Manipulace se sekvenčními daty
|
|
|
- Natálie Tomanová
- před 6 lety
- Počet zobrazení:
Transkript
1 Manipulace se sekvenčními daty
2 Získání a manipulace se sekvencemi Databases DNA NCBI-GenBANK DDBJ EBI-EMBL Protein PIR SWISSPROT EXPASY, PDB Entrez SRS Retrival System Softwares GCG SeqWEB Vector NTI GenoMAX CLC Workbench Information Sequnece, Pdb, Image GenBANK GCG FASTA Staden Image Formats Sequence Converter
3 Typy jednoduchých bioinformatických analýz 1. Přístup k datům 2. Manipulace se sekvenčními daty 3. Výpočetní analýza sekvencí 4. Manipulace se sekvencemi proteinů

4 1. Přístup k datům Přístup k nukleotidovým databázím NCBI EBI Přístup k proteinovým a strukturním databázím PDB Zobrazení záznamů v databázích Získávaní dat Konverze formátů Editace
 EMBL: http://www.ebi.ac.uk European Bioinformatics Institute (EBI) ExPASy: http://tw.expasy.")
5 Sdílení dat v základních databázích GenBank: National Center for Biotechnology Information (NCBI) DDBJ: National Institute of Genetics (NIG) EMBL: European Bioinformatics Institute (EBI) ExPASy: Expert Protein Analysis System
6 Zápis sekvence Sekvence zápis posloupnosti jednoznačných znaků odpovídajících jednotlivým zbytkům (monomerům), které se nacházejí v odpovídající posloupnosti v dané makromolekule DNA nebo RNA od 5 -konce k 3 -konci protein od N-konce k C-konci používají se jednopísmenové kódy dle pravidel IUPAC
7 Standardní kódy pro sekvence nukleových kyselin podle IUB/IUPAC A C G T U R Y K M S W adenosin cytidin guanidin thymidin uridin G/A (purin) T/C (pyrimidin) G/T (nukleosid s Keto skupinou) A/C (nukleosid s amino skupinou) G/C (silná = Strong vazba) A/T (slabá = Weak vazba) B G/T/C (not A) D G/A/T (not C) H A/C/T (not G) V G/C/A (not T) N A/G/C/T (jakýkoli) - mezera (gap) neurčené délky
8 Standardní kódy pro sekvence aminokyselin podle IUB/IUPAC A alanin B kys. asparagová nebo asparagin C cystein D kys. asparagová E kys. glutamová F fenylalanin G glycin H histidin I isoleucin K lysin L leucin M metionin N asparagin P prolin Q glutamin R arginin S serin T treonin U selenocystein V valin W tryptofan Y tyrosin Z kys. glutamová nebo glutamin X jakákoli aminokyselina * translační stop (terminační kodon) - mezera (gap) neurčené délky
9 Běžné formáty sekvencí FASTA Genbank EMBL GCG PIR ASN1 IG(Intelligenetics) Text
10 Formáty sekvencí obsahující mnohonásobná přiložení Multi FASTA Phylip PAUP / NEXUS Clustal MSF
11 PLAIN SEQUENCE FORMAT Obsahuje pouze IUPAC znaky Obsahuje jedinou sekvenci Příklad AACCTGCGGAAGGATCATTACCGAGTGCGGGTCCTTTGGGCCCAA CCTCCCATCCGTGTCTATTGTACCCTGTTGCTTCGGCGGGCCCGC CGCTTGTCGGCCGCCGGGGGGGCGCCTCTGCCCCCCGGGCCCGTG CCCGCCGGAGACCCCAACACGAACACTGTCTGAAAGCGTGCAGTC TGAGTTGATTGAATGCAATCAGTTAAAACTTTCAACAATGGATCT
12 FASTA FORMAT Může obsahovat více sekvencí Začíná specifickým záhlavím ( > ) Příklad: >U03518 Aspergillus awamori internal transcribed spacer 1 (ITS1) AACCTGCGGAAGGATCATTACCGAGTGCGGGTCCTTTGGGCCCAACCTCCCATCCGTGTCTATTGTACCC TGTTGCTTCGGCGGGCCCGCCGCTTGTCGGCCGCCGGGGGGGCGCCTCTGCCCCCCGGGCCCGTGCCCGC CGGAGACCCCAACACGAACACTGTCTGAAAGCGTGCAGTCTGAGTTGATTGAATGCAATCAGTTAAAACT TTCAACAATGGATCTCTTGGTTCCGGC
13 EMBL FORMAT Začíná řádkem s jedinečným identifikátorem (ID), následuje anotace. Sekvence zašíná symboly SQ a sekvence je ukončena // Může obsahovat více sekvencí Příklad: ID AA03518 standard; DNA; FUN; 237 BP. XX AC U03518; XX DE Aspergillus awamori internal transcribed spacer 1 (ITS1) and 18S DE XX SQ // rrna and 5.8S rrna genes, partial sequence. Sequence 237 BP; 41 A; 77 C; 67 G; 52 T; 0 other; aacctgcgga aggatcatta ccgagtgcgg gtcctttggg cccaacctcc catccgtgtc 60 tattgtaccc tgttgcttcg gcgggcccgc cgcttgtcgg ccgccggggg ggcgcctctg 120 ccccccgggc ccgtgcccgc cggagacccc aacacgaaca ctgtctgaaa gcgtgcagtc 180 tgagttgatt gaatgcaatc agttaaaact ttcaacaatg gatctcttgg ttccggc 237
14 GENBANK FORMAT Začíná řádkem LOCUS Začátek sekvence je vyznačen ORIGIN a sekvence je ukončena // Příklad: LOCUS AAU bp DNA PLN 04-FEB-1995 DEFINITION Aspergillus awamori internal transcribed spacer 1 (ITS1) and 18S rrna and 5.8S rrna genes, partial sequence. ACCESSION U03518 VERSION U GI BASE COUNT 41 a 77 c 67 g 52 t ORIGIN 1 aacctgcgga aggatcatta ccgagtgcgg gtcctttggg cccaacctcc catccgtgtc 61 tattgtaccc tgttgcttcg gcgggcccgc cgcttgtcgg ccgccggggg ggcgcctctg 121 ccccccgggc ccgtgcccgc cggagacccc aacacgaaca ctgtctgaaa gcgtgcagtc 181 tgagttgatt gaatgcaatc agttaaaact ttcaacaatg gatctcttgg ttccggc //
15 Poznámka k používaným fontům Proporcionální fonty Arial, Times Každý znak jiná šířka Nevhodné Neproporcionální fonty Vhodné k použití Všechny znaky stejná šíka Courier, Monospaced gaattttttt cttaaaaaaa gaattttttt cttaaaaaaa K editaci jsou vhodné editory, které neukládají informace o formátu textu (Notepad, vývojářské editory PSPad, aj.) Některé formáty jako např. GCG obsahují vnitřní kontrolní součty


16 Surová data elektroforetogramy ze sekvenování v kapiláře Různé formáty *.abi *.ab1 *.scf Prohlížeče Chromas ABIView Ridom Trace Edit Export FASTA Prostý text
17 Jednoduché formáty sekvencí mají omezení a neobsahují Data o expresi genů Variace a polymorfismy WWW odkazy na další informace Specifické informace o klonech
18 2. Manipulace se sekvenčními daty Přepis a překlad podle ústředního dogmatu Replikace Transkripce Translace genetický kód Převod informace mezi řetězci Reverse-complement Hledání motivů Přesné Podobné Sekvenční přiložení Párové Mnohonásobné Spojování, rozdělování Klonování in silico
19 Konverze formátů sekvencí UNIX-GCG To Genbank, To Fasta. From Genbank, From Fasta READSEQ, SEQRET SMS The Sequence Manipulation Suite v2 EMBL to FASTA GenBank to FASTA Reverse Complement Filter DNA / Protein
20 Assembly/ kompletace a sestavení reads Pokrytí oblastí >x-násobnou redundancí Identifikace překryvů, sekvenční přiložení a rekonstrukce sekvence
21 Překrývající se čtení Sort all k-mers in reads (k ~ 24) Find pairs of reads sharing a k-mer Extend to full alignment throw away if not >95% similar TACA TAGATTACACAGATTACT GA TAGT TAGATTACACAGATTACTAGA
22 Mapování Vytvoření sekvenčního přiložení z jednotlivých čtení TAGATTACACAGATTACTGA TAGATTACACAGATTACTGA TAG TTACACAGATTATTGA TAGATTACACAGATTACTGA TAGATTACACAGATTACTGA TAGATTACACAGATTACTGA TAG TTACACAGATTATTGA TAGATTACACAGATTACTGA
23 Odvození konsensní sekvence TAGATTACACAGATTACTGA TTGATGGCGTAA CTA TAGATTACACAGATTACTGACTTGATGGCGTAAACTA TAG TTACACAGATTATTGACTTCATGGCGTAA CTA TAGATTACACAGATTACTGACTTGATGGCGTAA CTA TAGATTACACAGATTACTGACTTGATGGGGTAA CTA TAGATTACACAGATTACTGACTTGATGGCGTAA CTA Derive multiple alignment from pairwise read alignments Derive each consensus base by weighted voting
24 Hledání motivů Hledání slov = uspořádaná množina znaků GAATTC GARYTC GAAN(1-50)TTC
25 Standardní příklady hledání Restrikční místa Repetice přímé Obrácené (vlásenky se smyčkou) Konsenzní vzory Uživatelem definované vzory Otevřené čtecí rámce
26 Restrikční analýza in silico Restrikčníendonukleázy třídy II Sekvenčně specifické endonukleázy, které štěpí DNA v rozpoznávaných sekvencích Přehled dostupný v databázi REBASE- Restriction Enzyme Database Sekvence rozpoznávacích míst Producent enzymu Reference Komerční dostupnost Sekvence genů Krystalografická data Citlivost k metylaci REBpredictor predikce rozpoznávací sekvence u nových enzymů Rebase genomes identifikace genů pro RE v genomech
27 Software pro restrikční mapování Konstrukce restrikčních map na základě analýzy sekvence DNA vyhledání restrikčních míst Nezbytný předpoklad pro klonování Interpretace RFLP polymorfizmů Simulace výsledků gelové elektroforézy restrikčních fragmentů Virtuální klonování Vytvoření kvalitní grafiky ilustrující restrikční mapy RestrictionMapper ( WebCutter ( NEB Cutter v2.0 ( EMBOSS Restrict ( Restriction Maps ( pdraw32 (
28 Výsledky restrikční analýzy in silico Enzymy výstup tabulka kompletní sada komerční sada které sekvenci neštěpí které štěpí počet a pozice rozpoznávacích míst Lineární nebo kružnicová mapa sekvence se znázorněním pozice restrikčních míst Grafika Identifikace ORF a translace do proteinu

