Intervaly spolehlivosti
|
|
|
- Simona Beránková
- před 6 lety
- Počet zobrazení:
Transkript
1 Intervaly spolehlivosti = intervalové odhady neznámého parametru (odhad pro π, µ, σ 2, ), odvozují se z příslušné CLV spolehlivost = 1 α = pravděpodobnost, že neznámá hodnota parametru je intervalem pokryta; nejčastěji volba 1 α = 0,95 (95% I.S.)
2 Oboustranné intervaly spolehlivosti Pro střední hodnotu μ při známém σ: _ x ± u σ/ n 1-α/2 Pro střední hodnotu μ při neznámém σ: _ x ± t s/ n 1-α/2 (n-1) kde n-1= počet stupňů volnosti (DF)


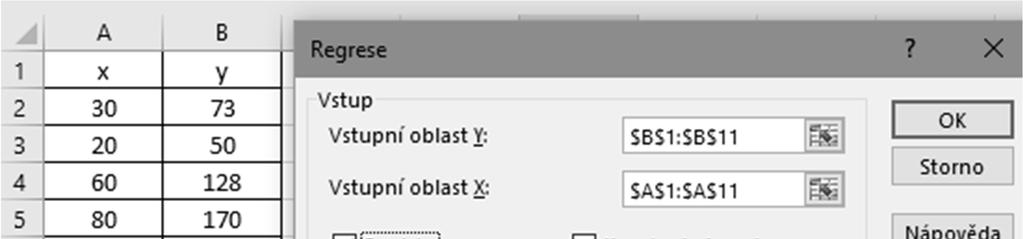
3 VSUVKA aktivace nástroje ANALÝZA DAT v Excelu


4 VSUVKA aktivace nástroje ANALÝZA DAT v Excelu



5 Oboustranné intervaly spolehlivosti Pro střední hodnotu μ (pomocí Excelu):



6 Oboustranné intervaly spolehlivosti Pro střední hodnotu μ (pomocí Excelu):



7 Oboustranné intervaly spolehlivosti Pro střední hodnotu μ (pomocí Excelu):


8 Oboustranné intervaly spolehlivosti Pro střední hodnotu μ (pomocí Excelu): dolní mez: 13,625-1,177= =12,448; horní mez: 13,625+1,177= =14,802
9 Oboustranné intervaly spolehlivosti Pro střední hodnotu μ (odpověď): S 95% spolehlivostí je střední věk čtenářů daného časopisu z rozmezí 12,448 až 14,802 roku. Zpřesnění odhadu (tj. zúžení IS)? a) zvýšit n (=změna dat); b) snížit spolehlivost (data stejná); c) snížit variabilitu (=změna populace).
10 Oboustranné intervaly spolehlivosti Ilustrace vlivu zvýšení n (viz ZVČ):
11 Jednostranné intervaly spolehlivosti hledáme jen jednu z obou mezí Princip: dle zadání úlohy hledáme jen dolní či jen horní mez podle oboustranného vzorce s tou změnou, že výraz 1-α/2 ve vzorci nahradíme výrazem 1-α.
12 Testování hypotéz Otestujte / ověřte / prokažte že střední věk (tj. µ) činí 40 let (=40) je alespoň 40 let (>40)
13 Testování hypotéz Otestujte / ověřte / prokažte zda hmotnost vejce závisí na jeho délce je různá dle typu snůšky
14 Testování hypotéz Nulová hypotéza H 0 : pevně daná forma (nerozhoduje slovní formulace problému!); u parametrických testů obsahuje H 0 rovnost, v jiných speciálních případech obsahuje H 0 např. tvrzení o nezávislosti Alternativní hypotéza H 1 : doplněk k H 0
15 Testování hypotéz Postup rozhodování při použití statistického SW (i např. Excel) nelze ručně : a) Z dat spočte počítač p-hodnotu (je vždy mezi 0-1) b) Porovnáme p-hodnotu s předem zvolenou α : c) Pokud je p α, zamítáme při daném α nulovou hypotézu ve prospěch hypotézy alternativní d) Pokud naopak je p>α, nelze při daném α zamítnout nulovou hypotézu ve prospěch hypotézy alternativní
16 Testování hypotéz Jaký význam má ono volené α? Možnosti při testování: Dle dat vyberu H 0 Doopravdy platí H 0 OK Doopravdy platí H 1 chyba 2. druhu Dle dat chyba 1. zamítnu H 0 druhu OK α=p(chyby 1.druhu) hladina významnosti
17 Jednovýběrový t-test Pro střední hodnotu μ : a) H 0 : μ=μ 0 H 1 : μ μ 0 (oboustranná alternativa) b) H 0 : μ=μ 0 H 1 : μ>μ 0 c) H 0 : μ=μ 0 H 1 : μ<μ 0 (jednostranné alternativy) Vždyμ 0 je konkrétní testovaná hodnota.
18 Jednovýběrový t-test Příklad: Dle věku osmi náhodně vybraných čtenářů dětského časopisu ověřte pravdivost tvrzení, že střední věk čtenářů tohoto časopisu je 14 let. Věky popořadě (viz interval spolehlivosti): 12, 14, 15, 12, 15, 14, 12, 15. H 0 : μ=14 H 1 : μ 14


19 Výsledek = p-hodnota
20
21 Jednovýběrový t-test Příklad (výsledek): p=0,48 (>0,05) nelze zamítnout H 0 Příklad (odpověď): Na 5% hladině významnosti nelze na základě dat zamítnout tvrzení, že střední věk čtenářů činí 14 let. Příklad (k zamyšlení): Je nějaký vztah mezi tímto výsledkem a intervalem spolehlivosti [12,448; 14,802]?
22 Párový t-test Sledujeme spojitou číselnou veličinu (např.): Hmotnost zvířete před uložením do zimního spánku a po probuzení; Změření výšky stromu dvěma metodami (standardní a novou, experimentální); Chceme prokázat: Způsobuje zimní spánek významné snížení hmotnosti? Jsou výškové údaje zjištěné novou, experimentální metodou, srovnatelné s údaji zjištěnými osvědčenou standardní metodou?
23 Párový t-test Data jsou ve tvaru párů, tj. uspořádaných dvojic (též tzv. závislé výběry dependent samples): (y 1 ;z 1 ),, (y n ; z n ), kde např. y i = hmotnost před zimním spánkem (i-té zvíře), z i = hmotnost po probuzení (i-té zvíře) i=1,,n n=počet zvířat (2n=počet údajů) y i = výška i-tého stromu zjištěná standardně, z i = výška i-tého stromu zjištěná novou metodou i=1,,n n=počet stromů (2n=počet údajů)
24 Párový t-test Řešení: Představíme-li si rozdíly (není je ale ani nutno skutečně počítat) x i = y i z i (i=1,,n) vznikla by rozdílová veličina X, jejíž střední hodnotu označíme μ
25 Párový t-test Řešení: pro rozdílovou veličinu X provedeme parametrický test s nulovou hypotézou H 0 : μ=0 (mezi hodnotami v párech není významný rozdíl) a s alternativou H 1 : μ 0 (mezi hodnotami v párech je významný rozdíl), příp. (často) s alternativou jednostrannou (viz příklad se zimním spánkem)
26 Párový t-test Příklad: Posuďte na základě uvedených dat, zda obě metody určují v průměru výšku objektů srovnatelně. Osm objektů měřeno, každý oběma metodami: Výška standardní metodou (m) 1,2 2,4 1,6 1,8 3,2 2,7 2,0 1,9 Výška experimentálně ověřovanou novou metodou (m) 1,3 2,4 1,8 1,7 3,3 3,1 1,8 2,2



27 Párový t-test Počítačové řešení (Excelem):



28 Párový t-test



29 Párový t-test p>α (0,2002>0,05) nelze zamítnout H 0
30 Excel rychle : =TTEST(B1:I1;B2:I2;2;1) R: Párový t-test Pro zkoumanou veličinu by ale měla platit NORMALITA; ne-li, co dělat?
31 Párový Wilcoxonův test neparametrická verze párového testu; netestujeme chování parametru µ testujeme shodu (H 0 ), resp. rozdílnost (H 1 ) polohy obou závislých výběrů:
32 Rozhodnutí: p=0,2702 > 0,05 Nelze zamítnout H 0. aneb: Data neprokázala významnou odlišnost mezi oběma metodami. aneb: Nová metoda měří srovnatelně s tou standardní.
33 Dvouvýběrové testy Sledujeme (spojité) číselné veličiny, např.: výšku ve skupině mužů a ve skupině žen; hmotnost vajec ptačích druhů A a B; Chceme prokázat: Je/není výška mužů a žen srovnatelná? Je/není mezi oběma ptačími druhy výrazný rozdíl ve hmotnosti vajec?
34 Dvouvýběrové parametrické testy Předpoklady: obě skupiny jsou nezávislé (např. u mužů a žen nejde o manželské páry) sledovaná veličina se v obou srovnávaných skupinách chová jako veličina normálně rozdělená
35 Dvouvýběrové parametrické testy Možnosti: a) v obou skupinách odlišné µ i σ 2
36 Dvouvýběrové parametrické testy Možnosti: b) v obou skupinách shodné µ, σ 2 odlišné
37 Dvouvýběrové parametrické testy Možnosti: c) v obou skupinách odlišné µ, σ 2 shodné
38 Dvouvýběrové parametrické testy Možnosti: d) v obou skupinách shodné µ i σ 2
39 Dvouvýběrové parametrické testy Testujeme tedy (popořadě): 1. Je v obou skupinách srovnatelná či naopak výrazně odlišná variabilita? ANEB: H 0 : σ a2 = σ b 2 versus H 1 : σ a2 σ b 2 Jde o tzv. F-test homogenity rozptylů.
40 Dvouvýběrové parametrické testy Příklad: Zjistěte, zda ve sledované populaci závisí chování veličiny věk na pohlaví. Jde o příklad testu (ne)závislosti spojité veličiny na veličině alternativní. Jinak řečeno, porovnáváme chování veličiny věk u mužů a u žen Je to tedy opravdu 2-výběrový test. Nejprve zjistíme, zda je v obou skupinách srovnatelná variabilita:
;")

41 Dvouvýběrové parametrické testy Výsledkem je p-hodnota (zde =0,522); protože p>0,05, nelze zamítnout H 0. Znamená to, že variabilita obou skupin je srovnatelná.
42 Dvouvýběrové parametrické testy Následně testujeme: 2. Jsou v obou skupinách srovnatelné či naopak výrazně odlišné střední hodnoty? ANEB: H 0 : µ a = µ b versus H 1 : µ a µ b Jde o tzv. 2-výběrový t-test. Na F-test navazuje proto, že existuje ve dvou variantách: při různých a při shodných rozptylech.

 u obou")
43 Dvouvýběrové parametrické testy Příklad - pokračování: Už víme, že veličina věk má ve sledované populaci srovnatelný rozptyl u mužů a u žen. Teď ověříme, zda je i střední hodnota (střední věk) u obou pohlaví srovnatelná, nebo zda se výrazně liší u mužů a u žen.

