Thursday, February 27, 14
|
|
|
- Jaroslav Mareš
- před 10 lety
- Počet zobrazení:
Transkript
1

2 DATABÁZE A VYHLEDÁVÁNÍ SEKVENCÍ MOLEKULÁRNÍ TAXONOMIE 2014 MARIAN NOVOTNÝ

3 PŘEDNÁŠEJÍCÍ Mgr. Marian NOVOTNÝ, PhD. vystudoval odbornou biologii na PřF UK, diplomka v laboratoři doc. Folka doktorát na Uppsalské univerzitě se specializací strukturní bioinformatika (Gerard Kleywegt) Marie Curie Fellow na Evropském Bioinformatickém Institutu (Janet Thornton & Roman Laskowski) ornitolog amatér
 Marie Curie Fellow na Evropském")
4 OSNOVA co je substrát pro molekulární taxonomii? kde se shromažďují data? jak data vyhledávat?

5 REKONSTRUKCE EVOLUČNÍ HISTORIE rekonstrukce na základě srovnávání znaků v molekulární taxonomii se používají sekvence sekvence (DNA, RNA, proteiny) se srovnávají tzv. alignmentem

6 KDE NAJÍT SEKVENCE?

7 BIOINFORMATICKÉ DATABÁZE úložiště dat (volně) dostupné pro kohokoliv snadno k nalezení lednové číslo Nucleid Acid Research (NAR)
 HTTP://NAR.OXFORDJOURNALS.")
8 LEDNOVÉ ČÍSLO NAR NUCLEOTIDE SEQUENCE DATABASES RNA SEQUENCE DATABASES PROTEIN SEQUENCE DATABASES STRUCTURE DATABASES GENOMICS DATABASES (NON-VERTEBRATE) METABOLIC AND SIGNALING PATHWAYS HUMAN AND OTHER VERTEBRATE GENOMES HUMAN GENES AND DISEASES MICROARRAY DATA AND OTHER GENE EXPRESSION DATABASES PROTEOMICS RESOURCES OTHER MOLECULAR BIOLOGY DATABASES ORGANELLE DATABASES PLANT DATABASES IMMUNOLOGICAL DATABASES

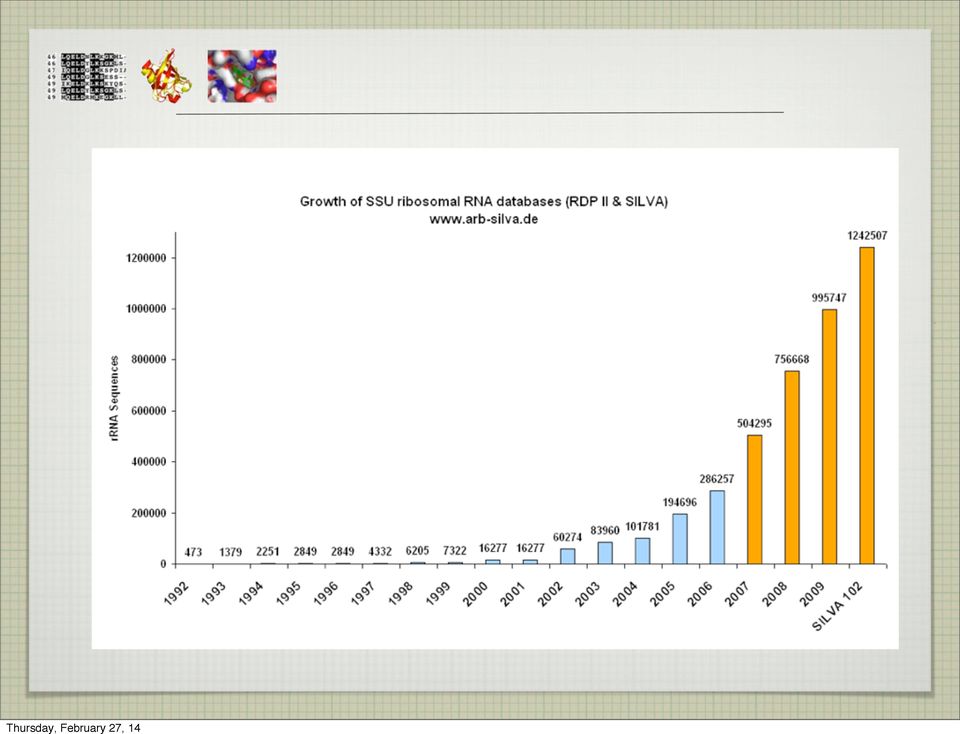
9 VLASTNOSTI DATABÁZE četnost aktualizace dat četnost aktualizace software redundance anotace dat anotace databáze

10
11
12

13
14 ...A NÁSTROJE
15 DNA DATABÁZE GenBank(NCBI) EMBL (EBI) DDJB (Japonsko)

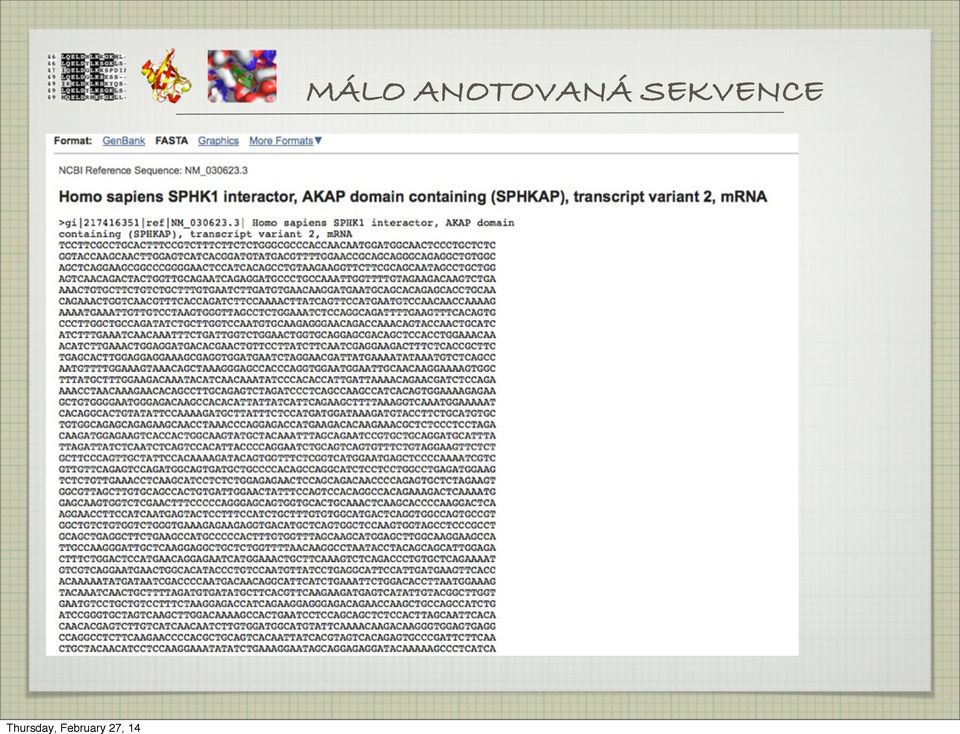
16 MÁLO ANOTOVANÁ SEKVENCE
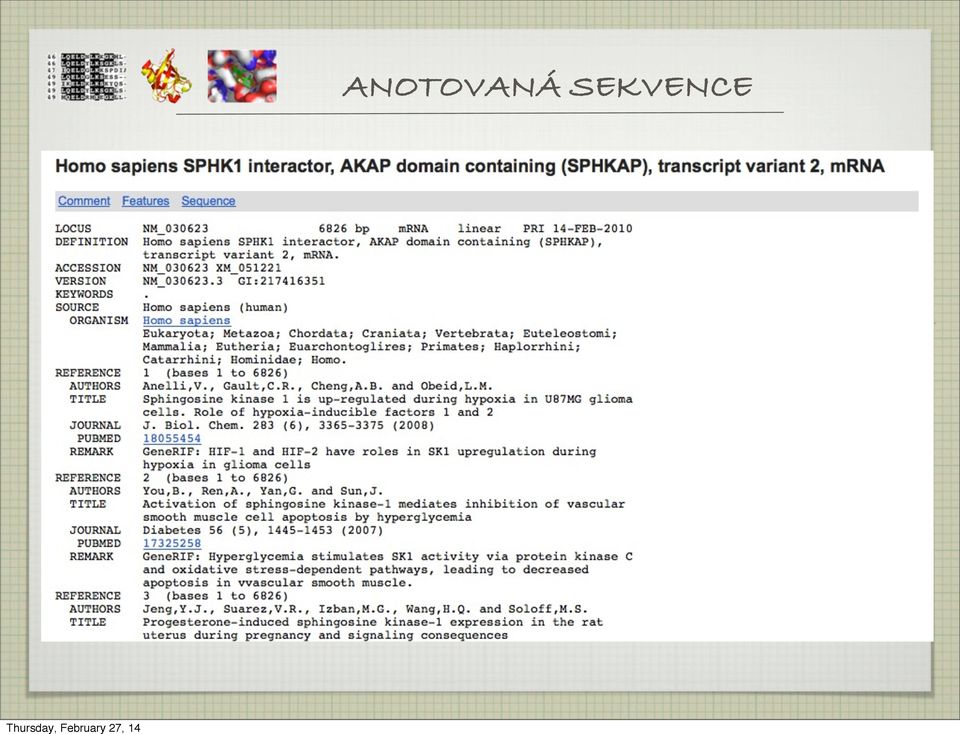
17 ANOTOVANÁ SEKVENCE
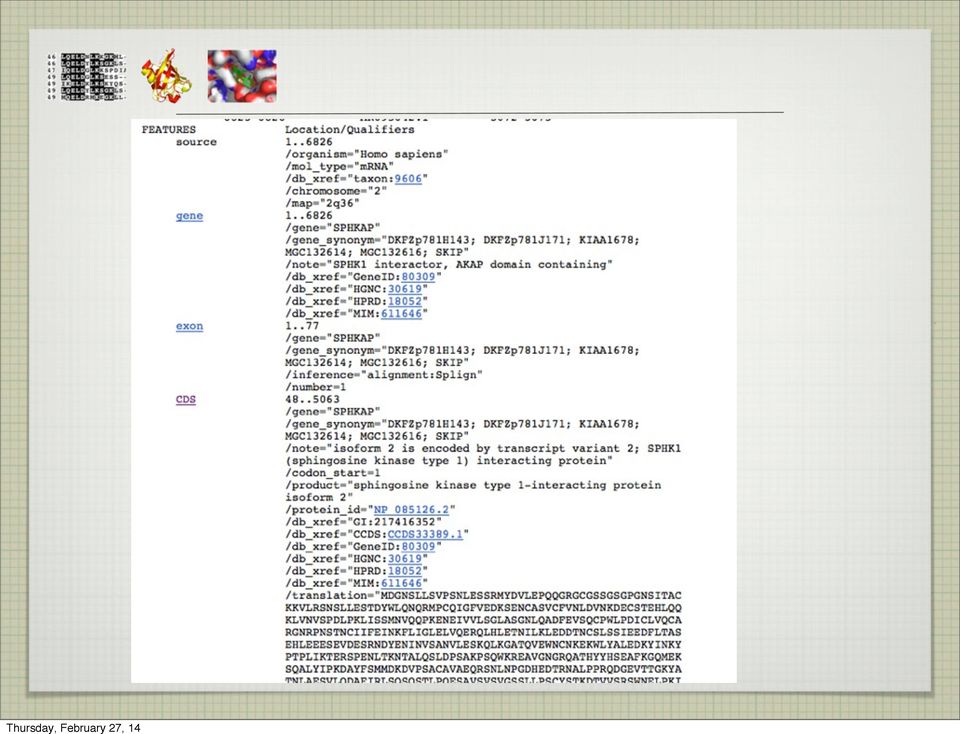
18
19 GENOMOVÉ DATABÁZE

20

21
22
23 PROTEINOVÉ DATABÁZE Uniprot - Swissprot + TrEMBL - 52,7 mil. sek. Swiss-prot - anotováno, ~ sekvencí GenPept - překládaný GenBank
24 UNIPROT + TREMBL AMINO ACID COMPOSITION 2.1 COMPOSITION IN PERCENT FOR THE COMPLETE DATABASE ALA (A) 8.57 GLN (Q) 3.88 LEU (L) 9.81 SER (S) 6.72 ARG (R) 5.47 GLU (E) 6.14 LYS (K) 5.30 THR (T) 5.61 ASN (N) 4.17 GLY (G) 7.08 MET (M) 2.45 TRP (W) 1.31 ASP (D) 5.28 HIS (H) 2.20 PHE (F) 4.03 TYR (Y) 3.06 CYS (C) 1.29 ILE (I) 6.00 PRO (P) 4.74 VAL (V) 6.71 ASX (B) GLX (Z) XAA (X) 0.06
