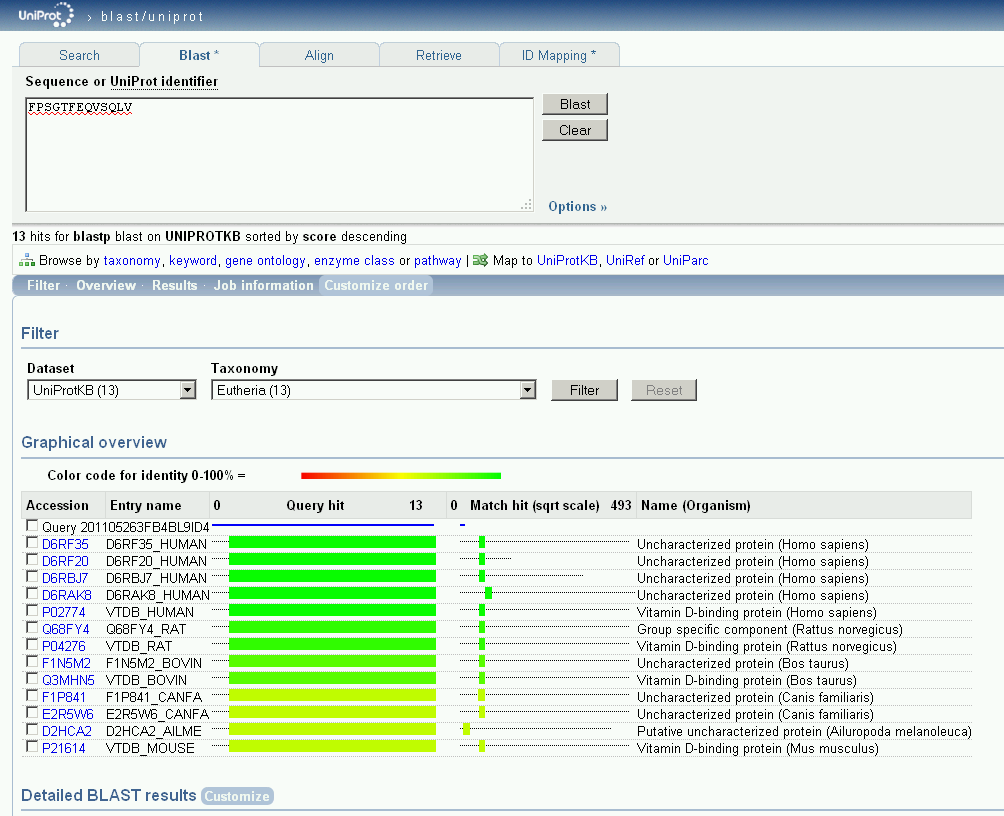
87 BLAST Basic Local Alignment Search Tool at NCBI ( porovnávání na úrovni nukleových kyselin porovnání na základě sekvencí proteinů další nástroje pro analýzy sekvencí
 zadávací formulář výběr databáze volba")
88 BLAST at NCBI ( zadávací formulář výběr databáze volba algoritmu
 sekvence z databáze přiřazená k")
89 BLAST at NCBI ( sekvence z databáze přiřazená k dotazu
90 Příklady ke cvičení
91 Informace o vzorku protein byl separován pomocí gelové elektroforézy redukce disulfidických můstků byla provedena dithiothreitolem, následná modifikace cysteinů byla provedena jodacetamidem (= Carbamidomethyl (C) ) enzymatické štěpení bylo provedeno v gelu pomocí trypsinu (štěpí za lysinem (K) a argininem (R), nenásleduje-li prolin) hmotnostní analýza byla provedena na hmotnostním spektrometru typu MALDI-TOF/TOF pro databázové vyhledávání použijte jeden z nástrojů
92 Nastavení databázového vyhledávání (Mascot) database: SwissProt enzyme: Trypsin missed cleavages: 1 taxonomy: All entries fixed modifications: Carbamidomethyl (C) variable modifications: Gln->pyro-Glu (N-term Q) Oxidation (M) Acetyl (Protein N-term) peptide tolerance: 30 ppm MSMS tolerance: 300 mmu mass values: [M+H] + Monoisotopic

93 zde doplnit svoje m/z hodnoty
94 Nastavení databázového vyhledávání (Protein Prospector) database: SwissProt digest: Trypsin max missed cleavages: 1 taxonomy: All fixed modifications: Carbamidomethyl (C) variable modifications: Peptide N-terminal Gln to pyroglu Oxidation of M Protein N-terminus Acetylated peptide tolerance: 30 ppm MSMS tolerance: 300 mmu mass are: monoisotopic
95 zde doplnit svoje m/z hodnoty
96 % Intensity Příklad MS spektra Refl ector Spec #1 M C=>BC[ BP = , 4573] získaný seznam píků hmotnostní spektrum Mass (m/z )
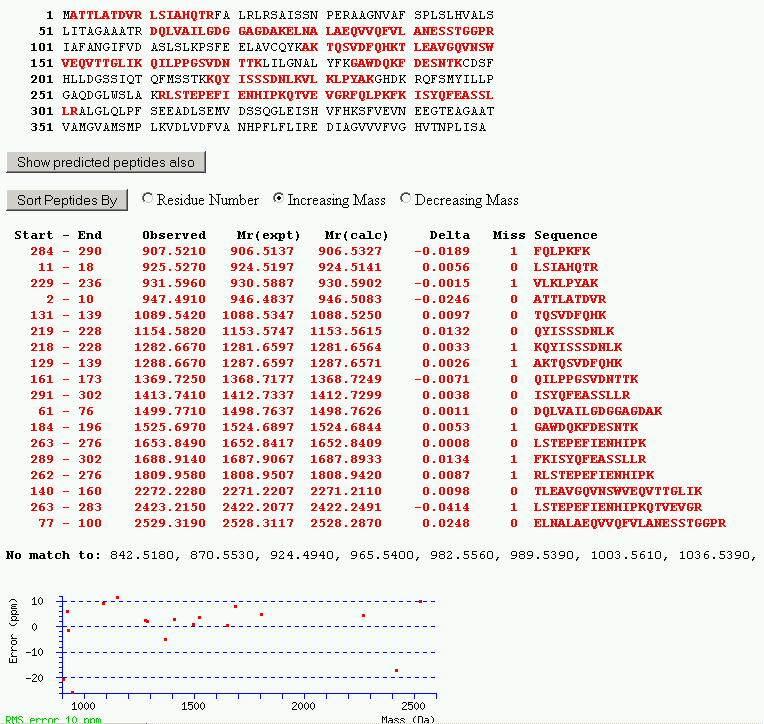
97 Výsledky vyhledávání z programu MS-Fit nejvyšší skóre identifikovaný protein exp. vs. teor. m/z hodnoty identifikované peptidové sekvence nástroje pro další analýzu nezidentifikovaných m/z hodnot
98 Výsledky vyhledávání z programu Mascot PMF hity mimo zelený rámeček jsou významné nejvyšší skóre identifikovaný protein parametry vyhledávání

99 Detailní popis výsledku vyhledávaní v programu Mascot PMF (I) skóre a expect hodnota molekulová hmotnost a pi sekvenční pokrytí

100 Detailní popis výsledku vyhledávaní v programu Mascot PMF (II) exp. vs. teor. m/z hodnoty identifikované peptidové sekvence rozložení experimentálních chyb flat file záznamu proteinu v databázi
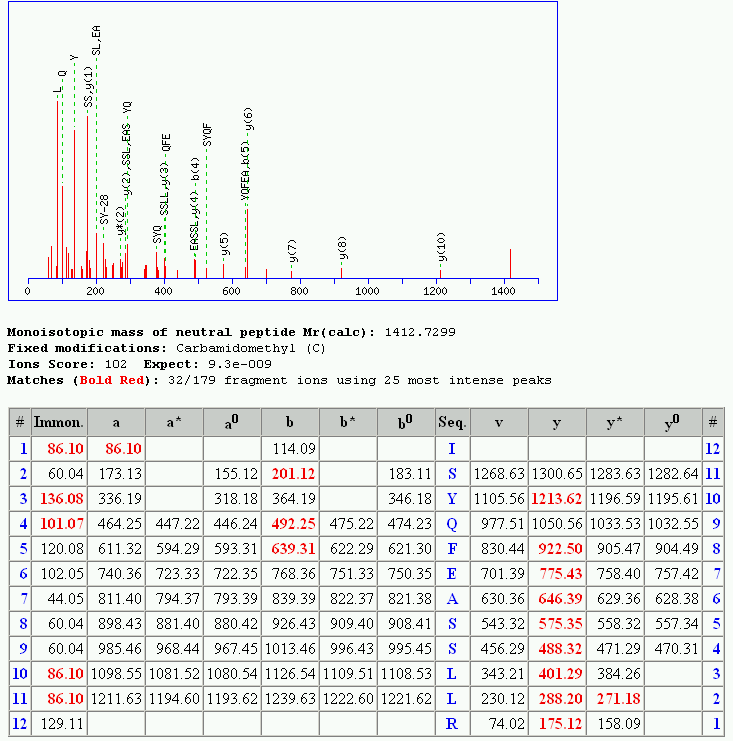
101 % Intensity Příklad MSMS spektra s označenými ionty MS/MS Precursor y13 ion type m/z y y y y y y y y y y y y y y14 40 y7 30 y y1 y2 y3 y4 y5 y6 y8 y9 y11 y Mass (m/z)
102 ion type m/z difference AA alt. AA y y V y L I y Q K y S y V y Q K y E y F y T y G y S y P y F odečítáme odspodu (protože y-ionty) sequence FPSGTFEQVSQLV
103
104 rozkliknout informace o parametrech vyhledávání

105 zde další informace a nástroje

106 Program mmass ( Ke stažení (Windows, Mac OSX, Linux) na adrese
107 Zpracování spektra v programu mmass detekce píků manuálně nebo automaticky

108 Zadání získaných dat do programu Mascot PMF

109 Detail dialogového okna programu Mascot PMF
110 Výsledek vyhledávání v programu Mascot PMF (zadáno z programu mmass)
")
111 Detailní popis výsledku vyhledávaní v programu Mascot PMF (I) skóre a expect hodnota molekulová hmotnost a pi sekvenční pokrytí (zde je vyšší oproti 43%)

112 Detailní popis výsledku vyhledávaní v programu Mascot PMF (II) exp. vs. teor. m/z hodnoty identifikované peptidové sekvence rozložení experimentálních chyb flat file záznamu proteinu v databázi

113 Vyhledávací program PROFOUND (pro PMF)

114 Detail dialogového okna programu PROFOUND
115 Detail dialogového okna programu MS-Fit v programu mmass
116 nejvyšší skóre Výsledky vyhledávání z programu MS-Fit identifikovaný protein identifikované peptidové sekvence exp. vs. teor. m/z hodnoty nástroje pro další analýzu nezidentifikovaných m/z hodnot

117 Automatický výběr píků v programu mmass
 mnoho falešných píků snižují skóre sekvenční pokrytí")
118 Výsledek vyhledávání v programu Mascot PMF (zadáno z programu mmass po automatickém výběru píků) mnoho falešných píků snižují skóre sekvenční pokrytí docela dobré
Hemoglobin a jemu podobní... Studijní materiál. Jan Komárek
 Hemoglobin a jemu podobní... Studijní materiál Jan Komárek Bioinformatika Bioinformatika je vědní disciplína, která se zabývá metodami pro shromážďování, analýzu a vizualizaci rozsáhlých souborů biologických
Hemoglobin a jemu podobní... Studijní materiál Jan Komárek Bioinformatika Bioinformatika je vědní disciplína, která se zabývá metodami pro shromážďování, analýzu a vizualizaci rozsáhlých souborů biologických
Základy genomiky. I. Úvod do bioinformatiky. Jan Hejátko
 Základy genomiky I. Úvod do bioinformatiky Jan Hejátko Masarykova univerzita, Oddělení funkční genomiky a proteomiky Laboratoř molekulární fyziologie rostlin Základy genomiky I. Zdrojová literatura ke
Základy genomiky I. Úvod do bioinformatiky Jan Hejátko Masarykova univerzita, Oddělení funkční genomiky a proteomiky Laboratoř molekulární fyziologie rostlin Základy genomiky I. Zdrojová literatura ke
Studijní materiály pro bioinformatickou část ViBuChu. úloha II. Jan Komárek, Gabriel Demo
 Studijní materiály pro bioinformatickou část ViBuChu úloha II Jan Komárek, Gabriel Demo Adenin Struktura DNA Thymin 5 konec 3 konec DNA tvořena dvěmi řetězci orientovanými antiparalelně (liší se orientací
Studijní materiály pro bioinformatickou část ViBuChu úloha II Jan Komárek, Gabriel Demo Adenin Struktura DNA Thymin 5 konec 3 konec DNA tvořena dvěmi řetězci orientovanými antiparalelně (liší se orientací
Osekvenované genomy. Pan troglodydes, 2005. Neandrtálec, 2010