29 NEB Cutter
30 Vyhledání otevřených čtecích rámců ORF (Open Reading Frame) Sada překládaných kodonů mezi iniciačním a terminačním kodonem Výsledek je závislý na použitém genetickém kódu U prokaryot, které nemají introny je základem hledání genů U eukaryot zpravidla využíváme analýzu sekvencí komplementární DNA (cdna)

31 ORF Finder (Open Reading Frame Finder)
32 Translace in silico 6 možných čtecích rámců Vymezené oblasti - exony Jaký genetický kód? Databáze genetických kódů v NCBI rintgc.cgi

33 EMBOSS Transeq

34 Příklady translace in silico

35 Příklady translace in silico
36 Další typy analýz sekvencí DNA 1. Analýza využití kodonů 2. Klonování in silico, konstrukce vektorů 3. Návrh sekvencí oligonukleotidů primery pro PCR primery pro sekvenování hybridizační sondy 4. Párové přiložení sekvencí, stanovení identity a podobnosti 5. Mnohonásobné přiložení sekvencí
37 Klonování in silico, konstrukce vektorů Kombinace segmentů sekvencí známé/neznámé funkce Plazmidy přebírané z databáze zpravidla známé funkce Inzerty obvykle nové sekvence charakterizované restrikční mapou charakterizované sekvencí DNA charakterizované funkcí Nomenklatura pro konstrukty není stanovena

38 Clone Manager (Sci-Ed Software)
39 3. Výpočetní analýza sekvencí Počet residuí Frekvence residuí Konverze formátů Analýza využití kodonů Design oligonukleotidů a primerů
40 Analýza využití kodonů (codon usage) Využití synonymních kodonů není náhodné je rozdílné u různých genomů, které mají určité preferované kodony pro určité aminokyseliny Databáze využití kodonů

41 Navrhování sekvencí primerů pro PCR Standardní primery Modifikované oligonukleotidy na 5'- konci pro klonování Oligonukleotidy jako hybridizační sondy pro real-time PCR specifičnost jedinečnost
42 PCR - Syntéza obou řetězců u specifické sekvence 5 3 TTGAGAAAGGAATAAGCAGAATTCGTTCCAAAAAGAATGAGCTGTTGTTTGCAGAAATCGAGTATATGC AACTCTTTCCTTATTCGTCTTAAGCAAGGTTTTTCTTACTCGACAACAAACGTCTTTAGCTCATATACG 3 Přímý (forward) 5 dntps 5 primer 3 DNAPOL TTGAGAAAGGAATAAGC AACTCTTTCCTTATTCGTCTTAAGCAAGGTTTTTCTTACTCGACAACAAACGTCTTTAGCTCATATACG TTGAGAAAGGAATAAGCAGAATTCGTTCCAAAAAGAATGAGCTGTTGTTTGCAGAAATCGAGTATATGC DNAPOL TCTTTAGCTCATATACG 3 5 dntps Zpětný (reverse) primer 5 3 TTGAGAAAGGAATAAGCAGAATTCGTTCCAAAAAGAATGAGCTGTTGTTTGCAGAAATCGAGTATATGC AACTCTTTCCTTATTCGTCTTAAGCAAGGTTTTTCTTACTCGACAACAAACGTCTTTAGCTCATATACG TTGAGAAAGGAATAAGCAGAATTCGTTCCAAAAAGAATGAGCTGTTGTTTGCAGAAATCGAGTATATGC AACTCTTTCCTTATTCGTCTTAAGCAAGGTTTTTCTTACTCGACAACAAACGTCTTTAGCTCATATACG
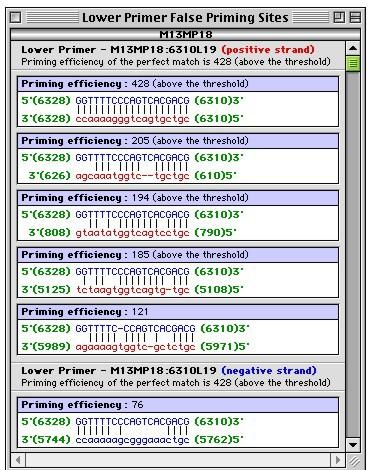
43 Výběr vhodné strategie před návrhem primerů K čemu jsou primery určeny Standardní end-point PCR Sekvenování Detekce jednonukleotidových polymorfizmů (SNP) nebo variací Studium metylace Real-time PCR Sondy pro microarray Degenerovaná PCR Multiplex PCR Z jakých dat vycházíme Jednoduchá sekvence DNA / proteinu Sekvenční přiložení DNA / proteinu GenBank ID/Gene ID/rsSNP ID
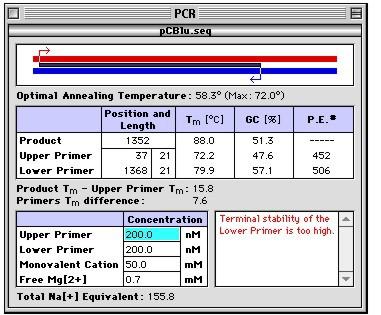
44 Pravidla pro design primeru pro PCR Relativně snadná výpočetní záležitost prohledávání sekvence a identifikace krátkých sekvencí splňujících určitá kritéria Délka primeru Obsah G+C Teplota Tm Specificita Komplementarita primerových sekvencí Sekvence 3 -konce
45 Jedinečnost primeru Na jedinečnost primeru a jeho hybridizační vlastnosti (annealing) má vliv délka primeru a velikost templátové DNA Délka (17 28 bází dlouhé) Možná hybridizační místa primeru by se také neměla nacházet na DNA tvořících případné kontaminace vzorků Templátová DNA 5...TCAACTTAGCATGATCGGGTA...GTAGCAGTTGACTGTACAACTCAGCAA...3 TGCT AGTTG A CAGTCAACTGCTAC TGCTAAGTTG Primer 1 5 -TGCTAAGTTG-3 Není jedinečný! Primer 2 5 -CAGTCAACTGCTAC-3 Jedinečný! 45
46 Zastoupení bází Zastoupení bází ovlivňuje vlastnosti hybridizace a reasociace primeru Žádoucí je náhodná distribuce bází bez oblastí bohatých na AT nebo GC Obvyklý obsah G+C, který poskytuje stabilní hybridy je %, ale závisí také na obsahu G+C templátu Templátová DNA 5...TCAACTTAGCATGATCGGGCA...AAGATGCACGGGCCTGTACACAA...3 TGCCCGATCATGCT 46
47 Teplota Tm (Melting temperature) mají T m teplotu C T = 0,3 T Primer + 0,7 T Produkt 25 a m m kde T Primer m je hodnota T m nejméně stabilního páru primer-matrice a T Produkt m je hodnota T m amplifikačního produktu. Orientačně lze vypočítat T a podle vztahu: T m = 2(A+T) + 4(G+C) T a = T m 5 C
48 Vnitřní sekvence a struktura primeru nejsou komplementární navzájem na 3 -koncích, takže nevytvářejí navzájem nebo samy se sebou duplexy neobsahují vnitřní sekundárnístruktury Chybně navržená dvojice primerů, která vytváří stabilní duplex na 3 - konci: Správně navržená dvojice primerů, která vytváří pouze málo stabilní duplex na 5 -konci; na 3 -konci je G nebo C zaručující stabilní párování s templátem: Chybně navržený primer, vytvářející vlásenku:
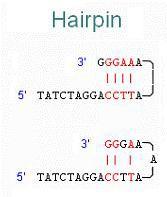
49
50 GC svorky a 3 - koncová stabilita GC svorka Přítomnost G nebo C mezi posledním 4 bázemi na 3 -konci primeru Zásadní pro zvýšení prevence falešného prodlužování a zvýšení specifičnosti primeru >3 G nebo C v blízkosti 3 -konce jsou však nežádoucí Maximální 3 -koncová stabilita Maximalizace ΔG posledních 5 bází na 3 - konci primeru.


51 Jedinečnost primerů na matricové DNA nemají falešná vazebná místa Nesprávně navržený primer s falešnými vazebnými místy na templátové DNA: Správně navržený primer, který nemá falešná vazebná místa na templátu:
52 Kdy je primer ještě primerem?


53 Pro návrh primerů se obvykle používá specializovaný software
54 Počítačový návrh primerů Umoňuje řada molekulárně biologických programů Některé jsou volně dostupné na internetu Primer3 Primer3Plus PrimerZ PerlPrimer BioTools WebPrimer Kalkulátory vlastností primerů IDT Oligo Analyzer ( BioMath ( PrimerBlast UCSC In-Silico PCR AutoDimer
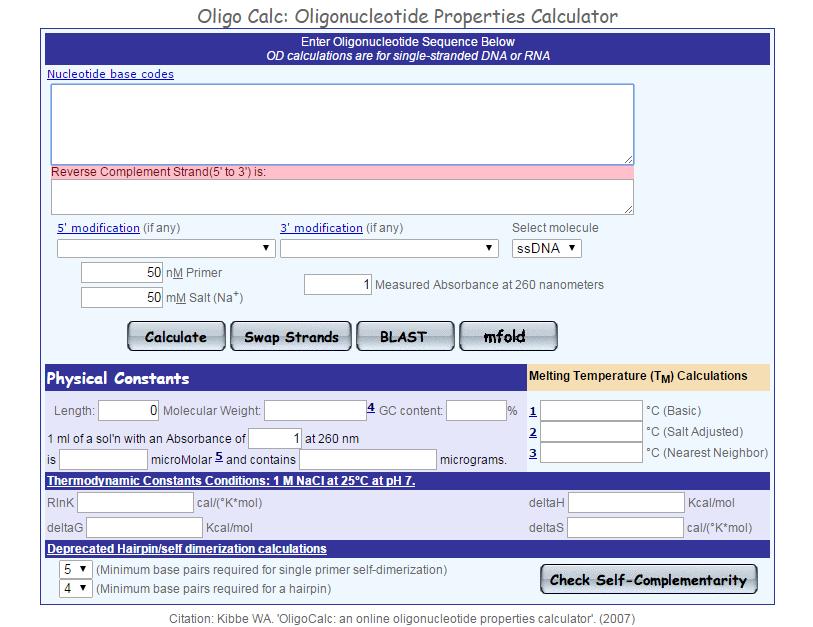
55 Oligo Calculator