25
26
27 JAK DATA VYHLEDÁVAT?
28 >ASTAKINE MKMRGVSVGVLVVAMMSGLAMAGSCNSQEPDCGPSECCLQGWMR YSTRGCAPLGEAGSSCNVFTQAPVKGFYIGMCPCRAGLVCTRPSATCQLPSQDNTLDSYY EXISTUJÍ PŘÍBUZNÉ SEKVENCE A KDE JE NAJÍT?
29 HLEDÁNÍ V DATABÁZÍCH - ALGORITMY tradiční algoritmy (Needleman-Wunsch, Smith-Waterman) pomalé pro prohledávání velkých databází používány heuristické metody - rychle vede k výsledku, který se blíží optimálnímu řešení (ale nezaručuje jej) -> pro vyšší rychlost je obětována přesnost (rule of thumb) v případě sekvenčního srovnávání se metoda vzdává jistoty nalezení optimálního alignmentu, aby v krátkém čase provedla srovnání se všemi sekvencemi v databázi (50-100x rychlejší) klasickými heuristickými metodami jsou FASTA a BLAST obě metody použitelné pro DNA i proteinové sekvence
30 FASTA metoda popsaná v 80. letech 20. století (Lipman & Pearson) rychlá, heuristická metoda (na úkor senzitivity), globální alignment zjednodušení v první fázi, sekvence rozděleny na krátké úseky program generuje všechny možné k-tuples o délce k z dané sekvence k = 1-2 pro proteiny, k = 4-6 pro DNA k-tuples jsou porovnávány s k-tuples sekvencí v databázích
31 FASTA hledání SHOD v k-tuples skórováni shod pomocí skórovací tabulky (Blosum 50) a rozšíření alignmentu (bez mezer) vysoce skórující shody vybrány vybere úseky, které budou součástí alignmentu dynamické programování pro konečný alignment (mezery)
32 BLAST BLAST = Basic Local Alignment Search Tool Altschul et al., 1990 sekvence rozděleny na slova (words) a slova skórována vůči databázi všech slov slova skórována skórovací tabulkou (Blosum 62) a jen ty, které dosáhnou předem nadefinovaného minimálního skóre (treshold) jsou dále používány slova se skóre větším než treshold nemusí nutně obsahovat jen shody ( na rozdíl od Fasty) v prvním kroku se porovnávají slova bez mezer
33 BLAST - HSP HSP - high scoring pair vyber jen taková slova, která dosahují alespoň skóre X (treshold) PEG versus PQA PEQ má s Blosum 62 skóre 15, PQA jen 12 pokud si stanovíme treshold 13, tak budeme dále hledat jen slovo PEQ
34 BLAST II takto vybráná slova jsou hledána v databázi modifikovaným Smith- Watermanem (50 x rychlejší) HSP jsou dále rozšiřovány na obě strany dokud skóre roste v posledním kroku jsou nejlépe skórující páry (HSP`s) podrobeny dynamickému programování, které produkuje výsledné skóre a alignment vzhledem k rostoucí velikosti databází je třeba algoritmus neustále modifikovat (dvě shody v okně definované velikosti) obvykle citlivější než FASTA implementován jako server na řadě míst (NCBI, EBI)
35 VERZE BLASTU blastn - hledá s DNA sekvencí (query) v DNA databázi blastp - hledá s proteinovou sekvencí v proteinové databázi blastx - hledá s DNA sekvencí (6 rámců) v proteinové databázi tblastn - hledá s proteinovou sekvencí v DNA databázi tblastx - překládaná DNA v překládané DNA databázi megablast - víc query najednou
36
37
38 BLAST - VÝBĚR databáze - DNA x protein, anotovaná x kompletní, strukturní, genomové, specializované (protilátky)... organismus datum - sekvence za poslední dva týdny skórovací tabulka - blosum 62 velikost slova low-complexity region filter - často P, D, N, E - false positive default nastavení algoritmu vhodné ve většině případů
39 BLOSUM BLOSUM 80 - tabulka vypočítaná na základě alignmentu bloku sekvencí s identitou 80 % BLOSUM 62 - tabulka vypočítaná na základě alignmentu bloku sekvencí s identitou 62 %
40 BLOSUM VERSUS PAM PAM 10 BLOSUM 90 PAM 250 BLOSUM 62 VELMI PŘÍBUZNÍ VZDÁLENĚ PŘÍBUZNÍ
41 VÝZNAMNOST NÁLEZU optimální alignment lze nalézt pro jakékoliv dvě sekvence dvě náhodné DNA sekvence = ~ 25% SI dvě náhodné proteinové sekvence = ~ 5% SI jak určit, že je alignment statisticky významný?
42 PARAMETRY VÝZNAMNOSTI P-value E-value pouze statistická významnost skóre -> biologickou relevanci záhodno ověřovat experimentálně
43 P-VALUE P-value - pravděpodobnost, že sekvence budou srovnány s nalezeným nebo vyšším skóre a zároveň nebudou příbuzné (false positive hit) P-value - pravděpodobnost, že bude skóre x nebo vyššího dosaženo náhodou pro účely výpočtu lze náhodu simulovat přeskládáváním sekvencí nebo výběrem vzorku z databáze druhá možnost lépe odpovídá realitě a poskytuje lepší výsledky (především u DNA)
44 EVD rozložení skóre lokálních alignmentů nepříbuzných sekvencí neodpovídá normálnímu rozdělení, ale rozdělení podle extrémních hodnot (EVD) při normálním rozdělení by docházelo k přeceňování významu dosažených skóre DUNDAS ET AL. BMC BIOINFORMATICS 2007
45 P-VALUE P-value (S>x) = 1-exp (-exp (-λ(x-u))), u = charakteristická hodnota = Kmn/λ m,n = délky sekvencí; K = konstanta; λ = decay factor K a λ mohou být kalkulovány z vlastností skórovací tabulky
46 E-VALUE E-value = pravděpodobnost, že bude dosaženo skóre x nebo vyššího náhodou v databázi dané velikosti E-value = P-value x N ; velikost databáze příklad: databáze o miliónu sekvencí a P-value = 10-6 cutoff (expect treshold) parametr v BLASTU - udává kolik lze průměrně očekávat false positives v databázi dané velikosti -> způsob jak vyvažovat senzitivitu a selektivitu nižší hodnota cutoff zvyšuje selektivitu, ale snižuje senzitivitu
47 E-VALUE E-value = pravděpodobnost, že bude dosaženo skóre x nebo vyššího náhodou v databázi dané velikosti E-value = P-value x N ; velikost databáze příklad: databáze o miliónu sekvencí a P-value = 10-6 E-value = 10-6 x 10 6 =1 cutoff (expect treshold) parametr v BLASTU - udává kolik lze průměrně očekávat false positives v databázi dané velikosti -> způsob jak vyvažovat senzitivitu a selektivitu nižší hodnota cutoff zvyšuje selektivitu, ale snižuje senzitivitu
48 BLAST / EVOLUČNÍ VZDÁLENOST říká nám BLAST něco o příbuznosti nalezených sekvencí? Je první hit evolučně nejpříbuznější query (hledané sekvenci)?