 GENOMOVÉ PROJEKTY Osekvenované genomy Haemophilus influenze, 1995 první osekvenovaná bakterie Saccharomyces cerevisiae, 1996 první osekvenovaný eukaryotický organimus Caenorhabditis elegans, 1998 první
GENOMOVÉ PROJEKTY Osekvenované genomy Haemophilus influenze, 1995 první osekvenovaná bakterie Saccharomyces cerevisiae, 1996 první osekvenovaný eukaryotický organimus Caenorhabditis elegans, 1998 první
Typy nukleových kyselin. deoxyribonukleová (DNA); ribonukleová (RNA).
; ribonukleová (RNA).") Typy nukleových kyselin Existují dva typy nukleových kyselin (NA, z anglických slov nucleic acid): deoxyribonukleová (DNA); ribonukleová (RNA). DNA je lokalizována v buněčném jádře, RNA v cytoplasmě a
Typy nukleových kyselin Existují dva typy nukleových kyselin (NA, z anglických slov nucleic acid): deoxyribonukleová (DNA); ribonukleová (RNA). DNA je lokalizována v buněčném jádře, RNA v cytoplasmě a
2. Z následujících tvrzení, týkajících se prokaryotické buňky, vyberte správné:
 Výběrové otázky: 1. Součástí všech prokaryotických buněk je: a) DNA, plazmidy b) plazmidy, mitochondrie c) plazmidy, ribozomy d) mitochondrie, endoplazmatické retikulum 2. Z následujících tvrzení, týkajících
Výběrové otázky: 1. Součástí všech prokaryotických buněk je: a) DNA, plazmidy b) plazmidy, mitochondrie c) plazmidy, ribozomy d) mitochondrie, endoplazmatické retikulum 2. Z následujících tvrzení, týkajících
Metody používané v MB. analýza proteinů, nukleových kyselin
 Metody používané v MB analýza proteinů, nukleových kyselin Nukleové kyseliny analýza a manipulace Elektroforéza (délka fragmentů, čistota, kvantifikace) Restrikční štěpení (manipulace s DNA, identifikace
Metody používané v MB analýza proteinů, nukleových kyselin Nukleové kyseliny analýza a manipulace Elektroforéza (délka fragmentů, čistota, kvantifikace) Restrikční štěpení (manipulace s DNA, identifikace
Molekulární základy dědičnosti. Ústřední dogma molekulární biologie Struktura DNA a RNA
 Molekulární základy dědičnosti Ústřední dogma molekulární biologie Struktura DNA a RNA Ústřední dogma molekulární genetiky - vztah mezi nukleovými kyselinami a proteiny proteosyntéza replikace DNA RNA
Molekulární základy dědičnosti Ústřední dogma molekulární biologie Struktura DNA a RNA Ústřední dogma molekulární genetiky - vztah mezi nukleovými kyselinami a proteiny proteosyntéza replikace DNA RNA
Exprese genetické informace
 Exprese genetické informace Tok genetické informace DNA RNA Protein (výjimečně RNA DNA) DNA RNA : transkripce RNA protein : translace Gen jednotka dědičnosti sekvence DNA nutná k produkci funkčního produktu
Exprese genetické informace Tok genetické informace DNA RNA Protein (výjimečně RNA DNA) DNA RNA : transkripce RNA protein : translace Gen jednotka dědičnosti sekvence DNA nutná k produkci funkčního produktu
Metody používané v MB. analýza proteinů, nukleových kyselin
 Metody používané v MB analýza proteinů, nukleových kyselin Nukleové kyseliny analýza a manipulace Elektroforéza (délka fragmentů, čistota, kvantifikace) Restrikční štěpení (manipulace s DNA, identifikace
Metody používané v MB analýza proteinů, nukleových kyselin Nukleové kyseliny analýza a manipulace Elektroforéza (délka fragmentů, čistota, kvantifikace) Restrikční štěpení (manipulace s DNA, identifikace
Centrum aplikované genomiky, Ústav dědičných metabolických poruch, 1.LFUK
 ové technologie v analýze D A, R A a proteinů Stanislav Kmoch Centrum aplikované genomiky, Ústav dědičných metabolických poruch, 1.LFUK Motto : "The optimal health results from ensuring that the right
ové technologie v analýze D A, R A a proteinů Stanislav Kmoch Centrum aplikované genomiky, Ústav dědičných metabolických poruch, 1.LFUK Motto : "The optimal health results from ensuring that the right
MENÍ A INTERPRETACE SPEKTER BIOMOLEKUL. Miloslav Šanda
 MENÍ A INTERPRETACE SPEKTER BIOMOLEKUL Miloslav Šanda Ionizaní techniky využívané k analýze biomolekul (biopolymer) MALDI : proteiny, peptidy, oligonukleotidy, sacharidy ESI : proteiny, peptidy, oligonukleotidy,
MENÍ A INTERPRETACE SPEKTER BIOMOLEKUL Miloslav Šanda Ionizaní techniky využívané k analýze biomolekul (biopolymer) MALDI : proteiny, peptidy, oligonukleotidy, sacharidy ESI : proteiny, peptidy, oligonukleotidy,
Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti. Translace, techniky práce s DNA
 Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti Translace, techniky práce s DNA Translace překlad z jazyka nukleotidů do jazyka aminokyselin dá se rozdělit na 5 kroků aktivace aminokyslin
Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti Translace, techniky práce s DNA Translace překlad z jazyka nukleotidů do jazyka aminokyselin dá se rozdělit na 5 kroků aktivace aminokyslin
V. letní škola metod molekulární biologie nukleových kyselin a genomiky 16. - 20. 6. 2014. Ústav morfologie, fyziologie a genetiky zvířat AF MENDELU
 V. letní škola metod molekulární biologie nukleových kyselin a genomiky 16. - 20. 6. 2014 Ústav morfologie, fyziologie a genetiky zvířat AF MENDELU Zemědělská 1, Budova A, 4. patro (učebny dle programu)
V. letní škola metod molekulární biologie nukleových kyselin a genomiky 16. - 20. 6. 2014 Ústav morfologie, fyziologie a genetiky zvířat AF MENDELU Zemědělská 1, Budova A, 4. patro (učebny dle programu)
Nukleové kyseliny Replikace Transkripce, RNA processing Translace
 ukleové kyseliny Replikace Transkripce, RA processing Translace Prokaryotická X eukaryotická buňka Hlavní rozdíl organizace genetického materiálu (u prokaryot není ohraničen) Život závisí na schopnosti
ukleové kyseliny Replikace Transkripce, RA processing Translace Prokaryotická X eukaryotická buňka Hlavní rozdíl organizace genetického materiálu (u prokaryot není ohraničen) Život závisí na schopnosti
Genomické databáze. Shlukování proteinových sekvencí. Ivana Rudolfová. školitel: doc. Ing. Jaroslav Zendulka, CSc.