 ve sledované populaci nebyla zjištěna")
44 Dvouvýběrové parametrické testy p-hodnota = 0,374 p>0,05 nelze zamítnout H 0 Nejen rozptyl věku, ale také střední věk mužů a žen je srovnatelný. Jinak řečeno (celkově) ve sledované populaci nebyla zjištěna závislost věku na pohlaví (situaci odpovídají Gaussovy křivky dle d)).
45 Dvouvýběrové parametrické testy Excel rychleji (příkaz určující jen p-hodnotu): =TTEST(data1;data2;1;2) jednostranně, shodné rozptyly =TTEST(data1;data2;2;2) oboustranně, shodné rozptyly =TTEST(data1;data2;1;3) jednostranně, různé rozptyly =TTEST(data1;data2;2;3) oboustranně, různé rozptyly R: (verze obecná, při neshodě rozptylů)
46 Mann-Whitney test =neparametrická verze 2-výběrového testu netestujeme chování parametru µ testujeme shodu (H 0 ), resp. rozdílnost (H 1 ) polohy obou nezávislých výběrů:
47 Sledujeme (např.): ANOVA Hmotnost jedinců tří psích plemen; Délku klasů u čtyř odrůd pšenice; Chceme prokázat (typické praktické otázky): je u všech tří plemen hmotnost jedinců srovnatelná, nebo se významně liší? závisí délka klasu na odrůdě?
48 ANOVA Předpoklady: všechny skupiny jsou nezávislé sledovaná veličina (hmotnost, délka, atp.) se ve všech srovnávaných skupinách chová jako veličina normálně rozdělená, a to se stejnou variabilitou (tzv. podmínka homogenity rozptylů)
49 Komentáře: ANOVA jde tedy o zobecnění 2-výběrových testů na případ dvou či více porovnávaných skupin zajímá nás vlastně, zda chování sledované normálně rozdělené veličiny Y (plat respondenta, resp. délka výlisku, ) závisí na příslušnosti do té či oné kategorie ANEB zda Y závisí na tzv. kategoriálním faktoru (na vzdělání, na typu stroje, ), odtud označení jednofaktorová ANOVA
50 ANOVA Značení: r počet rozlišovaných kategorií u daného faktoru (r>2) µ i střední hodnota Y v i-té kategorii (i=1 r) Testujeme: H 0 : µ 1 = =µ r H 1 : non H 0 ANEB nezávislost na faktoru ANEB závislost na faktoru
51 ANOVA Gaussovy křivky (3-kategoriální faktor):
52 ANOVA Data (3-kategoriální faktor):
53 ANOVA Značení: podmíněné průměry (po kategoriích)
54 ANOVA Značení: celkový průměr (všech skupin)
55 ANOVA Výpočty: součty čtverců Q TOT, Q m, Q v viz přehled vzorců:
56 ANOVA Výsledky tabulka ANOVY: hodnota meziskupinová vnitroskupinová součet stupně podíl čtverců volnosti Q m r 1 Q m /(r 1) Q v n r Q v /(n r) suma Q TOT n 1

57 ANOVA Příklad: Byly sledovány výnosy čtyř odrůd brambor (označme odrůdy A, B, C, D). Každá odrůda byla pěstována na sedmi srovnatelných polích. Zjistěte, zda je typ odrůdy faktorem, který ovlivňuje hektarový výnos brambor. Data jednotlivé výnosy (v Excelu): H 0 : nezávislost výnosů na odrůdě H 1 : závislost (aneb výnosy se významně liší)



58 ANOVA



59 ANOVA



60 ANOVA p = 3, = = 0,
61 ANOVA Výsledek: p=0, < 0,05 zamítáme H 0 Data prokázala, že výnosy jednotlivých 4 odrůd se významně liší ANEB že odrůda je faktorem, na němž výnos významně závisí.
62 ANOVA Poznámky: a) ANOVA = zkratka z analysis of variance b) DF = zkratka z degrees of freedom (stupně volnosti) c) pokud r=2, lze závislost na faktoru porovnat jak ANOVOU, tak 2-výběrovými testy (ty mají oproti ANOVĚ tu výhodu, že existují i v jednostranných variantách a lze tudíž případně posoudit, která z obou porovnávaných kategorií je lepší )
63 ANOVA Poznámky: d) Sice jsme prokázali významné rozdíly ve výnosech, můžeme dokonce porovnat zjištěné podmíněné průměry (viz Excel), ale NELZE hned tvrdit, že ANOVA prokázala, která odrůda je horší či lepší zatím víme jen, že jsou významné rozdílnosti
64 ANOVA post hoc testy ANOVA detekuje rozdílnost zjišťujeme dvou-výběrovými porovnáváními jednotlivých kategorií, které dvě se navzájem významně odlišují tzv. post-hoc testy Bonferroniho korekce: α* = α/m (m počet vzájemných porovnání)
65 Kruskal-Wallis test = neparametrická obdoba ANOVA testu testujeme shodu (H 0 ), resp. rozdílnost (H 1 ) polohy všech nezávislých výběrů R: kruskal.test(list(data1,data2,,datar)) nebo kruskal.test(datakomplet~faktorkomplet)
66 Test normality Jak posoudit, kdy postupovat ne/parametricky? Shapiro-Wilkův test normality H 0 : shoda dat s normálním modelem R: shapiro.test(data)
67 TEST א 2 DOBRÉ SHODY Sledujeme kategoriální veličinu X (např.): pohlaví (zastoupení samců a samic); kvalita výrobku (I.jakost, II.jakost, zmetek); Chceme prokázat: jsou obě pohlaví zastoupena rovnoměrně, tedy v poměru 1:1 (50:50 %)? jsou výrobky dle jakosti zastoupeny v poměru 3:1:1 (60:20:20 %)?
68 TEST א 2 DOBRÉ SHODY Testovaná dvojice hypotéz - obecně pro veličinu X s r-kategoriemi: H 0 : P(x 1 ) = π 1 ; P(x 2 ) = π 2 ; ; P(x r ) = π r H 1 : non H 0 kde π 1,,π r jsou konkr. čísla: π 1 + +π r = 1
69 TEST א 2 DOBRÉ SHODY Testovaná dvojice hypotéz konkr.: - u příkladu samci vs samice: H 0 : P(x 1 ) = 0,5 ; P(x 2 ) = 0,5 - u příkladu s jakostí: H 0 : P(x 1 ) = 0,6 ; P(x 2 ) = 0,2 ; P(x 3 ) = 0,2
70 TEST א 2 DOBRÉ SHODY Z dat určíme absolutní, tzv. pozorované četnosti n 1 ; n 2 ; ; n r přičemž n n r = n Pro jednotlivé kategorie spočteme tzv. očekávané četnosti o 1 ; o 2 ; ; o r a to podle vzorce: o i = n π i (i=1,,r)
71 TEST א 2 DOBRÉ SHODY Např. nechť při kontrole jakosti bylo 110 výrobků I. jakosti (n 1 = 110), 56 výrobků II. jakosti (n 2 = 56) 34 zmetků (n 3 = 34), tj. n= 200; při testu, zda π 1 =0,6;π 2 =0,2; π 3 =0,2 dostaneme jaké očekávané četnosti? o 1 = n π 1 = 200 0,6 = 120 o 2 = n π 2 = 200 0,2 = 40 o 3 = n π 3 = 200 0,2 = 40
72 TEST א 2 DOBRÉ SHODY Podstatou testové statistiky je porovnání četností pozorovaných s očekávanými: T = Σ (n i o i ) 2 / o i (i=1 r) Př. (pokrač.): T = ( ) 2 / (56 40) 2 / (34 40) 2 /40 = = 0,83 + 6,40 + 0,90 = 8,13


73 TEST א 2 DOBRÉ SHODY Řešení pomocí Excelu: p=0,017 tj.?
74 TEST א 2 DOBRÉ SHODY Poznámka: V principu lze takto testovat i normalitu; Sledovanou číselnou veličinu rozsekáme intervalovým rozdělením do kategorií a porovnáme pozorované četnosti v těchto kategoriích s očekávanými, které by odpovídaly pravděpodobnostem dle gaussovského modelu
75 TEST א 2 NEZÁVISLOSTI Sledujeme dvojici kategoriálních veličin X,Y např. u každého respondenta jeho pohlaví (M-Ž) a krevní skupinu (A-B-AB-0); nebo u každého výrobku jeho kvalitu (I.jakost, II.jakost, zmetek) a to, během jaké směny vznikl (dopolední odpolední - noční směna);
76 TEST א 2 NEZÁVISLOSTI Chceme prokázat: závisí nebo nezávisí krevní skupina na pohlaví? (ve smyslu, zda jsou nebo nejsou mezi muži a ženami významné rozdíly v zastoupení jednotlivých krevních skupin)
77 TEST א 2 NEZÁVISLOSTI Resp. (příklad s výrobky) chceme prokázat: závisí nebo nezávisí kvalita výrobku na tom, během jaké směny vznikl? (ve smyslu, zda jsou nebo nejsou mezi jednotlivými směnami významné rozdíly v zastoupení jednotlivých kvalitativních kategorií)
78 TEST א 2 NEZÁVISLOSTI Testovaná dvojice hypotéz: H 0 : nezávislost (mezi X a Y) H 1 : non H 0 (tj. závislost mezi X a Y)


79 Data: TEST א 2 NEZÁVISLOSTI


80 TEST א 2 NEZÁVISLOSTI Data přehledně kontingenční tabulka pozorovaných absolutních četností: r = počet řádkových kategorií s = počet sloupcových kategorií
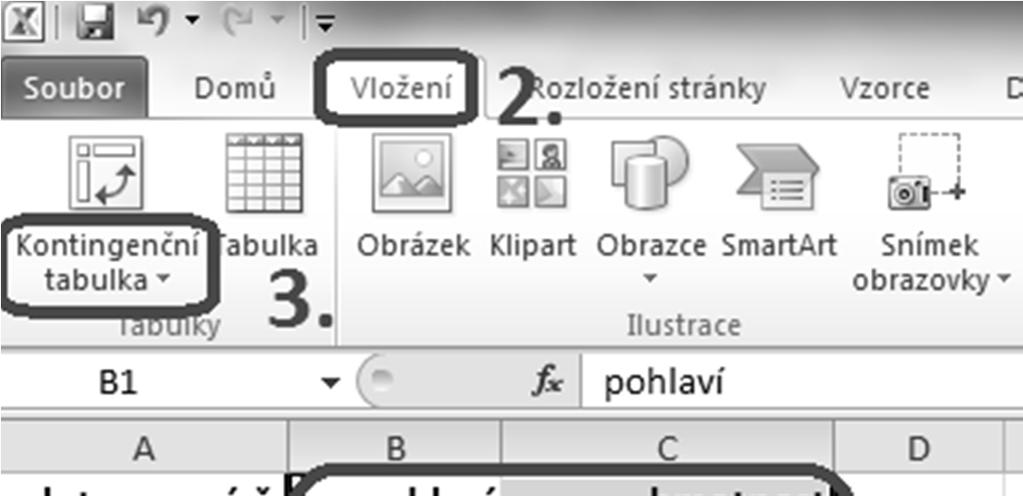