49 BLAST / EVOLUČNÍ VZDÁLENOST říká nám BLAST něco o příbuznosti nalezených sekvencí? Je první hit evolučně nejpříbuznější query (hledané sekvenci)? BLAST většinou nalezá příbuzné sekvence nejpříbuznější sekvence však mohou chybět v databázi lokální alignment - často skóruje nejlépe vzdálené příbuzné 7 % sekvencí E.coli mělo nejlépe skórující sekvenci mimo Bacteria
50
51
52 2JTK
53 SEQUENCE IDENTITA/HOMOLOGIE NEHOMOLOGNÍ PROTEINY ROST, 1999
54 SEQUENCE IDENTITA/HOMOLOGIE HOMOLOGNÍ PROTEINY ROST, 1999
55 SEQUENCE IDENTITA/HOMOLOGIE sekvenční identita > 35% - pravděpodobně homolog sekvenční identita = 20-35% ( twilight zone ; Doolittle) - může být homolog sekvenční identita < 20% - midnight zone (Rost) - sekvence zcela nedostatečná k určení homologie
56 SANDER ET AL., PREPRINT Average sequence identity of random alignments % Average sequence identity of remote homologues %
57 SSEARCH pokud máte moře času nebo počítačový klastr nebo jste zoufalí rigorózní Smith-Waterman - local alignment v databázi
58 DALŠÍ METODY HLEDÁNÍ V DATABÁZÍCH profilové metody HMM modely
59 PROFILY modifikují skórovací tabulky specificky pro skupiny proteinů a pozici v alignmentu (např. globiny) pro každou pozici v alignmentu jsou generovány specifická skóre jak pro záměnu za jakoukoliv aa, tak pro inzerci nebo deleci Prof (pos,aa) = Σtype N(pos,type) x S(type, aa) x 10 N(pos,type) = podíl výskytu aa x na pozici y S(type, aa) = skóre skórovací tabulky pro zaměňovaný pár
60 PŘÍKLAD PROFILU v alignmentu globinů se na pozici 3 vyskytuje 3x Ala, 6x Val, 1x Ile, používáme tabulku Blosum 62 jaké bude profilové skóre pro výskyt Ile a His? N(x,A) = 0.3, N(x,V) = 0.6, N(x, I) = 0.1 S(A,I) = -1, S(V,I) = 3, S(I,I) = 4 S(A,H) = -2, S(V,H) = -3, S(I,H) = -3 Prof (x, I) = 0.3 x x x 4 = 2.1 x 10 (v profilu) = 21 ( -1, 3, 4) Prof (x, H) = 0.3 x x x -3 = -2.7 x 10 = -27 (-2, -3, -3)
61 PSI-BLAST PSI-BLAST = Position Specific Iterative Blast Altschul et al., 1997 profilová metoda, používá Position Specific Scoring Matrix (PSSM) v prvním kole klasický BLAST, z vysoko skórujících alignmentů je generována PSSM v dalším kole hledání je už použita nová matrice a následně znovu generována nová PSSM opakováno libovolně dlouho (až ke konvergenci) benchmark metoda
62 HMM HMM = Hidden Markov Model profilová metoda, používána při rozhodování, zda protein spadá do jisté skupiny proteinů, typicky pro sekvence s nízkou %SI velmi citlivá metoda, která vytváří statistický model pro definovanou skupinu sekvencí na základě tréninku na sekvencích patřících do jedné skupiny (globiny) generuje pravděpodobnost nejen pro jednotlivé záměny a inzerce a delece, ale i pro přechody mezi nima dovede do modelu zahrnout i aminokyseliny, které se v tréninkové skupině nevyskytují alignment s největší pravděpodobností je optimální posuzuje jak dobře daná sekvence odpovídá modelu
63 HMM
64 SHRNUTÍ databáze by měly být pravidelně updatovány přehled dostupných biologických databází vždy v lednovém čísle NAR řada velmi specializovaných databází hledání v databázích povětšinou heuristickými metodami standard dnes BLAST nutno hodnotit statistickou významnost nálezu citlivější metodou PSI-Blast nebo HMM metody
DATABÁZE A VYHLEDÁVÁNÍ SEKVENCÍ
 DATABÁZE A VYHLEDÁVÁNÍ SEKVENCÍ MOLEKULÁRNÍ TAXONOMIE 2015 MARIAN NOVOTNÝ OSNOVA co je substrát pro molekulární taxonomii? kde se shromažďují data? jak data vyhledávat? REKONSTRUKCE EVOLUČNÍ HISTORIE rekonstrukce
DATABÁZE A VYHLEDÁVÁNÍ SEKVENCÍ MOLEKULÁRNÍ TAXONOMIE 2015 MARIAN NOVOTNÝ OSNOVA co je substrát pro molekulární taxonomii? kde se shromažďují data? jak data vyhledávat? REKONSTRUKCE EVOLUČNÍ HISTORIE rekonstrukce
DATABÁZE A VYHLEDÁVÁNÍ SEKVENCÍ
 DATABÁZE A VYHLEDÁVÁNÍ SEKVENCÍ MOLEKULÁRNÍ TAXONOMIE 2015 MARIAN NOVOTNÝ OSNOVA co je substrát pro molekulární taxonomii? kde se shromažďují data? jak data vyhledávat? REKONSTRUKCE EVOLUČNÍ HISTORIE rekonstrukce
DATABÁZE A VYHLEDÁVÁNÍ SEKVENCÍ MOLEKULÁRNÍ TAXONOMIE 2015 MARIAN NOVOTNÝ OSNOVA co je substrát pro molekulární taxonomii? kde se shromažďují data? jak data vyhledávat? REKONSTRUKCE EVOLUČNÍ HISTORIE rekonstrukce
Základy genomiky. I. Úvod do bioinformatiky. Jan Hejátko
 Základy genomiky I. Úvod do bioinformatiky Jan Hejátko Masarykova univerzita, Oddělení funkční genomiky a proteomiky Laboratoř molekulární fyziologie rostlin Základy genomiky I. Zdrojová literatura ke
Základy genomiky I. Úvod do bioinformatiky Jan Hejátko Masarykova univerzita, Oddělení funkční genomiky a proteomiky Laboratoř molekulární fyziologie rostlin Základy genomiky I. Zdrojová literatura ke
Studijní materiály pro bioinformatickou část ViBuChu. úloha II. Jan Komárek, Gabriel Demo
 Studijní materiály pro bioinformatickou část ViBuChu úloha II Jan Komárek, Gabriel Demo Adenin Struktura DNA Thymin 5 konec 3 konec DNA tvořena dvěmi řetězci orientovanými antiparalelně (liší se orientací
Studijní materiály pro bioinformatickou část ViBuChu úloha II Jan Komárek, Gabriel Demo Adenin Struktura DNA Thymin 5 konec 3 konec DNA tvořena dvěmi řetězci orientovanými antiparalelně (liší se orientací
Vyhledávání podobných sekvencí BLAST
 Vyhledávání podobných sekvencí BLAST Základní informace Následující text je součástí učebních textů předmětu Analýza sekvencí DNA a je určen hlavně pro studenty Matematické biologie. Může být ovšem přínosný
Vyhledávání podobných sekvencí BLAST Základní informace Následující text je součástí učebních textů předmětu Analýza sekvencí DNA a je určen hlavně pro studenty Matematické biologie. Může být ovšem přínosný
Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti URČOVÁNÍ PRIMÁRNÍ STRUKTURY BÍLKOVIN
 Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti URČOVÁNÍ PRIMÁRNÍ STRUKTURY BÍLKOVIN Primární struktura primární struktura bílkoviny je dána pořadím AK jejích polypeptidových řetězců
Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti URČOVÁNÍ PRIMÁRNÍ STRUKTURY BÍLKOVIN Primární struktura primární struktura bílkoviny je dána pořadím AK jejích polypeptidových řetězců
Inovace studia molekulární a buněčné biologie
 Inovace studia molekulární a buněčné biologie Tento projekt je spolufinancován Evropským sociálním fondem a státním rozpočtem České republiky. MBIO1/Molekulární biologie 1 Tento projekt je spolufinancován
Inovace studia molekulární a buněčné biologie Tento projekt je spolufinancován Evropským sociálním fondem a státním rozpočtem České republiky. MBIO1/Molekulární biologie 1 Tento projekt je spolufinancován
Využití internetových zdrojů při studiu mikroorganismů
 Využití internetových zdrojů při studiu mikroorganismů doc. RNDr. Milan Bartoš, Ph.D. bartosm@vfu.cz Přírodovědecká fakulta MU, 2012 Obsah přednášky 1) Práce se sekvenčními daty 2) Základní veřejně dostupné
Využití internetových zdrojů při studiu mikroorganismů doc. RNDr. Milan Bartoš, Ph.D. bartosm@vfu.cz Přírodovědecká fakulta MU, 2012 Obsah přednášky 1) Práce se sekvenčními daty 2) Základní veřejně dostupné
Genomické databáze. Shlukování proteinových sekvencí. Ivana Rudolfová. školitel: doc. Ing. Jaroslav Zendulka, CSc.
 Genomické databáze Shlukování proteinových sekvencí Ivana Rudolfová školitel: doc. Ing. Jaroslav Zendulka, CSc. Obsah Proteiny Zdroje dat Predikce struktury proteinů Cíle disertační práce Vstupní data
Genomické databáze Shlukování proteinových sekvencí Ivana Rudolfová školitel: doc. Ing. Jaroslav Zendulka, CSc. Obsah Proteiny Zdroje dat Predikce struktury proteinů Cíle disertační práce Vstupní data
Bioinformatika a funkční studie
 Bioinformatika a funkční studie Bioinformatika Vztah informace a funkce Sekvenování DNA Proteinů Databáze Primární Sekundární Integrované internetové zdroje informací Vyhledávání sekvenční podobnosti,
Bioinformatika a funkční studie Bioinformatika Vztah informace a funkce Sekvenování DNA Proteinů Databáze Primární Sekundární Integrované internetové zdroje informací Vyhledávání sekvenční podobnosti,
SEQUENCE ALIGNMENT MOLEKULÁRNÍ TAXONOMIE
 SEQUENCE ALIGNMENT gi 118094778 gi 68395523 Eat1 SpEat1 CG7206 DrEat1 C1orf26 46 LQELDNLKKGKML-----------------LHV-RQKAI 46 LQELDYLKSGKLS-----------------SKV-EDKAR 47 IQELDGLKKSPDIARDNDDTTN----QEHDRTI-GTLAR
SEQUENCE ALIGNMENT gi 118094778 gi 68395523 Eat1 SpEat1 CG7206 DrEat1 C1orf26 46 LQELDNLKKGKML-----------------LHV-RQKAI 46 LQELDYLKSGKLS-----------------SKV-EDKAR 47 IQELDGLKKSPDIARDNDDTTN----QEHDRTI-GTLAR
Cysteinové adukty globinu jako potenciální biomarkery expozice styrenu
 Cysteinové adukty globinu jako potenciální biomarkery expozice styrenu J. Mráz, I. Hanzlíková, Š. Dušková, E. Frantík, V. Stránský Státní zdravotní ústav Praha 1 Biomarkery expozice cizorodým látkám výchozí
Cysteinové adukty globinu jako potenciální biomarkery expozice styrenu J. Mráz, I. Hanzlíková, Š. Dušková, E. Frantík, V. Stránský Státní zdravotní ústav Praha 1 Biomarkery expozice cizorodým látkám výchozí
Proteiny Genová exprese. 2013 Doc. MVDr. Eva Bártová, Ph.D.