56 Primer 3 (
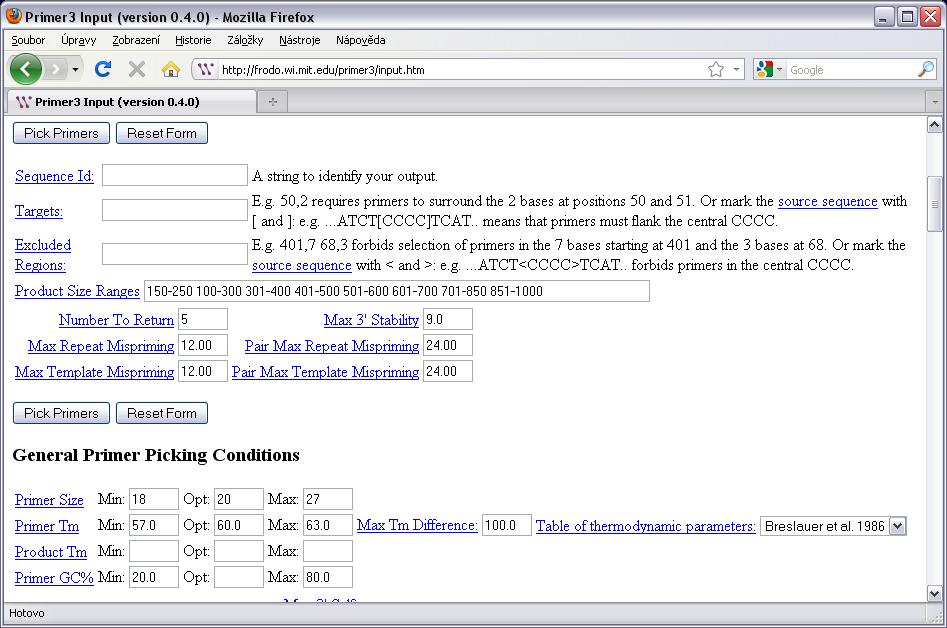
57
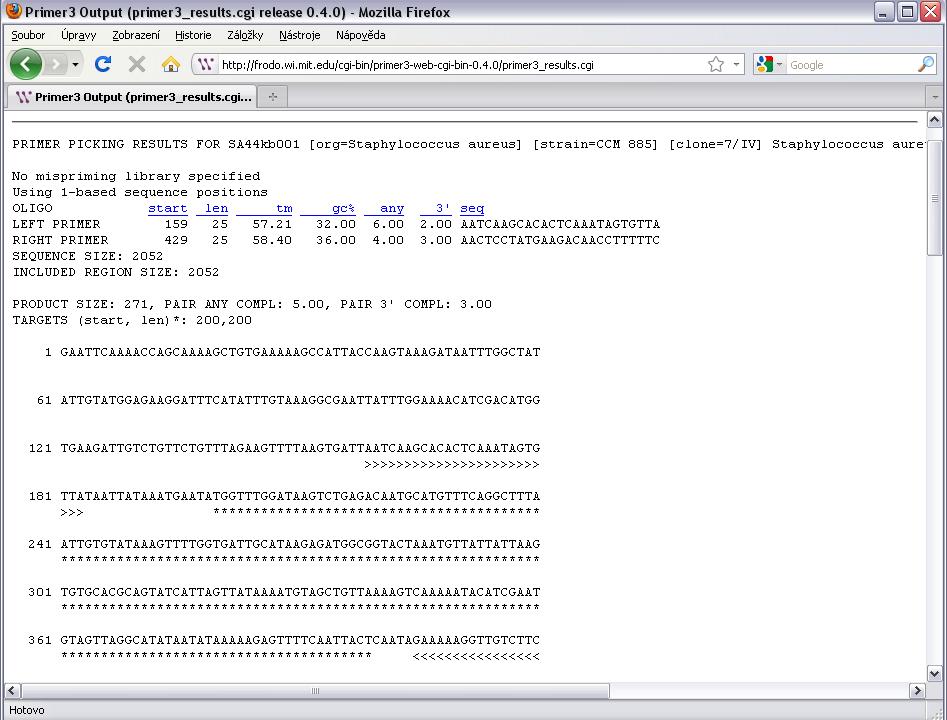
58

59 Primer3Plus rozšířené rozhraní (2007) Primer 3

60 Primer Z: streamlined primer design for promoters, exons and human SNPs
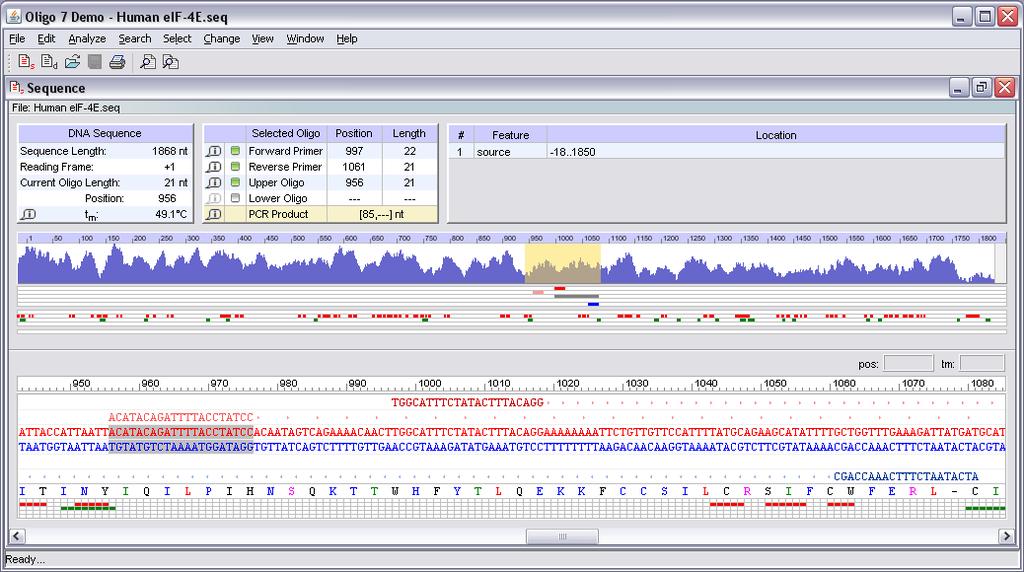
61 Oligo

62 PCR Primer Mapping UCSC In-Silico PCR
63 Výsledky Výběr optimálního páru primerů Sekvence primerů Délka primerů a hodnota Tm Velikost produktu Posouzení sekundárních struktur Podmínky reakce Alternativní primery
64 Pokročilý návrh primerů Alelově specifické primery Molekulární diagnostika Vícenásobné detekce - primery pro multiplex PCR Zajištění kompatibility primerů v reakci Konsenzní primery Pro klonování Pro PCR-RFLP (např. 16S rrna) Vyžaduje identifikaci konzervativních oblastí na základě mnohonásobných přiložení sekvencí (multiple alignment) Primery pro modifikaci konců produktů PCR

65 Modifikace konců DNA, Připojení sekvencí prostřednictvím 5 -konců primerů sticky foot Přidávané sekvence RE místa Promotory Terminátory Translační signály
66 Zdroje pro návrh multiplex PCR NCBI/ Primer-BLAST MultiPLX ( PrimerStation ( Lidský genom Specifikace exonů Vyloučení variabilních oblastí se SNP Oligo Explorer ( Posouzení dimerů primerů v multiplexovém uspořádání
67 Webové zdroje pro design primerů pro real-time PCR NCBI Probe Database RTPrimerDB Primer Bank qprimerdepot PCR-QPPD PerlPrimer Komerční databáze (např. ROCHE, )

68 NCBI Probe
69 Další technologie vyžadující návrh oligonukleotidů Real-time PCR TaqMan Molecular Beacons Primer extension Sekvenování Sangerovo sekvenování Pyrosekvenování Ligázová řetězová reakce Microarrays
70 4. Manipulace se sekvencemi proteinů Výpočet molekulové hmotnosti a PI Mutageneze Predikce sekundárních struktur Alignment struktur Vizualizace struktur
 Vector NTI (Life Technologies, Carlsbad, CA) CLC Genomics Workbench (CLC bio, Cambridge, MA) The Bioinformatics Toolbox rozšíření pro MATLAB Hitachi DNASIS MAX Sequence Analysis")
71 Nejčastěji používané softwarové balíky pro manipulaci se sekvencemi a jejich analýzu Accelrys GCG Package (Accelrys Inc., San Diego, CA) Vector NTI (Life Technologies, Carlsbad, CA) CLC Genomics Workbench (CLC bio, Cambridge, MA) The Bioinformatics Toolbox rozšíření pro MATLAB Hitachi DNASIS MAX Sequence Analysis Software (Helixx Technologies, Inc., Canada) DNASTAR Lasergene (DNASTAR, Inc., Madison, WI)