81 VSUVKA: KONTINGENČNÍ TABULKA(vytvoření)
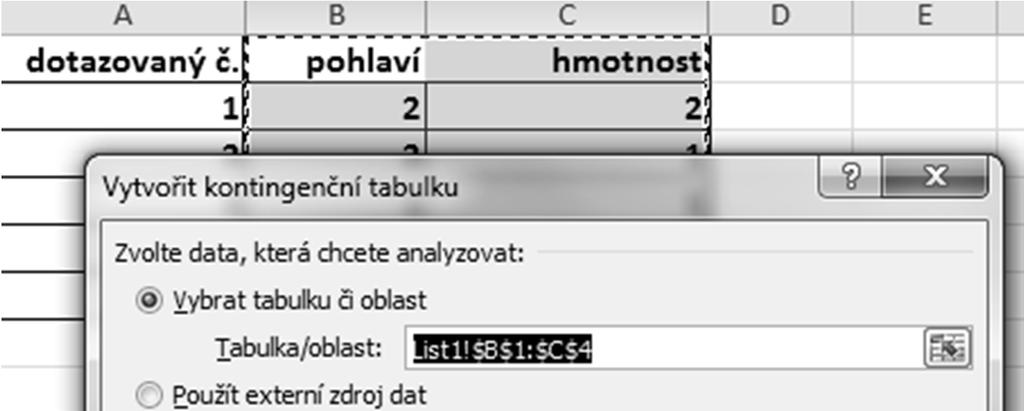

82 VSUVKA: KONTINGENČNÍ TABULKA(vytvoření)



83 Charakteristiky kategoriálních veličin
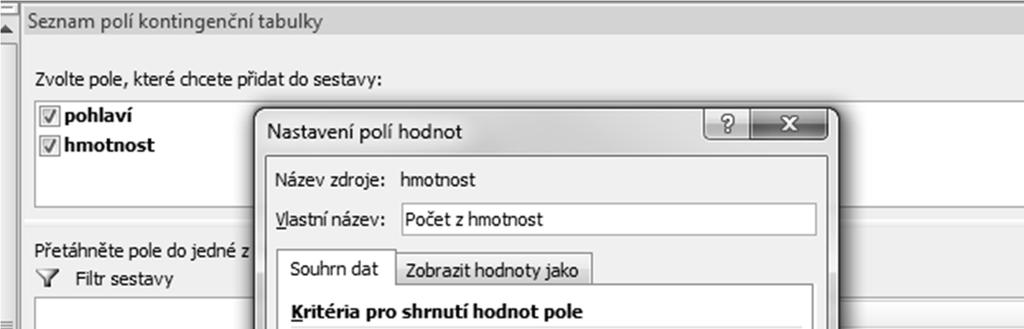

84 VSUVKA: KONTINGENČNÍ TABULKA(vytvoření)


85 TEST א 2 NEZÁVISLOSTI Kontingenční tabulka - příklad: např. n 12 = 15 n 21 = 7 n 1 = 38 n 1 = 23


86 TEST א 2 NEZÁVISLOSTI Připravíme tabulku očekávaných četností: o ij = n i n j / n např. o 12 = n 1 n 2 / n
: např.")

87 TEST א 2 NEZÁVISLOSTI Očekávané četnosti příklad (pokrač.): např. o 12 = n 1 n 2 / n = / 80 = 13,8! součty stejné jako původně (až na zaokr.)!


88 TEST א 2 NEZÁVISLOSTI Řešení pomocí Excelu: p=0,883 tj.?
89 TEST א 2 NEZÁVISLOSTI Podmínka použití: pozor u obou typů testu (dobré shody i nezávislosti) musí být všechny kategorie dostatečně zastoupeny, aneb všechny očekávané četnosti mají být aspoň 5; není-li splněno, doporučuje se sloučit některé (obvykle sousední) kategorie
90 Regrese jednoduchá regrese Cíl jednoduché (simple) regrese: najít model funkční závislosti (spojité) veličiny Y na jedné (spojité) veličině (na tzv. regresoru) X model lineární Y=β 0 +β 1 X kvadratický Y=β 0 +β 1 X+β 2 X 2 (tvar často napoví bodový graf dat) Příklad: závislost hmotnosti jedince na jeho tělesné výšce
91 Značení: Jednoduchá regrese (x i ; y i ) i=1,,n data Y i i=1,,n model e i = y i Y i i=1,,n reziduum
92 Regrese bodový graf
93 Jednoduchá lineární regrese y 1 = Y 1 +e 1 = (β 0 + β 1 x 1 ) + e 1 y 2 = Y 2 +e 2 = (β 0 + β 1 x 2 ) + e 2 y n = Y n +e n = (β 0 + β 1 x n ) + e n parametr prostý člen β 0 β 1 (průsečík grafu přímky s o Y ) parametr lineární člen (směrnice grafu přímky)




94 Jednoduchá lineární regrese aneb MATICOVĚ: y = F β + e kde
95 Jednoduchá lineární regrese Nechť e=0, pak: F b = y b =? Pozor: F je matice, nelze s ní dělit! Trikové úpravy (vlastnosti matic): F T F b = F T y (F T F) -1 F T F b = (F T F) -1 F T y b = (F T F) -1 F T y

96 Regrese (dokonce každý typ) b = (F T F) -1 F T y u modelu jednoduché lineární regrese:
97 Regrese (dokonce každý typ) b = (F T F) -1 F T y jde o univerzální (pro každý regresní model!) vzorec odhadu parametrů b, modely se liší jen konkr. tvarem F; b = tzv. odhad metodou nejmenších čtverců (MNČ); zaručuje minσ(e i ) 2
: k čemu Q e (součet reziduálních čtverců)?")
98 Jednoduchá lineární regrese Přehled vzorců (verze s průměry): k čemu Q e (součet reziduálních čtverců)?
99 Jednoduchá lineární regrese-příklad Př: Data - Westwood Company (Neter-Wasserman-Kutner, USA, 1990) X velikost staveniště Y počet hodin, odpracovaných dělníky x i y i
100 Jednoduchá lineární regrese-příklad Př: Data - Westwood Company
101 Jednoduchá lineární regrese-příklad Př: Data - Westwood Company x=50, y=110, x 2 =2840, y 2 =13466, xy=( )/10=6180 b 1 =( )/( )=2,0 b 0 = =10,0 (ne vždy celočíselně) Nalezený model: Y=10+2X


102 Jednoduchá lineární regrese-příklad V Excelu: b 1 = b 0 =
103 Jednoduchá lineární regrese-příklad Př: Data - Westwood Company
104 Jednoduchá lineární regrese-příklad Př: Data - Westwood Company Určete pro nalezený model Q e : Y 1 = =70, e 1 =73 70=3 Y 10 = =130, e 10 = =2 Q e = (-2) =60 A k čemu dál využít tuto hodnotu?
105 Korelovanost je obecně míra lineární závislosti V každém typu regresního modelu lze určit tzv. index determinace: I 2 = 1 Q e /Q Y _ kde Q Y =Σ(y i y) 2
106 Korelovanost Př: Data - Westwood Company Určete pro nalezený model (pro nějž vyšlo Q e =60) hodnotu I 2 : Q Y =(73 110) 2 + +( ) 2 = = =13660; I 2 = 1 60/13660 = 1 0,004 = 0,996
107 Korelovanost Př: Data - Westwood Company Interpretace: Nalezený model (Y=10+2X) vysvětluje z 99,6 % variabilitu proměnné Y ANEB jde o model velmi silné závislosti proměnné Y na proměnné X.
108 Korelace Korelace obecně je míra kvality (vhodnosti, těsnosti) nalezeného regresního modelu pro daná data; vychází z hodnot reziduí V každém typu regresního modelu lze použít index determinace I 2 (0 až 1, resp. 0 % až 100 %); vyjadřuje, z kolika % je variabilita závisle proměnné (Y) vysvětlena daným modelem

109 Korelace spec. pro model jednoduché lineární regrese Korelační koeficient (verze s průměry): kovariance
110 Korelace spec. pro model jednoduché lineární regrese Korelační koeficient vždy v rozmezí -1 až +1 (NE %!) záporný při klesající regresní přímce kladný při rostoucí regresní přímce čím DÁL od 0, tím silnější je lineární závislost ( korelovanost ) mezi X a Y platí: r 2 = I 2
111 Korelace spec. pro model jednoduché lineární regrese Př: Data - Westwood Company r = ( )/ ( ) ( ) = = 0,998 (platí: 0,998 2 =I 2 =0,996) Silná přímá* lineární závislost počtu prac. hodin na velikosti staveniště. * tj. dle rostoucí přímky (nepřímá=?)

112 Jednoduchá lineární regrese-příklad V Excelu: r =
113 Korelace spec. pro model jednoduché lineární regrese Př: Data Westwood Company (r=0,998)
114 Korelace spec. pro model jednoduché lineární regrese Př: Jiná data (r = -0,946)
115 Korelace spec. pro model jednoduché lineární regrese Př: Jiná data (r = -0,098)
116 Korelace spec. pro model jednoduché lineární regrese Př: Jiná data (r = 0,075)
117 Korelace spec. pro model jednoduché nelineární regrese Př: Stejná data, ale jiný, kvadratický model (kde už tedy nepočítáme r, jen I 2!)
118 Jednoduchá regrese různé modely? Lze tedy říct, že parabola je vždy LEPŠÍ model než přímka? NE: Parabola je vždy VÝSTIŽNĚJŠÍ, ale výhodou přímky je její JEDNODUCHOST Každý model = kompromis mezi výstižností a jednoduchostí
119 Jednoduchá regrese různé modely Adjustovaný index determinace R adj 2 R adj2 = 1 (1-I 2 ) (n-1)/(n-p) = % kvalita modelu při zohlednění počtu parametrů (p), i ten slouží k porovnání různých modelů pro tatáž data, a to dle hesla čím větší (je R adj2 ), tím lepší (je pro daná data příslušný model)
120 Testování - možnosti jednoduchá lineární regrese (p=2): H 0 : β 1 =0 versus H 1 : β 1 0 H 0.místo lineární funkce by jako model bývala stačila funkce konstantní (Y=β 0 ) aneb přímka s nulovou směrnicí ; H 1.do vhodného modelu je potřeba zahrnout nenulovou směrnici
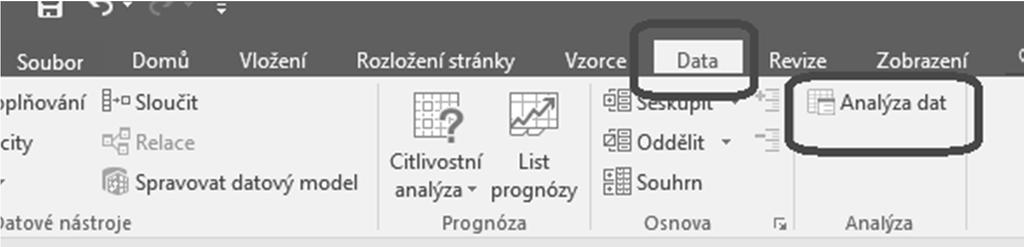