 Proteiny Genová exprese 2013 Doc. MVDr. Eva Bártová, Ph.D. Bílkoviny (proteiny), 15% 1g = 17 kj Monomer = aminokyseliny aminová skupina karboxylová skupina α -uhlík postranní řetězec Znát obecný vzorec
Proteiny Genová exprese 2013 Doc. MVDr. Eva Bártová, Ph.D. Bílkoviny (proteiny), 15% 1g = 17 kj Monomer = aminokyseliny aminová skupina karboxylová skupina α -uhlík postranní řetězec Znát obecný vzorec
Hemoglobin a jemu podobní... Studijní materiál. Jan Komárek
 Hemoglobin a jemu podobní... Studijní materiál Jan Komárek Bioinformatika Bioinformatika je vědní disciplína, která se zabývá metodami pro shromážďování, analýzu a vizualizaci rozsáhlých souborů biologických
Hemoglobin a jemu podobní... Studijní materiál Jan Komárek Bioinformatika Bioinformatika je vědní disciplína, která se zabývá metodami pro shromážďování, analýzu a vizualizaci rozsáhlých souborů biologických
Využití metod strojového učení v bioinformatice David Hoksza
 Využití metod strojového učení v bioinformatice David Hoksza SIRET Research Group Katedra softwarového inženýrství, Matematicko-fyzikální fakulta Karlova Univerzita v Praze Bioinformatika Biologické inspirace
Využití metod strojového učení v bioinformatice David Hoksza SIRET Research Group Katedra softwarového inženýrství, Matematicko-fyzikální fakulta Karlova Univerzita v Praze Bioinformatika Biologické inspirace
Aminokyseliny příručka pro učitele. Obecné informace: Téma otevírá kapitolu Bílkoviny, která svým rozsahem překračuje rámec jedné vyučovací hodiny.
 Obecné informace: Aminokyseliny příručka pro učitele Téma otevírá kapitolu Bílkoviny, která svým rozsahem překračuje rámec jedné vyučovací hodiny. Navazující učivo Před probráním tématu Aminokyseliny probereme
Obecné informace: Aminokyseliny příručka pro učitele Téma otevírá kapitolu Bílkoviny, která svým rozsahem překračuje rámec jedné vyučovací hodiny. Navazující učivo Před probráním tématu Aminokyseliny probereme
Bioinformatika a výpočetní biologie KFC/BIN. I. Přehled
 Bioinformatika a výpočetní biologie KFC/BIN I. Přehled RNDr. Karel Berka, Ph.D. Univerzita Palackého v Olomouci Definice bioinformatiky (Molecular) bio informatics: bioinformatics is conceptualising biology
Bioinformatika a výpočetní biologie KFC/BIN I. Přehled RNDr. Karel Berka, Ph.D. Univerzita Palackého v Olomouci Definice bioinformatiky (Molecular) bio informatics: bioinformatics is conceptualising biology
Osekvenované genomy. Pan troglodydes, 2005. Neandrtálec, 2010
 GENOMOVÉ PROJEKTY Osekvenované genomy Haemophilus influenze, 1995 první osekvenovaná bakterie Saccharomyces cerevisiae, 1996 první osekvenovaný eukaryotický organimus Caenorhabditis elegans, 1998 první
GENOMOVÉ PROJEKTY Osekvenované genomy Haemophilus influenze, 1995 první osekvenovaná bakterie Saccharomyces cerevisiae, 1996 první osekvenovaný eukaryotický organimus Caenorhabditis elegans, 1998 první
Určení molekulové hmotnosti: ESI a nanoesi
 Cvičení Určení molekulové hmotnosti: ESI a nanoesi ) 1)( ( ) ( H m z H m z M k j j j m z z zh M Molekula o hmotnosti M se nabije z-krát protonem, pík iontu ve spektru je na m z : ) ( H m z M z Pro dva
Cvičení Určení molekulové hmotnosti: ESI a nanoesi ) 1)( ( ) ( H m z H m z M k j j j m z z zh M Molekula o hmotnosti M se nabije z-krát protonem, pík iontu ve spektru je na m z : ) ( H m z M z Pro dva
Metabolismus bílkovin. Václav Pelouch
 ZÁKLADY OBECNÉ A KLINICKÉ BIOCHEMIE 2004 Metabolismus bílkovin Václav Pelouch kapitola ve skriptech - 3.2 Výživa Vyvážená strava člověka musí obsahovat: cukry (50 55 %) tuky (30 %) bílkoviny (15 20 %)
ZÁKLADY OBECNÉ A KLINICKÉ BIOCHEMIE 2004 Metabolismus bílkovin Václav Pelouch kapitola ve skriptech - 3.2 Výživa Vyvážená strava člověka musí obsahovat: cukry (50 55 %) tuky (30 %) bílkoviny (15 20 %)
Co se o sobě dovídáme z naší genetické informace
 Genomika a bioinformatika Co se o sobě dovídáme z naší genetické informace Jan Pačes, Mgr, Ph.D Ústav molekulární genetiky AVČR, CZECH FOBIA (Free and Open Bioinformatics Association) hpaces@img.cas.cz
Genomika a bioinformatika Co se o sobě dovídáme z naší genetické informace Jan Pačes, Mgr, Ph.D Ústav molekulární genetiky AVČR, CZECH FOBIA (Free and Open Bioinformatics Association) hpaces@img.cas.cz
Aminokyseliny. Gymnázium a Jazyková škola s právem státní jazykové zkoušky Zlín. Tematická oblast Datum vytvoření Ročník Stručný obsah Způsob využití
 Aminokyseliny Tematická oblast Datum vytvoření Ročník Stručný obsah Způsob využití Autor Kód Chemie přírodních látek proteiny 18.7.2012 3. ročník čtyřletého G Určování postranních řetězců aminokyselin
Aminokyseliny Tematická oblast Datum vytvoření Ročník Stručný obsah Způsob využití Autor Kód Chemie přírodních látek proteiny 18.7.2012 3. ročník čtyřletého G Určování postranních řetězců aminokyselin
Metabolismus aminokyselin. Vladimíra Kvasnicová
 Metabolismus aminokyselin Vladimíra Kvasnicová Aminokyseliny aminokyseliny přijímáme v potravě ve formě proteinů: důležitá forma organicky vázaného dusíku, který tak může být v těle využit k syntéze dalších
Metabolismus aminokyselin Vladimíra Kvasnicová Aminokyseliny aminokyseliny přijímáme v potravě ve formě proteinů: důležitá forma organicky vázaného dusíku, který tak může být v těle využit k syntéze dalších
Markovovy modely v Bioinformatice
 Markovovy modely v Bioinformatice Outline Markovovy modely obecně Profilové HMM Další použití HMM v Bioinformatice Analýza biologických sekvencí Biologické sekvence: DNA,RNA,protein prim.str. Sekvenování
Markovovy modely v Bioinformatice Outline Markovovy modely obecně Profilové HMM Další použití HMM v Bioinformatice Analýza biologických sekvencí Biologické sekvence: DNA,RNA,protein prim.str. Sekvenování
Využití strojového učení k identifikaci protein-ligand aktivních míst
 Využití strojového učení k identifikaci protein-ligand aktivních míst David Hoksza, Radoslav Krivák SIRET Research Group Katedra softwarového inženýrství, Matematicko-fyzikální fakulta Karlova Univerzita
Využití strojového učení k identifikaci protein-ligand aktivních míst David Hoksza, Radoslav Krivák SIRET Research Group Katedra softwarového inženýrství, Matematicko-fyzikální fakulta Karlova Univerzita
Molekulární genetika IV zimní semestr 6. výukový týden ( )
") Ústav biologie a lékařské genetiky 1.LF UK a VFN, Praha Molekulární genetika IV zimní semestr 6. výukový týden (5.11. 9.11.2007) Nondisjunkce u Downova syndromu 2 Tři rodokmeny rodin s dětmi postiženými
Ústav biologie a lékařské genetiky 1.LF UK a VFN, Praha Molekulární genetika IV zimní semestr 6. výukový týden (5.11. 9.11.2007) Nondisjunkce u Downova syndromu 2 Tři rodokmeny rodin s dětmi postiženými
Aplikovaná bioinformatika
 Aplikovaná bioinformatika Číslo aktivity: 2.V Název klíčové aktivity: Na realizaci se podílí: Implementace nových předmětů do daného studijního programu doc. RNDr. Michaela Wimmerová, Ph.D., Mgr. Josef
Aplikovaná bioinformatika Číslo aktivity: 2.V Název klíčové aktivity: Na realizaci se podílí: Implementace nových předmětů do daného studijního programu doc. RNDr. Michaela Wimmerová, Ph.D., Mgr. Josef
Bioinformatika. Jiří Vondrášek Ústav organické chemie a biochemie Jan Pačes Ústav molekulární genetiky
 Bioinformatika pro PrfUK 2006 Jiří Vondrášek Ústav organické chemie a biochemie vondrasek@uochb.cas.cz Jan Pačes Ústav molekulární genetiky hpaces@img.cas.cz http://bio.img.cas.cz/prfuk2006 syllabus Úterý,
Bioinformatika pro PrfUK 2006 Jiří Vondrášek Ústav organické chemie a biochemie vondrasek@uochb.cas.cz Jan Pačes Ústav molekulární genetiky hpaces@img.cas.cz http://bio.img.cas.cz/prfuk2006 syllabus Úterý,
Bioinformatika pro PrfUK 2003
 Bioinformatika pro PrfUK 2003 Jiří Vondrášek Ústav organické chemie a biochemie vondrasek@uochb.cas.cz Jan Pačes Ústav molekulární genetiky hpaces@img.cas.cz http://bio.img.cas.cz/prfuk2003 What is Bioinformatics?---The
Bioinformatika pro PrfUK 2003 Jiří Vondrášek Ústav organické chemie a biochemie vondrasek@uochb.cas.cz Jan Pačes Ústav molekulární genetiky hpaces@img.cas.cz http://bio.img.cas.cz/prfuk2003 What is Bioinformatics?---The
Biologie. Autorské řešení kvalifikační úlohy
 Biologie Autorské řešení kvalifikační úlohy Přepis sekvence ze sekvenátoru A C G T 5' C G T T C T A T A G A T A C G C G A T G A C G G T A T A C C A T C C G C A A A G T 3' http://blast.ncbi.nlm.nih.gov/
Biologie Autorské řešení kvalifikační úlohy Přepis sekvence ze sekvenátoru A C G T 5' C G T T C T A T A G A T A C G C G A T G A C G G T A T A C C A T C C G C A A A G T 3' http://blast.ncbi.nlm.nih.gov/
Molekulární biotechnologie č.9. Cílená mutageneze a proteinové inženýrství
 Molekulární biotechnologie č.9 Cílená mutageneze a proteinové inženýrství Gen kódující jakýkoliv protein lze izolovat z přírody, klonovat, exprimovat v hostitelském organismu. rekombinantní protein purifikovat
Molekulární biotechnologie č.9 Cílená mutageneze a proteinové inženýrství Gen kódující jakýkoliv protein lze izolovat z přírody, klonovat, exprimovat v hostitelském organismu. rekombinantní protein purifikovat