 Genomické databáze Shlukování proteinových sekvencí Ivana Rudolfová školitel: doc. Ing. Jaroslav Zendulka, CSc. Obsah Proteiny Zdroje dat Predikce struktury proteinů Cíle disertační práce Vstupní data
Genomické databáze Shlukování proteinových sekvencí Ivana Rudolfová školitel: doc. Ing. Jaroslav Zendulka, CSc. Obsah Proteiny Zdroje dat Predikce struktury proteinů Cíle disertační práce Vstupní data
Nukleové kyseliny Replikace Transkripce translace
 Nukleové kyseliny Replikace Transkripce translace Prokaryotická X eukaryotická buňka Hlavní rozdíl organizace genetického materiálu (u prokaryot není ohraničen) Život závisí na schopnosti buněk skladovat,
Nukleové kyseliny Replikace Transkripce translace Prokaryotická X eukaryotická buňka Hlavní rozdíl organizace genetického materiálu (u prokaryot není ohraničen) Život závisí na schopnosti buněk skladovat,
Exprese genetického kódu Centrální dogma molekulární biologie DNA RNA proteinu transkripce DNA mrna translace proteosyntéza
 Exprese genetického kódu Centrální dogma molekulární biologie - genetická informace v DNA -> RNA -> primárního řetězce proteinu 1) transkripce - přepis z DNA do mrna 2) translace - přeložení z kódu nukleových
Exprese genetického kódu Centrální dogma molekulární biologie - genetická informace v DNA -> RNA -> primárního řetězce proteinu 1) transkripce - přepis z DNA do mrna 2) translace - přeložení z kódu nukleových
Hybridizace nukleových kyselin
 Hybridizace nukleových kyselin Tvorba dvouřetězcových hybridů za dvou jednořetězcových a komplementárních molekul Založena na schopnosti denaturace a renaturace DNA. Denaturace DNA oddělení komplementárních
Hybridizace nukleových kyselin Tvorba dvouřetězcových hybridů za dvou jednořetězcových a komplementárních molekul Založena na schopnosti denaturace a renaturace DNA. Denaturace DNA oddělení komplementárních
OPVK CZ.1.07/2.2.00/
 OPVK CZ.1.07/2.2.00/28.0184 Základní principy vývoje nových léčiv OCH/ZPVNL Mgr. Radim Nencka, Ph.D. ZS 2012/2013 První kroky k objevu léčiva Nobelova cena za chemii 2013 Martin Karplus Michael Levitt
OPVK CZ.1.07/2.2.00/28.0184 Základní principy vývoje nových léčiv OCH/ZPVNL Mgr. Radim Nencka, Ph.D. ZS 2012/2013 První kroky k objevu léčiva Nobelova cena za chemii 2013 Martin Karplus Michael Levitt
USING OF AUTOMATED DNA SEQUENCING FOR PORCINE CANDIDATE GENES POLYMORFISMS DETECTION
 USING OF AUTOMATED DNA SEQUENCING FOR PORCINE CANDIDATE GENES POLYMORFISMS DETECTION VYUŽITÍ AUTOMATICKÉHO SEKVENOVÁNÍ DNA PRO DETEKCI POLYMORFISMŮ KANDIDÁTNÍCH GENŮ U PRASAT Vykoukalová Z., Knoll A.,
USING OF AUTOMATED DNA SEQUENCING FOR PORCINE CANDIDATE GENES POLYMORFISMS DETECTION VYUŽITÍ AUTOMATICKÉHO SEKVENOVÁNÍ DNA PRO DETEKCI POLYMORFISMŮ KANDIDÁTNÍCH GENŮ U PRASAT Vykoukalová Z., Knoll A.,
Molekulárn. rní. biologie Struktura DNA a RNA
 Molekulárn rní základy dědičnosti Ústřední dogma molekulárn rní biologie Struktura DNA a RNA Ústřední dogma molekulárn rní genetiky - vztah mezi nukleovými kyselinami a proteiny proteosyntéza replikace
Molekulárn rní základy dědičnosti Ústřední dogma molekulárn rní biologie Struktura DNA a RNA Ústřední dogma molekulárn rní genetiky - vztah mezi nukleovými kyselinami a proteiny proteosyntéza replikace
Genové knihovny a analýza genomu
 Genové knihovny a analýza genomu Klonování genů Problém: genom organismů je komplexní a je proto obtížné v něm najít a klonovat specifický gen Klonování genů Po restrikčním štěpení genomové DNA pocházející
Genové knihovny a analýza genomu Klonování genů Problém: genom organismů je komplexní a je proto obtížné v něm najít a klonovat specifický gen Klonování genů Po restrikčním štěpení genomové DNA pocházející
Nukleové kyseliny Replikace Transkripce translace
 Nukleové kyseliny Replikace Transkripce translace Figure 4-3 Molecular Biology of the Cell ( Garland Science 2008) Figure 4-4 Molecular Biology of the Cell ( Garland Science 2008) Figure 4-5 Molecular
Nukleové kyseliny Replikace Transkripce translace Figure 4-3 Molecular Biology of the Cell ( Garland Science 2008) Figure 4-4 Molecular Biology of the Cell ( Garland Science 2008) Figure 4-5 Molecular
Exprese genetické informace
 Exprese genetické informace Stavební kameny nukleových kyselin Nukleotidy = báze + cukr + fosfát BÁZE FOSFÁT Nukleosid = báze + cukr CUKR Báze Cyklické sloučeniny obsahující dusík puriny nebo pyrimidiny
Exprese genetické informace Stavební kameny nukleových kyselin Nukleotidy = báze + cukr + fosfát BÁZE FOSFÁT Nukleosid = báze + cukr CUKR Báze Cyklické sloučeniny obsahující dusík puriny nebo pyrimidiny
Hmotnostní detekce biologicky významných sloučenin pro biotechnologie část 3 - Provedení štěpení proteinů a následné analýzy,
 Laboratoř Metalomiky a Nanotechnologií Hmotnostní detekce biologicky významných sloučenin pro biotechnologie část 3 - Provedení štěpení proteinů a následné analýzy, vyhodnocení výsledků, diskuse Anotace
Laboratoř Metalomiky a Nanotechnologií Hmotnostní detekce biologicky významných sloučenin pro biotechnologie část 3 - Provedení štěpení proteinů a následné analýzy, vyhodnocení výsledků, diskuse Anotace
Biotechnologický kurz. II. letní škola metod molekulární biologie nukleových kyselin a genomiky 17. - 21. 6. 2013
 Biotechnologický kurz Biotechnologický kurz II. letní škola metod molekulární biologie nukleových kyselin a genomiky 17. - 21. 6. 2013 Ústav morfologie, fyziologie a genetiky zvířat AF MENDELU v Brně Zemědělská
Biotechnologický kurz Biotechnologický kurz II. letní škola metod molekulární biologie nukleových kyselin a genomiky 17. - 21. 6. 2013 Ústav morfologie, fyziologie a genetiky zvířat AF MENDELU v Brně Zemědělská