121 Testování regresních parametrů

122 Testování regresních parametrů


123 Testování regresních parametrů
124 Testování regresních parametrů Př: Data - Westwood Company (pokr.) p = 1, < 0,05 zamítáme H 0 model JE VÝZNAMNÝ
125 Regrese pomocí R:
126 GEOSTATISTIKA Samostatně, viz prezentace Přednáška ve studijních materiálech (nepovinné, pro zájemce)
Jednostranné intervaly spolehlivosti
 Jednostranné intervaly spolehlivosti hledáme jen jednu z obou mezí Princip: dle zadání úlohy hledáme jen dolní či jen horní mez podle oboustranného vzorce s tou změnou, že výraz 1-α/2 ve vzorci nahradíme
Jednostranné intervaly spolehlivosti hledáme jen jednu z obou mezí Princip: dle zadání úlohy hledáme jen dolní či jen horní mez podle oboustranného vzorce s tou změnou, že výraz 1-α/2 ve vzorci nahradíme
Tomáš Karel LS 2012/2013
 Tomáš Karel LS 2012/2013 Doplňkový materiál ke cvičení z předmětu 4ST201. Na případné faktické chyby v této presentaci mě prosím upozorněte. Děkuji. Tyto slidy berte pouze jako doplňkový materiál není
Tomáš Karel LS 2012/2013 Doplňkový materiál ke cvičení z předmětu 4ST201. Na případné faktické chyby v této presentaci mě prosím upozorněte. Děkuji. Tyto slidy berte pouze jako doplňkový materiál není
Intervalové odhady. Interval spolehlivosti pro střední hodnotu v N(µ, σ 2 ) Interpretace intervalu spolehlivosti. Interval spolehlivosti ilustrace
 Interpretace intervalu spolehlivosti. Interval spolehlivosti ilustrace") Intervalové odhady Interval spolehlivosti pro střední hodnotu v Nµ, σ 2 ) Situace: X 1,..., X n náhodný výběr z Nµ, σ 2 ), kde σ 2 > 0 známe měli jsme: bodové odhady odhadem charakteristiky je číslo) nevyjadřuje
Intervalové odhady Interval spolehlivosti pro střední hodnotu v Nµ, σ 2 ) Situace: X 1,..., X n náhodný výběr z Nµ, σ 2 ), kde σ 2 > 0 známe měli jsme: bodové odhady odhadem charakteristiky je číslo) nevyjadřuje
Intervalové odhady. Interval spolehlivosti pro střední hodnotu v N(µ, σ 2 ) Interpretace intervalu spolehlivosti. Interval spolehlivosti ilustrace
 Interpretace intervalu spolehlivosti. Interval spolehlivosti ilustrace") Intervalové odhady Interval spolehlivosti pro střední hodnotu v Nµ, σ 2 ) Situace: X 1,..., X n náhodný výběr z Nµ, σ 2 ), kde σ 2 > 0 známe měli jsme: bodové odhady odhadem charakteristiky je číslo) nevyjadřuje
Intervalové odhady Interval spolehlivosti pro střední hodnotu v Nµ, σ 2 ) Situace: X 1,..., X n náhodný výběr z Nµ, σ 2 ), kde σ 2 > 0 známe měli jsme: bodové odhady odhadem charakteristiky je číslo) nevyjadřuje
Tomáš Karel LS 2012/2013
 Tomáš Karel LS 2012/2013 Doplňkový materiál ke cvičení z předmětu 4ST201. Na případné faktické chyby v této presentaci mě prosím upozorněte. Děkuji. Tyto slidy berte pouze jako doplňkový materiál není
Tomáš Karel LS 2012/2013 Doplňkový materiál ke cvičení z předmětu 4ST201. Na případné faktické chyby v této presentaci mě prosím upozorněte. Děkuji. Tyto slidy berte pouze jako doplňkový materiál není
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz
 Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická
MÍRY ZÁVISLOSTI (KORELACE A REGRESE)
") zhanel@fsps.muni.cz MÍRY ZÁVISLOSTI (KORELACE A REGRESE) 2.5 MÍRY ZÁVISLOSTI 2.5.1 ZÁVISLOST PEVNÁ, VOLNÁ, STATISTICKÁ A KORELAČNÍ Jednorozměrné soubory - charakterizovány jednotlivými statistickými znaky
zhanel@fsps.muni.cz MÍRY ZÁVISLOSTI (KORELACE A REGRESE) 2.5 MÍRY ZÁVISLOSTI 2.5.1 ZÁVISLOST PEVNÁ, VOLNÁ, STATISTICKÁ A KORELAČNÍ Jednorozměrné soubory - charakterizovány jednotlivými statistickými znaky
PSY117/454 Statistická analýza dat v psychologii seminář 9. Statistické testování hypotéz
 PSY117/454 Statistická analýza dat v psychologii seminář 9 Statistické testování hypotéz Základní výzkumné otázky/hypotézy 1. Stanovení hodnoty parametru =stanovení intervalu spolehlivosti na μ, σ, ρ,
PSY117/454 Statistická analýza dat v psychologii seminář 9 Statistické testování hypotéz Základní výzkumné otázky/hypotézy 1. Stanovení hodnoty parametru =stanovení intervalu spolehlivosti na μ, σ, ρ,
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc.
 Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika 010 1.týden (0.09.-4.09. ) Data, typy dat, variabilita, frekvenční analýza
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika 010 1.týden (0.09.-4.09. ) Data, typy dat, variabilita, frekvenční analýza
Sever Jih Západ Plechovka Točené Sever Jih Západ Součty Plechovka Točené Součty
 Neparametrické testy (motto: Hypotézy jsou lešením, které se staví před budovu a pak se strhává, je-li budova postavena. Jsou nutné pro vědeckou práci, avšak skutečný vědec nepokládá hypotézy za předmětnou
Neparametrické testy (motto: Hypotézy jsou lešením, které se staví před budovu a pak se strhává, je-li budova postavena. Jsou nutné pro vědeckou práci, avšak skutečný vědec nepokládá hypotézy za předmětnou
Jednovýběrový Wilcoxonův test a jeho asymptotická varianta (neparametrická obdoba jednovýběrového t-testu)
") Jednovýběrový Wilcoxonův test a jeho asymptotická varianta (neparametrická obdoba jednovýběrového t-testu) Frank Wilcoxon (1892 1965): Americký statistik a chemik Nechť X 1,..., X n je náhodný výběr ze
Jednovýběrový Wilcoxonův test a jeho asymptotická varianta (neparametrická obdoba jednovýběrového t-testu) Frank Wilcoxon (1892 1965): Americký statistik a chemik Nechť X 1,..., X n je náhodný výběr ze
Statistika (KMI/PSTAT)
") Statistika (KMI/PSTAT) Cvičení dvanácté aneb Regrese a korelace Statistika (KMI/PSTAT) 1 / 18 V souboru 25 jedinců jsme měřili jejich výšku a hmotnost. Výsledky jsou v tabulce a grafu. Statistika (KMI/PSTAT)
Statistika (KMI/PSTAT) Cvičení dvanácté aneb Regrese a korelace Statistika (KMI/PSTAT) 1 / 18 V souboru 25 jedinců jsme měřili jejich výšku a hmotnost. Výsledky jsou v tabulce a grafu. Statistika (KMI/PSTAT)
ADDS cviceni. Pavlina Kuranova
 ADDS cviceni Pavlina Kuranova Testy pro dva nezávislé výběry Mannův Whitneyho test - Založen na Wilcoxnově statistice W - založen na pořadí jednotlivých pozorování (oba výběry spojeny do jednoho celku)
ADDS cviceni Pavlina Kuranova Testy pro dva nezávislé výběry Mannův Whitneyho test - Založen na Wilcoxnově statistice W - založen na pořadí jednotlivých pozorování (oba výběry spojeny do jednoho celku)
Testování hypotéz o parametrech regresního modelu
 Statistika II Katedra ekonometrie FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Lineární regresní model kde Y = Xβ + e, y 1 e 1 β y 2 Y =., e = e 2 x 11 x 1 1k., X =....... β 2,
Statistika II Katedra ekonometrie FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Lineární regresní model kde Y = Xβ + e, y 1 e 1 β y 2 Y =., e = e 2 x 11 x 1 1k., X =....... β 2,
Testování hypotéz o parametrech regresního modelu
 Testování hypotéz o parametrech regresního modelu Ekonometrie Jiří Neubauer Katedra kvantitativních metod FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Jiří Neubauer (Katedra UO
Testování hypotéz o parametrech regresního modelu Ekonometrie Jiří Neubauer Katedra kvantitativních metod FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Jiří Neubauer (Katedra UO
1 Tyto materiály byly vytvořeny za pomoci grantu FRVŠ číslo 1145/2004.
 Testy hypotéz na základě více než 2 výběrů 1 1 Tyto materiály byly vytvořeny za pomoci grantu FRVŠ číslo 1145/2004. Testy hypotéz na základě více než 2 výběrů Na analýzu rozptylu lze pohlížet v podstatě
Testy hypotéz na základě více než 2 výběrů 1 1 Tyto materiály byly vytvořeny za pomoci grantu FRVŠ číslo 1145/2004. Testy hypotéz na základě více než 2 výběrů Na analýzu rozptylu lze pohlížet v podstatě
letní semestr 2012 Katedra pravděpodobnosti a matematické statistiky Matematicko-fyzikální fakulta Univerzity Karlovy Matematická statistika
 Šárka Hudecová Katedra pravděpodobnosti a matematické statistiky Matematicko-fyzikální fakulta Univerzity Karlovy letní semestr 2012 Opakování t- vs. neparametrické Wilcoxonův jednovýběrový test Opakování
Šárka Hudecová Katedra pravděpodobnosti a matematické statistiky Matematicko-fyzikální fakulta Univerzity Karlovy letní semestr 2012 Opakování t- vs. neparametrické Wilcoxonův jednovýběrový test Opakování
{ } ( 2) Příklad: Test nezávislosti kategoriálních znaků
 Příklad: Test nezávislosti kategoriálních znaků") Příklad: Test nezávislosti kategoriálních znaků Určete na hladině významnosti 5 % na základě dat zjištěných v rámci dotazníkového šetření ve Šluknově, zda existuje závislost mezi pohlavím respondenta a
Příklad: Test nezávislosti kategoriálních znaků Určete na hladině významnosti 5 % na základě dat zjištěných v rámci dotazníkového šetření ve Šluknově, zda existuje závislost mezi pohlavím respondenta a
Statistika, Biostatistika pro kombinované studium. Jan Kracík
 Statistika, Biostatistika pro kombinované studium Letní semestr 2014/2015 Tutoriál č. 6: ANOVA Jan Kracík jan.kracik@vsb.cz Obsah: Testování hypotéz opakování ANOVA Testování hypotéz (opakování) Testování
Statistika, Biostatistika pro kombinované studium Letní semestr 2014/2015 Tutoriál č. 6: ANOVA Jan Kracík jan.kracik@vsb.cz Obsah: Testování hypotéz opakování ANOVA Testování hypotéz (opakování) Testování
Regresní analýza 1. Regresní analýza
 Regresní analýza 1 1 Regresní funkce Regresní analýza Důležitou statistickou úlohou je hledání a zkoumání závislostí proměnných, jejichž hodnoty získáme při realizaci experimentů Vzhledem k jejich náhodnému