ÚVOD DO BIOINFORMATIKY
 MSSSYITDQGPGSGLRVPARSWLNSDAPSLSLNGDWRFRLLPTAPGTPGAGSVLATGETVEAVASESFD DSSWDTLAVPSHWVLAEDGKYGRPIYTNVQYPFPIDPPFVPDANPTGDYRRTFDVPDSWFESTTAALTL RFDGVESRYKVWVNGVEIGVGSGSRLAQEFDVSEALRPGKNLLVVRVHQWSAASYLEDQDQWWLPGIFR
MSSSYITDQGPGSGLRVPARSWLNSDAPSLSLNGDWRFRLLPTAPGTPGAGSVLATGETVEAVASESFD DSSWDTLAVPSHWVLAEDGKYGRPIYTNVQYPFPIDPPFVPDANPTGDYRRTFDVPDSWFESTTAALTL RFDGVESRYKVWVNGVEIGVGSGSRLAQEFDVSEALRPGKNLLVVRVHQWSAASYLEDQDQWWLPGIFR
Struktura proteinů. - testík na procvičení. Vladimíra Kvasnicová
 Struktura proteinů - testík na procvičení Vladimíra Kvasnicová Mezi proteinogenní aminokyseliny patří a) kyselina asparagová b) kyselina glutarová c) kyselina acetoctová d) kyselina glutamová Mezi proteinogenní
Struktura proteinů - testík na procvičení Vladimíra Kvasnicová Mezi proteinogenní aminokyseliny patří a) kyselina asparagová b) kyselina glutarová c) kyselina acetoctová d) kyselina glutamová Mezi proteinogenní
Počítačové vyhledávání genů a funkčních oblastí na DNA
 Počítačové vyhledávání genů a funkčních oblastí na DNA Hodnota genomových sekvencí záleží na kvalitě anotace Anotace Charakterizace genomových vlastností s použitím výpočetních a experimentálních metod
Počítačové vyhledávání genů a funkčních oblastí na DNA Hodnota genomových sekvencí záleží na kvalitě anotace Anotace Charakterizace genomových vlastností s použitím výpočetních a experimentálních metod
Aminokyseliny a dlouhodobá parenterální výživa. Luboš Sobotka
 Aminokyseliny a dlouhodobá parenterální výživa Luboš Sobotka Reakce na hladovění a stres jsou stejné asi 4000000 let Přežít hladovění a akutní stav Metody sledování kvality AK roztoků Vylučovací metoda
Aminokyseliny a dlouhodobá parenterální výživa Luboš Sobotka Reakce na hladovění a stres jsou stejné asi 4000000 let Přežít hladovění a akutní stav Metody sledování kvality AK roztoků Vylučovací metoda
Univerzita Pardubice. Fakulta ekonomicko-správní
 Univerzita Pardubice Fakulta ekonomicko-správní Bioinformatika Simona Smejkalová Bakalářská práce 2009 Prohlašuji: Tuto práci jsem vypracovala samostatně. Veškeré literární prameny a informace, které
Univerzita Pardubice Fakulta ekonomicko-správní Bioinformatika Simona Smejkalová Bakalářská práce 2009 Prohlašuji: Tuto práci jsem vypracovala samostatně. Veškeré literární prameny a informace, které
Pravděpodobnost v závislosti na proměnné x je zde modelován pomocí logistického modelu. exp x. x x x. log 1
 Logistická regrese Menu: QCExpert Regrese Logistická Modul Logistická regrese umožňuje analýzu dat, kdy odezva je binární, nebo frekvenční veličina vyjádřená hodnotami 0 nebo 1, případně poměry v intervalu
Logistická regrese Menu: QCExpert Regrese Logistická Modul Logistická regrese umožňuje analýzu dat, kdy odezva je binární, nebo frekvenční veličina vyjádřená hodnotami 0 nebo 1, případně poměry v intervalu
Faculty of Nuclear Sciences and Physical Engineering Czech Technical University in Prague
 1 / 23 Faculty of Nuclear Sciences and Physical Engineering Czech Technical University in Prague 2 / 23 biologové často potřebují najít často se opakující sekvence DNA tyto sekvence bývají relativně krátké,
1 / 23 Faculty of Nuclear Sciences and Physical Engineering Czech Technical University in Prague 2 / 23 biologové často potřebují najít často se opakující sekvence DNA tyto sekvence bývají relativně krátké,
jednoduchá heuristika asymetrické okolí stavový prostor, kde nelze zabloudit připustit zhoršují cí tahy Pokročilé heuristiky
 Pokročilé heuristiky jednoduchá heuristika asymetrické stavový prostor, kde nelze zabloudit připustit zhoršují cí tahy pokročilá heuristika symetrické stavový prostor, který vyžaduje řízení 1 2 Paměť pouze
Pokročilé heuristiky jednoduchá heuristika asymetrické stavový prostor, kde nelze zabloudit připustit zhoršují cí tahy pokročilá heuristika symetrické stavový prostor, který vyžaduje řízení 1 2 Paměť pouze
11. Bioinformatika a proteiny II
 11. Bioinformatika a proteiny II David Potěšil Core Facility Proteomics CEITEC-MU Masaryk University Kamenice 5, A26 phone: +420 54949 8426 email: david.potesil@ceitec.muni.cz Proteomika, Podzim 2016 2
11. Bioinformatika a proteiny II David Potěšil Core Facility Proteomics CEITEC-MU Masaryk University Kamenice 5, A26 phone: +420 54949 8426 email: david.potesil@ceitec.muni.cz Proteomika, Podzim 2016 2
Počítačová analýza lokálních podobností mezi biologickými sekvencemi
 MASARYKOVA UNIVERZITA V BRNĚ Fakulta informatiky Michal VAVERKA Počítačová analýza lokálních podobností mezi biologickými sekvencemi Bakalářská práce Vedoucí práce: Ing. Matej Lexa, Ph.D. Brno 2006 Prohlašuji,
MASARYKOVA UNIVERZITA V BRNĚ Fakulta informatiky Michal VAVERKA Počítačová analýza lokálních podobností mezi biologickými sekvencemi Bakalářská práce Vedoucí práce: Ing. Matej Lexa, Ph.D. Brno 2006 Prohlašuji,
Bioinformatika. hledání významu biologických dat. Marian Novotný. Friday, April 24, 15
 Bioinformatika hledání významu biologických dat Marian Novotný Bioinformatika sběr biologických dat archivace biologických dat organizace biologických dat interpretace biologických dat 2 Biologové sbírají
Bioinformatika hledání významu biologických dat Marian Novotný Bioinformatika sběr biologických dat archivace biologických dat organizace biologických dat interpretace biologických dat 2 Biologové sbírají
Mutace jako změna genetické informace a zdroj genetické variability
 Obecná genetika Mutace jako změna genetické informace a zdroj genetické variability Doc. RNDr. Ing. Eva PALÁTOVÁ, PhD. Ing. Roman LONGAUER, CSc. Ústav zakládání a pěstění lesů LDF MENDELU Brno Tento projekt
Obecná genetika Mutace jako změna genetické informace a zdroj genetické variability Doc. RNDr. Ing. Eva PALÁTOVÁ, PhD. Ing. Roman LONGAUER, CSc. Ústav zakládání a pěstění lesů LDF MENDELU Brno Tento projekt
Metabolismus aminokyselin 2. Vladimíra Kvasnicová
 Metabolismus aminokyselin 2 Vladimíra Kvasnicová Odbourávání AMK 1) odstranění aminodusíku z molekuly AMK 2) detoxikace uvolněné aminoskupiny 3) metabolismus uhlíkaté kostry AMK 7 produktů 7 degradačních
Metabolismus aminokyselin 2 Vladimíra Kvasnicová Odbourávání AMK 1) odstranění aminodusíku z molekuly AMK 2) detoxikace uvolněné aminoskupiny 3) metabolismus uhlíkaté kostry AMK 7 produktů 7 degradačních
Struktury a vazebné energie iontových klastrů helia
 Společný seminář 11. června 2012 Struktury a vazebné energie iontových klastrů helia Autor: Lukáš Červenka Vedoucí práce: Doc. RNDr. René Kalus, Ph.D. Technický úvod Existují ověřené optimalizační algoritmy
Společný seminář 11. června 2012 Struktury a vazebné energie iontových klastrů helia Autor: Lukáš Červenka Vedoucí práce: Doc. RNDr. René Kalus, Ph.D. Technický úvod Existují ověřené optimalizační algoritmy
11. Tabu prohledávání
 Jan Schmidt 2011 Katedra číslicového návrhu Fakulta informačních technologií České vysoké učení technické v Praze Zimní semestr 2011/12 MI-PAA EVROPSKÝ SOCIÁLNÍ FOND PRAHA & EU: INVESTUJENE DO VAŠÍ BUDOUCNOSTI
Jan Schmidt 2011 Katedra číslicového návrhu Fakulta informačních technologií České vysoké učení technické v Praze Zimní semestr 2011/12 MI-PAA EVROPSKÝ SOCIÁLNÍ FOND PRAHA & EU: INVESTUJENE DO VAŠÍ BUDOUCNOSTI
Vytváření fylogenetických stromů na základě alignmentů. Tomáš Novotný Jaroslav Knotek
 Vytváření fylogenetických stromů na základě alignmentů Tomáš Novotný Jaroslav Knotek Alignmenty - opakování Existují dvě základní varianty alignmentů: globální a lokální Globální: Hledáme nejlepší zarovnání
Vytváření fylogenetických stromů na základě alignmentů Tomáš Novotný Jaroslav Knotek Alignmenty - opakování Existují dvě základní varianty alignmentů: globální a lokální Globální: Hledáme nejlepší zarovnání
Vyhledávání příbuzných enzymů s modifikovanou funkcí v proteinových databázích
 2015 http://excel.fit.vutbr.cz Vyhledávání příbuzných enzymů s modifikovanou funkcí v proteinových databázích Jiří Hon* Abstrakt Hledání příbuzných enzymů v biologických databázích patří mezi obvyklé činnosti
2015 http://excel.fit.vutbr.cz Vyhledávání příbuzných enzymů s modifikovanou funkcí v proteinových databázích Jiří Hon* Abstrakt Hledání příbuzných enzymů v biologických databázích patří mezi obvyklé činnosti
NGS analýza dat. kroužek, Alena Musilová
 NGS analýza dat kroužek, 16.12.2016 Alena Musilová Typy NGS experimentů Název Materiál Cílí na..? Cíl experimentu? amplikon DNA malý počet vybraných genů hledání variant exom DNA všechny geny hledání
NGS analýza dat kroužek, 16.12.2016 Alena Musilová Typy NGS experimentů Název Materiál Cílí na..? Cíl experimentu? amplikon DNA malý počet vybraných genů hledání variant exom DNA všechny geny hledání
Bioinformatika je nová disciplína na rozhraní počítačových věd, informačních technologií a biologie. Bioinformatika zahrnuje studium biologických dat
 Bioinformatika je nová disciplína na rozhraní počítačových věd, informačních technologií a biologie. Bioinformatika zahrnuje studium biologických dat a jejich praktické uchovávání, vyhledávání a modelování.