72 Příklad software Vector NTI
Manipulace se sekvenčními daty
 Manipulace se sekvenčními daty Získání a manipulace se sekvencemi Databases DNA NCBI-GenBANK DDBJ EBI-EMBL Protein PIR SWISSPROT EXPASY, PDB Entrez SRS Retrival System Softwares GCG SeqWEB Vector NTI GenoMAX
Manipulace se sekvenčními daty Získání a manipulace se sekvencemi Databases DNA NCBI-GenBANK DDBJ EBI-EMBL Protein PIR SWISSPROT EXPASY, PDB Entrez SRS Retrival System Softwares GCG SeqWEB Vector NTI GenoMAX
Hemoglobin a jemu podobní... Studijní materiál. Jan Komárek
 Hemoglobin a jemu podobní... Studijní materiál Jan Komárek Bioinformatika Bioinformatika je vědní disciplína, která se zabývá metodami pro shromážďování, analýzu a vizualizaci rozsáhlých souborů biologických
Hemoglobin a jemu podobní... Studijní materiál Jan Komárek Bioinformatika Bioinformatika je vědní disciplína, která se zabývá metodami pro shromážďování, analýzu a vizualizaci rozsáhlých souborů biologických
Molekulární základy dědičnosti. Ústřední dogma molekulární biologie Struktura DNA a RNA
 Molekulární základy dědičnosti Ústřední dogma molekulární biologie Struktura DNA a RNA Ústřední dogma molekulární genetiky - vztah mezi nukleovými kyselinami a proteiny proteosyntéza replikace DNA RNA
Molekulární základy dědičnosti Ústřední dogma molekulární biologie Struktura DNA a RNA Ústřední dogma molekulární genetiky - vztah mezi nukleovými kyselinami a proteiny proteosyntéza replikace DNA RNA
Studijní materiály pro bioinformatickou část ViBuChu. úloha II. Jan Komárek, Gabriel Demo
 Studijní materiály pro bioinformatickou část ViBuChu úloha II Jan Komárek, Gabriel Demo Adenin Struktura DNA Thymin 5 konec 3 konec DNA tvořena dvěmi řetězci orientovanými antiparalelně (liší se orientací
Studijní materiály pro bioinformatickou část ViBuChu úloha II Jan Komárek, Gabriel Demo Adenin Struktura DNA Thymin 5 konec 3 konec DNA tvořena dvěmi řetězci orientovanými antiparalelně (liší se orientací
SYNTETICKÉ OLIGONUKLEOTIDY
 Oddělení funkční genomiky a proteomiky Přírodovědecká fakulta Masarykovy university SYNTETICKÉ OLIGONUKLEOTIDY Hana Konečná CENTRÁLNÍ LABORATOŘ Masarykovy Univerzity v Brně ODDĚLENÍ FUNKČNÍ GENOMIKY A
Oddělení funkční genomiky a proteomiky Přírodovědecká fakulta Masarykovy university SYNTETICKÉ OLIGONUKLEOTIDY Hana Konečná CENTRÁLNÍ LABORATOŘ Masarykovy Univerzity v Brně ODDĚLENÍ FUNKČNÍ GENOMIKY A
Translace (druhý krok genové exprese)
") Translace (druhý krok genové exprese) Od RN k proteinu Milada Roštejnská Helena Klímová 1 enetický kód trn minoacyl-trn-synthetasa Translace probíhá na ribosomech Iniciace translace Elongace translace
Translace (druhý krok genové exprese) Od RN k proteinu Milada Roštejnská Helena Klímová 1 enetický kód trn minoacyl-trn-synthetasa Translace probíhá na ribosomech Iniciace translace Elongace translace
Genetický kód. Jakmile vznikne funkční mrna, informace v ní obsažená může být ihned použita pro syntézu proteinu.
 Genetický kód Jakmile vznikne funkční, informace v ní obsažená může být ihned použita pro syntézu proteinu. Pravidla, kterými se řídí prostřednictvím přenos z nukleotidové sekvence DNA do aminokyselinové
Genetický kód Jakmile vznikne funkční, informace v ní obsažená může být ihned použita pro syntézu proteinu. Pravidla, kterými se řídí prostřednictvím přenos z nukleotidové sekvence DNA do aminokyselinové
Molekulární genetika (Molekulární základy dědičnosti)
") Molekulární genetika (Molekulární základy dědičnosti) Struktura nukleové kyseliny Cukerná pentóza: 2-deoxy-D-ribóza D-ribóza Fosfátový zbytek: PO 4 3- Purin Pyrimidin Dusíkatá báze Adenin Guanin Tymin
Molekulární genetika (Molekulární základy dědičnosti) Struktura nukleové kyseliny Cukerná pentóza: 2-deoxy-D-ribóza D-ribóza Fosfátový zbytek: PO 4 3- Purin Pyrimidin Dusíkatá báze Adenin Guanin Tymin
2. Z následujících tvrzení, týkajících se prokaryotické buňky, vyberte správné:
 Výběrové otázky: 1. Součástí všech prokaryotických buněk je: a) DNA, plazmidy b) plazmidy, mitochondrie c) plazmidy, ribozomy d) mitochondrie, endoplazmatické retikulum 2. Z následujících tvrzení, týkajících
Výběrové otázky: 1. Součástí všech prokaryotických buněk je: a) DNA, plazmidy b) plazmidy, mitochondrie c) plazmidy, ribozomy d) mitochondrie, endoplazmatické retikulum 2. Z následujících tvrzení, týkajících
Proteiny Genová exprese. 2013 Doc. MVDr. Eva Bártová, Ph.D.
 Proteiny Genová exprese 2013 Doc. MVDr. Eva Bártová, Ph.D. Bílkoviny (proteiny), 15% 1g = 17 kj Monomer = aminokyseliny aminová skupina karboxylová skupina α -uhlík postranní řetězec Znát obecný vzorec
Proteiny Genová exprese 2013 Doc. MVDr. Eva Bártová, Ph.D. Bílkoviny (proteiny), 15% 1g = 17 kj Monomer = aminokyseliny aminová skupina karboxylová skupina α -uhlík postranní řetězec Znát obecný vzorec
Propojení výuky oborů Molekulární a buněčné biologie a Ochrany a tvorby životního prostředí. Reg. č.: CZ.1.07/2.2.00/
 Propojení výuky oborů Molekulární a buněčné biologie a Ochrany a tvorby životního prostředí Reg. č.: CZ.1.07/2.2.00/28.0032 Molekulární genetika (Molekulární základy dědičnosti) 0 Gen - historie 1909 Johanssen
Propojení výuky oborů Molekulární a buněčné biologie a Ochrany a tvorby životního prostředí Reg. č.: CZ.1.07/2.2.00/28.0032 Molekulární genetika (Molekulární základy dědičnosti) 0 Gen - historie 1909 Johanssen
Bioinformatika a výpočetní biologie KFC/BIN. I. Přehled
 Bioinformatika a výpočetní biologie KFC/BIN I. Přehled RNDr. Karel Berka, Ph.D. Univerzita Palackého v Olomouci Definice bioinformatiky (Molecular) bio informatics: bioinformatics is conceptualising biology
Bioinformatika a výpočetní biologie KFC/BIN I. Přehled RNDr. Karel Berka, Ph.D. Univerzita Palackého v Olomouci Definice bioinformatiky (Molecular) bio informatics: bioinformatics is conceptualising biology
Využití DNA markerů ve studiu fylogeneze rostlin
 Mendelova genetika v příkladech Využití DNA markerů ve studiu fylogeneze rostlin Ing. Petra VESELÁ Ústav lesnické botaniky, dendrologie a geobiocenologie LDF MENDELU Brno Tento projekt je spolufinancován
Mendelova genetika v příkladech Využití DNA markerů ve studiu fylogeneze rostlin Ing. Petra VESELÁ Ústav lesnické botaniky, dendrologie a geobiocenologie LDF MENDELU Brno Tento projekt je spolufinancován
Molekulárn. rní. biologie Struktura DNA a RNA
 Molekulárn rní základy dědičnosti Ústřední dogma molekulárn rní biologie Struktura DNA a RNA Ústřední dogma molekulárn rní genetiky - vztah mezi nukleovými kyselinami a proteiny proteosyntéza replikace
Molekulárn rní základy dědičnosti Ústřední dogma molekulárn rní biologie Struktura DNA a RNA Ústřední dogma molekulárn rní genetiky - vztah mezi nukleovými kyselinami a proteiny proteosyntéza replikace
Základy praktické Bioinformatiky
 Základy praktické Bioinformatiky PETRA MATOUŠKOVÁ 2018/2019 8/10 Základy praktické bioinformatiky Téma 8/10 Nukleotidová bioinformatika IV Cíle: Student bude schopen navrhnout primery pro kvantitativní
Základy praktické Bioinformatiky PETRA MATOUŠKOVÁ 2018/2019 8/10 Základy praktické bioinformatiky Téma 8/10 Nukleotidová bioinformatika IV Cíle: Student bude schopen navrhnout primery pro kvantitativní
b) Jak se změní sekvence aminokyselin v polypeptidu, pokud dojde v pozici 23 k záměně bázového páru GC za TA (bodová mutace) a s jakými následky?
 Jak se změní sekvence aminokyselin v polypeptidu, pokud dojde v pozici 23 k záměně bázového páru GC za TA (bodová mutace) a s jakými následky?") 1.1: Gén pro polypeptid, který je součástí peroxidázy buku lesního, má sekvenci 3'...TTTACAGTCCATTCGACTTAGGGGCTAAGGTACCTGGAGCCCACGTTTGGGTCATCCAG...5' 5'...AAATGTCAGGTAAGCTGAATCCCCGATTCCATGGACCTCGGGTGCAAACCCAGTAGGTC...3'
1.1: Gén pro polypeptid, který je součástí peroxidázy buku lesního, má sekvenci 3'...TTTACAGTCCATTCGACTTAGGGGCTAAGGTACCTGGAGCCCACGTTTGGGTCATCCAG...5' 5'...AAATGTCAGGTAAGCTGAATCCCCGATTCCATGGACCTCGGGTGCAAACCCAGTAGGTC...3'
Genové knihovny a analýza genomu
 Genové knihovny a analýza genomu Klonování genů Problém: genom organismů je komplexní a je proto obtížné v něm najít a klonovat specifický gen Klonování genů Po restrikčním štěpení genomové DNA pocházející
Genové knihovny a analýza genomu Klonování genů Problém: genom organismů je komplexní a je proto obtížné v něm najít a klonovat specifický gen Klonování genů Po restrikčním štěpení genomové DNA pocházející
Exprese genetické informace
 Exprese genetické informace Tok genetické informace DNA RNA Protein (výjimečně RNA DNA) DNA RNA : transkripce RNA protein : translace Gen jednotka dědičnosti sekvence DNA nutná k produkci funkčního produktu
Exprese genetické informace Tok genetické informace DNA RNA Protein (výjimečně RNA DNA) DNA RNA : transkripce RNA protein : translace Gen jednotka dědičnosti sekvence DNA nutná k produkci funkčního produktu
Genetický polymorfismus
 Genetický polymorfismus Za geneticky polymorfní je považován znak s nejméně dvěma geneticky podmíněnými variantami v jedné populaci, které se nachází v takových frekvencích, že i zřídkavá má frekvenci
Genetický polymorfismus Za geneticky polymorfní je považován znak s nejméně dvěma geneticky podmíněnými variantami v jedné populaci, které se nachází v takových frekvencích, že i zřídkavá má frekvenci
Struktura nukleových kyselin Vlastnosti genetického materiálu
 Struktura nukleových kyselin Vlastnosti genetického materiálu V předcházejících kapitolách bylo konstatováno, že geny jsou uloženy na chromozomech a kontrolují fenotypové vlastnosti a že chromozomy se