Regresní analýza 1 1 Regresní funkce Regresní analýza Důležitou statistickou úlohou je hledání a zkoumání závislostí proměnných, jejichž hodnoty získáme při realizaci experimentů Vzhledem k jejich náhodnému
4ST201 STATISTIKA CVIČENÍ Č. 7
 4ST201 STATISTIKA CVIČENÍ Č. 7 testování hypotéz parametrické testy test hypotézy o střední hodnotě test hypotézy o relativní četnosti test o shodě středních hodnot testování hypotéz v MS Excel neparametrické
4ST201 STATISTIKA CVIČENÍ Č. 7 testování hypotéz parametrické testy test hypotézy o střední hodnotě test hypotézy o relativní četnosti test o shodě středních hodnot testování hypotéz v MS Excel neparametrické
Regresní a korelační analýza
 Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Vzorová prezentace do předmětu Statistika
 Vzorová prezentace do předmětu Statistika Popis situace: U 3 náhodně vybraných osob byly zjišťovány hodnoty těchto proměnných: SEX - muž, žena PUVOD Skandinávie, Středomoří, 3 západní Evropa IQ hodnota
Vzorová prezentace do předmětu Statistika Popis situace: U 3 náhodně vybraných osob byly zjišťovány hodnoty těchto proměnných: SEX - muž, žena PUVOD Skandinávie, Středomoří, 3 západní Evropa IQ hodnota
676 + 4 + 100 + 196 + 0 + 484 + 196 + 324 + 64 + 324 = = 2368
 Příklad 1 Je třeba prověřit, zda lze na 5% hladině významnosti pokládat za prokázanou hypotézu, že střední doba výroby výlisku je 30 sekund. Přitom 10 náhodně vybraných výlisků bylo vyráběno celkem 540
Příklad 1 Je třeba prověřit, zda lze na 5% hladině významnosti pokládat za prokázanou hypotézu, že střední doba výroby výlisku je 30 sekund. Přitom 10 náhodně vybraných výlisků bylo vyráběno celkem 540
ANALÝZA DAT V R 7. KONTINGENČNÍ TABULKA. Mgr. Markéta Pavlíková Katedra pravděpodobnosti a matematické statistiky MFF UK.
 ANALÝZA DAT V R 7. KONTINGENČNÍ TABULKA Mgr. Markéta Pavlíková Katedra pravděpodobnosti a matematické statistiky MFF UK www.biostatisticka.cz PŘEHLED TESTŮ rozdělení normální spojité alternativní / diskrétní
ANALÝZA DAT V R 7. KONTINGENČNÍ TABULKA Mgr. Markéta Pavlíková Katedra pravděpodobnosti a matematické statistiky MFF UK www.biostatisticka.cz PŘEHLED TESTŮ rozdělení normální spojité alternativní / diskrétní
1 Tyto materiály byly vytvořeny za pomoci grantu FRVŠ číslo 1145/2004.
 Prostá regresní a korelační analýza 1 1 Tyto materiály byly vytvořeny za pomoci grantu FRVŠ číslo 1145/2004. Problematika závislosti V podstatě lze rozlišovat mezi závislostí nepodstatnou, čili náhodnou
Prostá regresní a korelační analýza 1 1 Tyto materiály byly vytvořeny za pomoci grantu FRVŠ číslo 1145/2004. Problematika závislosti V podstatě lze rozlišovat mezi závislostí nepodstatnou, čili náhodnou
INDUKTIVNÍ STATISTIKA
 10. SEMINÁŘ INDUKTIVNÍ STATISTIKA 3. HODNOCENÍ ZÁVISLOSTÍ HODNOCENÍ ZÁVISLOSTÍ KVALITATIVNÍ VELIČINY - Vychází se z kombinační (kontingenční) tabulky, která je výsledkem třídění druhého stupně KVANTITATIVNÍ
10. SEMINÁŘ INDUKTIVNÍ STATISTIKA 3. HODNOCENÍ ZÁVISLOSTÍ HODNOCENÍ ZÁVISLOSTÍ KVALITATIVNÍ VELIČINY - Vychází se z kombinační (kontingenční) tabulky, která je výsledkem třídění druhého stupně KVANTITATIVNÍ
Parametry hledáme tak, aby součet čtverců odchylek byl minimální. Řešením podle teorie je =
 Příklad 1 Metodou nejmenších čtverců nalezněte odhad lineární regresní funkce popisující závislost mezi výnosy pšenice a množstvím použitého hnojiva na základě hodnot výběrového souboru uvedeného v tabulce.
Příklad 1 Metodou nejmenších čtverců nalezněte odhad lineární regresní funkce popisující závislost mezi výnosy pšenice a množstvím použitého hnojiva na základě hodnot výběrového souboru uvedeného v tabulce.
SEMESTRÁLNÍ PRÁCE. Leptání plasmou. Ing. Pavel Bouchalík
 SEMESTRÁLNÍ PRÁCE Leptání plasmou Ing. Pavel Bouchalík 1. ÚVOD Tato semestrální práce obsahuje písemné vypracování řešení příkladu Leptání plasmou. Jde o praktickou zkoušku znalostí získaných při přednáškách
SEMESTRÁLNÍ PRÁCE Leptání plasmou Ing. Pavel Bouchalík 1. ÚVOD Tato semestrální práce obsahuje písemné vypracování řešení příkladu Leptání plasmou. Jde o praktickou zkoušku znalostí získaných při přednáškách
Cvičící Kuba Kubina Kubinčák Body u závěrečného testu
 1. Příklad U 12 studentů jsme sledovali počet dosažených bodů na závěrečném testu (od 0 do 60). Vždy 4 z těchto studentů chodili k jednomu ze 3 cvičících panu Kubovi, panu Kubinovi, nebo panu Kubinčákovi.
1. Příklad U 12 studentů jsme sledovali počet dosažených bodů na závěrečném testu (od 0 do 60). Vždy 4 z těchto studentů chodili k jednomu ze 3 cvičících panu Kubovi, panu Kubinovi, nebo panu Kubinčákovi.
II. Statistické metody vyhodnocení kvantitativních dat Gejza Dohnal
 Základy navrhování průmyslových experimentů DOE II. Statistické metody vyhodnocení kvantitativních dat Gejza Dohnal! Testování statistických hypotéz kvalitativní odezva kvantitativní chí-kvadrát test homogenity,
Základy navrhování průmyslových experimentů DOE II. Statistické metody vyhodnocení kvantitativních dat Gejza Dohnal! Testování statistických hypotéz kvalitativní odezva kvantitativní chí-kvadrát test homogenity,
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc.
 Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika 2010 1.týden (20.09.-24.09. ) Data, typy dat, variabilita, frekvenční analýza
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika 2010 1.týden (20.09.-24.09. ) Data, typy dat, variabilita, frekvenční analýza
12. cvičení z PST. 20. prosince 2017
 1 cvičení z PST 0 prosince 017 11 test rozptylu normálního rozdělení Do laboratoře bylo odesláno n = 5 stejných vzorků krve ke stanovení obsahu alkoholu X v promilích alkoholu Výsledkem byla realizace
1 cvičení z PST 0 prosince 017 11 test rozptylu normálního rozdělení Do laboratoře bylo odesláno n = 5 stejných vzorků krve ke stanovení obsahu alkoholu X v promilích alkoholu Výsledkem byla realizace
JEDNOVÝBĚROVÉ TESTY. Komentované řešení pomocí programu Statistica
 JEDNOVÝBĚROVÉ TESTY Komentované řešení pomocí programu Statistica Vstupní data Data umístěná v excelovském souboru překopírujeme do tabulky ve Statistice a pojmenujeme proměnné, viz prezentace k tématu
JEDNOVÝBĚROVÉ TESTY Komentované řešení pomocí programu Statistica Vstupní data Data umístěná v excelovském souboru překopírujeme do tabulky ve Statistice a pojmenujeme proměnné, viz prezentace k tématu
RNDr. Eva Janoušová doc. RNDr. Ladislav Dušek, Dr.
 Analýza dat pro Neurovědy RNDr. Eva Janoušová doc. RNDr. Ladislav Dušek, Dr. Jaro 2014 Institut biostatistiky Janoušová, a analýz Dušek: Analýza dat pro neurovědy Blok 3 Jak a kdy použít parametrické a
Analýza dat pro Neurovědy RNDr. Eva Janoušová doc. RNDr. Ladislav Dušek, Dr. Jaro 2014 Institut biostatistiky Janoušová, a analýz Dušek: Analýza dat pro neurovědy Blok 3 Jak a kdy použít parametrické a
VYBRANÉ DVOUVÝBĚROVÉ TESTY. Martina Litschmannová
 VYBRANÉ DVOUVÝBĚROVÉ TESTY Martina Litschmannová Obsah přednášky Vybrané dvouvýběrové testy par. hypotéz test o shodě rozptylů (F-test), testy o shodě středních hodnot (t-test, Aspinové-Welchův test),
VYBRANÉ DVOUVÝBĚROVÉ TESTY Martina Litschmannová Obsah přednášky Vybrané dvouvýběrové testy par. hypotéz test o shodě rozptylů (F-test), testy o shodě středních hodnot (t-test, Aspinové-Welchův test),
PRAVDĚPODOBNOST A STATISTIKA
 PRAVDĚPODOBNOST A STATISTIKA Testování hypotéz Nechť X je náhodná proměnná, která má distribuční funkci F(x, ϑ). Předpokládejme, že známe tvar distribuční funkce (víme jaké má rozdělení) a neznáme parametr
PRAVDĚPODOBNOST A STATISTIKA Testování hypotéz Nechť X je náhodná proměnná, která má distribuční funkci F(x, ϑ). Předpokládejme, že známe tvar distribuční funkce (víme jaké má rozdělení) a neznáme parametr
Analýza rozptylu. Ekonometrie. Jiří Neubauer. Katedra kvantitativních metod FVL UO Brno kancelář 69a, tel
 Analýza rozptylu Ekonometrie Jiří Neubauer Katedra kvantitativních metod FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Jiří Neubauer (Katedra UO Brno) Analýza rozptylu 1 / 30 Analýza
Analýza rozptylu Ekonometrie Jiří Neubauer Katedra kvantitativních metod FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Jiří Neubauer (Katedra UO Brno) Analýza rozptylu 1 / 30 Analýza
Statistické metody uţívané při ověřování platnosti hypotéz
 Statistické metody uţívané při ověřování platnosti hypotéz Hypotéza Domněnka, předpoklad Nejčastěji o rozdělení, středních hodnotách, závislostech, Hypotézy ve vědeckém výzkumu pracovní, věcné hypotézy
Statistické metody uţívané při ověřování platnosti hypotéz Hypotéza Domněnka, předpoklad Nejčastěji o rozdělení, středních hodnotách, závislostech, Hypotézy ve vědeckém výzkumu pracovní, věcné hypotézy
LINEÁRNÍ REGRESE. Lineární regresní model
 LINEÁRNÍ REGRESE Chemometrie I, David MILDE Lineární regresní model 1 Typy závislosti 2 proměnných FUNKČNÍ VZTAH: 2 závisle proměnné: určité hodnotě x odpovídá jediná hodnota y. KORELACE: 2 náhodné (nezávislé)
LINEÁRNÍ REGRESE Chemometrie I, David MILDE Lineární regresní model 1 Typy závislosti 2 proměnných FUNKČNÍ VZTAH: 2 závisle proměnné: určité hodnotě x odpovídá jediná hodnota y. KORELACE: 2 náhodné (nezávislé)
RNDr. Eva Janoušová doc. RNDr. Ladislav Dušek, Dr.
 Analýza dat pro Neurovědy RNDr. Eva Janoušová doc. RNDr. Ladislav Dušek, Dr. Jaro 2014 Institut biostatistiky Janoušová, a analýz Dušek: Analýza dat pro neurovědy Blok 4 Jak a kdy použít parametrické a