Bioinformatika je nová disciplína na rozhraní počítačových věd, informačních technologií a biologie. Bioinformatika zahrnuje studium biologických dat a jejich praktické uchovávání, vyhledávání a modelování.
Služby pro predikci struktury proteinů. Josef Pihera
 Služby pro predikci struktury proteinů Josef Pihera Struktura proteinů Primární sekvence aminokyselin Sekundární stáčení a spojování vodíkovými vazbami Supersekundární struktura přechod, opakovaná geometrická
Služby pro predikci struktury proteinů Josef Pihera Struktura proteinů Primární sekvence aminokyselin Sekundární stáčení a spojování vodíkovými vazbami Supersekundární struktura přechod, opakovaná geometrická
Využití DNA sekvencování v
 Využití DNA sekvencování v taxonomii prokaryot Mgr. Pavla Holochová, doc. RNDr. Ivo Sedláček, CSc. Česká sbírka mikroorganismů Ústav experimentální biologie Přírodovědecká fakulta Masarykova univerzita,
Využití DNA sekvencování v taxonomii prokaryot Mgr. Pavla Holochová, doc. RNDr. Ivo Sedláček, CSc. Česká sbírka mikroorganismů Ústav experimentální biologie Přírodovědecká fakulta Masarykova univerzita,
OPVK CZ.1.07/2.2.00/
 OPVK CZ.1.07/2.2.00/28.0184 Základní principy vývoje nových léčiv OCH/ZPVNL Mgr. Radim Nencka, Ph.D. ZS 2012/2013 První kroky k objevu léčiva Nobelova cena za chemii 2013 Martin Karplus Michael Levitt
OPVK CZ.1.07/2.2.00/28.0184 Základní principy vývoje nových léčiv OCH/ZPVNL Mgr. Radim Nencka, Ph.D. ZS 2012/2013 První kroky k objevu léčiva Nobelova cena za chemii 2013 Martin Karplus Michael Levitt
E-infrastruktura CESNET - partner výzkumné infrastruktury pro biologická data ELIXIR CZ
 E-infrastruktura CESNET - partner výzkumné infrastruktury pro biologická data ELIXIR CZ Life Science - od molekul k systému Slovník komponent Gramatika (interakce) Souvislosti a sítě (diagramy ) Atlas
E-infrastruktura CESNET - partner výzkumné infrastruktury pro biologická data ELIXIR CZ Life Science - od molekul k systému Slovník komponent Gramatika (interakce) Souvislosti a sítě (diagramy ) Atlas
Statistické metody v ekonomii. Ing. Michael Rost, Ph.D.
 Statistické metody v ekonomii Ing. Michael Rost, Ph.D. Jihočeská univerzita v Českých Budějovicích Test χ 2 v kontingenční tabulce typu 2 2 Jde vlastně o speciální případ χ 2 testu pro čtyřpolní tabulku.
Statistické metody v ekonomii Ing. Michael Rost, Ph.D. Jihočeská univerzita v Českých Budějovicích Test χ 2 v kontingenční tabulce typu 2 2 Jde vlastně o speciální případ χ 2 testu pro čtyřpolní tabulku.
7 Další. úlohy analýzy řeči i a metody
 Pokročilé metody rozpoznávánířeči Přednáška 7 Další úlohy analýzy řeči i a metody jejich řešení Výsledky rozpoznávání (slovník k 413k) frantisek_vlas 91.92( 90.18) [H= 796, D= 10, S= 60, I= 15, N=866,
Pokročilé metody rozpoznávánířeči Přednáška 7 Další úlohy analýzy řeči i a metody jejich řešení Výsledky rozpoznávání (slovník k 413k) frantisek_vlas 91.92( 90.18) [H= 796, D= 10, S= 60, I= 15, N=866,
Metabolismus aminokyselin - testík na procvičení - Vladimíra Kvasnicová
 Metabolismus aminokyselin - testík na procvičení - Vladimíra Kvasnicová Vyberte esenciální aminokyseliny a) Asp, Glu b) Val, Leu, Ile c) Ala, Ser, Gly d) Phe, Trp Vyberte esenciální aminokyseliny a) Asp,
Metabolismus aminokyselin - testík na procvičení - Vladimíra Kvasnicová Vyberte esenciální aminokyseliny a) Asp, Glu b) Val, Leu, Ile c) Ala, Ser, Gly d) Phe, Trp Vyberte esenciální aminokyseliny a) Asp,
Inovace studia molekulární a buněčné biologie reg. č. CZ.1.07/2.2.00/
 Inovace studia molekulární a buněčné biologie reg. č. CZ.1.07/2.2.00/07.0354 Tento projekt je spolufinancován Evropským sociálním fondem a státním rozpočtem České republiky Populační genetika (KBB/PG)
Inovace studia molekulární a buněčné biologie reg. č. CZ.1.07/2.2.00/07.0354 Tento projekt je spolufinancován Evropským sociálním fondem a státním rozpočtem České republiky Populační genetika (KBB/PG)
VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ BRNO UNIVERSITY OF TECHNOLOGY
 VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ BRNO UNIVERSITY OF TECHNOLOGY FAKULTA INFORMAČNÍCH TECHNOLOGIÍ ÚSTAV INFORMAČNÍCH SYSTÉMŮ FACULTY OF INFORMATION TECHNOLOGY DEPARTMENT OF INFORMATION SYSTEMS PREDIKCE ŠKODLIVOSTI
VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ BRNO UNIVERSITY OF TECHNOLOGY FAKULTA INFORMAČNÍCH TECHNOLOGIÍ ÚSTAV INFORMAČNÍCH SYSTÉMŮ FACULTY OF INFORMATION TECHNOLOGY DEPARTMENT OF INFORMATION SYSTEMS PREDIKCE ŠKODLIVOSTI
VÝBĚR A JEHO REPREZENTATIVNOST
 VÝBĚR A JEHO REPREZENTATIVNOST Induktivní, analytická statistika se snaží odhadnout charakteristiky populace pomocí malého vzorku, který se nazývá VÝBĚR neboli VÝBĚROVÝ SOUBOR. REPREZENTATIVNOST VÝBĚRU:
VÝBĚR A JEHO REPREZENTATIVNOST Induktivní, analytická statistika se snaží odhadnout charakteristiky populace pomocí malého vzorku, který se nazývá VÝBĚR neboli VÝBĚROVÝ SOUBOR. REPREZENTATIVNOST VÝBĚRU:
PROTEINY. Biochemický ústav LF MU (H.P.)
") PROTEINY Biochemický ústav LF MU 2013 - (H.P.) 1 proteiny peptidy aminokyseliny 2 Aminokyseliny 3 Charakteristika základní stavební jednotky proteinů geneticky kódované 20 základních aminokyselin 4 a-aminokyselina
PROTEINY Biochemický ústav LF MU 2013 - (H.P.) 1 proteiny peptidy aminokyseliny 2 Aminokyseliny 3 Charakteristika základní stavební jednotky proteinů geneticky kódované 20 základních aminokyselin 4 a-aminokyselina
Molekulárn. rní genetika
 Molekulárn rní genetika Centráln lní dogma molekulárn rní biologie cesta přenosu genetické informace: DNA RNA proteiny výjimkou reverzní transkripce retrovirů: RNA DNA Chemie nukleových kyselin dusíkaté
Molekulárn rní genetika Centráln lní dogma molekulárn rní biologie cesta přenosu genetické informace: DNA RNA proteiny výjimkou reverzní transkripce retrovirů: RNA DNA Chemie nukleových kyselin dusíkaté
VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ VYHLEDÁVÁNÍ HOMOLOGNÍCH GENŮ DIPLOMOVÁ PRÁCE
 VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ BRNO UNIVERSITY OF TECHNOLOGY FAKULTA ELEKTROTECHNIKY A KOMUNIKAČNÍCH TECHNOLOGIÍ ÚSTAV BIOMEDICÍNSKÉHO INŽENÝRSTVÍ FACULTY OF ELECTRICAL ENGINEERING AND COMMUNICATION DEPARTMENT
VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ BRNO UNIVERSITY OF TECHNOLOGY FAKULTA ELEKTROTECHNIKY A KOMUNIKAČNÍCH TECHNOLOGIÍ ÚSTAV BIOMEDICÍNSKÉHO INŽENÝRSTVÍ FACULTY OF ELECTRICAL ENGINEERING AND COMMUNICATION DEPARTMENT
Degradační produkty proteinových aduktů v moči jako nový typ biomarkerů v toxikologii
 28.Teisingerův den průmyslové toxikologie, 11. 6.2013 Degradační produkty proteinových aduktů v moči jako nový typ biomarkerů v toxikologii J. Mráz, I. Linhart *, I. Hanzlíková, Š. Dušková, L. Dabrowská,
28.Teisingerův den průmyslové toxikologie, 11. 6.2013 Degradační produkty proteinových aduktů v moči jako nový typ biomarkerů v toxikologii J. Mráz, I. Linhart *, I. Hanzlíková, Š. Dušková, L. Dabrowská,