Struktura nukleových kyselin Vlastnosti genetického materiálu V předcházejících kapitolách bylo konstatováno, že geny jsou uloženy na chromozomech a kontrolují fenotypové vlastnosti a že chromozomy se
NGS analýza dat. kroužek, Alena Musilová
 NGS analýza dat kroužek, 16.12.2016 Alena Musilová Typy NGS experimentů Název Materiál Cílí na..? Cíl experimentu? amplikon DNA malý počet vybraných genů hledání variant exom DNA všechny geny hledání
NGS analýza dat kroužek, 16.12.2016 Alena Musilová Typy NGS experimentů Název Materiál Cílí na..? Cíl experimentu? amplikon DNA malý počet vybraných genů hledání variant exom DNA všechny geny hledání
Počítačové vyhledávání genů a funkčních oblastí na DNA
 Počítačové vyhledávání genů a funkčních oblastí na DNA Hodnota genomových sekvencí záleží na kvalitě anotace Anotace Charakterizace genomových vlastností s použitím výpočetních a experimentálních metod
Počítačové vyhledávání genů a funkčních oblastí na DNA Hodnota genomových sekvencí záleží na kvalitě anotace Anotace Charakterizace genomových vlastností s použitím výpočetních a experimentálních metod
Využití internetových zdrojů při studiu mikroorganismů
 Využití internetových zdrojů při studiu mikroorganismů doc. RNDr. Milan Bartoš, Ph.D. bartosm@vfu.cz Přírodovědecká fakulta MU, 2012 Obsah přednášky 1) Práce se sekvenčními daty 2) Základní veřejně dostupné
Využití internetových zdrojů při studiu mikroorganismů doc. RNDr. Milan Bartoš, Ph.D. bartosm@vfu.cz Přírodovědecká fakulta MU, 2012 Obsah přednášky 1) Práce se sekvenčními daty 2) Základní veřejně dostupné
Molekulární biotechnologie č.9. Cílená mutageneze a proteinové inženýrství
 Molekulární biotechnologie č.9 Cílená mutageneze a proteinové inženýrství Gen kódující jakýkoliv protein lze izolovat z přírody, klonovat, exprimovat v hostitelském organismu. rekombinantní protein purifikovat
Molekulární biotechnologie č.9 Cílená mutageneze a proteinové inženýrství Gen kódující jakýkoliv protein lze izolovat z přírody, klonovat, exprimovat v hostitelském organismu. rekombinantní protein purifikovat
Klonování DNA a fyzikální mapování genomu
 Klonování DNA a fyzikální mapování genomu. Terminologie Klonování je proces tvorby klonů Klon je soubor identických buněk (příp. organismů) odvozených ze společného předka dělením (např. jedna bakteriální
Klonování DNA a fyzikální mapování genomu. Terminologie Klonování je proces tvorby klonů Klon je soubor identických buněk (příp. organismů) odvozených ze společného předka dělením (např. jedna bakteriální
Bioinformatika je nová disciplína na rozhraní počítačových věd, informačních technologií a biologie. Bioinformatika zahrnuje studium biologických dat
 Bioinformatika je nová disciplína na rozhraní počítačových věd, informačních technologií a biologie. Bioinformatika zahrnuje studium biologických dat a jejich praktické uchovávání, vyhledávání a modelování.
Bioinformatika je nová disciplína na rozhraní počítačových věd, informačních technologií a biologie. Bioinformatika zahrnuje studium biologických dat a jejich praktické uchovávání, vyhledávání a modelování.
Referenční lidský genom. Rozdíly v genomové DNA v lidské populaci. Odchylky od referenčního genomu. Referenční lidský genom.
 Referenční lidský genom Rozdíly v genomové DNA v lidské populaci Zdroj DNA: 60% sekvencí pochází ze sekvenování DNA od jednoho dárce (sekvenování a sestavování BAC klonů) některá místa genomu se nepodařilo
Referenční lidský genom Rozdíly v genomové DNA v lidské populaci Zdroj DNA: 60% sekvencí pochází ze sekvenování DNA od jednoho dárce (sekvenování a sestavování BAC klonů) některá místa genomu se nepodařilo
Amplifikační metody umožňují detekovat. k dispozici minimálně kopií DNA,
 Diagnostické amplifikační metody nevyužívající PCR Amplifikační metody umožňují detekovat jedinou kopii cílové DNA, zatímco při hybridizačních metodách musí být k dispozici minimálně 10 4-10 5 kopií DNA,
Diagnostické amplifikační metody nevyužívající PCR Amplifikační metody umožňují detekovat jedinou kopii cílové DNA, zatímco při hybridizačních metodách musí být k dispozici minimálně 10 4-10 5 kopií DNA,
MOLEKULÁRNÍ BIOLOGIE. 2. Polymerázová řetězová reakce (PCR)
") MOLEKULÁRNÍ BIOLOGIE 2. Polymerázová řetězová reakce (PCR) Náplň praktik 1. Izolace DNA z buněk bukální sliznice - izolační kit MACHEREY-NAGEL 2. PCR polymerázová řetězová reakce (templát gdna) 3. Restrikční
MOLEKULÁRNÍ BIOLOGIE 2. Polymerázová řetězová reakce (PCR) Náplň praktik 1. Izolace DNA z buněk bukální sliznice - izolační kit MACHEREY-NAGEL 2. PCR polymerázová řetězová reakce (templát gdna) 3. Restrikční
Co se o sobě dovídáme z naší genetické informace
 Genomika a bioinformatika Co se o sobě dovídáme z naší genetické informace Jan Pačes, Mgr, Ph.D Ústav molekulární genetiky AVČR, CZECH FOBIA (Free and Open Bioinformatics Association) hpaces@img.cas.cz
Genomika a bioinformatika Co se o sobě dovídáme z naší genetické informace Jan Pačes, Mgr, Ph.D Ústav molekulární genetiky AVČR, CZECH FOBIA (Free and Open Bioinformatics Association) hpaces@img.cas.cz
Inovace studia molekulární a buněčné biologie
 Inovace studia molekulární a buněčné biologie Tento projekt je spolufinancován Evropským sociálním fondem a státním rozpočtem České republiky. MBIO1/Molekulární biologie 1 Tento projekt je spolufinancován
Inovace studia molekulární a buněčné biologie Tento projekt je spolufinancován Evropským sociálním fondem a státním rozpočtem České republiky. MBIO1/Molekulární biologie 1 Tento projekt je spolufinancován
Základy genomiky. I. Úvod do bioinformatiky. Jan Hejátko
 Základy genomiky I. Úvod do bioinformatiky Jan Hejátko Masarykova univerzita, Oddělení funkční genomiky a proteomiky Laboratoř molekulární fyziologie rostlin Základy genomiky I. Zdrojová literatura ke
Základy genomiky I. Úvod do bioinformatiky Jan Hejátko Masarykova univerzita, Oddělení funkční genomiky a proteomiky Laboratoř molekulární fyziologie rostlin Základy genomiky I. Zdrojová literatura ke
Detekce Leidenské mutace
 Detekce Leidenské mutace MOLEKULÁRNÍ BIOLOGIE 3. Restrikční štěpení, elektroforéza + interpretace výsledků Restrikční endonukleasy(restriktasy) bakteriální enzymy štěpící cizorodou dsdna na kratší úseky
Detekce Leidenské mutace MOLEKULÁRNÍ BIOLOGIE 3. Restrikční štěpení, elektroforéza + interpretace výsledků Restrikční endonukleasy(restriktasy) bakteriální enzymy štěpící cizorodou dsdna na kratší úseky
Exprese genetické informace
 Exprese genetické informace Stavební kameny nukleových kyselin Nukleotidy = báze + cukr + fosfát BÁZE FOSFÁT Nukleosid = báze + cukr CUKR Báze Cyklické sloučeniny obsahující dusík puriny nebo pyrimidiny
Exprese genetické informace Stavební kameny nukleových kyselin Nukleotidy = báze + cukr + fosfát BÁZE FOSFÁT Nukleosid = báze + cukr CUKR Báze Cyklické sloučeniny obsahující dusík puriny nebo pyrimidiny
Inovace studia molekulární a buněčné biologie
 Inovace studia molekulární a buněčné biologie I n v e s t i c e d o r o z v o j e v z d ě l á v á n í reg. č. CZ.1.07/2.2.00/07.0354 Tento projekt je spolufinancován Evropským sociálním fondem a státním
Inovace studia molekulární a buněčné biologie I n v e s t i c e d o r o z v o j e v z d ě l á v á n í reg. č. CZ.1.07/2.2.00/07.0354 Tento projekt je spolufinancován Evropským sociálním fondem a státním
6. Kde v DNA nalézáme rozdíly, zodpovědné za obrovskou diverzitu života?
 6. Kde v DNA nalézáme rozdíly, zodpovědné za obrovskou diverzitu života? Pamatujete na to, co se objevilo v pracích Charlese Darwina a Alfreda Wallace ohledně vývoje druhů? Aby mohl mechanismus přírodního
6. Kde v DNA nalézáme rozdíly, zodpovědné za obrovskou diverzitu života? Pamatujete na to, co se objevilo v pracích Charlese Darwina a Alfreda Wallace ohledně vývoje druhů? Aby mohl mechanismus přírodního
Osekvenované genomy. Pan troglodydes, 2005. Neandrtálec, 2010
 GENOMOVÉ PROJEKTY Osekvenované genomy Haemophilus influenze, 1995 první osekvenovaná bakterie Saccharomyces cerevisiae, 1996 první osekvenovaný eukaryotický organimus Caenorhabditis elegans, 1998 první
GENOMOVÉ PROJEKTY Osekvenované genomy Haemophilus influenze, 1995 první osekvenovaná bakterie Saccharomyces cerevisiae, 1996 první osekvenovaný eukaryotický organimus Caenorhabditis elegans, 1998 první
Struktura a funkce nukleových kyselin
 Struktura a funkce nukleových kyselin ukleové kyseliny Deoxyribonukleová kyselina - DA - uchovává genetickou informaci Ribonukleová kyselina RA - genová exprese a biosyntéza proteinů Složení A stavební
Struktura a funkce nukleových kyselin ukleové kyseliny Deoxyribonukleová kyselina - DA - uchovává genetickou informaci Ribonukleová kyselina RA - genová exprese a biosyntéza proteinů Složení A stavební
Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti. Translace, techniky práce s DNA
 Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti Translace, techniky práce s DNA Translace překlad z jazyka nukleotidů do jazyka aminokyselin dá se rozdělit na 5 kroků aktivace aminokyslin
Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti Translace, techniky práce s DNA Translace překlad z jazyka nukleotidů do jazyka aminokyselin dá se rozdělit na 5 kroků aktivace aminokyslin
Metody molekulární biologie
 Metody molekulární biologie 1. Základní metody molekulární biologie A. Izolace nukleových kyselin Metody využívající různé rozpustnosti Metody adsorpční Izolace RNA B. Centrifugační techniky o Princip