Vyhledávání podobných sekvencí BLAST
 Vyhledávání podobných sekvencí BLAST Základní informace Následující text je součástí učebních textů předmětu Analýza sekvencí DNA a je určen hlavně pro studenty Matematické biologie. Může být ovšem přínosný
Vyhledávání podobných sekvencí BLAST Základní informace Následující text je součástí učebních textů předmětu Analýza sekvencí DNA a je určen hlavně pro studenty Matematické biologie. Může být ovšem přínosný
LABORATOŘ OBORU I ÚSTAV ORGANICKÉ TECHNOLOGIE (111) Použití GC-MS spektrometrie
 Použití GC-MS spektrometrie") LABORATOŘ OBORU I ÚSTAV ORGANICKÉ TECHNOLOGIE (111) C Použití GC-MS spektrometrie Vedoucí práce: Doc. Ing. Petr Kačer, Ph.D., Ing. Kamila Syslová Umístění práce: laboratoř 79 Použití GC-MS spektrometrie
LABORATOŘ OBORU I ÚSTAV ORGANICKÉ TECHNOLOGIE (111) C Použití GC-MS spektrometrie Vedoucí práce: Doc. Ing. Petr Kačer, Ph.D., Ing. Kamila Syslová Umístění práce: laboratoř 79 Použití GC-MS spektrometrie
DIAGNOSTICKÝ KIT PRO DETEKCI MINIMÁLNÍ REZIDUÁLNÍ CHOROBY U KOLOREKTÁLNÍHO KARCINOMU
 Úvod IntellMed, s.r.o., Václavské náměstí 820/41, 110 00 Praha 1 DIAGNOSTICKÝ KIT PRO DETEKCI MINIMÁLNÍ REZIDUÁLNÍ CHOROBY U KOLOREKTÁLNÍHO KARCINOMU Jednou z nejvhodnějších metod pro detekci minimální
Úvod IntellMed, s.r.o., Václavské náměstí 820/41, 110 00 Praha 1 DIAGNOSTICKÝ KIT PRO DETEKCI MINIMÁLNÍ REZIDUÁLNÍ CHOROBY U KOLOREKTÁLNÍHO KARCINOMU Jednou z nejvhodnějších metod pro detekci minimální
11. Bioinformatika a proteiny II
 11. Bioinformatika a proteiny II David Potěšil Core Facility Proteomics CEITEC-MU Masaryk University Kamenice 5, A26 phone: +420 54949 8426 email: david.potesil@ceitec.muni.cz Proteomika, Podzim 2016 2
11. Bioinformatika a proteiny II David Potěšil Core Facility Proteomics CEITEC-MU Masaryk University Kamenice 5, A26 phone: +420 54949 8426 email: david.potesil@ceitec.muni.cz Proteomika, Podzim 2016 2
PŘEHLED SEKVENAČNÍCH METOD
 PŘEHLED SEKVENAČNÍCH METOD Letní škola bioinformatiky 2014, Brno Ing.Matej Lexa, Phd (FI MU Brno) CO JE TO SEKVENACE A CO SE BUDE SEKVENOVAT? POŘADÍ NUKLEOTIDU V DNA SEKVENOVÁNÍ DNA od manuálních metod
PŘEHLED SEKVENAČNÍCH METOD Letní škola bioinformatiky 2014, Brno Ing.Matej Lexa, Phd (FI MU Brno) CO JE TO SEKVENACE A CO SE BUDE SEKVENOVAT? POŘADÍ NUKLEOTIDU V DNA SEKVENOVÁNÍ DNA od manuálních metod
Určení molekulové hmotnosti: ESI a nanoesi
 Cvičení Určení molekulové hmotnosti: ESI a nanoesi ) 1)( ( ) ( H m z H m z M k j j j m z z zh M Molekula o hmotnosti M se nabije z-krát protonem, pík iontu ve spektru je na m z : ) ( H m z M z Pro dva
Cvičení Určení molekulové hmotnosti: ESI a nanoesi ) 1)( ( ) ( H m z H m z M k j j j m z z zh M Molekula o hmotnosti M se nabije z-krát protonem, pík iontu ve spektru je na m z : ) ( H m z M z Pro dva
Bioinformatika a funkční studie
 Bioinformatika a funkční studie Bioinformatika Vztah informace a funkce Sekvenování DNA Proteinů Databáze Primární Sekundární Integrované internetové zdroje informací Vyhledávání sekvenční podobnosti,
Bioinformatika a funkční studie Bioinformatika Vztah informace a funkce Sekvenování DNA Proteinů Databáze Primární Sekundární Integrované internetové zdroje informací Vyhledávání sekvenční podobnosti,
DIAGNOSTICKÝ KIT PRO DETEKCI MINIMÁLNÍ REZIDUÁLNÍ CHOROBY U KARCINOMU PANKREATU
 Úvod IntellMed, s.r.o., Václavské náměstí 820/41, 110 00 Praha 1 DIAGNOSTICKÝ KIT PRO DETEKCI MINIMÁLNÍ REZIDUÁLNÍ CHOROBY U KARCINOMU PANKREATU Jednou z nejvhodnějších metod pro detekci minimální reziduální
Úvod IntellMed, s.r.o., Václavské náměstí 820/41, 110 00 Praha 1 DIAGNOSTICKÝ KIT PRO DETEKCI MINIMÁLNÍ REZIDUÁLNÍ CHOROBY U KARCINOMU PANKREATU Jednou z nejvhodnějších metod pro detekci minimální reziduální
Molekulárně biologické metody princip, popis, výstupy
 & Molekulárně biologické metody princip, popis, výstupy Klára Labská Evropský program pro mikrobiologii ve veřejném zdravotnictví (EUPHEM), ECDC, Stockholm NRL pro herpetické viry,centrum epidemiologie
& Molekulárně biologické metody princip, popis, výstupy Klára Labská Evropský program pro mikrobiologii ve veřejném zdravotnictví (EUPHEM), ECDC, Stockholm NRL pro herpetické viry,centrum epidemiologie
P ro te i n o vé d a ta b á ze
 Proteinové databáze Osnova Základní stavební jednotky proteinů Hierarchie proteinové struktury Stanovení proteinové struktury Důležitost proteinové struktury Proteinové strukturní databáze Proteinové klasifikační
Proteinové databáze Osnova Základní stavební jednotky proteinů Hierarchie proteinové struktury Stanovení proteinové struktury Důležitost proteinové struktury Proteinové strukturní databáze Proteinové klasifikační
Bioinformatika je nová disciplína na rozhraní počítačových věd, informačních technologií a biologie. Bioinformatika zahrnuje studium biologických dat
 Bioinformatika je nová disciplína na rozhraní počítačových věd, informačních technologií a biologie. Bioinformatika zahrnuje studium biologických dat a jejich praktické uchovávání, vyhledávání a modelování.
Bioinformatika je nová disciplína na rozhraní počítačových věd, informačních technologií a biologie. Bioinformatika zahrnuje studium biologických dat a jejich praktické uchovávání, vyhledávání a modelování.
Základy molekulární biologie KBC/MBIOZ
 Základy molekulární biologie KBC/MBIOZ Mária Čudejková 2. Transkripce genu a její regulace Transkripce genetické informace z DNA na RNA Transkripce dvou genů zachycená na snímku z elektronového mikroskopu.
Základy molekulární biologie KBC/MBIOZ Mária Čudejková 2. Transkripce genu a její regulace Transkripce genetické informace z DNA na RNA Transkripce dvou genů zachycená na snímku z elektronového mikroskopu.