Analýza dat pro Neurovědy RNDr. Eva Janoušová doc. RNDr. Ladislav Dušek, Dr. Jaro 2014 Institut biostatistiky Janoušová, a analýz Dušek: Analýza dat pro neurovědy Blok 4 Jak a kdy použít parametrické a
Regresní analýza. Eva Jarošová
 Regresní analýza Eva Jarošová 1 Obsah 1. Regresní přímka 2. Možnosti zlepšení modelu 3. Testy v regresním modelu 4. Regresní diagnostika 5. Speciální využití Lineární model 2 1. Regresní přímka 3 nosnost
Regresní analýza Eva Jarošová 1 Obsah 1. Regresní přímka 2. Možnosti zlepšení modelu 3. Testy v regresním modelu 4. Regresní diagnostika 5. Speciální využití Lineární model 2 1. Regresní přímka 3 nosnost
KGG/STG Statistika pro geografy
 KGG/STG Statistika pro geografy 9. Korelační analýza Mgr. David Fiedor 20. dubna 2015 Analýza závislostí v řadě geografických disciplín studujeme jevy, u kterých vyšetřujeme nikoliv pouze jednu vlastnost
KGG/STG Statistika pro geografy 9. Korelační analýza Mgr. David Fiedor 20. dubna 2015 Analýza závislostí v řadě geografických disciplín studujeme jevy, u kterých vyšetřujeme nikoliv pouze jednu vlastnost
Kontingenční tabulky, korelační koeficienty
 Statistika II Katedra ekonometrie FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Mějme kategoriální proměnné X a Y. Vytvoříme tzv. kontingenční tabulku. Budeme tedy testovat hypotézu
Statistika II Katedra ekonometrie FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Mějme kategoriální proměnné X a Y. Vytvoříme tzv. kontingenční tabulku. Budeme tedy testovat hypotézu
Kontingenční tabulky, korelační koeficienty
 Statistika II Katedra ekonometrie FVL UO Brno kancelář 69a, tel 973 442029 email:jirineubauer@unobcz Budeme předpokládat, že X a Y jsou kvalitativní náhodné veličiny, obor hodnot X obsahuje r hodnot (kategorií,
Statistika II Katedra ekonometrie FVL UO Brno kancelář 69a, tel 973 442029 email:jirineubauer@unobcz Budeme předpokládat, že X a Y jsou kvalitativní náhodné veličiny, obor hodnot X obsahuje r hodnot (kategorií,
Lineární regrese. Komentované řešení pomocí MS Excel
 Lineární regrese Komentované řešení pomocí MS Excel Vstupní data Tabulka se vstupními daty je umístěna v oblasti A1:B11 (viz. obrázek) na listu cela data Postup Základní výpočty - regrese Výpočet základních
Lineární regrese Komentované řešení pomocí MS Excel Vstupní data Tabulka se vstupními daty je umístěna v oblasti A1:B11 (viz. obrázek) na listu cela data Postup Základní výpočty - regrese Výpočet základních
RNDr. Eva Janoušová doc. RNDr. Ladislav Dušek, Dr.
 Analýza dat pro Neurovědy RNDr. Eva Janoušová doc. RNDr. Ladislav Dušek, Dr. Jaro 2014 Institut biostatistiky Janoušová, a analýz Dušek: Analýza dat pro neurovědy Blok 7 Jak hodnotit vztah spojitých proměnných
Analýza dat pro Neurovědy RNDr. Eva Janoušová doc. RNDr. Ladislav Dušek, Dr. Jaro 2014 Institut biostatistiky Janoušová, a analýz Dušek: Analýza dat pro neurovědy Blok 7 Jak hodnotit vztah spojitých proměnných
Regresní a korelační analýza
 Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Regresní a korelační analýza Mějme dvojici proměnných, které spolu nějak souvisí. x je nezávisle (vysvětlující) proměnná y je závisle (vysvětlovaná) proměnná Chceme zjistit funkční závislost y = f(x).
Statistická analýza jednorozměrných dat
 Statistická analýza jednorozměrných dat Prof. RNDr. Milan Meloun, DrSc. Univerzita Pardubice, Pardubice 31.ledna 2011 Tato prezentace je spolufinancována Evropským sociálním fondem a státním rozpočtem
Statistická analýza jednorozměrných dat Prof. RNDr. Milan Meloun, DrSc. Univerzita Pardubice, Pardubice 31.ledna 2011 Tato prezentace je spolufinancována Evropským sociálním fondem a státním rozpočtem
5 Vícerozměrná data - kontingenční tabulky, testy nezávislosti, regresní analýza
 5 Vícerozměrná data - kontingenční tabulky, testy nezávislosti, regresní analýza 5.1 Vícerozměrná data a vícerozměrná rozdělení Při zpracování vícerozměrných dat se hledají souvislosti mezi dvěma, případně
5 Vícerozměrná data - kontingenční tabulky, testy nezávislosti, regresní analýza 5.1 Vícerozměrná data a vícerozměrná rozdělení Při zpracování vícerozměrných dat se hledají souvislosti mezi dvěma, případně
Problematika analýzy rozptylu. Ing. Michael Rost, Ph.D.
 Problematika analýzy rozptylu Ing. Michael Rost, Ph.D. Úvod do problému Již umíte testovat shodu dvou středních hodnot prostřednictvím t-testů. Otázka: Jaké předpoklady musí být splněny, abyste mohli použít
Problematika analýzy rozptylu Ing. Michael Rost, Ph.D. Úvod do problému Již umíte testovat shodu dvou středních hodnot prostřednictvím t-testů. Otázka: Jaké předpoklady musí být splněny, abyste mohli použít
STATISTIKA A INFORMATIKA - bc studium OZW, 1.roč. (zkušební otázky)
") STATISTIKA A INFORMATIKA - bc studium OZW, 1.roč. (zkušební otázky) 1) Význam a využití statistiky v biologických vědách a veterinárním lékařství ) Rozdělení znaků (veličin) ve statistice 3) Základní a
STATISTIKA A INFORMATIKA - bc studium OZW, 1.roč. (zkušební otázky) 1) Význam a využití statistiky v biologických vědách a veterinárním lékařství ) Rozdělení znaků (veličin) ve statistice 3) Základní a
Technická univerzita v Liberci
 Technická univerzita v Liberci Ekonomická fakulta Analýza výsledků z dotazníkového šetření Jména studentů: Adam Pavlíček Michal Karlas Tomáš Vávra Anna Votavová Ročník: 2015/2016 Datum odevzdání: 13/05/2016
Technická univerzita v Liberci Ekonomická fakulta Analýza výsledků z dotazníkového šetření Jména studentů: Adam Pavlíček Michal Karlas Tomáš Vávra Anna Votavová Ročník: 2015/2016 Datum odevzdání: 13/05/2016
Pravděpodobnost a aplikovaná statistika
 Pravděpodobnost a aplikovaná statistika MGR. JANA SEKNIČKOVÁ, PH.D. 8. KAPITOLA STATISTICKÉ TESTOVÁNÍ HYPOTÉZ 22.11.2016 Opakování: CLV příklad 1 Zadání: Před volbami je v populaci státu 52 % příznivců
Pravděpodobnost a aplikovaná statistika MGR. JANA SEKNIČKOVÁ, PH.D. 8. KAPITOLA STATISTICKÉ TESTOVÁNÍ HYPOTÉZ 22.11.2016 Opakování: CLV příklad 1 Zadání: Před volbami je v populaci státu 52 % příznivců
Bodové a intervalové odhady parametrů v regresním modelu
 Statistika II Katedra ekonometrie FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Lineární regresní model Mějme lineární regresní model (LRM) Y = Xβ + e, kde y 1 e 1 β y 2 Y =., e
Statistika II Katedra ekonometrie FVL UO Brno kancelář 69a, tel. 973 442029 email:jiri.neubauer@unob.cz Lineární regresní model Mějme lineární regresní model (LRM) Y = Xβ + e, kde y 1 e 1 β y 2 Y =., e
Statgraphics v. 5.0 STATISTICKÁ INDUKCE PRO JEDNOROZMĚRNÁ DATA. Martina Litschmannová 1. Typ proměnné. Požadovaný typ analýzy
 Dichotomická proměnná (0-1) Spojitá proměnná STATISTICKÁ INDUKCE PRO JEDNOROZMĚRNÁ DATA Typ proměnné Požadovaný typ analýzy Ověření variability Předpoklady Testy, resp. intervalové odhad Test o rozptylu
Dichotomická proměnná (0-1) Spojitá proměnná STATISTICKÁ INDUKCE PRO JEDNOROZMĚRNÁ DATA Typ proměnné Požadovaný typ analýzy Ověření variability Předpoklady Testy, resp. intervalové odhad Test o rozptylu
Testy. Pavel Provinský. 19. listopadu 2013
 Testy Pavel Provinský 19. listopadu 2013 Test a intervalový odhad Testy a intervalové odhady - jsou vlastně to samé. Jiný je jen úhel pohledu. Lze přecházet od jednoho k druhému. Například: Při odvozování
Testy Pavel Provinský 19. listopadu 2013 Test a intervalový odhad Testy a intervalové odhady - jsou vlastně to samé. Jiný je jen úhel pohledu. Lze přecházet od jednoho k druhému. Například: Při odvozování
Statistika. Regresní a korelační analýza Úvod do problému. Roman Biskup
 Statistika Regresní a korelační analýza Úvod do problému Roman Biskup Jihočeská univerzita v Českých Budějovicích Ekonomická fakulta (Zemědělská fakulta) Katedra aplikované matematiky a informatiky 2008/2009
Statistika Regresní a korelační analýza Úvod do problému Roman Biskup Jihočeská univerzita v Českých Budějovicích Ekonomická fakulta (Zemědělská fakulta) Katedra aplikované matematiky a informatiky 2008/2009
Přednáška IX. Analýza rozptylu (ANOVA)
") Přednáška IX. Analýza rozptylu (ANOVA) Princip a metodika výpočtu Předpoklady analýzy rozptylu a jejich ověření Rozbor rozdílů jednotlivých skupin násobné testování hypotéz Analýza rozptylu jako lineární
Přednáška IX. Analýza rozptylu (ANOVA) Princip a metodika výpočtu Předpoklady analýzy rozptylu a jejich ověření Rozbor rozdílů jednotlivých skupin násobné testování hypotéz Analýza rozptylu jako lineární
(motto: An unsophisticated forecaster uses statistics as a drunken man uses lamp-posts - for support rather than for illumination.
 Neparametricke testy (motto: An unsophisticated forecaster uses statistics as a drunken man uses lamp-posts - for support rather than for illumination. Andrew Lang) 1. Příklad V následující tabulce jsou
Neparametricke testy (motto: An unsophisticated forecaster uses statistics as a drunken man uses lamp-posts - for support rather than for illumination. Andrew Lang) 1. Příklad V následující tabulce jsou
Jednofaktorová analýza rozptylu
 Jednofaktorová analýza rozptylu David Hampel Ústav statistiky a operačního výzkumu, Mendelova univerzita v Brně Kurz pokročilých statistických metod Global Change Research Centre AS CR, 5 7 8 2015 Tato