Metody molekulární biologie 1. Základní metody molekulární biologie A. Izolace nukleových kyselin Metody využívající různé rozpustnosti Metody adsorpční Izolace RNA B. Centrifugační techniky o Princip
Polymerázová řetězová reakce. Základní technika molekulární diagnostiky.
 Polymerázová řetězová reakce Základní technika molekulární diagnostiky. Kdo za to může? Kary Mullis 1983 Nobelova cena 1993 Princip PCR Polymerázová řetězová reakce (polymerase chain reaction PCR) umožňuje
Polymerázová řetězová reakce Základní technika molekulární diagnostiky. Kdo za to může? Kary Mullis 1983 Nobelova cena 1993 Princip PCR Polymerázová řetězová reakce (polymerase chain reaction PCR) umožňuje
DNA TECHNIKY IDENTIFIKACE ŽIVOČIŠNÝCH DRUHŮ V KRMIVU A POTRAVINÁCH. Michaela Nesvadbová
 DNA TECHNIKY IDENTIFIKACE ŽIVOČIŠNÝCH DRUHŮ V KRMIVU A POTRAVINÁCH Michaela Nesvadbová Význam identifikace živočišných druhů v krmivu a potravinách povinností každého výrobce je řádně a pravdivě označit
DNA TECHNIKY IDENTIFIKACE ŽIVOČIŠNÝCH DRUHŮ V KRMIVU A POTRAVINÁCH Michaela Nesvadbová Význam identifikace živočišných druhů v krmivu a potravinách povinností každého výrobce je řádně a pravdivě označit
Nukleosidy, nukleotidy, nukleové kyseliny, genetická informace
 Nukleosidy, nukleotidy, nukleové kyseliny, genetická informace Centrální dogma Nukleové kyseliny Fosfátem spojené nukleotidy (cukr s navázanou bází a fosfátem) Nukleotidy Nukleotidy stavební kameny nukleových
Nukleosidy, nukleotidy, nukleové kyseliny, genetická informace Centrální dogma Nukleové kyseliny Fosfátem spojené nukleotidy (cukr s navázanou bází a fosfátem) Nukleotidy Nukleotidy stavební kameny nukleových
MOLEKULÁRNĚ BIOLOGICKÉ METODY V ENVIRONMENTÁLNÍ MIKROBIOLOGII. Martina Nováková, VŠCHT Praha
 MOLEKULÁRNĚ BIOLOGICKÉ METODY V ENVIRONMENTÁLNÍ MIKROBIOLOGII Martina Nováková, VŠCHT Praha MOLEKULÁRNÍ BIOLOGIE V BIOREMEDIACÍCH enumerace FISH průtoková cytometrie klonování produktů PCR sekvenování
MOLEKULÁRNĚ BIOLOGICKÉ METODY V ENVIRONMENTÁLNÍ MIKROBIOLOGII Martina Nováková, VŠCHT Praha MOLEKULÁRNÍ BIOLOGIE V BIOREMEDIACÍCH enumerace FISH průtoková cytometrie klonování produktů PCR sekvenování
Nukleové kyseliny Replikace Transkripce translace
 Nukleové kyseliny Replikace Transkripce translace Figure 4-3 Molecular Biology of the Cell ( Garland Science 2008) Figure 4-4 Molecular Biology of the Cell ( Garland Science 2008) Figure 4-5 Molecular
Nukleové kyseliny Replikace Transkripce translace Figure 4-3 Molecular Biology of the Cell ( Garland Science 2008) Figure 4-4 Molecular Biology of the Cell ( Garland Science 2008) Figure 4-5 Molecular
Genetika zvířat - MENDELU
 Genetika zvířat DNA - primární struktura Několik experimentů ve 40. a 50. letech 20. století poskytla důkaz, že genetický materiál je tvořen jedním ze dvou typů nukleových kyselin: DNA nebo RNA. DNA je
Genetika zvířat DNA - primární struktura Několik experimentů ve 40. a 50. letech 20. století poskytla důkaz, že genetický materiál je tvořen jedním ze dvou typů nukleových kyselin: DNA nebo RNA. DNA je
Exprese genetického kódu Centrální dogma molekulární biologie DNA RNA proteinu transkripce DNA mrna translace proteosyntéza
 Exprese genetického kódu Centrální dogma molekulární biologie - genetická informace v DNA -> RNA -> primárního řetězce proteinu 1) transkripce - přepis z DNA do mrna 2) translace - přeložení z kódu nukleových
Exprese genetického kódu Centrální dogma molekulární biologie - genetická informace v DNA -> RNA -> primárního řetězce proteinu 1) transkripce - přepis z DNA do mrna 2) translace - přeložení z kódu nukleových
Základy molekulární a buněčné biologie. Přípravný kurz Komb.forma studia oboru Všeobecná sestra
 Základy molekulární a buněčné biologie Přípravný kurz Komb.forma studia oboru Všeobecná sestra Genetický aparát buňky DNA = nositelka genetické informace - dvouvláknová RNA: jednovláknová mrna = messenger
Základy molekulární a buněčné biologie Přípravný kurz Komb.forma studia oboru Všeobecná sestra Genetický aparát buňky DNA = nositelka genetické informace - dvouvláknová RNA: jednovláknová mrna = messenger
V. letní škola metod molekulární biologie nukleových kyselin a genomiky 16. - 20. 6. 2014. Ústav morfologie, fyziologie a genetiky zvířat AF MENDELU
 V. letní škola metod molekulární biologie nukleových kyselin a genomiky 16. - 20. 6. 2014 Ústav morfologie, fyziologie a genetiky zvířat AF MENDELU Zemědělská 1, Budova A, 4. patro (učebny dle programu)
V. letní škola metod molekulární biologie nukleových kyselin a genomiky 16. - 20. 6. 2014 Ústav morfologie, fyziologie a genetiky zvířat AF MENDELU Zemědělská 1, Budova A, 4. patro (učebny dle programu)
Využití rekombinantní DNA při studiu mikroorganismů
 Využití rekombinantní DNA při studiu mikroorganismů doc. RNDr. Milan Bartoš, Ph.D. bartosm@vfu.cz Přírodovědecká fakulta MU, 2014 1 2 Obsah přednášky 1) Celogenomové metody sekvenování 2) Sekvenování H.
Využití rekombinantní DNA při studiu mikroorganismů doc. RNDr. Milan Bartoš, Ph.D. bartosm@vfu.cz Přírodovědecká fakulta MU, 2014 1 2 Obsah přednášky 1) Celogenomové metody sekvenování 2) Sekvenování H.
Sekvenování nové generace. Radka Reifová
 Sekvenování nové generace Radka Reifová Prezentace ke stažení www.natur.cuni.cz/zoologie/biodiversity v záložce Přednášky 1. Přehled sekvenačních metod nové generace 2. Využití sekvenačních metod nové
Sekvenování nové generace Radka Reifová Prezentace ke stažení www.natur.cuni.cz/zoologie/biodiversity v záložce Přednášky 1. Přehled sekvenačních metod nové generace 2. Využití sekvenačních metod nové
Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti. Vztah struktury a funkce nukleových kyselin. Replikace, transkripce
 Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti Vztah struktury a funkce nukleových kyselin. Replikace, transkripce Nukleová kyselina gen základní jednotka informace v živých systémech,
Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti Vztah struktury a funkce nukleových kyselin. Replikace, transkripce Nukleová kyselina gen základní jednotka informace v živých systémech,
Biotechnologický kurz. II. letní škola metod molekulární biologie nukleových kyselin a genomiky 17. - 21. 6. 2013
 Biotechnologický kurz Biotechnologický kurz II. letní škola metod molekulární biologie nukleových kyselin a genomiky 17. - 21. 6. 2013 Ústav morfologie, fyziologie a genetiky zvířat AF MENDELU v Brně Zemědělská
Biotechnologický kurz Biotechnologický kurz II. letní škola metod molekulární biologie nukleových kyselin a genomiky 17. - 21. 6. 2013 Ústav morfologie, fyziologie a genetiky zvířat AF MENDELU v Brně Zemědělská
Nukleové kyseliny Replikace Transkripce translace
 Nukleové kyseliny Replikace Transkripce translace Prokaryotická X eukaryotická buňka Hlavní rozdíl organizace genetického materiálu (u prokaryot není ohraničen) Život závisí na schopnosti buněk skladovat,
Nukleové kyseliny Replikace Transkripce translace Prokaryotická X eukaryotická buňka Hlavní rozdíl organizace genetického materiálu (u prokaryot není ohraničen) Život závisí na schopnosti buněk skladovat,
Analýza DNA. Co zjišťujeme u DNA DNA. PCR polymerase chain reaction. Princip PCR PRINCIP METODY PCR
 o zjišťujeme u DN nalýza DN enetickou podstatu konkrétních proteinů Mutace bodové (sekvenční delece nebo inzerce nukleotidů), chromosomové aberace (numerické, strukturální) Polymorfismy konkrétní mutace,
o zjišťujeme u DN nalýza DN enetickou podstatu konkrétních proteinů Mutace bodové (sekvenční delece nebo inzerce nukleotidů), chromosomové aberace (numerické, strukturální) Polymorfismy konkrétní mutace,
Využití metod strojového učení v bioinformatice David Hoksza
 Využití metod strojového učení v bioinformatice David Hoksza SIRET Research Group Katedra softwarového inženýrství, Matematicko-fyzikální fakulta Karlova Univerzita v Praze Bioinformatika Biologické inspirace
Využití metod strojového učení v bioinformatice David Hoksza SIRET Research Group Katedra softwarového inženýrství, Matematicko-fyzikální fakulta Karlova Univerzita v Praze Bioinformatika Biologické inspirace
Nukleové kyseliny. DeoxyriboNucleic li Acid
 Molekulární lární genetika Nukleové kyseliny DeoxyriboNucleic li Acid RiboNucleic N li Acid cukr (deoxyrobosa, ribosa) fosforečný zbytek dusíkatá báze Dusíkaté báze Dvouvláknová DNA Uchovává genetickou
Molekulární lární genetika Nukleové kyseliny DeoxyriboNucleic li Acid RiboNucleic N li Acid cukr (deoxyrobosa, ribosa) fosforečný zbytek dusíkatá báze Dusíkaté báze Dvouvláknová DNA Uchovává genetickou
Hybridizace nukleových kyselin
 Hybridizace nukleových kyselin Tvorba dvouřetězcových hybridů za dvou jednořetězcových a komplementárních molekul Založena na schopnosti denaturace a renaturace DNA. Denaturace DNA oddělení komplementárních
Hybridizace nukleových kyselin Tvorba dvouřetězcových hybridů za dvou jednořetězcových a komplementárních molekul Založena na schopnosti denaturace a renaturace DNA. Denaturace DNA oddělení komplementárních
Molekulárně biologické metody princip, popis, výstupy
 & Molekulárně biologické metody princip, popis, výstupy Klára Labská Evropský program pro mikrobiologii ve veřejném zdravotnictví (EUPHEM), ECDC, Stockholm NRL pro herpetické viry,centrum epidemiologie
& Molekulárně biologické metody princip, popis, výstupy Klára Labská Evropský program pro mikrobiologii ve veřejném zdravotnictví (EUPHEM), ECDC, Stockholm NRL pro herpetické viry,centrum epidemiologie
Nukleové kyseliny. obecný přehled