Co se o sobě dovídáme z naší genetické informace
 Genomika a bioinformatika Co se o sobě dovídáme z naší genetické informace Jan Pačes, Mgr, Ph.D Ústav molekulární genetiky AVČR, CZECH FOBIA (Free and Open Bioinformatics Association) hpaces@img.cas.cz
Genomika a bioinformatika Co se o sobě dovídáme z naší genetické informace Jan Pačes, Mgr, Ph.D Ústav molekulární genetiky AVČR, CZECH FOBIA (Free and Open Bioinformatics Association) hpaces@img.cas.cz
Nukleové kyseliny. DeoxyriboNucleic li Acid
 Molekulární lární genetika Nukleové kyseliny DeoxyriboNucleic li Acid RiboNucleic N li Acid cukr (deoxyrobosa, ribosa) fosforečný zbytek dusíkatá báze Dusíkaté báze Dvouvláknová DNA Uchovává genetickou
Molekulární lární genetika Nukleové kyseliny DeoxyriboNucleic li Acid RiboNucleic N li Acid cukr (deoxyrobosa, ribosa) fosforečný zbytek dusíkatá báze Dusíkaté báze Dvouvláknová DNA Uchovává genetickou
Biotechnologický kurz. III. letní škola metod molekulární biologie nukleových kyselin a genomiky
 Biotechnologický kurz Biotechnologický kurz III. letní škola metod molekulární biologie nukleových kyselin a genomiky 18. - 22. 6. 2012 Ústav morfologie, fyziologie a genetiky zvířat AF MENDELU v Brně
Biotechnologický kurz Biotechnologický kurz III. letní škola metod molekulární biologie nukleových kyselin a genomiky 18. - 22. 6. 2012 Ústav morfologie, fyziologie a genetiky zvířat AF MENDELU v Brně
MOLEKULÁRNĚ BIOLOGICKÉ METODY V ENVIRONMENTÁLNÍ MIKROBIOLOGII. Martina Nováková, VŠCHT Praha
 MOLEKULÁRNĚ BIOLOGICKÉ METODY V ENVIRONMENTÁLNÍ MIKROBIOLOGII Martina Nováková, VŠCHT Praha MOLEKULÁRNÍ BIOLOGIE V BIOREMEDIACÍCH enumerace FISH průtoková cytometrie klonování produktů PCR sekvenování
MOLEKULÁRNĚ BIOLOGICKÉ METODY V ENVIRONMENTÁLNÍ MIKROBIOLOGII Martina Nováková, VŠCHT Praha MOLEKULÁRNÍ BIOLOGIE V BIOREMEDIACÍCH enumerace FISH průtoková cytometrie klonování produktů PCR sekvenování
NUKLEOVÉ KYSELINY. Základ života
 NUKLEOVÉ KYSELINY Základ života HISTORIE 1. H. Braconnot (30. léta 19. století) - Strassburg vinné kvasinky izolace matiére animale. 2. J.F. Meischer - experimenty z hnisem štěpení trypsinem odstředěním
NUKLEOVÉ KYSELINY Základ života HISTORIE 1. H. Braconnot (30. léta 19. století) - Strassburg vinné kvasinky izolace matiére animale. 2. J.F. Meischer - experimenty z hnisem štěpení trypsinem odstředěním
Sekvenování nové generace. Radka Reifová
 Sekvenování nové generace Radka Reifová Prezentace ke stažení www.natur.cuni.cz/zoologie/biodiversity v záložce Přednášky 1. Přehled sekvenačních metod nové generace 2. Využití sekvenačních metod nové
Sekvenování nové generace Radka Reifová Prezentace ke stažení www.natur.cuni.cz/zoologie/biodiversity v záložce Přednášky 1. Přehled sekvenačních metod nové generace 2. Využití sekvenačních metod nové
Nukleosidy, nukleotidy, nukleové kyseliny, genetická informace
 Nukleosidy, nukleotidy, nukleové kyseliny, genetická informace Centrální dogma Nukleové kyseliny Fosfátem spojené nukleotidy (cukr s navázanou bází a fosfátem) Nukleotidy Nukleotidy stavební kameny nukleových
Nukleosidy, nukleotidy, nukleové kyseliny, genetická informace Centrální dogma Nukleové kyseliny Fosfátem spojené nukleotidy (cukr s navázanou bází a fosfátem) Nukleotidy Nukleotidy stavební kameny nukleových
Metody používané v MB. analýza proteinů, nukleových kyselin
 Metody používané v MB analýza proteinů, nukleových kyselin Proteiny analýza a manipulace Izolace, purifikace (rozdělovací metody) Centrifugace Chromatografie Elektroforéza Blotting (identifikace, western
Metody používané v MB analýza proteinů, nukleových kyselin Proteiny analýza a manipulace Izolace, purifikace (rozdělovací metody) Centrifugace Chromatografie Elektroforéza Blotting (identifikace, western
19.b - Metabolismus nukleových kyselin a proteosyntéza
 19.b - Metabolismus nukleových kyselin a proteosyntéza Proteosyntéza vyžaduje především zajištění primární struktury. Informace je uložena v DNA (ev. RNA u některých virů) trvalá forma. Forma uskladnění
19.b - Metabolismus nukleových kyselin a proteosyntéza Proteosyntéza vyžaduje především zajištění primární struktury. Informace je uložena v DNA (ev. RNA u některých virů) trvalá forma. Forma uskladnění
Bioinformatika a výpočetní biologie KFC/BIN. I. Přehled
 Bioinformatika a výpočetní biologie KFC/BIN I. Přehled RNDr. Karel Berka, Ph.D. Univerzita Palackého v Olomouci Definice bioinformatiky (Molecular) bio informatics: bioinformatics is conceptualising biology
Bioinformatika a výpočetní biologie KFC/BIN I. Přehled RNDr. Karel Berka, Ph.D. Univerzita Palackého v Olomouci Definice bioinformatiky (Molecular) bio informatics: bioinformatics is conceptualising biology
Zpráva ze zahraniční odborné stáže
 Zpráva ze zahraniční odborné stáže Zahraniční odborná stáž byla realizována v rámci projektu ROZVOJ A POSÍLENÍ SPOLUPRÁCE MEZI AKADEMICKÝMI A SOUKROMÝMI SUBJEKTY SE ZAMĚŘENÍM NA CHEMICKÝ A FARMACEUTICKÝ
Zpráva ze zahraniční odborné stáže Zahraniční odborná stáž byla realizována v rámci projektu ROZVOJ A POSÍLENÍ SPOLUPRÁCE MEZI AKADEMICKÝMI A SOUKROMÝMI SUBJEKTY SE ZAMĚŘENÍM NA CHEMICKÝ A FARMACEUTICKÝ
První testový úkol aminokyseliny a jejich vlastnosti
 První testový úkol aminokyseliny a jejich vlastnosti Vysvětlete co znamená pojem α-aminokyselina Jaký je rozdíl mezi D a L řadou aminokyselin Kolik je základních stavebních aminokyselin a z čeho jsou odvozeny
První testový úkol aminokyseliny a jejich vlastnosti Vysvětlete co znamená pojem α-aminokyselina Jaký je rozdíl mezi D a L řadou aminokyselin Kolik je základních stavebních aminokyselin a z čeho jsou odvozeny
AUG STOP AAAA S S. eukaryontní gen v genomové DNA. promotor exon 1 exon 2 exon 3 exon 4. kódující oblast. introny
 eukaryontní gen v genomové DNA promotor exon 1 exon 2 exon 3 exon 4 kódující oblast introny primární transkript (hnrna, pre-mrna) postranskripční úpravy (vznik maturované mrna) syntéza čepičky AUG vyštěpení
eukaryontní gen v genomové DNA promotor exon 1 exon 2 exon 3 exon 4 kódující oblast introny primární transkript (hnrna, pre-mrna) postranskripční úpravy (vznik maturované mrna) syntéza čepičky AUG vyštěpení
Inovace studia molekulární a buněčné biologie
 Inovace studia molekulární a buněčné biologie Tento projekt je spolufinancován Evropským sociálním fondem a státním rozpočtem České republiky. MBIO1/Molekulární biologie 1 Tento projekt je spolufinancován
Inovace studia molekulární a buněčné biologie Tento projekt je spolufinancován Evropským sociálním fondem a státním rozpočtem České republiky. MBIO1/Molekulární biologie 1 Tento projekt je spolufinancován
Biotechnologický kurz. II. letní škola metod molekulární biologie nukleových kyselin a genomiky
 Biotechnologický kurz Biotechnologický kurz II. letní škola metod molekulární biologie nukleových kyselin a genomiky 20. - 24. 6. 2011 Ústav morfologie, fyziologie a genetiky zvířat AF MENDELU v Brně Zemědělská
Biotechnologický kurz Biotechnologický kurz II. letní škola metod molekulární biologie nukleových kyselin a genomiky 20. - 24. 6. 2011 Ústav morfologie, fyziologie a genetiky zvířat AF MENDELU v Brně Zemědělská
Klonování DNA a fyzikální mapování genomu
 Klonování DNA a fyzikální mapování genomu. Terminologie Klonování je proces tvorby klonů Klon je soubor identických buněk (příp. organismů) odvozených ze společného předka dělením (např. jedna bakteriální
Klonování DNA a fyzikální mapování genomu. Terminologie Klonování je proces tvorby klonů Klon je soubor identických buněk (příp. organismů) odvozených ze společného předka dělením (např. jedna bakteriální
Výzkumné centrum genomiky a proteomiky. Ústav experimentální medicíny AV ČR, v.v.i.