Jednofaktorová analýza rozptylu David Hampel Ústav statistiky a operačního výzkumu, Mendelova univerzita v Brně Kurz pokročilých statistických metod Global Change Research Centre AS CR, 5 7 8 2015 Tato
Mann-Whitney U-test. Znaménkový test. Vytvořil Institut biostatistiky a analýz, Masarykova univerzita J. Jarkovský, L. Dušek
 10. Neparametrické y Mann-Whitney U- Wilcoxonův Znaménkový Shrnutí statistických ů Typ srovnání Nulová hypotéza Parametrický Neparametrický 1 skupina dat vs. etalon Střední hodnota je rovna hodnotě etalonu.
10. Neparametrické y Mann-Whitney U- Wilcoxonův Znaménkový Shrnutí statistických ů Typ srovnání Nulová hypotéza Parametrický Neparametrický 1 skupina dat vs. etalon Střední hodnota je rovna hodnotě etalonu.
Katedra matematické analýzy a aplikací matematiky, Přírodovědecká fakulta, UP v Olomouci
 Zpracování dat v edukačních vědách - Testování hypotéz Kamila Fačevicová Katedra matematické analýzy a aplikací matematiky, Přírodovědecká fakulta, UP v Olomouci Obsah seminářů 5.11. Úvod do matematické
Zpracování dat v edukačních vědách - Testování hypotéz Kamila Fačevicová Katedra matematické analýzy a aplikací matematiky, Přírodovědecká fakulta, UP v Olomouci Obsah seminářů 5.11. Úvod do matematické
odpovídá jedna a jen jedna hodnota jiných
 8. Regresní a korelační analýza Problém: hledání, zkoumání a hodnocení souvislostí, závislostí mezi dvěma a více statistickými znaky (veličinami). Typy závislostí: pevné a volné Pevná závislost každé hodnotě
8. Regresní a korelační analýza Problém: hledání, zkoumání a hodnocení souvislostí, závislostí mezi dvěma a více statistickými znaky (veličinami). Typy závislostí: pevné a volné Pevná závislost každé hodnotě
Opakování. Neparametrické testy. Pořadí. Jednovýběrový Wilcoxonův test. t-testy: hypotézy o populačním průměru (střední hodnoty) předpoklad normality
 předpoklad normality") Opakování Opakování: Testy o střední hodnotě normálního rozdělení 1 jednovýběrový t-test 2 párový t-test 3 dvouvýběrový t-test jednovýběrový Wilcoxonův test párový Wilcoxonův test dvouvýběrový Wilcoxonův
Opakování Opakování: Testy o střední hodnotě normálního rozdělení 1 jednovýběrový t-test 2 párový t-test 3 dvouvýběrový t-test jednovýběrový Wilcoxonův test párový Wilcoxonův test dvouvýběrový Wilcoxonův
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc.
 Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika 2010 1.týden (20.09.-24.09. ) Data, typy dat, variabilita, frekvenční analýza
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika 2010 1.týden (20.09.-24.09. ) Data, typy dat, variabilita, frekvenční analýza
PARAMETRICKÉ TESTY. 1) Měření Etalonu. Dataset - mereni_etalonu.sta - 9 měření etalonu srovnáváme s PŘEDPOKLÁDANOU HODNOTOU 10.
 Měření Etalonu. Dataset - mereni_etalonu.sta - 9 měření etalonu srovnáváme s PŘEDPOKLÁDANOU HODNOTOU 10.") PARAMETRICKÉ TESTY Testujeme rovnost průměru - předpokladem normální rozdělení I) Jednovýběrový t-test 1) Měření Etalonu. Dataset - mereni_etalonu.sta - 9 měření etalonu srovnáváme s PŘEDPOKLÁDANOU HODNOTOU
PARAMETRICKÉ TESTY Testujeme rovnost průměru - předpokladem normální rozdělení I) Jednovýběrový t-test 1) Měření Etalonu. Dataset - mereni_etalonu.sta - 9 měření etalonu srovnáváme s PŘEDPOKLÁDANOU HODNOTOU
Matematické modelování Náhled do ekonometrie. Lukáš Frýd
 Matematické modelování Náhled do ekonometrie Lukáš Frýd Výnos akcie vs. Výnos celého trhu - CAPM model r it = r ft + β 1. (r mt r ft ) r it r ft = α 0 + β 1. (r mt r ft ) + ε it Ekonomický (finanční model)
Matematické modelování Náhled do ekonometrie Lukáš Frýd Výnos akcie vs. Výnos celého trhu - CAPM model r it = r ft + β 1. (r mt r ft ) r it r ft = α 0 + β 1. (r mt r ft ) + ε it Ekonomický (finanční model)
Korelační a regresní analýza
 Korelační a regresní analýza Analýza závislosti v normálním rozdělení Pearsonův (výběrový) korelační koeficient: r = s XY s X s Y, kde s XY = 1 n (x n 1 i=0 i x )(y i y ), s X (s Y ) je výběrová směrodatná
Korelační a regresní analýza Analýza závislosti v normálním rozdělení Pearsonův (výběrový) korelační koeficient: r = s XY s X s Y, kde s XY = 1 n (x n 1 i=0 i x )(y i y ), s X (s Y ) je výběrová směrodatná
Plánování experimentu
 Fakulta chemicko technologická Katedra analytické chemie licenční studium Management systému jakosti Autor: Ing. Radek Růčka Přednášející: Prof. Ing. Jiří Militký, CSc. 1. LEPTÁNÍ PLAZMOU 1.1 Zadání Proces
Fakulta chemicko technologická Katedra analytické chemie licenční studium Management systému jakosti Autor: Ing. Radek Růčka Přednášející: Prof. Ing. Jiří Militký, CSc. 1. LEPTÁNÍ PLAZMOU 1.1 Zadání Proces
letní semestr 2012 Katedra pravděpodobnosti a matematické statistiky Matematicko-fyzikální fakulta Univerzity Karlovy Matematická statistika t-test
 Párový Šárka Hudecová Katedra pravděpodobnosti a matematické statistiky Matematicko-fyzikální fakulta Univerzity Karlovy letní semestr 2012 motivační příklad Párový Příklad (Platová diskriminace) firma
Párový Šárka Hudecová Katedra pravděpodobnosti a matematické statistiky Matematicko-fyzikální fakulta Univerzity Karlovy letní semestr 2012 motivační příklad Párový Příklad (Platová diskriminace) firma
TESTOVÁNÍ HYPOTÉZ STATISTICKÁ HYPOTÉZA Statistické testy Testovací kritérium = B B > B < B B - B - B < 0 - B > 0 oboustranný test = B > B
 TESTOVÁNÍ HYPOTÉZ Od statistického šetření neočekáváme pouze elementární informace o velikosti některých statistických ukazatelů. Používáme je i k ověřování našich očekávání o výsledcích nějakého procesu,
TESTOVÁNÍ HYPOTÉZ Od statistického šetření neočekáváme pouze elementární informace o velikosti některých statistických ukazatelů. Používáme je i k ověřování našich očekávání o výsledcích nějakého procesu,
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc.
 Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika 2010 1.týden (20.09.-24.09. ) Data, typy dat, variabilita, frekvenční analýza
Pravděpodobnost a matematická statistika Doc. RNDr. Gejza Dohnal, CSc. dohnal@nipax.cz Pravděpodobnost a matematická statistika 2010 1.týden (20.09.-24.09. ) Data, typy dat, variabilita, frekvenční analýza
5. Závislost dvou náhodných veličin různých typů (kategoriální a metrická veličina)
") 5. Závislost dvou náhodných veličin různých typů (kategoriální a metrická veličina) Cílem tématu je správné posouzení a výběr vhodného testu v závislosti na povaze metrické a kategoriální veličiny. V následující
5. Závislost dvou náhodných veličin různých typů (kategoriální a metrická veličina) Cílem tématu je správné posouzení a výběr vhodného testu v závislosti na povaze metrické a kategoriální veličiny. V následující
Statistická analýza jednorozměrných dat
 Statistická analýza jednorozměrných dat Prof. RNDr. Milan Meloun, DrSc. Univerzita Pardubice, Pardubice 31.ledna 2011 Tato prezentace je spolufinancována Evropským sociálním fondem a státním rozpočtem
Statistická analýza jednorozměrných dat Prof. RNDr. Milan Meloun, DrSc. Univerzita Pardubice, Pardubice 31.ledna 2011 Tato prezentace je spolufinancována Evropským sociálním fondem a státním rozpočtem
Ilustrační příklad odhadu LRM v SW Gretl
 Ilustrační příklad odhadu LRM v SW Gretl Podkladové údaje Korelační matice Odhad lineárního regresního modelu (LRM) Verifikace modelu PEF ČZU Praha Určeno pro posluchače předmětu Ekonometrie Needitovaná
Ilustrační příklad odhadu LRM v SW Gretl Podkladové údaje Korelační matice Odhad lineárního regresního modelu (LRM) Verifikace modelu PEF ČZU Praha Určeno pro posluchače předmětu Ekonometrie Needitovaná
Zpracování náhodného vektoru. Ing. Michal Dorda, Ph.D.
 Ing. Michal Dorda, Ph.D. 1 Př. 1: Cestující na vybraném spoji linky MHD byli dotazováni za účelem zjištění spokojenosti s kvalitou MHD. Legenda 1 Velmi spokojen Spokojen 3 Nespokojen 4 Velmi nespokojen
Ing. Michal Dorda, Ph.D. 1 Př. 1: Cestující na vybraném spoji linky MHD byli dotazováni za účelem zjištění spokojenosti s kvalitou MHD. Legenda 1 Velmi spokojen Spokojen 3 Nespokojen 4 Velmi nespokojen
Měření závislosti statistických dat
 5.1 Měření závislosti statistických dat Každý pořádný astronom je schopen vám předpovědět, kde se bude nacházet daná hvězda půl hodiny před půlnocí. Ne každý je však téhož schopen předpovědět v případě
5.1 Měření závislosti statistických dat Každý pořádný astronom je schopen vám předpovědět, kde se bude nacházet daná hvězda půl hodiny před půlnocí. Ne každý je však téhož schopen předpovědět v případě
Cvičení ze statistiky - 9. Filip Děchtěrenko
 Cvičení ze statistiky - 9 Filip Děchtěrenko Minule bylo.. Dobrali jsme normální rozdělení Tyhle termíny by měly být známé: Inferenční statistika Konfidenční intervaly Z-test Postup při testování hypotéz
Cvičení ze statistiky - 9 Filip Děchtěrenko Minule bylo.. Dobrali jsme normální rozdělení Tyhle termíny by měly být známé: Inferenční statistika Konfidenční intervaly Z-test Postup při testování hypotéz
Návod na vypracování semestrálního projektu
 Návod na vypracování semestrálního projektu Následující dokument má charakter doporučení. Není závazný, je pouze návodem pro studenty, kteří si nejsou jisti výběrem dat, volbou metod a formou zpracování
Návod na vypracování semestrálního projektu Následující dokument má charakter doporučení. Není závazný, je pouze návodem pro studenty, kteří si nejsou jisti výběrem dat, volbou metod a formou zpracování