6. Kde v DNA nalézáme rozdíly, zodpovědné za obrovskou diverzitu života?
 6. Kde v DNA nalézáme rozdíly, zodpovědné za obrovskou diverzitu života? Pamatujete na to, co se objevilo v pracích Charlese Darwina a Alfreda Wallace ohledně vývoje druhů? Aby mohl mechanismus přírodního
6. Kde v DNA nalézáme rozdíly, zodpovědné za obrovskou diverzitu života? Pamatujete na to, co se objevilo v pracích Charlese Darwina a Alfreda Wallace ohledně vývoje druhů? Aby mohl mechanismus přírodního
MOLEKULÁRNÍ METODY V EKOLOGII MIKROORGANIZMŮ
 MOLEKULÁRNÍ METODY V EKOLOGII MIKROORGANIZMŮ (EKO/MMEM) ZPRACOVÁNÍ DGGE VÝSTUPŮ A SEKVENAČNÍCH DAT Zpracování výstupů z denaturační gradientové gelové elektroforézy (DGGE) práce s programem Gel2k Program
MOLEKULÁRNÍ METODY V EKOLOGII MIKROORGANIZMŮ (EKO/MMEM) ZPRACOVÁNÍ DGGE VÝSTUPŮ A SEKVENAČNÍCH DAT Zpracování výstupů z denaturační gradientové gelové elektroforézy (DGGE) práce s programem Gel2k Program
Zpracování informací a vizualizace v chemii (C2150) 1. Úvod, databáze molekul
 1. Úvod, databáze molekul") Zpracování informací a vizualizace v chemii (C2150) 1. Úvod, databáze molekul Organizační pokyny Přednášející: Martin Prokop Email: martinp@chemi.muni.cz Pracovna: INBIT/2.10 (v dubnu/květnu přesun do
Zpracování informací a vizualizace v chemii (C2150) 1. Úvod, databáze molekul Organizační pokyny Přednášející: Martin Prokop Email: martinp@chemi.muni.cz Pracovna: INBIT/2.10 (v dubnu/květnu přesun do
Inovace studia molekulární a buněčné biologie
 Inovace studia molekulární a buněčné biologie Tento projekt je spolufinancován Evropským sociálním fondem a státním rozpočtem České republiky. MBIO1/Molekulární biologie 1 Tento projekt je spolufinancován
Inovace studia molekulární a buněčné biologie Tento projekt je spolufinancován Evropským sociálním fondem a státním rozpočtem České republiky. MBIO1/Molekulární biologie 1 Tento projekt je spolufinancován
Výuka genetiky na Přírodovědecké fakultě UK v Praze
 Výuka genetiky na Přírodovědecké fakultě UK v Praze Studium biologie na PřF UK v Praze Bakalářské studijní programy / obory Biologie Biologie ( duhový bakalář ) Ekologická a evoluční biologie ( zelený
Výuka genetiky na Přírodovědecké fakultě UK v Praze Studium biologie na PřF UK v Praze Bakalářské studijní programy / obory Biologie Biologie ( duhový bakalář ) Ekologická a evoluční biologie ( zelený
Základy algoritmizace. Pattern matching
 Základy algoritmizace Pattern matching 1 Pattern matching Úloha nalézt v nějakém textu výskyty zadaných textových vzorků patří v počítačové praxi k nejfrekventovanějším. Algoritmy, které ji řeší se používají
Základy algoritmizace Pattern matching 1 Pattern matching Úloha nalézt v nějakém textu výskyty zadaných textových vzorků patří v počítačové praxi k nejfrekventovanějším. Algoritmy, které ji řeší se používají
Biotechnologický kurz. II. letní škola metod molekulární biologie nukleových kyselin a genomiky 17. - 21. 6. 2013
 Biotechnologický kurz Biotechnologický kurz II. letní škola metod molekulární biologie nukleových kyselin a genomiky 17. - 21. 6. 2013 Ústav morfologie, fyziologie a genetiky zvířat AF MENDELU v Brně Zemědělská
Biotechnologický kurz Biotechnologický kurz II. letní škola metod molekulární biologie nukleových kyselin a genomiky 17. - 21. 6. 2013 Ústav morfologie, fyziologie a genetiky zvířat AF MENDELU v Brně Zemědělská
ÚVOD DO MATEMATICKÉ BIOLOGIE I.
 ÚVOD DO MATEMATICKÉ BIOLOGIE I. setkání třetí prof. Ing. Jiří Holčík, CSc. UKB, pav.a29, RECETOX, dv.č.112 holcik@iba.muni.cz POJĎME SI HRÁT SE SLOVY MATEMATIKA INFORMATIKA BIOLOGIE MEDICÍNA? BIOMEDICÍNA??
ÚVOD DO MATEMATICKÉ BIOLOGIE I. setkání třetí prof. Ing. Jiří Holčík, CSc. UKB, pav.a29, RECETOX, dv.č.112 holcik@iba.muni.cz POJĎME SI HRÁT SE SLOVY MATEMATIKA INFORMATIKA BIOLOGIE MEDICÍNA? BIOMEDICÍNA??
Doprovodný materiál k práci s přípravným textem Biologické olympiády 2014/2015 pro soutěžící a organizátory kategorie B
 Doprovodný materiál k práci s přípravným textem Biologické olympiády 2014/2015 pro soutěžící a organizátory kategorie B Níže uvedené komentáře by měly pomoci soutěžícím z kategorie B ke snazší orientaci
Doprovodný materiál k práci s přípravným textem Biologické olympiády 2014/2015 pro soutěžící a organizátory kategorie B Níže uvedené komentáře by měly pomoci soutěžícím z kategorie B ke snazší orientaci
Dobývání znalostí. Doc. RNDr. Iveta Mrázová, CSc. Katedra teoretické informatiky Matematicko-fyzikální fakulta Univerzity Karlovy v Praze
 Dobývání znalostí Doc. RNDr. Iveta Mrázová, CSc. Katedra teoretické informatiky Matematicko-fyzikální fakulta Univerzity Karlovy v Praze Dobývání znalostí Pravděpodobnost a učení Doc. RNDr. Iveta Mrázová,
Dobývání znalostí Doc. RNDr. Iveta Mrázová, CSc. Katedra teoretické informatiky Matematicko-fyzikální fakulta Univerzity Karlovy v Praze Dobývání znalostí Pravděpodobnost a učení Doc. RNDr. Iveta Mrázová,
V. letní škola metod molekulární biologie nukleových kyselin a genomiky 16. - 20. 6. 2014. Ústav morfologie, fyziologie a genetiky zvířat AF MENDELU
 V. letní škola metod molekulární biologie nukleových kyselin a genomiky 16. - 20. 6. 2014 Ústav morfologie, fyziologie a genetiky zvířat AF MENDELU Zemědělská 1, Budova A, 4. patro (učebny dle programu)
V. letní škola metod molekulární biologie nukleových kyselin a genomiky 16. - 20. 6. 2014 Ústav morfologie, fyziologie a genetiky zvířat AF MENDELU Zemědělská 1, Budova A, 4. patro (učebny dle programu)
BIOSTIMULÁTOR AGRO-SORB ZDRAVÍ PRO POLE. VP AGRO, spol. s.r.o. Stehlíkova , Praha 6 - Suchdol
 BIOSTIMULÁTOR AGRO-SORB ZDRAVÍ PRO POLE VP AGRO, spol. s.r.o. Stehlíkova 977 165 00, Praha 6 - Suchdol 18 volných aminokyselin (L- alfa) 18 volných aminokyselin (L- alfa) 18 volných aminokyselin (L- alfa)
BIOSTIMULÁTOR AGRO-SORB ZDRAVÍ PRO POLE VP AGRO, spol. s.r.o. Stehlíkova 977 165 00, Praha 6 - Suchdol 18 volných aminokyselin (L- alfa) 18 volných aminokyselin (L- alfa) 18 volných aminokyselin (L- alfa)
Bílkoviny - proteiny
 Bílkoviny - proteiny Proteiny jsou složeny z 20 kódovaných aminokyselin L-enantiomery Chemická struktura aminokyselin R představuje jeden z 20 různých typů postranních řetězců R Hlavní řetězec je neměnný
Bílkoviny - proteiny Proteiny jsou složeny z 20 kódovaných aminokyselin L-enantiomery Chemická struktura aminokyselin R představuje jeden z 20 různých typů postranních řetězců R Hlavní řetězec je neměnný
NMR biomakromolekul RCSB PDB. Progr. NMR
 NMR biomakromolekul Typy biomakromolekul a možnosti studia pomocí NMR proteiny a peptidy rozmanité složení, omezení jen velikostí molekul nukleové kyseliny (RNA, DNA) a oligonukleotidy omezení malou rozmanitostí
NMR biomakromolekul Typy biomakromolekul a možnosti studia pomocí NMR proteiny a peptidy rozmanité složení, omezení jen velikostí molekul nukleové kyseliny (RNA, DNA) a oligonukleotidy omezení malou rozmanitostí
Biotechnologický kurz. III. letní škola metod molekulární biologie nukleových kyselin a genomiky
 Biotechnologický kurz Biotechnologický kurz III. letní škola metod molekulární biologie nukleových kyselin a genomiky 18. - 22. 6. 2012 Ústav morfologie, fyziologie a genetiky zvířat AF MENDELU v Brně
Biotechnologický kurz Biotechnologický kurz III. letní škola metod molekulární biologie nukleových kyselin a genomiky 18. - 22. 6. 2012 Ústav morfologie, fyziologie a genetiky zvířat AF MENDELU v Brně
UNIVERZITA PARDUBICE
 UNIVERZITA PARDUBICE Fakulta chemicko-technologická Katedra analytické chemie Licenční studium chemometrie na téma Statistické zpracování dat Předmět: 4.3 Zpracování velkých objemů dat, práce s databázemi.
UNIVERZITA PARDUBICE Fakulta chemicko-technologická Katedra analytické chemie Licenční studium chemometrie na téma Statistické zpracování dat Předmět: 4.3 Zpracování velkých objemů dat, práce s databázemi.
PRODUKTY. Tovek Tools
 jsou desktopovou aplikací určenou k vyhledávání informací, tvorbě různých typů analýz a vytváření přehledů a rešerší. Jsou vhodné pro práci i s velkým objemem textových dat z různorodých informačních zdrojů.
jsou desktopovou aplikací určenou k vyhledávání informací, tvorbě různých typů analýz a vytváření přehledů a rešerší. Jsou vhodné pro práci i s velkým objemem textových dat z různorodých informačních zdrojů.