 Výzkumné centrum genomiky a proteomiky Ústav experimentální medicíny AV ČR, v.v.i. Systém pro sekvenování Systém pro čipovou analýzu Systém pro proteinovou analýzu Automatický sběrač buněk Systém pro sekvenování
Výzkumné centrum genomiky a proteomiky Ústav experimentální medicíny AV ČR, v.v.i. Systém pro sekvenování Systém pro čipovou analýzu Systém pro proteinovou analýzu Automatický sběrač buněk Systém pro sekvenování
Centrální dogma molekulární biologie
 řípravný kurz LF MU 2011/12 Centrální dogma molekulární biologie Nukleové kyseliny 1865 zákony dědičnosti (Johann Gregor Mendel) 1869 objev nukleových kyselin (Miescher) 1944 genetická informace v nukleových
řípravný kurz LF MU 2011/12 Centrální dogma molekulární biologie Nukleové kyseliny 1865 zákony dědičnosti (Johann Gregor Mendel) 1869 objev nukleových kyselin (Miescher) 1944 genetická informace v nukleových
Základy molekulární biologie KBC/MBIOZ
 Základy molekulární biologie KBC/MBIOZ Ivo Frébort 4. Metody molekulární biologie I Izolace DNA a RNA Specifické postupy pro baktérie, kvasinky, rostlinné a živočišné tkáně U RNA nutno zabránit kontaminaci
Základy molekulární biologie KBC/MBIOZ Ivo Frébort 4. Metody molekulární biologie I Izolace DNA a RNA Specifické postupy pro baktérie, kvasinky, rostlinné a živočišné tkáně U RNA nutno zabránit kontaminaci
Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti ELEKTROMIGRAČNÍ METODY
 Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti ELEKTROMIGRAČNÍ METODY ELEKTROFORÉZA K čemu to je? kritérium čistoty preparátu stanovení molekulové hmotnosti makromolekul stanovení izoelektrického
Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti ELEKTROMIGRAČNÍ METODY ELEKTROFORÉZA K čemu to je? kritérium čistoty preparátu stanovení molekulové hmotnosti makromolekul stanovení izoelektrického
Chemická reaktivita NK.
 Chemické vlastnosti, struktura a interakce nukleových kyselin Bi7015 Chemická reaktivita NK. Hydrolýza NK, redukce, oxidace, nukleofily, elektrofily, alkylační činidla. Mutageny, karcinogeny, protinádorově
Chemické vlastnosti, struktura a interakce nukleových kyselin Bi7015 Chemická reaktivita NK. Hydrolýza NK, redukce, oxidace, nukleofily, elektrofily, alkylační činidla. Mutageny, karcinogeny, protinádorově
DNA TECHNIKY IDENTIFIKACE ŽIVOČIŠNÝCH DRUHŮ V KRMIVU A POTRAVINÁCH. Michaela Nesvadbová
 DNA TECHNIKY IDENTIFIKACE ŽIVOČIŠNÝCH DRUHŮ V KRMIVU A POTRAVINÁCH Michaela Nesvadbová Význam identifikace živočišných druhů v krmivu a potravinách povinností každého výrobce je řádně a pravdivě označit
DNA TECHNIKY IDENTIFIKACE ŽIVOČIŠNÝCH DRUHŮ V KRMIVU A POTRAVINÁCH Michaela Nesvadbová Význam identifikace živočišných druhů v krmivu a potravinách povinností každého výrobce je řádně a pravdivě označit
REPLIKACE A REPARACE DNA
 REPLIKACE A REPARACE DNA 1 VÝZNAM REPARACE DNA V MEDICÍNĚ Příklad: Reparace DNA: enzymy reparace nukleotidovou excizí Onemocnění: xeroderma pigmentosum 2 3 REPLIKACE A REPARACE DNA: Replikace DNA: 1. Podstata
REPLIKACE A REPARACE DNA 1 VÝZNAM REPARACE DNA V MEDICÍNĚ Příklad: Reparace DNA: enzymy reparace nukleotidovou excizí Onemocnění: xeroderma pigmentosum 2 3 REPLIKACE A REPARACE DNA: Replikace DNA: 1. Podstata
NGS analýza dat. kroužek, Alena Musilová
 NGS analýza dat kroužek, 16.12.2016 Alena Musilová Typy NGS experimentů Název Materiál Cílí na..? Cíl experimentu? amplikon DNA malý počet vybraných genů hledání variant exom DNA všechny geny hledání
NGS analýza dat kroužek, 16.12.2016 Alena Musilová Typy NGS experimentů Název Materiál Cílí na..? Cíl experimentu? amplikon DNA malý počet vybraných genů hledání variant exom DNA všechny geny hledání
Využití metod strojového učení v bioinformatice David Hoksza
 Využití metod strojového učení v bioinformatice David Hoksza SIRET Research Group Katedra softwarového inženýrství, Matematicko-fyzikální fakulta Karlova Univerzita v Praze Bioinformatika Biologické inspirace
Využití metod strojového učení v bioinformatice David Hoksza SIRET Research Group Katedra softwarového inženýrství, Matematicko-fyzikální fakulta Karlova Univerzita v Praze Bioinformatika Biologické inspirace
Exprese rekombinantních proteinů
 Exprese rekombinantních proteinů Exprese rekombinantních proteinů je proces, při kterém můžeme pomocí různých expresních systémů vytvořit protein odvozený od konkrétního genu, nebo části genu. Tento protein
Exprese rekombinantních proteinů Exprese rekombinantních proteinů je proces, při kterém můžeme pomocí různých expresních systémů vytvořit protein odvozený od konkrétního genu, nebo části genu. Tento protein
INTERPRETACE HMOTNOSTNÍCH SPEKTER
 INTERPRETACE HMOTNOSTNÍCH SPEKTER Hmotnostní spektrometrie hmotnostní spektrometrie = fyzikálně chemická metoda založená na rozdělení hmotnosti iontů v plynné fázi podle jejich poměru hmotnosti a náboje
INTERPRETACE HMOTNOSTNÍCH SPEKTER Hmotnostní spektrometrie hmotnostní spektrometrie = fyzikálně chemická metoda založená na rozdělení hmotnosti iontů v plynné fázi podle jejich poměru hmotnosti a náboje
Úvod do strukturní analýzy farmaceutických látek
 Úvod do strukturní analýzy farmaceutických látek Garant předmětu: doc. Ing. Bohumil Dolenský, Ph.D. A28, linka 4110, dolenskb@vscht.cz Hmotnostní spektrometrie II. Příprava předmětu byla podpořena projektem
Úvod do strukturní analýzy farmaceutických látek Garant předmětu: doc. Ing. Bohumil Dolenský, Ph.D. A28, linka 4110, dolenskb@vscht.cz Hmotnostní spektrometrie II. Příprava předmětu byla podpořena projektem
Determinanty lokalizace nukleosomů
 METODY STUDIA CHROMATINU Topologie DNA a nukleosomů Struktura nukleosomu 1.65-1.8 otáčky Struktura nukleosomu 10.5 nt 1.8 otáčky 10n, 10n + 5 146 nt Determinanty lokalizace nukleosomů mechanické vlastnosti
METODY STUDIA CHROMATINU Topologie DNA a nukleosomů Struktura nukleosomu 1.65-1.8 otáčky Struktura nukleosomu 10.5 nt 1.8 otáčky 10n, 10n + 5 146 nt Determinanty lokalizace nukleosomů mechanické vlastnosti
DIAGNOSTICKÝ KIT PRO DETEKCI MINIMÁLNÍ REZIUDÁLNÍ CHOROBY MRD EGFR
 Úvod IntellMed, s.r.o., Václavské náměstí 820/41, 110 00 Praha 1 DIAGNOSTICKÝ KIT PRO DETEKCI MINIMÁLNÍ REZIUDÁLNÍ CHOROBY MRD EGFR Jednou z nejvhodnějších metod pro detekci minimální reziduální choroby
Úvod IntellMed, s.r.o., Václavské náměstí 820/41, 110 00 Praha 1 DIAGNOSTICKÝ KIT PRO DETEKCI MINIMÁLNÍ REZIUDÁLNÍ CHOROBY MRD EGFR Jednou z nejvhodnějších metod pro detekci minimální reziduální choroby
Biologie buňky. systém schopný udržovat se a rozmnožovat
 Biologie buňky 1665 - Robert Hook (korek, cellulae = buňka) Cytologie - věda zabývající se studiem buňek Buňka ozákladní funkční a stavební jednotka živých organismů onejmenší známý uspořádaný dynamický
Biologie buňky 1665 - Robert Hook (korek, cellulae = buňka) Cytologie - věda zabývající se studiem buňek Buňka ozákladní funkční a stavební jednotka živých organismů onejmenší známý uspořádaný dynamický
MOLEKULÁRNÍ BIOLOGIE. 2. Polymerázová řetězová reakce (PCR)
") MOLEKULÁRNÍ BIOLOGIE 2. Polymerázová řetězová reakce (PCR) Náplň praktik 1. Izolace DNA z buněk bukální sliznice - izolační kit MACHEREY-NAGEL 2. PCR polymerázová řetězová reakce (templát gdna) 3. Restrikční
MOLEKULÁRNÍ BIOLOGIE 2. Polymerázová řetězová reakce (PCR) Náplň praktik 1. Izolace DNA z buněk bukální sliznice - izolační kit MACHEREY-NAGEL 2. PCR polymerázová řetězová reakce (templát gdna) 3. Restrikční
Inovace studia molekulární a buněčné biologie reg. č. CZ.1.07/2.2.00/
 Inovace studia molekulární a buněčné biologie reg. č. CZ.1.07/2.2.00/07.0354 Genomika (KBB/GENOM) Sekvenování genomů Ing. Hana Šimková, CSc. Cíl přednášky - seznámení se strategiemi celogenomového sekvenování,
Inovace studia molekulární a buněčné biologie reg. č. CZ.1.07/2.2.00/07.0354 Genomika (KBB/GENOM) Sekvenování genomů Ing. Hana Šimková, CSc. Cíl přednášky - seznámení se strategiemi celogenomového sekvenování,
Proteiny Genová exprese. 2013 Doc. MVDr. Eva Bártová, Ph.D.