Cvičení 12: Binární logistická regrese
 Cvičení 12: Binární logistická regrese Příklad: V roce 2014 konalo státní závěrečné zkoušky bakalářského studia na jisté fakultě 167 studentů. U každého studenta bylo zaznamenáno jeho pohlaví (0 žena,
Cvičení 12: Binární logistická regrese Příklad: V roce 2014 konalo státní závěrečné zkoušky bakalářského studia na jisté fakultě 167 studentů. U každého studenta bylo zaznamenáno jeho pohlaví (0 žena,
Testování statistických hypotéz
 Testování statistických hypotéz 1 Testování statistických hypotéz 1 Statistická hypotéza a její test V praxi jsme nuceni rozhodnout, zda nějaké tvrzeni o parametrech náhodných veličin nebo o veličině samotné
Testování statistických hypotéz 1 Testování statistických hypotéz 1 Statistická hypotéza a její test V praxi jsme nuceni rozhodnout, zda nějaké tvrzeni o parametrech náhodných veličin nebo o veličině samotné
Základy biostatistiky II. Veřejné zdravotnictví 3.LF UK - II
 Základy biostatistiky II Veřejné zdravotnictví 3.LF UK - II Teoretické rozložení-matematické modely rozložení Naměřená data Výběrové rozložení Teoretické rozložení 1 e 2 x 2 Teoretické rozložení-matematické
Základy biostatistiky II Veřejné zdravotnictví 3.LF UK - II Teoretické rozložení-matematické modely rozložení Naměřená data Výběrové rozložení Teoretické rozložení 1 e 2 x 2 Teoretické rozložení-matematické
Název testu Předpoklady testu Testová statistika Nulové rozdělení. ( ) (p počet odhadovaných parametrů)
 (p počet odhadovaných parametrů)") VYBRANÉ TESTY NEPARAMETRICKÝCH HYPOTÉZ TESTY DOBRÉ SHODY Název testu Předpoklady testu Testová statistika Nulové rozdělení test dobré shody Očekávané četnosti, alespoň 80% očekávaných četností >5 ( ) (p
VYBRANÉ TESTY NEPARAMETRICKÝCH HYPOTÉZ TESTY DOBRÉ SHODY Název testu Předpoklady testu Testová statistika Nulové rozdělení test dobré shody Očekávané četnosti, alespoň 80% očekávaných četností >5 ( ) (p
Parametrické testy hypotéz o středních hodnotách spojitých náhodných veličin
 Parametrické testy hypotéz o středních hodnotách spojitých náhodných veličin EuroMISE Centrum I. ÚVOD vv této přednášce budeme hovořit o jednovýběrových a dvouvýběrových testech týkajících se střední hodnoty
Parametrické testy hypotéz o středních hodnotách spojitých náhodných veličin EuroMISE Centrum I. ÚVOD vv této přednášce budeme hovořit o jednovýběrových a dvouvýběrových testech týkajících se střední hodnoty
PRAVDĚPODOBNOST A STATISTIKA
 PRAVDĚPODOBNOS A SAISIKA Regresní analýza - motivace Základní úlohou regresní analýzy je nalezení vhodného modelu studované závislosti. Je nutné věnovat velkou pozornost tomu aby byla modelována REÁLNÁ
PRAVDĚPODOBNOS A SAISIKA Regresní analýza - motivace Základní úlohou regresní analýzy je nalezení vhodného modelu studované závislosti. Je nutné věnovat velkou pozornost tomu aby byla modelována REÁLNÁ
UNIVERZITA OBRANY Fakulta ekonomiky a managementu. Aplikace STAT1. Výsledek řešení projektu PRO HORR2011 a PRO GRAM2011 3. 11.
 UNIVERZITA OBRANY Fakulta ekonomiky a managementu Aplikace STAT1 Výsledek řešení projektu PRO HORR2011 a PRO GRAM2011 Jiří Neubauer, Marek Sedlačík, Oldřich Kříž 3. 11. 2012 Popis a návod k použití aplikace
UNIVERZITA OBRANY Fakulta ekonomiky a managementu Aplikace STAT1 Výsledek řešení projektu PRO HORR2011 a PRO GRAM2011 Jiří Neubauer, Marek Sedlačík, Oldřich Kříž 3. 11. 2012 Popis a návod k použití aplikace
Zápočtová práce STATISTIKA I
 Zápočtová práce STATISTIKA I Obsah: - úvodní stránka - charakteristika dat (původ dat, důvod zpracování,...) - výpis naměřených hodnot (v tabulce) - zpracování dat (buď bodové nebo intervalové, podle charakteru
Zápočtová práce STATISTIKA I Obsah: - úvodní stránka - charakteristika dat (původ dat, důvod zpracování,...) - výpis naměřených hodnot (v tabulce) - zpracování dat (buď bodové nebo intervalové, podle charakteru
DVOUVÝBĚROVÉ A PÁROVÉ TESTY Komentované řešení pomocí programu Statistica
 DVOUVÝBĚROVÉ A PÁROVÉ TESTY Komentované řešení pomocí programu Statistica Úloha A) koncentrace glukózy v krvi V této části posoudíme pomocí párového testu, zda nový lék prokazatelně snižuje koncentraci
DVOUVÝBĚROVÉ A PÁROVÉ TESTY Komentované řešení pomocí programu Statistica Úloha A) koncentrace glukózy v krvi V této části posoudíme pomocí párového testu, zda nový lék prokazatelně snižuje koncentraci
Cvičení ze statistiky - 8. Filip Děchtěrenko
 Cvičení ze statistiky - 8 Filip Děchtěrenko Minule bylo.. Dobrali jsme normální rozdělení Tyhle termíny by měly být známé: Centrální limitní věta Laplaceho věta (+ korekce na spojitost) Konfidenční intervaly
Cvičení ze statistiky - 8 Filip Děchtěrenko Minule bylo.. Dobrali jsme normální rozdělení Tyhle termíny by měly být známé: Centrální limitní věta Laplaceho věta (+ korekce na spojitost) Konfidenční intervaly
13.1. Úvod Cílem regresní analýzy je popsat závislost hodnot znaku Y na hodnotách
 13 Regrese 13.1. Úvod Cílem regresní analýzy je popsat závislost hodnot znaku Y na hodnotách znaku X. Přitom je třeba vyřešit jednak volbu funkcí k vystižení dané závislosti a dále stanovení konkrétních
13 Regrese 13.1. Úvod Cílem regresní analýzy je popsat závislost hodnot znaku Y na hodnotách znaku X. Přitom je třeba vyřešit jednak volbu funkcí k vystižení dané závislosti a dále stanovení konkrétních
11. cvičení z PSI prosince hodnota pozorovaná četnost n i p X (i) = q i (1 q), i N 0.
 = q i (1 q), i N 0.") 11 cvičení z PSI 12-16 prosince 2016 111 (Test dobré shody - geometrické rozdělení Realizací náhodné veličiny X jsme dostali následující četnosti výsledků: hodnota 0 1 2 3 4 5 6 pozorovaná četnost 29 15
11 cvičení z PSI 12-16 prosince 2016 111 (Test dobré shody - geometrické rozdělení Realizací náhodné veličiny X jsme dostali následující četnosti výsledků: hodnota 0 1 2 3 4 5 6 pozorovaná četnost 29 15
ANALÝZA DAT V R 5. ZÁKLADNÍ STATISTICKÉ TESTY. Mgr. Markéta Pavlíková Katedra pravděpodobnosti a matematické statistiky MFF UK.
 ANALÝZA DAT V R 5. ZÁKLADNÍ STATISTICKÉ TESTY Mgr. Markéta Pavlíková Katedra pravděpodobnosti a matematické statistiky MFF UK www.biostatisticka.cz PRINCIPY STATISTICKÉ INFERENCE identifikace závisle proměnné
ANALÝZA DAT V R 5. ZÁKLADNÍ STATISTICKÉ TESTY Mgr. Markéta Pavlíková Katedra pravděpodobnosti a matematické statistiky MFF UK www.biostatisticka.cz PRINCIPY STATISTICKÉ INFERENCE identifikace závisle proměnné
Kategorická data METODOLOGICKÝ PROSEMINÁŘ II TÝDEN 7 4. DUBNA dubna 2018 Lukáš Hájek, Karel Höfer Metodologický proseminář II 1
 Kategorická data METODOLOGICKÝ PROSEMINÁŘ II TÝDEN 7 4. DUBNA 2018 4. dubna 2018 Lukáš Hájek, Karel Höfer Metodologický proseminář II 1 Typy proměnných nominální (nominal) o dvou hodnotách lze říci pouze
Kategorická data METODOLOGICKÝ PROSEMINÁŘ II TÝDEN 7 4. DUBNA 2018 4. dubna 2018 Lukáš Hájek, Karel Höfer Metodologický proseminář II 1 Typy proměnných nominální (nominal) o dvou hodnotách lze říci pouze
Z mých cvičení dostalo jedničku 6 studentů, dvojku 8 studentů, trojku 16 studentů a čtyřku nebo omluveno 10 studentů.
 Neparametricke testy (motto: Hypotézy jsou lešením, které se staví před budovu a pak se strhává, je-li budova postavena. Jsou nutné pro vědeckou práci, avšak skutečný vědec nepokládá hypotézy za předmětnou
Neparametricke testy (motto: Hypotézy jsou lešením, které se staví před budovu a pak se strhává, je-li budova postavena. Jsou nutné pro vědeckou práci, avšak skutečný vědec nepokládá hypotézy za předmětnou
Rozhodnutí / Skutečnost platí neplatí Nezamítáme správně chyba 2. druhu Zamítáme chyba 1. druhu správně
 Testování hypotéz Nechť,, je náhodný výběr z nějakého rozdělení s neznámými parametry. Máme dvě navzájem si odporující hypotézy o parametrech daného rozdělení: Nulová hypotéza parametry (případně jediný
Testování hypotéz Nechť,, je náhodný výběr z nějakého rozdělení s neznámými parametry. Máme dvě navzájem si odporující hypotézy o parametrech daného rozdělení: Nulová hypotéza parametry (případně jediný
Vybrané partie z biostatistiky
 1 Úvod Vybrané partie z biostatistiky 10.7.2017, Běstvina Marie Turčičová (turcic@karlin.mff.cuni.cz), MFF UK Pracovat budeme v programu R a jeho nástavbě RStudio, které si můžete bezplatně stáhnout zde:
1 Úvod Vybrané partie z biostatistiky 10.7.2017, Běstvina Marie Turčičová (turcic@karlin.mff.cuni.cz), MFF UK Pracovat budeme v programu R a jeho nástavbě RStudio, které si můžete bezplatně stáhnout zde:
Parametrické testy hypotéz o středních hodnotách spojitých náhodných veličin
 Parametrické testy hypotéz o středních hodnotách spojitých náhodných veličin EuroMISE Centrum Kontakt: Literatura: Obecné informace Zvárová, J.: Základy statistiky pro biomedicínskéobory I. Vydavatelství
Parametrické testy hypotéz o středních hodnotách spojitých náhodných veličin EuroMISE Centrum Kontakt: Literatura: Obecné informace Zvárová, J.: Základy statistiky pro biomedicínskéobory I. Vydavatelství
Úvod do analýzy rozptylu
 Úvod do analýzy rozptylu Párovým t-testem se podařilo prokázat, že úprava režimu stravování a fyzické aktivity ve vybrané škole měla vliv na zlepšené hodnoty HDLcholesterolu u školáků. Pro otestování jsme
Úvod do analýzy rozptylu Párovým t-testem se podařilo prokázat, že úprava režimu stravování a fyzické aktivity ve vybrané škole měla vliv na zlepšené hodnoty HDLcholesterolu u školáků. Pro otestování jsme