Bioinformatika. Alignment 2. http://bio.img.cas.cz. Jiří Vondrášek Ústav organické chemie a biochemie vondrasek@uochb.cas.cz
 Bioinformatika lignment http://bio.img.cas.cz Jiří Vondrášek Ústav organické chemie a biochemie vondrasek@uochb.cas.cz Jan Pačes Ústav molekulární genetiky hpaces@img.cas.cz typy alignmentů : :n n:n n
Bioinformatika lignment http://bio.img.cas.cz Jiří Vondrášek Ústav organické chemie a biochemie vondrasek@uochb.cas.cz Jan Pačes Ústav molekulární genetiky hpaces@img.cas.cz typy alignmentů : :n n:n n
Názvosloví cukrů, tuků, bílkovin
 Názvosloví cukrů, tuků, bílkovin SACARIDY CUKRY MNSACARIDY LIGSACARIDY PLYSACARIDY (z mnoha molekul monosacharidů) ALDSY KETSY -DISACARIDY - TRISACARIDY - TETRASACARIDY atd. -aldotriosy -aldotetrosy -aldopentosy
Názvosloví cukrů, tuků, bílkovin SACARIDY CUKRY MNSACARIDY LIGSACARIDY PLYSACARIDY (z mnoha molekul monosacharidů) ALDSY KETSY -DISACARIDY - TRISACARIDY - TETRASACARIDY atd. -aldotriosy -aldotetrosy -aldopentosy
PREDIKTOR VLIVU AMINOKYSELINOVÝCH SUBSTITUCÍ NA FUNKCI PROTEINŮ
 VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ BRNO UNIVERSITY OF TECHNOLOGY FAKULTA INFORMAČNÍCH TECHNOLOGIÍ ÚSTAV INFORMAČNÍCH SYSTÉMŮ FACULTY OF INFORMATION TECHNOLOGY DEPARTMENT OF INFORMATION SYSTEMS PREDIKTOR VLIVU
VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ BRNO UNIVERSITY OF TECHNOLOGY FAKULTA INFORMAČNÍCH TECHNOLOGIÍ ÚSTAV INFORMAČNÍCH SYSTÉMŮ FACULTY OF INFORMATION TECHNOLOGY DEPARTMENT OF INFORMATION SYSTEMS PREDIKTOR VLIVU
Vzdělávací materiál. vytvořený v projektu OP VK. Anotace. Název školy: Gymnázium, Zábřeh, náměstí Osvobození 20. Číslo projektu:
 Vzdělávací materiál vytvořený v projektu P VK Název školy: Gymnázium, Zábřeh, náměstí svobození 20 Číslo projektu: Název projektu: Číslo a název klíčové aktivity: CZ.1.07/1.5.00/34.0211 Zlepšení podmínek
Vzdělávací materiál vytvořený v projektu P VK Název školy: Gymnázium, Zábřeh, náměstí svobození 20 Číslo projektu: Název projektu: Číslo a název klíčové aktivity: CZ.1.07/1.5.00/34.0211 Zlepšení podmínek
Metody studia historie populací. Metody studia historie populací
 1) Metody studia genetické rozmanitosti komplexní fenotypové znaky, molekulární znaky. 2) Mechanizmy evoluce mutace, přírodní výběr, genový posun a genový tok 3) Anageneze x kladogeneze - co je vlastně
1) Metody studia genetické rozmanitosti komplexní fenotypové znaky, molekulární znaky. 2) Mechanizmy evoluce mutace, přírodní výběr, genový posun a genový tok 3) Anageneze x kladogeneze - co je vlastně
VYUŽITÍ PRAVDĚPODOBNOSTNÍ METODY MONTE CARLO V SOUDNÍM INŽENÝRSTVÍ
 VYUŽITÍ PRAVDĚPODOBNOSTNÍ METODY MONTE CARLO V SOUDNÍM INŽENÝRSTVÍ Michal Kořenář 1 Abstrakt Rozvoj výpočetní techniky v poslední době umožnil také rozvoj výpočetních metod, které nejsou založeny na bázi
VYUŽITÍ PRAVDĚPODOBNOSTNÍ METODY MONTE CARLO V SOUDNÍM INŽENÝRSTVÍ Michal Kořenář 1 Abstrakt Rozvoj výpočetní techniky v poslední době umožnil také rozvoj výpočetních metod, které nejsou založeny na bázi
Vojtěch Franc. Biometrie ZS Poděkování Janu Šochmanovi za slajdy vysvětlující AdaBoost
 Rozpoznávání tváří I Vojtěch Franc Centrum strojového vnímání, ČVUT FEL Praha Biometrie ZS 2013 Poděkování Janu Šochmanovi za slajdy vysvětlující AdaBoost Úlohy rozpoznávání tváří: Detekce Cíl: lokalizovat
Rozpoznávání tváří I Vojtěch Franc Centrum strojového vnímání, ČVUT FEL Praha Biometrie ZS 2013 Poděkování Janu Šochmanovi za slajdy vysvětlující AdaBoost Úlohy rozpoznávání tváří: Detekce Cíl: lokalizovat
Hardy-Weinbergův zákon - cvičení
 Genetika a šlechtění lesních dřevin Hardy-Weinbergův zákon - cvičení Doc. Ing. RNDr. Eva Palátová, PhD. Ústav zakládání a pěstění lesů LDF MENDELU Brno Tento projekt je spolufinancován Evropským sociálním
Genetika a šlechtění lesních dřevin Hardy-Weinbergův zákon - cvičení Doc. Ing. RNDr. Eva Palátová, PhD. Ústav zakládání a pěstění lesů LDF MENDELU Brno Tento projekt je spolufinancován Evropským sociálním
Bioinformatika a výpočetní biologie KFC/BIN. I. Přehled
 Bioinformatika a výpočetní biologie KFC/BIN I. Přehled RNDr. Karel Berka, Ph.D. Univerzita Palackého v Olomouci KFC/BIN - Podmínky Seminární práce: http://rosalind.info/ - alespoň 10 vyřešených problémů
Bioinformatika a výpočetní biologie KFC/BIN I. Přehled RNDr. Karel Berka, Ph.D. Univerzita Palackého v Olomouci KFC/BIN - Podmínky Seminární práce: http://rosalind.info/ - alespoň 10 vyřešených problémů
Vyhledávání nebo nalezení informací
 Vyhledávání nebo nalezení informací Vilém Sklenák sklenak@vse.cz Vysoká škola ekonomická, fakulta informatiky a statistiky, katedra informačního a znalostního inženýrství Inforum2012, 23. 5. 2012 Vilém
Vyhledávání nebo nalezení informací Vilém Sklenák sklenak@vse.cz Vysoká škola ekonomická, fakulta informatiky a statistiky, katedra informačního a znalostního inženýrství Inforum2012, 23. 5. 2012 Vilém
Nukleové kyseliny Replikace Transkripce translace
 Nukleové kyseliny Replikace Transkripce translace Prokaryotická X eukaryotická buňka Hlavní rozdíl organizace genetického materiálu (u prokaryot není ohraničen) Život závisí na schopnosti buněk skladovat,
Nukleové kyseliny Replikace Transkripce translace Prokaryotická X eukaryotická buňka Hlavní rozdíl organizace genetického materiálu (u prokaryot není ohraničen) Život závisí na schopnosti buněk skladovat,
Využití metagenomiky při hodnocení sanace chlorovaných ethylenů in situ Výsledky pilotních testů
 Využití metagenomiky při hodnocení sanace chlorovaných ethylenů in situ Výsledky pilotních testů Stavělová M.,* Macháčková J.*, Rídl J.,** Pačes J.** * Earth Tech CZ, s.r.o ** ÚMG AV ČR PROČ METAGENOMIKA?
Využití metagenomiky při hodnocení sanace chlorovaných ethylenů in situ Výsledky pilotních testů Stavělová M.,* Macháčková J.*, Rídl J.,** Pačes J.** * Earth Tech CZ, s.r.o ** ÚMG AV ČR PROČ METAGENOMIKA?
Molekulární základ dědičnosti
 Molekulární základ dědičnosti Dědičná informace je zakódována v deoxyribonukleové kyselině, která je uložena v jádře buňky v chromozómech. Zlomovým objevem pro další rozvoj molekulární genetiky bylo odhalení
Molekulární základ dědičnosti Dědičná informace je zakódována v deoxyribonukleové kyselině, která je uložena v jádře buňky v chromozómech. Zlomovým objevem pro další rozvoj molekulární genetiky bylo odhalení
Struktura a funkce biomakromolekul
 Struktura a funkce biomakromolekul KBC/BPOL 7. Interakce DNA/RNA - protein Ivo Frébort Interakce DNA/RNA - proteiny v buňce Základní dogma molekulární biologie Replikace DNA v E. coli DNA polymerasa a
Struktura a funkce biomakromolekul KBC/BPOL 7. Interakce DNA/RNA - protein Ivo Frébort Interakce DNA/RNA - proteiny v buňce Základní dogma molekulární biologie Replikace DNA v E. coli DNA polymerasa a
Gibbsovo samplování a jeho využití
 Gibbsovo samplování a jeho využití Regulace genů Hlavní pozornost výzkumů DNA je většinou věnována analýze genů Geny tvoří pouhá 3% lidské DNA Ukazuje se, že zbývající junk DNA má také velký význam Obsahuje
Gibbsovo samplování a jeho využití Regulace genů Hlavní pozornost výzkumů DNA je většinou věnována analýze genů Geny tvoří pouhá 3% lidské DNA Ukazuje se, že zbývající junk DNA má také velký význam Obsahuje
Populační genetika. ) a. Populační genetika. Castle-Hardy-Weinbergova zákonitost. Platí v panmiktické populaci za předpokladu omezujících podmínek
 a. Populační genetika. Castle-Hardy-Weinbergova zákonitost. Platí v panmiktické populaci za předpokladu omezujících podmínek") Poulační genetika Poulační genetika ORGANISMUS Součást výše organizované soustavy oulace POPULACE Soubor jedinců jednoho druhu Genotyově heterogenní V určitém čase má řirozeně vymezený rostor Velký očet
Poulační genetika Poulační genetika ORGANISMUS Součást výše organizované soustavy oulace POPULACE Soubor jedinců jednoho druhu Genotyově heterogenní V určitém čase má řirozeně vymezený rostor Velký očet
VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ
 VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ BRNO UNIVERSITY OF TECHNOLOGY FAKULTA ELEKTROTECHNIKY A KOMUNIKAČNÍCH TECHNOLOGIÍ ÚSTAV BIOMEDICÍNSKÉHO INŽENÝRSTVÍ FACULTY OF ELECTRICAL ENGINEERING AND COMMUNICATION DEPARTMENT
VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ BRNO UNIVERSITY OF TECHNOLOGY FAKULTA ELEKTROTECHNIKY A KOMUNIKAČNÍCH TECHNOLOGIÍ ÚSTAV BIOMEDICÍNSKÉHO INŽENÝRSTVÍ FACULTY OF ELECTRICAL ENGINEERING AND COMMUNICATION DEPARTMENT
Inovace studia molekulární a buněčné biologie reg. č. CZ.1.07/2.2.00/
 Inovace studia molekulární a buněčné biologie reg. č. CZ.1.07/2.2.00/07.0354 Tento projekt je spolufinancován Evropským sociálním fondem a státním rozpočtem České republiky Populační genetika (KBB/PG)
Inovace studia molekulární a buněčné biologie reg. č. CZ.1.07/2.2.00/07.0354 Tento projekt je spolufinancován Evropským sociálním fondem a státním rozpočtem České republiky Populační genetika (KBB/PG)
Tomáš Oberhuber. Faculty of Nuclear Sciences and Physical Engineering Czech Technical University in Prague
 Tomáš Faculty of Nuclear Sciences and Physical Engineering Czech Technical University in Prague Buňka buňka je základní stavební prvek všech živých organismů byla objevena Robertem Hookem roku 1665 jednodušší
Tomáš Faculty of Nuclear Sciences and Physical Engineering Czech Technical University in Prague Buňka buňka je základní stavební prvek všech živých organismů byla objevena Robertem Hookem roku 1665 jednodušší