 Proteiny Genová exprese 2013 Doc. MVDr. Eva Bártová, Ph.D. Bílkoviny (proteiny), 15% 1g = 17 kj Monomer = aminokyseliny aminová skupina karboxylová skupina α -uhlík postranní řetězec Znát obecný vzorec
Proteiny Genová exprese 2013 Doc. MVDr. Eva Bártová, Ph.D. Bílkoviny (proteiny), 15% 1g = 17 kj Monomer = aminokyseliny aminová skupina karboxylová skupina α -uhlík postranní řetězec Znát obecný vzorec
Klinická a farmaceutická analýza. Petr Kozlík Katedra analytické chemie
 Klinická a farmaceutická analýza Petr Kozlík Katedra analytické chemie e-mail: kozlik@natur.cuni.cz http://web.natur.cuni.cz/~kozlik/ 1 Spojení separačních technik s hmotnostní spektrometrem Separační
Klinická a farmaceutická analýza Petr Kozlík Katedra analytické chemie e-mail: kozlik@natur.cuni.cz http://web.natur.cuni.cz/~kozlik/ 1 Spojení separačních technik s hmotnostní spektrometrem Separační
Implementace laboratorní medicíny do systému vzdělávání na Univerzitě Palackého v Olomouci. reg. č.: CZ.1.07/2.2.00/
 Implementace laboratorní medicíny do systému vzdělávání na Univerzitě Palackého v Olomouci reg. č.: CZ.1.07/2.2.00/28.0088 Hybridizační metody v diagnostice Mgr. Gabriela Kořínková, Ph.D. Laboratoř molekulární
Implementace laboratorní medicíny do systému vzdělávání na Univerzitě Palackého v Olomouci reg. č.: CZ.1.07/2.2.00/28.0088 Hybridizační metody v diagnostice Mgr. Gabriela Kořínková, Ph.D. Laboratoř molekulární
DUM č. 10 v sadě. 37. Bi-2 Cytologie, molekulární biologie a genetika
 projekt GML Brno Docens DUM č. 10 v sadě 37. Bi-2 Cytologie, molekulární biologie a genetika Autor: Martin Krejčí Datum: 26.06.2014 Ročník: 6AF, 6BF Anotace DUMu: Procesy následující bezprostředně po transkripci.
projekt GML Brno Docens DUM č. 10 v sadě 37. Bi-2 Cytologie, molekulární biologie a genetika Autor: Martin Krejčí Datum: 26.06.2014 Ročník: 6AF, 6BF Anotace DUMu: Procesy následující bezprostředně po transkripci.
ENZYMY A NUKLEOVÉ KYSELINY
 ENZYMY A NUKLEOVÉ KYSELINY Autor: Mgr. Stanislava Bubíková Datum (období) tvorby: 28. 3. 2013 Ročník: devátý Vzdělávací oblast: Člověk a příroda / Chemie / Organické sloučeniny 1 Anotace: Žáci se seznámí
ENZYMY A NUKLEOVÉ KYSELINY Autor: Mgr. Stanislava Bubíková Datum (období) tvorby: 28. 3. 2013 Ročník: devátý Vzdělávací oblast: Člověk a příroda / Chemie / Organické sloučeniny 1 Anotace: Žáci se seznámí
TEST: GENETIKA, MOLEKULÁRNÍ BIOLOGIE
 TEST: GENETIKA, MOLEKULÁRNÍ BIOLOGIE 1) Důležitým biogenním prvkem, obsaženým v nukleových kyselinách nebo ATP a nezbytným při tvorbě plodů je a) draslík b) dusík c) vápník d) fosfor 2) Sousedící nukleotidy
TEST: GENETIKA, MOLEKULÁRNÍ BIOLOGIE 1) Důležitým biogenním prvkem, obsaženým v nukleových kyselinách nebo ATP a nezbytným při tvorbě plodů je a) draslík b) dusík c) vápník d) fosfor 2) Sousedící nukleotidy
Molekulární diagnostika
 Molekulární diagnostika Odry 11. 11. 2010 Michal Pohludka, Ph.D. Buňka základní jednotka živé hmoty Všechny v současnosti známé buňky se vyvinuly ze společného předka, tedy buňky, která žila asi před 3,5-3,8
Molekulární diagnostika Odry 11. 11. 2010 Michal Pohludka, Ph.D. Buňka základní jednotka živé hmoty Všechny v současnosti známé buňky se vyvinuly ze společného předka, tedy buňky, která žila asi před 3,5-3,8
Imunochemické metody. na principu vazby antigenu a protilátky
 Imunochemické metody na principu vazby antigenu a protilátky ANTIGEN (Ag) specifická látka (struktura) vyvolávající imunitní reakci a schopná vazby na protilátku PROTILÁTKA (Ab antibody) molekula bílkoviny
Imunochemické metody na principu vazby antigenu a protilátky ANTIGEN (Ag) specifická látka (struktura) vyvolávající imunitní reakci a schopná vazby na protilátku PROTILÁTKA (Ab antibody) molekula bílkoviny
Struktura a funkce biomakromolekul
 Struktura a funkce biomakromolekul KBC/BPOL 6. Struktura nukleových kyselin Ivo Frébort Struktura nukleových kyselin Primární struktura: sekvence nukleotidů Sekundární struktura: vzájemná poloha nukleotidů
Struktura a funkce biomakromolekul KBC/BPOL 6. Struktura nukleových kyselin Ivo Frébort Struktura nukleových kyselin Primární struktura: sekvence nukleotidů Sekundární struktura: vzájemná poloha nukleotidů
Bílkoviny a rostlinná buňka
 Bílkoviny a rostlinná buňka Bílkoviny Rostliny --- kontinuální diferenciace vytváření orgánů: - mitotická dělení -zvětšování buněk a tvorba buněčné stěny syntéza bílkovin --- fotosyntéza syntéza bílkovin
Bílkoviny a rostlinná buňka Bílkoviny Rostliny --- kontinuální diferenciace vytváření orgánů: - mitotická dělení -zvětšování buněk a tvorba buněčné stěny syntéza bílkovin --- fotosyntéza syntéza bílkovin
HMOTNOSTNÍ SPEKTROMETRIE
 HMOTNOSTNÍ SPEKTROMETRIE MASS SPECTROMETRY (MS) Alternativní názvy (spojení s GC, LC, CZE, ITP): Hmotnostně spektrometrický (selektivní) detektor Mass spectrometric (selective) detector (MSD) Spektrometrie
HMOTNOSTNÍ SPEKTROMETRIE MASS SPECTROMETRY (MS) Alternativní názvy (spojení s GC, LC, CZE, ITP): Hmotnostně spektrometrický (selektivní) detektor Mass spectrometric (selective) detector (MSD) Spektrometrie
Aplikovaná bioinformatika
 Aplikovaná bioinformatika Číslo aktivity: 2.V Název klíčové aktivity: Na realizaci se podílí: Implementace nových předmětů do daného studijního programu doc. RNDr. Michaela Wimmerová, Ph.D., Mgr. Josef
Aplikovaná bioinformatika Číslo aktivity: 2.V Název klíčové aktivity: Na realizaci se podílí: Implementace nových předmětů do daného studijního programu doc. RNDr. Michaela Wimmerová, Ph.D., Mgr. Josef
Sekvenování nové generace. Radka Reifová
 Sekvenování nové generace Radka Reifová Prezentace ke stažení www.natur.cuni.cz/zoologie/biodiversity v záložce Přednášky 1. Přehled sekvenačních metod nové generace 2. Využití sekvenačních metod nové
Sekvenování nové generace Radka Reifová Prezentace ke stažení www.natur.cuni.cz/zoologie/biodiversity v záložce Přednášky 1. Přehled sekvenačních metod nové generace 2. Využití sekvenačních metod nové
Pražské analytické centrum inovací Projekt CZ / /0002 spolufinancovaný ESF a Státním rozpočtem ČR
 Pražské analytické centrum inovací Projekt CZ.04.3.07/4.2.01.1/0002 spolufinancovaný ESF a Státním rozpočtem ČR SEPARACE PROTEINŮ Preparativní x analytická /měřítko, účel/ Zvláštnosti dané povahou materiálu