 Nukleové kyseliny obecný přehled Nukleové kyseliny objeveny r.1868, izolovány koncem 19.stol., 1953 objasněno jejich složení Watsonem a Crickem (1962 Nobelova cena) biopolymery nositelky genetické informace
Nukleové kyseliny obecný přehled Nukleové kyseliny objeveny r.1868, izolovány koncem 19.stol., 1953 objasněno jejich složení Watsonem a Crickem (1962 Nobelova cena) biopolymery nositelky genetické informace
Genomické databáze. Shlukování proteinových sekvencí. Ivana Rudolfová. školitel: doc. Ing. Jaroslav Zendulka, CSc.
 Genomické databáze Shlukování proteinových sekvencí Ivana Rudolfová školitel: doc. Ing. Jaroslav Zendulka, CSc. Obsah Proteiny Zdroje dat Predikce struktury proteinů Cíle disertační práce Vstupní data
Genomické databáze Shlukování proteinových sekvencí Ivana Rudolfová školitel: doc. Ing. Jaroslav Zendulka, CSc. Obsah Proteiny Zdroje dat Predikce struktury proteinů Cíle disertační práce Vstupní data
Molekulární základ dědičnosti
 Molekulární základ dědičnosti Dědičná informace je zakódována v deoxyribonukleové kyselině, která je uložena v jádře buňky v chromozómech. Zlomovým objevem pro další rozvoj molekulární genetiky bylo odhalení
Molekulární základ dědičnosti Dědičná informace je zakódována v deoxyribonukleové kyselině, která je uložena v jádře buňky v chromozómech. Zlomovým objevem pro další rozvoj molekulární genetiky bylo odhalení
Garant předmětu GEN: prof. Ing. Jindřich Čítek, CSc. Garant předmětu GEN1: prof. Ing. Václav Řehout, CSc.
 Garant předmětu GEN: prof. Ing. Jindřich Čítek, CSc. Garant předmětu GEN1: prof. Ing. Václav Řehout, CSc. Další vyučující: Ing. l. Večerek, PhD., Ing. L. Hanusová, Ph.D., Ing. L. Tothová Předpoklady: znalosti
Garant předmětu GEN: prof. Ing. Jindřich Čítek, CSc. Garant předmětu GEN1: prof. Ing. Václav Řehout, CSc. Další vyučující: Ing. l. Večerek, PhD., Ing. L. Hanusová, Ph.D., Ing. L. Tothová Předpoklady: znalosti
Biotechnologický kurz. III. letní škola metod molekulární biologie nukleových kyselin a genomiky
 Biotechnologický kurz Biotechnologický kurz III. letní škola metod molekulární biologie nukleových kyselin a genomiky 18. - 22. 6. 2012 Ústav morfologie, fyziologie a genetiky zvířat AF MENDELU v Brně
Biotechnologický kurz Biotechnologický kurz III. letní škola metod molekulární biologie nukleových kyselin a genomiky 18. - 22. 6. 2012 Ústav morfologie, fyziologie a genetiky zvířat AF MENDELU v Brně
Nukleové kyseliny Replikace DNA Doc. MVDr. Eva Bártová, Ph.D.
 Nukleové kyseliny Replikace DNA 2013 Doc. MVDr. Eva Bártová, Ph.D. Nukleové kyseliny 7% cytozin Monomer: NUKLEOTID, tvoří jej: uracil kyselina fosforečná pentóza (ribóza, deoxyribóza) tymin organická dusíkatá
Nukleové kyseliny Replikace DNA 2013 Doc. MVDr. Eva Bártová, Ph.D. Nukleové kyseliny 7% cytozin Monomer: NUKLEOTID, tvoří jej: uracil kyselina fosforečná pentóza (ribóza, deoxyribóza) tymin organická dusíkatá
Molekulární genetika
 Molekulární genetika Genetické inženýrství Technologie rekombinantní DNA Vektor Genomová DNA Štěpení RE Rozštěpení stejnou RE, lepivé konce Ligace Transformace Bakteriální chromozóm Rekombinantní vektor
Molekulární genetika Genetické inženýrství Technologie rekombinantní DNA Vektor Genomová DNA Štěpení RE Rozštěpení stejnou RE, lepivé konce Ligace Transformace Bakteriální chromozóm Rekombinantní vektor
Výzkumné centrum genomiky a proteomiky. Ústav experimentální medicíny AV ČR, v.v.i.
 Výzkumné centrum genomiky a proteomiky Ústav experimentální medicíny AV ČR, v.v.i. Systém pro sekvenování Systém pro čipovou analýzu Systém pro proteinovou analýzu Automatický sběrač buněk Systém pro sekvenování
Výzkumné centrum genomiky a proteomiky Ústav experimentální medicíny AV ČR, v.v.i. Systém pro sekvenování Systém pro čipovou analýzu Systém pro proteinovou analýzu Automatický sběrač buněk Systém pro sekvenování
Schéma průběhu transkripce
 Molekulární základy genetiky PROTEOSYNTÉZA A GENETICKÝ KÓD Proteosyntéza je složitý proces tvorby bílkovin, který zahrnuje proces přepisu genetické informace z DNA do kratšího zápisu v informační mrna
Molekulární základy genetiky PROTEOSYNTÉZA A GENETICKÝ KÓD Proteosyntéza je složitý proces tvorby bílkovin, který zahrnuje proces přepisu genetické informace z DNA do kratšího zápisu v informační mrna
Tomáš Oberhuber. Faculty of Nuclear Sciences and Physical Engineering Czech Technical University in Prague
 Tomáš Faculty of Nuclear Sciences and Physical Engineering Czech Technical University in Prague Buňka buňka je základní stavební prvek všech živých organismů byla objevena Robertem Hookem roku 1665 jednodušší
Tomáš Faculty of Nuclear Sciences and Physical Engineering Czech Technical University in Prague Buňka buňka je základní stavební prvek všech živých organismů byla objevena Robertem Hookem roku 1665 jednodušší
TRANSLACE - SYNTÉZA BÍLKOVIN
 TRANSLACE - SYNTÉZA BÍLKOVIN Translace - překlad genetické informace z jazyka nukleotidů do jazyka aminokyselin podle pravidel genetického kódu. Genetický kód - způsob zápisu genetické informace Kód Morseovy
TRANSLACE - SYNTÉZA BÍLKOVIN Translace - překlad genetické informace z jazyka nukleotidů do jazyka aminokyselin podle pravidel genetického kódu. Genetický kód - způsob zápisu genetické informace Kód Morseovy
Ivo Papoušek. Biologie 8, 2015/16
 Ivo Papoušek Biologie 8, 2015/16 Doporučená literatura: Metody molekulární biologie (2005) Autoři: Jan Šmarda, Jiří Doškař, Roman Pantůček, Vladislava Růžičková, Jana Koptíková Izolace nukleových kyselin
Ivo Papoušek Biologie 8, 2015/16 Doporučená literatura: Metody molekulární biologie (2005) Autoři: Jan Šmarda, Jiří Doškař, Roman Pantůček, Vladislava Růžičková, Jana Koptíková Izolace nukleových kyselin
Analýza DNA. Co zjišťujeme u DNA
 Analýza DNA Co zjišťujeme u DNA Genetickou podstatu konkrétních proteinů Mutace bodové (sekvenční delece nebo inzerce nukleotidů, záměny), chromosomové aberace (numerické, strukturní) Polymorfismy konkrétní
Analýza DNA Co zjišťujeme u DNA Genetickou podstatu konkrétních proteinů Mutace bodové (sekvenční delece nebo inzerce nukleotidů, záměny), chromosomové aberace (numerické, strukturní) Polymorfismy konkrétní
Metody studia exprese mrna. jádro a genová exprese 2007
 Metody studia exprese mrna Buněčné jádro a genová exprese 2007 Aktivita genu je primárn ě vyjád ř ena jeho transkripcí-prvním krokem vedoucím k syntéze kódovaného proteinu. Cíle metod Ur č ení mno ž ství
Metody studia exprese mrna Buněčné jádro a genová exprese 2007 Aktivita genu je primárn ě vyjád ř ena jeho transkripcí-prvním krokem vedoucím k syntéze kódovaného proteinu. Cíle metod Ur č ení mno ž ství
Polymorfizmy detekované. polymorfizmů (Single Nucleotide
 Polymorfizmy detekované speciálními metodami s vysokou rozlišovací schopností Stanovení jednonukleotidových polymorfizmů (Single Nucleotide Polymorphisms - SNPs) Příklad jednonukleotidových polymorfizmů
Polymorfizmy detekované speciálními metodami s vysokou rozlišovací schopností Stanovení jednonukleotidových polymorfizmů (Single Nucleotide Polymorphisms - SNPs) Příklad jednonukleotidových polymorfizmů
Centrální dogma molekulární biologie
 řípravný kurz LF MU 2011/12 Centrální dogma molekulární biologie Nukleové kyseliny 1865 zákony dědičnosti (Johann Gregor Mendel) 1869 objev nukleových kyselin (Miescher) 1944 genetická informace v nukleových
řípravný kurz LF MU 2011/12 Centrální dogma molekulární biologie Nukleové kyseliny 1865 zákony dědičnosti (Johann Gregor Mendel) 1869 objev nukleových kyselin (Miescher) 1944 genetická informace v nukleových
a) Primární struktura NK NUKLEOTIDY Monomerem NK jsou nukleotidy
 Primární struktura NK NUKLEOTIDY Monomerem NK jsou nukleotidy") 1 Nukleové kyseliny Nukleové kyseliny (NK) sice tvoří malé procento hmotnosti buňky ale významem v kódování genetické informace a její expresí zcela nezbytným typem biopolymeru všech živých soustav a)
1 Nukleové kyseliny Nukleové kyseliny (NK) sice tvoří malé procento hmotnosti buňky ale významem v kódování genetické informace a její expresí zcela nezbytným typem biopolymeru všech živých soustav a)
Enzymy v molekulární biologii, RFLP. Molekulární biologie v hygieně potravin 3, 2014/15, Ivo Papoušek
 Enzymy v molekulární biologii, RFLP Molekulární biologie v hygieně potravin 3, 2014/15, Ivo Papoušek Enzymy v molekulární biologii umožňují nám provádět celou řadu přesně cílených manipulací Výhody enzymů:
Enzymy v molekulární biologii, RFLP Molekulární biologie v hygieně potravin 3, 2014/15, Ivo Papoušek Enzymy v molekulární biologii umožňují nám provádět celou řadu přesně cílených manipulací Výhody enzymů:
Interakce proteinu p53 s genomovou DNA v kontextu chromatinu glioblastoma buněk
 MASARYKOVA UNIVERZITA V BRNĚ Přírodovědecká fakulta Ústav experimentální biologie Oddělení genetiky a molekulární biologie Interakce proteinu p53 s genomovou DNA v kontextu chromatinu glioblastoma buněk
MASARYKOVA UNIVERZITA V BRNĚ Přírodovědecká fakulta Ústav experimentální biologie Oddělení genetiky a molekulární biologie Interakce proteinu p53 s genomovou DNA v kontextu chromatinu glioblastoma buněk
Aminokyseliny. Gymnázium a Jazyková škola s právem státní jazykové zkoušky Zlín. Tematická oblast Datum vytvoření Ročník Stručný obsah Způsob využití
 Aminokyseliny Tematická oblast Datum vytvoření Ročník Stručný obsah Způsob využití Autor Kód Chemie přírodních látek proteiny 18.7.2012 3. ročník čtyřletého G Určování postranních řetězců aminokyselin
Aminokyseliny Tematická oblast Datum vytvoření Ročník Stručný obsah Způsob využití Autor Kód Chemie přírodních látek proteiny 18.7.2012 3. ročník čtyřletého G Určování postranních řetězců aminokyselin