Pražské analytické centrum inovací Projekt CZ.04.3.07/4.2.01.1/0002 spolufinancovaný ESF a Státním rozpočtem ČR SEPARACE PROTEINŮ Preparativní x analytická /měřítko, účel/ Zvláštnosti dané povahou materiálu
Základy molekulární biologie KBC/MBIOZ
 Základy molekulární biologie KBC/MBIOZ 4. Metody molekulární biologie I Izolace DNA a RNA Specifické postupy pro baktérie, kvasinky, rostlinné a živočišné tkáně U RNA nutno zabránit kontaminaci RNasami
Základy molekulární biologie KBC/MBIOZ 4. Metody molekulární biologie I Izolace DNA a RNA Specifické postupy pro baktérie, kvasinky, rostlinné a živočišné tkáně U RNA nutno zabránit kontaminaci RNasami
Struktura a funkce biomakromolekul
 Struktura a funkce biomakromolekul KBC/BPOL 7. Interakce DNA/RNA - protein Ivo Frébort Interakce DNA/RNA - proteiny v buňce Základní dogma molekulární biologie Replikace DNA v E. coli DNA polymerasa a
Struktura a funkce biomakromolekul KBC/BPOL 7. Interakce DNA/RNA - protein Ivo Frébort Interakce DNA/RNA - proteiny v buňce Základní dogma molekulární biologie Replikace DNA v E. coli DNA polymerasa a
Využití metagenomiky při hodnocení sanace chlorovaných ethylenů in situ Výsledky pilotních testů
 Využití metagenomiky při hodnocení sanace chlorovaných ethylenů in situ Výsledky pilotních testů Stavělová M.,* Macháčková J.*, Rídl J.,** Pačes J.** * Earth Tech CZ, s.r.o ** ÚMG AV ČR PROČ METAGENOMIKA?
Využití metagenomiky při hodnocení sanace chlorovaných ethylenů in situ Výsledky pilotních testů Stavělová M.,* Macháčková J.*, Rídl J.,** Pačes J.** * Earth Tech CZ, s.r.o ** ÚMG AV ČR PROČ METAGENOMIKA?
(molekulární) biologie buňky
 biologie buňky") (molekulární) biologie buňky Buňka základní principy Molecules of life Centrální dogma membrány Metody GI a MB Interakce Struktura a funkce buňky - principy proteiny, nukleové kyseliny struktura, funkce
(molekulární) biologie buňky Buňka základní principy Molecules of life Centrální dogma membrány Metody GI a MB Interakce Struktura a funkce buňky - principy proteiny, nukleové kyseliny struktura, funkce
GENOTOXICITA A ZMĚNY V GENOVÉ EXPRESI
 GENOTOXICITA A ZMĚNY V GENOVÉ EXPRESI INDUKOVANÉ PŮSOBENÍM ORGANICKÝCH LÁTEK Z PRACHOVÝCH ČÁSTIC V OVZDUŠÍ Kateřina Hanzalová Oddělení genetické ekotoxikologie Ústav experimentální medicíny AV ČR v.v.i.
GENOTOXICITA A ZMĚNY V GENOVÉ EXPRESI INDUKOVANÉ PŮSOBENÍM ORGANICKÝCH LÁTEK Z PRACHOVÝCH ČÁSTIC V OVZDUŠÍ Kateřina Hanzalová Oddělení genetické ekotoxikologie Ústav experimentální medicíny AV ČR v.v.i.
Tématické okruhy pro státní závěrečné zkoušky
 Tématické okruhy pro státní závěrečné zkoušky Obor Povinný okruh Volitelný okruh (jeden ze dvou) Forenzní biologická Biochemie, pathobiochemie a Toxikologie a bioterorismus analýza genové inženýrství Kriminalistické
Tématické okruhy pro státní závěrečné zkoušky Obor Povinný okruh Volitelný okruh (jeden ze dvou) Forenzní biologická Biochemie, pathobiochemie a Toxikologie a bioterorismus analýza genové inženýrství Kriminalistické
Inovace studia molekulární a buněčné biologie reg. č. CZ.1.07/2.2.00/
 Inovace studia molekulární a buněčné biologie reg. č. CZ.1.07/2.2.00/07.0354 Genomika (KBB/GENOM) Analýza transkriptomu Ing. Hana Šimková, CSc. Cíl přednášky - seznámení s moderními metodami komplexní
Inovace studia molekulární a buněčné biologie reg. č. CZ.1.07/2.2.00/07.0354 Genomika (KBB/GENOM) Analýza transkriptomu Ing. Hana Šimková, CSc. Cíl přednášky - seznámení s moderními metodami komplexní
5. Sekvenování, přečtení genetické informace, éra genomiky.
 5. Sekvenování, přečtení genetické informace, éra genomiky. Minulá přednáška nastínila zrod molekulární biologie a představila některé možnosti, jak pracovat s DNA - jak ji analyzovat na základě velikosti
5. Sekvenování, přečtení genetické informace, éra genomiky. Minulá přednáška nastínila zrod molekulární biologie a představila některé možnosti, jak pracovat s DNA - jak ji analyzovat na základě velikosti
Bioinformatika. Jiří Vondrášek Ústav organické chemie a biochemie Jan Pačes Ústav molekulární genetiky
 Bioinformatika pro PrfUK 2006 Jiří Vondrášek Ústav organické chemie a biochemie vondrasek@uochb.cas.cz Jan Pačes Ústav molekulární genetiky hpaces@img.cas.cz http://bio.img.cas.cz/prfuk2006 syllabus Úterý,
Bioinformatika pro PrfUK 2006 Jiří Vondrášek Ústav organické chemie a biochemie vondrasek@uochb.cas.cz Jan Pačes Ústav molekulární genetiky hpaces@img.cas.cz http://bio.img.cas.cz/prfuk2006 syllabus Úterý,
Translace (druhý krok genové exprese)
") Translace (druhý krok genové exprese) Od RN k proteinu Milada Roštejnská Helena Klímová 1 enetický kód trn minoacyl-trn-synthetasa Translace probíhá na ribosomech Iniciace translace Elongace translace
Translace (druhý krok genové exprese) Od RN k proteinu Milada Roštejnská Helena Klímová 1 enetický kód trn minoacyl-trn-synthetasa Translace probíhá na ribosomech Iniciace translace Elongace translace
Inovace studia molekulární a buněčné biologie
 Investice do rozvoje vzdělávání Inovace studia molekulární a buněčné biologie Tento projekt je spolufinancován Evropským sociálním fondem a státním rozpočtem České republiky. Investice do rozvoje vzdělávání
Investice do rozvoje vzdělávání Inovace studia molekulární a buněčné biologie Tento projekt je spolufinancován Evropským sociálním fondem a státním rozpočtem České republiky. Investice do rozvoje vzdělávání
Metody molekulární biologie
 Metody molekulární biologie 1. Základní metody molekulární biologie A. Izolace nukleových kyselin Metody využívající různé rozpustnosti Metody adsorpční Izolace RNA B. Centrifugační techniky o Princip
Metody molekulární biologie 1. Základní metody molekulární biologie A. Izolace nukleových kyselin Metody využívající různé rozpustnosti Metody adsorpční Izolace RNA B. Centrifugační techniky o Princip
Základy praktické Bioinformatiky
 Základy praktické Bioinformatiky PETRA MATOUŠKOVÁ 2018/2019 8/10 Základy praktické bioinformatiky Téma 8/10 Nukleotidová bioinformatika IV Cíle: Student bude schopen navrhnout primery pro kvantitativní
Základy praktické Bioinformatiky PETRA MATOUŠKOVÁ 2018/2019 8/10 Základy praktické bioinformatiky Téma 8/10 Nukleotidová bioinformatika IV Cíle: Student bude schopen navrhnout primery pro kvantitativní