Určení molekulové hmotnosti: ESI a nanoesi
 Cvičení Určení molekulové hmotnosti: ESI a nanoesi ) 1)( ( ) ( H m z H m z M k j j j m z z zh M Molekula o hmotnosti M se nabije z-krát protonem, pík iontu ve spektru je na m z : ) ( H m z M z Pro dva
Cvičení Určení molekulové hmotnosti: ESI a nanoesi ) 1)( ( ) ( H m z H m z M k j j j m z z zh M Molekula o hmotnosti M se nabije z-krát protonem, pík iontu ve spektru je na m z : ) ( H m z M z Pro dva
Co zjišťujeme u DNA ACGGTCGACTGCGATGAACTCCC ACGGTCGACTGCGATCAACTCCC ACGGTCGACTGCGATTTGAACTCCC
 Analýza DNA Co zjišťujeme u DNA genetickou podstatu konkrétních proteinů mutace bodové, sekvenční delece/inzerce nukleotidů, chromosomové aberace (numerické, strukturální) polymorfismy konkrétní mutace,
Analýza DNA Co zjišťujeme u DNA genetickou podstatu konkrétních proteinů mutace bodové, sekvenční delece/inzerce nukleotidů, chromosomové aberace (numerické, strukturální) polymorfismy konkrétní mutace,
Centrum aplikované genomiky, Ústav dědičných metabolických poruch, 1.LFUK
 ové technologie v analýze D A, R A a proteinů Stanislav Kmoch Centrum aplikované genomiky, Ústav dědičných metabolických poruch, 1.LFUK Motto : "The optimal health results from ensuring that the right
ové technologie v analýze D A, R A a proteinů Stanislav Kmoch Centrum aplikované genomiky, Ústav dědičných metabolických poruch, 1.LFUK Motto : "The optimal health results from ensuring that the right
Metody studia historie populací. Metody studia historie populací
 1) Metody studia genetické rozmanitosti komplexní fenotypové znaky, molekulární znaky. 2) Mechanizmy evoluce mutace, přírodní výběr, genový posun a genový tok 3) Anageneze x kladogeneze - co je vlastně
1) Metody studia genetické rozmanitosti komplexní fenotypové znaky, molekulární znaky. 2) Mechanizmy evoluce mutace, přírodní výběr, genový posun a genový tok 3) Anageneze x kladogeneze - co je vlastně
Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti NUKLEOVÉ KYSELINY
 Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti NUKLEOVÉ KYSELINY 3 složky Nukleotidy dusík obsahující báze (purin či pyrimidin) pentosa fosfát Fosfodiesterová vazba. Vyskytuje se mezi
Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti NUKLEOVÉ KYSELINY 3 složky Nukleotidy dusík obsahující báze (purin či pyrimidin) pentosa fosfát Fosfodiesterová vazba. Vyskytuje se mezi
Nukleové kyseliny Replikace Transkripce, RNA processing Translace
 Nukleové kyseliny Replikace Transkripce, RNA processing Translace Figure 6-2 Molecular Biology of the Cell ( Garland Science 2008) replikace Figure 4-8 Molecular Biology of the Cell ( Garland Science
Nukleové kyseliny Replikace Transkripce, RNA processing Translace Figure 6-2 Molecular Biology of the Cell ( Garland Science 2008) replikace Figure 4-8 Molecular Biology of the Cell ( Garland Science
Biotechnologický kurz. II. letní škola metod molekulární biologie nukleových kyselin a genomiky
 Biotechnologický kurz Biotechnologický kurz II. letní škola metod molekulární biologie nukleových kyselin a genomiky 20. - 24. 6. 2011 Ústav morfologie, fyziologie a genetiky zvířat AF MENDELU v Brně Zemědělská
Biotechnologický kurz Biotechnologický kurz II. letní škola metod molekulární biologie nukleových kyselin a genomiky 20. - 24. 6. 2011 Ústav morfologie, fyziologie a genetiky zvířat AF MENDELU v Brně Zemědělská
NUKLEOVÉ KYSELINY. Základ života
 NUKLEOVÉ KYSELINY Základ života HISTORIE 1. H. Braconnot (30. léta 19. století) - Strassburg vinné kvasinky izolace matiére animale. 2. J.F. Meischer - experimenty z hnisem štěpení trypsinem odstředěním
NUKLEOVÉ KYSELINY Základ života HISTORIE 1. H. Braconnot (30. léta 19. století) - Strassburg vinné kvasinky izolace matiére animale. 2. J.F. Meischer - experimenty z hnisem štěpení trypsinem odstředěním
TECHNIKY PCR. PCR - polymerase chain reaction -polymerázová řetězová reakce
 TECHNIKY PCR PCR - polymerase chain reaction -polymerázová řetězová reakce Přehled Molekulárně-biologický úvod, DNA struktura, replikace, DNA polymerasa Princip procesu PCR Optimalizace PCR Typy PCR Aplikace
TECHNIKY PCR PCR - polymerase chain reaction -polymerázová řetězová reakce Přehled Molekulárně-biologický úvod, DNA struktura, replikace, DNA polymerasa Princip procesu PCR Optimalizace PCR Typy PCR Aplikace
ENZYMY A NUKLEOVÉ KYSELINY
 ENZYMY A NUKLEOVÉ KYSELINY Autor: Mgr. Stanislava Bubíková Datum (období) tvorby: 28. 3. 2013 Ročník: devátý Vzdělávací oblast: Člověk a příroda / Chemie / Organické sloučeniny 1 Anotace: Žáci se seznámí
ENZYMY A NUKLEOVÉ KYSELINY Autor: Mgr. Stanislava Bubíková Datum (období) tvorby: 28. 3. 2013 Ročník: devátý Vzdělávací oblast: Člověk a příroda / Chemie / Organické sloučeniny 1 Anotace: Žáci se seznámí
Využití restriktáz ke studiu genomu mikroorganismů
 Využití restriktáz ke studiu genomu mikroorganismů doc. RNDr. Milan Bartoš, Ph.D. bartos.milan@atlas.cz Přírodovědecká fakulta MU, 2017 Obsah přednášky 1) Definice restrikčních endonukleáz, jejich přirozená
Využití restriktáz ke studiu genomu mikroorganismů doc. RNDr. Milan Bartoš, Ph.D. bartos.milan@atlas.cz Přírodovědecká fakulta MU, 2017 Obsah přednášky 1) Definice restrikčních endonukleáz, jejich přirozená
Pokročilé biofyzikální metody v experimentální biologii
 Pokročilé biofyzikální metody v experimentální biologii Ctirad Hofr 1/1 Proč biofyzikální metody? Biofyzikální metody využívají fyzikální principy ke studiu biologických systémů Poskytují kvantitativní
Pokročilé biofyzikální metody v experimentální biologii Ctirad Hofr 1/1 Proč biofyzikální metody? Biofyzikální metody využívají fyzikální principy ke studiu biologických systémů Poskytují kvantitativní
Metody používané v MB. analýza proteinů, nukleových kyselin
 Metody používané v MB analýza proteinů, nukleových kyselin Nukleové kyseliny analýza a manipulace Elektroforéza (délka fragmentů, čistota, kvantifikace) Restrikční štěpení (manipulace s DNA, identifikace
Metody používané v MB analýza proteinů, nukleových kyselin Nukleové kyseliny analýza a manipulace Elektroforéza (délka fragmentů, čistota, kvantifikace) Restrikční štěpení (manipulace s DNA, identifikace
AUG STOP AAAA S S. eukaryontní gen v genomové DNA. promotor exon 1 exon 2 exon 3 exon 4. kódující oblast. introny
 eukaryontní gen v genomové DNA promotor exon 1 exon 2 exon 3 exon 4 kódující oblast introny primární transkript (hnrna, pre-mrna) postranskripční úpravy (vznik maturované mrna) syntéza čepičky AUG vyštěpení
eukaryontní gen v genomové DNA promotor exon 1 exon 2 exon 3 exon 4 kódující oblast introny primární transkript (hnrna, pre-mrna) postranskripční úpravy (vznik maturované mrna) syntéza čepičky AUG vyštěpení
Gymnázium, Brno, Elgartova 3
 Gymnázium, Brno, Elgartova 3 Šablona: III/2 Inovace a zkvalitnění výuky prostřednictvím ICT Název projektu: GE Vyšší kvalita výuky Číslo projektu: CZ.1.07/1.5.00/34.0925 Autor: Mgr. Hana Křivánková Téma:
Gymnázium, Brno, Elgartova 3 Šablona: III/2 Inovace a zkvalitnění výuky prostřednictvím ICT Název projektu: GE Vyšší kvalita výuky Číslo projektu: CZ.1.07/1.5.00/34.0925 Autor: Mgr. Hana Křivánková Téma:
Enzymy používané v molekulární biologii
 Enzymy používané v molekulární biologii Rozdělení enzymů 1. Podle substrátové specifity: většina metod molekulární biologie je závislá na použití enzymů, jejichž substrátem jsou nukleové kyseliny. Tyto
Enzymy používané v molekulární biologii Rozdělení enzymů 1. Podle substrátové specifity: většina metod molekulární biologie je závislá na použití enzymů, jejichž substrátem jsou nukleové kyseliny. Tyto
Struktura, vlastnosti a funkce nukleových kyselin, DNA v jádře, chromatin.
 Struktura, vlastnosti a funkce nukleových kyselin, DNA v jádře, chromatin. Nukleové base - purinové a pyrimidinové Ribonukleosidy - base + ribosa Deoxyribonukleosidy base + 2 - deoxyribosa Nukleotidy,
Struktura, vlastnosti a funkce nukleových kyselin, DNA v jádře, chromatin. Nukleové base - purinové a pyrimidinové Ribonukleosidy - base + ribosa Deoxyribonukleosidy base + 2 - deoxyribosa Nukleotidy,
Typy nukleových kyselin. deoxyribonukleová (DNA); ribonukleová (RNA).
; ribonukleová (RNA).") Typy nukleových kyselin Existují dva typy nukleových kyselin (NA, z anglických slov nucleic acid): deoxyribonukleová (DNA); ribonukleová (RNA). DNA je lokalizována v buněčném jádře, RNA v cytoplasmě a
Typy nukleových kyselin Existují dva typy nukleových kyselin (NA, z anglických slov nucleic acid): deoxyribonukleová (DNA); ribonukleová (RNA). DNA je lokalizována v buněčném jádře, RNA v cytoplasmě a
PŘEHLED SEKVENAČNÍCH METOD
 PŘEHLED SEKVENAČNÍCH METOD Letní škola bioinformatiky 2014, Brno Ing.Matej Lexa, Phd (FI MU Brno) CO JE TO SEKVENACE A CO SE BUDE SEKVENOVAT? POŘADÍ NUKLEOTIDU V DNA SEKVENOVÁNÍ DNA od manuálních metod
PŘEHLED SEKVENAČNÍCH METOD Letní škola bioinformatiky 2014, Brno Ing.Matej Lexa, Phd (FI MU Brno) CO JE TO SEKVENACE A CO SE BUDE SEKVENOVAT? POŘADÍ NUKLEOTIDU V DNA SEKVENOVÁNÍ DNA od manuálních metod
Ivo Papoušek. Biologie 6, 2017/18
 Ivo Papoušek Biologie 6, 2017/18 Doporučená literatura: Metody molekulární biologie (2005) Autoři: Jan Šmarda, Jiří Doškař, Roman Pantůček, Vladislava Růžičková, Jana Koptíková Izolace nukleových kyselin
Ivo Papoušek Biologie 6, 2017/18 Doporučená literatura: Metody molekulární biologie (2005) Autoři: Jan Šmarda, Jiří Doškař, Roman Pantůček, Vladislava Růžičková, Jana Koptíková Izolace nukleových kyselin